Etcd学习笔记
分布式系统中,讨论原子系统读写场景时,反复提到的CAP原理:
- Consistency:(强)一致性,任意时刻所有节点上的数据保持同步,所有读写操作就是原子的、有序的
- Availability:可用性,任何非故障节点必须在有限时间内对请求作出响应
- tolerance to the Partition of network:出现网络分区、丢失任意多消息的情况下,系统仍然能工作
任何分布式系统无法同时满足CAP:
- 满足AP:如果在出现网络分区的情况下,还要保证可用性,则一致性C必须放弃。因为网络分区导致节点间存在无法通信的情况,为了可用性节点必须使用本地数据提供服务,则就导致了不一致
- 满足CP:如果在出现网络分区的情况下,还要保证一致性,那就意味着节点之间的数据同步一直阻塞,丧失可用性
- 满足CA:不出现网络分区的情况下,一致性、可用性可以满足
某些NoSQL数据库,为了换取基本的可用性,往往放弃强一致性,仅仅要求最终一致性,此所谓BASE理论。
为了防止单点故障导致数据不可用、丢失,分布式系统通常引入副本机制。保证副本的一致性,成为分布式系统的核心问题。
一致性这个术语,在计算机的不同领域对了三个英文单词:
- Coherence:在多核共享内存CPU中,各核心上的缓存的数据如何保持一致
- Consensus:强调多个提议者如何就某件事情达成共识,Paxos、Raft等协议解决的就是共识问题
- Consistency:强调并发状态下系统暴露给客户端的行为。CAP、ACID中的C都有这个意思
强一致性为何很难满足:
-
消息传递异步无序(Asynchronous):现实网络不是一个可靠的信道,存在消息延时、丢失,节点间消息传递做不到同步有序
-
节点宕机(fail-stop):节点持续宕机,数据损坏
-
节点宕机恢复(fail-recover):节点宕机后恢复,数据冲突
-
网络分区(Network partition):网络链路出现问题,将N个节点隔离成多个不能相互通信的部分
-
拜占庭将军问题(Byzantine Generals Problem):节点宕机或逻辑错误,甚至不按套路出牌抛出干扰决议的信息。大多数原则
即强一致性,也叫原子一致性,可线性化(Linearizability)。严格一致性要求
- 任何一次读操作,都能读取到数据的最近一次写的结果
- 所有进程看到的操作,其顺序均一致
也叫可序列化。所有进程都以相同的顺序看到所有的修改。允许进程没读到其它进程对数据的写更新,但是每个进程读到数据的不同值的顺序必须一致。
要求对一个数据的写操作,必然发生在,读取到此写操作结果的读操作之前。
这种模型从用户,而非数据的角度阐述一致性。
最终一致性属于弱一致性,允许用户读取到数据的更新存在延迟,此延迟叫做不一致性窗口。
包括etcd、ZooKeeper、HDFS在内的分布式系统,均遵循复制状态机模型。一个分布式的复制状态机,由多个复制单元组成。每个复制单元均是一个状态机,其状态保存在一组状态变量中。这些变量(也就是状态机的状态)仅仅能通过外部命令改变。
实现中,“一组状态变量“通常基于操作日志来实现。每个复制单元均存储操作日志,并且严格按顺序逐条执行日志中的操作指令。需要注意的是,执行顺序不一定需要和指令发起顺序完全一致,只需要保证所有复制单元是同样的顺序即可。
如果复制单元的初态相同,只需要保证操作日志(在它们之间)的一致性,就可以复制状态机的整体一致性。
拜占庭将军们依靠信差达成进攻or撤退的共识,在已知存在不可靠成员的情况下,忠诚将军们如何排除叛徒/间谍的影响?此即拜占庭将军问题。叛徒/间谍传递的虚假消息即拜占庭错误。
在分布式系统中,拜占庭错误可以是硬件错误、网络堵塞、连接断开、遭受攻击,等等。理论上说,要容忍N个拜占庭错误,则需要至少2N+1个复制节点。因此典型的一致性协议都要求半数以上的投票才能作出决定。
Etcd是一种分布式的键值存储,用于保存分布式系统中的关键信息。Etcd:
- 提供基于gRPC的面向用户的简单API
- 支持TLS和可选的客户端身份验证
- 每秒可以支持高达10000写操作
- 基于分布式共识算法Raft
- 可以用于配置管理、服务发现、机器探活
- 可以很轻松的实现分布式锁、选举、写屏障、事件监控、租约等分布式协同
默认情况下,Etcd使用TCP端口2379来监听客户端请求,使用TCP端口2380进行Peer之间的通信。
/etc是Unix下存放配置文件的地方,d表示分布式的意思。可以看出Etcd适用于存储非频繁更新的配置信息,而非海量数据,但是目前版本在处理100GB级别的大量数据下性能也不错。此外,整个Etcd集群只有单个“复制组”(没有分片机制),这限制了它的水平扩容能力。
Etcd用在那些需要强一致性、不能容忍脑裂的场景下,即使强一致性会影响可用性。
Etcd和ZooKeeper解决相同的问题,Etcd也从ZooKeeper得到很多启发。Etcd比ZooKeeper更先进的地方有:
- 支持动态的集群成员重新配置
- 在高负载下支持稳定的读写性能
- 多版本并发控制(MVCC)数据模型 —— 支持查询先前版本的键值对
- 可靠的键监控,绝不会丢弃事件
- 租约原语将连接、会话解耦
- 支持安全的分布式锁的API
- 基于gRPC协议的客户端
Etcd的设计目标是用来存放非频繁更新的数据,提供可靠的Watch插件,它暴露了键值对的历史版本,以支持低成本的快照、监控历史事件。这些设计目标要求它使用一个持久化的、多版本的、支持并发的数据数据模型。
当Etcd键值对的新版本保存后,先前的版本依旧存在。从效果上说,键值对是不可变的,Etcd不会对其进行in-place的更新操作,而总是生成一个新的结构。为了防止历史版本无限增加,Etcd的存储支持压缩(Compact)以删除老旧版本。
从逻辑角度看,Etcd的存储是一个扁平的二进制键空间,键空间有一个针对键(字节字符串)的词典序索引,因此范围查询的成本较低。
键空间维护了多个修订版(Revisions),每一个原子变动操作(一个事务可以由多个子操作组成)都会产生一个新的修订版。在集群的整个生命周期中,修订版都是单调递增的。
修订版同样支持索引,因此基于修订版的范围扫描也是高效的。
压缩操作需要指定一个修订版号,小于它的修订版会被移除。
一个键的一次生命周期(从创建到删除)叫做代(Generation),每个键可以有多个代。创建(修改)一个键时会增加键的版本(version),如果在当前修订版中键不存在则版本设置为1。删除一个键会创建一个墓碑(Tombstone),将版本设置为0,结束当前代。每次对键的值进行修改都会增加其版本号 —— 在同一代中版本号是单调递增的。
当压缩时,任何在压缩修订版之前结束的代,都会被移除。值在修订版之前的修改记录(仅仅保留最后一个)都会被移除。
Etcd将数据存放在一个持久化的B+树中,处于效率的考虑,每个修订版仅仅存储相对于前一个修订版的数据状态变化(Delta)。单个修订版中可能包含了B+树中的多个键。
键值对的键,是三元组 ( major, sub, type):
- major:存储键值的修订版
- sub:用于区分相同修订版中的不同键
- type:用于特殊值的可选后缀,例如t表示值包含墓碑
键值对的值,包含从上一个修订版的的Delta。
B+树按键的词法字节序排列,基于修订版的范围扫描速度快,可以方便的查找从一个修订版到另外一个的值变更情况。
Etcd同时在内存中维护一个B树索引,用于加速针对键的范围扫描。索引的键是物理存储的键面向用户的映射,索引的值则是指向B+树修改点的指针。
| 术语 | 说明 |
| Term | 选举任期,每次选举之后递增 |
| Vote | 选举时的一张投票 |
| Entry | Raft算法的日志的一个条目 |
| Candidate | 候选人,参与竞选以期称为下一任期的Leader的节点 |
| leader | 领导者,负责主动处理写入请求的节点 |
| Follower | 跟随者,不负责主动写入,仅仅从Leader同步数据 |
| Commit | 提交,持久化数据写入到日志中 |
| Apply | 将改变应用到状态机 |
| Propose | 提议,请求大部分节点同意数据写入 |
多个网站提供了Raft算法原理的动画展示,例如http://thesecretlivesofdata.com/raft/。
所有Etcd节点服务器节点都是复制单元,它们共同组成复制状态机:
- 由多个复制单元组成。每个单元都是一个状态机
- Raft算法负责管理来自客户端的状态机操控命令。这些命令保存在受控复制的日志中
- 所有复制单元以严格一致的顺序,处理日志中的命令,因此产生相同的输出
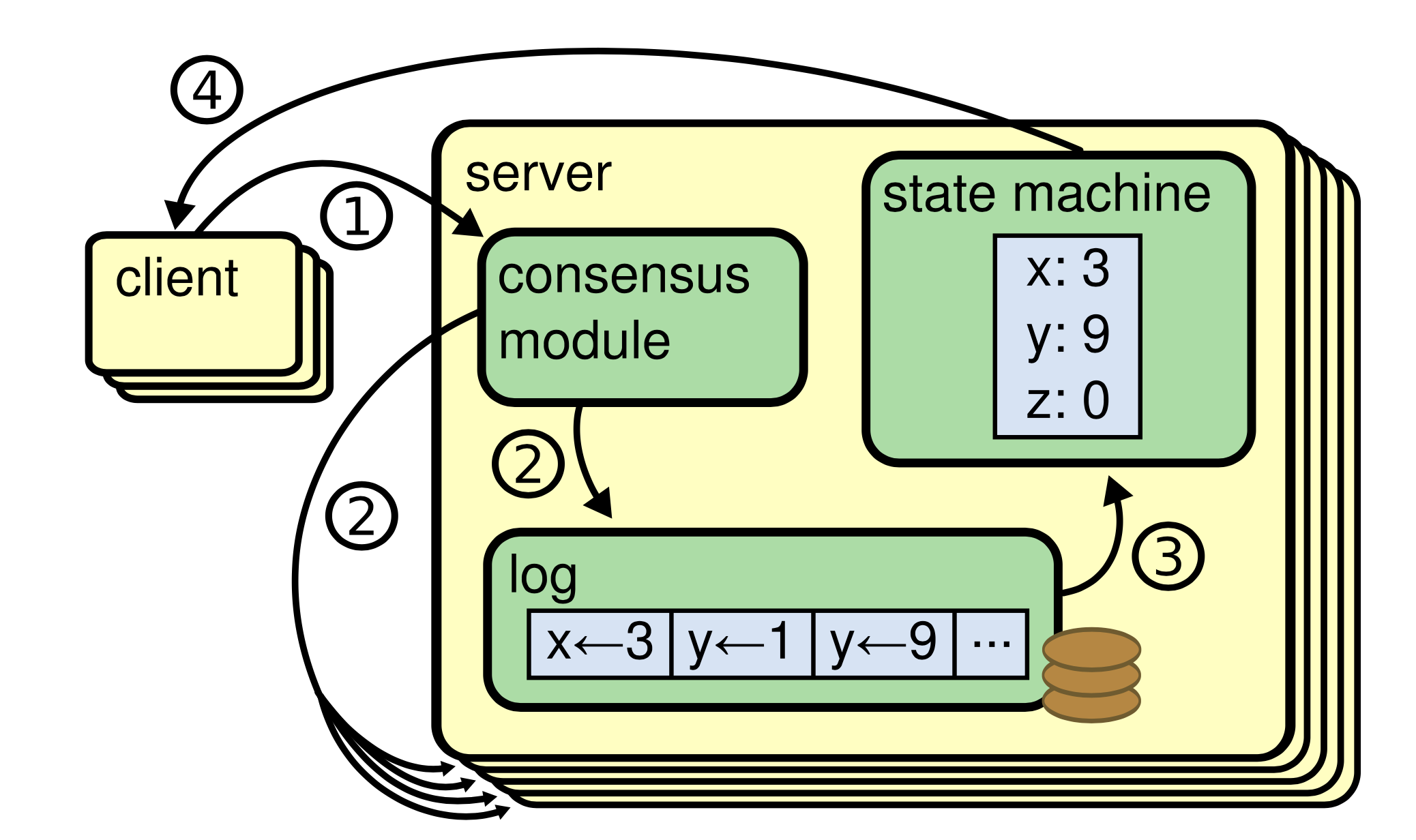
从外部看来,所有节点都读写复制状态机,从而实现协同,实际上,由单个Leader节点负责真正改变状态机,其它节点仅被动同步:
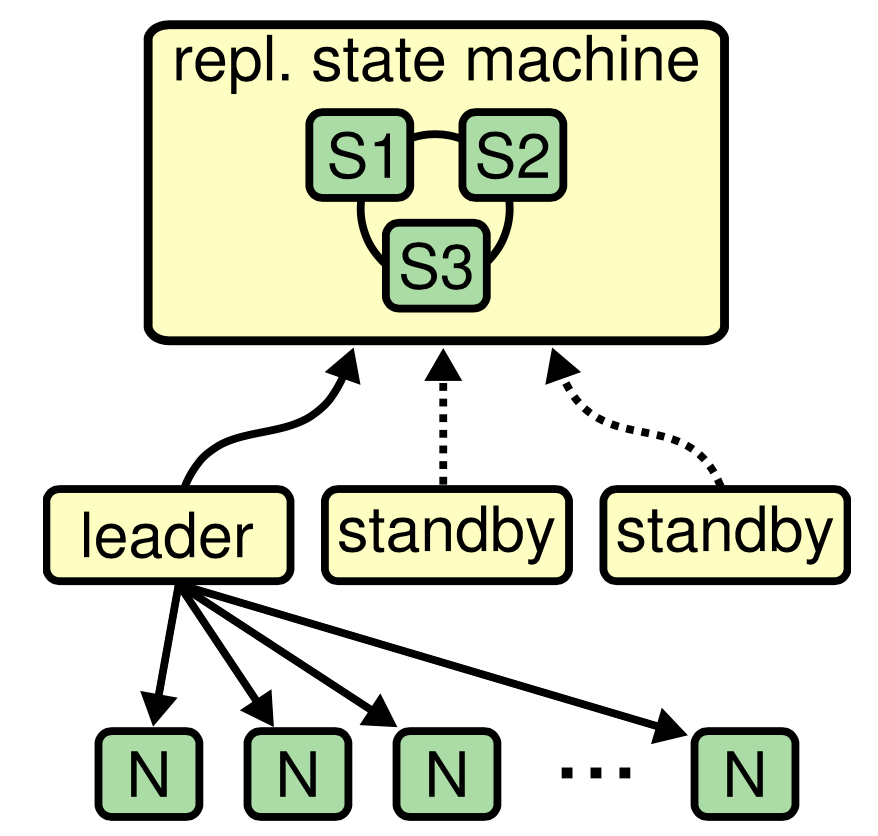
任何时候,Raft节点处于以下三种状态之一:
- Leader:领导者,一个集群里只能存在一个Leader
- Follower:跟随者,不主动负责数据更新,重定向写请求
- Candidate:候选人,切换到此状态后,发起一场选举
节点状态变化状态机:
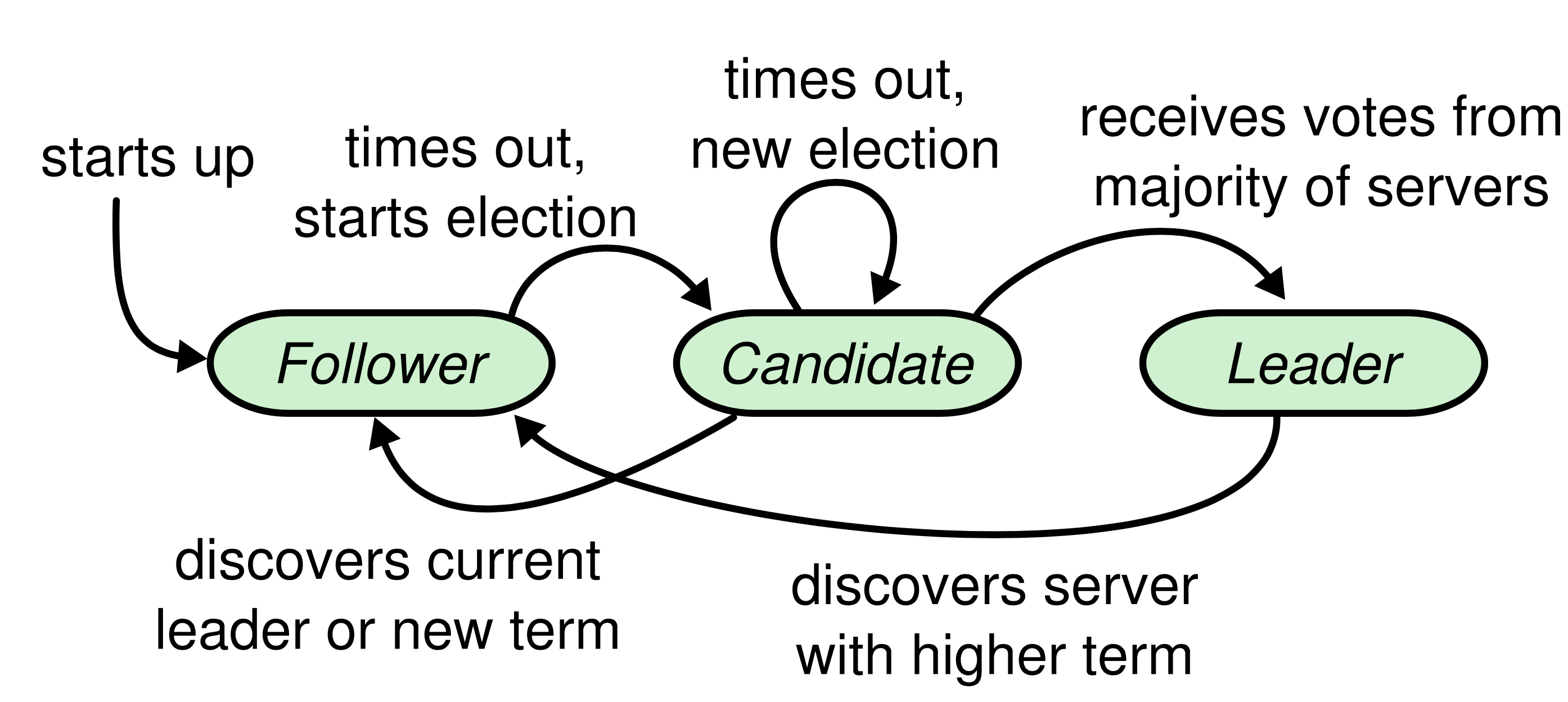
说明如下:
- start up:起始状态,节点刚启动的时候自动进入的是follower状态
- times out, starts election:follower在启动之后,将开启一个选举超时的定时器(Leader的心跳会重置定时器),当这个定时器到期时,将切换到candidate状态发起选举
- times out, new election:进入candidate 状态之后就开始进行选举,但是如果在下一次选举超时到来之前,都还没有选出一个新的leader,那么还会保持在candidate状态重新开始一次新的选举
- receives votes from majority of servers:当candidate状态的节点,收到了超过半数的节点选票,那么将切换状态成为新的leader
- discovers current leader or new term:candidate状态的节点,如果收到了来自leader的消息,或者更高任期号的消息,都表示已经有leader了,将切换回到follower状态
- discovers server with higher term:leader状态下如果收到来自更高任期号的消息,将切换到follower状态。这种情况大多数发生在有网络分区的状态下
Raft算法选举具有以下特点:
- 毛遂自荐:自荐为Candidate后,就会增加Term的值,拉票。从不会推荐别的节点为Candidate
- 先来后到:每个节点只有一票,优先投给先提议的Candidate
- 随机超时:150-300ms之间,避免同时出现多个Candidate
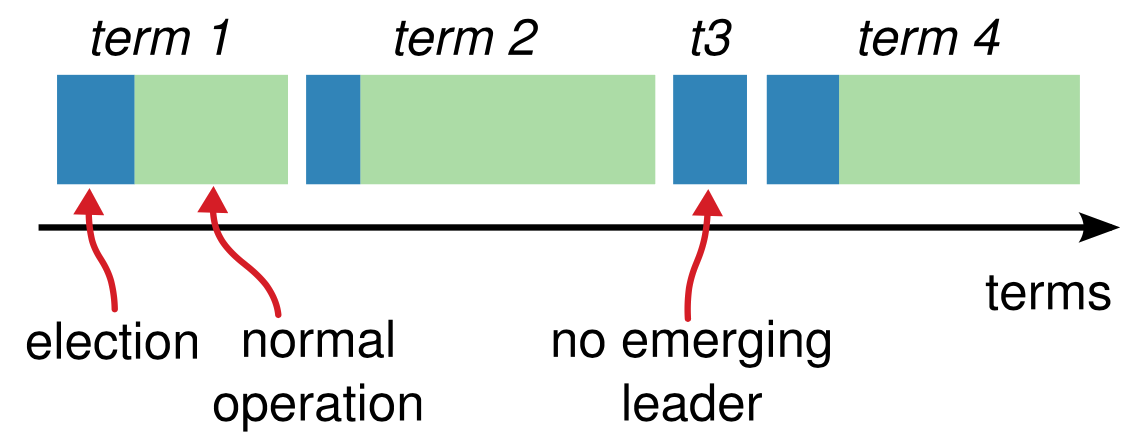
- 直到冒白烟:并非每个任期都必然有Leader,如果选举超时到达后仍然没有Leader,则增加任期并再次选举。直到选举成功否则不罢休,就像罗马教皇选举一样
下图显示了一个没有Leader的任期:
每个日志条目具有三要素:
- 任期:日志在哪个任期内产生
- 索引号:严格递增的序列号
- 命令:执行什么数据操作
日志复制算法的细节:
- 客户端写请求都会被重定向给Leader
- 在收到这些请求之后, Leader会首先在自己的日志中添加一条新条目
- 在本地添加完日志之后,Leader将向集群中其他节点发送AppendEntries gRPC请求以同步日志条目
- 日志条目被成功同步后Leader将日志输入到Raft状态机中执行
- 大部分节点应答AppendEntries gRPC请求后(这意味着大部分节点写了WAL日志,数据安全了),Leader应答客户端
下面是一个日志复制进度图:
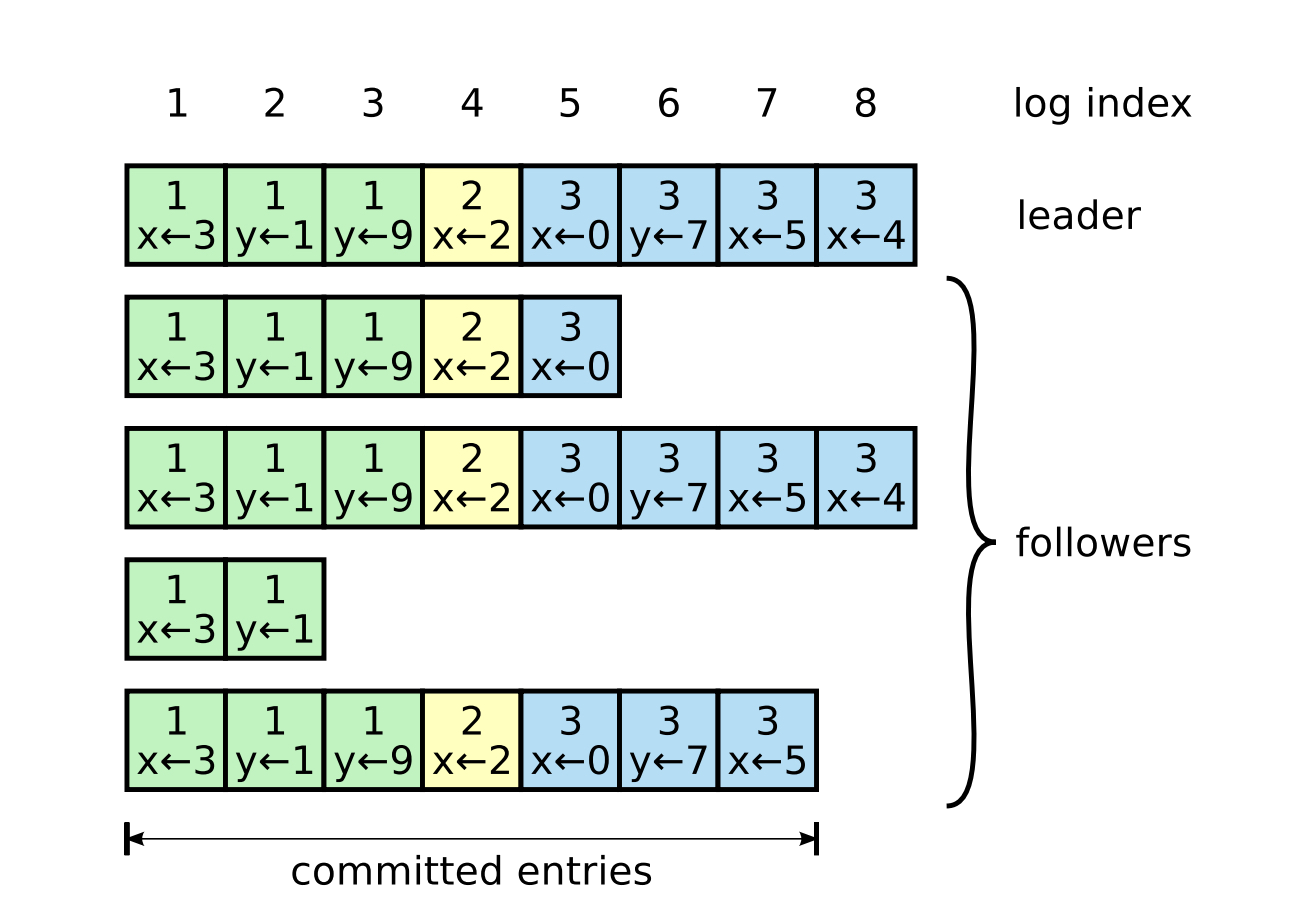
可以看到:
- x<-4 这个操作只有一个节点跟上了Leader
- x<-3 这个操作大部分节点都已经确认
- 第3个Follower落后严重,和Leader差了两个任期
Etcd支持以下两种读:
- Linearizable Read(默认):需要由Leader发起,Leader发送一个请求给所有节点,在收到多数节点的响应之后,才把结果返回给客户端。如果一个Follower收到linearizable read的请求,需要转发给leader来处理
- Serializable read(使用Get API的话要加WithSerializable选项): Leader和follower都可以在本地处理,时延低
etcdctl默认使用Linearizable读,可以指定读取方式:
|
1 |
etcdctl get --consistency=s / |
只有Etcd的Leader才能处理write。Follower在接到写请求后,要转发给leader来处理。
Etcd的性能基准测试在8 vCPU、16GB RAM、50GB SSD的GCE实例上进行,但是任何较为新的硬件架构+低延迟存储+若干GB内存的机器均可满足大部分场景。
由于数据存放在匿名内存而非内存映射文件,V2版本的数据比V3消耗更多内存。
需要Go 1.9以上版本:
|
1 2 3 4 5 |
cd $GOPATH/src/github.com mkdir etcd-io && cd etcd-io git clone https://github.com/etcd-io/etcd.git cd etcd ./build |
如果Etcd集群成员是已知的,具有固定的IP地址,则可以静态的初始化一个集群。
每个节点都可以使用如下环境变量:
|
1 2 |
ETCD_INITIAL_CLUSTER="radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380" ETCD_INITIAL_CLUSTER_STATE=new |
或者如下命令行参数:
|
1 2 |
--initial-cluster radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380 --initial-cluster-state new |
来指定集群成员。
完整的命令行示例:
|
1 2 3 4 5 6 7 8 |
etcd --name radon --initial-advertise-peer-urls http://10.0.2.1:2380 --listen-peer-urls http://10.0.2.1:2380 --listen-client-urls http://10.0.2.1:2379,http://127.0.0.1:2379 --advertise-client-urls http://10.0.2.1:2380 # 所有以-initial-cluster开头的选项,在第一次运行(Bootstrap)后都被忽略 --initial-cluster-token etcd.gmem.cc --initial-cluster radon=http://10.0.2.1:2380,neon=http://10.0.3.1:2380 --initial-cluster-state new |
Etcd支持基于TLS加密的集群内部、客户端-集群通信。每个集群节点都应该拥有被共享CA签名的证书:
|
1 2 3 4 5 6 7 8 9 10 |
# 密钥对、证书签名请求 openssl genrsa -out radon.key 2048 export SAN_CFG=$(printf "\n[SAN]\nsubjectAltName=IP:127.0.0.1,IP:10.0.2.1,DNS:radon.gmem.cc") openssl req -new -sha256 -key radon.key -out radon.csr \ -subj "/C=CN/ST=BeiJing/O=Gmem Studio/CN=Server Radon" \ -reqexts SAN -config <(cat /etc/ssl/openssl.cnf <(echo $SAN_CFG)) # 执行签名 openssl x509 -req -sha256 -in radon.csr -out radon.crt -CA ../ca.crt -CAkey ../ca.key -CAcreateserial -days 3650 \ -extensions SAN -extfile <(echo "${SAN_CFG}") |
初始化集群命令需要修改为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
etcd --name radon --initial-advertise-peer-urls https://10.0.2.1:2380 --listen-peer-urls https://10.0.2.1:2380 --listen-client-urls https://10.0.2.1:2379,https://127.0.0.1:2379 --advertise-client-urls https://10.0.2.1:2380 --initial-cluster-token etcd.gmem.cc # 指定集群成员列表 --initial-cluster radon=https://10.0.2.1:2380,neon=https://10.0.3.1:2380 --initial-cluster-state new # 初始化新集群时使用 --initial-cluster-state existing # 加入已有集群时使用 # 客户端TLS相关参数 --client-cert-auth --trusted-ca-file=/usr/share/ca-certificates/GmemCA.crt --cert-file=/opt/etcd/cert/radon.crt --key-file=/opt/etcd/cert/radon.key # 集群内部TLS相关参数 --peer-client-cert-auth --peer-trusted-ca-file=/usr/share/ca-certificates/GmemCA.crt --peer-cert-file=/opt/etcd/cert/radon.crt --peer-key-file=/opt/etcd/cert/radon.key |
某些情况下,集群成员的IP地址可能是未知、不固定的。典型场景包括云环境、使用DHCP网络。
这种情况下,启动Etcd集群需要依赖于成员发现,成员发现的方法有两种:
- Etcd发现服务
- DNS SRV记录
所有配置项参考:https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/configuration.md
| 配置 | 说明 |
| heartbeat-interval |
心跳间隔,Leader通知所有的followers,他还是Leader的频率 根据成员间网络RTT来确定适当的值,默认100ms |
| election-timeout |
选举超时,一个Foller节点等待大多数节点同意它成为Leader的心跳的最大时间,默认1000ms。超时后放弃 般可设置为RTT的0.5-1.5倍 |
| snapshot-count | 每发生多少次变更,就保存一次快照。V2后端快照是高成本操作 |
| max-snapshots | 最大保存的快照数量,默认5,0表示不限制 |
| quota-backend-bytes |
数据大小,默认是2G,当数据达到2G的时候就不允许写入,必须对历史数据进行压缩才能继续写入 默认2G,推荐8G |
| max-request-bytes | Raft消息最大字节数,默认1.5M,推荐10M |
| auto-compaction-retention |
Etcd存储多版本数据,随着写入的主键增加,历史版本需要定时清理。默认的历史数据是不会清理的,数据达到2G就不能写入,必须要清理压缩历史数据才能继续写入 该参数决定清理压缩间隔,单位小时 3.2.0默认每小时压缩一次 |
| initial-election-tick-advance | 如果设置为true,在Boot时会快进初始选举(fast-forward initial election)。目标是更快选举 |
| grpc-keepalive-min-time |
服务器ping客户端之前,等待的最小(没有活动的)时间,默认5s Etcd使用gRPC协议,gRPC协议基于HTTP/2,gRPC支持使用HTTP/2的Ping帧来保活 —— 度量RTT和探测一个gRPC连接是否坏掉了 |
| grpc-keepalive-interval | 服务器ping客户端的频率(当连接是alive)的,默认2h |
| grpc-keepalive-timeout | 在关闭不响应连接之前需要等待的时间,默认20s |
| log-level | 日志级别,默认info |
| data-dir | 数据存放目录 |
| wal-dir | 写前日志目录 |
| max-wals | WAL文件的最大数量,默认5,0表示不限制 |
| name | 成员的名字 |
| quota-backend-bytes | 后端存储超过指定的大小发起alarm |
| cors | CORS请求白名单 |
| initial-advertise-peer-urls | 向其它成员通知的,当前成员的Peer URL。默认 http://localhost:2380 |
| advertise-client-urls | 当前成员的接受客户端连接的地址 |
| initial-cluster | 初始的集群配置,逗号分隔的成员名车:Peer URL列表 |
| initial-cluster-state |
初始的集群状态:
|
| enable-v2 | 是否允许V2版本的客户端请求 |
|
1 2 3 4 5 6 |
# 无身份验证的集群 curl http://localhost:2379/metrics # 基于客户端证书进行身份验证的集群 curl --cacert=/etc/kubernetes/pki/ca.crt --key=client.key --cert=client.cert \ https://localhost:2379/metrics |
| 指标 | 说明 |
| 服务器基础指标 | |
| leader_changes_seen_total | Leader变换的次数。Leader频繁的变化严重的影响性能 |
| proposals_committed_total | 提交的Consensus Proposal总数。不同成员的该指标值应该差距较小,如果一个成员和Leader之间总是有很大差距,说明成员缓慢或不健康 |
| proposals_applied_total | 应用的Consensus Proposal总数。Etcd会异步的应用已经提交的Proposal。通常情况下Commit/Apply差距应该较小,高负载下也最多数K,如果差距持续变大,提示Etcf过载。过载可能发生在昂贵查询(大范围Range查询)、大的Txn操作时 |
| proposals_pending | 正在排队等候Commit的Proposal数量。数值过大提示客户端导致的高负载、或者成员无法Commit |
| proposals_failed_total | 失败的原因可能包括:由于Leader选举导致的临时失败,由于失去Quorum导致的集群宕机 |
| 磁盘相关指标 | |
| wal_fsync_duration_seconds | 写前日志的fsync延迟直方图(分布),Etcd会在Apply之前,将日志条目写入到磁盘 |
| backend_commit_duration_seconds | backend_commit的延迟直方图,当Etcd将最近变更的增量快照写入到磁盘时,调用backend_commit |
| 网络相关指标 | |
| peer_sent_bytes_total | 发送给特定成员的字节数 |
| peer_received_bytes_total | 从特定成员接收的字节数 |
| peer_sent_failures_total | 发送失败字节数 |
| peer_received_failures_total | 接收失败字节数 |
| peer_round_trip_time_seconds | RTT分布直方图 |
| client_grpc_sent_bytes_total | 发送给gRPC客户端的字节数 |
| client_grpc_received_bytes_total | 从gRPC客户端接收到的字节数 |
为了保持可靠性,Etcd集群需要周期性的运维。运维操作通常能够自动完成,并且不会宕机,仅仅稍微影响性能。
运维操作主要是管理Etcd键空间的存储资源,如果用尽磁盘配额,则集群进入维护模式,仅仅支持读/删键值的操作。为了避免这种情况,必须压缩键空间的修订版历史(就是丢弃旧版本)。此外,通过碎片整理,也能够回收存储资源。
通过周期性的对集群状态进行快照备份,也可以防止误操作导致的数据丢失。
配置项snapshot-count决定了执行Compaction(和键空间压缩是两回事)操作之前,暂存于内存中的Raft日志条目的数量。当数量到达时,服务器会:
- 将快照数据持久化到硬盘
- truncate旧的日志条目
如果一个缓慢的Follower请求已经被truncated的日志条目,则Leader强制Follower使用快照来覆盖其自身状态
如果snapshot-count取值很高,则内存中存储更多的日志条目,内存占用变高。于此同时,由于Leader维持更多的日志,因此慢Follower发生快照覆盖的几率更小。
从3.2开始,默认值从10000改为100000。
如果snapshot-count取值过大,可能会影响写吞吐量。内存中对象数据过多,会导致Go GC的Mark阶段变慢。
Etcd保留键空间的精确历史,旧的修订版需要被定期删除,避免影响性能甚至耗尽键空间存储资源。
键空间会自动进行周期性清理,你也可以调用命令手工触发清理:
|
1 2 3 4 5 |
# 清理掉修订版3以前的历史 etcdctl compact 3 # etcdctl get --rev=2 somekey # Error: rpc error: code = 11 desc = etcdserver: mvcc: required revision has been compacted |
使用下面的选项,可以每小时压缩一次:
|
1 |
etcd --auto-compaction-retention=1 |
在3.2.0,压缩操作默认就是每小时运行一次。
在3.3.0、3.3.1、3.3.2,支持额外的选项:
|
1 2 3 4 5 |
# 保留最新的1000个修订版,每5分钟压缩一次 etcd --auto-compaction-mode=revision --auto-compaction-retention=1000 # 每72/10小时压缩一次,保留72小时的 retention window -auto-compaction-mode=periodic --auto-compaction-retention=72h |
压缩键空间后,后端数据库中可能存在碎片,碎片是已经释放却无法使用的空间。
要整理某个成员的碎片,执行:
|
1 |
etcdctl defrag |
要整理和默认Endpoint关联的所有Endpoint的碎片,执行:
|
1 |
etcdctl defrag --cluster |
存储空间配额确保了Etcd集群可靠的运作。没有配额,Etcd可能会性能低下(键空间无限增长),或者直接耗尽磁盘空间(没有自动化整理的情况下)。
使用下面的选项来设置配额:
|
1 |
etcd --quota-backend-bytes=$((16*1024*1024)) |
应当周期性的将Etcd后端数据库进行备份: etcdctl snapshot save backup.db
| 选项 | 说明 |
| --cacert | 用于校验服务器证书的根证书 |
| --cert | 表明本客户端身份的证书 |
| --key= | 表明本客户端身份的私钥 |
| --debug | 启用客户端调试日志 |
| --dial-timeout=2s | 连接超时 |
| --command-timeout=5s | 短时运行的命令的超时 |
| --endpoints | gRPC端点列表 |
| --insecure-skip-tls-verify | 跳过服务器证书验证 |
| --insecure-transport | 禁用传输层安全 |
| --user=username[:password] | 基于口令进行身份验证 |
| -w --write-out="simple" | 输出格式:fields, json, protobuf, simple, table |
etcdctl命令的全局选项,前缀以ETCDCTL,改为大写下划线形式,即为对应环境变量:
| 环境变量 | 说明 |
| ETCDCTL_API | 对于3.4以前的版本,需要指定该环境变量为3,才能使用v3 API |
| ETCDCTL_ENDPOINTS | 访问的Etcd gRPC端点列表 |
| ETCDCTL_DIAL_TIMEOUT | 连接超时 |
| ETCDCTL_CACERT | 指定根证书 |
| ETCDCTL_CERT | 指定证书文件 |
| ETCDCTL_KEY | 指定密钥文件 |
| 子命令 | 说明 | ||||
| put |
格式:PUT [options] <key> <value> 选项: lease 附到键上的租约ID,租约和键的到期时间有关 示例:
|
||||
| get |
格式:GET [options] <key> [range_end] 选项: hex 打印为HEX格式 示例:
|
||||
| lock |
在指定的名字上请求一个分布式锁,一旦获取,则知道etcdctl命令退出,会一直占用锁 格式:LOCK [options] <lockname> [command arg1 arg2 ...] 选项: ttl 锁会话超时秒数 |
||||
| del |
格式:DEL [options] <key> [range_end] 选项: prefix 删除匹配前缀的键 示例:
|
||||
| txn |
从标准输入读取多个etcd请求,将它们作为单个事务执行。事务包括一个条件列表,以及当条件满足时需要执行的请求列表、一个条件不满足时需要执行的请求列表 格式:TXN [options] 事务语法:
示例:
|
||||
| compaction |
丢弃指定修订版之前的所有etcd事件历史。某些etcd使用MVCC模型,它会保留所有键更新为事件历史。当足够老旧的修订版不再需要时,可以执行该操作回收磁盘空间 格式:COMPACTION [options] <revision> 选项: physical 设置为true等到操作完成 示例:
|
||||
| watch |
监听针对指定键/键前缀/键范围的事件流,并在事件发生时执行命令。该命令会一直执行,知道用户请求停止或出错 格式:WATCH [options] [key or prefix] [range_end] [--] [exec-command arg1 arg2 ...] 选项: hex 打印为HEX格式 示例:
|
||||
| lease |
进行键的租约管理 示例:
|
||||
| member |
集群成员管理 示例:
|
||||
| endpoint |
查询端点信息 示例:
|
||||
| check perf |
在60s内测试etcd集群的性能。该命令会创建大量的键空间历史,这些历史可以被--auto-compact --auto-defrag选项自动清除 选项: load 性能检查的工作负载模型: s(small), m(medium), l(large), xl(xLarge) 示例:
|
||||
| check datascale | 测试存储数据需要的内存数量,选项同上 | ||||
| defrag |
对后端数据文件进行碎片整理。当etcd成员回收磁盘空间(因为删除/compact键)时,会留下很多空隙,这些空隙存储在一个free list中,数据文件的大小不会变化。 碎片整理操作会释放空闲空间到文件系统 注意:
选项: data-dir 指定数据目录,用于整理没有被etcd使用的数据目录 示例:
|
||||
| snapshot save |
将某个时间点的etcd后端数据库的快照保存为文件 示例:
|
||||
| snapshot restore |
从快照+新的集群配置中恢复出一个数据目录,供etcd集群成员使用。将快照恢复到新集群配置的所有成员,会初始化一个新的集群 选项: data-dir 数据目录的路径 示例:
|
||||
| snapshot status | 查看镜像的数据库哈希、修订版、键总数、尺寸信息:
|
||||
| move-leader | 修改集群Leader:
|
||||
| elect |
参与一个命名的选举。节点通过提供一个提议值(proposal value)来宣告自己的参选资格。该命令在Leader出现后退出,打印Leader的Proposal 选项: listen 观察选举,不作为候选人 |
||||
| auth enable | 启用etcd集群的身份验证功能 | ||||
| auth disable | 禁用etcd集群的身份验证功能 | ||||
| role | 管理角色,为角色授予特权:
|
||||
| user | 管理用户,为用户授予角色或特权:
|
||||
| make-mirror |
在另外一个镜像创建指定键前缀的镜像 |
||||
| migrate | 将V2格式的键值迁移为V3的MVCC存储 |
目前K8S存放在Etcd中的数据都是以Protobuf编码的,因此无法阅读,使用该工具可以解码、编码:
|
1 2 3 4 5 |
# 解码为YAML etcdctl get /registry/services/specs/kube-system/kube-dns | auger decode # 编码为Protobuf并写入到etcd cat kube-dns.yaml | auger encode | etcdctl put /registry/services/specs/kube-system/kube-dns |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key \ # 'https://etcd.gmem.cc:2379/v2/keys/path/to?recursive=true&sorted=true' { "action": "get", "node": { "key": "/galera/mariadb_galera", "dir": true, "nodes": [ { "key": "/galera/mariadb_galera/172.28.0.27", "dir": true, "nodes": [ { "key": "/galera/mariadb_galera/172.28.0.27/ipaddress", "value": "172.28.0.27", "modifiedIndex": 8, "createdIndex": 8 } ], "modifiedIndex": 8, "createdIndex": 8 } ] } } |
节点损坏,修复后重新加入集群报此错误,只需要将启动命令中的new换为existing即可:
|
1 |
--initial-cluster-state existing |
在我们的一个arm64的1000+节点K8S集群上,单节点的Etcd出现此报错,日志中还可以看到连接127.0.0.1:2380超时。观察发现APIServer的CPU占用很高,禁用HTTPS可以改善。
可能是防火墙问题
当Etcd的任何成员的磁盘空间配额到达,在集群范围内出现此报错。集群将进入维护模式,仅仅允许读、删操作,无法插入新数据。
集群失去法定人数(Quorum),正在建立新的Leader时出现此信息。
应用日志条目到状态机,消耗超过100ms的情况下报此错误。可能原因:
- 磁盘太慢:可以监控 commitduration_seconds指标,正常情况下P99应该小于25ms
- CPU饥饿:给Etcd分配给多的CPU资源,或者将Etcd部署到独立节点。Leader会周期性的发送心跳给Follower,这样才能维持自己的Leader身份,否则选举可能被触发
- 网络太慢:检查网络延迟和节点之间的丢包率
发送快照速度太慢,超过了千兆网络下预期的小于30s。
节点尝试加入到已经构建好的集群。
集群状态非法,成员无法加入。
Leave a Reply