Ceph学习笔记
Ceph是一个高性能、可扩容的分布式存储系统,它提供三大功能:
- 对象存储:提供RESTful接口,也提供多种编程语言绑定。兼容S3、Swift
- 块存储:由RBD提供,可以直接作为磁盘挂载,内置了容灾机制
- 文件系统:提供POSIX兼容的网络文件系统CephFS,专注于高性能、大容量存储
Ceph集群由一系列节点(机器)组成,在这些节点上运行以下组件:
- Ceph OSDs:OSD即对象存储守护程序,但是它并非针对对象存储。OSD负责存储数据、处理数据复制、恢复、回填(Backfilling)、再平衡。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor
- Monitors:监视器,维护集群状态的多种映射,同时提供认证和日志记录服务
- MDSs:元数据服务器,存储CephFS的元数据信息
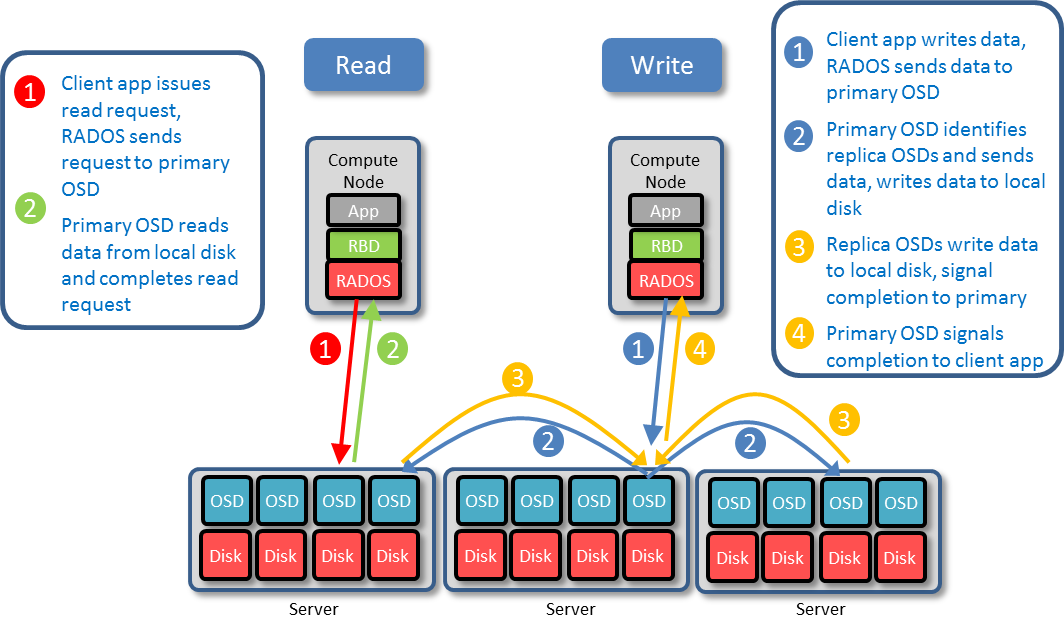
Ceph将客户端的数据作为对象存储在它的存储池中,基于CRUSH算法,Ceph计算出每个对象应该位于那个PG,计算哪个OSD负责存储PG
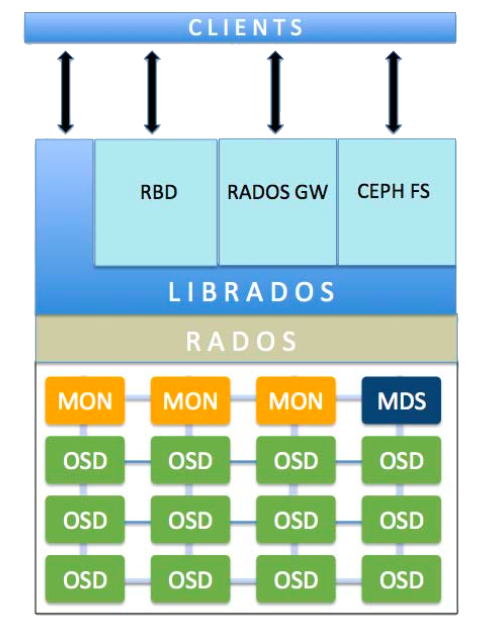
| 术语 | 说明 |
| RADOS |
可靠的、自动化的分布式对象存储(Reliable, Autonomic Distributed Object Store)是Ceph的核心之一 librados是RADOS提供的库,上层的RBD、RGW和CephFS都是通过librados访问RADOS的 |
| RGW | 即RADOS Gateway,指Ceph的对象存储API或者RGW守护进程 |
| RBD | 即RADOS Block Device,指Ceph提供的基于复制性的分布式的块设备。类似于LVM中的逻辑卷,RBD只能属于一个Pool |
| MDS | 即Ceph元数据服务器,是CephFS服务依赖的元数据服务 |
| CephFS | Ceph File System,是Ceph对外提供的文件系统服务 |
| Pool |
存储池是Ceph中一些对象的逻辑分组。它不是一个连续的分区,而是一个逻辑概念,类似LVM中的卷组(Volume Group) 存储池分为两个类型:
|
| PG |
归置组(Placement Group),PG是Pool组织对象的方式,便于更好的分配数据和定位数据,Pool由若干PG组成 PG 的数量会影响Ceph集群的行为和数据的持久性。集群扩容后可以增大PG数量:5个以下OSD设置为128即可 PG的特点:同一个PG中所有的对象,在相同一组OSDs上被复制。复制型Pool中PG可以有一个作为主(Primary)OSD,其它作为从OSD。一个对象仅仅属于一个PG,也就是说对象存储在固定的一组OSDs上 PG在OSD的/var/lib/ceph/osd/ceph-2/current目录下,表现为目录 |
| CRUSH |
CRUSH即基于可扩容哈希的受控复制(Controlled Replication Under Scalable Hashing),是一种数据分发算法,类似于哈希和一致性哈希。哈希的问题在于数据增长时不能动态添加Bucket,一致性哈希的问题在于添加Bucket时数据迁移量比较大,其他数据分发算法依赖中心的Metadata服务器来存储元数据因而效率较低,CRUSH则是通过计算、接受多维参数的来解决动态数据分发的场景 CRUSH算法接受的参数包括:
CRUSH与一致性哈希最大的区别在于接受的参数多了Cluster map和Placement rules,这样就可以根据目前Cluster的状态动态调整数据位置,同时通过算法得到一致的结果 基于此算法,Ceph存储集群能够动态的扩容、再平衡、恢复 |
| Object |
Ceph最底层的存储单元是Object,每个Object包含元数据和原始数据 一个RBD会包含很多个Object |
| OSD |
对象存储守护进程(Object Storage Daemon),负责响应客户端请求返回具体数据的进程。Ceph集群中有大量OSD 一个节点上通常只运行一个OSD守护进程,此守护进程在一个存储驱动器上只运行一个 filestore |
| EC |
Erasure Code(EC),即纠删码,是一种前向错误纠正技术(Forward Error Correction,FEC),主要应用在网络传输中避免包的丢失, 存储系统利用它来提高可靠性。相比多副本复制而言, 纠删码能够以更小的数据冗余度获得更高数据可靠性, 但编码方式较复杂,需要大量计算 。纠删码只能容忍数据丢失,无法容忍数据篡改,纠删码正是得名与此 EC将n份原始数据,增加m份数据,并能通过n+m份中的任意n份数据,还原为原始数据。即如果有任意小于等于m份的数据失效,仍然能通过剩下的数据还原出来 纠删码技术在分布式存储系统中的应用主要有三类:
|
监视器维护集群状态的多种映射—— 包monmap、OSD map、PG map、CRUSH map、MDS map,同时提供认证和日志记录服务。Ceph会记录Monitor、OSD、PG的每次状态变更历史(此历史称作epoch)。客户端连到单个监视器并获取当前映射就能确定所有监视器、 OSD 和元数据服务器的位置。依赖于CRUSH算法和当前集群状态映射,客户端就能计算出任何对象的位置,直连OSD读写数据。
Ceph客户端、其它守护进程通过配置文件发现mon,但是mon之间的相互发现却依赖于monmap的本地副本。所有mon会基于分布式一致性算法Paxos,确保各自本地的monmap是一致的,当新增一个mon后,所有现有mon的monmap都自动更新为最新版本。
使用多个mon时,每个mon都会检查其它mon是否具有更新的集群状态映射版本 —— 存在一个或多个epoch大于当前mon的最高epoch。太过落后的mon可能会离开quorum,同步后再加入quorum。执行同步时,mon分为三类角色:
- Leader:具有最新版本状态映射的mon
- Provider:同上,但是它的最新状态是从Leader同步获得
- Requester:落后于Leader,必须获取最新集群状态映射才能重回quorum
如果mon的时钟不同步,可能会导致:
- 守护进程忽略收到的消息(时间戳过时)
- 消息未及时收到时,超时触发得太快或太晚
OSD使用日志的原因有两个:
- 速度: 日志使得 OSD 可以快速地提交小块数据的写入, Ceph 把小片、随机 IO 依次写入日志,这样,后端文件系统就有可能归并写入动作,并最终提升并发承载力。因此,使用 OSD 日志能展现出优秀的突发写性能,实际上数据还没有写入 OSD ,因为文件系统把它们捕捉到了日志
- 一致性:OSD需要一个能保证原子化复合操作的文件系统接口。 OSD 把一个操作的描述写入日志,并把操作应用到文件系统。这确保了对象(例如归置组元数据)的原子更新。每隔一段时间(由filestore max sync interval 和 filestore min sync interval控制 ), OSD 会停止写入,把日志同步到文件系统,这样允许 OSD 修整日志里的操作并重用空间。若失败, OSD 从上个同步点开始重放日志。日志的原子性表现在,它不使用操作系统的文件缓存(基于内存),避免断电丢数据的问题
注意:OSD进程在往数据盘上刷日志数据的过程中,是停止写操作的。
通常使用独立SSD来存储日志,原因是:
- 避免针对单块磁盘的双重写入 —— 先写日志,再写filestore
- SSD性能好,可以降低延迟提升IOPS
| IN | OUT | |
| UP | 正常状态,OSD位于集群中,且接收数据 |
OSD虽然在运行,但是被踢出集群 —— CRUSH不会再分配归置组给它 |
| DOWN | 这种状态不正常,集群处于非健康状态 | 正常状态 |
在Luminous中,Bluestore已经代替Filestore作为默认的存储引擎。Bluestore直接管理裸设备,不使用OS提供的文件系统接口,因此它不会收到OS缓存影响。
使用Bluestore时,你不需要配备SSD作为独立的日志存储,Bluestore不存在双重写入问题,它直接把数据落盘到块上,然后在RockDB中更新元数据(指定数据块的位置)。
一个基于Bluestore的OSD最多可以利用到三块磁盘,例如下面的最优化性能组合:
- 使用HDD作为数据盘
- 使用SSD作为RockDB元数据盘
- 使用NVRAM作为RockDB WAL
一些概念:
- Acting Set:牵涉到PG副本的OSD集合
- Up Set:指Acting Set中排除掉Down掉的OSD的子集
Ceph依赖于Up Set来处理客户端请求。如果 Up Set 和 Acting Set 不一致,这可能表明集群内部在重均衡或者有潜在问题。
写入数据前,归置组必须处于 active 、而且应该是 clean 状态。假设一存储池的归置组有 3 个副本,为让 Ceph 确定归置组的当前状态,一归置组的主 OSD (即 acting set 内的第一个 OSD )会与第二和第三 OSD 建立连接,并就归置组的当前状态达成一致意见。
由于以下原因,集群状态可能显示为HEALTH WARN:
- 刚刚创建了一个存储池,归置组还没互联好
- 归置组正在恢复
- 刚刚增加或删除了一个 OSD
- 刚刚修改了 CRUSH 图,并且归置组正在迁移
- 某一归置组的副本间的数据不一致
- Ceph 正在洗刷一个归置组的副本
- Ceph 没有足够空余容量来完成回填操作
这些情况下,集群会自行恢复,并返回 HEALTH OK 状态,归置组全部变为active+clean。
| 状态 | 说明 |
| Creating |
在你创建存储池时,Ceph会创建指定数量的PG,对应此状态 创建PG完毕后,Acting Set中的OSD将进行互联,互联完毕后,PG变为Active+Clean状态,PG可以接受数据写入 |
| Peering |
Acting Set中的OSD正在进行互联,它们需要就PG中对象、元数据的状态达成一致。互联完成后,所有OSD达成一致意见,但是不代表所有副本的内容都是最新的 |
| Active | 互联完成后归置组状态会变为Active |
| Clean | 主OSD和副本OSD已成功互联,并且没有偏离的归置组。 Ceph 已把归置组中的对象复制了规定次数 |
| Degraded |
当客户端向主 OSD 写入数据时,由主 OSD 负责把数据副本写入其余副本 OSD 。主 OSD 把对象写入存储器后,在副本 OSD 创建完对象副本并报告给主 OSD 之前,主 OSD 会一直停留在 degraded 状态 如果OSD挂了, Ceph 会把分配到此 OSD 的归置组都标记为 degraded。只要它归置组仍然处于active 状态,客户端仍可以degraded归置组写入新对象 如果OSD挂了(down)长期( mon osd down out interval ,默认300秒)不恢复,Ceph会将其标记为out,并将其上的PG重新映射到其它OSD |
| Recovering | 当挂掉的OSD重启(up)后,其内的PG中的对象副本可能是落后的,副本更新期间OSD处于此状态 |
| Backfilling |
新 OSD 加入集群时, CRUSH 会把现有集群内的部分归置组重分配给它。强制新 OSD 立即接受重分配的归置组会使之过载,用归置组回填可使这个过程在后台开始 回填执行期间,你可能看到以下状态之一:
|
| Remapped | 负责某个PG的Acting Set发生变更时,数据需要从久集合迁移到新集合。此期间老的主OSD仍然需要提供服务,直到数据迁移完成 |
| Stale |
默认情况下,OSD每0.5秒会一次报告其归置组、出流量、引导和失败统计状态,此频率高于心跳 如果:
则MONs就会把此归置组标记为 stale 集群运行期间,出现此状态,所有PG的主OSD挂了 |
| Inactive | 归置组不能处理读写请求,因为它们在等着一个持有最新数据的 OSD 回到 up 状态 |
| Unclean | 归置组里有些对象的副本数未达到期望次数,它们应该在恢复中 |
| Down | 归置组的权威副本OSD宕机,必须等待其开机,或者被标记为lost才能继续 |
CRUSH 算法通过计算数据存储位置来确定如何存储和检索。 CRUSH授权Ceph 客户端直接连接 OSD ,而非通过一个中央服务器或代理。数据存储、检索算法的使用,使 Ceph 避免了单点故障、性能瓶颈、和伸缩的物理限制。
CRUSH 需要一张集群的 Map,利用该Map中的信息,将数据伪随机地、尽量平均地分布到整个集群的 OSD 里。此Map中包含:
- OSD 列表
- 把设备汇聚为物理位置的“桶”(Bucket,也叫失败域,Failure Domain)列表
- 指示 CRUSH 如何复制存储池中的数据的规则列表
通过CRUSH map来建模存储设备的物理位置,Ceph能够避免潜在的关联性故障 —— 例如一个机柜中的设备可能共享电源、网络供应,它们更加可能因为断电而同时出现故障,Ceph会刻意的避免把数据副本放在同一机柜。
新部署的OSD自动被放置到CRUSH map中,位于一个host节点(OSD所在主机名)。在默认的CRUSH失败域(Failure Domain) 设置中,副本/EC分片会自动分配在不同的host节点上,避免单主机的单点故障。在大型集群中,管理员需要更加仔细的考虑失败域设置,将副本分散到不同的Rack、Row。
OSD在CRUSH map中的位置,称为CRUSH location。此Location以如下形式来描述:
|
1 2 3 4 |
# 一系列键值对,虽然是有层次结构的,但是列出的顺序无所谓 # 键必须是有效的CRUSH type。默认支持root,regin, datacenter, room, row, pod, pdu, rack, chassis, host # 你不需要声明所有键,默认情况下Ceph自动把新OSD放在root=default host=hostname下,因此这两个键你可以不声明 root=default row=a rack=a2 chassis=a2a host=a2a1 |
你可以在Ceph配置文件中,用crush location选项来声明。每当OSD启动时,它会验证当前CRUSH map是否匹配crush location设置,如果不匹配会更新CRUSH map。设置下面的选项可以禁用此行为:
|
1 |
osd crush update on start = false |
CRUSH map是一个树状的层次结构,它是对存储设备物理位置松散的建模。
在这个层次结构中,叶子节点是Device,对应了OSD守护程序(通常管理一块或几块磁盘)。设备的以name.id来识别,通常是osd.N。设备可以关联一个设备类别(Device Class),取值例如hdd、ssd,CRUSH rule可以使用到设备类别。
除了叶子节点之外的,都称为桶(Bucket),每个桶都具有类型,默认支持的类型包括root,regin, datacenter, room, row, pod, pdu, rack, chassis, host。大部分集群仅仅使用一部分类型的桶。
每个节点都具有一个权重(Weight)字段,指示子树负责存储的数据的比例。权重应该仅仅在叶子节点上设置,由Ceph自动向上类加。权重的单位通常是TB。
执行命令 ceph osd crush tree可以查看CRUSH的层次,包括节点权重。
CRUSH rule定义了数据如何跨越设备分布的规则。大部分情况下你可以通过命令行来创建CRUSH rule,少数情况下需要手工便捷CRUSH map。
随着Ceph的发展,CRUSH算法被不断的优化。Ceph允许你自由选择新或旧的算法变体,这依赖Tunable实现。
要使用新的Tunable,客户端、服务器必须同时支持。Tunable的命名就是最初支持对应算法变体的那个Ceph版本的名称(例如jewel)。
用户空间的Ceph块设备实现(librbd)不能使用Linux的页面缓存,因此它自己实现了一套基于内存的LRU缓存——RBD Cacheing。
此缓存的行为类似于页面缓存,当OS发送屏障/Flush请求时,内存中的脏数据被刷出到OSD。
这是一个POSIX兼容的文件系统,它使用Ceph的存储集群来保存数据。
一个Ceph集群可以有0-N个CephFS文件系统,每个CephFS具有可读名称和一个集群文件系统ID(FSCID)。每个CephFS可以指定多个处于standby状态的MDS进程。
每个CephFS包含若干Rank,默认是1个。Rank可以看作是元数据分片。CephFS的每个守护进程(ceph-mds)默认情况下无Rank启动,Mon会自动为其分配Rank。每个守护进程最多持有一个Rank。
如果Rank没有关联到ceph-mds,则其状态为failed,否则其状态为up。
每个ceph-mds都有一个关联的名称,典型情况下设置为所在的节点的主机名。每当ceph-mds启动时,会获得一个GID,在进程生命周期中,它都使用此GID。
如果MDS进程超过 mds_beacon_grace seconds没有和MON联系,则它被标记为laggy。
Ceph对象存储网关是基于librados构建的一套RESTful服务,提供对Ceph存储集群的访问。此服务提供两套接口:
- S3兼容接口:Amazon S3的子集
- Swift兼容接口: OpenStack Swift的子集
这两套接口可以混合使用。
对象存储网关由守护程序radosgw负责,它作为客户端和Ceph存储集群之间的媒介。radosgw具有自己的用户管理系统。
从firefly版本开始,对象存储网关在Civetweb上运行,Civetweb内嵌在ceph-radosw这个Daemon中。在老版本中,对象网关基于Apache+FastCGI。
Ceph仪表盘是一个内置的、基于Web的管理/监控工具。通过它你能够管理集群中各种资源。仪表盘作为Ceph Manager的模块实现。
包含一系列集群编排有关的命令。
列出对编排器可见的服务:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
ceph orch ls [<service_type>] [<service_name>] [--export] [plain|json|json-pretty|yaml] [--refresh] ceph orch ls # 守护进程类型 数量 归置规则 使用的镜像 NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID alertmanager 1/1 77s ago 2w count:1 docker.io/prom/alertmanager:v0.20.0 0881eb8f169f crash 2/3 79s ago 2w * docker.io/ceph/ceph:v15 mix grafana 1/1 77s ago 2w count:1 docker.io/ceph/ceph-grafana:6.7.4 80728b29ad3f mds.cephfs 2/3 79s ago 2w ceph-1;ceph-2;ceph-3 docker.io/ceph/ceph:v15 mix mgr 1/1 77s ago 2w ceph-1 docker.io/ceph/ceph:v15 5b724076c58f mon 2/3 79s ago 40m count:3 docker.io/ceph/ceph:v15 mix nfs.ganesha 1/1 78s ago 7d count:1 docker.io/ceph/ceph:v15 5b724076c58f node-exporter 2/3 79s ago 2w * docker.io/prom/node-exporter:v0.18.1 mix osd.all-available-devices 2/3 79s ago 2w * docker.io/ceph/ceph:v15 mix prometheus 1/1 77s ago 2w count:1 docker.io/prom/prometheus:v2.18.1 de242295e225 rgw.china.zircon 2/3 79s ago 2w count:3 docker.io/ceph/ceph:v15 mix |
列出对编排器可见的守护进程,守护进程是服务的实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
orch ps [<hostname>] [<service_name>] [<daemon_type>] [<daemon_id>] [plain|json|json-pretty|yaml] [--refresh] ceph orch ps NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID alertmanager.ceph-1 ceph-1 running (69m) 3m ago 2w 0.20.0 docker.io/prom/alertmanager:v0.20.0 0881eb8f169f bef9ab4dcc98 crash.ceph-1 ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 3bb0c129d4d4 crash.ceph-2 ceph-2 error 3m ago 2w <unknown> docker.io/ceph/ceph:v15 <unknown> <unknown> crash.ceph-3 ceph-3 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f f5c22d2c854b grafana.ceph-1 ceph-1 running (69m) 3m ago 2w 6.7.4 docker.io/ceph/ceph-grafana:6.7.4 80728b29ad3f 17d84abdd9e6 mds.cephfs.ceph-1.nivqqf ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 4be1504a4c6f mds.cephfs.ceph-2.djnipz ceph-2 error 3m ago 2w <unknown> docker.io/ceph/ceph:v15 <unknown> <unknown> mds.cephfs.ceph-3.cgngbk ceph-3 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 7e514989bc6c mgr.ceph-1.adpioc ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f a66dd815c2b1 mon.ceph-1 ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 0c87ed6da097 mon.ceph-2 ceph-2 error 3m ago 2w <unknown> docker.io/ceph/ceph:v15 <unknown> <unknown> mon.ceph-3 ceph-3 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 836ec2a7c34d nfs.ganesha.ceph-3 ceph-3 running (68m) 3m ago 7d 3.3 docker.io/ceph/ceph:v15 5b724076c58f 440a1bcef7c5 node-exporter.ceph-1 ceph-1 running (69m) 3m ago 2w 0.18.1 docker.io/prom/node-exporter:v0.18.1 e5a616e4b9cf 26bf34b93188 node-exporter.ceph-2 ceph-2 error 3m ago 2w <unknown> docker.io/prom/node-exporter:v0.18.1 <unknown> <unknown> node-exporter.ceph-3 ceph-3 running (69m) 3m ago 2w 0.18.1 docker.io/prom/node-exporter:v0.18.1 e5a616e4b9cf fb60a5b31bfd osd.0 ceph-2 error 3m ago 2w <unknown> docker.io/ceph/ceph:v15 <unknown> <unknown> osd.1 ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 49cad5daf8f8 osd.2 ceph-3 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 17ef075e16a4 prometheus.ceph-1 ceph-1 running (69m) 3m ago 2w 2.18.1 docker.io/prom/prometheus:v2.18.1 de242295e225 7b61f27c6a0e rgw.china.zircon.ceph-1.dsctvb ceph-1 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f b7d6166aae36 rgw.china.zircon.ceph-2.ulzfto ceph-2 error 3m ago 2w <unknown> docker.io/ceph/ceph:v15 <unknown> <unknown> rgw.china.zircon.ceph-3.qjhszd ceph-3 running (69m) 3m ago 2w 15.2.10 docker.io/ceph/ceph:v15 5b724076c58f 5d1d6d6e6899 |
设置某种组件(服务/守护进程)的数量或者归置规则,格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 更新守护程序副本数量、归置规则,或者apply一段YAML格式的配置 orch apply [mon|mgr|rbd-mirror|crash|alertmanager|grafana|node-exporter|prometheus] [<placement>] [--dry-run] [plain|json|json-pretty|yaml] [--unmanaged] # 扩缩容iSCSI服务 orch apply iscsi <pool> <api_user> <api_password> [<trusted_ip_list>] [<placement>] [--dry-run] [plain|json|json-pretty|yaml] [--unmanaged] # 更新指定fs_name的MDS实例数 orch apply mds <fs_name> [<placement>] [--dry-run] [--unmanaged] [plain|json|json-pretty|yaml] # 扩缩容NFS服务 orch apply nfs <svc_id> <pool> [<namespace>] [<placement>] [--dry-run] [plain|json|json-pretty| yaml] [--unmanaged] # 创建OSD守护进程 orch apply osd [--all-available-devices] [--dry-run] [--unmanaged] [plain|json|json-pretty|yaml] # 为指定的Zone更新RGW实例的数量 orch apply rgw <realm_name> <zone_name> [<subcluster>] [<port:int>] [--ssl] [<placement>] [--dry-run] [plain|json|json-pretty|yaml] [--unmanaged] |
下面是一些简单的例子:
|
1 2 3 4 5 6 7 |
# 指定副本数 ceph orch apply mon 3 # 制定归置规则 ceph orch apply mon ceph-1 ceph-2 ceph-3 # 为所有空闲设备创建OSD ceph orch apply osd --all-available-devices |
管理守护进程。
add子命令,添加一个守护进程:
|
1 2 3 4 5 6 7 8 |
# 添加守护进程 ceph orch daemon add [mon|mgr|rbd-mirror|crash|alertmanager|grafana|node-exporter|prometheus [<placement>] ceph orch daemon add iscsi <pool> <api_user> <api_password> [<trusted_ip_list>] [<placement>] ceph orch daemon add mds <fs_name> [<placement>] ceph orch daemon add nfs <svc_id> <pool> [<namespace>] [<placement>] ceph orch daemon add osd [<svc_arg>] ceph orch daemon add rgw <realm_name> <zone_name> [<subcluster>] [<port:int>] [--ssl] [<placement>] |
redeploy子命令,重新部署某个守护进程,可以指定使用的镜像:
|
1 |
ceph orch daemon redeploy <name> [<image>] |
如果节点上的守护进程容器被意外删除,也就是 podman ps看不到对应容器,可以使用redeploy命令重新部署。
rm子命令,删除某个守护进程:
|
1 |
ceph orch daemon rm <names>... [--force] |
你也可以启动、停止、重启、重新配置某个守护进程:
|
1 |
ceph orch daemon start|stop|restart|reconfig <name> |
如果需要启动、停止、重启、重新配置某种服务的所有守护进程:
|
1 |
ceph orch start|stop|restart|redeploy|reconfig <service_name> |
管理块设备。
显示某些主机上的块设备:
|
1 |
ceph orch device ls [<hostname>...] [plain|json|json-pretty|yaml] [--refresh] [--wide] |
清除块设备上的内容:
|
1 |
ceph orch device zap <hostname> <path> [--force] |
管理主机。
添加主机,可选的,添加标签:
|
1 |
ceph orch host add <hostname> [<addr>] [<labels>...] |
为主机添加/移除标签:
|
1 2 |
ceph orch host label add <hostname> <label> ceph orch host label rm <hostname> <label> |
列出主机:
|
1 |
ceph orch host ls [plain|json|json-pretty|yaml] |
检查是否可以在不损害可用性的前提下,停止主机:
|
1 |
ceph orch host ok-to-stop <hostname> |
删除主机:
|
1 |
ceph orch host rm <hostname> |
修改主机地址:
|
1 |
ceph orch host set-addr <hostname> <addr> |
删除OSD实例:
|
1 |
ceph orch osd rm <svc_id>... [--replace] [--force] |
检查删除OSD操作的进度:
|
1 |
ceph orch osd rm status [plain|json|json-pretty|yaml] |
暂停编排器的后台任务
恢复暂停的编排器后台任务
选择编排器后端: ceph orch set backend <module_name>
显示使用的编排器后端,以及它的状态:
|
1 2 3 4 5 |
ceph orch status [plain|json|json-pretty|yaml] ceph orch status Backend: cephadm Available: True |
cephadm就是一个编排器后端,下文会有介绍。
升级相关操作:
|
1 2 3 4 5 6 |
orch upgrade check [<image>] [<ceph_version>] # 检查镜像可用版本 orch upgrade pause # 暂停升级 orch upgrade resume # 恢复暂停的省级 orch upgrade start [<image>] [<ceph_version>] # 触发升级 orch upgrade status # 升级状态 orch upgrade stop # 停止进行中的升级 |
查看日志:
|
1 2 3 4 |
ceph log last [<num:int>] [debug|info|sec|warn|error] [*|cluster|audit|cephadm] # 查看cephadm的最新日志 ceph log last cephadm |
Cephadm是最新的Ceph部署工具,他利用容器和Systemd,仅仅支持Octopus或者更新的版本。
Cephadm的外部依赖包括容器运行时(Docker或者Podman),以及Python3。
|
1 2 3 |
cd /tmp curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm chmod +x cephadm |
安装支持cephadm命令及其依赖:
|
1 2 |
./cephadm add-repo --release octopus ./cephadm install |
|
1 2 |
cephadm bootstrap --mon-ip 10.0.2.1 cephadm shell -- ceph -s |
上述命令会安装一个单MON节点的Ceph集群。改命令会:
- 创建MON和MGR守护进程到本机
- 为Ceph集群生成SSH密钥,并添加到roo用户的/root/.ssh/authorized_keys
- 生成最小化配置的 /etc/ceph/ceph.conf,用于和新集群通信
- 生成Ceph管理密钥 /etc/ceph/ceph.client.admin.keyring
- 复制公钥副本到/etc/ceph/ceph.pub
|
1 |
cephadm install ceph-common |
这样你就可以直接使用ceph命令了:
|
1 |
ceph status |
你需要提前为节点安装好Python3
列出现有节点:
|
1 |
ceph orch host ls |
orch子命令用于Ceph集群相关的编排。
将集群的公钥安装到新节点的authorized_keys:
|
1 2 |
ssh-copy-id -f -i /etc/ceph/ceph.pub root@10.0.2.2 ssh-copy-id -f -i /etc/ceph/ceph.pub root@10.0.2.3 |
添加节点,注意要提供主机名:
|
1 2 |
ceph orch host add ceph-2 ceph orch host add ceph-3 |
|
1 |
ceph orch host set-addr ceph-1 ceph-1.gmem.cc |
|
1 2 3 4 5 6 7 8 |
# 设置哪些子网中的主机可以作为MON ceph config set mon public_network 10.0.2.0/24 # 确保三个MON ceph orch apply mon 3 # 你也可以强制指定在哪些主机上部署MON ceph orch apply mon ceph-1 ceph-2 ceph-3 |
使用下面的命令,可以将集群主机所有空闲设备作为OSD:
|
1 |
ceph orch apply osd --all-available-devices |
将特定主机的特定磁盘作为OSD:
|
1 |
ceph orch daemon add osd ceph-1:/dev/vdb |
|
1 |
ceph fs volume create cephfs --placement="ceph-1 ceph-2 ceph-3" |
|
1 |
ceph orch apply rgw china beijing '--placement=3' --port=80 |
NFS Ganesha是一个用户模式的NFS,支持v3 4.0 4.1 4.2,可以同时运行这些协议。
使用下面的命令来部署NFS Ganesha网关。
|
1 2 3 4 |
# 为NFS创建存储池 ceph osd pool create nfs-ganesha 64 replicated # 服务ID 存储池 命名空间 ceph orch apply nfs ganesha nfs-ganesha china |
ceph-deploy是一个ceph部署工具,服务器只需要提供SSH、sudo、一些Python包即可完成ceph的安装部署。
准备好服务器集群后,选取一台作为管理主机,在其上执行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add - # debian-luminous echo deb https://download.ceph.com/debian-jewel/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list sudo apt-get update sudo apt-get install ceph-deploy # 也可以通过pip安装 apt install python-pip pip install ceph-deploy # BUG太多,直接Git最新源码安装吧 git clone https://github.com/ceph/ceph-deploy.git cd ceph-deploy chmod +x setup.py python setup.py install |
为了防止时钟不同步导致问题,建议安装NTP客户端,并保持和NTP服务器的同步。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 在所有节点上执行 ansible k8s -m raw -a 'useradd -d /home/ceph-ops -m ceph-ops' ansible k8s -m raw -a 'echo "ceph-ops ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph-ops' ansible k8s -m raw -a 'chmod 0440 /etc/sudoers.d/ceph-ops' ansible k8s -m raw -a 'echo "ceph-ops:password" | chpasswd' # 在管理节点上执行 # 生成密钥对,默认生成~/.ssh下的id_rsa和id_rsa.pub ssh-keygen # 将公钥拷贝到被管理机,便于免密码登陆 ansible k8s -m raw -a "mkdir /home/ceph-ops/.ssh" ansible k8s -m raw -a "scp -oStrictHostKeyChecking=no root@master-node:/root/.ssh/id_rsa.pub /home/ceph-ops/.ssh/authorized_keys" ansible k8s -m raw -a "chown -R ceph-ops:ceph-ops /home/ceph-ops/.ssh" |
在集群中的管理主机上,执行:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ceph-deploy install {hostname [hostname] ...} --release {code-name} # 示例: ceph-deploy --username ceph-ops install Carbon Radon Neon Boron Xenon --release jewel ceph-deploy --username ceph-ops install Carbon Radon Neon Boron Xenon --release luminous # 如果网络速度太慢,ceph-deploy会提前退出。这种情况下手工、通过代理安装为好 export http_proxy=http://10.0.0.1:8087 export https_proxy=http://10.0.0.1:8087 # 实际上就是安装这些软件 apt install ceph ceph-osd ceph-mds ceph-mon radosgw |
|
1 2 3 4 5 6 7 8 9 |
# 卸载软件 ceph-deploy uninstall {hostname [hostname] ...} # 示例: ceph-deploy --username ceph-ops uninstall Carbon Radon Neon # 下面的命令可以在Ubuntu上执行,清除配置文件 ceph-deploy purge {hostname [hostname] ...} # 示例: ceph-deploy --username ceph-ops purge Carbon Radon Neon |
|
1 2 3 4 |
# 在管理节点上执行: # 创建一个目录,存放ceph-deploy生成的配置文件 mkdir /tmp/ceph cd /tmp/ceph |
|
1 2 3 4 5 |
# 创建一个新集群,host为mon节点 ceph-deploy --cluster {cluster-name} new {host [host], ...} # 示例 ceph-deploy --username ceph-ops new Xenon |
|
1 2 3 4 5 6 7 |
# 修改好当前目录的ceph.conf,执行下面的命令,分发到所有节点的/etc/ceph目录 # ceph.conf至少要提供网络配置 # public network = 10.0.0.0/16 # cluster network = 10.0.0.0/16 # 示例 ceph-deploy --username ceph-ops --overwrite-conf config push Carbon Radon Neon Boron Xenon |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
[client] rbd_cache = true rbd_cache_max_dirty = 25165824 rbd_cache_max_dirty_age = 5 rbd_cache_size = 268435456 [global] fsid = 9b92d057-a4bc-473e-b6ab-462092fcf205 max_open_files = 131072 mon_initial_members = Carbon, Radon, Neon mon_host = 10.0.0.100,10.0.1.1,10.0.2.1 osd pool default min size = 1 osd pool default pg num = 384 osd pool default pgp num = 384 osd pool default size = 2 mon_max_pg_per_osd = 256 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx [mon] mon_allow_pool_delete = true [osd] public network = 10.0.0.0/16 cluster network = 10.0.0.0/16 filestore max sync interval = 15 filestore min sync interval = 10 filestore op thread = 32 journal max write bytes = 1073714824 journal max write entries = 10000 journal queue max bytes = 10485760000 journal queue max ops = 50000 ms_bind_port_max = 7100 osd_client_message_size_cap = 2147483648 osd_crush_update_on_start = true osd_deep_scrub_stride = 131072 osd_disk_threads = 4 osd_journal_size = 10240 osd_map_cache_bl_size = 128 osd_max_backfills = 4 osd_max_object_name_len = 256 osd_max_object_namespace_len = 64 osd_max_write_size = 512 osd_op_threads = 8 osd_recovery_op_priority = 4 |
执行下面的命令,部署初始mon节点,并收集key:
|
1 2 3 4 5 6 7 8 9 10 11 |
ceph-deploy --username ceph-ops mon create-initial # 将在当前目录生成以下文件: # ceph.client.admin.keyring # ceph.bootstrap-mgr.keyring # ceph.bootstrap-osd.keyring # ceph.bootstrap-mds.keyring # ceph.bootstrap-rgw.keyring # ceph.bootstrap-rbd.keyring # 目标主机的/etc/ceph/ceph.conf被创建,如果此文件已经存在,你必须用--overwrite-conf选项重新运行上述命令 |
|
1 2 3 4 5 6 7 8 |
# 增加 ceph-deploy mon create {host-name [host-name]...} # 删除 ceph-deploy mon destroy {host-name [host-name]...} # 示例: ceph-deploy --username ceph-ops mon create Radon ceph-deploy --username ceph-ops mon create Carbon |
以ceph-deploy作为工具,将一台主机作为OSD或MDS时,需要收集MON、OSD、MDS的初始keyring:
|
1 2 3 4 |
ceph-deploy gatherkeys {monitor-host} # 示例: ceph-deploy --username ceph-ops gatherkeys Carbon Radon Neon Boron Xenon |
不再使用ceph-deploy或者另外建立一个新集群时,需要删除管理主机、本地目录的密钥:
|
1 |
ceph-deploy forgetkeys |
|
1 2 3 |
ceph-deploy disk list {node-name [node-name]...} # 示例: ceph-deploy --username ceph-ops disk list Carbon Radon Neon Boron Xenon |
下面的命令可以擦净(删除分区表)磁盘,以供Ceph使用 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ceph-deploy disk zap {osd-server-name} {disk-name} # 示例(luminous): ceph-deploy --username ceph-ops disk zap xenial-100 /dev/vdb ceph-deploy --username ceph-ops disk zap xenial-100 /dev/vdc ceph-deploy --username ceph-ops disk zap Carbon /dev/sdb ceph-deploy --username ceph-ops disk zap Radon /dev/sdb ceph-deploy --username ceph-ops disk zap Neon /dev/sdb # 示例(jewel): ceph-deploy --username ceph-ops disk zap xenial-100:vdb ceph-deploy --username ceph-ops disk zap xenial-100:vdc ceph-deploy --username ceph-ops disk zap Carbon:sdb ceph-deploy --username ceph-ops disk zap Radon:sdb ceph-deploy --username ceph-ops disk zap Neon:sdb |
警告:所有数据会被删除。
此命令在ceph-deploy 2.0.0中已经废除
使用prepare命令来准备磁盘,会自动创建分区。在大部分OS中,activate会随后自动执行
|
1 2 3 4 5 6 |
ceph-deploy osd prepare {node-name}:{data-disk}[:{journal-disk}] # 示例: ceph-deploy --username ceph-ops osd prepare --fs-type xfs xenial-100:vdb ceph-deploy --username ceph-ops osd prepare --fs-type xfs xenial-100:vdc ceph-deploy --username ceph-ops osd prepare --fs-type xfs Carbon:sdb ceph-deploy --username ceph-ops osd prepare --fs-type xfs Radon:sdb |
建议:将日志存储在独立磁盘中以最优化性能,如果将日志和数据存储在一起,会有损性能。
此命令在ceph-deploy 2.0.0中已经废除
很多操作系统上,不需要手工激活OSD。
|
1 2 3 4 5 6 |
ceph-deploy osd activate {node-name}:{data-disk-partition}[:{journal-disk-partition}] # 示例 ceph-deploy --username ceph-ops osd activate xenial-100:vdb ceph-deploy --username ceph-ops osd activate xenial-100:vdc ceph-deploy --username ceph-ops osd activate Carbon:sdb ceph-deploy --username ceph-ops osd activate Radon:sdb |
激活之后,系统运行ceph-osd进程,OSD进入up+in状态。
即prepare + activate:
|
1 2 3 4 5 6 7 8 9 10 11 |
ceph-deploy osd create {node-name}:{disk}[:{path/to/journal}] # 示例 ceph-deploy osd create osdserver1:sdb:/dev/ssd1 # 示例(luminous): ceph-deploy --username ceph-ops osd create --data /dev/vdb --bluestore xenial-100 ceph-deploy --username ceph-ops osd create --data /dev/vdc --bluestore xenial-100 ceph-deploy --username ceph-ops osd create --data /dev/sdb --bluestore Carbon ceph-deploy --username ceph-ops osd create --data /dev/sdb --bluestore Radon # 指定分区也可以 ceph-deploy --username ceph-ops osd create --data /dev/sda3 --bluestore Carbon |
|
1 |
ceph-deploy --username ceph-ops mds create Carbon |
仅仅luminous支持,否则报错Error EACCES: access denied could not create mgr
|
1 |
ceph-deploy --username ceph-ops mgr create Carbon |
|
1 |
ceph-deploy --username ceph-ops rgw create Radon |
默认情况下RGW监听7480端口,你可以验证RGW是否正常工作:
|
1 |
curl http://Carbon:7480 |
如果只想清除 /var/lib/ceph 下的数据、并保留 Ceph 安装包,可以:
|
1 2 3 |
ceph-deploy purgedata {hostname} [{hostname} ...] # 示例: ceph-deploy --username ceph-ops purgedata Carbon Radon |
如果向同时清除数据、Ceph安装包:
|
1 |
ceph-deploy purge {hostname} [{hostname} ...] |
要允许某些主机以管理员权限执行 Ceph 命令,可以:
|
1 2 3 4 |
ceph-deploy admin {host-name [host-name]...} # 示例: ceph-deploy --username ceph-ops admin Carbon Radon Neon Boron Xenon |
上述命令执行后,当前目录中的ceph.client.admin.keyring被分发到所有指定的主机,在这些主机上可以执行ceph -s命令了。
要将修改过的、当前目录下的配置文件分发给集群内其它主机,可以:
|
1 |
ceph-deploy config push {host-name [host-name]...} |
要获取某台主机的配置文件,可以:
|
1 |
ceph-deploy config pull {host-name [host-name]...} |
启动Ceph服务时,初始化进程会启动一系列守护进程,这些进程至少包含两类:
- ceph-mon 监控进程
- ceph-osd Ceph OSD的守护进程
要使用Ceph文件系统功能,则需要额外运行:
- ceph-mds Ceph元数据服务
要使用Ceph对象存储功能,则需要额外运行:
- ceph-rgw RADOS网关守护进程
要列出当前使用的所有配置值,可以访问守护进程的管理套接字。
在节点上执行下面的命令,获得管理套接字的位置:
|
1 2 |
ceph-conf --name mon.$(hostname -s) --show-config-value admin_socket # /var/run/ceph/ceph-mon.a.asok |
调用下面的命令列出所有配置:
|
1 |
ceph daemon /var/run/ceph/ceph-mon.a.asok config show |
对于osd或者其它守护进程,也可以使用上述方式获取运行时配置。
所有守护进程从同一个配置文件ceph.conf中检索自己感兴趣的信息。该配置文件中包含了集群身份、认证配置、集群成员、主机名、主机 IP 地址、Keyring路径、日志路径、数据路径,以及其它运行时选项。
按照以下顺序来搜索,后面的可以覆盖前面的:
- 编译进二进制文件的默认值
- ceph-mon的集群中心配置数据库
- 本机上的配置文件:
- /etc/ceph/ceph.conf
- ~/.ceph/config
- ./ceph.conf
- 环境变量:$CEPH_CONF
- 命令行参数:-c path/path
- 管理员在运行时设置的选项
一个Ceph进程启动时,它会先从命令行、环境变量、本地配置文件收集配置项,然后连接ceph-mon读取集群中心配置信息,然后启动。
配置项的名称唯一,标准格式是小写字母 + 下划线
在命令行中指定配置项时,下划线_可以替换为短横线
在配置文件中指定配置项时,下划线可以替换为空格或短横线
| 配置项 | 说明 |
| 公共选项 [global] | |
| host | 用于指定节点的主机名 |
| mon host | 指定mon节点的地址,逗号分隔 |
| auth cluster required | 集群身份验证设置,默认值cephx。如果启用,集群守护进程之间必须相互验证身份 |
| auth service required | 服务身份验证设置,默认值cephx。如果启用,服务端需要验证客户端身份 |
| auth client required | 客户端身份验证设置,默认值cephx。如果启用,客户端需要验证服务端身份 |
| keyring |
钥匙串的位置 默认值:/etc/ceph/$cluster.$name.keyring,/etc/ceph/$cluster.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin |
| public network | 公共网络配置,CIDR格式,多个则用逗号分隔 |
| cluster network |
集群网络配置,CIDR格式,多个则用逗号分隔 如果配置了集群网, OSD 将把心跳、对象复制和恢复流量路由到集群网 |
| fsid | 存储集群的唯一标识,便于允许在同一套硬件上部署多个集群 |
| max open files |
设置操作系统级的 max open fds 建议值:131072 |
| fatal signal handlers | 如果设置为true,则安装 SEGV 、 ABRT 、 BUS 、 ILL 、 FPE 、 XCPU 、 XFSZ 、 SYS 信号处理器,用于产生有用的日志信息 |
| chdir | 进程一旦启动、运行就进入这个目录。默认 / |
| mon选项 [mon] | |
| mon addr |
监听地址:端口,可以针对每个mon.$id段分别配置,或者在mon段下配置: 10.0.0.10:6789,10.0.0.11:6789,10.0.0.12:6789 |
| mon data | mon存储数据的路径,默认/var/lib/ceph/mon/$cluster-$id |
| mon initial members |
集群初始化监视器ID,逗号分隔。这些MON必须在线以建立quorum,正确设置此参数可能让集群更快的可用 |
|
mon osd full ratio |
磁盘利用率总计多少认为满了,默认 .95 当Ceph集群利用率达到此比率时,作为防止数据丢失的安全措施,它会阻止你读写 OSD 注意:
|
| mon osd nearfull ratio | 磁盘利用率总计多少认为快满了,默认.85 |
| mon sync timeout | mon从其provider获取下一个更新消息的超时 |
| mon tick interval | 监视器的心跳间隔,单位为秒。默认5 |
| mon clock drift allowed | 监视器间允许的时钟漂移量。默认.050 |
| mon timecheck interval | 和 leader 的时间偏移检查间隔。默认300秒 |
| mon osd min down reports | OSD连续多少次向mon报告某个OSD宕掉,mon才采纳,默认3 |
| mon osd min down reporters | 类似上面,mon要求多少个OSD都报告某个OSD宕掉,才采纳,默认1 |
| mon osd min up ratio | 把 OSD 标记为 down 前,保持处于 up 状态的 OSD 最小比例。默认.3 |
| mon osd min in ratio | 把 OSD 标记为 out 前,保持处于 in 状态的 OSD 最小比例。默认.3 |
| mon osd auto mark in | 是否把任何启动中的 OSD 标记为在集群中。默认false |
| mon osd auto mark auto out in | 是否把正在启动、且被自动标记为 out 状态的 OSD 标记为 in 。默认true |
| mon osd auto mark new in | 是否把正在启动的新 OSD 标记为 in 。默认true |
| mon osd down out interval | 在 OSD 停止响应多少秒后把它标记为 down 且 out。默认300 |
| mon osd downout subtree limit | 最大可以把什么级别的CRUSH单元标记为out,默认rack |
| osd选项 [osd] | |
| osd data | osd存储数据的路径,默认/var/lib/ceph/osd/$cluster-$id |
| osd map cache size | OSD map缓存大小,默认500M,建议1024 |
| osd map cache bl size | OSD进程的In-Memory OSD map缓存大小,默认50,建议128 |
| osd heartbeat interval | 和其它OSD进行心跳检查的间隔,默认6秒 |
| osd heartbeat grace | 多久没有心跳,认为其它OSD宕掉 |
| osd max write size | OSD一次写入的最大尺寸,默认90MB,建议512 |
| osd mkfs options {fs-type} | 为OSD新建文件系统时的选项 |
| osd mount options {fs-type} | 为OSD挂载文件系统时的选项 |
| osd journal |
OSD 日志路径,可以指向文件或块设备(例如SSD分区) 默认 /var/lib/ceph/osd/$cluster-$id/journal |
| osd journal size |
日志文件的尺寸(MB),如果为0,且日志路径为块设备,则自动使用整个设备 推荐最少2G,有的用户则以 10GB 日志尺寸起步。合理的值是: osd journal size = {2 * (期望吞吐量* filestore max sync interval)} 期望吞吐量应考虑两个参数:硬盘吞吐量(即持续数据传输速率)、网络吞吐量,例如一个 7200 转硬盘的速度大致是 100MB/s 。硬盘和网络吞吐量中较小的一个是相对合理的吞吐量 |
| osd client message size cap | 客户端允许在内存中的最大数据量。默认524288000,建议2147483648 |
| crush location | 此OSD的CRUSH location设置 |
| crush location hook | 用于生成crush location的钩子 |
| osd max scrubs |
OSD 的最大并发洗刷操作数 除了为对象复制多个副本外, Ceph 还要洗刷归置组以确保数据完整性。这种洗刷类似对象存储层的 fsck ,对于每个归置组, Ceph 生成一个所有对象的目录,并比对每个主对象及其副本以确保没有对象丢失或错配。轻微洗刷(每天)检查对象尺寸和属性,深层洗刷(每周)会读出数据并用校验和方法确认数据完整性 |
| osd scrub begin hour | 被调度的洗刷操作,允许的运行区间起点,默认0 |
| osd scrub end hour | 被调度的洗刷操作,允许的运行区间终点,默认24 |
| osd scrub load threshold | 系统负载高于该值,不进行洗刷操作,默认0.5 |
| osd scrub min interval | 系统负载不高的前提下,多久进行一次洗刷,默认每天一次,60*60*24秒 |
| osd scrub max interval | 不论系统负载如何,最大多久进行一次洗刷,默认每周 |
| osd deep scrub interval | 深度洗刷的间隔,默认每周 |
| osd deep scrub stride | 深度洗刷允许读取的字节数。默认524288,建议131072 |
| osd op threads |
OSD 操作线程数, 0 禁用多线程。增大数量可以增加请求处理速度,默认2,建议8 增加此线程数会增大CPU开销 |
| osd disk threads |
硬盘线程数,用于在后台执行磁盘密集型操作,像数据洗刷和快照修复。默认1,建议4 增加此线程数会增大CPU开销 |
| osd max backfills |
当集群新增或移除 OSD 时,按照 CRUSH 算法应该重新均衡集群,它会把一些归置组移出或移入多个 OSD 以回到均衡状态。归置组和对象的迁移会导致集群运营性能显著降低,为维持运营性能, Ceph 用 backfilling 来执行此迁移,它可以使得 Ceph 的回填操作优先级低于用户读写请求 单个 OSD 允许的最大回填操作数。默认10,建议4 |
| osd backfill full ratio | OSD 的占满率达到多少时拒绝接受回填请求,默认85% |
| osd recovery op priority | 恢复操作优先级,取值1-63,值越高占用资源越高。默认10,建议4 |
| osd recovery delay start |
当集群启动、或某 OSD 守护进程崩溃后重启时,此 OSD 开始与其它 OSD 们建立互联(Peering),这样才能正常工作 如果某 OSD 崩溃并重启,通常会落后于其他 OSD ,也就是没有同归置组内最新版本的对象。这时, OSD 守护进程进入恢复模式并检索最新数据副本,并更新运行图。根据 OSD 宕掉的时间长短, OSD 的对象和归置组可能落后得厉害,另外,如果挂的是一个失效域(如一个机柜),多个 OSD 会同时重启,这样恢复时间更长、更耗资源 为保持性能, Ceph 进行恢复时会限制恢复请求数、线程数、对象块尺寸,这样在降级状态下也能保持良好的性能 对等关系建立完毕后, Ceph 开始对象恢复前等待的时间。默认0秒 |
| osd recovery max active | 每个OSD同时处理的活跃恢复请求最大数,增大此值能加速恢复,但它们会增加OSD的负担,甚至导致其无法提供服务 |
| osd recovery max chunk | 恢复时一次推送的数据块的最大尺寸,可以用于防止网络拥塞 |
| osd recovery threads | 数据恢复时的线程数,默认1 |
| osd mount options xfs | OSD的xfs挂载选项,默认rw,noatime,inode64,建议rw,noexec,nodev,noatime,nodiratime,nobarrier |
| rbd客户端调优 [client] | |
| rbd cache |
是否启用RBD缓存,默认true 用于用户空间块设备实现——librbd |
| rbd cache size | RBD缓存大小,默认33554432,建议268435456 |
| rbd cache max dirty | 缓存为write-back时允许的最大dirty字节数,如果为0,使用write-through。默认25165824,建议25165824 |
| rbd cache max dirty age | 在被刷新到存储盘前dirty数据存在缓存的时间,默认1秒,建议5 |
| filestore选项 [osd] | |
| filestore max inline xattr size | 每个对象在文件系统中存储XATTR(扩展属性)的最大尺寸,不得超过文件系统限制。默认值根据底层文件系统自动设置 |
| filestore max inline xattrs | 每个对象在文件系统中存储XATTR(扩展属性)的最大数量 |
| filestore max sync interval |
filestore 需要周期性地静默(暂停)写入、同步文件系统 —— 创建了一个提交点,然后就能释放相应的日志条目了。 较高的同步频率可减小执行同步的时间及保存在日志里的数据量,但是日志利用率较低 较低的频率使得后端的文件系统能优化归并较小的数据和元数据写入,因此可能使同步更有效 默认5秒。建议15 |
| filestore min sync interval | 从日志到数据盘最小同步间隔。默认.01秒,建议10 |
| filestore op threads | 并发文件系统操作数。默认2,建议32 |
| filestore flusher |
是否启用回写器(Flusher)。回写器强制使用sync file range 来写出大块数据,这样处理可能减小最终同步的代价,禁用回写器有时可能提高性能 默认false |
| filestore flusher max fds | 回写器的最大文件描述符数量。默认512 |
| filestore fsync flushes journal data | 在fsync时是否也回写日志数据 |
| filestore queue max ops |
文件存储在阻止新操作加入队列之前,可以接受的最大操作数。取值示例25000 |
| filestore queue max bytes | 文件存储单个操作的最大字节数。取值示例10485760 |
| filestore queue committing max ops | 文件存储单次可以提交的最大操作数 |
| filestore queue committing max bytes | 文件存储单次可以提交的最大字节数 |
| filestore journal parallel | 允许并行记日志,对 btrfs 默认开 |
| filestore journal writeahead | 允许预写日志,对 xfs 默认开 |
| journal选项 [osd] | |
| journal dio | 启用日志的Direct I/O,要求journal block align=true。默认true |
| journal aio | 使用libaio库进行日志的异步写,要求journal dio =true。0.61+默认true |
| journal block align | 日志按块对齐。默认true |
| journal max write bytes | 日志写操作单次最大字节数。建议1073714824 |
| journal max write entries | 日志写操作单次最大条目数。建议10000 |
| journal queue max ops | 排队等候日志写的操作最大数。建议50000 |
| journal queue max bytes | 排队等候日志写的最大字节数。建议10485760000 |
| journal align min size | 对于大于此尺寸的数据,进行对齐操作 |
| journal zero on create | 在创建文件系统( mkfs )期间用 0 填充整个日志 |
| pool/pg/crush相关 [global] | |
| osd pool default size | 对象默认副本份数 |
| osd pool default min size | 降级情况下,默认允许写操作的最小可用副本份数 |
| osd pool default pg num | 归置组的默认数量 |
| osd pool default pgp num | 为归置使用的归置组数量,默认值等同于 mkpool 的 pgp_num 参数。当前 PG 和 PGP 应该相同 |
| mon max pool pg num | 每个存储的最大归置组数量。默认65536 |
| mon pg create interval | 在同一个 OSD 里创建 PG 的间隔秒数。默认30 |
| mon pg stuck threshold | 多长时间无响应,则认为PG卡住了 |
| mon pg min inactive | 如果大于此数量的PG处于inactive状态超过mon_pg_stuck_threshold,则显示集群为HEALTH_ERR。默认1 |
| mon pg warn min per osd | 如果每OSD平均可用PG低于此数量,则显示集群为HEALTH_WARN。默认30 |
| mon pg warn max per osd | 如果每OSD平均可用PG高于此数量,则显示集群为HEALTH_WARN。默认300 |
| osd crush chooseleaf type | 在CRUSH 规则内用于 chooseleaf 的桶类型。用序列号而不是名字,默认1 |
| osd crush initial weight |
新加入到CRUSH map中的OSD的权重 默认情况下,权重是OSD的磁盘容量,单位TB |
| osd pool default crush rule |
创建复制型池时,使用的默认CRUSH规则。默认-1,表示使用ID最低的规则 |
| osd pool erasure code stripe unit | EC池中的对象条带尺寸 |
| osd pool default flags | 新存储池的默认标志 |
| ms选项 | |
| ms tcp nodelay | 禁用 nagle 算法,默认true |
| ms initial backoff | 出错时重连的初始等待时间 |
|
ms max backoff |
出错重连时等待的最大时间 |
| ms nocrc | 禁用网络消息的 crc 校验, CPU 不足时可提升性能 |
| mds选项 | |
| mds cache memory limit | MDS缓存最大使用多少内存 |
| 变量 | 说明 |
| $cluster | 展开为存储集群的名称,在相同硬件上运行多个集群时有用 |
| $type | 展开为守护进程类型,例如mds, osd, or mon |
| $id | 展开为守护进程或者客户端的标识符,对于osd.0其标识符为0 |
| $host | 展开为主机名 |
| $name | 展开为$type.$id |
| $pid | 展开为守护进程的PID |
配置文件是INI格式的,可以分为以下段落:
| 段落 | 用途 |
| global | 这里的配置影响 Ceph 集群里的所有守护进程 |
| osd | 影响存储集群里的所有 ceph-osd 进程,覆盖global相同选项 |
| mon | 影响集群里的所有 ceph-mon 进程,覆盖global相同选项 |
| mds | 影响集群里的所有 ceph-mds 进程,覆盖global相同选项 |
| client | 影响所有客户端(如挂载的 Ceph 文件系统、挂载的块设备等等) |
你还可以针对特定的实例配置段落:
- [osd.1],针对ID为1的OSD的配置
- [mon.HOSTNAME],针对名称为HOSTNAME的MON的配置
进程连接ceph-mon、进行身份验证、抓取集群中心配置信息时需要一些配置,这些配置必须存放在本地:
| 选项 | 说明 |
| mon_host | ceph-mon的主机列表 |
| mon_dns_serv_name | ceph-mon的DNS名称,默认 ceph-mon |
| mon_data, osd_data, mds_data, mgr_data | 守护进程在本地存放数据的路径 |
| keyring, keyfile,key | 连接ceph-mon进行身份验证时,使用的凭证 |
ceph-mon集群管理了配置配置选项的数据库,用于供整个集群来消费。为了简化管理,大部分的Ceph选项应该在此数据库中管理。
集群中心配置的分段情况,和上文的配置段落一致。
传入命令行选项 --no-mon-config,可以让进程不去读取集群中心配置,使用场景:
- 希望所有配置信息在本地文件中管理
- ceph-mon目前宕机,但是需要进行一些维护工作
集群中心配置的配置项,可以关联一个掩码,用于限定选项应用到哪种守护进程、哪种客户端。例如host:foo,限制foo选项仅仅应用到运行在host上的进程或客户端。
以下命令可以用于修改集群中心配置:
| 命令 | 说明 | ||
| ceph config dump | Dump出整个集群中心配置 | ||
| ceph config get [who] | 获取指定的客户端/守护进程存放在集群中心的配置,例如mds.a | ||
| ceph config set [who] [opt] [val] |
设置指定客户端/守护进程的配置项,示例:
|
||
| ceph tell [who] config set [opt] [val] | 临时设置配置项,目标重启后失效 | ||
| ceph config show [who] | 显示指定客户端/守护进程的当前使用的配置信息,可能和集群中心配置不一样 | ||
| ceph config assimilate-conf -i -o | 从-i选项读取所有配置信息,注入到集群中心配置。任何无法识别、无效的配置项存放到-o |
在运行时,你可以使用 ceph osd pool set命令来修改这些选项:
| 选项 | 说明 |
| size | 对象副本数 |
| min_size | I/O 需要的最小副本数 |
| crush_rule | 此存储池使用的CRUSH规则 |
| compression_algorithm | BlueStore使用的压缩算法,可选值lz4, snappy, zlib, zstd |
| compression_mode | BlueStore使用的压缩模式,可选值none, passive, aggressive, force |
| compression_min_blob_size compression_max_blob_size |
BlueStore启用压缩的阈值 |
| hashpspool | 设置或者取消HASHPSPOOL标记。1设置0取消 |
| nodelete | 设置或取消NODELETE标记。1设置0取消 |
| nopgchange | 设置或取消NOPGCHANGE标记 |
| nosizechange | 设置或取消NOSIZECHANGE标记 |
| write_fadvise_dontneed | 设置或取消WRITE_FADVISE_DONTNEED标记 |
| noscrub | 设置或取消NOSCRUB标记 |
| nodeep-scrub | 设置或取消NODEEP_SCRUB标记 |
| hit_set_type | 启用缓存存储池的命中集跟踪,设置命中集类型,生产环境仅仅支持bloom |
| hit_set_count | 为缓存存储池保留的命中集数量。此值越高, OSD消耗的内存越多 |
| hit_set_fpp | bloom 命中集类型的误检率(false positive probability) |
| cache_target_dirty_ratio | 缓存存储池包含的修改(脏)对象达到多少比例时就把它们回写到后端的存储池 |
| cache_target_dirty_high_ratio | 缓存存储池内包含的已修改(脏)对象达到什么比例时,缓存层代理就会更快地把脏对象刷回到后端存储池 |
| cache_target_full_ratio | 缓存存储池包含的干净对象达到多少比例时,缓存代理就把它们清除出缓存存储池 |
| target_max_bytes | 回写(Flushing)或清除(Evicting)对象的阈值,按字节数 |
| target_max_objects | 回写(Flushing)或清除(Evicting)对象的阈值,按对象数 |
| scrub_min_interval | 在负载低时,洗刷存储池的最大间隔秒数 |
| scrub_max_interval | 不管集群负载如何,都要洗刷存储池的最大间隔秒数 |
| deep_scrub_interval | 深度洗刷存储池的间隔秒数 |
Ubuntu系统下,基于ceph-deploy部署集群后,可以用这种方法来操控集群。
列出节点上所有Ceph进程:
|
1 |
initctl list | grep ceph |
启动节点上所有Ceph进程:
|
1 |
start ceph-all |
启动节点上特定类型的Ceph进程:
|
1 2 3 |
sudo start ceph-osd-all sudo start ceph-mon-all sudo start ceph-mds-all |
启动特定类型的Ceph进程的某个实例:
|
1 2 3 |
sudo start ceph-osd id={id} sudo start ceph-mon id={hostname} sudo start ceph-mds id={hostname} |
停止特定类型的Ceph进程的某个实例:
|
1 2 3 |
sudo stop ceph-osd id={id} sudo stop ceph-mon id={hostname} sudo stop ceph-mds id={hostname} |
在 CentOS 、 Redhat 、 Fedora 和 SLES 发行版上可以通过传统的 sysvinit 运行 Ceph , Debian/Ubuntu 的较老的版本也可以用此方法。
命令格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 启动、重启或停止 sudo /etc/init.d/ceph [options] [start|restart|stop] [daemonType|daemonID] # 示例: # -a 表示在所有节点执行 sudo /etc/init.d/ceph -a start sudo /etc/init.d/ceph -a stop sudo /etc/init.d/ceph start osd sudo /etc/init.d/ceph -a stop osd sudo /etc/init.d/ceph start osd.0 sudo /etc/init.d/ceph stop osd.0 |
执行 ceph status或则 ceph -s可以查看集群的状态:
- active+clean:说明集群健康运行
- undersized+degraded:如果有OSD节点宕机,可能进入此状态。降级后还是可以正常读写数据
- undersized+degraded+peered:如果超过min size要求的OSD宕机,则不可读写,显示为此状态。min size默认2,副本份数默认3。执行下面的命令可以修改min size:
1ceph osd pool set rbd min_size 1peered相当于已经配对(PG - OSDs),但是正在等待OSD上线
-
remapped+backfilling:默认情况下,OSD宕机5分钟后会被标记为out状态,Ceph认为它已经不属于集群了。Ceph会按照一定的规则,将已经out的OSD上的PG重映射到其它OSD,并且从现存的副本来回填(Backfilling)数据到新OSD
执行 ceph health可以查看简短的健康状态。
执行 ceph -w可以持续的监控发生在集群中的各种事件。
执行命令 ceph df可以查看集群的数据用量及其在存储池内的分布情况:
|
1 2 3 4 5 6 7 8 9 10 |
GLOBAL: # 已用存储空间总量(包括所有副本) SIZE AVAIL RAW USED %RAW USED 323G 318G 4966M 1.50 # 这一段显示的数值,不包含副本、克隆、快照的用量 POOLS: # 大概使用率 # 大概对象数 NAME ID USED %USED MAX AVAIL OBJECTS rbd 1 3539M 1.14 300G 1018 |
|
1 2 3 4 5 6 |
# 基本信息 ceph mon stat # 详细信息 ceph mon dump # 法定人数状态、monmap内容 ceph quorum_status -f json-pretty |
|
1 2 |
ceph mds stat ceph mds dump |
通过PG这个中间层,Ceph确保了数据不会被绑死在某个特定的OSD。要追踪错误根源,你需要检查归置组、以及底层的OSD。
执行下面的命令,获取最简短的OSD状态:
|
1 2 3 |
ceph osd stat # 输出 12 osds: 12 up, 12 in |
执行 ceph osd dump则可以获得详细信息,包括在CRUSH map中的权重、UUID、是in还是out:
|
1 2 |
osd.0 up out weight 0 up_from 70 up_thru 172 down_at 65 last_clean_interval [51,60) 10.5.39.13:6800/48 10.5.39.13:6801/48 10.5.39.13:6802/48 10.5.39.13:6803/48 exists,up 354a6547-3437-46d6-a928-f5633eb7f059 osd.1 up in weight 1 up_from 74 up_thru 327 down_at 63 last_clean_interval [55,60) 10.5.39.42:6800/48 10.5.39.42:6801/48 10.5.39.42:6802/48 10.5.39.42:6803/48 exists,up 0fb4bb77-7c84-45ac-919a-2cc350fc62b9 |
执行 ceph osd tree可以在OSD树中打印各OSD的位置、状态、权重。如果OSD的in数量大于up数量,可以通过此命令快速定位:
|
1 2 3 4 5 6 |
# 仅仅包含out的OSD ceph osd tree out # ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF # -1 4.89999 root default # -2 0 host k8s-10-5-38-25 # 2 hdd 0 osd.2 DNE 0 |
执行命令 ceph pg stat可以查看全局性的PG统计信息。
可以获取PG列表:
|
1 2 3 4 |
# 输出的第一列为PG ID ceph pg dump # 导出为JSON ceph pg dump -o {filename} --format=json |
执行下面的命令可以查看PG到OSD的映射关系:
|
1 2 3 4 |
# PG ID 格式为 存储池号.归置组ID,归置组ID为一个十六进制数字 ceph pg map 1.13d # 输出 osdmap e790 pg 1.13d (1.13d) -> up [4,6,5] acting [4,6,5] |
执行 ceph status也可以看到PG的统计性信息。
执行 ceph pg 1.13d query可以查看某个PG的非常细节的信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
MONID=Neon MONADDR=10.0.3.1:6789 # 创建目录 mkdir /var/lib/ceph/mon/ceph-$MONID # 获取密钥和monmap ceph auth get mon. -o /tmp/keyring ceph mon getmap -o /tmp/monmap # 初始化Mon sudo ceph-mon -i $MONID --mkfs --monmap /tmp/monmap --keyring /tmp/keyring # 启动Mon ceph-mon -i $MONID --public-addr $MONADDR |
|
1 |
ceph mon rm Xenon |
导出monmap:
|
1 |
ceph mon getmap -o monmap |
打印monmap的内容:
|
1 |
monmaptool --print monmap |
从monmap中删除一个MON:
|
1 |
monmaptool monmap --rm xenon |
添加一个MON到monmap中:
|
1 |
monmaptool monmap --add Xenon 10.0.5.1:6789 |
导入monmap到MON节点:
|
1 |
ceph-mon -i Xenon --inject-monmap monmap |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 空间使用率达到 near full 比率后, OSD 失败可能导致集群空间占满。因此,你需要提前扩容 # 执行下面的命令创建一个新的OSD,其OSD号会输出到控制台: # uuid、id可选,如果不指定则自动生成。不能和现有OSD的uuid、id重复。不建议手工指定id ceph osd create [{uuid} [{id}]] # 如果希望OSD使用独立磁盘或者分区,可以先创建好文件系统,再挂载到适当位置 sudo mkfs -t {fstype} /dev/{drive} # 示例 mkfs -t xfs -f /dev/sda3 # 挂载点 mkdir /var/lib/ceph/osd/ceph-{osd-num} # 挂载 mount /dev/sda3 /var/lib/ceph/osd/ceph-14 # 初始化OSD数据目录: ceph-osd -i {osd-num} --mkfs --mkkey # 注册OSD认证密钥: ceph auth add osd.{osd-num} osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/${cluster-name}-{osd-num}/keyring # 示例 ceph auth add osd.14 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-14/keyring # 你需要把OSD加入到CRUSH map,这样数据才会分配到此OSD上: # 把OSD加入到CRUSH树的适当位置(桶) # 如果指定了不止一个桶,则将OSD加入到最靠近叶子节点的桶中,并把此桶移动到你指定的其它桶中 # 如果你指定了root桶,则此OSD直接挂在root下,则是不建议的,CRUSH规则期望OSD位于主机这种桶类型的下级节点 ceph osd crush add {id-or-name} {weight} [{bucket-type}={bucket-name} ...] # 示例 ceph osd crush add 14 0.11589 # 如果设置osd_crush_update_on_start=true,则可以OSD启动后自动加入到CRUSH树并更新权重 # 警告,如果上述参数设置为false,且你没有将osd添加到适当位置,则osd可能无法承载PG |
|
1 2 3 4 5 6 7 8 9 |
ceph osd find 14 { "osd": 14, "ip": "10.0.1.1:6804/3146", "crush_location": { "host": "Carbon", "root": "default" } } |
一旦启动了 OSD ,其状态就变成了 up+in ,此时可以通过ceph -w来观察数据迁移。归置组状态会变为active, some degraded objects,最终变回active+clean
|
1 2 3 4 5 6 |
# Debian/Ubuntu 上用 Upstart: start ceph-osd id={osd-num} # CentOS/RHEL 上用 sysvinit: /etc/init.d/ceph start osd.{osd-num} # 基于systemd的系统 systemctl start ceph-osd@14.service |
删除OSD之前,应该评估集群容量,保证操作之后,集群不会到达 near full 比率
|
1 2 3 4 5 6 |
# 首先从CRUSH map中移除 ceph osd crush remove {name} # 删除其认证密钥 ceph auth del osd.{osd-num} # 删除OSD ceph osd rm {osd-num} |
|
1 |
ceph osd down {osd-num} |
踢出OSD后,Ceph会进行数据迁移,达到再平衡。归置组状态会变为active, some degraded objects,最终变回active+clean。
|
1 |
ceph osd out {osd-num} |
对于某些小型测试集群,踢出一个OSD即导致CRUSH进入临界状态,某些归置组一直卡在active+remapped状态。如果遇到这种情况,你可以:
|
1 2 3 4 |
# 把被踢出的集群重新加进来 ceph osd in {osd-num} # 将其权重标记为0,而非踢出 ceph osd crush reweight osd.{osd-num} 0 |
等待数据迁移完毕后,再将OSD踢出。
你可能需要更新CRUSH map才能让新进入的OSD接受数据:
|
1 |
ceph osd in {osd-num} |
标记OSD为lost,可能导致数据丢失,谨慎:
|
1 |
ceph osd lost {id} [--yes-i-really-mean-it] |
|
1 2 |
# 权重默认是以TB为单位 ceph osd reweight {osd-num} {weight} |
|
1 2 3 |
ceph osd scrub {osd-num} # 清理所有 ceph osd scrub all |
|
1 |
ceph osd deep-scrub all |
|
1 |
ceph osd repair N |
|
1 |
ceph tell osd.N bench [TOTAL_DATA_BYTES] [BYTES_PER_WRITE] |
Ceph不允许向满的 OSD 写入数据,以免丢失数据。在运营着的集群中,你应该能收到集群空间将满的警告。mon osd full ratio 默认为 0.95 ,也就是说达到 95% 时它将阻止客户端写入数据; mon osd backfillfull ratio 默认为 0.90 ,也就是说达到容量的 90% 时它会阻塞,防止回填启动; OSD 将满比率默认为 0.85 ,也就是说达到容量的 85% 时它会产生健康警告。
使用下面的命令临时修改设置,否则你可能没有机会清理不需要的RBD以腾出空间:
|
1 2 3 |
ceph osd set-nearfull-ratio 0.95 ceph osd set-full-ratio 0.99 ceph osd set-backfillfull-ratio 0.99 |
首先,在/var/lib/ceph/mds/mds.N创建一个数据挂载点。N是MDS的ID,通常就是主机名。
然后,修改Ceph配置,添加一个mds段。修改完毕后进行配置分发:
|
1 2 |
[mds.N] host = {hostname} |
如果启用了CephX,需要创建认证密钥:
|
1 2 |
sudo ceph auth get-or-create mds.N mon 'profile mds' mgr 'profile mds' mds 'allow *' osd 'allow *' > \ /var/lib/ceph/mds/ceph-N/keyring |
执行下面的命令将目标mds标记为宕机:
|
1 |
ceph mds fail <mds name> |
移除MDS的/var/lib/ceph/mds/ceph-NAME下对应目录,然后,删除/etc/systemd/system/ceph-mds.target.wants/下的对应项目:
|
1 2 3 |
systemctl stop ceph-mds@Neon.service systemctl disable ceph-mds@Neon.service rm -rf /var/lib/ceph/mds/ceph-Neon |
如果服务是通过/etc/init.d/ceph加载的,则:
|
1 2 |
service ceph stop update-rc.d ceph disable |
查看守护进程的简短状态:
|
1 |
ceph mds stat |
|
1 |
service ceph start mds.NAME |
你可以使用多种方式来引用一个MDS守护进程:
|
1 2 3 4 |
ceph mds fail 5446 # 基于GID ceph mds fail myhost # 基于名称 ceph mds fail 3:0 # 基于FSCID:rank ceph mds fail myfs:0 # 基于文件系统名称:rank |
和MDS进程的Standby行为相关的配置项包括:
|
1 2 3 4 5 6 7 8 |
# 如果设置为true则standby会持续的从Rank中读取元数据日志,从而维持一个有效的元数据缓存,这可以加速Failover mds_standby_replay = true # 仅仅作为具有指定名称的MDS的Standby mds_standby_for_name = Carbon # 仅仅作为指定Rank的Standby mds_standby_for_rank # 仅仅作为指定文件系统的Standby mds_standby_for_fscid |
如果不进行任何配置,没有持有Rank的那些MDS进程,可以作为任何Rank的Standby。
配置示例:
|
1 2 3 4 5 6 7 8 |
# a、b两个MDS互备,负责Rank 0 [mds.a] mds standby replay = true mds standby for rank = 0 [mds.b] mds standby replay = true mds standby for rank = 0 |
|
1 2 3 |
ceph tell mds.{mds-id} config set {setting} {value} # 示例 ceph tell mds.0 config set debug_ms 1 |
|
1 |
ceph mds stat |
标记当前活动MDS为失败,触发故障转移:
|
1 |
ceph mds fail 0 |
要创建一个文件系统,你至少需要两个存储池,一个存放数据,另外一个存放元数据。注意:
- 元数据池的副本份数要设置的高,因为任何元数据的丢失都会导致整个文件系统不可用
- 元数据池应该使用高速存储,例如SSD,因为这对客户端操作的延迟有直接影响
示例:
|
1 2 3 4 5 6 7 |
# ceph fs new <fs_name> <metadata> <data> # 示例,可以使用现有的存储池 ceph fs new cephfs rbd-ssd rbd-hdd # Error EINVAL: pool 'rbd-ssd' already contains some objects. Use an empty pool instead. # 出现上述错误,可以: ceph fs new cephfs rbd-ssd rbd-hdd --force |
创建了文件系统之后,在Luminous版本中,集群状态中显示:
|
1 |
mds: cephfs-1/1/1 up {0=Carbon=up:active} |
|
1 |
ceph fs ls |
查看CephFS的详细状态,包括MDS列表、Rank列表等:
|
1 |
ceph fs status |
|
1 |
ceph fs rm <filesystem name> [--yes-i-really-mean-it] |
|
1 |
mds set <fs_name> down true |
要获取某个文件系统的信息,可以:
|
1 |
ceph fs get cephfs |
|
1 2 3 4 5 |
fs set <filesystem name> <var> <val> # 示例 # 设置单个文件的大小,默认1TB fs set cephfs max_file_size 1099511627776 |
|
1 2 |
fs add_data_pool <filesystem name> <pool name/id> fs rm_data_pool <filesystem name> <pool name/id> |
如果集群中有多个文件系统,而客户端在挂载时没有明确指定使用哪个,则使用默认文件系统:
|
1 |
ceph fs set-default cephfs |
EC池可以作为Ceph的数据池,但是需要启用overwirte:
|
1 |
ceph osd pool set my_ec_pool allow_ec_overwrites true |
注意:EC池不能用来存储元数据。
CephFS支持对任何一个子目录进行配额。但是,需要注意以下限制:
- 需要客户端协作,因此被篡改过的客户端可以突破配额
- 配额不是非常精确的
- 内核客户端,仅仅在4.17+才支持配额。用户空间客户端fuse、libcephfs都支持配额
设置配额(设置为0则移除配额):
|
1 2 |
setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir # 按字节数 setfattr -n ceph.quota.max_files -v 10000 /some/dir # 按文件数 |
查看配额:
|
1 2 |
getfattr -n ceph.quota.max_bytes /some/dir getfattr -n ceph.quota.max_files /some/dir |
你可以直接使用Linux内核提供的驱动来挂载CephFS:
|
1 2 |
mkdir /mnt/cephfs mount -t ceph 10.0.1.1:6789:/ /mnt/cephfs |
如何启用了CephX,需要指定访问密钥,否则会报22错误:
|
1 2 3 |
mount -t ceph 10.0.1.1:6789:/ /mnt/cephfs -o name=admin,secret=AQDRNBZbCp3WMBAAynSCCFPtILwHeI3RLDADKA== # 或者指定包含密钥的文件 mount -t ceph 10.0.1.1:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret |
如果报can't read superblock,说明客户端内核不支持。
要实现自动挂载,你需要修改fstab:
|
1 2 3 4 |
{ipaddress}:{port}:/ {mountpoint} {fs-type} [name=username,secret=key|secretfile=file],[{mount.options}] # 示例 10.0.1.1:6789:/ /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/cephfs.key,noatime,_netdev 0 2 |
要在用户空间挂载CephFS,你需要:
- 将Ceph配置文件拷贝到客户端,命名为/etc/ceph/ceph.conf
- 将Keyring拷贝到客户端,命名为/etc/ceph/ceph.keyring:
1sudo scp -i ~/Documents/puTTY/gmem.key root@xenon.gmem.cc:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.keyring - 执行挂载:
1234sudo ceph-fuse -m 10.0.1.1:6789 /mnt/cephfs# ceph-fuse[847]: starting ceph client# 2018-06-07 19:18:25.503086 7fa5c44e1000 -1 init, newargv = 0x7fa5cd643b40 newargc=9# ceph-fuse[847]: starting fuse
如果有多个CephFS,你可以为ceph-fuse指定命令行选项--client_mds_namespace,或者在客户端的ceph.conf中添加client_mds_namespace配置。
要实现自动挂载,你需要修改fstab:
|
1 2 3 4 5 |
none /mnt/ceph fuse.ceph ceph.id={user-ID}[,ceph.conf={path/to/conf.conf}],_netdev,defaults 0 0 # 示例 none /mnt/ceph fuse.ceph ceph.id=admin,_netdev,defaults 0 0 none /mnt/ceph fuse.ceph ceph.id=admin,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0 |
|
1 2 3 |
# 设置新建存储池时使用的默认参数 osd pool default pg num = 128 osd pool default pgp num = 128 |
|
1 2 3 4 |
ceph osd pool set {pool-name} option-name num # 示例 ceph osd pool set .rgw.root pg_num 128 ceph osd pool set .rgw.root pgp_num 128 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 创建存储池 # crush-ruleset-name:使用的默认CRUSH规则集名称 # 复制型的默认规则集由选项osd pool default crush replicated ruleset控制 # ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] \ [crush-ruleset-name] [expected-num-objects] ceph osd pool create {pool-name} {pg-num} {pgp-num} erasure \ [erasure-code-profile] [crush-ruleset-name] [expected_num_objects] # 示例 ceph osd pool create rbd-ssd 384 replicated replicated_rule_ssd |
创建存储池之后,在管理节点上,使用rbd工具来初始化池:
|
1 |
rbd pool init <pool-name> |
|
1 2 3 4 |
# 修改存储池配置 ceph osd pool set {pool-name} {key} {value} # 读取存储池配置 ceph osd pool get {pool-name} {key} |
|
1 2 3 |
ceph osd lspools # 输出 # 1 rbd,3 rbd-ssd,4 rbd-hdd, |
|
1 2 |
# 列出存储池中的对象 rados -p rbd ls |
|
1 2 3 4 5 6 7 8 9 10 |
# 显示所有存储池的使用情况 rados df # 或者 ceph df # 更多细节 ceph df detail # USED %USED MAX AVAIL OBJECTS DIRTY READ WRITE RAW USED # 用量 用量百分比 对象数量 读速度 写数量 用量x副本份数 |
|
1 2 3 4 |
# 设置最大对象数量、最大字节数 ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}] # 示例: ceph osd pool set-quota data max_objects 10000 |
要取消配额,设置为0即可。
|
1 2 3 4 |
# 制作存储池快照 ceph osd pool mksnap {pool-name} {snap-name} # 删除存储池快照 ceph osd pool rmsnap {pool-name} {snap-name} |
|
1 2 3 4 5 6 |
# 删除存储池 ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it] # 示例 ceph osd pool rm rbd-ssd rbd-ssd --yes-i-really-really-mean-it ceph osd pool rm rbd-hdd rbd-hdd --yes-i-really-really-mean-it |
|
1 2 |
# 列出池中对象,逐个删除 for i in `rados -p rbd-ssd ls`; do echo $i; rados -p rbd-ssd rm $i; done |
镜像就是块设备,所谓块是一系列连续的字节序列(例如512KB)。基于块的存储接口,是磁盘、CD、软盘、甚至磁带都使用的,是存储对象最广泛使用的方式。
Ceph的块设备具有以下特点:thin-provisioned(精简配备)、可改变大小、跨越多OSD存储。
|
1 |
rbd ls {poolname} |
如果不指定池名称,则列出默认池中的镜像。
下面的命令可以列出池中延迟删除的镜像:
|
1 |
rbd trash ls {poolname} |
|
1 |
rbd du --pool rbd-ssd |
注意:rbd info输出的是thin provisioning的大小,不是实际磁盘空间占用。
除了上面的命令,还可以:
|
1 |
rbd diff k8s/kubernetes-dynamic-pvc | awk '{ SUM += $2 } END { print SUM/1024/1024 " MB" }' |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
rbd info {pool-name}/{image-name} rbd info {image-name} # 输出示例: rbd image 'kubernetes-dynamic-pvc-0783b011-6a04-11e8-a266-3e299ab03dc6': # 总大小(thin-provisioning的大小,不是实际占用磁盘大小),分布在多少个对象中 size 2048 MB in 512 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.7655b643c9869 format: 2 features: layering flags: create_timestamp: Thu Jun 7 11:36:58 2018 |
可以看到什么客户端在使用(watch)镜像:
|
1 2 3 |
rbd status k8s/kubernetes-dynamic-pvc-ca081cd3-01a0-11eb-99eb-ce0c4cdcd662 # Watchers: # watcher=192.168.106.18:0/756489925 client.254697953 cookie=18446462598732840981 |
|
1 2 3 4 |
rbd create --size {megabytes} {pool-name}/{image-name} # 示例 # 创建大小为1G的镜像 rbd create test --size 1G |
如果不指定存储池,则在默认池中创建镜像。
|
1 2 3 4 |
# 修改镜像大小 rbd --image test resize --size 2G # 不但可以扩大,还可以缩小 rbd --image test resize --size 1G --allow-shrink |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 将镜像映射为本地块设备,可以进行格式化、挂载 rbd map test # 格式化 mkfs.xfs -f /dev/rbd0 # 挂载 mount /dev/rbd0 /test # 显示映射到本地块设备的镜像 rbd showmapped # 卸载 umount /dev/rbd0 # 解除映射 rbd unmap /dev/rbd0 |
|
1 2 3 |
rbd rm {pool-name}/{image-name} rbd --image test rm |
|
1 2 3 4 5 6 |
# 放入回收站 rbd trash mv {pool-name}/{image-name} # 彻底删除 rbd trash rm {pool-name}/{image-id} # 还原 rbd trash restore {image-id} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 创建快照 rbd snap create --image test --snap test_snap # 列出镜像的所有快照 rbd snap ls --image test # 回滚到指定快照 rbd snap rollback --image test --snap test_snap # 另一种写法 rbd snap rollback rbd/test@test_snap # 删除快照,注意删除是异步进行的,空间不会立刻释放 rbd snap rm --image test --snap test_snap rbd snap purge --image test # 保护快照 rbd snap protect --image test --snap test_snap # 取消保护 rbd snap unprotect --image test --snap test_snap # 清除指定镜像的所有快照 rbd snap purge {pool-name}/{image-name} |
|
1 2 3 4 5 6 7 |
# 克隆镜像,注意只有镜像格式2才支持克隆 # 从快照创建克隆 rbd clone --image test --snap test_snap test_clone # 列出快照的所有克隆 rbd children --image test --snap test_snap # 将父镜像(被克隆的镜像的快照)的数据扁平化到子镜像,从而解除父子关联 rbd flatten --image test_clone |
从Jewel开始,RBD镜像可以异步的跨越两个集群进行镜像(Mirroring)。通过配置,你可以镜像池中的所有、或者一部分镜像。
|
1 2 3 4 5 |
rbd mirror pool enable {pool-name} {mode} # 启用名为local的集群的镜像复制,默认为pool rbd --cluster local mirror pool enable image-pool pool rbd --cluster remote mirror pool enable image-pool pool |
mode取值:
- pool,池中所有启用了journaling特性的镜像都被复制
- image,只有明确配置的镜像才进行复制
|
1 2 3 4 |
rbd mirror pool disable {pool-name} rbd --cluster local mirror pool disable image-pool rbd --cluster remote mirror pool disable image-pool |
|
1 2 3 |
# 在池中创建一个对象,其内容来自文件 echo "Hello World" > /tmp/file rados -p rbd put helloworld /tmp/file |
|
1 2 |
# 查看对象 rados -p rbd ls | grep helloworld |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 根据CRUSH Map,列出OSD树 ceph osd tree # 缩进显示树层次 # ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF # -1 5.73999 root default # -2 0.84000 host k8s-10-5-38-25 # 0 hdd 0.84000 osd.0 up 1.00000 1.00000 # -5 0.45000 host k8s-10-5-38-70 # 1 hdd 0.45000 osd.1 up 1.00000 1.00000 # 移动桶的位置 # 将rack01移动到{root=default} ceph osd crush move rack01 root=default |
|
1 2 3 4 5 6 7 8 9 10 |
# 显示镜像和PG的关系 ceph osd map rbd test # 此镜像存放在1.b5这个PG中 # 此PG位于 osd.3 osd.1 osd.6中 # 主副本 位于osd.3中 # osdmap e26 pool 'rbd' (1) object 'test' -> pg 1.40e8aab5 (1.b5) -> up ([3,1,6], p3) acting ([3,1,6], p3) # 显示PG和镜像的关系 ceph pg map 1.c0 # osdmap e1885 pg 1.c0 (1.c0) -> up [9,8] acting [9,8] |
Dump出所有PG:
|
1 2 3 |
pg dump {all|summary|sum|delta|pools|osds|pgs|pgs_brief [all|summary|sum|delta|pools|osds|pgs|pgs_brief...]} # 示例 ceph pg dump [--format {format}] # format取值plain或json |
Dump出卡在指定状态中的PG的统计信息:
|
1 2 |
# threshold默认30秒 ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format {format}] [-t|--threshold {seconds}] |
|
1 2 |
ceph pg repair 1.c0 # instructing pg 1.c0 on osd.9 to repair |
|
1 2 3 4 5 |
ceph pg force-backfill <pgid> [<pgid>...] ceph pg force-recovery <pgid> [<pgid>...] # 取消 ceph pg cancel-force-backfill <pgid> [<pgid>...] ceph pg cancel-force-recovery <pgid> [<pgid>...] |
参考官网的算法进行计算。
执行调整之前,必须保证集群处于健康状态。
为避免调整PG数量导致业务性能受到严重影响,应该调整一些参数:
|
1 2 |
ceph tell osd.* injectargs '--osd-max-backfills 1' ceph tell osd.* injectargs '--osd-recovery-max-active 1' |
其它相关的参数还包括:
|
1 2 3 4 |
osd_backfill_scan_min = 4 osd_backfill_scan_max = 32 osd recovery threads = 1 osd recovery op priority = 1 |
按照2的幂进行翻倍增长,例如原来32个,可以先调整为64个。
注意:不要一下子把PG设置为太大的值,这会导致大规模的rebalance,影响系统性能。
等到上一步操作后,集群变为Active+Clean状态后,再将pgp_num设置的和pg_num一致。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 在RGW节点安装软件 # yum install ceph-radosgw RGW_HOST=$(hostname -s) # 在RGW节点,配置ceph.conf cat << EOF >> /etc/ceph/ceph.conf [client.rgw.$RGW_HOST] rgw_frontends = "civetweb port=7480" EOF # 拷贝配置到所有Ceph节点 # 在RGW节点,创建数据目录 mkdir -p /var/lib/ceph/radosgw/ceph-rgw.$RGW_HOST # 在RGW节点,创建用户,输出Keyring ceph auth get-or-create client.rgw.$RGW_HOST osd 'allow rwx' mon 'allow rw' \ -o /var/lib/ceph/radosgw/ceph-rgw.$RGW_HOST/keyring chown -R ceph:ceph /var/lib/ceph/radosgw # 在RGW节点,启用Systemd服务 systemctl enable ceph-radosgw.target systemctl enable ceph-radosgw@rgw.$RGW_HOST systemctl start ceph-radosgw@rgw.$RGW_HOST |
|
1 2 |
[client.rgw.Carbon] rgw_frontends = "civetweb port=80" |
推送修改后的配置文件后,重启RGW服务:
|
1 |
systemctl restart ceph-radosgw.service |
|
1 2 3 4 5 |
[client.rgw.Carbon] # 指定包含了私钥和证书的PEM rgw_frontends = civetweb port=443s ssl_certificate=/etc/ceph/private/keyandcert.pem # Luminous开始,可以同时绑定SSL和非SSL端口 rgw_frontends = civetweb port=80+443s ssl_certificate=/etc/ceph/private/keyandcert.pem |
RGW在index_pool池中存放桶(Bucket)索引数据,此池默认名为.rgw.buckets.index。
从0.94版本开始,支持对桶索引进行分片,避免单个桶中对象数量过多时出现性能瓶颈:
|
1 2 |
# 每个桶的最大索引分片数,默认0,表示不支持分片 rgw_override_bucket_index_max_shards = 0 |
你可以在global段配置上面的选项。
要使用RGW的RESTful接口,你需要:
- 创建初始的S3接口的用户
- 创建Swift接口的子用户
- 验证用户可以访问网关
要创建S3接口用户,需要在网关机上执行:
|
1 |
radosgw-admin user create --uid="rgw" --display-name="rgw" |
access_key、secret_key会打印在屏幕上,要访问网关,客户端必须提供这两个key:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
{ "user_id": "rgw", "display_name": "rgw", "email": "", "suspended": 0, "max_buckets": 1000, "auid": 0, "subusers": [], "keys": [ { "user": "rgw", "access_key": "IN01UCU1M1996LK6OM88", "secret_key": "AuuAbroSUlWLykbQHCbFLVO6RU2ozUEjIFkYeoqc" } ], "swift_keys": [], "caps": [], "op_mask": "read, write, delete", "default_placement": "", "placement_tags": [], "bucket_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "user_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "temp_url_keys": [], "type": "rgw" } |
要创建Swift子用户,需要在网关机上执行:
|
1 |
radosgw-admin subuser create --uid=alex --subuser=alex:swift --access=full |
你需要为Swift子用户创建secret key:
|
1 |
radosgw-admin key create --subuser=alex:swift --key-type=swift --gen-secret |
现在,你可以用自己熟悉的语言的S3、Swift客户端来验证用户是否可用。
|
1 2 3 4 5 6 7 8 9 10 |
radosgw-admin bucket list # 列出桶 radosgw-admin bucket limit check # 显示桶的分片情况 radosgw-admin bucket link # 将桶链接到用户 radosgw-admin bucket unlink # 取消桶到用户的链接 radosgw-admin bucket stats # 显示桶的统计信息 radosgw-admin bucket rm # 删除桶 radosgw-admin bucket check # 检查桶索引 radosgw-admin bucket reshard # 对桶进行重分片 radosgw-admin bucket sync disable # 禁止桶同步 radosgw-admin bucket sync enable # 启用桶同步 |
要创建桶,你需要使用合法的User ID + AWS Access Key发起请求,Ceph没有提供对应的命令行。需要注意以下约束:
- 桶名称必须唯一
- 桶名称不能格式化为IP地址
- 桶名称在3-63字符之间
- 桶名称不得包含大写字母、下划线,但是可以包含短横线
- 桶名称必须以小写字母或数字开头
- 桶名称必须由一系列的标签组成,每个标签用点号.分隔
我们可以使用MinIO客户端创建桶:
|
1 2 3 4 5 6 |
# 添加配置 # access_key secret_key mc config host add rgw https://rgw.gmem.cc:7480 IN01UCU1M1996LK6OM88 AuuAbroSUlWLykbQHCbFLVO6RU2ozUEjIFkYeoqc # 创建桶 mc mb rgw/test |
现在通过Rgw命令行可以看到这个桶:
|
1 2 3 4 |
radosgw-admin buckets list # [ # "test" # ] |
Ceph默认开启了cephx协议,加密认证需要消耗少量的资源。
启用cephx后,Cephe会自动在包括/etc/ceph/ceph.$name.keyring在内的位置寻找钥匙串,你可以指定keyring选项来修改默认路径,但是不推荐。
在禁用了cephx的集群上,启用它的步骤为:
- 创建 client.admin 密钥:
12# 如果你使用的自动部署工具已经生成此文件,切勿执行此命令,会覆盖ceph auth get-or-create client.admin mon 'allow *' mds 'allow *' osd 'allow *' -o /etc/ceph/ceph.client.admin.keyring - 创建mon集群所需的钥匙串、密钥:
1ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' - 将上述钥匙串复制到所有mon的mon data目录,例如:
1cp /tmp/ceph.mon.keyring /var/lib/ceph/mon/ceph-a/keyring - 为每个OSD生成密钥:
1ceph auth get-or-create osd.{$id} mon 'allow rwx' osd 'allow *' -o /var/lib/ceph/osd/ceph-{$id}/keyring -
为每个 MDS 生成密钥:
1ceph auth get-or-create mds.{$id} mon 'allow rwx' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mds/ceph-{$id}/keyring -
添加以下内容到配置文件的global段:
123auth cluster required = cephxauth service required = cephxauth client required = cephx -
启动或重启Ceph集群:
123# 停止当前节点上的所有Ceph守护进程sudo stop ceph-allsudo start ceph-all
修改配置文件global段:
|
1 2 3 |
auth cluster required = none auth service required = none auth client required = none |
然后重启Ceph集群。
|
1 2 3 4 |
# 列出keyring ceph auth ls # 添加OSD的keyring ceph auth add {osd} {--in-file|-i} {path-to-osd-keyring} |
任何时后你都可以Dump、反编译、修改、编译、注入CURSH map。如果要完全基于手工方式管理,不使用自动生成的CRUSH map,可以设置:
|
1 |
osd crush update on start = false |
执行命令 ceph osd crush dump,可以将整个CRUSH导出为可读形式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 |
# 下面的输出时安装后最初的状态,没有任何OSD { # 设备列表,最初为空 "devices": [], # 桶类型定义列表 "types": [ { "type_id": 0, "name": "osd" }, { "type_id": 1, "name": "host" }, { "type_id": 2, "name": "chassis" }, { "type_id": 3, "name": "rack" }, { "type_id": 4, "name": "row" }, { "type_id": 5, "name": "pdu" }, { "type_id": 6, "name": "pod" }, { "type_id": 7, "name": "room" }, { "type_id": 8, "name": "datacenter" }, { "type_id": 9, "name": "region" }, { "type_id": 10, "name": "root" } ], # 桶列表,可以形成树状结构 "buckets": [ { "id": -1, "name": "default", "type_id": 10, "type_name": "root", "weight": 0, "alg": "straw2", "hash": "rjenkins1", "items": [] } # 加入一个OSD节点(基于目录),自动生成如下两个Bucket: { "id": -2, "name": "k8s-10-5-38-25", "type_id": 1, "type_name": "host", "weight": 55050, "alg": "straw2", "hash": "rjenkins1", "items": [ { "id": 0, "weight": 55050, "pos": 0 } ] }, { "id": -3, "name": "k8s-10-5-38-25~hdd", "type_id": 1, "type_name": "host", "weight": 55050, "alg": "straw2", "hash": "rjenkins1", "items": [ { "id": 0, "weight": 55050, "pos": 0 } ] }, ], # 规则列表 "rules": [ { "rule_id": 0, "rule_name": "replicated_rule", # 所属规则集 "ruleset": 0, # 此规则是否用于RAID,取值replicated 或 raid4 "type": 1, # 如果Pool的副本份数不在此范围内,则CRUSH不会使用当前规则 "min_size": 1, "max_size": 10, "steps": [ { # 选择一个桶,并迭代其子树 "op": "take", "item": -1, "item_name": "default" }, { # 在上一步的基础上,确定每个副本如何放置 "op": "chooseleaf_firstn", # 取值0,此Step适用pool-num-replicas个副本(所有) # 取值>0 & < pool-num-replicas,适用num个副本 # 取值<0,适用pool-num-replicas -num个副本 "num": 0, "type": "host" }, { "op": "emit" } ] } ], # 可微调参数,以及一些状态信息 "tunables": { "choose_local_tries": 0, "choose_local_fallback_tries": 0, "choose_total_tries": 50, "chooseleaf_descend_once": 1, "chooseleaf_vary_r": 1, "chooseleaf_stable": 1, "straw_calc_version": 1, "allowed_bucket_algs": 54, # 使用的Profile,执行ceph osd crush tunables hammer后此字段改变,连带其它tunables字段自动改变 "profile": "jewel", "optimal_tunables": 1, "legacy_tunables": 0, "minimum_required_version": "jewel", "require_feature_tunables": 1, "require_feature_tunables2": 1, "has_v2_rules": 0, "require_feature_tunables3": 1, "has_v3_rules": 0, "has_v4_buckets": 1, "require_feature_tunables5": 1, "has_v5_rules": 0 }, "choose_args": {} } |
执行下面的命令,导出当前Map:
|
1 |
ceph osd getcrushmap -o curshmap |
然后,需要反编译为文本:
|
1 |
crushtool -d curshmap -o curshmap.src |
源文件内容示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# begin crush map tunable choose_local_tries 0 tunable choose_local_fallback_tries 0 tunable choose_total_tries 50 tunable chooseleaf_descend_once 1 tunable chooseleaf_vary_r 1 tunable straw_calc_version 1 tunable allowed_bucket_algs 54 # devices # types type 0 osd type 1 host type 2 chassis type 3 rack type 4 row type 5 pdu type 6 pod type 7 room type 8 datacenter type 9 region.Values.storageclass.fsType type 10 root # buckets root default { id -1 # do not change unnecessarily # weight 0.000 alg straw2 hash 0 # rjenkins1 } # rules rule replicated_rule { id 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type host step emit } # end crush map |
我们可以根据实际需要,对源文件进行修改,例如将算法改为straw,解决CentOS 7上CEPH_FEATURE_CRUSH_V4 1000000000000特性不满足的问题:
|
1 |
sed -i 's/straw2/straw/g' curshmap.src |
修改源文件完毕后,执行下面的命令编译:
|
1 |
crushtool -c curshmap.src -o curshmap |
最后,注入最新编译的Map:
|
1 2 |
ceph osd setcrushmap -i curshmap # 会输出修订版号 |
默认情况下,Ceph自动根据硬件类型,设置OSD的设备类型为hdd, ssd或nvme。你可以手工进行设置:
|
1 2 3 4 5 6 7 8 9 |
# 你需要移除当前设置的设备类型,才能重新设置 ceph osd crush rm-device-class <osd-name> [...] # 示例 ceph osd crush rm-device-class osd.3 osd.4 osd.5 osd.6 osd.7 osd.8 osd.0 osd.10 osd.1 osd.12 osd.2 osd.13 ceph osd crush set-device-class <class> <osd-name> [...] # 示例 ceph osd crush set-device-class ssd osd.3 osd.4 osd.5 osd.6 osd.7 osd.8 osd.0 osd.10 osd.1 osd.12 osd.2 osd.13 |
列出集群中的CRUSH rule:
|
1 |
ceph osd crush rule ls |
Dump出规则的内容:
|
1 |
ceph osd crush rule dump |
|
1 |
ceph osd crush rule rm replicated_rule_ssd |
创建一个规则,仅仅使用指定类型的设备:
|
1 2 3 4 |
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class> # 示例:仅仅使用ssd类型的设备,失败域为host,也就是数据副本必须位于不同的主机上 ceph osd crush rule create-replicated replicated_rule_ssd default host ssd ceph osd crush rule create-replicated replicated_rule_hdd default host hdd |
为存储池指定所使用的规则:
|
1 2 3 4 5 |
ceph osd pool set <pool-name> crush_rule <rule-name> # 修改规则 ceph osd pool set rbd-ssd crush_rule replicated_rule_ssd # 创建存储池时指定规则 ceph osd pool create rbd-ssd 384 replicated replicated_rule_ssd |
CRUSH rule的语法如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
rule <rulename> { ruleset <ruleset> type [ replicated | erasure ] min_size <min-size> max_size <max-size> # 根据桶名称来选取CRUSH子树,并迭代,可限定设备类型 step take <bucket-name> [class <device-class>] # choose:选择指定数量、类型的桶 # chooseleaf:选择指定数量、类型的桶,并选择每个这些桶的一个叶子节点 step [choose|chooseleaf] [firstn|indep] <N> <bucket-type> step emit } |
示例一,将主副本存放在SSD中,第二副本存放在HDD中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
rule ssd-primary-affinity { ruleset 0 type replicated min_size 2 max_size 3 # 选择名为SSD的桶 step take ssd # 在上述桶中的host类型的子树中选择叶子节点,存储1个副本(第一个) step chooseleaf firstn 1 type host # 执行 step emit # 选择名为HDD的桶 step take hdd # 在上述桶中的host类型的子树中选择叶子节点,存储N-1个副本(所有其它副本) step chooseleaf firstn -1 type host step emit } |
示意二,在第一个机架上存储两个副本,第二个机架上存储一个副本:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
rule 3_rep_2_racks { ruleset 1 type replicated min_size 2 max_size 3 step take default # 选择一个Rack,存储2个副本 step choose firstn 2 type rack # 在上述选定的Rack中选择Host step chooseleaf firstn 2 type host step emit } |
如果要添加OSD到CRUSH map中,执行:
|
1 2 3 4 |
ceph osd crush set {name} {weight} root={root} [{bucket-type}={bucket-name} ...] # 示例 ceph osd crush set osd.14 0 host=xenial-100 ceph osd crush set osd.0 1.0 root=default datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1 |
|
1 |
ceph osd crush reweight {name} {weight} |
|
1 |
ceph osd crush remove {name} |
|
1 |
ceph osd crush add-bucket {bucket-name} {bucket-type} |
|
1 |
ceph osd crush move {bucket-name} {bucket-type}={bucket-name}, [...] |
|
1 |
ceph osd crush remove {bucket-name} |
|
1 2 3 4 5 6 7 8 |
# 自动优化 ceph osd crush tunables optimal # 最大兼容性,存在老旧内核的cephfs/rbd客户端时 ceph osd crush tunables legacy # 选择一个PROFILE,例如jewel ceph osd crush tunables {PROFILE} |
|
1 2 |
# weight在0-1之间,默认1,值越小,CRUSH 越避免将目标OSD作为主 ceph osd primary-affinity <osd-id> <weight> |
使用CRUSH rule,可以限定某个Pool仅仅使用一部分OSD:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# SSD主机 host ceph-osd-ssd-server-1 { id -1 alg straw hash 0 item osd.0 weight 1.00 item osd.1 weight 1.00 } # HDD主机 host ceph-osd-hdd-server-1 { id -3 alg straw hash 0 item osd.4 weight 1.00 item osd.5 weight 1.00 } # HDD的根桶 root hdd { id -5 alg straw hash 0 item ceph-osd-hdd-server-1 weight 2.00 } # SSD的根桶 root ssd { id -6 alg straw hash 0 item ceph-osd-ssd-server-1 weight 2.00 } # 仅仅使用HDD的规则 rule hdd { ruleset 3 type replicated min_size 0 max_size 10 step take hdd # 选择 step chooseleaf firstn 0 type host step emit } # 仅仅使用SSD的规则 rule ssd { ruleset 4 type replicated min_size 0 max_size 4 step take ssd step chooseleaf firstn 0 type host step emit } # 在SSD上存储主副本,其它副本存放在HDD rule ssd-primary { ruleset 5 type replicated min_size 5 max_size 10 step take ssd step chooseleaf firstn 1 type host step emit step take hdd step chooseleaf firstn -1 type host step emit } |
前提条件:
- 集群处于OK状态
- 所有PG处于active+clean状态
步骤,针对每个需要改变尺寸的OSD,一个个的处理:
- 修改Cephe配置,设置 osd_journal_size = NEWSIZE
- 禁止数据迁移(防止OSD进入out状态): ceph osd set noout
- 停止目标OSD实例
- 刷出缓存: ceph-osd -i OSDID --flush-journal
- 删除日志:
123# 基于Helm部署时,需要到宿主机上的osd_directory下寻找对应目录cd /var/lib/ceph/osd/ceph-osd.OSDIDrm journal - 创建一个新的日志文件: ceph-osd --mkjournal -i OSDID
- 启动OSD
- 验证新的日志尺寸被使用:
12# Helm安装的情况下,需要在OSD容器中执行ceph --admin-daemon /var/run/ceph/ceph-osd.OSDID.asok config get osd_journal_size -
确保集群处于OK状态,所有PG处于active+clean状态
处理完所有OSD后,执行: ceph osd unset noout,清除noout标记
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 默认4K,可以--io-size定制 # 默认16线程,可以--io-threads定制 # 随机读 rbd bench -p rbd-hdd --image benchmark --io-total 128M --io-type read --io-pattern rand # elapsed: 25 ops: 32768 ops/sec: 1284.01 bytes/sec: 5259316.53 # elapsed: 15 ops: 327680 ops/sec: 20891.46 bytes/sec: 85571410.91 # HDD差20倍 # 顺序读 rbd bench -p rbd-hdd --image benchmark --io-total 64M --io-type read --io-pattern seq # elapsed: 46 ops: 163840 ops/sec: 3528.06 bytes/sec: 14450938.87 # elapsed: 45 ops: 1638400 ops/sec: 35672.87 bytes/sec: 146116057.32 # HDD差10倍 # 随机写 rbd bench -p rbd-hdd --image benchmark --io-total 128M --io-type write --io-pattern rand # elapsed: 85 ops: 32768 ops/sec: 383.24 bytes/sec: 1569743.22 # elapsed: 111 ops: 327680 ops/sec: 2936.78 bytes/sec: 12029055.24 # HDD差7倍 # 顺序写 rbd bench -p rbd-hdd --image benchmark --io-total 128M --io-type write --io-pattern seq # elapsed: 3 ops: 32768 ops/sec: 9382.16 bytes/sec: 38429334.91 # elapsed: 17 ops: 327680 ops/sec: 18374.69 bytes/sec: 75262749.05 # HDD差1倍 |
要动态、临时(重启后消失)的修改组件的参数,可以使用tell命令。
|
1 2 3 4 5 6 |
# 临时修改所有OSD和恢复相关的选项 ceph tell osd.* injectargs '--osd-max-backfills 1' # 并发回填操作数 ceph tell osd.* injectargs '--osd-recovery-threads 1' # 恢复线程数量 ceph tell osd.* injectargs '--osd-recovery-op-priority 1' # 恢复线程优先级 ceph tell osd.* injectargs '--osd-client-op-priority 63' # 客户端线程优先级 ceph tell osd.* injectargs '--osd-recovery-max-active 1' # 最大活跃的恢复请求数 |
可以将RBD上的Watcher加入黑名单,这样可以解除RBD的Watcher,再其它机器上挂载RBD:
|
1 2 3 4 5 6 7 8 9 10 |
rbd status kubernetes-dynamic-pvc-22d9e659-6e31-11e8-92e5-c6b9f35768f0 # Watchers: # watcher=10.0.3.1:0/158685765 client.3524447 cookie=18446462598732840965 # 添加到黑名单 ceph osd blacklist add 10.0.3.1:0/158685765 # blacklisting 10.0.3.1:0/158685765 until 2018-08-21 18:04:31.855791 (3600 sec) rbd status kubernetes-dynamic-pvc-22d9e659-6e31-11e8-92e5-c6b9f35768f0 # Watchers: none |
|
1 2 3 |
ceph osd blacklist ls # listed 1 entries # 10.0.3.1:0/158685765 2018-08-21 18:04:31.855791 |
|
1 |
ceph osd blacklist rm 10.0.3.1:0/158685765 |
|
1 |
ceph osd blacklist clear |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 列出池 rados lspools .rgw.root default.rgw.control default.rgw.meta default.rgw.log rbd rbd-ssd rbd-hdd # 创建池pool-name,使用auid 123,使用crush规则4 mkpool pool-name [123[ 4]] # 复制池的内容 cppool pool-name dest-pool # 移除池 rmpool pool-name pool-name --yes-i-really-really-mean-it # 清空池中对象 purge pool-name --yes-i-really-really-mean-it # 显示每个池的对象数量、空间占用情况 rados df # 列出池中对象 rados ls -p rbd # 将池的所有者设置为auid 123 rados chown 123 -p rbd |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 列出池快照 rados lssnap -p rbd # 创建池快照 rados mksnap snap-name -p rbd # 删除池快照 rados rmsnap mksnap snap-name -p rbd # 从快照中恢复对象 rados rollback <obj-name> <snap-name> # 列出对象的快照 rados listsnaps <obj-name> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 读对象 rados get object-name /tmp/obj -p rbd # 使用指定的偏移量写对象 rados put object-name /tmp/obj --offset offset # 附加内容到对象 rados append <obj-name> [infile # 截断对象为指定的长度 rados truncate <obj-name> length # 创建对象 rados create <obj-name> # 移除对象 rados rm <obj-name> ...[--force-full] # 复制对象 rados cp <obj-name> [target-obj] |
|
1 2 3 4 5 6 7 8 9 10 11 |
# 列出扩展属性 rados listxattr <obj-name> # 获取扩展属性 rados getxattr <obj-name> attr # 设置扩展属性 rados setxattr <obj-name> attr val # 移除扩展属性 rados rmxattr <obj-name> attr # 显示属性 rados stat <obj-name> |
|
1 |
rados list-inconsistent-pg pool-name |
|
1 |
rados list-inconsistent-obj 40.14 --format=json-pretty |
|
1 |
rados list-inconsistent-snapset 40.14 |
|
1 |
ceph mgr module enable dashboard |
|
1 2 3 4 5 6 7 8 9 |
# 使用自签名证书 ceph dashboard create-self-signed-cert # 使用外部提供的证书 ceph dashboard set-ssl-certificate -i dashboard.crt ceph dashboard set-ssl-certificate-key -i dashboard.key # 禁用SSL ceph config set mgr mgr/dashboard/ssl false |
|
1 |
ceph dashboard ac-user-create admin administrator -i - <<<"pswd" |
|
1 2 3 4 5 6 7 8 9 |
# 创建用户 radosgw-admin user create --uid=rgw --display-name=rgw --system # 设置access_key和secret_key ceph dashboard set-rgw-api-access-key -i - <<< "$(radosgw-admin user info --uid=rgw | jq -r .keys[0].access_key)" ceph dashboard set-rgw-api-secret-key -i - <<< "$(radosgw-admin user info --uid=rgw | jq -r .keys[0].secret_key)" # 禁用SSL校验 ceph dashboard set-rgw-api-ssl-verify False |
注意:详尽的日志每小时可能超过 1GB ,如果你的系统盘满了,这个节点就会停止工作。
|
1 2 3 4 5 |
# 通过中心化配置下发 ceph tell osd.0 config set debug_osd 0/5 # 到目标主机上,针对OSD进程设置 ceph daemon osd.0 config set debug_osd 0/5 |
可以为各子系统定制日志级别:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# debug {subsystem} = {log-level}/{memory-level} [global] debug ms = 1/5 [mon] debug mon = 20 debug paxos = 1/5 debug auth = 2 [osd] debug osd = 1/5 debug filestore = 1/5 debug journal = 1 debug monc = 5/20 [mds] debug mds = 1 debug mds balancer = 1 debug mds log = 1 debug mds migrator = 1 |
子系统列表:
|
子系统 |
日志级别 |
内存日志级别 |
| default |
0 |
5 |
| lockdep |
0 |
1 |
| context |
0 |
1 |
| crush |
1 |
1 |
| mds |
1 |
5 |
| mds balancer |
1 |
5 |
| mds locker |
1 |
5 |
| mds log |
1 |
5 |
| mds log expire |
1 |
5 |
| mds migrator |
1 |
5 |
| buffer |
0 |
1 |
| timer |
0 |
1 |
| filer |
0 |
1 |
| striper |
0 |
1 |
| objecter |
0 |
1 |
| rados |
0 |
5 |
| rbd |
0 |
5 |
| rbd mirror |
0 |
5 |
| rbd replay |
0 |
5 |
| journaler |
0 |
5 |
| objectcacher |
0 |
5 |
| client |
0 |
5 |
| osd |
1 |
5 |
| optracker |
0 |
5 |
| objclass |
0 |
5 |
| filestore |
1 |
3 |
| journal |
1 |
3 |
| ms |
0 |
5 |
| mon |
1 |
5 |
| monc |
0 |
10 |
| paxos |
1 |
5 |
| tp |
0 |
5 |
| auth |
1 |
5 |
| crypto |
1 |
5 |
| finisher |
1 |
1 |
| reserver |
1 |
1 |
| heartbeatmap |
1 |
5 |
| perfcounter |
1 |
5 |
| rgw |
1 |
5 |
| rgw sync |
1 |
5 |
| civetweb |
1 |
10 |
| javaclient |
1 |
5 |
| asok |
1 |
5 |
| throttle |
1 |
1 |
| refs |
0 |
0 |
| compressor |
1 |
5 |
| bluestore |
1 |
5 |
| bluefs |
1 |
5 |
| bdev |
1 |
3 |
| kstore |
1 |
5 |
| rocksdb |
4 |
5 |
| leveldb |
4 |
5 |
| memdb |
4 |
5 |
| fuse |
1 |
5 |
| mgr |
1 |
5 |
| mgrc |
1 |
5 |
| dpdk |
1 |
5 |
| eventtrace |
1 |
5 |
如果磁盘空间有限,可以配置/etc/logrotate.d/ceph,加快日志滚动:
|
1 2 3 4 5 |
rotate 7 weekly size 500M compress sharedscripts |
然后设置定时任务,定期检查并清理:
|
1 |
30 * * * * /usr/sbin/logrotate /etc/logrotate.d/ceph >/dev/null 2>&1 |
为了将Ceph部署到K8S集群中,可以利用ceph-helm项目。 目前此项目存在一些限制:
- public和cluster网络必须一样
- 如果Storage的用户不是admin,你需要在Ceph集群中手工创建用户,并在K8S中创建对应的Secrets
- ceph-mgr只能运行单副本
执行下面的命令把ceph-helm添加到本地Helm仓库:
|
1 2 3 4 5 6 7 8 |
# 此项目使用Helm本地仓库保存Chart,如果没有启动本地存储,请启动 nohup /usr/local/bin/helm serve --address 0.0.0.0:8879 > /dev/null 2>&1 & git clone https://github.com/ceph/ceph-helm pushd ceph-helm/ceph make popd # 构建成功后Chart归档文件位于 ./ceph-0.1.0.tgz |
可用值的说明如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 |
# 部署哪些组件 deployment: ceph: true storage_secrets: true client_secrets: true rbd_provisioner: true rgw_keystone_user_and_endpoints: false # 修改这些值可以指定其它镜像 images: ks_user: docker.io/kolla/ubuntu-source-heat-engine:3.0.3 ks_service: docker.io/kolla/ubuntu-source-heat-engine:3.0.3 ks_endpoints: docker.io/kolla/ubuntu-source-heat-engine:3.0.3 bootstrap: docker.io/ceph/daemon:tag-build-master-luminous-ubuntu-16.04 dep_check: docker.io/kolla/ubuntu-source-kubernetes-entrypoint:4.0.0 daemon: docker.io/ceph/daemon:tag-build-master-luminous-ubuntu-16.04 ceph_config_helper: docker.io/port/ceph-config-helper:v1.7.5 # 如果使用官方提供的StorageClass,你需要扩展kube-controller镜像,否则报executable file not found in $PATH rbd_provisioner: quay.io/external_storage/rbd-provisioner:v0.1.1 minimal: docker.io/alpine:latest pull_policy: "IfNotPresent" # 不同Ceph组件使用什么节点选择器 labels: jobs: node_selector_key: ceph-mon node_selector_value: enabled mon: node_selector_key: ceph-mon node_selector_value: enabled mds: node_selector_key: ceph-mds node_selector_value: enabled osd: node_selector_key: ceph-osd node_selector_value: enabled rgw: node_selector_key: ceph-rgw node_selector_value: enabled mgr: node_selector_key: ceph-mgr node_selector_value: enabled pod: dns_policy: "ClusterFirstWithHostNet" replicas: rgw: 1 mon_check: 1 rbd_provisioner: 2 mgr: 1 affinity: anti: type: default: preferredDuringSchedulingIgnoredDuringExecution topologyKey: default: kubernetes.io/hostname # 如果集群资源匮乏,可以调整下面的资源请求 resources: enabled: false osd: requests: memory: "256Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "1000m" mds: requests: memory: "10Mi" cpu: "100m" limits: memory: "50Mi" cpu: "500m" mon: requests: memory: "50Mi" cpu: "100m" limits: memory: "100Mi" cpu: "500m" mon_check: requests: memory: "5Mi" cpu: "100m" limits: memory: "50Mi" cpu: "500m" rgw: requests: memory: "5Mi" cpu: "100m" limits: memory: "50Mi" cpu: "500m" rbd_provisioner: requests: memory: "5Mi" cpu: "100m" limits: memory: "50Mi" cpu: "500m" mgr: requests: memory: "5Mi" cpu: "100m" limits: memory: "50Mi" cpu: "500m" jobs: bootstrap: limits: memory: "1024Mi" cpu: "2000m" requests: memory: "128Mi" cpu: "100m" secret_provisioning: limits: memory: "1024Mi" cpu: "2000m" requests: memory: "128Mi" cpu: "100m" ks_endpoints: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "2000m" ks_service: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "2000m" ks_user: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "2000m" secrets: keyrings: mon: ceph-mon-keyring mds: ceph-bootstrap-mds-keyring osd: ceph-bootstrap-osd-keyring rgw: ceph-bootstrap-rgw-keyring mgr: ceph-bootstrap-mgr-keyring admin: ceph-client-admin-keyring identity: admin: ceph-keystone-admin user: ceph-keystone-user user_rgw: ceph-keystone-user-rgw # !! 根据实际情况网络配置 network: public: 10.0.0.0/16 cluster: 10.0.0.0/16 port: mon: 6789 rgw: 8088 # !! 在此添加需要的Ceph配置项 conf: # 对象存储网关服务相关 rgw_ks: config: rgw_keystone_api_version: 3 rgw_keystone_accepted_roles: "admin, _member_" rgw_keystone_implicit_tenants: true rgw_s3_auth_use_keystone: true ceph: override: append: config: global: mon_host: null osd: ms_bind_port_max: 7100 ceph: rgw_keystone_auth: false enabled: mds: true rgw: true mgr: true storage: # 基于目录的OSD,在宿主机上存储的路径 # /var/lib/ceph-helm/osd会挂载到容器的/var/lib/ceph/osd目录 osd_directory: /var/lib/ceph-helm mon_directory: /var/lib/ceph-helm # 将日志收集到/var/log,便于fluentd来采集 mon_log: /var/log/ceph/mon osd_log: /var/log/ceph/osd # !! 是否启用基于目录的OSD,需要配合节点标签ceph-osd=enabled # 存储的位置由上面的storage.osd_directory确定,沿用现有的文件系统 osd_directory: enabled: false # 如果设置为1,则允许Ceph格式化磁盘,这会导致数据丢失 enable_zap_and_potentially_lose_data: true # !! 基于块设备的OSD,需要配合节点标签ceph-osd-device-dev-***=enabled osd_devices: - name: dev-vdb # 使用的块设备 device: /dev/vdb # 日志可以存储到独立块设备上,提升性能,如果不指定,存放在device journal: /dev/vdc # 是否删除其分区表 zap: "1" bootstrap: enabled: false script: | ceph -s function ensure_pool () { ceph osd pool stats $1 || ceph osd pool create $1 $2 } ensure_pool volumes 8 # 启用的mgr模块 ceph_mgr_enabled_modules: - restful - status # 配置mgr模块 ceph_mgr_modules_config: dashboard: port: 7000 localpool: failure_domain: host subtree: rack pg_num: "128" num_rep: "3" min_size: "2" # 在部署/升级后,执行下面的命令 # 这些命令通过kubectl来执行 ceph_commands: - ceph osd pool create pg_num - ceph osd crush tunables # Kubernetes 存储类配置 storageclass: provision_storage_class: true provisioner: ceph.com/rbd # 存储类名称 name: ceph-rbd monitors: nullcurshmap.src # 使用的RBD存储池的名称 pool: rbd admin_id: admin admin_secret_name: pvc-ceph-conf-combined-storageclass admin_secret_namespace: ceph user_id: admin user_secret_name: pvc-ceph-client-key # RBD设备的镜像格式和特性 image_format: "2" image_features: layering endpoints: # 集群域名后缀 cluster_domain_suffix: k8s.gmem.cc identity: name: keystone namespace: null auth: admin: region_name: RegionOne username: admin password: password project_name: admin user_domain_name: default project_domain_name: default user: role: admin region_name: RegionOne username: swift password: password project_name: service user_domain_name: default project_domain_name: default hosts: default: keystone-api public: keystone host_fqdn_override: default: null path: default: /v3 scheme: default: http port: admin: default: 35357 api: default: 80 object_store: name: swift namespace: null hosts: default: ceph-rgw host_fqdn_override: default: null path: default: /swift/v1 scheme: default: http port: api: default: 8088 ceph_mon: namespace: null hosts: default: ceph-mon host_fqdn_override: default: null port: mon: default: 6789 |
Ext4文件系统上基于目录的OSD配置,覆盖值示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
network: public: 10.0.0.0/8 cluster: 10.0.0.0/8 conf: ceph: config: global: # Ext4文件系统 filestore_xattr_use_omap: true osd: ms_bind_port_max: 7100 # Ext4文件系统 osd_max_object_name_len: 256 osd_max_object_namespace_len: 64 osd_crush_update_on_start : false ceph: storage: osd_directory: /var/lib/ceph-helm mon_directory: /var/lib/ceph-helm mon_log: /var/log/ceph/mon osd_log: /var/log/ceph/osd # 和操作系统共享一个分区,基于目录的OSD osd_directory: enabled: true storageclass: name: ceph-rbd pool: rbd |
为Ceph创建名字空间:
|
1 |
kubectl create namespace ceph |
创建RBAC资源:
|
1 |
kubectl create -f ceph-helm/ceph/rbac.yaml |
为了部署Ceph集群,需要为K8S集群中,不同角色(参与到Ceph集群中的角色)的节点添加标签:
- ceph-mon=enabled,部署mon的节点上添加
- ceph-mgr=enabled,部署mgr的节点上添加
- ceph-osd=enabled,部署基于设备、基于目录的OSD的节点上添加
- ceph-osd-device-NAME=enabled。部署基于设备的OSD的节点上添加,其中NAME需要替换为上面 ceph-overrides.yaml中的OSD设备名,即:
- ceph-osd-device-dev-vdb=enabled
- ceph-osd-device-dev-vdc=enabled
对应的K8S命令:
|
1 2 3 4 5 |
# 部署Ceph Monitor的节点 kubectl label node xenial-100 ceph-mon=enabled ceph-mgr=enabled # 对于每个OSD节点 kubectl label node xenial-100 ceph-osd=enabled ceph-osd-device-dev-vdb=enabled ceph-osd-device-dev-vdc=enabled kubectl label node xenial-101 ceph-osd=enabled ceph-osd-device-dev-vdb=enabled ceph-osd-device-dev-vdc=enabled |
|
1 |
helm install --name=ceph local/ceph --namespace=ceph -f ceph-overrides.yaml |
确保所有Pod正常运行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# kubectl -n ceph get pods NAME READY STATUS RESTARTS AGE ceph-mds-7cb7c647c7-7w6pc 0/1 Pending 0 18h ceph-mgr-66cb85cbc6-hsm65 1/1 Running 3 1h ceph-mon-check-758b88d88b-2r975 1/1 Running 1 1h ceph-mon-gvtq6 3/3 Running 3 1h ceph-osd-dev-vdb-clj5f 1/1 Running 15 1h ceph-osd-dev-vdb-hldw5 1/1 Running 15 1h ceph-osd-dev-vdb-l4v6t 1/1 Running 15 1h ceph-osd-dev-vdb-v5jmd 1/1 Running 15 1h ceph-osd-dev-vdb-wm4v4 1/1 Running 15 1h ceph-osd-dev-vdb-zwr65 1/1 Running 15 1h ceph-osd-dev-vdc-27wfk 1/1 Running 15 1h ceph-osd-dev-vdc-4w4fn 1/1 Running 15 1h ceph-osd-dev-vdc-cpkxh 1/1 Running 15 1h ceph-osd-dev-vdc-twmwq 1/1 Running 15 1h ceph-osd-dev-vdc-x8tpb 1/1 Running 15 1h ceph-osd-dev-vdc-zfrll 1/1 Running 15 1h ceph-rbd-provisioner-5544dcbcf5-n846s 1/1 Running 4 18h ceph-rbd-provisioner-5544dcbcf5-t84bz 1/1 Running 3 18h ceph-rgw-7f97b5b85d-nc5fq 0/1 Pending 0 18h |
其中MDS、RGW的Pod处于Pending状态,这是由于没有给任何节点添加标签:
|
1 2 3 4 5 6 |
# rgw即RADOS Gateway,是Ceph的对象存储网关服务,它是基于librados接口封装的FastCGI服务 # 提供存储和管理对象数据的REST API。对象存储适用于图片、视频等各类文件 # rgw兼容常见的对象存储API,例如绝大部分Amazon S3 API、OpenStack Swift API ceph-rgw=enabled # mds即Metadata Server,用于支持文件系统 ceph-mds=enabled |
现在从监控节点,检查一下Ceph集群的状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# kubectl -n ceph exec -ti ceph-mon-gvtq6 -c ceph-mon -- ceph -s cluster: # 集群标识符 id: 08adecc5-72b1-4c57-b5b7-a543cd8295e7 health: HEALTH_OK services: # 监控节点 mon: 1 daemons, quorum xenial-100 # 管理节点 mgr: xenial-100(active) # OSD(Ceph Data Storage Daemon) osd: 12 osds: 12 up, 12 in data: # 存储池、PG数量 pools: 0 pools, 0 pgs # 对象数量 objects: 0 objects, 0 bytes # 磁盘的用量,如果是基于文件系统的OSD,则操作系统用量也计算在其中 usage: 1292 MB used, 322 GB / 323 GB avail # 所有PG都未激活,不可用 pgs: 100.000% pgs not active # undersize是由于OSD数量不足(复制份数3,此时仅仅一个OSD),peerd表示128个PG配对到OSD 128 undersized+peered # 将复制份数设置为1后,输出变为 pgs: 100.000% pgs not active 128 creating+peering # 过了一小段时间后,输出变为 pgs: 128 active+clean # 到这里,PVC才能被提供,否则PVC状态显示 Provisioning,Provisioner日志中出现类似下面的: # attempting to acquire leader lease... # successfully acquired lease to provision for pvc ceph/ceph-pvc # stopped trying to renew lease to provision for pvc ceph/ceph-pvc, timeout reached |
如果K8S集群没有默认StorageClass,可以设置:
|
1 |
kubectl patch storageclass ceph-rbd -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' |
这样没有显式声明StorageClass的PVC将自动通过ceph-rbd进行卷提供。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 创建具有384个PG的名为rbd的复制存储池 ceph osd pool create rbd 384 replicated ceph osd pool set rbd min_size 1 # 开发环境下,可以把Replica份数设置为1 ceph osd pool set rbd size 1 # min_size 会自动被设置的比size小 # 减小size后,可以立即看到ceph osd status的used变小 # 初始化池,最好在所有节点加入后,调整好CURSH Map后执行 rbd pool init rbd # 可以创建额外的用户,例如下面的,配合Value storageclass.user_id=k8s使用 ceph auth get-or-create-key client.k8s mon 'allow r' osd 'allow rwx pool=rbd' | base64 # 如果使用默认用户admin,则不需要生成上面这步。admin权限也是足够的 # 其它命令 # 查看块设备使用情况(需要MGR) ceph osd status +----+------------+-------+-------+--------+---------+--------+---------+-----------+ | id | host | used | avail | wr ops | wr data | rd ops | rd data | state | +----+------------+-------+-------+--------+---------+--------+---------+-----------+ | 0 | xenial-100 | 231M | 26.7G | 0 | 3276 | 0 | 0 | exists,up | | 1 | xenial-103 | 216M | 26.7G | 0 | 819 | 0 | 0 | exists,up | | 2 | xenial-101 | 253M | 26.7G | 0 | 0 | 0 | 0 | exists,up | | 3 | xenial-103 | 286M | 26.7G | 0 | 0 | 0 | 0 | exists,up | | 4 | xenial-101 | 224M | 26.7G | 0 | 1638 | 0 | 0 | exists,up | | 5 | xenial-105 | 211M | 26.7G | 0 | 0 | 0 | 0 | exists,up | | 6 | xenial-100 | 243M | 26.7G | 0 | 0 | 0 | 0 | exists,up | | 7 | xenial-102 | 224M | 26.7G | 0 | 2457 | 0 | 0 | exists,up | | 8 | xenial-102 | 269M | 26.7G | 0 | 1638 | 0 | 0 | exists,up | | 9 | xenial-104 | 252M | 26.7G | 0 | 2457 | 0 | 0 | exists,up | | 10 | xenial-104 | 231M | 26.7G | 0 | 0 | 0 | 0 | exists,up | | 11 | xenial-105 | 206M | 26.7G | 0 | 0 | 0 | 0 | exists,up | +----+------------+-------+-------+--------+---------+--------+---------+-----------+ |
可以先使用ceph命令尝试创建RBD并挂载:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 镜像格式默认2 # format 1 - 此格式兼容所有版本的 librbd 和内核模块,但是不支持较新的功能,像克隆。此格式目前已经废弃 # 2 - librbd 和 3.11 版以上内核模块才支持。此格式增加了克隆支持,未来扩展更容易 rbd create test --size 1G --image-format 2 --image-feature layering # 映射为本地块设备,如果卡住,可能有问题,一段时间后会有提示 rbd map test # CentOS 7 下可能出现如下问题: # rbd: sysfs write failed # In some cases useful info is found in syslog - try "dmesg | tail". # rbd: map failed: (5) Input/output error # dmesg | tail # [1180891.928386] libceph: mon0 10.5.39.41:6789 feature set mismatch, # my 2b84a042a42 < server's 40102b84a042a42, missing 401000000000000 # [1180891.934804] libceph: mon0 10.5.39.41:6789 socket error on read # 解决办法是把Bucket算法从straw2改为straw # 挂载为目录 fdisk /dev/rbd0 mkfs.ext4 /dev/rbd0 mkdir /test mount /dev/rbd0 /test # 测试性能 # 1MB块写入 sync; dd if=/dev/zero of=/test/data bs=1M count=512; sync # 512+0 records in # 512+0 records out # 536870912 bytes (537 MB) copied, 4.44723 s, 121 MB/s # 16K随机写 fio -filename=/dev/rbd0 -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=512M -numjobs=30 -runtime=60 -name=test # WRITE: bw=35.7MiB/s (37.5MB/s), 35.7MiB/s-35.7MiB/s (37.5MB/s-37.5MB/s), io=2148MiB (2252MB), run=60111-60111msec # 16K随机读 fio -filename=/dev/rbd0 -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=512M -numjobs=30 -runtime=60 -name=test # READ: bw=110MiB/s (116MB/s), 110MiB/s-110MiB/s (116MB/s-116MB/s), io=6622MiB (6943MB), run=60037-60037msec # 删除测试镜像 umount /test rbd unmap test rbd remove test |
确认Ceph RBD可以挂载、读写后,创建一个PVC:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: ceph-pvc namespace: ceph spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: ceph-rbd |
查看PVC是否绑定到PV:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
kubectl -n ceph create -f ceph-pvc.yaml kubectl -n ceph get pvc # NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE # ceph-pvc Bound pvc-43caef06-46b4-11e8-bed8-deadbeef00a0 1Gi RWO ceph-rbd 3s # 在Monitor节点上确认RBD设备已经创建 rbd ls # kubernetes-dynamic-pvc-fbddb77d-46b5-11e8-9204-8a12961e4b47 rbd info kubernetes-dynamic-pvc-fbddb77d-46b5-11e8-9204-8a12961e4b47 # rbd image 'kubernetes-dynamic-pvc-fbddb77d-46b5-11e8-9204-8a12961e4b47': # size 128 MB in 32 objects # order 22 (4096 kB objects) # block_name_prefix: rbd_data.11412ae8944a # format: 2 # features: layering # flags: # create_timestamp: Mon Apr 23 05:20:07 2018 |
需要在其它命名空间中使用此存储池时,拷贝一下Secret:
|
1 |
kubectl -n ceph get secrets/pvc-ceph-client-key -o json --export | jq '.metadata.namespace = "default"' | kubectl create -f - |
|
1 2 |
helm delete ceph --purge kubectl delete namespace ceph |
此外,如果要重新安装,一定要把所有节点的一下目录清除掉:
|
1 2 |
rm -rf /var/lib/ceph-helm rm -rf /var/lib/ceph |
只需要安装相应的Provisioner,配置适当的StorageClass即可。示例:
- Provisioner:https://git.gmem.cc/alex/helm-charts/src/branch/master/ceph-provisioners
- 安装脚本:https://git.gmem.cc/alex/k8s-init/src/branch/master/4.infrastructure/0.ceph-external.sh
Kubernetes卷的动态Provisioning,目前需要依赖于external-storage项目,K8S没有提供内置的Provisioner。此项目存在不少问题,生产环境下可以考虑静态提供。
Provisioner会自动在Ceph集群的默认CephFS中创建“卷”,Ceph支持基于libcephfs+librados来实现一个基于CephFS目录的虚拟卷。
你可以在默认CephFS中看到volumes/kubernetes目录。kubernetes目录对应一个虚拟卷组。每个PV对应了它的一个子目录。
- 监控节点对于集群的正确运行非常重要,应当为其分配独立的硬件资源。如果跨数据中心部署,监控节点应该分散在不同数据中心或者可用性区域
- 日志可能会让集群的吞吐量减半。理想情况下,应该在不同磁盘上运行操作系统、OSD数据、OSD日志。对于高吞吐量工作负载,考虑使用SSD进行日志存储
- 纠删编码(Erasure coding)可以用于存储大容量的一次性写、非频繁读、性能要求不高的数据。纠删编码存储消耗小,但是IOPS也降低
- 目录项(Dentry)和inode缓存可以提升性能,特别是存在很多小对象的情况下
- 使用缓存分层(Cache Tiering)可以大大提升集群性能。此技术可以在热、冷Tier之间自动的进行数据迁移。为了最大化性能,请使用SSD作为缓存池、并且在低延迟节点上部署缓存池
- 部署奇数个数的监控节点,以便仲裁投票(Quorum Voting),建议使用3-5个节点。更多的节点可以增强集群的健壮性,但是mon之间需要保持数据同步,这会影响性能
- 诊断性能问题的时候,总是从最底层(磁盘、网络)开始,然后再检查块设备、对象网关等高层接口
- 在大型集群里用单独的集群网络(Cluster Newwork)可显著地提升性能和安全性
- 限制最大文件大小,创建极大的文件会导致删除过程很缓慢
- 避免在生产环境下使用试验特性。你应该使用单个活动MDS、不使用快照(默认如此)
- 避免增大max_mds,可能导致大于1个的MDS处于Active
- 客户端选择:
- FUSE,容易使用、容易升级和服务器集群保持一致
- 内核,性能好
- 不同客户端的功能并不完全一致,例如FUSE支持客户端配额,内核不支持
- 对于Ceph 10.x,最好使用4.x内核。如果必须使用老内核,你应该使用FUSE作为客户端
OSD需要消耗CPU资源,可以将其绑定到一个核心上。如果使用纠删码,则需要更多的CPU资源。此外,集群处于Recovery状态时,OSD的CPU消耗显著增加
MON不怎么消耗CPU资源,几个G内存的单核心物理机即可。
MDS相当消耗CPU资源,考虑4核心或更多CPU。如果依赖于CephFS处理大量工作,应当分配专用物理机
MON/MDS需要不少于2G内存。OSD通常需要1G内存(和存储容量有关)。此外,集群处于Recovery状态时,OSD的内存消耗显著增加,因此配备2G内存更好
最好具有万兆网络,公共网络、集群网络需要物理隔离(双网卡连接到独立交换机)。对于数百TB规模的集群,千兆网络也能够正常工作
集群网络往往消耗更多的带宽,此外,高性能的集群网络对于Recovery的效率很重要。
如果交换机支持,应当启用Jumbo帧,可以提升网络吞吐量。
在生产环境下,最好让OSD使用独立的驱动器,如果和OS共享驱动,最好使用独立的分区。
通常使用SATA SSD作为日志存储,预算足够可以考虑PCIE SSD。Intel S3500的4K随机写 IOPS可达10K+
关于RAID:
- 最好不要使用RAID
- 如果有RAID卡,并且磁盘数量太多,而对应的内存数量不足(每个OSD大概需要2G内存),可以RAID0
- 不要使用RAID5,因为随机IO的性能降低
关于filestore:
- 建议使用SSD存储日志,以减少访问时间、读取延迟,实现吞吐量的显著提升
- 可以为创建SSD分区,每个分区作为一个OSD的日志存储,但是最好不要超过4个
- 启用超线程Hyper-Threading技术
- 关闭节能
- 关闭NUMA
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 修改pid max # 执行命令 echo 4194303 > /proc/sys/kernel/pid_max # 或者 sysctl -w kernel.pid_max=4194303 # read_ahead, 数据预读到内存,提升磁盘读操作能力 echo "8192" > /sys/block/sda/queue/read_ahead_kb # 禁用交换文件 echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf # I/O Scheduler:SSD使用用noop,SATA/SAS使用deadline echo "deadline" > /sys/block/sda/queue/scheduler echo "noop" > /sys/block/sda/queue/scheduler |
底层文件系统的稳定性和性能对于Ceph很重要。在开发、非关键部署时可以使用btrfs,这也是未来的方向。关键的生产环境下应该使用XFS。
在高可扩容性的存储环境下,XFS和btrfs相比起ext3/4有很大优势。XFS和btrfs都是日志式文件系统,更健壮,容易从崩溃、断电中恢复。日志文件系统会在执行写操作之前,把需要进行的变更记录到日志。
OSD依赖于底层文件系统的扩展属性(Extended Attributes,XATTRs),来存储各种内部对象状态和属性。XFS支持64KB的XATTRs,但是ext4就太小了,你应该为运行在ext4上的OSD配置:
|
1 2 |
# 新版本Ceph此配置项已经没了 filestore xattr use omap = true |
关于文件系统的一些知识:
- XFS 、 btrfs 和 ext4 都是日志文件系统
- XFS很成熟
- btrfs相对年轻,他是一个写时复制(COW)文件系统,因而支持可写文件系统快照。此外它还支持透明压缩、完整性校验
PG的数量应当总是和PGP相同。PGP是为了实现定位而创建的PG。再平衡仅仅再pgp_num被修改后才会触发,仅仅修改pg_num不会触发。
随着OSD数量的变化,选取适当的PG数量很重要。因为PG数量对集群行为、数据持久性(Durability,灾难性事件发生时保证数据堡丢失)有很大影响。此外,归置组很耗计算资源,所以很多存储池x很多归置组会导致性能下降。建议的取值:
- 对于小于5个OSD的集群:设置为128
- 5-10个OSD的集群:设置为512
- 10-50个OSD的集群:设置为1024
- 超过50个OSD的集群,需要自己权衡,利用pgcalc来计算适合的PG数量
《Ceph分布式存储学习指南》一书中建议的PG数量算法:
每个池的PG数量 = OSD总数 * 100 / 最大副本数 / 池数
计算结果需要向上舍入到2的N次幂。此外该书倾向于让所有池具有相同的PG数量。
- 加入新的OSD后,考虑设置权重为0,然后逐渐增加权重,这样可以避免性能下降
DigitalOcean开源了Ceph的Exporter,本文使用gmemcc的fork版本。Ceph Exporter和MON节点通信,所有信息都通过rados_mon_command()调用获得。
此Exporter可以在任意Ceph客户端节点上运行,和任何形式的Ceph客户端一样,你需要提供ceph.conf、ceph.USER.keyring两个配置文件。
| 选项 | 说明 |
| telemetry.addr | 监听的地址和端口,示例:*:9100 |
| telemetry.path | 查询指标的URL路径,示例:/metrics |
| ceph.config | Ceph配置文件路径 |
| ceph.user | 使用的Ceph用户,示例:admin |
| exporter.config | Ceph Exporter配置文件的位置,示例:/etc/ceph/exporter.yml |
| rgw.mode | 是否收集RGW的指标:0禁用,1启用,2后台 |
你可以直接使用预构建好的镜像: digitalocean/ceph_exporter:2.0.1-luminous
或者,从源码构建:
|
1 2 3 4 5 6 7 |
sudo apt install librados-dev git clone https://github.com/gmemcc/ceph_exporter.git cd ceph_exporter go install make docker build -t docker.gmem.cc/digitalocean/ceph_exporter . |
对于Luminous12.2或者Mimic13.2版本,MGR已经内置了Prometheus模块,不再需要ceph_exporter了。
执行下面的命令启用Prometheus模块:
|
1 |
ceph mgr module enable prometheus |
然后,你就可以访问任意MGR节点的http://MGR_HOST:9283/metrics,抓取指标了。Prometheus配置示例:
|
1 2 3 4 5 6 7 8 |
scrape_configs: - job_name: ceph static_configs: - targets: # 列出所有MGR节点,防止故障转移时数据丢失 - 10.0.1.1:9283 labels: cluster: ceph |
Grafana仪表盘可以参考这个示例:https://grafana.com/dashboards/7056
R表示必须支持的特性,S表示该版本内核可以支持,-*-表示从这个版本开始支持。
| Feature | OCT | 3.8 | 3.9 | 3.10 | 3.14 | 3.15 | 3.18 | 4.1 | 4.5 | 4.6 |
| CEPH_FEATURE_NOSRCADDR | 2 | R | R | R | R | R | R | R | R | R |
| CEPH_FEATURE_SUBSCRIBE2 | 10 | -R- | ||||||||
| CEPH_FEATURE_RECONNECT_SEQ | 40 | -R- | R | R | R | R | R | R | ||
| CEPH_FEATURE_PGID64 | 200 | R | R | R | R | R | R | R | R | |
| CEPH_FEATURE_PGPOOL3 | 800 | R | R | R | R | R | R | R | R | |
| CEPH_FEATURE_OSDENC | 2000 | R | R | R | R | R | R | R | R | |
| CEPH_FEATURE_CRUSH_TUNABLES | 40000 | S | S | S | S | S | S | S | S | S |
| CEPH_FEATURE_MSG_AUTH | 800000 | -S- | S | S | S | |||||
| CEPH_FEATURE_CRUSH_TUNABLES2 | 2000000 | S | S | S | S | S | S | S | S | |
| CEPH_FEATURE_REPLY_CREATE_INODE | 8000000 | S | S | S | S | S | S | S | S | |
| CEPH_FEATURE_OSDHASHPSPOOL | 40000000 | S | S | S | S | S | S | S | S | |
| CEPH_FEATURE_OSD_CACHEPOOL | 800000000 | -S- | S | S | S | S | S | |||
| CEPH_FEATURE_CRUSH_V2 | 1000000000 | -S- | S | S | S | S | S | |||
| CEPH_FEATURE_EXPORT_PEER | 2000000000 | -S- | S | S | S | S | S | |||
| CEPH_FEATURE_OSD_ERASURE_CODES*** | 4000000000 | |||||||||
| CEPH_FEATURE_OSDMAP_ENC | 8000000000 | -S- | S | S | S | S | ||||
| CEPH_FEATURE_CRUSH_TUNABLES3 | 20000000000 | -S- | S | S | S | S | ||||
| CEPH_FEATURE_OSD_PRIMARY_AFFINITY | 20000000000 | -S- | S | S | S | S | ||||
| CEPH_FEATURE_CRUSH_V4 **** | 1000000000000 | -S- | S | S | ||||||
| CEPH_FEATURE_CRUSH_TUNABLES5 | 200000000000000 | -S- | S | |||||||
| CEPH_FEATURE_NEW_OSDOPREPLY_ENCODING | 400000000000000 | -S- | S |
| 代码 | 版本 |
| Luminous | 12 |
| Jewel | 10 |
| 已归档版本 | |
| argonaut | 0.48 |
| bobtail | 0.56 |
| Cuttlefish | 0.61 |
| Dumpling | 0.67 |
| Emperor | 0.72 |
| Firefly | 0.80 |
| Giant | 0.87 |
| Hammer | 0.94 |
| Infernalis | 9.2.0 |
| Kraken | 11.0.2 |
- 纠删码支持
- 缓存分层
- 键/值 OSD后端
- 独立的RadosGW(使用civetweb)
- LRC纠删码
- CephFS日志恢复,诊断工具
- RGW对象版本化
- 对象桶分片
- Crush straw2算法
- 纠删码到达稳定,支持很多新特性
- 支持Swift API新特性,例如对象过期设置
- CephFS到达稳定
- RGW多站点可达(支持主/主配置)
- AWS4兼容
- RBD镜像(mirroring)
- 引入BlueStore
- BlueStore到达稳定
- AsyncMessenger
- RGW:通过ES来索引元数据
- S3桶生命周期API支持
- RGW:支持导出为NFS v3接口
- Rados支持在基于纠删码的池上进行overwrite操作
- 基于纠删码池的RBD卷
- 集成Web仪表盘Ceph Dashboard
- 直接管理裸设备的BlueStore到达稳定并且作为默认选项
- 纠删码池完全支持overwirte,可以和CephFS/RDB一起使用
- 引入组件ceph-mgr,如果该组件停止,则指标不会更新,某些依赖于指标的请求,例如ceph df,无法工作
- 可扩容能力提升,可部署10000OSD的集群
- 每个OSD支持关联一个设备类(例如hdd/ssd),允许CRUSH规则将数据简单地映射到系统中的设备的子集。通常不需要手动编写CRUSH规则或手动编辑CRUSH
- 支持优化CRUSH权重,以保持OSD之间数据的近乎完美的分布
- OSD可以根据后端设备是HDD还是SSD来调整其默认配置
- RGW引入了上传对象的服务器端加密,用于管理加密密钥的三个选项有:自动加密(仅推荐用于测试设置),客户提供的类似于Amazon SSE-C规范的密钥,以及通过使用外部密钥管理服务
- RGW具有初步的类似AWS的存储桶策略API支持。现在,策略是一种表达一系列新授权概念的方式。未来,这将成为附加身份验证功能的基础,例如STS和组策略等
- RGW通过使用rados命名空间合并了几个元数据索引池
- 引入组件rbd-mirror,负责RBD卷的镜像复制
- rbd trash命令支持延迟的镜像删除
- 镜像可以通过rbd mirroringreplay delay配置选项支持可配置的复制延迟
- 多Active MDS到达稳定状态
- 引入一个新的、全功能和美观的仪表盘 Dashboard V2
- RADOS:配置选项可被mon中心化存储和管理
- RADOS:在恢复和再平衡时,mon使用的磁盘大大减小
- RADOS:引入一个异步恢复特性,减少在OSD从错误恢复期间,请求的tail latency
- RGW:支持将一个Zone(或者Buckets的子集)复制到外部云服务,例如S3
- RGW:支持S3多因子身份验证
- RGW:前端Beast到达stable
- CephFS:使用多MDS时快照功能到达stable
- RBD:镜像克隆不需要显式的protect/unprotect步骤
- RBD:镜像支持深克隆(包含parent镜像、关联快照的数据的克隆)到新池,支持修改数据布局
- 仪表盘:增加很多新功能,全方位的查看各种指标,对Ceph进行管理
- RADOS:每个池的PG数量 ,现在可以随时减小了。集群可以根据用量和管理员的提示,自动优化PG数量
- RADOS:v2 wire protocol支持传输加密
- RADOS:mon/osd使用的物理设备的健康指标(例如SMART)可以得到跟踪,并且在预期出现磁盘失败前进行警告
- RADOS:在recovery/backfill时,OSD更有效的优先恢复重要的PG、对象
- RADOS:例如磁盘失败后的恢复,这样长期运行的后台操作的进度,在ceph status中报告
- RGW:Beast替换civetweb作为默认Web前端
- CephFS:MDS稳定性得到很大优化,特别是针对大缓存、长时间运行的具有大内存的客户端
- CephFS:在Rook管理的环境下,CephFS可以通过NFS-Ganesha集群暴露出去
- CephFS:支持查询进行中的针对MDS的scrub的进度
- RBD:镜像可以在最小宕机时间内进行迁移,这可以支持在池之间迁移镜像、修改镜像布局
- RBD:rbd perf image iotop 以及 rbd perf image iostat命令可以提供iostat风格的、针对所有RBD镜像的监控
- RBD:ceph-mgr的Prometheus Exporter支持暴露所有RBD镜像的IO监控指标
- RBD:在一个池中,可以使用命名空间来隔离RBD,实现多租户
- 新的工具cephadm,用于支持容器化部署
- Health警告可以被临时/永久的静默
- Dashboard:UI增强、安全性增强
- 管理功能的增强
- RADOS:从N版引入的PG括缩,默认启用
- RADOS:Bluestore包含了多项改进和性能增强
- RBD:镜像支持一种新的,基于快照的模式,不再依赖于journaling特性
- RBD:克隆操作保持源镜像的稀疏性(sparseness)
- RBD:改进了rbd-nbd 工具,可以使用新的内核特性
- RBD:缓存性能增强
创建新CephFS报错Error EINVAL: pool 'rbd-ssd' already contains some objects. Use an empty pool instead,解决办法:
|
1 |
ceph fs new cephfs rbd-ssd rbd-hdd --force |
断电后出现此问题。MDS进程报错: Error recovering journal 0x200: (5) Input/output error。诊断过程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 |
# 健康状况 ceph health detail # HEALTH_ERR mds rank 0 is damaged; mds cluster is degraded # mds.0 is damaged # 文件系统详细信息,可以看到唯一的MDS Boron启动不了 ceph fs status # cephfs - 0 clients # ====== # +------+--------+-----+----------+-----+------+ # | Rank | State | MDS | Activity | dns | inos | # +------+--------+-----+----------+-----+------+ # | 0 | failed | | | | | # +------+--------+-----+----------+-----+------+ # +---------+----------+-------+-------+ # | Pool | type | used | avail | # +---------+----------+-------+-------+ # | rbd-ssd | metadata | 138k | 106G | # | rbd-hdd | data | 4903M | 2192G | # +---------+----------+-------+-------+ # +-------------+ # | Standby MDS | # +-------------+ # | Boron | # +-------------+ # 显示错误原因 ceph tell mds.0 damage # terminate called after throwing an instance of 'std::out_of_range' # what(): map::at # Aborted # 尝试修复,无效 ceph mds repaired 0 # 尝试导出CephFS日志,无效 cephfs-journal-tool journal export backup.bin # 2019-10-17 16:21:34.179043 7f0670f41fc0 -1 Header 200.00000000 is unreadable # 2019-10-17 16:21:34.179062 7f0670f41fc0 -1 journal_export: Journal not readable, attempt object-by-object dump with `rados`Error ((5) Input/output error) # 尝试重日志修复,无效 # 尝试将journal中所有可回收的 inodes/dentries 写到后端存储(如果版本比后端更高) cephfs-journal-tool event recover_dentries summary # Events by type: # Errors: 0 # 2019-10-17 16:22:00.836521 7f2312a86fc0 -1 Header 200.00000000 is unreadable # 尝试截断日志,无效 cephfs-journal-tool journal reset # got error -5from Journaler, failing # 2019-10-17 16:22:14.263610 7fe6717b1700 0 client.6494353.journaler.resetter(ro) error getting journal off disk # Error ((5) Input/output error) # 删除重建,数据丢失 ceph fs rm cephfs --yes-i-really-mean-it ## 又一次遇到此问题 # 深度清理,发现200.00000000存在数据不一致 ceph osd deep-scrub all 40.14 shard 14: soid 40:292cf221:::200.00000000:head data_digest 0x6ebfd975 != data_digest 0x9e943993 from auth oi 40:292cf221:::200.00000000:head (22366'34 mds.0.902:1 dirty|data_digest|omap_digest s 90 uv 34 dd 9e943993 od ffffffff alloc_hint [0 0 0]) 40.14 deep-scrub 0 missing, 1 inconsistent objects 40.14 deep-scrub 1 errors # 查看RADOS不一致对象详细信息 rados list-inconsistent-obj 40.14 --format=json-pretty { "epoch": 23060, "inconsistents": [ { "object": { "name": "200.00000000", }, "errors": [], "union_shard_errors": [ # 错误原因,校验信息不一致 "data_digest_mismatch_info" ], "selected_object_info": { "oid": { "oid": "200.00000000", }, }, "shards": [ { "osd": 7, "primary": true, "errors": [], "size": 90, "omap_digest": "0xffffffff" }, { "osd": 14, "primary": false, # errors:分片之间存在不一致,而且无法确定哪个分片坏掉了,原因: # data_digest_mismatch 此副本的摘要信息和主副本不一样 # size_mismatch 此副本的数据长度和主副本不一致 # read_error 可能存在磁盘错误 "errors": [ # 这里的原因是两个副本的摘要不一致 "data_digest_mismatch_info" ], "size": 90, "omap_digest": "0xffffffff", "data_digest": "0x6ebfd975" } ] } ] } # 转为处理inconsistent问题,停止OSD.14,Flush 日志,启动OSD.14,执行PG修复 # 无效…… 执行PG修复后Ceph会自动以权威副本覆盖不一致的副本,但是并非总能生效, # 例如,这里的情况,主副本的数据摘要信息丢失 # 删除故障对象 rados -p rbd-ssd rm 200.00000000 |
通常可以认为属于Ceph的Bug。这些Bug可能因为数据状态引发,有些时候将崩溃OSD的权重清零,可以恢复:
|
1 2 |
# 尝试解决osd.17启动后立即宕机 ceph osd reweight 17 0 |
如果创建一个存储池后,其所有PG都卡在此状态,可能原因是CRUSH map不正常。你可以配置osd_crush_update_on_start为true让集群自动调整CRUSH map。
ceph -s显示如下状态,长期不恢复:
|
1 2 3 4 5 6 7 8 |
cluster: health: HEALTH_WARN Reduced data availability: 2 pgs inactive, 2 pgs peering 19 slow requests are blocked > 32 sec data: pgs: 0.391% pgs not active 510 active+clean 2 peering |
此案例中,使用此PG的Pod呈Known状态。
检查卡在inactive状态的PG:
|
1 2 3 4 5 |
ceph pg dump_stuck inactive PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY 17.68 peering [3,12] 3 [3,12] 3 16.32 peering [4,12] 4 [4,12] 4 |
输出其中一个PG的诊断信息,片断如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
// ceph pg 17.68 query { "info": { "stats": { "state": "peering", "stat_sum": { "num_objects_dirty": 5 }, "up": [ 3, 12 ], "acting": [ 3, 12 ], // 因为哪个OSD而阻塞 "blocked_by": [ 12 ], "up_primary": 3, "acting_primary": 3 } }, "recovery_state": [ // 如果顺利,第一个元素应该是 "name": "Started/Primary/Active" { "name": "Started/Primary/Peering/GetInfo", "enter_time": "2018-06-11 18:32:39.594296", // 但是,卡在向OSD 12 请求信息这一步上 "requested_info_from": [ { "osd": "12" } ] }, { "name": "Started/Primary/Peering", }, { "name": "Started", } ] } |
没有获得osd-12阻塞Peering的明确原因。
查看日志,osd-12位于10.0.0.104,osd-3位于10.0.0.100,后者为Primary OSD。
osd-3日志,在18:26开始出现,和所有其它OSD之间心跳检测失败。此时10.0.0.100负载很高,卡死。
osd-12日志,在18:26左右大量出现:
|
1 |
osd.12 466 heartbeat_check: no reply from 10.0.0.100:6803 osd.4 since back 2018-06-11 18:26:44.973982 ... |
直到18:44分仍然无法进行心跳检测,重启osd-12后一切恢复正常。
检查无法完成的PG:
|
1 2 3 4 5 6 7 |
ceph pg dump_stuck # PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY # 17.79 incomplete [9,17] 9 [9,17] 9 # 32.1c incomplete [16,9] 16 [16,9] 16 # 17.30 incomplete [16,9] 16 [16,9] 16 # 31.35 incomplete [9,17] 9 [9,17] 9 |
查询PG 17.30的诊断信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
// ceph pg 17.30 query { "state": "incomplete", "info": { "pgid": "17.30", "stats": { // 被osd.11阻塞而无法完成,此osd已经不存在 "blocked_by": [ 11 ], "up_primary": 16, "acting_primary": 16 } }, // 恢复的历史记录 "recovery_state": [ { "name": "Started/Primary/Peering/Incomplete", "enter_time": "2018-06-17 04:48:45.185352", // 最终状态,此PG没有完整的副本 "comment": "not enough complete instances of this PG" }, { "name": "Started/Primary/Peering", "enter_time": "2018-06-17 04:48:45.131904", "probing_osds": [ "9", "16", "17" ], // 期望检查已经不存在的OSD "down_osds_we_would_probe": [ 11 ], "peering_blocked_by_detail": [ { "detail": "peering_blocked_by_history_les_bound" } ] } ] } |
可以看到17.30期望到osd.11寻找权威数据,而osd.11已经永久丢失了。这种情况下,可以尝试强制标记PG为complete。
首先,停止PG的主OSD: service ceph-osd@16 stop
然后,运行下面的工具:
|
1 2 3 |
ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-16 --pgid 17.30 --op mark-complete # Marking complete # Marking complete succeeded |
最后,重启PG的主OSD: service ceph-osd@16 start
不做副本的情况下,单个OSD宕机即导致数据不可用:
|
1 2 3 4 5 |
ceph health detail # 注意Acting Set仅仅有一个成员 # pg 2.21 is stuck stale for 688.372740, current state stale+active+clean, last acting [7] # 但是其它PG的Acting Set则不是 # pg 3.4f is active+recovering+degraded, acting [9,1] |
如果OSD的确出现硬件故障,则数据丢失。此外,你也无法对这种PG进行查询操作。
定位出问题PG的主OSD,停止它,刷出日志,然后修复PG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ceph health detail # HEALTH_ERR 2 scrub errors; Possible data damage: 2 pgs inconsistent # OSD_SCRUB_ERRORS 2 scrub errors # PG_DAMAGED Possible data damage: 2 pgs inconsistent # pg 15.33 is active+clean+inconsistent, acting [8,9] # pg 15.61 is active+clean+inconsistent, acting [8,16] # 查找OSD所在机器 ceph osd find 8 # 登陆到osd.8所在机器 systemctl stop ceph-osd@8.service ceph-osd -i 8 --flush-journal systemctl start ceph-osd@8.service ceph pg repair 15.61 |
持有对象权威副本的OSD宕机或被剔除,会导致该问题出现。例如两个配对的OSD(共同处理某个PG):
- osd.1宕机
- osd.2独自处理了一些写操作
- osd1开机
- osd.1+osd2配对,由于osd.2独自的写操作,缺失的对象排队等候在osd.1上恢复
- 恢复完成之前,osd.2宕机,或者被移除
在上面这个事件序列中,osd.1知道权威副本存在,但是却找不到,这种情况下针对目标对象的请求会被阻塞,直到权威副本的持有者osd上线。
执行下面的命令,定位存在问题的PG:
|
1 2 3 4 |
ceph health detail | grep unfound # OBJECT_UNFOUND 1/90055 objects unfound (0.001%) # pg 33.3e has 1 unfound objects # pg 33.3e is active+recovery_wait+degraded, acting [17,6], 1 unfound |
进一步,定位存在问题的对象:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
// ceph pg 33.3e list_missing { "offset": { "oid": "", "key": "", "snapid": 0, "hash": 0, "max": 0, "pool": -9223372036854775808, "namespace": "" }, "num_missing": 1, "num_unfound": 1, "objects": [ { "oid": { // 丢失的对象 "oid": "obj_delete_at_hint.0000000066", "key": "", "snapid": -2, "hash": 2846662078, "max": 0, "pool": 33, "namespace": "" }, "need": "1723'1412", "have": "0'0", "flags": "none", "locations": [] } ], "more": false } |
如果丢失的对象太多,more会显示为true。
执行下面的命令,可以查看PG的诊断信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// ceph pg 33.3e query { "state": "active+recovery_wait+degraded", "recovery_state": [ { "name": "Started/Primary/Active", "enter_time": "2018-06-16 15:03:32.873855", // 丢失的对象所在的OSD "might_have_unfound": [ { "osd": "6", "status": "already probed" }, { "osd": "11", "status": "osd is down" } ], } ] } |
上面输出中的osd.11,先前已经出现硬件故障,被移除了。这意味着unfound的对象已经不可恢复。你可以标记:
|
1 2 3 4 |
# 回滚到前一个版本,如果是新创建对象则忘记其存在。不支持EC池 ceph pg 33.3e mark_unfound_lost revert # 让Ceph忘记unfound对象的存在 ceph pg 33.3e mark_unfound_lost delete |
/usr/lib/python2.7/dist-packages/ceph_deploy/osd.py第376行,替换为:
|
1 |
LOG.info(line.decode('utf-8')) |
应该安装ceph-deploy的1.5.39版本,2.0.0版本仅仅支持luminous:
|
1 2 |
apt remove ceph-deploy apt install ceph-deploy=1.5.39 -y |
在我的环境下,是因为MON节点识别的public addr为LVS的虚拟网卡的IP地址导致。修改配置,显式指定MON的IP地址即可:
|
1 2 3 4 5 6 7 8 9 10 11 |
[mon.master01-10-5-38-24] public addr = 10.5.38.24 cluster addr = 10.5.38.24 [mon.master02-10-5-38-39] public addr = 10.5.38.39 cluster addr = 10.5.38.39 [mon.master03-10-5-39-41] public addr = 10.5.39.41 cluster addr = 10.5.39.41 |
在我的环境下部署,出现一系列和权限有关的问题,如果你遇到相同问题且不关心安全性,可以修改配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# kubectl -n ceph edit configmap ceph-etc apiVersion: v1 data: ceph.conf: | [global] fsid = 08adecc5-72b1-4c57-b5b7-a543cd8295e7 mon_host = ceph-mon.ceph.svc.k8s.gmem.cc # 添加以下三行 auth client required = none auth cluster required = none auth service required = none [osd] # 在大型集群里用单独的“集群”网可显著地提升性能 cluster_network = 10.0.0.0/16 ms_bind_port_max = 7100 public_network = 10.0.0.0/16 kind: ConfigMap |
如果需要保证集群安全,请参考下面几个案例。
问题现象:
此Pod一直无法启动,查看容器日志,发现:
timeout 10 ceph --cluster ceph auth get-or-create mgr.xenial-100 mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mgr/ceph-xenial-100/keyring
0 librados: client.admin authentication error (1) Operation not permitted
问题分析:
连接到可以访问的ceph-mon,执行命令:
|
1 |
kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon -- ceph |
发现报同样的错误。这说明client.admin的Keyring有问题。登陆到ceph-mon,获取Keyring列表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon bash # ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth list installed auth entries: client.admin key: AQAXPdtaAAAAABAA6wd1kCog/XtV9bSaiDHNhw== auid: 0 caps: [mds] allow caps: [mgr] allow * caps: [mon] allow * caps: [osd] allow * client.bootstrap-mds key: AQAgPdtaAAAAABAAFPgqn4/zM5mh8NhccPWKcw== caps: [mon] allow profile bootstrap-mds client.bootstrap-osd key: AQAUPdtaAAAAABAASbfGQ/B/PY4Imoa4Gxsa2Q== caps: [mon] allow profile bootstrap-osd client.bootstrap-rgw key: AQAJPdtaAAAAABAAswtFjgQWahHsuy08Egygrw== caps: [mon] allow profile bootstrap-rgw |
而当前使用的client.admin的Keyring内容为:
|
1 2 3 4 5 6 7 |
[client.admin] key = AQAda9taAAAAABAAgWIsgbEiEsFRJQq28hFgTQ== auid = 0 caps mds = "allow" caps mon = "allow *" caps osd = "allow *" caps mgr = "allow *" |
内容不一致。使用auth list获得的client.admin的Keyring,可以发现是有效的:
|
1 2 |
ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth get client.admin > client.admin.keyyring ceph --name client.admin --keyring client.admin.keyyring # OKskydns_skydns_dns_cachemiss_count_total{instance="172.27.100.134:10055"} |
检查一下各Pod的/etc/ceph/ceph.client.admin.keyring,可以发现都是从Secret ceph-client-admin-keyring挂载的。那么这个Secret是如何生成的呢?执行命令:
|
1 |
kubectl -n ceph get job --output=yaml --export | grep ceph-client-admin-keyring -B 50 |
可以发现Job ceph-storage-keys-generator负责生成该Secret。 查看其Pod日志可以生成Keyring、创建Secret的记录。进一步查看Pod的资源定义,可以看到负责创建的脚本/opt/ceph/ceph-storage-key.sh挂载自ConfigMap ceph-bin中的ceph-storage-key.sh。
解决此问题最简单的办法就是修改Secret,将其修改为集群中实际有效的Keyring:
|
1 2 3 4 5 6 |
# 导出Secret定义 kubectl -n ceph get secret ceph-client-admin-keyring --output=yaml --export > ceph-client-admin-keyring # 获得有效Keyring的Base64编码 cat client.admin.keyyring | base64 # 将Secret中的编码替换为上述Base64,然后重新创建Secret kubectl -n ceph apply -f ceph-client-admin-keyring |
此外Secret pvc-ceph-client-key中存放的也是admin用户的Key,其内容也需要替换到有效的:
|
1 |
kubectl -n ceph edit secret pvc-ceph-client-key |
原因和上一个问题类似,还是权限问题。
查看无法绑定的PVC日志:
|
1 2 3 4 5 6 7 8 |
# kubectl -n ceph describe pvc Normal Provisioning 53s ceph.com/rbd ceph-rbd-provisioner-5544dcbcf5-n846s 708edb2c-4619-11e8-abf2-e672650d97a2 External provisioner is provisioning volume for claim "ceph/ceph-pvc" Warning ProvisioningFailed 53s ceph.com/rbd ceph-rbd-provisioner-5544dcbcf5-n846s 708edb2c-4619-11e8-abf2-e672650d97a2 Failed to provision volume with StorageClass "general" : failed to create rbd image: exit status 1, command output: 2018-04-22 13:44:35.269967 7fb3e3e3ad80 -1 did not load config file, using default settings. 2018-04-22 13:44:35.297828 7fb3e3e3ad80 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin: (2) No such file or directoryConnection to localhost closed by remote host. Connection to localhost closed.e3e3ad80 0 librados: client.admin authentication error (1) Operation not permitted |
rbd-provisioner需要读取StorageClass定义,获取需要的凭证信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# kubectl -n ceph get storageclass --output=yaml apiVersion: v1 items: - apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: general parameters: adminId: admin adminSecretName: pvc-ceph-conf-combined-storageclass adminSecretNamespace: ceph imageFeatures: layering imageFormat: "2" monitors: ceph-mon.ceph.svc.k8s.gmem.cc:6789 pool: rbd userId: admin userSecretName: pvc-ceph-client-key provisioner: ceph.com/rbd reclaimPolicy: Delete |
可以看到牵涉到两个Secret:pvc-ceph-conf-combined-storageclass、pvc-ceph-client-key,你需要把正确的Keyring内容写入其中。
症状:PVC可以Provision,RBD可以通过Ceph命令挂载,但是Pod无法启动,Describe之显示:
auth: unable to find a keyring on /etc/ceph/keyring: (2) No such file or directory
monclient(hunting): authenticate NOTE: no keyring found; disabled cephx authentication
librados: client.admin authentication error (95) Operation not supported
解决办法:把ceph.client.admin.keyring拷贝一份为 /etc/ceph/keyring即可。
原因和上一个问题一样。查看无法启动的容器日志:
|
1 2 3 4 |
kubectl -n ceph logs ceph-osd-dev-vdb-bjnbm -c osd-prepare-pod # ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring health # 0 librados: client.bootstrap-osd authentication error (1) Operation not permitted # [errno 1] error connecting to the cluster |
进一步查看,可以发现/var/lib/ceph/bootstrap-osd/ceph.keyring挂载自ceph-bootstrap-osd-keyring下的ceph.keyring:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# kubectl -n ceph get secret ceph-bootstrap-osd-keyring --output=yaml --export apiVersion: v1 data: ceph.keyring: W2NsaWVudC5ib290c3RyYXAtb3NkXQogIGtleSA9IEFRQVlhOXRhQUFBQUFCQUFSQ2l1bVY1NFpOU2JGVWwwSDZnYlJ3PT0KICBjYXBzIG1vbiA9ICJhbGxvdyBwcm9maWxlIGJvb3RzdHJhcC1vc2QiCgo= kind: Secret metadata: creationTimestamp: null name: ceph-bootstrap-osd-keyring selfLink: /api/v1/namespaces/ceph/secrets/ceph-bootstrap-osd-keyring type: Opaque # BASE64解码后: [client.bootstrap-osd] key = AQAYa9taAAAAABAARCiumV54ZNSbFUl0H6gbRw== caps mon = "allow profile bootstrap-osd" |
获得实际有效的Keyring:
|
1 2 3 4 5 |
kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon -- ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth get client.bootstrap-osd # 注意上述命令的输出的第一行exported keyring for client.bootstrap-osd不属于Keyring [client.bootstrap-osd] key = AQAUPdtaAAAAABAASbfGQ/B/PY4Imoa4Gxsa2Q== caps mon = "allow profile bootstrap-osd" |
修改Secret: kubectl -n ceph edit secret ceph-bootstrap-osd-keyring 替换为上述Keyring。
报错信息:
|
1 2 3 |
# kubectl -n ceph logs ceph-osd-dev-vdc-cpkxh -c osd-activate-pod ceph_disk.main.Error: Error: No cluster conf found in /etc/ceph with fsid 08adecc5-72b1-4c57-b5b7-a543cd8295e7 # 每个OSD都包同样的错误 |
对应的配置文件内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kubectl -n ceph get configmap ceph-etc --output=yaml apiVersion: v1 data: ceph.conf: | [global] fsid = a4426e8a-c46d-4407-95f1-911a23a0dd6e mon_host = ceph-mon.ceph.svc.k8s.gmem.cc [osd] cluster_network = 10.0.0.0/16 ms_bind_port_max = 7100 public_network = 10.0.0.0/16 kind: ConfigMap metadata: name: ceph-etc namespace: ceph |
可以看到,fsid不一致。修改一下ConfigMap中的fsid即可解决此问题。
报错信息:
describe pod报错:timeout expired waiting for volumes to attach/mount for pod
kubelet报错:executable file not found in $PATH, rbd output
原因分析:动态提供的持久卷,包含两个阶段:
- 卷提供,原本由控制平面负责,controller-manager中需要包含rbd命令,才能在Ceph集群中创建供K8S使用的镜像。目前这个职责由external_storage项目的rbd-provisioner完成
- 卷依附/分离,由使用卷的Pod所在的Node的kubelet负责完成。这些Node需要安装rbd命令,并提供有效的配置文件
解决方案:
|
1 2 3 4 5 |
# 安装软件 apt install -y ceph-common # 从ceph-mon拷贝以下文件: # /etc/ceph/ceph.client.admin.keyring # /etc/ceph/ceph.conf |
应用上述方案后,如果继续报错:rbd: map failed exit status 110, rbd output: rbd: sysfs write failed In some cases useful info is found in syslog。则查看一下系统日志:
|
1 2 3 4 5 |
dmesg | tail # [ 3004.833252] libceph: mon0 10.0.0.100:6789 feature set mismatch, my 106b84a842a42 # < server's 40106b84a842a42, missing 400000000000000 # [ 3004.840980] libceph: mon0 10.0.0.100:6789 missing required protocol features |
对照本文前面的特性表,可以发现内核版本必须4.5+才可以(CEPH_FEATURE_NEW_OSDOPREPLY_ENCODING)。
最简单的办法就是升级一下内核:
|
1 2 3 4 5 6 7 8 9 |
# Desktop apt install --install-recommends linux-generic-hwe-16.04 xserver-xorg-hwe-16.04 -y # Server apt install --install-recommends linux-generic-hwe-16.04 -y sudo apt-get remove linux-headers-4.4.* -y && \ sudo apt-get remove linux-image-4.4.* -y && \ sudo apt-get autoremove -y && \ sudo update-grub |
或者,将tunables profile调整到hammer版本的Ceph:
|
1 2 |
ceph osd crush tunables hammer # adjusted tunables profile to hammer |
报错信息:ERROR: osd init failed: (36) File name too long
报错原因:使用的文件系统为EXT4,存储的xattrs大小有限制,有条件的话最好使用XFS
解决办法:修改配置文件,如下:
|
1 2 |
osd_max_object_name_len = 256 osd_max_object_namespace_len = 64 |
报错信息:Fail to open '/proc/0/cmdline' error No such file or directory
报错原因:在CentOS 7上,将ceph-mon和ceph-osd(基于目录)部署在同一节点(基于Helm)报此错误,分离后问题消失。此外部署mon的那些节点还设置了虚IP,其子网和Ceph的Cluster/Public网络相同,这导致了某些OSD监听的地址不正确。
再次遇到此问题,原因是一个虚拟网卡lo:ngress使用和eth0相同的网段,导致OSD使用了错误的网络。
解决办法是写死OSD监听地址:
|
1 2 3 |
[osd.2] public addr = 10.0.4.1 cluster addr = 10.0.4.1 |
报错信息:Input/output error,结合dmesg | tail可以看到更细节的报错
报错原因,可能情况:
- CentOS7下报错,提示客户端不满足特性CEPH_FEATURE_CRUSH_V4(1000000000000)。解决办法,将Bucket算法改为straw。注意,之后加入的OSD仍然默认使用straw2,使用的镜像的标签为tag-build-master-luminous-ubuntu-16.04。
external storage中的CephFS可以正常Provisioning,但是尝试读写数据时报此错误。原因是文件路径过长,和底层文件系统有关,为了兼容部分Ext文件系统的机器,我们限制了osd_max_object_name_len。
解决办法,不使用UUID,而使用namespace + pvcname来命名目录。修改cephfs-provisioner.go,118行:
|
1 2 3 4 |
// create random share name share := fmt.Sprintf("%s-%s", options.PVC.Namespace,options.PVC.Name) // create random user id user := fmt.Sprintf("%s-%s", options.PVC.Namespace,options.PVC.Name) |
重新编译即可。
describe pod发现:
|
1 |
rbd image rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 is still being used |
说明有其它客户端正在占用此镜像。如果尝试删除镜像,你会发现无法成功:
|
1 2 3 4 5 6 |
rbd rm rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 librbd::image::RemoveRequest: 0x560e39df9af0 check_image_watchers: image has watchers - not removing Removing image: 0% complete...failed. rbd: error: image still has watchers This means the image is still open or the client using it crashed. Try again after closing/unmapping it or waiting 30s for the crashed client to timeout. |
要知道watcher是谁,可以执行:
|
1 2 3 |
rbd status rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 Watchers: watcher=10.5.39.12:0/1652752791 client.94563 cookie=18446462598732840961 |
可以发现10.5.39.12正在占用镜像。
另一种获取watcher的方法是,使用rbd的header对象。执行下面的命令获取rbd的诊断信息:
|
1 2 3 4 5 6 7 8 9 10 |
rbd info rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 rbd image 'kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6': size 8192 MB in 2048 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.134474b0dc51 format: 2 features: layering flags: create_timestamp: Wed Jul 11 17:49:51 2018 |
字段block_name_prefix的值rbd_data.134474b0dc51,将data换为header即为header对象。然后使用命令:
|
1 2 3 |
rados listwatchers -p rbd-unsafe rbd_header.134474b0dc51 watcher=10.5.39.12:0/1652752791 client.94563 cookie=18446462598732840961 |
既然知道10.5.39.12占用镜像,断开连接即可。 在此机器上执行下面的命令,显示当前映射的rbd镜像列表:
|
1 2 3 4 5 |
rbd showmapped id pool image snap device 0 rbd-unsafe kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 - /dev/rbd0 1 rbd-unsafe kubernetes-dynamic-pvc-0729f9a6-84f0-11e8-9b75-5a3f858854b1 - /dev/rbd1 |
此机器上的rbd0虽然映射,但是没有挂载。解除映射:
|
1 |
rbd unmap /dev/rbd0 |
再次检查rbd镜像状态,发现没有watcher了:
|
1 2 3 |
rbd status rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 Watchers: none |
kubectl describe报错Unable to mount volumes for pod... timeout expired waiting for volumes to attach or mount for pod...
检查发现目标rbd没有Watcher,Pod所在机器的Kubectl报错rbd: map failed signal: aborted (core dumped)。此前曾经在该机器上执行过rbd unmap操作。
手工 rbd map后问题消失。
报错信息:journal do_read_entry(156389376): bad header magic......FAILED assert(interval.last > last)
这是12.2版本已知的BUG,断电后可能出现OSD无法启动,可能导致数据丢失。
RGW实例无法启动,通过journalctl看到上述信息。
要查看更多信息,需要查看RGW日志:
|
1 2 3 |
2020-10-22 16:51:55.771035 7fb1b0f20e80 0 ceph version 12.2.5 (cad919881333ac92274171586c827e01f554a70a) luminous (stable), process (unknown), pid 2546439 2020-10-22 16:51:55.792872 7fb1b0f20e80 0 librados: client.rgw.ceph02 authentication error (22) Invalid argument 2020-10-22 16:51:55.793450 7fb1b0f20e80 -1 Couldn't init storage provider (RADOS) |
可以发现是和身份验证有关的问题。
通过 systemctl status ceph-radosgw@rgw.$RGW_HOST得到命令行,手工运行:
|
1 |
radosgw -f --cluster ceph --name client.rgw.ceph02 --setuser ceph --setgroup ceph -d --debug_ms 1 |
发现报错和上面一样。尝试增加--keyring参数,问题解决:
|
1 2 3 |
radosgw -f --cluster ceph --name client.rgw.ceph02 \ --setuser ceph --setgroup ceph -d --debug_ms 1 \ --keyring=/var/lib/ceph/radosgw/ceph-rgw.ceph02/keyring |
看来是Systemd服务没有找到keyring导致。
报错信息:Unhandled exception from module 'prometheus' while running on mgr.master01-10-5-38-24: error('No socket could
be created',)
解决办法: ceph config-key set mgr/prometheus/server_addr 0.0.0.0
原因是时钟不同步警告阈值太低,在global段增加配置并重启MON:
|
1 2 |
mon clock drift allowed = 2 mon clock drift warn backoff = 30 |
或者执行下面的命令即时生效:
|
1 2 |
ceph tell mon.* injectargs '--mon_clock_drift_allowed=2' ceph tell mon.* injectargs '--mon_clock_drift_warn_backoff=30' |
或者检查ntp相关配置,保证时钟同步精度。
深度清理很消耗IO,如果长时间无法完成,可以禁用:
|
1 2 |
ceph osd set noscrub ceph osd set nodeep-scrub |
问题解决后,可以再启用:
|
1 2 |
ceph osd unset noscrub ceph osd unset nodeep-scrub |
使用CFQ作为IO调度器时,可以调整OSD IO线程的优先级:
|
1 2 3 4 5 6 7 8 9 10 |
# 设置调度器 echo cfq > /sys/block/sda/queue/scheduler # 检查当前某个OSD的磁盘线程优先级类型 ceph daemon osd.4 config get osd_disk_thread_ioprio_class # 修改IO优先级 ceph tell osd.* injectargs '--osd_disk_thread_ioprio_priority 7' # IOPRIO_CLASS_RT最高 IOPRIO_CLASS_IDLE最低 ceph tell osd.* injectargs '--osd_disk_thread_ioprio_class idle' |
如果上述措施没有问题时,可以考虑配置以下参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
osd_deep_scrub_stride = 131072 # 每次Scrub的块数量范围 osd_scrub_chunk_min = 1 osd_scrub_chunk_max = 5 osd scrub during recovery = false osd deep scrub interval = 2592000 osd scrub max interval = 2592000 # 单个OSD并发进行的Scrub个数 osd max scrubs = 1 # Scrub起止时间 osd max begin hour = 2 osd max end hour = 6 # 系统负载超过多少则禁止Scrub osd scrub load threshold = 4 # 每次Scrub后强制休眠0.1秒 osd scrub sleep = 0.1 # 线程优先级 osd disk thread ioprio priority = 7 osd disk thread ioprio class = idle |
如果Watcher被黑名单,则尝试Unmap镜像时会报错:rbd: sysfs write failed rbd: unmap failed: (16) Device or resource busy
可以使用下面的命令强制unmap: rbd unmap -o force ...
部分PG状态卡死,可能原因是OSD允许的PG数量受限,修改全局配置项mon_max_pg_per_osd并重启MON即可。
此外注意:调整PG数量后,一定要进入A+C状态后,再进行下一次调整。
下面第二个镜像对应的K8S PV已经删除:
|
1 2 3 |
rbd ls # kubernetes-dynamic-pvc-35350b13-46b8-11e8-bde0-a2c14c93573f # kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4 |
但是对应的RBD没有删除,手工删除:
|
1 |
rbd remove kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4 |
报错:
2018-04-23 13:37:25.559444 7f919affd700 -1 librbd::image::RemoveRequest: 0x5598e77831d0 check_image_watchers: image has watchers - not removing
Removing image: 0% complete...failed.
rbd: error: image still has watchers
This means the image is still open or the client using it crashed. Try again after closing/unmapping it or waiting 30s for the crashed client to timeout.
查看RBD状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# rbd info kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4 rbd image 'kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4': size 8192 MB in 2048 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.1003e238e1f29 format: 2 features: layering flags: create_timestamp: Mon Apr 23 11:42:59 2018 #rbd status kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4 Watchers: watcher=10.0.0.101:0/4275384344 client.65597 cookie=18446462598732840963 |
到10.0.0.101这台机器上查看:
|
1 2 |
# df | grep e6e3339859d4 /dev/rbd2 8125880 251560 7438508 4% /var/lib/kubelet/plugins/kubernetes.io/rbd/rbd/rbd-image-kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4 |
重启Kubelet后可以删除RBD。
|
1 2 3 4 |
# 删除密钥 ceph auth del osd.9 # 重新收集目标主机的密钥 ceph-deploy --username ceph-ops gatherkeys Carbon |
|
1 2 3 4 5 |
pgs: 12.413% pgs unknown 20.920% pgs not active 768 active+clean 241 creating+activating 143 unknown |
可能是由于PG总数太大导致,降低PG数量后很快Active+Clean
报错信息:Orphaned pod "a9621c0e-41ee-11e8-9407-deadbeef00a0" found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them
临时解决办法:
rm -rf /var/lib/kubelet/pods/a9621c0e-41ee-11e8-9407-deadbeef00a0/volumes/rook.io~rook/
可能原因是OSD使用的keyring和MON不一致。对于ID为14的OSD,将宿主机/var/lib/ceph/osd/ceph-14/keyring的内容替换为 ceph auth get osd.14的输出前两行即可。
在没有停止OSD的情况下执行ceph-objectstore-tool命令,会出现此错误。
通过ceph-deploy添加MON节点时出现此错误,将public_network配置添加到配置文件的global段即可。
可能原因:
- 对应的PVC没有删除,还在引用此PV。先删除PV即可
OSD无法启动,报上面的错误,可以配置:
|
1 2 3 |
ceph: storage: osd_log: /var/log |
|
1 2 |
#池 # 功能 ceph osd pool application enable rbd block-devices |
Leave a Reply