Linux内核学习笔记(一)
| 代码目录 | 说明 |
| arch | 特定体系结构的代码 |
| block | 块I/O层 |
| crypto | 加密API |
| Documentation | 内核源代码文档 |
| drivers | 设备驱动 |
| firmware | 特定驱动需要的设备固件 |
| fs | VFS和各文件系统 |
| include | 内核头文件 |
| init | 内核启动和初始化 |
| ipc | 进程间通信的代码 |
| kernel | 核心子系统,例如进程调度器 |
| lib | 助手类例程 |
| mm | 内存管理子系统和虚拟内存 |
| net | 网络子系统 |
| samples | 样例代码 |
| scripts | 用于构建内核的脚本 |
| security | Linux安全模块 |
| sound | 声音子系统 |
| usr | 早期的用户空间代码 |
| tools | 开发Linux时有用的工具 |
| virt | 虚拟化基础设施 |
Linux内核使用C语言和汇编编写,其涵盖了ISO C99标准和GNU C的扩展特性。内核编程具有以下特点:
- 内联函数:C99和GNU C都支持内联函数,内联函数会在调用位置展开,从而避免函数调用的开销(寄存器存储与恢复),但是会导致代码变长,一般适用于小型、反复使用的函数。定义内联函数时需要使用 static inline 修饰之,内联函数一般在头文件中定义。在内核中为了安全和易读性,优先使用内联函数而不是复杂的宏
- 编译器可以根据gcc内建指令对分支语句进行优化: if(likely(error)){...} ,likely和unlikely分别用于提示编译器,该分支经常或者很少运行
- 没有内存保护机制:与用户程序不同,内核代码不具有内存保护机制,因此访问非法的内存地址可能导致oops,导致内核崩溃。此外,内核中的内存也不分页,因此每用掉一个字节,可用物理内存就少一个字节
- 浮点运算困难:应当尽量避免在内核中进行浮点运算
- 容积小而固定的栈:用户空间的程序可以在栈上分配大量空间来存放变量,甚至巨大的结构体、长度以千计的数组,自所以允许这样做是因为用户空间的栈比较大而且支持动态增长。内核栈的大小随着体系结构而变化,在x86上栈的大小在编译时配置,可以是4kb或者8kb,一般配置为2个页。每个处理器都有自己的栈
- 同步和并发问题较多
- 可移植性很重要:由于Linux是可以在多个平台上移植的OS,因此需要注重可移植性
Unix类系统将进程和它正在执行的程序做了清晰的划分。 fork() 和 _exit() 系统调用分别用于创建和终结进程。而 exec() 类的系统调用则用来加载一个程序,一旦该系统调用执行,进程将加载全新的地址空间并继续执行。
大多数现代操作系统支持多线程应用程序。多线程应用程序由若干个相对独立的执行流(execution flow)构成。这些执行流被称为“线程”(Thread),或者“轻量级进程(LWP)”,线程们共享地址空间、物理内存页、打开文件。
很多商业Unix变体的LWP是基于内核线程(kernel threads)实现的,而Linux则不同,它把LWP作为基本的执行上下文(execution context)看待。这样,对于Linux来说,线程和进程没有本质区别。它们都可以通过非标准系统调用 clone() 生成。
进程就是处于执行状态的程序,进程不仅仅局限于一段可执行代码(Unix称其为代码段,Text Section),还包括其它重要的资源,例如打开的文件、挂起的信号、内核内部数据、处理器状态、一个或者多个具有内存映射的地址空间、一个或者多个执行线程、存放全局变量的数据段。
执行线程,简称线程,是在进程中活动的对象。每个线程具有一个独立的程序计数器、进程栈、一组进程寄存器。内核调度的对象是线程而不是进程,传统Unix系统中一个进程只有一个线程,现在多线程的程序司空见惯。Linux并不特别区分线程和进程。
现代OS提供了两种进程虚拟机制:
- 虚拟处理器:虽然可能很多进程在分享处理器,但是虚拟处理器给进程一个假象,好像是它自己在独享CPU
- 虚拟内存:让进程在分配和管理内存的时候,觉得自己拥有整个系统的所有内存资源
线程之间可能共享虚拟内存,但是必然有各自的虚拟处理器。
进程的生命周期从创建时开始,在Linux中,这是通过 fork() 调用实现的,fork()以当前进程为蓝本复制一个子进程。fork()调用从内核返回两次,一次回到父进程,一次回到子进程。通常fork()之后会立即调用 exec() 以替换当前进程,以创建新的地址空间并载入新的程序。现代Linux系统中,fork()由系统调用 clone() 实现。
Linux内核通常把进程称为任务(Task)。
Linux支持进程组(Process group)的概念,用以表示一种作业(Job)的抽象。例如,在Shell里面执行: ls | sort | more 后,Shell会自动为三个进程创建一个组,就好像它们是一个单独实体。进程描述符包含一个字段,用来指明它属于的进程组。每一个进程组可以有一个领头进程,它的PID和进程组的ID相同。新创建的进程最初加入到其父进程所在组中。
Linux同时支持登录会话(Login session)的概念,一个会话包括了在特定终端上启动工作会话的进程的全部子进程。一个登录会话可以有多个同时运作的进程组,其中只有一个进程组一直处于前台,该组可以访问终端。很多发行版使用bg/fg命令,来把一个进程组(作业)放到后台/前台。
内核将进程的列表存放在称为“Task list”的双向循环链表中,其每一项均是定义在include/linux/sched.h中的 task_struct 结构,该结构被称为进程描述符(Process descriptor)。该描述符能完整的描述一个正在执行的程序。 current 宏代表了当前正在执行的进程的描述符。
Linux通过slab分配器来分配task_struct结构,该分配器会预先分配、重复使用task_struct,以避免动态分配和释放所带来的资源消耗。在2.6以前的内核中,各进程的task_struct存放在它们内核栈的尾端。由于现在使用slab动态分配器生成task_struct,只需要在栈底(对于向下增长的栈)创建一个 struct thread_info 结构即可,该结构依据体系结构的不同,定义有所差异,x86的定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
struct thread_info { struct task_struct *task; /* main task structure */ struct exec_domain *exec_domain; /* execution domain */ __u32 flags; /* low level flags */ __u32 status; /* thread synchronous flags */ __u32 cpu; /* current CPU */ int preempt_count; /* 0 => preemptable, BUG */ mm_segment_t addr_limit; struct restart_block restart_block; void __user *sysenter_return; #ifdef CONFIG_X86_32 unsigned long previous_esp; /* ESP of the previous stack in case of nested (IRQ) stacks */ __u8 supervisor_stack[0]; #endif int uaccess_err; }; |
注意该结构的第一个成员变量 struct task_struct包含了进程状态的主要信息,这些状态会被进程调度器使用:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 |
struct task_struct { volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; int lock_depth; /* BKL lock depth */ int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; /* 进程调度实体 */ struct sched_rt_entity rt; unsigned char fpu_counter; unsigned int policy; cpumask_t cpus_allowed; struct list_head tasks; struct plist_node pushable_tasks; struct mm_struct *mm, *active_mm; /* task state */ int exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ /* ??? */ unsigned int personality; unsigned did_exec:1; unsigned in_execve:1; /* Tell the LSMs that the process is doing an * execve */ unsigned in_iowait:1; /* Revert to default priority/policy when forking */ unsigned sched_reset_on_fork:1; pid_t pid; pid_t tgid; /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->real_parent->pid) */ struct task_struct *real_parent; /* real parent process */ struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */ /* * children/sibling forms the list of my natural children */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */ /* * ptraced is the list of tasks this task is using ptrace on. * This includes both natural children and PTRACE_ATTACH targets. * p->ptrace_entry is p's link on the p->parent->ptraced list. */ struct list_head ptraced; struct list_head ptrace_entry; /* * This is the tracer handle for the ptrace BTS extension. * This field actually belongs to the ptracer task. */ struct bts_context *bts; /* PID/PID hash table linkage. */ struct pid_link pids[PIDTYPE_MAX]; struct list_head thread_group; struct completion *vfork_done; /* for vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ cputime_t utime, stime, utimescaled, stimescaled; cputime_t gtime; cputime_t prev_utime, prev_stime; unsigned long nvcsw, nivcsw; /* context switch counts */ struct timespec start_time; /* monotonic time */ struct timespec real_start_time; /* boot based time */ /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ unsigned long min_flt, maj_flt; struct task_cputime cputime_expires; struct list_head cpu_timers[3]; /* process credentials */ const struct cred *real_cred; /* objective and real subjective task * credentials (COW) */ const struct cred *cred; /* effective (overridable) subjective task * credentials (COW) */ struct mutex cred_guard_mutex; /* guard against foreign influences on * credential calculations * (notably. ptrace) */ struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */ char comm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by setup_new_exec */ /* file system info */ int link_count, total_link_count; /* CPU-specific state of this task */ struct thread_struct thread; /* filesystem information */ struct fs_struct *fs; /* open file information */ struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; /* signal handlers */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */ struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; int (*notifier)(void *priv); void *notifier_data; sigset_t *notifier_mask; struct audit_context *audit_context; seccomp_t seccomp; /* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, * mempolicy */ spinlock_t alloc_lock; /* Protection of the PI data structures: */ raw_spinlock_t pi_lock; /* journalling filesystem info */ void *journal_info; /* stacked block device info */ struct bio_list *bio_list; /* VM state */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ struct task_io_accounting ioac; atomic_t fs_excl; /* holding fs exclusive resources */ struct rcu_head rcu; /* * cache last used pipe for splice */ struct pipe_inode_info *splice_pipe; struct prop_local_single dirties; /* * time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */ unsigned long timer_slack_ns; unsigned long default_timer_slack_ns; struct list_head *scm_work_list; } |
进程描述符在进程的内核栈中的位置示意如下:
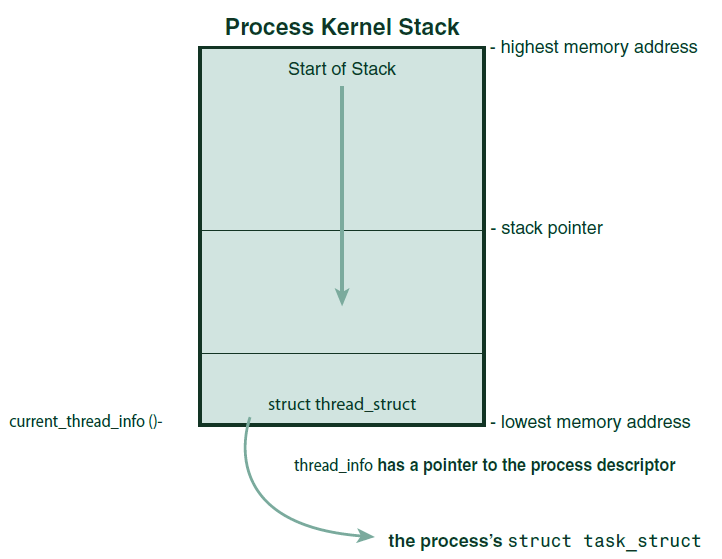
可以看到,每个进程的thread_info结构存放在内核栈的尾部,该结构中task字段为指向task_struct的指针。
内核通过唯一的进程标识符——PID来识别每个进程,PID表示为 pid_t 类型,其本质上就是一个int类型,该类型的默认最大值设置为32768以便与老版本的Unix兼容,该最大值受到linux/threads.h中定义的PID最大值限制。内核把某个进程的PID存放到它们各自的进程描述符中。
在内核中,需要频繁的访问进程的描述符,因此查找正在运行的进程的描述符的速度非常重要,内核通过current宏查找描述符,根据体系结构的不同,该宏的实现方式也不同。某些体系结构可以拿出一个专门的寄存器来存放指向当前task_struct的指针,在x86这样寄存器不是很富余的体系结构上就只能通过内核栈尾创建thread_info结构,通过计算偏移量间接查找task_struct结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//内核栈大小,在此配置下为8192 unsigned long THREAD_SIZE = ( ( ( 1UL ) << 12 ) << 1 ); /* 得到当前栈指针 */ register unsigned long current_stack_pointer asm("esp") __used; /* 得到当前进程信息的指针 */ static inline struct thread_info *current_thread_info( void ) { return ( struct thread_info * ) ( current_stack_pointer & ~ ( THREAD_SIZE - 1 ) ); //THREAD_SIZE - 1为13位:1111111111111,取反后与栈指针按位与,导致其低13位被置0 //即定位到该内存栈的最低地址,thread_struct所在。 } //获得task_struct current_thread_info()->task; |
进程描述符中的state字段描述进程的当前状态,每个进程必然处于以下五种状态之一:
| 状态 | 说明 |
| TASK_RUNNING | 运行。进程是可执行的,它或者正在CPU上执行,或者在运行队列里等待执行。这是进程在用户空间中执行的唯一可能的状态,这种状态也可以应用到在内核空间中正在执行的进程 |
| TASK_INTERRUPTIBLE | 可中断。进程正在睡眠(或者说被阻塞)以等待某个条件的达成,一但这些条件达成,内核就会将进程的状态设置为运行。处于此状态的进程也会因为接收到信号而提前被唤醒并随时准备投入运行 |
| TASK_UNINTERRUPTIBLE | 不可中断。除了即使接收到信号也不会被唤醒之外,与可中断一致。这个状态通常在进程必须在等待时不受干扰或者等待事件很快就会发生时出现。由于处于该状态的进程对信号不作响应,因此相比较可中断,该状态使用的少 |
| __TASK_TRACED | 被其它进程跟踪的进程,例如通过ptrace对调试程序进行跟踪 |
| __TASK_STOPPED | 进程停止运行。进程没有投入也不能投入运行。该状态通常发生在接收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU信号时出现。此外,在调试期间接收到任何信号,进程都会进入该状态 |
下图描述了进程状态的转化: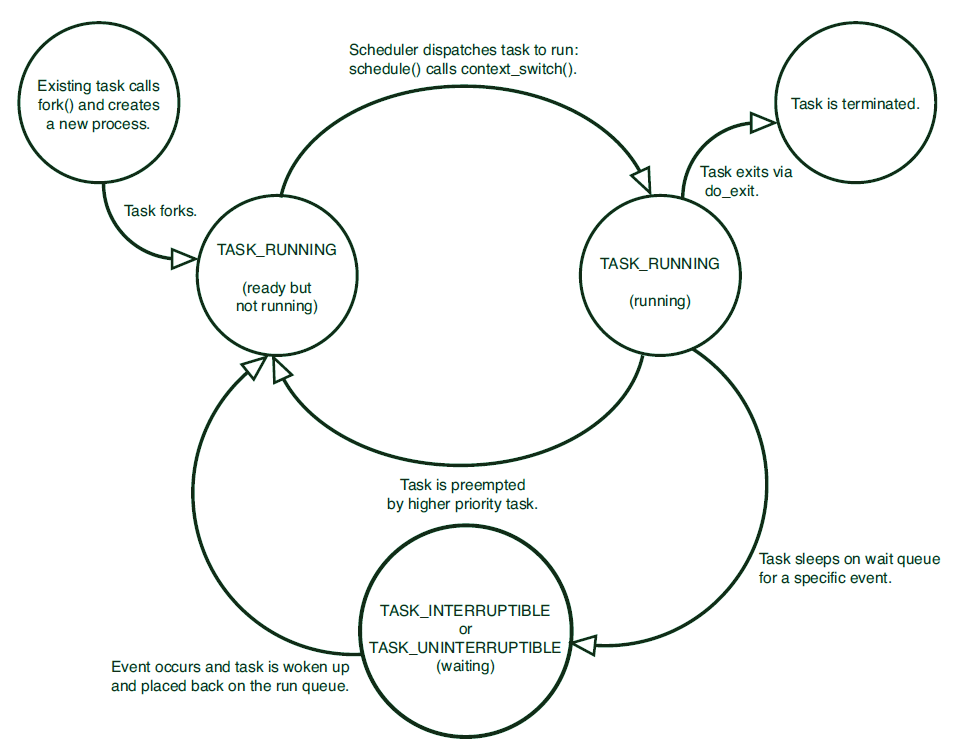
内核经常需要调整某个进程的状态,这时它会调用该函数:
|
1 2 3 4 |
//设置指定任务的状态,必要时,它会设置内存屏障来强制其它处理器作重新排序(一般只在对称多处理SMP系统中有此必要) set_task_state(task, state); //下面的函数与set_task_state(current, state)相同 set_current_state(state) |
可执行程序代码是进程的重要组成部分,这些代码从一个可执行文件载入到进程的地址空间执行。一般程序在用户空间执行。当一个程序调用了系统调用,或者触发了某个异常,它就会陷入内核空间,此时,我们称“内核代表进程执行”并处于进程上下文中。在此上下文中,current宏是有效的。除非在此间隙更高优先级的进程需要执行并由进程调度器做出响应调整,否则在内核退出的时候,程序恢复在用户空间的继续执行。
系统调用和异常处理程序是对内核明确定义的接口,进程只有通过这些接口才能陷入内核执行。
Unix系统进程之间具有明显的继承关系,所有进程都是PID=1的init的后代。内核在系统启动的最后阶段会启动init进程,该进程读取系统初始化脚本并执行其它相关程序,最终完成系统的启动。
进程之间的关系被存放在task_struct中,每个进程具有 task_struct *parent 以及名为children的链表,该链表包含所有子进程task_struct的指针。通过下面的代码可以访问父子进程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
//访问父进程 struct task_struct *my_parent = current->parent; //迭代子进程 struct task_struct *task; struct list_head *list; list_for_each(list, ¤t->children) { task = list_entry(list, struct task_struct, sibling); } //注意init进程的描述符是作为init_task变量静态分配的,因此下面的代码可以向上递归寻找父进程 struct task_struct *task; for (task = current; task != &init_task; task = task->parent) ; //for_each_process宏用于遍历整个进程链表 struct task_struct *task; for_each_process( task ) { printk( "%s[%d]\n", task->comm, task->pid ); } |
大部分操作系统提供了一种产生(spawn)进程的机制:首先在新的地址空间里创建进程,读入可执行文件,最后开始执行。
Unix系列系统则采用与众不同的分支(fork)方式,同时配合exec**()调用完成新进程的创建。该方式的特点如下:
- fork创建的子进程,相当于对父进程的克隆,区别仅仅在PID、PPID,以及某些资源、统计信息——比如挂起的信号——没有必要继承
- exec**读取可执行文件并将其载入地址空间开始执行
传统的fork()调用直接把所有的资源复制给子进程,这种做法效率较为低下,因为拷贝的数据可能并不共享给子进程,或者新进程可能一上来就exec**(),导致所有拷贝都是无用功。Linux的fork()使用写时拷贝页实现,可以延迟甚至免除数据拷贝,内核并不会复制进程的整个地址空间,而是让父子进程共享同一个拷贝。只有在需要写入的时候,数据才会被复制,从而是父子进程拥有各自的拷贝。
因此,Linux下fork()的实际必须的开销就是复制父进程的页表、以及给子进程分配唯一的进程描述符。这对Linux快速创建进程的能力非常重要。
Linux在底层通过clone()系统调用来实现fork(),该调用通过一系列参数指明父子进程需要共享的资源。fork()、vfork()、__clone()都是通过不同的参数调用clone(),后者则调用do_fork()。do_fork()完成大部分实质性的进程创建工作,其主要工作是在 copy_process 函数中完成的:
- 为新进程创建一个内核栈、thread_info结构、task_struct,其值与父进程相同,因此此时子进程的描述符与父进程完全一致
1p = dup_task_struct(current); - 检查并确保新创建这个子进程后,当前用户拥有的进程数没有超过资源限制
1234567if ( atomic_read(&p->real_cred->user->processes) >=task_rlimit( p, RLIMIT_NPROC ) ){if ( !capable( CAP_SYS_ADMIN ) && !capable( CAP_SYS_RESOURCE ) &&p->real_cred->user != INIT_USER )goto bad_fork_free;} - 将子进程和父进程区分开来。进程描述符中很多字段被清零或者设为初值
- 子进程的状态被设置为TASK_UNINTERRUPTIBLE,确保其不会投入运行
- copy_process()调用copy_flags()以更新task_struct的flags成员。表明进程是否拥有超级用户权限的PF_SUPERPRIV被置零,表明进程还没有调用exec**()函数的PF_FORKNOEXEC被设置
12345678910static void copy_flags(unsigned long clone_flags, struct task_struct *p){unsigned long new_flags = p->flags;new_flags &= ~PF_SUPERPRIV;new_flags |= PF_FORKNOEXEC;new_flags |= PF_STARTING;p->flags = new_flags;clear_freeze_flag(p);} - 调用alloc_pid()给进程分配有效的PID
123if (pid != &init_struct_pid){pid = alloc_pid(p->nsproxy->pid_ns); - 根据传递给clone()的参数标志,copy_process()拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间、命名空间等
- 进行一些清理工作,返回指向子进程的指针
copy_process()返回后,do_fork()会让新创建的子进程立即投入运行,内核会有意让子进程首先执行,因为子进程通常会马上调用exec()函数,这样可以避免写时拷贝的开销:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
/* * 第一次唤醒新创建的任务,该函数将处理每个新上下文必须进行的最初的调度信息统计, * 然后将新的任务存放到运行队列并唤醒之 */ void wake_up_new_task( struct task_struct *p, unsigned long clone_flags ) { unsigned long flags; struct rq *rq; int cpu __maybe_unused = get_cpu(); //获取一个CPU rq = cpu_rq( cpu ); //获取CPU运行队列 raw_spin_lock_irqsave( &rq->lock, flags ); BUG_ON( p->state != TASK_WAKING ); //断言 p->state = TASK_RUNNING; //设置新任务的状态为运行 update_rq_clock( rq ); activate_task( rq, p, 0 ); //激活任务,入队 trace_sched_wakeup_new( rq, p, 1 ); check_preempt_curr( rq, p, WF_FORK ); task_rq_unlock( rq, &flags ); put_cpu(); } |
该函数与fork()类似,只是不拷贝父进程的页表项。vfork()这样调用clone():
|
1 |
clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0); |
而最普通的fork()则是:
|
1 |
clone(SIGCHLD, 0); |
| 标记 | 含义 |
| CLONE_FILES | 父子进程共享打开的文件 |
| CLONE_FS | 父子进程共享文件系统信息 |
| CLONE_IDLETASK | 将PID设置为0(只供idle进程使用) |
| CLONE_NEWNS | 为子进程创建新的命名空间,命名空间是Linux内核级别的环境隔离机制,用于把进程分为相对独立的组,进行IPC、用户、网络、PID、挂载等方面的隔离 |
| CLONE_PARENT | 指定子进程与父进程具有同一个父进程 |
| CLONE_PTRACE | 继续调试子进程 |
| CLONE_SETTID | 将TID(线程标识符)回写至用户空间 |
| CLONE_SETTLS | 为子进程创建新的TLS(线程本地存储) |
| CLONE_SIGHAND | 父子进程共享信号处理函数以及被阻塞的信号槽设置 |
| CLONE_SYSVSEM | 父子进程共享System V的SEM_UNDO语义 |
| CLONE_THREAD | 父子进程放入相同的线程组 |
| CLONE_VFORK | 调用vfork(),父进程将睡眠等待子进程将其唤醒 |
| CLONE_UNTRACED | 防止跟踪进程在子进程上强制指向CLONE_PTRACE |
| CLONE_STOP | 以TASK_STOPPED状态开始进程 |
| CLONE_CHILD_CLEARTID | 清除子进程的TID |
| CLONE_CHILD_SETTID | 设置子进程的TID |
| CLONE_PARENT_SETTID | 设置父进程的TID |
| CLONE_VM | 父子进程共享地址空间 |
线程提供了在同一程序内共享内存地址空间运行多个执行序列的机制。这些执行序列就是线程。线程可以共享打开的文件和其它资源,在多处理器系统中,线程能保证真正的并行处理(Parallelism)。
Linux实现线程的机制很独特,从内核的角度来看,并没有线程的概念。Linux把所有线程作为进程来实现。内核没有特殊的调度算法或者数据结构来表征线程,相反,线程仅仅是和其它进程共享了某些资源的进程。每个线程都有隶属于自己的task_struct。
Windows的线程实现机制与Linux的差异非常大,前者专门提供了支持线程的机制,称为“轻量级进程(lightweight processes)”。其实这个命名本身就对比出了Linux进程设计的优雅性,Linux的进程设计已经足够轻量。
与创建普通进程非常相似,只是在clone()时传递一些参数,来指明需要共享的资源:
|
1 |
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0); |
内核经常需要在后台执行一些操作,这些操作可以通过内核线程(Kernel Thread) ——独立运行在内核空间的标准线程。内核线程与普通线程区别是:它没有独立的地址空间(执行地址空间的指针mm设置为NULL)。内核线程只在内核空间运行,不会切换到用户空间去,内核线程同样可以被调度和抢占。内核线程一般是在系统启动时创建,然后一直存在直到系统关闭。
内核线程自然只能有内核线程去创建,而它们的起源是一个叫kthreadd的内核进程,下面的函数声明了创建内核线程的方法:
|
1 2 3 4 5 6 |
struct task_struct *kthread_create( int (*threadfn)(void *data), // 新的内核线程执行的函数 void *data, // 传递给函数的参数 const char namefmt[], // printf格式的字符串,新线程的名称 ... ) |
上述创建的新内核线程不会自动运行,除非调用 wake_up_process() 函数明确的唤醒。内核线程启动后会一直运行直到调用 do_exit() 退出。内核的其它部分可以调用 kthread_stop(struct task_struct *k) 使内核线程退出。
进程终结时,内核将释放其占用的所有内存,并通过信号通知其父进程。
通常进程的终结是自发的,进程调用 exit() 系统调用时将终结自身。该系统调用可以被明确的调用,也可以由编译器在main()函数的return后面隐式的添加。进程接收到既不能忽略也不能处理的信号、或者异常时,也可能被自动的终结。
进程终结时需要做的大部分工作在下列函数中完成:
|
1 |
NORET_TYPE void do_exit(long code); |
该函数完成以下逻辑:
- 设置task_struct标记PF_EXITING
- 调用del_timer_sync()删除任何内核定时器,确保没有任何定时器在排队,没有任何定时器处理程序在运行
- 如果开启BSD记账功能,调用 acct_update_integrals() 输出记账信息
- 调用 exit_mm() 尝试释放 mm_struct ,如果没有其它进程使用,则彻底释放对应的地址空间
- 调用 sem_exit() 函数。如果进程排队等候IPC信号,则使进程离开队列
- 调用用 exit_files() 和 exit_fs() 分别递减文件描述符、文件系统的引用计数,如果计数为零,立即释放资源
- 设置 task_struct.exit_code 为exit()函数指定的值,供父进程随时检索
- 调用 exit_notify() 向父进程发送信号,并给子进程重新找养父(父进程可能先死),养父为线程组中其它线程或者init进程,设置进程的状态为 EXIT_ZOMBIE
- 调用 schedule() 切换到新的进程
由于处于 EXIT_ZOMBIE 状态的进程永远不会被调度,因此do_exit()函数永远不会返回,上述把就是僵尸进程最后执行的代码。
至此,进程相关的绝大部分资源都被释放了,进程不可运行(也没有地址空间供它运行)并处于僵尸态。它目前只占用几个内存区域:内核栈、thread_info结构、task_struct结构。 僵尸进程存在的唯一目的就是向父进程提供信息(退出码等),父进程检索到这些信息、或者通知内核它不关心子进程的信息后,进程占有的剩余内存全部归还系统。
上一小节提到进程的终结清理与其描述符的删除被分开处理,这是为了在进程终结后,其父进程尚能访问其退出码等信息。
父进程可以通过 wait4() 系统调用(通过wait**函数转调)来等待一个子进程的退出,并得到子进程的PID,并进而获取其进程描述符中的信息。当最终需要释放进程描述符时,会调用 release_task() 函数,该函数完成以下逻辑:
- 调用 _exit_signal() ,该函数调用 _unhash_process() ,后者则调用 detach_pid() 从pidhash、任务列表中删除该进程
- _exit_signal 释放僵尸进程的占用的所有残余资源,最终进行统计和记录
- 如果该僵尸进程是线程组的最后一个进程,并且领头进程已经是一个僵尸,那么通知领头进程的父进程
- 调用 put_task_struct 释放内核栈和thread_info结构所占据的页,释放task_struct占据的slab高速缓存
如果父进程先于子进程退出,必须有机制保证子进程能找到一个新父亲。否则,子进程将永远处于僵尸状态,浪费内存。Linux的做法是,当父进程do_exit()时,会调用 forget_original_parent() 而后者会调用 find_new_reaper() 来定位父进程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
/* * 进程终结时,将为所有子进程需找新的养父 * 默认是寻找线程组中的其它线程,如果找不到,则指定养父为 * 当前PID空间中的child reaper process(即init进程) */ static struct task_struct *find_new_reaper( struct task_struct *father ) { struct pid_namespace *pid_ns = task_active_pid_ns( father ); struct task_struct *thread; thread = father; //遍历当前线程组 while_each_thread( father, thread ) { if ( thread->flags & PF_EXITING ) continue; if ( unlikely( pid_ns->child_reaper == father ) ) pid_ns->child_reaper = thread; return thread; } //如果当前进程是PID空间的init进程 if ( unlikely( pid_ns->child_reaper == father ) ) { write_unlock_irq( &tasklist_lock ); if ( unlikely( pid_ns == &init_pid_ns ) ) panic( "Attempted to kill init!" ); zap_pid_ns_processes( pid_ns ); write_lock_irq( &tasklist_lock ); pid_ns->child_reaper = init_pid_ns.child_reaper; } //否则,返回init进程 return pid_ns->child_reaper; } |
找到养父后,只需要遍历子进程列表,设置其父进程即可。
进程调度程序是确保进程能有效工作的一个内核子系统,它决定哪个TASK_RUNNING的进程能够投入运行,可以运行多长时间。
2.6引入了一个重要的特性,就是内核抢占。这意味着多个处于特权模式(privileged mode)的执行流(即处于内核态的进程)可以任意的交叉执行,因此进程调度适用于很多内核态中的代码。
多任务操作系统能够同时执行多个进程,在单处理器系统中,同时运行只是一种幻觉,在多处理器系统中则真实的发生着。多任务操作系统可以让多个进程处于阻塞或者睡眠状态,这些进程不会真正的运行,直到等待的条件(例如键盘输入、网络数据到达、定时器)就绪。
多任务操作系统可以分为两类:
- 非抢占式多任务(Cooperative Multitasking):除非进程自己主动停止执行,否则它会一直占据CPU。进程主动挂起自己的操作称为让步(Yielding)。现在很少OS使用此模式
- 抢占式多任务(Preemptive Multitasking):Unix变体和许多现代OS采取的方式,在此模式下,调度程序确定何时停止一个进程的运行,以便其它进程获得执行机会,这个强制挂起正在执行进程的动作叫做抢占。进程在被抢占之前能够运行的时间是预先设定的,称为时间片(timeslice)。
从Linux1.0到2.4的内核,进程调度程序都比较简陋。2.5版本对调度程序做了大的改进,被称为O(1)调度器。该调度器能够在数以10计的多处理器环境下表现良好,但是对响应时间敏感(例如用户交互)的程序则表现的差强人意。
2.6版本开发初期,为了提高交互程序的调度性能,Linux开发团队引入了新的进程调度算法——完全公平调度算法(CFS),并在2.6.23内核版本中代替O(1)算法,
这是一种进程的分类方式:
- I/O消耗型:大部分时间用来提交I/O请求或者等待I/O请求,这类进程通常都是运行很短的时间,即被阻塞。引起阻塞的I/O资源可以是鼠标键盘输入、网络I/O等等。大部分GUI程序都是I/O消耗型的,因为其大部分时间需要等待用户交互
- 处理器消耗型:大部分时间用来执行代码(指令)。除非被强占,这类进程经常不停的执行。由于这类进程的I/O需求较小,因此调度系统会降低其调度频率,以提供系统的响应速度(允许其它I/O型程序能够尽快获得执行机会)。调度系统倾向于在降低调度频率的同时,延长这类进程的执行时间。处理器消耗型进程的典型例子是科学计算应用,极端例子是无限空循环
现实场景中,很多程序不能简单的划分到这两类之一,例如X Window服务既是I/O消耗型,也是处理器消耗型。
调度策略需要在响应时间(响应高速性,进程能否尽快的获取CPU)和吞吐量(最大系统利用率,单位时间执行的有效指令数量)两个目标之间寻求平衡,Linux更加倾向于优先调度I/O消耗型进程,以缩短响应时间。
基于优先级的调度是一种最基本的一类调度算法。通常(但为被Linux使用)的做法是,高优先级的进程先运行,低优先级的后运行,相同优先级的则以轮转的方式进行调度。某些系统中高优先级的进程使用的时间片也更长。
Linux使用了两种优先级度量:
- nice值:从-20到19之间,默认值0,该值越大,意味着优先级越低。nice值在不同的Unix系统中运用方式有所不同,例如Mac OS X中代表了分配给进程的时间片绝对值,而在Linux中则代表了时间片的比例
- 实时优先级:从0到99之间,该值越大,意味着优先级越高。所有实时进程的优先级都高于普通进程。使用命令 ps -eo state,uid,pid,ppid,rtprio,time,comm 可以查看进程的实时优先级,显示为“-”的是非实时进程
时间片是一个数值,用来表示进程被抢占前,能够持续运行的时间。时间片过长会导致人机交互的响应速度欠佳;时间片过短则明显增大进程切换的开销。I/O消耗型进程不需要太长时间片;CPU消耗型进程则希望时间片越长越好。
为了增加交互响应速度,很多OS把时间片设置为很短的绝对值,例如10ms。Linux的CFS调度器则是以占用CPU时间的比例来定义时间片,这就意味着进程获取的CPU时间和系统负载密切相关,这一比例进一步收到nice值的影响,低nice值的进程获得更多的CPU时间比例。
大部分抢占式系统中,一旦一个进程进入可运行状态,它是否立即投入运行(即抢占CPU上的当前进程),完全由进程的优先级和是否拥有时间片来决定,Linux的CFS调度使用更加复杂的算法:如果新的可运行进程已消耗的CPU时间比例比较小,则立即抢占,否则推迟执行
考虑一个系统中只有两个进程:
- 文本编辑器,交互式程序,需要立即得到响应,但是需要占用的CPU时间很少(人输入的速度相对于CPU来说非常慢)
- 视频编码器,非交互式程序,需要占用大量的CPU时间
如果上述两者的nice值相同,那么CFS分配给它们的CPU时间比例都是50%,则会发生如下的事件序列:
- 视频编码器开始工作,占用超过99%的CPU时间
- 用户击键,文本编辑器被唤醒,CFS发现该进程占用的CPU时间比例接近0%,而分配给它的比例是50%
- CFS立即抢占视频编码器,让文本编辑器立即运行
- 上面两步骤会不停的发生,因为文本编辑器实际消耗CPU时间比例总是非常小,远远小于分配给它的比例
Linux以模块的方式提供调度器,以便不同类型的进程可以选择不同的调度算法。这一模块化的结构被称为调度器类(Scheduler Classes),它允许多种可以动态添加的调度算法共存,并遵守以下规则:
- 每一个调度器负责调度自己管理的进程
- 每一个调度器具有一个优先级
- 调度器会按优先级高低被遍历,用于一个可运行进程的、最高优先级的调度器胜出
- 胜出的调度器决定下一个运行的进程
CFS是针对普通进程的调度器类,在Linux中被称为SCHED_NORMAL,定义在kernel/sched_fair.c中。
若将nice值映射为处理器绝对时间,必然会导致进程切换无法优化进行。例如将默认nice=0对应的时间片设置为100ms,那么+20则对应5ms,假定限制有0、+20两个进程都处于可运行状态,则0进程将获得20/21即100ms的CPU时间;如果有两个+20优先级的可运行进程,则它们每次只能获得5ms的CPU时间。问题是,高nice的进程往往是后台任务,计算密集型为多,它期望的是更长的运行时间,反之,普通进程往往是用户交互任务,它们期望快速响应。很明显,nice值映射到CPU绝对时间的调度机制,背离进程调度的初衷。
nice值映射为处理器绝对时间的另外一个问题,是CPU时间片比例的非线性变化,0和1分别是100ms、95ms,它们之间的差距很小,然后+19和+20也是差距一个步进,CPU时间片比例差距达1倍。这就导致了把nice值减一,以期望影响进程调度,其结果极大的取决于nice初值。
尽管某些变通的方法能解决上述Unix进程调度的问题,但是都回避了问题的实质:分配绝对的时间片引发的固定进程切换频率,给公平性造成了很大的变数。
Linux 2.6.23版本引入的CFS(completely fair schedule,完全公平调度)算法,很好的解决了Unix进程调度存在的问题,它对基于时间片的分配方式进行了彻底的重新设计,完全抛弃了时间片,改为分配给进程一个CPU使用的权重(nice越低权重越大)。通过这种方式,CPU确保了进程调度的公平性和动态变化的切换频率。
CFS算法是基于一个简单的理念:进程调度的效果应该如同系统具有一个完美调度器,该调度器能够让每个进程获得1/n的处理器时间,即使策略周期无穷小。传统Unix调度模型可能在10ms内让进程1运行5ms,然后让进程2运行5ms,在运行时每个进程都占用100%的CPU;但是对于完美调度器,从效果上说,它相当于在10ms内让进程1、2同时运行,而各自占用1/2的处理器能力。CFS算法的核心工作,就是在现有硬件的基础上,尽可能的接近完美调度器。
上述完美调度器是不现实的,因为调度引起的进程抢占本身就有代价:包括进程切换的上下文切换、缓存效率问题。因此,虽然我们期望进程只运行非常短的周期,但是CFS充分考虑到短周期带来的额外消耗,它允许每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行的进程,CFS将在所有可运行进程的总数的基础上、结合nice值计算出每个一个进程应该运行多久,而不是简单的依靠nice值计算绝对时间片。
同时,CFS为完美调度器的无限小调度周期设定一个近似目标,称为目标延迟。例如,如果目标延迟是20ms,两个同样nice的进程将可以在被抢占前运行10ms,如果有4个这样的进程则只能分别运行5ms……当任务数量趋向于无限时,抢占前运行时间接近于0,这意味着无限大的切换损耗。因此CFS引入每个进程能获得的时间片底线,称为最小粒度,默认该底线为1ms。这样一来,不管任务总数变得多大,每个进程最少能获得1ms的运行时间,确保切换损耗被控制在一定范围内。
CFS算法的实现代码位于kernel/sched_fair.c中,主要有四个重要的逻辑部分。
即对进程运行的时间进行记账,这是所有调度器都必须做的工作。传统Unix使用时间片机制,因此每次系统节拍发生时,时间片都会减去一个节拍周期,当时间片减少到0时,当前进程就会被时间片尚不为0的其它进程抢占。
虽然CFS不使用时间片,但是它仍然需要记录每个进程的运行时间,以确保每个进程只能在公平分配给它的处理器时间内运行,结构 sched_entity 被用来追踪进程运行记账:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//该结构作为成员变量se,存放在进程描述符task_struct中 struct sched_entity { struct load_weight load; /* for load-balancing */ struct rb_node run_node; struct list_head group_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; u64 last_wakeup; u64 avg_overlap; u64 nr_migrations; u64 start_runtime; u64 avg_wakeup; }; |
变量 vruntime 存放进程的虚拟运行时间(virtual runtime),虚拟运行时间是真实运行时间通过加权运算后得到的值。加权运算的权重,和进程的nice值有关,nice越大,则权重越小:
|
1 2 3 4 5 6 7 8 9 10 |
static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, }; |
系统定时器会定期调用 update_curr() 函数,来更新 vruntime ,不管进程是处于可运行还是阻塞状态,这样, vruntime 可用来准确的测量给定进程的运行时间,并推断下一个运行的进程是谁:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_of(cfs_rq)->clock; //当前任务运行时间的增量 delta_exec = (unsigned long)(now - curr->exec_start); __update_curr(cfs_rq, curr, delta_exec); curr->exec_start = now; } static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec) { unsigned long delta_exec_weighted; curr->sum_exec_runtime += delta_exec; //增加总计运行时间 //计算权重后的运行时间(虚拟运行时间) delta_exec_weighted = calc_delta_fair(delta_exec, curr); curr->vruntime += delta_exec_weighted; //虚拟运行时间增量 update_min_vruntime(cfs_rq); //修改进程队列红黑树的min_vruntime } static inline unsigned long calc_delta_fair(unsigned long delta, struct sched_entity *se) { //如果不是默认优先级才需要计算,否则虚拟运行时间和实际运行时间一致 if (unlikely(se->load.weight != NICE_0_LOAD)) delta = calc_delta_mine(delta, NICE_0_LOAD, &se->load); return delta; } #if BITS_PER_LONG == 32 # define WMULT_CONST (~0UL) #else # define WMULT_CONST (1UL << 32) #endif #define WMULT_SHIFT 32 //SRR (Shift right and round) #define SRR(x, y) (((x) + (1UL << ((y) - 1))) >> (y)) static unsigned long calc_delta_mine(unsigned long delta_exec, unsigned long weight, struct load_weight *lw) { u64 tmp; if (!lw->inv_weight) { if (BITS_PER_LONG > 32 && unlikely(lw->weight >= WMULT_CONST)) lw->inv_weight = 1; else lw->inv_weight = 1 + (WMULT_CONST-lw->weight/2) / (lw->weight+1); } //先乘以NICE_0_LOAD的权重 tmp = (u64)delta_exec * weight; /* * Check whether we'd overflow the 64-bit multiplication: */ if (unlikely(tmp > WMULT_CONST)) tmp = SRR(SRR(tmp, WMULT_SHIFT/2) * lw->inv_weight, WMULT_SHIFT/2); else tmp = SRR(tmp * lw->inv_weight, WMULT_SHIFT); return (unsigned long)min(tmp, (u64)(unsigned long)LONG_MAX); } |
从上面的代码可以看到,对于nice值为0的进程,其虚拟运行时间和真实运行时间一致,nice越低(优先级越高),则虚拟运行时间相对于真实运行时间的值就越小。虚拟运行时时间和真实运行时间的关系,接近以下公式:
进程虚拟运行时间 ≈ 进程真实运行时间 × 默认进程权重 / 当前进程权重
其中默认进程权重即NICE_0_LOAD,为常量值1024。
上一节我们介绍了虚拟运行时间(vruntime)的计算,CFS就是根据此vruntime决定下一个运行的进程的,CFS会选择vruntime最小的进程,这就是CFS的核心。
为了快速找到vruntime最小的进程,CFS使用红黑树(在Linux中称为rbtree,一种自平衡二叉搜索树)来组织可运行进程的队列,红黑树可以存储任意类型数据的节点,这些节点通过键(key)来识别,红黑树能够快速的定位到一个给定的键,其时间复杂度为O(logn)。
对于已经生成好的、存储所有可运行进程的红黑树,CFS只需要获取其最左侧节点,即可得到vruntime最小的进程:
|
1 2 3 4 5 6 7 8 9 10 |
static struct sched_entity *__pick_next_entity(struct cfs_rq *cfs_rq) { //红黑色的最左节点是被缓存起来的,没必要搜索之 struct rb_node *left = cfs_rq->rb_leftmost; if (!left) return NULL; //这意味着树中没有任何节点,也就是说没有可运行进程,调度器将选择idle任务运行 return rb_entry(left, struct sched_entity, run_node); } |
进程是什么时候被放入队列的呢?当通过fork()创建进程时,或者进程进入可运行状态时,下面的函数被调用,将其存入红黑树:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
static void enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATE)) se->vruntime += cfs_rq->min_vruntime; //更新当前任务的统计信息 update_curr(cfs_rq); account_entity_enqueue(cfs_rq, se); if (flags & ENQUEUE_WAKEUP) { place_entity(cfs_rq, se, 0); enqueue_sleeper(cfs_rq, se); } update_stats_enqueue(cfs_rq, se); check_spread(cfs_rq, se); if (se != cfs_rq->curr) __enqueue_entity(cfs_rq, se); //执行插入操作 } /* * Enqueue an entity into the rb-tree: */ static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { struct rb_node **link = &cfs_rq->tasks_timeline.rb_node; struct rb_node *parent = NULL; struct sched_entity *entry; s64 key = entity_key(cfs_rq, se); int leftmost = 1; //遍历节点,在红黑树中找到合适的位置 while (*link) { parent = *link; //既有的,作为被插入进程父节点的节点 entry = rb_entry(parent, struct sched_entity, run_node); if (key < entity_key(cfs_rq, entry)) { //平衡二叉树:如果键值小于当前节点,则需要转向树的左分支 link = &parent->rb_left; } else { link = &parent->rb_right; //平衡二叉树:如果键值大于当前节点,则需要转向树的右分支 //一旦向右(即使只有一次),就不可能是最左节点 leftmost = 0; } } //缓存最左节点 if (leftmost) cfs_rq->rb_leftmost = &se->run_node; //在最终确定的父节点下面插入当前进程 rb_link_node(&se->run_node, parent, link); //更新树的自平衡相关属性 rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline); } |
当进程被阻塞,或者进程终止时,则需要调用下面的函数将其移除出红黑树:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int sleep) { update_curr(cfs_rq); update_stats_dequeue(cfs_rq, se); clear_buddies(cfs_rq, se); if (se != cfs_rq->curr) //当前正在运行的进程不能被移除 __dequeue_entity(cfs_rq, se); account_entity_dequeue(cfs_rq, se); update_min_vruntime(cfs_rq); if (!sleep) se->vruntime -= cfs_rq->min_vruntime; } static void __dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) { //如果被删除节点是最左边的,需要重新计算rb_leftmost值 if (cfs_rq->rb_leftmost == &se->run_node) { struct rb_node *next_node; next_node = rb_next(&se->run_node); cfs_rq->rb_leftmost = next_node; } //rbtree既有的函数可以用来方便的删除红黑树节点 rb_erase(&se->run_node, &cfs_rq->tasks_timeline); } |
进程调度的入口函数定义在/kernel/sched.c的 void schedule(void) 中,该函数是内核其它部分调用进程调度器的入口。该函数会将工作委托给一个具体的调度类,后者有自己的可运行队列,并负责决定下一个运行的进程。该函数中最重要的逻辑是调用 pick_next_task() ,该函数以优先级为序,从高到低,依次检查每一个调度类,并且从最高优先级的调度类中,选择最高优先级的进程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
static inline struct task_struct * pick_next_task(struct rq *rq) { const struct sched_class *class; struct task_struct *p; //如果所有任务都在公平调度器中(所有可运行进程数量等于CFS可运行进程数量),则可以直接调度,由于CFS是普通进程的调度类,因此这里做了优化 if (likely(rq->nr_running == rq->cfs.nr_running)) { p = fair_sched_class.pick_next_task(rq); //每个调度器类都实现了该函数 if (likely(p)) return p; } class = sched_class_highest; for ( ; ; ) { p = class->pick_next_task(rq); if (p) return p; //不会返回NULL,因为idle调度器会返回一个p class = class->next; } } |
进程可能因为等待某个事件(磁盘I/O、键盘输入、尝试获取被占用的内核信号量)而进入休眠(被阻塞)状态,处于此状态的进程会被移出可运行红黑树。
在进程进入睡眠状态时:进程将自己标注为休眠状态,从可运行红黑树中移除,存放到等待队列;在进程被唤醒时:进程被设置为可运行状态,并被存放到可运行红黑树。
与睡眠相关的两种进程状态:TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE,唯一的区别是前者能够响应信号,当接收到信号后,会提前被唤醒并处理信号。睡眠通过等待队列处理,这两种状态的进程存放在同一个等待队列上。
内核使用wait_queue_head_t类型来表示等待队列:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
//等待队列头 struct __wait_queue_head { spinlock_t lock; //自旋锁,实现对task_list的互斥访问 struct list_head task_list; //双向循环链表,存放等待的进程 }; typedef struct __wait_queue_head wait_queue_head_t; //等待队列项,作为等待队列头的成员 typedef struct __wait_queue wait_queue_t; typedef int (*wait_queue_func_t)(wait_queue_t *wait, unsigned mode, int flags, void *key); int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags, void *key) { return try_to_wake_up(curr->private, mode, wake_flags); } struct __wait_queue { unsigned int flags; //可用于指示等待进程是否互斥进程,0表示非互斥进程,1表示互斥进程 #define WQ_FLAG_EXCLUSIVE 0x01 void *private; wait_queue_func_t func; struct list_head task_list; }; |
可以通过宏DECLARE_WAITQUEUE()静态创建或者init_waitqueue_head()动态创建等待队列:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#define __WAITQUEUE_INITIALIZER(name, tsk) { \ .private = tsk, \ .func = default_wake_function, \ .task_list = { NULL, NULL } } #define DECLARE_WAITQUEUE(name, tsk) \ wait_queue_t name = __WAITQUEUE_INITIALIZER(name, tsk) extern void __init_waitqueue_head(wait_queue_head_t *q, struct lock_class_key *); #define init_waitqueue_head(q) \ do { \ static struct lock_class_key __key; \ \ __init_waitqueue_head((q), &__key); \ } while (0) |
函数__init_waitqueue_head的定义位于:
|
1 2 3 4 5 6 |
void __init_waitqueue_head(wait_queue_head_t *q, struct lock_class_key *key) { spin_lock_init(&q->lock); lockdep_set_class(&q->lock, key); INIT_LIST_HEAD(&q->task_list); } |
在睡眠时,进程负责将自身放入等待队列,并标记为不可运行。当和等待队列关联的事件发生时,该队列上的进程被唤醒。 睡眠和唤醒必须合理的实现以避免竞态条件,以前某些被广泛使用的简单接口函数可能会导致竞态条件——条件(事件)已经为真(等待的事件已经发生)了,而进程还是陷入睡眠,这会导致进程无限的睡眠下去,为避免此问题,可以在内核中使用类似如下代码:
|
1 2 3 4 5 6 7 8 9 10 |
DEFINE_WAIT( wait ); //创建等待队列项 add_wait_queue(q, &wait); //q是期望在其上睡眠的等待队列(头),添加wait到其中 while (!condition) /*condition表示等待的事件*/ { prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE); //准备休眠,设置为可中断睡眠状态 if (signal_pending(current)) //伪唤醒(不是因为事件而唤醒)并处理信号 /* 在这里处理信号 */ schedule(); //执行调度,当前进程让出CPU } finish_wait(&q, &wait); //移出休眠队列,并恢复为可运行状态 |
与上述代码相关的宏和函数如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
// /include/linux/wait.h #define DEFINE_WAIT_FUNC(name, function) \ wait_queue_t name = { \ .private = current, \ .func = function, \ .task_list = LIST_HEAD_INIT((name).task_list), \ } #define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function) static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new) { list_add(&new->task_list, &head->task_list); } // /arch/x86/include/asm/current.h // /include/linux/list.h #define LIST_HEAD_INIT(name) { &(name), &(name) } #define current get_current() // /kernel/wait.c int autoremove_wake_function(wait_queue_t *wait, unsigned mode, int sync, void *key) { int ret = default_wake_function(wait, mode, sync, key); if (ret) list_del_init(&wait->task_list); //从链表中删除条目 return ret; } void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait) { unsigned long flags; wait->flags &= ~WQ_FLAG_EXCLUSIVE; spin_lock_irqsave(&q->lock, flags); //禁用当前处理器的中断并得到q关联的自旋锁,中断状态被存放在flags中 __add_wait_queue(q, wait); //将wait的task_list插入到q的task_list后面 spin_unlock_irqrestore(&q->lock, flags); //恢复中断状态并释放自旋锁 } static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new) { //这里添加的是task_list字段 //后续可以通过container_of,来获取task_list的容器wait_queue_t list_add(&new->task_list, &head->task_list); } //准备睡眠,与上面的函数类似,额外把进程设置为指定的状态 void prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state) { unsigned long flags; wait->flags &= ~WQ_FLAG_EXCLUSIVE; spin_lock_irqsave(&q->lock, flags); if (list_empty(&wait->task_list)) __add_wait_queue(q, wait); set_current_state(state); spin_unlock_irqrestore(&q->lock, flags); } void finish_wait(wait_queue_head_t *q, wait_queue_t *wait) { unsigned long flags; __set_current_state(TASK_RUNNING); if (!list_empty_careful(&wait->task_list)) { spin_lock_irqsave(&q->lock, flags); list_del_init(&wait->task_list); spin_unlock_irqrestore(&q->lock, flags); } } |
当需要唤醒处于睡眠中的进程时,需要调用wake_up()函数完成:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
//得到链表条目对应的结构,ptr为list_head指针,type为容器结构类型,member为list_head在容器结构中的字段名 #define list_entry(ptr, type, member) \ container_of(ptr, type, member) //迭代链表 #define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member), \ n = list_entry(pos->member.next, typeof(*pos), member); \ &pos->member != (head); \ pos = n, n = list_entry(n->member.next, typeof(*n), member)) #define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE) // /include/linux/wait.h #define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL) // /kernel/sched.c static void __wake_up_common(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, int wake_flags, void *key) { wait_queue_t *curr, *next; list_for_each_entry_safe(curr, next, &q->task_list, task_list) { unsigned flags = curr->flags; //调用唤醒函数(默认唤醒函数会调用try_to_wake_up) if (curr->func(curr, mode, wake_flags, key) && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive) break; } } /** * 唤醒阻塞在等待队列上的进程 * @q: 等待队列 * @mode: 哪些状态的进程被唤醒 * @nr_exclusive: 如果为0,唤醒所有等待进程;否则唤醒所有非互斥进程,以及一定数量的互斥进程 * @key: 直接作为入参传递给唤醒函数 * */ void __wake_up(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, void *key) { unsigned long flags; spin_lock_irqsave(&q->lock, flags); __wake_up_common(q, mode, nr_exclusive, 0, key); spin_unlock_irqrestore(&q->lock, flags); } |
可以看到,核心的唤醒逻辑存放在队列项的wait_queue_t的func字段中,其默认行为是调用定义在sched.中的 try_to_wake_up() ,该函数执行以下逻辑:
- 设置进程为TASK_RUNNING状态
- 调用enqueue_task()将进程存入红黑树
- 如果被唤醒进程比当前进程优先级高,需要设置need_resched标记
通常,哪段代码负责促使等待条件达成,则同时需要调用wake_up()函数,比如当磁盘数据到来时,VFS就负责对等待队列调用wake_up()。
注意存在虚假唤醒(spurious wake-ups)问题:进程被唤醒,不代表它等待的条件已经达成,因此总是要在循环结构中处理等待逻辑。
所谓上下文切换(Context Switching),就是从一个可执行进程切换到另一个可执行进程。定义在/kernel/sched.c的 context_switch() 函数负责上下文切换,它主要完成:
- 调用声明在asm/mmu_context.h的 switch_mm() 将虚拟内存映射(virtual memory mapping)切换到下一个进程,这可能涉及到页表与MMC相关的操作
- 调用声明在asm/system.h的 switch_to() 将处理器状态切换到下一个进程,这牵涉到存储和恢复栈信息、CPU寄存器信息(例如程序计数器PC、栈指针寄存器SP、通用寄存器、浮点寄存器、包括CPU状态信息的处理器控制寄存器、跟踪进程对RAM访问的内存管理寄存器……)以及其它和体系结构相关的信息
上下午切换时,存储和恢复的信息均通过进程描述符访问。
内核必须知道何时调用 schedule() ,用户代码可能永远不调用该函数,从而导致无限期执行。内核提供一个 need_reched 标记位用来指示是否应当进行一次新的调度。当某个进程被抢占(Preemption)时 scheduler_tick() 会设置该标记位;当一个高优先级进程进入可执行状态时 try_to_wake_up() 也会设置该标记位。
当返回用户空间、或者从中断返回时,内核会检查 need_reched 标记位,如果被设置,内核会在继续之前调用调度程序。
每个进程都包含一个need_reched 标记位,这是因为访问进程描述符内的数值比全局变量快(current宏很快且描述符通常位于高速缓存)。2.6+之后,该标记位存放为thread_info中一个位域字段的一个bit。
内核即将返回用户空间时,如果need_reched被设置,会导致调度器被调用,以选择一个更加合适的进程来运行。
从中断处理程序或者系统调用的返回路径依赖于体系结构,这些代码包含在entry.S文件中,该文件包含内核入口、退出的代码。
用户抢占的发生时机包括:
- 中断处理程序返回用户空间时
- 系统调用返回用户空间时
与大部分Unix变体和其它OS不同,Linux完整的支持内核抢占。
对于不支持内核抢占的OS,内核代码会一直运行直到它完成(返回用户空间或者明确阻塞)为止,内核没有办法在这种代码运行期间执行调度——内核中的任务是以协作方式调度的,不具有抢占性。
从2.6+开始,只要重新调度是安全的,内核就可以被抢占。当正运行在内核中的进程不持有锁(这里的锁被作为非抢占区域的标记),重新调度就是安全的。由于内核是SMP安全的,因此在不持有锁的情况下,当前代码是可重入的(reentrant,即多个进程可以同时执行,对于单处理器系统不存在重入问题)并且可以被抢占。
为支持内核抢占,进程的 thread_info 引入了 preempt_count 计数器,初值为0,每当使用锁的时候,计数增加,释放锁的时候则计数减小,因此preempt_count 为0时内核就可以被抢占。
当从中断返回内核空间时,内核会检查need_resched和preempt_count,如果need_resched被设置并且preempt_count为0,意味着有一个更加重要的任务可以安全的运行,因此会发生调度。
当进程所有的锁都被释放时,解锁代码负责检查need_resched是否被设置,如果是,调度也会发生。
某些内核代码需要允许或者禁止内核抢占。
如果内核代码被阻塞,或者显式的调用了 schedule() 则内核抢占也会发生,这种形式的内核抢占一直都支持。
内核抢占的发生时机包括:
- 中断处理程序退出,在返回内核空间之前
- 当内核代码从不可抢占变为可抢占时
- 内核中的任务显式调用schedule()前
- 内核中的任务被阻塞时
Linux提供了SCHED_FIFO、SCHED_RR这两种实时调度策略,相应的,普通的非实时调度策略是SCHED_NORMAL。基于调度器类框架,实时调度策略由定义在kernel/sched_rt.c中的特殊实时调度器管理(而非CFS)。
实时优先级的范围从0到MAX_RT_PRIO-1,MAX_RT_PRIO一般为99,因此实时优先级的范围通常是0-99,默认99。此优先级空间和SCHED_NORMAL的NICE值共享,默认的[–20,19]映射到[100, 139]
SCHED_FIFO策略实现了一个先入先出的、没有时间片的调度算法,一个可运行的SCHED_FIFO任务总是优先于SCHED_NORMAL任务运行,直到前者阻塞或者显式的让出CPU。由于没有时间片,SCHED_FIFO任务会一直执行,只有更高优先级的SCHED_FIFO/SCHED_RR任务才能抢占它。多个相同优先级的SCHED_FIFO任务会轮流执行,但是只有当前运行的SCHED_FIFO任务明确的让出CPU,其它任务同优先级的SCHED_FIFO任务才有机会运行。只有存在可运行的SCHED_FIFO任务,那么其它低优先级的任务只能等待它们都变为不可运行。
SCHED_RR基本和SCHED_FIFO一样,除了SCHED_RR提供时间片,当时间片耗尽后,同一优先级的其它实时进程获得执行机会。注意时间片只由于重新调度同一优先级的进程,低优先级的实时进程绝不能抢占高优先级的实时进程。
Linux的实时调度算法提供了一种软实时工作方式,即,内核尽力保证任务在限定时间到达前运行,但并不总是满足时间性要求。尽管如此,Linux实时调度算法的性能很不错,2.6+可以满足严格的时间要求。
某些Linux补丁,例如CONFIG_PREEMPT_RT 提供硬实时调度,硬实时调度经常用于工业控制领域(例如激光焊接),时效性非常重要。
Linux提供了一系列和进程调度有关的系统调用,用于执行进程优先级、调度策略、处理器绑定、让出CPU等操作:
| 系统调用 | 说明 |
| nice() | 设置进程的nice值。可以将进程的静态优先级增加一个量,只有超级用户才能提供负值以提升优先级。操控进程的task_struct.static_prio、prio |
| sched_setscheduler() | 设置/获取进程使用的调度策略 。操控进程的task_struct.policy |
| sched_getscheduler() | |
| sched_setparam() | 设置/获取进程的实时优先级。操控进程的task_struct.rt_priority |
| sched_getparam() | |
| sched_get_priority_max() | 获取实时进程优先级的最大/最小值 |
| sched_get_priority_min() | |
| sched_rr_get_interval() | 获取进程的时间片值 |
| sched_setaffinity() | 设置/获取进程和CPU的绑定关系。该绑定是强制绑定,操控task_struct.cpus_allowed位掩码 |
| sched_getaffinity() | |
| sched_yield() | 暂时让出处理器,显式的把CPU让给等待执行的RUNNABLE进程。当前进程不仅被抢占,而且会被放到过期队列中,这会让它在一段时间内不被执行(实时进程不会过期,这是个例外) |
链表(Linked Lists)是用于存放和操作可变数量元素(称为节点node)的数据结构,其特点是元素的动态插入和删除,无需连续内存区域。只能沿链表线性移动,而不支持直接的随机访问。
链表分类单向链表、双向链表两类,如果尾元素的*next指向首元素,则称为环形链表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//单向链表的元素 struct list_element { void *data; /* the payload */ struct list_element *next; /* pointer to the next element */ }; //双向链表的元素 struct list_element { void *data; struct list_element *next; struct list_element *prev; }; |
由于双向环形链表的灵活性,Linux内核使用的链表就是这种类型 。Linux使用了一种独到的方式实现链表——不是将数据载荷塞进链表节点,而把链表节点塞入数据结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
//常规的链表实现 struct fox { unsigned long tail_length; unsigned long weight; bool is_fantastic; struct fox *next; //数据载荷就处于链表节点中 struct fox *prev; }; //Linux的链表实现 //linux/list.h,通用链表节点结构体 struct list_head { struct list_head *next; struct list_head *prev; }; struct fox { unsigned long tail_length; unsigned long weight; bool is_fantastic; struct list_head list; //链表节点嵌入在数据载荷中,fox.list.prev指向上一个元素;fox.list.next指向下一个元素 //除非嵌入到结构中,list_head类型本身没有任何意义 }; |
这种链表设计很优雅,它避免了为每种数据类型单独设计链表类型。
注意,内核版本的链表,其节点的next/prev指向的上/下一个节点是 list_head 类型,而我们需要得到的是具有数据载荷的容器结构(上面代码中的struct fox),怎么办呢?内核提供了依据任意元素指针来获得其容器结构体的宏:
|
1 2 3 4 5 6 7 8 9 |
//依据元素member的指针ptr,获取其父结构体type的指针 #define container_of(ptr, type, member) ({ \ const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );}) //计算指针偏移量的宏,与具体编译器有关 #define offsetof(TYPE,MEMBER) __compiler_offsetof(TYPE,MEMBER) /include/linux/compiler-gcc4.h #define __compiler_offsetof(a,b) __builtin_offsetof(a,b) |
基于上述宏,内核链表可以很方便的得到链表元素:
|
1 2 3 |
//根据list_head指针获得载荷元素 #define list_entry(ptr, type, member) \ container_of(ptr, type, member) |
有两种方式来初始化链表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// /include/linux/list.h 初始化链表元素,将prev/next都指向自己 static inline void INIT_LIST_HEAD(struct list_head *list) { list->next = list; list->prev = list; } //运行时动态创建 struct fox *red_fox; red_fox = kmalloc( sizeof ( *red_fox ), GFP_KERNEL ); red_fox->tail_length = 40; red_fox->weight = 6; red_fox->is_fantastic = false; INIT_LIST_HEAD( &red_fox->list ); //编译期间静态创建的最简方式 struct fox red_fox = { .list = LIST_HEAD_INIT(red_fox.list), //{ &(red_fox.list), &(red_fox.list) } .tail_length = 40, .weight = 6, }; |
通过下面的宏可以初始化一个变量名为name的链表头:
|
1 2 |
#define LIST_HEAD(name) \ struct list_head name = LIST_HEAD_INIT(name) |
下表列出的函数,对链表进行增删元素、连接链表的操作,都提供O(1)的复杂性,亦即需要恒定时间来完成;对列表进行遍历的操作则提供O(n)的复杂性,亦即需要的时间和元素个数成正比:
| 函数/宏 | 说明 | ||
| list_add | list_add(struct list_head *new, struct list_head *head) 添加一个新节点new到节点head的后面。该函数可以用于实现Stack结构 | ||
| list_add_tail | list_add_tail(struct list_head *new, struct list_head *head) 添加一个新节点new到head的前面。该函数可以用于实现Queue结构 | ||
| list_del | list_del(struct list_head *entry) 从链表中删除entry节点,该操作不会释放entry持有的内存,或者其被嵌入的struct | ||
| list_del_init | list_del_init(struct list_head *entry) 删除entry并将其重新初始化 | ||
| list_move | list_move(struct list_head *list, struct list_head *head) 将list从它的链表位置中移除,并添加到head元素的后面,注意head可以位于同一个链表或者不同链表 | ||
| list_move_tail | list_move_tail(struct list_head *list, struct list_head *head) 与上面类似,但是添加到head的前面 | ||
| list_empty | list_empty(struct list_head *head) 检查链表是否为空,如果非空返回0,否则返回非0(true) | ||
| list_splice | list_splice(struct list_head *list, struct list_head *head) 把两个链表相连,前一个链表的list元素接在后一个链表head元素的后面 | ||
| list_splice_init | list_splice_init(struct list_head *list, struct list_head *head) 与上面类似,但是list指向的链表会被重新初始化 | ||
| list_for_each |
迭代整个链表:
|
||
| list_for_each_entry |
迭代整个链表,比上面的更易用:
类似的还有反向迭代器 list_for_each_entry_reverse() |
||
| list_for_each_entry_safe | 迭代整个列表,迭代期间支持节点的删除,类似的还有反向迭代器 list_for_each_entry_safe_reverse() |
队列是一种先入先出(FIFO)的数据结构,通常和生产者-消费者编程模型密切相关。
Linux内核队列 kfifo 和Java NIO的java.nio.Buffer比较类似,它使用两个指针分别指示读、写的偏移量,前者指向下一次出队(dequeue)位置(字节偏移),后者则指向下一次入队(enqueue)位置,读指针总是小于等于写指针。
当执行一次入队操作时,写指针将加上入队的元素个数,出队操作时类似。当写偏移量到达队列长度限制后,即无法再行入队数据,直到队列被重置。
可以通过下面的方式创建队列:
|
1 2 3 4 5 6 7 8 9 10 |
//创建一个队列,存放到fifo指针,尺寸size个字节 int kfifo_alloc( struct kfifo *fifo, unsigned int size, gfp_t gfp_mask ); //自己分配内存,buffer用于指定存放元素的缓冲区 void kfifo_init( struct kfifo *fifo, void *buffer, unsigned int size ); //静态方式定义队列,使用的较少 DECLARE_KFIFO( name, size ); INIT_KFIFO( name ); struct kfifo fifo; int ret = kfifo_alloc( &kifo, PAGE_SIZE, GFP_KERNEL ); //创建一个和页大小一致的队列 |
kfifo提供了以下重要函数:
| 函数/宏 | 说明 |
| kfifo_in | unsigned int kfifo_in(struct kfifo *fifo, const void *from, unsigned int len) 入队操作。如果成功,返回入队字节数;如果队列可用空间小于len,则返回的值可能小于len甚至为0 |
| kfifo_out | unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len) 出队操作。从队列取出len字节的数据存放到to,返回实际获得的字节数 |
| kfifo_out_peek | unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset) 窥看队列,不修改读指针。offset指定偏移量,如果为0则与kfifo_out类似,从队列头读取 |
| kfifo_size | static inline unsigned int kfifo_size(struct kfifo *fifo) 获取队列总计尺寸 |
| kfifo_len | static inline unsigned int kfifo_len(struct kfifo *fifo) 获取已入队的字节数 |
| kfifo_avail | static inline unsigned int kfifo_avail(struct kfifo *fifo) 获取可用的字节数 |
| kfifo_is_empty | static inline int kfifo_is_empty(struct kfifo *fifo) 判断队列是否为空,类似还有 kfifo_is_full |
| kfifo_reset | static inline void kfifo_reset(struct kfifo *fifo) 重置队列,抛弃其中全部内容 |
| kfifo_free | void kfifo_free(struct kfifo *fifo) 销毁一个由kfifo_alloc分配的队列。对于使用kfifo_init创建的队列,缓冲区由开发者自己销毁 |
映射也称为关联数组。尽管映射常常使用散列表的方式实现,但是基于自平衡二叉搜索树实现的话,可以在最坏情况下获得更好性能(对数复杂性vs线性复杂性),同时二叉树提供散列表没有的顺序保证,因此像 std::map 等映射是基于二叉树实现的。
Linux内核包含一个非通用目的的映射数据结构,用于将用户空间的唯一标识(UID,例如POSIX定时器ID)映射到内核中与之关联的数据结构上(例如k_itimer结构体)。该映射被命名为idr,函数 void idr_init(struct idr *idp) 用于定义一个idr。
idr还可以用来生成UID。
所谓树,是一种分层(多级)的数据结构。从数学角度来说,树是一个无环连接的有向图,每个图顶点(vertex,用树的术语称节点,node)具有0-N个出边(outgoing edges)以及0-1个入边(incoming edges)。二叉树就是每个节点最多有2个出边的树。
简称BST(Binary Search Trees),是一个节点有序的二叉树。其节点顺序一般遵循以下法则:
- 根的左侧分支中,节点的值都小于根节点
- 根的右侧分支中,节点的值都大于根节点
- 递归的,所有子树也都是二叉搜索树
由于这种有序性,在树中搜索一个给定值(对数复杂度)、按序遍历树(线性复杂度)都相当高效。
节点的深度是指:从根节点到达当前节点,需要经过的父节点数目。
自平衡(Self-Balancing)二叉搜索树是指树中所有叶子节点的深差不超过1的二叉搜索树。
红黑树是一种“半平衡”的自平衡二叉搜索树,所谓半平衡是指:深度最大的叶子节点,其深度不会大于最浅叶子节点的2倍。红黑树节点具有特殊的着色属性,并且具有下面6条特征,正是这些特征保证了它的“半平衡”:
- 任意节点,要么着红色,要么着黑色
- 根、叶子节点都是黑色
- 叶子节点不包含数据
- 所有非叶子节点都有两个子节点
- 如果一个节点是红色,那么它的子节点都是黑色
- 节点到其每个叶子节点的简单路径(路径中无重复节点),均包含相同数量的黑色节点
要使不同叶子节点的深差拉大,只能通过增加红色中间结点,由于第5条的限制,导致这种深度差距无法达到2倍。下面是一个合法红黑树的示意图:

红黑树较为复杂,但是可以保证良好的最坏情况性能。
当从结构上改变了红黑树后,为了仍然满足上述6条性质,可能需要:
- 对部分节点进行重新着色
- 调整部分指针的指向(左旋,右旋)
| 数据结构 | 适用场景 |
| 链表 |
如果对集合的操作主要是遍历,可以选用链表,没有任何数据结构能提供比线性复杂度更优的的遍历性能 当数据量小、性能不是优先考虑因素时,优先使用链表 |
| 队列 | 当逻辑符合生产者-消费者模式时,使用队列。特别是需要一个定长缓冲区时 |
| 映射 | 如果需要映射一个UID到内核对象 |
| 红黑树 | 如果需要存储大量数据,且要求检索迅速 |