Linux内核学习笔记(三)
Linux使用虚拟内存技术。它是一种位于应用程序内存请求与内存管理单元(MMU,一般是集成于CPU的硬件)硬件之间的抽象层。虚拟内存计数有以下优势:
- 多个进程可以同时并发的运行,使用重复的虚拟内存地址
- 应用程序所需内存大于物理内存时也可以运行
- 程序代码中,只有部分装入内存时,进程也可以执行程序
- 进程可以共享库函数或者程序的一份单一的内存映像
- 程序在物理内存中的位置可以重新定位
- 可以编写机器无关的代码,不用关心物理内存的组织结构
虚拟内存子系统的主要由虚拟地址空间(Virtual address space)组成,进程使用的虚拟内存地址不同于其物理内存地址,内核(提供页表)和MMU负责协调并定位物理地址。
机器的物理内存,除了开辟出一小部分专门用于存放内核映像(内核代码、内核静态数据结构)以外,其它部分通常都由虚拟内存子系统管理,并作以下三个主要用途:
- 满足内核对缓冲区、描述符和其它动态内核数据结构的请求
- 满足进程对一般内存区域的请求、对文件内存映射的请求
- 作为高速缓存的载体,让磁盘等I/O获得更好性能
虚拟内存子系统要解决的一个主要问题是内存碎片,由于内核常常需要物理上连续的内存空间,当碎片化严重时,即使物理内存富余,也可能导致失败。内核内存分配器(KMA)为解决内存碎片问题提供了很好的帮助,当前较好的KMA算法是Solaris发明的Slab。
本文分为以下章节,讲述虚拟内存子系统和相关的内核模块:
在内核中分配内存比在用户空间困难,原因包括:
- 内核不能像用户空间那样奢侈的使用内存,这是根本原因所在。内核不支持简单的内存分配方式
- 内核一般不能睡眠,这导致涉及到换页(潜在的睡眠)的内存分配受限
- 内核处理内存分配错误困难,参考第2条
每个进程都有一个页表,用于存储虚拟地址到物理地址,准确的说是页,的映射关系。
进程顶级页面包含一个项,此项的内容是全局共享的,描述内核空间中的虚拟-物理页映射关系。每个进程随时都可能访问内核空间,例如系统调用,这要求随时能够进行内核空间的地址映射。
内存管理单元,能够通过查找进程的页面,完成从虚拟地址到物理地址的转换。
MMU是由体系结构决定的,因此,页表的结构也和体系结构相关。
尽管CPU最小寻址单位通常为字(甚至字节),内存管理单元(MMU,管理内存并把虚拟地址转换为物理地址的硬件)却把物理页(也称页帧,Page frame)作为管理内存的基本单位——从虚拟内存角度看,页是最小单位,即页表(Page table)的最小条目是一个页。
体系结构不同,页的大小也不同(甚至某些体系结构支持多种页大小)。大部分32位体系结构的页大小为4KB,64位一般支持8KB。大部分Linux系统使用4KB页。
内核使用下面的结构来表示物理页:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
/* * 页描述符结构体 * * 每个物理页都对应这样的一个结构,以便内核能够跟踪当前时刻页被用来存放什么东西 * 注意:无法跟踪哪个任务在使用页 * * 该结构本质上和物理页有关,而不是虚拟页,因此该结构对页的描述是临时的 */ struct page { //位域标识,该标识存放多种状态,例如是否脏页、是否锁在内存中 unsigned long flags; //存放页的引用计数,如果为-1表示内核没有引用该页,在新的分配中可以使用它,内核代码调用page_count()检查此计数,返回0表示空闲 atomic_t _count; union { //这个页被映射到了几个进程的地址空间 atomic_t _mapcount; struct { u16 inuse; u16 objects; }; }; union { struct { //一个页可以作为私有数据使用 unsigned long private; /** * 该字段目前不用于内核空间 * 如果当前页用于页缓存,该字段用于访问缓存对应的文件。页缓存用于保存文件的逻辑内容,Linux用它加速磁盘访问 * 如果当前页是一个匿名页(anonymous page,依赖于swap的用户空间内存)则该字段指向anon_vma结构允许内核快速的找到包含该页的页表 */ struct address_space *mapping; }; #if USE_SPLIT_PTLOCKS spinlock_t ptl; #endif struct kmem_cache *slab; struct page *first_page;//指向slab中第一个空闲对象 }; union { pgoff_t index; //对于页缓存中的页,该字段指定了缓存映射的文件的偏移量 void *freelist;//如果页由slub或者slob分配器管理,则该字段指向空闲对象的列表 }; struct list_head lru; #if defined(WANT_PAGE_VIRTUAL) /** * 如果不为空,则指向页对应的内核空间虚拟地址,该字段不是很有用,因为地址可以很容易被计算出来 * 某些内存(比如高端内存,high memory,32位系统一般1GB以上)在内核地址空间中,不固定的映射到某个虚拟地址,此时该字段为NULL */ void *virtual; #endif #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; #endif #ifdef CONFIG_KMEMCHECK void *shadow; #endif }; |
可以看到上述结构的嵌套很复杂,这是出于节约空间的考虑,此结构每增加1B,内核占用内存就会增加若干MB。因为每个物理页都需要这样的一个结构,内存越大,这类结构占用的内存就越多——假定页大小为8KB,内存为4GB,那么page结构占用内核内存就是20MB。
由于硬件的限制,内核不能按照同样的方式处理所有的内存,例如某些硬件在内存寻址方面存在缺陷:
- 某些硬件设备只能对特定内存地址进行DMA(直接内存访问)
- 某些体系结构能够寻址的物理地址范围比虚拟地址大的多,结果是,某些内存不能永久性的映射到内核地址空间。例如32位Linux内核把4G虚拟地址中0-3G分配给用户空间,3-4G分配给内核空间——1GB,而x86_32架构支持的物理地址扩展(PAE)可以让物理寻址范围扩大到64G
为应对这些缺陷,内核使用区把相同性质的内存进行分组:
- ZONE_DMA:该区的页支持DMA操作,DMA允许硬件绕过CPU直接读写主存。x86_32该区域为物理内存0-16MB
- ZONE_DMA32:和上一区类似,但是这些页只能被32位设备访问,某些体系结构中该区比ZONE_DMA更大
- ZONE_NORMAL:包含能够正常映射的页
- ZONE_HIGHMEM:包含所谓高端内存(High memory),这些内存不能永久的映射到内核地址空间,需要动态映射。x86_32该区域为物理内存896M以上
区的分配和使用依赖于体系结构:
- 某些体系结构支持对任何地址进行DMA操作,这些体系结构中ZONE_DMA为空。而x86_32上ISA(Industry Standard Architecture,工业标准体系结构,只支持16位设备)设备只能在物理内存的前16MB进行DMA操作
- 某些体系结构支持所有内存的直接映射,这些体系结构中ZONE_HIGHMEM为空,例如x86_64。而x86_32中高于896M的都是高端内存
注意这些内存分区没有物理意义,只是逻辑分组。内核依照分区进行内存分配:
- 内存不能跨区分配
- 某些分配可以使用多个区,例如一般用途的内存既可以使用ZONE_NORMAL,也可以使用ZONE_DMA
区使用下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
struct zone { // 水位,通过*_wmark_pages(zone)宏访问,该数组持有当前区最小、低、高水位值 // 内核使用水位为每个区域设置合适的内存消耗基准,水位随着空闲内存的多少而变化 unsigned long watermark[NR_WMARK]; /* * 各区保留的内存的大小 * * 我们不确定分配出去的内存最终是否会被是否,因此,为了防止完全的浪费数GB的内存,我们必须预留低区域中的一些内存 * 防止地区与内存出现OOM而高区域还有大量的内存可用 * 该数组在运行时可能被重新计算,如果内核参数sysctl_lowmem_reserve_ratio被调整 */ unsigned long lowmem_reserve[MAX_NR_ZONES]; struct per_cpu_pageset __percpu *pageset; //该自旋锁防止此结构被并发访问 spinlock_t lock; int all_unreclaimable; struct free_area free_area[MAX_ORDER]; ZONE_PADDING (_pad1_) spinlock_t lru_lock; struct zone_lru { struct list_head list; } lru[NR_LRU_LISTS]; struct zone_reclaim_stat reclaim_stat; unsigned long pages_scanned; //区的标志位 unsigned long flags; //该区的统计信息 atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; int prev_priority; unsigned int inactive_ratio; ZONE_PADDING (_pad2_) wait_queue_head_t * wait_table; unsigned long wait_table_hash_nr_entries; unsigned long wait_table_bits; struct pglist_data *zone_pgdat; unsigned long zone_start_pfn; unsigned long spanned_pages; unsigned long present_pages; /* * 区域的名字,内核启动时初始化,三个区的名字分别为:DMA、Normal、HighMem */ const char *name; } ____cacheline_internodealigned_in_smp; |
这个结构较大,但是系统中只有三个区,因此该结构的实例只有三个。
通过内核提供的接口,我们可以在内核空间进行内存分配和释放。 内核提供了一种请求内存的底层机制,可以用来以页为单位分配内存:
|
1 2 3 4 5 6 7 8 9 10 |
//分配2^order个连续的物理页,并且返回执行第一个page结构的指针,如果出错返回NULL struct page * alloc_pages( gfp_t gfp_mask, unsigned int order ); //把页转换为它映射的逻辑地址 void * page_address( struct page *page ); //类似于alloc_pages,但是直接返回第一页的逻辑地址 unsigned long __get_free_pages( gfp_t gfp_mask, unsigned int order ); //下面两个函数分配单个页 struct page * alloc_page( gfp_t gfp_mask ); unsigned long __get_free_page( gfp_t gfp_mask ); |
分配内存后,必须进行错误检查,因为内存分配可能失败。
如果想让返回的页全部填充为0,可以调用:
|
1 |
unsigned long get_zeroed_page(unsigned int gfp_mask); |
该函数在为用户空间分配页时很有用,可以防止物理内存中的敏感数据被泄漏。
不再需要页时,应当释放之:
|
1 2 3 |
void __free_pages( struct page *page, unsigned int order ); void free_pages( unsigned long addr, unsigned int order ); void free_page( unsigned long addr ); |
需要注意的是,只能释放属于自己的页,这要求传递正确的struct page或者地址,传递错误的参数可能导致系统崩溃。
不管是按页分配,还是下面的按字节分配函数,都有一个标志参数可以设置。该标志参数可以包含多个位域,这些位域都声明在 linux/gfp.h 中声明,可以分为三类:
- 行为修饰符(大部分内存分配不需要直接指定):
标志 说明 __GFP_WAIT 内存分配器(allocator)可以睡眠 __GFP_HIGH 内存分配器可以访问紧急池(emergency pools) __GFP_IO 内存分配器可以启动磁盘I/O __GFP_FS 内存分配器可以启动文件系统I/O __GFP_COLD 内存分配器应该使用缓存中即将淘汰的页(cache cold pages) __GFP_NOWARN 内存分配器不打印失败警告 __GFP_REPEAT 如果分配失败,内存分配器重复尝试分配。注意这次重复尝试也可能失败 __GFP_NOFAIL 无限制重复尝试,分配不得失败 __GFP_NORETRY 如果分配失败,绝不重试 __GFP_NOMEMALLOC 不使用紧急预留区域 __GFP_HARDWALL 强制hardwall处理器集合范围,即只在允许访问的CPU上分配内存 __GFP_RECLAIMABLE 指定页是可回收的 __GFP_COMP 添加混合页元数据,在hugetlb代码内部使用 - 区修饰符(指定内存从何处分配,内核默认从ZONE_NORMAL开始):
标志 说明 __GFP_DMA 仅从ZONE_DMA分配 __GFP_DMA32 仅从ZONE_DMA32分配 __GFP_HIGHMEM 从ZONE_HIGHMEM或者ZONE_NORMAL分配。注意该标志不能和__get_free_pages()、kmalloc()使用,原因是这些函数返回逻辑地址,而不是page结构体,而高端内存分配后是没有自动映射到内核地址空间的。只有alloc_pages()才可以使用该标志,它返回page结构体而不是逻辑地址 - 类型标志(实际上是结合上面两种标志,更加简单、不容易出错):
标志 描述 GFP_ATOMIC __GFP_HIGH。用于中断处理程序、下半部、持有自旋锁以及其它不能睡眠的地方,例如中断处理程序、软中断、Tasklet GFP_NOWAIT 0。类似于上面,但是不会调用紧急内存池,因此增加了内存分配失败的可能性 GFP_NOIO __GFP_WAIT。可以阻塞,但是不会启动磁盘I/O,该标志用于不能引擎更多磁盘I/O的阻塞性I/O代码中 GFP_NOFS (__GFP_WAIT | __GFP_IO)。可以阻塞,也可能启动磁盘I/O,但是不会启动文件系统操作。在不能启动另外一个文件系统操作时使用,例如文件系统部分的某些代码中,防止再次调用自身导致死锁 GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)。常规分配方式,可能会阻塞,用于内核空间睡眠安全的进程上下文中,为了获得足够内存,内核会尽力而为,例如让调用者睡眠、交换页到硬盘 GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)。常规分配方式,可能会阻塞,用于用户空间 GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HIGHMEM | __GFP_HIGHMEM)。使用高端内存,用于为用户空间进程分配内存 GFP_DMA __GFP_DMA。获取支持DMA的内存,一般驱动程序可能使用该标志
类似于用户空间的内存分配函数 malloc() ,它分配逻辑、物理上都连续的以字节为单位的内核内存:
|
1 2 3 4 5 6 7 8 |
//该函数返回一个内存区域的指针,该区域至少有size大小,并且在物理上是连续的,如果出错则返回null void * kmalloc(size_t size, gfp_t flags); //用法示例 struct person *p; p = kmalloc( sizeof(struct person), GFP_KERNEL ); if ( !p ) ; |
该函数用于释放kmalloc()分配的内存:
|
1 2 3 |
void kfree(const void *ptr); //下面的调用是安全的: kfree(NULL); |
不得释放:
- 已经释放的内存
- 不是kmalloc()分配的内存
该函数与kmalloc()相似,但是只保证分配内存的虚拟地址是连续的,物理地址不必连续 。用户空间malloc()的工作方式也是这样的。该函数可以分配非连续的物理内存块,然后再修正页表,把这些分散的内存映射到逻辑地址空间的连续区域内。
大多数情况下,只有硬件设备需要连续的物理地址,这是因为硬件设备运作于MMC之外,不知道虚拟地址为何物。尽管如此,很多内核代码使用kmalloc(),这是出于性能的考虑——不连续的物理地址需要建立额外的页表项,导致大得多的TLB(Translation lookaside buffer,转译后备缓冲,一种硬件缓冲区,用来缓存虚拟地址到物理地址的映射关系,可以极大提升系统性能,因为大部分内存需要虚拟寻址)抖动。
vmalloc()只在不得已时使用,典型的是获得大块内存,例如模块被动态加载到内核时,使用该函数分配的空间装载内核。
该函数以及相应的释放函数如下:
|
1 2 3 4 5 |
//返回至少size的虚拟连续空闲内存,如果失败返回NULL //该函数可能睡眠,不得用于中断上下文或者任何不支持阻塞的地方 void * vmalloc(unsigned long size); //释放由vmalloc()分配的内存 void vfree(const void *addr); |
内核中内存的分配和回收非常频繁。为了提高性能,程序员常常使用空闲链表(free lists), 其中包含特定结构的空闲实例,需要使用时,从中获取一个,用完则放回去,空闲链表相当于对象高速缓冲(对象池),避免不必要的内存分配/回收动作。
这种分散的空闲链表机制难以全局控制,例如当内存紧缺的时候,无法通知这些链表收缩以腾出内存,因为内核根本不知道空闲链表的存在。为解决此问题Linux引入了slab层(即所谓slab分配器),充当通用数据结构缓存层。slab在以下原则之间维持平衡:
- 频繁使用的数据结构会导致频繁的内存分配/释放,因此应该缓存之
- 频繁的内存分配/释放导致内存碎片,为避免碎片,空闲链表的缓存应当连续存放
- 如果分配器知晓对象大小、页大小、总的高速缓存的大小,将有利于决定最佳算法
- 如果部分缓存为CPU独占,那么分配/释放可以避免SMP锁
- 如果分配器与NUMA(非统一内存存取,被共享的存储器物理上是分布式的)相关,那么它应该从相同的内存节点为请求者分配内存
- 可以对存放的对象进行着色,防止多个对象映射到相同的缓存行(cache line,CPU缓存被划分为多个大小固定的行)
依据对象类型的不同,slab层划分出多个高速缓存组:
- 存放进程描述符(struct task_struct)的组
- 存放索引节点对象(struct inode)的组
- 通用高速缓存组:kmalloc()接口基于该组
上述每个组,会划分为多个slab,每个slab由1-N个物理连续页(一般1个页)构成。每个slab在一个时刻可以是满、空、部分满三种状态,在分配时,优先使用部分满的slab,如果没有部分满slab,则使用空slab,如果空的也没有,则创建新的slab。这种使用策略有利于减少碎片。
高速缓存组使用结构 kmem_cache 表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
struct kmem_cache { /* 1) Per-CPU数据,每次分配/释放时访问 */ struct array_cache *array[NR_CPUS]; /* 2) 可调整参数,由cache_chain_mutex保护 */ unsigned int batchcount; unsigned int limit; unsigned int shared; unsigned int buffer_size; u32 reciprocal_buffer_size; /* 3) 每次分配/释放时从后端访问 */ unsigned int flags; /* constant flags */ unsigned int num; /* # of objs per slab */ /* 4) 缓存增长/收缩 */ /* 每个slab包含2^gfporder个页 */ unsigned int gfporder; /* 控制的GFP标志位 */ gfp_t gfpflags; size_t colour; /* 缓存着色范围 */ unsigned int colour_off; /* 着色偏移量 */ struct kmem_cache *slabp_cache; unsigned int slab_size; unsigned int dflags; /* 动态标志位 */ /* 构造函数 */ void (*ctor)(void *obj); /* 5) 缓存创建/移除 */ const char *name;//缓存组的名称 struct list_head next;//下一个缓存组 /* * 节点列表(长度一般就是1),该字段必须是最后一个字段 * */ struct kmem_list3 *nodelists[MAX_NUMNODES]; }; |
注意最后一个字段节点列表,它是 kmem_list3 结构的数组,该结构包含三个链表:slabs_full、slabs_partial、slab_empty,分别表示当前节点满、部分满、空的slab:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
struct kmem_list3 { struct list_head slabs_partial; /* 部分满的slab */ struct list_head slabs_full; /* 满的slab */ struct list_head slabs_free; /* 空闲的slab */ unsigned long free_objects; unsigned int free_limit; unsigned int colour_next; /* Per-node cache coloring */ spinlock_t list_lock; struct array_cache *shared; /* shared per node */ struct array_cache **alien; /* on other nodes */ unsigned long next_reap; /* updated without locking */ int free_touched; /* updated without locking */ }; |
这些链表包含所在高速缓存组所有的slab,后者使用slab描述符表示:
|
1 2 3 4 5 6 7 8 |
struct slab { struct list_head list; /* 数据结构链表,该链表可能是满的、空的或者部分满的 */ unsigned long colouroff; /* 着色偏移量 */ void *s_mem; /* 该slab中的第一个对象的指针 */ unsigned int inuse; /* 该slab已分配的对象数 */ kmem_bufctl_t free; /* 第一个空闲对象(如果有的话) */ }; |
slab描述符要么在slab外面另外分配内存存储,要么直接存放在slab的首部。
当缓存空间不足时,内核会调用低级内核页分配函数 kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid) 为缓存组创建新的slab,后者会则转调 __get_free_pages() 进行内存分配。通过 kmem_freepages() 则可以释放掉slab,它会调用 free_pages() 。
slab层存在的意义就是避免频繁的分配/释放内存,因此只有slab中没有可用空间时,才会分配新的slab;类似的,只有当内存紧缺、高速缓存被显式撤销时,才会释放slab。
下面的函数用于创建新的高速缓存组:
|
1 2 3 4 5 6 7 8 9 10 |
/** * 成功时返回指向高速缓存组的指针,否则返回NULL * 注意该函数不能在中断上下文调用,因为它可能睡眠 */ struct kmem_cache * kmem_cache_create( const char *name, //高速缓存(组)的名称 size_t size, //缓存中每个元素的大小 size_t align,//第一个对象的偏移,用来确保在页内进行特定的对齐,默认0(标准对齐) unsigned long flags,//标志位集合 void (*ctor)( void * ) );//高速缓存的构造函数,只有新的页追加到缓存中时,才会调用该函数,内核高速缓存不使用构造函数 |
要撤销高速缓存组,则可以调用:
|
1 |
int kmem_cache_destroy(struct kmem_cache *cachep); |
该函数常常在模块注销代码中使用,调用前必须保证:组中所有slab都为空;调用过程中、完毕后,不得再使用该缓存。
创建了高速缓存组后,可以调用下面的函数获取或者释放对象:
|
1 2 3 4 5 6 7 8 |
/** * 返回指向组中某个对象的指针,如果缓存组中任何slab都没有足够空间,就会触发新的slab的创建 */ void * kmem_cache_alloc( struct kmem_cache *cachep, gfp_t flags ); /** * 标注缓存池中的objp对象为空闲 */ void kmem_cache_free( struct kmem_cache *cachep, void *objp ); |
在用户空间,用户栈可以非常大、动态增长。 在内核空间则相反,内核栈固定且很小。内核栈的大小依赖于体系结构和编译时选项。在以前的内核版本中,每个进程都对应一个2页的内核栈,由于32/64位体系结构的页大小分别4/8KB,因此内核栈分别为8/16KB。在2.6版本,引入了一个设置单页内核栈的选项,激活该选项则内核栈只有1页大小。
由于内核栈很小,任何时候在其上进行大量的静态分配(比如大型数组、结构体)都很危险。栈溢出时会导致宕机甚至无声息的数据破坏。使用动态内存分配通常是明智的选择。
高端内存不能永久的映射到内核地址空间,因此通过 alloc_pages(__GFP_HIGHMEM, *) 分配的页,可能没有对应的逻辑地址。
在x86架构上,尽管处理器物理寻址范围达4G(启用PAE则64G),然而896M+的内存都是高端内存,高端内存的页一旦被分配,就必须映射到内核的逻辑地址空间上,在x86上内核用于映射高端内存的逻辑地址范围是3-4G。
要把一个页映射到内核地址空间,可以调用:
|
1 2 |
//映射页到逻辑地址,该函数可能会睡眠 void *kmap(struct page *page); |
不管是不是高端内存,上述函数都可用:
- 如果page属于低端内存,其(已经)映射到的虚拟地址直接作为返回值
- 如果page属于高端内存,则会立即永久的映射到一个内核逻辑地址,并返回该地址
由于可供映射的逻辑地址空间有限,因此高端内存不再需要的时候,必须解除映射:
|
1 |
void kunmap(struct page *page); |
必须映射高端内存,而当前上下文又不能睡眠时,可以使用内核提供的临时映射(temporary mappings)机制(亦称原子映射,atomic mappings)。内核预留了一些mappings,专供临时映射使用。调用下面的函数可以进行/解除临时映射:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
/** * 执行临时映射,该函数不会阻塞。 * 该函数会禁止内核抢占,这是因为mappings对每个CPU来说是唯一的,而内核抢占(调度程序)可能改变任务在哪个CPU上执行 */ void *kmap_atomic( struct page *page, enum km_type type ); //第二个参数为枚举,说明临时映射的目的 enum km_type { KM_BOUNCE_READ, KM_SKB_SUNRPC_DATA, KM_SKB_DATA_SOFTIRQ, KM_USER0, KM_USER1, KM_BIO_SRC_IRQ, KM_BIO_DST_IRQ, KM_PTE0, KM_PTE1, KM_PTE2, KM_IRQ0, KM_IRQ1, KM_SOFTIRQ0, KM_SOFTIRQ1, KM_SYNC_ICACHE, KM_SYNC_DCACHE, KM_UML_USERCOPY, KM_IRQ_PTE, KM_NMI, KM_NMI_PTE, KM_TYPE_NR }; /** * 解除临时映射,该函数不会阻塞 */ void kunmap_atomic( void *kvaddr, enum km_type type ); |
可以在SMP机器上使用Per-CPU数据,对于每个CPU,数据具有独特的副本。在2.4中,声明Per-CPU数据的方式是声明长度等于CPU数量的数组,例如:
|
1 |
unsigned long my_percpu[NR_CPUS]; |
然后就可以用下面的代码访问之:
|
1 2 3 4 5 |
int cpu; cpu = get_cpu(); /* 获得当前CPU并禁止内核抢占 */ /*操控变量*/ my_percpu[cpu]++; put_cpu(); /* 启用内核抢占 */ |
注意上述代码中没有锁,这是因为操控的数据对于CPU是专用的,不存在多CPU并发问题。但是需要禁止内核抢占,因为:
- 如果当前代码被重新调度到其它CPU,则Per-CPU变量无效,因为它指向的不是当前CPU
- 如果另外一个任务抢占当前代码,则可能在同一CPU上访问Per-CPU变量,导致竞态条件
2.6引入了新的接口percpu,可以简化Per-CPU数据的创建、操控:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
//编译时定义Per-CPU变量 DEFINE_PER_CPU( type, name ); //类似上面,某些情况下防止编译器警告 DECLARE_PER_CPU( type, name ); //禁止内核抢占,并得到Per-CPU变量的左值 #define get_cpu_var(var) (*({ \ preempt_disable(); \ &__get_cpu_var(var); })) //恢复内核抢占 #define put_cpu_var(var) do { \ (void)&(var); \ preempt_enable(); \ } while (0) //获取其它CPU上的Per-CPU数据,注意该函数既不提供锁保护,也不禁止内核抢占 //该宏定义是非SMP的版本,就是简单的获得变量var #define per_cpu(var, cpu) (*((void)(cpu), &(var))) |
注意,上述静态编译时声明的Per-CPU数据不能在模块内使用,要在模块中访问Per-CPU数据,需要动态创建:
|
1 2 3 4 5 |
//给每个CPU分配一个指定类型的对象实例,封装了__alloc_percpu宏,按单字节对齐(给定类型的自然边界) void *alloc_percpu( type ); //分配对象,size为尺寸,align表示按几个字节进行对齐 void *__alloc_percpu( size_t size, size_t align ); void free_percpu( const void * ); //释放Per-CPU数据 |
使用Per-CPU数据的好处如下:
- 减少锁定造成的开销:因为数据不存在并发问题,因此自然不需要加锁
- 大大减少缓存失效:失效发生在CPU试图使它们的缓存保持同步时,如果一个CPU需要操作某个数据,而该数据又存放在其它处理器的缓存中,则后者必须清理或者刷出自己的缓存。持续不断的缓存失效称为缓存抖动(thrashing the cache),会对系统性能产生很大影响
内核除了需要管理自己的内存外,还需要管理用户空间中进程的内存,该内存称为进程地址空间。Linux使用虚拟内存技术管理内存,因此系统中的每一个进程觉得自己可以使用全部物理内存——即使一个进程,其拥有的地址空间也远远大于系统物理内存。
每个进程都在其私有的进程地址空间上运行,在用户态下,进程可以访问进程地址空间的私有栈、数据区、代码区等信息;在内核态下,进程访问内核的数据区、代码区,并使用另外的私有栈(内核栈)。尽管每个进程都有自己的私有地址空间,实际上它们会共享一部分内存内容,这种共享可以由进程显式提出,也可以由内核自动完成以节约内存,比如对于程序、库的副本,尽管有多个进程访问它,只会加载一份在内存
进程地址空间由可寻址的虚拟内存组成, 每个进程有多达32或64位平坦的(flat,意味着连续、全部可用)空间。一些OS不提供平坦空间,而是分段式、不连续的,称为段地址空间,现在使用虚拟内存的OS很少使用这种模式了。两个进程即使使用相同的内存地址,也毫不相干。
内存地址是一个数值,其必须在地址空间的范围之内。
进程不一定有权访问其全部虚拟地址空间,地址空间中可以被进程合法访问的部分,称为内存区域(Memory areas),进程可以有多个内存区域,每个区域都是连续的一段虚拟地址区间。进程可以动态的给自己的地址空间添加/减少内存区域。内存区域具有关联的权限,例如可读、可写、可执行,进程必须遵守权限规则。如果进程访问不是内存区域的内存、或者以错误的方式访问,内核将终结进程,提示段错误(Segmentation Fault)。内存区域可以包含以下类型的对象:
- 可执行文件代码的内存映射,称为代码段(Text Section)
- 可执行文件已初始化的全局变量的内存映射,称为数据段(Data Section)
- 包含未初始化全局变量的零页(Zero page,全部存放零的页)的内存映射, 称为Bss Section
- 每个共享库(C库、动态库)的代码、数据、Bss段,也被载入进程的地址空间
- 任何内存映射文件
- 任何共享内存段
- 任何匿名(没有映射到实际文件,MAP_ANONYMOUS)的内存映射,比如 malloc() 分配的内存
内存区域不会重叠。可执行代码、已初始化全局变量、未初始化全局变量、共享库的代码和数据、内存映射文件、堆(匿名映射)、栈(用户态栈)都具有独立的区域,这些区域有些在程序通过 exec() 系统调用载入进程时,就会初始化。
进程拥有完整的虚拟地址空间 —— 不管是32/64位系统。地址空间分为用户、内核两部分。
出于性能的考虑,内核内存映射到任何进程的地址空间。但是,内核地址空间仅仅能由内核代码访问。
对于32位系统来说,Linux将最上面的1G内存用作内核虚拟地址,范围0xc0000000 - 0xffffffff。物理内存完全对应的映射到内核空间,这简化了内存管理。任何0-896M范围的内核虚拟地址,减去0xc0000000的偏移即得到物理地址。
对于64位系统来说,整个地址空间的高半部分,全部留给内核虚拟地址。
内核使用内存描述符来表示进程的地址空间:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
struct mm_struct { /** * 下面两个字段都在描述该地址空间中全部内存区域:一个链表形式,一个红黑树形式 * 这种冗余结构是为了快速遍历的同时,能够快速的搜索 */ struct vm_area_struct *mmap; /* 虚拟内存区域的链表 */ struct rb_root mm_rb; /* 虚拟内存区域(VMA)的红黑树 */ struct vm_area_struct *mmap_cache; /* 最后使用的虚拟内存区域 */ unsigned long free_area_cache; /* 地址空间的第一个空洞 */ pgd_t *pgd; /* 页全局目录 */ atomic_t mm_users; /* 正在使用该地址空间的进程数,多个线程可能共享一个地址空间 */ /** * 主(线程)引用计数,为0则该结构体可以被撤销 * 多线程程序中只有主线程会导致该计数增加;进程的线程全部退出后,该计数会变为0 */ atomic_t mm_count; int map_count; /* 内存区域数量 */ struct rw_semaphore mmap_sem; /* 内存区域信号量 */ spinlock_t page_table_lock; /* 页表自旋锁 */ /** * 所有内存描述符(mm_struct)形成的链表,该链表的首元素是init_mm描述符,它代表init进程的地址空间 * 操作该链表时需要持有mmlist_lock锁 */ struct list_head mmlist; unsigned long start_code; /* 代码段起始地址 */ unsigned long end_code; /* 代码段结束地址 */ unsigned long start_data; /* 数据段起始地址 */ unsigned long end_data; /* 数据段结束地址 */ unsigned long start_brk; /* 堆的起始地址 */ unsigned long brk; /* 堆的结束地址 */ unsigned long start_stack; /* 栈的起始地址 */ unsigned long arg_start; /* 命令行参数起始地址 */ unsigned long arg_end; /* 命令行参数结束地址 */ unsigned long env_start; /* 环境变量起始地址 */ unsigned long env_end; /* 环境变量结束地址 */ unsigned long rss; /* 分配的物理页 */ unsigned long total_vm; /* VMA总数 */ unsigned long locked_vm; /* 锁定VMA数量 */ unsigned long saved_auxv[AT_VECTOR_SIZE]; /* 保存的auxv */ cpumask_t cpu_vm_mask; /* lazy TLB switch mask */ mm_context_t context; /* 体系结构特有数据 */ unsigned long flags; /* 状态标志 */ int core_waiters; /* thread core dump waiters */ struct core_state *core_state; /* core dump support */ spinlock_t ioctx_lock; /* AIO I/O 链表自旋锁*/ struct hlist_head ioctx_list; /* AIO I/O 链表 */ }; |
内存描述符的指针存放在进程描述符的 task_struct.mm 字段,当前进程的内存描述符可以通过 current -> mm 访问。
fork() 函数利用 copy_mm() 将父进程的内存描述符拷贝给子进程。
内存描述符从slab缓存组中分配:
|
1 2 |
//从slab缓存组mm_cachep中分配内存描述符 #define allocate_mm() (kmem_cache_alloc(mm_cachep, GFP_KERNEL)) |
一般的每个进程都有自己独特的进程描述符,也就是独立的地址空间。如果父进程希望子进程与自己共享地址空间,可以在调用 clone() 时设置 CLONE_VM 标记,这样的子进程称作线程,指定该标记后,就不需要调用allocate_mm()宏来分配描述符了,只需要将子进程的mm指向父进程的内存描述符:
|
1 2 3 4 5 |
if (clone_flags & CLONE_VM) { atomic_inc(¤t->mm->mm_users); tsk->mm = current->mm; } |
进程退出时,内核调用定义在 /kernel/exit.c 中的 exit_mm() 来撤销内存描述符,该函数会:
- 执行一些清理工作,更新统计量
- 调用 mmput() 减少mm_users计数
- 如果mm_users为0则调用 mmdrop() 减少mm_count计数
- 如果mm_count为零,说明该内存描述符没人使用了,调用 free_mm() 宏,通过 kmem_cache_free() 把结构体释放,归还slab缓存组
内核线程没有进程地址空间,因此其进程描述符的mm字段为空,这是合理的——因为内核线程没有用户上下文。内核线程没有自己的内存描述符、页表。
尽管内核线程没有自己的页表,但是为了访问内核空间,它必须要使用页表。Linux的做法是,让内核线程使用前一个进程的页表:
- 当一个进程被调度,获得CPU时,其进程描述符mm字段所指向的地址空间被装载到内存。进程描述符的 active_mm 被更新,指向新的地址空间
- 内核线程没有自己的地址空间,因此它被调度时,内核会发现mm为NULL
- 这时,内核就会保留刚刚失去CPU的进程的内存描述符,并更新内核线程的 active_mm 使之指向此描述符
- 内核线程使用前一个进程的页表,从中查询和内核内存相关的信息。每个进程的页表都有描述内核空间的顶级Entry,此Entry的内容是全局共享的,不存在数据冗余
进程的内存区域在内核中常被称为“虚拟内存区域(VMA)”。 虚拟内存区域是地址空间的连续区间上一个独立内存范围,内核把每个内存区域作为独立对象进行管理,虚拟内存区域使用下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
struct vm_area_struct { struct mm_struct *vm_mm; /* 关联的内存描述符 */ //每个虚拟内存区域都对应地址空间内的连续区间,不同虚拟内存区域不会重叠 unsigned long vm_start; /* 区域首地址(包含) */ unsigned long vm_end; /* 区域尾地址(排除) */ struct vm_area_struct *vm_next; /* VMA的链表 */ pgprot_t vm_page_prot; /* 访问权限 */ unsigned long vm_flags; /* 标志位 */ struct rb_node vm_rb; /* 此区域在红黑树中的节点 */ union { /* 关联于 address_space->i_mmap 或者 address_space->i_mmap_nonlinear */ struct { struct list_head list; void *parent; struct vm_area_struct *head; } vm_set; struct prio_tree_node prio_tree_node; } shared; struct list_head anon_vma_node; /* 匿名VMA项 */ struct anon_vma *anon_vma; /* 匿名VMA对象 */ struct vm_operations_struct *vm_ops; /* VMA操作表 */ unsigned long vm_pgoff; /* 文件中的偏移量 */ struct file *vm_file; /* 映射的文件(如果有) */ void *vm_private_data; /* 私有数据 */ }; |
flags字段包含若干位标志,其含义如下:
| 标志 | 对VMA及其页面的影响 |
| VM_READ | 区域中的内存页是可读的 |
| VM_WRITE | 区域中的内存页是可写的 |
| VM_EXEC | 区域中的内存页是可执行的 |
| VM_SHARED | 区域中的内存页是被共享的,用于指示此区域包含的映射是否可以在多进程间共享。如果该标志被设置,称为“共享映射”;反之称为“私有映射” |
| VM_MAYREAD | VM_READ标志可以被设置 |
| VM_MAYWRITE | VM_WRITE标志可以被设置 |
| VM_MAYEXEC | VM_EXEC标志可以被设置 |
| VM_MAYSHARE | VM_SHARE标志可以被设置 |
| VM_GROWSDOWN | 区域可以向下增长 |
| VM_GROWSUP | 区域可以向上增长 |
| VM_SHM | 区域被用于共享内存 |
| VM_DENYWRITE | 区域映射了不可写文件 |
| VM_EXECUTABLE | 区域映射了可执行文件 |
| VM_LOCKED | 区域中的页面被锁定 |
| VM_IO | 区域映射了一个设备的I/O空间。通常在设备驱动程序执行nmap()函数进行I/O空间映射时才被设置,该标志也表示该区域不得包含在进程的core dump中 |
| VM_SEQ_READ | 区域可能被顺序读,提示内核进行有选择的预读(read-ahead),该标志可以通过系统调用 madvise() 设置 |
| VM_RAND_READ | 区域可能被随机读,类似上面,作用相反 |
| VM_DONTCOPY | 在fork()时,该区域不得拷贝 |
| VM_DONTEXPAND | 区域不能通过mremap()增长 |
| VM_RESERVED | 区域不得被交换出内存(swapped out),也是由设备驱动在进行映射时设置 |
| VM_ACCOUNT | 该区域是一个记账VM对象 |
| VM_HUGETLB | 区域使用了hugetlb页面 |
| VM_NONLINEAR | 区域是非线性映射的 |
vm_area_struct.vm_ops 字段定义了用于操作内存区域函数集合:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
struct vm_operations_struct { //当内存区域被加入到一个地址空间时,该函数被调用 void (*open)( struct vm_area_struct *area ); //当内存区域从地址空间中移除时,该函数被调用 void (*close)( struct vm_area_struct * ); //当访问该内存区域的页,而页不在物理内存中时,页面错误处理器(page fault handler)调用该函数 int (*fault)( struct vm_area_struct *, struct vm_fault * ); //当只读页被设置为可修改时,页面错误处理器调用该函数 int (*page_mkwrite)( struct vm_area_struct *vma, struct vm_fault *vmf ); //当get_user_pages()失败时,access_process_vm()调用该函数 int (*access)( struct vm_area_struct *, unsigned long, void *, int, int ); }; |
使用 /proc 文件系统和 pmap 工具可以查看给定进程的内存空间及其包含的内存区域:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
pmap $PID #输出内容: #开始地址(大小) 权限 (主:次设备号 inode) 文件 myprog[1426] 00e80000 (1212 KB) r-xp (03:01 208530) /lib/tls/libc-2.5.1.so #C库代码段 00faf000 (12 KB) rw-p (03:01 208530) /lib/tls/libc-2.5.1.so #C库数据段 00fb2000 (8 KB) rw-p (00:00 0) #C库bss段 08048000 (4 KB) r-xp (03:03 439029) /root/src/myprog #程序代码段 08049000 (4 KB) rw-p (03:03 439029) /root/src/myprog #程序数据段 40000000 (84 KB) r-xp (03:01 80276) /lib/ld-2.5.1.so #ld.so的代码段 40015000 (4 KB) rw-p (03:01 80276) /lib/ld-2.5.1.so #ld.so的代码段 4001e000 (4 KB) rw-p (00:00 0) #ld.so的bss段 bfffe000 (8 KB) rwxp (00:00 0) [ stack ] #栈 mapped: 1340 KB writable/private: 40 KB shared: 0 KB |
可以看到,该进程地址空间中被映射的总计1340KB,大约40KB是可写和私有的。如果一个内存范围是共享或不可写的, 那么内核只需要在内存中为文件(backing file)保留一份映射——这是安全的,也是合理的(避免内存浪费)。上面的C库就是不可写的例子。
没有映射文件的内存区域的设备标志为00:00,inode也设置为0,这样的区域属于零页——映射的内容全部是0。
内核常常需要在VMA上执行操作,这类操作非常频繁。内核在 linux/mm.h 中声明了若干VMA操作辅助函数:
检查某个地址是否包含在某个VMA中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
/** * 该函数搜索包含此地址的VMA,如果找不到返回NULL * * @param mm 内存描述符,指定了进程地址空间 * @param addr 需要寻找的地址 * @return 包含此地址的内存区域 */ struct vm_area_struct * find_vma( struct mm_struct *mm, unsigned long addr ) { struct vm_area_struct *vma = NULL; if ( mm ) { /** * 由于预期后续还会有更多的调用者查找目标VMA,因此在查找到VMA后,缓存在 * 内存描述符的mmap_cache字段中 */ vma = mm->mmap_cache; if ( ! ( vma && vma->vm_end > addr && vma->vm_start <= addr ) ) //如果没有命中缓存 { struct rb_node *rb_node; rb_node = mm->mm_rb.rb_node; vma = NULL; while ( rb_node ) //红黑树遍历 { struct vm_area_struct * vma_tmp; vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb); if ( vma_tmp->vm_end > addr ) //判断结束地址大于addr { vma = vma_tmp; if ( vma_tmp->vm_start <= addr ) //如果其实地址小于等于addr,则找到,返回 break; rb_node = rb_node->rb_left; //找不到,沿着左子节点 } else rb_node = rb_node->rb_right; //遍历红黑树,沿着右子节点 } if ( vma ) mm->mmap_cache = vma; } } return vma; } |
工作方式与上面的函数类似, 但是同时返回前一个VMA的指针
|
1 2 3 4 5 |
struct vm_area_struct * find_vma_prev( struct mm_struct *mm, unsigned long addr, struct vm_area_struct **pprev //在此指针中存放前一个VMA ); |
该宏用来判断VMA是否和指定的区间交叉,甚至包含该区间:
|
1 2 3 4 5 6 7 8 9 10 |
/* Look up the first VMA which intersects the interval start_addr..end_addr-1, NULL if none. Assume start_addr < end_addr. */ static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr) { struct vm_area_struct * vma = find_vma(mm,start_addr); if (vma && end_addr <= vma->vm_start) vma = NULL; return vma; } |
内核使用 do_mmap() 函数创建一个新的线性地址区间,但是该函数不一定会创建一个新的VMA——如果指定的地址空间与既有VMA相邻,那么将合并为一个VMA,否则创建新的VMA:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//如果有无效参数,返回负数 //如果需要创建新VMA,那么将从slab缓存组中获得一个vm_area_struct实例,并调用vma_link()将其新分配的内存区域加入链表和红黑树 //并更新内存描述符的total_vm字段 unsigned long do_mmap( /** * 被映射的文件 * 如果该参数为NULL且offset为0,表示这次映射没有和文件关联,称为“匿名映射(anonymous mapping.)” * 如果该参数不为零,则称为“文件映射(file-backed mapping)” */ struct file *file, unsigned long addr, //搜索空闲地址的起始点,可选 unsigned long offset, //文件起始偏移量 unsigned long len, //映射多长文件内容 unsigned long prot, //页保护标志:指定映射页的访问权限 unsigned long flag //映射类型标志:指定类型、改变映射行为 ); |
页保护标志的取值依赖于体系结构,定义在 asm/mman.h ,通用的取值如下表:
| 标志 | 说明 |
| PROT_READ | 对应权限VM_READ |
| PROT_WRITE | 对应权限VM_WRITE |
| PROT_EXEC | 对应权限VM_EXEC |
| PROT_NONE | 不得访问 |
映射类型标志定义在asm/mman.h ,取值如下:
| 标志 | 说明 |
| MAP_SHARED | 该映射可以共享 |
| MAP_PRIVATE | 该映射不得被共享 |
| MAP_FIXED | 新的区间必须开始于addr参数指定的位置 |
| MAP_ANONYMOUS | 该映射是匿名映射,不和文件关联 |
| MAP_GROWSDOWN | 对应VM_GROWSDOWN |
| MAP_DENYWRITE | 对应VM_DENYWRITE |
| MAP_EXECUTABLE | 对应VM_EXECUTABLE |
| MAP_LOCKED | 对应VM_LOCKED |
| MAP_NORESERVE | 不需要为映射保留空间 |
| MAP_POPULATE | 填充页表 |
| MAP_NONBLOCK | 在I/O操作上不阻塞 |
在用户空间可以调用mmap系统调用,间接使用do_mmap()函数,该系统调用如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
/** * mmap的第二个版本,原始版本的mmap()调用由POSIX定义,仍然在C库中作为mmap()方法使用, * 但在内核已经没有对应实现 */ void * mmap2(void *start, size_t length, int prot, int flags, int fd, off_t pgoff ); |
do_munmap() 函数用于从特定进程地址空间中删除指定的地址区间:
|
1 2 3 4 5 6 7 8 9 |
//如果成功返回0,否则返回负数作为错误码 int do_munmap( //内存描述符,指明地址空间 struct mm_struct *mm, //被删除区间的起始地址 unsigned long start, //被删除区间的长度 size_t len ); |
相应的,系统调用 munmap() 允许进程从自身地址空间删除指定区间:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//声明 int munmap(void *start, size_t length); //对应实现,对do_munmap()的简单包装 asmlinkage long sys_munmap( unsigned long addr, size_t len ) { int ret; struct mm_struct *mm; mm = current->mm; down_write( &mm->mmap_sem ); ret = do_munmap( mm, addr, len ); up_write( &mm->mmap_sem ); return ret; } |
应用程序操作的是虚拟地址,而CPU直接操作的是物理地址,虚拟地址到物理地址的转换通过页表机制完成。Linux使用三级页表完成地址转换(包括不支持三级页表的体系结构,例如仅支持两级页表或者散列表的体系结构),多级页表可以节约内存空间。在大部分体系结构上,页表的查找和处理是由硬件完成,但是作为前提,内核必须正确的设置页表。页表的基本原理是:将虚拟地址分段(chunk),每段虚拟地址作为索引指向页表(table),而页表项指向下一级页表或者物理页:
- 顶级页表称为“页全局目录”(PGD),它是一个pgd_t类型(大部分体系结构上是unsigned long)的数组,该数组的条目指向二级页表的条目
- 二级页表称为“页中间目录(PMD)”,它是pmd_t类型的数组,该数组的条目又指向三级页表中的条目
- 三级页表就叫做页表,它是页表条目pte_t的数组,页表条目指向物理页
从虚拟地址转换为物理地址的过程如下图所示:
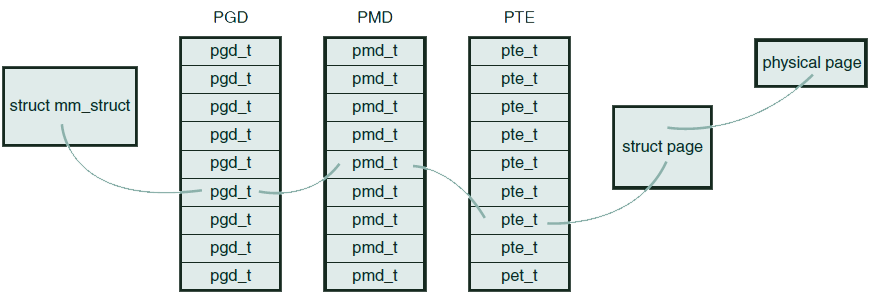
每个进程都有自己的页表(线程会共享页表),内存描述符的 pgd 字段就指向进程的页全局目录,操作页表时必须持有 page_table_lock 锁。页表对应的结构体依赖于体系结构,定义在相应的 asm/page.h
由于每次对虚拟内存中页面的访问都用到页表,因此其搜索性能非常关键。为提升性能,很多体系结构都实现了翻译后备缓冲(Translation lookaside buffer,TLB,也叫快表),TLB是将虚拟地址映射到物理地址的硬件缓存。有了TLB后,处理器都会优先检查TLB,如果缓存命中,则不去搜索页表。
TLB保存了最高频被访问的页表项。
物理内存的一大优势就是可以作为磁盘或者其它块设备的高速缓存,这是因为磁盘非常慢,常常成为系统的性能瓶颈。使用内存作为缓存后,可以延迟写磁盘的时间,或者避免不必要的读磁盘操作。
Linux内核实现了一种磁盘数据的缓存:页缓存(Page cache),该缓存把磁盘数据存放在物理内存中,以最小化磁盘I/O。为保证数据一致性,内核必须把页缓存中发生变更的数据同步到磁盘上,此过程称为页回写(Writeback)。
页缓存是现代OS不可或缺的组件,因为:
- 磁盘访问速度比内存差几个数量级,缓存可以显著提高性能
- 某个数据被访问后,该数据或者临近的数据在一定时间内很可能被密集的重复访问,这就是所谓的时间局部性(Temporal locality)。时间局部性意味着页缓存常常具有很高的命中率
页缓存由内存中的物理页组成,其中存放着对应的磁盘物理块,其数据被缓存的磁盘称为后备存储(Backing store)。页缓存的大小是动态变化的,它可能增长以消耗所有空闲内存,或者收缩以减轻内存压力。
当内核开始一个读操作(例如read系统调用)时,会首先检查数据是否存在于页缓存中,如果存在,则直接返回,否则内核需要调度I/O操作,从磁盘读取数据。
相应的,当内核执行写操作时,可能有三种方式和页缓存交互:
- 不缓存:即页缓存不去缓存任何写操作,写操作跳过缓存直接写入磁盘,同时让缓存中对应的数据失效
- 自动更新缓存:写操作在把数据写入磁盘的同时,更新内存缓存,这种方式称为“Write-through cache”
- 回写:这是Linux使用的方式。程序的写操作仅仅写入到缓存中,不更新磁盘。更新操作由回写进程在合适的时候刷出脏页到磁盘
当需要:
- 收缩缓存提供内存给其它程序使用时
- 将缓存中不重要的数据移除,腾出空间给重要数据缓存时
需要进行缓存回收。Linux的缓存回收策略是:替换非脏页,如果没有足够非脏页,则强制发起回写操作。决定哪些页被替换是最困难的部分,以下算法较为常见:
- 最近最少使用(LRU)算法:该算法跟踪每个页面的访问踪迹,以便回收时间戳最老的页面。该策略工作良好是基于这样的假设:如果缓存的数据越久没有被访问,则不太可能在近期被访问。LRU算法对那些仅仅被访问一次(最近访问一次,以后永远不会访问)的文件来说尤其失败
- 双链策略(Two-List Strategy):为解决LRU算法的缺陷,Linux对其进行改进,它使用两个列表(而不是LRU那样的单列表):活动列表、非活动列表。活动列表中的页是“热”的,不会被清除;非活动列表中的页则可以被清除。仅当处于非活动列表中的页被访问后,该页才会进入活动列表。两个列表都使用伪LRU(pseudo-LRU)方式管理:条目从尾部加入、头部移除(类似队列)。两个列表的大小保持动态平衡——如果活动列表过大,那么其列表头被移回非活动列表的尾部。双联策略解决了LRU中“仅一次”问题
- 双链策略可以泛化为多链策略
尽管System V引入的页缓存机制是专用来缓存文件系统数据的,但是Linux的目标是支持任何基于页的数据,Linux的页缓存内容可以来自普通文件系统文件、块设备文件、内存映射文件,等等。注意页缓存不一定缓存整个文件,可能缓存文件中的几个页。
缓存中的一页可以包含多个不连续的物理磁盘块(以x86为例,页大小4KB,而磁盘块一般512B,一个页可以存放8个块,此外文件本身很可能是分散存放在磁盘上的,因此这些块可能不连续),因此,检查某个页中是否包含特定的数据比较困难(否则的话,每个页只需要使用设备名称+块序号即可索引)。
为了避免和文件系统耦合,实现更加通用的页缓存,Linux专门设计了一个新结构管理页缓存中的条目: address_space ,可以认为该对象是虚拟内存区域 vm_area_struct 的物理对应物。打个比方,假设一个文件有10个虚拟内存区域(5个进程分别映射其2次),但是该文件只会对应一个address_space对象。
address_space这个命名具有误导性,可能叫page_cache_entity/physical_pages_of_a_file更加合理。该结构的定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
struct address_space { //此映射(当前页缓存条目)关联某种内核对象,一般就是inode,如果不是关联到inode(例如关联到swapper)则该字段为空 struct inode *host; /* 拥有此映射的inode */ struct radix_tree_root page_tree; /* 所有页面组成的基数树 */ spinlock_t tree_lock; /* page_tree的锁 */ unsigned int i_mmap_writable; /* VM_SHARED计数 */ /** * 优先搜索树,包含此映射中全部共享、私有的映射页面 * 该树很好的结合了堆和基数树,可以允许内核快速的找到与目标文件关联的映射 */ struct prio_tree_root i_mmap; struct list_head i_mmap_nonlinear; /* VM_NONLINEAR 链表 */ spinlock_t i_mmap_lock; /* i_mmap的锁 */ atomic_t truncate_count; /* 截断计数 */ unsigned long nrpages; /* 此条目包含的页总数 */ pgoff_t writeback_index; /* 回写的起始偏移量 */ struct address_space_operations *a_ops; /* 操作列表 */ unsigned long flags; /* gfp_mask和错误标记 */ struct backing_dev_info *backing_dev_info; /* 预读信息 */ spinlock_t private_lock; /* 私有锁 */ struct list_head private_list; /* 私有链表 */ struct address_space *assoc_mapping; /* 相关的缓冲 */ }; |
address_space对象的 a_ops 字段定义操控页缓存映射的操作:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
/** * 定义了管理页缓存的各种行为,例如读取、更新缓存数据 */ struct address_space_operations { int (*writepage)( struct page *, struct writeback_control * ); int (*readpage)( struct file *, struct page * ); int (*sync_page)( struct page * ); int (*writepages)( struct address_space *, struct writeback_control * ); int (*set_page_dirty)( struct page * ); int (*readpages)( struct file *, struct address_space *, struct list_head *, unsigned ); int (*write_begin)( struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata ); int (*write_end)( struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata ); sector_t (*bmap)( struct address_space *, sector_t ); int (*invalidatepage)( struct page *, unsigned long ); int (*releasepage)( struct page *, int ); int (*direct_IO)( int, struct kiocb *, const struct iovec *, loff_t, unsigned long ); int (*get_xip_mem)( struct address_space *, pgoff_t, int, void **, unsigned long * ); int (*migratepage)( struct address_space *, struct page *, struct page * ); int (*launder_page)( struct page * ); int (*is_partially_uptodate)( struct page *, read_descriptor_t *, unsigned long ); int (*error_remove_page)( struct address_space *, struct page * ); }; |
每个后备存储都实现了自己的 address_space_operations ,例如ext3文件系统的实现如下:
|
1 2 3 4 5 |
static const struct address_space_operations ext3_ordered_aops = { .readpage = ext3_readpage, .readpages = ext3_readpages, //... }; |
这些操作中, readpage() 和 writepage() 最重要,分别对应了页的读写操作。
页读操作的步骤如下:
- 内核尝试在页缓存中找到需要的数据:
1struct page *find_get_page(struct address_space *mapping, pgoff_t offset);参数mapping指定address_space,参数offset则指页偏移(即被缓存的文件偏移)
- 如果搜索的页没有存在页缓存中,上面的函数返回NULL,内核将分配一个新页面,并将之前搜索的页加入页缓存:
12345678struct page *page;int error;/* 分配页 */page = page_cache_alloc_cold( mapping );if (!page){/* 内存分配失败 */}/* ... 把新页加到页缓存 */error = add_to_page_cache_lru(page, mapping, index, GFP_KERNEL);if (error) {/*加入页缓存失败 */} - 然后,所需的数据从磁盘读入,加入页缓存,并返回给用户:
1error = mapping->a_ops->readpage(file, page);
页写操作不太一样,对于文件映射,当页被修改时,仅仅需要设置脏标记: SetPageDirty(page); 。内核会在稍后通过 writepage() 刷出页面修改到磁盘,具体步骤较为复杂,概括起来包括以下步骤:
- 搜索页缓存,找到需要的页。如果目标页不在缓存中,则分配一个新的空闲页
1page = __grab_cache_page(mapping, index, &cached_page, &lru_pvec); - 创建一个写请求
1status = a_ops->prepare_write(file, page, offset, offset+bytes); - 将数据从用户空间拷贝到内核空间
1page_fault = filemap_copy_from_user(page, offset, buf, bytes); - 将数据写出到磁盘
1status = a_ops->commit_write(file, page, offset, offset+bytes);
所有的页I/O操作都需要执行上面的步骤,因此所有页I/O必然通过页缓存进行。内核总是尝试先通过页缓存来满足读请求;对于写操作,页缓存更像是一个存储平台,所有要写出的页都加入到页缓存。
由于内核每次进行页I/O操作都需要检查目标页是否在缓存中存在,因此缓存检索必须足够快。如前面所见,搜索是通过一个address_space和offset进行的。每个address_space都包含一个唯一的radix树,对应字段page_tree。Radix树是二叉树的变体,通过它可以快速的查找需要的页(只需要提供文件偏移量), find_get_page() 、 radix_tree_lookup() 等函数都是通过检索Radix树来工作的。
Radix树的代码位于 lib/radix-tree.c ,使用该树需要包含头文件 linux/radix-tree.h
在2.6-的内核中,页缓存通过一个全局散列表而不是Radix树进行检索,该散列表维护系统中的所有页,此散列表的值是散列计算结果相同的缓存条目构成的双向链表。全局散列表有以下缺陷:
- 一个全局锁保护此散列表,锁争用导致性能问题
- 散列表过大,只有映射当前正在操作的文件的页才相关
- 散列查找失败后的性能较差
通过块I/O缓冲,单个的磁盘块也被存入到页缓存中,块I/O缓冲是单个磁盘块的内存映射,是内存页-磁盘块映射的描述符。我们把这一映射称为缓冲缓存(Buffer cache),它作为页缓存的一部分实现。
历史上缓存缓存、页缓存是两个完全不同的缓存,一个磁盘块可能同时出现在这两个缓存中,在2.4它们被合并了,从而避免了两个缓存之间的同步开销和内存浪费。尽管如此,作为块内存映射描述符的buffer_head仍然被内核使用。
由于页缓存的存在,写操作实际上会被延迟,当页缓存中的数据比后备存储中新时,我们称其为脏数据。内存中积累的脏页必须最终被写回到磁盘。在以下三种情况下,回写发生:
- 当空闲内存低于指定阈值时,内核必须回写脏页以释放内存——因为只有干净页才能被回收
- 当脏页驻留内存时间超过指定的阈值时,内核将超时的脏页写回磁盘
- 当用户进程调用 sync() 、 fsync() 系统调用时,内核按要求执行回写
这三项操作的目的完全不同,在旧内核中它们是由两个独立内核线程分别完成的。在2.6则是由一组内核线程——Flusher线程执行所有这三项操作。
第一项操作的目的是物理内存不足时,释放脏页以获得内存,何时启动该操作由内核参数(sysctl):dirty_background_ratio指定。当空闲内存占比小于此值时,内核调用 wakeup_flusher_threads() 唤醒一个或者多个Flusher,Flusher会调用 bdi_writeback_all () 并开始回写脏页。该函数接受一个参数,用于指定需要回写的页数量,该函数会一直运行,直到满足条件(或者没有脏页):
- 指定的最小回写页数量到达
- 空闲内存占比大于dirty_background_ratio
对于第二项操作,Flusher会定期唤醒,检查过期的脏页并回写。在系统启动后,定时器被设置,定期唤醒Flusher并执行 wb_writeback() 函数,该函数会把所有变脏超过dirty_expire_interval毫秒的页写出到磁盘。
Flusher线程的代码存放在 mm/page-writeback.c 和 mm/backing-dev.c ,回写相关逻辑位于 fs/fs-writeback.c
笔记本模式(Laptop mode)是一种特殊的页回写策略,其目的是最小化硬盘转动的机械行为,允许尽可能长的磁盘停滞,也延迟电池续航。该模式可以通过 /proc/sys/vm/laptop_mode 配置。和传统页回写行为相比,笔记本模式会增加额外判断,以避免主动激活磁盘运行。
多数Linux发行版在计算机接上/拔掉电池时,自动开启/关闭笔记本模式。
如果仅仅使用一个Flusher线程,那么很可能在回写任务繁重时出现阻塞。线程可能阻塞在单个繁忙的设备队列上(队列由等待提交到磁盘的I/O请求构成),导致其它设备的请求队列不能得到即时处理。为避免单个设备队列的拥塞影响整体性能,Flusher使用多线程模式,并且让每个设备对应一个Flusher线程。
Leave a Reply