操作系统知识集锦
在计算机领域,总线(来源于拉丁语omnibus)是用于在计算机内部组件之间进行数据传输的通信子系统。总线上传递的数据类型包括数据信息、地址信息、控制信息。
在个人计算机上,总线一般分为5类:
- 数据总线(Data Bus):在CPU与RAM或其它设备之间来回传送需要处理或是需要储存的数据。数据总线的宽度决定了CPU与外界数据交换的最大速率。数据总线有一系列的传输线组成,每条传输线同一时刻只能传输1bit的数据,如果数据总线位宽为64位,就意味着有64根传输线
- 地址总线(Address Bus):CPU通过地址总线来指定存储器的地址,地址总线决定了CPU能访问的最大内存空间大小
- 控制总线(Control Bus):将处理器控制单元(Control Unit)的信号传送到周边设备,一般常见的为USB总线
- 扩展总线(Expansion Bus):可连接扩展槽,以增添设备
- 局部总线(Local Bus):直接的连接CPU与部分扩展总线的插槽,避免扩展总线引入的性能瓶颈,提高数据吞吐量
在Intel的处理器产品线中,总线还可以按如下方式分类:
- 系统总线:一般特指PCI/PCIe总线,带宽高,支持热插拔。内部总线、外部总线都挂接在系统总线上
- 外部总线:诸如USB、SATA、IDE、1394、以太网等暴露在外的,都属于外部总线
- 内部总线:外部总线上的一些零散小芯片使用
- 前端总线:CPU与北桥、内存的连接总线,北桥是PCI/PCIe的发源地
CPU时钟频率速度(主频)=系统总线速率(外频)×倍频系数,某些主板可以通过跳线设置倍频系数、系统总线频率。
在早期,并没有倍频这一概念,CPU主频与外频是一致的。然而CPU的速率越来越快,开始出现倍频——让CPU主频与总线频率之间呈现倍数关系,这样CPU可以高速运作,而外设以低频运作。
在早期,系统总线、前端总线的工作频率也是一致的,目前前端总线往往是系统总线的数倍速度。
CPU设计初期是往高频率方向发展的,然而最终遭遇到物理极限的限制。这时为了继续提高处理能力,只能向多核心、多CPU的方向发展了。
CPU有多个,而内存是大家共享的,这时SMP架构出现了。所谓对称多处理(Symmetric multiprocessing,SMP)是指每个处理器核心的地位都是平等的(所谓对称),对所有计算机资源(特别是内存)具有相同的使用权限。
SMP的优点是并行度高,然而系统总线的带宽有限,因此处理器的数目不能无限添加,系统性能和处理器数量也不是线性关系。
Linux对SMP的早期支持依赖于一个全局大锁,直到2.6才有效的发挥SMP的能力。
SMP的最大问题在于总线带宽有限,当很多CPU都通过北桥来读写内存,北桥带宽的瓶颈很快就出现了。
为了解决此问题,硬件工程师开始把北桥中的内存控制器拆分,让CPU与特定内存插槽、内存控制器关联在一起。当CPU访问自己本地内存(Local Access)时,速度很快,而需要访问其它CPU的内存(Remote Access)时速度就慢了。这就是所谓非统一内存访问(Non-Uniform Memory Access,NUMA)的由来。
NUMA一定程度上保证了单台主机的扩容能力,然而操作系统面临的问题则是,如何尽可能的避免Remote Access。Linux的默认策略是:
- 优先尝试在请求线程当前所处的CPU的本地内存中进行分配
- 如果本地内存不足,尝试淘汰(Reclaim)其中无用的页
外设组件互连标准(Peripheral Component Interconnect),是一种连接电脑主板和外部设备的总线标准。基于PCI标准连接到主板的外设,要么嵌入到主板的集成电路中,要么通过主板上的PCI插槽连接。
目前PCI总线已经被更先进的技术,例如PCI Express(PCIe)逐步取代。
PCI子系统包含四级模块:
- Bus,一个PCI子系统最多256个Bus,常用的是Bus 0和Bus 1
- Device,即连接到Bus上的设备,如声卡,网卡等,每个Bus最多32个
- Function,每个Device有至少有一个Function 0,最多8个
- Register,每个Function有256字节的的Registers
SCSI是一种用于计算机和智能设备之间(硬盘、软驱、光驱、打印机、扫描仪等)系统级接口的独立处理器标准。与IDE最大的不同是,IDE的工作需要CPU全程参与,而SCSI卡自带处理器,因而CPU占用极低。
集因特网小型计算机系统接口(Internet Small Computer System Interface),又称为IP-SAN,是一种基于Internet和SCSI-3协议下的存储技术,与传统的SCSI相比,其优势为:
- 将原先仅用于单机的SCSI协议通过TCP/IP网络传输
- 连接的服务器数量没有限制,而SCSI-3有15的限制
iSCSI让计算机可以透过高速的局域网来把SAN模拟成为本地的储存装置。它让两个主机通过 IP 网络相互协商然后交换 SCSI 命令,用局域网仿真了高性能本地存储总线。与某些SAN协议不同,iSCSI 不需要专用的电缆,被认为是光纤通道(Fiber Channel)的一个低成本替代方法。
亦称指令集,是计算机体系结构(Computer Architecture)中与编程相关的部分,其包括了:基本(native)数据类型、指令、寄存器、寻址模式、内存架构、中断、异常处理、外部I/O几个方面的内容。指令集包括了一系列面向机器语言的操作码(Opcodes),这些操作码由特定的CPU实现。
复杂指令集计算机(CISC)、精简指令集计算机(RISC)是根据指令集的复杂度来区分的,前者包含很多不常使用的指令,并且导致指令长度不固定。大部分RISC具有固定的指令长度,通常与机器字一样长。
每条指令由一个Opcode、0个或者多个算子组成,这些算子可能是寄存器编号、内存位置或者字面值。
从功能上,指令可以分为以下几种类型:
- 数据读写操作指令:设置寄存器的值、读取寄存器的值、取出数据并计算、保存计算结果、从硬件读写数据
- 算术与逻辑运算指令:对两个寄存器中的值进行加减乘除、执行位操作、执行逻辑与、逻辑非、逻辑或、比较两个寄存器中数据的大小
- 控制流指令:分支——跳跃到某个地址继续执行、条件分支、间接分支——跳跃前,将下一条指令的位置存储起来,作为子程序的返回地址
注意术语“微架构”与指令集架构没有直接关系,前者代表了一种处理器硬件的设计方式,不同微架构的处理器可以实现同一套指令集。
x86包含了一系列指令集架构,它们都是可变指令长度的CISC,最早由英特尔在1978年面市的“Intel 8086”CPU上开发出来。三年后IBM PC开始使用8086,x86逐渐成为个人计算机的标准平台。
x86这个名称的由来是Intel早期CPU的名称:Intel 8086、80186、80286、80386、80486,后续的处理器由于商标的问题,改用“Pentium”之类的名称。现在Intel把x86-32称为IA-32,尽管x86系列包含16位处理器。与IA-32对应的是IA-64,这是早在1990年代就提出的,在安腾系列处理器中使用的独立64位架构,与IA-32完全不兼容。
除了Intel以外,还有若干厂商实现了x86指令集的CPU,其中包括AMD的Athlon系列处理器。有趣的是,2003年,AMD发布了针对x86架构的64位扩充,命名为AMD64,Intel则被迫推出了与AMD64兼容的CPU,并命名为Intel 64。不同操作系统厂商对AMD64使用不同的称呼:Apple称之为x86-64或者x86_64;Sun和微软称之为x64;BSD和Linux称之为amd64,并把32位版本成为i386。
在计算机领域,“字(Word)”是用于表示其自然的数据单位的术语,对应了CPU一次性处理事务的固定比特位宽度。字在多个方面有体现,例如大部分通用寄存器的尺寸是一个字长;CPU与内存之间数据传输的单位也是字长;内存地址也通常用字长来表示。
为了保证向后兼容,实际的体系结构下经常把字固定为某个长度,以Intel为例,由于后续的处理器都是对8086的扩充,所以IA-32、AMD64架构下,字一直保持16位的大小,对VC的数据类型WORD、DWORD执行sizeof可以明确的看到这一点。
64位、32位是人们经常提到的名词,但是所谓64位到底指的是什么?如果一颗处理器是64位的,通常是指:
- 该CPU的各种指针寄存器是64位的,因此理论上支持16EB的存储器
- 该CPU的通用寄存器是64位的,因此支持64位二进制整数的直接算术与逻辑运算
- 该CPU具有64位宽的地址、数据总线
现实的情况比较复杂,由于硬件设计、操作系统限制,64位机支持的存储器大小远远小于16EB,地址总线的宽度也往往没有64位。
可以认为是x86指令集的64位版本。AMD64理论上支持2^64比特(16EB)的寻址空间,并引入了若干64位通用寄存器和其它的特性增强。由于AMD64保留了全部16位、32位x86指令,因此它完全向后兼容(Backwards Compatible )16位、32位的x86代码。首片支持AMD64的CPU是2003年发布的AMD Opteron。
AMD64具有以下特性:
所有的通用寄存器被从32位扩充到64位,因此所有的64位算术、逻辑、寄存器-内存操作可以直接在64位整数上操作;压栈/弹出操作默认8字节步长;指针默认8字节宽。
除了扩展通用寄存器的长度外,其数量也被加倍,从8扩展到16,因此,可以在寄存器上存放更多的局部变量,而避免存放在栈上。
128位SSE寄存器的数量也从8增加到16。
AMD64定义了64位的虚拟地址格式,理论上最大支持16EB的地址空间,目前只使用了其中的低48位,因此支持256TB的虚拟地址空间。
AMD64的初始版本允许40位的物理地址,因此最大支持1TB的物理内存。当前版本的实现则使用48位物理地址,可以支持256TB的物理内存。由于页表条目结构的限制,未来最多可以扩展到52位物理地址。
当AMD64在遗留模式(实模式、保护模式)下运行时,PAE由36位扩展到52位,因此物理地址的限制与长模式一致。相比之下,32位的x86处理器在物理地址扩展(PAE)模式下最多支持64GB的物理内存,不使用PAE则最多4GB内存。
在AMD64架构下,允许根据当前指令指针(RIP)来访问相对位置的数据,可以实现位置无关代码(Position Independent Code),这在共享库、动态加载代码中更加高效。
NX位是页表的最高位,允许操作系统指定哪些虚拟地址空间的页可以包含executable代码,哪些不能。尝试执行NX页的代码,会导致内存访问违例(Memory Access Violation)。
| 运作模式 | 说明 |
| 实模式 |
即“真实地址模式”,是8086即以后的x86兼容CPU的一种运作模式。其特征是逻辑地址直接指向物理地址。实模式包含20位的分段的地址空间(仅仅1MB地址空间),必须将段地址左移4位,然后加上地址偏移量才能得到最终的20位地址。 实模式支持通过软件直接访问硬件、没有硬件级别的内存保护、多任务的概念。 80286以及以后的CPU在启动后首先处于实模式,80186只有一种运作模式,类似于实模式。
操作系统要求:16位实模式操作系统或者16/32/64位启动加载器(Boot Loader) |
| 保护模式 |
所谓保护模式,即“受保护的虚拟地址模式”,x86兼容机器不会直接进入保护模式,必须在操作系统设置好若干描述符表(GDT等)后,并且设置了控制寄存器(CR0)的PE位(Protection Enable)后才能生效。保护模式具有以下特性:
保护模式(16位)最初由80286引入,将可寻址的物理内存扩充到16MB,可寻址的虚拟内存最大到1GB。 16位保护模式相关参数: 操作系统要求:16位保护模式操作系统或者16/32/64位启动加载器
32位保护模式相关参数: 操作系统要求:32位保护模式操作系统或者32/64位启动加载器 |
| 虚拟8086模式 |
用于支持先前基于8086的程序不经修改的运行在80386下,支持与其它任务并发运行
操作系统要求:16/32位保护模式操作系统 |
| 长模式 |
在x86_84架构处理器中,长模式(Long mode)允许64位操作系统或者应用程序使用64位指令和寄存器,而32位、16位程序则以一种兼容子模式来运行。 不在长模式下(兼容模式)运行时,x86_64处理器与x86_32处理器的行为完全相同
16位兼容模式相关参数: 操作系统要求:64位保护模式操作系统 32位兼容模式相关参数: 操作系统要求:64位保护模式操作系统或者64位启动加载器 长模式相关参数: 操作系统要求:64位保护模式操作系统或者64位启动加载器 |
这里所说的虚拟内存与Windows面向用户的“虚拟内存是两回事”,后者实际上是分页技术(Paging)。
操作系统将大小一致的、代表连续虚拟地址空间的数据块称为“页(Page)”;相应的,物理地址空间上与页大小一致的连续空间则被称为“页帧(Page Frame)”。32位x86处理器的内存管理单元(MMU,CPU中的特殊硬件)支持从4KB到4MB大小的页。
虚拟内存是同时使用硬件、软件实现的一种内存管理技术。它将应用程序使用的内存地址(即虚拟地址,Virtual Addresses)映射到计算机内存(即主存,Main Storage)的物理地址(Physical Addresses)。在应用程序看来,内存是一个连续的地址空间,实际上则可能是分散在物理内存上的多个片段。
虚拟地址与物理地址的映射(即页与页帧之间的映射)是由MMU完成的。操作系统可以利用MMU,把多个虚拟地址映射到同一物理地址,从而在分页技术的支持下,允许应用程序引用大于实际物理内存的虚拟地址。
大部分操作系统使用“页表(Page Table)”来存储虚拟地址与物理地址的映射关系,页面通常是一个简单的数组,pageTable[v] = p,代表虚拟页v与物理页p具有关联关系。为了节省空间,通常会使用多级页表(Multilevel Page Table ),例如Linux在进行32位寻址时,使用二级页表。
分页是一种内存管理技术,允许从在主存、辅存之间存取、交换页,共应用程序使用。
当应用程序程序尝试访问的页当前没有映射到物理内存的情况,称为页面错误(Page fault),操作系统采取一种对程序透明的方式来处理页面错误:
- 确定页在辅存中的位置
- 获取一个空白的页帧(Page Frame)来作为数据的容器
- 加载辅存中的页到页帧
- 更新页表(Page Table),引用新的页帧
- 返回控制器给应用程序,重试导致页面错误的指令
如果处理页面错误时,发现没有足够的内存以获取一个空白页帧,则操作系统会使用一个页面替换算法,将某个现存的页帧从内存中清除,并将其持久化到辅存(如果其内容被修改过)。大部分操作系统使用LRU算法或者基于工作集的算法来进行页面替换。
工作集这一概念,用于确定进程在一定时间区间内需要的内存的量。
在Unix-like的操作系统中,使用术语“交换(Swap)”来描述页面替换这一动作。
| 寄存器 | 起源 | 位数 | 说明 |
| AX |
8086/ |
16 |
通用寄存器 尽管属于通用寄存器,但是每个都有附加的特殊用途,例如CX可以作为循环指令的计数器 每个寄存器可以拆分为两个使用,例如AH、AL分别访问AX的高8位、低8位 |
| BX | 16 | ||
| CX | 16 | ||
| DX | 16 | ||
| CS | 16 | 8086起引入,区段寄存器,用于存放绝对地址 CS:代码段寄存器,指向当前执行代码所在内存区域 DS:数据段寄存器,指向当前运行着的程序的数据段,可以将其指向任何具有所属数据的地址 SS:栈段寄存器,指向栈段 ES:额外的段寄存器, 通常跟DI一起用来做指针操作 |
|
| DS | 16 | ||
| SS | 16 | ||
| ES | 16 | ||
| IP | 16 | 指令指针寄存器,CS与IP共同决定了下一条CPU指令的内存地址,CS:IP相当于程序计数器(PC) | |
| SP | 16 | 栈顶指针寄存器 | |
| BP | 16 | 基指针,可以用来指向堆栈或存储器的其它地方,例如用来保存使用局部变量的地址 | |
| SI | 16 | 源/目标索引(指针)寄存器,这两个寄存器通常用来处理数组或字符串。SI通常指向源数组,DI通常指向目的数组,他们通常被用来成块地移动数据,比如移动数组或结构体 | |
| DI | 16 | ||
| FLAGS | 16 | 标记寄存器,每一位有单独用途,可以指示进位、溢出、结果为零等 | |
| EAX | 80386 | 32 | 通用寄存器,其低16位与原本的AX、BX、CX、DX重叠共用 |
| EBX | 32 | ||
| ECX | 32 | ||
| EDX | 32 | ||
| EIP | 32 | 指针寄存器,扩展对应16位版本 | |
| EBP | 32 | ||
| ESP | 32 | ||
| ESI | 32 | ||
| EDI | 32 | ||
| FS | 32 | 新增加的两个区段寄存器,没有特定用途
区段寄存器在32位模式下改做为存储器区块的选择子(Selector)寄存器。 |
|
| GS | 32 | ||
| EFLAGS | 32 | 标记寄存器,其低16位与原本的FLAGS重叠共用 | |
| MM0- MM7 |
MMX | 64 | MMX寄存器与对应 FPU(浮点运算器)重叠,MMX与浮点运算不可同时使用,必须通过切换选择使用其中一种。 |
| FP0- FP7 |
64 | ||
| RAX | 64 | 通用寄存器,其低32位与原本的EAX、EBX、ECX、EDX重叠共用 | |
| RBX | 64 | ||
| RCX | 64 | ||
| RDX | 64 | ||
| RIP | 64 | 指针寄存器,扩展对应32位版本 | |
| RBP | 64 | ||
| RSP | 64 | ||
| RSI | 64 | ||
| RDI | 64 | ||
| R8- R15 |
64 | 新增的八个通用寄存器 | |
| XMM0- XMM15 |
SSE | 128 |
单指令流多数据流(SIMD)寄存器 流式SIMD扩展(Streaming SIMD Extensions)是Intel在AMD的3D Now!发布一年后,在Pentium III中引入的指令集,是对MMX的扩充 SSE最初只加入了XMM0~XMM7这8个寄存器,AMD发布的x86_64加了额外的8个,这8个只能在64位模式下使用 |
| YMM0- YMM15 |
AVE | 256 |
单指令流多数据流(SIMD)寄存器 高级矢量扩展(Advanced Vector Extensions)是在2008年提出的x86指令集架构扩展,在2011年Sandy Bridge系列处理器中首次被支持 |
| ZMM0- ZMM31 |
AVX-512 | 512 |
单指令流多数据流(SIMD)寄存器 AVX-512在2013年首次提出,计划在2015年 Knights Landing 处理器中首次支持 |
ARM,即高级精简指令集机器(Advanced RISC Machine),是一种精简指令集的指令集架构,广泛的使用在嵌入式系统中。ARM具有低成本、高性能、低能耗的特点。到2011年,ARM占有了95%的智能手机、90%的硬盘驱动器、20%的移动电脑处理器份额。
ARM指令设计快速而精简,大多在一个CPU周期内执行,整体电路化,不使用微码。
引导扇区是磁盘、软盘或光盘上的一个区域。其中包含由计算机固件负责加载到内存的机器码。
引导扇区的意义是,允许计算机启动过程能加载相同磁盘上的一个程序(通常是操作系统)。在IBM PC兼容机上,BIOS选择一个启动设备,然后将它的第一扇区拷贝到内存的0x7C00地址。其它系统中,可能完全不一样。
第一扇区可能存放着: MBR、VBR或者任何可执行代码。
MBR(Master Boot Record 主引导记录)是已经被分区的磁盘上的第一个扇区。MBR能够定位到活动分区(Active partition,Bootable)并调用其VBR。
VBR(Volume Boot Record 卷引导记录)可以是未分区磁盘(软盘、U盘)的第一扇区,或者某个分区的第一扇区。VBR可能包含用于加载(当前磁盘/当前分区)操作系统的代码。VBR也可能加载第二阶段引导程序(Bootloader)。
一般的,可以把以下内容看作操作系统的组成部分:
- 内核
- 设备驱动程序
- 启动引导程序
- 命令行Shell
- 其它基本的用户界面工具、文件管理工具、系统管理工具
内核是操作系统的核心所在,通常包括以下部分:
- 负责响应中断的中断服务程序
- 负责管理多个进程从而分享处理器时间的调度程序
- 负责管理进程地址空间的内存管理程序
- 负责网络、进程间通信的系统服务程序
内核程序代码独立于普通应用程序,一般处于内核态(亦称系统态)运行。
这个概念最初的含义是:外在的事件打断正在执行的程序,转而执行处理这个事件的特定处理程序,处理结束后,回到被打断的程序继续执行。
在实模式下,BIOS提供的中断机制是依赖于以下两部分实现的:
- 中断向量表(Interrupt Vector Table):实模式中断机制的重要组成部分,表中记录所有中断号对应的中断服务程序的内存地址
- 中断服务程序(Interrupt Services):通过中断向量表的索引对中断进行响应,是一些具有特定功能的程序
在操作系统启动过程中,通常会关闭中断,并把BIOS在内存中的中断向量表、中断服务程序擦除,并替换为操作系统的中断处理机制,然后打开中断。
| 中断类型 | 说明 |
| 时钟中断 | 该中断在操作系统中频繁发生,例如Linux中可能每10ms就发生一次。时钟中断是进程轮询调度的基础 |
| 软中断 | 用户程序可以通过软中断来进入内核态,执行内核代码 |
操作系统的“缓冲区”是一个内存区域,主要作为主机与外设(例如硬盘等块设备)进行数据交互的中转站,让主内存区域与外设隔离。
缓冲区包含的数据有:硬盘引导块。
主内存区域存放进程的各种数据,例如程序代码。
系统调用是用户程序与操作系统内核交互的接口。通常,用户程序通过C库函数简洁的进行系统调用,库函数与系统调用并不一定是一一对应关系,比如printf函数中包含了write系统调用(将数据写到控制台),同时还包括了数据缓存、格式化等逻辑。
在Linux中,函数system_call是系统调用的总入口,用户程序可以产生“系统调用软中断”,操作系统经由system_call找到具体系统函数,并调用。
系统调用软中断将用户程序与内核隔离——出于安全方面的考虑,用户程序不能直接访问内核——通过触发软中断,用户进程的执行并暂停,并转入内核态执行系统调用函数,然后再返回用户进程暂停处恢复执行,可以说,系统调用是“内核代为执行”的。系统调用函数本质上都是软中断服务程序。
直接调用系统调用是效率低下的操作,因为进入内核态 - 执行内核代码 - 返回用户代码这一过程本身就需要开销。应当尽量减少系统调用的次数,操作系统附带的标准函数库通常可以用来实现这一目的,例如带有I/O缓冲功能的标准I/O库。
操作系统的内核代码一般在内核态运行,内核态意味着独立的、受保护的内存空间以及完全的硬件访问权限。内核态与用户态的根本不同在于硬件控制的特权等级。
应用程序的代码则在用户态运行, 它们只能看到允许它们使用的部分系统资源,并且只使用某些特定的系统功能,不能直接访问硬件,也不能访问内核划分给其它程序的内存范围。
但是,应用程序进程在执行过程中,往往需要使用操作系统内核提供的功能,这里就涉及到进程的“权限提升”的问题,亦即从用户态转换到内核态的问题。
80386及以后的CPU包含了若干种特权级别的定义,在段描述符中,包含两位数字用于标记当前所执行代码的特权级,共可表示0、1、2、3四个级别,用户态对应的优先级是3,内核态对应的优先级是0,进程在运行过程中,可能多次改变其特权级别。
降低特权级别的改变有几种方法,其中一种是“中断返回”。当CPU执行指令iret时,硬件会自动把特权级下降为3,即导致进程在用户态运行。Linux系统函数move_to_user_mode函数可以模拟这种中断返回(所谓模拟,是指不发生真正中断的情况下“返回”)。
相应的,用户代码触发(软)中断,则可进入内核态,即提升特权级别。
CPU的活动,在某个时间点上,其活动必然是三者之一:
- 运行于用户空间(用户态),执行用户进程
- 运行于内核空间(内核态),处于进程上下文, 代表某个特定的进程执行,内核执行系统调用时,就是这一情况
- 运行于内核空间(内核态),处于中断上下文, 与任何进程无关,处理某个特定的中断
当CPU空闲的时候,内核可能运行于一个空进程,处于进程上下文,但运行于内核空间。
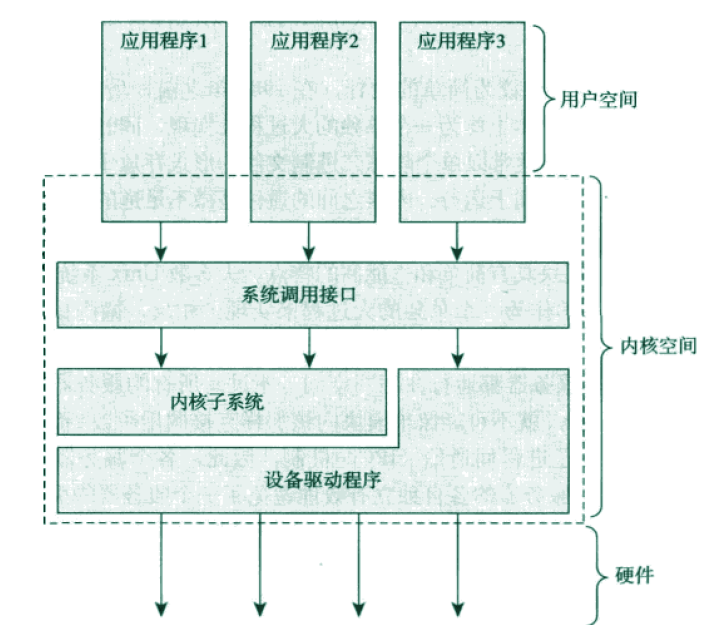
本段内容不区分进程、线程两个概念。
CPU同一时刻只能运行一条指令,因而它只能同时执行一个进程。在多任务操作系统中,CPU不断的切换其执行的进程,给用户一种多个任务同时在执行的假象。
进程切换可能发生在下列场景:
- 时间片用完时:每个进程在创建时,都被赋予有限的时间片,进程在用完时间片后,只要其处于用户态,就会立即切换到其它进程执行
- 进程不具备进一步执行(Unrunnable)的条件时:比如进程处于内核态,已经没有代码需要执行,或者下一步执行需要外设提供的数据。这种情况下就可以立即切换到其它进程,以免浪费CPU时间。这种情况典型的例子是等待网络I/O完成
发生进程切换的时候,必然意味着上下文切换。
除非特别提及,本段内容不区分进程、线程两个概念。
在计算机领域,上下文切换是指存储/恢复进程状态(即上下文)的处理过程,该过程可以使进程恢复到下一次执行的最后状态,从而允许多个进程共享单颗CPU。上下文切换是多任务操作系统的基本特性。
以下三种原因会导致上下文切换:
- 多任务(Multitasking):进程不具备进一步执行的条件时,会立即执行上下文切换;对于抢占式多任务系统(Preemptive Multitasking)而言,当进程的时间片( Time Slice)用完时,会触发时钟中断,强制的进行上下文切换
- 中断处理:当发生中断时,硬件会自动切换一部分上下文(至少允许中断处理器能返回到被中断的代码处),切换后得到的空间用于存放中断上下文,中断处理器的代码在此上下文中执行,执行完毕后,则恢复到中断前的上下文状态。现代处理器和操作系统倾向于最小化需要切换的上下文部分,以减少中断处理消耗的时间
- 内核态与用户态之间切换时:尽管单纯的内核态-用户态切换,并不需要上下文切换,但是某些操作系统还是可能在此时执行上下文切换
上下文包含的内容取决于CPU和操作系统,以Linux 2.6为例,以下内容需要被切换:
- CPU寄存器的值,即所谓“硬件上下文”,包含了大量进程实时状态信息
- 内核态栈:当进程进入内核态运行时,该栈会被自动创建
- 页全局目录(Page Global Directory):与虚拟地址空间有关
这是两种不同的操作系统内核设计方式:
- 单内核:内核整体上作为一个大的过程来实现,运行在单独的地址空间上。所有内核服务都运行在一个大的内核地址空间上,其间的通信开销是微不足道的
- 微内核:操作系统内核仅包含一个很小的函数集,通常包括几个同步原语、一个简单的调度程序、IPC机制,运行在内核之上的若干系统进程实现内存分配、系统调用处理、设备驱动等OS的核心功能。大部分微内核设计者最终都让系统进程运行于内核空间,例如Windows NT内核,这其实违背了微内核设计的原则
单内核设计的优点是:
- 设计简单,性能高:所有内核例程运行在单独地址空间上,没有IPC开销。内核例程之间也不会引入上下文切换
微内核设计的优点是:
- 模块化:微内核迫使程序员使用模块化方式设计,因为任何操作系统组件都是相对独立的程序,必须通过明确定义的接口与其他组件交互
- 易于移植:与硬件相关的代码可以被封装到微内核中
- 更加充分的利用内存:暂时不需要的系统进程可以被调出或撤销
Linux是单内核OS,为了达到微内核的优势,内核引入了模块(Module)机制,所谓模块就是一个目标文件,遵循了良好定义的接口,其代码可以在运行时链接到内核(或解除链接)。模块通常包括一组函数,用来实现文件系统、驱动程序等内核上层功能。
是IEEE发布的一套标准,该标准定义了一套API,从而使遵循POSIX的操作系统之间可以方便的进行应用程序的移植。所有类UNIX系统都遵循此标准。Windows NT内核也一定程度上实现了POSIX标准。
Leave a Reply