2015年7月架构师培训笔记
本文对我最近参加的架构师培训内容进行整理记录。
| 问题 | 分析与初步解决方案 |
| 技术选型困难,新框架适用性、使用难点,对开源技术不了解 |
今天在整个行业中,一个明显的趋势是:正在从厂家的产品转向开源的应用。开源框架百花齐放、缺少完善的培训体系、厂商服务。在这种趋势下,对开发人员的技术能力要求提高,特别是对开源框架的把握能力。 开源软件的架构具有相似性,基本上来说,这些架构只有20多种,如果掌握这些架构,那么理解开源框架将变得容易 |
| 是使用开源技术还是自己开发 |
如果有能力的话,建议自己开发,这样有100%的可控性。理解了开源框架的架构以后,自己开发难度并不是想象的那么大 |
| 如何解耦 | 在模块间通信时,使用(语言无关)消息代替(函数)调用。跨模块的通信应该是比较少的,如果特别多,说明模块划分有问题 |
| 架构细致到什么粒度 | 对于OO语言来说,类设计不属于架构设计,而是属于详细设计,架构设计应该精确到组件级。老师认为组件往往落在不同jar、dll、so等文件中,不过我觉得这样可能导致过多的jar,加大工程管理的难度,可能是行业、参与软件的规模差异较大吧 |
| 软件越做越难维护,如何重构 |
代码级重构可以经常做,架构级重构应当谨慎,往往一两年一次,在大版本升级时考虑,重构架构要求你有很强的架构设计能力。重构不应该是被逼无奈,那样会很被动 模块必须做到自包含(其它模块不要狗逮老鼠,而应该调用),比如订单管理模块只做订单的管理,而不应该包含生成凭证的代码,特别是不该复制凭证模块的代码。起码要做到基于接口调用,最好是基于消息机制解耦 重构的内容:服务架构重构、消息架构重构(两者有交叉,区别老师没有讲解,我觉得两者没有本质的区别,如果服务指的是WebService、消息基于基于文本的消息,那么只是形式的不同,可能消息架构更倾向于异步)、部署架构重构(改小机为PC)、数据架构重构(水平分区、读写分离) 重构时如何保证数据一致性:
由于重构不产生直接的业务价值,因此往往没必要向客户解释。 |
| 海量数据分析 |
PC集群+Hadoop MapReduce |
| 算法密集型系统的架构 |
面临的问题:计算密集型,单机(32G的基本工作站)部署,对单机的要求越来越高,硬件没法满足;算法实现难,团队难以扩大 能否对计算任务进行分解,进行分布式计算 对于安全和知识产权保护的问题,可以考虑SOA架构,对外出售服务而不是产品,可以搭建私有云 对于团队分工,建议将算法相关的部分独立出来由专家开发,应用部分由其他普通的、容易招聘的人员开发 |
| 平台的建设、产品线 |
软件的团队应当以产品来划分。传统的以组织型方式(开发部、测试部……)的方式划分团队,灵活性与沟通成本较高 |
| 对架构缺乏系统的了解 |
架构应该分为两个部分:
|
| 可维护性差怎么办 |
牵一发而动全身,代码耦合性高,可能需要架构级重构,引入组件化开发+面向消息的架构 |
| 手机Apps新旧版本的兼容性和维护 |
新旧版本APP的业务逻辑不一样。这个问题没有特别好的解决方法,可以考虑引入对旧版本的Adapter,主要还是工作量的问题 |
| 新旧技术的更替 |
面临的问题:技术更替较快,使用老技术的模块测试、运行良好,但是又不停引入新技术,导致人员同时需要懂得新旧技术,人力成本高 使用老技术模块的如果较为稳定、很少修改,可以继续沿用老技术 |
| 架构可扩展性、前瞻性的问题 |
对于可扩展性,标准的解决方案是组件化开发 |
| 高并发与海量数据的可落地的最佳实践 |
高并发:我们主要使用内存体系来增加并发能力。高并发分为并发接入、并发处理两个部分,单台PC服务器同时接入几万个是没有问题的,核心问题是并发处理的能力,一般通过内存体系来提高吞吐能力,例如基于Redis的缓存 海量数据:今天比较常见的,非常复杂的需求,通常采用Linux集群,通常会同时存在分布式计算的问题,今天Hadoop是常用的框架技术。但不是所有海量数据都使用NoSQL,RDBMS也是有的 |
通过提问,老师总结同事们广泛关注的焦点内容包括以下几个方面:
设计过程基本上分为两个步骤:
- 静态架构设计:模块划分、模块结构的分析、组件结构的分析、并发的设计、部署的设计(主要针对分布式系统)、分层设计、接口设计(WebService、RPC、数据共享)、通讯设计(主要是协议的选型,当然也牵涉到前面的技术选型)。这基本上是很多架构师当前正在做的事,但是可能没有做的这么细。类似于温老师的架构五视图,个人觉得概念不够精炼,但是可能比较实用吧
- 动态架构设计:这个主要是牵涉到系统的底层框架,主要满足非功能需求,包括健壮性、高性能、可扩展性,这里会介绍接近20种架构框架(架构模式),一般都有对应的开源框架,这一部分老师认为是最重要的、也是缺少具体书籍的,主要靠经验积累
上述20种框架,其中2-3种与解耦有关,解耦对某些系统特别重要,一旦代码量大了,可扩展性、可维护性问题会变得很严重,因此老师不管在考虑什么架构问题时,往往会首先想到解耦的问题。解耦问题解决了,很多东西会变得简单。
性能往往和数据有关,需要考虑如何处理数据让性能提高,这里包含5-6种框架,这些框架是比较重要的
其实很简单,如果掌握了静态、动态架构设计,你很容易看到系统中存在哪些缺陷。
重构的流程:看原有架构的问题 ➪ 改进的设计 ➪ 新的架构方案 ➪ 风险评估 ➪ 执行重构 ➪ 功能非功能测试 ➪ 系统试运行
为什么觉得重构困难,主要是架构级重构需要对系统具有全面的把握能力。
重构不一定是架构级的,也可能是模块级、代码级的。
- 软件架构的体系结构:什么是架构
- 架构的静态设计
- 架构的动态设计:框架
- 架构的重构问题
- 架构的管理
架构是什么?很多时候是系统的结构的定义,很多时候我们都认为架构是功能性的,例如功能模块的划分、如何将其落到层里。往往架构的非功能方面被忽略,这恰恰才是架构最重要的内容。例如在架构里面引入SSH,其实和功能是没有任何关系的,SSH解决的都是非功能问题。例如可扩展性、解耦。在比如房屋的建设,不是首先考虑那块作为卫生间、那边作为卧室,首先需要考虑的是房屋的框架结构,这些结构对房屋的功能无益、没有业务架构,甚至是有妨害的,例如立在房间中间的柱子。软件设计也类似,首先需要满足非功能需求,在满足非功能需求之后,才会满足功能需求。
架构的过程,是系统结构的定义,这个定义分为两个部分:
- 关注点隔离:高层分割,按住业务特性分成不同的部分。这是依据人类自然而然的分类思维来进行的。这样的关注点分离可以简化问题(床与房间的例子)。这种分割应该合理、易于别人理解,这种分割很多时候按照功能性进行的,其依据是需求,首先将系统划分为不同的关注点,或者叫业务模块
- 当把系统分隔为不同部分后,往往会发现一些通用的部分,这部分往往对应了非功能需求。不同的非功能需求,例如可扩展性和性能,本身就存在冲突,这里就牵涉到权衡
架构定义的引入,有几种定义方式:
- 架构组件划分,以及组件之间的关系、交互,这是当前很多团队的认识
- 架构是决策集,以前对决策集的描述都是文字性的,一个严重的问题是这些决策很难被下端业务模块开发人员全部遵循,因此这些决策现在都转换为Framework(例如使用Spring,其IoC、MVC注解体系就限制了开发人员必须遵循架构决策),通过Framework将非功能需求实现出来,结合上层的业务组件,形成架构的组成(Framework+上层组件)。Framework包括其核心设计思想、类图、代码,在大规模开发之前,应该将底层Framework的代码全部做好,然后开发其上层组件。使用Framework后,就形成了业务组件、Framework的分层,两者具有调用-被调用的关系,Framework的代码很少,可能小于5%,但是却大大的降低了开发难度
软件架构要做的第一件事:分解,将复杂的业务拆分到不同的模块,这也是静态架构设计的工作。拆分存在一个粒度的问题,要细致到什么粒度?
随着软件规模的不断扩大,渐渐引入新的封装技术:代码行 ➪ 面向过程(函数)➪ 面向对象(类)➪ 模块(很多类组成,一种虚拟的划分方式,例如Java的Package方式、C++的namespace方式)➪ 组件(在模块基础上提出,具有物理边界,组件是模块的体现形式,比模块细,可以表现为jar包、DLL、Linux的so)➪ 子系统。个人觉得模块、组件的关系比较含糊 ,有时是包含关系,有时是等同关系。
架构的粒度一般精确到子系统、组件级别。
除了组件划分以外,还有去分析通用的、解决非功能需求的框架。这些框架往往在系统间复用。一旦定义了框架,上面上百个业务组件都要使用该框架的API,因而牢牢的绑定这些业务组件的实现方式、落地架构决策。使用框架时,绝大部分复杂性封装在框架中,因此普通开发人员的工作难度大大降低、且代码相似度很高。
软件系统的架构对软件开发有什么好处:
- 在系统开发之初,就对系统的结构就有了非常清晰的定义——能够从需求实现到系统的静态结构映射。可以映射到什么程度——功能划分到什么组件中。架构上接目标、下接技术决策
- 有了架构后,可以控制系统的复杂度。首先,底层框架是复杂度最高的部分,但是代码量仅占5%,但是解决了95%的复杂性(解耦的例子);同时,架构划分了组件,不同功能划分到不同组件中,那么不同模块的复杂性都在各自的组件中(不影响组件间交互)
- 架构可以组织开发,有利于项目管理。架构划分了组件、接口,可以分配给不同的开发人员完成
- 可扩展性好的架构有利于迭代式开发,迭代是敏捷开发的重要思想。这当然要求功能解耦、组件化开发,敏捷开发对软件架构的要求很高
- 架构有利于基于产品线的开发:产品线开发的一个重要思想是平台。所谓平台是Framework+广义功能(即通用功能,我以前的叫法是基础服务)。产品线基于平台构建,产品会有一些自定义的功能实现。老师的产品线建设方式是:
- 平台有独立的团队,平台的大版本自己演变。通过可配置来实现具体产品的功能差异化
- 需要开发一个产品时,从平台中拿出一个稳定的版本,比如v3.0,在此基础上定制开发
- 定制开发的内容形成独立的工程,只在此工程中进行开发,不修改上述迁入的v3.0的代码。此工程的编译结果插入到平台中,形成产品
平台一般都要组件化开发,基本步骤:首先需要提取通用非功能需求,依此定义框架;然后需要提取所有产品的通用功能需求。
架构师到底要做什么:
- 整体对系统负责:系统的任何部分出现问题,架构师都可以清晰的指出,问题可能出现在什么地方。这个很重要,对于千万行级代码的系统,对于一个普通开发人员,他往往根本不知道自己所做的工作对系统有什么影响(Swimming in codes),这时需要一个全局上掌控的人
- 在设计架构时,要满足客户需求,包括功能、非功能需求
- 能够在整个研发过程,能够控制架构,对整个团队提供架构上的指导,协助开发人员的分工协同
软件开发的流程:需求分析 ➪ 系统架构设计 ➪ 得到系统整体的结构定义 ➪ 依据该定义进行分工 ➪ 由不同开发人员完成每个组件的详细设计和编码实现 ➪ 测试。因此在编码之前,架构为系统提供了整体定义,编码人员可以知道组件之间的关系。非功能需求基本都是在架构阶段去解决的。
架构设计的最终达到的目标:通过底层框架与上端业务模块的分割配合,最终实现利用底层框架来支撑整个业务组件的开发。框架性的代码API强制上层代码依照架构要求进行实现,不仅仅是文字性的指导原则。
好的架构,有一个重要的特点,去除一个组件,不会影响其它组件的正常运行。这样的架构例如Eclipse平台。
这里举了ERP的例子,原料管理与凭证管理。传统的基于interface的解耦有作用,但是是很局限的,主要是接口规格很难稳定。如果使用组件化开发+消息架构,则可以很好的解耦。在原料创建完毕后,需要创建凭证,这时它传递一个简单的消息(可能仅仅包括原料的ID),这个消息被凭证管理接收,凭证管理通过集中数据资源管理(内存体系)获得原料信息,生成凭证后再次通过消息通知原料管理。我觉得这种实现方式其实是观察者的变种,另外即使这样,也不可能完全解耦,在这个例子中,接口规格变化,可能意味着底层数据格式的变化。即使使用消息,原料管理模块也往往必须要修改。当然消息架构适合于模块间/组件间通信,对于模块内则不提倡,这是高内聚(模块内)、低耦合(模块间)原则,所谓高内聚低耦合实质上说的是一件事情,就是对象之间依赖关系的强度。函数调用是属于强依赖,调用次数越多,则内聚越高。模块内的类之间本身从业务上就是互相之间强依赖的,因此适合高内聚;模块间的类则从业务上说,关联相对较少,模块A的修改应该尽可能避免牵涉到模块B。因此适合低耦合。
观察者模式是一种间接调用的思想。老师比较反对通过MOM传递数据(消息),认为MOM传递消息的成本较大,建议只传递对象的标识符。
业务架构的实现过程。业务架构来源于需求,很多团队做需求存在问题:需求没有层次,是一块大饼。其实需求分为几个层面(老师称为CFSU):
- Concept:高层概念。定义了大方向,系统干什么?不干什么。简单的说,高层概念往往对应了一级菜单
- Features:特性,功能。具体的一个个业务功能,往往对应二、三甚至四级菜单
- Scenario:每个特性下的场景,每个功能至少有一个业务场景
- Use cases:每个场景下的用例,依据业务场景分析出的软件操作步骤、界面、业务逻辑、数据
这四个层面是自上而下、逐层分解。我们通过这种类似于剥洋葱的方式来一层层的分析需求,思路会很清晰,可以避免一片混乱的、跳来跳去的大饼式分析导致功能点遗失。
业务架构往往只需要涉及到1、2层,下面两层属于细节的业务需求。今天国内很多架构团队能做到的,也就仅仅是业务架构这一部分,静态架构、动态架构没有涉及。业务架构本质上应该属于系统分析(Systems Analysis)。
业务架构阶段,首先需要把需求分析清楚,然后使用UML将其建模出来,形成业务架构文档。业务架构需要做以下几个分析:
- 系统间的数据关系分析,这个我们称之为上下文(Context),使用UML包图表达
- 业务模块的调用关系分析,这个我们称为业务组织图(Business Organization Map,BOM),使用UML包图表达
- 功能的流程、前后关系分析,这个我们称为业务路线图(Business Road Map,BRM)使用UML活动图表达
- 此外,还应该进行领域模型分析(DMA),可以使用类图表达,描述核心实体类的关系
出这三类图之前,需要把Concept、Feature都列出来。那么如何能不遗漏的把Concept、Feature都列出来?
- 首先,我们要做项目的背景分析,分为两个部分:业务域分析、价值链分析,这个做完后应该得到系统的所有Concept
- 有了Concept之后,就可以基于Concept进行Context、BOM分析
- 之后,需要分析每个Context下的Feature
- Feature分析完后,可以进行BRM分析
甲方期望建设一个第三方支付平台(xpay),该平台共互联网上的商户、消费者使用,此外甲方还期望基于此支付平台建设一个电子商务平台(xeb)。
需求访谈的一些技巧:(我自己总结的)
- 尽量使用客户的行业语言,或者简单的语言。不要出现太多技术性名词
- 尊敬客户,不要无意识的让客户承认其自己的错误,让客户难堪。记住客户是付你钱的,是上帝
- 为客户着想,让客户看到系统能给他带来的价值、利益
- 复述、需求确认,特别是使用易懂的流程图复述
- 引导,对于客户不合理的需求,应当适当引导、变通,而不是生硬的拒绝
- 整理记录,如果允许,最好录音
通过需求访谈来了解项目背景,需求获取是比较依赖于行业经验的工作,最好由行业专家主导(讲课过程中需求访谈是交叉在业务分析过程中完成的,这里做了整理和部分修改):
客户:我们需要建设的平台类似于支付宝,但是主要是面对商业客户(2B),主要业务包括充值、支付、退款、提现、转账、调账等。(了解到了高层Cencept,要做哪些最核心的事情)此外我们还想基于次支付平台建设一个电商平台,电商平台可以直接使用支付平台的用户/账户(了解到了Context,后面还会继续了解)
需求:即两个平台使用一套账户体系,类似于天猫可以直接使用支付宝?
客户:是的,一方面电商平台可以方便的使用支付功能,另外支付平台可以对第三方系统提供服务。另外我们希望电商平台不需要管理用户,直接通过支付平台的用户名密码就可以登陆
需求:这可以通过单点登录、或者支付平台OAuth解决,电商平台根据OAuth验证结果,可以在数据库中自动生成电商用户
客户:我们不希望电商平台管理用户或者账户
需求:一个用户可以有多个账户么?(关键领域对象的关系)(口吻:不要出现什么one-to-many之类的名词)
客户:目前是有一个就可以了,我们不是银行,不需要管理一个人的多个账户
需求:充值的流程是怎么样的?
客户:用户将银行卡里面的钱充到支付平台的虚拟帐户中(Context)
需求:这需要银行的配合,需要使用银行支付网关,银行会收取费用
客户:支付网关的商务问题已经谈好
需求:支付业务在什么场景下使用?
客户:第三方商户平台向支付平台发起订单,用户可以通过我们支付平台支付订单,把钱划给商户(Context)
需求:这个业务与充值类似,只是银行的角色改为支付平台,我们可以在收到商户平台的订单后,引导用户去支付。这个支付的钱是来自之前充值的钱么?
客户:可以是虚拟帐户中的钱,也可以直接选银行支付
需求:是否需要类似于支付宝的快捷支付功能 (引导,行业专家的经验)
客户:这个功能很好,我们需要
需求:商户也使用支付平台的虚拟帐户?
客户:是的,任何接入的商户都要在我们的支付平台有一个虚拟帐户,用于接受款项
需求:好的,这样可以做一个类似于支付宝的收银台。退款业务又是怎么样的呢?
客户:消费者在电商平台购买的物品不满意,需要退货退款。电商平台同意后,我们就退款,把商户的钱划回去。用户支付的时候钱怎么来的,还原路返回
需求:如果商户的钱已经被提走了怎么办?支付平台是否需要审批退款?
客户:商户需要缴纳保证金,如果他的虚拟账户钱不够,就用保证金支付。审批退款是电商平台的事情,只要他们同意我们就退款
需求:保证金支付是否需要在平台中自动完成
客户:暂时不需要,人工处理吧
需求:提现就是将虚拟帐户中的钱提走,转移到银行卡中?提现是否需要审核?
客户:提现都人工审核
需求:提现到哪个银行卡,需要预先登记吧?
客户:是的,用户必须首先登记真实有效、实名验证的提现银行卡
需求:用户可以分为商户、消费者两类。消费者可以充值,用来消费商户的商品 ;消费者如果退货,则把商户虚拟账户中的钱原路返回;商户可以对销售收入进行提现。是这样吧?(访谈中对有疑问的地方及时复述,得到用户确认)
客户:是的。消费者也可以提现
需求:我们的支付平台需要和各大银行进行现金交易,因此需要在这些所有银行开户吧?
客户:是的,根据国内法规,支付平台在银行的账户是受到人行监管的特殊账户
需求:商户、消费者在支付平台中的虚拟账户中的虚拟余额,实际是存放在支付平台的银行账户中,当出现提现、充值、退款等业务时,会发生用户银行账户与支付平台银行账户之间的资金转移?(潜在的银行结算模块)
客户:没错
需求:转账业务什么商户做?
客户:用户可以输入转账金额、对方的XPay账号,就可以转账
需求:调账是什么样的功能?
客户:调账很简单,就是增加或者减少虚拟账户的余额
需求:不需要牵涉到银行那边的处理
客户:不需要,牵涉到的其它事务人工处理
需求:支付平台还有什么重要的业务吗?(不要丢失业务域)
客户: 还有风控、费率。所谓费率,是指:一,我们向商家收费;二,银行向我们收费。所谓风控:可以用于指定超过一个什么额度后,就需要记录下来
需求:向所有商户收费的费率一致么?所有银行的收费费率都一样么?
客户:都不一样
需求:好的,我们初步了解了系统的功能,回去后我们整理一个功能表出来,再和您确认
第一次需求访谈到此结束,需求人员回去后进行初步整理和分析(具体参考下面的业务域分析),并得到功能特性清单,与客户进行二次确认。
需求:昨天回去我们把需求整理一下,这是功能表,您看一下:
| 模块(Concept) | 功能点(Features) |
| 用户管理 | 用户注册、用户修改、用户查询、创建用户、开通用户、关闭用户 |
| 账户管理 | 账户添加、账户查询、银行卡管理、快捷支付设置、提现设置、账户开通、账户关闭、调账申请、调账审批 |
| 交易管理 | 充值、银行卡支付、账户余额支付、组合支付、退款、提现申请、提现审核、订单管理 |
| 银行结算 | 支撑性的与银行之间的后台结算功能 |
| 风控管理 | 风控规则设置、风险交易查询 |
| 费率管理 | 创建商户费率方案、设置商户费率方案、设置银行费率 |
客户:我们希望充值、支付、提现这些功能作为单独的菜单。另外调账是直接在账户查询中的链接上做的
需求:没关系,后续我们做界面设计时再详细讨论(UI组织与业务模块划分无关,甚至很多开发人员都没有认清这一点)
上面提到,业务架构的第一步是通过业务域分析、价值链分析,来得到系统的所有Concept,尽量避免遗漏。在案例中,老师主要使用了业务域分析技术。
什么叫业务域,就是业务中要干哪些事情。比如对于ERP,我们要做生产管理、订单管理、业务管理……
我们现在做xpay的业务域分析,xpay要干充值、支付、提现等等事情(这里要注意Concept的粒度,不要深入细节)。业务域的分析很重要,任何一个业务域的丢失对系统来说都是很大的风险。
用户管理分析:用户可以自助注册,支付平台的管理人员也可以在后台进行增删改(MIS系统需求分析时要自然而然想到CRUD、启禁)。商户的信息由平台管理人员手工录入,由于商户的信息和用户没有本质的区别,因此引入一个用户录入的功能
账户管理分析:账户对象是随着用户注册自动添加的。与账户相关的功能点还包括提现银行卡管理、快捷银行卡设置。此外处于风险控制的目的,账户还可以被关闭,账户关闭的时候用户仍然可以登录
充值业务分析:一般的流程:用户在xpay中输入充值金额、选择银行后,跳转到银行支付网关页面,与此同时支付平台在后端将银行发起消费请求(订单),这个订单信息会在用户浏览器上呈现。用户在银行支付网关输入卡号密码等信息并支付成功后,银行会将消费请求的处理结果发回给支付平台,同时浏览器跳转会到支付平台。
支付业务分析:和充值业务类似,流程:用户在商户网站上购买商品后,商户调用xpay提供的接口,将订单号、商品信息、金额等信息传递给xpay,同时商户跳转浏览器到xpay的收银台页面,用户可以直接通过帐户余额支付,亦可选择银行支付,如果选择银行支付,则再次执行类似于充值业务的流程。操作完毕后,跳转到商户的回调URL。对于快捷支付,不涉及页面跳转,是通过银行后台接口完成的
退款业务分析:商户平台中发生的退货申请,与xpay平台没有关系,只要商户平台同意退款,那么商户就调用xpay提供的接口,将订单号信息传递给xpay,xpay要么将商户账户的钱划给用户的虚拟帐户,要么将商户虚拟帐户的钱直接划走给银行,即原路退回。
提现业务分析:用户申请提现,审核通过后,xpay调用银行支付接口,将钱从xpay的银行账户划走到用户银行卡中,同时修改用户虚拟帐户的余额。
功能合并考虑:考虑到充值、支付、退款、提现业务上、技术上的相似性,合并为一个模块:交易管理;这些模块都牵涉到的与银行的接口,抽取为银行解散模块。
异常情况考虑:支付平台很多业务都牵涉到金钱,需要相当小心。如果充值时,银行处理成功,但是结果xpay却没收到,那么用户虚拟帐户的金额就偏少;如果提现业务银行处理成功,但是xpay没有收到处理结果,那么用户虚拟账户金额就偏多。虽然这些事情发生几率很小,但都可能导致严重的纠纷。按照行业一般性做法,我们可以进行每日对账,如果银行处理成功,xpay没有收到结果的,执行补单处理。(这个是分析出来的需求,不是用户原始需求)
需要注意的是,在业务分析阶段,不管是用户可见的模块,还是纯后台的功能,都要分析。只从业务角度分析,不管UI的组织方式:即使在单个UI页面上显示多个业务功能、或者没有任何UI,也与业务分析、模块划分无关。有时候用户会期望从UI的角度思考模块的划分(大菜单,二级菜单等),但是我们需求分析、架构人员则不能这么思考,起码在内部文档中,要保证前面提到的模块划分原则。
如果某个UI模块(展现层)依赖于我们这里分析的多个业务模块,那么可以在静态架构分析阶段,在此展现层模块使用多条线连接到关联的业务逻辑层模块。
在业务域分析的过程中,老师从来没有提到使用系统的角色,老师认为业务用例的分析不属于架构阶段,但是我认为既然业务架构本质上属于析分,那么就应该考虑到业务用例的角色。本平台的角色可以分为:平台管理者、消费者、商户、商户系统、银行支付网关等。
在业务域分析的基础上分析业务域的流程,考虑其依赖、前后关系:用户管理 ➪ 账户管理 ➪ 费率管理 ➪ 交易管理 ➪ 风控管理 ➪ 银行结算。
如果出现某个Concept不在价值链上是正常的。价值链可以方便你从高级别理解业务过程的顺序。
借用UML包图(老师推荐使用EA),来描述中当前系统与周围系统之间的数据流动关系,箭头从数据的来源指向数据的目的地。一般自己系统的颜色标记为浅色,外部系统的颜色标记为深色。这张图叫做:System Context。
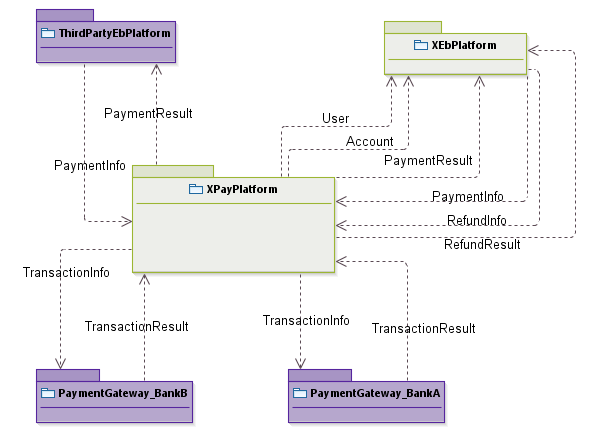
老师的图只画了箭头,没有标记文字,我觉得使用文字标注数据的简短描述更好。
使用UML包图,来描述系统内部各模块(Concept)之间的调用关系。箭头的方向从调用方指向被调用方。分析过程一般是:找到一个为起点,挨个分析它与周围模块的关系,第一个模块分析完后,再对第二个模块进行上述分析过程,直到分析完所有模块。牵涉到的外部系统也要参与分析。
下图以支付平台为例:
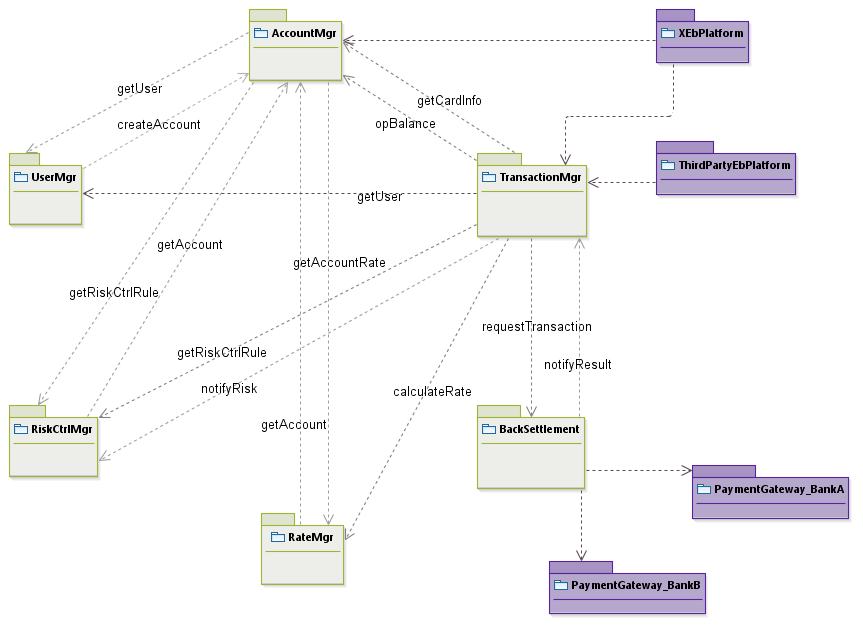
老师的图只画箭头,没有标记文字,我觉得使用文字标注数据的简短描述更好。如果调用关系过于复杂,则可以只画箭头,辅以文字描述
大家可以看到,这么简单的系统,模块间的关系就如此复杂,这个复杂性是没法避免的,因为业务就是这样,除非Concept划分不合理。这种业务上的复杂性可以在设计阶段,利用接口、消息等技术进行解耦,避免模块之间的强关联。
这张图在静态架构设计阶段,将构成业务逻辑层的主体。
在上面需求访谈、业务域分析的过程中已经完成。
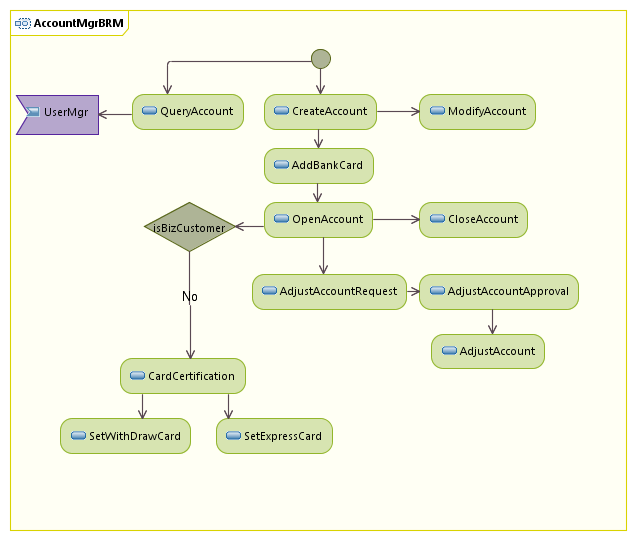
借用UML活动图来表示某个模块(Concept)内部的功能流程的关系,这个图中会画出模块中的Feature,并且画出Feature对外部模块的调用。
下图以支付平台的账户管理模块为例:
列出所有领域类,并识别它们之间的关系,列出所有属性。在业务分析阶段可以使用全中文。
支付平台中的领域类包括:用户、账户、银行卡、交易订单、风险规则、费率规则、风控日志等等。
上面我们完成了业务架构,业务架构之后是软件架构,软件架构包括静态、动态架构两部分,分别关心软件的功能、非功能部分。静态架构设计是直接依据业务架构导出的,有时候也称为逻辑(应用)架构设计,该阶段需要做以下事情:
- 做系统的整体结构的设计。即系统的高层分割,系统分为哪些模块。需要注意这些模块分为两类:系统性模块、功能性(业务)模块。所谓功能性模块来源于业务分析阶段识别出来的Concept、Feature,与业务紧密相关。而系统性模块则是因为技术需要而设计的模块,例如TCP/IP通信模块
- 进行组件的设计。把模块拆分为不同的组件,如果模块比较小,则可以只对应一个组件
- 完成接口的设计。接口分为系统内接口、系统间设计
- 完成通讯设计。老师所指通讯设计,主要是指模块间、系统间通信报文、传输方式的设计。我觉得属于接口设计
- 进行分层设计
- 进行进线程设计
- 进行部署设计。部署设计往往和网络有关,例如路由、交换机、服务器和软件组件之间的关系
- 把上面几步分析的内容形成4+1视图
- 进行架构机制(Pattern)的选型,这些选型会称为未来动态架构中Framework设计的基础
我们首先讲述架构机制,因为这一部分很重要。
- 框架可以提供API,业务模块使用这些API,降低了开发难度
- 保证架构的执行,保证代码风格一致
- 解决重复性问题
| 非功能需求 | 说明 |
| 可扩展性 Extensibility |
添加新功能,不用修改老功能。 量化标准:添加新功能,老代码修改的比例不超过N% |
| 可伸缩性 Scalability |
添加新硬件,不用修改软件。量化标准:添加新硬件,软件修改的比例不超过N% |
| 可配置性 Configurability |
系统可以通过修改配置文件,来定制系统的功能。量化标准:修改配置文件改变功能时,不需要修改任何代码 |
| 集中资源管理 Knowledgeability |
最常见的集中资源管理是指数据资源的管理。系统整体使用数据,而不是让数据在模块间传递。量化标准:系统把数据集中存放在一个地方,供模块去获取、修改 |
| 可维护性 Maintainability |
达到可扩展性、可伸缩性、可配置性、集中资源管理的要求,则认为软件是可维护的 |
| 性能 Performance |
包括若干指标:
并发度与吞吐量应该是结合考虑:
|
| 可靠性 Reliability |
系统持续稳定运行的能力。一般有两种量化标准:
一般维护时间会算在宕机时间中的,除非合同中明确规定。现在很多互联网系统是要求不宕机、热升级的,通常使用分区升级方式 |
| 健壮性 Robustness |
老师的翻译是Stability,但是该词的含义是稳定性,稳定性应该和可靠性是一回事 一般认为健壮性和抗误操作、容错能力有关。量化标准:宕机(出错)后恢复需要的时间。今天很多系统要求5秒恢复,要保证这样的健壮性,基本上需要双机热备或者集群技术 |
| 安全性 Security |
包括多个方面:
|
| 可移植性 Portability |
是否支持:数据库的迁移、多操作系统、多语言(人类语言)、可迁移性(系统是否能够向下兼容) |
| 易用性 Usability |
架构阶段不考虑,在需求阶段考虑 |
根据业务特性来识别非功能需求:
- 可扩展性:期望未来能够方便的添加新功能,互联网应用需要迅速的对市场做出反应
- 可伸缩性:面向互联网,在某些商户促销活动时,支付平台的压力会陡增,期望能够方便的添加新服务器以增强系统性能
- 性能:要求能够支持2000Trans/s的吞吐能力,每次支付能够在3秒内完成全部处理
- 安全性:牵涉资金,需要可靠的身份验证
- 可靠性:零宕机,每秒的宕机会导致大量的经济损失
识别出来的每一个非功能需求,都是我们的设计目标。有了设计目标后,架构师需要找出对应的技术实现框架机制(即架构模式)。常见的架构机制包括:
| 架构模式 | 分类 | 说明 |
| MVC | 用户界面架构 |
模型-视图-控制器模式,该模式可以很好的将表现层代码和业务逻辑分离,从而提高可扩展性,并且为系统提高可配置性,因此也就能够提升可维护性 MVC模式在现代GUI应用中几乎是必选 |
| AUI |
抽象用户视图模式,即通过配置的方式自动生成用户界面。这种技术从另外一个角度提高可维护性——少写代码。以前公司的MIS平台、我设计的两步视图技术、Breeze框架的实现,均使用这种模式 |
|
| RIA |
在浏览器中实现类似于C/S效果的复杂UI,提高易用性。ExtJS、Flex、SilverLight、JQuery、ActiveX等框架可以实现此模式 |
|
| IoC | 基本架构 | 控制反转模式,该模式在业务逻辑层解决组件实现之间的耦合问题,从而提高可扩展性 |
| AOP | 面向切面编程,该模式用于将被多个业务模块使用的系统模块独立出来,与业务模块完全解耦,从而提高可扩展性。典型框架是AspectJ | |
| ORM | 对象-关系映射,该模式用于将具体数据库隔离,对数据资源进行集中管理,可以提高可扩展性 | |
| CMF | 组件化管理框架,典型的代表是OSGI,可以非常好的解决可扩展性问题,更好的进行解耦 | |
| MF | 面向消息框架,也用于解耦,往往与CMF一起使用。典型实现包括MQ、ActiveMQ、Kafka等 | |
| InterfaceBus | 接口总线,解决接口的集中资源管理问题,可以提高可扩展性。典型的应用是ESB | |
| Cluster |
分布式网络架构 (DNA) |
集群模式,这是一种分布式架构,可以提高可靠性、健壮性、可伸缩性。今天绝大部分的集群是通过负载均衡NLB+Linux PC集群来实现。ZooKeeper也可以用于集群管理 |
| NLB | 网络负载均衡(Network Load Balancing)模式。可以提高可靠性、健壮性、可伸缩性。经常使用Nginx来实现,商业产品有F5 | |
| DMF | 双机热备。用于防止单点故障,可以提高可靠性、健壮性。可以使用Nginx来实现 | |
| VMF | 虚拟机框架。开源界有XEN,未来的趋势是Docker。VMF可以用于实现集群、NLB | |
| DSF | 分布式会话框架。可以配合Cluster、NLB、DMF等分布式架构,实现集群成员的无差别化 | |
| DFS | 分布式文件系统。可以提高性能、安全性、可伸缩性。典型代表是HDFS | |
| DC | 分布式计算。配合分布式文件系统实现大数据处理。如果数据达到TB级,应该考虑使用分布式计算。典型代表是Hadoop、Storm,分别用于处理存储上的静态数据、来自网络的流式数据,其它还有Spark | |
| DCF | 分布式缓存框架。可以提高性能。用的比较多的是Redis | |
| Cloud |
云架构,综合虚拟化技术、面向服务的设计思想,将基础设施、平台、软件等都作为服务对外提供。相关技术有OpenStack、CloudStack 云架构可以很好的解决突发的系统压力,同时不需要太多的运维、硬件成本 |
|
| SimpleDB | 数据库架构 | 简单的、不完全保证ACID的数据,用于存放一些不重要的数据,可以提高性能。典型实现是文档数据库MongoDB |
| ClusterDB | 集群关系型数据库,可以提高可伸缩性,例如Oracle的RAC | |
| ShardingDB | 分区数据库,可以提高可伸缩性,例如MySQL的Proxy,开源实现有Amoeba。主要做SQL的转发和结果的收集 | |
| RWS | 读写分离(Read/Write Splitting),通过主从(Master-Slave)复制手段,使用不同的数据库实例完成读、写操作 | |
| SPC | 页面缓存架构 | 静态页面缓存架构,通过对不需要改变的页面进行缓存、静态化,提高性能。电信的详单查询、门户网站新闻、统计报表适合使用该模式实现 |
| DPC | 动态页面缓存架构,通过动态生成的、隔一段时间会发生变化的页面进行缓存,提高性能。12306的车次信息适合使用该模式实现 | |
| CQRS | 其它 |
命令与查询责任分离(Command Query Responsibility Segregation):查询操作不会改变数据,属于幂等性操作,可以反复发起,可以基于缓存来提供性能,此外查询操作常常远多于命令操作;命令操作则会影响系统的状态,具有事务性要求,可能不需要返回值,因而可以异步处理。 由于查询与命令操作的差异性,将其分离处理——使用不同的模型来处理读、写——可以很好的提高系统的可扩容性、性能。axon framework是CQRS的实现 RESTful API适合暴露CQRS系统的功能 |
架构机制包括三个层次的内容:机制的核心思想、机制的详细设计、机制的代码和API。其中机制的核心思想是通用的,设计以及代码则依据具体实现各不相同。
确定系统需要使用哪些架构机制,可以通过两种分析方式:
- 自顶而下:架构师非常有经验,直接依据系统特点、个人经验判断使用哪些机制。缺点是可能引入不必要的机制,造成不必要的工作量
- 自底而上:开始时只使用简单的、必要的机制,根据业务需要,进行架构重构,引入新的机制。缺点是为未来重构的代价较大
根据上一节识别出来的xpay系统的非功能设计目标,可以考虑使用:MVC、IoC、CMF、MF、Cluster、DSF这几个框架机制。
高层分割,即整体结构设计,是系统的横向结构划分,需要践行以下原则:
- 软件模块中的主要模块,来自于业务模块,即:业务模块会称为软件模块的一部分。任何一个Concept都会成为软件模块,这些Concept会落在展现层、业务逻辑层等层次
- 所有的机制,都会成为软件模块,并形成Framework层的主要内容
- 模块的暴露方式应该是接口
- 模块间要避免循环依赖,如果存在循环依赖,应当使用消息/事件等方式解开
我们知道,在软件工程中,引入新的抽象层是屏蔽复杂性的通用方法。在确定软件模块后,应当进行分层设计,分层是系统的纵向结构划分。分层设计应当践行以下原则:
- 避免不必要的分层,过多的分层不但降低性能,还增加系统的复杂性
- 自上而下,逐层依赖,避免跨层调用。跨层调用破坏层的价值
- 严禁反向调用。在分层设计中,越底下的层越稳定,让稳定的层调用不稳定的层,将破坏其本身的稳定性。以前我们的平台就出现了高层代码入侵的情况
- 层间应该通过抽象接口来隔离。例如,我们的sshe平台通过自定义的接口隔离Hibernate
注意,架构师并不能完全保证不出现跨层调用,例如使用旧式的MVC框架时,控制层会依赖于Framework层的组件。出现跨层调用时,架构师应当给予充分的理由。
经典的分层模型为六层,足够适用于大部分的系统:
- 展现层:包含了UI组件
- 控制层:包含了MVC的控制器
- 业务逻辑层:包含了常规的业务模块
- 框架层:包含了所有架构机制,典型的会在框架层之上提供一个抽象接口层API。同时需要进行开源选型
- 中间件层:包含非平台性质的第三方产品,例如消息中间件、JavaEE容器,一些JDK标准化组件也被老师分在这一层
- 基础设施层: 包括硬件、操作系统、通信机制
分析后,将上面的分层绘制成图,具体的技术选型使用版型表示,越下面的层次使用越冷的颜色表示。层次间的调用使用箭头表示,如果上层大部分模块都需要调用下层模块,则不必画调用箭头。xpay的分层图如下:
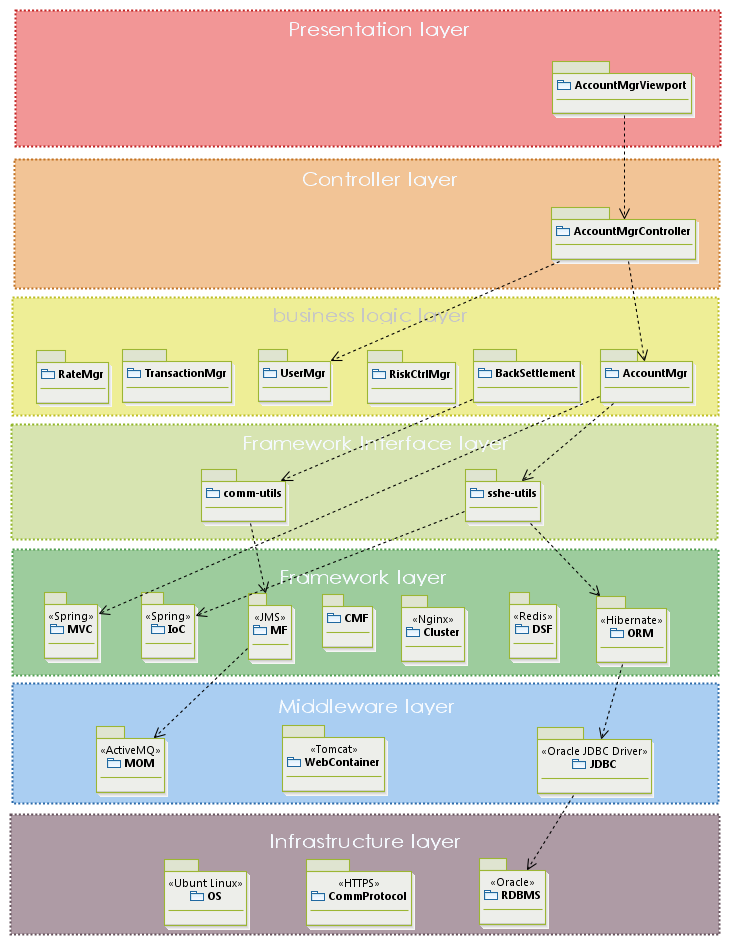
接口设计应当践行以下原则:
- 接口主要的目的是用于模块间、系统间的通信,分别称为内部接口、外部接口
- 接口由业务决定,应当逐一分析功能(Feature),来分析哪些功能需要对外暴露,并设计为接口
- 接口不应当由调用方决定,防止调用方的特殊需求导致调用方的逻辑混入接口提供方,长期下去会导致接口非常多。比如在xpay平台中,交易管理模块不应该直接响应某个模块要求的“查询交易额大于5000的交易记录”
- 在设计接口时,一个需要注意的是参数的类型,应当尽量使用领域模型而不是基本类型,特别是避免使用冗长的基本类型参数列表,以增强接口的稳定性
- 外部接口因为牵涉到远程调用,接口的粒度应当尽量粗,避免影响性能
在分析功能以识别接口的时候,应当从业务分析的BOM开始,BOM中已经标明Concept之间、Concept与外部系统之间的调用关系。然后进一步通过BRM来查看各Feature在业务活动中的位置、与其它Feature的前后关系,并从中识别出接口。
以xpay交易管理模块为例分析:
- 充值,会被本模块的页面调用,不需要暴露接口
- 交易查询,会被本系统的其它模块调用,暴露为内部接口:findTransaction
- 账户支付,会被第三方系统调用,需要暴露为外部接口:doPayment,需要进一步进行系统间通信方式的设计,例如基于HTTP的报文交换
- ……
接口设计应当完成接口规格的详细规定。
组件是模块的物理实体(往往在操作系统中表现为文件),组件一般是在模块下的细化。组件设计完成的任务类似于温老师的开发架构视图。
如果模块的功能较为复杂,可以根据业务的相关性分割组件;如果模块功能较为简单,可以直接作为单个组件。我倾向于把若干简单的模块划分到一个组件中,避免工程管理的复杂度
组件设计最终使用UML组件图来表示、使用版型说明组件的类型(例如jar、dll、so),以xpay交易管理模块为例:
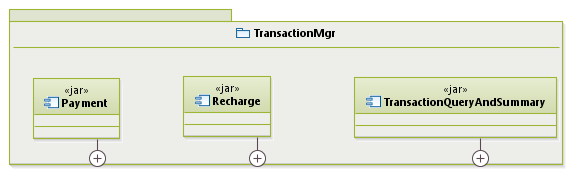
组件内部可以标出关键的包、类。
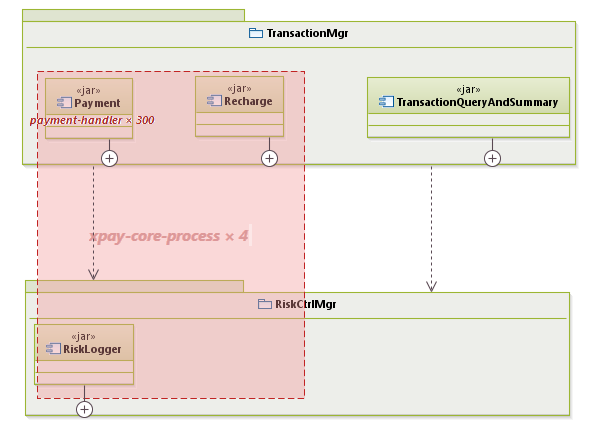
并发视图用来说明组件与进线程的对应关系。
实现并发的两种方式是:多进程和多线程,两者的本质区别是后者共享地址空间,性能较高,但是没有多进程安全(单个线程可能导致应用崩溃)、编程难度大。并发本身并不会提高性能,但是由于系统中大量I/O的存在,单线程可能因为I/O阻塞而浪费CPU资源,并发设计特别适用于I/O密集型系统,对CPU密集型系统的性能提高意义不大。
多CPU、分布式、计算的强度、事件驱动、并行计算等会导致并发设计的考虑。
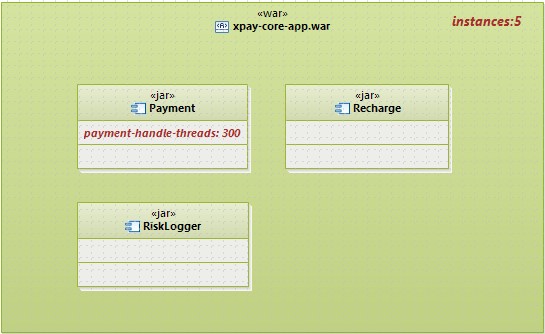
进行并发设计后,线程、进程一般都会在组件上提体现。我们在组件视图上使用红线框来标注进程、使用红线条标注多线程,并标注并发进线程数量,例如xpay进线程设计的片段如下:
个人觉得,没必要在并发视图上体现出模块与组件的关系,我倾向于使用部署图的Artifact来包围组件,形成并发视图:
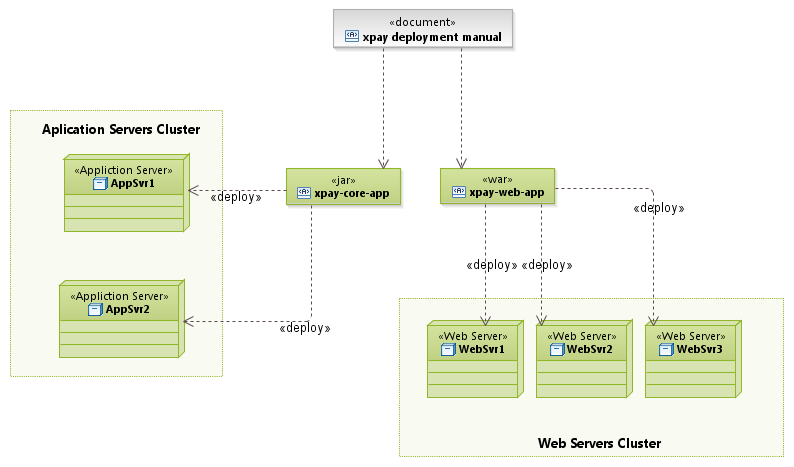
部署视图说明组件与服务器、网络的对应关系。
最早的应用程序,后台只部署一个数据库,所有业务逻辑都放在客户端(杀毒软件);后来发展到后台包含一台应用服务器,客户端处理一些简单的应用逻辑、图像渲染(网络游戏);再后来,发展到B/S,后端往往包含Web服务器和应用服务器,后者存放业务逻辑层(电子商务网站)。这些都是属于客户端/服务器架构。
除了客户端/服务器部署架构外,还有一种对等网络架构(Peer-to-Peer),它利用NAT穿透技术(UDP打洞),允许任意两个处于NAT设备背后的局域网机器建立通信。这种网络架构一方面可以减轻服务器的压力,另外一方面具有顽强的生存能力。
出于减轻单服务器负载、可伸缩性、更优性价比(二版的反例)等方面的考虑,大型复杂的系统都需要使用分布式架构。
通常网络环境由网络管理部门提供,我们需要在网络拓扑图上标记出组件与网络服务器的对应关系。(我觉得UML构件更合适,组件并不是运行时实体,而且组件可能被部署在多个不同用途的构件中)。UML中的部署图用来绘制部署视图,但是视觉效果较差,可以使用VISIO、亿图等工具绘制。
动态架构设计阶段需要:
- 根据静态架构阶段的架构机制选型,确定需要使用哪些开源框架,确定需要自主开发哪些框架
- 对于自主开发的框架,需要完成详细设计和代码编写
- 补充架构文档
在这个议题中,老师主要讲了一个案例。
NGEP希望能监控全球油田的油井的实时数据(压力、温度、粘度、频谱等),由于这些油井都在荒无人烟的地方,因此数据采集后需要上传到卫星,由卫星转发到位于数据中心的NGEP以便进行处理。NGEP有数千种应用,其中之一:由于地质条件的影响,油井的压力可能突然增高,导致井喷,进而破坏上端设备,为了防止井喷的发生,我们通过监控油管的压力,在到达一定的临界值后关闭油井出口钢板。
NGEP初期准备支持8万口油井的实时监控。数据采集的频率很高、每口油井每天大概产生几百M的数据,数据一般需要保留三年,8万口油井的累计数据最多可到达8000TB,初期准备了200台服务器。经过几年发展,发展到2000万口油井,因此NGEP的系统架构经历了多次重构:
| 阶段 | 架构说明与重构情况 |
| 平台建设初期:从有数百口油井,数台服务器发展到数万口油井,数百台服务器 |
在以前,很多团队根据组件对计算资源要求的不同,将其部署到不同的服务器上,比如对于实时计算的组件,将其多部署几台服务器,其它对计算资源要求较少的组件,例如数据采集,则少部署几台服务器。 这种部署方式随着系统规模的不断扩大,会带来很多运维负担,因为你需要不断的重新调整部署规划。按DNA架构的思路,每台服务器应该部署一样的组件集,并通过NLB机制进行请求转发。NGEP在初期开发了一个很简单NLB,就是通过random()函数进行随机的转发。应用了DNA架构后,就能够均匀的将负载分布在多台服务器上。为了防止服务器宕机导致请求处理失败,NGEP进一步开发了心跳监听,对每台服务器进行心跳监听,一旦服务器宕机就通知NLB。 NLB大大提供了系统的可靠性,NGEP逐渐的不再依赖于小机,而是转用PC服务器,此时PC + NLB的Cluster已经具备雏形。为了防止NLB分发节点的单点故障,NGEP引入了分发节点的双机热备 DNA也让应用程序部署、升级变得简单,只需要一个通用的部署脚本即可 由于硬件成本的降低,NGEP可以更低的价格提供服务,因而吸引了更多油井接入 |
| 运维的压力:60多万口油井,2000台服务器 |
后期引入的服务器,性能比老的服务器高,此时基于random()的NLB就不适用了,NGEP引入了monitor组件,该组件采集服务器的CPU、网络、I/O等参数,形成一个因子,影响NLB转发请求的策略 系统到达这个规模了,运营的压力非常大,NGEP开始寻找第三方的数据中心,最后找到位于奥斯丁的数据中心ODC,该数据中心连更换硬盘等工作都是机械手自动完成的 2000台服务器的脚本部署也是非常大的工作量,因此NGEP考虑引入虚拟机管理框架(VMF),他们选择XEN,并在最近考虑切换到Docker 有了VMF后,只需要将image复制到对应服务器上就可以完成部署,NGEP甚至根据服务器的负载,来决定部署虚拟机的数量 |
| 高资源消耗请求导致的负载不均衡 |
在之前的建设中,NGEP使用动态列表的方式进行Session相关性的请求转发,这导致了一个严重的问题:后续请求被关联到固定的服务器上。当出现大量高资源消耗的分析请求时,无法进行负载重新均衡。NGEP在运营过程中出现了1/3服务器空载,1/3服务器满载并且性能低下的情况。 为了解决该问题,NGEP引入DSF,配置一台大内存(数百G)服务器,并且自行开发Session接口,所有组件中涉及到Session操作的代码均改调此接口,为了避免此分布式会话服务器的单点故障,引入了双机热备 |
| 周边应用的引入 |
随着数据量的不断增加和NGEP平台的发展,大量周边应用(例如三维分析)被开发,最初这些周边应用是出售给客户,在它们自己的机房中部署,通过远程获取能源平台的数据进行处理分析的 后来客户提出要求,你们能不能把应用的运维也管起来?于是NGEP把这些周边应用也打包部署在数据中心、利用VMF自动化管理,客户只需要在NGEP的portal中注册、选取需要的服务、服务使用的时间,即可生成账单、使用服务 系统发展到这一步,实际上就是一个私有云了 |
- 项目简介、预期读者等描述性内容
- 逻辑视图,并对主要内容进行说明:首先做层的技术实现、职责的说明;然后做主要模块的描述
- 组件视图,把图中的组件拿出来,形成一张全是组件的图,并对每一个组件进行说明
- 并发视图,与组件视图是一张图,需要说明组件与进线程的关系
- 部署视图,并说明组件与物理计算机的关系
- 通信协议的说明
- 接口设计,包括内部、外部接口的详细说明
- 底层框架设计,对使用的所有框架挨个说明,并给出必要的使用规范
Leave a Reply