Linux内核学习笔记(四)
Linux的I/O系统的整体架构如下: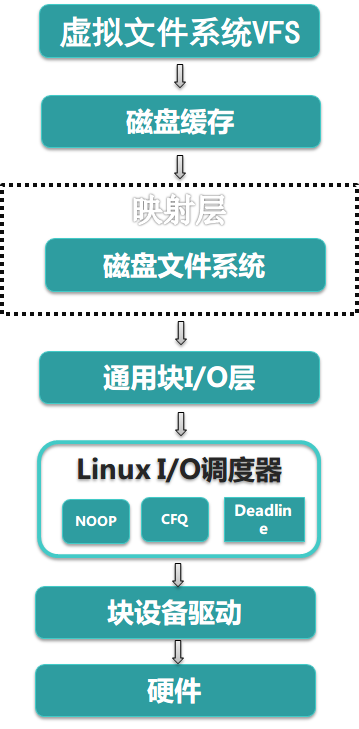
当Linux内核组件要读写一些数据时,并不是请求一发出,内核便立即执行该请求,而是将其推迟执行。当传输一个新数据块时,内核需要检查它能否通过。Linux IO调度程序是介于通用块层和块设备驱动程序之间,所以它接收来自通用块层的请求,试图合并请求,并找到最合适的请求下发到块设备驱动程序中。之后块设备驱动程序会调用一个函数来响应这个请求。
Linux整体I/O体系可以分为七层,它们分别是:
- VFS虚拟文件系统:内核要跟多种文件系统打交道,内核抽象了这VFS,专门用来适配各种文件系统,并对外提供统一操作接口
- 磁盘缓存:磁盘缓存是一种将磁盘上的一些数据保留在RAM中的软件机制,这使得对这部分数据的访问可以得到更快的响应。磁盘缓存在Linux中有三种类型:Dentry cache ,Page cache , Buffer cache
- 映射层:内核从块设备上读取数据,这样内核就必须确定数据在物理设备上的位置,这由映射层(Mapping Layer)来完成
- 通用块层:由于绝大多数情况的I/O操作是跟块设备打交道,所以Linux在此提供了一个类似vfs层的块设备操作抽象层。下层对接各种不同属性的块设备,对上提供统一的Block IO请求标准
- I/O调度层:大多数的块设备都是磁盘设备,所以有必要根据这类设备的特点以及应用特点来设置一些不同的调度器
- 块设备驱动:块设备驱动对外提供高级的设备操作接口
- 物理硬盘:这层就是具体的物理设备
open() 、 read() 、 write() 等系统调用可用来访问各种文件系统和媒体介质,这得益于现代操作系统引入的抽象层(对于Linux就是VFS)。作为内核子系统,VFS为内核其它部分、用户空间程序提供文件、文件系统相关的统一接口。所有底层文件系统依赖于VFS共存、协作,程序可以使用标准的Unix系统调用访问不同的文件系统,甚至是不同的媒体介质。
为了支持多文件系统,VFS提供了一个通用文件系统模型,囊括了常见文件系统的常用功能集和行为,该模型偏向于Unix风格的文件系统,但是支持FAT、NTFS等差异很大的文件系统。
在内核,除了文件系统本身以外,不需要了解文件系统的任何细节。例如下面这个简单的操作:
|
1 |
ret = write (fd, buf, len); |
将buf指向的缓冲区中len字节写入到文件描述符fd所代表的文件的当前位置,其处理过程如下图:
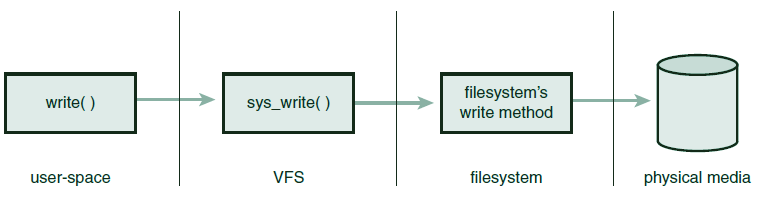
和具体文件系统相关的部分,被屏蔽在VFS层的下面,用户程序不知道页不需要知道文件系统是如何把数据写入到物理介质中的。
Unix使用了四个和文件系统相关的重要概念:文件、目录项、索引节点、挂载点(Mount point)。
文件系统本质上是一种特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。文件系统的通用操作包括创建、删除、安装等。在Unix中文件系统被安装在特定的挂载点上,挂载点在全局层次结构(近来Linux已经允许进程具有自己的层次结构)中被称为命名空间。所有安装的文件系统都作为根文件系统的枝叶节点出现,这和DOS/Windows基于盘符的命名空间划分截然不同。
文件可以看做是字节的有序串,为了系统和用户便于识别,每个文件被分配一个可读的名字。文件支持的典型操作包括读、写、创建、删除。Unix文件和面向记录的文件系统(例如OpenVMS的File-11)很不一样,后者提供更丰富的、结构化的表示。
文件通过目录进行组织,目录之间可以嵌套,形成文件路径,路径中每一部分称为目录条目(directory entry)。对于Unix来说,目录就是普通的文件,只是它列出其中包含的所有文件而已。由于VFS把目录作为文件看待,因此可以对目录和文件执行相同的操作。
Unix把描述文件的信息(文件元数据)和文件本身加以区分,元数据(权限、大小、所有者、修改日期…)被存储在单独的数据结构中,称为索引节点(inode,index node)。
上面这些概念都和文件系统本身的控制信息紧密相关,这些控制信息存放在超级块(superblock)中,超级块是包含整个文件系统相关信息的数据结构。
所有单个文件、文件系统本身的元数据,合称为文件系统元数据(filesystem metadata)。
Unix文件系统一直以来都是遵循上述描述设计和实现的,比如在磁盘上,文件(目录)信息按照inode形式存放在单独的块上,控制信息被集中存放在磁盘的超级块上。Linux的VFS就是要保证支持和实现了上述概念的文件系统能够协同工作。对于FAT或者NTFS之类的非Unix文件系统,VFS也提供支持,但是必须进行适配。
VFS子系统使用了OO思维设计,定义了一组结构体表示通用文件对象,这些结构在包含数据的同时包含操作(函数指针),这些操作由具体文件系统负责实现。VFS主要包含4个对象类型,每个类型包含了一个“操作对象”:
| 对象类型 | 说明 |
| 超级块对象 |
代表一个已安装的文件系统。操作对象: super_operations ,包含了内核可以针对文件系统进行的操作 |
| 索引节点对象 | 代表一个具体文件,注意VFS把目录作为文件看待,因此该对象也用于表示文件。操作对象: inode_operations ,包含了内核可以针对一个具体文件进行的操作 |
| 目录项对象 | 代表一个目录项,即路径的一部分。操作对象: dentry_operations ,包含了内核可以针对具体目录项进行的操作 |
| 文件对象 | 代表由进程打开的文件。操作对象: file_operations ,包含了进程可以针对已打开文件进行的操作 |
操作对象是包含若干函数指针的结构体,这些函数指针可以操控父对象。其中很多操作可以继承使用VFS提供的通用函数,如果通用函数不能满足需求,必须使用实际文件系统的独有方法填充这些函数指针。
除了上述4种基本的类型外,VFS还大量使用了其它结构体,例如:
- file_system_type:每个注册的文件系统类型使用该结构表示,描述文件系统及其性能参数
- vfsmount:表示一个挂载点
所有文件系统都必须实现超级块对象,以存放特定文件系统的信息:
- 对于基于磁盘的文件系统:超级块通常存放在磁盘特定扇区中的文件系统超级块或者文件系统控制块(control block)中
- 对于非磁盘文件系统:例如基于内存的sysfs,会即时(on-the-fly)在内存中创建超级块对象
超级块结构定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
struct super_block { struct list_head s_list; /* 指向所有超级块的链表 */ dev_t s_dev; /* 设备标识符 */ unsigned char s_dirt; /*修改(脏)标记*/ unsigned char s_blocksize_bits;/* 以位为单位的块大小 */ unsigned long s_blocksize; /*以字节为单位的块大小*/ loff_t s_maxbytes; /* 文件最大尺寸 */ struct file_system_type *s_type;/* 文件系统类型 */ const struct super_operations *s_op;/* 支持的操作的集合 */ const struct dquot_operations *dq_op;/*磁盘配额相关操作的集合 */ const struct quotactl_ops *s_qcop;/* 磁盘限额控制操作的集合 */ const struct export_operations *s_export_op;/* 导出相关操作的集合 */ unsigned long s_flags;/* 挂载标志 */ unsigned long s_magic; /* 文件系统的魔数 */ struct dentry *s_root; /* 目录挂载点 */ struct rw_semaphore s_umount; /* 卸载信号量 */ struct mutex s_lock;/* 超级块信号量 */ int s_count;/* 超级块引用计数*/ int s_need_sync; /* 尚未同步标志 */ atomic_t s_active;/* 活动引用计数*/ #ifdef CONFIG_SECURITY void *s_security; /* 和安全模块相关 */ #endif struct xattr_handler **s_xattr;/* 扩展属性操作的集合 */ struct list_head s_inodes; /*所有inode的链表 */ struct hlist_head s_anon; /* 用于nfs导出的匿名目录项 */ struct list_head s_files;/* 已经分配的文件的链表 */ /* s_dentry_lru和s_nr_dentry_unused由dcache_lock保护 */ struct list_head s_dentry_lru; /* 未使用目录项的LRU链表 */ int s_nr_dentry_unused; /* # of dentry on lru */ struct block_device *s_bdev;/* 相关联的块设备 */ struct backing_dev_info *s_bdi;/* */ struct mtd_info *s_mtd;/* 内存盘信息 */ struct list_head s_instances;/* 当前文件系统的实例 */ struct quota_info s_dquot; /* 配额相关的选项 */ int s_frozen;/* 冻结标志 */ wait_queue_head_t s_wait_unfrozen;/* 在freeze上的等待队列 */ char s_id[32]; /* 文本的名称 */ void *s_fs_info; /* 文件系统私有的信息 */ fmode_t s_mode; /*挂载的模式(权限)*/ /* Granularity of c/m/atime in ns. Cannot be worse than a second */ u32 s_time_gran; /* 时间戳的粒度 */ /* * 该字段仅和VFS有关,具体文件系统不需要访问 */ struct mutex s_vfs_rename_mutex; /* Kludge */ char *s_subtype; //文件系统子类型,/proc/mounts 会显示为 "type.subtype" char *s_options; //已保存挂载选项 }; |
创建、管理、撤销超级块对象的代码位于 fs/super.c 。超级块通过 alloc_super() 函数创建并初始化,在文件系统被安装时,文件系统会调用此函数从磁盘读取超级块,并将信息填充到内存的超级块对象中。
该结构对应了索引块对象的 s_op 字段,它是一系列函数指针的集合:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
/** * 这些函数执行文件系统和索引节点的底层操作 * 这些函数都由VFS在进程上下文中调用,大部分函数必要时会阻塞 */ struct super_operations { //在给定的超级块下面创建和初始化一个inode struct inode *(*alloc_inode)( struct super_block *sb ); //释放指定的inode void (*destroy_inode)( struct inode * ); //标记inode为脏的,日志文件系统(ext3/4)会调用该函数进行日志更新 void (*dirty_inode)( struct inode * ); //将指定索引节点写入磁盘 int (*write_inode)( struct inode *, struct writeback_control *wbc ); //在inode最后一个引用释放后,VFS调用该函数 void (*drop_inode)( struct inode * ); //从磁盘上删除指定的索引节点 void (*delete_inode)( struct inode * ); //卸载文件系统时由VFS调用,用来释放超级块,调用者必须持有s_lock void (*put_super)( struct super_block * ); //用给定的超级块对象更新磁盘上的超级块,用于超级块同步,调用者必须持有s_lock void (*write_super)( struct super_block * ); //使文件系统的元数据同步到文件系统 int (*sync_fs)( struct super_block *sb, int wait ); int (*freeze_fs)( struct super_block * ); int (*unfreeze_fs)( struct super_block * ); //由VFS调用以获得文件系统的统计信息 int (*statfs)( struct dentry *, struct kstatfs * ); //使用新的选项挂载文件系统,调用者必须持有s_lock int (*remount_fs)( struct super_block *, int * flags, char * ); //VFS调用该函数释放inode,清除包含相关数据的页面 void (*clear_inode)( struct inode * ); //VFS调用该函数中断挂载操作,由网络文件系统例如NFS使用 void (*umount_begin)( struct super_block * ); int (*show_options)( struct seq_file *, struct vfsmount * ); int (*show_stats)( struct seq_file *, struct vfsmount * ); #ifdef CONFIG_QUOTA ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t); ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t); #endif int (*bdev_try_to_free_page)( struct super_block*, struct page*, gfp_t ); }; |
这些函数指针中,一部分是可选的,如果设置为NULL,VFS会调用通用函数,或者什么也不作(取决于操作类型)。
在调用这些函数的时候,可能需要把超级块、inode对象传入,例如:
|
1 |
sb->s_op->write_super(sb); |
这是由于C语言没有面向对象的支持,不能像C++那样:
|
1 |
sb.write_super(); |
inode包含了内核操作文件或者目录时需要的全部信息。对于Unix来说,inode信息可以直接从磁盘读取。某些不支持inode的文件系统,通常将文件的描述信息(元数据)同文件一起存放。某些现代文件系统使用数据库来存放文件元数据。不管是那种情况,VFS必须在内存中创建inode对象。
inode使用下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
struct inode { struct hlist_node i_hash; //散列表 struct list_head i_list; /* inode链表 backing dev IO list */ struct list_head i_sb_list; //超级块链表 struct list_head i_dentry; //目录项链表 unsigned long i_ino; //索引节点号 atomic_t i_count; //引用计数 unsigned int i_nlink; //硬链接计数 uid_t i_uid; //所有者uid gid_t i_gid; //所有者gid dev_t i_rdev; //实际设备节点 u64 i_version; //版本号 loff_t i_size; //文件尺寸(字节数) #ifdef __NEED_I_SIZE_ORDERED seqcount_t i_size_seqcount; //对i_size进行串行计数 #endif struct timespec i_atime; //最后访问时间 struct timespec i_mtime; //最后修改时间 struct timespec i_ctime; //最后改变实际 unsigned int i_blkbits; //以位为单位的块大小 blkcnt_t i_blocks; //文件的块数 unsigned short i_bytes;//消耗的字节数 umode_t i_mode; //文件访问权限 spinlock_t i_lock; /* 自旋锁 */ struct mutex i_mutex; //互斥锁 struct rw_semaphore i_alloc_sem; //信号量 const struct inode_operations *i_op; //inode操作表 const struct file_operations *i_fop; //默认inode操作 struct super_block *i_sb; //关联的超级块 struct file_lock *i_flock; //文件锁链表 struct address_space *i_mapping;//关联的地址映射 struct address_space i_data; //关联的设备映射 #ifdef CONFIG_QUOTA struct dquot *i_dquot[MAXQUOTAS]; //索引节点的磁盘配额 #endif struct list_head i_devices; //块设备链表 union { struct pipe_inode_info *i_pipe; //管道信息 struct block_device *i_bdev; //块设备驱动 struct cdev *i_cdev;//字符设备驱动 }; __u32 i_generation; #ifdef CONFIG_FSNOTIFY __u32 i_fsnotify_mask; /* 该inode关心的所有事件 */ struct hlist_head i_fsnotify_mark_entries; /* fsnotify标记条目 */ #endif #ifdef CONFIG_INOTIFY struct list_head inotify_watches; //索引节点通知监听链表 struct mutex inotify_mutex; //保护上一个字段的互斥锁 #endif unsigned long i_state; //状态标识 unsigned long dirtied_when; //第一次变脏的时间 unsigned int i_flags; //文件系统标志 atomic_t i_writecount; //写者计数 #ifdef CONFIG_SECURITY void *i_security; //安全模块 #endif #ifdef CONFIG_FS_POSIX_ACL struct posix_acl *i_acl; struct posix_acl *i_default_acl; #endif void *i_private; //文件系统或者设备私有指针 }; |
inode代表文件系统中的一个文件,只有文件被访问时,inode才会在内存中创建。目标文件可以普通文件,也可以是设备、管道之类的特殊文件(此时i_bdev/i_pipe/icdev指向相关对象)。
某些文件系统不支持inode结构体中的某些字段,例如i_atime(文件访问时间),此时该字段如何存储取决于具体实现。
该结构对应了inode对象的 i_op 字段,它是一系列函数指针的集合:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
/** * 索引节点操作,这些函数可能由VFS调用,也可能由具体文件系统调用 */ struct inode_operations { //由系统调用create()/open()调用,从而为dentry对象创建一个新的inode int (*create)( struct inode *dir, struct dentry *dentry, int mode ); //在特定目录下寻找索引节点,索引节点必须匹配dentry给出的文件名 struct dentry * lookup( struct inode *dir, struct dentry *dentry ); //由系统调用link()调用,用来创建dir目录下old_dentry目录项所代表的文件的硬链接,此硬链接的名称由dentry指定 int (*link)( struct dentry *old_dentry, struct inode *dir, struct dentry *dentry ); //由系统调用unlink()调用,移除目录dir中dentry代表的inode int (*unlink)( struct inode *dir, struct dentry *dentry ); //由系统调用symlink()调用,创建符号链接 int (*symlink)( struct inode *dir, struct dentry *dentry, const char * symname ); //由系统调用mkdir()调用,创建新的目录 int (*mkdir)( struct inode * dir, struct dentry *, int mode ); //由系统调用rmdir()调用,从dir中移除dentry引用的目录 int (*rmdir)( struct inode *dir, struct dentry * dentry ); /** * 由系统调用mknod()调用,以创建一个特殊(设备、套接字、命名管道)文件 * 该文件关联的设备为rdev,该文件作为dir中的dentry文件 */ int (*mknod)( struct inode *dir, struct dentry *dentry, int mode, dev_t rdev ); //由VFS调用,负责移动文件 int (*rename)( struct inode *old_dir, struct dentry *old_dentry, struct inode *new_dir, struct dentry *new_dentry ); //由系统调用readlink()调用,拷贝dentry关联符号链接的最多buflen字节到buffer int (*readlink)( struct dentry *dentry, char *buffer, int buflen ); //由VFS调用,转换符号链接为其指向的inode,结果存放在nd中 void * (*follow_link)( struct dentry *dentry, struct nameidata *nd ); //由VFS调用,在follow_link()调用之后,进行清理 void (*put_link)( struct dentry *, struct nameidata *, void * ); //由VFS调用,截断文件的大小,调用前必须把inode.i_size设置为期望的大小 void (*truncate)( struct inode * ); //检查指定的权限模式是否被允许,如果是返回0 int (*permission)( struct inode *inode, int mask ); //读、写、列出、移除文件属性 int (*setattr)( struct dentry *, struct iattr * ); int (*getattr)( struct vfsmount *mnt, struct dentry *, struct kstat * ); int (*setxattr)( struct dentry *, const char *, const void *, size_t, int ); ssize_t (*getxattr)( struct dentry *, const char *, void *, size_t ); ssize_t (*listxattr)( struct dentry *, char *, size_t ); int (*removexattr)( struct dentry *, const char * ); void (*truncate_range)( struct inode *, loff_t, loff_t ); long (*fallocate)( struct inode *inode, int mode, loff_t offset, loff_t len ); int (*fiemap)( struct inode *, struct fiemap_extent_info *, u64 start, u64 len ); }; |
为了方便查找操作,VFS引入目录项(dentry)的概念,每个目录项代表路径中的一部分。以/usr/bin/vi为例,第一个/、usr、bin、vi都是目录项,前三个是目录,最后一个是普通文件。
一个有效的目录项必然对应一个inode;反之,一个inode则可能对应多个目录项,因为一个inode可以具有多个路径名(链接)。
目录项由下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
struct dentry { atomic_t d_count; /* 目录项引用计数器 */ unsigned int d_flags; /* 目录项标志位 */ spinlock_t d_lock; /* 当前目录项的自旋锁 */ int d_mounted; /* 该目录项是否代表一个挂载点 */ struct inode *d_inode; /* 与目录项关联的inode */ struct hlist_node d_hash; /* 通过该字段,当前目录项挂接到dentry_hashtable的某个链表中 */ struct dentry *d_parent; /* 父目录的目录项对象 */ struct qstr d_name; /* 目录项的名称 */ struct list_head d_lru; /* 如果当前目录项未被使用,则通过此字段挂接到dentry_unused队列中 */ union { struct list_head d_child; /* 父目录的子目录项所形成的链表 */ struct rcu_head d_rcu; /* RCU locking */ } d_u; struct list_head d_subdirs; /* 子目录链表 */ struct list_head d_alias; /* inode别名(目录项)的链表 */ unsigned long d_time; /* 重验证时间,由d_revalidate()调用使用 */ struct dentry_operations *d_op; /* 目录项操作集合 */ struct super_block *d_sb; /* 文件所属的超级块 */ void *d_fsdata; /* 文件系统私有数据 */ unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名 */ }; |
可以看到目录项结构牵涉到散列、树、链表等数据结构,这是VFS高效文件搜索、定位的基础。
与超级块、索引节点不同,目录项没有对应的磁盘数据结构(因而也没有脏、回写标志), VFS会根据字符串形式的路径现场创建目录项。
目录项对象具有三种有效的状态:
| 状态 | 说明 |
| 被使用 | 如果目录项对应了一个有效的索引节点(d_inode不为空)并且存在一个以上使用者(d_count正数),则目录项处于被使用状态。处于该状态的目录项被VFS使用并且指向有效数据,不得丢弃 |
| 未被使用 | 如果目录项对应了一个有效的索引节点(d_inode不为空)但d_count为0,则目录项处于未被使用状态。处于该状态的目录项可以缓存以备后用,但是回收内存时可以安全的丢弃 |
| 负状态(negative) | 如果目录项没有有效的索引节点,则处于该状态。处于该状态的目录项仍然可能被使用(比如某个进程读取一个不存在的文件时),但是可以被安全的丢弃 |
目录项对象释放后,可以被存放到slab缓存中去。
完整的路径解析的开销很大,要得到子目录项,必须读取父目录的内容,则会形成一个递归的处理过程。为避免反复解析路径中的所有元素,VFS将目录项对象缓存起来,该缓存称为目录项缓存(dcache),该缓存包含三项内容:
- “被使用的”目录项链表:此链表的头由目录项关联索引节点的inode.i_dentry指定(注意该链表的元素的不是inode而是entry,后者通过dentry.d_alias挂接到此链表),一个inode可能存在多个链接,因此就对应多个目录项
- “最近被使用的”双向链表:该链表包含未被使用、负状态的目录项对象,由于数据总是在链表头部插入,因此头部的数据总是更新。当内核必须回收内存时,将从尾部删除此链表
- 用以快速解析路径为目录项的散列表和对应散列函数。散列值由 d_hash() 函数计算,它是内核提供给文件系统的唯一散列函数;散列表的查找则通过 d_lookup() 函数进行,如果dcache中存在匹配的目录项则返回之,否则返回NULL
举例来说,如果现在你要打开文件/usr/local/jdk/bin/java,VFS为了避免解析这一路径,会先在dcache中查找此路径对应的目录项,如果找不到,才去查找文件系统,为每个路径分量解析目录项,解析完毕后,会把结果存入dcache中。
dcache实际上也缓存了inode,因为目录项会导致目标inode的使用计数为正,那么目录项驻留内存期间,inode也必然驻留。
因为文件访问呈现时间、空间局部性,因此目录项缓存常常具有较高的命中率:
- 时间局部性:程序往往反复的访问同一个文件
- 空间局部性:程序往往会访问同一目录下所有文件
目录项支持操作如下表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
struct dentry_operations { //判断目录项是否有效,当VFS从dcache中使用一个目录项时会调用。大部分实现设置为NULL,认为dcache中的目录项总是有效的 int (*d_revalidate)( struct dentry *, struct nameidata * ); //为目录项生成散列值,在加入散列表前由VFS调用 int (*d_hash)( struct dentry *, struct qstr * ); //VFS调用该函数比较两个文件名,大部分实现设置为NULL,除了像FAT这样不区分大小写的文件系统。调用该函数需要持有dcache_lock锁 int (*d_compare)( struct dentry *dentry, struct qstr *name1, struct qstr *name2 ); //当目录项对象的d_count为0时,VFS调用该函数。调用该函数需要持有dcache_lock、d_lock int (*d_delete)( struct dentry * ); //当目录项将被释放时,VFS调用该函数,默认实现不做任何事情 void (*d_release)( struct dentry * ); //当目录项对应的inode被删除时,VFS调用该函数,默认实现是调用iput()释放索引节点 void (*d_iput)( struct dentry *, struct inode * ); char *(*d_dname)( struct dentry *, char *, int ); }; |
该对象代表一个已打开的文件的内存表示,多个进程可能打开一个文件,因此同一个物理文件可能对应多个文件对象。从用户角度看待VFS,该对象将首先进入视野,因为用户程序直接处理的是文件而不是超级块、索引节点等。
文件对象使用下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
struct file { union { struct list_head fu_list; /* 文件对象的链表 */ struct rcu_head fu_rcuhead; /* 释放之后的RCU链表 */ } f_u; struct path f_path; /* 此结构包含对应的目录项 */ struct file_operations *f_op; /* 文件操作集合 */ spinlock_t f_lock; /* 每个文件的自旋锁 */ atomic_t f_count; /* 文件对象的使用计数 */ unsigned int f_flags; /* 打开文件时指定的标志位 */ mode_t f_mode; /* 文件的访问模式 */ loff_t f_pos; /* 文件偏移量(文件指针) */ struct fown_struct f_owner; /* owner data for signals */ const struct cred *f_cred; /* file credentials */ struct file_ra_state f_ra; /* 预读(read-ahead)状态 */ u64 f_version; /* 版本号 */ void *f_security; /* 安全模块 */ void *private_data; /* tty 设备驱动的钩子 */ struct list_head f_ep_links; /* list of epoll links */ spinlock_t f_ep_lock; /* epoll lock */ struct address_space *f_mapping; /* 页缓存映射 */ unsigned long f_mnt_write_state; /* 调试状态 */ }; |
和目录项类似,文件对象也没有对应的磁盘实体。
文件操作是标准Unix系统调用的基础,定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
struct file_operations { struct module *owner; //系统调用llseek()会调用该函数,将文件指针设置到指定的偏移量 loff_t (*llseek)( struct file *file, loff_t offset, int origin ); //系统调用read()会调用该函数,从偏移量offset处开始读取count字节到buf中,并更新文件指针 ssize_t (*read)( struct file *file, char *buf, size_t count, loff_t *offset ); //系统调用aio_read()会调用该函数,针对icob描述的文件启动异步读操作 ssize_t (*aio_read)( struct kiocb *iocb, char *buf, size_t count, loff_t offset ); //系统调用write()会调用该函数,把buf写入到file的offset偏移处,并更新文件指针 ssize_t (*write)( struct file *file, const char *buf, size_t count, loff_t *offset ); //系统调用aio_write()会调用该函数,针对icob描述的文件启动异步写操作 ssize_t (*aio_write)( struct kiocb *iocb, const char *buf, size_t count, loff_t offset ); //系统调用readdir()会调用该函数,返回目录列表中的下一个目录 int (*readdir)( struct file *file, void *dirent, filldir_t filldir ); //系统调用poll()会调用该函数,睡眠以等待目标文件上的活动(activity) unsigned int (*poll)( struct file *file, struct poll_table_struct *poll_table ); //系统调用ioctl()会调用该函数,用来给设备发送命令和参数对,文件必须是打开的设备节点,调用者必须持有大内核锁(BKL) int (*ioctl)( struct inode *inode, struct file *file, unsigned int cmd, unsigned long arg ); //类似上面,但是不持有BKL锁。这两个函数只需实现一个 long (*unlocked_ioctl)( struct file *file, unsigned int cmd, unsigned long arg ); //ioctl()的可移植变体,被设计为在64bits架构上对32位也是安全的,该函数能够进行必要的字(word)大小转换 //该函数不需要持有BKL锁 long (*compat_ioctl)( struct file *file, unsigned int cmd, unsigned long arg ); //系统调用mmap()会调用该函数,用于把文件映射到指定的地址空间上 int (*mmap)( struct file *, struct vm_area_struct * ); //系统调用open()会调用该函数,创建一个文件对象并关联到特定的inode int (*open)( struct inode *, struct file * ); //当已打开文件的引用计数减少时,VFS会调用该函数,其作用依赖于具体实现 int (*flush)( struct file *, fl_owner_t id ); //当已打开文件的最后一个引用注销时(例如最后一个共享文件描述符的进程调用close()或者退出时)该函数被VFS调用,其作用依赖于具体实现 int (*release)( struct inode *, struct file * ); //系统调用fsync()会调用该函数,把文件的所有缓存数据回写到磁盘 int (*fsync)( struct file *, struct dentry *, int datasync ); //系统调用aio_fsync()会调用该函数,把iocb描述的文件的所有被缓存数据回写到磁盘 int (*aio_fsync)( struct kiocb *, int datasync ); //启用或者禁用异步I/O的信号通知(signal notification) int (*fasync)( int, struct file *, int ); //操控指定文件的文件锁 int (*lock)( struct file *, int, struct file_lock * ); //系统调用readv()会调用该函数,从文件读取数据,并把结果存放到vector中,完毕后文件的偏移量增加 ssize_t (*readv)( struct file *file, const struct iovec *vector, unsigned long count, loff_t *offset ); //系统调用writev()会调用该函数,把vector中的数据写入到文件,完毕后文件的偏移量增加 ssize_t (*writev)( struct file *file, const struct iovec *vector, unsigned long count, loff_t *offset ); //系统调用sendfile()会调用该函数,用于在文件之间复制内容,整个拷贝在内核空间完成 ssize_t (*sendfile)( struct file *file, loff_t *offset, size_t size, read_actor_t actor, void *target ); //用于在文件之间拷贝数据 ssize_t (*sendpage)( struct file *, struct page *, int, size_t, loff_t *, int ); //获得未使用的地址空间(address space),用于映射指定的文件 unsigned long (*get_unmapped_area)( struct file *, unsigned long, unsigned long, unsigned long, unsigned long ); //系统调用flock()会调用该函数,用来实现advisory locking int (*flock)( struct file *, int, struct file_lock * ); ssize_t (*splice_write)( struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int ); ssize_t (*splice_read)( struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int ); int (*setlease)( struct file *, long, struct file_lock ** ); }; |
除了上述几种基础的数据结构外,内核还使用另外一些标准结构来管理文件系统的其它信息:
该结构用来描述特定的文件系统类型,例如ext3、ext4或者UDF。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
struct file_system_type { const char *name; /* 文件系统类型的名称 */ int fs_flags; /* 文件系统类型标志 */ /* 用于从磁盘读取超级块 */ struct super_block *(*get_sb)( struct file_system_type *, int, char *, void * ); /* 用于终止超级块的访问 */ void (*kill_sb)( struct super_block * ); struct module *owner; /* 文件系统所属的模块 */ struct file_system_type *next; /* 链表中的下一个文件系统 */ struct list_head fs_supers; /* 超级块对象列表 */ /* 下面的字段用于运行时锁定验证 */ struct lock_class_key s_lock_key; struct lock_class_key s_umount_key; struct lock_class_key i_lock_key; struct lock_class_key i_mutex_key; struct lock_class_key i_mutex_dir_key; struct lock_class_key i_alloc_sem_key; }; |
不管某种文件系统安装了多少个实例,都只有一个file_system_type对象;相应的每个文件系统实例对应各自的vfsmount对象。
该结构用来描述一个已挂载的文件系统实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
struct vfsmount { struct list_head mnt_hash; /* 散列表的链表 */ struct vfsmount *mnt_parent; /* 父文件系统 */ struct dentry *mnt_mountpoint; /* 挂载点的目录项 */ struct dentry *mnt_root; /* 该文件系统的根目录项 */ struct super_block *mnt_sb; /* 该文件系统的超级块 */ struct list_head mnt_mounts; /* 子文件系统链表 */ struct list_head mnt_child; /* 子文件系统链表 */ /** * 挂载标志 * MNT_NOSUID:禁止该文件系统的可执行文件设置setuid、setgid * MNT_MODEV:禁止访问该文件系统上的设备文件 * MNT_NOEXEC:禁止执行可执行文件 * * 这些标志在应对不被信任的移动设备时有意义 */ int mnt_flags; char *mnt_devname; /* 设备文件名称 */ struct list_head mnt_list; /* 描述符链表 */ struct list_head mnt_expire; /* entry in expiry list */ struct list_head mnt_share; /* entry in shared mounts list */ struct list_head mnt_slave_list; /* list of slave mounts */ struct list_head mnt_slave; /* entry in slave list */ struct vfsmount *mnt_master; /* slave's master */ struct mnt_namespace *mnt_namespace; /* 管理的命名空间 */ int mnt_id; /* 挂载标识符 */ int mnt_group_id; /* peer group identifier */ atomic_t mnt_count; /* 使用计数t */ int mnt_expiry_mark; /* is marked for expiration */ int mnt_pinned; /* pinned count */ int mnt_ghosts; /* ghosts count */ atomic_t __mnt_writers; /* 写者引用计数 */ }; |
系统中的每个进程都有自己的打开文件列表、根文件系统、当前工作目录、挂载点…等等。有三个数据结构把VFS层和系统中的进程联系在一起:files_struct、fs_struct和mnt_namespace。
一般的,每个进程具有自己独特的files_struct、fs_struct,但是使用 CLONE_FILES 或者 CLONE_FS 创建进程的话,将和父进程共享这两个结构。这种情况下结构的count字段用来做引用计数,防止仍然有进程使用这些结构时却销毁了它们。
默认的,所有进程共享同一个mnt_namespace,除非 clone() 进程时使用 CLONE_NEWNS 标记。
进程描述符 task_struct 的 struct files_struct *files 字段指向了该结构,进程所有关于打开文件、文件描述符的信息存放在其中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
struct files_struct { atomic_t count; /* 使用计数 */ struct fdtable *fdt; /* 指向其他文件描述符表 */ struct fdtable fdtab; /* base fd table */ spinlock_t file_lock; /* per-file lock */ int next_fd; /* cache of next available fd */ struct embedded_fd_set close_on_exec_init; /* list of close-on-exec fds */ struct embedded_fd_set open_fds_init; /** * 文件描述符数组,NR_OPEN_DEFAULT等于BITS_PER_LONG,在64位系统中是64,这意味着该数组可以存放64个对象 * 如果进程打开超过64个文件,内核会创建新的数组存放之,并让fdt指向该数组 */ struct file *fd_array[NR_OPEN_DEFAULT]; }; |
进程描述符的 struct fs_struct *fs 字段指向该结构,包含了进程相关的文件系统的信息:
|
1 2 3 4 5 6 7 8 9 |
struct fs_struct { int users; /* 用户计数 */ rwlock_t lock; /* 读写锁 */ int umask; /* umask */ int in_exec; /* currently executing a file */ struct path root; /* 进程的根目录 */ struct path pwd; /* 进程的当前工作目录,即$PWD */ }; |
进程描述符的 mnt_namespace 字段指向该结构,Per-process的挂载名字空间在2.4版本加入到内核,它允许每个进程看到已挂载到系统的文件系统的独特视图,而不仅仅是独特的根目录。该结构的定义如下:
|
1 2 3 4 5 6 7 8 |
struct mnt_namespace { atomic_t count; /* usage count */ struct vfsmount *root; /* 根目录 */ struct list_head list; /* 构成此名字空间的已挂载文件系统的链表 */ wait_queue_head_t poll; /* polling waitqueue */ int event; /* event count */ }; |
根据是否支持随机访问(不需要按照特定的顺序,或者说支持seek操作),设备可以分为两类:
- 块设备(Block device):可以随机的存取固定大小(称为chunk)的数据,这些chunk也称为块(block)。这类设备包括硬盘、软驱、光驱、U盘等。块设备一般都通过在其上建立文件系统,并挂载到系统中使用
- 字符设备(Character device):必须以流(Stream)的形式顺序的、一个字节一个字节的访问,当不被使用时,字符设备中的流是空的。这类设备包括串口、键盘等
对于内核来说,块设备的管理要比字符设备复杂的多:
- 内核设备只需要控制字符设备的一个位置——当前位置;而块设备的访问需要支持在介质中前后移动
- 块设备对执行性能的要求很高,块设备的复杂性也为性能优化提供了空间
因此内核包含专门管理块设备的子系统,这就是块I/O层
块设备中最小的可寻址单元是扇区(sector),又称为硬扇区、设备块,其的大小是2的N次方(常见512B)。扇区是所有块设备的基本单元,属于物理属性,块设备无法对比扇区更小的单元进行寻址和操作。
文件系统依据自己的需要,会设置自己的最小逻辑可寻址单元——块(block),又称为文件块、I/O块,(内核)基于文件系统访问,只能以块为最小单位。内核还对块大小提出更严格的要求:
- 必须是扇区大小的整数倍
- 必须是2的N次方
- 必须不大于页
因此块的大小常常是512B、1KB、4KB。
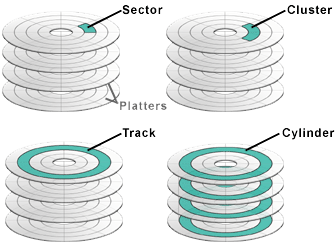
对于最常见的块设备——硬盘,还有一些常见的概念:
- 盘片(Platter):典型的硬盘由多个盘片堆叠而成
- 磁头(Head):每个盘片通常分配一个磁头,由于读取数据
- 簇(Cluster):文件系统能分配给文件的最小数据单元,由连续的扇区构成。这个概念主要是DOS使用,类似于块
- 磁道(Track):盘片上的一个圆周
- 柱面(Cylinder):所有盘片上等半径的磁盘形成的圆柱
- 碎片化(fragmentation):文件分散在物理上不连续的簇中的情况
硬盘结构如下图所示:
当一个块被调入内存时(读入后,写出前),它存储在一个缓冲区中,每个缓冲区对应一个块,缓冲区相当于块的内存表示,一个内存页可以容纳1-N个块。内核在处理缓冲区时,需要额外的控制信息(块属于哪个设备、块对应哪个缓冲区),因此每个缓冲区都关联了一个缓冲区头对象,用来描述磁盘块与物理内存缓冲区(特定页上的字节序列)的关系,缓冲区头用下面的结构表示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
struct buffer_head { unsigned long b_state; /* 缓冲区状态标志 */ struct buffer_head *b_this_page; /* 当前页的缓冲区的列表 */ struct page *b_page; /* 与缓冲区对应的内存物理页 */ sector_t b_blocknr; /* 与缓冲区对应的磁盘物理块索引号号 */ size_t b_size; /* 块的大小 */ char *b_data; /* 指向页中数据块其实位置的指针,此缓冲区的结束位置即此其实位置+b_size */ struct block_device *b_bdev; /* 关联的块设备 */ bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ struct list_head b_assoc_buffers; /* 关联的映射链表 */ struct address_space *b_assoc_map; /* 关联的地址空间 */ atomic_t b_count; /* 缓冲区使用计数,在操控缓冲区头前,应当使用get_bh()来增加计数,以防止缓冲区头不被再次分配,操控完毕后欧则调用put_bh()减少计数 */ }; |
其中 b_state 表示缓冲区的状态,可以是一系列值的组合,这些值枚举定义在:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
enum bh_state_bits { BH_Uptodate, /* 包含有效的数据 */ BH_Dirty, /* 缓冲区是脏的,其内容比磁盘中的块新,必须回写 */ BH_Lock, /* 缓冲区正在被I/O操作使用,并被锁定以防止并发访问 */ BH_Req, /* 已经提交I/O操作请求 */ BH_Uptodate_Lock,/* Used by the first bh in a page, to serialise IO completion of other buffers in the page */ BH_Mapped, /* 缓冲区映射到了一个磁盘块 */ BH_New, /* 缓冲区刚刚由get_block()映射到磁盘块,且尚未访问 */ BH_Async_Read, /* 正在通过end_buffer_async_read()进行异步读 */ BH_Async_Write, /* 正在通过end_buffer_async_write()进行异步写 */ BH_Delay, /* 缓冲区尚未在磁盘上分配(延迟分配) */ BH_Boundary, /* 此缓冲区是一系列连续块的边界,下一个块不再连续 */ BH_Write_EIO, /*此缓冲区在写操作上遭遇错误 */ BH_Ordered, /* 顺序写 */ BH_Eopnotsupp, /* 缓冲区遭遇不支持(not supported)错误 */ BH_Unwritten, /* 缓冲区对应的磁盘空间已经分配,但是数据尚未写出 */ BH_Quiet, /* 忽略此缓冲区上的错误 */ BH_PrivateStart, /*这不是一个可用的状态位,块I/O子系统不会使用比该标志更高的位,因此其它实体(例如驱动)可以安全的使用高位 */ }; |
在2.6以前的内核,缓冲区头的作用更加重要,缓冲区头作为内核中I/O操作单元——缓冲区头不仅仅描述映射,还是I/O操作的容器。将缓冲区头作为I/O操作单元有两个弊端:
- 缓冲区头是个很大、不易控制的结构体。对于内核来说它更倾向于操控页面结构,简便而高效,使用一个巨大的缓冲区头表示每一个独立的缓冲区效率低下。因此,在2.6中,许多I/O操作都是通过内核直接操作页面或者地址空间来完成,不再使用缓冲区头
- 缓冲区头只能描述单个缓冲区,当作为所有I/O操作的容器使用时,缓冲区头迫使内核将(潜在的)大块的I/O操作分解为针对多个缓冲区头的操作,这导致不必要的负担和空间浪费。为解决此问题,2.5版本引入新型、轻量级的容器——bio结构
当前版本内核中,使用bio作为块I/O操作的基本容器,该结构将正在进行的(活动的)I/O操作表示为片段(Segment)的数组。每个片段是内存中连续的一小块(chunk)。bio允许内核从多个内存位置针对单个缓冲区进行块I/O操作——这样的向量I/O(Vector I/O)称为分散-聚集I/O(Scatter-Gather I/O)。bio的结构如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
struct bio { sector_t bi_sector; /* 关联的磁盘扇区 */ struct bio *bi_next; /* 请求的链表 */ struct block_device *bi_bdev; /* 管理的块设备 */ unsigned long bi_flags; /* 状态和命令标志 */ unsigned long bi_rw; /* 区分读还是写 */ unsigned short bi_vcnt; /* 片段总数,即bi_io_vec数组的长度*/ /* bi_io_vec的当前索引,当块I/O层开始指向请求时,此字段会不断更新,总是指向当前的片段。 * 该字段用于跟踪I/O操作的完成进度 */ unsigned short bi_idx; unsigned short bi_phys_segments; /* 物理片段的数目 */ unsigned int bi_size; /* I/O 计数 */ unsigned int bi_seg_front_size; /* 第一个片段的大小 */ unsigned int bi_seg_back_size; /* 最后一个片段的大小 */ unsigned int bi_max_vecs; /* bio_vecs数目上限 */ unsigned int bi_comp_cpu; /* completion CPU */ /* 使用计数,如果为0则该bio应该被撤销并释放内存, * 通过bio_get/bio_put函数可以管理计数 */ atomic_t bi_cnt; /* 片段数组,该字段指向第一个片段,后续片段依次存放,共计bi_vcnt个片段 */ struct bio_vec *bi_io_vec; bio_end_io_t *bi_end_io; /* I/O completion method */ void *bi_private; /* bio结构创建者的私有域,只有创建者才能使用该字段 */ bio_destructor_t *bi_destructor; /* destructor method */ struct bio_vec bi_inline_vecs[0]; /* inline bio vectors */ }; |
下图反应了bio、bi_io_vec、page的关系:
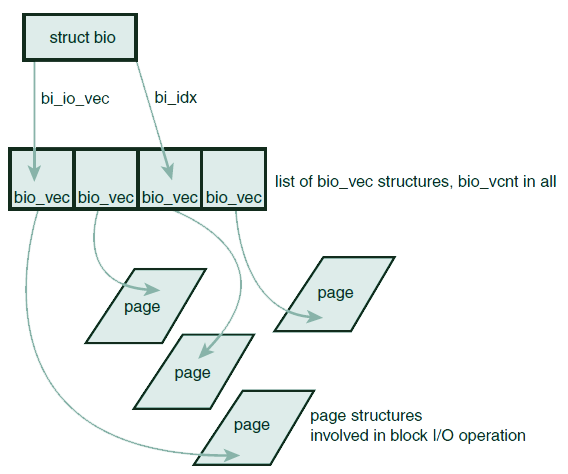
bi_io_vec 字段指向 bio_vec 的数组,该数组包含了特定I/O操作所需要的全部片段,构成了完整的缓冲区。 bio_vec 的结构如下:
|
1 2 3 4 5 6 7 8 9 10 |
//该结构描述一个特定的片段 struct bio_vec { /* 指向当前片段所驻留的内存页 */ struct page *bv_page; /* 当前片段的长度 */ unsigned int bv_len; /* 当前片段在页内的偏移量 */ unsigned int bv_offset; }; |
新的bio结构和缓冲区头存在显著差别:
- bio代表的是I/O操作,bio是轻量级的,它描述的(可能多个)块不需要连续的存储区
- buffer_head代表的是一个缓冲区,它仅仅描述磁盘中的一个块,当需要对多个块进行I/O操作时,会导致不必要的分割
用bio代替buffer_head可以获得以下好处:
- bio可以很容易的处理高端内存,因为它处理的是物理页而不是直接指针
- bio既可代表普通页I/O,页可以代表直接I/O(不通过页高速缓存的I/O操作)
- bio结构便于执行分散-聚集的块I/O操作,操作的数据可以来自多个物理页面
尽管如此,buffer_head这个概念还是需要的,毕竟它还负责磁盘块到页的映射。
块设备维护一个请求队列,以存储挂起(Pending)的块I/O请求:
|
1 2 3 4 |
struct request_queue { struct list_head queue_head; //请求的链表头 }; |
通过内核中文件系统之类的高层代码,I/O请求被加入到队列中,只要队列不为空,对应块设备的驱动程序就会从队列头获取请求,然后将其送入对应的块设备中。请求队列中的每一项表示一个请求,使用 request 结构表示,由于一个请求可能需要操控多个连续的磁盘块,因此每个请求可以由多个bio结构体组成:
|
1 2 3 4 5 6 |
struct request { struct request_queue *q; //指向请求队列 struct bio *bio; //每个队列请求包含一个或者多个bio结构,这里指向第一个 struct bio *biotail;//最后一个bio }; |
如果简单的按照内核产生请求的次序直接将请求发送给块设备,性能会很差,这是因为磁盘寻址是计算机中最慢的操作之一,每一次寻址(即将磁头定位到某个特定的扇区)都会消耗不少时间,减少寻道次数是提供I/O性能的关键。
为优化寻址操作(降低寻址总消耗时间),内核既不会简单的依据请求发生顺序发送、也不会立即发送请求给磁盘。相反:
- 在正式提交给磁盘前,内核会进行称为合并与排序的预操作,此操作可以极大的提升I/O性能
- 合并:将两个或者多个请求合并为一个新请求。例如如果请求B和请求A访问的磁盘扇区相邻,那么I/O调度器就可以将其合并为一个请求,这样只需要一条寻址指令、并把两次请求处理的开销压缩为一次
- 排序:让请求按照扇区增长的方向顺序排列,以尽量保持磁头单向移动,减少总和寻址时间。这种算法类似于电梯,电梯不会在楼层之间上下移动,它总是抵达同一方向的最后一次后,再折返,因此I/O调度又称电梯调度
- 内核会决定何时向磁盘提交请求
负责执行上面两个规则的子系统叫做I/O调度程序,其核心目的就是优化寻址以提高全局吞吐量(注意这可能导致对某些请求不公),它会服务所有挂起的请求,而不是向进程调度程序那样把资源分配给单个请求者。
这是2.4内核的默认调度程序,在2.6被其它两个算法代替。该算法相对简单,便于理解。
Linus电梯能够执行合并排序预处理:
- 当新请求加入队列时,它会判断新请求是否能和任一个挂起的请求合并。Linus电梯同时进行向前合并(新请求直接位于既有请求的前面)、向后合并(新请求直接位于一个既有请求后面)两种合并类型。由于文件的布局方式(通常是增长扇区号)和I/O操作的典型特征(一般都是从头向尾读),向前合并要少见的多,尽管如此Linus电梯同时检查这两种合并类型。对于不能合并的请求,可能执行下面三类操作:
- 如果队列中存在驻留时间过长的请求,那么新请求将被插入队列尾部,防止其它旧的请求饥饿:如果访问某个相近磁盘位置的请求过多,将导致访问其它磁盘位置的请求得不到执行机会
- 如果队列中存在合适的插入位置,新请求被插入,尽量保证顺序I/O
- 如果队列中不存在合适的插入位置,那么新请求被插入到队列尾部
Linus电梯防止饥饿的策略不是很有效,虽然改善了等待时间,但是还会导致请求饥饿现象的发生。特别的,一个对同一磁盘位置的持续请求流可能导致对较远磁盘位置的请求永远得不到执行机会。
一个更糟糕的情况是,普通请求饥饿还会带来一个特殊问题:写使读挨饿(writes starving reads)问题。写操作通常是在内核空闲时才提交给磁盘的,写操作常常和提交它的应用程序异步执行;而读操作则相反,通常一个应用程序提交读请求时,都需要阻塞直到读请求被满足,也就是说读操作常常和提交者同步执行。读请求的响应时间对应用程序非常重要,因此WSR问题比较严重。此问题可能进一步复杂化。读请求往往倾向于依赖于其它读请求,考虑一个读取一大批文件并逐行处理的场景,每个读请求都处理一小块数据,前一个读请求处理完毕前,程序可能不会读下一块数据(或者下一个文件)。
此外,不管是读还是写请求,都需要读取一系列的文件元数据(例如inode),读取这些块进一步的串行化了I/O操作。
饥饿问题是2.4内核I/O调度程序必须修改的缺陷,最终期限的调度器因而引入。该调度器致力于减少请求饥饿现象,特别是读请求饥饿。需要注意的是,减少请求饥饿必然是 以降低全局吞吐量为代价的。
在dealine调度程序中,每个请求具有一个超时时间:默认读请求500ms,写请求5s,这可以防止写使读挨饿,有限照顾了读请求。类似于Linus电梯,该调度器也按磁盘物理位置为次序排列维护请求队列,并称其为排序队列。该调度器的合并排序行为类似于Linus电梯,但是它会根据请求类型,将其插入到额外队列中:读请求按次序插入读FIFO队列;写请求插入写FIFO队列。
Deadline调度器以类似Linus电梯的方式操控排序队列,取出请求分发给设备。但是,当FIFO队列头请求超时时,它会立即从FIFO队列取出请求进行服务。这样,就避免了请求明显超期仍得不到服务的饥饿现象(但不能严格保证请求的响应时间)。此工作方式如下图所示:
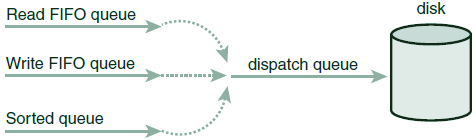
最后期限调度程序的实现代码位于 block/deadline-iosched.c 中。
最后期限调度程序为了降低读操作的响应时间做了很多工作,但是它降低了系统的吞吐量。预测调度器的目标是,在保持良好读响应时间的同时,提供良好的全局吞吐量。
预测调度器在最后期限调度器的基础上改进,同样由三个队列+分发队列,同样设置请求的超时时间,不同的是它具有预测启发能力:
- 当调度器提交超时读请求后,不会立即返回排序队列,而是会等待一小段时间(默认6ms,可配置),这段时间应用程序如果提交新的、相邻位置的请求,会得到立即处理。等待时间结束后,调度程序返回原来位置继续执行。如果等待的时间可以减少back-and-forth寻址操作,那么这6ms是值得的,特别是连续访问同样区域的读请求到来,将避免大量的寻址操作
- 上面的等待,是否有意义,取决于能否正确预测应用程序和文件系统的行为。这种预测依赖于一系列的启发和统计工作。预测调度器会跟踪每一个应用程序块I/O的习惯行为,以便正确预测其未来行为。如果预测正确,则既降低响应时间,也提供吞吐量
预测调度器的代码位于 block/as-iosched.c ,它是缺省的I/O调度程序,对于大部分的工作负载来说,效果良好。
CFQ调度器是为了专用工作负载而设计,但是实际应用中为其它工作负载也提供了良好的性能。它与前面的调度器有着根本的不同。该调度器把I/O请求放入特定队列中,这种队列按照引起I/O请求的进程来组织(例如每个进程一个队列),当新请求进入队列时,会发生合并排序。
CFQ调度器以时间片轮转的方式调度队列,从每个队列选取一定个数的请求(默认4),然后进行下一轮调度。这在进程级提供了公平。
CFQ调度器默认的工作负载是多媒体环境,该环境下公平性需要保证,例如音频播放器总是能够及时的填满自己的音频缓冲区。尽管主要推荐给桌面工作负载使用,CFQ在很多其它场景下亦工作良好。该调度器的代码位于 block/cfq-iosched.c 。
该调度器不做多少事情,它只会进行请求合并,然后维护近乎FIFO的顺序来处理请求。该调度器用于支持真正随机访问的块设备,例如SSD,这类设备没有或者仅有一点“寻道”的负担,因而没有必要进行插入排序。空操作调度器的代码位于 block/noop-iosched.c
可以使用内核命令行选项 elevator=name 来覆盖缺省的I/O调度程序。四种调度程序的名字分别为:
| 名称 | 调度器 |
| as | 预测I/O调度程序 |
| cfq | 完全公平I/O调度器程序 |
| deadline | 最后期限I/O调度程序 |
| noop | 空操作调度程序 |
在Linux和所有Unix系统中,设备分为三类:
- 块设备:通常缩写为blkdev,支持以块为单位寻址,块的大小取决于设备。块设备通常支持重定位(seeking)操作,即随机访问。块设备通过特殊文件“块设备节点(block device node)”访问,通常挂在为文件系统
- 字符设备:通常缩写为cdevs,一般不支持寻址,仅支持以流的方式、以字符为单位(byte)访问数据。字符设备通过特殊文件“字符设备节点(character device node)”访问,与块设备通过文件系统访问不同,应用程序直接通过设备节点与字符设备交互
- 网络设备: 网络设备打破了万物皆文件的设计原则,通过专门的Socket API访问。它允许通过网卡、利用某种协议来访问网络
Linux还提供一系列不常用的其它设备类型。一个特例是所谓“杂项设备(miscellaneous device,miscdev)”,杂项设备实际上是一个简化的字符设备,允许驱动程序很简单的表示一种简单设备。
并非所有设备驱动代表了物理设备,有些时候设备是“虚拟”的,我们称其为伪设备(pseudo devices),伪设备用于访问内核功能,常见的包括:
- 内核随机数发生器,可以通过/dev/random、/dev/urandom访问
- 空设备:/dev/null
- 零设备:/dev/zero
- 内存设备:/dev/mem
尽管Linux是单内核(monolithic)操作系统——整个内核运行在一个单独的地址空间中、子系统仅仅是逻辑上的划分。它同时却是模块化的,支持在运行时动态的插入、移除自身的代码。需要动态加载的模块的典型例子就是驱动程序,很多传统Unix做不到模块化。
这些代码——相关的子例程、数据、入口点和退出点被合并到单独的二进制镜像中,称为“模块”。支持模块机制可以让内核尽可能的小,而可选功能、驱动程序可以利用模块提供。
模块化使调试变得方便,而且支持在热拔插设备时通过命令加载新的驱动程序。
下面的代码示例了最简的内核模块:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#include <linux/init.h> #include <linux/module.h> #include <linux/kernel.h> /* * 入口点函数,模块加载时调用 * * 真实环境中的模块可能需要在这个函数中完成: * 1、注册资源 * 2、初始化硬件 * 3、分配数据结构 * * 如果当前源文件被编译入内核映像,那么入口点函数将在内核启动时运行 */ static int hello_init( void ) { printk( KERN_ALERT "Hello Kernel!\n" ); /** */ return 0; } /* * 退出点函数,模块卸载时调用 * 在真实环境中,可能需要进行资源清理,确保硬件处于一致性状态 * * 如果当前源文件被编译入内核映像,那么退出函数将不被包含,也永远不会被调用 */ static void hello_exit( void ) { printk( KERN_ALERT "Bye!\n" ); } module_init( hello_init ); //该宏负责注册模块初始化函数,其唯一参数是模块的初始化函数 module_exit( hello_exit );//该宏负责注册模块退出函数,其唯一参数是模块的退出函数 /** * 如果非GPL模块被载入内存,那么内核中会设置一个被污染标识 * 非GPL模块不能调用GPL_only符号 */ MODULE_LICENSE( "GPL" ); MODULE_AUTHOR( "Alex" ); MODULE_DESCRIPTION( "A Hello, Kernel Module" ); |
基于2.6的kbuild构建系统,模块的构建更加简单,第一步需要决定在何处管理模块源码,你可以:
- 把模块源码加入内核源代码树中
- 作为一个补丁,并最终合并到内核源代码树
- 在源代码树之外独立维护模块源码
在源代码树树中维护模块
这种方式最理想,虽然开始时候需要更多的维护。新开发的设备驱动一般放在 drivers/ 目录下,并根据具体设备的类型进一步组织。例如USB设备驱动可以放在usb子目录,但是USB设备也可以是字符设备,因此存放在char目录也无可厚非。如果你的模块有很多文件,最好建立目录进行管理。
假设需要开发一个USB网卡的驱动,可以建立目录drivers/usb/mywifi,并在上级目录drivers/usb的Makefile中添加:
|
1 2 |
#该指令通知构建系统,在编译模块时需要进入mywifi子目录 obj-m += mywifi/ |
或者更好的,使用特殊配置选项控制驱动程序的编译:
|
1 |
obj-$(CONFIG_USB_MYWIFI) += mywifi/ |
然后,修改mywifi目录的Makefile:
|
1 2 3 |
obj-m += mywifi.o #如果使用编译选项,则使用: obj-$(CONFIG_USB_MYWIFI) += mywifi.o |
这样,构建系统就会编译mywifi/mywifi.c,将其编译为mywifi.ko模块(注意模块编译后的扩展名自动为ko)。
如果模块包含多个源文件,则可以添加:
|
1 |
mywifi-objs := mywifi-main.o mywifi-sec.o |
如果需要额外的编译标记,可以在Makefile中添加:
|
1 |
EXTRA_CFLAGS += -DMYWIFI_DEBUG |
如果不建立独立目录,那么只需要把上面mywifi/Makefile中的内容存放在上级目录的Makefile中即可。
在内核代码外独立维护模块
Makefile和上一种方式是类似的:
|
1 2 |
obj-m += mywifi.o mywifi-objs := mywifi-main.o mywifi-sec.o |
区别主要在于如何构建,必须告知make如何找到内核源代码目录:
|
1 2 |
make -C /kernel/source/location SUBDIRS=$PWD modules #location是已经配置好的内核源代码树所在目录,注意不要使用/usr/src/linux中的源代码,最好复制一份放在别的地方 |
编译后的模块被装入 /lib/modules/内核版本/kernel 目录,该目录的每一个子目录都对应了内核源码树中的模块位置。
使用下面的命令可以安装编译的模块到合适的目录中:
|
1 |
make modules_install |
Linux模块之间存在依赖性,载入模块时,被依赖模块会被自动载入。
模块之间的依赖信息必须实现生成,大多数发行版支持自动生成依赖关系,并在每次启动时更新。可以通过下面的命令手工生成内核依赖关系信息:
|
1 2 |
depmod depmod -A #只为新模块生成依赖信息 |
生成的模块依赖信息会存放在 /lib/modules/内核版本/modules.dep 中。
使用下面的命令可以载入模块,该命令不会进行依赖分析或进一步错误检查:
|
1 2 3 |
insmod mywifi.ko #类似的,可以卸载模块: rmmod mywifi |
更智能的工具是modprobe,它提供模块依赖分析、错误智能检查、错误报告等功能:
|
1 2 3 4 |
#依赖的模块会被一并加载 modprobe module [ module parameters ] #下面的命令用于移除模块: modprobe –r modules #依赖的模块如果没有被使用,会一并卸载 |
前面小节我们使用了配置选项CONFIG_USB_MYWIFI,只要该选项被配置,USB网卡模块就会被自动编译。2.6引入的kbuild系统让添加新配置选项很容易,只需要向kconfig中添加一项即可,该文件通常和源代码处于同一目录。如果你新建了子目录,并且使用独立的kconfig文件,那么必须在一个已经存在的kconfig文件中引用它:
|
1 |
source "drivers/usb/mywifi/Kconfig" |
配置选项可以参考下面的格式声明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#第一行定义了配置选项,注意前缀CONFIG_不需要 config USB_MYWIFI #tristate表示该模块可以编译入内核映像(Y)、作为模块编译(M),或者根本不编译(N) #如果模块作为内核特性而非驱动程序,使用bool代替tristate #tristate/bool可以跟随 if NAME,如果CONFIG_NAME配置未指定,则当前配置不但被禁用,而且在配置工具中不可见 tristate "此选项在内核配置工具中显示的名称" default n #选项的默认值,可以是y m n,对于驱动一般默认n。后面也可接if help 帮助文本 #说明依赖的配置项,如果依赖配置项没有设置,当前选项自动禁用 #支持同时声明多个依赖,或者冲突排除,例如depends on MOD_DEP && !CONFLICT_MOD,如果CONFIG_CONFLICT_MOD被设置,当前配置被禁用 depends on MOD_DEP #自动开启的依赖配置,如果当前选项开启,依赖被强制开启,支持同时声明多个 select BAIT |
配置系统导出了一些元配置,以简化配置文件,例如:
- CONFIG_EMBEDDED 用于关闭用户想要禁止的关键功能,用于资源非常紧缺的嵌入式环境
- CONFIG_BROKEN_ON_SMP表示驱动程序不是多处理器安全的
- CONFIG_EXPERIMENTAL表示某些功能尚处于试验阶段
Linux允许模块声明参数,对于驱动程序来说,这些参数属于全局变量。模块参数会出现在sysfs文件系统中,便于灵活管理。在模块代码中可以通过下面的宏声明参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
//name同时是模块变量名和暴露给用户的参数 //type是参数类型,支持byte, short, ushort, int, uint, long, ulong, charp, bool,invbool //perm设置该参数对应sysfs文件系统中对应文件的访问权限 module_param(name, type, perm); //下面的宏用于为参数设置文档 MODULE_PARM_DESC(name, "description"); //下面是一个例子 //变量必须在前面手工声明 static int allow_11g_mode = 1; //默认开启 module_param(allow_11g_mode , bool, 0644); //声明bool型参数 //如果要使参数名与内部变量名不同,可以使用下面的宏 module_param_named(name, variable, type, perm); //示例 static unsigned int max_test = DEFAULT_MAX_LINE_TEST; module_param_named(maximum_line_test, max_test, int, 0); //指定字符串类型的参数 static char *name; module_param(name, charp, 0); //或者 static char species[BUF_LEN]; module_param_string(specifies, species, BUF_LEN, 0); |
所有相关的宏位于 linux/module.h
模块被加载后,被动态的链接到内核中,和用户空间的动态链接库类似,只有被显式导出的函数才能被模块调用。在内核中,可以使用特殊指令完成导出,导出的函数可以供模块使用。相比起内核镜像中的代码而言,模块代码的链接和调用规则更加严格,核心代码在内核中可以任意调用非static接口,因为所有核心代码被链接成同一个镜像。
导出的内核符号可以称为“内核API”,只需要在内核函数后添加宏声明即可:
|
1 2 3 4 5 6 |
unsigned long sport_curr_offset_rx(struct sport_device *sport) { unsigned long curr = get_dma_curr_addr(sport->dma_rx_chan); return (unsigned char *)curr - sport->rx_buf; } EXPORT_SYMBOL(sport_curr_offset_rx); |
如果想让函数只对GPL协议模块可用,可以使用 EXPORT_SYMBOL_GPL()
统一设备模型是2.6增加的一个新特性,设备模型提供了独立的机制专门用来管理设备,并描述其在系统中的拓扑结构,从而使系统:
- 重复代码最小化
- 提供诸如引用计数这样的统一机制
- 可以列举系统中的所有设备,观察它们的状态,查看它们连接的总线
- 可以把全部设备的以树状展示,包括所有总线和内部连接
- 可以将设备和对应的驱动关联起来
- 可以把设备按类型分类
- 可以从设备树的叶子向根遍历,确保能以正确的顺序关闭各设备的电源
上面最后一点正是引入设备模型的最初动机。
该结构是设备模型的核心,很容易创建树形结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
struct kobject { const char *name; //内核对象的名称 struct list_head entry; //当前对象在链表中的元素 struct kobject *parent; //父对象的指针 struct kset *kset; struct kobj_type *ktype; //内核对象类型 struct sysfs_dirent *sd; //指向sysfs中代表当前对象的目录项 struct kref kref; //引用计数 unsigned int state_initialized :1; unsigned int state_in_sysfs :1; unsigned int state_add_uevent_sent :1; unsigned int state_remove_uevent_sent :1; unsigned int uevent_suppress :1; }; |
kobject通常嵌入到其它结构中,例如字符设备的定义:
|
1 2 3 4 5 6 7 8 |
struct cdev { struct kobject kobj; //对应的内核对象 struct module *owner; const struct file_operations *ops; struct list_head list; dev_t dev; unsigned int count; }; |
当kobject被嵌入其它结构中后,后者就有了kobject提供的标准功能,更重要的时,后者可以称为对象层次结构中的一部分。
该结构用于表示kobject的类型,包含一类kobject公共的属性,避免逐个指定:
|
1 2 3 4 5 6 7 8 9 |
struct kobj_type { //当此类kobject引用计数为0时需要调用的析构函数 void (*release)( struct kobject *kobj ); //描述sysfs读写时的特性 const struct sysfs_ops *sysfs_ops; //定义此类kobject相关的默认属性,最后一项必须为NULL struct attribute **default_attrs; }; |
该结构定义了kobject的集合,可以把相关的kobject对象置于同一位置,具有相同ktype的koject可以被存放在不同的kset中:
|
1 2 3 4 5 6 7 8 9 10 11 |
struct kset { struct list_head list;//集合中所有kobject的集合 spinlock_t list_lock; //保护集合的自旋锁 struct kobject kobj; //代表了该集合的基类 /** * 指向一个结构体,用于处理集合中kobject对象的热拔插操作 * uevent是用户事件的意思,提供了与用户空间热拔插信息进行通信的机制 */ struct kset_uevent_ops *uevent_ops; }; |
尽管多数时候驱动开发人员不需要直接处理kobject,设备驱动子系统还是会使用到它。使用kobject的第一步是声明和初始化:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// @param kobj 需要初始化的内核对象,调用前kobj必须被清零,例如:memset(kobj, 0, sizeof (*kobj)); void kobject_init( struct kobject *kobj, struct kobj_type *ktype ); //示例 struct kobject *kobj; kobj = kmalloc( sizeof ( *kobj ), GFP_KERNEL ); if (!kobj) return -ENOMEM; memset(kobj, 0, sizeof (*kobj)); kobj->kset = my_kset; kobject_init( kobj, my_ktype ); //上面这些步骤可以直接用下面的函数完成 struct kobject * kobject_create(void); //示例 struct kobject *kobj; kobj = kobject_create(); if (!kobj) return -ENOMEM; |
kobject引入的一个主要特性是统一的引用计数系统,在初始化后kobject的引用计数被设置为1,只要计数不为0则对象持续钉在(pinned)在内存中。任何引用kobject的代码都会应该手工增加计数,在不使用后则减少计数:
|
1 2 3 4 |
//增加引用计数并获得引用本身 struct kobject * kobject_get(struct kobject *kobj); //减少引用计数 void kobject_put(struct kobject *kobj); |
一旦引用计数为0,定义在ktype上的析构函数就被调用,任何关联的内存被释放,kobject不复存在。
在引用计数系统内部,使用kref结构体,在内核中任何需要使用引用计数机制的地方,都可以使用该结构体:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
struct kref { atomic_t refcount; }; //初始化引用计数为1 void kref_init( struct kref *kref ) { atomic_set( &kref->refcount, 1 ); } //增加引用计数 void kref_get( struct kref *kref ) { WARN_ON( !atomic_read( &kref->refcount ) ); atomic_inc( &kref->refcount ); } //减少引用计数,如果为零,则执行指定的回调 int kref_put( struct kref *kref, void (*release)( struct kref *kref ) ) { WARN_ON( release == NULL ); WARN_ON( release == ( void (*)( struct kref * ) ) kfree ); if ( atomic_dec_and_test( &kref->refcount ) ) { release( kref ); return 1; } return 0; } |
sysfs是一个内存中的虚拟文件系统,它提供了kobject的层次视图,允许用户使用类似文件系统的方式来观察设备的拓扑结构。利用attributes,kobject可以暴露内核变量供读取或者(可选的)写入。
尽管设备模型最初目的是支持电源管理,其衍生品sysfs被很快导出为文件系统,以支持调试。该文件系统替换了原先位于/proc的设备相关文件,并提供了系统对象的层次视图。大部分系统中,sysfs挂载在 /sys 下。
/sys至少包含10个子目录:block, bus, class, dev, devices,firmware, fs, kernel, module, power,其中最重要的是devices,它体现了系统真实的设备拓扑结构,很多其它目录中的文件都是指向该目录的符号链接,例如:
|
1 2 3 4 5 |
ll /sys/class/net #输出 eth0 -> ../../devices/pci0000:00/0000:00:11.0/0000:02:01.0/net/eth0/ eth1 -> ../../devices/pci0000:00/0000:00:11.0/0000:02:06.0/net/eth1/ lo -> ../../devices/virtual/net/lo/ |
仅仅初始化kobject不会自动将其导出到sysfs中,必须调用:
|
1 |
int kobject_add( struct kobject *kobj, struct kobject *parent, const char *fmt, ... ); |
kobject在sysfs中的位置取决于其在对象层次中的位置。如果父指针被设置,那么kobject将映射为其父目录的子目录;否则, 将被映射为 kset-kobj 中的子目录,如果kobject的parent、kset都没有设置,则映射为sysfs的直接子目录。fmt参数用于创建目录的名字,使用printf()函数的格式化字符串。
辅助函数把kobject的创建、添加到sysfs合并为一个步骤:
|
1 |
struct kobject * kobject_create_and_add( const char *name, struct kobject *parent ); |
下面的函数用于从sysfs中移除kobject:
|
1 |
void kobject_del( struct kobject *kobj ); |
注意kobject映射到的是目录,因此仅仅能构成目录结构,不提供任何数据。
默认属性
kobject目录中包含的默认文件集合由kobject和kset的ktype字段提供,所有相同类型的kobject具有相同的文件集合。此集合由 kobj_type.default_attrs 提供,它是attribute结构的数组。这些属性负责把内核数据映射为sysfs中的文件:
|
1 2 3 4 5 6 |
struct attribute { const char *name; /* 属性名,亦即文件名 */ struct module *owner; /* 所属的模块 */ mode_t mode; /* 文件的访问权限 */ }; |
同时 kobj_type.sysfs_ops 定义了如何读写这些属性:
|
1 2 3 4 5 6 7 |
struct sysfs_ops { /* 读取一个sysfs文件时调用的函数 */ ssize_t (*show)( struct kobject *kobj, struct attribute *attr, char *buffer ); /* 写入一个sysfs文件时调用的函数 */ ssize_t (*store)( struct kobject *kobj, struct attribute *attr, const char *buffer, size_t size ); }; |
创建新属性
如果某个特定的kobject实例需要特殊属性,可以调用:
|
1 |
int sysfs_create_file( struct kobject *kobj, const struct attribute *attr ); |
注意,默认的sysfs_ops必须能够处理新添加的属性。
除了添加属性外,可能还需要在sysfs中建立一个符号链接 :
|
1 |
int sysfs_create_link( struct kobject *kobj, struct kobject *target, char *name ); |
销毁属性
通过下面的函数可以销毁属性:
|
1 |
void sysfs_remove_file( struct kobject *kobj, const struct attribute *attr ); |
类似的,移除符号链接:
|
1 |
void sysfs_remove_link(struct kobject *kobj, char *name); |
sysfs约定
当前sysfs文件系统代替了以前需要由 ioctl() (作用于设备节点)和procfs文件系统完成的功能。例如在设备映射的sysfs子目录添加一个属性,可以代替实现一个新的ioctl()。
为保持sysfs干净和直观,开发者必须遵守:
- sysfs属性应该保证每个文件只导出一个值(往往对应一个独立的内核变量),该值应该是文本形式而且映射为简单C类型。该约定的目的是避免数据过度结构化或凌乱,这正是/proc面临的问题
- 在sysfs中要以一个清晰的层次组织数据。父子关系、属性都要准确
- 由于sysfs提供内核到用户空间的服务,多少有点ABI的作用,因此任何时候都不应该改变既有文件
内核事件层实现了内核到用户的消息通知系统,该系统就建立在kobject之上。对于特别是桌面系统来说,将内核中事件传递给用户空间的需求一直存在,用户需要知道硬盘满了、处理器过热,等等…
早起的事件层没有使用kobject和sysfs,它们是“瞬时”的。现在的事件层把事件模拟为信号,信号从一个明确的kobject对象发出,每一个事件源都是一个sysfs中的路径。每个事件都被赋予一个动词或者动作字符串以表示发生的事情。最后,每个事件都有一个可选的payload,内核使用sysfs属性表示负载。
从内部实现来说,内核事件从内核传递到用户空间需要经过netlink,netlink是用于传递网络信息的多点套接字,使用netlink就意味着从用户空间获取内核事件就像使用套接字一样简单——从用户空间实现一个服务用于监听套接字,处理任何读到的信息。
在内核代码中,可以使用下面的函数向用户空间发送信号:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/** * @param kobj 事件源 * @param action 动词,用于描述信号,由一个枚举表示,这些枚举映射到一个字符串 */ int kobject_uevent( struct kobject *kobj, enum kobject_action action ); enum kobject_action { KOBJ_ADD, //add KOBJ_REMOVE, //remove KOBJ_CHANGE, //change KOBJ_MOVE, //move KOBJ_ONLINE, //online KOBJ_OFFLINE, //offline KOBJ_MAX //max }; |
Linux 从2.4内核开始支持I/O调度器,到目前为止有5种类型:Linux 2.4内核的 Linus Elevator、Linux 2.6内核的 Deadline、 Anticipatory、 CFQ、 Noop,其中Anticipatory从Linux 2.6.33版本后被删除了。目前主流的Linux发行版本使用Deadline、 CFQ、 Noop三种I/O调度器。
在2.4 内核中它是第一种I/O调度器。它的主要作用是为每个设备维护一个查询请求,当内核收到一个新请求时,如果能合并就合并。如果不能合并,就会尝试排序。如果既不能合并,也没有合适的位置插入,就放到请求队列的最后。
Anticipatory的中文含义是"预料的,预想的",顾名思义有个I/O发生的时候,如果又有进程请求I/O操作,则将产生一个默认的6毫秒猜测时间,猜测下一个进程请求I/O是要干什么的。这个I/O调度器对读操作优化服务时间,在提供一个I/O的时候进行短时间等待,使进程能够提交另外的I/O。Anticipatory算法从Linux 2.6.33版本后被删除了,因为使用CFQ通过配置也能达到Anticipatory的效果。
对Linus Elevator的一种改进,它避免有些请求太长时间不能被处理。另外可以区分对待读操作和写操作。DEADLINE额外分别为读I/O和写I/O提供了FIFO队列。
CFQ全称Completely Fair Queuing ,中文名称完全公平排队调度器,它是现在许多 Linux 发行版的默认调度器,CFQ是内核默认选择的I/O调度器。它将由进程提交的同步请求放到多个进程队列中,然后为每个队列分配时间片以访问磁盘。对于通用的服务器是最好的选择,CFQ均匀地分布对I/O带宽的访问。CFQ为每个进程和线程,单独创建一个队列来管理该进程所产生的请求,以此来保证每个进程都能被很好的分配到I/O带宽,I/O调度器每次执行一个进程的4次请求。该算法的特点是按照I/O请求的地址进行排序,而不是按照先来后到的顺序来进行响应。简单来说就是给所有同步进程分配时间片,然后才排队访问磁盘。
NOOP全称No Operation,中文名称电梯式调度器,该算法实现了最简单的FIFO队列,所有I/O请求大致按照先来后到的顺序进行操作。NOOP实现了一个简单的FIFO队列,它像电梯的工作主法一样对I/O请求进行组织。它是基于先入先出(FIFO)队列概念的 Linux 内核里最简单的I/O 调度器。此调度程序最适合于固态硬盘。
- Deadline适用于大多数环境,特别是写入较多的文件服务器,从原理上看,DeadLine是一种以提高机械硬盘吞吐量为思考出发点的调度算法,尽量保证在有I/O请求达到最终期限的时候进行调度,非常适合业务比较单一并且I/O压力比较重的业务,比如Web服务器,数据库应用等。CFQ 为所有进程分配等量的带宽,适用于有大量进程的多用户系统
- CFQ是一种比较通用的调度算法,保证对进程尽量公平,为所有进程分配等量的带宽,适合于桌面多任务及多媒体应用
- NOOP 对于闪存设备和嵌入式系统是最好的选择。对于固态硬盘来说使用NOOP是最好的,DeadLine次之,而CFQ效率最低
|
1 |
dmesg | grep -i scheduler |
|
1 2 |
cat /sys/block/sda/queue/scheduler # noop deadline [cfq] |
|
1 |
echo noop > /sys/block/sdb/queue/scheduler |
|
1 |
grubby --grub --update-kernel=ALL --args="elevator=deadline" |
或者直接编辑grub文件:
|
1 |
elevator= cfq |
当Linux中的用户程序执行一次磁盘写入操作时,对应的流程如下:
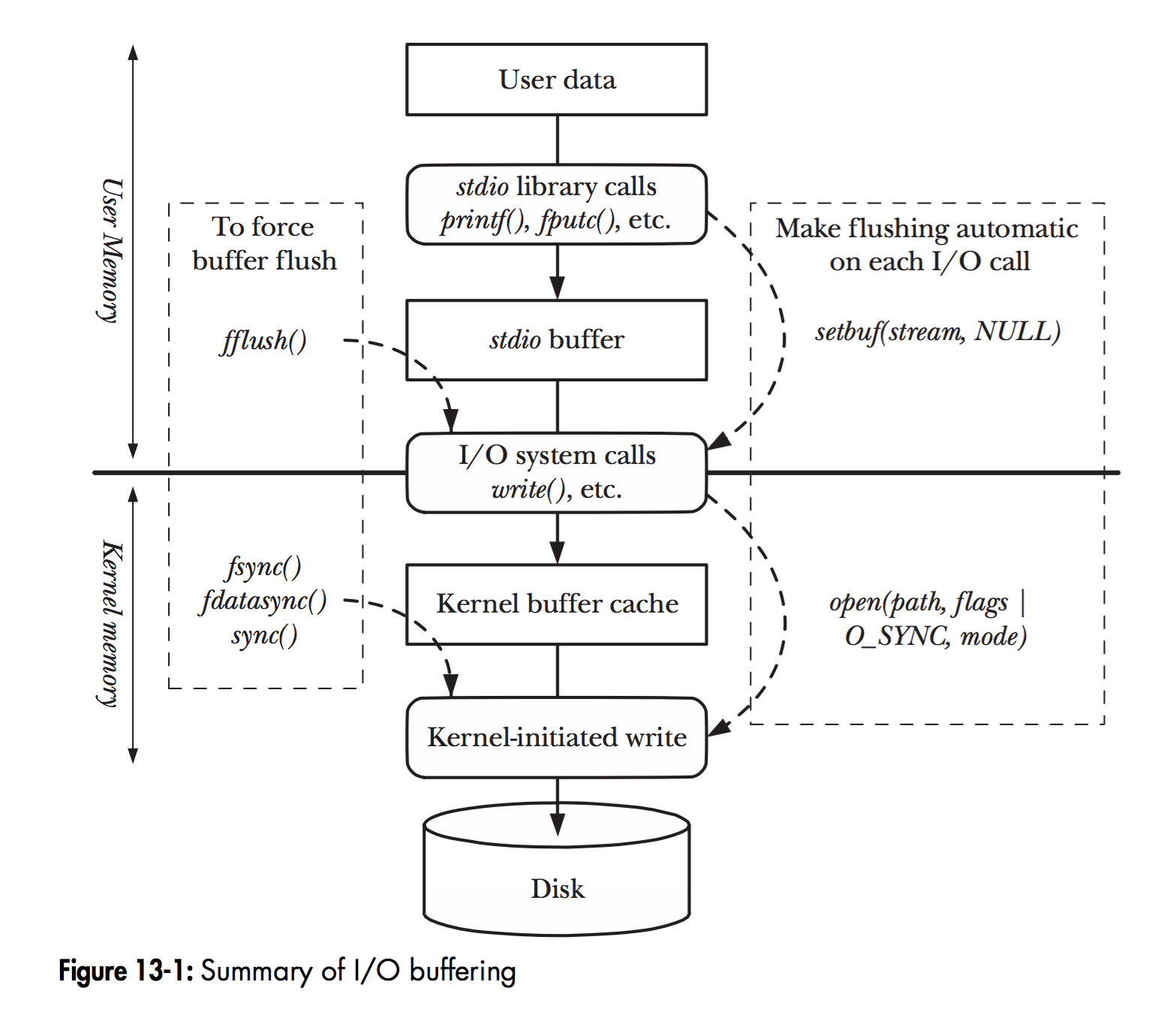
从发起系统调用write()到数据落盘,中间要经过Kernel Buffer Cache这一层。Kernel Buffer Cache由两个部分组成:Page Cache、Buffer Cache。
在读取磁盘时,内核会先检查 Page Cache 里是不是已经缓存了这个数据。如果数据存在于Page Cache中则直接返回,否则从磁盘加载页面并放入Page Cache中。
在写入磁盘时,内核会把数据写入到Page Cache,并把对应的页标记为Dirty,添加到脏页列表。内核会定期将脏页列表刷出到磁盘以保持数据一致性。
在Linux还没有引入虚拟内存技术之前,没有页的概念,那时候只有Buffer Cache。Buffer Cache以块(磁盘读写的最小单位)为单位进行缓存。
现在,基于文件的操作(例如write/read)、mmap()之后的块设备,都会经过Page Cache。而Buffer Cache 用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用,实际上负责所有对磁盘的 I/O 访问。
从2.4开始,Buffer Cache融合到Page Cahce中,不再独立存在,这避免了两个缓存之间数据同步的开销。
Leave a Reply