C语言学习笔记
- 栈(Stack):一种数据结构。其增长方向依赖于ABI(应用程序二进制接口),可以从高地址向低地址延伸,即栈底是最高地址
- 调用栈(Call Stack),亦称Execution stack、Control stack、Runtime stack、Machine stack,有时直接简称栈(The stack)。是一个基于栈的、记录当前正在执行例程信息的数据结构。尽管栈维护对正确的函数调用很重要,但是对于高级语言来说,程序员不需要关心,已经被自动化处理。为了能够实现函数调用返回,在调用指令发出的同时,需要把当前指令地址压栈。栈由一系列栈帧组成,栈帧必然是栈上的连续元素。如果一个例程DrawSquare调用了DrawLine,则调用栈的顶部可以如下图所示:
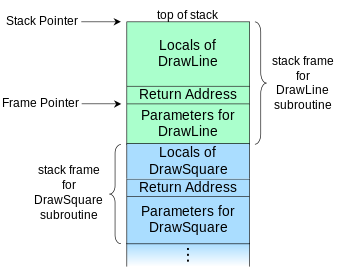 帧指针(Frame pointer):由于每个栈帧的大小不一致,因此无法根据栈指针直接完成栈帧的弹出(Pop),因此,函数返回时,需要把栈指针设置为帧指针,后者存放的就是函数被调用前的栈指针。
帧指针(Frame pointer):由于每个栈帧的大小不一致,因此无法根据栈指针直接完成栈帧的弹出(Pop),因此,函数返回时,需要把栈指针设置为帧指针,后者存放的就是函数被调用前的栈指针。 - 栈帧(Stack Frame):每一个未运行完的函数,对应一个栈帧,栈帧保存该函数的局部变量(包括入参)和返回地址。从逻辑角度看,栈帧就是函数的执行环境
- C语言的程序由函数(functions)、变量(variables)构成
- 表达式由操作数(变量、字面值等)和操作符组成。表达式加上 ; 即表示语句。用花括号包围的多个语句称为复合语句(亦称块)。变量可以定义在任何块中
- 动态分配内存生命周期管理最佳实践:
- 可以将动态内存的生命周期交由函数调用者管理,这要求入参提供一个指针
- 函数实现者管理生命周期,这要求提供一个配对的销毁函数
- 动态分配得到的内存,应当立即判断指针是否为NULL,因为内存分配会失败(内存耗尽)
- 对于数组、动态分配的内存,应当立即予以初始化,否则可能存在垃圾数据,不能作为右值使用
- 野(Wild)指针:对应的内存空间已经释放,而指针却没有置NULL,这样的指针就是野指针
- main()是一个特殊的函数,它是程序执行的入口点。它的返回值如果是0,往往表示执行成功
- 全局、静态变量的内存空间都是全局的,初始化发生在任何代码执行之前
- 调用函数时提供的变量列表称为参数(arguments)
- 双引号包围起来的字符序列称为字符串/字符串常量: "hello, world\n" 。反斜杠与其后面的一个符号共同代表一个字符,称为转义序列(escape sequence)
- C语言中的字符串以字符数组的形式存储,并且在数组结尾自动添加 \0
- 注释(comment)用于解释程序的功能,有两种形式的注释: /* comment */ 和 // comment
- 声明(declaration)用于说明变量的属性,任何变量必须先声明再使用: int lower, upper, step;
- 符号常量(Symbolic Constants): #define name replacement 将替换代码中所有name为replacement
- EOF:文件的结尾,经常用-1表示,因为其不可能是任何一个字符的值
- 声明数组的同时必须指定长度: int array[4];
- 在C语言中,所有的函数调用都是传值方式,即函数中的参数都是原始入参的拷贝。如果想修改原始入参,必须使用指针(Pointer)。但是需要注意的是,对于数组,可以安全的传递给函数,函数不会对入参数组进行深拷贝,数组传递的本质是对数组首地址进行传值
- 不包括函数体的函数声明称为原型(Prototype),原型中的参数可以没有名称,例如: int pow(int, int);
- 在函数体声明的普通变量,只对函数可见,在函数被调用时出现,函数调用结束时消失,称为局部变量(Local variable, Automatic variable)。局部变量的值必须显式初始化,否则可能存放着垃圾值
- 定义在函数外面的变量称为外部变量(External variable)。不同函数可以共同存取这类变量,并且函数退出后其值仍然被保留。外部变量必须仅仅被定义(Define)一次,定义为其分配存储空间。函数如果要使用外部变量,需要声明: extern int externVar; ,如果外部变量的定义出现在函数定义的前面,则函数可以省略外部变量的声明,直接使用
- 如果变量定义在file1.c: int i = 0; ,而file2.c也需要使用该变量,那么file2必须使用extern进行声明: extern int i; 让两个变量链接起来。如果不加extern,那么这两个文件中的i是独立的变量。跨文件共享的变量最好独立出来,存放在单独的头文件(Header)中
- 声明与定义的区别:前者指明了变量的特性,例如 int array[4]; ,后者分配了存储空间,例如 int array[4] = {0, 1, 2, 3};
- 取地址操作符 & :不能用于常量、表达式、register变量
- C语言提供了类型定义的功能:
typedef oldtype NEWTYPE ,相当于为既有类型定义一个别名。例如:
1234567891011121314151617181920212223242526#include#include#include//定义字符串类型typedef char* string;//定义一个函数指针typedef void (*sa_handler_t)( int );//定义一个结构体,它使用一个临时的名称__person_t//它使用别名person,它的指针类型的别名是ppersontypedef struct __person_t{int age;int gender;char* name;}*pperson, person;int main( int argc, char **argv ){size_t size = sizeof(person);printf( "Size of person: %d\n", size );pperson p = malloc( size );p->age = 29;p->name = "Alex";printf( "%s is %d years old\n", p->name, p->age );exit( 0 );} - sizeof:是一个编译时一元运算符,用于计算目标的长度(字节):
1234567891011121314151617181920struct person{char* name;ushort age;};int main( void ){struct person p;p.name = "Alex";p.age = 28;//以下语句后续的注释是AMD64平台的32位Windows7的运行结果//结构的长度不一定等于成员之和,因为对齐要求printf( "Size of struct person: %d\n", sizeof(struct person) ); //8printf( "Size of person: %d\n", sizeof p ); //8 实例的长度与类型一致printf( "Size of char*: %d\n", sizeof(char*) ); //4 指针的长度printf( "Size of ushort: %d\n", sizeof(ushort) ); //2 短整型的长度printf( "Size of int[10]: %d\n", sizeof(int[10]) ); //40 数组的长度为元素长度之和return 0;}
| 数据类型 | 说明 | ||
| int |
整型,长度范围依赖于机器,可能是16位(-32768 ~ +32767)或者32位 |
||
| float | 浮点型,通常32位,至少支持6位有效数字(从第一个非0开始到末位)以及10^-38~10^38之间的数量级 | ||
| char |
字符型,单字节。使用单引号包围一个字符值来表示。本质上char是整数,虽然可打印字符不会为负数,但是char类型却可以存放负数,为了保证可移植性,应当明确指定char为signed或者unsigned。直接量语法: char c = 'c'; |
||
| char* |
char指针作为C风格字符串使用,其特点是以0字符结束。直接量语法: char *str = "string"; |
||
| wchar_t |
宽字符,一般为双字节(定义为无符号short)。直接量语法: wchar_t wc = L'宽'; |
||
| wchar_t* |
与char*类似,也是以0字符结束。直接量语法: wchar_t *str = L"字符串"; |
||
| short | 短整型,等价于 short int,至少16位。 | ||
| long | 长整型,等价于long int,至少32位。 | ||
| double | 双精度浮点型。类似还有long double。 | ||
| enum |
该关键字用来声明枚举,例如: enum { FALSE, TRUE } 枚举本质上是整数,枚举值是不可变的:
|
||
| void | 空,表示一个不存在的值 | ||
| void* |
通用指针,可以与任何指针类型进行双向转换而不丢失信息。在void*出现之前,char*扮演通用指针的角色。 ANSI允许void*与其它类型的指针在赋值、关系表达式中混用。其它类型指针的混用则必须使用强制类型转换 |
当表达式中的操作数的类型不同时,就需要进行类型转换,类型转换准守以下几个规则:
- 将数值赋值给变量时,可能会发生自动的类型转换(以变量类型为转换的目标)
- 算术类型转换:在进行算术运算时,参与的操作数需要被转换为一个公共的类型,然后进行运算:
- 如果任何一个操作数为long double,那么另外一个被转换为long double。否则,
- 如果任何一个操作数为double,那么另外一个操作数被转换为double。否则,
- 如果任何一个操作数为float,那么另外一个操作数被转换为float。否则,
- 两个操作数进行整型提升。
- 如果一个操作数为unsigned long,则另外一个被转换为unsigned long。否则,
- 如果一个操作数为long,另外一个为unsigned int,则转换方式依赖于long能否表示所有unsigned int类型的值。如果能够,将后者转换为long;如果不能,两者都转换为unsigned long。否则,
- 如果一个操作数为long,将另外一个转换为long。否则
- 如果一个操作数为unsigned int,则将另外一个转换为unsigned int
- 在进行布尔值判断时,任何非0值被认为是“真”
- 当把较长的整数转换成较短的整数或字符时,超出的高位部分被丢掉
- 整型提升(Integer promotion):一个表达式中,凡是可以使用整型的地方,都可以使用signed/unsigned的char、short、int,甚至枚举。如果int可以表示所有原始类型的值,那么这些值被转换为int,否则转换为unsigned int
- 将任何整数转换为signed类型时,如果其值在新的类型中能够表示,则其值保持不变;否则,其值依赖于具体实现
- 浮点类型转换为整数时,其小数部分丢弃。如果整数部分无法在新类型中表示(例如将-1.0转换为unsigned),则转换结果未定义
- 整数转换为浮点数时,如果整数值在浮点数的表示范围但不能精确表示,则结果可能是下一个较高/较低的可表示值
- 低精度浮点数转换为高精度浮点数时,值不变;反之,高精度转换为低精度时,如果值在低精度类型的可表示范围,则结果可能是下一个较高/较低的可表示值,否则结果未定义
- 指针可以加上、减去一个整型表达式,其结果依然是指针
- 指向同一数组中同一类型对象的指针可以进行减法运算,其结果是整数
- 值为0的整型常量、被强转为void*的表达式,这两者可以通过强制转换、赋值,而被转换为任意类型的指针,其结果是空指针
- 指针可以转换为整型,但是此整型必须足够大;整数对象也可以显式的转换为指针
- 指向类型A的指针可以被转换为指向类型B的指针,但是如果转换后的指针所指向的对象不满足一定的存储对齐要求,则结果指针可能导致地址异常。指向某对象的指针可以转换为指向另外一个更小或者相同存储对齐限制的对象的指针,并可以保证原封不动的转换回来。存储对齐的概念依赖于具体实现,但是char类型具有最小的对齐限制
- 指针可以转换为同类型的指针,如果转换后增加了限定符,则新指针与原指针等价;如果删除了限定符,目标对象仍然受到其声明时的限定符的限制(例如const)
- 指向函数的指针,可以指向另外一个函数。调用转换后的指针对应的函数,其结果依赖于具体实现。但是,转换后的指针可以再次安全的转换回来
- void不能被显式、隐式的转换为任意非空类型。反之,可以强制把表达式转换为void类型,例如,可以使用 (void)func() 丢掉函数调用的返回值
- 可以将任意指针转换为void*,并且不会丢失信息,可以将void*再次转换为原始类型的指针,以恢复之
修饰变量的一类限定符。
| 限定符 | 说明 |
| auto |
自动变量,用作函数内部变量。当函数返回时自动丢弃 这是默认行为,不需要特别添加: auto int x = value; |
| extern | 外部变量 |
| register |
类似于auto,但是提示编译器此变量被访问的非常频繁,如果可能,将其存放在寄存器中 对于GCC来说,编译器通常能够很好的自动选择什么变量放在寄存器中,因此不需要手工使用此关键字 |
| static | 可以用作全局、局部变量。这样的变量仅仅对当前文件可见。用作函数内的static生命周期跨越函数调用 |
修饰变量的一类限定符。
提示编译器,变量可能被一些编译器无法感知的因素改变,例如操作系统、硬件、线程,编译器不应该对访问此变量的代码进行优化,而是总应当从主内存获取变量的最新值:
|
1 2 3 4 5 6 7 8 |
int i = 10; int j = i;// 从内存获取i的值,并赋值 int k = i;// 用上次获取的值,继续给k赋值,避免了一次内存访问 volatile int i = 10; int j = i;// 从内存获取i的值,并赋值 int k = i;// 再次从内存获取i的值,赋值。防止这两句执行期间,i的值被改变 |
常量是指在编译阶段其值就可以确定的量。常量表达式值仅由常量组成的表达式。各数据类型的常量字面值表示方式如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
//整数不加修饰的话默认int类型 //signed表示有符号数,数值范围是-2^(n-1) 至 2^(n-1)-1 //unsigned表示无符号数,数值范围是0 至 2^n-1 signed int i = 1234; //支持不同进制的表示方式: int i8 = 077, i16 = 0xFF; //long型的字面值,后缀大小写均可 long l1 = 1234l, l2 = 1234L, l16 = 0xFFL; unsigned long ul1 = 1234UL, ul16 = 0xFUL; unsigned int ui1 = 1234U; //浮点数不加修饰的话默认double类型 double d1 = 123.4, d2 = 1e-2; //支持科学计数法 //单精度浮点数 float f1 = 123.4F; //字符常量本质上使用整型表示,因此可以加signed/unsigned char c1 = 0x14; //字符常量使用单引号界定 c1 == '\x14'; //等价,十六进制转义 char c2 = '\024'; //八进制转义 char c0 = '\0' == 0; //NULL字符 //字符串常量使用双引号界定,底层经常用char[]表示,结尾使用\0 //因此要表示长度为10的字符串,至少需要char[11] char* s0 = "Hello " "World"; //等价于"Hello World",编译器自动连接 //枚举常量,除非指定值,否则第一个为0,第二个为1……类推 enum boolean { //不同枚举中的值名称必须唯一,也就是说,不能定义另外一个枚举包含NO NO, YES }; int no = NO; //引用枚举 //数组的初始化,如果不指定数组长度,编译器自动根据初始化式计算 int days[ ] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 }; //字符数组比较特殊,可以使用字符串进行初始化,下面两者是等价的: char pattern [] = "ould"; char pattern [] = { 'o', 'u', 'l', 'd' , '\0' }; |
变量必须先声明后使用,例如这是一个声明: int c; 。变量在声明时可以同时进行初始化,例如: int c = 1;
自动变量在每次进入方法或者语句块时被初始化。未显式初始化的自动变量、寄存器变量,其值是未定义的,可能存在垃圾数据。
非自动变量在程序启动时初始化,外部(extern,函数外部定义的变量)、静态(static)变量默认初始化为0,如果手工初始化,这些变量的初始化式必须是常量。此外,外部变量具有和程序相同的生命周期,可以用于在函数之间共享数据。
限定符: const 用于表示变量的值不会改变,对于数组来说,该限定符意味着元素的值不得修改。在函数形参数组中使用const,用于禁止函数对数组做改动,而不是要求传入的数组是const的: int strlen(const char[]); 。尝试对const进行修改的后果取决于具体实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//下面的语句声明了一个外部变量,但是没有定义它 extern int j; //下面的语句定义了(分配了存储空间)一个外部变量 //在程序的所有源文件中,一个外部变量可能被声明多次,但是只能被定义一次 int i; //外部变量被声明为静态的,表示该变量只能被当前文件的后续部分访问,不能被其他文件访问 static int a; int main( void ) { //内部变量如果被声明为静态的,那么不管函数是否被调用,该变量都一直存在 static int k; return 0; } //寄存器变量:提醒编译器,该变量在程序中使用频率很高,应当被存放在寄存器中 //寄存器变量值能用于自动变量、形参 void func( register int r ) { register int r0 = r; } |
按优先级降序排列:
| 操作符 | 结合性 |
| () [] -> . | 从左到右 |
| ! ~ ++ -- + - * (type) sizeof | 从右到左 |
| * / % | 从左到右 |
| + - | 从左到右 |
| << >> | 从左到右 |
| < <= > >= | 从左到右 |
| == != | 从左到右 |
| & | 从左到右 |
| ^ | 从左到右 |
| | | 从左到右 |
| && | 从左到右 |
| || | 从左到右 |
| ?: | 从右到左 |
| = += -= *= /= %= &= ^= |= <<= >>= | 从右到左 |
| , | 从左到右 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
// If-Else分支 if ( 1 ) // if语句测试的是表达式的数值,如果为0则测试失败,否则测试成功 if(1) ; else // 与最靠近的if搭配,除非用花括号限定 ; else if(1) ; else ; //Switch-Case结构,用于多路分支判断,将表达式与常量数值进行比较 switch ( v ) { case '0' : case '1' : case '2' : puts( v ); // break语句用于从switch-case结构中跳出,防止继续执行后续分支 // 如果不进行break,那么后续的分支会逐个执行,不进行值判断 break; // 如果表达式值与该常量匹配,则从该分支开始 case 0 : break; default : break; } //While循环:先判断,再执行 while ( 1 ) { ; } //Do-While循环:先执行,再判断 do { ; } while ( 0 ); OUTER : for ( int i = 0; i < 5; i++ ) { //先执行第一个语句,然后判断第二个语句是否为真 //如果为真,执行循环体,然后执行第三个语句,并进行下一次循环判断 //如果为假,退出循环 INNER : for ( int j = 0; j < 5; j++ ) { if ( j == i ) { //用于继续当前循环的下一次迭代,不执行当前迭代后续语句 continue; } else if ( i == j ) { //与continue等价 goto INNER; } else if ( j == i + 1 ) { //跳到外层循环,需要使用goto语句才能完成 goto OUTER; } else { //用于终止当前循环的迭代 break; } } } for ( ;; ) ; //无限循环 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
#include #include //函数的返回值声明可以省略,自动被认为是int类型 echo( char arg ) { //标准C语法中,嵌套的函数是不允许的 //在gcc扩展语法中,函数的定义可以嵌套在别的函数中,这些的函数只在块中可见 char echo( arg ) //函数的形参不指定类型也是合法的,自动被认为是int类型 { return arg; } printf( "%c\n", echo( arg ) ); return ( 0 ); //尽管不是必须,返回表达式两边可以加括号 //返回值也可以省略,表示不向调用者返回一个值,这样的话调用者获取的值是未定义的 } void varg( char arg0, ... ) { va_list arg_ptr; //指向变参的指针 va_start( arg_ptr, arg0 ); //必须传入最后一个定参 int arg1 = va_arg( arg_ptr, int ); //得到下一个变参的值,并移动指针到下一个变参 printf( "2nd arg is : %d\n", arg1 ); va_end( arg_ptr ); //清理指针 } //函数声明为静态的,表示该函数只能被当前文件后续的部分访问 static void sfunc() { } //如果函数没有形参列表,那么所有参数检查被关闭 //如果函数没有形参,应当使用void作为形参来显式的声明 int main( void ) { printf( "%d\n", echo( 'H' ) ); varg( 'A', 1, 2, 3 ); return 0; } //函数可以直接赋值给函数指针 int addInt( int n, int m ) { return n + m; } int (*functionPtr)( int, int ); functionPtr = &addInt; //是否对函数取地址,表达式中的函数都会被隐式的转换为它自己的指针 functionPtr = addInt; //因此这样也行,每次解引用后,还是会被隐式的转换为指针,因此可以反复解引用 functionPtr = *****addInt; |
对于某些中等规模的程序,最好是只使用一个头文件来存放程序中各个部分需要共享的实体;对于比较大的程序,需要做更精心的组织,使用更多的头文件。
C语言通过预处理程序提供了一些语言功能,预处理程序从理论上讲是编译过程中单独进行的第一个步骤。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
//include指令:用于在编译期间把指定文件的内容包含到当前文件,有两种形式: //include "header.h"方式提示在源程序所在位置寻找文件 //若找不到或者指定include ,则按具体实现定义的规则寻找文件 #include #include "lintcp.h" //define指令:定义“宏”,用任意字符序列取代一个标记 //宏定义中可以包含参数,在展开的时候一并按字面处理 //带了很多括号,防止产生歧义 #define max( A, B ) ( ( A ) > ( B ) ? ( A ) : ( B ) ) #define PORT 1 //取消宏定义 #undef PORT //条件包含 #if SYSTEM == SYSV #define HDR "sysv.h" #elif SYSTEM == BSD #define HDR "bsd.h" #elif SYSTEM == MSDOS #define HDR "msdos.h" #else #define HDR "default.h" #endif //防止重复包含 #if !defined( HDR ) // 类似:#ifdef #ifndef #define HDR #endif int main( void ) { //宏替换,只对单个单词起作用。宏替换是一个逐字的过程,不进行任何计算 max( 1, 2 ); // ( ( 1 ) > ( 2 ) ? ( 1 ) : ( 2 ) ); max( 88 + 2, 90 ); //( ( 88 + 2 ) > ( 2 ) ? ( 88 + 2 ) : ( 2 ) ) //对引号内的字符串无效 char* str = "max"; return 0; } |
在宏定义中,可以出现 # 以及 ## ,用法如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
//单井号用来表示将参数外面包围一对双引号 #define MKSTR(str) #str char *c1 = MKSTR( Hello ); //双井号表示连接两个参数 #define CONCAT(str1,str2) str1##str2 //注意,遇到#或者##时,如果操作数是宏引用,将不会再次展开 char *c2 = MKSTR( CONCAT( Hello, World ) ); //CONCAT( Hello, World ) //因此可以定义一个新的宏,简单的引用原有的宏,由于此新的宏定义不包含#,因此其参数会被展开 //处理时,先展开CONCAT,然后再展开MKSTR0 #define MKSTR0(str) MKSTR(str) char *c2 = MKSTR0( CONCAT( Hello, World ) ); |
在宏定义中,可以出现 __VA_ARGS__ ... _1 _2等符号,示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// 使用ASSERT宏 ASSERT(!shutdown_); // ASSERT宏的定义 // __VA_ARGS__表示可变参数列表 顺序很关键 展开原始的调用参数 #define ASSERT(...) _ASSERT_SELECTOR(__VA_ARGS__, _ASSERT_VERBOSE, _ASSERT_ORIGINAL)(__VA_ARGS__) // _ASSERT_SELECTOR宏的定义 // 可以有1-N个参数,如果N参数选取第1个宏,如果N-1参数选取第2个宏…… #define _ASSERT_SELECTOR(_1, _2, ASSERT_MACRO, ...) ASSERT_MACRO // 供调用_ASSERT_SELECTOR时选取 #define _ASSERT_ORIGINAL(X) RELEASE_ASSERT(X, "") #define _ASSERT_VERBOSE(X, Y) RELEASE_ASSERT(X, Y) #define RELEASE_ASSERT(X, DETAILS) \ do { \ if (!(X)) { \ const std::string& details = (DETAILS); \ } \ } while (0) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
//要操控入参的值,那么需要使用指针 //否则函数内部对入参的操控不会反应给调用者,因为C语言的传值风格 swap( int *a, int *b ) { *a ^= *b; *b ^= *a; *a ^= *b; } int main( void ) { // 定义10长数组,包含10个连续存储的int int a[10]; //为第1-4个元素赋初值为8 int array[10] = { [0 ... 3] = 8 }; // 指向第一个元素的指针 // 将星号和变量名放在一起是为了便于记忆,表示*ip(解引用)的结果是int int *pa = &a[0]; // 指向第二个元素,因为数组是连续存储的 pa++; //指针必须指向某个特定类型的对象,void*除外,后者可以和任意指针类型互转 void* pv = pa; pa = pv; ++*pa; //先取当前元素,然后增1 ( *pa )++; //与上面等价 *pa += 1; //与上面等价,解引用的结果可以作为左值 int x, y; swap( &x, &y ); int *px = &x; //指向整型的指针 int* *ppx = &px; //指向整型指针的指针 const int *pcx = &x; //指向长整型的指针 int * const cpx = &x; //指向整型的常指针 const int * const cpcx = &x; //指向const int类型的const指针 //[]的优先级比*高 char *cpa[10]; //变量名先与[]结合,形成数组的定义,因此该变量本质上是数组,其内容是char* char (*cap)[10]; //变量名先与*结合,形成指针的定义,因此该变量本质上是指针,指向char[10] //多维数组,低维的在外面 char d3[2][3][4] = { { { 1, 2, 3, 4 }, { 1, 2, 3, 4 }, { 1, 2, 3, 4 } }, { { 1, 2, 3, 4 }, { 1, 2, 3, 4 }, { 1, 2, 3, 4 } } }; d3[0][0][0]; //函数指针,变量名与*结合,说明它本质是一个指针 int ( *comp )( void*, void* ); //函数定义,返回值是int* int * comp( void*, void* ); } |
|
1 2 3 4 5 6 7 |
// 普通语法 char yellow[26] = {'y', 'e', 'l', 'l', 'o', 'w', '\0'}; // 字符串赋值给数组 char orange[26] = "orange"; char gray[] = {'g', 'r', 'a', 'y', '\0'}; // 注意字符串尾部总是隐含包含一个\0,因此推断的长度为7而非6 char salmon[] = "salmon"; |
结构体是一个或者多个变量的集合,这些变量可能是不同的类型,为了处理方便,将它们组织在一个名字之下。结构体类似于其他语言中的“记录”。结构体的简单声明如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
//关键字struct后面的名字是可选的,称为结构标记(structure tag) //结构标记用于为结构命名 struct point { int x; //结构体成员 int y; }; //匿名的结构体声明,变量名为point struct { int x; int y; } point; //可以和结构体标记使用重复的名字 point.x = 1; point.y = 1; // 不匿名结构体也可以附带声明变量 struct point {int x, int y} p1, p2, p3; //与C++不同,C语言在任何时候声明结构体的实例都需要带着struct关键字 struct point p; p.x = 1; p.y = 1; //指向结构的指针 struct point *pp = &p; //用于访问结构指针目标的成员的特殊语法: pp->x = 3; // 结构体初始化 struct point first_point = { 5, 10 }; struct point first_point = { .y = 10, .x = 5 }; // C99、C89的GNU扩展语法 struct point first_point = { y: 10, x: 5 }; // GNU扩展语法 // 定义结构时声明的变量,可以立即初始化 struct point {<br> int x, y;<br>} first_point = { 5, 10 }; // 可仅仅初始化部分成员变量 struct pointy { int x, y; char *p; }; struct pointy first_pointy = { 5 }; // x为5,y为0,p为NULL //结构体数组及其初始化 struct point pa[2] = { 1, 2, 3, 4 }; pa = { {1, 2}, {3, 4} }; //这种写法等价,但是更加清晰 // 结构嵌套及其初始化 struct point { int x, y; }; struct rectangle { struct point top_left, bottom_right; }; struct rectangle my_rectangle = { {0, 5}, {10, 0} }; //自引用结构,必须使用指针 struct node { struct node *parent; }; |
结构体仅仅支持少数几种操作:作为整体复制、赋值;&取地址;访问结构体成员。结构体之间不可以比较。
sizeof结构体取决于所有成员,在成员sizeof求和的基础上,可能需要额外包含padding,padding用于字节边界对齐,取决于平台。字节边界对齐的目的是加速结构体实例的内存访问,4字节/8字节对齐也是存在的。
联合体可以在不同时刻保存不同类型、长度的对象。联合体的本质上就是结构体,只是所有成员相对于基地址的偏移量都是0。联合体只能使用其第一个成员值进行初始化。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//该联合体在任一时刻只能表示int、flat、char*三种之一 union u { int ival; int float fval; char * sval; //联合体必须足够大以存储最大的成员,因此该联合体一般与char*长度一样 }; //联合体成员的访问方式类似于结构体 union u u; u.fval = 3.14; union u *up = &u; up->ival = 3; |
sizeof联合体,就是其最长成员的长度。
你可以定义结构体、联合体、枚举的不完整类型。所谓不完整,对于前两者是指不声明成员列表,对于枚举指不声明值:
|
1 |
struct point; |
并在之后某些时候,你需要使用完整类型的时候,在完善它:
|
1 2 3 4 |
struct point { int x, y; }; |
这个技巧在定义链表时广泛使用:
|
1 2 3 4 5 6 7 |
struct singly_linked_list { struct singly_linked_list *next; int x; /* other members here perhaps */ }; struct singly_linked_list *list_head; |
C语言提供了直接的语法来定义占用空间少于一个字节的对象,不需要使用手工实现的位掩码。
|
1 2 3 4 5 6 |
//以下结构定义了两个宽度为1位的字段 struct { unsigned int is_public :1; unsigned int is_virtual :1; } class_desc; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
void func( char * buf ) { for ( int i = 0; i != 10; i++ ) { //注意++总是在当前的整个表达式(例如下面函数第二个入参)估算结束后执行,即使*(buf++)也不会改变结果 //因此下面的语句从第1个元素开始打印 printf( "%02x ", *buf++ ); //打印1而不是2 } } ; int main( int argc, char **argv ) { char buf[10] = {1, 2}; func( buf ); //注意这里不要再取地址,数组可以自动转换为首元素的指针 return 0; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
typedef struct __person{ int gender; int age; } Person; //使用**,可以跨越函数调用传递指针的“引用”,在这里即Person的地址 void providePerson1(Person ** ppPerson){ Person *p = (Person *)malloc(sizeof(Person)); p->age = 10; *ppPerson = p; } //和上面的函数功能相当,但是占用了返回值 Person * providePerson2(){ return (Person *)malloc(sizeof(Person)); } //使用*,可以跨越函数传递对象(当然该对象也可以是指针),调用者必须知道对象如何创建(如果对象是指针,那么谁都会创建) void modifyPerson(Person *p){ p->gender = 1; } //传值,p被复制,C本质上都是传值,只不过传递的可能是对象,对象指针,指针的指针…… void modifyPerson(Person p){ } int _tmain(int argc, _TCHAR* argv[]) { { Person *pp = NULL; //需要得到Person地址,现在不知道地址是什么,初始化为空指针 providePerson1(&pp);//通过引用方式传递pp printf("%d",pp->age); pp=providePerson2(); modifyPerson(pp); } { //如果这样呢? Person *pp = (Person *) malloc(sizeof(Person)); //函数providePerson1当然可以设计为通过指针的指针传递对象,但是纯粹多此一举 //因此以**方式传递参数的,都不需要调用者如上一般开辟内存空间/创建对象 providePerson1(&pp); //这样的后果一般都是malloc分配的内存泄露 //而下面的代码又释放了不该当前代码管理的内存 free(pp); } return 0; } |
首先,两者不是一回事:
- char a[SIZE] 指明了变量a所在的位置是一个长度为SIZE的数组
- char* a 指明了变量a所在位置是指向char的指针。但是,指针可以通过数组语法来进行运算,例如 a[10] 表示当前指针增加10之后,所指向的值
在某些时候(例如函数调用时传递参数),char[]会“退化”为指向其第一个元素的char*。
编译器能够知晓数组的长度,而char*对应的字符串是多长,则无法得知:
|
1 2 3 4 5 |
char a[] = "hello"; char *p = "world"; sizeof( a ); #数组的长度为6 sizeof( p ); #返回的是指针类型的长度,依据平台的不同,可能是4/8字节 |
下面是一些与char[]、char*相关的技巧:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
char *a = malloc( 10 * sizeof(char) ); //动态分配长度为10的字符数组 if( a != NULL) { //分配成功,可以使用 int len = 10; //内存分配的长度 strlen( a ); //字符串的长度,一直计数到\0 } free( a ); //回收动态分配的内存空间 a[0] = 'H'; a[1] = 'e'; //手工将数组转换为第一个元素的指针 char* p = &a[0]; *( p + 2 ) = 'l'; //指针指向的值就是数组元素 *( p + 1) == a[1]; |
所谓存储对齐,是指数据在内存中的存储地址,必须满足一定的规则。
如果数据的地址恰好是其长度的整数倍,我们称为自然对齐。例如在32bit处理器上,int类型变量的地址如果为0x00000004或者0x00000016,那么它就是自然对齐的。在32bit处理器上,满足能int类型(4字节)自然对齐的内存地址称为4字节对齐(4-bytes aligned)。
自然对齐的必要性,与不同体系结构的CPU读取内存的方式有关。以X86为例,CPU通过总线读写内存,在每个总线周期访问32位的内存数据。假设一个int变量存储在0x00000002上,那么CPU需要2次读内存的操作才能得到该变量的值:
- 第一次读0-3字节,得到位于0x00000002上的short
- 第二次读4-7字节,得到位于0x00000004上的short
这就导致潜在的性能损失。某些体系结构有着严格的字节对齐要求,不满足则导致程序错误。某些特殊的CPU指令集对字节对齐有特殊要求,例如x86的SSE,需要操作的数据位于16字节对齐的地址上,
编译器通常默认让变量自然对齐,以保证最高的内存访问效率。我们可以改变这一行为,以GCC为例:
|
1 2 |
// 变量i被分配到16字节对齐的内存地址上,而不是默认的4字节对齐 int i __attribute__ ((aligned (16))) = 0; |
字节对齐衍生出的一个主题是结构体填充(Pad), 为了满足每个成员都能自然对齐,编译器可能在结构体中插入额外的空白字节。结构体填充虽然避免了性能损失,但却可能导致程序工作不正确——例如用结构体表示网络协议的数据时,是不能容许无意义空白字节的存在的。我们可以提示编译器禁用结构体填充:
|
1 2 3 4 5 6 7 8 |
/** * packed的目的是尽量少的占用内存,它告知编译器使用尽可能小的对齐,也就是1字节对齐 * 用于结构体时,相当于为每个成员添加packed属性。下面的结构体的大小将是5字节 */ struct __attribute__ ((packed)) my_struct { char c; int i; }; |
| 头文件 | 说明 | ||
| assert.h | 断言。其唯一目的是提供宏assert的定义。如果断言非真(expression==0),则程序会在标准错误流输出提示信息,并使程序异常中止调用
|
||
| ctype.h |
字符类测试,参见使用C语言进行文本处理 |
||
| errno.h | 部分库函数抛出的错误代码。错误代码有很多,用法举例:
|
||
| float.h | 浮点数运算。定义了若干与浮点数有关的常量。FLT*表示与float有关;DBL*表示与double有关;LDBL*表示与long double有关。 | ||
| limits.h | 检测整型数据类型值范围
|
||
| locale.h | 本地化 | ||
| math.h | 数学函数 | ||
| setjmp.h | 非局部跳转,允许程序流程立即从一个深层嵌套的函数中返回 | ||
| signal.h | 信号,提供了一些函数用以处理执行过程中所产生的信号 | ||
| stdarg.h | 可变参数列表 | ||
| stddef.h | 一些常数,类型和变量:
|
||
| stdio.h | 该库定义了用于输入和输出的函数、类型和宏:
|
||
| stdlib.h | 实用功能,包含了C语言的中最常用的系统函数
|
||
| string.h | 字符串函数,参见使用C语言进行文本处理 | ||
| wchar.h | 宽字符串处理函数,参见使用C语言进行文本处理 | ||
| time.h | 时间和日期函数,获取时间与日期、对时间与日期数据操作及格式化
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
char* fname = "/home/Suigintou/Test/ReadMe.txt"; //打开文件,mode可以为r/w/a/+的组合,分别表示读/写/追加/更新模式 //注意Linux不像MS-DOS那样区分二进制文件和文本文件,所有文件被作为二进制看待 // FILE *fopen( const char *filename, const char *mode ); FILE* file = fopen( fname, "r+b" ); char buf[64]; memset( buf, 0, 64 ); //从文件流stream中读取数据到buf中,读取nitems个条目,每个条目长度size //size_t fread( void *buf, size_t size, size_t nitems, FILE *stream ); fread( buf, 1, 64, file ); printf( "Read content from file %s: \n%s\n", fname, buf ); //从缓冲区里面读取数据并写入到输出流,返回写入条目的个数 //size_t fwrite( const void *buf, size_t size, size_t nitems, FILE *stream ); fwrite( buf, 1, 6, file ); fflush( file ); //刷空缓冲区 fseek( file, 25, SEEK_SET ); //移动读写指针到相对于文件首部25字节的偏移处 //得到文件中下一个字符并移动指针 printf( "Next char: %c\n", fgetc( file ) ); printf( "Next char: %c\n", fgetc( file ) ); fwrite( buf, 1, 2, file ); //覆盖了连个字符 fseek( file, 34, SEEK_SET ); //如果到达文件结尾,返回EOF(-1),需要通过ferror()或者feof()来区分 if ( fgetc( file ) == EOF && !feof( file ) ) { printf( "Failed to fgetc: %d", ferror( file ) ); } fseek( file, 25, SEEK_SET ); fputc( 'W', file ); //写入一个字符到文件流中 fflush( stdout ); char c = getchar(); //从标准输入中读取一个字符,等价于getc(stdin) fputc( c, file ); putchar( '\n' ); //写入一个字符到标准输出 memset( buf, 0, 64 ); //从文件流读取最多n个字符到缓冲区s中,如果遇到换行符、已经传输n-1字符、到达EOF,则终止 //该函数会把结尾的换行符,连同一个\0发送到缓冲区中,最多能读取n-1字符,因为必须包含\0 //返回缓冲区的指针,如果已经到达结尾,设置EOF标识并返回空指针;如果出错,返回空指针并设置EOF //char *fgets( char *s, int n, FILE *stream ); fflush( stdout ); fgets( buf, 32, file ); printf( "Result of fgets:%s\n", buf ); memset( buf, 0, 64 ); gets( buf ); //从标准输入中读取一行,丢弃结尾的换行符 //关闭文件流,使尚未写出的数据立即写出,因为stdio使用了缓冲机制,因此调用fclose很重要 fclose( file ); exit( 0 ); |
GNU C是由GNU Compiler Collection(GCC)实现的C。它兼容C89标准,实现了一部分C99特性,同时包含了一些特有的GNU扩展。默认情况下,GCC以C89 + GNU C扩展语法编译代码。
除了C89支持的关键字:
|
1 2 3 |
auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while |
之外,GNU扩展引入以下额外关键字:
| 关键字 | 说明 | ||
| __FUNCTION__ | 等价于C99的 __func__,包含当前函数名字的字符串 | ||
| __PRETTY_FUNCTION__ | 和上一个的区别仅仅对于C++函数,这个关键字打印C++函数的pretty签名 | ||
| __alignof __alignof__ |
用于查询变量的字节对齐边界:
|
||
| __asm __asm__ |
用于内联汇编,如果需要多个汇编指令,每行需要加引号,并以\n\t结尾:
|
||
| __attribute __attribute__ |
用于设置函数、变量或类型属性。支持的属性包括: at 将变量绝对定位到Flash或RAM的地址 aligned 设置结构体的字节对齐边界(几个字节对齐,即长度占用几个字节的整数倍) 这些属性可以前后加上双下划线,以防止头文件中有名字重复的宏定义,例如 __aligned__
|
||
| __builtin_offsetof | |||
| __builtin_expect |
将流水线引入CPU,让CPU可以预先取出下一条指令,提高CPU效率。错误的预取是浪费(分支判断错误)
|
||
| __builtin_va_arg | 用于实现可变参数 | ||
| __complex __complex__ |
用于支持复数 | ||
| __const | |||
| __extension__ | 使用-ansi选项时,抑制编译器对包含GCC扩展的头文件的警告 | ||
| __func__ | 函数名 | ||
| __imag __imag__ |
用于支持复数 | ||
| __inline __inline__ | 等价于inline | ||
| __label__ | 局部标签,允许所在作用域中的goto跳转到它。在宏定义中比较有用 | ||
| __null | 在g++中等价于C++11的nullptr | ||
| __real __real__ |
用于支持复数 | ||
| __restrict __restrict__ |
等价于C99的restrict。向编译器声明,在这个指针的生命周期中,只有这个指针本身或者直接由它产生的指针(例如 ptr + 1)能够用来访问该指针指向的对象。其作用是限制指针别名,帮助编译器做优化 | ||
| __signed __signed__ |
等价于signed | ||
| __thread | GNU C内置的线程本地变量支持:
|
||
| __typeof | 等价于typeof | ||
| __volatile __volatile__ |
等价于volatile |
|
1 2 3 |
# C99和GNU扩展都支持: long long int i = 1LL; unsigned long long int = 1ULL; |
|
1 2 3 4 5 6 7 8 9 |
# 复数支持,GNU扩展引入数据类型 __complex__ float __complex__ double __complex__ long double __complex__ int # 从复数中抽取实、虚部分,使用__real__、__imag__关键字 __complex__ float a = 4 + 3i; float b = __real__ a; /* b is now 4. */ float c = __imag__ a; /* c is now 3. */ |
GNU扩展支持零成员的结构体。这种结构体的size为零。
使用编译选项 -fpack-struct可以仅用结构体的字节边界对齐,结果可能是降低内存访问速度。
GNU扩展支持零长数组。用作可变长度对象的头的最后一个字段时有价值:
|
1 2 3 4 5 6 7 8 9 10 |
struct line { int length; char contents[0]; }; { struct line *this_line = (struct line *) malloc (sizeof (struct line) + this_length); this_line -> length = this_length; } |
GNU扩展允许用变量作为数组长度:
|
1 2 3 4 |
int my_function (int number) { int my_array[number]; } |
GNU扩展、C99支持乱序初始化数组元素:
|
1 2 3 4 |
int my_array[5] = { [2] 5, [4] 9 }; int my_array[5] = { [2] = 5, [4] = 9 }; # 上面两种语法等价 int my_array[5] = { 0, 0, 5, 0, 9 }; |
GNU扩展支持范围的初始化一系列元素:
|
1 |
int new_array[100] = { [0 ... 9] = 1, [10 ... 98] = 2, 3 }; |
这是C语言中唯一能够用来定义包含多行语句操作的宏的结构。示例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// __VA_ARGS__ 表示后续参数列表,与 ... 对应 #define FAIL_IF_ERROR( cond, ... )\ do\ {\ if( cond )\ {\ fprintf( stderr, __VA_ARGS__ );\ goto fail;\ }\ } while( 0 ) // 调用此宏的语法很自然: FAIL_IF_ERROR( 0, "err" ); // 如果去掉外围的do-while-0,则需要这样调用(尾部不应该有;) FAIL_IF_ERROR( 0, "err" ) |
|
1 2 3 4 5 6 7 8 9 10 11 |
do { // do something if ( error ) { break; } // do something else if ( error ) { break; } // etc.. } while ( 0 ); |
Leave a Reply