基于Rook的Kubernetes存储方案
Rook是专用于Cloud-Native环境的文件、块、对象存储服务。它实现了一个自我管理的、自我扩容的、自我修复的分布式存储服务。
Rook支持自动部署、启动、配置、分配(provisioning)、扩容/缩容、升级、迁移、灾难恢复、监控,以及资源管理。 为了实现所有这些功能,Rook依赖底层的容器编排平台。
Rook在初期专注于Kubernetes+Ceph。Ceph是一个分布式存储系统,支持文件、块、对象存储,在生产环境中被广泛应用。
{kind=link}
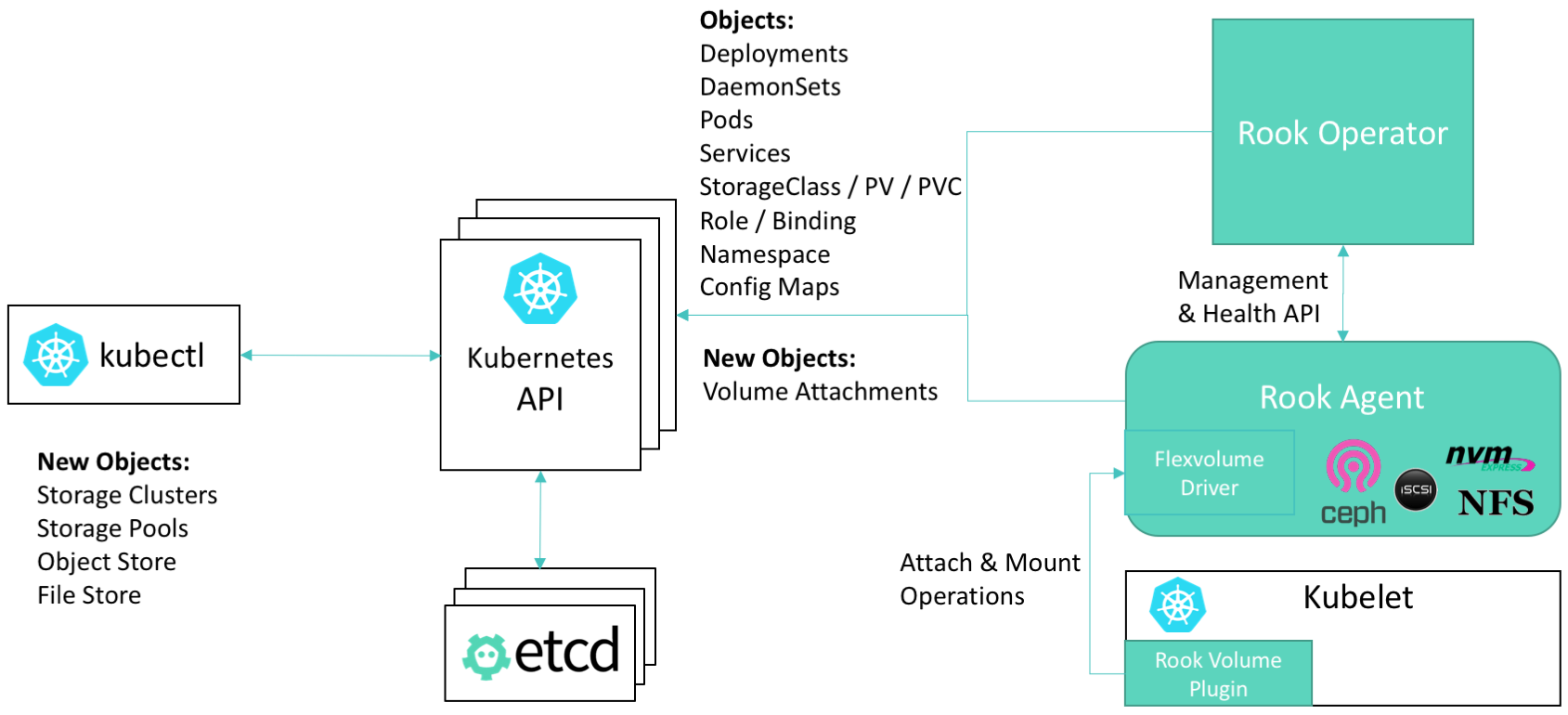
说明如下:
- Kubelet是K8S节点上运行的代理程序,负责挂载当前节点的Pod所需要的卷
- Rook提供了一种卷插件,扩展了K8S的存储系统。Pod可以挂载Rook管理的块设备或者文件系统
- Operator启动并监控:监控Ceph的Pods、OSD(提供基本的RADOS存储)的Daemonset。Operator还管理CRD、对象存储(S3/Swift)、文件系统。Operator通过监控存储守护程序,来保障集群的健康运行。Ceph监控Pod会自动启动和Failover。集群扩缩容时Operator会进行相应的调整
- Operator还负责创建Rook Agent。这些代理是部署在所有K8S节点上的Pod。每个代理都配置一个Flexvolume驱动,此驱动和K8S的卷控制框架集成。节点上的所有存储相关操作(例如添加网络存储设备、挂载卷、格式化文件系统)都Agent负责
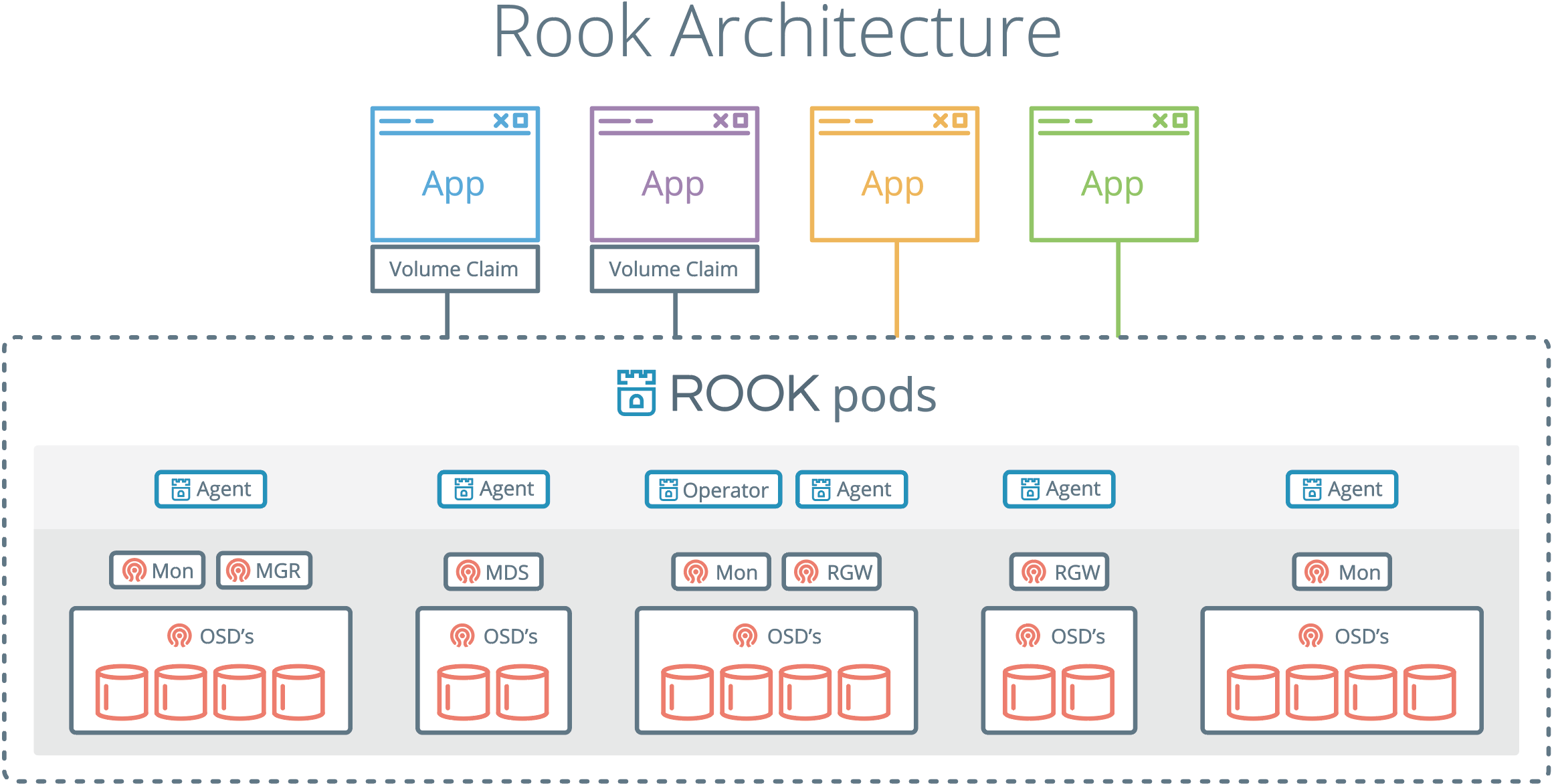
Rook守护程序(Mons, OSDs, MGR, RGW, MDS)被编译到单体的程序rook中,并打包到一个很小的容器中。该容器还包含Ceph守护程序,以及管理、存储数据所需的工具。
Rook隐藏了Ceph的很多细节,而向它的用户暴露物理资源、池、卷、文件系统、Bucket等概念。
要使用rook-ceph,必须满足:
- Kubernetes 1.11+版本
- 节点提供以下本地存储之一:
- 裸设备(没有分区、文件系统)
- 裸分区(没有文件系统),可以 lsblk -f查看,如果 FSTYPE不为空说明有文件系统
- 来自block模式的StorageClass提供的PV
使用下面的命令,创建一个简单的Rook集群:
|
1 2 3 4 5 |
git clone --single-branch --branch release-1.4 https://github.com/rook/rook.git cd rook/cluster/examples/kubernetes/ceph kubectl create -f common.yaml kubectl create -f operator.yaml kubectl create -f cluster.yaml |
集群启动后,你可以创建块/对象/文件系统存储。
一般情况下,使用Rook Operator来管理Rook集群,下面的命令安装此Operator:
|
1 2 3 4 5 |
cd cluster/examples/kubernetes/ceph kubectl create -f common.yaml kubectl create -f operator.yaml kubectl -n rook-ceph get pod |
你也可以通过Helm Chart安装:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
helm repo add rook-release https://charts.rook.io/release # Helm 3 helm install --namespace rook-ceph rook-ceph rook-release/rook-ceph # Helm 2 helm install --namespace rook-ceph --name rook-ceph rook-release/rook-ceph # 参数示例 helm install --namespace rook-ceph rook-ceph rook-release/rook-ceph \ --set image.repository=docker.gmem.cc/rook/ceph,logLevel=DEBUG \ --set csi.cephcsi.image=docker.gmem.cc/cephcsi/cephcsi:v3.1.0 \ --set csi.registrar.image=docker.gmem.cc/k8scsi/csi-node-driver-registrar:v1.2.0 \ --set csi.resizer.image=docker.gmem.cc/k8scsi/csi-resizer:v0.4.0 \ --set csi.provisioner.image=docker.gmem.cc/k8scsi/csi-provisioner:v1.6.0 \ --set csi.snapshotter.image=docker.gmem.cc/k8scsi/csi-snapshotter:v2.1.1 \ --set csi.attacher.image=docker.gmem.cc/k8scsi/csi-attacher:v2.1.0 |
使用自定义资源CephCluster来创建Rook Ceph集群:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
# 使用宿主机上的块设备 apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph namespace: rook-ceph spec: cephVersion: image: ceph/ceph:v15.2.4 dataDirHostPath: /var/lib/rook mon: count: 3 allowMultiplePerNode: true storage: useAllNodes: true useAllDevices: true # 使用PVC创建块设备 apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph namespace: rook-ceph spec: cephVersion: image: ceph/ceph:v15.2.4 dataDirHostPath: /var/lib/rook mon: count: 3 volumeClaimTemplate: spec: storageClassName: local-storage resources: requests: storage: 10Gi storage: storageClassDeviceSets: - name: set1 count: 3 portable: false tuneDeviceClass: false encrypted: false volumeClaimTemplates: - metadata: name: data spec: resources: requests: storage: 10Gi storageClassName: local-storage volumeMode: Block accessModes: - ReadWriteOnce # 使用特定设备 apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph namespace: rook-ceph spec: cephVersion: image: ceph/ceph:v15.2.4 dataDirHostPath: /var/lib/rook mon: count: 3 allowMultiplePerNode: true dashboard: enabled: true # cluster level storage configuration and selection storage: useAllNodes: false useAllDevices: false deviceFilter: config: metadataDevice: databaseSizeMB: "1024" # this value can be removed for environments with normal sized disks (100 GB or larger) nodes: - name: "172.17.4.201" devices: # specific devices to use for storage can be specified for each node - name: "sdb" # Whole storage device - name: "sdc1" # One specific partition. Should not have a file system on it. - name: "/dev/disk/by-id/ata-ST4000DM004-XXXX" # both device name and explicit udev links are supported config: # configuration can be specified at the node level which overrides the cluster level config storeType: bluestore - name: "172.17.4.301" deviceFilter: "^sd." |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 |
apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: # 内部名称,一般使用命名空间的名字,因为同一个命名空间仅仅支持一个集群 name: rook-ceph namespace: rook-ceph spec: # Rook可以连接到外部Ceph集群,而不是在K8S集群中创建自己管理的Ceph集群 external: # 使用外部集群(最低luminous 12.2.x),仅仅作为集群消费者。这种情况下,Rook仍然能够在K8S中创建 # 对象网关、MDS、NFS组件 # 除了cephVersion.image、dataDirHostPath之外的其它选项,都被忽略 # # Rook特性要求的Ceph版本 # 动态分配RBD:12.2.X # 配置额外的CR(object,file,nfs):13.2.3 # 动态分配CephFS:14.2.3 enabled: true # Ceph守护程序的版本信息 cephVersion: # 用于运行Ceph守护进程的镜像 image: ceph/ceph:v15.2.4 # 如果true则允许使用不支持的major Ceph版本 # 目前支持nautilus( 14.2.0 )、octopus( 15.2.0 ) allowUnsupported: true # 宿主机上的路径,在此路径下存储各Ceph服务的配置和数据 dataDirHostPath: /var/lib/rook # 如果设置为true,则升级时不会检查Ceph守护程序的新版本 skipUpgradeChecks: false # Ceph仪表盘设置 dashboard: # 启用仪表盘,以查看集群状态 enabled: true # URL前缀,反向代理场景下有用 urlPrefix: # 仪表盘端口 port: # 使用使用SSL,13.2.2+ ssl: true # 基于Prometheus的监控配置 monitoring: enabled: true # 部署PrometheusRule的命名空间,默认此CR所在命名空间 rulesNamespace: # 集群网络设置,如果不指定,使用默认的SDN network: # 可选 host multus(为Pod添加多个接口的开源项目,试验性支持) provider: host # 网络选择器,选择器的值必须匹配Multus的NetworkAttachmentDefinition对象 selectors # 客户端通信(读写)使用的网络 public: # 集群内部流量使用的网络 cluster: mon: # mon pod的数量 count: 3 # 允许在单个节点上部署多个mon pod allowMultiplePerNode: true # 用于创建mon存储的PersistentVolumeSpec,如果不支持,使用HostPath卷 volumeClaimTemplate: mgr: # 启用的mgr模块列表 modules: crashCollector: # 禁用crash collector,不再每个运行了Ceph守护进程的节点上创建crash collector pod disable: true # 针对所有节点的存储设备选择和配置,各节点可以覆盖 storage: # 是否将集群中所有节点作为Ceph节点。如果你使用nodes字段,必须设置为false useAllNodes: true # 按节点配置存储 nodes: # 匹配kubernetes.io/hostname的节点名 - name: xenial-100 devices: - name: sdb - name: sdc1 config: # 用于存放OSD元数据的设备名,使用低延迟设备例如SSD/NVMe可以提升性能 metadataDevice: # OSD的底层存储格式 storeType: bluestore # Bluestore WAL日志大小 walSizeMB: # Bluestore 数据库的大小 databaseSizeMB: # CRUSH设备类,如果不指定,Ceph会自动设置为hdd ssd nvme之一 deviceClass: # 设置各设备运行OSD的数量,NVMe这样的高性能设备可以运行多个OSD osdsPerDevice**: # 设置各设备是否使用dmcrypt加密 encryptedDevice**: # 是否自动将所有发现的裸设备/分区作为OSD useAllDevices: true # 参与OSD的设备,过滤表达式: # sdb 仅仅sdb # ^sd. 任何sd开头的设备 # ^[^r] 任何不以r开头的设备 # ^sd[a-d] sda sdb sdc sdd # ^s 任何s开头的设备 deviceFilter: sdb # 参与OSD的设备 devices: # sdb这样的设备名,或者udev的完整路径,例如/dev/disk/by-id/ata-ST4000DM004-XXXX - name: # 参见上面的config config: # 参见上面的config config: # 为各种Ceph组件添加的注解 annotations: all: mgr: mon: osd: # 为各种Ceph组件添加的亲和性设置 placement: mgr: nodeAffinity: podAffinity: podAntiAffinity: tolerations: topologySpreadConstraints: mon: osd: cleanup: all: # 为各种Ceph组件进行资源配额 resources: mon: requests: cpu: memory: limits: mgr: osd: mds: prepareosd: crashcollector: # 健康检查配置 healthCheck: daemonHealth: mon: disabled: false interval: 45s timeout: 600s osd: disabled: false interval: 60s status: disabled: false livenessProbe: mon: disabled: false mgr: disabled: false osd: disabled: false # 各组件的优先级类别名 priorityClassNames: # 删除CephCluster对象是,如何清理数据 cleanupPolicy: # kubectl -n rook-ceph patch cephcluster rook-ceph --type merge \ # -p '{"spec":{"cleanupPolicy":{"confirmation":"yes-really-destroy-data"}}}' # 仅仅当你要删除CephCluster时,才设置该字段。可选空值或者yes-really-destroy-data # 空值:仅仅删除Ceph元数据,除非你手工清理主机,否则无法重新安装CephCluster # yes-really-destroy-data:RookOperator回自动删除宿主机上的目录,清理宿主机上的块设备 confirmation: yes-really-destroy-data # yes-really-destroy-data时如何清理磁盘 sanitizeDisks: # 仅仅清理元数据,还是消毒整个磁盘 method: quick | complete # 消毒磁盘使用的随机字节来源 dataSource: zero | random # 反复消毒多次 iteration: 1 |
为了使用外部Ceph集群,Rook需要知道如何连接到Ceph。你可以通过脚本导入Rook需要的信息:
|
1 2 3 4 5 6 7 8 9 10 11 |
# 信息导入到什么命名空间 export NAMESPACE=rook-ceph-external # 外部集群的FSID export ROOK_EXTERNAL_FSID=3240b4aa-ddbc-42ee-98ba-4ea7b2a61514 # 外部集群的MON信息 export ROOK_EXTERNAL_CEPH_MON_DATA=a=172.17.0.4:6789 # 外部集群的管理Keyring export ROOK_EXTERNAL_ADMIN_SECRET=AQC6Ylxdja+NDBAAB7qy9MEAr4VLLq4dCIvxtg== # 执行导入 bash cluster/examples/kubernetes/ceph/import-external-cluster.sh |
然后,创建使用外部集群的CephCluster对象:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph-external # 命名空间和上面对应 namespace: rook-ceph-external spec: external: enable: true crashCollector: disable: true # 可选的,使用外部ceph-mgr暴露的Prometheus Exporter monitoring: enabled: true rulesNamespace: rook-ceph externalMgrEndpoints: - ip: 192.168.39.182 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 定义一个块存储池 apiVersion: ceph.rook.io/v1 kind: CephBlockPool metadata: # 池的名字 name: replicapool namespace: rook-ceph spec: failureDomain: host replicated: size: 3 --- # 定义一个StorageClass apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-block # 该SC的Provisioner标识,rook-ceph前缀即当前命名空间 provisioner: rook-ceph.rbd.csi.ceph.com parameters: # clusterID 就是集群所在的命名空间名 clusterID: rook-ceph # RBD镜像在哪个池中创建 pool: replicapool # RBD镜像格式,默认2 imageFormat: "2" # RBD镜像格式为2时,指定镜像特性,CSI RBD目前仅仅支持layering imageFeatures: layering # Ceph管理凭证配置 csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # 卷的文件系统类型,默认ext4,不建议xfs,因为存在潜在的死锁问题(超融合设置下卷被挂载到相同节点作为OSD时) # will set default as `ext4`. Note that `xfs` is not recommended due to potential deadlock csi.storage.k8s.io/fstype: ext4 # PVC被删除后,删除对应的RBD卷 reclaimPolicy: Delete |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: ceph.rook.io/v1 kind: CephBlockPool metadata: # 存储池的名称,会反映到底层Ceph name: replicapool namespace: rook-ceph spec: # 每个数据副本必须跨越不同的故障域分布,如果设置为host,则保证每个副本在不同机器上 failureDomain: host # 复制/纠删码,二选一 replicated: # 副本数量 size: 3 # 如果需要设置副本数量为1,则必须将该字段置为false requireSafeReplicaSize: false erasureCoded: dataChunks: 2 codingChunks: 1 # CRUSH设备类别,说明该池中的数据可以存放在哪些设备上 deviceClass: hdd # 该池使用的CRUSH map中的根节点 crushRoot: # 通过启用动态OSD性能计数器,从而实现per-rbd的IO统计 enableRBDStats: # 为存储池传递参数 # 可用参数参考 https://docs.ceph.com/docs/master/rados/operations/pools/#set-pool-values parameters: # 给Ceph一个提示,说明该池期望消耗集群的最大多少容量 target_size_ratio: # Bluestore压缩模式 compression_mode: |
目前,对多文件系统的支持仍然处于试验阶段,需要通过Rook Operator的环境变量 ROOK_ALLOW_MULTIPLE_FILESYSTEMS开启。默认情况下,一个Ceph集群仅仅支持单个文件系统。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# 定义文件系统 apiVersion: ceph.rook.io/v1 kind: CephFilesystem metadata: name: myfs namespace: rook-ceph spec: # 元数据池配置 metadataPool: replicated: size: 3 # 数据池配置 dataPools: - replicated: size: 3 # 该对象删除后,Ceph存储池怎么办 preservePoolsOnDelete: true # 元数据服务器一主一备 metadataServer: activeCount: 1 activeStandby: true --- # 定义一个StorageClass apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-cephfs # 注意前缀匹配Operator的命名空间 provisioner: rook-ceph.cephfs.csi.ceph.com parameters: # Operator所在命名空间,就是Ceph集群的ID clusterID: rook-ceph # CephFS 文件系统名 fsName: myfs # CephFS卷在哪个存储池中创建,如果provisionVolume: "true" 则此字段必须 pool: myfs-data0 # 可以使用既有的CephFS卷,需要指定卷的根路径 # 如果 provisionVolume: "false" 则此字段必须 rootPath: /absolute/path # 这些Ceph管理凭证由Operator自动生成 csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph reclaimPolicy: Delete |
CephFS的CSI驱动使用Quotas来强制应用PVC声明的大小,仅仅4.17+内核才能支持CephFS quotas。
如果内核不支持,而且你需要配额管理,配置Operator环境变量 CSI_FORCE_CEPHFS_KERNEL_CLIENT: false来启用FUSE客户端。
使用FUSE客户端时,升级Ceph集群时应用Pod会断开mount,需要重启才能再次使用PV。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
apiVersion: ceph.rook.io/v1 kind: CephFilesystem metadata: name: myfs namespace: rook-ceph spec: # 存放元数据的池的配置 metadataPool: failureDomain: host replicated: size: 3 # 存放数据的池的配置 dataPools: - failureDomain: host replicated: size: 3 # 删除该对象后,底层的存储池是否保留 preservePoolsOnDelete: true # 元数据服务器配置 metadataServer: # 主备元数据服务器数量 activeCount: 1 activeStandby: true # 注解 annotations: key: value # 亲和性 placement: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: role operator: In values: - mds-node tolerations: - key: mds-node operator: Exists podAffinity: podAntiAffinity: topologySpreadConstraints: # 配额 resources: limits: cpu: "500m" memory: "1024Mi" requests: cpu: "500m" memory: "1024Mi" |
Rook支持在集群内部创建一个支持S3接口的RGW网关:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 这个示例需要3个位于不同节点的Bluestore OSD apiVersion: ceph.rook.io/v1 kind: CephObjectStore metadata: name: my-store namespace: rook-ceph spec: metadataPool: failureDomain: host replicated: size: 3 dataPool: # 故障域设置为host,则意味着三个副本必须位于不同节点,也就是说需要3个节点 failureDomain: host # 使用纠删码方式,三副本中2个用作dataChunks,一个用于codingChunks erasureCoded: dataChunks: 2 codingChunks: 1 preservePoolsOnDelete: true gateway: type: s3 sslCertificateRef: port: 80 securePort: instances: 1 healthCheck: bucket: disabled: false interval: 60s |
Rook也可以直接连接到外部的RGW网关:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
apiVersion: ceph.rook.io/v1 kind: CephObjectStore metadata: name: external-store namespace: rook-ceph spec: gateway: port: 8080 externalRgwEndpoints: - ip: 192.168.39.182 healthCheck: bucket: enabled: true interval: 60s |
有了对象存储后,还需要创建Bucket,以便客户端读写数据。
你需要定义一个StorageClass,定义了基于此StorageClass创建的桶的回收策略、所依赖的对象网关:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-bucket # rook-ceph前缀必须和命名空间对应 provisioner: rook-ceph.ceph.rook.io/bucket # ObjectBucketClaim被删除后,删除RGW中的桶 reclaimPolicy: Delete parameters: # 底层对象存储的信息 objectStoreName: my-store objectStoreNamespace: rook-ceph region: us-east-1 |
有了上述StorageClass后,就可以使用下面的CR来创建Bucket:
|
1 2 3 4 5 6 7 8 9 10 |
apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: ceph-bucket namespace: default spec: # 生成的桶的名称 generateBucketName: ceph-bkt # 基于的StorageClass storageClassName: rook-ceph-bucket |
Rook Operator会创建名为ceph-bkt的桶,还会在ObjectBucketClaim所在命名空间下,创建和ObjectBucketClaim名字相同的:
- Configmap:包含Bucket的地址
- Secret:包含访问Bucket所需要的凭证信息
其中,Configmap内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: v1 data: BUCKET_HOST: rook-ceph-rgw-rgw.rook-ceph BUCKET_NAME: tcnp-5aca27d8-f74f-4687-b979-e336f4203459 BUCKET_PORT: "9000" BUCKET_REGION: "" BUCKET_SUBREGION: "" kind: ConfigMap metadata: name: ceph-bucket namespace: default |
Secret的内容如下:
|
1 2 3 4 5 6 7 8 9 |
apiVersion: v1 data: AWS_ACCESS_KEY_ID: RjZFRVUyTkUwWEZCWDRJVFgwWkE= AWS_SECRET_ACCESS_KEY: TUVPVU1panBFekM5emNQaDR2UkE3bHRwcFlaSnEzeGxFMmRmUFBQbw== kind: Secret metadata: name: ceph-bucket namespace: default type: Opaque |
如果你希望创建独立的访问S3端点的用户,可以使用下面的CR:
|
1 2 3 4 5 6 7 8 9 |
apiVersion: ceph.rook.io/v1 kind: CephObjectStoreUser metadata: name: my-user namespace: rook-ceph spec: # 对象存储的名字 store: my-store displayName: "my display name" |
Access Key和Secret Key 会创建到相同命名空间。
将rook-ceph-rgw-**服务暴露出去即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
apiVersion: ceph.rook.io/v1 kind: CephObjectStore metadata: # 对象存储的名字,影响相关Pod、其它资源的命名 name: rgw namespace: rook-ceph spec: # 用于对象存储元数据的池,必须使用replicated方式 metadataPool: failureDomain: host replicated: size: 3 # 用于对象存储数据的池,可以使用纠删码方式 dataPool: failureDomain: host erasureCoded: dataChunks: 2 codingChunks: 1 # 当前对象删除时,用于支持对象存储的池,是否被删除 preservePoolsOnDelete: true gateway: # 目前仅仅支持s3 type: s3 # 必须指定证书才能配置SSL,包含SSL证书的Secret名称 sslCertificateRef: # RGW Pod的HTTP端口 port: 80 # RGW Pod的HTTPS端口 securePort: # RGW Pod的数量 instances: 1 # 添加到RGW Pod的注解 annotations: key: value # 亲和性配置 placement: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: role operator: In values: - rgw-node tolerations: - key: rgw-node operator: Exists podAffinity: podAntiAffinity: topologySpreadConstraints: # 资源配额 resources: limits: cpu: "500m" memory: "1024Mi" requests: cpu: "500m" memory: "1024Mi" |
报错信息:failed to configure devices. failed to config osd 65. failed format/partition of osd 65. failed to partion device vdc. failed to partition /dev/vdc. Failed to complete partition vdc: exit status 4
报错原因:在我的环境下是节点(本身是KVM虚拟机)的虚拟磁盘太小导致,分配32G的磁盘没有问题,20G则出现上述报错
重启后出现,原因是逻辑卷没有激活,lsblk看到的块设备列表中没有Ceph管理的逻辑卷。执行:
|
1 2 3 4 5 6 7 |
# yum install lvm2 modprobe dm-mod # 扫描可用的卷组 vgscan # 激活逻辑卷 vgchange -ay |
进行激活,然后可以在/dev/mapper、/dev/VGNAME下看到块设备了,OSD也可以启动了。
如果块设备上已经有了文件系统,则无法prepare OSD。这个在重装Rook的情况下容易出现。需要手工清除磁盘:
|
1 2 3 4 5 6 |
wipefs --all /dev/vdb dmsetup remove ceph--164d13ee--d820--4da3--ac66--d1b2d83d8a28-osd--data--c29cedc6--f8ce--4e4b--b88b--4c7272866180 # 或者更优雅的 vgremove ceph-1fd08944-b4e0-4839-82a9-62ecc6f5861e wipefs --all /dev/vdb |
rook 现在已经被cncf认证了
前些日子试验觉得不是很稳定,因此我们直接使用Ceph作为存储了。相信rook会很快完善。
请问,在Kubernetes集群中添加了node节点以后,怎么实现添加rook-ceph-agent和rook-discover
不好意思,由于rook不太成熟,我们直接使用ceph了,因此最近没有跟进rook。
我打算把rook应用到测试环境中去,等rook在CNCF中毕业之后实现正式落地