Kubernetes学习笔记
Kubernates(发音 / kubə'neitis /,简称K8S)是一个容器编排工具,使用它可以自动化容器的部署、扩容、管理。使用K8S可以将应用程序封装为容易管理、发现的逻辑单元。使用K8S你可以打造完全以容器为中心的开发环境。
K8S的特性包括:
- 自动装箱:根据容器的资源需求和其他约束条件,自动部署容器到合适的位置,与此同时,不影响可用性。K8S可以混合管理关键负载、非关键负载并尽可能的有效利用资源
- 自我修复:当容器宕掉后自动重启它,当节点宕掉后重新调度容器。关闭不能正确响应自定义健康检查的容器,在容器准备好提供服务之前,不将他们暴露给客户端
- 水平扩容:手工(UI、命令行)或自动(根据CPU负载)进行自动的扩容/缩容
- 服务发现/负载均衡:不需要修改应用程序来使用第三方的服务发现机制,K8S为容器提供专有IP,同时为一组容器(类似Swarm中的Service)提供单一的DNS名称,应用程序可以基于DNS名称发现服务。K8S还内置的负载均衡支持
- 无缝滚动更新/回滚:支持逐步的将更新应用到程序或配置,与此同时监控程序的健康状况,避免同时杀死程序的所有实例。如果出现问题,K8S能够自动回滚更新
- 密码和配置管理:部署、更新应用程序的密码、配置信息时,不需要重新构建镜像,不需要在配置信息中暴露密码信息
- 存储编排:自动从本地磁盘、公有云、网络存储系统挂载存储系统
- 资源监控、访问并处理日志、调试应用、提供认证和授权功能……
K8S提供了PaaS的简单性、IaaS的灵活性,支持在各基础设施提供商之间迁移。
尽管K8S提供了部署、扩容、负载均衡、日志、监控等服务,但是它并不是传统的PaaS平台:
- 它不限制能支持的应用程序类型,不限制编程语言、SDK。只要应用能在容器中运行,就可以在K8S下运行
- 不内置中间件(例如消息总线)、数据处理框架(例如Spark)、数据库、或者存储系统
- 不提供服务市场来下载服务
- 允许用户选择日志、监控、报警系统
同时,很多PaaS平台可以运行在K8S之上,例如OpenShift、Deis,你可以在K8S上部署自己的PaaS平台,集成自己喜欢的CI环境,或者仅仅是部署容器镜像。
以Kubernetes为核心的技术生态圈,已经成为构建云原生架构的基石。
云原生架构没有权威的定义,但是基于这种架构的应用具有一系列的模式:
- 代码库:每个可部署的应用程序,都有独立的代码库,可以在不同环境部署多个实例
- 明确的依赖:应用程序的依赖应该基于适当的工具(例如Maven、Bazel)明确的声明,不对部署环境有任何依赖
- 配置注入:和发布环境(dev/stage/pdt)变化的配置信息,应该以操作系统级的环境变量注入
- 后端服务:数据库、消息代理应视为附加资源,并在所有环境中同等看待
- 编译、发布、运行:构建一个可部署的应用程序并将它与配置绑定,根据这个组件/配置的组合来启动一个或者多个进程,这两个阶段是严格分离的
- 进程:应用程序运行一个或多个无状态进程,不共享任何东西 —— 任何状态存储于后端服务
- 端口绑定:应用程序是独立的,并通过端口绑定(包括HTTP)导出任何服务
- 并发:并发通常通过水平扩展应用程序进程来实现
- 可任意处置:通过迅速启动和优雅的终止进程,可以最大程度上的实现鲁棒性。这些方面允许快速弹性缩放、部署更改和从崩溃中恢复
- 开发/生产平等:通过保持开发、预发布和生产环境尽可能的一致来实现持续交付和部署
- 日志:不管理日志文件,将日志视为事件流,允许执行环境通过集中式服务收集、聚合、索引和分析事件
- 管理任务:管理性的任务,例如数据库迁移,应该在应用程序运行的那个环境下,一次性的执行
关键字:环境解耦、无状态、微服务。
两者之间存在高度的功能重叠,例如服务发现、负载均衡。
Swarm的功能比K8S要弱的多,可以实现简单的负载均衡、HA等特性,小规模部署可以使用。


K8S网络包括CNI、Service网络、Ingress、DNS这几个方面的内容:
- CNI负责Pod到Pod的网络连接
- Service网络负责Pod到Service的连接
- Ingress负责外部到集群的访问
- DNS负责解析集群内部域名
取决于具体实现,节点可能可以直接访问CNI、Service的IP地址。
Pod到集群外部的访问,基于SNAT实现。
Pod在节点内部的连接,经典方案是veth pair + bridge,也就是说多个Pod会连接到同一个网桥上,实现互联。
Pod在节点之间的连接,经典方案是bridge、overlay,Calico等插件则基于虚拟路由。
Kubernetes容器网络由Kubenet或CNI插件负责,前者未来会被废弃。
Kubenet是K8S早期的原生网络驱动,提供简单的单机容器网络。需要用Kubelet参数 --network-plugin=kubenet启用。
Kubenet本身不实现跨节点网络连接、网络策略,它通常和云提供商一起使用来实现路由规则配置、跨主机通信。Kubenet也用到一些CNI的功能,例如它基于CNI bridge插件创建名为cbr0的Linux Bridge,为每个容器创建一对veth pair并连接到cbr0网桥。
Kubenet在CNI插件的基础上拓展了很多功能:
- 基于host-local IP地址管理插件,为Pod分配IP地址并定期释放分配而未使用的IP
- 设置sysctl的net.bridge.bridge-nf-call-iptables=1
- 为Pod的IP设置SNAT(MASQUERADE),以允许Pod 访问外部网络
- 开启Linux Bridge的hairpin、混杂模式,允许Pod访问自己所在的Service IP
- HostPort管理、设置端口映射
- 带宽控制。可以通过kubernetes.io/ingress-bandwith、kubernetes.io/egress-bandwith来配置Pod网络带宽限制
Kubenet会使用bridge、lo、host-local等几个CNI插件,默认在/opt/cni/bin中搜索这些插件的二进制文件。你可以通过--network-plugin-dir参数定制搜索位置。此外Kubenet来回去/etc/cni/net.d中搜索CNI配置文件。
支持通过Kubelet参数--network-plugin-mtu定制MTU,支持限制带宽。这两个特性是Kubenet不能被CNI完全代替的原因。
CNI是容器网络的标准,试图通过一段JSON来描述容器网络配置。CNI是K8S和底层网络插件之间的抽象层。
CNI包含以下接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
type CNI interface { AddNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) (types.Result, error) CheckNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error DelNetworkList(ctx context.Context, net *NetworkConfigList, rt *RuntimeConf) error GetNetworkListCachedResult(net *NetworkConfigList, rt *RuntimeConf) (types.Result, error) GetNetworkListCachedConfig(net *NetworkConfigList, rt *RuntimeConf) ([]byte, *RuntimeConf, error) AddNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) (types.Result, error) CheckNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) error DelNetwork(ctx context.Context, net *NetworkConfig, rt *RuntimeConf) error GetNetworkCachedResult(net *NetworkConfig, rt *RuntimeConf) (types.Result, error) GetNetworkCachedConfig(net *NetworkConfig, rt *RuntimeConf) ([]byte, *RuntimeConf, error) ValidateNetworkList(ctx context.Context, net *NetworkConfigList) ([]string, error) ValidateNetwork(ctx context.Context, net *NetworkConfig) ([]string, error) } type RuntimeConf struct { ContainerID string NetNS string IfName string Args [][2]string // A dictionary of capability-specific data passed by the runtime // to plugins as top-level keys in the 'runtimeConfig' dictionary // of the plugin's stdin data. libcni will ensure that only keys // in this map which match the capabilities of the plugin are passed // to the plugin CapabilityArgs map[string]interface{} // DEPRECATED. Will be removed in a future release. CacheDir string } type NetworkConfig struct { Network *types.NetConf Bytes []byte } |
AddNetwork负责在创建容器时,进行网络接口的配置;DelNetwork则在删除容器时,清理掉网络接口。参数NetworkConfig是网络配置信息,RuntimeConf则是容器运行时传入的网络命名空间信息。
CNI配置编写在如下形式的JSON文件中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ name: "mynet", // 使用bridge CNI插件 type: "bridge", bridge: "cni0", ipam: { // 基于host-local插件进行IP地址管理 type: "host-local", subnet: "10.0.0.0/16", routes: [ { "dst": "0.0.0.0/0" } ] } } |
上述配置文件,默认需要存在/etc/cni/net.d目录下,并且命名为*.conf,对应的插件二进制文件默认需要存放在/opt/cni/bin下。
在K8S中启用基于CNI的网络插件,需要配置Kubelet参数 --network-plugin=cni。CNI配置文件位置通过参数 --cni-conf-dir配置,如果目录中存在多个配置文件则仅仅取第一个。CNI插件二进制文件位置通过 --cni-bin-dir配置。
K8S对象是指运行在K8S系统中的持久化实体,K8S使用这些实体来表示你的应用集群的状态。例如:
- 哪些容器化应用程序在执行,在何处(Node)执行
- 上述应用程序可用的资源情况
- 和应用程序行为有关的策略,例如重启策略、升级策略、容错策略
通过创建一系列对象,你可以告诉K8S,你的集群的负载是什么样的,所谓集群的期望状态(desired state)。
要创建/修改/删除K8S对象,可以调用Kubernetes API。提供命令行kubectl可以间接的调用此API,你也可以在程序中调用这些API,目前支持Go语言。
K8S对象包括:
- Pod、Service、Volume、Namespace等基本对象
- ReplicaSet、Deployment、StatefulSet、DaemonSet、Job等高级对象,这些高级对象在上述基本对象之上构建,并且提供了额外功能、便利化功能
本章不会一一解释这些不同类型的对象。
任何K8S对象都有两个内嵌的字段:规格、状态。前者由你提供,声明对象期望状态(所谓对象的期望状态即集群的期望状态)。后者则表示某一时刻对象的实际状态,此状态由K8S更新,K8S控制平面会积极的管理对象的状态,使其尽可能满足规格。
例如,Kubernetes Deployment是描述运行在集群中的一个应用程序的K8S对象。你创建一个Deployment时,可能在规格中声明你需要3个应用程序的Replica。K8S会读取规格并启动3个应用实例,如果一段时间后宕掉1个实例,则K8S会检测到Spec和Status之间的不同,进而启动一个新的实例代替宕掉的那个。
调用K8S API创建对象时,你需要提供一个JSON格式的规格说明,其中包含期望状态和一些基本信息(例如应用的名称)。
通过kubectl创建对象时,你需要提供一个YML文件,kubectl会自动将其转换为JSON格式。
下面是对象规格(YML)的一个示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 如果K8S版本小于1.8则使用 apps/v1beta1 apiVersion: apps/v1beta2 # 对象类型 kind: Deployment # 对象元数据,唯一的识别对象,字段包括name、UID、namespace metadata: # 名字通常由客户端提供,每一个对象类型内部,名字不得重复。在资源URL中名字用于引用对象,例如/api/v1/pods/some-name # 名字应该仅仅包含小写字母、数字、-、.这几类字符 name: nginx-deployment # UID由K8S自动生成,全局唯一 # namespace 指定对象所属的名字空间 # 对象规格 spec: replicas: 3 # 标签选择器 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 # 端口名称,可以被Service引用 name: web protocol: TCP # 标签 labels: ... |
基于上述规格创建对象的命令示例:
|
1 |
kubectl create -f https://blog.gmem.cc/nginx-deployment.yaml --record |
K8S支持在一个物理集群上,创建多个虚拟集群,这些虚拟集群称为名字空间。名字空间为资源名称限定了作用域,同一名字空间内部名字不能重复,但是跨越名字空间则不受限制。
可以考虑使用名字空间的场景:
- 当跨越多个团队/项目的人员共享一套集群时,可以考虑使用名字空间机制。如果使用集群的人员仅仅在数十个级别,不需要使用名字空间
- 希望利用K8S的资源配额机制,在名字空间之间划分集群资源
- 在未来版本的K8S中,同一名字空间中的对象将具有一致的默认范围控制策略
如果两个资源仅仅有些许的不同,例如应用的两个版本,则不需要利用名字空间隔离。考虑使用标签(Label)来在名字空间内部区分这些资源。
大部分K8S资源(Pod、Service、Replication Controller...)都位于名字空间中。但是名字空间本身(也是资源)则不位于任何名字空间中。事件(Event)则可能位于、也可能不位于名字空间中,取决于事件的源对象。
执行下面的命令可以查看集群中现有的名字空间:
|
1 2 3 4 5 |
kubectl get namespaces # NAME STATUS AGE # default Active 1d # kube-system Active 1d # kube-public Active 1d |
上述命令输出了3个名字空间:
| 名字空间 | 说明 |
| default | 默认名字空间,没有显式指定名字空间的对象位于此空间 |
| kube-system | 由K8S系统创建的对象 |
| kube-public | 自动创建、可以被任何用户(包括未进行身份验证的)访问的名字空间。此名字空间基本上是保留供集群使用的,因为某些资源需要公开的、跨越整个集群的访问 |
要在单个命令请求中,指定名字空间,可以:
|
1 2 |
kubectl --namespace=ns-dev run nginx --image=nginx kubectl --namespace=ns-dev get pods |
要永久的为某个上下文切换默认名字空间,可以:
|
1 2 |
kubectl config set-context $(kubectl config current-context) --namespace=ns-pdt kubectl config view | grep namespace # 验证设置 |
当你创建一个服务时,相应的DNS条目自动创建。此条目的默认格式是: ..svc.cluster.local。如果容器仅仅使用来引用服务,则解析到当前名字空间。这种特性可以方便的在多个名字空间(开发、测试、生产)中使用完全相同的配置信息。如果需要跨名字空间引用服务,则必须使用FQDN。
所谓标签(Label)就是用户自定义的、关联到对象的键值对,这些标签和K8S的核心系统没有意义。你可以使用标签来管理、选择对象的子集。
你可以在创建对象的时候设置标签,也可以后续添加、修改标签。对于单个对象来说,标签的键必须是唯一的。
K8S会对标签进行索引/反向索引,以便对标签进行高效的查询、监控,在UI、CLI中对输出进行分组、排序。
标签提供一种松散耦合的风格,让用户自由的映射他们的组织结构到K8S对象,而不需要客户端记住这些映射关系。
服务部署、批处理流水线,常常都是多维的实体(多分区/部署、多个发行条线、多层、每层多个微服务)。对这些实体进行管理,常需要横切性的操作——打破严格的层次性封装,这些层次可能由基础设施死板的规定。
样例标签集:
- 区分发行条线:{ "release" : "stable", "release" : "canary" }
- 区分运行环境:{ "environment" : "dev", "environment" : "qa", "environment" : "production" }
- 区分架构层次:{ "tier" : "frontend", "tier" : "backend", "tier" : "cache" }
- 区分分区: { "partition" : "customerA", "partition" : "customerB" }
- 区分Track: { "track" : "daily", "track" : "weekly" }
标签的键,可以由两段组成:可选的前缀和名称,它们用 / 分隔:
- 名称部分必须63-字符,支持大小写字母、数字、下划线、短横线、点号
- 前缀如果存在,则必须是DNS子域名 —— 一系列以点号分隔的DNS标签,最后加上一个 /
- 如果前缀被省略,则暗示标签是用户私有的
- 前缀 kubernetes.io/ 为K8S核心组件保留
一系列对象常常具有相同的标签。利用标签选择器,客户端可以识别一组对象。标签选择器是K8S提供的核心分组原语。
目前K8S API提供两种标签选择器:
- equality-based。操作符=、==(和=同义)、!=。示例:environment = production,tier != frontend
- set-based。操作符in、notin、exists。示例:environment in (production, qa),tier notin (frontend, backend)
如果有多个选择器需要匹配,则使用逗号(作用类似于&&)分隔。
NULL选择器匹配空集,空白选择器则匹配集合中所有对象。
LIST、WATCH之类的操作可以指定标签选择器,以过滤对象。
基于CLI的例子:
|
1 2 3 |
kubectl get pods -l environment=production,tier=frontend kubectl get pods -l 'environment in (production),tier in (frontend)' kubectl get pods -l 'environment,environment notin (frontend)' |
某些K8S对象(Service、复制控制器)使用标签选择器指定关联的对象(例如Pod)。例如,作为服务目标的Pods是通过标签选择器指定的。replicationcontroller需要管理的pod生产,也是通过标签指定的。对象配置片断示例:
|
1 2 |
selector: component: redis |
ReplicaSet、Deployment、DaemonSet、Job等对象,支持set-based风格的标签选择器,来指定其需求:
|
1 2 3 4 5 6 |
selector: matchLabels: component: redis matchExpressions: - {key: tier, operator: In, values: [cache]} - {key: environment, operator: NotIn, values: [dev]} |
除了标签以外,你还可以使用注解(Annotations)来为K8S对象附加非识别性(non-identifying)元数据。客户端可以通过API获得这些元数据。
注意注解和标签不一样,后者可以用来识别、选择对象,前者则不能。此外注解的值大小没有限制。
注解也是键值对形式:
|
1 2 3 4 |
"annotations": { "key1" : "value1", "key2" : "value2" } |
节点是K8S中的Worker机器,之前被叫做minion。节点可以是物理机器,也可以是VM。节点上运行着一些服务,运行Pod需要这些服务,这些服务被Master组件管理。运行在节点上的服务包括Docker、kubelet、kube-proxy等。
节点应该是x86_64(amd64)架构的Linux系统。其它架构或系统有可能支持K8S。
以下几类信息用于描述节点的状态:
| 字段类别 | 说明 | ||
| Addresses |
这些字段的用法取决于你使用的云服务,或者裸金属的配置: HostName:由节点的内核报告,可以由kubelet的--hostname-override参数覆盖 |
||
| Condition |
这些字段描述运行中节点的状态信息: OutOfDisk:如果为True则意味着节点上没有足够空间供新Pod使用 节点的状态以JSON形式表示,例如:
如果节点的Ready状态为False/Unknown,并且持续时间大于pod-eviction-timeout(默认5分钟),则kube-controller-manager会接收到一个argument,该节点上所有Pods将被节点控制器调度以删除 某些情况下节点不可达,APIServer无法与其上运行的kubelet通信。这样Pods删除信息无法传递到被分区(partitioned,网络被隔离的)节点,因而知道网络通信恢复前,其上的Pods会继续运行 在1.5-版本中,节点控制器会强制的从APIServer中删除不可达Pods,1.5+版本后只有在确认这些Pods已经从集群中停止运行后才进行删除。这些运行在不可达节点上的Pod的状态可能为Terminating或者Unknown 某些情况下,K8S无法在基础设施层推断节点是否永久的离开了集群,管理员可能需要手工进行节点移除 移除节点将导致其上的所有Pod对象从APIServer上删除
从1.8开始K8S引入了一个Alpha特性,可以自动创建代表Condition的taints。要启用此特性,为APIServer、控制器管理器、调度器提供参数: --feature-gates=...,TaintNodesByCondition=true 当TaintNodesByCondition启用后,调度器会忽略节点的Conditions,代之以查看节点的taints、Pod的toleration。你可以选择旧有的调度模型,或者使用新的更加灵活的调度模型:
|
||
| Capacity | 描述节点上可用的资源,包括CPU、内存、最多可以在其上调度的Pod数量 | ||
| Info | 一般性信息,例如内核版本、K8S版本(kubelet/kube-proxy)、Docker版本 |
与Node/Service不同,节点不是K8S创建的,它常常由外部云服务(例如Google Compute Engine)创建,或者存在于你的物理机/虚拟机池子中。K8S中创建一个节点,仅仅是创建代表此节点的对象。在创建节点对象后,K8S会验证其有效性,例如下面的节点配置信息:
|
1 2 3 4 5 6 7 8 9 10 |
{ "kind": "Node", "apiVersion": "v1", "metadata": { "name": "10.240.79.157", "labels": { "name": "my-first-k8s-node" } } } |
执行创建后,K8S会基于metadata.name字段来检查节点的健康状态。如果节点是有效的(所有必须的服务在其上运行)则它有资格运行Pod,否则它会被任何集群活动排除在外,知道它变为有效状态。
除非显式删除,K8S会一致维护你创建的节点对象,并且周期性的检查其健康状态。
目前和节点接口交互的组件有三个:节点控制器、Kubelet、Kubectl。
节点控制器属于K8S管理组件,可以管理节点的方方面面:
- 当节点注册时,给节点分配一个CIDR块(如果CIDR分配打开)
- 在内部维护一个最新的节点列表。在云环境下,节点控制器会调用云提供商的接口,判断不健康节点的VM是否仍然可用,如果答案是否则则节点控制器从子集的节点列表中删除不健康节点
- 监控节点的健康状态。当节点不可达(节点由于某种原因不再响应心跳,例如宕机,默认40s)时,更新NodeStatus的NodeReady状态为ConditionUnknown。如果节点持续处于不可达状态(默认5m),则优雅的清除(Terminate)节点上所有Pods。控制器每隔--node-monitor-period秒检查节点状态
- 从1.6开始,节点控制器还负责清除运行在具有NoExecute taints节点上的Pods(如果Pod不容忍NoExecutes)
从1.4开始,K8S更新了节点控制器的逻辑,当Master节点本身网络出现问题导致大量节点不可达的场景被优化处理。在决定清除一个Pods时,节点控制器会查看集群中所有节点的状态。
大部分情况下,节点控制器限制了节点清除的速度。参数--node-eviction-rate默认为0.1,也就是每10秒最多从单个节点清除一个Pod。
当给定可用性区域(availability zone,集群可能跨越云服务的多个可用性区域,例如北美、亚太)中节点变得不健康时,节点清除行为会有改变。 节点控制器会计算可用性区域中不健康(NodeReady=ConditionUnknown or ConditionFalse)节点的百分比:
- 如果此比值不小于--unhealthy-zone-threshold(默认0.55)则清除速率降低。降低到--secondary-node-eviction-rate(默认0.01)
- 如果集群规模较小(小于--large-cluster-size-threshold,默认50)则清除行为停止
之所以按可用性区域来决定上述行为,是因为某些区域可能和Master之间形成网络分区,另外一些这和Master之间保持连通。
跨越可用性区域分布节点的关键原因是,当整个区域不可用时,工作负载可以迁移到健康的区域中。
当为Kubelet提供参数--register-node=true(默认)时,Kubelet会尝试自动的到API服务器上注册自己。自动注册相关的参数:
| 参数 | 说明 |
| --kubeconfig | 用于包含自己的身份验证信息的文件路径 |
| --cloud-provider | 指定云服务提供商信息,用于读取关于节点本身的元数据 |
| --register-node | 自动注册自己 |
| --register-with-taints | 使用指定的taints注册自己,多个taints用逗号分隔:=:,=: |
| --node-ip | 节点的IP地址 |
| --node-labels | 注册时附加到节点对象的标签集 |
| --node-status-update-frequency | 节点向Master提交自身状态的间隔 |
当前,Kubelet有权创建/修改任何节点资源,但是通常它仅应该修改自己的。
作为集群管理员,你可以随时创建、修改节点对象。你可以设置kubelet标记--register-node=false,仅仅允许手工的管理。
你可以管理节点的资源,例如设置标签、标记其为unschedulable:
|
1 2 |
# 设置节点为unschedulable kubectl cordon $NODENAME |
标记节点为unschedulable可以禁止新的Pods被分配到节点上,但是对节点上现有的Pod则没有影响。
注意DaemonSet控制器创建的Pod跳过了K8S的调度器,因而unschedulable标记为其无意义。
节点的容量(Capacity,CPU数量、内存量)属于节点对象属性的一部分。通常节点自我注册时会提供容量信息。如果你手工的注册节点,则必须提供容量信息。
K8S调度器会确保节点拥有足够的资源来运行分配给它的所有Pods,它会检查请求在节点上启动的容器(仅限kubelet启动的)所需总资源不大于节点的容量。
你可以显式的为非Pod进程保留节点资源:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 作为占位符的Pod apiVersion: v1 kind: Pod metadata: name: resource-reserver spec: containers: - name: sleep-forever image: gcr.io/google_containers/pause:0.8.0 resources: # 请求保留的资源数量 requests: cpu: 100m memory: 100Mi |
本节讨论Master(准确的说是APIServer)和K8S集群之间的通信。
集群到Master的通信路径,总是在APIServer处终结,因为其它的Master组件均不暴露远程接口。
在典型配置上,API服务器基于HTTPS协议监听443端口,并且启用1-N种客户端验证、授权机制。
节点应该被预先分配集群的根证书,以便能够使用有效的客户端证书链接到APIServer。
利用服务账户(Service Account),Pod可以和APIServer安全的通信,根据服务账户的配置,K8S会自动把根证书、不记名令牌(bearer token )注入到Pod中。所有名字空间中的K8S服务都配备了一个虚拟IP,通过kube-proxy重定向到APIServer上的HTTPS端点。
Master组件和APIServer基于非安全端口通信,此端口通常仅仅暴露在Master机器的localhost接口上。
从Master(APIServer)到集群的通信路径主要包括两条:
- 从APIServer到运行在各节点上的kubelet进程。这些通信路径用于:
- 抓取Pod的日志
- Attach到(利用kubectl)到运行中的Pod
- 提供Kubelet的端口转发功能
- 从APIServer到任何节点/Pod/Service,基于APIServer的代理功能
对于第1类通信路径,APIServer默认不会校验kubelet的服务器端证书,因而存在中间人攻击的可能性。使用--kubelet-certificate-authority标记可以为APIServer提供一个根证书,用于验证kubelet的服务器证书。
对于第2类通信路径,默认使用HTTP连接,不验证身份或加密。
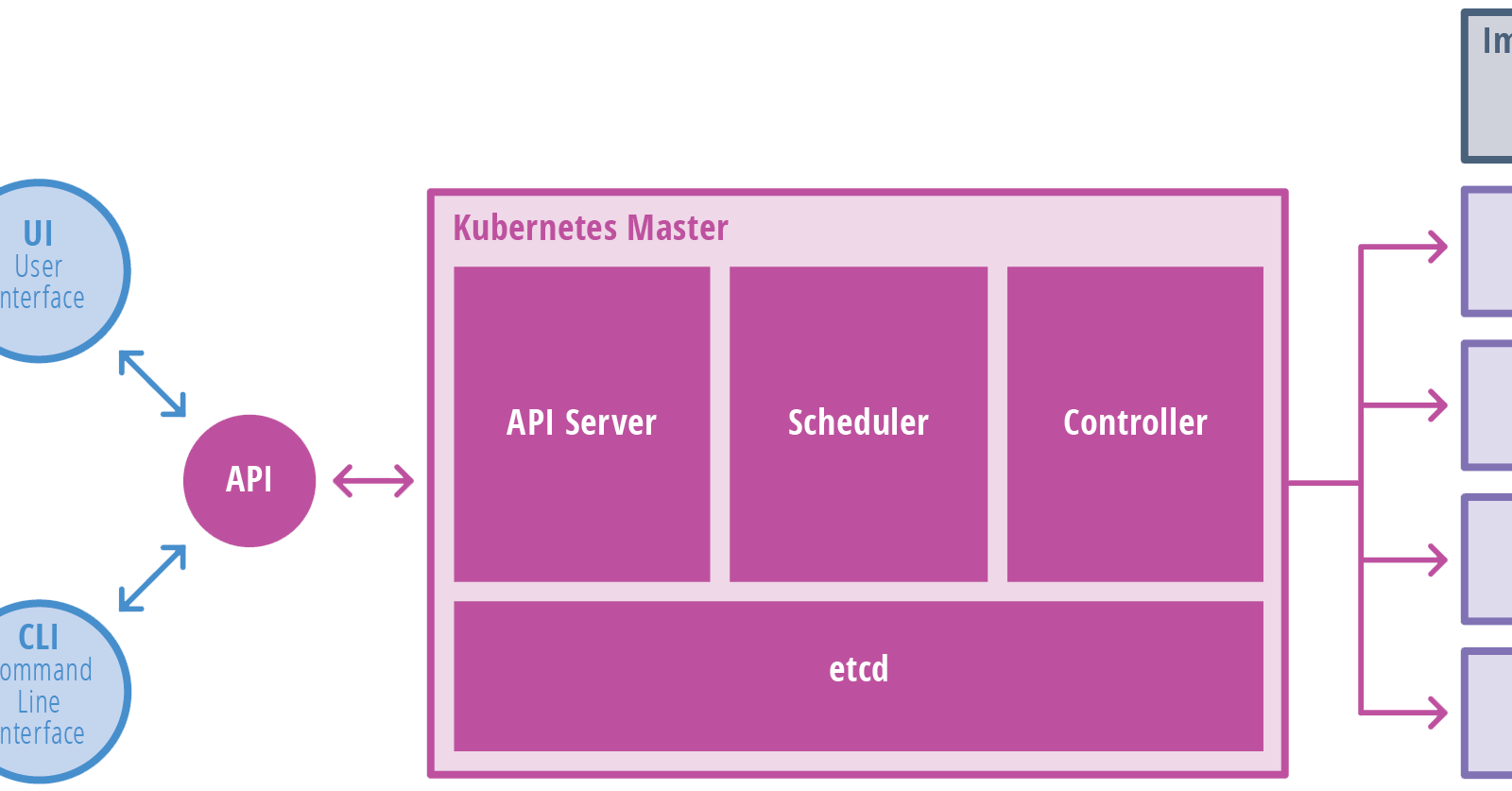
这类组件构成了K8S集群的控制平面(Plane),负责集群的全局性管理,例如调度、检测/响应集群事件。
Master组件可以运行在集群的任何节点上,你可以创建多Master的集群以获得高可用性。
Master组件主要包括kube-apiserver、kube-controller-manager、kube-scheduler
暴露K8S的API,作为控制平面的前端。此服务器本身支持水平扩容。
一个分布式的键值存储,K8S集群的信息全部存放在其中。要注意做好etcd的备份。
运行控制器。控制器是一系列执行集群常规任务的后台线程,控制器包括:
- 节点控制器:检测节点宕机并予以响应
- 复制控制器:为系统中每个复制控制器对象维护正确数量的Pod
- 端点控制器:产生端点对象
- 服务账号/令牌控制器:为新的名字空间创建默认账户、API访问令牌
运行和云服务提供商交互的控制器,1.6引入的试验特性。CCM和其它Master组件在一起运行,它也可以作为Addon启动(运行在K8S的上层)。
CCM的设计初衷是,让云服务商相关的代码和K8S核心解耦,相互独立演进。不使用CCM时的K8S集群架构如下:
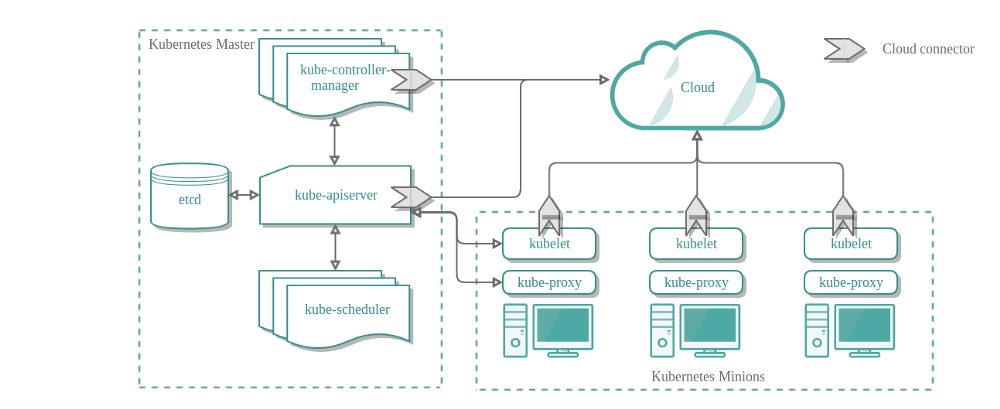
上述架构中,云服务和Kubelet、APIServer、KCM进行交互,实现集成,交互复杂,不符合最少知识原则。
使用CCM后,K8S集群架构变为:
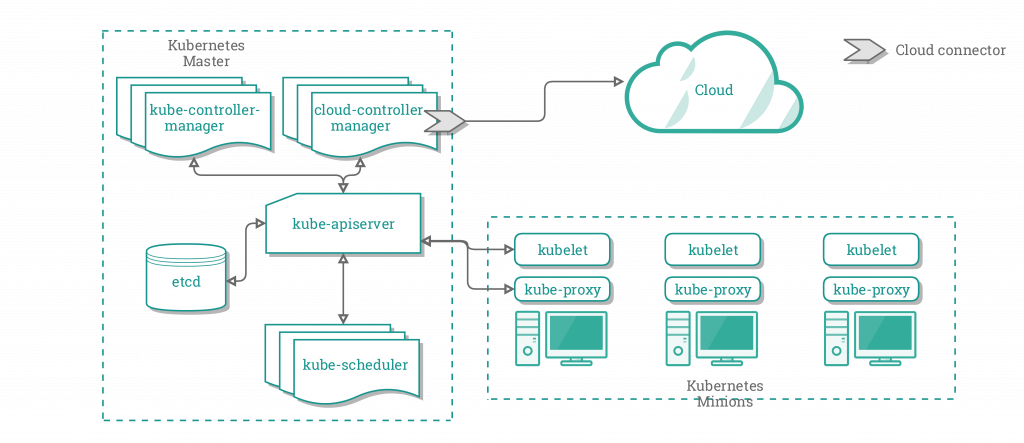
新的架构中,CCM作为一个Facade,统一负责和云服务的交互。CCM分离了部分KCM的功能,在独立进程中运行它们,分离的原因是这些功能是依赖于具体云服务的:节点控制器、 卷控制器、路由控制器、服务控制器。在1.8版本中CCM运行前述控制器中的:
- 节点控制器:通过从云服务获取运行在集群中的节点信息,来初始化节点对象。添加云服务特定的Zone/Regin标签、云服务特定的节点实例细节,获取节点网络地址和主机名,在节点不可用时调用云服务确认节点是否被删除(如果是则级联删除节点对象)
- 路由控制器:在云服务中配置路由,确保不同节点中运行的容器能够相互通信,仅用于GCE集群
- 服务控制器:监听服务的创建/更新/删除事件。它会根据K8S中当前服务的状态来配置云服务的负载均衡器
CCM还运行一个PersistentVolumeLabels控制器,用于在PersistentVolumes(GCP/AWS提供)上设置Zone/Regin标签。卷控制器没有作为CCM的一部分是刻意的设计,主要原因是K8S已经在剥离云服务相关的卷逻辑上做了很多工作。
CCM还包含了云服务特定的Kubelet功能。在引入CCM之前,Kubelet负责利用云服务特定的信息(例如IP、Regin/Zone标签、节点实例类型)初始化节点,引入CCM之后这些职责被转移。在新架构中,Kubelet初始化节点时不知晓云服务特定的信息,但是它会给节点添加一个taint,从而将节点标记为不可调度的。直到CCM初始化了云服务特定的信息,taint才被移除,节点可以被调度。
CCM基于Go开发,暴露了一系列的接口(CloudProvider),允许任何云服务实现这些接口
此接口定义在pkg/cloudprovider/cloud.go,包含的功能有:
- 管理第三层(TCP)负载均衡器
- 管理节点实例(云服务提供的)
- 管理网络路由
不是所有功能都需要实现,取决于K8S组件的标记如何设置。运行K8S也不一定需要此接口的实现,比如在裸金属上运行时。
监控新创建的、没有分配到Node的Pod,然后选择适当的Node供其运行。
加载项是实现了集群特性的Pod和服务,这些Pod可以被Deployments、ReplicationControllers等管理。限定了名字空间的加载项在名字空间kube-system中创建。加载项管理器创建、维护加载项资源。常见加载项如下:
| 加载项 | 说明 |
| DNS |
所有集群都需要此加载项,以提供集群DNS服务。此加载项为K8S服务提供DNS记录 K8S启动的容器自动使用此DNS服务 |
| Dashboard | 此加载项是一个一般用途的Web客户端,用户可以基于此加载项来管理集群、管理或者针对K8S集群中运行的应用程序 |
| CRM | 容器资源监控(Container Resource Monitoring)在中心数据库中记录容器的度量信息,并提供查看这些信息的UI |
| CIL | 集群级别日志(Cluster-level Logging)收集容器日志,集中保存,并提供搜索/查询接口 |
这些组件可以运行在集群中的任何节点上,它们维护运行中的Pods、提供K8S运行时环境。主要包括kubelet、kube-proxy。
主要的节点代理程序,监控分配到(通过APIServer或本地配置文件)当前节点的Pod,并且:
- 挂载Pod所需的卷
- 下载Pod的Secrets
- 通过Docker或rkt运行Pod的容器
- 周期性执行任何请求的容器存活探针
- 将Pod状态反馈到系统的其他部分
- 将节点状态反馈到系统的其它部分
在每个节点上映射K8S的网络服务的代理。提供在宿主机上维护网络规则、执行连接转发,来实现K8S服务抽象。
最早的版本完全在用户空间实现,性能较差。从1.1开始,K8S实现了基于Iptable代理模式的kube-proxy,从1.8开始,添加基于IPVS实现的kube-proxy。
用于运行容器。
轻量级的监控系统,用于确保kubelet、docker持续运行(宕机重启之)。
用于配合实现集群级别日志(CIL)。
在Pod中引用Docker镜像之前,你必须将其Push到Registry中。
container对象的image属性可以包含Registry前缀和Tag,这个命名规则和Docker是一致的。
默认的镜像拉取策略是IfNotPresent,如果镜像已经存在于本地,则Kubelet不会重复抓取。如果希望总是取抓取镜像,可以使用以下三种方法之一:
- 设置imagePullPolicy=Always
- 使用镜像的:latest标签
- 启用AlwaysPullImages这一admission controller
当不指定镜像tag时,默认即使用:latest,因而会导致每次都抓取最新镜像。:latest是应该尽可能避免使用的。
Docker将访问私服所需要的密钥信息存放在$HOME/.dockercfg或者$HOME/.docker/config.json文件中。如果在Kubelet的root的$home目录下存在这两个文件K8S会使用之。
可以使用如下Pod能验证私服能否正常访问:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Pod metadata: name: private-image-test-1 spec: containers: - name: uses-private-image image: $PRIVATE_IMAGE_NAME imagePullPolicy: Always command: [ "echo", "SUCCESS" ] # 创建Pod对象 kubectl create -f /tmp/private-image-test-1.yaml # 查看运行结果, 期望输出SUCCESS kubectl logs private-image-test-1 |
注意:
- 所有节点必须具有相同的.docker/config.json,否则可能出现Pod仅能在部分节点上运行的情况。例如,如果你使用节点自动扩容,则每个实例模板需要包含.docker/config.json文件或者挂载包含此文件的卷
- 只要私服的访问密钥被添加到config.json中,则任何Pod都有权访问这些私服中的镜像
K8S的容器环境,为容器提供了很多重要的资源:
- 一个文件系统,由镜像 + 1-N个卷构成
- 关于容器本身的信息:
- 容器的hostname就是容器所在的Pod的name,此名称可以通过hostname命令/gethostname函数获得
- 容器所属的Pod name和namespace还可以通过downward API获得
- 用户在Pod定义中声明的环境变量,对于容器都是可用的
- 关于集群中其它对象的信息:
- 容器创建时所有服务的列表,可以通过环境变量得到。例如名为foo的服务对应环境变量如下:
123# 在容器中可以访问环境变量:FOO_SERVICE_HOST=FOO_SERVICE_PORT= - 服务拥有专享的IP地址,容器可以基于DNS名称访问它(如果DNS Addon启用的话)
- 容器创建时所有服务的列表,可以通过环境变量得到。例如名为foo的服务对应环境变量如下:
利用容器生命周期钩子框架,你可以在Kubelet管理的容器启动、关闭时执行特定的代码。可用的钩子(事件)包括:PostStart、PreStop。
如果:
- 既不提供command和args,则使用Docker镜像中定义的默认值
- 如果仅提供了command,则Docker镜像中的CMD/ENTRYPOINT被忽略
- 如果仅提供了args,则使用Docker镜像中的ENTRYPOINT + args
- 如果同时提供了command和args,则Docker镜像中的CMD/ENTRYPOINT被忽略
Pod(本义:豆荚,箱子)是K8S对象模型中,最小的部署、复制、扩容单元 —— K8S中单个应用程序实例。
Pod封装了以下内容:
- 应用程序容器
- 存储资源
- 唯一的网络IP
- 管理容器运行方式的选项
Pod最常用的容器运行时是Docker,尽管其它容器运行时也被支持。
Pod的两种使用方式:
- 运行单个容器:容器和Pod呈现一对一关系,这是最常见的用法。你可以将Pod看作是容器的简单包装器,K8S管理Pod而不直接管理容器
- 运行多个容器:Pod封装了由多个较小的、紧耦合的、共享资源的容器相互协作而组成的应用,以及和这些容器相关的存储资源
Pod本身只是一套环境,因此容器可以重启,Pod则没有这一概念。
每个Pod对应一个应用程序实例,如果你需要水平扩容,则需要使用多个Pod。这种水平扩容在K8S中一般叫做复制(Replication)。复制的Pod由控制器创建、管理。
如果Pod包含多个容器,则这些容器一般被调度、运行在单个节点上。这些容器可以共享资源、依赖,相互通信,并且协调如何关闭(例如谁先关闭)。容器之间共享的资源主要有:
- 网络:每个Pod具有唯一性的IP地址,Pod中的每个容器共享网络名字空间,包括IP地址和端口。Pod内的容器之间可以通过localhost + 端口相互通信。当与外部实体通信时,这些容器必须协调如何共享网络资源(例如端口)
- 存储:Pod可以指定一系列的共享存储卷,所有容器可以访问这些卷。如果Pod中部分容器重启,这些卷仍然保持可用
- 容器之间也可以基于IPC机制进行通信,例如SystemV信号量、POSIX共享内存
在基于Docker时,Pod中的容器是共享名字空间、共享卷的Docker容器。
Pod可以和其它物理机器、其它Pod进行网络通信。
- 用户向API Server发送创建Pod的请求
- K8S Scheduler选取一个节点,将Pod分配到节点上
- 节点上的Kubelet负责Pod的创建:
- 调用CNI实现(dockershim、containerd等)创建Pod内的容器
- 第一个创建的容器是pause,它会允许一个简单的程序,进行永久的阻塞。该容器的作用是维持命名空间,因为Linux的命名空间需要其中至少包含一个进程才能存活
- 其他容器会加入到pause容器所在的命名空间
- 初始化容器网络接口,由kubenet(即将废弃)获CNI插件负责。CNI会在pause容器内创建eth0接口并分配IP地址
- 容器和主机的网络协议栈,通过veth pair连接
在Pod中,pause容器是所有其他容器的“父”容器,它:
- 是各容器共享的命名空间的基础
- 可以启用PID命名空间共享,为每个Pod提供init进程
pause容器的逻辑非常简单,它启动后就通过pause()系统调用暂停自己。当子进程变为孤儿进程(父进程提前出错退出)时,它会调用wait()防止僵尸进程的出现。
在1.8版本之前,默认启用PID命名空间共享,也就是说Pod的所有容器共享一个PID命名空间,之后的版本则默认禁用共享,可以配置 spec.shareProcessNamespace强制启用。不共享PID命名空间时,每个容器都有PID 1进程。
你很少需要直接创建单个Pod,甚至是单例(不复制)的Pod,这是因为Pod被设计为是短命的、可丢弃的实体。当Pod被(你直接、或控制器)创建时,它被调度到集群中的某个节点。直到进程退出,Pod会一直存在于节点上。如果缺少资源、节点失败,则Pod会被清除、Pod对象也被从APIServer中删除。
Pod本身没有自愈能力,如果Pod被调度到一个失败的节点,或者调度操作本身失败,则Pod会被删除。类似的,当资源不足或者节点维护时,Pod也会被删除。K8S使用控制器这一高层抽象来管理Pod实例。通常你都是通过控制器来间接使用Pod。
控制器能够创建、管理多个Pod,处理复制/回滚,并提供自愈(在集群级别)功能 —— 例如当节点失败时控制器会在其它节点上创建等价的Pod。一般来说,控制器使用你提供的Pod模板来创建Pod。
控制器主要有三类:
- Job:用于控制那些期望会终结的Pod,在批处理计算场景下用到。Job必须和restartPolicy为OnFailure/Never的Pod联用
- ReplicationController, ReplicaSet,Deployment:用于控制不期望终结的Pod,例如Web服务。这些控制器必须和restartPolicy=Always联用
- DaemonSet:用于某个机器上仅运行一个实例的Pod,用于提供机器特定的系统服务
这三类控制器都包含了对应的Pod模板。
Pod模板是包含在其它对象(复制控制器、Jobs、DaemonSets...)中的Pod的规格说明。控制器使用Pod模板来创建实际的Pod,模板示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: containers: - name: myapp-container image: busybox command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600'] |
Pod模板发生改变不会影响已经创建的Pod。
当用户请求删除Pod时,K8S首先发送TERM信号给每个容器的主进程,当超过时限(完整宽限期,Full Grace Period)后,则发送KILL信号,之后删除Pod对象。
如果在等待容器进程退出期间Kubelet、Docker守护进程重启,则重启后重新进行完整宽限期内的TERM,以及必要的KILL。
强制删除:这种删除操作会导致Pod对象立即从APIServer中移除,这样它的名字可以立即被重用。实际的Pod会在较短的宽限期内被清除。
在容器规格的SecurityContext字段中指定privileged标记,则容器进入特权模式。如果容器需要操作网络栈、访问设备,则需要特权模式。
Pod的status字段是一个PodStatus对象,后者具有一个phase字段。该字段是Pod所处生命周期阶段的概要说明:
- Pending:Pod已经被K8S系统接受,单是一或多个容器镜像尚未创建。此时Pod尚未调度到节点上,或者镜像尚未下载完毕
- Running:Pod已经被调度到某个节点,且所有容器已被创建,至少有一个容器处于运行中/重启中/启动中
- Succeeded:Pod的所有容器被正常终结,且不会再重启
- Failed:Pod的所有容器被终结,且至少一个被异常终结——要么退出码非0要么被强杀
- Unknown:Pod状态未知,通常由于和目标节点的通信中断导致
PodStatus具有一个 PodCondition数组,数组的每个元素具有type、status字段。type可选值是PodScheduled、Ready、Initialized、Unschedulable,status字段的可选值是True、False、Unknown。
通常情况下,重复你或者控制器销毁Pod,它不会小时。唯一的例外是,phase值为Succeeded/Failed,并持续一定时间(具体由Master确定),则Pod会因为过期而自动销毁。
如果节点和集群断开,则K8S会把该节点上所有的Pod的phase更新为Failed
Probe由Kubelet周期性的针对容器调用,以执行健康检查。Kubelet会调用容器实现的Handler,Handler包括三类:
- ExecAction:在容器内部执行特定的命令,如果命令为0则意味着诊断成功
- TCPSocketAction:针对容器的IP/端口进行TCP检查,如果端口打开则诊断成功
- HTTPGetAction:针对容器的IP/端口进行HTTP检查,如果响应码为[200,400)之间则诊断成功
每个探针的诊断结果可以是Success、Failure、Unknown
Kubelet可以在运行中的容器上执行两个可选探针,并作出反应:
- livenessProbe:探测容器是否还在运行。如果探测失败则杀死容器,并根据其重启策略决定如何反应。如果容器没有提供此探针,则总是返回Success
- readinessProbe:探测容器是否能提供服务。如果探测失败,端点控制器会从所有匹配Pod的服务的端点中移除Pod的IP地址。在Initial delay之前默认值Failure,如果容器没有提供此探针,则Initial delay之后默认Success。仅仅用于在Pod启动初期、延迟的把它加入到服务集群中,不能用于将Pod从服务集群中移除
注意,这些探针在Kubelet的网络名字空间中运行。
如果你的容器在出现问题时会自己崩溃,则不需要使用探针,只需要设置好restartPolicy即可。
基于HTTP的探针示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-http spec: containers: - args: - /server image: gcr.io/google_containers/liveness # 指定探针,在容器级别上指定 livenessProbe: httpGet: path: /healthz port: 8080 # 也可以使用命名端口(ContainerPort) httpHeaders: - name: X-Custom-Header value: Awesome # 第一次探针延迟多久执行 initialDelaySeconds: 15 # 每隔多久执行一次探针 periodSeconds: 5 # 探针执行超时,默认1秒 timeoutSeconds: 1 # 被判定为失败后,连续多少次探测没问题,才被重新认为是成功 successThreshold: 1 # 连续多少次探测失败,则认为无法恢复,自动重启 failureThreshold: 3 name: liveness |
基于命令的探针示例:
|
1 2 3 4 5 6 7 8 9 10 |
spec: containers: - name: runtime livenessProbe: exec: command: - cat - /app/liveness initialDelaySeconds: 5 periodSeconds: 5 |
要注意:命令的标准输出被收集,并在kubectl describe pod命令中显示为Unhealthy事件的原因,因此探针的标准输出应该简洁明了。
某些情况下,容器临时的不适合处理请求,例如其正在启动、正在加载大量数据。此时可以使用readiness探针。readiness探测失败的Pod不会接收到K8S Service转发来的请求。
readinessProbe的配置和livenessProbe没有区别。两个探针可以被同时执行。
PodSpec包含一个restartPolicy字段,可选值为:
- Always,默认值,应用到Pod的所有容器
- OnFailure
- Never
重启时如果再次失败,重启延迟呈指数增长(10s,20s,40s)但是最大5分钟。启动成功后,10m后清除重启延迟。
在PodSpec的containers字段之后,你可以声明一个初始化容器。这类容器在应用容器之前运行,可能包含应用镜像中没有的实用工具、安装脚本。
初始化容器可以有多个,K8S会按照声明顺序逐个执行它们,只有前一个初始化容器成功完成,后面的初始化容器才会被调用。如果某个初始化容器运行失败,K8S会反复重启它,直到成功,除非你设置其restartPolicy=Never。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: # 普通容器 containers: - name: myapp-container image: busybox command: ['sh', '-c', 'echo The app is running! && sleep 3600'] # 初始化容器 initContainers: - name: init-myservice image: busybox command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;'] - name: init-mydb image: busybox command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;'] |
PodPreset用于在创建Pod时,向Pod注入额外的运行时需求信息。你可以使用标签选择器来指定预设要应用到的Pod。当Pod创建请求出现时,系统中发生以下事件:
- 取得所有可用的PodPreset
- 检查是否存在某个PodPreset,其标签选择器匹配准备创建的Pod
- 尝试合并PodPreset中的各种资源到准备创建的Pod中
- 如果出错,触发一个事件说明合并出错。在不注入任何资源的情况下创建Pod
- 如果成功,标注被修改的PodSpec为已被PodPreset修改
要在集群中使用Pod预设功能,你需要:
- 确保API类型settings.k8s.io/v1alpha1/podpreset启用。可以设置APIServer的--runtime-config选项,包含settings.k8s.io/v1alpha1=true
- 确保PodPreset这一Admission controller已经启用。可以设置APIServer的--admission-control选项,包含PodPreset
- 在你需要使用的名字空间中,定义一个PodPreset对象
如果你在使用Kubeadm,则修改配置文件/etc/kubernetes/manifests/kube-apiserver.yaml即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
apiVersion: settings.k8s.io/v1alpha1 kind: PodPreset metadata: name: allow-database spec: selector: matchLabels: role: frontend # 支持的Pod配置项是有限的,仅仅支持: # 预设容器的环境变量 env: - name: DB_PORT value: "6379" - name: expansion value: $(REPLACE_ME) # 预设容器的环境变量,从ConfigMap读取变量 envFrom: - configMapRef: name: etcd-env-config # 预设容器的卷挂载 volumeMounts: - mountPath: /cache name: cache-volume - mountPath: /etc/app/config.json readOnly: true name: secret-volume # 预设Pod的卷定义 volumes: - name: cache-volume emptyDir: {} - name: secret-volume secret: secretName: config-details |
要构建基于K8S的高可用应用,就要明白Pod什么时候会被中断(Disrpution)。
Pod不会凭空消失,除非你或控制器销毁了它们,或者出现不可避免的软硬件错误。这些不可避免的错误被称为非自愿中断(Involuntary Disruptions),例如:
- 作为节点支撑的物理机器,出现硬件错误
- 集群管理员错误的删除了VM
- 云服务或者Hypervisor的错误导致VM消失
- 内核错误
- 网络分区导致节点从集群分离
- 节点资源不足导致Pod被清除
其它情况则称为自愿中断,中断操作可能由应用程序所有者、集群管理员触发。应用程序所有者的操作包括:
- 删除部署或者其它管理Pod的控制器
- 更新部署的Pod模板导致重启
- 直接意外的删除了Pod
集群管理员的操作包括:
- Drain了某个节点,进行硬件维护或软件升级
- Drain了某个节点,进行缩容
- 从节点移除Pod,流下资源供其他人使用
缓和非自愿中断造成的影响,手段包括:
- 确保Pod请求了其需要的资源
- 如果需要HA,启用(无状态/有状态)应用程序复制
- 如果需要进一步HA,启用跨机柜复制(anti-affinity)甚至跨区域复制(multi-zone cluster)
自愿中断发生的频率根据集群用法的不同,有很大差异。对于某些基本的集群,根本不会出现自愿中断。
集群管理员/云服务提供商可能运行额外的服务,进而导致自愿中断。例如,滚动进行节点的软件更新就可能导致这种中断。某些节点自动扩容的实现,可能进行节点的取碎片化,从而导致自愿中断。
K8S提供了中断预算(Disruption Budgets)机制,帮助在频繁的自愿中断的情况下,实现HA。
这是从1.8引入的特性,目前处于Alpha状态。该特性允许Pod具有优先级,并且能够在无法调度Pod时,从节点驱除低优先级的Pod。
从1.9开始,优先级影响Pod的调度顺序、资源不足时Pod的驱逐顺序。高优先级的Pod更早被调度,低优先级的Pod更早被驱除。
你需要为APIServer、scheduler、kubelet启用下面的特性开关:
|
1 |
--feature-gates=PodPriority=true,... |
同时在APIServer中启用scheduling.k8s.io/v1alpha1这个API以及Priority这个准许控制器:
|
1 |
--runtime-config=scheduling.k8s.io/v1alpha1=true --admission-control=Controller-Foo,Controller-Bar,...,Priority |
这是一类非名字空间化的对象,定义了一个优先级类的名称,以及一个整数的优先级值。最大取值为10亿,更大的值保留。规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: scheduling.k8s.io/v1alpha1 kind: PriorityClass metadata: # 名 name: high-priority # 值 value: 1000000 # 是否全局默认值,如果是,则没有定义PriorityClassName属性的Pod,其优先级均为此PriorityClass.value globalDefault: false # 供用户阅读的描述 description: "..." |
当Pod被创建后,它会列队等待调度。调度器会选取队列中的一个Pod并尝试调度到某个节点上,如果没有节点能满足Pod的需求,则抢占逻辑被激活:
- 尝试寻找这样的节点:其上具有更低优先级的Pod,并且将这些Pod驱除后,能满足正被调度的Pod的需求
- 如果找到匹配的节点,则对其上的低优先级Pod执行驱除,并调度当前Pod到节点
同一个Pod内的多个容器,可以通过共享卷(Shared Volume)进行交互。
卷天然是Pod内共享的,因为卷只能在Pod级别定义,而后任何一个容器都可以挂载它到自己的某个路径下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
kind: Pod spec: volumes: - name: shared-data # Pod被调度到某个节点上后,创建一个空目录 emptyDir: {} containers: - name: nginx-container image: nginx volumeMounts: - name: shared-data mountPath: /usr/share/nginx/html - name: debian-container image: debian volumeMounts: - name: shared-data mountPath: /pod-data command: ["/bin/sh"] # 修改共享卷的内容 args: ["-c", "echo Hello from the debian container > /pod-data/index.html"] |
注意,K8S的共享卷和Docker的--volumes-from不同。
跨斗,本指三轮摩托旁边的那个座位。
Sidecar用于辅助主要容器,让其更好的工作。例如Pod中的主容器是Nginx,它提供HTTP服务,Sidecar中运行一个Git,周期性的将最新的代码拉取过来,通过共享文件系统推送给Nginx。
使者模式,辅助容器作为一个代理服务器,主容器直接通过localhost(因为Pod内所有容器共享网络名字空间)访问外部的服务。
好处是,主容器可以和开发环境完全一致,因为在开发时常常所有东西都在localhost上。
不同容器输出的监控指标信息格式不一致,可以由一个配套的辅助容器对这些格式进行适配。
建议统一规划、配置标签:
- tier,标识应用所属的层次,取值:
- control-plane:K8S控制平面
- infrastructure:提供网络、存储等基础设施
- devops:开发、运维相关的工具
- middleware:中间件、数据库等
- application:业务域应用程序
- app,标识应用程序的类别
- comp,标识应用程序组件
- version,标识应用程序的版本
- release,标识Helm Release的名称,或者手工部署的应用程序的实例名
将此配置项设置为true,则Pod直接使用宿主机的网络。Pod直接在宿主机的网络接口上监听。
将Pod的Spec/Status字段注入为环境变量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: POD_SERVICE_ACCOUNT valueFrom: fieldRef: fieldPath: spec.serviceAccountName |
你可以指定Pod和Node的对应关系,让Pod只能(或优选)在某些节点上运行。具体实现方式有几种,都是基于标签选择器的。
大部分情况下你不需要强制指定对应关系,因为K8S会进行合理的调度。你需要这种细致的控制机制的场景包括:
- 确保Pod在具有SSD的机器上运行
- 让两个位于不同Service中的、频繁协作的Pod,能在同一个Zone内部运行
这是Pod规格的一个字段,规定有资格运行Pod的节点,所具有的标签集。
你需要首先为节点添加标签:
|
1 2 3 4 5 6 7 |
# 获取集群的节点列表 kubectl get nodes # 为某个节点添加标签 kubectl label nodes disktype=ssd # 显示节点标签 kubectl get nodes --show-labels |
然后,需要为Pod规格添加一个nodeSelector字段:
|
1 2 3 |
spec: nodeSelector: disktype: ssd |
执行命令: kubectl get pods -o wide可以看到Pod被分配到的节点。
截止1.4,K8S内置的节点标签有:
| 节点标签 |
| kubernetes.io/hostname |
| failure-domain.beta.kubernetes.io/zone |
| failure-domain.beta.kubernetes.io/region |
| beta.kubernetes.io/instance-type |
| beta.kubernetes.io/os |
| beta.kubernetes.io/arch |
Beta特性affinity,也可以用于将Pod分配到节点。但是这一特性更加强大:
- 表达能力更强,不是简单的限制于nodeSelector的那种 k == v && k == v
- 可以标注为“软规则”而非强制要求,如果调度器无法满足Pod的需求,Pod仍然会被调度
- 可以基于其它Pod上的标签进行约束,也就是说,可以让一系列的Pod同地协作( co-located)
Affinity分为两种类型:
- Node affinity:类似于nodeSelector,但是表达能力更强、可以启用软规则(对应上面的第1、2条)
- Inter-pod affinity:基于Pod标签而非Node标签进行约束(对应上面第3条)
包含两种子类型:requiredDuringSchedulingIgnoredDuringExecution(硬限制)、preferredDuringSchedulingIgnoredDuringExecution(软限制)。
“IgnoredDuringExecution“的含义是,如果在Pod调度到Node并运行后,Node的标签发生改变,则Pod会继续运行,nodeSelector的行为也是这样的。未来可能支持后缀“RequiredDuringExecution“,也就说当运行是Node的标签发生改变,导致不满足规则后,Pod会被驱除。
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
spec: affinity: nodeAffinity: # 硬限制 requiredDuringSchedulingIgnoredDuringExecution: # 加强版的节点选择器,值为数组。如果数组元素有多个,目标节点只需要匹配其中一个即可 nodeSelectorTerms: # 每个节点选择器可以包含多个表达式,如果表达式有多个,目标节点必须匹配全部表达式 - matchExpressions: # 必须在AZ(Availability Zone)e2e-az1或者e2e-az2中运行 - key: kubernetes.io/e2e-az-name # 支持的操作符包括 In, NotIn, Exists, DoesNotExist, Gt, Lt # 其中 NotIn,DoesNotExist 用于实现anti-affinity operator: In values: - e2e-az1 - e2e-az2 # 软限制 preferredDuringSchedulingIgnoredDuringExecution: # 权重,值越大越需要优先满足 - weight: 1 preference: # 节点选择器 matchExpressions: - key: another-node-label-key operator: In values: - another-node-label-value |
基于已经运行在节点上的Pod,而不是节点本身的标签进行匹配 —— 当前Pod应该/不应该运行在,已经运行了匹配规则R的Pod(s)的X上。其中:
- R表现为关联了一组名字空间的标签选择器
- X是一个拓扑域(Topology Domain),可以是Node、Rack、Zone、Region等等
和节点不同,Pod是限定名字空间的,因此它的标签也是有名字空间的。针对Pod的标签选择器必须声明其针对的名字空间。
Inter-pod affinity要求较大的计算量,因此可能拖累调度性能,不建议在大型集群(K+节点)上使用。
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
spec: affinity: # Pod亲和性 podAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 如果Zone(由topologyKey指定)上已经运行了具有标签security=S1的Pod,则当前Pod也必须调度到该Zone - labelSelector: matchExpressions: - key: security # 支持的操作符In, NotIn, Exists, DoesNotExist operator: In values: - S1 topologyKey: failure-domain.beta.kubernetes.io/zone # Pod反亲和性 podAntiAffinity: # 强制 requiredDuringSchedulingIgnoredDuringExecution: # 尽可能 preferredDuringSchedulingIgnoredDuringExecution: # 如果Host(节点)上已经运行了具有标签security=S2的Pod,则当前Pod不得调度到该Host - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: security operator: In values: - S2 topologyKey: kubernetes.io/hostname |
当需要保证高级对象(ReplicaSets, Statefulsets, Deployments)在同一拓扑域内运行时, podAffinity非常有用。
下面是一个示例,3实例的Redis集群 + 3实例的Nginx前端,每个Redis不在同一节点运行,每个Nginx也不在同一节点运行,每个Nginx必须在本地有个Redis:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
kind: Deployment metadata: name: redis-cache spec: replicas: 3 template: metadata: labels: app: store # Pod模板 spec: affinity: # 当前节点上不得存在Pod的标签是app=store,也就是说,复制集的每个实例都占据单独的节点 podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - store topologyKey: "kubernetes.io/hostname" containers: - name: redis-server image: redis:3.2-alpine |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
kind: Deployment metadata: name: web-server spec: replicas: 3 template: metadata: labels: app: web-store spec: affinity: podAntiAffinity: # 当前节点上不得存在Pod具有标签app=web-store # 也就是说当前复制集的实例,都不会在同一节点上运行 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - web-store topologyKey: "kubernetes.io/hostname" podAffinity: # 当前节点上的某个Pod必须具有app=store标签 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - store topologyKey: "kubernetes.io/hostname" containers: - name: web-app image: nginx:1.12-alpine |
前文讨论的Node affinity,可以把Node和Pod吸引到一起。Taints则做相反的事情,让Pod拒绝某些Node。
使用kubectl可以为节点添加一个Taint,例如:
|
1 2 3 4 5 6 |
# taint的键为key,值为value # taint effect为 NoSchedule,意味着Pod不能被调度到该节点,除非它具有匹配的toleration kubectl taint nodes node1 key=value:NoSchedule # 恢复Master节点的禁止调度 kubectl taint nodes master node-role.kubernetes.io/master=:NoSchedule |
|
1 2 |
# 删除Taint kubectl taint nodes --all node-role.kubernetes.io/master- |
下面的Pod都能容忍上述Taint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
tolerations: # 容忍 键、值、效果组合 - key: "node-role.kubernetes.io/master" # 操作符,不指定默认为Equal operator: "Equal" value: "value" effect: "NoSchedule" # 容忍 键、效果组合 tolerations: - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" # 容忍一切 tolerations: - operator: "Exists" # 容忍键和一切效果 tolerations: - key: "node-role.kubernetes.io/master" operator: "Exists" # 容忍某种效果 tolerations: - effect: NoSchedule operator: Exists |
| 取值 | 说明 | ||
| NoSchedule | 不能容忍Taint的Pod绝不会调度到节点 | ||
| PreferNoSchedule | 不能容忍Taint的Pod尽量不被调度到节点 | ||
| NoExecute |
如果Pod不能容忍此Effect且正在节点上运行,它会被从节点上被驱除:
|
| 场景 | 说明 |
| 专用节点 |
如果希望某些节点被特定Pod集专用,你可以为节点添加Taint、并为目标Pod添加匹配的Toleration。这样,目标Pod可以在专用节点上运行 如果要让目标Pod仅能在专用节点,可以配合nodeSelector |
| 特殊硬件节点 | 集群中可能存在一小部分具有特殊硬件(例如GPU)的节点,Taint可以让不需要特殊硬件的Pod和这些节点隔离 |
| 定制化Pod驱除 | 可以在节点出现问题时,为每个Pod定制驱除策略,这是一个Alpha特性 |
使用NoExecute可以导致已经运行在节点上的Pod被驱除,Pod配置tolerationSeconds可以指定驱除的Buffer时间。
从1.6开始,节点控制器会在节点状态变化时,自动添加Taint,包括:
| Taint | 说明 |
| node.kubernetes.io/not-ready | 节点没有准备好,对应NodeCondition.Ready=False |
| node.alpha.kubernetes.io/unreachable | 节点控制器无法连接到节点,对应NodeCondition.Ready=Unknown |
| node.kubernetes.io/out-of-disk | 节点磁盘空间不足 |
| node.kubernetes.io/memory-pressure | 节点面临内存压力 |
| node.kubernetes.io/disk-pressure | 节点面临磁盘压力 |
| node.kubernetes.io/network-unavailable | 节点的网络不可用 |
| node.cloudprovider.kubernetes.io/uninitialized | 当Kubelet通过“外部”云服务启动时,它会设置此Taint,当CCM初始化了节点后,移除此Taint |
PDB(PodDisruptionBudget)可以用来构建高可用的应用程序。
除非被人工或控制器删除,或者出现不可避免的软硬件错误,Pod不会消失。那些不可避免软硬件错误导致的Pod删除,称为非自愿中断(involuntary disruptions ),具体包括:
- 硬件故障
- 虚拟机故障,例如被误删除
- 内核崩溃
- 集群网络分区导致节点丢失
- 由于资源不足,Pod被kubelet驱除
要避免非自愿中断影响应用程序的可用性,可以考虑:
- 合理的配置资源请求
- 使用Deployment/StatefulSet
要避免资源中断影响应用程序的可用性,可以使用PDB。
PDB可以限制复制集中,同时由于自愿中断而宕掉的Pod的最大数量。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: zookeeper spec: # 最小保证2实例处于运行中,可以指定百分比,例如 25% minAvailable: 2 # 也可以指定最大宕机数量,可以指定百分比,例如 25% maxUnavailable:1 # 控制的目标应用程序 selector: matchLabels: app: zookeeper |
ConfigMap用于把配置信息和容器的镜像解耦,保证容器化应用程序的可移植性。
ConfigMap中文叫配置字典,下一章的Secrets中文叫保密字典,两者很类似,只是后者的内容是编码存储的。
命令格式:
|
1 2 3 4 5 6 |
# map-name是ConfigMap的名称 # data-source 目录、文件,或者硬编码的字面值 kubectl create configmap # 在ConfigMap对象中,data-source表现为键值对: # key:文件名,或者通过命令行提供的key # value:文件内容,或者通过命令行提供的字面值 |
下面是把目录作为数据源的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kubectl create configmap game-config --from-file=path-to-dir # ls path-to-dir # game.properties # ui.properties kubectl describe configmaps game-config # Name: game-config # Namespace: default # Labels: # Annotations: # Data # ==== # game.properties: 158 bytes # ui.properties: 83 bytes |
目录中文件的内容,会读取到ConfigMap的data段中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
apiVersion: v1 data: # 文件名为键,文件内容为值(字符串) # 如果要自定义键,可以 --from-file== game.properties: | enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30 ui.properties: | color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice kind: ConfigMap metadata: creationTimestamp: 2016-02-18T18:52:05Z name: game-config namespace: default resourceVersion: "516" selfLink: /api/v1/namespaces/default/configmaps/game-config uid: b4952dc3-d670-11e5-8cd0-68f728db1985 |
如果将文件作为数据源,可以指定--from-file多次,引用多个文件。
使用该选项可以从Env-File创建ConfigMap,例如文件:
|
1 2 3 |
enemies=aliens lives=3 allowed="true" |
可以创建ConfigMap:
|
1 |
kubectl create configmap game-config-env-file --from-env-file=game-env-file.properties |
结果ConfigMap为:
|
1 2 3 4 5 6 7 |
apiVersion: v1 data: # 注意是一个个键值对,而不是字符串 allowed: '"true"' enemies: aliens lives: "3" kind: ConfigMap |
使用该选项,直接通过命令行给出ConfigMap的数据:
|
1 2 |
kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm |
定义单个环境变量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Pod metadata: name: test spec: containers: - name: test env: # 定义一个环境变量 - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: # 环境变量的值,从名为special-config的ConfigMap中获取,使用其中的special.how的值 name: special-config key: special.how |
你可以把ConfigMap中的所有键值对导出为Pod的环境变量:
|
1 2 3 4 5 6 |
spec: containers: - name: test-container envFrom: - configMapRef: name: special-config |
使用特殊语法 $(VAR_NAME),例如:?
|
1 |
command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ] |
|
1 2 3 4 5 6 7 8 9 10 |
spec: containers: - name: test-container volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config |
这样,Pod启动后,/etc/config目录下会出现若干文件。这些文件的名字是configMap的键,内容是键对应的值。
你可以使用path属性指定某个ConfigMap键映射到的文件路径:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
spec: containers: - volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config items: # ConfigMap中条目的key - key: special.level # 映射到mountPath下的什么文件,默认为key path: special.lv |
special.level的内容会映射到容器路径:/etc/config/special.lv
加载为卷的ConfigMap被修改后,K8S会自动的监测到,并更新Pod的卷的内容。延迟取决于Kubelet的同步周期。
加载为环境变量的ConfigMap修改后不会刷新到已经运行的Pod。
挂载ConfigMap时,如果ConfigMap中包含多个配置文件,可以指定每个文件映射到容器的什么路径:
|
1 2 3 4 5 6 7 |
volumeMounts: # 卷名,必须是ConfigMap或者Secret卷 - name: dangconf # 挂载到容器路径 mountPath: /etc/dangdangconfig/digital/api.config # ConfigMap或Secret中的文件名 subPath: api-config.properties |
SubPath挂载的内容不会随ConfigMap变更,这可能是Kubernetes的Bug。
Secret是一种K8S对象,用于保存敏感信息,例如密码、OAuth令牌、SSH私钥。将这些信息存放在Secret(而不是Pod规格、Docker镜像)中更加安全、灵活。
你可以在Pod的规格配置中引用Secret。
K8S会自动生成一些Secret,其中包含访问API所需的凭证,并自动修改Pod以使用这些Secret。
你可以通过kubectl来创建Secret:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 创建一个名为db-user-pass的一般性Secret kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt # 创建用作Ingress TLS证书的Secret kubectl create secret tls tls-secret --cert=/home/alex/Documents/puTTY/k8s.gmem.cc/tls.crt --key=/home/alex/Documents/puTTY/k8s.gmem.cc/tls.key # 直接提供字面值 kubectl -n kube-system create secret generic chartmuseum --from-literal=BASIC_AUTH_USER=alex --from-literal=BASIC_AUTH_PASS=alex kubectl get secrets # NAME TYPE DATA AGE # db-user-pass Opaque 2 51s kubectl describe secrets/db-user-pass # ... # Type: Opaque # Data # ==== # password.txt: 12 bytes # username.txt: 5 bytes |
你也可以手工的指定Secret规格:
|
1 2 3 4 5 6 7 8 9 10 |
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: # 每个数据必须Base64处理 # echo -n "admin" | base64 username: YWRtaW4= password: MWYyZDFlMmU2N2Rm |
使用如下命令可以获得Secret的所有属性,并输出为YML格式:
|
1 |
kubectl get secret mysecret -o yaml |
然后你可以复制Base格式的数据并解码:
|
1 |
echo "MWYyZDFlMmU2N2Rm" | base64 --decode |
Secret可以作为数据卷挂载,示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
spec: containers: - name: mypod image: redis volumeMounts: # 把foo卷只读挂载到文件系统路径下 - name: foo mountPath: "/etc/foo" readOnly: true volumes: # 定义一个名为foo的卷,其内容为mysecret这个Secret - name: foo secret: secretName: mysecret |
默认的,Secret中的每个Data的key,都作为mountPath下的一个文件名。你可以定制Data到容器文件系统的映射关系:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
spec: containers: - name: mypod image: redis volumeMounts: - name: foo mountPath: "/etc/foo" readOnly: true volumes: - name: foo secret: secretName: mysecret items: - key: username # 在容器中,访问路径为/etc/foo/my-group/my-username path: my-group/my-username # 文件模式为0400,这里必须转为十进制 defaultMode: 256 |
在容器中读取Data映射文件时,获得的是明文。
Secret还可以映射为容器的环境变量:
|
1 2 3 4 5 6 7 8 9 10 |
spec: containers: - name: mycontainer image: redis env: - name: SECRET_USERNAME valueFrom: secretKeyRef: name: mysecret key: username |
当你通过kubectl访问集群时,APIServer基于特定的用户账号(默认admin)对你进行身份验证。
服务账号(ServiceAccount)为运行在Pod中的进程提供身份(Identity)信息,这样当这些进程联系APIServer时,也能够通过身份验证。对服务账号的授权由授权插件和策略负责。
三个组件进行协作,完成和SA相关的自动化:
- 服务账户准入控制器(Service account admission controller),是API Server的一部分,当Pod创建或更新时:
- 如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default
- 如果设置的ServiceAccount不存在则拒绝Pod
- 如果Pod不包含ImagePullSecrets设置,则将SA中的ImagePullSecrets拷贝进来
- 将一个用于访问API Server的Token作为卷挂载到Pod
- 将/var/run/secrets/kubernetes.io/serviceaccount下的VolumeSource添加到每个容器
- Token 控制器(Token controller),是controller-manager的一部分,异步方式来:
- 当SA创建后,创建对应的Secret,用于支持API 访问
- 当SA删除后,删除对应的Token Secret
- 当Token Secret删除后,在SA中去除对应的数组元素
- 当通过annotation引用了SA的ServiceAccountToken类型的Secret创建后,自动生成Token并更新Secret字段:
12345678apiVersion: v1kind: Secretmetadata:name: build-robot-secretannotations:# 提示此Secret为了哪个SAkubernetes.io/service-account.name: build-robottype: kubernetes.io/service-account-token
- 服务账户控制器(Service account controller)
- 确保每个命名空间具有default帐户
你需要通过 --service-account-private-key-file传递一个私钥给controller-manager,用于对SA的Token进行签名。
你需要通过 --service-account-key-file传递一个公钥给kube-api-server,以便API Server对Token进行校验。
v1.12引入的Beta特性。要启用此特性,需要给API Server传递:
- --service-account-issuer:SA Token颁发者的标识符,颁发者会断言颁发的Token的iss claim中具有此参数的值,字符串或URI,例如kubernetes.default.svc
- --service-account-signing-key-file:包含SA Token颁发者私钥的路径,需要打开特性TokenRequest
- --service-account-api-audiences:API的标识符
Kubelet能够把SA Token影射到Pod中,你需要提供必须的属性,包括audience、有效期:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - image: nginx name: nginx volumeMounts: - mountPath: /var/run/secrets/tokens name: vault-token serviceAccountName: build-robot volumes: - name: vault-token projected: sources: - serviceAccountToken: path: vault-token expirationSeconds: 7200 audience: vault |
对于上述配置,Kubelet会代表Pod来请求Token,并存储到对应位置,并且在80%有效期过去后,自动刷新Token。应用程序需要自己检测Token已经刷新。
当你创建Pod时,如果显式提供服务账号,则K8S在相同名字空间内为Pod分配一个默认账号(名为default),并自动设置到spec.serviceAccountName字段。
你可以在Pod内部调用K8S API,基于自动挂载的服务账号凭证(令牌)。从1.6开始,令牌的自动挂载可以禁用:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: v1 kind: ServiceAccount metadata: name: default # 在服务账号上禁用 automountServiceAccountToken: false --- apiVersion: v1 kind: Pod metadata: name: my-pod spec: serviceAccountName: default # 针对单个Pod禁用 automountServiceAccountToken: false |
每个名字空间都有一个名为default的默认服务账号,你可以自己创建新的账号。
执行下面的命令列出所有账号:
|
1 2 3 |
kubectl get serviceAccounts # NAME SECRETS AGE # default 1 1d |
ServiceAccount的规格很简单,上一节有示例。创建账号后,你可以利用授权插件来设置账号的权限。
要让Pod使用非默认账号,配置spec.serviceAccountName字段即可。
如果禁用了服务账号的自动凭证生成功能,你需要手工的创建令牌。令牌是一个Secret对象:
|
1 2 3 4 5 6 7 |
apiVersion: v1 kind: Secret metadata: name: build-robot-secret annotations: kubernetes.io/service-account.name: build-robot type: kubernetes.io/service-account-token |
ImagePullSecrets是用于访问镜像私服的Secret,假设你已经创建好一个名为gmemregsecret的Secret, 则可以使用下面的命令,为服务账号添加ImagePullSecrets:
|
1 |
kubectl patch serviceaccount default -p '{"imagePullSecrets": [{"name": "gmemregsecret"}]}' |
创建docker.gmem.cc的Secret:
|
1 2 3 4 |
# 创建名为gmemregsecret类型为docker-registry的secret kubectl create secret docker-registry gmemregsecret \ --docker-server=docker.gmem.cc --docker-username=alex \ --docker-password=pswd --docker-email=k8s@gmem.cc |
查看刚刚创建的Secret:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
kubectl get secret gmemregsecret --output=yaml # apiVersion: v1 # data: # .dockerconfigjson: eyJhdXRocyI6eyJkb2NrZXIuZ21lbS5jYzo1MDAwIjp7InVzZXJuYW1lIjoiYWxleCIsInBhc3N3b3JkIjoibGF2ZW5kZXIiLCJlbWFpbCI6Ims4c0BnbWVtLmNjIiwiYXV0aCI6IllXeGxlRHBzWVhabGJtUmxjZz09In19fQ== # kind: Secret # metadata: # creationTimestamp: 2018-02-11T14:04:52Z # name: gmemregsecret # namespace: default # resourceVersion: "1023033" # selfLink: /api/v1/namespaces/default/secrets/gmemregsecret # uid: 87db6e2e-0f34-11e8-92db-deadbeef00a0 # type: kubernetes.io/dockerconfigjson |
其中data字段为BASE64编码的密码数据,可以查看一下它的明文:
|
1 2 |
echo eyJhdXRocyI6eyJkb2NrZXIuZ21lbS5jYzo1MDAwIjp7InVzZXJuYW1lIjoiYWxleCIsInBhc3N3b3JkIjoibGF2ZW5kZXIiLCJlbWFpbCI6Ims4c0BnbWVtLmNjIiwiYXV0aCI6IllXeGxlRHBzWVhabGJtUmxjZz09In19fQ== | base64 -d # {"auths":{"docker.gmem.cc":{"username":"alex","password":"lavender","email":"k8s@gmem.cc","auth":"YWxleDpsYXZlbmRlcg=="}}}alex@Zircon:~$ |
现在你可以创建使用此Secret来拉取镜像的Pod了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: Pod metadata: name: digitalsrv-1 labels: tier: rpc app: digitalsrv spec: containers: - name: digitalsrv-1 image: docker.gmem.cc/digitalsrv:1.0 imagePullSecrets: - name: gmemregsecret |
执行 kubectl edit serviceaccounts default,修改为如下内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: ServiceAccount metadata: creationTimestamp: 2018-02-12T07:53:30Z name: default namespace: default resourceVersion: "1843" selfLink: /api/v1/namespaces/default/serviceaccounts/default uid: d0e062a3-0fc9-11e8-b942-deadbeef00a0 secrets: - name: default-token-j9zdx imagePullSecrets: - name: gmemregsecret |
或者,执行命令:
|
1 |
kubectl patch serviceaccount default -p '{"imagePullSecrets": [{"name": "gmemregsecret"}]}' |
下一代复制控制器,与Replication Controller仅仅的不同是对选择器的支持, ReplicaSet支持指定set-based的选择器(来匹配Pod),后者仅支持equality-based的选择器。
尽管ReplicaSet可以被独立使用,但是实际上它主要通过Deployment间接使用,作为编排Pod创建、更新、删除的工具。使用Deployment时你无需关心其自动创建的ReplicaSet对象。
ReplicaSet用于确保,在任何时刻,指定数量的Pod实例同时在集群中运行。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
apiVersion: apps/v1 kind: ReplicaSet metadata: name: frontend labels: app: guestbook tier: frontend spec: # 复制实例的数量,默认1 replicas: 3 # 选择器,用于匹配被控制的Pod # 只要匹配,即使Pod不是ReplicaSet自己创建的,也被管理 —— 这允许替换ReplicaSet而不影响已存在的Pod的控制 selector: matchLabels: tier: frontend matchExpressions: - {key: tier, operator: In, values: [frontend]} # template是spec段唯一强制要求的元素,提供一个Pod模板 # 此Pod模板的结构和Pod对象完全一样,只是没有apiVersion/kind字段 template: metadata: # ReplicaSet中的Pod模板必须指定标签、以及适当的重启策略 labels: app: guestbook tier: frontend spec: containers: - name: php-redis image: gcr.io/google_samples/gb-frontend:v3 resources: requests: cpu: 100m memory: 100Mi env: - name: GET_HOSTS_FROM value: dns # 如果集群没有配备DNS Addon,则可以从环境变量获取service的主机名 # value: env ports: - containerPort: 80 |
要删除ReplicaSet及其Pod,可以使用 kubectl delete命令。Kubectl会将ReplicaSet缩容为0,并在删除ReplicaSet之前等待其所有Pod的删除,使用REST API或者Go客户端库时,你需要手工缩容、等待Pod删除、并删除ReplicaSet。
要仅删除ReplicaSet,可以使用 kubectl delete --cascade=false命令。 使用REST API/Go客户端库时,简单删除ReplicaSet对象即可。
在删除ReplicaSet之后,你可以创建.spec.selector字段与之一样的新的ReplicaSet,这个新的RS会管理原先的Pod。但是现有Pod不会匹配新RS的Pod 模板,你可以通过滚动更新(Rolling Update)实现现有Pod的更新。
要从RS中隔离一个Pod,可以修改Pod的标签。注意,此Pod会很快被代替,以满足ReplicaSet的复制数量要求。
要对RS进行扩容/缩容,你仅仅需要更新.spec.replicas字段。
RS可以作为Pod水平自动扩容器(Horizontal Pod Autoscaler)的目标。HPA的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: frontend-scaler spec: # 扩容控制的目标 scaleTargetRef: kind: ReplicaSet name: frontend minReplicas: 3 maxReplicas: 10 targetCPUUtilizationPercentage: 50 |
v2版本的HPA示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: podinfo minReplicas: 1 maxReplicas: 5 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 50 |
针对上述配置文件调用kubectl create -f即可创建HPA。你也可以直接调用
|
1 |
kubectl autoscale rs frontend |
更加简便。
类似于ReplicaSet。ReplicaSet是下一代的复制控制器。
大部分支持ReplicationController的kubectl命令,同时也支持ReplicaSet,一个例外是rolling-update命令。此命令专门用于RC的滚动更新 —— 每次更新一个Pod。
此控制器为Pod或ReplicaSet提供声明式的更新支持。在Deployment中,你可以指定一个期望状态,Deployment控制器会以一定的控制速率来修改实际状态,让它和期望状态匹配。通过定义Deployment你可以创建新的ReplicaSet,或者移除现有的Deployment并接收其全部资源。
Deployment的典型应用场景:
- 创建一个Deployment,来rollout一个ReplicaSet。ReplicaSet会在后台创建Pod。检查rollout的状态来确认是否成功
- 更新Deployment的PodTemplateSpec部分,来声明Pods的新状态。一个新的复制集会被创建,Pod会已移动的速率,从老的复制集中移动到新的复制集
- 回滚到旧的部署版本,如果当前版本的部署不稳定,则可以回滚到旧的Deployment版本
- 扩容以满足负载需要
- 暂停部署,对PodTemplateSpec进行更新,然后恢复部署,进行rollout
- 将Deployment的状态作为rollout卡死的提示器
- 清除你不再需要的复制集
下面的例子创建了三个运行Nginx的Pod构成的复制集:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: # 复制集容量 replicas: 3 # 可选此控制器如何找到需要管理的Pod,必须匹配.spec.template.metadata.labels selector: matchLabels: app: nginx # 如何替换旧Pod的策略,Recreate或RollingUpdate,默认RollingUpdate # Recreate 当新的Pod创建之前,所有旧Pod被删除 # RollingUpdate 滚动更新(逐步替换) strategy.type: RollingUpdate # 更新期间,处于不可用状态的Pod的数量,可以指定绝对值或者百分比。默认25 strategy.rollingUpdate.maxUnavailable: 0 # 更新期间,同时存在的Pod可以超过期望数量的多少,可以指定绝对值或者百分比。默认25 strategy.rollingUpdate.maxSurge: 1 # 在报告failed progressing之前等待更新完成的最长时间 progressDeadlineSeconds: 60 # 新创建的Pod,最少在启动多久后,才被认为是Ready。默认0 minReadySeconds: 0 # 保留rollout历史的数量,默认无限 revisionHistoryLimit: # Pod的模板 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: # 打开端口80,供Pod使用 - containerPort: 80 |
根据上述规格创建Deployment:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
kubectl create -f nginx-deployment.yaml # 获取对象信息 kubectl get deployments # 部署名称 期望实例数 当前运行实体数 到达期望状态实例数 对用户可用实例数 应用运行时长 # UP-TO-DATE 意味着使用最新的Pod模板 # AVAILABLE的Pod至少进入Ready状态.spec.minReadySeconds秒 # NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE # nginx-deployment 3 0 0 0 1s # 要查看部署的rollout状态,可以执行: kubectl rollout status deployment/nginx-deployment # Waiting for rollout to finish: 2 out of 3 new replicas have been updated... # deployment "nginx-deployment" successfully rolled out # 一段时间后,再次获取对象信息 NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 3 3 3 3 18s # 要查看Deployment自动创建的复制集,执行 kubectl get rs # NAME DESIRED CURRENT READY AGE # nginx-deployment-2035384211 3 3 3 18s # 复制集名称的格式为 [DEPLOYMENT-NAME]-[POD-TEMPLATE-HASH-VALUE] # 要查看为Pod自动创建的标签,执行 kubectl get pods --show-labels # NAME READY STATUS RESTARTS AGE LABELS # nginx-deployment-2035384211-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211 # nginx-deployment-2035384211-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211 # nginx-deployment-2035384211-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211 |
部署的rollout仅仅在其Pod模板发生变化时才会触发。其它情况,例如进行扩容,不会触发rollout。
修改Pod使用的镜像,示例命令:
|
1 2 3 4 |
# 方式一 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 # 方式二 kubectl edit deployment/nginx-deployment |
Deployment能够控制在更新时:
- 仅一定数量的Pod可以处于宕机状态。默认值是,最多运行期望Pod数量 - 1个处于宕机状态
- 存在超过期望数量的Pod存在。默认值是,最多同时存在 期望Pod数量 + 1 个Pod。K8S会先创建新Pod,然后删除旧Pod,这会导致同时存在的Pod数量超过期望Pod数
Deployment允许多重同时进行中的更新(multiple updates in-flight),所谓Rollover。每当部署控制器监控到新的Deployment对象时,旧有的控制标签匹配.spec.selector而模板不匹配.spec.template的Pod复制集会缩容为0,新的复制集则会扩容到期望Pod数量。如果你更新Deployment时,它正在进行rollout,则新的复制集被创建(每次更新对应一个)并扩容,并且roll over 前一次更新创建的复制集 —— 将其加入到旧复制集列表,并进行缩容。举例来说:
- 某个部署创建了5实例的nginx:1.7.9
- 随后更新部署为5实例的nginx:1.9.1,此时nginx:1.7.9的3个实例已经被创建
- 这时,部署控制器会立刻杀死nginx:1.7.9的3个实例,随后开始创建nginx:1.9.1实例。而不是等待nginx:1.7.9的5个实例都创建完毕,再对其缩容
你也可以进行标签选择器的更新,但是这并不推荐,你应该预先规划好标签。
某些情况下你需要回滚一次部署,这通常是因为新版本存在问题,例如无限循环崩溃。
默认情况下,Deployment所有的rollout历史(revision)都会保存在系统中,方便你随时进行回滚。注意revision仅仅在Deployment的rollout被触发时才生成,也就是仅仅在Deployment的Pod模板变更时才生成。执行回滚后,仅仅Pod模板部分被回滚,扩容、标签部分不受影响。
相关命令:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 列出rollout历史 kubectl rollout history deployment/nginx-deployment # deployments "nginx-deployment" # REVISION CHANGE-CAUSE # 1 kubectl create -f docs/user-guide/nginx-deployment.yaml --record # 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 # 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91 # 查看某次rollout的详细信息 kubectl rollout history deployment/nginx-deployment --revision=2 # 回滚到上一个版本 kubectl rollout undo deployment/nginx-deployment # 回滚到指定的版本 kubectl rollout undo deployment/nginx-deployment --to-revision=2 |
设置Pod实例数量:
|
1 |
kubectl scale deployment nginx-deployment --replicas=10 |
如果集群启用了Pod自动水平扩容(horizontal pod autoscaling),你可以为Deployment设置autoscaler:
|
1 2 |
# 实例数量在10到15之间,尽可能让这些实例的CPU占用靠近80% kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80 |
在触发一个或多个更新之前,你可以暂停Deployment,避免不必要的rollout:
|
1 2 3 4 5 6 7 8 9 |
# 暂停rollout kubectl rollout pause deployment/nginx-deployment # 更新Deployment kubectl set image deploy/nginx-deployment nginx=nginx:1.9.1 kubectl set resources deployment nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi # 恢复rollout kubectl rollout resume deploy/nginx-deployment |
Deployment在其生命周期中,会进入若干不同的状态:
| 状态 | 说明 |
| progressing |
执行以下任务之一时,K8S将Deployment标记为此状态:
|
| complete |
如果具有以下特征,K8S将Deployment标记为此状态:
|
| fail to progress |
无法部署Deployment的最新复制集,可能原因是:
具体多久没有完成部署,会让Deployment变为此状态,受spec.progressDeadlineSeconds控制 一旦超过上述Deadline,则部署控制器为Deployment.status.conditions添加一个元素,其属性为 Type=Progressing,Status=False,Reason=ProgressDeadlineExceeded 注意,暂停中的Deployment不会超过Deadline |
执行下面的命令可以查看Deployment的状态:
|
1 |
kubectl rollout status |
设置Deployment的.spec.revisionHistoryLimit字段,可以控制更新历史(也就是多少旧的ReplicaSet)被保留,默认所有历史都保留。
原先叫做PetSet。该控制器用于管理部署、扩容Pod集。并提供一个保证:确保Pod的有序性、唯一性。
和Deployment类似,SS也能管理(基于相同的容器规格的一组)Pods,但是SS还能够维护每个Pod的粘性身份(Sticky Identity )。尽管这些Pod的规格完全一样,但是不能相互替换(有状态),每个Pod都有自己的持久化的唯一标识,即使发生重新调度,也不会改变。
SS的行为模式和其它控制器类似,你需要定义一个StatefulSet对象,说明期望的状态。StatefulSet控制器会执行必要的更新以达到此状态。
对于有以下需求的应用程序,考虑使用SS:
- 稳定(Pod重调度后不变)的、唯一的网络标识符(network identity)
- 稳定的、持久的存储
- 有序的、优雅的部署和扩容
- 有序的、优雅的删除和终结
- 有序的、自动化的滚动更新
如果不满足上述需求之一,你应该考虑提供无状态复制集的控制器,例如Deployment、ReplicaSet。
使用SS时,要注意:
- 在1.9之前处于Beta状态,1.5-版本完全不可用
- 和其它所有Alpha/Beta资源一样,SS可以通过APIServer参数--runtime-config禁用
- Pod所需的存储资源,要么由 PersistentVolume Provisioner 提供,要么由管理员预先提供
- 删除/缩容SS时,和SS关联的卷不会自动删除
- SS目前依赖Headless Service,后者负责维护Pod的网络标识符,此Service需要你来创建
Headless Service的规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 用于控制网络域(Network Domain) apiVersion: v1 kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx |
StatefulSet的规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: # 1.8-,如果spec.selector不设置,K8S使用默认值 # 1.8+,不设置和.spec.template.metadata.labels匹配的值会在创建SS时出现验证错误 selector: matchLabels: app: nginx # has to match .spec.template.metadata.labels # 管理此SS的Headless Service的名称 serviceName: "nginx" # 包含三个有标识的Pod中启动的Nginx容器 replicas: 3 template: metadata: labels: app: nginx # has to match .spec.selector.matchLabels spec: terminationGracePeriodSeconds: 10 containers: - name: nginx image: gcr.io/google_containers/nginx-slim:0.8 ports: - containerPort: 80 name: web # 将卷www挂载到目录树 volumeMounts: - name: www mountPath: /usr/share/nginx/html # 使用PersistentVolumeProvisioner提供的PersistentVolume,作为持久化的存储 volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] storageClassName: my-storage-class resources: requests: storage: 1Gi |
SS创建的Pod具有唯一性的身份,此身份对应了稳定的网络标识符、稳定的存储。 此身份总是关联到Pod,不管Pod被重新调度到哪个节点上。
序号索引:对于副本份数为N的SS,每个Pod被分配一个整数序号,值范围 [ 0, N)
稳定网络标识符:每个Pod的hostname的形式为 ${SS名称}-${序号索引}。例如上面的例子中,会创建web-0、web-1、web-2三个Pod。
SS可以利用Headless Service来控制其Pod的域名,HS的域名格式为 $(service name).$(namespace).svc.cluster.local,其中cluster.local是集群的域名,上例中的HS域名为nginx.default.svc.cluster.local。
在HS的管理下,Pod的域名格式为 $(podname).$(governing service domain),因此web-0的域名为web-0.nginx.default.svc.cluster.local
对于每个VolumeClaimTemplate,K8S会创建对应的PersistentVolume。在上面的例子中,每个Pod会被赋予StorageClass为my-storage-class的单个PersistentVolume,以及1GB的存储空间。如果不指定StorageClass使用默认值。
当Pod被重新调度时,volumeMounts指定的挂载规则会重新挂载PersistentVolume。此外,即使SS或Pod被删除,PersistentVolume也不会被自动删除,你必须手工的删除它。
SS创建一个新Pod时,会为其添加一个标签:statefulset.kubernetes.io/pod-name。通过此标签,你可以为某个Pod实例Attach一个服务。
- 当SS部署Pod时,会顺序的依次创建,从序号0开始逐个的
- 当SS删除Pod时,会逆序的依次删除,从序号N-1开始逐个的
- 水平扩容时,新序号之前的所有Pod必须已经Running & Ready
- 在Pod被终结时,其后面的所有Pod必须已经被完全关闭
SS不应该指定pod.Spec.TerminationGracePeriodSeconds=0。
该控制器能确保所有(或部分)节点运行Pod的单个副本。每当节点加入到集群时,Pod就被添加到其上;每当节点离开集群时,其上的Pod就被回收。删除DS会导致所有Pod被删除。
DS的典型应用场景包括:
- 运行集群级别的存储守护程序,例如glusterd、ceph这些程序每个节点仅需要一个
- 在每个节点运行日志收集程序,例如fluentd、logstash
- 在每个节点上运行监控程序,例如collectd
DS的规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-elasticsearch namespace: kube-system labels: k8s-app: fluentd-logging spec: selector: matchLabels: name: fluentd-elasticsearch template: metadata: labels: name: fluentd-elasticsearch spec: # 用于仅仅在部分节点上运行Pod nodeSelector: tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd-elasticsearch image: gcr.io/google-containers/fluentd-elasticsearch:1.20 resources: limits: memory: 200Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers |
要和DaemonSet中的Pod通信,有以下几种手段:
- Push:DS中的Pod可能配置为,向其它服务发送更新,例如向统计数据库
- 节点IP + 已知端口:Pod可能使用hostPort来暴露端口
- DNS:使用和DS相同的Pod选择器,创建一个Headless Service。然后你可以通过endpoints资源来发现DS
可以为DaemonSet的Pod声明hostPort,这样,宿主机的端口会通过iptables的NAT转发给Pod:
|
1 2 3 4 5 |
ports: - name: http containerPort: 80 protocol: TCP hostPort: 80 |
Job可以创建一或多个Pod,并且确保一定数量的Pod成功的完成。Job会跟踪Pod们的执行状态,并判断它们是否成功执行,当指定数量的Pod成功了,则Job本身的状态变为成功。删除Job会清理掉它创建的Pod。
Job的一个简单用例是,确保Pod成功执行完成。如果第一个Pod失败/被删除,则Job会启动第二个实例。
Job也支持并行的运行多个Pod。
Job的规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: batch/v1 kind: Job metadata: name: pi spec: template: metadata: name: pi spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: Never backoffLimit: 4 |
定期调度执行的Job,规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: # Cron表达式,每分钟执行 schedule: "*/1 * * * *" # 如果由于某些原因,错过了调度时间,那么在什么时间差异之内,允许启动Job。默认没有deadline,总是允许启动 startingDeadlineSeconds: 5 # 并发控制策略,此CronJob创建的多个Job如何并发运行 # Allow,默认,允许并发运行多个Job # Forbid,禁止并发运行,如果尝试调度时发现先前的Job仍然在运行,跳过本次调度 # Replace,禁止并发运行,如果尝试调度时发现先前的Job仍然在运行,替换掉先前的Job concurrencyPolicy: Allow # 如果设置为true,则暂停后续调度,已经存在的Job不受影响 suspend: false # 保留的成功、失败的Job的数量.超过限制则删除对应的K8S资源 successfulJobsHistoryLimit: 3 failedJobsHistoryLimit: 0 jobTemplate: # 下面的配置同Job spec: template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - date restartPolicy: OnFailure |
Kubernetes garbage collector是控制器的一种,它的职责是删除哪些曾经拥有,但是现在已经没有Owner的对象。
某些对象是其它对象的所有者(Owner),例如ReplicaSet是一系列Pod的所有者。被所有者管理的对象称为依赖者(Dependent )。任何依赖者都具有字段 metadata.ownerReferences,指向其所有者。
某些情况下,K8S会自动设置ownerReference。例如创建ReplicaSet时,对应Pod的ownerReference即自动设置。常作为所有者的内置资源类型包括ReplicationController, ReplicaSet, StatefulSet, DaemonSet, Deployment, Job和CronJob。
你也可以手工配置ownerReference字段,以建立所有者-依赖者关系。
在删除对象时,可以指定是否级联删除(Cascading deletion)其依赖者(依赖被删除对象的哪些对象)。级联删除有两种执行模式:前台删除、后台删除。
在这种模式下,根对象(被显式删除的顶级Owner)首先进入删除中“(deletion in progress)”状态。此时:
- 对象仍然可以通过REST API看到
- 对象的deletionTimestamp字段不再为空
- 对象的 metadata.finalizers数组包含元素“foregroundDeletion“
一旦进入“删除中”状态,垃圾回收器就开始删除对象的依赖者。一旦所有阻塞依赖者(ownerReference.blockOwnerDeletion=true)全被删除,根对象就被删除。
当某种控制器设置了ownerReferences,它也会自动设置blockOwnerDeletion,不需要人工干预。
根对象立即被删除。垃圾回收器异步的在后台删除依赖者。
通过设置删除请求的DeleteOptions.propagationPolicy,可以修改级联删除模式:
- Orphan,孤儿化,解除ownerReferences而不删除
- Foreground,前台级联删除
- Background,后台级联删除
准许控制器(Admission Controller)是一小片的代码,被编译到kube-apiserver的二进制文件中。它能够拦截针对APIServer的请求,具体拦截时机是:操控对象被持久化之前、请求通过身份验证之后。很多K8S的高级特性需要准许控制器的介入。
准许控制器可以具有两个行为:
- validating:不能修改其admit的对象
- mutating:能够修改其admit的对象
准许控制的流程分为两个阶段,首先运行mutating类控制器,然后运行validating类控制器,任何一个控制器在任何阶段拒绝请求,则客户端收到一个错误。需要注意某些控制器同时有mutating、validating行为。
控制器的执行顺序,等同于它们在--admission-control参数中声明的顺序。
对于1.9版本,建议按序开启以下准许控制器:
|
1 2 3 |
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel, DefaultStorageClass,ValidatingAdmissionWebhook,ResourceQuota, DefaultTolerationSeconds,MutatingAdmissionWebhook |
(静态)准许控制器本身不够灵活:
- 需要被编译到kube-apiserver镜像中
- 仅仅当API Server启动后才可以被配置
Admission Webhooks可以解决此问题,用它可以来开发代码独立(Out-of-tree)、支持运行时配置的准许控制器。
和静态的准许控制器一样,Webhook也分为validating、mutating两类。
Webhook实际上是由ValidatingAdmissionWebhook、MutatingAdmissionWebhook这两个静态准许控制器适配(到API Server)的,因此这两个遵顼控制器必须启用。
这种服务需要处理admissionReview请求,并将其准许决定封装在admissionResponse中。
admissionReview可以是版本化的,Webhook可以使用admissionReviewVersions字段声明它能处理的Review的版本列表。调用Webhook时API Server会选择此列表中、它支持的第一个版本,如果找不到匹配版本,则失败。
下面是Kubernetes官方提供的样例Webhook服务器代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
package main import ( "encoding/json" "flag" "fmt" "io/ioutil" "net/http" "k8s.io/api/admission/v1beta1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/klog" ) // 一个助手函数,创建内嵌error的AdmissionResponse func toAdmissionResponse(err error) *v1beta1.AdmissionResponse { return &v1beta1.AdmissionResponse{ Result: &metav1.Status{ Message: err.Error(), }, } } // 所有validators和mutators都由admitFunc类型的函数负责实现 type admitFunc func(v1beta1.AdmissionReview) *v1beta1.AdmissionResponse // 核心逻辑,API Server使用HTTP协议调用Webhook Server func serve(w http.ResponseWriter, r *http.Request, admit admitFunc) { var body []byte if r.Body != nil { if data, err := ioutil.ReadAll(r.Body); err == nil { body = data } } // 请求体校验 contentType := r.Header.Get("Content-Type") if contentType != "application/json" { klog.Errorf("contentType=%s, expect application/json", contentType) return } klog.V(2).Info(fmt.Sprintf("handling request: %s", body)) // 请求Review requestedAdmissionReview := v1beta1.AdmissionReview{} // 响应Review responseAdmissionReview := v1beta1.AdmissionReview{} deserializer := codecs.UniversalDeserializer() // 反串行化响应体为requestedAdmissionReview if _, _, err := deserializer.Decode(body, nil, &requestedAdmissionReview); err != nil { klog.Error(err) responseAdmissionReview.Response = toAdmissionResponse(err) } else { // 如果没有错误,则执行准许逻辑 responseAdmissionReview.Response = admit(requestedAdmissionReview) } // 返回相同的UID responseAdmissionReview.Response.UID = requestedAdmissionReview.Request.UID klog.V(2).Info(fmt.Sprintf("sending response: %v", responseAdmissionReview.Response)) respBytes, err := json.Marshal(responseAdmissionReview) if err != nil { klog.Error(err) } if _, err := w.Write(respBytes); err != nil { klog.Error(err) } } /* 各种validators和mutators */ func serveAlwaysDeny(w http.ResponseWriter, r *http.Request) { serve(w, r, alwaysDeny) } func serveAddLabel(w http.ResponseWriter, r *http.Request) { serve(w, r, addLabel) } func servePods(w http.ResponseWriter, r *http.Request) { serve(w, r, admitPods) } func serveAttachingPods(w http.ResponseWriter, r *http.Request) { serve(w, r, denySpecificAttachment) } func serveMutatePods(w http.ResponseWriter, r *http.Request) { serve(w, r, mutatePods) } func serveConfigmaps(w http.ResponseWriter, r *http.Request) { serve(w, r, admitConfigMaps) } func serveMutateConfigmaps(w http.ResponseWriter, r *http.Request) { serve(w, r, mutateConfigmaps) } func serveCustomResource(w http.ResponseWriter, r *http.Request) { serve(w, r, admitCustomResource) } func serveMutateCustomResource(w http.ResponseWriter, r *http.Request) { serve(w, r, mutateCustomResource) } func serveCRD(w http.ResponseWriter, r *http.Request) { serve(w, r, admitCRD) } type Config struct { CertFile string KeyFile string } func (c *Config) addFlags() { // 包含用于HTTPS的x509服务器证书,如果包含CA证书,则连接在服务器证书后面 flag.StringVar(&c.CertFile, "tls-cert-file", c.CertFile, "...") // 匹配上述服务器证书的私钥 flag.StringVar(&c.KeyFile, "tls-private-key-file", c.KeyFile, "...") } func configTLS(config Config) *tls.Config { sCert, err := tls.LoadX509KeyPair(config.CertFile, config.KeyFile) if err != nil { klog.Fatal(err) } return &tls.Config{ Certificates: []tls.Certificate{sCert}, // 下面一行用于启用mTLS,也就是对客户端(API Server)进行身份验证 // ClientAuth: tls.RequireAndVerifyClientCert, } } func main() { var config Config config.addFlags() flag.Parse() // 不同的URL路径,对应不同的Webhook,处理函数也不同 http.HandleFunc("/always-deny", serveAlwaysDeny) http.HandleFunc("/add-label", serveAddLabel) http.HandleFunc("/pods", servePods) http.HandleFunc("/pods/attach", serveAttachingPods) http.HandleFunc("/mutating-pods", serveMutatePods) http.HandleFunc("/configmaps", serveConfigmaps) http.HandleFunc("/mutating-configmaps", serveMutateConfigmaps) http.HandleFunc("/custom-resource", serveCustomResource) http.HandleFunc("/mutating-custom-resource", serveMutateCustomResource) http.HandleFunc("/crd", serveCRD) server := &http.Server{ Addr: ":443", TLSConfig: configTLS(config), } server.ListenAndServeTLS("", "") } |
此样例中包含很多Webhook的样板代码。下面选取几个分析。
addlabel.go是一个mutator,它为对象添加{"added-label": "yes"}标签:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
package main import ( "encoding/json" "k8s.io/api/admission/v1beta1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/klog" ) const ( addFirstLabelPatch string = `[ { "op": "add", "path": "/metadata/labels", "value": {"added-label": "yes"}} ]` addAdditionalLabelPatch string = `[ { "op": "add", "path": "/metadata/labels/added-label", "value": "yes" } ]` ) func addLabel(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { klog.V(2).Info("calling add-label") obj := struct { metav1.ObjectMeta Data map[string]string }{} // 从Review中提取原始对象(被拦截的API Server请求中的对象) raw := ar.Request.Object.Raw err := json.Unmarshal(raw, &obj) if err != nil { klog.Error(err) return toAdmissionResponse(err) } // 响应 reviewResponse := v1beta1.AdmissionResponse{} // 准许通过 reviewResponse.Allowed = true if len(obj.ObjectMeta.Labels) == 0 { // Patch原始对象 reviewResponse.Patch = []byte(addFirstLabelPatch) } else { reviewResponse.Patch = []byte(addAdditionalLabelPatch) } pt := v1beta1.PatchTypeJSONPatch reviewResponse.PatchType = &pt return &reviewResponse } |
pods.go提供了三个Webhook:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
package main import ( "fmt" "strings" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/api/admission/v1beta1" "k8s.io/klog" ) const ( podsInitContainerPatch string = `[ {"op":"add","path":"/spec/initContainers","value":[{"image":"webhook-added-image","name":"webhook-added-init-container","resources":{}}]} ]` ) // 校验Pod的规格 func admitPods(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { klog.V(2).Info("admitting pods") // 校验Review中的GVK podResource := metav1.GroupVersionResource{Group: "", Version: "v1", Resource: "pods"} if ar.Request.Resource != podResource { err := fmt.Errorf("expect resource to be %s", podResource) klog.Error(err) return toAdmissionResponse(err) } // 将原始对象转换为Pod raw := ar.Request.Object.Raw pod := corev1.Pod{} deserializer := codecs.UniversalDeserializer() if _, _, err := deserializer.Decode(raw, nil, &pod); err != nil { klog.Error(err) return toAdmissionResponse(err) } reviewResponse := v1beta1.AdmissionResponse{} // 默认准许通过 reviewResponse.Allowed = true var msg string // 演示各种不准许的情形 if v, ok := pod.Labels["webhook-e2e-test"]; ok { if v == "webhook-disallow" { reviewResponse.Allowed = false msg = msg + "the pod contains unwanted label; " } } for _, container := range pod.Spec.Containers { if strings.Contains(container.Name, "webhook-disallow") { reviewResponse.Allowed = false msg = msg + "the pod contains unwanted container name; " } } if !reviewResponse.Allowed { reviewResponse.Result = &metav1.Status{Message: strings.TrimSpace(msg)} } return &reviewResponse } // 修改Pod,Patch一个Init容器进去 func mutatePods(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { klog.V(2).Info("mutating pods") podResource := metav1.GroupVersionResource{Group: "", Version: "v1", Resource: "pods"} if ar.Request.Resource != podResource { klog.Errorf("expect resource to be %s", podResource) return nil } raw := ar.Request.Object.Raw pod := corev1.Pod{} deserializer := codecs.UniversalDeserializer() if _, _, err := deserializer.Decode(raw, nil, &pod); err != nil { klog.Error(err) return toAdmissionResponse(err) } reviewResponse := v1beta1.AdmissionResponse{} reviewResponse.Allowed = true if pod.Name == "webhook-to-be-mutated" { reviewResponse.Patch = []byte(podsInitContainerPatch) pt := v1beta1.PatchTypeJSONPatch reviewResponse.PatchType = &pt } return &reviewResponse } // 禁止kubectl attach to-be-attached-pod -i -c=container1请求 func denySpecificAttachment(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { klog.V(2).Info("handling attaching pods") if ar.Request.Name != "to-be-attached-pod" { return &v1beta1.AdmissionResponse{Allowed: true} } // 期望接收到的是Pod资源,attach子资源 podResource := metav1.GroupVersionResource{Group: "", Version: "v1", Resource: "pods"} if e, a := podResource, ar.Request.Resource; e != a { err := fmt.Errorf("expect resource to be %s, got %s", e, a) klog.Error(err) return toAdmissionResponse(err) } if e, a := "attach", ar.Request.SubResource; e != a { err := fmt.Errorf("expect subresource to be %s, got %s", e, a) klog.Error(err) return toAdmissionResponse(err) } raw := ar.Request.Object.Raw podAttachOptions := corev1.PodAttachOptions{} deserializer := codecs.UniversalDeserializer() if _, _, err := deserializer.Decode(raw, nil, &podAttachOptions); err != nil { klog.Error(err) return toAdmissionResponse(err) } klog.V(2).Info(fmt.Sprintf("podAttachOptions=%#v\n", podAttachOptions)) // 如果不使用Stdin,或者容器不是container1则允许,否则不允许 if !podAttachOptions.Stdin || podAttachOptions.Container != "container1" { return &v1beta1.AdmissionResponse{Allowed: true} } return &v1beta1.AdmissionResponse{ Allowed: false, Result: &metav1.Status{ Message: "attaching to pod 'to-be-attached-pod' is not allowed", }, } } |
可以直接作为Deployment部署在K8S集群内部,也可以部署在外面,需要对应的配置来配合。
Webhook的配置通过ValidatingWebhookConfiguration、MutatingWebhookConfiguration这两类K8S资源进行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
apiVersion: admissionregistration.k8s.io/v1beta1 kind: ValidatingWebhookConfiguration metadata: name: sidecar-injectors webhooks: # Webhoooks列表 - name: init-inject # 匹配任意一个规则,则API Server会发送AdmissionReview # 给clientConfig所指定的Webhook服务器 rules: - apiGroups: - "" apiVersions: - v1 operations: - CREATE resources: - pods scope: "Namespaced" clientConfig: # Webhook服务 service: namespace: kube-system name: sidecar-injector # 签名了服务器端证书的CA,PEM格式 # 有时候会设置为 caBundle: Cg== (\n),这是一个占位符,防止该CR被API Server拒绝。证书后续由程序自动更新 caBundle: pem encoded ca cert that signs the server cert used by the webhook admissionReviewVersions: - v1beta1 timeoutSeconds: 1 |
如果Webhook需要对API Server进行身份验证,则需要进行以下步骤:
- 为API Server提供 --admission-control-config-file参数,指定准许控制配置文件
- 在准许控制配置文件中,声明MutatingAdmissionWebhook、ValidatingAdmissionWebhook从何处读取凭证信息:
12345678910111213apiVersion: apiserver.k8s.io/v1alpha1kind: AdmissionConfigurationplugins:- name: ValidatingAdmissionWebhookconfiguration:apiVersion: apiserver.config.k8s.io/v1alpha1kind: WebhookAdmissionkubeConfigFile: /path/to/kubeconfig- name: MutatingAdmissionWebhookconfiguration:apiVersion: apiserver.config.k8s.io/v1alpha1kind: WebhookAdmissionkubeConfigFile: /path/to/kubeconfig - 凭证信息必须存放在KubeConfig文件中,示例:
123456789101112131415161718192021apiVersion: v1kind: Configusers:# 基于数字证书的身份验证# Webhook服务器的DNS名称- name: 'webhook1.ns1.svc'user:client-certificate-data: pem encoded certificateclient-key-data: pem encoded key# HTTP基本验证# 可以使用通配符- name: '*.webhook-company.org'user:password: passwordusername: name# 基于令牌的身份验证# 默认凭证- name: '*'user:token: <token>
总是允许所有请求通过。
总是拒绝所有请求通过,仅测试用。
修改所有新的Pod,将它们的镜像拉取策略改为Always。在多团队共享集群上有用,可以确保仅具有合法凭证的用户才能拉取镜像。
如果没有该AC,则一旦镜像被拉取到Node上,任何用户、Pod都可以不提供凭证的使用之。
监控PersistentVolumeClaim对象的创建过程,如果PVC没有要求任何存储类,则为其自动添加。
设置当Taint和Toleration不匹配时,默认能够容忍的最长时间。
禁止对以特权级别(privileged Pod、能访问宿主机IPC名字空间的Pod、能访问宿主机PID名字空间的Pod)运行的Pod执行exec/attach命令。
Alpha/1.9,可以缓和APIServer被事件请求泛洪的问题。
1.9引入的插件,辅助带有扩展资源(GPU/FPGA...)的节点的创建,这类节点应该以扩展资源名为键配置Taints。
该控制器自动为请求扩展资源的Pod添加Tolerations,用户不需要手工添加。
允许后端的webhook给出准许决策。
Alpha/1.7,根据现有的InitializerConfiguration来确定资源的初始化器。
监控Pod创建请求,如果容器没有提供资源用量请求/限制,该AC会根据基于相同镜像的容器的历史运行状况,自动为容器添加资源用量请求/限制。
拒绝任何这样的Pod,它的AntiAffinity(requiredDuringSchedulingRequiredDuringExecution)拓扑键是kubernetes.io/hostname之外的值。
监控入站请求,确保Namespace中LimitRange对象列出的任何约束条件不被违反。如果在部署中使用LimitRange,你必须启用该AC。
检查针对所有名字空间化的资源的请求,如果所引用的名字空间不存在,则自动创建名字空间。
检查针对所有名字空间化的资源的请求,如果所引用的名字空间不存在,则返回错误。
具有以下功能:
- 确保正在删除的名字空间中,不会由新的对象被创建
- 确保针对不存在名字空间的资源创建请求被拒绝
- 禁止删除三个系统保留名字空间:default, kube-system, kube-public
Namespace删除操作会级联删除其内部的Pod、Service等对象,为了确保删除过程的完整性,应当使用此AC。
限制Kubelet能够修改的Pod、Node对象。
自动将云服务商定义的Region/Zone标签附加到PV。可以用于保证PV和Pod位于相同的Region/Zone。
读取Namespace上的注解和全局配置,限制某个命名空间中的Pod能够运行在什么节点(通过nodeSelector)。
要启用此控制器,需要修改APIServer的配置/etc/kubernetes/manifests/kube-apiserver.yaml,在--enable-admission-plugins=后添加PodNodeSelector。
使用下面的注解,可以为命名空间中任何Pod添加默认nodeSelector:
|
1 2 3 4 5 6 |
apiVersion: v1 kind: Namespace metadata name: devops annotations: scheduler.alpha.kubernetes.io/node-selector: k8s.gmem.cc/dedicated-to=devops |
这样,此命名空间中创建的新Pod,都会具有nodeSelector:
|
1 2 |
nodeSelector k8s.gmem.cc/dedicated-to:devops |
此控制器首先校验Pod的容忍和命名空间的容忍,如果存在冲突则拒绝Pod创建。然后,它将命名空间的容忍合并到Pod的容忍中,合并后的结果进行命名空间容忍白名单检查,如果检查不通过则Pod被拒绝创建。
命名空间的容忍,使用注解scheduler.alpha.kubernetes.io/defaultTolerations配置,示例:
|
1 2 3 4 5 |
apiVersion: v1 kind: Namespace metadata: annotations: scheduler.alpha.kubernetes.io/defaultTolerations: '[{"key":"k8s.gmem.cc/dedicated-to","operator":"Equal","value":"devops","effect":"NoSchedule"}]' |
命名空间的容忍白名单,使用注解scheduler.alpha.kubernetes.io/tolerationsWhitelist配置。 此注解的值类似上面的注解。
打开特性开关ExpandPersistentVolumes后,你应该启用该AC。
此AC默认即用所有PVC的Resizing请求,除非PVC的存储类明确的启用(allowVolumeExpansion=true)
注入匹配的PodPreset中的规格字段。
使用priorityClassName字段并为Pod产生一个整数类型的优先级。如果目标priorityClass不存在则Pod被拒绝。
监控入站请求,确保没有违反Namespace中ResourceQuota对象所列出的资源配额限制。
如果你使用ResourceQuota对象,则必须启用此AC。
实现ServiceAccount的自动化。当使用ServiceAccount对象是应当启用此AC。
禁止那些尝试通过SecurityContext中某些字段实现权限提升的Pod。如果没有启用PodSecurityPolicy,应当考虑启用该控制器。
K8S中的Pod是有生命周期的,当Pod死掉后它无法复活。某些控制器会动态的创建、删除Pod。尽管Pod会获得一个IP地址,但是随着时间的推进,IP也不能作为联系它的可靠手段,因为IP会改变。
那么,如果某个Pod(后端)集向其它Pod(前端)集提供功能,那么前端如何找到、跟踪后端集中的Pod呢?Service能帮助你实现这一需求。
所谓Service,是一个抽象,它定义了:
- 一个逻辑的Pod集合。常常通过标签选择器来锚定
- 访问这些Pod的策略
Service有时候也被称为微服务(micro-service)。
举个例子,假设有一个图像处理后端,包括三个实例。这些实例是无状态的,因而前端不关心它调用的是哪一个。组成后端的Pod实例可能发生变化(宕机、扩容),如果前端跟踪其调用的Pod显然会造成耦合。Service这个抽象层可以实现解耦。
对于K8S-Native应用程序,K8S提供了Endpoints API。每当Service包含的Pod集发生变化后,即更新端点。对于非K8S-Native的应用程序,K8S为Service提供了一个基于虚拟IP的桥,用于将请求重定向到后端的Pod。
假设你有一组Pod,其标签为app=MyApp,并且都暴露了9376端口。你可以为它们定义如下服务:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
kind: Service apiVersion: v1 metadata: name: my-service spec: # 被服务管理的Pod selector: app: MyApp ports: - protocol: TCP # 服务的集群IP上的端口 port: 80 # Pod的端口,可以指定为Pod中定义的端口名 targetPort: 9376 |
Service本身也被分配一个IP(称为集群IP),此IP会被服务代理使用。
Service的selector会被不断的估算,其匹配结果会被发送给与Service同名的Endpoints对象。
Service能够进行端口映射。针对服务的请求可以被映射到Pod的端口。支持的网络协议包括TCP、UDP两种。
尽管Service通常用来抽象对Pod的访问,它也可以用来抽象其它类型的后端,例如:
- 在生产环境下你希望使用外部数据库集群,但是在开发/测试时你希望使用自己的数据库
- 你希望把服务指向其它名字空间中的服务,甚至其它集群中的服务
- 你在把一部分工作负载迁移到K8S,而让另一部分在外部运行
以上情况下,你都可以定义一个没有选择器的Service。由于没有选择器,Endpoints对象不会被创建。你可能需要手工映射服务到端点:
|
1 2 3 4 5 6 7 8 9 10 |
kind: Endpoints apiVersion: v1 metadata: name: my-service # 端点列表,这个例子中流量被路由给1.2.3.4:9376 subsets: - addresses: - ip: 1.2.3.4 ports: - port: 9376 |
这是一种特殊的Service,它即不选择端点,也不定义端口。它只用于提供集群外部的服务的别名,集群内的组件可以基于别名访问外部服务:
|
1 2 3 4 5 6 7 8 9 |
kind: Service apiVersion: v1 metadata: name: database namespace: prod spec: type: ExternalName # IP地址也支持 externalName: db.gmem.cc |
当集群内组件查找database.prod.svc.${CLUSTER_DOMAIN}时,集群的DNS服务会返回一个CNAME记录,其值为db.gmem.cc。
注意:经过试验,externalName填写IP地址也是可以的,这种情况下,集群DNS服务应该是做了一个A记录。
K8S集群中的每个节点都运行着kube-proxy组件。该组件负责为服务(除了ExternalName)提供虚拟IP。
在1.0版本,Service属于第四层(TCP/UDP over IP)构造,kube-proxy完全工作在用户空间。从1.1开始引入了Ingress API,用于实现第七层(HTTP)Service。基于iptables的代理也被添加,并从1.2开始成为默认操作模式。从1.9开始,ipvs代理被添加。
此模式下,kube-proxy监控Master,关注Service、Endpoints对象的添加和删除。
对于每个Service,KP会在本地节点随机打开一个代理端口,任何发向此端口的的请求会被转发给服务的某个后端Pod(从Endpoints对象中获取)。到底使用哪个Pod,取决于Service的SessionAffinity设置,默认选取后端的算法是round robin。KP会把转发规则写入到iptables中,捕获Service的集群IP(虚拟的)的流量。
这种模式下,需要在内核空间和用户空间传递流量。
此模式下,KP会直接安装iptables规则,捕获Service的集群IP + Service 端口的流量,转发给某个Service后端Pod,选择Pod的算法是随机。
这种模式下,不需要在内核空间和用户空间之间切换,通常比userspace模式更快、更可靠。但是,该模式不支持当第一次选择的Pod不响应后重新选择另外一个Pod,因此需要配合Readness探针使用。
关于IPVS的知识参考:IPVS和Keepalived
在1.9中处于Beta状态。
此模式下,KP会调用netlink网络接口,创建和K8S的Service/Endpoint对应的ipvs规则,并且周期性的将K/E和ipvs规则同步。当访问Service时,流量被转发给某个Pod。
类似于iptables,ipvs基于netfilter钩子函数,但是它使用哈希表作为底层数据结构,且运行在内核态。这意味着ipvs的流量转发速度会快的多,且同步代理规则时性能更好。
在未来的版本中,ipvs会提供更多的负载均衡算法,包括:
- rr:循环选择
- lc:最少连接(least connection)
- dh:目的地哈希(destination hashing)
- sh:源哈希(destination hashing)
- sed:最短预期延迟(shortest expected delay)
- nq:绝不排队(never queue)
注意,该模式要求节点上安装了IPVS内核模块。如果该模块没有安装,会自动fallback为iptables模式。
基于IPVS的K8S Service,都是使用NAT模式,原因是,只有NAT模式才能进行端口映射,让Sevice端口和Pod端口不一致。
IPVS模式下,客户端角色是当前节点(中的Pod,或者节点本身),Direct角色是当前节点,Real Server是当前或其它节点上的Pod。不同客户端,对应的网络路径不一样。IPVS模式仍然需要iptables规则进行一些配合。
考虑Service 10.96.54.11:8080,Pod 10.244.1.2:8080,基于Flannel构建容器网络,当前flannel.1的IP地址为10.244.0.0:
- 当前节点出现一个虚拟网络接口 kube-ipvs0,所有Service IP都绑定在上面,这是IPVS所要求的,Direct必须具有VIP。这也导致了IPVS模式下,VIP可Ping(iptables模式下不可以)
- OUTPUT链被添加如下规则:
123456789-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES# 如果源IP不是Pod IP,且目的IP是K8S Service(所有Service IP放在IPSet中,大大减少iptables规则条目数量)-A KUBE-SERVICES ! -s 10.244.0.0/16 -m comment--comment "Kubernetes service cluster ip + port for masquerade purpose"# 则打上标记-m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000不是Pod发出的对Service IP的请求,打标记0x4000/0x4000的目的是,后续进行SNAT。因为节点自身(而非其中的Pod)对VIP进行访问时,因为VIP就在本机网卡,所以它自动设置IP封包的源地址、目的地址均为10.96.54.11,这样的封包不做SNAT,仅仅DNAT到Pod上,回程报文是发不回来的(因为每个节点都具有所有VIP)
- POSTROUTING链被添加如下规则:
1234-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT"-m mark --mark 0x4000/0x4000 -j MASQUERADE如第2条所属,需要作SNAT, MASQUERADE意味着源地址取决于封包出口网卡
为了更深入的理解,可以看看地址映射的过程,在节点上访问curl http://10.96.54.11:8080时:
- 产生如下封包: 10.96.54.11:xxxxx -> 10.96.54.11:8080。原因是目标地址在kube-ipvs0这个本机网卡上
- 经过IPVS模块,选择一个RIP,进行DNAT:10.96.54.11:xxxxx -> 10.244.2.2:8080
- 经过OUTPUT、POSTROUTING链,进行SNAT:10.244.0.0:xxxxx -> 10.244.2.2:8080 。10.244.0.0是出口网卡flannel.1的地址,封包发给此网卡后,经过内核包装为vxlan UDP包,再由物理网卡发出去
Pod具有普通的IP地址,因为针对此IP的请求被路由到固定的位置。
Service的IP则是虚拟的 —— 它不会由某台固定的主机来应答。K8S使用Linux的iptables来定义透明、按需进行重定向的VIP。当客户端连接到VIP时,流量会透明的传输给适当的端点。Service相关的环境变量、DNS条目使用的都是Service的VIP和端口。
不管使用哪种代理模式,均保证:
- 任何从Service的集群IP:Port进入的流量,都被转发给适当的后端Pod。客户端不会感知到K8S、Service、Pod这些内部组件的存在
- 要实现基于客户端IP的会话绑定(session affinity ),可以设置service.spec.sessionAffinity = ClientIP (默认None)。你可以进一步设置service.spec.sessionAffinityConfig.clientIP.timeoutSeconds来指定会话绑定的最长时间(默认10800)
由于Iptables底层数据结构是链表,而IPVS则是哈希,IPVS比起iptables模式显著提高的性能,几乎不受服务规模增大的影响。现在的集群都使用IPVS模式的服务代理。
IPVS支持三种工作模式:DR(直接路由)、Tunneling(ipip)、NAT(Masq)。其中只有NAT模式支持端口映射(ClusterIP端口和Pod端口不一样),因此K8S使用NAT模式。此外,K8S还在NAT的DNAT(将对服务的请求的目的地址改为Pod IP)的基础上,进行SNAT(将对服务的请求的源地址改为入站网络接口的地址,否则Pod直接发送源地址为Pod IP的回程报文,客户端不接受),尽管fullNAT这种IPVS扩展可以支持DNAT+SNAT。
IPVS是在INPUT链上挂了钩子,运行复杂的负载均衡算法,然后执行DNAT后从FORWARD链离开本机网络栈。
让网络包进入INPUT链有两种方式:
- 将虚IP写到内核路由表中
- 创建一个Dummy网卡,将续IP绑定到此网卡
Kube Proxy使用的是第二种方式。一旦Service对象创建,Kube proxy就会:
- 确保Dummy网卡kube-ipvs0存在
- 将服务的虚IP绑定给kube-ipvs0
- 通过socket创建IPVS的virtual server。virtual server和service是N:1关系,原因是Service可能有多个虚拟IP,例如LoadBalancer IP + Cluster IP
当Endpoint对象创建后,Kube Proxy会:
- 创建IPVS的real server。real server和endpoint是1:1关系
即使使用IPVS模式,只能解决流量转发的问题。Kube Proxy的其它问题仍然依靠 Iptables 解决,它在以下情况下依赖Iptables:
- 如果配置启动参数 --masquerade--all=true,也就是所有经过kube-proxy的包都进行一次SNAT
- 启动参数指定了集群IP地址范围
- 对于LoadBalancer类型的服务,需要Iptables配置白名单
- 对于NodePort类型的服务,用于在封包从入站节点发往其它节点的Pod时进行MASQUERADE
Kube Proxy使用ipset来减少需要创建的iptables规则,IPVS模式下iptables规则的数量不超过5个
很多服务需要暴露多个端口,K8S支持在Service的规格中指定多个端口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: # 端口1 - name: http protocol: TCP port: 80 targetPort: 9376 # 端口2 - name: https protocol: TCP port: 443 targetPort: 9377 |
在创建Service时,你可以指定你想要的集群IP,设置spec.clusterIP字段即可。
你选择的IP地址必须在service-cluster-ip-range(APIServer参数)范围内,如果IP地址不合法,APIServer会返回响应码422。
K8S提供两种途径,来发现一个服务:环境变量、DNS。
当Pod运行时,Kubelet会以环境变量的形式注入每个活动的服务的信息。环境变量名称格式为{SVCNAME}_SERVICE_HOST、{SVCNAME}_SERVICE_PORT。其中SVCNAME是转换为大写、-转换为_的服务名。
例如服务redis-master,暴露TCP端口6379,获得集群IP 10.0.0.11。它会产生以下环境变量:
|
1 2 3 4 5 6 7 |
REDIS_MASTER_SERVICE_HOST=10.0.0.11 REDIS_MASTER_SERVICE_PORT=6379 REDIS_MASTER_PORT=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP_PROTO=tcp REDIS_MASTER_PORT_6379_TCP_PORT=6379 REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11 |
需要注意:服务必须在Pod之前就创建好,否则Pod的环境变量无法更新。
K8S提供了DNS Addon。此DNS服务器会监控新创建的Service,并为其提供DNS条目。集群中所有Pod都可以使用该DNS服务。
位于名字空间my-ns中的服务my-svc,创建的DNS条目是my-svc.my-ns。位于名字空间my-ns中的Pod可以直接通过my-svc访问服务,其它名字空间中的Pod则需要使用my-svc.my-ns访问服务。DNS名称解析的结果是服务的Cluster IP。
要访问ExternalName类型的Service,DNS是唯一的途径。
某些情况下,你不需要Service提供的负载均衡功能,也不需要单个Service IP。这种情况下你可以创建Headless Service,其实就是设置spec.clusterIP=None。
使用HS,开发者可以减少和K8S的耦合,自行实现服务发现机制。
HS没有Cluster IP,kube-proxy也不会处理这类服务,K8S不会为这类服务提供负载均衡机制。
DNS记录如何创建,取决于HS有没有配置选择器。
如果定义了选择器,端点控制器为HS创建Endpoints对象。并且修改DNS配置,返回A记录(地址),直接指向HS选择的Pod。
端点控制器不会为这类Service创建Endpoints对象,但是DNS系统会配置:
- 为ExternalName类型的Service配置CNAME记录
- 对于其它类型的Service,为和Service共享名称的任何Endpoints创建一条DNS记录
对于无选择器的HS,不会自动创建关联的Endpoints,因此我们有机会手工的关联Endpoints,从而实现:
- 指向一个集群外部的数据库
- 指向其它namespace或集群的服务
示例:
|
1 2 3 4 5 6 7 8 9 |
kind: Endpoints apiVersion: v1 metadata: name: my-service subsets: - addresses: - ip: 1.2.3.4 ports: - port: 1234 |
Endpoint的地址不能是Loopback、link-local、link-local多播地址。
对于应用程序中的某些部分(前端),你通常需要在外部(集群外部)IP上暴露一个服务。
K8S允许你指定为服务指定类型(ServiceTypes):
| 类型 | 说明 | ||
| ClusterIP |
在集群内部的IP地址上暴露服务,如果你仅希望在集群内部能访问到服务,则使用该类型 这是默认的类型 |
||
| NodePort |
在所有节点的IP上的一个静态端口上暴露服务。K8S会自动创建一个ClusterIP类型的服务,用于把NodePort类型的服务路由到适当的Pod 外部可以将任何Node作为入口,访问此类型的服务 K8S会自动分配一个范围内的端口(默认30000-32767),每个节点都会转发到此端口的请求。此端口表现在spec.ports[*].nodePort字段中 如果你需要手工指定端口,设置nodePort的值即可。手工指定的值必须在允许的端口范围之内,你还需要注意可能存在的端口冲突。建议自动分配端口 服务可以通过以下两种方式访问到:
NodePort是丐版的LoadBalancer,可供外部访问且成本低廉。但是在大规模集群上 |
||
| LoadBalancer |
向外部暴露服务,并使用云服务提供的负载均衡器。外部负载均衡器所需要的NodePort,以及ClusterIP会自动创建 服务的EXTERNAL-IP字段为云提供商的负载均衡器的IP 某些云服务(GCE、AWS等)提供负载均衡器,K8S支持和这种外部LB集成:
|
||
| ExternalName | 将外部服务映射为别名 |
注:修改服务的类型,不会导致ClusterIP重新分配。
如果你拥有一个或多个外部(例如公网)IP路由到集群的某些节点,则Service可以在这些外部IP上暴露。基于这些IP流入的流量,如果其端口就是Service的端口,会被K8S路由到服务的某个端点(Pod ...)上。
例如下面这个服务:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: - name: http protocol: TCP port: 80 targetPort: 9376 externalIPs: - 80.11.12.10 |
外部客户端可以通过80.11.12.10:80访问服务,流量会被转发给app=MyApp的Pod的9376端口。
当访问NodePort、LoadBalancer类型的Service时,流量到达节点后,可能再被转发到其它节点,从而增加了一跳。
要避免这种情况,可以设置:
|
1 2 3 4 |
kind: service spec: # 默认 Cluster externalTrafficPolicy: Local |
这样,K8S会强制将流量发往具有Service后端Pod的端点。注意ClusterIP类型的服务不支持这种局部性访问配置。
服务的端点,通常情况下对应到Pod的一个端口。带有选择器的Service通常自动管理Endpoint对象,你也可以定义不使用选择器的服务,这种情况下需要手工管理端点,Endpoints对象的名字和Service的名字要一致,位于相同命名空间。
所有网络端点都保存在同一个 Endpoints 资源中,这类资源可能变得非常巨大,进而影响控制平面组件性能,EndpointSlice可以缓解这一(大量端点)问题。此外涉及如何路由内部流量时,EndpointSlice 可以充当 kube-proxy 的决策依据。
默认情况下,单个端点切片最多包含100个端点,可以通过控制器管理器的标记 --max-endpoints-per-slice来定制。
下面是端点切片对象的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
apiVersion: discovery.k8s.io/v1beta1 kind: EndpointSlice metadata: name: example-abc labels: kubernetes.io/service-name: example # 端点的地址类型:支持IPv4 IPv6 FQDN addressType: IPv4 # 端口列表,适用于切片中所有端点 ports: - name: http protocol: TCP port: 80 endpoints: - addresses: - "10.1.2.3" # EndpointSlice存储了可能对使用者有用的、有关端点的状况。 这三个状况分别是 # ready 对应Pod的Ready状态,运行中的Pod的Ready为True # serving 如果Pod处于终止过程中则Ready不为True,此时应该查看serving获知Pod是否就绪 # 例外是spec.publishNotReadyAddresses的服务,这种服务的端点的Ready永远为True # terminating conditions: ready: true hostname: pod-1 # 拓扑感知,1.20废弃 topology: kubernetes.io/hostname: node-1 # 未来使用nodeName字段代替 topology.kubernetes.io/zone: us-west2-a |
通常情况下,由端点切片控制器自动创建、管理 EndpointSlice 对象。EndpointSlice 对象还有一些其他使用场景, 例如作为服务网格的实现。这些场景都会导致有其他实体 或者控制器负责管理额外的 EndpointSlice 集合。
为了确保多个实体可以管理 EndpointSlice 而且不会相互产生干扰,Kubernetes 定义了 标签 endpointslice.kubernetes.io/managed-by,用来标明哪个实体在管理某个 EndpointSlice。端点切片控制器会在自己所管理的所有 EndpointSlice 上将该标签值设置 为 endpointslice-controller.k8s.io。 管理 EndpointSlice 的其他实体也应该为此标签设置一个唯一值。
在大多数场合下,EndpointSlice 都由某个 Service 所有,这一属主关系是通过:
- 为每个 EndpointSlice 设置一个 owner引用
- 设置 kubernetes.io/service-name 标签来标明的,目的是方便查找隶属于某服务的所有 EndpointSlice
每个 EndpointSlice 都有一组端口值,适用于资源内的所有端点。 当为服务使用命名端口时,Pod 可能会就同一命名端口获得不同的端口号,因而需要 不同的 EndpointSlice。
控制面尝试尽量将 EndpointSlice 填满,不过不会主动地在若干 EndpointSlice 之间 执行再平衡操作。这里的逻辑也是相对直接的:
- 列举所有现有的 EndpointSlices,移除那些不再需要的端点并更新那些已经变化的端点
- 列举所有在第一步中被更改过的 EndpointSlices,用新增加的端点将其填满
- 如果还有新的端点未被添加进去,尝试将这些端点添加到之前未更改的切片中, 或者创建新切片
这里比较重要的是,与在 EndpointSlice 之间完成最佳的分布相比,第3步中更看重限制 EndpointSlice 更新的操作次数。例如,如果有 10 个端点待添加,有两个 EndpointSlice 中各有 5 个空位,上述方法会创建一个新的 EndpointSlice 而不是 将现有的两个 EndpointSlice 都填满。换言之,与执行多个 EndpointSlice 更新操作 相比较,方法会优先考虑执行一个 EndpointSlice 创建操作。
由于 kube-proxy 在每个节点上运行并监视 EndpointSlice 状态,EndpointSlice 的 每次变更都变得相对代价较高,因为这些状态变化要传递到集群中每个节点上。 这一方法尝试限制要发送到所有节点上的变更消息个数,即使这样做可能会导致有 多个 EndpointSlice 没有被填满。
在实践中,上面这种并非最理想的分布是很少出现的。大多数被 EndpointSlice 控制器 处理的变更都是足够小的,可以添加到某已有 EndpointSlice 中去的。并且,假使无法添加到已有的切片中,不管怎样都会快就会需要一个新的 EndpointSlice 对象。 Deployment 的滚动更新为 EndpointSlice重新打包提供了一个自然的机会,所有 Pod 及其对应的端点在这一期间都会被替换掉。
由于 EndpointSlice 变化的自身特点,端点可能会同时出现在不止一个 EndpointSlice 中。鉴于不同的 EndpointSlice 对象在不同时刻到达 Kubernetes 的监视/缓存中, 这种情况的出现是很自然的。 使用 EndpointSlice 的实现必须能够处理端点出现在多个切片中的状况。 关于如何执行端点去重(deduplication)的参考实现,你可以在 kube-proxy 的 EndpointSlice 实现中找到。
K8S支持在集群中调度DNS Service/Pod,并且让Kubelet告知每个容器,DNS服务器的IP地址。
集群中的每个服务,包括DNS服务本身,都被分配一个DNS名称。
默认的,Pod的DNS搜索列表会包含Pod自己的名字空间,以及集群的默认Domain。如果一个服务foo运行在名字空间bar中,则位于bar中的Pod可以通过foo引用服务,位于其它名字空间中的Pod则需要通过foo.bar引用服务。
普通服务被分配以A记录,格式:my-svc.my-namespace.svc.cluster.local,此记录解析到服务的Cluster IP。
Headless服务(无Cluster IP)也被分配如上的A记录,但是记录解析到服务选择的Pod的IP集(如果没有选择器则解析到什么IP取决于你给出的Endpoints配置),客户端应当使用此IP集或者使用Round-Robin方式从IP集中选取IP。
这类记录为服务的知名端口分配,SRV记录格式:_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.local。
对于普通服务,SRV记录解析为端口号 + CNAME(my-svc.my-namespace.svc.cluster.local)。
对于Headless服务,SVR记录解析到多个答复,每个对应服务选择的Pod:端口号 + Pod的CNAME(auto-generated-name.my-svc.my-namespace.svc.cluster.local)。
当启用后,Pod被分配一个DNS A记录:pod-ip-address.my-namespace.pod.cluster.local。例如:
|
1 2 |
# 一个名为influx的Pod,它位于dev名字空间中,IP地址为172.27.0.20 172-27-0-20.dev.pod.k8s.gmem.cc |
Pod被创建后,其hostname为metadata.name字段的值。
在Pod的Spec中你可以:
- 指定可选的hostname字段,可以手工指定hostname,比metadata.name的优先级高
- 指定可选可选的subdomain字段,说明指定Pod的子域。例如一个Pod的hostname为influxdb,subdomain为pods,名字空间为default,则Pod的全限定名为influxdb.default.dev.svc.k8s.gmem.cc
如果在Pod所在名字空间中,存在一个Headless服务,其名称与Pod的subdomain字段一致。则KubeDNS服务器会为Pod的全限定名返回一个A记录,指向Pod的IP地址。
你可以为每个Pod定义DNS策略(在规格中使用dnsPolicy字段)。目前K8S支持以下策略:
| 策略 | 说明 |
| Default | 从Pod所在节点继承DNS解析设置 |
| ClusterFirst | 任何不匹配集群DNS后缀(可以设置)的查询,转发给上游(从节点继承)DNS处理 |
| ClusterFirstWithHostNet | 运行在hostNetwork中的Pod应当明确的设置为该值 |
| None | 1.9 Alpha,忽略来自K8S环境的DNS设置。所有DNS设置从Pod规格的dnsConfig字段获取 |
1.9 Alpha。用户可以对Pod的DNS设置进行细粒度控制。要启用该特性,集群管理员需要为APIServer、kubelet启用特性开关(Feature Gate)CustomPodDNS,示例:--feature-gates=CustomPodDNS=true,... 从1.14开始默认开启。
当启用上述特性后,用户可以设置Pod规格的dnsPolicy=None,并添加dnsConfig字段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
apiVersion: v1 kind: Pod metadata: namespace: ns1 name: dns-example spec: containers: - name: test image: nginx dnsPolicy: "None" dnsConfig: # 此Pod使用的DNS服务器列表 nameservers: - 1.2.3.4 # DNS搜索后缀列表 searches: - ns1.svc.cluster.local - my.dns.search.suffix options: # 最大dot数量。最大值15 - name: ndots value: "1" # 重试另外一个DNS服务器之前,等待应答的最大时间,单位秒。最大值30 - name: timeout value: "5" # 放弃并返回错误给调用者之前,最大尝进行DNS查询的次数。最大值5 - name: attempts value: "2" # 使用round-robin风格选择不同的DNS服务器,向其发送查询 - name: rotate # 支持RFC 2671描述的DNS扩展 - name: edns0 # 串行发送A/AAAA请求 - name: single-request # 发送第二个请求时重新打开套接字 - name: single-request-reopen # 使用TCP协议发送DNS请求 - name: use-vc # 禁止自动重新载入修改后的配置文件,需要glibc 2.26+ - name: no-reload |
本节以Nginx服务为例,说明如何在K8S集群中连接应用程序和服务。
在讨论K8S的通信机制之前,我们先看一下普通的Docker网络如何运作。
默认情况下,Docker使用Host-private的网络,也就是说Docker容器仅能和同一台宿主机上的其它容器通信。为了让容器跨节点通信,它们必须在宿主机上暴露端口。这意味着,开发者需要仔细规划,让多个容器协调暴露宿主机的不同端口。
跨越多名开发者进行端口协调很麻烦,特别是进行扩容的时候,这种协调工作应该由集群负责,而不应该暴露给用户。
K8S假设所有Pod都是需要相互通信的,不管它们是不是位于同一台宿主机上。K8S为每个Pod分配集群私有IP地址,你不需要向Docker那样,为容器之间创建连接,或者暴露端口到宿主机的网络接口。
Pod内部的多个容器,可以利用localhost进行相互通信。
集群内所有Pod中的容器,都可以相互看到,不需要NAT的介入。
考虑下面的Pod规格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: apps/v1beta1 kind: Deployment metadata: name: my-nginx spec: replicas: 2 template: metadata: labels: run: my-nginx spec: containers: - name: my-nginx image: nginx ports: - containerPort: 80 |
你可以从集群的任何节点访问此Pod,执行下面的命令获得Pod的IP地址:
|
1 2 3 4 |
kubectl get pods -l run=my-nginx -o wide # NAME READY STATUS RESTARTS AGE IP NODE # my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m # my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd |
登陆到任何集群节点后,你都可以访问上面的两个IP地址。需要注意,Pod不会使用节点的80端口,也不会使用任何NAT机制来把流量路由到Pod。这意味着你可以在单个节点上运行containerPort相同的多个Pod。
你可以像Docker那样,把容器端口映射到节点端口,单由于K8S网络模型的存在,这种映射往往没有必要。
现在,我们有了两个Pod,它们运行着Nginx,IP位于一个扁平的、集群范围的地址空间中。 理论上说,应用程序可以和Pod直接通信,但是如何Pod所在节点宕机了会怎么样?Deployment会自动在另外一个节点上调度一个Pod,这个新的Pod的IP地址会改变。如果直接和Pod 通信,你就要处理这种IP地址可能改变的情形。
服务可以避免上述处理逻辑,它是Pod之上的抽象层,它定义了一个逻辑的Pod集,这些Pod提供一模一样的功能。当创建服务时,它被分配以唯一性的IP地址(Cluster IP),在服务的整个生命周期中,该IP都不会变化。
应用程序可以配置和服务(而非Pod)通信,服务会进行负载均衡处理,把请求转发给某个Pod处理。
针对上述Deployment的Service规格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: ports: # 服务暴露的端口 - port: 80 # 对接到Pod的端口 targetPort: 80 protocol: TCP selector: run: my-nginx |
创建服务后,可以查询其状态:
|
1 2 3 |
kubectl get svc my-nginx # NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE # my-nginx 10.0.162.149 80/TCP 21s |
服务的背后是一个Pod集,服务的选择器会不断的估算,来选择匹配的Pods。匹配的Pod会被发送到一个Endpoints对象中,该对象的名字也叫my-nginx(和服务同名)。当Pod死去时它会自动从Endpoints中移除,类似的当新Pod出生后也被加入到Endpoints中。
下面的命令可以获得端点的信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 获得服务关联的端点 kubectl describe svc my-nginx # Name: my-nginx # Namespace: default # Labels: run=my-nginx # Annotations: # Selector: run=my-nginx # Type: ClusterIP # IP: 10.0.162.149 # Port: 80/TCP # Endpoints: 10.244.2.5:80,10.244.3.4:80 # Session Affinity: None # Events: # 获得端点信息 kubectl get ep my-nginx # NAME ENDPOINTS AGE # my-nginx 10.244.2.5:80,10.244.3.4:80 1m |
注意:端点的IP/Port就是Pod的IP/Port。
现在,你可以在集群中任何节点上 wget :,再次强调,集群IP是纯粹的虚拟IP,它不会对应到哪一根网线。
K8S提供了两种服务访问方式:环境变量、DNS。
变量变量方式是开箱即用的,当Pod启动时,Kubelet会为其注入一系列的环境变量。这意味着在Pod创建之后才创建的服务,无法注入为环境变量。
K8S有一个DNS Addon,负责提供集群内的域名服务,执行下面的命令了解此服务是否启用:
|
1 2 3 4 |
# 服务名为kube-dns,运行在kube-system名字空间 kubectl get services kube-dns --namespace=kube-system # NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE # kube-dns 10.0.0.10 53/UDP,53/TCP 8m |
如果没有运行DNS服务,你需要启用它。
DNS服务运行后,会为每个服务都分配一个域名,映射到它的集群IP。
现在,在集群内部的任何节点,都可以正常访问服务,而且可以享受K8S提供的负载均衡、HA了。
在把服务暴露到因特网之前,你需要确保信道的安全性。例如:
- 提供数字证书,要么购买要么自签名
- 配置Nginx的HTTPS
- 配置一个Secret,让Pod都能访问证书
创建密钥和自签名证书,可以参考:
|
1 |
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /d/tmp/nginx.key -out /d/tmp/nginx.crt -subj "/CN=nginxsvc/O=nginxsvc" |
K8S提供了一些examples,可以简化第三步。执行下面的命令下载样例:
|
1 |
git clone https://github.com/kubernetes/examples.git |
下面使用examples中的工具,根据上面生成的密钥,产生一个Secret的规格文件:
|
1 2 3 |
# make和go必须已经安装 # 实际通过调用 make_secret.go 产生Secret,后者则是调用K8S的API make keys secret KEY=/tmp/nginx.key CERT=/tmp/nginx.crt SECRET=/tmp/secret.json |
使用规格文件,在K8S上创建一个Secret对象:
|
1 2 |
kubectl create -f /tmp/secret.json # secret "nginxsecret" created |
查看Secret对象列表:
|
1 2 3 4 |
kubectl get secrets # NAME TYPE DATA AGE # default-token-il9rc kubernetes.io/service-account-token 1 1d # nginxsecret Opaque 2 1m |
下一步,修改Deployment、Service的规格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# Deployment规格 apiVersion: apps/v1beta1 kind: Deployment metadata: name: my-nginx spec: replicas: 1 template: metadata: labels: run: my-nginx spec: # 声明一个卷,引用Secret volumes: - name: secret-volume secret: secretName: nginxsecret containers: - name: nginxhttps image: bprashanth/nginxhttps:1.0 ports: - containerPort: 443 - containerPort: 80 # 挂载Secret卷到对应位置 volumeMounts: - mountPath: /etc/nginx/ssl name: secret-volume # Service规格 apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type: NodePort ports: - port: 8080 targetPort: 80 protocol: TCP name: http - port: 443 protocol: TCP name: https selector: run: my-nginx |
要把服务暴露到集群外部的IP地址,可以使用NodePorts或者LoadBalancers。
这是一个API对象,可以管理到集群内部服务(通常是HTTP)的访问。Ingress能够提供:负载均衡、SSL Termination、基于名称的虚拟主机服务。
典型情况下,Service/Pod的IP地址仅仅能在集群内部路由到,所有流量到达边缘路由器(Edge Router,为集群强制应用了防火墙策略的路由器,可能是云服务管理的网关,也可能是物理硬件)时要么被丢弃,要么被转发到别的地方。
Ingress(入口)是一个规则集,允许进入集群的连接到达对应的集群服务。
要定义Ingress对象,同样需要经过APIServer。一个Ingress控制器负责处理Ingress。
Ingress从1.1+开始可用,目前处于Beta版本。
要使用Ingress,你需要配备Ingress控制器。你可以在Pod中部署任意数量的自定义Ingress控制器,你需要为每个控制器标注适当的class。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: test-ingress annotations: ingress.kubernetes.io/rewrite-target: / # 规格中包含了创建LB或代理服务器所需的全部信息 spec: # 匹配入站请求的规则列表 rules: # 目前仅支持HTTP规则 - http: # 将来自任何域名的/testpat这个URL下的请求,都转发给test服务处理 host: * paths: - path: /testpath backend: serviceName: test servicePort: 80 |
注意:Ingress控制器可以响应不同名字空间中的多个Ingress。
为了让Ingress对象能生效,集群中必须存在Ingress控制器。Ingress实际上仅仅声明了转发规则,没有能执行转发的程序。
大部分控制器都是kube-controller-manager这个可执行程序的一部分,并且随着集群的创建而自动启动。但是Ingress控制器不一样,它作为Pod运行,你需要根据集群的需要来选择一个Ingress控制器实现,或者自己实现一个。
Ingress Controller的实现非常多,大多以Nginx或Envoy为基础。可以参考文章:Comparing Ingress controllers for Kubernetes。
K8S目前实现并维护GCE和nginx两个Ingress控制器。下面是基于Nginx的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 |
# 默认后端,如果Nginx无处理请求,此后端负责兜底 apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: nginx-ingress chart: nginx-ingress-0.14.1 component: default-backend name: nginx-ingress-default-backend spec: replicas: 1 selector: matchLabels: app: nginx-ingress component: default-backend strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: creationTimestamp: null labels: app: nginx-ingress component: default-backend spec: containers: - image: k8s.gcr.io/defaultbackend:1.3 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /healthz port: 8080 scheme: HTTP initialDelaySeconds: 30 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 name: nginx-ingress-default-backend ports: - containerPort: 8080 protocol: TCP resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 60 --- apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: app: nginx-ingress component: default-backend name: nginx-ingress-default-backend spec: ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: nginx-ingress component: default-backend sessionAffinity: None type: ClusterIP --- apiVersion: v1 data: enable-vts-status: "false" kind: ConfigMap metadata: labels: app: nginx-ingress component: controller name: nginx-ingress-controller --- # 基于Nginx的Ingress Controller apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: nginx-ingress component: controller name: nginx-ingress-controller spec: selector: matchLabels: app: nginx-ingress component: controller strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: creationTimestamp: null labels: app: nginx-ingress component: controller spec: containers: - args: - /nginx-ingress-controller - --default-backend-service=kube-system/nginx-ingress-default-backend - --election-id=ingress-controller-leader - --ingress-class=nginx - --configmap=kube-system/nginx-ingress-controller env: - name: POD_NAME valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.namespace image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.12.0 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10254 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 name: nginx-ingress-controller ports: - containerPort: 80 name: http protocol: TCP - containerPort: 443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /healthz port: 10254 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always terminationGracePeriodSeconds: 60 --- # 在裸金属集群上使用NodePort服务,将所有节点的80/443暴露出去,任何节点都可以作为Ingress apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: app: nginx-ingress component: controller name: nginx-ingress-controller spec: externalTrafficPolicy: Cluster ports: - name: http # 此服务在所有节点上暴露的端口 nodePort: 80 # 此服务在集群IP上暴露的端口 port: 80 protocol: TCP # 上述两套80端口,转发给Pod的什么端口 targetPort: 80 - name: https nodePort: 443 port: 443 protocol: TCP targetPort: 443 selector: app: nginx-ingress component: controller sessionAffinity: None type: NodePort |
此控制器配合的Ingress如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# kubectl create secret generic gmemk8scert --from-file=./k8s.gmem.cc apiVersion: extensions/v1beta1 kind: Ingress metadata: name: nginx-ingress annotations: kubernetes.io/ingress.class: nginx # 如果后端服务本身就是以HTTPS方式暴露,则需要添加下面这行: nginx.ingress.kubernetes.io/secure-backends: "true" spec: tls: - hosts: - media-api.k8s.gmem.cc secretName: gmemk8scert rules: - host: media-api.k8s.gmem.cc http: paths: - backend: serviceName: media-api servicePort: 8800 |
如果Ingress资源上没有注解,则任何Ingress控制器都会处理此Ingress。
如果你希望仅仅让Nginx/Nginx Plus控制器来处理Ingress,则为后者添加Annotation:
|
1 |
kubernetes.io/ingress.class: "nginx" |
这样,其它种类的Ingress Controller自动忽视此Ingress。
--configmap 指定配置的namespace/name
--default-ssl-certificate 指定包含默认数字整数的secret
--enable-dynamic-configuration 通过使用Lua,尽可能的避免Nginx Reload操作的必要,某些特性必须要求启用或禁用此特性
--enable-ssl-passthrough 是否启用SSL穿透的特性,默认禁用
--status-port Nginx状态信息在什么端口暴露,默认18080
--watch-namespace 监控哪些命名空间的Ingress资源,默认所有命名空间
--v 更多日志:
2 显示配置文件的变动diff
3 显示服务、Ingress规则、endpoint的变化细节,并输出为JSON
5 让Nginx在Debug模式下运行
配置文件通过参数--configmap=kube-system/ngress-controller参数注入。ConfigMap示意:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
apiVersion: v1 data: # 返回客户端时添加响应头 add-headers: "false" # 指定返回客户端时需要隐藏的头 hide-headers: "" # 请求的缓冲和超时 client-header-buffer-size: "" client-header-timeout: "" client-body-buffer-size: "" client-body-timeout: "" enable-vts-status: "false" ssl-redirect: "false" # 启用压缩 use-gzip gzip-types: "" # 负载均衡算法 # 可选: # least_conn 最少连接,不得联合--enable-dynamic-configuration # ip_hash 不得联合--enable-dynamic-configuration,可以用nginx.ingress.kubernetes.io/upstream-hash-by代替 # ewma 峰值指数加权移动平均值算法,联合--enable-dynamic-configuration load-balance: "round_robin" kind: ConfigMap |
可用配置项非常多,可查看官方文档。 这些配置最终会填充到nginx配置文件模板中,模板变量和配置项名称并不对应,需要注意。
注解列表(默认前缀都是nginx.ingress.kubernetes.io/),这些注解可以附加在使用Nginx作为控制器的Ingress规则上:
| 注解 | 说明 | ||||
| affinity |
启用针对上游服务的会话绑定:
|
||||
| auth-tls-pass-certificate-to-upstream | 是否把客户端证书转发给上游服务,默认false | ||||
| default-backend | 指定默认后端,这个后端处理Ingress规则没有匹配的任何请求 | ||||
| configuration-snippet |
指定任意的Nginx配置片断,示例:
对于上述Ingress,控制器会在自己的Nginx配置文件中生成:
如果配置片断有错误,你会在控制器日志中发现: nginx: configuration file /tmp/nginx-*** test failed |
||||
| enable-cors |
是否启用跨站资源共享(CORS):
|
||||
|
force-ssl-redirect ssl-redirect |
如果某个Ingress启用了TLS,则默认会发送308永久重定向,将HTTP请求重定向到HTTPS,如果需要禁用此行为,可以在Nginx ConfigMap中设置:
如果要针对某个Ingress禁用SSL重定向,可以为此Ingress资源配置:
默认值true |
||||
| ssl-passthrough |
SSL穿透,允许在Pod上配置SSL服务端证书,而不是在Nginx上 |
||||
| limit-connections limit-rps limit-rpm |
限制单个Client IP能够使用的资源量,用于缓和DDoS攻击: limit-connections 单IP最大连接 |
||||
| rewrite-target |
某些情况下后端服务暴露的URL,和Ingress规则中的不同。如果不进行请求重写会导致404。示例:
|
||||
| secure-backends |
默认情况下Nginx使用HTTP协议访问后端服务,如果后端服务通过HTTPS暴露,需要在Ingress规则中设置:
|
||||
| service-upstream |
默认情况下,在Nginx配置中使用Pod的ip:port作为upstream服务器 设置此注解为true,则改用Service的集群IP,这可以避免反复Reload Nginx配置,防止Pod反复宕机导致可用性下降。但是需要注意:
|
||||
| load-balance | 使用何种负载均衡算法,最新版本的balancer.lua脚本中引用,可以选择chash、round_robin、sticky、ewma |
| 类型 | 说明 | ||||||
| 单服务 |
现有的Service类型可以向集群外部暴露单个服务。但是你也可以利用Ingress实现这种暴露:
创建Ingress对象后,执行下面的命令可以查看其状态:
其中107.178.254.228是Ingress控制器为此Ingress分配的IP地址。RULE为 - 表示,所有发送到107.178.254.228的流量都被重定向给testsvc服务 |
||||||
| Fanout |
前面提到过,Pod仅拥有集群内可用的IP,因此我们需要在集群的边界有那么一个组件,能够总揽所有入站请求,并转发给适当的端点,该组件常常是一个HA的负载均衡器。Ingress可以让你需要的负载均衡器数量尽可能小,例如下面这个流向示意:
对应的Ingress规格:
创建上述Ingress后,查看其状态:
Ingress控制器会提供一个负载均衡器(依赖于实现),以满足Ingress的规定。 ADDRESS列存放的是负载均衡器的地址 |
||||||
| 虚拟主机 |
根据URL中主机名字段的不同,将请求转发给不同的服务:
默认后端(Default Backend):所有不匹配任何规则的流量都被发送给默认后端,你可以使用默认后端来提供404页面 |
||||||
| TLS |
通过提供一个包含TLS私钥、证书的Secret,你可以让Ingress支持HTTPS。当前Ingress仅仅支持单个TLS端口(443) Secret对象规格示例:
启用TLS的Ingress的示例:
|
||||||
| 负载均衡 |
Ingress控制器自带某些负载均衡设置,会应用到所有Ingress,包括:负载均衡算法、后端权重规则(backend weight scheme)。更高级的负载均衡,例如持久会话、动态权重目前不支持,要使用这些特性可参考service-loadbalancer Ingress不直接支持健康检查,但是K8S提供了类似的特性,例如Readiness探针 |
NetworkPolicy对象指定了:
- 一组Pod是否允许和另外一组Pod通信
- 一组Pod是否允许和其它网络端点通信
网络策略由网络插件实现,也就是说你需要一个支持NetworkPolicy的CNI插件。
默认情况下Pod是非隔离的,任何来源的流量都可以访问它。
当某个NetworkPolicy选择(匹配)了Pod则它变成隔离的(isolated),这样,不被任何网络策略允许的流量,会被该Pod拒绝。
NetworkPolicy是叠加的,如果Pod被多个策略匹配,则所有这些策略的ingress/egress规则的union决定了Pod的连接性。
字段说明如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy namespace: default spec: # 选择/匹配的Pod podSelector: matchLabels: role: db # 此策略应用到匹配Pod的出站,还是入站,或者both流量 policyTypes: - Ingress - Egress # 允许哪些入站流量,每个元素是一个规则,每个规则由from+ports组成 ingress: - from: # 允许172.17.0.0/16中的实体,但是其中172.17.1.0/24不允许 - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 # 或者具有如下命名空间、标签的Pod - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend # 允许TCP 6379端口 ports: - protocol: TCP port: 6379 # 类似ingress,每个规则由to+ports组成 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978 # 如果有下面这个字段,则限定端口范围而非单个端口 # 需要特性开关: --feature-gates=NetworkPolicyEndPort=true,... endPort: 32768 |
下面是一些示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 默认禁止所有入站流量 apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: default-deny-ingress spec: podSelector: {} policyTypes: - Ingress # 默认允许所有入站流量 apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-all-ingress spec: podSelector: {} ingress: - {} policyTypes: - Ingress # 默认禁止所有出站流量 apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: default-deny-egress spec: podSelector: {} policyTypes: - Egress # 默认允许所有出站流量 apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-all-egress spec: podSelector: {} egress: - {} policyTypes: - Egress |
到1.21为止,NetworkPolicy不支持:
- 强制集群内部流量通过公共网关,可以考虑使用Service Mesh
- 任何TLS相关需求,可以考虑使用Service Mesh
- 特定于某个节点的策略
- 特定于某个服务(根据名称)的策略
- 应用到任何命名空间/Pod的默认策略
- 记录安全日志,也就是那些连接被禁止/接受
- 禁止loopback或者Pod所在节点(宿主命名空间)发来的流量
你可以在Pod规格中定义将会注入到/etc/hosts文件的条目:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
apiVersion: v1 kind: Pod metadata: name: hostaliases-pod spec: restartPolicy: Never # 条目列表 hostAliases: - ip: "127.0.0.1" hostnames: - "foo.local" - "bar.local" - ip: "10.1.2.3" hostnames: - "foo.remote" - "bar.remote" containers: - name: cat-hosts image: busybox # 启动后打印hosts文件内容 command: - cat args: - "/etc/hosts" |
容器本身的文件系统是临时的,如果容器崩溃,文件立刻丢失。使用Docker时,你可以挂载外部卷,解决此问题。
K8S在存储方面面临两个问题:
- 容器重新调度后文件丢失
- Pod内的多个容器常需要共享文件
K8S引入和Docker类似的概念:卷(Volume)解决上述问题。
Docker已经包含了卷的概念,但是这些卷是松散、缺乏管理的。Docker中的卷仅仅是磁盘中的一个目录,或者其它容器中的目录。最近版本Docker引入了卷驱动的概念,但是使用场景很受限。
K8S的卷,提供了明确的生命周期,就好像使用它的Pod那样。卷的寿命比引用它的容器更长,容器重启后数据不会丢失。当Pod停止存在时则卷也被删除。
K8S支持多种类型的卷,每个Pod可以同时使用其中的多种卷。
卷的核心就是一个目录,可能其中有一些数据,这个目录可以被容器访问。至于这目录从哪来,何种介质存储它,取决于具体的卷类型。
要使用一个卷,在Pod规格中定义spec.volumes字段,并且在容器spec.containers.volumeMounts字段中声明在何处挂载卷。
全部卷类型参考K8S官网。
| 类型 | 说明 | ||
| cephfs | 允许一个既有的CephFS卷被挂载到Pod中。对CephFS卷的修改会永久保留 | ||
| emptyDir |
这种卷在Pod第一次被调度到某个节点上时,在节点上创建。只要Pod还在节点上运行,这个卷就继续存在,当节点被迁移走后,卷被删除掉,容器崩溃不会导致卷被删除 emptyDir初始是一个空目录 示例:
默认情况下,emptyDir将数据存储在节点所在的媒体上(可能是SDD、网络存储)。你可以设置emptyDir.medium=Memory来挂载一个内存文件系统 |
||
| flocker |
Flocker是一个开源的,集群化的容器数据卷管理器。它能管理、编排基于多种存储后端的数据卷 这类卷可以将Flocker数据集挂载到Pod,如果数据集不存在,你需要使用Flocker API或者CLI创建之 |
||
| glusterfs | Glusterfs是一个开源网络文件系统,这类卷能够把Glusterfs卷挂载到Pod | ||
| hostPath |
从Node宿主机文件系统挂载一个文件/目录到Pod。示例:
|
||
| nfs |
挂载现有的NFS到Pod 容器中挂载点的File mode取决于NFS的对应目录 |
||
| persistentVolumeClaim |
用于挂载PersistentVolume到Pod,PersistentVolume是一种声明(claim)持久性(调度后不变)存储(例如GCE PersistentDisk、iSCSI卷)的方式,这种方式不需要知道特定云环境的细节 |
||
| projected | 能够影射多个现有的卷资源到同一目录 | ||
| secret |
这种卷用于传递敏感信息(例如密码)到Pod,你可以通过K8S API创建Sercret,再通过卷的方式挂载到Pod 这类卷总是由内存后备(tmpfs) |
卷在Pod级别上定义,而在容器级别上挂载。容器将卷挂载到某个路径后,此路径上原有的文件全部不可见,这个特性和docker --volume是一致的。
你可以声明一个卷是“可选的”:
|
1 2 3 4 5 6 |
volumes: - name: ingressgateway-certs secret: defaultMode: 420 optional: true # 可选 secretName: istio-ingressgateway-certs |
这样,即使目标ConfigMap、Secret、PVC不存在,Pod仍然可以启动。
注意:当目标ConfigMap、Secret在Pod启动后创建,仍然会自动、立即挂载到Pod相应路径。
用于将多个卷源影射为一个合并卷,当前,支持影射的卷类型包括:Secret、downwardAPI、ConfigMap、ServiceAccountToken。
所有需要影射的卷,必须和Pod在同一个命名空间。
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
apiVersion: v1 kind: Pod metadata: name: volume-test spec: containers: - name: container-test image: busybox volumeMounts: - name: all-in-one mountPath: "/projected-volume" readOnly: true volumes: - name: all-in-one projected: sources: - secret: name: mysecret items: - key: username path: my-group/my-username - secret: name: mysecret2 items: - key: password path: my-group/my-password mode: 511 |
持久卷子系统提供了一套API,将存储如何提供的细节分离出去,存储的消费者不需要关心这一细节。为实现这种分离K8S引入两类对象PersistentVolume、PersistentVolumeClaim。
PersistentVolume(PV)是集群中,以及由管理员提供好的一个存储资源。它是一种集群资源,就好像节点是一种集群资源一样。持久卷和上节的卷类似,都属于一种卷插件(Volume Plugin),但是持久卷的生命周期和任何使用它的Pod都没有关联,不会因为这些Pod被删除而删除(不管是删除对象还是存储的数据)。该对象封装了存储的实现细节(NFS、iSCSI、云服务特定存储...)。
PersistentVolumeClaim(PVC)是用户发起的存储请求,它和Pod类似:
- Pod消耗节点资源而PVC消耗PV资源
- Pod可以请求特定的资源级别(CPU和内存),PVC则可以请求特定的存储尺寸、访问模式(读/写)
注意:PV和PVC是一一绑定的关系,一个PV同时仅仅能绑定到一个PVC,但是一个PVC可以被多个Pod使用。一旦PVC被删除,其对应的PV会变为RELEASED状态。
尽管利用PersistentVolumeClaim,用户可以消费抽象的存储资源。但是要求具有一定特质(例如性能)的PersistentVolume是很常见的。集群管理员需要提供多种多样(不仅仅是尺寸、访问模式不同)的PersistentVolume,同时不向用户暴露PersistentVolume的实现细节。StorageClass对象提供了更多相关的内容。
PersistentVolume类型被实现为插件,目前K8S支持的插件包括:GCEPersistentDisk、AWSElasticBlockStore、Flocker、NFS、iSCSI、RBD、CephFS、Glusterfs等。
本地持久卷代表挂载到Pod运行节点的磁盘、分区或者目录。本地持久卷不支持动态Provisioning。
和HostPath相比,local卷具有数据持久性、可移植性。PV Controller和Scheduler会对Local PV做特殊的逻辑处理,确保Pod使用本地存储时,在发生reschedule的情况下能再次调度到Local PV所在的节点。如果节点宕机,则Local PV可能无法访问,应用程序需要容忍这种可用性降低的场景。
使用local卷时,你必须设置PV对象的nodeAffinity,以保证使用它的Pod被调度到恰当的节点:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
apiVersion: v1 kind: PersistentVolume metadata: name: example-pv spec: capacity: storage: 100Gi # 可以设置为Block,将原始块设备暴露出来 volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete # 必须声明SC,且该SC声明延迟绑定 storageClassName: local-storage local: # 卷在节点上的路径 path: /mnt/disks/ssd1 # 节点亲和性 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - example-node |
尽管本地持久卷不支持动态Provisioning,我们仍然需要为它创建StorageClass,用于延迟卷绑定(直到Pod调度完成) :
|
1 2 3 4 5 6 7 8 |
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-storage provisioner: kubernetes.io/no-provisioner # 延迟卷的创建和绑定到(使用它的)Pod调度完成之后,这样可以保证Kubernetes为PVC作出绑定决策的时候, # 能够同时评估使用它的Pod的约束(例如节点资源需求、Pod亲和性、节点亲和性、节点选择器) volumeBindingMode: WaitForFirstConsumer |
PV必须手工创建,工作负载通过声明PVC来匹配到这些已经存在的PV。如果你的集群大量使用Local PV,并且需要为不同工作负载提供不同性能的存储,你可能需要声明多个SC。
驱动Local Persistence Volume Static Provisioner可以改善Local PV的生命周期管理。它能够检测宿主机上的磁盘,并为它们创建PV,在PV被释放之后,清理磁盘。
Provisioning的含义是提供。PV是集群中的资源,PVC则是对资源的请求。它们之间的交互遵循以下生命周期。
K8S支持以两种方式提供PV:
- 静态提供:集群管理员创建一系列PV,这些PV映射到了底层的实际存储,这些PV存在于K8S API中,可以被消费
- 动态提供:当没有满足PVC要求的PV时,集群可以尝试动态的提供一个卷给PVC,如何提供取决于StorageClass:
- PVC需要请求一个StorageClass,而管理员必须预先创建、配置好StorageClass对象,以便满足动态提供的需要
- PVC如果设置StorageClass为"",则相当于禁止动态提供
要启用基于StorageClass的动态提供,集群管理员需要在APIServer启用准许控制器(Admission Controller)DefaultStorageClass。具体来说,就是在APIServer的选项--admission-control中附加DefaultStorageClass,注意该选项的值是逗号分隔的字符串列表。
用户创建声明了一定容量、访问模式的PVC后,Master上的控制循环会监控到PVC,找到一个匹配的PV,然后将PV和PVC进行绑定。PV和PVC是One-To-One关系,也就是说PVC对PV是独占使用的。
如果没有满足的PV,则PVC会一直处于未绑定状态。例如,集群提供了很多50G的PV,现在一个PVC要100G的,则PVC仅仅在集群中添加了100G+的PV后才能成功绑定。
PVC对象被删除后,其对应的PV对象可能被级联删除。
Pod将PVC作为卷使用,集群会找到PVC绑定的PV,并挂载到Pod中容器的指定目录下。
当不再需要时,用户可以通过K8S API删除PVC对象,让K8S回收资源。
当PVC被删除时,也就释放了和PV之间的绑定。PV的回收策略(persistentVolumeReclaimPolicy字段)指示了如何回收PV。
1.8引入的特性,Alpha状态。在1.9版本中以下类型的卷支持扩容:gcePersistentDisk、awsElasticBlockStore、Cinder、glusterfs、rbd。
| 回收策略 | 说明 |
| Retain |
PV保持存在,被标记为released,先前用户的数据仍然存在其中。管理员需要手工回收此PV,它才能被其它PVC使用。手工回收步骤:
|
| Recycle |
如果存储插件支持,则执行类似rm -rf的操作清除卷中的数据,并允许其被重新绑定 你也可以通过命令行参数为kube-controller-manager自定义回收器Pod模板,自定义清除数据的方式 |
| Delete |
如果存储插件支持,则删除PersistentVolume对象,同时删除关联的底层存储资源 动态提供的卷会从其StorageClass继承默认回收策略,此策略也是Delete |
每个卷在同一时刻只能使用一种访问模式,即使它可以支持多种模式。
| 模式 | 说明 |
| ReadWriteOnce | 可以被单节点挂载为读写,所有卷插件都支持 |
| ReadOnlyMany | 可以被多节点挂载为读 CephFS、Glusterfs、iSCSI、NFS、RBD等支持 |
| ReadWriteMany | CephFS、Glusterfs、NFS等支持 |
每个PV都包含一个规格、一个状态。下面是一个示例规格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
apiVersion: v1 kind: PersistentVolume metadata: name: pv0003 spec: # 卷的容量 capacity: storage: 5Gi # 卷模式,1.9之前都会在卷上创建文件系统,1.9支持设置为Block,即使用裸块 volumeMode: Filesystem accessModes: - ReadWriteOnce # 回收策略 persistentVolumeReclaimPolicy: Recycle # 类别 storageClassName: slow # 挂载选项 mountOptions: - hard - nfsvers=4.1 nfs: path: /tmp server: 172.17.0.2 |
PV可以有一个类型字段,其值为 StorageClass对象的名称。具有给定 StorageClass的PV,只能和请求相同 StorageClass的PVC进行绑定;没有指定 StorageClass的PV只能和没有请求 StorageClass的PVC绑定。
在过去,注解volume.beta.kubernetes.io/storage-class用于代替storageClassName属性,未来该注解可能被废弃。
某些持久卷类型(NFS、iSCSI、RBD、CephFS、Glusterfs等)支持挂载选项,当卷被挂载到节点时会应用这些选项。
在过去,注解volume.beta.kubernetes.io/mount-options用于代替mountOptions属性,未来该注解可能被废弃。
一个卷可以处于以下阶段:
| Phase | 说明 |
| Available | 游离的资源,没有绑定到PVC |
| Bound | 绑定到了一个PVC |
| Released | PVC被删除了,但是PV的资源尚未被集群回收 |
| Failed | 卷的自动回收失败了 |
和PV一样,每个PVC也都有一个规格、一个状态。下面是一个示例规格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: myclaim spec: # 我需要什么样的访问模式 accessModes: - ReadWriteOnce # 我需要什么样的卷模式(文件系统还是裸设备) volumeMode: Filesystem # 我需要多少资源 resources: requests: storage: 8Gi # 我需要的存储类 storageClassName: slow # 使用选择器对备选卷进行过滤 selector: matchLabels: release: "stable" matchExpressions: - {key: environment, operator: In, values: [dev]} |
其中storageClassName 如果指定为""则仅仅存储类为""的PV才能绑定。如果不指定该属性,则系统的行为取决于是否启用了准许控制器DefaultStorageClass:
- 如果启用,则集群管理员可以指定一个默认的StorageClass。这样所有不指定存储类的PVC都只能绑定到具有此默认存储类的PV
- 设置默认存储类的方法:为作为默认的StorageClass的storageclass.kubernetes.io/is-default-class注解设置为true
- 如果集群管理员没有设置默认StorageClass,创建PVC时你收到的提示和没有启用准许控制器DefaultStorageClass一样
- 如果将多个StorageClass注解为“默认”则准许控制器阻止任何PVC的创建
- 如果准许控制器没有启用,则不存在默认StorageClass这一概念。不指定storageClassName和指定为""效果一样
取决于集群安装方式,默认StorageClass可能被集群的Addon管理器在安装阶段部署。
如果PVC同时指定selector + storageClassName,则目标PV必须同时符合两个条件。注意:目前不支持对带有selector的PVC进行动态提供。
Pod可以将PVC作为卷来挂载,供容器使用。PVC必须和Pod位于同一个名字空间中,集群会找到绑定到PVC的PV,并将PV挂载给Pod。
声明使用PVC的Pod的规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kind: Pod apiVersion: v1 metadata: name: mypod spec: containers: - name: myfrontend image: dockerfile/nginx volumeMounts: - mountPath: "/var/www/html" name: mypd volumes: - name: mypd persistentVolumeClaim: claimName: myclaim |
在1.9引入的Alpha特性是对裸块卷(Raw Block Volume)的静态提供的支持,目前仅仅光纤通道(Fibre Channel,FC)是唯一支持此特性的插件。
PV规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: v1 kind: PersistentVolume metadata: name: block-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce volumeMode: Block persistentVolumeReclaimPolicy: Retain fc: targetWWNs: ["50060e801049cfd1"] lun: 0 readOnly: false |
PVC规格示例:
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: block-pvc spec: accessModes: - ReadWriteOnce volumeMode: Block resources: requests: storage: 10Gi |
如果你在编写能够在很大范围的集群上使用的配置模板/样例,且需要使用持久化存储,可以参考如下建议:
- 在Deployments/ConfigMap等配置中包含PersistentVolumeClaim声明
- 不要在配置中包含PersistentVolume对象,因为实例化配置的用户可能没有创建PV的权限
- 允许用户实例化配置模板时,提供storageClassName
- 监控PVC的绑定情况,如果一段时间后没有绑定成功,应当通知用户。绑定失败意味着集群可能没有动态存储支持(用户需要手工创建PV)
这一特性可以实现按需创建存储卷。如果没有动态提供,集群管理员必须手工调用云/存储提供商的接口,来创建新的存储卷,然后通过K8S API注册和存储卷对应的PV对象。
动态提供是基于API组storage.k8s.io中的StorageClass对象实现的。集群管理员可以定义任意数量的StorageClass,每个SC需要指定一个卷插件(也叫provisioner)和一组参数。卷插件基于这些参数来按需创建卷。对于一个存储系统,你可以定义多个SC,以暴露不同风味(例如速度快或慢)的存储资源。
要启用动态提供,一系列StorageClass需要被预先创建。下面的两个规格,分别创建了基于HDD的慢速SC和SDD的快速SC:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/gce-pd parameters: type: pd-standard --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd |
很多类型的卷没有内置的Provisioner,而动态提供需要由Provisioner来完成。你可能需要借助external-storage项目。
前面已经提到过,要使用动态提供,你需要为PVC声明storageClassName字段,也就是声明需要哪种风格的存储资源。
你也可以手工创建持久卷对象,不依赖于内置或外置的Provisioner。任何K8S支持的存储资源,并非必须依赖于Provisioner或者StorageClass才能使用。
下面是基于Ceph,创建静态持久卷的例子。持久卷定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
apiVersion: v1 kind: PersistentVolume metadata: name: maven-repository labels: name: maven-repository spec: accessModes: - ReadWriteMany capacity: storage: 16Gi cephfs: # Ceph MON节点列表 monitors: - xenial-100 - Carbon - Radon # 存储在默认CephFS的什么路径下 path: /maven-repository # 访问密钥 secretRef: name: pvc-ceph-key # 访问用户 user: admin |
Pod不能直接引用持久卷,因此需要创建一个PVC,关联到上面的PV:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: maven-repository spec: accessModes: # 访问模式,这里是允许多写 - ReadWriteMany storageClassName: "" resources: requests: storage: 16Gi selector: # 使用标签来匹配目标卷 matchLabels: name: maven-repository |
使用上面PV的Pod的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
kind: Pod apiVersion: v1 metadata: name: maven-repository-0 spec: containers: - name: maven-repository image: docker.gmem.cc/busybox command: - "/bin/sh" args: - "-c" - "sleep 365d" volumeMounts: - name: data mountPath: "/data" restartPolicy: "Never" volumes: - name: data persistentVolumeClaim: claimName: maven-repository |
持久卷示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: v1 kind: PersistentVolume metadata: name: datastore spec: capacity: storage: 1Ti accessModes: - ReadWriteMany nfs: server: 10.255.223.141 path: "/datastore" |
StorageClass(存储类)为集群管理员提供了一种方法,用于描述集群提供的存储的“类型”。不同的存储类,可能映射到了不同的QoS级别、备份策略,等等。K8S本身不对存储类表示什么进行解释,存储类的类似其它存储系统中的Profile。
每个SC对象都包含provisioner、parameters、reclaimPolicy字段,当属于此存储类的PersistentVolume需要被提供出去时,这些参数会被K8S使用。
StorageClass的名称很关键,因为用户根据其名称来请求特定的存储类。SC的所有属性都在管理员初次创建时指定,后续不能更改。
在启用准许控制器DefaultStorageClass的情况下,管理员可以设置默认StorageClass。这样不关心SC是何物的PVC可以使用默认的SC。
SC对象的规格示例:
|
1 2 3 4 5 6 7 8 9 10 |
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: standard provisioner: kubernetes.io/aws-ebs parameters: type: gp2 reclaimPolicy: Retain mountOptions: - debug |
该属性指定用于提供PV的存储插件,必须字段。K8S自带了一系列内部存储插件(以kubernetes.io/前缀开头) 。你也可以使用外部存储插件(服务K8S规范的独立程序)。K8S允许外部存储插件被非常自由的实现,一些可用的外部插件位于K8S孵化器中。
对于动态提供的PV,其回收策略从存储类继承。如果你没有给存储类指定该字段,默认为Delete。
由存储类动态创建的PV会继承此挂载选项。
存储类有一个parameters字段,用于描述存储类创建的卷是什么样的。parameters包含哪些子字段取决于provisioner。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: slow provisioner: kubernetes.io/aws-ebs parameters: # io1, gp2, sc1, st1,默认gp2 type: io1 # AWS区域,如果不指定,则在包含K8S节点的Zone上循环创建卷。zone指定单个值,zones指定逗号分隔的多个值 zones: us-east-1d, us-east-1c # 每GB数据在每秒内支持的IO次数,近用于io1 iopsPerGB: "10" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: # Gluster的REST服务/Heketi服务的URL,存储类依赖于此URL来提供卷 resturl: "http://127.0.0.1:8081" # Heketi用来提供卷的集群ID,可以是逗号分隔的多个值 clusterid: "630372ccdc720a92c681fb928f27b53f" # Gluster REST服务是否需要身份验证,如果是,则需要restuser字段、restuserkey或secretNamespace+secretName字段 restauthenabled: "true" restuser: "admin" secretNamespace: "default" secretName: "heketi-secret" # 存储类的GID范围 gidMin: "40000" gidMax: "50000" # 卷类型及其参数 volumetype: "replicate:3" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: fast provisioner: kubernetes.io/rbd parameters: # Ceph monitors,逗号分隔,必须 monitors: 10.16.153.105:6789 # 能够在池中创建image的 Ceph client ID adminId: kube # adminSecret的名字 adminSecretName: ceph-secret # adminSecret的名字空间 adminSecretNamespace: kube-system # Ceph RBD pool,默认rbd pool: kube # 用于映射RBD image的Ceph client ID,默认等于adminId userId: kube # user的Ceph Secret的名字必须和PVC位于同一名字空间。Secret的类型必须为kubernetes.io/rbd userSecretName: ceph-secret-user # 支持的文件类型 fsType: ext4 # Ceph RBD image 格式,1或2,默认1 imageFormat: "2" imageFeatures: "layering" |
要设置某个StorageClass为默认,执行:
|
1 |
kubectl patch storageclass ceph-rbd -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' |
这样,没有显示指定StorageClass的PVC,会自动使用ceph-rbd这个存储类。
K8S APIServer暴露了REST风格的API,所有组件之间的通信都基于此API进行,包括kubectl或kubeadm等Shell工具。
你也可以直接进行REST调用,或者使用对应编程语言的客户端库发起API调用。
K8S支持版本化的API,不同版本包含的字段可以不一样。版本号示例:/api/v1、/apis/extensions/v1beta1。
人类用户、服务账号(SA)都可以访问API,访问过程有三个阶段:
- 身份验证
- 访问控制(授权)
- Admission Control
典型情况下,APIServer使用端口443提供服务,它通常使用一个自签名的证书。客户端机器的$USER/.kube/config中通常包含了APIServer的根证书。
建立TLS连接后,API调用请求需要进行身份验证。自动创建集群的脚本,或者集群管理员,会为APIServer配置1-N个身份验证器(Authenticator)模块。身份验证器通常会检查客户端证书,或者HTTP请求头。
身份验证器模块包括:客户端证书、密码、明文Token、Bootstrap Token、JWT Token(SA使用)这几种。如果配置多个模块,会顺序尝试,直到成功。
如果身份验证失败,APIServer返回401错误。否则用户被验证为指定的Principal(用户名,username),某些身份验证器也提供了用户所属的组信息。K8S使用用户名进行后续的访问控制和日志记录。
集群的用户被分为两类:Service Account和普通用户,后者由外部系统管理,无法在K8S集群中进行登记。
Service Account由K8S API管理,绑定到特定的名字空间。API Server可能会自动创建SA,你也可以手工创建。SA关联到一系列保存了凭证的Secret中,例如,下面这个Secret就保存了Token这种凭证:
|
1 2 |
kubectl -n kube-system describe secret default-token-vgvll # token: ... |
K8S使用客户端证书、不记名令牌(bearer token)、 身份验证代理(authenticating proxy)、HTTP基本验证来对API请求者的身份进行验证。具体的验证工作由身份验证插件负责。
身份验证插件会尝试从请求中获取以下属性:
- 用户名,例如kube-admin或者alex@gmem.cc
- 用户标识符
- 用户组,用户所属的多个分组
- 身份验证插件可能需要的其它额外字段
你可以同时启用多种身份验证策略,并至少:
- 为SA提供基于Token的身份验证
- 为普通用户提供某种认证策略
当启用多种身份验证策略时,第一个成功的验证器获胜,K8S不保证验证器的执行顺序。
所有经过身份验证的用户都会归属于用户组:system:authenticated。
为API Server提供选项 --client-ca-file=/path/to/cafile,即可启用基于客户端证书的身份验证。指定的文件必须包含1-N个CA证书,这些证书将用户客户端证书的校验。如果客户端证书通过校验,则其Common name字段将作为用户名,如果要将用户关联到多个组,你需要指定多个organization证书字段。CSR示例:
|
1 |
openssl req -new -key alex.key -out alex.csr -subj "/CN=alex/O=app1/O=app2" |
为API Server提供选项--token-auth-file=/path/to/token,则API Server从文件中读取静态Token列表,修改Token文件后必须重启API Server。
静态Token是一个CSV文件,包含至少三个字段:Token、用户名、UID,可以包含一个分组字段,示例:
|
1 |
token,user,uid,"group1,group2,group3" |
设置请求头即可:
|
1 2 |
# 必须以Bearer开始,后面跟着Token内容 Authorization: Bearer 31ada4fd-adec-460c-809a-9e56ceb75269 |
为了方便的搭建新集群,K8S提供了一种动态管理的不记名Token —— Bootstrap Token这些Token存储为kube-system中的Secrets,可以被动态的创建和管理。
控制器管理器(Controller Manager)包含了一种控制器TokenCleaner,自动在过期后删除Bootstrap Token。
使用APIServer选项--experimental-bootstrap-token-auth来启用Bootstrap Token验证,使用 --controllers=***,tokencleaner来启用TokenCleaner。Kubeadm自动添加了这些选项。
基于Bootstrap Token认证的请求,其用户名设置为system:bootstrap:,分配到用户组system:bootstrappers。
为API Server提供选项--basic-auth-file=/path/to/passwd,则启用HTTP基本验证。密码文件也是CSV格式,形式如下:
|
1 |
password,user,uid,"group1,group2,group3" |
你必须提供如下格式的请求头来使用基本验证:
|
1 |
Authorization: Basic BASE64ENCODED(USER:PASSWORD) |
Service Account验证器(验证插件,authenticator)总是自动启用。这种验证器基于签名过的Bearer Token来验证请求。该插件使用以参数:
- --service-account-key-file 用于签名Bearer Token的PEM编码的私钥
- --service-account-lookup 被删除的Token自动吊销
SA通常由APIServer自动创建,并关联到集群中的Pod,关联行为由准许控制器ServiceAccount负责。使用serviceAccountName字段你可以显式的关联某个SA到Pod。
执行命令 kubectl create serviceaccount,你可以手工创建一个SA。K8S会自动创建与此SA关联的Secret,该Secret中包含:
- ca.crt,APIServer的证书,Base64编码
- token,签名后的JSON Web Token。你在请求中提供此Token则APIServer将你验证为对应的SA
SA的用户名为system:serviceaccount:(NAMESPACE):(SERVICEACCOUNT),分配到用户组system:serviceaccounts、system:serviceaccounts:(NAMESPACE)。
警告:用于SA的账户Token存放在Secret中,因此你向用户授予读Secret权限时要小心。任何获取Secret的人都可以伪装为SA。
从1.6+开始,如果使用了除AlwaysAllow之外的验证模式 ,则默认允许匿名访问。你可以使用APIServer选项--anonymous-auth=false显式禁用匿名访问。
匿名用户被分配用户名system:anonymous,分配用户组system:unauthenticated。从1.6开始,ABAC/RBAC授权器要求对匿名用户/组进行显式授权。
如果被授权,一个用户可以仿冒为任何其它用户,需要提供以下请求头:
- Impersonate-User,仿冒的目标用户。使用kubectl时,你可以用--as来指定
- Impersonate-Group, 仿冒的目标组。使用kubectl时,你可以用--as-group来指定
- Impersonate-Extra-***,用户的***动态字段
要仿冒其它用户,原用户必须被授权。对于启用RBAC的集群,可以定义如下ClusterRole:
|
1 2 3 4 5 6 7 8 9 |
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: impersonator rules: - apiGroups: [""] # 允许设置Impersonate-Extra-scopes头 resources: ["users", "groups", "serviceaccounts", "userextras/scopes"] verbs: ["impersonate"] |
经过身份验证后,请求(的username)还必须确认是否具有访问API的权限。请求中除了包含username之外,还包括需要执行的操作,操作针对的对象。
K8S支持多种授权模块,包括ABAC(基于属性的访问控制)、RBAC(基于角色的访问控制)、Webhook。管理员创建集群时,会配置使用的授权模块。
如果请求没有访问权限,APIServer返回403错误。
| 授权器 | 说明 |
| Node | 特殊用途的授权器,根据在节点上运行的Pod,来授予kubectl权限 |
| ABAC |
基于属性的访问控制(Attribute-based access control),通过文件来指定策略 策略(Policy)将访问权限分组到一起,用户被关联到策略,策略可以使用任何类型的属性——用户属性、资源属性、对象属性…… 使用API Server选项--authorization-mode=ABAC启用 |
| RBAC |
基于角色的访问控制(Role-based access control),通过API来创建、存储策略kind: ConfigMap 使用API Server选项--authorization-mode=RBAC启用该授权器 |
| AlwaysAllow |
允许所有访问,相当于禁止访问控制 使用API Server选项 --authorization-mode=AlwaysAllow启用该授权器 |
使用kubectl可以快速检查用户有没有特定的权限:
|
1 2 |
# 是否具有在dev创建deployment的权限 kubectl auth can-i create deployments --namespace dev |
这是使用最广泛的授权器,Kubeadm默认启用Node和RBAC两种授权器。
Role代表针对某个特定名字空间的一系列的权限(permissions),示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: # 针对default名字空间 namespace: default name: pod-reader rules: # "" 表示核心API组 - apiGroups: [""] # 可以访问核心API组的pods资源 resources: ["pods"] # 可以针对资源进行下面三类操作 verbs: ["get", "watch", "list"] |
某些API会牵涉到“子资源”,例如访问Pod的日志,URL为:GET /api/v1/namespaces/{namespace}/pods/{name}/log。如果你需要允许用户访问Pod,及其日志,需要这样配置:
|
1 |
resources: ["pods", "pods/log"] |
ClusterRole代表针对整个集群的一系列权限,支持Role的任何权限,此外还可以授权对以下资源的访问:
- 集群级别的资源,例如node
- 非资源端点,例如/healthz
- 跨越所有名字空间的namespaced资源,使用--all-namespace需要这种权限
示例:
|
1 2 3 4 5 6 7 8 9 |
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: # 没有名字空间,因为ClusterRole不是namespaced的资源 name: secret-reader rules: - apiGroups: [""] resources: ["secrets"] verbs: ["get", "watch", "list"] |
从1.9开始,K8S允许组合一个ClusterRole,产生新的ClusterRole:
|
1 2 3 4 5 6 7 8 9 10 11 |
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: monitoring # 根据标签匹配相关ClusterRole aggregationRule: clusterRoleSelectors: - matchLabels: rbac.example.com/aggregate-to-monitoring: "true" # 控制器管理器会自动填写下面的字段 rules: [] |
将角色绑定到一个或者一组用户(User、Group、SA),示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: read-pods namespace: default # 被授权的主体,可以是用户、组、或者Service Account subjects: - kind: User name: admin@gmem.cc apiGroup: rbac.authorization.k8s.io # 授予的角色 roleRef: kind: Role name: pod-reader apiGroup: rbac.authorization.k8s.io |
注意:roleRef可以引用ClusterRole,但是仅仅授予会当前名字空间的访问权限。
将集群角色绑定到一个或者一组用户,示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: read-secrets-global subjects: - kind: Group name: system:authenticated apiGroup: rbac.authorization.k8s.io - kind: ServiceAccount name: default namespace: kube-system roleRef: kind: ClusterRole name: secret-reader apiGroup: rbac.authorization.k8s.io |
使用命令:
|
1 |
kubectl create clusterrolebinding cluster-admin-default --clusterrole=cluster-admin --serviceaccount=tke:default |
API Server自动创建了一些ClusterRole、ClusterRoleBinding对象。大部分对象都具有system:前缀,提示这些对象供K8S基础设施使用,随意修改这些对象会导致集群不可用。所有这些对象都具有标签kubernetes.io/bootstrapping=rbac-defaults。
默认角色/绑定如下表:
| 角色 | 角色绑定(到组) | 说明 |
| system:basic-user | system:authenticated system:unauthenticated |
允许用户只读访问自己的基本信息 |
| cluster-admin | system:masters |
超级用户角色:
|
| admin | 允许针对名字空间的绝大部分操作,包括创建角色/绑定 | |
| edit | 允许针对名字空间的绝大部分资源进行写操作 | |
| view | 允许针对名字空间的绝大部分资源进行读操作 |
准许控制器是可以修改或者拒绝请求的软件模块。准许控制器能够访问被创建、修改、删除的对象的内容。
管理员可以配置多个准许控制器,这些控制器会按照顺序被调用。
如果存在任何准许控制器拒绝请求,则请求立即停止处理。
安全上下文(Security Context)定义操作系统相关的、Pod的安全性配置,例如uid、gid、SELinux角色。可以规定Pod级别或容器级别的安全上下文。
应用到所有容器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
apiVersion: v1 kind: Pod metadata: name: hello-world spec: securityContext: # 运行容器入口点脚本的UID runAsUser: 1000 # 提示容器必须以非超级用户身份执行,Kubelet会在运行时检查容器用户的PID,如果为0且此选项为true则拒绝启动容器 runAsNonRoot: false # 为容器PID为1的进程添加的额外组信息 supplementalGroups: [] # 支持所有权管理的那些卷,其所有者GID设置为下面的值,且允许下面的GID进行读写 # 如果读取挂载的PV时出现permission denied错误,可以考虑将该字段配置为运行Docker容器所使用的用户 fsGroup: 1000 supplementalGroups: [5678] # 支持SELinux标签的卷,允许别下面的标签访问 seLinuxOptions: level: "s0:c123,c456" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
apiVersion: v1 kind: Pod metadata: name: hello-world spec: containers: - name: my-container securityContext: # 是否在特权模式下执行容器,如果为true,则容器中进程的权限实际上等同于宿主机的root # 特权容器可以访问宿主机上的所有设备,非特权容器不能访问任何宿主机设备 # 如果容器需要操控网络栈、访问硬件,则需要特权模式 privileged: false # 容器的根文件系统是否为只读 readOnlyRootFilesystem: false # 容器以什么UID运行 runAsUser: 1000 # 容器以什么GID运行(primary group) runAsGroup: 1000 # 添加supplemental groups supplementalGroups: runAsNonRoot: false seLinuxOptions: level: "s0:c123,c456" |
该对象用于细粒度的控制Pod安全,可以限制Pod的创建/更新,或者为某些字段提供默认值。下面是一些例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
# 最少限制的Policy,等价于没有启用PodSecurityPolicy准入控制器 apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: privileged annotations: # 允许使用任何安全Porfile seccomp.security.alpha.kubernetes.io/allowedProfileNames: '*' spec: # 可以运行特权容器 privileged: true # 允许权限提升,直接决定是否向容器传递no_new_privs标记 # no_new_privs标记可以防止setuid的可执行文件改变它的Effective UID # 设置该字段为false,则容器中发起的子进程不会得到比父进程更多的权限,即使它setuid allowPrivilegeEscalation: true # 允许使用任何Linux Caps allowedCapabilities: - '*' # 允许使用任何类型的卷 volumes: - '*' # 允许使用宿主机网络命名空间 hostNetwork: true hostPorts: - min: 0 max: 65535 hostIPC: true hostPID: true runAsUser: rule: 'RunAsAny' seLinux: rule: 'RunAsAny' supplementalGroups: rule: 'RunAsAny' fsGroup: rule: 'RunAsAny' --- # 要求不得运行特权容器,禁止权限提升 apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: restricted # 限制允许的Apparmor/Seccomp模板 annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: 'docker/default,runtime/default' apparmor.security.beta.kubernetes.io/allowedProfileNames: 'runtime/default' seccomp.security.alpha.kubernetes.io/defaultProfileName: 'runtime/default' apparmor.security.beta.kubernetes.io/defaultProfileName: 'runtime/default' spec: # 禁止特权容器 privileged: false # 禁止提升为root allowPrivilegeEscalation: false # 这一条和禁止特权容器+禁止提升的功效重复,提供额外一层保护 requiredDropCapabilities: - ALL # 允许核心的卷类型 volumes: - 'configMap' - 'emptyDir' - 'projected' - 'secret' - 'downwardAPI' - 'persistentVolumeClaim' # 禁止使用宿主机的命名空间 hostNetwork: false hostIPC: false hostPID: false runAsUser: # 不得以root身份允许容器进程 rule: 'MustRunAsNonRoot' seLinux: # 假设节点运行AppArmor而非SELinux rule: 'RunAsAny' supplementalGroups: rule: 'MustRunAs' ranges: # 禁止加入root组 - min: 1 max: 65535 fsGroup: rule: 'MustRunAs' ranges: # 禁止加入root组 - min: 1 max: 65535 readOnlyRootFilesystem: false |
Pod安全策略被实现为Admission Controller,启用该控制器,但是不配置任何PodSecurityPolicy,则你无法创建任何Pod。
| 角度 | 字段名称 |
| 运行特权容器 | privileged |
| 使用宿主名字空间 | hostPID、hostIPC |
| 使用宿主的网络和端口 | hostNetwork, hostPorts |
| 控制卷类型的使用 | volumes |
| 使用宿主文件系统 | allowedHostPaths |
| 允许使用特定的 FlexVolume 驱动 | allowedFlexVolumes |
| 分配拥有 Pod 卷的 FSGroup 账号 | fsGroup |
| 以只读方式访问根文件系统 | readOnlyRootFilesystem |
| 器的用户和组 ID | runAsUser, runAsGroup, supplementalGroups |
| 限制 root 账号特权级提升 | allowPrivilegeEscalation, defaultAllowPrivilegeEscalation |
| Linux 权能字(Capabilities) | defaultAddCapabilities, requiredDropCapabilities, allowedCapabilities |
| 设置容器的 SELinux 上下文 | seLinux |
| 指定容器可以挂载的 proc 类型 | allowedProcMountTypes |
| 指定容器使用的 AppArmor 模版 | annotations |
| 指定容器使用的 seccomp 模版 | annotations |
| 指定容器使用的 sysctl 模版 | forbiddenSysctls,allowedUnsafeSysctls |
新创建的PodSecurityPolicy不起任何作用,发起请求的用户/Pod的SA必须对该PodSecurityPolicy具有use权限:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <role name> rules: - apiGroups: ['policy'] resources: ['podsecuritypolicies'] verbs: ['use'] resourceNames: - <list of policies to authorize> --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: <binding name> roleRef: kind: ClusterRole name: <role name> apiGroup: rbac.authorization.k8s.io subjects: # 授权给特定SA - kind: ServiceAccount name: <authorized service account name> namespace: <authorized pod namespace> # 授权给指定用户(不推荐) - kind: User apiGroup: rbac.authorization.k8s.io name: <authorized user name> |
如果使用RoleBinding而非ClusterRoleBinding,则仅仅特定命名空间下创建的Pod才可能获得PSP授权:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
--- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <binding name> namespace: default roleRef: kind: ClusterRole name: <role name> apiGroup: rbac.authorization.k8s.io subjects: # 该命名空间下所有SA获得授权,这些SA创建的Pod都可以使用目标PodSecurityPolicy - kind: Group apiGroup: rbac.authorization.k8s.io name: system:serviceaccounts # 该命名空间下所有认证过的用户获得授权(和上个元素等效) - kind: Group apiGroup: rbac.authorization.k8s.io name: system:authenticated |
如果创建Pod的用户具有多个Policy的use权限,那么选取Policy的规则如下:
- 不需要设置默认值、改变Pod规格的Policy,被优先使用
- 如果Pod必须被设置默认值 、修改规格,则使用按名称排序的第一个Policy
需要设置API Server的参数: --enable-admission-plugins=PodSecurityPolicy,...来启用此准入控制器。启用后,如果没有任何策略定义,则无法创建Pod。
为API Server启用准入控制器PodSecurityPolicy之后,你会发现API Server的Pod不见了,这是因为Kubelet没有被授予PSP。可以为它授予:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: privileged labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - policy resources: - podsecuritypolicies # 引用具有完整权限的PSP resourceNames: - privileged verbs: - use --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: psp-nodes namespace: kube-system annotations: kubernetes.io/description: 'Allow nodes to create privileged pods. Should be used in combination with the NodeRestriction admission plugin to limit nodes to mirror pods bound to themselves.' labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: 'true' roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: psp-privileged subjects: # 授权给Kubelet - kind: Group apiGroup: rbac.authorization.k8s.io name: system:nodes - kind: User apiGroup: rbac.authorization.k8s.io # Legacy node ID name: kubelet |
可以利用Kubectl插件kube-psp-advisor,它可以:
- 连接到现有K8S环境,根据其中的工作负载来创建PSP
- 读取一个YAML,根据其中的工作负载清单来创建PSP
执行命令: kubectl krew install advise-psp安装此插件,并且将 $HOME/.krew/bin加入到$PATH环境变量。
连接到K8S并为工作负载生成PSP/RBAC:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 打印匹配当前集群所有工作负载的一个PSP kubectl advise-psp inspect # 打印匹配当前工作负载的PSPs,附加RBAC规则 kubectl advise-psp inspect -g # 报告集群为什么需要PSP kubectl advise-psp inspect --report | jq . # 打印匹配指定命名空间的PSP kubectl advise-psp inspect --namespace=default |
读取包含Pod Spec的文件,并生成PSP:
|
1 2 |
# --podFile中可以包含Deployment/DaemonSet/StatefulSet/Pod等形式的工作负载定义 kubectl advise-psp convert --podFile=Documents/K8S/rook/toolbox.yaml --pspFile=/tmp/psp.yaml |
API Server支持审计功能,可以记录用户/K8S组件的活动,并可以指定监控到某些活动后的处理逻辑。
在处理请求的不同阶段,都可以生成审计事件,这些阶段包括:
- RequestReceived 审计处理器(Handler,API Server具有由一系列处理器的链条组成)接收到请求后,委托给其它Handler处理之前
- ResponseStarted 响应头发送之后,响应体发送之前。仅仅长时间运行的请求才有这个阶段,例如watch操作
- ResponseComplete 响应完全发送完毕后
- Panic 当发生panic时
审计事件回根据特定的策略进行预处理,记录到后端。支持的后端包括文件、Webhook。
你可以定义审计策略,格式如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
apiVersion: audit.k8s.io/v1 kind: Policy # 哪些阶段不做审计 omitStages: - "RequestReceived" rules: # 审计规则 # 审计级别: # None - 符合这条规则的日志将不会记录 # Metadata - 记录请求的元数据(请求的用户、时间戳、资源、动词等等), 但是不记录请求或者响应的消息体 # Request - 记录事件的元数据和请求的消息体,但是不记录响应的消息体。 不适用于非资源类型的请求 # RequestResponse - 记录事件的元数据,请求和响应的消息体。不适用于非资源类型的请求 - level: RequestResponse # 规则针对的资源 resources: - group: "" resources: ["pods", "deployments"] - level: Metadata resources: - group: "" resources: ["pods/exec", "pods/portforward", "pods/proxy", "services/proxy"] - level: Metadata omitStages: - "RequestReceived" |
下面这个示例,为所有请求在Metadata级别生成日志:
|
1 2 3 4 5 |
# 在 Metadata 级别为所有请求生成日志 apiVersion: audit.k8s.io/v1beta1 kind: Policy rules: - level: Metadata |
需要为API Server指定以下参数:
--audit-log-path 指定用来写入审计事件的日志文件路径。不指定此标志会禁用日志后端
--audit-policy-file 审计策略文件
--audit-log-maxage 定义了保留旧审计日志文件的最大天数
--audit-log-maxbackup 定义了要保留的审计日志文件的最大数量
--audit-log-maxsize 定义审计日志文件的最大大小(兆字节)
由于通常情况下,API Server以静态Pod的形式运行,因此,需要将宿主机上的策略文件、日志文件挂载为数据卷:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
volumeMounts: - mountPath: /etc/kubernetes/audit-policy.yaml name: audit readOnly: true - mountPath: /var/log/audit.log name: audit-log readOnly: false volumes: - name: audit hostPath: path: /etc/kubernetes/audit-policy.yaml type: File - name: audit-log hostPath: path: /var/log/audit.log type: FileOrCreate |
你需要开发一个Webhook服务器,它提供和API Server相同的API。
需要为API Server指定以下参数:
--audit-webhook-config-file webhook 配置文件的路径。Webhook 配置文件实际上是一个 kubeconfig 文件
--audit-webhook-initial-backoff 指定在第一次失败后重发请求等待的时间。随后的请求将以指数退避重试
不管使用哪种后端,都可以支持批处理,也就是缓存一批审计日志,然后一起发送给后端。默认情况下Log后端禁用批处理,Webhook后端启用批处理。
如果使用Webhook后端,你可以通过下面的参数配置批处理模式:
--audit-webhook-mode 定义缓存策略,可选值如下:
- batch 缓存事件,异步发送给后端。这是默认值
- blocking 在 API 服务器处理每个单独事件时,阻塞其响应
- blocking-strict 与 blocking 相同,不过当审计日志在 RequestReceived 阶段失败时,整个 API 服务请求会失效
当上述mode设置为batch时,你可以使用下面的额外参数:
--audit-webhook-batch-buffer-size 定义 batch 之前要缓存的事件数。 如果传入事件的速率溢出缓存区,则会丢弃事件
--audit-webhook-batch-max-size 定义一个 batch 中的最大事件数
--audit-webhook-batch-max-wait 无条件 batch 队列中的事件前等待的最大事件
--audit-webhook-batch-throttle-qps 每秒生成的最大批次数
--audit-webhook-batch-throttle-burst 在达到允许的 QPS 前,同一时刻允许存在的最大 batch 生成数
使用Log后端时,将上述参数的前缀都改为--audit-log。
开放策略代理(OPA,读音oh-pa)是一个开源的、一般用途(不依赖于K8S)的策略引擎。OPA提供接口:
- 声明式的语言Rego(读音ray-go),用来编写策略
- 简单的API,用于从其它应用来发起策略决策(policy decision-making)
当需要作出策略决策时,你需要查询OPA,以结构化数据作为输入。OPA根据输入、策略定义,来输出策略决策。OPA和Rego是业务无感知(domain-agnostic)的,你几乎用它来描述任何策略,例如:
- 什么用户可以访问什么资源
- 出口流量可以访问什么子网
- 工作负载必须部署到哪个集群
- 允许从何处下载容器镜像
- 容器可以使用哪些操作系统权能(Capability)
- 在什么时间允许访问系统
OPA和PSP之类的K8S内置安全机制比起来,功能更加广泛。
策略决策也不简单的是Yes/No,而可以是任何结构化的数据。
可以是任何结构化的数据。例如一个描述系统状态的JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// 这个数据结构描述了一个网络拓扑 { "servers": [ {"id": "app", "protocols": ["https", "ssh"], "ports": ["p1", "p2", "p3"]}, {"id": "db", "protocols": ["mysql"], "ports": ["p3"]}, {"id": "cache", "protocols": ["memcache"], "ports": ["p3"]}, {"id": "ci", "protocols": ["http"], "ports": ["p1", "p2"]}, {"id": "busybox", "protocols": ["telnet"], "ports": ["p1"]} ], "networks": [ {"id": "net1", "public": false}, {"id": "net2", "public": false}, {"id": "net3", "public": true}, {"id": "net4", "public": true} ], "ports": [ {"id": "p1", "network": "net1"}, {"id": "p2", "network": "net3"}, {"id": "p3", "network": "net2"} ] } |
此语言用于针对复杂数据结构(输入)来描述策略。语法类似于Go:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
// 访问接口输入的service数据结构 input.servers // 访问数组元素 input.servers[0].protocols[0] // 如果访问不存在的数据,则OPA返回undefined decision,表示OPA不能根据输入作出决策 input.deadbeef // 如果需要作出策略决策,你需要编写表达式 input.servers[0].id == "app" // Rego提供了一些内置函数 count(input.servers[0].protocols) >= 1 // 多个表达式可以使用逻辑与操作符 ; 链接在一起 input.servers[0].id == "app"; input.servers[0].protocols[0] == "https" // 等价于 input.servers[0].id == "app" input.servers[0].protocols[0] == "https" // 任何一个表达式结果不是true,或者是undefined,则决策结果是undefined decision // 变量 s := input.servers[0] s.id == "app" p := s.protocols[0] p == "https" // 迭代数据集 // 获得满足条件的network索引集合 some i; input.networks[i].public == true // 获得满足条件的server、protocol索引组合 some i, j; input.servers[i].protocols[j] == "http" // 变量可以被赋值给其它变量 some i, j id := input.ports[i].id input.ports[i].network == input.networks[j].id input.networks[j].public // +---+------+---+ // | i | id | j | // +---+------+---+ // | 1 | "p2" | 2 | // +---+------+---+ // 如果后续你不需要引用变量名,可以用_代替: input.servers[_].protocols[_] == "http" # true // 如果找不到什么匹配表达式的变量,则结果是undefined some i; input.servers[i].protocols[i] == "ssh" // undefined decision |
Rego支持将可复用逻辑封装为规则(Rule) 。
规则可以是完整的(Complete),这样的规则是一个if-then语句,并且分配单个值到变量:
|
1 2 3 4 5 6 7 |
package example.rules // 这里的true可以省略 any_public_networks = true { # 变量any_public_networks是true,如果 net := input.networks[_] # 存在某个网络 net.public # 并且它是public的 } |
规则由头、体两部分组成。如果规则体中的某种变量组合(例如上面的_取值为0)可以让规则体结果为true,那么规则头为true。
要调用上面的规则,使用它的名字即可 any_public_networks。规则产生的值存放在全局变量data中:
|
1 2 3 |
// 包名 值 data.example.rules.any_public_networks // true |
如果想定义一个常量,省略规则体即可:
|
1 2 3 |
package example.constants pi = 3.14 |
如果找不到任何变量组合,满足规则体的表达式,则规则是未定义的(undefined decision),
规则可以是部分(Partial)的,与完整规则生成一个值不同,部分规则生成一组值,并且将这组值分配给一个变量:
|
1 2 3 4 5 6 |
package example.rules public_network[net.id] { # net.id 作 public_network的元素,如果 net := input.networks[_] # 如果网络存在 net.public # 且它是public的 } |
你可以查询生成的数据集的值:
|
1 2 3 4 5 6 7 8 9 |
public_network // [ // "net3", // "net4" // ] // public_network["net3"] // "net3" |
通过部分规则,除了定义上面这种Set,还可以定义键值对(对象):
|
1 2 3 4 5 6 7 8 9 10 |
apps_by_hostname[hostname] = app { some i server := sites[_].servers[_] hostname := server.hostname apps[i].servers[_] = server.name app := apps[i].name } // apps_by_hostname["hello"] // "world" |
下面的语句,表示协议为telnet或者ssh, shell_accessible的值都是true:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
package example.logical_or // 如果所有具有此名字的规则的结果都是undefined,则设置默认值 default shell_accessible = false shell_accessible = true { input.servers[_].protocols[_] == "telnet" } shell_accessible = true { input.servers[_].protocols[_] == "ssh" } // shell_accessible // true |
针对部分规则进行逻辑或,则最终的Set,是参与逻辑或的规则的结果的并集:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package example.logical_or shell_accessible[server.id] { server := input.servers[_] server.protocols[_] == "telnet" } shell_accessible[server.id] { server := input.servers[_] server.protocols[_] == "ssh" } // shell_accessible // [ // "busybox", // "db" // ] |
针对上面的数据集, 假设我们需要检查拓扑是否满足安全策略:
- 所有可以通过Internet访问的服务器,不能暴露http协议
- 所有服务器不得暴露telnet协议
可以这样编写Rego规则:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
package example default allow = false # 除非明确定义,否则任何不满足策略 allow = true { # 如果违反集中没有成员,则满足策略 count(violation) == 0 } // 两个部分规则进行逻辑与 violation[server.id] { # 以下条件下服务器(的ID)加入违反集 some server public_server[server] # 它存在于public_server集 server.protocols[_] == "http" # 它暴露了http协议 } violation[server.id] { # 以下条件下服务器(的ID)加入违反集 server := input.servers[_] # 它属于输入的服务器集 server.protocols[_] == "telnet" # 它暴露了telnet协议 } // 下面的规则生成上面规则需要的public_server集 public_server[server] { # 以下条件下服务器加入public_server集 some i, j server := input.servers[_] # 服务器位于输入的服务器集中 server.ports[_] == input.ports[i].id # 服务器的ports定义在输入端口集中 input.ports[i].network == input.networks[j].id # 端口的network定义在输入的网络集中 input.networks[j].public # 网络是public的 } |
Gatekeeper将OPA整合到Kubernetes,它通过Validation Webhook和API Server对接,允许Kubernetes 管理员可以定义策略来保证集群的合规性,并符合最佳实践的要求。
使用Gatekeeper时,你需要在自定义资源中声明OPA规则。Gatekeeper会同步规则到OPA引擎中,当API Server接收到各种资源创建请求后,会转发给Gatekeeper进行策略检查。
GateKeeper使用此CR来存储OPA规则,下面的例子,禁止使用latest标签的镜像:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
apiVersion: templates.gatekeeper.sh/v1beta1 kind: ConstraintTemplate metadata: name: k8simagetagvalid spec: # 此模板生成的自定义资源 crd: spec: names: kind: K8sImageTagValid targets: - target: admission.k8s.gatekeeper.sh rego: | package k8simagetagvalid # 输入是传递给Webhook的请求对象 # 逻辑或构造违反集 # 规则1 violation[{"msg": msg, "details":{}}] { # 如果某个容器的镜像 image := input.review.object.spec.template.spec.containers[_].image # 没有指定tag部分 not count(split(image, ":")) == 2 # 则加入违反集,且构造出违反集元素 msg := sprintf("image '%v' doesn't specify a valid tag", [image]) } # 规则2 violation[{"msg": msg, "details":{}}] { # 如果某个容器的镜像名字以latest结尾 image := input.review.object.spec.template.spec.containers[_].image endswith(image, "latest") msg := sprintf("image '%v' uses latest tag", [image]) } # 隐含下面的规则 # allow = true { # count(violation) == 0 # } |
有了ContstraintTemplate,还不会对集群产生任何影响。你还需要定义对应的 Constraint —— 由ContstraintTemplate生成的自定义资源:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: constraints.gatekeeper.sh/v1beta1 # 类型是ContstraintTemplate创建的CRD的名字 kind: K8sImageTagValid metadata: name: valid-image-tag spec: # 如果启用dryrun,不会阻止资源的创建,而是仅仅记录违反策略的情况 enforcementAction: dryrun # 将策略应用到哪些类型的K8S资源 match: kinds: - apiGroups: [ "apps" ] kinds: [ "Deployment", "StatefulSet" ] |
在dryrun模式下,可以describe 上述资源,查询策略违反情况。
CNI即容器网络接口(Container Network Interface),比起Docker的CNI,对开发者以来更少,也不受限制于Docker。
在CNI中,网络插件是一个独立的可执行文件,它会被上层容器平台调用,并实现:
- 将容器加入到网络
- 将容器从网络中删除
调用时需要的信息,通过环境变量、或标准输入传递。
实现CNI很简单,只需要:
- 一个配置文件,描述CNI插件的版本、名称、描述等信息
- 开发CNI的可执行文件:
- 从环境变量或命令行中读取需要执行的操作、目标网络命名空间、容器网卡必要信息
- 实现两个操作:ADD/DEL
Kubernetes调用CNI的流程如下:
- 调用CRI创建pause容器,生成网络命名空间
- 调用网络驱动,即CNI驱动
- CNI驱动根据配置调用CNI插件
- CNI插件给pause容器配置正确的网络。Pod中其它容器都使用pause容器的网络栈
CNI具体负责的事情包括:
- 为容器分配IP地址
- 为荣庆网络接口绑定IP地址
- 实现多主机连接功能
flannel由CoreOS开发,能让集群内所有容器使用一个网络,每个主机从该网络中划分一个子网(防止IP地址冲突),主机创建容器中从子网分配一个IP地址。
为了解决容器之间的通信(路由)问题,flanne支持多种网络模式:
- overlay:早期使用的模式。这种模式下容器发出的数据包被flannel再次包装。新包头里面包含了主机本身IP,确保封包可以在底层网络中正确传递。再次包装的方式有:
- UDP:flannel自定义的一种协议。在用户态解包、封包
- VXLAN:在内核态解包、封包,性能比UDP好很多
- Host-Gateway模式:由运行在各节点上的Agent容器,将容器网络的路由信息同步到所有节点。这种模式不需要修改封包,性能甚至比Calico更好。问题是,Host-Gateway模式只能改节点的路由,底层网络必须是二层的,不像Calico的BGP那样可以将路由同步到路由器。由于广播封包问题,这种网络通常规模不能太大。近年来,也出现一些专门的设备,用以支持大规模二层网络,即所谓”大二层“
从架构上来说,flannel分为两部分:
- 控制平面:主要包含一个Etcd,用于协调各节点上容器网段的划分。控制平面没有服务器
- 数据平面,运行在节点上的flanneld进程,它会读取Etcd获取空闲网段,也把自己申请到的网段信息回填到Etcd中
对于”固定IP“这种需求,flannel天生无法支持,原因是节点和网络的绑定关系。
该插件将所有节点看做虚拟路由器,使用BGP协议,可以跨越多个二层网络。
除了提供网络连接外,Calico还支持网络策略,可以对容器、虚拟机工作负载、宿主机各节点之间的网络通信进行细粒度、动态的控制。
Calico还支持和Istio集成,在Service Mesh层面实施网络策略。
Calico允许容器漂移,在不同主机之前迁移容器不受限制。
Calico也支持隧道模式(ipip),性能稍差,但是对底层网络没有要求。
Cilium是一个CNI插件,是一个API感知的网络、安全开源软件,独特之处是安全,而且能理解RESTful、Kafka协议这样的API,因此比那种基于IP、端口的防火墙软件厉害的多。
在微服务时代,iptables无法满足安全策略的需求,一个安全策略的数量很多,而且需要频繁的更新。解决办法是利用BPF(Berkeley Packet Filter),它是一个内核中的高性能沙箱虚拟机,将内核变为可编程的。BPF可以在不影响安全、性能的前提下扩展Linux内核,进行网络数据包的处理。
BPF是类似于iptables的框架,允许在内核的多个挂钩点添加逻辑。
BPF是一个虚拟机,你可以将封包过滤规则以BPF虚拟机指令的形式写入内核,BPF会对指令进行验证,并JIT编译成CPU指令。任何网络报文都不能绕开BPF。
Cilium原生的理解服务、容器、Pod标志,能够理解gRPC、HTTP、Kafka等协议。
在服务网络方面,Cilium和IPVS具有同样的O(1)复杂度,可以用来作为Kube Proxy的代替。
Cilium甚至可以用来加速Istio。Istio的Sidecar可能引入10倍的性能损耗,原因是Istio使用iptables在数据包级别执行重定向,这导致每个数据包需要多次通过完整的网络栈。Linux内核基于BPF进行了一项所谓Sockmap的改进,可以直接在套接字层安全的进行重定向,QPS比iptables、甚至loopback网卡更高。
华为开源的CNI适配器,它允许你动态按需的切换底层CNI插件。它允许用户在同一个集群中使用多个底层CNI,为容器创建多个网络接口。
第一步是选择适当的部署方案。K8S支持单机、本地计算机集群、云服务、VM集群、裸金属等多种运行环境,你需要考虑以下几点:
- 是想在本机上学习K8S,还是需要搭建高可用、多节点的集群
- 为了实现HA,可以考虑跨Zone集群
- 某些服务商提供开箱即用的K8S集群,例如GKE
- 集群是内部部署(on-premises),还是在云端(IaaS)
- 对于内部部署的集群,你需要考虑使用何种K8S的网络模型
- 是否希望在裸金属或者VM上运行K8S
集群的日常管理任务包括:
- 集群生命周期管理:创建集群、升级Master/Worker节点、执行节点维护(例如内核升级)、升级API版本
- 对于多个团队共享的集群,需要进行配额的管理
安全性相关的管理主题包括:
- 数字证书管理
- K8S API的访问控制
- 身份验证和授权
- 准许控制器:能够在身份验证和授权后,拦截发送给K8S API服务器的请求
- 内核参数调整(sysctl)
- 审计,和K8S的审计日志交互
和Kubelet安全性相关的管理主题:
- 与Master节点的安全通信
- TLS支持
- Kubelet的身份验证/授权
要基于数字证书来进行客户端身份验证,你可以选用现有的部署脚本,或者使用easyrsa、openssl、cfssl之类的工具来生成数字证书。
现有部署脚本调用方式:
|
1 2 |
# subject-alternate-names格式为 IP: or DNS:的列表 cluster/saltbase/salt/generate-cert/make-ca-cert.sh ip-of-apiserver subject-alternate-names |
上述脚本产生三个文件:ca.crt, server.crt, server.key。然后修改API Server的启动参数:
|
1 2 3 |
--client-ca-file=/srv/kubernetes/ca.crt --tls-cert-file=/srv/kubernetes/server.crt --tls-private-key-file=/srv/kubernetes/server.key |
基于OpenSSL来手工生成证书的方法如下:
- 生成CA的密钥对: openssl genrsa -out ca.key 2048
- CA生成自签名证书: openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
- 生成API Server的密钥对: openssl genrsa -out server.key 2048
- 创建一个配置文件,用于生成API Server的证书签名请求(CSR):
123456789101112131415161718192021222324252627282930313233343536[ req ]default_bits = 2048prompt = nodefault_md = sha256req_extensions = req_extdistinguished_name = dn[ dn ]C =ST =L =O =OU =CN = <MASTER_IP>[ req_ext ]subjectAltName = @alt_names# 所有可能用于访问APIServer的域名或IP地址[ alt_names ]DNS.1 = kubernetesDNS.2 = kubernetes.default# 假设你使用cluster.local作为域名(后缀),这个可配置DNS.3 = kubernetes.default.svcDNS.4 = kubernetes.default.svc.clusterDNS.5 = kubernetes.default.svc.cluster.localIP.1 = <MASTER_IP># 往往是Servic CIDR中(由APIServer、控制器管理全的--service-cluster-ip-range参数指定)的第一个地址IP.2 = <MASTER_CLUSTER_IP>[ v3_ext ]authorityKeyIdentifier=keyid,issuer:alwaysbasicConstraints=CA:FALSEkeyUsage=keyEncipherment,dataEnciphermentextendedKeyUsage=serverAuth,clientAuthsubjectAltName=@alt_names - 生成CSR: openssl req -new -key server.key -out server.csr -config csr.conf
- 根据CSR来签名,生成APIServer的服务器证书:
123openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \-CAcreateserial -out server.crt -days 10000 \-extensions v3_ext -extfile csr.conf
然后,用相同的方法,修改APIServer的启动参数。
自签名证书可能不被客户端节点信任,你需要手工分发:
|
1 2 3 4 5 |
# 在每个客户端执行: # 复制CA证书到本地证书目录 sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt # 更新证书配置 sudo update-ca-certificates |
你可以使用certificates.k8s.ioAPI来提供数字证书。
很多应用程序需要多项K8S资源(对象),你可以在单个YAML中同时定义它们,只需要用 --- 分隔两项资源即可。
K8S会按照YAML中的声明顺序来创建资源,因此你应该先定义Service、再定义Deployment。
kubectl create也支持多个 -f参数,你可以同时指定多个配置文件。你还可以为-f指定一个配置目录,其中的yaml、yml、json文件都会被读取。你也可以为-f 指定为一个URL
K8S建议:
- 将和一个微服务/应用程序分层(Tier)相关的资源,放到同一配置文件中
- 将和你的整个应用程序相关的所有资源,放到同一目录中
- 如果你的应用程序各Tier通过DNS相互绑定,那么,你可以简单的一起部署所有组件
使用 -R参数可以递归的读取子目录中的配置文件,来创建对象。
使用 -o参数可以输出被创建对象的名称:
|
1 2 3 4 |
# -o name 输出resources/name格式 kubectl get $(kubectl create -f docs/user-guide/nginx/ -o name | grep service) # NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE # my-nginx-svc 10.0.0.208 80/TCP 0s |
除了创建资源,其它操作也支持批量式的操作。例如删除操作:
|
1 2 3 4 5 6 |
# 从指定目录中寻找资源配置,并删除对应的K8S对象 kubectl delete -f docs/user-guide/nginx/ # 删除多个对象,对象以 resources/name格式指定 kubectl delete deployments/my-nginx services/my-nginx-svc # 删除多个对象,根据标签 + 类型 kubectl delete deployment,services -l app=nginx |
集群的网络架构和Docker不同,它需要解决四个不同的网络问题:
- 高耦合容器之间的通信,在Pod内部,使用localhost相互通信
- Pod之间的通信,使用集群网络,是本节的主题
- Pod与Service之间的通信,利用K8S的Service机制解决
- 外部与Service之间的通信,也是利用K8S的Service机制解决
K8S假设所有Pod之间都有通信的需求,因此不去罗嗦的为容器之间指定link。K8S为每个Pod分配了IP地址,你几乎从不需要进行容器到宿主机的端口映射。
Pod更像是一个VM或者物理主机,不管从端口分配、命名、服务发现、负载均衡、应用程序配置、迁移等角度。
容器使用宿主机私有网络,它会创建一个名为docker0的虚拟网桥,并分配一个子网。每个创建的容器被分配一个虚拟以太网设备(veth),这些以太网卡被连接到网桥。在容器中veth被映射为eth0这个网络接口(使用了Linux名字空间机制,因此不会和宿主机冲突)。容器中的eth0被分配以网桥地址范围中的一个IP。
结果是,同一宿主机上,基于同一网桥(docker network)的容器可以相互通信。但是跨宿主机则无法通信,需要使用端口映射机制(映射到宿主机),你要么需要小心的分配端口,要么使用自动端口映射。
K8S强制要求了以下网络特性:
- 所有容器之间的通信,不使用NAT(端口映射)
- 所有节点 - 容器之间的通信不使用NAT
- 容器看到自己的IP地址,其它角色也能看到
K8S为每个Pod分配了一个IP地址,Pod中的容器共享此IP地址。在Docker中,实现方式是,利用一个容器持有网络名字空间,然后Pod中其它容器加入到此名字空间: --net=container:
可以利用多种技术来实现K8S的网络架构,例如Cilium、Contiv、Contrail、Flannel、GCE、Kube-router、Linux网桥、Multus、OpenVSwitch、OVN
应用和系统日志有利于了解集群中发生了什么,在调试问题和监控集群性能时日志非常有效。大部分应用程序都实现了某种日志机制,大部分容器引擎都支持某种日志收集方式,最常用的时标准输出/错误。
应用、容器的日志机制不能作为K8S的日志解决方案,容器可能崩溃、Pod可能被清除、节点也可能死掉,即使这些异常情况出现,你仍然需要访问自己的应用程序日志。
K8S引入集群级别日志(cluster-level-logging)的概念。CLL要求独立的日志存储机制,以便分析和查询。
K8S没有提供原生的日志数据存储方案,但是你可以把现有的方案集成进来。CLL假设你已经做好了位于集群内部/外部的存储方案
对于容器输出到标准输出的日志,可以使用命令直接查看:
|
1 2 3 |
kubectl logs counter # counter是Pod名 # 要查看先前的容器实例(已经崩溃)的日志,可以附加 --previous 参数 # 如果Pod中有多个容器,使用 -c CONTAINER 参数可以查看指定容器的日志 |
节点本地的Kubelet负责响应kubectl logs的请求。
所有容器化应用程序输出到stderr/stdout的信息都被容器引擎重定向到某个地方 。Docker将其重定向到一个日志驱动处,K8S配置了个日志驱动,将容器日志输出为JSON文件格式。
默认情况下,容器重启后,Kubelet保留被终结的容器及其日志。如果Pod被从节点清除,所有容器及其日志都被清除。
对于节点级日志,需要实现日志轮换,防止节点存储空间被耗尽。K8S本身目前不负责日志轮换,但是kube-up.sh脚本提供了logrotate工具,负责每小时处理日志轮换。你也可以自己启动容器来处理日志轮换(例如基于Docker的log-opt)。
K8S系统组件可以分为两类:
- 运行在容器中的组件,例如K8S Scheduler、kube-proxy。这类组件的日志总是写入到/var/log目录
- 直接运行在节点上的组件,例如Docker、Kubelet。在启用systemd的机器上,这些组件的日志写入到journald,没有启用systemd则写入到/var/log目录
查看日志的命令示例:
|
1 2 |
# Ubuntu 16.04 journalctl -u kubelet -f |
日志冗长级别说明:
|
1 2 3 4 5 6 7 8 |
--v=0 Generally useful for this to ALWAYS be visible to an operator. --v=1 A reasonable default log level if you don’t want verbosity. --v=2 Useful steady state information about the service and important log messages that may correlate to significant changes in the system. This is the recommended default log level for most systems. --v=3 Extended information about changes. --v=4 Debug level verbosity. --v=6 Display requested resources. --v=7 Display HTTP request headers. --v=8 Display HTTP request contents. |
要实现集群级别的日志,你可以参考一些通用的实现途径:
- 在每个节点上,使用节点级别的日志代理
- 在Pod中包含一个专用的、负责日志的容器
- 从应用程序中直接推送日志到一个后端实现
Kubelet的垃圾回收功能可以适时的清理无用的镜像、容器。默认镜像清理5min一次,容器清理1min一次。
镜像管理器(在cadvisor的协作下)负责管理image的生命周期。两个相关的因素为HighThresholdPercent、LowThresholdPercent。如果磁盘用量大于HighThresholdPercent则会触发镜像的回收,会按照LRU算法清理镜像,知道磁盘用量小于LowThresholdPercent。
要定制上述两个参数,修改Kubelet的启动选项:image-gc-high-threshold(默认90%)、image-gc-low-threshold(默认80%)
和容器回收的三个用户定义参数为:
- MinAge,容器的最小生命,超过此生命时间才能被回收。对应Kubelet启动选项minimum-container-ttl-duration
- MaxPerPodContainer,单个容器拥有的死亡容器个数。对应Kubelet启动选项maximum-dead-containers-per-container
- MaxContainers,总计最大死亡容器个数。对应Kubelet启动选项maximum-dead-containers
设置MinAge为0,MaxPerPodContainer、MaxContainers为负数则禁用回收。
某些应用场景下,你可能考虑使用多个K8S集群:
- 降低延迟:在不同区域(Regions)部署集群,让用户访问离的近的入口点
- 故障隔离:使用多个较小的集群,可能比一个大的集群更加容易隔离故障。你可以考虑在一个云服务商的多个Zone分别创建集群
- 扩容:单个K8S集群不能无限扩容,尽管对于大部分用户来说,单个K8S集群足够使用
- 混合云:你需要在多个云服务商、内部部署数据中心上创建多个集群
联邦(Federation)用于管理多个K8S集群,它的主要功能是:
- 跨集群同步资源,保证资源(例如Deployment)在多个集群之间保持同步
- 跨集群发现,支持基于来自多个集群的后端,来配置DNS和负载均衡器
- HA:防止整个集群的崩溃、断网导致的不可用
- 避免绑定到云服务商,因为可以方便的跨集群迁移应用程序
使用联邦时,单个集群的Scope应该保持在单个Zone/Availability Zone内部,原因是:
- 比起全局单一大集群,这样部署可以减少单点故障
- 可用性属性更加容易估算
- 开发者设计系统时,可以对网络延迟、带宽等进行有根据的假设
在单个Zone/Availability Zone部署多个集群也是可以的,但是K8S建议越少越好,原因是:
- 可以减少运维成本(但是随着运维工具、过程的成熟此优势会变小)
- 减少每集群的固定资源开销,例如APIServer VMs(但是对于大型集群来说,这点开销也不算什么)
Linux中的sysctl接口允许管理员在运行时修改内核参数。这些参数存在于虚拟文件系统/proc/sys/中。这些参数牵涉到多个子系统,例如:
- 内核(前缀kernel.)
- 网络(前缀net.)
- 虚拟内存(前缀vm.)
- MDADM(前缀dev.)
执行命令 sudo sysctl -a可以获得所有系统参数的取值。
很多sysctl支持名字空间,包括kernel.shm*、kernel.msg*、kernel.sem、fs.mqueue.*、net.*。也就是说,节点上的每个Node可以分别、独立的设置这些内核参数。
不支持名字空间的sysctl,叫做节点级sysctl,必须由管理员手工设定。
对于定制了sysctl的节点,最好标记为tainted,并且仅仅将需要这些特定的sysctl设置的Pod调度到其上。
Sysctls被划分为两组:安全、不安全。安全Sysctl必须能适当的在同节点上的Pod之间隔离:
- 不能对其它Pod产生任何影响
- 不能危害节点的健康
- 不能超过配额获取CPU、内存资源
对于K8S 1.4来说,以下Sysctl属于安全的:kernel.shm_rmid_forced、net.ipv4.ip_local_port_range、net.ipv4.tcp_syncookies
非安全的Sysctl默认是被禁用的,集群管理员必须手工在目标节点上启用:
|
1 2 3 4 |
# 对于Kubelet kubelet --experimental-allowed-unsafe-sysctls 'kernel.msg*,net.ipv4.route.min_pmtu' # 对于 Minikube minikube start --extra-config="kubelet.AllowedUnsafeSysctls=kernel.msg*,net.ipv4.route.min_pmtu"... |
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: v1 kind: Pod metadata: name: sysctl-example # 使用注解实现针对Pod的sysctl调优 annotations: security.alpha.kubernetes.io/sysctls: kernel.shm_rmid_forced=1 # Pod无法被调度到没有启用以下两个Unsafe sysctl的节点上,除非使用Taints security.alpha.kubernetes.io/unsafe-sysctls: net.ipv4.route.min_pmtu=1000,kernel.msgmax=1 2 3 spec: ... |
使用Kubernetes时,你会注意到多个不同的代理。
- 在用户的桌面或者Pod中运行
- 将localhost地址代理为K8S APIServer地址
- 客户端到代理使用HTTP连接,代理到APIServer使用HTTPS连接
- 负责定位APIServer
- 添加身份验证请求头
- 构建在APIServer内部
- 将集群外部的用户连接到集群IP,没有这种机制集群外部是无法直接访问集群IP的
- 在APIServer进程内部运行
- 客户端到此代理使用HTTPS协议,你也可以修改APIServer,使用HTTP协议
- 用于连接到任何节点、Pod、服务
- 当用于连接到服务时,负责负载均衡
- 在每个节点上运行
- 代理UDP、TCP流量
- 不理解HTTP
- 提供负载均衡功能
- 仅仅用于连接到服务
位于APIServer前面的代理或负载均衡器:
- 存在有否,实现方式依具体集群而不同
- 位于所有客户端和APIServers之间
- 如果集群存在多个APIServers,作为负载均衡器使用
- 由云服务提供商提供
- 定义LoadBalancer类型的服务时,自动创建
- 仅仅使用UDP/TCP
- 具体实现依赖于云服务商
- 定义配置时,指定最新版本的API,当前是v1
- 配置文件应当采用版本控制
- 使用YAML而不是JSON来编写配置文件
- 紧密耦合的一组对象,放在单个YAML中。应用程序的所有对象,可以放在单个目录中
- 不要指定默认值,让文件尽可能简短
- 将对象描述放到注解中
- 应当先创建Service,然后创建复制控制器(或者Deployment等)
- 尽可能避免映射到宿主机端口
- 尽可能避免使用hostNetwork
- 如果不需要kube-proxy负载均衡,可以使用Headless Service进行简单的服务发现
- 使用标签来识别应用、部署的语义属性,例如这些标签:{ app: myapp, tier: frontend, phase: test, deployment: v3 }。而不要简单粗暴的定义{service: myservice}
当多个团队共享一个固定节点数的集群时,需要进行资源的配额管理。
ResourceQuota对象用于定义资源的配额,为某个名字空间限定总计的最大资源消耗。包括:
- 每个K8S名字空间最多能创建多少个指定类型的对象
- 上述对象总计消耗的计算资源的总量
资源配额的工作机制为:
- 不同的团队使用不同的名字空间,因而可以依照名字空间来管理配额。目前名字空间是自愿加入的,未来K8S会对其施加ACL
- 管理员为每个名字空间创建一个或多个资源配额对象
- 用户会在名字空间中创建对象(Service、Pod等),配额系统会跟踪名字空间的资源用量,确保不超过限制
- 当创建、更新资源,导致违反配额约束时,请求会失败,并且获得HTTP响应码403
- 如果配额中限定了CPU、内存等计算资源的用量,那么你必须在请求中指定需要的用量,否则配额系统会拒绝Pod的创建
对于很多K8S发行版来说,资源配额支持是默认启用的。你可以设置--admission-control,添加ResourceQuota。
当名字空间中有ResourceQuota对象时,则该名字空间就启用了配额管理,每个名字空间最多有一个ResourceQuota对象。
在创建Pod时,你可以指定某个容器需要使用的CPU、内存资源数量。调度器会根据Pod的需求,将其调度到适当的节点上。
CPU、内存是主要的计算资源(compute resources,有时简称resources),计算资源和K8S API资源不是一个概念。计算资源可以被请求、分配、消耗。
每个容器的规格中,都可以包含以下数据项:
| 规格配置项 |
|
spec.containers[].resources.limits.cpu 容器最多可以使用的CPU资源 以CPU核心数为单位,可以指定小数,也可以使用m作为单位 1000m = 1 |
|
spec.containers[].resources.limits.memory 容器最多可以使用的内存资源 内存用量单位可以是E, P, T, G, M, k或者Ei, Pi, Ti, Gi, Mi, Ki,后者以2的次方计算 |
| spec.containers[].resources.requests.cpu 容器至少可以获得的CPU资源 |
| spec.containers[].resources.requests.memory 容器至少可以获得的内存资源 |
Pod占有的资源,即每个容器占用的资源的总和。
Pod的资源使用状况,被报告为Pod Status的一部分。
Describe节点的时候,可以看到其Capacity、Allocatable两个字段,它们表示节点总计的、可被K8S分配给Pod的资源量:
Allocatable = Node Capacity - kube-reserved - system-reserved - eviction-threshold
资源当前主要支持CPU、临时存储、内存者三类。至于磁盘IOPS、网络流量之类目前是无法配额的。
默认情况下,Pod可以使用Capacity指定的全部资源。这可能导致问题,因为K8S、操作系统本身需要运行一些守护程序,不做限制会导致Pod和守护程序竞争资源,导致系统卡死。
要使用资源预留,必须启用kubelet选项--cgroups-per-qos(默认启用)。该选项会将所有用户的Pod放在共同的、被kubelet管理的cgroups下面。
kubelet依赖于Cgroup驱动来管理cgroups,默认--cgroup-driver=cgroupfs,可以选取systemd。
为kubelet、容器运行时服务、节点问题检测器等守护程序预留资源。作为DaemonSet运行的守护程序,不在内。取值多少,通常是节点Pod密度的函数。
要启用其资源预留,指定kubelet参数--kube-reserved-cgroup,其值为现有的、作为父控制组的cgroups名称。建议指定顶级cgroups,例如基于systemd的系统上可以指定runtime.slice。
要指定预留资源量,指定kubelet参数:
|
1 2 |
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi] --kube-reserved-cgroup=/kube.service |
Cgroup目录一定要预先创建,否则kubelet启动失败。CentOS下示例:
|
1 2 3 |
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuset/kube.slice ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/memory/kube.slice ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/hugetlb/kube.slice |
为OS 守护程序、系统内核预留资源:
|
1 2 |
--system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi] --system-reserved-cgroup=/system.slice |
警告,上述限制可能导致关键OS服务遭遇OOM。
默认值为pods,表示为Pods进行Cgroups控制。要为kube组件和系统预留资源,需要设置为pods,kube-reserved,system-reserve。
|
1 |
--enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved] |
当资源不足时,Kubelet会采取一些措施,例如驱除Pod,以保证系统稳定运行。
Kubelet可以在资源耗尽前,主动的停止一或多个Pod。触发驱除的信号来自节点状态,包括:
| 信号 | 说明 |
| memory.available | 等于node.status.capacity[memory] - node.stats.memory.workingSet |
| nodefs.available |
等于node.stats.fs.available nodefs是Kubelet用作卷、守护进程日志的文件系统 |
| nodefs.inodesFree | 等于node.stats.fs.inodesFree |
| imagefs.available |
等于node.stats.runtime.imagefs.available 容器运行时用作存储镜像、可写层的文件系统 |
| imagefs.inodesFree | 等于node.stats.runtime.imagefs.inodesFree |
上述信号,均可以指定绝对值或者百分比。
驱除行为分为两类,分别为软驱除、硬驱除。后者没有grace period。
驱除阈值是kubelet命令行参数,指定Pod驱除发生的规则。包括: eviction-soft、 eviction-hard。阈值的语法为: [eviction-signal][operator][quantity],例如memory.available<10%、memory.available<1Gi。一个实际的例子:
|
1 |
--eviction-hard=memory.available<500Mi,nodefs.available<10% |
和软驱除相关的额外的命令行参数包括:
- eviction-soft-grace-period,优雅期长度,取值例如1m30s,阈值到达后,此优雅期到达前,不会触发清除
- eviction-max-pod-grace-period,执行delete pod操作的优雅期,单位秒
Kubelet默认的硬清除阈值是:内存小于100Mi、nodefs可用小于10%、imagefs可用小于15%、nodefs可用inode小于5%
计算取值阈值是否到达的时间间隔,由housekeeping-interval控制。
Kubelet将驱除信号映射为节点状态。当超过硬、软清除阈值时,会更新节点的Condition:
| Condition | Eviction Signal |
| MemoryPressure | memory.available |
| DiskPressure | nodefs.available, nodefs.inodesFree, imagefs.available, imagefs.inodesFree |
节点可能反复高于、低于软驱除阈值,且其切换周期低于软驱除优雅期。这导致NodeCondition反复在true/false之间变动,也导致Kubelet不能做出应当的驱除动作。
参数eviction-pressure-transition-period指定MemoryPressure、DiskPressure从true变为false至少需要等待的时间,避免振荡问题。
到达驱除阈值、并过了优雅期后,Kubelet会执行回收操作,直到低于阈值:
- 回收节点级资源,优先于回收Pod资源:
- nodefs信号处理:删除死掉的Pod及其容器
- imagefs信号处理:删除所有没有使用的镜像
- 驱除Pod:
- 驱除优先级排名规则:
- 第一级排序:那些使用资源大于requests量的Pod排前面
- 第二级排序:那些低优先级的Pod排前面
- 第三集排序:根据Pod的调度请求声明排序
- 驱除行为:
- BestEffort或Burstable的Pod,超量使用资源的,根据优先级,依次驱除
- Guaranteed且Burstable,没有使用超量资源的,最后驱除
- Guaranteed的且每个容器的requests=limits!=0的Pod,不会因为其它Pod的资源消耗而被驱除
- 驱除优先级排名规则:
DaemonSet创建的Pod永远不应该被驱除,因为控制器会立即重新创建。但是Kubelet目前没办法识别Pod是否由DS创建,为避免被误驱除,DaemonSet永远不应该创建BestEffort的Pod。
某些情况下,Kubelet虽然驱除了多个Pod,但是回收的资源量并不多。为了避免这种无效的大量驱除,可以设置参数:
|
1 |
--eviction-minimum-reclaim="memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi" |
这样,仅当Pod驱除后能回收500+内存,它才会被清除。
如果节点在kubelet回收内存之前经历了OOM事件,它将基于oom-killer进行响应。
你可以使用kubeconfig文件来组织集群、用户、名字空间、身份验证机制,等信息。
kubectl也使用kubeconfig来获得需要连接到的集群的信息。默认的,kubectl会寻找~/.kube/config文件。你可以使用环境变量KUBECONFIG或者--kubeconfig选项覆盖此默认行为。
执行命令 kubectl config view可以查看当前配置信息。
context元素用于在一个别名下组织集群、名字空间、用户这三类访问参数。默认的kubectl使用“当前Context”,要切换当前Context,可以执行:
|
1 |
kubectl config use-context |
命令行接口默认使用kubeconfig位于~/.kube/config。
添加Bash自动完成支持:
|
1 |
echo "source <(kubectl completion bash)" >> ~/.bashrc |
子命令如下表:
| 子命令 | 说明 | ||||||
| 基本命令 | |||||||
| create |
根据文件或者标准输入来创建一个资源,配置信息可以是YML或JSON格式 格式: kubectl create -f FILENAME [options] 选项: --dry-run=false 如果true则仅仅显示命令的后果,不实际执行 |
||||||
| expose |
将复制控制器、服务、部署、Pod暴露为K8S服务 格式: kubectl expose (-f FILENAME | TYPE NAME) [options] 选项: --cluster-ip='' 分配给服务的集群IP,为空则自动分配 |
||||||
| run |
在集群上运行特定的镜像,实际上是创建Deployment或Job 格式:
示例:
|
||||||
| debug |
使用交互式的调试容器来调试集群资源 该命令的行为可以是:
|
||||||
| set | 在对象上设置特性 | ||||||
| get |
列表形式显示一个或多个资源 格式:
资源类型: 支持的资源类型包括: all 选项: --all-namespaces 获取所有名字空间的资源 举例:
|
||||||
| explain | 显示资源的文档 | ||||||
| edit | 编辑一个资源 | ||||||
| delete |
根据文件名、Stdin、名称、标签来删除资源 格式: kubectl delete ([-f FILENAME] | TYPE [(NAME | -l label | --all)]) [options] 示例:
|
||||||
| cp |
在当前目录和Pod容器目录之间进行文件拷贝 格式: kubectl cp [options] 示例:
|
||||||
| 部署命令 | |||||||
| rollout |
管理资源的滚动更新,可以用于滚动更新复制集(Replica Set) 格式: kubectl rollout SUBCOMMAND [options] 子命令: 示例:
|
||||||
| rolling-update |
针对指定的复制控制器(Replication Controller)进行滚动更新。将指定的的复制控制器替换为新的复制控制器,每次更新其中一个Pod(使用新Pod模板) 格式:
|
||||||
| scale |
对 Deployment, ReplicaSet, Replication Controller, Job进行扩容 示例:
|
||||||
| autoscale |
对Deployment, ReplicaSet, ReplicationController进行自动扩容 格式:
示例:
|
||||||
| 集群管理命令 | |||||||
| certificate | 修改证书资源 | ||||||
| cluster-info | 显示集群信息 | ||||||
| top | 显示资源(CPU、内存、存储)用量 | ||||||
| cordon | 将节点标记为不可调度 | ||||||
| uncordon | 将节点标记为可调度 | ||||||
| drain |
抽干节点上部署的资源,准备进行节点维护。节点不再接受Pod调度 要恢复,执行:
|
||||||
| taint |
为一个或多个节点标记Taint,每个Taint可以包含三个部分:
目前仅仅支持在Node上添加Taint 格式:
示例:
|
||||||
| 调试诊断命令 | |||||||
| describe | 描述一个资源的详细信息 | ||||||
| logs | 查看容器日志 | ||||||
| attach | 连接到容器的控制台 | ||||||
| exec |
在容器上执行命令,示例:
|
||||||
| port-forward | 转发一个或多个本地的端口到Pod | ||||||
| proxy | 运行API Server的代理 | ||||||
| auth | 查看授权信息 | ||||||
| 网络命令 | |||||||
| port-forward |
端口转发,将指定的本地端口转发给K8S对象(Service、Pod等) 格式:
示例:
|
||||||
| 高级命令 | |||||||
| apply |
根据指定的文件或者Stdin来给资源应用一个配置 如果操控的资源尚不存在,则此命令会自动创建之 |
||||||
| patch |
更新资源的某些字段 可以用一段YAML来打补丁:
也可以用一段JSON来打补丁:
|
||||||
| replace | 根据指定的文件或者Stdin来替换掉资源 | ||||||
| convert | 在不同API版本之间转换配置文件 | ||||||
| 设置命令 | |||||||
| label |
为资源更新标签 示例:
|
||||||
| annotate | 为资源更新注解 | ||||||
| 客户端设置 | |||||||
| config |
此命令用于修改kubeconfig,即默认位于~/.kube/confg中的配置信息 格式: kubectl config SUBCOMMAND [options] 子命令: current-context 显示当前使用的上下文(集群+命名空间+用户的组合) 示例:
|
||||||
|
1 2 3 4 5 6 7 8 9 |
--v=0 用于那些应该 始终 对运维人员可见的信息,因为这些信息一般很有用 --v=1 如果您不想要看到冗余信息,此值是一个合理的默认日志级别 --v=2 输出有关服务的稳定状态的信息以及重要的日志消息,这些信息可能与系统中的重大变化有关。这是建议大多数系统设置的默认日志级别 --v=3 包含有关系统状态变化的扩展信息 --v=4 包含调试级别的冗余信息 --v=6 显示所请求的资源 --v=7 显示 HTTP 请求头 --v=8 显示 HTTP 请求内容 --v=9 显示 HTTP 请求内容而且不截断内容 |
Kubeadm是K8S提供的一个工具箱,用于快速安装、初始化多机器环境下的K8S集群。
- Ubuntu 16.04、Debian 9、Fedora 25等操作系统
- 2GB或者更多内存
- 2核心或者更多
- 所有节点之间的完整网络连接性
- 每个节点具有唯一的主机名、MAC地址、product_uuid。product_uuid可以利用命令 sudo cat /sys/class/dmi/id/product_uuid获得
- 必要的端口已经打开。可以简单的禁用防火墙: sudo ufw disable
- 禁用交换分区/文件: sudo swapoff -a ,这样kubelet才能正常工作
每个节点都需要安装Docker,推荐1.12,但是17.03、1.13、1.11等版本也可以使用。17.06+可能是可以的,但是没有经过K8S团队验证。安装方法:
|
1 2 3 4 5 6 7 |
# Ubuntu / Debian apt-get update apt-get install -y docker.io # CentOS / RHEL / Fedora yum install -y docker systemctl enable docker && systemctl start docker |
你需要确保Kubelet使用的Cgroup驱动和Docker的一致。要查看Docker当前的Cgroup驱动,执行:
|
1 2 |
docker info | grep Driver # Cgroup Driver: cgroupfs |
可选值是cgroupfs、systemd,如果要修改Docker的驱动,可以:
|
1 2 3 4 |
{ ... "exec-opts": ["native.cgroupdriver=systemd"] } |
或者,修改Kubelet的启动选项 --cgroup-driver=cgroupfs。
Kubeadm用于集群的自举,在所有节点安装。kubeadm不会帮你安装kubelet、kubectl,因此你需要自己确保后两者的版本和K8S控制平面(由kubeadm安装)兼容。
|
1 2 3 4 5 |
apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat |
选取一台机器作为Master,控制平面组件将在其上运行,包括etcd(集群数据库)和APIServer。执行命令:
|
1 2 3 4 5 |
kubeadm init --apiserver-advertise-address 10.28.191.166 # 会在下面这一步卡住很长时间,如果在国内,要正确配置docker pull的代理,否则位于私服gcr.io下的APIServer等镜像是无法下载的 # Kubelet的日志信息,在Ubuntu上可以到/var/log/syslog查看,但是因为APIServer镜像拉取非常慢,所以报6443无法连接的日志非常多 # This might take a minute or longer if the control plane images have to be pulled. |
执行完毕后,会提示:Your Kubernetes master has initialized successfully,并下载以下镜像:
|
1 2 3 4 5 6 7 8 |
docker images # REPOSITORY TAG IMAGE ID CREATED SIZE # gcr.io/google_containers/kube-proxy-amd64 v1.9.0 f6f363e6e98e 12 days ago 109 MB # gcr.io/google_containers/kube-apiserver-amd64 v1.9.0 7bff5aa286d7 12 days ago 210 MB # gcr.io/google_containers/kube-controller-manager-amd64 v1.9.0 3bb172f9452c 12 days ago 138 MB # gcr.io/google_containers/kube-scheduler-amd64 v1.9.0 5ceb21996307 12 days ago 62.7 MB # gcr.io/google_containers/etcd-amd64 3.1.10 1406502a6459 3 months ago 193 MB # gcr.io/google_containers/pause-amd64 3.0 99e59f495ffa 20 months ago 747 kB |
如果网络实在太慢,或者无法访问gcr.io,则kubeadm init最终会time out。可以到阿里云的海外站建立一个按时收费的VM,在其上执行kubeadm init并把Docker 镜像拷贝、下载到本地使用。 默认情况下镜像文件存放在/var/lib/docker/aufs目录中,/var/lib/docker/image下则是镜像的元数据。
记住控制台上输出的信息:
|
1 |
kubeadm join --token 24ae55.951196a500d44f96 10.28.191.166:6443 --discovery-token-ca-cert-hash sha256:1b99aad2ed25b8f05e14a4a2c20c9aa3e116dfb027f3544a7ac6a926669b3ed7 |
添加节点的时候需要使用。
首先要确保当前用户的kubectl的配置文件正确。
如果以root身份运行:
|
1 |
export KUBECONFIG=/etc/kubernetes/admin.conf |
其它用户可以使用如下方式指定kubectl配置文件:
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config |
然后,你可以执行命令查看组件状态:
|
1 2 3 4 5 |
kubectl get cs # NAME STATUS MESSAGE ERROR # controller-manager Healthy ok # scheduler Healthy ok # etcd-0 Healthy {"health": "true"} |
必须安装一个Pod Network Addon,这样Pod才能相互通信。安装Addon的通用命令格式为:
|
1 |
kubectl apply -f add-on.yaml |
Pod Network Addon必须在任何应用程序之前部署, 完成之前,kube-dns(集群DNS服务)不会启动。
Kubeadm仅仅支持基于容器网络接口(Container Network Interface,CNI)的网络,不支持kubenet(单机环境下的网络插件)。因此kubelet必须使用选项--network-plugin=cni。
CNI由一系列规范、用于编写插件的库组成,这些插件用于配置Linux容器的网络接口,目前已经有一系列CNI插件。CNI仅仅关注容器的连接性、容器删除时的资源回收。
有多个开源项目为K8S提供CNI网络支持,其中一些支持网络策略:
| Addon | 说明 | ||
| Calico |
一个安全的第三层网络连接,提供网络策略支持。仅仅支持amd64 要求kubeadm init参数: --pod-network-cidr=192.168.0.0/16 安装此Addon:
|
||
| Canal |
联合使用Flannel+Calico,提供网络连接和策略。仅仅支持amd64 要求kubeadm init参数: --pod-network-cidr=10.244.0.0/16 安装此Addon:
|
||
| Flannel |
一个覆盖网络实现,支持和K8S一起使用。支持amd64, arm, arm64, ppc64le,但是除了amd64之外需要手工的处理 要求kubeadm init参数: --pod-network-cidr=10.244.0.0/16 你需要设置: sysctl net.bridge.bridge-nf-call-iptables=1,将桥接的IPv4流量传递给iptables chain,确保某些CNI正常工作 安装此Addon:
|
||
| Kube-router |
提供网络连接、策略、高性能的基于IPVS(IP虚拟服务器)/LVS(Linux虚拟服务器)的服务代理 你需要设置: sysctl net.bridge.bridge-nf-call-iptables=1,将桥接的IPv4流量传递给iptables chain,确保某些CNI正常工作 Kube-router依赖于控制器管理器来为节点分配Pod CIDR,你需要指定--pod-network-cidr标记 |
||
| Weave Net |
支持amd64/arm/arm64且不需要额外的处理。默认设置hairpin mode,允许Pod通过它们的Service IP访问自己 你需要设置: sysctl net.bridge.bridge-nf-call-iptables=1,将桥接的IPv4流量传递给iptables chain,确保某些CNI正常工作 安装此Addon:
|
安装网络支持后,K8S需要到gcr.io下载三个镜像,如果网络不好的话又需要很长时间。你可以检查kube-dns是否进入Running状态:
|
1 |
kubectl get pods --all-namespaces | grep kube-dns |
如果是,则可以将节点加入到集群了。 否则,查看一下kube-dns这个Pod的详细状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# kube-system kube-dns-6f4fd4bdf-h84mc 0/3 Pending 0 1m kubectl --namespace=kube-system describe pod kube-dns-6f4fd4bdf-h84mc # Controlled By: ReplicaSet/kube-dns-6f4fd4bdf # Containers: # kubedns: # Requests: # cpu: 100m # memory: 70Mi # dnsmasq: # Requests: # cpu: 150m # memory: 20Mi # Events: # Type Reason Age From Message # ---- ------ ---- ---- ------- # Warning FailedScheduling 3m (x7 over 3m) default-scheduler 0/1 nodes are available: 1 NodeNotReady. # Warning FailedScheduling 2m (x2 over 2m) default-scheduler 0/1 nodes are available: 1 Insufficient cpu, 1 NodeNotReady. # Warning FailedScheduling 53s (x3 over 1m) default-scheduler 0/1 nodes are available: 1 Insufficient cpu. |
可以发现CPU资源不足会导致kube-dns无法运行。
默认情况下,集群不会在Master节点上调度Pod,主要是安全方面的考虑。如果你希望改变这一行为(例如仅仅有单个节点,开发用),可以去除taint:
|
1 2 |
# 移除所有节点上的Taint: node-role.kubernetes.io/master,这样调度器可以在任何地方调度Pod kubectl taint nodes --all node-role.kubernetes.io/master- |
执行kubeadm的最后,有一段用于加入节点的命令,执行执行它就可以加入到集群中。然后在Master节点上验证此新节点的加入:
|
1 2 3 4 |
kubectl get nodes # NAME STATUS ROLES AGE VERSION # izj6c2ryo8ck3lt8mzx0ezz Ready master 25m v1.9.0 # izj6cdwcrbnfjxwlznyjvnz Ready 1m v1.9.0 |
信息信息 在普通节点上,你都可以对集群进行控制,只需要将kubectl的配置文件拷贝过来就可以了:
|
1 2 |
scp root@10.28.191.166:/etc/kubernetes/admin.conf . kubectl --kubeconfig ./admin.conf get nodes |
你也可以从集群外部的节点来控制集群:
|
1 2 3 |
scp root@10.28.191.166:/etc/kubernetes/admin.conf . kubectl --kubeconfig ./admin.conf proxy # 现在可以通过http://localhost:8001/api/v1访问APIServer了 |
|
1 2 3 4 |
# 抽干节点,忽略DaemonSet控制器管理Pods kubectl drain izj6cdwcrbnfjxwlznyjvnz --delete-local-data --force --ignore-daemonsets # 从集群中删除节点 kubectl delete node izj6cdwcrbnfjxwlznyjvnz |
|
1 2 |
# 已经下载的镜像不会被删除,但是创建的容器会全部删除 kubeadm reset |
初始化一个K8S集群的Master节点。该子命令的工作流程如下:
- 执行一系列的pre-flight检查,验证系统状态。某些验证会导致警告,另一些则触发错误并终止流程
- 生成自签名CA(或者使用你提供的)来为每个集群组件创建identity。你可以把自己生成好的CA证书/密钥放入--cert-dir目录(默认/etc/kubernetes/pki),则此步骤可以跳过
- 为Kubelet、控制器管理器、调度器创建配置文件,放入/etc/kubernetes/目录。这些组件利用配置文件(自己的identity)连接到APIServer
- 创建一个名为admin.conf的kubeconfig
- 如果使用选项--feature-gates=DynamicKubeletConfig。则将Kubelet初始化配置写入/var/lib/kubelet/config/init/kubelet。此特性未来可能默认开启
- 为APIServer、控制器管理器、调度器生成静态Pod清单(manifests)。如果没有提供外部的etcd,则额外创建etcd的静态Pod清单
清单文件位于/etc/kubernetes/manifests目录下,Kubelet会监控此目录,并在启动时创建需要的Pod - 上一步会初始化、启动控制平面,一旦完成,流程继续
- 如果使用选项--feature-gates=DynamicKubeletConfig,则继续完成Kubelet的动态配置——创建ConfigMap、一些RBAC规则,更新节点将Node.spec.configSource指向刚刚创建的ConfigMap
- 为Master节点添加Label、Taints,不让工作负载在Master节点上运行
- 生成令牌,方便Worker节点注册,你可以通过--token手工提供令牌
- 进行必要的配置,允许节点通过Bootstrap Tokens 和 TLS Bootstrap加入到集群:
- 创建一个ConfigMap,添加加入集群所需的信息,创建相关的RBAC访问规则
- 让Bootstrap令牌访问CSR签名API
- 配置CSR请求的自动准许
- 为APIServer安装内部DNS、kube-proxy Addon组件。尽管DNS Pod被部署,但是CNI准备好之前它不会被调度
- 如果使用选项--feature-gates=SelfHosting=true。则基于静态Pod的控制平面被转换为自托管(self-hosted)控制平面
命令行参数可以用配置文件代替,传入 --config选项即可。配置文件格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
# --dry-run 仅仅输出会做什么 # --config 传入此配置文件 # --ignore-preflight-errors stringSlice 将错误看作警告,值IsPrivilegedUser,Swap,all # --skip-token-print 不在控制台上打印kubeadm join的令牌 apiVersion: kubeadm.k8s.io/v1alpha1 kind: MasterConfiguration api: # --apiserver-advertise-address string # APIServer在其上监听的网络接口,设置0.0.0.0则使用默认网络接口 advertiseAddress: <address|string> # --apiserver-bind-port int32 # APIServer监听端口,默认6443 bindPort: etcd: endpoints: - <endpoint1|string> - <endpoint2|string> caFile: <path|string> certFile: <path|string> keyFile: <path|string> dataDir: <path|string> extraArgs: : <value|string> : <value|string> # 使用定制的镜像,不从k8s.gcr.io拉取 image: networking: # --service-dns-domain string # 服务的DNS域名后缀,默认cluster.local dnsDomain: # --service-cidr string # 服务的虚拟IP地址范围,默认10.96.0.0/12 serviceSubnet: # --pod-network-cidr string # Pod网络的的IP地址范围 podSubnet: # --kubernetes-version string # 创建的控制平面版本 kubernetesVersion: cloudProvider: # --node-name string # 设置节点名称 nodeName: authorizationModes: - <authorizationMode1|string> - <authorizationMode2|string> token: # --token-ttl duration # Bootstrap令牌的寿命,默认24h tokenTTL: <time> selfHosted: # 用于覆盖、扩展APIServer的行为 # 示例: # apiServerExtraArgs: # feature-gates: APIResponseCompression=true apiServerExtraArgs: : <value|string> : <value|string> # 用于覆盖、扩展控制器管理器的行为 controllerManagerExtraArgs: : <value|string> : <value|string> # 用于覆盖、扩展调度器的行为 schedulerExtraArgs: : <value|string> : <value|string> apiServerExtraVolumes: - name: <value|string> hostPath: <value|string> mountPath: <value|string> controllerManagerExtraVolumes: - name: <value|string> hostPath: <value|string> mountPath: <value|string> schedulerExtraVolumes: - name: <value|string> hostPath: <value|string> mountPath: <value|string> # --apiserver-cert-extra-sans stringSlice # APIServer HTTPS证书的,额外的主体备选名字(Subject Alternative Names,SAN),可以指定IP和DNS名 apiServerCertSANs: - <name1|string> - <name2|string> # --cert-dir string # 数字证书存放目录,默认/etc/kubernetes/pki certificatesDir: # 不从k8s.gcr.io拉取镜像,从自定义位置拉取 imageRepository: # 使用其它的镜像作为控制平面组件 unifiedControlPlaneImage: # --feature-gates string # 特性开关,包括: # CoreDNS=true|false (ALPHA - default=false) # DynamicKubeletConfig=true|false (ALPHA - default=false) # SelfHosting=true|false (ALPHA - default=false) # StoreCertsInSecrets=true|false (ALPHA - default=false) featureGates: |
默认情况下,Kubeadm从k8s.gcr.io拉取镜像。如果使用的K8S是CI版本,则从gcr.io/kubernetes-ci-images拉取镜像。
你可以设置配置文件的imageRepository选项,指定从其它服务器拉取镜像。
默认情况下,Kubeadm为集群生成所有需要的证书。你只需要在证书目录放置自己生成的证书,即可改变此行为。
如果/etc/kubernetes/pki/ca.crt、/etc/kubernetes/pki/ca.key文件存在,则分别被用作CA证书和私钥。Kubeadm会使用它们对其它CSR进行签名。
Kubeadm包附带了一些配置文件,这些文件影响Kubelet的运行方式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
[Service] # --bootstrap-kubeconfig 一个kubeconfig文件,用于节点加入集群时得到客户端证书信息,此文件会被写入到--kubeconfig指定位置 # --kubeconfig 包含了APIServer的位置、Kubelet的凭证 Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" # --pod-manifest-path 从何处读取静态Pod的规格文件,这些Pod是控制平面的组件 # --allow-privileged 是否允许Kubelet执行特权Pod Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true" # --network-plugin 网络插件类型,Kubeadm仅仅支持CNI # --cni-conf-dir CNI规格文件位置 # --cni-bin-dir CNI可执行文件位置 Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin" # --cluster-dns 集群内部DNS的地址,会写入到Pod的/etc/resolv.conf的nameserver条目 # --cluster-domain 集群内部域名,会写入到Pod的/etc/resolv.conf的search条目 Environment="KUBELET_DNS_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local" # --authorization-mode 授权模式。Webhook表示通过POST一个SubjectAccessReview到APIServer来验证客户端 # --client-ca-file 用于验证的CA文件 Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt" # --cadvisor-port,设置为0表示禁用cAdvisor Environment="KUBELET_CADVISOR_ARGS=--cadvisor-port=0" # --rotate-certificates 证书过期后,自动向APIServer重新申请 # --cert-dir TLS证书目录 Environment="KUBELET_CERTIFICATE_ARGS=--rotate-certificates=true --cert-dir=/var/lib/kubelet/pki" ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_CADVISOR_ARGS $KUBELET_CERTIFICATE_ARGS $KUBELET_EXTRA_ARGS |
如果集群有多套网络,你需要明确选择其中一套时,可以:
- 初始化集群时指定APIServer监听端口: kubeadm init --apiserver-advertise-address=10.0.0.1
- 在Worker节点上安装好软件后,修改/etc/systemd/system/kubelet.service.d/10-kubeadm.conf,添加 --node-ip=10.0.0.x
- 调用kubeadm join时,确保其中的IP地址填写的是10.0.0.1
从1.8开始,K8S支持所谓自托管控制平面,当前处于Alpha状态。自托管控制平面中,APIServer、控制器管理器、调度器等关键组件将以 DaemonSet而不是静态Pod方式运行。
初始化一个K8S集群的Worker节点,并加入到集群中。
当加入基于Kubeadm初始化的集群时,需要双向的身份验证,这通过两部分达成:
- Discovery:让Worker信任Master
- TLS bootstrap:让Master信任Worker
Discovery主要有两种模式:
- 使用共享令牌 + APIServer的地址
- 使用一个文件,其内容是标准kubeconfig的子集
TLS bootstrap也是基于共享令牌驱动的,用于临时的向APIServer提交身份验证,以便发起CSR请求。默认情况下,Kubeadm会自动配置Master,以完成对CSR的准许和签名。此令牌以–tls-bootstrap-token参数传递。
该命令初始化Worker节点并加入到集群。主要步骤:
- 从APIServer下载必要的集群信息,默认的,使用Bootstrap令牌 + CA键的哈希来对信息进行验证
- 如果使用选项--feature-gates=DynamicKubeletConfig。则首先从Master下载Kubelet初始化配置,写入到磁盘。当Kubelet启动后Kubeadm更新节点的Node.spec.configSource属性
- 一旦集群信息获得,Kubelet可以启动TLS bootstrapping:
- 使用共享密钥临时和APIServer通信,提交CSRcat /etc/yum.repos.d/ceph.repo
- 默认的,控制平面会自动签名CSR
- Kubelet以后使用确定的Identity和APIServer通信
|
--config string 指定一个kubeadm配置文件 |
|
--cri-socket string 连接到的CRI(容器运行时接口,例如Docker)套接字,默认/var/run/dockershim.sock |
| --discovery-file string 用于加载集群信息的文件或者URL |
| --discovery-token string 用于验证加载到的集群信息的令牌 |
|
--discovery-token-ca-cert-hash stringSlice 对于基于共享令牌的发现,使用此哈希验证根CA的公钥 |
| --discovery-token-unsafe-skip-ca-verification 对于基于共享令牌的发现,此选项禁用根CA的验证 |
|
--feature-gates string 特性开关 |
| --ignore-preflight-errors stringSlice 忽略预先检查中出现的某些错误 |
| --node-name string 指定当前节点的名称 |
| --tls-bootstrap-token string 用于TLS bootstrap的共享令牌 |
| --token string 同时用于发现、TLS自举的令牌 |
等价的配置文件形式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用 --config选项传入此文件 apiVersion: kubeadm.k8s.io/v1alpha1 kind: NodeConfiguration caCertPath: <path|string> discoveryFile: <path|string> discoveryToken: discoveryTokenAPIServers: - <address|string> - <address|string> nodeName: tlsBootstrapToken: token: discoveryTokenCACertHashes: - - discoveryTokenUnsafeSkipCAVerification: |
Kubeadm提供了多种发现机制:
|
基于令牌的发现 + CA pinning 1.8+的默认机制。Kubeadm下载包括根CA在内的集群配置信息。使用令牌来验证配置信息,使用哈希来验证根CA公钥 缺点是:直到Master准备好之前,CA哈希是不知道的 |
|
基于令牌的发现,不验证CA 需要kubeadm --discovery-token-unsafe-skip-ca-verification 如果攻击者获得Bootstrap令牌,则他能够假扮(面向其它Worker)Master节点 |
|
基于文件/HTTPS的发现 需要kubeadm --discovery-file path-or-url 缺点是,需要有某种机制把发现信息从Master传输到正在Join的节点上 |
|
关闭Worker的CSR自动许可/签名 默认情况下,只要准备加入的Kubelet提供了合法的Bootstrap令牌,Master会自动准许其CSR。要关闭此特性,执行:
这样的话,除非你手工准许了CSR,工作节点的Join请求会阻塞。准许方法:
|
||||
|
关闭对集群信息ConfigMap的开放访问 |
升级一个K8S集群到更新的版本,它将复杂的升级逻辑包装到单条命令当中。
管理用于kubeadm join的令牌:
|
1 2 3 4 5 6 7 8 |
# 创建Bootstrap令牌 kubeadm token create [token] # 删除Bootstrap令牌 kubeadm token delete [token-value] # 产生一个Bootstrap令牌,打印到屏幕上,但是不创建令牌对象 kubeadm token generate # 列出令牌 kubeadm token list |
撤销init/join命令对宿主机做出的任何改变。
如果使用外部etcd,则需要手工清除其中的数据:
|
1 |
etcdctl del "" --prefix |
本集群由4台KVM虚拟机构成,静态IP地址分别为10.0.0.100-105,其中10.0.0.100作为Master节点。
由于本地网络访问Google存在困难,因此Docker镜像已经在云端下载并覆盖到各虚拟机。
集群初始化:
|
1 2 3 4 5 6 7 8 9 |
# 访问Google需要代理 export http_proxy="http://10.0.0.1:8088/" export https_proxy="http://10.0.0.1:8088/" # 如果要使用其它CIDR,修改calico.yaml中的CALICO_IPV4POOL_CIDR kubeadm init --apiserver-advertise-address 10.0.0.100 --pod-network-cidr=192.168.0.0/16 \ --service-dns-domain k8s.gmem.cc --kubernetes-version 1.9.0 # 拷贝kubeconfig cp -i /etc/kubernetes/admin.conf ~/.kube/config && chown $(id -u):$(id -g) ~/.kube/config |
完毕后,创建基于Calico的CNI网络:
|
1 |
kubectl apply -f https://docs.projectcalico.org/v3.0/getting-started/kubernetes/installation/hosted/kubeadm/1.7/calico.yaml |
等待所有控制平面组件Ready:
|
1 2 |
# 根据下面的命令输出判断 kubectl get pod --all-namespaces |
准备加入Worker节点,如果忘记了令牌,可以 这样查看:
|
1 |
kubeadm token list |
下面到Worker节点上执行:
|
1 |
kubeadm join --token f467bb.0cd7f59a071919a8 10.0.0.15:6443 --discovery-token-unsafe-skip-ca-verification |
可以拷贝Master上的kubeconfig,以便在Worker上执行集群管理:
|
1 2 |
mkdir ~/.kube scp root@10.0.0.15:/etc/kubernetes/admin.conf ~/.kube/config |
依次加入所有工作节点。然后验证所有节点均正常:
|
1 2 3 4 5 6 |
kubectl get nodes # NAME STATUS ROLES AGE VERSION # xenial-15 Ready master 12h v1.9.0 # xenial-16 Ready 28m v1.9.0 # xenial-17 Ready 6m v1.9.0 # xenial-18 Ready 5m v1.9.0 |
下面测试Pod联通性。先创建一个Pod:
|
1 |
kubectl create -f /home/alex/Vmware/k8s/pods/busybox/sleep-600.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Pod规格如下: apiVersion: v1 kind: Pod metadata: name: sleep-600 labels: app: sleep-600 spec: containers: - name: sleep-600-container image: busybox command: ['sh', '-c', 'sleep 600'] |
获得此Pod的基本信息:
|
1 2 3 4 |
kubectl describe pod sleep-600 | grep Node: # Node: xenial-17/10.0.0.17 kubectl describe pod sleep-600 | grep IP: # IP: 192.168.227.1 |
尝试在Master节点上Ping此Pod,成功。然后在创建另外一个Pod,Ping它:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: v1 kind: Podkind: ConfigMap apiVersion: v1 metadata: name: calico-config namespace: kube-system data: # The location of your etcd cluster. This uses the Service clusterIP defined below. etcd_endpoints: "http://10.5.38.24:2379,http://10.5.38.39:2379,http://10.5.39.41:2379" metadata: name: ping labels: app: ping spec: containers: - name: ping-container image: busybox command: ['sh', '-c', 'ping 192.168.227.1'] |
然后查看日志确认两个Pod可以联通: kubectl logs ping
|
1 2 3 4 5 6 7 8 9 |
cd ~/Documents/puTTY # 将加密的私钥转换为明文,根据提示输入密码 openssl rsa -in ca.gmem.cc.key -out ca.key # 到Master节点执行: mkdir -p /etc/kubernetes/pki/ cd /etc/kubernetes/pki/ scp alex@zircon.gmem.cc:/home/alex/Documents/puTTY/ca.gmem.cc.crt ca.crt scp alex@zircon.gmem.cc:/home/alex/Documents/puTTY/ca.key ca.key |
|
1 2 |
# 在客户端机器(不是Kubernetes集群成员,仅仅使用kubectl命令)上执行: scp -i ~/Documents/puTTY/gmem.key root@xenial-100.gmem.cc:/etc/kubernetes/admin.conf ~/.kube/config |
|
1 2 3 4 5 6 7 8 |
export http_proxy="http://10.0.0.1:8088/" export https_proxy="http://10.0.0.1:8088/" kubeadm init --apiserver-advertise-address 10.0.0.100 --service-dns-domain k8s.gmem.cc --pod-network-cidr=10.244.0.0/16 --kubernetes-version 1.9.0 cp -i /etc/kubernetes/admin.conf ~/.kube/config && chown $(id -u):$(id -g) ~/.kube/config kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml |
K8S要实现Master高可用,需要解决两个问题:
- Etcd的高可用,Etcd用于所有K8S状态信息的存储。建议在物理机上部署Etcd集群
- API Server的高可用/负载均衡。任何四层代理均可,例如Nginx、LVS
我们的方案是:Etcd三节点物理机部署、API Server三节点通过LVS负载均衡,架构图如下:
- 在物理节点上安装、配置好Etcd集群
- 在一台Master节点上执行 kubeadm init
- 将/etc/kubernetes目录拷贝到其它Master节点
- 在其它Master节点上执行 kubeadm init
- 配置LVS和Keepalived,作为API Server的负载均衡器
- 安装CNI,然后加入节点
Kubeadm配置文件样例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
apiVersion: kubeadm.k8s.io/v1alpha1 kind: MasterConfiguration api: # 这里填写虚IP advertiseAddress: 10.0.10.1 etcd: # 填写Etcd集群端点 endpoints: - http://10.0.1.1:2379 - http://10.0.2.1:2379 - http://10.0.3.1:2379 networking: podSubnet: 172.27.0.0/16 kubernetesVersion: 1.10.2 imageRepository: docker.gmem.cc/k8s apiServerCertSANs: - 10.0.10.1 - 10.0.1.1 - 10.0.2.1 - 10.0.3.1 apiServerExtraArgs: apiserver-count: "3" |
本章记录在Fedora 24上从零开始搭建K8S集群的详细步骤。
使用云服务时,你可能需要获取Cloud Provider,以管理TCP负载均衡、节点、网络路由。如果在本地VM、裸机上部署则不需要。
所有集群节点均应该是amd64的Linux。APIServer+etcd需要在1核/1G内存(10节点集群)或者更好的机器上运行。
K8S使用了特殊的网络模型。它会为每个Pod分配IP,你需要指定一个IP地址范围供Pod使用。Pod之间的连接性有两种达成途径:
- 基于Overlay网络:基于流量封装,对Pod网络隐藏底层网络结构
- 不使用Overlay网络:配置底层设备(例如交换机)让其知晓Pod地址,不需要Overlay的那种封装,性能会更好
具体实现方式,包括:
- 使用CNI网络插件,例如Calico、Flannel、Weave
- 将Cloud Provider模块的Routes接口实现,直接编译到K8S中
- 在外部配置网络路由
用于细粒度单Pod间网络流量控制,并非所有的网络实现支持。
你需要为每个集群起一个唯一性的名字,其用途为:
- kubectl用它来区分需要连接到哪个集群
- 区分属于不同集群的CloudProvider资源
| 软件 | 说明 |
| etcd | 存放集群数据的分布式存储 |
| CRI | 容器运行时,Docker或rkt |
| K8S | kubelet、kube-proxy、kube-apiserver、kube-controller-manager、kube-scheduler |
这些软件都可以通过K8S二进制发行版获得。
Docker、Kubelet、Kube-Proxy在容器外部运行。
etcd、kube-apiserver、kube-controller-manager、 kube-scheduler则推荐以容器的方式运行。
获取K8S组件相关镜像的途径包括:
- 使用GCR(Google Container Registry)提供的镜像:
- 例如gcr.io/google-containers/hyperkube:$TAG,其中TAG要和Kubelet/Kube-Proxy版本一致
- 此外hyperkube提供了All in On的二进制文件,使用hyperkube apiserver可以运行APIServer
- 构建自己的镜像,如果打算搭建私服,可以使用该方式。二进制发行版中的./kubernetes/server/bin/kube-apiserver.tar可以被转换为Docker镜像:
1docker load -i kube-apiserver.tar
获取etcd镜像的途径包括:
- 使用GCR提供的镜像,例如gcr.io/google-containers/etcd:2.2.1
- 使用DockerHub或者Quay提供镜像,例如quay.io/coreos/etcd:v2.2.1
- 构建自己的镜像:
1cd kubernetes/cluster/images/etcd; make推荐使用K8S二进制发行版中附带的etcd
两种访问APIServer的方式:
- 使用HTTP,需要利用防火墙保证安全
- 使用HTTPS ,推荐的方式,需要制作数字证书:
- Master需要数字证书,因为它的APIServer暴露HTTPS服务
- Kubelet需要(可选)数字证书,用于:
- APIServer的双向认证
- 自己也暴露HTTPS服务
除非你想花钱购买证书,否则都需要首先生成根CA密钥对并自签名,然后用根证书对Master、kubelet进行签名。
管理员(或其它用户)需要一个表明自己身份的令牌(密码),令牌仅仅是一个数字+字母的字符串。
|
1 2 3 4 5 6 |
wget https://github.com/kubernetes/kubernetes/releases/download/v1.9.0/kubernetes.tar.gz tar xzf kubernetes.tar.gz && rm kubernetes.tar.gz # 下载客户端、服务器二进制文件 ./kubernetes/cluster/get-kube-binaries.sh # 下载的服务器文件位于 .kubernetes/server/kubernetes-server-linux-amd64.tar.gz # 下载的客户端文件位于 .kubernetes/client/kubernetes-client-linux-amd64.tar.gz |
安装Docker:
|
1 2 3 |
yum install -y docker # 启动Docker systemctl enable docker && systemctl start docker |
安装镜像:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
docker pull gcr.io/google_containers/kube-proxy-amd64:v1.9.0 docker pull quay.io/calico/node:v2.6.5 docker pull quay.io/calico/kube-controllers:v1.0.2 docker pull quay.io/calico/cni:v1.11.2 docker pull gcr.io/google_containers/kube-proxy-amd64:v1.9.0 docker pull gcr.io/google_containers/kube-apiserver-amd64:v1.9.0 docker pull gcr.io/google_containers/kube-controller-manager-amd64:v1.9.0 docker pull gcr.io/google_containers/kube-scheduler-amd64:v1.9.0 docker pull weaveworks/weave-npc:2.1.3 docker pull weaveworks/weave-kube:2.1.3 docker pull quay.io/coreos/flannel:v0.9.1 docker pull quay.io/coreos/flannel:v0.9.1-amd64 docker pull gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.7 docker pull gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.7 docker pull gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.7 docker pull quay.io/calico/node:v2.6.2 docker pull quay.io/calico/cni:v1.11.0 docker pull gcr.io/google_containers/etcd-amd64:3.1.10 docker pull quay.io/coreos/etcd:v3.1.10 docker pull gcr.io/google_containers/pause-amd64:3.0 |
考虑到网络速度问题,将上述镜像Tag为私服镜像。实际编写K8S对象规格时,都使用私服镜像:
| 源镜像 | 本地私服镜像 |
| quay.io/calico/node:v2.6.5 | docker.gmem.cc/calico/node |
| quay.io/calico/kube-controllers:v1.0.2 | docker.gmem.cc/calico/kube-controllers |
| quay.io/calico/cni:v1.11.2 | docker.gmem.cc/calico/cni |
| gcr.io/google_containers/kube-proxy-amd64:v1.9.0 | docker.gmem.cc/kube-proxy-amd64 |
| gcr.io/google_containers/kube-apiserver-amd64:v1.9.0 | docker.gmem.cc/kube-apiserver-amd64 |
| gcr.io/google_containers/kube-controller-manager-amd64:v1.9.0 | docker.gmem.cc/kube-controller-manager-amd64 |
| gcr.io/google_containers/kube-scheduler-amd64:v1.9.0 | docker.gmem.cc/kube-scheduler-amd64 |
| weaveworks/weave-npc:2.1.3 | docker.gmem.cc/weave-npc |
| weaveworks/weave-kube:2.1.3 | docker.gmem.cc/weave-kube |
| quay.io/coreos/flannel:v0.9.1-amd64 | docker.gmem.cc/flannel |
| gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.7 | docker.gmem.cc/k8s-dns-sidecar-amd64 |
| gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.7 | docker.gmem.cc/k8s-dns-kube-dns-amd64 |
| gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.7 | docker.gmem.cc/k8s-dns-dnsmasq-nanny-amd64 |
| gcr.io/google_containers/etcd-amd64:3.1.10 | docker.gmem.cc/etcd-amd64 |
Kubernetes Dashboard是一个一般性用途的基于Web的UI工具。使用该工具你可以管理K8S集群中的应用程序,以及集群本身。
执行下面的命令部署Dashboard:
|
1 |
kubectl apply -f https://nginx.gmem.cc/k8s//dashboard/kubernetes-dashboard.yaml |
然后,你可以:
- 客户端运行 kubectl proxy,并通过浏览器访问http://localhost:8001/ui,使用仪表盘
- 或者,直接访问https://kubernetes-dashboard.kube-system.svc.k8s.gmem.cc
|
1 2 3 4 5 6 7 8 9 |
openssl genrsa -out kube-system.svc.k8s.gmem.cc.key openssl req -new -sha256 -key kube-system.svc.k8s.gmem.cc.key -out kube-system.svc.k8s.gmem.cc.csr openssl x509 -req -days 3650 -in kube-system.svc.k8s.gmem.cc.csr -CA ../ca.crt -CAkey ../ca.key -CAcreateserial -out kube-system.svc.k8s.gmem.cc.crt cp kube-system.svc.k8s.gmem.cc.key /tmp/cert/dashboard.key cp kube-system.svc.k8s.gmem.cc.crt /tmp/cert/dashboard.crt kubectl delete secret kubernetes-dashboard-certs -n kube-system kubectl create secret generic kubernetes-dashboard-certs --from-file=/tmp/cert -n kube-system |
建议使用Token。首先创建一个SA:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
apiVersion: v1 kind: ServiceAccount metadata: name: admin namespace: default imagePullSecrets: - name: gmemregsecret --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: admin-role-binding subjects: - kind: ServiceAccount name: admin namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io |
然后查找此admin用户的secret:
|
1 2 3 4 5 6 |
kubectl describe sa admin # Mountable secrets: admin-token-msnfp # Tokens: admin-token-msnfp kubectl describe secret admin-token-msnfp # token: ... |
将上面的token字段拷贝出来,即可登陆。
仪表盘的配置参数,可以通过修改Deployment对象设置:
- --token-ttl=0 会话过期时间,默认15分钟,设置为0永不过期
Kubernetic是一个支持OS X/Linux/Windows的桌面应用,可以查看各类K8S资源的状态。
这是一个优秀的、美观的开源时间序列数据分析、展示平台。
如果是通过kubeadm安装的单节点Master,可以在Master节点上执行:
|
1 2 3 |
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \ --cacert=/etc/kubernetes/pki/etcd/ca.crt --key=/etc/kubernetes/pki/etcd/peer.key \ --cert=/etc/kubernetes/pki/etcd/peer.crt ... |
|
1 2 |
# 全文搜索 functions.kubeless ... get /registry --prefix -w json | jq -r '.kvs[] | [.key,.value] | .[] ' | base64 -d | grep -a "functions.kubeless" |
|
1 |
... del /registry/apiextensions.k8s.io/customresourcedefinitions/functions.kubeless.io |
| 参数 | 说明 |
| --advertise-address |
在什么地址上声明当前API Server是集群的成员之一。指定的IP地址必须可以被集群的所有节点访问到 如果为空,默认使用--bind-address |
| --cors-allowed-origins strings | 允许CORS的源列表 |
| --external-hostname | 生成外部URL时(例如Swagger API文档)时,当前master的主机名 |
| --feature-gates mapStringBool | 用于开启或关闭特性 |
| --max-mutating-requests-inflight int | 等待处理的写请求最大数量,默认200,超过后API Server拒绝请求 |
| --max-requests-inflight int | 等待处理的读请求最大数量,默认400,超过后API Server拒绝请求 |
| --min-request-timeout int | 最小请求超时,API Server认定一个请求超时之前必须经过的时间,默认1800,此参数仅仅被watch请求使用,覆盖--request-timeout |
| --request-timeout duration | 请求超时,默认1m0s |
| --target-ram-mb | API Server的内存用量限制 |
| Etcd相关 | |
| --default-watch-cache-size int | 默认Watch缓存的大小,设置为0则没有默认Watch size的资源的Watch缓存被禁用,默认100 |
| --delete-collection-workers int | 用于DeleteCollection操作的工作线程数量,用于加速命名空间清理,默认1 |
| --deserialization-cache-size int | 反串行化到内存的JSON对象数量,这些对象做缓存用途 |
| --etcd-cafile string | SSL证书文件 |
| --etcd-prefix string | 所有资源存放的路径前缀,默认/registry |
| --etcd-compaction-interval duration | 压缩请求的间隔,如果为0则禁用API Server发出压缩请求,默认5m0s |
| --etcd-servers strings | 需要连接到的Etcd服务器地址列表,形式scheme://ip:port,scheme://ip:port... |
| --etcd-servers-overrides strings |
可以为不同资源指定不同的Etcd服务器,形式group/resource#servers,servers为Etcd服务器地址,形式如上一行 |
| --storage-backend | 存储后端,可选etcd3、etcd2 |
| --storage-media-type string | 存储MIME类型,默认application/vnd.kubernetes.protobuf |
| --watch-cache | 在API Server中启用Watch缓存,默认true |
| --watch-cache-sizes strings | 不同资源的Watch缓存大小,形式 resource[.group]#size |
| 安全选项 | |
| --bind-address ip | 在什么IP地址上监听--secure-port端口,默认0.0.0.0 |
| --secure-port int | HTTPS端口 |
| --cert-dir string | TLS证书存放目录,如果指定参数--tls-cert-file、--tls-private-key-file则此选项忽略 |
| --tls-cert-file string | TLS证书位置 |
| --tls-private-key-file string | TLS私钥位置 |
| --insecure-bind-address ip | HTTP监听地址 |
| --insecure-port | HTTP监听端口 |
| 审计选项 | |
| --audit-log-* | 审计日志相关 |
| --audit-webhook-* | 审计Webhook相关 |
| 特性选项 | |
| --contention-profiling | 在Profiling启用的前提下,启用锁争用Profiling |
| --enable-swagger-ui | 在/swagger-ui下暴露Swagger UI |
| 身份验证 | |
| --anonymous-auth=true |
允许对HTTPS端口的匿名请求,没有被另外一种身份验证机制拒绝的请求被看作匿名请求 匿名请求的用户名为system:anonymous,组为system:unauthenticated |
| --authentication-token-webhook-cache-ttl | 缓存webhook token authenticator响应的时长,默认2m0s |
| --authentication-token-webhook-config-file |
用于Token验证的Webhook配置文件路径,此文件必须为kubeconfig格式 API Server会查询远程服务,来决定对bearer token的身份验证 |
| --basic-auth-file string | 如果设置,该文件用于准许通过HTTP基本认证来访问API Server的请求 |
| --client-ca-file string | 教研客户端证书的CA证书,客户端身份存放在CommonName字段中 |
| --oidc-* | 和OpenID服务有关 |
| -requestheader-allowed-names | 哪些客户端(通过CommonName识别)可以在 --requestheader-username-headers中提供用户名信息,如果为空,任何通过CA认证的客户端均可 |
| --requestheader-client-ca-file | 在信任客户端请求头中声明的username之前,需要对客户端证书进行认证,该参数指定认证时使用的CA证书 |
| --requestheader-extra-headers-prefix | 请求头前缀,建议X-Remote-Extra- |
| --requestheader-group-headers | 用户所属组存放在什么请求头,建议X-Remote-Group |
| --requestheader-username-headers | 用户名存放在什么请求头,,建议X-Remote-User |
| --authorization-mode | 在安全端口上运行的授权插件列表, AlwaysAllow,AlwaysDeny,ABAC,Webhook,RBAC,Node,默认AlwaysAllow |
| --authorization-policy-file | CSV格式的授权策略文件,和--authorization-mode=ABAC连用 |
| --authorization-webhook-cache-authorized-ttl | 缓存来自Webhook authorizer的授权成功(authorized)响应的时长,默认5m0s |
| --authorization-webhook-cache-unauthorized-ttl | 缓存来自Webhook authorizer的授权失败(unauthorized)响应的时长,默认30s |
| --authorization-webhook-config-file | kubeconfig格式的Webhook配置文件路径 |
| API开关 | |
| --runtime-config mapStringString | 可以用户开启/关闭特定的API版本 |
| Admission参数 | |
| --admission-control | 启用的准许控制器列表,此选项废弃 |
| --admission-control-config-file | 包含准许控制配置的文件 |
| --disable-admission-plugins | 禁用的准许控制器列表,即使它们默认启用 |
| --enable-admission-plugins | 启用的准许控制器列表 |
| 杂项 | |
| --allow-privileged=false | 允许运行特权模式容器 |
| --apiserver-count=1 | 集群中API Server的数量 |
| --enable-aggregator-routing | 允许路由请求到Endpoint IP而非Cluster IP |
| --enable-logs-handler=true | 如果为true,则开启/logs端点,用于处理API Server日志 |
|
--endpoint-reconciler-type=lease |
|
| --event-ttl=1h0m0s | 事件历史的保留时间 |
| --kubelet-certificate-authority | 访问Kubelet的CA证书的路径 |
| --kubelet-client-certificate | 访问Kubelet的客户端证书路径 |
| --kubelet-client-key | 访问Kubelet的客户端私钥路径 |
| --kubelet-https=true | 通过HTTPS来访问Kubelet |
|
--kubelet-timeout=5s |
访问Kubelet的超时 |
| --max-connection-bytes-per-sec | 限流,每个用户连接每秒可以发送的字节数,当前仅仅允许长期运行的请求 |
| --service-account-signing-key-file | Service Account Token Issuer的私钥路径,Issuer使用此私钥来签名issued ID token |
| --service-cluster-ip-range | Cluster IP的地址范围,默认 10.0.0.0/24 |
| --service-node-port-range | NodePort范围,默认30000-32767 |
| 参数 | 说明 |
| --alsologtostderr | 设置true则日志输出到stderr,也输出到日志文件 |
| --bind-address 0.0.0.0 | 监听主机IP地址,0.0.0.0监听主机所有主机接口 ,默认0.0.0.0 |
| --cleanup | 如果设置为true,则清除iptables和ipvs规则并退出 |
| --cleanup-ipvs | 如果设置为true,在运行前kube-proxy将清除ipvs规则,默认true |
| --cluster-cidr string | 集群中 Pod 的CIDR范围。集群外的发送到服务集群IP的流量将被伪装,从pod发送到外部 LoadBalancer IP的流量将被定向到相应的集群IP |
| --config string | 配置文件路径 |
| --config-sync-period duration | 从apiserver同步配置的时间间隔,默认15m0s |
| --conntrack-max-per-core int32 |
每个CPU核跟踪的最大NAT连接数 0按原来保留限制并忽略conntrack-min,默认32768 |
| --conntrack-min int32 |
分配的最小conntrack条目,无视conntrack-max-per-core选项 设置conntrack-max-per-core=0保持原始限制,默认default 131072 |
| --conntrack-tcp-timeout-close-wait duration | 对于TCP连接处于CLOSE_WAIT阶段的NAT超时时间,默认1h0m0s |
| --conntrack-tcp-timeout-established duration | TCP连接的空闲超时,默认24h0m0s |
| --feature-gates mapStringBool | 打开特性 |
| --healthz-bind-address 0.0.0.0 |
健康检查服务器提供服务的IP地址及端口,默认0.0.0.0:10256 |
| --healthz-port int32 | 配置健康检查服务的端口,0表示禁止,默认10256 |
| --hostname-override string | 使用该名字作为标识而不是实际的主机名 |
| --iptables-masquerade-bit int32 | 对于纯iptables代理,则表示fwmark space的位数,用于标记需要SNAT的数据包。[0,31]之间,default 14 |
| --iptables-min-sync-period duration | 当endpoints和service变化,刷新iptables规则的最小时间间隔 |
| --iptables-sync-period duration | iptables刷新的最大时间间隔,默认30s |
| --ipvs-exclude-cidrs strings | ipvs proxier清理IPVS规则时不触及的CIDR以逗号分隔的列表 |
| --ipvs-min-sync-period duration | 当endpoints和service变化,刷新ipvs规则的最小时间间隔 |
| --ipvs-scheduler string | 当proxy模式设置为ipvs,ipvs调度的类型 |
| --ipvs-sync-period duration | ipvs刷新的最大时间间隔,默认30s |
| --kube-api-burst int32 | 发送到kube-apiserver每秒请求量,默认10 |
| --kube-api-content-type string | 发送到kube-apiserver请求的MIME类型,默认application/vnd.kubernetes.protobuf |
| --kube-api-qps float32 | 与kube-apiserver通信的qps,默认default 5 |
| --kubeconfig string | kubeconfig文件的路径 |
| --log-backtrace-at traceLocation file:N |
when logging hits line file:N, emit a stack trace (default :0) 当日志发生在什么代码位置时打印调用栈 |
| --log-dir string | 日志文件的存储位置 |
| --log-flush-frequency duration | 日志刷出的最大间隔,默认5s |
| --logtostderr | 日志输出到标准错误而非文件 |
| --masquerade-all | 纯 iptables 代理,对所有通过集群 service IP发送的流量进行 SNAT(通常不配置) |
| --master string | Kubernetes API server地址,覆盖kubeconfig的配置 |
| --metrics-bind-address 0.0.0.0 | metrics服务地址和端口,默认127.0.0.1:10249 |
| --nodeport-addresses strings |
NodePort使用哪些IP地址,示例1.2.3.0/24, 1.2.3.4/32,默认情况下所有本地地址都使用 |
| --oom-score-adj int32 | kube-proxy进程的oom-score-adj值,合法值范围[-1000, 1000] ,默认-999 |
| --profiling | 设置为true,通过web接口/debug/pprof查看性能分析 |
| --proxy-mode ProxyMode | 代理模式,可选值userspace / iptables / ipvs,默认iptables |
| --proxy-port-range port-range |
可以用于代理K8S Service流量的苏主机端口范围 |
| --stderrthreshold severity | 日志输出的最低级别,默认2 |
| --udp-timeout duration |
空闲UDP连接保持打开的时长,默认250ms |
| -v, --v Level | 日志冗余级别 |
| --version version[=true] | 打印版本信息并退出 |
| --vmodule moduleSpec | 逗号分隔的模式=N的列表文件,用以筛选日志记录 |
| --write-config-to string | 输出默认配置到文件并退出 |
| 参数 | 说明 |
| --address string | 监听主机IP地址,0.0.0.0监听主机所有主机接口 |
| --algorithm-provider string | 设置调度算法,ClusterAutoscalerProvider或DefaultProvider,默认为DefaultProvider |
| --alsologtostderr | 设置true则日志输出到stderr,也输出到日志文件 |
| --config string | 配置文件的路径 |
| --kube-api-burst int32 | 发送到kube-apiserver每秒请求量 ,默认100 |
| --kube-api-content-type string | 发送到kube-apiserver请求内容类型,默认application/vnd.kubernetes.protobuf |
| --kube-api-qps float32 | 与kube-apiserver通信的qps,默认50 |
| --kubeconfig string | kubeconfig配置文件路径 |
| --leader-elect | 多个master情况设置为true保证高可用,进行leader选举 |
| --leader-elect-lease-duration duration | 当leader-elect设置为true生效,选举过程中非leader候选等待选举的时间间隔,默认15s |
| --leader-elect-renew-deadline duration | leader选举过程中在停止leading,再次renew时间间隔,小于或者等于leader-elect-lease-duration duration,也是leader-elect设置为true生效,默认10s |
| --leader-elect-retry-period duration | 当leader-elect设置为true生效,获取leader或者重新选举的等待间隔,默认2s |
| --lock-object-name string | 定义lock对象名字,默认kube-scheduler |
| --lock-object-namespace string | 定义lock对象的namespace,默认kube-system |
| --log-backtrace-at traceLocation | 记录日志到file:行号时打印一次stack trace,默认0 |
| --log-dir string | 记录log的目录 |
| --log-flush-frequency duration | flush log的时间间隔,默认5s |
| --logtostderr | 写log到stderr,默认true |
| --master string | master的地址,会覆盖kubeconfig中的 |
| --port int | 没有认证鉴权的不安全端口,默认10251 |
| --profiling | 开启性能分析,通过host:port/debug/pprof/查看 |
| --scheduler-name string | 调度器名,由于哪些pod被调度器进行处理,根据pod的spec.schedulerName,默认default-scheduler |
| 参数 | 说明 | ||
| --allow-privileged=true | 允许容器请求特权模式 | ||
| --anonymous-auth=false |
允许匿名请求到 kubelet 服务。未被另一个身份验证方法拒绝的请求被视为匿名请求。匿名请求包含系统的用户名: anonymous ,以及系统的组名: unauthenticated,默认 true |
||
| --application-metrics-count-limit int | 每一个容器store最大application metrics,默认100 | ||
| --authentication-token-webhook-cache-ttl |
webhook 令牌身份验证缓存响应时间,默认2m0s |
||
| --authorization-mode string |
授权模式(AlwaysAllow/ Webhook),Webhook 模式使用 SubjectAccessReview API 来确定授权 |
||
| --authorization-webhook-cache-authorized-ttl |
webhook 模式认证响应缓存时间,默认5m0s |
||
| --authorization-webhook-cache-unauthorized-ttl | webhook 模式认证未响应缓存时间,默认30s | ||
| --authentication-token-webhook | 使用 TokenReview API 来确定不记名令牌的身份验证 | ||
| --bootstrap-kubeconfig |
kubelet 客户端证书的kubeconfig 文件路径 如果指定的文件不存在,将使用 bootstrap kubeconfig 从 API 服务器请求一个客户端证书,成功后生成证书文件和密钥的 kubeconfig 将被写入指定的文件,客户端证书和密钥将被保存在 --cert-dir 指定的目录 |
||
| --cadvisor-port=0 | cAdvisor 端口,默认 4194 | ||
| --cert-dir string | 客户端证书和密钥保存到的目录 | ||
| --cgroup-driver=cgroupfs | 可选值有cgroupfs和systemd,与docker驱动一致。默认cgroupfs | ||
| --cgroup-root string |
Pod的根cgroup |
||
| --cgroups-per-qos |
是否创建 QoS cgroup 层级,true 意味着创建顶级 QoS 和pod cgroups ,默认true |
||
| --client-ca-file | 集群CA证书,默认/etc/kubernetes/ssl/ca.pem | ||
| --cluster-dns | DNS 服务器的IP列表,逗号分隔 | ||
| --cluster-domain | 集群域名, kubelet 将配置所有容器除了主机搜索域还将搜索当前域 | ||
| --cni-bin-dir | CNI插件二进制文件路径,默认/opt/cni/bin | ||
| --cni-conf-dir | CNI插件配置文件的完整路径,默认/etc/cni/net.d | ||
| --container-runtime |
指定容器运行时引擎(CRI) |
||
| --cpu-cfs-quota |
开启cpu cfs配额来对容器指定cpu限制,默认true |
||
| --cpu-cfs-quota-period duration | 设置cpu cfs配置周期值,cpu.cfs_period_us,默认100ms | ||
|
--enable-controller-attach-detach |
开启attach/detach控制器来管理调度到该节点上的volume | ||
| --enforce-node-allocatable strings |
默认pods 如果为kube组件和System进程预留资源,则需要设置为pods,kube-reserved,system-reserve |
||
| --event-burst int32 |
突发事件记录的最大值 |
||
| --eviction-hard |
清理阈值的集合,达到该阈值将触发一次容器清理,示例:
|
||
| --eviction-minimum-reclaim |
资源回收最小值的集合,即 kubelet 压力较大时 ,执行 pod 清理回收的资源最小值,示例:
|
||
| --eviction-soft |
清理阈值的集合,如果达到一个清理周期将触发一次容器清理,示例:
|
||
| --eviction-soft-grace-period |
清理周期的集合,在触发一个容器清理之前一个软清理阈值需要保持多久:
|
||
| --fail-swap-on | 开启了SWAP的前提下,如果设置为true则启动kubelet失败。默认true | ||
|
--hairpin-mode string |
可选值promiscuous-bridge / hairpin-veth,NAT回环模式,默认promiscuous-bridge |
||
|
--healthz-bind-address |
健康检查服务的IP地址,默认127.0.0.1 |
||
| --healthz-port |
本地健康检查服务的端口号,默认10248 |
||
| --host-ipc-sources |
允许 pod 使用宿主机 ipc 命名空间列表,默认[*] |
||
| --host-network-sources | 允许 pod 使用宿主机 net 命名空间列表,默认[*] | ||
| --host-pid-sources | 允许 pod 使用宿主机 pid 命名空间列表,默认[*] | ||
| --hostname-override | 在K8S集群中的当前node name | ||
|
--http-check-frequency |
通过 http 检查新数据的周期,默认20s |
||
| --image-gc-high-threshold |
磁盘使用占比最大值,超过此值将执行镜像垃圾回收,默认85 |
||
| --image-gc-low-threshold | 磁盘使用率最大值,低于此值将停止镜像垃圾回收,默认80 | ||
| --image-pull-progress-deadline | 镜像拉取进度最大时间,如果在这段时间拉取镜像没有任何进展,将取消拉取,默认1m0s | ||
| --iptables-drop-bit |
用于标记丢弃数据包的 fwmark bit,取值范围[0,31],默认15 |
||
| --iptables-masquerade-bit |
标记 SNAT 数据包的 fwmark bit,取值范围[0,31],此参数与 kube-proxy 中的相应参数匹配,默认14 |
||
| --kube-api-burst | 与 kubernetes apiserver 会话时的并发数,默认 10 | ||
| --kube-api-qps | 与 kubernetes apiserver 会话时的 QPS,默认15 | ||
| --kube-reserved |
资源预留量,针对kubernetes 系统组件 ,示例:
|
||
| --kubeconfig | 用来指定如何连接到 API Server,默认/etc/kubernetes/kubelet.kubeconfig | ||
| --log-dir | 日志文件路径,默认/var/log/kubernetes | ||
| --logtostderr | 标准输出 | ||
| --max-pods | 可以运行的容器组数目,默认 110 | ||
| --network-plugin | 使用CNI插件 | ||
| --node-ip | 节点的IP地址,kubelet 将使用这个地址作为节点ip地址,主要针对多网卡环境 | ||
| --node-labels | 加入集群时为节点打标签,示例env=test | ||
| --pod-infra-container-image | 每个 pod 中的 network/ipc 命名空间容器将使用的pause镜像,默认k8s.gcr.io/pause:3.1 | ||
| --pod-manifest-path | 静态启动的容器组(主要针对控制平面)的路径,默认etc/kubernetes/manifests | ||
| --register-with-taints | 加入集群时自带的taint,示例:env=test:NoSchedule | ||
| --root-dir | kubelet 的工作目录 | ||
| --registry-burst=10 | 拉取镜像的最大并发数,允许同时拉取的镜像数,不能超过 registry-qps ,仅当 --registry-qps 大于 0 时使用,默认 10 | ||
| --serialize-image-pulls | 是否禁用串行化(一个个)拉取镜像模式 | ||
| --stderrthreshold | 日志输出阈值 | ||
| --system-reserved | 给系统预留资源,示例cpu=4,memory=5Gi | ||
| --tls-cert-file |
用于 https 服务的 x509 证书的文件。如果没有提供 --tls-cert-file 和 --tls-private-key-file , 将会生产一个自签名的证书及密钥给公开地址使用,并将其保存在 --cert-dir 指定的目录 默认/etc/kubernetes/pki/kubelet.crt |
||
| --tls-private-key-file | 包含 x509 私钥匹配的文件,默认/etc/kubernetes/pki/kubelet.key | ||
| --v | 日志级别 | ||
|
--address |
服务监听的IP地址,默认 0.0.0.0 |
推荐参数:
|
1 2 3 4 |
--serialize-image-pulls=false --image-pull-progress-deadline 5m0s --image-gc-high-threshold=75 --image-gc-low-threshold=60 |
| 参数 | 说明 |
| 调试参数 | |
| --contention-profiling | 如果启用了 profiling,则启用锁争用性分析 |
| --profiling | 开启profilling,通过web接口host:port/debug/pprof/分析性能 |
| 一般参数 | |
| --allocate-node-cidrs | 是否应在云提供商上分配和设置Pod的CIDR |
| --cidr-allocator-type string | CIDR分配器的类型,默认RangeAllocator |
| --cloud-config string | 云提供商配置文件路径,空代表没有配置文件 |
| --cloud-provider string | 云提供商,空代表没有云提供商 |
| --configure-cloud-routes | 是否在云提供商上配置allocate-node-cidrs分配的CIDR,默认true |
| --cluster-cidr string | 集群中Pod的CIDR范围,要求--allocate-node-cidrs为true |
| --cluster-name string | 集群的实例前缀,默认kubernetes |
| --controller-start-interval | 启动控制器管理器的间隔时间 |
| --controllers |
需要开启的控制器列表,默认*表示全部开启,foo表示开启foo,-foo表示禁用foo 可用控制器列表: attachdetach, bootstrapsigner, clusterrole-aggregation,cronjob, csrapproving, csrcleaner, csrsigning, daemonset,deployment, disruption, endpoint, garbagecollector,horizontalpodautoscaling, job, namespace, nodeipam, nodelifecycle,persistentvolume-binder, persistentvolume-expander, podgc, pv-protection,pvc-protection, replicaset, replicationcontroller,resourcequota, route, service, serviceaccount, serviceaccount-token,statefulset, tokencleaner, ttl,ttl-after-finished |
| --feature-gates | 开启特性 |
| --kube-api-burst | 发送到kube-apiserver每秒请求爆发量,默认100 |
| --kube-api-content-type | 发送到kube-apiserver的MIME类型,默认application/vnd.kubernetes.protobuf |
| --kube-api-qps |
与kube-apiserver通信的qps,默认50 |
| --leader-elect | 多个master情况设置为true保证高可用,进行leader选举 |
| --leader-elect-lease-duration | 当leader-elect设置为true生效,选举过程中非leader候选等待选举的时间间隔,默认15s |
| --leader-elect-renew-deadline | 当leader-elect设置为true生效,leader选举过程中在停止leading,再次renew的时间间隔,小于或者等于leader-elect-lease-duration,默认10s |
| --leader-elect-retry-period | 当leader-elect设置为true生效,leader或者重新选举的等待间隔,默认2s |
| --min-resync-period | 获取K8S资源的重新同步周期,默认12h0m0s |
| --route-reconciliation-period | 协调由云提供商为节点创建的路由的时间间隔,默认10s |
| --use-service-account-credentials |
是否为每个控制器设置独立的SA。如果设置为true,则Kubernetes为控制器管理器中的每个控制器创建SA: attachdetach-controller |
| 安全参数 | |
| --bind-address | 监听--secure-port端口的IP地 |
| -cert-dir | TLS证书所在的目录。如果提供了--tls-cert-file和--tls-private-key-file,则将忽略此标志 |
| --http2-max-streams-per-connection | API Server提供给 client 的HTTP / 2最大 stream 连接数 |
| --secure-port | 使用身份验证和授权提供服务的HTTPS端口 |
| --tls-cert-file | 文件包含HTTPS的默认x509证书的文件。如果启用了HTTPS服务,但是 --tls-cert-file和--tls-private-key-file 未设置,则会为公共地址生成自签名证书和密钥,并将其保存到--cert-dir的目录中 |
| --tls-cipher-suites | 逗号分隔的cipher suites列表 |
| --tls-min-version | 支持最低TLS版本,取值VersionTLS10,VersionTLS11,VersionTLS12 |
| --tls-private-key-file | 文件包括与 --tls-cert-file 匹配的默认x509私钥 |
| --tls-sni-cert-key | x509证书和私钥对的文件路径,例如example.crt,example.key |
| 身份验证 | |
| --authentication-kubeconfig | 有权创建tokenaccessreviews.authentication.k8s.io的kubeconfig,如果不设置所有Token请求视为匿名 |
| --authentication-skip-lookup | 如果设置false,authentication-kubeconfig用来在集群中查找缺失的authentication配置 |
| --authentication-token-webhook-cache-ttl | 来自webhook token authenticator的响应的缓存时间,默认10s |
| --client-ca-file | 如果设置,此参数指定的CA列表中任何CA签名的客户端证书,均身份验证成功,并且其身份标识从CommanName读取 |
| 授权 | |
| --authorization-always-allow-paths | 无需授权即可访问的URL列表,默认/healthz |
| --authorization-kubeconfig | 有权创建subjectaccessreviews.authorization.k8s.io的kubeconfig |
| --authorization-webhook-cache-authorized-ttl | 来自webhook authorizer的针对授权URL的响应的缓存时间,默认10s |
| --authorization-webhook-cache-unauthorized-ttl | 来自webhook authorizer的针对非授权URL的响应的缓存时间,默认10s |
| 节点控制器 | |
| --node-monitor-period | NodeController同步NodeStatus的时间间隔,默认5s |
| 服务控制器 | |
| --concurrent-service-syncs | 允许同时同步的 service 数量。 数字越大服务管理响应越快,但消耗更多 CPU 和网络资源 |
| Attachdetach控制器 | |
| --attach-detach-reconcile-sync-period | 卷attach、detach之间,Reconciler同步的等待时间,必须大于1m |
| --disable-attach-detach-reconcile-sync | 禁用卷attach/detach的Reconciler同步,禁用可能导致卷和Pod不匹配,小心 |
| 证书请求(CSR)签名控制器 | |
| --cluster-signing-cert-file | PEM编码的X509 CA证书,用于签发集群范围的证书,默认/etc/kubernetes/ca/ca.pem |
| --cluster-signing-key-file | 上述CA证书的私钥路径,默认/etc/kubernetes/ca/ca.key |
| Deployment控制器 | |
| --concurrent-deployment-syncs | 允许并行Sync的Deployment对象数量,默认5 |
| --deployment-controller-sync-period | 同步K8S资源的间隔,默认30s |
| Endpoint控制器 | |
| --concurrent-endpoint-syncs | 允许并行Sync的Endpoint对象数量,默认5 |
| Garbagecollector控制器 | |
| --concurrent-gc-syncs | 运行并行Sync的垃圾回收器Worker的数量,默认20 |
| --enable-garbage-collector | 是否启用垃圾回收器,必须和APIServer的参数匹配 |
| HPA控制器 | |
| --horizontal-pod-autoscaler-cpu-initialization-period | Pod启动后,多长时间内不进行CPU采样,默认5m0s |
| --horizontal-pod-autoscaler-downscale-stabilization | 扩容后,多长时间内不会所容,默认5m0s |
| --horizontal-pod-autoscaler-initial-readiness-delay | Pod启动后,多长时间内readiness的变更被看作最初的readiness(也就是Pod可以提供服务了),默认30s |
| --horizontal-pod-autoscaler-sync-period | 多长时间来同步Pod的数量信息,默认15s |
| --horizontal-pod-autoscaler-tolerance |
引发HPA考虑应当扩容的,监控指标的变化最小量,默认0.1 |
| Namespace控制器 | |
| --concurrent-namespace-syncs | 允许并行Sync的命名空间对象的数量,默认10 |
| --namespace-sync-period | 命名空间Sync间隔 |
| Nodeipam控制器 | |
| --node-cidr-mask-size | Node的CIDR的掩码大小,默认24 |
| --service-cluster-ip-range | K8S服务的CIDR范围 |
| Nodelifecycle控制器 | |
| --enable-taint-manager | 设置为true,则启用NoExecute Taint,并且驱除所有不能容忍Taint的Pod,默认true |
| --large-cluster-size-threshold | 多少节点的集群被认为是大集群,默认50。此控制器的逻辑会改变 |
| --node-eviction-rate | 当可用区(Zone)是健康的前提下,节点失败后需要驱除其上的Pod,那么每秒由多少节点上的Pod被删除,默认0.1 |
| --secondary-node-eviction-rate | 类似上面,但是集群被认为是小集群时自动置0 |
| --node-monitor-grace-period | 节点不响应心跳后,至少等待多久才能将其标记为不健康。必须是Kubelet的nodeStatusUpdateFrequency参数的N倍,默认40s |
| --node-startup-grace-period | 对于一个启动中的节点,在此时间之前不得标记为不健康,默认1m0s |
| --pod-eviction-timeout | 在失败节点上删除Pod的等待期,默认5m0s |
| --unhealthy-zone-threshold | 什么比例的Node处于NotReady状态,才认为整个Zone是不健康的 |
| Persistentvolume-binder控制器 | |
| --enable-dynamic-provisioning | 启用卷的动态提供,默认true |
| --enable-hostpath-provisioner | 启用HostPath PV的动态提供,主要用在非云环境,用于开发、测试目的 |
| --flex-volume-plugin-dir |
从什么目录来搜索额外的第三方Flex卷插件 默认/usr/libexec/kubernetes/kubelet-plugins/volume/exec/ |
| --pv-recycler-increment-timeout-nfs | 每Gi容量为NFS Scrubber Pod的ActiveDeadlineSeconds增加多少时间,默认30 |
| --pv-recycler-minimum-timeout-hostpath | HostPath Recycler Pod的最小ActiveDeadlineSeconds |
| --pv-recycler-minimum-timeout-nfs | NFS Recycler Pod的最小ActiveDeadlineSeconds |
| --pv-recycler-pod-template-filepath-nfs | NFS Recycler Pod的模板 |
| --pvclaimbinder-sync-period | 同步PV/PVC的间隔,默认15s |
除了标准的JSONPath之外,Kubernetes还额外支持:
- 可选的 $运算符,默认表达式从根对象开始
- 支持通过 ""引用JSONPath表达式中的文本
- 支持通过 range迭代列表
对于输入:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
{ "kind": "List", "items":[ { "kind":"None", "metadata":{"name":"127.0.0.1"}, "status":{ "capacity":{"cpu":"4"}, "addresses":[{"type": "LegacyHostIP", "address":"127.0.0.1"}] } }, { "kind":"None", "metadata":{"name":"127.0.0.2"}, "status":{ "capacity":{"cpu":"8"}, "addresses":[ {"type": "LegacyHostIP", "address":"127.0.0.2"}, {"type": "another", "address":"127.0.0.3"} ] } } ], "users":[ { "name": "myself", "user": {} }, { "name": "e2e", "user": {"username": "admin", "password": "secret"} } ] } |
可用的函数,以及示例如下:
| 函数 | 说明 | 示例 |
| text | 原始文本 | kind is {.kind},结果:kind is List |
| @ | 当前对象 | {@}输出和输入一致 |
| . 或 [] | 取子对象 | {.kind}, {['kind']}, {['name\.type']} |
| .. | 递归子对象 | {..name},结果:127.0.0.1 127.0.0.2 myself e2e |
| * | 通配,获取所有对象 | {.items[*].metadata.name},结果: [127.0.0.1 127.0.0.2] |
| [start:end :step] | 切片 | {.users[0].name},结果:myself |
| [,] | 联合 | {.items[*]['metadata.name', 'status.capacity']},结果:127.0.0.1 127.0.0.2 map[cpu:4] map[cpu:8] |
| ?() | 过滤 | {.users[?(@.name=="e2e")].user.password},结果:secret |
| range, end | 迭代列表 | {range .items[*]}[{.metadata.name}, {.status.capacity}] {end},结果:[127.0.0.1, map[cpu:4]] [127.0.0.2, map[cpu:8]] |
| '' | 因为转义字符 | {range .items[*]}{.metadata.name}{'\t'}{end},结果:127.0.0.1 127.0.0.2 |
在大规模集群中,对APIServer的监控需要调优,避免过于频繁的数据采集。特别是APIServer副本数很多的情况下,这会对Etcd造成巨大的读压力。
在大规模集群下开启NodeLease来降低API Server处理心跳的成本,可以降低50% CPU开销。
Etcd是Kubernetes集群正常运作的基石,但是多节点、强一致性的需求导致Etcd很容易出现性能瓶颈。
在云环境中,即使是规模仅有500节点的集群中,使用基于SSD的存储 + 万兆网络,也可能随机出现Etcd响应延迟过大的情况,延迟可达500ms。此问题的根本原因是Etcd存在大量顺序IO,对磁盘延迟敏感,而不是IOPS。使用本地SSD而非网络存储,可以将Etcd的写延迟降低10倍以上。
- 通过参数 -quota-backend-bytes调整Etcd最大存储大小,默认2GB
- 根据网络延迟来调整心跳间隔、选举超时
- 提升Etcd的网络、磁盘IO优先级
将相对次要,且产生数据量大的资源类型,存储到单独的Etcd集群中,例如Events:
|
1 |
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381 |
优化Etcd底层存储Bolt的B+树的空闲列表分配/释放算法的时间复杂度为O(1),解决超大数据量(100GB级别)下Etcd的性能瓶颈,操作延迟可以降低10倍。
- 根据应用场景调整:默认策略倾向于均摊负载到所有节点。对于批处理应用场景,可以修改调度策略,让负载集中,并释放空闲节点以节约资源
- 扩展调度器,支持基于负载IO需求、节点IO能力的调度
- 预选阶段优化:
- 根据集群规模调整参与可调度评分的节点比例,对于大规模集群(1000+),调低参数可以提升40%以上的调度性能:
12345apiVersion: componentconfig/v1alpha1kind: KubeSchedulerConfigurationalgorithmSource:provider: DefaultProviderpercentageOfNodesToScore: 50 - 预选短路,优先执行低成本的断言,并且一个断言失败即排除节点
- 根据集群规模调整参与可调度评分的节点比例,对于大规模集群(1000+),调低参数可以提升40%以上的调度性能:
每个节点上包含多个KubeDNS Pod没有意义,可以设置反亲和:
|
1 2 3 4 5 6 7 8 9 10 11 |
affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - weight: 100 labelSelector: matchExpressions: - key: k8s-app operator: In values: - kube-dns topologyKey: kubernetes.io/hostname |
在高性能计算集群中,可能需要增大节点的ARP缓存:
|
1 2 3 |
net.ipv4.neigh.default.gc_thresh1 = 80000 net.ipv4.neigh.default.gc_thresh2 = 90000 net.ipv4.neigh.default.gc_thresh3 = 100000 |
否则,在内核日志中可能看到neighbor table overflow!错误。
引入autopath插件,可以将针对外部DNS名称的查询QPS提升5倍。
设置Kubelet参数 --serialize-image-pulls=false, 注意需要配合设置Docker的存储驱动为Overlay2,提高 --max-concurrent-downloads的值。
最好将Docker数据目录挂载到本地磁盘。
设置Kubelet参数 --image-pull-progress-deadline=30m,来支持超大镜像的拉取,避免rpc error: code = 2 desc = net/http: request canceled错误
- kubeadm达到GA
- CSI达到GA
- CoreDNS作为默认DNS实现
- 支持第三方设备监控插件,Alpha
- 设备插件注册,达到稳定状态。此特性实现了一个通用的kubelet插件发现模型,用于各种节点级别的插件,例如设备插件、CSI、CNI和kubelet的交互
- 拓扑感知的卷调度,达到稳定状态
- APIServer DryRun达到Beta状态
- Kubectl Diff达到Beta状态,用于比较本地资源清单和K8S中对象的区别
- Windows支持达到生产可用,现在可以支持Windows工作节点,并向其调度Windows容器
- Kubectl插件机制达到稳定状态
- 继承Kustomize到Kubectl
- 本地PV达到生产可用
- Pod Ready++生产可用,此特性改进Readiness/Liveness探针的不足—— 在一些情况下,往往只是新的 Pod 完成自身初始化,系统尚未完成 Endpoint、负载均衡器等外部可达的访问信息刷新,老的 Pod 就立即被删除,最终造成服务不可用,允许用户通过ReadinessGates自定义Pod就绪条件
- Pod优先级和抢占式调度达到生产可用
- PID数量限制特性,达到Beta,使用kubelet参数 pod-max-pids开启
- Kubeadm支持在HA集群中自动执行控制平面的证书复制
- CRD进入GA,支持基于Structural Schema校验自定义资源的每个字段
- 支持在运行时进行CR不同版本之间的转换,通过Webhook
- CRD默认值,Alpha
- CRD未知字段裁剪,通过CRD的 spec.preserveUnknownFields: false启用
- Admission Webhook重新调用,如果某个Webhook修改了资源,可以重新调用Webhook进行校验
- 通过Device Monitoring Agent进行异构硬件监控,不需要修改Kubelet
- Scheduler Framework,Alpha, 加强调度器扩展定制能力。在原有的Priority/Predicates 接口的基础上增加了QueueSort, Prebind, Postbind, Reserve, Unreserve 和 Permit接口。Scheduler Framework 仍以 Pod 为单位进行调度,对于需要成组Pod一起调度的离线类(计算)业务,考虑使用Volcano之类的社区框架
- Kubeadm HA达到GA
- Admission Webhook达到GA
- 存储方面的改进,CSI的卷Resize的API达到Beta
- Kubeadm支持添加Windows工作节点,Alpha
- Windows节点的CSI插件支持,Alpha
- 能够支持更加强大的集群扩容、更灵活的网络地址处理的网络端点切片(Endpoint Slices)特性。EndpointSlice可以作为Endpoint的替代
- Ephemeral containers:在一个运行中的Pod中,临时运行一个容器,用于诊断目的
- Pod共享PID命名空间达到GA,可用于容器之间需要相互发信号的场景
- 拓扑感知服务路由,可以避免跨物理位置访问Service的Endpoint,Alpha状态
- Endpoints对象存放了服务的所有端点,1.17的EndpointSlice代替之,可扩容性更好。拓扑感知路由也依赖于EndpointSlice
- 可以在一个集群中同时支持IPv4和IPv6
- CSI:卷快照API到达Beta状态,支持拓扑感知
- 为Service Account Token Issuer提供OpenID Connect (OIDC)发现。SA可以基于Token(JWT)来请求K8S API Server,进行身份验证。目前K8S API Server是唯一能验证Token的服务,但是它不能从外部网络访问,这意味着某些工作负载需要使用单独的身份验证系统。OIDC发现可以让K8S的Token验证在集群外可用,实现方式是API Server提供OIDC发现文档(其中包含Token公钥),OIDC Authenticator可以基于此OIDC发现文档校验Token
- 支持定制单个HPA的扩容速度,以前的版本仅仅支持全局设置。为HPA添加以下设置:
123456789101112behavior:scaleUp:policies:- type: Percentvalue: 100periodSeconds: 15scaleDown:policies:- type: Podsvalue: 4periodSeconds: 60# 15秒内扩容到4个,60秒内缩容到2个 - CertificateSigningRequest接口,支持由K8S对证书请求进行签名
- kubectl debug,用于在运行中的Pod上进行调试,它可以创建一个Debug容器,或者使用新配置重新部署Pod
- Windows增强:
- 实现RuntimeClass
- 支持CRI-ContainerD
- 调度相关
- 支持多个调度Profile。不同工作负载的调度需求不同,对于Web服务,倾向于分散到不同节点上,对于某些延迟敏感的服务,则倾向于调度在同一节点上。在以前,可以配置多个调度器来满足差异化调度,但是这会引入竞态条件,因为每个调度器在同一时刻看到不同的集群视图。调度Profile允许同一调度器以多种配置运行,每个配置有自己的schedulerName,Pod仍然使用schedulerName来指定使用哪个Profile
- Beta:跨越多个故障域平均分布Pod,使用topologySpreadConstraints,可以定义如何在跨越区域(Zone)的大规模集群上平均调度Pod
- Alpha:跨越多个故障域平均分布Pod,支持配置默认规则
- 节点相关
- Hugepage支持,硬件优化会让大块内存访问更加快速,对于在内存中处理大量数据集的应用(例如数据库)、以及内存延迟敏感应用很有价值。现在Pod可以请求不同尺寸的Hugepage:
12345678910apiVersion: v1kind: Pod…spec:containers:…resources:requests:hugepages-2Mi: 1Gihugepages-1Gi: 2Gi - 统计Pod沙盒消耗的(而不是关联到特定容器)资源。启用PodOverhead特性门,则调度时考虑Pod沙盒的资源消耗,资源消耗在Admission期间计算并固化,其值和RuntimeClass有关
- 节点拓扑管理器(Node Topology Manager)是Kubelet的组件,负责专门协调硬件资源的分配。机器学习、科学计算、财务服务等都是计算密集型、低延迟要求的应用,这类应用锁定到特定的核心上会得到更好的性能,NTM能够执行这种锁定
- 延迟liveness探针执行:
123456startupProbe:httpGet:path: /healthzport: liveness-portfailureThreshold: 30periodSeconds: 10仅当此探针成功,才认为Pod启动完毕,然后才会执行其它探针,例如liveness
- Hugepage支持,硬件优化会让大块内存访问更加快速,对于在内存中处理大量数据集的应用(例如数据库)、以及内存延迟敏感应用很有价值。现在Pod可以请求不同尺寸的Hugepage:
- 网络
- NodeLocal DNSCache到达GA,此特性增强集群DNS性能,避免DNAT和conntrack导致的和UDP相关的竞态条件
- 存储
- 跳过卷所有权变更,在bind挂载卷到容器之前,它的文件权限会被改为fsGroup设置的值。如果卷很大,这个处理过程会很慢,而且这种修改会导致某些权限敏感的应用出问题,例如数据库。新增的FSGroupChangePolicy字段可以控制此行为,如果设置为Always行为依旧,如果设置为OnRootMismatch,则仅当卷的根目录的权限不匹配fsGroup时才设置权限
- 不可变ConfigMap和Secret:
1234567apiVersion: v1kind: Secretmetadata:…data:…immutable: true -
跳过non-attachable卷的Attach行为。这是个内部优化,简化了 不需要Attach/Detach操作的CSI驱动(例如NFS)的VolumeAttachment对象的创建
- 支持访问原始(Raw)块存储,BlockVolume到达GA。要访问原始卷(跳过文件系统,提升IO性能降低延迟),将volumeMode设置为block
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# 交叉编译,需要先安装交叉编译器 sudo apt-get install gcc-5-aarch64-linux-gnu sudo apt-get install gcc-aarch64-linux-gnu # 签出代码 mkdir -p $GOPATH/src/k8s.io cd $GOPATH/src/k8s.io git clone https://github.com/kubernetes/kubernetes cd kubernetes # 构建二进制文件 # 构建kubelet 设置版本号为v1.18.3 去除版本号的dirty make WHAT=cmd/kubelet KUBE_GIT_VERSION=v1.18.3 KUBE_GIT_TREE_STATE=clean # 为ARM平台构建 设置GOFLAGS KUBE_BUILD_PLATFORMS=linux/arm64 GOFLAGS="-tags=nokmem" # 打印帮助 make release-images PRINT_HELP=y # 跨平台编译 make cross # 校验,确保代码格式化完毕、Bazel依赖更新完毕 make verify # 执行所有更新脚本 make update # 执行单元测试 make test make test WHAT=./pkg/api/helper GOFLAGS=-v # 执行集成测试 make test-integration # release-skip-tests quick-release 只是默认参数不同 # 生成镜像 不跳过测试 镜像前缀 make release-skip-tests KUBE_RELEASE_RUN_TESTS=y KUBE_DOCKER_REGISTRY=docker.gmem.cc/tcnp # Base镜像前缀 KUBE_BASE_IMAGE_REGISTRY=registry.aliyuncs.com/google_containers # 不要总是尝试拉取镜像,某些镜像在国内拉取不到 打印更多的日志信息 KUBE_BUILD_PULL_LATEST_IMAGES=n KUBE_VERBOSE=5 # 生成镜像 交叉编译其它平台 make quick-release KUBE_FASTBUILD=false |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 仅编译linux二进制程序 build/run.sh make # 编译跨平台二进制程序 build/run.sh make cross # 指定组件与平台编译 build/run.sh make kubectl KUBE_BUILD_PLATFORMS=darwin/amd64 # 运行所有单元测试用例 build/run.sh make test # 运行集成测试用例 build/run.sh make test-integration # 运行命令行测试 build/run.sh make test-cmd # 把docker中的 _output/dockerized/bin 拷贝到本地的 _output/dockerized/bin build/copy-output.sh # 清理_output目录 build/make-clean.sh # 进入bash shell中进行编译 build/shell.sh |
现象: kubectl get node -o yaml | grep InternalIP -B 1 返回不期望的IP地址。
原因:具有多个可以相互连接的网络接口。
解决办法:
|
1 |
KUBELET_EXTRA_ARGS="--node-ip=10.0.4.1" |
然后重启kubelet即可。
报错信息:is invalid: spec.ports[0].nodePort: Invalid value: 80: provided port is not in the valid range. The range of valid ports is 30000-32767
解决方案:修改Master节点的/etc/kubernetes/manifests/kube-apiserver.yaml,添加参数:
--service-node-port-range=80-32767
如果Node宕机或者网络分区,Pod可能进入Unknown状态,因为1.5+版本仅仅当Master确认Pod不在集群中运行时才会重新调度之。
这种情况下,如果作为管理员的你知道Node是宕机了,可以:
- 强制删除 kubectl delete pod pod-name --grace-period=0 --force后重新创建之
|
1 2 3 4 5 6 7 8 9 10 |
volumeMounts: - name: tz-config # 常见的Linux发行版都从下面的文件中读取时区 mountPath: /etc/localtime volumes: - name: tz-config hostPath: # Ubuntu、CentOS等宿主机上都有下面的文件 path: /usr/share/zoneinfo/Asia/Shanghai |
报错信息:Failed to enforce System Reserved Cgroup Limits on "/system.slice": failed to set supported cgroup subsystems for cgroup /system.slice: Failed to set config for supported subsystems : failed to write 536870912 to memory.limit_in_bytes: write /sys/fs/cgroup/memory/system.slice/memory.limit_in_bytes: device or resource busy
报错原因:设置的限额,比当前system.slice组已经使用的不可压缩资源量(内存)更小,无法执行
报错信息:
Error: failed to start container "dubbo": Error response from daemon: OCI runtime create failed: container_linux.go:348:
starting container process caused "process_linux.go:402: container init caused \"rootfs_linux.go:58: mounting \\\"/var/lib/kubelet/pods/1df7c1e1-d8ef-11e8-8029-3863bb2bccdc/volume-subp
aths/tomcatconf/dubbo/3\\\" to rootfs \\\"/var/lib/docker/overlay2/2fb619c8c8911576b936b460711d229f85489c82f222918ce79c90013b95e640/merged\\\" at \\\"/var/lib/docker/overlay2/2fb619c8c8
911576b936b460711d229f85489c82f222918ce79c90013b95e640/merged/tomcat/conf/server.xml\\\" caused \\\"no such file or directory\\\"\"": unknown
原因:已知的缺陷,当挂载ConfigMap/Secret,使用subPath时,如果ConfigMap被修改(我们的问题场景下貌似没有修改),则容器(而不是Pod)重启(可能由于健康检查失败导致)会失败。
现象:换行符被替换为\n,无法阅读
原因:1.12版本中,只有任意一行以空格结尾,就会出现这种情况。
K8S没有提供重启Pod的功能,Pod只能删除。但是Pod删除后,容器的本地文件系统状态就丢失了。
可以通过杀死进程的方式,让Pod(的容器)重启:
|
1 |
kubectl exec -it ubuntu kill -- 1 |
注意不要kill -9,原因是PID 1是init进程,即使在PID命名空间中也是这样。PID 1不定义KILL的信号处理器,因此无法被SIGKILL杀死。
报错:unsupported docker version: 18.09.0
解决办法:为kubeadm添加参数 --ignore-preflight-errors=SystemVerification
删除旧证书:
|
1 |
/etc/kubernetes/pki/apiserver.* |
修改/etc/kubernetes/kubeadm-config.yaml,添加额外的SAN。
执行下面的命令生成新的API Server证书:
|
1 |
kubeadm init phase certs apiserver --config /etc/kubernetes/kubeadm-config.yaml |
通过Kubeadm安装的K8S集群,其控制平面证书有效期默认为1年,到期后你会遇到x509: certificate has expired or is not yet valid错误。
解决办法,通过kubeadm命令重新生成证书:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cd /etc/kubernetes/ rm -rf pki/apiserver.* pki/apiserver-kubelet-.* pki/front-proxy-* # apiserver API Server服务器证书 # apiserver-etcd-client API Server访问Kubelet使用的证书 # apiserver-kubelet-client 用于API Server连接到kubelet的证书 # ca 根证书 # sa 用于签名Service Account Token的证书 # front-proxy-ca 前置代理的自签名CA证书 # front-proxy-client 前置代理客户端证书 kubeadm alpha phase certs apiserver \ --apiserver-cert-extra-sans=k8s.gmem.cc,localhost,10.0.2.1,10.0.3.1,127.0.0.1,radon,neon kubeadm alpha phase certs apiserver-kubelet-clientkubec kubeadm alpha phase certs sa kubeadm alpha phase certs front-proxy-ca kubeadm alpha phase certs front-proxy-client # 配置文件也需要重新生成 rm -rf *.conf kubeadm alpha phase kubeconfig all --apiserver-advertise-address=10.0.2.1 cp admin.conf $HOME/.kube/config |
生成的文件中,除了front-proxy-client.crt之外的所有crt文件,都是基于/etc/kubernetes/pki/ca.*进行签名。
用于Service Account Token的签名和校验的sa.pub则仅仅是公钥,这也意味着,所有API Server必须共享一致的sa.key/sa.pub。
证书更新后,kube-proxy可能无法访问API Server,报错 Unauthorized,原因是重新生成了sa.*,签名用的密钥变了。其实sa.*不需要重新生成,它不牵涉证书过期的问题。清空所有Token,导致其重新自动生成即可解决此问题:
|
1 |
kubectl get secrets --all-namespaces --no-headers | grep service-account-token | awk '{system("kubectl -n "$1" delete secrets "$2)}' |
所有依赖于Service Account Token的Pod(基本上所有控制平面Pod都需要访问API Server)都需要重启:
|
1 2 3 |
# 否则,这些Pod访问API Server后,API Server会报错 # invalid bearer token, [invalid bearer token, square/go-jose: error in cryptographic primitive kubectl -n kube-system delete pod --all |
命令: kubectl -n kube-system logs tiller-deploy-79988f9658-874gs -v 9可以获得更加详细的错误。
logs和exec子资源最终调用kubelet,因此获取其它K8S资源时没有问题,可以考虑是否节点存在问题。
查看节点Kubelet日志,发现:Failed to set some node status fields: failed to validate nodeIP: node IP: "172.17.0.4" not found in the host's network interfaces。原来是Kind集群重启后,IP地址发生变化导致。
Kind的节点IP静态的写在 /var/lib/kubelet/kubeadm-flags.env文件中,可以修改之。
到目标节点上,进入/var/lib/kubelet/pods/***目录,查看etc-hosts文件内容,即可得知Pod的名字。
如果Pod已经不存在,可以删除***目录。防止继续出现此报错。
可能原因是内核参数取值太小: sudo sysctl fs.inotify.max_user_watches=1048576
是的,默认情况下你会无法Ping通集群IP,但是访问服务开放的端口是没问题的。
使用kubeadm时,自定义集群域名时,出现此现象。
解决办法,使用kubelet参数:--cluster-domain=k8s.gmem.cc
默认配置下,对节点宕机的响应速度较慢。可以进行以下调整。
默认每10秒上报当前节点的健康状态,可以调低:--node-status-update-frequency=3s
默认每5秒在Master上检测其它节点状态,可以调低:--node-monitor-period=3s
如果发现其它节点不响应了,默认需要过40秒(10 *4)才能认为节点处于Unhealthy状态。可以调低 --node-monitor-grace-period=12s ,取值必须是--node-status-update-frequency的整数倍。
如果节点处于Unhealthy状态,则经过5分钟后控制器管理器才开始清除其上的Pod,可以调低 --pod-eviction-timeout=36s
控制器管理器的配置文件位于/etc/kubernetes/manifests/kube-controller-manager.yaml。
|
1 2 3 |
# 如果以静态Pod方式运行 PODNAME=$(kubectl -n kube-system get pod -l component=kube-controller-manager -o jsonpath='{.items[0].metadata.name}') kubectl -n kube-system logs $PODNAME --tail 100 -f |
|
1 2 3 |
# 如果以静态Pod方式执行 PODNAME=$(kubectl -n kube-system get pod -l component=kube-scheduler -o jsonpath='{.items[0].metadata.name}') kubectl -n kube-system logs $PODNAME --tail 100 -f |
|
1 |
journalctl -u kubelet -f -p 0..7 |
|
1 |
kubectl -n kube-system get pod | grep kube-proxy |
|
1 |
kubectl -n ns podname containername |
如果只有一个容器,不需要指定containername,否则不指定containername会报错:
Error from server (BadRequest): a container name must be specified for pod maven-cddc1, choose one of: [** **]
Ingress必须添加注解: nginx.ingress.kubernetes.io/secure-backends: "true"
否则:
- Ingress Controller报错:upstream sent no valid HTTP/1.0 header while reading response header from upstream
- Chrome浏览器报错:ERR_SPDY_PROTOCOL_ERROR
Ingress必须添加注解: nginx.ingress.kubernetes.io/backend-protocol: "GRPC"
这个问题和Goland有关,去除环境变量:
|
1 |
unset GOFLAGS |
即可解决。
报错:Error executing 'postInstallation': EEXIST: file already exists, symlink '/opt/bitnami/redis/conf' -> '/opt/bitnami/redis/etc',但是实际上文件根本不存在。
原因:CentOS使用的内核存在缺陷,升级到最新版本内核即可。
报错信息:handshake failed: ssh: unable to authenticate, no supported methods remain
报错原因: 和VMware Fusion存在兼容性问题,Minikube的docker用户所需要的密钥没有正确拷贝
解决办法:
- 启动Minikube:
1234567minikube start --vm-driver=vmwarefusion -v=10 --kubernetes-version v1.15.0# 使用代理export PROXY=http://192.168.72.77:8087https_proxy=$PROXY minikube start --docker-env HTTP_PROXY=$PROXY \--docker-env HTTPS_PROXY=$PROXY --docker-env NO_PROXY=192.168.0.0/16 \--vm-driver=vmwarefusion -v=10 --kubernetes-version v1.15.0 - 在另外一个命令行窗口执行:
1234567'/Applications/VMware Fusion.app/Contents/Library/vmrun' -gu docker -gp tcuser \createDirectoryInGuest ~/.minikube/machines/minikube/minikube.vmx \/home/docker/.ssh'/Applications/VMware Fusion.app/Contents/Library/vmrun' -gu docker -gp tcuser \CopyFileFromHostToGuest ~/.minikube/machines/minikube/minikube.vmx \~/.minikube/machines/minikube/id_rsa.pub /home/docker/.ssh/authorized_keys
Leave a Reply