通过自定义资源扩展Kubernetes
Kubernetes是高度可配置、可扩展的,通常你不需要Fork其主项目代码或者打补丁。
对K8S的定制基本上可以分为两种方式:
- 配置,例如修改命令行参数、本地配置、API资源
- 扩展,在集群内外运行额外的程序或服务
本文主要讨论如何扩展K8S
扩展K8S的方式可以分为以下几类。
一种有效的编写客户程序的模式(Pattern)叫做控制器模式(Controller pattern),控制器负责执行例行性任务来保证集群尽可能接近其期望状态。典型情况下控制器读取.spec字段,运行一些逻辑,然后修改.status字段。K8S自身提供了大量的控制器,并由控制器管理器统一管理。
控制器是K8S的客户端。另一种扩展模式中,K8S作为客户端来访问外部服务。这种模式叫Webhook模式,被访问的外部服务叫做Webhook Backend。
和控制器一样,Webhook引入了故障点。
一段可执行的二进制程序,主要由kubelet、kubectl使用,例如 Flex卷插件、网络插件。
主要包括:
- 可以扩展kubectl,但是仅仅影响用户本地环境
- API访问扩展:API Server负责处理请求,它暴露了多个扩展点,允许对请求进行身份验证、基于内容阻塞请求、编辑请求内容、处理删除
- 自定义资源:可以和API访问扩展联用,定义你自己的资源类型
- 可以扩展调度器以调整Pod调度行为,可以完全替换为自己的实现
- 控制器:很大一部分K8S行为由控制器实现,控制器是API Server的客户端,常和自定义资源联用
- 定制网络插件、存储插件
“资源”对应着Kubernetes API中的一个端点(Endpoint),它存储了某种类型的API对象。自定义资源(Custom Resources)是对Kubernetes API的扩展,代表某种自定义的配置或独立运行的服务。
和内置资源一样,自定义资源本身仅仅是一段结构化数据,仅仅和相应自定义控制器联用后,才能作为声明式API。自定义资源描述了你期望的资源状态,由控制器来尽力达到此状态。
自定义控制器由用户部署到集群,这种控制器独立于集群本身的生命周期。尽管自定义控制器可以和任何类型的资源配合,但是对于自定义资源特别有意义。CoreOS提出的Operator Framework,就是自定义控制器联用自定义资源的例子。
有两种方法:
- 使用CRD(CustomResourceDefinition):
- 不需要编程
- 实现CRD控制器,可以使用任何编程语言
- 不需要额外的次级API Server,你不需要理解API聚合的概念
- 使用API聚合(Aggregation):
- 需要Go编程
- 可以对API行为进行更细粒度的控制——例如数据如何存储、如何在API版本之间转换
- 需要运行额外的API Server进程
- 需要自己处理多版本API的支持
CRD和API聚合都支持:
| 特性 | 说明 |
| CRUD | 通过HTTP或者kubectl,针对新端点进行增删改查操作 |
| Watch | 支持针对新端点的监控操作 |
| Discovery | 支持针对新端点的列出、查看、字段编辑等操作 |
| json-patch | 支持基于Content-Type: application/json-patch+json进行补丁操作 |
| merge-patch | 支持基于Content-Type: application/merge-patch+json进行补丁操作 |
| HTTPS | 支持HTTPS |
| 身份验证 | 支持K8S身份验证 |
| 访问控制 | 支持RBAC等内置的K8S访问控制 |
| Finalizers | 阻塞删除操作,直到外部清理操作完毕 |
| Admission Webhooks | 在CRUD时,提供资源的默认值、验证资源定义的合法性 |
| 标签和注解 | 支持Label和Annotation |
CRD是一种API资源,利用它你可以定义“自定义资源”,K8S负责CRD的存储。使用CRD而非API聚合可以免去编写次级API Server的烦恼,但是其灵活性不如API聚合。
CRD从1.7版本开始引入,到1.8版本进入Beta状态。最新的1.11版本CRD获得增强,支持scale、status子资源。
CRD/CR仅仅是一段声明信息,必须配合相应的控制器才有价值。
使用kubebuilder子项目controller-tools,配合一定的Tag,可以从CR类型源码生成CRD清单文件:
|
1 2 3 |
go run vendor/sigs.k8s.io/controller-tools/cmd/controller-gen/main.go \ # 寻找自定义资源Go类型的祖先目录 输出目录 crd paths=./pkg/apis/... output:dir=.pae/chart/crds |
controller-gen会读取多种kubebuilder标记(Marker),详情请阅读kubebuilder一章。
CRD实际上是自定义资源的Schema,简单的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: # CRD名称必须是: .格式 name: crontabs.k8s.gmem.cc spec: # 决定了REST API路径:/apis// group: k8s.gmem.cc # 此CRD支持的版本 versions: - name: v1 # 每个版本都可以被禁用或启用 served: true # 只有一个版本可以被标记为true,表示以此版本来存储 storage: true # 可选Namespaced或Cluster,表示此资源是命名空间限定的,还是全局的 scope: Namespaced names: # 决定了REST API路径: /apis/// plural: crontabs # 在CLI中的别名 singular: crontab # 驼峰式大小写的,正式的资源类型 kind: CronTab # 在CLI中可以使用的短名称 shortNames: - ct |
执行下面的命令创建CRD:
|
1 |
kubectl create -f crd.yaml |
监控CRD的condition Established,为true之后,可以通过API端点/apis/k8s.gmem.cc/v1/namespaces/*/crontabs/来管理自定义资源。
|
1 2 3 4 |
apiextensionsclientset "k8s.io/apiextensions-apiserver/pkg/client/clientset/clientset" apiextensionsClient, err := apiextensionsclientset.NewForConfig(cfg) createdCRD, err := apiextensionsClient.ApiextensionsV1beta1().CustomResourceDefinitions().Create(yourCRD) |
一旦CRD创建成功,你就可以创建对应类型的自定义资源(Custom Resource,CR)了。
自定义资源可以包含任意的自定义字段,例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: "k8s.gmem.cc/v1" kind: CronTab metadata: name: cron # 删除前钩子 finalizers: # 下面的形式非法 - finalizer.k8s.gmem.cc # 必须这样 - finalizer.k8s.gmem.cc/xxx spec: cronSpec: "* * * * */5" image: crontab:1.0.0 |
当删除CRD后,所有基于它的自定义资源都自动被删除。
Finalizers用于实现资源的异步pre-delete钩子。自定义资源和内置资源一样,支持这种钩子。
通过metadata.finalizers字段来指定finalizers的数组,每个条目都是一个字符串。如果metadata.finalizers不为空,则对资源的强制删除无法执行。你应该使用准许控制,来确保必要的Finalizers添加到被删除的CR上。
对于具有finalizers的资源,向其发起第一次删除请求时,仅仅是设置 metadata.deletionTimestamp 字段。用来控制CRD的控制器,应该在Reconcile循环中发现deletionTimestamp非空(意味着对象应该被删除),并且:
- 执行pre-delete钩子
- 移除钩子对应的metadata.finalizers元素
当所有钩子执行完毕,finalizers被清空后,对象被真正的删除。所有pre-delete钩子执行可以消耗的总计时间,由metadata.deletionGracePeriodSeconds控制。
可以通过additionalPrinterColumns声明CRD的实例通过kubectl可以显示的额外字段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: canaries.flagger.app spec: # 在资源名称后面,额外显示以下字段 additionalPrinterColumns: - name: Status type: string JSONPath: .status.phase - name: Weight type: string JSONPath: .status.canaryWeight - name: LastTransitionTime type: string JSONPath: .status.lastTransitionTime |
你可以通过CRD的validation字段,来(基于 OpenAPI v3 Schema)规定自定义资源的字段验证规则。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: canaries.flagger.app spec: validation: openAPIV3Schema: # 根对象包含的属性 properties: # spec属性规则 spec: # 必须具有以下子属性 required: - targetRef - service - canaryAnalysis # spec的子属性列表 properties: # 简单属性,指定类型 progressDeadlineSeconds: type: number # 对象属性 targetRef: type: object required: ['apiVersion', 'kind', 'name'] properties: apiVersion: type: string kind: type: string name: type: string # 复杂属性:可以是字符串,也可以是对象 autoscalerRef: anyOf: - type: string - type: object required: ['apiVersion', 'kind', 'name'] properties: apiVersion: type: string kind: type: string name: type: string service: type: object required: ['port'] properties: port: type: number skipAnalysis: type: boolean canaryAnalysis: properties: interval: type: string # 基于正则式验证 pattern: "^[0-9]+(m|s)" threshold: type: number maxWeight: type: number stepWeight: type: number metrics: type: array properties: items: type: object required: ['name', 'threshold'] properties: name: type: string interval: type: string pattern: "^[0-9]+(m|s)" threshold: type: number query: type: string webhooks: type: array properties: items: type: object required: ['name', 'url', 'timeout'] properties: name: type: string url: type: string format: url timeout: type: string pattern: "^[0-9]+(m|s)" |
自定义资源可以支持/status和/scale子资源。此特性在1.11版本中处于Beta状态且默认启用。你需要在CRD中进行定义才能启用这些子资源。
scale子资源支持让其他K8S组件(例如HorizontalPodAutoscaler和PodDisruptionBudget控制器)与你的CR进行交互。kubectl scale也可以利用该子资源对CR进行扩容。
status子资源可以让你把资源的规格和状态分开。
启用状态子资源后,自定义资源的/status URL可用:
- 数据对应资源的.status字段
- PUT /status仅仅会修改.status字段,也仅仅对该字段进行验证
- 对资源本身进行PUT/POST/PATCH操作,会忽视.status字段
- 每次修改.spec字段,都导致.metadata.generation ++
启用扩容子资源后,自定义资源的/scale URL可用,RESTful载荷类型为autoscaling/v1.Scale
要启用扩容子资源,CRD需要指定:
- SpecReplicasPath,指定自定义资源中对应Scale.Spec.Replicas的JSON路径。必须值
- StatusReplicasPath,指定自定义资源中对应Scale.Status.Replicas的JSON路径。必须值
- LabelSelectorPath,指定自定义资源中对应Scale.Status.Selector的JSON路径。可选值,和HPA联用则必须设置
示例:
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition spec: subresources: # 启用状态子资源 status: {} # 启用扩容子资源 scale: specReplicasPath: .spec.replicas statusReplicasPath: .status.replicas labelSelectorPath: .status.labelSelector |
用于指定资源所属的类别,例如all。示例:
|
1 2 3 4 5 6 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition spec: names: categories: - all |
通过kubectl get all可以访问到上述CRD的自定义资源。
如果你的CRD中有个字段,可能容纳任何类型的对象,可以用结构包裹一个interface{}:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
type ValueSpec struct { // valueSpec.default可以是任何类型 DefaultValue `json:",inline"` } // Wrapping struct,必须禁止自动deepcopy方法生成 // +k8s:deepcopy-gen=false type DefaultValue struct { Default interface{} `json:"default,omitempty"` } // 自己实现深拷贝函数,根据实际需要进行处理 func (in *DefaultValue) DeepCopyInto(out *DefaultValue) { } |
生成的CRD的OpenAPI校验,此字段校验规格自动为空: default: {}
helm-operator中的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
type HelmReleaseSpec struct { HelmValues `json:",inline"` } // +k8s:deepcopy-gen=false type HelmValues struct { helm.Values `json:"values,omitempty"` } // helm.Values定义: type Values map[string]interface{} // 自己实现深拷贝 func (in *HelmValues) DeepCopyInto(out *HelmValues) { if in == nil { return } b, err := yaml.Marshal(in.Values) if err != nil { return } var values helm.Values err = yaml.Unmarshal(b, &values) if err != nil { return } out.Values = values } |
在准许控制(Admission Control)方面,自定义资源和内置资源没有什么区别。
可以参考Kubernetes学习笔记。本节额外给出针对自定义资源的Webhook示例。
本节的例子检查提交的CRD的GV,必须是apiextensions.k8s.io/v1beta1才准许通过:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
package main import ( "fmt" apiextensionsv1beta1 "k8s.io/apiextensions-apiserver/pkg/apis/apiextensions/v1beta1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/api/admission/v1beta1" "k8s.io/klog" ) func admitCRD(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { crdResource := metav1.GroupVersionResource{Group: "apiextensions.k8s.io", Version: "v1beta1", Resource: "customresourcedefinitions"} if ar.Request.Resource != crdResource { err := fmt.Errorf("expect resource to be %s", crdResource) return toAdmissionResponse(err) } raw := ar.Request.Object.Raw crd := apiextensionsv1beta1.CustomResourceDefinition{} // 反串行化为CRD deserializer := codecs.UniversalDeserializer() if _, _, err := deserializer.Decode(raw, nil, &crd); err != nil { return toAdmissionResponse(err) } reviewResponse := v1beta1.AdmissionResponse{} reviewResponse.Allowed = true return &reviewResponse } |
本节的例子包含针对CR的validator、mutator:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
package main import ( "encoding/json" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/api/admission/v1beta1" "k8s.io/klog" ) const ( customResourcePatch1 string = `[ { "op": "add", "path": "/data/mutation-stage-1", "value": "yes" } ]` ) func mutateCustomResource(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { # 改变CR cr := struct { metav1.ObjectMeta // 没有使用具体的CR类型,而是反串行化到通用的Map中,这样的Webhook更加通用 Data map[string]string }{} raw := ar.Request.Object.Raw err := json.Unmarshal(raw, &cr) if err != nil { klog.Error(err) return toAdmissionResponse(err) } reviewResponse := v1beta1.AdmissionResponse{} reviewResponse.Allowed = true if cr.Data["mutation-start"] == "yes" { reviewResponse.Patch = []byte(customResourcePatch1) } pt := v1beta1.PatchTypeJSONPatch reviewResponse.PatchType = &pt return &reviewResponse } func admitCustomResource(ar v1beta1.AdmissionReview) *v1beta1.AdmissionResponse { klog.V(2).Info("admitting custom resource") cr := struct { metav1.ObjectMeta Data map[string]string }{} raw := ar.Request.Object.Raw err := json.Unmarshal(raw, &cr) if err != nil { klog.Error(err) return toAdmissionResponse(err) } reviewResponse := v1beta1.AdmissionResponse{} reviewResponse.Allowed = true for k, v := range cr.Data { if k == "webhook-e2e-test" && v == "webhook-disallow" { reviewResponse.Allowed = false reviewResponse.Result = &metav1.Status{ Reason: "the custom resource contains unwanted data", } } } return &reviewResponse } |
开发控制器时常使用Go语言,基于K8S客户端库client-go。 你可以使用代码生成器减轻编写样板代码的负担,也可以考虑使用Operator Framework这样的提供高层API的框架。本章主要讨论基于client-go开发的控制器。
在控制器中,你通常需要提供一个无限的控制循环,用于管理系统状态。K8S的系统状态通过API Server暴露。
不管是使用Client-go,还是下文会讨论的Controller-runtime或者Operator Framework,控制器的架构都是一样的: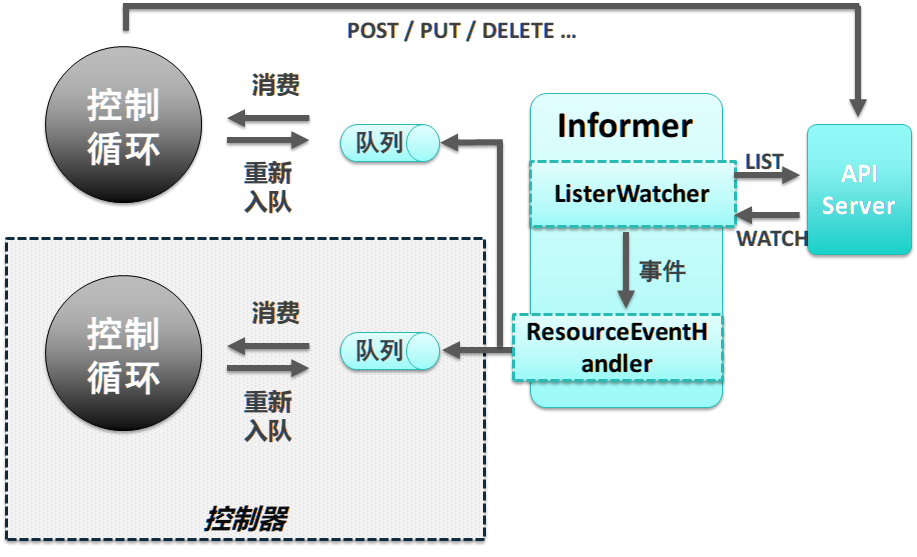
控制器主要使用以下client-go组件:
- Informer/SharedInformer:监控目标K8S资源的变化,并交由ResourceEventHandler处理
- ResourceEventHandler:通常是将事件发送到工作队列
- Workqueue :暂存资源变更事件,由控制循环取出事件并处理
此组件负责获取对象状态,通常你不会直接向API Server发请求,而是通过client-go提供的编程接口。client-go提供了缓存功能,避免反复从API Server获取数据。
如果仅仅需要关注对象的创建、修改、删除事件,可以使用ListerWatcher接口。该接口可以对特定的资源进行监控(watch)操作:
|
1 2 3 4 5 6 7 |
import "k8s.io/client-go/tools/cache" // 返回ListWatch结构,它实现了ListerWatcher接口 lw := cache.NewListWatchFromClient( client, // 客户端 &v1.Pod{}, // 被监控资源类型 api.NamespaceAll, // 被监控命名空间 fieldSelector) // 选择器,减少匹配的资源数量 |
有了ListerWatcher你就可以创建Informer了:
|
1 2 3 4 5 6 |
store, controller := cache.NewInformer ( &lw, &v1.Pod{}, // 监控的对象类型 resyncPeriod, // 如果非0则自动定期relist对象 cache.ResourceEventHandlerFuncs{} // ResourceEventHandler 事件发送给此对象处理 ) |
实际编程时并不常使用Informer,下文会提到的SharedInformer使用的更多。
此接口包含两个函数:
|
1 2 3 4 5 6 |
// ListerWatcher是任何支持对一个资源进行init list,并进行watch的对象 type ListerWatcher interface { List(options metav1.ListOptions) (runtime.Object, error) // watch能保证对资源进行持续不断的监控 Watch(options metav1.ListOptions) (watch.Interface, error) } |
上文调用的cache.NewListWatchFromClient,已经提供了ListWatcher的实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
func NewFilteredListWatchFromClient(c Getter, resource string, namespace string, optionsModifier func(options *metav1.ListOptions)) *ListWatch { // ListWatch已经实现List方法,并代理给其成员函数listFunc,Watch方法类似 listFunc := func(options metav1.ListOptions) (runtime.Object, error) { optionsModifier(&options) // 修改选项的回调 return c.Get(). // 获得*restclient.Request,此结构允许你以链式调用方式构建对API的请求 Namespace(namespace). // 限定命名空间 Resource(resource). // 限定资源类型 VersionedParams(&options, metav1.ParameterCodec). // 解析并限定资源版本 Do(). // 执行请求并获得Result Get() // 获取Result中的runtime.Object对象 } watchFunc := func(options metav1.ListOptions) (watch.Interface, error) { options.Watch = true optionsModifier(&options) return c.Get(). Namespace(namespace). Resource(resource). VersionedParams(&options, metav1.ParameterCodec). Watch() // 尝试对请求的API进行监控,返回watch.Interface } return &ListWatch{ListFunc: listFunc, WatchFunc: watchFunc} } |
通常在此接口中提供事件处理逻辑:
|
1 2 3 4 5 6 7 8 9 |
type ResourceEventHandler interface { // 当资源第一次加入到Informer的缓存后调用 OnAdd(obj interface{}) // 当既有资源被修改时调用。oldObj是资源的上一个状态,newObj则是新状态 // resync时此方法也被调用,即使对象没有任何变化 OnUpdate(oldObj, newObj interface{}) // 当既有资源被删除时调用,obj是对象的最后状态,如果最后状态未知则返回DeletedFinalStateUnknown OnDelete(obj interface{}) } |
规定每隔多久,控制器遍历缓存中所有对象,并调用OnUpdate。
如果控制器可能错过对象更新事件,或者先前的事件处理回调可能执行失败,则此配置参数很重要。
Informer会创建一个私有的缓存,其中包含它自己用到的所有资源。但是,在K8S中有很多控制器在运行,它们关注多种类型的对象。如果基于Informer实现这些控制器,就会有很多重复的缓存数据,增加资源占用。
SharedInformer能够创建一个共享的缓存,在多个控制器之间共享数据。此外,不管下游有多少个消费者,SharedInformer都仅仅对上游服务器建立一个Watch。因此SharedInformer同时降低了客户端的内存占用和服务器的负载。包含很多控制器的 kube-controller-manager使用SharedInformer。
SharedInformer直接提供了接受新增、更新、删除特定资源的钩子。
类似于Informer,cache模块也为SharedInformer提供了工厂函数:
|
1 2 3 |
func NewSharedInformer(lw ListerWatcher, objType runtime.Object, resyncPeriod time.Duration) SharedInformer { return NewSharedIndexInformer(lw, objType, resyncPeriod, Indexers{}) } |
由于SharedInformer是共享的,因此它不能跟踪每个控制器处理事件的进度。控制器必须提供自己的队列和重试(处理)机制。
当资源状态变化后,SharedInformer的ResourceEventHandler在Workqueue中添加一个Key。Key的格式是资源命名空间/资源名称,资源命名空间是可以省略的。
client-go/util/workqueue提供了多种工作队列的实现,包括:
- 延迟队列,延后一段时间再将元素入队,由接口DelayingInterface提供
- 限速队列,限定单位时间内能够入队的元素量,由接口RateLimitingInterface提供
下面的代码示意了如何创建限速队列:
|
1 |
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter()) |
一个Key在工作队列中的生命周期如下:
- queue.Add(key)入队
- queue.Get()获取第一个Key进行处理,如果:
- 处理成功,queue.Forget(key)清除掉Key
- 处理失败,在到达最大重试次数之前,控制器调用queue.AddRateLimited(key)重新入队
- queue.Forget(key)仅仅让队列不再跟踪事件的历史。控制器会最终调用queue.Done()彻底删除事件
控制器仅仅(如果自己实现,也应该遵守此准则)在缓存完整同步后,才调用Worker,处理Workqueue,原因是:
- 直到缓存同步完毕,列出的资源才是精确的
- 可以让针对单个资源的多次更新合并为一个,避免反复处理中间状态,浪费资源
本节展示一个简单的控制器的例子。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
package main import ( "flag" "k8s.io/client-go/kubernetes" "k8s.io/client-go/util/workqueue" "k8s.io/sample-controller/pkg/signals" "k8s.io/client-go/tools/cache" "k8s.io/client-go/tools/clientcmd" "github.com/golang/glog" "k8s.io/apimachinery/pkg/watch" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/runtime" utilruntime "k8s.io/apimachinery/pkg/util/runtime" apiv1 "k8s.io/api/core/v1" "fmt" "k8s.io/apimachinery/pkg/util/wait" "time" ) /* 控制器 */ type Controller struct { // 此控制器使用的客户端 clientset kubernetes.Interface // 此控制器使用的工作队列 queue workqueue.RateLimitingInterface // 此控制器使用的共享Informer,SharedIndexInformer可以维护缓存中对象的索引 informer cache.SharedIndexInformer } /* 主函数 */ var ( // 参数变量 masterURL string kubeconfig string ) // 启动控制器 func (c *Controller) Run(stopCh |
直接进行类型断言即可,前提是你明白自己在监控什么对象:
|
1 |
newDepl = new.(*appsv1.Deployment) |
你也可以用switch进行处理。
利用ObjectMeta.ResourceVersion,资源有变化后此字段即改变:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ // 资源添加到缓存中后调用(不是在集群中创建后) AddFunc: controller.handleObject, // 既有资源修改后调用。当执行resync后,该回调也被调用,即使资源没有任何变化 UpdateFunc: func(old, new interface{}) { newDepl := new.(*appsv1.Deployment) oldDepl := old.(*appsv1.Deployment) if newDepl.ResourceVersion == oldDepl.ResourceVersion { // 如果资源没有变化则直接返回 return } controller.handleObject(new) }, // 当既有资源被删除后调用,入参是资源的最终状态 // 如果最终状态未知,则入参是DeletedFinalStateUnknown。这种情况的原因可能是watch关闭而错过 // 资源的删除事件,直到下次relist控制器才意识到资源被删除 DeleteFunc: controller.handleObject, }) |
在1.7-版本中,操控CR需要基于client-go dynamic client,使用起来并不方便。
code-generator是K8S提供的一个代码生成器项目,可以用来:
- 开发CRD的控制器时,生成版本化的、类型化的客户端代码(clientset),以及Lister、Informer代码
- 开发API聚合时,在内部和版本化的类型、defaulters、protobuf编解码器、client、informer之间进行转换
K8S本身以及OpenShift也在使用此项目。
code-generator提供的,和CRD有关的生成器包括:
- deepcopy-gen:为每个T类型生成 func (t* T) DeepCopy() *T方法。API类型都需要实现深拷贝
- client-gen:为CustomResource API组生成强类型的clientset
- informer-gen:为CustomResources生成Informer
- lister-gen:为CustomResources生成Lister,Lister为GET/LIST请求提供只读缓存层
Informer和Lister是构建控制器(或者叫Operetor)的基本要素。使用这4个代码生成器可以创建全功能的、和K8S上游控制器工作机制相同的production-ready的控制器。
code-generator还包含一些其它的代码生成器。例如Conversion-gen负责产生内外部类型的转换函数、Defaulter-gen负责处理字段默认值。
crd-code-generation是使用代码生成器的一个示例项目,可以作为你的实际项目的起点。
code-generator基于k8s.io/gengo实现,两者共享一部分命令行标记。大部分的生成器支持--input-dirs参数来读取一系列输入包,处理其中的每个类型,然后生成代码:
- 部分代码生成到输入包所在目录,例如deepcopy-gen生成器。可以使用参数 --output-file-base "zz_generated.deepcopy"来定义输出文件名
- 其它代码生成到--output-package指定的目录(通常为pkg/client),例如client-gen、informer-gem、lister-gen等生成器
开发CRD时,你可以使用generator-group.sh脚本而不是逐个手工调用生成器。通常可以在项目中编写hack/update-codegen.sh:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 此脚本以项目的根目录为工作目录 #!/bin/bash set -o errexit set -o nounset set -o pipefail SCRIPT_ROOT=$(dirname ${BASH_SOURCE})/.. # 代码生成器包位置 CODEGEN_PKG=${CODEGEN_PKG:-$(cd ${SCRIPT_ROOT}; ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ${GOPATH}/src/k8s.io/code-generator)} # generate-groups.sh # 使用哪些生成器,可选值deepcopy,defaulter,client,lister,informer,逗号分隔,all表示全部使用 # 输出包的导入路径 # CR定义所在路径 # API组和版本 vendor/k8s.io/code-generator/generate-groups.sh all \ github.com/openshift-evangelists/crd-code-generation/pkg/client \ github.com/openshift-evangelists/crd-code-generation/pkg/apis \ example.com:v1 \ # 自动生成的源码,头部附加的内容 --go-header-file ${SCRIPT_ROOT}/hack/custom-boilerplate.go.txt |
执行上面的脚本后,所有API代码会生成在pkg/apis目录下,clientsets、informers、listers则生成在pkg/client目录下。
你可以进一步提供hack/verify-codegen.sh脚本,用于判断生成的代码是否up-to-date:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#!/bin/bash set -o errexit set -o nounset set -o pipefail # 先调用update-codegen.sh生成一份新代码,然后对比新老代码是否一样 SCRIPT_ROOT=$(dirname "${BASH_SOURCE}")/.. DIFFROOT="${SCRIPT_ROOT}/pkg" TMP_DIFFROOT="${SCRIPT_ROOT}/_tmp/pkg" _tmp="${SCRIPT_ROOT}/_tmp" cleanup() { rm -rf "${_tmp}" } trap "cleanup" EXIT SIGINT cleanup mkdir -p "${TMP_DIFFROOT}" cp -a "${DIFFROOT}"/* "${TMP_DIFFROOT}" "${SCRIPT_ROOT}/hack/update-codegen.sh" echo "diffing ${DIFFROOT} against freshly generated codegen" ret=0 diff -Naupr "${DIFFROOT}" "${TMP_DIFFROOT}" || ret=$? cp -a "${TMP_DIFFROOT}"/* "${DIFFROOT}" if [[ $ret -eq 0 ]] then echo "${DIFFROOT} up to date." else echo "${DIFFROOT} is out of date. Please run hack/update-codegen.sh" exit 1 fi |
除了通过命令行标记控制代码生成器之外,你还可以在go源码中使用tag来设定一些供生成器使用的属性。这些tag分为两类:
- 在doc.go的package语句之上提供的全局tag
- 在需要被处理的类型上提供的局部tag
tag的语法如下:
|
1 2 3 |
// +tag-name // 或者 // +tag-name=value |
也就是说,tag是以注释的形式存在的。tag的位置很重要,很多tag必须直接位于type或package语句的上一行,另外一些则必须和go语句隔开至少一行空白。
必须在目标包的doc.go文件中声明,典型路径是 pkg/apis///doc.go。 内容示例:
|
1 2 3 4 5 6 7 8 9 10 |
// 为包中任何类型生成深拷贝方法,可以在局部tag覆盖此默认行为 // register关键字现在已经不需要,它的含义是将深拷贝方法注册到scheme中, // 从1.9开始scheme不再负责runtime.Object的深拷贝 // 你只需要直接调用obj.DeepCopy/DeepCopyObject()即可 // +k8s:deepcopy-gen=package,register // groupName指定API组的全限定名 // 此API组的v1版本,放在同一个包中 // +groupName=example.com package v1 |
要么直接声明在类型之前,要么位于类型之前的第二个注释块中。下面的 types.go中声明了CR对应的go类型:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
// 为当前类型生成客户端,如果不加此注解则无法生成lister、informer等包 // +genclient // 提示此类型不基于/status子资源来实现spec-status分离,产生的客户端不具有UpdateStatus方法 // 否则,只要类型具有Status字段,就会生成UpdateStatus方法 // +genclient:noStatus // 为每个顶级API类型添加: // +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object // K8S资源,数据库 type Database struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"` Spec DatabaseSpec `json:"spec"` } // 不为此类型生成深拷贝方法 // +k8s:deepcopy-gen=false // 数据库的Spec type DatabaseSpec struct { User string `json:"user"` Password string `json:"password"` Encoding string `json:"encoding,omitempty"` } // +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object // K8S资源,数据库列表 type DatabaseList struct { metav1.TypeMeta `json:",inline"` metav1.ListMeta `json:"metadata"` Items []Database `json:"items"` } |
内嵌了metav1.TypeMeta的资源通常都是顶级类型,实现runtime.Object,一般需要为它们生成client。
对于集群级别(非命名空间内)的资源,你需要提供:
|
1 2 3 4 |
// +genclient:nonNamespaced // 无论何时,下面的Tag不能少 // +genclient |
你还可以控制客户端提供哪些HTTP方法:
|
1 2 3 4 5 6 7 8 |
// +genclient:noVerbs // +genclient:onlyVerbs=create,delete // +genclient:skipVerbs=get,list,create,update,patch,delete,deleteCollection,watch // 仅仅返回Status而非整个资源 // +genclient:method=Create,verb=create,result=k8s.io/apimachinery/pkg/apis/meta/v1.Status // 无论何时,下面的Tag不能少 // +genclient |
项目的源码:https://git.gmem.cc/alex/demo-k8s-codegen.git。
使用dep进行依赖管理:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
required = ["k8s.io/code-generator/cmd/client-gen"] [[constraint]] name = "k8s.io/apimachinery" branch = "release-1.12" [[constraint]] name = "k8s.io/client-go" branch = "release-9.0" [[constraint]] name = "k8s.io/code-generator" branch = "release-1.12" |
执行dep init 初始化项目,执行dep ensure下载依赖到vendor目录。
artifacts目录下存放CRD/CR的样例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: springbootapps.gmem.cc spec: group: gmem.cc names: kind: SpringBootApp listKind: SpringBootAppList plural: springbootapps scope: Namespaced version: v1 |
|
1 2 3 4 5 6 7 |
apiVersion: gmem.cc/v1 kind: SpringBootApp metadata: name: dubbo-exporter spec: jdkVersion: 1.8 source: https://github.com/gmemcc/dubbo_exporter.git |
此CRD没有对CR的字段进行任何限定,如果需要进行验证,请使用validation。
hack目录存放的是执行代码生成的脚本,参考crd-code-generation项目的脚本,修改一下即可:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/bin/bash set -o errexit set -o nounset set -o pipefail SCRIPT_ROOT=$(dirname ${BASH_SOURCE})/.. CODEGEN_PKG=${CODEGEN_PKG:-$(cd ${SCRIPT_ROOT}; ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ${GOPATH}/src/k8s.io/code-generator)} vendor/k8s.io/code-generator/generate-groups.sh all \ git.gmem.cc/alex/demo-k8s-codegen/pkg/client \ git.gmem.cc/alex/demo-k8s-codegen/pkg/apis \ gmem.cc:v1 |
pkg/apis里面存放的是自定义资源的Go源码,以及deepcopy生成的zz_generated.deepcopy.go。
pkg/client里面存放的全部是自动生成的代码,包括clientset、informers、listers。
首先执行一次 dep ensure。相关依赖会下载到vendor目录下,由于k8s.io/client-go没有被import,因此不会下载。
调用update-codegen.sh,会生成若干个源码文件,如下图褐色字体所示:
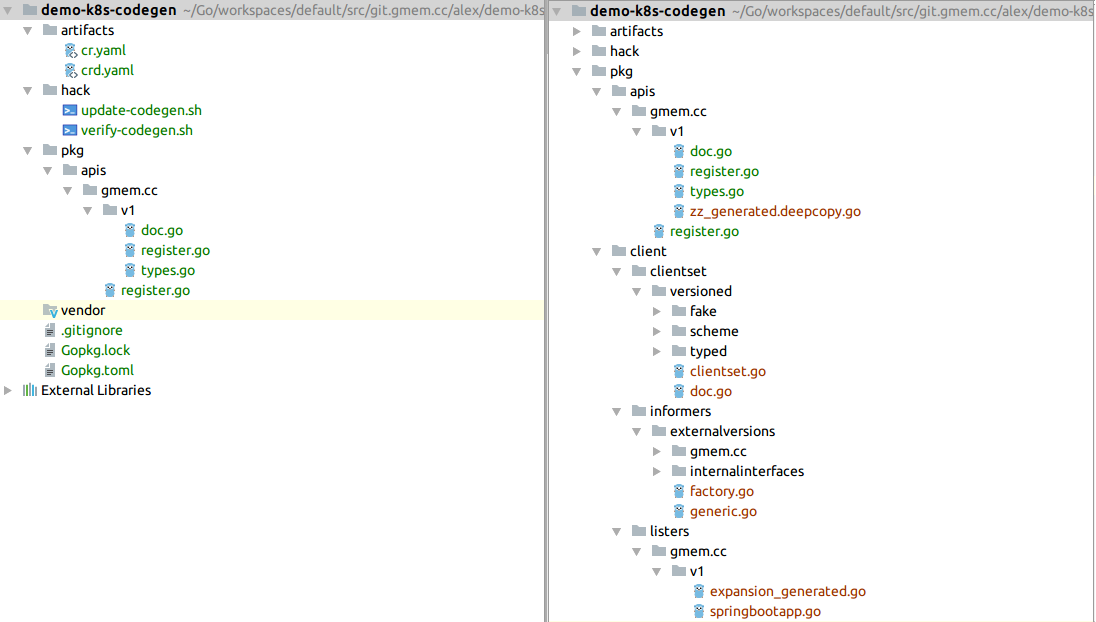 再执行一次
dep ensure。 缺少的client-go依赖会自动下载。
再执行一次
dep ensure。 缺少的client-go依赖会自动下载。
首先创建CRD:
|
1 |
kubectl apply -f artifacts/crd.yaml |
然后创建一个CR:
|
1 |
kubectl apply -f artifacts/cr.yaml |
执行下面的命令可以看到已经创建的CR列表:
|
1 |
kubectl get springbootapps |
然后,编写一段测试代码,使用上述自动生成的clientset:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
package main import ( gmem "git.gmem.cc/alex/demo-k8s-codegen/pkg/client/clientset/versioned" "k8s.io/client-go/tools/clientcmd" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "github.com/golang/glog" "flag" ) func main() { flag.Parse() cfg, _ := clientcmd.BuildConfigFromFlags("http://127.0.0.1:6443", "") clientset := gmem.NewForConfigOrDie(cfg) app, err := clientset.GmemV1().SpringBootApps("default").Get("dubbo-exporter", metav1.GetOptions{}) if err != nil { glog.Error(err) } println(app.Spec.JdkVersion) } |
Operator Framework是一个开源工具箱,用于更高效的、自动化的、支持扩容的管理K8S Native应用程序。 该工具箱由CoreOS开发,目前尚处于alpha阶段,但是由controller-runtime提供的核心API已经比较稳定。
Operator是打包、部署、管理K8S应用程序(这里指既部署在K8S上,也通过K8S API或kubectl管理的应用程序)的方法。从概念上说,Operator将运维人员的运维知识编码到软件中,使之更容易打包、和客户分享。Operator比运维人员的人工判断要敏捷的多,它可以观测集群/应用的当前状态并在若干毫秒之内作出合理的运维决定。
Operator遵循如下成熟度模型:
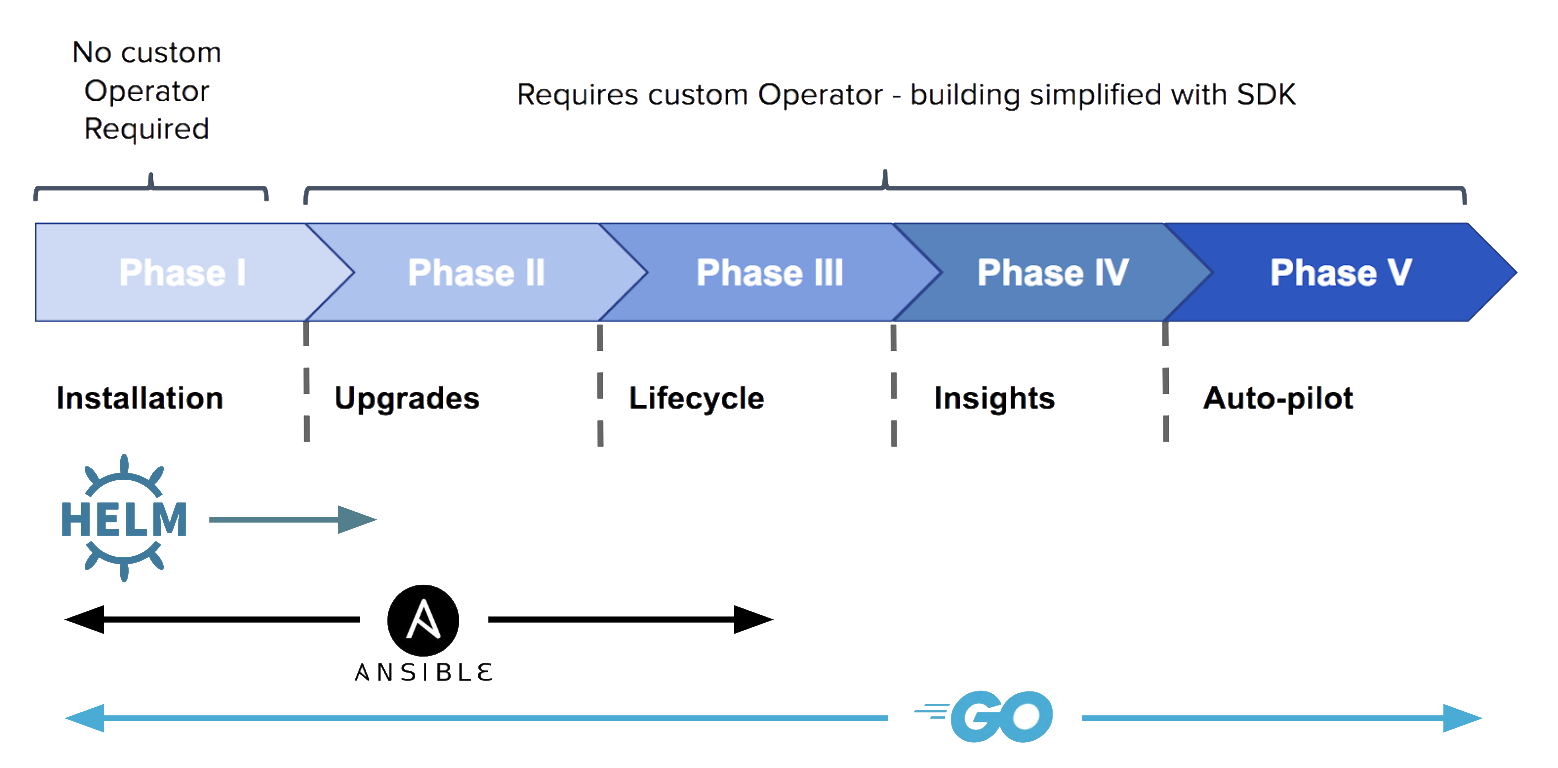 可以实现基本的自动化运维,也可以定制针对特定应用程序的逻辑。高级的Operator可以实现无缝升级、自动处理故障……
可以实现基本的自动化运维,也可以定制针对特定应用程序的逻辑。高级的Operator可以实现无缝升级、自动处理故障……
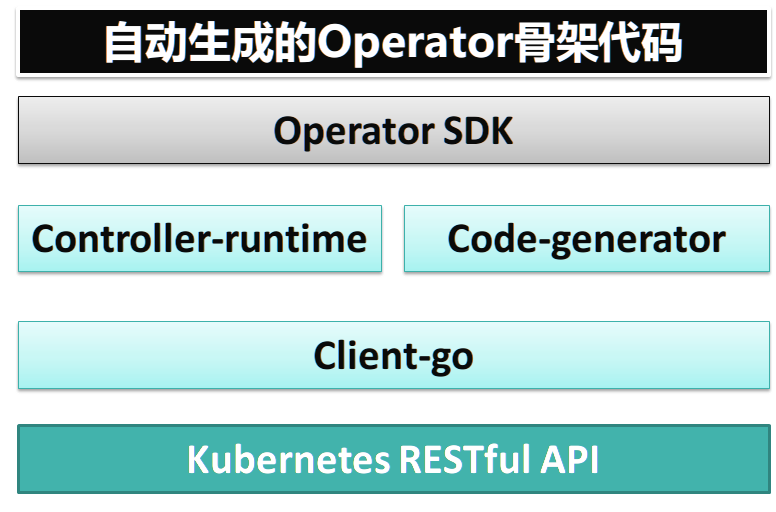
Operator Framework由以下三部分组成:
- Operator SDK:对开发者屏蔽K8S API的复杂性,简化Operator/Controller的开发
- Operator Lifecycle Management:管理应用的安装、升级,管理K8S集群中运行的所有Operator(以及关联的Service)的生命周期
- Operator Metering:提供Operator运行状况的监控指标
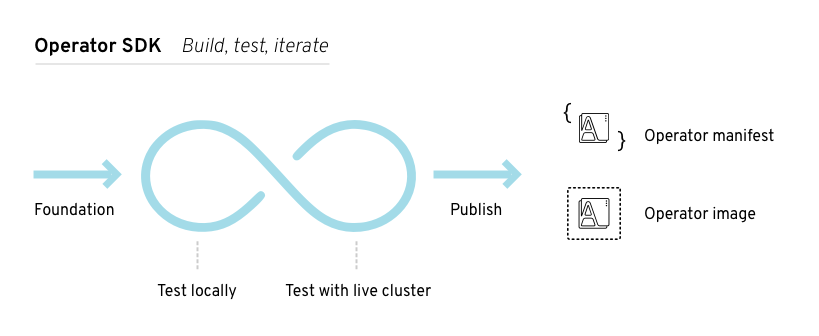
Operator SDK包含了构建、测试、打包Operator的工具。基于controller-runtime库,它提供了:
- 高层次的API和抽象,让你能编写更加直白的运维逻辑
- 用于快速开始一个新项目的代码生成器和脚手架
- 覆盖一些通用Operator用例的模式,不需要重复造轮子
是运行在集群中的各种Operator的总控中心,它可以控制哪些Operator可以在哪些命名空间中运行,哪些用户可以和Operator进行交互。Lifecycle Manager也负责Operator及其关联资源的整体上的生命周期管理 —— 例如触发Operator及其关联资源的更新。
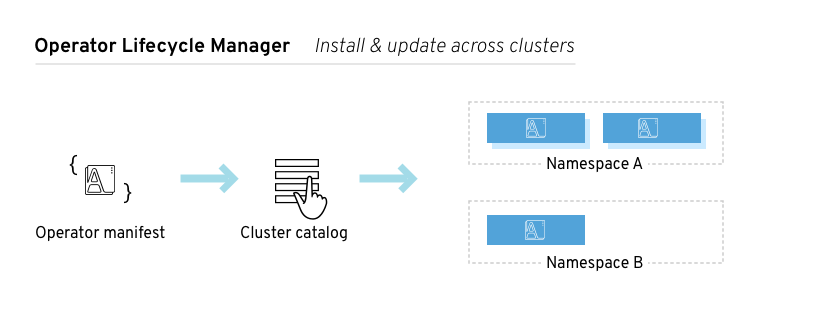 对于简单的无状态应用,无需编写代码,直接使用通用Operator(例如Helm Operator)即可。对于复杂的有状态应用,自定义Operator的价值更为突显,“云风格的”特性可以嵌入到Operator代码中,实现自动化的扩容、更新、备份,以提升用户体验。
对于简单的无状态应用,无需编写代码,直接使用通用Operator(例如Helm Operator)即可。对于复杂的有状态应用,自定义Operator的价值更为突显,“云风格的”特性可以嵌入到Operator代码中,实现自动化的扩容、更新、备份,以提升用户体验。
在未来,Operator Framework将提供度量应用程序指标的能力。
你可以基于Go/Ansible开发Opearator 。基于Go的典型工作流程如下:
- 使用SDK的CLI,创建一个新的Operator项目
- 添加CRD,并定义一个新的资源API
- 定义监控、调和(reconcile,通过适当的操作让资源接近期望状态)资源的控制器
- 使用SDK、controller-runtime API来开发调和逻辑
- 使用SDK CLI来构建、生成Operator的部署清单文件
开发Operator需要以下前置条件:dep 0.5+、git、go 1.10+、docker 17.03+、kubectl 1.11.0+,以及一个运行中的1.11.0+版本的K8S集群。
|
1 2 3 4 5 6 7 |
mkdir -p $GOPATH/src/github.com/operator-framework cd $GOPATH/src/github.com/operator-framework git clone https://github.com/operator-framework/operator-sdk cd operator-sdk git checkout master make dep make install |
最新版本的Operator SDK使用Go modules机制,你需要设置环境变量:
|
1 2 |
export GO111MODULE=on # 如果不设置该环境变量你会遇到Dependency manager "modules" has been selected but go modules are not active...错误 |
如果你的网络无法访问Google,设置环境变量:
|
1 2 |
# 设置Go模块下载代理站点 export GOPROXY=https://goproxy.io |
|
1 2 |
cd ~/Go/workspaces/default/src/git.gmem.cc/alex operator-sdk new demo-operator |
上述脚本执行后,会自动调用dep init创建项目,调用dep ensure下载依赖,并初始化Git仓库。
最新版本的Operator SDK基于Go modules作为依赖管理工具而非dep。
|
1 |
operator-sdk add api --api-version=gmem.cc/v1 --kind=SpringBootApp |
上述命令完成后,会在pkg/apis目录下自动生成一系列文件,类似于code-generator。
执行下面的命令,为上节的API(资源)生成控制器:
|
1 |
operator-sdk add controller --api-version=gmem.cc/v1 --kind=SpringBootApp |
上述命令完成后,会在pkg/controller目录生成控制器源码。
|
1 |
go mod vendor |
完成Operator逻辑开发后,执行下面的命令可以打包Docker镜像:
|
1 2 |
operator-sdk build docker.gmem.cc/operators/demo-operator docker push docker.gmem.cc/operators/demo-operator |
注意需要修改deploy/operator.yaml中的REPLACE_IMAGE为实际镜像名:
|
1 |
sed -i 's|REPLACE_IMAGE|docker.gmem.cc/operators/demo-operator|g' deploy/operator.yaml |
在开发期间,一般在本地运行Operator,以便快速测试和调试:
|
1 2 3 4 |
# 通过环境变量设置Operator名称 export OPERATOR_NAME=memcached-operator # 启动Operator,会自动使用$HOME/.kube/config。你可以用--kubeconfig=指定kubeconfig operator-sdk up local --namespace=default |
deploy目录下包括Operator对应的各种K8S资源,包括Deployment、Role、ServiceAccount,以及CRD和CR的样例。可以直接使用kubectl部署:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/gmem_v1_springbootapp_crd.yaml # Deploy the app-operator kubectl create -f deploy/operator.yaml # 清理 kubectl delete -f deploy/operator.yaml kubectl delete -f deploy/role.yaml kubectl delete -f deploy/role_binding.yaml kubectl delete -f deploy/service_account.yaml kubectl delete -f deploy/crds/gmem_v1_springbootapp_crd.yaml |
开发阶段完成后,建议使用Helm Chart打包封装。
基于operator-sdk生成的Operator项目,其目录结构如下:
| 目录/文件 | 说明 |
| cmd |
manager/main.go为主函数,它:
|
| pkg/apis | 包含CRD的API,开发人员需要编辑pkg/apis/GROUP/VERSION/KIND_types.go文件,为资源添加必要的字段 |
| pkg/controller | 包含控制器的实现,开发人员需要编辑pkg/controller/KIND/KIND_controller.go,实现KIND资源的Reconcile逻辑 |
| build | 包含Dockerfile,以及构建Operator所需的脚本 |
| deploy | YAML形式的K8S资源定义文件,用于注册CRD、创建RABC、Deployment等资源 |
| Gopkg.* | Go Dep的清单文件 |
| vendor | 为了满足项目import需要的外部依赖的副本 |
cmd/manager/main.go为Operator的入口点,它初始化一个Manager并运行。Manager会自动注册pkg/apis/下的自定义资源的Scheme,并运行pkg/controller/下的所有控制器。
Manager可以限制所有控制器可以监控的命名空间:
|
1 |
mgr, err := manager.New(cfg, manager.Options{Namespace: namespace}) |
默认情况下监控Operator所在的命名空间,要监控所有命名空间,可以:
|
1 |
mgr, err := manager.New(cfg, manager.Options{Namespace: ""}) |
要添加新的CRD,执行:
|
1 |
operator-sdk add api --api-version=cache.gmem.cc/v1alpha1 --kind=Memcached |
之后你可以修改CR的Spec和Status类型,添加新字段:
|
1 2 3 4 5 6 |
type MemcachedSpec struct { Size int32 `json:"size"` } type MemcachedStatus struct { Nodes []string `json:"nodes"` } |
修改*_types.go文件后,必须执行下面的命令,更新自动生成的代码:
|
1 |
operator-sdk generate k8s |
如果需要生成相应的Open API模型,还需要:
|
1 |
operator-sdk generate k8s |
你需要为每个CRD添加控制器:
|
1 |
operator-sdk add controller --api-version=cache.gmem.cc/v1alpha1 --kind=Memcached |
然后,你需要完成Operator调和逻辑的开发。例如,针对每个CR:
- 如果Deployment不存在,则创建之
- 确保Deployment的副本数满足MemcachedSpec.Size
- 更新MemcachedStatus,也就是CR的Status字段
每个控制器都有一个Reconciler对象,该对象具有Reconcile()方法。Reconcile方法中实现了调和循环。调和循环接受Request参数,这是一个结构,它包含Namespace/Name形式的字串,可用于从缓存中查询到实际的对象:
|
1 2 3 4 5 |
func (r *ReconcileMemcached) Reconcile(request reconcile.Request) (reconcile.Result, error) { memcached := &cachev1alpha1.Memcached{} err := r.client.Get(context.TODO(), request.NamespacedName, memcached) ... } |
根据你提供的返回值,Request可能被重新入队,导致调和循环再次触发:
|
1 2 3 4 5 6 |
// 调和成功,不再入队 return reconcile.Result{}, nil // 调和失败,重新入队 return reconcile.Result{}, err // 虽然成功,但是由于其它原因,重新入队 return reconcile.Result{Requeue: true}, nil |
你可以控制重新入队的延迟时间:
|
1 2 3 |
import "time" // 5秒后重新入队 return reconcile.Result{RequeueAfter: time.Second*5}, nil |
将控制器添加到Manager的时候,你需要发起资源监控,否则不会自动执行调和循环。
调用下面的方法可以监控针对CR的任何Add/Update/Delete事件,并发送Request对象给调和循环(Reconcile loop):
|
1 |
err := c.Watch( &source.Kind{Type: &cachev1alpha1.Memcached{}}, &handler.EnqueueRequestForObject{} ) |
调用下面的方法可以监控CR对应的Deployment(子对象),并发送Request —— 此Request将Deployment和它的Owner(也就是Memcached对象)关联起来:
|
1 2 3 4 |
err := c.Watch(&source.Kind{Type: &appsv1.Deployment{}}, &handler.EnqueueRequestForOwner{ IsController: true, OwnerType: &cachev1alpha1.Memcached{}, }) |
在本节我们分析一下Operator SDK自动生成的代码框架的逻辑。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
func main() { // 获取Operator需要监控的命名空间,通过环境变量设置命名空间 namespace, err := k8sutil.GetWatchNamespace() // 获取配置,如果命令行没有传递kubeconfig,master,则使用当前用户的.kube/config cfg, err := config.GetConfig() // 创建管理器,并创建共享组件,启动所有控制器 mgr, err := manager.New(cfg, manager.Options{Namespace: namespace}) // 为所有资源注册Scheme if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Fatal(err) } // 添加所有控制器 if err := controller.AddToManager(mgr); err != nil { log.Fatal(err) } // 启动缓存、所有控制器 mgr.Start(signals.SetupSignalHandler()) } |
manager.New函数负责初始化全局的管理器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
func New(config *rest.Config, options Options) (Manager, error) { options = setOptionsDefaults(options) // 返回一个meta.RESTMapper // 用于将资源映射为GroupVersionKind,将GroupKind映射到操控资源的接口 mapper, err := options.MapperProvider(config) // 创建写客户端 // Scheme 负责Go结构体和GroupVersionKind之间的映射,后者是包含Group + Version + Kind三字符串的结构体 // Mapper 负责GroupVersionKind和资源(GroupVersionResource)之间的映射 writeObj, err := options.newClient(config, client.Options{Scheme: options.Scheme, Mapper: mapper}) // 创建读客户端并注册Informer cache, err := options.newCache(config, cache.Options{Scheme: options.Scheme, Mapper: mapper, Resync: options.SyncPeriod, Namespace: options.Namespace}) // 创建recorder.Provider,此对象用于record.EventRecorder // EventRecorder用于为EventSource产生事件并放入队列等待发送 recorderProvider, err := options.newRecorderProvider(config, options.Scheme, log.WithName("events")) // 资源锁用于Leader选举 resourceLock, err := options.newResourceLock(config, recorderProvider, leaderelection.Options{ LeaderElection: options.LeaderElection, LeaderElectionID: options.LeaderElectionID, LeaderElectionNamespace: options.LeaderElectionNamespace, }) // 用于解码admission.Request admissionDecoder, err := options.newAdmissionDecoder(options.Scheme) // 控制器管理器结构体 return &controllerManager{ config: config, scheme: options.Scheme, admissionDecoder: admissionDecoder, errChan: make(chan error), cache: cache, fieldIndexes: cache, client: client.DelegatingClient{ Reader: &client.DelegatingReader{ CacheReader: cache, ClientReader: writeObj, }, Writer: writeObj, StatusClient: writeObj, }, recorderProvider: recorderProvider, resourceLock: resourceLock, mapper: mapper, runnables: nil, // 控制器集合,管理器会向其注入依赖,并启动 }, nil } |
创建控制器的逻辑在入口点中:
|
1 |
controller.AddToManager(mgr) |
AddToManager是自动生成的:
|
1 2 3 4 5 6 7 8 9 10 11 |
var AddToManagerFuncs []func(manager.Manager) error // 添加所有控制器到Manager func AddToManager(m manager.Manager) error { for _, f := range AddToManagerFuncs { if err := f(m); err != nil { return err } } return nil } |
每个控制器为AddToManagerFuncs添加一个成员,用于注册自己:
|
1 2 3 |
func init() { AddToManagerFuncs = append(AddToManagerFuncs, springbootapp.Add) } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
package springbootapp func Add(mgr manager.Manager) error { return add(mgr, newReconciler(mgr)) } func add(mgr manager.Manager, r reconcile.Reconciler) error { // 创建一个控制器对象 c, err := controller.New("springbootapp-controller", mgr, controller.Options{Reconciler: r}) // 监控主资源 —— SpringBootApp err = c.Watch(&source.Kind{Type: &gmemv1.SpringBootApp{}}, &handler.EnqueueRequestForObject{}) // 监控依赖主资源的dependent资源。这些dependent的Owner为SpringBootApp // 自动转换为SpringBootApp事件并入队 // 创建一个事件源,只需要指定资源类型即可 // 该函数最后会调用source.Start方法,后者会获得资源类型对应的Informer,并注册事件处理器 err = c.Watch(&source.Kind{Type: &corev1.Pod{}}, &handler.EnqueueRequestForOwner{ IsController: true, OwnerType: &gmemv1.SpringBootApp{}, }) return nil } |
控制器是通过调用Controller接口的Start方法实现的。此方法会启动协程,协程的逻辑和4.3节手工编写的控制器基本一样,它调用Reconciler.Reconcile进行调和。
自动生成的框架代码中,提供了Reconciler的样例逻辑 —— 创建Pod:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
func (r *ReconcileSpringBootApp) Reconcile(request reconcile.Request) (reconcile.Result, error) { // 存放资源的结构 instance := &gmemv1.SpringBootApp{} // 查询资源 err := r.client.Get(context.TODO(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // 资源找不到,可能在当前事件发生后,本调和循环执行前被删除了 // 资源管理的dependent会自动删除 // 如果需要实现额外的清理逻辑,考虑使用finalizers // 返回且不重新入队 return reconcile.Result{}, nil } // 其它错误,重新入队 return reconcile.Result{}, err } // 创建一个Pod pod := newPodForCR(instance) // 设置其Owner并结束调和 if err := controllerutil.SetControllerReference(instance, pod, r.scheme); err != nil { return reconcile.Result{}, err } // 查询看看目标Pod是否已经存在 found := &corev1.Pod{} err = r.client.Get(context.TODO(), types.NamespacedName{Name: pod.Name, Namespace: pod.Namespace}, found) if err != nil && errors.IsNotFound(err) { // 如果目标Pod不存在,则在API Server上创建之 err = r.client.Create(context.TODO(), pod) // 如果创建失败则重新入队 if err != nil { return reconcile.Result{}, err } return reconcile.Result{}, nil } else if err != nil { // 其它错误,不重现入队 return reconcile.Result{}, err } return reconcile.Result{}, nil } |
Kubebuilder是一个开发CRD的框架,Operator Framework也在使用它。Kubebuilder辅助项目创建、CRD创建、调和循环编写、测试、镜像制作等开发流程,它提供了注释驱动( //+)的代码生成器。
|
1 2 3 4 5 6 7 8 9 |
# 安装 kustomize go install sigs.k8s.io/kustomize/kustomize/v3 # 安装kubebuilder os=$(go env GOOS) arch=$(go env GOARCH) curl -sL https://go.kubebuilder.io/dl/2.0.1/${os}/${arch} | tar -xz -C /tmp/ sudo mv /tmp/kubebuilder_2.0.1_${os}_${arch}/* /usr/local/kubebuilder |
|
1 2 3 4 5 6 |
mkdir $GOPATH/src/cronjob cd $GOPATH/src/cronjob export GO111MODULE=on kubebuilder init --domain git.gmem.cc |
上述命令执行了,会自动生成一系列代码、配置文件,并且下载依赖包,最后进行构建。最终产生的目录结构如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
. ├── bin │ └── manager ├── config # 各种K8S配置文件,使用kustomize进行资源定制化 │ ├── certmanager # 证书管理器,用于生成Webhook服务器的证书 │ ├── default # kustomize base │ ├── manager # 控制器管理器 │ ├── rbac # 权限控制 │ └── webhook # Webhook服务器 ├── Dockerfile ├── go.mod ├── go.sum ├── hack │ └── boilerplate.go.txt ├── main.go # 入口点 ├── Makefile ├── PROJECT # kubebuilder元数据,用于生成新组件的框架代码 |
通过查看入口点代码可以看出,和Operator Framework一样,kubebuilder使用controller-runtime库:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
package main import ( "flag" "os" "k8s.io/apimachinery/pkg/runtime" clientgoscheme "k8s.io/client-go/kubernetes/scheme" _ "k8s.io/client-go/plugin/pkg/client/auth/gcp" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/log/zap" // +kubebuilder:scaffold:imports ) var ( // 任何一组控制器都需要一个Scheme scheme = runtime.NewScheme() setupLog = ctrl.Log.WithName("setup") ) func init() { // 注册Scheme,Scheme提供API Kind到Go类型的映射 _ = clientgoscheme.AddToScheme(scheme) // +kubebuilder:scaffold:scheme } func main() { var metricsAddr string var enableLeaderElection bool flag.StringVar(&metricsAddr, "metrics-addr", ":8080", "The address the metric endpoint binds to.") flag.BoolVar(&enableLeaderElection, "enable-leader-election", false, "Enable leader election for controller manager. Enabling this will ensure there is only one active controller manager.") flag.Parse() // 使用Zap作为日志库 ctrl.SetLogger(zap.Logger(true)) // Manager负责跟踪所有控制器、Webhook mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{ Scheme: scheme, // 可以限制watch哪个命名空间 Namespace: namespace, MetricsBindAddress: metricsAddr, LeaderElection: enableLeaderElection, Port: 9443, }) if err != nil { setupLog.Error(err, "unable to start manager") os.Exit(1) } // +kubebuilder:scaffold:builder setupLog.Info("starting manager") if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil { setupLog.Error(err, "problem running manager") os.Exit(1) } } |
要watch指定的几个命名空间,可以使用:
|
1 2 3 4 5 |
var namespaces []string mgr, err = ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{ NewCache: cache.MultiNamespacedCacheBuilder(namespaces), }) |
|
1 |
kubebuilder create api --group batch --version v1 --kind CronJob |
上述命令将在api目录中生成自定义资源的Go类型:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
package v1 import ( metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) type CronJobSpec struct { } type CronJobStatus struct { } // 下面注释称为标记(Marker)为负责代码/YAML生成的controller-tools提供额外的信息 // 告知object生成器,此类型是一个资源Kind,需要(在zz_generated.deepcopy.go文件中)自动实现runtime.Object接口 // +kubebuilder:object:root=true type CronJob struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"` Spec CronJobSpec `json:"spec,omitempty"` Status CronJobStatus `json:"status,omitempty"` } // +kubebuilder:object:root=true type CronJobList struct { metav1.TypeMeta `json:",inline"` metav1.ListMeta `json:"metadata,omitempty"` Items []CronJob `json:"items"` } func init() { // 注册此Kind到GV SchemeBuilder.Register(&CronJob{}, &CronJobList{}) } |
自定义资源的GV信息定义在另一个文件中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// +kubebuilder:object:generate=true // +groupName=batch.git.gmem.cc package v1 import ( "k8s.io/apimachinery/pkg/runtime/schema" "sigs.k8s.io/controller-runtime/pkg/scheme" ) var ( // Group前缀取决于你创建项目时的--domain参数 GroupVersion = schema.GroupVersion{Group: "batch.git.gmem.cc", Version: "v1"} SchemeBuilder = &scheme.Builder{GroupVersion: GroupVersion} AddToScheme = SchemeBuilder.AddToScheme ) |
创建API的时候,kubebuilder会交互式的提示,是否创建控制器。如果选择是,则会在controllers包生成控制器模板代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
package controllers import ( "context" "github.com/go-logr/logr" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" batchv1 "git.gmem.cc/cronjob/api/v1" ) type CronJobReconciler struct { client.Client Log logr.Logger } // 下面的标记用于生成控制器所必须的RBAC权限定义 // +kubebuilder:rbac:groups=batch.git.gmem.cc,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups=batch.git.gmem.cc,resources=cronjobs/status,verbs=get;update;patch func (r *CronJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) { _ = context.Background() _ = r.Log.WithValues("cronjob", req.NamespacedName) // 调和逻辑在此编写 return ctrl.Result{}, nil } func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error { // 注册到控制器管理器 return ctrl.NewControllerManagedBy(mgr).For(&batchv1.CronJob{}).Complete(r) } |
如果需要为CRD实现Admission Webhooks,仅仅实现Defaulter、 Validator接口即可。kubbuilder会自动完成其它工作:
- 创建Webhook服务器
- 确保Webhook服务器被控制器管理器管理
- 创建Webhook需要的Handlers
- 将Handler注册到URL路径
注意:大部分校验仅仅通过添加Marker即可实现,不需要Validating Webhook。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
package v1 import ( "github.com/robfig/cron" apierrors "k8s.io/apimachinery/pkg/api/errors" "k8s.io/apimachinery/pkg/runtime" "k8s.io/apimachinery/pkg/runtime/schema" validationutils "k8s.io/apimachinery/pkg/util/validation" "k8s.io/apimachinery/pkg/util/validation/field" ctrl "sigs.k8s.io/controller-runtime" logf "sigs.k8s.io/controller-runtime/pkg/runtime/log" "sigs.k8s.io/controller-runtime/pkg/webhook" ) // +kubebuilder:docs-gen:collapse=Go imports // 为webhook创建独立的日志器 var cronjoblog = logf.Log.WithName("cronjob-resource") // 注册到管理器 func (r *CronJob) SetupWebhookWithManager(mgr ctrl.Manager) error { return ctrl.NewWebhookManagedBy(mgr).For(r).Complete() } // 下面的Marker用于生成Mutating Webhook清单文件 // +kubebuilder:webhook:path=/mutate-batch-git-gmem-cc-v1-cronjob,mutating=true, // failurePolicy=fail,groups=batch.git.gmem.cc,resources=cronjobs, // verbs=create;update,versions=v1,name=mcronjob.kb.io // 实现该接口,为CRD字段提供默认值 var _ webhook.Defaulter = &CronJob{} func (r *CronJob) Default() { cronjoblog.Info("default", "name", r.Name) if r.Spec.ConcurrencyPolicy == "" { r.Spec.ConcurrencyPolicy = AllowConcurrent } } // 下面的Marker用于生成Validating Webhook清单文件 // 校验哪些操作 // +kubebuilder:webhook:verbs=create;update;delete,path=/validate-batch-git-gmem-cc-v1-cronjob, // mutating=false,failurePolicy=fail,groups=batch.git.gmem.cc, // resources=cronjobs,versions=v1,name=vcronjob.kb.io // 实现校验接口 var _ webhook.Validator = &CronJob{} func (r *CronJob) ValidateCreate() error { cronjoblog.Info("validate create", "name", r.Name) return r.validateCronJob() } func (r *CronJob) ValidateUpdate(old runtime.Object) error { cronjoblog.Info("validate update", "name", r.Name) return r.validateCronJob() } func (r *CronJob) ValidateDelete() error { cronjoblog.Info("validate delete", "name", r.Name) return nil } func (r *CronJob) validateCronJob() error { var allErrs field.ErrorList if err := r.validateCronJobName(); err != nil { allErrs = append(allErrs, err) } if err := r.validateCronJobSpec(); err != nil { allErrs = append(allErrs, err) } if len(allErrs) == 0 { return nil } return apierrors.NewInvalid(schema.GroupKind{Group: "batch.tutorial.kubebuilder.io", Kind: "CronJob"},r.Name, allErrs) } func (r *CronJob) validateCronJobSpec() *field.Error { return validateScheduleFormat(r.Spec.Schedule,field.NewPath("spec").Child("schedule")) } func validateScheduleFormat(schedule string, fldPath *field.Path) *field.Error { if _, err := cron.ParseStandard(schedule); err != nil { return field.Invalid(fldPath, schedule, err.Error()) } return nil } // +kubebuilder:docs-gen:collapse=Validate object name |
kubebuilder建议使用cert-manager来自动为Webhook Server提供数字证书。
cert-manager包含了一个名为CA injector的组件,能够自动为MutatingWebhookConfiguration、ValidatingWebhookConfiguration注入CA bundle。要使用该特性只需要添加特定的注解即可。参考下面的kustomize patch:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
apiVersion: admissionregistration.k8s.io/v1beta1 kind: MutatingWebhookConfiguration metadata: name: mutating-webhook-configuration annotations: # 变量CERTIFICATE_NAMESPACE、CERTIFICATE_NAME会被kustomize替换 certmanager.k8s.io/inject-ca-from: $(CERTIFICATE_NAMESPACE)/$(CERTIFICATE_NAME) --- apiVersion: admissionregistration.k8s.io/v1beta1 kind: ValidatingWebhookConfiguration metadata: name: validating-webhook-configuration annotations: certmanager.k8s.io/inject-ca-from: $(CERTIFICATE_NAMESPACE)/$(CERTIFICATE_NAME) |
你可以在控制器中实现一段pre-delete钩子,直接编写在Reconile逻辑中即可。
Finalizers会导致delete变为update,设置一个删除时间戳。具有此时间戳的资源正在被删除,可以在控制器管理器的缓存中看到。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
func (r *CronJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) { ctx := context.Background() log := r.Log.WithValues("cronjob", req.NamespacedName) var cronJob batch.CronJob if err := r.Get(ctx, req.NamespacedName, &cronJob); err != nil { log.Error(err, "unable to fetch CronJob") return ctrl.Result{}, ignoreNotFound(err) } // 自定义Finalizer的名字 myFinalizerName := "storage.finalizers.tutorial.kubebuilder.io" // 检查 DeletionTimestamp 以确定对象是否正在被删除 if cronJob.ObjectMeta.DeletionTimestamp.IsZero() { // 对象不是正在被删除状态 // 如果没有此Finalizer,注册之 if !containsString(cronJob.ObjectMeta.Finalizers, myFinalizerName) { cronJob.ObjectMeta.Finalizers = append(cronJob.ObjectMeta.Finalizers, myFinalizerName) if err := r.Update(context.Background(), cronJob); err != nil { return ctrl.Result{}, err } } } else { // 对象正在被删除,并且注册了我们的Finalizer if containsString(cronJob.ObjectMeta.Finalizers, myFinalizerName) { // 在这里实现删除钩子逻辑,例如清理外部资源 if err := r.deleteExternalResources(cronJob); err != nil { // 如果清理失败,可以返回err以重试 return ctrl.Result{}, err } // 完成删除钩子逻辑后,删除掉Finalizer cronJob.ObjectMeta.Finalizers = removeString(cronJob.ObjectMeta.Finalizers, myFinalizerName) if err := r.Update(context.Background(), cronJob); err != nil { return ctrl.Result{}, err } } return ctrl.Result{}, err } } |
标记(Marker)是单行的、具有特殊格式的注释,它会影响kubebuilder的行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// 空标记,没有参数 // +kubebuilder:validation:Optional // 匿名标记,单个值作为参数 // +kubebuilder:validation:MaxItems=2 // 多参数标记,具有多个命名的参数 // +kubebuilder:printcolumn:JSONPath=".status.replicas",name=Replicas,type=string // 参数的值可以是int,string,boo,slice,map // +kubebuilder:validation:ExclusiveMaximum=false // +kubebulder:validation:Format="date-time" // 简单字符串可以不要引号 // +kubebuilder:validation:Type=string // +kubebuilder:validation:Maximum=42 // 切片语法 // +kubebuilder:webhooks:Enum={"hello","world"} // 切片语法,简化 // +kubebuilder:validation:Enum=Wallace;Gromit;Chicken // 映射语法 // +kubebuilder:validation:Default={magic: {numero: 42, stringified: forty-two}} |
使用这些标记时,都需要 //+kubebuilder:前缀:
| 标记 | 说明 | ||
| printcolumn |
注释在类型上,为kubectl get增加输出列,属性列表: JSONPath 输出的属性路径 示例:
|
||
| resource |
注释在类型上,配置资源的命名、范围,属性列表: categories 所属目录 示例:
|
||
| skipversion | 注释在类型上,移除特定的资源版本 | ||
| storageversion | 注释在类型上,声明基于此版本存储CRD | ||
| subresource:scale |
注释在类型上,定义scale子资源
|
||
| subresource:status | 注释在类型上,定义状态子资源
|
||
| skip | 注释在包上,不将此包作为API版本看待 |
参考:https://book.kubebuilder.io/reference/markers/crd-validation.html
| 标记 | 说明 |
|
kubebuilder:webhook |
注释在类型上,决定生成的Webhook配置是什么样的,属性列表: failurePolicy,string:如果API Server无法访问Webhook Server会怎样 |
使用这些标记时,都需要 //+kubebuilder:前缀:
| 标记 | 说明 |
| object:generate | 注释在类型上,是否为类型启用deepcopy生成 |
| object:root | 注释在类型上,是否为类型启用接口实现的生成 |
| object:generate | 注释在包上,是否启用此包的deepcopy生成、接口(runtime.Object)实现生成 |
| 标记 | 说明 |
|
kubebuilder:rbac |
注释在包上,用于生成一个RBAC ClusterRole清单文件,属性列表: groups,[]string 支持操作的组 |
默认情况下,kubebuilder会在controllers/suite_test.go生成测试套件的骨架代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
package controllers import ( "path/filepath" "testing" . "github.com/onsi/ginkgo" . "github.com/onsi/gomega" "k8s.io/client-go/kubernetes/scheme" "k8s.io/client-go/rest" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/envtest" "sigs.k8s.io/controller-runtime/pkg/envtest/printer" logf "sigs.k8s.io/controller-runtime/pkg/log" "sigs.k8s.io/controller-runtime/pkg/log/zap" ubrv1 "git.code.oa.com/tcnp/ubr-operators/api/v1" // +kubebuilder:scaffold:imports ) // These tests use Ginkgo (BDD-style Go testing framework). Refer to // http://onsi.github.io/ginkgo/ to learn more about Ginkgo. var cfg *rest.Config var k8sClient client.Client var testEnv *envtest.Environment // 执行定义在controllers/下的测试用例 func TestAPIs(t *testing.T) { RegisterFailHandler(Fail) RunSpecsWithDefaultAndCustomReporters(t, "Controller Suite", []Reporter{printer.NewlineReporter{}}) } var _ = BeforeSuite(func(done Done) { logf.SetLogger(zap.LoggerTo(GinkgoWriter, true)) By("bootstrapping test environment") // 使用envtest创建一个本地的K8S API Server testEnv = &envtest.Environment{ // envtest集群从自动生成的目录读取CRD CRDDirectoryPaths: []string{filepath.Join("..", "config", "crd", "bases")}, } var err error // 启动envtest集群 cfg, err = testEnv.Start() Expect(err).ToNot(HaveOccurred()) Expect(cfg).ToNot(BeNil()) // 添加CRD到Scheme err = ubrv1.AddToScheme(scheme.Scheme) Expect(err).NotTo(HaveOccurred()) // 下面这个注解,使得新添加的API自动添加到Scheme // +kubebuilder:scaffold:scheme // 在测试中使用下面这个K8S客户端 k8sClient, err = client.New(cfg, client.Options{Scheme: scheme.Scheme}) Expect(err).ToNot(HaveOccurred()) Expect(k8sClient).ToNot(BeNil()) close(done) }, 60) var _ = AfterSuite(func() { By("tearing down the test environment") // 清理 err := testEnv.Stop() Expect(err).ToNot(HaveOccurred()) }) |
上述自动生成的代码并没有启动控制器,你需要添加相应逻辑:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
k8sManager, err := ctrl.NewManager(cfg, ctrl.Options{ Scheme: scheme.Scheme, }) Expect(err).ToNot(HaveOccurred()) err = (&BackupReconciler{ Client: k8sManager.GetClient(), Log: ctrl.Log.WithName("controllers").WithName("Backup"), }).SetupWithManager(k8sManager) Expect(err).ToNot(HaveOccurred()) go func() { err = k8sManager.Start(ctrl.SetupSignalHandler()) Expect(err).ToNot(HaveOccurred()) }() // 你可以从k8sManager得到客户端 k8sClient = k8sManager.GetClient() |
理想情况下,对应每个在test_suite.go中调用的控制器,仅仅对应一个测试文件<kind>_conroller_test.go:
| 目标 | 说明 |
| manifests | 生成各种K8S资源的清单文件(YAML) |
| generate | 生成代码 |
kubebuilder调用controller-gen命令来生成代码、YAML,controller-gen会读取各种标记。controller-gen支持多种生成器。
该项目包含若干Go库,用于快速构建控制器。Operator的SDK依赖于此项目。它使用controller-runtime的Client接口来实现针对K8S资源的CRUD操作。
用于启动( Manager.Start)控制器,管理被多个控制器共享的依赖,例如Cache、Client、Scheme。
为读客户端提供本地缓存,支持监听更新缓存的事件。
实现针对K8S API Server的CRUD操作。读写客户端通常是分离(split)的。
Operator SDK通过manager.Manager来创建client.Client。SDK生成的代码中包含创建Manager的逻辑,Manager持有一个Cache和一个Client。 默认情况下Reconciler持有的Client是一个DelegatingClient:
|
1 2 3 4 5 6 7 8 9 |
func newReconciler(mgr manager.Manager) reconcile.Reconciler { // 由Manager提供 return &ReconcileKind{client: mgr.GetClient(), scheme: mgr.GetScheme()} } type ReconcileKind struct { client client.Client scheme *runtime.Scheme } |
DelegatingClient从Cache中读取(Get/List),写入(Create/Update/Delete)请求则直接发送给API Server。使用Cache可以大大减轻API Server的压力,随着缓存的更新,读操作会达成最终一致。
开发人员可能需要使用自己定制的客户端,直接从API Server读取,绕开缓存。你可以调用下面的方法新建客户端:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
func New(config *rest.Config, options client.Options) (client.Client, error) // 创建客户端的选项 type Options struct { // Scheme,API对象的串行化/反串行化器,将Go结构映射到GroupVersionKinds // 如果不指定,默认的Scheme自动注册core/v1中的资源。你必须提供已经注册了CR的Scheme,才能识别相应的资源 Scheme *runtime.Scheme // Mapper, 将GroupVersionKinds映射到Resources Mapper meta.RESTMapper } // 示例: import ( "context" "k8s.io/api/core/v1" "k8s.io/client-go/kubernetes/scheme" "k8s.io/heapster/common/kubernetes" "k8s.io/node-problem-detector/pkg/apis" "net/url" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/client/apiutil" ) uri, err := url.Parse("http://k8s.gmem.cc:6444?inClusterConfig=false") cfg, err := kubernetes.GetKubeClientConfig(uri) mapper, err := apiutil.NewDiscoveryRESTMapper(cfg) scheme := scheme.Scheme apis.AddToScheme(scheme) c, err := client.New(cfg, client.Options{ Scheme: scheme, Mapper: mapper, }) service := &v1.Service{} err = c.Get(context.TODO(), client.ObjectKey{ Name: "kubernetes", Namespace: "default", }, service) |
通常使用默认客户端就足够了。
获取单个对象:
|
1 2 |
// ObjectKey是types.NamespacedName的别名 func (c Client) Get(ctx context.Context, key ObjectKey, obj runtime.Object) error |
示例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import ( "context" "github.com/example-org/app-operator/pkg/apis/cache/v1alpha1" "sigs.k8s.io/controller-runtime/pkg/reconcile" ) func (r *ReconcileApp) Reconcile(request reconcile.Request) (reconcile.Result, error) { app := &v1alpha1.App{} ctx := context.TODO() err := r.client.Get(ctx, request.NamespacedName, app) ... } |
查询一个对象列表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
func (c Client) List(ctx context.Context, opts *ListOptions, obj runtime.Object) error // ListOptions用于设置过滤器 type ListOptions struct { // 标签选择器,可以提供字符串形式的选择器并传递给SetLabelSelector方法 LabelSelector labels.Selector // 字段选择器,根据特定的一个字段过滤 // 对于基于缓存的客户端,必须使用已经添加到indexer的字段 FieldSelector fields.Selector // 指定获取哪个命名空间的对象,为空则访问所有命名空间的对象 // 对于非命名空间内的对象,也设置为空 Namespace string // 直接传递给API Server的选项,会导致LabelSelector和FieldSelector被忽略 Raw *metav1.ListOptions } |
示例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import ( "context" "fmt" "k8s.io/api/core/v1" "sigs.k8s.io/controller-runtime/pkg/client" "sigs.k8s.io/controller-runtime/pkg/reconcile" ) func (r *ReconcileApp) Reconcile(request reconcile.Request) (reconcile.Result, error) { opts := &client.ListOptions{} // 限制标签选择器 opts.SetLabelSelector(fmt.Sprintf("app=%s", request.NamespacedName.Name)) // 限制命名空间 opts.InNamespace(request.NamespacedName.Namespace) podList := &v1.PodList{} ctx := context.TODO() err := r.client.List(ctx, opts, podList) ... } |
创建一个新对象并提交到API Server:
|
1 |
func (c Client) Create(ctx context.Context, obj runtime.Object) error |
示例:
|
1 2 3 4 5 6 7 8 9 |
func (r *ReconcileApp) Reconcile(request reconcile.Request) (reconcile.Result, error) { app := &v1.Deployment{ // Any cluster object you want to create. ... } ctx := context.TODO() err := r.client.Create(ctx, app) ... } |
|
1 2 |
// obj必须是一个结构指针,这样它才能被API Server返回的内容填充 func (c Client) Update(ctx context.Context, obj runtime.Object) error |
示例:
|
1 2 3 4 5 6 7 8 |
dep := &v1.Deployment{} err := r.client.Get(context.TODO(), request.NamespacedName, dep) ... ctx := context.TODO() dep.Spec.Selector.MatchLabels["is_running"] = "true" err := r.client.Update(ctx, dep) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
func (c Client) Delete(ctx context.Context, obj runtime.Object, opts ...DeleteOptionFunc) error // 此函数用于操控DeleteOptions对象 type DeleteOptionFunc func(*DeleteOptions) type DeleteOptions struct { // 删除对象前等待的优雅期限,单位秒。取值0表示立即删除,为nil则使用默认优雅期 GracePeriodSeconds *int64 // 在执行删除之前必须满足的前置条件 Preconditions *metav1.Preconditions // 指明垃圾回收(删除关联对象)是否/如何执行,你指定指定此选项和OrphanDependents中的一个,而不能同时指定 // 默认策略取决于metadata.finalizers字段以及和资源相关的默认策略 // 取值: // Orphan 将子资源孤儿化 // Background 允许垃圾回收器在后台删除子资源 // Foreground 在前台级联删除 PropagationPolicy *metav1.DeletionPropagation // 直接传递给API Server的选项 Raw *metav1.DeleteOptions } |
示例:
|
1 2 3 4 5 6 7 8 9 10 |
pod := &v1.Pod{} err := r.client.Get(context.TODO(), request.NamespacedName, pod) ... ctx := context.TODO() if pod.Status.Phase == v1.PodUnknown { // 5秒后删除资源 err := r.client.Delete(ctx, pod, client.GracePeriodSeconds(5)) } |
|
1 2 3 4 5 6 7 8 9 |
type Controller interface { // 嵌套接口,调和器,提供调和循环 reconcile.Reconciler // 监控事件源,通过EventHandler把事件(reconcile.Requests)加入工作队列 Watch(src source.Source, eventhandler handler.EventHandler, predicates ...predicate.Predicate) error // 启动控制器(通常是调和循环) Start(stop |
controller持有一个Reconciler,此外它从Manager得到各种共享对象,它自己创建一个工作队列。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
func New(name string, mgr manager.Manager, options Options) (Controller, error) { ... // 大部分字段来自Manager c := &controller.Controller{ // 控制器的核心逻辑,即Reconciler Do: options.Reconciler, Cache: mgr.GetCache(), Config: mgr.GetConfig(), Scheme: mgr.GetScheme(), Client: mgr.GetClient(), Recorder: mgr.GetRecorder(name), // 请求队列 Queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), name), MaxConcurrentReconciles: options.MaxConcurrentReconciles, Name: name, } // 总是添加到Manager return c, mgr.Add(c) } |
控制器可能会监控多种类型的对象(例如Pod + ReplicaSet + Deployment),但是控制器的Reconciler一般仅仅处理单一类型的对象。
当A类型的对象发生变化后,如果B类型的对象必须更新以响应,可以使用EnqueueRequestFromMapFunc来将一种类型的事件映射为另一种类型。例如Deployment的控制器可以使用EnqueueRequestForObject、EnqueueRequestForOwner实现:
- 监控Deployment事件,并将Deployment的Namespace/Name入队
- 监控ReplicaSet事件,并将创建它的Deployment(Owner)的Namespace/Name入队
类似ReplicaSet的控制器也可以监控ReplicaSet和Pod事件。
reconcile.Request入队时会自动去重。也就是说一个ReplicaSet创建的多个Pod事件可能仅仅触发ReplicaSet控制器的单次调用。
在Operator Framework中,本小节的逻辑样板代码自动生成在KIND/KIND_controller.go文件中。
Reconciler是Controller的组件,是Controller的核心逻辑所在。它负责调和 —— 逼近期望状态。例如,当针对ReplicaSet对象调用Reconciler时,发现ReplicaSet要求5实例,但是当前系统中只有3个Pod,这时Reconciler应该创建额外的两个Pod,并且将这些Pod的OwnerReference指向前面的ReplicaSet。
Reconciler通常仅处理一种类型的对象,OwnerReference用于从子对象(例如Pod)触发父对象的调和(例如ReplicaSet)操作。
Reconciler实现reconcile.Reconciler接口,该接口暴露了一个Reconcile方法。该方法在集群内外事件发生时被调用,入参是reconcile.Request。Request不包含事件的细节,它仅仅提供查询资源所需的键,出参是reconcile.Result。Reconciler持有Client以便访问API Server:
|
1 2 3 4 5 6 7 8 9 10 11 |
// 调和Kind类型的对象 type ReconcileKind struct { // 客户端,从Cahce读,写入到API Server client client.Client // scheme定义了串行化、反串行化API对象的方法,它包含一个类型注册表,能够将Go Schema和 // Group、Version、Kind信息进行相互转换。Scheme还能够处理不同版本的API对象,是版本化的基础 scheme *runtime.Scheme } func (r *ReconcileKind) Reconcile(request reconcile.Request) (reconcile.Result, error) |
Admission Webhooks是扩展Kubernetes API的一种方式。API Server作为Webhook的客户端,当特定事件发生时,发送AdmissionRequest给Webhook。
Webhook分为两种:
- Mutating webhook:在API Server正式接受之前,修改核心API对象或者CRD实例
- Validating webhook:验证对象是否满足特定要求
它们都通过Handler来操作AdmissionReview中内嵌的对象。
resource.Source是提供给Controller.Watch的参数,提供事件的流。这些事件通常是通过Watch API Server得到的。
大多数情况下,你不需要自己实现Source。
handler.EventHandler是提供给Controller.Watch的参数,负责响应事件:
- EventHandler通常会为一个或多个对象产生reconcile.Request并入队
- EventHandler可能会将一种对象的事件,映射为同一种对象的Request
- EventHandler可能会将一种对象的事件,映射为另一种对象的Request —— 例如,将Pod对象的事件映射为拥有Pod的ReplicaSet的Request
- EventHandler可能会将一种对象的一个事件,迎合为相同/不同对象的多个Request
大多数情况下,你不需要自己实现EventHandler。
handler.EventHandler是提供给Controller.Watch的可选参数,用于实现事件的过滤,Predicate入参是一个事件,返回bool。
你应当尽量使用既有的Predicate实现。
Redis Operator是开源的Redis Cluster Operator, 它的目的是在K8S环境下使用Redis集群的自动化运维。本章通过解析它的源码来学习Operator开发的实战经验。本章使用的Redis Operator是gmemcc分支出的版本。
Redis Operator没有使用Operator SDK,但使用了code-generator进行代码生成。
|
1 2 3 4 5 6 7 8 |
type RedisCluster struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"` // 期望 Spec RedisClusterSpec `json:"spec,omitempty"` // 实际 Status RedisClusterStatus `json:"status,omitempty"` } |
描述Redis集群的配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
type RedisClusterSpec struct { // 主节点数量 NumberOfMaster *int32 `json:"numberOfMaster,omitempty"` // 复制因子,每个主节点有多少个从节点 ReplicationFactor *int32 `json:"replicationFactor,omitempty"` // 对应的K8S服务的名称 ServiceName string `json:"serviceName,omitempty"` // Redis服务Pod的详细规格。保留了精细化定制的能力,也从CR中隔离了和运维逻辑不相关的Redis配置细节 PodTemplate *kapiv1.PodTemplateSpec `json:"podTemplate,omitempty"` // 为各种子资源添加的标签 AdditionalLabels map[string]string `json:"AdditionalLabels,omitempty"` } |
描述Redis集群的状态,Operator负责分析真实状态并更新该结构。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
type RedisClusterStatus struct { // Conditions,一个描述运维工作流各阶段状况的数组 Conditions []RedisClusterCondition `json:"conditions,omitempty" patchStrategy:"merge" patchMergeKey:"type"` // 整体工作流状况:True, False, Unknown Status kapiv1.ConditionStatus `json:"status"` // 控制器启动此集群的运维工作流的时间,注意时间用metav1.Time而非time.Time,保证稳定的序列化 StartTime *metav1.Time `json:"startTime,omitempty"` // 最后一次Condition变化的简短原因 Reason string `json:"reason,omitempty"` // 最后一次Condition变化的易读的详细原因 Message string `json:"message,omitempty"` // 当前Redis的状态视图 Cluster RedisClusterClusterStatus } |
对RedisCluster运维工作流的某个Condition进行建模:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
type RedisClusterCondition struct { // Condition类型 Type RedisClusterConditionType `json:"type"` // 此Condition的状态,True, False, Unknown. Status kapiv1.ConditionStatus `json:"status"` // 此Condition的最后检查时间 LastProbeTime metav1.Time `json:"lastProbeTime,omitempty"` // 此Condition的最后变化时间 LastTransitionTime metav1.Time `json:"lastTransitionTime,omitempty"` // 最后一次Condition变化的简短原因 Reason string `json:"reason,omitempty"` // 最后一次Condition变化的易读的详细原因 Message string `json:"message,omitempty"` } |
Condition,字面意思是条件、状况。在K8S环境下,表示了资源的某种状态值,取值总是True、False、Unknown之一。 这些状态,有时候对应了资源生命周期的某个阶段,或者说是自动化运维流程的某个环节。
例如一个Pod的Condition类型包括:PodScheduled、Initialized、ContainersReady、Ready。而RedisCluster的Condition类型则包括:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
type RedisClusterConditionType string const ( // 集群正常 RedisClusterOK RedisClusterConditionType = "ClusterOK" // 集群正在扩容/缩容 RedisClusterScaling RedisClusterConditionType = "Scaling" // 集群正在重新平衡,Hashslot正在迁移 RedisClusterRebalancing RedisClusterConditionType = "Rebalancing" // 集群正在滚动更新每个节点 RedisClusterRollingUpdate RedisClusterConditionType = "RollingUpdate" ) |
描述Redis集群的状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
type RedisClusterClusterStatus struct { // 全局性状态值 Status ClusterStatus `json:"status"` // 主节点数量 NumberOfMaster int32 `json:"numberOfMaster,omitempty"` // 复制因子 MinReplicationFactor int32 `json:"minReplicationFactor,omitempty"` MaxReplicationFactor int32 `json:"maxReplicationFactor,omitempty"` NodesPlacement NodesPlacementInfo `json:"nodesPlacementInfo,omitempty"` // 节点数量、Ready节点数量、运行中的节点数量 NbPods int32 `json:"nbPods,omitempty"` NbPodsReady int32 `json:"nbPodsReady,omitempty"` NbRedisRunning int32 `json:"nbRedisNodesRunning,omitempty"` // 节点列表 Nodes []RedisClusterNode `json:"nodes"` } |
全局状态值:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
type ClusterStatus string const ( // 正常 ClusterStatusOK ClusterStatus = "OK" // 错误 ClusterStatusKO ClusterStatus = "KO" // 扩容中 ClusterStatusScaling ClusterStatus = "Scaling" // 再平衡计算中 ClusterStatusCalculatingRebalancing ClusterStatus = "Calculating Rebalancing" // 再平衡中 ClusterStatusRebalancing ClusterStatus = "Rebalancing" // 滚动更新中 ClusterStatusRollingUpdate ClusterStatus = "RollingUpdate" ) |
节点信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
type RedisClusterNode struct { // 节点标识 ID string `json:"id"` // 主还是从 Role RedisClusterNodeRole `json:"role"` // 地址和端口 IP string `json:"ip"` Port string `json:"port"` // 分配的HashSlot Slots []string `json:"slots,omitempty"` // 对于从节点,其Follow的主节点 MasterRef string `json:"masterRef,omitempty"` // 对应的Pod PodName string `json:"podName"` Pod *kapiv1.Pod `json:"-"` } |
|
1 2 3 4 5 |
type RedisClusterList struct { metav1.TypeMeta `json:",inline"` metav1.ListMeta `json:"metadata,omitempty"` Items []RedisCluster `json:"items"` } |
Redis Operator的入口点定义在redis-operator/cmd/operator/main.go中。程序启动时,首先利用pflag解析命令行参数,生成一个Config结构,然后创建Operator实例:
|
1 2 3 4 |
config := operator.NewRedisOperatorConfig() config.AddFlags(pflag.CommandLine) ... op := operator.NewRedisOperator(config) |
Operator构建完成后,调用其Run函数启动若干例程:
|
1 2 3 4 5 6 |
if err := run(op); err != nil { glog.Errorf("RedisOperator returns an error:%v", err) os.Exit(1) } os.Exit(0) |
NewRedisOperator函数的逻辑主要包括:
- 注册自定义资源RedisCluster的CRD到API Server
- 创建CR的客户端
- 创建K8S资源的Informer工厂,以及CR的Informer工厂
- 创建Controller对象
- 创建垃圾回收器对象
- 创建RedisOperator实例
- 初始化Operator的健康检查服务
NewRedisOperator会先初始化K8S客户端配置,然后尝试注册CRD:
|
1 2 3 4 |
// 获取apiextensions的客户端,可用于注册CRD extClient, err := apiextensionsclient.NewForConfig(kubeConfig) // 注册CRD _, err = rclient.DefineRedisClusterResource(extClient) |
下面是注册CRD的细节:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
func DefineRedisClusterResource(clientset apiextensionsclient.Interface) (*apiextensionsv1beta1.CustomResourceDefinition, error) { redisClusterResourceName := v1.ResourcePlural + "." + redis.GroupName // 创建CRD结构 crd := &apiextensionsv1beta1.CustomResourceDefinition{ ObjectMeta: metav1.ObjectMeta{ Name: redisClusterResourceName, }, Spec: apiextensionsv1beta1.CustomResourceDefinitionSpec{ Group: redis.GroupName, Version: v1.SchemeGroupVersion.Version, Scope: apiextensionsv1beta1.NamespaceScoped, Names: apiextensionsv1beta1.CustomResourceDefinitionNames{ Plural: v1.ResourcePlural, Singular: v1.ResourceSingular, // 反射获得类型名 Kind: reflect.TypeOf(v1.RedisCluster{}).Name(), ShortNames: []string{"rdc"}, }, }, } // 在API Server中创建CRD clientset.ApiextensionsV1beta1().CustomResourceDefinitions().Create(crd) // 等待CRD成功创建,最多60秒 err = wait.Poll(500*time.Millisecond, 60*time.Second, func() (bool, error) { crd, err = clientset.ApiextensionsV1beta1().CustomResourceDefinitions().Get(redisClusterResourceName, metav1.GetOptions{}) // 直到CRD的Condition Established = true for _, cond := range crd.Status.Conditions { switch cond.Type { case apiextensionsv1beta1.Established: if cond.Status == apiextensionsv1beta1.ConditionTrue { return true, err } case apiextensionsv1beta1.NamesAccepted: if cond.Status == apiextensionsv1beta1.ConditionFalse { glog.Errorf("Name conflict: %v\n", cond.Reason) } } } return false, err }) // 如果不能确认CRD状态,则尝试删除CRD if err != nil { deleteErr := clientset.ApiextensionsV1beta1().CustomResourceDefinitions().Delete(redisClusterResourceName, nil) if deleteErr != nil { // 将Error切片聚合为单个Error return nil, errors.NewAggregate([]error{err, deleteErr}) } return nil, err } return crd, nil } |
NewRedisOperator会根据kubeconfig来创建操控RedisCluster的客户端:
|
1 |
redisClient, err := rclient.NewClient(kubeConfig) |
NewClient的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
func NewClient(cfg *rest.Config) (versioned.Interface, error) { // scheme负责请求应答的编解码(串行化/反串行化) scheme := runtime.NewScheme() // 将RedisCluster添加到scheme,以保证可以对CR进行编解码 v1.AddToScheme(scheme) config := *cfg // 客户端使用的API组和版本 config.GroupVersion = &v1.SchemeGroupVersion // API的REST路径 config.APIPath = "/apis" // 使用何种串行化格式 config.ContentType = runtime.ContentTypeJSON // 使用scheme进行编解码 config.NegotiatedSerializer = serializer.DirectCodecFactory{CodecFactory: serializer.NewCodecFactory(scheme)} // 创建客户端 cs, err := versioned.NewForConfig(&config) return cs, nil } |
用于提供API Server的客户端缓存、Lister接口。
|
1 2 |
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30) redisInformerFactory := redisinformers.NewSharedInformerFactory(redisClient, time.Second*30) |
Redis Operator使用heptiolabs/healthcheck库,实现Operator本身的健康检查:
|
1 2 3 |
op.configureHealth() // 暴露/live和/ready端点 op.httpServer = &http.Server{Addr: cfg.ListenAddr, Handler: op.health} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
func (op *RedisOperator) configureHealth() { // 创建一个健康检查处理器 op.health = healthcheck.NewHandler() // LivenessCheck和ReadinessCheck都可以添加多个 op.health.AddReadinessCheck("RedisCluster_cache_sync", func() error { if op.controller.RedisClusterSynced() { return nil } return fmt.Errorf("RedisCluster cache not sync") }) op.health.AddReadinessCheck("Pod_cache_sync", func() error { if op.controller.PodSynced() { return nil } return fmt.Errorf("Pod cache not sync") }) op.health.AddReadinessCheck("Service_cache_sync", func() error { if op.controller.ServiceSynced() { return nil } return fmt.Errorf("Service cache not sync") }) op.health.AddReadinessCheck("PodDiscruptionBudget_cache_sync", func() error { if op.controller.PodDiscruptionBudgetSynced() { return nil } return fmt.Errorf("PodDiscruptionBudget cache not sync") }) } |
|
1 2 3 4 5 6 7 |
op := &RedisOperator{ kubeInformerFactory: kubeInformerFactory, redisInformerFactory: redisInformerFactory, controller: controller.NewController(controller.NewConfig(1, cfg.Redis), kubeClient, redisClient, kubeInformerFactory, redisInformerFactory), // 垃圾回收器,用于删除孤儿Pod GC: garbagecollector.NewGarbageCollector(redisClient, kubeClient, redisInformerFactory), } |
Redis Operator的信号处理部分利用了Context,使用Context可以方便的控制多个相互协作的Goroutine:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
ctx, cancelFunc := context.WithCancel(context.Background()) // 当接收到相关信号后,调用Context的Cancel函数,导致ctx.Done()通道被关闭 go signal.HandleSignal(cancelFunc) // 细节 func HandleSignal(cancelFunc context.CancelFunc) { sigc := make(chan os.Signal, 1) // 接收到以下信号后,转存到通道sigc中 signal.Notify(sigc, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT) // 阻塞,直到信号到达 sig := |
Redis Operator的所有例程都会等待Context.Done() 关闭,并结束处理逻辑。
Operator的Run方法启动若干例程:
|
1 |
func (op *RedisOperator) Run(stop |
核心逻辑在控制器中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
type Controller struct { // 访问K8S核心资源 kubeClient clientset.Interface // 访问CR资源(RedisCluster) redisClient rclient.Interface // 用于查询CR,RedisCluster redisClusterLister rlisters.RedisClusterLister RedisClusterSynced cache.InformerSynced // 用于查询Redis的Rod podLister corev1listers.PodLister PodSynced cache.InformerSynced // 用于查询Redis的Service serviceLister corev1listers.ServiceLister ServiceSynced cache.InformerSynced // 用于查询Redis的PodDisruptionBudget podDisruptionBudgetLister policyv1listers.PodDisruptionBudgetLister PodDiscruptionBudgetSynced cache.InformerSynced // 用于对Redis的Pod、Service、PodDisruptionBudget进行CRUD操作 podControl pod.RedisClusterControlInteface serviceControl ServicesControlInterface podDisruptionBudgetControl PodDisruptionBudgetsControlInterface updateHandler func(*rapi.RedisCluster) (*rapi.RedisCluster, error) // 事件队列 queue workqueue.RateLimitingInterface // RedisClusters to be synced recorder record.EventRecorder // 持有Redis配置信息 config *Config } |
各种Lister字段都是通过Informer工厂得到的:
|
1 2 3 4 5 |
// kubeinformers.SharedInformerFactory serviceInformer := kubeInformer.Core().V1().Services() podInformer := kubeInformer.Core().V1().Pods() // pkg/client/informers/factory.go中的SharedInformerFactory,自动生成的代码 redisInformer := rInformer.Redisoperator().V1().RedisClusters() |
各种Control属于Redis Operator的内部细节,用于对相应的API资源进行CRUD。
控制器的总体逻辑如下:
|
1 |
func (c *Controller) Run(stop |
封装在控制器的runWorker方法中:
|
1 |
go wait.Until(c.runWorker, time.Second, stop) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
func (c *Controller) runWorker() { for c.processNextItem() { } } func (c *Controller) processNextItem() bool { // 取出一个事件 key, quit := c.queue.Get() if quit { return false } // 总是标记为处理完成 defer c.queue.Done(key) needRequeue, err := c.sync(key.(string)) if err == nil { // 不需要重新入队 c.queue.Forget(key) } else { // 处理出错,重新入队 c.queue.AddRateLimited(key) return true } // 没有出错,但是需要重新入队 if needRequeue { c.queue.AddRateLimited(key) } return true } |
当创建一个新的RedisCluster对象,或者既有RedisCluster被修改后,此方法会被调和循环所调用。
首先从缓存中查询到RedisCulster对象,此对象应该只读访问:
|
1 2 3 |
namespace, name, err := cache.SplitMetaNamespaceKey(key) ... sharedRedisCluster, err := c.redisClusterLister.RedisClusters(namespace).Get(name) |
如果RedisCluster对象缺少必要的字段,则添加这些字段,并结束处理:
|
1 2 3 |
if !rapi.IsRedisClusterDefaulted(sharedRedisCluster) { ... } |
如果RedisCluster已经被请求删除,则不对事件进行处理:
|
1 2 3 |
if sharedRedisCluster.DeletionTimestamp != nil { return false, nil } |
如果Status.StartTime字段为空,则初始化之,并结束处理:
|
1 2 3 4 5 6 |
// 修改前,先深拷贝出副本 rediscluster := sharedRedisCluster.DeepCopy() if rediscluster.Status.StartTime == nil { rediscluster.Status.StartTime = &startTime ... } |
如果上面三个异常情况都不存在,则调用syncCluster方法,该方法包含了Redis Operator的核心业务逻辑。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
func (c *Controller) syncCluster(rediscluster *rapi.RedisCluster) (forceRequeue bool, err error) { forceRequeue = false redisClusterService, err := c.getRedisClusterService(rediscluster) ... /* 如果必要,创建Service、PodDisruptionBudge对象 */ if redisClusterService == nil { // 创建关联的Service对象 if _, err = c.serviceControl.CreateRedisClusterService(rediscluster); err != nil { return forceRequeue, err } } ... redisClusterPodDisruptionBudget, err := c.getRedisClusterPodDisruptionBudget(rediscluster) if redisClusterPodDisruptionBudget == nil { // 创建关联的PodDisruptionBudget对象 if _, err = c.podDisruptionBudgetControl.CreateRedisClusterPodDisruptionBudget(rediscluster); err != nil { return forceRequeue, err } } // 总是包含redis-operator.k8s.io/cluster-name标签 podselector, err := pod.CreateRedisClusterLabelSelector(rediscluster) ... // 根据选择器,列出关联的Pod redisClusterPods, err := c.podLister.List(podselector) ... /* 对于不可用的节点,以及删除其上的Redis Pod实例 */ // 将Pod分为两组,NodeLost的为一组,非NodeLost的为一组 Pods, LostPods := filterLostNodes(redisClusterPods) if len(LostPods) != 0 { for _, p := range LostPods { // 立即删除NodeLost状态的Pod err := c.podControl.DeletePodNow(rediscluster, p.Name) glog.Errorf("Lost node with pod %s. Deleting... %v", p.Name, err) } redisClusterPods = Pods } // RedisAdmin用于访问Pod中的Redis进程 admin, err := NewRedisAdmin(redisClusterPods, &c.config.redis) if err != nil { return forceRequeue, fmt.Errorf("unable to create the redis.Admin, err:%v", err) } // 总是关闭连接 defer admin.Close() // 获取集群每个节点的NodeInfos,NodeInfos包含了目标Redis节点的基本信息,以及它所看到的其它节点的基本信息 clusterInfos, errGetInfos := admin.GetClusterInfos() if errGetInfos != nil { if clusterInfos.Status == redis.ClusterInfosPartial { return false, fmt.Errorf("partial Cluster infos") } } // 通过节点信息、集群Pod列表、CR计算出集群实际状态 // 集群状态包括:是否正常、Ready的Pod数量、Master数量、运行中的Redis实例数量、Redis实例列表、复制因子等 clusterStatus, err := c.buildClusterStatus(admin, clusterInfos, redisClusterPods, rediscluster) if err != nil { return forceRequeue, fmt.Errorf("unable to build clusterStatus, err:%v", err) } // 如果CR中的集群状态(Status.Cluster)和实际情况不匹配,则更新 updated, err := c.updateClusterIfNeed(rediscluster, clusterStatus) if err != nil { return forceRequeue, err } // 如果Status被更新,则重新入队,等待下次处理 if updated { // 总是在“稳定的”集群上执行Redis运维操作,因此只要CR的Status变化,就返回,等待下次处理 forceRequeue = true return forceRequeue, nil } // 如果CR状态和Redis集群实际状态匹配,则检查是否需要进行调和 —— 让实际状态匹配期望状态 allPodsNotReady := true // 是否所有Redis实例都就绪 if (clusterStatus.NbPods - clusterStatus.NbRedisRunning) != 0 { allPodsNotReady = false } // 判断是否需要“清理” —— 存在鬼魂节点、不受信节点、卡在Terminating节点,或者Redis集群出现分裂 needSanitize, err := c.checkSanityCheck(rediscluster, admin, clusterInfos) // 如果所有Pod都没有准备好,且需要滚动更新(Pod和PodTemplate不匹配)、需要更多或更少Pod,或主节点数量、复制因子不对 // 或者,需要执行“清理” // 则,执行Redis集群管理操作,以逼近预期状态,并更新RedisCluster的状态 if (allPodsNotReady && needClusterOperation(rediscluster)) || needSanitize { var requeue bool forceRequeue = false // 执行集群管理操作,包括创建/删除Pod,并配置Redis requeue, err = c.clusterAction(admin, rediscluster, clusterInfos) if err == nil && requeue { forceRequeue = true } _, err = c.updateRedisCluster(rediscluster) return forceRequeue, err } // 重置所有Condition,调和完成 if setRebalancingCondition(&rediscluster.Status, false) || setRollingUpdategCondition(&rediscluster.Status, false) || setScalingCondition(&rediscluster.Status, false) || setClusterStatusCondition(&rediscluster.Status, true) { _, err = c.updateHandler(rediscluster) return forceRequeue, err } return forceRequeue, nil } |
此方法返回一个redis.AdminInterface接口,可以管理一组Redis节点,以及这些节点所属的Redis集群:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
func NewRedisAdmin(pods []*apiv1.Pod, cfg *config.Redis) (redis.AdminInterface, error) { nodesAddrs := []string{} // Redis必须在名为redis-node的容器中运行,且其连接端口名为redis for _, pod := range pods { redisPort := redis.DefaultRedisPort for _, container := range pod.Spec.Containers { if container.Name == "redis-node" { for _, port := range container.Ports { if port.Name == "redis" { redisPort = fmt.Sprintf("%d", port.ContainerPort) } } } } nodesAddrs = append(nodesAddrs, net.JoinHostPort(pod.Status.PodIP, redisPort)) } adminConfig := redis.AdminOptions{ ConnectionTimeout: time.Duration(cfg.DialTimeout) * time.Millisecond, RenameCommandsFile: cfg.GetRenameCommandsFile(), } return redis.NewAdmin(nodesAddrs, &adminConfig), nil } |
AdminInterface内部使用radix.v2 —— Redis的Go客户端 —— 来操控Redis集群。
执行Redis集群状态完整性检查,如果dryRun为true,则不对集群进行变更。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
func RunSanityChecks(admin redis.AdminInterface, config *config.Redis, podControl pod.RedisClusterControlInteface, cluster *rapi.RedisCluster, infos *redis.ClusterInfos, dryRun bool) (actionDone bool, err error) { // 强迫集群忘记鬼魂节点 —— 已经不存在,但是仍然被某些Redis节点仍然记着它 // 鬼魂节点,可以是失败的Pod、不存在于K8S的Pod,或者IP不通的Pod if actionDone, err = FixFailedNodes(admin, cluster, infos, dryRun); err != nil { return actionDone, err } else if actionDone { return actionDone, nil } // 如果Redis节点不受信任,则移除它并删除对应Pod // 如果调用forget nodes命令将节点从Redis集群中移除后,尝试重新加入,会出现这种情况 if actionDone, err = FixUntrustedNodes(admin, podControl, cluster, infos, dryRun); err != nil { return actionDone, err } else if actionDone { return actionDone, nil } // 用于处理卡在terminating状态的Pod if actionDone, err = FixTerminatingPods(cluster, podControl, 5*time.Minute, dryRun); err != nil { return actionDone, err } else if actionDone { return actionDone, nil } // 用于处理集群分裂(为多个独立集群)的情况 if actionDone, err = FixClusterSplit(admin, config, infos, dryRun); err != nil { return actionDone, err } else if actionDone { return actionDone, nil } return actionDone, err } |
对Redis Pod、Redis集群进行各种管理操作,以逼近期望状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
func (c *Controller) clusterAction(admin redis.AdminInterface, cluster *rapi.RedisCluster, infos *redis.ClusterInfos) (bool, error) { var err error // 总是判断是否需要清理 needSanity, err := sanitycheck.RunSanityChecks(admin, &c.config.redis, c.podControl, cluster, infos, true) if err != nil { return false, err } if needSanity { // 执行清理 return sanitycheck.RunSanityChecks(admin, &c.config.redis, c.podControl, cluster, infos, false) } // 如果节点数量不足,则创建新Pod并重新入队 if needMorePods(cluster) { // 设置扩容Condition为true if setScalingCondition(&cluster.Status, true) { // 更新资源 if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } // 创建需要的Pod,每次调和循环中最多会创建一个Pod,这简化了调和逻辑 pod, err2 := c.podControl.CreatePod(cluster) if err2 != nil { return false, err2 } return true, nil } // 当所有节点都创建好了,然后才会走下面的逻辑 // 如果节点数量充足,则重置扩容Condition为false if setScalingCondition(&cluster.Status, false) { if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } // 如果有必要,重新配置Redis集群,并重新入队 hasChanged, err := c.applyConfiguration(admin, cluster) if err != nil { return false, err } if hasChanged { return true, nil } return false, nil } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
func needMorePods(cluster *rapi.RedisCluster) bool { // 期望Pod数量取决于复制因子和Master数量 nbPodNeed := *cluster.Spec.NumberOfMaster * (1 + *cluster.Spec.ReplicationFactor) // 如果不是所有Pod都就绪,则不进行操作 if cluster.Status.Cluster.NbPods != cluster.Status.Cluster.NbPodsReady { return false } output := false // 默认配置下 0 6 if cluster.Status.Cluster.NbPods < nbPodNeed { output = true } return output } |
|
1 2 3 4 5 |
func (p *RedisClusterControl) CreatePod(redisCluster *rapi.RedisCluster) (*kapiv1.Pod, error) { pod, err := initPod(redisCluster) ... return p.KubeClient.CoreV1().Pods(redisCluster.Namespace).Create(pod) } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
func initPod(redisCluster *rapi.RedisCluster) (*kapiv1.Pod, error) { // 为Pod添加必要的标签,这些标签用于判定一个Pod是否受到Operator管理并且关联到某个RedisCluster desiredLabels := labels.Set{} if rediscluster.Spec.AdditionalLabels != nil { // CR规格中指定的额外标签 desiredLabels = rediscluster.Spec.AdditionalLabels } // PodTemplate中的标签 if rediscluster.Spec.PodTemplate != nil { for k, v := range rediscluster.Spec.PodTemplate.Labels { desiredLabels[k] = v } } // 总是添加redis-operator.k8s.io/cluster-name标签 desiredLabels[rapi.ClusterNameLabelKey] = rediscluster.Name // 产生的Pod总是以rediscluster为前缀 PodName := fmt.Sprintf("rediscluster-%s-", redisCluster.Name) pod := &kapiv1.Pod{ ObjectMeta: metav1.ObjectMeta{ Namespace: redisCluster.Namespace, Labels: desiredLabels, Annotations: desiredAnnotations, GenerateName: PodName, // 指向管理此Pod的父资源,即我们的CR,当CR被删除了,这些Pod会被自动删除 OwnerReferences: []metav1.OwnerReference{BuildOwnerReference(redisCluster)}, }, } // 从CR深拷贝PodTemplate pod.Spec = *redisCluster.Spec.PodTemplate.Spec.DeepCopy() ... return pod, nil } |
此方法可能会添加、删除Pod,或者对Redis进程进行配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
// 管理接口 CR func (c *Controller) applyConfiguration(admin redis.AdminInterface, cluster *rapi.RedisCluster) (bool, error) { asChanged := false // 期望的复制因子和主节点数量 cReplicaFactor := *cluster.Spec.ReplicationFactor cNbMaster := *cluster.Spec.NumberOfMaster // 适配,将CR转换为redis包中的结构 rCluster, nodes, err := newRedisCluster(admin, cluster) if err != nil { return false, err } // PodTemplate变更则需要滚动更新 if needRollingUpdate(cluster) { if setRollingUpdategCondition(&cluster.Status, true) { if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } // 配置Redis集群 return c.manageRollingUpdate(admin, cluster, rCluster, nodes) } // 如果不是需要滚定更新,则修改Condition if setRollingUpdategCondition(&cluster.Status, false) { if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } // 如果Pod数量大于预期 if needLessPods(cluster) { if setRebalancingCondition(&cluster.Status, true) { if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } // 配置Redis集群 return c.managePodScaleDown(admin, cluster, rCluster, nodes) } if setRebalancingCondition(&cluster.Status, false) { if cluster, err = c.updateHandler(cluster); err != nil { return false, err } } clusterStatus := &cluster.Status.Cluster if (clusterStatus.NbPods - clusterStatus.NbRedisRunning) != 0 { // 只有所有节点都Running后才进行后续处理 return false, err } // 选出期望数量的Master,将Hashslot分配给各Master,会尽可能将Master分散到不同的K8S节点 // 设置集群状态为Calculating Rebalancing newMasters, curMasters, allMaster, err := clustering.DispatchMasters(rCluster, nodes, cNbMaster, admin) if err != nil { glog.Errorf("Cannot dispatch slots to masters: %v", err) rCluster.Status = rapi.ClusterStatusKO return false, err } // 如果新旧Master数量不等 if len(newMasters) != len(curMasters) { asChanged = true } // 当前已经是Slave的节点 currentSlaveNodes := nodes.FilterByFunc(redis.IsSlave) // 新作为Slave的节点,它们即不是本次选出的新Master,也不已经是Slave newSlave := nodes.FilterByFunc(func(nodeA *redis.Node) bool { for _, nodeB := range newMasters { if nodeA.ID == nodeB.ID { return false } } for _, nodeB := range currentSlaveNodes { if nodeA.ID == nodeB.ID { return false } } return true }) if cNbMaster < int32(len(curMasters)) { // 正在缩容 // 先分配Slots if err := clustering.DispatchSlotToNewMasters(rCluster, admin, newMasters, curMasters, allMaster); err != nil { return false, err } // 再关联Slave到Master newRedisSlavesByMaster, bestEffort := clustering.PlaceSlaves(rCluster, newMasters, currentSlaveNodes, newSlave, cReplicaFactor) if bestEffort { rCluster.NodesPlacement = rapi.NodesPlacementInfoBestEffort } if err := clustering.AttachingSlavesToMaster(rCluster, admin, newRedisSlavesByMaster); err != nil { glog.Error("Unable to dispatch slave on new master, err:", err) return false, err } } else { // 正在扩容 // 先关联Slave到Master newRedisSlavesByMaster, bestEffort := clustering.PlaceSlaves(rCluster, newMasters, currentSlaveNodes, newSlave, cReplicaFactor) if bestEffort { rCluster.NodesPlacement = rapi.NodesPlacementInfoBestEffort } if err := clustering.AttachingSlavesToMaster(rCluster, admin, newRedisSlavesByMaster); err != nil { glog.Error("Unable to dispatch slave on new master, err:", err) return false, err } // 再分配Slots if err := clustering.DispatchSlotToNewMasters(rCluster, admin, newMasters, curMasters, allMaster); err != nil { glog.Error("Unable to dispatch slot on new master, err:", err) return false, err } } // 设置集群状态 rCluster.Status = rapi.ClusterStatusOK // 等待一小会,让Redis配置传播到所有实例 time.Sleep(1 * time.Second) return asChanged, nil } |
GitHub下载源码:
|
1 2 |
cd src/github.com/amadeusitgroup git clone https://github.com/gmemcc/Redis-Operator.git redis-operator |
构建:
|
1 2 3 4 5 6 7 8 |
# 构建bin make # 构建Docker镜像 make container # 构建并发布镜像 make DOCKER_REGISTRY="docker.gmem.cc" TAG=master push |
使用Helm部署Operator:
|
1 2 |
cd $GOPATH/src/github.com/amadeusitgroup/redis-operator/chart helm install --name redis-operator redis-operator |
|
1 2 |
cd $GOPATH/src/github.com/amadeusitgroup/redis-operator/chart helm install --name rediscluster-default --set clusterNameOverride=default,serviceName=rediscluster-default redis-cluster |
|
1 2 3 4 5 6 |
cp $GOPATH/src/github.com/amadeusitgroup/redis-operator/bin/kubectl-plugin ~/.kube/plugins/kubectl-rediscluster # 可以使用下面的命令调用此插件 kubectl rediscluster # NAME NAMESPACE PODS OPS STATUS REDIS STATUS NB MASTER REPLICATION # default default 6/6/6 ClusterOK OK 3/3 1-1/1 |
用Goland打开下载的项目,参考下图创建Debug Configuration:
通过学习Redis Operator的源码,我们了解到:
- 可以编程式的创建CRD
- 使用Condition来建模资源的生命周期阶段,例如“扩容中”
- 修改任何共享数据结构前,先深拷贝它
- 正确设置各种子资源的OwnerReferences,保证CR被删除后,它们能被级联的处理
- 如果资源的真实状态和CR.Status中记录的状态不一致,应当立即同步,然后将事件重新入队,结束本次处理
- 等待所有实例(Pod)准备好以后,再进一步调和
- 每次调和,做一点点事情,让逻辑简单可控。Redis Operator在单次调和中可能:
- 更新CR的Status字段
- 创建一个Pod
- 修改Redis集群配置
- Operator本身应该具有健康检查机制
报错信息:Dependency manager "modules" has been selected but go modules are not active. Activate modules then run "operator-sdk new helm-services"
解决方案:设置环境变量 GO111MODULE=on
报错: Failed to get API Group-Resources {"error": "Get \"https://10.0.3.1:6443/api?timeout=32s\": Access violation"}
原因是使用了代理。
非常好的文章,网上关于k8s operator开发的文章少之又少,读了大佬的文章,很受益