Graphite学习笔记
Graphite是一个开源项目,可以作为时间序列数据库(TSDB)使用,当你需要存储随着时间变化的数值时,应当考虑使用时间序列数据库。
除了数据的存储、查询外,Graphite还提供数据可视化(UI层)功能,它可以很好的在廉价的硬件上运行。你可以使用Graphite来监控网站、应用程序、网络服务器等的性能数据(Metrics),轻松实现基于时间维的分析。
Graphite本身不负责性能数据的采集,但是它提供了简单易用的接口,公共这些接口你可以把基于数字的性能数据存储到Graphite中。
| 术语 | 说明 |
| datapoint | 数据点,存放在timestamp bucket中的数值。timestamp bucket中的默认值是None |
| function | 时间序列( time-series)函数,用来转换、合并、计算多个series |
| resolution | 分辨率,也称precision。序列中,一个数据点所跨越(代表)的秒数。分辨率确定了存储数据点频率 如果一个series每N秒存储一个数据点,则其分辨率为N |
| retention | 驻留,series中包含的数据点的个数 |
| series | 一已命名的数据点的集合,每个series由其名称唯一确定,名称由点号分隔的字符串组成 也称为Metrics、Metric series |
| series list | 包含通配符的series名称,匹配多个series |
| target | 图形展示时的数据源,可以是metrics名称、metrics通配符、或者基于前两者的函数调用表达式 |
| timestamp | 数据点所关联的时间,1970-01-01到产生数据点那一刻的秒数 |
| timestamp bucket | 经过舍入后,能够整除分辨率的timestamp |
Graphite由三个组件构成:
- Carbon:一个基于Twisted(Python事件驱动网络框架)的守护程序,负责监听外部的时间序列数据
- Whisper:一个简单的存储时间序列数据的数据库,设计上和RRDtool类似
- Graphite-Web:一个基于Django(Python Web框架)的Web应用,使用Cairo(一个2D图形库)来渲染性能数据的图表,使用ExtJS作为基础UI框架
下面是Graphite的架构图: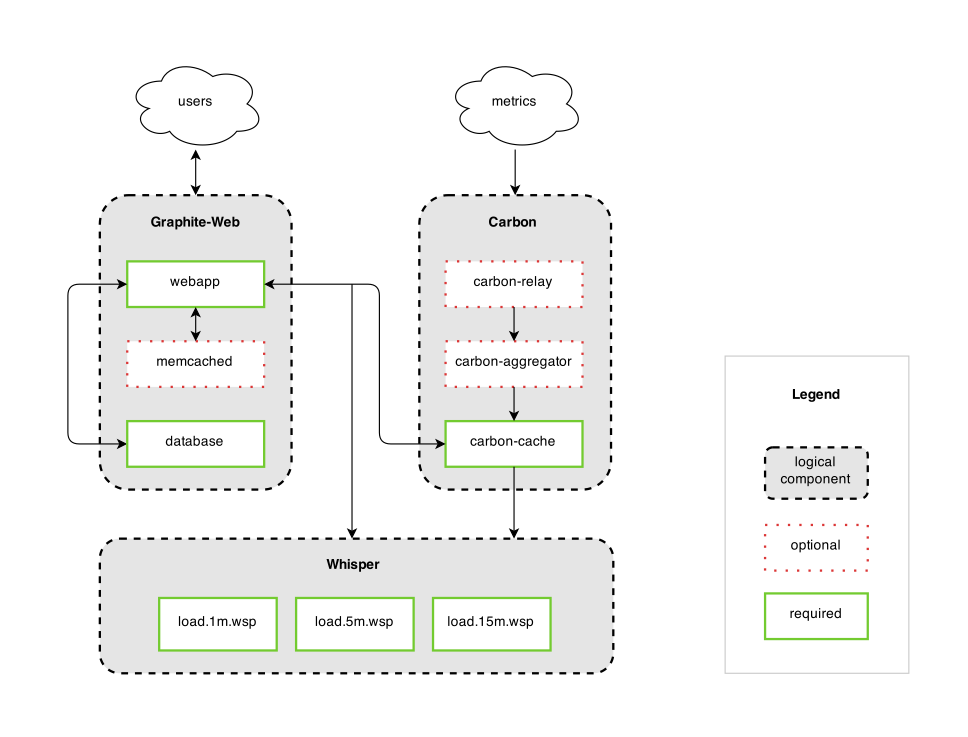
一旦你把数据送给Carbon,它就立刻可以在Webapp的图表中显示,因为数据在被写入文件系统之前,会驻留在缓存中。
除了使用Graphite Webapp,你也可以通过URL API,将图表嵌入到自己的应用程序中去。如何使用Graphite
使用Graphite来监控你的性能数据,你需要完成以下工作:
- 理解Graphite组件的职责和相互关系
- 安装Graphite及其依赖
- 基础的配置,让Graphite能运行起来
- 设计Metrics路径
- 配置Metrics的驻留规则、聚合规则等
- 向Graphite发送Metrics
- 从Graphite获取Metrics并展示
Metrics路径由点号分隔的字符串构成,类似于Python的包名称。路径是Metrics的标识。
你应当仔细的设计此路径的命名空间,以反映出所有Metrics之间的层次关系。例如servers.zircon.cpu,这个三级路径设计中,第一级表示设备类别,第二级表示设备名称,第三级表示监测点类型。
Carbon由一系列的守护进程组成,这些守护进程共同组成Graphite的存储后端。在最小化的安装下,只有一个守护进程carbon-cache.py。根据需要你可以启用carbon-relay.py、carbon-aggregator.py以便实现Metrics分发、定制聚合规则。各Carbon守护进程简介如下:
| 守护进程 | 说明 |
| 缓存进程 carbon-cache |
缓存进程的程序文件是carbon-cache.py。它通过多种协议接收Metrics,然后尽可能高效的将其写入磁盘。从实现角度来说,缓存进程先把Metrics存放在RAM中,然后定期的通过whisper库进行入库 缓存进程提供一个查询服务供Graphite Webapp使用,用来快速获取位于内存中的Metrics数据点 要定制此进程的行为,可以修改carbon.conf的[cache]段、storage-schemas.conf、storage-aggregation.conf |
| 中继进程 carbon-relay |
该进程可以担任这两个职责之一:复制(replication)和分片(sharding) 要定制此进程的行为,可以修改carbon.conf的[relay]段、relay-rules.conf |
| 前置聚合进程 carbon-aggregator |
前置于缓存进程运行,能够在存入whisper之前,缓冲、聚合Metrics。当不需要细粒度的数据时启用该进程,可以减少I/O和.wsp文件的大小 要定制此进程的行为,可以修改carbon.conf的[aggregator]段、aggregation-rules.conf |
Whisper是一个固定大小(fixed-size)的数据库,其设计和用途与RRD(round-robin-database)类似。它能提供快速、可靠的数值数据的存储。
Whisper能够对最近的数据进行高分辨率的存储,而对久远的历史数据,自动降低其存储精度(减少样本数量)。
在大多数场景下,Whisper有足够好的性能。它比RRDtool慢,主要原因是Whisper基于Python编写,这个性能差异很小,通常不需要考虑。
Whisper数据库以文件方式存放在磁盘上,扩展名.wsp。Carbon会为每个Metrics创建一个.wsp文件,路径的最后一节作为文件的basename,路径的其它部分形成目录层次。
在Whisper中存储的每一个数值,称为数据点(Data Points)。
在磁盘上,数据点以大端、双精度浮点数存储。每个数据还附带一个时间戳信息,时间戳为1970-01-01到数据采集时间的秒数。
一个Whisper数据库文件可以包含一个或者多个“归档”,归档是数据文件中的逻辑段。
每个归档具有不同的数据分辨率(一定时间段内,数据点数量越多,则分辨率越高)。归档以最高分辨率(最小驻留时间) —— 最低分辨率(最长驻留时间)的顺序,在数据库文件中顺序排列。
为了精确的从高分辨率向低分辨率的归档聚合,高分辨率归档和它之后的低分辨率归档,其分辨率应当具有整除关系。例如,第一个归档分辨率为60秒/数据点,那么第二个归档可以是300秒/数据点,第三个归档可以是3600秒/数据点。
一个数据库的总计驻留时间(存放的数据点跨越的时间),由最长驻留时间的(最后一个)归档确定。因为之前的那些归档,时间区间都是它的子区间。
把数据点转移到低分辨率归档时,面临着如何把多个数据点转变为单个数据点的问题。Whisper支持average、sum、last、max、min等聚合函数。
注意,这里的聚合和Carbon提供的前置聚合不是一回事。
当Whisper向一个多归档数据写入Metrics时,数据点将被同时写入到所有的归档中。这意味着聚合动作随时可能发生。
当从Whisper中获取数据时,第一个能完整覆盖所需区间的归档被使用。
Whisper的磁盘利用效率不高,因为:
- 每个数据点要附加一个时间戳信息
- 由于归档的时间区间有重叠,因此数据存在冗余
- 归档中的时间槽位(time-slots)总是占据着磁盘空间,不管有没有值存储在其中
这些特征是故意的,主要出于性能方面的考虑。
- RRD不能去填充以前的时间槽位。这意味着每一条数据都必须是更新的,不会“补录”
- RRD不能很好的支持不规则的数据更新。如果RRD接收到一条数据,但是后续数据没有到来,则前一条数据可能丢失
|
1 2 3 |
git clone https://github.com/graphite-project/graphite-web.git graphite-web/check-dependencies.py # 根据输出的提示来判断缺少哪些依赖,然后安装 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
yum -y install python-devel # Carbon 依赖于 Python Development Headers yum install pycairo # Cairo库的Python绑定 pip install django # Web框架 pip install django-tagging pip install pytz yum install fontconfig yum install -y memcached # 可选,缓存支持 pip install python-memcached # 可选,RDDTool yum install cairo-devel libxml2-devel pango-devel pango libpng-devel freetype freetype-devel libart_lgpl-devel rrdtool-devel pip install python-rrdtool # 可选,RRD支持 pip install whitenoise # 用于Web静态文件处理 yum install pyOpenSSL # OpenSSL的Python绑定 pip install service_identity # SSL相关 |
|
1 2 3 4 |
pip install https://github.com/graphite-project/ceres/tarball/master pip install whisper pip install carbon pip install graphite-web |
|
1 2 3 4 5 |
sudo groupadd graphite sudo usermod -a -G graphite root sudo usermod -a -G graphite apache sudo chgrp -R graphite /opt/graphite/storage sudo chmod -R 770 /opt/graphite/storage |
Whisper被安装到Python全局site-packages目录,另外两个Graphite组件安装到 /opt/graphite,该目录(记为 $GRAPHITE_ROOT )的布局如下:
| 子目录 | 说明 |
| bin | 一些脚本 |
| conf | 配置文件 |
| lib | 一些Python依赖库,Carbon的PYTHONPATH |
| storage | 存储SQLite数据文件。该目录记为 $STORAGE_DIR |
| storage/log | Carbon和Graphite-web的日志 |
| storage/rrd | 待读取的RRD文件 |
| storages/whisper | Whisper数据文件 |
| webapp |
Graphite-web的Web资源、PYTHONPATH |
| webapp/graphite |
标准的Django工程结构 |
| webapp/content | 静态Web资源 |
你需要让Graphite-web的底层框架Django执行数据库的初始化。此数据库被用来存放用户设置、仪表盘,以及支持事件功能。
默认情况下,Graphite-web使用位于$STORAGE_DIR/graphite.db的SQLite数据库。如果要运行多个Graphite-web实例,则必须使用MySQL等数据库以便多个实例可以共享数据。
执行下面的命令初始化SQLite数据库:
|
1 2 |
PYTHONPATH=/opt/graphite/webapp django-admin.py migrate --settings=graphite.settings --run-syncdb # 完毕后 $STORAGE_DIR/graphite.db自动创建 |
Django应用需要在Web服务器中运行,Web服务器需要对SQLite数据文件有读写权限。假设你使用Apache2,运行Apache2的用户为apache,则需要执行:
|
1 |
sudo chgrp graphite /opt/graphite/storage/graphite.db |
Graphite不建议修改settings.py,所有定制化的配置,都应该在此文件中进行。常用的设置项如下表:
| 设置项 | 说明 | ||||
| TIME_ZONE | 时区,规范化的时区名称。默认America/Chicago | ||||
| DEBUG | 是否启用Django错误页面。默认False | ||||
| FLUSHRRDCACHED | 如果设置,在从RRD文件获取数据前,执行
rrdtool flushcached 设置为rrdcached的地址或者Socket(例如unix:/var/run/rrdcached.sock) |
||||
| MEMCACHE_HOSTS | 如果设置,启用对计算出的目标、渲染过的图片的缓存。如果运行Graphite Web应用集群,则每个实例应当设置为一样的值 设置为memcached主机的数组,例如:['10.10.10.10:11211', '10.10.10.12:11211'] |
||||
| DEFAULT_CACHE_DURATION | 数据、图片默认缓存时间。默认值60 | ||||
| DEFAULT_CACHE_POLICY | 默认缓存策略。为元组的数组,每个元组指定最小查询时间、数据缓存时间 通过该设置,你可以让大的查询缓存更长时间。例如:
|
||||
| GRAPHITE_ROOT | Graphite的安装目录。默认/opt/graphite | ||||
| CONF_DIR | 额外Graphite-web配置文件目录。默认/opt/graphite/conf | ||||
| STORAGE_DIR | 存储目录。WHISPER_DIR、RRD_DIR、LOG_DIR、INDEX_FILE参照的基准目录 | ||||
| STATIC_ROOT | Graphite-web的静态文件目录。默认/opt/graphite/static 该目录一开始会不存在,你需要在设置STATIC_ROOT、STATIC_URL后执行:
你还需要在Web服务器中把/static这个前缀映射到此目录,里Apache2为例:
如果你安装了whitenoise包,静态文件可以直接由Graphite webapp来处理,不通过Web服务器 |
||||
| DASHBOARD_CONF | 仪表盘的配置文件。默认$CONF_DIR/dashboard.conf | ||||
| GRAPHTEMPLATES_CONF | 图形模板的配置文件。默认$CONF_DIR/graphTemplates.conf | ||||
| WHISPER_DIR | Whisper数据文件目录。默认/opt/graphite/storage/whisper | ||||
| RRD_DIR | RRD数据文件目录。默认/opt/graphite/storage/rrd | ||||
| LOG_DIR | Graphite webapp的日志目录。默认$TORAGE_DIR/log/webapp | ||||
| INDEX_FILE | 搜索索引位置。默认/opt/graphite/storage/index 由build-index.sh脚本生成,运行Web应用的用户必须有写权限 |
||||
| URL_PREFIX | URL前缀 |
我们的配置如下:
|
1 2 |
# 如果不设置,会导致报错:AttributeError: 'Settings' object has no attribute 'URL_PREFIX URL_PREFIX = '/' |
多种Web服务器可以用于运行基于Django的Web应用,这里我们选择Apache2。在CentOS下安装Apache2:
|
1 |
yum install httpd |
要让Apache2能够运行Python Web应用,需要安装模块mod_wsgi。参考Django学习笔记完成mod_wsgi的构建与安装。
在/opt/graphite/examples/目录下,example-graphite-vhost.conf可以作为Apache虚拟主机的模板,复制该文件到/etc/httpd/conf.d/目录下,然后修改:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<IfModule !wsgi_module.c> LoadModule wsgi_module modules/mod_wsgi.so </IfModule> WSGISocketPrefix run/wsgi <VirtualHost *:7767> ServerName xcentos7.local DocumentRoot "/opt/graphite/webapp" ErrorLog /opt/graphite/storage/log/webapp/error.log CustomLog /opt/graphite/storage/log/webapp/access.log common WSGIDaemonProcess graphite processes=5 threads=5 display-name='%{GROUP}' inactivity-timeout=120 WSGIProcessGroup graphite WSGIApplicationGroup %{GLOBAL} WSGIImportScript /opt/graphite/conf/graphite.wsgi process-group=graphite application-group=%{GLOBAL} WSGIScriptAlias / /opt/graphite/conf/graphite.wsgi Alias /content/ /opt/graphite/webapp/content/ <Directory /opt/graphite/webapp/content/> Require all granted </Directory> <Directory /opt/graphite/conf/> Require all granted </Directory> </VirtualHost> |
如果配置没有问题,启动Web服务器后访问: http://GRAPHITE_HOST:GRAPHITE_PORT/render ,会显示一张330x250大小的图片,上面写着No Data。
所有Carbon守护进程可以基于多种通信协议,监听时间序列数据,并且对数据进行不同的处理。
Carbon的配置文件位于/opt/graphite/conf/目录,默认情况下没有预置的配置文件,但是Graphite提供了若干配置文件样例。你可以复制这些配置文件并定制:
|
1 2 3 |
pushd /opt/graphite/conf cp carbon.conf.example carbon.conf cp storage-schemas.conf.example storage-schemas.conf |
这是主配置文件,为每个Carbon守护进程定义配置项。该配置文件按段区分不同守护进程的配置:
| 配置项段 | 配置项 | 说明 |
| [cache] |
ENABLE_LOGROTATION |
是否启用每日的日志轮转,启用后每天创建一个日志 |
| USER | 运行该进程的用户 | |
| MAX_CACHE_SIZE | 内存中Metrics缓存的最大尺寸 | |
| MAX_UPDATES_PER_SECOND | 每秒执行whisper的update_many()调用的最大次数,对应磁盘IO的次数,该配置项避免过度的磁盘使用 | |
| MAX_CREATES_PER_MINUTE | 对每分钟最多创建的.wsp文件的个数进行软限制。超过限制的新Metrics对应的.wsp文件不会被创建,Metrics也被丢弃 | |
| LINE_RECEIVER_INTERFACE | 接收文本格式数据的监听端口,默认0.0.0.0:2003 | |
| LINE_RECEIVER_PORT | ||
| PICKLE_RECEIVER_INTERFACE |
接收Pickle格式数据的监听端口,默认0.0.0.0:2004 | |
| PICKLE_RECEIVER_PORT | ||
| ENABLE_UDP_LISTENER | 是否启用UDP监听 | |
| UDP_RECEIVER_INTERFACE | 通过UDP接收数据的监听端口,默认0.0.0.0:2003 | |
| UDP_RECEIVER_PORT | ||
| LOG_LISTENER_CONNECTIONS | 对成功的连接请求记录日志 | |
| CACHE_QUERY_INTERFACE | 缓存查询服务的监听端口,默认0.0.0.0:7002 | |
| CACHE_QUERY_PORT | ||
| USE_FLOW_CONTROL | 是否进行流量控制。如果设置为True,那么达到MAX_CACHE_SIZE后,会暂停接收数据,直到缓存占用小于MAX_CACHE_SIZE的95% | |
| CACHE_WRITE_STRATEGY | 按何种顺序将缓存从内存中移除,并写入到磁盘的策略:sorted、max、naive | |
| [relay] | LINE_RECEIVER_INTERFACE |
接收文本格式数据的监听端口,默认0.0.0.0:2003 |
| LINE_RECEIVER_PORT | ||
| PICKLE_RECEIVER_INTERFACE | 接收Pickle格式数据的监听端口,默认0.0.0.0:2004 | |
| PICKLE_RECEIVER_PORT | ||
| LOG_LISTENER_CONNECTIONS | 对成功的连接请求记录日志 | |
| USER | 运行该进程的用户 | |
| RELAY_METHOD |
设置为rules:则该进程可以代替carbon-cache.py,然后中继所有Metrics给多个作为后端的carbon-cache.py 设置为consistent-hashing:则依据DESTINATIONS定义的分片策略,分发Metrics给多个作为后端的carbon-cache.py |
|
| REPLICATION_FACTOR | RELAY_METHOD=consistent-hashing时,可以指定N,从而把每个数据点分发到N台机器 | |
| DESTINATIONS | 转发的目标,每个目标的格式是IP:PORT RELAY_METHOD=rules时relay-rules.conf每个servers都要在此字段定义 |
|
| MAX_DATAPOINTS_PER_MESSAGE | 单个转发报文中包含的数据点的最大个数 | |
| MAX_QUEUE_SIZE | 待转发的队列最大包含多少数据点 | |
| QUEUE_LOW_WATERMARK_PCT | 队列低水位的百分比,0-1之间 | |
| USE_FLOW_CONTROL | 是否进行流量控制。如果设置为True,那么达到MAX_QUEUE_SIZE后,会暂停接收数据,直到转发队列低于QUEUE_LOW_WATERMARK_PCT | |
| [aggregator] | LINE_RECEIVER_INTERFACE | 接收文本格式数据的监听端口,默认0.0.0.0:2023 |
| LINE_RECEIVER_PORT | ||
| PICKLE_RECEIVER_INTERFACE | 接收Pickle格式数据的监听端口,默认0.0.0.0:2004 | |
| PICKLE_RECEIVER_PORT | ||
| LOG_LISTENER_CONNECTIONS | 对成功的连接请求记录日志 | |
| USER | 运行该进程的用户 | |
| FORWARD_ALL | 如果设置为True,除了根据aggregation-rules.conf进行聚合外,还把原始数据转发给DESTINATIONS | |
| DESTINATIONS | 聚合后的数据发送到的地方 | |
| REPLICATION_FACTOR | 如果设置为N,则把数据转发给N个DESTINATION | |
| MAX_QUEUE_SIZE | 待转发的队列最大包含多少数据点 | |
| USE_FLOW_CONTROL | 是否进行流量控制。如果设置为True,那么达到MAX_QUEUE_SIZE后,会暂停接收数据,直到转发队列低于80% | |
| MAX_DATAPOINTS_PER_MESSAGE | 单个转发报文中包含的数据点的最大个数 | |
| MAX_AGGREGATION_INTERVALS | 控制最多记住多少数据点,只有这些数据点才参与聚合 仅最近MAX_AGGREGATION_INTERVALS * intervalSize秒内的数据点会被记住 |
这个配置文件用于定义Metrics的驻留率( retention rates)——即Metrics的数据点(datapoints)以什么频率保存,保存多长时间。关于该配置文件,需要注意:
- 该配置文件可以由多个段(Section)组成。每个段定义一个存储规则
- 这些规则按照从上到下的顺序对Metrics进行匹配,第一个匹配的规则对Metrics生效
- 匹配Metrics时,采用的是正则表达式
- 对于一个Metrics,其存储规则在接收到第一个数据时固化。因而修改此配置文件不会影响到既有的.wsp文件。要应用到既有的.wsp可以调用whisper-resize.py
每个规则由三个部分组成:
|
1 2 3 4 5 6 7 8 |
# 段名称(规则名称),主要是文档用途。在匹配段的Metrics被创建时,日志creates.log中会显示此名称 [rulename] # 匹配Metrics路径(Metrics的全限定名称,点号分隔)的正则式 # 举例:^servers\.www.*\.workers\.busyWorkers$ pattern=regex # 驻留率表达式,数据点间隔:存留天数,时间后缀s,m,h,d,y分别表示秒、分、小时、天、年 # 举例:10s:14d 表示每个数据点表示10秒(相当于每10秒采集数据一次),并且存储14天的数据 retentions=retention rate |
注意,你可以指定多重驻留率表达式(retention rate),逗号分隔每个表达式。一般从最高精度:最短存留时间开始指定,直到最低精度:最长存留时间。例如: 15s:7d,1m:21d,15m:5y 表示7天内每15秒存留一个采样,而大于21天小于5年的则每15分钟一个采样。
设置多重驻留率表达式,可以在保存足够长时间的历史数据的前提下,尽量减少磁盘I/O和消耗的存储空间。当跨越驻留表达式的时间区间(上例中7天,21天)后,whisper会自动降低采样率(downsamples),默认算法是取平均值,可以通过storage-aggregation.conf定制聚合方式
这个配置文件定义如何在降低采样率(转换为低精度存储时) 如何对数据进行聚合。该文件的格式与storage-schemas.conf类似:
|
1 2 3 4 5 6 |
[rulename] pattern = rexexp # 0-1之间的浮点数,默认0.5。聚合区间内的值,至少多少比例为非空,聚合后的值才是非空 xFilesFactor = 0.5 # 数据聚合方式,默认average aggregationMethod = average | sum | min | max | last |
同样的,修改此文件不会影响已经生成的.wsp文件, 要应用到既有的.wsp文件,可以调用whisper-set-aggregation-method.py。
这个配置文件指定中继规则——即需要把何种Metrics转发给何种后端。中继由Carbon的中继进程负责执行。该文件格式如下:
|
1 2 3 |
[rulename] pattern = regex servers = ip:port,ip:port,... |
该配置文件定义聚合出来的Metrics——由几个Metrics聚合而成的新的Metrics。聚合由Carbon的聚合进程负责执行。
注意:这里的聚合storage-aggregation.conf提及的聚合不同。后者用于单一Metrics的降低采样,而前者用于生成新的Metrics。
与其它配置文件不同,该文件一旦更改,立即生效。
该文件的格式如下:
|
1 2 3 4 |
# 捕获任何匹配input_pattern的Metrics,使用method聚合成新的Metrics:output_template # frequency:每隔多久执行一次聚合 # method:可选sum/avg output_template (frequency) = method input_pattern |
举例,假设你的Metrics的命名规则是:
|
1 |
<env>.applications.<app>.<server>.<metric> |
这是你可以配置如下聚合规则,来计算所有应用程序的请求的总数:
|
1 |
<env>.applications.<app>.all.requests (60) = sum <env>.applications.<app>.*.requests |
在此规则下,下面的Metrics:
|
1 2 3 4 |
test.applications.pems.221.request test.applications.pems.6.request test.applications.pems.5.request test.applications.pems.201.request |
会每个60秒求和并生成 test.applications.pems.all.request 的一个数据点。
该配置文件定义Metrics名称的改写规则。 与其它配置文件不同,该文件一旦更改,立即生效。该文件的格式如下:
|
1 2 3 4 5 |
[pre] # pre段的规则,在接收到数据后立即执行改写 [post] # post段的规则,在聚合完毕后执行改写 regex-pattern = replacement-text |
举例:
|
1 2 3 |
# \1表示第一个捕获,即[a-z0-9]+ ^collectd\.([a-z0-9]+)\. = \1.system. # collectd.prod.cpu-0.idle-time 会被改写为 prod.system.cpu-0.idle-item |
Carbon提供黑白名单功能。白名单:仅仅接受其中列出的Metrics;黑名单:拒绝其中列出Metrics。
要启用黑白名单功能,需要修改carbon.conf,设置 USE_WHITELIST = True
如何启动Graphite Webapp依赖于其运行的Web服务软件,以Apache为例:
|
1 2 |
# CentOS 7 systemctl restart httpd |
Carbon组件需要执行下面的命令来启动:
|
1 |
/opt/graphite/bin/carbon-cache.py start |
SQLite是一个“文件数据库”,不需要启动。如果Graphite Webapp使用其它数据库,例如MySQL,则需要启动之。
你可以通过多种方式向Graphite(的Carbon组件)发送Metrics数据点。主要的三种数据格式是:Plaintext、Pickle、AMQP
这种方式非常简单,你可以用如下格式来发送一条Metrics数据点:
|
1 2 3 |
<metric path> <metric value> <metric timestamp> # 举例: servers.zircon.cpu 85 1470303923 |
出于测试目的,你可以直接通过命令向Carbon发送Metrics数据:
|
1 2 3 |
PORT=2003 SERVER=127.0.0.1 echo "servers.zircon.cpu 85 `date +%s`" | nc ${SERVER} ${PORT} |
Pickle是Python下的对象串行化框架,Pickle协议即它的串行化格式协议。使用该协议,你可以一次发送多个Metrics,并且串行化后的数据比较紧凑,因此Pickle协议性能更好。
下面是构建Pickle报文的示例代码:
|
1 2 3 4 5 6 7 8 |
listOfMetricTuples = [ (path, (timestamp, value)), ... ] payload = pickle.dumps(listOfMetricTuples, protocol=2) header = struct.pack("!L", len(payload)) message = header + payload # 然后通过Socket把message发送出去即可 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import pickle import socket import struct import sys import time from time import sleep import psutil def get_cpu_load(): load = psutil.cpu_percent() print load return load if __name__ == '__main__': CARBON_HOST = '172.16.87.132' CARBON_PORT = 2004 s = socket.socket() try: s.connect((CARBON_HOST, CARBON_PORT)) while True: data = [ ('servers.zircon.cpu', (time.time(), get_cpu_load())) ] pkg = pickle.dumps(data, 1) s.sendall(struct.pack('!L', len(pkg))) s.sendall(pkg) sleep(5) except socket.error: raise SystemExit("Failed to connect to %(host)s:%(port)" % {'host': CARBON_HOST, 'port': CARBON_PORT}) except KeyboardInterrupt: sys.stderr.write("\nExiting on CTRL-C\n") sys.exit(0) |
要从Graphite获取数据用于展示,可以使用Graphite Webapp暴露的Render URL API(RUA)。你可以通过
|
1 |
http://GRAPHITE_HOST:GRAPHITE_PORT/render |
访问此API。要向RUA传递参数,可以使用URL请求参数方式: &name=value 。注意大部分的参数名、函数名是大小写敏感的。
下面列出几个RUA的URL示例:
|
1 2 3 4 5 6 |
# Zircon的CPU负载图,获取800x600的图片 http://graphite/render?target=servers.zircon.cpu&height=800&width=600 # 最近12小时,所有服务器的CPU负载平均值 http://graphite/render?target=averageSeries(servers.*.load)&from=-12hours # 获取原始数据而不是图片,JSON格式 http://graphite/render?target=servers.zircon.cpu&format=json |
该参数用来指定从何处获取数据,你可以指定:
- 单个Metrics路径
- 带有通配符的的Metrics路径,匹配多个Metrics
- 函数调用,针对作为入参的Metrics进行各种转换、合并操作
你可以在路径中使用三种风格的通配符:
- * 可以匹配0-N个字符,例如 servers.dev-*.cpu ,可以匹配所有开发服务器的CPU负载Metrics。
- [...] 可以匹配列表中枚举的单个字符,例如 servers.dev-[a-z0-9].cpu ,可以匹配dev-0、dev-1等服务器的CPU负载Metrics。
- {...} 可以匹配列表中枚举的单个字符串,例如 servers.{dev-0,dev-1}.cpu ,匹配dev-0、dev-2的CPU负载Metrics。
注意:所有通配符都不能跨越点号。
你可以指定target为template函数调用,从而在Metrics路径中使用变量,例如:
|
1 2 3 4 5 6 7 8 9 |
# $varname 用来声明变量占位符 # template[varname]参数用来传递变量值 &target=template(servers.$servername.cpu)&template[servername]=zircon # 可以使用数字代替变量名 &target=template(servers.$1.cpu)&template[1]=zircon # template可以内嵌其它函数 &target=template(constantLine($number))&template[number]=123 |
可用的函数较多,这里不一一列举说明,参见官方文档。
这两个可选参数用来指定相对或者绝对的时间区间(time period)。from表示区间起点,如果忽略,默认值是24小时之前;until表示区间终点,如果或略,默认值是当前时间点。
如果要使用相对时间,需要加上 - 前缀(负号),后面跟着数值和时间单位。时间单位包括:
| 时间单位 | 说明 |
| s | 秒 |
| min | 分钟 |
| h | 小时 |
| d | 天 |
| w | 周 |
| mon | 月(30天) |
| y | 年(365天) |
你可以指定 HH:MM_YYYYMMDD 、 YYYYMMDD 、 MM/DD/YY 等格式的时间绝对值。
该参数用来指定要获取的数据的格式。 支持以下取值:
| 格式 | 说明 | ||||
| png | 根据指定的width、height,直接把数据渲染为PNG图片 | ||||
| raw | 原始数据,分为多行,每行格式为:
示例:
|
||||
| csv | 基于逗号分隔符的格式,每行表示一个数据点。示例:
|
||||
| json |
JSON数组格式,示例:
可以和jsonp参数联用,以便把数据包装成函数调用,进行跨域请求 可以和maxDataPoints参数联用,限定最大的数据点个数。超过数量的数据点将被压缩掉 可以和noNullPoints参数联用,移除所有Null值的数据点 |
||||
| svg | 渲染为SVG图片格式 | ||||
| 渲染为PDF文档 | |||||
| dygraph | dygraphs是一个快速、灵活的JavaScript图表(Chart)库。该格式返回dygraphs支持的数据格式。示例:
|
||||
| rickshaw | rickshaw是一个简单的JavaScript图表库。该格式返回rickshaw支持的数据格式。示例:
|
||||
| pickle | 返回Pickle串行化格式,设置MIME类型为application/pickle。反串行化后的对象示例:
|
你可以指定多个参数,来控制生成的图形的样式:
| 参数 | 说明 | ||
| areaAlpha | 启用areaMode时,填充区域的透明度。0-1之间的浮点数 | ||
| areaMode | 填充曲线与X轴之间的区域,形成Area图,可以取值: none 不进行填充 first 填充第一个目标 all 填充所有目标 stacked 堆叠模式,填充所有目标,一个目标的取值为前面所有其它目标的取值+该目标的取值 |
||
| bgcolor | 背景颜色。示例:
|
||
| cacheTimeout | 被渲染出的图形,其有效缓存时间 | ||
| colorList | 多个Target时,每个Target的颜色,逗号分隔颜色代码 | ||
| drawNullAsZero | 是否把空值渲染为0 | ||
| fontBold | 是否使用粗体 | ||
| fontItalic | 是否使用斜体 | ||
| fontName | 字体名称,该字体必须安装在Graphite服务器上 | ||
| fontSize | 字体大小,大于1的浮点数 | ||
| graphOnly | 是否不显示网格线、X/Y轴和图例 | ||
| graphType | 图表类型,line或者pie | ||
| hideLegend | 是否隐藏图例 | ||
| hideAxes | 是否隐藏X/Y轴 | ||
| hideXAxis | |||
| hideYAxis | |||
| hideGrid | 是否隐藏网格线 | ||
| height | 图形的高度、宽度,单位像素 | ||
| width | |||
| leftColor | 在双Y轴模式下,设置与左轴关联的Metrics的颜色 | ||
| rightColor | 在双Y轴模式下,设置与右轴关联的Metrics的颜色 | ||
| leftDashed | 在双Y轴模式下,是否以虚线绘制与左轴关联的Metrics | ||
| rightDashed | 在双Y轴模式下,是否以虚线绘制与右轴关联的Metrics | ||
| leftWidth | 在双Y轴模式下,设置与左轴关联的Metrics的线条宽度 | ||
| rightWidth | 在双Y轴模式下,设置与右轴关联的Metrics的线条宽度 | ||
| lineMode | 设置线条绘制的行为: slope:从一个数据点向下一个数据点绘制斜线,Null值的区间不被绘制 connected:与slope类似,但是数据点总是被连接起来,无论它们之间是否存在Null值 staircase:绘制直方图 |
||
| lineWidth | 线条的宽度 | ||
| majorGridLineColor | 网格线主色 | ||
| minorGridLineColor | 网格线从色 | ||
| minorY | 每两个网格主线之间,有几个从线,Y方向 | ||
| margin | 图形四周的边距 | ||
| maxDataPoints | 使用 | ||
| minXStep |
两个连续的数据点之间,间隔的最小像素 如果数据点过多,则压缩,以满足此配置 |
||
| noCache | 禁止图片缓存 | ||
| pieLabels | 饼图标签如何显示,horizontal或者rotated | ||
| pieMode | 饼图聚合方式: average,取series中非空数据点的平均值 maximum,取series中非空数据点的最大值 minimum,取series中非空数据点的最小值 |
||
| valueLabels | 如何显示饼图分块的标签: none,不显示 numbers,显示原始值 percent,显示百分比 |
||
| valueLabelsColor | 如何显示饼图分块的标签的颜色 | ||
| valueLabelsMin | 饼图中,分块占比小于此数值的分块,不显示其标签 | ||
| title | 在图形顶端显示的标题 | ||
| vtitle | Y轴标题,垂直显示 | ||
| vtitleRight | 双Y轴模式下,右Y轴的标题 | ||
| tz | 用于显示时间值的时区 |
上一章内容我们讨论了如何获取Graphite数据。通过Render URL API,我们不但可以获得文本数据,还可以直接获得渲染好的图片。这意味着通过Render URL API本身就可以实现Metrics的渲染,你只需要把生成的图片嵌入到自己的应用程序中即可。
Graphite Webapp本身提供了基于ExtJS的一个管理界面,你可以通过 http://GRAPHITE_HOST:GRAPHITE_PORT/admin 浏览Metrics。
Graphite生成的Metrics曲线的图片,不是非常美观,而静态图片也缺乏交互性。因此,实际项目中常常结合使用第三方基于JavaScript的Charts库来做展示,例如:
- Grafana:UI比较绚丽,支持设计仪表盘、时间区间联动。参见:使用Grafana展示时间序列数据
- Graphene:一个较为简单的,基于D3.js和Backbone.js的Graphite仪表盘工具
除了简单的,基于Key/Value的Metrics数据,Graphite还可以存储、展示随机出现的数据——事件。
事件不适合存储在Whisper中,因此它被存储在Graphite的Webapp的数据库中(默认使用SQLite)。
通过向 http://GRAPHITE_HOST:GRAPHITE_PORT/events/ 发送POST请求,即可发布Graphite事件。事件使用JSON格式编码在请求体中:
|
1 2 3 4 5 |
{ "what": "事件类型", "tags": "标签", "data": "事件相关的数据" } |
指定target为 event(*tags) 函数调用,即可通过 /render 查询事件,例如
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[ { "target" : "events(mytag)", "datapoints" : [ [ 1, 1388966651 ], [ 3, 1388966652 ] ] } ] |
你也可以通过 /render/events/get_data 获得原始的事件数据,例如:
|
1 2 3 4 5 6 7 8 9 |
[ { "when" : 1392046352, "tags" : "mytag", "data" : "...", "id" : 2, "what" : "Event - deploy" } ] |
Django的request对象曾经有一个属性REQUEST,用来获得通过GET或者POST请求传递的请求参数,在1.9版本中此属性已经移除。
Graphite代码没有即时更新,存在不兼容的问题,修改一下即可:
|
1 2 |
def parseOptions(request): queryParams = request.GET # request.REQUEST已经被移除 |
还有很多其它views.py存在同样的问题,最好搜索一下一并修改。如果觉得麻烦可以安装兼容版本的Django:
|
1 |
pip install django==1.8.14 |
Leave a Reply