Kubefed学习笔记
集群联邦(Federation)的目的是实现单一集群统一管理多个Kubernetes集群的机制,这些集群可能是跨地区(Region),也可能是在不同公有云供应商上,亦或者是公司内部自行建立的集群。一但集群进行联邦后,就可以利用Federation API资源来统一管理多个集群的Kubernetes API资源,如定义Deployment如何部署到不同集群上,其集群所需的副本数等。
通过集群联邦,你可以:
- 简化管理多个集群的Kubernetes 组件,如Deployment, Service 等
- 在多个集群之间分散工作负载,以提升应用的可靠性
- 跨集群的资源编排,依据编排策略在多个集群进行应用部署
- 在不同集群中,能更快速更容易地迁移应用
- 跨集群的服务发现,服务可以实现地理位置感知,以降低延迟
- 实践多云(Multi-cloud)或混合云(Hybird Cloud)的部署
Federation v1在Kubernetes v1.3左右时,就已经着手设计,并在Kubernetes v1.6时,进入了Beta阶段。之后一直没有发展,并在1.11被废弃。
V1在架构上有很多问题,包括:
- 控制平面组件会因为发生问题,而影响整体集群效率
- 无法兼容新的Kubernetes API 资源
- 无法有效的在多个集群管理权限,如不支持RBAC
- 联邦层级的设定与策略依赖API 资源的Annotations
Federation v1的控制平面类似于K8S,包括组件:
- federation-apiserver:提供Federation API资源,只支持部分Kubernetes API resources
- federation-controller-manager:协调不同集群之间的状态,如同步Federated资源与策略
- etcd:储存Federation的状态
Federation v1的API Server通过k8s.io/apiserver套件开发,这种是采用API Aggregation方式来扩充Kubernetes API。
Federation v1写死了K8S资源版本,例如extensions/v1beta1的Deployment,写成apps/v1的Deployment则不支持。内置支持(管理的)K8S资源类型很少,如果想新增,必须在Federation types新增对应的Adapter,然后通过Code Generator产生API的client-go组件给Controller Manager操作API使用,最后重新建构一版本来更新API Server与Controller Manager以提供对其他资源与版本的支持,非常麻烦。
Federation v1在设计之初未考虑RBAC与CRD,这也是致命缺点。
Federation v2也叫Kubernetes Cluster Federation,或者KubeFed。和V1比起来,优势包括:
- 简化扩展Federated API过程
- 加强跨集群服务发现与编排的功能
- 模块化、可定制化,可以随着K8S生态一起演进
- 移除了API Server,通过CRD机制来完成Federated Resources的扩充。这些资源由KubeFed Controller管理
利用Kubefed(Kubernetes Cluster Federation)你可以用宿主集群(Host Cluster)中的单套API来协调多个K8S集群的配置。Kubefed刻意提供了低级别的API,用来应用复杂部署场景,包括跨地理位置应用部署、灾难恢复。
使用Kubefed你需要提供两类配置信息:
- Type配置:声明Kubefed需要处理的API类型
- Cluster配置:声明Kubefed需要管理的目标集群
术语 Propagation 表示将资源分发到对应集群的机制。
Type配置包含三个基本要素:
- Templates 定义资源在所有集群中共同的部分
- Placement 定义资源应该出现在哪些集群中
- Overrides 定义集群对Template字段的覆盖
高层API基于这些基本要素:
- Status:收集被分发到所有集群的资源的状态
- Policy:决定一个资源应当被分发到联邦集群的什么子集中
- Scheduling:决定工作负载如何跨越不同集群分布
| 术语 | 说明 |
| Federate | 将若干K8S集群联邦起来,提供一套公共接口,可以针对这个集群池操作,从而跨越多个K8S集群部署应用程序 |
| KubeFed | Kubefed是v2版本的K8S集群联邦,让用户联合多个K8S集群,实现:资源分发、服务发现、跨集群高可用 |
| Host Cluster | 一个用于暴露KubeFed API、运行KubeFet控制平面的集群 |
| Cluster Registration | 一个K8S集群可以通过 kubefedctl join加入到Host Cluster(加入到联邦) |
| Member Cluster |
一个集群通过KubeFed API注册并加入到联邦,则成为成员,KubeFed控制器在此之后获得该集群的访问凭证 Host Cluster是Member Cluster |
| ServiceDNSRecord | 一个关联到1-N个K8S Service的、包含了这些Service访问方式的资源。这种资源中还包括构造Service的DNS记录的Scheme |
| IngressDNSRecord | 一个关联到1-N个K8S Ingress的、包含了这些Ingress访问方式的资源。这种资源中还包括构造Ingress的DNS记录的Scheme |
| DNSEndpoint | 包装Endpoint资源的CRD |
| Endpoint | 表示DNS资源记录的资源 |
直接到:https://github.com/kubernetes-sigs/kubefed/releases 下载即可。
KubeFed可以在kind、Minikube、GKE等多种K8S环境下运行。你可以通过Chart方式来安装:
|
1 2 3 4 5 |
helm repo add kubefed https://raw.githubusercontent.com/kubernetes-sigs/kubefed/master/charts helm install kubefed/kubefed --name kubefed --namespace kube-federation-system \ --set controllermanager.replicaCount=1 \ --set controllermanager.repository=docker.gmem.cc/kubernetes-multicluster |
卸载时可能导致命名空间一直处于Terminating状态。根因是FederatedTypeConfig类型的CR上具有finalizer core.kubefed.io/federated-type-config。此finalizer导致CRD卡死在InstanceDeletionInProgress状态。
相关Issue:https://github.com/kubernetes/kubernetes/issues/60538
可以通过kubefedctl来将集群加入到联邦,你需要将所有集群的配置信息收集到KUBECONFIG中,分别作为一个context。
|
1 2 3 |
# 你需要修改默认的context名称,因为其中的@是特殊字符,会导致报错 kubefedctl join k8s --cluster-context k8s --host-cluster-context k8s --v=2 kubefedctl join kind --cluster-context kind --host-cluster-context k8s --v=2 |
|
1 2 3 4 5 |
kubectl -n kube-federation-system get kubefedclusters # NAME AGE READY # k8s 117m True # 如果READY不为True,则提示联邦控制平面无法访问到该成员的API Server # kind 117m |
|
1 |
kubefedctl unjoin kind --cluster-context=kind --host-cluster-context=k8s |
你可以启用任何K8S API类型的联邦支持,包括CRD。只有启用了联邦支持的API,才能够由联邦控制平面管理,分发给成员集群。
ClusterRole、Configmap、Deployment、Ingress、Job、Namespace、ReplicaSet、Secrets、ServiceAccount、Service默认情况下已经启用。
假设你有一个API名为deployment.k8s.gmem.cc,由于它和内置的Deployment资源同名,在启用它的联邦时,你需要指定一个组名:
|
1 |
kubefedctl enable deployments.gmem.cc --federated-group kubefed.gmem.cc |
原因是deployment.types.kubefed.io这个名字已经被占用。
要支持你的自定义资源(CR)的联邦,必须启用customresourcedefinitions(CRD)的联邦:
|
1 |
kubefedctl enable customresourcedefinitions |
上述命令执行后,会创建一个CRD:federatedcustomresourcedefinitions.types.kubefed.io。并且,在在Kubefed的控制平面所在命名空间,会创建一个federatedtypeconfigs.core.kubefed.io:
|
1 2 |
kubectl -n kube-federation-system get federatedtypeconfigs.core.kubefed.io # federatedcustomresourcedefinitions.types.kubefed.io 2020-05-27T11:10:59Z |
执行下面的命令执行某种CRD的联邦:
|
1 |
kubefedctl federate crd envoyfilters.networking.istio.io |
上述命令会执行类型为CRD的,名字为envoyfilters.networking.istio.io的资源的联邦。它会创建一个federatedcustomresourcedefinitions.types.kubefed.io资源,在其中描述如何在联邦中分发这个CRD:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: types.kubefed.io/v1beta1 kind: FederatedCustomResourceDefinition metadata: finalizers: - kubefed.io/sync-controller name: envoyfilters.networking.istio.io spec: # 需要分发到哪些集群 placement: clusterSelector: matchLabels: {} # 模板,即EnvoyFilter这个CRD的内容 template: metadata: labels: app: istio-pilot chart: istio spec: conversion: strategy: None group: networking.istio.io names: categories: - istio-io - networking-istio-io kind: EnvoyFilter status: # 已经分发的集群列表 clusters: - name: kind - name: k8s |
如果一切顺利,你应该很快在kind、k8s这两个集群中,看到名为envoyfilters.networking.istio.io的CRD。
执行了CRD的联邦了,CRD就可以分发到成员集群了。在此前提下,你可以启用对应CR的联邦:
|
1 |
kubefedctl enable envoyfilters.networking.istio.io |
上述命令会:
- 创建一个名为federatedenvoyfilters.types.kubefed.io的CRD
- 在Kubefed控制平面所在命名空间,创建一个名为envoyfilters.networking.istio.io的FederatedTypeConfig
FederatedTypeConfig负责将联邦类型和目标类型关联启用,启用联邦资源(转换为目标类型)传播(到成员集群):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
apiVersion: core.kubefed.io/v1beta1 kind: FederatedTypeConfig metadata: finalizers: - core.kubefed.io/federated-type-config name: envoyfilters.networking.istio.io namespace: kube-federation-system spec: # 联邦类型 federatedType: group: types.kubefed.io kind: FederatedEnvoyFilter pluralName: federatedenvoyfilters scope: Namespaced version: v1beta1 # 是否启用分发 propagation: Enabled # 目标类型 targetType: group: networking.istio.io kind: EnvoyFilter pluralName: envoyfilters scope: Namespaced version: v1alpha3 status: observedGeneration: 1 propagationController: Running statusController: NotRunning |
到这里,你就可以执行某个EnvoyFilter的联邦了 —— 指定哪些资源,需要分发到哪些集群中,各集群如何覆盖资源的某些字段。
这是最关键的主题,我们在下一章详细学习。
要禁止某一类API资源的分发,需要将FederatedTypeConfig的propagation设置为false:
|
1 2 |
kubectl patch --namespace kube-federation-system federatedtypeconfigs envoyfilters.networking.istio.io \ --type=merge -p '{"spec": {"propagation": "Disabled"}}' |
这样SyncController就会停止 envoyfilters的分发。
如果要永久的禁用联邦,则可以执行disable命令:
|
1 |
kubefedctl disable envoyfilters.networking.istio.io |
对应的FederatedTypeConfig资源会被删除。
这里我们以CoreDNS(启用Etcd插件)作为ExternalDNS的DNS Provider,利用MetalLB来提供LoadBalancer类型的Service,来试验MCIDNS功能。
CoreDNS、Etcd、ExternalDNS、MetalLB的安装步骤这里不详述,可以参考上段文字中的连接。本文强调一下用在Kubefed场景下差异化的部分。
ExternalDNS安装时,使用如下配置:
|
1 2 3 4 5 6 7 8 9 |
helm install bitnami/external-dns --name kubefed-external-dns --namespace=kube-federation-system \ --set global.imageRegistry=docker.gmem.cc \ --set global.imagePullSecrets[0]=gmemregsecret \ --set provider=coredns \ --set coredns.etcdEndpoints=http://kubefed-etcd:2379 \ --set sources={crd} \ --set crd.apiversion=multiclusterdns.kubefed.io/v1alpha1 \ --set crd.kind=DNSEndpoint \ --set logLevel=debug |
执行某个资源的联邦就是:修改某个的资源模板,为某些成员集群应用差异化的模板变量,然后分发到这些成员集群中。其前提条件是启用该资源类型的联邦支持,在上一章我们已经讨论如何做到这一点。
kubefedctl federate命令负责执行联邦,它会以一个现有的目标资源为模板(Template),创建对应的联邦资源,默认情况下以所有成员集群为分发(Placement)目标。命令格式如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
kubefedctl federate <target kubernetes API type> <target resource> [flags] # 可用标记 # -c, --contents 仅当联邦命名空间时有意义,如果指定,则在联邦完命名空间后, # 联邦其中的资源 # -s, --skip-api-resources # -c时,需要跳过的资源类型 # --dry-run 不发起API请求 # -f, --filename 从文件中读取需要联邦的资源列表,并且仅仅是将联邦后的结果输出到标准输出 # -n, --namespa 目标资源所在命名空间 # -o, --output 输出到标准输出,而非创建联邦资源 |
下面的例子,联邦了位于my-namespace中的ConfigMap my-configmap:
|
1 |
kubefedctl federate configmaps my-configmap -n my-namespace |
联邦命名空间时,你可以选择将其中的所有/部分类型资源都进行联邦:
|
1 |
kubefedctl federate namespace my-namespace --contents --skip-api-resources "configmaps,apps" |
要了解联邦资源分发的进度,你需要查看联邦资源的状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
apiVersion: types.kubefed.io/v1beta1 kind: FederatedNamespace metadata: name: myns namespace: myns spec: placement: clusterSelector: {} status: conditions: - type: Propagation # True意味着分发已经完毕 status: True lastTransitionTime: "2019-05-08T01:23:20Z" lastUpdateTime: "2019-05-08T01:23:20Z" # 下面两个集群已经接收到最新的myns clusters: - name: cluster1 - name: cluster2 |
如果Propagation的Status为False,则Reason会说明分发未完成的原因:
| 原因 | 说明 | ||
| CheckClusters |
一个或多个集群不在期望状态。这种情况下,clusters.status字段会显示具体原因:
|
||
| ClusterRetrievalFailed | 无法获取成员集群 | ||
| ComputePlacementFailed | 计算Placement时出错 | ||
| NamespaceNotFederated | 包含资源的命名空间没有被联邦 |
除了CheckClusters,其它原因都会产生一个K8S事件。
CheckClusters时,可能出现的某个集群错误status包括:
| Status | 说明 |
| AlreadyExists | 目标资源已经存在于集群,但是由于adoptResources被禁用,无法收养(adopted) |
| ApplyOverridesFailed | 向模板覆盖字段时出错 |
| CachedRetrievalFailed | 提取缓存的目标资源时出错 |
| ClientRetrievalFailed | 创建目标成员集群的API客户端时出错 |
| ClusterNotReady | 目标集群的健康检查失败 |
| ComputeResourceFailed | 生成资源在目标集群中应有形式时失败 |
| CreationFailed | 创建目标资源失败 |
| CreationTimedOut | 创建目标资源超时 |
| DeletionFailed | 删除失败 |
| DeletionTimedOut | 删除超时 |
| FieldRetentionFailed | Retain一个或多个字段时出错,例如Service的clusterIP |
| LabelRemovalFailed | 移除KubeFed标签失败 |
| LabelRemovalTimedOut | 移除KubeFed标签超时 |
| ManagedLabelFalse | 无法管理具有kubefed.io/managed: false标签的资源 |
| RetrievalFailed | 无法从目标集群检索资源 |
| UpdateFailed | 更新失败 |
| UpdateTimedOut | 更新超时 |
| VersionRetrievalFailed | 无法获取最新版本的资源 |
| WaitingForRemoval | 目标资源已经被标记为正在删除,等待垃圾回收器 |
由Sync Controller管理的联邦资源,具有Finalizer:kubefed.io/sync-controller。此Finalizer阻止资源的删除,直到Sync Controller有机会执行前置清理操作。
前置清理操作,就是要从受管成员集群中移除联邦资源对应的目标资源。
如果想在删除联邦资源后,仍然保留目标资源,则需要在执行删除操作之前,给联邦资源加上注解: kubefed.io/orphan: true,你可以通过命令完成:
|
1 2 3 4 5 6 |
# 启用孤儿化 kubefedctl orphaning-deletion enable <federated type> <name> # 查看孤儿化状态 kubefedctl orphaning-deletion status <federated type> <name> # 禁用孤儿化 kubefedctl orphaning-deletion disable <federated type> <name> |
要指定某个联邦资源需要分发到哪些集群,只需要设置联邦资源的spec.placement:
|
1 2 3 4 5 6 7 8 9 |
spec: placement: # 根据集群名字 clusters: - name: cluster1 # 根据集群标签 # 这样打标签:kubectl label kubefedclusters -n kube-federation-system cluster1 foo=bar clusterSelector: foo: bar |
一旦设置,已经分发到cluster2的资源,会自动删除。
如果placement设置为 {}则不分发到任何集群。
在分发资源给目标集群时,你可以进行差异化的修改。修改在联邦资源的spec.overrides中进行,语法是jsonpatch的子集:
- op 定义执行的操作:
- replace 替换,默认
- add 添加到对象或数组
- remove 从对象或数组移除
- path 定义需要操作的字段所在路径,必须以/开始:
- 例如 /spec/replicas
- 索引语法 /spec/template/spec/containers/0/image
- value 定义字段的值。对于remove操作,忽略
下面是一个例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
kind: FederatedDeployment ... spec: ... overrides: # 针对cluster1的Override - clusterName: cluster1 clusterOverrides: # 设置副本数为5 - path: "/spec/replicas" value: 5 # 设置第一个容器的镜像 - path: "/spec/template/spec/containers/0/image" value: "nginx:1.17.0-alpine" # 确保注解存在 - path: "/metadata/annotations" op: "add" value: foo: bar # 确保注解删除 - path: "/metadata/annotations/foo" op: "remove" # 插入第一个容器命令参数 - path: "/spec/template/spec/containers/0/args/0" op: "add" value: "-q" |
在计算目标集群中,联邦资源应该生成的形态时,使用如下算法:
- 从Template 计算出新的资源
- 如果该资源已经存在于目标集群,应当保留(retention)的字段,被保留
- 执行override
- 设置受管labels
目标集群中资源的大部分字段,都会被从联邦资源生成的最新版本代替,例外如下:
| 资源类型 | 字段 | 保留策略 | 说明 |
| All | metadata.annotations | Always | 期望被成员集群中某些控制器管理的注解 |
| All | metadata.finalizers | Always | 期望被成员集群中某些控制器管理的Finazlier |
| All | metadata.resourceVersion | Always | 用于并发控制 |
| Scalable | spec.replicas | Conditional | HPA控制器可能负责管理该字段 |
| Service | spec.clusterIP spec.ports |
Always | 某个控制器可能负责修改这些字段 |
| ServiceAccount | secrets | Conditional | 某个控制器可能负责修改这些字段 |
利用Kubefed提供的底层FederatedXxx API(具有template、placement、override字段),以及关联的控制器,我们可以构建出高级别的API。Kubefed自身提供了一些高级别API。
多集群Ingress DNS(Multi-Cluster Ingress DNS)提供以编程方式管理K8S Ingress资源的DNS记录的能力。MCIDNS的目的不是替换CoreDNS这样的DNS Provider,而是通过集成ExternalDNS,来在支持DNS Provider(例如一些云服务商的DNS服务)中管理外部DNS记录。
MCIDNS的工作流程图:
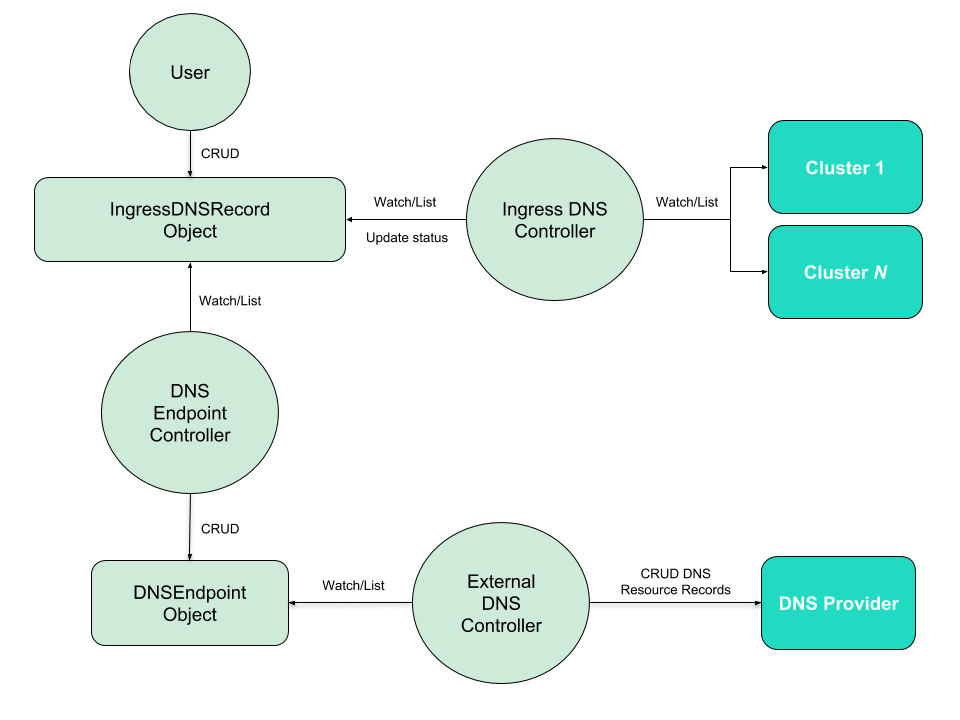
典型的工作流说明:
- 用户创建FederatedDeployment、FederatedService、FederatedIngress资源
- Kubefed的Sync Controller将对应的目标资源传播到成员K8S集群中
- 用户创建一个IngressDNSRecord资源,此资源标识期望的DNS名,以及可选的DNS记录参数
- MCIDNS的Ingress DNS Controller监控IngressDNSRecord,用匹配(成员集群中命名空间、名字与IngressDNSRecord一致的)的Ingress资源的IP地址(这个地址由Ingress Controller填充)来更新IngressDNSRecord的Status
- MCIDNS的DNS Endpoint Controller监控IngressDNSRecord,创建对应的DNSEndpoint
- DNSEndpoint包含必要的信息,外部DNS系统(例如ExternalDNS)负责监控此对象,利用其中的信息,在DNS Provider中创建DNS记录
要启用MCIDNS,你首先需要创建Kubefed控制平面,并加入成员集群。然后:
- 如有必要,在DNS Provider创建一个域名,或者,将某个DNS子域代理给ExternalDNS。具体操作方式咨询你的DNS Provider
- 安装ExternalDNS,必须指定参数:
12345--source=crd--crd-source-apiversion=multiclusterdns.kubefed.io/v1alpha1--crd-source-kind=DNSEndpoint--registry=txt--txt-prefix=cname -
创建一个样例的联邦 Deployment+Service+Ingress来进行测试:
- Ingress的域名设置为第一步中提及的域名的子域名
- 等待Ingress Controller将Ingress的IP地址设置好
- 创建IngressDNSRecord资源,必须注意,hosts字段和FederatedIngress的host字段要匹配:
123456789apiVersion: multiclusterdns.kubefed.io/v1alpha1kind: IngressDNSRecordmetadata:name: test-ingressnamespace: test-namespacespec:hosts:- test.kubefed.gmem.ccrecordTTL: 300 -
DNS Endpoint Controller将会使用目标Ingress中的IP地址来生成DNSEndpoint的targets字段,例如:
1234567891011121314apiVersion: multiclusterdns.kubefed.io/v1alpha1kind: DNSEndpointmetadata:name: ingress-test-ingressnamespace: test-namespacespec:endpoints:- dnsName: ingress.example.comrecordTTL: 300recordType: Atargets:- $CLUSTER1_INGRESS_IP- $CLUSTER2_INGRESS_IPstatus: {} - ExternalDNS的控制器会监控DNSEndpoint对象,在DNS Provider中为每个目标Ingress创建A记录和TXT记录。例如:
123NAME TYPE TTL DATAtest.kubefed.gmem.cc. A 300 $CLUSTER1_INGRESS_IP,$CLUSTER2_INGRESS_IPtest.kubefed.gmem.cc. TXT 300 "heritage=external-dns,external-dns/owner=my-identifier"
和MCIDNS类似,区别:
- ServiceDNSRecord监控Service的IP地址,类似于IngressDNSRecord从Ingress同步IP地址信息
- DNSEndpoint控制器会创建3个A记录,格式分别为:
123<service>.<namespace>.<federation>.svc.<federation-domain><service>.<namespace>.<federation>.svc.<region>.<federation-domain><service>.<namespace>.<federation>.svc.<availability-zone>.<region>.<federation-domain>
参考如下步骤:
- 准备Kubefed环境,需要支持LoadBalancer类型的服务
- Ingress的域名设置为第一步中提及的域名的子域名
- 安装ExternalDNS
- 创建一个样例的联邦 Deployment+Service(LoadBalancer)来进行测试:
- 服务的EXTERNAL-IP就绪后,创建Domain和ServiceDNSRecord:
1234567891011121314151617181920212223apiVersion: multiclusterdns.kubefed.io/v1alpha1kind: Domainmetadata:# 对应DNS记录中的 <federation> 段name: test-domain# 运行 kubefed-controller-manager的命名空间namespace: kube-federation-system# 在DNS Provider中配置好的域名或子域名domain: kubefed.gmem.cc---apiVersion: multiclusterdns.kubefed.io/v1alpha1kind: ServiceDNSRecordmetadata:# 测试服务的名字name: test-service# 测试服务的命名空间namespace: test-namespacespec:# 引用Domain对象domainRef: test-domainrecordTTL: 300 -
DNSEndpoint会自动创建3个A记录、3个TXT记录:
123456test-service.test-namespace.test-domain.svc.kubefed.gmem.cc. A 300 $CLUSTER1_SERVICE_IP,$CLUSTER2_SERVICE_IPtest-service.test-namespace.test-domain.svc.kubefed.gmem.cc. TXT 300 "heritage=external-dns,external-dns/owner=my-identifier"test-service.test-namespace.test-domain.svc.us-west1.kubefed.gmem.cc. A 300 $CLUSTER1_SERVICE_IP,$CLUSTER2_SERVICE_IPtest-service.test-namespace.test-domain.svc.us-west1.kubefed.gmem.cc. TXT 300 "heritage=external-dns,external-dns/owner=my-identifier"test-service.test-namespace.test-domain.svc.us-west1-b.us-west1.kubefed.gmem.cc. A 300 $CLUSTER1_SERVICE_IP,$CLUSTER2_SERVICE_IPtest-service.test-namespace.test-domain.svc.us-west1-b.us-west1.kubefed.gmem.cc. TXT 300 "heritage=external-dns,external-dns/owner=my-identifier"
- 服务的EXTERNAL-IP就绪后,创建Domain和ServiceDNSRecord:
RSP提供了一种机制,来自动化的机制来维护所有成员集群中、Deployment/Replicaset类型工作负载的副本总数。
在用户提供的偏好(RSP的某些字段)中,指定了集群的权重、副本数量最小、最大值。如果某些集群中Pod维持在unscheduled状态,还可以配置重新分发副本(给其它集群)。
RSP控制器负责监控RSP资源,以及namespace/name匹配的FederatedDeployment或(取决于spec.targetKind)FederatedReplicaset资源。如果目标资源存在,它会根据配置,将 spec.totalReplicas分发到当前健康成员集群中。如果没有设置针对单个集群的偏好,则均匀分发。
如果RSP对象存在,则匹配的FederatedXxx资源中的副本数声明被忽略。RSP控制器负责更新FederatedXxx中的副本Overrides,实际传播工作仍然由Sync Controller完成。
如果指定了spec.rebalance,则RSP控制器会进行副本数再平衡,即将无法调度的Pod(成员集群资源不足)调度到其它健康集群中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
apiVersion: scheduling.kubefed.io/v1alpha1 kind: ReplicaSchedulingPreference metadata: name: test-deployment namespace: test-ns spec: targetKind: FederatedDeployment totalReplicas: 9 # 或者 apiVersion: scheduling.kubefed.io/v1alpha1 kind: ReplicaSchedulingPreference metadata: name: test-deployment namespace: test-ns spec: targetKind: FederatedDeployment totalReplicas: 9 clusters: "*": weight: 1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: scheduling.kubefed.io/v1alpha1 kind: ReplicaSchedulingPreference metadata: name: test-deployment namespace: test-ns spec: targetKind: FederatedDeployment totalReplicas: 9 clusters: A: weight: 1 B: weight: 2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: scheduling.kubefed.io/v1alpha1 kind: ReplicaSchedulingPreference metadata: name: test-deployment namespace: test-ns spec: targetKind: FederatedDeployment totalReplicas: 9 clusters: A: minReplicas: 4 maxReplicas: 6 weight: 1 B: minReplicas: 4 maxReplicas: 8 weight: 2 |
- https://github.com/kubernetes-sigs/kubefed
- https://www.kubernetes.org.cn/5702.html
Leave a Reply