MongoDB学习笔记
MongoDB是一个开源的文档数据库(Document Database),具有高性能、高可用性、自动化的可扩容性。
高性能的持久化能力,主要体现在:
- 对内嵌数据模型的支持,减少了数据库系统的I/O活动
- 支持索引,加快了查询速度。可以包含来自内嵌文档、数组的索引键
高可用性由MongoDB的数据复制机制 —— 复制集(Replica set,一系列持有相同数据集的MongoDB实例)提供,主要体现在:
- 自动的故障转移
- 数据冗余
水平可扩容性主要体现在:
- 分片(Sharding)机制,在集群中分布数据
- 从3.4开始,支持基于分片键(Shard key)来划分数据区域(Zone)。在平衡化的集群中,MongoDB把读写操作定向到包含目标数据的区域中
所谓文档数据库,是指数据库中的每一条记录是一个“文档”。MongoDB的记录(文档)格式类似于JSON,由一系列字段组成,每个字段的值可以是文档、文档的数组、简单的值。文档格式的优势在于:
- 文档很自然的对应了主流编程语言中的原生数据结构(对象)
- 内嵌的文档、数组避免了关系型数据库昂贵的Join操作
- 由于支持动态Schema(动态字段),因此对动态的支持很轻松
MongoDB提供了富查询语言(Rich Query Language),除了支持读写操作以外,还支持数据聚合、文本搜索、地理空间查询。
MongoDB支持可拔插的存储引擎,你可以自己依据API开发存储引擎,或者使用开箱即用的WiredTiger、MMAPv1
MongoDB存储记录 —— BSON文档(JSON的二进制形式)到集合(Collection)中,数据库中包含多个集合。集合的概念类似于RDBMS的表。
要指定使用的数据库,可以通过use语句:
|
1 2 3 |
use newdb # 下面的命令列出现有的数据库 show dbs |
如果newdb不存在,MongoDB会在你第一次向其中存储数据时自动创建。类似的,使用不存在的集合时,也会自动的创建:
|
1 2 3 4 5 |
// 执行下面的语句时,会自动创建数据库newdb和集合newcoll db.newcoll.insertOne({x:1}); // 你也可以显式的创建集合,并提供参数,例如最大尺寸、文档验证规则 db.createCollection() |
在3.2版本之前,集合中存放的文档的Schema是任意的。3.2开始,你可以提供文档验证规则(Document Validation Rules)来限制某个集合中文档的结构。插入/更新文档时,必须满足规则。
除了定义数据记录之外,MongoDB在很多地方使用文档结构,包括但是不限于:
- 查询过滤器
- 更新规格文档(update specifications documents)
- 索引规格文档(update specifications documents)
BSON类似于JSON,但是它的字段具有更丰富的类型,例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var mydoc = { // 类似于UUID,但是支持快速生成,且有序 _id: ObjectId( "5099803df3f4948bd2f98391" ), // 内嵌文档 name: { first: "Alan", last: "Turing" }, // 日期 birth: new Date( 'Jun 23, 1912' ), death: new Date( 'Jun 07, 1954' ), // 数组 contribs: [ "Turing machine", "Turing test", "Turingery" ], views: NumberLong( 1250000 ) } |
BSON字段的命名限制:
- 名称_id保留用作主键,即指必须在集合中唯一、不可变。其类型可以是除了数组之外的任何类型
- 字段名不得以 $开头
- 字段名不得包含 . 号
- 字段名不得包含空字符(\0)
BSON支持重名字段,但是大部分MongoDB客户端使用哈希呈现文档,哈希不支持重名key。MongoDB进程产生的某些文档会使用重名字段,但是绝不会向用户定义的文档中添加重名字段。
对于被索引集合(Indexed collections),被索引的字段的值的长度,受到最大索引键长度的约束。
要访问内嵌文档、数组的元素,需要使用点号标记:
|
1 2 |
mydoc.name.first mydoc.contribs.2 |
BSON文档的最大尺寸是16MB。要存储更大的文档,可以使用GridFS API。
文档中字段的顺序,和插入文档时指定的顺序一致,除了两点例外:
- _id总是作为第一个字段
- 重命名字段名的操作可能导致文档中的字段重排序。从2.6开始,MongoDB积极的尝试保持字段顺序
| 类型 | 序号 | 别名 | 说明 | ||
| Double | 1 | double | |||
| String | 2 | string |
BSON字符串以UTF-8格式编码。各语言的驱动将语言内部字符串编码为UTF-8再进行存储 MongoDB的$regex查询支持在正则式中使用UTF-8字符 由于sort()操作使用C的strcmp函数,某些字符的排序处理可能不正确 |
||
| Object | 3 | object | |||
| Array | 4 | array | |||
| Binary data | 5 | binData | |||
| Undefined | 6 | undefined | 废弃 | ||
| ObjectId | 7 | objectId |
较小、很可能唯一、快速生成、有序的标识符类型。由12字节组成:
对此类字段进行排序,粗略的等同于按创建时间排序 |
||
| Boolean | 8 | bool | |||
| Date | 9 | date |
BSON日期类型是一个64位整数,表示UNIX时间戳(毫秒),支持表示最近29000万年时间范围 |
||
| Null | 10 | null | |||
| Regular Expr | 11 | regex | |||
| DBPointer | 12 | dbPointer | 废弃 | ||
| JavaScript | 13 | javascript | |||
| Symbol | 14 | symbol | 废弃 | ||
| JavaScript (with scope) | 15 | javascriptWithScope | |||
| 32-bit integer | 16 | int | |||
| Timestamp | 17 | timestamp |
特殊的类型,供MongoDB内部使用,与Date类型不同,它包含64个位:
在单个mongod实例内,每个时间戳都是唯一的 在主从复制时,oplog包含一个ts字段,其类型是timestamp 当你插入空的Timestamp字段到顶级文档中时,MongoDB服务器自动将其替换为当前时间戳:
|
||
| 64-bit integer | 18 | long | |||
| Decimal128 | 19 | decimal | 3.4引入 | ||
| Min key | -1 | minKey | |||
| Max key | 127 | maxKey |
集合中的每一个文档,都必须具有作为主键的_id字段。
如果用户没有指定该字段,MongoDB驱动会自动生成一个ObjectId类型的_id,如果驱动没有生成_id则mongod会生成ObjectId类型的_id。此规则适用于插入操作,以及指定了upsert: true的更新操作。
在创建集合的过程中,MongoDB在_id上创建唯一性索引。
你可以考虑使用以下数据类型作为_id:
- ObjectId类型
- 可以考虑使用自然键,可以节省空间并减少索引
- 使用自增长数字
- 在应用程序中生成UUID,可以保存为BinData以节省空间
当比较不同BSON类型的值时,MongoDB使用如下(从低到高)比较顺序:MinKey、Null、Numbers (ints, longs, doubles, decimals)、Symbol, String、Object、Array、BinData、ObjectId、Boolean、Date、Timestamp、Regular Expression、MaxKey (internal type)
在比较时,MongoDB把某些BSON类型当做一种类型看待,例如各种数字类型。
比较字符串时,默认使用简单的二进制比较的方式。从3.4开始,支持所谓排序规则(Collation) —— 用于指定语言相关(是否大小写敏感、是否有声调)的排序算法。排序规则的规格如下:
|
1 2 3 4 5 6 7 8 9 10 |
{ locale: <string>, // 该字段必须 caseLevel: <boolean>, caseFirst: <string>, strength: <int>, numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> } |
比较数组时,小于比较/升序排序基于数组的最小元素进行,大于比较/降序排序基于数组的最大元素进行。
比较BinData时,按照以下顺序进行:
- 比较数据的长度
- 根据BSON单字节子类型比较
- 执行逐字节比较
从3.4版本开始,MongoDB支持在现有的集合、其它视图之上,创建只读的视图(View)。
要创建视图,你可以使用create命令,指定viewOn、pipeline选项,可选的,指定一个collation选项:
|
1 2 3 4 5 6 |
db.runCommand( { create: <view>, viewOn: <source>, pipeline: <pipeline>, collation: <collation> } ) // 也可以使用新引入的Shell助手: db.createView(<view>, <source>, <pipeline>, <collation> ) |
那些用于列出集合列表的操作,例如db.getCollectionInfos()、db.getCollectionNames(),它们的输出包含视图。
要删除视图,可以使用命令: db.collection.drop()
- 只读,对视图进行写操作导致错误
- 索引与排序:视图使用其底层的集合上的索引,你不能在视图上使用$natural排序
- 投影操作限制:在视图上进行find()操作,不支持以下投影操作:$、$elemMatch、$slice、$meta
- 视图的名字不可改变
视图在读操作发生时,按需的进行计算。在视图上执行的读操作,是底层聚合管道( aggregation pipeline)的一部分,因此,视图不支持:
- db.collection.mapReduce()
- $text操作符,因为聚合中的$text仅仅对于第一阶段(first stage)有效
- geoNear命令以及$geoNear管道阶段(pipeline stage)
如果底层集合是分片的,则视图也是分片的。因此不能为$lookup、$graphlookup操作的from字段指定一个分片的视图。
- 在创建视图时,可以指定一个默认的排序规则(collation,判断两个比较项谁大谁小的准则)。如果不指定,视图的默认排序规则是简单的二进制比较排序规则。视图不会从底层集合继承排序规则
- 在视图上进行字符串比较,使用视图默认排序规则。尝试修改视图默认排序规则的操作会失败
- 如果基于其它视图创建新视图,你不能指定不同于源视图的排序规则
- 当执行牵涉到多个视图的聚合操作时,例如$lookup、$graphlookup,所有牵涉到的视图必须具有一致的排序规则
定长集合(Capped Collections)是用于支持高吞吐量操作(插入、按插入顺序读取)的、具有固定尺寸的集合。定长集合的工作方式类似于环形缓冲,一旦空间占满,最老的文档会被覆盖。
创建定长集合的方法:
|
1 2 3 4 |
// size 集合的最大字节数,小于4096则MongoDB自动设置为4096。否则,自动舍入到最接近的256的倍数 db.createCollection( "log", { capped: true, size: 100000 } ) // 可以指定max,集合包含的文档的最大数量 db.createCollection("log", { capped : true, size : 5242880, max : 5000 } ) |
当你使用find()来操作定长集合,并且没有指定顺序时,MongoDB保证结果的顺序和文档插入的顺序一致。要逆插入序获得结果,可以:
|
1 |
db.cappedCollection.find().sort( { $natural: -1 } ) |
可以使用集合的isCapped方法检测定长集合:
|
1 |
db.collection.isCapped() |
普通集合可以被转换为定长集合:
|
1 |
db.runCommand({"convertToCapped": "mycoll", size: 100000}); |
- 定长集合记住文档的插入顺序, 查询时不需要基于索引以得到文档。没有了维护索引的负担,定长集合支持更高的插入吞吐量
- 定长集合具有 _id 字段,并在其上默认建立了索引
- 如果你需要对定长集合中的文档进行update操作,应当建立索引,避免全集合扫描
- 定长集合不支持删除文档,如果更新/替换操作改变了文档的尺寸,会失败
- 定长集合不支持分片
- 聚合管道操作符$out不能把结果输出到定长集合
|
1 2 3 4 |
# 在容器中运行MongoDB docker run --name mongodb -p 27017:27017 -v ~/Docker/volumes/mongodb/data/db:/data/db -d mongo:3.4 # 登录到MongoDB管理Shell docker exec -it mongodb mongo admin |
Mongo Shell是交互式的、基于JavaScript语言的MongoDB接口。使用此Shell你可以查询、插入数据,或者执行管理任务。
要启动Mongo Shell,cd到安装目录,执行mongo命令。不加任何参数时,Shell尝试连接到localhost:27017。Shell启动时默认会读取~/.mongorc.js文件,并执行其中的JavaScript脚本。
|
1 2 3 4 5 6 |
# 连接到本地 27017 mongo # 连接到复制集 mongo --host rs1/mongo-11.gmem.cc,mongo-12.gmem.cc,mongo13.gmem.cc # 使用指定的用户登陆到服务器,连接到bais数据库,基于admin数据库进行身份验证 mongo -u root -p root --host mongo-11.gmem.cc --authenticationDatabase admin bais |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// 显示当前正在使用的数据库 db // 切换数据库 use mydb // Shell不支持使用名字中包含空格或者以数字开始的集合,需要改变语法: mydb.3test.find() // 错误 mydb["3test"].find() mydb.getCollection("3test").find() // 美化输出 db.myCollection.find().pretty() // 打印输出 print() // 转换为JSON并打印,等价于printjson() print(tojson(obj)) // 退出Shell quit() |
当输入行以花、圆、方括号结尾时,下面的行自动以...开头,直到所有开括号的匹配关闭括号都输入了,再回车,输入才会被估算。
默认的命令提示符是 >,你可以使用如下代码定制:
|
1 2 3 4 5 6 7 8 9 10 11 |
// 显示计数器 cmdCount = 1; prompt = function() { return (cmdCount++) + "> "; } // 显示数据库和主机信息 host = db.serverStatus().host; prompt = function() { return db+"@"+host+"$ "; } |
你可以在MongoDB Shell中使用自己喜欢的编辑器,只需要在启动Shell之前设置环境变量: export EDITOR=vim即可。
这样,你就可以编辑变量或者函数了: edit myFunc
db.collection.find()会返回一个游标,但是,在Shell中没有把游标赋值给一个变量的情况下,Shell会自动迭代游标20次,并打印结果到屏幕上。这个迭代的次数是可以定制的:
|
1 |
DBQuery.shellBatchSize = 10; |
你可以使用JavaScript语言编写一段脚本,交由Shell执行,以完整数据操控、管理工作:
|
1 2 3 4 5 6 |
# 命令行中提供脚本 mongo test --eval "printjson(db.getCollectionNames())" # 文件方式提供脚本 mongo localhost:27017/test myjsfile.js # 在Shell中加载JS load("myjstest.js") |
|
1 2 3 4 5 |
conn = new Mongo(); db = conn.getDB("myDatabase"); // 也可以使用connect函数 db = connect("localhost:27020/myDatabase"); |
不能在JavaScript中使用任何Shell助手,因为不是合法的JavaScript表达式。等价写法如下表:
| Shell助手 | 等价JS代码 |
| show dbs, show databases | db.adminCommand('listDatabases') |
| use <db> | db = db.getSiblingDB('<db>') |
| show collections | db.getCollectionNames() |
| show users | db.getUsers() |
| show roles | db.getRoles({showBuiltinRoles: true}) |
| show log <logname> | db.adminCommand({ 'getLog' : '<logname>' }) |
| show logs | db.adminCommand({ 'getLog' : '*' }) |
| it | cursor = db.collection.find() if ( cursor.hasNext() ){ cursor.next(); } |
BSON提供了很多数据类型,不同驱动都根据其宿主编程语言,提供了Native的类型映射。Shell类似,提供了助手类以支持这些数据类型。
| BSON类型 | Shell助手类说明 |
| Date |
Shell提供多种方法来返回日期对象:
示例: ISODate('2008-08-08T08:08:08.888Z') |
| ObjectId | Shell提供ObjectId包装器类,要生成一个新的ObjectId,你可以 new ObjectId或者 ObjectId() |
| NumberLong | Shell提供NumberLong包装器类,你可以: NumberLong("1111") |
| NumberInt | Shell提供NumberInt包装器类 |
| NumberDecimal |
3.4版本引入。默认情况下Shell把所有数字作为64bit双精度浮点数看待,使用NumberDecimal()可以明确的构造128bit浮点数,在牵涉到货币的领域使
|
要检测对象的数据类型,可以使用:
|
1 2 3 |
mydoc._id instanceof ObjectId // 或者 typeof mydoc._id |
在MongoDB中,写操作在单个文档上是原子的,即使在修改多个内嵌的文档的情况下。
相反的,当一个写操作操控了多个文档的情况下,整个操作默认不是原子的。多个写操作可能会发生交叉(interleave)、而且不会在中途出错后回滚
如果要为影响了多个文档的单个写操作建立隔离性语义,可以使用 $isolated操作符,该操作符可以避免其它写操作交叉进来。直到写操作完成后,其它进程不能看到结果。
注意:
- 该操作符不能与分片集群(Sharded Clusters)协同工作
- 该操作符不能提供all-or-nothing的原子性语义。如果中途发生错误,已经发生的修改不会回滚
- 该操作符符导致当前操作获得目标集合上的独占锁,即使在使用支持文档级锁的引擎(WiredTiger)的情况下
$isolated产生的隔离效果,在修改了第一个文档后显现。
由于MongoDB支持内嵌文档,因此在很多应用场景下,单文档级别的原子性足够应付。
如果多个写操作需要在单个事务中执行,可以考虑在代码中实现两阶段提交(two-phase commit )模式 。注意这只能提供类似于事务的语义,用于保证数据一致性,却不能避免中间结果被其它操作看到
一致性控制允许多个程序并发的执行,而不导致数据不一致或者冲突。
实现一致性控制的可选方式:
- 在应当具有唯一性值的(一个或者多个)字段上创建一个唯一性索引,以阻止重复的数据插入
- 使用查询断言(Query predicate)指定某个字段的当前期望值
为保证数据一致性,MongoDB使用锁机制来管理多客户端的并发读写。
MongoDB使用多粒度的锁,操作可能在全局、数据库、集合级别进行锁定。同时允许存储引擎实现更加细粒度的锁定,例如WiredTiger支持文档级别的锁定。
MongoDB使用读写锁(共享锁S,独占锁X),允许多个读操作共享同一资源。对于MMAPv1,写操作权限仅仅能赋予单个写操作。
除了S、X锁以外,MongoDB还支持读意向锁(IS)、写意向锁(IX),表示操作将要对(比被意向锁定的资源)更加细粒度的资源进行读写操作,IX是可以共享的,意向锁可以减少不必要的锁检查。当在某一级别进行锁定时,更高级别(粗粒度)资源被意向锁定。举例来说,当X锁一个集合进行写操作时,对应的数据库、全局必须上IX锁。
单个数据库可以同时被IS、IX锁。X锁不能与其它锁共存。S锁仅仅能和IS锁共存。
MongoDB的锁是公平的,操作依据排队的顺序被授予锁。但是为了吞吐量的考虑,兼容的锁可能被一并授予,而不考虑排队情况。
| 存储引擎 | 说明 |
| WiredTiger |
从3.0开始,MongoDB引入该引擎 对于大部分的读写操作,该引擎使用乐观并发控制。WiredTiger仅仅在全局、数据库、集合级别使用意向锁。当检测到两个操作之间存在冲突时,其中一个操作会透明的重试 某些全局性的(通常是短暂的牵涉到多数据库的)操作,仍然要求全局(实例级别)的锁。drop之类的操作仍然要求数据库级别的独占锁 |
| MMAPv1 | 从3.0开始,MMAPv1引擎使用集合级别的锁 |
某些情况下,读写操作可能让出它们占有的锁。长时间运行的读写操作,可能在多种情况下让出锁。对于影响到多个文档的操作,锁让出可能在修改每个文档前后发生。
MMAPv1引擎会在认为需要读取的数据不在物理内存的时候,让出锁,等MongoDB把目标数据加载到内存之后,再重新获得锁。
| 操作 | 锁定 |
| 发起查询 | S |
| 从游标抓取数据 | S |
| 插入数据 | X |
| 删除数据 | X |
| 更新数据 | X |
| MapReduce | S、X锁,除非操作被指定为非原子性的。Map Reduce任务的某些部分可以并发执行 |
| 创建索引 | 在前端(默认)创建索引,导致数据库级别的锁 |
| aggregate() | S |
| 读取未提交 |
在MongoDB中,客户端可以在写操作持久化(durable)之前,即看到其结果:
注意:local是默认的读关注 读取未提交是单实例mongod、复制集,以及分片集群的默认隔离级别 |
| 读取未提交&单文档原子性 |
写操作对于单个文档是原子性的,因而任何客户端都不会读取到只更新了一部分字段的文档 对于单实例mongod,针对某个特定文档的一系列读写操作,是可串行化的(serializable) 对于复制集,仅仅在不存在回滚的情况下,针对某个特定文档的一系列读写操作,是可串行化的(serializable) |
| 读取未提交&多文档写操作 |
对于操作了多个文档的单个写操作,作为整体来说它不是原子性的,其它写操作可能与之产生交错。你可以使用$isolated操作符改变此行为,使用此操作符时MongoDB的行为如下:
|
MongoDB游标可能出现反常行为 —— 迭代同一个文档超过一次。发生这种现象的原因是,在游标迭代期间,某个写操作交叉进来并修改了某个文档。如果:
- 被修改文档存储位置发生移动(例如文档大小增长导致)
- 或者查询所使用的索引对应的字段值被修改
则可能出现重复迭代。
要防止此情形的出现,你可以使用 cursor.snapshot()调用来隔离游标。注意:
- 该调用不能保证查询返回的数据是某个时间点的快照,不能和其它写操作隔离
- 不支持分片集群
- 不能和游标方法sort()、hint()联用
另一个防止此情形的方法是,在不会修改的字段上建立唯一索引,然后使用hint()强制使用该索引,可以产生类似于snapshot()的效果。
所为单调写(Monotonic Writes),是指写操作扩散的顺序和它们逻辑上的顺序一致。MongoDB针对单实例mongod、复制集、分片集群提供单调写保证。
3.4引入的新特性。
针对在主节点上执行的读、写操作。使用linearizable读关注发起的读操作,和使用m:majority发起的写操作,如果这些读写操作针对单个文档进行操作,其效果就好像单个线程在执行这些读写一样,也就是说它们的实时顺序获得保证。
使用分片集群,你可以在多个mongod组成的服务器群中进行数据的分区,该分区对于应用程序来说几乎是透明的。
在分片集群中,客户端向关联到集群的某个mongos(路由器)实例发起操作请求,后者将请求转发给适当的分片:
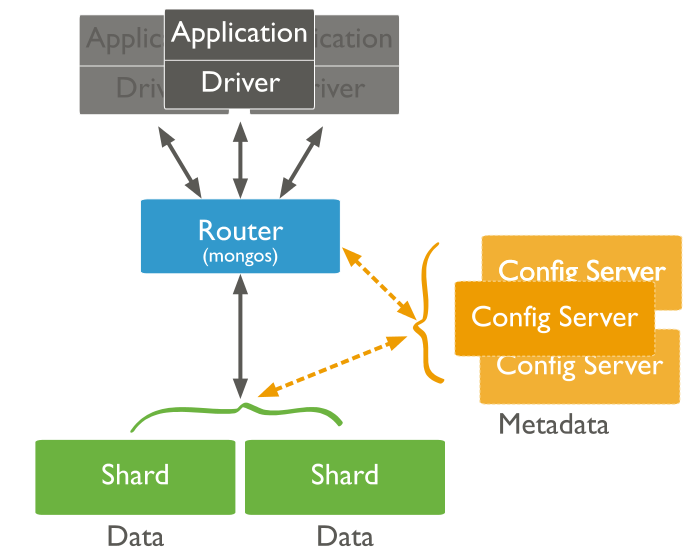
当被转发到单个特定的分片上时,针对分片集群的读操作效率最高。
针对分片集合的查询,应当包含集合的分片键(Shard key),这样mongos可以基于集群元数据(来自配置服务器)进行准确的路由。如果不包含分片键,则必须向所有mongod实例转发请求并聚合响应,这种分散 - 聚集(scatter gather )模式通常效率不高。
对于复制集分片,发送给从节点的读操作可能和主节点的最新状态不一致(不确定的延迟)。这种行为可能导致牵涉到多个从节点的非单调读 —— 后入库的数据比先入库的数据先被读到。
默认情况下,客户端针对复制集的主节点进行读操作。但是客户端可以使用Read perference把读请求定向到复制集的其它成员。例如,客户端可以配置以便从最近的节点进行读取以达成以下目标:
- 在跨数据中心部署的情况下,减少延迟
- 可以分散大量读请求以增大吞吐量
- 执行备份操作
- 在新的主节点被选举出来前,仍然可以执行读操作
针对从节点进行读操作,得到的可能不是主节点的最新状态,重定向到不同从节点的读操作可能导致非单调读。
对于分片集群中的分片集合,mongos负责把写操作分发到负责对应数据集的那些分片,路由时mongos从配置数据库(config database,位于config server)中查询元数据信息,并判断如何分发写操作。
MongoDB依据分片键的值范围(支持Hash方式么)来进行数据分区,之后把这些分区(chunks)发布到某些分片上(Shard,即mongod实例)。
对于update类操作来说,如果:
- 针对单个文档,更新操作必须包含分片键或者_id字段
- 针对多个文档,如果更新操作包含分片键性能在某些情况下会更好,但是有时仍然会广播操作到所有分片
如果分片键的值在每次插入时总是递增/递减,那么连续的很多插入操作会落到同一个分片中,产生性能瓶颈。
在复制集中,所有写操作都针对主节点。 主节点应用写操作,然后把操作记录在自己的操作日志(oplog)中。oplog是可重做的写操作流水,所有从节点都会复制该日志并应用,从节点的操作均是异步的,因此不能假设何时主从节点状态完全一致。
这是一种编程模式,当你进行多文档“事务”操作时,你可以实现类似关系型数据库的回滚功能。
在MongoDB中单文档的写操作总是原子的,但是写操作牵涉到多个文档时(通常称为多文档事务)则没有原子性保证。由于MongoDB支持任意复杂度的内嵌文档,因此很多应用场景下不需要多文档操作。
尽管如此,某些情况下你不得不进行多文档写操作。当执行由一系列写操作序列构成的事务时,可能面临以下需求:
- 原子性:如果操作中途失败,前面已经完成的操作需要回滚
- 一致性:如果重大错误(网络、硬件)中断了事务,数据库必须有能力恢复到一个一致性的状态
考虑转账的应用场景:你需要从账户A转账到账户B。使用关系型数据库时,你需要在单个事务中,减去A账户的余额并加到B账户中去。使用MongoDB时,你可以手工实现两阶段提交,模拟一个类似的结果。
在该场景中,我们使用集合accounts来存储账户信息,transactions存储交易信息。
正常交易流程的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
// 初始化账户信息,下面的调用返回一个BulkWriteResult对象 db.accounts.insert( [ { _id: "A", balance: 1000, pendingTransactions: [] }, { _id: "B", balance: 1000, pendingTransactions: [] } ] ) // 初始化交易(转账)信息,state反应交易的状态,可以取值initial, pending, applied, done, canceling,canceled db.transactions.insert( { _id: 1, source: "A", destination: "B", value: 100, state: "initial", lastModified: new Date() } ) // 使用两阶段提交来转账 // 1、找到一个初始状态的交易记录 var t = db.transactions.findOne( { state: "initial" } ) // 2、更新交易状态,如果返回值的nMatched、nModified为零,说明被上一步找到的记录,被其它客户端处理过, // 返回第1步,获取下一条记录 db.transactions.update( { _id: t._id, state: "initial" }, { $set: { state: "pending" }, $currentDate: { lastModified: true } } ) // 3、把交易关联到两个账户,过滤条件pendingTransactions可以防止重复转账 db.accounts.update( { _id: t.source, pendingTransactions: { $ne: t._id } }, { $inc: { balance: -t.value }, $push: { pendingTransactions: t._id } } ) db.accounts.update( { _id: t.destination, pendingTransactions: { $ne: t._id } }, { $inc: { balance: t.value }, $push: { pendingTransactions: t._id } } ) // 4、更新交易状态为applied db.transactions.update( { _id: t._id, state: "pending" }, { $set: { state: "applied" }, $currentDate: { lastModified: true } } ) // 5、更新账户第pending交易列表 db.accounts.update( { _id: t.source, pendingTransactions: t._id }, { $pull: { pendingTransactions: t._id } } ) db.accounts.update( { _id: t.destination, pendingTransactions: t._id }, { $pull: { pendingTransactions: t._id } } ) // 6、设置交易状态为done db.transactions.update( { _id: t._id, state: "applied" }, { $set: { state: "done" }, $currentDate: { lastModified: true } } ) |
交易的关键之处在于,能够从各种错误场景中恢复,而不是简单完成上述6个步骤。
两阶段提交模式允许应用程序应用程序执行一个操作序列,以便恢复事务到一致性的状态 —— 这种能力由代码中刻意安排的filter保证。你可以在应用程序启动时,或者周期性的执行恢复操作,以便捕获并处理那些未完成的事务。
事务经历多就没有完成,则需要恢复,取决于应用程序的需要,我们刻意使用lastModified判断事务的最后操作时间。
找到需要恢复的事务后,根据state确定尚未完毕的后续步骤,并执行。
某些时候(例如交易被撤销,或者目标账户在交易过程中被关闭),你需要回滚(撤销,传统意义的回滚,在MongoDB中rollback这个术语通常情况下不是这个含义)一个事务操作。
两阶段提交模式中,你需要手工实现“补偿行为”来进行回滚。
各类驱动连接MongoDB时,均需要提供一个连接字符串,其格式为:
|
1 2 3 |
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]] # 示例 mongodb://172.21.3.1:27017,172.21.3.2:27017/?replicaSet=rs3&connectTimeoutMS=300000 |
其中:
| 项 | 说明 | ||
| mongodb:// | 固定的前缀 | ||
| username:password@ | 使用指定的密码来登录 | ||
| host* |
服务器的主机名、IP地址或者UNIX Domain Socket 对于复制集,指定复制集成员的信息 对于分片集群,指定mongos的信息 |
||
| port* | 服务器的监听端口,默认27017 | ||
| /database | 可选,当提供用户名密码时,针对哪个数据库进行验证,默认admin | ||
| options |
连接选项: replicaSet,指定连接到的复制集,连接到复制集时应该至少指定两个host:port并且指定复制集名称,如果不指定,客户端创建的是针对Standalone的mongod的连接 ssl,如果为true,以SSL协议发起连接,不是所有驱动都支持 connectTimeoutMS,连接超时的毫秒数 maxPoolSize,连接池中最大的连接数,默认100 w,指定默认写关注的w选项值,可以指定数字、majority、标签集名称 readConcernLevel,指定默认读隔离级别,可选local、majority
authSource,指定存放用户认证信息的数据库的名称,默认来自连接串的database项 |
这类操作添加新的文档到集合中,如果目标集合不存在,会自动创建。MongoDB提供以下插入文档的方法:
|
1 2 3 4 |
# 插入一个文档 db.collection.insertOne() # 插入多个文档 db.collection.insertMany() |
从单个文档级别上来看,所有MongoDB的写操作都是原子的。
|
1 2 3 4 5 6 7 |
use local db.users.insertOne({ name : 'Alex', age : 29, gender : 'M'}) db.users.insertMany([ { name: 'Meng', age: 26, gender : 'F'}, { name: 'Cai', age: 2, gender : 'F'}, { name: 'Dang', age: 0, gender : 'M'}, ]) |
|
1 2 3 4 5 6 7 8 9 |
from pymongo import MongoClient if __name__ == '__main__': client = MongoClient('mongodb://localhost:27017/') db = client.local # 或者 client['local'] db.users.insert_one({ 'name': 'FengYu', 'age': 59, 'gender': 'F' }) |
引入依赖:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<!-- 同步驱动 --> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongodb-driver</artifactId> <version>3.4.2</version> </dependency> <!-- 异步驱动,支持更快的非阻塞的IO --> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongodb-driver-async</artifactId> <version>3.4.2</version> </dependency> |
MongoDB的Java驱动提供了同步、异步两套接口。同步代码示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
package cc.gmem.study; import com.mongodb.MongoClient; import com.mongodb.client.MongoCollection; import com.mongodb.client.MongoDatabase; import org.bson.Document; import org.junit.Test; public class CRUDTest { @Test public void insertDoc() { MongoClient client = new MongoClient( "localhost", 27017 ); MongoDatabase db = client.getDatabase( "local" ); MongoCollection<Document> coll = db.getCollection( "users" ); Document doc = new Document( "name", "CongHua" ).append( "age", 55 ).append( "gender", "M" ); coll.insertOne( doc ); } } |
异步代码示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
package cc.gmem.study; import com.mongodb.async.SingleResultCallback; import com.mongodb.async.client.MongoClient; import com.mongodb.async.client.MongoClients; import com.mongodb.async.client.MongoCollection; import com.mongodb.async.client.MongoDatabase; import org.bson.Document; import org.junit.Test; import java.util.concurrent.CountDownLatch; public class CRUDTest { @Test public void insertDoc() throws InterruptedException { // 这个客户端相当于连接池,即使你有很多并发操作,也不需要第二个实例 MongoClient client = MongoClients.create( "mongodb://localhost" ); MongoDatabase db = client.getDatabase( "local" ); MongoCollection<Document> coll = db.getCollection( "users" ); Document doc = new Document( "name", "GuangFang" ).append( "age", 55 ).append( "gender", "F" ); // 这里采用同步机制等待异步操作完成 final CountDownLatch latch = new CountDownLatch( 1 ); coll.insertOne( doc, ( result, t ) -> { System.out.println( "OK" ); latch.countDown(); } ); latch.await(); } } |
安装MongoDB的Node.js驱动:
|
1 |
npm install mongodb |
|
1 2 3 4 5 6 7 8 9 |
const mongo = require( 'mongodb' ); let client = mongo.MongoClient; client.connect( 'mongodb://localhost:27017/local' ).then( db => { return db.collection( 'users' ).insertOne( { name: 'GuangLiang', age: 55, gender: 'M' } ); } ).then( result => console.log( result.insertedId ) ); |
这类操作从集合中检索并返回若干文档。MongoDB提供以下方法:
|
1 2 3 |
db.collection.find(<query>, <projection>) # 可以指定一个参数作为查询文档(Query Document),查询文档提供查询条件 db.collection.find( { 'name' : 'Alex' } ) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
client = MongoClient('mongodb://localhost:27017/') db = client['local'] # 传入空文档作为查询过滤器,得到所有文档,返回值是一个游标 cursor = db.users.find({}) # { <field1>: <value1> } 表示相等过滤,例如 cursor = db.users.find({'gender': 'F'}) # { <field1>: { <operator1>: <value1> } } 使用查询操作符,例如 cursor = db.users.find({'age': {'$gt': 30}}) # 逻辑与 cursor = db.users.find({'gender': 'F', 'age': {'$gt': 30}}) # 逻辑或 cursor = db.users.find({ '$or': [{'gender': 'F'}, {'age': {'$gt': 30}}] }) |
查询操作的返回值是一个游标。你可以对其进行遍历操作:
|
1 2 3 4 5 6 |
cursor = db.trades.find({'state': 'A'}) for trade in cursor: print(trade) # 对于PyPy、Jython以及其它不使用引用计数垃圾回收的Python实现,需要调用 cursor.close() |
上面代码中,$or、$gt等以$开头的键,属于查询操作符(Query Operator),是操作符的一种。常用的查询操作符如下表:
| 操作符 | 说明 | ||
| $eq | 匹配等于指定值的字段值 | ||
| $gt | 匹配大于指定值的字段值 | ||
| $gte | 匹配大于等于指定值的字段值 | ||
| $lt | 匹配小于指定值的字段值 | ||
| $lte | 匹配小于等于指定值的字段值 | ||
| $ne | 匹配不等于指定值的字段值 | ||
| $in | 匹配等于数组中元素之一的字段值 | ||
| $nin | 匹配不等于数组中任何元素的字段值 | ||
| $or | 逻辑或 | ||
| $and | 逻辑与 | ||
| $not | 逻辑非 | ||
| $nor | 逻辑非或,逻辑或取反 | ||
| $exists |
匹配具有指定字段的文档,示例:
|
||
| $type | 匹配字段类型是指定类型的文档,类型使用数字或者别名表示 | ||
| $mod |
执行取模操作,示例:
|
||
| $regex |
匹配其值匹配指定正则式的字段,格式:
|
||
| $text |
对建立了文本索引(text index)的字段进行文本搜索与匹配,格式:
|
||
| $where |
传递一个包含JavaScript表达式或者完整JavaScript函数的字符串给查询系统。尽管提供了很强的灵活性,这种操作符需要遍历所有文档,需要注意 要引用当前正在处理的文档,可以使用变量 this或者 obj |
||
| $geoWithin | 匹配某个地理位置字段的值,在指定的多边形范围之内,2dsphere /2d 索引支持该查询操作符 | ||
| $geoIntersects | 选择其地理空间数据与指定的GeoJSON对象交叉的文档,2dsphere /2d 索引支持该查询操作符 | ||
| $near | 选择其地理空间数据接近指定的点的文档,需要地理空间索引(geospatial index),2dsphere /2d 索引支持该查询操作符 | ||
| $nearSphere | 选择其地理空间数据接近指定的点(在球面上)的文档,需要地理空间索引(geospatial index),2dsphere /2d 索引支持该查询操作符 | ||
| $all | 匹配包含此操作符指定的数组中所有元素的数组字段 | ||
| $elemMatch |
匹配这样的数组字段:至少有一个元素满足该操作符指定的查询条件,例如:
|
||
| $size | 匹配数组字段的尺寸 | ||
| $bitsAllSet | 匹配这样的数字/二进制字段:该操作符指定的那些位的值均为1 | ||
| $bitsAnySet | 匹配这样的数字/二进制字段:该操作符指定的那些位的值至少一个为1 | ||
| $bitsAllClear | 匹配这样的数字/二进制字段:该操作符指定的那些位的值均为0 | ||
| $bitsAnyClear | 匹配这样的数字/二进制字段:该操作符指定的那些位的值至少一个为0 |
要根据内嵌文档进行查询过滤,只需要依次指出内嵌文档各字段的值:
|
1 2 3 4 |
# bson.son.SON类似于Python的字典,但是保持字段的顺序 # 匹配宽高为21/14cm的货物: {"size": SON([("h", 14), ("w", 21), ("uom", "cm")])} # 这种匹配,要求内嵌文档与查询条件完全相同,包括字段的顺序 |
要根据内嵌文档的某个字段进行查询过滤,可以使用点号导航:
|
1 2 3 |
db.inventory.find({"size.uom": "cm"}) # 和简单字段一样,可以使用查询操作符 db.inventory.find({"size.h": {"$lt": 15}}) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 匹配标签字段等于["red", "blank"]的存货 db.inventory.find({"tags": ["red", "blank"]}) # 匹配标签字段包含"red", "blank"这两个元素的存货 db.inventory.find({"tags": {"$all": ["red", "blank"]}}) # 匹配标签字段包含"red"元素的存货 db.inventory.find({"tags": "red"}) # 匹配size数组中至少有一个元素大于25的存货 db.inventory.find({"size": {"$gt": 25}}) # 匹配dim_cm数组中至少有一个元素大于15的存货、一个元素小于20的存货。可以单个元素同时满足连个条件 db.inventory.find({"dim_cm": {"$gt": 15, "$lt": 20}}) # 匹配dim_cm数组中至少有一个元素同时满足多个条件的存货 db.inventory.find({"dim_cm": {"$elemMatch": {"$gt": 22, "$lt": 30}}}) # 限定dim_cm的第2个元素的最小值 db.inventory.find({"dim_cm.1": {"$gt": 25}}) # 限定数组的大小 db.inventory.find({"tags": {"$size": 3}}) |
默认情况下,查询操作返回匹配文档的全部字段。为了减少传递给应用程序的数据量,你可以指定一个投影文档(Projection document)以限制返回的字段:
|
1 2 3 |
# 仅仅返回name字段 # 投影文档(第二个参数)的字段值,1表示结果包含此字段,0表示不包含,默认的_id被包含 db.users.find( { gender: 'F' }, { name: 1, _id: 0 } ) |
注意,除了_id字段之外,所有投影文档字段的值必须相等,当值:
- 都为0的时候,表示结果排除这些字段
- 都为1的时候 ,表示结果仅包含这些字段
要包含/排除内嵌文档中字段到查询结果,可以使用点号导航:
|
1 2 3 4 |
# 包含地址的邮编字段 db.users.find( {}, { name: 1, address.zip: 1 } ) # 包含最后一个孩子 db.users.find( {}, { name: 1, children: { "$slice": -1 } } ) |
上例中的$slice也是操作符,它属于投影操作符的一种:
| 操作符 | 说明 | ||||||
| $ |
投影并得到数组的第一个元素,该操作符根据查询文档(find第一个参数)中某些查询条件进行投影 语法格式:
注意,被限制的数组字段,必须存在于查询文档之中,value可以是查询操作符表达式 针对某个数组字段进行投影时,有如下限制:
示例代码:
可以看到,增加了$操作符后,满足查询文档的查询结果中,对应数组字段,仅返回了第一个元素 注意,数组元素是简单值的情况下,此操作符同样适用 |
||||||
| $elemMatch |
投影并得到数组的第一个满足额外条件的元素,该操作符明确指定投影条件,你可以基于不存在于查询文档中的条件进行投影、或者基于数组元素(内嵌文档)的字段进行投影。该操作符对处理结果进行二次过滤 示例代码:
|
||||||
| $meta | 投影文档在$text操作期间被分配的分数 | ||||||
| $slice |
限制匹配数组所返回的元素的数量,示例:
|
注意,针对视图进行的find()操作不支持上表中的投影操作符。
不同查询操作符处理null值的方式是不一样的,需要注意:
- 等于操作符: { item : null }匹配item为null或者不包含item字段的文档
- 类型检查操作符: { item : { $type: 10 } }仅仅匹配item值为null的文档
- 存在性检查: { item : { $exists: false } }仅仅匹配不包含item字段的文档
这类操作修改既有的文档,MongoDB提供以下方法:
|
1 2 3 4 5 |
# 更新文档 db.collection.updateOne(<filter>, <update>, <options>) db.collection.updateMany(<filter>, <update>, <options>) # 替换掉文档 db.collection.replaceOne(<filter>, <replacement>, <options>) |
参数filter类似于查询文档,update表示更新文档 —— 使用更新操作符来指定哪些字段需要怎么样被更新,replacement则是替换文档,直接替换掉原有的文档。
更新文档的格式:
|
1 2 3 4 5 |
{ <update operator>: { <field1>: <value1>, ... }, <update operator>: { <field2>: <value2>, ... }, ... } |
更新代码示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
db.inventory.update( # 过滤器,指定查询条件:item为paper {'item': 'paper'}, # 更新文档: { # 可以同时设置多个字段 '$set': {'size.uom': 'cm', 'status': 'P'}, '$currentDate': {'lastModified': True} } ) # 更新多个满足条件的文档 db.inventory.update_many( {'qty': {'$lt': 50}}, { '$set': {'size.uom': 'in', 'status': 'P'}, '$currentDate': {'lastModified': True} } ) |
- 原子性:对于单个文档来说,更新操作总是原子性的
- _id字段:该字段不能被更新
- 文档大小:当更新后,文档的尺寸大于先前分配的空间,则另外在磁盘上分配空间给它
- 字段顺序:_id总是保持在最前面。包含重命名操作的更新操作可能会改变字段的顺序
| 选项 | 说明 |
| upsert | 如果设置为true,则当满足filter的文档不存在时,新的文档会依据更新文档来创建,并插入 |
| 操作符 | 说明 | ||
| 更新字段的操作符 | |||
| $inc | 增加目标字段的值到给定的增量 | ||
| $mul | 将目标字段的值乘以一定的倍数 | ||
| $rename | 重命名字段 | ||
| $setOnInsert |
当一个更新操作导致了文档的插入时,设置以一个字段的值。当更新操作是对既有文档进行修改时,该操作符不起任何作用 |
||
| $set | 设置一个字段的值 | ||
| $unset | 移除某个字段 | ||
| $min | 仅当指定的值比目标字段当前值大的时候,进行更新 | ||
| $max | 仅当指定的值比目标字段当前值小的时候,进行更新 | ||
| $currentDate |
设置目标字段的值为当前日期:
|
||
| $bit |
对目标字段进行按位操作:
|
||
| $isolated |
阻止影响到多个文档的写操作,在彻底完成之前,中间结果被其它客户端看到。示例:
|
||
| 更新数组的操作符 | |||
| $ |
更新数组的第一个元素的值:
|
||
| $addToSet | 如果指定的元素不存在数组中,则将其加入 | ||
| $pop | 移除数组的第一个或者最后一个元素 | ||
| $pullAll | 移除数组中所有匹配的元素 | ||
| $pull | 移除所有匹配查询的数组元素 | ||
| $push | 添加一个元素 | ||
| $each |
修改$push、$addToSet 的行为,使之能够同时添加多个元素:
|
||
| $slice |
修改$push的行为,限制被更新数组的长度:
num的含义:
|
||
| $sort | 修改$push的行为,对数组元素进行排序 | ||
| $position | 修改$push的行为,指定新元素的插入位置 | ||
所谓替换,就是指替换掉文档的所有字段 —— _id除外。
这类操作删除既有的文档。MongoDB提供以下方法:
|
1 2 3 4 |
db.collection.deleteOne(<filter>) db.collection.deleteMany(<filter>) # 如果过滤文档为空文档,则集合中所有文档被删除 db.collection.remove() # 删除匹配过滤文档的文档,有多少删除多少 |
过滤文档的格式参考查询文档。
- 原子性:对于单个文档来说,删除操作是原子的
- 对索引的影响:删除操作不会drop掉索引,即使集合中所有文档都被删除
MongoDB为客户端提供了批量写操作能力。批量写操作影响单个集合。 应用程序可以为批量写操作指定一个可接受的确认级别(acknowledgement level)。
下面的方法用于执行批量插入、更新或者删除操作:
|
1 |
db.collection.bulkWrite(<bulkOperationArray>, <options>) |
bulkWrite支持insertOne、updateOne、updateMany、replaceOne、deleteOne、deleteMany这些写操作:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
client.connect( 'mongodb://localhost:27017/local' ).then( db => { // 批量写仍然是针对单个集合的操作 return db.collection( 'users' ).bulkWrite( [ { insertOne: { document: { _id: 1, name: 'Alex', age: 30 } } }, { insertOne: { document: { _id: 2, name: 'Meng', age: 27, gender: 'F' } } }, { updateOne: { filter: { name: 'Alex' }, update: { $set: { gender: 'M' } } } } ] ); } ).then( result => console.log( result ) ); |
批量写操作支持有序、无序两种方式:
- 有序:串行化的执行,如果其中某个操作失败,则MongoDB会返回,不处理后续的操作
- 无序:并发的执行,如果其中某个操作失败,别的操作不受其影响
对于分片集合,无序批量写操作通常比有序的快。
默认的,MongoDB进行有序批量写,除非你指定选项: ordered : false
大批量的数据插入操作可能影响分片集群(Sharded cluster)的性能,对于批量插入,考虑以下策略:
- 集合预切分(Pre-split):如果分片集合当前是空的,则集合仅仅包含一个位于单个分片中的初始块(initial chunk)。MongoDB必须花费时间来接收数据、切分数据,然后把切分好的数据块发送到可用的分片中。要避免此性能损失,可以考虑集合的与切分
- 使用无序写:使用无序写选项可以提高性能,MongoDB会尝试把数据同时发送给多个分片
- 避免单调递增瓶颈(Monotonic Throttling):如果你的分片键( shard key )在插入过程中单调的递增,则所有插入的数据都会进入集合的最后一个块 —— 总是在单个分片上
查询选项 readConcern用于复制集、复制集分片,决定为查询返回什么数据:
|
1 |
readConcern: { level: <"majority"|"local"|"linearizable"> } |
支持该选项的操作包括:find、aggregate 、distinct、count 、parallelCollectionScan 、geoNear 、geoSearch。
注意:节点上的最新数据,不代表是复制集系统中的最新数据
该选项可以取以下值:
| 级别 | 说明 |
| local | 默认值。查询返回实例最新的数据,不保证这些数据已经写入到复制集中大部分节点或者已经持久化到磁盘。类似于读取未提交 |
| majority |
MMAPv1引擎不支持 查询返回实例最新的、已经确认被复制集中大部分节点写入的数据。要使用该级别,你需要:
|
| linearizable |
3.4版本新加入,用于确保读取到最新鲜(任何发生在之前的写操作都可以读到)、持久化的数据(不会被回滚) 查询返回尽可能新的数据,数据由这样的写操作产生:
对于 writeConcernMajorityJournalDefault=true的复制集,该级别返回绝不会被回滚的数据 对于 writeConcernMajorityJournalDefault=false的复制集,MongoDB不等待majority级别写操作持久化到磁盘,即确认相应的写操作。因此,在复制集成员丢失的情况下,majority级别写操作可能回滚 你只能在复制集的主节点上指定该读级别。并且,上文所述保证,仅仅在查询的过滤器精确的匹配单个文档时有效 |
写关注(Write concern)描述写操作请求的确认级别。这些写操作可以应用在单独的mongod、复制集或者分片集群。 对于分片集群,mongos实例会把写关注级别传递给分片。
从2.6开始,写操作的新协议集成了写关注,你不再需要在写操作之后紧跟着一个getLastError调用来指定写关注级别。
写关注相关的选项包括:
|
1 |
{ w: <value>, j: <boolean>, wtimeout: <number> } |
其中:
- w选项:要求当前写操作已经传播到指定数量的mongod实例,或者具有指定tag的mongod实例
- j选项:要求当前写操作已经写入到磁盘日志
- wtimeout:等到上述两个条件达成的超时,防止无限阻塞
| 取值 | 说明 |
| <number> |
要求写操作请求已经传播到指定数量的mongod实例:
大于1的取值,仅仅针对复制集有意义。即要求确认写操作传播到包括主节点在内的N个复制集成员 |
| majority |
要求确认写操作已经传播到大部分的投票节点,包括主节点 当基于此取值的写操作调用返回后,使用 readConcern:majority的客户端可以读取到其写入的数据 |
| <tag set> | 要求确认写操作已经传播到复制集中具有指定标签(tag)的节点 |
j: true从MongoDB获得确认:写操作已经被写到日志(journal)中。该选项本身不保证写操作不被回滚,回滚的原因可能是复制集的主节点发生故障转移。
从3.2开始,该选项导致写操作仅仅在:指定数量(w选项)的复制集节点都写了日志后才返回,之前仅仅要求主节点写了日志就返回(因而就不存在主节点故障转移导致的回滚问题?)
指定一个毫秒的限制,但是仅仅用于w取值大于1的情况。如果不指定此选项或者指定为0,可能导致永久的阻塞。
当超时到达后,调用立即以一个错误返回,然而后续所要求的写关注可能成功。 当返回后,MongoDB不会撤销已经执行的数据修改。
| w取值 | 不指定j | j:true | j:false |
| 单独实例(Standalone) | |||
| w: 1 | 确认写入到内存 | 确认写入到磁盘日志 | 确认写入到内存 |
| w: "majority" | 如果启用了日志,确认写入到日志 | 确认写入到磁盘日志 | 确认写入到内存 |
| 复制集(Replica Sets) | |||
| w: "majority" |
行为取决于writeConcernMajorityJournalDefault:
|
确认写入到磁盘日志 | 确认写入到内存 |
| w: <number> | 确认写入到内存 | 确认写入到磁盘日志 | 确认写入到内存 |
默认情况下,当客户端消费了游标中所有结果集后,MongoDB会自动关闭游标。
但是,对于定长(Capped)集合来说,你可以使用可追加游标(Tailable Cursor)。该游标在客户端耗尽所有结果集后仍然保持打开状态。从概念上来说,这种游标类似于UNIX命令tail -f。当客户端插入新数据到集合中后,可追加游标会继续取回文档。
在高写入量、不适用索引的定长集合上,可以使用这种游标。例如,MongoDB本身的复制机制,就是在主节点的oplog这个定长集合上使用可追加游标。
注意可追加游标的以下特性:
- 该游标不使用索引,以自然顺序—— 在磁盘上的存储顺序 ——返回文档
- 由于不使用索引,可追加游标的最初扫描代价很高,但是一旦最初扫描的结果被耗尽后,再取回新的文档,成本很低
- 可追加游标可能变得不可用,可能的情况包括:
- 查询返回结果为空
- 游标返回位于集合尾部的文档,而应用程序随后删除了此文档
MongoDB的查询优化器会分析查询,然后选择最高效的执行计划。后续执行相同查询时,会使用同样的执行计划。
查询优化器会缓存执行计划,但是仅仅缓存那些可以有多个执行路径的查询形状(Query shape,指查询断言、排序、投影的组合)。
查询规划器(query planner )针对每个查询,搜索执行计划缓存,寻找匹配查询形状的计划。如果匹配的计划不存在,查询规划器会生成候选的计划,在“试用期间”评估它们,然后选取其中最高效的,并缓存该执行计划。
如果匹配的计划存在,查询规划器则会通过replanning机制重新评估其性能,如果评估不通过对应的缓存条目被清除。在发生清除的情况下,查询规划器会按照正常流程重新选择执行计划并缓存。
上述逻辑的流程图如下:
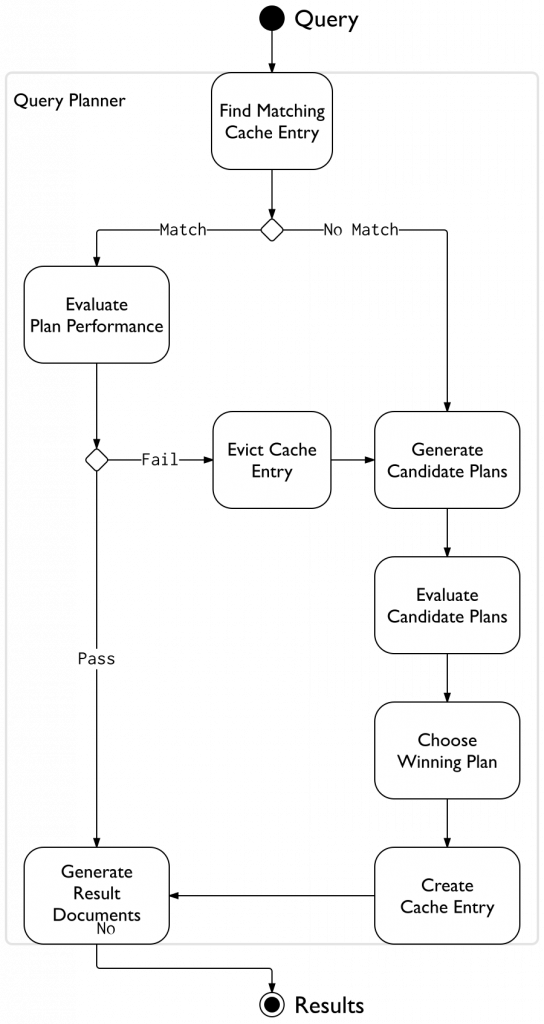
你可以使用 db.collection.explain()或者 cursor.explain()调用获得目标查询的执行计划的统计信息。这些信息有助于帮助你分析如何建立索引。
当mongod重新启动或者关闭后,所有执行计划的缓存都被清除。
从2.6开始,提供了一些方法来控制缓存: PlanCache.clear()清除所有缓存, PlanCache.clearPlansByQuery()清除特定缓存。
索引过滤器决定查询优化器使用哪些索引来评估查询形状。当为查询形状指定了索引过滤器时,仅过滤器中包含的索引会被用来优化查询。
索引过滤器存在时,MongoDB会忽略 hint()调用。鉴于此,谨慎的使用之。
要检查索引过滤器是否存在,获取db.collection.explain()或者cursor.explain()返回值的 indexFilterSet字段。
在服务器关闭后,索引过滤器不会持久化。MongoDB也提供了手工移除索引过滤器的命令。
本节内容简单的介绍一些优化查询的方向。
通过减少查询操作需要处理的数据的量,索引可以提升读操作、更新操作以及聚合管线部分阶段的性能。
如果你的业务通常基于某个、某些字段对集合进行查询,你可以考虑在字段上创建索引、复合索引。这可以避免查询操作进行全集合扫描。创建索引的示例代码:
|
1 |
db.inventory.createIndex( { type: 1 } ) |
除了优化读操作外,索引还可以用来支持排序操作、优化存储空间利用。
由于MongoDB支持升序、降序读取索引,因此对于单键索引来说,其方向不重要。
在大部分情况下,查询优化器都会选择合适的索引。如果你需要强制指定一个索引,可以调用 hint()
该操作符用于增加或者减少字段的值。它在服务器端工作,不需要把原先的值取到客户端。
该操作符也避免了多个客户端同时get-and-set时的竞态条件。
如果知道需要返回的数据的量,可以使用limit():
|
1 |
db.posts.find().sort( { timestamp : -1 } ).limit(10) |
另外,可以使用投影,仅仅返回需要的字段。
Query Selectivity用来度量查询断言(条件)过滤掉集合中文档的强度,针对主键的唯一性查询的选择性最高 —— 因为它只会匹配单个文档。查询选择性决定了是否能高效的使用索引,甚至是能否使用索引。
低选择性的常见例子是$nin、$ne查询操作符,它们通常都会匹配索引值域的很大一部分。这导致使用索引有时还不如直接全文档扫描快,因此索引不被使用。
如果使用正则式来指定字段值(条件),查询的选择性取决于正则式本身
所谓Covered Query是指索引即可满足查询所需的全部字段,不需要执行文档扫描的情况,需要配合投影使用:
|
1 2 3 4 5 6 7 |
# 复合索引 db.inventory.createIndex( { type: 1, item: 1 } ) # 覆盖查询 db.inventory.find( { type: "food", item:/^c/ }, { item: 1, _id: 0 } # 被覆盖,注意指定_id:0排除了主键字段,确保了覆盖 ) |
覆盖查询通常具有很高的性能(相对那些需要检索文档的查询),原因包括:
- 索引键值通常要比对应的文档小
- 索引常常驻留内存,或者在磁盘上顺序的分布
以下情况下,索引无法覆盖查询:
- 任意索引字段,在任意一个文档中存储了数组时。当索引字段存储了数组后,索引称为多键索引(Multi-key Index),这种索引不支持覆盖查询
- 任何断言字段(条件)、投影字段(返回)是位于嵌入文档中的字段时
针对分片集群的限制:当索引不包含分片键的时候,它不能覆盖针对分片集合的查询。一个例外是,查询断言仅针对_id且投影仅仅返回_id,即使_id不是分片键,也可以做到覆盖查询。
使用 db.collection.explain()调用可以查看目标查询是否是覆盖查询。
集合上的每个索引,都增加了写入操作的成本。
对于插入/删除操作,MongoDB需要插入/删除集合上所有索引中的文档键。更新操作可能导致索引的一个子集的变更。
对于使用MMAPv1引擎的mongod,更新操作可能导致文档增长,超过为其分配的空间。这时MMAPv1需要把文档移动到一个新的地方,并更新索引索引,指向文档的新位置。这些成本较高,但是发生频率较低。
通常来说,索引带来的读性能提升,值得损耗写性能。尽管如此,不要盲目的创建索引,要评估既有索引是否真的有用。
更新操作可能会改变文档的尺寸,例如添加新的字段。
对于MMAPv1引擎来说,如果更新操作导致文档尺寸超过当前分配尺寸,MongoDB会在磁盘上重新分配文档,确保有足够的连续空间可以存放文档。需要重新分配空间的更新操作,其效率更加低,特别是结合使用索引的情况下,因为需要修改文档的位置信息。
默认的,从3.0开始MongoDB总是分配2的N次方大小的空间。这可以尽量减少重新分配、高效的重用删除操作回收的空间,但是不能消除重新分配。
存储系统的硬件因子——随机存取能力、磁盘预读取、RAID等——对MongoDB写操作的性能影响很大。对于随机性的工作负载,SSD能够提供比HDD高100倍的性能。
为了防止意外宕机导致数据丢失,MongoDB使用预写式日志(write ahead logging)—— 变更首先发生在内存中,然后首先写入到日志。不直接写入存储引擎是因为日志文件是顺序写,速度快。如果MongoDB需要终止服务进程或者遭遇错误,可以使用日志文件恢复,把尚未完成的操作应用到存储引擎的数据文件中。
日志和数据文件的写入,存在对存储能力的争用,特别是二者保存在同一物理设备上时。
如果应用程序指定包含j选项的写关注,则mogod会减少日志写操作之间的间隔,从而增大总体的写负载。
日志写间隔可以通过运行时配置 commitIntervalMs来设置,减少此参数会增加写操作的数量,从而降低MongoDB的写容量。反之减少量写操作数量,却有更大概率在宕机时丢失数据。
使用db.collection.explain()、cursor.explain()方法以及explain命令都可以获得执行计划相关的信息(包括执行统计信息)。
执行计划(上述方法或命令的结果)以阶段(stage)树的形式呈现。每个stage把自身的结果(例如文档或者索引键)传递给父节点。叶子节点访问文档或者索引,中间节点操控文档或者索引键,根节点是最终的stage,MongoDB从中获得结果集。
Stage是操作的描述,例如:
- COLLSCAN 全集合扫描
- IXSCAN 索引键扫描
- FETCH 读取文档
- SHARD_MERGE 合并来自分片的结果
- AND_SORTED 可在索引交叉时出现
- AND_HASH 可在索引交叉时出现
执行计划以JSON格式输出,重要的字段包括:
| 字段 | 说明 | ||
|
queryPlanner 被查询优化器选取的执行计划的详细信息 示例输出:
|
|||
| namespace | 查询在什么名字空间上运行,例如<database>.<collection> | ||
| indexFilterSet | 应用到此查询形状的索引过滤器 | ||
| winningPlan |
被查询优化器选中的执行计划的细节信息,以Stage的树的形式呈现 |
||
| w***P.stage | Stage的名称 | ||
| w***P.inputStage | Stage的输入(单个子节点) | ||
| w***P.inputStages | Stage的输入(多个子节点) | ||
| w***P.shards | 针对每个分片的信息 | ||
| rejectedPlans | 被拒绝的候选计划的列表 | ||
|
executionStats 被选中计划的执行情况 示例输出:
|
|||
| nReturned | 匹配查询的文档数量 | ||
| executionTimeMillis | 包含查询计划选择、计划执行在内的总计消耗时间 | ||
| totalKeysExamined | 总计扫描的索引条目数量 | ||
| totalDocsExamined | 总计扫描的文档的数量 | ||
| executionStages | 被选中计划各阶段的执行细节统计信息zbook g4 | ||
| e***S.works |
该阶段执行的工作单元数量,查询执行过程把整个工作划分为细小的单元。一个单元可能包括:
|
||
| e***S.advanced | 返回(或者提升,advance)到父Stage的中间结果数量 | ||
| e***S.needTime | 不是用来返回中间结果到父Stage的工作周期数。例如一个索引扫描Stage可能花费一个工作周期来定位索引的下一个位置,不是把所有工作周期都用来向父节点返回索引键 | ||
| e***S.needYield | 存储层请求查询系统让出它的锁的次数 | ||
| e***S.isEOF | 指出Stage是否到达的流的尾部 | ||
| e***S.shards | 针对每个分片的信息 | ||
| e***S.inputStage.keysExamined |
对于扫描索引的Stage(例如IXSCAN),该字段表示被检查的键的总数:
|
||
| e***S.inputStage.docsExamined |
该字段出现在文档扫描(COLLSCAN)阶段,或者FETCH之类取回文档的阶段 总计扫描的文档数量 |
||
| serverInfo 返回MongoDB实例的信息 | |||
准备数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
db.collection( 'inventory' ).insertMany( [ { "_id": 1, "item": "f1", type: "food", quantity: 500 }, { "_id": 2, "item": "f2", type: "food", quantity: 100 }, { "_id": 3, "item": "p1", type: "paper", quantity: 200 }, { "_id": 4, "item": "p2", type: "paper", quantity: 150 }, { "_id": 5, "item": "f3", type: "food", quantity: 300 }, { "_id": 6, "item": "t1", type: "toys", quantity: 500 }, { "_id": 7, "item": "a1", type: "apparel", quantity: 250 }, { "_id": 8, "item": "a2", type: "apparel", quantity: 400 }, { "_id": 9, "item": "t2", type: "toys", quantity: 50 }, { "_id": 10, "item": "f4", type: "food", quantity: 75 } ] ) |
获取不使用索引时的执行计划:
|
1 2 3 4 5 6 7 8 9 10 |
require( 'promise.prototype.finally' ).shim(); client.connect( 'mongodb://localhost:27017/local' ).then( db => { db.collection( 'inventory' ).find( { quantity: { $gte: 100, $lte: 200 } } ).explain( "executionStats" ).then( r => { console.log( r.queryPlanner.winningPlan.stage ); // COLLSCAN 表示全集合扫描 console.log( r.executionStats.nReturned ); // 匹配并返回3条数据 console.log( r.executionStats.totalDocsExamined ); // 总计检查10条(全部)数据 } ).catch( e => console.log( e ) ).finally( () => process.exit() ); } ); |
创建一个索引:
|
1 |
db.collection( 'inventory' ).createIndex( { quantity: 1 } ) |
执行计划现在为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
console.log( r.queryPlanner.winningPlan.inputStage.stage ); // IXSCAN 表示索引扫描(在子Stage完成) console.log( r.queryPlanner.winningPlan.stage ); // FETCH 直接抓取数据 console.log( r.executionStats.nReturned ); // 匹配并返回3条数据 console.log( r.executionStats.totalDocsExamined ); // 总计检查3条数据 // 打印整个计划: const util = require( 'util' );<br>console.log( util.inspect( r, { depth: null, colors: true } ) ); // 输出: { queryPlanner: { plannerVersion: 1, namespace: 'local.inventory', indexFilterSet: false, parsedQuery: { '$and': [ { quantity: { '$lte': 200 } }, { quantity: { '$gte': 100 } } ] }, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { quantity: 1 }, indexName: 'quantity_1', isMultiKey: false, multiKeyPaths: { quantity: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { quantity: [ '[100, 200]' ] } } }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 3, executionTimeMillis: 0, totalKeysExamined: 3, totalDocsExamined: 3, executionStages: { stage: 'FETCH', nReturned: 3, executionTimeMillisEstimate: 0, works: 4, advanced: 3, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, invalidates: 0, docsExamined: 3, alreadyHasObj: 0, inputStage: { stage: 'IXSCAN', nReturned: 3, executionTimeMillisEstimate: 0, works: 4, advanced: 3, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, invalidates: 0, keyPattern: { quantity: 1 }, indexName: 'quantity_1', isMultiKey: false, multiKeyPaths: { quantity: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { quantity: [ '[100, 200]' ] }, keysExamined: 3, seeks: 1, dupsTested: 0, dupsDropped: 0, seenInvalidated: 0 } }, allPlansExecution: [] }, serverInfo: { host: '226ce0b60d62', port: 27017, version: '3.4.5', gitVersion: '520b8f3092c48d934f0cd78ab5f40fe594f96863' }, ok: 1 } |
本节介绍几种评估MongoDB操作性能的技术。
MongoDB提供了一个数据库剖析器(database profiler ),它能够显示数据库中每个查询的性能特征。使用该剖析器可以定位运行缓慢的读写操作。
该调用可以显示当前mongod实例上正在执行的操作的各项参数。调用方式:
|
1 2 3 |
db.currentOp({filterDocument}) // 示例 db.currentOp( { query: { $exists: true } , ns: 'bais.corps' } ).inprog |
可以传递一个过滤文档作为参数,该文档可以包含以下字段:
- $ownOps,如果设置为true,仅仅显示当前用户的操作
- $all,如果设置为true,返回所有操作的信息,包括那些空闲连接上的操作、系统操作
- 任何输出字段都可以作为过滤条件使用
在单个mongod实例、复制集上,该调用的输出格式为:
|
1 2 3 4 |
{ "inprog" : [/* 正在执行的操作列表 */], "ok" : 1.0 } |
在分片集群的mongos上,该调用的输出格式为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ // 每个分片的情况 "raw" : { // 分片名称为键 "rs1/mongo-11.gmem.cc:27017,mongo-12.gmem.cc:27017,mongo-13.gmem.cc:27017" : { "inprog" : [/* 正在执行的操作列表 */], "ok" : 1.0, "$gleStats" : { "lastOpTime" : Timestamp(0, 0), "electionId" : ObjectId("7fffffff000000000000000e") } } }, // 当前mongos上的情况 "inprog" : [/* 正在执行的操作列表 */], "ok" : 1.0 } |
上述输出的核心是inprog属性,它包括以下字段:
| 字段 | 说明 |
| desc | 客户端的描述,其中包含了connectionId |
| threadId | 用于处理此数据库连接的线程标识 |
| connectionId | 发起操作的连接的标识符 |
| client | 客户端的地址和端口,例如 "client" : "172.21.1.1:44938" |
| appName | 客户端提供的应用程序名称 |
| opid | 操作的标识符,可以传递给 db.killOp() |
| active |
提示该操作是否已经启动的布尔值:true表示操作已经启动;false表示操作空闲(idle)。当一个操作让出锁(yielded)给其它操作的情况下,此字段仍然为true |
| secs_running | 操作已经持续的时间 。仅仅active=true时存在 |
| microsecs_running | 操作已经持续的时间,以微秒计算。仅仅active=true时存在 |
| op |
该操作的类型:none、update、insert、query、command、getmore、remove、killcursors 其中:
|
| ns | 操作针对的名字空间, <database>.<collection>形式 |
| insert | 如果op为insert则存在,包含正在被插入的文档 |
| query | 如果op不为insert则存在,包含查询、删除、更新的过滤文档。对于getmore操作,包含了对应的find的过滤文档或者aggregate的Stages文档 |
| planSummary | 执行计划的概要信息,便于调试缓慢查询 |
| locks |
当前操作持有的锁的类型:
以及锁定模式:
|
| waitingForLock | 当前操作是否在等待锁 |
| msg | 描述操作状态、进度的字符串 |
| progress | 描述mapReduce或者索引构建的进度 |
| killPending | 当前操作是否被标记为要杀死。当操作进入下一个安全点后会终结 |
| numYields | 当前操作让出锁以便其它操作进行的次数 |
| fsyncLock | 当前数据库是否被db.fsyncLock()锁定 |
| info | 仅仅fsyncLock为true时存在,描述如何解锁数据库 |
| lockStats |
对于每类锁(类型+模式组合),报告以下统计信息:
|
这是一个命令行工具,查看读写最繁忙的集合。该命令不能在mongos上执行。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mongotop -u root -p root --authenticationDatabase admin # ns total read write 2017-08-25T15:33:53+08:00 # local.oplog.rs 1ms 1ms 0ms # admin.system.roles 0ms 0ms 0ms # admin.system.users 0ms 0ms 0ms # admin.system.version 0ms 0ms 0ms # bais.corps 0ms 0ms 0ms # bais.corptypes 0ms 0ms 0ms # bais.orgs 0ms 0ms 0ms # bais.system.indexes 0ms 0ms 0ms # bais.trades 0ms 0ms 0ms # local.me 0ms 0ms 0ms |
这是一个命令行工具,可以快速的查看当前mongos/mongod的概览信息,类似于vmstat:
|
1 2 3 |
mongostat -u root -p root --authenticationDatabase admin # insert query update delete getmore command flushes mapped vsize res faults qrw arw net_in net_out conn time # *0 *0 *0 *0 0 2|0 0 0B 300M 19.0M 0 0|0 0|0 288b 16.8k 8 Aug 25 15:15:14.827 |
该命令的输出,反映每秒的平均统计指标。字段列表:
| 字段 | 说明 |
| inserts | 插入文档数量 |
| query | 查询操作的数量 |
| update | 更新操作的数量 |
| update | 删除操作的数量 |
| getmore | 游标抓取操作的数量 |
| command | 执行命令的数量,在复制集的从节点上,输出为local|replicated格式 |
| flushes | 对于 WiredTiger,为触发的检查点数量;对于 MMAPv1,为fsync操作数量 |
| dirty | 仅WiredTiger,WiredTiger缓存中脏字节占比 |
| used | 仅WiredTiger,WiredTiger缓存当前正被使用的占比 |
| mapped | 仅 MMAPv1,从上次mongostat调用以后,累计映射到内存的数据量(MB) |
| vsize | 从上次mongostat调用以后,虚拟内存用量(MB) |
| non-mapped | 仅 MMAPv1,从上次mongostat调用以后,累计没有映射到内存的数据量(MB)。仅仅使用--all 选项时出现 |
| res | 从上次mongostat调用以后,MongoDB进程使用的驻留内存累计数量 |
| faults | 仅 MMAPv1,页面错误次数 |
| lr | 仅 MMAPv1,多少百分比的读操作必须等待锁 |
| lw | 仅 MMAPv1,多少百分比的写操作必须等待锁 |
| lrt | 仅 MMAPv1,等待读锁消耗的平均时间 |
| lwt | 仅 MMAPv1,等待写锁消耗的平均时间 |
| idx miss | 仅 MMAPv1,导致页面错误的索引访问操作的占比 |
| qr | 等待读操作的队列深度 |
| qw | 等待写操作的队列深度 |
| ar | 活动的、正在执行读操作的客户端数量 |
| aw | 活动的、正在执行写操作的客户端数量 |
| netIn | 入站网络流量,单位字节 |
| netOut | 出站网络流量,单位字节 |
| conn | 打开的连接数 |
| repl | 成员的复制状态: M 主节点 SEC 从节点 REC 正在恢复 UNK 未知 SLV 主从复制模式的从节点 RTR mongos节点 ARB 仲裁节点 |
方法 cursor.explain()和 db.collection.explain()可以返回关于查询的执行计划,例如选取什么索引、执行的统计信息。
你可以在queryPlanner、executionStats 、allPlansExecution三种模式下运行这些方法,获取多或少的信息。
聚合操作处理数据记录,并返回计算过后的结果。这类操作将多个文档中的数值进行分组,通过多种数学计算将其合并为单个数值。
MongoDB提供三种聚合操作途径:聚合管线(aggregation pipeline)、Map-Reduce函数(map-reduce function)、单意图聚合方法(single purpose aggregation methods) 。
MongoDB的聚合框架,以数据处理管线的概念进行建模 —— 多个文档进入由多个阶段(stage)构成的管道,并被管道转换为单个聚合后的结果。每个阶段都会对文档进行某种转换。每个阶段的输入、输出文档没有一一对应关系,一个文档可以产生多个新文档,多个文档也可能被合并为单个文档。
最基本管线stage,提供过滤器功能,工作方式类似于查询和文档转换,修改输出文档的形式。
其它管线stage,提供依据指定字段来分组、排序文档的工具,以及聚合数组(包括文档的数据)内容的工具。此外,管线stage可以使用操作符来计算平均值、连接字符串…等操作。
通过MongoDB内置的native操作,管线可以提供高效的数据聚合能力。管线是最优选的聚合途径。
聚合管线可以支持分片集合。
在某些stage,聚合管线会利用索引来改善性能。聚合管线声明周期中,具有内部的优化阶段。
要使用聚合管线,可以调用 db.collection.aggregate( arrayOfStages )或者 aggregate命令。
某些stage需要一个管线表达式来作为操作数,管线表达式说明如何来转换输入文档。表达式的格式类似于文档,并且可以包含其它表达式。
管线表达式仅可以操作管线中的当前文档,无法引用其它文档中的数据。通常来说,表达式都是无状态的,例外是那些累加器表达式。累加器用在 $group阶段,需要维护自身状态(例如总数、最大值)。
从3.2开始,某些累加器可以用在 $project阶段。 但是用在此阶段时不能跨文档的维护自身的状态。
聚合管线操控单个集合,在逻辑上,是把整个集合推到管线上进行处理。为了优化性能,仅可能的使用以下策略避免全集合扫描:
- 管线操作符和索引:当出现在管线的开头时,$match、$sort等管线操作可以使用索引。$geoNear 可以使用地理空间索引。从3.2开始,索引可以覆盖聚合管线,而避免扫描集合
- 尽早的过滤:如果聚合操作仅仅需要集合的一个子集,可以使用$match、$limit、$skip等stage来限制进入管线开头的文档数量
- 内部优化阶段(optimization phase)
聚合管线内部有一个优化阶段,会尝试对管线进行塑形,以改善性能。要了解此优化阶段是如何工作的,以explain选项来调用aggregate()方法。随着MongoDB的版本发布,管线优化的实现可能会变化。
|
结果集大小的限制 从2.6开始,aggregate命令可以返回一个游标,或者把结果存储在一个集合中。每个文档的大小限制当前为16MB(BSON文档尺寸限制),如果某个文档超过此限制,命令会报错。注意这个限制仅仅针对作为结果的文档,在管线中间流转的文档不受限制。 从2.6开始aggregate()方法默认返回游标。对于aggregate命令来说,如果不指定cursor选项,也不在集合中存储结果,结果集会存放在一个大的文档中,该文档可能超过16MB限制而报错 |
|
内存限制 管线的stage使用内存的限制是100MB,如果某个stage超过此限制,MongoDB会报错。为了处理大型数据集,应该使用allowDiskUse选项,以便stage的临时结果可以存储在磁盘上 从3.4开始,$graphLookup 阶段必须受限于100MB内存,allowDiskUse: true对该stage无效 |
聚合管线支持针对分片集合进行操作,但是具有一些特殊的行为。
如果管线以精确匹配针对某个分片键的$match开头,则整个管线在匹配的分片上运行。在3.2之前的行为是,管线分拆在所有管线上运行,并且由主分片负责合并最后结果。
对于必须运行在多个分片上的聚合操作,如果不是必须在主分片上运行,这些操作会把结果路由到随机的分片上,由该分片负责合并结果,避免增加主分片的负担。$out、$lookup操作必须在主分片上运行。
db.collection.aggregate()方法的参数是一个数组,每个数组元素表示一个阶段(Stage)。阶段是单键对象,键的名称以$开头,列于下面的表格中。
除了 $out、 $geoNear之外的所有Stage都可以出现多次。
| Stage | 说明 | ||||
| $collStats |
依据集合或者视图来返回统计信息,3.4新增:
输出文档包含以下字段: |
||||
| $project |
对输入文档进行重新构形: { $project: { <specification(s)> } } 规格可以包含以下形式的字段: |
||||
| $match |
对输入文档集进行过滤,仅仅允许满足条件的文档进入下一Stage:
查询条件的规格,与读操作的过滤条件语法一致 |
||||
| $redact |
根据文档本身存储的内容,来限制文档的内容: { $redact: <expression> } |
||||
| $limit | 限制传递到下一Stage的文档数量: { $limit: <positive integer> } | ||||
| $skip | 跳过指定数量的文档,然后把剩下的传递到下一Stage: { $skip: <positive integer> } | ||||
| $unwind | 展开某个数组字段,每个数组元素替换该字段形成一个输出文档,对于N元素的数组字段,形成N个输出文档 | ||||
| $group |
根据指定的_id表达式来分组文档,可选的,应用一个或者多个累加器表达式 对于每个特定的_id表达式组合,输出一个文档 |
||||
| $sample | 从输入中随机选择指定数量的文档 | ||||
| $sort |
根据指定的key重新排序文档流,改变的仅仅是顺序,每个文档不会改变:
|
||||
| $geoNear |
根据距离指定地理空间点的远近对文档流进行排序,输出文档包括额外的distance字段,还可以包含地理位置标识符字段:
注意:
示例:
|
||||
| $lookup |
对同一数据库中的另外一个非分片集合执行左外连接操作:
示例:
|
||||
| $out | 必须作为最后一个Stage,把输入文档写到目标集合中: { $out: "<output-collection>" } | ||||
| $indexStats | 返回集合中每个索引使用情况的统计信息 | ||||
| $facet | 在单个Stage中处理多个聚合管线,这些管线针对同一组输入文档进行 | ||||
| $bucket |
基于指定的表达式和桶边界,将输入文档划分到称为桶(bucket)的组中:
|
||||
| $bucketAuto |
与$bucket,只是boundaries不需要指定,根据需要的桶的数量自动划分:
|
||||
| $sortByCount |
根据指定表达式的值对输入文档进行分组,并且计算每个分组中文档的数量:
|
||||
| $addFields |
为每个输入文档添加额外的字段:
|
||||
| $replaceRoot | 提升输入文档中的一个内嵌文档,将其作为根文档,代替原有文档 | ||||
| $count | 计算输入文档的总数: { $count: <field_name> } | ||||
| $graphLookup |
在集合上执行递归的检索:
|
使用聚合管线时,很多的值可以使用表达式。表达式包括:
| 表达式类型 | 说明 | ||
| 字段路径 | 用于读取输入文档中的字段,包括内嵌文档字段,以前缀 $开始,例如$user、$user.name | ||
| 系统变量 | 一些预置的特殊对象,以前缀 $$开始。例如 $$CURRENT通常表示当前正在被处理的输入文档,因此$$CURRENT.<field>通常等价于$<field> | ||
| 字面值 |
可以使用 { $literal: <value> }形式指定,例如:
|
||
| 操作符表达式 |
类似于接受参数的函数:
MongoDB提供了很多聚合管线专用操作符,对应了各类操作符表达式,主要包括: |
||
| 累加器表达式 |
聚合管线专用操作符中有一类特殊的累加器操作符,只能用于$group阶段,从3.2开始,部分可用在$project阶段(stage)。主要包括:$sum、$avg、$first、$last、$max、$min、$push、$addToSet等 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
// 每条数据的结构 { "_id": "10280", // 邮编 "city": "NEW YORK", // 市 "state": "NY", // 州 "pop": 5574, // 人口 "loc": [ // 经纬 -74.016323, 40.710537 ] } // 人口大于1000万的州 db.zipcodes.aggregate( [ // 输出文档的_id作为分组的依据 // 该stage决定的输出文档的结构,使用$xxx可以引用输入文档的字段 // totalPop字段通过$sum操作符(聚合表达式)计算出 { $group: { _id: "$state", totalPop: { $sum: "$pop" } } }, // 该stage针对上一stage的结果进行匹配 { $match: { totalPop: { $gte: 10 * 1000 * 1000 } } } ] ); // 返回每州的平均城市人口 db.zipcodes.aggregate( [ // 支持依多字段分组。先获得 州 - 市 - 人口总和 { $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } }, // 再次分组,州总人口除以城市数量。注意点号导航 { $group: { _id: "$_id.state", avgCityPop: { $avg: "$pop" } } } ] ); // 返回每个州里面最大和最小的城市 db.zipcodes.aggregate( [ { // 按照州、市进行分组,统计人口总数 $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } }, // 根据人口升序排列 { $sort: { pop: 1 } }, // 第二次分组,$last、$first分别取最后、最前的组内文档中的值 { $group: { _id: "$_id.state", biggestCity: { $last: "$_id.city" }, biggestPop: { $last: "$pop" }, smallestCity: { $first: "$_id.city" }, smallestPop: { $first: "$pop" } } }, // 投影stage,重命名_id字段为state字段 // 把城市名称、人口合并为文档 // 注意投影是针对输入文档每个条目执行的 { $project: { _id: 0, // 设置为0表示明确的在输出文档中禁用该字段 state: "$_id", biggestCity: { name: "$biggestCity", pop: "$biggestPop" }, smallestCity: { name: "$smallestCity", pop: "$smallestPop" } } } ] ); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
20// 每条数据的结构 { _id : "jane", joined : ISODate("2011-03-02"), likes : ["golf", "racquetball"] } { _id : "joe", joined : ISODate("2012-07-02"), likes : ["tennis", "golf", "swimming"] } // 规范化数据结构,_id转换为大写,命名为name,然后根据name升序排列 db.users.aggregate( [ { $project: { name: { $toUpper: "$_id" }, _id: 0 } }, { $sort: { name: 1 } } ] ); // 根据加入的月份升序排列 db.users.aggregate( [ { $project: { // 取得月份 month_joined: { $month: "$joined" }, name: "$_id", _id: 0 // 明确禁用_id字段,该字段是默认包含的 } }, { $sort: { month_joined: 1 } } ] ); // 获得每月加入的总数,根据月份升序排列 db.users.aggregate( [ { $project: { month_joined: { $month: "$joined" } } }, { $group: { _id: { month_joined: "$month_joined" }, number: { $sum: 1 } } }, { $sort: { "_id.month_joined": 1 } } ] ); // 获得五个最被喜爱的体育运动 db.users.aggregate( [ // 展开likes数组,意味着对于likes.lengt = 5的输入文档,将展开为5个输出文档 { $unwind: "$likes" }, // 根据喜爱的单项体育运动分组,统计总数(每个人只能喜爱一次,因此sum:1) { $group: { _id: "$likes", number: { $sum: 1 } } }, // 逆序排列 { $sort: { number: -1 } }, // 取前五条 { $limit: 5 } ] ); |
Map-reduce是一种数据处理范式,用于浓缩海量的数据为有意义的聚合数据。
MongoDB支持map-reduce风格的聚合操作。总体上说,map-reduce操作由以下阶段组成:
- map阶段,处理多个文档,并针对每个输入文档产生一个或者多个键值对。此阶段由map函数中的emit语句完成
- reduce阶段,处理map阶段的输出,把这些输出合并起来。对于具有相同键的所有值,应用reduce函数,聚合(累积)为一个值
- 可选的finalize阶段,对结果进行最终的修改
类似于其它聚合操作,map-reduce也允许指定查询条件、排序方式、限制输入文档数量。
你需要自定义JavaScript函数来提供map、reduce、finalize逻辑。和聚合管线比起来,JavaScript函数可以提供巨大的灵活性,但是更加低效和复杂。
在Shell中,你可以调用 mapReduce命令,编程时则调用 db.collection.mapReduce()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
db.collection.mapReduce( // map函数关联一个value到key,在map阶段之后产生若干key:[values]形式的键值对,作为reduce阶段的输入 // map函数要求: // 1、使用this引用当前文档 // 2、不得出于任何目的访问数据库 // 3、必须是纯函数,不得有任何副作用 // 4、单个emit调用可产生半数于BSON最大文档尺寸的键值对 // 5、可以调用多次emit(key,value)以产生键值对 <map>, // reduce整个[values]为单个对象,可以作为finalize阶段的输入 // reduce函数要求: // 1、不得出于任何目的访问数据库 // 2、不得影响外部系统 // 3、对于只包含一个值的key,MongoDB不会调用reduce函数 // 4、可以访问定义在scope中的全局变量 // 5、由于针对同一key,reduce函数可能被调用多次,因此reduce函数的返回值的类型必须和map函数emit的value类型一致 // 6、以下表达式必须成立: // associative reduce(key, [ C, reduce(key, [ A, B ]) ] ) == reduce( key, [ C, A, B ] ) // idempotent reduce(key, [ reduce(key, valuesArray) ] ) == reduce( key, valuesArray ) // commutative reduce( key, [ A, B ] ) == reduce( key, [ B, A ] ) <reduce>, // 选项: { // 指定mapReduce结果的输出目的地,你可以指定 // 1、一个集合的名字 // 2、action:collection_name,输出到集合前应用指定的action // 3、inline,针对主节点进行mapReduce时可以输出到集合,针对从节点则只能inline out: { // action取值: // replace 如果collectionName存在,则替换其内容 // merge 合并当前结果到collectionName,如果存在相同的key则覆盖之 // reduce reduce当前结果到collectionName,对于相同的key(_id),使用此mapReduce的reduce函数进行reduce // collectoinName中文档的原型:{ "_id" : key, "value" : reducedValue } <action>: <collectionName>, // 在内存中完成mapReduce操作,并返回结果,指定此字段,则不能指定任何其它out字段 inline : 1 // [, db: <dbName>] // 可以选择其它数据库 [, sharded: <boolean> ] // 设置为true则对输出集合启用分片,使用_id(即map的key)字段对输出集合进行分片 [, nonAtomic: <boolean> ] // 如果设置为true,则mapReduce的后处理阶段不会全局锁 }, // 用于过滤输入文档 query: <document>, // 用于排序输入文档,可以优化性能。如果sort和emit的键一致,则可以减少reduce操作的次数。必须是集合的某个索引字段 sort: <document>, // 限制进入map阶段的最大文档数量 limit: <number>, // 早reduce完成之后,对最终结果进行修改,例如求平均 finalize: <function>, // 定义map、reduce、finalize函数中可以访问的全局变量 scope: <document>, jsMode: <boolean>, // 如果为true,则在result信息中包含耗时统计信息 verbose: <boolean> } ) |
map-reduce支持将分片集合作为输入,并且其结果可以输出到分片集合上。
当作为输入时,MongoDB会自动把map-reduce任务派发到各分片上来并行执行,并等到所有分片上的任务全部完成。
当作为输出时,如果mapReduce的out字段具有sharded值,则MongoDB自动以_id为分片键,输出到分片集合中。
Map-reduce操作由一系列的任务组成,这些任务的职责包括:从输入集合读取数据、执行map函数、执行reduce函数、在处理过程中输出到临时集合、写入到输出集合等。
在处理过程中,Map-reduce持有以下锁:
- 在读阶段,持有读锁,每次锁100个文档
- 写入临时集合时,持有写锁,每次写操作持有一次
- 如果输出集合不存在,创建输出集合时持有写锁
- 如果输出集合存在,则输出操作(merge、replace、reduce等)持有写锁。此写锁是全局的,会阻塞mongod实例上所有其它操作
考虑一个订单集合,其文档原型如下:
|
1 2 3 4 5 6 7 8 |
{ cust_id: "1000", // 客户号 ord_date: new Date( "2015-01-05" ), // 订单日期 status: 'A', price: 25, // 订单金额 // 订单详情 items: [ { sku: "mmm", qty: 5, price: 3 }, { sku: "nnn", qty: 5, price: 2 } ] } |
下面的map-reduce操作,可以获得每个客户的订单总额:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
db.collection( 'order' ).mapReduce( // 注意map函数必须是纯函数 function () { // this为当前正在处理的文档 // 调用emit可以生成输出文档 emit( this.cust_id, this.price ); }, // 按照客户ID分组,所有价格构成数组。这样一个键值对送给reduce函数处理 function ( keyCustId, valuesPrices ) { return Array.sum( valuesPrices ); }, // 选项,指定结果的输出集合 { out: "order_prices" } ) |
如果需要被处理的数据集持续增长,你可能需要进行增量mapReduce,而不是每次都针对完整数据集进行mapReduce。
要进行增量mapReduce,你需要:
- 针对当前集合执行mapReduce,把结果存放到另外一个集合中
- 当更多的数据入库时,执行后续的mapReduce操作。使用query参数来过滤,仅仅匹配新的文档
- 使用finalize处理reduce之后的数据,例如求平均值
统计用户会话时长信息的例子:
文档原型:
|
1 2 |
// ts为登录时间戳,是增量mapReduce的关键 { userid: "a", ts: ISODate('2011-11-03 14:17:00'), length: 95 } |
增量mapReduce:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
db.collection( 'sessions' ).mapReduce( // map,注意平均时间仅仅是占位符 function () { var key = this.userid; var value = { userid: this.userid, total_time: this.length, count: 1, avg_time: 0 }; emit( key, value ); }, // reduce,总计在线时间、登录次数累加,平均登录时间再此无法计算 function ( key, values ) { var reducedObject = { userid: key, total_time: 0, count: 0, avg_time: 0 }; values.forEach( function ( value ) { reducedObject.total_time += value.total_time; reducedObject.count += value.count; } ); return reducedObject; }, { // 增量:仅仅处理新增数据 query: { ts: { $gt: ISODate( '2011-01-01 00:00:00' ) } }, // reduce到统计集合,此集合必须最初的全量mapReduce初始化 out: { reduce: "session_stat" }, // 本次增量数据reduce到统计集合之后,才能计算平均时间 finalize: function ( key, reducedValue ) { if ( reducedValue.count > 0 ) reducedValue.avg_time = reducedValue.total_time / reducedValue.count; return reducedValue; } } ) |
db.collection.count()、 db.collection.distinct()这些函数用于特殊目的的聚合操作,比较简单。
MongoDB支持对字符串内容进行检索查询。为了使用这种文本搜索功能,你需要使用文本索引(text index)以及 $text操作符。注意视图不支持文本搜索。
全文检索不是MongoDB的核心功能,如果有复杂的搜索需求,建议配合使用全文搜索引擎,例如Solr。
MongoDB的全文搜索会忽略一些语言相关的单词,例如英语中的there、and、the等单词,这些词作为搜索关键字,没有意义。
如果某个文档包含单词blueberry,则你搜索blue不会有结果,但是搜索blueberries则匹配。即全文搜索支持复数形式的识别。
这类索引用于支持对字符串内容的检索。文本索引可以包含任何类型为字符串、字符串数组的字段。要支持文本搜索,你必须首先为集合创建文本索引:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
db.stores.insert( [ { _id: 1, name: "Java Hut", description: "Coffee and cakes" } ] ) # 创建文本索引,该索引将针对name、description两个字段 db.stores.createIndex( { name: "text", description: "text" } ) # 删除文本索引,需要先查询到索引的名字 db.collection.getIndexes() # 传入名字以删除 db.trades.dropIndex("name_text") |
注意:每个集合只能拥有一个文本索引,但是该索引可以覆盖多个字段。
使用该操作符,可以对启用了文本索引的集合进行文本搜索:
|
1 2 3 4 |
// 返回包含 java、coffee shop两个词语的文档 db.stores.find( { $text: { $search: "java \"coffee shop\"" } } ) // 返回包含java、shop,但是不包含coffee的文档 db.stores.find( { $text: { $search: "java shop -coffee" } } ) |
$search用于指定关键字,多个关键字使用空格分隔,如果某个关键字内部包含空格,必须以双引号包围整个关键字。MongoDB对所有关键字进行逻辑或操作。
文本搜索的结果默认是无序的。文本搜索会为每个匹配的文档计算一个相关性分数(relevance score),你可以访问该分数用来排序:
|
1 2 3 4 5 |
db.stores.find( { $text: { $search: "java coffee shop" } }, // 把相关性分数投影为score字段 { score: { $meta: "textScore" } } ).sort( { score: { $meta: "textScore" } } ) |
在聚合框架中使用文本搜索时,你需要在$match阶段使用$text操作符。类似的,要进行排序,你需要在$sort阶段使用$meta投影操作符。
在聚合管线中使用文本搜索,受到以下限制:
- 包含$text操作符的$match必须是管线的第一个Stage
- $text操作符仅能够在管线中出现一次
- $text操作符不可出现在$and或者$or内部
- 默认搜索结构没有按照相关性排序,请使用$sort 阶段实现
文本搜索支持多种语言,从3.2开始,MongoDB Enterprise可以支持中文全文检索。
为了支持中文和阿拉伯文等语言,MongoDB Enterprise集成了RLP( Basis Technology Rosette Linguistics Platform ),来完成正规化、分词、分句、词干提取(stemming)、符号化等全文检索领域的职责。
在MongoDB中,你可以GeoJSON对象的形式或者遗留的坐标对形式,来存储地理空间数据。
要沿着类似于地球的球面,进行几何计算,你应当使用GeoJSON来存储位置数据。即使用这样的内嵌文档:
- 包含一个名为type的字段,指定此GeoJSON对象的类型,例如Point、LineString、Polygon等
- 包含一个名为coordinates的字段,指定构成此GeoJSON对象的所有坐标值。如果指定经纬度坐标,则经度在前、纬度在后
GeoJSON对象示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// 格式: <field>: { type: <GeoJSON type> , coordinates: <coordinates> } // 点: location: { type: "Point", coordinates: [-73.856077, 40.848447] } // 线 scope: { type: "LineString", coordinates: [ [ 40, 5 ], [ 41, 6 ] ] } |
针对GeoJSON类型字段上的查询,计算行为是在球面上进行的,使用WGS84坐标参考系统。
要在欧几里得平面上计算距离,在坐标对中存储位置信息同时使用2d索引。
通过 2dsphere索引并且把坐标对转换为GeoJSON对象,MongoDB支持遗留坐标对的球面计算。
坐标对的示例:
|
1 2 3 4 5 6 |
// 数组形式,推荐 <field>: [ <x>, <y> ] <field>: [<longitude>, <latitude> ] // 内嵌文档形式 <field>: { <field1>: <x>, <field2>: <y> } |
这种索引用于支持在类似于地球的球面上执行几何计算。创建这类索引的方法为:
|
1 2 |
// location field必须为GeoJSON或者坐标对字段 db.collection.createIndex( { <location field> : "2dsphere" } ) |
这种索引用于支持在二维平面上进行的几何运算。尽管这种索引可以支持 $nearSphere以实现球面几何运算,最好还是使用2dsphere索引。创建这类索引的方法为:
|
1 |
db.collection.createIndex( { <location field> : "2d" } ) |
地理空间索引不能作为分片键使用,但是分片集合的普通字段上可以存在地理空间索引。
对于分片集合,$near、$nearSphere等查询操作符不被支持,你可以考虑使用$geoNear聚合管线。
地理空间索引不能够覆盖任何查询。
相关的查询操作符包括:$geoWithin、$geoIntersects、$near、$nearSphere。
相关的查询命令为:geoNear。
相关的聚合管线Stage为:$geoNear。
关系型数据库具有严格的Schema —— 例如表结构定义,但是MongoDB则允许你使用非常灵活的Schema,集合中文档的结构不被限制。这种灵活性可以让文档很方便的对应到一个复杂的实体。
实践中,一个集合中的文档的结构都是相似的。
对实体进行建模的关键挑战是在应用程序需求、数据库引擎的性能特征、数据检索图式之间寻求平衡。
为MongoDB设计数据模型的关键决策是,如何表示数据之间的关系。关系的表达有两种风格:引用、内嵌文档。
规范化数据模型:使用一个字段来引用目标对象的_id,来建立两者的关系。
以下情况下,考虑使用引用:
- 当内嵌文档会导致数据冗余,但是却不能提供足够高效的读性能时(相对其数据冗余的代价)
- 表示复杂的M2M关系时
- 对大型的层次化结构进行建模时
引用的缺点是,客户端可能需要发起更多的查询请求。
非规范化数据模型:把目标对象的全部/部分数据以内嵌文档的形式,直接存放在当前对象中。这样,访问关联对象的时候不需要发出额外的查询。
以下情况下,考虑使用内嵌文档:
- 两个实体之间是合成关系
- O2M关系中,M总是通过O来访问时
需要注意,内嵌文档/数组在MMAPv1引擎下,可能导致文档增长而产生磁盘数据块移动、碎片化,影响性能。
从3.0开始MongoDB使用2^N尺寸的空间分配,以最小化数据碎片化的可能性。
多个方面的因素影响你如何建模。
某些update操作会导致即有文档尺寸增长,例如添加数组元素、增加字段。
使用MMAPv1引擎时,文档增长是影响建模的考虑因素。因为文档尺寸超过预分配的大小时,引擎会重新在磁盘上分配空间,则意味着数据移动和可能的碎片化。
如果需要进行频繁的改变文档大小的update操作,考虑使用引用而非内嵌文档。你也可以使用预分配(pre-allocation)策略来避免文档增长。
从3.0开始的2^N尺寸分配可以减少重新分配空间的几率,并有效的重用因为移动文档而释放的空间。
在MongoDB中,针对单个文档的写操作是原子的。因此内嵌文档风格可以用来保证原子性需求。
如果以读操作为主,考虑增加索引。索引可以提升查询性能,MongoDB自动为_id创建唯一索引。注意索引的以下行为:
- 每个索引至少要求8KB的空间
- 索引对写操作有一定的负面影响。对于写读比很高的集合,索引的代价相对较高
- 每一个活动的索引都消耗磁盘、内存空间。
通常情况下,使用大量的集合对性能没有太大影响,但是可能改善性能。创建大量集合时,要注意:
- 每个集合需要至少占用若干KB的空间
- 每个集合至少有一个索引,因此需要占用至少8KB空间
- 对于每个数据库,一个名字空间文件<database>.ns存储了数据库的所有元数据。这些元数据包含每个集合及其索引的信息
- MMAPv1限制了名字空间的数量,可以 db.system.namespaces.count()查询
如果某个集合中存放了大量的小文档(例如GPS轨迹记录),你可能需要考虑使用内嵌文档或数组,以改善性能。小文档本身表示了独立实体时例外。
如果小文档仅仅包含几个字节,需要考虑存储空间的优化:
- 明确指定_id字段。如果不指定,MongoDB默认生成12字节的ObjectId,可能太长了
- 使用简短的字段名,MongoDB会把字段名附带在每一个文档中
集合可以具有TTL特性,让文档在一定时间后自动过期而被删除。
如果应用程序仅仅需要使用最近插入的文档,考虑定长集合。
索引用于提升查询性能,没有索引,MongoDB查询必须进行全集合扫描,性能低下。
索引是一种特殊的数据结构,它有序的保存了集合的一小部分信息。索引存储的是特定字段、字段集的值,以值的大小顺序存储 —— 因而能够支持高效的相等性查找、范围查找。 从算法上讲,MongoDB和RDBMS的索引类似。
索引可以在后台构建,这样可以避免影响运行中的应用程序。
要创建索引,可以调用:
|
1 |
db.collection.createIndex( <key and index type specification>, <options> ) |
在集合最初被创建时,MongoDB在_id字段上创建唯一性索引。
使用分片集合时,如果_id不作为分片键,则应用程序负责确保在集群范围内_id的唯一性。
顾名思义,就是针对单个字段创建的索引。
针对直接字段创建索引的示例:
|
1 2 3 4 |
// 升序索引 db.records.createIndex( { score: 1 } ) // 降序索引 db.records.createIndex( { score: -1 } ) |
对于单字段索引,升序/降序并不重要,因为MongoDB可以两端访问索引。
类似的,还可以在内嵌文档字段上创建索引:
|
1 2 |
// 使用点号导航 db.records.createIndex( { "location.state": 1 } ) |
MongoDB支持复合索引,即持有多个字段引用的单个索引。复合索引最多引用31个字段。要创建复合索引,调用:
|
1 2 |
// type取值1或者-1 db.collection.createIndex( { <field1>: <type>, <field2>: <type2>, ... } ) |
注意:
- 已经创建了哈希索引的字段不能包含在复合索引中
- 字段的顺序非常重要,第一个字段最优先排序,该字段值相同的记录,按照第二字段排序。注意索引按此排序存储在磁盘上
- 复合索引支持针对索引前缀(Prefix)的查询,例如字段一、字段二或者字段一。如果查询条件不包含第一个字段,则索引肯定无法使用
复合索引中,字段的索引类型(升降)决定了索引能否支持排序操作。例如:
|
1 2 3 4 5 6 |
db.events.createIndex( { "username" : 1, "date" : -1 } ) // 上述索引可以支持下面两种排序操作 db.events.find().sort( { username: 1, date: -1 } ) // 正序访问索引,读出的就是排序好的 db.events.find().sort( { username: -1, date: 1 } ) // 逆序访问索引,读出的就是排序好的 // 而不能支持下面的排序操作 db.events.find().sort( { username: 1, date: 1 } ) // 无论以什么方向读取索引,都需要额外的处理才能获得正确的顺序 |
为了能够索引数组字段,MongoDB需要为每个数组元素创建索引键。这种多键(每元素)索引可以很好的支持针对数组字段的查询。
创建多键索引不需要特殊的API,MongoDB会自动发现目标字段是数组,进而自动创建多键索引。
从3.2开始,MongoDB引入了第3版的全文索引,关键特性包括:
- 改善大小写不敏感性
- 支持音调不敏感
- 额外的分界符
要创建全文索引,以text作为索引类型:
|
1 2 3 4 5 6 |
// 在comments字段上创建全文索引 db.reviews.createIndex( { comments: "text" } ) // 针对多个字段的全文索引 db.reviews.createIndex( { subject: "text", comments: "text" } ) // 针对所有包含字符串数据的字段进行索引 db.collection.createIndex( { "$**": "text" } ) |
基于Hash的分片需要在分片键上使用这种索引。使用哈希分片可以更加随机的分布数据。
要创建哈希索引,以hashed为索引类型:
|
1 |
db.collection.createIndex( { _id: "hashed" } ) |
创建了哈希索引的字段,不能包含在复合索引中。
创建索引时,第二个参数文档可以指定以下选项:
| 选项 | 说明 | ||||
| background |
默认情况下,创建索引会导致当前数据库(而不仅仅是当前集合)的所有读写操作被阻塞 设置该选项为true,则可以避免阻塞其它操作(但是发起索引创建的客户端总是被阻塞)。从2.4开始,支持在后台同时构建多个索引 没有完全构建好的索引,不会影响查询。在索引构建完毕之前,你不能执行影响索引所在集合的任何管理性操作,例如repairDatabase、drop目标集合 后台索引构建使用一种增量的、较为缓慢的方式(比起前台索引构建) 如果索引构建被中断(例如宕机),下次mongod启动时会以前台线程构建索引,这种情况下索引构建失败mongod会继续宕机 |
||||
| unique | 默认false。是否创建唯一性索引,可以防止重复数据的插入 | ||||
| name | 为索引指定一个名称 | ||||
| partialFilterExpression |
用于创建部分索引 —— 仅仅对集合中部分文档进行索引。可以降低存储空间占用和性能影响 如果指定,则索引仅仅引用匹配过滤表达式的文档。过滤表达式包括$eq、$exist:true、$gt, $gte, $lt, $lte、$type以及位于顶级的$and 。示例:
所有索引类型均支持该选项 如果会导致不完整的结果集,则MongoDB不会使用部分索引。这意味着,要使用部分索引,你的查询条件必须包含过滤表达式(或者其子集)。例如:
比起稀疏索引,部分索引更加灵活,可以满足特殊需求 |
||||
| sparse |
是否创建稀疏索引,如果是则占用较少的空间,但是行为会发生变化 稀疏索引仅仅针对包含了索引字段的那些文档进行索引,即使字段的值为null文档也会被索引 如果会导致不完整的结果集,则MongoDB不会使用稀疏索引,除非你使用hint明确指定使用稀疏索引 2dsphere v2、geoHaystack、text这几种索引总是稀疏的 |
||||
| expireAfterSeconds |
TTL索引是一种特殊的单字段索引,控制MongoDB保存文档的时间。适用于事件记录、日志类数据,例如:
后台线程负责读取索引中的值,并删除过期的文档。对于复制集成员,后台线程仅仅在当前是主节点的情况下才执行删除操作。此操作会通过Replication机制传播到从节点 注意:
|
||||
| storageEngine | 指定使用的存储引擎: { <storage-engine-name>: <options> } | ||||
| 排序规则相关选项 | |||||
| collation |
设置索引的排序规则,示例:
|
||||
| 全文索引相关选项 | |||||
| weights | 以{ <field>: <weight> }的形式设置字段的权重,权重值范围1-99999 | ||||
| default_language | 使用的默认语言 | ||||
从2.6开始,复制集的从节点支持在后台构建索引,而之前的版本从节点必须在前台构建。
当主节点在后台构建好索引后,从节点自动在后台开始构建索引。对于分片集群,mongos会发送createIndex命令到每个分片上的复制集的主节点。
推荐使用本节的步骤来为复制集构建索引,避免影响数据库性能。
注意:
- 确保oplog足够大,这样当索引创建操作完毕后,从节点不会太过落后而无法赶上主节点的节奏
- 该推荐步骤每次把一个成员移出复制集,因此不会影响所有从节点
要为从节点构建索引,针对所有从节点执行:
- 停止一个从节点,并以独立模式启动(不带 --replSet选项):
12// 不使用默认的27017端口,防止构建索引期间,复制集的成员、客户端连接到该节点mongod --port 47017 - 使用createIndex命令创建索引
- 重新启动mongod,并添加到复制集中:
1mongod --port 27017 --replSet rs0该节点将和主节点同步
要为主节点构建索引,你可以:
- 在主节点上触发后台索引构建
- 或者,调用 rs.stepDown()让主节点优雅的变成从节点,集群会重新选择主节点。然后,对其执行从节点构建索引的推荐步骤
从2.6开始,MongoDB能够使用多个索引的交叉来满足查询。典型的索引交叉牵涉到两个索引,但是MongoDB支持多个索引、内嵌索引的交叉。
假设集合orders在qty和item上有索引,则查询:
|
1 |
db.orders.find( { item: "abc123", qty: { $gt: 15 } } ) |
会用到索引交叉 —— 即使用item、qty两个索引的扫描结果进行逻辑与操作。查看执行计划,你可以看到AND_SORTED或者AND_HASH这样的Stage。
复合索引的前缀可以参与到索引交叉中。
由于字段顺序、升序/降序都对复合索引有影响,复合索引可能无法满足某些查询:
- 没有指定合理前缀作为查询条件
- 不匹配的升/降序排序规则
这些情况下,索引交叉能够代替复合索引提升查询性能。
创建哪些索引最合适,取决于很多因素,例如:
- 期望的查询的形状
- 读写比
- 系统的可用内存
如果能够让整个索引位于内存之中,则可以避免磁盘扫描,获得很快的处理速度。执行: db.collection.totalIndexSize() 可以获得某个集合的全部索引的尺寸。你的内存必须足够大,才能保证索引完整载入内存。
注意:索引并非总是需要完全载入内存。假设索引字段的值随着insert不断增长,而且查询总是针对最新添加的文档,则MongoDB仅仅需要在内存中载入部分索引内容。
查看集合上现存的索引:
|
1 |
db.collection.getIndexes() |
移除单个索引:
|
1 |
db.collection.dropIndex() |
移除除了_id之外的全部索引:
|
1 |
db.collection.dropIndexes() |
重新构建集合上的全部索引:
|
1 2 3 4 |
// 对于复制集,该操作不会传播到从节点 // 如果索引在创建时,指定了background:true,则索引会在后台重新创建 // 但是,_id的索引总是在前台创建,导致数据库写锁定 db.collection.reIndex() |
你可以使用这一聚合管线Stage来获得索引的使用情况统计信息。
在 executionStats模式下获得执行计划,可以获得查询的统计信息,包括使用的索引、扫描的文档数量、消耗的时间。
要强制查询使用某个索引,可以调用此方法:
|
1 2 3 4 5 6 7 |
db.people.find( { name: "John Doe", zipcode: { $gt: "63000" } } ) // 强制使用zipcode索引 .hint( { zipcode: 1 } ) // 阻止使用任何索引 .hint( { $natural: 1 } ) |
存储引擎是MongoDB的一个核心组件,它决定了数据如何被存储(内存和磁盘)。MongoDB支持多存储引擎,以便你根据不同的工作负载进行选择。
从3.2开始,这是默认的存储引擎。适用于大部分工作负载,推荐新项目使用该引擎。
WiredTiger提供文档级的并发模型、检查点、压缩以及其它特性。
最初的存储引擎,3.2之前的默认存储引擎。适用于大量读写的工作负载,以及in-place更新。
仅在MongoDB Enterprise中可用,在内存中保存数据,速度快。
WiredTiger使用文档级并发来控制写操作。因此,多个客户端可以在同时修改某个集合中的不同文档。
对于大部分的读写操作,WiredTiger使用乐观并发控制。它仅仅在全局、数据库、集合级别使用意向锁。当引擎检测到两个操作之间存在冲突时,会透明的重试其中会引起写冲突的操作。
某些全局操作,通常是牵涉多个数据库的短暂操作,仍然使用全局(实例级别)的锁。某些其它操作,例如drop集合,仍然需要数据库级别的独占锁。
WiredTiger支持多版本并发控制( MultiVersion Concurrency Control ,MVCC)。在操作开始时,引擎提供数据集在那个时间点的精确快照 —— 位于内存中的一致性视图。
当写入到磁盘时,引擎以一种一致性的方式,把快照中的数据写入到所有相关的数据文件中。快照中的数据集,在数据文件中可以作为检查点(checkpoint),数据库可以恢复到检查点之前的状态。
默认的,WiredTiger每60秒、或者每产生2GB日志文件后,创建检查点。
在写入新检查点的过程中,以前的检查点仍然可用。因此,如果正在写入检查点时MongoDB崩溃,重启后它能够恢复到上一个检查点。
当WiredTiger原子的把对检查点的引用写入到元数据表(metadata table)之后,新的检查点变得可访问、永久化。一旦新检查点变得可访问,旧检查点的页被释放。
使用WiredTiger时,即使没有启用日志(journaling)。MongoDB仍然能够从上一个检查点恢复。但是要想恢复上一检查点后面的变动,需要日志的配合。
WiredTiger使用预写式(Write-ahead)日志,联合检查点,来确保数据的安全性。日志(Journal)对上一个检查点以来的所有数据修改都进行了持久化。如果MongoDB宕机,可以重放(Replay)从上一检查点依赖的所有数据修改。日志文件存放在 $dbPath/journal/WiredTigerLog.<sequence>,其中sequence时从0000000001开始的序号。
WiredTiger为客户端发起的每一个操作,创建一条日志记录(journal record),该记录操作触发Mongod对数据库进行修改(包括集合、索引)的全部信息。
WiredTiger使用内存来作为日志记录的缓冲,多个线程协作以分配、拷贝自己的那部分缓冲。在以下情况下,日志记录缓冲被刷入磁盘:
- 从3.2开始,每50ms
- 一旦检查点被创建
- 使用写关注j:true执行了写操作后
- 每当新的日志文件被创建后。MongoDB限制日志文件大小为100MB,因此每超过此大小,就同步日志缓冲到磁盘
WiredTiger日志利用snappy库进行压缩,你可以通过 storage.wiredTiger.engineConfig.journalCompressor来指定其它压缩算法或者禁用压缩。日志条目最小128字节,如果条目内容小于128字节,则不会进行压缩。
设置 storage.journal.enabled为false可以禁用日志,以减少日志维护的成本。在独立MongoDB服务器上,禁用日志可能导致上一个检查点以来的数据丢失。在复制集上,数据丢失的可能性较小。
使用WiredTiger引擎时,MongoDB支持所有集合、索引的压缩。压缩通过CPU时间来换取存储空间的节省。
默认的,WiredTiger利用snappy库对集合、索引前缀进行压缩。对于集合来说,还可选zlib进行压缩。你可以设置:
- storage.wiredTiger.collectionConfig.blockCompressor来改变集合的压缩算法
- storage.wiredTiger.indexConfig.prefixCompression来禁用索引前缀压缩
压缩可以在集合、索引级别设置,你可以在创建集合、索引的时候指定对应的选项。
在大部分的工作负载下,默认压缩算法在时间和空间之间保持了一个平衡。
使用WiredTiger时,MongoDB同时利用WiredTiger内部缓存、文件系统缓存。
从3.4开始,WiredTiger 内部缓存的内存用量,默认取内存总量/2 -1GB 和256MB两个值中较大的那个。参数 storage.wiredTiger.engineConfig.cacheSizeGB用于自定义内存用量。
通过文件系统缓存,MongoDB可以利用所有空闲内存,文件系统缓存中的数据是被压缩的。
这是MongoDB最初的,基于内存映射文件的引擎。当面临大量插入、读取、原地(in-place,不需要移动文档)更新时,性能比WiredTiger更好。从3.2开始,该引擎不再是MongoDB的默认存储引擎。
当写操作发生时,MMAPv1更新内存视图。如果启用了日志内存中的改变首先被写到日志中而不是直接写到数据文件中。
为了确保所有数据集能够正确的持久化。MMAPv1使用磁盘日志,写磁盘日志比数据文件更加频繁,因为其效率较高。
使用默认配置的情况下,MMAPv1每60秒写一次磁盘(可以通过 storage.syncPeriodSecs修改),每100ms左右写一次日志文件(可以通过 storage.journal.commitIntervalMs 修改)。
MMAPv1的所有文档都是连续的存储在磁盘上的。如果文档update后变得过大,则必须重新分配磁盘空间。这意味着文档本身的移动、全部索引的更新,会影响性能并引起存储碎片化。
从3.0开始,MongoDB使用2^N尺寸的空间分配策略,多余的空间作为补白(padding),可以降低文档移动的几率。原来的精确适合(exact fit)空间分配策略,使用不包含update/delete操作的场景。
MMAPv1自动使用机器的全部空闲内存作为它的缓存,但是,一旦其它进程需要使用内存,MongoDB占据的内存会立即释放。
典型情况下,操作系统的虚拟内存系统管理MongoDB的内存使用,如果内存不够,MongoDB缓存会被交换到磁盘中。配备足够的内存,可以很大程度的提高性能。
GridFS是一套规范,用于存放那些大于BSON文档尺寸限制(16MB)的文件。
GridFS不是把文件存放在文档中,而是将其切分成多个部分(chunks),然后把这些部分分别存放在文档中。默认情况下,GridFS使用255KB的chunk,因此除了最后一个之外的chunk具有一致的大小。
GridFS使用两个集合来存放文件:
-
fs.chunks,用于存放文件的chunks,文档原型如下:
123456{"_id" : <ObjectId>, // 块的唯一标识"files_id" : <ObjectId>, // 所属的文件的唯一标识"n" : <num>, // 从0开始的序号"data" : <binary> // BinData类型的数据块} -
fs.files,用于存放文件的元数据,文档原型如下:
1234567891011{"_id" : <ObjectId>, // 文件的唯一标识"length" : <num>, // 文件的长度"chunkSize" : <num>, // 块的数量"uploadDate" : <timestamp>, // 存放到GridFS中的时间"md5" : <hash>, // 散列值"filename" : <string>, // 人类可读的可选的文件名"contentType" : <string>, // 可选的MIME类型"aliases" : <string array>, // 别名数组"metadata" : <dataObject>, // 任意额外的自定义元数据}
当你查询GridFS以取回文件时,驱动程序负责把chunks装配成文件。GridFS支持针对文件进行范围查询,或者skip一定的长度。
如果你需要存放大于16MB的文件时,应当使用GridFS。否则,考虑使用BinData类型存储在集合中。
某些情况下,在MongoDB中存储大文件比在文件系统中直接存放更加高效:
- 如果文件系统限制目录中最大文件数,MongoDB没有此限制
- 如果你想访问大文件的一小部分,而不希望把整个文件加载到内存
- 如果你想获得复制集带来的文件安全性
chunks、files两个集合自带一部分索引(由驱动创建),以提升性能。你也可以创建自己的索引,以满足需要。
chunks上具有唯一性的复合索引:files_id + n,这让chunk的检索非常高效,示例查询:
|
1 |
db.fs.chunks.find( { files_id: myFileID } ).sort( { n: 1 } ) |
如果驱动没有创建此索引(不满足规范),可以手工创建:
|
1 |
db.fs.chunks.createIndex( { files_id: 1, n: 1 }, { unique: true } ); |
files上具有filename、uploadDate两个索引,你可以很方便的根据名称、日志进行文件检索。
如果驱动没有创建此索引(不满足规范),可以手工创建:
|
1 |
db.fs.files.createIndex( { filename: 1, uploadDate: 1 } ); |
如果需要分片chunks,考虑以 { files_id : 1, n : 1 }或者 { files_id : 1 }作为分片键。 files_id是单调递增字段。对chunks进行分片时,不能使用哈希分片。
files集合仅仅包含元数据,通常不需要分片。
复制集(replica set )是指一组mongod进程,它们维护相同的数据集。复制集提供了数据冗余、高可用性,对于生产环境来说复制集基本是标配。
在某些情况下,复制集可以提供额外的读容量,因为客户端可以把请求分发给复制集中的任意成员。对于跨地域部署的应用程序来说,分别在不同数据中心的复制集节点可以大大降低网络延迟。
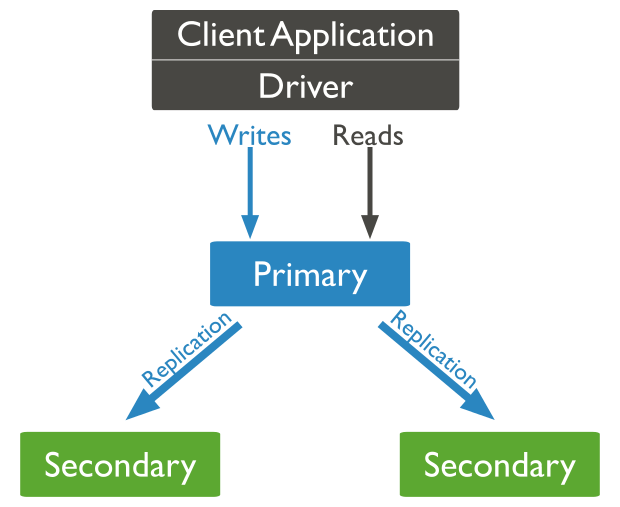
每个复制集可以具有N个数据存储节点,和一个可选的仲裁(arbiter)节点。存储节点中有且仅有一个是主(primary)节点,其它均为从(secondary)节点。
主节点接收所有写操作请求,此节点负责确认{ w: "majority" }写关注。主节点把自己对数据集的全部变更存放在日志 —— oplog中。这些oplog随后被异步的传播到所有从节点,确保所有节点的数据集一致:
当主节点不可用时(和其它成员超过10s不进行通信),一个从节点会被选举为新的主节点。你可以额外配置一个mongod实例作为仲裁节点,这类节点不维护数据集,它的职责仅仅是响应心跳、应答其它节点的选举(投票)请求。当存储节点数量为偶数时,添加一个仲裁节点,可以满足投票的大多数(majority)原则。仲裁节点不需要专用的硬件,可以和某个存储节点部署在一起。
尽管所有成员都可以接受读请求,但是默认的,应用程序会把读请求重定向给主节点。
这类从节点没有称为主节点的资格,没有资格触发选举(从节点总是自荐为主节点以触发选举),但是可以进行投票。在多数据中心部署的情况下,要避免某个数据中心产生主节点,则将其中的节点均配置为priority0从节点。
默认的,没有任何节点是priority0从节点。你需要手工设置节点的priority为0。
注意当前主节点不支持设置priority为0,因此,如果你想把主节点变为priority,先需要将其变为从节点。 rs.reconfig()可以导致当前主节点立即优雅的关闭( step down)从而导致重新选举主节点。在step down期间mongod会关闭所有客户端,通常会花费10-20秒,最好在例行维护期间进行这种操作。
调用 cfg = rs.conf()获得复制集的配置文档,该文档有一个 members字段,它是一个数组,包含复制集每个成员的配置信息。要设置第N个节点为priority0,执行 members[n].priority = 0。直到你重新配置复制集位置,priority设置不会生效。执行 rs.reconfig(cfg)可以重新配置复制集。
之类从节点维持主节点数据集的拷贝,但是对客户端不可见。隐藏从节点必须是priority0节点。
由于对客户端不可见,隐藏从节点的流量仅仅包括来自主节点的数据复制流。你可以使用隐藏从节点执行专门任务,你如报表分析、备份。在分片集群中,mongos不会和隐藏从节点交互。
当使用隐藏从节点执行备份时,需要注意:
- 如果使用MMAPv1引擎,使用 db.fsyncLock()和 db.fsyncUnlock()操作可以在备份期间flush所有写操作并且锁定mongod,这样可以不必为了备份而停止隐藏节点
- 从3.2开始db.fsyncLock()可以保证数据文件不改变,不管使用MMAPv1还是WiredTiger 引擎,因此可以保证备份期间的数据一致性。在之前的版本,不保证WiredTiger下的数据一致性
延迟从节点也维持主节点数据集的拷贝,但是其状态对应了主节点一个早先的状态,例如一小时前。
由于此特性,延迟从节点可以用做滚动备份(rolling backup),当出现人为操作错误时,可以恢复到先前的数据状态。
延迟节点必须是priority0节点,而且应当是隐藏节点。配置文档示例:
|
1 2 3 4 5 6 7 |
{ "_id" : <num>, "host" : <hostname:port>, "priority" : 0, "slaveDelay" : <seconds>, "hidden" : true } |
仲裁者节点不维护数据拷贝,不能变为主节点,它仅仅在选举主节点时起作用。 仲裁者总是具有1张选票,因此它可用于确保总是有奇数张选票,以满足大多数原则。
注意:不要在部署了复制集主节点、从节点的机器上部署仲裁节点。
一个节点被作为仲裁者加入到复制集之前,行为与普通mongod无异,它会创建一系列的数据文件、全尺寸的日志文件。为了最小化默认文件的创建,可以配置仲裁节点的配置文件:
- 设置 storage.journal.enabled为false
- 对于MMAPv1 引擎,设置 storage.mmapv1.smallFiles为true
为复制集添加仲裁节点的参考步骤如下:
- 指定复制集名称、数据库路径,启动mongod:
1mongod --port 30000 --dbpath /data/arb --replSet rs - 在复制集主节点中执行先的命令,把上一步的mongod添加为仲裁者:
1rs.addArb("HOST:30000")
操作日志(Oplog)是一个特殊的定长集合,保存了所有修改了数据集的操作的滚动记录。MongoDB会在主节点上应用写操作,并将这些操作记录到主节点的Oplog。 复制集中的从节点会在之后异步的读取此定长集合,并将其中的操作应用到自己本地的数据库。
所有复制集成员都在 local.oplog.rs包含一个Oplog副本,便于本地数据库的当前状态。为了进行复制,复制集成员之间相互发送心跳,任意成员可以从其它任意成员那里读取到Oplog条目。
Oplog中的条目是幂等的,也就是说,这些条目应用一次还是多次,其产生的效果是一致的。
当以第一次复制集成员身份启动mongod时,会自动创建默认尺寸的Oplog。默认尺寸对于In-Memory引擎来说是5%内存大小,对于其它引擎默认5%磁盘空闲空间大小。
在第一次启动前,你可以指定 oplogSizeMB参数,来设置Oplog的大小。之后如果需要改变此大小,需要特殊的操作步骤。
某些可能需要大尺寸Oplog的场景:
- 同时更新很多文档:为了确保幂等性,Oplog必须把批量更新操作拆分成很多单条操作
- 删除的文档和更新的文档数量相近:这种情况下,数据库文件可能增长不大,但是Oplog会较大
- 还量的In-place更新
调用 rs.printReplicationInfo()可以查看Oplog的状态,包括尺寸和操作的时间范围。
在某些异常情况下,从节点的Oplog更新可能过于延迟,达不到性能要求。在从节点调用 db.getReplicationInfo()可以查看复制状态、延迟。
为了维护最新的共享数据集,从节点需要从其它节点同步(sync)或者拷贝数据。MongoDB使用两种形式的数据同步:
- 初始同步(initial sync):为新的从节点提供完整的数据集
- 复制(replication):在初始数据集之上同步增量数据
MongoDB执行初始同步的流程如下:
- 克隆除了local之外的所有数据库,注意:
- 从3.4开始,所有的索引也被构建,之前的版本仅仅克隆_id索引
- 从3.4开始,在克隆过程中新产生的Oplog也被拉取过来。你需要确保新的从节点的local数据库有足够的磁盘空间
- 新从节点应用所有克隆来的数据,并应用Oplog
初始同步完毕后,新从节点的复制集成员状态从STARTUP2变为SECONDARY
为了防止偶发的网络错误,初始同步内置了重试逻辑作为容错措施。
在初始同步之后,从节点会不断的复制增量数据 —— 异步的拷贝Oplog并应用到数据库中。
从节点会根据PING延迟、其它节点的复制状态,自动切换拷贝Oplog的源节点。 但是:
- 从3.2开始,投票权1的节点不得把投票权0的节点作为源
- 会避免将延迟从节点、因从从节点作为源
- 如果当前节点的复制集配置 members[n].buildIndexes为true,则仅此配置也为true的其它节点,才能作为源。此配置默认true
为了增强性能,MongoDB会使用多线程来应用Oplog,日志中的条目被按照名字空间(MMAPv1)、文档标识(WiredTiger)分组,每个组一个线程,同时入库。日志的入库顺序总是和主节点上相同,在分组批量入库期间,从节点阻塞所有读请求,因此不会读到主节点上不存在的数据
对于MMAPv1引擎来说,MongoDB会抓取包含了受到影响的数据、索引的内存页,用于辅助增强应用Oplog条目的性能。
此索引预抓取可以最小化应用Oplog时持有写锁的时间,默认的从节点预抓取所有索引。配置项 secondaryIndexPrefetch与该特性有关。
复制集的架构影响其容量和能力。
通常情况下,生产环境中使用3成员的复制集,这保证了数据冗余和容错,同时也避免过于复杂的部署。请结合应用程序需要,并注意:
- 复制集最多具有50个成员,但是能投票的最多7个成员。因此,如果复制集已经有7个成员,再添加节点必须是非投票成员
- 投票成员数量应为奇数,必要时添加一个仲裁节点,确保此规则
- 为了满足特殊的需求,考虑添加延迟、隐藏从节点
- 负载均衡与大量读负载:如果应用面临很高的读负载,可以将负载分发到从节点以提升性能。如果应用跨地域分布,可以考虑在不同数据中心部署从节点
- 异地灾备:为了防止数据中心出现重大灾难而导致数据丢失,至少应当部署一个异地的从节点。为了确保主数据中心的的节点优先被选举为主节点,配置异地节点的 members[n].priority为更小的值
- 为从节点应用标签集(Tag set):你可以为节点应用一系列标签,从而把读操作引向特定的节点,或者定制写关注——从其它节点获得请求确认
- 使用日志防止断电导致的数据丢失:MongoDB默认启用了写前日志(journaling ),可以有效的防止断电、宕机导致的数据丢失
- 网络、计算资源受限的节点,应该避免称为主节点,使用priority0
如果你的应用程序连接到多个复制集,则每个复制集需要具有唯一的名称,某些驱动根据此名称对复制集进行分组。
这是典型的、最小化的复制集架构。三个成员中,可以有一个作为仲裁节点。
使用三个数据节点时,数据具有三份拷贝,提供了容错和HA。如果主节点宕机,一个从节点会被选举为新主节点。宕机主节点恢复后,自动重新加入复制集。
在异地数据中心部署节点,可以抵御断电、网络中断甚至自然灾害。
要实现异地灾备,至少在其它数据中心部署一个从节点。可能的话,使用奇数个数的数据中心。要尽可能保证,即使一个数据中心完全不可用,复制集仍然能保证majority原则。
部署示例:
- 三成员复制集:
- 两数据中心:DC1两成员,DC2一成员,如果有仲裁者,部署在DC1。当DC1不可用时复制集变为只读;当DC2不可用时DC1继续运行(大多数原则)
- 三数据中心:每个数据中心一个节点。不管哪个数据中心不可用,复制集仍然可读写
- 五成员复制集:
- 两数据中心:DC1三成员,DC2两成员。当DC1不可用时复制集变为只读;当DC2不可用时DC1继续运行(大多数原则)
- 三数据中心:DC1两成员,DC2两成员,DC3一成员。不管哪个数据中心不可用,复制集仍然可读写(大多数原则)
利用自动的故障转移机制,复制集提供高可用性。故障转移即当主节点不可用时,某个从节点被选举为新主节点的过程。
从3.2开始,MongoDB引入版本1((protocolVersion: 1)的复制协议,降低了故障转移消耗的时间,加速重复主节点检测速度。新创建的复制集会自动使用版本1的协议。
复制集使用选举机制来确定谁作为主节点,在以下情况下,发生选举:
- 初始化一个复制集时
- 当主节点变得不可用时
主节点的选举需要时间,在选举完成之前,复制集不能接受写请求,所有节点呈只读状态。
如果复制集的大部分节点对于主节点不可访问,则主节点会setp down并变成从节点。这样复制集就不能接受写请求了,但是如果配置了在从节点上执行查询,则剩余节点仍然支持读操作。
影响主节点选举的因素包括:
- 复制协议:从3.2引入的版本1提高了性能
- 心跳:复制集成员每2秒向各成员发送心跳,如果心跳应答10秒没有返回,标记为不可达(inaccessible)
- 成员优先级:选举算法会仅可能的让高优先级的从节点触发选举。优先级影响选举的耗时和结果,因为高优先级的节点会更快的触发选举并很可能赢得选举。但是,低优先级的成员也可能临时的被选举为主节点,此时选举会继续,直到最高优先级的成员当选
- 数据中心不可用:多数据中心部署的情况下,某个数据中心整体不可用可能导致无法选举
- 否决:版本1协议取消了否决机制。但是版本0中任何成员均具有否决权
复制集成员的配置 members[n].votes以及其状态(state)决定了它是否具有投票资格:
- members[n].votes=1的节点具有投票资格,要禁止某个节点投票,可以设置为0。从3.2开始,非投票节点的priority必须为0
- 仅仅以下状态的节点可以参与投票:PRIMARY、SECONDARY、RECOVERING、ARBITER、ROLLBACK
回滚导致前主节点上的写操作被撤销,当此“前主节点”重新加入到复制时。回滚仅仅在主节点已经应用了写操作,但是此写操作没有来得及在step down之前被成功复制的情况下。回滚保证了数据一致性。
如果写操作被任意从节点复制,并且此从节点可以被大多数节点访问,则回滚不会发生。
对于复制集,默认写关注 {w: 1}仅仅要求主节点的确认,这样存在回滚的可能,但是客户端认为数据已经持久化。要避免这种回滚,使用 w: "majority"。另外:
- 如果writeConcernMajorityJournalDefault设置为false,即使使用前面的写关注,仍然不能保证不会回滚,因为写操作可能没有持久化到磁盘
- 不管写关注设置为什么,local读关注都可能看到甚至没有被写者确认的数据。local可能读到之后被回滚的数据
一个mongod不支持回滚超过300MB的数据。你可以在mongod日志中看到:
|
1 |
[replica set sync] replSet syncThread: 13410 replSet too much data to roll back |
如果系统需要回滚超过300MB的数据,你必须手工介入,强制初始同步 —— 删除前主节点的dbPath目录。
从客户端角度来说,mongod以独立方式运行,还是作为复制集成员,是透明的。但是,MongoDB提供了额外的读写选项,提供数据一致性保证。
对于复制集,默认写关注仅要求来自主节点的确认。你可以改变此选项,要求来自指定数量/大多数节点的确认。例如,使用w:2时写操作的处理流程如下: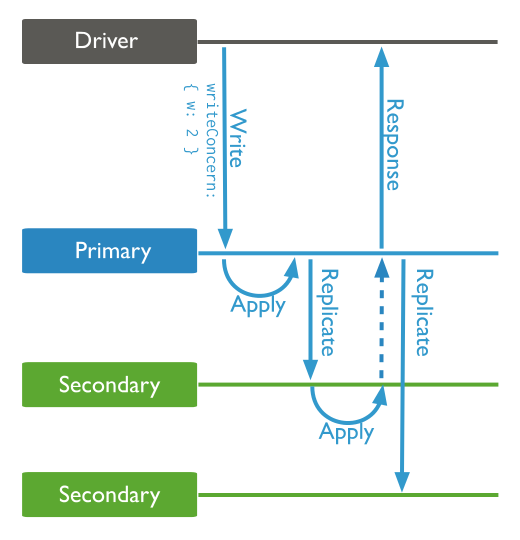
要修改默认写关注选项,可以为复制集配置 settings.getLastErrorDefaults选项,示例代码:
|
1 2 3 |
cfg = rs.conf() cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 } rs.reconfig(cfg) |
读设置描述MongoDB如何把读操作请求路由到某个复制集成员。默认情况下,应用程序把读请求发送给复制集中的主节点。读设置与直接连接到单个mongod的那些客户端没有关系。修改读设置时需要小心,从节点可能返回陈旧的数据,原因是复制的异步性。
使用Shell时,可以调用游标的 cursor.readPref(mode,tagset)方法进行读设置,执行查询时,可以这样进行读设置:
|
1 2 |
// 从最近的节点读取数据,仅仅从东部数据中心读取(根据节点的标签集) db.collection.find().readPref('nearest', [ { 'dc': 'east' } ]) |
读设置的mode可以取值:
| 取值 | 说明 |
| primary | 默认模式,所有读请求发送给主节点 |
| primaryPreferred | 使用主节点,主节点不可用时才使用从节点 |
| secondary | 所有读请求分发给从节点 |
| secondaryPreferred | 使用从节点,从节点不可用时才使用主节点 |
| nearest | 从网络延迟最低的节点读取,不管其类型 |
标签集用于指定仅具有特定标签的复制集成员才可以接收读操作请求。除了primary模式外,都可以指定该选项。
3.4引入的 maxStalenessSeconds,用于指定一个最大的复制延迟值,如果某个节点的延迟超过此值,则不用它进行读操作。除了primary模式外,都可以指定该选项。
读设置适用于通过mongos连接到分片集群的客户端。mongos连接到某个以复制集形式出现的分片时,遵守此读设置。
使用非主读设置的应用场景:
- 运行不影响前端应用程序的系统操作
- 对跨地域分布的应用程序提供本地读功能,考虑使用读设置 nearest,以获得低延迟
- 在故障转移期间维持可用性,考虑使用读设置 primaryPreferred,这样正常情况下读取主节点,如果主节点不可用则允许读取(只读)可能陈旧的数据
在一般场景下,不要使用 secondary或者 secondaryPreferred来提供额外的读容量,因为:
- 复制集中的大部分成员的写流量是差不多的,因而,从节点不会比主节点具有更大的读能力
- 复制是异步进行的,你可能读取到过时的数据,从不同的从节点读取数据,可能导致非单调读
- 对于针对分片集合的查询,对于启用负载均衡器的集群,由于不完整的chunk迁移,从节点可能返回重复的、丢失的数据
要扩容,分片通常是更加优先的选择,因为它利用了多台机器的计算资源。
每个mongod都拥有一个名为local的数据库,其中存放有关工作集复制处理过程用到的数据、以及其它实例相关的数据,该数据库对Replication是不可见的。
该数据库包含以下集合:
| 集合 | 说明 |
| 所有mongod实例都有的集合 | |
| startup_log |
在启动时,monod向此集合插入一条诊断信息: _id 由主机名和时间戳组成 |
| 复制集成员拥有的集合 | |
| system.replset | 保存复制集配置对象,单个文档,调用 rs.conf()可以查看该对象 |
| oplog.rs | 保存oplog的定长集合,复制集配置项oplogSizeMB决定其大小 |
| replset.minvalid | 内部使用,追踪复制状态 |
| 代码 | 状态 | 说明 |
| 0 | STARTUP | 尚不是某个复制集的活动成员,每个成员在启动时最初处于这一状态。在此状态时成员会读取复制集配置文档 |
| 1 | PRIMARY | 作为主节点存在于复制集 |
| 2 | SECONDARY | 作为从节点存在于复制集 |
| 3 | RECOVERING | 正在进行启动时自检,或者正在进行回滚、resync。具有投票权 |
| 5 | STARTUP2 | 加入到了工作集,并在进行初始同步 |
| 6 | UNKNOWN | 不知道该节点的状态 |
| 7 | ARBITER | 作为仲裁者存在于复制集 |
| 8 | DOWN | 该节点已经关闭 |
| 9 | ROLLBACK | 正在进行回滚,不支持读操作 |
| 10 | REMOVED | 曾经是某个复制集的成员,但是现在被移除了 |
| 方法 | 说明 |
| rs.add() | 为复制集添加一个新成员 |
| rs.addArb() | 为复制集添加一个仲裁者成员 |
| rs.conf() |
获得复制集的配置文档 对应数据库命令replSetGetConfig |
| rs.freeze() |
在一段时间内,阻止当前成员提起选举自己为主节点 对应数据库命令replSetFreeze |
| rs.help() | 打印复制集相关方法的简短帮助 |
| rs.initiate() |
初始化一个复制集 对应数据库命令replSetInitiate |
| rs.printReplicationInfo() | 从主节点的角度,打印复制集的状态 |
| rs.printSlaveReplicationInfo() | 从从节点的角度,打印复制集的状态 |
| rs.reconfig() |
根据传入的配置文档,对复制集进行重新配置 对应数据库命令replSetReconfig |
| rs.remove() | 移除一个复制集成员 |
| rs.slaveOk() | 设置当前连接的slaveOk属性,一般不再使用 |
| rs.status() |
获得复制集状态 对应数据库命令replSetGetStatus |
| rs.stepDown() |
优雅的关闭当前主节点,让其成为从节点并触发选举 对应数据库命令replSetStepDown |
| rs.syncFrom() |
指定当前从节点的复制源节点 对应数据库命令replSetSyncFrom |
下表仅仅列出没有对应Shell方法的数据库命令:
| 命令 | 说明 |
| replSetMaintenance | 启用/禁用维护模式,可以将一个从节点置于RECOVERING状态 |
| resync | 强制当前节点从主节点重新同步,仅仅用于主从复制 |
| isMaster | 显示当前成员在复制集中的角色 |
解决扩容性问题的两种手段,主要是:
- 垂直扩容(Vertical Scaling):增加单机的能力,例如更换更强的CPU、增加内存条、增加硬盘等。这种扩容方式有极限,而且成本是指数级增加的。使用云服务时,则不能进行垂直扩容
- 水平扩容(Horizontal Scaling):将数据集切分到多个廉价服务器上,通过增加服务器即可提升系统容量
分片(Sharding)是跨越多态机器分发、存储数据的手段,属于水平扩容。MongoDB使用分片来支持海量数据集和高吞吐量需求。MongoDB在集合的级别进行分片。
分片的优势包括:
- 读/写:进行分片后,MongoDB的读写操作均可以被很好的扩容。当查询包含分片键(前缀)条件时,mongos仅仅发送查询请求给相关的Shard
- 存储容量:可以使用廉价硬件无限扩展
- 高可用性:在部分Shard不可用的情况下,仍然能够进行部分的读写操作。配置服务器可以作为复制集部署,保证高可用性
执行分片前,应当考虑:
- 分片增加了调试、运维的复杂度
- 小心的选择分片键,不合理的选择会影响性能
- 某些需要scatter/gather,因而消耗较多时间
一个MongoDB分片集群(sharded cluster )由以下成员组成:
- 分片(Shard):由单个mongod或者一个复制集组成,维护一个数据分片。在生产环境下,每个分片可以定义为3成员复制集
- 路由器(mongos):作为查询路由器存在,作为客户端应用和分片集群之间的接口。你可以在每个应用服务器上都部署mongos,或者定义一组mongos并提供前置负载均衡器/代理给应用程序使用
- 配置服务器:保存分片集群的元数据、配置信息。从3.4开始,复制服务器必须作为复制集部署(CSRS)。在生产环境下,可以定义为3成员复制集
下图示意了这些成员之间的关系:
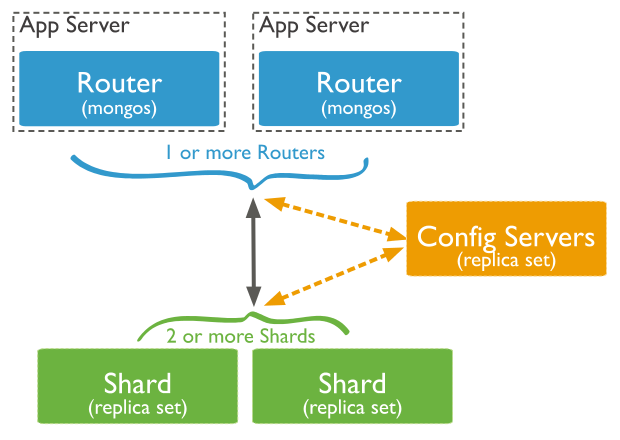
应用程序(MongoDB客户端)要想和集群进行交互,必须连接到mongos —— 不管你要使用的是分片还是非分片集合,客户端绝不该直接连接到某个Shard,除了执行分片本地管理、维护工作的时候。
分片集群中的每个数据库都有一个主分片(Primary Shard),该分片存放数据库上所有未分片的集合。
当创建新数据库时,mongos会选取集群中保存数据最少的分片,作为数据库的主分片。要改变主分片,可以调用 movePrimary命令,迁移主分片的操作可能消耗很长时间,完毕前不应访问其中的集合。
执行 sh.status()可以看到分片集群的整体状态信息,包括:
- 数据库的主分片信息
- Chunk在Shard中的分布情况
这类服务器存放分片集群的元数据,元数据记录了:
- 分片集群中所有数据、组件的状态和组织
- Chunk对应的值范围
- 每个分片包含的Chunks
此外,配置服务器还:
- 存储身份验证配置信息,例如基于角色的访问控制、内部验证设置
- 管理分布式锁
mongos会缓存以上信息,以便对读写操作进行路由。当元数据变更后mogos的缓存会自动更新。
从3.4开始,配置服务器必须使用满足以下要求的复制集:
- 具有0个仲裁者
- 不存在延迟节点
- 任何节点的buildIndexes设置不得为false
配置服务器具有config、admin数据库。
admin数据库包含与认证/授权相关的集合,以及 system.*集合(内部使用)。
config数据库包含了分片集群的元数据,当元数据变更(例如chunk迁移、chunk分裂)时MongoDB会写此数据库,而mongos会读取该数据库。客户端不应该直接写此数据库。读写此数据库时,均使用关注级别majority。
如果配置服务器复制集的主节点宕机,并且不能选举出新的主节点,则集群的元数据变为只读状态。你仍然可以对分片进行读写操作,但是不能进行Chunk迁移、分裂。
如果配置服务器复制集完全不可用,则分片集群不支持任何操作。但是mongos会缓存元数据,因而在重新启动mongos之前,仍然能进行分片的读写。
由于配置服务器非常重要,并且数据量很小,应该重视对其进行备份。
路由器(mongos)这样路由查询:
- 确定需要接收查询请求的Shard列表
- 在所有目标分片上建立一个游标
- 合并各Shard返回的查询结果,返回结果文档给客户端
要确保客户端连接到的是MongoDB实例是路由器,你可以执行isMaster命令,其返回值:
|
1 2 3 4 5 6 |
{ "ismaster" : true, "msg" : "isdbgrid", "maxBsonObjectSize" : 16777216, "ok" : 1 } |
中的msg字段如果为isdbgrid,则说明他是mongos。
进行分片时,需要决定每一条数据应该存放到哪个Shard上,这依赖于分片键。分片键由集合中每个文档都具有的、不变的(immutable)字段构成。一旦选择好分片键,以后就不能再修改,每个分片集合有且只有一个分片键。分片键的选择影响性能、可扩容性。
要对某个集合进行分片,执行:
|
1 2 3 4 5 |
# namespace:<database>.<collection> # key 索引规格文档,用于指定分片键 # unique 对分片键进行唯一性约束,哈希分片键不支持。非空集合的唯一性索引必须提前手工创建好 # options.numInitialChunks 使用哈希分片键来创建空的分片集群时,最初创建的Chunk的数量 sh.shardCollection( namespace, key, unique, options ) |
分片集合必须有一个支持分片键的索引:此索引要么在分片键上创建,要么以分片键开头。如果:
- 集合是空的,并且分片键上没有索引,则sh.shardCollection()自动在分片键上创建索引
- 集合是非空,你必须在调用sh.shardCollection()之前,手工创建索引
对于分片集合,仅仅_id、位于分片键字段的索引、以分片键字段开头的索引可以是唯一性索引。不满足此条件的集合无法分片,分片后你无法在不满足此条件的字段上新建唯一性索引。
如果对分片键使用唯一性索引(sh.shardCollection指定unique为true),则MongoDB可以保证分片键取值的唯一性。如果分片键包含多个字段,则保证其整体上的唯一性而非某个字段。
分片键长度不能超过512字节。要么对索引键进行索引,要么以其为索引前缀。可以对分片键建立哈希索引。多键索引、文本索引、地理空间索引均不支持。
分片键是不可变的,如果你必须改变分片键的值,按以下步骤:
- 把索引数据Dump出来
- Drop原先的分片集合
- 使用新的分片键进行分片
- Pre-split分片键范围,确保均匀的数据分布
- 把Dump出的数据导入到数据库
分片键的值是不可变的:你不能修改分片键字段的值。
理想的分片键,应该让MongoDB仅可能均匀的把文档分发到各分片上。
分片键的基数(cardinality,候选取值数量)决定了负载均衡器能够创建的Chunks的最大数量,进而影响水平扩容的有效性。一个特定的分片键值,任何时刻仅仅能存在于一个Chunk上,因此如果分片键的基数为4,则最多创建4个Chunk,因而最多使用4个分片(服务器),添加额外的服务器得不到任何好处。
如果数据模型要求在低基数字段上分片,可以考虑联合某个高基数字段建立联合索引。
尽管具有高基数的分片键可以更好的支持水平扩容,但是它不能保证数据均匀分布在各分片,因为各键值对应的记录数量(Frequency)差异可能很大。分片键频率(Shard Key Frequency)用来描述一个特定的分片键值出现的频率。如果某些分片键取值具有非常高的Frequency,那么存储高Frequency的Chunks将出现性能瓶颈,并且这些Chunk可能无法再次分裂(单个键值无法再分裂)。
如果数据模型要求在高Frequency字段上分片,可以考虑联合某个低Frequency/Unique字段建立联合索引。
单调变化的分片键可能限制集群的插入吞吐量。因为一段时间内索引的插入可能都被分发到同一个分片(开区间的第一个、最后一个Chunk)上:
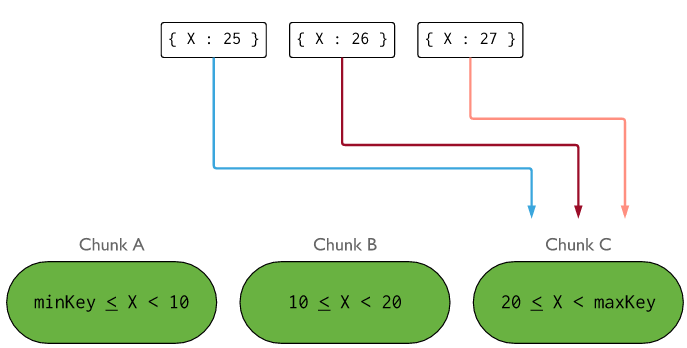
在上图中,如果分片键单调递增,则后续所有insert都分发到Chunk C;如果单调递减,则都分发到Chunk A。
如果数据模型要求在单调递增字段上分片,可以考虑使用哈希分片。
MongoDB支持两种分片策略。
所谓哈希分片,是指使用单字段的哈希索引来作为分片键的分片策略。哈希分片导致基于分片键的范围查询难以匹配单个/少量分片(查询隔离,Query Isolation),往往需要广播到所有分片。但是,哈希分片让数据更加均匀的分布在各Shard中,特别是在分片键单调递增/减的情况下(例如自增长)。
这种分片策略需要对每一个分片键字段的值计算哈希,每个Chunk对应一个哈希值区间。
如果对空集合进行哈希分片,MongoDB默认为每个Shard创建两个空的Chunk,所有这些Chunks覆盖哈希值域。在执行分片时,可以指定numInitialChunks来定制Chunk的数量。
用作哈希分片的字段,应当具有高基数(大量不同的取值),哈希分片适用于时间戳、ObjectId之类的单调变化的值类型,你可以基于自动生成的_id进行哈希分片。
要执行哈希分片,调用命令:
|
1 |
sh.shardCollection( "database.collection", { <field> : "hashed" } ) |
注意:MongoDB的哈希索引会在计算哈希值之前,把浮点数截断为64-bit的整数,并且不支持大于2^53的浮点数。为防止哈希冲突,你可能需要将分片键乘以10^N后存储。
这是MongoDB默认的分片策略,它直接根据分片键字段的值来划分Chunk,分片键值相近的文档,可能分布在同一个Shard/Chunk中。这样,进行范围查询时往往能够实现查询隔离。
选择范围分片键时,要注意前文所述的:高基数、低Frequency、非单调变化原则。
要执行范围分片,调用命令:
|
1 |
sh.shardCollection( "database.collection", { <shard key> } ) |
MongoDB把数据划分为Chunk。 MongoDB可以使用分片集群负载均衡器进行跨Shard的Chunk迁移,以保证每个Shard被合理利用。
每个Shard上存储0-N个Chunk,每个Chunk对应了一个分片键取值区间,区间总是[ 闭,开 ) 形式的。所有Chunk正好覆盖分片键的键空间。
将数据集和Chunk而不是Shard进行关联,其好处是:
- 可以按需添加新的机器(Shard),然后轻易的再平衡数据集(迁移Chunk)
- 在必要时(假设某个Chunk过大),可以进行Chunk分裂,然后进行再平衡
如果块增长超过配置的尺寸,MongoDB会执行块分裂(Split),插入、更新操作都可能引发块分裂。只要块包含超过1个的分片键值,就可以被分裂。
MongoDB默认的Chunk尺寸是64MB。修改此默认值时,要注意:
- 小尺寸的Chunk可以让数据分布更加均匀,代价是更加频繁的数据迁移。性能影响产生在mongos层
- 大尺寸的Chunk导致的迁移较少,因而从网络、mongos角度是高效的。但是可能导致数据不均匀分布
- Chunk尺寸影响Chunk能够包含的最大文档数量(一旦超过此数量就会发生分裂)
- 分片既有集合时,Chunk尺寸影响集合的最大尺寸
- 实际的分裂行为只能被插入、更新操作触发
- 分裂不能被撤销,如果你增大Chunk尺寸,那些分裂产生的Chunk不会合并回去
在实际应用中,不要为了追求一点点更加平均的分布,而盲目设置过小的Chunk尺寸。
块分裂本身是高效的元数据级别的操作,不牵涉到数据迁移(跨Shard)。但是,当数据分布不均匀时,集群的负载均衡器可能会自动重新分布Chunks。
为了在Shard之间更加均匀的分布数据,MongoDB会执行块的迁移 —— 将一个Chunk移动到另外一个Shard上并更新元数据。
块迁移可以:
- 手工执行,你仅仅在一些特殊情况下才需要进行手工迁移
- 自动执行,当超过迁移阈值时,负载均衡器自动执行
负载均衡器(balancer)是专门负责Chunk迁移的后台进程。如果拥有最大、最小数量Chunk的Shards的Chunk数量差超过迁移阈值,负载均衡器启动迁移。Zone的配置影响负载均衡器的行为。
如果一个Chunk仅仅包含一个分片键值,则它可能超过Chunk尺寸而继续增大,成为巨块(jumbo chunk)。因为近包含一个分片键值,这种块无法再分裂,可能形成性能瓶颈。
2.6/3.0版本的 sharding.archiveMovedChunks参数默认开启,迁移源Shard会自动把被迁移的Chunks归档到storage.dbPath/moveChunk目录下。
如果迁移过程中出现错误,这些归档文件可以用于数据恢复。一旦迁移完成,这些文件不再有用,你可以将其删除。要判断迁移是否已经完成,连接到mongos并执行命令 sh.isBalancerRunning()
某些场景下,MongoDB自动创建的Chunk不足以满足吞吐量需求。这些场景例如:
- 当你希望对位于单个Shard上的大集合进行分片时
- 当你希望导入大量数据到一个负载不均衡的集群,或者导入可能导致负载不均衡时 —— 例如使用范围分片的情况下进行单调递增数据导入
上面的场景对资源敏感,原因是:
- 块迁移要求将Chunk中所有数据进行跨Shard的移动
- 任何Shard在同一时刻仅仅能参与一次迁移活动,负载均衡器会串行化的迁移Chunk。从3.4开始限制解除,变为:具有n个分片的集群,负载均衡器最多同时进行n/2个迁移活动
- 块分裂仅仅会在数据插入/更新后发生
要进行预分裂(Pre-split,创建满足需要的Chunks数量),你可以执行 split命令。
警告:你只能在空集合上执行预分裂操作。如果集合已经包含数据,MongoDB在你执行集合分片时自动创建Chunks。后续再进行手工创建Chunks可能导致不可预测的Chunk范围/尺寸,以及低效的负载均衡行为。
当Chunk尺寸到达限制后,MongoDB会自动分裂Chunk。但是某些场景下你可能期望手工执行分裂,例如:
- 你有少量Chunks,但是要部署大量的数据到集群中
- 你需要部署大量可能落到单个Chunk/Shard中的数据,例如分片键值200-500归属于一个Chunk,现在你要插入海量分片键值300-400之间的数据
根据需要,负载均衡器可能立即迁移刚刚分裂出来的Chunk,不考虑它是自动还是手工创建的。
调用 sh.status()可以了解当前Chunk对应的值区间。要手工分裂,调用split命令,或者Shell助手: sh.splitFind()、 sh.splitAt()。
调用 mergeChunks命令,可以把空Chunk合并到同一Shard上的相邻Chunk上。所谓空Chunk,是值其键值范围内没有文档。
以下场景下,你可能需要手工合并:
- 预创建(Pre-split)了过多的块
- 你删除了很多文档,导致某些Chunk变空
如果Chunk包含的文档数量大于:
- 250000,或者
- 1.3 * Chunk尺寸 / 平均文档尺寸。平均文档尺寸通过db.collection.stats().avgObjSize得到
则此Chunk无法被移动。
在分片集群中,你可以依据分片键来创建分片数据的区域(zone)。一个Zone可以关联1-N个Shard,每个Shard可以关联到任意个不冲突的Zone(多对多)。在启用负载均衡的集群里,Chunk仅仅在Zone内部迁移。
需要使用Zone的场景包括:
- 在一个Shard集上,隔离某个数据子集
- 确保相关的数据分布于地理位置相近的Shard上
- 根据Shard的硬件性能来路由
考虑下面这个Zone配置:
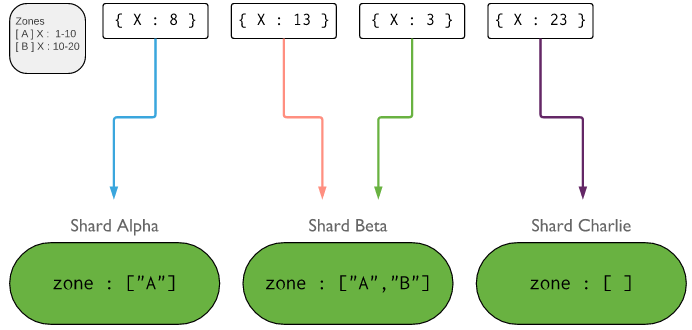
分片键值位于1-10之间的,归属于Zone A;10-20之间的归属于Zone B。Shard A属于Zone A,Shard B属于Zone A和B。这样,键值位于1-10之间的数据子集仅仅能在Shard A、B之间迁移。
每个Zone可以覆盖1-N个键值区间。这些区间总是[ 闭,开 ) 形式的。所有Zone的键值区间不得重叠,一个Zone的每个键值区间也不能重叠。
负载均衡器会尝试把分片集合的Chunks均匀分发在所有Shard上。
对于标记为待迁移的Chunk,负载均衡器根据Zone配置来确定其可选的目标Shard。如果Chunk的值范围没有落到任何Zone里,则可能被迁移到任意Shard上。
如果负载均衡器发现任何Chunk违反了Zone定义(例如进行了Zone配置),它会将其进行迁移。
进行了Zone配置后,集群可能需要一定时间来执行Chunk迁移,迁移由负载均衡器在下一次 balancing rounds执行。
定义Zone覆盖的值范围时,必须使用分片键或者分片键前缀字段。
MongoDB的集群负载均衡器是一个后台进程,它监控每个Shard上Chunk的数量。当最多 - 最少Chunk数量(按Shard)打到迁移阈值后,负载均衡器尝试进行Chunk迁移,使所有Shard持有仅可能平均数量的Chunks。
负载均衡器的行为对于用户、应用程序是完全透明的,但是迁移过程可能对性能产生影响。
从3.4开始,负载均衡器在配置服务器的主节点上运行。一旦其进程激活,就会修改配置服务器的lock集合上的一个文档,获得一个“锁”,这个锁一直不会释放。
从2.6开始,负载均衡器可能影响磁盘使用,因为迁移会导致源Shard对被迁移chunk进行归档。
负载均衡器会带来带宽、工作负载方面的成本,从而影响数据库的整体性能。它通过下面的措施使影响最小化:
- 任何时刻仅能执行一个Chunk的迁移。从3.4开始,允许N个Shard的集群同时进行N/2个块迁移
- 仅仅当到达迁移阈值(migration threshold)时才启动负载均衡周期(balancing round)
你可以临时的禁用负载均衡器,以执行维护任务。你也可以限制负载均衡器运行的时间窗口,防止对生产环境产生不利影响。
添加Shard到集群时,会导致负载不均衡的出现,因为新的Shard不持有任何Chunk,达到再平衡需要一定的时间。
从集群中移除Shard时,其中的Chunk必须被重新分发,达到再平衡需要一定的时间,切勿再迁移完成前关闭被移除Shard对应的服务器。
所有块迁移均遵循以下流程:
- 负载均衡器向源Shard发送moveChunk命令
- 源Shard使用内部moveChunk命令启动。在迁移完成之前,路由到被移动Chunk的读写请求仍然由源Shard负责
- 目标Shard构建接纳Chunk所需要的、尚不存在的索引
- 目标Shard开始请求Chunk中的文档,接收数据拷贝并入库
- 接收完最后一个文档后,目标Shard启动一个同步进程,确保在迁移过程中,对被迁移Chunk的写操作被应用
- 当完全同步后,源Shard连接到配置数据库,并更新集群元数据,写入Chunk的新位置
- 元数据写入完毕后,一旦没有针对打开的被迁移Chunk的游标,源Shard删除本地的Chunk数据拷贝。如果负载均衡器需要针对源Shard进行下一个Chunk迁移,它不会等待删除操作的完成。从2.6开始,被迁移Chunk会在源Shard归档
此阈值考虑Shard上的Chunk数量的最大差。默认取值:
| Chunk数量 | 阈值 |
| < 20 | 2 |
| 20-79 | 4 |
| >=80 | 8 |
配置项_secondaryThrottle的值,决定了负载均衡器何时处理Chunk中下一个被迁移的文档(在目标Shard?):
- 如果取值为true,则当前文档必须至少被复制到一个从节点,才处理下一个文档,相当于写关注{ w :2 }
- 如果取值为false,则不等待复制到从节点,直接处理下一个文档
从3.4开始,如果使用 WiredTiger引擎,该配置的默认值false, MMAPv1引擎的默认值仍然为true。
此外,不管_secondaryThrottle如何取值,迁移工作流的某些阶段,遵行如下复制策略:
- 在更新集群元数据(第6步)之前,MongoDB会短暂的暂停针对源Shard上被迁移集合的读写操作。在更新元数据的前后,要求移动Chunk的写操作被复制集大多数节点确认
- 在执行源Shard清理(第7步)或者新的Chunk迁移之前,写操作必须被目标Shard复制集的大多数节点确认
| 方法 | 说明 |
| sh._adminCommand() | 针对admin数据库执行一个数据库命令 |
| sh.getBalancerLockDetails() | 报告负载均衡器锁的详细信息 |
| sh._checkMongos() | 检查当前Shell是否连接到mongos |
| sh._lastMigration() | 报告最后一次发生的块迁移 |
| sh.addShard() |
添加一个分片到集群中 对应数据库命令addShard |
| sh.addShardTag() | sh.addShardToZone()的别名 |
| sh.addShardToZone() |
关联一个Shard到一个Zone 对应数据库命令addShardToZone |
| sh.addTagRange() | sh.updateZoneKeyRange()的别名 |
| sh.updateZoneKeyRange() | 关联一个分片键值范围到一个Zone。每个Zone可以关联多个值范围区间 |
| sh.removeTagRange() | sh.removeRangeFromZone()的别名 |
| sh.removeRangeFromZone() | 解除一个分片键值范围与Zone的关联 |
| sh.disableBalancing() | 针对单个分片集合禁用负载均衡功能 |
| sh.enableBalancing() | 针对单个分片集合启用负载均衡功能 |
| sh.enableSharding() |
针对某个特定的数据库启用分片功能 对应数据库命令enableSharding |
| sh.getBalancerState() | 返回一个布尔值,说明负载均衡器是否启用(全局的) |
| sh.help() | 显示分片集群的Shell方法的简短帮助 |
| sh.isBalancerRunning() | 负载均衡器是否正在迁移Chunk |
| sh.moveChunk() | 在分片集群中移动一个Chunk |
| sh.removeShardTag() | sh.removeShardFromZone()的别名 |
| sh.removeShardFromZone() |
从Zone中移除一个Shard 对应数据库命令removeShardFromZone |
| sh.setBalancerState() | 启用或者禁用负载均衡器(全局的) |
| sh.shardCollection() |
对一个集合进行分片 对应数据库命令shardCollection |
| sh.splitAt() | 以分片键的某个值为分割点,把一个Chunk分割为两个 |
| sh.splitFind() | 将包含满足查询条件的Chunk分割为两个近似相等的新Chunks |
| sh.startBalancer() |
启用负载均衡器并等待负载均衡触发 对应数据库命令balancerStart |
| sh.status() | 报告分片集群的状态 |
| sh.stopBalancer() |
禁用负载均衡器并等待可能正在进行的负载均衡操作完毕 对应数据库命令balancerStop |
下表仅仅列出没有对应Shell方法的数据库命令:
| 命令 | 说明 |
| flushRouterConfig | 强制清空mongos的分片集群配置元数据缓存 |
| balancerStatus | 报告负载均衡器的状态信息 |
| cleanupOrphaned | 清理孤儿数据,所谓孤儿数据,是指其分片键值超越了某个Shard拥有的Chunk范围的数据 |
| listShards | 列出集群中的分片 |
| removeShard | 从集群中移除一个分片。集群将把该分片的Chunks迁移到其它分片上,这需要时间 |
| mergeChunks | 合并单个分片上的多个Chunk |
| shardingState | 报告当前mongod是否某个分片集群的成员 |
| split | 创建一个新的Chunk |
| movePrimary | 当从集群移除分片时,用于重新分片某个数据库的主分片 |
| isdbgrid | 检查进程是否是mongos |
| updateZoneKeyRange | 添加/删除一个Zone关联的分片键值区间 |
启动mongos、mongod实例时,可以指定一个配置文件,提供必要的选项。MongoDB的配置文件是YAML-based格式的,不支持tab,要使用space代替。
要使用配置文件,指定命令行选项:
|
1 2 3 |
# -f 是 --config 的别名 mongod --config /etc/mongod.conf mongos --config /etc/mongos.conf |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 |
# 日志选项 systemLog: # 默认日志级别,0-5之间,默认0,越大日志越详细 # 要指定某个MongoDB组件的日志级别,使用 systemLog.component.<name>.verbosity verbosity: <int> # 安静模式,布尔,可以减少日志输出 quiet: <boolean> # 截断异常信息,布尔 traceAllExceptions: <boolean> # 记录到syslog使用的facility级别,默认user syslogFacility: <string> # 输出到指定的文件,而不是syslog中 path: <string> # 默认false,是否追加内容到日志文件中 logAppend: <boolean> # 日志轮转方式,rename / reopen logRotate: <string> # 日志记录目标,syslog / file ,选择file则必须设置systemLog.path destination: <string> # 日志时间戳格式,ctime / iso8601-utc / iso8601-local # 默认iso8601-local,示例 1969-12-31T19:00:00.000-0500 timeStampFormat: <string> # 配置特定MongoDB组件的日志选项 # 组件:accessControl / command / control / ftdc / geo / index / network / query / # replication / sharding / storage / storage.journal / write component: accessControl: verbosity: <int> command: verbosity: <int> # 进程管理选项 processManagement: # 默认false,是否以daemon方式来启动mongos/mongod,默认不是daemon方式 # MongoDB的Linux包期望此选项为默认值 fork: <boolean> # PID文件的路径 pidFilePath: <string> # 网络选项 net: # 监听连接的端口,默认27017 port: <int> # 监听的网络接口,默认0.0.0.0 bindIp: <string> # mongos/mongod允许的最大连接数,默认65536 maxIncomingConnections: <int> # 默认true,对每个客户端请求进行校验,防止插入无效、恶意的BSON到数据库 wireObjectCheck: <boolean> # 默认false,是否启用IPv6支持 ipv6: <boolean> # 在UNIX Domain套接字上监听 unixDomainSocket: # 是否启用 enabled: <boolean> # 套接字路径前缀,默认/tmp pathPrefix: <string> # 套接字文件权限,默认 0700 filePermissions: <int> # 提供RESTful API的HTTP接口,不要在生产环境使用 http: # 是否启用 enabled: <boolean> # 是否支持JSONP JSONPEnabled: <boolean> # 是否提供RESTful接口 RESTInterfaceEnabled: <boolean> ssl: # SSL的运作模式:disabled禁用;allowSSL服务器互联不使用,允许客户端连接使用; # preferSSL服务器互联默认使用,允许客户端不适用;requireSSL 强制所有连接使用SSL mode: <string> # 同时包含证书和密钥的.pem文件 # 如果连接时没有指定--sslCAFile则使用系统CA来验证服务器证书 PEMKeyFile: <string> # 如果.pem加密,这里提供密码 PEMKeyPassword: <string> # 用于集群成员、复制集成员相互认证的pem文件 clusterFile: <string> # 如果.pem加密,这里提供密码 clusterPassword: <string> # 包含了根证书链的.pem文件 CAFile: <string> # 包含了证书吊销列表的.pem文件 CRLFile: <string> # 是否允许客户端不提供证书(单向认证) allowConnectionsWithoutCertificates: <boolean> # 是否允许使用无效证书(集群中其它服务器) allowInvalidCertificates: <boolean> # 是否允许 TLS/SSL 证书和主机名不匹配 allowInvalidHostnames: <boolean> # 禁用的入站协议类型TLS1_0、TLS1_1、TLS1_2 disabledProtocols: <string> # 是否启用OpenSSL的FIPS模式 FIPSMode: <boolean> # 是否启用服务器之间,服务器与Shell之间的数据压缩 compression: compressors: <string> # 压缩器,例如snappy # 安全选项 security: # 对分片集群、复制集中其它成员进行认知的共享密钥所在的文件 keyFile: <string> # 集群的认证方式:keyFile共享密钥文件;sendKeyFile发送共享密钥但是也允许其它节点以X509方式请求本节点 # sendX509发送X509但是也允许其它节点以共享密钥方式请求本节点;x509 推荐,仅X509 clusterAuthMode: <string> # 默认disabled,可选disabled。是否启用基于角色的访问控制(RBAC),对应命令行选项 --auth authorization: <string> # 默认false,3.4新增。允许mongos/mongd接受/创建到其它mongos/mongd的认证/非认证连接 transitionToAuth: <boolean> # 是否启用服务器端的JS执行,默认true。如果禁用,则无法使用$where、db.collection.mapReduce()、db.collection.group()等 javascriptEnabled: <boolean> # 设置MongoDB服务器参数 setParameter: <parameter1>: <value1> <parameter2>: <value2> # 存储选项 storage: # mongod实例存储数据的位置,默认/data/db dbPath: <string> # 默认true,是否在下一次启动时构建未完成的索引 indexBuildRetry: <boolean> # 当mongod以--repair进行修复启动时,使用的工作目录 repairPath: <string> # 是否启用日志,64bit默认true,32bit默认false journal: # 是否启用 enabled: <boolean> # 允许写入日志的最小间隔,默认100ms commitIntervalMs: <num> # 是否为每个数据库新建子目录,默认false directoryPerDB: <boolean> # 每隔多久把数据刷入数据文件中,默认60s,通常不需要修改。如果设置为0从不把内存映射文件刷入磁盘 syncPeriodSecs: <int> # 使用的存储引擎,mmapv1 / wiredTiger / inMemory engine: <string> # 引擎特定选项 mmapv1: # 是否预分配数据文件的磁盘空间 preallocDataFiles: <boolean> # 名字空间文件的大小,每个集合、索引都被认为是名字空间 # 默认16MB,允许大概24000个名字空间 nsSize: <int> quota: # 是否限制每个数据库能够拥有的数据文件的数量 enforced: <boolean> # 每个数据库的最大数据文件数量,默认8 maxFilesPerDB: <int> # 使用小数据文件,设置为true则减小数据文件的初始大小,且不允许超过512MB # 设置为true,同时导致日志文件的最大尺寸从1G变为128MB # 可能导致创建大量的数据文件,从而影响性能 smallFiles: <boolean> journal: debugFlags: <int> commitIntervalMs: <num> # 引擎特定选项 wiredTiger: engineConfig: # 为所有数据准备的内部缓存的大小,最小256MB,默认RAM /2 - 1GB # 避免修改此配置,因为该引擎可以利用OS所有空闲内存作为缓存 # 使用容器时,配合容器可用内存设置该选项 cacheSizeGB: <number> # 日志的压缩算法 snappy / zlib journalCompressor: <string> # 是否在不同子目录存放索引、数据 directoryForIndexes: <boolean> collectionConfig: # 集合的默认压缩算法 none / snappy / zlib # 你可以在创建集合的时候覆盖 blockCompressor: <string> indexConfig: # 是否启用索引前缀压缩 prefixCompression: <boolean> # 引擎特定选项 inMemory: engineConfig: # 使用的内存量 inMemorySizeGB: <number> # 性能剖析选项 operationProfiling: # 超过多少ms,操作被剖析器认为是缓慢的 slowOpThresholdMs: <int> # 剖析模式: off / slowOp / all mode: <string> # 复制集选项 replication: # Oplog的大小,对于64bit系统,默认5%可用磁盘空间 oplogSizeMB: <int> # 该实例所属的复制集的名称 replSetName: <string> # 仅mmapv1引擎,是否预抓取索引 secondaryIndexPrefetch: <string> # 设置读关注为majority enableMajorityReadConcern: <boolean> # 以下子项仅仅用于mongos localPingThresholdMs: <int> # 分片选项 sharding: # 当前分片在集群中的角色,configsvr / shardsvr clusterRole: <string> # 是否对被迁移的Chunk进行归档保存 archiveMovedChunks: <boolean> # 以下子项仅仅用于mongos configDB: <string> # 审计选项 auditLog: # 审计日志的目的地 syslog / console / file destination: <string> # 审计日志格式 JSON / BSON format: <string> # 审计日志存放路径 path: <string> # 过滤器文档,不匹配的不记录 filter: <string> # SNMP监控选项 snmp: # 是否作为subagent运行 subagent: <boolean> # 是否作为master运行 master: <boolean> # 全文搜索选项 basisTech # Basis Technology Rosette Linguistics Platform 安装目录 basisTech.rootDirectory |
|
1 2 3 4 5 6 7 8 9 10 11 |
# 启动mongod进程,默认数据目录/data/db,端口27017 mongod # 以守护进程的方式启动,并把日志记录到指定位置 mongod --fork --logpath /var/log/mongodb.log # 停止服务 use admin db.shutdownServer() # 停止服务,方式二 mongod --shutdown |
主节点的mongod的停止流程如下:
- 检查从节点的复制进度
- 如果没有任何从节点延迟小于10s,mongod会返回一个信息,提示不能停止。要强行停止,可以为shutdown命令提供force参数:
1db.adminCommand({shutdown : 1, force : true})如果要持续检查指定的时间,在此时间内有从节点跟上复制进度则关闭,跟不上则不关闭,可以执行:
123db.adminCommand({shutdown : 1, timeoutSecs : 5})# 或者db.shutdownServer({timeoutSecs : 5}) - 如果由节点延迟小于10s,主节点会Stepdown,并等待从节点跟上复制进度
- 从节点跟上复制进度,或者60s之后,主节点关闭
可以指定查询、命令的最长执行耗时:
|
1 2 3 4 |
db.collection.find(...).maxTimeMS(30) db.runCommand( { maxTimeMS: 45 } ) # 如果查询、命令因为超时而被终止,可以通过db.getLastError() 或者db.getLastErrorObj()得到相关信息 |
你可以调用 db.killOp(<opId>)来强制终止某个操作,注意,不要对任何数据库内部操作执行此调用。 执行 db.currentOp()得到正在运行的操作的列表。
| 引擎 | 说明 |
| MMAPv1 |
2.2以前的版本:实例级别的全局锁,同一时刻只能有一个客户端执行写操作 2.2 - 2.6版本:每个数据库有一个读写锁,允许针对数据库的并发读,但是不允许针对数据库的并发写。也就是说,同一时刻只能有一个客户端在写某个数据库 3.0以后的版本:每个集合有一个读写锁,允许多个客户端同时对多个不同的集合进行写操作 |
| WiredTiger |
支持文档级别的并发读写,一个线程可以修改集合C的文档A,同时另外一个线程可以修改集合C的文档B 在写操作进行的过程中,读操作不受限制 |
| 数据库特性 | 说明 |
| 日志 |
MongoDB使用预写式磁盘日志,这种日志写入很快,只要写入了该日志,宕机后可以恢复数据,即使没有写到数据文件中 该日志默认开启,要保证宕机后不影响数据一致性,就不要关闭它 |
| 读关注 |
当使用majority、linearizable两种读关注时,必须配合写关注{ w: "majority" },这样可以确保线程可以读到它自己先前的写操作 当使用读关注majority时:
|
| 写关注 | 写关注影响写操作的返回数据,强写关注导致返回更慢,但是可以更好的确保数据一致性 |
你应当总是在受信任的网络中运行MongoDB,使用合理的防火墙策略来阻止非受信任的机器、系统、网络。通常,仅仅应用服务器、监控服务、其它MongoDB组件需要MongoDB的访问权限。
默认情况下,MongoDB的授权系统是关闭的,任何人都可以访问,需要注意。
MongoDB提供了一个用于检查服务器状态、执行查询的HTTP接口,此接口默认是关闭的,不要在生产环境中开启此接口。
避免盲目调整mongos/mongod的连接池大小,以满足你的需要。 connPoolStats命令显示当前数据库中打开的连接数。
| 存储引擎 | 说明 |
| MMAPv1 |
由于其并发性,你不需要为MMAPv1分配过多的CPU资源,但是应该保证mongos/mongod能够访问两个真实CPU 增加MongoDB可访问的内存量可以减少页错误发生的频率 注意MMAPv1不会使用Swap |
| WiredTiger |
该引擎是多线程的,能够利用另外的CPU。特别是,活动线程数(并发操作数)与可用CPU的比值,可以影响性能:
mongostat输出的ar/aw列可以显示活动读/写数量 使用该引擎时,MongoDB同时利用WiredTiger内部缓存、OS缓存。 从3.4开始,WiredTiger缓存默认使用256MB、总RAM/2 - 1GB之中较大的内存量。可以通过 storage.wiredTiger.engineConfig.cacheSizeGB配置。在容器(例如Docker)中运行MongoDB时,应该设置此配置,使之小于容器可使用内存的量 要了解缓存的统计信息、清除率,运行 serverStatus命令并查看wiredTiger.cache字段 MongoDB会使用所有空闲内存作为OS缓存(文件系统缓存),OS缓存中的数据是被压缩的,存放MongoDB数据文件的映射 |
使用SSD,MongoDB可以获得更好的性能、更高的性价比。 SSD的随机I/O能力可以很好的适应MMAPv1的更新模型。
注意为系统分配Swap,避免内存争用,或者因为OOM导致mongod被杀死。当使用MMAPv1时,其映射数据文件到内存的行为,导致永远不会使用Swap空间。
当面向MongoDB性能低下时,其原因往往和数据库访问策略、硬件、并发操作数有关、错误/不当索引、低效的Schema设计相关。排除了前述可能性之后,数据库可能已经满载运行了,或许需要进行水平扩容。
你应该保证应用的工作集(Working set,最常使用的数据)能够全部装入内存,这样对性能提升有很大帮助,特别是使用MMAPv1引擎时。
某些情况下性能问题是临时的,通常由于突发的高并发导致。
为了确保数据一致性,MongoDB采用了一套锁系统。长时间运行、队列形式的操作可能导致性能降低,因为它们持有锁导致后续请求被迫等待。
要查看锁是否影响了系统性能,执行命令: db.runCommand( { serverStatus: 1 } )并查看输出的locks、globalLock段。
locks.timeAcquiringMicros / locks.acquireWaitCount的结果近似的反映了等待某种特定锁模式所消耗的平均时间。
locks.deadlockCount表示锁请求导致死锁的次数。
如果globalLock.currentQueue.total计数总是很高,意味着可能大量的操作在等待一个锁,提示存在影响性能的并发问题。
如果globalLock.totalTime / uptime的比值较高,意味着数据库很长时间处于一个锁状态。
耗时漫长的操作可能由于:
- 低效的索引
- 低效的Schema设计
- 低效的查询语句
- 内存不足,导致页错误而产生磁盘读操作
MMAPv1引擎使用内存映射文件来存储数据。对于一个尺寸足够大的数据集,MMAPv1会分配尽可能多的系统内存供其使用。
判断内存是否对于数据集来说是足够的并不容易,查看 serverStatus的mem段可以查看MongoDB的内存使用情况。mem.resident记录MongoDB驻留工作集使用的内存,如果该值超过系统可用内存,并且还有很多数据没有映射到内存中,说明达到了系统的最大容量。
mem.mapped字段记录了MongoDB使用的内存映射文件大小,如果此值操作系统内存总大小,意味着某些读操作会触发页面错误而导致磁盘读。
serverStatus.extra_info.page_faults记录了MongoDB发生页面错误的数量。如果此计数快速增加,则可能是:
- 系统内存过小
- 正在访问大量数据、扫描整个集合
导致。偶尔发生的页面错误不要紧,但是大量累积的页面错误意味着存在I/O性能问题。
当遇到页面错误的时候,MongoDB可能放弃读锁,这样在换页期间其它数据库进场可以进行读写操作,这种行为提升了吞吐量、并发能力。
处理内存不足的方法是,水平或者垂直扩容。
某些情况下,客户端和数据库之间的连接数会超过服务器的处理能力。serverStatus输出的以下字段可以提供相关信息:
- globalLock.activeClients,当前正在执行操作、或者排队等待操作的客户端数量
- connections.current,连接到服务器的客户端数量
- connections.available,空闲的可以供新客户端使用的连接数
如果并发连接数持续的高,可能系统需要扩容。对于读过载的应用考虑复制集,对于写过载的应用考虑分片集群。
MongoDB本身没有对并发连接数的限制,操作系统本身的限制,例如UNIX,考虑设置ulimit。
MongoDB自带了一个剖析器,用于识别和分析低效的查询、操作。要为某个数据库启用剖析器,执行:
|
1 2 3 4 5 6 7 8 9 |
# 0 不启用剖析 # 1 仅仅剖析缓慢操作,设置项slowOpThresholdMs决定了缓慢查询的判断标准 # 2 剖析所有操作 db.setProfilingLevel(1) # 输出示例: {"was" : 0, "slowms" : 100, "ok" : 1 } # 先的命令检查剖析设置 db.getProfilingStatus() |
要为整个mongod启用剖析器,使用选项: mongod --profile 1 --slowms 15。
注意,剖析对数据库性能具有负面影响,因而默认是关闭的。你可以针对单个mongod实例、单个数据库进行设置,这些设置不会传播到整个复制集或者分片集群。不支持对整个分片集群设置剖析,你必须针对单个mongod进行设置。
剖析器收集MongoDB写操作、游标、数据库命令的细粒度信息。收集的信息被存放到定长集合 system.profile中。执行 show profile或者: db.system.profile.find( { millis : { $gt : 100 } } ) 可以查看剖析器的输出。输出示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
{ // 操作类型 "op" : "query", // 操作针对的对象 "ns" : "test.c", // 使用的查询文档,对于insert操作来说,则是插入的文档 "query" : { "find" : "c", "filter" : { "a" : 1 } }, // 执行update操作时,使用的更新文档 "updateobj" :.., // query、getmore操作使用的游标ID "cursorid" :..., // 执行的命令 "command" : .., // 别名system.profile.nscanned,为了完成操作MongoDB扫描的索引值数量 "keysExamined" : 2, // 别名system.profile.nscannedObjects,为了完成操作MongoDB扫描的文档数量 "docsExamined" : 2, // 仅MMAPv1引擎,为了完成操作,在磁盘上移动文档的数量 "nmoved" :..., // 操作删除的文档数量 "ndeleted" :..., // 操作插入的文档数量 "ninserted" :..., // update操作修改文档的数量 "nModified" :..., // 是否为upsert操作 "upsert" :..., // 如果通过索引不能得到需要的排序,则出现此Stage "hasSortStage" : ..., "cursorExhausted" : true, // 写操作插入的索引键数量 "keysInserted" : 0, // 删除的索引键数量 "keysDeleted" : 0, // 写操作冲突文档数量,所谓冲突即多个update操作尝试修改同一文档的情况 "writeConflicts" : 0, // 让出锁以便其它操作能够进行的次数,这意味着当前操作需要读取不在内存中的数据 "numYield" : 0, // 原来该字段叫lockStats "locks" : { // 锁类型:{剖析信息} // Global 全局锁 // MMAPV1Journal 该引擎特定的,用于同步日志写操作的锁 // Database 数据库锁 // Collection 集合锁 // Metadata 元数据锁 // oplog Oplog锁 "Global" : { // 请求锁的次数 "acquireCount" : { // 锁模式: // R 共享锁,W 独占锁,r 意向共享锁,w 意向独占锁 "r" : NumberLong(2) } "acquireWaitCount" :..., // 等待获得锁的次数 "timeAcquiringMicros" :..., // 累积等待锁消耗的微秒数 "deadlockCount" :..., // 等待锁时遭遇死锁的次数 } }, // 操作返回文档的数量 "nreturned" : 2, // 返回文档的字节长度 "responseLength" : 108, // 从mongod角度来看,操作完整消耗的时间 "millis" : 0, // 执行统计信息,参考执行计划 "execStats" : {}, // 操作的时间戳 "ts" : ISODate("2015-09-03T15:26:14.948Z"), // 发起操作的客户端地址 "client" : "127.0.0.1", // 发起操作的应用名称,驱动支持设置应用名称 "appName" : "MongoDB Shell", // 当前会话认证的所有用户的数组 "allUsers" : [ ], // 执行此操作的用户 "user" : "" } |
需要修改剖析日志的容量时,参考以下步骤:
|
1 2 3 4 5 6 |
db.setProfilingLevel(0) db.system.profile.drop() db.createCollection( "system.profile", { capped: true, size:4000000 } ) db.setProfilingLevel(1) # 如果要修改从节点的剖析日志容量,首先需要以standalone模式启动之,然后执行上述修改 |
透明巨页(Transparent Huge Pages)是一种Linux的内存管理系统,用于减少转译后备缓冲区(Translation Lookaside Buffer ,TLB)的查询成本。由于THP倾向于导致稀疏而非连续的内存访问模式,因而不适合数据库工作负载。
要禁用透明巨页特性,参考:
|
1 2 3 4 |
# Ubuntu sudo update-rc.d disable-transparent-hugepages defaults # CentOS sudo chkconfig --add disable-transparent-hugepages |
大部分类UNIX系统提供了按用户/进程来控制文件、线程、网络连接等系统资源使用数量的手段 —— ulimits。
ulimit的默认值对于MongoDB可能太低了,需要调整。
可以基于Linux下的LVM进行文件系统级的备份/恢复。创建快照的命令示意:
|
1 2 3 4 5 6 7 |
# 针对卷组vg0中的mongodb卷创建一个名为mdb-snap01的快照 # 快照容量100M,存放此快照与文件系统最终状态的diff lvcreate --size 100M --snapshot --name mdb-snap01 /dev/vg0/mongodb # 归档压缩 umount /dev/vg0/mdb-snap01 dd if=/dev/vg0/mdb-snap01 | gzip > mdb-snap01.gz |
要基于快照恢复,可以执行:
|
1 2 3 4 5 6 |
# 在卷组vg0中创建一个名为mdb-new的逻辑卷,大小1G(根据实际MongoDB占用磁盘空间确定) lvcreate --size 1G --name mdb-new vg0 # 把之前的快照导入到逻辑卷 gzip -d -c mdb-snap01.gz | dd of=/dev/vg0/mdb-new # 挂载逻辑卷,挂载点直线 mount /dev/vg0/mdb-new /srv/mongodb |
命令mongodump/mongorestore实现基于BSON格式的备份与恢复,适合小型数据库。要实现弹性、无缝的备份,建议使用文件系统、块设备级别的快照功能进行备份。
mongodump/mongorestore需要和运行中的mongod进行交互,因而会影响数据库性能。除了网络流量方面的开销外,这两个工具还需要通过内存来读取数据。MongoDB会因此载入很少使用的数据并把常用数据清除出内存。
备份命令示例:
|
1 2 3 4 5 6 7 |
mongodump --host 172.21.2.1 --port 27017 --out /data/backup/ # 可以限制导出的数据库,甚至集合 --db cluster --collection corps # 如果服务器启用了身份验证,可以指定密码 --username user --password "passwd" # 在dump期间收集oplog,形成指向特定时间点的备份 --oplog |
恢复命令示例:
|
1 2 3 4 5 |
mongorestore --host 172.21.2.1 --port 27017 # 重做oplog --oplogReplay # 备份所在位置 /data/backup/ |
如果单机mongod禁用了日志,则意外宕机可能导致数据处于不一致状态,启动时报错: Detected unclean shutdown - mongod.lock is not empty。在数据文件目录下会存在非空的 mongod.lock 文件。这种情况下,你需要修复数据库:
- 备份数据文件目录
- 以修复模式启动数据库: mongod --dbpath /data/db --repair
要读取复制集的配置对象,调用 rs.conf()方法或者在admin数据库上调用:
|
1 |
db.runCommand( { replSetGetConfig: 1 } ) |
要修改复制集配置,调用 rs.reconfig()并传入一个配置文档:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
{ // 复制集的名称,一旦设置,不可更改。必须和配置replication.replSetName或者命令行参数--replSet一致 _id: <string>, // 递增的配置版本号,用于区分复制集配置的修订版 version: <int>, // 选举协议的版本,从3.2开始默认1 protocolVersion: <number>, // 3.4新增,protocolVersion为1默认true,否则默认false。指示{ w: "majority" }是否隐含{ j: true } writeConcernMajorityJournalDefault: <boolean>, // 指示当前复制集是否用作分片集群的配置服务器 configsvr: <boolean>, // 成员配置文档的数组 members: [ { // 成员标识符,0-255,一旦设置不得修改 _id: <int>, // 成员主机名,或者host:port,主机名必须可以从任何复制集成员进行DNS解析 host: <string>, // 布尔,用于指示该成员是否为仲裁者 arbiterOnly: <boolean>, // 默认true,mongod是否在此成员上构建索引。仅在添加复制集成员时可以设置,不得改变 // 在下列条件全部满足时,设置为false可能有用: // 1、仅仅使用该成员执行mongodump // 2、该成员从不接受查询 // 3、维护索引的成本让硬件受不了 // 即使设置为false,也会构建_id索引 // 设置为false时必须同时设置priority为0 // 其它成员不能从buildIndexes = false的成员进行复制 buildIndexes: <boolean>, // 如果设置为true,db.isMaster()的输出不包含此成员,阻止读操作转发给该成员 hidden: <boolean>, // 默认1.0,0-100之间,优先级权重,值越高,越有资格被选举为主节点 priority: <number>, // 标签集文档,可以包含任意键值对映射。用于定制读写关注,使其感知数据中心 tags: <document>, // 单位秒,默认0,用于配置延迟从节点 slaveDelay: <int>, // 投票权,默认1,可选0。仲裁者总是1 votes: <number> }, ... ], settings: { // 默认true,如果true,则允许从节点从其它从节点复制,而不仅仅时主节点 chainingAllowed : <boolean>, // 内部使用,复制集成员需要不断的相互发送心跳,确认可达性 heartbeatIntervalMillis : <int>, // 心跳超时时间,默认10s heartbeatTimeoutSecs: <int>, // 默认10000ms,用于检测主节点不可用的延迟时间。高取值延长故障转移时间但是降低对不稳定网络的敏感性 electionTimeoutMillis : <int>, // 新选举的主节点,其数据可能不是最新的,此时需要从最新的从节点同步 // 高取值避免从节点回滚数据的可能,但是延长了故障转移时间 // 同步完成之前,主节点不接受写请求 catchUpTimeoutMillis : <int>, // 用于定义扩展的写关注值,可以提供数据中心感知,例如: // { getLastErrorModes: { eastCoast: { "east": 1 } } } 允许使用写关注: // { w: "eastCoast" },表示要求写操作传播到具有east:1标签的节点上 getLastErrorModes : <document>, // 用于指定默认的写关注 getLastErrorDefaults : <document>, // 此复制集的内部唯一标识,自动创建不可更改 replicaSetId: <ObjectId> } } |
调用 rs.status()或者在admin数据库执行replSetGetStatus命令,查看当前复制集的状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
{ // 复制集名称 "set" : "replset", // 当前时间 "date" : ISODate("2016-11-02T20:02:16.543Z"), // 当前节点的复制状态 "myState" : 1, // 选举发生的次数(本节点知晓的),使用协议版本0时总是返回-1 "term" : NumberLong(1), // 心跳频率 "heartbeatIntervalMillis" : NumberLong(2000), // 用于了解复制信息细节的时间信息 "optimes" : { // 从当前节点角度看,最近一次已经传播到大部分复制集成员的写操作的发生时间 "lastCommittedOpTime" : { "ts" : Timestamp(1478116934, 1), // 操作发生的时间 "t" : NumberLong(1) // 操作发生在那次term }, // 从当前节点角度看,最近一次能满足majority读关注的操作的发生时间 "readConcernMajorityOpTime" : { "ts" : Timestamp(1478116934, 1), "t" : NumberLong(1) }, // 从当前节点角度看,最近一次应用到当前节点的操作的发生时间 "appliedOpTime" : { "ts" : Timestamp(1478116934, 1), "t" : NumberLong(1) }, // 从当前节点角度看,最近一次应用到当前节点、且已经写入日志的操作的发生时间 "durableOpTime" : { "ts" : Timestamp(1478116934, 1), "t" : NumberLong(1) } }, // 复制集成员状态 "members" : [ { "_id" : 0, "name" : "m1.example.net:27017", // 仅当前节点出现:用于指示当前节点 "self" : true, // 仅非当前节点出现:是否宕机 "health" : 1, // 复制集成员状态 "state" : 1, "stateStr" : "PRIMARY", // 此成员已经在线的时间 "uptime" : 269, // 该成员最后一次从oplog应用写操作的时间 "optime" : { "ts" : Timestamp(1478116934, 1), "t" : NumberLong(1) }, "optimeDate" : ISODate("2016-11-02T20:02:14Z"), "infoMessage" : "could not find member to sync from", // 选举发生的时间 "electionTime" : Timestamp(1478116933, 1), "electionDate" : ISODate("2016-11-02T20:02:13Z"), // 该成员最后一次从oplog应用写操作、且已经写入日志的时间 "optimeDurable" : { "ts" : Timestamp(1478116934, 1), "t" : NumberLong(1) }, "optimeDurableDate" : ISODate("2016-11-02T20:02:14Z"), // 最后一次该成员发送心跳的时间 "lastHeartbeat" : ISODate("2016-11-02T20:02:15.619Z"), // 最后一次从该成员收到心跳的时间,与上一字段的差值体现了两节点之间的网络延迟 "lastHeartbeatRecv" : ISODate("2016-11-02T20:02:14.787Z"), // PING该节点消耗的时间 "pingMs" : NumberLong(0), // 该节点的复制源 "syncingTo" : "m1.example.net:27018", // 该节点使用的复制集配置版本号 "configVersion" : 1 } ], "ok" : 1 } |
成员状态的含义参考复制集成员状态。
在生产环境下部署复制集,应当保证以下前置条件:
- 仅可能把mongod部署在不同的物理机器上。如果使用虚拟机,应当使虚拟机对应不同的物理机器。应当确保物理机器之间有冗余电路、冗余网络路径
- 保证所有节点可以相互通信
配置文件添加复制集配置:
|
1 2 |
replication: replSetName: rs0 |
创建三成员复制集:
|
1 2 3 4 |
# 创建三个mongod实例 docker run --name mongo-00 --network local --ip 172.21.0.100 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-01 --network local --ip 172.21.0.101 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-02 --network local --ip 172.21.0.102 -d docker.gmem.cc/mongo --config /etc/mongod.conf |
启动所有实例,然后在其中一个实例上,打开MongoDB Shell,执行:
|
1 2 3 4 |
rs.initiate( { _id : "rs0", members: [ { _id : 0, host : "172.21.0.100:27017" } ] }) |
现在可以执行 rs.conf() 查看复制集的配置信息,可以看到当前复制集有一个成员。接着把另外两个成员加入到复制集中:
|
1 2 |
rs.add("172.21.0.101:27017") rs.add("172.21.0.102:27017") |
现在调用 rs.status()可以看到复制集及其三个成员的状态。
注意以下几点:
- 每个复制集最多7个投票成员,如果已经有7个成员,再添加成员必须设置votes=0,或者移除既有成员的投票权
- 可以添加先前被移除的成员,如果该成员的数据没有被删除且足够新,它有可能跟得上oplog的节奏而不需要完全同步
- 如果你拥有既有成员的足够新的数据备份,拷贝备份到新成员对应dbPath目录下,可以快速添加新成员
以类似创建上面三成员的方式,再创建一个成员,启动后,在既有成员节点上执行:
|
1 |
rs.addArb("172.21.0.103:27017") |
可以执行命令:
|
1 |
rs.remove("172.21.0.102:27017") |
或者:
|
1 2 3 |
cfg = rs.conf() cfg.members.splice(2,1) rs.reconfig(cfg) |
|
1 2 3 |
cfg = rs.conf() cfg.members[0].host = "172.21.0.105" rs.reconfig(cfg) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cfg = rs.conf() # 设置优先级,范围0-1000,非投票节点的优先级必须是0 cfg.members[0].priority = 0.5 # 设置优先级为0可以阻止它成为主节点 cfg.members[1].priority = 0 # 隐藏成员对客户端不可见, isMaster的输出中不包含 cfg.members[0].hidden = true # 配置复制延迟 cfg.members[0].slaveDelay = 3600 # 禁用投票权 cfg.members[4].votes = 0 # 设置标签集 cfg.members[1].tags = { "dc": "east", "use": "reporting" } # 必须重新配置才能生效 # 注意,下面的方法会导致主节点step down然后触发选举,step down期间MongoDB会关闭所有客户端连接 # 这可能耗时10-20秒 rs.reconfig(cfg) |
这类环境下,你可能没有足够多的机器可用,只需要在命令行指定合适的端口、数据库路径、参与的复制集名称,就可以在一台机器上部署属于多个复制集的mongod:
|
1 2 3 |
mongod --port 27010 --dbpath /data/rs0-0 --replSet rs0 --smallfiles --oplogSize 128 mongod --port 27011 --dbpath /data/rs0-1 --replSet rs0 --smallfiles --oplogSize 128 mongod --port 27012 --dbpath /data/rs0-2 --replSet rs0 --smallfiles --oplogSize 128 |
通过MongoDB Shell连接时,指定端口即可连接到不同实例:
|
1 |
mongo --port 27010 |
注意以下几点:
- 网络安全性:保证成员之间、客户端与复制集之间流量的安全性。手段包括VPN、防火墙配置、启用MongoDB认证和授权机制
- 使用标签集实现数据中心感知
- 最好能保证某个数据中心完全不可用时,复制集仍然能够工作
- 不要超过7个投票成员
要对复制集成员进行维护,一般性流程如下:
- 首先对各从节点执行维护,最后对主节点进行维护
- 对于每一个节点,执行:
- 以独立模式重启mongod,对于主节点要stepDown
- 在独立模式运行的mongod下执行维护任务
- 以复制集成员方式重新启动mongod
oplog本质上是一个定长集合,默认的尺寸通常够用。可能需要增大oplog的场景例如:执行影响大量数据的update操作。
如果要修改复制集的oplog,你必须轮流对每个成员进行操作:
- 将被操作成员切换到独立运行模式:
- 如果该成员是主节点,一定要通过 rs.stepDown()将其优雅的变为从节点
- 调用 db.shutdownServer()关闭从节点
- 不带--replSet参数、以不同端口重新启动该成员
- 可选的,创建oplog的备份: mongodump --db local --collection 'oplog.rs' --port 37017
- 以新尺寸创建oplog集合:
123456789101112131415# 或者 db = db.getSiblingDB('local')use local# 创建一个临时集合,存放oplog集合的内容db.temp.drop()# 备份oplog,以自然反序排列(最新条目排在最前)db.temp.save( db.oplog.rs.find( { }, { ts: 1, h: 1 } ).sort( {$natural : -1} ).limit(1).next() )# 删除oplogdb.oplog.rs.drop()# 重建oplogdb.runCommand( { create: "oplog.rs", capped: true, size: (2 * 1024 * 1024 * 1024) } )# 导入临时集合中最后(最新)的oplog条目db.oplog.rs.save( db.temp.findOne() ) - 以复制集成员的方式重新启动该节点
要强制某个从节点成为主节点,你可以将其优先级调为最高;类似的,优先级设置为0则可以让从节点永远不能成为主节点。
通过设置高优先级来强制主节点:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 假设复制集成员 0 1 2 目前0是主节点,现在希望强制2为主节点 # 执行: cfg = rs.conf() cfg.members[0].priority = 0.5 cfg.members[1].priority = 0.5 cfg.members[2].priority = 1 rs.reconfig(cfg) # 上面的语句调用后,会发生以下时间序列: # 1、成员1/2和0进行同步(通常10秒内完成) # 2、主节点发现自己的优先级不是最高,通常会stepDown # 如果2的同步进度远远落后,则不会stepDown,等待2的optime差距在10s以后再stepDown # 3、选举发生,2当选 |
如果某个从节点复制进度远远落后,则oplog中尚未被该从节点应用到本地的条目可能已经被覆盖(定长集合循环覆盖),则该从节点变得Stale,必须进行完整的重新同步 —— 移除数据,重新执行初始同步。
执行重新同步时,应该选择一个带宽比较空闲的时机。
重新同步有两种方式:
- 将Stale节点的数据目录清空,启动后会自动执行initial sync
- 从其它复制集成员拷贝数据目录,启动后可以增量同步。注意要一并拷贝local数据库的内容
启用链式复制的情况下,从节点可以从其它从节点复制,不一定非要主节点。
启用或者禁用链式复制:
|
1 2 3 |
cfg = rs.config() cfg.settings.chainingAllowed = true | false rs.reconfig(cfg) |
要修改某个从节点的复制源,可以:
|
1 |
rs.syncFrom("hostname<:port>"); |
|
查看状态 调用 rs.status()可以查看复制集、复制集成员的当前状态 |
||
|
检查复制日志 复制延迟是指从节点应用来自主节点的oplog的落后时间,复制延迟是复制集部署中较为严重的问题:
要查看复制延迟,执行 rs.printSlaveReplicationInfo(),输出如下:
复制延迟的原因可能是:
|
||
|
无法选举 同时重启多个从节点时,要确保可投票节点的大部分在线,否则主节点会stepDown并变为从节点,客户端会被断开连接 |
||
|
查看oplog信息 调用 rs.printReplicationInfo()可以查看oplog的尺寸和条目信息,输出如下:
|
首先,①部署配置服务复制集,生产环境下应该部署最少3个成员。
配置文件添加分片集群角色配置:
|
1 2 3 4 5 |
replication: replSetName: rsc sharding: clusterRole: configsvr |
创建复制集的三成员:
|
1 2 3 |
docker run --name mongo-c1 --network local --ip 172.21.1.1 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-c2 --network local --ip 172.21.1.2 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-c3 --network local --ip 172.21.1.3 -d docker.gmem.cc/mongo --config /etc/mongod.conf |
连接到其中一个成员,进行复制集的初始化:
|
1 2 3 4 5 6 7 8 9 10 11 |
rs.initiate( { _id: "rsc", configsvr: true, members: [ { _id : 0, host : "172.21.1.1:27017" }, { _id : 1, host : "172.21.1.2:27017" }, { _id : 2, host : "172.21.1.3:27017" } ] } ) |
一旦配置服务复制集(CSRS)创建完毕,即可②创建分片复制集,生产环境下,每个分片复制集因该部署最少3个成员。
第一个分片复制集的配置:
|
1 2 3 4 5 |
replication: replSetName: rs0 sharding: clusterRole: shardsvr |
创建复制集的三成员:
|
1 2 3 |
docker run --name mongo-51 --network local --ip 172.21.5.1 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-52 --network local --ip 172.21.5.2 -d docker.gmem.cc/mongo --config /etc/mongod.conf docker run --name mongo-53 --network local --ip 172.21.5.3 -d docker.gmem.cc/mongo --config /etc/mongod.conf |
连接到其中一个成员,进行复制集的初始化:
|
1 2 3 4 5 6 7 8 9 10 |
rs.initiate( { _id : "rs5", members: [ { _id : 0, host : "172.21.5.1:27017" }, { _id : 1, host : "172.21.5.2:27017" }, { _id : 2, host : "172.21.5.3:27017" } ] } ) |
参考以上方法,创建更多的分片复制集。
③创建一个路由器(mongos)并连接到配置复制集,使用如下配置文件:
|
1 2 3 4 5 6 7 |
net: port: 27017 bindIp: 0.0.0.0 sharding: configDB: rsc/172.21.1.1:27017,172.21.1.2:27017,172.21.1.3:27017 # 至少需要指定一个配置复制集成员的地址 |
创建mongos:
|
1 |
docker run --name mongo-s1 --network local --ip 172.21.99.1 -d docker.gmem.cc/mongo mongos --config /etc/mongos.conf |
④连接到mongos: mongo --host 172.21.99.1
⑤将分片复制集添加到集群中:
|
1 2 3 4 |
# 添加一个复制集 sh.addShard( "rs2/172.21.2.1:27017") # 你也可以添加独立MongoDB实例 sh.addShard( "172.21.0.1:27017") |
⑥为数据库启用分片支持,只有这样,该数据库中才可以有分片集合:
|
1 |
sh.enableSharding("cluster") |
现在,你可以查看分片集群的状态,在mongos上执行 sh.status(),输出如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
--- Sharding Status --- # 这一段显示配置数据库的基本信息 sharding version: { # 配置元数据的唯一标识 "_id" : 1, # 配置服务器最小的兼容版本号 "minCompatibleVersion" : 5, # 当前配置元数据的版本 "currentVersion" : 6, # 分片集群的唯一标识 "clusterId" : ObjectId("5982e147eb7a3c5622dd9bc3") } # 此集群中包含的分片 shards: # _id 分片的唯一标识 # host 分片的主机,如果复制集,显示所有成员的地址 # state 分片的状态 # tags,分片的标签集 { "_id" : "rs2", "host" : "rs2/172.21.2.1:27017,172.21.2.2:27017,172.21.2.3:27017", "state" : 1 } { "_id" : "rs3", "host" : "rs3/172.21.3.1:27017,172.21.3.2:27017,172.21.3.3:27017", "state" : 1 } { "_id" : "rs4", "host" : "rs4/172.21.4.1:27017,172.21.4.2:27017,172.21.4.3:27017", "state" : 1 } { "_id" : "rs5", "host" : "rs5/172.21.5.1:27017,172.21.5.2:27017,172.21.5.3:27017", "state" : 1 } # 活动的mongos的版本和数量 active mongoses: # 版本:数量 "3.4.5" : 1 # 是否启用了Chunk自动分裂 autosplit: Currently enabled: yes # 负载均衡器的状态 balancer: # 目前集群是否启用了负载均衡器 Currently enabled: yes # 负载均衡器是否正在工作(迁移Chunk) Currently running: no Balancer lock taken at Thu Aug 03 2017 08:39:36 GMT+0000 (UTC) by ConfigServer:Balancer # 最近五次负载均衡尝试,失败的次数,如果Chunk迁移失败,则负载均衡失败 Failed balancer rounds in last 5 attempts: 0 # 最近24小时迁移的数量 Migration Results for the last 24 hours: No recent migrations # 此集群中包含的数据库 databases: # _id 数据库的名称 # primary 主分片所在 # partitioned 该数据库是否支持分片 { "_id" : "cluster", "primary" : "rs2", "partitioned" : true } |
创建范围分片的集合示例:
|
1 |
sh.shardCollection("cluster.corps", { regNo : 1 }, true ) |
再次查看分片集群状态,可以看到databases段有新增内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 集合的名称 cluster.corps # 分片键: { <shard key> : <1 or hashed> } shard key: { "regNo" : 1 } # 是否对分片键应用了唯一性约束 unique: true # 是否对该集合启用了负载均衡 balancing: true # 块的详细信息 chunks: # 下面是一个列表,以Shard名称:拥有块的数量显示 rs2 1 # 分片键范围对应的Shard,以及最后修改的时间 # { <shard key>: <min range1> } -->> { <shard key> : <max range1> } on : <shard name> <last modified timestamp> { "regNo" : { "$minKey" : 1 } } -->> { "regNo" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0) |
如果配置管理服务器复制集变为只读状态(无主节点)则分片集群不支持对元数据的写操作,因而Chunk分裂、迁移无法执行。这种情况下,你应该尽快修复或者替换损坏的配置管理复制集成员。替换成员的步骤:
- 以选项--configsvr --replSet启动新成员
- 在成员节点上,将新成员添加到复制集rs.add()
- 关闭被替换的成员
- 在成员节点上,移除被替换成员rs.remove()
- 可选的,更新mongos的--configdb选项
|
列出支持分片的数据库
|
||
|
列出所有分片
|
||
|
查看集群详细信息 调用db.printShardingStatus()或者sh.status() |
如果要把整个分片集群迁移到新的硬件上,可以参考以下步骤:
- 禁用负载均衡器 sh.stopBalancer(),这样可以防止Chunk迁移、元数据写。如果当前正在Chunk迁移,负载均衡器会等待其终止
- 单独的迁移各个配置服务器。从3.4开始,配置服务器应以复制集的方式部署,使用 WiredTiger引擎。另外注意,此复制集必须:没有仲裁者、没有延迟成员、启用buildIndexes。具体迁移步骤:
- 在新硬件上开启一个配置服务实例(使用适当的选项启动mongod,例如--configsvr --replSet rsc)
- 添加到配置服务器复制集中
- 移除被替换的旧硬件成员,主节点要先StepDown
- 从复制集中移除被替换成员
- 循环上面4步,直到所有成员都迁移
- 重新启动mongos,指向新的配置服务器
- 进行分片的迁移,一个个分片的迁移,先迁移从节点,最后主节点。具体迁移步骤:
- 调用shutdown命令,关闭一个成员,主节点要先StepDown
- 移动数据目录(dbPath)到新硬件
- 在新硬件上启动mongod,并连接到当前主节点
- 如果主机名/IP变化了,要执行rs.reconfig()来重新配置复制集
- 等待此节点恢复正常,调用rs.status()查看节点状态
- 循环上面5步,直到所有成员都迁移
- 重新启用负载均衡器
从分片集群中添加、删除分片,可能会导致负载再平衡(Chunk迁移)。估算一下总计的迁移数据量,抽生产环境空闲的时段执行增减。
增加分片的方式:
- 配置好分片复制集
- 调用 sh.addShard()增加分片
删除分片的方式:
- 确保负载均衡器被启用,因为移除分片必然面临Chunk迁移
- 执行 db.adminCommand( { listShards: 1 } )来决定要移除的分片
- 在admin数据库上执行移除命令:
12use admindb.runCommand( { removeShard: "mongodb0" } ) - 验证Chunk迁移完成,再次调用上述命令,系统会报告迁移进度:
123456789101112{// 正在迁移被移除节点上的Chunk"msg" : "draining ongoing","state" : "ongoing","remaining" : {// 剩余的Chunk数量"chunks" : 42,// 剩余的主分片位于被移除Shard的数据库数量"dbs" : 1},"ok" : 1}反复检查此命令,直到remaining为0
- 移动未分片集合。如果被删除分片是某个数据库的主分片,则需要转移主分片:
- 检查主分片分布情况
sh.status():
12# 数据库products的主分片为mongodb0(被删除分片){ "_id" : "products", "partitioned" : true, "primary" : "mongodb0" } -
移动主分片,执行命令:
12# 移动数据库products的主分片到mongodb1db.runCommand( { movePrimary: "products", to: "mongodb1" })该命令会阻塞,直到移动完成
- 检查主分片分布情况
sh.status():
- 再次执行命令以清除所有元数据:
12use admindb.runCommand( { removeShard: "mongodb0" } )理想的输出应该是:
123456{"msg" : "removeshard completed successfully","state" : "completed", // 删除分片成功"shard" : "mongodb0","ok" : 1}
如果某个Chunk超过指定的大小,或者包含的文档数量超过限制,则MongoDB将其标记为 jumbo。如果元数据变更后,jumbo不再超过限制,则MongoDB自动取消其标记。
如果要手工清除标记,执行:
- 对于可分裂(Divisible)Chunk,最好的方式是将其split,分裂成功后,MongoDB会清除jumbo标记:
- 通过客户端连接到mongos
- 执行
sh.status(true)找到jumbo,例如:
1234test.fooshard key: { "x" : 1 }...{ "x" : 2 } -->> { "x" : 4 } on : shard-a Timestamp(2, 2) jumbo - 对于上面这个分片键值范围为[2,4),因此可以从分片键值3一分为二。分裂成功后jumbo标记自动清除:
1sh.splitAt( "test.foo", { x: 3 })
- 对于不可见(Indivisible)Chunks,某些情况下jumbo不能再次分裂,比如它仅仅包含一个分片键值,此时的清除步骤如下:
- 临时的停止负载均衡器
- 备份config数据库: mongodump --db config --port <config server port> --out <output file>
- 连接到mongos
- 执行sh.status(true)找到不可再分的Chunk,例如:
1{ "x" : 2 } -->> { "x" : 3 } on : shard-a Timestamp(2, 2) jumbo可以看到,该jumbo仅仅一个分片键值2,因此无法再分裂
- 手工修改配置数据库:
12345db.getSiblingDB("config").chunks.update({ ns: "test.foo", min: { x: 2 }, jumbo: true },# 清除标记{ $unset: { jumbo: "" } }) - 重新启动负载均衡器
- 刷空元数据缓存: db.adminCommand({ flushRouterConfig: 1 } )
集群的配置数据库包含了集群的所有元数据,特别是Chunk如何映射到Shard,应该定期备份防止丢失。
备份步骤:
- 停止负载均衡器
- 关闭一个配置服务器复制集的成员
- 拷贝其dbPath下所有数据文件,备份起来
- 启动关闭的配置服务器复制集成员
- 重新启用负载均衡器
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
#!/bin/bash run_docker(){ type=$1 ipfx=$type shrole=shardsvr if [[ $type = "c" ]]; then : ipfx= shrole=configsvr fi num=$2 docker run --name mongo-$type$num --network local --ip 172.21.1.$ipfx$num -d docker.gmem.cc/mongo --auth \ --replSet=rs$type --$shrole --config /etc/mongod.conf (( num++ )) docker run --name mongo-$type$num --network local --ip 172.21.1.$ipfx$num -d docker.gmem.cc/mongo --auth \ --replSet=rs$type --$shrole --config /etc/mongod.conf (( num++ )) docker run --name mongo-$type$num --network local --ip 172.21.1.$ipfx$num -d docker.gmem.cc/mongo --auth \ --replSet=rs$type --$shrole --config /etc/mongod.conf } init_rs(){ type=$1 ipfx=$type cfgsvr= if [[ $type = "c" ]]; then : ipfx= cfgsvr="configsvr: true," fi num=$2 num1=$num (( num++ )) num2=$num (( num++ )) num3=$num read -d '' scr <<EOF rs.initiate( { _id: "rs$type", $cfgsvr members: [ { _id : 0, host : "172.21.1.$ipfx$num1:27017" }, { _id : 1, host : "172.21.1.$ipfx$num2:27017" }, { _id : 2, host : "172.21.1.$ipfx$num3:27017" } ] } ) EOF echo Prepare to execute Replica Set init script on mongo-$type$2: echo "$scr" docker exec mongo-$type$2 mongo --eval "$scr" } docker stop mongo-11 mongo-13 mongo-22 mongo-31 mongo-33 mongo-42 mongo-51 mongo-53 mongo-c7 \ mongo-s1 mongo-12 mongo-21 mongo-23 mongo-32 mongo-41 mongo-43 mongo-52 mongo-c6 mongo-c8 docker rm mongo-11 mongo-13 mongo-22 mongo-31 mongo-33 mongo-42 mongo-51 mongo-53 mongo-c7 mongo-s1 \ mongo-12 mongo-21 mongo-23 mongo-32 mongo-41 mongo-43 mongo-52 mongo-c6 mongo-c8 run_docker c 6 run_docker 1 1 run_docker 2 1 run_docker 3 1 run_docker 4 1 run_docker 5 1 sleep 3 init_rs c 6 init_rs 1 1 init_rs 2 1 init_rs 3 1 init_rs 4 1 init_rs 5 1 docker run --name mongo-s1 --network local --ip 172.21.1.1 -d docker.gmem.cc/mongo mongos \ --configdb=rsc/172.21.1.6:27017,172.21.1.7:27017,172.21.1.8:27017 --config /etc/mongos.conf read -d '' scr <<EOF sh.addShard( "rs1/172.21.1.11:27017") sh.addShard( "rs2/172.21.1.21:27017") sh.addShard( "rs3/172.21.1.31:27017") sh.addShard( "rs4/172.21.1.41:27017") sh.addShard( "rs5/172.21.1.51:27017") db.getSiblingDB('admin').createUser( { user: "root", pwd: "root", roles: [ { role: "root", db: "admin" } ] } ) EOF docker exec mongo-s1 mongo --eval "$scr" |
要改变使用的认证机制,设置mongod/mongos的参数 authenticationMechanisms。
支持的认证机制列表:
| 机制 | 说明 |
| SCRAM-SHA-1 | 3.0之前的版本,MongoDB使用MONGODB-CR作为默认的,质询/响应式的身份验证机制。之后的版本默认使用SCRAM-SHA-1 |
| MONGODB-CR | |
| x.509 | 基于数字证书的身份验证,该机制支持外部验证(客户端)、内部验证(复制集/分片集群) |
这种认证机制要求使用TLS/SSL连接,X509可以实现客户端验证和内部验证。在生产环境中使用时,你需要具有单个CA签发的有效证书。可以选择自己维护CA。
客户端可以提供X.509证书来代替用户名/密码,进行登录验证。复制集/分片集群成员可以用X.509来代替keyfile进行相互验证。
所谓外部验证,是指针对MongoDB客户端的身份验证和访问控制。
注意,当没有创建任何用户时,通过localhost匿名登录不受访问限制(Localhost Exception)。但是,一旦创建了任意用户,就不能再用匿名登录。你创建的第一个用户,必须具有创建新用户的权限 —— 针对admin数据库具有 userAdmin 或者userAdminAnyDatabase 权限的用户,后续使用该用户管理普通的MongoDB用户,例如创建、授权、角色管理。
启用步骤:
- 不启用身份验证的情况下,启动mongod
- 通过Shell连接到mongod
- 创建管理员用户(注意,用户一旦创建,以后你就不能通过localhost匿名登录了):
12345678use admindb.createUser({user: "root",pwd: "root",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]}) - 启用身份验证,重启mongod: mongod --auth
- 通过Shell连接,你可以:
- 提供身份信息连接: mongo --port 27017 -u "root" -p "root" admin
- 不提供身份信息,连接到Shell后,调用 db.auth("root","root")进行验证
- 添加普通用户:
123456789use clusterdb.createUser({user: "cluster",pwd: "cluster",roles: [ { role: "readWrite", db: "cluster" },{ role: "read", db: "reporting" } ]})
keyfiles基于SCRAM-SHA-1认证机制。keyfile的内容作为集群成员的共享密钥使用。密钥的长度在6-1024字节之间,仅仅支持base64字符,空白符被自动去除。在UNIX系统中,keyfile不得授予组、全局访问权限。
对于相互连接的所有mongos/mongod实例,它们必须具有相同的keyfile,否则无权加入到复制集或者连接到分片集群。keyfile通过配置项 security.keyFile指定。
为复制集启用keyfiles认证的步骤:
- 创建keyfile,可以使用openssl生成随机密钥:
12openssl rand -base64 756 > <path-to-keyfile>chmod 400 <path-to-keyfile> - 拷贝keyfile到所有复制集成员
- 关闭复制集,连接到每一个mongod,并执行:
12use admindb.shutdownServer() - 在启用访问控制的情况下启动复制集:
12security:keyFile: <path-to-keyfile> - 使用Shell连接到主节点
- 创建管理员用户:
1234567db.getSiblingDB('admin').createUser({user: "root",pwd: "root",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]}) - 以管理员身份登录: db.getSiblingDB("admin").auth("root", "root" )
- 可选的,创建具有clusterAdmin角色的集群(能管理整个复制集、分片集群)管理用户:
1234567db.getSiblingDB("admin").createUser({"user" : "ca","pwd" : "ca",roles: [ { "role" : "clusterAdmin", "db" : "admin" } ]})
为分片集群启用keyfiles认知的步骤:
- 创建keyfile
- 拷贝keyfile到所有分片集群成员
- 禁用负载均衡器:
123sh.stopBalancer()# 查看负载均衡器状态,确保停止后进行下一步sh.getBalancerState() - 关闭所有mongos实例,通过Shell连接到mongos,执行
1db.getSiblingDB("admin").shutdownServer() - 关闭所有配置服务器实例,类似步骤4
- 关闭所有分片复制集的所有成员,类似步骤4
- 修改所有mongos、mongod的配置文件,启用security.keyFile选项
- 启动分片,可选的,创建分片本地管理员用户。通过Shell连接到分片复制集的主节点进行创建
- 启动mongos,通过localhost匿名登录,创建管理员,至少需要userAdminAnyDatabase角色
- 以管理员身份登录mongos,创建具有clusterAdmin角色的集群管理用户
- 使用集群管理用户登录
- 启动负载均衡器
MongoDB使用基于角色的访问控制(RBAC)。一个用户被授予1-N个角色,这些角色决定了用户能够对数据库进行哪些操作。
在配置文件中启用 security.authorization设置,或者使用 --auth命令行选项,即可启用访问控制。
所谓角色,即特权(privileges)的组合,每个特权可以针对某个资源进行某种操作。角色可以存在继承层次,子角色继承父角色的所有特权。
要查看角色具有哪些特权,执行:
|
1 2 3 4 5 6 7 |
db.runCommand({ rolesInfo: { role: <name>, db: <db> }, # 设置为true则显示角色的特权 showPrivileges: <Boolean>, # 如果设置为true,则db.runCommand({rolesInfo:1})的输出包含内部角色 showBuiltinRoles: <Boolean> }) |
内置角色列表:
| 角色 | 说明 |
|
数据库用户角色 每个数据库都具有以下两个角色
|
|
| read |
读取所有非系统集合、system.indexes、system.js、system.namespaces上的数据 |
| readWrite | 读写所有非系统集合、system.js上的数据 |
|
数据库管理角色 每个数据库都具有以下角色 |
|
| dbAdmin | 执行Schema相关的管理,管理索引,收集统计信息 |
| dbOwner | readWrite, dbAdmin,userAdmin的组合 |
| userAdmin | 管理数据库上的角色和用户 |
|
集群管理角色 admin数据库具有以下角色 |
|
| clusterAdmin | 对集群有很宽泛的管理权,合并clusterManager, clusterMonitor,hostManager,且支持dropDatabase操作 |
| clusterManager | 对集群进行管理监控,可以访问config、local数据库 |
| clusterMonitor | 只读权限 |
| hostManager | 监控和管理服务器 |
|
备份还原角色 admin数据库具有以下角色 |
|
| backup | 支持数据库备份操作 |
| restore | 支持数据库还原操作 |
|
全数据库角色 admin数据库具有以下角色,自动应用到除了local、config之外的所有数据库 |
|
| readAnyDatabase | 对除了local、config之外的所有数据库(包括集群中)进行读操作 |
| readWriteAnyDatabase | 对除了local、config之外的所有数据库(包括集群中)进行读写操作 |
| userAdminAnyDatabase | 对除了local、config之外的所有数据库(包括集群中)进行用户管理操作 |
| dbAdminAnyDatabase | 对除了local、config之外的所有数据库(包括集群中)具有类似于dbAdmin的特权 |
| 超级用户角色 | |
| root | readWriteAnyDatabase, dbAdminAnyDatabase, userAdminAnyDatabase,clusterAdmin, restore,backup的组合 |
特权即: 资源和针对该资源可以进行的操作。资源可以是:数据库、集合、一系列集合、集群。
默认情况下,复制集仅仅允许在主节点上执行读操作,要允许在从节点上进行读,在主节点上执行: rs.slaveOk()
在MongoDB Shell中执行命令: DBQuery.shellBatchSize = 100
Leave a Reply