Apache Storm学习笔记
Apache Storm是一个分布式的实时计算系统,它能够可靠的对无边界的数据流进行处理。与Hadoop的批量处理方式不同,Storm对数据进行的是实时处理。Storm很简单,支持很多编程语言。
Storm的应用场景包括:实时分析、在线机器学习、持续计算、分布式RPC、分布式ETL。
Storm的性能很好,每个节点在一秒内能够处理多达100万个元组。Storm支持无限制扩容、容错、并且保证数据能够被处理。
你可以让既有的数据库、消息队列系统和Storm进行集成。Storm拓扑消费数据流,以任意复杂的方式处理数据流,数据流可以在任何计算阶段(Stage)重新分区。
实时计算的逻辑被封装到Storm拓扑中,拓扑和MapReduce的Job类似。一个关键的区别是,MapReduce Job最终会结束,而拓扑则一直运行下去。
你可以使用TopologyBuilder构建一个拓扑。
Storm把每个具体的工作委托给多种类型的组件处理。这些组件都装配在拓扑中。
拓扑可以跨越Storm集群的多个工作节点运行。
流是Storm的核心抽象,它是无边界的元组的序列。流以分布式的风格被并行的创建、处理。流的元素是元组,元组可以包含整数、字符串、浮点数、布尔、比特数组等类型的字段。你可以自己实现串行化器,支持任何自定义数据类型。
你可以使用OutputFieldsDeclarer来声明流以及流的Schema。在声明的时候,每个流被赋予一个标识符。仅仅释放单个流的Spout很常见,因此OutputFieldsDeclarer提供了声明单个流的便捷方法,不需要指定标识符,流的标识符自动设置为default。
Storm中被处理的数据的基本单元,本质上就是一个预定义的字段的值列表。
Spout可以释放出元组,不同的Bolt可以读取同一Spout产生的元组,并释放不同格式的元组,供其它Bolt消费。
在拓扑中,Spout是流的来源。一般来说,Spout从外部读取元组,并释放(Emit)出元组的流(Spout本意即喷射口)。Spout可以是可靠的(Reliable )或者不可靠的。可靠的Spout支持在处理失败后重复(Replay)元组。所有Spout必须实现IRichSpout接口。
Spout可以释放不止一个流,你可以多次调用 OutputFieldsDeclarer的 declareStream。你可以指定 SpoutOutputCollector.emit调用释放哪个流。
Spout的主要方法是nextTuple,调用它可以释放一个新的元组到拓扑中,如果没有可用的元组,该方法应该简单的返回。Storm强制要求所有Spout实现类的nextTuple方法是非阻塞性的,因为Storm在单个线程中调用Spout的所有方法。
其它重要的方法包括ack、fail,这些方法仅仅针对可靠Spout调用,分别在元组顺利通过拓扑后、处理失败后调用,将处理结果通知给Spout。
Spout将数据传递给Bolt这种组件进行实质上的逻辑处理。拓扑中最主要的内容就是Bolt构成的链条。
拓扑中所有处理逻辑发生在Bolt中,Bolt可以进行过滤、聚合、Join等操作,可以和数据库进行交互。
Bolt可以进行简单的流变换(Stream Transformation),复杂的流变换通常需要多个步骤,也就需要多个Bolt。
Bolt可以释放不止一个流,你可以多次调用 OutputFieldsDeclarer的 declareStream。你可以指定 OutputCollector.emit调用释放哪个流。
在声明Bolt的输入流时,你需要订阅其它组件的某个特定流,如果要订阅某个组件的多个流,你需要逐个订阅。InputDeclarer提供了订阅具有默认标识符的流的快捷方法,例如 declarer.shuffleGrouping("1")订阅组件1的 DEFAULT_STREAM_ID流。在构建拓扑时,你也可以声明这种流订阅。
Bolt的主要方法是execute,此方法接受一个元组输入。Bolt使用OutputCollector对象释放新的元组。Bolt会针对每个输入元组调用OutputCollector.ack方法,以通知Storm目标元组已经处理成功,这些ack调用最终导致Spout.ack被调用。大部分Bolt根据输入元组输出0-N个输出元组。IBasicBolt提供自动确认(Ack)功能。
在Bolt中启动新线程进行异步处理是很好的做法,OutputCollector是线程安全的,你可以在任何时候调用它。
Bolt的基础接口是IRichBolt。要设计进行过滤、简单function的Bolt可以选择实现IBasicBolt接口。Bolt调用OutputCollector来释放元组到它的输出流中。
定义拓扑的一部分工作是,指定每个Bolt能够接受哪些流作为其输入。流分组(Stream Grouping)指定了如何在Bolt的Task之间进行流的分区(Partition)。
Storm可以保证每个元组都被拓扑处理。为了确认元组的处理过程,Storm对Spout释放出的元组树进行跟踪,并以此确定何时元组树被成功处理。每个拓扑都具有一个消息超时属性,如果在此超时到达之前没有检测到元组已经处理成功,则认定处理失败,并Replay目标元组。
之所有叫元组树,是因为在任何一个Bolt中,一个源元组可能产生多个目标元组,这样经过多个Bolt后,就形成树状依赖关系。注意,目的和源的依赖关系需要编程式的声明,一个目标元组可以依赖于多个源元组。
每个Spout、Bolt在集群中执行一定数量的Task,每个Task对应一个执行线程。流分组决定了元组如何从一组Task分发到另外一组Task。调用TopologyBuilder的setSpout/setBolt方法可以设置并发度。
Topology跨越1-N个工作进程执行,每个工作进程都是一个JVM实例,负责执行拓扑中所有Task的一个子集。Storm会尝试尽可能平均的分配Task给Worker。例如,一个总和并行度为300的拓扑,分配了50个工作进程,则每个进程需要执行6个Task。
Storm集群包含两类节点:
- 主节点(Master):这类节点运行一个名为Nimbus的守护程序。此程序负责在集群中分发代码(处理逻辑)、向工作节点分配Task、监控Task是否执行失败
- 工作节点(Worker):这类节点运行一个名为Supervisor的守护程序。此程序负责执行拓扑的某个部分
Storm支持在本地磁盘或者ZooKeeper上保存集群的所有状态信息,因此守护程序宕机不会对系统的健康状况产生影响。
Storm和Hadoop的核心概念的对应关系如下图:
| Storm | Hadoop | |
| 组件 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| Child | Worker | |
| 应用 | Job | Topology |
| 接口 | Mapper/Reducer | Spout /Bolt |
Storm提供四类内置的调度器: DefaultScheduler, IsolationScheduler, MultitenantScheduler, ResourceAwareScheduler。
Storm有两种运行模式(Operation Modes)。
在此模式下,Storm的拓扑在本地机器中单个JVM中运行。此模式主要用于开发、测试和调试。
在此模式下,我们需要将定义好的拓扑提交到Storm集群中。集群通常由运行在很多机器中的进程组成。远程模式下不会显示调试信息,通常用于产品环境。
你也可以在单台机器上进行远程模式的部署。
Storm包含若干不同的守护进程,Nimbus能够调度Worker进程,Supervisors负责启动、杀死Worker进程。Logger View让你能够访问日志。Web服务器让你能够通过GUI查看Storm状态。
当Worker进程死掉后,Supervisor会重新启动它。如果Worker反复死掉并且不能完成到Nimbus的心跳检测,Nimbus会重新调度此Worker。
当节点宕机后,Nimbus会重新分配在节点上执行的Task给其它节点。
Nimbus/Supervisor被设计为无状态的,所有状态信息存放在ZooKeeper或者磁盘上。因此它们宕机后,你可以安全的重启它们。你应该考虑使用daemontools/monit之类的工具监控这类进程的状态,并在它们死掉后立即重启。
如果Nimbus节点(Master)宕机,Worker节点仍然会继续工作。此外Supervisor仍然会自动重启死掉的Worker进程。但是没有Nimbus就不能把Worker节点分配到其它机器上。从1.0.0开始,Storm支持Nimbus的HA。
在本章,我们创建一个简单的,分析动力环境监测值的拓扑。
此类型模拟监测值采集程序,以随机的方式产生监测值:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
package cc.gmem.study.storm.mv; import com.fasterxml.jackson.databind.ObjectMapper; import org.apache.commons.lang3.RandomUtils; import org.apache.commons.lang3.Range; import org.apache.commons.lang3.mutable.MutableInt; import org.apache.commons.lang3.tuple.Pair; import org.slf4j.Logger; import java.util.*; import java.util.concurrent.TimeUnit; import static org.slf4j.LoggerFactory.getLogger; public class MessageSource extends Thread { private Map<String, Pair<Double, Double>> config; private ObjectMapper om; Queue<String> messages; private static final Logger LOGGER = getLogger( MessageSource.class ); private boolean term; public MessageSource( Map<String, Pair<Double, Double>> config ) { super(); this.config = config; this.messages = new LinkedList<>(); this.om = new ObjectMapper(); start(); } @Override public void run() { setName( "MessageSource" ); LOGGER.debug( "Starting monitoring value source thread" ); while ( true ) { if ( term ) { LOGGER.debug( "Terminating monitoring value source" ); break; } List<Map<String, Object>> mvs = new ArrayList<>(); MutableInt idPfx = new MutableInt( 10 ); config.forEach( ( type, pair ) -> { int n = RandomUtils.nextInt( 1, 5 ); for ( int i = 0; i < n; i++ ) { Map<String, Object> mv = new LinkedHashMap<>(); double value = RandomUtils.nextDouble( pair.getLeft(), pair.getRight() ); mv.put( "id", idPfx.intValue() + RandomUtils.nextInt( 1, 5 ) ); mv.put( "type", type ); mv.put( "value", value ); mvs.add( mv ); } idPfx.add( 10 ); } ); LOGGER.debug( "Generated new message with {} monitoring value", mvs.size() ); try { String msg = om.writeValueAsString( mvs ); messages.offer( msg ); TimeUnit.SECONDS.sleep( 10 ); } catch ( Exception e ) { LOGGER.error( e.getMessage(), e ); } } } public boolean available() { return !messages.isEmpty(); } public String nextMessage() { return messages.poll(); } public void singalTerm() { this.term = true; } } |
MessageReader是此拓扑中唯一的Spout,从MessageSource中读取监测值报文并直接传递给Bolt处理。
任何Spout需要实现IRichSpout接口,你可以选择继承缺省适配BaseRichSpout。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
package cc.gmem.study.storm.mv; import org.apache.commons.lang3.tuple.ImmutablePair; import org.apache.commons.lang3.tuple.Pair; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.IRichSpout; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.LinkedHashMap; import java.util.List; import java.util.Map; import java.util.concurrent.TimeUnit; public class MessageReader implements IRichSpout { private static final Logger LOGGER = LoggerFactory.getLogger( MessageReader.class ); private MessageSource msgSrc; private SpoutOutputCollector collector; /** * 当前组件的任一个Task在集群的某个工作节点中初始化时,自动调用此方法 * * @param conf 配置信息,在创建拓扑时指定的配置合并到当前机器的集群配置而成 * @param context 拓扑的上下文信息,可以获得组件ID、Task ID、输入输出信息 * @param collector 输出收集器,线程安全,应该作为实例变量 * 此收集器可以在任何时候调用,以释放元组供下游组件消费 */ @Override public void open( Map conf, TopologyContext context, SpoutOutputCollector collector ) { LOGGER.debug( "Spout {}/{} opening", context.getThisComponentId() ,context.getThisTaskId()); Map<String, Pair<Double, Double>> config = new LinkedHashMap<>(); // 读取配置信息 List<List<Object>> msgSrcCfg = (List<List<Object>>) conf.get( "msgSrcCfg" ); msgSrcCfg.forEach( typeCfg -> { config.put( (String) typeCfg.get( 0 ), new ImmutablePair( (Double) typeCfg.get( 1 ), (Double) typeCfg.get( 2 ) ) ); } ); this.msgSrc = new MessageSource( config ); this.collector = collector; } /** * 当此Spout即将被关闭时调用 * <p> * 注意:此方法通常不保证一定被调用,因为在集群中Supervisor会以kill -9杀死工作进程。 * 当以本地模式运行Storm时,此方法保证被调用 */ @Override public void close() { LOGGER.debug( "Spout closing" ); msgSrc.singalTerm(); } /** * 当Spout被激活后调用,激活后nextTuple很快被调用 * 使用Storm客户端可以激活或者禁用Spout */ @Override public void activate() { } /** * 当Spout被禁用后调用,处于禁用状态的Spout的nextTuple不会被调用 */ @Override public void deactivate() { } /** * 此方法会被周期性的调用,释放下一个元组 */ @Override public void nextTuple() { if ( !msgSrc.available() ) { try { // 休眠至少10ms再返回,避免无限制的CPU占用 TimeUnit.MILLISECONDS.sleep( 10 ); return; } catch ( InterruptedException e ) { } } // Values是对ArrayList<Object>的简单封装,其值可以是任何可串行化的Java对象 String msg = msgSrc.nextMessage(); LOGGER.debug( "Emit new tuple: {}", msg ); this.collector.emit( new Values( msg ) ); } /** * 当此Spout释放出的具有指定ID的元组已经成功通过拓扑之后,Storm调用此方法 * 此方法的典型实现是,将对应数据从队列中移除并且阻止它被Replay * * @param msgId 元组的ID */ @Override public void ack( Object msgId ) { LOGGER.debug( "Tuple with id {} acknowledged", msgId ); } /** * 当此Spout释放出的具有指定ID的元组在某个环节处理失败后,Storm调用此方法 * 此方法的典型实现是,将对应数据放回队列,以便后续Replay * * @param msgId 元组的ID */ @Override public void fail( Object msgId ) { LOGGER.debug( "Tuple with id {} failed", msgId ); } /** * 此方法来自IComponent接口,用于声明针对此组件的配置。仅topology.*之下的配置可以被覆盖 * 当通过TopologyBuilder构建拓扑时,这里声明的配置可能被覆盖 * * @return */ @Override public Map<String, Object> getComponentConfiguration() { return null; } /** * 此方法来自IComponent接口,声明输出元组包含的字段 */ @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { // 为当前组件的默认输出流声明字段 // 你还可以调用 declarer.declareStream( streamId,fields ) 声明新的输出流 declarer.declare( new Fields( "message" ) ); } } |
这是一个Bolt,读取监测值报文并解析之,释放多个监测值信息元组。
任何Bolt都需要实现IRichBolt接口。你可以选择实现IBasicBolt(继承BaseBasicBolt),这样Storm会自动进行元组确认(Ack),使用IBasicBolt时你可以抛出FailedException表示当前元组处理失败。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
package cc.gmem.study.storm.mv; import com.fasterxml.jackson.databind.ObjectMapper; import org.apache.commons.lang3.mutable.MutableInt; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.IRichBolt; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import org.slf4j.Logger; import java.io.IOException; import java.util.List; import java.util.Map; import static org.slf4j.LoggerFactory.getLogger; public class MessageParser implements IRichBolt { private static final Logger LOGGER = getLogger( MessageParser.class ); private ObjectMapper om; private OutputCollector collector; /** * 当前组件的任一个Task在集群的某个工作节点中初始化时,自动调用此方法 * 类似Spout的open方法 */ @Override public void prepare( Map stormConf, TopologyContext context, OutputCollector collector ) { LOGGER.debug( "Bolt {}/{} preparing", context.getThisComponentId(), context.getThisTaskId() ); om = new ObjectMapper(); this.collector = collector; } /** * 处理单个输入元组,每当接收到新元组此方法都被调用 * Tuple对象包含一些元数据信息:此元组来自什么component/stream/task * 调用Tuple#getValue可以获得元组的实际数据 * <p> * Bolt不一定要立刻处理元组,例如你可能暂存它并在后续进行聚合或连接操作 * 每个元组都需要在未来某个时刻被ack/fail,否则Storm无法确认Spout释放的原初元组释放已经被完整除了 * 子接口IBasicBolt支持在execute()执行完毕后自动ack * <p> * 如果此Bolt要释放元组,需要调用prepare传入的OutputCollector * * @param input The input tuple to be processed. */ @Override public void execute( Tuple input ) { // 一个Bolt获得的元组可能来自不同的流 LOGGER.debug( "Received input tuple from {}", input.getSourceStreamId() ); // 元组字段可以根据名称或者索引读取 String msg = input.getStringByField( "message" ); try { List<Map<String, Object>> mvs = om.readValue( msg, List.class ); MutableInt count = new MutableInt( 0 ); mvs.forEach( mv -> { collector.emit( new Values( mv.get( "id" ), mv.get( "type" ), mv.get( "value" ) ) ); count.increment(); } ); LOGGER.debug( "{} monitoring value parsed", count.intValue() ); } catch ( IOException e ) { collector.fail( input ); } collector.ack( input ); } /** * 此Bolt即将被关闭时调用,此调用不保证一定发生 * 类似Spout的close方法 */ @Override public void cleanup() { } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { declarer.declare( new Fields( "id", "type", "value" ) ); } @Override public Map<String, Object> getComponentConfiguration() { return null; } } |
这是一个Bolt,它读取MessageParser释放的监测值元组,然后进行实时统计分析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
package cc.gmem.study.storm.mv; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; import org.slf4j.Logger; import java.math.BigDecimal; import java.math.RoundingMode; import java.util.Map; import static java.math.BigDecimal.ONE; import static java.math.BigDecimal.ZERO; import static org.slf4j.LoggerFactory.getLogger; public class MonitorValueCounter extends BaseBasicBolt { private static final Logger LOGGER = getLogger( MonitorValueCounter.class ); BigDecimal[] counter; @Override public void prepare( Map stormConf, TopologyContext context ) { LOGGER.debug( "Bolt {}/{} preparing", context.getThisComponentId(), context.getThisTaskId() ); counter = new BigDecimal[]{ ZERO /*计数*/, ZERO /*平均*/, BigDecimal.valueOf( Integer.MAX_VALUE ) /*最小*/, ZERO /*最大*/ }; } @Override public void execute( Tuple input, BasicOutputCollector collector ) { String type = input.getStringByField( "type" ); BigDecimal value = BigDecimal.valueOf( input.getDoubleByField( "value" ) ); if ( counter[2].compareTo( value ) > 0 ) counter[2] = value; if ( counter[3].compareTo( value ) < 0 ) counter[3] = value; if ( counter[0].equals( ZERO ) ) { counter[0] = ONE; counter[1] = value; } else { BigDecimal newCount = counter[0].add( ONE ); counter[1] = counter[1].multiply( counter[0] ).add( value ).divide( newCount, RoundingMode.HALF_EVEN ); counter[0] = newCount; } LOGGER.debug( "Type: " + type + ", Count: {}, Avg: {}, Min: {}, Max: {}", counter ); } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { } } |
主程序,创建拓扑并提交到集群中执行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
package cc.gmem.study.storm.mv; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.generated.StormTopology; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import java.util.ArrayList; import java.util.List; import java.util.concurrent.TimeUnit; public class MonitorValueStatTopology { public static void main( String[] args ) throws InterruptedException { TopologyBuilder builder = new TopologyBuilder(); // 每个组件都具有一个ID,供其它组件引用,以消费此组件的输出 builder.setSpout( "message-reader", new MessageReader() ); builder.setBolt( "message-parser", new MessageParser() ) .shuffleGrouping( "message-reader" ); // 消费message-reader的默认流,随机、均匀分发元组给当前Bolt builder.setBolt( "monitor-value-counter", new MonitorValueCounter() ) // 设置并发度 .setNumTasks( 3 ) // 消费message-parser的默认流,根据输入元组的type字段分发到不同的Task // 如果Task数量不足,则type字段值不同的元组会被分发给同一个Task .fieldsGrouping( "message-parser", new Fields( "type" ) ); Config conf = new Config(); List<Values> msgSrcCfg = new ArrayList<>(); msgSrcCfg.add( new Values( "温度", new Double( 0 ), new Double( 40 ) ) ); msgSrcCfg.add( new Values( "湿度", new Double( 0 ), new Double( 100 ) ) ); msgSrcCfg.add( new Values( "电压", new Double( 0 ), new Double( 360 ) ) ); conf.put( "msgSrcCfg", msgSrcCfg ); conf.setDebug( true ); // 对于每一个Spout Task,处于未决状态的元组最大数量 // 所谓未决,即元组尚未被ack/fail conf.put( Config.TOPOLOGY_MAX_SPOUT_PENDING, 1 ); // 创建一个本地模式的Storm集群 LocalCluster cluster = new LocalCluster(); // 创建拓扑 StormTopology topology = builder.createTopology(); // 提交拓扑到集群 cluster.submitTopology( "monitor-value-stat-topology", conf, topology ); TimeUnit.SECONDS.sleep( 60 ); // 关闭集群 cluster.shutdown(); } } |
Storm对于下述运行在集群中的拓扑中的实体:
- 工作进程(Worker processes)
- 执行器(Executors,线程)
- 任务(Task)
进行了明确的区分:
- Storm集群中的节点(机器)可以运行0-N个工作进程,这些工作进程可以属于1-N个拓扑。每个工作进程就是一个JVM,它仅仅为单个拓扑运行Executor。也就是说Worker不能被两个拓扑共享
- 单个Worker进程中可以运行1-N个Executor,每个Executor都是Worker进程产生的线程。每个Executor运行单个拓扑的单个组件的1-N个Task。也就是说Executor不能被两个组件共享
- 任务进行实际的数据处理,它执行Spout或者Bolt中的代码逻辑。它由Executor来执行
可以看到:
- 工作进程执行一个拓扑的子集,它只能属于一个拓扑
- 工作进程可以运行多个执行器线程,这些线程可以运行不同的组件。但是每个线程只能运行一种组件的任务
- 任务必须在执行器线程内部运行
要对并行度进行配置,参考并发度配置。
流分组指定了如何在Bolt的Task之间进行流的分区(Partition)——流的每个元组应该由哪个Task处理。
在定义拓扑的时候,你可以为Bolt指定流分组,指定流分组的同时也就指定了Bolt的数据源。你可以针对一个bolt多次指定流分组,也就是指定多个输入流:
|
1 2 3 4 |
builder.setBolt( "monitor-value-counter", new MonitorValueCounter() ) .fieldsGrouping( "message-parser", new Fields( "type" ) ) // 为Bolt指定另一个输入:signals-reader组件的signals流 .allGrouping("signals-reader","signals"); |
要实现自己的流分组,需要实现CustomStreamGrouping接口。通常情况下,你应该优先考虑使用Storm内置的流分组。
| 流分组 | 说明 | ||
| Shuffle | 最常用的一种流分组。元组被随机的分发给Bolt的Task,此实现保证每个Task接受相等数量的元组 | ||
| Fields |
根据元组的字段值进行分组,字段值相同的元组被分发给同一个Task 可以基于1-N个字段的值进行分组 |
||
| Partial Key | 元组首先按照字段分组的方式被分区,并进一步的被两个下游的Bolt进行负载均衡 | ||
| All |
输入流的每个元组被复制到Bolt的所有实例(Task) 需要执行某种广播逻辑时,考虑使用这种流分组 |
||
| Global | 整个流被转发给单个具有最小Id的那个Task | ||
| None | 表示不关心如何进行分组,当前此分组的行为和Shuffle类似。Storm在处理这种方式分组的流时,上游Spout/Bolt和下游Bolt使用同一执行线程 | ||
| Direct |
上游Spout/Bolt(生产者)直接决定元组分发给下游Bolt(消费者)的哪个Task 这种分组方式仅仅能应用到被声明为直接流(Direct Stream)的流上。要释放元组到直接流上,必须调用OutputCollector.emitDirect方法。获得消费者的Task Id途径可以是:
示例代码:
|
||
| Local or shuffle | 如果下游Bolt在相同(与释放流的组件)工作进程(Work Process)中行运行着一个或者更多的Task,则元组被分发给这些进程内的Task。否则,行为与Shuffle grouping相同 |
实现CustomStreamGrouping、Serializable接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
package cc.gmem.study.storm.mv; import org.apache.storm.generated.GlobalStreamId; import org.apache.storm.grouping.CustomStreamGrouping; import org.apache.storm.task.WorkerTopologyContext; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.Serializable; import java.util.List; import static org.slf4j.LoggerFactory.getLogger; // 实现Serializable接口,Storm需要跨JVM分发此对象 public class DeviceStreamGrouping implements CustomStreamGrouping, Serializable { private static final Logger LOGGER = getLogger( DeviceStreamGrouping.class ); private List<Integer> targetTasks; /** * 初始化流分组实例,告知流分组必要的信息 * * @param context 拓扑上下文 * @param stream 此分组应用到的流 * @param targetTasks 接收流的bolt的Task Id的列表 */ @Override public void prepare( WorkerTopologyContext context, GlobalStreamId stream, List<Integer> targetTasks ) { LOGGER.debug( "Apply grouping on stream {}.{}", stream.get_componentId(), stream.get_streamId() ); this.targetTasks = targetTasks; } /** * 确定元组分发到哪个Task * * @param taskId 源组件产生当前元组的那个Task的Id * @param values 当前元组 * @return 接受此元组的Task Id列表 */ @Override public List<Integer> chooseTasks( int taskId, List<Object> values ) { return targetTasks; } } |
使用上述自定义流分组:
|
1 |
builder.setBolt(...).customGrouping( "message-parser", new DeviceStreamGrouping() ); |
此类用于在当前JVM中建立一个本地模式的集群。通常在开发阶段使用,可以方便的对各种拓扑进行调试:
|
1 2 3 4 |
LocalCluster cluster = new LocalCluster(); StormTopology topology = builder.createTopology(); // 提交到本地集群 cluster.submitTopology( "topology-name", conf, topology ); |
此类用于将拓扑提交到一个远程Storm集群中运行。与本地模式不同,你不能对远程集群进行控制。
|
1 |
StormSubmitter.submitTopology("monitor-value-stat-topology", conf, builder.createTopology()); |
下文有一个实际的例子。
通过storm客户端命令,也可以将拓扑提交到远程集群。首先你需要打JAR包,然后执行:
|
1 2 3 4 |
# 提交执行,需要指定main方法及其参数,main方法调用了StormSubmitter.submitTopology storm jar topology.jar cc.gmem.study.storm.mv.MonitorValueStatTopology arg0 arg1... # 要终止提交的拓扑,需要传入其Id storm kill monitor-value-stat-topology |
注意,JAR的入口函数必须调用submitTopology。
本节列出常见的拓扑模式(Pattern)。
很多情况下,出于效率的考虑,你可能希望一批批的处理元组,而不是一个个的。例如,你可能希望批量的将元组入库,以利用数据库的吞吐能力。
你可以简单的将元组存储到实例变量中,等到积累的足够多了,批量的处理它们然后统一Ack。
如果执行批处理的Bolt释放元组,你可能需要使用多重锚定,确定输出元组和输入元组之间的因果关系。
很多Bolt都是读取一个输入元组、处理后根据此元组释放0-N个元组,最后对输入元组进行Ack。基于IBasicBolt可以获得此模式的封装。
经过字段分组之后,该字段一样的元组总是由同一个Bolt处理。假设Bolt需要根据该字段进行某种转换,那么在Bolt实例变量中缓存这种转换结果,其缓存性能会较高。
例如,一个Bolt负责接收短URL并展开它,展开需要通过HTTP来调用第三方服务,因此缓存展开URL很有必要。可以在Bolt中创建一个短URL到展开URL的HashMap作为缓存。配合字段分组,让相同短URL总是分发给同一Bolt实例,这样上述缓存的命中率会比不分组高得多。
某些情况下,你需要处理很多输入元组,并且释放出其中最xx的10个元组。
最简单的方案是,使用全局流分组,也就是让所有元组都输入到单个Bolt实例中。这种方案可能会导致性能瓶颈。
一个改进的方案是,让多个Bolt都进行TopN计算,在一个下游的Bolt中,重新进行一次TopN计算:
|
1 2 3 4 |
builder.setBolt("rank", new RankObjects(), parallelism) .fieldsGrouping("objects", new Fields("value")); // 字段分组,每个实例进行自己的TopN计算 builder.setBolt("merge", new MergeObjects()) .globalGrouping("rank"); // 全局分组,但是要处理的数据量很少,不会出现瓶颈 |
我们知道,基于ack/fail可以保证消息:
- 要么完全通过拓扑
- 要么,可选的,进行Replay
问题是,如果进行Replay时,如何保证事务性?或者说,如何保证某些逻辑不会重复执行。
从0.7开始,Storm引入了事务性拓扑,可以保证Replay安全的进行,确保它们仅仅被处理一次。
在事务性拓扑中,Storm混合使用并行、串行的元组处理流。Spout生成的一批元组,被并行的发送给Bolt处理。某些Bolt被称为Committer,它们按照严格有序的方式提交已经被处理过的元组批次。
例如,Spout释放两个元组批次,每个批次包含5个元组,这两个元组被并发的交付Bolt处理,但是,如果链条中存在Committer Bolt,则在此Bolt批次必须严格有序的串行化 —— 它不会在第一个批次成功提交之前,提交第二个批次。
Storm事务由两个部分阶段组成:
- 处理阶段:完全并行阶段,很多批次可以被同时的执行
- 提交阶段:完全有序阶段,保证批次按照顺序逐一执行
我们以一个Twitter分析工具的例子来了解事务性拓扑的工作机制。此工具的逻辑如下:
- 读取Tweets并存储到Redis
- 通过若干Bolt处理Tweets
- 将处理结果存放到另一个Redis数据库,处理结果包括:所有主题标签(Hashtag)的及其出现次数、用户及其出现在Tweet中的次数、主题标签和用户出现在同一Tweet中的次数
用于构建此工具的拓扑示意如下:
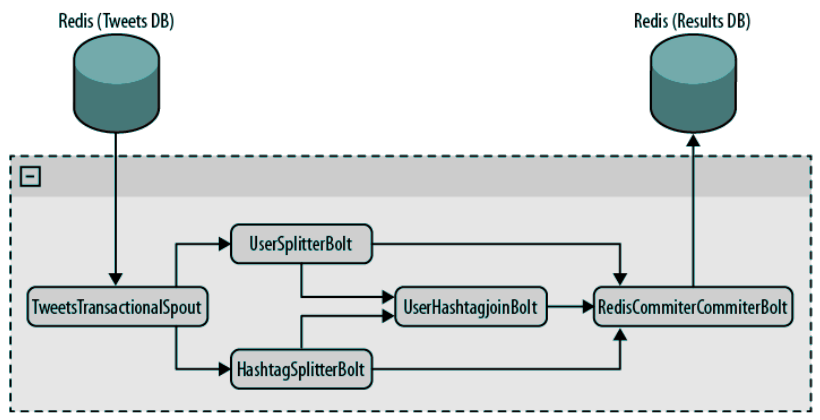
说明如下:
- TweetsTransactionalSpout连接到数据源,读取并释放元组批次到拓扑
- 随后的两个Bolt会接受所有元组
- UserSplitterBolt,从Tweet中搜索用户(@之后的单词)
- HashatagSplitter,从Tweet中搜索主题标签(#之后的单词)
- 后面的UserHashtagJoinBolt,对前面两个Bolt的结果进行Join,获得每个用户+标签的组合同时出现的次数。此Bolt是BaseBatchBolt的子类型
- 最后的RedisCommitterBolt是一个Committer,它接受3个流。进行各种统计,并在处理完一批次后进行入库
相关说明已经附加在源码注释:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 |
package cc.gmem.study.storm.twt; import org.apache.storm.coordination.BatchOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.topology.base.BaseBatchBolt; import org.apache.storm.topology.base.BaseTransactionalBolt; import org.apache.storm.topology.base.BaseTransactionalSpout; import org.apache.storm.transactional.ICommitter; import org.apache.storm.transactional.ITransactionalSpout; import org.apache.storm.transactional.TransactionAttempt; import org.apache.storm.transactional.TransactionalTopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import redis.clients.jedis.Jedis; import redis.clients.jedis.Transaction; import java.io.Serializable; import java.math.BigInteger; import java.util.*; public class TwitterAnalyticsTool { /* 封装Redis相关操作 */ public static class RQ { // 存放下一个读取游标的键 public static final String NEXT_READ = "NEXT_READ"; // 存放下一个写入游标的键 public static final String NEXT_WRITE = "NEXT_WRITE"; Jedis jedis; public RQ() { jedis = new Jedis( "localhost" ); } /* 可读Tweet量 */ public long getAvailableToRead( long current ) { return getNextWrite() - current; } public long getNextRead() { String sNextRead = jedis.get( NEXT_READ ); if ( sNextRead == null ) return 1; return Long.valueOf( sNextRead ); } public long getNextWrite() { return Long.valueOf( jedis.get( NEXT_WRITE ) ); } public void close() { jedis.disconnect(); } public void setNextRead( long nextRead ) { jedis.set( NEXT_READ, "" + nextRead ); } /* 从指定游标from开始,读取quantity条Tweet */ public List<String> getMessages( long from, int quantity ) { String[] keys = new String[quantity]; for ( int i = 0; i < quantity; i++ ) keys[i] = "" + ( i + from ); return jedis.mget( keys ); } } /** * 事务元数据,释放元组批次时用到此元数据: * from 事务的起始游标 * quantity 事务处理Tweet的数量 * <p> * 元数据必须包含Replay此事务所牵涉到的批次的所需要的全部信息 */ public static class TransactionMetadata implements Serializable { private static final long serialVersionUID = 1L; long from; int quantity; public TransactionMetadata( long from, int quantity ) { this.from = from; this.quantity = quantity; } } /** * 协调器,整个拓扑中仅仅有单个协调器实例 */ public static class TweetsTransactionalSpoutCoordinator implements ITransactionalSpout.Coordinator<TransactionMetadata> { private static final long MAX_TRANSACTION_SIZE = 16; RQ rq = new RQ(); long nextRead = 0; public TweetsTransactionalSpoutCoordinator() { nextRead = rq.getNextRead(); } /** * 根据上一次事务的元数据,确定本次事务的元数据 * <p> * 元数据必须包含Replay此事务所牵涉到的批次的所需要的全部信息 * <p> * 元数据被存放在ZooKeeper中,以txid为键。如果事务失败,Storm可以通过Emtter重放此事务 * * @param txid 本次事务标识符,此事务从未被提交过 * @param prevMetadata 上一个事务的元数据 * @return 本次事务的元数据 */ @Override public TransactionMetadata initializeTransaction( BigInteger txid, TransactionMetadata prevMetadata ) { long quantity = rq.getAvailableToRead( nextRead ); quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity; TransactionMetadata ret = new TransactionMetadata( nextRead, (int) quantity ); nextRead += quantity; return ret; } /** * 如果可以发起新事务,返回true。如果不可以,应当睡眠一段时间然后返回false * 如果此方法返回true,initializeTransaction()被调用 * * @return */ @Override public boolean isReady() { return rq.getAvailableToRead( nextRead ) > 0; } @Override public void close() { rq.close(); } } /** * 发射器,根据事务元数据,从数据源读取一批次数据,并释放到流中 */ public static class TweetsTransactionalSpoutEmitter implements ITransactionalSpout.Emitter<TransactionMetadata> { RQ rq = new RQ(); /** * 释放一个批次,此方法的实现一定要能够重复执行 ———— 根据txId、txMeta必须可以重新释放此批次 * * @param tx 当前事务尝试 * @param txMeta 事务元数据 * @param collector 用于释放元组 */ @Override public void emitBatch( TransactionAttempt tx, TransactionMetadata txMeta, BatchOutputCollector collector ) { // 移动读游标 if ( tx.getAttemptId() == 0 ) { // attempt id存放当前事务重复的次数,由此可以推断是否Replay rq.setNextRead( txMeta.from + txMeta.quantity ); } // 读取一批消息 List<String> messages = rq.getMessages( txMeta.from, txMeta.quantity ); long tweetId = txMeta.from; // 下面释放的消息都在批次中 for ( String message : messages ) { collector.emit( new Values( tx, String.valueOf( tweetId ), message ) ); tweetId++; } } @Override public void cleanupBefore( BigInteger txid ) { } @Override public void close() { rq.close(); } } /** * 和普通的Spout不同,事务性Spout扩展自泛型接口BaseTransactionalSpout */ public static class TweetsTransactionalSpout extends BaseTransactionalSpout<TransactionMetadata> { /* 指定用来协调批次生成的协调器 */ @Override public Coordinator<TransactionMetadata> getCoordinator( Map conf, TopologyContext context ) { return new TweetsTransactionalSpoutCoordinator(); } /* 指定发射器,负责读取源中的一批元组,并释放到流中 */ @Override public Emitter<TransactionMetadata> getEmitter( Map conf, TopologyContext context ) { return new TweetsTransactionalSpoutEmitter(); } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { declarer.declare( new Fields( "txid", "tweet_id", "tweet" ) ); } } /* 针对当前Tweet中每个@的用户,释放一个 tweetId,userId 元组 */ public static class UserSplitterBolt extends BaseBasicBolt { private static final long serialVersionUID = 1L; @Override public void execute( Tuple input, BasicOutputCollector collector ) { String tweetId = input.getStringByField( "tweet_id" ); String tweet = input.getStringByField( "tweet" ); StringTokenizer strTok = new StringTokenizer( tweet, " " ); TransactionAttempt tx = (TransactionAttempt) input.getValueByField( "txid" ); HashSet<String> users = new HashSet<String>(); while ( strTok.hasMoreTokens() ) { String user = strTok.nextToken(); // 如果一个Tweet中,用户出现两次,仅仅计算一次 if ( user.startsWith( "@" ) && !users.contains( user ) ) { // 释放到users流 collector.emit( "users", new Values( tx, tweetId, user ) ); users.add( user ); } } } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { // 声明非默认流 declarer.declareStream( "users", new Fields( "txid", "tweet_id", "user" ) ); } } /* 针对当前Tweet中每个主题标签,释放一个 tweetId,hashTag 元组 */ public static class HashtagSplitterBolt extends BaseBasicBolt { @Override public void execute( Tuple input, BasicOutputCollector collector ) { String tweet = input.getStringByField( "tweet" ); String tweetId = input.getStringByField( "tweet_id" ); StringTokenizer strTok = new StringTokenizer( tweet, " " ); TransactionAttempt tx = (TransactionAttempt) input.getValueByField( "txid" ); HashSet<String> words = new HashSet<String>(); while ( strTok.hasMoreTokens() ) { String word = strTok.nextToken(); if ( word.startsWith( "#" ) && !words.contains( word ) ) { collector.emit( "hashtags", new Values( tx, tweetId, word ) ); words.add( word ); } } } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { // 声明非默认流 declarer.declareStream( "hashtags", new Fields( "txid", "tweet_id", "hashtag" ) ); } } /** * UserHashtagJoinBolt是一个BaseBatchBolt,这意味着: * 1、execute处理接收到的元组,但是不释放任何新元组 * 2、在本批次的元组处理完毕后,Storm自动调用finishBatch */ public static class UserHashtagJoinBolt extends BaseBatchBolt { /* 每个Tweet都有哪些Tag */ private Map<String, Set<String>> tweetHashtags; /* 每个用户都被哪些Tweet @ */ private Map<String, Set<String>> userTweets; private BatchOutputCollector collector; private Object id; private void add( Map<String, Set<String>> map, String key, String val ) { Set<String> vals = map.get( key ); if ( vals == null ) { vals = new HashSet<>(); map.put( key, vals ); } vals.add( val ); } /** * 对于每一个事务,都会调用此方法 * * @param id 事务标识符 */ @Override public void prepare( Map conf, TopologyContext context, BatchOutputCollector collector, Object id ) { tweetHashtags = new HashMap<>(); userTweets = new HashMap<>(); this.collector = collector; this.id = id; } /* 生成两个映射关系 */ @Override public void execute( Tuple tuple ) { String source = tuple.getSourceStreamId(); String tweetId = tuple.getStringByField( "tweet_id" ); if ( "hashtags".equals( source ) ) { String hashtag = tuple.getStringByField( "hashtag" ); add( tweetHashtags, tweetId, hashtag ); } else if ( "users".equals( source ) ) { String user = tuple.getStringByField( "user" ); add( userTweets, user, tweetId ); } } /* 处理完当前批次后调用。进行JOIN操作,得到每个用户和每个主题标签一起被提及的频率 */ @Override public void finishBatch() { for ( String user : userTweets.keySet() ) { Set<String> tweets = getUserTweets( user ); HashMap<String, Integer> hashtagsCounter = new HashMap<String, Integer>(); for ( String tweet : tweets ) { Set<String> hashtags = getTweetHashtags( tweet ); if ( hashtags != null ) { for ( String hashtag : hashtags ) { Integer count = hashtagsCounter.get( hashtag ); if ( count == null ) count = 0; count++; hashtagsCounter.put( hashtag, count ); } } } for ( String hashtag : hashtagsCounter.keySet() ) { int count = hashtagsCounter.get( hashtag ); collector.emit( new Values( id, user, hashtag, count ) ); } } } private Set<String> getTweetHashtags( String tweet ) { return tweetHashtags.get( tweet ); } private Set<String> getUserTweets( String user ) { return userTweets.get( user ); } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { declarer.declare( new Fields( "txid", "user", "hashtag", "count" ) ); } } /** * RedisCommiterCommiterBolt是一个Committer,这是由标记性接口ICommitter指定的。 * 你也可以TransactionalTopologyBuilder.setCommiterBolt将一个Bolt设置为Committer * <p> * 和普通BaseBatchBolt不同之处是,Committer的finishBatch方法仅仅在可以提交的时候才执行,也就是说 * 只有当前面的所有事务均成功提交之后,Committer才会提交当前事务。 * <p> * 同一拓扑中所有事务,在Committer都是串行执行的 */ public static class RedisCommiterCommiterBolt extends BaseTransactionalBolt implements ICommitter { public static final String LAST_COMMITED_TRANSACTION_FIELD = "LAST_COMMIT"; TransactionAttempt id; BatchOutputCollector collector; Jedis jedis; HashMap<String, Long> hashtags = new HashMap<String, Long>(); HashMap<String, Long> users = new HashMap<String, Long>(); HashMap<String, Long> usersHashtags = new HashMap<String, Long>(); private void count( HashMap<String, Long> map, String key, int count ) { Long value = map.get( key ); if ( value == null ) value = (long) 0; value += count; map.put( key, value ); } @Override public void prepare( Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt id ) { this.id = id; this.collector = collector; this.jedis = new Jedis( "localhost" ); } @Override public void execute( Tuple tuple ) { String origin = tuple.getSourceComponent(); if ( "users-splitter".equals( origin ) ) { String user = tuple.getStringByField( "user" ); count( users, user, 1 ); } else if ( "hashtag-splitter".equals( origin ) ) { String hashtag = tuple.getStringByField( "hashtag" ); count( hashtags, hashtag, 1 ); } else if ( "user-hashtag-merger".equals( origin ) ) { String hashtag = tuple.getStringByField( "hashtag" ); String user = tuple.getStringByField( "user" ); String key = user + ":" + hashtag; Integer count = tuple.getIntegerByField( "count" ); count( usersHashtags, key, count ); } } /** * 一定要记住:保存上一次事务的ID,在执行提交时,再次检查此ID是否和当前事务ID重复 * * 这样可以防止Replay时,入库逻辑被重复执行 */ @Override public void finishBatch() { // 获得上一次事务ID String lastCommitedTransaction = jedis.get( LAST_COMMITED_TRANSACTION_FIELD ); String currentTransaction = String.valueOf( id.getTransactionId() ); // 当前事务已经提交过,直接返回 if ( currentTransaction.equals( lastCommitedTransaction ) ) return; // 开启Redis事务 Transaction multi = jedis.multi(); // 更新上一次事务ID multi.set( LAST_COMMITED_TRANSACTION_FIELD, currentTransaction ); Set<String> keys = hashtags.keySet(); // 更新统计信息 for ( String hashtag : keys ) { Long count = hashtags.get( hashtag ); multi.hincrBy( "hashtags", hashtag, count ); } keys = users.keySet(); for ( String user : keys ) { Long count = users.get( user ); multi.hincrBy( "users", user, count ); } keys = usersHashtags.keySet(); for ( String key : keys ) { Long count = usersHashtags.get( key ); multi.hincrBy( "users_hashtags", key, count ); } multi.exec(); } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { } } @SuppressWarnings( "deprecation" ) public static void main( String[] args ) { // 可以使用TransactionalTopologyBuilder构建事务性拓扑,目前此类的功能已经被Trident代替 String topoId = "twitter-analytics-tool"; // 拓扑的标识符,Storm基于此标识符在ZooKeeper中存储事务性Spout的状态 String spoutId = "spout"; // Spout的标识符 TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder( topoId, spoutId, new TweetsTransactionalSpout() ); builder.setBolt( "users-splitter", new UserSplitterBolt(), 4 ).shuffleGrouping( "spout" ); builder.setBolt( "hashtag-splitter", new HashtagSplitterBolt(), 4 ).shuffleGrouping( "spout" ); builder.setBolt( "user-hashtag-merger", new UserHashtagJoinBolt(), 4 ) .fieldsGrouping( "users-splitter", "users", new Fields( "tweet_id" ) ) .fieldsGrouping( "hashtag-splitter", "hashtags", new Fields( "tweet_id" ) ); builder.setBolt( "redis-committer", new RedisCommiterCommiterBolt() ) .globalGrouping( "users-splitter", "users" ) .globalGrouping( "hashtag-splitter", "hashtags" ) .globalGrouping( "user-hashtag-merger" ); } } |
事务性拓扑提供了一种可靠的批量处理语义,其关键在于:
- 提供了组装元组批次,也就是事务的机制,并且信息持久化在ZooKeeper中,不会因为宕机而丢失
- 提供了串行有序执行语义,你只需要记录一个事务标识符 —— 上一个事务的标识符,因为任何时刻只会有一个事务正在准备提交
流是连续不断的元组序列。任何Spout、Bolt都可以释放0-N个流。
通过 JoinBolt,Storm支持将多个流合并为一个。JoinBolt是一个窗口化(Windowed)的Bolt,它会等待进行合并的多个流的Window duration匹配,确保流依据窗口边界对齐。
每个参与合并的流,必须是根据Join字段进行分fieldsGrouping,也就是说,Join字段一样的元组必须由同一Task处理。
考虑如下SQL语句:
|
1 2 3 4 5 |
select userId, key4, key2, key3 from table1 inner join table2 on table2.userId = table1.key1 inner join table3 on table3.key3 = table2.userId left join table4 on table4.key4 = table3.key3 |
对应的流连接如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
JoinBolt jbolt = new JoinBolt("spout1", "key1") // from spout1 // 我组件 我键 他组件 .join ("spout2", "userId", "spout1") // inner join spout2 on spout2.userId = spout1.key1 .join ("spout3", "key3", "spout2") // inner join spout3 on spout3.key3 = spout2.userId .leftJoin ("spout4", "key4", "spout3") // left join spout4 on spout4.key4 = spout3.key3 // 选择输出字段 .select ("userId, key4, key2, spout3:key3") // chose output fields // 滚动窗口,时长10分钟 .withTumblingWindow( new Duration(10, TimeUnit.MINUTES) ) ; // 你也可以调用withWindow()配置滑动窗口 topoBuilder.setBolt("joiner", jbolt, 1) // 参与连接的流必须以Join字段分组 .fieldsGrouping("spout1", new Fields("key1") ) .fieldsGrouping("spout2", new Fields("userId") ) .fieldsGrouping("spout3", new Fields("key3") ) .fieldsGrouping("spout4", new Fields("key4") ); |
在Join某个流之前,你必须先引入它:
|
1 2 3 4 |
new JoinBolt( "spout1", "key1") // arg0引入 arg2连接到 .join( "spout2", "userId", "spout3") // 错误:spout3尚未引入 .join( "spout3", "key3", "spout1"); |
实际Join发生的顺序,就是用户声明的顺序。
上面流连接的例子中,都使用了组件名称,而不是流名称。Storm支持基于流名称连接,但是很多组件仅仅释放一个流,且流名称默认为default,要基于流名称连接,必须先定义好命名流。
|
1 2 3 4 5 |
// 提示此JoinBolt基于流名称而非组件名称引用参与连接的流 new JoinBolt(JoinBolt.Selector.STREAM, "stream1", "key1").join("stream2", "key2"); topoBuilder.setBolt("joiner", jbolt, 1) // 配置流分组时要指定流的名称 .fieldsGrouping("bolt1", "stream1", new Fields("key1") ) |
- 目前仅仅支持内连接(INNER)和左连接(LEFT)
- SQL支持针对一个表,通过多个字段分别Join。Storm不支持,每个流有且仅有一个字段能用于Join,该字段用于流分组,确保键相同的分组发送给同一Task
- 要使用多字段连接,你需要将它们合并为单个字段
- 连接操作可能占用很高的CPU和内存。当前窗口中累积的数据越多,则连接消耗的时间越长。使用滑动窗口时,越短的滑动间隔导致越频繁的连接操作。因此太长的窗口、太短的滑动间隔都可能导致性能问题
- 使用滑动窗口时,多个窗口之间可能存在重复的Joined记录,这是因为这些记录的源元组可能跨越多个窗口存在
- 如果使用消息超时,应当正确设置topology.message.timeout.sec,确保它能够匹配窗口大小,同时考虑拓扑中其它组件可能消耗的时间
- 连接两个流时,假设窗口大小分别为M、N,那么最坏的情况下可能产生M x N个输出元组,下游Bolt将会释放更多的ACK。这种情况下,Storm的消息子系统可能面临很大的压力,不小心使用可能导致拓扑运行缓慢。下面是管理消息子系统的一些建议:
- 增加Worker的堆大小: topology.worker.max.heap.size.mb
- 如果拓扑不需要ACK,可以禁用它: topology.acker.executors=0
- 禁用事件记录器: topology.eventlogger.executor=0
- 禁用拓扑调试功能: topology.debug=false
- topology.max.spout.pending设置要匹配完整窗口需要的大小,附加额外的一些空间。这可以避免消息子系统过载时Spout仍然不停释放元组,该项设置为null时更容易发生此情况
- 在能够满足需求的情况下,窗口应该尽量的小
本章主要讨论设计拓扑入口点 —— Spout的通用策略,以及如何让Spout支持容错。
在设计拓扑时,考虑消息可靠性需求是一个重要事项。当一个消息无法完成处理时,你需要决定针对此消息进行怎样的处理?整个拓扑有应该有怎样的行为。打个比方,在处理银行存款业务时,每个交易消息都不能丢失;单是在处理百万级数据的统计信息时,丢失一部分消息则不会对结果精确性产生太大影响。
在Storm中,拓扑的设计者负责保证消息的可靠性。这常常需要权衡考虑,因为拓扑需要更多的资源以管理消息不丢失。
你可以在释放元组时为其指定标识符:
|
1 2 |
// 此重载版本为SpoutOutputCollector特有,Bolt使用的OutputCollector没有此方法 collector.emit(new Values(...),tupleId) |
如果不指定标识符,Storm会自动生成一个。在消费者中可以调用 input.getMessageId()获得元组的Id。
当消费者针对元组进行ack/fail操作时,生产者的ack/fail回调会被调用,并传入确认/失败的那个元组。至于如何处理失败的元组,需要根据具体业务场景决定,常见的做法是放回消息队列。
引起元组失败的原因有两种:
- 消费者调用 collector.fail(tuple)
- 元组处理的时间超过配置的时限, Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS
最简单的接入方式是Spout直接连接到数据源(Message Emitter)。如果数据源是明确的(Well-known)的设备(在这里是一个抽象概念,理解为一般性的数据源即可)或者设备组,这种方式实现起来很简单。
所谓明确的,是指在拓扑启动时设备就就是已知的(Known)并且在拓扑运行期间它保持不变。所谓未知设备,就是在拓扑运行之后才添加进来的。
所谓明确设备组,就是其中所有设备都是已知的一组设备。
下面是一个基于Twitter流API的拓扑,它使用直接连接的接入方式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
package cc.gmem.study.storm.twt; import com.esotericsoftware.kryo.util.IdentityMap; import com.fasterxml.jackson.databind.ObjectMapper; import org.apache.storm.shade.org.apache.http.HttpResponse; import org.apache.storm.shade.org.apache.http.StatusLine; import org.apache.storm.shade.org.apache.http.client.CredentialsProvider; import org.apache.storm.shade.org.apache.http.client.methods.HttpGet; import org.apache.storm.shade.org.apache.http.impl.client.DefaultHttpClient; import org.apache.storm.spout.SpoutOutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichSpout; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.Map; public class TwitterStreamSpout extends BaseRichSpout { private static final String STREAMING_API_URL = "..."; private CredentialsProvider credentialProvider; private String track; private ObjectMapper om; private SpoutOutputCollector collector; @Override public void open( Map conf, TopologyContext context, SpoutOutputCollector collector ) { // 任何组件都可以访问拓扑上下文,其中包含了拓扑的所有全局性信息 // 获得当前Spout的实例数量 int spoutsSize = context.getComponentTasks( context.getThisComponentId() ).size(); // 获得当前Spoput实例的Id int myIdx = context.getThisTaskIndex(); String[] tracks = ( (String) conf.get( "track" ) ).split( "," ); StringBuffer tracksBuffer = new StringBuffer(); for ( int i = 0; i < tracks.length; i++ ) { // 让各Spout实例处理不同的track关键字 if ( i % spoutsSize == myIdx ) { tracksBuffer.append( "," ); tracksBuffer.append( tracks[i] ); } } this.track = tracksBuffer.substring( 1 ); this.collector = collector; } @Override public void nextTuple() { // 通过HTTP获取消息 DefaultHttpClient client = new DefaultHttpClient(); client.setCredentialsProvider( credentialProvider ); // 让每个Spout实例跟踪不同的track关键字 HttpGet get = new HttpGet( STREAMING_API_URL + this.track ); HttpResponse response; try { response = client.execute( get ); StatusLine status = response.getStatusLine(); if ( status.getStatusCode() == 200 ) { InputStream inputStream = response.getEntity().getContent(); BufferedReader reader = new BufferedReader( new InputStreamReader( inputStream ) ); String in; // 逐行读取 while ( ( in = reader.readLine() ) != null ) { // 解析并释放元组 Object json = om.readValue( in, Map.class ); collector.emit( new Values( this.track, json ) ); } } } catch ( IOException e ) { // 连接到Twitter API失败,可以休眠一段时间后重试 } } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { declarer.declare( new Fields( "track", "content" ) ); } } |
注意上面的例子中用到Storm的一个重要特性 —— 在任何组件中访问TopologyContext。利用TopologyContext你可以感知到Spout的Task数量,然后将不同数据源映射到不同的Task,增加拓扑的并行度。
上面是连接到明确的设备的例子,通过类似的方式,可以直接连接到未知设备。但是你需要一个协调(Coordinator)系统来维护可用设备的列表。例如,当进行Web服务器日志分析时,Web服务器的列表可能动态变化。当一个新的Web服务器加入后,Coordinator检测到并为其创建一个Spout。
当建立连接时,应当总是由Spout发起,而不是由数据源发起。因为运行Spout的服务器宕机后Storm可能在另外一台机器上重启此Spout,数据源难以精确的定位到Spout。
除了直接连接,你还可以使用消息队列系统。Spout连接到消息队列读取消息,数据源则把消息发布到消息队列。
消息中间件软件通常都提供可靠性、持久化等保证,这简化了开发任务。使用消息中间件后Spout对数据源毫无感知。
使用消息列队这种接入方式时,如果想增加Spout并行度,可以:
- 让Spout循环轮询(Round-robin Poll)同一队列
- 基于哈希再分发:根据哈希值将消息分发给不同Spout,或者分发到不同的子队列。Spout读取子队列。Kafka是一个很好的支持子队列(分区)的消息中间件
Bolt是拓扑中的关键组件,大部分逻辑都发生在Bolt链中。
Bolt这类组件,以元组为输入,可选的,它也能够输出元组。
在创建Bolt时,你需要实现IRichBolt接口。Bolt在客户端创建,然后串行化到拓扑,最后整个拓扑被提交到Storm集群的Master节点。集群会启动工作节点(JVM进程)来运行拓扑组件,Bolt会被反串行化,其prepare方法会被调用,然后开始接受元组。
Storm确保Spout释放的所有元组都能传递给相应的Bolt,至于Bolt是否保证信息堡丢失,由开发人员决定。
拓扑是组件构成的网络,Spout释放的元组,是网络中传递的信息。信息经过不同组件之后,可能分裂、合并,这和Bolt灵活的Tuple处理机制有关:
- 可以根据一个输入元组产生多个输出元组
- 可以根据多个输入元组产生一个输出元组
从框架角度来说,无法自动推导输入、输出元组的对应关系。因此在Storm中你需要利用锚定(Anchoring)技术手工指定。
以从Spout发出的原初元组为根,其衍生的任何元组被fail,则此原初元组也就fail,发起此元组的Spout的fail回调自动被调用。
每个Spout/Bolt都可以声明多个输出流,标识符为default的默认流自动声明。要声明新的流,可以调用:
|
1 |
declarer.declareStream( streamId, fields ); |
要向指定的流释放元组,调用:
|
1 |
collector.emit( streamId, tuple ); |
前面提到过,要追踪信息流动方向,需要使用锚定技术。也就是指定输入、输出元组之间的关联关系:
|
1 2 |
// 此重载版本为OutputCollector特有 collector.emit( inputTuple, outputTuple ); |
有了这种调用后,Storm才可以对原初元组进行有效的追踪。
如果输出元组基于多个输入元组推导出,可以一起锚定它们:
|
1 2 3 4 |
List<Tuple> anchors = new ArrayList<Tuple>(); anchors.add( inputTuple1 ); anchors.add( inputTuple2 ); collector.emit( anchors, outputTuple ); |
如果outputTuple失败,则产生inputTuple1、inputTuple2的Spout都会得到通知。
Storm会在此接口的实现的execute()执行后,自动调用ack,如果execute()抛出异常,则自动调用fail。你可以考虑继承BaseBasicBolt。
Storm提供了一个抽象,允许Bolt存储/取回其操作的状态信息。该抽象有两个实现,一个是基于内存的默认实现,另一个以Redis作为后备存储。
需要状态管理功能的Bolt,需要实现IStatefulBolt接口或者继承BaseStatefulBolt,并实现initState方法。Storm在初始化Bolt实例时,调用initState并传入上次存储的状态,调用发生在prepare之后,处理任何元组之前。
当前仅仅支持的状态实现是org.apache.storm.state.KeyValueState。
分布式远程过程调用(Distributed Remote Procedure Call)利用Storm的计算能力进行远程调用。Storm提供了一系列DRPC的支持工具。
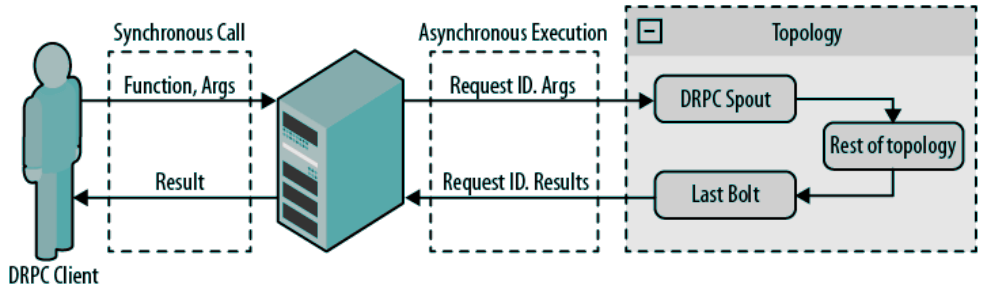
说明:
- 客户端向DRPC服务器发起同步调用
- DRPC将请求转发给DRPC Spout,进而在拓扑异步的处理
- 处理结果由最后一个Bolt返回给DRPC服务器。并返回给客户端
DRPC服务器是客户端和Storm拓扑之间的桥梁,它作为拓扑中Spout的源运行。
DRPC服务器接受需要执行的函数及其参数,它可以执行多个函数,函数通过名称唯一识别。
对于每一次函数调用,服务器分配一个请求Id,用于在拓扑中唯一的识别调用请求。当拓扑中最后一个Bolt执行完毕后,此Bolt必须释放出包含请求Id、调用结果的数组,DRPC会把结果分发给正确的客户端。
注意:目前此类已经被废弃,其功能由Trident代替。
用于构建DRPC拓扑的抽象。此Builder生成的拓扑会:
- 自动创建DRPCSpouts,连接DRPC服务器读取请求,并释放元组到拓扑的其它部分
- 对Bolts进行包装,让调用结果从最后一个Bolt返回
所有添加到LinearDRPCTopologyBuilder的Bolt均按序依次执行
要提交拓扑到Storm集群,可以调用LinearDRPCTopologyBuilder的createRemoteTopology(而不是createLocalTopology),此方法会利用Storm配置中的DRPC相关配置。
要连接到DRPC服务器,使用此类,此类是ThriftClient的子类型。
DRPC服务器暴露了基于Thrift的API,可以在很多语言中使用此API。并且,不管DRPC服务器是本地还是远程的,API完全一样。
下面是一个简单的加法计算器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
package cc.gmem.study.storm.drpc; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.LocalDRPC; import org.apache.storm.drpc.LinearDRPCTopologyBuilder; import org.apache.storm.generated.StormTopology; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Tuple; import org.apache.storm.tuple.Values; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class DrpcAdder { private static final Logger LOGGER = LoggerFactory.getLogger( DrpcAdder.class ); public static class AdderBolt extends BaseBasicBolt { @Override public void execute( Tuple input, BasicOutputCollector collector ) { // 元组第一个参数是RPC请求Id Object rpcId = input.getValue( 0 ); // 元组第二个参数是RPC请求参数 String args = input.getString( 1 ); String[] numbers = args.split( "," ); Integer added = 0; for ( String num : numbers ) { added += Integer.parseInt( num ); } collector.emit( new Values( rpcId, added ) ); } @Override public void declareOutputFields( OutputFieldsDeclarer declarer ) { // 作为最后一个Bolt,需要释放RPC请求Id declarer.declare( new Fields( "id", "result" ) ); } } public static void main( String[] args ) { // 和DRPCClient一样是DistributedRPC.Iface的实现 LocalDRPC drpc = new LocalDRPC(); // 拓扑对应一个远程调用函数 LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder( "add" ); builder.addBolt( new AdderBolt(), 2 ); Config conf = new Config(); conf.setDebug( true ); LocalCluster cluster = new LocalCluster(); // 创建本地拓扑,需要传入客户端对象 StormTopology topology = builder.createLocalTopology( drpc ); cluster.submitTopology( "drpc-adder-topology", conf, topology ); // 进行一次调用 String result = drpc.execute( "add", "1,-1" ); LOGGER.debug( "DRPC result {}", result ); cluster.shutdown(); drpc.shutdown(); } } |
Storm使用调度器在集群中进行拓扑的调度,它提供了四种内置的调度器实现:DefaultScheduler, IsolationScheduler, MultitenantScheduler, ResourceAwareScheduler。
要实现自己的调度器,实现IScheduler接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
package cc.gmem.study.storm; import org.apache.storm.scheduler.Cluster; import org.apache.storm.scheduler.IScheduler; import org.apache.storm.scheduler.Topologies; import java.util.Map; public class Scheduler implements IScheduler { @Override public void prepare( Map conf ) { } /** * 为需要调度的拓扑设置Assignment,调用cluster.getAssignments()可以得到最新设置的Assignment * * @param topologies 提交到集群中所有的拓扑,某些拓扑需要被调度 * 这里的拓扑对象仅仅包含拓扑的静态信息,Assignment、Slot等信息存在于cluster中 * @param cluster 拓扑所在的Storm集群,此对象包含开发新调度器所需的全部信息,例如: * Supervisor信息、可用Slot、当前Assignment */ @Override public void schedule( Topologies topologies, Cluster cluster ) { } } |
要切换调度器,修改配置文件 storm.yaml的 storm.scheduler配置项。
此调度器可以让多个拓扑安全、简单的共享单个集群。此调度器允许你隔离某些拓扑 —— 让它在一组专用的机器上执行,其它拓扑不能使用这些专用机器。被隔离的拓扑优先享用集群资源,被所有隔离拓扑占用内,剩下的机器,所有非隔离拓扑共享之。
要启用此调度器,在Nimbus节点的配置文件中进行如下设置:
|
1 2 3 4 5 6 |
storm.scheduler: org.apache.storm.scheduler.IsolationScheduler # 拓扑名称:专用机器数量的映射 isolation.scheduler.machines: "my-topology": 8 "tiny-topology": 1 "some-other-topology": 3 |
Storm支持对一组落到同一“窗口”的元组进行统一的处理。所谓窗口,是被特定条件限定的、连续的元组集合。限定条件有两种:
- 窗口的长度:包含元组的数量,或者持续的时间
- 窗口的滑动:每隔多长窗口向前滑动
长度/间隔有两种度量方式:时间、元组数量。
窗口具有一定的长度,并且每隔一段时间,窗口就向前滑动一次。例如下面的滑动窗口示意:
........| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
-5 0 5 10 15 -> time
|<------- w1 -->|
|<---------- w2 ----->|
|<-------------- w3 ---->|
窗口的长度是10秒,滑动间隔是5秒。注意元组可能属于多个窗口,每个窗口包含的元组数量可以变化。
窗口具有固定的长度,不同元组仅仅会属于单个窗口。下面是滚动窗口的示意:
| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
0 5 10 15 -> time
w1 w2 w3
窗口长度是5秒,窗口之间不存在重叠。
要获得窗口化支持,Bolt需要实现IWindowedBolt接口:
|
1 2 3 4 5 6 7 |
public interface IWindowedBolt extends IComponent { void prepare(Map stormConf, TopologyContext context, OutputCollector collector); // 处理落到窗口中的元组,可选的,释放新的元组 // 每当一个窗口激活(满了)时,该方法就被调用 void execute(TupleWindow inputWindow); void cleanup(); } |
通常情况下,你可以选择继承BaseWindowedBolt类,该类提供了一些指定窗口长度、滑动间隔的方法:
|
1 2 3 4 5 |
builder.setBolt("slidingwindowbolt", // 滑动窗口长度 30 元组,滑动间隔 10 元组 // 要指定滚动窗口,使用withTumblingWindow方法,要基于时间而非长度,使用Duration new SlidingWindowBolt().withWindow(new Count(30), new Count(10)), 1).shuffleGrouping("spout"); |
默认的,窗口以Bolt处理元组的时间为计算窗口边界的基准。Storm还支持以元组字段给出的时间戳为基准:
|
1 2 3 4 5 6 |
// 根据fieldName字段指定的时间(Long型)计算窗口边界 // 如果fieldName字段不存在,导致异常 BaseWindowedBolt.withTimestampField(String fieldName); // 另外一种方式,提供一个能够从元组中抽取时间戳的回调函数 BaseWindowedBolt.withTimestampExtractor(TimestampExtractor timestampExtractor); |
除了指定时间戳获取方式之外,Storm还允许指定一个最大的延迟参数:
|
1 |
BaseWindowedBolt.withLag(Duration duration); |
如果Bolt接收到一个时间戳为06:00:05的元组,且最大延迟为5s,那么后续不应该再接收到时间戳小于06:00:00的元组。如果的确接收到这样的过期(Late)元组,Storm默认不会处理,仅仅在Worker日志中以INFO级别记录。
要改变上述默认行为,可以调用:
|
1 2 3 |
// 过期元组将被释放到streamId流中,后续可以通过WindowedBoltExecutor.LATE_TUPLE_FIELD访问此流 // 必须和withTimestampField一起调用,否则IllegalArgumentException BaseWindowedBolt.withLateTupleStream(String streamId); |
当基于元组字段时间戳计算窗口边界时,Storm内部基于接收到的元组的时间戳来计算水位。所谓水位,就是所有输入流中,所有元组中最晚的那个时间戳减去乱序延迟后得到的数值。
Storm周期性的释放出水位时间戳,此时间戳将作为判断窗口边界是否已经到达的标准。周期默认1s,要修改周期可以调用:
|
1 |
BaseWindowedBolt.withWatermarkInterval(Duration interval) |
在协同多个输入流,进行窗口化处理时,水位时间戳相当于一个标准时钟。一旦窗口右边界小于等于此时间戳,就会立刻被处理,且小于此时间戳的后续元组均过期。如果多个输入流释放元组的速度差距很大,那么慢的那些流的元组甚至可能全部成为过期元组。
举个例子,假设基于元组字段时间戳的窗口参数如下:
Window length = 20s, sliding interval = 10s, watermark emit frequency = 1s, max lag = 5s
当前墙上时间为09:00:00,在 09:00:00-09:00:01之间接收到以下元组:
e1(6:00:03), e2(6:00:05), e3(6:00:07), e4(6:00:18), e5(6:00:26), e6(6:00:36)
墙上时间到达09:00:01时,水位时间戳06:00:31(最晚元组时间戳-乱序延迟5)被释放,后续任何时间戳小于06:00:31的元组均过期。水位时间戳导致三个窗口被处理:
05:59:50 - 06:00:10 e1 e2 e3
06:00:00 - 06:00:20 e1 e2 e3 e4
06:00:10 - 06:00:30 e4 e5
将第一个元组的时间戳针对滑动间隔向上取整(这确保它落在第一个窗口中),得到06:00:10,作为第一个窗口的右边界。这样有多少个窗口,窗口边界是哪里都可以推算出来。
元组e6没有落在适当的窗口中,因此此时暂不会被处理。
在09:00:01-09:00:02之间接收到以下元组:
e7(8:00:25), e8(8:00:26), e9(8:00:27), e10(8:00:39)
墙上时间戳到达09:00:02时,水位是按戳08:00:34被释放。水位时间戳导致三个窗口被处理:
06:00:20 - 06:00:40 e5 e6
06:00:30 - 06:00:50 e6
08:00:10 - 08:00:30 e7 e8 e9
第一个窗口的左边界,等于上一批次首个窗口的左边界 + 滑动间隔10。第二个窗口继续右滑10s。
向右滑动跳过N多空窗,得到从08:00:10开始的非空窗,包含了e7-e9。e10所属窗口右边界超出水位时间戳,因此暂不处理。
Storm的窗口化功能,可以提供最少一次处理的保证。
在方法 execute(TupleWindow inputWindow)中释放的元组,自动锚定到inputWindow中所有元组。下游Bolt应当Ack从WindowedBolt接收的元组,以完成元组树的处理。如果不Ack元组需要回放,窗口计算也会重新进行。过期的元组会自动被确认。
对于基于时间的窗口,配置参数topology.message.timeout.secs应当远大于windowLength + slidingInterval,否则元组可能来得及处理之前就超时,导致Replay。
对于基于计数的窗口,配置参数topology.message.timeout.secs应当调整,保证windowLength + slidingInterval个元组能够在超时前得到处理。
Storm提供了一个分布式缓存API,利用它可以高效的分发巨大的、在拓扑生命周期内可能变化的文件(或者叫Blob),这些文件的大小可能在KB-GB之间。
对于小的,不需要动态更新的数据集,可以考虑将其嵌入在JAR中。但是过大的文件则不行,会导致拓扑启动非常缓慢。这种情况下使用分布式缓存可以加快拓扑的启动速度。
在拓扑启动时,用户可以指定拓扑所需要的文件集。在拓扑运行期间,用户可以查询分布式缓存中的任何文件,并更换为新版本。更新行为遵从最终一致性模型。在分布式缓存中,文件基于LRU算法管理。Worker负责确认什么文件不再需要,并删除以释放磁盘空间。
分布式缓存的接口是BlobStore,目前它有两种实现:LocalFsBlobStore、HdfsBlobStore
这是基于本地文件系统的缓存实现。
|
1 2 |
# 复制因子4,任何人可以读写管,键key1,文件内容在README.txt中 storm blobstore create --file README.txt --acl o::rwa --replication-factor 4 key1 |
文件的创建由接口ClientBlobStore负责,其实现是NimbusBlobStore。在使用基于本地文件系统的缓存时,NimbusBlobStore调用Nimbus,在其本地文件系统创建文件。
拓扑提交时,JAR和配置文件也是在BlobStore的帮助下上传的,就好像一个普通文件一样。
拓扑启动后,被分配负责运行它的节点的Supervisor会从Nimbus下载JAR、配置文件,并根据topology.blobstore.map确定此拓扑需要使用哪些缓存文件并下载到本地。
在提交拓扑的时候,可以指定该拓扑需要使用哪些文件:
|
1 2 3 |
storm jar /path/to/jar class # 文件key1在拓扑中基于名称blob_file访问,不压缩 -c topology.blobstore.map='{"key1":{"localname":"blob_file", "uncompress":"false"},"key2":{}}' |
和基于本地文件系统的缓存实现类似,但是容错性已经由HDFS提供了。
LocalFsBlobStore需要在ZooKeeper中存储状态信息,以便支持Nimbus HA。
文件创建、下载、更新由HdfsClientBlobStore负责。
BlobStore基于键、版本来生成一个哈希码,作为Blob的文件名。Blob存放在blobstore.dir指定的目录,默认值对于本地实现来说是storm.local.dir/blobs,对于HDFS实现是一个类似的路径。
一旦Blob被提交,BlobStore即读取配置并为文件创建元数据,元数据用于访问Blob以及对访问者的进行授权。
对于本地实现,Supervisor节点的缓存大小软限制为10240MB,每隔600s会自动根据LRU算法清理超过软限制的那部分blob。
HDFS实现能够减少Nimbus的负载,而且容错性也不受到Nimbus数量的限制。Supervisor进行blob下载时不需要和Nimbus通信,因此减少了对Nimbus的依赖。
Storm的Master是运行在单台机器上的,在监控工具保护下的进程。一般情况下,Nimbus宕机后会由监控工具重启,不会造成太大问题。但是当Nimbus所在机器出现硬件问题时,例如磁盘损坏,Nimbus就无法启动了。
如果Nimbus无法启动,现有的拓扑能够继续运行,但是无法提交新拓扑。现有的拓扑也不能被杀死、激活、禁用。此外,如果某个Supervisor宕掉,Worker重新分配也无法进行。
因此,实现Nimbus的HA是有必要的,以便:
- 增加Nimbus总体可用时间
- 允许Nimbus主机在任何时候加入、离开集群
- 如果Nimbus宕机,不需要进行任何拓扑重提交
- 活动的拓扑绝不丢失
实现HA,需要在多个Nimbus节点中选择Leader。Nimbus服务器基于如下接口进行Leader选举:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public interface ILeaderElector { /** * 排队等待获取Leader锁,该方法立即返回,调用者应该检查自己是否Leader */ void addToLeaderLockQueue(); /** * 将自己从等待Leader锁的队列中移除,如果当前持有锁,释放之 */ void removeFromLeaderLockQueue(); /** * 当前节点是否持有了Leader锁 */ boolean isLeader(); /** * 返回当前Leader的地址,如果当前没有节点持有锁,则抛出异常 */ InetSocketAddress getLeaderAddress(); /** * 返回所有Nimbus节点的地址 */ List<InetSocketAddress> getAllNimbusAddresses(); } |
Storm提供了基于ZooKeeper的ILeaderElector实现。
为实现Nimbus故障转移,所有状态、数据必须在所有Nimbus节点之间复制,或者存储在外部的分布式存储系统中。BlobStore就可以用作这样的存储系统。
用户可以通过 topology.min.replication.count声明一个代码复制因子N,在拓扑启动前,其代码、Jar、配置必须复制到至少N个Nimbus节点。使用基于本地文件系统的BlobStore时,当发生故障转移后,如果某个Blob丢失,Nimbus会在需要的时候去下载。也就是说,成为Leader的时候Nimbus不一定在本地存储了所有Blob。
当使用基于本地文件系统的BlobStore时,所有Blob的元数据在ZooKeeper中存储;而使用基于HDFS的BlobStore时,HDFS负责管理。
基于Storm CLI使用分布式缓存的方法,请参考blobstore命令。本节给出相应的Java API的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import org.apache.storm.utils.Utils; import org.apache.storm.blobstore.ClientBlobStore; import org.apache.storm.blobstore.AtomicOutputStream; import org.apache.storm.blobstore.InputStreamWithMeta; import org.apache.storm.blobstore.BlobStoreAclHandler; import org.apache.storm.generated.*; // 创建BlobStore客户端 Config conf = new Config(); conf.putAll(Utils.readStormConfig()); ClientBlobStore clientBlobStore = Utils.getClientBlobStore(conf); // 创建ACL String stringBlobACL = "u:username:rwa"; AccessControl blobACL = BlobStoreAclHandler.parseAccessControl(stringBlobACL); List<AccessControl> acls = new LinkedList<AccessControl>(); acls.add(blobACL); SettableBlobMeta settableBlobMeta = new SettableBlobMeta(acls); settableBlobMeta.set_replication_factor(4); // ACL的复制因子 // 创建Blob,并授予ACL AtomicOutputStream blobStream = clientBlobStore.createBlob("some_key", settableBlobMeta); blobStream.write("Some String or input data".getBytes()); blobStream.close(); // 更新Blob String blobKey = "some_key"; AtomicOutputStream blobStream = clientBlobStore.updateBlob(blobKey); // 更改ACL String blobKey = "some_key"; AccessControl updateAcl = BlobStoreAclHandler.parseAccessControl("u:USER:--a"); // u:USER:-w- List<AccessControl> updateAcls = new LinkedList<AccessControl>(); updateAcls.add(updateAcl); SettableBlobMeta modifiedSettableBlobMeta = new SettableBlobMeta(updateAcls); clientBlobStore.setBlobMeta(blobKey, modifiedSettableBlobMeta); // 设置Blob元数据 // 设置、读取复制因子 String blobKey = "some_key"; BlobReplication replication = clientBlobStore.updateBlobReplication(blobKey, 5); int replication_factor = replication.get_replication(); // 读取Blob String blobKey = "some_key"; InputStreamWithMeta blobInputStream = clientBlobStore.getBlob(blobKey); BufferedReader r = new BufferedReader(new InputStreamReader(blobInputStream)); String blobContents = r.readLine(); // 删除Blob String blobKey = "some_key"; clientBlobStore.deleteBlob(blobKey); // 列出所有Blob Iterator <String> stringIterator = clientBlobStore.listKeys(); |
从0.6.0版本开始,Storm使用Kryo作为串行化库,Kryo是一个高性能、灵活的Java串行化框架。它可以产生较紧凑的串行化格式。
默认情况下,Storm能够串行化基本类型、字符串、字节数组、ArrayList、HashMap、HashSet、Clojure集合类型。如果你希望在元组中使用其它类型,需要提供自定义的串行化器。
在声明输出字段时,Storm不支持指定字段的类型。你仅仅需要把对象放入元组,Storm负责动态的识别其类型并串行化。
这个行为和Hadoop不同,Hadoop对键、值进行强制类型,这需要你提供大量的注解。Hadoop这种强制静态类型往往得不偿失。除了出于简单的目的,下面两条也是Storm选择动态类型的原因:
- 没有办法很好的静态确定元组字段类型。Storm很灵活,一个Bolt可能订阅了多个流,这些流释放的元组字段各不相同
- 为了便于和JRuby、Clojure这样的动态语言配合
要自定义串行化器,你需要实现Kryo的某些接口。要注册这些串行化器,你需要配置拓扑的topology.kryo.register,此配置项的值是一个列表:
|
1 2 3 4 5 |
topology.kryo.register: # 形式一:指定需要串行化的类型,这种情况下使用Kryo的FieldsSerializer来串行化该类型 - com.mycompany.CustomType1 # 形式二:指定类型到串行化器(com.esotericsoftware.kryo.Serializer)的映射 - com.mycompany.CustomType2: com.mycompany.serializer.CustomType2Serializer |
调用 Config.registerSerialization也可以自定义串行化。
配置项 Config.TOPOLOGY_SKIP_MISSING_KRYO_REGISTRATIONS设置为true时,Storm忽略所有找不到的串行化器类,如果设置为false则抛出异常。
如果Storm遇到某个元组字段,它没有可用的串行化器,则转用Java原生的串行化机制。如果该字段无法基于Java串行化,Storm抛出异常。
注意:Java串行化的成本很高,CPU占用高、输出格式尺寸大。应当尽量避免使用。
配置项 Config.TOPOLOGY_FALL_BACK_ON_JAVA_SERIALIZATION设置为false,则禁用Java串行化。
Storm提供了钩子机制,允许你在任何Storm事件发生时注入自定义代码。扩展BaseTaskHook类,覆盖对应你关心事件的方法即可实现钩子。相关方法包括:emit、spoutAck、spoutFail、boltAck、boltFail、boltExecute。
注册钩子的方法有两种:
- 在Spout的open、Bolt的prepare方法中,调用TopologyContext的方法注册
- 通过拓扑配置项topology.auto.task.hooks注册,这样钩子会应用到任何Spout、Bolt。在和外部监控系统集成时,可以使用这种方式
Storm暴露了一个度量(metrics)接口,用于报告整个拓扑的统计信息。在Storm内部,此接口用于元组计数、处理延迟统计、Work堆用量统计,等等。
任何度量都需要实现IMetric接口,该接口仅包含一个方法getValueAndReset,此方法用于执行必要的统计并重置度量为初始值。Storm提供的度量子类型有:
| 类型 | 说明 |
| AssignableMetric | 支持设置度量为一个明确的值 |
| CombinedMetric | 可以被关联更新的度量的通用接口 |
| CountMetric | 计数性的度量,其方法 incr()用于增加1个计数, incrBy(n)用于增加n个计数 |
| MultiCountMetric | CountMetric的HashMap |
| ReducedMetric |
MeanReducer:用于求平均值 MultiReducedMetric:ReducedMetric的HashMap |
你可以在Bolt中编程式的声明度量、并通过TopologyContext注册:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
private transient CountMetric countMetric; public void prepare(Map conf, TopologyContext context, OutputCollector collector) { // 注册度量 countMetric = new CountMetric(); // 每60秒自动调用countMetric.getValueAndReset()以重置度量 context.registerMetric("execute_count", countMetric, 60); } public void execute(Tuple input) { // 更新度量值 countMetric.incr(); } |
要注册Worker级别度量,可以配置:
- Config.WORKER_METRICS:针对集群中所有Worker
- Config.TOPOLOGY_WORKER_METRICS:针对某个拓扑的所有Worker
上述两个配置的取值都是度量名到度量类的HashMap。
Worker级别度量具有以下限制:
- 通过SystemBolt注册,不暴露给用户Task
- 基于默认构造器创建,不会进行任何属性或配置的注入
要消费度量值实现 IMetricsConsumer接口。通过注册消费者,你可以监听、处理拓扑的度量数据。编程式注册:
|
1 |
conf.registerMetricsConsumer(org.apache.storm.metric.LoggingMetricsConsumer.class, 1); |
通过配置文件:
|
1 2 3 4 5 6 7 8 |
topology.metrics.consumer.register: - class: "org.apache.storm.metric.LoggingMetricsConsumer" parallelism.hint: 1 - class: "org.apache.storm.metric.HttpForwardingMetricsConsumer" # 消费者对应的Bolt的并行度 parallelism.hint: 1 # 消费者的prepare方法接收此参数 argument: "http://example.com:8080/metrics/my-topology/" |
注册消费者后,Storm会在内部为每个消费者添加一个MetricsConsumerBolt(到拓扑),每个MetricsConsumerBolt都会订阅来自任何Task的度量信息。
MetricsConsumerBolt的并行度由parallelism.hint指定,其组件ID为 __metrics_consumerClassFQName#SEQ,其中SEQ仅仅在多次注册同一个消费者类时出现。
注意:消费者仅仅是一个普通的Bolt,如果它本身性能低下,则很多度量值会因而出现偏差。
Storm提供了一些内置的度量消费者,你可以使用它们来了解拓扑提供了哪些度量:
| 消费者 | 说明 |
| LoggingMetricsConsumer | 监听度量值,以TSV格式存储到文件 |
| HttpForwardingMetricsConsumer | 监听度量值,以HTTP Post方式发送到外部服务器 |
为了调整Nimbus、Supervisor、运行中拓扑的行为,Storm提供了多种配置信息。 某些配置信息是系统级的,不能为每个拓扑定制。
所有配置项的默认值记录在defaults.yaml中。要覆盖默认值,在Nimbus、Supervisor的Classpath下放置一个storm.yaml文件。
通过 StormSubmitter提交拓扑时,你可以连同自定义配置项一起提交,这些配置项必须以topology.开头。
从Storm 0.7开始,某些配置项可以在Spout/Bolt级别上定制,包括:
- topology.debug
- topology.max.spout.pending
- topology.max.task.parallelism
- topology.kryo.register
通过Java API,你可以为组件指定上述配置信息,途径有两种:
- 组件内部配置:覆盖getComponentConfiguration方法
- 组件外部配置:调用TopologyBuilder的setSpout/setBolt的返回值的addConfiguration/addConfigurations方法。此会覆盖途径1的配置项
配置信息的优先级,从低到高:defaults.yaml ⇨ storm.yaml ⇨ 拓扑配置 ⇨ 组件内部配置 ⇨ 组件外部配置
通过此助手类,可以为拓扑指定配置,此类包含了很多对应了配置项Key的常量值。
要配置一个拓扑在整个集群上,拥有的工作进程的数量,可以使用Config.TOPOLOGY_WORKERS配置项。
要提示为每个组件创建执行线程的数量,可以在setSpout/setBolt时传递parallelism_hint参数,指定初始的执行器数量。
要设置某个组件的任务数量,可以使用Config.TOPOLOGY_TASKS配置项。或者调用 ComponentConfigurationDeclarer.setNumTasks()方法。
调用命令 storm rebalance 可以在运行期间修改拓扑工作进程数量、拓扑组件的执行器数量,示例:
|
1 2 3 4 |
# 使用5个执行线程 # 组件blue-spout使用3个执行器 # 组件yellow-bolt使用10个执行器 storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 |
# Native库的位置 java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib" ### storm.* 一般性配置 # JAR存放位置 storm.local.dir: "storm-local" # 使用的日志实现 storm.log4j2.conf.dir: "log4j2" # 使用的ZooKeeper服务器列表 storm.zookeeper.servers: - "localhost" # 使用的ZooKeeper服务器端口 storm.zookeeper.port: 2181 # 使用的ZooKeeper根节点 storm.zookeeper.root: "/storm" # 常规性ZooKeeper配置项 storm.zookeeper.session.timeout: 20000 storm.zookeeper.connection.timeout: 15000 storm.zookeeper.retry.times: 5 storm.zookeeper.retry.interval: 1000 storm.zookeeper.retry.intervalceiling.millis: 30000 storm.zookeeper.auth.user: null storm.zookeeper.auth.password: null storm.exhibitor.port: 8080 storm.exhibitor.poll.uripath: "/exhibitor/v1/cluster/list" # 集群运行模式:distributed、local storm.cluster.mode: "distributed" storm.local.mode.zmq: false storm.thrift.transport: "org.apache.storm.security.auth.SimpleTransportPlugin" storm.thrift.socket.timeout.ms: 600000 storm.principal.tolocal: "org.apache.storm.security.auth.DefaultPrincipalToLocal" storm.group.mapping.service: "org.apache.storm.security.auth.ShellBasedGroupsMapping" storm.group.mapping.service.params: null storm.messaging.transport: "org.apache.storm.messaging.netty.Context" storm.nimbus.retry.times: 5 storm.nimbus.retry.interval.millis: 2000 storm.nimbus.retry.intervalceiling.millis: 60000 storm.auth.simple-white-list.users: [] storm.auth.simple-acl.users: [] storm.auth.simple-acl.users.commands: [] storm.auth.simple-acl.admins: [] storm.cluster.state.store: "org.apache.storm.cluster_state.zookeeper_state_factory" storm.meta.serialization.delegate: "org.apache.storm.serialization.GzipThriftSerializationDelegate" storm.codedistributor.class: "org.apache.storm.codedistributor.LocalFileSystemCodeDistributor" storm.workers.artifacts.dir: "workers-artifacts" storm.health.check.dir: "healthchecks" storm.health.check.timeout.ms: 5000 storm.disable.symlinks: false ### nimbus.* configs are for the master nimbus.seeds : ["localhost"] nimbus.thrift.port: 6627 nimbus.thrift.threads: 64 nimbus.thrift.max_buffer_size: 1048576 nimbus.childopts: "-Xmx1024m" nimbus.task.timeout.secs: 30 nimbus.supervisor.timeout.secs: 60 nimbus.monitor.freq.secs: 10 nimbus.cleanup.inbox.freq.secs: 600 nimbus.inbox.jar.expiration.secs: 3600 # Nimbus节点多久尝试同步本地缺少的代码Blob nimbus.code.sync.freq.secs: 120 nimbus.task.launch.secs: 120 nimbus.file.copy.expiration.secs: 600 nimbus.topology.validator: "org.apache.storm.nimbus.DefaultTopologyValidator" # 最低复制因子,拓扑的代码、JAR、配置复制到多少Nimbus节点后,Leader才能将拓扑标记为Active并开始分配Worker topology.min.replication.count: 1 # 等待topology.min.replication.count满足的最大时间 # 超过此时间,则不等待复制完成,立即启动拓扑 # 设置为-1表示一直等待 topology.max.replication.wait.time.sec: 60 nimbus.credential.renewers.freq.secs: 600 nimbus.queue.size: 100000 scheduler.display.resource: false ### ui.* configs are for the master ui.host: 0.0.0.0 ui.port: 8080 ui.childopts: "-Xmx768m" ui.actions.enabled: true ui.filter: null ui.filter.params: null ui.users: null ui.header.buffer.bytes: 4096 ui.http.creds.plugin: org.apache.storm.security.auth.DefaultHttpCredentialsPlugin ui.http.x-frame-options: DENY logviewer.port: 8000 logviewer.childopts: "-Xmx128m" logviewer.cleanup.age.mins: 10080 logviewer.appender.name: "A1" logviewer.max.sum.worker.logs.size.mb: 4096 logviewer.max.per.worker.logs.size.mb: 2048 logs.users: null drpc.port: 3772 drpc.worker.threads: 64 drpc.max_buffer_size: 1048576 drpc.queue.size: 128 drpc.invocations.port: 3773 drpc.invocations.threads: 64 drpc.request.timeout.secs: 600 drpc.childopts: "-Xmx768m" drpc.http.port: 3774 drpc.https.port: -1 drpc.https.keystore.password: "" drpc.https.keystore.type: "JKS" drpc.http.creds.plugin: org.apache.storm.security.auth.DefaultHttpCredentialsPlugin drpc.authorizer.acl.filename: "drpc-auth-acl.yaml" drpc.authorizer.acl.strict: false # 用于Trident拓扑中Spout相关的元数据的存储 # 存储的根路径 transactional.zookeeper.root: "/transactional" # 用于存储的ZooKeeper集群信息 transactional.zookeeper.servers: null transactional.zookeeper.port: null ## blobstore configs # Supervisor用于和BlobStore通信的客户端类 # 如果使用HDFS实现,改为org.apache.storm.blobstore.HdfsClientBlobStore supervisor.blobstore.class: "org.apache.storm.blobstore.NimbusBlobStore" # Supervisor上用于并行下载Blob的线程数量 supervisor.blobstore.download.thread.count: 5 # 下载失败后,最大重试次数 supervisor.blobstore.download.max_retries: 3 # 本地缓存最大尺寸 supervisor.localizer.cache.target.size.mb: 10240 # 本地缓存清理间隔,超过最大尺寸的部分,以LRU算法清除 supervisor.localizer.cleanup.interval.ms: 600000 # 分布式缓存实现(BlobStore)实现类 nimbus.blobstore.class: "org.apache.storm.blobstore.LocalFsBlobStore" # 通过Master和Blobstore交互时,会话过期时间,单位秒 nimbus.blobstore.expiration.secs: 600 # 所有Blob存储的位置,对于本地文件系统实现,对应了Nimbus本地目录,对于HDFS实现,对应hdfs文件路径 blobstore.dir: $storm.local.dir/blobs # 上传Blob时,缓冲区大小 storm.blobstore.inputstream.buffer.size.bytes: 65536 # Storm客户端用于和BlobStore通信的客户端类 client.blobstore.class: "org.apache.storm.blobstore.NimbusBlobStore" # BlobStore中每个Blob的复制因子 # topology.min.replication.count用于设置拓扑的数据的复制因子 # topology.min.replication.count 应该小于等于 blobstore.replication.factor storm.blobstore.replication.factor: 3 # For secure mode we would want to change this config to true storm.blobstore.acl.validation.enabled: false ### supervisor.* configs are for node supervisors # Define the amount of workers that can be run on this machine. Each worker is assigned a port to use for communication supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 supervisor.childopts: "-Xmx256m" supervisor.run.worker.as.user: false #how long supervisor will wait to ensure that a worker process is started supervisor.worker.start.timeout.secs: 120 #how long between heartbeats until supervisor considers that worker dead and tries to restart it supervisor.worker.timeout.secs: 30 #how many seconds to sleep for before shutting down threads on worker supervisor.worker.shutdown.sleep.secs: 3 #how frequently the supervisor checks on the status of the processes it's monitoring and restarts if necessary supervisor.monitor.frequency.secs: 3 #how frequently the supervisor heartbeats to the cluster state (for nimbus) supervisor.heartbeat.frequency.secs: 5 supervisor.enable: true supervisor.supervisors: [] supervisor.supervisors.commands: [] supervisor.memory.capacity.mb: 3072.0 #By convention 1 cpu core should be about 100, but this can be adjusted if needed # using 100 makes it simple to set the desired value to the capacity measurement # for single threaded bolts supervisor.cpu.capacity: 400.0 ### worker.* configs are for task workers worker.heap.memory.mb: 768 worker.childopts: "-Xmx%HEAP-MEM%m -XX:+PrintGCDetails -Xloggc:artifacts/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=artifacts/heapdump" worker.gc.childopts: "" # Unlocking commercial features requires a special license from Oracle. # See http://www.oracle.com/technetwork/java/javase/terms/products/index.html # For this reason, profiler features are disabled by default. worker.profiler.enabled: false worker.profiler.childopts: "-XX:+UnlockCommercialFeatures -XX:+FlightRecorder" worker.profiler.command: "flight.bash" worker.heartbeat.frequency.secs: 1 # check whether dynamic log levels can be reset from DEBUG to INFO in workers worker.log.level.reset.poll.secs: 30 # control how many worker receiver threads we need per worker topology.worker.receiver.thread.count: 1 task.heartbeat.frequency.secs: 3 task.refresh.poll.secs: 10 task.credentials.poll.secs: 30 task.backpressure.poll.secs: 30 # now should be null by default topology.backpressure.enable: false backpressure.disruptor.high.watermark: 0.9 backpressure.disruptor.low.watermark: 0.4 zmq.threads: 1 zmq.linger.millis: 5000 zmq.hwm: 0 storm.messaging.netty.server_worker_threads: 1 storm.messaging.netty.client_worker_threads: 1 storm.messaging.netty.buffer_size: 5242880 #5MB buffer # Since nimbus.task.launch.secs and supervisor.worker.start.timeout.secs are 120, other workers should also wait at least that long before giving up on connecting to the other worker. The reconnection period need also be bigger than storm.zookeeper.session.timeout(default is 20s), so that we can abort the reconnection when the target worker is dead. storm.messaging.netty.max_retries: 300 storm.messaging.netty.max_wait_ms: 1000 storm.messaging.netty.min_wait_ms: 100 # If the Netty messaging layer is busy(netty internal buffer not writable), the Netty client will try to batch message as more as possible up to the size of storm.messaging.netty.transfer.batch.size bytes, otherwise it will try to flush message as soon as possible to reduce latency. storm.messaging.netty.transfer.batch.size: 262144 # Sets the backlog value to specify when the channel binds to a local address storm.messaging.netty.socket.backlog: 500 # By default, the Netty SASL authentication is set to false. Users can override and set it true for a specific topology. storm.messaging.netty.authentication: false # Default plugin to use for automatic network topology discovery storm.network.topography.plugin: org.apache.storm.networktopography.DefaultRackDNSToSwitchMapping # default number of seconds group mapping service will cache user group storm.group.mapping.service.cache.duration.secs: 120 ### topology.* configs are for specific executing storms # 是否启用消息处理超时 topology.enable.message.timeouts: true # 释放禁用拓扑调试 topology.debug: false topology.workers: 1 # ACK线程的数量,设置为0则禁用ACK topology.acker.executors: null # 事件记录器线程数量,设置为0则禁用事件记录 topology.eventlogger.executors: 0 topology.tasks: null # maximum amount of time a message has to complete before it's considered failed topology.message.timeout.secs: 30 topology.multilang.serializer: "org.apache.storm.multilang.JsonSerializer" topology.shellbolt.max.pending: 100 topology.skip.missing.kryo.registrations: false topology.max.task.parallelism: null # 对于事务性拓扑,表示能够同时处理的元组批次的数量 # 对于非事务性拓扑,如果启用了消息确认(ACK),则拓扑中尚未ACK的原初元组的数量,超过此数量不再继续释放原初元组 topology.max.spout.pending: null topology.state.synchronization.timeout.secs: 60 topology.stats.sample.rate: 0.05 topology.builtin.metrics.bucket.size.secs: 60 topology.fall.back.on.java.serialization: true topology.worker.childopts: null topology.worker.logwriter.childopts: "-Xmx64m" topology.executor.receive.buffer.size: 1024 #batched topology.executor.send.buffer.size: 1024 #individual messages topology.transfer.buffer.size: 1024 # batched topology.tick.tuple.freq.secs: null topology.worker.shared.thread.pool.size: 4 topology.spout.wait.strategy: "org.apache.storm.spout.SleepSpoutWaitStrategy" topology.sleep.spout.wait.strategy.time.ms: 1 topology.error.throttle.interval.secs: 10 topology.max.error.report.per.interval: 5 topology.kryo.factory: "org.apache.storm.serialization.DefaultKryoFactory" topology.tuple.serializer: "org.apache.storm.serialization.types.ListDelegateSerializer" topology.trident.batch.emit.interval.millis: 500 topology.testing.always.try.serialize: false topology.classpath: null topology.environment: null topology.bolts.outgoing.overflow.buffer.enable: false topology.disruptor.wait.timeout.millis: 1000 topology.disruptor.batch.size: 100 topology.disruptor.batch.timeout.millis: 1 topology.disable.loadaware.messaging: false topology.state.checkpoint.interval.ms: 1000 # Configs for Resource Aware Scheduler # topology priority describing the importance of the topology in decreasing importance starting from 0 (i.e. 0 is the highest priority and the priority importance decreases as the priority number increases). # Recommended range of 0-29 but no hard limit set. topology.priority: 29 topology.component.resources.onheap.memory.mb: 128.0 topology.component.resources.offheap.memory.mb: 0.0 topology.component.cpu.pcore.percent: 10.0 # Worker进程的最大堆尺寸 topology.worker.max.heap.size.mb: 768.0 topology.scheduler.strategy: "org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy" resource.aware.scheduler.eviction.strategy: "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy" resource.aware.scheduler.priority.strategy: "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy" dev.zookeeper.path: "/tmp/dev-storm-zookeeper" pacemaker.host: "localhost" pacemaker.port: 6699 pacemaker.base.threads: 10 pacemaker.max.threads: 50 pacemaker.thread.timeout: 10 pacemaker.childopts: "-Xmx1024m" pacemaker.auth.method: "NONE" pacemaker.kerberos.users: [] #default storm daemon metrics reporter plugins storm.daemon.metrics.reporter.plugins: - "org.apache.storm.daemon.metrics.reporters.JmxPreparableReporter" # configuration of cluster metrics consumer storm.cluster.metrics.consumer.publish.interval.secs: 60 |
前面我们提到过,Storm支持两种运行模式:本地模式、远程模式。在本地模式中你可以在单JVM进程中调试整个拓扑。
开发环境就是包含了所有Storm组件的环境,你可以在本地模式下开发、测试Storm拓扑。或者将集群提交到远程集群,启动/停止远程集群上的拓扑。
你的开发机器和远程集群的关系是这样的:远程集群被主节点——Nimbus所管理,你的机器和Nimbus交互,提交JAR格式的拓扑。随后拓扑在集群中被调度、执行。你的机器可以通过命令行客户端storm和Nimbus交互,此客户端仅仅支持远程模式。
首先,下载最新版本的Storm,解压后,把bin子目录放到PATH环境变量中。bin目录中包含客户端脚本。
要想管理远程集群,将集群连接信息存放到 ~/.storm/storm.yaml文件中。
主要步骤包括:
- 创建ZooKeeper集群
- 在Nimbus、Worker节点上安装依赖
- 在Nimbus、Worker节点上下载并解压Storm
- 在storm.yaml中添加必须的配置
- 使用你选择的监控工具,通过storm命令启动守护程序。
请参考:ZooKeeper学习笔记
安装Java 7+以及Python 2.6.6,不赘述。
Python 3应该也可以工作,但是没有经过详尽的测试。
请参考:搭建开发环境
打开$STORM_HOME/ conf/storm.yaml文件,添加以下配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 指定ZooKeeper集群的主机列表: storm.zookeeper.servers: - "zookeeper-1.gmem.cc" - "zookeeper-1.gmem.cc" - "zookeeper-3.gmem.cc" storm.zookeeper.port: 2181 # 当前节点的名称,默认自动根据主机名获取 storm.local.hostname: "storm-n1.gmem.cc" # Nimbus/Supervisor需要在本地文件系统中存放少量状态数据,例如 jars, confs # 此目录需要提前创建,并授予适当的读写权限 storm.local.dir: "/home/alex/JavaEE/middleware/storm/data/local" # 工作节点需要知道哪些机器是Master节点的候选,以便从这些节点下载拓扑JAR、配置文件 # 你应该列出目标机器的全限定域名(FQDN)。如果使用Nimbus HA,要列出所有运行Nimbus进程的机器 nimbus.seeds: ["storm-n1.gmem.cc"] # 对于每个工作节点,你需要指定它运行多少个工作进程。每个工作进程需要独特的端口来接收消息 # 这里指定多少端口,就创建多少工作进程。默认创建6700-6703这4个端口 supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 |
Storm允许你提供一些脚本,让Supervisor定期的执行,以监控节点的健康状态。如果脚本监测到节点不健康,它应当在标准输出打印一行以ERROR开头的文字。Supervisor会周期性的执行脚本,一旦发现ERROR,就会关闭节点上所有Worker进程并退出。
在监控工具下运行守护进程时,你可以考虑调用storm node-health-check命令确认节点健康状态,进一步决定是否继续运行守护进程。
|
1 2 3 4 |
# 指定健康检测脚本所在目录 storm.health.check.dir: "healthchecks" # 脚本执行超时时间 storm.health.check.timeout.ms: 5000 |
如果需要支持外部库、自定义插件,可以把相关的JAR存放到extlib、extlib-daemon目录下。需要注意, extlib-daemon中的JAR仅仅能被守护进程(不能被Worker也就是拓扑逻辑)使用。
你也可以使用STORM_EXT_CLASSPATH、STORM_EXT_CLASSPATH_DAEMON这两个环境变量。
|
1 2 3 4 5 6 7 8 |
# 仅Nimbus节点 # UI服务器配置 ui.host: 0.0.0.0 ui.port: 6600 # 日志查看器配置 logviewer.port: 6601 |
强烈推荐在监控工具下(supervision tool)启动守护程序,这样意外崩溃后可以立即重启。Storm守护程序被设计为快速失败、无状态的,重启后拓扑不会受到影响:
- 要启动Nimbus,执行 storm nimbus命令
- 要启动Supervisor,在每个Worker节点执行 storm supervisor命令
- 要运行Storm UI服务器,在Nimbus节点执行 storm ui,默认Web端口8080
所有守护程序的日志默认存放在logs目录下。
安装此监控工具参考:Ubuntu下使用monit。服务条目示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
check process storm-nimbus matching daemon.name=nimbus start program = "/home/alex/JavaEE/middleware/storm/bin/storm nimbus" as uid alex and gid alex stop program = "/bin/kill -9 $MONIT_PROCESS_PID" as uid alex and gid alex check process storm-ui matching daemon.name=ui start program = "/home/alex/JavaEE/middleware/storm/bin/storm ui" as uid alex and gid alex stop program = "/bin/kill -9 $MONIT_PROCESS_PID" as uid alex and gid alex check process storm-drpc matching daemon.name=drpc start program = "/home/alex/JavaEE/middleware/storm/bin/storm drpc" as uid alex and gid alex stop program = "/bin/kill -9 $MONIT_PROCESS_PID" as uid alex and gid alex check process storm-log matching daemon.name=logviewer start program = "/home/alex/JavaEE/middleware/storm/bin/storm logviewer" as uid alex and gid alex stop program = "/bin/kill -9 $MONIT_PROCESS_PID" as uid alex and gid alex |
请参考:官方Docker镜像。
拉取镜像: docker pull storm:1.1.1
用法示例:
|
1 2 3 4 5 6 |
# 以本地模式运行一个拓扑 docker run -it -v topology.jar:/topology.jar storm storm jar /topology.jar pkg.Topology # 运行nimbus docker run -d --restart always --name nimbus storm storm nimbus # 运行supervisor docker run -d --restart always --name supervisor storm storm supervisor |
此镜像使用的默认配置是defaults.yaml,改变配置的方式由两种:
- 使用命令行参数,例如 -c storm.zookeeper.servers='["zookeeper"]'
- 在容器文件系统路径 /conf/storm.yaml放置配置文件
数据和日志的存储目录位于/data、/logs,这两个目录的所有者为storm。
|
1 |
docker run --name storm-s1 --hostname storm-s1 --network local --ip 172.21.2.1 --dns 172.21.0.1 -d docker.gmem.cc/storm storm supervisor -c storm.local.hostname='storm-s1.gmem.cc' |
Storm拓扑的调试主要依赖于日志,特别是在远程集群中运行的情况下。
你可以通过Storm UI或者命令行动态的改变某个包前缀的日志级别,方式类似于设置Log4J的日志级别。
通过Storm UI首页找到需要调试的拓扑,点击链接进入,可以看到类似下面的页面:
此页面提供了和拓扑相关的大量信息:
- 顶部的搜索栏,可以对Worker的日志进行搜索
- 按钮区域,提供了激活、禁用、Rebalance、杀死、起停调试功能,还可以设置日志级别
- 拓扑的名称、状态、Worker数量、Executor数量、Task数量等基本信息
- 释放、传输(释放并发送给1-N个Bolt)元组的数量、延迟时间,Ack、Fail的数量
- Spout、Bolt的各类统计信息
- 拥有的Worker在集群中的分布情况,组件和Worker的对应关系
- 可以查看图形化的拓扑结构(蓝色表示Spout)
- 拓扑的配置信息
要通过Storm UI修改日志级别,点击Change Log Level链接,填写表单然后Apply即可。Logger字段可以填写你的代码中使用的日志器前缀(包名前缀)。Timeout指明本次日志级别调整激活多久。
参见命令行客户端。
通过Logviewer不能直接查看Worker的日志文件。Worker的所有日志存放在 ${storm.log.dir}/workers-artifacts/${topologyId}/${port}目录下。worker.log即为工作日志文件,worker.log.err则包含错误级别的日志。
你可以在上述Storm UI界面的顶部,输入关键字(例如Exception)来搜索Worker日志,右上角的放大镜按钮也可以用来进行搜索(默认针对所有拓扑)。
要进行动态JVM剖析,点击拓扑的某个组件,可以看到Profiling and Debugging面板。点选下面的Executors面板的条目,然后点击对应的按钮:
- JStack:生成Thread Dump
- Start:启动剖析
- Heap:生成Heap Dump
点击My Dump Files可以下载上述按钮生成的剖析文件。
| 配置 | 说明 |
| worker.profiler.command | 指定剖析工具 |
| worker.profiler.enabled | 可能被禁用,如果JDK不支持JFR记录、剖析插件也不可用的话 |
拓扑事件查看器能够用来确定元组如何穿过拓扑的每一个Stage,实时查看元组处理过程时,不会对拓扑运行产生影响。
默认事件记录功能被禁用,你可以设置 topology.eventlogger.executors为大于0的值,以启用之。取值1表示每个拓扑一个日志记录Task,取值nil表示每个Worker一个日志记录Task。
要启动事件记录,点击Topolog Actions面板上的Debug按钮。
要查看被处理的元组,进入对应Spout/Bolt组件的页面,在Component summary面板中,点击events链接。
Storm中的日志记录Bolt利用IEventLogger接口实现事件日志,此接口的默认实现是FileBasedEventLogger。你可以扩展此接口实现更加复杂的逻辑,例如记录到数据库。
Storm提供了一个名为storm的客户端程序,用于和远程集群进行交互。
调用格式:
|
1 2 3 4 5 6 7 |
storm jar topology-jar-path class # 逗号分隔 --jars your-local-jar.jar,your-local-jar2.jar # 逗号分隔,^用于排除依赖 --artifacts "redis.clients:jedis:2.9.0,org.apache.kafka:kafka_2.10:0.8.2.2^org.slf4j:slf4j-log4j12" # 指定下载构件的仓库,^用作分隔符 --artifactRepositories "jboss-repository^" |
调用class的main函数,需要的配置文件和依赖的jar包(例如storm的jar),放置于~/.storm目录。main函数通常调用StormSubmitter,并导致topology-jar-path被上传到Nimbus。
如果存在依赖的、没有打包到topology-jar-path的其它jar包,可以使用--jars选项。如果想使用Maven构件的方式指定依赖,可以使用--artifacts选项。
依赖会同时上传作为Worker进程的classpath条目。
调用格式: storm sql sql-file topology-name --jars --artifacts --artifactRepositories
编译SQL为Trident拓扑,并提交到Storm集群。
调用格式: storm kill topology-name [-w wait-time-secs]
杀死具有指定名称的拓扑,最多等待wait-time-secs秒。
Storm会首先禁用Spout,然后等待一定时间(默认是拓扑的消息处理超时),让正在处理的消息完成。之后,Storm会关闭Worker进程并清理状态。
调用格式: storm activate topology-name
激活指定拓扑的Spout
调用格式: storm deactivate topology-name
禁用指定拓扑的Spout
调用格式:
|
1 |
storm rebalance topology-name [-w wait-time-secs] [-n workers-num] [-e component=parallelism]* |
某些时候你希望把拓扑的Worker进程均匀分布到更多的机器上。
举例来说,假设你有个10台机器的集群,每个运行4个工作进程。现在,又添加了10个节点,你需要使用这些机器的运算能力,让每个节点运行2个工作进程。一种方法是,杀死并重新提交拓扑,但是rebalance提供了更加简单的方法。
rebalance首先禁用指定的拓扑Spout(等待到消息超时或者-w),然后,在集群中均匀的创建Worker进程,最后激活拓扑。
rebalance也可以用来改变拓扑的并发度: -n用来改变Worker进程数量;-e用来指定组件的Executor数量(线程数量,和Task数量不是一回事)
调用格式: storm repl
开启Clojure REPL环境。
调用格式: storm classpath,打印客户端的classpath信息。
调用格式: storm localconfvalue conf-name
打印配置项conf-name的本地值,本地配置是~/.storm/storm.yaml合并了defaults.yaml的结果。
调用格式: storm remoteconfvalue conf-name
必须在集群中的节点上执行,打印集群的配置项。集群配置是$STORM-PATH/conf/storm.yaml合并了defaults.yaml的结果。
调用格式: storm nimbus。启动Nimbus守护进程,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式: storm supervisor。启动Supervisor守护进程,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式: storm ui。启动Web UI服务器守护进程,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式: storm drpc。启动DRPC服务器守护进程,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式: storm blobstore cmd。管理Storm的分布式缓存。子命令列表:
| 子命令 | 说明 |
| list [KEY...] | 列出当前存储的blob |
| cat [-f FILE] KEY | 读取一个blob,写入到文件或者stdout |
| create [-f FILE] [-a ACL ...] [--replication-factor NUMBER] KEY |
创建一个blob,其内容来自文件或者stdin ACL是一个逗号分隔的列表,条目格式[uo]:[username]:[r-][w-][a-] |
| update [-f FILE] KEY | 更新一个blob的内容 |
| delete KEY | 删除一个blob |
| set-acl [-s ACL] KEY | 设置一个blob的访问控制列表 |
| replication --read KEY | 读取blob的复制因子 |
onitor
调用格式:
storm dev-zookeeper
启动一个全新的zookeeper服务器,使用dev.zookeeper.path作为其本地目录,使用storm.zookeeper.port作为其端口。仅仅用于开发/测试。
调用格式: storm get-errors topology-name
获得指定拓扑的最新的错误信息。返回结果是component-name: component-error的键值对JSON
调用格式: storm heartbeats [cmd]
调用格式: storm kill_workers
杀死运行在此Supervisor节点上的Worker进程,必须在Supervisor节点上调用。
调用格式: storm list。列出集群中运行的拓扑,以及这些拓扑的状态。
调用格式: storm logviewer。启动日志查看器进程,此进程提供Web UI,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式:
|
1 2 3 4 5 |
storm monitor topology-name [-i interval-secs] # 默认4秒轮询一次 [-m component-id] # 默认所有组件 [-s stream-id] # 默认default [-w [emitted | transferred]] # 默认emitted |
交互式的对指定拓扑的吞吐量进行监控。
调用格式: storm node-health-check。在本地Supervisor上运行健康状态检测。
调用格式: storm pacemaker。启动Pacemaker进程,此进程提供Web UI,此命令应该在 daemontools、 monit之类的supervision工具中调用。
调用格式:
|
1 2 3 4 5 6 7 8 9 10 |
storm set_log_level # 日志级别ALL, TRACE, DEBUG, INFO, WARN, ERROR, FATAL, OFF # timeout 秒,整数 -l [logger name]=[log level][:optional timeout] -r [logger name] topology-name # 示例 storm set_log_level -l ROOT=DEBUG:30 my-topology storm set_log_level -l com.myapp=WARN my-topology |
动态的控制拓扑的日志级别。
调用格式: storm upload_credentials topology-name [credkey credvalue]*
更新credentials集到运行中的拓扑。
Trident(音标/'traɪd(ə)nt/)是Storm提供的另外一种访问接口,它提供一些高层抽象,包括:
- 精确的一次处理语义
- 事务性数据持久化
- 一些通用的流分析功能
使用Trident你可以无缝的将低延迟分布式查询和高吞吐量(每秒百万级消息)、有状态流处理混合。如果你对Pig、Cascading之类的高层批处理工具熟悉,理解起Trident会很容易。Trident有类似的连接(Join)、聚合(Aggregation)、分组(Grouping)、函数(Function)、过滤器(Filter)概念,此外Trident还提供在任何数据库、存储机制基础上进行有状态、增量处理的原语。
考虑两个流处理需求:
- 从输入流中统计每个姓名出现的次数
- 能够传入一个姓名列表,获得这些姓名出现的总次数
非线性随机名字生成器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 |
package cc.gmem.study.bdg; import org.apache.commons.lang3.RandomUtils; import org.apache.commons.lang3.StringUtils; import java.util.function.BiFunction; public class RandomNameGenerator { private static String COMMON_FIRST_NAMES[] = new String[]{ "伟", "芳", "秀", "英", "娜", "敏", "静", "丽", "强", "磊", "军", "洋", "勇", "艳", "杰", "娟", "涛", "明", "超", "兰", "霞", "平", "桂", "诚", "先", "敬", "震", "振", "壮", "会", "思", "群", "豪", "心", "邦", "承", "乐", "绍", "功", "松", "善", "厚", "裕", "河", "哲", "江", "亮", "政", "谦", "亨", "奇", "固", "之", "轮", "翰", "朗", "伯", "宏", "言", "海", "山", "仁", "波", "宁", "福", "生", "龙", "元", "全", "国", "胜", "学", "祥", "才", "发", "武", "新", "利", "毅", "俊", "峰", "保", "东", "文", "辉", "力", "永", "健", "世", "广", "鸣", "朋", "斌", "行", "时", "泰", "博", "磊", "民", "友", "志", "清", "坚", "庆", "若", "德", "彪", "盛", "雄", "琛", "钧", "冠", "策", "腾", "楠", "榕", "风", "航", "弘", "义", "兴", "良", "飞", "彬", "富", "和", "梁", "栋", "维", "启", "克", "伦", "翔", "旭", "鹏", "泽", "晨", "辰", "士", "以", "建", "家", "致", "树", "炎", "蕊", "薇", "菁", "梦", "岚", "苑", "婕", "馨", "瑗", "琰", "韵", "融", "园", "艺", "咏", "卿", "聪", "澜", "纯", "爽", "琬", "茗", "羽", "希", "宁", "欣", "飘", "育", "滢", "馥", "筠", "柔", "竹", "霭", "凝", "晓", "欢", "霄", "伊", "亚", "宜", "可", "姬", "舒", "影", "荔", "枝", "芬", "芳", "燕", "莺", "媛", "珊", "莎", "蓉", "好", "君", "琴", "毓", "悦", "昭", "冰", "枫", "芸", "菲", "寒", "锦", "玲", "秋", "秀", "娟", "英", "华", "慧", "巧", "美", "淑", "惠", "珠", "翠", "雅", "芝", "玉", "萍", "红", "月", "彩", "春", "菊", "凤", "洁", "梅", "琳", "怡", "宝" }; private static String COMMON_LAST_NAMES[] = { "李", "王", "张", "刘", "陈", "杨", "赵", "黄", "周", "吴", "徐", "孙", "胡", "朱", "高", "林", "何", "郭", "马", "罗", "梁", "宋", "郑", "谢", "韩", "唐", "冯", "于", "董", "萧", "程", "曹", "袁", "邓", "许", "傅", "沈", "曾", "彭", "吕", "苏", "卢", "蒋", "蔡", "贾", "丁", "魏", "薛", "叶", "阎", "余", "潘", "杜", "戴", "夏", "钟", "汪", "田", "任", "姜", "范", "方", "石", "姚", "谭", "廖", "邹", "熊", "金", "陆", "郝", "孔", "白", "崔", "康", "毛", "邱", "秦", "江", "史", "顾", "侯", "邵", "孟", "龙", "万", "段", "漕", "钱", "汤", "尹", "黎", "易", "常", "武", "乔", "贺", "赖", "龚", "文", "庞", "樊", "兰", "殷", "施", "陶", "洪", "翟", "安", "颜", "倪", "严", "牛", "温", "芦", "季", "俞", "章", "鲁", "葛", "伍", "韦", "申", "尤", "毕", "聂", "丛", "焦", "向", "柳", "邢", "路", "岳", "齐", "沿", "梅", "莫", "庄", "辛", "管", "祝", "左", "涂", "谷", "祁", "时", "舒", "耿", "牟", "卜", "路", "詹", "关", "苗", "凌", "费", "纪", "靳", "盛", "童", "欧", "甄", "项", "曲", "成", "游", "阳", "裴", "席", "卫", "查", "屈", "鲍", "位", "覃", "霍", "翁", "隋", "植", "甘", "景", "薄", "单", "包", "司", "柏", "宁", "柯", "阮", "桂", "闵", "欧阳", "解", "强", "柴", "华", "车", "冉", "房", "边" }; // 初值即为终值 public static final BiFunction<Integer, Integer, Integer> REMAPPING_NO = ( value, max ) -> value; public static class RemappingFunctionPower implements BiFunction<Integer, Integer, Integer> { private Integer powerOf; public RemappingFunctionPower( int powerOf ) { this.powerOf = powerOf; } @Override public Integer apply( Integer value, Integer max ) { double pos = (double) value / (double) max; return (int) ( Math.pow( pos, powerOf ) * max ); } } // 二次方映射,一系列随机初值的映射结果向靠近0的方向集中 public static final BiFunction<Integer, Integer, Integer> REMAPPING_POW_2 = new RemappingFunctionPower( 2 ); // 四次方映射 public static final BiFunction<Integer, Integer, Integer> REMAPPING_POW_4 = new RemappingFunctionPower( 4 ); // 八次方映射 public static final BiFunction<Integer, Integer, Integer> REMAPPING_POW_8 = new RemappingFunctionPower( 8 ); private BiFunction<Integer, Integer, Integer> remappingFunc; private String firstNames[]; private String lastNames[]; public RandomNameGenerator() { this.firstNames = COMMON_FIRST_NAMES; this.lastNames = COMMON_LAST_NAMES; this.remappingFunc = REMAPPING_NO; } public RandomNameGenerator( BiFunction<Integer, Integer, Integer> func ) { this(); this.remappingFunc = func; } private String randomFirstName() { int length = firstNames.length; int rand = RandomUtils.nextInt( 0, length ); return firstNames[remappingFunc.apply( rand, length )]; } private String randomLastName() { int length = lastNames.length; int rand = RandomUtils.nextInt( 0, length ); return lastNames[remappingFunc.apply( rand, length )]; } public String randomNameBatch( int size ) { String names[] = new String[size]; for ( int i = 0; i < size; i++ ) { String lastName = randomLastName(); String firstName = randomFirstName(); if ( RandomUtils.nextInt( 1, 3 ) == 2 ) { firstName += randomFirstName(); } names[i] = lastName + firstName; } return StringUtils.join( names, " " ); } } |
Storm代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
package cc.gmem.study.storm.trident; import org.apache.commons.lang3.RandomUtils; import org.apache.commons.lang3.StringUtils; import org.apache.storm.task.TopologyContext; import org.apache.storm.trident.TridentState; import org.apache.storm.trident.TridentTopology; import org.apache.storm.trident.operation.TridentCollector; import org.apache.storm.trident.operation.builtin.Count; import org.apache.storm.trident.operation.builtin.FilterNull; import org.apache.storm.trident.operation.builtin.MapGet; import org.apache.storm.trident.operation.builtin.Sum; import org.apache.storm.trident.spout.IBatchSpout; import org.apache.storm.trident.testing.MemoryMapState; import org.apache.storm.trident.testing.Split; import org.apache.storm.tuple.Fields; import org.apache.storm.tuple.Values; import java.util.Map; public class NameCounterTridentTopology { private static final Logger LOGGER = getLogger( NameCounterTridentTopology.class ); public static final String F_NAMES = "names"; public static final String F_NAME = "name"; // IBatchSpout是ITridentDataSource的子接口,作为Trident的数据源 public static class RandomNameBatchSpout implements IBatchSpout { @Override public void open( Map conf, TopologyContext context ) { } // 为一个批次生成元组集,元组集的长度由你决定,注意考虑输入吞吐量的大小 @Override public void emitBatch( long batchId, TridentCollector collector ) { // 随机生成一批名字 int batchSize = RandomUtils.nextInt( 10, 100 ); for ( int i = 0; i < batchSize; i++ ) { int size = RandomUtils.nextInt( 10, 1000 ); // 每次释放的元组具有单个字段,字段内容是空格分隔的人名 String names = new RandomNameGenerator( REMAPPING_POW_8 ).randomNameBatch( size ); LOGGER.debug( "Batch {} item {} : {}", new Object[]{ batchId, i + 1, names } ); collector.emit( new Values( names ) ); } } @Override public void ack( long batchId ) { } @Override public void close() { } @Override public Map<String, Object> getComponentConfiguration() { return null; } @Override public Fields getOutputFields() { return new Fields( F_NAMES ); } } public static void main( String[] args ) { /** * TridentTopology暴露构建Trident计算拓扑的接口 * 拓扑图由三类节点构成:操作(operation),分区(partition,例如分组和洗牌),Spout * 每个操作节点具有finishBatch方法,且可以作为Committer(有序串行化)节点 */ TridentTopology topology = new TridentTopology(); String txId = "randomNamesSpout"; // Trident在ZooKeeper中存储数据使用的键 TridentState nameCounts = topology /** * 声明一个Trident输入流,返回值trident.Stream类型。实际项目中常用的输入流包括Kafka、Kestrel等队列代理 * Trident在ZooKeeper中存储一小部分数据,表示输入流的状态(被消费的情况) */ .newStream( txId, new RandomNameBatchSpout() ) // 对于上述流的每个元组,执行Function操作,使用Split函数以空格分割,分割的结果存放在字段name中 // 返回值trident.Stream类型 .each( new Fields( F_NAMES ), new Split(), new Fields( F_NAME ) ) // 执行Grouping操作,返回值GroupedStream类型 .groupBy( new Fields( F_NAME ) ) // 执行Aggregation操作,聚合方式为统计总数,返回值TridentState类型 .persistentAggregate( new MemoryMapState.Factory(), new Count(), new Fields( "nameCount" ) ) .parallelismHint( 2 ); } } |
Trident以较小的批次的方式来处理输入流,根据输入throughput的不同,一个批次包含的元组数量可以在数千到数百万之间。
Trident提供了全特性的API,用于处理元组批次。这些API和Pig、Cascading等Hadoop高层抽象很类似。Trident提供了跨越批次进行聚合、持久化存储(可以在内存、Redis等“状态源”中)聚合结果的功能。此外,Trident还具有查询实时状态源的功能,这些状态可以被Trident更新,状态源也可以是独立于Trident维护的。
回到上面的人名统计代码中:
- Spout释放包含单个字段names的元组,names字段实际上是空格分隔的人名列表
- 我们使用Split函数对每个names字段进行分割,每个输入元组可能产生多个输出元组,输出元组包含单个字段name。Split函数的实现:
123456789public class Split extends BaseFunction {// 处理一个输入元组,可以释放任意个输出元组public void execute(TridentTuple tuple, TridentCollector collector) {String sentence = tuple.getString(0);for(String word: sentence.split(" ")) {collector.emit(new Values(word));}}} - 我们使用groupBy对人名进行分组,相同的名字分为一组
- 我们使用聚合器Count对分组进行聚合,并调用persistentAggregate对聚合结果进行持久化。此方法知道如何存储、更新位于状态源中的聚合结果。在此例中我们使用内存作为状态源,实际项目中你可以使用Memcached、Cassandra、Redis等持久化存储,例如:
1.persistentAggregate(MemcachedState.transactional(serverLocations), new Count(), new Fields("nameCount"));注意:persistentAggregate所存储的值,是输入流发出的所有批次的总的聚合结果
- persistentAggregate把流转换为TridentState对象。在本例中,TridentState对象包含了所有人名的计数结果。使用此TridentState对象可以实现需求的分布式查询部分
Trident的一个很酷的地方是,它提供完全的容错、精确的一次处理语义,这可以很好的简化实时处理逻辑。通过巧妙的存储状态,Trident能够在出错而需要重试时,不会对相同的源数据进行重复的入库(例如聚合到Memcached)。
人名统计需求的第一部分已经实现,拓扑运行后,TridentState不断更新,记录了当前各人名出现的总次数。
需求的第二部分是实现对统计结果的低延迟、实时查询。对于一个空格分隔的人名列表,我们要返回这些名字出现的次数的总和。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
package cc.gmem.study.storm.trident; import org.apache.storm.Config; import org.apache.storm.security.auth.SimpleTransportPlugin; import org.apache.storm.security.auth.plain.PlainSaslTransportPlugin; import org.apache.storm.thrift.TException; import org.apache.storm.utils.DRPCClient; import org.slf4j.Logger; import java.util.Arrays; import static org.slf4j.LoggerFactory.getLogger; public class NameCounterQueryClient { private static final Logger LOGGER = getLogger( NameCounterQueryClient.class ); public static void main( String[] args ) throws TException { Config conf = new Config(); conf.put( Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList( "zookeeper-1.gmem.cc", "zookeeper-2.gmem.cc", "zookeeper-3.gmem.cc" ) ); conf.put( Config.STORM_ZOOKEEPER_PORT, 2181 ); conf.put( Config.STORM_ZOOKEEPER_CONNECTION_TIMEOUT, 2000 ); conf.put( Config.STORM_THRIFT_TRANSPORT_PLUGIN, "org.apache.storm.security.auth.SimpleTransportPlugin" ); conf.put( Config.STORM_NIMBUS_RETRY_TIMES, 3 ); conf.put( Config.STORM_NIMBUS_RETRY_INTERVAL, 10 ); conf.put( Config.STORM_NIMBUS_RETRY_INTERVAL_CEILING, 20 ); conf.put( Config.DRPC_MAX_BUFFER_SIZE, 1048576 ); DRPCClient client = new DRPCClient( conf, "storm-n1.gmem.cc", 3772 ); // JSON编码的结果 String result = client.execute( "nameCountFunc", "汪静好 汪震" ); LOGGER.debug( result ); } } |
可以看到,查询客户端和普通的RPC客户端没有区别, 只是它的请求可以在Storm集群中并行的处理。类似于这种小的查询请求,其延迟可以低达10ms。
我们需要对上面的拓扑进行扩展,让它作为DRPC服务器:
|
1 2 3 4 5 6 7 8 9 10 |
topology.newDRPCStream( "nameCountFunc" ) // 供客户端调用的函数名称 // 对请求参数进行分隔 .each( new Fields( "args" ), new Split(), new Fields( "name" ) ) .groupBy( new Fields( "name" ) ) // 获取每个名字的当前计数,namsCount即TridentState .stateQuery( nameCounts, new Fields( "name" ), new MapGet(), new Fields( "nameCount" ) ) // 过滤空计数 .each( new Fields( "nameCount" ), new FilterNull() ) // 求和聚合 .aggregate( new Fields( "nameCount" ), new Sum(), new Fields( "allNameCount" ) ); |
查询服务器业务逻辑说明:
- 每个DRPC请求被作为一个独立的小批处理任务来看待,整个请求参数被作为单个元组处理。此元组仅仅包含一个args字段,对应客户端传递来的请求参数字符串
- 首先,Split函数对请求参数进行分割
- 操作符stateQuery能够对TridentState对象进行查询。TridentState对象由拓扑前一部分的persistentAggregate调用暴露 —— 持久化后的聚合结果允许后续的查询操作。stateQuery接受三个参数:
- 状态源,在本例中即持久化的人名统计结果
- 用于查询的函数,在本例中是MapGet,输入字段name作为函数入参
- 查询结果输出字段
- 上一步的返回值是一个流,我们用FilterNull这个过滤器进行过滤,把空值去掉
- 最后,调用聚合器Sum进行聚合,结果仍然是一个流。此流会被Trident自动发送给等待结果的客户端
本例中的拓扑需要提交到Storm集群才能运行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Config conf = new Config(); // 下面4个参数,指定前两个、后两个均可以,不必同时指定 conf.put( Config.NIMBUS_SEEDS, Arrays.asList( "storm-n1.gmem.cc" ) ); conf.put( Config.NIMBUS_THRIFT_PORT, 6627 ); conf.put( Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList( "zookeeper-1.gmem.cc", "zookeeper-2.gmem.cc", "zookeeper-3.gmem.cc" ) ); conf.put( Config.STORM_ZOOKEEPER_PORT, 2181 ); conf.put( Config.DRPC_SERVERS, Arrays.asList( "storm-n1.gmem.cc" ) ); conf.setDebug( true ); conf.setNumWorkers( 8 ); // 此拓扑总计使用的Worker进程数量 // 下面的属性指定打包好的、包含了拓扑依赖的JAR的位置,StormSubmitter会自动读取此属性,并上传JAR到Nimbus // 此JAR被上传到${storm.local.dir}/nimbus/inbox/目录下 System.setProperty( "storm.jar", "/home/alex/JavaEE/projects/idea/storm-study/target/storm-study-1.0-SNAPSHOT-jar-with-dependencies.jar" ); // 提交拓扑,提交后拓扑立即持续运行,除非被杀死 StormSubmitter.submitTopologyWithProgressBar( "name-counter-trident-topology", conf, topology.build() ); |
下面是一个纯粹的DRPC拓扑,用于计算按需计算URL的Reach值。Reach值针对单个URI,统计暴露于此URI的用户的数量。具体算法是,针对给定的URI,获取所有推特了此URI的用户、以及这些用户的Follower,并将所有这些用户去重、计数。
计算Reach对于单台机器来说,计算密集度太高了,它可能上千个数据库查询、上千万的元组处理。利用Trident可以很轻松的实现并行处理。
该DRPC拓扑拓扑会读取两个状态源:一个映射URI到推特了此URI的用户的列表;另外一个映射用户到其Follower的列表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
package cc.gmem.study.storm.twt; import org.apache.storm.trident.TridentState; import org.apache.storm.trident.TridentTopology; import org.apache.storm.trident.operation.Aggregator; import org.apache.storm.trident.operation.CombinerAggregator; import org.apache.storm.trident.operation.builtin.Count; import org.apache.storm.trident.operation.builtin.MapGet; import org.apache.storm.trident.state.StateFactory; import org.apache.storm.trident.tuple.TridentTuple; import org.apache.storm.tuple.Fields; public class ReachCounter { public static void main( String[] args ) { TridentTopology topology = null; // 创建两个代表外部数据库的TridentState对象,注意针对这些状态源的查询会自动批量处理以提升性能 TridentState urlToTweeters = topology.newStaticState( getUrlToTweetersState() ); TridentState tweetersToFollowers = topology.newStaticState( getTweeterToFollowersState() ); // 定义一个reach函数 topology.newDRPCStream( "reach" ) // 读取参数URI,查询urlToTweeters获得推特了此URI的用户,结果存入tweeters字段 .stateQuery( urlToTweeters, new Fields( "args" ), new MapGet(), new Fields( "tweeters" ) ) // 展开列表 .each( new Fields( "tweeters" ), new ExpandList(), new Fields( "tweeter" ) ) // 下一步查询的计算密集度很高,因此洗牌,让所有tweeter平均的分布到拓扑的所有Worker中 .shuffle() // 针对每个用户,查询其Followers .stateQuery( tweetersToFollowers, new Fields( "tweeter" ), new MapGet(), new Fields( "followers" ) ) // 并行度提示 .parallelismHint( 200 ) // 展开Follower并分组 .each( new Fields( "followers" ), new ExpandList(), new Fields( "follower" ) ) .groupBy( new Fields( "follower" ) ) // 使用聚合器One进行聚合,实际上就是去重 .aggregate( (Aggregator) new One(), new Fields( "one" ) ) .parallelismHint( 20 ) // 统计总数 .aggregate( new Count(), new Fields( "reach" ) ); } // CombinerAggregator知道如何进行局部聚合,避免发送大量网络数据 public static class One implements CombinerAggregator<Integer> { // 根据未聚合前的元组,计算其单个元素的聚合值 public Integer init( TridentTuple tuple ) { return 1; } // 聚合两个值 public Integer combine( Integer val1, Integer val2 ) { return 1; } public Integer zero() { return 1; } } } |
Trident能够智能的决定如何执行拓扑,让性能最大化。在上面的例子中,我们应当注意一些有趣的细节:
- 对于需要对状态源进行读、写的操作(persistentAggregate、stateQuery),会自动的批量式的和源交互。如果当前批次需要对状态源进行20个更新操作,Trident会自动将这20个操作进行批量提交,不管是20个写还是读。也就是说Trident仅仅和状态源进行一次交互
- Trident的聚合器是高度优化的,它不会把分组中所有的元组传递给单台机器,然后进行聚合。它会尽可能的多执行局部聚合,避免跨越网络发送不必要的流量。例如聚合器Count会在每个节点上进行部分计数,把部分计数通过网络发送,最终获得总合计数。这种行为特点和MapReduce的combiners类似
Trident数据模型由TridentTuple表示,和普通Storm元组一样,它也是命名值的列表。
在Trident拓扑中,操作节点通常将若干输入字段作为参数,并释放一系列函数字段(function Fields),这些新字段被添加到元组中。
考虑一个流stream,释放三元素x、y、z构成的元组,下面的过滤器仅仅把y字段作为输入:
|
1 2 3 4 5 6 7 |
// 将每一个元组的y字段暴露给过滤器处理 stream.each(new Fields("y"), ( new BaseFilter() { // 此操作节点仅仅能够访问y字段 public boolean isKeep(TridentTuple tuple) { return tuple.getInteger(0) < 10; } })()); |
上述过滤器将仅保留y小于10的那些元组。 再看看下面的函数:
|
1 2 3 4 5 6 7 8 |
stream.each( new Fields( "x", "y" ), ( new BaseFunction() { public void execute ( TridentTuple tuple, TridentCollector collector){ int i1 = tuple.getInteger( 0 ); int i2 = tuple.getInteger( 1 ); // 释放两个字段 collector.emit( new Values( i1 + i2, i1 * i2 ) ); } }),new Fields( "added", "multiplied" ) /* 定义函数释放字段的名称 */); |
该函数以x、y字段为输入字段,同时定义了两个输出字段 —— 这些输出字段是添加到输入元组上的,这导致输入元组现在有5个字段:x、y、z、added、multiplied。
使用聚合器的情况下,输出字段则是代替了输入字段,此外输入输出元组也不是一一对应关系:
|
1 2 |
// 收集所有输入元组的x字段并求和,求和存放到唯一一个输出元组的sum字段 stream.aggregate(new Fields("x"), new Sum(), new Fields("sum")); |
使用分组+聚合器的情况下,输出字段同时包含分组所依据的字段:
|
1 2 3 |
stream.groupBy(new Fields("x")) .aggregate(new Fields("y"), new Sum(), new Fields("sum")); // 输出字段为x,sum |
类似于原始Storm API,Trident的数据来源也是Spout。
你可以在Trident中使用原始的Spout,这种Spout是非事务性的:
|
1 2 3 |
// 所有Trident拓扑中的Spout必须具有唯一性的id。注意,必须是全局唯一,在集群中所有拓扑里都唯一 // Trident使用此id在ZooKeeper中记录Spout被消费的状态,包括txid以及其它相关元数据 topology.newStream("spoutid", new IRichSpout(){/**/}); |
要定制ZooKeeper相关参数,修改transactional.zookeeper.*配置项。
Trident拓扑的默认行为是,每次处理一个批次。当前批次成功或者失败后,才可能处理下一个批次。
通过管线化批次的处理流,可以大大提升拓扑的吞吐能力、降低单个批次的处理延迟。要定制同时能够处理的批次的最大数量,修改topology.max.spout.pending参数。
即使同时处理多个批次,Trident的严格有序语义保持不变 —— 状态更新总是串行化、有序的执行。以单词统计为例,当Batch 1进行全局聚合的时候,Batch 2...10不能进行全局聚合,但是它们可以进行分区的部分聚合。
Trident提供以下专有类型的Spout:
| Spout类型 | 说明 |
| ITridentSpout | 最通用的接口,可以用于实现事务性、非透明事务性语义 |
| IBatchSpout | 每次释放一个元组批次的非事务性Spout |
| IPartitionedTridentSpout | 从分区数据源(例如Kafka集群)读取数据的事务性Spout |
| IOpaquePartitionedTridentSpout: | 从分区数据源(例如Kafka集群)读取数据的非透明事务性Spout |
实时计算的一个关键问题是,如何管理状态——包括外部数据源的状态、拓扑的内部状态——以确保当失败、重试发生时,对状态的更新是幂等的。 在生产环境中,失败是常态,当节点宕机或者出现其它问题,只能重试处理元组批次。所谓幂等,可以简单的理解为,每个元组批次导致的状态更新,仅仅发生一次。
Trident确保幂等性的机制是:
- 每个元组批次被赋予唯一性的ID,所谓事务ID。如果发生重试,批次的事务ID保持不变
- 不同批次之间的状态更新,是严格有序的。也就是说,Batch3对状态源的更新动作不会发生,直到Batch2的状态更新动作完成
这种处理机制和Storm中的事务性拓扑类似。但是,你不需要像事务性拓扑那样,自己记录txid、比较txid、存储多个数据项,这些工作已经由Trident的状态抽象封装起来了。
你可以选择任何期望的策略来存储状态。例如存放在外部数据库中、存放在内存中并以HDFS作为后备。
状态信息也非必须永久保存,你可以考虑使用内存状态存储,并仅仅保留最近N个小时的数据。
可能和容错相关的Spout有三类:非事务性的、事务性的、不透明事务性的,相应的,对应了三类状态对象:
| Spout | 说明 | ||||||
| 事务性Spout |
事务性Spout有以下特性:
这是最理想、简单的情况。例如storm-contrib提供的支持Kafka的事务性Spout实现:TransactionalTridentKafkaSpout 事务性Spout对应的状态实现,利用了txid和元组集的绝对对应关系。用一个例子说明,现在有一个Trident拓扑,用于统计单词出现数量,并持久化到一个键(单词)值(计数)数据库中。为了支持事务性,仅仅存储键值对是不够的,你必须知道哪些批次已经入库。由于Trident批次的严格有序性,额外引入一个值字段,记录上一次处理完成的txid就可以了。当Replay时,如果发现库中txid和当前批次的txid一样,跳过入库步骤即可 更具体化一些,假设txid 3包含元组: ["man"] ["man"] ["dog"],当前数据库状态如下:
可以看到,单词man计数3,上一次成功的txid不等于当前txid3,因此应当把本批次的man计数2入库。再强调一下,由于批次的严格有序性,只要库中的txid不等于当前txid,那么它必然是前面批次的txid而绝不会是后面的。再看看dog记录的txid和当前txid一致,因此本批次dog计数1不应该入库 为什么上一次提交出现dog入库成功,man入库失败的情况呢?这牵涉到底层数据源的工作机制,我们假设它不支持原子的写两个键值 那么需要担心txid 没有处理完成么?不需要,还是严格有序性问题,一旦txid3执行到更新状态源这一步了,说明前面所有txid都成功完成了 |
||||||
| 不透明事务性Spout |
为什么不仅仅使用事务性Spout?原因是,保证完全的容错可能需要更苛刻的外部条件,而这种容错级别可能并非必要 以TransactionalTridentKafkaSpout为例,它的一个批次中的元组,可能来自Kafka主题的所有分区。一旦某个批次被释放,为了满足事务性语义,未来它处理失败需要Replay时,所有分区都必须可读。如果某个Kafka节点宕机(假设没有启用Replication)了呢?那么分区就读不到,相应的就无法满足事务性,整个Trident拓扑就卡住了 不透明(Opaque)事务性拓扑用于解决上述问题。它允许丢失某些数据源节点,但是仍然保证一次性处理语义 不透明事务性拓扑的特性是:
OpaqueTridentKafkaSpout是不透明事务性Spout的例子,它允许Kafka主题的某个分区节点临时宕机。不管什么时候,它总是从上一批次最后一个Kafka记录(对应元组)的偏移量处读取下一个批次。这确保每个记录仅仅被一个批次成功处理 使用不透明事务时,记录txid字段的技巧不再有效,因为批次Replay时它包含的元组可能不同。但是,引入更多的状态字段,仍然可以达成容错目标。仍然看单词计数的例子,假设当前状态源的数据如下:
现在来了包含元组 ["man"] ["man"]的txid2,也就是和数据库记录的txid相同。这意味着什么?txid2的上一次尝试失败了。由于同一事务的两个批次的元组集可能不同,因此上次尝试记录的value是无效的。应当以prevValue为基准加上本批次包含的元组数量2,成功处理后数据变为:
然后,又来了包含元组 ["man"] ["man"]的txid3,也就是和数据库记录的txid不同。这意味着上一次批次处理成功了,因此数据库中记录的value是有效的。应当以value为基准加上本批次包含的元组数量2,成功处理后数据变为:
这种机制的关键仍然是严格有序性,一旦txid3准备入库,就可以确信txid2是成功的,因此其value就有效,否则,必须回滚为prevValue再行计算 |
||||||
| 非事务性Spout |
不对批次中包含的内容作任何保证 |
三种Spout必须搭配对应类型的状态实现使用:
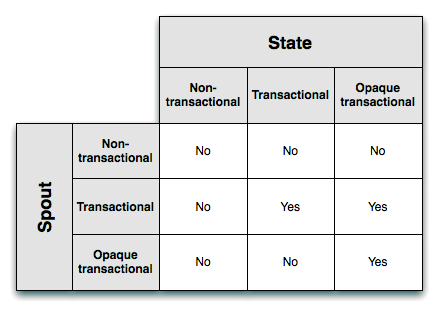
其中非透明事务性状态具有最强的容错能力,但是要为每个状态数据存储额外的两个字段。事务性状态仅需要存储一个额外的字段,但是它只能和事务性Spout搭配使用。
上节讨论的复杂的存储细节,并不需要开发者自行实现。Trident已经把它们全部封装到状态API中了。
调用partitionPersist、persistentAggregate等方法,即可创建一个状态对象,例如:
|
1 2 3 4 5 6 7 8 |
TridentState wordCounts = topology.newStream("spout", spout) .each(new Fields("sentence"), new Split(), new Fields("word")) .groupBy(new Fields("word")) // 所有管理不透明事务状态的逻辑,都封装在MemcachedState.opaque()返回的状态(工厂)中 // 更新的批量处理逻辑,也被封装在状态中 .persistentAggregate(MemcachedState.opaque(serverLocations), new Count(), new Fields("count")) .parallelismHint(6); |
状态(源)是一个接口,它很简单:
|
1 2 3 4 5 6 |
public interface State { // 更新开始时,获得通知 void beginCommit(Long txid); // 更新结束时,获得通知 void commit(Long txid); } |
Trident不对你的状态的工作方式做任何假设,它不规定调用什么方法可以更新状态,调用什么方法可以读取状态。
假设有一个存储用户位置的数据库,你想通过Trident访问它,可以这样实现State:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
public class LocationDB implements State { public void beginCommit(Long txid) { } public void commit(Long txid) { } public void setLocation(long userId, String location) { // 更新位置 } public String getLocation(long userId) { // 读取位置 } } // 除了实现State,还需要提供配套的StateFactory public class LocationDBFactory implements StateFactory { public State makeState(Map conf, int partitionIndex, int numPartitions) { return new LocationDB(); } } |
为了支持状态的查询,Trident提供了QueryFunction接口。 为了支持状态的更新,Trident提供了StateUpdater接口。状态和状态的支持的操作被解耦,如此设计是因为Trident难以对特定状态源的工作方式作出合理假设。
沿用上面的例子,QueryFunction的实现示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// QueryFunction总是针对状态源 + 结果类型的组合(泛型参数) public class QueryLocation extends BaseQueryFunction<LocationDB, String> { // 第一步:以输入元组inputs为查询参数,获得一系列结果 // 结果的元素和inputs的元素一一对应,输入元组有几个,则输出结果有几个 public List<String> batchRetrieve(LocationDB state, List<TridentTuple> inputs) { List<String> ret = new ArrayList(); // State可以暴露批量查询的接口,避免类似下面这种细粒度的交互 for(TridentTuple input: inputs) { ret.add(state.getLocation(input.getLong(0))); } return ret; } // 第二步:每对输入-输出的组合,被传递给下面的方法。你可以在此释放元组,供拓扑的下一节点处理 public void execute(TridentTuple tuple, String location, TridentCollector collector) { collector.emit(new Values(location)); } } |
使用上述QueryFunction的代码示例:
|
1 2 3 4 |
TridentState locations = topology.newStaticState(new LocationDBFactory()); topology.newStream("spout", spout) // 通过QueryFunction对State发起查询,输入元组字段userid,查询结果保存字段location .stateQuery(locations, new Fields("userid"), new QueryLocation(), new Fields("location")); |
StateUpdater的实现示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class LocationUpdater extends BaseStateUpdater<LocationDB> { // 将一批元组tuples更新到状态源state中 public void updateState(LocationDB state, List<TridentTuple> tuples, TridentCollector collector) { List<Long> ids = new ArrayList<Long>(); List<String> locations = new ArrayList<String>(); for(TridentTuple t: tuples) { ids.add(t.getLong(0)); locations.add(t.getString(1)); } // 应当实现批量更新 state.setLocationsBulk(ids, locations); } } // 你可以调用collector来释放新的元组,这些元组的流可以通过TridentState.newValuesStream()方法获得 |
使用上述StateUpdater的代码示例:
|
1 2 3 4 5 |
TridentState locations = topology.newStream("locations", locationsSpout) // 将输入元组的分区入库 .partitionPersist(new LocationDBFactory(), new Fields("userid", "location"), new LocationUpdater()); // 返回代表将会被更新的状态源 |
除了partitionPersist,Trident提供的另外一类可以更新状态源的API是persistentAggregate。此API是建立在partitionPersist上的一层抽象,它知道如何使用Trident聚合器,将聚合后的数据更新到状态源。
你可以针对GroupedStream调用persistentAggregate,参数必须提供MapState接口的实现。此接口的签名如下:
|
1 2 3 4 5 6 7 8 |
public interface MapState<T> extends State { // 以多个元组(keys)作为参数,获取对应的值 List<T> multiGet(List<List<Object>> keys); // 对每个元组,用相应的ValueUpdater更新之 List<T> multiUpdate(List<List<Object>> keys, List<ValueUpdater> updaters); // 存储多个元组及其对应的状态值 void multiPut(List<List<Object>> keys, List<T> vals); } |
如果要对非分组流进行(全局性)聚合,State对象必须实现下面的接口:
|
1 2 3 4 5 |
public interface Snapshottable<T> extends State { T get(); T update(ValueUpdater updater); void set(T o); } |
MemoryMapState、MemcachedState 实现了 MapState、Snapshottable接口。
当实现自己的MapState时,你不需要从零开始。Trident提供了OpaqueMap、TransactionalMap、NonTransactionalMap类,并把容错相关逻辑封装其中。你需要做的是,为这三个类提供IBackingMap实现:
|
1 2 3 4 5 6 7 |
// 你仅仅需要关注如何读取、存储键值 public interface IBackingMap<T> { List<T> multiGet(List<List<Object>> keys); // 对于OpaqueMap,T必须是OpaqueMap;对于TransactionalMap,T必须是TransactionalValue; // 对于NonTransactionalMap,T就是裸的聚合值 void multiPut(List<List<Object>> keys, List<T> vals); } |
Trident提供了基于LRU缓存算法的IBackingMap实现:CachedMap,继承它以实现具有缓存特性的状态源。
Trident提供了SnapshottableMap,可以把MapState转变为Snapshottable,其实就是全局使用单个key进行分组。
Trident拓扑会被尽可能编译为高效的Storm拓扑,仅仅在发生数据重分区(例如洗牌、分组)时,元组才通过网络传输。
一个可能的Trident拓扑和Storm拓扑的对应关系如下图: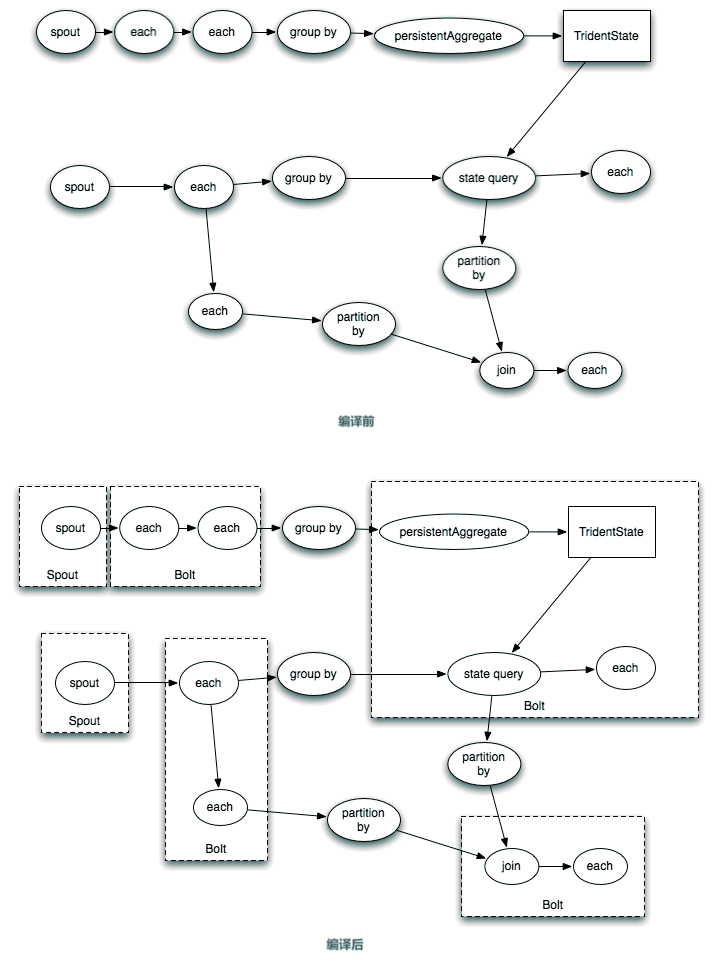
可以看到,Storm以分区节点为界,从Trident拓扑划分出多个Bolt。这些Bolt内部可能包含了多个Trident节点,它们可能被分配到一个Worker中执行,避免了不必要的网络数据拷贝。
Trident的核心数据模型是流,流由一系列的元组批次构成。流可能跨越集群的多个节点而分区,应用到流的操作针对每个分区并行执行。
Trident的操作包含五种类型:
- 在分区本地运行,不牵涉到网络流量的
- 重新分区操作,仅仅对流进行重新分区,不改变流的内容
- 聚合操作,产生一定的网络流量
- 针对分组(Grouped)流的操作
- 合并、连接操作
| 操作 | 说明 | ||
| Function |
函数根据一系列输入字段,经过计算产生0-N个输出字段。这些输出字段被添加到原始的输入元组中,构成新的字段 如果函数没有释放新字段,则对应的元组被过滤掉 要创建函数,考虑继承BaseFunction,要在Trident中使用函数,调用流的each方法 |
||
| Filter |
过滤器以元组为输入,决定它是否被保留 要创建过滤器,考虑继承BaseFilter,要在Trident中使用过滤器,可以调用流的filter方法 |
||
| map |
针对每个元组进行1:1的转换,输出为转换后的元组 要创建Map函数,考虑继承MapFunction,要在Trident中使用它,调用map方法 |
||
| flatMap |
针对每个元组进行1:N的转换,输出为转换后的元组 要创建flatMap函数,考虑继承FlatMapFunction,要在Trident中使用它,调用flatMap方法 |
||
| peek |
用于针对每个元组进行额外的操作,例如查看每个元组如果经过处理管线。可以用于调试目的 peek不会影响流的后续处理 |
||
| project |
仅仅保留选中的输入元组字段,示例:
|
||
| min / minBy | 对一个元组批次的每一个分区,返回该分区中指定字段的值最小的那个元组。你可以自定义比较器函数 | ||
| max / maxBy | 对一个元组批次的每一个分区,返回该分区中指定字段的值最大的那个元组。你可以自定义比较器函数 | ||
| Windowing | 后文详述 | ||
| partitionAggregate |
针对批次的每个分区进行内部的聚合操作,其输出替换掉输入元组,示例:
|
||
| stateQuery | 查询状态源 | ||
| partitionPersist | 更新状态源 |
这类操作运行一个函数,来决定分组如何在不同Task之间分配。重新分区后,分区数量可能改变,你可以调用 parallelismHint()改变并行度亦即分区数量。
重新分区操作可能导致网络流量,支持的重新分区函数有:
| 重新分区操作 | 说明 |
| shuffle | 随机轮回方式将元组均匀的分配给所有分区 |
| broadcast | 将每个元组广播(重复)到所有分区 |
| partitionBy | 根据一系列字段进行语义分区,先根据字段值计算哈希,然后针对分区数量取模,取模结果相同的元组被发给同一分区 |
| global | 所有元组被发送给单个分区,所有批次也都发送给该分区 |
| batchGlobal | 所有元组被发送给单个分区,不同批次可以发送给不同分区 |
| partition | 传入一个重分区函数(实现CustomStreamGrouping接口)进行分区操作 |
Trident提供两个全局性(针对所有分区)的聚合操作:
| 聚合操作 | 说明 |
| aggregate | 针对每个批次(的所有分区)进行聚合操作 |
| persistentAggregate | 针对流的所有批次进行聚合操作,并且将结果存放在状态源 |
| 分组流操作 | 说明 |
| groupBy |
该操作产生一个GroupedStream —— 根据某些字段,把字段值相同的元组分到一个区里面 也就是说,该操作依据字段进行重新分区操作 针对GroupedStream执行聚合操作时,聚合在每个分区(组)内部进行,而不是针对整个批次 针对GroupedStream调用persistentAggregate时,结果存储到MapState对象中,其键为分组所依据的字段 类似于普通流,GroupedStream也支持聚合的链式调用 |
这些定义在TridentTopology上的API用于把不同的流合并到一起:
| 操作 | 说明 | ||
| merge |
将多个流合并为一个,示例: topology.merge(stream1, stream2, stream3); 合并产生的新流,其字段根据第一个输入流的字段决定 |
||
| join |
类似于SQL的连接操作。当连接发生在来自不同Spout的流之间时,这些Spout将被同步 —— 每个批次将包含来自每个Spout的元组 如果要实现窗口化连接(Windowed Join) —— 例如,来自流A的元组仅仅后过去一小时产生的流B的元组进行连接,可以考虑利用partitionPersist、stateQuery,最近一小时的数据以轮换(Rotated)方式存储在状态源中,并且以连接字段为键。这样,stateQuery就很容易查询到最近一小时的数据了 示例:
|
注意:针对全局性聚合使用:
- ReducerAggregator或者Aggregator时,流首先被重分区到单个分区,然后聚合器在此新分区上执行
- CombinerAggregator时,首先进行局部聚合,然后重分区到单个分区,最后完成聚合操作
局部聚合可以大大减少网络流量,因此应该尽可能使用CombinerAggregator。
partitionAggregate、aggregate、persistentAggregate等操作,在调用时需要传入聚合器。聚合器相关的接口有三种:
| 聚合器接口 | 说明 | ||
| CombinerAggregator |
接口签名:
此聚合器返回单个字段构成的单一元组作为输出 进行aggregate(而非partitionAggregate)时,此聚合器接口的优势体现在,Trident能够自动优化,尽可能的进行局部聚合,避免发送网络流量 |
||
| ReducerAggregator |
接口签名:
可以和persistentAggregate一起使用 |
||
| Aggregator |
这个是最一般化的接口:
|
某些情况下,你需要连续执行多个聚合器,参考如下方式:
|
1 2 3 4 5 |
stream.chainedAgg() // 开始链式聚合 .partitionAggregate(new Count(), new Fields("count")) .partitionAggregate(new Fields("b"), new Sum(), new Fields("sum")) .chainEnd(); // 结束链式聚合 // 上述代码针对流进行计数、求和操作,其结果是两个元素构成的单一元组 ["count", "sum"] |
Trident支持窗口化(Windowing),即对元组批次中,处于同一窗口中的那些元组进行处理,并释放聚合后的结果给下一个操作。
两种风格的窗口被支持:
- 滚动窗口(Tumbling window)—— 元组依据单个窗口分组,分窗要么基于处理时间要么基于元组计数。每个元组只能属于一个窗口(不重叠):
12345678910111213/*** 返回一个新流,新流元组由当前流窗口内元组基于aggregator聚合而成* 窗口为滚动窗口,每隔windowCount个元组,新建一个窗口*/public Stream tumblingWindow(int windowCount, WindowsStoreFactory windowStoreFactory,Fields inputFields, Aggregator aggregator, Fields functionFields);/*** 返回一个新流,新流元组由当前流窗口内元组基于aggregator聚合而成* 窗口为滚动窗口,每隔windowDuration这么长时间,新建一个窗口*/public Stream tumblingWindow(BaseWindowedBolt.Duration windowDuration, WindowsStoreFactory windowStoreFactory,Fields inputFields, Aggregator aggregator, Fields functionFields); - 滑动窗口(Sliding window)—— 分窗依据和上面类似,但是每个一定的间隔(处理时间或元组计数),窗口就向前滑动。元组可以属于多个窗口(重叠):
1234567891011/*** 滑动窗口,每个窗口包含windowCount个元组,每处理slideCount个元组则窗口向前滑动*/public Stream slidingWindow(int windowCount, int slideCount, WindowsStoreFactory windowStoreFactory,Fields inputFields, Aggregator aggregator, Fields functionFields);/*** 滑动窗口,每个窗口时长为windowDuration,每经过slidingInterval则窗口向前滑动*/public Stream slidingWindow(BaseWindowedBolt.Duration windowDuration, BaseWindowedBolt.Duration slidingInterval,WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields);
除了上面两套API外,Trident还支持一个通用的窗口API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/** * 创建一个窗口 * @param windowConfig 可以是以下之一: * SlidingCountWindow.of(int windowCount, int slidingCount) * SlidingDurationWindow.of(BaseWindowedBolt.Duration windowDuration, BaseWindowedBolt.Duration slidingDuration) * TumblingCountWindow.of(int windowLength) * TumblingDurationWindow.of(BaseWindowedBolt.Duration windowLength) * @param windowStoreFactory 用于存储接收到的元组以及聚合结果,HBaseWindowsStoreFactory是基于HBase的一个实现 * @param inputFields * @param aggregator * @param functionFields * @return */ public Stream window( WindowConfig windowConfig, WindowsStoreFactory windowStoreFactory, Fields inputFields, Aggregator aggregator, Fields functionFields ); |
Trident的资源感知调度器(Resource Aware Scheduler,RAS)API可以用于限制Trident拓扑的资源消耗。此API和基本的Storm RAS API类似,区别只是该API针对Trident流而非Bolts、Spouts调用。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
TridentTopology topo = new TridentTopology(); // 默认资源配额,每个Bolt至少获得这么多资源 topo.setResourceDefaults(new DefaultResourceDeclarer(); .setMemoryLoad(128) .setCPULoad(20)); TridentState wordCounts = topology .newStream("words", feeder) // 针对特定操作步骤(除了grouping、shuffling、shuffling)进行资源配额 // 由于多个操作可能被合并为单个Bolt,因而结果Bolt的资源是组成它的操作的资源之和 .parallelismHint(5) .setCPULoad(20) .setMemoryLoad(512,256) .each( new Fields("sentence"), new Split(), new Fields("word")) .setCPULoad(10) .setMemoryLoad(512) .each(new Fields("word"), new BangAdder(), new Fields("word!")) .parallelismHint(10) .setCPULoad(50) .setMemoryLoad(1024) .each(new Fields("word!"), new QMarkAdder(), new Fields("word!?")) .groupBy(new Fields("word!")) .persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")) .setCPULoad(100) .setMemoryLoad(2048); |
- 元组处理代码要尽可能轻量,execute方法中的代码要能够尽快执行完毕。当扩容部署时,性能影响会成倍增加
- 当内存需求较小(1GB以下)时,考虑使用Guava实现Bolt本地缓存
- 当需要跨越多个Bolt共享数据时,考虑使用HBase、Phoenix、Redis或者Memcached
- 尽可能将配置信息外部化到属性文件中,可以避免运维期间不必要的代码重编译
要防止拓扑重部署后,消息被重复处理。使用KafkaSpout时,要确保:
- SpoutConfig的id、zkroot在重部署后要保持不变。Storm使用这这两个属性决定偏移量在ZooKeeper中的存储路径
- 注意在生产环境中设置forceFromStart为false。如果设置为true,KafkaSpout会忽略ZooKeeper中存储的偏移量信息,从头开始消费。开发环境下经常设置为true,以重复测试一批消息
- 如果需要部署同一拓扑的多个版本,则应当分配不同的ClientID,Kafka将不同ClientID作为单独Consumer看待,可以独立的跟踪偏移量
- 工作进程的个数,设置为节点(机器)数量的整数倍。并行度设置为工作进程数量的整数倍。kafka分区的数量设置为Spout并行度的整数倍
- 考虑为每个(拓扑,机器)组合启动单个Worker进程
- 启动较少较大的聚合组件,这类组件在Worker节点上运行一个实例
- 每个Worker使用一个Acker,0.9开始这是默认值
- 监控JVM垃圾回收器活动,如果一切正常,应该很少出现Major GC
- 设置Trident的批量处理延迟为你的应用的端对端延迟的1/2
- 将Spout最大未决元组数量的初值设置的很小,对于Trident可以设置为1或者拓扑执行器线程数量。然后逐步增加设置值,直到流运行状况稳定。最终到达的值可能接近于:\[2 \times \frac{throughputInSecs}{sec} \times endToEndLatency \]
Worker进程的总数由Supervisor来设置。每个Supervisor都管理若干JVM Slot。你在拓扑上设置的参数,实际上是声明Slot的数量。
对于每个(拓扑,机器)的组合,没有太大必要使用超过1个的Worker。对于一个运行在3个8核节点上的拓扑,并行能力提示是24,每个Bolt在每个机器上配备8个执行器线程。3工作进程 x 8执行器线程的方案,比起24工作进程的方案,有三个优势:
- 数据被重新分区(shuffle/group-bys)时,分发给的执行器如果在同一进程内,不需要进程间传递数据。本机进程间传递数据缓存需要Work发送 - 本地套接字 - Work接收,尽管不需要使用网卡,仍然比进程内直接调用慢
- 对于执行聚合功能的组件来说3个使用大后备缓存(backing cache)的组件比起24个使用小缓存的组件,具有更小的effect of skew和更高的LRU效能
- 较少的Worker进程,意味着较少的控制逻辑流量
- 检查是否对日志目录具有写权限
- 检查JVM的堆大小
- 检查是否所需的库都安装到Worker进程
- 检查ZooKeeper连接配置
- 是否正确的为每个Worker节点设置了唯一性机器名,并且写到Storm配置文件中
- 检查防火墙,允许所有Worker节点、Master节点、ZooKeeper之间的双向通信
典型症状:本地模式下运行正常,但是部属到集群中后工作节点启动即崩溃
可能原因:子网的配置可能有问题,导致节点无法根据hostname相互发现。有时ZeroMQ会因为无法解析主机名而崩溃
解决方案:
- 在hosts文件中配置主机名和IP地址的映射关系
- 使用内部DNS服务器
典型症状:
- 所有的元组均处理失败
- 处理流程不工作
解决方案:
- 注意Storm不支持IPv6,可以考虑设置Supervisor的 Child JVM系统属性-Djava.net.preferIPv4Stack=true
- 子网配置可能有问题,参考上一个问题
典型症状:
- 一开始处理正常,但是一段时间后,突然停止处理,Spout的元组开始集体fail
解决方案:
- 可能和ZeroMQ版本有关,可以从2.1.10降级为2.1.7
典型症状:
- 某些Supervisor不出现在Storm UI中
- Storm UI刷新后,Supervisor列表发生变化
解决方案:
- 确保每个Supervisor的本地目录是独立的,不要通过NFS共享本地目录
- 尝试删除Supervisor的本地目录并重启守护程序。由于Supervisor会为自己创建一个UUID并存放在本地,如果此ID复制到其它节点,Storm集群会出现问题
一定要保证构建JAR时使用的Storm版本和集群使用的Storm版本一致
输出元组中的对象必须实现不变模式。一旦你释放元组到OutputCollector,你就不应该在修改它。
在Storm生命周期中,拓扑会被串行化并存储到ZooKeeper中。这意味着Spout/Bolt必须支持串行化,包括它们的属性。如果某些属性无法支持串行化,考虑在Spout/Bolt的prepare方法中初始化它。这些方法在拓扑组件被分发给Worker进程后才会执行。
报错信息:Caused by: java.lang.RuntimeException: java.io.IOException: Found multiple defaults.yaml resources. You're probably bundling the Storm jars with your topology jar. [jar:file:/apache-storm-1.1.1/storm-local/supervisor/stormdist/name-counter-trident-topology-2-1508312849/stormjar.jar!/defaults.yaml, jar:file:/apache-storm-1.1.1/lib/storm-core-1.1.1.jar!/defaults.yaml]
报错原因:打包时把Storm的JAR包也打到拓扑的JAR包中会导致这个情况的发生。
配置拓扑时,需要指明DRPC服务器的位置:
|
1 |
conf.put( Config.DRPC_SERVERS, Arrays.asList( "storm-n1.gmem.cc" ) ); |
我正想学习呢