Prometheus学习笔记
Prometheus是一个开源监控系统,它既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控。对于现在流行的微服务,Prometheus的多维度数据收集和数据筛选查询语言也是非常的强大。
Prometheus的主要特性包括:
- 多维度数据模型
- 灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自治的
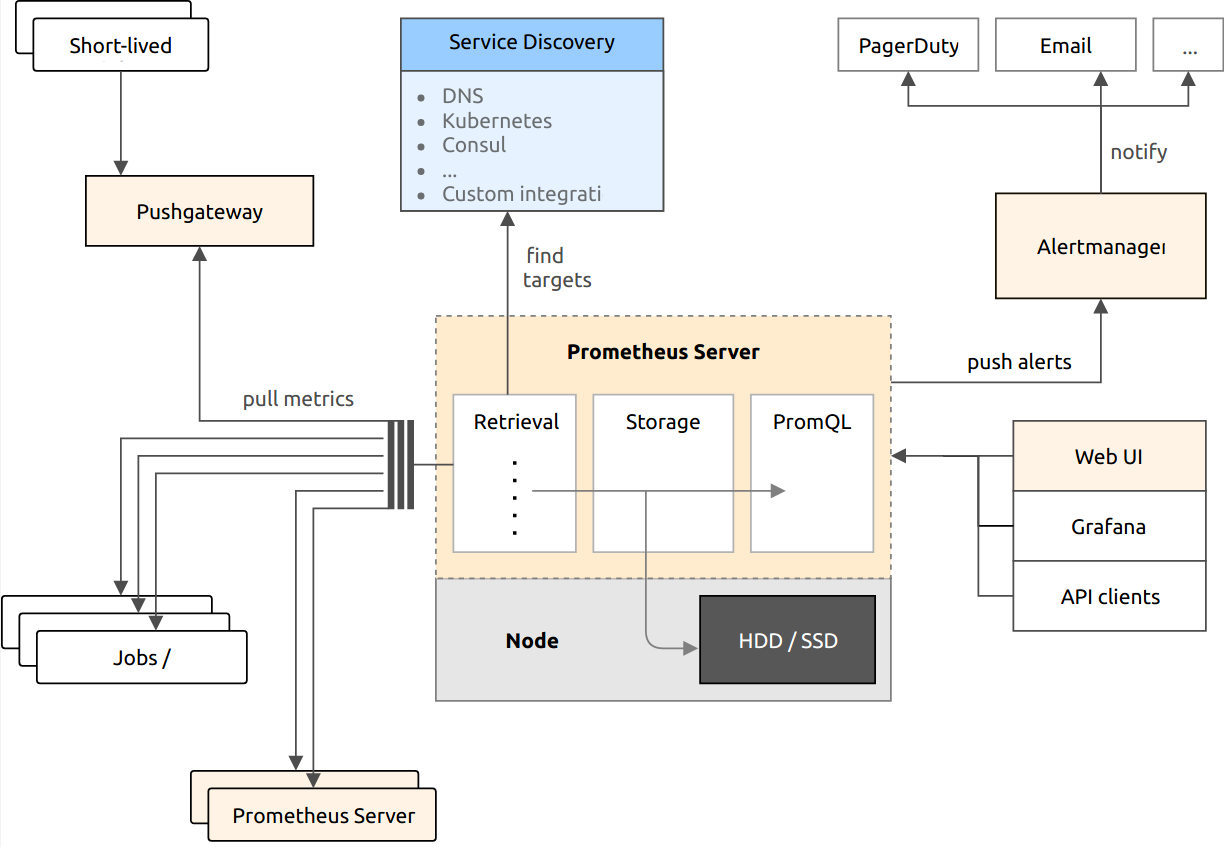
- 通过服务(sd,准确的说是监控目标)发现或者静态配置,来发现目标服务对象
- 支持多种多样的图表和界面展示,可以和Grafana集成
- 数据采集方式:
- Pull:通过HTTP协议定期去采集指标,只要被监控系统提供HTTP接口即可接入
- Push:被监控系统主动推送指标到网关,Prometheus定期从网关Pull
Prometheus包括以下组件:
- Prometheus Server:负责抓取和存储时间序列数据
- Push Gateway:推送网关,第三方可以推送数据到此网关,Prometheus Server再从此网关拉取数据
- 多种导出工具,支持导出Graphite、StatsD等所需的格式
- 命令行查询工具
- Alert Manager:告警管理器
- PromQL查询语言
Prometheus中所有数据都存放为时间序列——具有时间戳的数据流,这些数据属于同一指标、以及由一系列标签定义的维度集。每个时间序列由指标名+标签集唯一的识别,标签由键、值组成。时间序列通常使用如下记号表示:
|
1 2 3 |
<metric name>{<label name>=<label value>, ...} # 示例: api_http_requests_total{method="POST", handler="/messages"} |
指标名是需要监控系统特性的一般性名称,例如http_requests_total可以表示HTTP请求计数。
标签为一个具体的指标“实例”提供维度信息。使用PromQL你可以基于标签进行过滤、分组。增加、修改、删除某个标签,则新的时间序列会被创建。标签名只能ASCII字符,但是标签值可以是任何Unicode字符。
样本(Sample)构成了实际的时间序列的数据点。样本由float64类型的数值+毫秒精度的时间戳组成。
Prometheus的客户端库区分了4种指标类型,目前服务器端不理解这些类型的不同,但是未来可能改变。
| 指标类型 | 说明 | ||||
| counter | 单调递增的计数器 | ||||
| gauge | 可以任意变化的数值 | ||||
| histogram |
长尾问题:某个API的绝大部分请求延迟100ms,但是个别请求延迟高达5s。这种情况下使用指标平均值无法分析出问题所在 为了区分延迟是平均的、普遍的,还是由于长尾问题造成的。最简单的方式是统计延迟在0-50ms的请求有多少,50-100ms的请求有多少…… Prometheus的指标类型histogram、summary都可以用于这种样本分布的分析 histogram对监控得到的数值(例如请求用时、响应大小)进行采样,并在可配置的Bucket(例如请求用时区间、响应大小区间)中对采样进行计数,同时提供对所有监控数值的求和 具有名称<basename>的histogram,暴露以下几个时间序列:
下面是一个例子:
从上面的例子中,很容易发现绝大部分的样本都落在1.6e+6到2.6e+7这个区间 对于Histogram的指标,我们还可以通过histogram_quantile()函数在服务器端拟合出其值的分位数:
|
||||
| summary |
类似于histogram,基于滑动窗口来计算可配置的分位数(quantile) 下面是一个例子:
|
一个你可以从中抓取监控数据的endpoint称为实例(Instance),实例通常对应一个进程,例如NodeExporter、RedisExporter……
一系列相同目的的实例,称为Job。多实例的原因可能是为了可靠性、扩容。
当Prometheus服务器抓取数据时,它会自动为时间序列添加标签:
- job,抓取目标所属的Job的名称
- instance,目标从什么host:port抓取得到
如果上述两个标签已经存在于抓取的数据上,则配置项honor_labels影响服务器的行为。
除了添加标签之外,还会为以下时间序列添加样本:
- up{job="<job-name>", instance="<instance-id>"}:1/0。如果实例可达则取值1,否则0
- scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}:抓取目标消耗的时间
- scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}:指标重打标签后,剩余的样本数量
- scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}: 目标暴露的样本数量
Graphite专注于作为一个被动的时间序列数据库,同时提供查询语言、图形化特性。Prometheus则是一个全功能的监控和趋势分析系统,内置主动拉取、存储、图形化、报警功能。
Graphite存储数字采样,但是其元数据模型不如Prometheus丰富。Graphite的指标名称使用点号分隔的单词,暗含维度信息。Prometheus则将维度信息作为明确的标签存储。Prometheus更容易支持过滤、分组操作。
Graphite在本地磁盘上,以Whisper格式存储时间序列数据。每个时间序列存储一个文件,一段时间后,新采样会覆盖旧采样,此外采样频率是固定的。Prometheus也是每个时间序列对应一个文件,但是采样频率是动态的,新数据简单的Append到文件尾部。
InfluxDB的持续查询类似于Prometheus的Recording规则。Kapacitor类似于Recording规则、Alerting规则和Alertmanager的通知功能的组合。Alertmanager具有额外的分组、去重、静默功能。
InfluxDB的Tag和Prometheus的Label一样,都是键值对形式的维度信息。InfluxDB还提供第二级的“标签”——字段(Field)
| 名词 | 说明 |
| Alert | Prometheus中报警规则的输出,从Prometheus服务器发送给报警管理器 |
| Alertmanager | 接收Alert,聚合成组、去重、应用 silence、throttles,然后发送电子邮件或者发送到Slack、Pagerduty |
| Bridge | 从客户端库提取采样,暴露给非Prometheus监控系统的组件 |
| Collector | Exporter的一部分,可以收集单个或者多个指标 |
| Exporter | 收集指标的应用程序,将各种指标转化为Prometheus支持的数据处理格式 |
| Notification | Altermanger发出的各种通知 |
| PromQL | Prometheus查询语言。支持聚合、分片、切割、断言和连接操作 |
| Silence | 根据标签(Label)匹配来禁用警告 |
| Target | 需要抓取(Scrape)的对象的定义,包括以下信息:需要增加的标签、身份验证信息、如何抓取 |
|
1 |
helm install gmem/prometheus --name prometheus --namespace=kube-system |
此Chart的定义位于:https://github.com/gmemcc/charts/tree/master/prometheus
安装完毕,到https://prometheus.k8s.gmem.cc/targets可以查看各监控目标的状态。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.linux-amd64.tar.gz tar xzf prometheus-2.2.1.linux-amd64.tar.gz rm prometheus-2.2.1.linux-amd64.tar.gz mv prometheus-2.2.1.linux-amd64 prometheus cd prometheus ./prometheus --config.file="prometheus.yml" # 指定配置文件 --web.listen-address="0.0.0.0:9090" # UI/API/Telemetry监听地址 --storage.tsdb.path="data/" # 时间序列数据库存储路径 --storage.tsdb.retention=15d # 时间序列数据存储时长 # 等待处理的的告警管理器通知队列长度 --alertmanager.notification-queue-capacity=10000 --alertmanager.timeout=10s # 发送告警给告警管理器的超时 |
Prometheus通过命令行、配置文件进行配置。命令行参数可以配置一些不变的系统参数,例如存储位置、存留在内存和磁盘中的数据量。配置文件则用于指定Job、Instance、Rule的配置。
配置文件的格式是YAML,使用--config.file指定配置文件的位置。本节列出重要的配置项。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
global: # 默认抓取周期,可用单位ms、smhdwy [ scrape_interval: <duration> | default = 1m ] # 默认抓取超时 [ scrape_timeout: <duration> | default = 10s ] # 估算规则的默认周期 [ evaluation_interval: <duration> | default = 1m ] # 和外部系统(例如AlertManager)通信时为时间序列或者警情(Alert)强制添加的标签列表 external_labels: [ <labelname>: <labelvalue> ... ] # 规则文件列表 rule_files: [ - <filepath_glob> ... ] # 抓取配置列表 scrape_configs: [ - <scrape_config> ... ] # 和Alertmanager相关的配置 alerting: alert_relabel_configs: [ - <relabel_config> ... ] alertmanagers: [ - <alertmanager_config> ... ] # 和远程读写特性相关的配置 remote_write: [ - <remote_write> ... ] remote_read: [ - <remote_read> ... ] |
配置一系列的目标,以及如何抓取它们的参数。一般情况下,每个scrape_config对应单个Job。
目标可以在scrape_config中静态的配置,也可以使用某种服务发现机制动态发现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# 任务名称,自动作为抓取到的指标的一个标签 job_name: <job_name> # 抓取周期 [ scrape_interval: <duration> | default = <global_config.scrape_interval> ] # 每次抓取的超时 [ scrape_timeout: <duration> | default = <global_config.scrape_timeout> ] # 从目标抓取指标的URL路径 [ metrics_path: <path> | default = /metrics ] # 当添加标签发现指标已经有同名标签时,是否保留原有标签不覆盖 [ honor_labels: <boolean> | default = false ] # 抓取协议 [ scheme: <scheme> | default = http ] # 可选的请求参数 params: [ <string>: [<string>, ...] ] # 身份验证信息 basic_auth: [ username: <string> ] [ password: <secret> ] [ password_file: <string> ] # Authorization请求头取值 [ bearer_token: <secret> ] # 从文件读取Authorization请求头 [ bearer_token_file: /path/to/bearer/token/file ] # TLS配置 tls_config: [ <tls_config> ] # 代理配置 [ proxy_url: <string> ] # DNS服务发现配置 dns_sd_configs: [ - <dns_sd_config> ... ] # 文件服务发现配置 file_sd_configs: [ - <file_sd_config> ... ] # K8S服务发现配置 kubernetes_sd_configs: [ - <kubernetes_sd_config> ... ] # 此Job的静态配置的目标列表 static_configs: [ - <static_config> ... ] # 目标重打标签配置 relabel_configs: [ - <relabel_config> ... ] # 指标重打标签配置 metric_relabel_configs: [ - <relabel_config> ... ] # 每次抓取允许的最大样本数量,如果在指标重打标签后,样本数量仍然超过限制,则整个抓取认为失败 # 0表示不限制 [ sample_limit: <int> | default = 0 ] |
使用该配置,可以从K8S API Server暴露的REST API中发现抓取目标,并且和K8S集群保持同步。你可以配置以下role,以发现目标:
| role | 说明 |
| node |
为每个集群节点发现一个目标,目标的端口是Kubelet的HTTP端口、目标的地址是K8S节点对象的NodeInternalIP、NodeExternalIP、NodeLegacyHostIP或NodeHostName 可用的元标签: __meta_kubernetes_node_name 节点的名称 节点的instance标签被设置为从API Server获取的节点名 |
| service |
为每个服务的端口发现一个目标,一般用于服务的黑盒监控。目标地址为服务的DNS名称 可用的元标签: __meta_kubernetes_namespace 服务所在命名空间 |
| pod |
发现所有Pod并将其容器暴露为目标。对于每个容器+声明端口的组合,生成独立的目标。如果容器没有指定端口则仅仅为容器生成一个目标,在重打标签阶段可以为这种目标添加端口 可用的元标签: __meta_kubernetes_namespace Pod所在命名空间 |
| endpoints |
为服务的每个端点发现目标,每个Endpoint+Port的组合生成一个目标。如果Endpoint是基于Pod的,则Pod的任何端口都生成目标 可用的元标签: 如果endpoint是基于Pod的,则role: pod发现的所有元标签可用 __meta_kubernetes_namespace 端点的命名空间 对于Endpoint中定义的Pod端口,以下元标签可用: |
| ingress |
为所有Ingress的每个路径发现目标,一般用于Ingress的黑盒监控。目标地址设置为Ingress的host字段 可用的元标签: __meta_kubernetes_namespace 所属命名空间 |
通常,你会给相关K8S资源添加以下注解:
|
1 2 3 4 |
annotations: prometheus.io/path: /metrics prometheus.io/port: "8080" prometheus.io/scrape: "true" |
并配合以下Relabel配置,提示这些资源需要作为Prometheus的抓取目标:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ |
重打标签是动态修改目标的标签集的强大工具。每个抓取配置可以定义多个重打标签步骤,这些步骤按照声明顺序依次执行、在实际抓取指标数据之前执行。
在一开始,除了为每个目标配置的标签之外,目标的:
- job标签被设置为抓取配置的job_name字段
- __address__标签被设置为目标的<host>:<port>
在重打标签之后,目标的:
- instance标签默认被设置为__address__,如果没有此标签的话
- __scheme__标签被设置为http或https
- __metrics_path__标签被设置为目标的指标路径,即URL路径
- __param_<name>标签为请求时使用的每个参数
在重打标签期间,额外的 __meta_ 开头的元标签可用,这些标签由服务发现机制自动添加。
在重打标签结束后,以__开头的标签会被移除。
如果某个步骤需要临时的设置一些标签,仅仅作为后续步骤的输入,应当以__tmp作为前缀。
每个重打标签步骤(relabel_configs的元素)具有以下子配置项:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 从已有的标签中选取值 [ source_labels: '[' <labelname> [, ...] ']' ] # 并且使用下面的分隔符连接那些值 [ separator: <string> | default = ; ] # 然后基于下面的正则式进行匹配,或者保留,或者替换,或者删除 # 对于替换操作来说,替换为的目标标签的名字,可以使用正则式捕获组 [ target_label: <labelname> ] # 用于匹配源标签值的正则式 [ regex: <regex> | default = (.*) ] # 用于获取源标签值的哈希的模数 [ modulus: <uint64> ] # 如果正则式匹配,使用什么替换值,可以使用正则式捕获组 [ replacement: <string> | default = $1 ] # 如果正则式匹配,执行何种操作 # replace 如果正则式匹配source_labels的值,则设置target_label为指定的内容 # keep 如果正则式匹配,维持目标不变 # drop 如果正则式匹配,丢弃目标 # hashmod 设置target_label标签名为source_labels的值的哈希的取模 # labelmap 针对所有标签名来匹配regex,然后将匹配的标签的值拷贝到replacement所指定的新标签中 # labeldrop 针对所有标签来匹配regex,不匹配的标签都丢弃 # labelkeep 针对所有标签来匹配regex,匹配的标签都丢弃 [ action: <relabel_action> | default = replace ] |
重打标签配置示例:
|
1 2 3 4 |
# 将元标签__meta_kubernetes_pod_node_name替换为nodename - source_labels: [__meta_kubernetes_pod_node_name] action: replace target_label: nodename |
在存储(ingestion)样本数据之前,作为最后一个步骤,配置同上。可以用于屏蔽存储成本过高的时间序列。
Prometheus使用YAML格式的配置文件,默认的配置文件内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Prometheus服务器的全局配置 global: # 拉取Target的间隔,默认1分钟 scrape_interval: 15s # 执行Rule的间隔,默认1分钟 evaluation_interval: 15s # 拉取Target的超时时间 scrape_timeout: 10s # 报警管理器配置 alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 # 加载规则文件,并每evaluation_interval执行规则一次 rule_files: - "first_rules.yml" - "second_rules.yml" # 拉取配置,说明Prometheus需要监控什么 scrape_configs: # 这个默认抓取任务,监控Prometheus服务器自己(Prometheus通过HTTP暴露了自己的Metrics) - job_name: 'prometheus' metrics_path: /metrics scheme: http static_configs: # 此Job仅具有一个目标 - targets: ['localhost:9090'] |
Prometheus提供了一种查询语言,用来实时的查询、聚合时间序列数据。查询结果可以在Prometheus的WebUI中展示,或者通过HTTP API暴露给第三方系统。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 返回一个指标的所有时间序列 http_requests_total # 返回一个指标具有特定Label的时间序列 http_requests_total{job="apiserver", handler="/api/comments"} # 在满足上一条的前提下,返回5分钟内所有时间序列,并形成范围矢量(range vector) http_requests_total{job="apiserver", handler="/api/comments"}[5m] # 支持使用正则式来匹配Label http_requests_total{job=~".*server"} # 反向匹配 http_requests_total{status!~"4.."} # 以最近5分钟的范围矢量为基础,统计每秒的数据增量 rate(http_requests_total[5m]) # 按Label job进行分组统计 sum(rate(http_requests_total[5m])) by (job) # 如果两个指标具有相同的Label(维度信息),则可以对指标值进行运算 sum( instance_memory_limit_bytes - instance_memory_usage_bytes ) by (app, proc) / 1024 / 1024 # 取前三 topk(3, sum(rate(instance_cpu_time_ns[5m])) by (app, proc)) |
| 数据类型 | 说明 |
| Instant vector | 一系列时间序列,每个时间序列包含单个采样 |
| Range vector | 一系列时间序列,每个时间序列包含多个采样,采样分布在特定的时间区间 |
| Scalar | 单个浮点数 |
| String | 单个字符串 |
匹配单个时间点的一个或多个时间序列的采样:
|
1 2 3 4 |
# 选择指标的所有时间序列 http_requests_total # 根据标签匹配 http_requests_total{job="prometheus",group="canary"} |
匹配标签时可以使用四种操作符:=、!=、=~、!~,前两者用于精确匹配,后两者用于正则式匹配:
|
1 |
http_requests_total{environment=~"staging|testing|development",method!="GET"} |
只需要在瞬时矢量选择器后面添加 [timePeriod] 即可,时间的单位可以是s、m、h、d、w、y。示例:
|
1 |
http_requests_total{job="prometheus"}[5m] |
|
1 2 3 4 5 |
# 获取相对当前查询时间,之前5分钟的数据 http_requests_total offset 5m # 一周前的每秒请求数 rate(http_requests_total[5m] offset 1w) |
算术:加减乘除、取模、乘方(^)。可以在两个标量、标量vs瞬时矢量、 两个瞬时矢量之间进行。
比较:== != > >= < <=。可以在两个标量、标量vs瞬时矢量、 两个瞬时矢量之间进行。
逻辑:and or unless。仅仅用于两个瞬时矢量之间:
- and,取v1 v2中具有完全一致Label的那些时间序列,构成v3返回
- or,取v1所有时间序列,外加v2中那些Label在v1中不存在的时间序列,构成v3返回
- unless,取v1中那些没有在v2中具有相同Label的时间序列
对两个瞬时矢量应用操作符时,牵涉到如何找到左侧矢量元素在右侧矢量中的匹配元素的问题。匹配都是基于Label的。
矢量匹配的行为有两种:1对1匹配,1对多匹配:
| 一对一 |
语法格式: vector1 <operator> vector2 默认情况下,如果两个元素的标签集完全一致则匹配,可以使用ignoring或者on关键字来限制哪些标签需要匹配:
示例:
|
||||
| 一对多 |
操作符列表:
| 操作符 | 说明 | 操作符 | 说明 |
| min | 最小值 | max | 最大值 |
| sum | 求和 | avg | 求平均 |
| count | 统计数量 | count_values | 统计同值元素量 |
| bottomk | 最小N元素 | topk | 最大N元素 |
| quantile | 分位数(例如求中位数) |
语法:
|
1 2 3 4 5 6 7 8 9 10 |
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)] # parameter:仅count_values, quantile, topk, bottomk需要 # without:从结果矢量中移除指定的标签 # by:仅仅保留指定的标签 # 示例: sum(http_requests_total) without (instance) sum(http_requests_total) by (application, group) count_values("version", build_version) topk(5, http_requests_total) |
| 函数 | 说明 |
| abs(iv) | 将输入瞬时矢量的元素的采样值取绝对值 |
| absent(iv) | 如果输入矢量没有元素,返回空矢量,否则返回包含单个元素,采样值为1的矢量 |
| ceil(iv) round(v) |
取整 |
| changes(rv) | 对于范围矢量中每个时间序列,获取其值的变更次数,返回瞬时矢量 |
| day_of_month() day_of_week() days_in_month() hour() minute() month() year() |
时间转换 |
| delta(rv) | 对于范围矢量中每个时间序列,获取首尾两个采样的差值 |
| idelta(rv) | 对于范围矢量中每个时间序列,获取最后两个采样的差值 |
| rate(rv) | 对于范围矢量中每个时间序列,依据首尾两个采样的差值,计算每秒平均增量 |
| irate(rv) | 对于范围矢量中每个时间序列,依据最后两个采样的差值,计算每秒平均增量 |
| resets(rv) | 返回counter重置次数,只要值变小就认为被重置 |
| sort(iv) sort_desc(iv) |
对矢量进行排序 |
| AGG_over_time() | 对范围矢量中每个时间序列进行基于时间的聚合操作,AGG可以是avg、min、max、sum、count等 |
不能对已经聚合过的数据再进行rate,只能对原始counter进行rate。正确的示例:
|
1 2 3 4 5 |
# 对平均值,按service进行分组 # 对每个指标求每分钟平均值 sum(rate(dubbo_consumer_elapsed_ms{kubernetes_namespace="$namespace"}[2m]) * 60) by (service) / # 分组之后的数据仍然可以进行算术运算,按service值分别进行运算 sum(rate(dubbo_consumer_success_count{kubernetes_namespace="$namespace"}[2m]) * 60) by (service) |
这里使用Helm Chart方式安装,Chart的源码位于:
https://git.gmem.cc/alex/helm-charts/src/branch/master/prometheus。
安装脚本如下:
|
1 2 3 |
rm -rf prometheus helm fetch gmem/prometheus --untar helm install prometheus --name=prometheus --namespace=kube-system -f prometheus/overrides/gmem.yaml |
上面的Chart默认配置了以下Job:
| Job | 说明 |
| kubernetes-apiservers | 通过API Server采集指标,例如API的用量 |
| kubernetes-nodes | 采集节点的监控指标 |
| kubernetes-nodes-cadvisor | 采集容器的监控指标 |
| kubernetes-service-endpoints | 监控K8S的服务端点 |
| kubernetes-services | 监控K8S的服务 |
| kubernetes-pods | 监控K8S的Pod |
| prometheus-pushgateway | 从推送网关拉取指标 |
| prometheus | 自我监控 |
启动Prometheus后,访问http://localhost:9090/metrics可以查看Prometheus本身的指标信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# curl http://localhost:9090/metrics # 输出示意片断 # HELP http_requests_total Total number of HTTP requests made. # TYPE http_requests_total counter # 指标名 {标签=值,标签=值...} 指标值 http_requests_total{code="200",handler="graph",method="get"} 3 http_requests_total{code="200",handler="label_values",method="get"} 5 http_requests_total{code="200",handler="prometheus",method="get"} 4105 http_requests_total{code="200",handler="query",method="get"} 13 http_requests_total{code="200",handler="query_range",method="get"} 3 http_requests_total{code="200",handler="static",method="get"} 26 http_requests_total{code="304",handler="static",method="get"} 20 # 在http://localhost:9090/graph的控制台中输入http_requests_total进行查询,也可以得到上面的输出 |
http_requests_total是Prometheus暴露(Export)的关于自身的指标 —— 接受的HTTP请求总数,包括了多个时间序列数据。这些时间序列数据的指标名都一样,但是具有不同的标签,这些标签用于区分不同类型的HTTP请求。
我们可以在控制台输入 http_requests_total{code="200"},表示仅仅查询具有标签code=200的HTTP请求数。
类似的,还可以使用表达式 count(http_requests_total),来统计指标http_requests_total具有的时间序列数据的数量。
在http://localhost:9090/graph页面,点击Graph选项卡,可以生成图表。例如表达式 rate(http_requests_total[1m]) 表示生成最近一分钟的HTTP请求总数的图表,每个时间序列产生一条曲线。
Node Exporter是Prometheus提供的,用于监控Linux系统的组件。对于Windows,则有功能类似的WMIExporter。
下载NodeExporter后运行,它默认会在9100端口上暴露本机的各项指标。你可以访问http://localhost:9100/metrics来查看。修改Prometheus默认配置文件尾部的9090端口为9100即可采集这些指标。
这个项目是Google开源的,专门采集容器资源用量、性能指标。cAdvisor嵌入在kubelet中运行。
此项目可以暴露JMX管理Beans给Prometheus采集。它作为Java Agent运行,开启一个HTTP端口,对外提供本地JVM的各项指标。
为JVM添加参数: -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9100:config.yaml即可运行此Exporter。其中9100为暴露的端口号,config.yaml为配置文件路径。要采集指标,访问http://host:9100/metrics即可。
格式为YAML:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 延迟于JVM启动HTTP端口的时间 startDelaySeconds: 0 # 如果连接到远程JVM,采集JMX信息,则要么指定hostPort,要么指定jmxUrl hostPort: 127.0.0.1:1234 jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi # 远程JMX身份验证信息 username: password: # 远程JMX是否通过SSL连接 ssl: false # 是否小写化指标名、标签名 lowercaseOutputName: false lowercaseOutputLabelNames: false # 是否采集的ObjectNames的白、黑名单。默认采集所有mBeans whitelistObjectNames: ["org.apache.cassandra.metrics:*"] blacklistObjectNames: ["org.apache.cassandra.metrics:type=ColumnFamily,*"] # 规则列表,从上往下执行,遇到匹配的规则则终止 # 不匹配的Attributes不被采集,默认情况下,以默认格式采集所有 rules: # 匹配mBean Attributes的正则式 - pattern: 'org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)' # 指标名 name: cassandra_$1_$2 # 指标值 value: $3 # 指标值需要乘以的系数 valueFactor: 0.001 # 标签,可以使用捕获组 labels: {} # 指标帮助信息 help: "Cassandra metric $1 $2" # 指标类型 type: GAUGE # 转换为下划线 + 小写风格 attrNameSnakeCase: false |
如果没有任何配置内容,则以默认格式采集本地JVM的所有指标。
官方提供了若干中间件的示例配置文件。
传递给配置文件rules.pattern的格式为:
|
1 2 3 4 5 6 |
# domain mBean的名称,JMX ObjectNames的冒号前的部分 # beanProperyName/Value mBean属性列表,JMX ObjectNames的冒号后的部分 # keyN 如果是组合或表格数据,则包含键列表 # attrName 属性的名称,如果是表格数据,则为列名称。如果设置了attrNameSnakeCase则转换为下划线小写 # value 属性值 domain<beanpropertyName1=beanPropertyValue1, beanpropertyName2=beanPropertyValue2, ...><key1, key2, ...>attrName: value |
不经配置,输出的默认指标格式为:
|
1 |
domain_beanPropertyValue1_key1_key2_...keyN_attrName{beanpropertyName2="beanPropertyValue2", ...}: value |
Prometheus提供了主流语言的客户端库。要使用Prometheus的Go客户端库,导入:
|
1 |
import "github.com/prometheus/client_golang/prometheus" |
该结构是任何Prometheus指标都需要使用的描述符,它本质上是指标(Metrics)的不可变元数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
struct { // 全限定名称,由命名空间 - 子系统 - 名称组成 fqName string // 指标的帮助信息 help string // 常量标签键值 constLabelPairs []*dto.LabelPair // 可变标签的名字 variableLabels []string // 基于ConstLabels和fqName生成的哈希,所有注册的Desc都必须具有独特的值 // 以作为Desc的唯一标识 id uint64 // 维度哈希,所有常量/可变标签的哈希,所有具有相同fqName的Desc必须具有相同的dimHash // 这意味着每个fqName对应的标签集是固定的 dimHash uint64 // 构造时出现的错误,注册时报告 err error } |
所有指标的通用接口,表示需要导出到Prometheus的单个采样值+关联的元数据集 。此接口的实现包括Gauge、Counter、Histogram、Summary、Untyped。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
type Metric interface { // 幂等的返回该指标的、不可变的描述符 // 不能描述子集的指标,必须返回一个无效的描述符。无效描述符通过NewInvalidDesc创建 Desc() *Desc // 将指标对象编码为ProtoBuffer数据传输对象 // 指标实现必须考虑并发安全性,因为对指标的读可能随时发生,任何阻塞操作都会影响 // 所有已经注册的指标的整体渲染性能 // 理想的实现应该支持并发读 // // 除了产生dto.Metric,实现还负责确保Metric的ProtoBuf合法性验证 // 建议使用字典序排序标签,LabelPairSorter可能对指标实现者有帮助 Write(*dto.Metric) error } |
此结构表示用于bundle全限定名称、标签值有所不同的指标。通常不会直接使用此结构,而是将它作为具体指标向量GaugeVec, CounterVec, SummaryVec, UntypedVec的一部分:
|
1 2 3 4 5 6 7 8 9 |
type MetricVec struct { mtx sync.RWMutex // 保护元素的锁 children map[uint64][]metricWithLabelValues // 所有指标实例(值+标签集) desc *Desc // 描述符 newMetric func(labelValues ...string) Metric // 以指定的标签值创建新指标 hashAdd func(h uint64, s string) uint64 hashAddByte func(h uint64, b byte) uint64 } |
创建大部分的指标类型时,可以通过该接口提供选项:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
type Opts struct { // Namespace, Subsystem, Name是指标的全限定名称的组成部分,这些部分使用下划线连接 // 仅仅Name是必须的 Namespace string Subsystem string Name string // 帮助信息,单个全限定名称,其帮助信息必须一样 Help string // 常量标签用于为指标提供固定的标签,单个全限定名称,其常量标签集的所包含的标签名必须一致 // 注意在大部分情况下,标签的值会变化,这些标签通常由指标矢量收集器(metric vector collector)来 // 处理,例如CounterVec、GaugeVec、UntypedVec,而ConstLabels则仅用于特殊情况,例如: // vector collector (like CounterVec, GaugeVec, UntypedVec). ConstLabels // 1、在整个处理过程中,标签的值绝不会改变。这种标签例如运行中的二进制程序的修订版号 // 2、在具有多个收集器(collector)来收集相同全限定名称的指标的情况下,那么每个收集器收集的 // 指标的常量标签的值必须有所不同 // 如果任何情况下,标签的值都不会改变,它可能更适合编码到全限定名称中 ConstLabels Labels } |
任何Prometheus用来收集指标的对象,都需要实现此接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
type Collector interface { // 将此收集器收集的指标的所有可能的描述符发送到参数提供的通道。并且在最后一个描述符 // 发送成功后返回。发送的描述符必须满足Desc文档声明的一致性、唯一性要求 // // 同一收集器发送重复的描述符是允许的,重复自动忽视 // 但是两个收集器不得发送重复的描述符 // // 如果不发送任何描述符,则收集器标记为unchecked状态,也就是说在注册时,不会进行任何检查 // 收集器以后可能产生任何匹配它的Collect方法签名的指标 // // 该方法在收集器的生命周期里,幂等的发送相同的描述符 // // 该方法可能被并发的调用,实现时需要注意线程安全问题 // // 如果在执行该方法的过程中收集器遇到错误,务必发送一个无效的描述符(NewInvalidDesc)来提示注册表 Describe(chan<- *Desc) // 在收集指标时,该方法被Prometheus注册表(Registry)调用。方法的实现必须将所有它收集到的指标 // 经由参数提供的通道发送,并且在最后一个指标发送后返回 // // 每个发送的指标的描述符,必须是Describe方法提供的之一(除非收集器是Unchecked) // 发送的共享相同描述符的指标,其标签集必须有所不同 // // // 该方法可能被并发的调用,实现时需要注意线程安全问题 // // 阻塞会导致影响所有已注册的指标的渲染性能,理想情况下,实现应该支持并发读 Collect(chan<- Metric) } |
收集器必须被注册(Registerer.Register)才能收集指标值。
内置的指标类型实现了此接口,包括GaugeVec、CounterVec、HistogramVec、SummaryVec。
注册表,此结构实现了Registerer、Gatherer接口。
Registerer接口为注册表提供注册/反注册功能:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
type Registerer interface { // 注册一个需要包含在指标集中的收集器。如果收集器提供的描述符非法、 // 或者不满足metric.Desc的一致性/唯一性需求,则返回错误 // // 如果相等的收集器已经注册过,返回AlreadyRegisteredError,其中包含先前注册的收集器的实例 // // 其Describe方法不产生任何Desc的收集器,视为Unchecked,对这种收集器的注册总是成功 // 重现注册它时也不会有检查。因此,调用者必须负责确保不会重复注册 Register(Collector) error // 注册多个收集器,并且在遇到第一个失败时就Panic MustRegister(...Collector) // 反注册 Unregister(Collector) bool } |
Gatherer为注册表提供汇集(gathering)功能 —— 将已经收集的指标汇集到若干指标族(MetricFamily)中:
|
1 2 3 4 5 6 7 8 9 10 |
type Gatherer interface { // 该方法调用所有已经注册的收集器的Collect方法,然后将获得的指标存放到一个字典序排列 // 的MetricFamily的切片中。该方法保证返回的切片是有效的、自我一致的,可以用于对外 // 暴露(给Prometheus服务器)该方法容忍相同指标族中具有不同标签集的指标 // // 即时发生错误,该方法也会尝试尽可能收集更多的指标。因此,当该方法返回非空error时 // 同时返回的dto.MetricFamily切片可能是nil(意味着致命错误)或者包含一定数量的 // MetricFamily —— 切片可能是不完整的 Gather() ([]*dto.MetricFamily, error) } |
表示gauge类型的指标:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
type Gauge interface { // 实现的接口 Metric Collector // 设值 Set(float64) // 增1 Inc() // 减1 Dec() // 加上一个值 Add(float64) // 减去一个值 Sub(float64) } |
要创建一个Gauge,可以调用:
|
1 2 3 4 5 6 7 8 9 |
func NewGauge(opts GaugeOpts) Gauge { // func newValue(desc *Desc, valueType ValueType, val float64, labelValues ...string) *value return newValue(NewDesc( BuildFQName(opts.Namespace, opts.Subsystem, opts.Name), opts.Help, nil, opts.ConstLabels, ), GaugeValue, 0) } |
GaugeVec表示Gauge的向量:
|
1 2 3 |
type GaugeVec struct { *MetricVec } |
表示histogram类型的指标。
Histogram对可配置的Bucket(观察值的区间)中的事件或样本流,基于Bucket进行独立计数观察。它支持对观察值(observations)进行计数,或者求和。
在Prometheus中,分位数可以基于Histogram,通过函数histogram_quantile计算得到。Histogram依赖于用户定义的、适当的buckets,一般来说精确度相对较低,但是和Summary比起来,Histogram的性能成本较低。
|
1 2 3 4 5 6 7 |
type Histogram interface { Metric Collector // 添加一个观察值 Observe(float64) } |
默认的Buckets如下,主要用于测量网络响应延迟的场景:
|
1 |
DefBuckets = []float64{.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10} |
对于其它场景,你应当自己定义Buckets。
我们不会直接操控指标,而是使用它们的向量 —— GaugeVec、CounterVec、HistogramVec、SummaryVec。这些向量都是Collector接口的实现。
要创建向量,需要调用prometheus.New***Vec方法,例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
func NewGaugeVec(opts GaugeOpts, labelNames []string) *GaugeVec { // 描述符,关键信息是全限定名 + 标签集 desc := NewDesc( BuildFQName(opts.Namespace, opts.Subsystem, opts.Name), opts.Help, labelNames, opts.ConstLabels, ) return &GaugeVec{ metricVec: newMetricVec(desc, func(lvs ...string) Metric { // 第二个参数是回调,标签集创建一个Metric —— 指标,准确的说是时间序列 if len(lvs) != len(desc.variableLabels) { panic(makeInconsistentCardinalityError(desc.fqName, desc.variableLabels, lvs)) } result := &gauge{desc: desc, labelPairs: makeLabelPairs(desc, lvs)} result.init(result) // Init self-collection. return result }), } } |
下面的例子创建一个Gauge向量:
|
1 2 3 4 5 |
weight := prometheus.NewGaugeVec(prometheus.GaugeOpts{ Subsystem: "flagger", Name: "canary_weight", Help: "The virtual service destination weight current value", }, []string{"workload", "namespace"}) // 注意标签顺序 |
获取具有指定标签值的Gauge(时间序列):
|
1 2 |
// 注意标签值的顺序,和上面对应 gauge := cr.weight.WithLabelValues(cd.Spec.TargetRef.Name, cd.Namespace) |
产生一个指标值:
|
1 |
gauge.Set(float64(canary)) |
下面的例子使用默认Bucket创建Histogram向量:
|
1 2 3 4 5 6 |
duration := prometheus.NewHistogramVec(prometheus.HistogramOpts{ Subsystem: controllerAgentName, Name: "canary_duration_seconds", Help: "Seconds spent performing canary analysis.", Buckets: prometheus.DefBuckets, }, []string{"name", "namespace"}) |
产生一个指标值:
|
1 |
cr.duration.WithLabelValues(cd.Spec.TargetRef.Name, cd.Namespace).Observe(duration.Seconds()) |
Prometheus客户端提供了开箱即用的默认注册表: prometheus.DefaultRegisterer
你可以调用以下函数来创建注册表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// 不预先注册任何收集器的注册表 func NewRegistry() *Registry { return &Registry{ collectorsByID: map[uint64]Collector{}, descIDs: map[uint64]struct{}{}, dimHashesByName: map[string]uint64{}, } } // 创建一个严格的注册表。该注册表在收集期间,检查 // 1、每个指标是否和它的Desc一致 // 2、指标的Desc是否已经注册到注册表 // Unchecked的收集器不被检查 func NewPedanticRegistry() *Registry { r := NewRegistry() r.pedanticChecksEnabled = true return r } |
示例:
|
1 |
registry = prometheus.NewPedanticRegistry() |
|
1 2 3 4 5 6 7 8 9 |
// 进行注册 if err := registry.Register(gauge); err != nil { // 如果已经注册 if are, ok := err.(prometheus.AlreadyRegisteredError); ok { // 返回先前注册的收集器 return are.ExistingCollector, nil } return nil, err } |
Prometheus客户端不能直接将指标发送给Prometheus服务器。只能通过网络端口暴露一个Exporter。
如果要基于HTTP协议暴露,将promhttp包提供的Handler传递给你的HTTP服务器,每个Handler读取单个注册表,从中收集指标信息,生成HTTP响应:
|
1 2 3 4 5 6 |
// 使用默认注册表创建Handler func Handler() http.Handler { return InstrumentMetricHandler( prometheus.DefaultRegisterer, HandlerFor(prometheus.DefaultGatherer, HandlerOpts{}), ) } |
如果你需要使用非默认注册表,直接调用:
|
1 |
func HandlerFor(reg prometheus.Gatherer, opts HandlerOpts) http.Handler {} |
然后将Handler传递给你的ServeMux即可:
|
1 2 3 |
mux := http.NewServeMux() import "github.com/prometheus/client_golang/prometheus/promhttp" mux.Handle("/metrics", promhttp.Handler()) |
[…] LIS资料: https://blog.gmem.cc/prometheus-study-note […]