ZooKeeper学习笔记
ZooKeeper是Hadoop的子项目,实现高可靠的分布式协调服务。它可以提供分布式的配置、同步、命名、集群服务。ZooKeeper暴露了一系列简单的接口,具有Java、C语言绑定。
为了正确构建复杂的服务,ZooKeeper提供以下保证:
- 顺序一致性:来自客户端的更新,按照它们被发送的顺序应用
- 原子性:更新要么成功要么失败
- 单一系统镜像:不管客户端连接到哪个ZooKeeper实例,它都看到服务的一致性视图
- 可靠性:一旦更新被写入,即是永久的
- Timeliness:客户端看到的系统视图确保在一定时间范围内更新到最新状态
ZooKeeper由以下组件构成:
- 服务器:运行在ZooKeeper ensemble节点上的Java服务器
- 客户端:一个Java类库,用于链接到ZooKeeper集群
- Native客户端:基于C实现的客户端
- 其它可选组件
Native客户端和可选组件仅仅支持Linux。
除了Request Processor之外,所有ZooKeeper实例持有一模一样的组件:
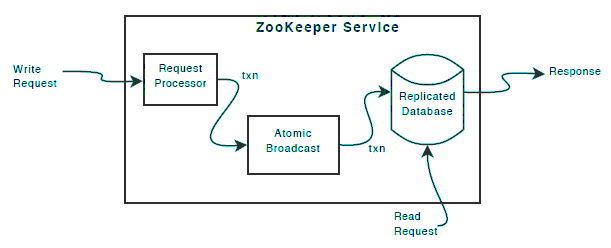
- replicated database,一个内存数据库,包含整个名字空间。对此数据库的更新被刷入磁盘,以便重启后恢复
- 每个ZooKeeper实例都可以接受客户端请求,读请求基于本地的数据库处理,更新服务状态的写请求基于 agreement protocol处理。此协议:
- 将一个实例作为leader,其它实例作为followers
- follower从leader接收消息提议,并同意消息递送
- 消息层负责leader的故障转移、follower与leader的同步
- ZooKeeper使用一个定制化的原子消息协议,保证消息层是原子性的。这种原子性保证了本地数据库不会出现数据不一致性
ZooKeeper很简单,它允许分布式进程通过一个共享的、有层次的名字空间来相互交互。这个名字空间的组织就像文件系统一样,名字空间由数据寄存器(data registers) —— 所谓znodes组成,类似于文件系统的目录/文件,ZooKeeper的数据是驻留内存的,而不是像文件系统那样写在磁盘上。
就像被它管理的分布式进程,ZooKeeper本身也倾向于跨越一组宿主机(所谓ensemble)复制,整体上形成一个ZooKeeper服务。只要大部分节点可用,则ZooKeeper服务可用。
客户端连接到单个ZooKeeper节点,通过一个TCP连接来:
- 发送请求
- 获得响应
- 获得监听的事件
- 发送心跳
如果此TCP连接丢失,客户端可能连接到另外一个节点。
ZooKeeper使用数字标注每个update,以反应所有ZooKeeper事务的顺序。后续操作可以使用此数字序号实现高层次的抽象,例如同步原语。
ZooKeeper非常高速,特别是在读为主的应用场景下。在上千台机器上运行的ZooKeeper应用,其性能在读写比10:1左右最好。
ZooKeeper提供的名字空间非常类似于Linux目录树,由一系列以 / 分隔的路径元素组成,名字空间中的每个节点以完整路径唯一识别。
ZooKeeper使用多种方式来追踪时间:
- Zxid:即ZooKeeper事务ID。每次对ZooKeeper的状态做出修改,都对应一个这样的ID。这个ID是单调递增的
- 版本号:对节点的修改会导致其某个版本号字段变更
- 时间单元(Ticks):在集群中,ZooKeeper使用时间单元来界定状态上传、会话过期、Peer连接过期的最小时间间隔
- 真实时间:节点的创建、修改时间使用真实时间记录
客户端利用C/Java语言绑定库建立会话:
- 客户端发起调用时,可以指定连接字符串、会话超时、默认Watcher等参数,连接字符串包括逗号分隔的多个ZooKeeper实例的host:port列表
- 客户端创建一个到ZooKeeper服务集群的句柄(Handle),句柄被创建后,进入CONNECTING状态。这时,ZooKeeper会:
- 创建一个代表会话ID的64位整数并分配给客户端
- 同时,发送一个会话密码给客户端,客户端重连时需要用到此密码
- 根据客户端请求的会话超时ms,确定一个允许的(受限于时间单元,必须在2-20倍之间)会话超时
- 绑定库尝试建立到某个ZooKeeper实例的TCP连接。连接建立后,句柄进入CONNECTED状态
- 如果出现不可恢复的错误,包括会话过期、身份验证失败、客户端显式的关闭句柄,则句柄进入CLOSED状态
- 如果客户端发现连接意外断开,则尝试连接列表中下一个实例,直到重新连接上。客户端重新连接时,会在握手时携带自己的会话ID、密码
- 客户端重新连接上之后,可能发现会话已经过期
- 默认Watcher可以在会话状态发生变化(例如连接断开、会话过期)后,通知客户端
从3.2开始,连接字符串可以有一个chroot后缀,例如 127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/pems/webmgr ,其意义是,将客户端的根znode设置为/pems/webmgr,所有绝对、相对路径均假设此znode为根。
客户端通过发送PING心跳来保活,这样双方都可以知道连接是否断开。
客户端可以变更连接字符串,也就是变更服务器列表。此变更可能触发一个负载均衡算法,并导致客户端重连到其它服务器。
名字空间的每个节点被称为znode,类似于文件系统的目录。znode有以下特点:
- 路径是znode的唯一标识
- znode可以具有关联的数据,还可以具有子节点
- znode关联的数据通常很小,一般最大KB级别
- znode具有一个状态结构(Stat Structure),存放版本号、数据长度、修改时间戳等信息
- znode的数据发生变化,版本号就递增
- znode同时保存数据的多个版本
- 读写znode数据的操作都是原子性的,写操作替换掉数据
- 每个节点包含一个访问控制列表(ACL)用于限制谁能做什么
- znode可以被监控(watch),一旦数据修改、子节点变化,即可通常关注此znode的客户端。这是ZooKeeper的核心特性
所谓临时(EPHEMERAL)节点,仅仅在创建它的Session存在期间存在。ZooKeeper的客户端Session基于TCP长连接,通过心跳来保活。
当创建一个znode时,你可以要求ZooKeeper在路径尾部自动附加单调递增的计数器。对于父节点来说,此计数器具有唯一性。计数器十位左侧补零,示例: <path>0000000001
计数器的下一个值,存储在父节点中。如果计数超过2147483647 会出现溢出。
3.6版本新增。这类节点的所有子节点都消失后,可能在未来的某个时间点被自动删除。
| 字段 | 说明 |
| czxid | 创建此节点的zxid |
| mzxid | 最后一次修改此节点的zxid |
| pzxid | 最后一次修改子节点的zxid |
| ctime | 此节点创建的时间 |
| mtime | 此节点被修改的时间 |
| version | 关联数据变更版本号 |
| cversion | 子节点变更版本号 |
| aversion | ACL版本号 |
| ephemeralOwner |
如果此节点是临时节点,则此字段存放节点创建者的会话ID 如果不是临时节点,值为0 |
| dataLength | 关联数据的长度 |
| numChildren | 子节点的数量 |
ZooKeeper支持监控(Watch)的概念——一次性的事件监听器。它有三个要点:
- 一次性的:当被监控数据发生变化后,事件发送且仅一次。例如 getData("/znode1", true)导致当znode1的关联数据发生变化后客户端得到通知,但是后续znode1的数据再发生变化则不会自动得到通知
- 发送给客户端:事件被异步的发送给客户端,并且ZooKeeper提供顺序性保证,客户端不可能在收到通知之前就看到目标数据的变化
- 监控什么数据:getData/exists针对关联数据进行监控,getChildren()则针对子节点进行监控
ZooKeeper中所有的读操作,包括 getData()、 getChildren()、 exists(),都可选设置Watch。
Watch仅仅在客户端所连接到的服务器上维护,但如果客户端发生重连,则新服务器负责维护客户端之前注册的Watch。有一种情况下,Watch会遗漏监控:
- 客户端设置了exists监控,然后客户端断开
- 被监控节点创建,然后又被删除
- 客户端重连,此时它不会收到Watch
客户端可以调用removeWatches来移除监控。
ZooKeeper对Watch提供以下保证:
- 先发生的事件,其Watcher先被通知
- 针对同一事件先注册的Watcher先被通知
- 先得到Watch通知,然后才能看到目标znode数据的变化
使用Watch时需要注意:
- 一次性,如果需要获得后续变更通知,需要再次注册Watcher
- 由于再次注册会有网络延迟,这期间目标znode可能已经发生了多次变化,这些变化是捕获不到的
- 在连接断开期间,接收不到通知
| 事件类型 | 可监控该事件的API |
| 节点创建 | exists |
| 节点删除 | exists / getData / getChildren |
| 节点数据改变 | getData |
| 子节点的创建、删除、改变 | getChildren |
ZooKeeper支持基于ACL对znode进行访问控制。其实现有些类似UNIX文件模式,不同的是,ZooKeeper没有user/group/world这三种角色,它允许定义无限数量的角色(ID),并为这些角色授权。此外ACL不是递归的,也就是子节点不会继承父节点的授权设置。
ZooKeeper支持可拔插的身份验证方案(scheme)。ID的形式则为 scheme:id,例如ip:172.16.16.1表示IP验证方案下的实体172.16.16.1。
当客户端登录ZooKeeper并对自己进行身份验证时,ZooKeeper将所有对应此客户端的ID都分配给它。当客户端访问znode时,这些ID用来进行ACL验证。
ACL中每个条目的格式为 (scheme:expression, perms),其中expression取决于scheme,覆盖1-N个ID。例如 (ip:172.21.0.0/16, READ)表示授予172.21网段所有客户端读权限。
| Scheme | 说明 |
| world | 此模式仅包含单个id —— anyone,表示任何人 |
| auth | 此模式没有id,表示任何通过身份验证的人 |
| digest | 基于username:password字符串生产id,用在ACL条目中密码显示为Base64编码的SH1摘要 |
| ip | 使用客户端IP地址作为id |
| x509 | 使用数字整数进行验证,在ACL条目中使用X500主体名称作为id |
| Perm | 说明 |
| CREATE | 允许创建子节点 |
| READ | 允许读取数据、列出子节点 |
| WRITE | 允许修改节点的关联数据 |
| DELETE | 允许删除子节点 |
| ADMIN | 允许设置权限 |
首先保证1.7或者更高版本的JDK已经安装,然后到稳定频道下载二进制压缩包,解压到合适的目录中。
要启动ZooKeeper服务,需要创建一个配置文件conf/zoo.cfg:
|
1 2 3 4 5 6 |
# 基本的时间单元对应的毫秒数,心跳每个时间单元发送一次,会话过期最小时间2时间单元 tickTime=2000 # 内存数据库的快照存放目录 dataDir=/data # 监听客户端连接的端口 clientPort=2181 |
独立运行的ZooKeeper可以用户开发、测试目的。在产品环境下,你需要在复制(Replication)模式下运行ZooKeeper。一组复制的ZookKeeper称为Quorum,它们必须共享一致的配置文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 # 连接到Leader超时时间单元 initLimit=5 # Follower最多落后Leader多少时间单元 syncLimit=2 quorumListenOnAllIPs=true # 服务器列表,server.X中的X是实例ID,在运行时,每个实例检查自己数据目录下的myid文件,其中以ASCII写着自己的ID # 前一个端口供Follower连接到Leader使用;后一个端口用于选举Leader server.1=172.21.0.1:2888:3888 server.2=172.21.0.2:2888:3888 server.3=172.21.0.3:2888:3888 |
每个Quorum最少应该包含3个ZooKeeper实例,并且应当配置奇数个数的实例。
官方镜像的配置文件路径为/conf/zoo.cfg,下面的命令创建容器:
|
1 2 3 |
# ZOO_MY_ID 用于设置myid文件,此镜像假设数据目录是/data docker run -e "ZOO_MY_ID=2" --name zookeeper-2 --network local --ip 172.21.0.2 -d docker.gmem.cc/zookeeper docker run -e "ZOO_MY_ID=3" --name zookeeper-3 --network local --ip 172.21.0.3 -d docker.gmem.cc/zookeeper |
环境变量 ZOO_LOG_DIR用于指定ZooKeeper运行期间产生的日志的存放目录。包括log4j日志和守护程序的stdout都存放在此目录中。
环境变量 ZOO_LOG4J_PROP用于设置log4j的日志级别、启用的Appender。此变量的默认值是INFO, CONSOLE,也即是将最低INFO级别的日志输出到标准输出。可以设置为 ERROR,ROLLINGFILE,以使用滚动日志。
|
1 2 3 4 5 6 7 8 9 |
# 在后台启动ZooKeeper服务 zkServer.sh start # 在前台启动ZooKeeper服务 zkServer.sh start-foreground # 停止ZooKeeper服务 zkServer.sh stop # 启动CLI客户端 zkCli -server 127.0.0.1:2181 |
ZooKeeper具有非常简单的编程接口,它仅仅提供以下操作:
| 操作 | 说明 |
| create | 在名字空间树中创建一个节点 |
| delete | 删除一个节点 |
| exists | 测试某个路径上的节点是否存在 |
| get data | 读取节点数据 |
| set data | 写入节点数据 |
| get children | 获取子节点列表 |
| sync | 等待数据传播到整个集群 |
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.10</version> </dependency> |
使用模式EPHEMERAL可以创建有序节点,反复针对同一路径创建有序节点,会自动后缀单调递增的编号。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
ArrayList<ACL> acl = ZooDefs.Ids.OPEN_ACL_UNSAFE; byte[] data = { 0 }; // 临时节点不支持子节点 try { // 同步创建 zk.create( "/tmp", data, acl, CreateMode.PERSISTENT ); } catch ( KeeperException e ) { if ( e.code() != KeeperException.Code.NODEEXISTS ) throw e; } // 异步创建 zk.create( "/tmp/no", data, acl, CreateMode.EPHEMERAL_SEQUENTIAL, ( rc, path, ctx, name ) -> { // rc: OK path: /tmp/no, name: /tmp/no0000000000 // rc: OK path: /tmp/no, name: /tmp/no0000000001 // rc: OK path: /tmp/no, name: /tmp/no0000000002 LOGGER.debug( "rc: {} path: {}, name: {}", new Object[]{ KeeperException.Code.get( rc ), path, name } ); }, this ); TimeUnit.SECONDS.sleep( 1 ); |
这个例子中,我们使用一个Agent来:
- 管理到ZooKeeper的连接,一旦会话过期即重连
- 转发ZooKeeper发来的事件通知给客户端
- 对事件机制进行简单封装,实现了:
- 隔离客户端和ZooKeeper
- 会话过期后,自动重新注册Watch
Agent代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
package cc.gmem.study; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.data.Stat; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentLinkedDeque; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.function.Consumer; public class ZooKeeperAgent implements Watcher { private static final Logger LOGGER = LoggerFactory.getLogger( ZooKeeperAgent.class ); private ZooKeeper zk; private String connectString; private int timeout; private Map<Event.EventType, Map<String, Queue<Consumer<EventResolver>>>> allListeners; // 对WatchedEvent进行简单包装,支持获取znode数据,对客户端屏蔽ZooKeeper public class EventResolver { private WatchedEvent event; public EventResolver( WatchedEvent event ) { this.event = event; } public WatchedEvent getEvent() { return event; } public byte[] getData() { return getData( null ); } public byte[] getData( Stat stat ) { if ( stat == null ) { stat = new Stat(); } try { return zk.getData( event.getPath(), false, stat ); } catch ( Exception e ) { throw new RuntimeException( e.getMessage(), e ); } } } public ZooKeeperAgent( String connectString, int timeout ) { this.connectString = connectString; this.timeout = timeout; allListeners = new ConcurrentHashMap<>(); allListeners.put( Event.EventType.NodeCreated, new ConcurrentHashMap<>() ); allListeners.put( Event.EventType.NodeDataChanged, new ConcurrentHashMap<>() ); allListeners.put( Event.EventType.NodeDeleted, new ConcurrentHashMap<>() ); allListeners.put( Event.EventType.NodeChildrenChanged, new ConcurrentHashMap<>() ); allListeners = Collections.unmodifiableMap( allListeners ); createZooKeeper(); } public void on( Event.EventType eventType, String path, Consumer<EventResolver> listener ) { Map<String, Queue<Consumer<EventResolver>>> listenersOfType = this.allListeners.get( eventType ); Queue<Consumer<EventResolver>> listeners; synchronized ( this ) { listeners = listenersOfType.get( path ); if ( listeners == null ) { listeners = new ConcurrentLinkedQueue<>(); listenersOfType.put( path, listeners ); } } listeners.add( listener ); watch( eventType, path ); } private void watch( Event.EventType eventType, String path ) { try { switch ( eventType ) { case NodeCreated: // 这里可以传递一个Watcher类型,也可以传入boolean // 如果为true,使用构造ZooKeeper时提供的Watcher ———— 所谓defaultWatcher zk.exists( path, this ); break; case NodeDataChanged: Stat stat = new Stat(); zk.getData( path, this, stat ); break; case NodeDeleted: zk.exists( path, this ); break; case NodeChildrenChanged: zk.getChildren( path, this ); break; } } catch ( Exception e ) { LOGGER.error( e.getMessage(), e ); } } private void createZooKeeper() { try { zk = new ZooKeeper( connectString, timeout, this ); // 新会话,Watch需要重新注册 allListeners.entrySet().stream().flatMap( entry -> { Event.EventType eventType = entry.getKey(); return entry.getValue().keySet().stream().map( path -> { return new Object[]{ eventType, path }; } ); } ).forEach( args -> watch( (Event.EventType) args[0], (String) args[1] ) ); } catch ( IOException e ) { throw new RuntimeException( e.getMessage(), e ); } } public void process( WatchedEvent event ) { switch ( event.getType() ) { case None: onKeeperStateEvent( event ); break; default: onZnodeEvent( event ); } } private void onKeeperStateEvent( WatchedEvent event ) { switch ( event.getState() ) { case SyncConnected: LOGGER.debug( "Connected to server with session id {}", zk.getSessionId() ); break; case Expired: LOGGER.debug( "Session expired, recreating" ); // 一旦会话过期,ZooKeeper对象就废了 createZooKeeper(); break; } } private void onZnodeEvent( WatchedEvent event ) { Queue<Consumer<EventResolver>> consumers = allListeners.get( event.getType() ).get( event.getPath() ); if ( consumers != null ) { consumers.forEach( consumer -> consumer.accept( new EventResolver( event ) ) ); // 继续监控 watch( event.getType(), event.getPath() ); } } } |
客户端代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
package cc.gmem.study; import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.data.Stat; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.concurrent.TimeUnit; import static org.apache.zookeeper.Watcher.Event.EventType.*; /** * Created by alex on 8/10/16. */ public class WatchClient { private static final Logger LOGGER = LoggerFactory.getLogger( WatchClient.class ); public static void main( String[] args ) throws InterruptedException { String connectString = "172.21.0.1:2181,172.21.0.2:2181,172.21.0.3:2181"; ZooKeeperAgent agent = new ZooKeeperAgent( connectString, 2000 * 20 ); agent.on( NodeCreated, "/user", ( resolver ) -> { Stat stat = new Stat(); LOGGER.debug( "znode craeted with data: {}", new String( resolver.getData( stat ) ) ); } ); agent.on( NodeDataChanged, "/user", ( resolver ) -> { Stat stat = new Stat(); LOGGER.debug( "znode data: {}, version: {}", new String( resolver.getData( stat ) ), stat.getVersion() ); } ); agent.on( NodeDeleted, "/user", ( resolver ) -> { LOGGER.debug( "znode deleted" ); } ); TimeUnit.DAYS.sleep( 1 ); } } |
ZooKeeper名字空间可以直接当做类似于JNDI的命名服务使用,ZooKeeper和JNDI都可以把目录节点关联到特定的资源(但是JNDI的资源是Java对象),ZooKeeper还具有与生俱来的高可用性。
ZooKeeper可以用来管理分布式系统中的配置项,如果多个应用服务实例需要共享很多系统参数,可以交由ZooKeeper来管理,通过Watch的方式,应用服务可以在配置变更后获得通知。
ZooKeeper可以管理服务的集群:
- 当新增服务器、删除服务器(服务器宕机)时,客户端、ZooKeeper、集群成员可以得到通知。实现原理是:
- 每个集群成员启动后,都在某个znode下创建临时子节点,这个子节点依赖于TCP长连接保活
- 一旦集群成员宕机,临时子节点由于TCP连接的断开而自动删除
- 关注者可以在父节点上调用getChildren( parentPath, true)进行watch,一旦子节点发生增减,此调用即返回
- 在集群成员中选取Leader(Master)。实现原理是:
- 每个成员创建不但是临时,还是有序(SEQUENTIAL)的子节点
- 序号最小的成员,总是作为Leader
- 如果当前Leader宕机,则次小的成员被选作Leader
要实现独占锁,可以把多个协作者共享的资源抽象为一个znode,然后:
- 需要占用此资源的协作者,在znode 下创建一个临时、有序子节点
- 协作者判断自己这个节点序号是否最小:
- 如果是,意味着获得锁
- 如果否,则在父节点上watch。收到通知后,继续执行步骤2
- 当需要是否资源时,删除自己创建的子节点即可
所谓屏障(Barrier),即协作者到达某个状态后,等待其它协作者都到达此状态,然后一起继续。基于ZooKeeper可以这样实现屏障:
- 每个协作者到达状态后,均创建一个子节点
- 判断子节点总数是否足够:
- 如果是,跨越屏障继续执行业务逻辑
- 如果否,则在父节点上watch。收到通知后,继续执行步骤2
报错信息:
2017-08-09 17:53:03,750 [myid:1] - ERROR [/172.21.1.1:3888:QuorumCnxManager$Listener@763] - Exception while listening
java.net.BindException: Cannot assign requested address (Bind failed)
解决办法:配置文件添加 quorumListenOnAllIPs=true
可以通过JMX查看,通过Oracle Mission Controll连接到名为 org.apache.zookeeper.server.quorum.QuorumPeerMain 的JVM,在MBean Browser选项卡中可以看到相关信息。
此文件是ZooKeeper运行期间的标准输出,要指定它的存放位置,可以设置 ZOO_LOG_DIR这个环境变量。
注意,上述环境变量同时也作为log4j的日志输出目录。
Leave a Reply