人工智能知识 - Transformers和大模型
这一篇聚焦现代大模型主线,内容从 Transformer 架构出发,延伸到语言模型、多模态模型、预训练与微调,以及推理阶段优化。前一篇已经建立了神经网络与训练机制,这一篇继续回答现代基础模型是如何堆叠出来、如何适配任务、又如何在部署侧提升吞吐、延迟与显存效率;最后一篇将转入上下文工程、RAG 与 Agent 系统。
Transformer 是现代大模型最核心的统一架构。它最初被提出用于序列到序列(Sequence-to-Sequence)任务,但很快演化成大语言模型(Large Language Model, LLM)、视觉 Transformer、多模态模型以及各类基础模型(Foundation Model)的共同骨架。它之所以重要,不只是因为“效果好”,更因为它提供了一种高度模块化、可并行扩展、易于堆叠放大的建模方式:输入被表示成一串 token,对这些 token 的关系建模主要依赖注意力(Attention),而每一层又通过前馈网络(Feed-Forward Network, FFN / MLP)继续做非线性变换与特征重组。
从工程角度看,Transformer 的成功来自三件事的结合:第一,注意力机制让模型能直接建模长距离依赖,而不必像循环网络那样逐步传递状态;第二,层与层之间结构统一,非常适合在 GPU / TPU 上做大规模并行训练;第三,模型规模可以沿着层数、隐藏维度、注意力头数、词表大小与训练数据量持续扩展,于是它天然适合作为“可放大”的通用架构。
因此,理解 Transformer 不应只停留在“注意力公式怎么写”,还要把它看成一条完整的信息处理流水线:token 如何变成向量,向量如何在注意力里彼此通信,MLP 如何重组和放大模式,残差流(Residual Stream)如何把各层计算串接起来,最后这些中间表示又如何被任务头(Task Head)读出,变成分类结果、生成 token 或其他下游输出。![]()
Transformer 的“基本计算单元”是一个 Transformer block:把注意力子层(Attention Sublayer)与前馈子层(FFN Sublayer)串联起来,并在每个子层外包一层残差连接(Residual Connection)与归一化(Normalization)。注意力子层的输出核心是作为中间表示继续送入 FFN 与下一层 Transformer block,逐层构建更抽象的特征。
典型层结构(概念上)可以写成:
\[H'=\mathrm{Add\&Norm}(H,\ \mathrm{Attention}(H)),\quad H^{\text{next}}=\mathrm{Add\&Norm}(H',\ \mathrm{FFN}(H'))\]这条式子描述的是一个 Transformer block 内部最核心的两步。这里 \(H\) 表示进入当前层的隐藏状态矩阵(Hidden States),形状通常是 \(L\;\times d_{\text{model}}\): \(L\) 是序列长度, \(d_{\text{model}}\) 是每个 token 的隐藏维度。 \(\mathrm{Attention}(H)\) 表示注意力子层对整段序列做一次“彼此通信”后的结果:每个 token 会结合其他位置的信息,得到新的上下文化表示。
第一步 \(H'=\mathrm{Add\&Norm}(H,\ \mathrm{Attention}(H))\) 中,Add 表示残差相加:把原输入 \(H\) 与注意力输出相加;Norm 表示再做归一化(通常是 LayerNorm)。残差的作用是保留原始信息并让梯度更容易穿过深层网络,归一化的作用是让数值尺度更稳定。经过这一步后,得到的 \(H'\) 可以理解为“已经完成一次上下文交互”的中间表示。
第二步 \(H^{\text{next}}=\mathrm{Add\&Norm}(H',\ \mathrm{FFN}(H'))\) 则把 \(H'\) 送入前馈网络(Feed-Forward Network, FFN)。FFN 对每个位置的向量分别做非线性变换与特征重组,不负责 token 之间的信息交换。它更像是在每个 token 内部重新编码:放大有用模式、抑制无关模式,并把低层线索组合成更抽象的表示。再经过一次“残差相加 + 归一化”后,输出 \(H^{\text{next}}\),作为下一层 Transformer block 的输入。
因此,这个公式的阅读顺序可以概括为:先让 token 之间通过注意力交换信息,再让每个 token 自己通过 FFN 重组特征。多层堆叠之后,模型就会沿着这条路径逐层把原始输入变成越来越适合任务头读取的高层表示。
这里还需要区分 Pre-LN(Pre-LayerNorm)与 Post-LN(Post-LayerNorm)。它们的区别在于 LayerNorm 放在子层计算之前,还是放在残差相加之后。
若是 Post-LN,概念上更接近前面那条写法:先做子层计算,再与输入做残差相加,最后归一化。例如注意力子层可写成 \(H'=\mathrm{LN}(H+\mathrm{Attention}(H))\)。若是 Pre-LN,则顺序改成“先归一化,再做子层计算,再走残差”:注意力子层更接近 \(H'=H+\mathrm{Attention}(\mathrm{LN}(H))\),FFN 子层同理。
两者表达的功能主线相同:信息都要经过注意力与 FFN,再靠残差流向后传递。差异主要体现在训练动力学(Training Dynamics)上。Post-LN 更贴近原始 Transformer 论文的写法,直观上像“每次子层更新完,再把结果规范一下”;Pre-LN 则让梯度更容易沿残差路径稳定传播,因此在很深的大模型里更常见。工程实现会在 Pre-LN / Post-LN 之间选择,这会影响训练稳定性、学习率可用范围以及深层可训练性,但不会改变我们对 block 主流程的理解:注意力负责跨 token 交互,FFN 负责单 token 特征重组,残差负责让信息与梯度顺畅穿层流动。
Transformer 这个名字源自 “Attention Is All You Need” 论文:模型从依赖循环结构来处理序列转向通过注意力把序列表示不断变换(Transform)为更适合预测的表征。
Transformer 的参数(Parameters)核心是一组可学习张量的集合,主要包括嵌入(Embedding)、注意力投影(Attention Projections)、前馈网络(FFN)以及归一化的缩放/平移参数等。
| 参数组 | 符号 | 典型形状(Typical Shape) | 备注 |
| Token Embedding | \(E\) | \(\mathbb{R}^{V\;\times d_{\text{model}}}\) | 词表大小 \(V\);常与输出头权重共享(Weight Tying)。 |
| 位置嵌入(Learned) | \(P\) | \(\mathbb{R}^{L_{\max}\;\times d_{\text{model}}}\) | 仅当使用可学习绝对位置嵌入时存在;正弦位置编码无此参数。 |
| 注意力投影 | \(W_Q,W_K,W_V\) | \(\mathbb{R}^{d_{\text{model}}\;\times d_{\text{model}}}\) | 实现上常把多头合并成一次线性投影,等价于 \(\mathbb{R}^{d_{\text{model}}\;\times (H d_k)}\)。 |
| 注意力输出投影 | \(W_O\) | \(\mathbb{R}^{d_{\text{model}}\;\times d_{\text{model}}}\) | 对拼接后的多头输出做线性混合;并非 \(H\;\times d_v\;\times d_{\text{model}}\) 的三维张量。 |
| FFN | \(W_1,W_2\) | \(W_1\in\mathbb{R}^{d_{\text{model}}\;\times d_{\text{ff}}},\ W_2\in\mathbb{R}^{d_{\text{ff}}\;\times d_{\text{model}}}\) | 通常 \(d_{\text{ff}}\gg d_{\text{model}}\)。 |
| LayerNorm | \(\gamma,\beta\) | \(\mathbb{R}^{d_{\text{model}}}\) | 每个 LayerNorm 有一组缩放与平移参数。 |
| 输出头(LM Head) | \(W_{\text{vocab}},b\) | \(W_{\text{vocab}}\in\mathbb{R}^{d_{\text{model}}\;\times V}\) | 把隐藏状态映射为词表 logits;常与 \(E\) 共享权重。 |
不同 Transformer 变体在维度设置上差异很大。下面列的是几类典型公开模型的常见配置,既包括中等尺寸的主流模型,也包括 2025 到 2026 年仍处前沿位置的开源大模型。它们的共同点在于:即使是“中等尺寸”的主流模型,隐藏维度、层数、头数和 FFN 宽度也已经足够大;而到了开源前沿模型阶段,参数扩展往往已经从靠加深层数扩展到同时叠加更宽的隐藏维度、更大的 FFN、MoE(Mixture of Experts)和更激进的注意力/KV 设计,因此模型内部表示天然是高维、分布式且跨层叠加的。
| 模型 | 架构类型 | 参数规模 | 层数 | 隐藏维度 \(d_{\text{model}}\) | 注意力头数 | KV 头数 | FFN / Intermediate 维度 |
| BERT-base | Encoder-only | 110M 级(dense) | 12 | 768 | 12 | 12 | 3072 |
| GPT-2 Small | Decoder-only | 124M 级(dense) | 12 | 768 | 12 | 12 | 3072 |
| Mistral 7B | Decoder-only | 7B 级(dense) | 32 | 4096 | 32 | 8 | 14336 |
| Llama 3.1 8B | Decoder-only | 8B 级(dense) | 32 | 4096 | 32 | 8 | 14336 |
| Qwen2.5 7B | Decoder-only | 7B 级(dense) | 28 | 3584 | 28 | 4 | 18944 |
| Qwen3-235B-A22B | Decoder-only + MoE | 235B 总参 / 22B 激活 | 94 | 4096 | 64 | 4 | 12288(dense)/ 1536(per-expert) |
| DeepSeek-V3 系列 | Decoder-only + MoE + MLA | 671B 总参 / 37B 激活 | 61 | 7168 | 128 | 128 | 18432(shared)/ 2048(per-expert) |
这张表也说明了一个很重要的趋势。到 2026 年,开源前沿模型已经从沿着“单纯加深层数”这一条路线演化转向出现了明显分化:Qwen3-235B-A22B 把层数推到 94 层,同时保持相对克制的隐藏维度,并通过 128 个专家、每 token 激活 8 个专家来放大总容量;DeepSeek-V3 系列则维持 61 层,但把隐藏维度提升到 7168,并叠加 DeepSeekMoE 与 MLA(Multi-head Latent Attention)来同时优化容量与推理成本。也就是说,前沿模型的“强”并不只表现为更深,而更多表现为深度、宽度、专家稀疏性与注意力工程的联合扩展。
对闭源顶级模型的层数,外界通常拿不到可靠公开配置,因此只能做工程上的区间推断。若它们仍以 Transformer block 为主体,那么从公开开源前沿模型的尺度看,显式层数大概率仍落在数十层到一百多层这一带,而非简单增长到几百层甚至上千层;更常见的扩展手段,是增大隐藏维度、放大 FFN、引入 MoE、延长上下文、增加训练 token,或在同等层数下叠加稀疏注意力、递归计算与工具链调用。因此,对 GPT、Claude、Gemini 这类闭源顶级模型,更稳妥的判断核心是“它们很可能已经处在百层级上下、并辅以更复杂的宽度与稀疏化设计”。
![]() Transformer 的不可解释性(Lack of Interpretability)核心是由整体机制共同产生:表示是分布式(Distributed)且高维的,多层叠加的非线性变换把因果链条变长;注意力权重可视化能提供线索,但它并非完整解释。
Transformer 的不可解释性(Lack of Interpretability)核心是由整体机制共同产生:表示是分布式(Distributed)且高维的,多层叠加的非线性变换把因果链条变长;注意力权重可视化能提供线索,但它并非完整解释。
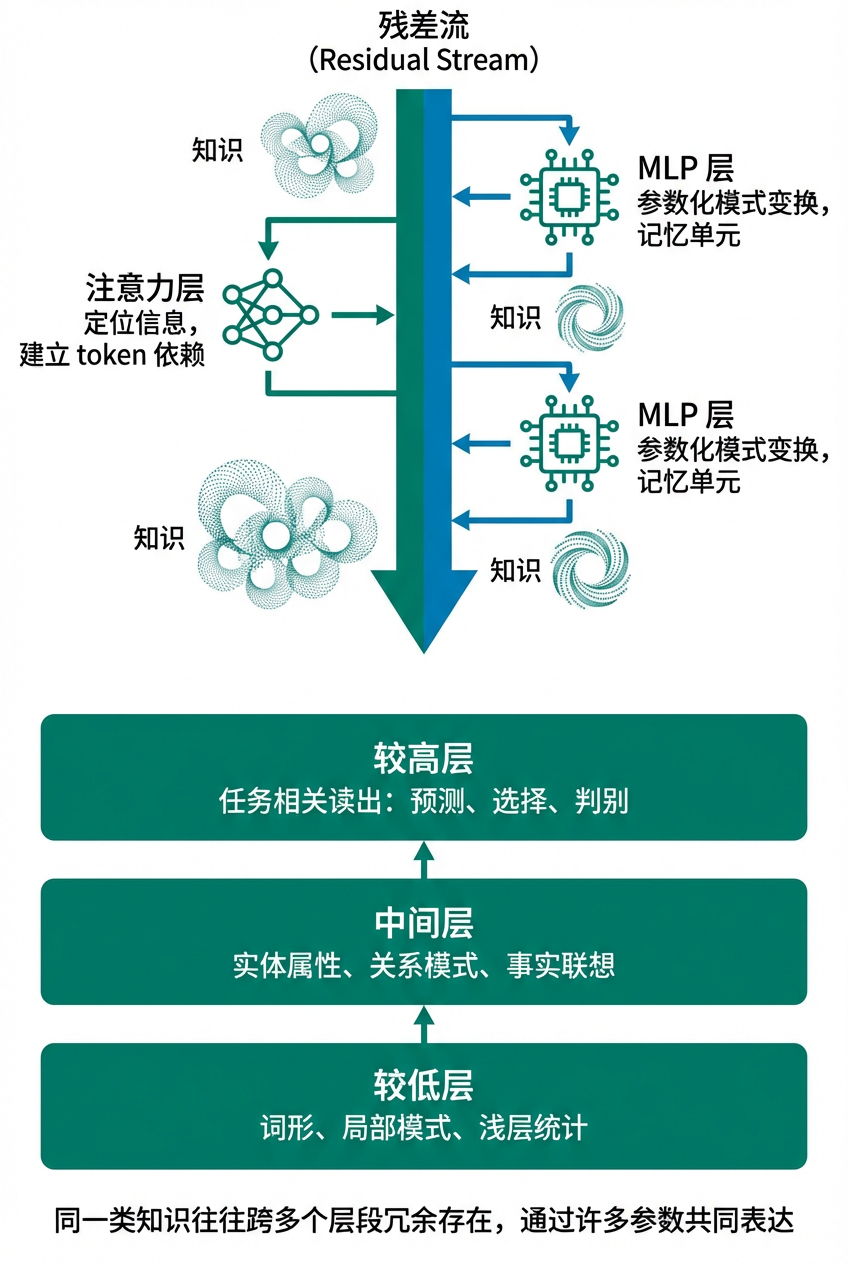
大模型中的知识通常以分布式表示(Distributed Representation)的形式分散在大量参数里,而非由某一个感知机单独存储一条事实。单个单元更像一个局部特征探测器(Feature Detector):它只对某种模式敏感;许多单元级联后,网络才能把低层简单模式组合成高层抽象概念。模型规模越大、层数越深、参数越多,可被编码的模式组合也越丰富,这正是大模型具备强表达能力与“知识容量”的原因之一。
对于 Transformer 这样的模型,知识并更像是沿着残差流(Residual Stream)在多层之间不断被提取、重组、放大和读出。注意力层更擅长在上下文中定位相关信息、建立 token 之间的依赖;MLP 层则更像参数化的模式变换器或记忆单元,会把某些已经被触发的模式映射成更强的语义方向,再写回主表示中。
从经验上看,这种知识分布有一些常见规律。较低层往往更接近词形、局部模式与浅层统计相关性;中间层更容易出现实体属性、关系模式和事实联想的组合;较高层则更接近任务相关读出,也就是更接近“最后怎样把内部表示变成具体输出”的阶段,例如下一 token 预测、答案选择或标签判别。但这更像统计趋势,而非严格分工:同一类知识往往会跨多个层段冗余存在,并通过许多参数共同表达。
因此,对知识分层的理解应落在“不同层在知识处理流水线里承担了什么功能”上,而非机械地追问“第几层存了什么知识”。有的层更偏检索线索,有的层更偏关系组合,有的层更偏把结果变成可供输出头使用的表示。单个 MLP 模块有时可以表现出类似键值记忆(Key-Value Memory)的行为,但真正稳定的知识通常仍然是跨层、跨参数、跨方向分布的。分布式编码既带来了较强的知识容量,也使模型难以直接解释和精确定位。
编码器-解码器(Encoder–Decoder)结构对应经典 Seq2Seq:编码器先对输入序列做双向自注意力(Bidirectional Self-Attention)编码,即编码器里的每个 token 都可以直接看到源序列中的其他 token,不使用因果掩码(Causal Mask),因此更擅长形成充分的上下文化输入表示;随后解码器在自回归生成(Autoregressive Generation)时,一边做因果自注意力(Causal Self-Attention),只看已经生成的前缀,一边通过交叉注意力(Cross-Attention)读取编码器输出。于是,编码器负责把“输入内容本身”编码清楚,解码器负责在“已生成前缀 + 编码器语义表示”条件下逐步生成输出。典型用于机器翻译、摘要、问答等“输入到输出”的条件生成任务(Conditional Generation),代表模型如 T5、BART。
仅编码器(Encoder-only)结构使用双向自注意力(Bidirectional Self-Attention):位置 \(i\) 可以看见所有位置(不做因果屏蔽)。它更擅长做“理解与表示”(Representation Learning),常见预训练目标是掩码语言建模(Masked Language Modeling, MLM):把输入里部分 token 替换为 \([\mathrm{MASK}]\),训练模型根据上下文预测被遮住的 token。代表模型如 BERT、RoBERTa;ELECTRA 则用“替换检测(Replaced Token Detection)”作为预训练任务,但架构仍是 Encoder-only。
注意“掩码(Mask)”在这里指的是 MLM 的 token masking,并非自回归解码里的因果 attention mask。
仅解码器(Decoder-only)结构使用因果自注意力(Causal Self-Attention):位置 \(i\) 只能看见 \(j\le i\) 的历史 token,通过三角形掩码避免“偷看未来”。它天然对应自回归语言建模(Causal Language Modeling, CLM):最大化 \(\prod_t p(x_t|x_{<t})\)。代表模型如 GPT 系列、LLaMA、Qwen。
这里的“掩码(Mask)”指的是 attention 里的因果屏蔽,与 MLM 的 \([\mathrm{MASK}]\) token 概念不同。
对生成式 Transformer,尤其是 Decoder-only 模型以及 Encoder–Decoder 中的解码器侧,推理过程通常可分成两个阶段:预填充(Prefill)与解码(Decode)。Prefill 先把整段已知提示词(Prompt)一次性送入模型,计算每一层的隐藏状态,并把各层的 Key / Value 写入 KV Cache;Decode 则在此基础上逐步生成新 token,每一步只新增一个位置,再与历史缓存做注意力计算。
Prefill 阶段虽然仍然使用因果掩码(Causal Mask),但因为整段 prompt 在进入模型时已经全部已知,所以输入处理过程中所有 token 仍可并行处理:同一层里的 Query / Key / Value 投影、矩阵乘法以及 masked attention 都可以一次性并行完成。因果掩码只负责限制“当前位置不能看未来位置”,并不会把已知 prompt 重新变回按时间步串行处理。
生成阶段则通常是串行的。因为每一个新输出 token 都要作为前缀的一部分,参与下一个 token 的预测,所以 token 与 token 之间存在真实的自回归依赖,不能像 Prefill 那样沿序列长度整段并行展开。此时系统仍然可以利用 batch 并行、head 并行、张量并行、专家并行和内核并行,但在“生成顺序”这一维上通常必须逐步推进。因此,长 prompt 场景下常说系统先经历一次计算密集(Compute-bound)的 Prefill,而进入连续生成后,瓶颈又经常转向 KV Cache 读取、显存带宽与调度开销主导的 Decode。
这个两阶段视角非常重要,因为后续很多工程优化都直接对应其中一个阶段:FlashAttention 对长序列 Prefill 的收益通常最显著;KV Cache、GQA / MQA、Paged Attention、Prompt Caching 与 Speculative Decoding 等,则更多是在优化 Decode 或同时兼顾两者。理解了 Prefill 与 Decode 的分工,再看 Transformer 推理优化时,许多“为什么这里快、那里慢”的现象就会变得自然。
Decoder-only 成为主流之后,架构创新集中在“稳定性、KV Cache 成本与训练效率”三个轴:归一化/激活影响深层训练稳定性;注意力侧的 KV 结构决定长上下文推理成本;FFN 稠密/稀疏(MoE)与训练目标改造影响单位算力的有效学习信号。
| 技术点 | 常见选项 | 动机 | 影响 |
| 归一化(Normalization) | LayerNorm / RMSNorm | 提升深层训练稳定性 | RMSNorm 省掉去均值,算子更简单;实际表现依赖整体配方 |
| 激活/FFN(Activation/FFN) | GELU / SwiGLU / GLU 变体 | 门控提升表达力与稳定性 | 通常带来更好效果,但实现与吞吐会受内核支持影响 |
| KV Cache 压力 | MHA / GQA / MQA | 减少 KV heads,降低显存与带宽 | 长上下文收益显著;可能牺牲部分表示自由度 |
| KV 压缩(Latent KV) | 低秩/潜变量压缩(如把 KV 投影到低维潜空间) | 进一步压缩 KV Cache | 上下文长度与并发能力提升,但架构更复杂、实现更依赖细节 |
| FFN 稠密 vs 稀疏 | Dense / MoE | 用稀疏激活扩大参数容量 | 训练更复杂(路由/负载均衡);推理吞吐依赖专家并行与缓存 |
| 预训练目标 | Next-token / Multi-token Prediction(MTP) | 提升单位 token 的监督信号密度 | MTP 可能提高训练效率,但会改变解码对齐与训练配方 |
Transformer 并不直接处理原始字符串。文本进入模型之前,必须先经过一条输入处理流水线:文本规范化、切分为 token、映射为 token id,再查表转成向量表示。只有完成这一步,后续的注意力、FFN 和位置编码才有可计算的离散输入。输入处理决定了模型“看见世界的最小单位”是什么,因此它不仅影响参数规模与推理效率,也会影响稀有词覆盖、跨语言能力、长度利用率以及生成结果的边界质量。
Tokenization 的核心任务是把连续文本切分成模型可处理的离散符号序列。这个离散化过程看似只是“切词”,实际上定义了词表(Vocabulary)、序列长度、未知词处理方式以及字符到语义表示的映射粒度。若切得过粗,词表会过大、稀有词泛化差;若切得过细,序列会变长、计算成本升高。因此,现代语言模型通常采用子词分词(Subword Tokenization):用有限词表在“整词”和“字符”之间取得平衡。
分词并不只是训练前的一道预处理工序,它深度参与了模型能力边界的形成。相同一句文本,换一种 tokenizer,模型看到的 token 序列长度、常见片段分布、数字和符号的切分方式都会变化,进而影响上下文利用率、训练效率、长文本成本、代码与多语言表现,甚至影响困惑度(Perplexity)等指标的可比性。因此,跨模型比较时,若 tokenizer 不同,很多“每 token 指标”都不能直接横向解读。
此外,现代 tokenizer 通常不只负责“切分”,还负责一组配套约定:例如保留哪些特殊 token(Special Tokens),如何处理大小写、空格、换行、标点、表情与 Unicode 字符,以及遇到词表里没有的片段时如何回退。像 [UNK] 这样的未知词标记(Unknown Token)就是早期整词分词里常见的退路:当输入片段不在词表中时,直接映射成一个统一的“未知”符号。它的问题是信息损失很大,不同未知词都会塌缩成同一个 token。子词分词与字节分词之所以重要,一个核心原因就是它们大幅减少了对 [UNK] 的依赖。
从风格上看,分词大致可以分为四类。第一类是整词分词(Word-level Tokenization):把单词当作基本单位,优点是语义直观,缺点是词表会迅速膨胀,且对未登录词(Out-of-Vocabulary, OOV)非常敏感。第二类是字符分词(Character-level Tokenization):把每个字符都当作 token,几乎没有 OOV 问题,但序列会显著变长,模型需要自己学习更多组合关系。第三类是子词分词(Subword Tokenization):用常见片段构成词表,让高频词保持完整、低频词拆成片段,这是现代 NLP 最主流的折中路线。第四类是字节分词(Byte-level Tokenization):直接在字节层处理输入,覆盖能力最强,跨语言和特殊符号最稳,但序列通常更长,对模型容量和训练配方要求更高。
因此,不同分词风格的本质取舍是:词表越大,单个 token 的语义通常越完整,但 OOV 与稀疏性越严重;词表越小,覆盖越稳,但序列越长、建模负担越重。现代大模型之所以大量采用 BPE、WordPiece、SentencePiece 或 byte-level BPE,本质上都是在这条权衡曲线上寻找更合适的工程平衡点。
| 分词风格 | 基本单位 | 主要优点 | 主要代价 | 常见场景 |
| 整词分词 | 单词 | 语义直观;序列较短 | 词表膨胀;OOV 严重 | 早期 NLP;规则较强的封闭词表任务 |
| 字符分词 | 字符 | 覆盖稳定;几乎无 OOV | 序列长;组合学习负担大 | 鲁棒输入建模;字符级任务 |
| 子词分词 | 高频片段 / 子词 | 词表与序列长度折中较好 | 切分方式影响语义边界 | BERT、T5、LLaMA 等主流文本模型 |
| 字节分词 | 字节 | 覆盖最强;特殊符号与多语言稳健 | 序列更长;训练成本更高 | byte-level BPE、多语言与噪声文本 |
BPE(Byte Pair Encoding)从字符(或字节)开始,通过统计合并高频相邻符号对(Pair Merge)逐步构建子词(Subword)词表。它的核心收益是用有限词表覆盖开放词汇:常见词被合并成整体,罕见词被拆成更小片段,减少 \([\mathrm{UNK}]\)。
BPE 的直觉可以概括为“把最常一起出现的片段逐步固化成一个 token”。例如,若训练语料里 t 和 h 经常相邻,就可能先合并成 th;若 th 与 e 又高频共现,就可能继续合并成 the。经过大量合并之后,词表里会同时存在完整高频词、常见词根、后缀、数字片段和标点组合。这样一来,模型既能用短序列表达常见模式,又不必为每个罕见词都预留独立词条。
从工程谱系上看,GPT 家族总体属于 BPE 路线的延伸:早期 GPT / GPT-2 风格 tokenizer 采用 byte-level BPE,把文本先映射到字节层,再做 BPE 合并;这种设计能更稳地覆盖任意 Unicode 文本、空格和特殊符号。对 OpenAI 当前模型生态而言,官方开发工具链中程序化分词通常使用 tiktoken;它对应的是面向具体模型的 encoding 体系,但核心思想仍然是 BPE 家族的子词压缩与高覆盖率路线。对开发者来说,更重要的实践结论是:GPT 核心是按 BPE 家族 tokenizer 切成子词或字节片段;同一个自然语言单词,可能被切成一个 token,也可能被切成多个 token,取决于它在词表中的合并状态。
WordPiece 与 BPE 同属子词分词(Subword Tokenization),但合并准则更偏向最大化语言模型似然(Likelihood)。BERT 系列常用 WordPiece,因此会看到以 ## 标记的子词前缀(如 play + ##ing)。
SentencePiece 是一种分词器(Tokenizer)训练与推理框架(常见算法包括 BPE 与 Unigram LM)。它可以直接在原始文本上训练(不依赖空格分词),因此在多语言与无空格语言(如中文、日文)上更常用;LLaMA 等模型的 tokenizer 通常基于 SentencePiece。
Token Embedding 的核心是一个可训练的嵌入表(Embedding Table,也常被称为嵌入矩阵(Embedding Matrix)):
\[E\in\mathbb{R}^{V\;\times d_{\text{model}}}\]其中 \(V\) 是词表大小(Vocabulary Size),每一行对应一个 token 的向量表示。给定输入 token id 序列 \((t_1,\dots,t_L)\),查表得到输入嵌入序列(Embedding Output):
\[X=\begin{bmatrix}E_{t_1}\\ \vdots\\ E_{t_L}\end{bmatrix}\in\mathbb{R}^{L\;\times d_{\text{model}}}\]一些材料会把 \(E\)(参数表)和 \(X\)(某次输入的嵌入结果)都叫“嵌入矩阵”,容易混淆。区分的一个简单方式是:E 是全词表参数,X 是当前输入的嵌入输出。
在语言模型里,这张输入嵌入表常与输出处理中的语言模型头(LM Head)共享参数,即权重共享(Weight Tying)。这里先记住这一点即可;它的具体计算方式与工程含义放在后面的“输出处理”中展开。
位置编码(Positional Encoding)解决一个根本问题:注意力机制本身对输入顺序是置换不变(Permutation-Invariant)的,如果不显式注入位置信息,模型无法区分“AB”和“BA”。因此需要把“位置”以某种方式编码进每个 token 的表示。
绝对位置编码(Absolute Positional Encoding)最常见的做法之一是学习一个位置嵌入表(Position Embedding Table):
\[P\in\mathbb{R}^{L_{\max}\;\times d_{\text{model}}}\]\(L_{\max}\) 是模型支持的最大位置索引数量(Maximum Position Index)。对长度为 \(L\) 的输入序列,取 \(P_{0:L}\)(或 \(P_{1:L}\),取决于实现)得到当前序列的位置嵌入矩阵 \(P_{\text{seq}}\in\mathbb{R}^{L\;\times d_{\text{model}}}\)。
Transformer 通常用逐元素相加把 token 嵌入与位置嵌入融合:
\[H^{(0)} = X + P_{\text{seq}}\]这里 \(H^{(0)}\) 仍然是 \(d_{\text{model}}\) 维向量序列,并非“位置标量”。位置是否用一个标量并不重要;重要的是这种表示能让后续的线性层与注意力计算利用位置关系。高维位置向量提供了更丰富的可学习空间。
“相加会不会把信息混在一起、无法区分?”这个直觉常见,但对表示学习而言关键核心是可用性:模型不需要从 \(H^{(0)}\) 精确还原 \(X\) 与 \(P_{\text{seq}}\),只需要用它们的组合完成预测。并且在高维空间里,模型可以把“语义”和“位置”分配到近似正交(Approximately Orthogonal)的方向,使得线性变换能有效解耦。
一个二维玩具例子:令 token 向量 \(x=(1,0)\),位置向量 \(p=(0,0.1)\),则 \(h=x+p=(1,0.1)\)。如果模型的某个线性读出只看第二维(例如乘以 \((0,10)\)),就能强烈感知位置而几乎不受语义影响。真实模型在上千维空间里有更大的自由度(Degree of Freedom, DOF)。
把位置“拼接”(Concatenation)到额外维度也能工作,但它会改变隐藏维度,影响后续层形状与参数规模;而加法保持 \(d_{\text{model}}\) 不变,是一种参数与工程都更稳定的设计选择。
另一类绝对位置编码是正弦位置编码(Sinusoidal Positional Encoding),它用不同频率的正弦/余弦把位置 \(\text{pos}\) 映射为向量(原始 Transformer 的设计):
\[\mathrm{PE}(\text{pos},2i)=\sin\!\left(\frac{\text{pos}}{10000^{2i/d_{\text{model}}}}\right),\quad \mathrm{PE}(\text{pos},2i+1)=\cos\!\left(\frac{\text{pos}}{10000^{2i/d_{\text{model}}}}\right)\]为什么要成对使用 \(\sin\) 与 \(\cos\)(而非全用 \(\sin\))?因为对同一频率而言,\((\sin\phi,\cos\phi)\) 组成一个二维正交基(Orthogonal Basis),位置平移 \(\phi\mapsto \phi+\Delta\) 等价于二维平面上的旋转(Rotation):
\[\begin{bmatrix}\sin(\phi+\Delta)\\ \cos(\phi+\Delta)\end{bmatrix}=\begin{bmatrix}\cos\Delta & \sin\Delta\\ -\sin\Delta & \cos\Delta\end{bmatrix}\begin{bmatrix}\sin\phi\\ \cos\phi\end{bmatrix}\]这让“相对位移”变成一个固定的线性变换,从而更容易被后续线性层和点积注意力利用;如果只用 \(\sin\),相位信息会丢失,平移不再能用线性变换稳定表达。
若只取一个最小的 4 维例子,即 \(d_{\text{model}}=4\),那么位置编码就会具体化成:
\[\mathrm{PE}(\text{pos})=\big[\sin(\text{pos}),\ \cos(\text{pos}),\ \sin(\text{pos}/100),\ \cos(\text{pos}/100)\big]\]这时每个位置都从“一个编号”转向一个 4 维向量。前两维变化很快,负责较短尺度的位置区分;后两维变化很慢,负责较长尺度的位置区分。例如 \(\text{pos}=0\) 时编码是 \([0,1,0,1]\);\(\text{pos}=1\) 时约为 \([0.84,0.54,0.01,1.00]\);\(\text{pos}=2\) 时约为 \([0.91,-0.42,0.02,1.00]\)。因此,不同位置会同时在多种频率刻度上留下痕迹,而非只靠一个单调递增的数字区分。
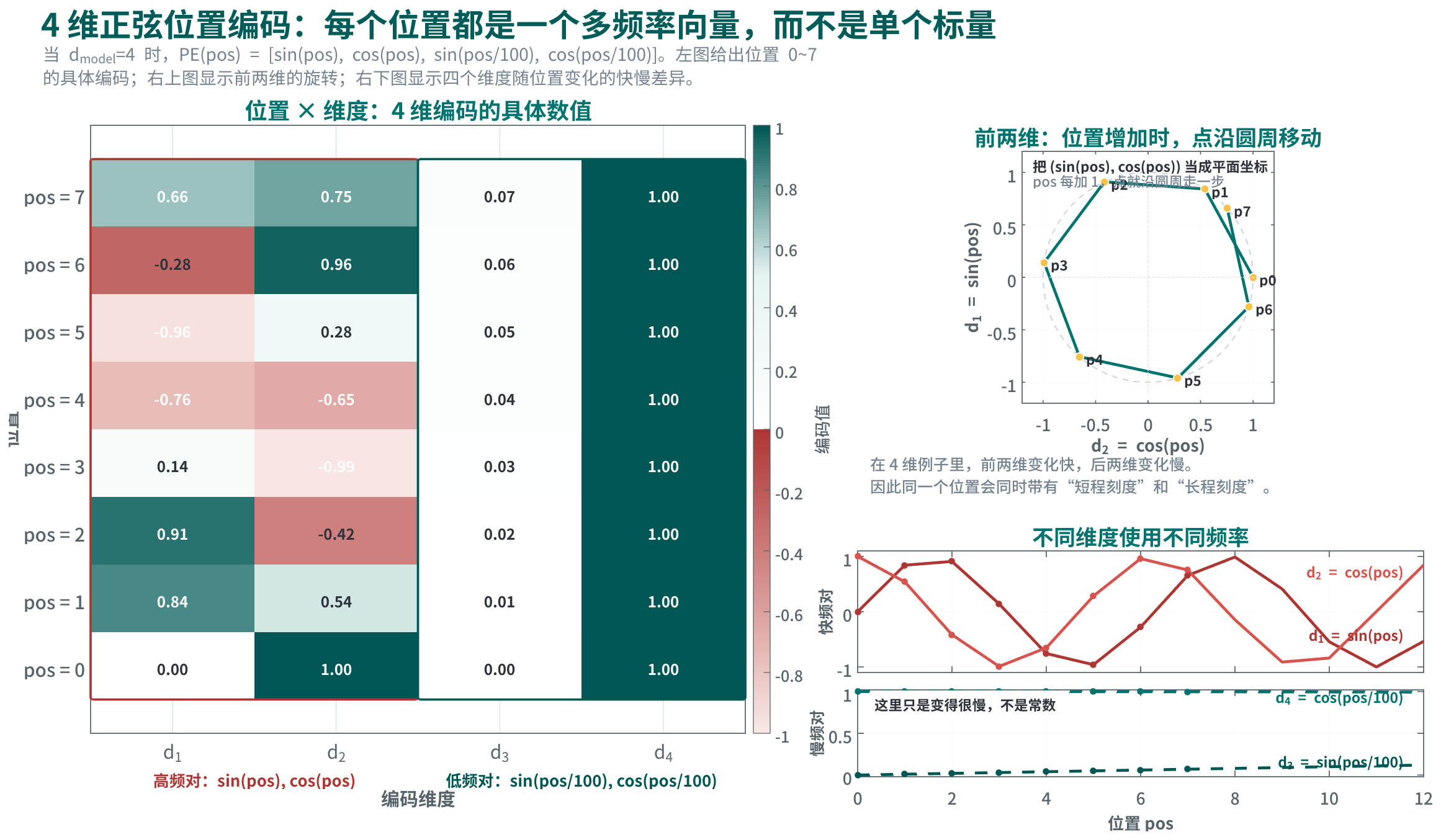
上图把这个 4 维例子拆成三种读法。左侧热力图直接列出位置 \(0\sim 7\) 在四个维度上的编码值;右上角把前两维 \((\sin(\text{pos}),\cos(\text{pos}))\) 直接当成二维平面坐标,因此可以把它理解成:位置每增加一点,平面上的点就沿圆周往前走一步;右下角则把快频对与慢频对分开画出。图里第 3、4 维之所以先前看起来几乎是平的,核心是因为在标准公式里它们对应更低频率:在 \(\text{pos}=0\sim 12\) 这样很短的区间上, \(\sin(\text{pos}/100)\) 只从 0 变化到约 0.12, \(\cos(\text{pos}/100)\) 只从 1 下降到约 0.99,必须单独放大才容易看见变化。
模型利用这套编码的方式,可以直接理解成“拿多把不同刻度的尺子同时量位置关系”。同一对 token 的距离,在高频维度上会表现成较快的相位差,在低频维度上会表现成较慢的相位差;于是模型看到的是一组跨多个尺度同时变化的模式。对于很近的 token,高频维度会给出很敏感的区分;对于距离更远的 token,低频维度仍然能保留稳定变化,不会太快绕回去。注意力层随后会在训练中学习:某些相位差组合通常意味着“相邻修饰”“短程依赖”,另一些更慢变化的组合更像“跨句呼应”或“长程对应”。这里并不存在一个必须被显式恢复出来的“角度标量”或“距离标量”。只要位置变化能够稳定地改变表示与点积结果,后续线性层和注意力头就可以把这种差异当作可利用特征。正弦位置编码的作用正是在于把位置关系改写成一组可被模型利用的周期信号,让模型自己在不同频率上学会读出距离与相对顺序。
相对位置编码(Relative Positional Encoding)不直接编码“绝对索引”,通常会让注意力更显式地依赖 token 之间的相对距离 \(i-j\)。典型做法是在注意力打分里加入相对位置偏置(Relative Position Bias):
\[\alpha_{ij}\propto \exp\!\left(\frac{q_i k_j^\top}{\sqrt{d_k}} + b_{i-j}\right)\]这条式子描述的是:位置 \(i\) 的 query 去看位置 \(j\) 的 key 时,未归一化注意力权重会受到两部分共同决定。第一部分 \(\frac{q_i k_j^\top}{\sqrt{d_k}}\) 是标准内容相关性打分:其中 \(q_i\) 是第 \(i\) 个位置的查询向量(Query Vector),\(k_j\) 是第 \(j\) 个位置的键向量(Key Vector),二者点积 \(q_i k_j^\top\) 衡量“位置 \(i\) 当前想找的信息,与位置 \(j\) 持有的信息是否匹配”;\(d_k\) 是 key/query 的维度,除以 \(\sqrt{d_k}\) 是为了控制数值尺度,避免维度增大后 softmax 过早饱和。
第二部分 \(b_{i-j}\) 是只由相对距离决定的偏置项(Bias Term)。若 \(i-j=1\),表示当前 token 正在看它左边紧邻的位置;若 \(i-j=10\),表示它正在看更远的上文。这个偏置可以通过查表得到:给每一种相对距离,或给若干距离分桶(bucket)后的区间,各分配一个可学习标量;也可以由一个小网络根据 \(i-j\) 生成。它的作用是把“距离本身是否重要”直接加进打分,而不必完全依赖内容向量自己去隐式学出这种规律。
式子左边的 \(\alpha_{ij}\) 表示位置 \(i\) 对位置 \(j\) 的注意力权重;这里写成 \(\propto\) 而非等号,是因为右边还只是指数化前的未归一化权重。真正的注意力概率还要在固定 \(i\) 后,对所有 \(j\) 一起做 softmax 归一化:
\[\alpha_{ij}=\frac{\exp\!\left(\frac{q_i k_j^\top}{\sqrt{d_k}} + b_{i-j}\right)}{\sum_{j'}\exp\!\left(\frac{q_i k_{j'}^\top}{\sqrt{d_k}} + b_{i-j'}\right)}\]因此,相对位置编码的含义可以概括为:注意力不只比较“内容是否匹配”,还显式比较“这个位置离我有多远”。很多语言现象更依赖相对距离而非绝对序号,例如局部搭配、邻近修饰、长程指代和句法依赖,因此把 \(i-j\) 直接写进打分,往往比单纯依赖绝对位置索引更贴近任务结构。
RoPE(Rotary Position Embedding)把位置信息以“旋转”的方式注入到 \(Q\)/\(K\) 中。若按实数矩阵来写,就是把向量的每两维视为一个二维平面,再用角度与位置成正比的旋转矩阵作用在这两维上。对第 \(i\) 个二维分量,令 \(\theta_{m,i}\) 表示位置 \(m\) 在该(每两维一个)频段上的旋转角,则
\[\begin{bmatrix}x'_{2i}\\ x'_{2i+1}\end{bmatrix}=\begin{bmatrix}\cos\theta_{m,i} & -\sin\theta_{m,i}\\ \sin\theta_{m,i} & \cos\theta_{m,i}\end{bmatrix}\begin{bmatrix}x_{2i}\\ x_{2i+1}\end{bmatrix}\]实现上,RoPE 核心是对每个位置的 \(Q\) 和 \(K\) 都各自按该位置做旋转;随后不同位置之间再做点积匹配。这样一来,位置 \(m\) 的 \(Q_m\) 和位置 \(n\) 的 \(K_n\) 在相遇时,二者各自携带的位置相位就会共同决定匹配结果。通常只有 \(Q\)/\(K\) 参与这种旋转, \(V\) 不旋转,因为位置信息的关键作用点在“如何计算注意力权重”,而非在“被加权汇总的内容值”本身。
上述矩阵式在实现上是正确的,但从理解角度看仍然偏“机械”。更直接的方式是用复数视角(Complex Perspective):把每两维 \((x_{2i},x_{2i+1})\) 看成一个复数
\[z_i = x_{2i} + \mathrm{i}x_{2i+1}\]于是 RoPE 的位置注入就可以写成一个极其紧凑的式子:
\[z_i' = z_i \, e^{\mathrm{i} m \theta_i}\]这里 \(m\) 是位置索引, \(\theta_i\) 是第 \(i\) 个频段的基础角速度, \(e^{\mathrm{i} m \theta_i}\) 表示“在复平面上旋转 \(m\theta_i\) 角”。这时 RoPE 的直觉就变得很清楚:同一个向量本身不变,变化的是它在不同位置上附带的相位(phase)。位置越靠后,相位就继续往前转。
这种写法的关键价值在于:相对位置会自然地从乘法里浮现出来。若位置 \(m\) 的 query 与位置 \(n\) 的 key 都经过旋转,则它们的匹配项可写成
\[q_m^{(i)} e^{\mathrm{i} m \theta_i}\cdot \overline{k_n^{(i)} e^{\mathrm{i} n \theta_i}} = q_m^{(i)} \overline{k_n^{(i)}} e^{\mathrm{i}(m-n)\theta_i}\]这里上划线表示复共轭(Complex Conjugate)。前文“二维向量的复数表示”已经给出同一条基本关系:二维点积可以写成复共轭乘积的实部,因此把二维块写成复数后,位置相位会直接进入匹配项。最重要的结果是指数项里只剩下 \((m-n)\theta_i\):绝对位置 \(m\) 与 \(n\) 被自动折叠成了相对位移 \(m-n\)。因此,RoPE 核心是通过“给每个位置乘一个相位因子”的方式,让相对位移直接出现在注意力匹配里。
若用一句更通俗的话概括,RoPE 做的事情是:给每个位置的 \(Q\)/\(K\) 都拧上一点角度;两个位置一做点积,位置差就会体现在匹配分数里。矩阵形式更像工程实现的展开式,复数形式更接近它的数学本质。模型并不需要在内部先还原出一个单独的“角度值”再决定如何注意;它只需要利用这种旋转所造成的分数差异与模式差异。只要某类相位关系稳定对应某类局部依赖、顺序关系或长程对应,训练过程就会把这些模式吸收到注意力头和后续层的参数里。也正因为这种“相对位移直接进入匹配”的结构,RoPE 在 Decoder-only 大模型中成为主流选择(例如 LLaMA 系列)。
RoPE 的旋转角随位置线性增长。若训练阶段最大长度为 \(L_{\text{train}}\),推理时直接扩展到 \(L_{\text{test}}\gg L_{\text{train}}\),部分频段会出现“过快旋转”:模型开始在比训练时更长得多的位置区间上继续累积相位,而这些大角度相位组合在训练中几乎没有见过。结果是远距离 token 之间的相对相位关系超出训练分布,注意力更容易退化为近邻偏好,长上下文检索与推理准确率下降。
典型评测是大海捞针(Needle in a Haystack):在很长的上下文中埋入一条关键信息(needle),要求模型在指定问题下准确复述该信息。常见现象是针落在开头/结尾时表现更好,但针落在中间位置时准确率显著下降;这通常与位置编码外推、注意力实现细节与 KV Cache 行为共同相关。
工程上常见的 RoPE 外推改造包括:
- 位置插值(Position Interpolation, PI):把推理位置按比例压缩回训练范围,相当于把 RoPE 角速度整体放慢。
- NTK-aware 缩放(NTK-aware Scaling):按“有效核宽度”视角调整频率谱,缓和远距离相对位移失真。
- YaRN:对不同频段做分段/渐变缩放,尽量同时保住短程精度与长程外推。
以 PI 为例,一个常用写法等价于把 RoPE 的位置 \(\text{pos}\) 映射为 \(\text{pos}'=\text{pos}/s\)(\(s=L_{\text{test}}/L_{\text{train}}\)),从而把角度压回训练范围:
\[\theta'_{\text{pos},i}=\frac{\text{pos}/s}{\text{base}^{2i/d}},\quad s=\frac{L_{\text{test}}}{L_{\text{train}}}\]| 方法 | 是否需要再训练 | 核心超参 | 优势 | 风险/备注 |
| PI | 建议配合长上下文继续预训练/微调 | 缩放因子 \(s\) | 实现简单;可在保持短程行为的同时扩展长度 | 若只做推理时改造,可能出现分布错配;需用 needle 测试验证“中间段”能力 |
| NTK-aware scaling | 可仅推理侧启用;配合微调更稳 | 频谱/基数缩放规则 | 对远距离更平滑;常用于把“可用上下文”拉长 | 不同实现差异大;需关注与 KV Cache、GQA/MQA 等工程优化的耦合 |
| YaRN | 通常建议配合继续预训练 | 分段/渐变缩放参数 | 兼顾短程精度与长程外推;对 needle 中段退化更友好 | 超参更多;需要系统评测(含不同位置、不同检索难度) |
ALiBi(Attention with Linear Biases)直接在注意力 logits 上加一个与距离线性相关的偏置,而不改变表示维度,也不引入位置向量:
\[\alpha_{ij}\propto \exp\!\left(\frac{q_i k_j^\top}{\sqrt{d_k}} - m\cdot (i-j)\right),\quad j\le i\]其中斜率 \(m\) 可按 head 设置。直觉上它鼓励模型更关注近邻 token,同时具备较好的长度外推(Length Extrapolation)行为。
注意力机制(Attention Mechanism)是序列模型中的动态信息选择机制。对于一个由多个 token 构成的输入序列,模型不会把所有上下文位置等量混合,会会针对当前正在计算的位置,动态判断哪些位置更相关、相关程度有多大,以及这些位置的信息应当如何组合成新的表示。这个过程本质上是一个与输入内容相关的加权汇聚:当前位置先形成查询信号,再在上下文中寻找与之匹配的位置,最后把这些位置承载的信息按权重聚合回来。
这种设计改变了传统序列建模的信息传递路径。循环结构主要依赖状态沿时间步逐步传递,卷积结构主要依赖固定大小的局部感受野,而注意力机制允许任意两个位置直接建立联系,并且联系强度由内容决定而非由距离预先写死。长距离依赖(Long-Range Dependency)因此可以被更直接地建模:一个 token 可以立刻读取很远处但与当前语义高度相关的信息,而不必等待信息穿过很长的递归链条或许多层局部卷积。
Transformer 将注意力机制置于核心位置。自注意力(Self-Attention)让同一序列内部的各个 token 相互读取;交叉注意力(Cross-Attention)让一个序列读取另一个序列的表示;因果注意力(Causal Attention)则通过掩码限制当前位置只能访问过去的信息,从而支撑自回归生成(Autoregressive Generation)。这些形式都遵循同一条主线:先计算相关性分数,再把分数归一化为权重,最后对承载内容的向量做加权求和。其最经典、最常见的数学形式就是缩放点积注意力(Scaled Dot-Product Attention)。
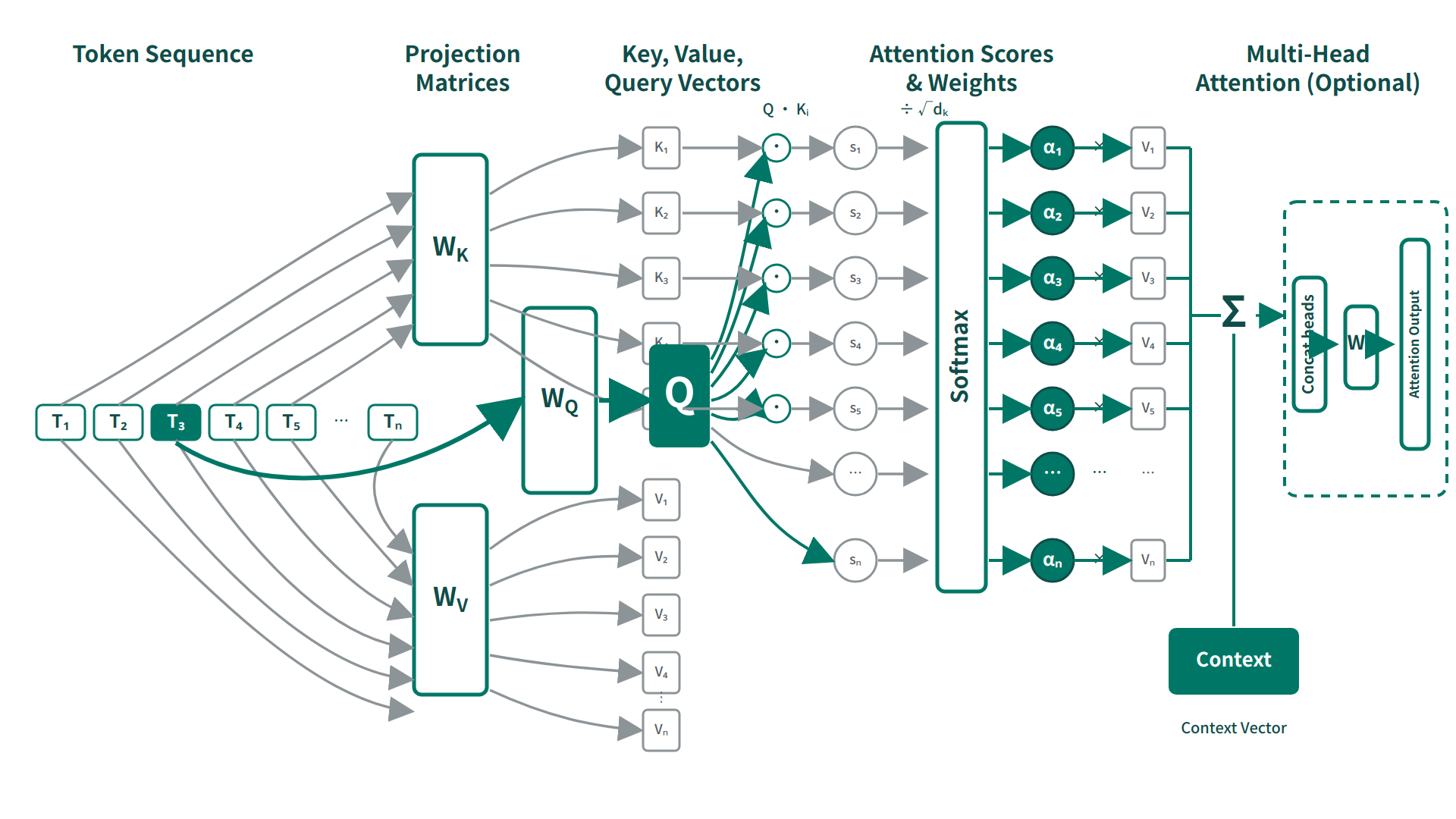
自注意力(Self-Attention)中,输入表示 \(X\) 通过三组参数投影为:
\[Q=XW_Q,\quad K=XW_K,\quad V=XW_V\]注意力输出为:
\[\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]其中 \(W_Q,W_K,W_V\)(以及多头里的 \(W_O\))都是模型参数(Parameters),训练的目标核心是在损失函数(Loss)下通过梯度下降(Gradient Descent)把它们优化到能完成任务的取值。
把公式按 token 展开更清楚。设当前只看一个注意力头,序列长度为 \(L\)。对第 \(i\) 个 token,模型先取出它的查询向量 \(q_i\in\mathbb{R}^{d_k}\),再与序列中每个位置 \(j=1,\dots,L\) 的键向量 \(k_j\in\mathbb{R}^{d_k}\) 做点积,得到一个标量打分:
\[s_{ij}=q_i k_j^\top\]这里 \(d_k\) 表示每个头里 Key / Query 向量的维度,也就是 \(q_i\) 与 \(k_j\) 的长度。它之所以记作 \(d_k\),是因为这个维度首先由 Key 空间定义;而 Query 必须与 Key 处在同样维度里,才能做点积匹配。因此 \(q_i\) 和 \(k_j\) 的长度通常相同。Value 向量的维度记作 \(d_v\);实践中常见设置是 \(d_v=d_k\),但这并非数学上的硬要求。
接着,对第 \(i\) 个 query 的整行打分做缩放和 softmax,得到一组对所有位置的注意力权重:
\[\alpha_{ij}=\mathrm{softmax}_j\!\left(\frac{s_{ij}}{\sqrt{d_k}}\right)=\frac{\exp\!\left(s_{ij}/\sqrt{d_k}\right)}{\sum_{t=1}^{L}\exp\!\left(s_{it}/\sqrt{d_k}\right)}\]因此,对固定的 \(i\) 来说, \(\alpha_{i1},\dots,\alpha_{iL}\) 构成一个标量概率分布:它们都非负,且总和为 1。这个分布回答的是“第 \(i\) 个 token 应该从整段序列的哪些位置读取多少信息”。
输出 \(o_i\) 则是一个向量(Vector),由所有 Value 向量 \(v_j\in\mathbb{R}^{d_v}\) 按权重加权求和得到:
\[o_i=\sum_{j=1}^{L}\alpha_{ij} v_j\]把这一步画成示意图会更直观:固定第 \(i\) 个 query 后,先得到一组对各位置 \(j\) 的注意力权重;再用这些权重去加权汇总对应的 Value 向量;右侧输出向量的每一维,都是左侧各个 Value 向量对应维度的加权和。
查询向量(Query)与键向量(Key)负责“匹配打分”;值向量(Value)承载被聚合的信息内容。把注意力看作“内容寻址(Content-based Addressing)”:先用 \(QK^\top\) 计算“应该看谁”,再用权重对 \(V\) 做加权求和得到“看到了什么”。
缩放因子 \(\sqrt{d_k}\) 的作用是控制数值尺度。由于 \(q_i\) 与 \(k_j\) 的点积是 \(d_k\) 个乘积项的求和,若各维分量方差相近,则点积分数的方差通常会随着 \(d_k\) 增长。维度一大, \(s_{ij}\) 的绝对值就更容易变大,softmax 会更快进入饱和区:某几个位置的权重接近 1,其余位置接近 0,梯度也会变小。除以 \(\sqrt{d_k}\) 后,分数尺度被拉回更稳定的范围,不同 head 维度设置下的 softmax 行为会更可控。
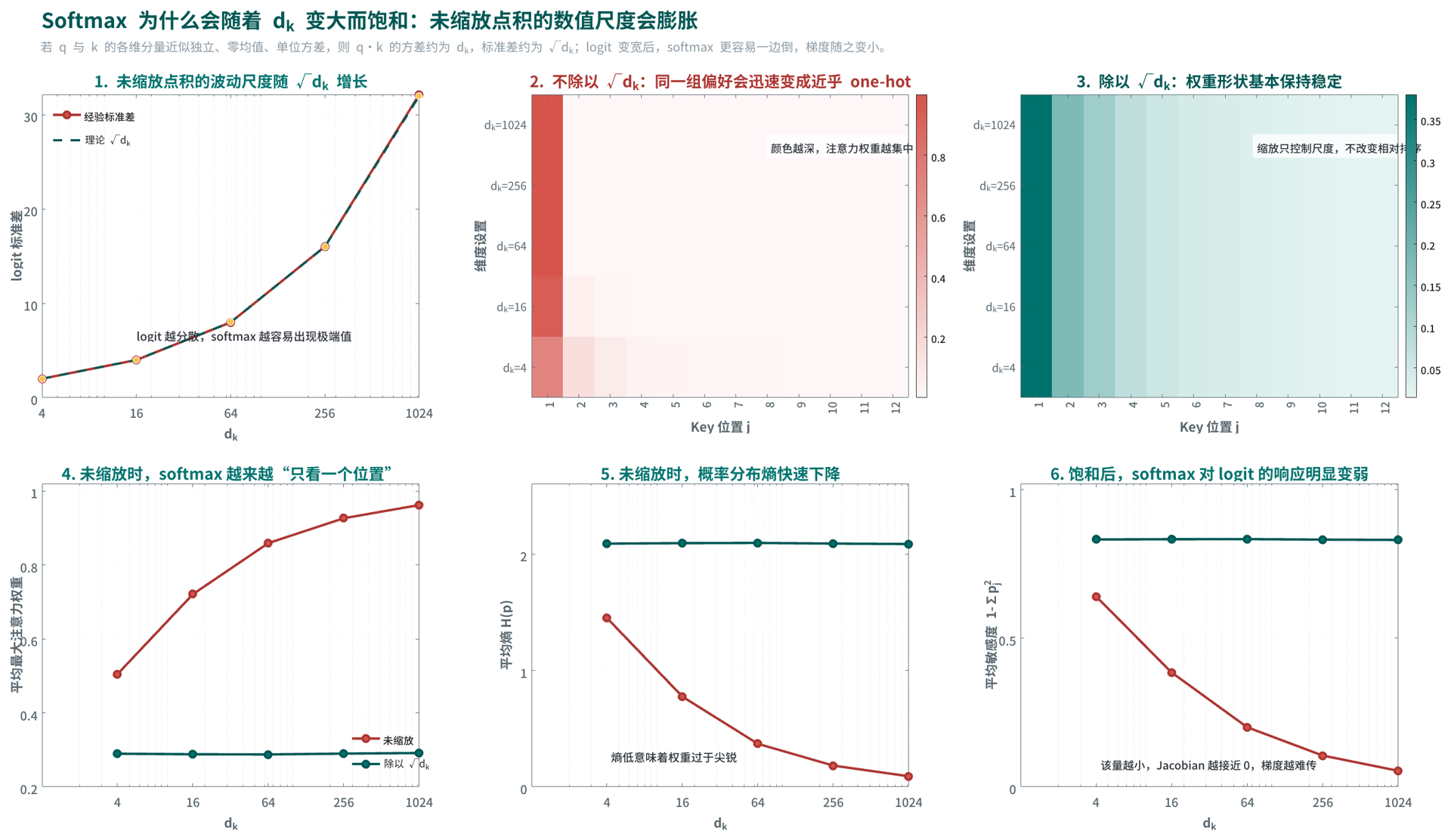
理论上可以让寻址与内容共用投影(例如令 \(V=K\) 或直接取 \(V=X\)),但实践中通常把 Q/K 与 V 分开,是为了让“打分空间”和“内容表示空间”解耦,提升表示能力与训练稳定性。
一个极简数值例子:若某个 Query 与 3 个 Key 的相似度(未缩放)为 \([2,1,0]\),softmax 权重大约是 \([0.665,0.245,0.090]\),输出就是把三个 Value 按这个比例加权求和。
Masked Attention(因果注意力 / Causal Attention)在自回归(Autoregressive)生成中使用:通过掩码(Mask)禁止位置 \(i\) 看到未来位置 \(j>i\)。实现上通常是在 softmax 前把被禁止位置的打分加上一个极小值(如 \(-\infty\))。
若把未加掩码的打分矩阵记为 \(S=\frac{QK^\top}{\sqrt{d_k}}\in\mathbb{R}^{L\times L}\),则因果掩码可写成一个上三角被屏蔽的矩阵 \(M\)。以 \(L=4\) 为例:
\[M=\begin{bmatrix} 0 & -\infty & -\infty & -\infty\\ 0 & 0 & -\infty & -\infty\\ 0 & 0 & 0 & -\infty\\ 0 & 0 & 0 & 0 \end{bmatrix}\]然后在 softmax 之前做逐元素相加:
\[P=\mathrm{softmax}(S+M)\]这里主对角线及其左下区域为 0,表示当前位置及其历史位置允许被访问;右上区域为 \(-\infty\),表示未来位置被强制屏蔽。softmax 之后,这些位置的权重会变成 0,因此第 \(i\) 行只能在 \(j\le i\) 的范围内分配概率。
从矩阵形状看,这就是一个保留下三角、屏蔽上三角的结构。它保证了解码器在位置 \(i\) 计算注意力时,只能读取已经出现的 token,而不能偷看未来 token。
注意力机制在训练阶段和推理阶段都会执行。区别在于:训练时通常一次性输入整段序列(Teacher Forcing)并使用因果掩码;推理时逐 token 解码,并结合 KV Cache 避免重复计算历史。
交叉注意力(Cross-Attention)让一个序列“去读另一个序列”。在 Encoder–Decoder Transformer 里:解码器当前状态提供 Query,编码器输出提供 Key/Value。若编码器输出为 \(H_{\text{src}}\in\mathbb{R}^{L_{\text{src}}\times d}\),解码器输入为 \(H_{\text{tgt}}\in\mathbb{R}^{L_{\text{tgt}}\times d}\),则
\[Q=H_{\text{tgt}}W_Q,\quad K=H_{\text{src}}W_K,\quad V=H_{\text{src}}W_V\] \[\mathrm{CrossAttn}(H_{\text{tgt}},H_{\text{src}})=\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]它与自注意力(Self-Attention)的区别仅在于 \(K,V\) 来自“别的序列”,因此能把“源序列信息”按需注入到“目标序列生成”中。
在交叉编码器(Cross-Encoder)语境里,很多实现并不显式写 cross-attention:它们把两段文本拼接成一个序列,用全连接自注意力直接建模跨序列交互;从效果上看等价于“允许任意 token 互相注意”。
Decoder-only 架构本身没有 cross-attention 子层;只有在做 Seq2Seq(有 encoder 输出)或显式引入外部记忆(Memory)时,才会在解码器里加入 cross-attention。
多头注意力(Multi-Head Attention)把注意力拆成 \(H\) 个头(Heads),每个头在不同的子空间里独立做一次注意力,然后在特征维度上拼接(Concatenation)并用输出矩阵混合:
\[\text{head}_h=\mathrm{Attention}(XW_Q^{(h)},XW_K^{(h)},XW_V^{(h)})\] \[\mathrm{MultiHead}(X)=\mathrm{Concat}(\text{head}_1,\dots,\text{head}_H)W_O\]若 \(d_{\text{model}}\) 固定,常见做法是每个头的维度 \(d_k=d_v=d_{\text{model}}/H\),拼接后回到 \(d_{\text{model}}\)。多头的收益来自“并行关注不同关系”:有的头偏向局部邻域,有的头偏向长程依赖,有的头学到语法/实体指代等不同模式。
这种分工在标准训练里通常核心是优化过程中的自发结果。每个头都拥有各自独立的 \(W_Q^{(h)},W_K^{(h)},W_V^{(h)}\) 参数,因此即使输入相同,它们也会把表示投影到不同子空间里,形成不同的匹配规则。随机初始化首先打破了头与头之间的对称性;随后,损失函数只约束“多头合起来的整体输出”是否有利于完成任务,而不要求每个头承担同一种功能。在这种条件下,若多个头完全重复,整体表示效率往往偏低;优化更容易把不同头推向不同关系模式,于是逐渐出现局部邻近、长程依赖、分隔符、指代、句法边界等不同偏好。
这种功能分化并非严格保证。实际模型里常能观察到部分头高度相似,部分头贡献很小,甚至剪掉后性能几乎不变。若希望更强地控制不同头学习不同东西,就需要额外机制,例如对不同头加入多样性正则(Diversity Regularization)、局部窗口约束、特定监督信号,或在训练后做 head pruning / head specialization 分析。
从多头注意力再往下走一步,就会遇到一个非常重要的工程分叉:Query 头数与 Key/Value 头数是否必须一一对应。标准 MHA 默认每个 Query head 都有自己独立的 Key/Value head;而在长上下文大模型里,工程重点往往会进一步转向KV Cache 到底有多大、带宽到底有多贵。GQA 与 MQA 的区别,正是在回答这个问题。
GQA(Grouped Query Attention)用“更少的 KV 头”服务“更多的 Query 头”。它的核心做法是:多个 Query heads 共享同一组 Key/Value heads,从而显著降低 KV Cache 的显存与带宽压力。若仍记 Query 头数为 \(n_q\),KV 头数为 \(n_{\text{kv}}\),则 GQA 满足 \(1<n_{\text{kv}}\ll n_q\)。
对比标准多头注意力,GQA 的本质是把“每个 head 都独立维护一套 KV”改成“若干 Query head 结成一组,共享一套 KV”。注意力仍然按 head 计算,但 KV 表示从完全一一对应转向以组为单位共享。在长上下文推理中,它带来的收益往往比对算力的节省更关键:KV Cache 与内存带宽近似按 \(n_{\text{kv}}/n_q\) 比例下降。
因此,很多现代大模型把 GQA 当作默认配置。它在表达能力与缓存成本之间提供了一个很实用的折中:比 MHA 便宜得多,但通常又比最极端的共享方案更稳。
MQA(Multi-Query Attention)可以看作 GQA 的极端情形,即 \(n_{\text{kv}}=1\)。这意味着全部 Query heads 共用同一套 Key / Value 表示。于是,KV Cache 被进一步压到最小,推理阶段的显存和带宽压力也达到最强压缩。
它的优点非常明确:在超长上下文和高并发解码场景下,MQA 往往是最省缓存的一类头部组织方式。缺点也同样明确:表示自由度下降得最厉害,不同 Query heads 看到的 Key/Value 空间过于相似,因此更容易带来质量损失。工程上通常会用更大的模型维度、更多 Query heads、或更强的 FFN 来补偿这种压缩。
因此,三者的关系可以概括成一条连续谱:MHA 表达最自由、成本最高;MQA 成本最低、共享最强;GQA 则处在两者之间,提供最常用的工程折中。进一步降低 KV Cache 成本的路线,还包括 Latent KV / MLA 一类潜空间压缩,以及 TurboQuant 一类面向内积保真的 KV 量化压缩。它们优化的仍然是长上下文推理里的 KV 存储与带宽,只是已经不再停留在“头数共享”这一层。
线性注意力(Linear Attention)是在注意力层内部改写计算顺序,使代价不再显式依赖完整的 \(L\times L\) 注意力矩阵。标准 softmax 注意力可写为:
\[\mathrm{Attn}(Q,K,V)=\mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]其中 \(Q\in\mathbb{R}^{L\times d_k}\) 是整段序列的 query 矩阵, \(K\in\mathbb{R}^{L\times d_k}\) 是 key 矩阵, \(V\in\mathbb{R}^{L\times d_v}\) 是 value 矩阵; \(L\) 是序列长度, \(d_k\) 是 query / key 维度, \(d_v\) 是 value 维度。矩阵 \(QK^\top\in\mathbb{R}^{L\times L}\) 的第 \((i,j)\) 项就是 \(q_i^\top k_j\),表示第 \(i\) 个位置对第 \(j\) 个位置的原始匹配分数。也就是说,标准注意力需要让每个 query 与每个 key 两两打分,因此时间与显存压力通常都是 \(\mathcal{O}(L^2)\) 级别。线性注意力的目标,就是把这种“先算完整两两相互作用,再做归一化”的流程,改写成“先把历史信息压缩成一组可累计统计量,再让每个 query 去读取这些统计量”。
标准注意力里,第 \(i\) 个位置的输出可以写成
\[o_i=\sum_{j=1}^{L}\alpha_{ij}v_j,\qquad \alpha_{ij}=\frac{\exp(q_i^\top k_j/\sqrt{d_k})}{\sum_{\ell=1}^{L}\exp(q_i^\top k_\ell/\sqrt{d_k})}\]这里 \(q_i\in\mathbb{R}^{d_k}\) 是第 \(i\) 个位置的 query 向量,表示“当前位置想找什么信息”; \(k_j\in\mathbb{R}^{d_k}\) 是第 \(j\) 个位置的 key 向量,表示“这个历史位置提供什么匹配线索”; \(v_j\in\mathbb{R}^{d_v}\) 是同一位置真正承载内容的 value 向量; \(\alpha_{ij}\) 是归一化后的注意力权重,表示第 \(i\) 个 query 最终给第 \(j\) 个位置分了多少注意力; \(o_i\) 则是当前位置输出。于是 softmax 注意力的本质很明确:先用 \(q_i\) 和所有 \(k_j\) 算相似度,再用这些权重去加权求和所有 \(v_j\)。
这里的 \(\phi\) 是特征映射(Feature Map)或核特征映射(Kernel Feature Map)。它把原本位于 \(\mathbb{R}^{d_k}\) 的 query / key 向量,映射到另一个通常更容易做内积分解的空间 \(\mathbb{R}^{m}\):
\[\phi:\mathbb{R}^{d_k}\rightarrow\mathbb{R}^{m}\]其中 \(m\) 是映射后的特征维度。直观上, \(\phi\) 的作用是把原来的向量变成另一种表示,使得原本难以直接拆开的相似度,能够改写成内积形式。
若某种相似度函数 \(\kappa(q,k)\) 可以写成
\[\kappa(q,k)=\phi(q)^\top \phi(k)\]其中 \(\kappa(q,k)\) 是 query 与 key 的相似度函数;右边写成 \(\phi(q)^\top \phi(k)\) 之后,相似度就被拆成了“只依赖 query 的一项”和“只依赖 key 的一项”的内积形式。这样一来,注意力里“query 与所有 key 的逐一比较”就能被拆成两部分:一部分只和 key/value 有关,另一部分只和当前 query 有关。对单个 query \(q_i\) 而言,若记
\[S=\sum_{j=1}^{L}\phi(k_j)v_j^\top,\qquad z=\sum_{j=1}^{L}\phi(k_j)\]其中 \(S\in\mathbb{R}^{m\times d_v}\) 是把整段历史中“key 的特征表示”和“对应的 value 内容”绑定后累计起来得到的矩阵,可以理解为一份带内容的历史摘要; \(z\in\mathbb{R}^{m}\) 只累计 key 的特征表示,用来充当归一化分母。则输出可改写为
\[o_i\approx\frac{\phi(q_i)^\top S}{\phi(q_i)^\top z}\]其中分子 \(\phi(q_i)^\top S\) 表示“当前 query 去读取带内容的历史摘要”,分母 \(\phi(q_i)^\top z\) 用来做归一化,防止输出尺度失控。这一步是线性化的核心。因为 \(S\) 与 \(z\) 可以沿着序列顺序递推累计,不需要先显式构造完整的 \(L\times L\) 打分矩阵。于是复杂度从“所有 token 两两交互”转成“每个 token 更新一次全局统计量并读取一次统计量”,在很多实现里就能接近 \(\mathcal{O}(L)\) 的序列复杂度。
为什么这里可以做近似,关键在于 softmax 注意力本身也可以被看成一种核化相似度。softmax 的未归一化权重本质上依赖 \(\exp(q^\top k/\sqrt{d_k})\);如果能找到某个 \(\phi\),使得
\[\exp\!\left(\frac{q^\top k}{\sqrt{d_k}}\right)\approx \phi(q)^\top \phi(k)\]就能用可分解的内积结构近似原来的指数核。不同线性注意力方法对 \(\phi\) 的选择并不相同:有的方法用显式正特征映射,例如 \(\mathrm{ELU}(x)+1\) 之类的正值变换;有的方法用随机特征(Random Features)去逼近 softmax kernel;还有一些方法更进一步,直接放弃“精确逼近 softmax”,转而定义一种新的核化注意力族。于是“线性注意力”在数学上是一大类可分解注意力路线,数学上并不总是同一条公式。
“什么样的核函数能够做这件事”可以分成两类理解。第一类是可显式近似 softmax 的核。例如 Performer 使用 FAVOR+(Fast Attention Via Positive Orthogonal Random Features)路线,用随机特征把指数核 \(\exp(q^\top k)\) 近似成有限维内积 \(\phi(q)^\top\phi(k)\)。这里的 \(\phi\) 从一个随手指定的非线性转向专门为逼近指数核构造出来的随机特征映射。
第二类是直接改用另一种正核。例如早期 Linear Transformer 一类方法常取 \(\phi(x)=\mathrm{ELU}(x)+1\) 或其他保持正值的映射。这样做的重点不在于把 softmax 严格逼近得多么精确,而在于构造一个满足非负性、可递推累计、数值上相对稳定的核化注意力形式。此时模型学到的已经并非“softmax 的近似实现”,而更接近“另一种可线性化的注意力定义”。
设序列里只有两个历史位置,当前位置的 query 为 \(q\),历史 key / value 分别为 \((k_1,v_1)\) 与 \((k_2,v_2)\)。标准注意力会先显式算出两个分数:
\[s_1=q^\top k_1,\qquad s_2=q^\top k_2\]再做 softmax:
\[\alpha_1=\frac{e^{s_1}}{e^{s_1}+e^{s_2}},\qquad \alpha_2=\frac{e^{s_2}}{e^{s_1}+e^{s_2}}\]最后输出
\[o=\alpha_1 v_1+\alpha_2 v_2\]线性注意力则尝试把这一步改写成“先对历史做摘要,再让 \(q\) 读取摘要”。若有某个 \(\phi\) 使得 \(e^{q^\top k}\approx \phi(q)^\top\phi(k)\),那么先预计算
\[S=\phi(k_1)v_1^\top+\phi(k_2)v_2^\top,\qquad z=\phi(k_1)+\phi(k_2)\]然后输出近似为
\[o\approx\frac{\phi(q)^\top S}{\phi(q)^\top z}\]这里的关键变化很明确:原公式需要先单独算 \(q\) 对 \(k_1\)、\(k_2\) 的两个打分;而线性化后的公式把历史两项先合成 \(S\) 与 \(z\),后续任何新 query 都直接读取这个摘要即可。把“两项历史”换成“\(L\) 项历史”时,这种先摘要、后读取的结构才真正体现出线性复杂度优势。
从直觉上看,标准注意力像是“每个 query 都把整张历史表逐行翻一遍,再决定该关注谁”;线性注意力则像是“先把历史 key/value 在特征空间里压缩成一个可累计的摘要,再由每个 query 去读取这份摘要”。前者保留了最细粒度的两两比较,后者牺牲了一部分精细交互,换取长序列下更低的显存与更高的吞吐。
一个典型形式(省略实现细节)是:
\[\mathrm{Attn}(Q,K,V)\approx \frac{\phi(Q)\big(\phi(K)^\top V\big)}{\phi(Q)\big(\phi(K)^\top \mathbf{1}\big)}\]线性注意力更适合“极长序列下的吞吐/显存”目标,但它往往需要在表示、数值稳定性与效果之间做取舍;在通用 LLM 上,主流路径仍然是“精确注意力 + 更好的内核 + 更强的位置/缓存工程”,线性注意力更多作为特定场景或混合架构的选项。
flash-linear-attention 常缩写为 fla。它更适合被理解为线性注意力、递推更新与部分状态空间模块的高性能实现库,而非一种独立的新模型家族。它提供的是面向 GPU 前向路径的高效 kernel:通过融合、分块、块内累计和更紧凑的中间状态组织,降低长序列计算中的访存与中间张量开销。
从运行阶段看,fla 的影响并不局限于训练。只要模型在推理时仍然调用同一套由 fla 实现的层或算子,推理阶段也会直接受益,因为推理本质上只是在执行前向传播(Forward Pass)。这意味着它通常会同时带来两类收益:第一,延迟下降,因为前向 kernel 更快;第二,显存占用下降,因为融合实现往往减少了中间张量写回与额外缓存。序列越长,这类收益通常越明显。
不过,fla 的收益并非无条件出现。若模型本身根本没有使用 fla 支持的模块,而只是标准 Transformer 加普通 PyTorch attention,那么安装 fla 不会自动带来变化;若部署时已经把模型导出到另一套不支持相应 kernel 的执行引擎,例如某些 ONNX / 图编译推理链路,原本的加速路径也可能丢失;若运行环境是 CPU,或 GPU / Triton / CUDA 条件不满足,系统通常会回退到普通实现,此时收益会显著减弱甚至完全消失。
它与 FlashAttention 的关系也需要分清。两者都属于“前向路径加速会同时惠及训练与推理”的工程优化,但作用对象并不相同:FlashAttention 优化的是精确 softmax 注意力的实现,数学结果保持不变;fla 更常服务于线性注意力、递推或 SSM 风格模块的高效实现。因此,是否影响推理,关键不在于“训练还是推理”,而在于推理时走的是否仍是那条由 fla 支撑的前向计算路径。
标准密集自注意力(Dense Self-Attention)会让每个位置与所有可见位置计算打分,因此在长度 \(L\) 上通常带来 \(O(L^2)\) 级别的注意力矩阵与计算压力。稀疏注意力(Sparse Attention)的核心思路,就是预先限制“每个 token 允许看哪些位置”,只保留一部分连接,从而把长上下文建模的代价降下来。
稀疏注意力是一类注意力连接模式的总称。它可以是局部窗口(Local Window)、块状稀疏(Block Sparse)、跨步连接(Strided Pattern)、少量全局 token(Global Tokens),也可以是这些模式的组合。Longformer、BigBird 这类长序列模型,都属于这条路线的经典代表。它保留 softmax 注意力的基本定义,同时把原本“谁都能看谁”的全连接关系改成一个更受约束的稀疏图。
从 2026 年的工程现实看,稀疏注意力仍然重要,但它已经并非通用旗舰语言模型的默认路线。它更常出现在长文档理解、超长上下文、显存/带宽受限,或专门强调长序列效率的模型中;而很多主流通用基座仍然更常采用密集因果注意力,再叠加 GQA、KV Cache、FlashAttention、KV 压缩等优化。这是因为稀疏模式虽然更省,但也会直接限制单层里可建立的依赖范围,训练与实现复杂度通常更高。
滑动窗口注意力(Sliding Window Attention)是稀疏注意力里最常见、也最工程化的一种形式:位置 \(i\) 只看距离自己最近的一段窗口,例如前面 \(w\) 个 token。这样单层注意力的代价就从“与整段长度线性增长的每行宽度”,压缩成“与固定窗口宽度相关”的局部计算。
它的优点是非常直接:局部模式、邻近依赖和短程语义通常仍能被稳定捕捉,而长上下文成本显著下降。代价是,两个相距很远的位置无法在同一层里直接交互,只能依靠多层传播,或额外引入全局层、全局 token、周期性全注意力层等机制来弥补。因此很多实际架构会采用“局部层 + 少量全局层”的混合设计,而非把所有层都做成纯局部窗口。
到 2026 年,滑动窗口注意力仍然被部分主流模型持续使用,尤其是在长上下文或高性价比路线中;例如 Mistral 一类模型会显式采用 Sliding Window Attention,Gemma 2/3 一类模型也会在 local / global hybrid 结构中交替使用局部注意力层。但它并非所有主流模型的统一默认配置。更准确的说法是:通用“稀疏注意力”并非当代旗舰模型的普遍默认架构,而“滑动窗口注意力”则仍是今天主流工程实践里一条活跃的局部注意力路线。一旦局部窗口再与全局 token、周期性全注意力层或其他远程连接模式联合使用,它就进入了混合注意力的范畴。
混合注意力(Hybrid Attention)是一类设计思想:在同一个模型、同一层或同一组层里,同时组合两种或多种不同的注意力模式,让它们分别承担不同职责。可被混合的对象很多,例如局部窗口与全局连接、稠密与稀疏、未压缩与压缩表示、不同层采用不同注意力机制。它的核心目标始终一致:在不牺牲太多表达能力的前提下,同时兼顾局部细节、长程依赖和计算成本。
之所以需要“混合”,是因为单一注意力模式往往只能在一个方向上做到极致。纯密集注意力最通用,但长上下文成本太高;纯局部窗口注意力便宜,但单层看不到远处;纯压缩注意力能把上下文做得很长,但容易丢掉近邻精细结构。因此现代模型越来越多地采用“让不同注意力模式协作分工”的路线:局部部分负责细节保真,全局部分负责长距离背景,稀疏部分负责把计算集中在最重要的位置,压缩部分负责控制 KV Cache 和 FLOPs。
从实现方式看,混合注意力至少有三种常见形态。第一种是同层混合:在同一层里并行放入两条注意力分支,再把结果合并,例如局部窗口分支加全局分支。第二种是按层交替:不同层使用不同的注意力模式,例如一层偏局部,一层偏全局。第三种是主干 + 补充分支:主体注意力负责主要读写,同时再加一个窗口分支、全局 token 分支或压缩块分支补足缺失的信息路径。前面的滑动窗口路线,以及后文的 DeepSeek V4 `CSA / HCA`,都可以放在这条“混合注意力”主线上理解。
这里需要把两类经常被混在一起的优化明确分开。第一类是架构级注意力创新:它直接改写注意力层内部的参数化方式、KV 表示形式或 block 级计算路径,例如 MLA(Multi-head Latent Attention)以及 DeepSeek V4 的 CSA / HCA(Compressed Sparse Attention / Heavily Compressed Attention)。第二类是推理期运行时优化:它在部署阶段降低显存、带宽或调度开销,不改变模型训练时学到的注意力结构,例如 Paged Attention、Prompt Caching、KV 量化等。
这一区分很重要,因为 MLA、CSA、HCA 都属于主干网络内部的注意力设计。它们直接定义了模型在训练时看到的注意力几何结构:哪些历史信息会先被压缩,哪些块会被稀疏选中,局部窗口与压缩块如何共同参与注意力,Query 与压缩 KV 在什么空间里交互,这些都属于主干网络本身的前向计算路径。DeepSeek V4 也把 Hybrid Attention Architecture、mHC 和 Muon 并列为架构与优化升级,并明确说明该系列模型是在这些设计下完成超大规模预训练的。这说明 `CSA / HCA` 从一开始就是训练期与推理期共同生效的主干设计,而非训练完以后再附加的后处理层。
更具体地说,MLA 把“每个 token 的 KV 应该以什么潜空间形式被缓存和恢复”写进了注意力层;CSA / HCA 则把“历史序列该怎样在序列轴上压缩、检索与混合”写进了注意力层。模型在预训练阶段就必须适应这种信息流,因此它们会同时影响表示学习、优化稳定性、长程依赖建模和最终推理成本。与之相对,KV 量化和 Paged Attention 更接近部署侧技术:即使它们也会显著影响可用上下文和吞吐,它们通常不要求模型从头按该结构重新预训练。
其中 DeepSeek V4 的 `CSA + HCA` 应被明确看作一种混合注意力机制。它把 CSA 这种“压缩后做稀疏重点检索”的模式,与 HCA 这种“重压缩后做全局粗读”的模式组合起来,并额外保留滑动窗口分支补足局部细节。因此它同时具备“局部 / 全局”“稀疏 / 稠密”“轻压缩 / 重压缩”三层混合特征。把 `CSA / HCA` 只理解成 KV Cache 压缩技巧并不充分;更准确的定位是:它首先是一种混合注意力架构,其次才带来显著的缓存和 FLOPs 压缩收益。
因此,从文章结构看,DeepSeek 这一类注意力创新应当先在“注意力机制”这里出现,作为混合注意力的长上下文分支做总引;后文“KV Cache 压缩”再展开它们为何能显著降低缓存和 FLOPs、各自内部具体有哪些组件。这样章节关系才准确:前者回答“它是否属于注意力机制本身的创新”,后者回答“这种创新最终把成本压到了哪里”。
KV Cache(Key-Value Cache)是自回归(Autoregressive)解码的关键工程优化:生成到第 \(t\) 步时,历史 token 的 Key/Value 已经在前序计算中得到;缓存它们可以避免每一步都重算整段历史的 K/V。
形式上,单层注意力在序列长度为 \(L\) 时需要缓存:
\[K,V\in\mathbb{R}^{L\times n_{\text{kv}}\times d_k}\]其中 \(n_{\text{kv}}\) 是 KV 头数量(对标准多头注意力通常等于头数;对 GQA/MQA 通常更小),\(d_k\) 是每个 head 的维度。忽略实现细节(对齐、分块、paged layout)时,KV Cache 的显存规模近似线性增长:
\[\mathrm{Mem}_{\mathrm{KV}}\approx 2\cdot N_{\text{layers}}\cdot B\cdot L\cdot n_{\text{kv}}\cdot d_k\cdot \text{bytes}\]这里前面的 2 来自同时缓存 K 与 V;\(B\) 是并发请求(batch)数;\(\text{bytes}\) 是每元素字节数(FP16/BF16 为 2)。因此 KV Cache 常成为长上下文与高并发推理的显存瓶颈。
KV Cache 的典型优化方向包括:
- 减少 \(n_{\text{kv}}\),例如使用 GQA / MQA。
- 压缩 KV,例如 KV 量化、低秩表示、选择性缓存。
- 改进分配与复用,例如 Paged Attention、前缀缓存(Prompt Caching)。
FlashAttention 是一种对标准注意力(Standard Attention)的高性能精确实现:它通过分块(Tiling)、融合计算与在线 softmax,减少大规模中间矩阵在 HBM 与片上存储之间的来回搬运。因此,它首先是一种注意力算子实现优化,而非新的模型结构。应用阶段上,训练与推理都可以使用 FlashAttention;在推理里,它最典型地加速的是预填充(Prefill)阶段,因为这时需要对整段输入做完整注意力计算,序列长、 \(QK^\top\) 代价高,FlashAttention 的收益最明显。到了逐 token 解码(Decode)阶段,单步 query 很短,瓶颈更常转向 KV Cache 读取、采样与调度,此时仍可使用面向解码优化的 Flash-Decoding / FlashAttention 变体,但收益模式已不同于预填充阶段。
从软件栈位置看,FlashAttention 可以放在内核级别(Kernel-level)/ 后端级别(Backend-level)来理解:上层框架仍然调用“注意力”这个算子,但底层可以改由高度融合的 GPU kernel 完成,而不一定走朴素的矩阵乘法 + softmax + 再乘 \(V\) 三步显式实现。是否真的启用 FlashAttention,取决于框架版本、后端实现、数据类型、head 维度、掩码形式以及硬件架构是否匹配。工程上常见支持平台是 NVIDIA 的 Ampere / Ada / Hopper,以及 AMD ROCm 生态中的部分高端 GPU;若硬件或后端条件不满足,框架通常会自动回退到 memory-efficient attention、cuDNN attention 或更普通的数学实现。
FlashAttention要解决的是标准注意力(Standard Attention)在长序列上的 中间张量 IO 成本 过高。标准缩放点积注意力(Scaled Dot-Product Attention)可写为:
\[S=\frac{QK^\top}{\sqrt{d_k}},\quad P=\mathrm{softmax}(S),\quad O=PV\]其中:
- \(Q\in\mathbb{R}^{N\times d_k}\):查询矩阵(Query Matrix),\(N\) 是序列长度, \(d_k\) 是每个 head 的查询/键维度。
- \(K\in\mathbb{R}^{N\times d_k}\):键矩阵(Key Matrix),与 \(Q\) 做点积打分。
- \(V\in\mathbb{R}^{N\times d_v}\):值矩阵(Value Matrix),\(d_v\) 是每个 head 的值维度。
- \(S\in\mathbb{R}^{N\times N}\):注意力分数矩阵(Score Matrix),其中 \(S_{ij}\) 表示第 \(i\) 个 query 对第 \(j\) 个 key 的未归一化打分。
- \(P\in\mathbb{R}^{N\times N}\):softmax 归一化后的注意力权重矩阵(Attention Probability Matrix)。
- \(O\in\mathbb{R}^{N\times d_v}\):最终输出矩阵(Output Matrix)。
问题集中在 \(S\) 和很多实现中的 \(P\):它们都是 \(N\times N\) 规模。序列一长,中间矩阵就会迅速膨胀。计算复杂度依然是 \(\mathcal{O}(N^2)\) 级别,但在 GPU 上更先撞上的往往核心是高带宽显存(High Bandwidth Memory, HBM)与片上共享内存 / SRAM(Static Random Access Memory, SRAM)之间的数据搬运成本。
传统实现通常经历三步:先算出整个 \(S=QK^\top\) 并写回显存;再把它读出来做 softmax,得到 \(P\) 并再次写回;最后再把 \(P\) 读出来与 \(V\) 相乘得到 \(O\)。这意味着真正拖慢速度的往往核心是对 \(N^2\) 中间结果的反复显式物化(Materialization)与反复搬运。
一个直接类比是流水线工厂。普通注意力像“先把全部半成品都堆进仓库,再统一拿出来做下一道工序”;仓库本身就成了瓶颈。FlashAttention 则像“边加工边流转”的流水线:中间块只在车间里短暂停留,不建立巨大的中间仓库。
FlashAttention 的核心可以压缩成一句话:分块(Tiling)+ 在线 softmax(Online Softmax)+ 融合输出(Fused Output Accumulation)。
它并不改变注意力的数学目标,仍然精确计算同一个 \(\mathrm{softmax}(QK^\top/\sqrt{d_k})V\);它改变的是计算顺序与中间结果的存储方式。具体来说,FlashAttention 从把整个 \(N\times N\) 的注意力矩阵一次性算完并落到 HBM 中转向把 \(Q,K,V\) 切成若干小块(tiles),每次只在 SRAM 中处理一小块分数、归一化和输出累加。
设查询块(query tile)为 \(Q_i\in\mathbb{R}^{B_q\times d_k}\),键块和值块分别为 \(K_j\in\mathbb{R}^{B_k\times d_k}\) 与 \(V_j\in\mathbb{R}^{B_k\times d_v}\)。这里 \(B_q\) 和 \(B_k\) 是 tile 大小,远小于完整序列长度 \(N\)。FlashAttention 每次只把这样的局部块搬进 SRAM,在块内完成当前 query tile 对当前 key/value tile 的全部贡献计算。
对第 \(i\) 个 query 块和第 \(j\) 个 key/value 块,先计算块级分数矩阵:
\[S_{ij}=\frac{Q_iK_j^\top}{\sqrt{d_k}},\qquad S_{ij}\in\mathbb{R}^{B_q\times B_k}\]其中:
- \(S_{ij}\):当前块内的注意力打分矩阵。
- \(S_{ij}[r,c]\):query 块中第 \(r\) 行与 key 块中第 \(c\) 行的打分。
- \(\sqrt{d_k}\):缩放因子,用于抑制点积随维度增长而导致的 softmax 饱和。
难点在于 softmax 的分母依赖整行所有 key:对一个 query 而言,必须把它对所有位置的打分都考虑进去,才能完成归一化。FlashAttention 的关键突破是:不必先看到整行全部元素,再做 softmax;可以用在线算法维护“到目前为止的最大值、分母和分子累加量”,随着块不断读入而精确更新。
对当前 query 块 \(Q_i\),FlashAttention 维护三个按行统计的状态:
\[\mathbf{m}_i\in\mathbb{R}^{B_q},\qquad \boldsymbol{\ell}_i\in\mathbb{R}^{B_q},\qquad R_i\in\mathbb{R}^{B_q\times d_v}\]- \(\mathbf{m}_i\):每个 query 行到目前为止见过的最大分数(row-wise running max)。
- \(\boldsymbol{\ell}_i\):每个 query 行当前的 softmax 分母累加量。
- \(R_i\):每个 query 行对输出向量的未归一化加权和(unnormalized weighted sum)。
初始时可设:
\[\mathbf{m}_i=-\infty,\qquad \boldsymbol{\ell}_i=\mathbf{0},\qquad R_i=0\]当读入第 \(j\) 个块时,先求该块每一行的局部最大值:
\[\tilde{\mathbf{m}}_{ij}=\mathrm{rowmax}(S_{ij})\]这里 \(\mathrm{rowmax}(\cdot)\) 表示对矩阵每一行取最大值,因此输出是长度为 \(B_q\) 的向量。再把旧最大值和当前块最大值合并成新的全局参考点:
\[\mathbf{m}_i^{\mathrm{new}}=\max\!\left(\mathbf{m}_i,\tilde{\mathbf{m}}_{ij}\right)\]这里的 \(\max\) 是逐元素最大值(element-wise max),因为每个 query 行都维护自己的 softmax 参考值。
接着把当前块的指数项按新参考点重写:
\[P_{ij}=\exp\!\left(S_{ij}-\mathbf{m}_i^{\mathrm{new}}\mathbf{1}^\top\right)\]其中:
- \(P_{ij}\in\mathbb{R}^{B_q\times B_k}\):当前块中按新最大值平移后的指数权重。
- \(\mathbf{1}\in\mathbb{R}^{B_k}\):全 1 向量,用于把 \(\mathbf{m}_i^{\mathrm{new}}\) 广播到块内每一列。
- \(\exp(\cdot)\):逐元素指数函数。
然后更新分母累加量:
\[\boldsymbol{\ell}_i^{\mathrm{new}}=\exp\!\left(\mathbf{m}_i-\mathbf{m}_i^{\mathrm{new}}\right)\odot \boldsymbol{\ell}_i+\mathrm{rowsum}(P_{ij})\]这里 \(\odot\) 表示逐元素乘法, \(\mathrm{rowsum}(P_{ij})\) 表示对 \(P_{ij}\) 每一行求和。这个式子的含义是:旧块已经累积的分母,先因为参考最大值改变而按 \(\exp(\mathbf{m}_i-\mathbf{m}_i^{\mathrm{new}})\) 重新缩放,再加上当前块的新贡献。
再更新输出分子的累加量:
\[R_i^{\mathrm{new}}=\mathrm{Diag}\!\left(\exp\!\left(\mathbf{m}_i-\mathbf{m}_i^{\mathrm{new}}\right)\right)R_i+P_{ij}V_j\]其中:
- \(\mathrm{Diag}(\cdot)\):把向量放到对角线上形成对角矩阵,用于按行缩放 \(R_i\)。
- \(P_{ij}V_j\in\mathbb{R}^{B_q\times d_v}\):当前块对输出的新增贡献。
所有 \(K_j,V_j\) 块处理完之后,当前 query 块的最终输出为:
\[O_i=\mathrm{Diag}\!\left((\boldsymbol{\ell}_i)^{-1}\right)R_i\]这里 \((\boldsymbol{\ell}_i)^{-1}\) 表示对向量每个元素取倒数,作用是把“未归一化加权和”除以 softmax 分母,从而得到真正的注意力输出。
FlashAttention 通过一种保持数值等价的累计方式精确计算 softmax。设某一行已经处理过的旧分数集合为 \(\mathcal{A}\),其旧最大值为 \(m_{\mathrm{old}}\),旧分母为:
\[\ell_{\mathrm{old}}=\sum_{x\in\mathcal{A}} e^{x-m_{\mathrm{old}}}\]新读入一块分数集合 \(\mathcal{B}\) 后,若新的全局最大值变成 \(m_{\mathrm{new}}\),则旧部分相对于新参考点的分母贡献恰好变成:
\[\sum_{x\in\mathcal{A}} e^{x-m_{\mathrm{new}}}=e^{m_{\mathrm{old}}-m_{\mathrm{new}}}\sum_{x\in\mathcal{A}} e^{x-m_{\mathrm{old}}}=e^{m_{\mathrm{old}}-m_{\mathrm{new}}}\ell_{\mathrm{old}}\]这正是在线更新公式里那一项缩放因子的来源。分子累加量 \(R_i\) 也是同样的道理:旧部分先按新参考点缩放,再加上新块贡献。因此块级处理结束后得到的 \(O_i\) 与一次性对整行做 softmax 再乘 \(V\) 的结果完全一致。
| 维度 | 普通 Attention | FlashAttention |
| 数学目标 | 计算 \(\mathrm{softmax}(QK^\top/\sqrt{d_k})V\) | 计算同一个精确结果,不改目标函数 |
| 中间矩阵 | 常显式存 \(S\),很多实现还显式存 \(P\) | 不显式存完整 \(N\times N\) 矩阵,只保留 tile 级临时块与行级累加状态 |
| 计算顺序 | 先全部算完分数,再整体 softmax,再乘 \(V\) | 边读块边更新 softmax,边把当前块对输出的贡献累加进去 |
| 显存特征 | 中间激活常呈 \(\mathcal{O}(N^2)\) 增长 | 额外中间存储近似降到 \(\mathcal{O}(N)\) 级别 |
| 性能瓶颈 | 更容易受 HBM 读写限制,属于强 memory-bound 场景 | 显著减少 HBM 往返,更接近 compute-bound |
FlashAttention 的速度优势主要来自 IO 模式优化,而非渐近计算复杂度下降。它的核心收益主要来自四点:
- 减少 HBM 访问:不再反复把 \(S\) 与 \(P\) 这类 \(N^2\) 中间张量写回、读回。
- 提升 SRAM 复用:一个 tile 被搬进片上后,会在同一块内连续完成分数计算、归一化和输出累加。
- 算子融合(Kernel Fusion):原本分散的 \(QK^\top\)、softmax、\(PV\) 被压成一条更短的数据通路。
- 数值稳定:在线 softmax 仍然使用减最大值(max trick),避免指数溢出,也避免了“先大矩阵 softmax 再回写”带来的额外数值压力。
因此,FlashAttention 的本质是减少无效搬运,而非改变注意力本身的数学定义。从硬件视角看,它把一个明显受内存带宽制约的算子,改造成更能吃满矩阵乘法单元和 Tensor Core 的实现。
复杂度上需要严格区分“算了多少”和“存了多少”。FlashAttention 与普通注意力在算术复杂度上仍然同阶,因为每个 query 与每个 key 的交互并没有消失:
\[\text{FLOPs: }\mathcal{O}(N^2d_k)\quad\text{vs.}\quad \mathcal{O}(N^2d_k)\]但中间激活的显存复杂度发生了根本变化。若只看注意力算子额外需要保留的中间结果,则:
\[\text{普通 Attention: }\mathcal{O}(N^2),\qquad \text{FlashAttention: }\mathcal{O}(N)\]这里的 \(\mathcal{O}(N)\) 指的是按行维护的 softmax 统计量与输出累加量;tile 临时块的大小由 \(B_q,B_k\) 控制,不随完整序列平方增长。工程直觉可以概括为:算力阶数没变,但仓库规模从平方级中间仓库变成了线性级流水线缓存。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
for each query tile Q_i: m_i = -inf l_i = 0 R_i = 0 for each key/value tile (K_j, V_j): S_ij = Q_i K_j^T / sqrt(d_k) m_new = max(m_i, rowmax(S_ij)) P_ij = exp(S_ij - m_new) l_i = exp(m_i - m_new) * l_i + rowsum(P_ij) R_i = diag(exp(m_i - m_new)) * R_i + P_ij * V_j m_i = m_new O_i = diag(1 / l_i) * R_i |
这段伪代码对应的正是“边看块、边归一化、边输出”的流水线结构。与普通实现相比,最大的变化核心是调度顺序。
FlashAttention 的关键价值不仅在前向传播(Forward Pass),也在反向传播(Backward Pass)。训练时真正吃显存的不只是前向输出,还包括为了求梯度而保留的中间激活。如果 backward 仍然要求把完整的 \(S\) 或 \(P\) 存下来,那么前向省出来的显存会被反向阶段重新吃掉。因此,FlashAttention backward 的核心原则与前向一致:在 backward 中按块重算(recompute)它们,不保存 \(N\times N\) 注意力矩阵。
设前向定义为:
\[S=\frac{QK^\top}{\sqrt{d_k}},\qquad P=\mathrm{softmax}(S),\qquad O=PV\]设损失函数为 \(\mathcal{L}\),并记上游传回的输出梯度为:
\[G=\frac{\partial \mathcal{L}}{\partial O},\qquad G\in\mathbb{R}^{N\times d_v}\]这里:
- \(\mathcal{L}\):整个模型的标量损失(scalar loss)。
- \(G\):损失对注意力输出 \(O\) 的梯度,也就是 backward 进入注意力层时收到的上游信号。
普通 attention 的 backward 可以按链式法则拆成四步。先对 \(V\) 求梯度:
\[\frac{\partial \mathcal{L}}{\partial V}=P^\top G\]这个式子表示:某个 value 向量 \(v_j\) 对多少个 query 产生了贡献,就会按相应注意力权重 \(P_{ij}\) 把这些上游梯度累加回来。
再对概率矩阵 \(P\) 求梯度:
\[\frac{\partial \mathcal{L}}{\partial P}=GV^\top\]这里 \(\frac{\partial \mathcal{L}}{\partial P}\in\mathbb{R}^{N\times N}\) 的第 \((i,j)\) 项表示:若第 \(i\) 行第 \(j\) 列的注意力权重略有变化,会怎样影响损失。
关键一步是 softmax 的梯度。对第 \(i\) 行,记 \(p_i\) 为第 \(i\) 行概率向量, \(g_i^P\) 为 \(\frac{\partial \mathcal{L}}{\partial P}\) 的第 \(i\) 行,则:
\[\frac{\partial \mathcal{L}}{\partial s_i}=p_i\odot \left(g_i^P-\delta_i\mathbf{1}\right),\qquad \delta_i=\sum_{j=1}^{N} g_{ij}^P p_{ij}\]其中:
- \(s_i\):分数矩阵 \(S\) 的第 \(i\) 行。
- \(\odot\):逐元素乘法。
- \(\delta_i\):第 \(i\) 行 softmax Jacobian 压缩后的标量项,用来扣掉“整行归一化”带来的耦合影响。
- \(\mathbf{1}\in\mathbb{R}^{N}\):全 1 向量。
把所有行拼起来,可写成矩阵形式:
\[D=\mathrm{rowsum}\!\left(\frac{\partial \mathcal{L}}{\partial P}\odot P\right),\qquad \frac{\partial \mathcal{L}}{\partial S}=P\odot \left(\frac{\partial \mathcal{L}}{\partial P}-D\mathbf{1}^\top\right)\]这里 \(D\in\mathbb{R}^{N}\) 是逐行标量向量,第 \(i\) 个分量就是 \(\delta_i\)。最后再通过 \(S=QK^\top/\sqrt{d_k}\) 回传到 \(Q\) 与 \(K\):
\[\frac{\partial \mathcal{L}}{\partial Q}=\frac{\partial \mathcal{L}}{\partial S}\frac{K}{\sqrt{d_k}},\qquad \frac{\partial \mathcal{L}}{\partial K}=\left(\frac{\partial \mathcal{L}}{\partial S}\right)^\top\frac{Q}{\sqrt{d_k}}\]若直接照这些公式实现,最大问题是:看起来必须先拿到完整的 \(P\) 和 \(\frac{\partial \mathcal{L}}{\partial P}\),而它们又都是 \(N\times N\)。FlashAttention backward 的突破在于,真正必须永久保存的量远比这少。
第一,前向阶段只需保存每一行的 log-sum-exp 统计量(Log-Sum-Exp Statistics),而不必保存整张 \(P\)。若前向某一行的最大值为 \(m_i\),归一化因子为 \(\ell_i\),则可存:
\[L_i=m_i+\log \ell_i=\log\sum_{j=1}^{N} e^{S_{ij}}\]这里 \(L_i\) 是第 \(i\) 行 softmax 分母的对数。只要 backward 时重新算出某个块的分数 \(S_{ij}\),就可以把该块的概率精确重建为:
\[P_{ij}=\exp\!\left(S_{ij}-L_i\mathbf{1}^\top\right)\]这说明 backward 不需要读取前向保存下来的整张 \(P\);它只需要 \(Q\)、\(K\)、行级统计量 \(L_i\),就能按块把局部概率重新算出来。
第二,softmax backward 中的行级标量 \(\delta_i\) 也可以用一个更紧凑的等价式,避免通过整张 \(\frac{\partial \mathcal{L}}{\partial P}\) 显式求和:
\[\delta_i=\sum_{j=1}^{N} g_{ij}^P p_{ij}=g_i^\top o_i\]其中 \(g_i\) 是上游梯度矩阵 \(G\) 的第 \(i\) 行, \(o_i\) 是前向输出 \(O\) 的第 \(i\) 行。这个恒等式来自:
\[g_i^P=g_iV^\top,\qquad o_i=p_iV\]于是:
\[\sum_{j=1}^{N} g_{ij}^P p_{ij}=\sum_{j=1}^{N}(g_i v_j^\top)p_{ij}=g_i\left(\sum_{j=1}^{N}p_{ij}v_j\right)^\top=g_i o_i^\top\]这一步非常关键,因为它说明 softmax backward 所需的行级校正项 \(\delta_i\),可以直接由前向输出 \(O\) 和上游梯度 \(G\) 得到,而不需要显式展开整个 \(N\times N\) 概率矩阵。
因此,FlashAttention backward 的块级流程可以概括为:
- 读取一个 query tile \(Q_i\)、对应输出 tile \(O_i\)、上游梯度 tile \(G_i\),以及该 tile 的行级统计量 \(L_i\)。
- 逐块读取 \(K_j,V_j\),重算当前块分数 \(S_{ij}=Q_iK_j^\top/\sqrt{d_k}\)。
- 由 \(L_i\) 重建当前块概率 \(P_{ij}=\exp(S_{ij}-L_i\mathbf{1}^\top)\)。
- 用 \(G_iV_j^\top\) 得到当前块的 \(\frac{\partial \mathcal{L}}{\partial P_{ij}}\),再结合 \(\delta_i=g_i^\top o_i\) 计算当前块的 \(\frac{\partial \mathcal{L}}{\partial S_{ij}}\)。
- 把该块对 \(dQ_i\)、\(dK_j\)、\(dV_j\) 的贡献直接累加到输出梯度中。
写成块级公式,就是:
\[dV_j \mathrel{+}= P_{ij}^\top G_i\] \[dP_{ij}=G_iV_j^\top\] \[dS_{ij}=P_{ij}\odot \left(dP_{ij}-\delta_i\mathbf{1}^\top\right)\] \[dQ_i \mathrel{+}= dS_{ij}\frac{K_j}{\sqrt{d_k}},\qquad dK_j \mathrel{+}= dS_{ij}^\top\frac{Q_i}{\sqrt{d_k}}\]这里 \(dQ_i,dK_j,dV_j\) 分别表示当前块对 \(\frac{\partial \mathcal{L}}{\partial Q}\)、\(\frac{\partial \mathcal{L}}{\partial K}\)、\(\frac{\partial \mathcal{L}}{\partial V}\) 的局部累加贡献;符号 \(\mathrel{+}=\) 表示“把当前块的贡献继续累加到已有梯度里”,而非一次性覆盖赋值。
这个设计的代价是:backward 需要重算部分前向中的块级分数和概率,因此算术量会比“全存中间矩阵”的朴素实现略多;但现代 GPU 上,额外矩阵乘法通常比反复读写 \(N^2\) HBM 张量便宜得多。于是 FlashAttention backward 的工程哲学可以概括为:用少量重算换大幅节省显存与 IO。
一个直观类比是:普通 backward 像把前向每一道工序的全部半成品都堆满仓库,等回头算梯度时再逐件取出来;FlashAttention backward 则更像保留每条流水线的关键账本和最终产物,真正需要某段中间细节时,再按原流程快速重演一小段。仓库变小了,流水线也更连贯。
FlashAttention v1 的核心贡献在于算法层:它首先把“注意力必须显式存下 \(N\times N\) 矩阵”这一默认前提打破,给出了一种精确、稳定、块级流式的注意力实现。v1 的关键词是 memory optimization:让注意力从“被中间矩阵拖慢”转向“更像一个流式矩阵核”。
在这个阶段,最重要的是先证明:在不物化注意力矩阵的条件下,仍然可以精确完成前向与反向计算,并把显存墙显著后移。GPU 利用率优化属于后续问题。它首先解决的是“能不能这样算”的问题。
FlashAttention v2 保留了 v1 的数学等价性与在线 softmax 思路,但把优化重点从“省内存”推进到“把 GPU 吃满”。它关注的是并行工作划分(Work Partitioning):如何把 query 块、head 维度、batch 维度和线程块(Thread Block)组织得更均匀,让更多流式多处理器(Streaming Multiprocessor, SM)同时处于忙碌状态。
v1 的一个现实限制是:虽然显存访问已经大幅减少,但某些场景下并行粒度仍然偏粗,导致 GPU 占用率(Occupancy)不够高。v2 因此重写了 kernel 调度策略,让同一个大任务能够拆给更多线程块并行处理,同时尽量减少线程同步(Synchronization)带来的停顿。
从本质上看,v2 做的核心是“同一公式在 GPU 上的更优任务分发”。如果说 v1 的问题是“别把中间矩阵落盘”,那么 v2 的问题就是“别让 GPU 的很多 SM 闲着”。
这也是 v2 在反向传播(Backward Pass)上价值很高的原因。前向只解决一半问题;训练吞吐还取决于 backward kernel 能否在不恢复 \(N^2\) 显存占用的前提下保持高并行度。v2 在这一点上比 v1 更成熟,因此更适合作为训练时的高性能默认实现。
FlashAttention v3 的重点进一步从并行层推进到硬件协同设计(Hardware Co-design),尤其针对 NVIDIA Hopper / H100 这类新一代 GPU。它已经从关心“块怎么切、线程怎么分”扩展到进一步追问:数据加载、矩阵计算、结果写回能否形成异步流水线。
v3 的几个代表性关键词包括:
- 异步流水线(Asynchronous Pipeline):加载下一块数据时,当前块已经在计算,从而重叠 load 与 compute。
- Warp 专职分工(Warp Specialization):不同 warp 分别负责搬运、计算、写回,减少彼此等待。
- Tensor Core 深度利用:tile 尺寸与数据流更贴近 Tensor Core 最擅长的矩阵乘法路径。
- 更适合低精度数据类型:如 FP16、BF16,以及面向新硬件的 FP8 路径。
如果把 v1 看成“算法上不建大仓库”,把 v2 看成“让更多工人同时开工”,那么 v3 更像“把整座工厂变成不停顿的装配线”:搬运、计算、写回三条流水同时进行,尽量让每一级硬件资源都不空转。
| 版本 | 主要优化层次 | 核心目标 | 本质关键词 |
| v1 | 算法层 | 避免 \(N^2\) 中间矩阵物化 | 分块、在线 softmax、融合计算 |
| v2 | 并行层 | 提高 Occupancy,减少同步,提升训练吞吐 | 更细粒度 work partitioning |
| v3 | 硬件层 | 让 load / compute / store 深度重叠 | 异步流水线、warp specialization、Tensor Core 对齐 |
因此,FlashAttention 的演进可以概括为三层推进:v1 解决“能否不存矩阵”、v2 解决“如何把 GPU 跑满”、v3 解决“如何贴着新硬件的数据通路跑”。三代版本的数学目标完全一致,差异主要体现在实现层面对 IO、并行性与硬件流水的挖掘深度。
状态空间模型(State Space Model, SSM)用“隐状态递推(State Recurrence)”建模序列:每步用一个小状态 \(s_t\) 累积历史信息,避免显式构造 \(L\times L\) 注意力矩阵。经典线性 SSM 的抽象形式是:
\[s_{t+1}=As_t+Bx_t,\quad y_t=Cs_t+Dx_t\]近年的 Mamba 等结构可理解为在此基础上引入输入依赖的选择性/门控机制(Selective / Input-dependent Dynamics),使得模型在保持线性复杂度的同时具备更强的表征能力。工程上,SSM 的优势通常体现在长序列吞吐与显存;代价是“按内容随机访问历史”的能力不如注意力直观,因此在需要强检索/对齐的任务上常见的是混合架构或与注意力模块组合使用。
| 路线 | 序列复杂度 | 显存瓶颈 | 强项 | 典型代价 |
| 精确注意力(FlashAttention 等) | \(\mathcal{O}(L^2)\) | 注意力中间张量 + KV Cache | 强检索/对齐;通用能力稳健 | 长上下文成本陡增;需要大量工程优化(GQA/分页/缓存) |
| 线性注意力 | 近似 \(\mathcal{O}(L)\) | 缓存布局与数值稳定性 | 极长序列吞吐/显存友好 | 近似误差;需要专门核函数/特征映射设计 |
| SSM / Mamba | \(\mathcal{O}(L)\) | 状态与算子实现 | 长序列吞吐;流式友好 | 随机访问历史不如注意力直观;常需混合架构补齐能力 |
Transformer 层里的前馈网络(Feed-Forward Network, FFN)本质上就是一个位置前馈(Position-wise)MLP:它对每个 token 的向量独立作用,不在序列维度做混合(序列维度的混合由注意力完成)。典型形式是两层线性变换加非线性:
\[\mathrm{FFN}(x)=\sigma(xW_1+b_1)W_2+b_2\]这里为了贴近工程实现,把单个 token 表示写成行向量 \(x\in\mathbb{R}^{1\;\times d_{\text{model}}}\)。若中间宽度为 \(d_{\text{ff}}\),则 \(W_1\in\mathbb{R}^{d_{\text{model}}\;\times d_{\text{ff}}}\)、\(W_2\in\mathbb{R}^{d_{\text{ff}}\;\times d_{\text{model}}}\),因此这层先把 \(d_{\text{model}}\) 维表示升到更宽的 \(d_{\text{ff}}\) 维,再投回原宽度。很多教材把它叫“MLP 模块”,强调的是它在每层里与注意力并列构成 Transformer block 的两大子层。
“升维(Up-Projection)”指的是用线性投影把输入映射到更高维的特征空间。新维度并非补零得到的,也并非旧特征的简单复制。若
\[h_{\text{up}}=xW_1+b_1\in\mathbb{R}^{1\;\times d_{\text{ff}}}\]则第 \(j\) 个中间维度满足
\[(h_{\text{up}})_j=\sum_{i=1}^{d_{\text{model}}}x_i(W_1)_{ij}+b_{1j}\]这意味着:升出来的每一维都在重新组合输入特征。有些维度更像“检测某种局部模式”,有些维度更像“混合多种语义线索”,中间宽度越大,可供模型学习的组合方式就越多。随后,非线性函数 \(\sigma\)(常见如 GELU / ReLU)对这些组合结果做逐元素变换,把线性组合提升为非线性特征。
“降维(Down-Projection)”也核心是再做一次线性组合:
\[h_{\text{down}}=\sigma(h_{\text{up}})W_2+b_2\in\mathbb{R}^{1\;\times d_{\text{model}}}\]因此,经典 FFN 的结构可以概括成:先在更宽的特征空间里生成大量候选特征,再把有用的那部分重新组合回模型主宽度。这就是“升维—非线性—降维”的真正含义。
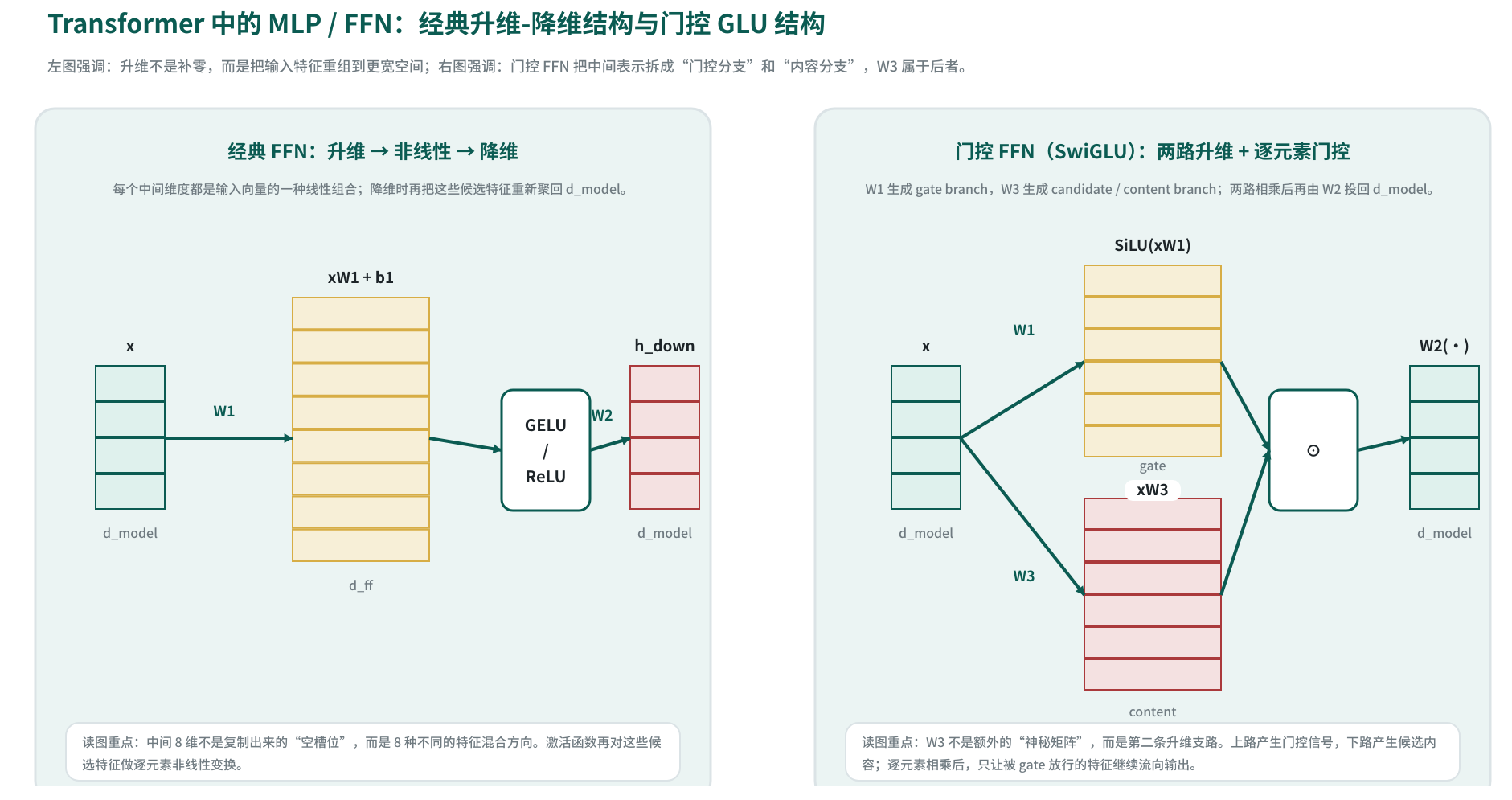
很多现代大模型会用门控线性单元(Gated Linear Unit, GLU)的变体替代“Linear → 激活 → Linear”的经典 FFN,例如 SwiGLU(Swish-Gated Linear Unit):把中间层拆成两路并行投影,再做逐元素门控:
\[\mathrm{SwiGLU}(x)=\Big(\mathrm{SiLU}(xW_1)\odot (xW_3)\Big)W_2\]若仍按行向量写法,则 \(W_1,W_3\in\mathbb{R}^{d_{\text{model}}\;\times d_{\text{ff}}}\), \(W_2\in\mathbb{R}^{d_{\text{ff}}\;\times d_{\text{model}}}\)。这里 \(W_1\) 与 \(W_3\) 都是“升维投影”,但角色不同: \(xW_1\) 经过 \(\mathrm{SiLU}\) 后形成门控分支(gate branch),决定每个中间维度应当放大、通过还是抑制; \(xW_3\) 则形成内容分支(value / candidate branch),携带候选特征本身。两者做逐元素乘法 \(\odot\) 后,得到“被门控筛选过的中间表示”,最后再由 \(W_2\) 投回 \(d_{\text{model}}\)。
因此, \(W_3\) 核心是门控 FFN 里的第二条并行升维支路。没有它,模型只有“激活后的门”,却没有“真正被门控制的候选内容”;有了它,FFN 才能表达“哪些特征值得通过、哪些特征应被压制”这一层选择机制。
这种“哪些维度打开、哪些维度抑制”的规则核心是通过训练从数据中学出来的。对第 \(j\) 个中间维度,门控值可以写成 \(g_j=\mathrm{SiLU}((xW_1)_j)\),候选内容写成 \(c_j=(xW_3)_j\),二者相乘后该维输出为 \(m_j=g_j c_j\)。若某类输入模式下,让这个维度更大能够降低最终损失,则反向传播会推动 \(W_1\) 和 \(W_3\) 把对应的 \(g_j\) 与 \(c_j\) 调到更有利的方向;若某个维度会带来噪声、干扰或错误特征,则梯度会推动该维在这类输入上变小,于是门控值逐渐靠近 0,内容即使存在也难以通过。
因此,门控学习到的核心是一组随输入变化的连续缩放系数。某些维度在数学推理样本上可能长期被放大,在闲聊样本上则被压弱;某些维度对代码括号、缩进、关键字组合更敏感,另一些维度则更偏向实体关系或长距离语义线索。门控 FFN 的本质,是让模型在更宽的中间空间里先生成大量候选特征,再由可学习的输入相关门控决定哪些特征应该被保留、哪些应被抑制。
门控(Gating)让 FFN 具备“按特征选择通过 / 抑制”的能力,在相近参数规模下常带来更好的效果与训练稳定性。与经典两层 FFN 相比,门控 FFN 核心是把中间表示拆成“控制信号”和“候选内容”两路,再在中间宽空间里完成细粒度筛选。
从能力角度看,增大 \(d_{\text{ff}}\) 会增加中间表征的自由度(Degree of Freedom, DOF)与参数量,使模型能构造更丰富的非线性特征;但“维度更高”不同于“信息一定更多”,它提供的是可学习的表示空间与容量(Capacity),是否有效取决于数据与训练目标。
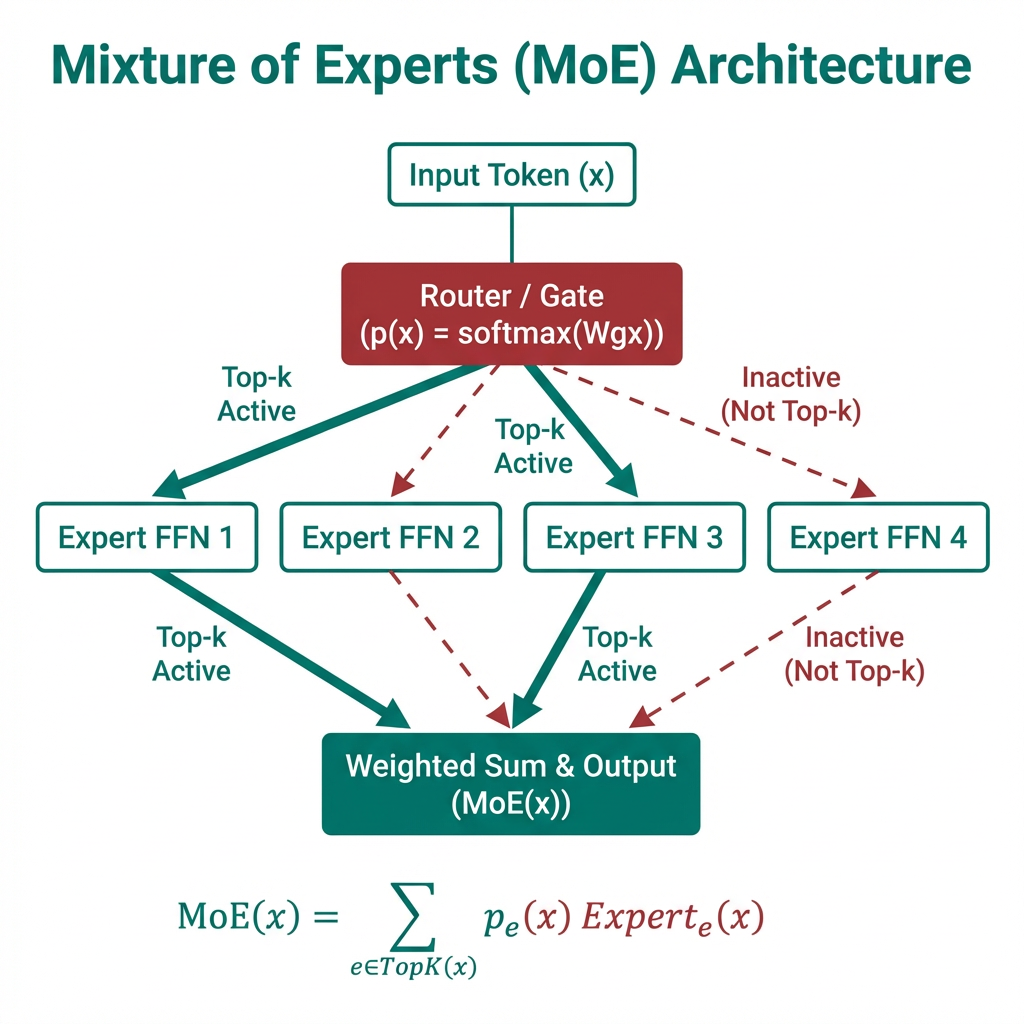
MoE(Mixture of Experts)把 FFN 子层替换成“多个专家网络(Experts)+ 路由器(Router/Gate)”:对每个 token,路由器只激活少数几个专家(Top-k),因此计算量近似不随专家总数线性增长,但参数容量可以大幅增加。
一种常见形式(概念表达)是:
\[\mathrm{MoE}(x)=\sum_{e\in\mathrm{TopK}(x)} p_e(x)\,\mathrm{Expert}_e(x),\quad p(x)=\mathrm{softmax}(W_g x)\]其中 \(p_e(x)\) 是路由概率,专家通常就是不同参数的 FFN。与稠密 FFN 的区别在于:稠密 FFN 对每个 token 都执行同一套参数;MoE 则先由路由器决定“这个 token 该送去哪些专家”,再只计算被选中的少数几个专家。
专家的差异化(Specialization)来源于路由选择、梯度暴露和训练约束共同塑造的长期分工。随机初始化只负责打破完全对称;真正让专家“越学越不一样”的,是后续每个专家持续处理不同 token 子分布,并在这些子分布上反复累积参数更新。
这个过程通常由以下几类机制共同推动:
- 稀疏路由:每个 token 前向时通常只进入 top-k 个专家,因此反向传播时,也只有被选中的专家接收到该 token 的主要梯度。不同专家长期看到的训练样本分布因此不再相同,参数更新方向也随之分化。
- 路由—能力自增强:路由器先按当前表示给专家打分;某个专家一旦更常处理一类模式,就会在这类模式上进一步拟合得更好;下一轮遇到相似 token 时,路由器又更容易把它们送回这个专家。久而久之,专家会演化成代码型、数学型、长句法型或领域词汇型等不同处理器。
- 负载均衡损失:若完全放任训练,路由器容易把大量 token 都送往少数“热门专家”,其余专家几乎得不到梯度。负载均衡(Load Balancing)辅助损失会惩罚这种失衡,推动更多专家获得稳定训练信号,从而保留分工空间,而非塌缩成少数几个超忙专家。
- 容量限制:工程实现常给每个专家设置每个 batch 最多接收多少 token 的上限。热门专家一旦满载,后续 token 就必须改道到其他专家。这相当于在训练期强行制造“分流”,避免所有高频模式都被同一专家垄断。
- 路由噪声与探索:训练早期常在路由分数上加入噪声(Noisy Gating / Jitter)或采用更平滑的选择策略,使模型不会过早把某些专家永久冷启动掉。它的作用类似探索机制:先让更多专家接触不同 token,后续再由训练结果把分工逐步固化。
- Top-k 竞争结构:当多个专家为同一 token 竞争有限的 top-k 名额时,路由器天然在做离散化分配。专家之间核心是在竞争中各自吸附不同区域的输入分布。这比稠密加权平均更容易形成明确边界。
- 专家参数独立:每个专家有自己独立的 FFN 权重,因此一旦早期路由稍有偏向,后续参数更新就会沿不同轨迹不断放大差异。若专家共享大部分参数,仅保留极少差异分支,则这种专门化能力会明显减弱。
- 数据分布本身的可分性:训练语料若天然包含代码、自然语言、表格、数学推导、多语种等明显子分布,专家更容易形成稳定分工;若数据分布高度均匀、模式差异很弱,则专家专门化也会更弱,更接近“多份相似 FFN”。
这些机制叠加后,MoE 中“每个专家学不同东西”就已经从参数副本的偶然漂移扩展到带有明确结构约束的分工过程。与多头注意力主要依赖独立参数的自发分化不同,MoE 额外利用显式路由、稀疏梯度、负载约束与容量分流来持续放大专家之间的功能差异。
MoE 结构本身不必然引入随机性。若路由使用确定性的 top-k,且推理使用确定性算子,则同一输入在同一权重下输出应是确定的。训练阶段常见的随机性主要来自 dropout、路由噪声(Noisy Gating)以及硬件/并行计算的非确定性;这些会影响训练轨迹,但不等价于“模型本质随机”。
层归一化(Layer Normalization, LayerNorm)在每个 token 的特征维度上做归一化(Normalization),与 BatchNorm 不同,它不依赖 batch 统计量,因此更适合变长序列与自回归推理。对向量 \(x\in\mathbb{R}^{d_{\text{model}}}\):
\[\mathrm{LN}(x)=\gamma\odot \frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta,\quad \mu=\frac{1}{d}\sum_{i=1}^{d}x_i,\ \sigma^2=\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2\]其中 \(\gamma,\beta\) 是可学习的缩放与平移参数(Learnable Scale/Shift),\(\epsilon\) 是一个很小的正数,用于数值稳定性(Numerical Stability)。归一化本质上要除以标准差或均方根;若当前 token 的各维几乎相同,分母就可能非常接近 0,进而导致输出或梯度被异常放大,甚至出现 NaN / Inf。加入 \(\epsilon\) 相当于给分母设置一个下界。它通常很小,只在“方差或 RMS 过小”时介入;若 \(\epsilon\) 取值过大,则会把分母中的真实尺度差异压平,使归一化变弱,模型对幅值变化的敏感度下降。
当前主流的 Transformer 几乎都采用“token 内部归一化”,而非跨 batch 的 BatchNorm:经典 Transformer、BERT、ViT 这一路架构以 LayerNorm 为主;许多更新的 Decoder-only 大模型则把每个残差块写成 Pre-Norm 结构,并进一步用 RMSNorm 取代标准 LayerNorm。
Pre-LN(Pre-LayerNorm)指先做归一化,再进入 Attention 或 MLP 子层,最后与残差分支相加;其典型形式可写为:
\[y=x+\mathrm{Sublayer}(\mathrm{LN}(x))\]这种写法把归一化放进残差支路内部,有利于维持深层网络中的梯度流稳定。结合后文残差连接的分析来看,Pre-LN 的一个直接优势是:梯度更容易沿着 \(x\to x+\cdots\) 这条恒等主路向后传播,而不会在进入子层之前就先经历一次“相加后再归一化”的整体重标定。与之对应,Post-LN 会写成 \(y=\mathrm{LN}(x+\mathrm{Sublayer}(x))\);它在早期 Transformer 中出现较多,但随着层数、上下文窗口和参数规模持续增大,Pre-LN 在大模型训练中更常见。
BatchNorm 很少出现在 Transformer 主干中的原因,是它要求当前表示依赖同一 batch 里其他样本的统计量。对于序列模型,这会带来几个直接问题:
- 变长序列和 padding 会污染 batch 统计。
- 训练与推理使用的统计规则不同,自回归逐 token 生成时尤其不自然。
- 大模型训练常依赖小 batch、梯度累积和跨设备切分,batch 统计噪声更大。
LayerNorm / RMSNorm 则完全避免了这些问题,因为每个 token 的归一化只依赖其自身特征。
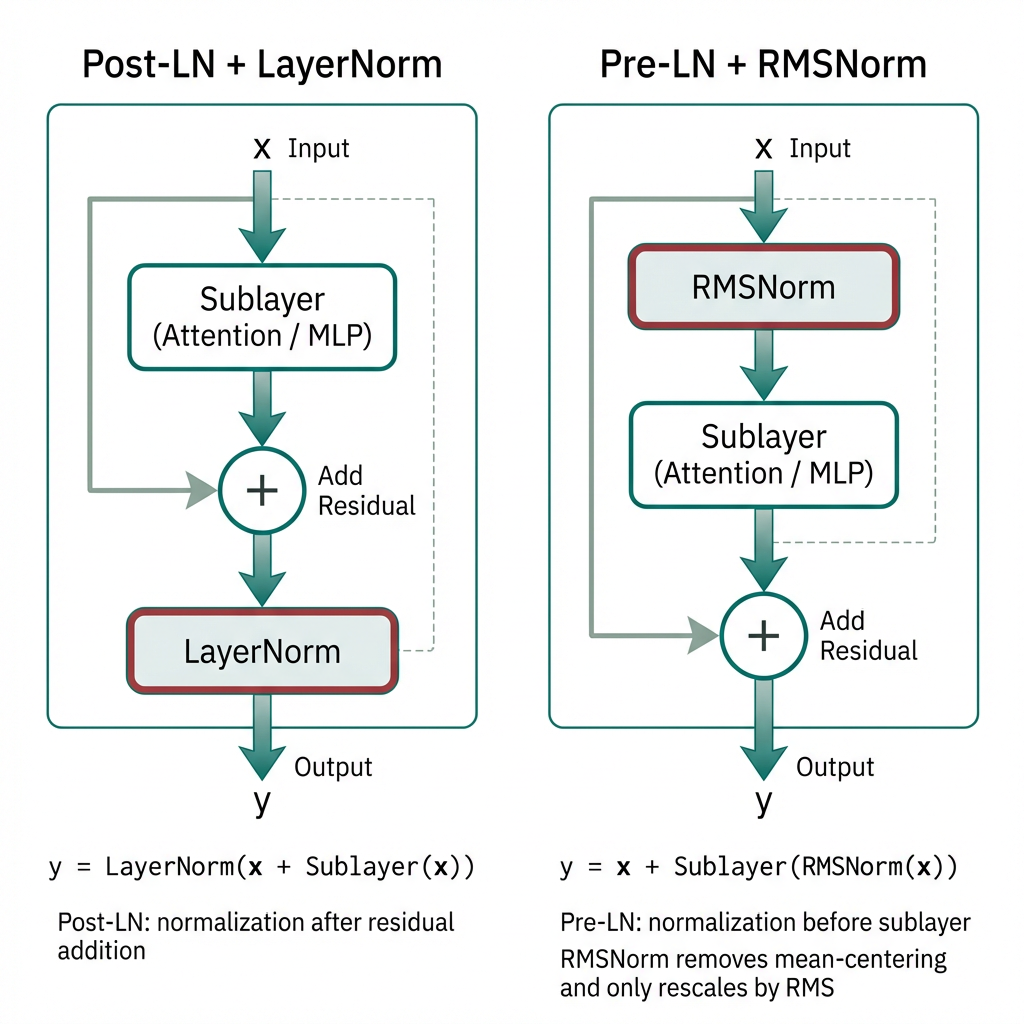
RMSNorm(Root Mean Square Normalization)与 LayerNorm 的相同点是:都在每个 token 的特征维度上做归一化;不同点是 RMSNorm 不做去均值,只按均方根(RMS)缩放:
\[\mathrm{RMSNorm}(x)=\gamma\odot \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_i^2+\epsilon}}\]其中 \(\gamma\in\mathbb{R}^{d}\) 是可学习缩放参数(通常不需要 \(\beta\)),\(\epsilon\) 则是数值稳定项(Numerical Stability Term)。当 RMS 很小时,若没有 \(\epsilon\),分母会过小,微小噪声也可能被异常放大;若 \(\epsilon\) 过大,又会把不同 token 之间本应存在的尺度差异压平,使归一化变弱。RMSNorm 省掉了均值计算,算子更简单,因此在许多 Decoder-only 大模型中被广泛采用(例如 LLaMA 系列)。
RMSNorm 之所以使用均方根,而非直接对各维做算术平均,是因为这里要刻画的是向量整体有多大,而非“各维带符号求平均后的中心位置”。若直接用 \(\frac{1}{d}\sum_i x_i\),正负分量会彼此抵消:例如 \((10,-10)\) 的算术平均是 0,但这个向量的整体幅值显然并不小。均方根先平方再平均,保留了各维对整体能量的贡献,又与二范数只差一个 \(\sqrt d\) 的常数因子,因此很适合用来刻画表示的整体尺度。
RMSNorm 即使不做去均值,仍然常常有效,原因正在于此。对 Transformer 主干而言,更核心的问题通常核心是表示的整体尺度能否在深层网络中保持稳定。残差流里真正容易失控的,往往是表示向量的整体幅值在层与层之间持续放大或缩小,进而影响梯度传播、残差叠加与数值稳定。RMSNorm 保留了各维之间的相对方向与相对比例,只对整体大小做统一缩放,因此不会反复改写表示基线;对深层 Transformer 来说,这种“只管尺度、不强行去中心”的处理往往已经足够,而且算子更轻,更适合大规模训练与推理。因此,归一化与残差连接通常总是一起出现:前者负责稳定尺度,后者负责保留主通路。
残差连接(Residual Connection)把子层输出与输入做逐元素相加:
\[y=x+\mathrm{Sublayer}(x)\]它不改变主表示的维度(Dimension)——前提是 \(x\) 与 \(\mathrm{Sublayer}(x)\) 形状相同。这个写法的核心价值,核心是把深层网络的每一层改写成:在已有表示上追加一小步修正,而非每层都彻底重写整份表示。
若没有残差,网络某一层必须直接学出从输入到输出的完整映射;有了残差后,子层只需学习增量项 \(\Delta(x)=\mathrm{Sublayer}(x)\)。当最优行为接近恒等映射时,学习“加多少修正”通常比学习“整层重新变换成什么样”更容易。这也是残差连接与恒等映射(Identity Mapping)关系紧密的原因:主通路默认保留原信息,子层负责在其上叠加必要变化。
从优化角度看,残差连接直接改变了梯度传播路径。若把一层的输入 \(x\) 看成 \(d\) 维向量,输出写成 \(y=x+f(x)\),那么这里的求导就从标量对标量的导数转向向量对向量的 Jacobian 矩阵。
先看最简单的恒等映射 \(g(x)=x\)。若 \(x=(x_1,\dots,x_d)^\top\),则 \(g_i(x)=x_i\)。它的 Jacobian 第 \((i,j)\) 个元素是
\[\frac{\partial g_i}{\partial x_j}=\frac{\partial x_i}{\partial x_j}=\begin{cases}1,& i=j\\0,& i\ne j\end{cases}\]因此,向量对自身的导数核心是恒等矩阵:
\[\frac{\partial x}{\partial x}=I\]再对残差块 \(y=x+f(x)\) 求导,就得到
\[\frac{\partial y}{\partial x}=\frac{\partial x}{\partial x}+\frac{\partial f(x)}{\partial x}=I+\frac{\partial f(x)}{\partial x}\]这里的 \(I\) 正对应那条“把输入原样传过去”的恒等分支。它并不表示整层没有维度之间的交互,而只表示:在这条直连路径上,每一维对自身的导数是 1、对其他维的导数是 0。真正的维度混合、特征重组与 token 间交互,仍然由 \(\frac{\partial f(x)}{\partial x}\) 负责。含义是:即使子层 \(f(x)\) 的局部 Jacobian 很小、很噪,或训练初期还没有学好,梯度仍然可以沿着这条恒等路径直接穿过该层,而不必完全依赖 \(\frac{\partial f(x)}{\partial x}\)。深层网络因此更不容易出现梯度迅速衰减,训练也更稳定。
从表示角度看,残差连接建立了一条贯穿全网的主通道,这正是前面多次出现的残差流(Residual Stream)。在 Transformer 中,注意力子层负责跨 token 交换信息,MLP / FFN 负责对单个 token 做非线性重组,而它们的输出都核心是写回这条主通道。于是每一层都更像是在同一块工作记忆上持续读写:有的层补充局部依赖,有的层补充长程关系,有的层强化事实模式或语法结构。
残差连接还有一个很重要的工程意义:它允许模型在“保留已有信息”和“注入新特征”之间取得平衡。若某层子层输出很弱,网络行为就更接近恒等传递;若某层确实学到了有价值的新模式, \(f(x)\) 就会沿某些表示方向显著写回主通道。后续层不需要把两部分精确拆开,只需要继续利用这个叠加后的结果即可,因为后续线性映射、注意力和归一化会在新的坐标方向上重新组织这些信息。
从反向传播(Backpropagation)的角度看,残差连接的价值同样直接。若没有残差,深层网络中的梯度必须连续穿过许多子层 Jacobian,相当于做多次矩阵连乘;当这些局部导数长期偏小,梯度就容易逐层衰减,出现梯度消失(Vanishing Gradient);当它们长期偏大,又可能造成梯度爆炸(Exploding Gradient)。加入残差后,每一层的局部导数从 \(\frac{\partial f(x)}{\partial x}\) 变成了 \(I+\frac{\partial f(x)}{\partial x}\),于是梯度不再只能依赖子层本身,而始终保留了一条沿恒等分支传播的主路径。可以把它概括成一句话:前向传播时保留原信息,反向传播时保留主梯度通路。这正是残差连接能显著缓解深层网络优化困难的根本原因。
因此,残差连接几乎成为现代深网络的标准部件。对于非常深的模型,真正困难的核心是层数增加后,前向信息更容易被后续变换不断改写,反向梯度也更容易在长链路中衰减或失稳。残差连接用一条恒等主路同时缓解了这两个问题:前向上保留原信息,反向上保留主梯度通路。因此,ResNet、Transformer、扩散模型乃至许多大型序列模型,都会把它作为主干结构的一部分。
标准残差连接默认只有一条主残差流:每层都在同一条表示通道上执行 \(x\mapsto x+f(x)\)。Hyper-Connections(HC)则把这条单通道残差流扩展成多通道残差流,使不同子流之间可以在层与层之间发生受控混合。若把第 \(l\) 层的多路残差状态记为 \(X_l\in\mathbb{R}^{n_{\text{hc}}\times d}\),则 HC 可以抽象写成
\[X_{l+1}=B_lX_l+C_lF_l(A_lX_l)\]这里 \(A_l\) 负责把多路残差流混合后送入子层 \(F_l\), \(C_l\) 负责把子层输出写回多路残差流, \(B_l\) 则负责更新“残差主路本身如何在多路之间流动”。与标准残差相比,这相当于把单车道恒等高速路扩展成多车道互通系统:信息不再只能沿一条固定车道直行,而可以在若干并行残差流之间重新分配与汇合。
这类设计的收益是表达力增强。不同残差子流可以承担不同功能,有的更偏局部模式,有的更偏全局抽象,有的更像中间缓存或专家路由;层间的线性混合再把这些信息重新编排。但问题也随之出现:一旦 \(B_l\) 这类残差映射矩阵完全自由学习,原本标准残差中那条稳定的恒等主路就可能被破坏。于是多路残差虽然更灵活,却可能丢掉残差连接最宝贵的性质,即深层堆叠时对信号传播稳定性的保障。
DeepSeek 在这一点上引入了 mHC(Manifold-Constrained Hyper-Connections)。它的核心是把其中最关键的残差映射 \(B_l\) 约束到一个具备稳定性的矩阵流形上。具体地,mHC 要求 \(B_l\) 位于双随机矩阵(Doubly Stochastic Matrix)构成的集合中:
\[\mathcal{M}_{\text{DS}}=\{B\in\mathbb{R}^{n\times n}\mid B\mathbf{1}=\mathbf{1},\ \mathbf{1}^{\top}B=\mathbf{1}^{\top},\ B_{ij}\ge 0\}\]这个约束意味着 \(B_l\) 的每一行和每一列都和为 1,而且所有元素非负。它不再允许残差主路做任意线性变换,而只能做一种“总量守恒的流间混合”。从矩阵角度看,这相当于要求残差信息在多条流之间重新分配时,既不能凭空放大,也不能通过正负抵消把主信号抹掉。
这类约束有三层直接好处。第一,双随机矩阵的谱范数满足 \(\|B_l\|_2\le 1\),因此残差主路是非扩张的(Non-expansive),有助于抑制深层堆叠中的信号爆炸。第二,双随机矩阵在矩阵乘法下保持封闭;也就是说,多层残差主路连续相乘后,整体仍然保持同类结构,因此稳定性不会在深度方向上迅速丢失。第三,双随机矩阵构成所谓的 Birkhoff polytope,它等价于置换矩阵集合的凸包。这给出了非常清晰的几何解释:mHC 中的残差混合,本质上是在若干“重排残差子流”的方式之间做加权平均,而非任意扭曲整条残差高速路。
若把标准残差看成只有一条车道,因此主路映射固定为 \(1\);那么 mHC 的意义就是把系统扩展到多车道,但所有匝道与分流规则都必须满足“车流守恒、不会凭空放大、也不会相互抵消”的交通约束。这样一来,模型既获得了多路残差混合带来的表达力,又保住了恒等映射思想强调的稳定主路。这也是它与普通可学习残差混合最根本的区别。
在参数化与实现上,mHC 会先学习一个一般实矩阵,再通过类似 Sinkhorn-Knopp 的投影步骤把它拉回双随机矩阵流形,从而确保约束在训练过程中始终成立。DeepSeek V4 把这一路径用于大规模 Transformer 主干,实质上是在回答一个非常具体的问题:当模型层数、上下文长度和 MoE 结构都继续扩张时,残差连接如何在保留稳定性的前提下容纳更复杂的信息路由。mHC 给出的答案是:残差连接仍然是主干,但主干不必永远只有一条线;只要多路混合被限制在合适的几何约束内,残差主路依然可以稳定。
放回 DeepSeek V4 的整体结构里看,这种“多路残差混合”并非只在层尾出现一次。图中的 Pre-Block Mixing、Residual Mixing 与 Post-Block Mixing,可以理解为 mHC 在 block 内不同位置的具体落地:进入注意力前先混一次,把多路残差流整理成当前子层更适合读取的输入;注意力后在残差主路上再混一次,决定新信息如何写回;进入 MoE 前再混一次,把表示重新组织成更适合专家路由与前馈扩展的形态。也就是说,mHC 不仅给残差连接“加一个约束矩阵”,还在每个 block 的读入、写回和子层衔接处共同维护多路残差流的稳定传播。
Transformer 主干(Backbone)本身的直接产物通常核心是一组上下文化隐藏状态(Contextual Hidden States)。也就是说,在一次标准前向计算里,模型会先处理当前输入序列中的所有 token,把每个位置都编码成上下文化表示;若输入序列长度为 \(T\),模型宽度为 \(d_{\text{model}}\),经过最后一层后常得到:
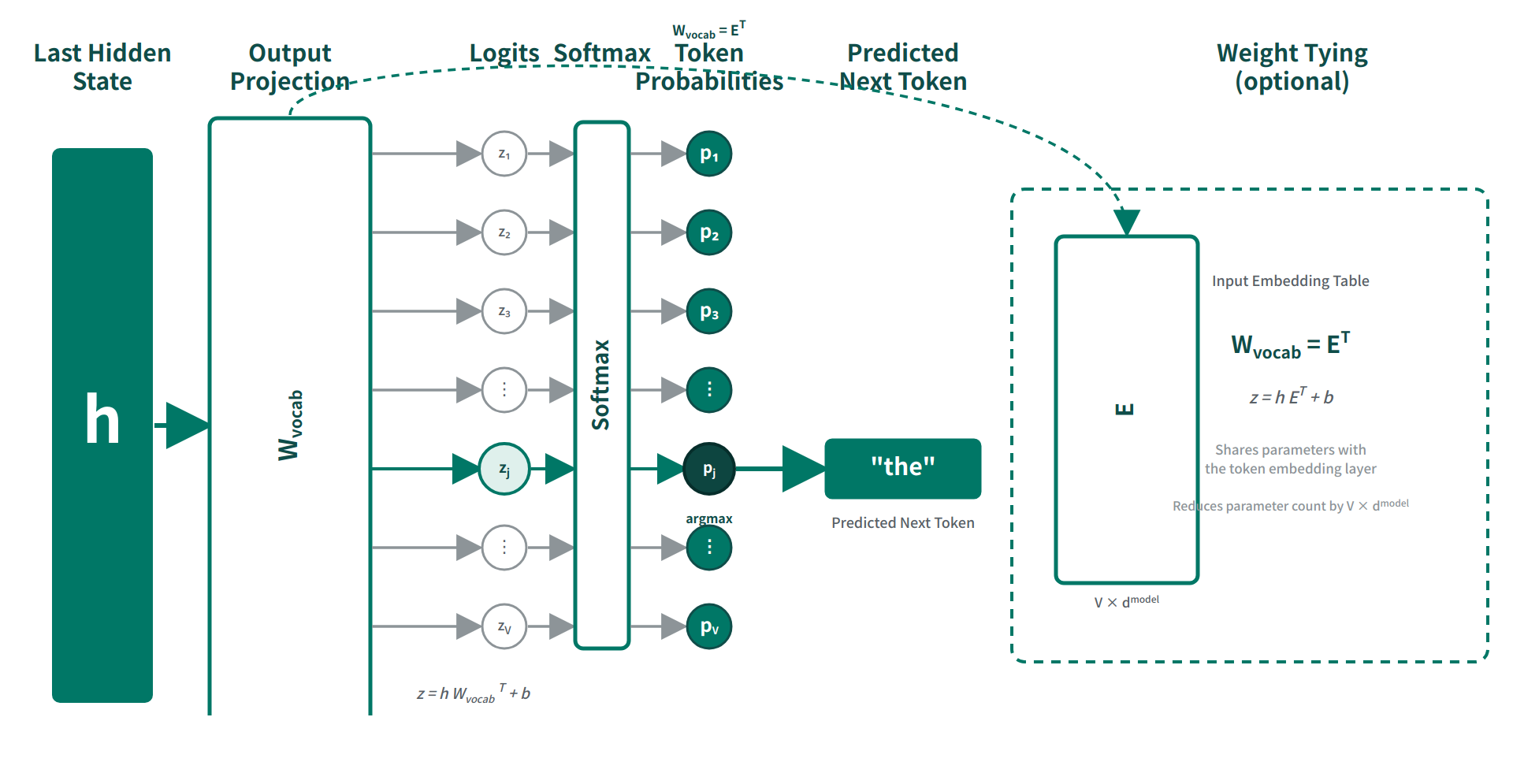
\[H^{(L)}\in\mathbb{R}^{T\;\times d_{\text{model}}}\]其中 \(L\) 是 Transformer 层数,因此 \(H^{(L)}\) 表示“经过第 \(L\) 层之后得到的隐藏状态矩阵”; \(T\) 是当前序列的 token 数,所以这个矩阵一共有 \(T\) 行,每一行对应一个位置。若把第 \(t\) 个位置那一行单独记作 \(h_t^{(L)}\),它表示的就是:第 \(t\) 个 token 在通过全部 \(L\) 层、吸收了上下文信息之后得到的最终向量表示。输出处理(Output Processing)的任务,就是把这组隐藏状态映射到具体任务所需的输出空间:可以是词表概率、类别分数、序列标签、起止位置分数,或回归数值。这里常说的读出(Readout),指的就是:主干网络先形成内部表示,再由最后的输出层把这种表示转换成任务空间里的可解释结果。更准确地说,Transformer 主干先产生整段序列的隐藏表示,再由具体任务的输出层决定如何读取这些表示:有的任务会逐位置读出,有的任务只取某个聚合位置;生成任务则在当前前缀对应的隐藏状态基础上,继续决定下一个 token 的输出。
最常见的输出处理是在线性读出(Linear Readout)层中,把 \(d_{\text{model}}\) 维隐藏状态投影到目标维度 \(d_{\text{out}}\)。若按 token 逐位置读出,可写成:
\[Z=HW_{\text{out}}+\mathbf{1}b^\top\]这里 \(H\in\mathbb{R}^{T\;\times d_{\text{model}}}\) 是最后一层隐藏状态; \(W_{\text{out}}\in\mathbb{R}^{d_{\text{model}}\;\times d_{\text{out}}}\) 是输出投影矩阵; \(b\in\mathbb{R}^{d_{\text{out}}}\) 是偏置; \(\mathbf{1}\in\mathbb{R}^{T}\) 是全 1 列向量,用来把同一个偏置加到每个位置; \(Z\in\mathbb{R}^{T\;\times d_{\text{out}}}\) 则是每个位置对应的输出分数。若任务是词表预测,则 \(d_{\text{out}}=V\), \(V\) 是词表大小;若任务是 token 分类,则 \(d_{\text{out}}=C\), \(C\) 是标签类别数。
并非所有任务都对每个 token 独立读出。序列分类常从整段序列中先取一个聚合表示,再做线性映射。例如 BERT 类模型常使用 \([\mathrm{CLS}]\) 位置的隐藏状态 \(h_{\mathrm{CLS}}\),再输出:
\[z=h_{\mathrm{CLS}}W_c+b_c\]其中 \(z\in\mathbb{R}^{C}\) 是整句的类别 logits。跨度抽取(Span Extraction)任务则常对每个位置分别给出“作为起点”和“作为终点”的分数;序列到序列任务中,解码器则对每个时间步读出一个词表分布。
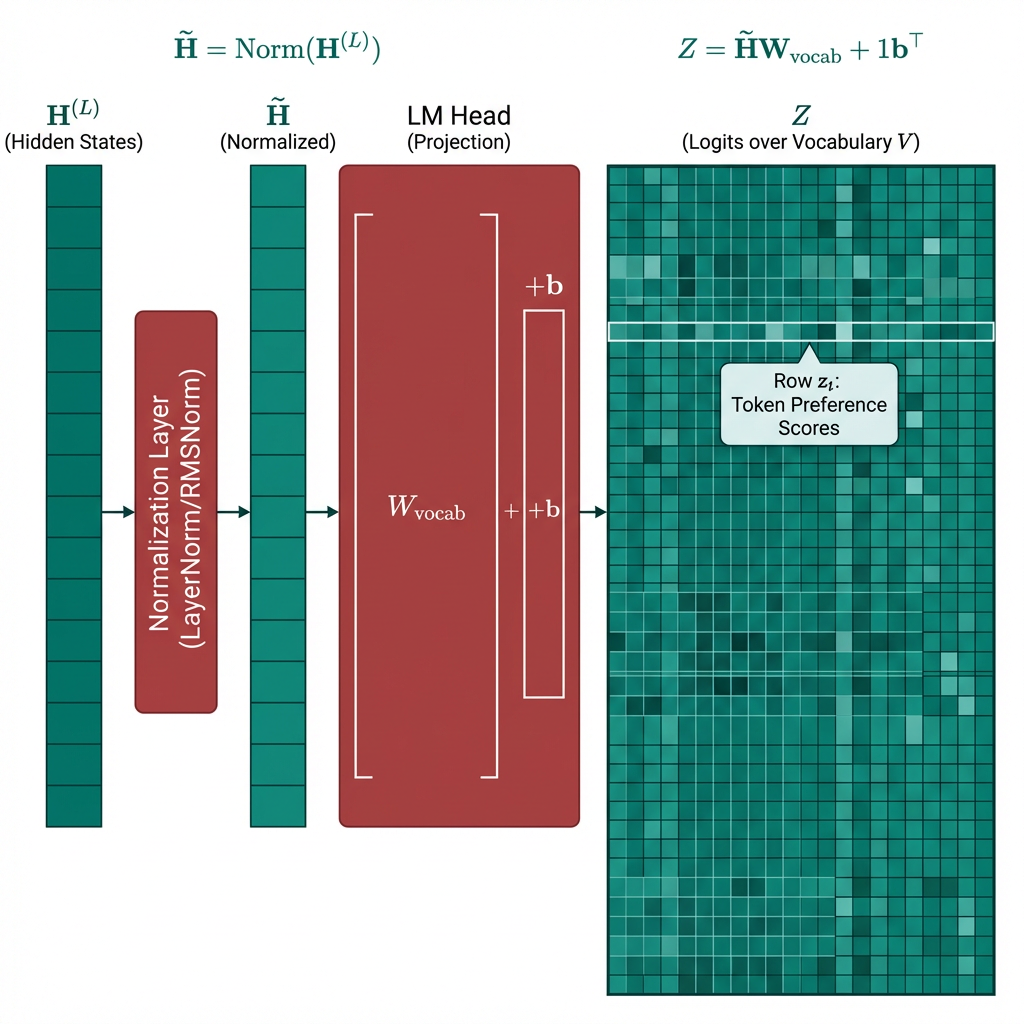
在 Decoder-only 或 Encoder-Decoder 的生成端,输出处理通常还包含最后一次归一化层(如 LayerNorm 或 RMSNorm)以及语言模型头(Language Modeling Head, LM Head)。概念上可写成:
\[\tilde H=\mathrm{Norm}(H^{(L)}),\qquad Z=\tilde H W_{\mathrm{vocab}}+\mathbf{1}b^\top\]这里 \(\tilde H\in\mathbb{R}^{T\;\times d_{\text{model}}}\) 是最终归一化后的隐藏状态; \(W_{\mathrm{vocab}}\in\mathbb{R}^{d_{\text{model}}\;\times V}\) 是词表投影矩阵; \(Z\in\mathbb{R}^{T\;\times V}\) 是每个位置对整个词表的 logits。矩阵第 \(t\) 行 \(z_t\in\mathbb{R}^{V}\) 描述的是:当模型已经看到当前位置之前允许访问的上下文后,当前位置对每个候选 token 的偏好分数。
这里最后再做一次归一化,核心是把“主干内部的表示空间”整理成更适合词表读出的数值形态。Transformer 主干中的隐藏状态一路沿着残差流(Residual Stream)传播,虽然语义信息已经形成,但向量整体尺度仍可能随着层数、上下文和激活模式发生波动。若直接把 \(H^{(L)}\) 送入 \(W_{\mathrm{vocab}}\),这些尺度变化会被直接放大到 logits 上,使 softmax 有时过尖、有时过平,输出分布与梯度都更难稳定。
最后一次归一化的作用,是在进入词表空间之前先把隐藏状态重新放回一个稳定坐标系里:一方面减弱“幅值忽大忽小”对 logits 的直接干扰,另一方面让 LM Head 更专注于“当前表示朝哪个语义方向更接近某个 token”,而非过度依赖向量长度本身。换言之,主干网络负责把内容表示出来,最后的归一化负责把这种内容整理到一个尺度可控、便于读出的状态,再交给 \(W_{\mathrm{vocab}}\) 做最终投影。这也是许多现代 Decoder-only 大模型会在输出头前保留一层 LayerNorm 或 RMSNorm 的原因。
语言模型里常把输入嵌入表 \(E\in\mathbb{R}^{V\;\times d_{\text{model}}}\) 与输出头权重绑定为同一组参数。若不共享,输出头通常写成 \(W_{\mathrm{vocab}}\in\mathbb{R}^{d_{\text{model}}\;\times V}\);若共享,则直接令
\[W_{\mathrm{vocab}}=E^\top\]这核心是让同一个参数矩阵在前向计算的两个位置重复使用:输入阶段按 token id 取出 \(E\) 的某一行作为该 token 的嵌入;输出阶段则把隐藏状态 \(h\) 与所有 token 向量做点积,得到整张词表的 logits:
\[z=hE^\top+b\]这里 \(z\in\mathbb{R}^{V}\),第 \(i\) 个分量 \(z_i=h\cdot E_i+b_i\) 表示当前隐藏状态 \(h\) 与第 \(i\) 个 token 向量 \(E_i\) 的匹配分数。输入嵌入回答“这个 token 进来时长什么样”,输出头回答“当前语境最像词表里的哪个 token”;Weight Tying 让这两种词向量语义共用同一个坐标系。
这里共享的是参数。训练时,这张矩阵同时接收两类梯度:一类来自输入查表路径,更新当前 batch 真正出现过的 token 行;另一类来自输出 softmax 路径,推动隐藏状态与目标 token 更接近、与竞争 token 拉开。自动求导会把这两部分梯度加到同一份参数上,形成联合更新。因此它通常能减少参数量、增强输入与输出语义空间的一致性,并起到一定正则化(Regularization)作用。
只有在输入嵌入维度与输出读出维度一致时,这种共享才最直接。若模型在读出前额外引入了投影层,使输出维度不再等于 \(d_{\text{model}}\),则需要先做维度变换,或不共享。Weight Tying 因此是常见做法,但并非所有架构都必须采用的硬规则。
输出处理的最后一步,是把 logits 变成任务可用的结果。训练时,很多损失函数会直接接收 logits,例如交叉熵损失(Cross-Entropy Loss)内部会把 softmax 与负对数似然(Negative Log-Likelihood)合并计算,以提高数值稳定性。推理时,则通常再做显式后处理:分类任务对 logits 做 softmax 或 sigmoid 得到概率;序列标注任务可在 logits 之上接 CRF 解码;生成任务则对词表 logits 做 softmax 后,再通过贪心搜索(Greedy Decoding)、束搜索(Beam Search)、Top-k 采样或 Top-p 采样等策略选择下一个 token。
以生成任务为例,若当前位置的词表 logits 为 \(z_t\in\mathbb{R}^{V}\),则先得到条件分布:
\[p(x_{t+1}=i\mid x_{\le t})=\frac{e^{z_{t,i}}}{\sum_{j=1}^{V}e^{z_{t,j}}}\]这里 \(V\) 是词表大小, \(z_{t,i}\) 是第 \(t\) 个位置对第 \(i\) 个候选 token 的 logit, \(p(x_{t+1}=i\mid x_{\le t})\) 则是在当前前缀 \(x_{\le t}\) 下,下一个 token 取第 \(i\) 个词的概率。解码策略的区别,不在于 logits 或 softmax 公式不同,而在于:拿到这组概率之后,究竟用什么规则选出真正输出的 token。
贪心搜索(Greedy Decoding)是最直接的策略:每一步都选当前概率最大的那个 token。写成公式,就是
\[x_{t+1}=\arg\max_{i} \ p(x_{t+1}=i\mid x_{\le t})\]它的优点是速度快、实现简单、结果确定;缺点是过于短视。因为它每一步都只看“眼前概率最高”,而不考虑“当前稍差一点、但后续整体更优”的路径。于是贪心搜索很容易陷入局部最优:第一步看起来最稳的选择,不一定能导向整句概率最好的结果。
直觉上,它像每到路口都选眼前最宽的一条路,而不回头评估整条路线是否更通畅。因此贪心适合需要稳定、低延迟输出的场景,但在开放生成任务里往往较保守,也更容易重复。
束搜索(Beam Search)是在每一步同时保留多个高分候选前缀,而非像贪心那样只保留 1 条路径。设束宽(Beam Width)为 \(B\),则在第 \(t\) 步,算法会维护 \(B\) 条当前最优候选序列;每条序列再向外扩展多个 token,最后从所有扩展结果中重新筛出新的 \(B\) 条最高分路径继续前进。
若一条候选序列为 \(x_{1:T}\),其常见打分方式是对数概率和:
\[\mathrm{score}(x_{1:T})=\sum_{t=1}^{T}\log p(x_t\mid x_{<t})\]因为概率连乘会非常小,所以实现里通常比较对数概率之和,而非直接比较概率乘积。有时还会加长度惩罚(Length Penalty),避免模型系统性偏爱过短序列。
束搜索的优点是全局性比贪心更强,常用于机器翻译、摘要等更强调整体序列质量的任务;缺点是计算量更高,而且它本质上仍是“找高分路径”的搜索,不会主动引入随机性,因此输出可能仍然偏保守、偏模板化。
Top-k 采样(Top-k Sampling)先把概率最高的 \(k\) 个 token 保留下来,其余 token 概率全部截断为 0,然后在这 \(k\) 个候选里重新归一化并随机采样。设保留下来的候选集合为 \(\mathcal{K}_k\),则采样分布可写成:
\[p_k(i)= \begin{cases} \frac{p_i}{\sum_{j\in \mathcal{K}_k}p_j}, & i\in \mathcal{K}_k\\ 0, & i\notin \mathcal{K}_k \end{cases}\]这里 \(p_i\) 是 softmax 后原始概率, \(\mathcal{K}_k\) 是当前概率最高的 \(k\) 个 token 集合。这样做的效果是:极小概率的长尾 token 不再参与抽样,从而降低胡言乱语或离谱跳转的风险;同时又保留了随机性,不会像贪心那样永远输出同一条路径。
Top-k 的关键超参数是 \(k\)。 \(k\) 太小,分布会重新变得接近贪心; \(k\) 太大,又会把很多低质量候选放回来。它本质上是在“稳定性”和“多样性”之间做硬截断式折中。
Top-p 采样(Top-p Sampling, Nucleus Sampling)先按概率从高到低排序,不固定保留多少个 token,再取最小的前缀集合 \(\mathcal{N}_p\),使其累计概率至少达到阈值 \(p\):
\[\sum_{i\in \mathcal{N}_p} p_i \ge p\]然后只在这个“概率核心区”里重新归一化并随机采样。与 Top-k 相比,Top-p 的保留集合大小是动态变化的:如果当前分布非常尖锐,可能只需要少数几个 token 就能覆盖 90% 或 95% 的概率质量;如果当前分布较平,保留下来的 token 数量就会自动增多。
这种自适应机制更贴合语言生成的实际状态:有些位置模型非常确定,例如固定短语或语法闭合,此时候选空间本来就应很小;有些位置模型不那么确定,例如开放内容展开,此时候选空间应更大。Top-p 因而通常比固定的 Top-k 更灵活,也是现代大模型推理中非常常见的采样策略。
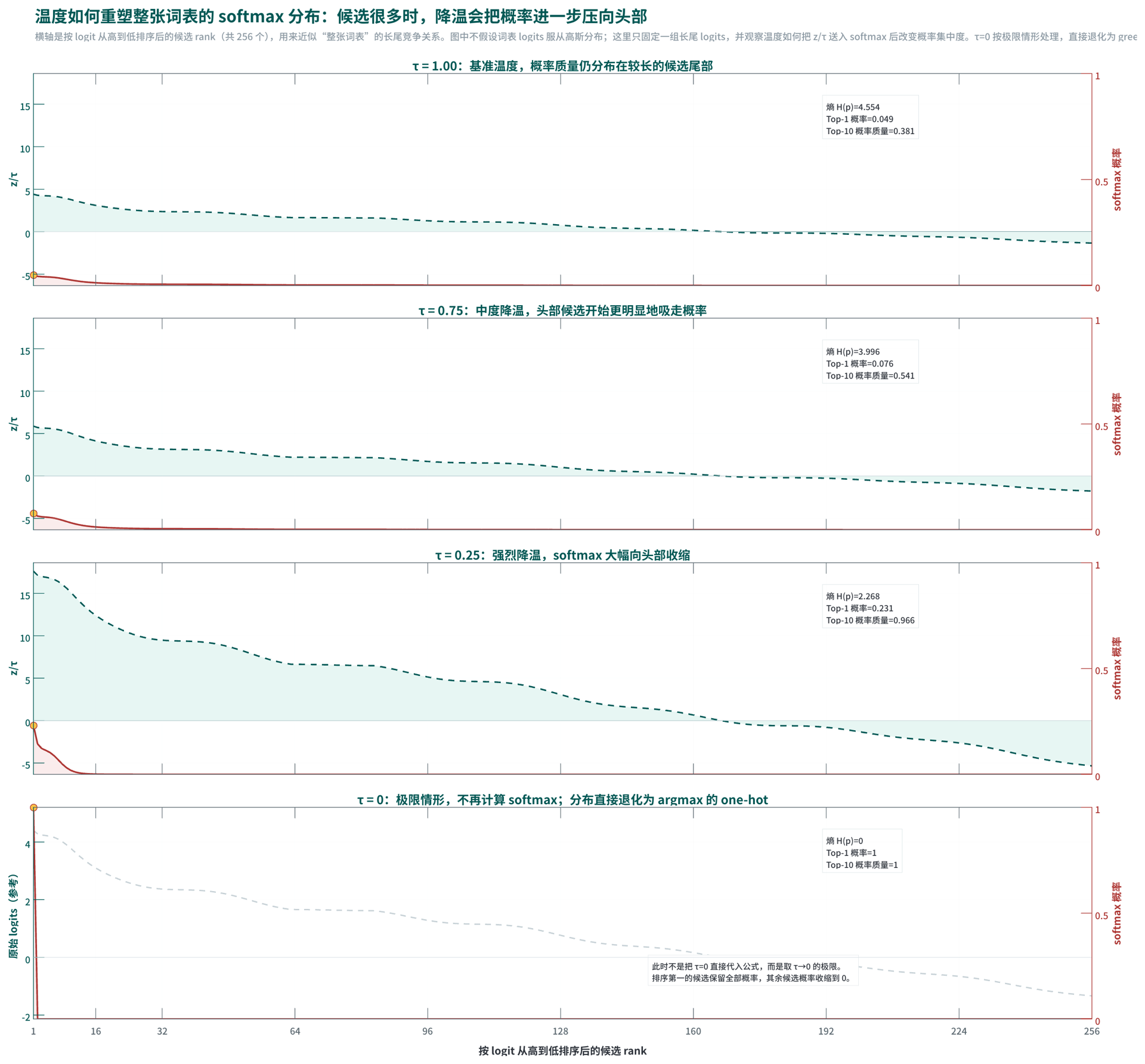
温度(Temperature)常与上述采样策略配合使用。若把 logits \(z_{t,i}\) 除以温度 \(\tau\) 后再做 softmax,则有:
\[p_\tau(i)=\frac{e^{z_{t,i}/\tau}}{\sum_{j=1}^{V}e^{z_{t,j}/\tau}}\]当 \(\tau<1\) 时,分布会变尖,模型更保守;当 \(\tau>1\) 时,分布会变平,采样更发散。于是,解码策略的工程取舍可以概括为:
- 贪心搜索:最快、最稳定,但最短视。
- 束搜索:更重视整句高分路径,但计算更贵、表达更保守。
- Top-k 采样:固定候选数,简单直接,易于控制长尾噪声。
- Top-p 采样:候选数自适应,通常更自然、更适合开放生成。
当温度设为 \(0\) 时,工程语境里通常就是把系统推向“只取当前最大概率 token”的极限,也就是接近贪心解码(Greedy Decoding)。若模型权重固定、算子实现固定、数值计算路径也完全固定,这种解码理论上应当是确定的;同一输入会得到同一输出。但在线推理系统里,结果仍可能出现轻微不一致,因为真实部署环境常包含非确定性来源(Non-determinism),例如并行归约时浮点加法顺序不同、不同硬件或 kernel 实现带来微小数值差异,以及服务端动态调度、缓存策略或批处理拼接方式改变了底层执行路径。
因此,\(\text{temperature}=0\) 只能说明“解码策略本身不再主动引入随机采样”,并不自动等于“整条推理链路绝对确定”。若业务确实需要强确定性,工程上通常还要同时满足几件事:禁用 Top-k、Top-p 等采样选项,固定随机种子(Seed)(若框架支持),并尽量启用确定性计算(Deterministic Kernels)或等价的确定性执行模式。温度控制的是分布如何被取样,强确定性还取决于数值计算路径是否也被锁死。
仅靠解码策略本身,往往还不足以避免模型进入重复、啰嗦或机械回环的状态。例如开放生成时,模型可能连续输出相同短语,或不断在几个近义表达之间打转。工程上因此常在 logits 层再加入一类后处理规则:对已经出现过的 token 施加惩罚,从而改变下一步的候选分布。
最常见的一类是重复惩罚(Repetition Penalty)。它的思想很直接:若某个 token 已经在当前上下文中出现过,就下调它再次被选中的倾向。实现细节在不同框架里略有差异,一种常见写法是对已出现 token 的 logit \(z_i\) 施加按符号分段的缩放:
\[z_i'= \begin{cases} z_i / r, & z_i>0\\ z_i \cdot r, & z_i\le 0 \end{cases},\qquad r>1\]这里 \(r\) 是重复惩罚系数。这样处理的目的,是在不破坏 logit 正负号语义的前提下,整体压低“已经出现过的 token 再次被选中”的优势。 \(r\) 越大,惩罚越强;过大则可能把正常重复也压掉,使输出变得生硬。
另一类常见控制项是 presence penalty(出现惩罚)与 frequency penalty(频次惩罚)。它们的共同目标是抑制重复,但力度来源不同:前者只关心“出现过没有”,后者关心“已经出现了多少次”。若原始 logit 为 \(z_i\),token \(i\) 在当前已生成文本中的出现次数为 \(c_i\),则一个常见抽象写法是:
\[z_i' = z_i - \lambda_{\mathrm{pres}}\mathbf{1}[c_i>0] - \lambda_{\mathrm{freq}}c_i\]这里 \(\lambda_{\mathrm{pres}}\) 是 presence penalty 系数, \(\mathbf{1}[c_i>0]\) 是指示函数:只要 token \(i\) 出现过至少一次,就减去一个固定惩罚; \(\lambda_{\mathrm{freq}}\) 是 frequency penalty 系数, \(c_i\) 越大,惩罚越强。因此:
- presence penalty 更像“出现过就提醒一次”,主要鼓励模型换新词、开新话题。
- frequency penalty 更像“出现越多罚越重”,主要抑制机械重复和啰嗦堆叠。
三者的作用位置都在 softmax 之前:先修改 logits,再重新归一化成概率。它们核心是在推理阶段临时改写候选分布。因此,它们更像输出控制器(Output Controller),而非模型能力本身的一部分。
工程上,这些惩罚项通常与温度、Top-k、Top-p 一起调节。若目标是严谨、稳定、少跑偏的回答,常采用较低温度并只施加较轻的重复控制;若目标是创意写作或开放发散,则可能提高温度,同时保留较温和的 presence penalty,鼓励内容展开但避免原句循环。它们解决的核心是模型在已知概率分布下,最终说话风格如何被约束。
因此,Transformer 的“输出”需要分成两个层次理解。主干网络输出的是高维隐藏表示;真正面向任务的可解释结果,来自这些隐藏表示经过归一化、线性读出、概率映射与解码后的最终读出。输出处理连接了通用表示学习与具体任务目标,是 Transformer 从“会表示”走向“会预测、会生成、会决策”的最后一跳。
语言模型(Language Model)是对自然语言序列概率分布进行建模的模型。给定一段上下文,它学习并估计后续词元(token)或整个序列出现的概率,从而捕捉语言中的词法、语法、语义以及长程依赖结构。现代语言模型通常由参数化神经网络实现,其本质是把语言规律压缩进一个可计算的概率模型中。
从严格定义看,语言模型处理的对象是有顺序的 token 序列,而非无序词集合。若把一句话写成 \(x_1,x_2,\dots,x_T\),语言模型的核心任务就是为这段序列分配概率;等价地,它也可以被看成在每一步根据已有上下文估计下一个 token 的条件概率。
\[p(x_1,\dots,x_T)=\prod_{t=1}^{T}p(x_t\mid x_1,\dots,x_{t-1})\]这一定义说明了为什么语言模型天然关心词序、上下文依赖与条件生成。无论后续采用 n-gram 统计模型还是 Transformer,本质上都在近似这类序列概率分布。
这里的分词(Tokenization)指的是:把原始文本切分成模型实际处理的 token 序列,并据此映射到词表(Vocabulary)中的离散 id。它服务于语言模型建模本身,决定模型看到的基本单位是什么。
这与全文检索(Full-text Retrieval)里的“分词”并非同一个概念。检索系统里的分词更强调索引构建、倒排表匹配与查询召回;语言模型里的 tokenization 更强调如何把文本编码成适合训练与推理的离散序列。一个 token 不一定等于自然语言里的“词”,它也可能是子词、单字、标点、空格片段,甚至字节。更具体的 tokenizer 类型与工程差异,见 Transformers 部分的 Tokenization 小节。
词袋模型(Bag of Words, BoW)本质上只做一件事:统计一段文本里各个词出现了多少次,或只记录它是否出现。它把文本表示成词表上的计数向量 \(\mathbf{c}\in\mathbb{R}^{|\mathcal{V}|}\),其中每一维对应某个词的出现次数。除了这些词频统计之外,BoW 不保留任何顺序信息,也不建模句法结构、上下文依赖或条件概率。
因此,BoW 严格说核心是一种早期文本表示方法。它常与朴素贝叶斯(Naive Bayes)、逻辑回归(Logistic Regression)或 TF-IDF 一起用于文本分类、检索和主题分析。它的重要性在于:它展示了“先把文本映射成向量,再交给下游模型处理”的经典思路;但由于它仅仅统计词是否出现以及出现次数,无法区分“我喜欢你”和“你喜欢我”这类序列差异,也不能承担现代语言模型那种条件生成任务。
词嵌入(Word Embedding)把每个词映射到一个低维稠密向量。与 BoW 的计数统计不同,词嵌入从把每个词看成彼此独立的离散符号转向让共现模式或语义相近的词在向量空间里彼此接近。Word2Vec、GloVe 和 FastText 都属于这一类方法。
经典词嵌入通常是静态的:同一个词在任何上下文里共享同一个向量。以 bank 为例,在 open a bank account 中它指银行,在 sit on the river bank 中它指河岸;传统词嵌入一般仍会给它同一组参数,因此无法在表示层直接区分这两种词义。这也是后来上下文化表示(Contextual Representation)变得重要的原因。
句子嵌入(Sentence Embedding)进一步把整句或整段文本表示为一个向量。它关注的对象从单词层面的局部语义转向整个输入的综合语义,常用于分类、检索、匹配与聚类。
历史上,基于循环神经网络(Recurrent Neural Network, RNN)的序列到序列模型(Sequence-to-Sequence, Seq2Seq)曾经采用“先编码成一个固定长度向量,再由解码器生成输出”的路径。Sutskever、Vinyals 和 Le 在 2014 年提出的 Seq2Seq 工作,就用深层 LSTM 把输入序列压缩为固定维度向量;这种单向量压缩在长句上容易形成信息瓶颈,而 RNN 本身的串行计算方式也限制了并行效率,并使长程依赖建模变得困难。Bahdanau、Cho 和 Bengio 在 2014 年提出的注意力机制(Attention Mechanism)开始缓解这一问题:解码器在每一步都能直接参考输入序列的不同位置,而不必把整句信息全部压缩进单一向量中。
真正的结构转折点来自 2017 年的 Attention Is All You Need。这篇论文提出了 Transformer 架构,用自注意力(Self-Attention)替代 RNN 的递归路径,使模型更擅长并行训练,也更有效地建模长距离依赖。当前主流句子嵌入方法,通常都建立在 Transformer 之上:无论是编码单句得到表示的 Encoder-only 模型,还是用于检索的双编码器(Bi-Encoder)结构,如 SBERT、E5、BGE 和 text-embedding 系列,都属于这一路线的延伸。
从表示形式看,无论词嵌入还是句子嵌入,本质上都属于稠密向量:用较低维的实值向量承载词、句子或文档的信息。向量的每一维从直接对应某个具体词转向由训练过程自动学习得到;因此,模型可以把共现模式、语义相似性以及部分上下文规律压缩进连续向量空间。
这也是后文嵌入模型(Embedding Model)、Word2Vec、Sentence-BERT 和 text-embedding 系列的共同基础。它们的差异在于:表示对象是词、句子还是文档,训练目标是预测上下文、对比学习还是任务特化微调;但核心思想一致,都是让语义结构在向量空间中变得可计算。
上述内容回答的是“文本如何被表示”。回到语言模型本身,还需要进一步区分模型究竟在学什么、输出什么、内部结构如何组织,以及它在工程系统中承担什么角色。
理解语言模型时,至少需要区分四个互相独立但彼此关联的维度:第一,模型在预训练时学的是什么;第二,模型最终主要输出什么;第三,模型内部的信息流结构如何组织;第四,模型在工程上是通用基座、指令对齐模型,还是任务特定模型。它们回答的是四个不同问题,因此一个模型完全可以同时拥有多重身份。例如,BERT 可以同时被描述为“掩码语言模型(Masked Language Model, MLM)+ 表示模型(Representation Model)+ Encoder-only 模型”;GPT / Qwen / LLaMA 则通常是“自回归语言模型(Autoregressive Language Model)+ 生成模型(Generative Model)+ Decoder-only 模型”。
| 分类维度 | 它回答的问题 | 典型类别 |
| 按预训练目标 | 模型在预训练阶段究竟被要求预测什么 | 掩码语言模型、自回归语言模型、替换检测、去噪重建 |
| 按输出与用途 | 模型最终主要产出向量、表示还是可直接生成的文本 | 嵌入模型、表示模型、生成模型 |
| 按架构信息流 | 模型内部如何读取上下文、如何组织编码与生成 | Encoder-only、Decoder-only、Encoder–Decoder |
| 按工程形态 | 模型在实际系统里扮演什么角色 | 通用预训练基座、指令对齐模型、任务特定模型 |
按预训练目标分类,关注的是模型在大规模无标注文本上被要求完成什么自监督任务。这一维决定了模型最初学会的信息组织方式,但不直接等价于它最终能做什么任务。最经典的两类是掩码语言模型与自回归语言模型。
| 类别 | 核心训练目标 | 上下文可见性 | 典型模型 | 更常见优势 |
| 掩码语言模型(MLM) | 遮住部分 token,再根据其余上下文恢复被遮住内容 | 通常可双向看左右文 | BERT、RoBERTa、DeBERTa | 表示学习强;适合理解、分类、匹配、序列标注 |
| 自回归语言模型(CLM / ARLM) | 根据前文预测下一个 token | 因果约束,只看历史上下文 | GPT、LLaMA、Qwen、Mistral | 生成自然;统一接口强;适合对话、续写、代码生成 |
两者的差异首先体现在条件概率分解方式上。自回归语言模型直接建模整段文本的联合概率:
\[p(x_1,\dots,x_T)=\prod_{t=1}^{T}p(x_t\mid x_{<t})\]这里 \(x_t\) 是第 \(t\) 个 token, \(x_{<t}\) 表示它之前所有 token;模型在第 \(t\) 步输出的是“下一个 token 的词表分布”。掩码语言模型则核心是在输入中随机挑出若干位置 \(M\) 做遮蔽,训练目标可写成:
\[\max \sum_{i\in M}\log p(x_i\mid x_{\setminus M})\]其中 \(M\) 是被遮住的位置集合, \(x_{\setminus M}\) 表示其余未遮住 token。它学到的是“给定上下文,如何恢复缺失信息”,而非“如何一步步把整段文本续写出来”。因此,MLM 天然更偏表示学习;ARLM 天然更偏生成建模。
这一维并不只有两类。ELECTRA 的替换检测(Replaced Token Detection, RTD)不直接恢复 mask,通常会判断 token 是否被替换;T5、BART 的去噪重建(Denoising Reconstruction)则通过破坏输入再让模型恢复原文。因此,“掩码 vs 自回归”是最核心的一条主线,但并非全部可能性。
按输出与用途分类,关注的是模型最终主要产出什么,以及这些产出在工程系统里被如何使用。这里最容易混淆的是“嵌入模型”和“表示模型”。两者都能产出向量,但优化目标和默认使用方式并不相同。
| 类别 | 主要输出 | 优化重点 | 典型用途 | 典型代表 |
| 嵌入模型(Embedding Model) | 固定维度向量 | 让语义相近样本在向量空间里更近 | 检索、聚类、召回、语义匹配 | Word2Vec、SBERT、BGE、E5、text-embedding 系列 |
| 表示模型(Representation Model) | 上下文化隐藏表示 | 学到可迁移的中间表示,再交给任务头读出 | 分类、序列标注、匹配、判别式 NLU | BERT、RoBERTa、DeBERTa、ModernBERT |
| 生成模型(Generative Model) | 逐步生成的 token 分布与文本序列 | 最大化生成质量、上下文延续性与指令跟随能力 | 对话、写作、摘要、翻译、代码生成、结构化输出 | GPT、Qwen、LLaMA、T5、BART |
嵌入模型的关键特征是:它的向量空间本身就是最终产品。用户真正拿来用的是向量之间的距离、余弦相似度或最近邻结构。表示模型则更像通用特征提取器:它输出的隐藏状态通常还要再接一个任务头(Task Head)或额外池化层,才能变成分类分数、序列标签或其他任务结果。生成模型的最终输出则是一个条件词表分布,经过解码后形成文本或结构化序列。
同一底座模型有时可以被改造成不同用途。例如,BERT 原本是表示模型,但经过对比学习和专门池化后可以变成句向量嵌入模型;Decoder-only 大模型原本是生成模型,但也可以通过取隐藏状态做 embedding。不过从默认训练目标与最强项看,这三类仍然应当区分。
按架构分类,关注的是模型内部如何读取上下文,以及输入和输出是如何在网络中流动的。这一维对应的是结构设计,而非预训练目标本身。
| 架构类别 | 信息流特征 | 注意力方式 | 典型任务 | 典型代表 |
| Encoder-only | 把输入编码成上下文化表示,不直接负责逐步生成 | 通常是双向自注意力 | 分类、检索、匹配、序列标注 | BERT、RoBERTa、DeBERTa、ELECTRA |
| Decoder-only | 按时间步自回归地产生输出 | 因果自注意力 | 对话、续写、代码生成、开放式问答 | GPT、LLaMA、Qwen、Mistral、DeepSeek |
| Encoder–Decoder | 先编码输入,再由解码器条件生成输出 | 编码器双向自注意力 + 解码器因果自注意力 + 交叉注意力 | 翻译、摘要、改写、条件生成 | T5、BART |
这一维与前两维经常联动,但并非一一对应。Encoder-only 模型常与 MLM 或 RTD 结合,Decoder-only 模型常与自回归目标结合,Encoder–Decoder 模型则常与去噪或条件生成目标结合;但它们分别回答的是“结构长什么样”和“训练时学什么”的两个不同问题。
在工程落地中,还需要区分模型处于哪种产品化形态。通用预训练基座(Base Model)强调语言知识与可迁移能力;指令对齐模型(Instruction-tuned Model)强调遵循人类指令、对话风格与格式约束;任务特定模型(Task-specific Model)则围绕某个明确监督目标继续微调,并常配合专门任务头工作。
| 工程形态 | 核心特点 | 适合场景 | 典型例子 |
| 通用预训练基座 | 保留通用语言知识,强调可迁移性与再训练空间 | 继续预训练、SFT、LoRA、蒸馏 | BERT base、LLaMA base、Qwen base |
| 指令对齐模型 | 通过指令微调与偏好优化提升对话和任务遵循能力 | 问答助手、Agent、工具调用、结构化生成 | ChatGPT 类、Qwen-Instruct、LLaMA-Instruct |
| 任务特定模型 | 围绕明确任务输出继续微调,并常接专门任务头 | NER、分类、匹配、排序、信息抽取 | DeBERTa-CRF、BERT 分类器、LLM + PEFT |
把四个维度合在一起看,模型的定位会变得清晰得多:
- BERT:更接近 MLM + 表示模型 + Encoder-only + 常作为任务特定模型底座。
- SBERT 或 BGE:更接近 表示 / 对比学习 + 嵌入模型 + 常为双编码检索结构。
- GPT / Qwen / LLaMA:更接近 自回归 + 生成模型 + Decoder-only + 常见指令对齐形态。
- T5 / BART:更接近 去噪或 text-to-text 目标 + 生成模型 + Encoder–Decoder。
到 2026 年,表示型语言模型(Representation Model)的工程格局已经明显分成两条主线。第一条是以 Encoder-only 为核心的判别式表示模型,主要服务于分类、自然语言推断(Natural Language Inference, NLI)、命名实体识别(Named Entity Recognition, NER)、抽取式问答等理解任务;第二条是专门为句向量、检索、聚类和召回设计的嵌入模型。前者仍沿着 BERT 家族演化,后者则越来越多地直接采用 BGE、E5、Qwen3-Embedding、jina-embeddings 这类专门路线。因此,讨论“更好的表示模型”时,必须先区分目标到底是任务头微调,还是直接产出高质量向量表示。
BERT(Bidirectional Encoder Representations from Transformers)是典型的 Encoder-only 模型:用双向注意力做表示学习,预训练目标以掩码语言建模(Masked Language Modeling, MLM)为主。原始 BERT 还包含下一句预测(Next Sentence Prediction, NSP)任务:输入通常写成句段 A [SEP] 句段 B,模型需要根据最终的 [CLS] 表示判断 B 是否真的是 A 在原语料中的下一句,而非随机抽来的另一句。与 Word2Vec 常见的负采样训练不同,BERT 的核心预训练是在被遮住的位置上直接做词表预测;而 NSP 则为句级判别额外提供了一条监督路径。输入序列开头通常会加入一个特殊的 [CLS] token,用来聚合整段输入的信息;经过编码后,这个位置的输出隐藏状态常被当作整个序列的语义摘要,并接到分类头上用于文本分类、自然语言推断(NLI)等下游任务。
但这里必须把两件事分开。 [CLS] 很适合做任务读出位置(readout position),却不天然等于“最好的通用句向量”。它之所以能被拿来接分类头,首先是因为它在结构上位于序列最前面,经过每一层双向自注意力后,都可以从整句其它 token 汇聚信息;其次是因为原始 BERT 的预训练里确实给过它专门监督:在下一句预测(Next Sentence Prediction, NSP)任务中,最终的分类就是直接读 [CLS] 的输出隐藏状态,再接一个二分类头。也就是说, [CLS] 从一开始就被当成“适合给任务头读取”的位置来训练。正因为如此,原始 BERT 的 [CLS] 既是首位置隐藏状态,也是被句级判别任务直接塑形过的读出接口。
不过, [CLS] 的训练目标并非“把整句压缩成一个适合做余弦相似度的几何向量”。在 MLM(Masked Language Modeling)中,直接受监督的是被 mask 的 token 位置,而非整句的句向量质量; [CLS] 只会通过多层自注意力间接参与这些预测。在 NSP 里,它学到的是“这一对句子是否连续”这种特定判别目标,而非“语义相近的句子在向量空间中应彼此靠近”。因此, [CLS] 更像是为分类器准备的汇总接口,而非为检索、聚类或最近邻搜索专门对齐过的句表示。
这也是它不能自然代替显式池化(Explicit Pooling)的根本原因。显式池化会把所有 token 的隐藏状态用平均、最大值或加权汇聚的方式整合成句向量,例如平均池化可写成
\[e(x)=\frac{1}{n}\sum_{i=1}^{n} h_i\]这里每个 token 的最终表示都会直接进入句向量构造过程;而 [CLS] 路线则把整句压缩任务隐含地交给某一个特殊位置去完成,相当于要求模型把所有句级信息都写入单个状态向量中。对分类任务,这种单点读出通常足够,因为后面还有任务头继续适配;但对通用句嵌入,这种“单位置承担全部汇总”的方式往往不如显式池化稳定,也更容易受到预训练目标偏置的影响。
从几何上看,这个差异会进一步表现为表示各向异性(Anisotropy):原始 BERT 的 [CLS] 向量常常集中在高维空间的少数主方向上,不同句子的向量分布会显得过于拥挤,余弦相似度缺乏足够区分度。显式池化本身并不能自动解决所有问题,但它至少把“句向量由哪些 token 共同构成”这件事写成了可控、透明的操作;一旦再叠加 Sentence-BERT 这类句对监督或对比学习目标,模型就会直接围绕池化后的句向量去优化距离结构,而非依赖 [CLS] 在预训练阶段顺带形成的间接汇总能力。
BERT 以及其他表示型语言模型通常先在海量通用语料上做预训练,从而学到词法模式、句法结构、语义关系以及一定程度的世界知识。正因为这些知识并非为某一个具体任务单独学习出来的,它们非常适合作为通用特征提取器(General-purpose Feature Extractor):在迁移学习框架下,只需接上分类头、序列标注头或匹配头,并在目标任务数据上继续微调,就可以把通用表示快速适配到具体自然语言处理任务。
BERT系列“是否支持中文”关键在词表与分词器(Tokenizer)。英文 BERT-base 的 WordPiece 词表主要覆盖英文子词;对中文文本可能会大量落到 \([\mathrm{UNK}]\) 或被切成极碎片段,效果通常不理想。要做中文任务更常用中文 BERT、mBERT(multilingual BERT)或以 SentencePiece 为主的多语模型。
RoBERTa(Robustly Optimized BERT Approach)延续 BERT 的 Encoder-only 架构,但通过更大规模数据与训练配方改进(例如更长训练、更大 batch、动态 masking、移除或弱化 NSP 等)显著提升表示质量。它的工程意义在于:在不改变基本架构的前提下,训练细节足以带来可观收益。
RoBERTa 证明了一个重要事实:Encoder-only 模型的性能上限,不完全取决于“是否换了新架构”,训练数据规模、batch 策略、masking 方式和目标设计本身就足以显著改变表示质量。
chinese-roberta-wwm-ext 是哈工大-讯飞联合实验室(HFL)推出的中文 RoBERTa 路线基座之一,定位上属于典型的 BERT-base 量级 Encoder-only 中文判别式底座。它延续了中文 BERT 全词掩码(Whole Word Masking, WWM)路线,并采用 RoBERTa 风格的训练配方改进,例如去掉 NSP、延长训练与强化 MLM 训练过程。它与后续的 Chinese MacBERT、Chinese ELECTRA 等中文预训练模型位于同一条中文 Encoder 演化谱系中。
从工程历史看,它是 2020 年前后到 2022 年中文 NLU 的事实标准之一:社区验证充分,微调范式成熟,适配文本分类、句对匹配、自然语言推断(Natural Language Inference, NLI)与命名实体识别(Named Entity Recognition, NER)都非常稳定。到 2026 年,这个模型的优势仍然清晰存在:中文语料预训练充分、生态成熟、部署经验丰富、对中小规模监督数据通常相当稳健。它特别适合作为中文闭集理解任务的经典强基线,用于给新模型或新训练策略提供可复现、低风险的比较参考。
它的局限也同样明确。架构主体仍然停留在 BERT-base 时代:上下文长度通常围绕 512 token,长文档处理能力有限;注意力与推理路径没有吸收长上下文时代的高效实现;分词与词表路线也仍属于较早一代中文 Encoder 设计。因此,若把它放到 2025-2026 年的主流表示模型谱系里,更准确的定位是成熟、稳定、中文友好的经典底座,而非长上下文或现代高吞吐判别式编码器的前沿代表。
替代方案的选择应按目标分层。若目标仍是中文单语分类、NER、句对匹配,且优先级是稳定微调与成熟生态,那么继续使用 chinese-roberta-wwm-ext 完全合理;若希望在保持中文专训路线的同时提高整体效果,HFL 自己后续的 MacBERT 往往是更自然的同谱系升级方向。若目标转向更强的跨语言迁移、更新的判别式结构或更大的英文生态复用,则 DeBERTa-V3 / mDeBERTa-V3 一类底座通常更接近 2026 年的主流高质量选择。若任务明显受制于长输入、长文档分类或现代推理吞吐,则 ModernBERT 这类原生 8K 上下文的现代编码器会更有吸引力;但这类模型主要按英文与代码语料设计,直接替换到中文任务上并不自动保证优于中文专训底座,最终仍需以具体任务与中文语料上的微调结果为准。
围绕 chinese-roberta-wwm-ext 做替换时,更有效的比较方式核心是先判断替换发生在同一参数量级,还是直接切换到更大规模 encoder。两类替换的收益来源、工程代价和失败模式并不相同。
| 模型 | 优势 | 劣势 |
| Chinese ModernBERT-base | 22 层、词级 BPE 词表、RoPE、8192 上下文、现代 bf16 推理路径 | 在某些 MIL 架构中文任务里,直接替换 base encoder 的收益可能并不明显;瓶颈未必在 encoder 本身 |
| MacBERT(hfl/chinese-macbert-base) | 用近义词替代 [MASK],缓解预训练与微调之间的目标落差;是中文 BERT / RoBERTa 谱系里最自然的升级点之一 | 上下文长度通常仍限于 512 token;长文档场景帮助有限 |
| PERT(hfl/chinese-pert-base) | 基于排列式预训练,对语序敏感任务有潜在优势 | 社区采用度、教程与工程生态都弱于 RoBERTa / MacBERT |
| Chinese ELECTRA(hfl/chinese-electra-180g-base) | 判别式预训练效率高,在分类与 NER 任务上常有竞争力 | 长文本仍受 512 左右上下文限制;与中文 RoBERTa 相比迁移收益取决于具体任务 |
这一层的替换更像是在相近预算内调整预训练目标、词表与工程实现。收益通常来自更合适的中文训练配方或更现代的编码实现,而非简单的“参数更多”。若现有系统已经有成熟的特征聚合层、样本构造策略或 MIL 结构,encoder 升级未必自动转化成同幅度任务收益。
| 模型 | 规模 | 更适合的场景 |
| hfl/chinese-roberta-wwm-ext-large | 约 325M,24 层 | 推理资源允许、且任务确实受语义表达上限约束时,直接切到 large 版往往比横向换同级 base 更容易获得稳定增益 |
| Chinese ModernBERT-large | 约 395M,更深且原生长上下文 | 长上下文分类、长文档理解、需要更强语义建模且能接受显著更高推理成本的场景 |
若任务真正受限于表达容量而非训练配方,扩大 encoder 往往比在多个 base 模型之间横向切换更容易带来可见提升。代价也非常直接:显存、延迟、吞吐和微调稳定性压力都会同步上升。因此 large 路线适合作为“资源换上限”的升级,而非默认替代。
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)仍属于 Encoder-only 模型,但它不再让主模型只做“把被遮住的词猜出来”的掩码语言建模(Masked Language Modeling, MLM)。它先用一个较小的生成器替换部分 token,再让主模型判断每个位置上的 token 是原词还是替换词,这就是替换检测(Replaced Token Detection, RTD)。这种训练方式让模型几乎在每个 token 上都获得监督信号,因此在相近预训练预算下通常比纯 MLM 更高效。
DeBERTa(Decoding-enhanced BERT with Disentangled Attention)可以看作对 BERT / RoBERTa 的一次结构级强化。它仍然是典型的判别式 Encoder-only 语言模型,因此特别适合文本分类、自然语言推断(Natural Language Inference, NLI)、命名实体识别(Named Entity Recognition, NER)和情感分析等理解类任务;但它直接对注意力机制本身做了精细改造,而不满足于只靠“更大数据、更长训练”来变强。
它最核心的突破是解耦注意力(Disentangled Attention)。在传统 BERT 中,词的内容信息与位置信息通常会较早融合;DeBERTa 则把“这个 token 是什么”和“这个 token 在哪里”分开处理。对位置 \(i\) 与 \(j\) 的注意力打分,可直观写成三部分:
\[A_{i,j}=\underbrace{C_iC_j^\top}_{\text{内容-内容}}+\underbrace{C_iP_{j|i}^\top}_{\text{内容-相对位置}}+\underbrace{P_{i|j}C_j^\top}_{\text{相对位置-内容}}\]其中 \(C_i\) 表示第 \(i\) 个位置的内容表示(Content Representation),\(P_{j|i}\) 和 \(P_{i|j}\) 表示相对位置表示(Relative Position Representation)。这个拆分的意义在于:模型不必把“词义”和“位置”混成一个整体再去匹配,而可以更精细地学习“哪个内容会关注什么位置关系”。对于短语修饰、依存关系和实体边界判定这类任务,这种改造往往更有利。
DeBERTa 的第二个关键设计是增强型掩码解码器(Enhanced Mask Decoder, EMD)。它的动机是:相对位置固然重要,但在掩码预测时,绝对位置有时也能提供额外信息。因此 DeBERTa 在接近输出端的位置再次显式注入绝对位置信息,让模型在做 MLM 预测时同时利用相对与绝对位置信号。这相当于在保持主体编码过程解耦的前提下,在最后的“读答案”阶段补上一层位置提醒。
从工程结果看,DeBERTa 长期是判别式 NLU 的强基线之一。它的重要性不只在于“分数更高”,还在于它说明了一个事实:Encoder-only 模型的上限不只是由数据和算力决定,内容表示、位置表示和解码方式本身的结构设计也会显著影响表示质量。后续的 DeBERTa-V3 又把替换检测(RTD)这类更高效的预训练目标引入进来,进一步改善了训练效率与效果,使其在很多精细理解任务里依然保持很强竞争力。
ModernBERT 代表的是 BERT 风格双向编码器在 2025 年之后的一次现代化重写。它仍然属于 Encoder-only,但从停留在 2018 年 BERT 的上下文长度、注意力实现和推理路径上转向把长上下文支持与现代高效实现直接纳入底座设计。其官方模型卡给出的关键信息包括:预训练规模达到 2T tokens,原生上下文长度扩展到 8192 token,并引入 RoPE、本地-全局交替注意力(Local-Global Alternating Attention)、unpadding 和 Flash Attention 等现代工程机制。
与原始 BERT 还有一个重要区别在于 [CLS] 的默认训练来源。ModernBERT 官方定位是纯粹的掩码语言模型(Masked Language Model, MLM):预训练时默认存在的是 MLM head,而非像原始 BERT 那样再额外叠加 NSP 这种句级二分类目标。这意味着 ModernBERT 的 [CLS] 主要是作为首位置隐藏状态在 MLM 路线下间接形成的可读出表示,而非被预训练阶段的句级分类任务直接塑形过的“现成分类接口”。因此,ModernBERT 当然仍然适合做分类,但更准确的理解应是:它提供了一个现代化、长上下文、可高效微调的编码底座;真正的分类头通常仍要在下游任务里显式接上并训练出来。
这类改造的意义非常直接。传统 BERT 家族最舒服的输入长度通常仍停留在几百 token 到一两千 token 量级,而 ModernBERT 这一路则把长文档分类、长文本检索、代码检索和大段上下文理解一并纳入可用范围。于是,在英文或以英文 / 代码为主的判别式任务里,ModernBERT 往往比 DeBERTa-V3 更接近 2026 年的默认新基线;DeBERTa-V3 仍然是高质量经典强基线,但 ModernBERT 明显更符合当前对长上下文与吞吐效率的要求。
它的交替局部-全局注意力也进一步改变了人们对 [CLS] 的直觉。经典 BERT 可以把 [CLS] 看成每层都在做全局汇总的位置;ModernBERT 则只在周期性的全局层里进行真正的全局信息混合,局部层更强调效率与长序列处理能力。因此,把 ModernBERT 的 [CLS] 直接理解成“天然全局句向量”会更加不准确;它更像一个可被下游读取的首位置表示,而非默认就已经为通用句嵌入优化好的几何向量。
多语表示模型的选型逻辑与英文单语场景并不完全相同。XLM-R(XLM-RoBERTa)仍然是经典多语 Encoder-only 基线之一:其预训练覆盖 100 种语言,核心价值是把多语文本映射到共享表示空间,再用于序列分类、序列标注和问答等下游任务。mDeBERTa-V3 则把 DeBERTa-V3 的结构与训练目标迁移到多语场景,在跨语言自然语言推断等零样本迁移任务上,相比 XLM-R-base 给出更强的官方基线结果。因此,若目标是稳定、成熟、适合任务头微调的多语编码器,XLM-R 与 mDeBERTa-V3 依然是 2026 年非常现实的主流选择。
更前沿的一支则沿着 ModernBERT 的方向继续推进。2025 年发布的 mmBERT 直接把 ModernBERT 的现代编码器路线扩展到大规模多语场景,官方介绍强调其训练覆盖 3T 以上 token 和 1800 多种语言,并把它定位为首个在性能和速度上同时明显超过 XLM-R 的新一代多语编码器。这说明多语表示学习也正在从“经典 XLM-R 世代”向“ModernBERT 世代”迁移,只是就生态成熟度与工程复用性而言,XLM-R / mDeBERTa-V3 仍然更稳,mmBERT 更像下一阶段的高端新底座。
| 模型 | 架构 | 预训练目标 | 特点 | 常见用途 |
| BERT | Encoder-only | MLM(+ NSP 变体) | 经典通用基线;生态成熟 | 分类、匹配、序列标注 |
| RoBERTa | Encoder-only | MLM | 更强训练配方;经典英文 NLU 强基线 | 理解类任务强基线 |
| chinese-roberta-wwm-ext | 中文 Encoder-only | MLM(WWM;RoBERTa 风格训练) | 经典中文 NLU 强基线;生态成熟;微调稳定 | 中文分类、句对任务、NER、NLI |
| ELECTRA | Encoder-only | 替换检测(Replaced Token Detection) | 训练效率高;对小算力友好 | 理解类任务、低成本预训练 |
| DeBERTa-V3 | Encoder-only | MLM / RTD | 解耦注意力 + 更高效预训练;经典高精度 NLU 底座 | 高精度 NLU、NER、文本分类 |
| ModernBERT | Encoder-only | MLM | 2T tokens 预训练、8192 上下文、现代高效实现 | 长文档分类、长文本理解、代码检索、现代英文编码任务 |
| XLM-R | 多语 Encoder-only | MLM | 100 语言经典共享表示空间;多语生态成熟 | 多语分类、NER、问答、跨语言迁移 |
| mDeBERTa-V3 | 多语 Encoder-only | MLM / RTD | DeBERTa-V3 的多语延伸;零样本迁移更强 | 多语 NLU、多语分类、跨语言推断 |
| Qwen3-Embedding / BGE-M3 / multilingual-e5 / jina-embeddings-v3 | 专用表示模型 | 对比学习 / 指令化检索 / 检索特化目标 | 直接优化向量空间质量,而非以任务头分类为首要目标 | 语义检索、聚类、召回、RAG、跨语言匹配 |
因此,到 2026 年若任务是分类、序列标注、NLI 或抽取式问答,主流候选通常已经变成 DeBERTa-V3、ModernBERT,以及多语场景下的 XLM-R / mDeBERTa-V3。若任务明确是中文单语理解, chinese-roberta-wwm-ext 仍然是值得保留的经典强基线,只是它在架构代际上已经偏老,更适合承担“稳健基准”而非“前沿默认底座”的角色。若任务本质上是检索、聚类、向量召回或 RAG,则应直接转向后文的主流嵌入模型,而非继续把通用 Encoder-only 分类底座当作最优句向量来源。
GPT 系列是典型 Decoder-only:以 CLM(自回归 next-token)为主目标,把各种任务统一为“续写”。工程上其优势来自统一接口与强 in-context learning;代价是推理成本高(尤其长上下文与高并发场景)。
LLaMA 系列是开源 Decoder-only 基座的重要代表,强调稳定的训练配方与生态可用性(tokenizer、推理支持、微调社区)。它常作为“可控、可复现”的研究/工程基线,用于 SFT、LoRA、RAG 与本地部署。
Qwen 系列同属开源 Decoder-only 生态,中文与多语言能力通常更受关注;在工具调用、代码与多模态等方向也有较多衍生版本。工程上,它常被用作中文业务与多语言场景的基座候选。
Mistral 系列强调“更高性价比的推理与训练”:通过架构与工程优化在相近成本下获得更强的生成质量与吞吐表现,常见于高并发推理与轻量级部署场景。
DeepSeek 系列更强调训练与推理效率的极致:在注意力 KV 压缩、稀疏结构(MoE)与训练目标(如 Multi-Token Prediction)等方向探索更激进的工程取舍,目标是在同等算力预算下提升有效容量与上下文能力。
若从 block 级结构看,DeepSeek V4 的主干把三条路线绑在同一层里协同工作,远超“普通 Transformer 换一个注意力模块”:CSA / HCA 负责注意力,mHC 负责多路残差混合,DeepSeekMoE 负责前馈容量扩展。一层的阅读顺序可以概括为:输入 token 先进入 embedding;随后经过 mHC 的 Pre-Block Mixing,把多路残差流混合后送入当前 block;注意力子层再按层使用 CSA 或 HCA;其输出经过 Residual Mixing 写回残差主路;接着通过 Post-Block Mixing 送入 DeepSeekMoE;MoE 输出再写回主干,进入下一层。V4 的每个 Transformer block 内部实际上是“混合注意力 + 流形约束残差 + 稀疏 MoE”的三件套,不由单一算子主导全层行为。
这也解释了 CSA 与 HCA “如何交替堆叠”这个问题。它们核心是 block 内部的注意力实现位。某一层装配的是 CSA,这一层就更偏向“压缩后召回重点块”;某一层装配的是 HCA,这一层就更偏向“极粗粒度地扫全局背景”。而同一层前后的 mHC mixing 与 DeepSeekMoE 保持不变,于是模型能够在同一主干框架里,让不同层承担不同的阅读粒度,同时继续依靠统一的残差主路和稀疏专家容量维持深层表达。
在训练端,DeepSeek V4 也并非只在最后接一个普通 LM Head。其顶层除标准语言模型损失外,还叠加了多 token 预测(Multi-Token Prediction, MTP)这一辅助监督信号。于是从整体上看,V4 的设计是四层联动的:注意力层解决百万上下文,mHC 解决深层稳定性,MoE 解决有效容量,MTP 解决训练信号密度。也正因为这几部分是一起设计的,DeepSeek V4 不能被简单归类成“只是 MLA 的延伸”或“只是更大的 MoE 模型”。
| 家族 | 定位 | 常见优势 | 常见代价 |
| LLaMA | 稳健开源基座 | 生态成熟;微调与推理支持广 | 配置与版本较多,需选对上下文/推理配方 |
| Qwen | 多语言/中文友好基座 | 中文场景覆盖好;衍生模型多 | 需关注 tokenizer/指令对齐数据分布 |
| Mistral | 高性价比推理 | 吞吐与质量兼顾;工程落地友好 | 不同版本/配方差异会影响最佳实践 |
| DeepSeek | 效率优先(MoE/压缩) | 在算力/显存约束下追求更强能力 | 架构复杂度更高;推理与部署依赖实现细节 |
Word2Vec 用一个简单的自监督目标(Self-supervised Objective)学习词向量(Word Embeddings):监督信号来自文本的共现上下文(Context),而非人工标签。
它可以理解为学习两个嵌入表:输入词向量 \(V\in\mathbb{R}^{|{\cal V}|\times d}\) 与输出词向量 \(U\in\mathbb{R}^{|{\cal V}|\times d}\)(\(|{\cal V}|\) 为词表大小)。训练结束后,常用 \(V\)(或 \((V+U)/2\))作为词向量。
Word2Vec 有两种经典训练方式:CBOW(Continuous Bag of Words)根据上下文预测中心词,Skip-gram 则根据中心词预测上下文。二者的预测方向相反,但都利用局部共现关系学习词向量。下面以 Skip-gram 为例说明它最核心的训练机制。
Word2Vec 的样本核心是通过滑动窗口(Sliding Window)在语料上自动生成。设窗口半径为 \(m\),当滑动窗口扫到位置 \(t\) 时,中心词 \(x_t\) 会与它左右 \(m\) 个位置内的上下文词组成正样本对;越靠近句首句尾,可用上下文自然会变少。对单个中心词,Skip-gram 的局部目标可写成:
\[\sum_{-m\le j\le m,\ j\ne 0}\log p(x_{t+j}\mid x_t)\]这意味着:窗口每向前滑动一步,模型就把“中心词与邻近词共同出现”当作新的监督信号。CBOW 则反过来,把窗口内多个上下文词聚合起来预测中心词;但两者的训练样本都来自同一套滑动窗口机制。
在 Skip-gram 中,给定中心词(center word)\(w_c\),预测窗口内的上下文词(context word)\(w_o\)。若用 full softmax:
\[p(w_o|w_c)=\frac{\exp\left(u_{w_o}^\top v_{w_c}\right)}{\sum_{w\in{\cal V}}\exp\left(u_{w}^\top v_{w_c}\right)}\]如果保留这个完整 softmax,模型会被迫在整个词表上做归一化比较;真实上下文概率升高时,其他词的概率就必须相应下降。但如果改成更便宜的“只学习哪些词对是真的”而又只提供正样本,模型就会立刻出现投机空间:它完全可以把几乎所有词对都打成高分,因为目标里从来没有人告诉它哪些配对是假的。于是,只基于正样本训练一个二分类式共现目标,最容易学到的往往是“永远预测真”,而非稳定的语义结构。
因此,实践里常用负采样(Negative Sampling):对每个正样本对 \((w_c,w_o)\),再随机采样 \(K\) 个噪声词 \(w_k\),把 \((w_c,w_k)\) 当作负样本,并最大化
\[\log\sigma(u_{w_o}^\top v_{w_c})+\sum_{k=1}^{K}\log\sigma(-u_{w_k}^\top v_{w_c})\]第一项要求真实共现词对的内积更大,第二项要求随机噪声词对的内积更小。这样模型学到的就从“所有词都彼此相似”转向“哪些词在局部上下文里更可能共同出现”。这里的“模型参数”主要就是这些词向量;模型输入通常是 token id(或 one-hot)经查表得到的 \(v_{w_c}\)。
Word2Vec 的负样本通常也不需要过度精心设计。经典做法就是按词频分布的 \(0.75\) 次方做随机采样,让高频词仍然更常被抽到,但不会垄断全部负样本。它的核心目标核心是持续给模型提供足够多的噪声对照,让真实共现和随机拼接之间产生可学习的区分。后来的对比学习常会显式挖掘 hard negatives,但在经典 Word2Vec 里,简单而稳定的随机负采样通常已经足够有效。
GloVe(Global Vectors for Word Representation)用全局共现统计学习词向量:目标是让词向量的内积拟合共现概率(或其对数)。与 Word2Vec 相比,它更强调全局统计的一致性;但二者都属于“静态词向量”(Static Embedding),无法像 Transformer 那样根据上下文动态改变词义表示。
Sentence-BERT(SBERT)是文本嵌入(Text Embedding)中的经典双编码器(Bi-Encoder / Dual Encoder)范式。它与后面的 text-embedding 系列并非两种不同任务;二者都把文本映射为向量,用于相似度计算、检索、聚类与召回。区别主要在于:SBERT 更像一条开源方法路线,而 text-embedding 系列更像近年的通用嵌入模型或 API 产品家族。
在 SBERT 之前,句子嵌入任务通常沿用交叉编码器(Cross-Encoder)+ BERT 的范式实现相似度建模:把两个句子同时输入 Transformer 网络,常见形式是将句子 A 与句子 B 拼接成单个序列,中间用分隔符隔开,然后在原始 BERT 顶部增加分类头或回归头,直接输出这一对句子的相似度分数。这种架构的优势在于两个句子的 token 可以在同一次自注意力计算中充分交互,因此非常擅长做细粒度匹配判断;但它输出的是“句对分数”,而非两个可独立复用的句向量。
这会直接带来大规模计算问题。若要在一个包含 10000 个句子的集合中找出相似度最高的匹配对,交叉编码器原则上需要对几乎所有句对分别做一次联合编码,计算量约为 \(\frac{10000\times 9999}{2}=49{,}995{,}000\) 次前向比较。也就是说,问题规模从“编码 10000 个句子”膨胀成了“编码近五千万个句对”。由于每个候选句子都必须与其他句子重新拼接、重新过一遍 BERT,这类方法几乎无法承担大规模语义检索、聚类或召回的第一阶段计算。SBERT 的关键突破,正是在保留 BERT 语义建模能力的同时,把句子表示改造成可预先编码、可缓存、可直接做余弦相似度比较的独立向量。
因此,SBERT 的核心价值首先体现在计算结构的改变上:它把原本“对句对打分”的问题,改写成“分别编码句子,再比较向量距离”的问题。这样一来,候选句子可以预先编码并缓存,检索阶段只需要做向量相似度计算,而不必让每一对候选都重新经过一次完整的 BERT 联合编码。
它与 Cross-Encoder 的关键差异在于计算结构:
- 双编码器:两个输入分别编码,可离线预计算候选向量,适合大规模检索(ANN)。
- 交叉编码器(Cross-Encoder):把两个输入拼接后一起编码,匹配更精细但无法离线索引,适合重排序(Reranking)。
在结构上,SBERT 的核心是孪生架构(Siamese Architecture):两侧使用一模一样的编码器,参数完全共享,但分别接收一个句子作为输入。训练时,句子对会分别经过这两个共享权重的编码塔,各自得到固定维度的句向量,再基于余弦相似度、三元组损失(Triplet Loss)或对比损失(Contrastive Loss)优化距离关系。共享权重保证了两个句子被投射到同一个表示空间中,因此向量之间的距离才具有可比较性。
SBERT 的训练过程可以拆成两个步骤。第一步是把每个句子单独编码成向量。设句子 \(x=(t_1,\dots,t_n)\),经过共享编码器后得到逐 token 的隐藏状态 \(H=[h_1,\dots,h_n]\);随后用池化(Pooling)把它压缩成句向量 \(e(x)\in\mathbb{R}^d\)。经典实现最常用平均池化:
\[e(x)=\frac{1}{n}\sum_{i=1}^{n} h_i\]有些实现还会继续做 L2 归一化,得到 \(\hat e(x)=e(x)/\|e(x)\|_2\),以便后续直接用余弦相似度比较方向。这里的关键点是:左右两侧核心是同一组参数共享的编码器分别处理句子 A 和句子 B,最终得到 \(\hat e_a\) 与 \(\hat e_b\) 两个可独立复用的句向量。
训练语料的形状也必须与损失函数匹配。最常见的几类数据形式如下:
- 带连续分数的句对:形如 \((x_a,x_b,y)\),其中 \(y\) 是 0 到 1、或 0 到 5 再归一化后的语义相似度分数。这类数据最适合 STS(Semantic Textual Similarity)任务,监督信号核心是“到底有多像”。
- 二元正负句对:形如 \((x_a,x_b,y)\),其中 \(y\in\{0,1\}\)。这里 \(y=1\) 表示复述句、同义问法、相关 query-document 或其它正样本对;\(y=0\) 表示语义无关、错误匹配或人工拒绝的负样本对。
- 检索式正配对:形如 \((q,p)\),只显式给出 query 与其正确匹配的正样本,不单独列出负样本。训练时,通常把同一 batch 中其它 \(p_j\) 当作 \(q_i\) 的负例,这就是批内负样本(In-batch Negatives)的基本数据组织方式。
- 三元组:形如 \((a,p,n)\),其中锚点 \(a\) 与正样本 \(p\) 应靠近,而与负样本 \(n\) 应拉开距离。这类数据天然适合排序与检索,因为它直接表达了“哪个比哪个更相关”。
因此,SBERT 训练并不要求数据必须带精确分数;它既可以吃连续相似度打分,也可以吃正负标签,甚至只需要 query-positive 配对或三元组。真正关键的是,训练样本必须能清楚告诉模型:哪些句子应该靠近,哪些句子应该远离,以及这种关系是绝对打分还是相对排序。
第二步是根据标注关系定义损失。若训练数据给的是连续相似度分数,例如 0 到 1 之间的语义相似度标签 \(y\),最直接的做法是先计算两向量的余弦相似度
\[s(\hat e_a,\hat e_b)=\cos(\hat e_a,\hat e_b)=\frac{\hat e_a^\top \hat e_b}{\|\hat e_a\|_2\|\hat e_b\|_2}\]再让模型输出的相似度逼近人工标签,例如最简单的回归式目标可以写成
\[L=(s(\hat e_a,\hat e_b)-y)^2\]这时,相似句子的标签 \(y\) 更高,损失会推动两向量余弦相似度上升;不相似句子的标签更低,损失则推动相似度下降。原始 SBERT 在 STS(Semantic Textual Similarity)类任务上,常用的正是这种“句对回归到相似度分数”的训练方式。
若训练数据只有二元标签,即“相似”或“不相似”,则更常见的是对比式损失(Contrastive Loss)。设距离 \(d(\hat e_a,\hat e_b)\) 可以取欧氏距离,也可以取 \(1-\cos(\hat e_a,\hat e_b)\),则典型形式为
\[L=y\cdot d(\hat e_a,\hat e_b)^2+(1-y)\cdot \max(0,m-d(\hat e_a,\hat e_b))^2\]其中 \(y=1\) 表示正样本对,损失会逼迫距离变小;\(y=0\) 表示负样本对,损失会要求两句至少相隔一个 margin \(m\)。这就把“相似句子拉近,不相似句子推远”写成了显式几何约束。
若任务更接近检索或召回,现代实践更常用批内负样本(In-batch Negatives)或多负样本排序损失(Multiple Negatives Ranking Loss)。设一个 batch 中第 \(i\) 个查询句子的正样本是 \(p_i\),其余 \(p_j\) 都视为负例,则可写成
\[L_i=-\log \frac{\exp(s(\hat e_{q_i},\hat e_{p_i})/\tau)}{\sum_{j=1}^{B}\exp(s(\hat e_{q_i},\hat e_{p_j})/\tau)}\]其中 \(\tau\) 是温度(Temperature)参数。这个目标直接把同一 batch 里的其它正样本当作自己的负样本,无需显式为每个查询单独准备大量负样本;于是优化方向很清楚:正确配对的句子相似度必须高于 batch 中所有错误配对。许多现代 embedding 模型,包括大量 SBERT 派生模型,都是沿着这条路线训练出来的。
另一类经典形式是三元组损失(Triplet Loss)。它已经从看一对句子扩展到同时给出锚点 \(a\)、正样本 \(p\) 和负样本 \(n\),要求锚点与正样本的距离小于锚点与负样本的距离,且至少留出一个 margin:
\[L=\max\bigl(0,\ d(\hat e_a,\hat e_p)-d(\hat e_a,\hat e_n)+m\bigr)\]它表达的仍然是同一个原则:相似句子靠近,不相似句子远离;只是监督信号从“单对标签”变成了“相对排序关系”。
前文已经提到,原始 BERT 的 [CLS] 表示更适合接分类头,而非直接充当高质量通用句向量;同样地,若未经句向量任务优化就简单平均最后一层表示,效果通常也不理想。SBERT 的关键改动,正是在共享权重的双编码训练框架中,把池化和句对监督显式写入训练过程,使生成出来的 \(e(x)\) 已经从“顺手拿来的中间表示”扩展到被专门优化成适合做余弦相似度、最近邻检索与聚类的句向量。其改进原因之一,正是缓解了原始 BERT 表示的各向异性(Anisotropy)问题:向量不再高度挤在高维空间的少数方向上,余弦相似度也因此更有区分度。
这里也需要区分 Sentence-BERT 与 sentence-transformers。前者更严格地指 2019 年提出的 SBERT 方法路线:在 BERT、RoBERTa 等编码器基础上,通过孪生网络(Siamese Network)/三元组网络(Triplet Network)或后续对比式训练,把原本不适合作为通用句向量的表示空间改造成更适合相似度计算的句向量空间。后者则主要指围绕这一路线发展出来的开源框架与模型生态,用于统一训练、评测、发布和调用各类句向量模型。因此,sentence-transformers 更像 SBERT 方法在工程上的延伸与集合。
从工程角度看,SBERT 仍然有明确实用价值:它特别适合私有化部署、领域微调、本地低延迟语义检索,以及“双编码器召回 + Cross-Encoder 重排”的两阶段检索流水线。它核心是在开源可控、可微调、可离线部署这些约束下依然非常常用。
如果把 SBERT 看作“如何训练和使用句向量”的经典范式,那么 text-embedding 系列代表的就是近年的通用嵌入模型实现。BGE、E5、GTE、OpenAI 的 text-embedding、Cohere Embed 等,本质上都属于同一任务族:生成可用于相似度、检索、聚类、召回的向量表示。它们的主要差异不在“是否属于 embedding”,而在训练数据、模型规模、多语言能力、上下文长度、向量维度压缩策略,以及是开源模型还是托管 API 服务。
通用嵌入模型(General-purpose Embedding Model)的目标通常是“语义相似近、语义无关远”,因此天然适配检索与聚类。也可以把嵌入模型微调成“任务特化嵌入”(Task-specialized Embedding):用监督标签构造正/负样本对(同类为正、异类为负),用对比学习目标把同类拉近、异类推远,然后用最近邻/类原型(Prototype)实现分类。
与“表示模型 + 分类头(Representation Model + Classifier Head)”相比,二者取舍通常是:
- 特化嵌入:推理时只算一次向量 + 相似度,便于大规模检索/多标签扩展;但输出是距离分数,概率校准与细粒度判别能力通常不如专门的分类头。
- 分类头微调:直接最小化分类损失,闭集分类效果与可解释的概率输出更强;但对大规模候选检索不友好,且不同任务往往需要不同 head。
| 类别 | 代表模型/服务 | 特点 | 适用场景 | 备注 |
| 开源通用嵌入(General-purpose) | BGE / E5 / GTE | 部署可控;可做领域微调 | 私有化 RAG;向量检索;聚类 | 选型关注多语言、长度与 license |
| 商用 API 嵌入 | text-embedding-3 / Cohere Embed | 效果稳定;无需运维 | 快速上线;跨团队复用 | 成本与数据合规是主约束 |
| 领域特化嵌入(Task-specialized) | 对比学习微调后的 embedding | 对业务分布拟合更强 | 垂直领域检索;闭集分类 | 需要高质量正/负样本构造 |
| 多向量/late interaction | ColBERT 类 | token-level 匹配更细 | 高精度检索;精排候选压缩 | 索引与存储成本更高 |
T5(Text-to-Text Transfer Transformer)是典型 Encoder–Decoder:把所有任务统一为“文本到文本”的生成问题(text-to-text)。它既可用于摘要、翻译等生成任务,也可用于分类,此时模型直接生成类别名对应的 token 序列。
在预训练阶段,T5采用的是掩码式去噪目标(Denoising Objective),但它核心是会对连续的 token span 做遮掩(Span Corruption)。输入中的若干片段会被替换为哨兵标记(Sentinel Token),模型则在解码端按顺序生成这些被遮住的片段。这样的训练方式既保留了“根据上下文恢复缺失内容”的掩码语言建模思想,又让模型从一开始就以 Encoder–Decoder 的生成方式学习条件重建。
在后续适配阶段,T5 延续了统一的 text-to-text 框架:翻译、摘要、问答、分类等任务都写成文本输入到文本输出的形式。沿着这条路线继续发展后,研究者又引入了更大规模的多任务指令微调(Instruction Tuning):把大量带自然语言任务描述的监督任务混合起来训练,迫使模型学习“读懂任务说明,再按说明生成答案”。FLAN-T5 就是这一路线的代表,即在 T5 底座之上经过 FLAN 指令微调得到的系列模型;它相比原始 T5 更强调零样本(Zero-shot)和少样本(Few-shot)泛化能力。
BART(Bidirectional and Auto-Regressive Transformers)同属 Encoder–Decoder,但预训练更强调去噪自编码(Denoising Autoencoding):对输入做扰动(mask、shuffle、delete 等),让模型恢复原文。它在摘要、生成式改写与条件生成任务上常用作强基线。
| 模型 | 架构 | 预训练直觉 | 强项 |
| T5 | Encoder–Decoder | 统一 text-to-text | 任务统一;文本生成与分类都自然 |
| BART | Encoder–Decoder | 去噪重建 | 摘要与生成式改写强基线 |
任务特定语言模型(Task-specific Language Model)指在通用预训练模型基础上,围绕某个明确监督任务附加任务头(Task Head)并继续微调的模型。常见任务包括句段级分类、token 级序列标注、文本匹配、排序与信息抽取。这里“句段级”指分类对象是一段独立文本,可以是单句,也可以是能够整体输入模型的段落。工程上它核心是“预训练主干 + 任务头 + 对应损失函数”的组合:同样是 BERT、DeBERTa、T5 或大语言模型(Large Language Model, LLM),接什么头、优化什么目标,决定了它最终服务什么任务。
对 BERT 类 Encoder-only 模型,多分类通常采用“句向量 + 线性分类头(Linear Classification Head)”的形式。设句子表示为 \(h\in\mathbb{R}^{d}\),类别数为 \(K\),则分类头输出 logits:
\[z=Wh+b,\quad W\in\mathbb{R}^{K\times d},\quad b\in\mathbb{R}^{K}\]其中 \(h\) 是主干模型抽取出的整句语义表示,常取自 [CLS] 对应隐藏状态或池化结果;\(W\) 把 \(d\) 维表示映射到 \(K\) 个类别;\(b\) 是偏置项;\(z_k\) 是第 \(k\) 类的原始分数(logit)。若需要概率,可再经过 softmax:
\[p(y=k|x)=\frac{e^{z_k}}{\sum_{j=1}^{K}e^{z_j}}\]训练时通常直接把 logits \(z\) 输入交叉熵(Cross-Entropy)损失,softmax 与对数运算一般由损失函数内部完成,以获得更好的数值稳定性;推理时若需要概率分布、阈值决策或置信度排序,再显式做 softmax。实践中还常在分类头前加入 Dropout,以降低小样本场景下的过拟合风险。
命名实体识别(Named Entity Recognition, NER)等 token 级任务的输出结构不同。设序列长度为 \(T\),第 \(t\) 个 token 的隐藏状态为 \(h_t\),则每个位置的标签打分可写成:
\[z_t=Wh_t+b,\quad t=1,\dots,T\]此时分类头从输出“整句一个类别”转向为每个 token 输出一组 BIO / BIOES 标签 logits。若任务更强调标签转移的一致性,还可在 token 分类头后叠加条件随机场(Conditional Random Field, CRF),显式约束标签序列的合法转移。
因此,任务头的输出形式始终取决于任务本身:句子分类输出 \(\mathbb{R}^{K}\) 上的一组 logits,token 分类为每个位置输出一组 logits,匹配/排序任务常输出单个相关性分数,生成任务则在词表维度输出下一 token 的 logits。主干负责提供中间表示(Intermediate Representation),任务头负责把这种表示投影成可直接优化的任务空间。
到 2026 年,任务特定语言模型的工程选型已经稳定分化。对高并发、闭集标签、边界清晰且标注数据相对充足的文本分类与 NER,DeBERTa、ModernBERT 一类 Encoder-only 模型仍然具有极高性价比:延迟低、吞吐高、概率校准更稳、部署成本更可控。若任务明确是中文单语理解, chinese-roberta-wwm-ext 仍然是值得保留的经典稳健基线,MacBERT 则通常是更自然的同路线升级点。这里的输入并不只限于单句;传统 Encoder-only 模型常见有效长度大约在 512 tokens,而较新的长上下文 Encoder-only 模型已经普遍扩展到 8K tokens,因此数百字的段落在 2026 年通常也仍属于可直接处理的范围。对样本极少、语义规则复杂、输出结构开放,或需要“理解 + 生成”一体化的任务,LLM 配合参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)通常更有优势。
在这类 LLM 任务里,LoRA 仍然是默认起点:它最适合指令跟随、风格迁移、格式约束、轻量领域适配等大多数常规需求。若显存是第一约束,QLoRA 往往是最自然的落点;若任务要求更接近全参数微调的表达力,例如深领域知识吸收、复杂推理、困难边界判别或更强的稳定性,则可优先考虑 DoRA 或 Q-DoRA。全参数微调仍然保留在少数高门槛场景:领域迁移极深、训练数据极大,或需要改动词表、上下文长度、位置编码等底层结构时,它仍然提供最高上限。
| 任务形态 | 更常见方案 | 主要原因 | 典型模型 |
| 闭集文本分类 | Encoder-only + 分类头 | 判别边界清晰;推理便宜;概率输出稳定 | BERT / RoBERTa / DeBERTa / ModernBERT |
| 标准 NER / 序列标注 | Encoder-only + token head(可叠加 CRF) | 天然适配 token 级标签;边界学习直接 | BERT-CRF / DeBERTa-CRF |
| 低资源复杂分类 | LLM + LoRA / QLoRA | 预训练知识丰富;少样本泛化强;显存门槛低 | Qwen / Llama / Gemma + LoRA |
| 复杂结构抽取 / JSON 输出 | LLM + PEFT 或指令微调 | 可同时完成理解、抽取、归纳与结构化生成 | Qwen / Llama / Mistral 系列 |
| 高难推理 / 深领域适配 | LLM + DoRA / Q-DoRA | 比普通 LoRA 更接近全参数微调;适合高质量知识注入 | Qwen / Llama + DoRA |
| 极致吞吐线上服务 | LLM 标注或蒸馏,Encoder-only 上线 | 兼顾数据质量、速度与运维成本 | LLM 教师 + DeBERTa 学生 |
| 生成式嵌入 | Decoder-only / Encoder–Decoder 隐藏状态池化 | 复用生成模型语义能力与长上下文能力,将隐藏状态读出为向量 | Qwen / Llama / T5 派生 embedding |
| 检索精排 / RAG 重排 | 基于表示模型的重排:Encoder-only Cross-Encoder + ranking/classification head | 经典精排路线;query 与候选在同一次编码中交互,延迟和成本低于 LLM reranker | BGE Reranker / monoBERT / cross-encoder/ms-marco |
| 复杂语义精排 / 长文档重排 | 基于生成模型的重排:LLM 交叉编码 + 标量打分或 yes/no token 打分 | 更适合复杂指令、长文档、多跳证据和需要语义推理的少量候选 | Qwen Reranker / LLM reranker |
| 超大规模深度迁移 / 底层结构改造 | 全参数微调 | 需要改动表示空间本身,低秩适配容量不足 | 领域基座继续训练或全量 SFT |
工业系统中也常采用混合路线:先用强 LLM 做数据清洗、弱标注、难例发现或标签体系归并,再把任务蒸馏到更轻的 Encoder-only 模型上线。这种做法利用了 LLM 的语义泛化能力,也保留了小模型在延迟、吞吐与稳定性上的优势。
基于生成模型的嵌入(Generative-model-based Embedding)指用 GPT、LLaMA、Qwen、T5 这类生成式主干产生文本向量。计算过程通常不执行开放式解码;系统在一次前向计算中读取模型内部隐藏状态(Hidden States),再经过池化、投影和归一化,把整段输入压缩成可用于检索、聚类、匹配或分类的向量。
设输入文本被 tokenizer 转成 token 序列 \(x=(t_1,\dots,t_T)\),生成模型最后一层输出隐藏状态
\[H=f_\theta(x)=[h_1,\dots,h_T],\quad h_t\in\mathbb{R}^{d}\]其中 \(f_\theta\) 是生成模型主干,\(h_t\) 是第 \(t\) 个 token 在最后一层的上下文化表示,\(d\) 是隐藏维度。嵌入模型不会直接使用完整的 \(H\),而会定义一个池化函数 \(\mathrm{Pool}(\cdot)\):
\[e(x)=\mathrm{Normalize}\left(W_p\cdot \mathrm{Pool}(H)\right)\]这里 \(\mathrm{Pool}(H)\) 可以取最后一个有效 token 的隐藏状态、EOS token 的隐藏状态、attention mask 下的平均池化,或经过专门训练的 pooling head;\(W_p\) 是可选投影矩阵,用于把模型隐藏维度映射到最终向量维度;\(\mathrm{Normalize}(\cdot)\) 通常是 L2 归一化,方便后续用内积或余弦相似度比较。
Decoder-only 模型有一个特殊点:因果注意力让第 \(t\) 个位置只能看见 \(t\) 之前的上下文,因此最后一个有效 token 的隐藏状态往往最自然,因为它已经读取了整段输入的前缀信息。平均池化也可使用,但早期 token 的隐藏状态没有看到后续内容,直接平均会混入“只看过局部前缀”的表示。很多生成式 embedding 路线会通过 EOS pooling、特殊汇聚 token、双向化注意力、对比学习微调或专门 pooling head 来缓解这个问题。
这种路线的价值在于复用生成模型的语义知识、指令理解能力和长上下文能力。对于“给定查询,找出最相关段落”这类任务,可以把 query 写成带任务说明的输入,让模型在隐藏状态中形成“面向当前检索目标”的表示;对于长文档场景,也可以利用生成模型已经扩展过的上下文长度,把更长的段落编码成单个向量。代价同样明确:Decoder-only 主干通常比专门 Encoder embedding 模型更慢,向量质量也依赖 pooling 方式和对比训练目标,不能直接假设任意 LLM 的最后层隐藏状态天然就是高质量句向量。
基于表示模型的重排(Representation-model-based Reranking)是经典的 reranker 路线。这里的“表示模型”主要指 BERT、RoBERTa、DeBERTa、ModernBERT、BGE Reranker 这类以隐藏状态表示为核心产物的 Encoder-only 模型或交叉编码器(Cross-Encoder)。它把 query 与候选文档拼接成同一个输入序列,让两者的 token 在同一次自注意力计算中充分交互,然后读取 \([\mathrm{CLS}]\)、首 token、最后 token 或池化后的隐藏状态,通过一个标量打分头输出相关性分数。
设查询为 \(q\),候选文档为 \(d\)。Cross-Encoder reranker 的输入通常写成:
\[x=[\mathrm{CLS}]\ q\ [\mathrm{SEP}]\ d\ [\mathrm{SEP}]\]模型前向得到隐藏状态矩阵:
\[H=f_\theta(x)=[h_1,\dots,h_T]\]若使用 \([\mathrm{CLS}]\) 表示作为句对表示,则重排分数可以写成:
\[s(q,d)=w^\top h_{\mathrm{CLS}}+b\]其中 \(s(q,d)\) 是 query-document 的相关性分数;\(h_{\mathrm{CLS}}\) 是编码后 \([\mathrm{CLS}]\) 位置的隐藏状态;\(w\) 和 \(b\) 是打分头参数。训练时可以用二分类交叉熵处理相关 / 不相关标签,也可以用 pairwise 或 listwise 排序损失直接优化候选顺序。
这条路线是检索系统里非常成熟的两阶段范式:第一阶段用 BM25、dense embedding 或 hybrid retrieval 快速召回候选;第二阶段用 Cross-Encoder reranker 对 top-k 候选做精排。它比双编码 embedding 更慢,因为每个候选都要和 query 一起前向;但它比生成式 LLM reranker 更轻,通常吞吐更高、延迟更低、训练更直接,适合作为生产 RAG、搜索和问答系统中的默认强基线。
基于表示模型的重排和基于生成模型的重排共享“联合读取 \((q,d)\)”这一思想。差别在于,表示模型 reranker 的输出通常是一个判别式分数,模型主体多为 Encoder-only 架构;生成式 reranker 复用 LLM 的生成主干,可以用 yes/no token、自然语言判断或显式打分头输出相关性。工程选型上,表示模型 reranker 更适合作为成本可控的精排主力;生成式 reranker 更适合复杂指令、长文档、多跳证据或需要强语义推理的少量候选。
基于生成模型的重排(Generative-model-based Reranking)把 query 与候选文档放进同一次模型前向,让生成模型直接判断相关性。它通常用于两阶段检索系统的第二阶段:第一阶段由 BM25、向量检索或混合检索召回几十到几百个候选,第二阶段由更强但更慢的生成模型 reranker 对候选重新排序。
设查询为 \(q\),候选文档为 \(d\)。重排输入通常会被组织成一个明确的判断提示,例如“Query: ... Document: ... 判断文档是否回答查询”。模型前向后得到最后位置隐藏状态 \(h_{\mathrm{end}}\)。若采用显式打分头,可以写成:
\[s(q,d)=w^\top h_{\mathrm{end}}+b\]其中 \(s(q,d)\) 是 query-document 相关性分数,\(w\) 和 \(b\) 是 reranker 新增或微调得到的标量打分参数。训练时可以使用二分类交叉熵,让相关文档得分高、不相关文档得分低;也可以使用 pairwise/listwise 排序损失,让同一 query 下的正例排在难负例之前。
另一种常见做法是利用生成模型原本的 LM Head,把相关性判断改写成极短的生成问题。模型读完 \((q,d)\) 后,只比较下一个 token 是“yes”还是“no”的 logits:
\[P(\mathrm{yes}\mid q,d)=\frac{\exp(z_{\mathrm{yes}})}{\exp(z_{\mathrm{yes}})+\exp(z_{\mathrm{no}})}\]这里 \(z_{\mathrm{yes}}\) 和 \(z_{\mathrm{no}}\) 是模型在下一个 token 位置对 yes/no 两个标签词给出的原始分数。实际系统常把 \(P(\mathrm{yes}\mid q,d)\) 或 \(z_{\mathrm{yes}}-z_{\mathrm{no}}\) 当作重排分数。这个方法依然依赖隐藏状态,因为 token logits 本质上来自 \(h_{\mathrm{end}}\) 经过输出头投影后的词表分布。
生成式 reranker 与 embedding 的核心差异在计算结构。Embedding 模型分别编码 query 和文档,适合离线建索引和大规模召回;reranker 把 query 与文档拼在一起联合编码,token 之间可以在同一次注意力计算中交互,因此更擅长处理细粒度匹配、否定、条件限制、多跳证据和“看起来相似但其实答非所问”的候选。它的代价是每个候选都要单独前向,无法像 embedding 那样提前为所有文档算好一次向量。
推荐系统也经常以“任务特定模型”的方式落地,尤其是在召回(Recall)阶段。若每首歌曲都能通过歌词、标题、风格标签、歌手简介或多模态信息编码成一个向量 \(e_i\),那么系统就可以把用户已经选择、收藏或反复播放的歌曲向量聚合成一个用户兴趣表示 \(u\)。一个最常见的做法是把若干已选歌曲的嵌入做平均或加权平均:
\[u=\frac{1}{N}\sum_{i=1}^{N} e_i\]随后,对候选歌曲 \(s_j\) 计算它与用户兴趣向量的相似度,例如余弦相似度(Cosine Similarity):
\[\mathrm{score}(u,s_j)=\cos(u,e_j)\]得分越高,说明该歌曲与用户已选择歌曲在嵌入空间里越接近,也就越可能在风格、主题、情绪或语义上相似。于是,如果用户最近连续选择了几首节奏轻快、独立流行、以失恋叙事为主题的歌曲,系统就会优先召回在向量空间中靠近这些歌曲的其它曲目,而非只依赖“同歌手”或“同标签”的硬规则。
这类推荐的关键核心是把“用户喜欢什么”和“歌曲像什么”统一表示到同一嵌入空间,再用最近邻搜索完成相似歌曲推荐。工程上它通常对应双塔模型(Two-Tower Model)或文本/多模态嵌入模型:一侧编码用户历史,一侧编码候选歌曲,训练时用点击、收藏、完整播放等行为构造正样本,再配合负采样或对比学习把用户喜欢的歌曲拉近、不感兴趣的歌曲推远。这样得到的推荐结果,本质上是基于语义相关性而非基于精确关键词匹配。
一条常见路线是把 BERT、RoBERTa、DeBERTa 这类表示模型(Representation Model)当作固定特征提取器(Feature Extractor)使用:先用预训练基座把输入文本编码成一个向量表示,再在其上训练一个轻量分类器,而不继续更新基座模型参数。这种做法的重点核心是直接利用其已经学到的通用语义表示。
工程上,一个典型流程是:先冻结(Freeze)BERT 系列底座的全部参数,只保留前向编码功能;然后对每条输入文本提取句级表示 \(h\in\mathbb{R}^{d}\),这个表示可以取自 [CLS] 位置,也可以取池化后的整句向量;最后在 \(h\) 之上训练一个分类器。若用逻辑回归(Logistic Regression)或等价的线性 softmax 分类头,则可写成:
\[z=Wh+b,\quad p(y=k\mid x)=\frac{e^{z_k}}{\sum_{j=1}^{K}e^{z_j}}\]这里 \(W\) 与 \(b\) 是新训练的分类器参数,而 BERT 底座参数保持不变。这样做的优点是训练成本低、显存压力小、过拟合风险更可控,也便于把同一个表示底座复用到多个小任务上。代价是分类边界完全依赖预训练表示的可分性:如果任务与通用语料差距较大,或标签语义非常细,冻结底座通常不如继续微调主干模型灵活。
与此相近的还有基于嵌入模型(Embedding Model)的分类。它的做法更直接:先用 SBERT、BGE、E5、GTE 或 text-embedding 一类嵌入模型,把整段文本映射成一个句向量 \(e(x)\in\mathbb{R}^{d}\);然后直接在这个嵌入向量后面接一个分类器,例如逻辑回归、线性分类器或一个很小的 MLP,学习从嵌入空间到类别空间的映射。
若使用最简单的线性分类器,这条路线在形式上与前面的表示模型分类并没有本质区别,仍然可以写成
\[z=We(x)+b\]不同之处不在“后面接不接分类器”,而在于前面的底座向量是怎么来的:表示模型通常是为理解类任务设计的上下文化表示;嵌入模型则更强调在向量空间中保持语义距离结构,使相似文本彼此接近、不相似文本彼此远离。因此,基于嵌入模型的分类与基于表示模型的分类,主要区别在底座优化目标而非分类头形式。表示模型更偏向判别式理解,输出表示通常更适合直接服务闭集分类、序列标注和细粒度 NLU;嵌入模型更偏向语义检索与相似度结构,优势在于跨任务复用、向量检索兼容性和“分类 + 召回”一体化。
工程上可以把两者概括成一句话:表示模型分类强调“先得到适合判别的表示,再做分类”;嵌入模型分类强调“先得到适合度量的向量,再在其上学习分类边界”。如果任务是标准闭集分类、标签边界清晰、追求最高分类精度,BERT 一类表示模型通常更自然;如果系统本身已经以 embedding 为中心,例如既要分类又要相似检索、聚类、召回或原型匹配,那么直接在嵌入模型后接分类器会更统一,也更容易复用同一套向量基础设施。
嵌入模型(Embedding Model)的另一条典型用途是文本聚类(Text Clustering)。代表性方法如 BERTopic:先用句向量模型把文档映射到嵌入空间,再做降维与聚类,最后从每个簇中抽取代表词或主题词。这里真正决定簇结构的并不只有嵌入模型;降维模型与聚类模型本身仍然是经典机器学习方法。
一个通用流程通常分成三步:
- 使用嵌入模型将文档转换为向量表示,例如把每篇文档编码为 \(e(x_i)\in\mathbb{R}^{d}\)。
- 使用降维模型把高维向量压缩到更适合聚类的低维空间。
- 使用聚类模型在降维后的表示上得到簇标签,或进一步识别离群点。
降维阶段的典型选型是 PCA(Principal Component Analysis)或 UMAP(Uniform Manifold Approximation and Projection)。PCA 是线性方法,适合作为快速、稳定的基线;UMAP 更擅长保留非线性邻域关系与整体簇结构,因此在文本聚类里往往更常见。工程上常把 UMAP 先降到 5 到 10 维,作为后续聚类的默认起点;这个范围通常已经足以保留主要结构,同时明显降低噪声与计算成本。
UMAP 的一些常见设置也会直接影响聚类形状。 min_dist 控制低维空间中点与点允许靠得多近;若把它设为 0,低维表示通常会形成更紧密的簇。距离度量常设为 cosine,因为文本表示在高维空间中更常体现为方向相似性;无论是高维稀疏词向量还是高维稠密嵌入,欧氏距离都容易出现判别力下降的问题。
聚类阶段则常见 K-means 或 HDBSCAN。K-means 适合簇数大致已知、簇形状相对规则的场景;HDBSCAN 更适合密度不均、簇形状复杂,或希望显式识别“不属于任何簇”的离群文档。BERTopic 之所以常见,正是因为它把“嵌入模型 + UMAP + HDBSCAN + 主题表示”这条工程链路封装成了一个相对稳定的默认方案。
基于嵌入模型的主题建模(Topic Modeling)与上一节的聚类路线一脉相承:先把文档映射为向量,再做降维与聚类;不同之处在于,这里还要继续回答“每个簇到底在谈什么”。因此,在聚类结果之上还需要增加一个主题提取(Topic Extraction)步骤,为每个簇生成一组能概括其内容的主题关键词。
这一步的典型做法是 c-TF-IDF(class-based TF-IDF)。它核心是先把同一簇里的所有文档拼接成一个“类别文档”,再统计词在该簇中的相对频率,并结合它在其它簇中的区分度计算权重。于是,一个词若在当前簇中频繁出现、但在其它簇中并不常见,它的 c-TF-IDF 权重就会更高;反之,那些在所有簇里都常见的泛化词,其权重会被压低。这样提取出来的关键词,描述的是“这个簇相对于其它簇最有代表性的内容”,而非“整个语料里最常见的词”。
从工程流程看,这条路线可以写成四步:先用嵌入模型得到文档向量,再用降维与聚类得到簇,随后用向量化器统计每个簇中的词项分布,最后用 c-TF-IDF 为每个簇生成主题词。BERTopic 的核心价值就在于,它把“嵌入模型 + UMAP + HDBSCAN + c-TF-IDF”串成了一个统一框架,因此既保留了 embedding 在语义空间中的表达能力,也保留了词袋统计在主题解释上的可读性。
不过,c-TF-IDF 产出的关键词顺序仍然主要依赖词频统计与类间区分度,语义相关性未必总是最优。于是 BERTopic 又提供了主题表示微调(Representation Tuning)机制:先用 c-TF-IDF 生成候选关键词,再对这些候选词做重新排序。这里最常见的表示模型之一是 KeyBERTInspired。它会先利用 c-TF-IDF 为每个主题挑出一组代表性文档,把这些代表文档聚合成该主题的语义表示,再用与文档编码相同的嵌入模型去计算“候选关键词与主题表示”的语义相似度,最后按相似度重排关键词顺序。在实践中,这种表示方式通常还能进一步压低停用词在最终主题表示中的占比,使主题词列表更干净。
因此,KeyBERTInspired 并非重新做一遍聚类,也并非替代 c-TF-IDF;它更像是在 c-TF-IDF 给出的候选集之上增加一层语义重排序。这样做的结果通常是:靠前的主题词更连贯、停用词和噪声词更少,主题标签也更接近人类对“这个簇在讲什么”的直觉。对 BERTopic 而言,这一步属于主题表示优化,而非主题发现本身。
即便经过上述处理,主题关键词之间仍可能存在明显冗余,例如多个高频近义词反复出现在同一主题里。此时还可以进一步使用最大边际相关性(Maximal Marginal Relevance, MMR)做关键词多样化:它在选择下一个关键词时,同时考虑“该词与主题表示有多相关”以及“该词与已经选中的关键词有多相似”,从而找到一组彼此具有差异性、但仍然和目标文档或主题表示保持相关的关键词。于是,MMR 的作用核心是让最终主题表示更分散、更少重复,也更适合人工阅读与命名。
在此基础上,还可以再走一步:把已经得到的一组主题关键词交给生成模型(Generative Model),例如 FLAN-T5,让模型基于这些关键词生成一个更短、更自然的主题标签或一小段摘要式说明。这样做把“关键词列表”进一步压缩成更适合展示给用户阅读的主题名称。
嵌入模型还可以直接用于零样本分类(Zero-shot Classification)。做法是先把每个候选类别改写成自然语言标签描述,无需训练额外分类器,再把输入文本与这些标签描述同时编码到同一嵌入空间中,通过相似度完成类别判断。若影评任务只有“正面”和“负面”两类,就可以构造两个标签文本,例如“这是一条正面影评”和“这是一条负面影评”,然后分别计算影评向量与两个标签向量的余弦相似度:
\[\mathrm{score}_k=\cos(e(x),e(t_k))\]其中 \(x\) 是待分类影评,\(t_k\) 是第 \(k\) 个类别对应的标签描述。若 \(\mathrm{score}_{\text{positive}}\) 高于 \(\mathrm{score}_{\text{negative}}\),系统就把该影评判为正面评价。这个过程本质上是把分类问题改写为“文本与标签描述谁更接近”的相似度匹配问题。
这条路线的优点是部署快、几乎不需要任务专用标注数据,也不必重新训练分类头;只要标签语义写得足够清晰,就可以立刻在新任务上工作。它的代价同样直接:由于模型并未使用该任务的监督信号显式学习分类边界,零样本分类的准确率通常低于有标注数据时训练出的监督式分类器,尤其在标签定义细、类别边界接近、文本包含反讽或领域术语时更明显。
另一条更轻量的工程路线是基于生成模型(Generative Model)做分类,即直接调用大语言模型(Large Language Model, LLM),通过提示词工程(Prompt Engineering)把分类任务表述为指令,例如要求模型在读完一段文本后只输出“正面”或“负面”。这种做法本质上是把分类看作条件生成:模型先理解输入,再生成最符合提示约束的类别标签。这里的“生成模型”不只包括 Decoder-only LLM;像 T5 这样的 Encoder–Decoder 模型,虽然结构上属于编解码器,也同样可以在不给额外训练的情况下,直接通过输入提示词完成分类,因此在使用方式上也可以视作这一类路线。
它的优点是上手快、改标签体系方便、对少样本或零样本任务尤其灵活;局限是输出稳定性、延迟和成本通常不如专门训练的分类器,而且类别边界是否清晰、提示词是否严格,会明显影响结果一致性。因此,这条路线更适合作为快速原型、弱标注工具或低频复杂任务的分类接口,而非高吞吐、强约束场景下的默认方案。
多模态模型(Multimodal Model)的主线,核心是不同模态如何进入同一套表示、同一套推理链路、同一套训练目标。从技术演进看,这条路线大致经历了四步:先有稳定的单模态编码器,再有跨模态对齐模型,然后发展出“视觉编码器 + 大语言模型”的连接式系统,最后才逐步走向原生多模态(Native Multimodality)。
| 阶段 | 核心做法 | 代表能力 | 主要局限 |
| 单模态编码器 | 分别把图像、文本、音频编码成各自表示 | 分类、检索、单模态理解 | 模态之间没有统一语义空间 |
| 对齐式多模态 | 用对比学习把不同模态映射到同一嵌入空间 | 图文检索、零样本分类 | 生成与复杂推理能力有限 |
| 连接式 VLM | 视觉编码器输出特征,经连接器送入 LLM | 看图问答、视觉对话、OCR 推理 | 融合发生在后端,仍有模态鸿沟 |
| 原生多模态 | 多模态尽量共享表示、主干与训练过程 | 更细粒度的跨模态理解与生成 | 训练成本、数据对齐和系统复杂度都更高 |
ViT(Vision Transformer)本身并非多模态模型,因为它只处理图像,不直接处理文本、语音或视频。它更准确的定位是视觉编码器(Visual Encoder)或视觉骨干网络(Backbone):把原始像素转换成可供下游检索、分类或跨模态建模使用的视觉表示。
ViT 的关键做法是把图像切成固定大小的 patch,再把每个 patch 视作一个视觉 token。每个 patch 先被展平,再经线性投影映射到统一维度的向量空间,最后叠加位置编码送入 Transformer。这样,二维图像就被改写成了一维 token 序列,Transformer 可以像处理文本序列那样处理图像局部块之间的关系。
因此,ViT 的意义不在于“它已经实现了多模态”,而在于它为后续的多模态系统提供了一个稳定、强大的图像侧前端。无论是 CLIP、BLIP-2 还是 LLaVA,一类很常见的路径都是:先让 ViT 之类的视觉编码器把图像变成高层特征,再考虑如何与文本模型对齐或融合。
第一代真正有代表性的多模态突破,核心是先把模态对齐。CLIP(Contrastive Language-Image Pre-training)的核心做法是:图像编码器与文本编码器分别输出向量,再通过对比学习(Contrastive Learning)让匹配的图文对更接近、不匹配的图文对更远离。这样,图像与文本就被压到同一嵌入空间中。
这种路线的价值非常直接。只要图像和文本已经进入同一向量空间,就可以做图文检索、文本检索图片、图片检索文本,以及把类别标签写成自然语言描述来完成零样本分类(Zero-shot Classification)。OpenCLIP 则把这条路线做成了可复现、可扩展的开源基础设施,因此在研究和工程里都比原始 CLIP 更常作为起点。
对齐式多模态的贡献是打通跨模态语义空间。模型开始能够理解“这张图和这段文字在说同一件事”,而不再只是各自做各自的单模态任务。但它的能力边界也很清楚:对齐不同于复杂推理,更不同于自由生成。双编码器模型很擅长相似度匹配,却不天然擅长长链推理、细粒度问答和多轮对话。
因此,对齐式系统更像是在给多模态建模打地基。它先解决“不同模态能否进入同一个语义坐标系”这个问题,再把更复杂的生成与推理问题留给下一阶段的系统去解决。
在多模态系统的下一阶段,重点从“把图文对齐”转向“让大语言模型真正看见图像并围绕图像说话”。这就形成了视觉-语言模型(Vision-Language Model, VLM)的主流范式:视觉编码器负责看图,语言模型负责生成,中间再用一个连接器(Connector / Projector)把二者接起来。
BLIP-2 的方法论非常有代表性。它尽量复用两边已经训练好的单模态模型,而非从零联合训练整个多模态系统:视觉侧使用预训练视觉编码器,语言侧使用预训练大语言模型(Large Language Model, LLM),中间只训练一个较轻量的桥接模块。这样做的目的,是在保留两侧成熟能力的前提下,用较小成本建立跨模态接口。
这个桥接模块在论文中的标准名称是 Q-Former(Querying Transformer)。它通过一组可学习的 query,从视觉编码器输出的图像特征中抽取最适合语言模型消费的信息,再把这些压缩后的视觉表示投影到 LLM 的输入空间。它本质上解决的是“图像特征如何变成语言模型能理解的前缀表示”这个接口问题。
LLaVA(Large Language and Vision Assistant)把这条路线进一步推向“视觉对话”与“视觉指令遵循”。它通常采用视觉编码器提取图像特征,再通过投影层把视觉特征接入语言模型,然后用视觉指令微调(Visual Instruction Tuning)训练模型按图像与文本指令联合回答问题。这样,模型已经从做相似度匹配扩展到可以围绕图像展开问答、描述、解释与推理。
这类系统已经比 CLIP 更接近通用助手,但从结构上看,它仍然属于连接式多模态:图像先由视觉模型单独处理,文本再由语言模型主导生成,融合主要发生在后期接口层,而非从一开始就在统一主干里共同建模。
原生多模态(Native Multimodality)讨论的是多模态是否在模型内部形成统一的信息流。判断重点不在“支持几种输入”,而在输入表示、时间对齐、主干推理、输出链路和训练过程是否都尽量摆脱“先拆开、后拼接”的流水线。当前前沿系统已经把这个问题分成两条路线:一条偏理解与推理,例如 Gemini 与 Qwen Omni;另一条偏生成,例如 Seedance 这类原生音视频生成模型。
工程上,原生多模态通常核心是一组连续特征。系统越是在模型内部统一处理模态,越接近原生;越依赖外部桥接、先转文本再推理、先出文本再外接语音或视频模块,越接近连接式系统。
| 层面 | 连接式系统 | 更原生的系统 |
| 输入表示 | 图像、语音、视频先各自编码,再压缩成少量前缀特征送入 LLM | 多模态 token 或 embedding 直接进入统一上下文,尽量减少外部转译 |
| 时间与空间对齐 | 对齐更多依赖外部模块或后处理 | 在模型内部显式建模时序、位置和跨模态同步关系 |
| 主干推理 | 视觉负责“看”,LLM 负责“说”,中间靠连接器传递摘要 | 不同模态共享更大的隐藏状态流或统一主干,跨模态约束在中间层持续传播 |
| 输出链路 | 文本作为中心中介,再外接 TTS、配音或视频模块 | 直接输出语音 codec、视觉 latent 或联合音视频表示 |
| 训练方式 | 先训单模态,再训桥接层 | 更多采用联合训练、端到端微调或统一后训练流程 |
原生多模态的第一层难点,是把不同模态改写成模型能共同消费的内部对象。图像相对容易,因为静态图像只需要处理二维空间;音频和视频更难,因为它们天然带有时间轴。模型既要知道“看到了什么”,也要知道“什么时候发生”,还要知道多个模态之间是否同步。
因此,当前更先进的系统不只做“把图像变成 token”这一步,还会显式处理跨模态时间对齐。例如在实时音视频交互场景中,视频帧和音频片段必须在同一时间轴上组织,否则模型很难稳定理解口型、说话节奏、环境声音与画面事件之间的对应关系。原生多模态在这里解决的已经核心是跨模态时空对齐。
更进一步的区别出现在主干网络和输出端。连接式 VLM 往往已经能把图像看懂,但输出通常仍然以文本为中心;若要说话,就再接一个语音模块;若要生成视频,再接另一套生成器。原生多模态希望把这条链路收进同一系统,让“理解图像”“围绕图像推理”“输出文本”“输出语音”“生成视频”之间的中间状态尽量共享。
这一步对语音和视频尤其关键。文本生成更多是离散 token 的自回归;自然语音需要兼顾内容、音色、韵律和实时延迟;视频生成则同时要控制空间结构、时间连续性、镜头运动和角色一致性。当前真正具有代表性的原生系统,往往会在输出链路上引入更专门的设计,而非把一切都压成单一路径。
从公开资料看,当前最值得拿来理解原生多模态的代表,大致分成三类:理解优先的长上下文 omni 模型、端到端语音交互模型,以及原生音视频联合生成模型。生成侧里,Seedance 2.0 代表了技术报告完整、控制能力非常强的闭源工业路线;HappyHorse 1.0 则代表了近期受到高度关注的开源路线。
| 代表模型 | 更接近哪类原生能力 | 值得关注的架构点 | 说明了什么 |
| Gemini 1.5 / 2.5 | 理解与推理优先 | 多模态 MoE、超长上下文、视频与音频直接进入同一推理上下文 | 原生多模态可以首先体现在统一感知与统一推理上,而不必先追求所有模态都直接生成 |
| Qwen2.5-Omni / Qwen3-Omni | 实时 omni 交互 | 交错音视频序列、时间对齐位置编码、Thinker-Talker、流式语音生成 | 原生多模态的难点会从“看见图像”转向“实时理解并自然说出来” |
| Seedance 2.0 / HappyHorse 1.0 | 原生音视频联合生成 | 前者强调统一多模态参考与编辑控制;后者强调统一 Transformer、联合音视频生成与开源部署 | 生成侧的原生多模态不仅要出画面,还要同时控制声音、时序同步、镜头连续性与工程可用性 |
Gemini 路线的代表意义,在于它把“原生”首先落在统一感知与统一推理上。Gemini 1.5 技术报告已经把它定义为高效的多模态 MoE 系统,强调可以在百万级上下文中处理长文档、音频和长视频;Gemini 2.5 则进一步把思维链式推理、长上下文和多模态理解合到同一代模型中。这条路线说明:原生多模态并不只等于“模型会出语音或会生成视频”,更重要的是不同模态能否在同一个长上下文里被一起检索、比较、归纳和推理。
Qwen2.5-Omni 和 Qwen3-Omni 展示了另一种更彻底的做法:系统不仅统一感知文本、图像、音频和视频,还直接生成实时语音响应。其关键难点不在“多接几种输入”,而在音视频时间对齐与输出干扰控制。Qwen2.5-Omni 采用交错组织的音视频序列与时间对齐位置编码 TMRoPE,再用 Thinker-Talker 把“负责推理的语言主干”和“负责流式说话的语音输出链路”拆开但端到端协同;Qwen3-Omni 则进一步把这一路线升级到 MoE,并围绕首包延迟和 codec 级语音生成做了更强的流式优化。
生成侧的原生多模态,目标已经核心是直接联合生成视频与音频。ByteDance 在 2026 年 2 月正式发布的 Seedance 2.0,把这一方向推进到更完整的工业化形态:统一的多模态音视频联合生成架构,同时支持文本、图像、音频和视频输入,并把参考、编辑、扩展、镜头控制与音视频同步放进同一系统。它解决的重点,是如何让复杂控制信号真正进入视频生成主干,而非只靠提示词描述一个大概方向。
HappyHorse 1.0 则体现了另一条值得关注的路线:更强调开源可部署与统一 Transformer 架构。公开模型页把它描述为 15B 参数、统一自注意力 Transformer、联合生成视频与同步音频,并突出 1080p、7 语种 lip-sync 和较快推理。和 Seedance 2.0 相比,它当前公开的技术透明度明显更低,缺少完整论文级技术报告,但它的重要性在于:原生音视频生成已经不再只是少数闭源大厂的能力,开源路线也开始逼近前沿体验。
因此,这两类模型放在一起看,技术含义很清楚。Seedance 2.0 更像“高控制度、强参考编辑、面向专业生产工作流”的路线;HappyHorse 更像“统一架构、快速推理、可开源落地”的路线。它们共同说明,视频生成已经从单纯比较单帧画质,转向比较时序稳定性、音视频同步、镜头叙事、可控性与部署形态。
原生多模态的训练与部署成本明显高于连接式系统,原因并不神秘:它要处理的问题本来就更多。连接式 VLM 主要解决“视觉特征如何喂给 LLM”;原生系统还要额外处理时序同步、多模态采样率差异、输出链路异构、流式延迟、模态之间的训练平衡,以及更复杂的安全过滤。
| 难点 | 为什么更难 |
| token / 序列爆炸 | 视频帧、语音片段和高分辨率图像会迅速放大上下文长度,训练和推理的注意力成本明显高于纯文本 |
| 跨模态同步 | 模型需要在内部保持“画面发生了什么”和“声音何时出现”之间的稳定对应,而非事后补对齐 |
| 输出异构 | 文本、语音 codec、视觉 latent 的统计结构不同,统一输出链路远比单一文本解码复杂 |
| 训练配比 | 文本数据规模通常远大于高质量音视频数据,若配比失衡,模型会重新退回“文本中心”的偏态系统 |
| 服务复杂度 | 实时语音和视频生成要求更低延迟、更稳定的缓存和更强的流式调度,远重于普通文本 API |
这也是为什么连接式 VLM 仍然长期存在。它更容易复用成熟视觉编码器与 LLM,训练成本更低,部署链路更稳定。原生多模态代表的是能力上限更高的方向,而非所有场景都必须立即切换到的唯一范式。
图像与视频生成模型可以看作多模态生成的一条重要分支:输入通常是文本、图像或更复杂的条件信号,输出是图像或视频。它们处理的核心是“模型如何把条件约束转成可感知内容”。因此,它们和视觉-语言问答系统同属多模态,但核心目标不同。
DALL-E 与 Imagen 都属于文本到图像(Text-to-Image, T2I)生成路线的代表。工程上更关心的是文本-图像对齐、提示词控制、风格一致性与安全过滤,而非单一的像素级指标。它们的共同点是:都把文本条件作为生成控制信号,让图像生成过程服从语言约束。
Stable Diffusion 则代表开源扩散模型(Diffusion Model)路线。它通常在潜空间(Latent Space)中进行扩散与去噪,再把潜变量解码回图像。它的工程意义尤其大,因为这条路线不仅支持文本生成图像,还容易叠加 LoRA、ControlNet、风格微调与本地部署,因此形成了非常完整的开源工作流生态。
视频生成比图像生成多了一个真正困难的维度:时间。模型不只要把单帧画出来,还要保证人物身份、动作轨迹、镜头运动、物理连续性和叙事节奏在多帧之间保持稳定。因此,视频生成天然更接近原生多模态问题,因为它几乎总要同时处理空间、时间,进一步还可能处理语音、音乐和环境音。
这一方向的前沿已经从“无声文本生视频”继续推进到音视频联合生成。Seedance 2.0 已经把文本、图像、音频和视频都纳入同一个参考与编辑框架,并支持多段素材混合输入、多镜头音视频输出和更稳定的复杂动作场景;这意味着视频模型开始更像“可编排的生成引擎”,而不只是一次性吐出一段短片。HappyHorse 1.0 则把另一条路线推到台前:以统一 Transformer 和开源权重为卖点,把文本/图片到视频、同步音频和多语言 lip-sync 打包成更容易部署的开源系统。
这两条路线各有强调。前者更重多模态参考、编辑与专业创作控制,后者更重统一架构、开源可用性与推理效率。但它们都在说明同一件事:视频生成的比较标准已经从“画得像不像”升级成“是否能稳定控制时间、镜头、声音和角色一致性”。
| 类别 | 代表 | 优势 | 常见用途 |
| 商业 T2I | DALL-E / Imagen | 效果稳定;产品化成熟 | 通用创作、商业生成、提示词控制 |
| 开源扩散 | Stable Diffusion | 可本地部署;可深度定制 | LoRA、ControlNet、工作流编排、私有化部署 |
| 视频 / 音视频生成 | Seedance 2.0、HappyHorse 1.0 | 同时建模时序、镜头、同步音频,以及更强的控制或部署能力 | 文本生视频、图像生视频、参考驱动编辑、原生音视频生成 |
语音也是多模态体系中的重要一支。它一方面可以单独形成语音识别(ASR)和语音合成(TTS)任务,另一方面也可以作为更大多模态系统中的输入或输出模态,与文本和视觉共同构成统一交互链路。
自动语音识别(Automatic Speech Recognition, ASR)把音频转成文本。Whisper 是这一方向的代表之一。它本身更接近“语音到文本”的专用模型,而非完整的原生多模态基础模型;但它在工程上非常重要,因为许多语音助手和语音 Agent 系统的第一步,仍然是先把音频稳定转写为文本,再进入后续语言推理链路。
语音合成(Text-to-Speech, TTS)则反过来把文本转成音频波形。工程关注点通常包括音色一致性(Voice Consistency)、韵律(Prosody)、延迟控制与多说话人能力。对多模态系统而言,TTS 的意义不仅“朗读文本”,还把文本侧推理结果重新投射到语音模态,使系统具备完整的语音交互闭环。
传统语音系统更像流水线:ASR 先把音频转写成文本,语言模型基于文本做推理,最后 TTS 再把文本回答合成为语音。原生多模态路线则倾向于减少这种层层转译,尽量让语音中的情绪、停顿、说话风格和实时交互信号直接进入统一推理链路。语音也因此逐步从“单独外接模块”变成原生多模态系统中的一等模态。
对生成式大语言模型(Large Language Model, LLM)而言,训练通常核心是一个逐层收紧目标的三阶段过程。第一阶段是预训练(Pretraining):让模型“学会语言”,掌握通用世界知识、语言统计规律与基础生成能力。第二阶段是监督微调(Supervised Fine-Tuning, SFT):让模型“学会按指令做事”,把通用生成能力收束到更明确的任务格式、回复风格和指令遵循能力上。第三阶段是偏好对齐(Preference Alignment):让模型“生成得更好”,在多个候选答案中更稳定地偏向人类认为更有帮助、更安全、更相关的输出。
这三步也对应了三种不同的模型状态。只做完预训练的模型通常称为基础模型(Base Model):它拥有语言能力,但并不天然理解“用户现在真正想要什么”。经过监督微调后,模型开始具备指令理解与任务对齐能力,这一步常被称为指令微调(Instruction Tuning)。再往后,通过偏好对齐把模型行为进一步向人类目标、价值约束和回答偏好靠拢,这一步才构成更完整的对齐(Alignment)过程。当前主流通用助手模型,基本都建立在这条“预训练 → SFT → 偏好对齐”的标准范式之上。
| 阶段 | 核心目标 | 主要训练信号 | 产出能力 |
| 预训练(Pretraining) | 学会语言与通用知识 | 大规模通用语料上的自监督目标,如 next-token prediction | 基础语言建模能力,形成 Base Model |
| 监督微调(SFT) | 学会遵循指令与任务格式 | 高质量指令-回答、任务输入-输出配对数据 | 更稳定的指令理解、格式控制与领域适配能力 |
| 偏好对齐(Preference Alignment) | 让输出更符合人类偏好 | 偏好排序、奖励模型(Reward Model)、RLHF / DPO 等对齐信号 | 更有帮助、更安全、更符合人类判断的回答 |
从工程视角看,微调的本质是在保留预训练通用能力的前提下,对模型进行二次开发。领域适配、风格约束、指令遵循、安全边界和用户体验优化,几乎都发生在预训练之后。微调是把“会说话的模型”变成“可用的产品模型”的关键环节。
模型训练并非所有因素等权叠加的黑箱过程。不同决策对结果的影响层级并不相同:有些因素决定性能上限,有些因素决定能否稳定逼近这个上限,还有些因素更多只影响复现实验时的波动。把这些层级看清,比机械扩大超参数搜索空间更重要。
一个足够稳定的工程经验是:数据定义与数据质量决定上限,训练目标决定模型究竟被要求学什么,模型架构决定它擅长表达什么,超参数主要决定训练能否稳定地逼近该上限,随机种子则决定同一方案在局部范围内会波动多少。这五类因素都重要,但重要性的层级并不相同。
| 因素 | 主要作用 | 更像决定上限还是逼近速度 | 典型失败形式 |
| 数据质量与标注定义 | 决定模型到底能学到什么,以及标签边界是否自洽 | 更接近决定上限 | 噪声标签、分布偏移、长尾缺失、数据泄露使所有后续优化失真 |
| 训练目标 / 损失函数 | 决定模型被奖励什么、惩罚什么 | 同时影响上限与训练方向 | 目标错配导致模型学会与业务目标不一致的行为 |
| 模型架构 | 决定模型的归纳偏置、容量与可表达结构 | 更接近决定可达到的能力形态 | 用不合适的结构处理任务,容量再大也会吃亏 |
| 超参数与优化配置 | 决定训练是否稳定、是否高效收敛 | 更接近逼近速度与稳定性 | 学习率、batch、正则化失衡导致发散、欠收敛或过拟合 |
| 随机种子与运行噪声 | 决定实验波动与边缘差异能否复现 | 主要影响方差,不直接创造新能力 | 小数据任务里不同 seed 结果差异过大,误判方案优劣 |
在大多数真实任务里,数据问题比超参数问题更早构成瓶颈。标注标准不一致、负样本定义含混、类别长尾覆盖不足、训练集与线上分布偏移、重复样本过多、低信息密度样本占比过高,这些问题会直接抬低性能天花板。此时即使继续精细搜索学习率、dropout 或 warmup 步数,得到的往往也只是对现有缺陷数据的更精致拟合。
因此,训练停滞时最先应排查的通常核心是以下四件事:监督信号是否可信,训练数据是否覆盖真实决策边界,验证集是否真的代表部署分布,以及坏例是否能被归纳成明确的数据缺口。若这些环节存在结构性问题,数据集工程(Dataset Engineering)通常比额外的超参数搜索更有价值。
不同模型家族里,各因素的影响力分布并不完全一样。传统机器学习模型更依赖显式特征与模型假设是否匹配;Transformer 一类现代深度模型则更依赖数据规模、训练目标与训练配方是否成熟。两者的优化重点不能混成一套。
| 因素 | 传统机器学习 / 早期深度模型 | Transformer / 大模型体系 |
| 数据 | 高质量特征与标签定义最关键;样本量常比模型复杂度更早成为瓶颈 | 数据规模、质量、清洗、去重与配比直接决定基座能力分布,影响通常最大 |
| 架构 | 模型假设差异很大,线性模型、树模型、核方法之间的选型影响巨大 | 同一家族成熟配方下,架构差异仍重要,但往往弱于数据分布与训练目标的主导作用 |
| 损失函数 / 目标函数 | 对分类、排序、回归、异常检测等任务边界影响直接,错配会立刻拉低效果 | 预训练目标、对齐目标和辅助损失的设计会深刻塑造能力形态,影响非常大 |
| 超参数 | 常更敏感,尤其是 SVM、Boosting、早期 RNN / CNN 等体系 | 现代 Transformer 在成熟优化器、残差连接和归一化配方下通常更宽容,但学习率、batch、warmup、weight decay 仍然是高杠杆参数 |
| 随机种子 | 在小数据、非凸训练或高方差集成场景中影响明显 | 大规模预训练中单次 seed 影响相对被平均,但小样本微调、PEFT 和 few-shot 任务中仍可能显著波动 |
对传统模型而言,常见主线是“先把特征、标签定义和模型假设对齐,再调超参数”;对 Transformer 而言,常见主线更接近“先把数据、目标和基座路线做对,再用一套成熟训练配方稳定落地”。因此,现代大模型工程里最常见的成功路径,核心是先建立可信基线,再围绕数据与目标做高价值迭代。
训练是否健康,不能只看“loss 最后降到了多少”。真正有经验的训练监控,关注的是曲线形态、不同指标之间是否彼此一致,以及这些指标是否在给出同一种信号。例如训练损失下降但验证损失持续恶化,说明问题往往不在“模型没学到”,而在泛化;学习率正常但梯度范数突然飙升,则更像数值稳定性问题。
| 监控项 | 说明 |
| 训练损失(Training Loss) 常见名称: loss、 train_loss |
反映模型在当前训练批次或当前 epoch 上的拟合误差。它通常应随训练推进整体下降,但短期抖动是正常现象。若长期不降,常见原因是学习率过低、数据管线异常、标签错误或目标函数设置不当。 |
| 验证损失(Validation Loss) 常见名称: val_loss、 eval_loss |
反映模型在未参与参数更新的数据上的误差,是观察泛化状态的核心指标之一。训练损失下降而验证损失持续升高,通常意味着过拟合、分布不一致,或训练目标与评估目标之间存在错配。 |
| 验证指标(Validation Metric) 常见名称: val_accuracy、 eval_f1、 val_auc、 eval_bleu |
用于直接衡量任务目标是否改善。分类任务常看 Accuracy、F1、AUC,生成任务常看 BLEU、ROUGE、Win Rate 或人工偏好指标。它与验证损失应结合解读,因为 loss 变差而任务指标稳定,往往意味着概率校准恶化而非决策边界崩溃。 |
| Token 级准确率(Token-level Accuracy) 常见名称: token_accuracy、 eval_token_acc、 eval_mean_token_accuracy |
衡量验证集上 token 级别的预测正确率,常用于自回归语言模型、CoT 生成任务和结构化生成任务。它比整序列 loss 更贴近“模型是否持续生成更多正确 token”,尤其适合观察答案 token 或关键推理片段是否在变好;但它仍然不能完全替代任务级正确率,因为不同等价表达、长度差异与标点格式都可能影响统计结果。 |
| 学习率(Learning Rate) 常见名称: lr、 learning_rate |
表示当前优化步长,是判断训练是否按预期执行 warmup、衰减或重启调度的关键参考。许多“训练突然变坏”的问题,本质上来自学习率曲线与预期不符,例如 warmup 未生效、scheduler 配错或恢复训练时学习率状态丢失。 |
| 梯度范数(Gradient Norm) 常见名称: grad_norm、 gradient_norm |
表示当前一步所有可训练参数梯度向量的 L2 范数,也就是“这一步模型想更新多大幅度”。它稳定在合理范围通常说明训练平稳;若突然飙到很大,常提示梯度爆炸、异常 batch 或数值不稳定;若长期极小,则可能是梯度消失、学习率过低或大部分参数几乎没有被更新。 |
| 参数范数(Parameter Norm / Weight Norm) 常见名称: param_norm、 weight_norm |
反映模型权重整体尺度。它不像梯度范数那样高频用于日常看板,但在长训练或大模型微调中很有用。若参数范数异常膨胀,常提示权重衰减过弱、优化不稳或 logit scale 正在失控。 |
| 步耗时(Step Time / Iteration Time) 常见名称: step_time、 iter_time、 time_per_step |
表示每一步训练耗时,是判断吞吐和系统瓶颈的重要指标。若步耗时突然上升,常见原因包括数据加载阻塞、远程存储抖动、NCCL 通信问题、动态 padding 失控或某类样本序列长度突然变长。 |
| 吞吐量(Throughput) 常见名称: samples_per_second、 tokens_per_second、 it/s |
反映单位时间内处理的数据量,是评估训练效率和成本的核心指标。吞吐下降而 loss 曲线形态不变,通常说明问题在系统层;吞吐下降且梯度统计异常,则可能是训练图、batch 组成或显存压力同时发生了变化。 |
| 显存占用(GPU Memory Usage) 常见名称: gpu_memory、 memory_allocated、 max_memory_reserved |
用于观察 batch size、序列长度、激活检查点、KV 缓存或 mixed precision 设置是否按预期生效。显存占用逐步爬升且不回落,往往提示内存泄漏、缓存未释放、日志持有张量引用,或某些框架回调在累积中间状态。 |
| 数值稳定性信号(Numerical Stability) 常见名称: loss_scale、 overflow、 nan_count |
在混合精度训练里尤其重要。若频繁出现 overflow、loss_scale 持续下降,或日志中出现 NaN/Inf,问题通常来自学习率过高、梯度异常、算子数值不稳或输入样本存在极端值。它们往往是训练真正崩坏之前最早出现的预警信号。 |
其中,grad_norm 常被误读成“某层梯度大小”或“loss 的导数值”。更准确地说,它是当前这一步所有可训练参数梯度拼成一个大向量后的 L2 范数,因此表示的是整体更新冲动的强弱。若训练初期较大、随后回落并稳定在适中区间,通常是健康现象;若突然从稳定区间跃升到极大值,则应优先排查异常 batch、学习率、混合精度溢出与梯度裁剪是否失效。
梯度范数(Gradient Norm)的标准写法是把所有可训练参数的梯度看成一个整体向量,再计算这个整体向量的 L2 范数:
\[\mathrm{grad\_norm}=\left\|\nabla_\theta L\right\|_2=\sqrt{\sum_i \left\|g_i\right\|_2^2}\]其中,\(\theta\) 是所有可训练参数,\(L\) 是当前 batch 或当前累积步对应的损失函数,\(g_i\) 是第 \(i\) 个参数张量上的梯度。这个值越大,表示当前 batch 诱导出的参数更新方向越“用力”;这个值越小,表示当前 batch 对参数的推动越弱。它描述的是更新强度,不直接等同于模型好坏,也不等同于验证集效果。
| 曲线形态 | 常见含义 | 优先排查 |
| 训练初期偏大,随后下降并进入稳定区间 | 模型从随机或预训练参数出发,早期需要较大修正;进入稳定区间后,优化器开始围绕较平滑的区域更新。 | 通常属于健康信号,继续结合 loss、验证指标和学习率曲线观察。 |
| 某一步突然尖峰,随后 loss 也变成 NaN/Inf | 更像梯度爆炸、异常 batch、标签异常、输入极端值或混合精度溢出。 | 检查该 batch 的样本、学习率、loss scale、梯度裁剪阈值、序列长度分布和数据预处理。 |
| 长期接近 0,训练 loss 也几乎不动 | 更像学习率过低、梯度消失、参数被冻结、loss 没有正确连接到模型输出,或 AMP 下小梯度被下溢。 | 检查可训练参数列表、requires_grad、optimizer 参数组、loss.backward 是否执行、GradScaler 状态。 |
| grad_norm 稳定,但验证指标持续恶化 | 数值更新本身可能平稳,问题更可能来自过拟合、数据分布错配或停止指标选择不当。 | 检查验证集分布、early stopping 指标、正则化、数据泄漏与任务指标。 |
| grad_norm 跟学习率同步出现异常拐点 | 常见于 warmup、scheduler、resume 训练状态恢复错误,或梯度累积步数改变后未同步调整学习率。 | 检查 scheduler step 粒度、global_step、optimizer state、恢复训练时的 lr 与 warmup 位置。 |
梯度裁剪(Gradient Clipping)和 grad_norm 密切相关。按范数裁剪时,系统会先计算当前梯度的总范数;若它超过阈值 \(c\),就把整组梯度按比例缩小到阈值附近:
\[g \leftarrow g\cdot \frac{c}{\max(\left\|g\right\|_2,c)}\]其中,\(g\) 表示所有梯度拼成的整体向量,\(c\) 是裁剪阈值。这个操作不会改变梯度方向,只会限制更新幅度。因此,日志里同时记录 grad_norm 和是否触发裁剪,可以区分“训练本来平稳”和“训练靠频繁裁剪勉强压住”。如果几乎每一步都触发裁剪,通常需要重新审视学习率、batch 组成、loss 尺度或模型初始化。
一条实用经验是:不要孤立解读单个监控项。训练健康与否,通常要联立观察“训练损失、验证损失、验证指标、学习率、梯度范数、吞吐和显存”这几条曲线。只有当这些信号彼此一致时,结论才可靠;若它们相互矛盾,真正的问题往往就藏在这种矛盾里。
一个极常见的问题是:如果训练集已经很大,例如有 200 万条样本,是否 1 个 epoch 就一定够了。答案是否定的。epoch 数从来并非脱离任务、模型容量、batch size 和学习率调度单独成立的“固定真理”。数据量很大时,重复看同一批数据的边际收益确实会下降;但这并不自动意味着“只看一遍就已经充分收敛”。真正该判断的,核心是模型在当前 step 数、当前噪声水平和当前优化配方下,是否已经把这批数据中的稳定规律吸收进去。
从优化角度看,epoch 表示“把整个训练集完整扫过几遍”,而训练真正发生更新的基本单位是 step。若训练集大小为 \(N\),全局 batch size 为 \(B\),则每个 epoch 的更新步数近似为
\[\text{steps per epoch}\approx \left\lceil \frac{N}{B}\right\rceil\]这条式子解释了为什么“同样是 1 个 epoch”,训练强度可能完全不同。若 \(N=2{,}000{,}000\) 且 \(B=2{,}048\),那么 1 个 epoch 约等于 977 步;若 \(B=128\),则 1 个 epoch 已经接近 15625 步。前者可能连 warmup 和衰减都还没完全展开,后者却已经给了优化器大量迭代机会。因此,真正需要关注的是总更新步数是否足够、学习率曲线是否有足够空间完成收敛,而非孤立地看 epoch 数字本身。
当数据量相对模型容量已经非常充足,或者任务本身建立在强预训练基座之上时,1 个 epoch 确实可能足够。最典型的例子是大语言模型预训练和大模型微调。预训练阶段若数据规模巨大,重复多次扫同一语料的收益会迅速递减,甚至更容易把模型推向记忆高频样本而非继续扩大有效覆盖;微调阶段若基座已经很强,而 200 万样本又足够多,1 到 2 个 epoch 往往已经能把任务信号写进模型。
这种情形之所以成立,核心是因为模型在第一轮扫描中就已经见到了足够多的新模式,额外重复的边际知识增量开始下降。换一个表述,真正够用的核心是“这 1 个 epoch 已经包含足够多有效、不同且信息密度高的更新”。
相反,即使样本数已经达到百万级,多 epoch 仍然可能有必要。第一种情形是模型容量很大、任务本身又不只是表面分类,而需要模型充分吸收细粒度规律;此时 1 个 epoch 可能只是让模型“看过”,还未真正“消化”。第二种情形是 batch size 很大,导致每个 epoch 的 step 数偏少,学习率调度甚至还没完全展开,训练就已经结束。第三种情形是数据噪声较大或任务边界本身较模糊,多几轮迭代有助于模型在不同 mini-batch 组合中逐步稳定参数,而非过度受一次随机采样影响。
从优化器视角看,多 epoch 的价值不只是“重复看数据”,还包括让随机梯度下降在更多 mini-batch 路径上反复修正参数。一次 epoch 中,每个样本通常只参与一次梯度更新,但 SGD 的更新方向本身带噪声;多轮迭代使优化器有机会在不同 batch 组合下持续磨平这种噪声,更接近一个稳定解。
多跑 epoch 的好处是提高数据利用率,坏处则是重复过度后更容易过拟合。这里的过拟合并不一定表现为“训练损失不再下降”,更常见的是训练损失持续变好,而验证损失、验证指标或校准状态开始恶化。对去重不充分的数据,这个问题会更严重:重复样本本身已经降低了有效样本量,再叠加多 epoch,就会把模型进一步推向记忆。
因此,epoch 数的合理区间通常核心是存在一个任务相关的甜蜜点。预训练里这个甜蜜点往往很靠前,因为数据足够大、重复收益低;中小模型从头训练时甜蜜点通常更靠后,因为模型需要更多轮次才能把有限数据中的模式真正吃透;大模型微调和 SFT 则常介于二者之间。
| 场景 | 更常见的 epoch 区间 | 为什么 |
| 大规模预训练 | 常接近 1,或不足 1 到 2 | 数据覆盖极广,重复收益下降快,更看重新 token 覆盖而非反复回看 |
| 大模型监督微调 / 指令微调 | 常见 1 到 3 | 基座能力已强,过多重复更容易带来风格过拟合、遗忘或行为退化 |
| 分类 / NER / 中等规模任务微调 | 常见 2 到 5 | 需要多轮收敛,但又必须严防验证集开始转坏 |
| 中小模型从头训练 | 常明显高于 5,甚至更多 | 模型需要靠多轮迭代逐步建立表示,单轮往往不够吸收规律 |
所有经验法则最终都应回到验证集信号。若训练损失持续下降,而验证损失 \(\texttt{val\_loss}\) / \(\texttt{eval\_loss}\) 不再下降甚至开始上升,就说明继续增加 epoch 很可能只是在拟合训练集细节。相反,若训练到 1 个 epoch 时验证损失和验证指标仍在稳定改善,那么因为“样本很多”就强行提前停止,反而可能让模型欠收敛。
|
1 2 3 4 |
Epoch 1: train_loss=2.1 val_loss=2.3 Epoch 2: train_loss=1.8 val_loss=2.0 Epoch 3: train_loss=1.5 val_loss=1.9 Epoch 4: train_loss=1.2 val_loss=2.0 |
这类曲线就是最典型的判断依据。前 3 个 epoch 中,训练损失与验证损失同步下降,说明模型既在学习训练集,也在改善泛化;到第 4 个 epoch,虽然 train_loss 还在继续下降,但 val_loss 已经从 1.9 回升到 2.0,信号已经转向“继续记住训练细节,而非继续学到可泛化规律”。这时更合理的做法通常是在第 3 个 epoch 附近 early stop,或回滚到验证集表现最好的 checkpoint。
上文已经系统列过训练监控项,这里只强调一个更容易被误用的原则:early stopping 的判断不能死板地绑定单一指标。停止准则必须跟任务目标、模型架构和损失函数对齐。对 BERT 一类 Encoder-only 模型的二分类任务,若最终部署关心的是固定阈值下的分类正确率、召回率或 F1,而非输出概率本身是否校准,那么 checkpoint 选择往往应优先盯住 val_f1 或 val_acc,而不能仅凭 val_loss 上升就立刻停止。
| Epoch | train_loss | val_loss | val_acc | val_f1 | 解读 |
| 1 | 0.4106 | 0.3122 | 87.1% | 0.8994 | 首个可用 checkpoint |
| 2 | 0.2878 | 0.2461 | 90.8% | 0.9250 | 验证指标同步改善 |
| 3 | 0.1914 | 0.3646 | 90.0% | 0.9165 | val_loss 反弹,但任务指标只是小幅震荡 |
| 4 | 0.1059 | 0.4341 | 91.4% | 0.9314 | val_f1 创新高,应保存 |
这类曲线在二分类里并不少见。若损失函数采用二元交叉熵(Binary Cross-Entropy, BCE)或交叉熵(Cross-Entropy),那么 val_loss 衡量的是概率分布与标签的一致性,对“模型是否越来越自信”极其敏感;而 val_f1 衡量的是阈值后的离散决策结果。模型进入后期时,logit 可能变得更极端,导致概率校准变差、损失上升,但只要决策边界仍在朝正确方向移动,F1 仍然可能继续提升。
因此,在这类 BERT 二分类任务中,更合理的策略通常是:把 early stopping 的耐心值绑定在 val_f1、 val_acc 或业务主指标上,而把 val_loss 主要当作校准与过度自信的辅助信号。只有当任务需要直接使用概率分数做路由、排序、拒识或温度缩放校准时, val_loss 才应重新上升为主导停止准则。
在 CoT(Chain-of-Thought)生成任务里,这个问题会更明显。更常见的情况是 eval_loss 覆盖的是整条推理链与答案 token 的交叉熵;而推理链本身往往存在大量等价表达,写法稍有变化就会改变 loss,却未必伤害最终答案质量。于是就会出现这样一种典型背离: eval_loss 在后期微涨,但 token_accuracy、答案正确率或下游分类指标仍继续上升。例如在某次早停patience=1的训练任务中:
| 模型 | 最佳 eval_loss | 后续现象 | 更合理的解读 |
| 0.8B / 2B / 4B / 9B 同组 CoT 训练 | 普遍在 epoch 3 附近达到最低 | epoch 4 时 eval_loss 只微涨 0.01 到 0.02,但 token_accuracy 仍继续上升 | 更像早停准则过紧,或停止指标与任务目标错配,而非已经进入明显过拟合 |
这类现象尤其容易误伤大模型或较晚才兑现能力的配置。若 9B 模型的绝对 eval_loss 在所有尺寸中最低,却因为 patience=1 且过度依赖 eval_loss 而被提前截断,那么“9B 没赢 4B”并不能直接推出“9B 欠容量”。更稳妥的解释,往往是停止准则先砍掉了它后续 1 到 2 个 epoch 的收益。
因此,还要把三个容易混淆的判断分开。欠拟合(Underfitting) 是现象层描述,表示训练集和验证集都做不好;欠容量(Undercapacity) 是成因层判断,表示模型或可训练适配器的表达能力确实不够,导致训练误差下不去;而停止准则误判 则是监控层问题,表示模型本来还在朝任务目标变好,却被不合适的指标提前停掉。
| 状态 | 常见信号 | 更像该怎么处理 |
| 欠拟合 | 训练集和验证集指标都偏低,二者差距不大;继续训练短时间内也上不去 | 优先查训练是否充分、特征是否有效、目标是否合理 |
| 欠容量 | 训练 loss 本身下不去,训练指标长期受限;增大模型尺寸、LoRA rank 或可训练模块后,训练集与验证集一起改善 | 增加表达能力,或放宽可训练参数写入范围 |
| 停止准则误判 | eval_loss 微涨,但 token_accuracy、F1 或下游任务指标仍继续上升 | 放宽 patience,并把 early stopping 绑定到真正代表任务成败的指标 |
因此,更可靠的工程结论核心是:先根据任务类型给出一个合理初值,再把停止准则绑定到真正代表任务成败的验证信号上。epoch 只是外层计数单位,停止条件必须服务于任务目标,而非机械服从某一条曲线。
超参数仍然重要,但它们最主要的作用通常是把一个合理方案从“训不动”推到“训得稳”,再从“训得稳”推到“训得更高效”,而非凭空创造数据与目标之外的新能力。学习率、batch size、warmup、weight decay、dropout、梯度裁剪与调度策略都属于高杠杆参数,因为它们直接影响优化轨迹;但一旦进入成熟配方附近,继续做大规模穷举搜索,边际收益往往迅速下降。
因此,工程上更强调经验调参(Empirical Baselines)。先从社区已验证的默认范围起步,再围绕少数真正高杠杆参数做小范围、可解释的搜索,通常比无约束网格搜索更高效,也更不容易把验证集偶然性误判成模型能力提升。若一个方案必须依赖极其苛刻的超参数才能成立,它通常也更难在新数据、新种子和新硬件上稳定复现。
随机种子并非主导因素,但也绝并非噪声到可以忽略的细节。初始化、数据打乱顺序、负样本采样、dropout 路径和混合精度下的数值非确定性,都会让两次训练出现差异。数据越少、任务越难、可训练参数越多,这种波动通常越明显。小样本微调、few-shot 提示学习、PEFT 与不平衡分类任务,都经常出现“只换一个 seed,指标就有明显起伏”的现象。
因此,实验纪律至少应包括三点:第一,重要结论不要基于单次运行下判断;第二,对关键方案记录 seed、数据切分、依赖版本和硬件环境;第三,若不同 seed 方差已经接近方案之间的提升幅度,就不应把这点差异解读为方法突破。工程上真正可信的改进,应当在多次运行、不同切分或更接近真实分布的验证下仍能站住。
若把训练优化压缩成一条实用顺序,通常是:先校正任务定义与评估指标,再修数据分布与标签质量,然后确定模型家族与训练目标,接着使用成熟经验配方建立基线,最后才对少数关键超参数做有节制的搜索。这个顺序并不保证一步到位,但它能最大限度避免把大量算力消耗在低回报环节上。
预训练首先是一条数据管线(Data Pipeline)。对大语言模型而言,模型最终学到什么、遗漏什么、偏向什么,首先取决于它看到了哪些语料,以及这些语料在进入训练前经历了怎样的筛选、清洗与混合。训练配方当然重要,但在大规模预训练里,数据分布本身往往比单个优化技巧更具决定性。
第一步通常是收集训练数据。来源往往包括公开网页、百科、书籍、论文、新闻、论坛、代码仓库、问答站点、对话语料以及经过授权的专有文本。不同来源的作用并不相同:网页和百科提供广覆盖的语言统计与世界知识,代码语料强化程序生成与形式化模式,论文和书籍提升长程结构与知识密度,对话数据则更贴近后续助手形态。预训练阶段谈“知识注入”,最底层的载体首先就是这些原始语料源。
第二步是数据清洗(Data Cleaning)。原始互联网语料通常充满模板页、导航栏、广告、乱码、截断文本、语言混杂、低信息密度页面和大规模重复内容,直接拿来训练只会把噪声写进模型。常见清洗动作包括:语言识别、文本抽取、HTML / Markdown 噪声剥离、异常字符过滤、长度过滤、文档质量评分、敏感内容过滤,以及近重复或完全重复文档去除。它的目的核心是把明显无价值、重复或高风险的部分尽量挡在训练集之外。
第三步是数据去重与质量过滤。对现代大模型来说,重复数据并不只是浪费 token 预算,还会放大训练分布中的头部模式,使模型更容易过拟合少数高频模板、降低有效数据多样性,并污染后续评测。于是,工程上通常既要做文档级去重,也要做段落级、片段级甚至近似语义去重;同时配合质量分类器、启发式规则或小模型过滤,把低信息密度、机器生成垃圾、SEO 内容农场和错误密集文本压低占比。
第四步是数据配比(Data Mixture)。预训练通常核心是会显式控制不同来源、语言、领域和模态的采样比例。原因在于:不同语料的规模差异极大,若完全按原始数量采样,网页噪声和头部来源往往会淹没更高质量但规模更小的数据,例如书籍、论文和代码。数据配比的本质,是决定模型应该把多少训练预算分配给广覆盖、多少分配给高质量、多少分配给特定能力方向。
这种配比通常带来直接的能力权衡。代码比例升高,模型的程序生成和形式化推理往往更强,但自然语言对话风格未必同步变好;高质量书面语比例升高,模型的行文稳定性和知识密度往往改善,但口语互动和开放域覆盖可能下降;多语比例升高,则跨语言泛化更强,但单语极致性能未必最优。因此,数据配比核心是预训练目标函数之外最重要的能力分配器之一。
第五步才是把整理后的语料送入真正的训练阶段。前面已经做过收集、清洗、去重和配比,后面的“初期训练、中期训练、退火训练”才有明确的数据基础:初期通常强调大规模广覆盖混合,中后期再逐步提高高质量数据、特定能力语料或长上下文样本的权重。阶段化训练并非独立于数据工程存在的,它建立在先构造可控数据分布,再按阶段调整采样分布这一前提之上。
现代大语言模型的预训练,通常并非把同一种数据、同一种上下文长度和同一组优化超参数一路跑到结束,而更接近一种分阶段课程学习(Curriculum Training)。所谓“知识注入”,本质上也核心是通过逐步调整数据分布、上下文长度、学习率和训练目标,让模型先建立通用语言统计骨架,再吸收更高质量、更长程或更专业的模式。
工程上常见的三段式可以概括为:
- 初期训练。这一阶段通常以海量、多样、相对较短的上下文为主,重点是尽快建立词法、句法、语义组合、事实共现与基础推理的统计骨架。之所以大量使用短上下文,是因为在标准注意力下,序列长度增加会显著抬高训练成本;在固定算力预算下,较短序列通常能换来更多 token 更新和更稳定的早期收敛。
- 中期训练(Mid-training)。当模型已经具备基本语言能力后,训练重点会从“广覆盖”逐步转向“高价值分布塑形”。这一阶段更常看到更严格过滤的高质量语料、代码、推理数据、专业领域语料,或逐步扩展的上下文长度。它的作用核心是把模型的能力重心推向更有用的区域,例如更强的代码能力、更稳的长程依赖、更贴近目标领域的表达分布。
- 退火训练(Annealing Phase)。这是预训练后段的精修阶段,通常伴随更小的学习率、更保守的更新幅度,以及更精选、更低噪声的数据混合。它的目标核心是收束参数、压低噪声影响、强化高质量模式,并把模型最终的能力形态稳定下来。很多现代配方会把更专业或更高质量的数据留到这一阶段,以获得更好的下游表现。
从“注入什么知识”的角度看,这三段关注的重点并不相同。初期训练主要注入广覆盖的语言统计、世界常识共现和通用结构先验;中期训练主要注入能力相关的分布偏好,例如代码、推理、长文档和领域语料;退火训练则更像把高价值知识和高质量行为模式做最后收束,使模型从“已经学会很多”走向“把重要能力学得更稳”。
长上下文能力也常在这一框架下被放到中后期处理。原因并不神秘:长上下文训练既昂贵,又更容易让优化目标与数据工程复杂化;如果在模型尚未建立稳定短程语言骨架时就大规模拉长序列,单位算力的有效学习信号往往并不划算。因此,很多训练配方会先用短上下文把基础能力打牢,再在中后段逐步扩展到更长上下文,或者单独追加一段上下文扩展训练。
因此,预训练阶段谈“知识注入”时,更准确的理解核心是按训练阶段逐步改变模型看到的分布与约束条件:先学会语言,再学会更有价值的语言分布,最后把这些能力收束成一个更稳定的基座模型。
自回归语言建模(Causal Language Modeling, CLM)把文本建模为从左到右的条件概率连乘:给定前缀 \(x_{<t}\) 预测下一个 token \(x_t\)。训练目标是最小化 next-token 交叉熵:
\[\mathcal{L}_{\mathrm{CLM}}(\theta)=-\sum_{t=1}^{L}\log p_\theta(x_t\mid x_{<t})\]CLM 与 Decoder-only 架构天然匹配:因果 attention mask 保证模型只能看见历史 token,避免训练-推理不一致。绝大多数通用生成式大模型都以 CLM 为主目标。
多 token 预测(Multi-Token Prediction, MTP)是在 CLM 基础上的“监督信号加密”:除了预测 \(x_{t+1}\),还额外让模型在同一隐藏状态上预测更远的未来 token(例如 \(x_{t+2}\)、\(x_{t+3}\)),从而在相同序列长度下产生更多训练信号。一个抽象写法是:
\[\mathcal{L}_{\mathrm{MTP}}(\theta)=-\sum_{t=1}^{L}\sum_{j=1}^{K}\log p_\theta(x_{t+j}\mid x_{<t})\]MTP 通常作为辅助损失(Auxiliary Loss)提升训练效率或长程规划能力;但推理阶段是否能“真正一次生成多个 token”取决于解码与验证策略,不能简单由训练目标推出。
掩码语言建模(Masked Language Modeling, MLM)随机遮住输入中的一部分 token(替换为 \([\mathrm{MASK}]\) 或其他扰动),训练模型用双向上下文预测被遮住位置的 token。它是 Encoder-only 表示模型(如 BERT 系列)的典型预训练目标:
\[\mathcal{L}_{\mathrm{MLM}}(\theta)=-\sum_{t\in \mathcal{M}}\log p_\theta(x_t\mid x_{\setminus \mathcal{M}})\]其中 \(\mathcal{M}\) 是被 mask 的位置集合。MLM 的优势是能学到更强的双向表示,但它与生成式解码不天然一致,因此“理解类任务”更常用 MLM 预训练模型,“生成类任务”更常用 CLM。
对比学习预训练(Contrastive Pre-training)把“相似样本拉近、非相似样本推远”作为核心目标。它广泛用于句向量/图像-文本对齐等场景:例如 CLIP 用图像编码器与文本编码器产生表示,对匹配对最大化相似度;Sentence-BERT 等句向量模型也常用对比目标训练。
典型形式是 InfoNCE:对 batch 内正对(Positive Pair)与负对(Negative Pair)做 softmax,对每个 query 只奖励其匹配的 key:
\[\mathcal{L}=-\sum_{i}\log \frac{\exp(\mathrm{sim}(q_i,k_i)/\tau)}{\sum_{j}\exp(\mathrm{sim}(q_i,k_j)/\tau)}\]其中 \(\tau\) 是温度(Temperature),\(\mathrm{sim}\) 常用余弦相似度或内积。
| 目标 | 代表架构 | 擅长 | 典型下游 |
| CLM | Decoder-only | 生成(Generation) | 对话、写作、代码生成 |
| MLM | Encoder-only | 表示学习(Representation) | 分类、匹配、序列标注、reranking |
| 对比学习 | Dual Encoder / 多塔 | 对齐与检索(Alignment/Retrieval) | Embedding、图文检索、聚类 |
继续预训练(Continual Pre-training)位于“通用预训练”与“下游微调”之间。它不直接把模型改造成某个具体任务的分类器或助手,通常会先用目标领域的大规模无标注语料,对已经完成通用预训练的模型再训练一段时间,让参数分布、词汇统计、上下文共现和知识重心向目标领域迁移。对 Encoder-only 模型,这一步通常仍以掩码语言建模(Masked Language Modeling, MLM)为主;对 Decoder-only 生成模型,则通常继续做自回归语言建模(Autoregressive Language Modeling)。
它的核心价值是先让底座学会“这个领域怎样说话”,再让它学会“这个任务怎样输出”。若直接拿通用模型去做医疗、法律、金融、代码仓库、企业内部知识库等垂直场景的监督微调,模型往往会同时面对两类落差:一类是领域词汇和表达方式本身就不熟,另一类是下游任务的标签或指令又要求它立即做出稳定判断。继续预训练先处理前一类问题,把底座拉近目标域分布,后续监督微调只需要处理任务映射,训练通常会更稳定,也更节省标注数据。
因此,继续预训练本质上是一种领域自适应预训练(Domain-Adaptive Pretraining, DAPT)。如果继续预训练的语料更进一步贴近最终任务的输入分布,而不只来自某个大领域,例如只使用某个具体产品线、某类工单、某种法律文书或某一学科论文语料,那么它也可以被视作任务自适应预训练(Task-Adaptive Pretraining, TAPT)。两者的区别不在训练算法,而在语料与最终应用的距离:DAPT 更强调“进入这个领域”,TAPT 更强调“贴近这个任务”。
领域适配能带来的收益通常体现在四个层面。第一,模型会更熟悉目标域词汇和短语共现,例如医学缩写、金融术语、企业内部专有名词、代码 API 与日志模式。第二,模型对目标域上下文的概率分布会重新校准,原本罕见的搭配在该领域里会变成高频结构。第三,后续监督微调需要学习的东西会减少,因为模型不必一边补语言常识、一边学任务映射。第四,在低标注数据场景下,继续预训练常常比一上来就重监督微调更稳,因为它先利用了最容易获得的大规模原始文本。
继续预训练最适合三类场景:
- 领域语料很多、标注很少。这是最经典的适用条件,因为继续预训练最能利用大规模无标注文本,而不要求先构造高成本监督数据。
- 目标文本分布与通用互联网语料差异极大。例如长文档、半结构化记录、专业术语密集文本、代码与自然语言混合语料;这类差异首先是语言分布差异,而非标签定义差异。
- 模型需要吸收的变化更接近“知识与表达分布迁移”,而非单纯“输出标签变了”或“格式要求变了”。后者通常更适合直接做监督微调或 PEFT。
从训练流程看,更合理的顺序通常是:先完成通用预训练,再做领域继续预训练,最后再进入监督微调、参数高效微调或偏好对齐。原因很简单:继续预训练改变的是基座对语言分布和知识结构的建模,而监督微调改变的是输出行为。先做基座适配,再做行为适配,优化目标更清晰,也更符合迁移学习的层次结构。
继续预训练的主要风险,是灾难性遗忘(Catastrophic Forgetting)。它指的是模型在吸收新分布时,原来在通用语料上学到的能力被明显冲掉:例如领域内术语理解变强了,但通用语言理解、跨领域泛化、常识问答、原始格式鲁棒性或多语言能力反而下降。这个问题并非继续预训练独有的,但在“新语料分布很窄、训练步数又较长”时尤其容易出现。
其根本原因在于参数共享。神经网络并不会为“旧知识”和“新知识”自动分出两套互不干扰的存储区;当优化器持续在窄领域语料上更新同一组权重时,原先支持通用能力的参数方向会被新的梯度不断改写。如果新领域文本的语言风格、词频结构和任务偏置都高度集中,模型就会把有限参数容量优先分配给当前最常见的模式,从而牺牲原本更广的覆盖面。
灾难性遗忘最常见的外在表现包括:继续预训练阶段训练损失持续下降,但回到通用基准或旧任务验证集上时指标明显退化;模型在目标领域内更流畅,却在开放域输入上变得更僵硬、更偏模板化;对窄领域高频术语反应更强,但对跨域问题的泛化能力下降。这些现象都说明模型核心是在重新分配有限表示能力。
缓解灾难性遗忘有几条经典路线:
- 控制继续预训练强度。包括减少训练步数、降低学习率、使用更保守的 warmup 与衰减策略,避免模型在窄分布上过度漂移。
- 混合语料训练。在领域语料之外保留一定比例的通用语料,让模型在吸收新分布的同时持续回顾旧分布。
- 参数隔离。例如只对部分层做继续预训练,或采用 Adapter、LoRA 这类参数高效路径,把领域偏移写进新增参数,而非完全重写主干。
- 保留旧能力验证。继续预训练不应只看领域损失,还应并行跟踪若干通用验证集,否则模型退化往往到很晚才会被发现。
因此,继续预训练并非“领域语料越多、训练越久越好”。更准确的目标应当是:在尽量少破坏通用能力的前提下,把模型的统计重心向目标领域移动。它追求的核心是在通用底座之上增加一层更贴近目标分布的适配。工程上真正好的继续预训练,通常表现为领域内显著增益、领域外可控退化,甚至几乎无退化,而非单纯把领域损失压到最低。
监督微调(Supervised Fine-Tuning, SFT)用“输入 ➡ 期望输出”的监督数据继续训练预训练模型,使其在特定分布上更符合目标行为。对自回归语言模型(Autoregressive LM)而言,SFT 仍然是 next-token 交叉熵:给定提示词 \(x\) 与目标回复 \(y\),最小化
\[\mathcal{L}_{\mathrm{SFT}}(\theta)=-\sum_{t}\log \pi_\theta\!\left(y_t\mid x,y_{<t}\right)\]其中 \(\pi_\theta\) 表示由参数 \(\theta\) 决定的模型条件概率分布,也就是“在给定前缀条件下,模型对下一个 token 的预测分布”;\(\pi_\theta\!\left(y_t\mid x,y_{<t}\right)\) 就表示模型在看到提示词 \(x\) 和目标回复此前各 token \(y_{<t}\) 时,对当前位置正确 token \(y_t\) 赋予的概率。
训练通常使用教师强制(Teacher Forcing):把 \(x\) 与 \(y\) 拼接作为输入,但只在目标回复 token 上计算损失(对提示词部分做标签掩码,label masking),避免模型被迫“复述提示词”。
SFT 的必要性,来自基础模型(Base Model)与“可用助手模型”之间的行为差异。基础模型的原始目标只是预测下一个 token,因此它本质上擅长的是续写(Completion),而非理解人类正在发出什么指令。给它一句 “The car is”,它自然会继续补全常见续文;给它一个问题 “What is 1+1?”,它在没有对齐之前也完全可能把这当成一段待续写文本,而非一个必须回答的任务。SFT 的作用,就是把这种“见到前缀就续写”的行为,重塑成“读懂输入意图,再输出目标答案”的行为。
全量微调(Full Fine-tuning)更新模型的全部参数,表达能力最强,但训练成本高、对数据规模与分布漂移更敏感,也更容易出现灾难性遗忘(Catastrophic Forgetting)。它与预训练在优化形式上并没有本质断裂,区别主要在于数据:预训练依赖海量无标注通用语料,全量微调则依赖规模更小但质量更高、目标更明确的标注数据集。正因为所有参数都会被更新,它在特定任务上的性能上限通常最高,但显存、训练时间和权重存储成本也最高;每做一次完整微调,本质上都在生成一个完整的新模型副本。
部分参数微调(Partial Fine-tuning / Selective Fine-tuning)处在全量微调与参数高效微调(PEFT)之间。它的基本做法核心是只解冻原模型中一部分已有参数,其余参数保持冻结。这样做的直接收益是显存占用更低、训练更快、过拟合风险更可控;代价则是可调空间受限,性能上限通常低于全量微调。
这类方法的核心思想是:并非每个任务都需要改写整套参数。若下游变化主要集中在输出读出方式、输入符号分布或某一局部计算结构,那么只更新最相关的一小部分参数,往往就足以完成适配。它与后文的 LoRA、Adapter 有一个重要区别:部分参数微调优化的是原模型内部已经存在的参数子集;PEFT 则更常通过新增低秩矩阵、瓶颈层或软提示,把任务偏移写进额外参数。
输出层微调(Output-layer Fine-tuning)只更新模型最靠近输出读出的部分,例如语言建模头(LM Head)、分类头(Classification Head)、奖励头(Reward Head),或最后少数几层与任务头直接相连的参数,而把主体 Transformer 基本冻结。它最适合“底层表示已经足够好,但最终读出方式需要重塑”的场景。
对表示模型,这通常意味着冻结编码器主体,只训练顶层分类器;对生成模型或对齐流程,则常见于基于已有 SFT 模型训练奖励模型:保留主干表示层,移除原 LM Head,换成输出单一分数的奖励头,再主要围绕这个输出读出层继续训练。它的优势是参数量极小、训练稳定、成本最低;局限在于它基本不改变主干内部表示,因此当任务真正需要重排中间语义结构时,单靠输出层往往不够。
输入层微调(Input-layer Fine-tuning)主要更新输入嵌入相关参数,例如 token embedding、位置嵌入,或与新词表、新符号、新模态入口直接相连的输入投影层,而冻结大部分主体网络。它适合输入分布变化显著、但主体推理与表示能力仍然可复用的场景,例如新增领域术语、扩展专有 token、接入特殊控制符,或需要让模型先学会“看懂新输入”。
这条路线在词表扩展与领域符号接入时尤其有价值。因为很多变化并不在“模型不会推理”,而在“模型还没有为这些新符号建立合适入口”。此时先调输入层,可以把新 token 映射到已有表示空间附近,减少一开始就全模型漂移的风险。在一些更重的训练配方里,也会先单独训练输入嵌入,再逐步解冻更深层参数做融合;但其本质始终是先处理输入接口适配,再决定是否需要更深层的结构性更新。
局部结构微调(Local-structure Fine-tuning)只选择模型内部某些特定结构或参数类型来更新,例如仅训练偏置项的 BitFit、仅训练归一化参数的 LayerNorm Tuning、只解冻注意力层参数的 Attention Tuning,或只解冻最后若干层的局部 block。它的共同点是:参数选择核心是按网络内部哪类结构最可能承载任务偏移来划分。
这类方法适合算力极其受限、数据量较小,或已经对任务偏移位置有较强先验的场景。例如,若任务主要要求重新标定特征尺度或阈值边界,LayerNorm Tuning 可能就足够;若任务更多是在改变“关注哪里、聚合哪些信号”,只调注意力层可能比盲目放开全部层更高效;若只是希望用极低成本给模型一点任务校正能力,BitFit 这类只训偏置的方案也有现实价值。它们的上限通常不如更强的 PEFT,但在轻量实验、消融研究和极端资源约束环境中依然很有意义。
BitFit 的做法极端简单:冻结几乎所有权重矩阵,只训练偏置项(Bias Terms)。若某一层的线性变换写成 \(h'=Wh+b\),BitFit 只更新其中的 \(b\),而把 \(W\) 保持不动。它的参数量因此极小,通常只占全模型参数的很小一部分。
它背后的核心假设是:对不少下游任务而言,预训练模型已经学到了足够强的表示空间与主要变换方向,任务适配真正需要的,未必是重写整块权重矩阵,而可能只是调整各层激活的平移、阈值和默认响应水平。从这个角度看,BitFit 更像是在重新标定网络内部各单元的“触发基线”,而非重建新的特征子空间。
这也解释了它为什么在一些小数据分类、文本匹配或轻量行为校正任务里常常表现得比直觉预期更强:如果任务边界与预训练表示已经高度接近,那么改变少量偏置,就足以让原本已经存在的特征更容易被激活,或更容易跨过最终判别阈值。反过来,当任务需要新的知识写入、复杂结构重排或明显不同的推理路径时,BitFit 往往会很快触到容量上限,因为它几乎无法改变表示之间的主导交互方向。
LayerNorm Tuning 只更新归一化层中的可学习缩放与偏移参数,典型写法可记为:
\[\mathrm{LN}(h)=\gamma\odot \frac{h-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta\]这里 \(\gamma\) 与 \(\beta\) 就是主要可训练对象,而主体权重矩阵保持冻结。它的参数量同样很小,但比 BitFit 更直接作用于每层隐藏状态的尺度(Scale)与中心(Shift)。
它背后的假设是:很多任务偏移并不需要创造全新的特征,只需要重新调节已有特征在各层中的相对幅度与数值范围。因为 Transformer 中大量残差路径都会经过归一化,LayerNorm 参数对信息流的“放大 / 压低 / 重新居中”有全局影响。于是,只调归一化参数,就可能在不改写主干矩阵的前提下,系统性地改变哪些特征更容易穿过后续层并主导输出。
这类方法尤其适合已经拥有较强基座、但需要重新校准风格、阈值、稳定性或局部行为边界的场景。它通常比 BitFit 稍强,因为它直接控制每层表示的尺度结构;但它仍然主要是在重标定现有表示,而非构造新的复杂变换,因此面对大幅领域迁移或新知识注入时,上限仍然有限。
Attention Tuning 只解冻注意力模块中的参数,例如 \(W_Q,W_K,W_V,W_O\),而继续冻结 FFN / MLP 与其他大部分结构。它的核心判断是:不少任务真正需要改变的,核心是模型在当前任务中应该关注哪些 token、怎样聚合远近信息、如何在上下文中分配注意力。
它背后的假设比 BitFit 更强,也更结构化:预训练模型中的知识与模式大体已经存在,任务适配更多是在改变“信息路由(Information Routing)”而非“知识存储(Knowledge Storage)”。如果这个假设成立,只调整注意力层就能显著改变模型的上下文读取方式,例如更关注结尾句、否定词、实体关系、长程依赖或某些格式锚点,而无需重写 FFN 中更重的参数块。
Attention Tuning 在行为调整类任务上常有不错的性价比,原因也正在这里:它比 BitFit 和 LayerNorm Tuning 拥有更强的表示重排能力,又比全量微调和大范围 PEFT 更轻。但它的边界也很清楚。若任务核心是注入新事实、学习新术语本体、补足模型原本缺失的知识映射,仅靠改变注意力路由通常不够,因为许多稳定知识关联最终仍要落在 FFN / MLP 所承载的表示重编码里。
从整体上看,部分参数微调提供的是一种选择性解冻原参数的思路:输出层微调优先改读出,输入层微调优先改入口,局部结构微调优先改网络内部某个被认为最关键的子结构。若这些选择性更新已经足够,就没有必要进入更重的全量微调;若它们的容量仍然不够,下一步才更自然地转向后文的 LoRA、Adapter、Prefix Tuning 这类参数高效微调路线。
指令微调(Instruction Tuning)是 SFT 的一种数据组织方式:把任务描述(Instruction)显式写进输入,使模型学习“读懂指令并按指令输出”。典型样本是三元组:指令(instruction)、输入(input,可为空)、输出(output)。
|
1 |
{"instruction":"回答以下问题","input":"世界上最高的山是什么?","output":"珠穆朗玛峰。"} |
对话/FAQ 场景更常用多轮消息格式(Chat Format),把 role(system/user/assistant)显式编码进序列;训练时同样只在 assistant 角色对应的目标 token 上计算损失。
|
1 2 3 4 5 |
{"messages":[ {"role":"system","content":"你是一个严谨的技术助手。"}, {"role":"user","content":"解释什么是交叉熵损失。"}, {"role":"assistant","content":"交叉熵损失用于衡量预测分布与真实分布的差异……"} ]} |
数据规模没有统一答案,但工程上最关键的是质量(Quality)与覆盖(Coverage)。常见实践:
- 领域 SFT:从 \(10^3\sim10^5\) 级别的高质量样本起步,先跑通指标与错误分析,再扩充数据与任务覆盖。
- 通用指令微调:更常见的是 \(10^5\sim10^6+\) 的多任务指令样本,用多样性换泛化。
- 偏好对齐数据:比较对(Preference Pairs)常在 \(10^4\sim10^6\) 级别,且对标注一致性要求更高。
拒绝采样微调(Rejection Sampling Fine-Tuning)本质上仍然属于监督微调路线。这里讨论的是 rejection sampling fine-tuning 这一路线,而非近年某些语境里也会写成 RFT 的 reinforcement fine-tuning。它的核心做法是:监督数据从完全来自人工直接编写转向先由模型生成多个候选,再通过规则、验证器(Verifier)、奖励模型(Reward Model)或人工筛选,只保留其中最优或通过阈值的样本,最后把这些“被接受”的输出重新写回监督数据集,再按普通 SFT 的方式继续训练。
若把提示词记为 \(x\),候选回答记为 \(\{y^{(k)}\}_{k=1}^{K}\sim \pi_{\mathrm{old}}(\cdot|x)\),评分函数记为 \(s(x,y)\),那么拒绝采样微调通常先从这组候选中选出满足 \(s(x,y)\ge \tau\) 的回答,或直接取最高分回答 \(y^\star=\arg\max_k s(x,y^{(k)})\),再把 \((x,y^\star)\) 当作新的监督样本。后续优化目标并没有变成策略梯度或显式偏好损失,仍然是标准的 next-token 交叉熵。
因此,它可以被理解为一种先筛选、再监督的微调方式。与普通 SFT 相比,它利用模型自身采样与外部评分器把“哪种输出更好”这层信息先转成更高质量的目标答案;与 DPO、PPO 这类偏好优化相比,它并不直接学习候选之间的相对排序关系,通常会把筛选结果硬化成新的监督标签。工程上,它经常处在普通 SFT 与显式偏好优化之间,既比纯手工 SFT 更能利用自动评估信号,又比完整 RLHF 或 DPO 更容易复用现有监督训练栈。
这条路线尤其适合存在较强可验证信号的任务,例如数学推导、代码生成、结构化输出、工具调用轨迹筛选,以及能用单元测试、规则校验、解析器或外部判分器稳定判断好坏的场景。因为一旦评分器足够可靠,拒绝采样就能把“生成多个候选、只留下正确或更优的那个”直接转化为高质量训练样本。
它的边界同样明确。若评分器本身噪声很大,或任务质量强依赖开放式偏好、语气细节、多维安全判断,那么把复杂偏好硬压成“通过 / 不通过”很容易损失信息;筛选过严还会让训练分布变得过窄,导致模型只会复现少数高分写法而削弱多样性。因此,拒绝采样微调更像一种高质量数据再蒸馏手段,而非偏好对齐的终极替代品。
聊天微调(Chat Fine-tuning)强调多轮对话一致性:除单轮问答外,还需要覆盖上下文承接、拒答策略、工具调用格式、长对话记忆等。它通常仍是 SFT,只是数据分布更贴近真实对话。
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)把“微调”从“更新全部参数”变成“冻结基座(Base Model),只训练一小部分新增参数”。它仍然是当前大模型落地的主流选择之一:成本更低、训练更快、便于为不同任务保存多份轻量适配(例如每个业务一套 LoRA)。PEFT 并不只包含 LoRA、Adapter、IA3 这类“在模型内部加参数”的方法,也包含 Prefix Tuning、Prompt Tuning 这类软提示(Soft Prompt)路线;它们的共同点核心是都遵循“冻结大部分预训练参数,只训练极小任务参数”这一基本范式。
Adapter 是插在每个 Transformer block 内部的一条很窄的可训练残差支路。设某一层原本输出为 \(h\in\mathbb{R}^{d}\),Adapter 会先把它投影到一个远小于 \(d\) 的瓶颈维度 \(r\),经过非线性后再投影回原维度,再以残差形式加回主干:
\[\mathrm{Adapter}(h)=W_{\mathrm{up}}\;\sigma\!\left(W_{\mathrm{down}}h+b_{\mathrm{down}}\right)+b_{\mathrm{up}},\quad h'=h+\mathrm{Adapter}(h)\]其中 \(W_{\mathrm{down}}\in\mathbb{R}^{r\times d}\) 负责降维, \(W_{\mathrm{up}}\in\mathbb{R}^{d\times r}\) 负责升维,且通常有 \(r\ll d\)。这就是所谓的瓶颈结构(Bottleneck Structure):主干隐藏维度也许是几千,而 Adapter 内部只开放几十到几百维的可训练通道,因此新增参数量远小于全量微调。
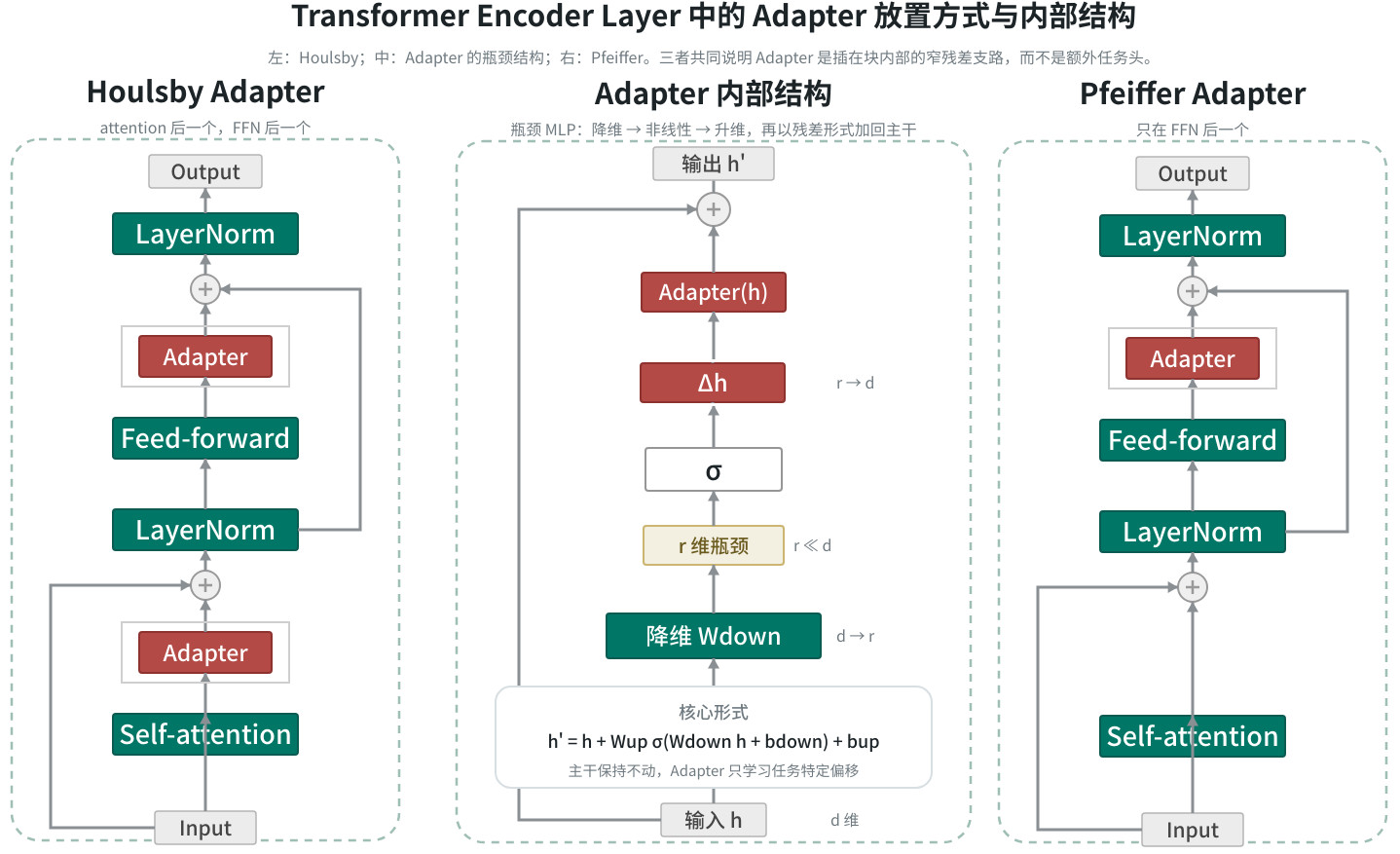
它通常插在自注意力子层或前馈网络子层之后,也就是“原子层输出 + LayerNorm / 残差”附近的位置。最常见的做法是在每个 block 中放两处:一处跟在 attention 输出之后,另一处跟在 FFN 输出之后。这样设计的直觉很直接:主干模型仍负责保留通用语言能力,而 Adapter 只学习相对于原模型的任务特定偏移。由于它是加法残差支路,模型一开始可以非常接近原始基座;随着训练推进,Adapter 再逐步学会把主干表示往当前任务需要的方向轻推一把。
Adapter 常被初始化为近似恒等映射,原因也正在这里:例如让升维层初始非常小,使 \(\mathrm{Adapter}(h)\approx 0\)。这样做的效果是,训练初期模型几乎等同于原始基座,不会因为新增模块而立刻破坏预训练表示;随后再通过反向传播逐步放大这条残差分支,让它承担领域偏移、标签边界重塑或任务路由修正。与“直接改写主干权重”相比,这种路径更稳定,也更容易控制灾难性遗忘。
从参数量角度看,单个 Adapter 的主要新增参数就是两次线性映射,大约是 \(2dr\) 量级,而非全层的 \(d\times d\) 或 \(d\times d_{\mathrm{ff}}\) 量级。因此,只要瓶颈维度 \(r\) 足够小,就能在保持表达力的同时,把训练显存、优化器状态和存储成本压到很低。这一点与 LoRA 的“低秩更新”在精神上相近,但它们的结构并不相同:Adapter 是显式新增一条小型 MLP 支路,LoRA 则是在原线性层内部参数化一个低秩增量。
工业实践里,Adapter 通常核心是分布式地插入到所有 Transformer block 中,从而让每一层都具备任务适配能力。它的一个重要工程优势是“插拔式(Plug-and-play)”任务切换:同一个基座模型可以加载不同任务的 Adapter 包,在情感分析、NER、检索重排等任务之间快速切换,而不必为每个任务都保存一整份完整模型。这也是 Adapter 在多任务部署和组织内模型复用场景中一直很有吸引力的原因。
LoRA(Low-Rank Adaptation)学习一个低秩增量,同时保持原权重 \(W\) 不变 \(\Delta W\):
\[W' = W + \Delta W,\quad \Delta W = BA,\quad B\in\mathbb{R}^{d_{\text{out}}\times r},\ A\in\mathbb{R}^{r\times d_{\text{in}}},\ r\ll \min(d_{\text{in}},d_{\text{out}})\]由于 \(r\) 很小,可训练参数与优化器状态显著减少。实践里常把 LoRA 加在注意力投影(如 \(W_Q,W_K,W_V,W_O\))和/或 FFN 上。
截至 2026 年,LoRA 仍然是大语言模型参数高效微调里最常见的默认方案。原因并不神秘:它与主流 Transformer 线性层天然兼容,适配器权重体积小,便于为不同任务单独保存、热切换与合并;同时它对训练框架、推理框架和量化框架的兼容性也最成熟。因此,工程上常把 LoRA 看成 PEFT 的基线接口:后续很多方法,本质上都是在 LoRA 的参数化、量化方式或更新几何上继续细化。
在上面的记号里, \(A\in\mathbb{R}^{r\times d_{\text{in}}}\) 负责把原始输入方向投影到一个 \(r\) 维低秩子空间, \(B\in\mathbb{R}^{d_{\text{out}}\times r}\) 再把这个低维表示映射回输出空间。因此,对输入向量 \(x\) 而言,LoRA 增量的作用顺序是:
\[\Delta y=\Delta Wx=BAx\]也就是说,先由 \(A\) 做“进低秩空间”的投影,再由 \(B\) 做“回原输出空间”的回投。直觉上, \(A\) 更像在问“哪些组合方向值得被拿出来单独调”, \(B\) 则更像在问“这些低维方向最终该怎样广播回原模型的输出通道”。
不同实现里,A、B 的命名和矩阵形状有时会看起来对调,这是因为有的库按数学乘法顺序命名,有的库按代码中参数张量的存储顺序命名。但概念并没有变:总有一个矩阵负责把高维输入压到低秩子空间,另一个矩阵负责把低秩更新再映射回原空间。只要抓住“先降到 \(r\) 维,再升回原维度”这一点,就不会被不同实现的符号差异干扰。
LoRA 的经典初始化也依赖这两个矩阵的不同角色。常见做法是让其中一个矩阵采用小随机初始化,而另一个矩阵初始化为 0;在当前这组记号下,更常见的叙述是让 \(A\) 随机初始化、 \(B\) 零初始化,于是训练开始时有:
\[\Delta W = BA = 0\]这样做有两个直接好处。第一,训练初始时模型输出与原基座完全一致,不会因为 LoRA 分支突然注入随机扰动而破坏预训练能力。第二,参数不会陷入完全对称的零状态:若两边都初始化为 0,梯度传播会受阻;若两边都随机初始化,训练一开始又会平白给模型加上不必要的噪声。采用“单边随机、单边为零”的非对称初始化,既保证了初始增量为零,又保留了可学习性,这是 LoRA 训练稳定性的关键细节之一。
从梯度角度看,这个设计也有非常直接的理由。若记损失对增量矩阵的梯度为 \(G=\frac{\partial \mathcal{L}}{\partial \Delta W}\),则有:
\[\frac{\partial \mathcal{L}}{\partial B}=GA^\top,\qquad \frac{\partial \mathcal{L}}{\partial A}=B^\top G\]因此,当 \(A\) 随机、 \(B=0\) 时,训练开始的第一步通常会先更新 \(B\),因为 \(\frac{\partial \mathcal{L}}{\partial B}=GA^\top\) 一般不为 0;而 \(\frac{\partial \mathcal{L}}{\partial A}=B^\top G=0\),所以 \(A\) 会在后续几步中随着 \(B\) 脱离零状态后再开始获得梯度。LoRA 的非对称初始化并不会“学不起来”,它只是让学习过程以一种更平稳的方式启动。
LoRA 真正需要重点理解的超参数并不多,但每一个都在控制不同维度的权衡:容量、增量强度、挂载范围、正则化和训练稳定性。它们之间并非简单的“越大越好”关系。
| 参数 | 控制对象 | 理论含义与实践影响 |
| rank \(r\) | 低秩子空间维度 | 决定 \(\Delta W\) 最多能沿多少个独立方向修改原权重。 \(r\) 越小,参数越省、正则效应越强,但容量也越受限; \(r\) 越大,表达力更强,却更容易抬高显存、训练成本与过拟合风险。 |
| \(\alpha\) | 增量缩放强度 | 通常与 \(r\) 一起通过 \(\frac{\alpha}{r}\) 作用在 LoRA 分支上。它控制的是“已经学到的低秩方向到底以多大幅度影响原模型”,因此更接近幅值旋钮,而非容量旋钮。调大 \(\alpha\) 不能替代更高的 \(r\);它只能放大已有方向,而不会创造新方向。 |
| target_modules | 挂载位置 | 决定 LoRA 写入模型的哪一部分。只挂注意力投影时,参数最省、更偏行为与路由调整;把 MLP / FFN 一并纳入时,容量更强,也更适合知识关系与复杂边界适配,但训练更重。 |
| lora_dropout | 适配器正则化 | 主要用于抑制小数据或高重复语料上的过拟合。它在训练时降低低秩分支对局部样本模式的过度依赖,不改变 LoRA 的基本结构。数据量很小时更有价值;数据充分且任务稳定时常保持较低甚至关闭。 |
| 学习率 | 优化步长 | 虽然学习率并非 LoRA 独有参数,但 LoRA 对学习率通常比全参数微调更敏感。因为可训练参数很少、每一步更新更集中,学习率过高时更容易直接把行为边界推歪;而 \(\alpha\) 较大时,这种不稳定会被进一步放大。 |
这几个参数里,最容易被混淆的是 \(r\) 与 \(\alpha\)。 \(r\) 控制的是“允许模型沿多少个方向改”, \(\alpha\) 控制的是“这些方向的改动最终放大到多强”。前者对应容量,后者对应强度。增加 \(r\) 会改变可表达子空间本身;增加 \(\alpha\) 只是把已存在的低秩更新放大。
从经验上看,LoRA 的调参顺序通常也应当遵循这个逻辑:先确定挂载哪些模块、需要多大 rank 才能容纳任务偏移,再去调节 \(\alpha\) 与学习率,让训练稳定落在合适幅度上。若一开始就只靠提高 \(\alpha\) 去追求效果,得到的往往核心是更剧烈的扰动。
LoRA 挂在哪些线性层上,并非纯工程细节,而与希望改变模型的哪一部分能力直接相关。若目标更偏风格迁移、格式控制、对话行为调整或路由方式改变,注意力投影层上的 LoRA 往往已经能带来明显效果;但若目标是注入新的领域术语、事实关联、实体属性映射或专业概念之间的稳定关系,FFN / MLP 往往更关键。原因在于:Transformer 里的 MLP 常被视为知识写入与模式重编码的重要位置,因此很多“新知识”最终要落到这些大规模前馈权重所张成的表示子空间里。
这也是为什么在不少实践中,LoRA 不只挂在 \(W_Q,W_K,W_V,W_O\) 上,还会同时挂在 FFN 的线性层上,甚至在资源允许时为 FFN 分配更高的秩(Rank)。低秩更新的本质是在原有权重空间附近增加一个受限的可训练子空间;如果希望修改的是知识关联本身,而不仅是信息流动方式,那么只改注意力层常常不够,需要让 MLP / FFN 也获得足够的适配容量。沿着这条思路发展的变体,如 DoRA(Weight-Decomposed Low-Rank Adaptation),本质上也是在不做全参数微调的前提下,给参数更新更强的表达能力。
这里的低秩假设作用于微调增量 \(\Delta W\),而非作用于预训练知识本身的存储方式。预训练模型中的知识通常以分布式表示(Distributed Representation)的方式编码在大量参数 \(W\) 里;LoRA 近似的是“为了适配当前任务,需要沿哪些方向改动这些参数”。前者讨论的是 \(W\) 如何承载知识,后者讨论的是 \(\Delta W\) 如何改变模型行为与输出边界。
很多微调任务并不要求模型写入大规模新知识,重点是要求它重新组织已有表示:调整回答风格、强化指令跟随、遵守输出格式、放大某些线索、抑制另一些线索。这类任务的有效更新方向往往集中在少数子空间中,小秩 \(r\) 就足以带来明显收益。若任务要求模型稳定吸纳新的领域本体(Ontology)、术语体系、事实关系或复杂规则,适配增量的有效维度通常会上升,低秩近似就更容易成为容量瓶颈。
分布式存储也不意味着所有参数同等重要。即便在全参数微调(Full Fine-tuning)中,显著变化的往往也是少数关键方向;LoRA 的核心假设是,这些方向可以被一个较低维的子空间有效覆盖。当任务迁移幅度较小,这个假设通常成立;当关键更新分散在许多彼此独立的方向上,就需要更高的秩、更广的挂载范围,尤其是让 FFN / MLP 参与适配,必要时再转向 DoRA 或全参数微调。工程上,这体现为一条清晰的权衡:LoRA 优先优化效率,全参数微调提供更高上限;二者对应的是不同任务内在维度(Intrinsic Dimension)下的不同最优解。
LoRA 的一个工程优势是“可合并(Mergeable)”:推理前可把增量权重并入基座权重,从而不引入额外前向分支。对单个 LoRA,合并后得到的有效权重就是 \(W_{\text{merged}}=W+\Delta W\)(实践中常包含缩放系数)。
当存在多份 LoRA(多任务/多领域适配)时,最简单的合并是对增量做加权和:
\[W' = W + \sum_{j=1}^{M}\lambda_j\,\Delta W^{(j)}\]这种“线性缝合”实现简单,但容易出现任务干扰(Interference):不同 LoRA 在同一参数子空间里叠加,可能让模型对多个任务都变差。若你需要同时服务多个领域,更稳健的方案往往是“运行时选择哪一份 LoRA”或引入路由(Routing)机制,而非把它们永久混成一份权重。
LoRA 的低秩增量在工程实现里通常写成带缩放的形式,而非直接写成 \(\Delta W=BA\):
\[\Delta W=\frac{\alpha}{r}BA\]这里的 \(r\) 是秩(Rank),决定低秩子空间的维度;\(\alpha\) 是缩放系数(Scaling Factor),决定这条增量支路最终以多大强度作用于原权重。把 \(\alpha\) 与 \(r\) 放在一起,核心是为了在改变 rank 时尽量保持更新量的数值尺度处于可控范围。若只增大 \(r\) 而不做归一化,低秩分支的整体幅度往往也会随之增大,使不同配置之间难以直接比较。
因此, \(\alpha\) 控制的是“LoRA 支路有多强”, \(r\) 控制的是“LoRA 支路能沿多少个方向改动权重”。前者更接近幅值控制,后者更接近容量控制。单纯调大 \(\alpha\),只是放大既有低秩方向的影响;单纯调大 \(r\),则是在扩大可表达的更新子空间。
缩放在合并时同样不会消失。真正并回基座的核心是已经乘上系数后的有效增量,因此合并后的权重应写成:
\[W_{\text{merged}}=W+\frac{\alpha}{r}BA\]工程上,较小数据集与较轻任务迁移通常更适合温和缩放,因为此时更重要的是在保留基座先验的同时做局部修正;当任务迁移更深、希望 LoRA 更积极地重写行为边界或知识关联时,才会提高 \(\alpha\) 或放宽 \(r\)。它本质上是在调节“基座保守性”与“任务增量强度”之间的平衡。
DoRA(Weight-Decomposed Low-Rank Adaptation)的核心是先把原始权重 \(W\) 按“幅值(Magnitude)+ 方向(Direction)”重写,再只让低秩更新作用在方向部分。对第 \(j\) 个输出通道,也就是权重矩阵的第 \(j\) 列,可先写成:
\[W_{:,j}=\left\|W_{:,j}\right\|_2\cdot \frac{W_{:,j}}{\left\|W_{:,j}\right\|_2}=m_j\,\hat v_j,\quad \left\|\hat v_j\right\|_2=1\]这里的 \(\frac{W_{:,j}}{\left\|W_{:,j}\right\|_2}\) 就是“把一个向量除以自己的 \(\ell_2\) 范数(L2 Norm)”。这样得到的新向量长度恰好等于 1,因此它不再携带原来的大小信息,只保留方向信息,也就是单位方向向量(Unit Direction Vector)。
这里 \(m_j\) 是一个标量,表示这一列权重的整体长度; \(\hat v_j\) 是单位向量,表示这一列“指向哪里”。这一步只是重参数化(Reparameterization):没有改动原模型,只是把每一列从“一个普通向量”改写成“长度 × 单位方向”。
DoRA 的更新写法通常记为:
\[W'_{:,j}=m'_j\frac{V_{:,j}+\Delta V_{:,j}}{\left\|V_{:,j}+\Delta V_{:,j}\right\|_2},\quad \Delta V=BA\]理解这条式子的关键,在于分清谁在控制方向,谁在控制大小。分式里的 \(V_{:,j}+\Delta V_{:,j}\) 先经过 \(\ell_2\) 归一化,因此无论 \(\Delta V\) 本身把这个向量拉长还是压短,归一化之后保留下来的都只有方向信息。换句话说,LoRA 产生的低秩增量 \(BA\) 在这里主要决定“这一列朝哪个方向偏转”,而不会直接把这一列的范数放大或缩小,因为范数已经被分母除掉了。
真正决定输出通道大小的是前面的标量 \(m'_j\)。如果把 \(m'_j\) 固定住,那么更新后的列向量范数始终满足 \(\left\|W'_{:,j}\right\|_2=m'_j\),此时低秩更新确实只在改方向、不改大小;如果把 \(m'_j\) 设为可学习参数,那么 DoRA 就是在两个通道里分别学习:低秩分支 \(\Delta V\) 负责方向修正,标量 \(m'_j\) 负责幅值修正。无论是哪一种,方向与大小都不再像原始 LoRA 那样纠缠在同一个增量矩阵里。
这也是 DoRA 比原始 LoRA 更接近全参数微调的原因之一。普通 LoRA 直接对 \(W\) 加一个低秩增量 \(\Delta W\),因此“方向变化”和“范数变化”混在同一个更新里;DoRA 则把这两件事显式拆开,使优化器可以分别决定“该往哪里转”与“该放大多少”。当任务需要更深地改写领域知识、重塑复杂判别边界或吸收更稳定的专业概念关系时,这种解耦往往更有表达力;代价则是额外的参数、归一化计算与实现复杂度。
QLoRA 在 LoRA 基础上进一步把基座权重量化(Quantize)到低比特(常见 4-bit),以极小显存加载大模型;训练时仍只更新 LoRA 参数。它把“能不能放得下”从硬约束变成可控工程问题,是许多个人/小团队微调 7B/13B 的关键技术路径之一。
其核心思路是:冻结量化后的基座权重,只在前向/反向计算时对它们做解量化(Dequantize),而真正需要学习的仍是低秩增量。一个简化写法是:
\[Y=X\,\mathrm{Dequant}(W_q)+\frac{\alpha}{r}XBA,\quad W_q=\mathrm{Quant}(W)\]其中 \(X\) 是输入激活, \(W_q\) 是量化后冻结的基座权重, \(\mathrm{Dequant}(W_q)\) 表示把低比特权重恢复到计算精度后的近似值, \(\frac{\alpha}{r}BA\) 是 LoRA 分支, \(\alpha\) 是缩放系数(Scaling Factor),用来控制低秩增量对原模型的影响强度。
这里的“解量化”指:权重在显存或存储中仍以低比特形式保存,只是在一次具体矩阵乘法发生时,临时把对应块恢复成计算所需的近似浮点值,再与输入激活相乘。也就是说,量化主要解决的是存储与显存占用,而解量化解决的是如何让这些低比特权重仍然参与正常线性计算。
因此,所谓“解量化计算路径”指的是:训练框架是否知道如何从低比特权重 \(W_q\) 出发,在前向过程中正确恢复近似浮点表示、完成矩阵乘法,并在反向传播时把梯度只传给 LoRA 分支而非错误地写回量化权重本体。若这条路径存在,那么量化基座虽然被冻结,仍然可以作为可计算的主干参与训练;若这条路径不存在,量化权重就只是某种压缩后的静态文件,能用于推理加载,却不能自然地嵌入 QLoRA 的训练图中。
这里的前提核心是必须拥有一份训练兼容的冻结量化基座。如果基座本身已经是可被训练框架直接加载、解量化并挂接 PEFT 的 4-bit / 8-bit 版本,那么它完全可以直接作为 QLoRA 起点;但如果它只是面向推理部署的静态量化模型,例如某些只强调推理速度或离线压缩格式的 checkpoint,那么它往往并不适合作为 QLoRA 的训练底座。决定因素不在于“是关键在于这种量化形式是否仍然保留了训练时所需的解量化计算路径与 PEFT 兼容性。
QLoRA 的关键不仅“4-bit”,还分块量化(Block-wise Quantization):权重不会用一套全局刻度统一压缩,会被划分成许多小块,每块各自保存缩放因子。若第 \(g\) 个块的量化码为 \(\hat{w}^{(g)}\),对应缩放因子为 \(s_g\),则可抽象写成:
\[w^{(g)}\approx s_g\,\hat{w}^{(g)}\]这个“分块”通常核心是按固定块大小(例如若干连续权重为一组)直接切开。原因很简单:连续切块最容易实现,也最适合 GPU 并行。对每一个块,系统会单独估计一个比例尺 \(s_g\),再用这个块自己的尺度去压缩和还原权重。于是更完整的写法通常是:
\[w^{(g)}\approx s_g\cdot Q\!\left(\frac{w^{(g)}}{s_g}\right)\]这里的 \(Q(\cdot)\) 表示把归一化后的数值映射到低比特量化码。也就是说,比例尺 \(s_g\) 的作用是先把第 \(g\) 个块拉到一个统一的局部数值范围,再交给 4-bit 码本处理;反量化时再乘回 \(s_g\)。在最朴素的实现里, \(s_g\) 可以由该块的最大绝对值、均方根,或其他稳健统计量导出,本质都是在问同一个问题:这一小块权重大致处在什么量级上。
一个极小的数值例子能说明为什么需要逐块比例尺。假设某一块权重大致落在 \([-0.1,0.1]\),另一块却落在 \([-3,3]\)。如果整个张量只共享一个全局比例尺,那么为了容纳大块的幅度,小块里的许多细微差异都会被压扁,量化后落到相同的低比特值;而若分别为这两块设置 \(s_1\) 与 \(s_2\),两块都能在自己的局部范围里充分利用有限的 4-bit 表示能力。分块量化因此比全局共用一个缩放因子保留了更多有效信息,尤其更能缓解离群值(Outlier)对整体刻度的污染。
NF4(Normalized Float 4)进一步改进的核心是块内映射到哪一套 4-bit 码本。普通均匀量化更像是把一个区间机械地分成若干等宽小段;NF4 则利用很多 Transformer 权重在局部块内常呈现零中心、近似正态分布的事实,预先设计一套更贴近这种分布的离散代表值。于是块内每个权重更接近写成:
\[w_i^{(g)}\approx s_g\cdot c_{q_i}\]其中 \(c_{q_i}\) 是 NF4 码本中的代表值, \(q_i\) 是对应的 4-bit 索引。它核心是先按块做尺度归一化,再用更贴近正态权重分布的码本去逼近这些局部值。
双重量化(Double Quantization)与分页优化器(Paged Optimizer)则是在这套分块量化之上继续做工程压缩。前者的思路是:每个块都要保存自己的 \(s_g\) 或相关元数据,这些量的数量虽然远少于权重数,但它们的精度通常更高,而且每个因子只服务一个较小的权重块,因此把这部分成本均摊回“每个参数”之后,并不总能忽略。举例说,若一个缩放因子用 32 bit 保存、对应一个 64 权重的块,那么仅缩放因子这一项就相当于给每个参数额外分摊了 \(32/64=0.5\) bit;在 4-bit 权重场景里,这已经并非一个可以随手忽略的附加成本。双重量化做的,就是把这些缩放因子或相关元数据再压一层,继续降低这笔“元数据税”。后者则借鉴操作系统的分页思想,把优化器状态按页在 GPU 与 CPU 内存之间调度,从而避免 Adam 一类优化器把峰值显存推得过高。它们在工程层面继续压低“把大模型微调跑起来”的资源门槛。
Q-DoRA 可以看作 QLoRA 与 DoRA 的组合:基座仍采用低比特量化以节省显存,但更新形式从普通 LoRA 转向“量化基座 + 方向/尺度解耦”的 DoRA 结构。一个简化表达是:
\[W'_{:,j}=m_j\frac{\mathrm{Dequant}(W_{q,:,j})+\Delta V_{:,j}}{\left\|\mathrm{Dequant}(W_{q,:,j})+\Delta V_{:,j}\right\|_2},\quad \Delta V=BA\]它的工程含义很直接:用 QLoRA 解决“显存放不下”的问题,用 DoRA 缓解“低秩更新表达力不够”的问题。若资源非常紧、任务主要是格式控制与轻量指令对齐,普通 QLoRA 往往已经足够;若任务更偏逻辑推理增强、专业知识注入、复杂边界判别或高质量垂直领域适配,Q-DoRA 往往是更稳妥的折中。对应代价是训练更慢、实现更复杂,且并非所有推理栈都像原始 LoRA 那样原生支持。
LoRA-MoE 可以理解为“适配器级的 MoE”:保留基座不变,不把 FFN 变成稀疏专家,准备多份 LoRA 作为“领域专家”,再用一个路由器(Router)按请求/句子/甚至 token 选择或加权组合这些 LoRA。直觉上,它用极小的可训练参数,为同一个基座提供多域能力,同时避免把所有任务硬合并到一份权重里。
一种抽象表达是把输出写成“基座 + 适配器混合”:
\[h' = f_{\text{base}}(h) + \sum_{e\in \mathcal{E}} g_e(x)\,f_{\text{lora},e}(h),\quad \sum_e g_e(x)=1\]其中 \(g_e(x)\) 是路由权重,可以来自显式分类器(域识别)、检索到的任务标签,或一个可训练的 gating 网络。工程上,LoRA-MoE 的关键不在公式,而在路由与评测:你需要定义“什么输入该走哪套 LoRA”,并防止路由错误导致质量抖动。
截至 2026 年,LoRA-MoE 的实际地位更接近高级可选架构,而非参数高效微调里的默认主流基线。它已经形成了一条持续演进的方法线,说明“多 LoRA + 路由”并非概念玩具;但在更常见的工业部署里,成熟默认方案仍然往往是“单基座 + 多个独立 LoRA 适配器”,按请求或租户切换,而非把路由器永久并入模型主干。原因并不神秘:LoRA-MoE 除了要训练适配器本身,还要额外处理路由质量、专家利用不均、冷专家几乎不被激活、线上可观测性以及请求分布变化带来的稳定性问题。只有当任务确实需要在同一个运行图里动态融合多域能力,而非简单地在不同 LoRA 之间切换时,LoRA-MoE 的额外复杂度才更值得支付。
比 LoRA-MoE 更常见、也更容易落地的方案,是多个独立 LoRA 共享同一个基座模型。这里的共享核心是让基座参数在 GPU 中只保留一份;不同请求到来时,再按请求绑定对应的适配器。这样做的直接收益是:显存里最重的那部分参数不需要为每个任务重复存一遍,而任务差异主要体现在额外加载的轻量增量权重上。
从推理执行角度看,这种“热切换”并不意味着每来一个请求就重新加载整个模型。更常见的做法是:基座常驻显存,LoRA 适配器按需驻留在 GPU 或 CPU 侧缓存中;请求只需声明“当前使用哪一份适配器”,调度器就会在对应层上把这一份 LoRA 增量接入当前 forward。若某个适配器近期很少被访问,它可以被换出;当请求再次到来时,再从本地盘、对象存储或 Hub 拉回。于是系统真正管理的是适配器缓存与调度,而非整模型重载。
这条路线之所以在 2026 年更主流,是因为它把“多域能力”问题拆成了两个更容易控制的子问题:第一,训练阶段各自产出独立 LoRA,任务之间天然隔离;第二,推理阶段只做选择和缓存,不必额外训练路由器,也不会把多个领域永久混到同一组权重里。代价主要落在工程侧:适配器的 rank、目标模块集合、张量并行配置与基座版本必须兼容;同时服务系统还要决定 GPU 能同时保留多少份 LoRA、超出容量时按什么策略驱逐,以及批内是否允许不同请求混用不同适配器。
截至 2026 年,这已经核心是主流高吞吐推理框架的标准能力之一。vLLM 支持按请求选择 LoRA,既可以在服务启动时预注册,也支持通过运行时 API 与解析插件动态加载;SGLang 支持同一批次中的不同序列绑定不同 LoRA,并提供适配器加载、驱逐、后端 kernel 与批内 LoRA 数量控制;Hugging Face TGI 也支持在启动时加载多份 LoRA 并在请求中指定 adapter;TensorRT-LLM 则已经提供多 LoRA 推理示例与运行时请求绑定接口。换句话说,多 LoRA 共享基座在今天更像是一种成熟的服务形态,而非实验性质的技巧。
| 方案 | 参数/存储 | 推理开销 | 多域能力 | 主要风险 |
| 多 LoRA 合并 | 单份权重 | 最低(一次 forward) | 不稳定(易相互干扰) | 合并策略难;回滚困难 |
| LoRA-MoE(路由) | 多份 LoRA + 路由器 | 低~中(取决于是否多专家叠加) | 强(可按域选择) | 路由错误;线上一致性与可观测性要求更高 |
| 全量 MoE(FFN 专家) | 多专家权重 | 中(Top-k 专家计算) | 强(容量大) | 训练与部署复杂;负载均衡与稳定性 |
与 LoRA、Adapter 这类“直接改模型内部参数化”的路线不同,基于 Prompt 的微调把任务适配写在输入条件上。它的核心是构造一小段能够引导模型行为的任务条件,让模型在保持基座冻结的前提下,沿着这段条件生成更符合目标任务的输出。
这里需要先把两类 Prompt 区分开。硬提示(Hard Prompt)是人工编写的离散文本提示,本质上属于提示工程(Prompt Engineering),而非参数高效微调;软提示(Soft Prompt)则是一组可训练的连续向量,通常可以看成“不对应真实词表 token 的虚拟 token embedding”。前者没有训练参数,可解释性强但搜索空间受限;后者进入连续空间后更容易通过梯度优化找到有效解,因此才构成 Prompt Tuning、Prefix Tuning、P-Tuning、P-Tuning v2 这一路软提示微调家族。
从机制上看,软提示路线的共同点是:人为构造或学习一小段任务向量,把它们拼接到原始输入或注意力状态中,再让这些额外向量参与模型的注意力计算,从而影响后续真实 token 的生成和判别。它的工程优势非常明确:主干参数无需为每个任务复制一份,多任务场景下只需切换不同的 Prompt 参数即可。
| 路线 | 作用位置 | 可训练参数量 | 主要优点 | 主要边界 |
| 硬提示 | 输入文本 | 0 | 可读、可解释、适合快速验证 | 离散搜索困难,效果上限受人工设计限制 |
| Prompt Tuning | 输入层 | 极少 | 最轻、最易多任务切换 | 只影响输入端,表达力最弱 |
| Prefix Tuning | 各层注意力 | 很少 | 比纯输入层软提示更强,能在每层引导注意力 | 实现更复杂,与模型结构耦合更深 |
| LoRA / QLoRA | 模型内部线性层 | 较少 | 效果更稳、更通用 | 需要改写模型参数化与训练图 |
因此,硬提示、软提示与 LoRA 的差异,不仅“参数多少”,还任务条件被写入模型的层次不同。硬提示只改自然语言输入;Prompt Tuning 把任务条件写进输入嵌入;Prefix Tuning 把任务条件送进每层注意力;LoRA 则直接改写模型内部线性映射的参数化。条件写得越深,通常表达力越强,但实现和系统复杂度也越高。
Prefix Tuning 属于软提示类 PEFT。它学习的核心是一组连续可训练向量(Continuous Prefix),并把这组向量作为每一层注意力里的额外 Key / Value 注入。若某层原本的注意力键值对为 \(K,V\),则 Prefix Tuning 可以理解为把它们扩展成 \([K_{\text{prefix}};K]\) 与 \([V_{\text{prefix}};V]\),让后续 token 在每一层都能访问这段任务特定“前缀记忆”。
它的关键不仅“在输入前加几个向量”,还在所有层分别注入前缀状态。不同层的前缀通常并不共享;每一层都有自己的 prefix 参数,因为浅层和深层承担的表示功能并不相同。于是,Prefix Tuning 更像是在每一层都额外挂上一小段可学习上下文,让模型在整条前向路径中持续感知任务条件,而非只在输入口看一眼提示后就完全交给主干自行传播。
若前缀长度记为 \(m\)、模型隐藏维度记为 \(d\)、层数记为 \(L\),那么最粗略的参数量量级可以理解为 \(O(Lmd)\)。这也是它为什么通常比全量微调和 LoRA 更轻,但又明显重于单纯输入层 Prompt Tuning:它的参数量来自“每层各有一小段前缀”,而非只在输入层保存一组虚拟 token。
直接把前缀向量当作自由参数去优化,并不总是最稳定。因为这些向量一开始就要进入每层注意力,如果初始化过于随意,训练前期很容易让注意力分布出现较大抖动。为此,Prefix Tuning 的经典实现常引入一层小型重参数化网络,例如用一个 MLP 先把较低维或更结构化的中间表示映射成真正送入各层的 prefix Key / Value。
这种做法的本质是把训练阶段的优化空间改造成更平滑、更容易收敛的形式。训练完成后,这个 MLP 生成出的前缀状态通常可以被直接缓存或固化,推理时未必需要继续保留完整重参数化模块。因此,它更像一种训练期稳定化技巧,而非 Prefix Tuning 必须背负的长期结构成本。
它与 Prompt Tuning 的差别不在于“前缀长短”,而在于注入位置。Prompt Tuning 只在输入嵌入层增加一小段软提示;Prefix Tuning 则把任务参数直接送进每层注意力,因此它通常更有表达力,也更接近“在每层引导模型如何读写上下文”。代价是实现更复杂,模型结构耦合更深,训练与推理栈也更需要原生支持。
到 2026 年,Prefix Tuning 仍然是成立且标准的 PEFT 方法,但它在主流大语言模型指令微调里的存在感已经明显弱于 LoRA。它最有价值的场景通常是:希望极小参数量地控制条件生成行为、使用 Encoder-Decoder 或较经典的条件生成架构,或者研究上需要把“任务条件”明确写进每层注意力。若任务是当代 Decoder-only LLM 的通用指令对齐、风格迁移或领域适配,LoRA / QLoRA 往往仍是默认起点:更稳、更通用、推理框架支持也更成熟。
Prompt Tuning(软提示/Soft Prompt)同样属于 PEFT,但它比 Prefix Tuning 更轻:只在输入嵌入层前面拼接一小段可训练“虚拟 token embedding”,而不改动 Transformer 内部层的参数结构。设输入嵌入序列为 \(E(x)\),软提示为 \(P\in\mathbb{R}^{m\times d}\),则模型实际看到的是拼接后的序列 \([P;E(x)]\)。训练时更新的只有 \(P\),基座参数保持冻结。
它的核心假设是:对于某些任务,模型原本的能力已经足够,真正缺少的只是一个足够好的“任务启动条件”。如果这组输入层虚拟 token 能把模型推到合适的工作点,后面的冻结主干就能沿着原有能力完成任务。因此,Prompt Tuning 在参数量上往往可以做到比 LoRA 还小一个量级,尤其适合“大量轻任务共享同一基座”的场景。
Prompt Tuning 与 Prefix Tuning 的根本区别,不在于二者都用了虚拟 token,而在于任务条件写入的深度不同。Prompt Tuning 只在输入层插入软提示,后续所有层看到的都是这段输入在主干网络中自然传播后的结果;Prefix Tuning 则直接在每一层注意力中附加前缀状态,使任务条件持续存在于整条注意力链路中。前者最轻,后者更强。
Prompt Tuning 在超大模型上有时会随着基座规模增大而变得更有效,因为大模型本身已经足够强,输入端的一点点软条件就足以触发所需能力;而在中小模型或需要强行为控制的任务上,它往往不如 Prefix Tuning、LoRA 稳定。
围绕这一路线还发展出 P-Tuning、P-Tuning v2 等变体。它们的共同目标,都是让软提示不仅停留在“输入前拼一小段向量”这么简单,还通过更强的参数化或更深层的注入方式,提高在理解类任务和较小模型上的表现。若把家族关系压缩来看:Prompt Tuning 是最轻的输入层软提示;Prefix Tuning 把软提示推进到各层注意力;P-Tuning / P-Tuning v2 则在“如何生成这些提示、提示该注入多深”上继续增强。
到 2026 年,Prompt Tuning 仍然实用,但更像轻量特化选项而非主流默认路线:当目标是极小参数、海量任务复用、低存储部署或 prompt-adapter 风格服务时,它仍有现实价值;当目标是指令遵循、复杂格式约束、长对话行为修正或稳定领域适配时,LoRA / QLoRA 往往更稳妥,Prefix Tuning 也通常比纯输入层软提示更有表达力。
前面列出的全量微调、部分参数微调、Prompt 系软提示、Adapter、LoRA、QLoRA 核心是针对不同约束条件的不同最优解。真正决定选型的,通常核心是四个问题同时成立时的交集:样本量够不够、GPU 预算有多紧、任务到底是在改行为还是改知识、上线时更看重单任务极致效果还是多任务复用与切换。
样本量是第一道分界线。数据很少时,更应优先考虑冻结主干参数的路线,例如 Prompt Tuning、Prefix Tuning、LoRA、QLoRA 或更轻的部分参数微调。原因不仅“省显存”,还冻结主干更容易保留预训练先验,降低小数据把模型硬拉向局部模式的风险。数据足够大、分布足够稳定、目标能力又确实需要深度改写时,全量微调才更值得支付它的高成本,因为只有在这种条件下,放开全部参数带来的表达上限才真正有机会被利用。
GPU 资源是第二道分界线。若显存非常紧,QLoRA 往往是生成模型微调的现实起点;若任务更轻、希望一个基座承载大量小任务,Prompt Tuning 或 Prefix Tuning 的存储优势会更突出;若 GPU 充裕且追求最强任务特化,上限仍然在全量微调一侧。换句话说,量化 LoRA 解决的是“放不放得下”,LoRA 解决的是“如何低成本改行为”,而全量微调解决的是“是否要把整套模型一起重写”。
任务性质决定第三道分界线。若变化主要发生在输入接口,例如新增专有 token、符号或特殊控制标记,输入层微调与软提示通常比全模型更新更自然;若变化主要体现在最终读出或评分方式,输出层微调往往就够;若目标是稳定调整指令遵循、格式约束、风格边界、多轮行为或一般性领域适配,LoRA / QLoRA 通常是默认解;若真正需要吸收大量新知识、重构深层表示、改变词表、上下文长度或位置编码等底层设定,则继续预训练或全量微调才更匹配问题本质。
推理形态决定第四道分界线。多任务在线服务最看重“一个基座 + 多个轻量增量”时,LoRA 及其热切换形态通常最实用;Prompt Tuning 与 Prefix Tuning 也具备同样的任务切换优势,只是主流推理框架与工业实践对 LoRA 的支持更成熟。Adapter 虽然同样具备插拔式优点,但它会在前向路径里保留额外计算分支,因此在当代大模型场景里通常不再是默认首选。若目标是最低推理延迟,合并后的 LoRA 与单体全量微调模型通常更占优;若目标是海量任务共享一个基座、频繁热切换,则运行时加载轻量适配器更灵活。
| 微调技术 | 何时优先考虑 | 主要优点 | 主要代价或边界 |
| 全量微调 | GPU 资源充足、样本量充足、任务需要深度改写模型能力 | 表达上限最高,最适合深领域迁移与强任务特化 | 显存、时间和存储成本最高,也最容易削弱通用泛化 |
| 部分参数微调 | 只需要改特定层或特定结构,或现有框架不便直接接入 PEFT | 选择性强,能用较低成本试探“真正该改哪里” | 容量有限,往往更像折中方案而非通用默认解 |
| Prompt Tuning / Prefix Tuning | 样本较少、任务很多、希望极小增量复用同一基座 | 参数极少,保留主干泛化,适合多任务轻量切换 | 表达力通常弱于 LoRA;Prefix 实现更复杂,Prompt 在复杂行为控制上更弱 |
| Adapter | 需要显式模块化、任务插拔或特定架构兼容路径 | 结构清晰、任务隔离好、便于组织内复用 | 前向路径保留额外分支,在大模型场景里主流度已弱于 LoRA |
| LoRA | 通用生成模型微调、多任务适配、需要效果与效率平衡 | 效果稳、生态成熟、可合并、可热切换,是当前主流默认基线 | 仍需选择 rank、挂载位置与训练稳定性权衡;深知识注入时可能容量不足 |
| QLoRA / 量化 LoRA | GPU 资源非常有限,但仍需要微调较大生成模型 | 显著降低显存门槛,让 7B / 13B 级模型微调更可落地 | 训练链路更复杂;若任务要求极强表达力,最终仍可能需要更重路线 |
因此,微调技术选型可以压缩成一条很实际的经验顺序:先判断是否根本不该训练参数,而应优先做参数外优化;若需要训练,再判断任务是否只是轻量行为适配,此时 LoRA / QLoRA 往往是默认起点;若样本极少且强调多任务极致轻量切换,软提示路线才更有吸引力;若任务要求深度改写底座知识或结构,再考虑继续预训练与全量微调。只有当这些路线都无法满足目标时,才值得继续向更重、更贵的训练方式推进。
再往前走一步,就是下一节的偏好对齐问题:如果模型已经学会了任务本身,却仍然不会在多个可行回答中稳定偏向人类真正想要的那个,那么问题就已经从“选哪种微调技术”扩展到要不要进入奖励模型、DPO、PPO、GRPO 这一层相对偏好优化。
| 路线 | 直接监督信号来自哪里 | 参考模型的作用 | 如何防止偏离 SFT 太远 |
| RLHF + PPO | 奖励模型输出的 reward;奖励模型本身来自人类偏好数据 | 作为参考策略 \(\pi_{\mathrm{ref}}\),通常是 SFT 模型的冻结副本 | 显式加入 KL 项,把当前策略锚定在参考分布附近 |
| DPO | 显式偏好对 \((x,y_w,y_l)\) | 作为锚点,比较“当前模型相对参考模型是否更偏向好答案、远离差答案” | 不单独写 KL 惩罚项,但在损失中隐式约束模型不要脱离参考模型过远 |
| GRPO | 同一 prompt 下一组回答的评分、排序或规则反馈 | 常作为参考策略或 KL 正则锚点;具体是否使用取决于实现 | 通过组内相对优势更新,必要时再叠加参考模型 KL 约束 |
强化学习对齐(RL-based Alignment)更准确的说法是“偏好对齐(Preference Alignment)”:用偏好信号把模型输出推向“更符合人类/评审标准”的区域。监督微调(SFT)解决的是“模型是否会按指令作答”,偏好对齐解决的则是“在多个看似都能回答问题的候选答案中,模型是否会稳定偏向更有帮助、更安全、更符合人类预期的那个”。两者前后衔接为两层约束,并不重复。
监督微调本身当然可以承担一部分对齐工作。只要训练数据里显式包含拒答样例、安全边界、好坏答案对照、批判依据(Critique Rationale)、自我修正链路,模型就能通过有监督学习吸收相当一部分“什么回答风格更合适、什么回答应当避免”的行为模式。很多现代对齐流程的第一步,本来就是把这些规则先写进 SFT 数据,再让模型学会基础行为边界。
但 SFT 的学习目标本质上仍然是给定输入,去拟合某个目标输出。若把提示词记为 \(x\)、参考答案记为 \(y\),那么它优化的是 \(\log \pi_\phi(y|x)\) 这一类似然目标。即使数据里同时给出“好答案、坏答案、批判依据”,SFT 也主要是在学习如何复现这些文本本身,而非直接学习“在多个候选回答之间,哪个应该被稳定偏好”。这意味着它更擅长教会模型怎样说,却不天然等价于教会模型怎样在多个可行答案里做排序。
拒绝采样微调可以看作这两层之间的一条中间路线。它先让模型对同一提示词生成多个候选,再借助验证器、规则或奖励信号只保留最好的一部分,把筛选结果重新写回监督数据,再继续做 SFT。这样做比纯手工监督更能利用自动评估,但仍然没有显式保留“胜者为何优于败者”的相对排序结构,因此它更像把偏好信号先离散化成高质量目标答案,再交给监督微调吸收。
偏好对齐之所以需要单独成层,关键就在这里。很多真实问题存在一组“都不算错、但质量不同”的候选回答,而非唯一标准答案:有的更完整,有的更安全,有的更符合语气预期,有的虽然事实没错却明显不够有帮助。把这种问题压成单一参考答案做 SFT,模型容易学到某一种写法,却未必真正学到“为什么 A 应优于 B”。批判依据也有同样的局限:模型可以学会输出一段像样的批判文本,但这并不自动保证它在自由生成时,会稳定地把这些批判原则内化为回答排序规则。
因此,今天更准确的技术分层是:SFT 可以完成基础行为对齐,而偏好优化负责处理相对偏好排序。前者让模型学会回答、学会拒答、学会遵守基本格式;后者让模型在多个都看似合理的答案之间,更稳定地偏向人类真正想要的那个。也正因为如此,现代对齐并不必然等于“强化学习”本身:PPO / RLHF 是一条路线,DPO、ORPO 等把偏好直接写进损失的路线则是另一条路线。它们解决的是同一个问题,只是优化手段不同。
这一层之所以重要,还因为大模型的质量并不能被单一指标完整刻画。古德哈特定律(Goodhart's Law)指出:一旦某个指标变成优化目标,它往往就不再是一个好的指标。放到模型对齐里,这意味着如果只盯住某个狭窄基准分数,模型很可能学会迎合该指标,却牺牲真正的可用性、稳健性与安全性。偏好对齐因此更强调相对排序、多维度评审与参考模型约束,而非把“好答案”简化成单一静态分数。
从工程上看,主流路线分为两类:
- 显式奖励:先训练奖励模型(Reward Model),再用 PPO 等策略优化算法做 RLHF。
- 直接偏好:不显式训练奖励模型,直接用偏好对优化策略(例如 DPO)。
奖励函数(Reward Function)是偏好对齐里最容易被低估的一层。它决定策略优化阶段真正追求什么,也决定模型会把哪些行为当成“值得更常生成”的行为。若奖励函数只覆盖格式,模型会优先学格式;若奖励函数只奖励短答案,模型会压缩回答;若奖励模型存在系统性偏差,策略优化会把这种偏差放大。
从理论变量看,奖励函数可以写成 \(r(x,y)\):给定提示词 \(x\) 和模型回答 \(y\),输出一个标量分数、排序信号或结构化反馈。这个信号随后进入优势估计(Advantage Estimation)和策略更新,影响模型提高哪些回答的概率、压低哪些回答的概率。
| 奖励类型 | 典型来源 | 适合任务 | 主要风险 |
| 规则奖励 | 答案匹配、JSON schema、正则解析、格式约束、长度约束 | 数学、结构化抽取、格式化输出、闭集问答 | 规则覆盖不足时,模型会学会利用解析器漏洞或输出模板化答案。 |
| 执行奖励 | 代码单测、SQL 执行、工具调用成功率、沙箱结果 | 代码、数据库、工具 Agent、可验证工作流 | 执行成本高,需要隔离、超时控制、重试和安全边界。 |
| 奖励模型 | 人类偏好数据训练出的 pairwise reward model | 开放式问答、写作、客服、安全和主观偏好 | 分布外误判、长度偏置、模板偏置和奖励黑客。 |
| LLM-as-judge | rubric 打分、成对比较、多维自动评审 | 快速评估开放式质量、人工标注前的数据筛选 | judge 的偏差、幻觉和位置偏好会进入训练闭环。 |
| 混合奖励 | 正确性、格式、长度、安全、KL、工具结果的加权组合 | 真实产品任务,单一指标不足以覆盖全部质量维度 | 各项尺度不一致时,最大的一项会吞掉其他目标。 |
奖励函数设计应先明确主目标与护栏目标。主目标直接对应任务成败,例如答案正确、代码测试通过、检索命中或用户偏好胜出;护栏目标限制模型用不健康方式拿分,例如超长输出、重复模板、格式投机、拒答过度或安全越界。两类目标最好分别记录日志,再在训练目标中加权组合。若只保留合成后的单一 reward,训练后很难判断模型到底是在变聪明,还是只是在钻某个奖励项的空子。
奖励函数还必须经过独立验证。训练前应在固定样本集上检查 reward 的均值、方差、零分比例、满分比例、长度相关性,以及人工查看高分坏例和低分好例。对在线 RL 来说,奖励函数本身就是“教师”;教师错得稳定,学生也会稳定地学错。
TRL、OpenRLHF、verl、LLaMA-Factory、Axolotl 这类系统属于偏好对齐的实现层。它们本身通常不改变“偏好信号如何定义”的理论问题,主要把 rollout、奖励计算、参考模型约束、策略更新、checkpoint、分布式资源和日志追踪组织成可运行系统。理解这些框架时,应先把它们映射回前面的对齐变量。
| 框架里的名字 | 理论含义 | 在偏好对齐中的作用 |
| actor / policy | 当前可训练策略 \(\pi_\phi(y|x)\) | 根据 prompt 生成候选回答,并在训练中被梯度更新。 |
| rollout | 从当前策略采样 \(y\sim \pi_\phi(\cdot|x)\) | 产生用于打分和更新的模型回答。vLLM、SGLang 等引擎主要服务这一阶段。 |
| reward model / reward function / rubric | 奖励函数 \(r(x,y)\) | 把回答质量转成标量、排序或结构化反馈,可来自人类偏好模型、规则、单元测试、rubric 或外部裁判模型。 |
| reference policy | 冻结参考策略 \(\pi_{\mathrm{ref}}(y|x)\) | 提供 KL 锚点,限制当前策略远离 SFT 起点过快,降低奖励黑客和语言退化风险。 |
| critic / value model | 价值函数 \(V(x,y_{<t})\) 或 baseline | PPO 中用于降低策略梯度方差。GRPO、RLOO 等方法会弱化或移除显式 critic,用组内统计或留一基线替代。 |
| advantage estimator | 优势估计 \(\hat{A}\) | 把 reward、baseline、KL 项和组内统计转成“这条回答相对应该被鼓励还是压低”的训练信号。 |
从这张映射表可以看出,RL 后训练框架关注的是同一个闭环:当前策略生成回答,奖励系统给出反馈,优势估计器把反馈转成更新方向,参考模型约束策略漂移,训练后端负责真正更新参数。PPO、GRPO、RLOO、ReMax、REINFORCE++ 等算法的差异,主要体现在 advantage、baseline、KL 和采样组织方式上。
不同框架的理论重心也不同。TRL 更接近“把 SFT、DPO、GRPO、RewardTrainer 做成一组训练器”;OpenRLHF 更强调多角色在线 RLHF,把 actor、critic、reward、reference 和 rollout 引擎拆成分布式服务;verl 更强调 HybridFlow 风格的统一 worker、资源池和多算法切换;LLaMA-Factory、Axolotl 更像配方层,把 SFT、DPO、PPO、GRPO 等训练路线整理成配置化流程。它们最终都服务同一个目标:让模型在多个可行回答中更稳定地偏向高质量输出。
奖励模型(Reward Model, RM)把(提示词 \(x\),回复 \(y\))映射为一个标量分数 \(r_\theta(x,y)\in\mathbb{R}\)。它的职责核心是充当自动评审器:输入“问题 + 回答”,输出一个可比较的质量信号,用来近似人类对回答质量的偏好判断。
奖励模型的训练数据通常是成对偏好数据,而非单条样本加绝对分数。对同一提示词 \(x\),先让模型生成多个候选回答,再由人工标注员或更强的评审模型选择其中更优的一条,形成三元组 \((x,y_w,y_l)\):其中 \(y_w\) 是被接受的回答(chosen response),\(y_l\) 是被拒绝的回答(rejected response)。
这种二选一偏好标注通常比直接打 1 到 5 分更稳定。原因并不复杂:绝对分数依赖个人尺度,主观漂移大;相对偏好只要求判断 A 和 B 谁更好,一致性通常更高,标注成本也更低。因此,现代偏好对齐流程更常见的监督信号是排序关系,而非绝对评分。
奖励模型通常以已经完成 SFT 的语言模型为骨干(Backbone)进行改造,而非从零开始训练:保留主体 Transformer 表示层,移除原先用于生成下一个 token 的语言建模头(LM Head),换成一个输出单一标量的质量头(Reward Head)。这样做的好处是,奖励模型继承了 SFT 模型对指令与回答结构的理解,只需要继续学习“哪种回答更好”这一层偏好判断。
对一对“胜/负”样本 \((x,y_w,y_l)\),常用 Bradley–Terry / Logistic 形式把分数差转为偏好概率:
\[\Pr(y_w \succ y_l\mid x)=\sigma\!\left(r_\theta(x,y_w)-r_\theta(x,y_l)\right)\]并用对数损失训练:
\[\mathcal{L}_{\mathrm{RM}}(\theta)=-\log \sigma\!\left(r_\theta(x,y_w)-r_\theta(x,y_l)\right)\]关键点:sigmoid 用在“分数差”上,而非对每个 \(r_\theta(x,y)\) 再套一层 sigmoid。分数本身不需要限制在 \([0,1]\);概率来自差值的 logistic 映射。
参数 \(\theta\) 表示奖励模型的参数集合(Parameter Set),包含全部权重矩阵与偏置项,并非单一标量。
单调性视角:因为 \(\sigma\) 单调递增且 \(-\log(\cdot)\) 在 \((0,1)\) 上单调递减,所以 \(\mathcal{L}_{\mathrm{RM}}\) 对分数差 \(\Delta r=r_\theta(x,y_w)-r_\theta(x,y_l)\) 单调递减。训练会推动 \(\Delta r\) 变大,从而把胜者分数推高、败者分数压低。
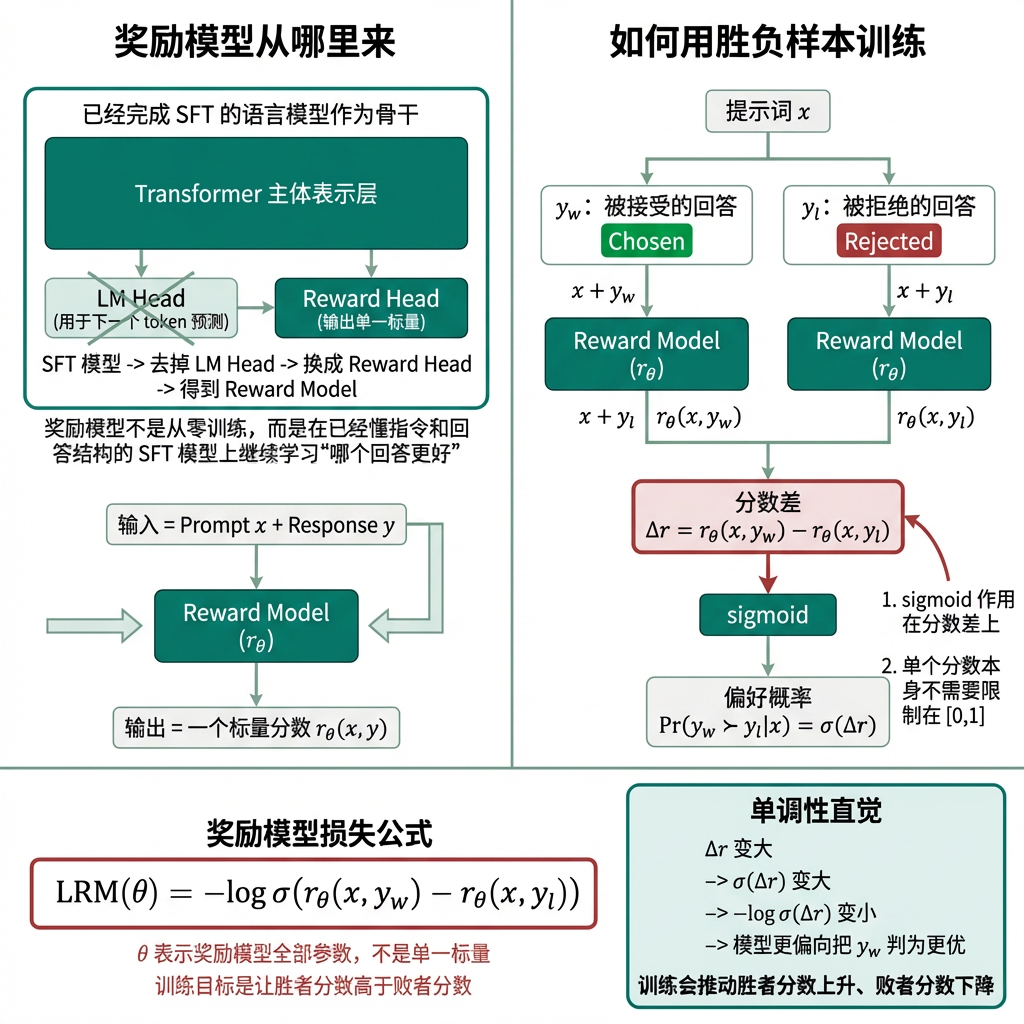
RLHF(Reinforcement Learning from Human Feedback)把整个偏好对齐流程拆成三段:先收集偏好数据,再训练奖励模型,最后用奖励模型为主语言模型提供优化信号。它的核心贡献不在于“使用了强化学习”本身,而在于把原本昂贵、缓慢、难以规模化的人类评审,转化成可以自动计算的奖励分数。
在 RLHF 里,语言生成被改写为一个强化学习问题:token 是动作(Action),策略是语言模型 \(\pi_\phi(y|x)\),奖励来自 \(r_\theta(x,y)\)。早期最经典、也最具代表性的做法,是以 PPO(Proximal Policy Optimization)作为策略更新算法,用奖励模型给出的分数提高高质量回答的生成概率,同时压低低质量回答的概率。常见目标写成:
\[\max_{\phi}\ \mathbb{E}_{y\sim \pi_\phi(\cdot|x)}\big[r_\theta(x,y)\big]-\beta\,D_{\mathrm{KL}}\!\left(\pi_\phi(\cdot|x)\,\|\,\pi_{\mathrm{ref}}(\cdot|x)\right)\]这里的 \(\pi_{\mathrm{ref}}\) 通常并非额外训练出来的一套神秘模型,而就是PPO 开始前那一版 SFT 模型的冻结副本。标准顺序通常是:先从预训练基座得到 SFT 模型,再把这份 SFT checkpoint 复制成两路,一路继续作为可训练策略 \(\pi_\phi\),一路冻结为参考模型 \(\pi_{\mathrm{ref}}\)。因此并不存在“先有参考模型还是先有策略模型”的循环依赖;二者都来自同一个 SFT 起点,只是一个继续更新,一个保持不动。
式子里的 KL 项与 KL 散度(Kullback–Leibler Divergence)是直接对应的关系:这里所谓的“KL 项”,就是目标函数中的 \(\beta\,D_{\mathrm{KL}}(\pi_\phi\|\pi_{\mathrm{ref}})\) 这一项,只不过前面再乘了一个权重系数 \(\beta\)。它的作用核心是作为正则约束,把当前策略锚定在 SFT 参考分布附近,防止模型为了讨好奖励模型而偏离过远,出现奖励黑客(Reward Hacking)、语言退化或能力崩塌。PPO 在这类任务里长期被广泛采用,原因正是它对策略更新幅度加了“护栏”,能在追求更高奖励和保持原有能力之间维持相对稳定的折中。
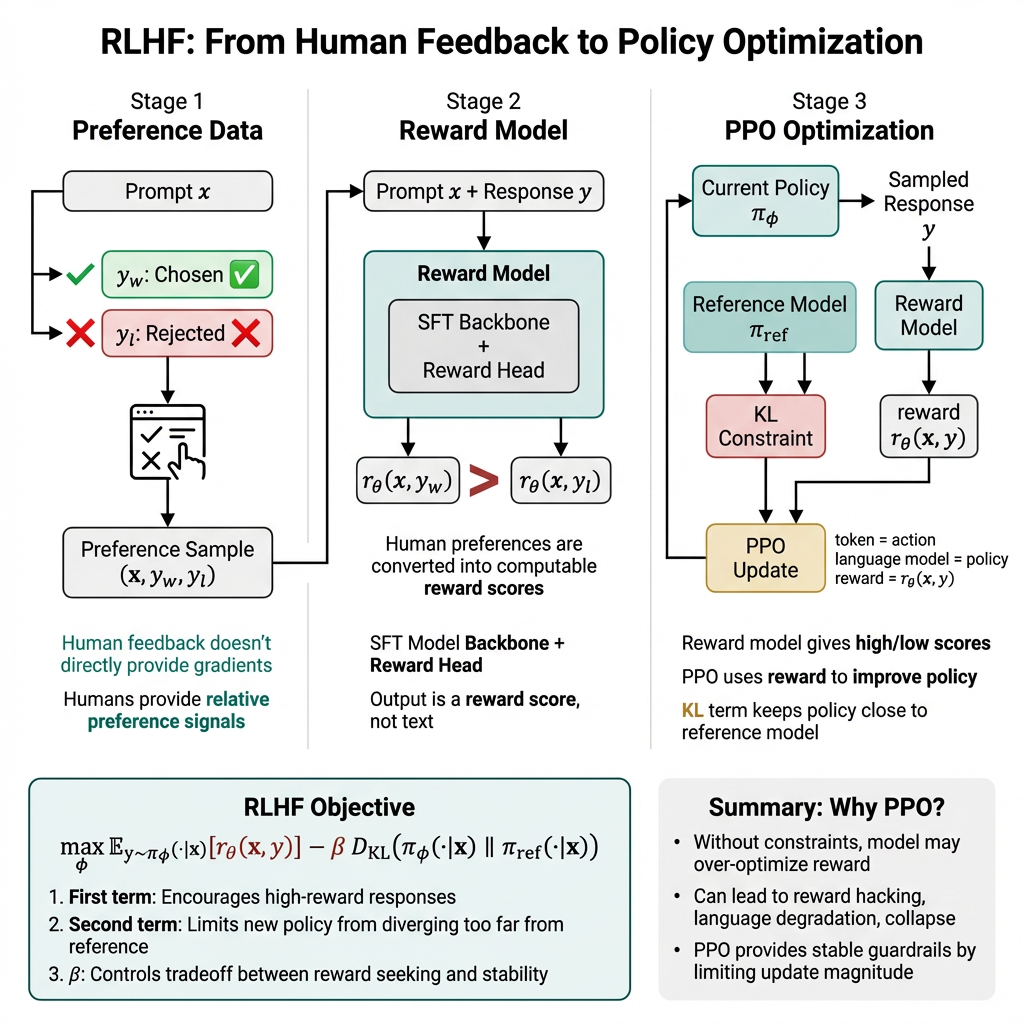
PPO(Proximal Policy Optimization)之所以长期是 RLHF 的默认优化器,核心是因为它足够稳。普通策略梯度(Policy Gradient)的问题在于:一旦某次更新把策略推得过远,语言模型就可能突然偏离原有分布,表现为回复风格失真、可读性下降、奖励黑客,甚至整体能力退化。PPO 的核心改进就是限制“这一步最多改多少”,让策略朝高奖励方向移动,但每次只允许小步修正。
它最经典的形式是 clipped objective。若当前策略与旧策略的概率比记为 \(\rho_t=\frac{\pi_\phi(a_t|s_t)}{\pi_{\phi_{\mathrm{old}}}(a_t|s_t)}\),对应优势函数(Advantage Function)为 \(A_t\),则目标可写成:
\[\mathcal{L}_{\mathrm{PPO}}(\phi)=\mathbb{E}_t\left[\min\left(\rho_t A_t,\ \mathrm{clip}(\rho_t,1-\epsilon,1+\epsilon)A_t\right)\right]\]这里的 \(\epsilon\) 是更新护栏宽度。若某次更新让概率比偏离 1 太远,clip 就会截断继续放大的收益,阻止模型为了追求更高奖励而走得过猛。对 LLM 而言,这个机制尤其重要,因为语言模型的输出分布非常高维,只要少量 token 的条件概率被过度放大,就可能连锁改变整段回答的行为模式。
放到 RLHF 流程里,PPO 的完整闭环通常是:先用当前策略对同一提示词采样若干回答,再用奖励模型评分,并结合参考模型的 KL 惩罚构造最终回报;随后估计优势 \(A_t\),再用 clipped objective 更新策略。也正因为这里同时牵涉采样、奖励模型、参考模型、旧策略快照与优势估计,PPO 路线的工程链条明显比 DPO 更长,训练成本和调参复杂度也更高。
工业实践中,奖励往往也并非单一维度。一个典型做法是分别训练“有用性(Helpfulness)”与“安全性(Safety)”奖励模型,再按加权和形成总奖励,例如 \(R_{\mathrm{total}}=\alpha R_{\mathrm{helpful}}+\beta R_{\mathrm{safety}}\)。这样可以显式控制不同对齐目标之间的权重,而非把所有偏好都压缩进一个不可分解的单一评分器里。
到了大模型对齐阶段,很多方法在问题定义上仍然属于强化学习,但在算法形态上已经明显偏离经典强化学习教材中的标准样子。原因并不神秘:LLM 对齐面对的是一种极其特殊的决策问题。若强行套用经典 RL 映射,可以把状态(State)理解为“当前提示词 + 已生成 token 序列”,把动作(Action)理解为“从巨大词表中选择下一个 token”,把奖励(Reward)理解为“整段回答生成完之后得到的评分”,把环境(Environment)理解为模型自身的自回归生成过程。这个映射在概念上成立,但工程代价极高。
困难主要集中在三点。第一,动作空间极大:每一步都要在成千上万个 token 中做选择。第二,奖励高度延迟:很多时候只有整段回答生成完毕后,才能得到一个总体评分,时间信用分配(Temporal Credit Assignment)比经典控制任务更棘手。第三,策略优化链条极重:若完整采用 PPO 式 RLHF,训练时往往要同时维护可训练策略、旧策略快照、参考模型、奖励模型,很多实现里还要有价值网络(Value / Critic),显存、吞吐和稳定性压力都非常大。
因此,大模型对齐逐渐出现了一条清晰演化路径:保留强化学习的问题定义,重写强化学习的求解形态。所谓“保留问题定义”,指的是目标仍然来自评估性反馈(Evaluative Feedback)而非逐步给定的标准答案;模型仍然要学会在多个候选回答之间偏向更优者。所谓“重写求解形态”,指的是从机械照搬经典 Actor-Critic 或全流程在线 RL转向通过数学消元、离线偏好优化、组内相对比较、弱化价值网络等方式,把问题改写成更适合大模型训练的目标。
从这个视角看,DPO 与 GRPO 都核心是对经典算法形态的工程重构。DPO 走得更远:它把“奖励建模 + 策略优化”折叠成一个静态偏好对损失,形式上已经非常接近监督学习或对比学习。GRPO 则保留了“采样 - 评分 - 更新”的策略优化闭环,但用组内相对优势替代显式价值网络,属于一种极简化的策略优化路线。前者更像对 RL 目标的解析化改写,后者更像对 PPO 结构的裁剪与瘦身。
DPO(Direct Preference Optimization)是这种“非典型 RL 形态”里最典型的一类:它直接用偏好对 \((x,y_w,y_l)\) 优化策略,不显式训练奖励模型,也不需要 PPO rollout。它的出发点很明确:既然手里已经有“哪个回答更好”的偏好数据,那么没有必要再额外训练一个奖励模型,再把奖励模型嵌入完整强化学习闭环;可以直接把偏好关系作用到策略本身。
DPO 仍然保留一个冻结的参考模型 \(\pi_{\mathrm{ref}}\) 作为锚点,并同时比较当前可训练模型与参考模型在“被接受回答”和“被拒绝回答”上的相对概率。这里的概率核心是整条回答在 token 级对数概率上的汇总,因此本质上是在比较“当前模型是否比参考模型更偏向好答案、同时更远离差答案”。典型目标写成:
\[\mathcal{L}_{\mathrm{DPO}}(\phi)=-\log \sigma\!\Big(\beta\big[\log\pi_\phi(y_w|x)-\log\pi_\phi(y_l|x)-\log\pi_{\mathrm{ref}}(y_w|x)+\log\pi_{\mathrm{ref}}(y_l|x)\big]\Big)\]直觉上,DPO 直接增大“胜者相对败者”的对数概率优势(log-odds margin),同时用参考模型作为锚点。它把 RLHF 中“奖励建模 + PPO 优化”的两步折叠成一步有监督式偏好优化,因此工程更轻、训练更稳定,也更容易复用现有 SFT 训练栈。正因为这一点,DPO 已经成为许多中小团队进行偏好对齐时的默认起点。
从经典 RL 的角度看,DPO 最“不像强化学习”的地方在于:它几乎拿掉了在线探索、环境交互和显式优势估计这些传统组件,直接在离线偏好数据上优化策略。这也是为什么它在形式上看起来更像监督学习;但它解决的仍然是评估性反馈下的偏好优化问题,而非普通的标签拟合问题。
DPO 训练并非要把“好样本相对差样本的概率优势”硬拉到某个固定阈值才算结束。它优化的是整个偏好数据集上的相对排序损失,而非某个预设的绝对 margin。对容易区分的样本,胜者优势会很快变大,梯度也随之减弱;对天然模糊、偏好边界不清的样本,这个优势不可能无限扩大。若继续强行训练,模型更可能开始过拟合偏好数据、放大表面写法差异,甚至损害生成分布稳定性。因此,DPO 的停止标准本质上仍然是验证集偏好指标、生成质量与分布稳定性是否已经饱和,而非“margin 必须大于某个固定常数”。
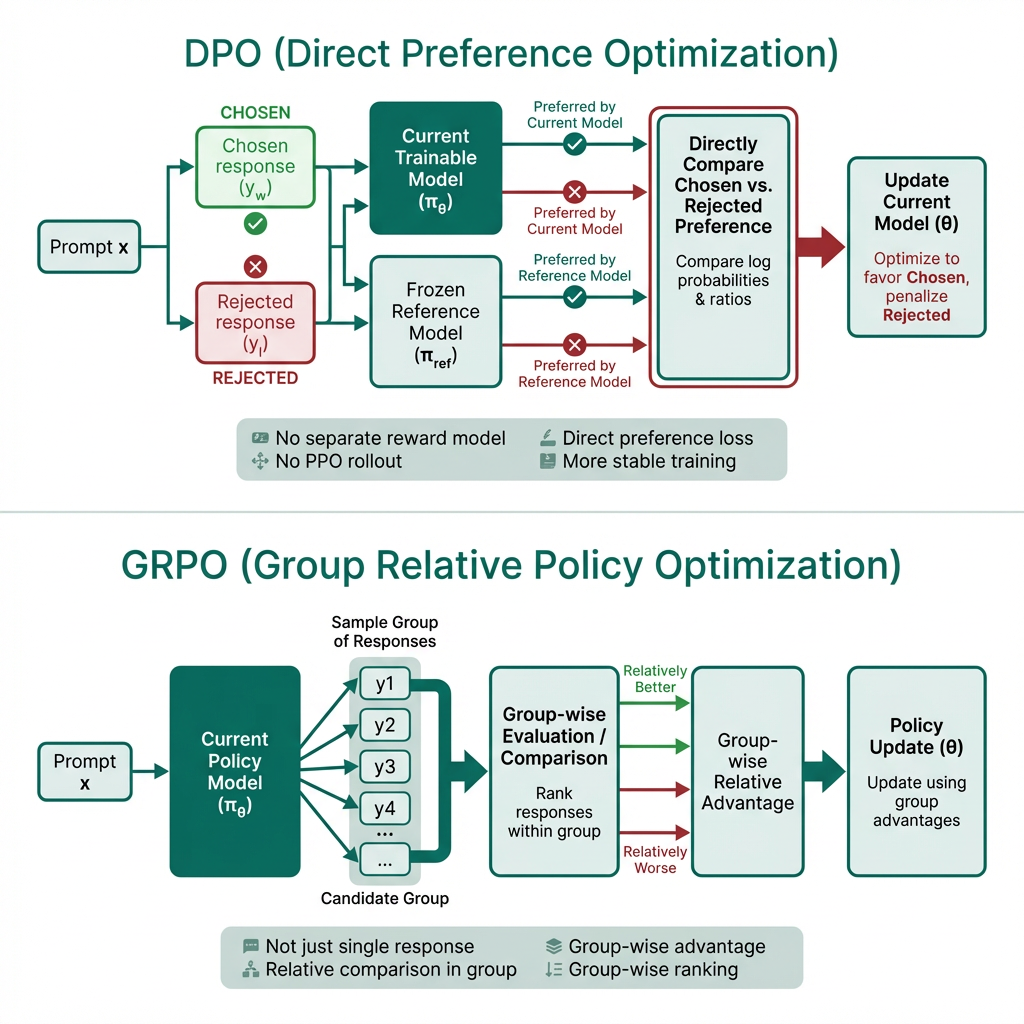
GRPO(Group Relative Policy Optimization)比 DPO 更接近经典策略优化,但它同样属于“非典型 RL 形态”:对同一个提示词 \(x\) 采样一组候选回复 \(\{y_k\}_{k=1}^{K}\),用奖励/偏好信号在组内排序或打分,再把“相对好坏”转成策略梯度更新。它的核心动机是:用 组内比较 构造优势(Advantage)或基线(Baseline),从而减少对显式价值网络(Critic / Value Function)的依赖。
一种常见的做法是把组内奖励做标准化得到相对优势:
\[A_k=\frac{r_k-\mu_r}{\sigma_r+\epsilon},\quad \mu_r=\frac{1}{K}\sum_{k=1}^{K}r_k,\ \sigma_r^2=\frac{1}{K}\sum_{k=1}^{K}(r_k-\mu_r)^2\]并用 PPO 风格的 clipped objective 更新策略(仍然可带 KL 正则到参考模型):
\[\max_{\phi}\ \mathbb{E}\Big[\min\big(\rho_k A_k,\ \mathrm{clip}(\rho_k,1-\epsilon,1+\epsilon)\,A_k\big)\Big]-\beta D_{\mathrm{KL}}\!\left(\pi_\phi\,\|\,\pi_{\mathrm{ref}}\right),\quad \rho_k=\frac{\pi_\phi(y_k|x)}{\pi_{\phi_{\mathrm{old}}}(y_k|x)}\]真正决定“奖惩”的核心是它在同组候选中的相对位置。若某个回答的组内奖励 \(r_k\) 高于这一组的平均水平 \(\mu_r\),则 \(A_k>0\),训练会提高模型再次生成这类回答的概率;若某个回答低于组内平均水平,则 \(A_k<0\),训练会压低模型对这类回答的偏好。换句话说,GRPO 奖励的是“在同一个 prompt 下,比同组其他回答更好的样本”,惩罚的是“在同一个 prompt 下,相对更差的样本”,而非单独给每个回答设一个全局固定门槛。
从优化角度看,这种“压制”核心是让该回答在目标函数里贡献负优势(Negative Advantage)更新。结果上,它等价于让这类回答对应的策略概率逐步下降:模型以后再采样到相似回答时,会更倾向于远离它,而非继续强化它。
因此,GRPO 与经典 PPO 的最大差别,并不在于“还有没有策略梯度”,而在于它把传统 Actor-Critic 结构大幅裁剪了。经典 PPO 往往依赖一个显式价值网络去估计 baseline,以降低方差;GRPO 则直接用同组候选回答之间的相对分数生成基线,把“谁比平均更好、谁比平均更差”写进组内统计量。这使它在大模型场景下明显更省显存,也更容易扩展到规则打分、程序验证和裁判模型评分等复杂奖励来源。
这种机制尤其适合答案质量强依赖上下文、很难用一个全局绝对分数刻画的场景。对某些 prompt,70 分的回答可能已经是组内最优,应当被正向强化;对另一些 prompt,80 分的回答仍可能只是组内倒数,应当被压制。GRPO 的核心就在于:目标模型核心是因为它在同题候选集合里相对更优而受到正向更新。
GRPO 仍然需要某种奖励/偏好信号(显式奖励模型、规则打分、对比标注等);它改变的是“如何用这些信号构造稳定的更新”,而非免除奖励来源本身。把几条路线放在一起看,会更清楚:RLHF + PPO 强调显式奖励建模与稳定策略更新,DPO 强调跳过奖励模型后的直接偏好优化,GRPO 则强调用组内相对比较构造更稳定的优势信号。它们共享同一个目标,只是在“偏好信号如何表达、如何被模型消化”这件事上采取了不同工程路径。
参数外优化(Parameter-free Optimization)指的是:在不更新模型权重的前提下,通过改写提示词(Prompt)、输出约束、示例组织、工具说明、工作流与评估闭环来提升系统表现。它优化的对象核心是模型与任务之间的接口层。
这条路线之所以重要,是因为很多任务的瓶颈并不在模型“不会”,而在任务描述不够精确、输出约束不够严格、示例覆盖不足,或评估回路设计不清。此时,更合理的第一步往往核心是先做参数外优化:不改模型参数,只改模型使用方式。
自动化 Prompt 优化(Automatic Prompt Optimization, APO)的核心思想是:把人工反复修改 Prompt 的经验循环,改写成一个自动化搜索与评估过程。它把 Prompt 本身当作待优化对象,不更新模型权重,再用验证集上的错误信号驱动 Prompt 迭代。换句话说,APO 优化的核心是模型与任务之间的接口描述。
这条路线之所以重要,是因为很多任务的误差并不来自“模型完全不会”,而来自任务定义不够精确、输出约束不够严格、规则优先级表达不清,或者 few-shot 示例没有覆盖真正的边界情况。对这些问题,先做 Prompt 优化通常比直接微调更便宜,也更容易定位问题来源。
APO 可以概括为一个闭环迭代过程。
- 从当前 Prompt 出发,在固定验证集上运行模型,得到一轮可量化的表现。
- 收集错误样本,重点关注 false positive、false negative 以及模型在边界样本上的失误模式。
- 把这些错误样本与当前 Prompt 一起交给一个更强的语言模型,要求它分析当前 Prompt 的缺陷,例如规则表述含糊、优先级冲突、示例覆盖不足、输出格式不稳定,或对某些语义模式缺乏约束。
- 基于这些分析生成若干候选 Prompt。候选改动可以包括:重写系统提示、重排规则顺序、增加约束语句、补充反例、加入 few-shot 示例,或强化输出格式说明。
- 用同一个验证集重新评估这些候选 Prompt,并按预先定义的指标选出当前最优版本。
- 重复这一过程,直到验证集指标收敛,或进一步修改已经不能带来稳定收益。
这个闭环的本质是“用验证集驱动 Prompt 搜索”。人工调 Prompt 时,工程师通常也是先看错例,再猜原因,再改写提示词,再重新评估;APO 只是把这条经验流程交给模型辅助完成,并把迭代过程系统化。
要让 APO 真正有效,至少要具备三样东西:
- 高质量验证集:它不一定需要极大规模,但必须足够准确,且覆盖关键边界情况。
- 清晰的评价指标:分类任务通常可以直接使用 Accuracy、Precision、Recall、F1;抽取、排序、生成任务则需要对应的可重复评价标准。
- 被优化对象必须足够明确:例如系统提示词、用户提示模板、few-shot 示例集、输出格式约束或工具调用说明。
如果缺少这三者中的任意一个,APO 都很容易退化成“让模型随意重写 Prompt”,最终只是在做风格漂移,而非真正基于验证信号优化任务表现。因此,APO 的核心是“能否把 Prompt 修改纳入可验证的实验闭环”。
参数外优化对验证信号质量极其敏感。因为它直接把验证集上的错误模式反向写入 Prompt 结构,缺少海量训练样本的噪声平均效应,所以一旦验证集标签本身含糊、冲突或混入大量低置信样本,优化器就很容易朝错误方向改写规则。高质量、边界清晰的验证集通常能显著提升 APO 的稳定性;相反,模糊数据会让优化过程更像是在追逐评测噪声,而非纠正模型真实缺陷。
| 维度 | 微调 | APO |
| 优化对象 | 模型权重 | Prompt、示例、输出约束 |
| 资源需求 | 通常需要训练框架、显存和数据管线 | 通常只需要验证集与可调用的模型 |
| 成本 | 高 | 低 |
| 可解释性 | 较弱,行为被写入权重 | 强,Prompt 变更可直接审查 |
| 性能上限 | 更高,可把规则和模式内化进模型 | 受限于基座模型自身能力 |
| 更适合 | 数据充足、任务长期稳定、性能要求高 | 快速迭代、规则频繁变化、数据量有限 |
因此,APO 和微调并更像两层不同成本的优化手段。若模型本身已经具备足够能力,但任务接口还没有调顺,先做 APO 往往收益最高;若 Prompt 已经被压到比较成熟,但模型仍然持续犯系统性错误,才更适合进入微调阶段。
APO 最适合规则可文本化、评估指标清晰、且基座模型本身已经具备足够语义理解能力的任务。例如分类、抽取、轻量结构化生成、审核规则执行、问答格式控制和工具调用提示约束,往往都能从 APO 中获益。尤其当任务规则经常变化、人工需要频繁更新 Prompt 时,APO 的价值会非常明显。
它的边界同样清晰。若任务需要模型学习新的领域知识、记住稳定事实、吸收大量风格样本,或长期存在系统性能力缺口,那么单纯修改 Prompt 的收益通常很快见顶。此时,Prompt 优化可以继续作为上层控制手段存在,但性能提升的主战场已经会转移到微调与继续预训练。
AMPO(Automatic Multi-Branched Prompt Optimization)可以看作 APO 的结构化升级版。普通 APO 往往默认“只有一条主 Prompt 流程”,优化方式主要是改写文字、调整规则顺序或补充示例;AMPO 则进一步把 Prompt 看作一种可演化的决策结构。它的目标不仅把单条 Prompt 写得更好,还让 Prompt 从单流程逐步生长为多分支结构,使模型在面对不同输入模式时,能够沿着更合适的子路径完成判断。
这种思路来自一个很强的人类专家直觉:复杂任务往往核心是靠“先识别情形,再走对应流程”。因此,AMPO 的真正创新不仅自动改 Prompt,还把 Prompt 优化从“文案修订”提升成“结构搜索”。在这种框架下,提示词已经不只是几句话,而更像一个树状决策蓝图。
当任务内部同时包含多种错误模式时,单分支 Prompt 很容易不断堆叠例外说明,最后变成冗长、脆弱且难以维护的规则串。AMPO 的判断是:如果不同错误模式对应的是不同处理逻辑,就应允许 Prompt 显式分叉,而非强行把它们揉进同一段线性指令。这样做有三个直接收益。第一,结构更清晰:每个分支各自负责一类模式,规则可解释性更强。第二,复杂场景适应性更好:模型先定位情形,无需在一条过长指令中硬找适用规则,再走对应分支。第三,后续维护更容易:新增模式时可以局部增补或重构特定分支,而不必重写整个 Prompt。
AMPO 的核心流程可以分成三个协同模块:模式识别(Pattern Recognition)、分支调整(Branch Adjustment)和分支剪枝(Branch Pruning)。这三个模块合在一起,构成了一个从错误样本出发、逐步生长并控制复杂度的优化回路。
模式识别负责把零散坏例归纳成少数根因模式。它通常核心是采用角色分工:一个分析器(Analyzer)逐个解释失败原因,另一个总结器(Summarizer)把这些解释压缩成更高层的模式,并给模式分配重要性。这样做的关键价值在于:优化目标从“修这几个具体坏例”转成“修这一类错误背后的共同规则缺口”。
分支调整负责决定 Prompt 结构该如何变化。这里最重要的决策核心是“深化已有分支,还是新增分支”。若新模式与某个已有分支高度相关,只需补充约束或细节,那么更合理的做法是深化;若新模式与现有逻辑明显不同,继续堆进原分支只会制造冲突,就应当拓宽,新增一个独立子分支。AMPO 优化的核心是 Prompt 的控制流结构。
分支剪枝负责抑制过拟合。多分支优化的自然风险是:随着迭代次数增加,Prompt 可能长出大量只服务于少数训练样本的局部规则,最终在未知数据上退化。AMPO 因此显式引入两层剪枝:
- 预剪枝(Pre-pruning):相当于基于独立验证集的早停机制。若新增分支不再带来稳定收益,就停止继续扩张。
- 后剪枝(Post-pruning):要求优化器在输出最终 Prompt 前重新审视各分支,删掉不必要、过于具体或明显带有训练集记忆痕迹的规则。
AMPO 的一个很有代表性的设计,是每轮只抽取很少量的代表性坏例,例如固定 \(K=5\),而非分析大量失败样本。这是一种典型的小样本归纳策略:在模式识别任务里,最前面的少数高信息量样本往往已经足以揭示一类错误的共性,而继续增加样本数量,边际信息收益会快速下降。对具备较强归纳能力的 LLM 来说,少量围绕同一主题的坏例通常已经足够提炼出根本模式。
更重要的是,AMPO 并不要求 \(K\) 随总坏例数量成比例扩大。固定的小 \(K\) 让每轮优化的成本更可控,也避免分析器被大量重复、低信息量坏例淹没。参数外优化的关键核心是“看足够有代表性的错误”。
AMPO 还提供了一个很重要的方法论提醒:分析错误原因时,并不总是必须把模型当轮生成的失败输出显式提供给分析器。很多时候,输入、当前 Prompt、正确标签以及“这条样本被判错了”这一事实,已经足以让分析器定位规则缺失。因为优化器真正需要回答的问题是“当前指令为什么会把模型引向这类错误”。当失败输出本身噪声较大、措辞随机性较强时,强行把它加入分析,反而可能干扰模式归纳。
换言之,参数外优化的关注重点应当放在规则缺口而非错误表面上。一个高质量分析器更像在做“指令失效诊断”,而非对错误回答做逐字复盘。
AMPO 还强化了一个现实而重要的工程模式:用于分析与重写 Prompt 的优化器模型,并不必与实际执行任务的目标模型相同。前者更强调总结、重写和结构设计能力,后者则更关注线上推理成本、延迟、稳定性和部署约束。把“谁负责优化 Prompt”和“谁负责执行 Prompt”解耦,往往能在成本与效果之间得到更好的组合。
从论文记录呈现的实验关注点看,AMPO 主要验证了三件事。第一,优化效率:多分支结构在复杂任务上往往能更快探索到高质量 Prompt,而非在单分支上做无穷尽的局部修补。第二,收敛性:随着迭代推进,Prompt 结构会逐步稳定下来,说明这种优化并非纯随机搜索。第三,消融结果:模式识别、分支调整和分支剪枝都并非装饰性组件,拿掉任一模块,性能与稳定性都会受到影响。与普通 APO 相比,AMPO 的价值不仅“Prompt 更长”,还 Prompt 结构更像一个经过错误模式驱动后生长出来的决策树。
因此,参数外优化不应只被理解成“自动改几个词”。从 APO 到 AMPO,它实际上形成了一条清晰的演进路径:先把 Prompt 当作可搜索的文本接口,再把 Prompt 当作可演化的结构接口。前者已经足以覆盖大量规则型任务,后者则更适合复杂、异质、边界模式较多的任务。
分布式训练(Distributed Training)处理的核心问题是:当单张 GPU 已经无法同时满足吞吐量、显存容量、模型规模或上下文长度要求时,训练过程应如何拆分到多张卡乃至多台机器上执行。它覆盖一组并行策略,分别对应不同的设备组织方式。不同策略的差别,主要体现在四个对象如何被分配:数据(data)、模型参数(parameters)、梯度(gradients)和优化器状态(optimizer states)。
工程上最常见的切分方向有两类。第一类是数据并行:每张卡保留完整模型,但处理不同批次数据,再通过通信把梯度同步。第二类是状态分片:参数、梯度或优化器状态本身也被拆到多张卡上,以换取更高的显存上限。前者首先解决训练速度与中等规模显存压力,后者进一步解决“模型单卡放不下”或“长上下文导致激活太重”的问题。
| 策略 | 数据如何分 | 模型状态如何放置 | 典型通信 | 最适合的场景 |
| DDP | 每张 GPU 读取不同 mini-batch | 每张 GPU 保留完整模型、完整梯度与完整优化器状态 | AllReduce 同步梯度 | 模型单卡放得下,主要目标是提升吞吐与缩短训练时间 |
| DataParallel (DP) | 主卡切分 batch 后分发到其他 GPU | 前向复制模型,主卡负责聚合输出与梯度 | 主卡 gather / scatter | 原型验证、老代码兼容;现代训练中通常不再是首选 |
| FSDP | 每张 GPU 处理不同 mini-batch | 参数、梯度、优化器状态按 shard 分布到多卡 | AllGather + ReduceScatter | 模型或长上下文训练已接近或超过单卡显存上限 |
| DeepSpeed ZeRO | 通常也是数据并行 | 按 Stage 逐步切分优化器状态、梯度与参数 | AllGather + ReduceScatter + 参数协调 | 超大模型、多机多卡、显存非常紧张的训练任务 |
DDP 是 PyTorch 最标准的多 GPU 训练策略。它的基本机制很直接:每张 GPU 持有一份完整模型副本,各自处理不同数据,各自完成前向与反向传播,然后把梯度做 AllReduce 平均,最后用同一份平均梯度同步更新参数。由于每张卡的参数初值一致、梯度同步后也一致,因此各副本在每一步更新后仍保持相同权重。
若以 4 卡训练为例,每张 GPU 的本地 batch size 为 4,那么单个 step 中实际处理的样本数就是 16。更一般地,全局批大小满足 \(B_{\mathrm{global}} = B_{\mathrm{local}} \times N_{\mathrm{gpu}} \times N_{\mathrm{accum}}\)。其中 \(N_{\mathrm{accum}}\) 是梯度累积(Gradient Accumulation)步数。这个公式决定了训练稳定性、学习率缩放和吞吐估算,是理解 DDP 的第一条工程量纲。
DDP 最适合模型本体仍能放进单卡,但单卡训练已经过慢或单卡 batch 太小的场景。例如一个三亿参数量级的 Encoder,序列长度达到 4096 时,单卡既可能吞吐不足,也可能无法同时容纳更大的 batch。DDP 将这类压力分摊到多卡后,每张卡只需处理自己的本地 batch,整体吞吐通常接近线性增长,同时又保持实现逻辑相对简单。因此,在“模型放得下,但训练想更快、更稳”这一档场景里,DDP 仍然是默认起点。
DataParallel 是更早一代的单进程多 GPU 封装。它同样试图做数据并行,但实现方式与 DDP 不同:主进程通常位于 GPU 0,负责把一个 batch 切分后分发到其他 GPU,前向结果和反向梯度也要回到主卡聚合。这个结构会带来两个直接后果。第一,GPU 0 的负担显著更重,容易形成瓶颈;第二,单进程多线程模型更容易受到 Python 调度和通信组织方式的影响。
因此,DP 的优势主要只剩“接入非常简单”。一旦进入正式训练,尤其是多卡 batch 较大、模型通信频繁或训练周期较长时,DDP 几乎总是更稳、更快,也更接近现代 PyTorch 的标准实践。工程上可以把 DP 理解为历史过渡方案:适合快速原型与兼容旧代码,不适合作为持续训练体系的默认选择。
FSDP 仍然属于数据并行范式,但它把“每卡完整持有模型状态”这件事拆开了。参数、梯度和优化器状态会被分片(shard)到不同 GPU 上;在某一层真正参与计算之前,系统才临时执行 AllGather 把这一层所需参数拼回;反向传播结束后,再通过 ReduceScatter 等通信把梯度重新切回各自分片。其核心收益是显存占用大幅下降,因为大部分时间里,每张卡只保存全模型状态的一部分。
这种收益伴随更复杂的通信与调度开销。FSDP 的目标从来核心是让原本单卡放不下的模型,或原本因为长上下文而极难训练的配置,进入可训练区间。当模型参数规模、激活开销或优化器状态已经逼近单卡上限时,FSDP 往往比单纯增加 DDP 卡数更有效,因为后者只扩展数据吞吐,并不缩小单卡必须持有的模型状态。
ZeRO(Zero Redundancy Optimizer)是 DeepSpeed 最核心的一组大模型训练技术。它的思想与 FSDP 接近,目标都是减少多卡间重复保存的状态,但切分粒度与工程形态更体系化。常见 Stage 可按三步理解:Stage 1 切分优化器状态,Stage 2 再切分梯度,Stage 3 进一步切分模型参数。随着 Stage 提升,单卡显存压力持续下降,但通信和实现复杂度也会同步上升。
ZeRO 的价值在大模型时代尤为明显,因为优化器状态和梯度本身就可能比参数还占显存。对数十亿参数模型、超长上下文训练或多机多卡集群而言,单纯复制完整状态几乎不可持续,ZeRO 这类分片机制就成为前提能力。DeepSpeed 在此基础上还会继续叠加通信优化、内存卸载(offload)、流水并行等工程能力,因此它通常更适合训练规模继续上升、需要复杂集群优化的团队环境。
分布式训练策略和高层框架并不处在同一抽象层。DDP、FSDP、ZeRO 描述的是“参数与梯度如何跨设备组织”;Accelerate、Lightning、Transformers Trainer、Keras 3、MMEngine 描述的则更多是“如何把训练循环、设备启动、日志、checkpoint 与策略配置组织起来”。前者是并行机制,后者是工程入口。
PyTorch 是这一组策略最常见的底座。DDP 与 FSDP 都属于 PyTorch 原生分布式能力,训练脚本最终仍然依赖其自动求导、张量通信和优化器更新。对需要精细控制训练循环的工程团队而言,直接基于 PyTorch 编写分布式训练脚本,通常拥有最高灵活度。
Accelerate 的定位是多设备执行抽象。它将 DDP、FSDP 与 ZeRO 等策略接入到更统一的设备管理接口中,同时封装设备发现、进程启动、混合精度与梯度同步。其核心价值在于:同一份以 PyTorch 为中心的训练代码,可以较平滑地从单卡扩展到多卡,再扩展到 FSDP 或 DeepSpeed,而不必大规模重写训练循环。
Lightning 把分布式训练放进更规范的训练引擎里。开发者主要定义模型、优化器和 step 逻辑,Trainer 再根据配置选择 DDP、FSDP、DeepSpeed 等 strategy。它适合希望减少样板代码、统一日志与 checkpoint 管理,同时保留 PyTorch 生态兼容性的团队。其代价是抽象层更高,定制极复杂训练细节时需要理解 Lightning 的生命周期约束。
Transformers 的 Trainer 更偏“模型生态入口”。当任务建立在 Hugging Face 模型、tokenizer 与数据集流水线之上时,Trainer 可以通过 Accelerate 或相关配置接入 DDP、FSDP 与 DeepSpeed。它特别适合标准微调、标准评测与模型复现实验;一旦训练流程开始高度定制,开发者通常会逐步回到原生 PyTorch 或 Accelerate 层。
Keras 3 也提供分布式 API,但其分布式能力更依赖所选后端。若后端是 TensorFlow,实际执行往往落在 TensorFlow 的分布式策略;若后端切到 JAX 或 PyTorch,则并行细节又会由各自后端负责。它适合追求统一高层建模接口、同时希望在不同后端间迁移的场景,但在超大模型训练里,社区主流实践仍然更多集中在 PyTorch + FSDP / DeepSpeed 这条路线。
MMEngine 更像视觉任务中的训练控制台。它能够把 Runner、Hook、配置系统和分布式启动流程组织起来,使检测、分割、姿态估计等复杂视觉实验更容易批量管理。其分布式能力本质上仍然建立在底层框架之上,通常不会取代 DDP / FSDP 这类并行机制本身,会把它们纳入统一工程范式中。
在进入具体训练场景之前,通常应先判断任务应该建立在什么类型的基座模型之上。这个选择会直接决定后续数据形态、训练目标、推理链路与上线成本。很多项目的真正分水岭并不在 LoRA、QLoRA、DPO 这些技术细节,而在于一开始是否选对了模型范式:到底应当使用 BERT 一类表示模型(Representation Model),还是使用 Decoder-only 生成模型(Generative Model)。
BERT、RoBERTa、DeBERTa 一类 Encoder-only 模型,最擅长的是把输入压缩成稳定表示,再围绕固定目标做判别。它们特别适合闭集分类(Closed-set Classification)、文本匹配、检索、序列标注、重排序,以及“输入充分、标签空间明确、输出形式固定”的任务。只要目标可以被表述为“给这段输入打一个标签”或“判断这两段文本是否匹配”,表示模型通常都是更高效、更便宜、也更容易评估的选择。
这里需要明确一点:BERT 并非完全没有顺序信息。它同样通过位置编码(Positional Encoding)与自注意力看到序列先后关系,因此能区分“先发生什么、后发生什么”。真正的限制不在“看不到顺序”,而在于它通常把整段输入压缩为一个判别表示,再直接映射到标签空间。对于需要显式执行规则、动态权衡多段证据、并把局部冲突统一到最终结论上的任务,这种一次性判别路径往往不够灵活,也缺乏可解释的中间推理结构。
生成式大语言模型的优势出现在另一类任务中:任务目标本身包含开放式语义判断、复杂规则执行、跨轮次状态整合,或者需要先形成中间结论,再决定最终输出。这类任务往往不仅“看完文本后打标签”,还要求模型先判断哪些证据重要、哪些证据只是过程噪声,再决定最终答案。对这类问题,生成模型更容易通过指令约束、上下文推理和多步语义整合完成任务,因此更适合作为基座。
例如,在对话满意度判定中,若规则是“过程中的波折、局部负面情绪视为过程成本,只要最终方案被接受、问题收尾清晰,就优先按已解决处理”,任务本质上就不再是简单情感分类。模型需要区分中间波折与最终状态,识别“收尾是否清晰”,并对冲突信号做优先级排序。这里最困难的部分核心是执行一条带有结尾优先、过程降权结构的规则。生成模型在这种场景下通常更稳,因为它更容易在长上下文中整合多段证据,并按指令执行“先看结尾,再回看过程”的判断逻辑。
只要任务满足以下条件,BERT 类模型通常仍然足够胜任:
- 输出空间固定且较小,例如满意 / 不满意、风险 / 非风险、升级 / 不升级。
- 决定标签的证据主要是局部可见、模式稳定的文本特征,而非依赖复杂跨轮推理。
- 规则可以被充分体现在标注数据里,使模型通过监督学习稳定内化这种判别边界。
典型例子包括情感分类、意图分类、FAQ 匹配、实体识别、工单主题归类,以及大量结构清晰的客服路由任务。
若任务开始依赖以下能力,BERT 类模型的风险就会显著上升:
- 需要对长对话做结尾优先的全局判断。
- 需要把中间负面情绪降权,但又不能完全忽略。
- 需要区分“问题解决了但过程不愉快”与“问题根本没解决”。
- 需要持续引入新规则,并要求模型在推理时可控地遵循这些规则。
此时,即使通过多段编码、层级聚合、结尾加权或级联分类等工程技巧勉强构造出一个系统,上限通常也受限于任务本身的推理复杂度,而且系统维护成本往往会迅速上升。
| 任务特征 | 更合适的基座 | 原因 |
| 固定标签分类、匹配、检索、序列标注 | BERT 类表示模型 | 判别目标清晰,推理链短,部署成本低,训练与评估都更直接 |
| 需要开放式回答、格式生成、工具调用、复杂指令遵循 | 生成式模型 | 输出本身就是生成任务,Encoder-only 模型不适合作为主干 |
| 多轮对话总结、结尾优先判断、冲突证据加权、规则动态注入 | 生成式模型 | 需要跨轮整合与规则执行,往往不能稳定压缩成一次性判别 |
| 局部模式强、业务规则稳定、标注数据充分的分类任务 | BERT 类表示模型 | 表示模型更省资源,延迟更低,也更适合大规模批量预测 |
因此,基座模型选择的真正问题是“任务本质上是在做判别,还是在做规则驱动的语义决策”。前者优先考虑 BERT 一类表示模型,后者通常应直接进入生成式模型范式。把这一步判断做对,后面的训练场景、微调路径和评估方式才会自然收敛。
小数据集微调(Small-data Fine-tuning)讨论的核心是“可用于更新模型权重的有效监督信号是否足够”。到了 2026 年,这个问题已经出现一个很值得重视的经验转向:在小数据场景里,微调容量并非越大越好。很多情况下,越轻量的适配反而越稳,尤其当数据本身同时带有长尾、噪声、分布偏移和验证波动时更是如此。
小数据微调最容易误判的一点,是把“任务复杂”直接等同于“应该开放更多可训练参数”。在大多数小样本任务里,真正需要学习的往往只是沿少数方向对基座模型做任务相关偏移。更大的可训练子空间确实提高了拟合训练集的能力,但也更容易把头部模式、局部模板、错标样本和偶然噪声一起写进参数更新,最终损害泛化。
因此,小样本适配的默认逻辑通常核心是先用更强约束保护基座模型,再按验证集证据逐步放大更新空间。以 LoRA 为例,低 rank 更新 \(\Delta W = AB\) 的价值不仅是省显存,更是把参数更新限制在一个低维子空间中,使模型更难直接记忆训练集表面模式。这也是为什么在低资源任务里,参数效率与泛化能力往往核心是同一套约束机制的两个结果。
小数据集微调不仅要决定“调多大”,还要决定“调哪里”。这个问题通常有两个维度:第一,更新哪些层;第二,更新每层里的哪些矩阵。它们共同决定模型最终学到的是局部表面模式,还是更稳定的高层语义偏移。
从层位分工看,Transformer 各层的注意力并非完全同质的。浅层通常更偏局部句法、词性与相邻词关系,通用性最强,因此往往不应轻易扰动;中层开始形成更复杂的语义组合,处理跨句指代、因果联系和较长范围的信息整合;深层则更接近任务特定的高层语义,情感、意图、分类边界和最终决策信号通常更多集中在这里。对于情感判断、满意度判断、意图识别等高层语义任务,优先从中深层,尤其是后部层开始微调,通常更符合信号分布。
从矩阵类型看,小数据行为调整任务通常应先从注意力侧开始,而非默认同时打开 FFN。Q 决定“向哪里发起关注”,V 决定“实际取出什么信息”,因此它们往往最直接影响模型如何组织证据与整合线索;K 和 O 也会影响结果,但通常并非最低成本起点。若任务主要是在已有知识之上重排注意力优先级、加强长程依赖或改变决策依据,先调 Q、V 往往最稳。只有当验证集持续显示模型确实缺少领域知识写入或表示重编码能力时,再逐步把 FFN、K 或 O 纳入更新范围更合适。
小数据场景的核心矛盾是有效监督信号稀疏,模型容量却仍然巨大。如果数据高度重复、标签边界模糊、头部模式占据绝大多数样本,或者训练集与真实线上分布存在偏移,那么模型面对的就是“少量规律 + 大量重复与噪声”。这时,训练往往下降得过快、记忆得过深。
其中最容易被低估的是长尾问题。头部样本会主导梯度方向,新增容量也最容易先被头部模式吸收;结果是总体指标继续上涨,尾部类别、边界样本和罕见情形却未必同步改善,甚至可能恶化。平均 Accuracy 往往会掩盖这种退化,因此小数据微调若不单独观察尾部表现,很容易把“更会处理常见样本”误判成“整体更强”。
实践中,以下信号通常说明当前瓶颈不在容量不足,而在数据质量、长尾覆盖、验证设计或规则表达:
- 训练损失快速下降而验证集停滞。这通常说明模型正在高效记忆训练集,却没有学到可迁移的判别规律,额外容量只会让这种记忆更彻底。
- 总体指标改善但尾部类别恶化。这说明新增容量主要被头部模式吸收,模型对高频样本更熟练,却以牺牲罕见场景为代价换取平均分提升。
- 不同随机种子之间波动很大。这意味着当前结果对初始化、数据划分或训练噪声过于敏感,说明监督信号本身不稳定。这里的不稳定,通常就来自数据分布不均、标签质量不足或验证集设计过小,例如头部样本占绝大多数、尾部样本只出现几次,或同类边界样本在不同标注员之间标准并不一致。继续放大可训练空间通常只会把这种不确定性进一步放大。
- 新增参数带来的提升只集中在头部模式。这表明模型并没有真正学到更普适的决策边界,只是更深地贴合样本最密集的局部区域。
- 模型开始出现明显的风格漂移与任务外退化。这往往意味着局部小数据已经开始覆盖预训练先验,模型虽然在当前任务里更贴近训练分布,却损伤了原本更广泛的泛化能力。
小数据场景下,更稳妥的默认策略是按证据逐步放开可训练空间:
- 把轻量适配作为默认起点。若使用 LoRA / QLoRA,应优先把它理解为控制更新容量的手段,而不只是省显存工具。
- 先尝试只调后半层的 Q、V,或更保守地只调最后三分之一层。它的参数量最小,过拟合风险也最低,适合监督极少、验证集波动较大的情况。
- 若验证集显示模型对长程结构或中层语义组合仍然适配不足,再比较全层 Q、V 的极低 rank 配置。这样做的出发点是:任务信号不一定只存在于最深层,中层也可能承担一部分长程整合与语义组合;给所有层一点点可调空间,有时比只改最后几层更容易保持泛化。
- 只有当这些方案仍然显示出明确的知识注入或表示重编码瓶颈,再把 K、O 或 FFN 逐步放开。
- 把验证集当作主导信号,而非训练损失。小数据场景下,训练集拟合速度通常极快,真正有意义的是验证集是否持续改善,以及尾部样本是否同步获益。
- 把参数选择和数据问题一起看。若长尾、噪声和分布偏移没有处理好,继续增加微调容量往往只会更快过拟合这些问题。
这条顺序的核心是把可训练空间按证据逐步展开,避免在一开始就把过大的自由度交给少量数据,而非追求一次命中最优结构。更成熟的理解方式,是把小数据集微调视为受强约束的增量适配,而非缩小版的大规模微调。
嵌入模型(Embedding Model)并不天然等于“通用语义相似度模型”。它可以围绕特定目标进行训练,使向量空间优先保留某一类任务真正关心的判别信号。例如在情感分类(Sentiment Classification)场景里,模型更关心“正面 / 负面 / 中性”的倾向是否一致,而不一定关心两段文本在主题或措辞上是否高度相似。于是,训练得到的嵌入空间可能会把“物流很快,体验很好”和“包装一般,但整体满意”拉得较近,因为它们在情感方向上同属正向;反过来,即使两条评论都在谈“物流”,只要情感倾向相反,也可能被推向更远位置。
从更抽象的角度看,无论目标是情感、相关性、意图、风险、偏好还是图文匹配,嵌入模型始终都在学习一件事:让与当前任务定义下“相关”的文档特征在向量空间中更接近,让“不相关”或“应被区分”的特征更远离。区别只在于“相关”的定义来自哪里。通用 embedding 把相关性主要定义为语义相似;任务特化 embedding 则把相关性改写为某个业务目标下的等价关系,例如同一标签、同一情感、同一用户意图、同一风险等级,或“查询与正确答案匹配”。
正因为如此,嵌入训练与对比学习(Contrastive Learning)天然契合。只要能够构造正样本对与负样本对,就可以把任务目标转写成“哪些样本应靠近、哪些样本应分开”的几何约束。监督标签、点击行为、人工偏好、检索点击日志、FAQ 配对、复述句、图文配对,最终都可以落回这一范式:通过对比式目标把任务真正关心的结构写进表示空间。这样得到的 embedding 既可以直接用于最近邻检索、聚类和召回,也可以作为下游分类器或 reranker 的输入表示。Sentence-BERT 就是文本领域最常见的一条对比式嵌入技术路线之一,前文已经展开其结构,这里只把它当作训练范式的代表。
这里尤其要强调替代选项(Alternative Option)的重要性。对嵌入训练而言,替代选项本质上就是负样本:模型不只要知道“什么应该靠近什么”,还要知道“它为什么并非另一个看起来也很像的东西”。如果没有负样本,模型最容易学到的是一组宽泛、正确但区分度不足的共有特征;只有把相似但不同的替代选项放进训练过程,表示空间的边界才会真正被压实。
例如,如果想教模型理解“马”这一概念,只告诉它“有嘴巴、有鼻子、四条腿、长尾巴”,这些特征当然不算错,但它们并不能有效区分马和斑马,因为斑马同样满足这些描述。真正有区分度的,反而更可能是“有没有条纹”、更接近哪种奔跑方式、整体体态和纹理模式这类能把两者分开的特征。把“马”和“斑马”作为相互竞争的替代选项放进对比训练后,模型才会被迫降低那些共有特征的权重,转而提升真正决定分类边界的特征权重。这也是为什么高质量负样本往往比继续堆更多正样本更能提升 embedding 的判别力。
如果把特定目标的 embedding 训练落到一个可执行流程,通常可以分成六步。
但无论流程写得多完整,训练或微调 embedding 模型的主要难点始终都不在 Trainer 本身,而在数据。可用数据不仅要足够大,质量门槛也很高;正例对通常相对容易收集,例如复述句、点击匹配、NLI 蕴含对、FAQ 问答对,但真正困难的是构造高质量的难负例,因为它们既要足够接近真实混淆项,又不能把本该相关的样本误标为负例。
- 构造对比样本。最常见的起点是自然语言推断(Natural Language Inference, NLI)类句对数据,因为它天然提供“哪些句子应该更近、哪些句子应该更远”的监督信号。以蕴含(Entailment)关系作为正例、以矛盾(Contradiction)关系作为负例,是非常常见的做法;中立(Neutral)样本则可按任务目标决定是作为弱负例还是直接舍弃。工程实践里,经常直接使用 SNLI、MNLI 或二者合并后的 AllNLI。GLUE(General Language Understanding Evaluation)则更适合作为上层参照系:它汇总了九个语言理解任务,可用于分析模型在句对理解、推断和相似度相关任务上的整体表现,但并非把九个任务原样全部转成对比样本。
- 定义评估器。训练过程不能只看训练损失,还需要一套稳定的验证指标。最常见的选择是 STS-B(Semantic Textual Similarity Benchmark):它由人工标注句子对相似度,原始标签通常位于 1 到 5 的区间,适合评估句向量是否学到了连续的语义距离。若需要更全面的外部评估,则可以进一步使用 MTEB(Massive Text Embedding Benchmark)一类综合基准,它覆盖多类嵌入任务与大量数据集,能更系统地检查模型在检索、聚类、分类和语义匹配等场景中的迁移能力。
- 选择基座模型。特定目标的嵌入训练通常从一个现成的 Encoder-only Transformer 开始,例如 microsoft/mpnet-base、BERT、RoBERTa 或其领域变体。若任务更接近通用句向量,也可以直接从已经具备较强句向量能力的基座继续微调;若任务明显偏领域化,则优先选择语料分布更接近业务场景的编码器。
- 调用 sentence-transformers 进行训练。它提供了从数据集封装、池化、损失函数到 Trainer 的完整流水线。默认情况下,模型参数并不会被自动冻结,整个编码器都会参与更新;虽然也可以手动冻结底层若干层以节省显存或降低训练不稳定性,但对 embedding 任务而言,表示空间往往需要全层共同调整,因此在资源允许时,全量解冻通常比只训练顶部少数层更容易得到更好的句向量。
- 设置超参数。最关键的超参数通常是训练轮次(Epochs)、批次大小(Batch Size)和学习率预热(Learning Rate Warmup)。批次大小会直接影响 in-batch negatives 的数量,因此不仅关系到吞吐,也关系到对比学习的难度;训练轮次决定模型能否真正把目标关系写入向量空间;预热则用于降低训练初期的梯度震荡,避免刚开始就把预训练表示空间破坏掉。
- 选择损失函数。若目标是得到高质量 embedding,一般不建议把 SoftmaxLoss 当作默认选项,因为它更偏向“把当前任务做成分类”,而非直接优化向量空间的几何结构。若手里有连续相似度分数,常用余弦相似度相关目标,例如 CosineSimilarityLoss;若任务是检索、召回或通用句向量训练,MultipleNegativesRankingLoss 往往是默认优先尝试的方案之一,因为它会把同一 batch 中其他样本自然当作负例,直接优化“正确匹配更近、错误匹配更远”的排序关系。不过它并非所有任务上的统一最优解,最终仍取决于数据格式、负样本质量和任务目标。
这六步背后的主线始终一致:先定义“相关”和“不相关”,再把这种关系写进向量空间。任务标签、蕴含关系、点击行为和人工偏好只是构造这种几何关系的不同来源;一旦正负样本定义清楚,训练目标就会自然收敛到对比学习的框架里。
在这条主线里,难负例(Hard Negatives) 往往能够显著提升嵌入模型的判别力。随机负例通常太容易,模型很快就能把它们推远;真正能继续塑造决策边界的,往往是那些“表面上很像、但在任务定义下并不相关”的样本。对检索、匹配和语义区分任务而言,负例越接近真实混淆项,模型越容易学到更有区分度的表示。
一个常见的负例收集流程如下:
- 获取简单负例(Easy Negatives)。最直接的方法是从训练集里随机采样文档或句子,和当前 query/anchor 拼成负样本对。这一步成本最低,适合快速建立基础对比信号,但训练到中后期往往会变得过于容易。
- 获取半难负例(Semi-hard Negatives)。可以先用一个预训练 embedding 模型遍历训练集,为每个样本召回一批“看起来较相似”的候选,再排除真实正例、重复样本和语义等价样本,把剩余候选作为半难负例。这类负例已经靠近当前表示空间的边界,通常比随机负例更能提升检索质量。
- 获取难负例(Hard Negatives)。更强的做法是人工构造,或借助数据合成(Data Synthesis)生成高混淆样本。例如为同一个 query 人工编写“主题相关但答案错误”的文档,或利用大模型生成与正例高度相似但标签相反、结论错误、实体错配的文本。这样的负例最有训练价值,但也最容易混入假负例(False Negatives),因此质量控制必须更严格。
难负例并非越难越好。若负例实际上与正例同样合理,或者只是标注遗漏导致的“假负例”,模型就会被迫把本应接近的样本推远,反而损害 embedding 空间的结构。真正有效的 hard negative,是对模型足够难、但在任务定义下又明确应该分开的样本。
从头训练嵌入模型(Embedding Model)通常并非多数团队的首选路径。原因并不神秘:它既需要大规模高质量句对或 query-document 数据,也需要持续的负例挖掘、评估基准建设和较长训练周期;若多语言还要兼顾长文本、跨语言检索和任务泛化,成本会进一步抬升。对绝大多数工程团队而言,更高效的做法是从一个已经具备稳定表示空间的基座继续微调(Fine-tuning),把现有 embedding 几何结构朝业务目标方向“推一小步”,而非从零发明一整个向量空间。
这也是为什么 embedding 项目的真正瓶颈往往不在“有没有训练框架”或“能不能跑通微调”,而在于能否拿到足够多、足够干净、又足够贴近业务分布的数据。正例对开发相对直接,难的是负例设计,尤其是高价值 hard negatives:它们决定模型能否学会区分那些最容易混淆、最接近真实线上错误的样本。
Sentence-BERT(SBERT)路线的实用价值就在这里体现得很明显:它并不要求必须从头构建一个新的 embedding 模型,重点是允许直接以现有 SentenceTransformer 模型或预训练编码器为基础继续训练。这样做的收益有两个。第一,预训练阶段已经学到大量通用语言结构,微调只需要重塑与当前任务最相关的距离关系。第二,训练资源会集中花在“任务适配”而非“重新学习基本语言知识”上,因此更适合企业内部检索、垂直领域分类、多语言 RAG 和跨语言匹配这类目标明确的场景。
实际选基座时,不应只看单一榜单名次,而应同时看四个因素:语言覆盖、上下文长度、是否指令化(Instruction-aware)、以及微调成本。榜单可以帮助筛掉明显过时的模型,但真正决定工程效果的,往往是“它是否与你的数据形态和训练预算匹配”。截至 2026 年 3 月,下面几类开源基座尤其值得优先考虑,尤其是在多语言场景中。
| 基座 | 多语言能力 | 核心特点 | 更适合的微调目标 |
| Qwen3-Embedding-8B / 4B / 0.6B | 100+ 语言 | 当前公开多语言榜单前列的强基座;支持指令感知、最长 32K 上下文、可自定义输出维度 | 多语言检索、跨语言召回、长文档检索、代码与自然语言混合语料 |
| BGE-M3 | 100+ 语言 | 同时支持 dense / sparse / multi-vector;最长 8192 token;对混合检索和 RAG 结构非常友好 | 多语言 RAG、混合检索、长文档场景、需要兼容 BM25 风格稀疏信号的系统 |
| multilingual-e5-large-instruct | 94 语言 | 指令式 embedding 路线成熟;query 端显式带任务描述;体量相对可控 | 任务定义清晰的检索、问答召回、跨语言语义匹配 |
| jina-embeddings-v3 | 多语言;重点调优 30 种语言 | 8192 token 长上下文;内置任务 LoRA 适配器;支持 Matryoshka 截断维度 | 一套基座服务多任务、需要分类 / 检索 / text-matching 共用底座的系统 |
若强调“当前最强的开源多语言底座”,Qwen3-Embedding 系列是首先应试的对象;若强调“检索形态复杂、需要 dense + sparse + rerank 协同”,BGE-M3 的工程灵活性仍然非常突出;若更在意成熟的指令式 query-document 训练范式,multilingual-E5-large-instruct 依然是很稳的起点;若希望在同一基座上兼顾多任务并降低任务切换成本,jina-embeddings-v3 的任务适配设计更有吸引力。
因此,特定目标的嵌入微调并非“随便挑一个 embedding 模型然后继续训”。更合理的顺序是:先根据任务选择合适的基座拓扑,再设计正负样本与评估器,最后用微调把表示空间朝业务目标压缩。对今天的大多数团队来说,真正的竞争力很少来自“从零训练一个全新 embedding 模型”,而更多来自“是否用合适的底座,把微调目标、负例设计和评测体系做对”。
基于生成模型的嵌入训练适合三类目标。第一类是长上下文检索:候选文档明显超过传统 Encoder embedding 的舒适长度,需要利用 LLM 的长上下文窗口读取更多原文。第二类是指令感知检索:同一段文本在不同任务下应形成不同向量,例如“按法律风险检索”和“按客户情绪检索”关注的语义方向不同。第三类是希望复用已有生成模型生态的私有化系统:团队已经围绕 Qwen、LLaMA、Mistral 或 T5 建好了 tokenizer、权重管理和推理环境,希望在同一主干上扩展 embedding 能力。
这条路线的训练目标依然是 embedding 目标,普通 next-token prediction 只提供语言建模信号,不能直接保证向量空间可检索。模型最终要输出稳定向量,训练过程必须直接优化向量距离、排序关系或检索指标。若只拿一个未经适配的 chat LLM,读取最后一层隐藏状态再做余弦相似度,通常只能得到一个粗糙基线;真正可用的生成式 embedding 需要围绕 pooling、投影、归一化和对比损失进行专门训练。
基座选择取决于训练预算与上线约束。若目标是多语言、中文和长文档检索,Qwen 系列或其它已经在目标语言上表现稳健的 Decoder-only 基座通常更合适;若目标是 text-to-text 任务延伸,例如把检索 query 写成明确任务指令,再输出可读答案,T5 / FLAN-T5 一类 Encoder–Decoder 基座也可以作为起点;若系统极度看重吞吐与低成本召回,专门 Encoder embedding 模型仍然应作为强基线,不应因为 LLM 更大就默认替换。
对 Decoder-only 基座,必须先决定读出位置。最常见的是最后一个有效 token、EOS token 或额外添加的汇聚 token。若采用最后 token pooling,训练样本应保证输入末尾存在稳定边界,例如统一追加 EOS 或专门的结束标记;若采用平均池化,则要明确 attention mask 与 padding 处理,并意识到因果注意力下早期 token 没有读取完整后文。很多实践会再加一个投影层 \(W_p\),把隐藏状态从模型维度压到更适合检索的维度,例如 768、1024 或 1536,并在输出前做 L2 归一化。
一个可执行流程通常分成七步。
- 定义检索任务。先明确向量要服务的目标:FAQ 召回、RAG 文档召回、跨语言检索、代码搜索、相似案例检索,还是基于业务标签的近邻分类。目标不同,正负样本定义会完全不同。
- 准备 query-document 或 text-pair 数据。检索型 embedding 最常见的数据形态是 \((q,p^+)\),其中 \(q\) 是查询,\(p^+\) 是正确文档。若有人工相关性分数或点击日志,也可以构造成 \((q,p,y)\)。
- 构造负样本。先用随机负例建立基础区分,再用 BM25、旧 embedding 模型或线上召回日志挖掘 hard negatives。生成模型 embedding 尤其需要高质量难负例,因为它的语义容量很强,太简单的负例很快失去训练价值。
- 确定输入模板。query 端和 document 端可以使用不同前缀,例如“Represent this query for retrieval:”与“Represent this document for retrieval:”。指令前缀能让同一基座根据任务目标调整隐藏状态方向,但模板必须固定,否则模型会把格式差异也写进向量空间。
- 前向提取隐藏状态。每条文本独立输入生成模型,得到最后层隐藏状态 \(H\),再通过最后 token pooling、EOS pooling 或训练好的 pooling head 得到 \(e(q)\) 与 \(e(p)\)。
- 优化对比损失。最常见目标仍是 Multiple Negatives Ranking Loss。对一个 batch 中的 \(B\) 组正配对,可写成 \(L_i=-\log \frac{\exp(s(q_i,p_i)/\tau)}{\sum_{j=1}^{B}\exp(s(q_i,p_j)/\tau)}\)。其中 \(s(q_i,p_j)\) 通常是归一化向量内积,\(\tau\) 是温度参数。
- 评估检索指标。训练过程应直接看 Recall@K、MRR、nDCG、Hit Rate 或 MTEB 子任务,不能只看训练损失。Embedding 的最终产品是排序质量,损失下降但召回不升,说明正负样本、模板或 pooling 仍需调整。
训练策略上,通常不必一开始全参数更新。对 7B 以上的 Decoder-only 基座,可以先冻结主干,只训练 pooling/projection head,观察向量是否能形成初步检索结构;随后再用 LoRA / QLoRA 打开中高层注意力与 MLP 投影,让隐藏状态本身朝 embedding 目标移动。若训练数据非常充足、目标域与基座差异很大,再考虑更大范围更新。这样做可以把风险分阶段暴露:先确认读出方式有效,再确认任务监督足够支撑主干变化。
上线时,生成式 embedding 模型仍然按双编码器使用:文档侧离线编码并写入向量库,query 侧在线编码,再做 ANN 检索。与普通 Encoder embedding 相比,需要重点控制三个成本:第一,Decoder-only 主干更慢,批处理和 KV cache 对 embedding 前向的收益有限;第二,长文本直接编码会增加显存与延迟,必要时仍要分块或分层聚合;第三,指令模板必须和训练阶段一致,query 端模板和 document 端模板不能在线上随意漂移。
基于表示模型的重排训练适合搜索、RAG、FAQ、问答和电商检索中的精排阶段。第一阶段召回器负责覆盖率,把可能相关的候选取出来;表示模型 reranker 负责精度,在几十到几百个候选里判断哪些真正满足 query。它尤其适合“主题相似但答案不同”“关键词相同但实体不同”“文档只回答部分问题”这类 embedding 相似度容易混淆的场景。
这条路线的优势是工程成熟。Encoder-only Cross-Encoder 的输入长度、显存成本和延迟通常比 LLM reranker 更可控;输出是明确的标量分数,容易接入搜索排序、阈值过滤、A/B 测试和离线评测。很多生产系统会先用表示模型 reranker 做默认精排,再把生成式 reranker 放在更小候选集或更复杂 query 上。
基座通常选择已经具备强表示能力的 Encoder-only 模型或现成 reranker 底座。英文检索可以从 monoBERT、cross-encoder/ms-marco、MiniLM reranker、DeBERTa 系列开始;中文或多语言 RAG 可优先考虑 BGE Reranker、mDeBERTa、XLM-R 或 ModernBERT 派生模型。基座选择主要看四个约束:目标语言、候选文本长度、线上延迟预算和是否已有领域点击 / 标注数据。
打分头通常很简单。模型读入 \((q,d)\) 后,取 \([\mathrm{CLS}]\) 或池化表示,接一个线性层输出 \(s(q,d)\)。若训练标签是二元相关性,可把 \(\sigma(s(q,d))\) 作为相关概率;若标签是 0 到 3 或 0 到 5 的分级相关性,也可以把它作为回归分数或排序分数。
一个典型训练流程可以拆成七步。
- 固定第一阶段召回器。先确定候选来自 BM25、dense embedding、hybrid retrieval 还是业务规则召回。Reranker 应该学习真实候选分布;只区分随机负例无法充分训练精排能力。
- 构造 query-document 样本。基础样本形态是 \((q,d,y)\),其中 \(y\) 表示相关性标签。标签可以来自人工标注、点击日志、问答对、RAG 引用命中、业务转化或教师模型打分。
- 挖掘难负例。对每个 query,保留召回器排在前列但实际无关的候选。它们最能训练模型区分“主题相似”和“真正回答”。
- 设计输入模板。最常见格式是 \([\mathrm{CLS}]\ q\ [\mathrm{SEP}]\ d\ [\mathrm{SEP}]\)。若使用多语言或指令式 reranker,也可以加入简短任务说明,但模板应在训练和线上保持一致。
- 选择损失函数。二元标签可用 \(L=-y\log\sigma(s)-(1-y)\log(1-\sigma(s))\);成对排序可用 \(L=\max(0,m-s(q,d^+)+s(q,d^-))\);列表排序可用 softmax cross-entropy 或 LambdaRank 类目标。
- 控制输入长度。Cross-Encoder 的复杂度随拼接长度增长。训练时要明确 query 和 document 的截断策略,优先保留标题、命中片段、邻近上下文和字段结构,避免把答案证据截掉。
- 按排序指标评估。核心指标是 nDCG@K、MRR@K、Precision@K、Recall after rerank,以及 RAG 最终引用命中率。分类准确率只能作为辅助指标,因为线上目标是排序质量。
训练时最容易低估的是负例质量。随机负例通常太容易,模型很快能区分;真正有价值的是第一阶段召回器会误召回的 hard negatives。一个较小的 Cross-Encoder 若训练在真实 hard negatives 上,常常比更大但只见过随机负例的 reranker 更可靠。
上线时,表示模型 reranker 通常位于召回之后、生成之前。流程是:召回器取 top-k 候选;reranker 分别计算 \(s(q,d_i)\);系统按分数排序,截取 top-n 进入回答生成、摘要、推荐或展示层。为了控制延迟,top-k 通常不能无限增大;常见做法是先用便宜召回覆盖,再用表示模型 reranker 精排,最后只在少量高价值请求上追加生成式 reranker 或 LLM 验证。
这条路线的工程边界也很清楚:它无法像 embedding 一样提前为全部文档建一个可复用向量索引,因为 query 和 document 必须一起编码;但它也不需要像 LLM reranker 那样执行复杂生成接口。对大多数检索系统而言,基于表示模型的重排仍然是“效果、成本、稳定性”三者最均衡的精排基线。
生成式重排训练适合 RAG、搜索和问答系统中的精排阶段。第一阶段召回已经把候选压到较小规模,例如 top 50 或 top 100;第二阶段需要判断“这段文档是否真正回答当前 query”。这类判断经常涉及否定、限定条件、实体错配、时间错配、表述改写和多段证据整合,单独的向量相似度容易把主题相似但答案错误的文档排到前面。
生成式 reranker 的优势来自联合编码。输入是完整的 \((q,d)\) 对,模型在同一次注意力计算中读取 query 与候选文档,因此可以比较“查询要求什么”和“文档实际提供什么”。它不需要为文档提前生成可复用向量,代价是每个候选都要单独前向,适合候选规模已经被召回器压缩后的阶段。
基座通常优先选择指令跟随能力强、长上下文能力足够、目标语言表现稳定的生成模型。中文或多语言 RAG 可从 Qwen、LLaMA 派生多语言模型、Mistral 派生模型或已有 reranker 基座开始;若需要更低成本,也可以先使用较小的 0.5B、1.5B、3B 级模型做 reranker,再把大模型作为教师生成训练标签。若候选文档很长,基座上下文窗口要覆盖 query、文档和判断模板,否则模型会在截断后学习错误的相关性。
打分形式通常有两种。第一种是显式标量头:读取最后位置隐藏状态 \(h_{\mathrm{end}}\),训练一个线性打分头 \(s=w^\top h_{\mathrm{end}}+b\)。第二种是 yes/no token 打分:让模型在最后一步预测“yes”或“no”,用 \(z_{\mathrm{yes}}-z_{\mathrm{no}}\) 或 \(P(\mathrm{yes}\mid q,d)\) 作为相关性分数。前者更像传统 Cross-Encoder reranker,后者更贴近生成模型原生接口,容易和 prompt 语义结合。
一个典型训练流程可以拆成八步。
- 确定召回来源。先固定第一阶段召回器,例如 BM25、dense embedding、hybrid retrieval 或 GraphRAG。Reranker 的训练数据应来自真实召回分布,否则训练出的模型会擅长区分随机负例,却无法处理线上最常见的混淆候选。
- 构造 query-document 标签。最基础标签是二元相关性 \(y\in\{0,1\}\);更细的训练可以使用 0 到 3 或 0 到 5 的 graded relevance,表示完全无关、主题相关但未回答、部分回答、完全回答等层级。
- 挖掘难负例。对每个 query,保留召回器排在前列但人工判为无关或弱相关的候选。它们通常和 query 共享关键词或主题,是训练 reranker 的核心样本。
- 设计判断模板。模板应稳定包含 query、document、判断标准和输出形式。例如要求模型只判断“文档是否足以回答 query”,避免把“主题相似”误当作“答案相关”。
- 选择打分目标。若采用标量头,可使用二分类交叉熵 \(L=-y\log\sigma(s)-(1-y)\log(1-\sigma(s))\);若采用 yes/no token,可直接对 yes/no 标签词做交叉熵。
- 加入排序目标。对同一个 query 下的正例 \(d^+\) 和负例 \(d^-\),可以增加 pairwise margin loss: \(L=\max(0,m-s(q,d^+)+s(q,d^-))\)。它直接要求正确文档分数高于混淆文档。
- 用 LoRA / QLoRA 微调。多数情况下先冻结基座,只训练 LoRA 和打分头就足够。LoRA 可挂在注意力投影和 MLP 投影上,因为 reranking 同时需要证据对齐、条件判断和语义重编码。
- 按排序指标评估。核心指标应是 nDCG@K、MRR@K、Recall after rerank、Precision@K,以及 RAG 最终回答的引用命中率。Yes/no 准确率只能作为辅助指标,线上目标是排序质量。
实际训练中,数据组织比模型规模更重要。一个 3B reranker 若拥有高质量 hard negatives,往往可以超过缺少真实混淆样本的更大模型。尤其在 RAG 场景里,负例应覆盖“同主题不同答案”“实体名称相似但对象不同”“时间版本错误”“只回答部分问题”“包含答案但证据不足”这几类常见错误。这样训练出的 reranker 才会真正改变候选顺序,降低“语义相似但答案错误”的候选排名。
上线时,生成式 reranker 通常放在召回之后、生成之前。流程是:先由召回器取 top-k 候选;再把每个 \((q,d_i)\) 输入 reranker 得到 \(s_i\);随后按 \(s_i\) 排序,选择 top-n 进入最终 RAG prompt。为了控制成本,候选数量通常不能太大;若 top-k 很高,可以先用轻量 Cross-Encoder 或规则过滤到更小集合,再调用生成式 reranker 做最后精排。
这条链路的关键指标是端到端收益:reranker 自身 nDCG 提升必须转化为最终回答准确率、引用正确率和用户满意度提升。若 reranker 把答案片段排高,却导致上下文过长、生成模型忽略证据或成本不可接受,系统仍需重新调候选数量、截断策略和证据融合方式。
在标注数据非常有限的场景里,增强型 SBERT(Augmented SBERT)提供了一条经典而务实的路径:用少量高质量标注,扩展出一套足够大的嵌入训练集。它利用的是双编码器(Bi-Encoder)与交叉编码器(Cross-Encoder)的互补性:双编码器推理快、适合检索,但通常需要较多训练数据;交叉编码器推理慢,却能在句对打分上提供更高精度。因此,可以先让交叉编码器学会目标任务,再利用它为大量未标注句对生成伪标签,最后反过来训练一个可高效部署的 SBERT。
这个方法的关键不在于引入全新的模型结构,而在于重新组织数据生产流程。少量人工标注但可靠的数据,构成黄金数据集(Gold Dataset);由交叉编码器离线打标生成的大规模伪标签数据,构成白银数据集(Silver Dataset)。黄金数据集负责提供可信监督,白银数据集负责放大覆盖面。两者组合后,就能把“标注稀缺”的问题转化成“高精度慢模型辅助生成训练信号”的问题。
因此,增强型 SBERT 本质上是一种低数据场景下的数据增强(Data Augmentation)与知识蒸馏(Knowledge Distillation)策略:先用少量黄金数据把交叉编码器调准,再让交叉编码器把自己的句对判断能力迁移给双编码器。最终得到的核心是一个依然可以做大规模向量检索、但在目标任务上明显更强的嵌入模型。
增强型 SBERT 的整体流程可以概括为四步。
- 先用少量黄金数据集微调交叉编码器。这里的黄金数据通常规模不大,但标签质量高,足以让交叉编码器学会“在当前任务里什么样的句对应该更相似,什么样的句对应该更远”。
- 再生成一批新的候选句子对。这一步既可以来自额外的未标注语料,也可以从现有语料中重新组合样本,目的是构造一个远大于黄金数据集的候选池。
- 然后让已经微调好的交叉编码器为这些候选句子对打分,生成白银数据集。这里的标签核心是高精度模型给出的伪标签,因此质量通常高于简单启发式规则,却又远比全人工标注便宜。
- 最后用“黄金数据集 + 白银数据集”一起训练双编码器。这样训练出来的 SBERT 保留了双编码器可预编码、可缓存、可做向量检索的速度优势,同时通过白银数据学到了更多与目标任务一致的距离关系。
白银数据集的质量,决定了增强型 SBERT 能否真正成立。若手里本来就有大量未标注句对或 query-document 数据,最直接的做法就是把它们交给交叉编码器离线标注,再转成伪标签训练集。这是最标准也最稳定的路径,因为候选样本来自真实语料分布,白银数据更接近真实任务。
如果没有现成的大规模未标注句对,也可以从现有黄金数据出发构造更多候选样本。例如把不同句子的前半部分与后半部分重新组合,或把不同 query 与 candidate 文档重新配对,生成新的候选对。但纯随机组合通常会制造过多明显不相似的负例,导致数据分布过于偏斜,模型学到的主要是“轻松区分非常不像的样本”,而非处理真正困难的边界。
因此,更有效的做法通常是先用一个预训练 embedding 模型做粗检索:为每个句子或 query 召回若干看起来较相似的候选,再把这些候选送给交叉编码器做精标。这样生成的白银数据会包含更多“高混淆但仍可判别”的样本,训练价值明显高于随机拼接。换句话说,预训练 embedding 在这里负责提高候选样本质量,不负责给出最终标签;真正的伪标签仍然由交叉编码器给出。
增强型 SBERT 的价值,在低资源场景下尤其明显。少量黄金数据本身往往不足以直接把 SBERT 微调到理想状态,因为双编码器更依赖足够多的成对训练信号去塑造向量空间;但这同一小批黄金数据,往往已经足够把交叉编码器调成一个“能较准打分”的教师模型。之后,只要有额外候选样本,教师模型就能持续扩充白银数据集,从而把训练信号放大很多倍。
这也是它与普通监督微调的根本差别:普通微调直接把少量标注样本喂给双编码器;增强型 SBERT 则多加了一层“教师打标”环节,用交叉编码器把少量高质量监督扩展成大量可用监督。因此,它特别适合文本匹配、语义检索、问答匹配、句子对排序等 pairwise sentence scoring 任务。
增强型 SBERT 并非“数据越少越万能”。它仍然要求黄金数据足够准确,否则交叉编码器会先学歪,再把错误批量复制到白银数据里。它也要求候选样本池与真实任务分布足够接近,否则伪标签再多,也只是把错误分布放大。更关键的是,白银数据集并不能替代最终评估:真正决定模型是否可用的,仍应是人工标注的黄金验证集与测试集。
因此,这条路线最适合的场景核心是“有少量高质量标注、但不足以直接训练出强双编码器”。在这种情况下,增强型 SBERT 提供了一条非常自然的过渡路径:先用高精度慢模型吸收黄金数据,再把这种判断能力蒸馏成一个推理高效的嵌入模型。
增强型 SBERT 已经把监督数据需求压得很低,但它仍然依赖少量黄金数据去微调交叉编码器。再往前推进一步,现实里还存在更苛刻的场景:没有人工标注句对,甚至没有可靠的点击日志、排序日志或问答配对数据。此时,嵌入模型训练只能转向无监督学习(Unsupervised Learning)或更准确地说,自监督学习(Self-supervision):训练信号不再来自显式标签,而来自原始语料自身的结构、扰动视图(Augmented Views)或重建目标。
因此,无监督嵌入模型训练处理的是“零标注”条件下的表示学习问题。它核心是把监督信号改写为模型可以从原始文本中自动构造出的约束:哪些表示应该在扰动前后保持一致,哪些句子应被视为同一语义对象的不同视图,哪些带噪输入必须恢复到原始句子。这类方法尤其适合冷启动和领域适配,因为垂直领域最容易获得的往往核心是大量原始文本。
无监督嵌入训练的核心目标仍然是学习一个有判别力的句向量空间,只是实现方式不同。当前常见路线可以概括为四类。
| 方法 | 全称 | 核心原理 | 特点 |
| SimCSE | Simple Contrastive Learning of Sentence Embeddings | 把同一句子在不同 dropout 下得到的表示视为正例,用 batch 内其他句子作负例做对比学习 | 结构极简,是无监督句嵌入的经典标杆路线 |
| CT | Contrastive Tension | 通过对比张力机制重新调整预训练表示,使语义相近样本更聚合、无关样本更分离 | 强调对预训练表示的语义重调 |
| TSDAE | Transformer-based Sequential Denoising Auto-Encoder | 先破坏原句,再要求模型从带噪输入重建原句,逼迫编码器学习句级语义压缩 | 在无监督训练和领域适配中都非常强,是这一节的重点 |
| GPL | Generative Pseudo-Labeling | 从无标签语料出发自动生成 query 与伪标签,再训练 dense retriever | 更接近弱监督,但非常适合无人工标注的检索场景 |
这些方法的共同点是:都在尝试从原始文本中自动制造训练信号;差别在于信号是来自对比、重建,还是生成式伪标签。无监督训练真正的难点依然是数据,只不过难点从“标注是否充足”转移成“自监督信号是否有效”。如果正样本过于容易、负样本过于随机,模型学到的往往只是表面相似性;若扰动方式破坏了核心语义,模型又会被迫学习错误的不变性。
TSDAE(Transformer-based Sequential Denoising Auto-Encoder)是无监督句嵌入中非常重要的一条路线,尤其适合领域适配(Domain Adaptation)。它的核心思想可以概括为“破坏 - 重建”:先对原始句子加噪,例如随机删除部分词、打乱局部结构或施加其他轻度破坏;再让模型从这个带噪版本重建原始句子。模型若想完成这项任务,就不能只记住局部 token,而必须把句子的整体语义压缩到编码表示中。
TSDAE 与掩码语言建模(Masked Language Modeling, MLM)的差别也很关键。MLM 主要学习“根据上下文补出被遮住的词”,重点仍然是词级预测;TSDAE 学习的是“从受损输入恢复整个句子”,目标天然更偏句级语义表示。因此,TSDAE 训练出来的编码器更容易直接拿来生成句嵌入,而不必再从词级预测目标里间接提炼句向量。
这条路线在垂直领域里尤其有效。原因是领域适配最常见的现实条件正是:有大量目标域原始文本,但缺乏成对标注数据。TSDAE 可以先在这些无标签文本上训练一个更贴近目标领域分布的编码器,把通用嵌入空间向领域语义挪动;随后若再获得少量黄金数据,就可以继续用常规 SBERT 或增强型 SBERT 做最后一步任务对齐。
从工程角度看,最有价值的是把“监督训练”“少样本微调”“无监督训练”看成一条连续路线,而非彼此割裂。标注充足时,直接做监督训练;标注很少时,用增强型 SBERT 放大黄金数据;标注几乎为零但有大量原始语料时,先做 TSDAE 或类似无监督适配,再在后续叠加少量监督微调。这样就形成了一个完整闭环:覆盖有监督、低监督到零监督三种数据条件。
因此,无监督嵌入训练并不天然优于监督微调。它的价值在于为 embedding 模型打地基,并在领域迁移时先把表示空间校正到目标语料分布附近。若后续能够获得少量高质量黄金数据,再叠加监督微调,通常会比单独依赖无监督训练更稳,也更接近真实业务目标。
表示模型继续预训练(Continued Pretraining)处理的是这样一种典型情况:基座表示模型已经在通用开放语料上完成预训练,例如互联网文本、维基百科、新闻语料或大规模网页数据,因此具备稳定的通用语言能力;但它并不天然掌握特定领域知识,例如医学术语、金融表述、法律条文、企业内部缩写和业务语境。此时,问题往往不在于模型“不会语言”,而在于模型虽然懂通用语言,却还不够懂目标领域。
这正是继续预训练的切入点。传统 BERT 路线通常只有两阶段:先在通用语料上做预训练,再直接在下游分类或序列标注任务上微调。继续预训练在两者之间插入了一个新的中间层,形成通用预训练 → 领域继续预训练 → 下游任务微调的三阶段流程。它的目标核心是先用目标领域的无标注文本,重新校正编码器的词汇分布、上下文统计与语义偏好,让表示空间先贴近领域,再去做具体任务。
通用预训练模型对“movie”“doctor”“interest”“appeal”这类词的理解,默认来自开放语料中的统计分布;一旦进入垂直场景,这些词的含义和搭配方式可能会明显变化。医学文本中的 drug、lesion、metastasis,金融文本中的 guidance、yield、hedging,法律文本中的 plaintiff、statute、liability,都承载着更窄、更稳定、更专业的语境。如果直接拿通用模型去做下游微调,模型往往会在专业术语、长尾表达和领域共现关系上吃亏。
继续预训练的价值就在于:它允许模型先用领域无标注数据补上这层知识,再进入任务微调阶段。因此它本质上是一种领域自适应预训练(Domain-Adaptive Pretraining, DAPT)策略。医疗领域的 BioBERT、金融领域的 FinBERT、法律领域的 LawBERT,本质上都属于这一路线的不同落地版本。
对 BERT 一类 Encoder-only 表示模型而言,继续预训练最经典的目标仍然是掩码语言建模(Masked Language Modeling, MLM)。它可以理解成一种受控的“完形填空”:随机选择输入序列中约 15% 的 token 作为预测目标,其中 80% 替换成 [MASK],10% 替换成随机 token,剩余 10% 保持不变,但仍要求模型预测原始 token。这样做的目的,是迫使模型根据双向上下文恢复被遮蔽的信息,从而继续学习领域语料中的词汇、搭配和上下文统计。
在继续预训练场景中,MLM 的关键价值不在于“学会猜词”本身,而在于让词向量与上下文表示持续向领域分布靠拢。通用 BERT 看到 What a horrible [MASK]! 时,可能只学到通用情绪词与常见名词;若继续在影评语料上做 MLM,它会更容易把 horror、ending、premise、performance 这类领域表达织进表示空间。医学、金融、法律乃至企业内部文档都是同样的道理。
如果把表示模型继续预训练落到一个可执行的理论流程,通常可以分成六步。
- 确定基础模型。起点通常是一个已经完成通用预训练的表示模型,例如 BERT、RoBERTa、DeBERTa 或其领域相近变体。这里直接继承已有语言能力,无需从头训练模型。
- 收集目标领域的无标注语料。继续预训练最重要的资源核心是高质量领域文本。它既可以来自公开领域语料,例如 PubMed 医学文献、金融新闻、法律判例,也可以来自企业内部数据,例如业务文档、客服对话、知识库与工单记录。
- 完成分词与语料预处理。继续预训练阶段通常不再保留下游标签,只保留原始文本并转换成模型输入序列。此时最重要的是保证文本清洗、截断策略、特殊符号处理与分词器保持一致,因为模型更新的是对领域文本分布的内部表示,而非标签映射。
- 选择掩码策略。最基础的是词元掩码(Token Masking),即对子词粒度随机掩码;若希望模型更充分学习完整术语和专业表达,也可以使用整词掩码(Whole Word Masking, WWM),让一个完整单词的所有子词同时被遮蔽。整词掩码通常训练更难、收敛更慢,但在领域术语密集的场景下更有价值。
- 执行继续预训练。用领域无标注语料继续运行 MLM 目标,让模型参数在不丢失通用语言能力的前提下,逐步适配目标领域。这个阶段更新的核心是整个编码器本身,因此它更像“重塑表示空间”,而非“学习某个具体任务标签”。
- 切换到下游微调。等继续预训练完成后,再把更新后的表示模型接到具体任务上,例如文本分类、语义搜索、命名实体识别(Named Entity Recognition, NER)或关系抽取。此时,下游微调面对的已经核心是一个更懂目标领域语境的表示模型。
继续预训练在企业内部尤其有价值。很多企业缺的是可公开复用的标注数据,文本本身并不稀缺。客服对话、知识库、工单、合同、操作手册、会议纪要、内部 wiki,这些数据天然带有组织级语境和术语。如果直接把通用模型拿去做企业任务微调,模型经常会在缩写、术语和内部表述上显得迟钝;但若先用这些无标注内部数据继续预训练,再做客服主题分类、语义搜索或实体识别,下游效果通常会明显更稳。
因此,继续预训练最适合的核心是“目标领域有大量原始文本,但通用模型对其语境仍然陌生”的场景。它本身核心是一个连接通用语言能力与领域任务能力的中间适配层。
除了直接训练 embedding 模型,另一条非常常见的路线是围绕分类目标(Classification Objective)微调表示模型(Representation Model)。这类方法的基本结构是:以预训练编码器作为基座,在顶层接一个专用分类头(Classification Head),然后用分类损失共同优化表示与决策边界。它适用于情感分类、主题分类、风险识别、意图分类等闭集标签任务,目标核心是让表示尽可能服务于当前分类边界。
在这种设定下,基座模型参数既可以冻结(Freeze),也可以与分类头一起更新。冻结时,训练只发生在分类头,优点是显存占用小、训练稳定、对小数据集更保守;缺点是表示空间几乎不变,模型只能在既有语义表征上学习一个浅层决策边界。若不冻结,则分类头与基座参数会在训练中协同进化:分类头不断把梯度传回编码器,编码器又持续调整自己的表示方式去配合分类目标,最终得到更贴近任务边界的内部表征。这通常能带来更高上限,但也更依赖数据质量、学习率设置和正则化控制。
从经验上看,把基座模型全部冻结后,分类微调效果通常会明显受限,尤其当任务分布与预训练语料存在偏移时更是如此。资源受限时,部分解冻(Partial Unfreezing)是一种常见折中:只更新分类头往往太弱,而全量解冻又可能超出显存或训练预算。在某些具体实验里,只解冻少数几个 Transformer 模块就已经能得到足够好的结果。对文本分类而言,更常见、更合理的做法通常是优先解冻靠后的高层模块,因为后层表示更接近任务语义与决策边界;前层更偏向词法与局部句法特征,保留冻结状态往往问题不大。若任务与预训练域差异很大,或输入风格明显特殊,再考虑进一步向下解冻更多层。部分解冻的关键不在于固定解冻“哪 N 层”,而在于把有限资源优先用在最可能影响任务边界的高层表示上。
以烂番茄影评数据集(Rotten Tomatoes Movie Review Dataset)的情感分类为例,分类目标表示模型微调通常可以拆成六步。
- 选择任务与数据集。烂番茄影评数据集是二分类情感任务:输入是一段影评文本,输出是正面或负面标签。它非常适合说明“表示模型 + 分类头”这一路线,因为情感边界往往依赖整体语义与局部措辞共同决定。
- 加载数据并完成划分。最基本的划分是训练集(Training Set)与测试集(Test Set);若训练流程中还需要调超参数或做早停,则还应额外保留验证集(Validation Set)。这里的重点核心是保证测试集不参与模型选择,从而让最终分类指标具有解释价值。
- 加载基座模型与分词器(Tokenizer)。基座通常选择预训练 Transformer 编码器,例如 BERT、RoBERTa、DeBERTa 或更轻量的蒸馏版本;分词器负责把原始文本转成 token 序列、attention mask 以及模型可接收的输入张量。模型与 tokenizer 必须配套,因为词表、特殊 token 和预训练时的文本规范共同决定了输入表示。
- 进行分词与样本编码。文本在进入模型前需要完成截断(Truncation)、编码与必要的长度控制。这个阶段的目标核心是把“原始语言序列”转换成“可被编码器稳定处理的张量化输入”。序列最大长度、是否保留句首句尾、以及是否对长文本做裁剪策略,都会直接影响分类效果。
- 构建专用数据整理器(Data Collator)。它负责把长度不一的样本动态组织成批次(Batch),例如按当前 batch 的最长序列做填充(Padding),并同步构建 attention mask,保证同一批次内张量形状一致。更进一步,数据整理器也可以承载轻量数据增强策略,例如随机裁剪、句段保留或噪声注入;但它的最基本职责仍然是稳定、高效地完成批次构造,而非单纯“把数据拼起来”。
- 定义评估指标函数。分类目标的训练不仅需要损失函数,还需要一组与业务目标对齐的评估指标。最基本的是 Accuracy;若类别不平衡或更关心误报 / 漏报,则通常还要同时看 Precision、Recall 与 F1。对情感分类这类任务,宏平均 F1(Macro-F1)往往比单独 Accuracy 更能反映模型是否真正学到了稳定的标签边界。
这种训练路线与前文 embedding 微调的根本区别在于优化目标。embedding 微调强调“让相关样本在向量空间中更近,让无关样本更远”;分类目标微调强调“让表示空间直接服务于当前标签决策”。前者更适合检索、聚类、匹配与召回,后者更适合闭集判别任务。实际工程中,两条路线并不冲突:很多系统会先训练或微调一个较强的 embedding / encoder 基座,再在其上叠加分类头完成特定标签任务。
少量样本分类目标微调(Few-shot Classification Fine-tuning)处理的是另一类很常见的现实约束:标签体系已经明确,但每个类别只有极少数标注样本,往往只有 8、16、32 或几十个例子。这类场景下,直接按常规监督流程全量微调一个分类模型,很容易过拟合到表面措辞或偶然噪声;真正有效的方法通常核心是换用对低样本更友好的训练机制。
少样本分类本质上仍然属于监督学习,只是把“每类有大量标注样本”的常规设定,收缩成“每类只有极少量高质量样本”的稀缺设定。它特别适合标注成本高、样本获取慢、但标签体系明确的任务,例如小众领域文本分类、垂直领域情感分析、专业工单归类或内部知识标签识别。少样本方法的核心,核心是尽可能榨出每一条标注样本中的监督信号。
SetFit(Sentence Transformer Fine-tuning)是少样本文本分类里最实用的一条路线之一。它基于 sentence-transformers 生态构建,但并不直接把少量样本喂给一个普通分类器,通常会先把这些样本改写成大量句子对训练信号,再用两阶段流程完成分类。它的核心价值在于:仅靠极少量标注样本,就能让嵌入模型学到任务相关的类别结构,随后再用一个很轻量的分类头完成判别。
SetFit 的完整流程可以概括为三步:
- 采样训练数据。先基于少量原始标注样本构造句子对:同一类别下任意两个文本组成正例,不同类别下的文本组成负例。这样一来,即使每类只有 2 到 8 条样本,也能通过类内 / 类间组合迅速扩展出大量训练对。少样本的关键不再只是“原始样本有多少”,而变成“能否从这些样本中构造出足够有判别力的相似 / 不相似关系”。
- 微调嵌入模型。利用这些正负句子对,对预训练的 Sentence Transformer 做对比学习微调。正例要求模型把同类文本的句向量拉近,负例要求模型把异类文本推远。这个阶段优化的是表示模型本身,也就是 SetFit 的 body。
- 训练分类器。等嵌入模型被调到更适配当前任务后,再用这些高质量句向量作为特征,训练一个轻量分类头(head),例如逻辑回归、线性分类器或其他简单监督分类器。最终推理时,文本先被编码成嵌入,再由分类头输出类别概率。
这套设计的本质是两阶段训练:第一阶段先让嵌入空间学会“同类靠近、异类远离”;第二阶段再在这个已经整理过的表示空间里学习分类边界。相比直接对大模型做全参数分类微调,这种路线对小样本更稳定,也更节省资源。
SetFit 的优势主要体现在四个方面。第一,少样本效率高:每类只需极少数标注样本,就可能逼近常规大数据分类微调的效果。第二,无需提示词:它不像提示式 few-shot 方法那样依赖 prompt 或 verbalizer 设计。第三,训练成本低:大部分计算都集中在句向量微调和轻量分类头训练上。第四,数据利用率高:通过句子对采样,有限标注被最大化放大。
以烂番茄影评(Rotten Tomatoes)这类二分类情感任务为例,SetFit 的典型做法是先按类别均衡抽取极少量样本,例如每类 16 条;之后通过正负配对把几十条原始样本扩展成上千个训练对,再完成对比学习与分类头训练。这个例子最能说明 SetFit 的关键巧思:真正被放大的核心是文本之间的监督关系。
SetFit 也有边界。它最适合短文本、句子级、闭集标签明确的分类任务;若类别语义高度重叠、任务严重依赖复杂推理,或标签本身更像开放式生成目标,那么单纯依赖句向量空间分离的办法未必最优。在这些场景里,提示式 few-shot 或更强的生成式模型可能更有优势。
另一大类主流方案是提示式(Prompt-based)few-shot 微调,其代表方法包括 PET(Pattern-Exploiting Training)和 LM-BFF(Better Few-shot Fine-tuning of Language Models)。它们从直接把分类任务看成“输入文本 → 标签 id”转向把任务改写成 cloze 风格或自然语言提示,让预训练语言模型去预测标签词(label words)或完成模式匹配。PET 的特点是利用 prompt 把少样本监督对齐到语言模型原本更擅长的预训练目标,并进一步用少量标注模型为未标注样本分配软标签;LM-BFF 则把 prompt 搜索、label word 选择和 demonstration 设计系统化,以提高 few-shot 稳定性。
这类方法在标签语义清晰、prompt 设计得当时非常强,但工程代价通常高于 SetFit。它们更依赖 prompt 模板、verbalizer 质量以及不同随机种子的稳定性,迁移到新任务时也往往需要额外搜索和调参。提示式 few-shot 的上限很高,工程摩擦也更大。
第三类主流路线是参数高效微调(Parameter-Efficient Fine-Tuning, PEFT),例如 LoRA、IA3、Prefix Tuning、Prompt Tuning 等。它们的共同点是:大部分预训练参数保持冻结,只训练一小部分新增参数或适配器参数,从而显著降低显存与存储成本。这类方法更直接解决“模型太大,如何降低微调成本”的问题,因此在大基座模型上尤其有价值。
PEFT 与 SetFit 的关注点并不相同。SetFit 解决的是“样本太少,如何更高效地榨出监督信号”;PEFT 更直接解决“模型太大,如何降低微调成本”。在少样本分类里,二者并不互斥:完全可以把少样本策略与参数高效策略叠加。例如,当基座模型较大、显存非常紧张时,可以优先采用 LoRA / IA3 这类方法;若样本极少且更看重训练稳定性与部署成本,则 SetFit 往往是更直接的起点。
如果任务是典型的短文本或句子级闭集分类,且每类只有极少样本,SetFit 往往是首选起点,因为它训练快、对样本效率高、工程上也最直接。若任务标签本身具有很强自然语言语义,且团队愿意投入 prompt 设计与搜索成本,PET / LM-BFF 这类提示式 few-shot 往往有更高上限。若主要矛盾核心是模型太大、显存和部署预算太紧,则应优先考虑 LoRA、IA3 或其他 PEFT 方案。实际系统中,最稳妥的做法通常核心是先判断当前瓶颈究竟是样本、算力,还是 prompt 工程复杂度。
生成模型高效微调(Parameter-Efficient Fine-Tuning for Generative Models)面向的是 Decoder-only 大语言模型(Large Language Model, LLM)的指令对齐与领域适配场景。它处理的核心是如何在显存、训练时间和存储预算都有限的条件下,让基座生成模型学会遵循指令、稳定输出目标格式,并吸收特定领域的表达习惯。对绝大多数 7B、13B 乃至更大规模的开源生成模型而言,基于 QLoRA 的 PEFT 已经成为默认起点。
这一路线最适合三类任务。第一类是指令微调(Instruction Tuning),即让基座模型从“擅长续写”转向“稳定遵循用户指令”;第二类是风格或格式约束,例如客服回复风格、结构化 JSON 输出、企业内部答复模板;第三类是轻量领域适配,例如让模型更熟悉某个组织、行业或产品线的术语与常见问答模式。若主要瓶颈是显存不足,QLoRA 往往优于全量微调;若目标是深度改写模型底层知识、继续预训练大规模领域语料,或修改上下文长度、词表与位置编码等底层结构,则继续预训练或全参数微调仍然更合适。
从理论上看,基于 QLoRA 的生成模型高效微调通常遵循六步流程。
- 确定基座模型与任务目标。基座一般选择已经具备稳定因果语言建模能力的生成模型,例如 Llama、Qwen、Mistral 或 TinyLlama 一类架构;任务目标则通常是监督微调(Supervised Fine-Tuning, SFT)意义上的指令跟随,而非从头学习语言能力。
- 构造高质量指令数据。训练样本通常采用instruction / input / output三段式结构,或更一般的多轮对话消息结构。这里最关键的核心是格式与质量:用户角色、助手角色、轮次边界、结束标记、系统提示词都必须稳定一致。若基座模型已经绑定特定 chat template,就应沿用同一模板组织训练语料;否则模型学到的首先核心是混乱的对话边界。实际工程里,过滤后的 UltraChat 风格指令对话之所以常被拿来做示例,核心原因也正在于此:它提供了相对稳定、结构清晰的监督信号。
- 以低比特方式加载基座。QLoRA 的“Q”来自量化(Quantization):基座权重以 4-bit 形式存储,常见配置包括 NF4、双重量化以及 BF16 / FP16 计算精度。这样做的目的核心是把静态权重占用压到足够低,使更大模型能够在有限显存中完成微调。NF4 尤其适合这一场景,因为它针对 Transformer 权重常见的零中心、近似正态分布做了量化设计。
- 挂接 LoRA 适配器。QLoRA 的训练对象核心是附加在目标投影层上的低秩适配器参数。实践中通常会把 LoRA 挂到注意力层的 \(q\) / \(k\) / \(v\) / \(o\) 投影上,必要时再扩展到 MLP 的 up / down / gate 投影。这样得到的是“冻结量化基座 + 可训练低秩分支”的结构:原模型保留通用语言能力,增量参数专门负责吸收任务相关行为。
- 执行监督微调。训练过程本质上仍然是自回归下一个 token 预测,只是训练语料已经被改写为指令遵循格式。由于显存约束依然存在,单卡 batch size 往往较小,因此通常依靠梯度累积(Gradient Accumulation)来获得更合理的等效批大小;学习率调度常采用 warmup 后接 cosine 衰减;优化器常配合分页优化器以压低峰值显存;最大序列长度则决定模型一次看到多少上下文,也直接决定训练成本。
- 导出训练产物。训练完成后,最常见的保存形式有两种:一种是只保存 LoRA 适配器,部署时与同一基座模型组合使用,这最适合多任务、可插拔部署;另一种是把适配器权重合并回基座,得到单体模型,便于独立推理与分发。前者更省存储、更灵活,后者更接近传统“一个模型直接上线”的部署习惯。
QLoRA 的表现很大程度上由少数关键超参数决定。它们分别约束适配器容量、优化稳定性、上下文覆盖范围与显存预算。
| 超参数 | 控制对象 | 实践含义 |
| LoRA rank \(r\) | 低秩适配器的容量 | \(r\) 越大,适配器表达力越强,但显存与训练成本也越高;过小容易欠拟合,过大则削弱 PEFT 的资源优势。 |
| lora_alpha | LoRA 更新量的缩放强度 | 它决定适配器增量对原模型输出的影响幅度,通常与 \(r\) 配合设置;过大容易训练不稳,过小则适配不足。 |
| target_modules | LoRA 挂接位置 | 只覆盖 \(q\) / \(v\) 投影时最省资源;同时覆盖注意力与 MLP 投影时,通常有更高上限,但训练更重。 |
| lora_dropout | 适配器分支正则化 | 小数据集或高重复训练语料更容易过拟合,适度 dropout 有助于稳定;数据充足时则通常保持较低取值。 |
| 学习率(Learning Rate) | 参数更新步长 | QLoRA 只训练少量适配器参数,因此学习率通常可以高于全参数微调;但过高仍会导致输出风格漂移、格式崩溃或损失震荡。 |
| 批大小与梯度累积 | 等效 batch 规模 | 单卡显存通常只允许很小的 per-device batch size,因此需要靠梯度累积换取更稳定的优化轨迹。真正重要的是等效 batch,而非单步看到多少样本。 |
| 最大序列长度(Max Sequence Length) | 单样本上下文覆盖范围 | 序列越长,训练成本增长越快;过短又会截断多轮对话、长指令或结构化输出。它是质量与成本之间最直接的杠杆之一。 |
| 计算精度与优化器 | 数值稳定性与显存占用 | 支持时优先使用 BF16;否则常退回 FP16。分页 AdamW 一类优化器更适合量化微调,因为它们能显著压低优化器状态带来的峰值显存。 |
| 学习率调度器(Scheduler) | 训练初期稳定性与后期收敛 | cosine 衰减配合短 warmup 是常见默认配置:前期避免梯度过猛,后期逐步收敛到更稳的解。 |
QLoRA 的核心优势是把“生成模型微调”从高门槛算力工程,压缩成可在有限资源上反复迭代的日常流程。因此,只要任务主要是指令跟随、格式控制、轻量领域适配或特定风格注入,它通常都应作为第一选择。它的边界同样明确:当任务需要深度改写基座知识、吸收大规模新领域语料、重构模型底层能力或逼近全参数微调的极限上限时,QLoRA 更适合作为基线而非终点。此时更合理的路线通常是继续预训练、Q-DoRA,或直接转向更重的全参数微调。
生成模型拒绝采样微调处理的是这样一类场景:模型已经具备基本生成能力,甚至已经完成一轮 SFT,但仍希望进一步提高答案正确率、格式稳定性或可验证任务表现;同时,团队又不希望立刻进入完整 RLHF、PPO 或 DPO 训练链路。此时,最自然的做法往往核心是先让模型对同一提示词生成多个候选,再通过外部评分器筛选出最优答案,把它重新写回 SFT 数据,再继续监督训练。
从训练形态上看,它通常遵循五步流程。
- 确定起点模型。起点通常是 Base Model 经过一轮指令微调后的模型,因为拒绝采样依赖“先能生成基本可读候选”这一前提;若模型连任务格式都不稳定,后续筛选只会浪费大量采样预算。
- 为每个提示词生成多个候选。生成阶段的目标核心是提供一个足够有区分度的候选池,因此通常会适度提高采样多样性,让模型在同一问题上给出若干不同解法、表述或结构。
- 使用外部评分器做筛选。评分器可以是规则校验、可执行验证、单元测试、格式解析器、奖励模型、人类打分,或它们的组合。只要能较稳定地区分“明显更好”和“明显更差”,就足以支撑拒绝采样式数据构造。
- 把通过筛选的样本回写成监督数据。最常见的做法是只保留每个提示词下得分最高或达到阈值的候选,把它们整理成新的 prompt-response 数据集。这样做之后,后续训练仍然是标准 SFT,而非显式偏好优化。
- 按监督目标继续训练,并周期性重新采样。随着模型能力提升,旧一轮采样得到的高分样本可能不再代表新的最优边界,因此很多实践会多轮迭代:采样、筛选、回写、再训练,再用更新后的模型继续采样。
这条路线的关键超参数主要有五类:每个提示词生成多少候选、采样温度与 top-p 等多样性控制、接受阈值或保留比例、评分器本身的一致性与噪声水平,以及每轮回写数据占原始 SFT 数据的比例。它们共同决定一个核心权衡:候选越多、筛选越严格,样本平均质量可能越高,但成本也越高,且更容易把训练分布压窄;候选太少或筛选过松,则回写数据与原始 SFT 的差异不够明显,改进幅度往往有限。
与 DPO 相比,拒绝采样微调不会直接保留“胜者优于败者”这层相对关系,只把胜者留下来,因此信息利用率更低,但训练链路更简单;与 PPO 相比,它没有显式策略优化与在线回报建模,因此更容易稳定落地。工程上,它特别适合答案是否正确较容易验证的任务,而对开放式偏好、帮助性、安全性与语气细粒度排序,更常需要再叠加 DPO、RLHF 或其他偏好优化方法。
生成模型直接偏好调优(Direct Preference Tuning for Generative Models)处理的是生成模型训练中的下一层目标:模型已经通过监督微调(SFT)学会了基本的指令跟随,但在多个可行回答之间,仍未必稳定偏向人类真正想要的输出。此时,训练重点从“把任务教给模型”转向“把偏好写进模型”。在当前工程实践里,DPO(Direct Preference Optimization)是最典型、也最实用的直接偏好调优方案。
它之所以称为“直接”,就在于它绕开了“先训练奖励模型,再用 PPO 做强化学习”的显式 RLHF 流程,直接用偏好数据本身更新策略。对资源受限、希望复用现有 SFT 训练栈的团队而言,这通常是比传统 RLHF 更轻、更稳的选择。
直接偏好调优几乎总是建立在一个已经完成 SFT 的模型之上,而非直接从 Base Model 开始。原因很直接:偏好数据表达的是“在两个都还算合理的回答之间,哪个更好”;如果模型连基本指令都还不会遵循,那么偏好优化得到的首先核心是更混乱的行为。因此,标准路径通常是Base Model → SFT / QLoRA SFT → DPO。若显存非常紧,DPO 阶段也仍然可以继续沿用 LoRA / QLoRA 这一类参数高效微调方案。
从工程与理论结合的角度看,生成模型直接偏好调优通常可以拆成六步。
- 确定起点模型。直接偏好调优的起点通常核心是已经完成指令微调的模型。若前一阶段使用的是 LoRA / QLoRA,则这里有两种常见路径:要么先把 SFT 适配器合并回模型,再继续挂接新的 DPO 适配器;要么保留 SFT 结果作为起始状态,在其之上继续叠加偏好调优适配器。无论采用哪条路径,本质都一样:DPO 学习的是“在 SFT 行为之上继续排序优化”,而非重新学习指令能力。
- 构造偏好数据集。训练样本的基本形态是三元组:提示词(prompt)、被接受回答(chosen)、被拒绝回答(rejected)。它要求两条回答都与同一个提示词对应,并且都具备一定可读性,否则优化信号会退化成“学会排除明显坏答案”,而非学习细粒度偏好边界。高质量 DPO 数据的关键,不只是 chosen 比 rejected 更好,还在于两者足够接近、足够可混淆,这样模型才会被迫学习真正决定人类偏好的因素,例如信息完整性、语气、格式遵循、安全边界与事实可靠性。
- 建立参考模型。DPO 不显式训练奖励模型,但仍然需要一个冻结的参考模型(Reference Model)作为锚点。这个参考模型通常就是 SFT 后的模型快照,它定义了“原本模型认为哪些回答更可能”。训练模型的目标核心是相对于参考模型,进一步提高 chosen 的相对优势,并压低 rejected 的相对优势,从而避免模型在优化偏好时过度漂移。
- 配置可训练参数。若采用 PEFT 路线,训练对象通常仍是 LoRA 适配器,而非全参数更新。此时需要重新决定 DPO 阶段的 LoRA 容量与挂载范围。实践中,一个常见选择是让 DPO LoRA 覆盖注意力投影与 MLP 投影,因为偏好优化往往既涉及回答内容选择,也涉及风格、结构和安全边界的重排。若只覆盖极少数层,偏好容量可能不足;若覆盖过广,则训练成本与过拟合风险都会上升。
- 执行直接偏好优化。DPO 训练时会同时比较当前模型和参考模型在 chosen / rejected 两条回答上的条件概率。优化目标可以概括为:让当前模型比参考模型更偏向 chosen,同时更远离 rejected。与 PPO 不同,这一过程不需要 rollout、奖励建模或价值函数估计,因此训练流程更接近“带特殊损失函数的 SFT”,也更容易保持数值稳定。
- 保存与合并训练产物。若使用 LoRA / QLoRA,训练完成后最常见的产物仍然是 DPO 适配器,而非完整模型。部署时可以只加载适配器与基座组合使用;若希望得到单体模型,也可以按顺序把 SFT 适配器与 DPO 适配器依次合并。这个顺序很重要,因为偏好调优是在指令能力之上继续修正输出排序,若跳过 SFT 阶段直接只保留 DPO 适配器,模型通常不会得到预期行为。
直接偏好调优的关键超参数主要决定四件事:偏好优化强度、可训练容量、序列覆盖范围,以及在有限显存下能否稳定收敛。
| 参数 | 控制对象 | 实践含义 |
| beta | DPO 偏好强度 / 正则化强度 | 它决定 chosen 相对 rejected 的概率优势要被放大到什么程度。取值过大,模型容易偏离参考模型过快;取值过小,偏好信号又会过弱。工程上常把它理解为“偏好更新的力度旋钮”。 |
| 学习率(Learning Rate) | 更新步长 | DPO 阶段通常比早期 SFT 更接近“行为微调”而非“能力学习”,因此学习率往往需要更保守。学习率过高时,最先损坏的往往核心是回复风格、格式一致性与安全边界。 |
| 批大小与梯度累积 | 等效 batch 规模 | DPO 每个样本都包含 prompt、chosen、rejected 三部分,显存压力通常高于普通单输出 SFT,因此更依赖小 batch 配合梯度累积来换取稳定训练。 |
| max_prompt_length | 提示词截断长度 | 它控制参考上下文保留多少信息。过短会丢失任务条件,过长则显著抬高显存与计算成本。 |
| max_length | 整体序列长度上限 | 它决定 prompt 与回答总共能占多少 token。对多轮对话、长解释和结构化输出任务而言,这个参数直接影响偏好信号能否覆盖完整回答。 |
| warmup_ratio | 训练初期学习率预热比例 | 偏好训练通常数据量小、梯度信号陡峭,预热有助于避免一开始就把模型推离参考分布。 |
| 优化器与精度 | 显存与数值稳定性 | 若沿用 QLoRA 路线,分页 AdamW、混合精度与梯度检查点通常仍是默认组合,它们解决的是“偏好训练能否在消费级显存下跑稳”的问题,而非损失函数本身的问题。 |
| LoRA 的 \(r\)、\(\alpha\)、target_modules、dropout | 可训练容量与挂载位置 | 这些参数控制 DPO 阶段到底允许模型改动多大子空间。偏好差异若主要体现在语气、格式和细粒度行为边界上,低秩适配器通常足够;若 chosen / rejected 差异深度依赖复杂知识、推理链条或长程一致性,则更高秩或更广覆盖范围往往更稳。 |
推理优化(Inference Optimization)目标是在质量约束下同时降低延迟(Latency)、显存(Memory)和成本(Cost)。主线方法包括量化(Quantization)、KV Cache 优化、推测解码(Speculative Decoding)和连续批处理(Continuous Batching)。
量化(Quantization)通过降低数值精度减少带宽与显存占用。常见路径:FP16/BF16 到 INT8/INT4/FP8。大模型推理最常见的是权重量化(Weight-only Quantization),因为它实现简单、收益稳定;进一步的激活量化(Activation Quantization)能带来更大的加速空间,但对硬件与校准(Calibration)更敏感。
常见概念:
- PTQ(Post-Training Quantization):训练后量化,依赖少量校准数据估计尺度(Scale)与零点(Zero-point)。
- QAT(Quantization-Aware Training):训练时模拟量化误差,通常精度更好但成本更高。
- 按粒度:per-tensor / per-channel / group-wise,粒度越细通常越准但开销更高。
- INT8:8-bit 整数量化,精度与兼容性通常最稳,常作为权重量化的保守起点。
- INT4:4-bit 整数量化,压缩率更高,但更依赖量化算法、分组方式与校准质量。
- FP8:8-bit 浮点格式,动态范围通常优于 INT8,更适合高端硬件上的高吞吐推理与训练。
- GGML:最早的本地 CPU/GPU 推理张量库与算子生态,强调轻量、本地部署与量化推理。
- GGUF:建立在 GGML 生态上的统一模型文件格式,用于封装权重、词表、量化元数据和模型配置,已成为 llama.cpp 一类本地推理工具的主流分发格式。
KV 缓存(Key-Value Cache, KV Cache)用于避免重复计算历史 token 的 Key/Value。在解码器(Decoder-only)模型中,生成第 \(t\) 个 token 时需要与前 \(t-1\) 个位置做注意力;若不缓存,每一步都会重复算一遍历史的 K/V,代价极高。
代价分解常用“预填充(Prefill)+ 解码(Decode)”来理解:Prefill 处理提示词(Prompt)并写入 KV;Decode 每生成一个 token 只需计算新 token 的 Q/K/V,并与缓存做一次注意力。这把每步成本从“重算整段历史”降为“读取缓存并做一次加权求和”。
KV Cache 的主要代价是显存:缓存规模与层数、头数、上下文长度线性增长,因此优化会围绕缓存布局(如 Paged Attention)、压缩(如 KV 量化)与复用策略展开。
粗略的量级估算:若每层缓存张量形状近似为 \(K,V\in\mathbb{R}^{L\times n_{\text{kv}}\times d_k}\),则单 batch 的显存规模约为
\[\mathrm{Mem}_{\mathrm{KV}}\approx 2\cdot N_{\text{layers}}\cdot B\cdot L\cdot n_{\text{kv}}\cdot d_k\cdot \text{bytes}\]其中 \(n_{\text{kv}}\) 在 GQA/MQA 中显著小于 Query 头数,因此 GQA/MQA 往往是降低 KV Cache 的一阶有效手段;进一步的手段包括 KV 量化、Paged KV(按块管理与回收)、以及对重复前缀做复用/持久化(Prompt Caching)。
Paged Attention 是一种面向推理阶段的 KV Cache 分页管理与访问机制。它把逻辑上连续的一段 KV 序列拆成固定大小的块(Blocks / Pages),再用块表把请求看到的连续上下文,映射到物理上未必连续的显存块,从而支持动态分配、回收与复用。
它解决的重点核心是“如何把不断增长的 KV Cache 更高效地组织、分配和访问”。
这种设计的收益主要有三点。第一,减少显存碎片(Fragmentation):请求长度不断变化时,不再需要为每条序列预留一整段连续大内存。第二,提升动态批处理与并发调度效率:不同请求可以共享统一的块分配与回收机制,更容易在在线服务里做 token 级调度。第三,和前缀复用天然兼容:当某段前缀已经生成过,对应的 KV blocks 可以直接挂到新请求的块表上,而不必搬移整段缓存。
因此,Paged Attention 的本质是KV Cache 的分页管理与访问优化,而非新的注意力数学形式。它不改变注意力结果本身,改变的是推理引擎如何在显存里存放和调度这些历史状态。它通常与连续批处理(Continuous Batching)、Prompt Caching 和块级回收策略一起出现,是高吞吐推理引擎里的基础设施级组件。
若沿用传统的连续分配思路,系统通常需要为每条请求预留一大段连续显存,用来容纳“未来可能继续增长”的 KV Cache。但生成长度在服务开始时并不可知:有的请求很快结束,有的请求会持续生成很长文本。于是,预留得太保守会频繁扩容甚至失败,预留得太激进又会浪费大量显存。
这会同时带来两类碎片。内部碎片(Internal Fragmentation)来自“已经预留但尚未使用”的那部分连续空间;外部碎片(External Fragmentation)则来自请求不断进入和退出后,显存里出现许多零散空洞。即使总空闲显存仍然足够,也可能因为拿不到一整段足够长的连续区域,而无法容纳新的长请求。Paged Attention 的出发点正是消除这种“连续大块内存”假设。
Paged Attention 借鉴了虚拟内存(Virtual Memory)的分页思想。推理引擎先把可用于 KV Cache 的显存切成大量固定大小的物理块(Physical Blocks),每个块只容纳固定数量 token 的 K/V。对单条序列而言,模型逻辑上仍然看到一段从位置 1 到位置 \(t\) 的连续上下文;但在物理层,这些 token 对应的 KV 可能分散存放在许多互不相邻的块里。
块表(Block Table)负责维护这种映射关系:逻辑上的第 \(i\) 个块,对应显存中的哪一个物理块。当当前尾块写满后,系统只需从空闲池中再取一个新块,把它挂到块表末尾即可,并不要求新块和前一块在物理地址上相邻。这样一来,序列增长就从“申请更长的一整段连续空间”变成了“追加一个固定大小的新块”。
这种布局把碎片问题压到很小的范围内。内部浪费通常只会出现在最后一个尚未写满的尾块中,而不会沿整条序列累计;外部碎片则因为不再要求大块连续空间而大幅缓解。工程上真正被频繁分配和回收的对象,从“整条请求的整段缓存”转向细粒度、等尺寸的块。
在 Paged Attention 中,注意力访问路径(Access Path)指的是:当前 query 如何找到并读取历史 token 对应的 Key / Value,再完成注意力计算。它改变的是这条访问路径,而非注意力公式本身。对当前 query 而言,模型仍然需要与全部历史 token 的 Key / Value 交互;不同之处在于,这些历史状态从通过一块连续显存读取转向由 kernel 按块表顺序逐块定位、聚合并完成注意力计算。逻辑上的序列连续性由块表保证,物理上的离散布局由运行时屏蔽。
因此,Paged Attention 的更贴切定义是一种分页式 KV 访问内核。它要求注意力实现能够接受“逻辑连续、物理离散”的缓存布局,并在 kernel 内高效完成地址映射、块级遍历和结果聚合。Paged Attention 核心是需要推理 runtime 与注意力 kernel 协同设计的系统级能力。
分页布局还自然支持前缀共享(Prefix Sharing)。当多个请求拥有相同前缀时,它们可以在块表层共同指向同一组前缀块,而不必各自复制一份完整的前缀 KV。这种共享对系统提示词固定、多轮追问、束搜索(Beam Search)或树状探索都很重要,因为这些场景往往存在大段公共前缀。
一旦不同请求在后续 token 上开始分叉,系统再为各自分配新的尾部块即可;已经共享的旧块保持只读并可继续复用。这就是写时复制(Copy-on-Write)的典型思想:真正发生差异时才复制,未分叉前尽量共享。后文的 Prompt Caching 可以看作这种能力在“跨请求、跨时间窗口前缀复用”上的工程化延伸。
Prompt Caching(前缀缓存)缓存的是“提示词前缀的 KV Cache”,目标是避免在多轮对话或重复前缀场景下反复做 Prefill:当新请求的开头 token 序列与某个已缓存前缀完全一致时,推理引擎可以直接复用这段前缀的 KV blocks,只对新增 token 做增量计算。
它直接优化两个指标:
- 首 token 延迟(Time To First Token, TTFT):减少或跳过重复前缀的 Prefill。
- 成本:若推理服务对缓存命中(Cache Hit)的前缀按更低费率计费,则输入 token 成本显著下降。
Prompt Caching 的工程前提是“字节级一致(Exact Prefix Match)”:通常要求 tokenizer 后的 token 序列完全一致,任何空格/标点/系统提示词差异都会导致 cache miss。因此它更适合“系统提示词固定 + 文档前缀固定 + 多次追问”的产品形态,而非随意变化的自由对话。
这类缓存的生命周期通常更像一种受显存压力驱动的短生命周期缓存。最常见的形态是直接驻留在 GPU 显存里,只要显存充足就保留,一旦新请求挤压缓存池,就按 LRU 等策略优先淘汰不活跃前缀。也有系统会把不活跃的 KV blocks 下沉到 CPU 内存形成分层缓存,以换取更长的可复用时间;但完整 KV Cache 很少作为常规路径直接落盘长期持久化,因为它体积大、回读慢、反序列化开销高,往往不如重新做一次 Prefill 划算。
在共享推理后端中,Prompt Caching 必须严格做多租户隔离(Multi-tenancy Isolation):缓存命中不能只依赖“前缀文本哈希”,还需要把租户/用户身份与模型版本纳入缓存键(Cache Key),避免跨用户“串台”与侧信道泄露。典型复合键(Composite Key)包括:
- 租户 ID(Org/User ID)
- 模型版本(Model/Weights Version)
- 前缀 token 哈希(Prefix Hash)与长度等元数据
缓存生命周期通常很短:KV Cache 占用显存,后端会用 LRU(Least Recently Used)等策略在压力下淘汰缓存;因此“隔天再聊成本回到原价”是常见现象。若业务需要跨小时/跨天复用长前缀,工程上一般转向两类手段:长效上下文缓存(Context Caching,若服务支持)或 RAG/摘要把长前缀变成可检索的外部状态。
KV Cache 压缩(KV Cache Compression)讨论的是:在不显著破坏注意力行为的前提下,把每个 token 需要缓存的 Key / Value 表示存得更小。它的直接目标核心是长上下文推理时的显存占用、带宽压力和并发能力。因此,从优化对象看,Latent KV、MLA、KV 量化、TurboQuant 都属于推理阶段优化;只是从实现方式看,它们并不全是推理后处理技巧,有些方法需要在模型架构和训练阶段就内建进去。
一条路线是潜空间压缩(Latent-space Compression)。它核心是先把每个 token 的 KV 投影到更低维的潜空间(Latent Space),缓存潜变量;当需要参与注意力计算时,再由模型内部结构把潜变量还原成用于打分和聚合的表示。这类方法常被概括为 Latent KV,典型代表就是 MLA(Multi-head Latent Attention)。
这类方法的本质是一种架构级的推理友好设计。它服务的是推理阶段的 KV 成本问题,但并非像 KV 量化那样在现成模型外部直接套一个压缩器;模型通常需要在训练时就学会如何在潜空间里存储和恢复有效的注意力信息。因此,它应被放在推理优化里讨论,但不能误解成“任何现有模型都可无缝加上的后处理插件”。
相对于 GQA/MQA 只是在“头数”上减少缓存,Latent KV / MLA 更进一步,直接压缩每个 token 的 KV 表示维度。收益通常体现为更长上下文、更高并发和更低带宽占用;代价则是算子更复杂、实现更依赖内核与数值稳定性,而且表示压缩本身会改变模型的内部信息流,因此往往需要专门的训练配方与模型容量补偿。
DeepSeek V4 在 KV Cache 压缩上的推进,已经从压缩“每个 token 的 KV 向量有多宽”扩展到进一步压缩“历史序列里需要保留多少条 KV 条目”。这条路线的代表就是混合注意力(Hybrid Attention)中的 CSA(Compressed Sparse Attention)与 HCA(Heavily Compressed Attention)。如果说 MLA 关注的是单条缓存的表示维度,那么 CSA / HCA 关注的就是整段历史在序列轴上的压缩与检索。
设历史序列中已有 \(n\) 个 token 的 KV 条目,普通注意力会让当前位置的 Query 直接面对这 \(n\) 条历史记录。CSA / HCA 的共同思路是:先把相邻若干条 KV 条目聚合成压缩块,再让 Query 对这些压缩块做注意力。若每 \(m\) 个 token 压成一个块,则序列级缓存长度大致从 \(n\) 降到 \(\frac{n}{m}\);若压缩率更大,长度还会进一步下降。这时压缩块可抽象写成
\[\tilde c_i=\sum_{j=mi}^{m(i+1)-1}\alpha_{ij}c_j,\qquad \sum_j \alpha_{ij}=1,\ \alpha_{ij}\ge 0\]其中 \(c_j\) 表示原始 KV 条目, \(\tilde c_i\) 表示第 \(i\) 个压缩块,权重 \(\alpha_{ij}\) 由模型学习得到。这个式子表达的核心是带位置偏置与内容权重的可学习块聚合:一个压缩块内部,哪些 token 更该代表这一段历史,由模型自己决定。
若按组件拆开看,CSA 基本可以分成三步。第一步是 Token-Level Compressor:把每 \(m\) 个 token 压成一个压缩块。第二步是 Lightning Indexer:先用一个更轻的索引器对压缩块打粗分,避免让每个 Query 暴力遍历所有压缩块,再做 top-k 选择。第三步是 Shared KV MQA:被选中的压缩块从分开维护多组 Key / Value转向以共享 KV 的 Multi-Query Attention 方式参与核心注意力。图里的“先压缩、再挑重点、最后精读”正对应这三层结构。
CSA 的关键在于“先压缩,再稀疏检索”。它先把历史 KV 压成较细粒度的压缩块,然后再为当前 Query 构造一个轻量索引器,对这些压缩块打分,只保留最相关的 top-k 块参与核心注意力。若把被选中的块集合记为 \(\mathcal{S}_t\),则当前位置 \(t\) 的核心注意力可写成
\[o_t=\mathrm{Attn}\bigl(q_t,\{\tilde c_i\}_{i\in \mathcal{S}_t}\bigr),\qquad \mathcal{S}_t=\mathrm{TopK}\bigl(\mathrm{score}(q_t,\tilde c_i),k\bigr)\]这意味着 CSA 从让 Query 面对全部历史转向先在压缩后的历史摘要中做一次粗检索,再只对最值得关注的若干块做精算。它本质上是一种“压缩后的稀疏注意力”:既利用块压缩降低历史长度,又利用 top-k 选择避免在所有压缩块上做全量注意力。这里的 Lightning Indexer 之所以重要,是因为它把“找哪些块值得看”这件事从昂贵的全量注意力里剥离出来,先用一个更便宜的门禁系统完成粗召回。
HCA 的设计更激进。它同样先做块压缩,但压缩率 \(m'\) 更高,而且从对压缩块做 top-k 稀疏选择转向直接在这些高度压缩后的全局摘要上做稠密注意力。若把 HCA 的压缩块记为 \(\hat c_i\),则它的核心形式更接近
\[o_t=\mathrm{Attn}\bigl(q_t,\{\hat c_i\}_{i=1}^{n/m'}\bigr),\qquad m' \gg m\]因此,HCA 牺牲的是块内细节,换来的是一种非常便宜的全局视野:每次注意力看到的是“高度概括过的整段上下文骨架”。它和 CSA 最大的结构差异有两点。第一,HCA 的压缩更重,例如官方配置里常见 \(m=4\) 对应 CSA,而 \(m'=128\) 对应 HCA。第二,HCA 没有 Lightning Indexer,直接在这些高度压缩后的块上做稠密注意力,不做 top-k 挑块。因此,CSA 更像“压缩后再精确召回”,HCA 更像“极粗粒度的全局扫视”。二者混合使用,形成的就是一条局部更细、全局更粗、但总体成本受控的长上下文建模路径。
从直观上看,可以把它类比成查阅一本极长的技术手册。MLA 做的是“把每一页字缩得更紧一些,但页数不变”;CSA 做的是“先把相邻几页整理成摘要,再从这些摘要里只抽最相关的若干段精读”;HCA 做的是“先把整本书压成更粗的章节提要,再快速通览全部章节提要”。三者都在降成本,但压缩的对象并不相同。
DeepSeek V4 还在 CSA / HCA 外围加入了一组保证可用性的细节。其一,压缩后的 Query 与 KV 条目在进入核心注意力前还会再做一次 RMSNorm,以控制 attention logits 的数值尺度;其二,只对最后一部分维度施加部分旋转位置编码(Partial RoPE),避免压缩后的表示完全丢失相对位置信息;其三,额外保留一条滑动窗口注意力分支,让最近若干 token 仍以未压缩形式参与计算,从而补回块压缩天然会削弱的局部精细依赖。于是整个混合注意力的真实行为核心是远处靠压缩块,近处靠局部窗口;全局靠 HCA,重点靠 CSA。
这张图里“精读 + 略读”这个比喻还有一个很关键但容易被忽略的实现含义:DeepSeek V4 核心是把它们按层交替堆叠(interleaved)。官方给出的 Pro 配置是 61 层,其中前两层先用 HCA,后续层再让 CSA 与 HCA 交替出现。这样做的好处是,让不同层在长程建模里分工,避免每一层同时承担“精细检索”和“全局粗读”两套昂贵职责:有些层负责重点块召回,有些层负责全局背景扫描。
从技术谱系上看,CSA / HCA 也说明 KV Cache 优化已经分成两条正交路线:一条是 MLA 这类表示维压缩,压缩每个 token 自身的 KV 宽度;另一条是 CSA / HCA 这类序列维压缩,压缩需要保留的历史条目数量。前者更像“把每张卡片做薄”,后者更像“把很多卡片归并成索引块”。它们解决的是同一个 KV Cache 瓶颈,但发力点不同。
KV 量化(KV Quantization)指的是:在保留 Key / Value 语义角色不变的前提下,把 KV Cache 从 FP16 / BF16 等较高精度压缩到更低 bit 的数值格式,以减少存储开销与读取带宽。它服务的仍然是原始注意力结构,只是把缓存表示改成更节省显存和带宽的低比特形式。
这条路线保留原始 Key / Value 的语义角色,不依赖潜空间替换,直接压缩缓存张量。这类方法更接近传统意义上的推理后处理:对现有模型更友好,工程接入成本通常低于 Latent KV / MLA,但量化误差是否会放大到注意力分布中,是成败关键。
TurboQuant 是一种面向 KV Cache 的内积保真量化(Inner-product-preserving Quantization)方法。它属于 KV 量化路线,但优化目标不仅在坐标层面重建原向量,还尽量保住注意力计算真正依赖的内积关系。
这正是它与普通低比特量化的关键区别。对 Key 而言,最重要的核心是尽量保住 \(q\cdot k\) 这类内积关系,因为注意力分数本身就是由这些内积驱动的。TurboQuant 优先保护的是注意力几何结构,而不只是原始向量外形。
如果只从存储角度看,KV Cache 似乎只是把一串浮点数改成更低 bit 的数字格式;但注意力核心是先计算
\[s_i=\frac{q\cdot k_i}{\sqrt{d_k}},\quad \alpha_i=\mathrm{softmax}(s_i)\]然后再用 \(\alpha_i\) 去聚合对应的 \(v_i\)。这意味着,Key 上很小的量化误差,一旦改变了 \(q\cdot k_i\) 的相对大小,就可能在 softmax 之后被放大成明显不同的注意力分布。因此,普通“逐坐标尽量还原”的量化器未必就能得到好的注意力质量,因为它优化的是向量外形,而注意力真正依赖的是内积排序与相对间隔。
从这个角度看,TurboQuant 更像一种面向在线内积估计的向量量化,而非普通的低比特存储。它特别适合 KV Cache 这类在线场景:缓存必须边生成边写入,解码时又要反复读取并参与 \(QK^\top\) 计算,因此量化器不能只在离线重建误差上表现好,还必须在在线注意力分数上尽量稳定。
TurboQuant 的核心直觉可以概括为一句话:先把向量变成更容易量化的形状,再用极低成本修补量化后最关键的内积偏差。如果把原始向量直接送进低比特量化器,少数高能量坐标、异常值和不均匀分布往往会主导误差;而注意力最敏感的是“整体内积关系是否还成立”。因此,TurboQuant 把压缩过程分成主压缩与内积校正两个层次,而非一次简单的数值离散化。
它的整体结构可以理解为两阶段。第一阶段负责主量化(Main Quantization):先对向量施加随机旋转(Random Rotation),再执行高质量的低比特量化。第二阶段负责残差校正(Residual Correction):从追求把每个坐标补得更精确转向针对第一阶段留下的残差,额外附加一个极轻量的编码,用来降低量化后内积估计的系统偏差。这样一来,TurboQuant 的目标就从“压缩向量”推进成了“压缩后仍尽量保住注意力分数”。
若用概念来源去理解,这条路线可以看成“PolarQuant 风格的主量化 + QJL 风格的残差校正”的组合。前者解决“怎么把向量本体存得足够省且失真足够低”,后者解决“怎么让压缩后内积估计不要系统性跑偏”。因此,TurboQuant 看上去像一个量化方法,实际上却比普通低比特缓存更接近一个面向注意力运算的压缩管线。
随机旋转的作用是改善向量分布的可量化性,而非“制造随机性”。原始 KV 向量往往各维统计特性差异很大,有的维度能量特别集中,有的维度接近冗余;直接低比特量化时,少数尖峰维度会迫使量化器把刻度对齐到这些极端值,结果是大量普通维度的有效分辨率被浪费掉。随机正交旋转之后,向量能量会更均匀地摊到各个方向上,各维统计特性更接近,量化器就更容易在固定 bit 预算下稳定工作。
更直观地说,随机旋转做的是“先把难量化的尖峰分布打散,再做统一压缩”。这一步并不改变向量之间真正的几何关系,却显著改变了逐坐标量化时面对的数值形态。因此,它服务的核心是后续低比特编码的数值条件。
如果只有第一阶段,TurboQuant 仍然只是一个“更会量化向量”的方法,还不能真正保证注意力分数稳定。问题在于:即使主量化已经把总体失真压得很低,内积估计仍可能存在系统偏差,而 softmax 对这种偏差非常敏感。于是第二阶段从继续追求全面重建转向把预算集中用在“修正内积”这件事上。
这种设计背后的判断非常重要:在注意力里,全面重建所有坐标并非最高优先级,优先级更高的是让“谁该被关注、关注强度大概多大”不要被量化误差改写。因此,TurboQuant 的第二阶段看起来只加了很轻的一层编码,却能显著改变注意力保真度,因为它修补的是最承重的误差,而非平均分摊误差。
TurboQuant 的收益并不主要体现在“把某个向量压缩得多漂亮”,而体现在相同显存下能缓存更长上下文,或在相同上下文下支持更高并发。它直接作用于解码阶段最贵的那部分状态,即各层持续增长的 KV Cache。对长上下文推理而言,这通常比单步算子优化更承重,因为一旦缓存存不下,系统就会被迫降低 batch、缩短上下文,或转向更慢的外部交换路径。
但这类收益能否真正转化为吞吐提升,还取决于实现细节。若压缩后每一步都要做很重的解码、解包和额外访存,理论上的存储优势就可能被运行时开销抵消。因此,TurboQuant 不只是一个“理论上更省”的方法,它是否好用还取决于推理引擎是否能把旋转、量化、残差校正与注意力计算做成足够紧的执行路径。
因此,TurboQuant 与 Latent KV / MLA 的差异非常明确。TurboQuant 是量化压缩,核心是把同一个 KV 向量存得更省,同时尽量保住注意力内积;Latent KV / MLA 是潜空间压缩,核心是先换成更低维的内部表示再缓存。前者更接近推理栈里的压缩器,后者更接近模型架构层面的推理优化设计。它们都属于 KV Cache 压缩,但技术路线和接入条件并不相同。
| 场景 | 策略 | 成本 | 延迟 | 风险/约束 |
| 连续多轮对话(分钟级) | Prompt Caching | 低(命中时前缀“打折”) | 低(TTFT 改善明显) | 要求前缀严格一致;缓存易被淘汰 |
| 跨小时/跨天复用长文档前缀 | Context Caching / 预热 | 中(通常含存储费) | 中-低 | 依赖服务能力;需要明确缓存生命周期与权限 |
| 大规模文档问答 | RAG(检索增强生成) | 低且稳定 | 稳定 | 需要索引构建、召回/重排与证据注入治理 |
| 长对话状态维护 | 滚动摘要(Rolling Summary) | 低 | 稳定 | 摘要漂移与可验证性问题;需结构化约束 |
推测解码(Speculative Decoding)用一个更小更快的草稿模型(Draft Model)一次提出多个候选 token,再由大模型(Target Model)并行验证并接受其中尽可能长的前缀。若接受率高,就能显著减少大模型需要执行的解码步数;若接受率低,则会退化并产生额外验证开销。实际收益取决于草稿模型速度、分布匹配程度与实现细节。
批处理(Batching)讨论的是:如何把多个请求或多个 token 步骤拼到同一轮计算里,以提高硬件利用率。它本质上是在吞吐(Throughput)、单请求延迟(Latency)和调度复杂度之间做权衡。推理系统里常见的批处理并不只有一种,固定批处理、动态批处理和连续批处理服务的是不同流量形态。
固定批处理(Static Batching)是最传统的做法:先攒够固定数量的请求,再统一组成一个 batch 执行。它的优点是实现简单、执行路径稳定、硬件利用方式容易预测,因此很适合离线推理、批量评测、Embedding 批处理或输入长度相近的后台任务。
它的问题同样直接。第一,等待时间明显:如果系统必须凑满 batch 才发车,单请求延迟会被批量收集时间拉长。第二,padding 浪费常常很大:当同一批次中的序列长度差异明显时,短序列必须补到与长序列对齐,等于用无效 token 占用了算力。因此,固定批处理通常更适合“任务离线、流量可控、长度相近”的环境,而不适合作为通用在线 LLM 服务的主调度方式。
动态批处理(Dynamic Batching)是在固定批处理上的现实改进。系统从死等“凑满固定 batch”转向在一个较短时间窗口内,把相近时间到达的请求尽量拼进同一批次里。这样做的好处是:既能保留一部分并行执行收益,又能避免固定批处理带来的长时间等待。
它适合中等并发的在线推理服务,尤其是在请求长度相对可控、生成长度不算太长的场景里表现不错。但它仍然主要以“请求”为单位成批,而非以“token 步骤”为单位重组,因此当不同请求的生成过程拉得很长、长度分化越来越大时,批次内部的同步等待和 padding 问题依然存在。动态批处理改善了固定批处理的僵硬性,但还没有真正解决 LLM 自回归解码里的异步性问题。
连续批处理(Continuous Batching)面向在线服务:请求不断到达、序列长度各不相同。与“固定 batch + padding”相比,连续批处理按 token 粒度调度,把不同请求的下一步解码拼到同一个批次里,从而提升吞吐并减少 padding 浪费。它从把“一整条请求”视为不可拆分的调度单位转向把系统里所有活跃序列都当作可持续重组的解码状态。
这类方法之所以重要,是因为 LLM 解码阶段天然是异步的:有的请求很快结束,有的请求仍在长输出,有的请求刚刚进入系统。若继续用请求级批处理,GPU 经常会被“最慢那几个序列”拖住;而连续批处理允许系统在每一步把已经完成的序列移出,再把新请求或其他活跃序列的下一步补进来,使 batch 始终维持较高利用率。
静态批处理的问题不仅“padding 多一点”这么简单,还它把一整条请求当成不可拆分的运行单元。假设同一批里有四个请求,其中三个很快生成结束,另一个却还要继续生成很长一段文本,那么 GPU 在后续很多步里实际上只能继续为这一个长请求服务,原先空出来的位置却不能被新请求及时填补。这样造成的核心是硬件空转:算力被“批次里最慢的那个请求”绑住了。
因此,连续批处理真正改变的核心是调度颗粒度。传统静态批处理按“请求”调度,连续批处理按“下一 token 的解码步”调度。只要某个请求结束、被取消、或暂时被抢占,调度器就可以立刻把它从运行队列中移出,再用等待队列里的新请求补位。
在 vLLM 这类系统里,所谓“连续”指的是:调度器会以 decode 迭代为粒度,持续重组当前运行中的请求集合,而非一次性固定一个 batch 直到所有请求全部结束。连续批处理的“连续”,本质上是运行队列和解码步的持续流动。
具体来说,调度器会在几乎每一次 decode 迭代之后重新审视当前运行集合。若当前正在运行的请求集合记为 \(\mathcal{R}_t\),每个请求在第 \(t\) 轮各生成一个新 token,那么在进入第 \(t+1\) 轮之前,系统就会检查:哪些请求已经生成到结束符、达到最大长度或被上层中断;哪些等待中的新请求应被拉入运行队列。于是,运行中的 batch 核心是在 decode 过程中持续流动。
因此,连续批处理本质上更像token 级流水调度,而非传统意义上的“把若干完整请求捆成一批”。高吞吐来自这种持续补位机制:只要有位置空出来,调度器就尝试让新的工作立刻进来,从而保持 GPU 上活跃序列数尽量稳定。
连续批处理的工程难点在于,新进来的请求并不处在和老请求相同的计算阶段。老请求通常已经进入逐 token 解码(Decode),而新请求刚到达时还需要先完成整段提示词的预填充(Prefill)。这两个阶段的计算特征并不相同:Prefill 更接近长序列的大矩阵计算,往往更偏计算密集;Decode 则更依赖 KV Cache 读取与单步增量计算,往往更偏带宽与调度密集。
高吞吐推理引擎的关键能力之一,就是能把这两类工作纳入同一套调度体系,而非强制等所有 Prefill 做完才统一进入 Decode。于是,新请求在进入系统后会先经历一次 Prefill,把提示词对应的 KV 写入缓存;随后它就能在下一个调度周期加入解码队列,和其他正在生成的请求一起按 token 粒度推进。工程实现上是否在同一次前向里混合执行 Prefill 与 Decode,取决于具体 runtime 的算子与调度设计;但从系统抽象看,它们必须被统一编排,否则连续批处理就无法真正发挥价值。
连续批处理之所以直到近年的高吞吐推理引擎才真正成熟,一个核心原因就在 KV Cache 管理。若每条请求都必须占据一整段预留好的连续显存,那么请求不断进出时,显存会迅速碎片化:短请求结束后留下很多小空洞,长请求却可能因为拿不到足够长的一段连续内存而无法被调度进去。此时即使调度逻辑想连续补位,底层显存布局也会把它卡死。
这正是 Paged Attention / Paged KV 发挥作用的地方。通过把 KV Cache 切成固定大小的块,再用块表去描述逻辑上的连续序列,系统就不再要求“每个请求必须拥有一整段连续显存”。于是,块可以被细粒度分配、回收、复用和共享,连续批处理才真正有了工程基础。在现代 LLM 服务栈里,Paged KV 与 Continuous Batching 几乎总是成对出现:前者解决“缓存如何活着”,后者解决“调度如何持续流动”。
它的实现难点也最高。连续批处理要和 KV Cache 管理、Paged Attention、块分配/回收、抢占策略和流式输出协同设计,还必须在吞吐与 P99 延迟之间做持续权衡。因此,它通常核心是高吞吐推理引擎的核心调度机制。
推理框架(Inference Serving Stack)把“模型权重 + 推理图 + 调度策略”封装成可部署的服务。选型时优先看三件事:是否支持你的模型与精度(Compatibility)、是否能把 KV Cache 与批处理调度做对(Scheduler + KV Management)、以及在你的硬件上能否稳定达到目标吞吐/延迟(Performance Envelope)。
| 框架 | 定位 | 强项 | 代价/约束 | 适用场景 |
| vLLM | 生产级高吞吐推理 | Paged KV + 连续批处理;并发与吞吐强 | 部署与调优门槛更高;更依赖 CUDA 与服务化环境 | 多租户在线服务;RAG/Agent 高并发;企业 API |
| TensorRT-LLM | NVIDIA 推理加速栈 | 内核与图级优化;低延迟上限高 | 构建/调参成本高;硬件绑定强 | 对延迟敏感的核心服务;固定模型部署 |
| TGI(Text Generation Inference) | 通用推理服务 | 生态成熟;易集成;支持常见部署形态 | 极致吞吐/显存利用率取决于具体模型与配置 | 快速上线;标准化 HuggingFace 模型服务 |
| TEI(Text Embeddings Inference) | 嵌入 / 重排推理服务 | 面向 embedding、reranker 与序列分类模型;接口与部署路径贴近 Hugging Face 生态 | 不负责自回归文本生成;长文本、模型类型和 pooling 方式会影响吞吐与效果 | RAG 向量化、批量 embedding、rerank 精排、语义分类服务 |
| SGLang | 面向 LLM 应用的推理与编排 | 更贴近应用侧的执行模型;对复杂推理/工具调用友好 | 需要接受其编排抽象;生态仍在快速演进 | 复杂 Agent/RAG pipeline;结构化推理任务 |
| llama.cpp(GGUF) | 本地/边缘推理 | CPU/小 GPU 友好;量化生态完善;分发简单 | 吞吐与模型规模受硬件限制;在线并发能力有限 | 个人/离线实验;边缘设备;小规模服务 |
| Ollama | 本地运行与分发工具 | 安装简单;模型拉取、管理与切换顺手 | 更偏单机体验而非高并发服务性能 | 个人原型验证;本地开发;小规模离线使用 |
Ollama 是面向本地开发的模型运行与分发工具,核心目标是降低“把模型跑起来”的工程摩擦。它把模型下载、量化版本管理、本地 API、命令行交互和模型切换封装到统一入口里,让个人开发者或小团队可以快速验证模型行为。
它适合本地实验、离线原型、隐私敏感的小规模应用、插件开发和边缘设备探索。对这类场景,优先级通常是快速拉取模型、在消费级机器上运行、用稳定的本地接口接入脚本和应用;极限吞吐并非首要目标。
Ollama 的边界也很明确。它更偏单机可用性与本地体验;当系统进入多租户、高并发、细粒度监控、多 GPU 调度或复杂服务治理阶段,通常需要更专门的服务端推理栈承接。换句话说,Ollama 很适合作为模型行为验证与本地开发入口,但不应被当成所有生产推理场景的统一答案。
vLLM 是面向大模型推理的高吞吐推理引擎(Inference Engine),核心目标是在显存受限的情况下提升并发与吞吐。它的代表性设计是 PagedAttention:把 KV Cache 按固定大小切成块(Blocks),用块表(Block Table)把“逻辑连续的序列”映射到“物理上不必连续的显存块”。
这样做的收益是:按需分配 KV、降低内存碎片(Fragmentation),并支持前缀共享(Prefix Sharing):当多个请求共享同一段前缀(例如相同系统提示词/相同文档前缀)时,可以复用同一份缓存块,从而节省显存并降低 Prefill 成本。
vLLM 的真正价值并不只在某个单独算子,而在于它把KV Cache 管理、连续批处理、调度和服务接口统一成了面向高并发场景的整体系统。具体到调度层,它做的正是前文展开的那种 token 级连续批处理:每一轮 decode 之后重审运行队列,把已经结束的序列移出,再让等待中的新请求完成 Prefill 并尽快补入后续 decode 周期。对企业级 API、RAG 服务、多轮聊天机器人或多租户平台而言,请求通常不会整齐地同时开始和结束;连续批处理能让系统在 decode 过程中持续吸纳新请求,而非死板地按静态 batch 切分,这正是它在生产环境里更占优势的原因。
它的边界也很清楚。vLLM 本身核心是给工程团队做吞吐、延迟、监控和资源利用率优化的 runtime。于是它更适合有明确服务化目标的团队:需要 API 暴露、监控指标、批处理调优、多 GPU 并行和较强可观测性时,vLLM 往往比本地导向工具更自然;但在单机小显存、低并发、快速原型阶段,它未必是最省力的第一选择。
TensorRT-LLM 是面向 NVIDIA GPU 的大模型推理加速栈,重点在于高效算子(Kernel)与图级优化(Graph-level Optimization):通过更强的算子融合、更贴近硬件的精度与布局选择(例如 FP16/BF16/FP8、weight-only quantization),把通用 Transformer 计算编译成更高吞吐、更低延迟的推理执行计划。
它更偏“部署与性能工程”路径:需要围绕目标 GPU、精度与 batch/seq 长度做构建与调优;换来的是更稳定的延迟与更高的吞吐上限。
TGI(Text Generation Inference)是面向 HuggingFace 模型生态的通用推理服务:提供标准化的 HTTP/gRPC 接口与常见的批处理/流式输出能力,适合把“能跑的模型”快速变成“可用的服务”。它的价值在于工程整合与稳定性,而非把每个场景都推到极致性能。
TEI(Text Embeddings Inference)是 TGI 的自然同级组件。TGI 面向文本生成模型,把 prompt 转成流式 token 输出;TEI 面向嵌入、重排和序列分类模型,把文本转成向量、相关性分数或分类分数。它们都服务 Hugging Face 模型生态,但优化对象不同:TGI 的核心负载是自回归解码,TEI 的核心负载是批量编码与打分。
在 RAG 系统里,TEI 通常位于生成模型之前。索引阶段可以用它批量计算文档 embedding,并写入向量库;查询阶段可以用它在线计算 query embedding,或调用 reranker 模型对召回候选做精排。若模型是 BGE、E5、GTE、Jina、Qwen Embedding、BGE Reranker 或其它兼容的 embedding / rerank 模型,TEI 的职责就是把这些模型稳定包装成可服务化的 HTTP/gRPC 接口。
TEI 与 vLLM、TGI 的分工也很清楚。vLLM 和 TGI 更常承载最终回答生成、对话续写和工具调用;TEI 承载检索前后的表示与排序计算。一个常见生产链路是:TEI 负责 embed(query) 和 rerank(query, docs),向量库负责 ANN 召回,TGI / vLLM 负责基于证据生成最终回答。这样拆分后,embedding、rerank 和 generation 可以独立扩缩容,也可以分别选择最适合的模型与硬件。
SGLang 强调“把推理当作可编排的程序执行”:当应用需要多步生成、结构化输出、工具调用或复杂控制流时,推理框架不仅要快,还要能把控制逻辑表达清楚并与 KV Cache 调度协同。它更像是服务端的“推理 DSL + runtime”。
llama.cpp 是一套本地/边缘推理 runtime:围绕 GGUF/量化权重与 CPU/GPU 混合执行做了大量工程优化。它在“把模型放到普通机器上跑起来”这一目标上极具性价比,但并不追求云端多租户场景下的极限吞吐。
Leave a Reply