人工智能知识 - 主要应用领域
这一篇从常用算法进入机器学习基础概念、经典机器学习与神经网络,重点讨论“模型如何被构造、训练、评估与正则化”。前一篇给出了数学语言,这一篇开始进入真正的建模问题:数据怎样表示,损失怎样定义,优化怎样推进,不同模型家族各自擅长什么;再往后才会过渡到 Transformer 与大语言模型。
这一节处理的核心问题是:当面对搜索、更新、统计、调度、最短路径、依赖分析或训练流水线等任务时,数据应该怎样组织,操作应该怎样执行,才能既正确又高效。数据结构(Data Structure)决定“数据在内存里如何表示”,算法(Algorithm)决定“在这种表示上如何完成查询、插入、删除、遍历、排序与优化”。很多系统性能问题,本质上来自底层组织方式与操作方式不匹配。
可以把它理解成“仓库布局与搬运规则”的组合:同样一批货物,若排成连续货架、串成链式节点、组织成树状目录,或连接成路网,后续的查找、插入、合并与运输成本会完全不同。现代 AI 工程虽然把注意力集中在模型上,但数据加载器、特征流水线、参数缓存、向量检索、计算图调度、图学习和索引系统,最终都建立在这些基础结构之上。
| 结构 / 算法 | 核心能力 | 典型复杂度 | 常见场景 |
| 数组 / 动态数组 | 按下标随机访问;顺序扫描效率高 | 访问 \(O(1)\);中间插入/删除 \(O(n)\) | 张量、批数据、embedding、排序、滑动窗口 |
| 链表 | 已知位置后插入/删除代价低 | 局部插删 \(O(1)\);查找 \(O(n)\) | LRU、任务拼接、频繁重排的序列 |
| 栈(Stack) | 后进先出(LIFO) | push / pop / top 均为 \(O(1)\) | 递归展开、表达式解析、单调栈 |
| 队列(Queue) | 先进先出(FIFO) | enqueue / dequeue 均为 \(O(1)\) | BFS、任务队列、流式缓冲 |
| 哈希表(Hash Table) | 按键快速索引 | 平均查找/插入/删除 \(O(1)\) | 字典、词表、缓存、去重 |
| Bloom Filter | 近似集合成员查询 | 插入/查询均为 \(O(k)\) | 缓存预检查、去重预过滤、存储层键存在性判断 |
| 树(Tree) | 表达层次关系与有序结构 | 平衡查找常为 \(O(\log n)\) | 索引、优先队列、前缀匹配、规则分裂 |
| 图(Graph) | 表达任意对象之间的关系 | 遍历通常为 \(O(|V|+|E|)\) | 社交网络、知识图谱、路线规划、依赖分析 |
复杂度表只给出渐近上界,不能直接替代工程判断。真实系统还要同时考虑缓存友好性(Cache Locality)、常数项、并发开销、内存占用和实现复杂度。例如链表在理论上支持常数时间插入,但它对 CPU 缓存并不友好;数组在理论上中间插入较慢,但顺序扫描极快,因此在现代硬件上经常更有优势。
数组(Array)处理的核心问题是:当元素类型一致、数量可以按顺序编号时,如何支持最低成本的随机访问与批量扫描。它的关键性质是连续内存(Contiguous Memory)。若每个元素大小为 \(s\),首地址为 \(\text{base}\),则第 \(i\) 个元素地址为
\[\text{addr}(a_i)=\text{base}+i\cdot s\]这个式子说明数组访问为何是 \(O(1)\):位置可以直接计算,不需要沿指针逐步跳转。矩阵、张量、mini-batch、时间序列缓存、本地特征块和 embedding 表中的一行,本质上都依赖这种“地址可算”的结构。
数组的代价也非常明确:若在中间插入或删除元素,后面的元素必须整体搬移,因此复杂度通常是 \(O(n)\)。这意味着数组适合“读多写少、顺序稳定”的任务,不适合“在任意位置频繁插入”的任务。
动态数组(Dynamic Array)是在数组上的工程扩展:容量不足时申请更大的连续空间,把原有元素整体拷贝过去,再继续追加。一次扩容代价很高,但若容量按倍数增长,则追加操作的均摊(Amortized)复杂度仍可视为 \(O(1)\)。Python 的 list、C++ 的 vector、Java 的 ArrayList 都遵循这一思想。
直觉上,数组像按编号排好的货架:拿第 137 件货非常快,但若要把一件货塞进中间,后面整排货物都要整体后移。
链表(Linked List)处理的是另一类问题:当序列顺序经常变化时,能否避免数组那样的大规模搬移。链表不要求连续内存,重点是让每个节点(Node)保存数据和指向下一个节点的指针(Pointer);双向链表(Doubly Linked List)还会额外保存前驱指针。
若已经拿到某个节点的位置,那么在其前后插入或删除节点只需要调整局部指针,代价通常是 \(O(1)\)。但链表无法像数组那样通过下标直接定位第 \(i\) 个元素,查找往往必须从头逐个走过去,因此通常是 \(O(n)\)。
链表适合做“结构改动频繁、定位方式按已有节点句柄而非下标”的任务。例如 LRU 缓存中,经常需要把刚访问的元素移到头部;若配合哈希表记录节点位置,链表就能高效完成重排。
链表像一串用绳子串起来的标签。改顺序很方便,但想直接摸到第 500 个标签,就只能沿着绳子一个个数过去。
栈(Stack)定义的是一种后进先出(Last In First Out, LIFO)的访问约束。它处理的问题是“怎样强制最近进入的状态最先退出”。典型操作包括入栈 push、出栈 pop 与查看栈顶 top,它们都发生在同一端,因此实现代价通常是 \(O(1)\)。
函数调用栈、递归回溯、表达式求值、括号匹配、深度优先搜索中的显式状态保存,都依赖这种结构。其本质是把“尚未处理完的上下文”按嵌套顺序压起来,等内部任务结束后再按相反顺序恢复。
单调栈(Monotonic Stack)是栈在算法中的重要变体。它通过维护一个单调递增或单调递减的栈,把“下一个更大元素”“柱状图最大矩形”等问题从 \(O(n^2)\) 降到 \(O(n)\)。原因在于每个元素最多入栈和出栈各一次。
队列(Queue)定义的是先进先出(First In First Out, FIFO)的访问约束。进入得早的元素先被处理,后来进入的元素排在尾部等待。它适合表达“任务排队、波前扩张、按到达顺序消费”的过程。
广度优先搜索(Breadth-First Search, BFS)之所以使用队列,正是因为 BFS 要按距离层层扩展:先处理距离起点为 1 的节点,再处理距离为 2 的节点。这个“分层推进”机制与 FIFO 完全一致。
循环队列(Circular Queue)通过把底层数组首尾相连,可以避免频繁搬移;双端队列(Deque)则允许两端都做插入和删除,因此能够支持滑动窗口最值、0-1 BFS 等更复杂的算法模式。
哈希表(Hash Table)处理的核心问题是:当数据按“键(Key)”组织,而非按位置组织时,如何快速找到对应的值(Value)。其思想是先通过哈希函数(Hash Function)把键映射成一个整数,再把这个整数映射到桶(Bucket)或槽位(Slot)上。
若哈希函数分布均匀,且装载因子(Load Factor)控制合理,则查找、插入和删除的平均复杂度都可接近 \(O(1)\)。这正是词表映射、去重、缓存索引、参数名字典和特征 ID 映射大量采用哈希表的原因。
哈希表的难点在冲突(Collision)处理。多个键可能映射到同一位置,常见解决方案包括链地址法(Separate Chaining)和开放定址法(Open Addressing)。因此“哈希表平均 \(O(1)\)”并不意味着永远常数时间,它依赖于哈希函数质量、负载控制和冲突处理策略。
Bloom Filter 本质上属于概率型数据结构(Probabilistic Data Structure),更准确地说,是一种近似集合成员查询结构(Approximate Membership Query, AMQ)。它解决的问题是“用极小内存快速判断某元素是否可能出现过”。因此它通常作为哈希表、数据库索引或缓存系统之前的一层预过滤结构。
Bloom Filter 由一个长度为 \(m\) 的比特数组 \(B\in\{0,1\}^m\) 和 \(k\) 个哈希函数 \(h_1,\dots,h_k\) 构成,其中每个哈希函数都把元素 \(x\) 映射到区间 \(\{0,1,\dots,m-1\}\) 中的一个位置。插入元素 \(x\) 时,执行
\[B[h_1(x)]=B[h_2(x)]=\cdots=B[h_k(x)]=1\]查询元素 \(x\) 时,检查 \(B[h_1(x)],\dots,B[h_k(x)]\)。只要其中至少有一个位置为 0,就可以断定 \(x\) 一定不在集合中;若这些位置全部为 1,则只能说明 \(x\) 可能在集合中。
这一定义直接带来 Bloom Filter 最重要的判定性质:它允许假阳性(False Positive),但不允许假阴性(False Negative)。原因在于,不同元素可能把同一批 bit 位置反复置为 1,于是一个从未插入过的元素也可能“碰巧”命中全 1;但只要某个位置仍为 0,就说明没有任何已插入元素覆盖过这条哈希路径,因此该元素一定不存在。
设一共插入了 \(n\) 个元素,则某个 bit 在所有插入结束后仍为 0 的概率近似为 \(\left(1-\frac{1}{m}\right)^{kn}\approx e^{-kn/m}\)。于是查询一个未出现元素时, \(k\) 个位置恰好都为 1 的假阳性概率近似为
\[p\approx \left(1-e^{-kn/m}\right)^k\]这里 \(m\) 是 bit 数组长度, \(n\) 是已插入元素数, \(k\) 是哈希函数数目, \(p\) 是假阳性概率。这个公式揭示了 Bloom Filter 的基本权衡: \(m\) 越大,冲突越少; \(n\) 越大,数组越接近被“染满”; \(k\) 太小会降低区分能力,太大则会过度占满 bit 位。固定 \(m\) 与 \(n\) 时,常见的近似最优选择是
\[k\approx \frac{m}{n}\ln 2\]直觉上,Bloom Filter 像一排共享的指示灯。每来一个元素,就按亮若干盏灯;查询时,只要对应灯中有一盏没亮,就可以确认它从未出现过。若全部亮着,也只能说明“这些灯曾被某些元素点亮过”,却不能保证就是当前这个元素点亮的。
Bloom Filter 最适合用于“先快速排除绝大多数不存在项,再把少量可疑项交给精确结构复核”的场景。例如缓存系统可先判断某个 key 是否可能在缓存中,若 Bloom Filter 直接给出“不在”,就可以避免无意义回源;LSM-Tree 存储系统可用它判断某个键是否可能存在于某个 SSTable;爬虫去重、黑名单预过滤、向量检索候选预筛都大量使用这一思想。
Bloom Filter 的边界也很明确。第一,它不保存原始元素,因此不能枚举集合内容,也不能像哈希表那样返回关联值。第二,标准 Bloom Filter 不支持安全删除,因为把某个 bit 清零可能误伤其他元素留下的痕迹;若确实需要删除,通常要改用计数 Bloom Filter(Counting Bloom Filter)。第三,当假阳性代价非常高、系统需要完全精确的成员判断时,应优先使用哈希表、B 树或其他精确索引结构。

树(Tree)处理的是“层次结构”和“递归划分”问题。树中的节点之间具有父子关系,除了根节点(Root)外,每个节点都有唯一父节点。它天然适合表达目录层级、决策分裂、区间划分、优先级组织与前缀共享。
树之所以重要,在于它把原本线性的搜索空间组织成递归结构,使很多操作能通过“向左还是向右”“进入哪个子树”逐步缩小问题规模。若每次都能把候选空间缩小到原来的一半,复杂度就会从线性级下降到对数级。
二叉树(Binary Tree)规定每个节点至多有两个孩子。前序遍历(Preorder)、中序遍历(Inorder)、后序遍历(Postorder)和层序遍历(Level-order)分别对应不同的信息读取顺序:前序适合序列化结构,中序适合读取二叉搜索树中的有序键,后序适合先处理子问题再合并,层序适合按深度观察整体形状。
二叉搜索树(Binary Search Tree, BST)在每个节点上保持“左子树键值更小、右子树键值更大”的顺序约束,因此查找、插入和删除都可以沿着比较路径进行。若树高度为 \(h\),这些操作的复杂度一般与 \(O(h)\) 成正比。
问题在于普通 BST 在极端情况下会退化成链表,此时 \(h=n\)。平衡树(Balanced Tree)如 AVL 树、红黑树(Red-Black Tree)通过旋转(Rotation)维护高度受控,使 \(h=O(\log n)\),从而把查找、插入和删除稳定在对数复杂度。数据库索引和有序映射容器大量依赖这一思想。
堆(Heap)维护的是局部顺序,而非整棵树的全局有序性:在最小堆(Min-Heap)中,每个父节点都不大于子节点,因此根节点始终是全局最小值;最大堆(Max-Heap)则相反。它通常用数组实现,父子下标关系可以直接计算。
堆最适合实现优先队列(Priority Queue):每次都要快速取出当前最重要、最小或最大的元素时,插入和弹出都只需 \(O(\log n)\)。Dijkstra、A* 搜索、任务调度、Top-K 维护和流式中位数都大量依赖优先队列。
Trie 树(Prefix Tree)把字符串按前缀共享组织起来。若插入单词集合 \(\{w_1,\dots,w_m\}\),公共前缀只存一次,因此“是否存在某个前缀”“以某前缀开头的词有多少”都可以沿字符路径直接完成。
Trie 特别适合词典匹配、自动补全、敏感词过滤和子词切分。它牺牲了一部分空间,换来按字符长度而非按词典规模进行搜索的能力。
图(Graph)处理的是最一般的关系结构。若顶点集合为 \(V\),边集合为 \(E\),则图可写成 \(G=(V,E)\)。树本质上是图的一个特殊子类,但图允许环、允许多条连接、允许方向和权重,因此能表达社交关系、知识链接、网页跳转、道路网络、依赖图与神经网络计算图。
图的常见表示方式有邻接矩阵(Adjacency Matrix)和邻接表(Adjacency List)。前者适合稠密图,能 \(O(1)\) 判断两点是否相连;后者适合稀疏图,空间复杂度更低,遍历邻居更高效。
广度优先搜索(BFS)与深度优先搜索(DFS)是图遍历的两种基本组织方式。BFS 使用队列按层推进,适合无权最短路、层次扩展与最少步数问题;DFS 使用递归或显式栈沿一条路径尽量走深,适合回溯、环检测、拓扑排序、强连通分量与树形动态规划。
对邻接表表示的图,两者的时间复杂度通常都是 \(O(|V|+|E|)\)。区别不在渐近复杂度,而在访问顺序:BFS 保证按距离层层扩展,DFS 更擅长描述“先深入、后回退”的结构性问题。
最短路径(Shortest Path)问题处理的是:从起点到终点,总代价最小的路径是什么。若图无权,BFS 就能得到边数最少的路径;若边权非负,常用 Dijkstra 算法。它每次从优先队列中取出当前距离估计最小的顶点,并尝试松弛(Relax)相邻边。
Dijkstra 的核心更新为
\[\mathrm{dist}[v]=\min\big(\mathrm{dist}[v],\mathrm{dist}[u]+w(u,v)\big)\]其中 \(\mathrm{dist}[u]\) 是当前已知的从源点到 \(u\) 的最短距离估计, \(w(u,v)\) 是边权。这个公式表达的是最短路的本质:若“先到 \(u\),再走到 \(v\)”更便宜,就更新对 \(v\) 的距离认知。
拓扑排序(Topological Sort)处理的是有向无环图(Directed Acyclic Graph, DAG)中的依赖顺序。若边 \(u\to v\) 表示“\(u\) 必须先于 \(v\)”,那么拓扑序就是一种满足全部先后约束的线性排列。
课程先修关系、编译依赖、工作流调度、神经网络计算图执行次序,本质上都属于这一问题。拓扑排序的价值不仅“排出一个顺序”,还把依赖图转成一条能够实际执行的流水线。
最小生成树(Minimum Spanning Tree, MST)处理的是这样的问题:给定一个连通无向带权图 \(G=(V,E)\),需要从边集合 \(E\) 中选出一部分边,把所有顶点连成一个整体,同时不产生环,并使总权重最小。若把所有生成树的集合记为 \(\mathcal{T}(G)\),则标准形式可以写成
\[T^*=\arg\min_{T\in \mathcal{T}(G)}\sum_{e\in T} w(e)\]其中 \(T^*\) 是最优生成树;\(w(e)\) 是边 \(e\) 的权重;\(\sum_{e\in T} w(e)\) 表示树中全部边的总代价。这里的“生成树”有三个同时成立的约束:第一, \(T\subseteq E\);第二,图在边集 \(T\) 下必须连通;第三, \(T\) 不能含环,因此边数必然满足 \(|T|=|V|-1\)。
这个定义明确了 MST 核心是在所有能够覆盖全部顶点的无环连通方案中做全局最小化。只强调“连通”会多出冗余边,只强调“边权小”又可能导致图不连通;MST 同时满足这两个条件。
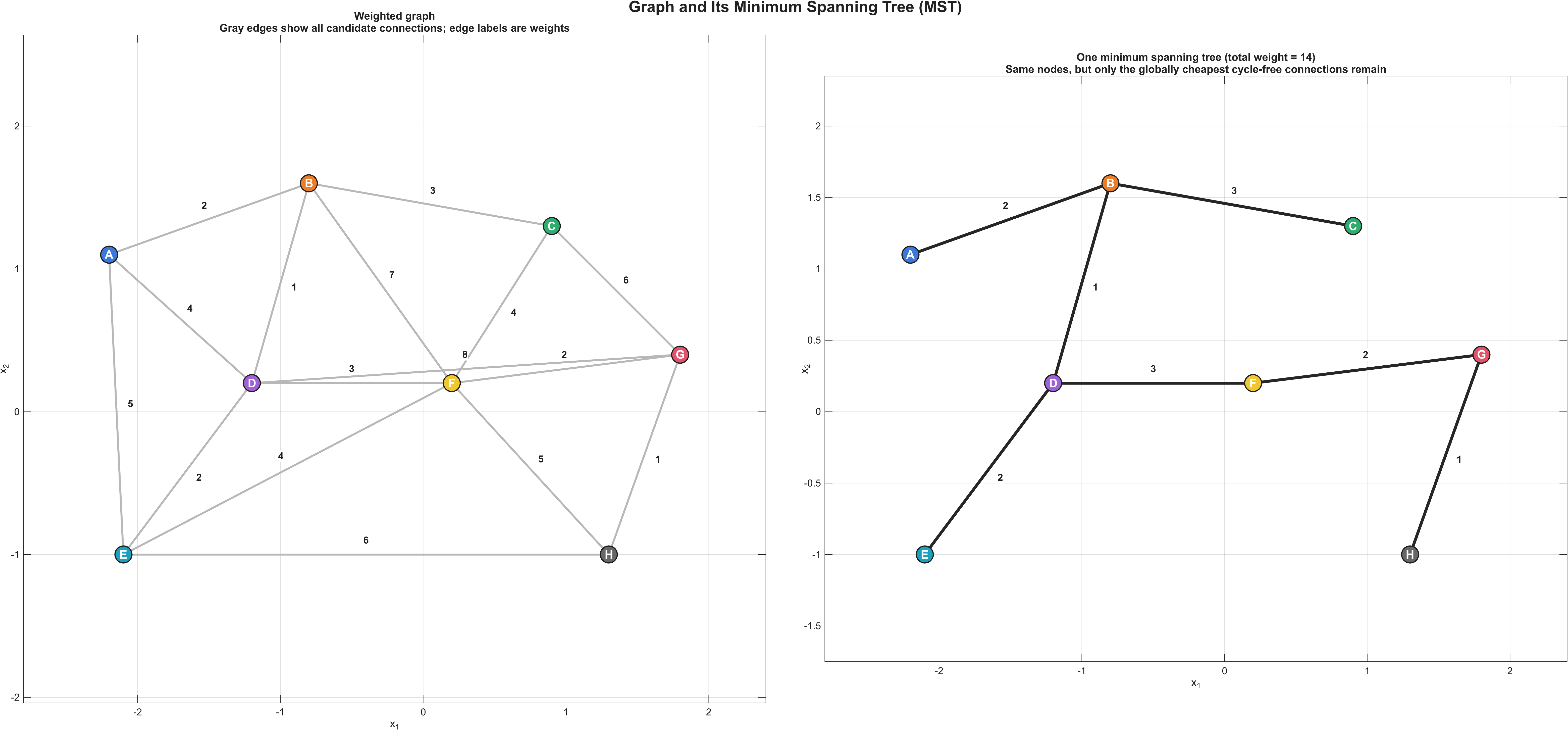
直觉上,可以把 MST 理解成“以最低总造价把一组城市接通,但不修多余的回路”。如果形成了环,说明这条网络中至少有一条边是重复支出;如果某些城市没有接入,说明方案根本不可用。MST 就是在“全覆盖”和“最低成本”之间取得最紧的平衡。
MST 成立的核心理论基础是割性质(Cut Property):把顶点集切成两个不相交部分后,跨越这个切分的最小权边,一定存在于某棵最小生成树中。这个性质的含义是:局部最便宜的“安全边(Safe Edge)”可以被逐步加入,而不会破坏全局最优性。Prim 与 Kruskal 虽然组织方式不同,但本质上都在不断选择这样的安全边。
Prim 算法的思路是“从一个起点向外生长一棵树”。设当前已经纳入树中的顶点集合为 \(S\),则 Prim 每一步都在所有满足 \(u\in S,\ v\notin S\) 的边中,选择权重最小的一条,把新顶点接入当前树。这个过程像不断把新城市接入已经建好的主干网,因此特别适合用优先队列维护“当前边界上最便宜的边”。若图用邻接表存储并配合二叉堆实现优先队列,时间复杂度通常为 \(O(|E|\log |V|)\)。
Kruskal 算法的思路是“按全图范围从便宜到昂贵依次选边”。它先对所有边按权重升序排序,然后从小到大扫描:若当前边连接的是两个不同连通块,就把它加入结果;若会在当前结构中形成环,就跳过。为了高效判断“两个端点是否已经连通”,Kruskal 通常配合并查集(Disjoint Set Union, DSU)。排序代价主导总复杂度,因此复杂度通常写成 \(O(|E|\log |E|)\),与 \(O(|E|\log |V|)\) 在数量级上接近。
两种算法解决的是同一个优化问题,但适合的工程语境不同。Prim 更像“从局部网络不断扩张”,适合稠密图或从某个核心节点逐步向外建设的场景;Kruskal 更像“全局看所有候选边,再逐一合并连通块”,在边集天然可排序、图较稀疏时实现尤其直接。
一个最小例子可以把公式和过程连起来。设四个顶点 \(A,B,C,D\),边权为: \(w(A,B)=1\), \(w(B,C)=2\), \(w(A,C)=4\), \(w(B,D)=3\), \(w(C,D)=5\)。Kruskal 会先按边权排序: \((A,B),(B,C),(B,D),(A,C),(C,D)\)。前 3 条边分别把 \(A\) 与 \(B\)、 \(B\) 与 \(C\)、 \(B\) 与 \(D\) 连起来,此时已经得到 \(|V|-1=3\) 条边,且图连通无环,于是生成树为
\[T=\{(A,B),(B,C),(B,D)\}\]其总代价为
\[\sum_{e\in T}w(e)=1+2+3=6\]若改选边集 \(\{(A,B),(A,C),(B,D)\}\),总代价是 \(1+4+3=8\);若再加入 \((B,C)\),虽然成本局部看不高,但边数会超过 \(|V|-1\) 并形成环,因此不再是树。这个例子把“最低成本”“连通”“无环”三项约束如何同时生效展示得很清楚。
MST 常见于网络布线、电力传输、骨架路网设计、图像分割、聚类和图压缩。层次聚类中的单链接(Single Linkage)就可以通过图的最小生成树来理解:先把点看成顶点,把样本间距离看成边权,再在 MST 上剪断最长的若干条边,就得到若干连通簇。因此,MST 不只是图论题型,也是很多数据分析与机器学习方法的底层结构。
MST 也有明确边界。它只适用于无向、连通、带权图上的“全连通最低总成本”问题;若任务要求的是“从源点到其余点的最短路”,应使用最短路径算法;若图有方向,目标就不再是普通 MST,而会进入最小树形图(Minimum Arborescence)等更复杂的问题。
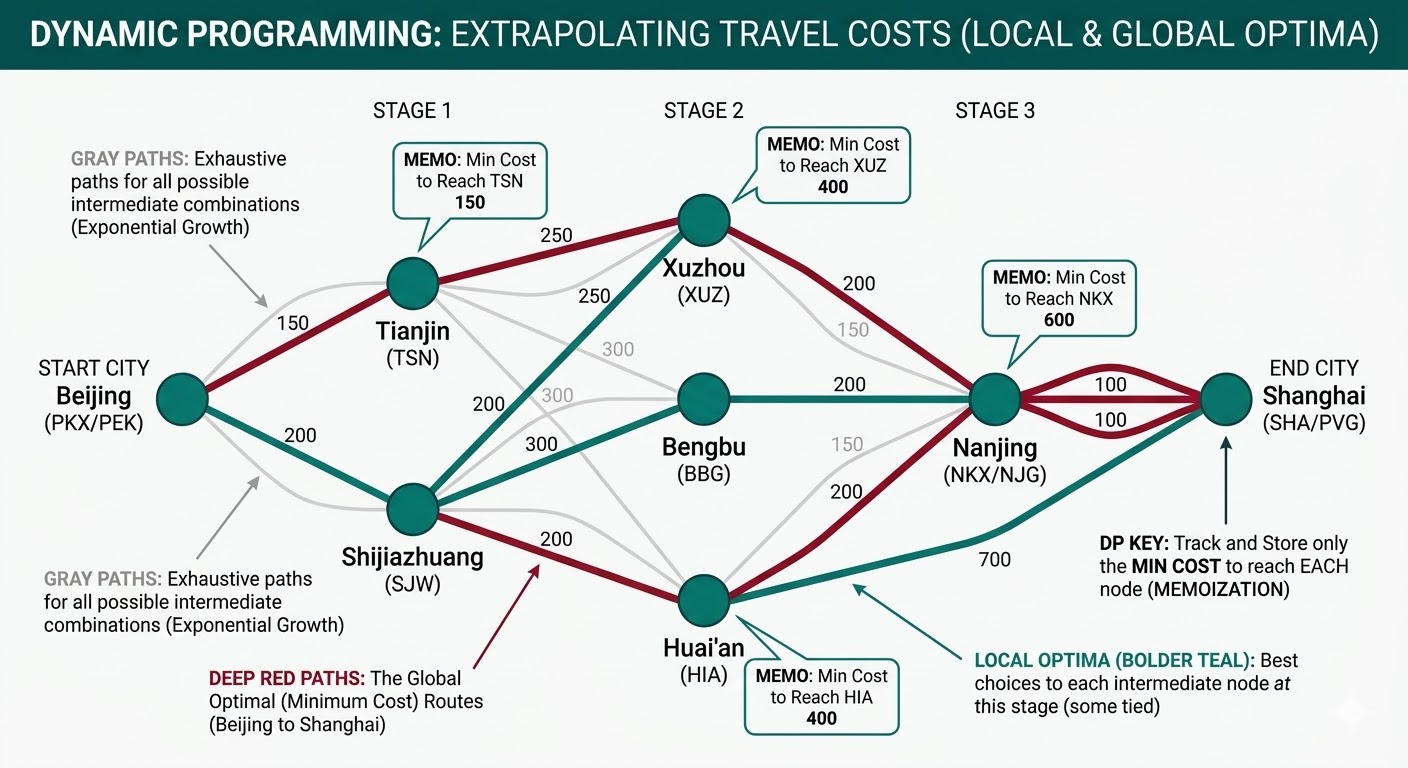
动态规划(Dynamic Programming, DP)处理的是这样一类问题:目标是求一个全局最优值、最优路径,或所有路径的总和,但如果直接把所有可能性全部枚举出来,计算量会迅速爆炸。它常见于序列决策、路径规划、字符串匹配、图搜索,以及隐马尔可夫模型(HMM)、条件随机场(CRF)这类结构化预测模型。
这类问题通常有两个共同特征。第一,重叠子问题(Overlapping Subproblems):同一个中间子问题会被反复计算。第二,最优子结构(Optimal Substructure):大问题的最优解可以由小问题的最优解递推得到。例如,在长度为 \(T\) 的序列上,若每一步有 \(|\mathcal{S}|\) 个可能状态,直接枚举所有状态路径往往需要考虑 \(|\mathcal{S}|^T\) 条候选路径;当 \(T\) 稍大时,这种暴力方法几乎不可用。
动态规划的核心在于:先定义能够代表子问题的状态,再写出状态之间的递推关系,并把已经算过的结果缓存下来复用。因此,它本质上是一种计算组织方式,而非某个固定公式。
一个直观比喻是出差换乘。设想要从起点出发,经过很多站点,最终到达目的地。暴力法会把“到达每一站的所有走法”全部记下来;动态规划不会这样做。它只会为每个中间站保留一份最有价值的摘要,例如“到达这个站的最低成本”或“到达这个站的最大得分”。当继续前往下一站时,系统只需要查这份账本,而不必回头展开所有历史路径。
因此,动态规划通常包含四个步骤:定义状态、定义边界条件、写出转移方程、确定计算顺序。状态定义决定“中间结果要存什么”;边界条件决定“第一步从哪里开始”;转移方程决定“当前结果如何从更小问题得到”;计算顺序则保证所有依赖项在使用前已经计算完毕。
动态规划能够丢弃大量“暂时看起来不够好”的前缀路径,前提是状态(State)已经完整刻画了未来决策所需的全部信息。一旦这个条件成立,到达同一状态的两条前缀路径,未来能够接上的可行后缀集合完全相同,因此只需要保留其中更优的那一条。
设两条前缀路径都到达同一状态 \(s\),其当前累计代价分别为 \(f_1(s)\) 与 \(f_2(s)\),且 \(f_1(s)\le f_2(s)\)。若从状态 \(s\) 出发,后续任意可行决策产生的附加代价记为 \(g(s)\),并且这个附加代价只由当前状态决定,而不再依赖此前的完整历史,则有
\[f_1(s)+g(s)\le f_2(s)+g(s)\]这个不等式表明:在同一状态上,较差的前缀会被较优前缀完全支配(Dominated)。无论后面接哪一段后缀路径,较差前缀都不可能反超。因此 Bellman 最优性原理允许动态规划只保留“到达该状态的最优值”,而不必保留全部历史路径。
所谓“一个当前次优的路径,后来却通向全局最优”,本质上对应另一种情形:这条路径与当前更优路径虽然看起来到达了同一个位置,但它们对未来的可行动作并不相同。此时它们实际上并不属于同一个状态,这种情况说明状态定义缺失了关键信息。
一个典型例子是带资源约束的路径规划。若状态只写成当前位置 \((i,j)\),那么两条到达同一格子的路径会被合并;但若其中一条还保留一次传送机会,另一条已经把传送用掉,则它们未来的决策空间显然不同。正确的状态应扩展为 \((i,j,\mathrm{used})\) 或 \((i,j,\mathrm{fuel})\) 这类更完整的形式。只有在状态把“剩余资源、上一步动作、已使用预算、是否持仓”等会影响未来的因素都编码进去后,动态规划的剪枝才是安全的。
因此,动态规划处理“局部次优可能导向全局最优”的方式,核心是通过正确设计状态,使真正会影响未来的差异体现在不同状态上。同一状态内部只保留最优前缀;不同状态之间分别递推。动态规划的正确性,最终依赖的正是这一点:未来只依赖当前状态,而不依赖通向当前状态的完整历史。
若记 \(t\) 为阶段或时间步, \(s\) 为当前状态,一个非常典型的动态规划写法是:
\[\mathrm{DP}[t,s]=\max_{s'\in \mathrm{Prev}(s)}\left(\mathrm{DP}[t-1,s']+\mathrm{score}(s',s,t)\right)\]这条式子表达的是:要得到“第 \(t\) 步处于状态 \(s\) 时的最优值”,无需重新枚举所有完整路径,只需查看所有能够转移到 \(s\) 的前驱状态 \(s'\),并在它们已有的最优值基础上,加上这一步的局部得分,再从中取最大。
- \(\mathrm{DP}[t,s]\):第 \(t\) 步、状态为 \(s\) 的最优子问题值。
- \(\mathrm{Prev}(s)\):所有可以转移到状态 \(s\) 的前驱状态集合。
- \(\mathrm{score}(s',s,t)\):从 \(s'\) 转移到 \(s\) 时,在第 \(t\) 步新增的局部得分或代价。
- \(\max\):表示当前任务要找“最好的一条路径”。若任务目标是最小代价,则可改为 \(\min\);若任务目标是把所有路径概率加总,则可改为 \(\sum\)。
边界条件通常写成:
\[\mathrm{DP}[1,s]=\mathrm{init}(s)+\mathrm{local}(s,1)\]其中 \(\mathrm{init}(s)\) 表示序列从状态 \(s\) 开始的初始代价或初始分数, \(\mathrm{local}(s,1)\) 表示第一步在该状态产生的局部贡献。没有这个起点,后续递推就无从展开。
动态规划真正带来的收益来自复杂度压缩。以一阶序列模型为例,若每一步有 \(|\mathcal{S}|\) 个候选状态、总长度为 \(T\),暴力枚举往往需要考虑 \(|\mathcal{S}|^T\) 条完整路径;而若采用“时间步 + 当前状态”的动态规划状态定义,则通常只需在每个时间步枚举所有前驱状态,计算复杂度可以降为 \(O(T|\mathcal{S}|^2)\)。这种从指数级到多项式级的下降,正是动态规划在序列模型中不可替代的原因。
若任务不仅要求最优值,还要求恢复最优路径,则通常还会额外保存“当前最优值来自哪个前驱状态”的回溯信息(Backpointer)。这意味着动态规划不仅能回答“最优值是多少”,还能回答“这条最优路径具体怎么走”。
更重要的是,动态规划并不只对应一种运算。对于最优路径问题,递推中的核心运算往往是 \(\max\) 或 \(\min\);对于总概率、配分函数这类问题,核心运算则是 \(\sum\)。因此,HMM 的维特比算法、前向算法,以及 CRF 的前向后向算法,虽然目标不同,但都属于动态规划。
前向后向算法(Forward-Backward Algorithm)是链式结构上的动态规划。前向递推从左到右,缓存“到当前位置和当前状态为止”的累计结果;后向递推从右到左,缓存“从当前位置和当前状态出发到序列结尾”的累计结果。两者合起来,可以高效计算整条序列的总概率、配分函数,以及单个位置或相邻位置的边缘概率。
抽象地看,前向递推可以写成:
\[\mathrm{forward}_t(s)=\operatorname{Agg}_{s'\in \mathrm{Prev}(s)}\ \mathrm{Combine}\left(\mathrm{forward}_{t-1}(s'),\mathrm{local}(s',s,t)\right)\]后向递推则反向汇总后继状态:
\[\mathrm{backward}_t(s)=\operatorname{Agg}_{s''\in \mathrm{Next}(s)}\ \mathrm{Combine}\left(\mathrm{local}(s,s'',t+1),\mathrm{backward}_{t+1}(s'')\right)\]这里 \(s\) 是当前位置状态, \(s'\) 是前一位置的候选状态, \(s''\) 是后一位置的候选状态。不同模型的差别主要来自 \(\operatorname{Agg}\) 和 \(\mathrm{Combine}\) 采用什么运算:概率空间里通常是求和与相乘,log 空间里通常是 \(\operatorname{logsumexp}\) 与加法。
在 HMM 中,前向算法累积的是概率质量。若隐藏状态为 \(z_t\),观测为 \(x_t\),则前向量可写成:
\[\alpha_t(j)=p(x_{1:t},z_t=j)\]递推使用“对前驱求和 + 概率相乘”:
\[\alpha_t(j)=p(x_t\mid z_t=j)\sum_i \alpha_{t-1}(i)p(z_t=j\mid z_{t-1}=i)\]HMM 的后向量表示“当前状态已知时,后续观测序列出现的概率”:
\[\beta_t(i)=p(x_{t+1:T}\mid z_t=i)\]对应递推为:
\[\beta_t(i)=\sum_j p(z_{t+1}=j\mid z_t=i)p(x_{t+1}\mid z_{t+1}=j)\beta_{t+1}(j)\]前向量和后向量可以在同一位置相乘,再除以整条观测序列概率,从而得到隐藏状态的后验边缘概率:
\[p(z_t=j\mid x_{1:T})=\frac{\alpha_t(j)\beta_t(j)}{p(x_{1:T})}\]在线性链 CRF 中,输入 \(x\) 已经固定,前向算法累积的是所有标签路径的未归一化分数,用来计算配分函数(Partition Function):
\[Z(x)=\sum_y \exp(\mathrm{score}(x,y))\]工程实现通常在 log 空间中递推:
\[\alpha_t(j)=\operatorname{logsumexp}_i\left(\alpha_{t-1}(i)+\mathrm{transition}(i,j)+\mathrm{emission}_t(j)\right)\]后向递推同样在 log 空间中从右向左汇总:
\[\beta_t(i)=\operatorname{logsumexp}_j\left(\mathrm{transition}(i,j)+\mathrm{emission}_{t+1}(j)+\beta_{t+1}(j)\right)\]CRF 训练需要这些边缘量来计算梯度:真实标签路径提供一组实际计数,模型分布下的所有可能路径提供一组期望计数,二者之差决定参数更新方向。因此,前向后向算法不只是为了算一个归一化常数,也为训练时的期望统计提供高效计算方式。
因此,HMM 和 CRF 的前向后向算法共享同一个动态规划骨架。HMM 是生成模型,前向后向算法围绕观测序列概率和隐藏状态后验展开;CRF 是条件模型,前向后向算法围绕给定输入下的配分函数和标签边缘概率展开。维特比算法也使用同一张链式状态网格,但它把求和或 \(\operatorname{logsumexp}\) 换成最大值,用来选择最好的一条路径。
在 HMM 中,动态规划最典型地体现在两类问题上。第一类是维特比算法(Viterbi Algorithm):它要求“给定观测序列后,哪一条隐藏状态路径最可能”,因此递推中的核心运算是 \(\max\)。第二类是前向算法(Forward Algorithm):它要求“所有隐藏状态路径合起来,总概率是多少”,因此递推中的核心运算是 \(\sum\)。两者使用的是同一张状态网格,只是“每一步如何聚合前驱信息”不同。
在 CRF 中,动态规划同样是核心计算工具。训练时,需要对所有可能标签路径做归一化,这对应配分函数(Partition Function)的计算;解码时,需要找得分最高的那条标签路径,这对应最优路径搜索。在线性链 CRF 中,这两件事都可以通过“时间步 + 当前标签”的动态规划状态来高效完成,否则若直接枚举所有标签序列,计算量会随序列长度呈指数增长。
因此,在机器学习语境里,动态规划可以概括为:把原本必须整体枚举的结构化问题,改写成一系列局部状态上的递推计算,并通过缓存中间结果把重复计算消掉。一旦看到“序列路径很多、局部决策可递推、同类子问题会重复出现”这三个信号,通常就应该优先考虑动态规划。
设字符串 \(A=a_1a_2\dots a_m\) 与 \(B=b_1b_2\dots b_n\)。编辑距离要回答的问题是:至少经过多少次插入、删除、替换,才能把 \(A\) 变成 \(B\)。若直接枚举所有编辑序列,可能性会指数增长;但若定义 \(\mathrm{DP}[i,j]\) 表示“把 \(A\) 的前 \(i\) 个字符变成 \(B\) 的前 \(j\) 个字符所需的最小编辑次数”,问题就能递推解决。
\[\mathrm{DP}[i,j]=\min\begin{cases}\mathrm{DP}[i-1,j]+1\\ \mathrm{DP}[i,j-1]+1\\ \mathrm{DP}[i-1,j-1]+\mathbf{1}(a_i\ne b_j)\end{cases}\]这里三项分别对应:删除 \(a_i\)、插入 \(b_j\)、或把 \(a_i\) 替换成 \(b_j\)(若本来相同,则替换代价为 0)。边界条件是 \(\mathrm{DP}[0,j]=j\)、\(\mathrm{DP}[i,0]=i\),因为空串变成长度为 \(j\) 的串需要做 \(j\) 次插入,反之需要做 \(i\) 次删除。这个例子非常典型地体现了动态规划:状态是前缀长度,转移是三种编辑操作,目标是求最小总代价。
设一个 \(m\times n\) 网格,每个格子 \((i,j)\) 都有进入代价 \(w_{i,j}\),只能向右或向下移动。问题是:从左上角走到右下角的最小总代价是多少。若定义 \(\mathrm{DP}[i,j]\) 表示“到达格子 \((i,j)\) 的最小总代价”,则递推很直接:
\[\mathrm{DP}[i,j]=w_{i,j}+\min\big(\mathrm{DP}[i-1,j],\mathrm{DP}[i,j-1]\big)\]因为到达 \((i,j)\) 只有两种可能:从上方 \((i-1,j)\) 走下来,或从左侧 \((i,j-1)\) 走过来。边界条件是第一行与第一列只能沿单一路径累计。这个例子说明,动态规划并不局限于字符串或序列模型;只要问题具有“局部来源有限、全局目标可递推”的结构,就可以用同样的思路求解。
贪心算法(Greedy Algorithm)处理的是这样一类问题:希望快速构造一个全局可行解,并且每一步都只做当前看来最优的局部选择,而不回头修改已经作出的决定。它广泛出现在排序、调度、压缩、近似优化,以及许多机器学习训练与推断流程中。
贪心的核心假设是:当前最好的局部选择,能够导向全局最优,或至少导向足够好的近似解。它像走山路时每一步都先选眼前最高、最稳的落脚点,而非先把整座山的所有路径都完全规划出来。贪心的优势是快、简单、容易实现;风险是局部最优未必等于全局最优。
若记第 \(t\) 步可选动作集合为 \(\mathcal{A}_t\),一个抽象的贪心选择可写为:
\[a_t^*=\arg\max_{a\in\mathcal{A}_t}\ \mathrm{score}(a\mid \text{current state})\]这里 \(\mathrm{score}(a\mid \text{current state})\) 是当前状态下动作 \(a\) 的局部收益;\(\arg\max\) 表示从所有可选动作里挑出得分最高的那个。贪心算法关心的是“眼下哪一步最好”,而非“未来所有步骤联合起来后哪条完整路径最好”。
因此,贪心方法是否正确,取决于问题本身是否满足贪心选择性质(Greedy-choice Property)。如果这个性质成立,局部最优就能拼成全局最优;如果不成立,贪心通常只能作为启发式方法或近似算法。
决策树训练就是一个典型例子。每个节点都不会提前规划整棵树的全局最优结构,只在当前节点上选择信息增益、基尼下降或误差下降最大的切分。这个过程本质上就是贪心:每一步都先把当前最值得切的地方切开。它训练快、解释性强,但也正因为是局部选择,单棵树通常并非全局最优树结构。
分治算法(Divide and Conquer)处理的是“大问题可以被拆成若干个同结构小问题”的场景。它广泛出现在排序、搜索、矩阵运算、索引构建,以及大规模数据处理与并行计算中。
分治的思想可以概括为三步:分解(Divide)— 递归求解(Conquer)— 合并(Combine)。它像整理一大堆文档时,先按主题拆成若干小堆,再分别处理,最后再合并成有序结果。与动态规划不同,分治更强调“子问题相互独立”,而非“子问题结果需要反复复用”。
分治算法的时间复杂度常写成递推式:
\[T(n)=aT\left(\frac{n}{b}\right)+f(n)\]这里 \(n\) 是问题规模;\(a\) 表示被拆成多少个子问题;\(n/b\) 是每个子问题的规模;\(f(n)\) 是“分解 + 合并”本身的额外代价。这个式子不告诉我们具体怎么做,但它准确描述了分治算法的结构骨架。
例如,归并排序(Merge Sort)把长度为 \(n\) 的数组分成两个规模约为 \(n/2\) 的子数组,递归排好序后再线性合并,因此它的复杂度递推就是 \(T(n)=2T(n/2)+O(n)\)。
在机器学习工程中,分治思想常见于大规模近邻索引构建。例如构建 kd-tree 时,算法会按某个维度把样本集递归切成两半,再在左右子集上继续构树。这样得到的层次化空间划分,能显著加速后续的近邻搜索。它的本质是通过递归拆分把原本需要全表扫描的搜索过程组织得更高效。
许多软件与机器学习问题都可以抽象成图(Graph):节点(Node)表示状态、样本、词、网页或知识实体,边(Edge)表示转移、相似性、依赖关系或可达关系。图搜索与最短路径算法要回答的问题是:如何从起点高效找到目标节点,或找到总代价最小的一条路径。
图搜索的核心是“沿着边扩展状态空间,但尽量避免无意义的重复探索”。无权图最短路径常用广度优先搜索(BFS),因为它按层扩展,第一次到达目标通常就是步数最少的路径;带非负权图常用 Dijkstra,因为它总是优先扩展当前总代价最小的候选节点。
带权最短路径算法里的基本更新步骤通常写成“松弛(Relaxation)”:
\[\mathrm{dist}(v)=\min\big(\mathrm{dist}(v),\ \mathrm{dist}(u)+w(u,v)\big)\]这里 \(\mathrm{dist}(u)\) 是当前已知从起点到节点 \(u\) 的最小代价, \(w(u,v)\) 是边 \(u\rightarrow v\) 的权重, \(\mathrm{dist}(u)+w(u,v)\) 则是“先到 \(u\) 再走到 \(v\)”这条新候选路径的总代价。若它比当前记录的 \(\mathrm{dist}(v)\) 更小,就更新。
这个式子看起来和动态规划很像,原因是二者都在做“由已知子结果递推新结果”。区别在于:图搜索更强调如何选择下一个要扩展的节点,以及如何在一般图结构中避免重复访问。
在语音识别、机器翻译和图搜索推断中,解码过程经常会把候选状态组织成图或格(Lattice)。此时,寻找最优输出序列本质上就是图上的路径搜索问题。很多动态规划解码器也可以从“图上最优路径”的角度理解,因此图搜索是连接通用软件算法与结构化机器学习推断的重要桥梁。
二分查找(Binary Search)处理的是“搜索空间有序,或可行性判断具有单调性”的问题。它不仅用于有序数组查找,也广泛用于阈值搜索、参数调优、数值逼近和工程系统中的边界定位。
二分查找的核心是:每次利用单调性砍掉一半搜索空间。它像猜数字游戏:如果知道答案一定在某个区间里,而且中点左侧和右侧满足不同性质,那么每问一次都能把候选范围减半。
若当前搜索区间为 \([l,r]\),中点通常取:
\[\mathrm{mid}=\left\lfloor\frac{l+r}{2}\right\rfloor\]接着依据单调判定函数 \(\mathrm{check}(\mathrm{mid})\) 缩小区间:
- 若 \(\mathrm{check}(\mathrm{mid})\) 为真,说明答案在左半边或恰好是中点,则令 \(r=\mathrm{mid}\)。
- 若为假,说明答案在右半边,则令 \(l=\mathrm{mid}+1\)。
算法正确性的关键不在于公式本身,而在于维护区间不变式(Invariant):在每一步更新后,真正的答案仍然留在当前区间中。
在机器学习里,二分查找常用于阈值定位。例如,当需要找到“使召回率至少达到某个目标值的最小分类阈值”时,只要阈值越大召回率越低这一单调关系成立,就可以在阈值区间上做二分查找,而不必逐点穷举。类似地,很多数值求根、超参数边界搜索、分位数定位问题也都可写成二分框架。
随机采样(Random Sampling)处理的是这样一类问题:总体太大、精确计算太贵,或者目标本身就是概率性的,因此只能通过抽样近似整体行为。它是统计学习、蒙特卡洛估计、bootstrap、自助重采样、mini-batch 训练和负采样的共同基础。
随机采样的核心是:通过足够有代表性的随机子样本估计总体性质,无需每次都看完整总体。它像民意调查:不可能每天逐个询问所有人,但若抽样方式合理,少量样本也能给出相对稳定的总体估计。
若目标是估计随机变量 \(X\) 下某个函数 \(f(X)\) 的期望 \(\mathbb{E}[f(X)]\),最常见的蒙特卡洛估计写为:
\[\hat{\mu}=\frac{1}{n}\sum_{i=1}^{n} f(x_i),\qquad x_i\sim p(x)\]这里 \(x_i\sim p(x)\) 表示样本 \(x_i\) 是按分布 \(p(x)\) 随机抽到的; \(n\) 是样本数; \(\hat{\mu}\) 是用样本均值近似真实期望的估计量。样本越多,估计通常越稳定,但代价也越高。
这一思想在机器学习里非常普遍:SGD 核心是用 mini-batch 的样本均值近似全数据梯度;negative sampling 核心是随机抽一小部分负样本近似完整目标。
bootstrap 是一个很典型的例子。随机森林训练时,会对原始训练集做有放回采样,得到多份不同的 bootstrap 子集,再分别训练多棵树。这里真正起作用的核心是随机采样制造了多个略有差异的数据视角,从而让集成后的模型更稳。
Top-K 问题处理的是:在 \(n\) 个候选中,只需要找出分数最高的 \(k\) 个。完整排序的复杂度通常是 \(O(n\log n)\),但 Top-K 并不需要知道所有元素之间的完整顺序,因此可以更便宜。
常见做法有三类。第一,维护一个大小为 \(k\) 的最小堆,扫描全部元素时,只保留当前前 \(k\) 大,复杂度为 \(O(n\log k)\)。第二,使用 Quickselect 这类选择算法,平均复杂度接近 \(O(n)\),先找到第 \(k\) 大的阈值,再取出所有超过阈值的元素。第三,使用 partial sort,只把前 \(k\) 个候选排好序,适合最终还需要按分数返回候选列表的场景。
在生成模型中,Top-K 直接出现在解码阶段。模型先输出词表 logits,再只保留分数最高的 \(k\) 个 token,把其余 token 的概率置为 0,随后在这个小集合内归一化采样。若词表大小为 \(V\),完整排序整个词表会很浪费;工程实现通常使用专门的 top-k kernel 或部分选择算子。
在检索和推荐中,Top-K 也同样关键。召回层可能从百万级文档中取出几百个候选,粗排再取几十个,精排最终返回少量结果。每一层都在做“保留足够好的候选,同时尽早丢掉明显无关项”的选择算法。
滑动窗口(Sliding Window)处理的是连续区间上的局部统计。给定序列 \(x_1,\dots,x_n\),窗口通常写成 \([l,r]\),算法每次移动左端点或右端点,并维护窗口内的计数、和、最大值、最小值或其他摘要。
滑动窗口的核心是把“重新计算整个区间”改成“只处理进入窗口和离开窗口的元素”。固定窗口适合长度已知的局部统计;双指针适合窗口长度随约束动态变化的场景;单调队列则适合在窗口移动时同步维护最大值或最小值。
固定长度窗口的均值可以写成
\[\bar{x}_{t}=\frac{1}{w}\sum_{i=t-w+1}^{t}x_i\]这里 \(w\) 是窗口长度, \(\bar{x}_{t}\) 是时刻 \(t\) 之前最近 \(w\) 个值的平均。若每次都重新求和,代价是 \(O(w)\);若维护滚动和,则每步只需减去离开的元素、加上新进入的元素,代价降为 \(O(1)\)。
双指针(Two Pointers)适合窗口长度不固定、但约束具有单调性的场景。例如要找“token 数不超过上限的最长片段”,右指针不断扩张,超限后左指针收缩。长文本切块、按 token budget 裁剪上下文、日志窗口统计,都可以用这种模式。
单调队列(Monotonic Queue)用于在线维护窗口最大值或最小值。队列内部保持单调顺序,新元素进入时把更弱的尾部元素弹出;窗口左端移动时再移除过期元素。每个元素最多进队和出队各一次,因此总复杂度为 \(O(n)\)。在流式监控中,它可用于快速得到最近一段时间内的最大延迟、最高 GPU 显存占用或最高请求队列长度。
前缀和(Prefix Sum)把一段序列的累积量预先存起来,使任意区间求和可以常数时间完成。差分数组(Difference Array)则从另一个方向解决大量区间更新问题。
前缀和把区间查询改写成两个累积值相减,差分数组则把区间更新改写成两个边界点的修改。二者互为镜像:前缀和适合“多次查询”,差分适合“多次批量更新后统一恢复”。
则区间 \([l,r]\) 的和为
\[\sum_{i=l}^{r}x_i=S_r-S_{l-1}\]这里 \(S_i\) 是前 \(i\) 个元素的累计和。构建前缀和需要 \(O(n)\),之后每次区间查询只需 \(O(1)\)。
AI 工程中,前缀和常用于 token 长度累计、batch 分桶边界、文档切块位置、mask 区间统计和 span 覆盖数量计算。例如把若干段文本拼成一个长序列后,可以用前缀长度快速定位“第 \(t\) 个 token 属于哪篇文档、哪一段句子”。
差分数组(Difference Array)处理的是大量区间更新。若原数组为 \(a\),差分数组可定义为 \(d_i=a_i-a_{i-1}\)。要把区间 \([l,r]\) 全部加上 \(v\),只需执行
\[d_l\leftarrow d_l+v,\qquad d_{r+1}\leftarrow d_{r+1}-v\]最后对差分数组再做一次前缀和,就能恢复全部更新后的值。NER 标注中,如果需要统计每个 token 被多少个候选 span 覆盖,差分数组比逐 token 更新更合适。
字符串匹配(String Matching)处理的是:如何在长文本 \(T\) 中查找模式串 \(P\)。朴素算法会在每个位置重新尝试匹配,最坏复杂度可达 \(O(|T||P|)\)。更高效的算法会复用已经匹配过的前缀信息。
KMP(Knuth-Morris-Pratt)算法为模式串预先构建失配表。失配表记录“当前匹配失败后,模式串可以安全回退到哪个前缀长度”。因此主串指针不需要回退,整体复杂度为 \(O(|T|+|P|)\)。它适合单模式串、确定性要求强的文本扫描。
Rabin-Karp 使用滚动哈希(Rolling Hash)。它把每个长度为 \(|P|\) 的窗口映射成哈希值,窗口右移时可以快速更新哈希。设窗口哈希为 \(H_t\),右移一位后可以在常数时间内移除旧字符并加入新字符。它适合多模式串粗筛,但需要处理哈希碰撞。
Aho-Corasick 自动机(Aho-Corasick Automaton, AC Automaton)适合一次匹配大量词典项。它把所有模式串建成 Trie,再为每个节点加入失败指针(Failure Link)。扫描文本时,自动机沿字符转移;若当前路径失败,就沿失败指针跳到最长可复用后缀。构建完成后,可以用接近 \(O(|T|+\text{matches})\) 的代价找出所有命中的词典项。
在 AI 项目里,AC 自动机常用于敏感词过滤、词典 NER、gazetteer 特征、规则召回和数据清洗。它的优势是稳定、可解释、延迟低;边界是只能匹配显式词典或规则,无法理解上下文语义。
有限状态自动机(Finite State Automaton, FSA)把文本处理写成“状态 + 转移”的形式。确定有限自动机(DFA)在每个状态和输入字符下只有一个下一状态,非确定有限自动机(NFA)允许多个可能路径。正则表达式引擎、词法分析器、tokenizer 的一部分规则,都可以用自动机解释。
有限状态转换器(Finite State Transducer, FST)在状态转移时不仅读取输入,还产生输出。它常用于分词、规范化、语音识别中的发音词典和加权解码图。若边上带权重,就得到加权 FST(Weighted FST, WFST),可以把候选路径搜索转成图上的最短路径或最优路径问题。
大规模语料处理中,完全相同的样本容易用哈希表去重;近重复样本更难,因为它们可能只是改了标题、顺序、标点或少量词。相似去重的目标是在不做两两全量比较的条件下,快速找到高度相似的文本或文档。
相似去重的核心是把昂贵的两两比较改成紧凑签名比较。MinHash 面向集合相似度,SimHash 面向向量方向相似,LSH 则把“相似样本更容易进同一个桶”做成索引机制。它们共同服务于一个目标:先快速缩小候选,再做更精确的复核。
MinHash 用来近似 Jaccard 相似度。设两个集合为 \(A\) 和 \(B\),Jaccard 相似度定义为
\[J(A,B)=\frac{|A\cap B|}{|A\cup B|}\]MinHash 的关键性质是:对一个随机排列 \(\pi\),两个集合最小哈希值相等的概率等于它们的 Jaccard 相似度:
\[\Pr[\min(\pi(A))=\min(\pi(B))]=J(A,B)\]这里 \(\pi(A)\) 表示把集合 \(A\) 中每个元素经过同一个随机排列或哈希映射后的结果。工程上会用多个哈希函数形成签名向量,再比较签名相等比例,从而近似估计文档相似度。预训练语料去重中,通常先把文档切成 n-gram shingles,再用 MinHash 生成紧凑签名。
SimHash 更适合近似余弦相似。它先把每个特征哈希成一个带符号的随机向量,再按特征权重累加,最后取每一维的符号位形成二进制指纹。两个文本越相似,它们的 SimHash 指纹汉明距离通常越小。搜索引擎和网页去重里常用 SimHash 做近重复检测。
局部敏感哈希(Locality-Sensitive Hashing, LSH)是一类把相似对象更可能映射到同一桶的哈希方法。它牺牲精确性,换取候选集合的大幅缩小。MinHash-LSH 常用于 Jaccard 相似,随机投影 LSH 常用于余弦相似。其工程模式通常是:先用 LSH 生成少量候选,再用精确相似度或模型重新打分。
这类方法在 AI 数据工程里价值很高。预训练语料若存在大量近重复文本,模型容易过度记忆常见模板;评测集若泄漏到训练集,相似去重可以降低虚高指标风险;RAG 知识库若重复段落太多,检索结果会被冗余内容挤占。
流式近似统计处理的是“数据太大、不能完整保存、还要在线估计”的问题。它通常用固定或近似固定内存维护摘要,适合日志监控、语料统计、在线特征计数和训练数据质量看板。
流式近似统计用可合并、可更新的小摘要替代完整数据。它接受有限误差,换取固定内存、在线更新和跨机器聚合能力。Count-Min Sketch 估计频率,HyperLogLog 估计基数,Reservoir Sampling 保留均匀样本,Quantile Sketch 估计分位数。
Count-Min Sketch 用一个二维计数表和多组哈希函数估计元素频率。插入元素 \(x\) 时,每一行按对应哈希函数定位一个桶并加 1;查询时,取这些桶计数的最小值:
\[\hat c(x)=\min_{j=1}^{d}C_{j,h_j(x)}\]这里 \(C\) 是计数表, \(d\) 是哈希函数数量, \(h_j(x)\) 是第 \(j\) 个哈希函数给出的桶位置。由于碰撞只会把其他元素的计数加进来,估计值通常不会低于真实频率。它适合找高频 token、高频 URL、高频错误码或高频用户行为。
HyperLogLog 用于估计不同元素数量,也就是基数(Cardinality)。它基于一个观察:若哈希结果足够随机,某个哈希值二进制前导零越多,说明看到这么“稀有”模式所需的不同元素数通常越大。HyperLogLog 把元素分到多个寄存器中,记录最大前导零长度,再用调和平均得到基数估计。它常用于估计语料中唯一文档数、唯一用户数、唯一 prompt 模板数。
Reservoir Sampling 用固定大小的水库从未知长度的数据流中抽取均匀样本。第 \(i\) 个元素到来时,若水库大小为 \(k\),则以概率 \(k/i\) 接受它;接受后再随机替换水库中的一个旧元素。这样即使不知道数据流最终长度,每个元素最终被保留的概率仍相同。
分位数草图(Quantile Sketch)用于估计 P50、P90、P99 这类分位数。推理服务监控中,平均延迟远远不够,P99 延迟经常决定用户体验。TDigest、KLL Sketch 等结构可以在有限内存下估计分位数,并支持跨机器合并摘要。
向量检索处理的是高维空间中的近似最近邻搜索(Approximate Nearest Neighbor Search, ANN)。给定查询向量 \(q\) 和向量库 \(\{x_i\}_{i=1}^{N}\),目标是找到距离最近或相似度最高的若干向量。暴力搜索需要计算 \(N\) 次距离,库很大时成本过高。
HNSW(Hierarchical Navigable Small World)把向量组织成多层小世界图。高层图稀疏,用于快速跳到查询附近;底层图更密,用于局部精细搜索。搜索过程从高层入口点开始,贪心地走向更接近查询的邻居,再逐层下降。它的优势是召回率高、延迟低、工程表现稳定,因此被大量向量数据库采用。
IVF(Inverted File Index)先用聚类把向量空间划分成多个粗簇。查询时,先找到离 \(q\) 最近的若干簇,只在这些簇内部继续搜索。若簇数为 \(C\),每次只探查 \(n_{\mathrm{probe}}\) 个簇,就能显著减少候选数量。 \(n_{\mathrm{probe}}\) 越大,召回越高,延迟也越高。
PQ(Product Quantization)把高维向量拆成多个子空间,并在每个子空间里用码本近似。原始浮点向量可被压缩成若干个短码,从而降低内存和距离计算成本。OPQ(Optimized Product Quantization)会先对向量做旋转变换,使各子空间更适合量化,通常能提升压缩后的检索质量。
RAG 系统常采用“ANN 召回 + 精排”的两阶段结构。向量索引用 HNSW、IVF 或 PQ 快速拿到候选文档;随后用 cross-encoder、LLM reranker 或规则特征重新排序。ANN 负责快,精排负责准。若只依赖向量索引的近似距离,长尾问题、同义改写和领域术语容易被误排。
缓存算法处理的是有限内存如何分配给最有价值的数据。AI 系统里的缓存对象很多:tokenizer 结果、embedding、检索候选、prompt 前缀、模型输出、KV cache、特征向量、远程 API 响应。缓存命中率直接影响延迟和成本。
LRU(Least Recently Used)淘汰最近最久未使用的对象。它基于时间局部性:刚访问过的数据短期内更可能再次访问。典型实现是“哈希表 + 双向链表”:哈希表负责 \(O(1)\) 定位节点,链表负责 \(O(1)\) 移动节点和淘汰尾部。
LFU(Least Frequently Used)淘汰访问频率最低的对象。它适合热点长期稳定的场景,例如常见 embedding、热门知识片段或高频用户特征。TTL Cache 给每个条目设置过期时间,适合外部数据会变化、缓存不能无限持久的场景。实际系统常把 LRU、LFU、TTL 和容量限制组合使用。
一致性哈希(Consistent Hashing)用于把 key 分配到多台机器上,并在节点增删时减少迁移量。它把节点和 key 都映射到一个哈希环上,key 归属于顺时针遇到的第一个节点。若增加或删除一个节点,只影响环上相邻区间,而不会打乱全部 key。
Rendezvous Hashing 也称最高随机权重哈希(Highest Random Weight Hashing)。对每个 key,计算它与每个节点的哈希得分,选择得分最高的节点。它实现简单,节点变化时迁移也较少,常用于分布式缓存、向量库分片和推理实例路由。
限流算法控制请求进入系统的速度,避免后端被瞬时流量打爆。Token Bucket(令牌桶)维护一个以固定速率补充的令牌池;请求到来时必须消耗令牌,令牌不足则等待或拒绝。它允许短时间突发,因为桶里可以预先积累一部分令牌。
限流负责控制进入速度,退避负责控制失败后的重试节奏,调度负责决定排队任务的执行顺序。三者共同决定系统在高压下是平稳降级,还是被突发流量、同步重试和长队列拖垮。
若令牌补充速率为 \(r\),桶容量为 \(B\),则任意时间长度 \(T\) 内允许通过的请求数最多约为
\[B+rT\]这里 \(B\) 决定突发容量, \(r\) 决定长期平均速率。LLM API 网关、推理服务入口、爬虫抓取和异步任务提交都经常使用令牌桶。
Leaky Bucket(漏桶)以固定速率放出请求,更强调平滑输出流量。它像一个固定出水速度的桶:上游请求可以突发进入,但下游看到的是更稳定的处理速率。它适合保护对突发极其敏感的服务。
指数退避(Exponential Backoff)用于失败重试。第 \(t\) 次失败后的等待时间可写成
\[\Delta_t=\min(\Delta_{\max},\Delta_0\cdot 2^t)\]这里 \(\Delta_0\) 是初始等待时间, \(\Delta_{\max}\) 是最大等待时间。工程上通常再加入随机抖动(Jitter),避免大量客户端在同一时刻重试,形成新的流量尖峰。
调度算法决定队列里的任务按什么顺序执行。Round Robin 轮询各队列,适合公平性要求较强的多租户场景;Weighted Fair Queue 给不同队列不同权重,适合区分付费等级、业务优先级或模型类型;Priority Scheduling 优先处理高优先级任务,但需要防止低优先级任务长期饥饿。推理服务中的动态 batching、训练集样本混合、多任务数据采样,本质上都带有调度问题。
Backpressure(反压)是流式系统里的保护机制。当下游处理不过来时,上游必须减速、暂停或丢弃低价值任务。没有反压的系统会把压力堆积成内存膨胀、队列延迟和级联故障。
区间合并(Interval Merge)处理的是多个区间可能重叠时,如何得到不重叠的合并结果。典型做法是先按左端点排序,再从左到右扫描:若新区间左端点不超过当前合并区间右端点,就扩展右端点;否则开启一个新区间。
NER 后处理经常会遇到重叠 span。例如模型同时预测了“纽约”和“纽约大学”,或者规则系统和模型各给出一组实体候选。区间合并、优先级排序和冲突消解决定最终输出哪些实体。若实体有类型、置信度和来源,还需要在区间合并上叠加排序规则。
扫描线(Sweep Line)把几何或区间问题转成按事件排序的过程。每个区间 \([l,r]\) 产生两个事件: \(l\) 处加入, \(r\) 处移除。按坐标扫描时维护当前活跃集合,就能计算最大重叠数、重叠区域、版面块关系或时间段并发量。
并查集(Disjoint Set Union, DSU)维护一组动态连通分量,支持查找代表元 find 和合并 union。路径压缩与按秩合并后,单次操作的均摊复杂度接近常数。其核心用途是把“若干对象因为某些证据应归为一组”的过程高效维护起来。
实体链接、聚类后处理、重复样本合并和图连通块分析都常用 DSU。例如多个 mention 通过别名、ID、URL 或 embedding 相似度被判定为同一实体,就可以逐步 union,最后每个连通块对应一个候选实体簇。
压缩算法降低存储和传输成本。RLE(Run-Length Encoding)把连续重复值写成“值 + 次数”,适合长段重复结构;Huffman Coding 根据符号频率分配变长编码,高频符号用短码,低频符号用长码;Arithmetic Coding 把整段消息编码成一个区间中的数,压缩率通常更接近熵极限。
通用压缩工具如 gzip、zstd、lz4 背后通常结合字典匹配、熵编码和块压缩策略。AI 数据集、日志、JSONL 语料、特征文件和 checkpoint 传输都依赖压缩。训练吞吐有时会受解压速度限制,因此压缩率和解压速度需要一起权衡。
校验算法用于发现传输或存储错误。CRC 更偏向快速检测随机错误,常用于文件块和网络传输;SHA-256 这类密码学哈希更适合内容完整性校验和内容寻址。若文件内容完全相同,其哈希值应相同;内容一变,哈希值就会显著变化。
内容寻址(Content Addressing)把对象地址定义为内容哈希,不依赖人为命名路径。数据集版本、模型制品、缓存 key、Docker layer、特征快照都可以用内容哈希管理。这样能避免“文件名相同但内容已变”的隐性错误,也便于去重和复现实验。
AI 工程离不开配置、模板和结构化文本。训练配置可能来自 YAML,推理请求可能包含 JSON,工具调用需要 schema,prompt 可能包含变量插槽和条件片段。解析算法负责把这些文本变成可验证、可执行的数据结构。
递归下降解析(Recursive Descent Parsing)把语法规则写成一组互相调用的函数。若语法天然分层,例如表达式、函数调用、列表、对象、字段访问,就可以用递归函数逐层解析。它实现直观,适合小型 DSL、配置表达式和 prompt 模板语言。
Pratt Parser 常用于表达式解析,尤其适合处理不同优先级和结合性的运算符。每个 token 定义自己的前缀或中缀解析行为,并配合绑定力(Binding Power)控制解析顺序。表达式越复杂,Pratt Parser 相比手写多层优先级函数越简洁。
Schema 校验处理的是“结构正确”与“语义可用”。例如工具调用参数必须包含必填字段、字段类型必须匹配、枚举值必须合法。LLM 工具调用、Agent 配置和训练任务配置都需要严格校验,否则错误会延迟到运行时才暴露。
变长序列训练和推理中,padding 浪费非常常见。一个 batch 里的样本长度差异越大,模型花在无效填充 token 上的计算越多。
Padding-aware batching 进一步把 batch size 从“样本条数”改成“token 数或帧数预算”。例如每个 batch 限制最多 \(N\) 个 token,短样本可以放更多条,长样本则放更少条。这样 GPU 看到的计算量更稳定,训练吞吐也更可控。
若一个 batch 内最长序列长度为 \(L_{\max}\),第 \(i\) 条样本真实长度为 \(L_i\),则 padding token 数为
\[\sum_i (L_{\max}-L_i)\]这些 padding token 通常不贡献有效监督,却会占用显存和计算。长度分桶(Bucketing)会把相近长度的样本放到同一批里,降低 \(L_{\max}\) 与平均长度之间的差距。NLP、语音、OCR 和视频训练都大量使用这一策略。
动态 batching 常用于推理服务。服务端在极短时间窗口内收集多个请求,把它们合并成一个 batch 送入模型。窗口太短,batch 太小,GPU 利用率低;窗口太长,单个请求等待时间增加。高质量推理系统会在吞吐和延迟之间动态折中,并结合优先级队列、超时策略和最大 token 预算控制。
大模型推理中的 continuous batching 进一步允许不同请求在生成过程中动态进入和退出 batch。某个请求生成完毕后,它占用的 slot 可以立刻被新请求接上。相比传统“一批请求全部结束后再处理下一批”,continuous batching 更适合输出长度差异很大的 LLM 服务。
机器学习基础概念(Machine Learning Foundations)回答四类核心问题:数据从哪里来、模型在学什么、模型为什么能泛化、结果该如何评价。把这些问题分开看,会比死记算法名称更有效:学习范式决定监督信号来自哪里,假设空间与归纳偏置决定模型愿意相信什么,数据集工程决定模型实际看到了什么,模型评估决定这些学习结果是否真的能迁移到未见样本。
这四个词描述的是同一条“训练=优化”的概念链,但位于不同层级。把层级理清后,公式与实现会自然对齐:模型 \(f_\theta\) 先给出预测,再用损失函数把预测变成数值误差,最后把误差在数据集上汇总成代价函数,并加入正则/约束得到最终的目标函数。
假设函数(Hypothesis Function)也常被直接称为模型(Model)或预测函数(Predictor),记作 \(f_\theta\)。它回答的问题是:给定输入 \(x\),模型输出什么。参数 \(\theta\) 决定这条映射的具体形状。
线性回归(Linear Regression)的假设函数是最经典的例子:
\[\hat y=f_\theta(x)=\mathbf{w}^\top x+b,\quad \theta=(\mathbf{w},b)\]目标函数(Objective Function)记作 \(J(\theta)\),是优化器真正要优化的函数。工程上最常见、也最清晰的写法是:目标函数 = 代价函数 + 正则化项(没有正则化时可视为正则项为 0,因此 \(J(\theta)=L(\theta)\))。
\[J(\theta)=L(\theta)+\lambda\,\Omega(\theta)\]在线性回归里,若用 L2 正则(Ridge / Weight Decay),常见目标函数可以写成:
\[J(\theta)=L(\theta)+\lambda\|\mathbf{w}\|_2^2\]把 \(L(\theta)\) 展开后,就是:
\[J(\theta)=\frac{1}{N}\sum_{i=1}^{N}(\mathbf{w}^\top x_i+b-y_i)^2+\lambda\|\mathbf{w}\|_2^2\]代价函数/成本函数(Cost Function)记作 \(L(\theta)\),通常指把样本损失在训练集上做平均或求和后的整体量,也就是经验风险(Empirical Risk)。不少教材会把它直接称为训练损失(training loss),并且在不引起歧义时把它与目标函数混用。
在线性回归里,常用“均方误差的平均”作为代价函数:
\[L(\theta)=\frac{1}{N}\sum_{i=1}^{N}\ell_i(\theta)\]把 \(\ell_i(\theta)\) 取为平方误差后,等价写法是:
\[L(\theta)=\frac{1}{N}\sum_{i=1}^{N}(\mathbf{w}^\top x_i+b-y_i)^2\]损失函数(Loss Function)记作 \(\ell\),通常定义在单个样本上,把“预测与目标的差距”映射为一个标量。它回答的问题是:这一条样本我错了多少。
在线性回归里,最常见的单样本损失是平方误差:
\[\ell_i(\theta)=\ell(\hat y_i,y_i)=(\hat y_i-y_i)^2,\quad \hat y_i=f_\theta(x_i)\]同一份训练数据,之所以会被不同模型学出完全不同的规律,根源在于每个模型都自带一套“允许学什么、不允许学什么”的结构约束。假设空间(Hypothesis Space)、模型容量(Model Capacity)与归纳偏置(Inductive Bias)共同描述的,就是这套约束。
假设空间(Hypothesis Space)是模型可表达函数的集合,常记为 \(\mathcal{H}\):
\[\mathcal{H}=\{f_\theta:\theta\in\Theta\}\]这里 \(f_\theta\) 是由参数 \(\theta\) 决定的预测函数, \(\Theta\) 是参数可取的范围。这个定义的关键不在于“参数有多少”,而在于模型最终允许出现哪些映射形状。例如,一元线性回归的假设空间只包含直线;二次多项式回归的假设空间包含抛物线;深度神经网络的假设空间则更大,能表示复杂得多的非线性函数。
因此,训练核心是在某个特定假设空间里找一个最合适的函数。假设空间太小,真实规律可能根本装不进去;假设空间太大,模型又容易把偶然噪声也解释成模式。
模型容量(Model Capacity)描述的是假设空间的表达能力有多强,也就是模型能拟合多复杂规律。容量高,不代表一定更好;它只表示模型“有能力”表示复杂函数。是否真的学得好,还取决于数据量、正则化、优化过程和任务本身。
容量可以从多个角度理解。参数更多通常意味着容量更高,但这并非唯一标准;树的深度、核方法的核函数形式、特征维度、网络层数、隐藏维度、注意力头数,都会改变容量。工程上常用一个朴素判断:如果模型连训练集主要结构都拟合不了,容量偏低;如果训练集几乎完美、验证集却明显变差,容量往往偏高或约束不足。
容量与复杂度控制始终是一组平衡。表格数据上的浅层树模型可能已经足够;图像、语音、自然语言这类高度复杂任务,则通常需要更高容量的模型族。容量本身并非缺点,关键在于它是否与数据规模和任务难度匹配。
欠容量(Undercapacity)指模型或可训练适配器的表达能力不足,无法为当前任务提供足够大的可行函数空间。它讨论的是模型有没有能力表示这类规律,因此属于成因层概念。
这和欠拟合不同。欠拟合是结果层现象,表示当前训练结果不够好;欠容量只是欠拟合的一种常见原因。一个模型可能因为容量太小而欠拟合,也可能因为学习率不对、训练步数不足、输入被截断、特征表达差而欠拟合。反过来,一个高容量模型如果训练明显不充分,也会暂时呈现欠拟合外观。
工程上判断欠容量,常见信号包括:训练 loss 长期降不下去;训练集指标存在明显硬上限;增大模型尺寸、隐藏维度、树深、LoRA rank 或可训练模块后,训练集和验证集一起改善。若这些现象同时出现,就更像是表达能力本身不够,而非单纯还没训练够。
归纳偏置(Inductive Bias)是模型在有限样本下从已见数据推广到未见数据时,默认采用的结构性偏好。只靠训练集上有限个点,无法唯一确定整个输入空间上的函数;模型之所以还能做出泛化判断,是因为它隐含地偏好某些解释,而排斥另一些解释。
把学习目标写成经验风险最小化时,这一点会更清楚:
\[\hat f=\arg\min_{f\in\mathcal{H}}\hat R_n(f),\qquad \hat R_n(f)=\frac{1}{n}\sum_{i=1}^{n}\ell(f(x_i),y_i)\]这里 \(\hat R_n(f)\) 是经验风险(Empirical Risk),表示函数 \(f\) 在训练集上的平均损失; \(\hat f\) 是最终选出的模型。关键约束正是 \(f\in\mathcal{H}\):优化核心是在一个被模型结构预先限制过的空间里找解。这个限制本身就是归纳偏置。
归纳偏置的来源很多。线性模型偏好线性关系;KNN(K-Nearest Neighbors)偏好局部相似样本给出相似输出;卷积神经网络(CNN)偏好局部连接与平移等变(Translation Equivariance);树模型偏好分段常数的轴对齐切分;Transformer 则偏好通过注意力在 token 之间建立可变依赖。正则化、数据增强、参数共享、预训练初始化、优化器的更新轨迹,也都会进一步塑造模型的归纳偏置。
在统计学习(Statistical Learning)里,训练目标可以从三个层次来理解:期望风险(Expected Risk)描述模型在真实数据分布上的平均误差;经验风险(Empirical Risk)描述模型在有限训练集上的平均误差;结构风险(Structural Risk)则在经验风险之外,把模型复杂度一并纳入考虑。三者回答的是同一个问题的不同版本:模型到底应该怎样才算“学得好”。
期望风险也常被称为真实风险(True Risk)或总体风险(Population Risk)。若真实数据来自未知分布 \(P(X,Y)\),模型为 \(f\),单样本损失为 \(\ell(f(x),y)\),则期望风险定义为:
\[R(f)=\mathbb{E}_{(x,y)\sim P}\big[\ell(f(x),y)\big]\]这条式子的含义很直接:把模型放到所有可能出现的真实样本上,计算平均损失。理论上,这才是机器学习真正想最小化的对象,因为泛化能力最终取决于模型在未知数据上的表现,而非只取决于训练集上的表现。
困难在于,真实分布 \(P(X,Y)\) 并不可见。训练时手里只有有限样本,而没有“全体可能数据”的上帝视角。因此,期望风险通常不能被直接计算,只能被估计。
经验风险是用训练集对期望风险做出的现实近似。设训练集为 \(\mathcal{D}=\{(x_i,y_i)\}_{i=1}^{n}\),则经验风险定义为:
\[\hat R_n(f)=\frac{1}{n}\sum_{i=1}^{n}\ell\big(f(x_i),y_i\big)\]它就是模型在当前这批已观测样本上的平均损失。工程上常见的 training loss,本质上反映的正是经验风险,或它的 mini-batch 近似。经验风险最小化(Empirical Risk Minimization, ERM)的训练逻辑也很朴素:既然期望风险不可直接计算,就先把训练集上的平均损失压低。
ERM 的关键前提是:训练集足够代表真实分布。当样本数量增加且采样足够合理时,经验风险通常会更接近期望风险;但在有限样本条件下,两者并不相等。二者之间的差距,本质上就是泛化误差(Generalization Gap)的来源。若模型只是把训练集中的偶然模式、局部噪声和标注误差也一并记住,那么 \(\hat R_n(f)\) 可以很低,而 \(R(f)\) 仍然很高,这正是过拟合(Overfitting)的典型形式。
结构风险(Structural Risk)是在经验风险之外,再把模型复杂度或假设空间规模纳入考虑的目标。它对应的思想是结构风险最小化(Structural Risk Minimization, SRM):模型不仅要在训练集上拟合得好,还要避免复杂到足以随意记忆有限样本。
在统计学习理论的严格表述中,SRM 常写成在一族嵌套假设空间之间做选择;在工程实践里,它更常以“经验风险 + 复杂度惩罚”的形式出现,例如:
\[J(f)=\hat R_n(f)+\lambda\,\Omega(f)\]这里 \(\Omega(f)\) 是复杂度项(Complexity Penalty), \(\lambda\) 控制数据拟合与复杂度约束之间的权衡。L2 正则化(L2 Regularization)、L1 正则化(L1 Regularization)、Weight Decay、早停(Early Stopping)以及对模型深度、宽度和树复杂度的限制,都可以看作结构风险最小化思想的具体实现。
因此,结构风险核心是对 ERM 的补充:在有限样本条件下,仅仅把训练误差压到最低,并不能保证模型在真实分布上表现最好。模型必须同时控制复杂度,才能让“训练集上学到的规律”更有机会迁移到未见样本。
这三者共同构成了机器学习里最基本的张力。期望风险是理论上真正想优化的目标,但它不可直接见;经验风险是训练时可观测、可优化的替代量;结构风险则提醒我们,有限样本下不能把“训练集表现更好”直接等同于“真实世界表现更好”。监督学习不仅是在找一个拟合训练集的函数,更是在有限数据和有限模型约束下,寻找一个最可能泛化的解释。
从这里继续往下,就会自然出现另一个问题:如果高维真实数据本身就带有强结构约束,那么经验风险为何常能在有限样本下逼近期望风险,模型又为何能够泛化到未见样本?流形假设(Manifold Hypothesis)正是对这个问题的一条几何回答:真实数据并不会任意填满整个高维空间,会集中在某个低维、连续、受约束的结构附近。
流形假设(Manifold Hypothesis)给出了现代机器学习里一条极其重要的几何直觉:现实世界中有意义的数据,虽然表面上嵌在极高维空间里,但真正有效的变化自由度通常远低于表观维度。也就是说,高维观测往往核心是集中分布在一个低维流形(Low-dimensional Manifold)附近。
图像是最容易理解的例子。一个 \(1024\times 1024\) 的 RGB 图像在像素空间中维度极高,但自然图像并不会均匀占据这个巨大空间:物体形状、光照条件、视角变化、相机成像规律与纹理结构都受到强约束。因此,“像真实猫照片”的图像实际上只落在高维像素空间中的极小区域里。文本也类似。一个长度为 \(T\) 的 token 序列组合数极其巨大,但真正同时符合语法、语义和任务约束的文本,只占离散组合空间中很小的一部分。模型之所以能够泛化,一个重要原因正是:它并不需要学会覆盖整个高维空间,而只需要学会沿着这些低维结构建模。
流形(Manifold)首先是一个几何对象。它的关键性质核心是局部上看起来像普通的低维欧几里得空间,整体上却可以弯曲、卷曲并嵌入到更高维空间中。更正式地说,若一个集合对其上每一点,都存在一个足够小的邻域,可以用 \(\mathbb{R}^d\) 中的局部坐标平滑描述,那么这个集合就可以看作一个 \(d\) 维流形。
地球表面是最直观的例子。站在操场或街道上时,局部地面几乎是平的,可以用二维坐标定位;但从整体看,地球表面显然核心是嵌入三维空间中的弯曲曲面。因此,地球表面就是一个嵌在三维空间里的二维流形。对只能沿地面运动的观察者而言,真正相关的核心是地表上那两个局部自由度。
机器学习教材里常见的瑞士卷(Swiss Roll)把这个概念进一步可视化。可以先想象一张二维纸,再把它卷进三维空间。卷起来之后,样本点在外部看来落在三维空间里,但沿着纸面定位某一点时,真正需要的仍然只是二维坐标。外在维度变高了,内在结构却没有变。这正是流形概念在机器学习里最重要的几何直觉:数据的表观维度可以很高,但它的内在维度却可能很低。
这类卷曲结构还带来另一个机器学习里非常关键的后果:嵌入空间中的欧氏距离(Euclidean Distance)与流形上的测地距离(Geodesic Distance)并不一定一致。两点在外部空间里看起来可能很近,因为一条直线可以直接“穿过空气”连接它们;但若真实数据只能沿流形本身变化,那么真正相关的距离应当是沿曲面或曲线走过去的那条路径长度。流形学习(Manifold Learning)之所以强调邻域图、测地近似和局部结构,正是因为外部直线距离经常不能反映数据在内在结构上的真实远近关系。
放到高维数据上,这个判断尤其关键。一张 \(1000\times1000\) 的灰度图像在像素空间里有一百万维,但“真实人脸图像”显然不会填满整个一百万维空间。姿态、光照、表情、年龄、拍摄距离等因素彼此耦合,使真实样本只落在高维像素空间中一个极薄、极小、受连续约束的区域附近。文本也是同样的逻辑:虽然 token 组合空间极其巨大,但真正同时满足语法、语义、上下文与任务约束的句子,只会沿着某种低维结构变化,而不会任意填满整个离散组合空间。
因此,在机器学习语境中谈流形,真正想表达的核心是一个更直接的判断:有意义的数据并不会随机散落在高维空间中,会集中在某个低维、连续、受约束的结构附近。后面关于自由度、主成分、隐空间、低维近似以及 LoRA 任务子空间的讨论,都是围绕这个判断展开的不同形式化视角。
沿着前面“表观维度高、内在结构低”的判断继续往下走,就会自然落到自由度(Degrees of Freedom)这个概念上。表观维度说的是“数据在形式上有多少个坐标轴”;自由度说的是“这些数据实际上有多少种彼此独立的有效变化方式”。二者并不相同。一个对象可以嵌在极高维空间里,但真正能变化的自由度却很少。
例如,一张脸部图片在像素空间里有数百万维,但很多像素并不能独立随意变化:头部转向、光照强弱、表情变化、年龄纹理、拍摄距离这些因素彼此耦合,共同决定了大部分像素的联动变化。因此,“一张脸”看起来是高维数组,真正支配它变化的自由度却远小于像素总数。文本也一样。句子表面上由许多 token 组成,但语法结构、主题、语气、说话者意图与上下文约束,使它不可能在每个位置上完全独立自由地变化。
这也是流形假设真正重要的地方:它核心是在说有效自由度远少于表观维度。一旦把这层理解清楚,后面关于主成分、隐空间、隐主题、低秩近似乃至 LoRA 的很多思想都会变得顺理成章,因为它们都在试图用更少的自由度,去抓住决定数据或参数变化的核心结构。
一旦接受了“高维数据实际靠近低维结构”这一点,后面许多术语就会自然连起来。主成分(Principal Components)强调几何视角:在一组高维数据里,哪些方向承载了最主要的变化。隐空间(Latent Space)强调表示视角:把原始高维观测压缩到一个更低维、但仍保留关键信息的内部空间。隐主题(Latent Topics)则更偏语义视角:在文本与文档分解里,低维方向常常可以被解释为若干潜在语义因素,例如“体育”“金融”“法律”这类人类能命名的主题轴。
这三个词并不完全同义,但常常指向同一个底层事实:高维观测可以通过少数主导方向或潜在因子来近似描述。主成分更强调方差最大的坐标轴;隐空间更强调模型内部那间低维“房间”;隐主题则是在某些任务里,对这些低维方向做出的语义解释。它们分别对应几何、表示与语义三种语言,但共享同一条低维结构主线。
PCA(Principal Component Analysis)是这条思路最经典、也最直接的算法形式。它在无监督条件下寻找方差最大的几个方向,并把数据投影到这些方向张成的低维子空间中。若数据矩阵为 \(X\),PCA 本质上是在找一个低维线性子空间,使投影后的重建误差尽量小。在线性代数上,这与奇异值分解(SVD)直接对应:保留最大的前 \(r\) 个奇异值及其奇异向量,就得到最佳的 rank-\(r\) 近似。
这类思想并不只存在于经典降维里。自动编码器(Autoencoder)通过瓶颈层学习隐空间;潜在语义分析(Latent Semantic Analysis, LSA)和主题模型在文档-词矩阵里抽取潜在主题;词向量、句向量与深度表示模型把高维离散符号压缩到稠密向量空间。它们的目标函数和可解释性不同,但都默认:原始高维观测背后存在一个更低维、更有结构的变化空间。
LoRA(Low-Rank Adaptation)通过把参数更新 \(\Delta W\) 限制在一个低秩子空间中,实现对大模型的参数高效微调(PEFT)。它的核心做法核心是把更新写成两个低秩矩阵的乘积:
\[\Delta W = BA,\quad B\in\mathbb{R}^{d_{\text{out}}\times r},\ A\in\mathbb{R}^{r\times d_{\text{in}}},\ r\ll \min(d_{\text{in}},d_{\text{out}})\]LoRA 应放在“低维结构”这条主线上理解,但不能把它与 PCA 直接等同。它的核心是对模型参数更新施加低秩约束。
这个约束的含义是:模型不能在完整高维参数空间中任意改动,而只能在一个 rank-\(r\) 的低维更新子空间里移动。从思想上看,它确实与“只保留主导方向”高度相似;若事后对某个全量更新矩阵做 SVD,最佳低秩近似也会只保留最主要的奇异方向。但 LoRA 学到的核心是对当前任务损失下降最有用的低维更新方向。前者是无监督的统计主轴,后者是由反向传播和任务目标共同决定的优化子空间。
因此,把 LoRA 理解为“逼迫模型只在少数主导方向上修改参数”是成立的;但这些方向更准确地说是任务相关的低维适配方向,而非直接等同于原始数据的 PCA 主成分。LoRA 与内在维度(Intrinsic Dimension)讨论天然相连:如果一个下游任务真正需要修改的有效自由度本来就不高,那么让模型只在一个低秩子空间里更新,不仅不会显著损失性能,反而会自动抑制大量无意义的噪声方向。
这里先按监督信号来源划分学习范式。监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、自监督学习(Self-supervised Learning)和强化学习(Reinforcement Learning)回答的是同一个问题:模型训练时的监督信号究竟来自哪里。它们属于同一分类标准,因此可以并列讨论。
监督学习(Supervised Learning)使用带标签的数据对 \((x,y)\) 训练模型:输入 \(x\) 是特征(Feature),输出 \(y\) 是目标或标签(Label)。模型学习的核心是学习一个映射 \(f_\theta:x\to y\),使它对新样本也能给出合理预测。
但“学一个映射”还不够,训练时还必须回答另一个更具体的问题:怎样才算模型学得好。监督学习里最常见的回答,是在训练集上逐个比较预测与真实标签的差距,再把这些差距汇总成一个总体目标;这就导向经验风险最小化(Empirical Risk Minimization, ERM)。
经验风险最小化的典型目标写成:
\[\frac{1}{N}\sum_{i=1}^{N}\ell\big(f_\theta(x_i),y_i\big)\]这里 \(N\) 是样本数, \(f_\theta(x_i)\) 是模型预测, \(y_i\) 是真实标签, \(\ell\) 是损失函数(Loss Function)。这条式子的含义是:逐个样本计算“预测错了多少”,再取平均,把平均错误压到尽可能小。
例:垃圾邮件分类里, \(x\) 可以是邮件文本特征, \(y\in\{0,1\}\) 表示“正常/垃圾”;房价预测里, \(x\) 可以是面积、地段、楼龄, \(y\) 是价格。前者是分类(Classification),后者是回归(Regression),但“有标签地学映射、再用损失函数衡量误差”这一训练逻辑完全一致。
分类任务(Classification)要预测的是离散类别,也就是样本属于哪一类。输出可以是一个类别 id,也可以是一组类别概率。例如二分类里常见输出 \(P(y=1|x)\),表示“给定特征 \(x\) 时,样本属于正类的概率”。
垃圾邮件识别、肿瘤良恶性判断、情感分析、图像里的猫狗识别都属于分类任务。它更像“做选择题”:模型最终要在有限候选里做判断。训练时常配合交叉熵(Cross-Entropy)这类损失,因为模型不仅要选对类别,还要给正确类别足够高的置信度。
回归任务(Regression)要预测的是连续数值,也就是标签核心是在某个数值区间内连续变化。输出通常直接是一个实数,或一个多维连续向量。
房价预测、销量预测、温度预测、广告点击率中的停留时长估计都属于回归任务。它更像“做填空题”:模型不能只说“高”或“低”,而必须给出具体数值。训练时常配合均方误差(MSE)或平均绝对误差(MAE),因为关心的是预测值与真实值到底差了多少。
分类与回归都属于监督学习,因为它们都有标签;真正的区别在于标签空间的形状:分类的标签空间是离散集合,回归的标签空间是连续区间。这个区别会直接决定模型输出层形式、损失函数选择以及评估指标。
弱监督学习(Weakly Supervised Learning)仍然使用标签信号训练模型,但这些标签并不像标准监督学习那样完整、精确且逐样本对齐。它处理的核心情形是:标签存在,但监督结构不够理想,例如标签只存在于更粗粒度层面、标签本身含噪,或只有部分样本带标签。
从概念上看,弱监督核心是一组监督不完备情形的总称。常见形式包括:标签不完整(incomplete supervision),即只有部分样本带标签;标签不精确(inexact supervision),即标签附着在聚合层级而非实例层级;标签不准确(inaccurate supervision),即标签本身带噪或来自启发式规则、远程监督(Distant Supervision)与弱标注器。它与标准监督学习的边界在于:监督信号依然存在,但标签质量、粒度或覆盖度不足以直接当作“干净答案册”。
多实例学习(Multi-Instance Learning, MIL)是弱监督学习中的一个经典范式。它的关键设定是:标签附着在一个由多个实例组成的包(bag)上,而非单个实例(instance)。设训练集由若干包 \(\{B_1,B_2,\dots,B_n\}\) 构成,其中第 \(i\) 个包可写成
\[B_i=\{x_{i1},x_{i2},\dots,x_{im_i}\},\qquad y_i\in\{0,1\}\]这里 \(x_{ij}\) 是包内第 \(j\) 个实例, \(m_i\) 是该包包含的实例数, \(y_i\) 是包级标签。训练时只知道整个包的标签,不知道每个实例自己的标签。
MIL 最经典的标准假设(Standard MI Assumption)是:正包中至少存在一个正实例,负包中所有实例都为负。写成逻辑形式就是:
\[y_i=1 \iff \exists j,\ z_{ij}=1;\qquad y_i=0 \iff \forall j,\ z_{ij}=0\]其中 \(z_{ij}\) 表示实例级未知标签。这个设定特别适合两类问题:第一,真正决定结果的证据只稀疏地存在于少数关键实例中,其余实例更像背景或噪声;第二,获取实例级标签成本高,只能拿到更粗粒度的聚合标签。
因此,MIL 的关键不仅“把很多实例放在一起”,还要学习一条从实例集合到包级判断的聚合规则。早期方法常用最大池化、均值池化或手工设计的聚合函数;深度学习阶段则更常引入可学习聚合,例如注意力式 MIL(Attention-based MIL),用可训练权重自动决定哪些实例对最终包标签贡献更大。这使 MIL 不只具有表达能力,也更容易给出“模型主要关注了哪些实例”的解释线索。
MIL 的适用性可以用一个抽象例子来理解。若一条完整客服对话被视作一个包,其中每轮发言是实例,而整体满意度评分是包级标签,那么模型面对的就是“整体有标签、逐轮无标签”的典型结构。此时,MIL 的任务核心是在只有整体评分的前提下,学习哪些局部发言更可能决定整段会话的最终判断。
无监督学习(Unsupervised Learning)只有输入 \(x\),没有人工标签 \(y\)。它的目标核心是从数据中发现结构(Structure),例如聚类(Clustering)、降维(Dimensionality Reduction)、密度估计(Density Estimation)与异常检测(Anomaly Detection)。
一个直观类比是:监督学习像“拿着答案册做题”,无监督学习像“没有答案册,只能自己把一堆材料按相似性归类”。例如电商用户没有现成“用户类型”标签,但可以根据浏览、购买、停留时间等行为聚成“价格敏感型”“冲动购买型”“高价值复购型”等群体,用于运营分层。
从任务形态上看,无监督学习通常沿三条主线展开。第一条是聚类分析,目标是把样本按几何接近性、密度连通性、层次结构或图上的社区结构自动分组,典型方法包括 K-Means、层次聚类、DBSCAN、HDBSCAN,以及基于图的 Leiden / Louvain;第二条是概率密度估计,目标是刻画数据在哪些区域更常出现,从而支持异常检测、生成建模与风险评分,常见路线包括 GMM、核密度估计、One-Class SVM,以及更现代的自编码器(Autoencoder, AE)、受限玻尔兹曼机(RBM)和对抗式路线;第三条是可视化与降维,目标是在压缩表示的同时尽量保留关键结构,典型方法包括 PCA、t-SNE 与 UMAP。
这三条路线并非彼此割裂的。聚类往往依赖一个合适的低维表示;异常检测常常等价于“找低密度区域”;可视化又经常被用来检查聚类是否真的形成结构、异常样本是否落在边缘地带。因此无监督学习不仅“没有标签时随便看看数据”,还在没有人工答案的条件下,用几何、密度与表示结构去重建数据内部秩序。
自监督学习(Self-supervised Learning)介于监督与无监督之间:原始数据没有人工标签,但任务标签可以由数据本身自动构造出来。核心思想是从数据内部制造预测任务,让模型在完成这些任务的过程中学到可迁移表示(Representation)。
语言模型的下一个 token 预测就是最典型的自监督任务:前文是输入,后一个 token 是由原始文本自动给出的“监督信号”。图像领域里,旋转预测、遮挡恢复、不同增强视角匹配也属于同一路线。
掩码预测(Masked Prediction)把输入中的一部分信息故意遮住,再要求模型恢复。例如 BERT 会把句子中的部分 token 替换成特殊标记 \([MASK]\),模型要根据上下文预测被遮住的词。
类比来看,这像完形填空:你核心是学会根据上下文推断缺失信息。它迫使模型同时利用左侧和右侧上下文,因此特别适合编码器(Encoder)型表示学习。
半监督学习(Semi-supervised Learning)位于监督学习与无监督学习之间:一小部分样本带标签,大量样本没有标签。它关心的核心问题是:如何利用未标注数据提供的结构信息,帮助少量标签发挥更大监督作用。与弱监督相比,半监督更强调“标签覆盖不足”,而不一定意味着标签本身粗糙或带噪。
经典路线包括 Self-Training、Co-Training、半监督 SVM、生成式方法和图半监督学习。Self-Training 会先用当前模型给未标注样本打伪标签,再把高置信样本并回训练集;Co-Training 要求样本存在两个相对独立但互补的视角,让两个模型彼此教对方;半监督 SVM 试图在利用标签的同时,把决策边界推向低密度区域;图半监督学习则利用样本相似图把少量标签沿图结构传播到邻近无标签样本。
主动学习(Active Learning)经常和半监督一起出现,但它的关注点略有不同:主动学习核心是选择最值得标注的样本去获取人工标签。从数据效率角度看,半监督学习在“少标签 + 多无标签”条件下尤其重要,而主动学习解决的是“有限标注预算该花在哪些样本上”。
强化学习(Reinforcement Learning, RL)研究的是:智能体(Agent)在环境(Environment)中持续交互,根据奖励(Reward)学习策略(Policy),使长期累计回报(Cumulative Return)尽可能大。它关心的核心是一串连续动作最终能否带来更高的长期收益。
强化学习的基本循环可以概括为:在时刻 \(t\),智能体观察状态 \(s_t\),选择动作 \(a_t\),环境转移到新状态 \(s_{t+1}\),并返回奖励 \(r_{t+1}\)。策略记为 \(\pi(a\mid s)\),它回答的是“在当前状态下,动作应该怎样选”。
很多任务里,奖励并不会在正确动作发生的那一刻立刻显现。下棋时,一步好棋可能要十几步后才体现价值;推荐系统里,一次推荐是否合理,也要看后续点击、停留和转化。因此强化学习优化的核心是长期回报:
\[J(\pi)=\mathbb{E}_{\pi}\!\left[\sum_{t=0}^{\infty}\gamma^t r_{t+1}\right]\]这里 \(\gamma\in[0,1)\) 是折扣因子(Discount Factor)。\(\gamma\) 越接近 1,策略越重视长期收益;越小,策略越偏向短期收益。这个目标函数的含义很直接:在所有可能的策略中,找到那个平均下来总分最高的行为规则。
监督学习通常基于带标签样本 \((x,y)\) 训练静态映射 \(x\mapsto y\);强化学习面对的是动态环境中的序贯决策。监督学习收到的是“正确答案应当是什么”的指导性反馈,强化学习收到的是“这一步或这条轨迹好不好”的评估性反馈。前者的误差归因通常较直接,后者则需要把最终回报回溯到一串历史动作,这就是时间信用分配(Temporal Credit Assignment)的难点来源。
因此,强化学习的训练数据也并非静态不变的。当前策略会决定智能体之后访问哪些状态,于是数据分布本身会随着策略更新而改变。这一点使强化学习同时面对建模问题、探索问题和训练稳定性问题。
强化学习的标准数学框架是马尔可夫决策过程(Markov Decision Process, MDP)。一个 MDP 通常写成五元组 \((\mathcal{S},\mathcal{A},P,R,\gamma)\),其中 \(\mathcal{S}\) 是状态空间, \(\mathcal{A}\) 是动作空间, \(P(s'|s,a)\) 是状态转移概率, \(R(s,a)\) 或 \(R(s,a,s')\) 是奖励函数, \(\gamma\) 是折扣因子。
“马尔可夫”这个词的核心含义是:如果当前状态已经把决策所需的信息概括完整,那么未来只取决于当前状态和当前动作。它并不要求系统真的没有历史,重点是要求当前状态已经足够代表历史中与决策相关的部分。
强化学习里最重要的两个量是状态价值函数(State-value Function)和动作价值函数(Action-value Function):
\[V^\pi(s)=\mathbb{E}_\pi[G_t\mid s_t=s],\qquad Q^\pi(s,a)=\mathbb{E}_\pi[G_t\mid s_t=s,\ a_t=a]\]\(V^\pi(s)\) 描述“在状态 \(s\) 下,按策略 \(\pi\) 继续行动,长期回报大约是多少”;\(Q^\pi(s,a)\) 则更进一步,描述“在状态 \(s\) 下先做动作 \(a\),再按策略 \(\pi\) 继续行动,长期回报大约是多少”。
Bellman 方程(Bellman Equation)把“长期回报”写成“即时奖励 + 下一步价值”的递归形式。对固定策略 \(\pi\),状态价值满足:
\[V^\pi(s)=\mathbb{E}_\pi\big[r_{t+1}+\gamma V^\pi(s_{t+1})\mid s_t=s\big]\]这条式子的直觉非常重要:一个状态值多少钱,不需要把未来整条轨迹一口气全部展开,只要看“这一步先拿到多少,再加上下一状态值多少钱”。这就是动态规划思想在强化学习中的核心落点。
若目标是最优控制,则最优动作价值函数满足 Bellman 最优方程:
\[Q^*(s,a)=\mathbb{E}\big[r_{t+1}+\gamma\max_{a'}Q^*(s_{t+1},a')\mid s_t=s,\ a_t=a\big]\]它表达的是:当前动作的最优价值,等于这一步的即时奖励,加上下一状态里最佳后续选择的折扣价值。价值型方法、时序差分学习(Temporal-Difference Learning, TD)以及 Q-Learning,都是围绕这个递归结构展开的。
价值型方法(Value-Based Methods)先估计“某个状态或状态-动作对值多少钱”,再根据价值做决策。最经典的做法是 Q-Learning。它不直接记住“这一步该做什么”,通常会维护一个动作价值估计 \(Q(s,a)\),让模型逐步学会哪些动作长期更划算。
Q-Learning 的标准更新写成:
\[Q(s,a)\leftarrow Q(s,a)+\alpha\Big(r+\gamma\max_{a'}Q(s',a')-Q(s,a)\Big)\]这里 \(r+\gamma\max_{a'}Q(s',a')\) 是新的目标值(TD target),它把“这一步拿到的即时奖励”和“下一步开始最好还能拿到多少”拼接在一起;括号里的整体差值是 TD 误差(TD error),表示旧估计和新观察之间的偏差。Q-Learning 每见到一次新的转移样本,就用它修正一次账本。
当状态空间很小,例如离散网格迷宫,价值可以直接存成 Q 表;当状态变成图像、传感器序列或高维特征时,就需要用神经网络近似 \(Q(s,a)\),这就是 DQN(Deep Q-Network)。它没有改变基本思想,只是把“查表记账”升级成“让网络来估值”。
SARSA(State-Action-Reward-State-Action)则代表另一种重要的 on-policy 时序差分路线。它把 Q-Learning 中的 \(\max_{a'}Q(s',a')\) 替换成策略实际下一步会采取的动作 \(a'\),因此更新式写成
\[Q(s,a)\leftarrow Q(s,a)+\alpha\Big(r+\gamma Q(s',a')-Q(s,a)\Big)\]这一区别意味着:Q-Learning 更像“按最优后续动作记账”,SARSA 更像“按当前策略真实会怎么走来记账”。前者更激进,后者更保守;理解这一区别,有助于看清 on-policy 与 off-policy 方法的核心分野。
策略型方法(Policy-Based Methods)直接参数化策略,不先学习价值表 \(\pi_\theta(a\mid s)\)。给定状态,模型直接输出动作概率分布或连续控制参数,再通过优化把高回报动作的概率提高、低回报动作的概率压低。它尤其适合连续动作空间,因为这类问题往往很难穷举所有动作再逐个估值。
策略梯度(Policy Gradient)的基本形式是:
\[\nabla_\theta J(\theta)=\mathbb{E}\big[\nabla_\theta \log \pi_\theta(a_t\mid s_t)\,G_t\big]\]它的含义可以概括成一句话:最终效果好的动作,以后更常做;最终效果差的动作,以后更少做。问题在于,直接用 \(G_t\) 更新通常方差很大,训练容易抖动。
于是就出现了 Actor-Critic。Actor 负责输出策略,也就是“怎么行动”;Critic 负责评估当前状态或动作值,也就是“这一步大概值多少”。Critic 提供更稳定的基线或优势估计,Actor 再沿着这个更平滑的信号更新策略。这样做的结果是:策略更新方向仍然由回报决定,但梯度噪声显著更可控。
PPO(Proximal Policy Optimization)可以看作一种工程上非常成功的 Actor-Critic 变体。它的核心思想核心是给策略更新加护栏,限制新旧策略之间的偏移幅度,避免一步改得过猛导致训练失稳。因此,PPO 在机器人控制、游戏智能体和大模型对齐里都很常见。
强化学习始终要面对探索与利用(Exploration vs. Exploitation)的权衡。利用意味着优先选择当前已知回报较高的动作;探索意味着尝试那些暂时不确定、但可能更优的动作。只利用,策略可能很快卡在局部最优;只探索,又会浪费大量样本在明显不好的选择上。
这个矛盾在强化学习里是结构性的,因为策略会影响后续看到的数据。常见做法包括 \(\epsilon\)-greedy、熵正则化(Entropy Regularization)、Boltzmann exploration、上置信界(UCB)等。它们形式不同,但共同目标一致:既让模型敢于试错,又不至于长期停留在无意义的随机行动里。
另一条常见划分标准是 model-based 与 model-free。二者的区别不在于是否使用神经网络,而在于是否显式学习或利用环境动力学。
| 类型 | 核心思路 | 优势 | 代价 |
| Model-Based RL | 显式学习或已知状态转移与奖励模型,再据此规划或生成模拟轨迹 | 样本效率通常更高;能做前瞻规划 | 环境模型一旦学偏,规划也会被带偏;实现更复杂 |
| Model-Free RL | 不显式建模环境,直接从交互样本学习价值函数或策略 | 实现相对直接;适合复杂高维环境 | 样本效率通常较低;对真实交互成本更敏感 |
价值型方法如 Q-Learning、DQN,策略型方法如 REINFORCE、PPO,多数都属于 model-free 路线;若先学习一个世界模型(World Model)或已知环境转移,再基于模型做搜索和规划,则属于 model-based 路线。实际系统也常把两者混合使用。
大模型时代出现的 RLHF、PPO-based alignment、GRPO 等方法,属于强化学习思想在语言模型上的应用层。它们沿用的仍然是策略、奖励、回报、优势函数和策略优化这些通用概念,只是把环境替换成“基于 prompt、回答和偏好反馈构成的交互过程”。因此,理解通用强化学习基础之后,再进入后文的强化学习对齐,会更容易看清哪些是 RL 本体,哪些是大模型场景下的特化设计。
统计学习(Statistical Learning)强调从数据由某种概率机制生成这一视角理解机器学习。前面的概率论与统计已经介绍了概率、似然、MLE、MAP、边缘化与随机过程;这里把这些概念收束成机器学习里的几条主线:模型究竟在建模什么分布,隐藏变量怎样进入问题,推断为什么会变难,以及“相关”与“因果”为什么并非同一件事。
从统计学习视角看,很多模型的区别首先不在神经网络层数或树的深度,而在于它们选择建模哪一种概率对象。判别式模型(Discriminative Model)直接学习 \(p(y\mid x)\) 或决策边界,关心“给定输入后标签怎么判”;生成式模型(Generative Model)则更关心 \(p(x,y)\)、\(p(x\mid y)\) 或带隐藏变量的联合分布,关心“数据是如何被生成出来的”。
这种划分并不同于“一个更先进、一个更落后”。判别式方法通常更直接服务于分类或回归目标;生成式方法则更容易表达不确定性、缺失变量和隐含结构。朴素贝叶斯、高斯混合模型(GMM)、隐马尔可夫模型(HMM)偏生成式;逻辑回归、支持向量机(SVM)、条件随机场(CRF)偏判别式。HMM 与 CRF 的细节放在后面的经典机器学习部分展开,这里只强调它们在统计建模立场上的差异。
概率图模型(Probabilistic Graphical Model, PGM)用图结构表达随机变量之间的条件独立关系,并把高维联合分布拆成较小的局部因子。它的核心价值核心是把哪些变量直接相互作用、哪些依赖可以被切断写成显式结构,从而让建模、推断和解释都更清晰。
| 对象 | 关注点 | 典型形式 | 备注 |
| 贝叶斯网络(Bayesian Network) | 有向依赖与条件独立 | 有向无环图(DAG) | 适合表达“父节点影响子节点”的生成结构 |
| 因子图(Factor Graph) | 联合分布如何分解为若干局部因子 | 变量节点 + 因子节点二部图 | 更强调分解结构,常作为统一表达方式 |
| HMM / CRF | 序列中的局部依赖 | 链式图结构 | HMM 偏生成式,CRF 偏判别式 |
贝叶斯网络适合表达“一个变量如何通过若干中间变量影响另一个变量”的有向依赖;因子图则更偏向把复杂联合分布拆成局部势函数(Factor)相乘的形式。若问题具有明显序列结构,HMM 和 CRF 就是最典型的链式概率图模型实例。它们之所以重要,不仅因为历史地位高,还因为许多现代模型虽然实现方式更复杂,仍然在利用“局部分解 + 全局归一化/推断”这条思想主线。
统计学习里很多问题之所以变难,核心是因为模型里存在隐藏变量(Latent Variable)\(z\)。一旦联合分布写成 \(p(x,z)\),训练或预测往往都要面对边缘化:
\[p(x)=\sum_z p(x,z)\quad \text{或} \quad p(x)=\int p(x,z)\,dz\]当这个求和或积分无法直接算清时,推断(Inference)就成为核心问题。EM(Expectation-Maximization)适合一类带潜变量的参数估计问题:E 步先根据当前参数估计隐藏变量的后验分布或其期望统计量,M 步再在这些期望量上更新参数。GMM 的训练、HMM 的 Baum-Welch 算法,都是这一路线的经典例子。
若后验分布本身也难以精确求解,就需要近似推断。变分推断(Variational Inference, VI)的思路是:选一个可计算的近似分布来避免直接计算真实后验 \(p(z\mid x)\) \(q(z)\) 去逼近它。于是问题从“直接求后验”转化为“在一个可处理的分布族里找最接近后验的那个近似”。这一思路后来也自然延伸到了现代深度生成模型,例如变分自编码器(VAE)的训练就建立在变分推断框架之上。
统计相关性回答的是“变量经常一起变化吗”,因果推断(Causal Inference)回答的则是“如果我主动干预一个变量,另一个变量会怎样变”。这两类问题在形式上很接近,但含义完全不同。观察性条件概率 \(p(y\mid x)\) 只说明在看到 \(x\) 时, \(y\) 通常是什么样;干预分布 \(p(y\mid \mathrm{do}(x))\) 讨论的是把 \(x\) 强行设定为某个值后, \(y\) 会怎样变化。
因果图(Causal Graph)通常也写成有向无环图,但它表达的已经从统计依赖扩展到因果生成结构。混杂因素(Confounder)、中介变量(Mediator)和碰撞点(Collider)之所以重要,正是因为它们决定了哪些相关性可以被解释为因果效应,哪些只是共同原因或选择偏差造成的表象相关。do-calculus 则是一套把干预分布改写成可识别表达式的规则系统,用来判断在给定图结构下,目标因果效应是否能够从可观测分布中恢复出来。
在这份速查里,因果推断只保留这一层定位:它是统计学习向更强解释目标的延伸。普通监督学习通常停在“预测得准”,统计学习进一步讨论“不确定性和隐藏结构怎么处理”,而因果学习则继续追问“如果系统被主动改变,结果会不会跟着改变”。三者核心是建模目标逐步增强的不同层级。
与“学习范式”不同,下面这些概念从按监督信号来源分类转向分别回答另外几个问题:表示该怎样学、计算该怎样近似、已有知识该怎样迁移、在极少样本下又该怎样适配。因此它们更适合看成与学习范式并列的训练目标或训练策略。
表示学习(Representation Learning)讨论的是:如何把原始输入自动变换成更有用的特征表示,使后续任务更容易处理。它关心的不只是“最后预测对不对”,还关心模型内部是否学到了稳定、可迁移、对任务有判别力的中间表示。
传统特征工程(Feature Engineering)与表示学习处理的是同一个核心问题:如何把原始输入变成更适合下游任务的表示。但二者的方法论不同。特征工程主要依赖人工设计表示,例如词频、n-gram、统计量、规则特征与人工交叉特征;表示学习则强调由模型通过优化过程自动学出表示,例如 PCA、自编码器、词向量、上下文化表示以及深度网络中的隐藏状态。因此,传统手工特征本身通常不直接归入表示学习;只有当表示是通过训练自动获得时,它才更准确地属于表示学习范畴。
从 one-hot、BoW、词嵌入,到 BERT 的上下文化表示、Sentence-BERT 的句向量,主线始终一致:把原始符号或原始观测映射到更适合计算的表示空间。监督学习、自监督学习、对比学习都可以被用来学习表示;区别只在于监督信号来自哪里、训练目标如何设计。
对比学习(Contrastive Learning)通过“拉近正样本、推远负样本”学习表示。这里的关键核心是样本之间的相对关系:哪些应该相似,哪些必须区分。因此它特别适合表示学习、检索、多模态对齐和度量学习(Metric Learning)。
它的真正价值不只在于“学会匹配”,更在于学会区分性特征(Discriminative Features)。如果训练信号只告诉模型“这两个文本有关”,模型很容易停留在泛泛的共性描述上;而当训练持续提供“相似对”和“不相似对”,模型就被迫回答更尖锐的问题:究竟是什么让这两个文本属于同一语义区域,又是什么让它们必须分开。对比学习因此天然擅长抑制“表面上正确但没有区分度”的表示,转而强化真正决定语义边界的特征。
例如在商品评论表示学习里,句子“物流很快,包装也完整”和“物流很快,但东西是坏的”都包含“物流很快”这类高频表述。若模型只抓住表面词汇重叠,就可能把二者编码得非常接近;但在对比学习里,前者可能与“发货速度快、体验不错”构成正样本,后者则会与“收到商品后无法使用”“质量有问题”这类负面评价更接近。模型因此会逐步学会:真正决定语义边界的,核心是“包装完整”“东西是坏的”这类改变整体语义走向的区分性片段。
从几何角度看,对比学习学到的是一个更有结构的向量空间。语义接近的文本会在局部形成簇(Cluster),语义无关或语义相反的文本则被推向更远位置。情感分析、语义检索、重复问句检测、意图聚类之所以能直接建立在 embedding 之上,本质上就是因为模型已经把“哪些内容应当靠近、哪些内容应当远离”编码进了空间结构,而不只是输出一个任务特定的分类分数。
在 NLP 中,这条路线并非突然出现的。Word2Vec 已经体现了早期的对比式思想:真实共现词是正样本,随机采样词是负样本,模型通过区分“真实上下文”和“噪声配对”学习词向量。后来的句向量和文档向量模型,则把这种思想从词级扩展到句子级和文档级:正样本可以是复述句、问答配对、查询与相关文档,负样本则是不相关句子或困难反例(Hard Negatives)。
一个常见形式是 InfoNCE 损失:
\[-\log \frac{\exp(\mathrm{sim}(z_i,z_i^+)/\tau)}{\sum_{j}\exp(\mathrm{sim}(z_i,z_j)/\tau)}\]其中 \(z_i\) 是当前样本表示, \(z_i^+\) 是与它匹配的正样本表示, \(\mathrm{sim}(\cdot,\cdot)\) 是相似度函数(常用余弦相似度), \(\tau\) 是温度参数(Temperature),控制分布尖锐程度。这个目标的含义是:在一堆候选中,让正确配对拿到最高分,同时把不相关样本推远。
对比学习在句向量任务中的意义尤其大。交叉编码器(Cross-Encoder)把两个句子拼接后联合编码,能够做非常细的交互判断,但它直接输出的是“这一对句子有多像”,而非可复用的独立句向量;一旦候选集合很大,计算量会迅速爆炸。双编码器(Bi-Encoder)路线则把两个文本分别编码成独立向量,再用余弦相似度或点积比较。SBERT 正是这一路线的经典代表:它通过孪生网络(Siamese Network)与对比式微调,把原本不适合作为通用句向量的 BERT 表示空间,改造成适合检索、聚类与语义匹配的 embedding 空间。
工程上,负样本既可以来自同一 batch 中的其他样本(In-batch Negatives),也可以来自专门构造的困难负样本(Hard Negatives)。所谓困难负样本,指的核心是在表面上很像、但语义上不应被判为同一项的样本。例如检索里,与查询主题相近但并不真正回答问题的文档;句向量训练里,措辞高度相似却语义立场不同的句子;推荐里,风格相近但用户最终没有点击或转化的候选。它们之所以“困难”,正是因为模型若只依赖浅层词汇重叠、模板结构或主题相近性,很容易把这类负样本误判成正样本。
困难负样本的价值在于:它迫使模型放弃过于粗糙的匹配捷径,转而学习更细粒度的区分信号。随机负样本通常太容易分开,训练后期提供的梯度会迅速变弱;而困难负样本更接近真实决策边界,能持续推动表示空间学习“看起来相似但本质不同”的区别。不过它也有代价:若负样本挖掘质量不高,容易把本来就相关的样本错当成负例,形成假负样本(False Negatives),反而会伤害表示质量。因此,现代检索和 embedding 训练里,Hard Negatives 往往与 in-batch negatives、教师模型挖掘(teacher mining)或 reranker 筛选结合使用,而非完全依赖人工拍脑袋构造。
CLIP、Sentence-BERT、现代检索 embedding、推荐召回模型,乃至许多 query-document dual encoder,本质上都在利用这种“正样本拉近、负样本推远”的训练逻辑。区别主要不在原理,而在样本如何构造、负样本如何选择,以及表示对象是词、句子、文档还是跨模态对。
负采样(Negative Sampling)是与对比学习和词向量训练密切相关的一类近似策略。它的核心动机是:当候选空间极大时,没有必要每次都与所有候选比较;只保留 1 个正样本和少量负样本,就能得到足够强的判别信号。它把原本代价高昂的“大规模归一化选择问题”,近似成若干个“真配对还是噪声配对”的二分类判断。
在 Word2Vec 的 Skip-gram 中,若直接对全词表做 softmax,分母需要对 \(|{\cal V}|\) 个词求和,计算代价很高。负采样则对每个正样本对 \((w,c)\) 只保留少量噪声词 \(w_i\),并最大化:
\[\log\sigma(v_w^\top v_c)+\sum_{i=1}^{k}\log\sigma(-v_w^\top v_{w_i})\]这里 \(\sigma\) 是 sigmoid 函数,第一项鼓励真实配对的内积更大,第二项鼓励噪声配对的内积更小。这样一来,计算量就从与词表大小同阶,降到与 \(1+k\) 个样本同阶。负样本也不一定完全随机:Word2Vec 常按词频的 \(0.75\) 次方采样;现代对比学习则常用 in-batch negatives 或 hard negative mining。推荐系统召回、知识图谱嵌入、句向量训练等任务里,这种思想到今天仍然非常常见。
迁移学习(Transfer Learning)讨论的是:先在数据更丰富、任务更通用的源任务上学到参数或表示,再把这些知识迁移到目标任务。它核心是一种跨任务复用知识的训练策略。现代大模型先预训练、再微调,本质上就是迁移学习。
BERT 就是这一思路的典型例子。它通常先在大规模通用文本上做语言建模预训练,例如维基百科(Wikipedia)这类覆盖面很广的语料;模型先学到词法、句法、语义关系以及上下文表示能力。随后再把这一预训练模型迁移到具体任务上,例如情感分类、自然语言推断(NLI)、命名实体识别(NER)或文本匹配,只需接上任务头并用该任务的数据继续微调,就能把通用语言知识转化为面向目标任务的能力。
它与对比学习不在同一层面。对比学习回答的是“预训练阶段该用什么目标来学表示”;迁移学习回答的是“学到的表示如何迁到新任务”。两者经常配合出现:例如先在海量无标签图像上用对比学习预训练视觉编码器,再把该编码器迁移到医学影像分类、工业缺陷检测或小样本识别任务上。
少样本学习(Few-shot Learning)处理的是“每个任务只有极少标注样本”时如何仍然快速泛化。它通常建立在迁移学习或预训练模型之上:模型先学到一套通用表示,再在很少示例下快速适配新任务。困难不在于单个任务本身,而在于模型必须把以往经验迁移到新任务上。直觉上,它更像“学会如何快速学习”,而非“把一个任务彻底学透”。
零样本(Zero-shot)指模型在目标任务上没有任何专门示例,也能凭借已有知识完成任务。大语言模型通过指令理解实现的很多能力都属于这一类。例:不给任何情感分类样例,只写“判断下面评论是正面还是负面”,模型仍可能完成分类。
单样本(One-shot)指只给 1 个示例。这个示例的价值核心是告诉模型“输出格式、任务边界和你想要的判别标准”。例如先给一条“商品评论 → 正面”的例子,再让模型判断下一条评论。
K 样本(K-shot)指给每类或每任务提供 \(K\) 个示例。随着 \(K\) 增大,模型更容易对任务意图和判别标准形成稳定估计。工程上,prompt 中的 few-shot 示例本质上就是在上下文窗口里做一种“临时任务适配”。
元学习(Meta-learning)研究“让模型更快适应新任务”。MAML(Model-Agnostic Meta-Learning)的核心是学一个好的初始化参数 \(\theta\),使模型只需少量梯度更新就能适配新任务。
MAML 的外层目标可概括为:
\[\min_\theta \sum_{\mathcal{T}} \mathcal{L}_{\mathcal{T}}\big(\theta-\alpha\nabla_\theta \mathcal{L}_{\mathcal{T}}(\theta)\big)\]其中 \(\mathcal{T}\) 表示一个任务, \(\alpha\) 是内层更新步长。读法是:先用当前参数在某任务上走一步,再看更新后的参数在该任务上的表现好不好;如果“一步后就变好”,说明初始化是好的。类比来看,MAML 训练的核心是“只要老师讲一遍就能迅速举一反三的学生”。
原型网络(Prototypical Networks)把每个类别表示成嵌入空间中的一个“类中心(Prototype)”。对类别 \(k\),其原型定义为该类支持集(Support Set)样本嵌入的平均:
\[c_k=\frac{1}{|S_k|}\sum_{(x_i,y_i)\in S_k,\ y_i=k} f_\theta(x_i)\]这里 \(f_\theta(x_i)\) 是样本的向量表示, \(S_k\) 是类别 \(k\) 的支持样本集合。分类时,把新样本映射到嵌入空间,看它离哪个原型最近。直觉上,这像“每一类先算一个代表点,新样本按离哪个代表点最近来归类”。在 few-shot 图像分类中,这种方法往往比直接训练复杂分类头更稳。
池化(Pooling)可以先按一句人话来理解:把一组相邻或相关的特征,压缩成更短、更稳定、更容易继续处理的摘要。它核心是对已有特征做聚合(Aggregation)或下采样(Downsampling)。这里的下采样指:沿某些维度减少位置数或采样点数,让表示尺寸变小、分辨率变粗。例如把 \(4\times 4\) 的特征图压成 \(2\times 2\),或把一长段序列压成更短的摘要向量,都属于下采样。
若把一组输入特征记为 \(x_1,\dots,x_k\),则池化可以抽象写成
\[y=\mathrm{Pool}(x_1,\dots,x_k)\]这里 \(\mathrm{Pool}\) 可以是最大值(Max Pooling)、平均值(Average Pooling)、求和(Sum Pooling)或更复杂的加权聚合。它们做的事不同,但主线一致:把“多个位置/多个元素的表示”变成“更少的表示”。
池化之所以重要,是因为很多任务并不需要保留每个细节位置的完整分辨率。图像分类不一定关心边缘恰好落在第 17 个还是第 18 个像素;句子分类也不一定要求记住某个情绪词出现在第 6 个还是第 7 个 token。此时,把局部细节适度压缩,往往能提升稳定性、降低计算量,并让后续层更关注“有没有出现模式”,而非“模式的坐标是否一模一样”。
这里单独把下采样拎出来,是因为它比“池化”更宽。池化当然是一类下采样,但下采样并不同于池化。只要一个操作会让表示在某个维度上的位置数减少、采样点变稀或分辨率变粗,它就属于下采样。最大池化、平均池化、步幅卷积(Strided Convolution)、序列 patch 化、音频降采样、时间窗口聚合,本质上都在做这件事。
若一维序列长度从 \(T\) 变成 \(\lfloor T/s\rfloor\),或二维特征图从 \(H\times W\) 变成 \(\lfloor H/s\rfloor\times \lfloor W/s\rfloor\),其中 \(s>1\) 是下采样倍率,那么模型面对的网格会从密集坐标转向更稀疏、更粗粒度的表示空间。收益通常有三类:计算量下降,后续层感受野相对扩大,以及模型更容易聚焦高层模式而非微小位置抖动。
代价也同样明确。下采样会压缩细节,因此边界、尖峰、高频纹理和短时突发模式都可能被抹平。若信号里存在高频成分,而下采样前又没有足够平滑或低通处理,这些高频成分还会折叠成错误的低频模式,也就是混叠(Aliasing)。因此,下采样从来核心是在分辨率、稳定性、感受野和信息保真度之间做结构性取舍。
最大池化(Max Pooling)保留一组特征里最强的那个响应。若某个窗口里有一个边缘、某个关键词或某个邻居信号特别强,最大池化会把它留下来。它更像在问:这一小块区域里,最显著的模式有没有出现。
平均池化(Average Pooling)对一组特征取平均,更强调整体趋势而非最强局部点。它更像在问:这一块区域总体上激活强不强、语义平均水平如何。
求和池化(Sum Pooling)常见于图网络和集合建模,用于累积总量信息。若节点数量本身有意义,求和会把“有多少邻居/总共多强”也编码进去;平均池化则更强调归一化后的平均强度。
全局池化(Global Pooling)表示已经从看局部窗口扩展到直接把整张特征图、整段序列或整个节点集合压成一个向量。例如全局平均池化(Global Average Pooling, GAP)会把一整个空间维度平均掉,得到“每个通道在全局上的平均响应”。自适应池化(Adaptive Pooling)则把输出尺寸预先固定,例如无论输入特征图多大,最终都压成 \(1\times 1\) 或 \(7\times 7\)。
在卷积神经网络(CNN)里,池化最经典的含义是沿空间维度做局部下采样。例如一张特征图经过 \(2\times 2\) 最大池化后,宽高会缩小,局部最强响应被保留下来。它的直接收益有三点:减小特征图尺寸、扩大后续层的感受野(Receptive Field)、并降低模型对小幅平移和局部扰动的敏感度。
在时序模型和文本模型里,池化更常表示沿时间或序列长度维度做聚合。例如把所有 token 表示做平均池化,得到整句向量;把一段音频帧表示做最大池化,得到“这一整段里最强的模式”。这里池化的重点从二维空间下采样转向把变长序列压成固定长度表示,方便做分类、检索或相似度计算。
在图神经网络(GNN)里,池化有两层常见含义。第一层是邻域聚合(Neighborhood Aggregation):一个节点把邻居表示做均值、求和或最大值,再更新自己;这可以理解为“节点级局部池化”。第二层是图级读出(Graph-level Readout):把整张图的节点表示再做一次全局聚合,得到整个图的表示,用于图分类、图回归等任务。
在 Transformer 里,池化通常不再以“池化层”这一模块形式高频出现,但概念仍然存在。句子分类常取 \([\mathrm{CLS}]\) 位置表示,或对所有 token 做平均池化;Embedding 模型也常对最后一层隐藏状态做 mean pooling / max pooling 得到句向量。进一步看,注意力(Attention)本身也可以理解成一种带内容依赖的加权聚合:区别只在于普通池化的规则通常固定,而注意力的权重是由输入动态决定的。
池化保留的是摘要信息,丢掉的是更精细的位置细节。最大池化更偏向“是否出现过显著模式”,平均池化更偏向“整体平均状态如何”,求和池化则更偏向“总量有多大”。因此,池化总带有一种 trade-off:表示更紧凑、更稳、更省算力,但精确定位能力会下降。
因此,不同任务会选择不同聚合方式。图像分类往往欢迎一定程度的位置不敏感,因此池化很自然;语义检索希望一整句压成一个句向量,因此句级池化很常见;但像语义分割、目标检测、序列标注这类任务,输出本身依赖逐位置判断,就不能过早把位置信息池掉,否则细粒度边界会被抹平。
机器学习更关心模型离开训练集之后能否维持稳定表现。泛化(Generalization)、过拟合(Overfitting)、欠拟合(Underfitting)与偏差—方差权衡(Bias–Variance Tradeoff)描述的,就是这件事。
泛化(Generalization)指模型在未见样本上的表现。若训练数据与未来输入都来自同一数据分布 \(P(X,Y)\),则模型的总体风险可写成:
\[R(f)=\mathbb{E}_{(x,y)\sim P}\big[\ell(f(x),y)\big]\]这里 \(R(f)\) 是真实风险(Population Risk),表示模型 \(f\) 在整个真实分布上的平均损失; \(\ell(f(x),y)\) 是单样本损失;期望 \(\mathbb{E}\) 表示对所有可能样本做平均。训练时真正能看到的只有有限样本,因此优化的通常是经验风险 \(\hat R_n(f)\),而非这个理想化的总体风险。
训练误差与测试误差之间的差距,常称为泛化间隙(Generalization Gap)。间隙小说明模型在未见数据上比较稳定;间隙大则说明模型过度依赖训练样本中的偶然细节。
内插(Interpolation)与外推(Extrapolation)描述的是:模型面对未见样本时,究竟是在已观测范围之内补全规律,还是在已观测范围之外延伸规律。二者都属于预测,但难度和风险完全不同。
以一维回归为例,若训练样本的输入主要落在区间 \([a,b]\) 内,那么对 \(x\in[a,b]\) 附近新样本做预测,更接近内插;对明显落在这个范围之外的 \(x\) 做预测,则更接近外推。内插依赖的是“训练数据已经覆盖了这片区域”;外推依赖的是“模型学到的规律在未见区域仍然继续成立”。后者显然要求更强。
在机器学习里,大多数标准泛化讨论其实都更接近内插。只要训练集与测试集近似满足独立同分布(IID)假设,测试样本通常仍然落在训练分布支持集(Support)附近,模型主要是在已知数据流形附近做平滑补全。因此,现代高容量模型即使参数极多,只要训练分布覆盖充分,仍然能在测试集上表现得相当稳定。
外推对应的则是更困难的分布外泛化(Out-of-Distribution Generalization, OOD Generalization)。此时,测试输入已经从训练分布中的轻微变化扩展到进入了训练时很少见、甚至从未见过的区域。自动驾驶模型若只在晴天高速公路上训练,却要在暴雪、泥地和夜间乡道上决策;医学模型若主要见过成人数据,却被要求用于儿童病例;金融模型若只在平稳市场阶段训练,却要应对极端波动期,这些都属于外推问题。
外推之所以困难,根源在于经验风险最小化并不自动保证“规律可被安全延伸到训练分布之外”。模型完全可能在训练分布内部拟合得很好,却在一旦离开这片区域后迅速失效。因此,外推能力往往比普通测试集精度更能检验模型究竟学到了稳定结构,还是只学会了训练分布内部的高质量插值。
大语言模型里有一种非常典型的外推形式:长度外推(Length Extrapolation)。若模型训练时主要见到 \(4\mathrm{K}\) 或 \(8\mathrm{K}\) 上下文,却在推理时被要求处理 \(128\mathrm{K}\) 甚至更长序列,那么它面对的就已经从“在熟悉长度范围内继续理解”扩展到在训练长度之外延伸位置建模规律。RoPE 缩放、NTK-aware 调整、YaRN 等方法,本质上都是在尽量让模型把短上下文中学到的位置规律外推到更长序列上。
因此,可以把两者压缩成一句话:内插更像在已知区域里补全空白,外推更像拿着已总结出的规律去穿越未知边界。前者是标准机器学习评测里的常态,后者则更接近真实系统进入新环境时会遭遇的硬问题。
过拟合(Overfitting)指模型在训练集上持续吸收局部细节、噪声与偶然模式,但这些信息不能稳定迁移到未见样本上。它的典型外观是:训练集表现继续改善,而验证集或测试集表现停止改善、开始恶化,二者之间的泛化间隙(Generalization Gap)不断扩大。
过拟合描述的是一种训练现象,本身并不自动等于“模型已经不可用”。更准确的分析方式,是区分模型到底过拟合了什么。分类任务里最常见的两类退化并不完全相同:一类是决策边界本身开始贴合训练集偶然性;另一类是分类边界大体没变,但模型对既有判断越来越极端,概率校准逐步恶化。
| 类型 | 退化对象 | 训练期常见信号 | 主要后果 |
| 决策边界过拟合 | 模型学到只在训练集上成立的判别规则 | 训练 F1 / Accuracy 持续上升,验证 F1 / Accuracy 停滞或下降;训练 loss 很低而验证指标回落 | 真正损害分类泛化,换一批数据就更容易判错 |
| 置信度过拟合 | 模型对已有判断越来越极端,logit 持续膨胀 | 验证 F1 基本稳定,但验证 loss、Brier Score、ECE 等校准指标恶化;预测概率更频繁地逼近 0 或 1 | 硬分类结果可能不变,但概率值本身变得不可信 |
前一类退化直接伤害模型的判别泛化,后一类退化主要伤害概率校准(Calibration)。因此,若系统只需要固定阈值之后的硬标签,置信度过拟合通常是次一级问题;若系统依赖概率值本身做风险分层、阈值调度、排序融合或人工兜底,置信度过拟合就会立刻变成工程问题。
识别过拟合时,不能只盯着单一 loss,而要同时观察训练集指标、验证集指标、概率分布形状与误差结构。最典型的信号包括:
- 训练 loss 持续下降,但验证 loss 在某个阶段后停止下降,随后回升。
- 训练 Accuracy / F1 继续提高,而验证 Accuracy / F1 停滞甚至下滑。这通常提示决策边界开始贴近训练集特有模式。
- 验证 F1 基本稳定,但验证 loss 明显变差。这类“指标稳、loss 崩”的组合,更接近置信度过拟合而非判别边界崩坏。
- logit 绝对值持续增大,softmax 或 sigmoid 输出更集中到接近 0 和 1 的两端,说明模型在继续放大自信度。
- 训练后期错误样本逐渐集中在少量硬样本,而 easy case 的置信度仍在继续极化,说明模型已经从学新的判别规律转向在强化已有判断的幅度。
- 不同随机种子、不同验证切分下的波动变大,说明模型开始依赖训练样本中的偶然结构。
过拟合并不只由“参数太多”导致。更常见的诱因包括:样本量不足、类别长尾、标签噪声、训练集与线上分布不一致、数据泄露、训练时间过长、正则化过弱、batch 过小导致梯度噪声放大,以及高重复语料让模型过度记忆头部模式。对深度模型而言,容量大只是风险放大器,真正决定是否过拟合的,通常是模型自由度与有效监督信号之间是否失衡。
欠拟合(Underfitting)指模型连训练数据中的主要结构都没有学出来,表现为训练集和验证集都做不好。它对应的是高偏差(High Bias)状态:模型的平均预测长期偏离真实目标,也就是模型拟合能力不够,或训练过程根本还没有进入足够低误差的区域。
与过拟合相比,欠拟合的特征通常核心是两边都差,而且差得很一致。训练集上的 loss 仍然偏高,训练 Accuracy / F1 也上不去,说明模型尚未把任务主结构写进参数中。
这里还要把现象与成因拆开:欠拟合强调“结果还不行”,欠容量强调“表达上限可能不够高”。若换更大模型、增加可训练参数或放宽结构限制后,训练集与验证集同步改善,说明此前更接近欠容量;若只是把训练跑满、把学习率调顺、把输入截断问题修掉后性能就明显提升,则原先更接近训练不足或优化不足。
- 训练 loss 和验证 loss 都较高,而且两者相差不大。
- 训练 Accuracy / F1 与验证 Accuracy / F1 同时偏低,没有形成明显的泛化间隙。
- 训练到后期时,两条曲线仍然一起缓慢下降,说明模型可能还没收敛;若提前停止训练,问题更接近“没训练够”。
- 即使继续训练较长时间,训练指标仍然明显低于任务应有上限,说明容量、特征或优化配置本身不足。
- 错误不仅集中在边界样本或少数难例,还连大量 easy case 都无法稳定学会。
欠拟合常见于模型容量过小、特征表达弱、模型结构与任务不匹配、正则化过强、学习率设置不当、训练轮数不够、输入信息被过度截断,或任务本身需要非线性组合而模型只允许非常受限的线性表达。工程上,欠拟合也经常伪装成“模型很稳但一直不强”:曲线不震荡、训练不发散,却始终到不了可接受的性能区间。
一个实用判断准则是先看训练集是否已经被充分学会。若训练集指标本身就很差,优先考虑欠拟合;若训练集指标很好而验证集开始回落,优先考虑过拟合;若验证集分类指标基本不动,但验证 loss 与校准指标变差,则更接近置信度过拟合。把这三种状态区分清楚,后续的调参与正则化方向才不会混淆。
坍缩(Collapse)描述的是训练过程中的一种退化解(Degenerate Solution):模型表面上仍在输出结果,但内部表示、预测分布或优化轨迹已经失去有效多样性,学习过程塌到某种简单、无用或几乎无信息的模式上。它和过拟合不同。过拟合仍然在“认真地区分训练样本”,只是把训练集细节学得过头;坍缩则意味着模型逐渐失去区分能力,或者训练目标退化为某种几乎不再提供有效学习信号的状态。
| 类型 | 典型表现 | 例子 |
| Mode Collapse | 不管输入如何变化,输出都向少数模式收缩,预测类别或生成模式高度单一 | 分类器几乎把所有样本都判成“满意”;GAN 只会生成少数几种图像 |
| Representation Collapse | 编码器输出趋于相同或近似相同的向量,样本间表示几何结构被压扁 | 所有 hidden state / embedding 都高度相似,下游分类器只能依赖噪声做区分 |
| Objective / Loss Collapse | 训练目标迅速退化到近乎恒定的无信息状态,loss 长时间停在极低、极高或近乎不变的单一水平,梯度也可能同步衰减 | 自监督目标被模型用常数解“钻空子”;梯度消失后 loss 几乎不再变化;某些错误实现让目标函数被提前满足 |
其中前两类最常见也最容易直观理解。Mode Collapse 强调输出空间的多样性消失;Representation Collapse 强调内部表示空间的多样性消失。第三类常被笼统地称作 loss collapse,但更准确的理解是“优化目标退化”或“训练目标坍缩”:loss 本身只是一个观测信号,真正的问题在于模型已经进入某种几乎不再产生有效学习内容的状态。
判断坍缩时,关键核心是看输出分布、表示分布与样本间差异是否还存在。若某个 epoch 中同时出现极低 loss 样本和极高 loss 样本,说明模型仍在把 easy case 与 hard case 区分开,训练信号仍有明显异质性;这更像正常训练中的难度分层,而非已经坍缩。真正的坍缩通常会伴随更一致的退化迹象,例如预测类别快速单一化、embedding 方差急剧缩小、梯度长期接近 0,或者 loss 在大多数样本上收缩到近乎同一个无信息水平。
坍缩在不同任务中的诱因并不相同。对比学习(Contrastive Learning)里若缺少 stop-gradient、predictor、负样本或方差保持机制,表示空间很容易整体塌平;生成模型里,判别器与生成器失衡会诱发 mode collapse;分类任务里,极端类别不平衡、错误的损失实现、过强正则化或训练数据本身标签塌缩,都可能把模型推向低信息输出。工程上监控坍缩,通常需要同时看 loss、预测类别分布、embedding 方差、梯度范数与验证集指标,而不能只盯着单一数值曲线。
偏差(Bias)与方差(Variance)是分析泛化误差来源的经典视角。对平方损失(Squared Loss),常见分解写成:
\[\mathbb{E}\big[(Y-\hat f(X))^2\big]=\mathrm{Bias}^2+\mathrm{Variance}+\sigma^2\]左边的 \(\mathbb{E}[(Y-\hat f(X))^2]\) 是模型的平均平方误差; \(\mathrm{Bias}^2\) 表示模型平均预测与真实函数之间的系统性偏离; \(\mathrm{Variance}\) 表示模型对训练样本波动的敏感度; \(\sigma^2\) 是数据本身不可约的噪声(Irreducible Noise),即使模型和训练过程都完美,也无法完全消除。
更直白地说,偏差看的是“模型平均预测离真实值有多远”,代表模型的拟合能力;方差看的是“换一份训练集后模型预测会抖动多大”,代表模型的稳定性。偏差高通常对应欠拟合,因为模型学不到足够有效的数据规律;方差高通常对应过拟合,因为模型过度依赖某一份训练集的细节,离开训练集后泛化能力变差。
工程上,降低偏差常靠更强模型、更好特征和更充分训练;降低方差常靠更多数据、正则化、数据增强、早停(Early Stopping)和集成学习(Ensemble Learning)。很多建模决策,本质上都是在“预测还不够准”和“预测太不稳定”之间做权衡。下表用几类典型树模型把这种权衡具体化。
| 模型 | 偏差与方差的典型状态 | 为什么会这样 |
| 决策树 | 高偏差 + 高方差风险并存 | 没有集成机制时,树过浅会欠拟合、偏差高;树过深又会对训练集细节极敏感、方差高,因此属于“双风险”模型 |
| 随机森林 | 低偏差 + 低方差 | 单棵深树先把偏差压低,再通过 Bagging 平均掉树与树之间的高方差 |
| GBDT / XGBoost | 低偏差 + 低方差 | 串行累加很多棵浅树持续降低偏差,而单棵浅树本身方差较低,再配合学习率、正则化与早停控制整体方差 |
因此,偏差与方差核心是在解释不同模型为什么会“学不动”或“学过头”。看树模型尤其直观:单树的问题是两头都可能出错;随机森林主要靠并行平均压方差;Boosting 家族主要靠串行纠错压偏差,再用浅树和正则化把方差稳住。
大部分监督学习训练都可以概括成同一条主线:先定义单样本损失,再在训练集上取平均形成经验风险,最后通过优化算法把它压低。正则化(Regularization)是在这条主线之上加入额外约束,用来控制复杂度并改善泛化。
经验风险最小化(Empirical Risk Minimization, ERM)是统计学习的基本训练原则。设训练集为 \(\mathcal{D}=\{(x_i,y_i)\}_{i=1}^{n}\),则经验风险定义为:
\[\hat R_n(f)=\frac{1}{n}\sum_{i=1}^{n}\ell(f(x_i),y_i)\]这里 \(n\) 是样本数, \(f(x_i)\) 是模型对第 \(i\) 个样本的预测, \(y_i\) 是真实标签, \(\ell\) 是损失函数。经验风险最小化就是在假设空间 \(\mathcal{H}\) 中寻找让这条平均损失最小的函数:
\[\hat f_{\mathrm{ERM}}=\arg\min_{f\in\mathcal{H}}\hat R_n(f)\]这条原则覆盖范围极广。线性回归最小化的是平方误差经验风险,逻辑回归和多分类神经网络最小化的是交叉熵经验风险,序列标注模型最小化的是序列级条件对数似然。算法形式不同,骨架是一致的。
正则化(Regularization)是在经验风险之外,再加入一个偏好“更简单、更平滑、更稳定”解的约束项。常见写法是:
\[\hat f=\arg\min_{f\in\mathcal{H}}\hat R_n(f)+\lambda\,\Omega(f)\]这里 \(\Omega(f)\) 是正则项(Regularizer),刻画模型复杂度; \(\lambda\) 是正则化强度,决定“拟合训练集”和“控制复杂度”之间的权衡。 \(\lambda\) 越大,模型越保守;越小,模型越自由。
L2 正则(L2 Regularization)偏好较小权重,常写成 \(\Omega(f)=\|\mathbf{w}\|_2^2\);L1 正则(L1 Regularization)偏好稀疏解,常写成 \(\Omega(f)=\|\mathbf{w}\|_1\)。更广义地看,早停、Dropout、数据增强、权重共享、标签平滑、参数冻结、低秩适配,都是在不同层面对模型自由度施加约束,因此都可以看作正则化思想的工程实现。
机器学习中的很多训练与评估结论,都建立在一个默认前提上:训练样本与未来样本来自同一统计机制。这个前提通常写成 IID(Independent and Identically Distributed,独立同分布)假设。只要这个前提破坏,训练集表现与线上表现之间就可能出现明显断裂。
设样本对 \((x_i,y_i)\) 来自某个联合分布 \(P(X,Y)\),IID 假设写成:
\[(x_1,y_1),\dots,(x_n,y_n)\overset{\mathrm{iid}}{\sim}P(X,Y)\]这里“独立(Independent)”表示一个样本是否出现,不影响另一个样本的生成;“同分布(Identically Distributed)”表示所有样本都来自同一个联合分布 \(P(X,Y)\)。这个假设让训练集平均损失能够作为总体风险的近似,也让交叉验证、置信区间和很多泛化理论成立。
IID 是理想化近似,而非自然界的铁律。时间序列、推荐系统、金融交易、医疗数据、A/B 实验日志、用户行为数据,常常都存在相关性、群组效应、时间漂移或采样偏差,因此不能机械套用 IID 设定。
当训练分布与测试分布不一致时,就发生了分布偏移(Distribution Shift):
\[P_{\mathrm{train}}(X,Y)\neq P_{\mathrm{test}}(X,Y)\]分布偏移有几种常见形式。协变量偏移(Covariate Shift)指 \(P(X)\) 变化,而 \(P(Y|X)\) 基本稳定;例如线上用户年龄结构变了,但“给定用户画像时是否点击”的规律没明显变。标签偏移(Label Shift)指 \(P(Y)\) 变化,例如欺诈率在促销期突然上升。概念漂移(Concept Drift / Concept Shift)指 \(P(Y|X)\) 本身发生变化,例如垃圾邮件发送策略升级后,原来有效的文本模式不再可靠。
因此,训练集、验证集与测试集的切分不能只追求随机均匀,还必须尽量模拟未来部署环境。若线上是时间推进场景,测试集就应按时间后移;若线上按用户或设备泛化,切分就应按实体隔离;若业务分布持续漂移,还需要做持续监控、重训和再校准。分布偏移核心是机器学习系统走向生产后的主要失效来源之一。
OOD 是 Out-of-Distribution 的缩写,意为分布外(Out-of-Distribution)。它强调的是:当前输入已经落到训练分布覆盖较弱、甚至根本没有覆盖的区域。与一般意义上的“有点噪声”不同,OOD 更像是模型被带到了一个不熟悉的世界里。
例如,一个文本分类模型训练时主要见到的是规范书面语,部署后却大量遇到拼写错误、口语、英文混杂、模板化投诉和新产品名称;一个视觉模型训练时主要见到晴天白昼图像,线上却开始接收夜间、雨雪和红外图像。这类输入即使形式上仍然属于同一任务,也可能已经超出训练分布支持范围。OOD 检测与分布外泛化因此成为真实系统里的关键问题:模型不只要尽量判对,还要在“不熟悉”时知道自己不熟悉。
数据漂移(Data Drift)强调的是线上数据分布会随着时间持续变化。它和 OOD 高度相关,但语境更偏工程系统:核心是整体数据来源、用户群体、业务流程或采集方式正在逐步改变。
若输入分布 \(P(X)\) 发生变化,常称为数据漂移或协变量漂移;若标签分布 \(P(Y)\) 变化,常表现为类别比例变化;若 \(P(Y|X)\) 也改变,则更接近概念漂移。现实系统里,这些变化往往同时发生。例如促销活动带来全新的用户结构,新功能改变用户行为路径,标注口径调整导致同类样本的标签规则也跟着变化。数据漂移的工程含义很直接:离线验证通过,并不意味着模型可以长期稳定在线上工作,监控、告警、回灌和重训机制必须跟上。
鲁棒性(Robustness)指模型在噪声、扰动、输入变形和分布变化下,性能是否仍能维持稳定。它关心的不只是“在标准测试集上最高能到多少分”,更关心输入一旦变脏、变偏、变怪,模型会不会立刻失效。
鲁棒性与 OOD、数据漂移并非同一概念,但三者紧密相关。OOD 和数据漂移描述的是输入环境发生了什么变化;鲁棒性描述的是模型面对这些变化时的承受能力。一个鲁棒性差的模型,可能在干净样本上分数很高,却会被轻微拼写错误、格式扰动、图像模糊、特征缺失或采样偏移迅速击穿。真实生产系统里,鲁棒性通常比单次 benchmark 分数更接近“模型能否长期可用”这个问题。
数据集工程(Dataset Engineering)决定了模型看到什么、以什么尺度看到、又会被哪些偏差误导。很多所谓“模型问题”,根源其实是数据问题:标签噪声、分布漂移、类别极不均衡或特征泄漏,都会直接扭曲训练结果。
数据集工程里常见一个实用分层:黄金数据集(Gold Dataset)与白银数据集(Silver Dataset)。黄金数据集通常指由高质量人工标注、规则严格审核或专家确认得到的小而精数据,标签噪声低,适合做最终评测、关键验证集或高价值监督信号;白银数据集则通常来自启发式规则、弱监督(Weak Supervision)、模型打标、日志回收或大规模自动清洗,规模更大、成本更低,但噪声也更高。实际工程中,常见策略核心是用白银数据集提供覆盖面和规模,用黄金数据集提供校准、纠偏与最终可信评估。
数据划分的目标,是把学参数、做模型选择、汇报最终结果这三件事严格隔离开。若同一批数据既用来训练参数,又用来调超参数,最后还拿来汇报效果,评估结果通常会乐观得不真实,因为模型已经间接“看过”了答案。
从统计学习角度看,这三类数据分别承担三种不同职责:训练集负责让模型学习参数;验证集负责帮助人或训练流程做工程决策;测试集负责模拟真正的未知数据,给出最后一次、尽量无偏的泛化评估。三者分工清楚,模型评估才有可信度。
训练集(Training Set)用于更新模型参数。监督学习中,训练集包含输入 \(x\) 与标签 \(y\);模型在这批样本上计算损失(Loss)、反向传播梯度(Gradient)并更新参数,因此训练集直接决定“模型学到了什么”。它回答的问题是:在已观测样本上,模型有没有学会输入与输出之间的对应关系。
训练集通常应占数据的大头,因为参数学习需要足够多的样本来稳定估计模式。实践中常见比例是 70% 到 80%,但这并非固定规则:若数据总量非常大,训练集比例可以更高;若数据本来就少,则往往需要把更多精力放在交叉验证(Cross Validation)而非死守固定比例。
训练集上的误差通常是三者里最低的,这并不说明模型已经具有泛化能力。一个模型完全可能在训练集上表现极好,却只是记住了样本中的噪声与偶然性。训练集成绩更多反映“拟合能力”,而非“真实上线表现”。
验证集(Validation Set)用于模型选择(Model Selection)和超参数调优(Hyperparameter Tuning)。它不直接参与参数更新,但会影响训练流程中的关键决策,例如学习率(Learning Rate)、正则化强度、模型深度、树的数量、batch size、阈值选择,以及是否执行 Early Stopping。
验证集回答的问题是:在若干候选配置里,哪一个更可能在新数据上表现最好。因此,验证集像训练过程中的“模拟考试”:它并非最终成绩单,但会决定你在训练期间如何改模型、如何调参数、何时停止训练。
验证集通常占总数据的 10% 到 15% 左右。若数据量很小,单独留出一份验证集的代价会较高,此时更常见的做法是使用 \(K\) 折交叉验证,让每个样本轮流充当验证数据,以减少一次随机划分带来的偶然性。交叉验证的细节放在后面的“模型评估”部分展开。
测试集(Test Set)用于最终评估模型的泛化能力(Generalization)。它应尽量只在方案冻结之后使用:模型结构、超参数、训练策略、阈值和后处理规则都不再修改时,才在测试集上做一次最终评估。它回答的问题是:如果把模型部署到真实世界,它在新样本上的表现大致会怎样。
测试集通常占总数据的 10% 到 15%。它的重要性不在于比例有多大,而在于它必须保持“未参与决策”。如果开发过程中反复查看测试集结果,并据此继续改模型,那么测试集就已经被污染,不再是独立评测,而变成了另一个隐性的验证集。
因此,测试集更像真正的“高考卷”或“盲测集”:它的价值在于最后一次、尽量无偏的评估,而非参与训练流程本身。
最常见的简单划分是训练集 / 验证集 / 测试集 = 70% / 15% / 15%,或 80% / 10% / 10%。这种划分适合样本量较大、类别分布较稳定的任务,因为单次随机切分已经足以给出相对稳定的训练与评估结果。
当数据量较小、类别极不平衡、或者不同子群体差异明显时,划分策略就必须更谨慎。分类任务常采用分层抽样(Stratified Split),确保训练、验证、测试三部分的类别比例大致一致;时间序列任务则必须按时间顺序切分,避免未来信息泄漏到过去;用户级、设备级、病人级任务常需要按实体分组切分,防止同一实体的样本同时出现在训练集和测试集中,造成过于乐观的结果。
因此,“如何划分”本身就是建模的一部分。划分方式若与真实部署场景不一致,即使指标很好,也可能只是评估设定过于宽松,而非真正泛化能力强。
分层抽样(Stratified Sampling)先按关键属性把样本划成若干层(Strata),再在每一层内部独立抽取训练、验证和测试样本。分类任务最常见的分层变量是标签 \(y\);多语言、多地区、多设备或多业务线任务中,也可以使用“标签 + 语言”“标签 + 来源”“标签 + 用户类型”等组合变量。它的目标是让每个子集都保留总体中的重要比例结构,避免少数类或小子群只落在某一个集合里。
执行流程通常分四步。第一,确定分层变量,优先选择会显著影响模型表现和评估可信度的字段,例如类别标签、语言、场景来源或风险等级。第二,统计每一层的样本数,检查是否存在样本极少的层;若某一层只有一两个样本,强行切成三份会制造空层,需要合并相近层、降低切分粒度,或改用交叉验证。第三,在每一层内部按同样比例随机切分,例如 80% / 10% / 10%,再把各层的切分结果合并成最终训练集、验证集和测试集。第四,切分后重新检查各集合中的标签比例、关键子群比例和样本数量,确认没有出现明显偏移。
分层抽样的核心约束可以写成:
\[\frac{n_{k,\mathrm{train}}}{n_{\mathrm{train}}}\approx\frac{n_{k,\mathrm{valid}}}{n_{\mathrm{valid}}}\approx\frac{n_{k,\mathrm{test}}}{n_{\mathrm{test}}}\approx\frac{n_k}{n}\]其中 \(k\) 表示第 \(k\) 个层, \(n_k\) 是总体中该层样本数, \(n_{k,\mathrm{train}}\)、 \(n_{k,\mathrm{valid}}\)、 \(n_{k,\mathrm{test}}\) 分别是训练、验证、测试集合中该层的样本数。这个式子表达的是比例近似一致,而非每一层都必须精确相等;当样本数较小时,整数取整会带来轻微偏差。
分层变量不宜无限叠加。若同时按标签、语言、来源、时间段和用户类型分层,组合层数会迅速膨胀,许多层只剩极少样本,最终切分反而不稳定。工程上通常先保证最重要的维度,例如分类标签;若业务强依赖语言或来源,再加入第二个维度。时间序列、用户级泛化和病人级泛化任务还要优先满足时间后移或实体隔离,分层抽样只能在这些约束内部执行,不能为了比例好看而让同一用户或未来样本泄漏到训练集。
子采样(Subsampling)是在可用数据中选取一部分样本参与训练或实验。它不等同于数据划分:数据划分负责隔离训练、验证和测试职责,子采样负责控制训练阶段实际看到的数据规模、类别比例或样本难度。大规模训练中,子采样常用于快速建立基线、降低单轮实验成本、压低冗余样本影响,以及处理多数类过大的类别不平衡问题。
训练从子采样中获益的前提,是被删除的样本对有效监督信号贡献较低。若训练集里存在大量重复文本、近重复日志、模板化样本或极易分类的多数类样本,模型反复看这些样本只会增加计算成本,并可能强化头部模式。适度子采样可以让每个 epoch 更短,让实验迭代更快,也能提高少数类、困难样本或高质量样本在梯度更新中的相对权重。
常见做法包括三类。第一类是均匀子采样,从大训练集中随机抽取固定比例,适合快速 sanity check 和建立 baseline。第二类是分层子采样,在每个类别、语言或来源内部按比例抽样,既缩小规模,又尽量保留关键分布结构。第三类是目标导向子采样,例如下采样多数类、保留 hard examples、提高高质量标注样本比例,或在推荐和语言模型中只抽取一部分负样本。第三类收益更高,但也更容易引入人为偏差。
子采样应优先作用在训练集上,验证集和测试集通常不应为了训练效率而随意缩小或重配比例。验证集可以在早期实验中使用一个小型 dev subset 做快速反馈,但最终模型选择仍应回到完整验证集;测试集更应保持稳定,避免把采样策略本身变成评估结果的一部分。若子采样改变了训练分布,例如下采样多数类或上调困难样本比例,训练时还需要记录采样规则,并在必要时用类别权重、阈值校准或真实分布验证来修正部署阶段的概率偏差。
数据泄露(Data Leakage)指测试集或验证集中的信息以直接或间接方式进入训练过程,从而导致模型评估结果虚高。它的危险不在于“代码报错”,而在于模型会表现得看似极好,却无法在真实新数据上复现。
最常见的数据泄露有几类。第一类是先对全量数据做预处理,再切分数据,例如先用全量数据计算标准化均值和方差,再划分训练 / 测试集;这样测试集的信息已经进入了训练流程。第二类是用测试集反复调参,例如每改一次模型就看一次测试集成绩,直到测试集最好看为止。第三类是特征中混入未来或标签信息,例如用预测时不可能知道的字段做输入,或把目标变量的某种变形偷偷带进特征。
避免数据泄露的原则只有一句:任何依赖数据分布统计量、特征构造规则、模型选择决策或阈值选择的步骤,都只能在训练集内部完成,再把同样的变换应用到验证集和测试集。标准化、特征选择、缺失值填补、目标编码(Target Encoding)、降维(PCA)和重采样(Resampling)都要遵守这一原则。
因此,数据集划分不仅“把数据分三份”这么简单,还整个实验设计(Experimental Design)的一部分。只有训练集、验证集、测试集的职责边界清晰,交叉验证使用得当,且数据泄露被严格控制,模型指标才具有解释价值和可复现实验意义。
归一化(Normalization)与标准化(Standardization)都在解决“不同特征量纲和尺度差异过大”问题,但含义不同。最常见的最小-最大归一化把数据映射到固定区间:
\[x'=\frac{x-x_{\min}}{x_{\max}-x_{\min}}\]它把特征压到 \([0,1]\),适合像像素值、比例值这类天然有上下界的量。标准化则是减去均值、再除以标准差:
\[z=\frac{x-\mu}{\sigma}\]标准化后的特征均值为 0、标准差为 1,更适合线性模型、距离模型和很多神经网络优化过程。类比来看,归一化像“把不同长度的尺子都缩到同一长度区间”;标准化像“先平移到共同中心,再按波动尺度统一单位”。
特征工程(Feature Engineering)是把原始数据加工成更利于模型学习的表示。它核心是在把领域知识编码进输入空间。例:时间戳可以拆成小时、星期、是否节假日;用户行为日志可以构造近 7 天点击次数、转化率、时间衰减统计;文本可以做 TF-IDF、n-gram 或实体抽取。
类比来看,特征工程像做菜前的备料:同样的原料,如果已经切片、去骨、配好比例,后续烹饪会顺畅得多。经典机器学习对特征工程高度依赖;深度学习则把一部分特征学习自动化了,但在表格数据、推荐、广告和风控里,特征工程仍然决定上限。
类别不平衡(Class Imbalance)指某些类别样本远多于另一些类别。欺诈检测、故障检测、医学筛查里最典型:正类往往极少。如果不处理,模型可能通过“永远预测多数类”获得看似不错的 Accuracy,却在关键少数类上彻底失效。
常见处理方法包括:重采样(过采样少数类、欠采样多数类)、类别加权(Class Weighting)、阈值调整(Threshold Tuning)和使用更合适的指标(如 Precision、Recall、PR-AUC)。例如在信用卡欺诈场景中,正类只占 0.1%,此时“全判正常”会有 99.9% Accuracy,但业务价值几乎为 0。
超参数(Hyperparameters)是训练开始前由人或外部搜索过程设定的配置变量。它们与模型参数(Parameters)不同:模型参数如线性回归的权重、神经网络的矩阵和偏置,是通过训练数据学出来的;超参数则决定模型该以什么结构、什么训练节奏、什么正则化强度去学习。学习率、batch size、树深、dropout、LoRA rank 都属于超参数,而非训练过程中直接被梯度更新出来的参数。
从作用层面看,超参数大致分成三类。第一类决定模型结构,例如树的最大深度、神经网络层数、隐藏维度、注意力头数;第二类决定优化过程,例如学习率、batch size、训练轮数、warmup 步数;第三类决定复杂度控制,例如正则化强度、dropout、weight decay、早停耐心值。它们共同定义了“模型允许学成什么样、以及训练过程会沿哪条轨迹逼近这个结果”。
因此,超参数优化核心是在搜索哪一套训练配置更可能在验证集上泛化得最好。超参数搜索天然依赖验证集,而不能依赖测试集。
有些超参数跨很多模型家族都反复出现,它们更像训练流程级控制杆,而非某个算法私有旋钮。最常见的一组可概括如下:
| 超参数 | 主要控制什么 | 常见影响 |
| 学习率(Learning Rate) | 每步更新幅度 | 过大易震荡或发散,过小则收敛过慢或停在高误差区 |
| batch size | 每次梯度估计使用多少样本 | 影响吞吐、显存占用、梯度噪声和有效学习率范围 |
| 训练轮数 / 训练步数(Epochs / Steps) | 训练总时长 | 过少易欠拟合,过多则更易过拟合 |
| 正则化强度(Regularization Strength) | 复杂度惩罚有多强 | 过强会欠拟合,过弱则更易记忆训练集细节 |
| weight decay | 参数收缩强度 | 常用于控制神经网络权重规模与泛化 |
| dropout | 随机屏蔽单元的比例 | 抑制共适应,但过强会削弱表示能力 |
| 学习率调度(Scheduler) | 训练过程中学习率如何变化 | 直接影响早期稳定性与后期收敛质量 |
| warmup | 前期学习率爬升过程 | 对 Transformer 和大 batch 训练尤为重要 |
| 早停耐心值(Early Stopping Patience) | 验证集多久不提升才停止 | 影响训练预算与过拟合控制 |
另一类超参数只在特定模型家族里出现。它们往往直接对应某个算法的结构假设,因此不能简单迁移到别的模型上。
| 模型家族 | 典型超参数 | 控制什么 |
| KNN | \(k\)、距离度量 | 邻域大小与“相似”的定义 |
| SVM | \(C\)、kernel、\(\gamma\) | 间隔惩罚与核函数形状 |
| 决策树 / 随机森林 | max depth、min samples leaf、树数 | 树的复杂度与集成规模 |
| Boosting / XGBoost / LightGBM | learning rate、树数、max depth、采样比例 | 弱学习器叠加节奏与复杂度 |
| CNN | 卷积核大小、通道数、stride、pooling 配置 | 局部感受野与空间降采样方式 |
| RNN / LSTM | 隐藏维度、层数、截断长度 | 时序记忆容量与反向传播范围 |
| Transformer | 层数、隐藏维度、头数、最大上下文长度 | 表示容量、并行结构与长程建模能力 |
| PEFT / LoRA | rank、alpha、target modules、adapter dropout | 低秩适配容量与写入位置 |
因此,“超参数”不能被理解成一张固定清单。不同模型真正敏感的旋钮并不相同。对树模型,max depth 和叶节点约束常是核心;对 Transformer,学习率、warmup、weight decay、batch 与上下文长度往往更关键;对 LoRA,rank 与挂载模块会直接决定可写入容量。
超参数搜索(Hyperparameter Search)指用验证集表现,在若干候选配置中选择更优组合。它本质上是在搜索哪套训练配方更值得被固定下来。搜索空间越大,找到更优组合的机会通常越高,但实验成本、验证集过拟合风险和复现难度也会同步上升。
贪婪串行登山(Greedy Sequential Hill Climbing)是一种非常实用的超参数搜索策略。它的核心规则是:每次只调整一个超参数,在当前其余超参数固定不变的条件下,选择验证集上更优的方向走一步;确定后先固定该值,再去调下一个超参数。在离散候选集上,它可以看作一种坐标式局部搜索。
例如先固定 dropout 和 batch size,只比较若干学习率;一旦找到当前最优学习率,就暂时锁定它,再去比较 dropout;然后再固定前两者去比较 batch size。这样做的优点是实验次数通常近似线性增长,适合“训练一次代价不低、超参数数量又不算很多”的场景。
贪婪串行登山常伴随一种棘轮式锁定(Ratchet-style Fixing):某一轮一旦选定一个更优取值,就先不回头重开这个维度。这样做能显著缩小后续搜索空间,但代价也很明确:较早做出的局部最优决策,会限制后面组合空间的探索。
它最容易出问题的地方,是参数交互(Hyperparameter Interaction)。若两个超参数彼此强相关,例如学习率和 batch size、学习率和 warmup、LoRA rank 和 target modules,那么“在当前默认值下看起来更优”的选择,未必能和后续维度组成真正最优的整体组合。棘轮式锁定会把这类交互提前屏蔽掉。
| 维度 | 说明 |
| 优点 | 简单、可解释、实验次数少,适合作为快速锁定大方向的工程基线 |
| 局限 1 | 容易停在局部最优,因为它不会接受“短期下降、长期更优”的探索路径 |
| 局限 2 | 默认把超参数近似看成可分离维度,但现实中经常存在强交互 |
| 局限 3 | 若反复依赖同一验证集做很多轮决策,更容易把验证集偶然性误判成真实提升 |
| 策略 | 实验成本 | 能否捕捉参数交互 | 典型特点 |
| 贪婪串行登山 | 较低 | 较弱 | 工程上快速、便宜、可解释,但更局部 |
| 网格搜索(Grid Search) | 高,常随维度指数增长 | 强 | 穷举规则清楚,但高维时代很快失去性价比 |
| 随机搜索(Random Search) | 可控 | 中等 | 在高维空间常比网格搜索更高效,是强基线 |
| 贝叶斯优化(Bayesian Optimization) | 中等到较高 | 较强 | 利用历史试验结果自适应建议下一个点,适合昂贵实验 |
因此,何时使用哪种策略,取决于训练代价与搜索空间形状。若一次训练就要数十分钟甚至数小时,且可调超参数并不多,贪婪串行登山往往已经足够作为第一轮工程方案;若参数交互明显、预算允许,随机搜索或贝叶斯优化通常更稳。无论使用哪一种方法,最关键的前提都不变:搜索必须由验证集驱动,而测试集必须保持未参与决策。
模型评估(Model Evaluation)回答的核心是“模型在新数据上是否可靠,以及错误代价如何”。不同任务对应的指标重点不同:分类关心类别区分,回归关心数值偏差,排序关心相对顺序。
交叉验证(Cross Validation)在数据较少时特别重要。最常见的 \(K\) 折交叉验证把数据分成 \(K\) 份:每次用其中 1 份做验证、其余 \(K-1\) 份训练,循环 \(K\) 次,最后对 \(K\) 个验证结果取平均。
它的作用像“轮流把不同一份数据拿出来当模拟考试卷”,从而降低一次随机划分带来的偶然性。对小数据集而言,单次划分可能刚好“运气好或坏”;交叉验证则给出更稳定的泛化估计。
校准(Calibration)讨论的是:模型给出的概率值,是否真的能当概率解释。分类模型不只输出“判成哪一类”,还常输出一个置信分数,例如 \(0.9\)。若一个模型在所有“预测概率约为 0.9”的样本子集上,最终真的有约 90% 预测正确,那么它就是校准良好的;若它经常把只有 60% 把握的样本说成 90%,就属于过度自信(Overconfident)。
二分类中,若模型输出正类概率 \(\hat p(x)\in[0,1]\),理想校准条件可写成:
\[P(Y=1\mid \hat p(X)=p)=p\]这里左边表示:在所有预测概率等于 \(p\) 的样本中,真实为正类的条件概率;右边的 \(p\) 是模型自己报出的概率。两者相等时,概率输出就与真实频率一致。多分类场景下,常把模型最大类别概率当作置信度,并检验“报 80% 置信度的样本,是否真的大约 80% 正确”。
校准与准确率并非同一件事。一个模型可以分类很准,但概率不可靠;也可以概率尺度较准,但分类边界并不最优。前者常见于深层神经网络:argmax 分类结果不错,但 softmax 概率偏尖,置信度系统性偏高。涉及风险控制、医学筛查、自动驾驶、检索重排、多阶段决策时,概率是否可信往往和“分对多少”同样重要,因为阈值决策、人工复核和代价加权都依赖这个概率尺度。
校准的可视化工具通常是可靠性图(Reliability Diagram)。做法是把预测置信度分成若干区间,例如 \([0.0,0.1),[0.1,0.2),\dots\),然后对每个区间分别计算平均置信度与真实准确率。若图上的点接近对角线 \(y=x\),说明校准较好;若点普遍落在对角线下方,说明模型报得比实际更自信;若点在对角线上方,则说明模型偏保守。
常用数值指标是期望校准误差(Expected Calibration Error, ECE):
\[\mathrm{ECE}=\sum_{m=1}^{M}\frac{|B_m|}{n}\,\big|\mathrm{acc}(B_m)-\mathrm{conf}(B_m)\big|\]这里 \(M\) 是置信度分箱数, \(B_m\) 是第 \(m\) 个置信度区间中的样本集合, \(|B_m|\) 是该区间样本数, \(n\) 是总样本数, \(\mathrm{acc}(B_m)\) 是该区间的实际准确率, \(\mathrm{conf}(B_m)\) 是该区间的平均预测置信度。ECE 的含义很直接:把每个置信区间里“说得多准”和“实际多准”的差值取绝对值,再按样本占比加权平均。ECE 越小,表示整体校准越好。
另一类常见指标是 Brier Score。对二分类,它定义为:
\[\mathrm{Brier}=\frac{1}{n}\sum_{i=1}^{n}(\hat p_i-y_i)^2\]这里 \(\hat p_i\) 是第 \(i\) 个样本的预测正类概率, \(y_i\in\{0,1\}\) 是真实标签。它既惩罚分类错误,也惩罚概率刻度不准,因此兼顾区分能力与概率质量。与单纯 Accuracy 不同,Brier Score 会区分“错得有多离谱”:把一个负样本报成 \(0.51\) 和报成 \(0.99\),代价并不相同。
工程上最常见的后处理方法是温度缩放(Temperature Scaling)。设原始 logits 为 \(z_i\),则缩放后的 softmax 概率写成:
\[p_i=\frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)}\]这里 \(T>0\) 是温度参数。 \(T>1\) 会把分布拉平,降低过度自信; \(T<1\) 会把分布压尖,提高置信度。温度参数通常在验证集上通过最小化负对数似然(Negative Log-Likelihood, NLL)来拟合,然后固定用于测试或部署阶段。它不会改变类别排序,因此常能在几乎不影响 Accuracy 的前提下改善概率校准。
分类指标通常从混淆矩阵(Confusion Matrix)出发。设正类预测结果统计为真阳性 \(TP\)、假阳性 \(FP\)、真阴性 \(TN\)、假阴性 \(FN\)。不同指标本质上是在回答不同问题:是看“总共判对多少”,还是看“判成正类时有多准”,还是看“真实正类抓到了多少”。
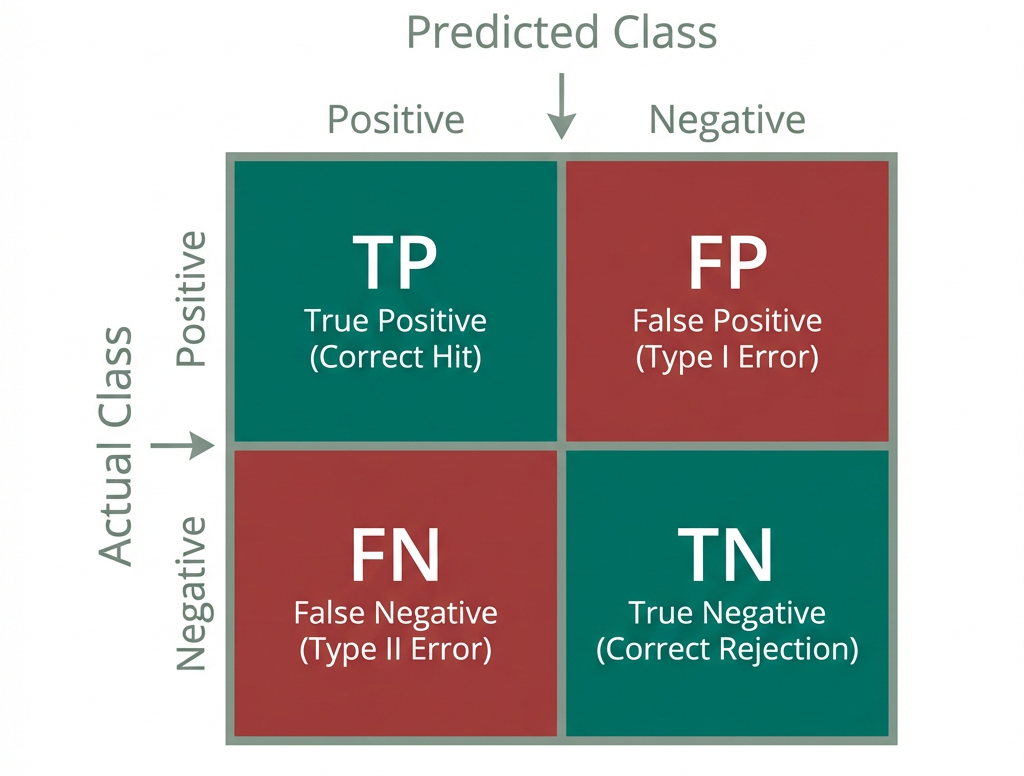
准确率(Accuracy)定义为
\[\mathrm{Accuracy}=\frac{TP+TN}{TP+TN+FP+FN}\]它衡量“总体上判对了多少比例”,适合类别相对平衡、不同错误代价接近的场景。但在类别极不平衡时会误导:例如癌症筛查里,99% 都是阴性时,模型全判阴性也可能有 99% Accuracy,却毫无检测价值。
精确率(Precision)定义为
\[\mathrm{Precision}=\frac{TP}{TP+FP}\]它回答的是:“所有被模型判成正类的样本里,有多少真的为正。”当误报成本很高时,Precision 特别重要。例:垃圾邮件过滤里,如果把正常邮件误判成垃圾邮件代价很高,就要关心 Precision。
召回率(Recall)定义为
\[\mathrm{Recall}=\frac{TP}{TP+FN}\]它回答的是:“所有真实正类里,有多少被模型找出来了。”当漏报成本很高时,Recall 更关键。例:医学筛查里漏掉患者可能比多做一次复检更危险,因此 Recall 往往比 Precision 更重要。
F1 值(F1 Score)是 Precision 与 Recall 的调和平均:
\[F_1=\frac{2\cdot \mathrm{Precision}\cdot \mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}\]之所以用调和平均而非普通平均,是因为它会惩罚“一高一低”的不平衡情况。若一个模型 Precision 极高但 Recall 很低,它并不能拿到高 F1。F1 适合正负样本不平衡、且希望兼顾漏报与误报的场景。
AUC-ROC 衡量模型在不同分类阈值下区分正负样本的整体能力。ROC 曲线横轴是假阳性率(False Positive Rate),纵轴是真阳性率(True Positive Rate)。AUC 是曲线下面积,范围在 \([0,1]\);越接近 1,说明模型越能把正样本排在负样本前面。
它不依赖某一个固定阈值,因此适合比较“排序能力”。但在极端不平衡数据上,PR 曲线(Precision-Recall Curve)常更敏感,因为 ROC 容易被大量真阴性“冲淡”。
回归指标(Regression Metrics)衡量预测值与真实值之间的数值偏差。它们关注的核心是“偏差有多大、对大误差是否敏感、模型解释了多少波动”。以房价预测为例,预测 300 万和真实 320 万之间的差距,就是典型回归误差。
平均绝对误差(Mean Absolute Error, MAE)定义为
\[\mathrm{MAE}=\frac{1}{N}\sum_{i=1}^{N}|\hat y_i-y_i|\]它直接度量“平均差了多少个原始单位”,解释最直观。若房价单位是万元,MAE=12 就表示平均误差约 12 万元。由于使用绝对值,MAE 对离群点没有 MSE 那么敏感。
均方误差(Mean Squared Error, MSE)定义为
\[\mathrm{MSE}=\frac{1}{N}\sum_{i=1}^{N}(\hat y_i-y_i)^2\]平方会放大大误差,因此 MSE 对离群点更敏感。它常用于你希望“大错要被重罚”的场景。高斯噪声假设下,最小化 MSE 还对应最大似然估计,因此它不仅是工程指标,也是概率建模结果。
均方根误差(Root Mean Squared Error, RMSE)是
\[\mathrm{RMSE}=\sqrt{\mathrm{MSE}}\]它保留了 MSE 对大误差更敏感的性质,同时把单位拉回原始量纲,因此更易解释。若房价 RMSE 为 20 万元,可以直接理解为“典型误差量级约 20 万元”。
\[R^2\](决定系数,Coefficient of Determination)回答的是:相比于最朴素的瞎猜基线,你的回归模型到底把预测提升了多少。要理解它,只需要在脑子里放两条线:一条是“什么都不知道时只能猜平均值”的水平线,另一条是模型给出的预测曲线。
先看最朴素的基线。假设你要预测一批房子的价格,但你手里没有面积、地段、楼龄这些特征,别人却逼着你给出预测。此时最不容易挨打的办法,核心是对所有房子都猜样本平均价 \(\bar y\)。在散点图上,这对应一条横向的水平线。
真实房价 \(y_i\) 会散落在这条平均线的上下。每个点到平均线的垂直距离 \(y_i-\bar y\),就是“瞎蒙平均值”时犯下的误差。把这些误差平方后全部加起来,就得到
\[\sum_i(y_i-\bar y)^2\]这就是公式里的分母。它衡量的核心是这批数据本身原来就有多分散、多混乱。也可以把它理解为目标变量的总波动、总混沌程度,或者说“在完全不用特征时,世界原本有多少东西解释不了”。
现在再看你的模型。你训练出一个回归模型,它根据输入特征给出预测 \(\hat y_i\)。在图上,预测结果从那条死板的水平线转向一条试图穿过散点云中心的预测曲线。模型当然不可能完美,所以每个真实值 \(y_i\) 与预测值 \(\hat y_i\) 之间仍会有垂直误差,这个误差就是残差(Residual)。
把这些模型仍然没解释掉的误差平方后加起来,就得到
\[\sum_i(\hat y_i-y_i)^2\]这就是公式里的分子,也叫残差平方和(Residual Sum of Squares, RSS)。它代表模型已经尽力之后,世界上依然残存的混沌。分子越小,说明模型越贴近真实数据;分子越大,说明模型虽然复杂,但其实没把问题解释清楚。
于是
\[R^2=1-\frac{\sum_i(\hat y_i-y_i)^2}{\sum_i(y_i-\bar y)^2}\]这条式子就可以直接读成一句大白话:先看模型还剩下多少解释不了的波动,再除以最开始总共有多少波动,得到“模型搞不定的比例”;最后用 1 减掉它,剩下的就是模型成功解释掉的波动比例。
因此,若 \(R^2=0.8\),意思核心是目标变量原本有 100 份波动,模型大约解释掉了其中 80 份,只剩 20 份还没解释;若 \(R^2=0\),说明你的模型折腾半天,效果和“永远预测平均值”完全一样;若 \(R^2<0\),则表示模型比这个最朴素基线还差,常见原因是模型设错了、特征没信息,或实现上有 bug。
从老板视角看, \(R^2\) 的灵魂拷问其实只有一句:相比直接拿平均值糊弄事,你这个复杂回归模型到底多解释了多少真实波动。因此, \(R^2\) 特别适合回答“模型有没有真正利用特征学到东西”,但它不能替代 MAE、RMSE——因为 \(R^2\) 讲的是解释比例,而非误差到底有多少个原始单位。
优化算法(Optimization Algorithms)解决的问题非常朴素:模型参数该往哪个方向改,才能让损失函数持续下降。只要训练目标能写成“最小化某个损失函数”,背后就需要一套更新参数的规则。线性回归、逻辑回归、神经网络、大语言模型训练,本质上都绕不开这个问题。
这里要先分清两件事。优化(Optimization)关心的是“训练损失能不能降下来”;泛化(Generalization)关心的是“模型在新样本上好不好”。一个优化器可能把训练集拟合得很好,但泛化依然一般;反过来,一个优化器如果连训练损失都压不下去,模型通常也谈不上有效。因此优化算法决定的是你如何走向一个解,而非直接保证这个解一定最好。
梯度下降(Gradient Descent)是最核心的一阶优化思想。设损失函数为 \(L(\theta)\),参数为 \(\theta\),则梯度 \(\nabla_\theta L(\theta)\) 给出“损失上升最快的方向”。既然梯度指向上坡,那么要让损失下降,就应沿着它的反方向更新参数:
\[\theta_{t+1}=\theta_t-\eta\,\nabla_\theta L(\theta_t)\]这里 \(\theta_t\) 是第 \(t\) 步的参数, \(\eta\) 是学习率(Learning Rate),决定每一步走多大; \(\nabla_\theta L(\theta_t)\) 是当前位置的斜率信息。学习率太大,容易一步跨过谷底甚至震荡发散;学习率太小,又会下降得极慢。它像蒙着雾下山:梯度告诉你脚下哪边更陡,学习率决定你每次迈多大步。
为什么很多模型不直接“解公式”,而要反复迭代?因为在深度学习里,参数维度极高,损失面又往往非凸(Non-convex),通常没有漂亮的闭式解(Closed-form Solution)。这时最现实的办法核心是利用局部斜率,一步一步把损失往下压。
当总损失是逐样本损失的平均时,梯度下降还可以写得更具体:
\[L(\theta)=\frac{1}{N}\sum_{i=1}^{N}\ell(\theta;x_i)\] \[\nabla_\theta L(\theta)=\frac{1}{N}\sum_{i=1}^{N}\nabla_\theta \ell(\theta;x_i)\]这也回答了“为什么可以批量喂输入”:梯度对求和是线性的,整体梯度等于逐样本梯度的平均,所以可以并行算每个样本的梯度,再求平均后统一更新参数。
满足这种“逐样本求和/求平均”结构的损失函数其实非常多。典型例子包括:线性回归里的均方误差(MSE)、平均绝对误差(MAE),二分类里的 logistic loss / binary cross-entropy,多分类里的交叉熵(Cross-Entropy),语言模型训练里的负对数似然(Negative Log-Likelihood, NLL)。它们都可以写成“每个样本先各自算一份损失,再在整个数据集上取平均”的形式,因此天然适合 mini-batch 训练。
但并非所有目标都能严格写成这种完全独立的逐样本平均。若损失显式依赖样本之间的相对关系,情况就会复杂一些。例如排序学习里的 pairwise/listwise loss、度量学习中的 triplet loss,以及对比学习里的 InfoNCE,都会让一个样本的损失依赖同一个 batch 中的其他样本。此时虽然仍然可以按 batch 计算梯度,但它已经并非“每个样本各算各的、最后简单平均”那么干净的分解了。
工程上还常见另一种情况:目标函数可以写成“逐样本平均损失 + 正则项(Regularization)”。例如
\[L(\theta)=\frac{1}{N}\sum_{i=1}^{N}\ell(\theta;x_i)+\lambda\Omega(\theta)\]其中 \(\Omega(\theta)\) 可以是 \(\|\theta\|_2^2\) 这类参数惩罚项。前半部分仍然按样本分解,后半部分则是直接作用于参数本身,而不对应某一个单独样本。很多现代训练目标,本质上都是这两部分的组合。
几个常用训练量需要先分清:
- 批大小(Batch Size):一次更新使用多少个样本。
- 步(Step / Iteration):一次参数更新。
- 轮(Epoch):完整遍历一次训练集。
若训练集大小为 \(N\),batch size 为 \(B\),则每个 epoch 的步数约为 \(\lceil N/B\rceil\)。工程里经常会说“训练了多少 step”,因为真正发生参数变化的是 step,而非 epoch 这个更粗的计数单位。
批量梯度下降(Batch Gradient Descent, BGD)每次都用整个训练集来计算一次精确梯度,再更新参数。这里的 batch 指的核心是“整批训练数据”。它的优点是方向最稳定、梯度方差最小;缺点是每一步都很贵,数据一大就几乎不可用。它更适合小数据集、凸优化问题,或教材里说明“梯度下降原理”时使用。
随机梯度下降(Stochastic Gradient Descent, SGD)每次只用一个样本的梯度做更新。它的方向噪声很大,看起来像“跌跌撞撞地下山”,但每一步极便宜、更新极频繁,因此在数据流式到来或样本极多时很有价值。
- 优点:更新快、内存开销小、天然适合在线学习(Online Learning)与流式数据(Streaming Data)。
- 优点:梯度噪声有时反而会带来好处,更容易离开鞍点(Saddle Point)和较差的局部极小。
- 缺点:轨迹抖动大,若学习率控制不好,训练容易不稳定。
它像店长根据每一位新顾客的反馈立刻调价:反应很快,但也容易被个别顾客带偏。
适用场景:当你需要用最新样本尽快产生参数更新时,SGD(batch size=1)是最直接的选择,典型包括:
- 在线学习(Online Learning)/流式数据(Streaming Data):样本持续到来,要求增量更新,而非离线反复扫全量数据。
- 分布漂移(Distribution Shift)与非平稳(Non-stationary)环境:用户偏好、市场、策略对抗等持续变化,需要快速跟踪新分布。
- 低延迟更新需求:例如广告/推荐/风控的在线校准,需要“见到一条新反馈就更新一点”。
- 资源受限或样本极大:内存无法容纳大 batch 或无法频繁计算全量梯度时,用单样本更新换取更低的每步计算与存储成本。
在现代深度学习里,若使用 GPU/TPU 训练,大多数时候会用小批量梯度下降来兼顾吞吐与稳定性;纯 SGD 更常出现在在线/增量训练与部分强化学习(Reinforcement Learning, RL)设置中。
小批量梯度下降(Mini-batch SGD)是在 BGD 与 SGD 之间折中:每次用一个 batch 的平均梯度更新。它既能利用 GPU 的并行算力,又保留一定梯度噪声,因此现代深度学习几乎都在这个范式下训练。
batch 太小,梯度估计噪声会很大;batch 太大,虽然每步更稳定,但显存压力更高、更新频率更低,有时还会让优化和泛化都变钝。因此 batch size 核心是吞吐、稳定性、显存和泛化之间的折中。
单纯的梯度下降在“峡谷形”损失面里很容易左右来回震荡:沿陡峭方向上下摆动,沿真正有用的谷底方向前进却很慢。动量法(Momentum)的直觉是:不要只看当前这一脚的斜率,而要把过去几步的方向累积成一种“惯性”。
\[v_{t+1}=\beta v_t+(1-\beta)g_t,\quad \theta_{t+1}=\theta_t-\eta v_{t+1}\]其中 \(g_t\) 是当前梯度, \(v_t\) 是累计出来的速度, \(\beta\in[0,1)\) 控制“记住过去多少信息”。 \(\beta\) 越大,方向越平滑、惯性越强;越小,则越接近普通梯度下降。类比来看,它像推一个有重量的小球下山:不会因为脚下的微小凸凹就频繁改道,而会沿长期更一致的下降方向滚动。
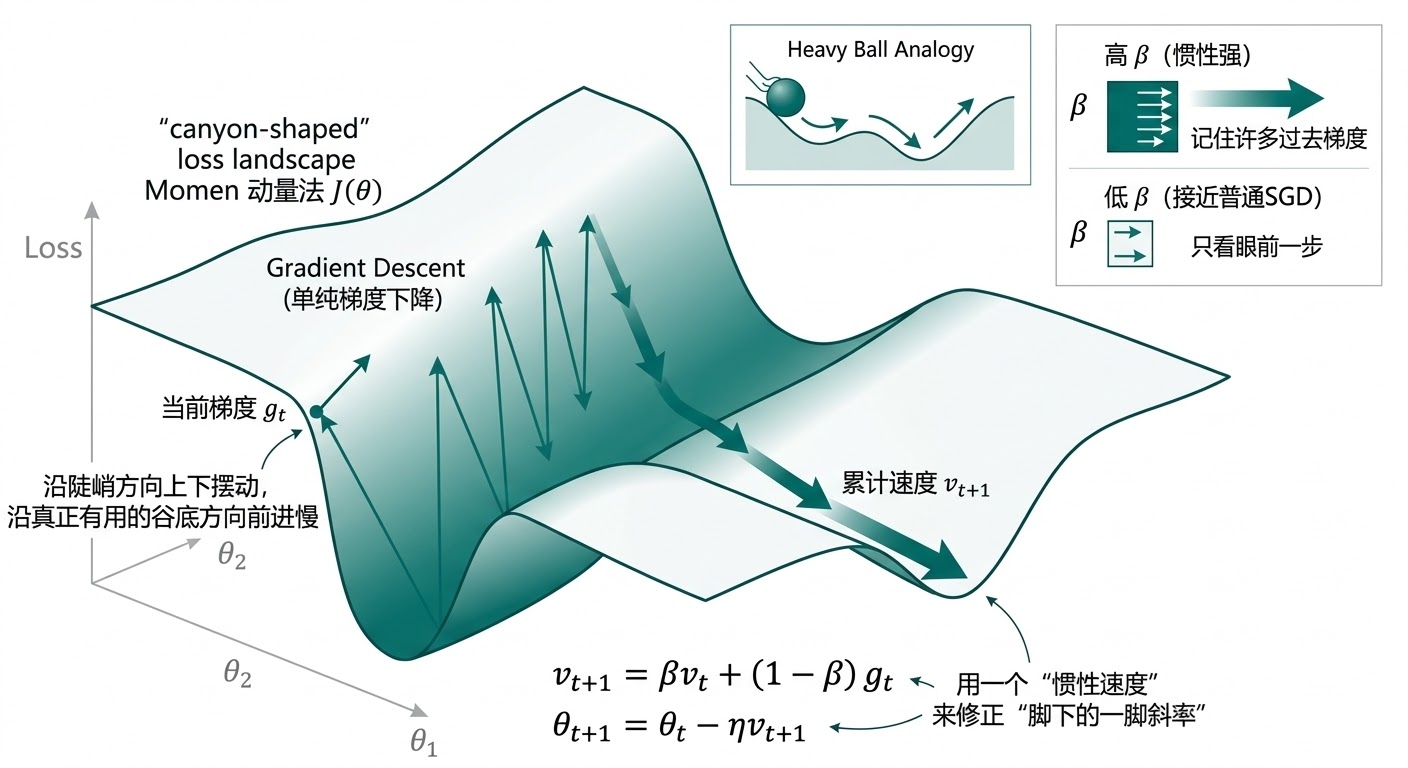
AdaGrad 与 RMSProp 属于自适应学习率(Adaptive Learning Rate)方法。它们的核心思想是:不同参数的梯度尺度不同,不应该所有维度都用同一个固定步长。历史上梯度很大的维度,后续步子要缩小;梯度稀疏或很小的维度,则可以走得更积极。
AdaGrad 累积历史平方梯度:
\[s_{t+1}=s_t+g_t\odot g_t,\quad \theta_{t+1}=\theta_t-\eta\,\frac{g_t}{\sqrt{s_{t+1}}+\epsilon}\]其中 \(g_t\odot g_t\) 表示逐元素平方, \(\epsilon\) 是数值稳定项。这样一来,历史上梯度一直很大的维度会被自动缩小学习率。AdaGrad 在稀疏特征(Sparse Features)任务里很有效,例如早期的文本与推荐场景;但它的问题是 \(s_t\) 只增不减,训练到后期学习率可能衰减得过头,参数几乎不再动。
RMSProp 用指数滑动平均替代“无限累积”,缓解这个问题:
\[s_{t+1}=\rho s_t+(1-\rho)(g_t\odot g_t),\quad \theta_{t+1}=\theta_t-\eta\,\frac{g_t}{\sqrt{s_{t+1}}+\epsilon}\]这样历史信息会逐步“遗忘”,使学习率缩放更关注近期梯度尺度。可以把 AdaGrad 理解成“终身记账”,而 RMSProp 更像“滚动记账”。
Adam(Adaptive Moment Estimation)把动量法(Momentum)的一阶矩估计与 RMSProp 的二阶矩估计结合起来,因此它同时解决优化中的两个核心痛点:方向感(往哪走)与节奏感(每步走多大)。直觉上,可以把它理解为“带惯性的方向盘 + 自动变速箱”:方向由平均梯度决定,步长由梯度的尺度自动缩放。
- 索引约定:第 \(t\) 次更新先在 \(\theta_t\) 处计算 \(g_t\),再把它并入动量得到 \(m_{t+1}\);下标 \(t+1\) 表示“更新后状态”,并非未来信息。
- \(m_{t+1}\):并入 \(g_t\) 后的一阶矩(动量)估计。
- 右边第一项 \(\beta_1 m_t\):把历史动量按系数 \(\beta_1\) 保留下来,表示“历史方向对新方向的贡献”。
- 右边第二项 \((1-\beta_1)g_t\):把当前梯度按系数 \(1-\beta_1\) 注入动量,表示“当前观测对新方向的贡献”。
- \(g_t\):第 \(t\) 步的梯度,通常由当前 mini-batch 估计得到(\(g_t=\nabla_\theta L(\theta_t)\))。
- \(m_t\):一阶矩估计的滑动平均(动量项),可理解为“平均梯度方向”。
- \(\beta_1\in[0,1)\):动量衰减系数,越大表示记忆越长、方向越平滑。
两项系数满足 \(\beta_1+(1-\beta_1)=1\),因此这是指数滑动平均(Exponential Moving Average, EMA,越近发生的事情,参考价值越大;越久远的事情,参考价值越小)。当 \(m_0=0\) 时,可把它展开为:
\[m_{t+1}=(1-\beta_1)\sum_{k=0}^{t}\beta_1^{t-k}g_k\]上式说明:越久远的梯度 \(g_k\) 权重按 \(\beta_1^{t-k}\) 指数衰减;经验上可把有效记忆长度理解为 \(O\!\left(\frac{1}{1-\beta_1}\right)\)。因此 \(\beta_1\) 越大,平均窗口越长,方向越平滑但响应越慢;\(\beta_1\) 越小,平均窗口越短,方向更敏捷但更易受噪声影响。
RMSProp(Root Mean Square Propagation)用梯度平方的指数滑动平均(Exponential Moving Average, EMA)来估计每个参数维度的“尺度”,再用该尺度对当前梯度做逐元素归一化,从而把更新步伐控制在更稳定的量级。
\[v_{t+1}=\beta_2 v_t+(1-\beta_2)(g_t\odot g_t),\quad \tilde g_t=\frac{g_t}{\sqrt{v_{t+1}}+\epsilon}\]- 索引约定:第 \(t\) 次更新先在 \(\theta_t\) 处计算 \(g_t\),再用它更新得到 \(v_{t+1}\);用 \(v_{t+1}\) 缩放 \(g_t\) 表示“用本次更新后的尺度估计做归一化”,不涉及未来信息。
- \(v_t\):上一轮更新结束后的二阶原点矩估计(EMA 状态,“更新前的尺度缓存”)。
- \(v_{t+1}\):梯度的二阶原点矩(Second Raw Moment)估计,逐(梯度)维近似 \(\mathbb{E}[g^2]\),刻画“历史梯度大小”的典型尺度。
- \(g_t\odot g_t\):当前梯度的逐元素平方(\(\odot\) 为 Hadamard 乘积),只保留幅度信息。
- \(\sqrt{v_{t+1}}\):均方根(Root Mean Square, RMS)尺度;平方使量纲变为 \(g^2\),开方把量纲还原到 \(g\),从而可与 \(g_t\) 相除。
- \(\tilde g_t\):按 RMS 尺度归一化后的梯度;分式表示逐元素相除(每个参数维度各自缩放)。
- \(\beta_2\in[0,1)\):衰减系数,控制尺度估计的记忆长度;越大表示对历史尺度更“长记忆”。
- \(\epsilon\):数值稳定项,避免分母为 0 或过小。
该缩放把“方向”和“尺度”解耦:方向仍由 \(g_t\) 给出;步长由 \(\sqrt{v_{t+1}}\) 自适应调节。若某维长期梯度偏大,则 \(\sqrt{v_{t+1}}\) 变大、该维更新被压小;若某维长期梯度偏小,则分母较小、该维相对步子更大。
若把 RMSProp 作为独立优化器使用,参数更新可写为 \(\theta_{t+1}=\theta_t-\eta\,\tilde g_t\)。在 Adam 中,同样的 RMS 缩放作用在一阶矩估计上:用 \(\hat m_{t+1}\) 替代 \(g_t\) 作为分子,并在下一节通过偏置修正得到 \(\hat v_{t+1}\) 作为分母。
因为 \(m_0=v_0=0\),训练初期的滑动平均会系统性偏小(“没热起来”)。Adam 用偏置修正把它拉回合理尺度:
\[\hat m_{t+1}=\frac{m_{t+1}}{1-\beta_1^{t+1}},\quad \hat v_{t+1}=\frac{v_{t+1}}{1-\beta_2^{t+1}}\]- \(\hat m_{t+1},\hat v_{t+1}\):偏置修正后的估计,用来抵消初始化为 0 导致的早期偏小。
- 分母 \(1-\beta^{t+1}\):校正“冷启动偏小”的缩放因子。由于初始化为 0,指数滑动平均在经历 \(t+1\) 次更新时只积累了约 \(1-\beta^{t+1}\) 的有效权重,因此会偏小;除以它相当于把估计值按同样比例放大回去。
更严格地说:若假设 \(\mathbb{E}[g_t]=\mu\) 近似稳定,则由递推可得 \(\mathbb{E}[m_{t+1}]=(1-\beta_1^{t+1})\mu\),因此 \(\hat m_{t+1}=\frac{m_{t+1}}{1-\beta_1^{t+1}}\) 是把它改成近似无偏估计。同理可得 \(\hat v_{t+1}\) 的修正。
- \(\theta_t\):第 \(t\) 步参数(权重向量/张量)。
- \(\eta\):学习率(全局步长系数)。
- \(\sqrt{\hat v_{t+1}}\):逐元素开方;整项 \(\frac{\hat m_{t+1}}{\sqrt{\hat v_{t+1}}+\epsilon}\) 表示逐元素相除。
- \(\epsilon\):数值稳定项,避免除以 0 或极小数。
分子给方向,分母给节奏。一个极端例子能看出为什么 Adam 用 \(\mathbb{E}[g^2]\) 而非方差:若某维梯度连续很多步都是 \(g_t=10\),方差为 0 会导致除法不稳定;但 \(\mathbb{E}[g^2]\approx 100\) 给出稳定尺度,最终更新量级约为 \(10/\sqrt{100}=1\)(再加 \(\epsilon\) 保底)。
Adam 往往更易调参、早期收敛更快,因此在 Transformer、扩散模型和很多深度网络里是默认起点。但它并非无条件最好:有些任务上,最终泛化仍可能不如精心调过的 SGD。实践中,配合权重衰减(Weight Decay)时,通常会使用 AdamW,把权重衰减从梯度自适应缩放里解耦出来,效果更稳。
AdamW(Adam with Decoupled Weight Decay)把权重衰减(Weight Decay)从 Adam 的自适应梯度缩放里解耦出来。原因是:在 Adam 这类自适应方法里,如果你把 L2 正则化写进损失(等价于把 \(\lambda\theta\) 加到梯度里),这个正则项也会被二阶矩 \(\hat v_t\) 的缩放影响,从而导致不同参数维度的“衰减强度”不再可控。
正则化本来应该是一个可控的、与梯度尺度无关的收缩力度;解耦后 \(\lambda\) 的含义更稳定。
对比两种写法会更清楚:
- 把 L2 正则化并入目标(常被口语化地称为“weight decay”,但在自适应优化器里并不等价):先算 \(g_t=\nabla_\theta L(\theta_t)+\lambda\theta_t\),再把这个 \(g_t\) 送入 Adam 的 \(m_t,v_t\) 与自适应步长。
- AdamW(解耦权重衰减):先算纯数据梯度 \(g_t=\nabla_\theta L(\theta_t)\) 并完成 Adam 的自适应更新,然后单独对参数做一次权重衰减。
AdamW 的参数更新可写成:
\[\theta_{t+1}=\theta_t-\eta\,\frac{\hat m_{t+1}}{\sqrt{\hat v_{t+1}}+\epsilon}-\eta\,\lambda\,\theta_t\]- 前半段 \(-\eta\,\frac{\hat m}{\sqrt{\hat v}+\epsilon}\):Adam 的自适应梯度更新(由数据损失驱动)。
- 后半段 \(-\eta\,\lambda\,\theta_t\):解耦的 weight decay(参数按比例收缩),其中 \(\lambda\) 是衰减强度。
其中第一项是 Adam 的自适应更新,第二项是独立的权重衰减(等价于每步把权重按比例拉向 0)。这种分离让 \(\lambda\) 更像一个真正可解释的“收缩强度”,在 Transformer 等模型上通常更稳定、更好调。工程实现里常见做法是:对 bias 与归一化层参数(如 LayerNorm 的 \(\gamma,\beta\))不做 weight decay,以免对尺度/偏置项造成不必要的收缩。
Adadelta、Adamax、Nadam 都可以看作对前述优化器的延伸,而非完全独立的新思想。Adadelta 试图修正 AdaGrad 学习率持续衰减的问题,用滑动窗口近似代替无限累积,并显式比较“更新量尺度”和“梯度尺度”;它在今天不再是默认主线,但在理解自适应学习率演进史时很重要。
Adamax 是 Adam 在 \(L_\infty\) 范数下的变体,用无穷范数尺度替代二阶矩尺度;Nadam 则把 Nesterov 动量思想引入 Adam。它们都并非 2026 年主流深度学习训练的默认首选,但属于常见优化器家族成员,因此在工程文档、旧代码或特定框架默认配置里仍会频繁出现。
Muon 是一种面向神经网络隐藏层(Hidden Layer)权重矩阵(Weight Matrix)的优化器。它与 Adam/AdamW 的根本差异在于:AdamW 会为每个参数维度单独估计更新尺度,并对梯度/更新量做逐元素(Element-wise)归一化;Muon 则把一个二维权重张量视为一个整体,直接利用矩阵结构来塑造更新方向。因此,Muon 更像一种矩阵感知(Matrix-aware)的优化器。
到 2026 年,Muon 已经不仅优化器研究里的边缘尝试,还进入了前沿大模型训练实践。DeepSeek V4 在其公开技术说明中,明确把 Muon Optimizer 列为核心训练升级之一,和混合注意力、mHC 并列。这个信号很重要:它说明在超大规模 Transformer 训练里,优化器设计已经已经从“AdamW 一统天下”扩展到开始针对隐藏层矩阵更新的几何结构做专门优化。
它的核心做法核心是改变“更新张量应该具有什么几何形状”。典型写法可以概括为:先对梯度做动量(Momentum)累积,再把这个矩阵更新做一次正交化(Orthogonalization)后处理,然后才真正更新参数:
\[M_{t+1}=\beta M_t+(1-\beta)G_t\] \[\Delta W_t=\mathrm{Orth}(M_{t+1}),\quad W_{t+1}=W_t-\eta\,\Delta W_t\]这里 \(G_t\) 是当前梯度矩阵, \(M_t\) 是动量缓冲, \(\mathrm{Orth}(\cdot)\) 表示把更新矩阵变换到更“接近正交(Orthogonal)”的形状。工程实现里,这一步通常用 Newton-Schulz 迭代(Newton-Schulz Iteration)高效近似完成,因此 Muon 常被概括为“对动量更新做正交化”。
DeepSeek V4 选择 Muon,核心是因为它同时满足了三条对超大模型训练非常现实的要求。
第一,Muon 与 Transformer / MoE 的参数形态高度匹配。DeepSeek V4 的主干里,大量最承重的可训练参数都来自注意力投影矩阵、MLP 线性层以及 MoE 专家里的大矩阵;而 Muon 正是把二维权重矩阵当作整体对象来优化,而非像 AdamW 那样把每个坐标近似看成相互独立。对这种“模型大头是矩阵,且矩阵内部几何结构很重要”的体系,Muon 天然比纯逐元素缩放更对口。
第二,Muon 在大模型训练中的可扩展性,已经被专门论文论证过。早期 Muon 更像“小模型上效果很好”的优化器;但后续《Muon is Scalable for LLM Training》这篇论文给出了两个把它真正推到大规模训练里的关键条件:加入 weight decay,以及仔细控制每参数更新尺度(per-parameter update scale)。论文的 scaling law 结果进一步表明,在 compute-optimal 训练设定下,Muon 相对 AdamW 可达到大约 2 倍的计算效率。这意味着 Muon 对前沿团队的吸引力,不仅“理论上可能更好”,还同样预算下更可能更快逼近目标性能。
第三,DeepSeek V4 的官方技术报告给出的目标非常直接:他们使用 Muon,是为了获得更快收敛(faster convergence)和更强训练稳定性(greater training stability)。这与 Muon 的优化逻辑是吻合的。Muon 不仅“把梯度缩一缩”,还试图把矩阵更新限制在更有结构的几何方向上,减少那些虽然逐元素看似合理、但从矩阵整体看会破坏谱结构和训练稳定性的更新。DeepSeek V4 的公开算法还进一步加入了 Nesterov 风格的动量组合、Hybrid Newton-Schulz 正交化,以及更新 RMS 重缩放,说明它们采用的核心是一套为大规模训练显式工程化过的版本。
因此,可以把 DeepSeek V4 选择 Muon 的原因压缩成一句话:当模型的主要学习对象本来就是大量巨型矩阵,并且训练预算、收敛速度与稳定性都成为一等约束时,矩阵感知型优化器会比纯逐元素自适应方法更有吸引力。Muon 正好提供了这样一条路线。
- 优势:对线性层/MLP/注意力里的二维权重矩阵,Muon 往往能给出更结构化的更新方向;在一些大模型训练设定下,它的训练效率与收敛速度优于 AdamW。
- 边界:Muon 并非全参数通吃的默认方案。它通常只用于隐藏层的二维参数;embedding、bias、归一化参数、输出层等非二维或语义不同的参数,实践中常继续交给 AdamW。
- 工程特征:它强调更新矩阵的谱结构(Spectral Structure),而非单个坐标的独立缩放;因此超参数分组与参数类型划分比 AdamW 更重要。
可以把 AdamW 与 Muon 的差别记成一句话:AdamW 解决“每个参数该走多大步”,Muon 进一步关心“整个矩阵应该以什么形状移动”。因此 Muon 更像是隐藏层矩阵优化的专用工具,而非对所有参数一视同仁的通用默认项。
学习率(Learning Rate)往往是最敏感的超参数之一。即使优化器相同,只要学习率设错,训练就可能完全失败。学习率调度(Learning Rate Scheduling)/退火(Annealing)的核心思想是:前期用相对大的步长快速下降,后期逐渐减小步长做精细收敛。
常见调度方式包括:
- Step decay:按 epoch 或 step 乘以固定因子衰减,简单直接。
- Linear decay:线性下降到较小值或 0,常用于大模型训练后段。
- Warmup + decay:先小步热身,再进入正常学习率,最后逐步衰减;对 Transformer 和大 batch 训练尤其常见。
- 余弦退火(Cosine Annealing):将学习率从较大值逐步衰减到较小值,把优化从“高温探索”过渡到“低温收敛”,在训练后期降低梯度噪声(gradient noise)与过冲(overshoot)风险,使参数能在极小值附近稳定细化。余弦曲线在起点与终点的一阶导数为 0,避免阶梯式衰减的突变,因而衰减更平滑、后期更柔和。
Warmup 为什么有用?因为训练刚开始时,参数还处在一个非常“生”的区域,梯度统计不稳定,若一上来就用很大学习率,模型容易发散。先用较小步长热身几百或几千步,再拉到目标学习率,通常更稳。
余弦退火的典型写法(从 \(\eta_{\max}\) 衰减到 \(\eta_{\min}\))为:
\[\eta(t)=\eta_{\min}+\frac{1}{2}(\eta_{\max}-\eta_{\min})\left(1+\cos\left(\pi\frac{t}{T}\right)\right)\]- \(\eta(t)\):第 \(t\) 步使用的学习率。
- \(\eta_{\max}\) / \(\eta_{\min}\):一个退火周期内的最大学习率与最小学习率。
- \(t\):当前步数(通常从 0 开始计),\(T\):该周期的总步数。
这个公式可以直接做两次代入来验证边界:当 \(t=0\) 时,\(\cos(0)=1\),所以 \(\eta(0)=\eta_{\max}\);当 \(t=T\) 时,\(\cos(\pi)=-1\),所以 \(\eta(T)=\eta_{\min}\)。中间学习率按半个余弦周期平滑下降。
通过余弦(Cosine)提供了一个非常干净的端点平滑(smooth endpoints)性质:在起点和终点处变化率为 0。对上式求导可得
\[\frac{d\eta}{dt}=-\frac{1}{2}(\eta_{\max}-\eta_{\min})\frac{\pi}{T}\sin\left(\pi\frac{t}{T}\right)\]因此 \(\sin(0)=\sin(\pi)=0\),学习率在周期开始与结束都不会出现突兀的“拐点”。相比之下,step decay 有不连续跳变,linear decay 在末端通常会突然到达下限并停止变化(出现不光滑的折点)。在非凸深度网络里,这种平滑退火往往更稳:前期保持较大步长便于探索,后期自然减小步长便于精细收敛。
工程上常见扩展是余弦重启(Cosine Annealing with Warm Restarts, SGDR):把训练过程切成多个周期,每个周期把 \(t\) 重新从 0 开始计(并可逐周期拉长 \(T\))。在标准 SGDR 中,学习率在周期边界是不连续的:它会在一个周期末端衰减到 \(\eta_{\min}\),并在下一个周期起点从 \(\eta_{\max}\) 重新开始(参数 \(\theta\) 不会重置)。
这种“重启”的作用核心是把优化过程从“后期小步精修”短暂切回“较大步长探索”,以应对非凸问题中的平台区(plateau)与次优盆地(suboptimal basin)。学习率拉高会增大每步更新幅度与梯度噪声(gradient noise)的有效影响,帮助轨迹跳出当前区域并探索新的吸引域;而如果当前区域确实是更稳健的平坦极小值(flat minimal),后续退火通常会把参数再次拉回并在附近更精细地收敛。工程上常见做法是把 \(\eta_{\max}\) 设在“不会破坏稳定性”的范围内;若重启瞬间仍担心不稳定,也可以在每次重启后加一个很短的 warmup,让学习率在少量步数内从较小值爬升到 \(\eta_{\max}\)。
没有一种调度策略对所有任务都最好。真正有效的做法是结合损失曲线、梯度稳定性、验证集表现和训练预算一起看:如果前期降不动,往往学习率偏小;如果剧烈震荡甚至发散,往往学习率偏大;如果后期长期卡在平台区,通常需要更细的衰减策略。
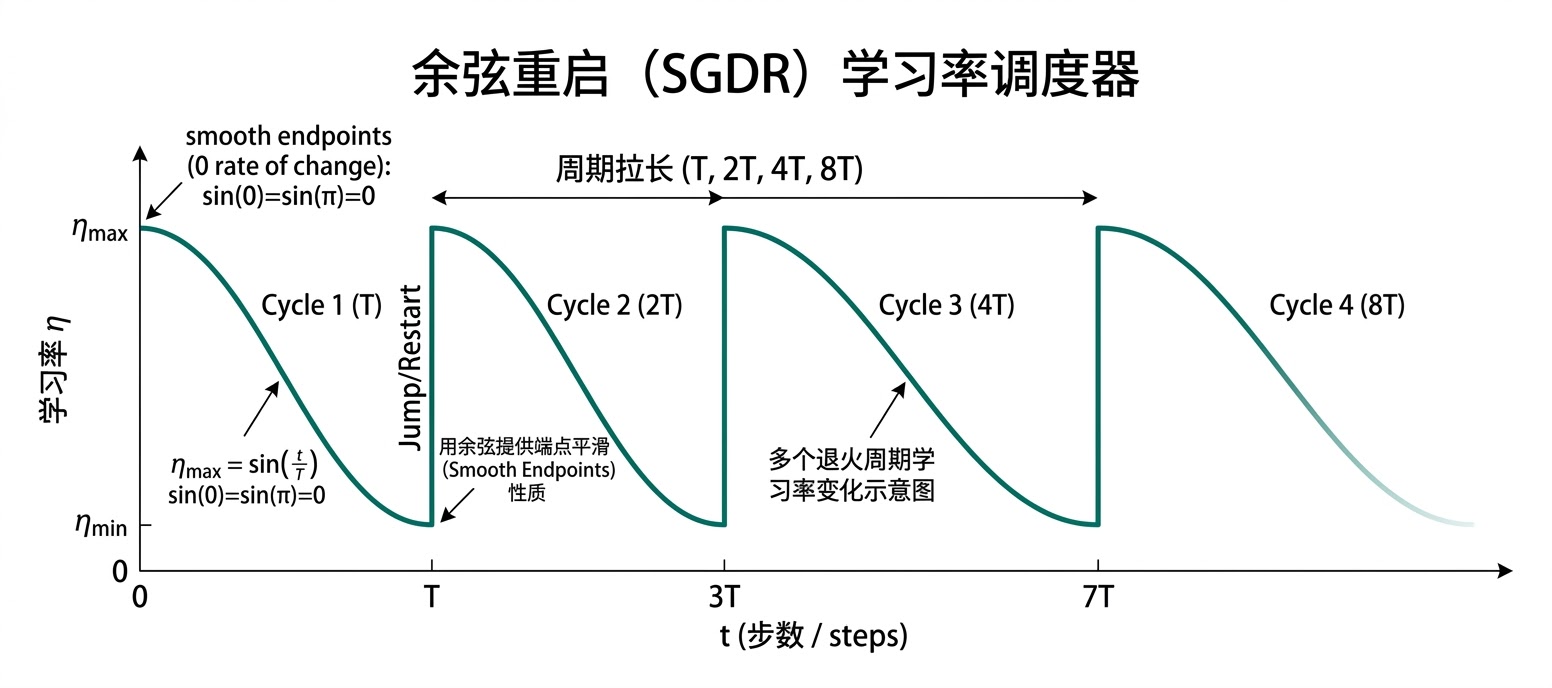
集成学习(Ensemble Learning)的核心思想是:让多个模型以某种组织方式共同决定结果,而非把预测完全押在一个模型上。它背后的统计直觉并不神秘:如果多个模型的误差来源不完全相同,那么组合后的总误差通常会更小、更稳、更抗偶然扰动。
从误差分解视角看,集成学习最常见的两条路线分别在处理两种不同问题。Bagging 更擅长压低方差(Variance),适合“单个模型很容易被训练集波动带偏”的情形;Boosting 更擅长逐步降低偏差(Bias),适合“单个弱学习器表达力不够,但可以通过连续修正变强”的情形。树模型恰好非常适合这两条路线:单棵深树高方差,适合拿去做 Bagging;浅层回归树可作为局部纠错器,适合拿去做 Boosting。
| 维度 | Bagging | Boosting | Stacking |
| 核心目标 | 降低方差,让模型更稳 | 降低偏差,让模型更准 | 学习如何组合不同模型,让互补性显式变成一个新模型 |
| 训练方式 | 多个基模型并行独立训练 | 多个弱学习器串行依次训练 | 先训练多个基模型,再训练一个元学习器做组合 |
| 每轮关注什么 | 同一个原始任务,但训练数据子集和特征视角不同 | 前一轮没有拟合好的误差、残差或负梯度 | 不同基模型的输出在什么条件下更可信 |
| 最终聚合 | 平均或投票 | 加权累加 | 由元学习器学习组合规则 |
| 典型代表 | 随机森林 | GBDT、XGBoost、LightGBM、CatBoost | 多模型堆叠集成 |
| 更像什么 | 多位评委独立打分后求平均 | 接力纠错,每个人只补前面没做好的部分 | 多位专家先各自判断,再由总负责人学习何时该信谁 |
Bagging(Bootstrap Aggregating)的核心做法是对训练集进行多次自助采样(bootstrap sampling),即反复执行有放回采样(sampling with replacement)生成多个训练子集,并在这些子集上分别训练基模型,以降低方差(Variance)。由于每个模型见到的数据子集略有差异,学到的决策边界不会完全一致;最后对预测结果做平均或多数投票,可抵消一部分过拟合噪声。
Bagging 的关键不在“模型一定很多”,而在人为制造模型之间的差异性。如果每个基模型看到的训练数据完全相同、特征也完全相同、优化过程也完全相同,那么把它们重复训练很多次并不会带来真正互补的信息。bootstrap 采样、特征子采样、不同随机初始化,本质上都在做同一件事:让多个模型不要犯完全一样的错。
例:如果单棵决策树很容易被训练集中的偶然样本带偏,那么训练 100 棵在不同 bootstrap 样本上的树,再投票,通常会比只用 1 棵树稳定得多。这也是随机森林的核心直觉。
Boosting 的思路与 Bagging 相反:它核心是“串行训练一串弱学习器(Weak Learners),让后一个模型专门修正前一个模型没做好的部分”。因此它更像“老师批改作业”:每一轮都盯着上轮最容易出错的题继续强化。
以加法模型视角看,Boosting 逐步构造
\[F_M(x)=\sum_{m=1}^{M}\alpha_m h_m(x)\]其中 \(h_m(x)\) 是第 \(m\) 个弱学习器, \(\alpha_m\) 是它的权重。公式核心是在表达:最终模型是“很多个简单模型的加权和”,每一轮都往当前模型上加一小块“修正项”。
这类“接力纠错”最直观的理解,是把当前模型与真实目标之间的差距看成下一轮的新任务。回归里,这个差距常直接表现为残差;更一般地,在可微损失下,它表现为损失对当前预测的负梯度。于是每一轮从去重学整个标签转向只学“接下来该往哪里补”。这就是 GBDT 家族能持续逼近目标函数的根本原因。
这里还可以再区分两种常见实现。较早的 Boosting,如 AdaBoost,更强调把之前分错的样本权重调高,让后续弱学习器更多关注难样本;GBDT 这一支则更强调直接拟合当前损失的残差或负梯度。两者都属于“串行纠错”,只是把“错误信息”传给下一轮的方式不同。
Boosting 也解释了为什么这类模型通常使用较浅的小树作为基学习器。因为每一棵树的职责核心是在当前模型基础上补一个局部修正。如果每棵树都长得很深、很强,单轮就可能把训练集吃得过满,后续串行叠加更容易过拟合;若每棵树只做小而稳的修正,再配合学习率与早停,整体通常更可控。
Stacking(堆叠集成)不仅平均多个模型输出,还再训练一个元学习器(Meta-Learner)去学习“什么时候该信哪个模型”。例如一个基模型擅长处理稀疏文本特征,另一个擅长处理数值特征,Stacking 可以学会在不同样本上动态加权它们。
它像“专家会诊 + 总负责人”:若文本模型和表格模型各有专长,元模型就负责综合判断谁在当前病例上更可信。
机器学习编程(Machine Learning Programming)处理的核心问题是:当一个模型被写成代码并真正运行起来时,谁负责组织训练流程,谁负责表达数学操作,谁又负责在具体硬件上把这些操作算快。这三层通常分别对应编程框架(Framework)、算子(Operator)和内核(Kernel)。理解这三个层次,有助于把“模型公式”与“工程实现”连接起来。
它们核心是一条自上而下的执行链。研究者或工程师先在框架里定义模型结构与训练流程;框架再把模型拆成一系列算子,例如矩阵乘法、卷积、归一化、激活、softmax;每个算子最终还需要落到某个硬件相关的内核实现上,才能在 CPU、GPU、TPU 或其他加速器上真正执行。因此,框架决定开发体验,算子决定计算图语义,内核决定实际运行效率。
框架(Framework)并非单一层次的概念。在现代机器学习工程里,至少要区分两层:一层是基础框架(Foundational Framework),负责张量(Tensor)、自动求导(Automatic Differentiation)、算子调度与底层执行;另一层是高层框架(High-level Framework),负责把某一类模型、某一类训练范式或某一类工程流程封装成更直接的接口。前者提供“地基”,后者提供“脚手架”和“现成结构”。
因此,PyTorch、TensorFlow、JAX 这类系统更适合放在基础框架层;而 Transformers、DeepSpeed、ModelScope、Lightning 这类工具,则更适合放在高层框架层。它们之间核心是典型的上下层关系:高层框架通常建立在基础框架之上,用更强的任务抽象、更少的模板代码和更完整的工程能力,把常见训练与推理流程直接组织起来。
从工程使用频率看,开发者最常接触的是一组已经按职责分层的常见框架:高层框架负责组织训练与推理流程,基础框架负责真正执行张量计算,某些系统还进一步偏向执行优化与部署。把这些名字放回分层结构里理解,比孤立记忆框架名称更清楚。
在深度学习框架之下,机器学习工程还依赖一层更基础的 Python 数据与实验组件。它们通常不直接定义神经网络,却决定数据是否能被稳定读取、清洗、切分、评估和复现。第 6 篇会从安装、API、目录结构和代码示例角度展开;这里先给出分层位置。
| 组件 | 分层位置 | 主要负责什么 | 和训练框架的关系 |
| NumPy | 数值计算底座 | ndarray、shape、stride、dtype、broadcasting、向量化计算 | 很多张量框架的用户心智来自 NumPy;数据进入 PyTorch/JAX/TensorFlow 前,经常先在 NumPy 里完成整理。 |
| pandas / Polars / PyArrow | 表格与列式数据层 | CSV/Parquet/Arrow IPC、表格清洗、列式扫描、memory map、大规模离线预处理 | 训练前的数据清洗与特征整理通常发生在这一层,再转成 Dataset、DataLoader 或 Parquet shard。 |
| Hugging Face Datasets | 机器学习数据集抽象 | 数据集加载、map/filter、cache、streaming、train/validation split | 和 Transformers/TRL/PEFT 生态衔接紧,常作为 LLM 微调和评估脚本的数据入口。 |
| tokenizers / tiktoken / SentencePiece | 文本输入标准化层 | 分词、编码、特殊 token、token budget、chat template 前后的长度估算 | tokenizer 的输出直接决定模型输入张量、attention mask、labels 和训练成本。 |
| scikit-learn | 经典机器学习 API 层 | fit/predict/predict_proba、Pipeline、ColumnTransformer、预处理、模型选择与指标 | 表格 baseline、特征工程和小模型评估常以它为基准,深度学习模型也经常复用其指标和切分工具。 |
| MLflow / W&B / TensorBoard / Langfuse | 实验跟踪与可观测性层 | 指标、参数、artifact、trace、prompt/response 日志、LLM 调用链观测 | 训练框架产出 loss/metric/checkpoint;观测系统负责长期记录、比较和审计。 |
高层框架的核心价值在于,它们在基础框架之上增加更强的任务语义、训练编排、模型生态或分布式能力。很多工程里,开发者日常接触最多的其实是这一层。
| 高层框架 | 主要依赖的基础框架 | 核心定位 | 替你封装了什么 | 最适合的场景 | 与基础框架的关系 |
| Transformers | 以 PyTorch 为主,也支持 TensorFlow 与 JAX / Flax | 预训练 Transformer 模型与任务头生态 | 模型定义、权重加载、tokenizer / processor、Trainer、pipeline、任务头 | NLP、LLM、多模态模型的微调与推理 | 通常核心是调用底层框架完成张量计算与反向传播 |
| DeepSpeed | 主要建立在 PyTorch 之上 | 大模型训练与推理优化框架 | ZeRO、参数分片、优化器状态管理、分布式训练编排、推理加速 | 超大模型训练、多卡 / 多机扩展、显存受限训练 | 本质上是对 PyTorch 训练过程的增强与重写,而非替代 PyTorch |
| Unsloth | 主要建立在 PyTorch 之上,并与 Transformers、PEFT、TRL 等 Hugging Face 生态深度协同 | 面向 LLM 微调与对齐的性能导向高层框架 | 快速加载与训练配方、QLoRA / DoRA / RL 配置、量化微调、长上下文训练、导出到 GGUF / Ollama / vLLM / Hugging Face | 单卡或少卡进行 LLM 微调、偏好对齐、消费级显卡上的高性价比实验 | 它在 PyTorch 或 Transformers 之上把“高效微调 + 导出部署”这条链路进一步封装并做性能优化 |
| TRL | PyTorch、Transformers、PEFT、Datasets | Hugging Face 生态里的后训练框架 | SFTTrainer、DPOTrainer、GRPOTrainer、RewardTrainer、奖励函数接口、偏好数据处理 | 中小规模 SFT、DPO、GRPO、奖励模型训练和快速算法验证 | 属于 Transformers 生态上的训练器层,底层模型、tokenizer、数据集和适配器仍主要来自 Hugging Face 生态 |
| OpenRLHF | PyTorch、Ray、DeepSpeed、vLLM | 面向在线 RLHF 的多角色分布式训练框架 | actor、critic、reference policy、reward model、vLLM rollout、Ray 调度、DeepSpeed ZeRO 配置 | 需要大规模在线 rollout、远程 reward 服务、PPO / DPO / GRPO / KTO 等后训练任务 | 把强化学习后训练拆成多个远程角色,并用 Ray 与 DeepSpeed 组织执行 |
| verl | PyTorch、Ray、FSDP / FSDP2、Megatron-LM、vLLM、SGLang | LLM 强化学习后训练框架 | HybridFlow 风格的单控制器编程、Ray 资源池、Actor-Rollout-Ref Worker、RewardManager、PPO / GRPO / RLOO / ReMax / REINFORCE++ 等算法入口 | SFT 之后的 RLHF、RLVR、GRPO、PPO、规则奖励或奖励模型驱动的大规模后训练 | 在基础训练框架和推理引擎之上组织完整 RL 后训练系统,训练计算仍落到 PyTorch / FSDP / Megatron 等后端 |
| ModelScope | 主要建立在 PyTorch 之上,也兼容其他学习框架与平台能力 | 模型社区 + SDK + 训练 / 推理工作流 | 模型获取、pipeline、训练入口、评测、部署衔接、领域模型集成 | 中文生态、多模态任务、快速调用开源模型并做微调 | 更像“模型平台层 + 高层开发框架”,下层训练仍要落到基础框架执行 |
| PyTorch Lightning | PyTorch | 训练流程组织框架 | Trainer、设备放置、日志、checkpoint、验证循环、分布式训练模板 | 希望保留 PyTorch 灵活性,同时减少训练样板代码 | 把 PyTorch 代码组织得更规范,但底层模型与梯度仍然是 PyTorch |
| Accelerate | PyTorch | 分布式训练与多设备执行抽象 | 多 GPU / 多机启动、混合精度、设备管理、统一训练脚本适配 | 想在尽量少改代码的前提下把 PyTorch 训练扩展到分布式环境 | 让同一份 PyTorch 代码更容易跨设备运行,定位是补充分布式启动与设备编排,而非取代 PyTorch 训练代码 |
| Keras 3 | 可运行在 TensorFlow、JAX、PyTorch 之上,推理还可对接 OpenVINO | 高层模型开发接口 | Layer / Model 抽象、训练接口、callback、分布式 API、生态组件 | 需要高层建模接口且希望在多后端之间切换 | 处于基础框架之上,强调统一建模接口,而非直接取代底层后端 |
| Sentence Transformers | 主要建立在 Transformers 与 PyTorch 之上 | Embedding 与 reranker 高层框架 | 文本向量化、相似度训练、检索 / rerank 训练器、评测工具 | 语义检索、向量召回、文本匹配、reranking | 属于面向特定任务族的高层框架,下层依赖 Transformers 与 PyTorch |
| MMEngine / OpenMMLab | 主要建立在 PyTorch 之上 | 通用训练引擎与视觉算法框架底座 | Runner、Hook、Config、数据流、训练 / 验证 / 测试流程组织 | 检测、分割、姿态估计等视觉任务 | 用统一工程抽象组织 PyTorch 训练,尤其适合复杂视觉实验体系 |
这一层最容易让人产生“它自己就能训练模型”的直觉,但从执行链条看,它们大多只是把训练过程组织得更高级。以 Transformers 为例,Trainer 可以发起训练,但底层的张量、梯度、优化器、自动求导与设备执行,通常仍然由 PyTorch 负责;Lightning、Accelerate、DeepSpeed 也是同样的逻辑,只是它们封装的侧重点不同。
TRL、OpenRLHF、verl、LLaMA-Factory、Axolotl 这类系统适合归入高层框架。它们通常不重新定义张量和自动求导,主要在 PyTorch、Transformers、DeepSpeed、FSDP、Megatron、vLLM、SGLang 之上组织训练任务。对 LLM 后训练而言,这一层封装的对象已经不只是“前向、损失、反向、优化器”,还包括 rollout 生成、奖励计算、reference policy、KL 约束、actor / critic 角色、权重同步、checkpoint 导出和实验追踪。
因此,后训练框架的选型首先取决于系统复杂度。TRL 更偏 trainer 接口,适合快速实验和 Hugging Face 生态内的算法验证;OpenRLHF 更偏 Ray + DeepSpeed + vLLM 的在线 RLHF 编排;verl 更偏统一 worker、资源池和多算法切换;LLaMA-Factory / Axolotl 更偏配置化工作台和批量实验管理。它们处在同一个分层位置,但工程抽象的重心不同。
Unsloth 最适合放在高层框架这一层理解。它基于 PyTorch、Transformers、PEFT、TRL 这一整套既有生态之上,把大语言模型(Large Language Model, LLM)的高频训练流程重新组织成更偏性能导向的开发体验。它解决的核心问题是怎样在尽可能小的显存和尽可能少的工程样板下,把 LLM 微调、对齐、导出与部署这条链路跑通。
从开发者视角看,Unsloth 的典型工作流通常仍然是“加载 Hugging Face 模型 → 挂接 PEFT 适配器 → 用监督微调(SFT)或强化学习(RL)训练 → 导出到下游推理栈”。它的价值在于把这条链上几个最痛的环节一起压平:第一,量化微调(如 LoRA / QLoRA)与长上下文训练更容易直接落地;第二,针对 GRPO 等对齐训练给出更直接的入口;第三,把训练后的模型或适配器导出到 GGUF、Ollama、vLLM、SGLang、Hugging Face 等下游环境的路径做得更短。换言之,Unsloth 核心是把已有生态串得更紧,并对其中最贵的显存、最长的上下文和最复杂的导出环节做专项优化。
它与其他高层框架的边界也需要分清。Transformers 的优势在于模型家族与任务头生态最通用;Accelerate 更像多设备执行抽象;DeepSpeed 更偏分布式训练、参数分片与大规模集群优化;Unsloth 则把重心压在“单机到小规模多卡场景下,如何更快、更省显存地完成 LLM 微调与对齐”。因此,它尤其适合消费级 GPU、本地实验、小团队快速验证、Notebook 驱动的训练流程,以及以 LoRA / QLoRA / RL 为主的大模型增量训练。若任务是超大规模集群预训练或需要复杂的跨机并行策略,DeepSpeed / Megatron 一类系统通常仍然更中心;若任务是通用模型调用与标准微调,Transformers 仍然是最基础的入口。
工程上可以把 Unsloth 看成“面向 LLM 微调的高性能工作台”。它一端连接 Hugging Face 模型与适配器生态,另一端连接本地推理、GGUF、Ollama、vLLM、SGLang 等部署路径,中间则用一套更偏性能调优的训练封装把它们粘起来。对初学者,它降低的是上手门槛:少改几处配置就能跑通量化微调或 RL;对熟悉生态的工程师,它降低的是试验成本:同样的显存预算下,能尝试更长上下文、更复杂的对齐流程,或更快地把训练结果导出到不同推理栈。它的本质依然是高层工程抽象,而非底层深度学习框架的替代品。
| 比较维度 | Transformers | DeepSpeed | Unsloth |
| 核心目标 | 统一模型与任务接口 | 放大训练规模与显存效率 | 压低 LLM 微调 / 对齐门槛并提升单机效率 |
| 最擅长的问题 | 模型加载、任务头、Trainer、pipeline | ZeRO、分布式并行、大模型集群训练 | QLoRA、GRPO、长上下文、快速导出部署 |
| 典型使用者 | 几乎所有 NLP / LLM 开发者 | 大模型平台与多机训练团队 | 本地实验者、个人开发者、小团队 LLM 微调工程师 |
| 与 PyTorch 的关系 | 调用其张量与训练能力 | 增强其训练与并行系统 | 在其之上重组 LLM 微调与导出流程 |
第 6 篇把训练、推理、RAG、Agent 与观测组件拆成了更细的工程章节。放回机器学习编程的总图里,它们大致可以按“训练组织、分布式系统、推理服务、检索应用、编排观测”五条线理解。
| 层次 | 代表组件 | 解决的问题 | 选型时先看什么 |
| 高层训练与微调工作台 | PEFT、PaddleNLP、LLaMA-Factory、Axolotl、Unsloth、ModelScope | 把模型加载、数据模板、LoRA/QLoRA、SFT/DPO/GRPO、导出部署组织成更少的配置和脚本。 | 底层生态是 Hugging Face、Paddle 还是 ModelScope;团队偏手写脚本、YAML 工作台还是 WebUI。 |
| 分布式训练系统 | DeepSpeed、Megatron-LM / Megatron Core、NeMo、ColossalAI、MindSpeed、PyTorch FSDP | 处理 ZeRO/FSDP 参数分片、TP/PP 并行、offload、分布式 checkpoint、集群 launcher 和通信优化。 | 硬件是 NVIDIA GPU 还是 Ascend NPU;训练是微调、继续预训练还是从零预训练;checkpoint 是否要跨并行拓扑迁移。 |
| 推理引擎与服务系统 | vLLM、SGLang、LMDeploy、TGI、TensorRT-LLM / Triton、llama.cpp、Ollama | 把模型权重变成可承载并发请求的服务,管理 KV cache、continuous batching、量化、OpenAI-compatible API 和多 GPU 部署。 | 目标是高吞吐、低延迟、本地运行、国产模型适配,还是 NVIDIA 深度优化部署。 |
| RAG 与向量检索 | Sentence Transformers、Haystack、FAISS、pgvector、Chroma、Qdrant、Milvus、Weaviate、TCVectorDB | 把文档分块、embedding、向量索引、BM25/hybrid retrieval、rerank 和生成链路组织起来。 | 数据规模、过滤/权限复杂度、是否需要托管服务、是否要把 RAG pipeline 做成可测试组件图。 |
| Agent 编排与工具协议 | LangChain、LangGraph、LlamaIndex、DSPy、AutoGen、CrewAI、MCP、OpenAI-compatible tool calling | 把模型调用、工具调用、状态机、长任务、审批、人机协同和外部系统连接起来。 | 流程是简单链式调用、可恢复状态图、数据/索引中心,还是多角色协作。 |
| 实验管理与可观测性 | TensorBoard、MLflow、Weights & Biases、Langfuse | 记录训练指标、配置、产物、LLM 调用链、prompt/response、用户反馈和线上回放。 | 关注训练实验对比、模型注册、LLM trace、生产审计还是团队协作看板。 |
基础框架直接定义张量运算、计算图、自动求导、优化器、算子调度与设备执行能力。它们离硬件更近,也离“神经网络真正怎样被算出来”更近。高层框架能否存在,首先取决于这一层是否提供了足够稳定和强大的底座。
| 基础框架 | 核心抽象 | 主要优势 | 最适合的场景 | 典型局限 |
| PyTorch | Tensor、 nn.Module、autograd、动态图(Dynamic Computation Graph) | 灵活、直观、研究生态最强,训练与调试体验优秀 | 研究、论文复现、大模型训练、需要自定义训练逻辑的任务 | 如果完全手写训练循环,工程样板代码较多,部署链路常需额外工具配合 |
| TensorFlow | Tensor、Layer / Model、自动求导、图执行与编译 | 训练与部署体系完整,服务化、端侧与工业链路成熟 | 企业级生产环境、需要完整训练到部署闭环的场景 | 研究阶段的编码与调试直观性通常不如 PyTorch |
| JAX | 数组(Array)+ 函数变换 + XLA 编译 | 编译优化强,函数式表达清晰,适合大规模并行数值计算 | 需要强编译能力、自定义并行策略、科研数值实验的任务 | 函数式编程习惯要求更高,工程生态相对更偏高级用户 |
| PaddlePaddle | Tensor、动态图 / 静态图、训练与产业工具链 | 中文生态与产业落地支持强,训练推理工具链完整 | 产业应用、教育场景、中文任务与本土化生态 | 国际社区规模与通用论文实现数量通常少于 PyTorch |
| MindSpore | Tensor、动态图 / 静态图、图编译、自动并行 | 与 Ascend NPU、CANN、MindFormers、MindSpeed 等生态协同紧密 | 昇腾集群、端边云协同、需要国产硬件栈深度适配的训练和推理任务 | 迁移 PyTorch/Transformers/DeepSpeed 资产时需要评估算子、checkpoint 与训练脚本改造成本 |
| OneFlow | Global Tensor、placement、SBP(Split / Broadcast / Partial) | 分布式张量布局表达清晰,适合研究并行计算与训练系统 | 需要显式描述张量在多设备网格上的切分、复制和归约路径 | 通用 LLM 微调生态规模通常小于 PyTorch / Hugging Face 主线 |
如果把机器学习工程比作建楼,那么基础框架提供的是钢筋、水泥、电路和承重结构。高层框架之所以能让开发速度显著提升,正是因为底层这些张量、梯度和算子能力已经由基础框架稳定提供。
除了高层框架和基础框架,还存在一类经常与“框架”混称、但职责不同的系统:执行与部署系统。它们的核心目标核心是让已经定义好的模型在特定硬件上更快、更省、更稳定地运行。
| 系统 | 主要定位 | 最常见作用 | 典型场景 | 与前两层的关系 |
| ONNX Runtime | 跨框架推理执行系统 | 加载 ONNX 图,做图优化、算子调度与多后端执行 | 统一部署、跨框架导出后的推理执行 | 位于模型定义之后,更接近运行时(Runtime)而非训练框架 |
| TensorRT | NVIDIA GPU 推理优化系统 | 图优化、层融合、量化与 kernel 自动选择 | 低延迟在线推理、高吞吐批量服务 | 通常接收上层框架导出的模型,再做更深的硬件侧优化 |
| TensorRT-LLM | NVIDIA LLM 推理优化系统 | 为大语言模型构建 engine,优化 attention、KV cache、并行切分和低精度推理 | 对吞吐、延迟和 GPU 利用率要求极高的生产推理服务 | 比通用推理框架更靠近硬件和 engine 构建流程,部署成本也更高 |
| vLLM / SGLang / TGI / LMDeploy | LLM 在线推理服务端 | OpenAI-compatible API、batching、KV cache、流式输出、多 GPU 服务和生成参数管理 | 把 LLM 权重交付成 HTTP 服务,承载 chat、RAG、Agent 和 rollout 请求 | 位于模型权重和业务 API 之间,重点是服务调度与请求生命周期管理 |
| llama.cpp / Ollama | 本地与边缘 LLM runtime | GGUF 权重加载、量化推理、本地 API、低运维成本运行 | 个人开发、离线演示、边缘设备、小模型本地服务 | 更关注部署便利性和本地运行,和大规模 GPU 服务的目标不同 |
| OpenVINO | Intel 硬件推理栈 | 模型转换、图优化、Intel CPU / iGPU / VPU 推理 | Intel 服务器与边缘设备部署 | 更接近部署后端,而非通用训练框架 |
| TVM | 深度学习编译栈 | 自动调优、代码生成、异构硬件适配 | 边缘部署、自定义芯片、性能工程 | 站在算子和内核之间,为不同硬件生成更优执行实现 |
因此,讨论“框架”时最好先分清是哪一层:高层框架负责把任务和流程组织起来,基础框架负责把张量与梯度真正算出来,执行与部署系统负责把已经定义好的模型在目标硬件上跑到更优。这三层一旦混在一起,很多看似相近的名词就会失去边界。
算子(Operator)是计算图(Computation Graph)的基本运算单元。它定义一个明确的数学变换:输入什么张量(Tensor)、输出什么张量、张量的形状(Shape)和数据类型(Data Type)如何变化,以及反向传播时梯度如何计算。框架层写出的模块、层、网络块,最终都会被拆解成一串更细粒度的算子。
从工程实现上看,算子这一层负责表达“数学语义”。例如一个线性层(Linear Layer)会被拆成 MatMul 与 Bias Add;一个自注意力(Self-Attention)模块会被拆成 Q/K/V 投影、MatMul、Scale、Mask、Softmax、再一次 MatMul、Dropout、LayerNorm 等。高层模块能否被编译优化,本质上取决于这些算子能否被识别、融合与高效执行。
常用算子可以分成四大类:线性代数与张量形状类、神经网络前向计算类、序列与索引操作类、训练与优化类。下面的表格按这一方式展开。
| 算子 | 核心作用 | 常见输入 / 输出 | 典型出现位置 | 实现与使用要点 |
| MatMul / GEMM | 矩阵乘法,完成线性投影与特征混合 | 二维或更高维张量,输出新的线性组合 | 全连接层、注意力投影、MLP | 最核心的高密度算子之一,常直接决定训练吞吐 |
| Batch MatMul | 批量矩阵乘法,多个矩阵对并行相乘 | 三维及以上张量 | 多头注意力(Multi-Head Attention) | 常与转置、缩放、mask 连用 |
| Add / Bias Add | 逐元素加法 | 两个可广播张量 | 残差连接、偏置项、特征融合 | 常被融合到前后算子中减少访存 |
| Sub / Mul / Div | 逐元素减法、乘法、除法 | 逐元素张量运算 | 归一化、门控、缩放 | 广播规则必须和张量形状匹配 |
| Scale | 用常数或向量对张量缩放 | 输入张量与标量 / 向量 | attention 中的 \(1/\sqrt{d_k}\) 缩放 | 经常被编译器与前后算子融合 |
| Transpose / Permute | 重排维度顺序 | 输入张量到相同元素、不同布局的张量 | NCHW / NHWC 转换,多头维度重排 | 逻辑上不改值,但常改变内存访问模式 |
| Reshape / View | 改变张量形状而不改变元素总数 | 同样的数据,不同 shape | 展平、分头、合并头、batch 展开 | 若内存不连续,可能触发额外复制 |
| Expand / BroadcastTo | 按广播规则扩展维度 | 低维张量扩展为高维张量 | 偏置广播、mask 扩展 | 逻辑扩展不一定真实复制数据 |
| Squeeze / Unsqueeze | 删除或插入长度为 1 的维度 | 维度数变化,数据值不变 | batch / channel 维调整 | 常用于接口对齐和算子拼接 |
| Concat / Stack | 拼接多个张量 | 多个同类型张量合并为一个 | 多特征合并、多分支网络 | Concat 沿已有维度拼接,Stack 会新增维度 |
| Split / Chunk | 将一个张量拆成多个子张量 | 一个张量拆成若干块 | Q/K/V 切分、多分支路径 | 与 Concat、Stack 常成对出现 |
| ReduceSum / ReduceMean / ReduceMax | 沿某些维度做聚合 | 高维张量压缩成低维张量 | 池化、loss 聚合、统计量计算 | 归约(Reduction)通常对并行实现要求较高 |
| EinSum | 用爱因斯坦求和规则表达复合张量运算 | 多个张量到一个张量 | 复杂线性代数、注意力原型实现 | 表达力强,但实际性能往往依赖后端是否能分解优化 |
| 算子 | 核心作用 | 常见输入 / 输出 | 典型出现位置 | 实现与使用要点 |
| Convolution | 局部感受野加权求和 | 特征图与卷积核,输出新的特征图 | CNN、视觉 backbone、语音模型 | 步幅、填充、分组卷积会显著影响性能与感受野 |
| Depthwise / Group Convolution | 按通道组或单通道卷积 | 特征图到特征图 | MobileNet、轻量视觉网络 | 减少计算量,但对 kernel 实现要求更高 |
| Pooling(Max / Avg) | 局部下采样与聚合 | 特征图压缩为空间更小的特征图 | CNN、时序聚合 | 降低分辨率与计算量,也带来信息损失 |
| Adaptive Pooling | 把输入压到固定输出尺寸 | 任意空间尺寸到固定尺寸 | 视觉分类头、全局池化 | 方便不同输入尺寸统一到下游全连接层 |
| ReLU | 负值截断为 0 的激活函数 | 逐元素非线性变换 | MLP、CNN、分类头 | 实现简单,稀疏性强 |
| GELU | 平滑激活,保留小负值的连续变化 | 逐元素非线性变换 | Transformer、LLM MLP | 现代语言模型最常见的激活之一 |
| SiLU / Swish | 输入与 sigmoid 门控的乘积 | 逐元素非线性变换 | 高性能视觉与语言模型 | 平滑、效果稳定,常见于新型 backbone |
| Sigmoid | 把实数映射到 \((0,1)\) | 逐元素概率化 | 门控单元、二分类输出、多标签任务 | 饱和区梯度小,深层网络中通常不作主激活 |
| Tanh | 把实数映射到 \((-1,1)\) | 逐元素非线性变换 | 早期 RNN、门控结构 | 零中心,但同样存在饱和问题 |
| Softmax | 把一组分数归一化为概率分布 | 类别分数到概率 | 多分类头、attention 权重 | 常与交叉熵和 mask 配合,数值稳定性关键 |
| LayerNorm | 对单个样本的最后若干维做归一化 | 输入张量到同 shape 张量 | Transformer、LLM | 不依赖 batch 统计量,适合变长序列 |
| BatchNorm | 利用 batch 统计量做归一化 | 输入张量到同 shape 张量 | CNN、视觉任务 | 训练与推理行为不同,小 batch 时效果可能下降 |
| RMSNorm | 基于均方根做归一化 | 输入张量到同 shape 张量 | 许多现代大语言模型 | 比 LayerNorm 更简洁,计算更轻 |
| Attention / SDPA | 基于相似度对值向量加权聚合 | Q、K、V 到上下文表示 | Transformer、跨模态模型 | 高层看是算子族,底层常映射到 FlashAttention 等 kernel |
| Embedding Lookup | 根据离散索引查表取向量 | token id 到 embedding 向量 | NLP、推荐系统、类别特征 | 本质是参数矩阵的索引读取,并非普通 MatMul |
| 算子 | 核心作用 | 常见输入 / 输出 | 典型出现位置 | 实现与使用要点 |
| Gather | 按给定索引抽取元素或切片 | 源张量与索引张量 | embedding、beam search、采样 | 访问模式离散,容易受内存带宽限制 |
| Scatter / ScatterAdd | 按索引写回或累加 | 目标张量、索引、更新值 | 图神经网络、稀疏更新 | 并发写冲突和原子操作代价常是性能瓶颈 |
| Index Select | 按某一维选取指定位置 | 张量与一维索引 | 子序列抽取、类别筛选 | 语义上比通用 gather 更窄,但常更清晰 |
| Slice / Narrow | 截取连续区间 | 大张量切出子张量 | 窗口注意力、局部特征抽取 | 若数据连续,可几乎零开销视图化 |
| Mask Fill / Select | 按布尔掩码选择或填充值 | 张量与 mask | attention mask、padding 屏蔽 | 对变长序列与非法位置处理非常关键 |
| Where | 按条件在两个值之间选择 | 条件张量与候选张量 | 条件计算、loss 屏蔽、数值裁剪 | 本质是逐元素条件分支 |
| Argmax / Argmin | 返回最大 / 最小值所在索引 | 张量到索引 | 分类预测、贪心解码 | 输出是位置而非概率,通常不可导 |
| TopK | 返回前 \(k\) 个值及其索引 | 张量到值与索引 | 检索、beam search、采样截断 | 常与排序、候选筛选结合 |
| Sort / Argsort | 排序并返回顺序 | 张量到排序结果 | 排序损失、候选重排 | 复杂度高,尽量只在必要路径中使用 |
| Pad | 在边界补零或补指定值 | 原张量到更大张量 | 卷积前处理、batch 对齐、序列补齐 | padding 策略会影响有效计算比例 |
| Pack / Unpack Sequence | 压缩或还原变长序列表示 | 变长序列与紧凑表示之间转换 | RNN、语音与时序模型 | 用于减少 padding 带来的无效计算 |
| Position Encoding Add | 注入位置信息 | token 表示与位置编码 | Transformer、序列模型 | 绝对位置、相对位置、RoPE 在实现形式上不同 |
| 算子 | 核心作用 | 常见输入 / 输出 | 典型出现位置 | 实现与使用要点 |
| Dropout | 训练时随机失活部分单元 | 输入张量到稀疏化后的张量 | MLP、attention、分类头 | 训练和推理行为不同,推理阶段通常关闭 |
| Cross-Entropy Loss | 衡量预测分布与真实类别的差距 | logits 与标签到标量损失 | 分类、语言模型、token 分类 | 实现中常与 log-softmax 融合提高稳定性 |
| NLL Loss | 负对数似然损失 | 对数概率与标签到损失 | 分类任务、序列建模 | 通常接在 log-softmax 之后 |
| MSE Loss | 均方误差 | 预测值与目标值到损失 | 回归、蒸馏、表示对齐 | 对异常值较敏感 |
| L1 / SmoothL1 Loss | 绝对误差或平滑绝对误差 | 预测值与目标值到损失 | 目标检测、鲁棒回归 | 比 MSE 对异常值更稳 |
| KL Divergence | 衡量两个分布之间的差异 | 两个概率分布到标量 | 知识蒸馏、VAE、分布对齐 | 输入通常需要是概率或对数概率 |
| Backward / Gradient | 沿计算图反向传播梯度 | 损失到各参数梯度 | 所有训练流程 | 框架自动求导的核心能力就体现在这里 |
| Gradient Clip | 限制梯度范数或幅值 | 梯度到裁剪后梯度 | RNN、大模型训练 | 控制梯度爆炸,提升训练稳定性 |
| Optimizer Step(SGD / Adam / AdamW) | 根据梯度更新参数 | 参数、梯度、状态到新参数 | 每一步训练迭代 | 常被实现为 fused optimizer kernel 以减少开销 |
| Weight Decay | 对参数施加正则化收缩 | 参数到受约束更新 | 分类、语言模型、视觉模型 | 现代实现常与 AdamW 解耦 |
| AllReduce | 跨设备聚合梯度或统计量 | 多卡张量到同步后的张量 | 数据并行训练 | 严格说更接近通信算子,但在训练图中极常见 |
| AllGather / ReduceScatter | 跨设备收集或切分张量 | 多设备张量通信 | 张量并行、序列并行、ZeRO | 大模型分布式训练不可缺少 |
因此,算子层是连接“模型定义”和“底层执行”的语义中枢。看懂模型实际调用了哪些算子,基本就等于看懂了它在做哪些数学步骤,以及这些步骤能否被进一步融合和加速。
内核(Kernel)是算子的底层实现。它规定了某个算子如何映射到具体硬件:线程如何组织、数据如何分块、是否使用共享内存(Shared Memory)、是否调用向量化指令、是否走 Tensor Core、是否把多个小算子融合成一次执行。若说算子定义的是“做什么”,那么内核定义的就是“怎样在这台机器上把它做快”。
从性能工程角度看,内核层回答的是:同一个数学算子,针对不同硬件、数据形状、精度格式和访存模式,哪种实现最优。因此,表面上同样是 MatMul、LayerNorm 或 Attention,不同框架和后端的速度会相差很大。
常见内核或内核族可以按下表理解:
| 内核 / 内核族 | 主要服务的算子 | 典型硬件 / 后端 | 核心优化手段 | 最典型的收益 | 常见场景 |
| cuBLAS GEMM kernel | MatMul、Linear、Batch MatMul | NVIDIA GPU | tile blocking、Tensor Core、流水线、寄存器复用 | 把矩阵乘法做到接近硬件峰值吞吐 | 全连接层、attention 投影、MLP |
| cuDNN Convolution kernel | Convolution、Pooling、部分归一化与激活 | NVIDIA GPU | direct convolution、im2col + GEMM、Winograd、FFT 自动选择 | 按输入形状自动切换最优卷积路径 | CNN、视觉 backbone、语音前端 |
| oneDNN / MKL kernel | MatMul、Convolution、Normalization | x86 CPU | SIMD 向量化、cache blocking、线程并行 | 提升 CPU 推理与训练效率 | 服务器 CPU 推理、无 GPU 环境 |
| NCCL communication kernel | AllReduce、AllGather、ReduceScatter、Broadcast | NVIDIA 多 GPU | 环形通信(Ring)、树形通信(Tree)、链路拓扑优化 | 降低多卡同步开销 | 数据并行、张量并行、大模型训练 |
| FlashAttention kernel | Scaled Dot-Product Attention | NVIDIA GPU 及其他支持相应实现的加速器 | 分块、在线 softmax、kernel fusion、减少 HBM 访存 | 把 attention 从显存瓶颈拉回到更接近计算瓶颈 | Transformer、LLM、长序列建模 |
| Fused LayerNorm / RMSNorm kernel | LayerNorm、RMSNorm、Bias Add、Residual Add | GPU / CPU 后端 | 多步逐元素运算融合为一次访存 | 显著降低 memory-bound 算子的开销 | Transformer block、LLM 推理 |
| Fused MLP kernel | Bias Add、GELU / SiLU、Dropout、Residual | GPU | 把连续逐元素算子合并,减少中间张量写回 | 减少 kernel launch 次数与显存读写 | MLP block、前馈网络 |
| Triton custom kernel | 任意自定义算子或 fused operator | GPU | 开发者手写 tile、访存布局与并行策略 | 在通用库缺少最优实现时获得定制性能 | 大模型训练、研究型性能优化、自定义融合 |
| TensorRT generated kernel | 部署图中的卷积、MatMul、激活、归一化、量化路径 | NVIDIA GPU | 图优化、层融合、低精度选择、kernel autotuning | 显著降低推理时延并提升吞吐 | 在线推理服务、边缘推理 |
| XLA generated kernel | JAX / TensorFlow 图中的可融合算子子图 | GPU、TPU 等 | 图级融合、静态形状分析、编译生成目标代码 | 让一串算子整体下沉为更大的执行单元 | JAX 训练、TPU 训练、编译型执行场景 |
| TVM generated kernel | 自定义张量表达式对应的算子 | CPU、GPU、边缘加速器 | 自动调度、自动搜索、代码生成 | 跨异构硬件获得针对性实现 | 端侧部署、自定义芯片适配 |
| PagedAttention / KV-cache kernel | 增量解码中的 attention 与缓存访问 | LLM 推理后端 | 分页管理 KV cache、优化随机访问和 batch 合并 | 提升长上下文与多请求并发推理效率 | 大语言模型在线推理 |
理解内核时最重要的一点是:一个算子并不对应唯一实现。同样是卷积,可以选 direct convolution、Winograd 或 FFT;同样是 attention,可以选普通分步实现、FlashAttention 或推理场景下的 paged attention。真正的差异往往不在数学定义,而在访存方式、融合策略、并行粒度和硬件利用率上。
因此,内核并非建模阶段最先暴露给用户的对象,却往往决定模型最终的吞吐、时延、显存占用、能耗和成本。模型结构决定“上限在哪里”,内核质量决定“这个上限能兑现多少”。
把三者串起来看,一个卷积层或注意力层的执行路径通常是这样的:开发者先在 PyTorch 或 JAX 中写出一个模块;框架把它拆成若干算子,例如 MatMul、Softmax、LayerNorm 或 Convolution;运行时再为每个算子选择对应硬件上的 kernel,例如 cuBLAS 的 GEMM kernel、cuDNN 的 convolution kernel,或 Triton 写成的自定义 fused kernel。整个训练与推理过程由框架负责调度,算子负责表达数学语义,内核负责把语义变成高性能机器代码。
可以用一个具体例子来理解。若在 PyTorch 中定义一个卷积层,那么:
- PyTorch 作为框架负责接收模块定义、组织张量、记录梯度关系并调度执行。
- 卷积(Convolution)作为算子表示“输入特征图与卷积核做局部加权求和”这一数学操作。
- 底层可能调用 cuDNN 提供的卷积 kernel,在 GPU 上以高度优化的方式完成真正计算。
同样地,在 Transformer 中写一层自注意力时,框架会组织前向与反向图;MatMul、Softmax、Mask、LayerNorm 等作为算子组成计算链;而 FlashAttention、fused LayerNorm、paged attention 这类高性能实现,则属于内核或 kernel-level optimization 的范畴。
因此,这三个层次的关系可以概括为:框架管理整个建模与执行流程,算子定义模型中的数学步骤,内核负责把这些步骤在具体硬件上高效落地。从研究到工程落地的能力鸿沟,往往正体现在能否同时理解这三层。
经典机器学习的模型选择,本质上是在任务形式、数据规模、特征形态、可解释性要求、训练与推断成本之间做匹配。只要先判断“有没有标签”“输出是什么类型”“样本量有多大”“特征是否稀疏或非线性”“是否需要概率或规则解释”,大多数任务都可以迅速缩小到少数几个候选模型。
本章中的模型核心是按建模假设来区分。线性模型假设边界或关系接近线性;树模型更擅长表格数据中的非线性交互;概率模型更强调分布解释;近邻模型依赖局部相似性;聚类与降维模型关注无监督结构;HMM(Hidden Markov Model, HMM)和条件随机场(Conditional Random Field, CRF)则处理序列标签之间存在依赖的结构化预测问题。
下面的表格核心是直接服务于选型。每一行都回答五个问题:什么情况下优先选它、它最依赖什么数据条件、它能解决什么核心诉求、为什么它在该场景里合适、以及什么情况下应当换模型。在大多数工程场景里,先按这些表格缩小范围,再进入具体模型细节,效率最高。
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 逻辑回归 | 需要稳定强基线、需要概率输出、需要解释每个特征如何影响类别 | 特征可以线性分离到一定程度;高维稀疏特征尤其合适,如 one-hot、词袋、统计特征 | 训练快、概率自然、权重可解释,适合作为第一版可上线模型 | 类别边界高度非线性、特征交互复杂且没有显式特征工程时 |
| 支持向量机(SVM) | 样本中小规模、类别边界较清晰、希望用最大间隔提升泛化稳健性 | 特征需要做尺度统一;核 SVM 更适合中小规模,不适合超大样本 | 对边界样本建模强,在线性不可分但结构仍较规整时往往优于纯线性模型 | 数据量很大、需要快速训练与部署、或者必须输出天然概率时 |
| 决策树 | 需要把模型直接解释成规则路径,或业务天然是“按阈值分流”的形式 | 表格特征、混合数值与类别特征都可;不强依赖标准化 | 规则可视化最直接,便于和业务规则、审计规则对齐 | 追求最稳泛化性能时;单树通常方差高,容易过拟合 |
| 随机森林 | 表格分类需要稳健基线、希望少调参、担心单棵树过拟合 | 适合中等规模表格数据;对噪声、缺失和特征尺度通常更宽容 | 比单树稳定,通常先于复杂 boosting 模型给出可靠结果 | 追求表格任务的极致精度,或需要很小的模型体积时 |
| 梯度提升树(GBDT) | 表格分类精度优先,特征中存在明显非线性与交互效应 | 适合结构化特征,不要求线性关系;通常需要一定调参 | 能逐轮修正前一轮错误,在中等规模表格任务上常是强力基线 | 需要极快训练、极少调参,或数据已经极大到串行 boosting 成本明显偏高时 |
| XGBoost | 工业表格分类、竞赛任务、缺失值与正则化处理都很重要 | 适合中大规模结构化数据;对特征工程和超参数较敏感,但工程支持成熟 | 精度高、鲁棒、缺失值处理成熟,是很多表格分类任务的首选之一 | 极端大规模、极度强调训练速度与内存效率时,LightGBM 往往更优先 |
| LightGBM | 大规模表格分类、高维稀疏特征、需要更快训练与更低内存消耗 | 适合样本量大、特征维度高的结构化任务;对类别特征和稀疏特征较友好 | 训练快、工程效率高,在工业 CTR、风控、推荐特征场景很常见 | 数据量较小且噪声较大时;叶子生长策略若不控制,容易过拟合 |
| 朴素贝叶斯 | 需要极快文本分类基线、小样本启动、希望先验证特征是否有判别力 | 最适合词袋、词频、计数类高维稀疏特征;默认接受条件独立近似 | 训练和推断都极快,在垃圾邮件、主题粗分类等任务上常有效 | 强依赖复杂特征相关性、类别边界非线性明显、或需要高精度概率校准时 |
| K 近邻(KNN) | 样本规模小、相似样本应有相似标签、希望不做显式训练 | 距离度量必须有意义;所有特征应标准化,且维度不能过高 | 局部模式直观,适合做小数据原型验证或相似样本检索式分类 | 高维稀疏特征、大规模数据、低延迟在线推断场景 |
| 线性判别分析(LDA) | 有监督分类同时希望压缩特征维度,且类别统计结构较稳定 | 更适合每类近似高斯、类内协方差可估计的情况;样本数不能太少 | 把“降维”和“分类判别”结合起来,适合先压缩再分类的流程 | 类别分布非常复杂、强非高斯、强非线性时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 线性回归 | 需要连续值预测、希望建立可解释、可审计、可稳定复现的基线 | 目标与特征大致满足线性关系,或经过变换后接近线性 | 系数解释直观,便于分析“哪个因素把目标推高或拉低” | 目标关系明显呈现复杂分段、交互或强非线性时 |
| Lasso(L1 正则化) | 特征很多、怀疑只有少数特征真正有效、希望模型自动做变量筛选 | 高维特征尤其适合;允许部分权重被压到 0 | 回归同时完成特征选择,适合构建更稀疏、更简洁的模型 | 大量强相关特征共同起作用时;它可能只保留其中部分特征 |
| 岭回归 / L2 正则化 | 特征共线性明显、担心普通线性回归权重不稳定 | 适合多个相关特征共同解释目标,而不希望稀疏淘汰其中一部分 | 通过收缩权重降低方差,使模型在相关特征场景下更稳定 | 首要目标是做特征筛选、希望很多系数直接变成 0 时 |
| Elastic Net(L1 + L2 正则化) | 既想做特征选择,又不希望在相关特征组上过于不稳定 | 高维、相关特征并存的回归任务最常见 | 综合 Lasso 与岭回归的优点,在稀疏性和稳定性之间折中 | 特征数量不多、模型目标非常简单时;其调参成本高于纯 L1 或 L2 |
| 决策树 | 目标值与输入关系近似分段函数,或业务逻辑天然围绕阈值展开 | 表格特征、混合类型特征都可;不需要严格线性假设 | 能学出“满足什么条件时预测值跳到哪个区间”的规则 | 希望预测曲线平滑、稳定,或希望泛化误差尽可能低时 |
| 随机森林 | 希望回归稳健、抗噪声、少调参,先拿到可靠效果 | 表格回归场景最常见;对特征尺度和局部异常较稳 | 综合多个树模型平均结果,通常比单树更不容易过拟合 | 要求外推能力强,或希望模型极度轻量、延迟极低时 |
| 梯度提升树(GBDT) | 表格回归精度优先,目标和特征之间存在复杂非线性 | 适合异构表格特征;对异常值和长尾目标通常也较有韧性 | 在房价、评分、收益、风险等典型表格回归中常是强基线 | 算力非常紧、需要极低训练成本时 |
| XGBoost / LightGBM | 工业级表格回归、大规模特征、希望兼顾精度与工程效率 | 适合结构化数据;XGBoost 更稳健成熟,LightGBM 更强调速度与规模 | 常作为表格回归默认候选,能直接处理大量非线性和特征交互 | 数据关系本来就简单线性、并且强依赖系数解释时 |
| K 近邻(KNN) | 局部相似样本的目标值应当接近,希望用邻域平均直接预测 | 小数据、低维、有意义的距离度量是前提 | 局部平滑性强时实现简单有效,适合作为相似样本回归基线 | 高维、大样本、分布稀疏或在线延迟敏感时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| K-Means | 需要快速把样本分成若干组,并且预期每组都围绕某个均值中心展开 | 簇大致是球形或凸形;欧氏距离有意义;需要先给定 \(K\) | 速度快、实现简单,适合作为无监督分群第一选择 | 簇形状复杂、密度差异大、离群点很多或无法预先估计簇数时 |
| 层次聚类 | 不仅想得到分组结果,还想知道各组是如何逐层合并成层级结构的 | 更适合中小规模数据;需要能接受 \(O(N^2)\) 级别距离矩阵成本 | 能输出树状图,适合做群体结构分析与多粒度解释 | 数据量很大、只关心最终聚类标签、不关心层级关系时 |
| DBSCAN | 希望识别任意形状簇,并把稀疏孤立点单独作为噪声剔除 | 密度尺度相对统一;距离度量有意义;参数 \(\epsilon\) 邻域半径和最小点数可估计 | 不需要预设簇数,能自然处理非凸簇和离群点 | 不同区域密度差异很大时;单一密度阈值难兼顾所有簇 |
| HDBSCAN | 簇的密度明显不一致,希望保留 DBSCAN 的密度思想但更自适应 | 数据存在多密度结构;仍需合理距离度量 | 比 DBSCAN 更能处理“有的簇很密、有的簇较松”的真实数据 | 只需要一个快速、简单、可复现的基础分群结果时 |
| Leiden | 样本更适合先构成相似图,再按图上的社区结构分群;或者本身就是网络数据 | 已有图结构,或可以稳定构造 kNN / 相似图;更关心连通社区而非欧氏球形簇 | 能直接在图上优化社区划分,通常比 Louvain 更稳定,且更能避免内部断裂社区 | 原始特征空间中的欧氏距离本身就足够表达簇结构,且不希望引入构图步骤时 |
| 高斯混合模型(GMM) | 希望得到软聚类结果,或者认为每个簇更像椭球形概率团块 | 连续特征较适合;默认每个簇可近似为一个高斯成分 | 不仅给簇标签,还给每个样本属于各簇的概率 | 簇形状非常复杂、非高斯、多峰结构难用少量高斯逼近时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 主成分分析(PCA) | 希望做线性降维、压缩冗余特征、去噪或为下游模型降成本 | 主要结构能由少数线性主方向解释;不依赖标签 | 保留最大方差方向,是最稳健、最常用的无监督降维起点 | 真正关心的是类别判别性而非总体方差,或数据结构强非线性时 |
| 线性判别分析(LDA) | 有标签并希望把不同类别拉开后再做分类或可视化 | 类别标签可靠;类内散度与类间散度都可稳定估计 | 直接围绕“可分性”找投影,比 PCA 更贴近分类目标 | 没有标签、类别边界强非线性、或类别数太少导致可降维空间有限时 |
| t-SNE | 想把高维嵌入压到二维或三维,只为看局部邻域是否形成簇 | 更适合可视化,不适合直接做可逆特征压缩 | 局部邻域展示能力强,适合分析表征是否把相似样本聚到一起 | 需要把降维结果直接送入生产模型,或需要保留严格全局距离关系时 |
| UMAP | 希望做更快的大规模可视化,兼顾局部结构与部分全局连通性 | 适合高维嵌入、文本向量、图表示等复杂表征 | 通常比 t-SNE 更快,也更容易保留大体流形结构 | 需要线性可解释主方向,或需要结果完全稳定可重复到坐标级别时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 孤立森林(Isolation Forest) | 通用表格异常检测,希望先得到一个稳健、扩展性好的异常分数 | 适合中大规模数据;不要求明确概率分布形式 | 通过随机切分隔离少数样本,通常是异常检测第一基线 | 异常定义依赖非常精细的局部密度差异时 |
| 局部异常因子(LOF) | 异常核心是“在本地邻域里显得稀疏” | 距离度量必须合理;样本规模不宜过大 | 能发现那些整体位置不极端、但局部密度明显偏低的点 | 高维距离失真严重、或需要高吞吐在线检测时 |
| 单类支持向量机(One-Class SVM) | 只有正常样本,目标是学习正常数据的封闭边界 | 特征需标准化;更适合中小规模;核方法对边界形状有帮助 | 适合“正常类定义清楚、异常类没有稳定样本”的场景 | 数据量很大、特征维度很高、参数难以稳定选择时 |
| 高斯混合模型(GMM) | 希望把异常定义为低概率区域,并明确得到似然分数 | 连续数据更合适;分布能用若干高斯混合近似 | 异常判定有明确概率语义,适合风险评分和阈值分析 | 数据分布非常复杂、非高斯、或异常并不等价于低密度时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 隐马尔可夫模型(HMM) | 序列较短、转移规律明显、希望在较小数据和较强先验下完成基础序列建模 | 状态转移与观测发射假设大致成立;问题适合生成式描述 | 结构清晰、推断高效,适合作为经典序列建模入门和小规模基线 | 标签强依赖全局上下文、特征复杂、需要大量判别式特征时 |
| 最大熵模型 / MEMM | 希望直接建模条件概率,并用丰富离散特征做局部判别 | 手工特征、局部上下文和当前位置证据较强;可接受局部归一化 | 训练方便、可解释性较强,是传统 NLP 判别式序列建模的重要过渡路线 | 标签偏置(Label Bias)明显、需要整条路径全局归一化或强结构一致性时 |
| 条件随机场(CRF) | 输出是整条标签序列而非单点分类,并且相邻标签的合法性非常关键 | 一维链式序列最合适;上游特征或表示需要至少能提供较强局部证据 | 通过整体解码约束标签转移,使最终标签序列更一致、更符合任务结构 | 长距离语义主要由强表征模型决定、标签约束作用很弱,或任务更适合 span 建模时 |
| 结构化感知机 | 希望直接按任务评价函数更新结构化输出,强调错误驱动的大间隔修正 | 需要一个可解码的结构空间,例如序列、依存树或其他组合输出 | 训练目标直接对准“预测结构和真实结构的差异”,实现简洁、更新高效 | 需要良好概率解释、后验分数或复杂不确定性估计时 |
| 模型 | 优先选择条件 | 数据与特征前提 | 最主要价值 | 不建议优先使用的情况 |
| 朴素贝叶斯 | 希望快速得到后验概率分类器,并接受条件独立近似 | 高维稀疏离散特征最合适,如文本词频、词出现计数 | 概率形式直接、估计简单,适合快速建模和在线系统 | 特征依赖结构复杂、需要精细表达联合分布时 |
| 高斯混合模型(GMM) | 希望显式建模连续数据分布,或需要软聚类与密度估计统一完成 | 连续数据、多峰分布、可近似为若干高斯成分 | 每个样本都能得到各成分责任概率,解释和阈值分析都较自然 | 分布极端复杂、重尾严重、或高斯成分数难合理确定时 |
| 隐马尔可夫模型(HMM) | 不仅要建模观测分布,还要建模隐藏状态在时间上的转移机制 | 观测是序列,且状态依赖主要体现在相邻时刻 | 把“序列生成机制”和“时序转移规律”统一到一个概率模型里 | 长程依赖很强、局部马尔可夫假设明显不成立时 |
若只是要一个工程上可执行的默认起点,可以进一步压缩成如下规则:表格分类与回归优先从随机森林、GBDT、XGBoost、LightGBM 和线性模型里选;文本高维稀疏分类优先看逻辑回归和朴素贝叶斯;无监督分群先看 K-Means,再根据簇形状和噪声情况转向 DBSCAN、HDBSCAN 或 GMM;需要可视化时先区分是要线性压缩还是只要展示结构,再在 PCA、LDA、t-SNE、UMAP 中选择;涉及标签序列依赖时再进入 HMM 与 CRF。
线性模型(Linear Models)的核心是先用一个可解释、可优化、常常足够强的基线去刻画输入与输出的关系。很多复杂模型也可以看作“在线性读出层之前先做更强的特征变换”。
线性回归(Linear Regression)在回归任务中建模“输入特征的加权求和如何产生连续输出”。它的价值在于:可解释(权重直接对应特征影响)与可优化(凸问题,训练稳定)。
给定训练集 \(\{(\mathbf{x}_i,y_i)\}_{i=1}^{N}\),其中 \(\mathbf{x}_i\in\mathbb{R}^d\) 是第 \(i\) 个样本的特征向量, \(y_i\in\mathbb{R}\) 是对应标签。线性回归假设单样本预测为:
\[\hat y_i=\mathbf{w}^\top \mathbf{x}_i+b\]- \(\hat y_i\):对 \(y_i\) 的预测。
- \(\mathbf{w}\in\mathbb{R}^d\):权重向量(每个维度对应一个特征)。
- \(b\in\mathbb{R}\):偏置(Bias),用于整体平移。
- \(\mathbf{w}^\top \mathbf{x}_i\):内积(Dot Product),表示“按特征加权求和”。
把全部样本写成矩阵形式。令设计矩阵(Design Matrix)\(\mathbf{X}\in\mathbb{R}^{N\times d}\) 的第 \(i\) 行为 \(\mathbf{x}_i^\top\),标签向量 \(\mathbf{y}\in\mathbb{R}^{N}\) 的第 \(i\) 个分量为 \(y_i\),全 1 向量 \(\mathbf{1}\in\mathbb{R}^{N}\)。则:
\[\hat{\mathbf{y}}=\mathbf{X}\mathbf{w}+b\mathbf{1}\]直觉类比:它像“按因素打分再加总”。例如房价预测里,面积、地段评分、楼龄都可作为特征;权重正负决定影响方向,绝对值大小决定影响强弱。
最常见的训练目标是最小化均方误差(Mean Squared Error, MSE)的总和(或平均):
\[\min_{\mathbf{w},b}\ J_{\text{EN}}(\mathbf{w},b)=\frac{1}{N}\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\|_2^2+\lambda_1\|\mathbf{w}\|_1+\lambda_2\|\mathbf{w}\|_2^2\]这个目标可以拆成三部分理解:第一项 \(\frac{1}{N}\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\|_2^2\) 是数据拟合误差,其中 \(\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\) 是所有样本的残差向量;第二项 \(\lambda_1\|\mathbf{w}\|_1\) 倾向把一部分权重直接压到 0;第三项 \(\lambda_2\|\mathbf{w}\|_2^2\) 倾向把权重整体缩小得更平滑。这里 \(N\) 是样本数, \(\lambda_1,\lambda_2\) 是正则化强度。若两者都取 0,就退化为普通最小二乘。
- \(J(\mathbf{w},b)\):目标函数(Objective)。
- \(\|\cdot\|_2\):二范数(Euclidean Norm),向量的长度。
平方项会对大残差施加更大惩罚,因此训练会优先修正“偏得很离谱”的样本。并且在高斯噪声假设下,最小二乘等价于最大似然估计(Maximum Likelihood Estimation, MLE)导出的解。
把偏置吸收到特征中更方便:定义增广特征 \(\tilde{\mathbf{x}}_i=[\mathbf{x}_i;1]\in\mathbb{R}^{d+1}\),增广参数 \(\tilde{\mathbf{w}}=[\mathbf{w};b]\in\mathbb{R}^{d+1}\),增广矩阵 \(\tilde{\mathbf{X}}=[\mathbf{X},\mathbf{1}]\in\mathbb{R}^{N\times(d+1)}\)。则 \(\hat{\mathbf{y}}=\tilde{\mathbf{X}}\tilde{\mathbf{w}}\),目标为 \(\min_{\tilde{\mathbf{w}}}\|\mathbf{y}-\tilde{\mathbf{X}}\tilde{\mathbf{w}}\|_2^2\)。若 \(\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}\) 可逆,则正规方程(Normal Equation)给出闭式解:
\[\tilde{\mathbf{w}}^*=\left(\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}\right)^{-1}\tilde{\mathbf{X}}^\top\mathbf{y}\]这里 \(\tilde{\mathbf{w}}^*\) 表示最优增广参数,前 \(d\) 维对应原权重 \(\mathbf{w}\),最后一维对应偏置 \(b\)。 \(\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}\) 汇总了特征之间的相关结构, \(\tilde{\mathbf{X}}^\top\mathbf{y}\) 汇总了特征与标签之间的相关程度,因此这个闭式解本质上是在“用整体相关关系一次性解出最优线性系数”。
- \(\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}\in\mathbb{R}^{(d+1)\times(d+1)}\):Gram 矩阵,度量特征之间的相关性。
- \((\cdot)^{-1}\):矩阵逆;不可逆时通常用伪逆(Pseudo-inverse)或加正则化处理。
工程实现中,直接求逆并不推荐;更稳定的做法是解线性方程组或用 QR/SVD 分解。
用一维数据拟合 \(y\approx wx+b\)。给定三点 \((x,y)\in\{(0,1),(1,3),(2,5)\}\)。构造增广矩阵与标签:
\[\tilde{\mathbf{X}}=\begin{bmatrix}0 & 1\\ 1 & 1\\ 2 & 1\end{bmatrix},\quad \mathbf{y}=\begin{bmatrix}1\\ 3\\ 5\end{bmatrix}\]这个增广矩阵的每一行对应一个样本;第一列是原始特征 \(x\),第二列固定为 1,用来把偏置 \(b\) 并入矩阵乘法。标签向量 \(\mathbf{y}\) 则把三个样本的真实输出按顺序堆叠起来。
计算:
\[\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}=\begin{bmatrix}5 & 3\\ 3 & 3\end{bmatrix},\quad \tilde{\mathbf{X}}^\top\mathbf{y}=\begin{bmatrix}13\\ 9\end{bmatrix}\]左边的矩阵可以看成所有样本在“特征与偏置”两个方向上的二阶统计量: \(5\) 来自 \(0^2+1^2+2^2\), \(3\) 来自 \(0+1+2\),右边向量 \(\tilde{\mathbf{X}}^\top\mathbf{y}\) 则分别对应 \(\sum_i x_i y_i\) 与 \(\sum_i y_i\)。这正是正规方程所需要的汇总量。
解线性方程 \(\left(\tilde{\mathbf{X}}^\top\tilde{\mathbf{X}}\right)\tilde{\mathbf{w}}=\tilde{\mathbf{X}}^\top\mathbf{y}\),即:
\[\begin{cases}5w+3b=13\\ 3w+3b=9\end{cases}\Rightarrow w=2,\ b=1\]这组方程的未知量只有两个:斜率 \(w\) 和偏置 \(b\)。解出 \(w=2\) 表示特征每增加 1,预测值增加 2;解出 \(b=1\) 表示当 \(x=0\) 时,模型基线输出为 1。
因此预测为 \(\hat y=2x+1\),恰好穿过三点。这个例子展示了:正规方程把“最小化平方误差”的优化问题,转换成一个线性方程组。
- 需要可解释的特征贡献(权重)与可校验的线性关系。
- 表格数据(Tabular)中,关系接近线性或可通过特征变换/交互项线性化。
- 作为强基线:先用线性模型定位数据问题、特征质量与噪声水平,再决定是否需要更复杂模型。
- 高维稀疏特征(如 one-hot、文本 bag-of-words)下,配合正则化可获得稳定解。
当特征很多、共线性(Collinearity)强或数据量相对不足时,普通最小二乘(Ordinary Least Squares, OLS)会出现高方差:训练集拟合很好、验证集误差上升。正则化(Regularization)通过惩罚参数规模,把“拟合训练误差”与“控制模型复杂度”写进同一个目标函数。
Lasso 把参数惩罚写成一范数(\(L_1\) Norm):
\[\min_{\mathbf{w},b}\ J_{\text{lasso}}(\mathbf{w},b)=\frac{1}{N}\left\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\right\|_2^2+\lambda\|\mathbf{w}\|_1\]这个式子里,前半部分仍然是拟合误差,衡量预测和真实标签之间差多少;后半部分 \(\lambda\|\mathbf{w}\|_1\) 是稀疏惩罚,其中 \(\|\mathbf{w}\|_1=\sum_j |w_j|\) 会优先把不重要的权重压成 0。于是 Lasso 不仅“把权重变小”,还经常顺带完成特征选择。
- \(\lambda\ge 0\):正则化强度(Regularization Strength)。越大表示越强的收缩。
- \(\|\mathbf{w}\|_1=\sum_{j=1}^{d}|w_j|\):一范数,鼓励稀疏(Sparsity)。
- 通常不惩罚偏置 \(b\);否则会把整体均值也一起往 0 拉。
- Lasso 由于 \(|\cdot|\) 在 0 点不可导,一般没有像岭回归那样简洁的闭式解;常用坐标下降(Coordinate Descent)、近端梯度(Proximal Gradient)或 LARS 等算法求解。
Lasso 的关键作用是让一部分权重被压到精确 0,而非均匀缩小全部权重。它更像给参数设置了一个阈值:弱相关、贡献不足以抵消惩罚的特征,会被直接剔除。因此 Lasso 同时完成复杂度控制与特征选择(Feature Selection)。
几何上,在相同训练误差轮廓线下, \(L_1\) 约束对应菱形/正八面体;这些尖角更容易与最优点相交在坐标轴上,因此常出现某些 \(w_j=0\) 的解。
- 适合高维稀疏特征、希望自动筛特征的场景,例如广告、推荐、文本 one-hot 特征。
- 当特征高度相关时,Lasso 往往只保留其中少数几个,因此解的稳定性通常弱于岭回归。
岭回归把参数惩罚写成二范数平方(\(L_2\) Norm Squared):
\[\min_{\mathbf{w},b}\ J_{\text{ridge}}(\mathbf{w},b)=\frac{1}{N}\left\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\right\|_2^2+\lambda\|\mathbf{w}\|_2^2\]岭回归的结构与普通线性回归相同,只是在误差项之外额外加入了 \(\lambda\|\mathbf{w}\|_2^2\)。这里 \(\|\mathbf{w}\|_2^2=\sum_j w_j^2\) 会连续惩罚过大的权重,因此它更擅长缓解共线性和过拟合,而非像 Lasso 那样主动做稀疏选择。
- \(\lambda\ge 0\):正则化强度。越大表示越强的收缩。
- \(\|\mathbf{w}\|_2^2=\sum_{j=1}^{d}w_j^2\):二范数平方,连续惩罚大权重。
- 通常不惩罚偏置 \(b\);否则会把整体均值也一起往 0 拉。
从梯度角度看,惩罚项 \(\lambda\|\mathbf{w}\|_2^2\) 对单个参数 \(w_j\) 的梯度贡献是 \(2\lambda w_j\)。这就是 \(L_2\) 正则化在深度学习中被称为权重衰减(Weight Decay)的原因:它持续把权重按比例拉回 0。若取 \(\lambda=1\),当 \(w_j=10\) 时,梯度为 \(20\);优化器会施加强烈收缩,把这个大权重猛拉回去。当 \(w_j=0.1\) 时,梯度只有 \(0.2\);往 0 拉的力量就很弱。也就是说,参数一旦变大, \(L_2\) 惩罚立刻增强;参数已经很小时,它几乎不再干预。
岭回归仍是凸二次问题,并有闭式解(忽略/已中心化处理 \(b\) 的情况):
\[\mathbf{w}^*=\left(\mathbf{X}^\top\mathbf{X}+N\lambda\mathbf{I}\right)^{-1}\mathbf{X}^\top\mathbf{y}\]与普通最小二乘相比,这里多出来的 \(N\lambda\mathbf{I}\) 是沿对角线加入的一项稳定化修正。 \(\mathbf{I}\) 是单位矩阵,它不会改变特征之间的相对结构,但会让矩阵更容易求逆,因此在特征高度相关时更稳定。
- \(\mathbf{I}\in\mathbb{R}^{d\times d}\):单位矩阵(Identity Matrix)。
- \(\mathbf{X}^\top\mathbf{X}+N\lambda\mathbf{I}\):对角线上加了 \(N\lambda\) 的稳定项,缓解共线性导致的病态(Ill-conditioning)。
用一个最小可算的例子说明 \(\lambda\) 如何改变解。考虑无偏置的一维回归 \(\hat y=wx\),目标为:
\[J(w)=\sum_{i=1}^{N}(y_i-wx_i)^2+\lambda w^2\]这是单变量岭回归的简化形式。前一项把所有样本的平方误差加总,后一项 \(\lambda w^2\) 惩罚过大的斜率。它清楚展示了岭回归的核心:既要求拟合数据,又限制参数不要长得太大。
对 \(w\) 求导并令其为 0 得:
\[\frac{\mathrm{d}J}{\mathrm{d}w}=-2\sum_{i=1}^{N}x_i(y_i-wx_i)+2\lambda w=0\Rightarrow w^*=\frac{\sum_{i=1}^{N}x_i y_i}{\sum_{i=1}^{N}x_i^2+\lambda}\]这个结果说明岭回归解和普通最小二乘解非常接近,只是分母里多了一个 \(\lambda\)。它会把估计值往 0 方向收缩: \(\lambda\) 越大,分母越大,得到的 \(w^*\) 就越保守。
可见 \(\lambda\) 直接进入分母,把 \(w^*\) 持续拉向 0。岭回归不会像 Lasso 那样大量制造精确 0,会把所有权重更平滑地压小,因此更像“把所有旋钮都往小一点拧”,让模型整体更保守、更稳健。
- 适合特征高度相关、希望保留全部特征但降低方差的场景;常见于经济学、医学和一般表格数据。
- 当既希望稀疏,又希望在强相关特征间保持稳定时,Elastic Net(\(L_1+L_2\))通常比纯 Lasso 更稳。
Elastic Net 把 \(L_1\) 与 \(L_2\) 惩罚合并到同一个目标中:
\[\min_{\mathbf{w},b}\ J_{\text{EN}}(\mathbf{w},b)=\frac{1}{N}\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\mathbf{1}\|_2^2+\lambda_1\|\mathbf{w}\|_1+\lambda_2\|\mathbf{w}\|_2^2\]它同时保留两类效应: \(L_1\) 项负责产生稀疏性(Sparsity),把一部分弱特征压到 0; \(L_2\) 项负责平滑收缩,在特征高度相关时提高解的稳定性。因此 Elastic Net 通常用于“既希望自动做特征选择,又不希望在强相关特征之间选得过于激进”的场景。
- 当 \(\lambda_2=0\) 时,退化为 Lasso。
- 当 \(\lambda_1=0\) 时,退化为岭回归(Ridge Regression)。
- 当特征高度相关且维度很高时,Elastic Net 往往比纯 Lasso 更稳,也比纯岭回归更稀疏。
逻辑回归(Logistic Regression)是二分类的标准基线:它先用线性函数产生打分,再把该打分通过 sigmoid(Logistic Function)映射到 \((0,1)\),从而得到条件概率模型。
对二分类,令标签随机变量(Random Variable)\(Y\in\{0,1\}\),其中 \(1\) 表示正类, \(0\) 表示负类。给定输入 \(\mathbf{x}\) 后,先定义线性打分:
\[z=\mathbf{w}^\top\mathbf{x}+b\]再定义 sigmoid 函数:
\[\sigma(z)=\frac{1}{1+e^{-z}}\]于是,在给定输入 \(\mathbf{x}\) 的条件下,标签取正类的条件概率写成:
\[p(Y=1\mid \mathbf{x})=\sigma(z)=\sigma(\mathbf{w}^\top\mathbf{x}+b)\]这里 \(\mid\) 表示“在给定……条件下”;左侧 \(Y=1\) 表示事件“标签随机变量取值为正类 1”。因此这个式子表示:在输入 \(\mathbf{x}\) 已知时,事件 \(Y=1\) 发生的概率。
相应地,负类概率为:
\[p(Y=0\mid \mathbf{x})=1-\sigma(z)\]- \(\mathbf{x}\in\mathbb{R}^d\):特征向量。
- \(\mathbf{w}\in\mathbb{R}^d\):权重向量(Weight Vector)。
- \(b\in\mathbb{R}\):偏置(Bias)。
- \(z\in\mathbb{R}\):线性打分;它也是 logit(对数几率,log-odds)。
- \(\sigma(\cdot)\):把任意实数映射到 \((0,1)\) 的非线性函数。
logit 的含义来自恒等式:
\[\log\frac{p(Y=1\mid \mathbf{x})}{1-p(Y=1\mid \mathbf{x})}=z=\mathbf{w}^\top\mathbf{x}+b\]这里的 \(\frac{p(Y=1\mid \mathbf{x})}{1-p(Y=1\mid \mathbf{x})}\) 称为几率(Odds),表示“正类概率与负类概率之比”;再对它取对数,就得到 logit(对数几率,log-odds):\(\log\frac{p}{1-p}\)。因此上式说明:逻辑回归把正类概率的对数几率建模为输入特征的线性函数。
换言之,在二分类逻辑回归里, \(z=\mathbf{w}^\top\mathbf{x}+b\) 就是线性部分的原始输出值,而这个原始输出值恰好等于 logit。它本身并非概率,可以取任意实数;经过 sigmoid 之后才变成 \((0,1)\) 内的概率。多分类情形中,softmax 之前那一组线性输出通常统称为 logits。
因此 \(w_j\) 可以被解释为:特征 \(x_j\) 增加一个单位,会把对数几率增加 \(w_j\)(在其他特征不变时)。这就是逻辑回归的核心可解释性。
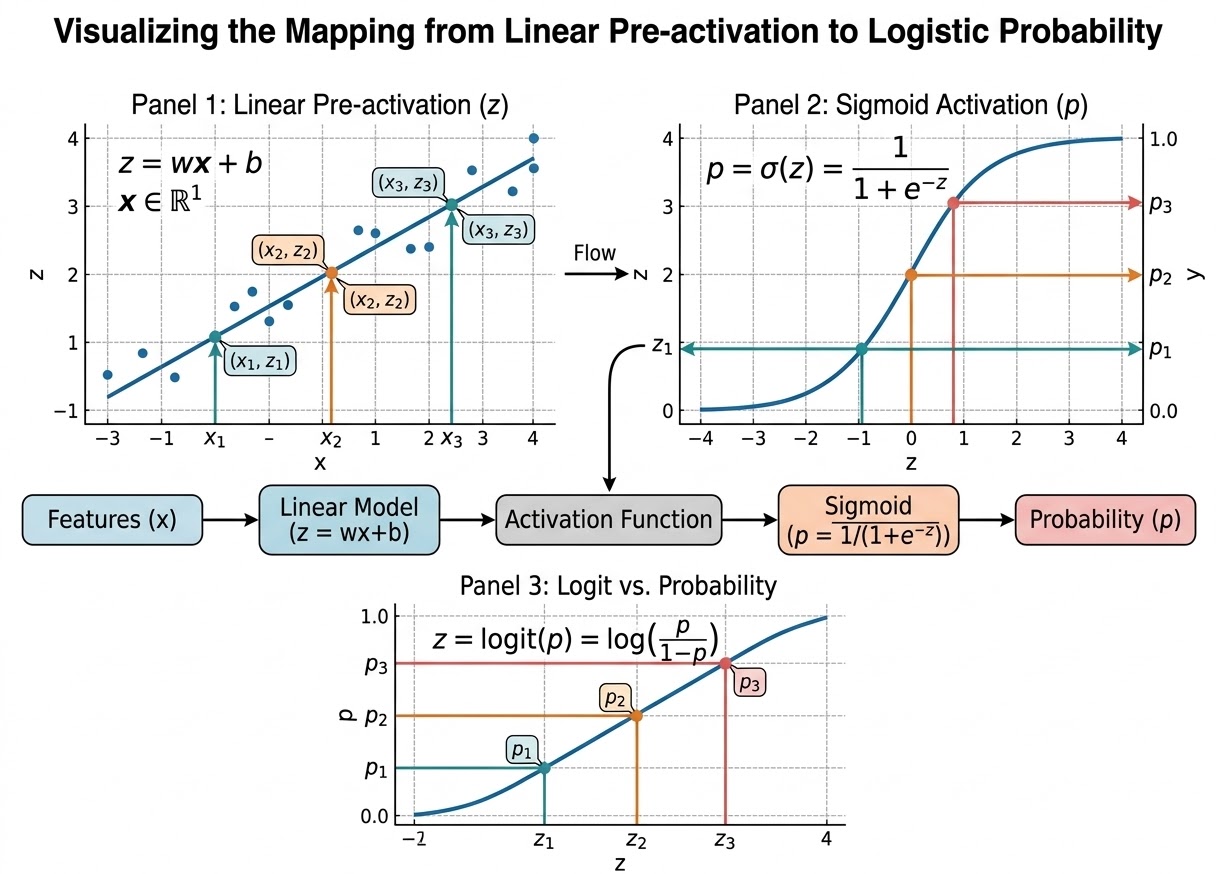
给定训练集 \(\{(\mathbf{x}_i,y_i)\}_{i=1}^{N}\),记 \(p_i=\sigma(\mathbf{w}^\top\mathbf{x}_i+b)\)。逻辑回归通过最大化似然(Likelihood)训练;等价地,它最小化负对数似然(Negative Log-Likelihood, NLL),也即二分类交叉熵(Binary Cross-Entropy):
\[\min_{\mathbf{w},b}\ L(\mathbf{w},b)=-\sum_{i=1}^{N}\left(y_i\log p_i+(1-y_i)\log(1-p_i)\right)\]- \(\log p_i\):当 \(y_i=1\) 时,鼓励 \(p_i\) 变大。
- \(\log(1-p_i)\):当 \(y_i=0\) 时,鼓励 \(p_i\) 变小。
加入 \(L_2\) 正则化时,常见形式为 \(L(\mathbf{w},b)+\lambda\|\mathbf{w}\|_2^2\)(通常不惩罚 \(b\))。该目标是凸的,因此不存在“坏局部最优”的训练不稳定问题。
把样本堆叠成矩阵 \(\mathbf{X}\)、标签向量 \(\mathbf{y}\),预测概率向量 \(\mathbf{p}\)(第 \(i\) 个分量为 \(p_i\))。则无正则项时梯度为:
\[\nabla_{\mathbf{w}}L=\mathbf{X}^\top(\mathbf{p}-\mathbf{y}),\quad \frac{\partial L}{\partial b}=\mathbf{1}^\top(\mathbf{p}-\mathbf{y})\]这两个梯度式子都围绕同一个误差向量 \(\mathbf{p}-\mathbf{y}\) 展开:它表示“模型给出的正类概率”和“真实标签”之间的偏差。 \(\mathbf{X}^\top(\mathbf{p}-\mathbf{y})\) 表示把这种偏差按特征方向汇总起来,从而告诉每个权重该往哪个方向改; \(\mathbf{1}^\top(\mathbf{p}-\mathbf{y})\) 则把所有偏差直接相加,用来更新偏置。
这两个式子揭示了训练机制:如果某个样本真实标签是 1 但模型给出小概率(\(p_i-y_i<0\)),则梯度会推动 \(\mathbf{w}\) 朝着增加该样本 logit 的方向更新;反之亦然。
考虑一维特征 \(x=2\),参数 \(w=1,b=-1\),则 \(z=wx+b=1\),概率:
\[p=\sigma(1)=\frac{1}{1+e^{-1}}\approx 0.731\]若真实标签 \(y=1\),该样本的负对数似然为:
\[\ell=-\log p\approx 0.313\]该样本对 \(w\) 的梯度为(单样本形式):
\[\frac{\partial \ell}{\partial w}=(p-y)x=(0.731-1)\cdot 2\approx -0.538\]用学习率 \(\eta\) 做一次梯度下降: \(w\leftarrow w-\eta\frac{\partial\ell}{\partial w}\)。由于梯度为负,更新会把 \(w\) 增大,从而增大 \(z\)、提升 \(p\),使模型更倾向把该样本判为正类。
- 二分类且需要概率输出/可校准阈值(例如欺诈检测、流失预测、医学风险评分)。
- 高维稀疏特征(如 one-hot、文本 bag-of-words),逻辑回归常是强基线。
- 对可解释性、训练稳定性要求高的工程场景(可用权重做审计/特征诊断)。
- 当决策边界高度非线性且特征工程不足时,需要树模型或神经网络补上非线性。
支持向量机(Support Vector Machine, SVM)是一类以最大间隔分类为核心原则的判别模型。对线性可分的二分类问题,它要寻找一个超平面(Hyperplane),使两类样本被正确分开,同时边界到两侧样本的最小距离尽可能大。这个最小距离对应的缓冲区称为间隔(Margin)。
也正因为优化目标是最大间隔,SVM 核心是要找那条对两类样本都留出最大安全缓冲区的边界。边界离两类样本都越远,模型对噪声、标注扰动与局部数据波动通常越稳。
从数学形式看,SVM 最终会落到二次规划(Quadratic Programming, QP)。所谓二次规划,就是:目标函数是变量的二次函数,约束是线性等式或线性不等式。SVM 的目标是最小化 \(\frac{1}{2}\|\mathbf{w}\|_2^2\),约束则是每个样本都必须被放到正确一侧并留出至少 1 的函数间隔,因此它正好属于这一类优化问题。
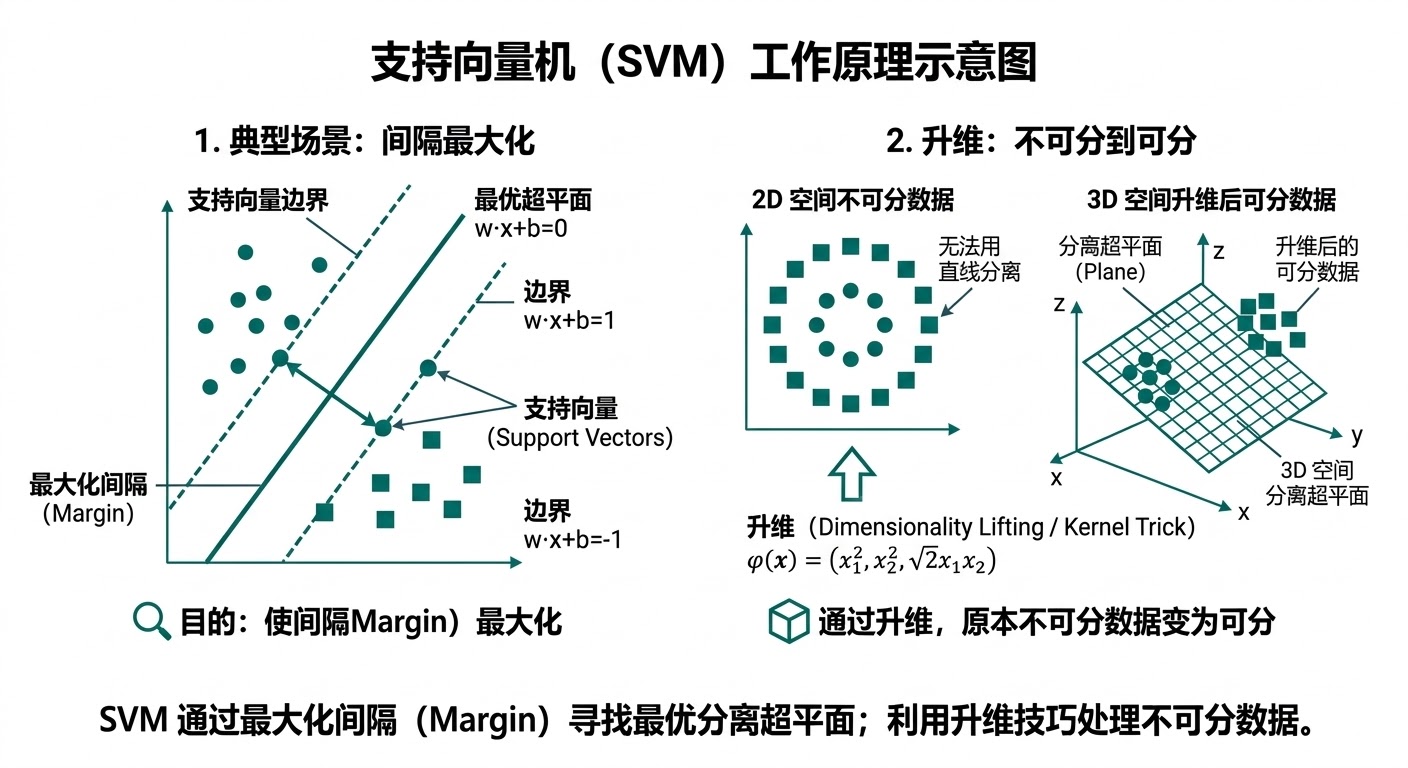
从结构上看,SVM 把三件事连在一起:
- 几何:先定义“什么叫分得开”,以及“什么叫分得最稳”。
- 优化:把“最稳的边界”写成一个可求解的凸二次规划。
- 对偶:把问题改写成只依赖样本内积的形式,从而自然导出核技巧(Kernel Trick)。
对二分类任务,设标签 \(y_i\in\{-1,+1\}\)。线性分类器先计算一个打分函数(Score Function):
\[f(\mathbf{x})=\mathbf{w}^\top\mathbf{x}+b\]这里最好先把“函数写法”和“几何边界写法”区分清楚。像 \(y=x\) 这样的形式,强调的是“给定自变量(Independent Variable) \(x\),应变量(Dependent Variable) \(y\) 如何变化”;但对分类器来说,更关键的问题是哪些点恰好落在边界上,以及点位于边界哪一侧。因此同一条直线在几何里通常改写成隐式形式(Implicit Form) \(x-y=0\)。
一旦写成 \(x-y=0\),就能直接看成二维超平面方程 \(\mathbf{w}^\top\mathbf{x}+b=0\):令 \(\mathbf{x}=(x,y)^\top\)、\(\mathbf{w}=(1,-1)^\top\)、\(b=0\),便有 \(\mathbf{w}^\top\mathbf{x}+b=x-y\)。此时直线方向向量(Direction Vector)可以取 \(\mathbf{v}=(1,1)^\top\),因为沿这条线移动时 \(y\) 与 \(x\) 同时增加;而 \(\mathbf{w}^\top\mathbf{v}=1\cdot 1+(-1)\cdot 1=0\),说明 \(\mathbf{w}\) 与直线切向方向正交,所以它正是这条直线的法向量(Normal Vector)。更一般地,对任意边界 \(\mathbf{w}^\top\mathbf{x}+b=0\),系数向量 \(\mathbf{w}\) 都垂直于边界,因此天然决定“正侧、负侧”和距离的度量方向。
再用它的符号做判别:
\[\hat y=\mathrm{sign}(f(\mathbf{x}))=\mathrm{sign}(\mathbf{w}^\top\mathbf{x}+b)\]这里 \(\mathbf{w}\) 是超平面的法向量(Normal Vector)。沿 \(\mathbf{w}\) 方向移动, \(f(\mathbf{x})\) 会增大;沿反方向移动, \(f(\mathbf{x})\) 会减小。因此:
- \(f(\mathbf{x})=0\):点就在分类超平面上。
- \(f(\mathbf{x})>0\):点落在法向量 \(\mathbf{w}\) 指向的那一侧。
- \(f(\mathbf{x})<0\):点落在另一侧。
超平面把空间分成正半空间(Positive Half-space)与负半空间(Negative Half-space);分数的正负号直接给出样本位于哪一侧。
令 \(\mathcal{H}=\{\mathbf{x}:\mathbf{w}^\top\mathbf{x}+b=0\}\) 表示超平面,令单位法向量(Unit Normal Vector)为 \(\mathbf{n}=\mathbf{w}/\|\mathbf{w}\|_2\)。对样本 \(\mathbf{x}_i\),记 \(\mathbf{x}_{\Pi,i}\) 为它在超平面 \(\mathcal{H}\) 上的正交投影点(Orthogonal Projection),因此 \(\mathbf{w}^\top\mathbf{x}_{\Pi,i}+b=0\),且 \(\mathbf{x}_i-\mathbf{x}_{\Pi,i}\) 与 \(\mathbf{w}\) 平行。点 \(\mathbf{x}_i\) 到超平面的带符号距离(Signed Distance)定义为该位移在单位法向量方向上的投影长度:
\[\mathrm{dist}_{\pm}(\mathbf{x}_i,\mathcal{H})=\mathbf{n}^\top(\mathbf{x}_i-\mathbf{x}_{\Pi,i})=\frac{\mathbf{w}^\top\mathbf{x}_i+b}{\|\mathbf{w}\|_2}\]分子 \(\mathbf{w}^\top\mathbf{x}_i+b\) 衡量点在法向量方向上偏离超平面的代数量;分母 \(\|\mathbf{w}\|_2\) 对法向量做归一化,去掉“同一个超平面可写成不同倍数方程”的尺度影响;符号保留样本位于超平面哪一侧的信息。
带符号距离区分了超平面的两侧,但正类样本与负类样本的正确侧相反。将标签 \(y_i\in\{-1,+1\}\) 乘入后,得到几何间隔(Geometric Margin):
\[\gamma_i=\frac{y_i(\mathbf{w}^\top\mathbf{x}_i+b)}{\|\mathbf{w}\|_2}\]几何间隔是用标签修正后的带符号距离。因此:
- \(\gamma_i>0\):样本在正确一侧,被正确分类。
- \(\gamma_i=0\):样本正好压在边界上。
- \(\gamma_i<0\):样本落到错误一侧,被误分类。
SVM 的目标是让所有训练样本中最小的那个 \(\gamma_i\) 尽可能大,即最大化“最坏样本到边界的正确方向距离”:
\[\gamma=\min_i \gamma_i\]这就是最大间隔(Maximum Margin)的含义:核心是让最危险、最靠近边界的样本也尽量安全。
先看线性可分(Linearly Separable)的情形。所谓线性可分,就是存在某个 \((\mathbf{w},b)\),使每个样本都在与自己标签一致的一侧。这件事可以统一写成:
\[y_i(\mathbf{w}^\top\mathbf{x}_i+b)>0,\quad \forall i\]为什么这里是 \(>0\)?因为它等价于“符号一致”:当 \(y_i=+1\) 时,要求 \(\mathbf{w}^\top\mathbf{x}_i+b>0\),即正类样本必须落在正半空间;当 \(y_i=-1\) 时,要求 \(\mathbf{w}^\top\mathbf{x}_i+b<0\),即负类样本必须落在负半空间。若只等于 0,则样本恰好压在分类边界上,不属于严格可分,因为此时它没有任何安全间隔,符号判别也处在临界点。
不过, \(y_i(\mathbf{w}^\top\mathbf{x}_i+b)\) 还并非几何距离,因为把 \((\mathbf{w},b)\) 同时乘以任意正常数 \(t>0\),超平面 \(\mathbf{w}^\top\mathbf{x}+b=0\) 完全不变,但这个量会整体乘上 \(t\)。因此它只是一个未归一化的间隔量,通常称为函数间隔(Functional Margin)。
为了消掉这个缩放自由度,SVM 采用一个标准定标:强制所有样本的最小函数间隔等于 1,也就是要求
\[y_i(\mathbf{w}^\top\mathbf{x}_i+b)\ge 1,\quad \forall i\]这条约束把两类样本同时编码进来:当 \(y_i=+1\) 时,它变成 \(\mathbf{w}^\top\mathbf{x}_i+b\ge 1\);当 \(y_i=-1\) 时,它变成 \(\mathbf{w}^\top\mathbf{x}_i+b\le -1\)。于是分类边界两侧又出现两条平行的“间隔边界”(Margin Boundaries):
\[\mathbf{w}^\top\mathbf{x}+b=+1,\quad \mathbf{w}^\top\mathbf{x}+b=-1\]因为平行超平面 \(\mathbf{w}^\top\mathbf{x}+b=c_1\) 与 \(\mathbf{w}^\top\mathbf{x}+b=c_2\) 之间的距离是 \(|c_1-c_2|/\|\mathbf{w}\|_2\),所以这两条间隔边界之间的宽度为
\[\frac{|(+1)-(-1)|}{\|\mathbf{w}\|_2}=\frac{2}{\|\mathbf{w}\|_2}\]在这个定标下,离分类边界最近的样本几何间隔恰好是
\[\gamma=\min_i \frac{y_i(\mathbf{w}^\top\mathbf{x}_i+b)}{\|\mathbf{w}\|_2}=\frac{1}{\|\mathbf{w}\|_2}\]因此,最大化几何间隔就等价于最小化 \(\|\mathbf{w}\|_2\);为了得到标准的凸二次目标,通常写成:
\[\min_{\mathbf{w},b}\ \frac{1}{2}\|\mathbf{w}\|_2^2\quad \text{s.t.}\quad y_i(\mathbf{w}^\top \mathbf{x}_i+b)\ge 1\]这就是硬间隔 SVM 的原始问题(Primal Problem)。现在“二次规划”这个术语也具体了:目标函数 \(\frac{1}{2}\|\mathbf{w}\|_2^2\) 是关于参数的凸二次函数,而约束 \(y_i(\mathbf{w}^\top \mathbf{x}_i+b)\ge 1\) 对 \((\mathbf{w},b)\) 是线性的,所以这是一个凸二次规划,并且可以求到全局最优解。
这一段只回答一个问题:训练集中明明有很多样本,为什么最后真正决定分类边界的,往往只有少数几个点。这个结论的严格来源是 KKT 条件,但它的直观含义并不抽象:只有那些真正把最大间隔边界“卡住”的样本,才会在最优解里留下非零权重。
硬间隔 SVM 的原始问题是:
\[\min_{\boldsymbol{w},b}\frac{1}{2}\|\boldsymbol{w}\|_2^2\quad \text{s.t.}\quad y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)\ge 1,\ \forall i\]这里目标函数 \(\frac{1}{2}\|\boldsymbol{w}\|_2^2\) 想把边界做得尽量“简单”,也就是让法向量尽量短,从而把间隔做大;而每个训练样本都在提出自己的硬约束:它不仅要被分对,还必须距离边界至少有 1 个单位的函数间隔。把这两股力量写到同一个式子里,就得到拉格朗日函数(Lagrangian):
\[\mathcal{L}(\boldsymbol{w},b,\boldsymbol{\alpha})=\frac{1}{2}\|\boldsymbol{w}\|_2^2-\sum_{i=1}^{N}\alpha_i\big(y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)-1\big),\quad \alpha_i\ge 0\]其中 \(\alpha_i\) 是第 \(i\) 个样本对应的拉格朗日乘子(Lagrange Multiplier)。在 SVM 里,可以把它直接理解为“第 \(i\) 个样本对当前分类边界施加了多大压力”。压力越大,说明这个样本越在真正影响边界的位置;压力为 0,说明这个样本虽然在训练集里,但最优边界并不需要它来支撑。
这个问题的读法可以想成一个“边界往外推、样本往回顶”的平衡过程:
- 模型一侧 想让 \(\|\boldsymbol{w}\|_2\) 尽量小,从而把间隔尽量做大。
- 约束一侧 则由每个样本通过 \(\alpha_i\) 施加压力:谁越接近边界、越可能破坏间隔,谁就越值得保留权重。
于是,离边界很远的样本会发生什么,就变得非常直观。若某个样本满足
\[y_i(\boldsymbol{w}^\top\boldsymbol{x}_i+b)>1\]说明它不仅分对了,而且还有额外安全余量。这个点对“边界能否继续外推”没有形成真正阻碍,因此最优时它对应的 \(\alpha_i\) 会被压到 0。相反,若某个样本恰好满足
\[y_i(\boldsymbol{w}^\top\boldsymbol{x}_i+b)=1\]它就正贴在间隔边界上,是“再往外推一点就会出问题”的临界点。这样的样本才有资格在最优解中保留非零权重。
KKT 条件(Karush–Kuhn–Tucker Conditions)把这个直觉写成严格公式。第一条来自驻点条件(Stationarity):
\[\nabla_{\boldsymbol{w}}\mathcal{L}=0\Rightarrow \boldsymbol{w}=\sum_{i=1}^{N}\alpha_i y_i \boldsymbol{x}_i\]这条式子的含义非常重要。它说明最终的法向量 \(\boldsymbol{w}\) 核心是由训练样本的加权和决定的。这里:
- \(\boldsymbol{x}_i\) 是第 \(i\) 个训练样本;
- \(y_i\alpha_i\) 是它的“带符号权重”;
- 若 \(\alpha_i=0\),该样本就完全不会出现在 \(\boldsymbol{w}\) 的表达式里。
第二条关键条件是互补松弛(Complementary Slackness):
\[\alpha_i\big(y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)-1\big)=0\]这条式子可以直接逐项阅读:
- \(\alpha_i\) 是第 \(i\) 个样本对边界施加的压力;
- \(y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)-1\) 是该样本相对于间隔边界的“松弛量”;当它大于 0 时,说明样本在安全区里;当它等于 0 时,说明样本正好贴边。
由于这两个量的乘积必须等于 0,所以只可能出现两种情况:
- 若 \(y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)-1>0\),说明该样本有安全余量,那么必须有 \(\alpha_i=0\)。
- 若 \(\alpha_i>0\),说明该样本仍在对边界施压,那么必须有 \(y_i(\boldsymbol{w}^\top \boldsymbol{x}_i+b)=1\)。
这就是支持向量(Support Vector)的严格定义来源:在硬间隔 SVM 中,只有恰好贴在间隔边界上的样本,才可能对应非零 \(\alpha_i\);这些样本共同决定最终超平面的位置。其余样本虽然被正确分类,但因为离边界还有余量,所以在最优解里不再起作用。
如果继续沿着这个结论往下看,就会发现 SVM 的稀疏性完全核心是 KKT 的直接产物。训练集里可以有大量“安全样本”,但最优边界只需要被少数临界样本支撑起来。名字“支持向量”说的正是这件事:这些点核心是真正在几何上把边界撑住的点。
前面已经看到:KKT 让 \(\alpha_i\) 变成了“谁在真正顶住边界”的刻度。但如果这里只停在 KKT,还是会留下一个疑问:对偶问题到底是怎么从原始问题里长出来的?关键动作只有一步:先把 \(\alpha_i\) 固定住,把拉格朗日函数当成关于 \(\mathbf{w},b\) 的函数来最小化;然后再回过头,只对 \(\alpha\) 做最大化。
也就是说,原始问题里我们直接求“哪条边界最好”:
\[\min_{\mathbf{w},b}\ \frac{1}{2}\|\mathbf{w}\|_2^2\quad \text{s.t.}\quad y_i(\mathbf{w}^\top\mathbf{x}_i+b)\ge 1\]而引入拉格朗日乘子之后,可以先看下面这个函数:
\[\mathcal{L}(\mathbf{w},b,\alpha)=\frac{1}{2}\|\mathbf{w}\|_2^2-\sum_{i=1}^{N}\alpha_i\Big(y_i(\mathbf{w}^\top \mathbf{x}_i+b)-1\Big),\quad \alpha_i\ge 0\]对固定的 \(\alpha\),它就是一个关于 \(\mathbf{w},b\) 的凸函数。于是我们先做内层最小化:
\[g(\alpha)=\min_{\mathbf{w},b}\ \mathcal{L}(\mathbf{w},b,\alpha)\]这里的 \(g(\alpha)\) 就叫对偶函数(Dual Function)。它表示:假设每个样本的施压强度已经给定,边界那一侧最好的回应会是什么。
这一步的好处是, \(\mathbf{w},b\) 可以被显式消掉。对 \(\mathbf{w}\) 和 \(b\) 求驻点条件,有:
\[\frac{\partial \mathcal{L}}{\partial \mathbf{w}}=0\Rightarrow \mathbf{w}=\sum_{i=1}^{N}\alpha_i y_i\mathbf{x}_i\] \[\frac{\partial \mathcal{L}}{\partial b}=0\Rightarrow \sum_{i=1}^{N}\alpha_i y_i=0\]这两条式子非常关键:第一条说明法向量 \(\mathbf{w}\) 完全由训练样本线性组合出来;第二条说明正负两类样本的“总施压”必须平衡。把它们代回去,原来依赖 \(\mathbf{w},b\) 的问题就变成只依赖 \(\alpha\) 的问题:
\[\max_{\alpha}\ \sum_{i=1}^{N}\alpha_i-\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j\] \[\text{s.t.}\quad \alpha_i\ge 0,\quad \sum_{i=1}^{N}\alpha_i y_i=0\]这就是 SVM 的对偶问题(Dual Problem)。现在可以看出它为什么叫“对偶”:它问题从“\(\mathbf{w},b\) 应该是多少”改成“每个样本应该分到多大的权重 \(\alpha_i\),才能共同把最优边界顶出来”。
这样改写有两个直接收益。第一,支持向量为什么稀疏会变得一眼可见:若某个样本最终 \(\alpha_i^*=0\),它就自动从 \(\mathbf{w}=\sum_i \alpha_i y_i\mathbf{x}_i\) 里消失。第二,对偶目标里出现的样本方式只剩内积 \(\mathbf{x}_i^\top\mathbf{x}_j\),这正是后面引入核函数(Kernel)的入口。
把最优权重 \(\alpha_i^*\) 求出来后,分类器可以直接写成:
\[f(\mathbf{x})=\mathrm{sign}\left(\sum_{i=1}^{N}\alpha_i^* y_i\,\mathbf{x}_i^\top \mathbf{x}+b^*\right)\]这个式子的含义很具体:新样本 \(\mathbf{x}\) 会与训练样本做内积(Inner Product),也就是计算相似度;每个训练样本按自己的类别符号 \(y_i\) 和影响系数 \(\alpha_i^*\) 投一票;最后把这些票加总,再加上偏置 \(b^*\),看结果落在哪一侧。
由于绝大多数样本的 \(\alpha_i^*=0\),真正参与这次投票的通常只有支持向量。因此 SVM 的预测阶段常带有一个很强的稀疏性(Sparsity):并非所有训练样本都在持续发声,真正起作用的只是边界附近那一小部分点。
偏置 \(b^*\) 可以用任一支持向量恢复。若 \(\mathbf{x}_k\) 是一个支持向量,则它满足 \(y_k(\mathbf{w}^{*\top}\mathbf{x}_k+b^*)=1\),因此
\[b^*=y_k-\mathbf{w}^{*\top}\mathbf{x}_k\]对偶问题真正重要的地方,不仅“把变量从 \(\mathbf{w},b\) 换成了 \(\alpha_i\)”,还它把 SVM 的全部数据依赖压缩成了样本之间的内积(Inner Product):
\[\mathbf{x}_i^\top\mathbf{x}_j\]这一步非常关键,因为它说明:SVM 在对偶形式里并不需要直接看到样本坐标本身,它只需要知道样本彼此有多相似。只要这种“相似度”还能写成某个空间里的内积,SVM 的训练与预测公式就都可以照搬。
于是核技巧(Kernel Trick)的引入就变得自然了。设有一个特征映射(Feature Map)\(\phi(\mathbf{x})\),它把原始样本送到更高维、甚至无限维的特征空间(Feature Space)。如果我们真的显式去算这个高维向量,代价往往很大;但对偶形式只关心内积,因此只要能直接计算
\[K(\mathbf{x}_i,\mathbf{x}_j)=\phi(\mathbf{x}_i)^\top\phi(\mathbf{x}_j)\]就等价于“隐式地”在特征空间里做线性 SVM,而不必真的把 \(\phi(\mathbf{x})\) 写出来。这个直接在原空间里计算特征空间内积的技巧,就叫核函数(Kernel Function)或核技巧(Kernel Trick)。
这也解释了为什么 kernel 是从 dual 里长出来的,而非额外拼上去的:若你还停留在原始问题里,眼前看到的仍是显式参数 \(\mathbf{w}\);而一旦进入对偶形式,表达式里只剩 \(\mathbf{x}_i^\top\mathbf{x}_j\),把它替换成别的“合法相似度”就成了最自然的一步。
于是决策函数从
\[f(\mathbf{x})=\mathrm{sign}\left(\sum_{i=1}^{N}\alpha_i^* y_i\,\mathbf{x}_i^\top \mathbf{x}+b^*\right)\]变成
\[f(\mathbf{x})=\mathrm{sign}\left(\sum_{i=1}^{N}\alpha_i^* y_i\,K(\mathbf{x}_i,\mathbf{x})+b^*\right)\]要点是:特征空间里仍然是线性超平面;只是映回原空间后,边界看起来变成了弯的。因此 kernel 核心是“先把数据换到更容易线性可分的表示里,再继续做线性 SVM”。
从直觉上看,核函数本质上是在重新定义“两个样本像不像”。线性核(Linear Kernel)比较原始方向是否一致;多项式核(Polynomial Kernel)强调特征之间的组合关系;RBF / Gaussian 核更强调局部邻近性,因此很容易形成局部、弯曲的决策边界。
- 线性核(Linear Kernel):\(K(\mathbf{x},\mathbf{z})=\mathbf{x}^\top\mathbf{z}\)。
- 多项式核(Polynomial Kernel):\(K(\mathbf{x},\mathbf{z})=(\mathbf{x}^\top\mathbf{z}+c)^d\)。
- RBF / Gaussian 核:\(K(\mathbf{x},\mathbf{z})=\exp(-\gamma\|\mathbf{x}-\mathbf{z}\|_2^2)\)。
一个典型例子是“同心圆”二分类:在二维平面里,内圈和外圈无法用一条直线分开;但如果映射到包含半径平方等特征的空间,类别就可能被一个超平面分开。核方法的价值就在这里:原空间里看到的是弯曲边界,特征空间里做的仍然是线性分类。
现实数据通常含噪声、离群点(Outlier)或类别重叠。若仍然要求“所有点都必须在间隔之外”,硬间隔 SVM 很可能根本无解,或者被少数异常点强行拉歪。软间隔 SVM(Soft-margin SVM)因此引入松弛变量(Slack Variable)\(\xi_i\ge 0\),允许个别样本违反间隔约束:
\[\min_{\mathbf{w},b,\xi}\ \frac{1}{2}\|\mathbf{w}\|_2^2+C\sum_{i=1}^{N}\xi_i\quad \text{s.t.}\quad y_i(\mathbf{w}^\top \mathbf{x}_i+b)\ge 1-\xi_i,\ \xi_i\ge 0\]这个式子只表达一件事:边界仍然希望尽量大,但违约要交罚款,罚款强度由 \(C\) 决定。对单个样本, \(\xi_i\) 的含义可以直接按大小来读:
- \(\xi_i=0\):样本分类正确,且在间隔边界上或之外。
- \(0<\xi_i\le 1\):样本仍在正确一侧,但已经挤进了间隔内部。
- \(\xi_i>1\):样本跨过了分类边界,已经被误分。
\(C\) 控制的是“对违约有多敏感”:
- \(C\) 大:更重视把训练集分对,边界更硬,对噪声也更敏感。
- \(C\) 小:更重视大间隔和整体稳定性,允许少量训练误差。
软间隔下,支持向量的范围也更宽:不仅贴着间隔边界的点重要,落在间隔内部甚至被误分的点也会直接影响最优解。对应到对偶变量,常见情形是 \(0<\alpha_i<C\) 的点贴在间隔上,而 \(\alpha_i=C\) 的点往往是间隔内样本或误分类样本。
把松弛变量消去后,软间隔 SVM 还可以写成更常见的合页损失(Hinge Loss)形式:
\[\min_{\mathbf{w},b}\ \frac{1}{2}\|\mathbf{w}\|_2^2+C\sum_{i=1}^{N}\max\big(0,\ 1-y_i(\mathbf{w}^\top \mathbf{x}_i+b)\big)\]第一项限制模型复杂度,第二项惩罚分类违约。SVM 因此可以被看作“大间隔 + 违约惩罚”的组合,而支持向量则是这两股力量平衡后仍然留在最前线的样本。
这一类方法处理的核心问题是:当输入与输出之间存在明显非线性、阈值效应与高阶特征交互时,线性模型往往表达力不足,但工程上仍然希望模型具备较强可解释性、对表格数据友好、并且训练稳定。树模型通过递归切分(Recursive Partitioning)把输入空间划成若干局部区域;集成方法则进一步通过 Bagging 或 Boosting 提升泛化能力与精度。
| 模型 | 模型数量与训练逻辑 | 集成策略 / 学习机制 | 单棵树特点 | 主要在优化什么 | 过拟合风险 | 更适合什么场景 |
| 决策树 | 单棵独立模型,直接在原始数据上递归切分,没有集成过程 | 无;直接学习输入到输出的分段规则 | 树深完全由数据与约束参数决定;过深会记住噪声,过浅又会表达不足 | 没有显式“降偏差 / 降方差”分工,偏差和方差都要靠剪枝、树深和叶子约束一起控制 | 高;单树很容易把训练集中的偶然模式学进去 | 可解释性要求极高的简单任务、规则基线、集成模型的基学习器 |
| 随机森林 | 多棵树并行独立训练,树与树之间无依赖,可利用多核 CPU 并行 | Bagging:bootstrap 采样 + 特征子采样 + 投票 / 平均 | 单棵树通常故意训练得较深,先把单树偏差压低,再依靠集成抵消高方差 | 主要降低方差,让整体模型更稳、更抗数据扰动 | 低;Bagging 和平均机制天然有正则化效果 | 中小规模表格数据、强 baseline、噪声较大且希望训练稳定的场景 |
| GBDT / XGBoost | 多棵树严格串行训练;后一棵树必须等前一棵树完成后,才能开始学习新的修正项 | Boosting:拟合残差或负梯度,逐轮加权累加 | 单棵树通常较浅,只负责局部纠错;单树偏差高,但方差相对更低 | 主要降低偏差,通过接力纠错不断提升拟合能力 | 中等;若树数太多、学习率太大或树过深,容易持续把训练集吃满 | 结构化数据里追求高精度的任务,如风控、推荐、广告、竞赛 |
| LightGBM | 仍然属于串行 Boosting,但单棵树训练做了更激进的近似和工程优化 | Boosting + 直方图分桶 + leaf-wise 生长 + GOSS / EFB | 单棵树依然是浅到中等深度的纠错器,但 leaf-wise 会把最值得细分的局部继续挖深 | 继续降低偏差,同时极力优化训练速度与内存效率 | 中等偏高;若 leaf-wise 缺少足够约束,局部树会很快长深 | 大规模表格数据、高维稀疏特征、需要频繁重训的工业流水线 |
| CatBoost | 仍然属于串行 Boosting,但重点放在类别特征处理与训练偏移控制 | Boosting + ordered target statistics + ordered boosting + symmetric tree | 单棵树结构更规整,对称树推理快;模型内部原生吸收类别特征统计信息 | 继续降低偏差,同时尽量减少类别编码带来的泄露与偏移 | 中等;总体可控,但仍需学习率、树数和正则化配合 | 类别特征很多、希望少做手工编码、快速起一个强模型的表格任务 |
这张表背后的逻辑可以压缩成一句话:决策树是基础,随机森林主要靠并行平均降低方差,GBDT 家族主要靠串行纠错降低偏差,而 XGBoost、LightGBM、CatBoost 则是在 GBDT 主线上的工业级强化。因此它们虽然都属于“树模型”,训练逻辑、误差控制方式和工程侧优势并不相同。
决策树(Decision Tree)把预测过程写成一串逐层切分的规则:内部节点负责提问,边负责根据答案分流,叶节点负责输出最终结果。它的优势不在于公式复杂,而在于模型结构与业务规则天然同构:每一条从根到叶的路径,都对应一条可读的判断链。
决策树是总称;分类树(Classification Tree)与回归树(Regression Tree)是它在两类监督学习任务上的具体形式。三者共享同一种树结构,但目标变量、切分准则与叶子输出不同。
| 概念 | 预测目标 | 叶子输出 | 常用切分准则 |
| 决策树(Decision Tree) | 树模型的总称 | 取决于具体任务 | 取决于具体任务 |
| 分类树(Classification Tree) | 离散标签(如“流失/不流失”) | 类别或类别概率 | 基尼不纯度(Gini)、熵(Entropy)、信息增益(Information Gain) |
| 回归树(Regression Tree) | 连续数值(如“价格”“时长”) | 一个数值常数 | 平方误差(Squared Error)、MSE / SSE 下降 |
因此不要把“决策树”和“分类树”当成并列概念。更准确的表述是:分类树与回归树都是决策树;前者预测类别,后者预测数值。
设某个节点上落入的样本集合为 \(S\),大小为 \(|S|\)。对某个候选切分(Split)\(\phi\),例如“第 \(j\) 个特征 \(x_j\le t\)”,样本会被分成左右两个子节点:
\[S_L(\phi)=\{(\mathbf{x}_i,y_i)\in S:\ x_{i,j}\le t\},\quad S_R(\phi)=S\setminus S_L(\phi)\]其中 \(S_L\) 是满足切分条件的样本集合,\(S_R\) 是剩余样本集合。树在每个节点都会尝试多个候选切分 \(\phi\),并保留收益最大的那个。
为了避免分别记忆分类树与回归树的训练目标,可以先写成统一形式。设 \(I(S)\) 表示“节点 \(S\) 当前有多乱”或“在该节点上预测误差有多大”,则一次切分的收益可统一写成:
\[\mathrm{Gain}(S,\phi)=I(S)-\frac{|S_L(\phi)|}{|S|}I\!\left(S_L(\phi)\right)-\frac{|S_R(\phi)|}{|S|}I\!\left(S_R(\phi)\right)\]这条式子的含义非常直接:
- \(I(S)\):切分前,这个节点有多混乱。
- \(I(S_L),I(S_R)\):切分后,左右子节点各自还有多混乱。
- \(\frac{|S_L|}{|S|},\frac{|S_R|}{|S|}\):左右子节点占父节点样本的比例。要乘这个比例,是因为大子节点对总体误差的影响更大,小子节点不能和大子节点拥有同样权重。
- \(\mathrm{Gain}(S,\phi)\) 越大,说明这次切分越有效。
分类树与回归树的差别,正体现在 \(I(S)\) 具体取什么。
在贷款审批(Loan Approval)场景中,决策树可以直接写成规则链。根节点先按负债收入比(Debt-to-Income Ratio)切分;若负债收入比过高,再看是否有逾期记录;若负债收入比正常,再看信用评分(Credit Score)与近 6 个月收入稳定性。最终某个叶节点可能对应“直接通过”,另一个叶节点对应“人工复核”,再另一个叶节点对应“拒绝”。这就是决策树最重要的工程价值:它不只是给出一个分数,还给出一条可追溯的判断路径。
分类树的目标是让每个叶节点里的标签尽量单一。若一个节点里几乎都是同一类样本,这个节点就“纯”;若各类样本混在一起,这个节点就“不纯”。
设类别集合为 \(\mathcal{K}\),类别 \(k\) 在节点 \(S\) 中的占比记为:
\[p_k(S)=\frac{\text{节点 }S\text{ 中标签为 }k\text{ 的样本数}}{|S|}\]常用的不纯度(Impurity)有两种。
基尼不纯度(Gini Impurity):
\[G(S)=1-\sum_{k\in\mathcal{K}}p_k(S)^2\]它可以读成“随机抽两个样本时,标签不一致的倾向有多强”。若节点里全是同一类,则某个 \(p_k=1\)、其余为 0,此时 \(G(S)=0\),说明节点已经纯净;若二分类里两类各占一半,则 \(G(S)=1-(0.5^2+0.5^2)=0.5\),说明混杂程度较高。
熵(Entropy):
\[H(S)=-\sum_{k\in\mathcal{K}}p_k(S)\log p_k(S)\]熵衡量的是“不确定性”。若节点里全是同一类,则不需要再猜,熵为 0;若各类比例接近,说明不确定性高,熵也更大。
信息增益(Information Gain)就是“切分前的不确定性”减去“切分后的加权不确定性”:
\[\mathrm{IG}(S,\phi)=H(S)-\frac{|S_L(\phi)|}{|S|}H\!\left(S_L(\phi)\right)-\frac{|S_R(\phi)|}{|S|}H\!\left(S_R(\phi)\right)\]这条公式的每一部分都对应一个明确动作:
- 第一项 \(H(S)\) 是切分前的混乱程度。
- 后两项是切分后左右子节点各自的混乱程度,并按样本占比加权求和。
- 两者相减,就是这次切分让节点“变纯”了多少。
有些实现使用基尼下降而非信息增益,本质上是同一件事:选择那个能让子节点更纯、让标签更集中的切分。
设任务是预测“一个用户未来 30 天是否流失”。标签只有两类:流失 / 未流失,因此这是典型分类树问题。候选特征可以包括:最近 7 天登录次数、最近 30 天是否投诉、是否还有未使用优惠券、最近一次下单距今天数。
假设根节点先尝试切分“最近 7 天登录次数 < 2”。这次切分后,左子节点里的用户大多已经很久不活跃,且流失比例显著升高;右子节点里的用户则活跃度更高、留存率更好。此时无论用基尼还是熵计算,左右节点的加权不纯度都会明显低于父节点,因此这会成为一个高质量切分。
继续往下,左子节点还可以再按“最近 30 天是否投诉”切分:低活跃且有投诉的用户,叶节点里可能出现“82% 最终流失”;低活跃但无投诉的用户,叶节点里可能是“61% 流失”。此时叶子不只给出类别,还可给出经验概率。工程上,这样的输出就能直接用于运营动作:高风险叶子推召回优惠券,中风险叶子推客服回访,低风险叶子不干预。
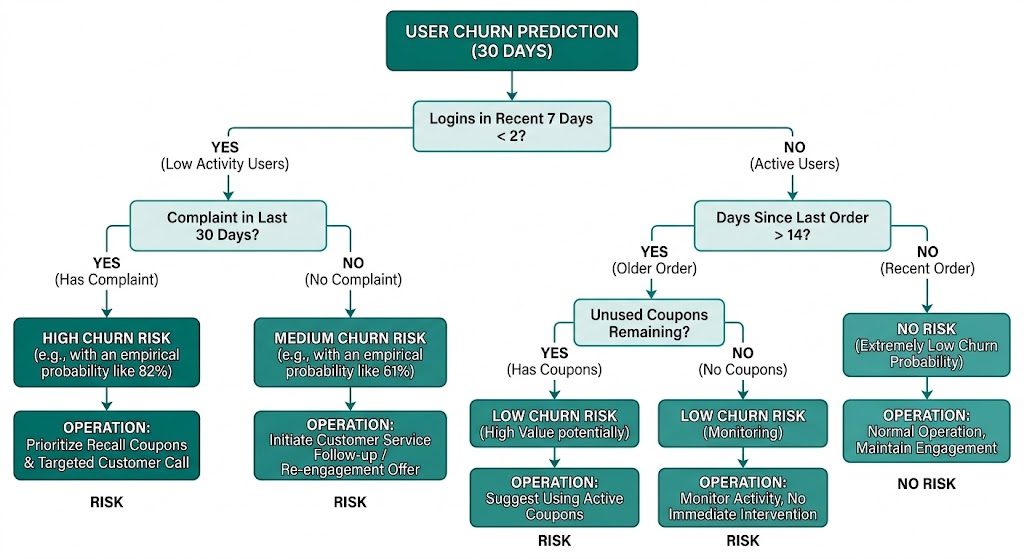
回归树处理的是连续数值目标,例如价格、时长、销量、能耗。它不追求“类别更纯”,而追求“同一个叶节点里的数值尽量接近”。
若某个叶节点 \(S\) 最终只输出一个常数 \(c\),那么在平方误差(Squared Error)下,最优输出核心是均值:
\[c^*(S)=\arg\min_c\sum_{(\mathbf{x}_i,y_i)\in S}(y_i-c)^2=\frac{1}{|S|}\sum_{(\mathbf{x}_i,y_i)\in S}y_i\]之所以是均值,是因为平方误差会把所有偏差向两边拉平,而均值正是使平方偏差和最小的那个常数。
在这个叶节点上,最小平方误差和(Sum of Squared Errors, SSE)为:
\[\mathrm{SSE}(S)=\sum_{(\mathbf{x}_i,y_i)\in S}\left(y_i-c^*(S)\right)^2\]它表示节点里所有样本值围绕叶子预测值 \(c^*(S)\) 的总波动。SSE 越大,说明这个节点里的样本值越分散,单用一个常数代表它们的效果越差。
因此一次切分的目标是让切分后的总误差尽量小,也可写成误差下降尽量大:
\[\Delta(S,\phi)=\mathrm{SSE}(S)-\mathrm{SSE}\!\left(S_L(\phi)\right)-\mathrm{SSE}\!\left(S_R(\phi)\right)\]若更喜欢看平均误差,也可以把它写成 MSE(Mean Squared Error)形式:
\[\mathrm{MSE}(S)=\frac{1}{|S|}\mathrm{SSE}(S)\]等价地,也可以最小化切分后的加权平均误差:\[\frac{|S_L|}{|S|}\mathrm{MSE}(S_L)+\frac{|S_R|}{|S|}\mathrm{MSE}(S_R)\]
两种写法完全等价:SSE 强调总误差,MSE 强调平均误差;本质都是寻找让子节点内部数值更集中的切分。
设任务是预测一笔订单从接单到送达需要多少分钟。这是连续数值目标,因此属于回归树。候选特征可以包括:配送距离、是否下雨、是否晚高峰、商家出餐速度、骑手当前手中订单数。
根节点可能先按“配送距离是否大于 3 公里”切分。因为近距离订单与远距离订单的时长分布差异很大,这一步通常能显著降低节点内部方差。对远距离子节点,再按“是否下雨”切分;下雨天路况更慢、波动更大。对近距离子节点,则可能按“是否处于午晚高峰”切分。
假设某个叶节点对应“距离 > 3 公里、下雨、晚高峰”这类订单,这个叶节点里的训练样本平均送达时长是 47 分钟,那么该叶子的预测值就是 47。另一个叶节点若对应“距离 < 2 公里、不下雨、非高峰”,其平均时长可能只有 18 分钟。回归树的预测逻辑核心是把不同业务情境分段,再在每段内给出一个局部平均值。
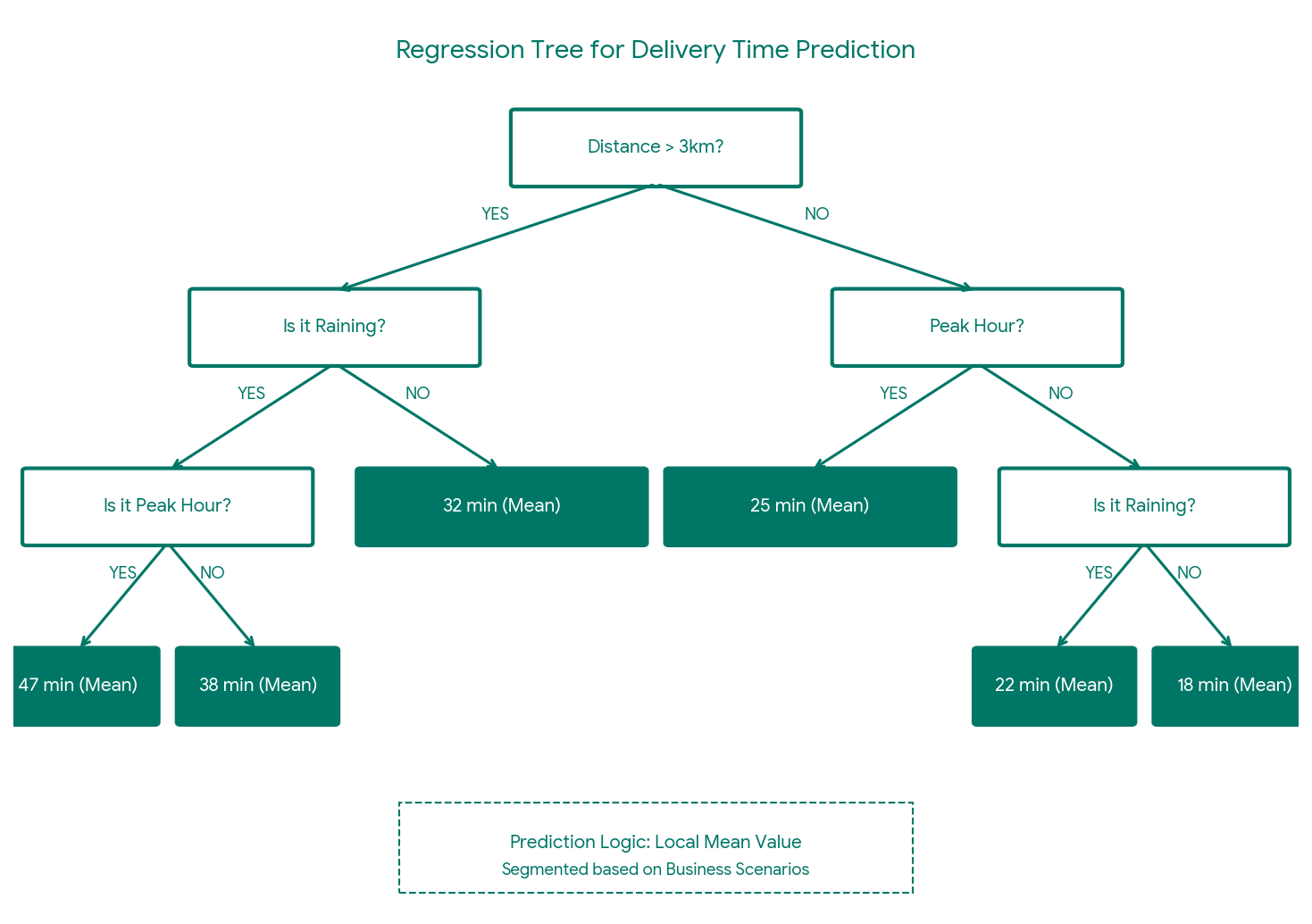
- 需要把模型输出翻译成可审计规则,例如风控、审批、运营分层、客服分流。
- 数据以表格(Tabular)为主,且存在显著非线性、阈值效应或特征交互。
- 希望同时处理连续特征与离散特征,并保留较强可解释性。
- 注意:单棵树方差高、容易过拟合,通常需要限制最大深度、最小叶子样本数或配合集成方法。
随机森林(Random Forest)是 Bagging(Bootstrap Aggregating)在树模型上的经典实现:用 bootstrap 采样生成多份训练子集,训练多棵通常偏差较低、但对训练数据扰动高度敏感(高方差)的决策树,再把它们的输出聚合,以显著降低整体方差并提升鲁棒性。
这里的“高方差(High Variance)”指模型的估计方差(Estimator Variance)或预测方差(Prediction Variance):如果训练集稍有变化,单棵树学到的分裂结构与最终预测就可能明显变化。随机森林利用多棵树的平均/投票,把这种由数据扰动带来的波动相互抵消。
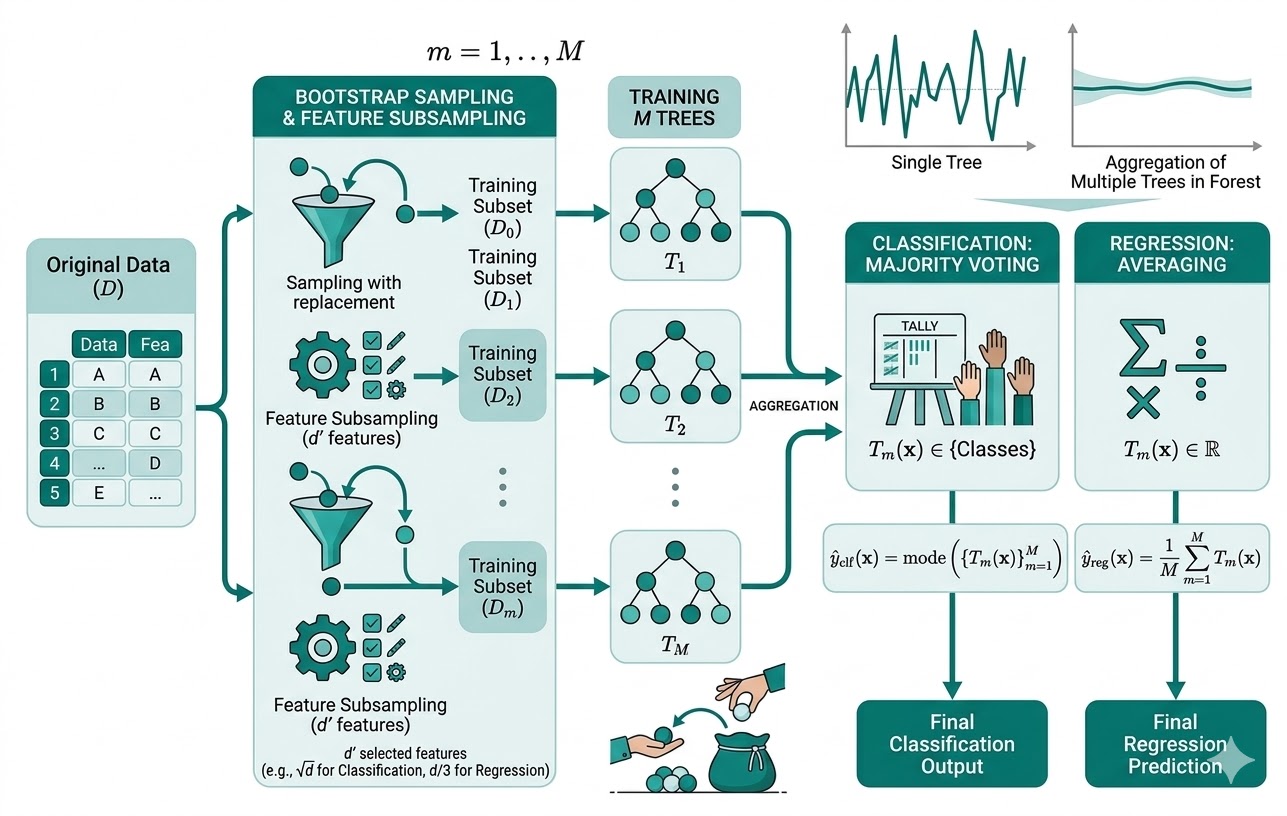
随机森林并非“很多棵树简单叠起来”这么粗糙。单棵树的主要问题,是一旦在上层节点做出某个早期切分,后面的整条子树都会被这个局部选择锁定,因此对数据扰动极敏感。随机森林通过 bootstrap 采样与特征子采样,让每棵树在“数据视角”和“可用特征视角”上都略有不同,再把这些不同视角的判断平均起来,从而大幅削弱某一棵树早期错误切分的破坏力。
给定训练集 \(D=\{(\mathbf{x}_i,y_i)\}_{i=1}^{N}\)。对 \(m=1,\dots,M\):
- bootstrap 采样:从 \(D\) 有放回采样 \(N\) 次得到 \(D_m\)。所谓“有放回(Sampling with Replacement)”,是指每次抽到一个样本后,都先把它放回原数据集,再进行下一次抽样;因此同一个样本可能被重复抽中,而有些样本在这一轮里一次也没有被抽到。
- 训练一棵树 \(T_m\):每个节点分裂时,只在随机选取的 \(d'\) 个特征上搜索最优切分(特征子采样,feature subsampling)。
预测时,回归取平均,分类取多数投票:
\[\hat y_{\text{reg}}(\mathbf{x})=\frac{1}{M}\sum_{m=1}^{M}T_m(\mathbf{x}),\quad \hat y_{\text{clf}}(\mathbf{x})=\mathrm{mode}\left(\{T_m(\mathbf{x})\}_{m=1}^{M}\right)\]这里 \(T_m(\mathbf{x})\) 表示第 \(m\) 棵树对样本 \(\mathbf{x}\) 的预测。回归任务把所有树的输出做平均,以减少波动;分类任务取众数 \(\mathrm{mode}(\cdot)\),也就是票数最多的类别。随机森林的稳定性正来自这种“多棵树共同决定”的聚合机制。
- \(M\):树的数量。
- \(d'\):每次分裂考虑的特征数(常见经验:分类用 \(\sqrt{d}\),回归用 \(d/3\))。
若单棵树预测的方差为 \(\sigma^2\),不同树之间的相关系数近似为 \(\rho\)(\(0\le\rho\le 1\)),则平均后的方差近似为:
\[\mathrm{Var}\!\left(\frac{1}{M}\sum_{m=1}^{M}T_m(\mathbf{x})\right)\approx \sigma^2\left(\rho+\frac{1-\rho}{M}\right)\]这个近似式子把随机森林为什么有效说得很清楚: \(\sigma^2\) 是单棵树自身的预测波动, \(\rho\) 是树与树之间的相关性, \(M\) 是树数。树越多, \(\frac{1-\rho}{M}\) 越小;树之间越不相似, \(\rho\) 越低,最终平均后的波动就越小。
因此随机森林有两条主线:
- 增加 \(M\) 降低 \((1-\rho)/M\) 项。
- 通过 bootstrap + 特征子采样降低相关性 \(\rho\),让集成真正“互补”。
bootstrap 采样会重复抽到某些样本。对固定样本 \(i\),一次采样中没被抽到的概率为 \((1-\frac{1}{N})^N\approx e^{-1}\approx 0.368\)。因此每棵树大约有 36.8% 的样本是袋外(Out-of-Bag, OOB)样本,可用它们评估该树对未见数据的表现,并对全森林给出近似验证误差。
这里 \((1-\frac{1}{N})\) 表示“一次抽样没抽到某个固定样本”的概率,连续做 \(N\) 次后得到 \((1-\frac{1}{N})^N\)。当 \(N\) 足够大时,它逼近 \(e^{-1}\),也就是约 36.8%。这就是为什么随机森林天然拥有一批“没参与这棵树训练”的 OOB 样本。
- 表格数据(Tabular)的强默认基线:非线性、特征交互、缺失值与尺度不一致都较鲁棒。
- 对超参数不敏感、训练稳定;可用特征重要性(Feature Importance)做解释与特征筛查。
- 当需要极致精度时,GBDT 家族往往更强;当需要更快推理/更小模型时,线性/浅层模型更合适。
梯度提升树(Gradient Boosting Decision Tree, GBDT)是一类按序叠加回归树的加法模型(Additive Model)。模型从简单的初始预测 \(F_0\) 出发,在每一轮加入一棵新树,用于修正当前模型尚未拟合好的部分,从而逐步降低训练集上的经验风险(Empirical Risk)。
每一轮新增的树都对应一个修正函数(Correction Function)。它不直接重新学习标签 \(y\),通常会拟合当前模型输出与目标之间尚未被解释的差异。多轮修正连续叠加后,模型会从粗糙预测逐步逼近目标函数。
一个直观比喻是:GBDT 像一组按顺序接手的阅卷老师。第一位老师先给出一个粗略分数,后面的每一位老师都不重做整张卷子,只专门检查前面模型错得最明显的地方,并在这些地方补上修正意见。树一棵接一棵叠加后,最终预测会越来越接近真实值。
这里每棵小树都核心是一个局部纠错器。它关心的是当前模型还没解释好的误差:哪些样本被高估了,哪些被低估了,以及这些误差集中出现在哪些特征区域。“梯度”对应当前损失下降最快的修正方向,“提升”则表示把这些小修正持续累加成一个更强的整体模型。
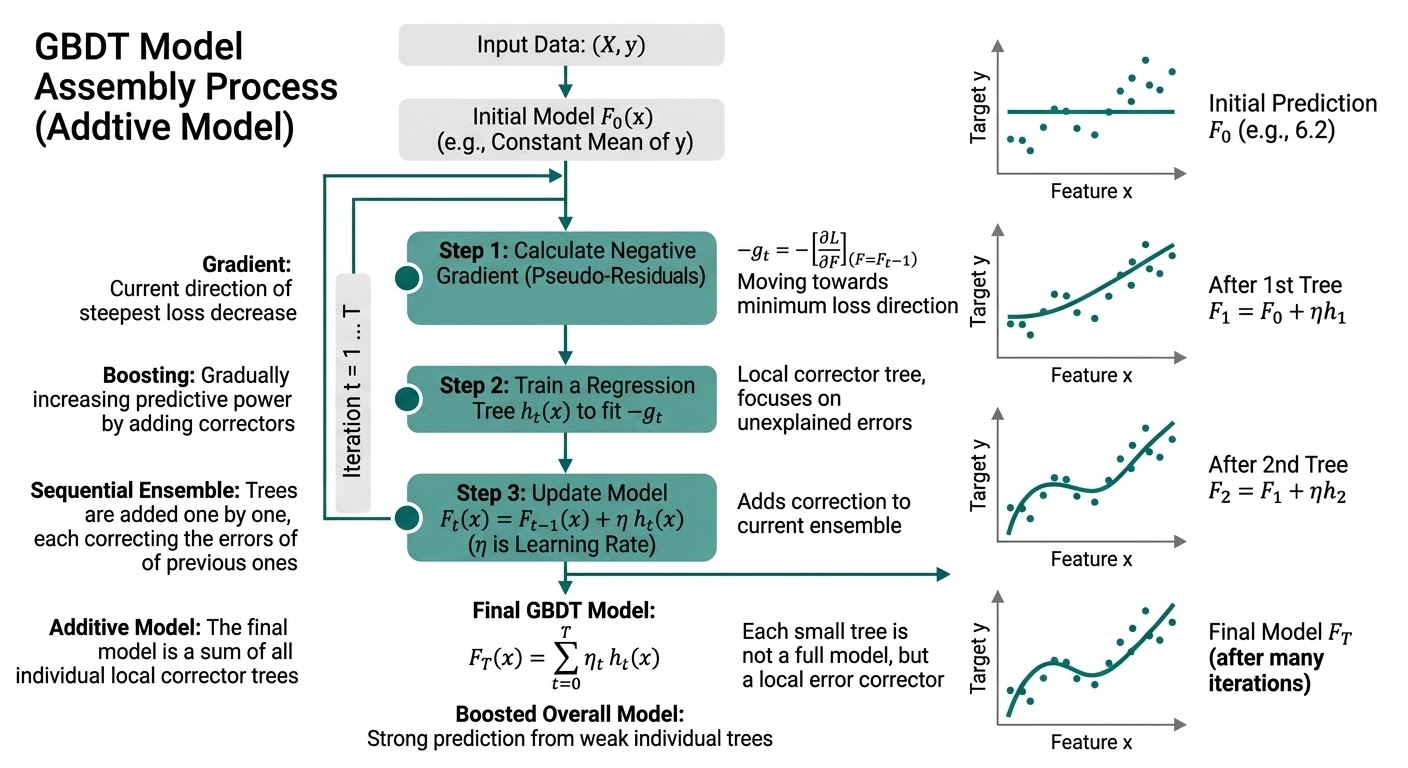
GBDT 背后的目标非常直接:寻找一个函数 \(F\),使训练集上的总损失最小:
\[ \min_F\ \sum_{i=1}^{N}\ell\big(y_i,F(\mathbf{x}_i)\big) \]这里 \(\ell(y,F(\mathbf{x}))\) 是单样本损失函数,平方损失、对数损失等都可以放进来。难点在于:函数 \(F\) 核心是一个复杂的预测函数;如果一次性同时优化所有树的结构和叶子输出,组合空间过大,几乎不可直接求解。
因此 GBDT 采用前向分步加法(Forward Stagewise Additive Modeling):把 \(F\) 写成逐步累加的形式,避免一次性求完整函数,只在第 \(m\) 轮新增一个修正函数 \(f_m\):
\[ F_M(\mathbf{x})=F_0(\mathbf{x})+\nu\sum_{m=1}^{M}f_m(\mathbf{x}) \]这里 \(F_M(\mathbf{x})\) 表示:模型经过总共 \(M\) 轮提升后,对输入样本 \(\mathbf{x}\) 输出的最终预测值。下标 \(M\) 表示“已经累计做了 \(M\) 次修正”,并非幂次,也并非某一棵单独的树。GBDT 的最终模型是许多轮小修正叠加后的总结果。
- \(\mathbf{x}\):一个输入样本的特征向量。
- \(F_0(\mathbf{x})\):初始模型对样本 \(\mathbf{x}\) 的预测,常取常数 \(c\) 使 \(\sum_i \ell(y_i,c)\) 最小。它可以理解为模型在还没有长出任何树之前给出的第一版粗略判断。
- \(f_m(\mathbf{x})\):第 \(m\) 轮新增的回归树在样本 \(\mathbf{x}\) 上给出的修正值,负责弥补当前模型尚未拟合好的部分。
- \(\sum_{m=1}^{M}f_m(\mathbf{x})\):把前 \(M\) 轮所有修正树的输出加起来,得到总修正量。
- \(\nu\in(0,1]\):学习率(Shrinkage),控制每一步修正只走多大。它的作用核心是缩小步长,使训练更稳定、泛化更好。
这个公式也可以按“底稿 + 反复批改”来理解: \(F_0(\mathbf{x})\) 是第一版预测,后面的每个 \(f_m(\mathbf{x})\) 都是在已有结果上补一小笔修正,最终的 \(F_M(\mathbf{x})\) 就是经历 \(M\) 次修正后的版本。
\[ f_m=\arg\min_f\sum_{i=1}^{N}\ell\big(y_i,F_{m-1}(\mathbf{x}_i)+f(\mathbf{x}_i)\big) \]这条式子表示:在第 \(m\) 轮,模型要寻找一个新的修正函数 \(f_m\),使它加到旧模型 \(F_{m-1}\) 上之后,训练集的总损失尽可能小。这里的 \(\arg\min_f\) 可以读作“在所有候选函数 \(f\) 里,找出那个能让目标最小的函数”。因此,求出来的核心是当前这一轮最合适的新树。
- \(F_{m-1}(\mathbf{x}_i)\):前 \(m-1\) 轮模型在第 \(i\) 个样本上的当前预测值。
- \(f(\mathbf{x}_i)\):候选新树在第 \(i\) 个样本上的修正值。
- \(F_{m-1}(\mathbf{x}_i)+f(\mathbf{x}_i)\):把新树加进去之后,这个样本的新预测值。
- \(\ell\big(y_i,F_{m-1}(\mathbf{x}_i)+f(\mathbf{x}_i)\big)\):该样本在新预测下的损失。
- \(\sum_{i=1}^{N}\ell(\cdot)\):把所有样本的损失加总,得到这一轮希望尽量压低的整体目标。
这一轮之所以写成 \(F_{m-1}+f\),而非重新求一个全新的 \(F_m\),原因在于 GBDT 采用的是逐步修正策略:旧模型已经学到的部分先保留,新树只负责补上当前还没有拟合好的误差。这样每一轮只解决一个更小的局部问题,计算上更可行,也更符合“不断纠错”的直觉。
第 \(m\) 轮只优化新增的修正函数 \(f_m\),而把已有模型 \(F_{m-1}\) 视为固定量。这样做把原本难以整体求解的函数优化问题,拆成了一系列可逐步求解的局部优化问题。
上面的子问题仍然不容易直接做,因为“最佳新树”本身还是一个复杂的函数搜索问题。GBDT 的关键近似是:在当前模型 \(F_{m-1}\) 附近,对损失做一阶展开,只看局部下降方向。
对单个样本 \(i\),把新增修正记为 \(f(\mathbf{x}_i)\),则有:
\[ \ell\big(y_i,F_{m-1}(\mathbf{x}_i)+f(\mathbf{x}_i)\big) \approx \ell\big(y_i,F_{m-1}(\mathbf{x}_i)\big) + \frac{\partial \ell(y_i,F(\mathbf{x}_i))}{\partial F(\mathbf{x}_i)}\Big|_{F=F_{m-1}} f(\mathbf{x}_i) \]一阶展开表明,新增函数 \(f\) 的最优局部方向由损失对模型输出的负梯度决定。因此第 \(m\) 轮的伪残差(Pseudo-residual)定义为:
\[ r_i^{(m)}=-\left.\frac{\partial \ell\left(y_i,F(\mathbf{x}_i)\right)}{\partial F(\mathbf{x}_i)}\right|_{F=F_{m-1}} \]接下来的动作就自然了:用一棵回归树去拟合这些伪残差,而非直接拟合标签 \(y_i\) \(r_i^{(m)}\)。这棵树学到的,就是“当前模型在输入空间不同区域里,应该往哪个方向、修正多大”的分段常数近似。
模型更新写成:
\[ F_m(\mathbf{x})=F_{m-1}(\mathbf{x})+\nu f_m(\mathbf{x}) \]“梯度提升”这一名称对应的正是上述更新方式:优化对象核心是预测函数本身;每一轮更新都沿着损失在函数空间中的负梯度方向加入一个新的修正函数。
若损失取平方损失
\[ \ell(y,F)=\frac{1}{2}(y-F)^2 \]则对模型输出求导:
\[ \frac{\partial \ell(y,F)}{\partial F}=F-y \]因此第 \(m\) 轮的负梯度为:
\[ r_i^{(m)}=-\left(F_{m-1}(\mathbf{x}_i)-y_i\right)=y_i-F_{m-1}(\mathbf{x}_i) \]这正是当前预测与真实值之间的残差(Residual)。所以在回归任务里,人们常把 GBDT 说成“不断拟合残差”;这核心是平方损失下负梯度公式的直接结果。
“每轮拟合残差”只在平方损失下最直观。更一般地,GBDT 拟合的是当前损失对模型输出的负梯度,因此不同任务下,每轮新树学到的对象并不完全相同。
| 任务 / 损失 | 当前轮拟合的量 | 含义 |
| 平方损失(MSE) | \(y-F(x)\) | 真实值与当前预测的残差 |
| 绝对损失(MAE) | \(\mathrm{sign}(y-F(x))\) | 只关心修正方向,不强调误差幅度;对异常值更鲁棒 |
| 二分类对数损失(Log Loss) | \(y-p(x)\) | 真实标签与当前预测概率之间的差 |
因此,GBDT 核心是一套更一般的函数优化框架。平方损失下它表现为残差学习;分类任务下,它表现为不断修正当前概率估计。
因为树天然产生分段常数(Piecewise Constant)的局部修正。若某一轮中,一棵树把样本空间切成若干区域 \(R_1,\dots,R_J\),那么它输出的是:
\[ f_m(\mathbf{x})=\sum_{j=1}^{J}\gamma_j\mathbf{1}(\mathbf{x}\in R_j) \]这意味着:模型核心是在每个局部区域里分别加一个常数修正 \(\gamma_j\)。这正适合处理表格数据里的阈值效应、非线性和特征交互。
在平方损失下,若某个叶子覆盖的样本集合为 \(S\),并用常数 \(\gamma\) 拟合这一叶内的残差 \(r_i\),则该叶子的局部目标是:
\[ \min_{\gamma}\sum_{i\in S}(r_i-\gamma)^2 \]对 \(\gamma\) 求导并令其为 0:
\[ \frac{d}{d\gamma}\sum_{i\in S}(r_i-\gamma)^2=-2\sum_{i\in S}(r_i-\gamma)=0 \] \[ \sum_{i\in S}r_i-|S|\gamma=0 \] \[ \gamma^*=\frac{1}{|S|}\sum_{i\in S}r_i \]因此叶子输出之所以是均值,核心是平方损失下这个局部最小二乘问题的解析解。每一轮加入一棵树,本质上是在每个局部区域里补上一段“平均残差修正”。
- 初始化 \(F_0\),通常取使总体损失最小的常数模型。
- 对第 \(m\) 轮,计算所有样本的伪残差 \(r_i^{(m)}\)。
- 训练一棵回归树 \(f_m\) 去拟合 \((\mathbf{x}_i,r_i^{(m)})\)。
- 把这棵树按学习率 \(\nu\) 缩小后加到当前模型上。
- 重复多轮,直到验证集误差不再下降,或达到预设树数。
GBDT 的本质,是把复杂的函数优化问题拆成许多轮局部修正,并在每一轮用一棵小树逼近当前损失下降最快的方向。
- 结构化表格任务中的强模型:广告、推荐、风控、运营排序、传统特征工程场景。
- 对特征尺度、非线性、缺失值较鲁棒;能自动学习高阶交互。
- 注意:对超参数更敏感(树深、学习率、树数、采样比例);需要用验证集早停(Early Stopping)防止过拟合。
GBDT 家族在表格数据上长期强势,并非偶然。表格任务里常见的模式,本来就很适合树模型表达:阈值效应、离散规则、局部非线性、特征交互、缺失值路径、不同子群体的分段行为。树的分裂结构天然能把“收入高且近期投诉过的老用户”和“收入低但活跃度高的新用户”这类组合规则直接切出来,而不需要像线性模型那样依赖大量手工交叉特征。
但同样的归纳偏置,在高维稀疏文本、图像、语音这类输入上就未必占优。因为这些任务的有效模式通常核心是分布在海量维度上的连续结构、局部平滑模式或长程依赖。此时树模型虽然能做基线,但往往不如专门面向非结构化数据的线性稀疏模型、卷积网络或 Transformer。
| 维度 | 说明 |
| 优点 | 表格数据精度高;对特征缩放不敏感;可处理非线性与高阶交互;通常还能给出特征重要性 |
| 局限 1 | 串行训练,训练速度通常慢于随机森林等并行集成 |
| 局限 2 | 对学习率、树数、树深、采样比例等超参数较敏感,容易出现“稍调不慎就欠拟合或过拟合” |
| 局限 3 | 在超高维稀疏文本或图像等非结构化输入上,通常并非最自然的主力模型 |
XGBoost(Extreme Gradient Boosting)是在梯度提升树(Gradient Boosting Decision Tree, GBDT)基础上的工程化强化版本。它关注的是:在保持高表达能力的同时,让树的生长过程更稳定、目标函数更明确、复杂度控制更系统。
XGBoost 仍然采用加法模型(Additive Model):当前模型由多棵树的输出求和得到,第 \(t\) 轮只学习一棵新树 \(f_t\) 作为修正项。它的关键强化点有两条:第一,把新增树的学习写成显式的带正则优化问题;第二,对该目标做二阶近似,同时利用梯度(Gradient)和海森(Hessian)信息计算叶子输出与分裂增益。
设第 \(t\) 轮预测为 \(\tilde y_i^{(t)}=\tilde y_i^{(t-1)}+f_t(\boldsymbol{x}_i)\)。XGBoost 在第 \(t\) 轮优化的目标可写为:
\[\text{Obj}^{(t)}=\sum_{i=1}^{N} \ell(y_i,\tilde y_i^{(t)})+\Omega(f_t)+\text{const}\]在这个目标里, \(\ell(y_i,\tilde y_i^{(t)})\) 衡量第 \(i\) 个样本在第 \(t\) 轮更新后的预测误差, \(\Omega(f_t)\) 惩罚新树本身的复杂度, \(\text{const}\) 则表示与当前轮新树无关的常数项。也就是说,XGBoost 每一轮都在平衡“把误差降下去”和“不要把树长得太复杂”。
其中正则项通常取:
\[\Omega(f)=\gamma T+\frac{\lambda}{2}\sum_{j=1}^{T}w_j^2\]这里 \(T\) 是叶子数, \(\gamma T\) 惩罚“树长出太多叶子”, \(\frac{\lambda}{2}\sum_j w_j^2\) 惩罚“每个叶子的输出值过大”。前者控制结构复杂度,后者控制数值幅度,两者合起来让模型更稳。
对损失在当前预测附近做二阶泰勒展开,定义:
\[g_i=\frac{\partial \ell(y_i,\tilde y_i)}{\partial \tilde y_i}\Big|_{\tilde y_i=\tilde y_i^{(t-1)}},\qquad h_i=\frac{\partial^2 \ell(y_i,\tilde y_i)}{\partial \tilde y_i^2}\Big|_{\tilde y_i=\tilde y_i^{(t-1)}}\]\(g_i\) 是一阶导数,表示“当前这个样本朝哪个方向改,损失下降最快”; \(h_i\) 是二阶导数,表示“这个方向有多陡、多稳定”。XGBoost 同时使用这两项信息,所以比只用一阶梯度的做法更精细。
则近似目标为:
\[\tilde{\text{Obj}}^{(t)}\approx \sum_{i=1}^{N} \left(g_i f_t(\boldsymbol{x}_i)+\frac{1}{2}h_i f_t(\boldsymbol{x}_i)^2\right)+\Omega(f_t)\]这条近似目标里, \(f_t(\boldsymbol{x}_i)\) 是新树在样本 \(i\) 上给出的修正值。线性项 \(g_i f_t(\boldsymbol{x}_i)\) 反映“沿当前方向修正是否有利”,二次项 \(\frac{1}{2}h_i f_t(\boldsymbol{x}_i)^2\) 反映“修正过大时会不会带来额外代价”。
若固定树结构,记落在叶子 \(j\) 的样本集合为 \(I_j\),并定义 \(G_j=\sum_{i\in I_j}g_i\)、\(H_j=\sum_{i\in I_j}h_i\),则该叶子的最优输出为:
\[w_j^*=-\frac{G_j}{H_j+\lambda}\]这里 \(G_j\) 是第 \(j\) 个叶子里所有样本一阶梯度的总和, \(H_j\) 是二阶梯度总和。分子告诉模型这个叶子整体应该往哪个方向修正,分母则用二阶信息和正则项 \(\lambda\) 把修正幅度稳住。
某次分裂把父叶拆成左右两叶后的增益(Gain)为:
\[\text{Gain}=\frac{1}{2}\left(\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{G^2}{H+\lambda}\right)-\gamma\]这个增益式子比较的是“父叶不分裂”和“分成左右两叶”谁更划算。 \(G_L,H_L\) 与 \(G_R,H_R\) 分别是左右子叶的梯度统计量, \(G,H\) 是父叶统计量;最后减去 \(\gamma\),表示每多长一个叶子都要付复杂度代价。
这说明 XGBoost 的分裂同时考虑“收益”和“复杂度惩罚”,并以此控制结构扩张。
XGBoost 的工程优势并不只来自“实现更快”。它把几项在工业界非常关键的能力同时做扎实了:显式复杂度正则化、二阶梯度优化、行采样与列采样、对稀疏特征的处理、缓存友好的分裂搜索,以及成熟的早停和监控接口。因此,它长期被视作结构化数据建模的稳健默认选项。
- 正则化更明确:通过叶子数惩罚与叶子权重 L2 正则显式控制树复杂度。
- 分裂选择更精细:同时使用一阶梯度与二阶梯度,不只看“该往哪边改”,还看“这一步有多稳”。
- 随机化更充分:支持样本子采样 \(\text{subsample}\) 和列采样 \(\text{colsample\_bytree}\),既降计算量也降过拟合。
- 工程实现更成熟:对稀疏输入、缓存访问和大规模数据训练都做了专门优化。
- 用当前模型计算每个样本的一阶梯度 \(g_i\) 与二阶梯度 \(h_i\)。
- 在候选特征与候选阈值上搜索分裂增益最大的切分。
- 固定树结构后,利用 \(w_j^*\) 计算每个叶子的最优输出。
- 把新树加入现有模型,继续下一轮迭代。
- 预测时把所有树的输出累加,再映射到分类或回归结果。
XGBoost 在工程实践里常配合较大的树数上限和验证集早停一起使用。做法通常核心是给一个偏大的上限,再观察验证集误差或任务指标何时不再提升。这样,树数不再是拍脑袋设定的固定值,而变成由验证集驱动的可学习训练预算。
这对 Boosting 家族尤其重要,因为学习率较小时,往往需要更多轮小步修正;若学习率较大,又更容易在后期进入过拟合区域。早停在这里的作用,是把“拟合能力很强”与“不要无限继续纠错”之间的边界交给验证集来判定。
在点击率预估(CTR Prediction)中,用户、广告和上下文之间往往存在复杂交互。XGBoost 可以通过逐轮加树自动学习“什么样的用户在什么时间、看到什么样的广告更容易点击”这类组合规则,因此在工业级表格任务中长期保持强竞争力。
- 优点:表格数据表现强,目标函数清晰,正则化明确,工程生态成熟。
- 局限:超参数较多;树深、学习率、树数、采样比例之间存在明显耦合。
- 适用场景:风控、广告、推荐、排序与一般结构化表格建模。
LightGBM 是面向大规模数据与高维稀疏特征优化的 GBDT 实现。它关注的核心问题是:当样本量和特征维度都很大时,如何降低分裂搜索的时间与内存成本,同时尽量不牺牲精度。
LightGBM 的两个关键设计是直方图分桶(Histogram Binning)和叶子优先生长(Leaf-wise Growth)。前者把连续特征离散到有限个桶上,后者每一步都继续分裂当前收益最大的叶子,从而在相同叶子预算下更快降低训练误差。
在优化目标上,LightGBM 与 GBDT / XGBoost 一致,仍然是逐轮加入树来降低损失。它的区别主要体现在计算方式:若某个连续特征被离散到 \(B\) 个桶,则算法只需在桶边界上搜索分裂点,而不必在所有实数取值上逐一枚举。这样,每个节点维护的是桶级梯度统计量,而非逐样本的原始实数值。
叶子优先生长意味着:算法始终选择当前分裂增益最大的叶子继续向下扩展。它通常比按层生长(Level-wise)更激进,因而在同样叶子数限制下更容易得到较低训练误差,但也更容易在局部区域长出很深的树。
LightGBM 的“快”核心是多项近似与工程策略叠加的结果。
- 直方图分桶:把连续特征先离散到有限个桶,例如默认 255 或 256 个桶。这样找切分点时,复杂度从“遍历大量原始取值”变成“遍历固定桶边界”。
- Leaf-wise 生长:每一轮只扩展当前最值得继续分裂的叶子,在相同叶子预算下往往比 level-wise 更快压低误差。
- GOSS(Gradient-based One-Side Sampling):优先保留梯度较大的样本,因为这些样本更能代表当前模型最需要修正的区域;对梯度较小的样本只随机保留一部分,以减少计算量。
- EFB(Exclusive Feature Bundling):把互斥的稀疏特征打包到同一组表示里,降低高维稀疏输入的有效维度。
其中 GOSS 和 EFB 的意义非常工程化。前者服务于“大样本下不必每轮都看全量样本”,后者服务于“高维稀疏特征下不必把所有稀疏列都单独维护”。因此,LightGBM 尤其适合推荐、广告、风控这类既大规模又高度稀疏的表格任务。
LightGBM 也因此更依赖约束配套。leaf-wise 生长虽然更激进,但如果不同时限制 max_depth、 num_leaves、 min_data_in_leaf 这类参数,局部树会很快长得过深,训练误差降得很漂亮,验证集却未必跟着受益。
- 将连续特征离散到有限个桶,并统计桶级梯度信息。
- 在每个节点上基于桶统计量搜索最优切分。
- 选择全局增益最大的叶子继续分裂。
- 使用最大深度、最大叶子数、最小叶子样本数等约束抑制过拟合。
- 预测时沿树路径到达叶子并累加所有树的输出。
在大规模推荐粗排任务中,输入特征通常极高维且高度稀疏。LightGBM 能在保留较强拟合能力的同时显著缩短训练时间,因此非常适合需要频繁重训的工业流水线。
- 优点:训练快、内存占用低,对大规模稀疏特征友好。
- 局限:叶子优先策略若约束不足,局部树会过深,过拟合风险更高。
- 适用场景:超大规模表格数据、稀疏特征建模、追求训练效率的工业场景。
CatBoost 是另一条非常重要的 Boosting 工业路线。它关注的核心问题是:当数据里有大量高基数类别特征时,如何在不引入严重数据泄露和预测偏移的前提下,把这些特征真正用好。广告、推荐、电商、用户画像、商品属性等任务里,这个问题尤其关键。
CatBoost 的两项代表性设计是有序目标统计(Ordered Target Statistics)与有序提升(Ordered Boosting)。前者处理类别特征,后者处理训练偏移。它们共同服务于同一个目标:不要让模型在训练时偷看到本不该知道的目标信息。
对树模型而言,类别特征的难点不只是“字符串不能直接喂进去”,更在于很多类别列的取值空间极大,例如用户 ID、商品 ID、城市、品牌、广告位、渠道来源。若简单做 one-hot 编码,维度会迅速膨胀;若直接用目标均值编码,又很容易把标签信息泄露进训练过程,导致离线效果虚高、线上泛化变差。
CatBoost 的思路是:用类别对应的目标统计量来表示类别,但计算某个样本的统计量时,只允许使用它之前样本的信息,而不允许看见它自己以及它之后的样本标签。这样得到的类别表示虽然仍然利用了监督信号,却显著降低了数据泄露与目标泄露风险。
设某个类别值为 \(c\),其编码值可以理解为“在训练顺序中,当前位置之前出现过的同类样本的目标统计量,再配合一个全局先验做平滑”。这样一来,模型在看到当前样本时,只能利用“过去”信息,不能直接偷看当前标签。
同样的思路也延伸到 Boosting 训练本身。传统目标编码或普通 Boosting 在训练时,常会让同一批样本之间发生微妙的信息穿透,形成预测偏移(Prediction Shift)。CatBoost 通过 ordered boosting 尽量让每一步的残差估计更接近“真正未见样本上的估计误差”,从而让训练分布和推理分布更一致。
CatBoost 还大量使用对称树(Symmetric Tree,也常称 Oblivious Tree):同一层的所有节点共享同一个切分规则。这种树结构比一般决策树更受约束,表达上没那么自由,但推理路径规整、计算高效,也更利于工程实现和高吞吐推断。
从工程角度看,CatBoost 的价值就在于把“类别特征处理”从手工特征工程里拿回模型内部。很多场景里,团队从需要先在外部纠结 one-hot、频次编码、目标编码、平滑规则和泄露控制转向可以把类别列直接交给模型,让训练流程自己处理这套问题。
- 优点:对类别特征支持最好,默认配置往往更稳,推理效率高。
- 局限:当类别特征优势不明显时,未必总能胜过 XGBoost 或 LightGBM;训练生态也没有前两者那么普遍。
- 适用场景:类别特征很多、ID 类特征很多、需要尽量减少手工编码工作的表格任务。
这一类方法处理的核心问题是:模型不仅要给出“预测是什么”,还要明确回答“这个结果有多可信、数据是如何生成的、隐藏结构是什么”。因此它们直接建模概率分布(Probability Distribution)、隐变量(Latent Variables)或序列依赖关系,在分类、密度估计、软聚类、序列推断与不确定性表达中具有统一优势。
朴素贝叶斯(Naive Bayes)用于分类问题。给定特征 \(\boldsymbol{x}\),它要估计样本属于每个类别 \(y\) 的后验概率 \(p(y|\boldsymbol{x})\)。该方法尤其适合高维稀疏、小样本或需要快速概率基线的任务。
朴素贝叶斯的核心假设是:在给定类别 \(y\) 的条件下,各个特征条件独立(Conditional Independence)。这个假设通常并不严格成立,但它把高维联合分布的估计问题,转化为多个一维条件分布的估计问题。
由贝叶斯公式:
\[p(y|\boldsymbol{x})=\frac{p(\boldsymbol{x}|y)p(y)}{p(\boldsymbol{x})}\]这个贝叶斯公式把后验概率拆成三部分: \(p(y|\boldsymbol{x})\) 是看到特征后属于类别 \(y\) 的概率; \(p(\boldsymbol{x}|y)\) 是该类别生成这组特征的可能性; \(p(y)\) 是类别先验; \(p(\boldsymbol{x})\) 则是对所有类别做归一化的总证据。
由于 \(p(\boldsymbol{x})\) 对所有类别相同,分类时只需比较:
\[p(y|\boldsymbol{x})\propto p(y)\prod_{j=1}^{d}p(x_j|y)\]这里的 \(\propto\) 表示“成正比”。因为对同一个样本来说,分母 \(p(\boldsymbol{x})\) 对所有类别都相同,所以比较类别大小时只需看右边:先验 \(p(y)\) 乘上每个特征条件概率 \(p(x_j|y)\) 的连乘积。
其中 \(p(y)\) 是先验概率(Prior), \(p(x_j|y)\) 是条件似然(Likelihood)。根据特征类型不同,可以得到高斯朴素贝叶斯、伯努利朴素贝叶斯、多项式朴素贝叶斯等变体。
- 从训练集统计每个类别的先验概率 \(p(y)\)。
- 估计每个类别下各特征的条件分布 \(p(x_j|y)\)。
- 推断时计算各类别的对数后验分数 \(\log p(y)+\sum_j \log p(x_j|y)\)。
- 选择分数最大的类别作为预测输出。
在垃圾邮件检测中,若某些词在垃圾邮件中显著更常见,那么这些词对应的条件概率会被估得更大,从而把包含这些词的邮件判到垃圾类别。
- 优点:训练快、推断快、对高维稀疏特征友好。
- 局限:条件独立假设常被破坏;概率校准有时较弱。
- 适用场景:文本分类、垃圾邮件过滤、简单可靠的概率基线。
高斯混合模型(Gaussian Mixture Model, GMM)处理的是“数据由多个潜在高斯成分混合生成”的建模问题。与 K-Means 只输出硬划分不同,GMM 希望估计每个样本属于各个簇的概率,并允许不同簇有不同的协方差结构。
GMM 引入潜变量 \(z\) 表示样本来自哪一个高斯成分。整体分布由多个高斯分布按混合系数加权得到,因此每个样本对各个簇的归属是软的(Soft Assignment),并以概率形式表达。
一个直观比喻是:把数据想成混在一起的几类人群,只能看到每个人的外在特征,却看不到他原本属于哪一类。每一类人群都有自己的“中心位置”和“分散形状”,对应一个高斯成分;整个数据集则像这些人群按不同比例叠在一起形成的总体分布。与 K-Means 把每个样本硬塞进某一个簇不同,GMM 会给出“这个样本更像第 1 类,也有一部分像第 2 类”这样的软归属结果。
因此,混合系数 \(\pi_k\) 可以理解为各类人群在总体中的占比,均值 \(\boldsymbol{\mu}_k\) 是每类人群的中心,协方差 \(\boldsymbol{\Sigma}_k\) 描述该群体沿不同方向的扩散方式,而责任度 \(\gamma_{ik}\) 则表示“样本 \(i\) 有多大程度属于第 \(k\) 类”。这也是 GMM 比 K-Means 更灵活的原因:它允许边界模糊,也允许簇具有不同大小、方向和椭球形状。
对样本 \(\boldsymbol{x}\),GMM 的概率密度写为:
\[p(\boldsymbol{x})=\sum_{k=1}^{K} \pi_k \mathcal{N}(\boldsymbol{x}\mid \boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k)\]这条式子说明 GMM 的整体密度核心是 \(K\) 个高斯成分的加权和。 \(\pi_k\) 决定第 \(k\) 个成分在总体中的占比, \(\mathcal{N}(\boldsymbol{x}\mid \boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k)\) 描述样本 \(\boldsymbol{x}\) 在该成分下有多典型。
其中 \(\pi_k\) 是混合系数,满足 \(\pi_k\ge 0\) 且 \(\sum_k \pi_k=1\)。给定样本后,其属于第 \(k\) 个成分的责任度(Responsibility)为:
\[\gamma_{ik}=p(z_i=k|\boldsymbol{x}_i)=\frac{\pi_k \mathcal{N}(\boldsymbol{x}_i\mid \boldsymbol{\mu}_k,\boldsymbol{\Sigma}_k)}{\sum_{j=1}^{K}\pi_j \mathcal{N}(\boldsymbol{x}_i\mid \boldsymbol{\mu}_j,\boldsymbol{\Sigma}_j)}\]责任度 \(\gamma_{ik}\) 是“样本 \(i\) 属于成分 \(k\) 的后验概率”。分子表示“成分 \(k\) 解释这个样本的能力”,分母则把所有成分对该样本的解释能力加总起来做归一化,因此所有 \(\gamma_{ik}\) 加起来等于 1。
GMM 的参数通常通过期望最大化(Expectation-Maximization, EM)求解。E 步计算责任度,M 步更新参数:
\[N_k=\sum_{i=1}^{N}\gamma_{ik},\qquad \pi_k=\frac{N_k}{N}\]这里 \(N_k\) 核心是软计数:每个样本只按自己的责任度贡献一部分。于是混合系数更新为 \(\pi_k=\frac{N_k}{N}\),表示第 \(k\) 个成分在总体中的相对权重。
\[\boldsymbol{\mu}_k=\frac{1}{N_k}\sum_{i=1}^{N}\gamma_{ik}\boldsymbol{x}_i,\qquad \boldsymbol{\Sigma}_k=\frac{1}{N_k}\sum_{i=1}^{N}\gamma_{ik}(\boldsymbol{x}_i-\boldsymbol{\mu}_k)(\boldsymbol{x}_i-\boldsymbol{\mu}_k)^\top\]均值更新式说明:每个样本按责任度大小对中心 \(\boldsymbol{\mu}_k\) 做加权贡献;协方差更新式则是在该加权中心周围统计离散程度。责任度越大,样本对该成分的中心和形状影响越大。
- 初始化混合系数、均值和协方差。
- E 步:计算每个样本对各高斯成分的责任度。
- M 步:根据责任度更新参数。
- 重复 E / M,直到对数似然收敛。
在用户分群中,若人群天然分成多个椭球状子群体,那么 GMM 不仅能给出簇划分,还能输出“某个用户属于每个群体的概率”,这比 K-Means 的硬分配更细致。
- 优点:软聚类、概率解释清晰、能建模不同协方差形状。
- 局限:对初始化敏感;高维时协方差估计代价高。
- 适用场景:软聚类、密度估计、带概率解释的聚类分析。
隐马尔可夫模型(Hidden Markov Model, HMM)用于序列建模,尤其适合处理序列标注(Sequence Labeling)问题。序列标注的任务形式是:给定一个按时间或位置排列的输入序列,为序列中的每个位置分配一个标签。例如,在词性标注中,句子“我爱北京天安门”的每个词或字都需要对应一个词性标签;在语音识别中,一段连续声学信号需要对应到一串离散文字或音素标签。
HMM 是序列模型中的经典早期方法,在语音识别等领域长期具有重要地位。它的优势在于结构清晰、推断高效,能够以较低的计算成本处理序列决策;与此同时,它主要依赖局部状态转移和局部发射关系,所使用的上下文信息相对有限。
HMM 的建模方式是:观测序列 \(\boldsymbol{x}_{1:T}\) 可以看到,但生成这些观测的状态序列 \(\boldsymbol{z}_{1:T}\) 看不到。这里的隐藏状态通常对应词性、命名实体类别或发音状态等潜在标签。围绕这一模型,核心问题通常包括计算某段观测序列的概率、恢复最可能的隐藏状态路径,以及估计模型参数。
HMM 的核心由两条条件独立假设组成。第一,隐藏状态满足一阶马尔可夫性(First-order Markov Property):当前隐藏状态只依赖前一个隐藏状态,即 \(p(z_t\mid z_{1:t-1})=p(z_t\mid z_{t-1})\)。第二,观测满足观测条件独立性(Observation Conditional Independence):当前观测只依赖当前隐藏状态,即 \(p(x_t\mid z_{1:T},x_{1:t-1})=p(x_t\mid z_t)\)。前者给出状态转移链,后者给出发射概率。
一个直接的比喻是:无法直接看到远方朋友每天所处的天气,但可以持续看到他发布的活动,例如“去游泳”“去逛街”或“在家睡觉”。在这个比喻里,天气是隐藏状态 \(z_t\),活动是观测 \(x_t\)。HMM 的生成逻辑正是先生成隐藏状态序列,再由每个状态发射对应观测。
如果今天是晴天,明天仍然晴天的概率通常较高;如果今天下雨,朋友在家休息的概率通常高于去游泳。这分别对应 HMM 中的状态转移概率 \(p(z_t|z_{t-1})\) 和发射概率 \(p(x_t|z_t)\)。因此,HMM 把序列建模为一个“剧本模拟器”:先按转移规律生成一条看不见的天气轨迹,再按照每一天的天气生成看得见的活动记录。
“发射”本质上是条件概率,而不必理解为真实世界里的物理因果。符号 \(p(x_t|z_t)\) 表示:在当前隐藏状态 \(z_t\) 已知的条件下,观测 \(x_t\) 出现的概率。HMM 选择这个方向,是因为它属于生成式模型(Generative Model):建模时描述“状态如何产生观测”,推断时再根据已经看到的观测反推最可能的隐藏状态路径。
这会形成一个很重要的方向差异。建模方向是 \(z_t\rightarrow x_t\),也就是隐藏状态发射观测;解码方向是根据 \(\boldsymbol{x}_{1:T}\) 反推 \(\boldsymbol{z}_{1:T}\),也就是寻找最可能解释这串观测的隐藏状态序列。HMM 的训练目标并非一个直接的 \(p(z_t|x_t)\) 分类器;它先定义 \(p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})\),再通过贝叶斯推断和动态规划完成反推。
| HMM 概念 | 比喻中的对应物 | 含义 |
| 隐藏状态 \(z_t\) | 每天的天气 | 真实存在,但观察者不能直接看到。 |
| 观测 \(x_t\) | 朋友圈里的活动 | 可以直接看到,用来反推隐藏状态。 |
| 初始分布 \(p(z_1)\) | 第一天各种天气出现的概率 | 序列从什么状态开始。 |
| 转移概率 \(p(z_t|z_{t-1})\) | 天气从今天到明天的变化规律 | 例如“晴天后仍是晴天”的概率较高。 |
| 发射概率 \(p(x_t|z_t)\) | 某种天气下出现某种活动的概率 | 例如下雨时更可能“在家睡觉”。 |
| 隐藏状态序列 \(\boldsymbol{z}_{1:T}\) | 整段天气变化轨迹 | 模型希望恢复的潜在过程。 |
| 观测序列 \(\boldsymbol{x}_{1:T}\) | 整段活动记录 | 模型的输入数据。 |
这个比喻也解释了 HMM 的优势与局限。它简单、快速、可解释,因为联合概率能够拆成局部转移和局部发射的乘积,并可用动态规划高效推断。但它的条件独立假设也很强:某一天的活动只由当天的天气决定,不直接依赖前后活动。在词性标注等任务中,一个词的标签往往同时受左右上下文影响,这种假设就会限制表达能力。
HMM 的联合分布写为:
\[p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})=p(z_1)\prod_{t=2}^{T}p(z_t|z_{t-1})\prod_{t=1}^{T}p(x_t|z_t)\]这个公式从左到右可以拆成四个层次:
- \(p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})\) 是整条观测序列和整条隐藏状态序列的联合概率。这里 \(T\) 是序列长度;\(t\) 是当前时刻或当前位置;\(x_t\) 是第 \(t\) 个观测值,例如第 \(t\) 个词、一次活动记录或一个传感器读数;\(z_t\) 是第 \(t\) 个隐藏状态,例如该词的词性标签、当天的真实天气或系统的潜在状态。\(\boldsymbol{x}_{1:T}=(x_1,\dots,x_T)\) 表示从第 \(1\) 个时刻到第 \(T\) 个时刻的全部观测;\(\boldsymbol{z}_{1:T}=(z_1,\dots,z_T)\) 表示对应的全部隐藏状态。
- \(p(z_1)\) 是初始状态概率。它回答“序列刚开始时,隐藏状态落在 \(z_1\) 的概率是多少”。在天气例子里,它就是第一天是晴天、雨天或阴天的先验概率;在词性标注里,它就是句子第一个词属于某个词性标签的初始概率。
- \(\prod_{t=2}^{T}p(z_t|z_{t-1})\) 是状态转移链。乘积符号 \(\prod\) 表示把从 \(t=2\) 到 \(T\) 的所有相邻转移概率连乘起来;\(p(z_t|z_{t-1})\) 表示“已知上一时刻状态 \(z_{t-1}\) 后,当前时刻转到 \(z_t\) 的概率”。这就是 HMM 的一阶马尔可夫假设:当前隐藏状态只直接依赖前一个隐藏状态。
- \(\prod_{t=1}^{T}p(x_t|z_t)\) 是观测发射链。它把每个时刻“隐藏状态 \(z_t\) 生成观测 \(x_t\)”的概率连乘起来;\(p(x_t|z_t)\) 是条件概率,表示在状态 \(z_t\) 已经给定时看到观测 \(x_t\) 的概率。天气例子里是“雨天时出现室内活动”的概率;词性标注里是“某个词性标签发射出某个词”的概率。这里的“发射”是模型假设中的生成方向,不等同于现实中的强因果断言。
这条联合分布引出 HMM 的三类基本计算问题:
- 概率评估(Evaluation):给定观测序列 \(\boldsymbol{x}_{1:T}\),计算模型看到这条序列的概率 \(p(\boldsymbol{x}_{1:T})\)。这回答“这段观测在当前模型下有多合理”。
- 状态解码(Decoding):给定观测序列 \(\boldsymbol{x}_{1:T}\),恢复最可能的隐藏状态路径 \(\boldsymbol{z}_{1:T}\)。这回答“最可能的潜在过程是什么”。
- 参数学习(Learning):给定训练序列,估计初始分布、转移矩阵和发射分布。若隐藏状态有标注,可以直接计数;若隐藏状态不可见,需要通过期望最大化(Expectation-Maximization, EM)估计。EM 会在“估计隐藏状态的后验分布”和“用这些估计更新参数”之间交替迭代。
这三类问题都会遇到同一个计算瓶颈:推断阶段的观测序列 \(\boldsymbol{x}_{1:T}\) 已经固定,系统看到的是某一句话、某段活动记录或某段声学信号,因此不需要枚举所有可能的观测序列。真正会爆炸的是隐藏状态路径 \(\boldsymbol{z}_{1:T}\)。若每个位置有 \(K\) 种隐藏状态,长度为 \(T\) 的序列共有 \(K^T\) 条候选路径,暴力枚举不可行。
HMM 的局部分解让动态规划可以安全地复用中间结果:到达时刻 \(t\) 且当前状态为 \(j\) 的所有历史路径,可以被压缩成一个中间量;继续向后计算时,只需考虑上一时刻状态 \(i\) 到当前状态 \(j\) 的转移。这样,每一步大约有 \(K^2\) 个转移组合,整条序列复杂度约为 \(O(TK^2)\)。
先看概率评估。给定观测序列后,隐藏路径不可见,需要把所有可能隐藏路径的联合概率加起来:
\[p(\boldsymbol{x}_{1:T})=\sum_{\boldsymbol{z}_{1:T}}p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})\]这个求和就是对隐藏状态序列做边缘化(Marginalization):从联合概率 \(p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})\) 中把看不见的 \(\boldsymbol{z}_{1:T}\) 消掉,只留下观测序列自身的概率 \(p(\boldsymbol{x}_{1:T})\)。当这条概率被用于训练数据时,也称为观测序列的边缘似然(Marginal Likelihood)。
前向算法(Forward Algorithm)就是高效计算上式的动态规划方法。它从左到右逐步汇总“走到当前位置和当前状态”的所有路径概率,最后得到整条观测序列的总概率。若记初始分布为 \(\pi\),转移矩阵为 \(A\),发射分布为 \(B\),则前向算法的核心量为:
\[\alpha_t(j)=p(x_{1:t},z_t=j)\]\(\alpha_t(j)\) 的含义是:看到前 \(t\) 个观测,同时当前时刻隐藏状态恰好是第 \(j\) 个状态的联合概率。更具体地说,它已经把所有“最终走到状态 \(j\) 的历史隐藏路径”的概率加总进来了,因此可以把“历史观测信息”和“当前落在哪个状态”压缩成一个可递推的中间量。
初始化为:
\[\alpha_1(j)=\pi_j B_j(x_1)\]这里 \(\pi_j\) 是第一个隐藏状态就是 \(j\) 的概率, \(B_j(x_1)\) 是状态 \(j\) 发射第一个观测 \(x_1\) 的概率。之后按如下递推向右推进:
\[\alpha_t(j)=\left[\sum_i \alpha_{t-1}(i)A_{ij}\right]B_j(x_t)\]递推式可以分成两步看:先对所有上一时刻隐藏状态 \(i\) 求和,用 \(A_{ij}\) 累积“从 \(i\) 转到 \(j\) 的可能性”;再乘上 \(B_j(x_t)\),表示当前状态 \(j\) 发射出观测 \(x_t\) 的概率。整条观测序列的概率在最后一步把所有可能的结束状态加起来:
\[p(\boldsymbol{x}_{1:T})=\sum_j \alpha_T(j)\]概率评估关心“所有路径加起来有多大概率”,状态解码关心“哪一条路径最可能”。维特比算法(Viterbi Algorithm)解决的是 HMM 的状态解码问题:给定观测序列 \(\boldsymbol{x}_{1:T}\),找出最可能产生这条观测的隐藏状态路径 \(\boldsymbol{z}_{1:T}\)。它对应的目标是:
\[\arg\max_{\boldsymbol{z}_{1:T}}p(\boldsymbol{z}_{1:T}\mid \boldsymbol{x}_{1:T})\]由于观测序列 \(\boldsymbol{x}_{1:T}\) 已经固定,上式等价于寻找联合概率 \(p(\boldsymbol{x}_{1:T},\boldsymbol{z}_{1:T})\) 最大的隐藏状态路径。和前向算法相比,维特比算法把“对所有路径求和”改成“在所有路径中取最大值”。它的核心量可写成:
\[\delta_t(j)=\max_{z_{1:t-1}}p(x_{1:t},z_{1:t-1},z_t=j)\]\(\delta_t(j)\) 表示:在第 \(t\) 步落到隐藏状态 \(j\) 的所有路径中,概率最高的那一条路径的概率。它保留的是“到达当前状态 \(j\) 的最佳部分路径”,并没有直接丢弃其他当前状态;每个候选状态 \(j\) 都会保留自己的最佳部分路径。因此,维特比算法属于全局路径动态规划。逐步贪心只保留一个局部最优状态,容易丢掉后续能形成更高整体概率的路径。
初始化为:
\[\delta_1(j)=\pi_j B_j(x_1)\]对应递推为:
\[\delta_t(j)=\left[\max_i \delta_{t-1}(i)A_{ij}\right]B_j(x_t)\]这条式子先枚举所有上一时刻隐藏状态 \(i\),计算“到达 \(i\) 的最佳路径概率”乘以“从 \(i\) 转到 \(j\) 的概率”,再从中选出最大的一个,最后乘上当前状态 \(j\) 发射观测 \(x_t\) 的概率。
为了最后恢复完整路径,算法还会保存 \(\psi_t(j)\):
\[\psi_t(j)=\arg\max_i \delta_{t-1}(i)A_{ij}\]\(\psi_t(j)\) 表示“到达当前状态 \(j\) 时,概率最高的路径来自哪一个上一时刻隐藏状态”。这个上一时刻隐藏状态也常称为最佳前驱状态(Best Predecessor State),本质上就是回溯指针(Backpointer)。当递推走到最后一个时刻后,先选出终点概率最高的状态,再沿着这些回溯指针从后往前还原整条隐藏状态路径。
训练或拟合阶段取决于隐藏状态是否有标注。若训练数据同时给出观测序列和隐藏状态序列,例如词和词性标签都已标好,HMM 参数可以直接用计数估计:初始分布来自每条序列第一个标签的频率,转移矩阵来自相邻标签对的频率,发射分布来自“标签发射观测”的频率。
若训练数据只有观测序列,隐藏状态 \(\boldsymbol{z}_{1:T}\) 未知,训练目标就是最大化前面定义的边缘似然。对多条训练序列 \(\{\boldsymbol{x}^{(n)}_{1:T_n}\}_{n=1}^{N}\),通常最大化对数边缘似然:
\[\mathcal{L}(\theta)=\sum_{n=1}^{N}\log p_\theta(\boldsymbol{x}^{(n)}_{1:T_n})\]这里 \(\theta\) 表示 HMM 的全部参数,包括初始分布、转移矩阵和发射分布。难点在于:每条观测序列背后可能有大量隐藏路径,模型需要估计“每个状态、每条转移大概被用了多少次”,再用这些估计值更新参数。
Baum-Welch 算法就是 HMM 上的 EM 具体实例。E 步使用前向后向算法(Forward-Backward Algorithm)计算软计数。前向量 \(\alpha_t(i)\) 汇总“从开头走到时刻 \(t\)、并落在状态 \(i\)”的概率;后向量 \(\beta_t(i)\) 汇总“从状态 \(i\) 出发,继续生成后续观测”的概率:
\[\beta_t(i)=p(x_{t+1:T}\mid z_t=i)\]把前向量和后向量相乘并归一化,就能得到第 \(t\) 个位置处于状态 \(i\) 的后验概率:
\[\gamma_t(i)=p(z_t=i\mid \boldsymbol{x}_{1:T})=\frac{\alpha_t(i)\beta_t(i)}{p(\boldsymbol{x}_{1:T})}\]类似地,相邻两步发生转移 \(i\rightarrow j\) 的后验概率可写成:
\[\xi_t(i,j)=p(z_t=i,z_{t+1}=j\mid \boldsymbol{x}_{1:T})\]\(\gamma_t(i)\) 和 \(\xi_t(i,j)\) 就是“软计数”:它们按概率把计数分摊给多个可能状态和转移,而非把某个位置硬分配给唯一状态。M 步再用这些软计数更新初始分布、转移矩阵和发射分布。
- 先定义状态空间、观测空间、初始分布、转移概率和发射概率的参数形式。
- 有隐藏状态标注时,用频率计数估计初始分布、转移矩阵和发射分布。
- 隐藏状态未标注时,用 Baum-Welch 反复执行“前向后向求软计数”和“按软计数更新参数”。
- 参数确定后,用前向 / 后向算法计算序列概率或边缘状态分布,用维特比算法输出最可能状态路径。
在词性标注中,观测是单词序列,隐藏状态是词性标签。HMM 会同时利用“某个词在某种词性下更常见”的发射规律和“词性之间如何转移”的序列规律完成整体解码。
例如,对序列“我 / 爱 / 北京 / 天安门”,模型看到的是词本身,看不到的是背后的标签序列。HMM 会比较多种候选路径,如“代词(Pronoun)→ 动词(Verb)→ 专有名词(Proper Noun)→ 专有名词(Proper Noun)”与其他不合理组合的概率。由于“我”更容易由代词状态发射,“爱”更容易由动词状态发射,而“代词后接动词、动词后接名词性成分”又符合常见转移规律,这条标签路径就会获得更高概率。这个过程可以理解为:模型一边根据词本身猜标签,一边检查整条词性路径是否顺畅。
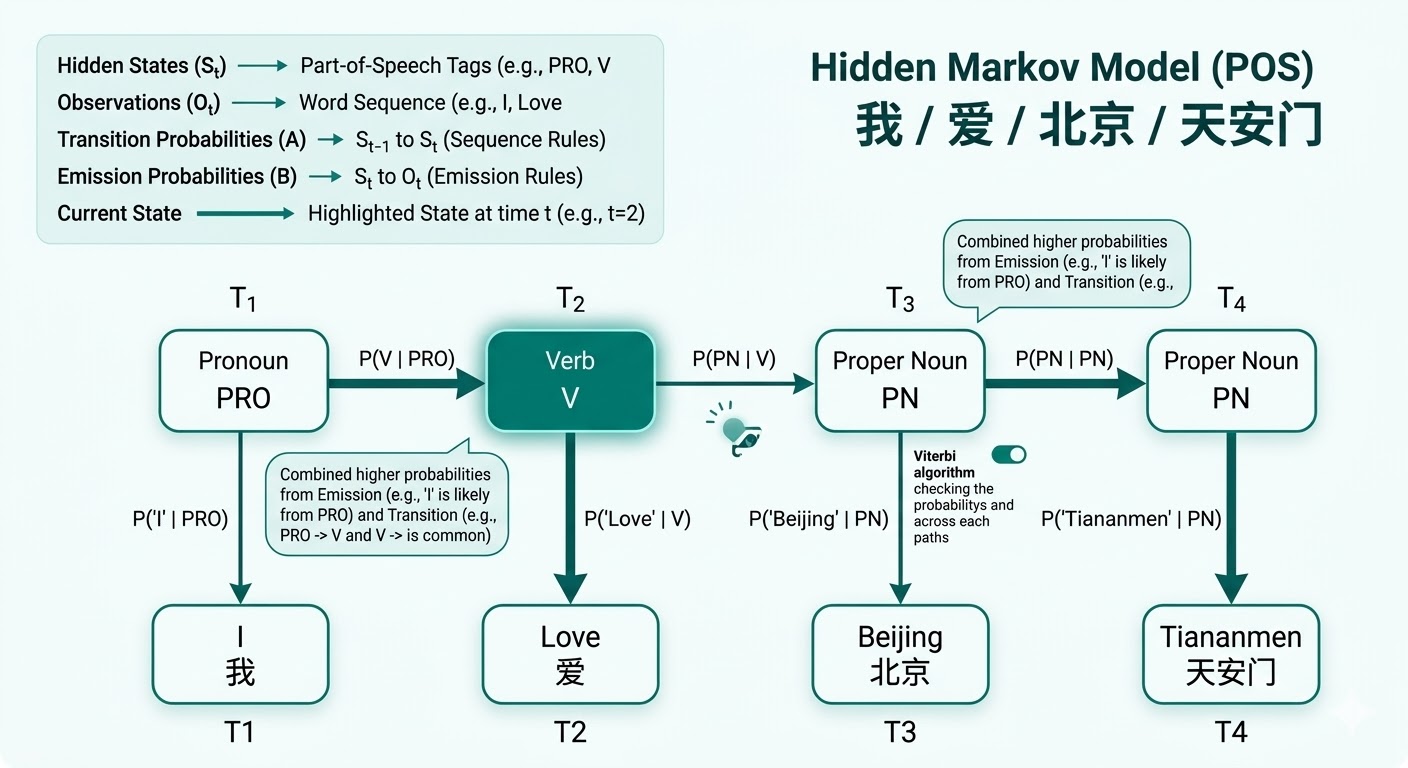
- 优点:序列结构清晰,动态规划推断高效,可解释性强。
- 局限:一阶马尔可夫假设较强,表达能力有限。
- 适用场景:基础序列标注、时间状态切换建模、中小规模序列任务。
最大熵模型(Maximum Entropy Model, MaxEnt)处理的是:在已知若干特征约束的前提下,如何选择一个既满足这些约束、又不过度引入额外假设的条件概率模型。它在经典 NLP 中极其重要,因为很多任务的关键证据核心是来自大量离散、稀疏、可人工设计的特征,例如当前词、前后词、词形、词性、是否出现在词典中等。
若只看单个位置分类,MaxEnt 的数学形式与多项逻辑回归(Multinomial Logistic Regression)本质一致:它直接建模 \(p(y\mid x)\)。当它被串到序列建模里时,最典型的扩展是最大熵马尔可夫模型(Maximum Entropy Markov Model, MEMM):当前位置标签的条件概率不仅依赖输入特征,也依赖前一个标签,因此可用于序列标注。
“最大熵”这个名字的含义是:在所有满足已知统计约束的分布中,选择熵(Entropy)最大的那一个,也就是额外承诺最少、最不武断的那一个。放到工程上,它导向的是指数族(Exponential Family)形式的条件模型:把各类特征函数加权求和,再通过归一化得到概率。
因此,MaxEnt 可以理解为特征驱动的判别式概率模型。它直接回答“在这些特征都成立时,这个标签有多大概率”。这使它特别适合传统 NLP 中大量规则化、稀疏化、模板化的人工特征。
多分类最大熵模型通常写成:
\[p(y\mid x)=\frac{\exp\left(\sum_k \lambda_k f_k(x,y)\right)}{\sum_{y'}\exp\left(\sum_k \lambda_k f_k(x,y')\right)}\]这里 \(f_k(x,y)\) 是第 \(k\) 个特征函数,衡量“输入 \(x\) 与标签 \(y\) 是否满足某种模式”; \(\lambda_k\) 是对应权重。分子给出某个候选标签的未归一化分数,分母把所有标签的分数加总后做归一化,因此输出是一个真正的条件概率分布。
若进一步用于序列,第 \(t\) 个位置的 MEMM 局部条件分布可写成:
\[p(y_t\mid y_{t-1},x,t)=\frac{\exp\left(\sum_k \lambda_k f_k(y_{t-1},y_t,x,t)\right)}{\sum_{y'}\exp\left(\sum_k \lambda_k f_k(y_{t-1},y',x,t)\right)}\]这条式子说明:在 MEMM 里,当前位置标签 \(y_t\) 的概率是对“给定上一标签和当前输入特征”的局部 softmax。它保留了丰富特征表达能力,但归一化只在当前状态的出边上进行,这正是后文 CRF 要解决的标签偏置(Label Bias)来源。
- 设计特征函数,把当前位置、局部上下文和标签关系编码成离散特征。
- 通过最大条件对数似然训练权重 \(\lambda_k\),通常配合 \(L_2\) 正则化。
- 若是独立分类任务,直接取条件概率最大的标签。
- 若是 MEMM 这类链式模型,则结合维特比或束搜索在局部概率之上做整条序列解码。
在传统命名实体识别中,可以为当前位置构造特征:当前词是否首字母大写、前一个词是否是头衔、后一个词是否是公司后缀、前一个标签是否已经是 \(B\text{-}ORG\)。MaxEnt 或 MEMM 会把这些证据线性加权,再输出当前位置属于组织名、人名或其他类别的条件概率。
- 优点:判别式训练、可直接接入丰富特征、概率输出直观。
- 局限:若做链式局部归一化,容易出现标签偏置;强依赖特征工程。
- 适用场景:传统 NLP 局部分类、特征模板丰富的序列标注过渡方案、理解 CRF 之前的判别式建模主线。
条件随机场(Conditional Random Field, CRF)主要用于结构化预测(Structured Prediction),尤其是序列标注。它处理的问题是:在给定输入序列 \(\boldsymbol{x}\) 的条件下,如何联合预测输出标签序列 \(\boldsymbol{y}\),并显式建模标签之间的依赖关系。
CRF 可以看作对 HMM 的进一步发展:它把问题从生成式建模(Generative Modeling)转向判别式建模(Discriminative Modeling)。这里的“生成式”指 HMM 这类模型会描述隐藏标签如何转移、每个标签如何发射观测 token,也就是建模 \(p(\boldsymbol{x},\boldsymbol{y})\) 或 \(p(\boldsymbol{x}\mid\boldsymbol{y})p(\boldsymbol{y})\);“判别式”指 CRF 直接在给定输入 \(\boldsymbol{x}\) 的条件下比较不同标签序列 \(\boldsymbol{y}\) 的合理性,建模 \(p(\boldsymbol{y}\mid\boldsymbol{x})\)。
这里的全局特征(Global Feature)指的是:特征不再只服务于单个位置的局部分类,而会参与整条候选标签路径的总分。例如在天气和活动的比喻里,HMM 通常把“某天活动由当天隐藏天气发射出来”作为局部关系;CRF 则可以给“连续三天都出现游泳,因此连续晴天这条天气路径更合理”这样的整段模式加分。这个特征虽然仍可在每个位置上累积计算,但它影响的是整条天气序列的总评分。
更灵活的上下文依赖指的是:CRF 的特征函数可以直接查看给定输入序列 \(\boldsymbol{x}\) 的多个位置,而不必被 HMM 的“当前观测只依赖当前隐藏状态”限制住。仍用天气例子,判断第 \(t\) 天是否下雨时,模型可以同时利用当天活动、前一天活动、后一天活动、是否连续多天出现同类活动、相邻天气标签是否自然等证据。放到 NLP 里,这对应“当前词、前后词、词形、词典命中、相邻标签组合”等特征共同影响整条标签路径。通过这些设计,CRF 缓解了 HMM 仅依赖局部独立假设所带来的信息不足。在深度学习广泛进入 NLP 之前,CRF 长期是各类标注任务中的核心方法。
CRF 的核心是在给定观测序列的条件下,对整条标签序列进行全局评分,而非显式描述数据生成过程。仍以天气和活动的比喻来理解:已知一整周的活动记录后,CRF 会把各种可能的天气序列都拿来比较,判断哪一种与这组活动整体最一致。它建模的是条件分布 \(p(\boldsymbol{y}|\boldsymbol{x})\),而非 HMM 那样的联合分布 \(p(\boldsymbol{x},\boldsymbol{y})\)。
这种“全局把控”体现在两个层面。第一,CRF 的打分对象是完整的标签路径,而非每个位置互相独立的局部决策;第二,打分依据可以是灵活定义的特征函数(Feature Function)。例如,若连续三天都出现“游泳”,对应“连续晴天”的标签组合就应得到更高分;若一周中出现“滑雪”这类活动,与“夏天”一致的天气标签组合就应被显著压低。特征函数可以同时利用当前位置、前后邻域以及相邻标签之间的组合关系。
因此,CRF 可以视为一个面向整条序列的打分系统:输入固定,模型比较不同标签序列的相对合理性,并选择得分最高的一条。它的优势是能够充分利用复杂上下文和标签依赖,在序列标注任务中通常比 HMM 更准确;代价是训练和推断都更重,需要计算整条序列上的归一化与动态规划。
线性链 CRF 的条件分布通常写为:
\[p(\boldsymbol{y}|\boldsymbol{x})=\frac{1}{Z(\boldsymbol{x})}\exp\left(\sum_{t=1}^{T}\sum_k \lambda_k f_k(y_{t-1},y_t,\boldsymbol{x},t)\right)\]这个式子最好分三层看。先看最里面的 \(\sum_{t=1}^{T}\sum_k \lambda_k f_k(y_{t-1},y_t,\boldsymbol{x},t)\):它表示对整条标签序列逐位置累积特征得分。再看外面的指数 \(\exp(\cdot)\):它把“总得分”变成一个始终为正的数,而且总得分越大,这个数就越大。最后再除以 \(Z(\boldsymbol{x})\),把这些正数正规化成概率。因此,CRF 的计算顺序可以理解为:先打分,再变成正权重,最后归一化成概率。
为了看清楚 \(Z(\boldsymbol{x})\) 在做什么,可以先临时把分子记成一个“未归一化分数”:
\[\tilde{p}(\boldsymbol{y}|\boldsymbol{x})=\exp\left(\sum_{t=1}^{T}\sum_k \lambda_k f_k(y_{t-1},y_t,\boldsymbol{x},t)\right)\]这里特意加波浪号,是为了强调它还并非概率。原因很简单:把所有可能标签序列的 \(\tilde{p}(\boldsymbol{y}|\boldsymbol{x})\) 加起来,结果一般不会恰好等于 1。它只是每条路径的相对权重,表达“这条标签路径有多合理”。
这时配分函数(Partition Function)就出现了:
\[Z(\boldsymbol{x})=\sum_{\boldsymbol{y}} \exp\left(\sum_{t=1}^{T}\sum_k \lambda_k f_k(y_{t-1},y_t,\boldsymbol{x},t)\right)\]之所以你会觉得它“和上面那个公式一样”,是因为它确实就是把上式分子对所有可能的标签序列整体求和。上面的 \(p(\boldsymbol{y}|\boldsymbol{x})\) 针对的是某一条固定标签序列 \(\boldsymbol{y}\);而这里的 \(Z(\boldsymbol{x})\) 核心是把所有可能路径都算一遍,再全部加起来。所以它核心是“分子在全标签空间上的总和”。
于是条件概率就变成:
\[p(\boldsymbol{y}|\boldsymbol{x})=\frac{\tilde{p}(\boldsymbol{y}|\boldsymbol{x})}{Z(\boldsymbol{x})}\]现在这个式子就容易理解了:某条路径的概率,等于“这条路径自己的权重”除以“所有路径权重的总和”。这和 softmax 的归一化逻辑完全一致,只不过 softmax 是在有限个类别上归一化,而 CRF 是在所有可能的标签序列上归一化。
配分函数这个名字来自统计物理,但在这里不需要物理背景也能理解:它本质上就是一个归一化常数。没有它,模型只能说“路径 A 比路径 B 更合理”;有了它,模型才能进一步说“路径 A 的概率是多少”。也正因为 \(Z(\boldsymbol{x})\) 需要把所有可能标签路径都考虑进去,CRF 训练时才必须借助动态规划,而不能暴力枚举。
- \(f_k(y_{t-1},y_t,\boldsymbol{x},t)\):第 \(k\) 个特征函数,描述当前位置、相邻标签和输入之间的某种局部模式。
- \(\lambda_k\):该特征的权重;越大表示模型越重视这个模式。
- \(\boldsymbol{x}\):固定输入序列;在讨论 \(Z(\boldsymbol{x})\) 时,它不变。
- \(\boldsymbol{y}\):某一条候选标签序列;计算 \(Z(\boldsymbol{x})\) 时要对所有可能的 \(\boldsymbol{y}\) 求和。
- \(\sum_{t=1}^{T}\sum_k \lambda_k f_k(\cdot)\):整条标签序列的总得分。
- \(\exp(\cdot)\):把总得分映射成正权重,并放大高分路径与低分路径之间的差异。
- \(Z(\boldsymbol{x})\):所有候选标签路径未归一化权重的总和,用于把相对权重变成概率。
训练时最大化条件对数似然,解码时用维特比算法寻找最优标签序列。
- 定义特征函数,描述输入与标签、标签与标签之间的关系。
- 用前向后向算法计算配分函数与梯度。
- 通过梯度法优化参数 \(\lambda_k\)。
- 推断时用维特比算法输出最优标签序列。
在命名实体识别(NER)中,局部分类器可能会把某个词单独判成人名,但 CRF 会进一步考虑相邻标签是否合法,从而减少孤立的局部误判。这里“是否合法”指的核心是标签序列是否符合该任务定义下允许出现的邻接模式。例如,在常见的 BIO 标注体系中, \(B\) 表示 Begin,即实体开始; \(I\) 表示 Inside,即实体内部; \(O\) 表示 Outside,即不属于任何实体。也有一些任务使用 BIOES 标注体系,其中 \(E\) 表示 End, \(S\) 表示 Single。与 BIO 相比,BIOES 会把实体结束位置和单字实体显式标出来,因此边界信息更细。于是,标签 \(B\text{-}PER\) 表示一个人名实体的开始, \(I\text{-}PER\) 表示该人名实体的内部, \(O\) 表示不属于任何实体。于是, \(B\text{-}PER\rightarrow I\text{-}PER\) 是常见且合法的相邻转移, \(O\rightarrow B\text{-}PER\) 也合法;但 \(O\rightarrow I\text{-}PER\) 通常不合法,因为一个实体内部标签不能无缘无故直接开始,前面必须先有对应的开始标签。同样, \(B\text{-}LOC\rightarrow I\text{-}PER\) 这类“实体类型突然不一致”的连接也通常应被压低分数。
例如,在句子“张三 在 北京 工作”中,若任务要识别人名(PER)和地点(LOC),一个合理的 BIO 标注序列可能是“张三 / 在 / 北京 / 工作”对应 \(B\text{-}PER, O, B\text{-}LOC, O\)。这里首先需要区分两件事:某个位置更像哪一种实体类型,以及这些局部判断连起来是否构成一条合理的标签序列。前者主要来自输入本身提供的证据,例如“张三”在词形上很像中文人名,“北京”本身强烈像地点名词,而“在 北京 工作”这种上下文也会继续加强“北京是地点”的判断。传统 CRF 会把这些信息写成特征函数,例如“当前词是否常见于人名词表”“当前词是否带有地名后缀”“左邻词是否是介词‘在’”“右邻词是否是动作词‘工作’”等;每个特征都会给某个候选标签加分或减分。
CRF 的作用是在这些局部类型证据之上,再做一次全局一致性的联合解码。换言之,实体类型 A 还是 B,并非和 CRF 完全无关;但也并非由 CRF 凭空决定的。更准确地说,实体类型的语义判断主要来自输入特征,CRF 负责把这些局部判断放到整条序列里统一协调。例如,如果“北京”这个位置单看局部证据时,对 LOC 的分数高于 PER,那么 CRF 会倾向保留“地点”这一判断;但它还会进一步检查,当前位置前后的标签连接是否自然。如果某条候选路径把“张三”切成 \(B\text{-}PER, O\),或者把“北京”接成 \(B\text{-}PER\rightarrow I\text{-}LOC\),即使某个局部位置的分数不低,整条路径仍会因为边界断裂或类型转移不一致而被整体压低。于是 CRF 做的核心是“局部类型打分 + 全局路径约束”的联合决策。
从工程实现上看,这个分工在不同年代的模型里表现形式不同。在传统 CRF 中,“局部类型打分”通常来自人工设计的特征模板,例如当前词、前后词、词性、字形、是否出现在人名词典或地名词典中;CRF 再把这些手工特征组合成整条序列的全局分数。在 BiLSTM-CRF 或 BERT-CRF 这类现代模型中,局部证据从主要依赖手工模板转向先由 BiLSTM 或 BERT 生成上下文化表示(Contextual Representation),再由线性层给出每个位置对各标签的局部分数,最后仍由 CRF 层负责建模标签转移和整条路径解码。也就是说,上游编码器主要回答“这个位置像什么类型”,CRF 层主要回答“这些位置判断拼在一起是否构成一条最合理的标签序列”。
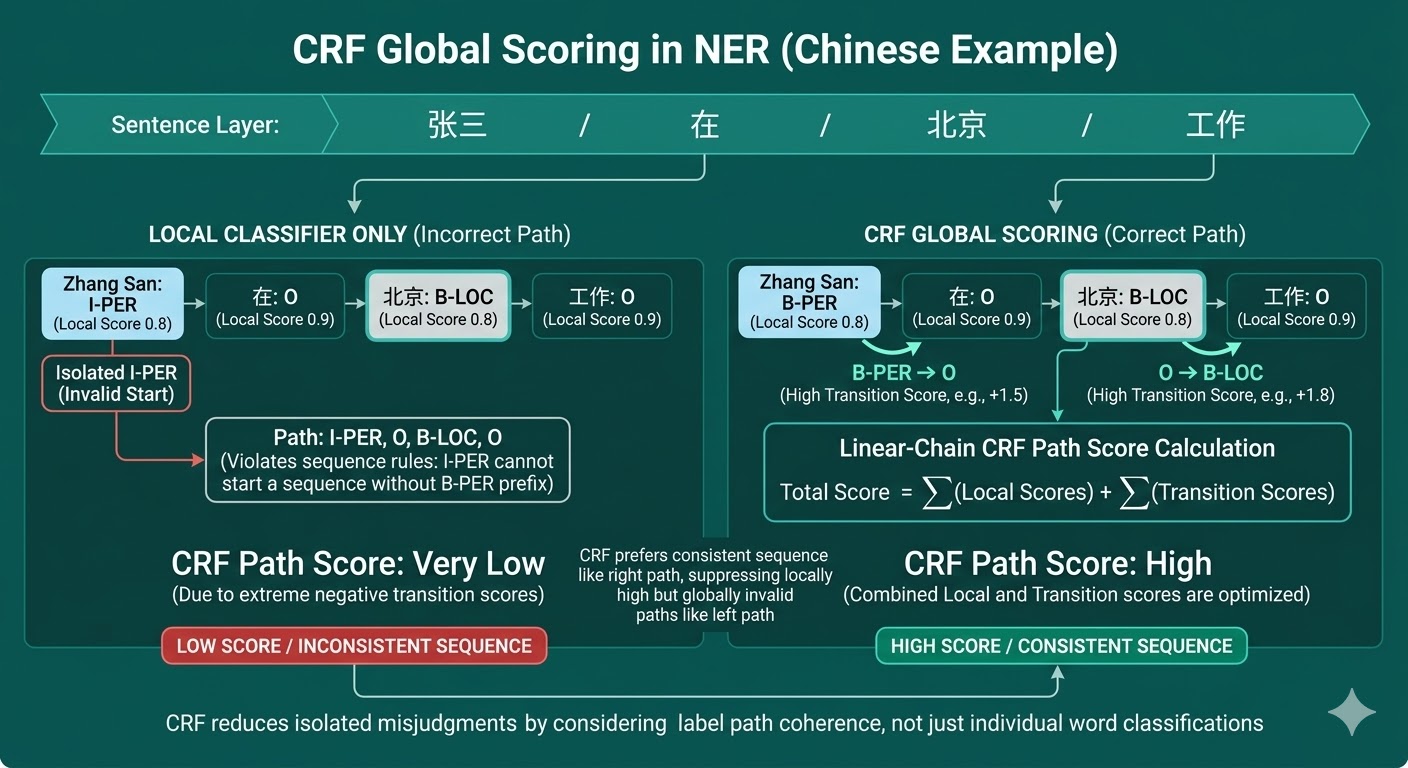
类似的全局打分思想也可以推广到依存句法分析(Dependency Parsing, DEP)这类结构化任务。句子中的每个词都需要找到自己的中心词(head),模型的目标核心是评估整棵依存树是否合理。例如,在“她 喜欢 自然语言处理”中,“喜欢”通常更可能作为中心谓词,“她”依附到“喜欢”形成主谓关系,“自然语言处理”整体依附到“喜欢”形成宾语关系。若某个局部决策把“她”错误地连到“自然语言处理”,单看两个词的局部相似度未必很低,但放到整棵树的全局结构中就会显得不协调。CRF 的价值正体现在这里:它通过全局归一化和结构约束,偏好整体验证一致的输出结构,而非一组彼此冲突的局部最优决策。
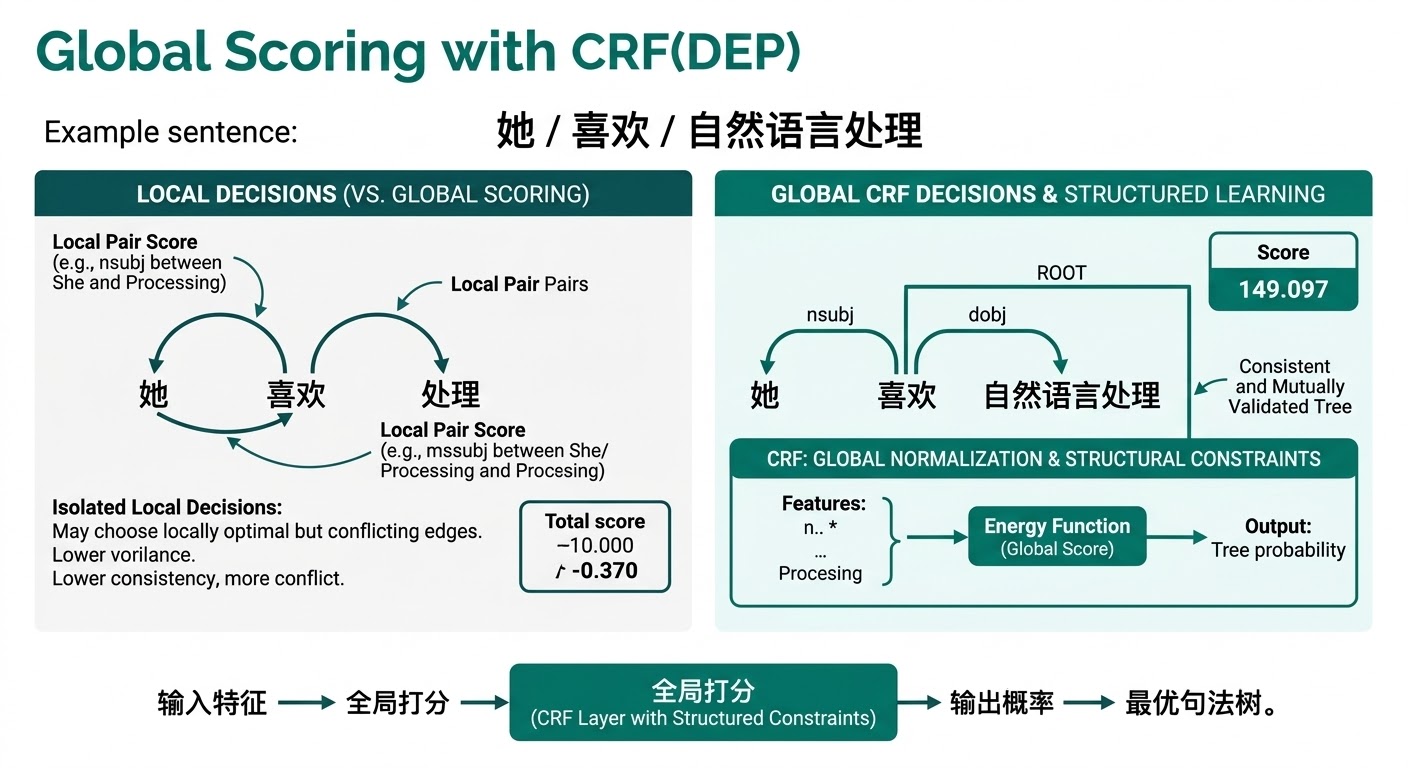
- 优点:适合结构化输出,能显式编码标签依赖。
- 局限:训练与推断成本高于普通独立分类器。
- 适用场景:序列标注、分词、命名实体识别等条件结构化预测任务。
结构化感知机(Structured Perceptron)处理的是:输出本身核心是整条序列、整棵树或其他组合结构时,如何直接根据“预测结构与真实结构的差异”更新参数。它可以看作普通感知机从单点分类推广到结构化输出空间后的版本。
它在自然语言处理中长期用于序列标注、分词、依存句法分析等任务,因为这些问题都具有一个共同特征:模型必须在巨大的候选结构空间里找一个最优结构,而非只在几个类别之间做选择。
结构化感知机不要求输出概率分布,重点是直接定义一个结构打分函数 \(s(x,y)\),然后让真实结构的分数高于错误结构。若当前样本 \(x\) 上预测出的结构 \(\hat y\) 与真实结构 \(y\) 不同,就把参数朝“提高真实结构分数、降低错误结构分数”的方向更新。
这种做法的优点是训练目标与推断目标贴得很近。模型训练时关心的核心是“最终解码出来的结构对不对”。因此它属于典型的错误驱动(Mistake-driven)结构化学习方法。
若结构打分函数写成线性形式:
\[s(x,y)=\mathbf{w}^\top \Phi(x,y)\]其中 \(\Phi(x,y)\) 是输入与候选结构联合产生的特征向量,预测时做:
\[\hat y=\arg\max_{y'\in\mathcal{Y}(x)} \mathbf{w}^\top \Phi(x,y')\]若 \(\hat y\ne y\),则一次典型更新为:
\[\mathbf{w}\leftarrow \mathbf{w}+\Phi(x,y)-\Phi(x,\hat y)\]这个更新式非常直白:真实结构出现过但预测结构没有出现的特征,会把参数往正方向推;错误结构特有的特征,则会被压低。随着训练进行,模型会逐渐提高正确结构在解码时被选中的概率,尽管它本身并不显式输出概率。
- 定义联合特征 \(\Phi(x,y)\) 与结构解码器。
- 对每个样本解码出当前最优预测结构 \(\hat y\)。
- 若预测错误,则按真实结构与预测结构的特征差做更新。
- 重复多轮,并常配合参数平均(Averaged Perceptron)提升泛化稳定性。
在中文分词里,模型可以把一句话的切分结果看作一个结构。若当前参数把“自然 语言 处理”切成了错误边界,而真实答案是“自然语言 处理”,结构化感知机会直接比较这两个切分结构的特征差,把支持真实切分的特征加权抬高,把支持错误切分的特征压低。
- 优点:训练简单、更新高效、目标与最终解码结构高度一致。
- 局限:缺少概率语义,对噪声和解码误差较敏感,训练稳定性通常不如全概率模型。
- 适用场景:传统分词、句法分析、序列标注等可解码结构任务,或作为理解结构化大间隔学习的入门方法。
这一类方法处理的核心问题是:在缺少可靠全局函数形式时,是否可以直接依赖“局部相似样本通常有相似输出”这一假设完成预测。近邻模型把相似性度量(Similarity Metric)本身作为建模中心,不急于学习显式参数化函数:先找邻居,再由邻居投票、平均或加权得到结果。
K 近邻(K-Nearest Neighbors, KNN)用于分类与回归。给定一个待预测样本 \(\boldsymbol{x}\),它要根据训练集中与其最相似的样本来决定输出。
KNN 的基本假设是局部平滑性(Local Smoothness):在特征空间中彼此接近的样本,往往具有相近的标签或数值。它不显式学习参数化模型,训练集本身就是局部比较的参照集。
给定距离函数 \(d(\boldsymbol{x},\boldsymbol{x}')\) 与邻居数 \(K\),若 \(N_K(\boldsymbol{x})\) 表示 \(\boldsymbol{x}\) 的 \(K\) 个最近邻,则分类时可写为:
\[\hat y=\mathrm{mode}\left(\{y_i:(\boldsymbol{x}_i,y_i)\in N_K(\boldsymbol{x})\}\right)\]这里 \(N_K(\boldsymbol{x})\) 是样本 \(\boldsymbol{x}\) 的 \(K\) 个最近邻集合,花括号中收集的是这些邻居的标签, \(\mathrm{mode}(\cdot)\) 则返回出现次数最多的类别。也就是说,KNN 分类本质上就是“看最近的邻居们大多数是谁”。
回归时常取邻居标签平均:
\[\hat y=\frac{1}{K}\sum_{(\boldsymbol{x}_i,y_i)\in N_K(\boldsymbol{x})}y_i\]回归版 KNN 只是把“多数投票”换成“数值平均”。 \(\frac{1}{K}\sum\) 表示把最近 \(K\) 个邻居的输出做均值,因此预测值会受到局部邻域中所有数值样本的共同影响。
若距离使用欧氏距离,则默认所有特征尺度可比,因此标准化(Standardization)通常是必要前处理。
- 训练阶段几乎不做参数学习,只保存全部训练样本。
- 推断时计算待测样本到训练样本的距离。
- 选出最近的 \(K\) 个样本。
- 分类取多数投票,回归取平均或距离加权平均。
在简单的手写数字识别中,如果一张新图片与训练集中大量“3”的图像都很接近,而与“8”的图像明显更远,那么 KNN 会依据局部邻域投票把它判为 3。
- 优点:概念简单、无需复杂训练、局部非线性表达能力强。
- 局限:推断成本高;对特征尺度和无关特征敏感;维度灾难会削弱距离判别力。
- 适用场景:中小规模数据、快速基线、基于相似度的简单分类与回归。
聚类处理的核心问题是:在没有标签的前提下,如何仅根据样本之间的几何关系、密度结构或层次关系,把数据自动分成若干组。这里不存在唯一正确的“簇”定义:K-Means 假设簇围绕中心分布,层次聚类强调多粒度组织结构,DBSCAN / HDBSCAN 则把簇理解为高密度连通区域。因此,聚类算法的选择本质上是在选择“什么样的结构应被视为同一类”。
K-Means 处理的是无监督聚类问题:给定一组没有标签的样本,希望把它们分成 \(K\) 个簇,使同一簇内样本尽量接近,不同簇之间尽量分开。
K-Means 用“每个簇由一个中心点代表”的方式近似数据分布。算法不断重复两件事:把样本分配给最近的中心;再用簇内样本均值更新中心。它本质上是在最小化簇内平方误差。
目标函数为:
\[\min_{\{c_k\},\{z_i\}} \sum_{i=1}^{N} \|\boldsymbol{x}_i-c_{z_i}\|_2^2\]这个目标里, \(c_k\) 是第 \(k\) 个簇中心, \(z_i\) 表示样本 \(i\) 被分到哪个簇, \(\|\boldsymbol{x}_i-c_{z_i}\|_2^2\) 是样本到所属簇中心的平方距离。K-Means 想做的,就是让所有样本离各自中心都尽可能近。
其中 \(c_k\) 是第 \(k\) 个簇中心, \(z_i\in\{1,\dots,K\}\) 表示样本 \(\boldsymbol{x}_i\) 属于哪个簇。固定簇分配时,最优中心是该簇样本均值:
\[c_k=\frac{1}{|S_k|}\sum_{\boldsymbol{x}_i\in S_k} \boldsymbol{x}_i\]这里 \(S_k\) 是第 \(k\) 个簇里所有样本的集合, \(|S_k|\) 是该簇样本数。这个更新式说明簇中心就是簇内样本的算术平均,因此 K-Means 的“中心”确实是均值意义上的代表点。
- 初始化 \(K\) 个簇中心。
- 分配步骤:把每个样本分到最近中心。
- 更新步骤:用各簇样本均值更新中心。
- 重复迭代直到簇分配稳定或目标下降很小。
在用户分群中,若特征是消费频次与客单价,K-Means 往往会自动形成“高频低客单”“低频高客单”“中频中客单”等若干均值中心明确的群体。
- 优点:实现简单、可扩展、训练速度快。
- 局限:需要预先指定 \(K\);对初始化与离群点敏感;不适合非凸簇。
- 适用场景:簇近似球形、需要快速聚类或作为预处理的任务。
层次聚类(Hierarchical Clustering)输出的是一个由粗到细的聚类层次结构,因此簇数可以在观察树状图后再决定。它适合需要观察“簇是如何逐步合并或拆分”的任务。
凝聚式层次聚类(Agglomerative Clustering)从每个样本单独成簇开始,每一步合并当前最相近的两个簇;分裂式层次聚类则从一个大簇开始不断拆分。实践中更常见的是凝聚式版本。
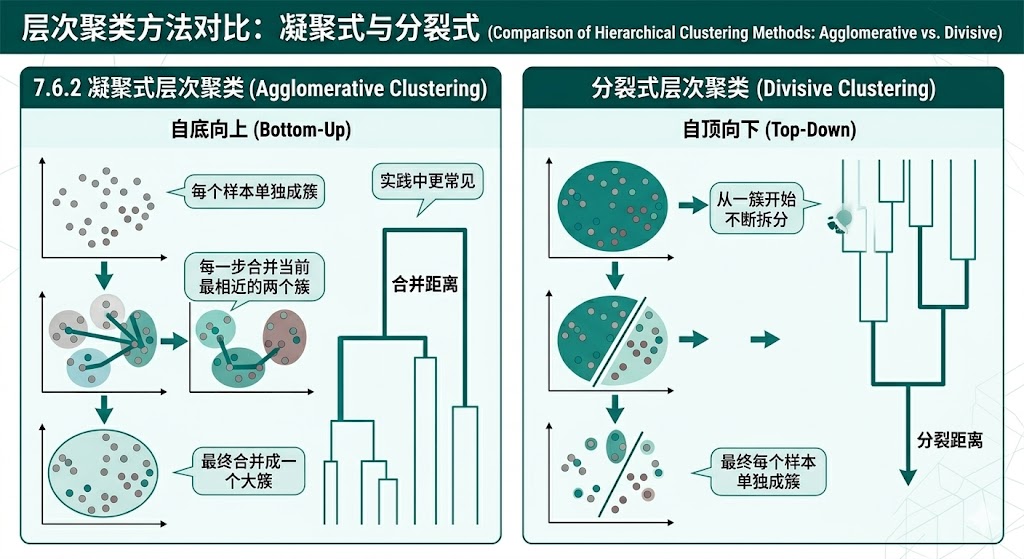
关键在于定义簇间距离。常见联接准则(Linkage Criteria)包括:
\[d_{\text{single}}(A,B)=\min_{\boldsymbol{x}\in A,\boldsymbol{y}\in B} d(\boldsymbol{x},\boldsymbol{y})\]单链距离只看两簇之间最近的那一对点,因此它很容易把“靠得最近的局部桥梁”连起来,适合发现链式结构,但也更容易被噪声点串联。
\[d_{\text{complete}}(A,B)=\max_{\boldsymbol{x}\in A,\boldsymbol{y}\in B} d(\boldsymbol{x},\boldsymbol{y})\]完全链距离只看两簇之间最远的那一对点,因此它会避免把跨度过大的簇合并到一起,更偏好紧凑、直径较小的簇。
\[d_{\text{average}}(A,B)=\frac{1}{|A||B|}\sum_{\boldsymbol{x}\in A,\boldsymbol{y}\in B} d(\boldsymbol{x},\boldsymbol{y})\]平均链则对两簇之间所有点对的距离取平均。这里 \(|A||B|\) 是点对总数,因此它不仅看最近点或最远点,还综合考虑两簇整体的平均接近程度。
不同联接方式对应不同簇形偏好:单链更容易形成链式簇,完全链更偏向紧凑簇,平均链则居中。
- 初始化每个样本为单独一个簇。
- 计算簇间距离矩阵。
- 反复合并距离最近的两个簇,并更新距离矩阵。
- 得到树状图(Dendrogram)后,在某个高度切开即可获得聚类结果。
在文档聚类中,层次聚类不仅能区分“体育”“财经”“科技”等大类,还能进一步展示每一大类内部的细粒度层级关系。
- 优点:无需预先指定簇数;可以输出多层次聚类结构。
- 局限:计算与存储成本较高;早期合并错误通常无法回退。
- 适用场景:中小规模数据、需要树状关系解释的聚类分析。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)用于识别任意形状的高密度簇,并显式发现噪声点。它尤其适合处理非球形簇与含离群点数据。
DBSCAN 通过局部密度定义簇。若一个点周围半径 \(\epsilon\) 内有足够多的邻居,则它是核心点(Core Point);核心点可以把周围密度可达(Density-Reachable)的样本不断扩展成一个簇。既不够密、又不属于任何核心点邻域的样本被视为噪声。
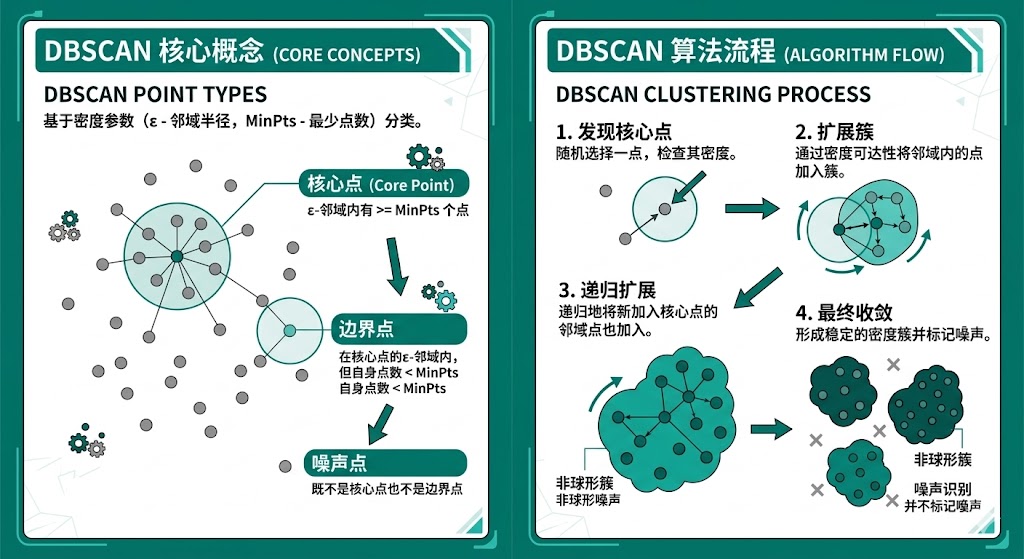
记 \(N_{\epsilon}(\boldsymbol{x})\) 为点 \(\boldsymbol{x}\) 的 \(\epsilon\) 邻域。若:
\[|N_{\epsilon}(\boldsymbol{x})|\ge \text{minPts}\]判断核心点只需看两件事: \(N_{\epsilon}(\boldsymbol{x})\) 是点 \(\boldsymbol{x}\) 在半径 \(\epsilon\) 内的邻域集合, \(|N_{\epsilon}(\boldsymbol{x})|\) 是邻域里有多少点。只要这个数量不小于 \(\text{minPts}\),就说明该点周围密度足够高,可以作为簇扩张的核心。
则 \(\boldsymbol{x}\) 是核心点。若某点落在某个核心点邻域中但自身并非核心点,则为边界点(Border Point);不属于任何簇的点为噪声(Noise)。
- 遍历未访问样本,计算其 \(\epsilon\) 邻域。
- 若邻居数少于 \(\text{minPts}\),则暂记为噪声或边界候选。
- 若为核心点,则以它为起点递归扩展所有密度可达的点。
- 重复直到所有样本都被标记。
在地理位置聚类中,餐馆、商圈、交通枢纽附近的点位通常形成形状复杂的密集区域。DBSCAN 可以识别这些非凸热点,同时把零散孤立点保留为噪声。
- 优点:无需预设簇数;可识别任意形状簇;对离群点鲁棒。
- 局限:对 \(\epsilon\) 和 \(\text{minPts}\) 敏感;难以同时适配不同密度簇。
- 适用场景:空间聚类、热点区域发现、非凸簇与带噪声数据。
HDBSCAN(Hierarchical DBSCAN)用于缓解 DBSCAN 的单一密度阈值问题。它面对的核心困难是:真实数据中的簇密度常常并不一致,用一组固定的 \(\epsilon\) 和 \(\text{minPts}\) 很难同时兼顾所有簇。
HDBSCAN 会在多个密度尺度上构建层次结构,再从中选出稳定簇(Stable Clusters)作为结果。这让它比 DBSCAN 更适合处理密度差异显著的数据。
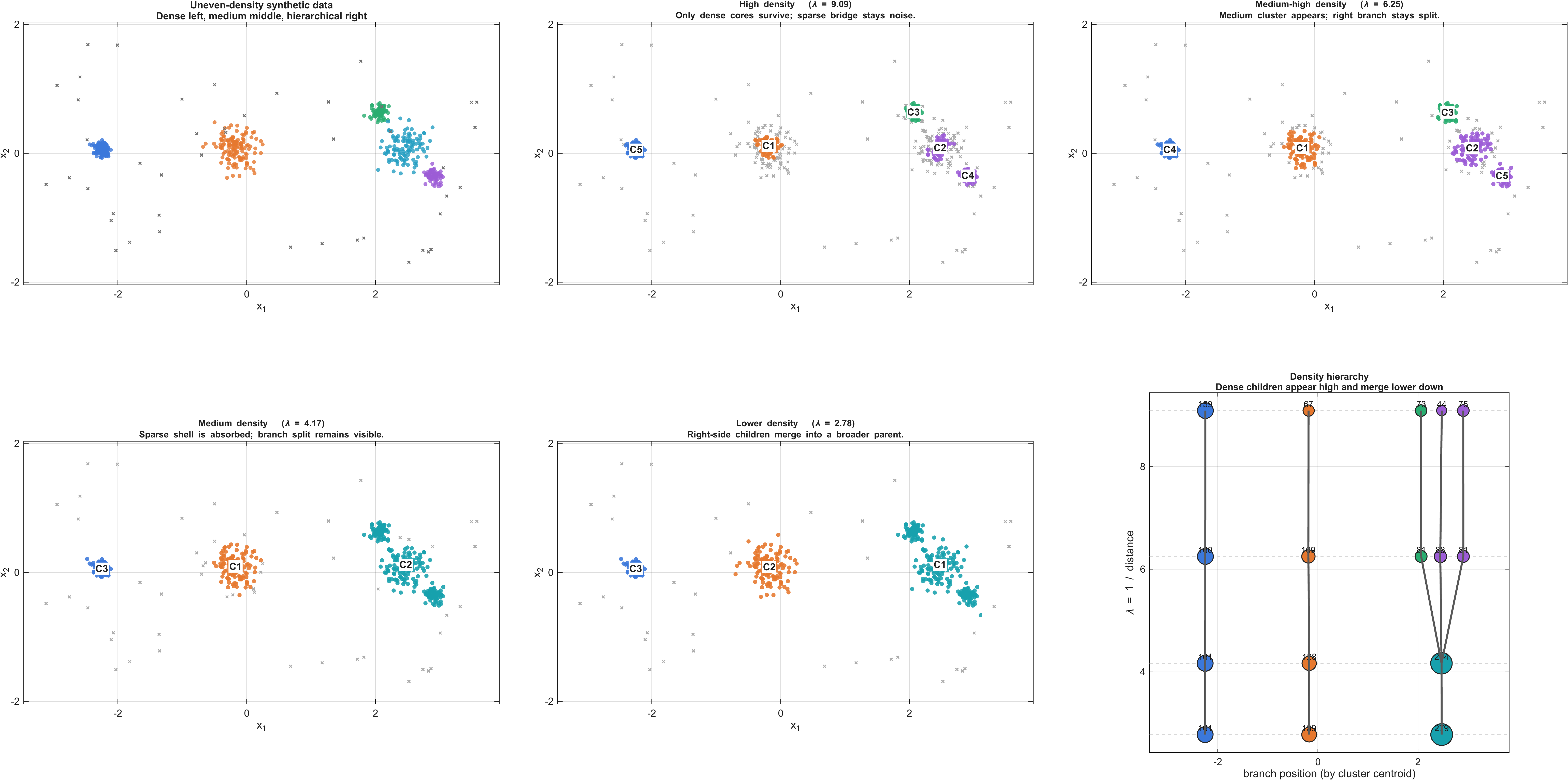
给定参数 \(k\),先定义核心距离(Core Distance)为点到其第 \(k\) 近邻的距离,再定义互可达距离(Mutual Reachability Distance):
\[d_{\text{mreach},k}(\boldsymbol{x},\boldsymbol{y})=\max\big(\text{core}_k(\boldsymbol{x}),\text{core}_k(\boldsymbol{y}),d(\boldsymbol{x},\boldsymbol{y})\big)\]互可达距离把三个量取最大值:点 \(\boldsymbol{x}\) 的核心距离、点 \(\boldsymbol{y}\) 的核心距离,以及它们之间的原始距离。这样做的效果是:低密度区域的点会被“拉远”,从而更清楚地暴露不同密度簇之间的结构边界。
随后算法在互可达图上构建最小生成树(Minimum Spanning Tree),再转成聚类层次,并依据簇稳定性选择最终输出。
- 计算所有点的核心距离。
- 基于互可达距离构造图并求最小生成树。
- 从图中得到随密度变化的层次聚类结构。
- 在压缩树(Condensed Tree)上选择稳定簇作为结果。
在用户行为嵌入空间中,有些兴趣群体很紧密,有些较松散。HDBSCAN 可以同时保留这两类簇,而不需要强行用同一个密度阈值描述它们。
- 优点:对多密度簇更稳健,仍保留噪声识别能力。
- 局限:实现更复杂,计算与内存开销通常高于 DBSCAN。
- 适用场景:嵌入聚类、用户分群、不同密度簇共存的数据。
Leiden 适合这样一类聚类问题:样本之间的关系,与其说是“在欧氏空间里围着某个中心聚成一团”,不如说是“先形成一张相似关系图,再在图上出现若干连接更紧密的社区(Community)”。因此,Leiden 的标准语境核心是先得到图 \(G=(V,E)\),再把图上的节点划分成若干社区。
这类方法本质上属于基于图的聚类(Graph-based Clustering)或社区发现(Community Detection)。社交网络里的“朋友圈”、引文网络里的“研究主题群”、单细胞分析中的细胞群、句向量或图像嵌入上的 kNN 图分群,都属于这一类任务。与 K-Means 假设“簇围绕均值中心分布”不同,Leiden 假设“簇对应图上内部连边更密、外部连边更稀的社区结构”。
从方法谱系上看,图聚类至少有三条常见路线。第一条是谱聚类(Spectral Clustering),通过图拉普拉斯矩阵的特征向量把节点映射到一个新空间,再做传统聚类;第二条是社区质量优化路线,通过优化 modularity 或 CPM 之类的目标函数直接切分图,Louvain 和 Leiden 就属于这一路线;第三条是图神经网络后的下游分群,即先学图表示,再在表示或近邻图上用 Leiden、K-Means 等算法做分群。Leiden 因此核心是一个更基础的图聚类算法。
Leiden 的核心思想可以压缩成一句话:不要直接看点到中心的距离,而要看节点在图中是否形成内部紧密、外部稀疏、并且社区内部真正连通的结构。它通常从一个已有分区出发,不断尝试把节点移动到更合适的社区,使社区质量目标持续上升。
如果只停在这里,Leiden 和 Louvain 看起来会很像。两者确实都属于“局部移动 + 社区聚合”的贪心优化路线,但 Leiden 多做了一步关键的refinement(细化):它会在局部改进之后进一步检查社区内部是否真的连得足够好,避免出现“从目标函数上看像一个社区,但内部其实由几个弱连接甚至不连通子块拼出来”的结果。这正是 Leiden 相比 Louvain 最重要的改进。
Leiden 常优化的目标包括 modularity(模块度)和 CPM(Constant Potts Model)。为了把原理讲清楚,先用最常见的 modularity 写法说明。设图的加权邻接矩阵为 \(A_{ij}\),节点 \(i\) 的度为 \(k_i=\sum_j A_{ij}\),图的总边权满足 \(2m=\sum_i k_i=\sum_{i,j}A_{ij}\)。若 \(c_i\) 表示节点 \(i\) 所在社区,则模块度可写为:
\[Q=\frac{1}{2m}\sum_{i,j}\left(A_{ij}-\gamma\frac{k_i k_j}{2m}\right)\mathbf{1}[c_i=c_j]\]这个式子里, \(A_{ij}\) 是节点 \(i\) 和 \(j\) 之间真实存在的边权; \(\frac{k_i k_j}{2m}\) 是一个随机零模型(Null Model)下“如果只保留节点度大小,随机连边时它们本应有多大连接强度”; \(\mathbf{1}[c_i=c_j]\) 是指示函数,表示只有当两个节点被分进同一社区时,这一对节点才会对目标函数产生贡献; \(\gamma\) 是分辨率参数(Resolution Parameter),控制社区切得更粗还是更细。
因此,模块度优化本质上在回答这样一个问题:如果把一组节点放进同一个社区,那么它们之间的真实连接强度,是否显著高于“只是因为这些节点度数大,所以随机也容易连上”的基线。若答案是肯定的,把它们归到同一社区就能提高 \(Q\);若答案是否定的,说明这种合并只是表面热闹,并不能带来真正的社区结构收益。
因此,Leiden 适合处理 kNN 图、相似度图和社交图。它衡量的核心是“哪些节点在统计意义上比随机期望更紧密地相互连在一起”。如果社区内部真实连边明显超出基线,目标函数就会上升;反之,跨社区连边过多或社区内部稀薄,目标函数就会下降。
在一些场景里,人们更偏好 CPM,因为 modularity 存在分辨率限制(Resolution Limit):小社区可能在大图里被吞掉。CPM 的思想是直接给同社区节点对设置固定惩罚阈值,以更直接地控制社区粒度。实践里,Leiden 常允许在 modularity 和 CPM 之间切换,但二者共享同一个高层逻辑:把图划分成若干“内部连接收益高、外部混杂成本低”的社区。
可以把 Leiden 想成“给城市划街区”。如果只按地图上的直线距离切分,很可能会把一条大河两岸、一个高架桥两侧、或被工业区隔开的居民区误划到一起,因为它们几何上靠得近。但如果先把城市道路、步行通路、地铁换乘、商业往来都画成图,再看哪些区域内部来往频繁、对外联系相对稀少,划出来的“街区”就更接近真实城市结构。
图聚类处理高维嵌入时也是同样道理。点在原空间中也许并不围绕单一中心分布,但只要它们在近邻图中高度互联,就仍然可能属于同一个社区。Leiden 做的正是这件事:它核心是在问“谁和谁构成了一个内部往来密切、外部联系较弱的关系团块”。
- 先构图。若输入本身就是图,可直接使用;若输入是向量样本,通常先基于欧氏距离、余弦相似度或共享近邻构造 kNN 图,并给边赋相似权重。
- 初始化分区。最常见的起点是每个节点各自形成一个单独社区。
- 局部移动(Local Moving)。依次尝试把一个节点移动到邻居社区,只要目标函数 \(Q\) 能提升,就接受该移动。
- 细化(Refinement)。对当前社区内部再做检查和重组,避免把内部连接脆弱、甚至不连通的部分勉强保留在同一社区中。
- 聚合(Aggregation)。把当前每个社区收缩成一个超节点(Supernode),构成更粗粒度的新图。
- 重复以上过程,直到目标函数不再显著提升,社区结构稳定为止。
这套流程里最重要的核心是“局部改进之后要进一步验证社区内部是否真的足够连通”。Louvain 的问题恰好出在这一步缺失:它可以得到目标函数不错、但内部连通性并不理想的社区。Leiden 则通过 refinement 把这个结构性缺陷补上。
Louvain 的经典优点是快,但它有一个著名弱点:社区优化过程只关心目标函数是否上升,不额外保证社区内部强连通或良好连通。因此,一个社区可能只是因为若干桥接边被贪心合并到一起,结果内部出现细长链条、弱耦合子块,甚至在某些定义下并不连通。
Leiden 通过 refinement 改变了这一点。它不满足于“这个合并在目标函数上看起来有利”,而要求社区内部结构也达到更合理的连通性。于是,在很多真实图上,Leiden 会比 Louvain 给出更稳定、更细致、也更符合局部结构直觉的划分。因此,在单细胞分析、图嵌入分群和网络社区发现里,Leiden 已经大幅替代 Louvain 成为默认选择。
在单细胞 RNA 测序中,常见流程是先把细胞表达矩阵降维到 PCA 或潜在嵌入空间,再构造 kNN 图,最后用 Leiden 分群。这里簇的含义是“在细胞近邻图中形成内部高度互联的一群细胞”。这正符合细胞状态连续变化、局部流形结构明显的特点。
在文本或图像嵌入聚类中,也经常先用编码模型得到向量,再构造近邻图,然后用 Leiden 做社区发现。与直接在嵌入空间上跑 K-Means 相比,这条路线往往更能保留局部语义结构,尤其适合簇形复杂、边界弯曲、局部连通性比全局中心更重要的场景。
- 优点:能直接利用图结构;适合非球形、非凸簇;通常比 Louvain 更稳定,社区内部结构也更合理。
- 局限:结果依赖构图质量;分辨率参数和近邻图参数会显著影响簇粒度;不如 K-Means 那样易于用“均值中心”解释。
- 适用场景:单细胞分群、社交网络社区发现、图嵌入或句向量的近邻图聚类、推荐或用户画像中的相似图分群。
升维(Feature Expansion / Lifting)处理的问题,与降维正好互补。降维试图把高维表示压缩到更低维空间,以减少冗余、噪声与计算量;升维则试图把原始特征映射到一个更高维的表示空间,使原本难以表达、难以分离或难以拟合的结构,在新空间里变得更容易处理。它的目标核心是通过增加表示自由度,把非线性关系改写为更容易由简单模型处理的形式。
许多经典机器学习模型本体是线性的,例如线性回归、逻辑回归、线性支持向量机(Support Vector Machine, SVM)。它们直接在原始输入空间中学习一个线性决策函数或线性预测函数。若数据关系本身高度非线性,那么模型能力可能不足。升维的思路因此是:先把输入映射为一个更高维的新表示,再在新表示上使用线性模型。模型形式仍然简单,但由于工作空间改变了,整体表达能力会显著提升。
更一般地,若原始输入为 \(\boldsymbol{x}\in \mathbb{R}^d\),则升维映射可写成:
\[\tilde{\boldsymbol{x}}=\phi(\boldsymbol{x}),\qquad \phi: \mathbb{R}^d\to \mathbb{R}^D,\qquad D>d\]这里 \(\boldsymbol{x}\) 是原始输入; \(\tilde{\boldsymbol{x}}\) 是升维后的新特征; \(\phi(\boldsymbol{x})\) 是特征映射; \(D>d\) 表示新的表示空间维度高于原空间维度。若后续模型写成 \(f(\boldsymbol{x})=\boldsymbol{w}^\top \tilde{\boldsymbol{x}}+b\),那么它虽然在新空间中仍然是线性的,但在原始输入 \(\boldsymbol{x}\) 上通常已经对应一个非线性函数。
升维的直观含义,是把原来“纠缠在一起”的关系展开。例如在二维平面里,某些数据可能无法被一条直线分开;但若把 \((x_1,x_2)\) 映射成 \((x_1,x_2,x_1^2,x_2^2,x_1x_2)\) 这样的更高维特征,原本的弯曲边界就可能对应高维空间中的一个超平面。于是复杂性被转移到了特征映射 \(\tilde{\boldsymbol{x}}=\phi(\boldsymbol{x})\) 上。
这也是经典机器学习里一个非常常见的套路:先做特征构造或特征展开,再用结构简单、优化稳定的线性模型。因此,升维常常常以多项式特征、基函数展开、核方法、one-hot 编码、N-gram 稀疏特征、随机特征等形式出现。
升维后的线性模型通常写成:
\[f(\boldsymbol{x})=\boldsymbol{w}^\top \tilde{\boldsymbol{x}}+b\]这里 \(\tilde{\boldsymbol{x}}\) 是由原始输入 \(\boldsymbol{x}\) 构造出来的高维特征向量; \(\boldsymbol{w}\in \mathbb{R}^D\) 是新空间中的参数; \(b\) 是偏置。关键点在于:模型在 \(\tilde{\boldsymbol{x}}\) 空间里仍然是线性的,但如果 \(\phi(\boldsymbol{x})\) 含有平方项、交叉项、基函数或核映射,那么 \(f(\boldsymbol{x})\) 相对于原始输入 \(\boldsymbol{x}\) 就会表现出非线性。
以二次多项式特征为例,若原始输入为 \(\boldsymbol{x}=(x_1,x_2)\),则可构造:
\[\tilde{\boldsymbol{x}}=(x_1,x_2,x_1^2,x_2^2,x_1x_2)\]此时线性模型
\[f(\boldsymbol{x})=w_1x_1+w_2x_2+w_3x_1^2+w_4x_2^2+w_5x_1x_2+b\]在参数上仍然是线性的,但在输入上已经能够表达二次曲面或二次决策边界。这正是升维最核心的数学作用:把原空间中的非线性关系,改写成高维空间中的线性关系。
| 方式 | 升维形式 | 核心作用 | 典型场景 |
| 多项式特征 | 加入平方项、立方项、交叉项 | 把低阶线性模型扩展为可拟合非线性关系 | 线性回归、逻辑回归、线性分类器 |
| 基函数展开 | 高斯基、样条基、傅里叶基等 | 用一组预定义函数把局部或周期结构显式展开 | 回归、广义加性模型、核近似 |
| 核方法 | 通过核函数隐式映射到高维甚至无限维空间 | 在不显式展开特征的情况下提升可分性 | SVM、核岭回归、核 PCA |
| One-hot 编码 | 把离散类别映射为高维稀疏向量 | 让类别变量进入线性模型并保持类别独立性 | 表格特征、推荐、广告、点击率预估 |
| N-gram / 词袋 | 把文本映射为高维稀疏词项空间 | 显式展开局部共现与组合模式 | 传统文本分类、检索、朴素贝叶斯、线性 SVM |
| 随机特征 | 用随机映射近似某些核空间 | 在显式高维表示与核方法之间做折中 | Random Fourier Features、核近似 |
其中,核方法是经典机器学习里最有代表性的升维思想。以 SVM 为例,若定义特征映射 \(\tilde{\boldsymbol{x}}=\phi(\boldsymbol{x})\),则线性分类器可写成 \(f(\boldsymbol{x})=\boldsymbol{w}^\top \tilde{\boldsymbol{x}}+b\)。核技巧(Kernel Trick)直接通过核函数计算,避免显式构造 \(\tilde{\boldsymbol{x}}\)
\[K(\boldsymbol{x},\boldsymbol{x}')=\phi(\boldsymbol{x})^\top \phi(\boldsymbol{x}')\]计算升维后特征空间中的内积。这样既保留了高维映射的表达力,又避免了显式展开到巨大维度的代价。因此,SVM 是很多人最先感受到“升维威力”的经典模型。
在圆形可分但线性不可分的数据中,原始二维平面上一条直线无法把内圈与外圈分开;但若加入半径相关的二次特征,例如 \(x_1^2+x_2^2\),则问题可以转写为更高维空间中的线性分离。文本任务里,N-gram 稀疏特征同样是一种典型升维:原始句子是离散序列,经过词袋或 N-gram 展开后,就变成了数万维甚至更高维的稀疏向量,随后再交给逻辑回归、朴素贝叶斯或线性 SVM 处理。
表格任务中的类别变量处理也体现了同样思想。一个城市字段看起来只是一个离散取值,但 one-hot 编码后,它会被展开成一个高维稀疏向量,使模型能够为每个类别学习独立参数。推荐系统、广告点击率预估、工业风控中的大规模离散特征,长期都高度依赖这种升维方式。
经典机器学习也会使用升维,但通常更谨慎。原因在于,维度一旦上去,过拟合风险、存储开销与计算开销都会迅速增加,这就是维度灾难(Curse of Dimensionality)的典型体现。于是经典方法常把“升维”与“控制复杂度”配套使用:一边通过特征展开提升表达能力,一边用正则化(Regularization)、特征选择(Feature Selection)或后续降维来抑制过拟合。
因此,在经典机器学习里,常见工作流核心是两者交替配合:先做有针对性的特征展开,让结构变得更容易表达;再通过正则化、筛选或压缩保留真正有效的部分。升维是在展开表达能力,降维是在压缩冗余信息,它们核心是围绕表示空间做的两种互补控制。
维度灾难(Curse of Dimensionality)指的是:当特征维度不断升高时,许多在低维空间中直观、有效的统计与几何规律会迅速恶化,导致数据需求、计算成本与建模难度同时上升。它核心是一组高维效应的统称,包括样本空间体积指数级膨胀、样本变得极其稀疏、局部邻域难以稳定估计、距离与密度统计的判别力下降,以及模型更容易用复杂边界去记忆训练集。
其中一个最重要的现象确实是:高维里距离往往会变得不再像低维那样有区分力。直观地说,当维度很多时,样本之间的最近距离和最远距离可能越来越接近,导致“谁是真正近邻”这件事变得没那么清晰。依赖距离或局部邻域的方法,例如 KNN、聚类、核密度估计、局部异常检测等,往往会因此退化。因此,高维数据上的距离度量、标准化、特征筛选和嵌入学习会变得格外重要。
但“高维更容易过拟合”并不只因为距离失去意义。更根本的原因是:当维度升高后,表示空间的自由度与可容纳的划分方式急剧增加,而训练样本相对于整个空间显得越来越稀疏。模型于是更容易找到一些只对训练集成立、却不能推广到新样本的偶然边界或偶然相关性。距离退化主要伤害的是邻域、相似度与密度估计;过拟合风险上升则更直接地来自空间稀疏化、参数自由度增加和有效样本覆盖不足。
因此,经典机器学习在做升维时往往必须同步引入约束:一方面用特征展开提升表达能力,另一方面通过正则化(Regularization)、特征选择(Feature Selection)、降维(Dimensionality Reduction)或更强的数据先验,限制模型不要把高维空间当成“背题空间”。维度灾难核心是在提醒:维度每增加一层,模型就需要更多数据、更强归纳偏置和更谨慎的复杂度控制,才能让新增维度真正转化为有效表达能力。
深度学习中的很多操作,本质上也在做升维。Transformer 的前馈网络(Feed-Forward Network, FFN / MLP)常把 \(d_{\text{model}}\) 升到更大的 \(d_{\text{ff}}\),再降回原维度;这与经典机器学习里“先展开、再用简单变换处理”的思想是一脉相承的。差别在于,经典方法里的升维往往是人工设计或固定形式的,而深度学习中的升维通常是可学习的线性投影与非线性组合。
因此,若从表示学习角度看,升维在机器学习中并不罕见。SVM 的核空间、逻辑回归的多项式特征、文本的 N-gram 稀疏向量、推荐系统的 one-hot 离散展开,以及 Transformer MLP 中的中间维度扩张,本质上都属于同一条主线:把原本难以处理的关系,展开到一个更容易表达与分离的表示空间里。
降维处理的核心问题是:高维数据往往包含冗余、相关性与噪声,既增加计算成本,也削弱可视化与建模稳定性。目标核心是在压缩表示的同时尽量保留有用结构——这个“有用”可以是方差、类别可分性、局部邻域、全局流形,具体取决于所采用的方法。
主成分分析(Principal Component Analysis, PCA)处理的是线性降维问题:在尽量保留数据主要变化信息的前提下,把高维样本映射到更低维空间。它常用于压缩维度、去相关、可视化与噪声抑制。
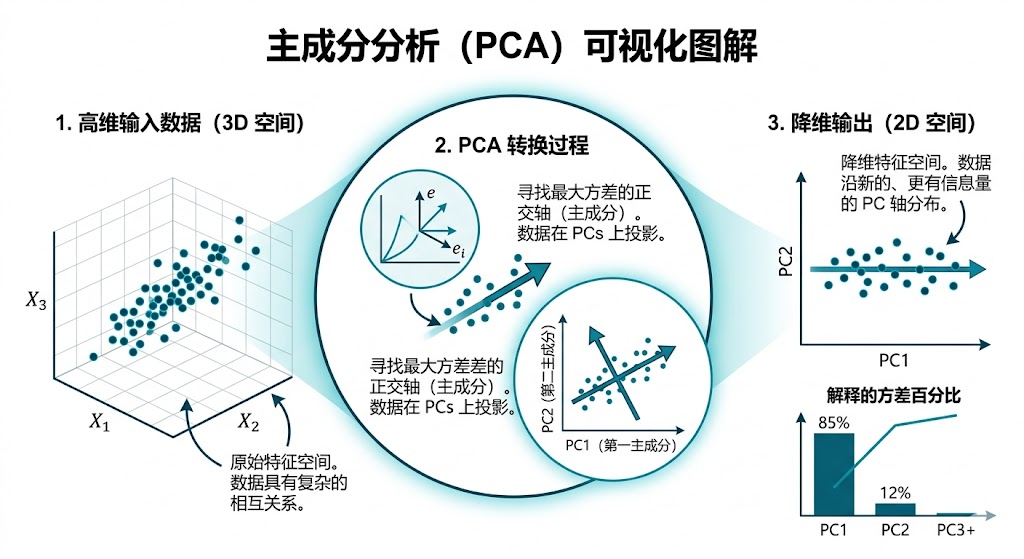
PCA 用方差(Variance)近似衡量信息量。若数据在某个方向上的投影变化很大,说明该方向承载了更多结构;于是 PCA 选择能最大化投影方差的一组正交方向作为新的表示基底。
给定中心化后的数据矩阵 \(\boldsymbol{X}_c\in\mathbb{R}^{N\times d}\),协方差矩阵为:
\[\boldsymbol{\Sigma}=\frac{1}{N}\boldsymbol{X}_c^\top \boldsymbol{X}_c\]这里 \(\boldsymbol{X}_c\) 是已经减去均值后的数据矩阵, \(\boldsymbol{X}_c^\top \boldsymbol{X}_c\) 汇总了各个特征之间如何共同变化;再除以 \(N\),就得到平均意义下的协方差矩阵 \(\boldsymbol{\Sigma}\)。PCA 正是从这个矩阵里找“变化最大的方向”。
第一主成分对应的优化问题为:
\[\max_{\boldsymbol{u}} \quad \boldsymbol{u}^\top \boldsymbol{\Sigma}\boldsymbol{u} \quad \text{s.t.} \quad \|\boldsymbol{u}\|_2=1\]\(\boldsymbol{u}\) 是候选投影方向, \(\boldsymbol{u}^\top \boldsymbol{\Sigma}\boldsymbol{u}\) 表示数据投影到该方向后的方差,约束 \(\|\boldsymbol{u}\|_2=1\) 则防止通过把向量无限放大来虚增方差。于是这个优化问题真正寻找的是“单位长度下最能保留变化信息的方向”。
其解是协方差矩阵最大特征值对应的特征向量。取前 \(k\) 个主成分组成矩阵 \(\boldsymbol{U}_k\) 后,样本 \(\boldsymbol{x}\) 的低维表示为:
\[\boldsymbol{z}=\boldsymbol{U}_k^\top(\boldsymbol{x}-\boldsymbol{\mu})\]这里 \(\boldsymbol{\mu}\) 是原始数据均值, \(\boldsymbol{x}-\boldsymbol{\mu}\) 先把样本中心化, \(\boldsymbol{U}_k\) 由前 \(k\) 个主成分方向组成,最终 \(\boldsymbol{z}\) 就是样本在这组主方向上的低维坐标。
- 对数据做中心化,必要时再做标准化。
- 计算协方差矩阵或直接对数据矩阵做奇异值分解(SVD)。
- 取前 \(k\) 个主成分方向。
- 把数据投影到这些方向上得到低维表示。
在人脸图像压缩中,大量像素变化往往由少数全局因素驱动。PCA 可以用少量主成分保留大部分有效变化,从而显著降低特征维度。
- 优点:线性、稳定、可解释,常用作预处理和可视化。
- 局限:只能捕捉线性结构;对异常值敏感。
- 适用场景:线性降维、特征压缩、去相关与噪声过滤。
线性判别分析(Linear Discriminant Analysis, LDA)用于监督降维与分类。与 PCA 只看输入分布不同,LDA 利用类别标签寻找一个投影空间,使同类样本尽量聚集、异类样本尽量分开。
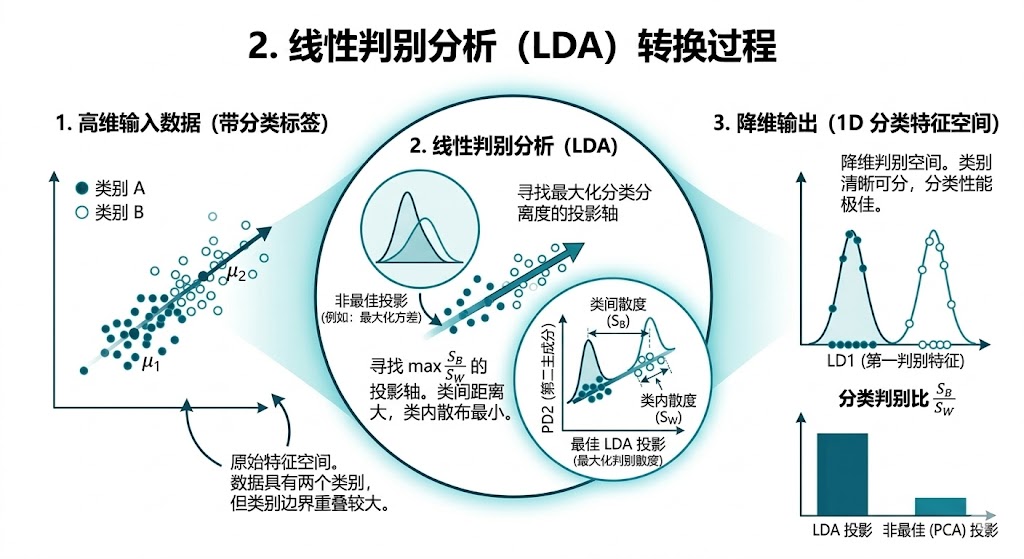
LDA 同时考虑类内散度(Within-class Scatter)和类间散度(Between-class Scatter)。好的投影方向应当让类间距离大、类内波动小,因此它优化的核心是判别性。
定义类内散度矩阵:
\[\boldsymbol{S}_W=\sum_{k=1}^{C}\sum_{\boldsymbol{x}_i\in \mathcal{C}_k}(\boldsymbol{x}_i-\boldsymbol{\mu}_k)(\boldsymbol{x}_i-\boldsymbol{\mu}_k)^\top\]类内散度矩阵 \(\boldsymbol{S}_W\) 统计的是“同一类内部有多分散”。 \(\mathcal{C}_k\) 是第 \(k\) 类的样本集合, \(\boldsymbol{\mu}_k\) 是该类均值。若类内样本围绕各自均值分布得很紧, \(\boldsymbol{S}_W\) 就会较小。
类间散度矩阵:
\[\boldsymbol{S}_B=\sum_{k=1}^{C}N_k(\boldsymbol{\mu}_k-\boldsymbol{\mu})(\boldsymbol{\mu}_k-\boldsymbol{\mu})^\top\]类间散度矩阵 \(\boldsymbol{S}_B\) 统计的是“各类中心彼此有多分开”。其中 \(\boldsymbol{\mu}\) 是全局均值, \(N_k\) 是第 \(k\) 类样本数,因此样本多的大类会对类间结构贡献更大权重。
LDA 寻找投影向量 \(\boldsymbol{w}\) 使 Fisher 判别准则最大:
\[J(\boldsymbol{w})=\frac{\boldsymbol{w}^\top \boldsymbol{S}_B \boldsymbol{w}}{\boldsymbol{w}^\top \boldsymbol{S}_W \boldsymbol{w}}\]Fisher 准则的分子衡量“投影后类间有多分开”,分母衡量“投影后类内有多混在一起”。因此 \(J(\boldsymbol{w})\) 越大,说明方向 \(\boldsymbol{w}\) 越有助于把不同类别拉开、同时保持同类紧凑。
该问题可转化为广义特征值问题 \(\boldsymbol{S}_B\boldsymbol{w}=\lambda \boldsymbol{S}_W\boldsymbol{w}\)。对 \(C\) 类问题,最多能得到 \(C-1\) 个有效判别方向。
- 根据标签统计每一类的均值与全局均值。
- 构造类内散度矩阵和类间散度矩阵。
- 求解广义特征值问题,选择主要判别方向。
- 将样本投影到低维判别子空间中做分类或可视化。
在手写数字分类中,LDA 关注的是“哪些方向最有助于把不同数字分开”,因此在有标签监督时,它往往比只最大化总体方差的 PCA 更适合分类前降维。
- 优点:利用标签信息,投影方向更有判别性。
- 局限:线性假设较强;类内散度矩阵可能奇异。
- 适用场景:有标签监督的降维、分类前特征压缩、判别性可视化。
t-SNE(t-distributed Stochastic Neighbor Embedding)主要用于二维或三维可视化。它主要关注如何在低维图上尽量保留高维空间中的局部邻域关系。
t-SNE 把“样本彼此接近”转写为概率相似度:在高维空间中,接近的样本应当有较大概率互为邻居;在低维嵌入中,也希望这种邻近关系继续成立。优化的目标是让两种邻域概率分布尽可能接近。
在高维空间中,先定义邻域概率 \(p_{ij}\);在低维空间中,对嵌入点 \(\boldsymbol{y}_i\) 定义:
\[q_{ij}=\frac{(1+\|\boldsymbol{y}_i-\boldsymbol{y}_j\|_2^2)^{-1}}{\sum_{a\ne b}(1+\|\boldsymbol{y}_a-\boldsymbol{y}_b\|_2^2)^{-1}}\]这里 \(\boldsymbol{y}_i\) 和 \(\boldsymbol{y}_j\) 是低维嵌入坐标,分子把距离越近的点赋予越大的相似度,分母则把所有点对的相似度加总起来做归一化,因此 \(q_{ij}\) 可以被解释成低维空间里的邻域概率。
t-SNE 最小化高维邻域分布与低维邻域分布之间的 KL 散度:
\[\text{KL}(P\|Q)=\sum_{i\ne j} p_{ij} \log \frac{p_{ij}}{q_{ij}}\]KL 散度衡量的是“低维邻域分布 \(Q\) 与高维邻域分布 \(P\) 相差多少”。若某对样本在高维里很近,即 \(p_{ij}\) 很大,但在低维里被拉得太开, \(q_{ij}\) 就会过小,从而产生较大惩罚。
低维中采用重尾 Student-t 分布,主要是为了缓解拥挤问题(Crowding Problem),使远处点更容易被拉开。
- 根据高维距离计算样本间的邻域概率。
- 随机初始化低维坐标。
- 计算低维相似度 \(q_{ij}\)。
- 通过梯度下降最小化 KL 散度并更新低维坐标。
在词向量或图像嵌入可视化中,t-SNE 常把语义相近的样本压到局部团簇中,从而帮助研究者直观看到表示空间里是否出现了合理分群。
- 优点:二维可视化效果强,局部邻域保持能力好。
- 局限:全局距离与簇间相对位置不稳定;对超参数和随机初始化敏感。
- 适用场景:嵌入可视化、表示质量诊断、探索性数据分析。
UMAP(Uniform Manifold Approximation and Projection)同样用于低维可视化与非线性降维。它面对的任务与 t-SNE 类似,但更强调在保留局部结构的同时,尽量维持一定的全局几何关系,并提升速度与可扩展性。
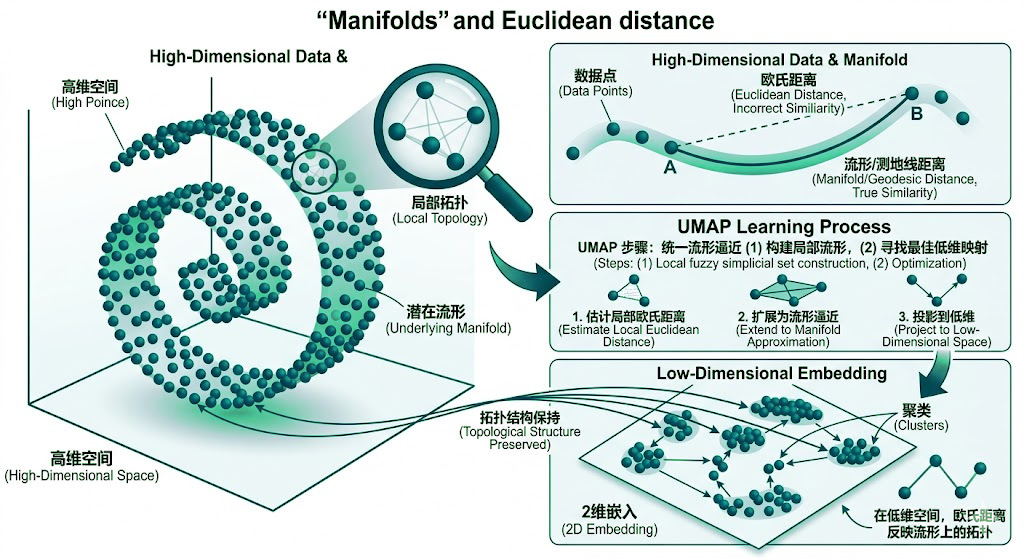
UMAP 先在高维空间构建一个加权近邻图,把数据视为流形(Manifold)上的离散采样;随后在低维空间中寻找一张新图,使低维图与高维图的模糊连通结构尽量一致。它本质上是在匹配两张图的连通结构,而不只是在匹配两组欧氏距离。
这里的流形可以先从一个标准定义理解:设样本位于高维空间 \(\mathbb{R}^D\) 中,若它们实际上集中在某个低维集合 \(\mathcal{M}\subseteq\mathbb{R}^D\) 附近,并且对 \(\mathcal{M}\) 上任一点,都能在一个足够小的邻域内用 \(d\) 维坐标平滑描述,其中 \(d\ll D\),那么这个集合就可以看作一个 \(d\) 维流形。流形的关键性质核心是它在局部看起来像低维欧氏空间,在全局上则可以嵌入到更高维空间并发生弯曲、卷曲或拉伸。
在数据分析里,这个概念表示:虽然原始特征有很多维,但样本分布在某种低维结构附近,并没有真正填满整个高维空间。例如一组人脸图像在像素空间里维度极高,但由姿态、光照、表情等少数潜在因素变化时,样本往往只覆盖其中一个低维子区域。UMAP 的出发点正是:若数据主要几何结构由这个低维流形决定,那么局部近邻关系比“全局欧氏直线距离”更能反映真实结构。
“离散采样”则表示:真实流形 \(\mathcal{M}\) 本身是连续对象,但我们手里只有有限个样本点 \(\{x_i\}_{i=1}^N\)。UMAP 通过近邻图近似这些点在流形上的局部连通关系,再在低维空间中寻找一组坐标 \(\{y_i\}_{i=1}^N\),使这种局部连通关系尽量被保留下来。因此它核心是在有限样本层面恢复流形的邻域结构。
与 t-SNE 相比,UMAP 更强调“样本来自某个低维流形,并且近邻图是在近似这个流形的局部连通结构”;t-SNE 的核心对象则更偏向“高维邻域概率分布与低维邻域概率分布的匹配”。两者都重视局部关系,但 UMAP 的表述更几何化,t-SNE 的表述更概率化。
若高维图边权为 \(p_{ij}\),低维图边权常写为:
\[q_{ij}=\frac{1}{1+a\|\boldsymbol{y}_i-\boldsymbol{y}_j\|_2^{2b}}\]UMAP 用这个函数把低维距离转换成连通强度。 \(a\) 和 \(b\) 控制曲线形状:距离很近时 \(q_{ij}\) 接近 1,距离变远时迅速衰减到接近 0,因此它可以把“近邻关系”转写成平滑的图边权。
其中 \(a,b\) 决定低维距离与连接强度的映射形状。UMAP 的优化目标通常是高维图与低维图之间的交叉熵(Cross-Entropy):既鼓励高维中相连的点在低维中也靠近,也鼓励高维中不相连的点在低维中适当分开。
- 计算近邻图,并为边赋予模糊连通权重。
- 初始化低维坐标。
- 通过随机优化最小化高维图与低维图之间的交叉熵。
- 得到二维或三维嵌入用于可视化或下游分析。
在单细胞测序、文本嵌入或推荐向量分析中,UMAP 常被用来把高维表示映射到二维平面,从而观察群体结构、类别分布与异常点。
- 优点:通常比 t-SNE 更快,较好兼顾局部与部分全局结构。
- 局限:嵌入结果仍依赖超参数与随机种子;二维距离不能机械等同于原空间距离。
- 适用场景:大规模嵌入可视化、非线性降维、聚类前的低维表示。
异常检测处理的核心问题是:正常样本通常大量存在,而异常样本稀少、形态多变、甚至在训练阶段根本拿不到完整标签。模型因此从主要学习“类别之间如何区分”转向学习“什么算正常”以及“偏离正常结构有多严重”。不同方法对“异常”的定义并不相同:有的依赖隔离难易度,有的依赖局部密度,有的学习正常区域边界。
在业务语境里,“异常”并不同于“数值特别大”或“离均值很远”。更准确地说,异常是相对于当前业务规则、历史模式或同类群体而言,不应当出现、很少出现、或者一旦出现就值得额外关注的样本。因此异常是一个“相对概念”,必须依赖参照系:相对于谁、在哪个时间段、在什么上下文里、以什么代价衡量。
例如,单笔消费 5000 元在全国范围内不一定异常,但若这位用户平时只在本地便利店做几十元交易,而这次交易突然发生在异地、高风险设备、深夜时段,并伴随支付习惯突变,那么它在风控上就可能是异常。类似地,服务器 CPU 使用率 85% 在大促期间可能是正常负载,在凌晨低峰却可能意味着任务堆积;工厂传感器温度轻微升高若同时伴随振动模式变化,也可能预示故障正在形成。
这说明业务上的异常通常至少包含三类含义。第一类是统计稀有:样本落在低概率区域。第二类是行为失配:它与该对象自己的历史模式不一致。第三类是群体失配:它在全局上不一定极端,但相对于同类群体显著不同。异常检测算法的差异,本质上就在于它们分别更擅长刻画哪一种“失配”。
因此,做异常检测时首先要回答的核心是“业务到底把什么视为异常”。若异常意味着“明显稀少且容易与大部队分开”,隔离式方法更合适;若异常意味着“在本地邻域里显得稀疏”,应优先考虑密度比较;若正常样本边界清楚、异常样本类型杂乱,则更适合只学习正常区域。算法核心是在实现业务已经确定的异常标准。
孤立森林(Isolation Forest)用于无监督异常检测:在没有可靠异常标签时,仅根据数据分布本身识别“容易被孤立”的异常样本。它尤其适合高维表格数据与大规模检测场景。
孤立森林利用一个非常直接的直觉:异常点通常更稀少、更孤立,因此在随机切分下更容易被提早隔离。路径越短,越可能是异常;路径越长,越像处于正常群体内部。若把正常样本理解为“扎堆生活在高密度区域里的大群体”,那么它们往往需要经过很多次随机切割才会被单独分离出来;而那些落在边缘、稀疏区域、或与主体分布明显脱节的样本,只需少量切分就会被单独留在某个叶节点里。
这种思路和距离或密度方法非常不同。K 近邻(K-Nearest Neighbors, KNN)或局部异常因子(Local Outlier Factor, LOF)会显式比较“离别人有多远”或“局部密度有多低”;孤立森林则直接把异常检测改写成一个更具操作性的判据:一个样本在随机树里平均多快会被单独隔开。因此它用“隔离难易度”来近似刻画异常性,不先估计复杂概率分布,也不依赖全局距离结构。
图中的示意数据由两个主要正常簇和若干离散分布的异常点构成。背景等高线展示的是孤立森林学到的“异常分数地形”:颜色越深,表示该区域样本平均路径长度越长,更接近模型眼中的正常高密度区域;颜色越浅,表示样本更容易在随机切分中被提早隔离,因此更接近潜在异常区域。
图中圆形点对应被模型判为正常的样本,它们主要聚集在两个深色中心附近;叉号对应被模型判为异常的样本,它们更多分布在边缘、簇间空白带或浅色区域。这种可视化非常适合帮助理解孤立森林的工作方式:它核心是在表达“哪里更容易被随机树迅速切出来”。因此,等高线的深浅更接近一种“隔离难度地图”,而非传统分类器意义上的硬分类边界。
隔离树(Isolation Tree, iTree)可以理解成一棵专门为了“把样本逐步切开”而构造的随机二叉树。它与决策树(Decision Tree)在外形上相似,但目标完全不同:决策树是在找最有区分力的切分规则,隔离树则故意随机选择一个特征,再在该特征当前取值范围内随机选择一个切分点,把样本递归分到左右子节点。
设当前节点包含样本集合 \(S\),随机选到的特征为第 \(j\) 维,其切分阈值为 \(\tau\),则一次切分可写成
\[S_{\mathrm{left}}=\{\boldsymbol{x}\in S\mid x_j<\tau\},\qquad S_{\mathrm{right}}=\{\boldsymbol{x}\in S\mid x_j\ge \tau\}\]递归继续进行,直到某个节点只剩下 1 个样本,或所有样本在当前节点上已经无法再被有效区分。对一个本来就远离主体、所在区域又很稀疏的样本而言,随机切分往往只需要很少几步就能把它单独留在某个叶节点中;而对处在高密度正常群体内部的样本,通常要经过更多次切分才能被单独隔离。隔离树因此把“异常”转写为“被随机切分提早单独分离”的难易度。
对样本 \(\boldsymbol{x}\),记它在一棵隔离树中的路径长度为 \(h(\boldsymbol{x})\)。在多棵树上取平均路径长度 \(\mathbb{E}[h(\boldsymbol{x})]\) 后,异常分数定义为:
\[s(\boldsymbol{x},n)=2^{-\mathbb{E}[h(\boldsymbol{x})]/c(n)}\]这里 \(h(\boldsymbol{x})\) 是样本在一棵树里被隔离所需的路径长度, \(\mathbb{E}[h(\boldsymbol{x})]\) 是在整片森林中的平均值, \(c(n)\) 是针对样本规模 \(n\) 的归一化常数。路径越短,指数里的值越小,异常分数 \(s(\boldsymbol{x},n)\) 就越接近 1。
其中 \(c(n)\) 是平均路径长度的归一化常数,用来把不同样本规模下的路径长度放到可比较的尺度上。它常写为 \(c(n)=2H_{n-1}-2(n-1)/n\),其中 \(H_{n-1}\) 是第 \(n-1\) 个调和数(Harmonic Number)。若某点明显比普通样本更早被切分隔离,则其平均路径长度更小,异常分数更接近 1。
- 从训练集中随机抽取多个子样本。
- 为每个子样本构建随机隔离树。
- 对待测点计算其在所有树中的平均路径长度。
- 将平均路径长度映射为异常分数。
在交易风控中,若某条交易在金额、时间、地点、设备等多个维度上都明显偏离正常模式,它往往能在随机切分下被较早隔离出来,因此会获得更高异常分数。
- 优点:无需显式估计密度,也不依赖两两距离矩阵;因此在大规模数据上通常比基于邻域或密度的方法更高效。
- 优点:对高维表格数据较友好,对随机噪声通常也有较强鲁棒性,因为最终判断来自多棵随机树上的平均隔离行为,而非某一次局部切分。
- 局限:对特征编码和特征尺度的业务含义仍然敏感;若异常与正常高度混叠、或者异常本身并不更容易被切开,隔离优势会下降。
- 适用场景:风控、日志异常、设备故障、指标监控等无监督异常检测,尤其适合作为高维表格场景中的强基线。
局部异常因子(Local Outlier Factor, LOF)主要解决“全局上不远,但在局部邻域中显著稀疏”的异常检测问题。当数据不同区域密度差异很大时,只看全局距离通常不够稳定。
LOF 比较的是“这个点相对于其邻居是否更稀疏”。若一个点周围的局部密度显著低于邻居自己的局部密度,则它更像局部异常。它识别的核心是相对于自己所在局部环境显得不协调的点。因此,当不同区域本来就有不同密度时,LOF 往往比只看全局距离的方法更稳。
图中的实心圆点表示样本点,围绕样本点的空心圆圈大小表示该点的 LOF 分数大小。圆圈越小,说明该点的局部密度与其邻居相近,更像正常簇中的内部样本;圆圈越大,说明该点所在位置相对于邻居显得更稀疏,因此更可能是局部异常点。
这张图直观展示了 LOF 的核心判断方式:它先比较“这个点和自己周围那一圈邻居相比,是否显得过于稀疏”。因此,大圆圈对应的未必是全局最远的点,而更可能是那些周围邻居仍然较密、但它自己明显脱离了局部密度水平的点。
若把这张示意图看作两个高密度簇与少量随机噪声点的组合,则邻居数 \(k\) 决定了算法观察“局部环境”的尺度。 \(k\) 较小时,模型更敏感于非常局部的扰动; \(k\) 较大时,密度比较更平滑,但也可能削弱对细粒度异常的敏感性。
给定邻居数 \(k\),设 \(N_k(\boldsymbol{p})\) 表示点 \(\boldsymbol{p}\) 的 \(k\) 个最近邻集合。LOF 的计算可以拆成三层:先算可达距离(Reachability Distance),再算局部可达密度(Local Reachability Density, LRD),最后比较邻居密度与自身密度,得到局部异常因子(Local Outlier Factor, LOF)。
先定义可达距离(Reachability Distance):
\[\mathrm{rd}_k(\boldsymbol{p},\boldsymbol{o})=\max\big(\text{k-distance}(\boldsymbol{o}),d(\boldsymbol{p},\boldsymbol{o})\big)\]可达距离会把两个量取最大值:邻居点 \(\boldsymbol{o}\) 自己的第 \(k\) 邻距离,以及点对之间的真实距离。这样做可以防止极近的点对把局部密度估得过于夸张,使密度估计更稳。
再定义局部可达密度(Local Reachability Density, LRD):
\[\mathrm{lrd}_k(\boldsymbol{p})=\left(\frac{1}{|N_k(\boldsymbol{p})|}\sum_{\boldsymbol{o}\in N_k(\boldsymbol{p})} \mathrm{rd}_k(\boldsymbol{p},\boldsymbol{o})\right)^{-1}\]局部可达密度 \(\mathrm{lrd}_k(\boldsymbol{p})\) 本质上是“平均可达距离”的倒数:平均距离越小,周围越拥挤,密度越大;平均距离越大,周围越稀疏,密度越小。
最终的 LOF 分数为:
\[\mathrm{LOF}_k(\boldsymbol{p})=\frac{1}{|N_k(\boldsymbol{p})|}\sum_{\boldsymbol{o}\in N_k(\boldsymbol{p})} \frac{\mathrm{lrd}_k(\boldsymbol{o})}{\mathrm{lrd}_k(\boldsymbol{p})}\]LOF 分数比较的是“邻居的局部密度”和“自己本身的局部密度”。若 \(\mathrm{lrd}_k(\boldsymbol{p})\) 明显小于邻居的密度,分数就会大于 1,说明该点相对周围环境显得更孤立。更具体地说,分子是邻居局部密度的平均水平,分母是点 \(\boldsymbol{p}\) 自己的局部密度,因此这个比值本质上是在问:你周围的人都很挤,而你自己是否站得太空。
结果通常可以这样解读:
- \(\mathrm{LOF}_k(\boldsymbol{p})\approx 1\):该点的局部密度与邻居相近,通常属于正常样本。
- \(\mathrm{LOF}_k(\boldsymbol{p})<1\):该点甚至比邻居更密集,往往处于簇的核心区域。
- \(\mathrm{LOF}_k(\boldsymbol{p})>1\):该点局部密度低于邻居,越大越像异常点。
因此,LOF 回答的是“这个点在自己的局部邻域里是否显得过于稀疏”,而非“这个点离全局中心远不远”。这也是它能识别局部异常、却对距离度量与邻居数 \(k\) 较敏感的根本原因。
- 为每个样本找到 \(k\) 个近邻。
- 计算可达距离与局部可达密度。
- 比较样本与邻居的局部密度,得到 LOF 分数。
- 按分数排序或设置阈值输出异常点。
在消费行为数据中,某一线城市用户的高消费在全国范围内未必异常,但在“同年龄、同区域、同收入”的邻域里可能明显偏离。LOF 正是通过这种局部密度比较识别这类异常。
- 优点:适合不同密度区域共存的数据,能识别“全局上不极端、但局部上明显失配”的异常。
- 优点:解释性较强,因为 LOF 分数直接来自“邻居密度 / 自身密度”的局部比较,便于回答异常是相对于谁显得异常。
- 局限:对距离度量、标准化和邻居数 \(k\) 很敏感; \(k\) 太小会放大噪声,太大又可能抹平真正的局部异常。
- 局限:大规模近邻搜索成本较高,因此在超大数据上常需要索引加速或近似近邻方法配合。
- 适用场景:局部离群检测、消费异常、群体内部行为异常、同类用户或设备群体中的行为失配识别。
单类支持向量机(One-Class Support Vector Machine, One-Class SVM)用于“只有正常样本、缺少可靠异常样本”的异常检测任务。它的目标是学习一个描述正常样本区域的边界。
One-Class SVM 通过核映射把样本送到高维特征空间,再寻找一个把大多数正常样本与原点分开的超平面。等价地看,它学习的是一个“包住正常样本”的高维边界,边界外的点更可能是异常。
一种标准形式为:
\[\min_{\boldsymbol{w},\rho,\boldsymbol{\xi}} \frac{1}{2}\|\boldsymbol{w}\|_2^2+\frac{1}{\nu N}\sum_{i=1}^{N} \xi_i-\rho\]One-Class SVM 的目标由三部分组成: \(\frac{1}{2}\|\boldsymbol{w}\|_2^2\) 控制边界不要太复杂, \(\frac{1}{\nu N}\sum_i \xi_i\) 惩罚落在边界外或靠得太近的样本, \(-\rho\) 则鼓励把正常区域尽量向外推开。 \(\nu\) 越大,对违约样本的容忍度越高。
\[\text{s.t.} \quad \boldsymbol{w}^\top \phi(\boldsymbol{x}_i) \ge \rho-\xi_i,\qquad \xi_i \ge 0\]这些约束表示:样本映射到特征空间后,其投影值至少要达到阈值 \(\rho\);若做不到,就用非负松弛变量 \(\xi_i\) 记录违约程度。于是模型允许少量样本越界,但必须为此付出代价。
其中 \(\boldsymbol{w}\) 是超平面法向量, \(\rho\) 是阈值, \(\xi_i\) 是松弛变量, \(\nu\in(0,1]\) 控制允许落在边界外的比例与支持向量比例。判别函数为:
\[f(\boldsymbol{x})=\text{sign}\left(\boldsymbol{w}^\top \phi(\boldsymbol{x})-\rho\right)\]判别函数先计算样本在特征空间里相对边界的位置:若 \(\boldsymbol{w}^\top \phi(\boldsymbol{x})-\rho\) 为正,说明样本位于学习到的正常区域一侧;若为负,则更可能落在边界之外,被视为异常。
若使用核函数 \(K(\boldsymbol{x},\boldsymbol{x}')\),则该边界可以是非线性的,因此能表达复杂的正常区域。
- 只用正常样本训练模型,选择核函数与超参数 \(\nu\)。
- 在特征空间中学习分离超平面。
- 对新样本计算判别函数值。
- 若分数低于边界阈值,则判为异常。
在设备健康监控中,异常故障类型往往变化很大,难以完整收集,但正常运行数据很多。One-Class SVM 可以只基于正常样本学习边界,一旦新样本落出该区域,就触发异常告警。
- 优点:只依赖正常样本;核方法可表达复杂边界。
- 局限:对特征缩放和核参数敏感;大规模训练较重。
- 适用场景:设备监控、入侵检测、质量控制等“正常样本丰富、异常样本稀缺”的任务。
神经网络(Neural Network)的基本想法出现得很早:用大量简单计算单元和可调连接权重,去近似复杂的输入输出关系。早期感知机(Perceptron)证明了机器可以从样本中学习线性分类边界,但单层结构无法表达 XOR 这类简单非线性关系,导致连接主义路线一度进入低潮。
多层网络重新获得生命力,关键在于反向传播(Backpropagation)把“怎样训练多层可微模型”变成了可计算的工程流程。1980 年代,David Rumelhart、Geoffrey Hinton 和 Ronald Williams 推广了反向传播在多层网络中的训练方式,使隐藏层权重可以通过链式法则高效更新。这个贡献的重要性在于:隐藏层可以在任务损失的驱动下自动学习中间表示,而不再依赖手工设计的特征变换。
Geoffrey Hinton 在神经网络复兴中尤其关键。他长期推动分布式表示(Distributed Representation)、玻尔兹曼机(Boltzmann Machine)、深度信念网络(Deep Belief Network)和深层网络训练研究;在 2000 年代中期,他和合作者展示了逐层预训练对深层网络训练的帮助,使“深网络可以训练起来”重新成为现实工程路线。到 2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 的 AlexNet 在 ImageNet 上取得突破性结果,GPU、大规模数据、ReLU、Dropout 和卷积网络一起把深度学习推向主流。
这段历史说明,神经网络的成功依赖一整套条件共同成熟:表达能力、训练算法、数据规模、硬件并行、正则化和软件框架。通用近似定理回答的是“网络有没有能力表示足够复杂的函数”;反向传播、优化器、归一化、残差连接和数据工程回答的是“这种能力能否被稳定训练出来”。
通用近似定理(Universal Approximation Theorem)是神经网络表达能力的基础结果之一。它讨论的是函数类本身的表达能力;训练过程属于另一个问题。给定一个足够宽、带非线性激活函数的前馈神经网络,它可以在有限闭区间或更一般的紧集(Compact Set)上,把任意连续函数逼近到任意预先指定的精度。
一维情形可以写成下面的形式。设 \(f\) 是区间 \([a,b]\) 上的连续函数, \(\epsilon>0\) 是允许误差,则存在足够大的隐藏单元数 \(m\)、权重 \(\alpha_i,w_i,b_i\),使得
\[\sup_{x\in[a,b]}\left|f(x)-\sum_{i=1}^{m}\alpha_i\,\sigma(w_i x+b_i)\right|<\epsilon\]这里 \(\sigma\) 是非线性激活函数, \(\sigma(w_i x+b_i)\) 是第 \(i\) 个隐藏单元输出, \(\alpha_i\) 是输出层给这个隐藏单元分配的权重。 \(\sup\) 表示看整个区间上最大的绝对误差;因此,这个公式表达的是“在整个区间上都足够接近”,比只在若干采样点上接近更强。
一种常用的构造方式使用 logistic / sigmoid 激活函数:
\[\sigma(z)=\frac{1}{1+\exp(-z)}\]其中 \(z=wx+b\) 是神经元的线性输入, \(w\) 控制曲线陡峭度, \(b\) 控制曲线在数轴上的左右位置。 \(\exp(-z)\) 是指数函数。 \(z\) 很小时, \(\sigma(z)\) 接近 0; \(z\) 很大时, \(\sigma(z)\) 接近 1;中间区域是一段平滑过渡。把 \(|w|\) 调大后,过渡区会变窄,sigmoid 就越来越像一个可移动的软开关。
这个软开关构造出“局部块”的方式很直接。取两个位置 \(a<b\),并使用同样陡峭度的 sigmoid:
\[g(x)=\sigma(k(x-a))-\sigma(k(x-b))\]其中 \(k\) 控制两个开关的陡峭度, \(a\) 是左侧开关位置, \(b\) 是右侧开关位置。第一个开关在 \(x\approx a\) 附近从 0 变到 1,第二个开关在 \(x\approx b\) 附近从 0 变到 1。二者相减后, \(x<a\) 时两者都接近 0,输出接近 0; \(a<x<b\) 时第一个接近 1、第二个接近 0,输出接近 1; \(x>b\) 时两者都接近 1,输出再次接近 0。于是,两个 sigmoid 神经元就形成了一个局部脉冲块。
脉冲块的宽度由 \(b-a\) 决定,位置由 \(a,b\) 决定,高度由输出层权重决定。如果给每个小区间放一个这样的块,再让输出层给每个块分配不同高度,就得到一条阶梯函数。连续函数在足够小的区间内变化有限,因此当小区间越来越窄、局部块越来越多时,这条阶梯函数就能把目标曲线压到任意小误差内。这就是“一对神经元形成一个局部块,很多块拼出曲线”的构造性直觉。
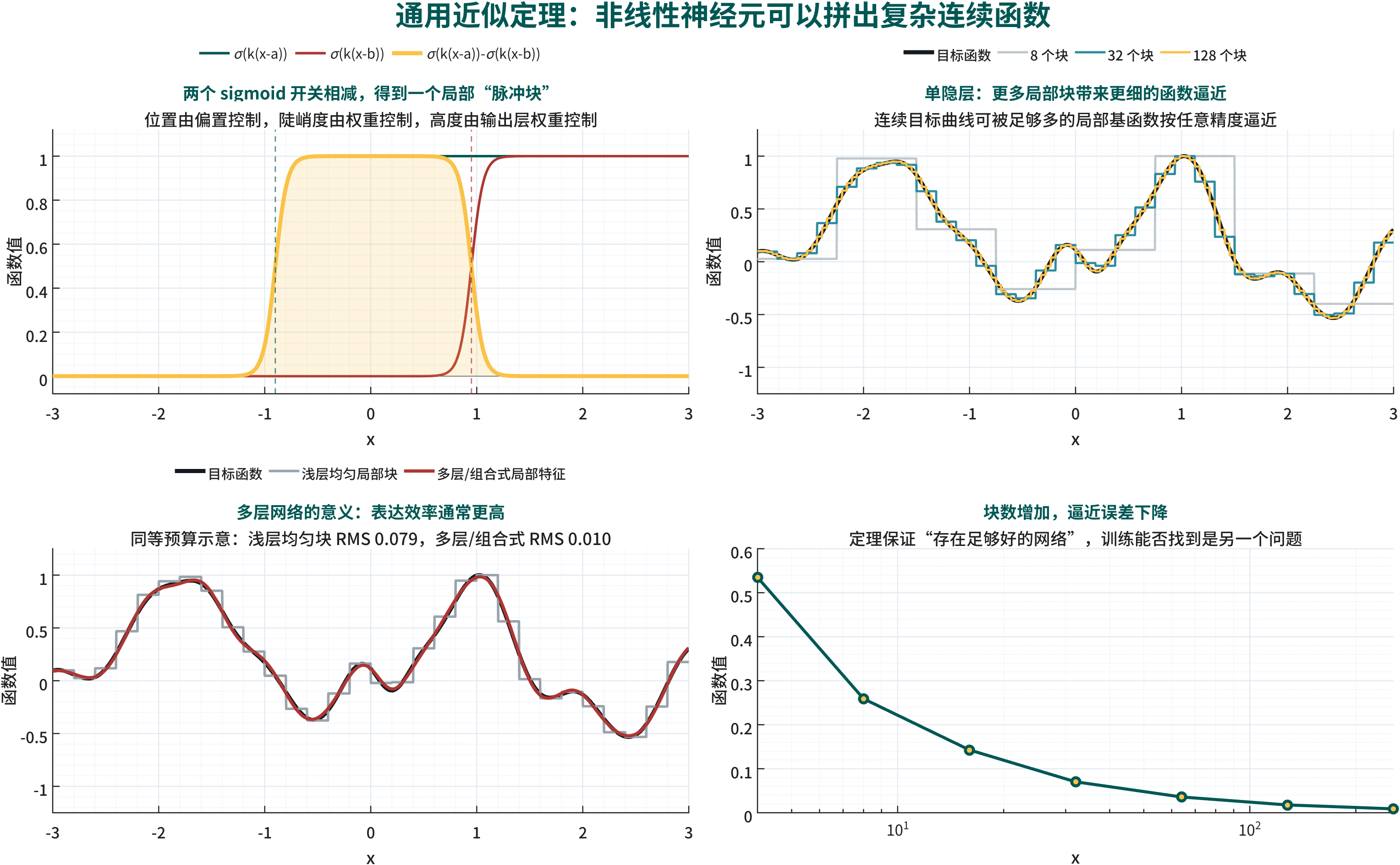
这张图对应四个层次。左上角展示两个 sigmoid 开关相减得到局部脉冲块;右上角展示单隐层网络用更多局部块逼近同一条连续目标曲线;左下角用同等预算示意浅层均匀块和多层组合式特征的效率差异;右下角展示块数增加时逼近误差下降。图中的多层曲线只是表达效率的直观示意,不表示某个特定训练过程必然收敛到该曲线。
定理的边界同样重要。第一,它要求目标函数在讨论区域内连续;带跳跃断点的函数不满足经典连续函数版本的结论。第二,它保证“存在”足够好的网络,不保证梯度下降一定能找到这些参数。第三,它不保证所需隐藏单元数很小;单隐层理论上足够,但可能需要非常多神经元。第四,它不直接保证泛化能力;训练集上拟合得好,仍可能在分布外样本上失败。
深层网络的意义主要体现在表达效率和组合结构上。许多真实任务中的目标函数具有层级组合结构:局部边缘组合成纹理,纹理组合成部件,部件组合成物体;词语组合成短语,短语组合成句子语义。深层网络可以让不同层分别学习不同层级的中间表示,用更少参数表达复杂复合函数。单隐层定理说明“浅层网络有足够表达能力”,深度学习实践进一步说明“深度结构往往更高效、更容易匹配数据生成机制”。
因此,通用近似定理给神经网络提供的是表达能力的底层保证:非线性神经元经过加权组合,可以逼近广泛的连续函数。训练算法、优化稳定性、数据规模、正则化、架构归纳偏置和泛化能力,仍然是后续章节必须单独讨论的问题。
感知机(Perceptron)是最早的神经元模型之一,也是现代神经网络最基本的计算原型。无论是 MLP、CNN、RNN,还是 Transformer,本质上都由大量“线性变换 + 非线性变换”的单元堆叠而成;从这个意义上说,理解感知机,就是理解大型模型最小的功能部件。
最原始的感知机先做线性组合,再经过一个阈值函数给出二分类输出:
\[\hat y=\mathrm{sign}(\mathbf{w}^\top \mathbf{x}+b)\]这里 \(\mathbf{x}\) 是输入特征, \(\mathbf{w}\) 是权重, \(b\) 是偏置。 \(\mathbf{w}^\top \mathbf{x}+b\) 的含义是“沿着权重指定的方向对输入做加权打分”,而 \(\mathrm{sign}(\cdot)\) 则把连续分数变成离散决策:高于阈值判为正类,低于阈值判为负类。
需要特别区分的是:最早的感知机确实直接做分类,但现代神经网络里的大多数“感知机式单元”并不直接输出最终类别。隐藏层单元更常见的形式是 \(h=\phi(\mathbf{w}^\top \mathbf{x}+b)\),它们输出的是中间表示(Intermediate Representation),职责是检测局部模式、重组特征并为后续层提供更有用的表示;只有最后的任务头(Task Head)才把这些中间表示转成分类、回归或生成输出。
这里的中间表示(Intermediate Representation)本质上就是一组可被后续层继续计算的数值特征。它既可以是向量(Vector),也可以是矩阵(Matrix),更一般地说,它通常是张量(Tensor)。向量和矩阵都只是张量的特殊情形:若只看单个样本的 MLP 隐层输出,最常见的是向量 \(\boldsymbol{h}\in\mathbb{R}^{d}\);若看 Transformer 对整段序列的隐藏状态,常写成矩阵 \(H\in\mathbb{R}^{L\times d}\);若再把 batch 维也带上,则会变成三维张量 \(\mathcal{H}\in\mathbb{R}^{B\times L\times d}\)。在卷积网络(Convolutional Neural Network, CNN)里,中间表示则常是特征图张量(Feature Map Tensor) \(\mathcal{H}\in\mathbb{R}^{C\times H\times W}\),或带 batch 的 \(\mathbb{R}^{B\times C\times H\times W}\)。
因此,“中间表示”并非某种神秘对象,它就是网络在某一层对输入所形成的内部编码。它把输入重写成更适合下一层处理的坐标系。例如,文本模型中的某一层隐藏状态可能同时编码词义、上下文关系、句法位置和任务相关线索;图像模型中的某一层特征图则可能突出边缘、纹理、局部部件或更高层形状。后续层与任务头读到的,正是这些内部编码。
感知机的重要性不止在于历史地位,更在于今天大型模型中的知识,本质上仍然是通过这类权重结构逐层编码进去的。训练过程并不会把知识像数据库那样逐条写成显式记录,会不断调整参数,使某些输入模式被放大、某些输入模式被抑制。于是,模型在数据中反复见到的统计规律——词与词的共现、图像局部纹理、特征之间的组合关系——都会被压缩进参数矩阵的数值结构中。
更准确地说,大模型中的知识通常核心是以分布式表示(Distributed Representation)的形式分散在大量参数里。单个单元更像一个局部特征探测器(Feature Detector):它只对某种模式敏感;许多单元级联后,网络才能把低层简单模式组合成高层抽象概念。模型规模越大、层数越深、参数越多,可被编码的模式组合也越丰富,这正是大模型具备强表达能力与“知识容量”的原因之一。
感知机能学会线性可分任务,但无法处理 XOR 这类线性不可分问题,这正是多层网络出现的动机:当一个超平面不够时,就需要通过多层组合把输入空间逐步重写成更容易分开的表示。
多层感知机(Multi-Layer Perceptron, MLP)就是最典型的全连接神经网络(Fully Connected Neural Network)。它处理的核心问题是:当输入与输出之间的关系并非一个超平面就能表达时,如何通过多层可学习变换,把原始特征逐步改写成更容易完成任务的表示。它由多层线性变换与逐元素非线性激活交替组成,是最基本也最通用的前馈网络结构。
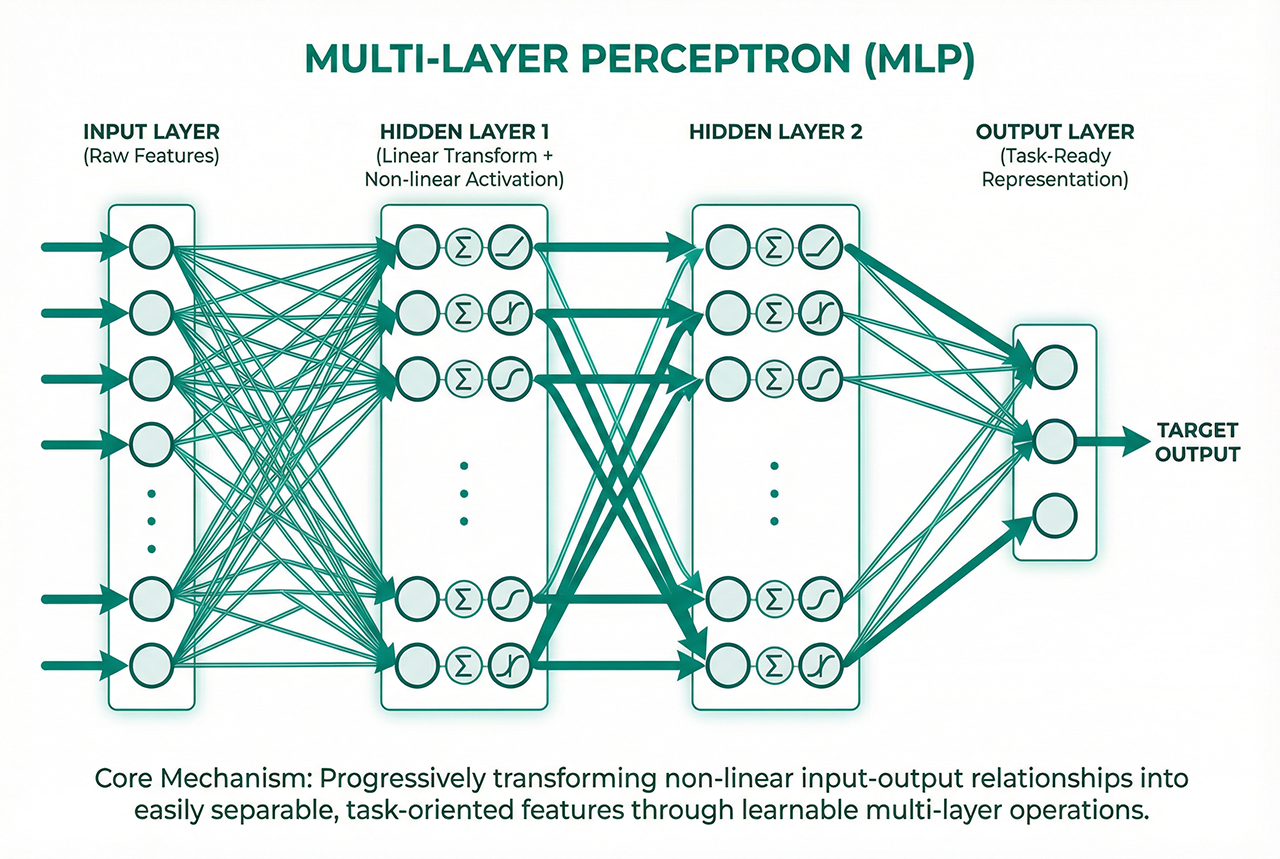
单层可写成:
\[\mathbf{h}=\phi(W\mathbf{x}+\mathbf{b})\]多层堆叠后,可写为:
\[\mathbf{h}^{(1)}=\phi(W^{(1)}\mathbf{x}+\mathbf{b}^{(1)}),\quad \mathbf{h}^{(2)}=\phi(W^{(2)}\mathbf{h}^{(1)}+\mathbf{b}^{(2)}),\quad \hat{\mathbf{y}}=W^{(3)}\mathbf{h}^{(2)}+\mathbf{b}^{(3)}\]这里 \(W^{(l)}\) 和 \(\mathbf{b}^{(l)}\) 是第 \(l\) 层参数, \(\mathbf{h}^{(l)}\) 是第 \(l\) 层隐藏表示。所谓“逐层重写表示”,就是每一层都在回答一个更具体的问题:哪些原始模式值得保留、哪些组合值得放大、哪些方向更利于后续任务。于是,早期层往往捕捉较局部、较简单的模式,后期层则把这些模式组合成更抽象的语义结构。
MLP 比单层感知机强,关键不在“层数更多”本身,而在于层与层之间插入了非线性激活函数 \(\phi\)。如果没有非线性,多层线性变换满足
\[W^{(2)}(W^{(1)}\mathbf{x}+\mathbf{b}^{(1)})+\mathbf{b}^{(2)}=\tilde W\mathbf{x}+\tilde{\mathbf{b}}\]最终仍然等价于一层线性变换,表达能力不会因为堆叠而提升。只有加入非线性后,网络才能把输入空间切分、折叠、拉伸并重新组合,形成复杂的分段线性或平滑非线性决策边界。
从几何角度看,单层模型像“用一个超平面切一次”;而多层 MLP 则是在表示空间中反复做坐标变换和非线性折叠,把原本难分的数据逐步变成线性头也能分开的形状。文中的激活函数对比图展示的正是这个过程:不同激活函数会把同一个三层网络变成完全不同的几何变换器。
在现代大模型中,MLP 的作用远不只是“附属模块”。在 Transformer 里,注意力层负责在 token 之间路由信息,而 MLP / Feed-Forward Network(FFN)则负责在每个位置上做通道维度的非线性特征变换,把路由来的信息重新编码进更强的表示。因此,很多语义模式、组合规则与任务相关知识,最终都会沉淀到这些大规模参数化的 MLP 权重中。
更进一步说,在 Transformer 的常见解释框架里,MLP / FFN 往往被看作事实性知识的重要载体之一。一个常见直觉是把 FFN 看成参数化的“键值存储器(Key-Value Memory)”:第一层线性变换更像在检测当前输入是否匹配某种模式或概念,第二层线性变换则把与该模式相关的语义方向重新写回残差流(Residual Stream)。这里的残差流,可以理解为 Transformer 里那条贯穿各层的主表示通道:每一层注意力与 MLP 的输出,都会通过残差相加的方式写回这条主通道,再交给后续层继续处理。因此,诸如“实体—属性”“术语—定义”“模式—响应”这类较稳定的关联,常常更容易在 MLP 权重里留下痕迹。
但这并不意味着“一个神经元就存一条事实”。更准确的描述是:知识通常以分布式方式存在于许多层、许多通道和许多参数方向里。单个神经元有时会对某种关系或概念特别敏感,因而出现所谓“知识神经元(Knowledge Neurons)”现象;但更稳定的事实表示,通常仍然依赖一组共同激活的单元和跨层传递的表示。可以把两类子层的分工概括为:注意力更擅长“去哪里找、和谁建立联系”,MLP 更擅长“把匹配到的模式变成可供后续层使用的语义内容”。因此,说 MLP 是知识的主要载体之一是合理的;说知识只存在于 MLP、完全不在注意力里,则过于简单。
激活函数(Activation Function)的作用是给线性层引入非线性。如果没有激活函数,多层线性层叠起来仍然等价于一层线性变换,深度就失去了意义。
先给出一个实用的选型总表。它不代替后文的机制分析,但可以先回答工程上最常见的问题:某个激活函数通常应该放在输出层、隐藏层,还是特定结构里。
| 激活函数 | 输出范围 | 典型适用场景 | 主要原因 |
| Sigmoid | \((0,1)\) | 二分类输出层;LSTM / GRU 门控 | 天然给出概率或开关强度,但隐藏层易饱和 |
| Tanh | \((-1,1)\) | 较浅网络;需要零中心有界激活的结构 | 比 sigmoid 更利于优化,但深层仍会饱和 |
| ReLU | \([0,+\infty)\) | 深层前馈网络、CNN 的默认隐藏层 | 不饱和、计算便宜、分段线性、优化稳定 |
| Leaky ReLU | \((-\infty,+\infty)\) | 担心 Dying ReLU 的深层隐藏层 | 保留 ReLU 优点,同时避免负半轴完全断梯度 |
| ELU | \((-\alpha,+\infty)\) | 希望激活更平滑、且均值更接近 0 的隐藏层 | 负区间平滑并可取负值,但计算开销高于 ReLU |
| GELU | \((-\infty,+\infty)\) | Transformer、BERT 类模型的隐藏层 | 选择性强且过渡平滑,兼顾表达能力与优化平滑性 |
| Swish / SiLU | \((-\infty,+\infty)\) | 现代卷积网络;部分大模型隐藏层 | 软门控、平滑、比硬截断更柔和 |
| Softmax | 各分量在 \((0,1)\) 且总和为 1 | 多分类输出层;语言模型词表分布输出 | 把 logits 归一化为概率分布,不用于普通隐藏层 |
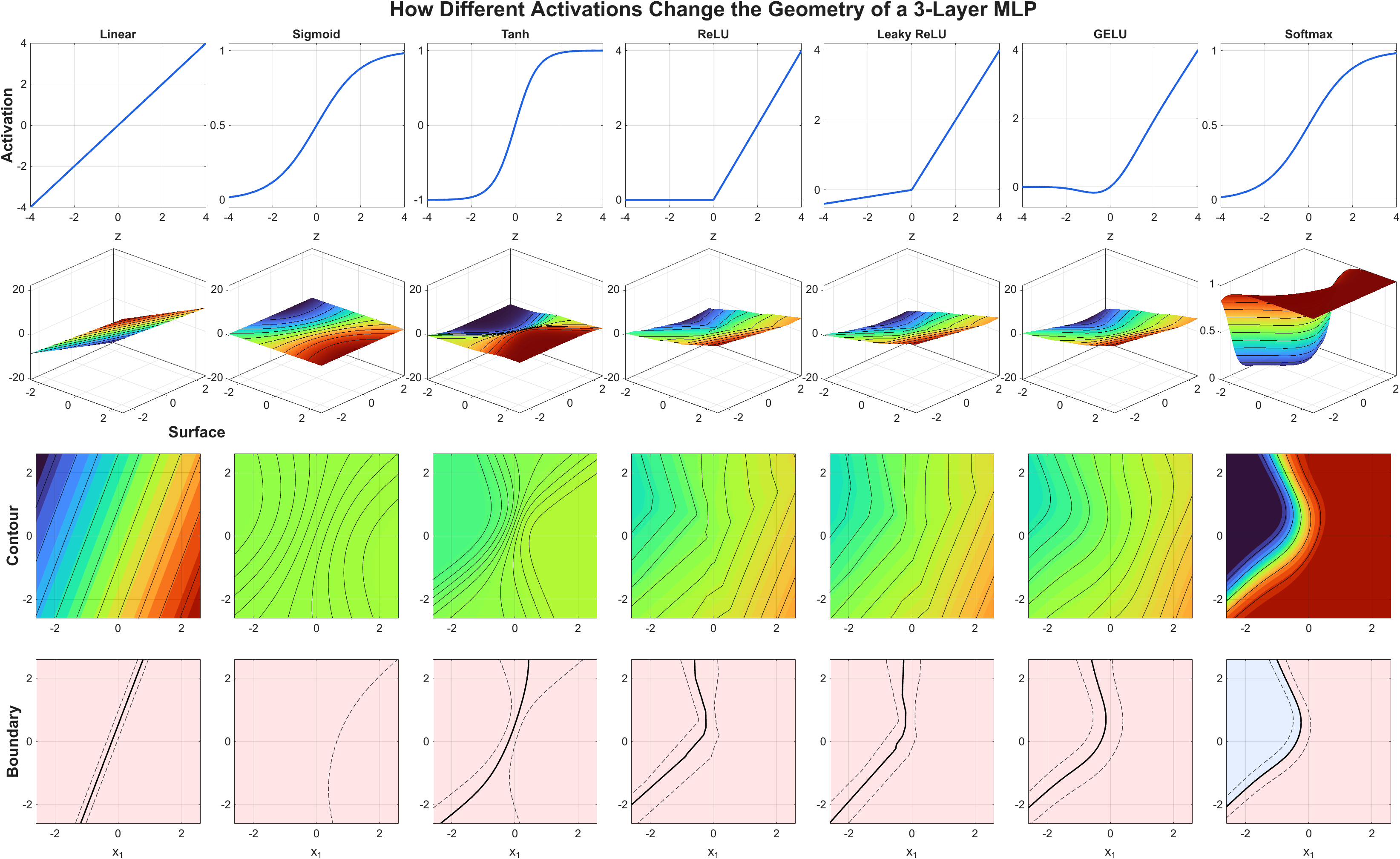
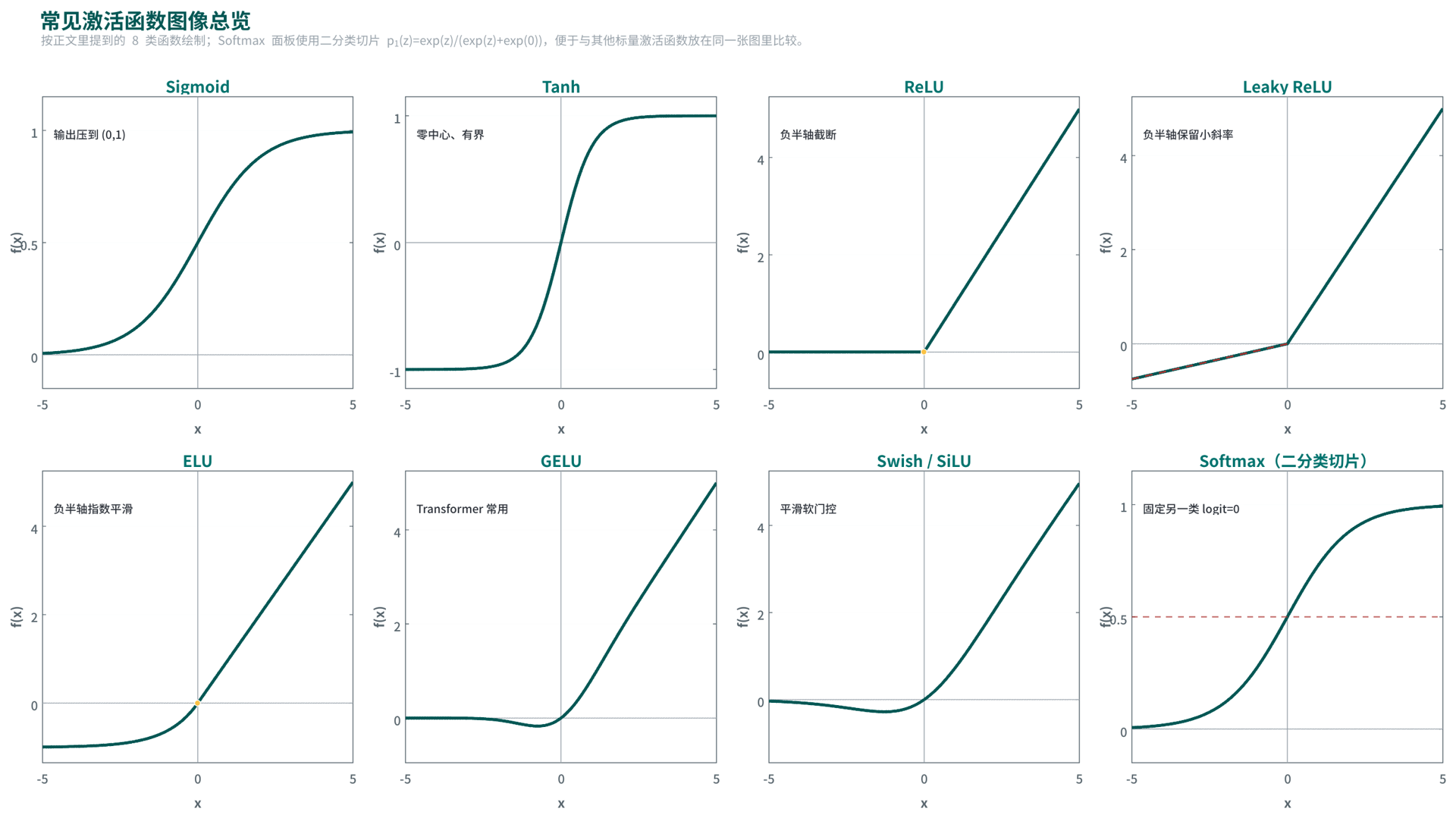
Sigmoid 把实数压到 \((0,1)\):
\[\sigma(x)=\frac{1}{1+e^{-x}}\]Sigmoid 的优势在于输出天然落在 \((0,1)\),因此非常适合表示概率,尤其常用于二分类输出层或门控结构中。但它在隐藏层里的主要问题是饱和(saturation):当输入绝对值较大时,函数会迅速贴近 0 或 1,此时导数接近 0,梯度在反向传播时会被不断压缩,深层网络因此容易出现梯度消失(Vanishing Gradient)。从优化角度看,这意味着前面层参数即使有误,也很难收到足够强的更新信号。
此外,sigmoid 的输出始终为正,不以 0 为中心,这会使后续层接收到带偏移的激活分布,通常不利于优化动态的稳定性。因此,sigmoid 今天更多保留在“需要概率解释”的输出层,或在 LSTM / GRU 等门控结构中充当开关函数,而不再是深层前馈隐藏层的默认选择。
Tanh 的输出范围是 \((-1,1)\):
\[\tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}\]Tanh 可以看作“零中心版 sigmoid”:它同样会在大幅度输入时饱和,但输出分布位于 \((-1,1)\) 且以 0 为中心,这通常比 sigmoid 更利于优化,因为后续层接收到的激活不再整体偏向正侧。对于需要表达“正负方向”差异的隐藏表示,tanh 往往也比 sigmoid 更自然。
不过,tanh 并没有解决饱和带来的根本问题:当 \(|x|\) 很大时,导数仍接近 0,深层网络中的梯度传播依然会变弱。因此,在较深的前馈网络里,tanh 通常不如 ReLU 家族稳定;它更多出现在较浅网络、早期神经网络设计,或某些希望激活有界且零中心的结构中。
ReLU(Rectified Linear Unit)定义为
\[\mathrm{ReLU}(x)=\max(0,x)\]ReLU 看起来几乎“过于简单”,但它之所以长期有效,关键不在公式花哨,而在于它同时满足了深层优化最需要的几条性质。第一,ReLU 在正半轴不饱和(non-saturating):当 \(x>0\) 时导数恒为 1,梯度穿过这一单元时不会像 sigmoid / tanh 那样被持续压小,因此更有利于深层网络中的梯度传播。第二,ReLU 保留了非线性,但正半轴仍是线性的,这使整个网络变成分段线性(piecewise linear)系统:表达能力足够强,同时局部优化形状又比高度弯曲的饱和函数更“规整”。第三,负半轴直接截断会带来自然的稀疏激活(sparse activation):并非所有单元都会在每个样本上同时活跃,这通常有助于提升表示分解能力,并降低无效共适应(co-adaptation)。这里的共适应,指多个神经元在训练中形成了过强的相互依赖:某个单元之所以有效,核心是因为它总是和另外几个特定单元“成套工作”。一旦输入分布变化,或其中某些单元没有按训练时那样响应,这种脆弱的协同关系就容易失效,从而削弱泛化能力。
从工程角度看,ReLU 的优势还包括计算代价极低,只需一次比较运算;这在大规模训练中会被成千上万层和数十亿次前向/反向传播放大。更深层的原因是:深度网络真正需要的核心是一个既能打破线性、又不会在大范围内把梯度压扁、还能让优化器容易工作的非线性。ReLU 恰好在这三点之间取得了非常实用的平衡,这就是为什么一个形式上极其朴素的函数,反而成为现代深度学习最成功的默认选择之一。它的代价也很明确:负区间梯度为 0,单元可能长期失活,这就是后面 Leaky ReLU、ELU、GELU 等变体继续改进的出发点。
Leaky ReLU 给负半轴保留一个很小的斜率:
\[\mathrm{LeakyReLU}(x)=\max(\alpha x,x),\quad \alpha\ll 1\]这样做是为了缓解“死亡 ReLU(Dying ReLU)”问题:若某神经元长期落在负区间,普通 ReLU 的梯度可能一直为 0,而 Leaky ReLU 仍保留一点更新信号。
从机制上看,Leaky ReLU 的核心改动很小,但很有针对性:它保留了 ReLU 在正半轴的不饱和与分段线性优点,同时避免把负半轴完全切断。这样即使某个单元暂时落入负区间,参数仍有机会通过非零梯度被重新拉回活跃状态。因此,Leaky ReLU 可以看作对 ReLU 的保守修正:表达风格几乎不变,但训练风险更低。
ELU(Exponential Linear Unit)在负半轴使用指数平滑:
\[\mathrm{ELU}(x)=\begin{cases}x,&x>0\\ \alpha(e^x-1),&x\le 0\end{cases}\]它的目标是兼顾 ReLU 的优化优势和负区间的平滑性,使激活均值更接近 0。
与 Leaky ReLU 相比,ELU 在负半轴从简单直线转向用指数曲线平滑衰减到负饱和值。这带来两个效果:一是避免了 ReLU 在 0 点附近过于生硬的折线结构;二是允许激活出现稳定的负值,从而减轻隐藏表示整体偏正的问题。代价是计算比 ReLU 更重,且负区间在极小值处同样会逐渐饱和,因此它通常被视为“更平滑、更零中心”的 ReLU 变体,而非彻底不同的一类激活。
GELU(Gaussian Error Linear Unit)可理解为“按输入大小平滑地决定保留多少信号”。它对小正值和小负值做连续、概率化的保留,避免 ReLU 式硬截断,因此在 0 附近更平滑。
这种设计的价值在于:它仍然保留了 ReLU 家族的选择性——并非所有信号都被同等对待——但又避免了硬截断带来的尖锐折点和完全失活区。于是,GELU 往往能在“表达选择性”和“优化平滑性”之间取得更好的折中,这也是它在 Transformer、BERT 及其后续大量变体中被广泛采用的重要原因。
Swish / SiLU 定义为
\[\mathrm{SiLU}(x)=x\,\sigma(x)\]它是平滑、非单调的激活函数,在某些深层网络里表现优于 ReLU。其结构可以直接读成“输入值 \(x\) 乘上一个 sigmoid 门控 \(\sigma(x)\)”:当 \(x\) 很大时, \(\sigma(x)\approx 1\),信号几乎原样通过;当 \(x\) 很小时, \(\sigma(x)\approx 0\),信号被显著压低;在 0 附近则是连续、平滑的软过渡。
这种形式的价值在于:它既不像 ReLU 那样做硬截断,也避免像 sigmoid 那样把输出彻底压进固定区间,让网络学到一种“按输入强度自适应通过多少”的软门控机制。结果是,SiLU / Swish 往往能在保持优化平滑性的同时,保留较强的表达灵活性,因此在一些现代卷积网络与大模型变体中表现良好。它可以看作介于 ReLU 家族与门控激活之间的一种折中设计。
SELU(Scaled Exponential Linear Unit)是为自归一化网络(Self-Normalizing Neural Network)设计的激活函数。它在 ELU 的基础上再加缩放系数,目标是让层间激活均值和方差自动朝稳定区间收敛。它在特定网络设计里很有理论吸引力,但现代主流 Transformer 和大规模视觉模型并不常把它作为默认激活。
Softplus 定义为 \(\mathrm{Softplus}(x)=\log(1+e^x)\),可以看作 ReLU 的平滑版;Softsign 定义为 \(\mathrm{Softsign}(x)=\frac{x}{1+|x|}\),则是比 tanh 更缓和的有界非线性。它们在激活函数发展史上很常见,也有特定结构会采用,但在现代大模型与主流深度网络里,工程默认仍更偏向 ReLU 家族、GELU、SiLU 与门控变体。
Softmax 把一组实数分数(scores)映射为概率分布(Probability Distribution)。在分类与语言模型里,这组分数通常称为 logit(Logits):它们是 softmax 之前的未归一化输出。
\[\mathrm{softmax}(z)_i=\frac{e^{z_i}}{\sum_{j=1}^{V} e^{z_j}}\]logits 的两个关键性质:
- logits 不需要是概率,可以是任意实数;softmax 才把它变成 \([0,1]\) 且和为 1 的分布。
- softmax 对整体平移不敏感:对任意常数 \(c\),有 \(\mathrm{softmax}(z)=\mathrm{softmax}(z+c\mathbf{1})\)。因此实现里常用 \(z\leftarrow z-\max_i z_i\) 做数值稳定(Numerical Stability)。
这说明 softmax 真正关心的是各个 logit 之间的相对差值,而非某个 logit 的绝对数值。若把所有分数同时加 10,模型对“哪一类更占优”的判断不会改变,因为指数项会在分子和分母里同时乘上 \(e^{10}\),最终完全约掉。改变 softmax 输出的,是某个类别相对其他类别高了多少,而非整体抬高或压低所有分数。
因此,logit 更适合理解为“未归一化偏好分数(unnormalized preference scores)”,而非“概率雏形”。例如两类 logits 从 \((1,2)\) 变成 \((101,102)\),softmax 输出完全相同;但若从 \((1,2)\) 变成 \((1,5)\),第二类相对第一类的优势被显著拉大,概率才会明显变化。
在语言模型(Language Model)中,给定最后一层隐藏状态 \(h\in\mathbb{R}^{d_{\text{model}}}\),线性输出头产生词表大小 \(V\) 的 logits: \(z=hW_{\text{vocab}}+b\),再经 softmax 得到下一个 token 的分布。若采用权重共享(Weight Tying),则输入嵌入表 \(E\in\mathbb{R}^{V\;\times d_{\text{model}}}\) 与输出头满足 \(W_{\text{vocab}}=E^\top\),于是可直接写成 \(z=hE^\top+b\)。
在多分类任务里,这几个概念实际上是一条连续的计算链:任务头先输出 logits \(z\in\mathbb{R}^{C}\),softmax 把它们变成条件概率 \(p(y=i|x)\),再取真实类别 \(c\) 的负对数概率作为单样本损失,也就是负对数似然(Negative Log-Likelihood, NLL)。
\[p(y=i|x)=\mathrm{softmax}(z)_i=\frac{e^{z_i}}{\sum_{j=1}^{C}e^{z_j}},\qquad \ell_{\mathrm{NLL}}(z,c)=-\log p(y=c|x)\]把两步合起来,NLL 可以直接写成 logits 的函数:
\[\ell_{\mathrm{NLL}}(z,c)=-\log\frac{e^{z_c}}{\sum_{j=1}^{C}e^{z_j}}=-z_c+\log\sum_{j=1}^{C}e^{z_j}\]这个式子把训练目标拆成了两部分:第一项 \(-z_c\) 要求真实类别的 logit 足够大;第二项 \(\log\sum_j e^{z_j}\) 是归一化项(log-sum-exp),它把所有类别的竞争都算进去。因此训练核心是要让它相对其他类别更占优势。
softmax 的平移不变性(Translation Invariance)在这里也能直接看见。对任意常数 \(a\),若把所有 logits 同时改为 \(z+a\mathbf{1}\),则 softmax 概率不变,NLL 也不变:
\[\mathrm{softmax}(z+a\mathbf{1})_i=\mathrm{softmax}(z)_i,\qquad \ell_{\mathrm{NLL}}(z+a\mathbf{1},c)=\ell_{\mathrm{NLL}}(z,c)\]因此 logits 的绝对零点没有意义,真正有意义的是类别之间的相对差值。工程实现里常把 \(z\) 先整体减去 \(\max_i z_i\),再计算 softmax 或 log-sum-exp。这样不会改变概率与损失,但能显著降低指数溢出的风险。
术语区分:假设函数(Hypothesis Function)/模型 \(f_\theta\) 定义“模型在做什么映射”;样本损失(Loss Function)定义在单样本上;代价函数/成本函数(Cost Function)是把样本损失在全数据集上做平均或求和后的经验风险;目标函数(Objective Function)是优化器真正要优化的函数,最常见写法是 \(J(\theta)=L(\theta)+\lambda\Omega(\theta)\)。
均方误差(Mean Squared Error, MSE)定义为
\[\ell_{\mathrm{MSE}}(y,\hat y)=(\hat y-y)^2\]平方的作用是让大误差被放大处罚。若一个样本错 10,另一个样本错 1,那么前者在 MSE 里核心是“重 100 倍”。因此 MSE 很适合你明确希望重罚大错的场景,也对应前面讲过的高斯噪声假设。
平均绝对误差(Mean Absolute Error, MAE)对应单样本形式
\[\ell_{\mathrm{MAE}}(y,\hat y)=|\hat y-y|\]它直接度量偏差大小,对离群点更鲁棒,因为不会像平方那样把大误差急剧放大。若做房价预测,数据中存在一批价格远高于主体分布的豪宅样本时,MAE 往往比 MSE 更稳;这里的“主体分布”指的是样本中占大多数的普通住宅价格区间,而豪宅样本相对它明显偏高。这样一来,哪怕豪宅样本数量不多,它们也会在 MSE 下因为误差被平方而获得过大的影响力。
Huber Loss 结合了 MSE 与 MAE:误差小时像平方误差,误差大时像绝对误差。设阈值 \(\delta\),则
\[\ell_\delta(r)=\begin{cases}\frac{1}{2}r^2,&|r|\le \delta\\ \delta(|r|-\frac{1}{2}\delta),&|r|>\delta\end{cases},\quad r=\hat y-y\]这条式子的直觉是:小误差区间内保持平滑、便于优化;大误差区间内降低对离群点的过度敏感。它像“正常误差严肃处理,极端异常别让它一票否决整个模型”。
二分类交叉熵(Binary Cross-Entropy, BCE)用来训练输出概率 \(p\in(0,1)\) 的二分类器。这里 \(p\) 通常表示模型预测“正类”的概率, \(y\in\{0,1\}\) 是真实标签: \(y=1\) 表示正类, \(y=0\) 表示负类。
\[\ell_{\mathrm{BCE}}(y,p)=-\Big(y\log p+(1-y)\log(1-p)\Big)\]左边的 \(\ell_{\mathrm{BCE}}(y,p)\) 表示“单个样本在真实标签为 \(y\)、模型预测正类概率为 \(p\) 时的 BCE 损失值”。也就是说,这核心是一个标量惩罚:预测越符合真实标签,它越小;预测越违背真实标签,它越大。
这条公式会根据 \(y\) 的取值自动选择应当惩罚哪一项。当 \(y=1\) 时,式中的 \((1-y)=0\),因此第二项消失,损失化简为 \(-\log p\);当 \(y=0\) 时,第一项中的 \(y=0\),因此第一项消失,损失化简为 \(-\log(1-p)\)。于是它惩罚的本质就是:让真实类别对应的概率尽可能高。
数值例子(自然对数):若 \(y=1\) 且 \(p=0.9\),则 \(\ell\approx 0.105\);若 \(p=0.1\),则 \(\ell\approx 2.303\)。正确但不自信会被罚,错误且自信会被重罚。
多分类交叉熵(Categorical Cross-Entropy, CE)与 softmax 通常配套使用。这里 \(y_i\) 是真实分布(Ground-Truth Distribution)在第 \(i\) 类上的概率质量, \(p_i\) 是模型预测分布(Predicted Distribution)在第 \(i\) 类上的概率。若类别总数为 \(C\),则单样本损失写成:
\[\ell_{\mathrm{CE}}(y,p)=-\sum_{i=1}^{C} y_i\log p_i\]左边的 \(\ell_{\mathrm{CE}}(y,p)\) 表示“当真实标签分布为 \(y\)、模型预测分布为 \(p\) 时,这个样本对应的交叉熵损失值”。其本质是:用真实标签分布 \(y\) 作为权重,对预测分布的负对数概率 \(-\log p_i\) 做加权平均。
当 \(y\) 是 one-hot 分布时,只有真实类别 \(c\) 那一维的权重为 1,其余维度权重都为 0,因此求和会自动塌缩成单项:
\[\ell=-\log p_c\]这正是分类任务里最常见的形式。它与最大似然估计(Maximum Likelihood Estimation, MLE)完全一致:最小化交叉熵等价于最大化真实类别的对数似然。
若 \(y\) 从 one-hot 转向一个在多个类别上分配了非零概率质量的分布,那么交叉熵就已经从读取单个类别 \(p_c\) 扩展到对整条标签分布做加权。常见来源有两类。
第一类是软标签(Soft Label)。它指真实监督信号本身就是一个概率分布,而非“只有一个绝对正确类别”的硬标签(Hard Label)。例如一张图像可能被标注为“70% 像猫、30% 像狐狸”,或一个样本本身就带有多标注者投票汇总后的类别分布。在这种情况下, \(y_i\) 直接表示第 \(i\) 类的目标概率,交叉熵自然要对所有类别一起计算。
第二类是教师分布蒸馏(Knowledge Distillation from Teacher Distribution)。知识蒸馏(Knowledge Distillation)的做法是:让学生去拟合教师模型(Teacher Model)给出的类别分布,而非只依赖人工标签单独监督学生模型(Student Model)。若教师在某个样本上输出 \(q\),学生输出 \(p\),则训练目标常包含 \(-\sum_i q_i\log p_i\) 这样的交叉熵或等价的 KL 散度项。它传递的不只是“哪一类是对的”,还传递“其余类别分别有多像”,因此常被称为暗知识(Dark Knowledge)。
这两种情况的共同点是:标签本身已经核心是一条分布。于是交叉熵的计算对象就已经从“真实类别那一项”扩展到整个目标分布与预测分布之间的匹配程度。Label Smoothing 也会把 one-hot 改成软分布,但它承担的是训练目标修正的角色,因此放在后文“分类任务正则化”里更清晰。
从信息论角度看,交叉熵的标准定义是两个分布 \(P\) 与 \(Q\) 之间的
\[H(P,Q)=-\sum_x P(x)\log Q(x)\]分类里的 \(\ell_{\mathrm{CE}}(y,p)\) 与这个定义并不矛盾,它只是把信息论中的 \(P\) 和 \(Q\) 分别具体化成了“单个样本对应的真实标签分布 \(y\)”与“模型在这个样本上的预测分布 \(p\)”。若标签是 one-hot,那么 \(P\) 退化成一个只在真实类别处取值为 1 的离散分布,于是信息论里的交叉熵自然退化成 \(-\log p_c\)。
进一步地,交叉熵与 KL 散度(Kullback–Leibler Divergence)的关系可以直接写成:
\[H(P,Q)=H(P)+D_{\mathrm{KL}}(P\|Q)\]这里 \(H(P)=-\sum_x P(x)\log P(x)\) 是真实分布 \(P\) 自身的熵(Entropy),只由数据分布决定; \(D_{\mathrm{KL}}(P\|Q)=\sum_x P(x)\log\frac{P(x)}{Q(x)}\) 是 KL 散度,用来衡量预测分布 \(Q\) 相对真实分布 \(P\) 的偏离程度。于是,在训练数据固定时, \(H(P)\) 是常数,最小化交叉熵 \(H(P,Q)\) 就等价于最小化 \(D_{\mathrm{KL}}(P\|Q)\)。
因此,“最小化交叉熵就是最小化 KL 散度”这句话在监督学习里通常成立,但更准确的表述是:在真实分布固定不变时,最小化交叉熵与最小化预测分布对真实分布的 KL 偏离是等价的。KL 散度确实可以理解为“与真实分布的差异或偏离”,但它并非对称距离(Symmetric Distance):一般有 \(D_{\mathrm{KL}}(P\|Q) \neq D_{\mathrm{KL}}(Q\|P)\),也不满足严格距离函数的三角不等式,因此更准确的名称是分布失配(distribution mismatch)或相对熵(relative entropy)。
若进一步把 \(p\) 写成 softmax 作用在 logits \(z\) 上,则多分类交叉熵可直接写成:
\[\ell_{\mathrm{CE}}(z,c)=-\log\mathrm{softmax}(z)_c=-z_c+\log\sum_{j=1}^{C}e^{z_j}\]这条式子把任务头和损失函数直接接起来:线性头先输出 logits,softmax 把它们归一化为概率,交叉熵再读取真实类别的负对数概率。由于 softmax 具有平移不变性,给所有 logits 同时加上同一个常数不会改变这个损失,因此实现中通常直接从 logits 计算交叉熵(log-sum-exp 形式),并先减去 \(\max_j z_j\) 做数值稳定,而非显式先算 softmax 再取 log。
Focal Loss 常用于类别极不平衡的分类任务,尤其是目标检测(Object Detection)这类“负样本远多于正样本”的场景。它核心是在交叉熵前再乘一个与样本难度相关的调制因子,使已经分得很对的容易样本贡献变小,把梯度预算更多留给困难样本:
\[\ell_{\mathrm{focal}}(p_t)=-(1-p_t)^\gamma\log p_t\]这里 \(p_t\) 表示“真实类别对应的预测概率”:若真实标签 \(y=1\),则 \(p_t=p\);若 \(y=0\),则 \(p_t=1-p\)。因此 \(-\log p_t\) 就是普通交叉熵,而前面的 \((1-p_t)^\gamma\) 是额外加上的难度调制项。参数 \(\gamma\ge 0\) 控制聚焦强度: \(\gamma=0\) 时,Focal Loss 退化回普通交叉熵; \(\gamma\) 越大,对容易样本的压低越明显。
这个机制的关键在于样本难度如何反映到权重上。若某个样本已经分得很对,例如真实类别概率 \(p_t=0.99\),则调制因子 \((1-p_t)^\gamma\) 会非常小;以 \(\gamma=2\) 为例,权重大约只有 \((0.01)^2=10^{-4}\),这意味着它对总损失和梯度的影响被大幅削弱。相反,若某个样本很难,例如 \(p_t=0.2\),则权重约为 \((0.8)^2=0.64\),其损失会被较大程度保留。于是训练过程不再被海量“早就分对的简单样本”主导,而会持续关注误分样本、边界样本和少数类样本。
目标检测是最典型的应用例子。以单阶段检测器(One-stage Detector)为例,一张图像上往往有成千上万个候选框(Anchors),但真正包含目标的正样本只占极少数;绝大多数候选框都是背景。若直接使用普通交叉熵,训练会被这些“背景且容易判断”的负样本淹没:它们单个损失虽小,但数量太多,累积后仍然主导梯度。Focal Loss 的作用正是把这批容易背景样本的权重压下去,让模型把更多注意力放在少数正样本、遮挡目标、边界模糊目标,以及那些看起来像目标但其实是背景的困难负样本上。这样做通常会显著改善长尾检测与前景-背景极不平衡时的训练效果。
Hinge Loss 是 SVM 常用的分类损失:
\[\ell_{\mathrm{hinge}}(y,f)=\max(0,1-yf),\quad y\in\{-1,+1\}\]其中 \(f\) 是模型分数而非概率。当 \(yf\ge 1\) 时,说明不仅分类正确,而且留出了足够间隔,损失为 0;当 \(yf<1\) 时,就要受罚。它强调的不仅“分对”,还“分对且留有安全距离”。
度量学习(Metric Learning)不直接预测类别,通常会学习一个表示空间,让“应该相似的样本靠近,不该相似的样本拉远”。这类损失在检索、人脸识别、推荐召回和 embedding 学习中非常常见。
Contrastive Loss 处理样本对(pair)。若一对样本应相似,则拉近它们;若应不同,则至少推开到某个间隔 \(m\) 之外:
\[\ell=y\,d^2+(1-y)\max(0,m-d)^2\]这里 \(d\) 是两者在嵌入空间中的距离, \(y=1\) 表示正对, \(y=0\) 表示负对。它像“朋友要坐得近,陌生人至少别挤在一起”。
Triplet Loss 使用三元组:锚点(Anchor)、正样本(Positive)、负样本(Negative)。目标是让锚点离正样本比离负样本更近至少一个 margin:
\[\ell=\max\big(0,\ d(a,p)-d(a,n)+m\big)\]这条式子表达的是一种相对排序约束,而非绝对相似度分数。它非常适合“谁比谁更像”的任务,例如人脸验证:同一个人的两张照片应比不同人的照片更近。
InfoNCE 是现代对比学习最常见的损失之一。对一个锚点来说,它把正样本放进一堆候选里,要求模型把正样本打分最高:
\[-\log \frac{\exp(\mathrm{sim}(z_i,z_i^+)/\tau)}{\sum_j \exp(\mathrm{sim}(z_i,z_j)/\tau)}\]分子是正确配对,分母是所有候选。这个结构和 softmax 分类非常像,只不过类别从固定标签转向“在一堆候选里,谁才是真正匹配的那个”。在大语言模型 embedding、图像表征学习和多模态对齐里,它几乎是标准配置。
任务头(Task Head)是把主干网络(Backbone)产出的隐藏表示(Hidden Representation)映射到具体任务输出空间的模块。主干负责抽取通用特征,任务头负责把特征“读出来”并对齐到目标形式(类别、数值、序列标签、跨度、关系等)。在工程上,绝大多数“用 Transformer 做下游任务”都可以写成:Transformer backbone + task head + task loss。
主干网络输出的隐藏表示(Hidden Representation)是任务头的输入,任务头则是把这种内部表示读成具体任务输出的最后一层或最后几层变换。若把主干输出记为 \(h\)、\(H\) 或更一般的张量 \(\mathcal{H}\),则任务头通常先做一次线性读出(Linear Readout)得到分数,再视任务类型决定是否接 sigmoid、softmax、CRF 解码或直接保留实数输出。
logits 就是在这个读出阶段最常见的中间产物。它们是任务头输出、但尚未归一化或尚未解码的原始分数。例如,多分类头常先产生 \(z\in\mathbb{R}^{C}\),这里 \(C\) 是类别数, \(z_c\) 表示模型对第 \(c\) 类的偏好分数;softmax 之后这些分数才变成概率。对 token 分类任务,task head 产生的核心是一整张 logits 矩阵 \(Z\in\mathbb{R}^{L\times C}\);对语言模型,输出则是词表 logits \(Z\in\mathbb{R}^{L\times V}\),其中 \(V\) 是词表大小。
因此,关系可以概括为:输入先被 backbone 编码成中间表示,中间表示再被 task head 读成 logits 或其他任务分数,最后再由概率映射、解码器或损失函数把这些分数变成最终预测。logits 核心是“距离最终任务输出只差一步”的那类任务分数;它们通常由任务头生成,而非由主干网络中间每一层都显式生成。
不同任务头的差异,最核心地体现在“直接输出什么张量、这些张量后面还要经过什么处理”这两个问题上。下面这张表把常见任务头的输入形状、直接输出和后续处理并列起来,便于从工程实现角度快速对照。
| 任务类型 | 任务头常见输入 | 任务头直接输出 | 后续处理 |
| 二分类 | 单样本表示 \(h\in\mathbb{R}^{d}\) | 标量 logit \(z\in\mathbb{R}\),或二维 logits \(\mathbf{z}\in\mathbb{R}^{2}\) | sigmoid 或 softmax,得到类别概率 |
| 多分类 | 单样本表示 \(h\in\mathbb{R}^{d}\) | 类别 logits 向量 \(\mathbf{z}\in\mathbb{R}^{C}\) | softmax 后得到 \(C\) 类概率 |
| 多标签分类 | 单样本表示 \(h\in\mathbb{R}^{d}\) | 每个标签一个 logit,组成 \(\mathbf{z}\in\mathbb{R}^{C}\) | 对每一维独立做 sigmoid,而非在类别间做 softmax |
| 回归 | 单样本表示 \(h\in\mathbb{R}^{d}\) | 实数或向量 \(\hat{\mathbf{y}}\in\mathbb{R}^{m}\) | 通常不做概率归一化,直接配合回归损失 |
| Token 分类 / NER | 序列表示 \(H\in\mathbb{R}^{L\times d}\) | token-level logits 矩阵 \(Z\in\mathbb{R}^{L\times C}\) | 逐 token softmax,或接 CRF 做全局解码 |
| 语言模型 / 文本生成 | 序列表示 \(H\in\mathbb{R}^{L\times d}\) | 词表 logits \(Z\in\mathbb{R}^{L\times V}\) | 对每个位置在词表维做 softmax,得到 next-token 分布 |
| 跨度抽取(Span Extraction) | 序列表示 \(H\in\mathbb{R}^{L\times d}\) | 起点 logits \(\mathbf{a}\in\mathbb{R}^{L}\) 与终点 logits \(\mathbf{b}\in\mathbb{R}^{L}\),或 span 分数矩阵 | 在起止位置上做 softmax 或联合评分,输出片段边界 |
| 依存句法 / 关系抽取 | 成对表示 \(h_i,h_j\) 或序列表示 \(H\) | 边分数矩阵 \(S\in\mathbb{R}^{L\times L}\),或关系分数张量 \(\mathcal{S}\in\mathbb{R}^{L\times L\times C}\) | argmax、biaffine 解码或图结构约束解码 |
| 度量学习 / 检索 | 单样本表示 \(h\in\mathbb{R}^{d}\) | embedding 向量 \(e\in\mathbb{R}^{d'}\) | 不直接输出 logits;后续用相似度函数或对比损失比较 |
这张表的关键在于区分“任务头直接输出什么”和“用户最终看到什么”。很多任务头直接输出的核心是 logits、边分数、起止位置分数或 embedding。概率、标签、生成 token、依存边、异常分数等最终结果,通常还需要经过归一化、解码、阈值化或搜索过程才能得到。
分类头(Classification Head)的核心职责,是把主干网络输出的表示 \(h\in\mathbb{R}^{d}\) 变成类别分数(Class Scores)或 logits。最常见的做法是一层线性映射:
\[\mathbf{z}=W\mathbf{h}+\mathbf{b}\]这里 \(\mathbf{h}\in\mathbb{R}^{d}\) 是单个样本的隐藏表示, \(W\) 是任务头权重矩阵, \(\mathbf{b}\) 是偏置向量, \(\mathbf{z}\) 是未归一化类别分数。分类任务的关键区别不在于“有没有线性层”,而在于:输出空间是否互斥、每个样本允许几个标签成立、以及这些分数之后接什么归一化与损失。
直觉上,这个线性头就是一个“可学习的读出(Readout)”:在高维表示空间里用超平面(Hyperplane)切分区域,或用线性映射把表示投影到目标坐标系。这里的“读出”指的是:主干网络先把输入编码成内部表示,而任务头再把这种内部表示转换成模型真正需要输出的量,例如类别 logits、词表 logits、回归值、span 分数或关系分数。换言之,读出核心是把已经形成的表示翻译成任务空间中的可判定分数。
二分类(Binary Classification)要求每个样本只在两个互斥类别中选一个,例如“垃圾 / 非垃圾”“欺诈 / 正常”“阳性 / 阴性”。最常见的写法是输出一个标量 logit:
\[z=\mathbf{w}^\top \mathbf{h}+b\]然后通过 sigmoid 得到正类概率:
\[p=P(y=1\mid x)=\sigma(z)=\frac{1}{1+e^{-z}}\]这里 \(z\) 是模型对正类的原始偏好分数, \(p\) 是正类概率,负类概率则是 \(1-p\)。训练时通常配合二分类交叉熵(Binary Cross-Entropy, BCE)。工程上也可以输出二维 logits \(\mathbf{z}\in\mathbb{R}^{2}\),再接 softmax;但若任务确实只有两个互斥类别,单 logit + sigmoid 更常见,也更经济。
多分类(Multi-class Classification)要求每个样本在 \(C\) 个互斥类别中恰好选一个类别,例如“猫 / 狗 / 鸟”“体育 / 财经 / 科技 / 娱乐”。此时任务头不会只输出一个标量,会输出长度为 \(C\) 的 logits 向量:
\[\mathbf{z}=W\mathbf{h}+\mathbf{b},\qquad W\in\mathbb{R}^{C\times d},\ \mathbf{z}\in\mathbb{R}^{C}\]其中第 \(c\) 维 \(z_c\) 表示模型对第 \(c\) 个类别的原始偏好分数。由于这些类别互斥,后续通常接 softmax,把整组分数归一化成概率分布:
\[p(y=c\mid x)=\frac{e^{z_c}}{\sum_{j=1}^{C}e^{z_j}}\]这条式子的含义很直接:分子 \(e^{z_c}\) 是第 \(c\) 类的相对强度,分母 \(\sum_{j=1}^{C}e^{z_j}\) 把所有类别一起归一化,因此最终得到的 \(p(y=c\mid x)\) 落在 \((0,1)\) 之间,且所有类别概率和为 1。也正因为总和必须为 1,多分类头天然表达的是“类间竞争”:某一类概率上升,其他类的总概率就必须下降。
训练时通常直接把 logits \(\mathbf{z}\) 输入多分类交叉熵(Cross-Entropy)损失,而非手动先算 softmax 再取对数。这样做的原因是数值稳定:损失函数内部会把 softmax 与对数合并成 log-sum-exp 形式,避免指数溢出。推理时若只关心类别标签,直接取 \(\arg\max_c z_c\) 或 \(\arg\max_c p(y=c\mid x)\) 即可;若需要概率、阈值或校准,再显式使用 softmax。
多标签分类(Multi-label Classification)与多分类名字相近,但任务结构完全不同。它核心是同一个样本可以同时拥有多个标签。例如一篇文章可以同时属于“AI、NLP、Transformer”,一张图片可以同时打上“室内、人物、宠物”三个标签。
这种任务里,标签之间不再互斥,因此不能使用 softmax。若仍用 softmax,所有标签概率会被强制归一化为和 1,相当于错误地假设“只能有一个标签成立”。多标签头通常输出 \(C\) 个 logits:
\[\mathbf{z}=W\mathbf{h}+\mathbf{b},\qquad \mathbf{z}\in\mathbb{R}^{C}\]但后续核心是对每一维独立做 sigmoid:
\[p_i=\sigma(z_i),\qquad i=1,\dots,C\]这里 \(p_i\) 表示“第 \(i\) 个标签是否成立”的独立概率。训练时通常使用逐维二分类交叉熵,即把每个标签都当作一个独立的二分类问题,再在标签维上求和或取平均:
\[\ell_{\mathrm{multi\mbox{-}label}}=-\sum_{i=1}^{C}\Big(y_i\log p_i+(1-y_i)\log(1-p_i)\Big)\]因此,多标签头的关键核心是这 \(C\) 维之间不竞争,每一维都在独立回答一个 yes/no 问题。推理时也核心是对每一维做阈值判断,例如输出所有满足 \(p_i>0.5\) 的标签,或按业务分别设定不同标签阈值。
回归头(Regression Head)直接输出连续数值(Continuous Value)或连续向量,不负责在离散类别之间做判别。最常见的形式仍然是一层线性映射:
\[\hat{\mathbf{y}}=W\mathbf{h}+\mathbf{b},\qquad \hat{\mathbf{y}}\in\mathbb{R}^{m}\]这里 \(m\) 是回归目标维度。若 \(m=1\),就是标量回归,例如房价预测、评分预测、温度预测;若 \(m>1\),则是多维回归,例如边界框坐标回归、姿态参数回归或多目标数值预测。
回归头通常不接 softmax,也不强制输出落在 \((0,1)\)。原因很简单:回归任务关心的是数值大小本身,而非类别概率竞争。训练时常配合均方误差(MSE)、平均绝对误差(MAE)或 Huber Loss。只有当目标值本身有明确范围约束时,才会额外接 sigmoid、tanh 或其他变换,把输出压到指定区间。
语言模型头(Language Modeling Head, LM Head)是把隐藏表示映射回词表空间的输出头。只要任务目标是“在若干位置上对词表中的 token 做预测”,就会出现这一类头;因此它不只存在于 Decoder-only 大模型,也存在于 Encoder-only 的掩码语言模型(Masked Language Model, MLM)以及 Encoder-Decoder 的生成端。它读取主干网络在每个位置输出的隐藏状态 \(H\in\mathbb{R}^{L\;\times d_{\text{model}}}\),并把每个位置的表示投影到整张词表空间,得到词表 logits:
\[Z = HW_{\text{vocab}} + \mathbf{1}b^\top,\quad W_{\text{vocab}}\in\mathbb{R}^{d_{\text{model}}\;\times {V}},\ Z\in\mathbb{R}^{L\;\times {V}}\]这条式子先描述整体矩阵,再自然落到单个位置。这里 \(L\) 是序列长度,表示当前一共有多少个位置; \(d_{\text{model}}\) 是隐藏维度; \(V\) 是词表大小(Vocabulary Size)。因此,隐藏状态矩阵 \(H\in\mathbb{R}^{L\;\times d_{\text{model}}}\) 的每一行对应一个位置的表示,输出权重矩阵 \(W_{\text{vocab}}\in\mathbb{R}^{d_{\text{model}}\;\times {V}}\) 的每一列对应“词表中某个 token 作为候选答案时的读出方向”,最终得到的 \(Z\in\mathbb{R}^{L\;\times {V}}\) 就是一个“位置 \(\times\) 词表”的打分表:行表示位置,列表示候选 token。
把这张打分表聚焦到第 \(t\) 行,就得到 \(Z_{t,:}\in\mathbb{R}^{V}\),也就是“第 \(t\) 个位置对整张词表所有 token 的一整行 logits”。这里 \(H_t\in\mathbb{R}^{d_{\text{model}}}\) 表示第 \(t\) 个位置的隐藏状态,冒号 \(:\) 表示该行的全部列;若写成 \(Z_{:,i}\),则表示第 \(i\) 列,也就是“所有位置对第 \(i\) 个 token 的分数”。继续缩小到单个元素 \(Z_{t,i}\),它表示“在第 \(t\) 个位置,把词表中第 \(i\) 个 token 作为下一个输出时的原始分数”。
把矩阵形式按单个位置、单个候选 token 展开后,打分可写成:
\[Z_{t,i}=H_t\cdot W_{\text{vocab},:,i}+b_i\]这里 \(W_{\text{vocab},:,i}\) 表示输出权重矩阵的第 \(i\) 列,也就是与词表第 \(i\) 个 token 对应的参数向量; \(b_i\) 是该 token 的偏置项。这个公式的读法是:拿第 \(t\) 个位置的隐藏表示 \(H_t\),与“token \(i\) 的读出向量”做一次点积,再加偏置,就得到该 token 在该位置的 logit。
LM Head 与分类头的根本区别在于输出空间。普通分类头通常只需输出 \(C\) 个类别分数;LM Head 则要在每个位置输出 \(V\) 个分数,而 \(V\) 往往达到几万甚至几十万。因此,LM Head 本质上是“逐位置的大规模多分类器”:每一步都在问“下一个 token 应该是词表中的哪一个”。
同一个 LM Head 公式,在不同 Transformer 架构里的使用方式并不相同。对 Encoder-only 模型,LM Head 通常服务于掩码语言建模:模型先用双向注意力得到各位置隐藏状态,再只在被遮蔽的位置上读取 \(Z_{t,:}\) 来预测原 token;这一过程通常是一次性编码,不涉及自回归生成,也没有 KV Cache 逐步增长的问题。对 Decoder-only 模型,LM Head 用于 next-token 预测:第 \(t\) 个位置的隐藏状态对应预测 \(x_{t+1}\),推理时会逐步生成,因此会配合因果注意力(Causal Self-Attention)和 KV Cache。对 Encoder-Decoder 模型,LM Head 位于解码器一侧:编码器先产出源序列表示,解码器再在因果自注意力与交叉注意力(Cross-Attention)的共同作用下生成目标侧隐藏状态,最后由 LM Head 映射到词表。
训练时,自回归语言模型(Autoregressive Language Model)通常采用 next-token 目标:第 \(t\) 个位置的隐藏状态 \(H_t\) 用来预测真实的下一个 token \(x_{t+1}\)。对应损失可写成:
\[\mathcal{L}_{\mathrm{LM}}=-\sum_{t=1}^{L-1}\log \frac{\exp(Z_{t,x_{t+1}})}{\sum_{i=1}^{V}\exp(Z_{t,i})}\]这个损失公式也可以逐项拆开理解。左边的 \(\mathcal{L}_{\mathrm{LM}}\) 是整段序列的语言模型损失;求和下标 \(t=1,\dots,L-1\) 表示:前 \(L-1\) 个位置都要各自预测一次下一个 token。分子里的 \(\exp(Z_{t,x_{t+1}})\) 表示“真实下一个 token 在第 \(t\) 个位置对应的指数化分数”;这里 \(x_{t+1}\) 是真实的下一个 token id,所以 \(Z_{t,x_{t+1}}\) 表示在位置 \(t\) 对这个真实 token 的 logit。分母 \(\sum_{i=1}^{V}\exp(Z_{t,i})\) 则把整张词表所有候选 token 的分数全部加起来做归一化。因此整个分式就是“在位置 \(t\) 预测真实下一个 token 的概率”,外面的负对数再把它变成训练损失。
推理时则核心是先对 \(Z_{t,:}\) 做 softmax 得到下一个 token 的条件分布。这里的 \(Z_{t,:}\) 核心是长度为 \(V\) 的向量,包含位置 \(t\) 对整张词表每个 token 的分数。对这整行做 softmax 后,得到的是:
\[p(x_{t+1}=i\mid x_{\le t})=\frac{e^{Z_{t,i}}}{\sum_{j=1}^{V}e^{Z_{t,j}}},\qquad i=1,\dots,V\]这条式子表示:在已经看到前缀 \(x_{\le t}\) 的条件下,下一个 token 取词表中第 \(i\) 个词的概率是多少。随后再配合贪心搜索(Greedy Decoding)、束搜索(Beam Search)、温度采样(Temperature Sampling)、top-k / top-p 等策略,从这组概率中选出真正生成的 token。也就是说,LM Head 负责把隐藏表示变成“词表级候选分数”,真正的文本生成还要再经过一层解码(Decoding)策略。
很多 LLM 还会使用权重共享(Weight Tying):把输入嵌入表 \(E\in\mathbb{R}^{V\;\times d_{\text{model}}}\) 与输出头绑定,使 \(W_{\text{vocab}}=E^\top\)。这样一来,输入端“一个 token 的向量表示”与输出端“一个 token 作为候选答案时的原型向量”共用同一套参数空间。它通常既能减少参数量,也让输入和输出语义空间保持更强一致性。
从工程角度看,LM Head 往往比分类头更贵,因为它直接与词表大小 \(V\) 成正比:词表越大,最后一层的矩阵乘法、softmax 和采样都越重。因此,大模型的推理优化常会专门围绕 LM Head 展开,例如 fused softmax、采样优化、logits processor、词表裁剪或 speculative decoding 等。本质上,这些优化都在解决同一个问题:如何更高效地从词表 logits 走到最终生成 token。
序列标注(Sequence Labeling)/Token 分类(Token Classification)要求对每个 token 预测一个标签(例如 NER)。设主干输出 \(H\in\mathbb{R}^{L\times d}\)(长度 \(L\),隐藏维 \(d\)),则逐 token 线性头为:
\[Z=HW^\top+\mathbf{1}b^\top,\quad W\in\mathbb{R}^{C\times d},\ Z\in\mathbb{R}^{L\times C}\]对第 \(t\) 个 token,用 softmax 得到 \(p(y_t|x)\) 并用逐 token 交叉熵训练。该做法把每个位置的标签看作条件独立,能工作,但会忽略标签之间的结构约束(例如 BIO 体系中不允许 I-ORG 紧跟 O)。
例:对 “Apple Inc. is in California” 的 NER(Named Entity Recognition),合理标签序列可能是 B-ORG I-ORG O O B-LOC。若逐 token softmax 独立预测,模型可能输出不合法的组合;这类“结构错误”通常需要结构化任务头(Structured Head)来显式建模。
线性链条件随机场(Linear-chain Conditional Random Field, CRF)在 token 分类头上增加一个转移矩阵(Transition Matrix)\(A\in\mathbb{R}^{C\times C}\),对整段标签序列做归一化建模。令发射分数(Emission Score)为 \(s_t(y)=Z_{t,y}\),则序列 \(y_{1:L}\) 的总分为:
\[\mathrm{score}(x,y)=\sum_{t=1}^{L}\Big(A_{y_{t-1},y_t}+s_t(y_t)\Big)\]并定义条件概率:
\[p(y|x)=\frac{\exp(\mathrm{score}(x,y))}{\sum_{y'}\exp(\mathrm{score}(x,y'))}\]训练最小化负对数似然(Negative Log-Likelihood);解码用 Viterbi 算法(动态规划)求 \(\arg\max_y \mathrm{score}(x,y)\)。CRF 的收益是把“标签合法性/连贯性”学进转移项,从而显著减少结构错误。
双仿射(Biaffine)任务头常用于“成对打分”(Pairwise Scoring),例如依存句法(Dependency Parsing)里的“当前词应依附到哪个词”,或关系抽取(Relation Extraction)里的“两个实体之间是否存在某种关系”。它的名字可以按层级直接理解:对一个变量, \(Wx\) 是线性, \(Wx+b\) 是仿射;对两个变量, \(h_i^\top U h_j\) 是双线性(Bilinear);在这个双线性项之外再加上线性项和偏置项,就得到双仿射(Biaffine)。因此,双仿射的本质是:既建模两个表示之间的交互,又保留各自单独的角色偏好。
\[s(i,j)=h_i^\top U h_j + w^\top [h_i;h_j] + b\]这条式子可以逐项拆开读。 \(h_i,h_j\in\mathbb{R}^{d}\) 是两个待配对对象的表示向量;在依存句法里,它们可分别表示“当前词”和“候选 head”;在关系抽取里,它们可分别表示“实体 1”和“实体 2”。 \(U\in\mathbb{R}^{d\times d}\) 是双线性参数矩阵,因此 \(h_i^\top U h_j\) 建模的是二者之间的交互强度:核心是看“这两个向量放在一起是否匹配”。把它展开后就是 \(\sum_{p=1}^{d}\sum_{q=1}^{d}(h_i)_p\,U_{pq}\,(h_j)_q\),因此 \(U_{pq}\) 可以理解为“第 \(p\) 个 dependent 特征与第 \(q\) 个 head 特征同时出现时,该给多少分”。
若任务需要一次输出多类关系分数,工程实现通常会为每个类别各放一张矩阵 \(U^{(k)}\),或直接使用三阶参数张量。这样不同关系类型就能拥有不同的交互模式,而不必共用同一套 \(U\)。
\([h_i;h_j]\in\mathbb{R}^{2d}\) 表示把两个向量直接拼接; \(w^\top [h_i;h_j]\) 是普通仿射项,可以进一步拆成“只依赖 \(h_i\) 的线性项 + 只依赖 \(h_j\) 的线性项”。它的作用是补充单边信息:即使暂时不看两者之间的乘性交互,某些 token 或实体本身也可能更像 head、更像 dependent,或更像某类关系的一端。最后的 \(b\) 是全局偏置,给整类配对提供一个基线分数。
具象地看, \(h_i^\top U h_j\) 像在问“这两个人之间是否搭得上”, \(w^\top [h_i;h_j]\) 像在问“这两个人各自单独看,是否本来就带某种角色倾向”。把两部分合起来,模型既能利用配对关系,也不会丢掉单个对象自身的类型线索。这正是双仿射通常比纯双线性更稳、更有表达力的原因。
把 \(s(i,j)\) 对所有 \((i,j)\) 组合都算出来,就能形成一个 \(L\times L\) 的分数矩阵;对每个位置 \(i\),再在所有候选 \(j\) 上做 \(\arg\max\) 或 softmax 分类,就能得到“它最可能依附到谁”或“它与谁最可能存在某种关系”。这种头的关键点在于:任务监督信号作用在“对”的层面,而非单点分类。
解析式 NLP(Analytical NLP)指一类“结构化输出”的语言任务:输出核心是标签序列、树或图。这类任务的工程难点通常不在 backbone,而在输出结构约束、标注成本、以及错误后果(例如信息抽取用于合规/风控)。
| 任务 | 输出结构 | 常见任务头 | 数据/标注成本 | 蒸馏难度 |
| NER | BIO 标签序列 | Token 分类;CRF(可选) | 中(需要一致的标注规范) | 低~中(教师模型能稳定给出 token-level 或 span-level 标签) |
| DEP(Dependency Parsing) | 树(每 token 一个 head) | Biaffine / 图解析器(Parser) | 高(标注复杂;语言差异大) | 中~高(结构约束更强;蒸馏需覆盖长尾句式) |
| SDP(Semantic Dependency Parsing) | 有向图(多 head / 多边) | 图结构头(Graph Head) | 很高(语义标注成本高) | 高(输出空间更大;错误更难用局部规则修正) |
同一个 backbone 可以挂多个任务头(Multi-head / Multi-task):共享表示学习带来数据效率,但不同任务的梯度可能冲突,需要权衡损失权重(Loss Weighting)与采样策略。工程上也常见“同任务多头”:例如同时输出 token 标签与 span 边界,或同时输出检索 embedding 与分类 logits,用不同头对齐不同指标。
反向传播(Backpropagation)描述的是训练阶段中“如何把损失函数对输出的误差信号传回网络内部,并进一步求出各层参数梯度”的过程。理解这一章时,可以把它拆成三件事:前向传播先把值算出来,反向传播再把梯度传回去,而链式法则与 Jacobian 则给出这件事的数学形式。
前向传播(Forward Propagation)是训练与推理中首先发生的计算过程:给定输入 \(x\) 和当前参数 \(\theta\),按照网络定义从前到后依次计算各层输出、最终预测 \(\hat y\),以及训练时对应的损失 \(L\)。若把网络写成函数复合
\[h_1=f_0(x),\quad h_2=f_1(h_1),\quad \cdots,\quad h_L=f_{L-1}(h_{L-1}),\quad \hat y=g(h_L),\quad L=\ell(\hat y,y)\]那么前向传播做的就是按 \(x\to h_1\to h_2\to \cdots \to h_L\to \hat y \to L\) 的顺序把这些值算出来。它回答的问题是:在当前参数下,这个样本会被模型算成什么结果,以及这个结果与真实标签相差多大。
前向传播的产物不仅是最终预测,还包括中间激活值(Activation)。这些中间量一方面构成模型当前这次推理的内部表示,另一方面也是后续反向传播计算梯度时必须依赖的节点。因此,训练过程总是先有前向传播,再有反向传播:前者负责算值,后者负责算这些值对参数的敏感度。
反向传播(Backpropagation)是深度学习里用于高效计算梯度(Gradient)的算法。训练神经网络的目标,是最小化损失函数(Loss Function)\(L(\theta)\);而要用梯度下降(Gradient Descent)或 Adam 之类的优化器更新参数,就必须先知道每个参数对损失的影响,也就是 \(\frac{\partial L}{\partial \theta}\)。
这个需求在深层网络里会立刻变得庞大。一个模型往往包含从数万到数十亿个参数;如果对每个参数都单独做一次数值扰动,逐个估计“它变一点时损失会怎么变”,计算代价会高得无法训练。反向传播出现的直接原因,就是要把这个原本几乎不可做的问题,变成一次前向传播(Forward Pass)加一次反向传播(Backward Pass)即可完成的梯度计算流程。
它的来源并不神秘:神经网络本质上是许多简单函数的复合。线性层、激活函数、归一化、注意力、损失函数,都会把前一层输出当作后一层输入。只要这些局部变换可导(Differentiable)或几乎处处可导,就可以对整条复合链应用链式法则(Chain Rule)。反向传播就是把链式法则改写成一种适合计算图(Computational Graph)执行的程序:前向时保存必要的中间结果,反向时从最终损失出发,把局部导数一层层乘回去,并把梯度分发给每个中间变量和参数。
因此,反向传播核心是链式法则在复合函数上的工程化实现。它做的事情可以概括为两步:第一步,前向传播先算出各层激活值与最终损失;第二步,从 \(\frac{\partial L}{\partial L}=1\) 出发,把损失敏感度沿着依赖边反向传回去,依次得到 \(\frac{\partial L}{\partial h_l}\)、 \(\frac{\partial L}{\partial W_l}\)、 \(\frac{\partial L}{\partial b_l}\) 等量。到这一步为止,反向传播完成的是梯度计算;参数真正如何更新,则属于优化器(Optimizer)的职责。
最简单的梯度下降(Gradient Descent)更新写成
\[\theta \leftarrow \theta - \eta \nabla_{\theta} L\]这里更适合写梯度符号 \(\nabla_{\theta}L\),因为 \(\theta\) 往往是整个参数向量或参数集合,而非单个标量。若只讨论某一个标量参数,才可写成 \(\theta \leftarrow \theta - \eta \frac{\partial L}{\partial \theta}\)。从计算方式看,反向传播对应自动微分(Automatic Differentiation)中的反向模式(Reverse Mode AD)。它特别适合“输入参数很多、输出损失很少”的场景;而神经网络训练恰好就是这种结构:参数维度极大,但最终通常只关心一个标量损失。因此,反向传播成为现代深度学习训练的标准机制。
先看一个只多加一层激活函数(Activation)的最小网络。设输入 \(x=2\),参数为权重 \(w=1\) 与偏置 \(b=-1\),先做仿射变换(Affine Transform)
\[z=wx+b=1\cdot 2-1=1\]再经过 ReLU 激活函数
\[a=\mathrm{ReLU}(z)=\max(0,z)=1\]把激活值当作最终预测,即 \(\hat y=a\)。若真实标签 \(y=0\),损失取平方损失(Squared Loss)
\[L=\frac12(\hat y-y)^2=\frac12(1-0)^2=0.5\]前向传播链条现在是
\[x\ \longrightarrow\ z\ \longrightarrow\ a=\hat y\ \longrightarrow\ L\]反向传播先从损失对输出的导数开始:
\[\frac{\partial L}{\partial \hat y}=\hat y-y=1\]由于这里 \(\hat y=a\),所以
\[\frac{\partial L}{\partial a}=1\]再经过激活函数这一层。因为当前 \(z=1>0\),ReLU 的导数为
\[\frac{\partial a}{\partial z}=\mathrm{ReLU}'(z)=1\]于是梯度传回仿射层输出:
\[\frac{\partial L}{\partial z}=\frac{\partial L}{\partial a}\cdot\frac{\partial a}{\partial z}=1\cdot 1=1\]最后再看仿射层对参数的局部导数:
\[\frac{\partial z}{\partial w}=x=2,\qquad \frac{\partial z}{\partial b}=1\]因此
\[\frac{\partial L}{\partial w}=\frac{\partial L}{\partial z}\cdot\frac{\partial z}{\partial w}=1\cdot 2=2\] \[\frac{\partial L}{\partial b}=\frac{\partial L}{\partial z}\cdot\frac{\partial z}{\partial b}=1\cdot 1=1\]若学习率 \(\eta=0.1\),梯度下降更新后
\[w\leftarrow 1-0.1\cdot 2=0.8,\qquad b\leftarrow -1-0.1\cdot 1=-1.1\]这个版本比纯线性例子多了一站 \(z\to a\),因此链式法则也多乘了一个局部导数 \(\frac{\partial a}{\partial z}\)。这正是反向传播的一般形式:误差信号每穿过一层,就乘上这一层自己的局部导数。若这里的 \(z<0\),则 ReLU 导数为 0,上游梯度也会在这一层被截断。
反向传播(Backpropagation)本质是链式法则(Chain Rule)在计算图(Computational Graph)上的系统化应用:把最终损失对中间变量的导数沿依赖关系向后传。
固定一个训练样本 \((x,y)\) 后,损失 \(L\) 最终当然可以看成参数 \(\theta\) 的函数;训练时真正要更新的也确实是权重(Weight)。但在计算图里, \(L(\theta)\) 核心是先经过各层线性变换、激活值(Activation)和输出再到损失。因此,反向传播会先求 \(\frac{\partial L}{\partial h_l}\) 这类“损失对中间激活值的敏感度”,再由这些中间梯度继续求出 \(\frac{\partial L}{\partial \theta_l}\)。
Jacobian 一节已经给出局部线性化:若 \(h_{l+1}=f_l(h_l)\),则在当前点附近有 \(dh_{l+1}\approx J_l\,dh_l\),其中 \(J_l=\frac{\partial h_{l+1}}{\partial h_l}\)。这条式子描述的是输入扰动如何向前传到输出扰动;反向传播关心的是相反方向的问题:输出端的损失敏感度如何传回输入端。
先看一层。由于损失 \(L\) 是标量,若采用与前文 Jacobian 一致的分子布局(Numerator Layout),把 \(\frac{\partial L}{\partial h_l}\) 记成 \(1\;\times d_l\) 的行向量,则向量链式法则写成:
\[\frac{\partial L}{\partial h_l}=\frac{\partial L}{\partial h_{l+1}}\frac{\partial h_{l+1}}{\partial h_l}=\frac{\partial L}{\partial h_{l+1}}J_l\]这条式子最好按符号逐个读。先看 \(h_l\) 与 \(h_{l+1}\):它们分别表示第 \(l\) 层的输入表示和该层输出表示。若 \(h_l\) 有 \(d_l\) 个分量, \(h_{l+1}\) 有 \(d_{l+1}\) 个分量,那么
\[\frac{\partial L}{\partial h_{l+1}}=\begin{bmatrix}\frac{\partial L}{\partial h_{l+1,1}} & \frac{\partial L}{\partial h_{l+1,2}} & \cdots & \frac{\partial L}{\partial h_{l+1,d_{l+1}}}\end{bmatrix}\in\mathbb{R}^{1\;\times d_{l+1}}\]它表示:损失 \(L\) 对第 \(l+1\) 层每个输出分量分别有多敏感。这里把它写成行向量,是因为前文采用的是分子布局(Numerator Layout)。
再看 Jacobian:
\[J_l=\frac{\partial h_{l+1}}{\partial h_l}\in\mathbb{R}^{d_{l+1}\;\times d_l}\]其中第 \((i,j)\) 个元素是
\[(J_l)_{ij}=\frac{\partial h_{l+1,i}}{\partial h_{l,j}}\]意思是:第 \(l\) 层第 \(j\) 个输入分量变化一点,会让第 \(l+1\) 层第 \(i\) 个输出分量变化多少。因此,Jacobian 记录的是“输入各分量 \(\to\) 输出各分量”的局部影响表。
现在看乘法
\[\frac{\partial L}{\partial h_l}=\frac{\partial L}{\partial h_{l+1}}J_l\]左边最终应该是一个关于 \(h_l\) 各分量的梯度,所以它必须有 \(d_l\) 个分量。维度上, \(\frac{\partial L}{\partial h_{l+1}}\) 是 \(1\;\times d_{l+1}\), \(J_l\) 是 \(d_{l+1}\;\times d_l\),两者相乘后确实得到 \(1\;\times d_l\)。
如果把第 \(j\) 个分量单独展开,这个乘法其实就是
\[\frac{\partial L}{\partial h_{l,j}}=\sum_{i=1}^{d_{l+1}}\frac{\partial L}{\partial h_{l+1,i}}\frac{\partial h_{l+1,i}}{\partial h_{l,j}}\]这时含义就完全显出来了:第 \(l\) 层第 \(j\) 个输入分量,会通过第 \(l+1\) 层的所有输出分量共同影响损失;因此要把“损失对每个输出分量的敏感度”乘上“该输出分量对当前输入分量的局部导数”,再对所有输出分量求和。矩阵乘法只是把这组求和一次性写成了紧凑形式。
把这条一层公式沿网络递推展开,对深度网络 \(h_{l+1}=f_l(h_l)\) 可得:
\[\frac{\partial L}{\partial h_0}=\frac{\partial L}{\partial h_L}J_{L-1}J_{L-2}\cdots J_0,\qquad J_l=\frac{\partial h_{l+1}}{\partial h_l}\]这条公式的读法非常具体:前向传播按 \(h_0\to h_1\to\cdots\to h_L\) 计算;反向传播则从最终梯度 \(\frac{\partial L}{\partial h_L}\) 出发,依次乘上最后一层到第一层的 Jacobian,把敏感度一层层传回去。矩阵乘法满足结合律(Associativity),因此可以逐层累积;但不满足交换律,乘法顺序不能改,因为每个 Jacobian 都对应不同层的局部坐标变换。
一个最小可算例可以把这件事完全写开。设输入 \(x\) 是标量,第一层有两个参数 \(w_{11},w_{12}\),输出二维隐藏表示:
\[h_1=\begin{bmatrix}h_{1,1}\\h_{1,2}\end{bmatrix}=\begin{bmatrix}w_{11}x\\w_{12}x\end{bmatrix}\]第二层有两个参数 \(w_{21},w_{22}\),把二维隐藏表示读成一个标量预测:
\[\hat y=w_{21}h_{1,1}+w_{22}h_{1,2}\]损失取最简单的平方损失(Squared Loss):
\[L=\frac12(\hat y-y)^2\]这里总参数一共四个,但反向传播不会直接去“猜” \(\frac{\partial L}{\partial w_{11}}\)、 \(\frac{\partial L}{\partial w_{12}}\) 等结果,会先沿着计算图写出中间量:
\[x\ \longrightarrow\ h_1\ \longrightarrow\ \hat y\ \longrightarrow\ L\]先看第二层的局部 Jacobian。因为 \(\hat y\) 是标量、 \(h_1\in\mathbb{R}^2\),所以
\[J_1=\frac{\partial \hat y}{\partial h_1}=\begin{bmatrix}w_{21}&w_{22}\end{bmatrix}\]再看第一层的局部 Jacobian。因为 \(h_1\in\mathbb{R}^2\)、 \(x\) 是标量,所以
\[J_0=\frac{\partial h_1}{\partial x}=\begin{bmatrix}w_{11}\\w_{12}\end{bmatrix}\]损失对最终输出的导数最容易先算:
\[\frac{\partial L}{\partial \hat y}=\hat y-y\]于是,损失对隐藏表示的梯度由链式法则得到:
\[\frac{\partial L}{\partial h_1}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial h_1}=(\hat y-y)\begin{bmatrix}w_{21}&w_{22}\end{bmatrix}\]这一步已经把“损失对输出的敏感度”传回到了中间激活值 \(h_1\)。继续往回乘第一层 Jacobian,就得到损失对输入的梯度:
\[\frac{\partial L}{\partial x}=\frac{\partial L}{\partial \hat y}J_1J_0\] \[=(\hat y-y)\begin{bmatrix}w_{21}&w_{22}\end{bmatrix}\begin{bmatrix}w_{11}\\w_{12}\end{bmatrix}\] \[=(\hat y-y)(w_{21}w_{11}+w_{22}w_{12})\]对参数的梯度也是同样的思路。第二层参数直接作用在 \(\hat y\) 上,因此
\[\frac{\partial L}{\partial w_{21}}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial w_{21}}=(\hat y-y)h_{1,1}\] \[\frac{\partial L}{\partial w_{22}}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial w_{22}}=(\hat y-y)h_{1,2}\]第一层参数不直接连到损失,通常会先影响 \(h_1\),再影响 \(\hat y\) 和 \(L\),所以必须经过中间激活值这一站:
\[\frac{\partial L}{\partial w_{11}}=\frac{\partial L}{\partial h_{1,1}}\frac{\partial h_{1,1}}{\partial w_{11}}=[(\hat y-y)w_{21}]\,x\] \[\frac{\partial L}{\partial w_{12}}=\frac{\partial L}{\partial h_{1,2}}\frac{\partial h_{1,2}}{\partial w_{12}}=[(\hat y-y)w_{22}]\,x\]若取一组具体数值 \(x=2\)、 \(y=1\)、 \(w_{11}=1\)、 \(w_{12}=-1\)、 \(w_{21}=0.5\)、 \(w_{22}=2\),则前向传播先得到
\[h_1=\begin{bmatrix}2\\-2\end{bmatrix},\qquad \hat y=0.5\cdot 2+2\cdot(-2)=-3,\qquad \frac{\partial L}{\partial \hat y}=\hat y-y=-4\]于是反向传播依次得到
\[\frac{\partial L}{\partial h_1}=-4\begin{bmatrix}0.5&2\end{bmatrix}=\begin{bmatrix}-2&-8\end{bmatrix}\] \[\frac{\partial L}{\partial x}=\begin{bmatrix}-2&-8\end{bmatrix}\begin{bmatrix}1\\-1\end{bmatrix}=6\] \[\frac{\partial L}{\partial w_{21}}=-4\cdot 2=-8,\qquad \frac{\partial L}{\partial w_{22}}=-4\cdot(-2)=8\] \[\frac{\partial L}{\partial w_{11}}=(-2)\cdot 2=-4,\qquad \frac{\partial L}{\partial w_{12}}=(-8)\cdot 2=-16\]这个最小例子把反向传播的结构完整展示了出来:损失函数最终是参数的函数,但梯度并非“绕开中间层直接对权重求”。它必须先通过 \(\frac{\partial L}{\partial \hat y}\)、 \(\frac{\partial L}{\partial h_1}\) 这样的中间敏感度逐步回传。激活值因此核心是计算图中必经的节点。
若改用深度学习里更常见的列向量梯度记号 \(\nabla_{h_l}L\in\mathbb{R}^{d_l}\),同一件事会写成
\[\nabla_{h_l}L=J_l^\top \nabla_{h_{l+1}}L\]这与上面的公式没有本质区别,只是把“左乘 Jacobian 的行向量记号”改写成了“右侧乘 Jacobian 转置的列向量记号”。工程实现里常见的 Vector-Jacobian Product,本质上就是这一步。
对参数的梯度也是同一个模式。若第 \(l\) 层含参数 \(\theta_l\),则
\[\frac{\partial L}{\partial \theta_l}=\frac{\partial L}{\partial h_{l+1}}\frac{\partial h_{l+1}}{\partial \theta_l}\]因此 backward 的核心是复用每一层的局部 Jacobian,把同一个上游梯度分别传给输入变量和参数。
梯度消失(Vanishing Gradients)与梯度爆炸(Exploding Gradients)通常来自连乘的数值尺度:若这些雅可比的有效增益(Effective Gain)的奇异值(Singular Values)长期小于 1,则梯度指数级衰减;长期大于 1 则指数级放大。
在 RNN 的 BPTT 中,这种现象尤其明显:同一递归矩阵在时间轴上重复相乘。粗略地看,若 \(W_{hh}\) 的谱半径(Spectral Radius)\(\rho(W_{hh})\) 明显大于 1,梯度更易爆炸;明显小于 1 更易消失。但这并非“只要 \(\lambda>1\) 就一定爆炸”的二选一结论,因为实际还受到激活函数导数、归一化、残差/门控结构、以及数据分布的共同影响。
“梯度随训练慢慢变小是否正常?”在接近最优点时,梯度范数下降是预期现象;需要警惕的是训练早期就出现系统性消失(例如大量饱和激活导致导数接近 0)或出现不稳定爆炸(loss/梯度频繁变成 NaN/Inf)。
常见应对:
- 梯度裁剪(Gradient Clipping):抑制爆炸。
- 合理初始化(Xavier/He)、归一化(BatchNorm/LayerNorm)、残差连接(Residual)。
- 门控结构(Gated Units):LSTM/GRU 通过门控缓解长程梯度问题。
权重初始化(Weight Initialization)的目标核心是控制信号在层间传播的数值尺度。设第 \(l\) 层的线性部分为 \(z^{(l)}=W^{(l)}h^{(l-1)}+b^{(l)}\)。若 \(z^{(l)}\) 的二阶原点矩(Second Raw Moment)在层间持续放大,前向激活与反向梯度都会倾向爆炸;若持续衰减,则会出现梯度消失。
对单个神经元,写成 \(z=\sum_{i=1}^{n}w_i x_i+b\)。初始化分析里通常进一步假设 \(w_i\) 与 \(x_i\) 相互独立,且权重满足 \(\mathbb{E}[w_i]=0\)。这里的 \(\mathbb{E}[w_i]=0\) 核心是在分析初始化时,把权重看作从一个以 0 为中心的随机分布中抽样得到;这样做的目的,是避免网络在一开始就对某一方向产生系统性偏置,并让前向输出的均值计算更干净。基于这一初始化假设,在线性部分有
\[\mathbb{E}[z]=0,\quad \mathbb{E}[z^2]=n\,\mathrm{Var}(w)\,\mathbb{E}[x^2]\]当输入也近似零均值时, \(\mathbb{E}[x^2]\approx \mathrm{Var}(x)\),于是常写成 \(\mathrm{Var}(z)\approx n\,\mathrm{Var}(w)\,\mathrm{Var}(x)\)。这里 \(n\) 就是 fan_in。因此初始化的核心约束可以概括为:让 \(n\,\mathrm{Var}(w)\) 保持在 1 附近。
更严格地说,深度初始化分析常跟踪的是 \(\mathbb{E}[h^2]\),而非所有层都精确使用方差;因为经过 ReLU 之后,激活不再零均值,此时二阶原点矩与方差不再完全相同。但在线性层与零均值近似下,两者是一致的,因此“保持方差稳定”仍是准确的工程表述。
两种朴素做法都会失败:若所有权重都初始化为 0,则各神经元保持完全对称,反向传播得到相同更新,网络退化为“许多拷贝的同一个单元”;若直接令 \(\mathrm{Var}(w)=1\),则线性输出的尺度会随层数按 fan_in 连乘,深层网络极易数值失稳。偏置(Bias)通常初始化为 0 或很小的常数;真正决定尺度的是权重矩阵的方差结构。
这里的 fan_in 与 fan_out 可以直接按“这层连接了多少路信号”来理解。对某个线性层中的一个输出神经元,fan_in 是流入它的输入通道数;输入通道越多,很多随机小贡献叠加后,输出就越容易变大。对某个输入神经元,fan_out 是它连接到下一层多少个输出通道;fan_out 越大,这个输入方向上的梯度在反向传播时就会被分发到更多支路。因此,fan_in 主要约束前向激活的放大量级,fan_out 主要约束反向梯度的放大量级。
具象地看,一个神经元像一个汇流节点:fan_in 决定有多少根水管把信号同时灌进来,fan_out 决定这股信号会被分流到多少个下游节点。初始化如果不考虑这两个连接数,网络就会在“汇流过猛”与“分流过弱”之间失衡。Xavier 正是在前向与反向之间做折中,He 则进一步把激活函数本身带来的能量损失也纳入补偿。
导图里把初始化方法拆成正态分布、均匀分布、常数和正交四类,这种分法是成立的,因为它们回答的是两个不同层面的问题。正态分布初始化(Normal Initialization)与均匀分布初始化(Uniform Initialization)回答的是“权重样本从哪一种随机分布里抽”;常数初始化(Constant Initialization)回答的是“是否所有参数起点都相同”;正交初始化(Orthogonal Initialization)则进一步约束权重矩阵的几何结构,使不同方向在初始阶段尽量保持独立、不过度放大或压缩。
常数初始化最容易说明为什么会失败。若一个全连接层里所有权重都初始化为同一个常数,哪怕这个常数并非 0,各神经元在前向时看到的输入组合仍完全一致,反向时梯度也完全一致,结果就是整层神经元始终学习同一组特征,无法打破对称性。因此,偏置可以常数初始化,但权重矩阵通常不能整体常数初始化。
正态分布与均匀分布本身并没有绝对优劣,关键在于方差尺度是否合理。若只是“从一个随机分布里抽”,但不控制 fan_in / fan_out,网络一样会出现层间尺度失衡。因此工程实践里真正有意义的,通常是“用 Xavier 正态”“用 Xavier 均匀”“用 He 正态”“用 He 均匀”。分布族决定采样形状,方差公式决定数值稳定性。
正交初始化(Orthogonal Initialization)则更进一步。若 \(W^\top W\approx I\) 或 \(WW^\top\approx I\),线性变换对向量长度的扭曲会更受控,信息在不同方向上的耦合也更弱。这对深层线性网络、RNN 的递归矩阵,以及某些残差结构尤其有价值,因为它能更好地维持奇异值谱接近 1,缓解梯度在层间或时间步之间迅速爆炸或衰减。
因此,这四类方法的关系可以概括为:常数初始化主要是反例和边界条件;正态与均匀是随机采样家族;Xavier / He 是方差控制规则;正交初始化是额外的矩阵几何约束。实际工程里最常见的组合是“Xavier/He + 正态或均匀采样”,以及在特定循环或深层结构中使用正交初始化。
Xavier 初始化(Xavier Initialization)也称 Glorot 初始化(Glorot Initialization),针对近似线性的激活工作区间设计,例如 tanh 与 sigmoid 在原点附近的局部线性区域。它的目标是同时控制前向激活与反向梯度的尺度,使它们在穿过每一层时不发生系统性放大或衰减。
若暂时忽略激活函数对二阶原点矩的额外缩放,则前向保持尺度不变要求 \(\mathrm{Var}(w)\approx 1/\mathrm{fan\_in}\);反向对应地要求 \(\mathrm{Var}(w)\approx 1/\mathrm{fan\_out}\)。Glorot 给出的折中形式因此写成:
\[\mathrm{Var}(w)=\frac{2}{\mathrm{fan\_in}+\mathrm{fan\_out}}\]常见实现包括正态版 \(w\sim\mathcal{N}\!\left(0,\frac{2}{\mathrm{fan\_in}+\mathrm{fan\_out}}\right)\),以及均匀版 \(w\sim U\!\left[-\sqrt{\frac{6}{\mathrm{fan\_in}+\mathrm{fan\_out}}},\sqrt{\frac{6}{\mathrm{fan\_in}+\mathrm{fan\_out}}}\right]\)。
从直觉上看,Xavier 初始化像是在给每一层设置一个“不过度放大、也不过度压缩”的中性增益(neutral gain)。可以把一层线性变换想成一组并联的混音器:输入信号从上一层流入,经过许多权重通道混合后送到下一层。Xavier 的目标就是让这组混音器在初始状态下近似保持“总音量”不变,使信号既不会层层变得越来越吵,也不会层层变得越来越弱。
Xavier 的局限在于:它默认激活函数不会系统性丢失太多能量。对 ReLU 这类半波整流(Half-wave Rectification)激活,这个假设不再成立;即使线性层前后的尺度匹配,经过激活后信号的二阶原点矩仍会明显下降。
He 初始化(He Initialization)也称 Kaiming 初始化(Kaiming Initialization),专门处理 ReLU 家族的整流效应。若线性输出 \(z\) 近似关于 0 对称,经过 \(\mathrm{ReLU}(z)=\max(0,z)\) 后,大约一半的质量被截断为 0,并且
\[\mathbb{E}[\mathrm{ReLU}(z)^2]=\frac{1}{2}\mathbb{E}[z^2]\]因此,若仍使用 Xavier 量级,信号的二阶原点矩会随层数持续衰减。He 初始化通过把权重方差提高到
\[\mathrm{Var}(w)=\frac{2}{\mathrm{fan\_in}}\]来补偿这一半波损失。对应实现可写为正态版 \(w\sim\mathcal{N}\!\left(0,\frac{2}{\mathrm{fan\_in}}\right)\),或均匀版 \(w\sim U\!\left[-\sqrt{\frac{6}{\mathrm{fan\_in}}},\sqrt{\frac{6}{\mathrm{fan\_in}}}\right]\)。
具象地看,ReLU 像一道只允许正值通过的闸门:一批近似对称分布的信号经过后,负半边会被直接截成 0,等于天然损失了一部分能量。He 初始化做的事情就是在闸门前把信号预先放大一些,使它通过这道“半波闸门”之后,整体尺度仍能维持在稳定区间。Xavier 假定通道基本不漏能量,He 则明确把 ReLU 的漏损补偿计入初始化方差。
对 Leaky ReLU/PReLU,补偿因子可推广为 \(\frac{2}{(1+a^2)\,\mathrm{fan\_in}}\),其中 \(a\) 是负半轴斜率。实践上,ReLU 及其变体默认优先使用 He 初始化;tanh/sigmoid 更适合 Xavier。归一化层与残差连接可以进一步放宽初始化的容错区间,但不能替代合理的初始尺度控制。
Transformer / 大语言模型(Large Language Model, LLM)里的初始化通常不按“整模统一套 Xavier”或“整模统一套 He”来理解,而更像一套围绕残差流(Residual Stream)稳定性、归一化层和深度扩展设计的小方差初始化配方。原因在于:LLM 的主干核心是由自注意力、残差连接、LayerNorm / RMSNorm、MLP / SwiGLU 等子结构共同组成;纯粹以某个激活函数为中心推导的 Xavier / He,只能覆盖其中一部分局部直觉。
工程上最常见的做法是:嵌入层与线性层权重用零均值的小方差正态分布初始化,偏置置零或省略;随后依靠 LayerNorm / RMSNorm 与残差结构维持训练初期的数值稳定。BERT、GPT-2 一类经典 Transformer 常见做法是使用标准差约为 \(0.02\) 的正态或截断正态初始化;很多更现代的 Decoder-only LLM 仍延续“小方差高斯初始化”这一主线,只是在具体投影层上再叠加按隐藏维度、层数或残差分支做缩放的配方。
从直觉上看,LLM 初始化更像是在给一条很深的多车道主干道设置初始车流密度。若注意力里的 \(Q/K/V/O\) 投影、FFN 的升维/降维投影以及其他会把结果写回残差流的线性层初始尺度过大,残差分支会把信号越叠越猛,训练初期容易震荡;若尺度过小,几十层上百层残差块叠起来后,真正进入有效学习区的信号又会太弱。因此,现代 LLM 初始化的重点往往核心是让残差支路在深层网络中既能传递信息,又不会在训练一开始就把数值尺度推离稳定区。
具体到模块分工,也可以这样理解:MLP 内部若使用 ReLU 家族激活,He 的补偿思想仍然成立;若使用 GELU、SiLU、SwiGLU 这类更平滑或带门控的激活,则实现里往往直接采用统一的小方差正态初始化,再由归一化、残差和训练配方共同保证稳定性。LLM 把 Xavier / He 背后的“方差守恒”原则嵌入到了更完整的 Transformer 初始化策略里,并没有抛弃这套原则。
| 方法 | 核心方差 | 适用激活 | 主要问题 / 逻辑 |
| 零初始化 | \(\mathrm{Var}(w)=0\) | 无 | 破坏对称性;所有神经元学到相同特征 |
| 标准正态随机 | \(\mathrm{Var}(w)=1\) | 无 | 尺度随深度快速放大;易导致爆炸 |
| Xavier / Glorot | \(\frac{2}{\mathrm{fan\_in}+\mathrm{fan\_out}}\) | Tanh、Sigmoid | 兼顾前向与反向尺度;假设激活近似线性 |
| He / Kaiming | \(\frac{2}{\mathrm{fan\_in}}\) | ReLU、Leaky ReLU | 补偿 ReLU 的半波截断;保持二阶原点矩稳定 |
| LLM 常用小方差高斯初始化 | 常取固定小标准差,或再叠加按宽度 / 深度缩放 | Transformer 模块整体 | 服务残差流、归一化层与深层稳定训练;并非单纯按某一种激活推导 |
正则化(Regularization)在经验风险(Empirical Risk)上增加复杂度惩罚,缓解过拟合(Overfitting)。假设函数/模型 \(f_\theta\) 决定预测;样本损失 \(\ell\) 度量单样本误差;代价函数/成本函数 \(L(\theta)\) 汇总训练集误差;目标函数 \(J(\theta)\) 则是 \(L(\theta)\) 加上正则化项: \(J(\theta)=L(\theta)+\lambda\Omega(\theta)\)。
\[J(\theta)=\frac{1}{m}\sum_{i=1}^{m}\ell\!\left(f_{\theta}(x^{(i)}),y^{(i)}\right)+\lambda\Omega(\theta)\]L1 正则化(L1 Regularization)使用 \(\Omega(\theta)=\|\theta\|_1\)。它倾向产生稀疏解(Sparsity),即一部分权重被直接压到 0,因此可同时做参数学习和特征选择(Feature Selection)。
从优化角度看,L1 的梯度是次梯度(Subgradient):对单个参数 \(\theta_k\),当 \(\theta_k\ne 0\) 时有 \(\frac{\partial}{\partial \theta_k}\|\theta\|_1=\mathrm{sign}(\theta_k)\);在 0 点是一段区间 \([-1,1]\)。这使得优化过程更容易把小权重“推过 0”,形成精确稀疏。
在很多实现中,会用近端算子(Proximal Operator)给出更清晰的“压到 0”机制:对标量 \(w\),软阈值化(Soft-Thresholding)是
\[\mathrm{soft}(w,\alpha)=\mathrm{sign}(w)\max(|w|-\alpha,0)\]当 \(|w|\le \alpha\) 时直接变为 0。
L2 正则化(L2 Regularization)使用 \(\Omega(\theta)=\|\theta\|_2^2\)。它倾向均匀缩小参数,但通常不会把参数精确压到 0。直观上,L1 在 0 点不可导,更容易触发“阈值化”解;L2 是光滑二次惩罚,更新更连续。
梯度层面,L2 会在原梯度上叠加一个“拉回原点”的项:若目标为 \(\ell(\theta)+\lambda\|\theta\|_2^2\),则 \(\nabla_\theta=\nabla \ell(\theta)+2\lambda\theta\)。工程上常把这个效果称为权重衰减(Weight Decay):每一步都把权重按比例缩小。
需要区分一个常见细节:在自适应优化器(如 Adam)里,“把 \(\lambda\|\theta\|_2^2\) 加到损失里”与“直接做 weight decay”在数值上并不完全等价;因此实践中常用解耦权重衰减(Decoupled Weight Decay,典型实现是 AdamW)来获得更可控的正则化行为。
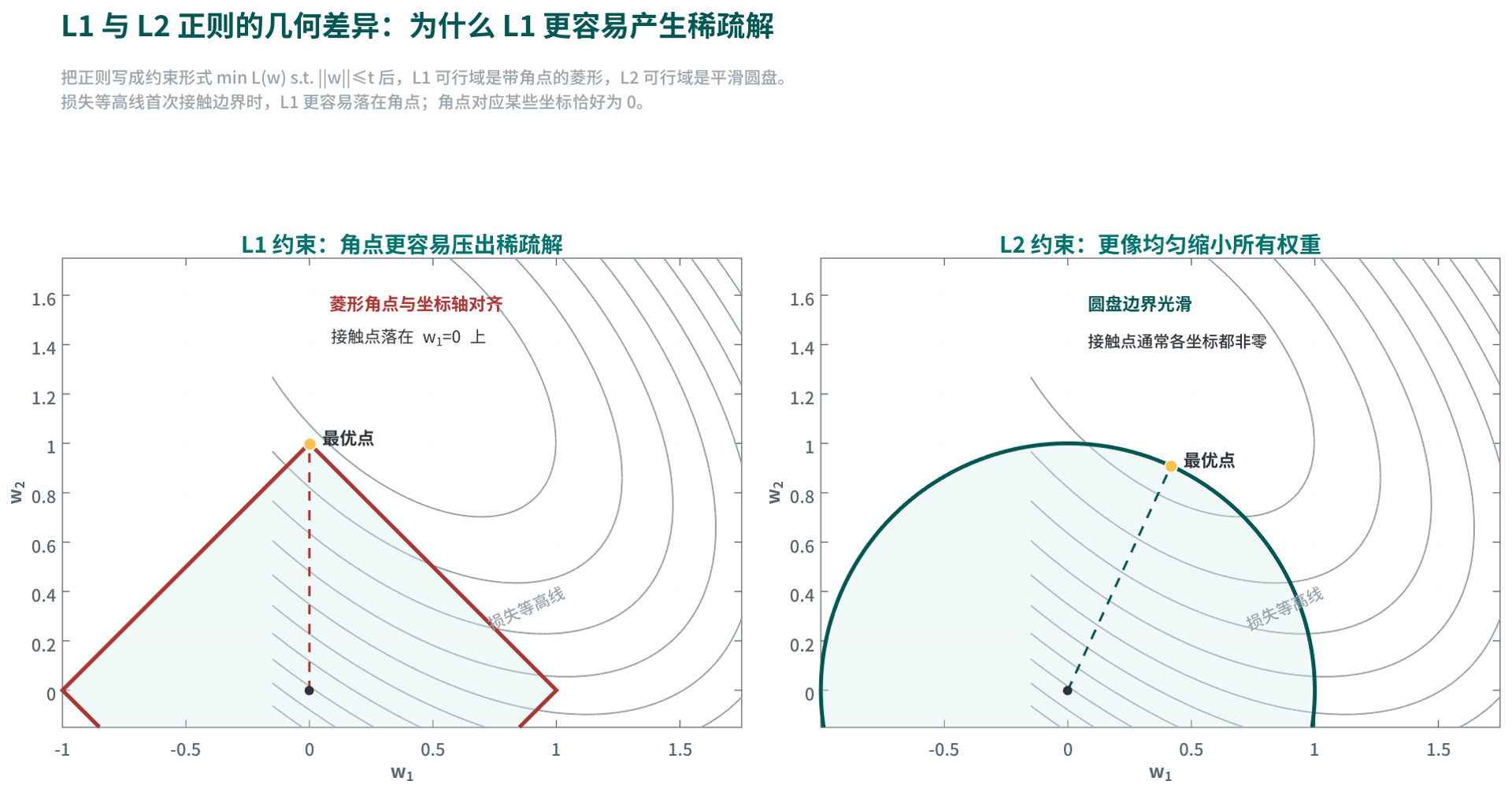
把带惩罚的目标改写成约束形式后,几何差异会非常直观: \(\min_\theta L(\theta)\ \mathrm{s.t.}\ \|\theta\|_1\le t\) 的可行域在二维里是菱形, \(\min_\theta L(\theta)\ \mathrm{s.t.}\ \|\theta\|_2\le t\) 的可行域则是圆盘。损失等高线从外向内收缩时,第一次接触 \(L_1\) 边界,往往更容易落在角点;角点恰好对应某些坐标精确等于 0。 \(L_2\) 边界处处光滑,接触点通常只是把所有坐标一起缩小,而非把其中一部分直接压成 0。
从一维更新机制看,这个差异也对应两种不同的收缩方式。 \(L_2\) 更像连续比例收缩:权重越大,拉回原点的力越强,但通常不会在有限步内变成精确 0。 \(L_1\) 则对应软阈值化(Soft-Thresholding):一旦 \(|w|\) 小于阈值,就会被直接压成 0。因此, \(L_1\) 不仅“把权重变小”,还会主动把一部分坐标从模型中删掉,这就是稀疏性(Sparsity)的来源。
Dropout 通过随机屏蔽部分神经元输出,减少共适应(Co-adaptation),等价于在训练时对网络做一种随机子网络集成(Ensemble)。这里的共适应,是指若干神经元彼此形成了固定搭配:模型过度依赖它们同时出现、按特定组合共同完成判断,而非让每个单元都学到相对独立、稳健的特征。Dropout 随机拿掉其中一部分单元后,网络不能再把能力押注在某一组固定配合上,只能把有用模式分散到更稳健的表示里。令隐藏向量为 \(h\),mask \(m_i\sim \mathrm{Bernoulli}(p)\),常见的 inverted dropout 写法为:
\[\tilde h = \frac{m\odot h}{p}\]其中 \(p\) 是保留概率(Keep Probability)。这样推理时可直接使用原网络(不再采样 mask),避免额外缩放。
在 NLP 中,Dropout 还经常有更具体的变体。Word Dropout 会在训练时随机把一部分 token 替换成未知词、占位符或空输入,从而降低模型对某些高频词项的脆弱依赖;Variational Dropout 则在 RNN 等结构中对时间维共享同一个 dropout mask,避免每个时间步都采样不同 mask 破坏时序稳定性。它们都服务于同一个目标:让模型不要过度依赖局部偶然线索。
对抗训练(Adversarial Training)通过在输入或嵌入空间中加入微小、朝最坏方向设计的扰动,迫使模型在局部邻域内保持预测稳定。它并不只属于安全研究,在文本分类、序列标注和对比学习中也常被用来提升鲁棒性。对 NLP 而言,常见做法是在 embedding 上加入小扰动,再用额外损失约束模型在扰动前后保持一致或仍能正确预测。
Batch Normalization(BatchNorm)在训练时用 mini-batch 的均值/方差做归一化,并学习缩放/平移参数。对特征维上的某个分量 \(x\),典型形式是:
\[\mathrm{BN}(x)=\gamma\cdot \frac{x-\mu_{\text{batch}}}{\sqrt{\sigma_{\text{batch}}^2+\epsilon}}+\beta\]推理阶段通常使用训练过程累积的运行均值(Running Mean)与运行方差(Running Variance),因此训练/推理行为不同。BatchNorm 在 CNN 中极常见,因为卷积特征图在同一通道上的空间位置具有较强同质性,跨样本统计量较容易稳定;但在 Transformer 中,主流做法核心是使用与 batch 统计无关的 LayerNorm 或 RMSNorm。
原因在于 Transformer 的基本计算单元是 token 表示。序列长度常常可变,batch size 在训练与推理中也经常变化,尤其大模型训练会受到显存限制而使用较小、波动甚至分布式切分后的 micro-batch。若使用 BatchNorm,某个 token 的归一化结果会显式依赖同一 batch 中其他样本与其他位置的统计量,这会引入跨样本耦合,使训练和推理的数值语义不一致,也不利于自回归解码阶段逐 token 稳定生成。
Layer Normalization(LayerNorm)对每个样本(或每个 token)的特征维做归一化,不依赖 batch 统计量,因此更适合变长序列与自回归推理。对向量 \(x\in\mathbb{R}^{d}\):
\[\mathrm{LN}(x)=\gamma\odot \frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta,\quad \mu=\frac{1}{d}\sum_{i=1}^{d}x_i,\ \sigma^2=\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2\]这里的均值 \(\mu\) 与方差 \(\sigma^2\) 都只在当前样本、当前 token 的特征维内部计算,因此每个 token 都能独立完成归一化。这个性质与 Transformer 的残差流(Residual Stream)非常匹配:无论 batch 如何变化、序列如何裁剪、推理时是否一次只输入一个 token,归一化规则都保持一致。
当前主流的 Transformer 归一化实践可以概括为两类。Encoder-only 与很多 Vision Transformer(ViT)架构通常沿用 LayerNorm;Decoder-only 大语言模型(Large Language Model, LLM)则大量采用 Pre-Norm 残差块,并进一步把 LayerNorm 简化为 RMSNorm。前者保留去均值与方差缩放,后者只保留尺度归一化,计算更轻,也更适合超大规模训练。
Early Stopping 用验证集指标监控训练过程,在泛化性能不再提升时提前停止,从而避免在训练集上继续拟合噪声。工程上常用“耐心(Patience)”:若验证集指标连续 \(K\) 次评估都未改善,则停止训练并回滚到最佳 checkpoint。它属于训练流程级的隐式正则化(Implicit Regularization)。
分类任务正则化(Regularization for Classification Tasks)直接作用在分类训练的监督方式、样本混合方式或概率分布形状上。它的主要目标包括:缓解过度自信、减轻类别不平衡造成的梯度偏置、降低标签噪声影响,以及让决策边界在训练样本之间保持更平滑的过渡。
Label Smoothing(标签平滑)把 one-hot 标签从“真实类为 1、其余类为 0”改写成更平滑的目标分布。对 \(C\) 分类问题,常见写法是:
\[y_i^{\mathrm{LS}}=(1-\varepsilon)\mathbf{1}[i=c]+\frac{\varepsilon}{C}\]这里 \(c\) 是真实类别, \(\varepsilon\in(0,1)\) 是平滑系数。真实类别仍占最大权重,但其他类别也会分到一小部分概率质量。训练因此不再持续奖励模型把正确类别概率推到 1、把其余类别压到 0,输出分布通常会更平滑,概率校准(Calibration)也更稳定。
在固定阈值或直接取 \(\arg\max\) 的分类系统里,Label Smoothing 带来的收益往往更多体现在 loss 曲线与概率可信度上,而非直接转化为同等幅度的 F1 提升。若模型输出概率还会进入阈值调优、排序、融合、拒识或风险控制,这种校准改进的价值会更明显。
类别重加权(Class Reweighting)与重采样(Resampling)主要处理类别不平衡(Class Imbalance)。其核心思想是让少数类样本在训练中获得更大的有效权重,避免优化过程被大量易分类的多数类样本主导。加权交叉熵的常见形式为:
\[\ell_{\mathrm{wCE}}(y,p)=-\sum_{i=1}^{C}\alpha_i y_i\log p_i\]这里 \(\alpha_i\) 是第 \(i\) 类的损失权重。若某类样本极少,可以给它更大的 \(\alpha_i\),使模型在误分该类时承担更高代价。重采样则直接改变 mini-batch 的类别组成,例如过采样少数类、欠采样多数类,或用类别均衡采样器(Class-balanced Sampler)保证 batch 内标签分布更均衡。
这类方法的直接效果,是让决策边界不再默认偏向多数类。代价则是:过强的重加权会放大少数类中的噪声标签,过强的过采样会提高过拟合风险。因此它通常要与验证集上的 Precision / Recall / F1 一起调节,而不只盯着训练损失。
Mixup 与 CutMix 通过构造“介于两个训练样本之间”的新样本,显式约束分类器在样本间插值区域上的行为,从而平滑决策边界。Mixup 的典型形式是:
\[\tilde x=\lambda x_i+(1-\lambda)x_j,\qquad \tilde y=\lambda y_i+(1-\lambda)y_j\]这里 \(\lambda\in[0,1]\) 通常从 Beta 分布采样。输入和标签都被线性混合,于是模型被要求在 \(x_i\) 与 \(x_j\) 之间给出相应的插值预测。CutMix 则核心是把一张图像中的局部区域替换为另一张图像的对应区域,同时按被替换面积比例混合标签。
这类方法对图像分类尤其有效,因为它们直接惩罚“决策边界贴着训练样本走”的过拟合行为。换一个视角看,Mixup / CutMix 核心是在告诉模型:输入空间里两点之间的过渡区域也应当保持语义上的平滑可解释。
置信度惩罚(Confidence Penalty)和熵正则(Entropy Regularization)直接约束输出分布不要过早塌缩到极端尖锐形状。一个常见做法是在交叉熵之外,再加入预测分布熵的奖励项:
\[\mathcal{L}=\mathcal{L}_{\mathrm{CE}}-\beta H(p),\qquad H(p)=-\sum_{i=1}^{C}p_i\log p_i\]这里 \(\beta>0\) 控制正则强度。由于熵越大表示分布越平滑,这一项会抑制模型过快形成极端概率。它和 Label Smoothing 的方向相近,但切入点不同:Label Smoothing 改的是监督目标分布,置信度惩罚改的是模型预测分布本身。
两者都常用于需要更好概率校准的分类系统。相比之下,Focal Loss 更强调“把梯度预算留给困难样本”,因此它在类别不平衡或难例挖掘场景更常见;Label Smoothing 与熵正则则更偏向控制过度自信与改善概率形状。
回归任务正则化(Regularization for Regression Tasks)除了常见的参数惩罚外,还经常直接约束预测函数 \(f(x)\) 的形状。回归目标是连续值,因此“曲线是否足够平滑、是否满足单调关系、是否具有合理曲率”往往和任务正确性本身直接相关。
平滑性正则化(Smoothness Regularization)要求回归函数不要在输入空间里出现不必要的高频震荡。最典型的形式是惩罚导数,尤其是二阶导数:
\[J(f)=\sum_{i=1}^{N}(y_i-f(x_i))^2+\lambda\int (f''(x))^2\,dx\]第二项就是经典的样条平滑惩罚(Smoothing Spline Penalty)。它惩罚曲率过大,相当于抑制函数频繁弯折。 \(\lambda\) 越大,拟合曲线越平滑; \(\lambda\) 越小,模型越愿意追随样本中的局部波动。很多非参数回归(Nonparametric Regression)与时间序列平滑,本质上都在做这种“数据拟合 + 曲率惩罚”的权衡。
Total Variation(TV)正则与 Fused Lasso 适合分段平滑(Piecewise Smooth)的回归目标。它们允许少数突变点存在,不强求函数处处光滑,同时惩罚过多的相邻跳变。离散形式的 TV 惩罚常写成:
\[\Omega_{\mathrm{TV}}(f)=\sum_{t=2}^{T}|f_t-f_{t-1}|\]若同时对参数本身加 \(L_1\) 惩罚,再对相邻参数差分加 \(L_1\) 惩罚,就得到 Fused Lasso:
\[J(\beta)=L(\beta)+\lambda_1\sum_j |\beta_j|+\lambda_2\sum_{j=2}^{d}|\beta_j-\beta_{j-1}|\]这类方法非常适合信号去噪、时序回归、基因拷贝数分段估计,以及任何“整体大致平稳、局部允许少数结构突变”的问题。与样条惩罚相比,它更偏好形成平坦区段,而非全局光滑弯曲曲线。
很多回归任务天然带有单调先验:广告出价上升,曝光概率通常不应系统性下降;贷款风险特征上升,违约风险不应系统性降低;药物剂量增加,效应在一定区间内通常应单调增强。单调性约束(Monotonicity Constraint)把这种领域知识直接写进模型:
\[\frac{\partial f(x)}{\partial x_k}\ge 0\quad \text{或}\quad \frac{\partial f(x)}{\partial x_k}\le 0\]这里 \(x_k\) 是某个具有明确方向含义的特征。在线性模型里,这等价于约束对应权重非负或非正;在树模型和神经网络里,则可以通过结构限制、投影步骤或软惩罚项来实现。单调约束的价值不只在提高泛化,还在于提升可解释性与业务一致性。
当回归函数预期具有凸性(Convexity)、凹性(Concavity)或有限曲率时,可以继续对二阶导数施加方向性约束。例如一维凸函数满足:
\[f''(x)\ge 0\]这类约束在成本函数建模、供需曲线估计、剂量反应建模和某些经济学回归问题里非常常见。即使不要求严格凸性,也常通过曲率上界控制函数不要弯折过猛,例如惩罚 Hessian 范数或二阶差分幅度。它们的作用与平滑惩罚相近,但强调的是“弯曲方向和弯曲强度应满足领域结构”,而不只是单纯地压低高频波动。
Lipschitz 约束(Lipschitz Constraint)控制的是输入微小变化会把输出放大多少。若存在常数 \(K\),使得
\[|f(x)-f(x')|\le K\|x-x'\|\]则函数变化速度受到统一上界控制。对可导函数,一个常见做法是直接惩罚输入梯度范数:
\[J(\theta)=L(\theta)+\lambda\,\mathbb{E}_{x}\|\nabla_x f_\theta(x)\|_2^2\]这种正则化常用于需要鲁棒输出的回归系统,例如物理量估计、坐标回归和噪声敏感的传感器建模。它抑制模型对局部输入扰动过度敏感,也能缓解高维回归中出现的不稳定尖峰。
概率回归(Probabilistic Regression)不仅预测均值,还会预测方差、分位数或整个条件分布。此时正则化对象不再只有均值函数,还包括分布参数之间的结构关系。例如异方差回归(Heteroscedastic Regression)中,方差参数必须保持正值;分位数回归(Quantile Regression)中,不同分位点曲线应尽量避免交叉(Quantile Crossing)。
若模型同时预测多个分位点 \(\hat q_{\tau_1}(x),\hat q_{\tau_2}(x)\) 且 \(\tau_1<\tau_2\),则理想上应满足:
\[\hat q_{\tau_1}(x)\le \hat q_{\tau_2}(x)\]工程上常通过排序约束、投影修正或惩罚项来维持这种分布一致性。对高斯 NLL、混合密度网络(Mixture Density Network)或生存分析模型,也会对尺度参数、危险率函数或累积分布形状加入额外约束,使预测分布既拟合数据,又保持统计上可解释、数值上稳定。
深度学习(Deep Learning)是以多层神经网络为核心、通过大规模数据和梯度优化自动学习表示的建模范式。若上一章讨论的是神经网络的基本部件,例如线性层、激活函数、损失函数、反向传播、初始化与正则化;这一章讨论的则是这些部件在更深层、更大规模、更强归纳偏置下,如何组合成现代模型家族,并在视觉、语音、语言、生成和图结构任务上形成方法论分水岭。
“深度”并不只是层数更多。更关键的变化是:模型开始把原始输入逐层改写成越来越抽象的中间表示,从边缘、纹理、局部模式,逐步组合到部件、对象、语义关系与任务决策。于是,模型能力的来源已经从最后那一层分类器扩展到整条表示变换链本身。
下文的卷积神经网络(CNN)、循环神经网络(RNN)、Transformer、生成模型(Generative Model)、图神经网络(GNN)和 ONNX,分别对应深度学习里几条非常重要的主线:空间局部归纳偏置、时序递推建模、自注意力驱动的通用序列建模、生成式分布学习、关系数据表示学习,以及模型部署交换格式。它们共同构成了现代深度学习的主要版图。其中 Transformer 因为后续内容体量很大,会在第 3 篇中单独展开;这里先给出它在技术演进中的位置。
在传统机器学习流程里,特征工程和预测器常常是分开的:先由人手设计特征,再把这些特征交给线性模型、树模型或核方法完成分类与回归。深度学习把这两步合并进同一个可微计算图。前面的层负责把原始输入转写为更有判别力、更有结构感的表示,后面的层负责完成具体任务,所有参数围绕同一个目标函数联合优化。这就是端到端学习(End-to-End Learning)的核心含义。
表示学习(Representation Learning)之所以重要,是因为感知任务真正困难的部分,往往不在“最后怎么分一下类”,而在“怎样把原始信号变成对任务友好的坐标系”。图像像素、语音波形、文本序列和图结构都高度高维、局部相关且语义分散。深度网络的价值,在于它能用层级结构自动提取适合当前任务的中间表示,而不再完全依赖人工定义纹理统计量、边界特征、语言规则或图特征模板。
深度学习会改变整个方法栈,原因正在这里。过去很多系统的主要工作量放在“特征怎么造”;深度学习之后,工作重心逐渐转向“架构如何设计、数据如何构造、训练如何稳定、预训练如何迁移、部署如何落地”。从研究到工业实践,核心竞争力开始沿着表示学习能力重新分布。
多层神经网络并非 2010 年代才出现的新概念。真正的转折点在于,一系列条件在同一时期同时成熟,使深网络第一次具备了大规模可训练、可迁移、可复用的现实基础。深度学习成为里程碑,靠的核心是数据、算力、优化、架构和软件工程几条线一起闭环。
| 关键条件 | 作用 | 为什么重要 |
| 大规模数据 | 提供足够多样的监督信号与统计规律 | 深网络参数量大,若没有足够样本,表达能力会迅速转化为过拟合风险 |
| GPU / 并行算力 | 把大规模矩阵乘法、卷积和反向传播变成可承受的训练过程 | 很多深层模型在理论上可定义,但在工程上长期“训不动” |
| 优化技术成熟 | ReLU、Xavier / He 初始化、BatchNorm、残差连接、门控结构等共同提升可训练性 | 它们解决的是梯度消失、数值失稳和深层退化等根本瓶颈 |
| 强归纳偏置的架构 | CNN 利用空间局部性,RNN 利用时序递推,GNN 利用图邻接关系 | 深度并不自动等于有效,架构必须贴合数据结构 |
| 预训练与迁移学习 | 先在大数据上学通用表示,再迁移到下游任务 | 这使深度学习从“每个任务从零训练”转向“共享表征资产” |
| 框架与工程生态 | 自动求导、分布式训练、模型导出和部署工具日益成熟 | 研究原型和生产系统之间的距离被显著缩短 |
从方法史角度看,深度学习真正改变的是“模型从何处获得有用表示”。经典机器学习更多依赖人工抽取特征,再用较浅模型做判别;深度学习则把表示构造本身纳入训练。这个变化一旦与数据和算力结合,就会呈现出非常强的规模效应。
AlexNet 是现代深度学习史上的标志性节点。它的意义不仅 ImageNet 分类精度显著提升,还证明了一个足够深、足够宽、用 GPU 训练、配合 ReLU 和数据增强的卷积网络,能够系统性压过人工特征加浅层分类器的旧路线。视觉领域由此从“设计特征”转向“训练特征”。
这次转折的后果极其深远。分类只是起点,检测、分割、检索、视频理解和视觉问答很快都转向以深层 backbone 为中心的范式。很多后续工作从从零设计整套视觉特征转向围绕预训练卷积网络做迁移、微调和多任务扩展。
在序列任务上,深度学习的关键进展并不只来自更强的 RNN / LSTM / GRU,还来自编码器-解码器(Encoder-Decoder)和注意力(Attention)机制。Seq2Seq 让模型能够把输入序列映射为输出序列,最早大规模改变了机器翻译、语音识别和摘要生成等任务;注意力则突破了“所有信息都必须挤进一个固定长度向量”的瓶颈,使解码器可以在生成每一步时,动态读取输入序列中最相关的部分。
这条技术线的重要性在于,它把序列建模从“单纯递推记忆”推进到“按需访问上下文”。Transformer 正是在这条线上进一步把注意力从辅助机制推到主干架构,因此 Seq2Seq 与 Attention 构成了通往下一篇 Transformer 主线的直接前史。
Transformer 可以看作深度学习在序列建模上的又一次架构级跃迁。它从把循环或卷积作为主干转向以自注意力(Self-Attention)为核心,让每个位置都能直接与其他位置建立依赖关系。这样做的结果是:长距离关系更容易建模,训练更适合并行化,模型也更容易沿着数据规模、参数规模和上下文长度继续扩展。
Transformer 最初在机器翻译中取得突破,随后迅速扩展到语言建模、视觉、语音、多模态和生成任务,最终成为大模型时代最核心的基础架构之一。从深度学习的全局版图看,它核心是建立在表示学习、端到端训练、注意力机制、残差连接和大规模预训练这些深度学习主线之上的综合结果。后续第 3 篇会专门展开它的结构与演进。
深度学习早期最强的成果主要集中在识别任务,而 GAN 把研究重点大幅推进到“高质量生成”本身。它展示了深网络不仅能判断图像属于什么类别,还能学习数据分布并生成逼真的新样本。这使图像合成、风格迁移、超分辨率、图像到图像翻译等方向迅速发展,也改变了人们对“模型能力边界”的直觉。
GAN 之后,生成式建模继续沿着 VAE、流模型、扩散模型等路线演进。它们关注的问题已经不仅判别准确率,还样本质量、潜空间结构、可控生成和条件生成。生成模型因此成为深度学习内部一条独立而强势的方法线,后文会单独展开。
深度学习的另一个方法学跃迁,是从“每个任务都从随机初始化开始学”转向“先学通用表示,再迁移到具体任务”。在视觉里,这条线最初体现为 ImageNet 预训练 backbone;在语音和语言里,则逐步发展为更大规模的自监督预训练。迁移学习显著降低了下游任务对标注数据量的依赖,也让模型参数本身成为可复用资产。
这一变化与大模型时代直接相连。大语言模型核心是深度学习在预训练、表示共享和规模扩展三条线上持续推进后的自然结果。因此,把深度学习理解成“大模型之前的旧阶段”并不准确;更贴切的说法是,大模型建立在深度学习已经完成的方法论基础之上。
深度学习真正变成“深”这件事,并非把层数机械堆高就结束了。模型一旦变深,前向信号尺度、反向梯度传播、优化地形和参数更新路径都会迅速恶化。也就是说,网络的理论表达能力和它能否被稳定训练,根本并非同一回事。可训练深度(Trainable Depth)讨论的正是这个问题:怎样让几十层、上百层甚至更深的网络,不仅写得出来,还真的训得动。
深层网络的困难,不能只概括成“梯度消失或爆炸”。那当然是重要问题,但并非全部。更本质地说,随着层数增加,模型必须在一连串非线性变换里同时维持三件事:有用信息不能太快丢失,梯度不能在回传时彻底衰减或失控,优化器还要能在高维参数空间里找到稳定下降方向。哪怕某个更深模型在理论上至少不比浅模型差,训练出来的结果也可能反而更糟,这就是深层退化(Degradation)问题。
若把一个深层块写成 \(H(x)\),传统堆叠要求这一组层直接学习完整映射 \(x\mapsto H(x)\)。问题在于,当最优映射本身接近恒等映射,或只需要对输入做很小修正时,让网络从零学习整张映射会非常低效。层数越多,这种“每一层都要重新写一遍答案”的负担就越重。
ResNet(Residual Network)对这个难题给出的回答是残差学习(Residual Learning)。它不要求若干层直接学习 \(H(x)\),重点是改学相对输入的增量 \(F(x)=H(x)-x\),于是输出变成
\[y=F(x)+x\]这里 \(x\) 是块输入, \(F(x)\) 是卷积、归一化和非线性组成的残差分支, \(y\) 是块输出。这个重写非常关键,因为它把“学习完整映射”改成了“在已有表示上做局部修正”。若当前层不需要大改输入,只要让 \(F(x)\approx 0\) 即可;若需要修正,再通过残差分支逐步补上。
这等于给深层网络提供了一条默认可行的起点:最坏情况下,信息至少可以沿着恒等路径往后传,而不必在每一层都被迫经过强变换。ResNet 因此核心是在重新定义深层块应该学什么。
残差连接(Residual Connection)之所以有效,可以从前向和反向两条路同时理解。前向上,主表示已经从能依赖一串层层覆盖的非线性变换扩展到有一条更短、更稳定的通道把已有信息直接送到后面;这使模型更容易保留低层有用特征,不会因为层数增加而过快破坏已有表示。反向上,梯度也多了一条更直接的传播路径,因此不会被所有中间层的局部导数连续压缩。
若把损失记为 \(\mathcal{L}\),残差块输出为 \(y=x+F(x)\),则对输入的梯度满足
\[\frac{\partial \mathcal{L}}{\partial x}=\frac{\partial \mathcal{L}}{\partial y}\left(I+\frac{\partial F(x)}{\partial x}\right)\]这个式子的意义是:即使残差分支 \(\frac{\partial F(x)}{\partial x}\) 在某些区域学得不理想,梯度仍然至少能通过恒等项 \(I\) 保留一条直接路径。因此,残差连接缓解的核心是深层优化本身的困难。
具象地看,普通深网络像要求每一层都重写一遍完整草稿;残差网络则允许每一层只在上一版稿子旁边批注修改。真正需要改动的地方写入残差,不需要改的地方直接保留原文。这个抽象后来成为深层网络设计中极其通用的模式。
ResNet 最早在视觉里爆发,但残差学习的影响远远超出 CNN。Transformer 的每一层都依赖残差连接把注意力子层和 MLP 子层写回主表示流;扩散模型中的 U-Net 主干大量使用残差块;很多现代语音、视频、多模态和图模型也都把 skip connection 当作默认部件。原因很简单:残差连接解决的是深层网络的通用训练稳定性,而非某种视觉特有问题。
因此,在知识体系里,ResNet 一方面是 CNN 家族中的里程碑架构,另一方面又代表了一条跨架构的方法学原则。后文在卷积神经网络部分仍会把 ResNet 作为经典视觉架构展开;这里更强调它在整个深度学习版图中的地位:它让“更深的网络”第一次大规模变成了工程上可持续扩展的现实路线。
深度学习之所以成为主流,核心是因为它在大量真实任务上持续改写了系统能力边界。它最擅长的场景,通常具备三个特征:输入高维、原始信号结构复杂、手工特征难以穷尽。只要这三个条件同时出现,表示学习的优势就会迅速放大。
| 应用方向 | 深度学习在做什么 | 典型模型或系统 | 关键价值 |
| 图像分类、检测与分割 | 从像素中直接学习目标、边界和语义区域的层级表示 | CNN backbone、Faster R-CNN、U-Net、Mask R-CNN | 显著降低人工视觉特征设计需求,并统一多类视觉任务的表示基础 |
| 人脸识别与设备认证 | 学习稳定的人脸嵌入,用于身份匹配、聚类和检索 | FaceNet、ArcFace、Face ID 一类终端系统 | 把“看起来像不像”变成可度量的特征空间距离,并兼顾鲁棒性与低误识率 |
| 语音识别与语音合成 | 把连续波形映射为音素、文本或声学表示,再进一步合成自然语音 | Deep Speech、Conformer、Tacotron、WaveNet | 显著提升端到端语音系统的准确率与自然度 |
| 机器翻译与序列理解 | 学习跨语言或跨序列位置的上下文依赖与对齐关系 | Seq2Seq、Attention、Transformer | 把规则驱动和短上下文模型推进到可扩展的端到端序列建模 |
| 医学影像与工业质检 | 从高维图像中识别微小异常、边界结构和组织模式 | ResNet、U-Net、3D CNN | 在噪声高、细节密、人工判读成本高的场景中放大模型辅助价值 |
| 推荐、排序与多模态检索 | 把用户、内容、上下文和行为序列编码进共享表示空间 | Wide & Deep、DeepFM、双塔检索模型 | 提升匹配能力,并支持召回、排序、粗排到精排的分层建模 |
人脸识别本身毫无疑问属于深度学习的典型落地方向,而 Face ID 这类系统则更接近“深度学习模型 + 传感器 + 活体检测 + 安全芯片 + 阈值策略”的产品级集成。深度网络负责学习人脸表征与匹配规则,但真正可商用的身份认证系统,还必须处理深度信息、环境光变化、攻击对抗、设备端隐私隔离和误识率控制等工程问题。这类例子很能说明:模型往往是核心能力来源,但完整系统从来不只是一张网络结构图。
卷积(Convolution)在连续形式下定义为函数重叠积分:
\[(f*g)(t)=\int_{-\infty}^{+\infty} f(\tau)\,g(t-\tau)\,d\tau\]在离散二维图像中常写为:
\[(I*K)(i,j)=\sum_m\sum_n I(i-m,j-n)\,K(m,n)\]深度学习框架里多数“卷积层”实现的是互相关(Cross-Correlation)而非严格翻转核的数学卷积,但工程上沿用“卷积”命名。卷积核(Kernel)共享权重(Weight Sharing),天然利用局部性(Locality)与平移等变(Translation Equivariance)。
直观上,卷积层做的事情是:对每个位置取一个局部窗口,把窗口里的像素与卷积核做加权求和,得到该位置的响应。不同卷积核学习不同的局部模式(边缘、纹理、角点等)。
一维互相关示例:输入 \(x=[0,0,1,1,1,0,0]\),核 \(w=[1,0,-1]\),则在从左到右滑动时,核会对“上升沿/下降沿”给出大幅响应(本质上是比较左右两侧的差异)。这就是经典的边缘检测直觉在离散信号上的对应。
卷积的“系统视角”能统一理解 CNN 与信号处理:把卷积核看作响应函数(Response Kernel),输出就是对历史输入的加权累积。参见“微积分 ➡ 卷积(Convolution)”中的因果卷积与“打点滴累积药效”直觉例子。
池化(Pooling)是卷积网络里最经典的一类分辨率操作。最大池化(Max Pooling)和平均池化(Average Pooling)都会把局部窗口压缩成更小的表示,因此它们首先属于下采样(Downsampling)。把这一点说清楚之后,再讨论与之相对的上采样(Upsampling),结构才是完整的。
更一般地说,上采样与下采样讨论的是:在神经网络或信号处理中,怎样改变表示的分辨率、采样密度或时间粒度。图像里它通常表现为特征图宽高的变化;音频里表现为采样率变化;时间序列里则表现为时间轴被压缩或展开。它们核心是一类跨模态的基础操作。
下采样的目标是把表示变粗。若二维特征图 \(X\in\mathbb{R}^{H\times W}\) 经过步幅为 \(s\) 的下采样后,输出空间尺寸通常近似变成 \(\lfloor H/s\rfloor \times \lfloor W/s\rfloor\)。最常见的方式包括最大池化(Max Pooling)、平均池化(Average Pooling)和步幅卷积(Strided Convolution)。它带来的直接收益是:计算量下降、后续层感受野扩大、模型更容易聚焦高层语义;代价则是细边界、小目标和高频细节可能被抹掉。
上采样的目标是把表示变细。若输入特征图大小为 \(H\times W\),放大倍率为 \(r\),则输出空间尺寸会变成 \(rH\times rW\)。最常见的方法包括最近邻插值(Nearest Neighbor Interpolation)、双线性插值(Bilinear Interpolation)、转置卷积(Transposed Convolution)、反池化(Unpooling)与 Pixel Shuffle。它的任务核心是把低分辨率表示重新投影到更细网格上,使后续模块能够输出与原输入同尺度的结果。
二者经常成对出现。分类骨干网络通常不断下采样,把原始像素压缩成更抽象的低分辨率语义表示;分割、超分辨率、生成模型和部分语音/时序重建任务则需要再把这些粗表示上采样回去。U-Net、FPN 和 encoder-decoder 结构长期流行,正是因为它们在回答同一个问题:如何在压缩信息、扩大感受野的同时,仍然把输出恢复到需要的空间或时间分辨率。
这里还要区分“降采样有信息丢失”和“升采样无法保证恢复全部细节”这两个事实。若下采样前没有做足够的低通滤波(Low-pass Filtering),高频成分会折叠成错误的低频模式,产生混叠(Aliasing);若上采样只依赖插值,则新位置往往只是旧值的平滑填充,而非恢复出真正的新结构。因此在工程上,很多高质量系统会把下采样后的高层语义与浅层高分辨率特征通过跳跃连接(Skip Connection)重新融合,再做上采样,以减轻细节损失。
扩张卷积(Dilated Convolution)处理的核心问题是:在不显著增加参数量和计算量的前提下,如何让卷积层看到更大的上下文。它通过在卷积核元素之间插入空洞(dilation gap),把原本紧密相邻的采样点拉开,从而扩大感受野(Receptive Field)。
若一维卷积核长度为 \(k\)、扩张率为 \(r\),则其有效感受野长度可写成:
\[k_{\mathrm{eff}}=k+(k-1)(r-1)\]这条式子说明:当 \(r=1\) 时,它退化为普通卷积;当 \(r>1\) 时,在不增加核参数个数的情况下,有效覆盖范围会迅速变大。以 \(k=3\) 为例,若 \(r=2\),有效感受野就从 3 扩展到 5;若 \(r=4\),则扩展到 9。
扩张卷积特别适合语义分割、语音建模、时间序列和需要多尺度上下文的视觉任务,因为它兼顾了两件事:一方面保留卷积的局部共享权重结构,另一方面又能在较浅层就看到更远范围的信息。它的代价是采样点变稀,若扩张率设计不当,容易出现栅格效应(Gridding Effect),也就是某些局部细节被系统性跳过。因此工程上常把不同扩张率交替堆叠,或与普通卷积、残差块结合使用。
LeNet 可以看作现代卷积神经网络(Convolutional Neural Network, CNN)的原型。它面对的是手写数字识别这类“局部笔画决定整体类别”的任务,因此核心思想很直接:先用卷积层提取局部边缘、角点和笔画,再用池化(Pooling)降低分辨率与局部扰动敏感性,最后把高层特征送入全连接层做分类。
经典 LeNet-5 的结构可以概括为“卷积 - 池化 - 卷积 - 池化 - 全连接”。前面的卷积层负责把原始像素变成越来越抽象的特征图(Feature Map),后面的全连接层负责把这些局部特征整合成类别判断。它的重要性不只是“识别数字有效”,更在于证明了三件事可以协同工作:局部感受野(Local Receptive Field)、权重共享(Weight Sharing)和层级特征提取(Hierarchical Feature Learning)。
卷积层里的一个典型计算是:
\[y_{i,j}^{(k)}=\sum_{u}\sum_{v}\sum_{c} W_{u,v,c}^{(k)}\,x_{i+u,j+v,c}+b^{(k)}\]这里 \(x\) 是输入图像或上一层特征图, \(W^{(k)}\) 是第 \(k\) 个卷积核, \(c\) 是输入通道索引, \((i,j)\) 是空间位置, \(y_{i,j}^{(k)}\) 是输出特征图在该位置上的响应。这个公式表达的就是:用同一个卷积核在整张图上滑动,寻找“哪里出现了我关心的局部模式”。
训练上,LeNet 已经体现出现代深度学习的基本闭环:前向传播得到类别 logits,损失函数衡量预测与真实标签的差距,反向传播把梯度传回卷积核和全连接层参数,再用梯度下降更新权重。它最典型的应用是 MNIST 手写数字识别,也常被用作理解 CNN 的第一块教学样板,因为结构短、计算图清晰、局部模式学习的直觉非常强。
AlexNet 标志着深度卷积网络在大规模视觉识别上的突破。它面对的核心是 ImageNet 级别的彩色自然图像,因此核心思想从“能提特征”进一步推进到“更深、更宽、更可训练”:增加网络容量,用 ReLU(Rectified Linear Unit)加快优化,用 Dropout 缓解过拟合,用数据增强提升泛化,再借助 GPU 让大模型真正训得动。
其典型结构是多层卷积堆叠后接全连接层,早期卷积核较大、步幅较大,用于迅速降采样并提取低层纹理;中后期卷积核变小,重点转向更细粒度的组合特征。AlexNet 还使用了局部响应归一化(Local Response Normalization, LRN)这一今天较少使用、但在当时有历史意义的设计。整体上,它把 CNN 从“可用于小型任务的模型”推向了“可以在大规模视觉基准上碾压传统方法的通用架构”。
它最有代表性的非线性是 ReLU:
\[\mathrm{ReLU}(z)=\max(0,z)\]其中 \(z\) 是线性层或卷积层的输出。与 sigmoid / tanh 相比,ReLU 在正半轴不饱和,梯度传播更直接,因此深层网络更容易优化。AlexNet 的历史意义之一,就是把“激活函数的选择会显著影响深网络可训练性”这件事变成了工程共识。
训练上,AlexNet 典型地结合随机裁剪、翻转、颜色扰动等数据增强,并在全连接层使用 Dropout。它的直接应用是大规模图像分类;更深远的影响则是推动了整个视觉领域转向“预训练 CNN + 迁移学习”的工作流。很多后续检测、分割与检索系统,都曾把 AlexNet 当作特征提取骨干网络(Backbone)。
VGG 的核心思想是:用结构极其规整的小卷积核反复堆叠,把网络做深。它放弃了早期“大卷积核 + 大步幅”的粗放设计,转而几乎全程使用 \(3\times 3\) 卷积,通过增加层数来扩大感受野、提高非线性表达能力,并让整套架构在工程上更统一、更易复用。
VGG 的典型结构非常整齐:若干个 \(3\times 3\) 卷积层组成一个 stage,stage 之间通过池化层下采样,最后再接全连接分类头。它的重要工程思想是“深度本身就是能力来源之一”。相较于更杂糅的早期网络,VGG 的层次感非常强:浅层提边缘和纹理,中层提局部部件,高层提更完整的语义结构。
为什么反复使用 \(3\times 3\) 卷积有效,可以从感受野和参数量两方面理解。两个连续的 \(3\times 3\) 卷积,其有效感受野接近一个 \(5\times 5\) 卷积,但中间多了一次非线性变换,参数量通常还更少。若忽略通道数变化,单层 \(5\times 5\) 卷积大约有 25 个核参数,而两层 \(3\times 3\) 卷积一共是 18 个核参数。
训练上,VGG 比 AlexNet 更依赖较好的初始化、较强的正则化和更大的算力预算,因为它的参数量尤其在全连接部分非常大。它的直接应用是图像分类,但工程上更著名的是作为“通用视觉特征提取器”:在风格迁移、感知损失(Perceptual Loss)、检测与分割早期系统中,VGG 特征长期是强基线。它的代价也很明显:参数多、推理重、显存占用高,这直接推动了后续更高效架构的出现。
若把上一节的“残差学习”放回视觉主线里看,ResNet(Residual Network)就是它在卷积神经网络中的代表性实现。它的关键突破核心是重新设计“深层网络应该学什么”。它提出残差学习(Residual Learning):一层或一组层学习相对于输入的增量,无需直接学习完整映射 \(H(x)\) \(F(x)=H(x)-x\)。这样网络输出就写成:
\[y=F(x)+x\]这里 \(x\) 是块输入, \(F(x)\) 是若干卷积层、归一化和激活组成的残差分支输出, \(y\) 是该残差块的最终输出。若最优映射本身就接近恒等映射(Identity Mapping),那么让网络学习“只改一点点”通常比“从零重建整个映射”更容易优化。
具象地看,普通深网络像要求每一层都重新写一遍完整答案;ResNet 则允许每一层在原答案旁边写批注:需要修改的地方补上增量,不需要改的地方直接走捷径。这个“捷径连接(Skip Connection)”让梯度能沿更短路径传播,因此网络深到几十层、上百层时仍可训练。ResNet 解决的核心问题是深层优化退化(Degradation):层数增加后,训练误差反而上升。
训练上,ResNet 通常结合 BatchNorm、较深的 stage 结构和全局平均池化(Global Average Pooling)来替代庞大的全连接头。它在图像分类上大获成功后,很快成为检测、分割、关键点、视频理解等视觉任务的主流骨干网络。更深远的影响是:残差连接后来成为 Transformer、扩散模型和许多现代深网络的标准部件,因为它本质上是在为深层优化建立稳定的信息主通路。
循环神经网络(Recurrent Neural Network, RNN)按时间步(Time Step)处理序列。第 \(t\) 个时刻输入是 \(x_t\),隐藏状态(Hidden State)递推为:
\[h_t=\phi(W_{xh}x_t+W_{hh}h_{t-1}+b_h),\quad y_t=W_{hy}h_t+b_y\]\(W_{xh}\)(输入到隐层)与 \(W_{hh}\)(隐层到隐层)在所有时刻共享,这是 RNN 能在变长序列上泛化的关键。
把它展开(Unroll)到时间轴上会更直观:同一套参数在每个时间步重复使用,形成一个深度为 \(T\) 的计算图。这也是 RNN 训练常说的“通过时间的反向传播(Backpropagation Through Time, BPTT)”。
RNN 的经典难点是梯度消失/爆炸(Vanishing/Exploding Gradients):反向传播时会反复乘以 \(W_{hh}\) 的雅可比,从而导致梯度范数指数级衰减或增长。LSTM/GRU 通过门控(Gating)与更“线性”的记忆通道缓解这一问题。
Seq2Seq(Sequence-to-Sequence)是任务范式,不限定具体单元。早期 Seq2Seq 常由 RNN/LSTM/GRU 的编码器-解码器(Encoder-Decoder)实现;后续被 Transformer 大规模替代。
“乘法 + 加法 + 非线性”为何有效:线性变换负责特征重表达,非线性激活(Nonlinearity)提供函数逼近能力,时间递推提供记忆路径,三者叠加形成高表达力。
LSTM(Long Short-Term Memory)是为了解决普通 RNN 难以稳定保留长程信息的问题而设计的门控循环结构。它的核心思想核心是显式维护一个记忆单元(Cell State) \(c_t\),并用门控决定“忘掉什么、写入什么、读出什么”。这使得序列中的关键信息可以沿着一条更接近线性的通道向后传播,而不必在每个时间步都被强非线性反复改写。
LSTM 的典型更新写成:
\[f_t=\sigma(W_f x_t+U_f h_{t-1}+b_f),\quad i_t=\sigma(W_i x_t+U_i h_{t-1}+b_i)\] \[\tilde c_t=\tanh(W_c x_t+U_c h_{t-1}+b_c),\quad c_t=f_t\odot c_{t-1}+i_t\odot \tilde c_t\] \[o_t=\sigma(W_o x_t+U_o h_{t-1}+b_o),\quad h_t=o_t\odot \tanh(c_t)\]其中 \(x_t\) 是当前输入, \(h_{t-1}\) 是前一时刻隐藏状态, \(c_{t-1}\) 是前一时刻记忆单元; \(f_t\) 是遗忘门(Forget Gate),控制旧记忆保留多少; \(i_t\) 是输入门(Input Gate),控制当前候选记忆 \(\tilde c_t\) 写入多少; \(o_t\) 是输出门(Output Gate),控制当前记忆暴露给隐藏状态多少; \(\sigma\) 是 sigmoid,把门值压到 \((0,1)\) 区间; \(\odot\) 是逐元素乘法。
具象地看,LSTM 像一条带阀门的记忆水管。普通 RNN 每走一步都把旧信息和新输入一锅重拌,长距离信息容易被冲淡;LSTM 则允许旧记忆沿主管道直接往后流,同时用三个阀门分别控制“放掉旧水”“注入新水”“输出多少”。这正是它能比普通 RNN 更稳定地记住长距离依赖的原因。
训练上,LSTM 仍然通过时间反向传播(BPTT)学习参数,但门控结构显著改善了梯度流。它曾长期是机器翻译、语音识别、语言建模、时间序列预测和序列标注的主力模型。在 Transformer 出现之前,大量 Seq2Seq 系统都建立在双向 LSTM 或多层 LSTM 之上;在某些中小规模时序任务里,LSTM 今天仍然是强而稳的基线。
GRU(Gated Recurrent Unit)可以看作 LSTM 的简化版本。它保留了“用门控控制信息保留与更新”的核心思想,但把记忆单元与隐藏状态合并,不再单独维护 \(c_t\),从而用更少参数换取更紧凑的结构与更快的训练速度。
GRU 的一组典型公式是:
\[z_t=\sigma(W_z x_t+U_z h_{t-1}+b_z),\quad r_t=\sigma(W_r x_t+U_r h_{t-1}+b_r)\] \[\tilde h_t=\tanh(W_h x_t+U_h(r_t\odot h_{t-1})+b_h)\] \[h_t=(1-z_t)\odot h_{t-1}+z_t\odot \tilde h_t\]这里 \(z_t\) 是更新门(Update Gate),决定旧状态保留多少、新候选状态写入多少; \(r_t\) 是重置门(Reset Gate),决定在构造候选状态 \(\tilde h_t\) 时,历史信息应当被参考到什么程度。若 \(z_t\) 很小,模型更倾向保留旧记忆;若很大,模型更倾向用新信息刷新状态。
从直觉上看,GRU 把 LSTM 的三道阀门压缩成两道更紧凑的控制逻辑:一方面决定“要不要更新”,另一方面决定“生成候选更新时要不要忘掉旧状态的一部分”。这让它在很多任务上能以更少参数达到与 LSTM 相近的效果,尤其适合数据量不极大、模型容量受限或推理效率敏感的场景。
训练上,GRU 与 LSTM 一样使用 BPTT。应用上,它常见于语音、时序预测、较轻量的编码器-解码器模型,以及很多工业界的表格时间序列任务。若需要更强的显式记忆控制,LSTM 往往更稳;若更看重结构简洁和训练效率,GRU 常是更自然的选择。
导图里的递归神经网络(Recursive Neural Network)与循环神经网络名字相近,但建模对象不同。RNN 按时间顺序在链式序列上递推;Recursive Neural Network 则沿树结构自底向上组合表示,更适合句法树、短语树或其他层次结构输入。Tree-RNN、Matrix-Vector RNN、Syntactically-Unified RNN 都属于这一支。它们在早期句法分析、情感组合性建模和结构化语义表示中很重要,但在 2026 年已经明显并非主流通用底座,更多作为结构归纳偏置的历史代表存在。
与之相邻的另一条工程线,是在链式序列模型上继续堆叠和增强,例如 Stacked LSTM、LSTM-CRF、Highway Connection。Stacked LSTM 通过多层递推增加表示深度;LSTM-CRF 把序列编码器与结构化解码结合,长期是序列标注强基线;Highway Connection 则让层间信息可以部分直通,缓解深层递推网络的优化困难。它们共同代表了 Transformer 出现之前,序列建模系统如何通过门控、堆叠与结构化解码不断逼近更强表达力的那条主线。
生成模型(Generative Model)关注的核心问题是“数据本身是如何产生出来的”。更形式化地说,它试图学习数据分布 \(p(x)\),或条件分布 \(p(x|c)\),从而能够采样、重建、补全、去噪或按条件生成新样本。不同生成模型的主要差别在于它们选择了不同的概率建模路径:有的学隐变量,有的学博弈过程,有的学逐步去噪,有的更偏重表示压缩。
自编码器(Autoencoder, AE)的核心思想是“先压缩,再重建”。它把输入 \(x\) 通过编码器(Encoder)映射到低维或受约束的隐表示(Latent Representation) \(z\),再通过解码器(Decoder)把 \(z\) 重建回 \(\hat x\)。如果模型在受限瓶颈下仍能较好重建输入,就说明 \(z\) 抓住了数据中的关键结构。
其基本形式可以写成:
\[z=f_{\theta}(x),\qquad \hat x=g_{\phi}(z)\] \[\mathcal{L}_{\mathrm{AE}}=\|x-\hat x\|_2^2\quad \text{或}\quad -\sum_i x_i\log \hat x_i\]这里 \(f_{\theta}\) 是编码器, \(g_{\phi}\) 是解码器, \(z\) 是瓶颈表示, \(\hat x\) 是重建结果。若输入是连续值,常用均方误差;若输入近似二值或归一化到概率意义,常用逐维交叉熵。这个目标迫使模型学习“怎样用更紧凑的表示保存足够重建原样本的信息”。
自编码器本身并不天然是强生成模型,因为它主要学会的是“给定输入怎么重建自己”,而非如何从一个规则、可采样的潜空间中稳定地产生新样本。它更适合理解为表示学习或降维模型。通过在结构或训练目标上增加限制,例如稀疏自编码器(Sparse AE)、去噪自编码器(Denoising AE)或收缩自编码器(Contractive AE),它可以学到更稳健的隐表示。
应用上,AE 常用于降维、异常检测、去噪、预训练和表征学习。例如在工业异常检测里,模型只用正常样本训练,推理时若某个输入无法被良好重建,重建误差就可能提示该样本偏离了正常分布。
变分自编码器(Variational Autoencoder, VAE)是在 AE 基础上把“隐空间可采样”这件事做成概率建模的方案。它从把编码器输出一个确定的潜向量转向输出一个潜变量分布 \(q_{\phi}(z|x)\);同时假设存在生成分布 \(p_{\theta}(x|z)\)。这样,模型既能重建输入,又能从一个规则的潜空间里采样新样本。
VAE 的核心训练目标是证据下界(Evidence Lower Bound, ELBO):
\[\mathcal{L}_{\mathrm{VAE}}=\mathbb{E}_{q_{\phi}(z|x)}[\log p_{\theta}(x|z)]-D_{\mathrm{KL}}\big(q_{\phi}(z|x)\,\|\,p(z)\big)\]其中第一项是重建项,鼓励给定 \(z\) 时能把 \(x\) 生成回来;第二项是 KL 散度(Kullback-Leibler Divergence),把编码器输出的后验近似分布 \(q_{\phi}(z|x)\) 拉向先验分布 \(p(z)\),通常取标准高斯 \(\mathcal{N}(0,I)\)。这一步的作用是把隐空间整理成“规则、连续、可插值、可采样”的形状。
训练上的关键技巧是重参数化(Reparameterization Trick):若直接从 \(q_{\phi}(z|x)\) 采样,梯度难以回传;VAE 通常把采样写成 \(z=\mu+\sigma\odot \epsilon\),其中 \(\epsilon\sim\mathcal{N}(0,I)\),而 \(\mu,\sigma\) 由编码器输出。这样随机性被转移到与参数无关的 \(\epsilon\) 上,梯度就能顺利穿过 \(\mu,\sigma\) 回传。
应用上,VAE 特别适合做潜空间操作,例如插值生成、属性控制、缺失补全和概率建模。与 GAN 相比,VAE 生成结果往往更平滑、更稳定,但图像清晰度常较弱;与扩散模型相比,VAE 在采样效率上更高,但生成质量上通常并非最强路线。
生成对抗网络(Generative Adversarial Network, GAN)的核心思想是对抗式学习:让生成器(Generator)负责“伪造样本”,让判别器(Discriminator)负责“分辨真假”,两者在博弈中共同提高。生成器学会把随机噪声变成越来越像真实数据的样本,判别器则学会识别这些样本是否来自真实分布。
经典 GAN 的目标写成:
\[\min_G\max_D\ V(D,G)=\mathbb{E}_{x\sim p_{\mathrm{data}}}[\log D(x)]+\mathbb{E}_{z\sim p(z)}[\log(1-D(G(z)))] \]这里 \(z\) 是从先验分布中采样的随机噪声, \(G(z)\) 是生成器产生的假样本, \(D(x)\) 输出输入样本为真样本的概率。判别器希望让真实样本分数高、伪样本分数低;生成器则希望骗过判别器,让 \(G(z)\) 看起来足够真实。
具象地看,GAN 像“伪造者”和“鉴定师”的对抗升级。鉴定师越强,伪造者就被迫学会更精细的伪造技巧;伪造者越强,鉴定师也必须学会更细致的辨别规则。理论上,这种动态会把生成分布推向真实数据分布;工程上,它带来的最大问题是训练不稳定,常见现象包括模式崩塌(Mode Collapse)、震荡和判别器过强导致生成器梯度过弱。
GAN 在图像生成、图像翻译、超分辨率和风格迁移里曾经极其成功,因为它特别善于生成锐利、感知上真实的图像纹理。但它对训练技巧依赖很强,后来在大规模高保真图像生成上逐渐被扩散模型压过;即便如此,GAN 在需要低步数快速生成或特定视觉变换任务中仍然很有生命力。
扩散模型(Diffusion Model)的核心思想是:把“直接学会生成复杂数据”拆成“先逐步加噪,再逐步去噪”这条更稳定的路径。前向过程把真实样本一步步污染成近似高斯噪声,反向过程则训练一个神经网络学会在每一步去掉一小部分噪声。最终从纯噪声出发,经过多步反向去噪,就能逐步生成结构清晰的样本。
记号上,前向扩散链从真实样本 \(x_0\) 出发,依次得到 \(x_1,x_2,\dots,x_T\)。因此 \(x_0\) 表示原始数据样本, \(x_t\) 表示第 \(t\) 步加噪后的样本。
一个常见的前向加噪过程写成:
\[q(x_t|x_{t-1})=\mathcal{N}\!\left(x_t;\sqrt{1-\beta_t}\,x_{t-1},\beta_t I\right)\]这里 \(\beta_t\) 是第 \(t\) 步的噪声强度:它控制从 \(x_{t-1}\) 走到 \(x_t\) 时,原信号衰减多少、随机噪声注入多少。训练时常把从 \(x_0\) 到 \(x_t\) 的若干步合并写成
\[x_t=\sqrt{\bar\alpha_t}\,x_0+\sqrt{1-\bar\alpha_t}\,\epsilon,\qquad \epsilon\sim\mathcal{N}(0,I)\]这里 \(\bar\alpha_t\) 是由噪声日程(Noise Schedule)累乘得到的系数,控制到第 \(t\) 步时,原始信号保留了多少、噪声混入了多少。实际训练中,网络通常不直接预测 \(x_0\),通常会预测噪声 \(\epsilon\),典型损失是:
\[\mathcal{L}_{\mathrm{diff}}=\mathbb{E}\big[\|\epsilon-\epsilon_{\theta}(x_t,t)\|_2^2\big]\]这条路径之所以有效,在于“预测一步噪声”比“直接一次生成整张复杂图片”更容易优化。训练上,扩散模型相对稳定,较少出现 GAN 那种对抗不平衡;代价是采样通常需要多步迭代,推理速度较慢。应用上,扩散模型已经成为图像生成、文生图、图像编辑、超分辨率、视频生成和分子设计的重要主线。Stable Diffusion 一类系统,本质上就是把扩散过程放到了潜空间(Latent Space)里执行,以降低像素空间扩散的计算成本。
图神经网络(Graph Neural Network, GNN)处理的对象核心是由节点(Node)和边(Edge)组成的图(Graph)。它的核心问题是:当样本之间存在不规则连接关系时,如何让一个节点的表示同时反映“自己的特征”和“邻居结构中的上下文”。因此,GNN 的基本直觉核心是让节点在图上传递消息、聚合邻居信息,再更新自身表示。
图卷积网络(Graph Convolutional Network, GCN)把卷积思想推广到图结构上。它的核心思想是:一个节点的新表示,不应只由自己决定,还应由其邻居节点的表示共同决定;但这种聚合不能简单相加,而需要根据图结构做适当归一化,否则高度节点会在信息聚合中占据过大权重。
GCN 的经典一层更新公式写成:
\[H^{(l+1)}=\sigma\!\left(\tilde D^{-1/2}\tilde A\tilde D^{-1/2}H^{(l)}W^{(l)}\right)\]其中 \(H^{(l)}\) 是第 \(l\) 层所有节点的表示矩阵; \(W^{(l)}\) 是该层可学习权重; \(\tilde A=A+I\) 表示在原邻接矩阵 \(A\) 上加自环(Self-loop),让节点保留自己的信息; \(\tilde D\) 是 \(\tilde A\) 的度矩阵(Degree Matrix); \(\sigma\) 是非线性激活。中间那项对邻居求和并按度做归一化,本质上是在做“平滑的邻居平均”。
具象地看,GCN 像在社交网络里更新一个人的画像:不仅看这个人自己填写的特征,还参考他一跳邻居的大致特征,再做归一化,避免“朋友特别多的人”把自己的表示稀释得过于严重。多层堆叠后,一个节点就能间接接触到两跳、三跳甚至更远范围的信息。
训练上,GCN 常用于节点分类、图分类和链路预测。它的经典应用包括引文网络分类、分子图预测和推荐系统图表示学习。局限也很典型:层数太深时,节点表示会越来越相似,出现过平滑(Oversmoothing);大图上直接用全图邻接矩阵训练也会带来显存与计算压力。
图注意力网络(Graph Attention Network, GAT)在 GCN 的“统一归一化邻居平均”之上进一步提出:不同邻居的重要性不应被预先固定,而应由模型动态学习。它的核心思想是把注意力机制引入图结构,使每个节点在聚合邻居时,能够自适应决定“更该听谁的话”。
一层 GAT 的典型计算是:
\[e_{ij}=a(Wh_i,Wh_j),\qquad \alpha_{ij}=\frac{\exp(e_{ij})}{\sum_{k\in \mathcal{N}(i)}\exp(e_{ik})}\] \[h_i'=\sigma\!\left(\sum_{j\in \mathcal{N}(i)} \alpha_{ij}\,Wh_j\right)\]这里 \(h_i\) 是节点 \(i\) 的输入表示, \(W\) 是线性变换矩阵, \(a(\cdot,\cdot)\) 是注意力打分函数, \(e_{ij}\) 是节点 \(j\) 对节点 \(i\) 的未归一化重要性分数, \(\alpha_{ij}\) 是在邻居集合 \(\mathcal{N}(i)\) 内 softmax 归一化后的注意力权重。
与 GCN 相比,GAT 的关键收益是更灵活:若某个邻居特别重要,模型可以给它更高权重;若某个邻居噪声较大,则可自动抑制。训练上,GAT 仍通过监督或自监督目标学习节点表示,常用多头注意力(Multi-head Attention)稳定训练。应用上,它常见于异质关系更复杂、邻居重要性差异显著的图任务,例如社交网络分析、知识图谱局部推断和分子性质预测。
GraphSAGE(Graph Sample and Aggregate)的核心思想是把 GNN 从“转导式(Transductive)图编码”推进到“归纳式(Inductive)图表示学习”。传统 GCN 常依赖整张训练图;GraphSAGE 则强调:即使测试时出现训练中未见过的新节点,只要能拿到它的邻居特征,也应能在线生成它的表示。
其典型更新形式是先采样邻居,再做聚合:
\[h_{\mathcal{N}(v)}^{(k)}=\mathrm{AGG}^{(k)}\big(\{h_u^{(k-1)}:u\in \mathcal{N}(v)\}\big)\] \[h_v^{(k)}=\sigma\!\left(W^{(k)}[h_v^{(k-1)}\|h_{\mathcal{N}(v)}^{(k)}]\right)\]这里 \(h_v^{(k)}\) 是节点 \(v\) 在第 \(k\) 层的表示, \(\mathcal{N}(v)\) 是其邻居集合, \(\mathrm{AGG}\) 可以是均值、池化或 LSTM 聚合器, \([\cdot\|\cdot]\) 表示向量拼接。GraphSAGE 的关键工程点是“采样”,因为超大图中不可能每次把全部邻居完整展开。
具象地看,GraphSAGE 像为每个节点建立一套“从邻居摘要中构造自我画像”的规则。它不要求记住整张训练图中每个节点的专属嵌入,重点是学会一套可迁移的邻域聚合函数。这正是它能处理新节点、动态图和大规模图数据的原因。
应用上,GraphSAGE 在推荐系统、社交网络、风控图谱和工业知识图谱中非常常见,因为这些场景经常不断出现新节点、新边,归纳式能力比单纯在固定图上做转导预测更重要。
消息传递(Message Passing)核心是理解 GNN 的统一抽象框架。无论是 GCN、GAT 还是 GraphSAGE,本质上都可以拆成两步:第一步,节点从邻居那里接收消息;第二步,把这些消息与自己的旧表示结合,更新成新的节点表示。
这一抽象常写成:
\[m_v^{(l+1)}=\mathrm{AGG}\Big(\{M^{(l)}(h_v^{(l)},h_u^{(l)},e_{uv})\,:\,u\in\mathcal{N}(v)\}\Big)\] \[h_v^{(l+1)}=U^{(l)}\big(h_v^{(l)},m_v^{(l+1)}\big)\]其中 \(h_v^{(l)}\) 是节点 \(v\) 在第 \(l\) 层的表示, \(e_{uv}\) 是边特征, \(M^{(l)}\) 是消息函数,决定一条边上传递什么信息; \(\mathrm{AGG}\) 是聚合函数,如求和、均值、最大值或注意力加权和; \(U^{(l)}\) 是更新函数,把旧表示与聚合后的消息合成为新表示。
这个框架的重要性在于,它把看似不同的图模型放进了一套统一语言里:GCN 相当于使用归一化线性消息与均值式聚合,GAT 相当于把注意力权重写进聚合,GraphSAGE 相当于强调采样与归纳式聚合。理解了消息传递,就能把很多图模型看成“消息函数、聚合函数、更新函数”三处设计选择的不同组合。
训练上,消息传递式 GNN 常用于三类任务:节点级任务(例如节点分类)、边级任务(例如链路预测)、图级任务(例如分子性质预测)。它们的共同难点包括:过平滑、邻居爆炸(Neighborhood Explosion)、异质图关系复杂,以及深层堆叠后长程依赖难以稳定传播。很多现代 GNN 改进,本质上都在围绕这几个瓶颈重新设计消息传递规则。
ONNX(Open Neural Network Exchange,开放神经网络交换格式)是一种描述机器学习模型的开放标准。它的核心作用,核心是把已经定义并训练好的神经网络表示成一种可交换、可部署、跨框架可读的中间格式,使模型能够从训练环境转移到不同推理环境中运行。
训练阶段常用 PyTorch、TensorFlow、JAX 等框架;部署阶段则常落到 ONNX Runtime、TensorRT、OpenVINO、移动端推理引擎或嵌入式执行环境。问题在于,这些系统各自拥有不同的内部表示方式、图执行器和算子实现,原生模型格式并不天然互通。ONNX 解决的正是这条链路中的“中间表示”问题。
可以把 ONNX 理解为模型世界里的 PDF:训练框架先把网络导出为 .onnx 文件,部署侧再由相应 runtime 读取、优化并执行。它并不同于某一种具体推理引擎,而更像一个让不同框架与部署后端彼此对接的交换层。
从结构上看,ONNX 文件本质上是一份静态计算图(Static Computation Graph)加权重参数的描述。其中通常包含四类核心信息:
- 计算图:模型由哪些算子组成,例如卷积(Conv)、矩阵乘法(MatMul)、归一化、激活、注意力等。
- 张量元信息:输入、输出与中间张量的形状(Shape)和数据类型(Data Type)。
- 参数权重:训练后得到的权重矩阵、偏置和其他可学习参数;大模型也可能采用外部权重文件。
- 算子版本信息:模型依赖的 ONNX opset 版本,以及每个算子的语义约定。
这种表示方式的关键价值,是把“Python 前向代码如何写”转写成“部署时应该执行哪条算子图”。一旦导出完成,部署系统通常从依赖训练时的 Python 类定义转向按 ONNX 图里的算子与依赖关系直接执行。
| 场景 | 说明 |
| 部署加速 | 交给 ONNX Runtime、TensorRT 等后端做图优化、算子融合、低精度执行和量化推理 |
| 跨框架部署 | 例如用 PyTorch 训练,再导出 ONNX,交由另一套推理栈加载运行 |
| 多端适配 | 同一模型可进一步转接到服务器、边缘设备、移动端或嵌入式环境,前提是目标引擎支持相应算子 |
在 PyTorch 生态里,ONNX 最常见的入口是导出。开发者通常先在 PyTorch 中定义并训练模型,再用 torch.onnx.export(...) 把模型转换成 ONNX 图。这个过程的本质,是把 PyTorch 里的前向路径从“解释执行的 Python 模块”改写成“显式算子图”。
导出之后,部署侧执行的已从原始 Python 前向代码转向 ONNX 图中的算子序列。因此,依赖复杂动态控制流、框架私有算子或运行时分支逻辑的模型,在导出时往往需要额外改写、简化或替换成更可静态化的结构。
ONNX 的价值很大,但它并非“只要导出就一定能无缝部署”的万能格式。第一,并非所有训练框架中的算子都存在完美的 ONNX 映射,复杂模型可能导出失败,或需要改写成等价但更标准的图结构。第二,不同推理引擎对 ONNX 的支持程度并不完全一致:即使同样读取 ONNX 文件,也可能只支持某些 opset 版本或某一部分算子子集。第三,ONNX 更适合表达相对稳定的前向计算图;当模型强依赖高度动态的运行逻辑时,静态导出路径会更受约束。
因此,ONNX 的更贴切定位是训练环境与部署环境之间的中间表示层。它的意义在于把模型从原始框架内部释放出来,交给更适合推理、优化和跨平台执行的后端系统。
Leave a Reply