Apache Drill学习笔记
Apache Drill是一个模式自由(Schema-free )的、低延迟的、分布式的、可扩容的SQL查询引擎,可以让你使用熟悉的SQL语法对各种非关系型数据库进行操作。Drill支持针对PB级别数据的即席查询。Drill支持大量NoSQL数据和文件系统,包括MongoDB、HBase、HDFS。支持对不同数据源中的数据进行join操作。Drill支持Windows/Linux/Mac系统,可以很容易的在服务器集群中扩容。
Drill的优势包括:
- 支持模式自由的JSON模型,Drill是第一个、目前也是唯一的不对Schema做任何要求的分布式SQL引擎。这种模式自由类似于MongoDB。Drill在查询执行过程中可以自动发现Schema
- 即席的查询复杂的、半结构化的数据。你不需要对数据进行任何转换,Drill对SQL进行了直观的扩展,方面处理内嵌数据,就好像内嵌数据是普通的SQL列一样
- 真实的SQL语言,Drill支持标准的SQL 2003语法。支持DATE, INTERVAL, TIMESTAMP, VARCHAR等数据类型,以及关联子查询、JOIN子句
- 方便的和既有BI工具集成
- 针对Hive表的交互式查询
- 同时访问多个数据源
- 用户自定义函数支持,直接支持Hive用户定义函数
- 高性能、可扩容
Drill的核心是Drillbit服务,它负责接受客户请求、处理查询、返回查询结果。Drillbit可以被安装到并运行在数据库集群的所有节点上,这样在执行查询时可以减少网络流量。Drill通过ZooKeeper来维护集群成员状态、检查健康状况。
当你以SQL的形式发起一个查询时,查询被发送给Drill集群中的一个Drillbit,这个Drillbit成为领头(Foreman),它负责协作其它Drillbit以完成查询执行:
- 解析SQL语句,将SQL操作符转换为Drill理解的逻辑操作符。这些逻辑操作符共同组成了逻辑执行计划,描述了生成查询结果所需的操作、哪些数据源需要参与其中
- Foreman把逻辑计划发送给基于成本的优化器,优化操作符的顺序,最终转换为物理执行计划
- Foreman中的并行器(parallelizer)把物理计划分为多个阶段 —— major/minor fragments。这些片断会并行的在所配置的数据源中执行
构成执行计划的一个阶段,每个阶段可以由1-N个主片断构成,这些片断代表完成此阶段Drill必须执行的操作。Drill为每个主片段分配一个ID。
例如,为了针对两个文件进行哈希聚合,Drill可能创建具有两个阶段的查询计划,每个计划包含一个主片断。第一个阶段专注于扫描文件,第二个阶段则专注于数据的聚合。
Drill使用exchange operator来分隔多个主片段,所谓exchange可以是:
- 数据位置的变化,或/和
- 物理计划的并行化
一个exchange由sender/receiver组成,允许数据在节点之间流动。
主片断本身不负责任何查询任务的实际执行。每个主片段包含若干个从片断,从片断负责执行并完成查询。
你可以获得物理计划的JSON表示,修改之,然后通过Drill的SUBMIT PLAN命令提交执行。
每个主片断被并行化为多个从片断。从片断是运行在一个线程内的逻辑工作单元(也叫slice)。每个从片断被分配一个ID。
Foreman中的并行器在执行期间把一个主片段拆分为1-N个从片断。Drill会根据数据局部性(data locality)把从片断调度到特定的节点上,并尽快的执行从片断(根据上流数据需求)。
从片断包含1-N个关系操作符,关系操作符执行关系型操作,例如scan, filter, join,group by。
从片断们可以形成树形结构,并分为root、intermediate、leaf三种角色。这种执行树仅仅包含一个运行在Foreman上的root从片断,需要执行的操作逐级下发,直到leaf从节点。leaf从节点与存储层交互或者访问磁盘数据,得到部分的结果,由上级节点进行聚合操作。
每个Drillbit都由以下模块组成:
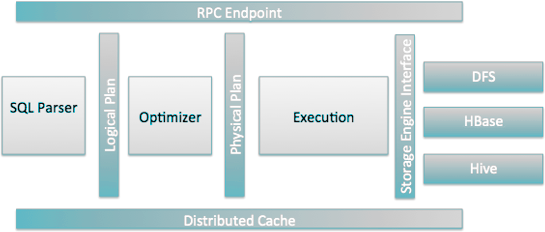
Drill暴露的低资源消耗的RPC协议,用于客户端连接。客户端可以直接连接到Drillbit,或者通过ZooKeeper连接。推荐使用后一种方式,以隔离Drill集群变化造成的影响。
基于开源SQL解析器Calcite实现,用于解析客户端请求。解析结果是语言无关、计算机友好的逻辑计划。
屏蔽特定数据存储的差异性。存储插件的功能包括:
- 从数据源获取元数据
- 读写数据
- 数据位置感知、一系列优化规则
访问Drill的途径包括:
- Drill Shell
- Drill Web Console
- ODBC/JDBC
- C++ API
如果仅仅在单个节点上使用Drill,可以使用嵌入式安装。这种模式下,不需要安装ZooKeeper,也不需要进行配置。当你启动Drill shell时,本地的Drillbit服务自动启动。
安装步骤:
|
1 2 |
wget http://apache.mirrors.hoobly.com/drill/drill-1.11.0/apache-drill-1.11.0.tar.gz tar xzf apache-drill.tar.gz |
要运行Drill,执行下面的命令以打开Drill Shell:
|
1 2 3 4 5 6 |
drill-embedded 0: jdbc:drill:zk=local> # 命令提示符说明: # 0 表示连接到drill的连接数 # jdbc为连接类型 # zk=local 作为ZooKeeper的代替 |
或者执行 sqlline -u "jdbc:drill:zk=local"
要退出Drill Shell,在Shell中输入 !quit
要访问Web Console,在浏览器地址栏输入 http://127.0.0.1:8047/
要在Hadoop集群环境下使用Drill,可以使用分布式安装。ZooKeeper的分布式集群是必须的前提,你也需要对Drill进行配置,才能连接到各种数据源。
下载、解压后,修改配置文件:
|
1 2 3 4 5 6 |
drill.exec: { # Drill集群标识符 cluster-id: "drillbits", # ZooKeeper连接字符串 zk.connect: "172.21.0.1:2181,172.21.0.2:2181,172.21.0.3:2181" } |
要以集群模式启动Drill,首先需要在集群的每个节点上启动守护程序Drillbit:
|
1 2 |
# 命令格式:drillbit.sh [--config <conf-dir>] (start|stop|status|restart|autorestart) /home/alex/JavaEE/middleware/drill/bin/drillbit.sh --config /home/alex/JavaEE/middleware/drill/conf start |
要连接到分布式部署的Drill Shell,可以:
- 执行drill-conf,此脚本使用conf/drill-override.conf配置
- 执行drill-localhost连接到运行在本机的ZooKeeper
连接上以后,可以执行 SELECT * FROM sys.drillbits;查询Drill集群成员信息。
参考如下Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
FROM openjdk:8-jre ENV CLUSTER_ID drillbits ENV ZK_CONNECT 172.21.0.1:2181 RUN apt-get install -y wget tar ADD docker-entrypoint.sh . ADD apache-drill.tar.gz . RUN chmod +x docker-entrypoint.sh && mv apache-drill-1.11.0 /opt/drill ENTRYPOINT ["/docker-entrypoint.sh"] |
入口脚本:
|
1 2 3 4 5 6 7 8 9 10 |
#!/usr/bin/env bash cat << EOF > /opt/drill/conf/drill-override.conf drill.exec: { cluster-id: "$CLUSTER_ID", zk.connect: "$ZK_CONNECT" } EOF /opt/drill/bin/drillbit.sh --config /opt/drill/conf run |
创建并运行容器:
|
1 2 |
docker run -e ZK_CONNECT=172.21.0.1:2181,172.21.0.2:2181,172.21.0.3:2181 --name drill-14 \ --network local --ip 172.21.1.14 -d docker.gmem.cc/drill |
你可以配置分配给Drillbit的用于处理查询的直接内存的量。默认配置是8G,在高负载下可能需要16G或者更多。
Drill使用Java的直接内存来存储执行中的操作,除非必须,它不会使用磁盘。这和MapReduce不同,后者将任务每个阶段的输出都存放在磁盘上。JVM的堆内存不限制Drillbit能够使用的直接内存。Drillbit的堆内存通常设置到4-8G就足够了,因为Drill避免在堆中写数据。
从1.5版本开始,Drill使用新的直接内存分配器,可以更好的使用、跟踪直接内存。由于这一变化,sort操作符可能因为内存不足而失败。
系统选项 planner.memory.max_query_memory_per_node 设置单个Drillbit中每个查询的sort操作符能够使用的内存量。如果一个查询计划中包含多个sort操作符,它们共享这一内存。如果sort查询出现内存问题,考虑增加此选项的值。如果问题仍然存在,考虑减小系统选项planner.width.max_per_node的值,该值控制单个节点的并行度。
在drill-env.sh中设置环境变量:
|
1 2 3 4 |
# 如果堆内存没有设置,将其设置为4G export DRILL_HEAP=${DRILL_HEAP:-"4G”} # 如果直接内存没有设置,将其设置为8G export DRILL_MAX_DIRECT_MEMORY=${DRILL_MAX_DIRECT_MEMORY:-"8G"} |
Drill提供两种角色:
| 角色 | 说明 |
| USER | 可以对具有访问权限的数据执行查询。每个存储插件负责读写权限的管理 |
| ADMIN |
当启用身份验证时,仅仅具有Drill集群管理员角色的用户能够执行以下任务:
|
用户身份模拟(Impersonation)允许一个服务代表客户端执行某个操作。默认的,身份模拟被关闭。
Drill支持基于Linux PAM的身份验证。PAM允许和系统密码文件(/etc/passwd)或者LDAP等PAM实体进行交互以完成身份验证。
使用PAM验证时,运行Drill查询的用户必须存在于每一个Drill节点上。
Drill支持Kerberos v5网络认证、客户端 - Drill的通信加密。需要配合JDBC驱动来使用该认证方式。
在启动时,一个Drillbit必须被验证。在运行时Drill使用和KDC共享的keytab文件,Drill使用该文件来验证票据的合法性。
配置 security.user.encryption.sasl.enabled参数为true,可以启用Kerberos加密 —— 保证客户端到Drillbit的数据安全。
你需要为Drill创建principal,可以:
|
1 2 3 4 |
kadmin # 一个集群使用单个实体 # addprinc <username>/<clustername>@<REALM>.COM addprinc drill/drillbits@GMEM.CC |
你需要为上面的principal创建一个keytab文件:
|
1 |
ktadd -k /home/alex/JavaEE/middleware/drill/conf/drill.keytab drill/drillbits@GMEM.CC |
然后,为Drill配置文件添加:
|
1 2 3 4 5 6 7 8 9 |
drill.exec: { security: { user.auth.enabled: true, user.encryption.sasl.enabled: true, auth.mechanisms: ["KERBEROS"], auth.principal: "drill/drillbits@GMEM.CC", auth.keytab: "/home/alex/JavaEE/middleware/drill/conf/drill.keytab" } } |
并重启。
你可以在conf/drill-override.conf中配置启动选项,其中最常用的如下表:
| 选项 | 说明 |
| drill.exec.http.ssl_enabled | 布尔(TRUE|FALSE),默认FALSE。是否启用HTTPS支持 |
| drill.exec.sys.store.provider.class | 设置持久化存储提供者(PStore),PStore保存配置数据、Profile |
| drill.exec.buffer.size | 缓冲区大小,增加此配置可以加快查询速度 |
| drill.exec.sort.external.spill.directories | 进行Spool操作时使用的目录 |
| drill.exec.zk.connect | 提供ZooKeeper连接字符串 |
| drill.exec.profiles.store.inmemory | 布尔,默认FALSE。是否在内存中存放查询Profiles |
| drill.exec.profiles.store.capacity | 上个选项取值TRUE时,内存中最多存放的查询Profiles数量 |
Drill通过存储插件(Storage)连接到底层数据源。存储插件通常负责:
- 连接到数据源,例如数据库、文件
- 优化Drill查询的执行
- 提供数据的位置信息
- 配置工作区、文件格式以读取数据
常用的几个存储插件跟随Drill一起安装
所谓插件配置,就是连接到目标数据源的配置信息。Drill默认注册了这几个默认的插件配置:
| 插件配置 | 说明 |
| cp | 指向Drill类路径中的JAR文件,你可以对其中的文件进行查询 |
| dfs | 指向本地文件系统。你可以使用对应的存储引擎配置指向任意分布式系统,例如Hadoop |
| hbase | 提供到HBase的连接 |
| hive | 将Drill和Hive的元数据抽象(文件、HBase)机制集成 |
| mongo | 提供到MongoDB的连接 |
通过Web Console连接(地址示例:http://172.21.1.14:8047/storage),可以注册插件配置。
点击Disable按钮可以禁用当前的配置,禁用后,show databases中对应的条目消失。点击Enable可以启用某个可用配置。输入存储插件名称,点击Create,可以建立新的插件配置。
插件配置都是JSON格式,MongoDB配置的示例:
|
1 2 3 4 5 |
{ "type": "mongo", "connection": "mongodb://root:root@mongo-s1.gmem.cc:27017/", "enabled": true } |
打开drill-conf,输入命令验证连接是否正常:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
0: jdbc:drill:> show databases; +---------------------+ | SCHEMA_NAME | +---------------------+ | INFORMATION_SCHEMA | | mongo.admin | | mongo.bais | | mongo.config | | sys | +---------------------+ # 上面的结果意味着已经连接到此配置,注意数据库名称的前缀,就是配置的名称 use mongo.bais; select regNo,stocks[0].stockName as stock0Name from corps; +----------------+-------------+ | regNo | stock0Name | +----------------+-------------+ | 3208261000000 | 汪震 | +----------------+-------------+ # 上面的结果意味着查询测试成功 |
除了Shell、Web Console以外,Drill还提供C++ API以及JDBC、ODBC驱动。
添加依赖以使用此驱动:
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.drill.exec</groupId> <artifactId>drill-jdbc</artifactId> <version>1.11.0</version> </dependency> |
|
1 2 |
# jdbc:drill:zk={ZooKeeper连接字符串}/drill/{Drill集群标识符};schema={存储插件配置.数据库名称} jdbc:drill:zk=zookeeper-1.gmem.cc:2181,zookeeper-2.gmem.cc:2181,zookeeper-3.gmem.cc:2181/drill/drillbits;schema=mongo.bais |
|
1 2 3 4 5 6 7 8 |
Class.forName( "org.apache.drill.jdbc.Driver" ); String url = "jdbc:drill:zk=zookeeper-1.gmem.cc:2181/drill/drillbits;schema=mongo.bais"; Connection connection = DriverManager.getConnection( url ); Statement st = connection.createStatement(); ResultSet rs = st.executeQuery( "select regNo,stocks[0].stockName as stock0Name from corps" ); while ( rs.next() ) { System.out.println( rs.getString( 2 ) ); } |
所谓复杂数据结构,是指与关系型数据库那种简单的表格形式(行、字段)不同的,具有复杂数据类型字段(内嵌结构)的数据结构。
Drill可以在执行查询请求的时候,发现数据的结构。类似于JSON、Parquet之类的嵌套数据结构不仅仅可以被简单的访问,Drill还提供特殊的操作符、函数对其进行钻取操作。这些操作符、函数能够:
- 引用内嵌数据结构的值
- 访问数组元素、嵌套数组
你可以使用SQL标准的join子句来连接两个表或/和文件。示例:
|
1 |
select c.regNo, c.corpName, o.name from corps as c join orgs as o on c.belongOrg = o._id where c.regCapi > 10000; |
|
1 2 3 4 5 |
-- 访问内嵌文档 select c.address.detail as addr from corps as c; -- 访问内嵌数组 select c.stocks[0].stockName from corps as c; select c.stocks[0].stockName, c.stocks[0].subsCapi from corps as c; |
Drill使用Logback作为默认的日志系统,日志配置位于conf/logback.xml。
默认的,日志被输出到文件系统,位于$DRILL_HOME/logs目录下,你可以在drill-env.sh中设置$DRILL_HOME环境变量。在每个Drill节点上,文件drillbit_queries.json记录每个查询的ID、profile信息。
要获得查询的执行计划,执行 explain plan for语句,示例:
|
1 |
explain plan for select regNo,corpName from bais.corps; |
从输出结果中,可以看到Drill如何访问底层数据源:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# explain plan for select regNo,corpName from bais.corps where regNo like '3208%'; 00-00 Screen 00-01 Project(regNo=[$0], corpName=[$1]) 00-02 UnionExchange 01-01 Scan(groupscan=[MongoGroupScan [MongoScanSpec=MongoScanSpec [dbName=bais, collectionName=corps, filters=null], columns=[`regNo`, `corpName`]]]) # 没有过滤器,意味着需要全表扫描 # explain plan for select regNo,corpName from bais.corps where regNo > '320800100' and regNo < '320800200' limit 10; 00-00 Screen 00-01 Project(regNo=[$0], corpName=[$1]) 00-02 SelectionVectorRemover 00-03 Limit(fetch=[10]) 00-04 UnionExchange 01-01 SelectionVectorRemover 01-02 Limit(fetch=[10]) 01-03 Scan(groupscan=[MongoGroupScan [MongoScanSpec=MongoScanSpec [dbName=bais, collectionName=corps, filters=Document{{$and=[Document{{regNo=Document{{$gt=320800100}}}}, Document{{regNo=Document{{$lt=320800200}}}}]}}], columns=[`regNo`, `corpName`]]]) # 这里可以看到使用了MongoDB的查询过滤,可能利用到索引 |
Drill支持ANSI标准SQL,你可以使用统一的语法查询各种数据源。为了支持嵌套数据结构,Drill提供特殊的操作符和函数。
| 数据类型 | 说明 |
| BIGINT | 8字节有符号整数 |
| BINARY | 变长二进制字符串,示例:B@e6d9eb7 |
| BOOLEAN | 布尔值,示例:true |
| DATE | YYYY-MM-DD格式的日期 |
| DECIMAL(p,s) DECIMAL(p,s) NUMERIC(p,s) | 38位精度数字 |
| FLOAT | 4字节浮点数 |
| DOUBLE | 8字节浮点数 |
| INTEGER INT | 4字节有符号整数 |
| INTERVAL | 日/月时间间隔 |
| SMALLINT | 2字节有符号整数 |
| TIME | HH:mm:ss格式的日期 |
| TIMESTAMP | yyyy-MM-dd HH:mm:ss.SSS格式的时间戳 |
| CHARACTER VARYING CHARACTER CHAR VARCHAR | UTF-8字符串 |
| Map | 键值对形式的容器,KVGEN、FLATTEN函数用于处理此类型 |
| Array | 数组形式的容器,FLATTEN函数用于处理此类型 |
使用CAST、CONVERT TO/FROM、TO_CHAR、TO_DATE、TO_NUMBER、TO_TIMESTAMP,可以进行显式的类型转换。某些类型之间可以进行隐式转换,NULL可以转换到任何类型。示例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
-- CAST (<expression> AS <data type>) CAST( regNo as INT ) -- 把目标列转换为字节 CONVERT_TO (column, type) -- 把regNo作为大端整数,转换为字节 CONVERT_TO(regNo , 'INT_BE') -- 把字节转换为type CONVERT_FROM(column, type) -- 把字符串转换为JSON map CONVERT_FROM('{x:100, y:215.6}' ,'JSON') -- TO_CHAR (expression, 'format') 转换数字、日期、时间、时间戳为字符串形式 SELECT TO_CHAR(1256.789383, '#,###.###') FROM (VALUES(1)); -- 1,256.789 TO_CHAR((CAST('2008-2-23' AS DATE)), 'yyyy-MMM-dd') -- 2008-Feb-23 TO_CHAR(CAST('12:20:30' AS TIME), 'HH mm ss' -- 12 20 30 TO_CHAR(CAST('2015-2-23 12:00:00' AS TIMESTAMP), 'yyyy MMM dd HH:mm:ss') -- 2015 Feb 23 12:00:00 -- TO_DATE (expression [, 'format']) 转换字符串或者UNIX时间戳为日期 TO_DATE('2015-FEB-23', 'yyyy-MM-dd') -- TO_TIME (expression [, 'format']) 转换为时间 TO_TIME('12:20:30', 'HH:mm:ss') TO_TIME(82855000) -- TO_TIMESTAMP (expression [, 'format']) TO_TIMESTAMP('2008-2-23 12:00:00', 'yyyy-MM-dd HH:mm:ss') |
主要分为数学、日期、字符串、聚合等函数,参考官方文档。
窗口函数针对一系列行进行计算操作,并为每一行返回单个值。这些值虽然归属到某个行,但是它可能取决于其它多个行(这些行就是所谓窗口)。
你可以使用 OVER()来定义一个窗口,此子句将窗口函数与其它的聚合类函数区分开来,一个查询可以使用多个窗口函数(对应一个或者多个窗口定义)。OVER()子句能够:
- 定义对行进行分组(partition)的标准,聚合函数在这些分组上进行。这通过PARTITION BY子句实现
- 在一个分组内部,对行进行排序。这通过ORDER BY子句实现
对于窗口函数,你需要注意:
- 仅仅支持在查询的SELECT、ORDER BY字句中使用窗口函数
- Drill在WHERE, GROUP BY, HAVING之后处理窗口函数
- 在聚合函数之后跟随OVER()导致其作为窗口函数使用
- 使用窗口函数,你可以针对窗口帧中任意数量的行进行聚合
- 如果要针对FLATTEN子句的生成的结果集执行窗口函数,应该在子查询中使用FLATTEN
窗口函数完整的调用语法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- window_function指定一种窗口函数,这些函数可能和普通的聚合函数同名,识别它是否为窗口函数的唯一方法就是看看 -- 后面有没有OVER关键字。窗口函数在窗口内部进行聚合 -- expression 为列表达式 -- PARTITION BY关键字定义了窗口: -- expr_lists 可以是 expression | column_name [, 其它expr_list ] -- ORDER BY 定义窗口内排序规则,如果没有PARTITION BY则针对整个表格排序 -- order_lists 可以是 expression | column_name [ASC | DESC] [ NULLS { FIRST | LAST } ] [, 其它 order_list ] -- frame_clause 可以是: -- { RANGE | ROWS } frame_start -- { RANGE | ROWS } BETWEEN frame_start AND frame_end -- frame_start 格式:UNBOUNDED PRECEDING 或者 CURRENT ROW -- frame_end 格式:CURRENT ROW 或者 UNBOUNDED FOLLOWING window_function (expression) OVER ( [ PARTITION BY expr_list ] [ ORDER BY order_list ][ frame_clause ] ) |
| 窗口函数分类 | 说明 |
| 聚合 | AVG() 计算平均值、COUNT()计算总数、MAX()计算最大值、MIN()计算最小值、SUM()求和 |
| 排名 | 返回当前行在分组中的排名:
|
| 值 |
|
|
1 2 3 4 5 |
-- 查询企业信息,为结果集的每一行增加列:当前企业类型的平均注册资金 select cast(c.corpName as char) corpName, c.corpType, avg( c.regCapi ) over( partition by c.corpType) as avgRegCapi from bais.corps c where c.regNo >= '320100100' and c.regNo < '320100200'; |
嵌套数据函数用于访问内嵌式的数据结构,包括数组、映射、重复标量类型。不要在GROUP BY、ORDER BY子句或者在比较操作符中使用前述内嵌数据。Drill不支持 VARCHAR:REPEATED之间的比较。
把嵌套数据结构分解为单独的记录(行),示例:
|
1 2 |
-- 每个企业包含多个股东,股东为数组 SELECT FLATTEN(stocks) FROM bais.corps WHERE stocks IS NOT NULL; |
从一个映射中抽取键值对
返回数组的长度: REPEATED_COUNT (array)
在数组中搜索指定的关键字: REPEATED_CONTAINS(array_name, keyword),返回布尔值
原因:DNS将当前主机名解析到本地环回地址,可能需要更改/etc/hosts文件
原因:DNS没有正确配置
解决办法:如果网络中没有启用DNS服务,可以静态的修改/etc/hosts文件
可以用这种方式来指定中文查询条件:
|
1 |
select * from bais.trades where name like _UTF16'%农产品%'; |
原因:如果分片集群启用了身份验证,不但需要建立集群上的用户,还要为每个复制集创建本地用户。如果报错信息中有servers=[{address=****而且地址是分片的(而不是mongos的)地址,说明就是分片的身份验证出错。
Leave a Reply