Galera学习笔记
MariaDB提供了兼容MySQL的数据库解决方案,它本身是MySQL的一个Fork。
MySQL中复制(Replication)是异步的、单向的。其中一个服务器作为Master,其它的作为Slave。所谓主主模式,是两个服务器分别配置为对方的Slave。MariaDB提供主主复制、主从复制。
MySQL 的默认二进制日志格式是基于行的,而在 MariaDB 中,默认的二进制日志格式是混合式的。
MariaDB支持二进制日志压缩(log_bin_compress)。
MySQL提供shared-nothing的集群支持,通过自动分区的方式将数据分发到不同节点。在内部MySQL使用同步的、两阶段的提交,确保数据被写入到多个分片。
MariaDB使用Galera Cluster实现多主,从10.1开始MariaDB内置Galera,只需要配置参数即可启用集群模式。
MariaDB支持更多的存储引擎:XtraDB(10.2-的默认引擎,InnoDB增强版)、InnoDB(10.2+默认引擎)、MariaDB ColumnStore、Aria、Archive、Blackhole、Cassandra Storage Engine、Connect、CSV、FederatedX、Memory、Merge、Mroonga、MyISAM、MyRocks、QQGraph、Sequence Storage Engine、SphinxSE、Spider、TokuDB
MariaDB 上可用,MySQL 不支持该功能。这个功能允许创建不再 SELECT * 语句中出现的列,而在进行插入时,如果它们的名字没有出现在 INSERT 语句中,就不需要为这些列提供值。
从 5.7 版本开始,MySQL 支持由 RFC 7159 定义的原生 JSON 数据类型,可以高效地访问 JSON 文档中的数据。
MariaDB 没有提供这一增强功能,认为 JSON 数据类型不是 SQL 标准的一部分。但为了支持从 MySQL 复制数据,MariaDB 为 JSON 定义了一个别名,实际上就是一个 LONGTEXT 列。
MariaDB 支持连接线程池,这对于短查询和 CPU 密集型的工作负载(OLTP)来说非常有用。在 MySQL 的社区版本中,线程数是固定的,因而限制了这种灵活性。MySQL 计划在企业版中增加线程池功能。
MariaDB Galera Cluster提供MariaDB多主集群,仅仅对XtraDB/InnoDB存储引擎提供支持。
从MariaDB 10.1开始,MySQL-wsrep补丁被合并到MariDB,这意味着使用标准的MariaDB+Galera wsrep提供者库即可构建Galera集群。该补丁由Codership开发,提供wsrep API支持。
Galera的主要特性包括:
- 几乎同步的(virtually synchronous )的复制
- Active-Active多主拓扑支持,不需要failover
- 针对集群的任何节点进行读写操作
- 自动的集群成员控制,失败的节点能够自动的移出集群
- 自动节点加入
- 真正的(从底层)并行复制
- 不需要读写分离
- Slave支持多线程以提升性能
基于Galera的集群的主要优势包括:
- 没有Slave的延迟
- 不会丢失事务
- 读操作的可扩容性
- 更小的客户端延迟
Galera的使用场景包括:
- 从Master读写:Galera支持这种传统场景,但是和MariaDB传统主从复制相比,任何一个节点都可以随时成为Master,而其它节点仅仅是客户端将其作为Slave看待而以。由于Slave可以并行的应用writeset,集群的吞吐量会快的多,此外复制的延迟也被消除
- 广域网集群:可以支持这种网络下的几乎同步复制,可能会存在延迟,取决于RTT。这些延迟仅仅影响commit操作
- 灾难恢复:广域网集群的子用例。这种情况下,位于某个数据中心的节点仅被动接受复制,不处理任何客户端事务。由于Galera的几乎同步的复制,它不会丢失数据,并可以在主节点宕机后立即升级为新的主节点
- 延迟消除:让客户端访问靠近自己的节点,可以消除读操作的延迟。延迟仅仅在写操作时才发生
MariaDB、Galera库、wsrep API版本对应关系如下:
| MariaDB | Galera/wsrep提供者库 | wsrep API |
| MariaDB 10.4+ | 4 | 26 |
| MariaDB 10.3- | 3 | 25 |
使用包名galera-4安装Galera 4 wsrep provider。版本26.4.6对应MariaDB的版本是10.5.7 / 10.4.16
使用包名galera安装Galera 3 wsrep provider。版本25.3.31对应MariaDB的版本是10.3.26 / 10.2.35 / 10.1.48
Galera复制功能实现为一个共享库,可以连接到任何实现了wsrep API的事务处理系统。它是由一系列组件组成的协议栈,提供准备、复制、应用事务writeset的功能。
在Galera 4很多组件被重新设计。
即写入集复制API(writeset replication API),它定义了Galera Replication和MariaDB之间的接口,以及各自的职责。
在RDBMS引擎中的wsrep集成点。
为Galera库实现wsrep API。
尽管galera provider负责在提交时,在所有节点认证writeset,但是writeset不需要被立即apply到节点。实际上writeset被放置在节点的接收队列上,由节点的某个galera slave thread最终apply到数据库中。
Galera slave thread的数量可以通过系统变量 wsrep_slave_threads配置。
Galera slave thread们负责自行判断哪些writeset可以被安全的并行apply,但是,如果节点经常出现数据一致性问题,可以将线程数量设置为1。
负责准备writeset,执行认证测试。
管理复制协议,提供整体上的排序能力(ordering capabilities)
为Group Communication系统(GCS)提供插件化架构。很多GCS实现可以被适配。内置实现是vsbes、gemini
所谓状态转移是指从现有节点复制数据,以使得新节点/宕机后恢复的节点到达同步状态的操作。
在一次State Snapshot Transfers / SST中,集群通过从一个节点拷贝完整的数据集,来创建新节点。
当新节点加入集群后,它会触发一次SST。
在一次Incremental State Transfers /IST中,集群从正常节点,拷贝某个节点缺失的writeset。
如果节点离开集群时间比较短,则IST通常比SST更块。
在Galera集群中,服务器在提交(Commit)期间进行事务复制。其做法是,将事务关联的写入集(writeset)广播到所有节点。
同步复制能够保证:如果一个节点上的数据发生变更,那么这些变更会同时发生在其它节点上。
异步复制不提供上述保证,这意味着,在第一个节点上发生变更后,复制完成之前该节点宕机,可能会导致数据丢失。
同步复制的优势:
- 使用同步复制的集群,总是能保证HA和数据一致性。节点崩溃不会导致数据丢失
- 同步复制允许事务在所有节点上并行的执行。而不是进行Replay
- 因果律保证:如果先在A节点发生事务,然后在B节点执行查询,那么该查询一定能看到A节点那个事务的结果
典型的同步复制利用两阶段提交或者分布式锁来实现,非常缓慢。再加上实现的复杂度,导致MySQL、PostgreSQL等传统RDBMS都仅仅支持异步复制,或者所谓半同步复制(主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到Relay log中才返回给客户端)。
Galera使用基于认证的复制(Certification-based replication),实现几乎完全同步(virtually synchronous)的数据复制。
Galera的基本思想是乐观执行( optimistic execution):假设不存在冲突,正常执行事务,直到达到提交点(commit point),在提交之前,通过认证来检查冲突
Galera的核心机制包括:
- 分组通信(group communication):定义了数据库节点之间的通信pattern,保证复制数据的一致性
- 写入集(writeset):将若干数据库写操作合并为一个消息,避免了每次数据库操作都引发节点之间的协作。writeset中包含了事务的所有必要信息
- 数据库状态机(database state machine):只读事务仅在节点本地执行。非只读事务首先在单个节点本地执行,然后广播writeset到其它节点,认证并apply到数据库
- 全局事务排序(global transaction reordering):在复制期间,Galera为每个事务分配一个全局的序号即seqno,每个节点将以相同的顺序接收(和应用)事务。当事务到达提交点时,节点会检查上一次成功的事务的seqno。这两次事务seqno的差值,提示了尚未apply的事务数量。节点会对这些没处理的事务进行主键冲突检查,发现冲突则触发认证失败

Galera执行数据复制的流程如下:
-
当客户端发出一个 commit 指令,在事务在服务器端被正式(数据已经写入,只差)提交之前,所有对数据库的更改都会被writeset收集起来,并且将 writeset 纪录广播给其他节点
-
writeset 将在每个节点(包括发起writeset的原始节点)上、基于主键进行决定性认证测试(deterministic certification test,),测试结果决定节点能否 apply writeset
-
如果认证测试失败:节点丢弃writeset,集群回滚原始事务
- 如果认证测试成功:事务被正式提交,其余节点则apply writeset
只有所有节点都认证成功,达成共识,那么发起事务的原始节点就可以正式提交并给客户端响应。在这个时间点,用户的写入集已经同步到了所有节点,不会因为原始节点故障而导致数据丢失
关于从普通MariaDB转到Galera的TIPS,参考:https://mariadb.com/kb/en/tips-on-converting-to-galera/
对任何其它引擎的表的写入,包括系统表(mysql.*,使用MyISAM引擎)都不会复制到其它节点。例外情况是DDL语句,这些语句虽然修改mysql.*表,但是却会被复制。
对MyISAM复制目前提供试验性支持,设置系统变量:wsrep_replicate_myisam。
FLUSH PRIVILEGES 不会被复制。
LOCK TABLES、FLUSH TABLES (table list) WITH READ LOCK等语句不被支持,可以通过适当的事务控制来达到相同效果。
全局性的锁操作,例如FLUSH TABLES WITH READ LOCK则可以被支持。
所有表必须具有主键(支持复合主键)。针对无主键表的DELETE操作是不支持的。没有主键的表,可能在不同节点上的顺序不同。
普通查询日志、缓慢查询日志,不支持写入到表中。如果启用这些日志,你必须设置log_out=FILE
尽管Galera没有明确限制,但是writeset被存储在内存中,这隐含了对事务尺寸的限制。
为了避免非常大的事务严重影响节点性能。系统变量的默认值设置为:
- wsrep_max_ws_rows 事务最大影响行数,128K
- wsrep_max_ws_size 事务最大尺寸(写入集大小)2GB
此外根据社区的反馈,大尺寸事务可能有额外的不可忽略的开销。你写入100K的行,可能需要额外200-300MB甚至数G内存。
你的DML语句操作一个锁,而另外一个DDL已经发起。正常情况下MySQL会等待元数据锁,但是Galera则会立即执行DML。甚至仅有单个节点的情况下,也会发生这种情况。
不要假设自增长的列是一个个顺序增长的。Galera为了保证没有冲突,为每个节点的自增长键都设置了空虚。
当出现网络分区,并且当前节点不再大多数节点所在分区。命令会导致ER_UNKNOWN_COM_ERROR:WSREP has not yet prepared node for application use / Unknown command。这个报错是为了放置数据不一致。网络分区状态可以通过检查 wsrep_ready变量发现。
少部分节点所在的分区,节点可能会丢弃所有客户端连接,这个行为可能比较意外 —— 因为客户端可能是空闲的,甚至不知道发生什么连接就忽然断了。
这种被分区的节点重新连接到集群后,可能有大量数据需要同步。在同步完成之前,它仍然会报告unknown command。
在运行时修改binlog格式,不但会导致复制失败,还会导致其它节点崩溃。
根据Galera的设计,集群的整体性能取决于最慢的节点。
此外,即使只有一个节点。性能也可能比非集群模式的MariaDB低很多,特别是对于大事务。
在MariaDB Galera Cluster 5.5.40, MariaDB Galera Cluster 10.0.14以及MariaDB 10.1.2之前,需要设置query_cache_size=0以禁用查询缓存。
启用异步复制模式的情况下,不支持在Slave节点上进行并行复制(slave-parallel-threads 大于1)。
节点的表结构可能不一致,特别是在执行rolling schema upgrade期间。
读写分离不是必须的,但是仍然建议做读写分离,未来底层架构可能变化。
所有状态变量具有一致的前缀:
|
1 |
SHOW STATUS LIKE 'wsrep%'; |
| 变量 | 说明 |
| wsrep_applier_thread_count | 当前applier线程的数量,这种线程负责将writeset写入到数据库 |
| wsrep_apply_oooe | writeset被乱序的apply的频繁程度,可以提示并行处理的效率 |
| wsrep_apply_oool | 具有高序列号的writeset,在具有低序列号的writeset之前被apply —— 这种情况发生的频繁程度,可以提示处理缓慢的writeset |
| wsrep_apply_window | 并发的被apply的writeset的最高、最低序列号的平均差值 |
| wsrep_cert_deps_distance | 可能被并行apply的writeset序列号的平均差值,提示潜在的并行度 |
| wsrep_cert_index_size | 认证索引中的条目数量 |
| wsrep_cert_interval | 在一个事务被复制期间,平均接收到的新事务的数量 |
| wsrep_cluster_conf_id | 集群成员关系发生变化的总次数 |
| wsrep_cluster_size | 集群成员当前数量 |
| wsrep_cluster_state_uuid | 集群当前状态的唯一标识。如果和wsrep_local_state_uuid相同,意味着本节点和集群同步(in sync) |
| wsrep_cluster_status |
集群组件状态,可能值:
|
| wsrep_cluster_weight | 当前集群成员们的总weight,即当前Primary Component中的节点的pc.weight的求和 |
| wsrep_commit_oooe | 事务被乱序commit的频繁程度 |
| wsrep_commit_window | 并发的被commit的最大、最小seqno的平均差值 |
| wsrep_connected | MariaDB是否连接到wsrep provider,值ON/OFF |
| wsrep_desync_count | 需要节点临时失去同步状态的、进行中的操作数量 |
| wsrep_evs_delayed | 当前节点在哪些节点上注册到了delayed list |
| wsrep_evs_evict_list | 从集群驱除的节点的UUIDs。在重启mysqld进程之前,被驱逐的节点无法重新加入集群 |
| wsrep_evs_repl_latency |
提示组通信(group communication)的复制(replication)延迟。即从消息发出到消息接收的时延(秒) 由于复制是组操作(group operation),因此该参数提示了最慢的ACK和最长的RTT时间 |
| wsrep_evs_state | 显示EVS协议的内部状态 |
| wsrep_flow_control_paused | 由于流控而导致复制暂停的时长,从上一个FLUSH STATUS命令开始记时 |
| wsrep_flow_control_paused_ns | 总计处于暂体状态的纳秒数 |
| wsrep_flow_control_recv | 从最近一次状态查询以来,FC_PAUSE事件的接收总数 |
| wsrep_flow_control_sent | 从最近一次状态查询以来,FC_PAUSE事件的发送总数 |
| wsrep_gcomm_uuid | 节点的UUID(用于组通信) |
| wsrep_incoming_addresses | 在cluster component中的incoming服务器地址列表 |
| wsrep_last_committed | 最近一次事务的seqno |
| wsrep_local_bf_aborts | 被slave transcation中断的本地事务的总数,中断由于认证失败(存在冲突)导致 |
| wsrep_local_cached_downto | writeset缓存(GCache)中最小的seqno值 |
| wsrep_local_cert_failures | 在认证测试中失败(存在冲突)的本地事务总数 |
| wsrep_local_commits | 在本节点上提交的本地事务总数 |
| wsrep_local_index | 集群中本节点的索引,索引zero-based |
| wsrep_local_recv_queue | 当前接收队列长度,即等待被apply的writeset数量 |
| wsrep_local_recv_queue_avg | 自最近一次状态查询以来,接收队列的平均长度 |
| wsrep_local_recv_queue_max | 自最近一次FLUSH STATUS以来,接收队列的最大长度 |
| wsrep_local_recv_queue_min | 自最近一次FLUSH STATUS以来,接收队列的最小长度 |
| wsrep_local_replays | 由于asymmetric lock granularity导致replay的事务的总量 |
| wsrep_local_send_queue | 当前发送队列的长度,即等待被发送的writeset数量 |
| wsrep_local_send_queue_avg | 自最近一次状态查询以来,发送队列的平均长度 |
| wsrep_local_send_queue_max | 自最近一次FLUSH STATUS以来,发送队列的最大长度 |
| wsrep_local_send_queue_min | 自最近一次FLUSH STATUS以来,发送队列的最小长度 |
| wsrep_local_state | 内部Galera Cluster FSM state |
| wsrep_local_state_comment |
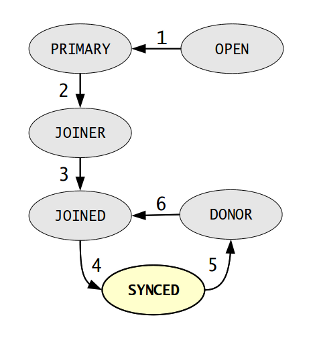
上个字段的可读文本 如果节点是Primary Component的成员,则值可能是: Joining, Waiting on SST, Joined, Synced, Donor 如果节点不是PC成员,则值是:Initialized 节点状态转换示意图:
|
| wsrep_local_state_uuid | 节点的UUID状态,如果和wsrep_cluster_state_uuid相同则本节点保持了同步 |
| wsrep_open_connections | 在wsrep provider中打开的连接数量 |
| wsrep_open_transactions |
在wsrep provider中已经注册的、本地运行中的事务的数量 这个变量提示了生成writeset的事务的数量,只读事务不在统计中 |
| wsrep_protocol_version | wsrep协议版本 |
| wsrep_provider_name | wsrep提供者名称 |
| wsrep_provider_vendor | wsrep提供者vendor |
| wsrep_provider_version | wsrep提供者版本 |
| wsrep_ready | wsrep提供者是否就绪 |
| wsrep_received | 从其它节点接收到的writeset数量 |
| wsrep_received_bytes | 从其它节点接收到的writeset字节数 |
| wsrep_repl_data_bytes | 复制的数据字节数 |
| wsrep_repl_keys | 复制的键数量 |
| wsrep_repl_keys_bytes | 复制的键字节数 |
| wsrep_repl_other_bytes | 复制的其它bits数量 |
| wsrep_replicated | 复制到其它节点的writeset数量 |
| wsrep_replicated_bytes | 复制到其它节点的writeset字节数 |
| wsrep_rollbacker_thread_count | rollbacker线程数量 |
| wsrep_thread_count | wsrep线程(applier/rollbacker)总数 |
| 变量 | 说明 |
| wsrep_auto_increment_control |
如果设置为1(默认),自动根据集群规模调整auto_increment_increment/auto_increment_offset 集群规模变化时也会调整 避免由于auto_increment导致的复制冲突 |
| wsrep_causal_reads |
默认OFF。如果设置为ON,确保集群范围内的隔离级别:读取已提交 如果master比slave apply的速度快很多,意味着失去同步。该选项设置为ON,则让slave在事件处理完毕之前,不去处理查询 设置为ON,会导致更大的读延迟 已经废弃:用 wsrep_sync_wait=1 代替 |
| wsrep_certification_rules |
集群中使用的认证规则(certification rules ),可选值:
|
| wsrep_certify_nonPK | 默认ON。如果设置为ON,允许复制没有PK的表,但是可能导致未定义的行为 |
| wsrep_cluster_address |
节点启动时连接的地址,格式: <schema>://<cluster_address>[?option1=value1[&option2=value2]] 示例: gcomm://192.168.0.1:1234?gmcast.listen_addr=0.0.0.0:2345 建议指定所有可能的节点地址: gcomm://<node1 or ip:port>,<node2 or ip2:port>,<node3 or ip3:port> 如果指定空白(gcomm://)则节点会发起一个新的集群 option指的是wsrep provider选项。这些选项的默认值来自 wsrep_provider_options ,这里可以覆盖之 某些配置下,该变量可以在运行时修改,这会导致节点断开现有连接,并连接到其它集群 |
| wsrep_cluster_name | 集群的名称,节点不能连接到和不同名称的集群 |
| wsrep_convert_LOCK_to_trx |
将LOCK/UNLOCK TABLES语句转换为BEGIN/COMMIT,用于适配老的应用程序(免修改) 谨慎使用,可能导致巨大的writeset |
| wsrep_data_home_dir | wsrep provider存储内部文件的目录 |
| wsrep_dbug_option | 向wsrep provider传递调试选项 |
| wsrep_debug |
wsrep调试日志级别。NONE(默认), SERVER, TRANSACTION, STREAMING, CLIENT 开启日志,可以记录冲突的事务 |
| wsrep_desync |
默认OFF。当节点接收太多writeset,无法即使消化(apply),则事务被存放到接收队列中。如果接收队列积蓄的writeset太多(由于wsrep选项gcs.fc_limit指定),则节点enage流控 如果将此字段设置为ON,则针对desync的节点禁用流控(flow control)。desync的节点会继续慢慢悠悠的处理队列中的writeset,这可能导致积累越来越多 |
| wsrep_dirty_reads | 可session,默认OFF。默认情况下,如果节点没有和群组(集群)同步(状态wsrep_ready=OFF),则它会拒绝除了SET/SHOW之外的任何查询请求。如果将此选项设置为ON,那么不会导致数据变化的查询请求可以被节点所接受 |
| wsrep_drupal_282555_workaround | 默认OFF。如果启用,这启用针对缺陷Drupal/MySQL/InnoDB bug #282555的workaround。该缺陷可能导致向AUTO_INCREMENT列插入DEFAULT值时产生重复KEY |
| wsrep_forced_binlog_format |
覆盖任何session级别binlog格式设置 取值:STATEMENT, ROW, MIXED, NONE |
| wsrep_gtid_domain_id | 用于wsrep GTID(Global Transaction ID)模式的GTID domain ID |
| wsrep_gtid_mode |
wsrep GTID mode尝试在所有节点上,保持writeset的GTID的一致性。在加入新节点时,通过SST将GTID状态复制到节点 如果打算使用MariaDB Replication,启用wsrep GTID mode可能有用 |
| wsrep_gtid_seq_no | 仅session,设置WSREP GTID seqno |
| wsrep_ignore_apply_errors |
apply错误应该被忽略,还是报告给provider: 0 不跳过任何错误 |
| wsrep_log_conflicts | 默认OFF。如果设置为ON,冲突的MDL以及InnoDB所的详细信息被记录 |
| wsrep_max_ws_rows |
一个writeset允许的最大行数 为了保证向后兼容,默认值0,表示允许任意大小 |
| wsrep_max_ws_size | 一个writeset允许的最大bytes |
| wsrep_mysql_replication_bundle |
可以被分组到一起处理的复制事件的数量。一个试验性的实现允许辅助一个slave节点处理commit时延 默认0,不支持分组 |
| wsrep_node_address | 节点的网络地址。默认0.0.0.0:4567 |
| wsrep_node_incoming_address | 监听客户端连接的地址 |
| wsrep_node_name | 节点的名称,可以用在wsrep_sst_donor中 |
| wsrep_notify_cmd | 每当节点状态或集群成员关系发生变化时调用的命令 |
| wsrep_on |
可session,默认OFF。是否启用wsrep复制,如果设置为OFF则无法加载wsrep provider,不能加入集群 如果在session级别设置为OFF,则该会话的操作不会被复制,但是其它会话、applier线程仍然正常工作 |
| wsrep_OSU_method |
指定在线Schema更新方法(schema upgrade method) :
|
| wsrep_patch_version | wsrep补丁版本 |
| wsrep_provider |
wsrep provider库的位置,可能位置:
|
| wsrep_provider_options | 传递给wsrep provider的、分号(;)分隔的选项列表 |
| wsrep_recover | 如果在服务器启动时设置为ON,则节点会尝试恢复最近一次apply的writeset的seqno,并让服务器退出 |
| wsrep_reject_queries |
用于进入维护状态,节点会继续apply writeset,但是客户端查询会导致Error 1047: Unknown command错误。取值:
|
| wsrep_replicate_myisam | 是否对MyISAM表的DML可以被复制。试验性功能 |
| wsrep_restart_slave | 默认OFF。如果设置为ON,则节点重新加入集群后replication slave自动重启 |
| wsrep_retry_autocommit |
在报告客户端以错误之前,因为集群范围冲突而导致无法提交的auto-commit请求重试的次数 默认1。设置为0则不会重试 |
| wsrep_slave_FK_checks | 默认ON。如果设置为ON,则applier slave thread会执行外键约束检查 |
| wsrep_slave_UK_checks | 默认OFF。如果设置为ON,则applier slave thread会执行辅助索引的唯一性检查 |
| wsrep_slave_threads | 默认1。用于并行apply writeset的slave thread的总数。这些线程能够自行决定writeset 能否被安全的并行apply,但是,如果你发现集群中频繁出现不一致性问题,考虑设置为1 |
| wsrep_sr_store | streaming replication fragments的存储方式 |
| wsrep_sst_auth | SST时使用的身份验证信息 |
| wsrep_sst_donor | SST的偏好的源节点 |
| wsrep_sst_donor_rejects_queries | 默认OFF。如果设置为ON则供给(donor)节点在SST期间拒绝查询请求并返回UNKNOWN COMMAND |
| wsrep_sst_method | 默认rsync。SST方法 |
| wsrep_sst_receive_address | 供给节点(donor)连接到此地址,来发送状态转移更新 |
| wsrep_strict_ddl | 默认OFF。如果设置为ON,则禁止对不支持Galera Replication的表(即非InnoDB)的DDL |
| wsrep_sync_wait |
在该参数指定的操作类型执行之前,执行causality checks 以确保操作在完全同步的前提下执行 在causality check期间,所有查询请求被阻塞,以保证节点应用了所有到发起check那个时间点的所有更新。一旦check结束,操作开始在节点上执行 操作类型: 0 - 禁用等待同步(默认) |
| wsrep_trx_fragment_size |
对于流式复制(streaming replication),事务分片( transaction fragments)的大小 单位由wsrep_trx_fragment_unit指定 |
| wsrep_trx_fragment_unit) |
事务分片的单位: bytes 事务的binlog事件缓冲的字节数 |
为了安装MariaDB Galera Cluster,需要以下包:
- 支持Galera的MariDB
- Galera wsrep提供者库
为了支持基于SST的备份,可能需要额外的包。
添加源配置:
|
1 2 3 4 5 6 7 8 |
# MariaDB 10.5 CentOS repository list - created 2021-01-15 07:44 UTC # http://downloads.mariadb.org/mariadb/repositories/ [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.5/centos8-amd64 module_hotfixes=1 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1 |
执行安装:
|
1 2 |
dnf install MariaDB-server systemctl start mariadb |
|
1 |
dnf install galera4 |
集群的第一个节点需要以下面的命令行选项来自举(bootstrap):
|
1 |
mysqld --wsrep-new-cluster |
这个选项告诉MariaDB,不需要连接到既有集群。对于一个现有的节点,以该选项重启,会导致创建新的识别集群身份的UUID,并且它不会再连接到老集群。
对于使用Systemd的系统,应该使用下面的命令创建新集群:
|
1 |
galera_new_cluster |
要添加新节点,需要通过wsrep_cluster_address选项指定集群地址,如果第一个节点的地址是192.168.0.1,则可以用下面的配置加入新节点:
|
1 2 3 |
[mariadb] ; 支持IP地址或DNS名称 wsrep_cluster_address=gcomm://192.168.0.1 |
使用上述配置,新节点将会连接到一个既有集群节点,并随后发现所有的节点。最好在此配置中,指定所有集群成员的地址,免得因为单点的故障 导致无法加入集群。
当所有成员加入到集群,状态不一致的集群可能通过IST/SST来达到一致性。
当集群所有节点关闭后,需要依次重启节点。
如果第一个节点以常规方式启动, 则它会尝试连接到wsrep_cluster_address中的其它节点,这必然失败。因此,集群完全关闭之后,需要对第一个节点进行bootstrap操作。
第一个节点,必须是数据最新的节点。如果节点检测到它可能不是数据最新(如果它不是最后一个关闭的,或者它是崩掉的)的节点,它会拒绝bootstrap。
查看所有节点的grastate.dat文件,其中seqno字段的值最大的,就是数据最新的节点。如果节点是崩掉的且seqno=-1,则可以使用下面的命令恢复seqno:
|
1 |
mysqld --wsrep_recover |
确定数据最新节点后,可以修改它的数据目录下的grastate.dat文件,设置:
|
1 |
safe_to_bootstrap=1 |
使用Systemd的情况下,节点的seqno可以通过命令: galera_recovery恢复。 galera_recovery脚本调用mysqld时,错误日志会写入到/tmp/wsrep_recovery.XXXXXX。错误日志会有类似下面的内容:
|
1 2 |
# 集群group id seqno [Note] WSREP: Recovered position: 7bff636d-50c7-11eb-81c8-6f8dd75e7fb4:1202 |
启用Galera时,MariaDB的Systemd服务会在启动数据库之前自动运行galera_recovery。
和Galera相关的状态变量,都放在wsrep_前缀下:
|
1 |
SHOW GLOBAL STATUS LIKE 'wsrep_%'; |
参考在K8S中运行一节。
| 配置 | 说明 |
| 基础配置 | |
| wsrep_provider | wsrep提供者库的位置 |
| wsrep_cluster_name | Galera集群名称 |
| wsrep_cluster_address |
集群地址配置 格式:<schema>://<cluster_address>[?option1=value1[&option2=value2]] |
| binlog_format | 二进制日志格式,默认ROW |
| default_storage_engine | 要设置为InnoDB |
| innodb_autoinc_lock_mode | 生成AUTO_INCREMENT值时的锁模式,要设置为2(interleaved lock mode) |
| innodb_doublewrite |
保持默认值1,也就是说InnoDB在写入数据文件之前,首先将数据存储到一个双重写入缓冲(InnoDB Doublewrite Buffer),以提升容错能力 双重写入缓冲用于从不完全写入的page中恢复,如果InnoDB在将页写入磁盘时断电,会出现不完全写入的问题 |
| query_cache_size | 对于5.5.40- 10.0.14- 以及10.1.2,需要设置为0 |
| wsrep_on | 设置为ON,启用wsrep复制,10.1.2+ |
| 性能配置 | |
| innodb_flush_log_at_trx_commit | 可以设置为0,尽管在标准的MariaDB中设置为0会有丢数据的风险,但是在Galera中要安全,因为数据的不一致性总是可以从另外一个节点恢复 |
| 复制行为控制 | |
| log_slave_updates |
设置为ON,则节点将接收到的writeset写入到binlog,默认不写入 如果你希望节点作为传统MariaDB Replication的Master,开启此选项 |
| binlog_do_db | 影响到此选项列出的数据库的DML操作,被写入binlog |
| binlog_ignore_db | 影响到此选项列出的数据库的DML操作,不写入binlog |
| replicate_wild_do_table | 只有该选项匹配的表的DML才被应用到此slave |
| replicate_wild_ignore_table | 该选项匹配的表的DML被当前slave丢弃 |
| wsrep_sst_auth | SST的 username:password配置,mysqldump SST需要 |
| 端口配置 | |
| wsrep_node_address | wsrep复制使用的地址端口,默认0.0.0.04567 |
| ist.recv_addr | IST端口,默认4568 |
| wsrep_sst_receive_address | SST端口,默认4444。对于任何除mysqldump之外的状态快照转移方式,都使用此端口 |
当新加入一个节点到Galera集群时,此节点需要从集群节点获取数据,这个复制过程被称作状态转移(State Transfer),Galera支持两种状态传输方式:
- State Snapshot Transfers (SST) 传输一个节点的完整状态(即所有数据),全量复制
- Incremental State Transfers (IST) 只传输缺失的数据,增量复制
使用 IST 的方式时,集群会判断加入集群的节点所缺失的数据,而不必传输完整的数据集。使用 IST 必须满足特定的条件:
- 加入节点的 state UUID 必须和此集群的相同
- 加入节点所缺失的数据都在 donor 节点的 writeset cache 中存在
如果上述条件满足,供给节点会发送加入节点上缺失的事务,按照顺序replay它们,直到加入节点赶上集群进度。
IST不会阻塞供给节点
使用 IST 最重要的参数是 donor 节点的 gcache.size 大小,这个参数表示分配多少空间用于缓存 writeset。缓存的空间越多,能够使用 IST 的几率就越大
所谓状态快照转移(SST),就是指集群通过将某个up-to-date节点的数据集,完整的拷贝到另外一个节点的过程/操作。
从概念上来看,存在两种状态转移方式。
即mysqldump SST,该SST方法,实际上是调用mysqldump,从源节点获取数据库的逻辑dump文件。
要使用mysqldump SST,新加入的节点必须完全初始化,并且准备好接受连接。
该SST方法会阻塞源节点,在状态转移期间,无法对源节点进行修改。该SST方法是最慢的一种,在高负载集群中可能导致问题。
这类SST方法将数据文件从源节点拷贝到新加入的节点。节点需要在状态转移之后再完成初始化。mariabackup SST等属于这一类别。
这类方法比mysqldump SST快很多,但是具有一些限制条件:
- 只能在服务器启动时使用
- 新节点必须和源节点配置很相似,例如 innodb_file_per_table取值必须相同
这类方法中的某些,例如mariabackup SST,是非阻塞的,也就是说,在状态转移期间源节点可以继续处理请求。
通过设置全局系统变量,可以修改使用的SST方法:
|
1 |
SET GLOBAL wsrep_sst_method='mariabackup'; |
SST方法也可以在配置文件中修改:
|
1 2 |
[mariadb] wsrep_sst_method = mariabackup |
注意:源节点和新节点必须使用相同的SST方法。 建议所有节点使用一致的SST方法。
| SST方法 | 说明 |
| mariabackup |
利用工具mariabackup执行SST,这是两种非阻塞的SST方法之一 如果希望在SST期间,能够在源节点上执行查询,推荐使用该方法 该方法需要在节点上安装socat |
| rsync |
默认SST方法,使用rsync来创建源节点的数据快照。在执行SST期间,源节点使用使用读锁锁定 这是速度最快的SST方法,特别是对于大数据集(因为仅仅拷贝文件) 如果不希望SST期间,源节点上可以执行查询,推荐使用该方法 |
| mysqldump | 在源节点上执行mysqldump,然后通过管道发送给连接新节点的mysql客户端 |
| xtrabackup-v2 |
使用Percona XtraBackup 执行SST,这是两种非阻塞的SST方法之一 需要安装额外的软件 |
| xtrabackup | 已经被xtrabackup-v2代替 |
除了rsync SST之外,都需要配置基于用户名:密码的身份验证:
|
1 |
SET GLOBAL wsrep_sst_auth = 'mariabackup:password'; |
或者修改配置文件:
|
1 2 |
[mariadb] wsrep_sst_auth = mariabackup:password |
某些身份认证插件,例如unix_socket或gssapi,不需要密码,这种情况下只需要指定用户名:
|
1 2 |
[mariadb] wsrep_sst_auth = mariabackup: |
为了防止脑裂的出现,推荐最小集群规模为3。
另外一个需要3节点的原因是,当SST阻塞了源节点时,仍然可以有一个节点能响应查询。
如果状态转移失败,新节点一般是不可用的。
如果使用mysqldump SST,可能还需要手工恢复某些MariaDB管理表。
本节介绍如何使用这种SST方法。
修改配置文件:
|
1 2 |
[mariadb] wsrep_sst_method = mariabackup |
或者通过命令行设置:
|
1 |
SET GLOBAL wsrep_sst_method='mariabackup'; |
该SST方法需要在所有供给(donor)节点上进行本地身份验证。
首先需要创建专用的数据库账号:
|
1 2 |
CREATE USER 'mariabackup'@'localhost' IDENTIFIED BY 'mypassword'; GRANT RELOAD, PROCESS, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'mariabackup'@'localhost'; |
然后修改配置文件或执行命令行设置:
|
1 2 |
[mariadb] wsrep_sst_auth = mariabackup:mypassword |
|
1 |
SET GLOBAL wsrep_sst_auth = 'mariabackup:mypassword'; |
可以使用unix_socket身份认证插件,这样就不需要指定密码:
|
1 2 |
CREATE USER 'mysql'@'localhost' IDENTIFIED VIA unix_socket; GRANT RELOAD, PROCESS, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'mysql'@'localhost'; |
当mariadbbackup在供给(donor)节点创建备份时,它需要在备份最后创建一个全局的锁:
- 在10.3-,锁通过 FLUSH TABLES WITH READ LOCK实现
- 在10.4+,锁通过 BACKUP STAGE BLOCK_COMMIT实现
如果集群中某个节点正作为“主”节点来使用 —— 也就是说应用程序连接到它来写入数据,那么该节点不应该用作SST源,因为全局锁会干扰应用程序的写操作。
可以通过下面的系统变量,来设置偏好使用哪些节点作为源:
|
1 2 3 4 5 |
[mariadb] ; 如果集群由 node1, node2, node3, node4, node5构成。node1作为主使用 ; 那么node2可以这样配置: wsrep_sst_donor=node3,node4,node5, ; 结尾的逗号表示,如果偏好的节点不可用,允许选择任何节点作为源 |
mariabackup SST具有独立的日志,不和数据库日志在一起:
|
1 2 3 4 5 |
[sst] sst-log-archive=1 sst-log-archive-dir=/var/log/mysql/sst/ ; 记录到syslog中 sst-syslog=1 |
Galera Load Balancer(GLB)是一个简单的、特地为Galera设计负载均衡器。该LB支持多种负载均衡策略。
节点可以被设置不同的权重,优先使用高权重的节点,根据选择的策略,低权重节点可能被忽略(除非高权重节点挂掉)。
一个轻量级的守护进程glbd负责接收客户端连接,并执行LB算法,重定向客户端请求到适当的节点。
- 可以在运行时配置后端节点列表
- 支持drain节点,也就是不分配新的连接给它,但是不会kill服务器 —— 让它优雅关闭
- 使用epool提升性能
- 支持多线程,可以利用多核心CPU
- 支持可选的watchdog来监控后端并调整路由表
GLB支持以下负载均衡策略:
- least connected: 最少连接,新连接并分发给连接最少的节点,需要考虑节点权重
- round-robin:依次循环调度给每个节点
- single:所有连接调度给最高权重的节点,除非此节点挂了,或者引入一个新的、更高权重的节点
- random:随机调度
- source tracking:来自同一源地址的连接,总是被调度给同一节点
推荐的部署模式是3节点以上,奇数节点。
如果部署第3个节点(例如只有两个数据中心)的成本过高,可以考虑引入仲裁节点(Galera Arbitrator)以防止脑裂。仲裁节点:
- 参与投票,来决定Primary Component。当两节点集群出现网络分区时,能够看到仲裁节点的那个构成Primary Component
- 不参与复制。尽管仲裁节点不参与复制,但是它会接收所有数据(但是不存储),这意味着你不能将其放置在网络连接差的地方,否则可能导致很差的集群性能
仲裁节点还有另外一个用途——用于备份,它可以请求数据库状态的一致性快照。
由独立的守护进程garbd来运行仲裁节点:
|
1 2 3 |
garbd --group=example_cluster \ --address="gcomm://192.168.1.1,192.168.1.2,192.168.1.3" \ --option="socket.ssl_key=/etc/ssl/galera/server-key.pem;socket.ssl_cert=/etc/ssl/galera/server-cert.pem;socket.ssl_ca=/etc/ssl/galera/ca-cert.pem;socket.ssl_cipher=AES128-SHA256"" |
配置信息也可以放在独立文件中:
|
1 2 |
group = example_cluster address = gcomm://192.168.1.1,192.168.1.2,192.168.1.3 |
|
1 |
garbd --cfg /path/to/arbitrator.config |
由于Galera集群的复制特性,执行备份时我们只需要在一个节点上进行。而在恢复时,也仅仅需要在一个节点上执行,剩下节点的同步,可以依靠状态转移自动完成。
任何时候,都可以针对某个Galera节点,使用常规的MariaDB备份工具进行备份。
上文中的内置SST方法,对应了各种备份工具,混合使用多种备份方法,能够提高额外的数据安全性。这里挑选几个工具说明用法:
| 备份工具 | 说明 | ||||||||||||
| mysqldump |
逻辑备份工具,也就是说它是面向SQL的,适合在不同版本的数据库之间进行数据迁移 备份时可以使用 --single-transaction选项,这样可以得到InnoDB表的一致性备份 mysqldump实际上使用SELECT * FROM table的方式来加载数据,这样会有个问题,数据量大的时候,会导致InnoDB缓冲池反复刷新,导致节点性能严重下降,进而导致整个Galera集群性能下降 —— Galera集群性能取决于最慢的那个节点。如果设置 wsrep_desync=OFF,让备份中的节点临时的不再同步,则集群其他节点的性能不会受到影响
|
||||||||||||
| xtrabackup |
物理备份工具,针对数据块,支持全量备份、增量备份。该工具来自Percona,包含一个C语言编写的xtrabackup、Perl语言编写的innobackupex,支持备份InnoDB、XtraDB、MyIASM等引擎的表 在备份期间,xtrabackup不会锁定(热备份)数据库。对于100G+的大数据库,它的恢复性能要比mysqldump好的多 基于xtrabackup的备份/恢复流程包括三个步骤:备份、准备、恢复 使用--backup子命令,可以进行备份。
命令将会启动一个文件拷贝线程,拷贝ibdata文件,一个日志扫描线程,复制事务日志:
备份完毕后,备份存放目录下,会出现类似下面的文件:
--backup子命令得到的备份,需要进行--prepare操作后,才能实现针对某个特定时间点的、数据文件的一致性。这是由于,不同数据文件是在不同时间点拷贝的,在这个拷贝过程中,先前的数据文件可能又存在新的修改。使用这些数据文件去启动数据库,InnoDB可能会检测到数据损坏并拒绝启动 --prepare子命令调用方式如下:
此时的备份是满足数据一致性,可以用于恢复。直接拷贝数据文件即可:
注意:xtrabackup仅仅备份InnoDB数据文件,你需要额外备份MySQL系统数据库、MyISAM数据、表定义文件(.frm)等。或者使用innobackupex让这一切都自动化:
|
由于所有Galera节点具有相同的数据,因此你可以使用常规的MariaDB备份工具进行备份,但是这种方式存在缺点 —— 缺少全局事务ID信息(GTID)。使用这种备份来恢复,不能让节点进入良好定义的状态。此外,某些备份工具会阻塞节点,这也需要注意。
因此,理想的备份方式是发起一次SST:
- 节点会在一个良好定义的点发起备份
- 节点会将GTID关联到备份
- 备份期间,节点从集群desync,避免影响性能 —— 备份过程可能阻塞节点
- 集群知道节点正在进行备份,因此不会将其选为donor
我们需要利用仲裁节点来发起备份:
|
1 2 3 4 5 |
# garbd可以以函数方式执行,调用一个命令 # 如果在集群节点上发起,则4567已被占用,另外选择一个端口 garbd --address gcomm://192.168.1.2?gmcast.listen_addr=tcp://0.0.0.0:4444 \ # 机器名称 供给节点名称 在供给节点上执行的脚本的后缀 --group example_cluster --donor galera-3 --sst backup_mysqldump |
你也可以通过配置文件指定各种选项:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
; 填写集群的wsrep_cluster_name group='example_cluster' ; 填写集群的wsrep_cluster_address address="gcomm://172.31.30.39:4567,172.31.18.53:4567,172.31.26.106:4567" ; 填写集群的wsrep_provider_options。listen_addr添加garbd进程的监听端口 options="gmcast.listen_addr=tcp://0.0.0.0:4444" ; 指定哪个节点执行备份 donor="galera-3" ; 日志文件路径 log='/var/log/garbd.log' ; 备份节点上的备份脚本的后缀,对于下面的后缀,脚本名是wsrep_sst_backup_mysqldump sst='backup_mysqldump' |
下面是一个脚本的示例,它使用了bash + mysqldump,但是任何脚本语言、备份工具都是可以的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#!/bin/bash # SET VARIABLES db_user='admin_backup' db_passwd='Rover123!' backup_dir='/backup' backup_sub_dir='temp' today=`date +"%Y%m%d"` # Dump文件路径 backup_today="galera-mysqldump-$today.sql" # GTID文件路径 gtid_file="gtid-$today.dat" # 加载此脚本,它提供GTID变量 . /usr/bin/wsrep_sst_common # 备份配置文件 cp /etc/my.cnf $backup_dir/$backup_sub_dir/ cp /etc/garb.cnf $backup_dir/$backup_sub_dir/ # 备份GTID echo "GTID: ${WSREP_SST_OPT_GTID}" > $backup_dir/$backup_sub_dir/$gtid_file # 进行数据库Dump mysqldump --user="$db_user" --password="$db_passwd" \ --flush-logs --all-databases \ > $backup_dir/$backup_sub_dir/$backup_today # 打包 cd $backup_sub_dir tar -czf $backup_dir/$backup_today.tgz * --transform "s,^,$backup_today/," |
将备份恢复到一个新集群,或者既有集群,可以使用相同的步骤:
- 选择一个节点,作为恢复节点
- 停止其它节点
- 关闭恢复节点的Galera Replication,进入Standalone模式:
12345678910111213SET GLOBAL wsrep_provider = 'none';SHOW STATUS LIKE 'wsrep_connected';+-----------------+-------+| Variable_name | Value |+-----------------+-------+| wsrep_connected | OFF |+-----------------+-------+ - 调用备份工具,执行恢复
- 在恢复节点上重新开启Galera Replication
- 启动被停止的节点重新加入集群,并通过SST重新获得同步
用于存放writeset的特殊缓存,叫作writeset cache或GCache。GCache支持三种存储:
- Permanent In-Memory Store:直接使用操作系统的内存,适合有很多空余内存的系统,默认情况是禁用的
- Permanent Ring-Buffer File:在缓存初始化时就预先分配的一块磁盘空间,默认情况下,它的大小是 128Mb
- On-Demand Page Store:根据需要在运行时动态分配内存映射页文件,默认情况下是 128Mb,但如果需要更大的 write-set,它可以动态的增长。当 page file 不再使用时,Galera Cluster 会删除这些文件,可以对 page file 的总大小进行限制
Galera Cluster 的缓存分配算法会按上面的顺序来分配缓存空间,gcache.dir 参数可以指定缓存保存在磁盘的位置。
Galera允许一个节点根据需要来暂停/恢复复制,这叫作Flow Control。FC可以节点在apply事务方面,过于落后其它节点。
我们知道,所有节点收到writeset并进行认证之后,原始的接收请求的节点就可以在本地完成提交并应答客户端了。此时,其它节点不一定也apply/commit了事务(取决于配置)。尚未apply/commit的事务(writeset)会存放在接收队列中。
如果某个节点速度缓慢,那么它的接收队列会不断积压,到达一定程度之后,就会触发FC:
- 暂停复制
- 处理接收队列的积压
- 当队列到达可管理的大小之后,再恢复复制
在Galera中,需要去分单节点内的、集群范围的事务隔离级别。单节点内的事务隔离级别不必多提,参考MariaDB提供的配置项即可。
集群范围的事务隔离,受到复制协议的影响,不同节点上发起的事务,可能不会完全等同的隔离。
集群中能互相保持心跳通信的节点的集合叫作Component,两个Component之间存在网络分区,无法相互通信。理想情况下,集群只有一个Component。
大部分节点组成的Component叫作Primary Component —— PC必须满足大多数原则,在三节点集群中,至少两个节点才能组成PC。
只有位于PC中的节点,才能继续修改数据库状态。
Galera Cluster 会周期性的检查每个节点的连接是否正常, evs.inactive_check_peroid 参数可以设置检查的周期。如果一个节点的失效时间超过了 evs.suspect_timeout 的值,那么节点将被标记为 suspect。如果 Primary Component 中的所有节点都将某个节点标记为 suspect ,那么此节点被移出集群。
如果一个节点的失效时间超过了 evs.inactive_timeout 的值,此节点将直接被移出集群而不需要协商。故障的节点将不可读不可写。
在计算是否构成Primary Component / Quorum时,节点是可以被加权的。节点的权重通过pc.weight配置。例如下面的配置:
|
1 2 3 |
node1: pc.weight = 2 node2: pc.weight = 1 node3: pc.weight = 0 |
即使同时杀掉node2和node3,node1仍然构成PC
提供者选项在系统变量 wsrep_provider_options 中配置,选项之间用;隔开。
| 选项 | 说明 |
| base_dir | 数据目录 |
| base_host | 默认127.0.0.1。内部使用,不要设置 |
| base_port | 默认4567。内部使用,不要设置 |
| cert.log_conflicts | 默认no。是否记录认证失败的详细信息 |
| cert.optimistic_pa |
默认yes。控制在slave上并行apply的行为 如果设置,允许认证算法( certification algorithm)所确定(determined)的全范围并行化(full range of parallelization ) 如果不设置,并行apply窗口(parallel applying window)不会超过在master上看到的窗口。并且,一旦它所看到的master上操作被commit之后,立即开始apply |
| debug | 默认no。是否启用调试 |
| evs.auto_evict |
触发自动驱除协议(Auto Eviction protocol)之前,允许一个落后(delayed)节点的entry的数量 每当接收到某个节点的一个delayed response,就在delayed list中添加一个entry 默认0,表示禁用 |
| evs.debug_log_mask |
开启EVS调试日志,要求wsrep_debug=on |
| evs.delay_margin |
在此节点加入一个entry到delayed list之前,响应时间的延迟可达到多少。必须设置的比节点之间的RTT大 其实就是,evs.delay_margin决定了多慢的情况下进行一次计数,evs.auto_evict决定了计数多少次后发起驱除 |
| evs.delayed_keep_period | 如果一个节点被当前节点加入自己的delayed list,那么该节点要持续多长时间不再缓慢,才能从延迟列表移除 |
| evs.evict |
如果设置为当前节点的gcomm UUID,则当前节点从集群移除 如果设置为空,则当前节点的eviction list被清空 |
| evs.inactive_check_period | 检测不活动成员(peer)(即响应延迟的节点)的周期。超过此周期之后,节点才可能被加入到delayed list,并在之后进行驱除 |
| evs.inactive_timeout | 节点被断定为挂掉之前,inactive的最大持续时间 |
| evs.info_log_mask | 记录额外EVS信息的日志 |
| evs.install_timeout | 等待install message确认的超时时间 |
| evs.join_retrans_period | 组成集群成员关系时,EVS join消息重传的频率 |
| evs.keepalive_period | 没有其它流量时,多就发送一次心跳 |
| evs.max_install_timeouts | 默认3。install message允许的超时总次数 |
| evs.send_window |
单次允许复制的packet的数量。必须比evs.user_send_window大 仅仅影响数据包,在WAN环境下可以设置的比默认值(4)大的多,例如512 |
| evs.stats_report_period | 报告EVS统计信息的周期 |
| evs.suspect_timeout | 在此超时之后,节点被怀疑已经挂了。如果所有节点怀疑它挂了,那么在evs.install_timeout之前节点会被移除集群 |
| evs.use_aggregate | 默认true。如果为true则在可能的情况下小的packet会被聚合为大的 |
| evs.user_send_window |
单次允许复制的packet的数量。必须比evs.send_window小,推荐 1/2 |
| evs.version | EVS协议版本 |
| evs.view_forget_timeout | 从view history中移除之前需要经过的时间 |
| gcache.dir |
GCache存放的目录 |
| gcache.keep_pages_size | 缓存页的总数量 |
| gcache.mem_size | GCache缓存使用内存大小 |
| gcache.name | GCache缓存ring buffer文件的名字 |
| gcache.page_size | GCache缓存页面映射文件的大小 |
| gcache.recover | 在节点启动时,是否进行GCache恢复。如果能够恢复GCache,则节点加入集群后可以提供IST —— 这在集群完全重启的时候有用 |
| gcache.size | 缓存ring buffer大小,即用于缓存writeset的空间大小,启动时分配 |
| gcomm.thread_prio | Gcomm线程策略和优先级 |
| gcs.fc_debug | 默认0,大于0时会输出SST流控信息 |
| gcs.fc_factor | 默认1.0,接收队列中writeset数量跌到gcs.fc_limit的多少比例后,恢复复制 |
| gcs.fc_limit | 默认16。接收队列中writeset超过此数量后,复制暂停。在master-slave用法下,可以大大增加 |
| gcs.fc_master_slave | 默认no。是否假设集群仅仅有一个master —— 就是所有客户端都连接到一个节点进行写查询 |
| gcs.max_packet_size | 最大packet大小,超过此大小则writeset被分片 |
| gcs.max_throttle |
在状态转移时,为了避免内存消耗过大,可以进行复制限流 默认0.25。设置为0则为了完成状态转移,可以暂停复制 |
| gcs.recv_q_hard_limit |
接收队列大小的硬限制。超过此大小则服务器终止运作 推荐设置为内存的 1/2 + swap大小 |
| gcs.recv_q_soft_limit |
接收队列软限制。相对于gcs.recv_q_hard_limit的因子,默认0.25 到达软限制后,即开始限流。限流的速度随着队列积压,线性增加 |
| gcs.sync_donor |
默认no。是否集群其它成员需要和donor保持同步 如果设置为yes,则当donor因为状态转移而阻塞时整个集群被阻塞 |
| gmcast.listen_addr | 默认tcp:0.0.0.0:4567。Galera监听来自其它节点的连接的地址 |
| gmcast.mcast_addr |
默认空。如果设置,则使用UDP组播进行复制,所有节点必须设置一致 示例:gmcast.mcast_addr=239.192.0.11 |
| gmcast.mcast_ttl | 组播的TTL值 |
| gmcast.peer_timeout | initiating message relaying的连接超时 |
| gmcast.segment |
定义节点属于的段(segment)。默认情况下,所有节点都在段0。通常将同一数据中心的节点放在同一个段 Galera协议数据,仅仅会重定向到同一段中的单个节点,然后由该节点再repay给段中其它节点 可以降低跨数据中心的流量 取值0-255之间 |
| ist.recv_addr | 监听IST的地址 |
| pc.ignore_quorum |
默认false。是否忽略quorum计算 如果设置为true,如果master和其它slaves产生了网络分区,它仍然继续工作。但是会导致master-slave模式下slave不能自动重新连接到master |
| pc.ignore_sb | 默认false。是否允许脑裂情况下继续处理数据修改,在multi-master模式下会导致数据不一致 |
| pc.recovery | 默认true。如果设置为true,则Primary Component状态被存储在磁盘中。当集群完全崩溃后,可以进行自动恢复,后续的集群优雅完全重启会要求从一个新的Primary Component自举 |
| pc.wait_prim | 默认true。如果设置为true,节点会在pc.wait_prim_timeout之内等待Primary Component。用于启动non-primary component并使通过pc.bootstrap使之称为primary |
| pc.wait_prim_timeout | 等待Primary Component的超时 |
| pc.weight | 节点的权重,用于quorum计算 |
| protonet.backend | 传输后端,目前仅仅支持ASIO |
| repl.causal_read_timeout | causal reads(读取已提交)超时 |
| repl.commit_order |
是否、何时允许乱序commit: 0 BYPASS 不监控commit顺序 |
Orange开发了一个Galera Operator,简化K8S中的Galera的部署和运维。支持的特性包括:
- 创建、销毁集群
- 集群规模括缩容
- 垂直括缩:修改容器CPU/内存、持久卷大小
- 节点崩溃后自动故障转移
- 备份Galera集群到外部S3存储
- 从外部备份恢复Galera集群
来自 severalnines / galera-docker-mariadb。此方案在K8S中运行Maria DB 10.1,支持Galera,需要同时运行一个Etcd集群。
逻辑比较乱,主要是通过查询Etcd来获得集群节点列表、各节点的seqno信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 |
#!/bin/bash set -e # if command starts with an option, prepend mysqld if [ "${1:0:1}" = '-' ]; then CMDARG="$@" fi [ -z "$TTL" ] && TTL=10 if [ -z "$CLUSTER_NAME" ]; then echo >&2 'Error: You need to specify CLUSTER_NAME' exit 1 fi DATADIR="$("mysqld" --verbose --help 2>/dev/null | awk '$1 == "datadir" { print $2; exit }')" echo >&2 "Content of $DATADIR:" ls -al $DATADIR if [ ! -s "$DATADIR/grastate.dat" ]; then # 没有grastate.dat文件,意味着集群尚未初始化 INITIALIZED=1 if [ -z "$MYSQL_ROOT_PASSWORD" -a -z "$MYSQL_ALLOW_EMPTY_PASSWORD" -a -z "$MYSQL_RANDOM_ROOT_PASSWORD" ]; then echo >&2 'error: database is uninitialized and password option is not specified ' echo >&2 ' You need to specify one of MYSQL_ROOT_PASSWORD, MYSQL_ALLOW_EMPTY_PASSWORD and MYSQL_RANDOM_ROOT_PASSWORD' exit 1 fi mkdir -p "$DATADIR" chown -R mysql:mysql "$DATADIR" # 初始化MariaDB echo 'Running mysql_install_db' mysql_install_db --user=mysql --datadir="$DATADIR" --rpm echo 'Finished mysql_install_db' # 在后台启动MariaDB mysqld --user=mysql --datadir="$DATADIR" --skip-networking & pid="$!" mysql=(mysql --protocol=socket -uroot) # 等待MariaDB初始化完毕 for i in {30..0}; do if echo 'SELECT 1' | "${mysql[@]}" &>/dev/null; then break fi echo 'MySQL init process in progress...' sleep 1 done if [ "$i" = 0 ]; then echo >&2 'MySQL init process failed.' exit 1 fi # sed is for https://bugs.mysql.com/bug.php?id=20545 mysql_tzinfo_to_sql /usr/share/zoneinfo | sed 's/Local time zone must be set--see zic manual page/FCTY/' | "${mysql[@]}" mysql if [ ! -z "$MYSQL_RANDOM_ROOT_PASSWORD" ]; then MYSQL_ROOT_PASSWORD="$(pwmake 128)" echo "GENERATED ROOT PASSWORD: $MYSQL_ROOT_PASSWORD" fi # 在本地(禁止复制)创建root xtrabackup等用户 "${mysql[@]}" <<-EOSQL -- What's done in this file shouldn't be replicated -- or products like mysql-fabric won't work SET @@SESSION.SQL_LOG_BIN=0; DELETE FROM mysql.user ; CREATE USER 'root'@'%' IDENTIFIED BY '${MYSQL_ROOT_PASSWORD}' ; GRANT ALL ON *.* TO 'root'@'%' WITH GRANT OPTION ; CREATE USER 'xtrabackup'@'localhost' IDENTIFIED BY '$XTRABACKUP_PASSWORD'; GRANT RELOAD,LOCK TABLES,REPLICATION CLIENT ON *.* TO 'xtrabackup'@'localhost'; GRANT REPLICATION CLIENT ON *.* TO monitor@'%' IDENTIFIED BY 'monitor'; DROP DATABASE IF EXISTS test ; FLUSH PRIVILEGES ; EOSQL if [ ! -z "$MYSQL_ROOT_PASSWORD" ]; then mysql+=(-p"${MYSQL_ROOT_PASSWORD}") fi # 创建额外的数据库、用户 if [ "$MYSQL_DATABASE" ]; then echo "CREATE DATABASE IF NOT EXISTS \`$MYSQL_DATABASE\` ;" | "${mysql[@]}" mysql+=("$MYSQL_DATABASE") fi if [ "$MYSQL_USER" -a "$MYSQL_PASSWORD" ]; then echo "CREATE USER '"$MYSQL_USER"'@'%' IDENTIFIED BY '"$MYSQL_PASSWORD"' ;" | "${mysql[@]}" if [ "$MYSQL_DATABASE" ]; then echo "GRANT ALL ON \`"$MYSQL_DATABASE"\`.* TO '"$MYSQL_USER"'@'%' ;" | "${mysql[@]}" fi echo 'FLUSH PRIVILEGES ;' | "${mysql[@]}" fi if [ ! -z "$MYSQL_ONETIME_PASSWORD" ]; then "${mysql[@]}" <<-EOSQL ALTER USER 'root'@'%' PASSWORD EXPIRE; EOSQL fi if ! kill -s TERM "$pid" || ! wait "$pid"; then echo >&2 'MySQL init process failed.' exit 1 fi echo echo 'MySQL init process done. Ready for start up.' echo fi chown -R mysql:mysql "$DATADIR" function join { local IFS="$1" shift echo "$*" } # 将当前MariaDB实例加入到Galera集群,通过访问Etcd获取必要信息 if [ -z "$DISCOVERY_SERVICE" ]; then cluster_join=$CLUSTER_JOIN else echo echo '>> Registering in the discovery service' etcd_hosts=$(echo $DISCOVERY_SERVICE | tr ',' ' ') flag=1 echo # 寻找健康Etcd节点 for i in $etcd_hosts; do echo ">> Connecting to https://${i}/health" curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key https://${i}/health || continue if curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key https://$i/health | jq -e 'contains({ "health": "true"})'; then healthy_etcd=$i flag=0 break else echo >&2 ">> Node $i is unhealty. Proceed to the next node." fi done # 如果没有Etcd节点则放弃 if [ $flag -ne 0 ]; then echo ">> Couldn't reach healthy etcd nodes." exit 1 fi echo echo ">> Selected healthy etcd: $healthy_etcd" if [ ! -z "$healthy_etcd" ]; then URL="https://$healthy_etcd/v2/keys/galera/$CLUSTER_NAME" set +e echo >&2 ">> Waiting for $TTL seconds to read non-expired keys.." # 防止刚刚死去的Galera节点的注册信息仍然存在 sleep $TTL # 获取活动Galera节点列表 echo >&2 ">> Retrieving list of keys for $CLUSTER_NAME" addr=$(curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key $URL | jq -r '.node.nodes[]?.key' | awk -F'/' '{print $(NF)}') cluster_join=$(join , $addr) ipaddr=$(hostname -i | awk {'print $1'}) [ -z $ipaddr ] && ipaddr=$(hostname -I | awk {'print $1'}) echo if [ -z $cluster_join ]; then # 没有活动Galera节点。集群尚未初始化,或者集群完全宕机后重启(需要bootstrap) echo >&2 ">> KV store is empty. This is a the first node to come up." echo echo >&2 ">> Registering $ipaddr in https://$healthy_etcd" # 写入当前节点信息到Etcd curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key $URL/$ipaddr/ipaddress -X PUT -d "value=$ipaddr" else # 存在活动的Galera节点,看看有没有Synced的 curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key ${URL}?recursive=true\&sorted=true >/tmp/out running_nodes=$(cat /tmp/out | jq -r '.node.nodes[].nodes[]? | select(.key | contains ("wsrep_local_state_comment")) | select(.value == "Synced") | .key' | awk -F'/' '{print $(NF-1)}' | tr "\n" ' ' | sed -e 's/[[:space:]]*$//') echo echo ">> Running nodes: [${running_nodes}]" if [ -z "$running_nodes" ]; then # 没有Synced节点,必须恢复本节点的seqno,如果本节点最大,则可以自举 TMP=/var/lib/mysql/$(hostname).err echo >&2 ">> There is no node in synced state." echo >&2 ">> It's unsafe to bootstrap unless the sequence number is the latest." echo >&2 ">> Determining the Galera last committed seqno using --wsrep-recover.." echo # 恢复seqno mysqld_safe --wsrep-cluster-address=gcomm:// --wsrep-recover cat $TMP seqno=$(cat $TMP | tr ' ' "\n" | grep -e '[a-z0-9]*-[a-z0-9]*:[0-9]' | head -1 | cut -d ":" -f 2) # 此容器是新启动的,才会设置INITIALIZED。对于新节点,seqno设置为0 if [ $INITIALIZED -eq 1 ]; then echo >&2 ">> This is a new container, thus setting seqno to 0." seqno=0 fi echo if [ ! -z $seqno ]; then # 将当前节点的seqno写入到Etcd echo >&2 ">> Reporting seqno:$seqno to ${healthy_etcd}." WAIT=$(($TTL * 2)) curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key $URL/$ipaddr/seqno -X PUT -d "value=$seqno&ttl=$WAIT" else seqno=$(cat $TMP | tr ' ' "\n" | grep -e '[a-z0-9]*-[a-z0-9]*:[0-9]' | head -1) echo >&2 ">> Unable to determine Galera sequence number." exit 1 fi rm $TMP echo echo >&2 ">> Sleeping for $TTL seconds to wait for other nodes to report." sleep $TTL echo echo >&2 ">> Retrieving list of seqno for $CLUSTER_NAME" bootstrap_flag=1 # Retrieve seqno from etcd curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key ${URL}?recursive=true\&sorted=true >/tmp/out cluster_seqno=$(cat /tmp/out | jq -r '.node.nodes[].nodes[]? | select(.key | contains ("seqno")) | .value' | tr "\n" ' ' | sed -e 's/[[:space:]]*$//') for i in $cluster_seqno; do if [ $i -gt $seqno ]; then # 如果存在其它节点的seqno更大,本节点不处理bootstrap bootstrap_flag=0 echo >&2 ">> Found another node holding a greater seqno ($i/$seqno)" fi done echo if [ $bootstrap_flag -eq 1 ]; then # 本节点seqno最大,处理bootstrap # Find the earliest node to report if there is no higher seqno # node_to_bootstrap=$(cat /tmp/out | jq -c '.node.nodes[].nodes[]?' | grep seqno | tr ',:\"' ' ' | sort -k 11 | head -1 | awk -F'/' '{print $(NF-1)}') ## The earliest node to report if there is no higher seqno is computed wrongly: issue #6 node_to_bootstrap=$(cat /tmp/out | jq -c '.node.nodes[].nodes[]?' | grep seqno | tr ',:"' ' ' | sort -k5,5r -k11 | head -1 | awk -F'/' '{print $(NF-1)}') if [ "$node_to_bootstrap" == "$ipaddr" ]; then echo >&2 ">> This node is safe to bootstrap." cluster_join= else echo >&2 ">> Based on timestamp, $node_to_bootstrap is the chosen node to bootstrap." echo >&2 ">> Wait again for $TTL seconds to look for a bootstrapped node." sleep $TTL curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key ${URL}?recursive=true\&sorted=true >/tmp/out # Look for a synced node again running_nodes2=$(cat /tmp/out | jq -r '.node.nodes[].nodes[]? | select(.key | contains ("wsrep_local_state_comment")) | select(.value == "Synced") | .key' | awk -F'/' '{print $(NF-1)}' | tr "\n" ' ' | sed -e 's/[[:space:]]*$//') echo echo >&2 ">> Running nodes: [${running_nodes2}]" if [ ! -z "$running_nodes2" ]; then cluster_join=$(join , $running_nodes2) else echo echo >&2 ">> Unable to find a bootstrapped node to join." echo >&2 ">> Exiting." exit 1 fi fi else # seqno不是最大的,不处理bootstrap echo >&2 ">> Refusing to start for now because there is a node holding higher seqno." echo >&2 ">> Wait again for $TTL seconds to look for a bootstrapped node." sleep $TTL # Look for a synced node again curl -s -k --cacert /etc/etcd/ca.crt --cert /etc/etcd/client.crt --key /etc/etcd/client.key ${URL}?recursive=true\&sorted=true >/tmp/out running_nodes3=$(cat /tmp/out | jq -r '.node.nodes[].nodes[]? | select(.key | contains ("wsrep_local_state_comment")) | select(.value == "Synced") | .key' | awk -F'/' '{print $(NF-1)}' | tr "\n" ' ' | sed -e 's/[[:space:]]*$//') echo echo >&2 ">> Running nodes: [${running_nodes3}]" if [ ! -z "$running_nodes2" ]; then cluster_join=$(join , $running_nodes3) else echo echo >&2 ">> Unable to find a bootstrapped node to join." echo >&2 ">> Exiting." exit 1 fi fi else # if there is a Synced node, join the address cluster_join=$(join , $running_nodes) fi fi set -e echo echo >&2 ">> Cluster address is gcomm://$cluster_join" else echo echo >&2 '>> No healthy etcd host detected. Refused to start.' exit 1 fi fi echo echo >&2 ">> Starting reporting script in the background" nohup /report_status.sh root $MYSQL_ROOT_PASSWORD $CLUSTER_NAME $TTL $DISCOVERY_SERVICE & # set IP address based on the primary interface sed -i "s|WSREP_NODE_ADDRESS|$ipaddr|g" /etc/my.cnf echo echo >&2 ">> Starting mysqld process" if [ -z $cluster_join ]; then export _WSREP_NEW_CLUSTER='--wsrep-new-cluster' # set safe_to_bootstrap = 1 GRASTATE=$DATADIR/grastate.dat [ -f $GRASTATE ] && sed -i "s|safe_to_bootstrap.*|safe_to_bootstrap: 1|g" $GRASTATE else export _WSREP_NEW_CLUSTER='' fi exec mysqld --wsrep_cluster_name=$CLUSTER_NAME --wsrep-cluster-address="gcomm://$cluster_join" --wsrep_sst_auth="xtrabackup:$XTRABACKUP_PASSWORD" $_WSREP_NEW_CLUSTER $CMDARG |
该脚本会每TTL报告一次当前Galera容器的状态。
| 环境变量 | 说明 |
| MYSQL_ROOT_PASSWORD |
MySQL数据库的密码
|
| XTRABACKUP_PASSWORD |
此方案使用的SST方法是XtraBackup SST,它使用用户xtrabackup@localhost,如果需要定制密码,设置该变量 |
| CLUSTER_NAME | Galera集群的名称 |
| DISCOVERY_SERVICE |
如果需要启用发现服务(目前仅仅支持Etcd),需要配置该变量,形式IP:PORT,多个地址需要逗号分隔 容器会访问发现服务,使用CLUSTER_NAME来查询,如果发现已经存在对应的Galera集群,则加入;否则创建新的Galera集群 |
| CLUSTER_JOIN |
如果不启用发现服务,则需要设置此变量:
|
| TTL |
如果节点是alive的(wsrep_cluster_state_comment=Synced),每TTL - 2秒,report_status.sh会报告自身的状态 如果节点宕掉了,那么Etcd中的key无法刷新,因为过期而删除,这样构建Galera通信地址URI时就会跳过宕掉的节点 |
如果Galera集群名字为my_wsrep_cluster,则此方案会在Etcd中存储以下数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
// url -s "http://192.168.55.111:2379/v2/keys/galera/my_wsrep_cluster?recursive=true" { "action": "get", "node": { "createdIndex": 10049, "dir": true, "key": "/galera/my_wsrep_cluster", "modifiedIndex": 10049, "nodes": [ { "createdIndex": 10067, "dir": true, // 每个节点在 /galera/$CLUSTER_NAME/下有个键 "key": "/galera/my_wsrep_cluster/10.255.0.6", "modifiedIndex": 10067, "nodes": [ { "createdIndex": 10075, "expiration": "2016-11-29T10:55:35.37622336Z", // 存储节点seqno "key": "/galera/my_wsrep_cluster/10.255.0.6/wsrep_last_committed", "modifiedIndex": 10075, "ttl": 10, "value": "0" }, { "createdIndex": 10073, "expiration": "2016-11-29T10:55:34.788170259Z", // 存储节点状态 "key": "/galera/my_wsrep_cluster/10.255.0.6/wsrep_local_state_comment", "modifiedIndex": 10073, "ttl": 10, "value": "Synced" } ] }... ] } } |
Leave a Reply