MySQL知识集锦
| 术语 | 说明 | ||
| change buffer |
变更缓冲。由于insert、delete、purge等操作导致相应的索引变化需要写入,这些变化往往意味着随机I/O,为避免性能问题,后台线程周期性的执行索引变更的写入 |
||
| dirty page |
在InnoDB缓冲池中,已经被修改的,但是尚未刷出到数据文件的页,相对的叫clean page |
||
| double buffer |
双重缓冲是InnoDB引入的文件刷出技术,在把页写入到数据文件之前,首先将其写到一个连续的、称为双重缓冲的区域。只有在这一写入完毕后,InnoDB才把页写到数据文件的相应位置。如果在写数据文件期间出现OS、存储子系统或者MySQL进程的崩溃,InnoDB可以很好的从双重缓冲恢复数据 |
||
| extent |
表空间中的一组页,对于默认的16KB页,一个extend包含64页。对于4/8/16KB的页,extent的大小始终为1MB |
||
| Record Lock |
记录锁,是InnoDB行锁的一种,锁定一个索引记录(Index record)。记录锁总是锁定索引而不是数据行本身,即便表没有任何索引,InnoDB也会创建一个隐藏的聚簇索引,并用该索引执行记录的锁定 |
||
| gap lock |
间隙锁,是InnoDB行锁的一种。在2个索引记录之间的间隙上的锁定,或者在第一个索引记录之前、最后一个索引记录之后的间隙上的锁定 扫描普通索引时,InnoDB会对当前索引值与下一个索引值之间的间隙进行锁定 如果间隙锁导致了性能问题,可以设置隔离级别为READ-COMMITTED或者开启innodb_locks_unsafe_for_binlog,这相当于禁用索引扫描/搜索的间隙锁,间隙锁将仅仅被用于外键约束检查或者重复键检查 |
||
| Next-key lock |
下一键锁。默认情况下InnoDB工作在隔离级别 REPEATABLE READ下,并且系统变量innodb_locks_unsafe_for_binlog=OFF,这种设置下InnoDB使用下一键锁来进行索引扫描/搜索,同时避免幻影读问题。 下一键锁联合使用了Record lock以及Gap lock,在锁定住索引记录的同时,该索引记录前面的gap也被锁定。因此,如果一个会话持有索引记录R的共享或者独占锁,那么其它会话无法插入一个直接位于R之前(按索引顺序)的记录 下面的例子说明下一键锁的效果:
|
||
| metadata lock |
5.5.3+引入元数据锁定机制,来管理对数据库对象(而不是表中的数据)的并发访问,并保证数据一致性(防止结构性变更)。除了表以外,元数据锁定还应用到schema、存储对象(procedures、functions、triggers、scheduled events)。下面是元数据锁工作方式的示例:
在5.5.3版本之前,元数据锁的等价机制会在语句级别得到并释放结构性锁 |
||
| log |
在MySQL中,日志可能指:
|
||
| log buffer | 主要针对InnoDB重做日志,这是一个内存区域,其中包含将要写入到ib_logfile*文件的数据。其大小由innodb_log_buffer_size控制 | ||
| log file | 主要针对InnoDB重做日志,即ib_logfile*文件 | ||
| log group | 主要针对InnoDB重做日志,日志组,通常由ib_logfile0、ib_logfile1等组成 | ||
| page |
页,用来表示在任何时候,InnoDB在磁盘(数据文件)和内存(缓冲池)之间传递数据的最小单位。每个页存放1-N行数据,如果1行数据都放不下,InnoDB会创建额外的指针结构,确保行的相关信息被存放在一个页中 当InnoDB批量读写页以提高吞吐量时,每次执行一个extent 在5.6之前,InnoDB页大小固定为16KB,此后则可以是4KB、8KB或者16KB,由innodb_page_size控制 |
||
| purge |
由专用线程周期性执行的垃圾清理工作:
|
||
| redo log |
即InnoDB的重做日志,它是一种基于磁盘的数据结构,用于在崩溃恢复时纠正被不完整事务写入的数据。在常规操作中,重做日志编码并存储对InnoDB表数据的写请求(这些请求可能来自SQL语句或者低级别的API)为redo,在宕机恢复时,尚未来得及写入到数据文件的写操作被回放,并写入到数据文件。 在5.6.3之前,重做日志文件最大4GB,此后可达512GB 重做日志的磁盘布局受到innodb_log_file_size、innodb_log_group_home_dir、 innodb_log_files_in_group的控制,最后一个很少使用 |
||
| row lock | 锁定一行数据,防止其他事务对其执行不兼容的访问,表中的其他行可以被自由访问。行锁由InnoDB的DML操作自动发起 | ||
| savepoint | 保存点,用于帮助实现嵌套事务 | ||
| segment |
段,InnoDB表空间中的一部分,如果用目录类比表空间,那么段相当于文件,段可以增长、新建。 对于每表一文件模式,表数据在一个段中,而每一个关联的索引在各自的段中;对于所有表一文件模式,所有表的段都位于系统表空间中。系统表空间还会包括一个或者多个回滚段,供撤销日志使用 随着数据的插入和删除,段会自动增长和收缩。当段需要额外的空间时,它以extent为单位(1MB)增加;反之,当一个extent中的数据都不需要时,这个extent的空间被释放 |
||
| Temporary Tables |
某些情况下MySQL服务器会在创建内部使用的临时表,以便处理查询。临时表可能基于memory引擎被存放在内存中;或者基于MyISAM引擎并存放在磁盘中。服务器往往最初把临时表存放在内存中,当表过大时,转移到磁盘中 临时表的使用场景包括:
如果需要确定某个查询语句是否使用了临时表,可以通过解释计划的Extra列判断,Using temporary提示使用了临时表,但是注意解释计划可能不对衍生表或者物化临时表显示Using temporary |
||
| undo | 撤销。在事务的整个生命周期内被维护的日志信息,该日志信息记录了所有数据库改变,以便在回滚发生时,这些改变能够被撤销。该日志被存放在位于系统表空间或者独立的undo表空间中的撤销日志中 | ||
| undo log |
撤销日志,也称为undo buffer。存放被活动事务修改前的数据的副本,如果其他事务需要读取原始数据,MySQL将从undo log中获取。默认撤销日志位于系统表空间中。从MySQL 5.6开始,可以配置innodb_undo_tablespaces、innodb_undo_directory来将撤销日志分散到1-N个独立的表空间文件中,并可选的存放在独立的硬盘,例如SSD中 撤销日志被划分为不同的部分,包括insert undo buffer和update undo buffer |
| 命令 | 说明 | ||
| show full processlist; | 显示线程列表。如果显示Copying to tmp table,或者时间太大,要注意语句性能问题 | ||
| show variables; |
显示服务器系统变量
|
||
| show status; |
显示服务器状态变量,连同session范围的计数器
|
||
| flush status; | 刷空多种统计性的服务器状态变量 | ||
| show global status; | 显示服务器启动以来的计数器 | ||
|
show innodb status; show engine innodb status; |
显示innodb实时状态信息 5.6使用 |
||
| show table status; |
显示当前数据库的表状态,列信息: Name 表的名称 |
||
| select @@global.tx_isolation; | 显示系统的事务隔离级别 | ||
| alter table t_rt_val_his engine=myisam; | 修改表的引擎 | ||
| show create table t_table; | 显示DDL语句 | ||
| mysql -uuser -ppasswd dbname < path |
数据库导入命令 -h MySQL主机名或IP |
||
|
mysqldump -uuser -ppasswd dbname [tab1 tab2 tab3……] > path |
数据库导出命令,如果不指定表名,则导出整个库 -h MySQL主机名或IP |
||
| start transaction; select @a:=sum(salary) from t1; update t2 SET sum=@a; commit; |
命令行中开启事务 |
||
|
set autocommit=0; |
在会话(当前连接)中明确禁止自动提交 |
||
|
set profiling = 1; |
启用剖析 参考:剖析单个查询 |
||
|
set session transaction isolation level read committed; |
在会话(当前连接)中 设置事务隔离级别 |
||
|
check table mytable; |
检查表上的错误 |
||
|
explain |
解释执行计划 explain extended select * from tab; explains partitions --- 检查使用的分区表 |
||
|
mysqld |
mysqld是MySQL服务器端的主程序,使用mysqld --verbose --help | less 可以查看详细帮助 --defaults-file=/path-to/my.cnf 指定配置文件 |
||
|
create database |
创建新的数据库,例如: create database newdb; |
||
| mysql_install_db |
初始化MySQL数据库。5.7之前,会创建一个空密码的本地root用户,5.7之后使用随机密码,密码存放在~/.mysql_secret中。举例:
|
在MySQL中 create user 语句用于创建用户,相应的 alter user 、 drop user 用于修改、删除用户。MySQL在 mysql.user 表中存储用户。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE USER [IF NOT EXISTS] -- 目标规格,格式 user [ auth_option ] -- 其中user必须是'username'@'host'格式,引号可以省略 -- host中可以出现%,用于通配,例如192.168.0.%通配所有192.168.0子网的主机 -- %.gmem.cc则通配所有gmem.cc下的主机 -- auth_option指定身份验证方式,可以是: -- IDENTIFIED BY 'auth_string' | DENTIFIED BY PASSWORD 'hash_string' -- IDENTIFIED WITH auth_plugin | IDENTIFIED WITH auth_plugin BY 'auth_string' -- IDENTIFIED WITH auth_plugin AS 'hash_string' -- 其中auth_string表示明文,hash_string则为身份验证插件处理后的散列值,皆存放在authentication_string字段 user_specification [, user_specification] ... -- tsl_option,指定与SSL相关的选项,语法和CREATE USER相同,可以是: -- SSL | X509 | CIPHER 'cipher' | ISSUER 'issuer' | SUBJECT 'subject' [REQUIRE {NONE | tsl_option [[AND] tsl_option] ...}] -- resource_option,指定用户的资源配额,可以是: -- MAX_QUERIES_PER_HOUR count | MAX_UPDATES_PER_HOUR count -- MAX_CONNECTIONS_PER_HOUR count | MAX_USER_CONNECTIONS count [WITH resource_option [resource_option] ...] -- password_option 密码选项,可以是: -- PASSWORD EXPIRE | PASSWORD EXPIRE DEFAULT -- PASSWORD EXPIRE NEVER | PASSWORD EXPIRE INTERVAL N DAY -- lock_option 账户锁定选项,可以是: -- ACCOUNT LOCK | ACCOUNT UNLOCK [password_option | lock_option] ... |
|
1 2 3 4 5 6 |
-- 创建一个可从所有主机上登录的用户 create user 'newuser'@'%' identified by 'newpasswd'; -- 创建一个可从192.168.0网段登录的用户 create user 'newuser'@'192.168.0.%' identified by 'newpasswd'; -- 创建一个只能从服务器本机登录的用户,不授予密码 create user 'newuser'@'localhost'; |
|
1 2 3 |
SET PASSWORD [FOR user] = PASSWORD('auth_string'); # 举例 set password for gmem = password('gmem'); |
在MySQL中, grant 语句用于给MySQL用户授权,相应的 revoke 命令用于收回权限。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- 要给其它用户授权,当前用户必须具有GRANT OPTION权限,同时拥有那些即将授出的权限 -- 如果系统变量read_only启用,则需要额外的权限SUPER GRANT -- 权限类型,可以指定多个。括号内的列列表,用于指定特殊的权限级别——列 priv_type [(col_list)] [,priv_type [(col_list)]]... ON -- 可选的对象类型,可以是:TABLE、FUNCTION、PROCEDURE [object_type] -- 权限级别,授权应用到哪个库的哪些对象,可以是: -- * | *.* | db_name.* | db_name.tbl_name | tbl_name | db_name.routine_name priv_level TO -- 目标用户,格式 user [ auth_option ] -- 其中user为'username'@'host'格式 -- auth_option可以是: -- IDENTIFIED BY 'auth_string' | DENTIFIED BY PASSWORD 'hash_string' -- IDENTIFIED WITH auth_plugin | IDENTIFIED WITH auth_plugin BY 'auth_string' -- IDENTIFIED WITH auth_plugin AS 'hash_string' user_specification [, user_specification] ... -- tsl_option,指定与SSL相关的选项,语法和CREATE USER相同,可以是: -- SSL | X509 | CIPHER 'cipher' | ISSUER 'issuer' | SUBJECT 'subject' [REQUIRE {NONE | tsl_option [[AND] tsl_option] ...}] -- GRANT OPTION 表示新用户可以向其它人授权 -- resource_option,指定用户的资源配额,可以是: -- MAX_QUERIES_PER_HOUR count | MAX_UPDATES_PER_HOUR count -- MAX_CONNECTIONS_PER_HOUR count | MAX_USER_CONNECTIONS count [WITH {GRANT OPTION | resource_option} ...]; |
MySQL支持以下权限类型:
| 权限 | 说明 |
| ALL [PRIVILEGES] | 授予所有权限,除了GRANT OPTION |
| ALTER | 允许执行ALTER TABLE,支持的权限级别:全局、数据库、表 |
| ALTER ROUTINE | 允许修改或删除存储过程(stored routines),支持的权限级别:全局、数据库、存储过程(procedure) |
| CREATE | 允许创建数据库、表,支持的权限级别:全局、数据库、表 |
| CREATE ROUTINE | 允许创建存储过程,支持的权限级别:全局、数据库 |
| CREATE TABLESPACE | 允许创建、修改、删除表空间和日至文件组,支持的权限级别:全局 |
| CREATE TEMPORARY TABLES | 允许执行CREATE TEMPORARY TABLE,支持的权限级别:全局、数据库 |
| CREATE USER | 运行执行fCREATE USER、DROP USER、RENAME USER、REVOKE ALL PRIVILEGES,支持的权限级别:全局 |
| CREATE VIEW | 允许创建或修改视图,支持的权限级别:全局、数据库、表 |
| DELETE | 允许执行DELETE,支持的权限级别:全局、数据库、表 |
| DROP | 允许删除数据库、表、视图,支持的权限级别:全局、数据库、表 |
| EVENT | 允许使用事件调度机制(例如CREATE EVENT...),支持的权限级别:全局、数据库 |
| EXECUTE | 允许执行存储过程,支持的权限级别:全局、数据库、表 |
| FILE | 允许导致服务器读写文件,支持的权限级别:全局 |
| GRANT OPTION | 允许向其它用户授权,支持的权限级别:全局、数据库、表、存储过程、代理 |
| INDEX | 允许创建或删除索引,支持的权限级别:全局、数据库、表 |
| INSERT | 允许执行INSERT语句,支持的权限级别:全局、数据库、表、列 |
| LOCK TABLES | 允许对具有SELECT权限的表执行LOCK TABLES,支持的权限级别:全局、数据库 |
| PROCESS | 允许通过SHOW PROCESSLIST查看所有进程,支持的权限级别:全局 |
| PROXY | 允许使用用户代理 |
| REFERENCES | 允许创建外键,支持的权限级别:全局、数据库、表、列 |
| RELOAD | 允许执行FLUSH操作,支持的权限级别:全局 |
| REPLICATION CLIENT | 允许用户询问master/slave服务器在哪里,支持的权限级别:全局 |
| REPLICATION SLAVE | 允许从二进制日志中读取来自master的事件记录,支持的权限级别:全局 |
| SELECT | 允许执行SELECT语句,支持的权限级别:全局、数据库、表、列 |
| SHOW DATABASES | 允许执行SHOW DATABASES,支持的权限级别:全局 |
| SHOW VIEW | 允许执行SHOW CREATE VIEW,支持的权限级别:全局、数据库、表 |
| SHUTDOWN | 允许执行命令mysqladmin shutdown,支持的权限级别:全局 |
| SUPER | 允许使用其它管理性操作,例如 CHANGE MASTER TO、KILL、PURGE BINARY LOGS、SET GLOBAL以及执行mysqladmin debug命令,支持的权限级别:全局 |
| TRIGGER | 允许创建、删除表上的触发器,支持的权限级别:全局、数据库、表 |
| UPDATE | 允许执行UPDATE语句,支持的权限级别:全局、数据库、表、列 |
| USAGE | 无特权(no privileges)的同义词 |
|
1 2 3 4 |
-- 把数据库database的object对象的全部权限授予newuser,并允许他把这些权限授予别人 grant all privileges on database.object to 'newuser'@'%' with grant option; -- 把所有数据库的所有权限授予newuser grant all privileges on *.* to 'newuser'@'%'; |
| MySQL函数 | 说明 | ||
| CURDATE |
以YYY-MM-DD或YYYYMMDD格式得到当前日期,示例:
|
||
| CURTIME | 以H:MM:SS或者HHMMSS.uuuuuu格式得到当前时间 | ||
| MONTH |
从日期中抽取月份字段,示例:
|
||
| YEAR | 从日期中抽取4位数的年度字段 | ||
| CONCAT |
连接多个字符串,示例:
|
MySQL系统变量包含一系列配置信息,它们都具有默认值,并且大部分可以在运行时使用SET命令动态的修改,在表达式中,亦可引用系统变量。可以通过多种方式来查看这些系统变量的值:
|
1 2 3 4 5 6 7 8 |
-- 使用mysqladmin命令查看 mysqladmin variables; -- 通过information_schema数据库查看 select * from information_schema.SESSION_STATUS; -- 查看包含了编译时默认值和配置文件合并的系统参数列表 mysqld --verbose --help -- 查看编译时默认值的系统参数列表 mysqld --no-defaults --verbose --help |
这些变量和选项(以下统称参数)用来定制MySQL服务器的配置,或者优化性能。基于文件进行配置时,应该把参数列在my.cnf的[mysqld]段。下面列出MySQL 5.6版本的参数说明:
| 选项 | 说明 | ||
| abort_slave_event_count | 默认0。如果设置为正数N,那么slave的SQL线程启动后,能接收来自master的N个事件,之后不再接收,就好像与master之间的网络被断开一样 | ||
| archive | 默认ON。是否启用ARCHIVE插件 | ||
| auto_increment_increment | 默认1, 1_65535之间。自增长列的递增值 | ||
| auto_increment_offset |
默认1, 1_65535之间,不得大于auto_increment_increment。确定自增长列的值的起始点,仅在auto_increment_increment !=1时有意义。第N行的自增长列的取值按:auto_increment_offset + N × auto_increment_increment计算 注意:当该参数被修改时,新生成的自增长列值的计算,不会依赖于既有的列值,还是固定按上述公式得出 |
||
| autocommit | 默认TRUE,注意TRUE/FALSE可以用1/0代替,下同。是否在每一个语句执行后自动提交 | ||
| back_log | 默认80。排队中连接请求的最大数目,当MySQL服务器服务大量短时连接时,可以调整该参数 | ||
| basedir | 默认$INS_DIR。MySQL安装目录,很多其它目录通常相对于该目录解析 | ||
| big_tables | 默认FALSE。 通过存储到文件来允许大结果集,可以避免大部分"table full"错误 | ||
| bind_address | 默认0.0.0.0。 绑定的监听地址 | ||
| binlog_cache_size | 默认32768。 二进制日志中,用于事务性引擎的事务性缓存的大小。如果经常使用包含大量语句的事务,可以增加该参数的值 | ||
| binlog_direct_non_transactional_updates | 默认FALSE。 如果使用语句格式的二进制日志,打开此选项后,非事务性引擎执行的更新会直接写入二进制日志。注意,打开此选项必须确保事务性、非事务性表之间没有依赖(反例:insert into myisam select * from innodb),否则会导致slave和master不一致 | ||
| binlog_do_db | 明确指定master二进制日志针对的数据库名称,其它数据库不被记录日志 | ||
| binlog_ignore_db | 指定不需要记录二级制日志的数据库名称 | ||
| binlog_error_action | 当语句由于致命错误无法写入二进制日志时的动作,可以忽略或导致master终止 | ||
| binlog_format | 默认STATEMENT。 二级制日志的格式, ROW表示基于行的二进制日志;STATEMENT表示基于语句的二进制日志;MIXED表示尽量使用基于语句的格式,除非导致歧义(例如牵涉到时间、用户定义函数) | ||
| binlog_order_commits | 默认TRUE。 是否在内部发起与事务相同顺序的commit操作 | ||
| binlog_row_event_max_size | 默认8192。 基于行的二进制日志,每个事件最大字节数,多个行会尽可能合并到一个事件中,该值必须是256的倍数 | ||
| binlog_rows_query_log_events | 默认FALSE。 允许写入查询日志事件到二进制日志中 | ||
| binlog_stmt_cache_size | 默认32768。 非事务性引擎的语句缓存大小,如果经常使用语句更新大量的行,可以增加该参数的值 | ||
| blackhole | 默认ON。 是否启用BLACKHOLE插件 | ||
| bulk_insert_buffer_size | 默认8388608。 用于优化批量插入的tree cache的大小,该参数针对单个线程,增加该参数可以有效的提升批量插入的性能 | ||
| character_set_client_handshake | 默认TRUE。 是否在握手阶段考虑客户端的编码方式 | ||
| character_set_filesystem | 默认binary。 文件系统字符集 | ||
| character_set_server | 默认latin1。服务器默认字符集 | ||
| character_sets_dir | 默认$INS_DIR/share/charsets/。存放字符集的目录 | ||
| chroot | 在启动时设置mysqld的根目录 | ||
| collation_server | 默认latin1_swedish_ci。 默认排序规则 | ||
| concurrent_insert | 默认AUTO。 对于MyISAM,是否使用并发插入,可用值NEVER, AUTO, ALWAYS | ||
| connect_timeout | 默认10。 服务器等待客户端发送连接数据包(connect packet)的超时秒数,超时后服务器发送Bad handshake给客户端 | ||
| console | 默认FALSE。 是否保留控制台窗口 | ||
| datadir | 数据文件的根目录 | ||
| date_format | 默认%Y_%m_%d。 日期格式 | ||
| datetime_format | 默认%Y_%m_%d %H:%i:%s。 日期时间格式 | ||
| default_storage_engine | 默认InnoDB。 新创建表的默认存储引擎 | ||
| default_time_zone | 默认时区 | ||
| default_tmp_storage_engine | 默认InnoDB。 新的明确创建的临时表使用的存储引擎 | ||
| des_key_file | 从文件加载des_encrypt()的加密密钥 | ||
| disconnect_on_expired_password | 默认TRUE。 如果密码过期,断开连接 | ||
| expire_logs_days | 默认0。 二进制日志过期的天数,如果禁用,启用二进制日志会导致磁盘耗尽 | ||
| external_locking | 默认FALSE。 使用外部(系统级)锁定,开启后,可以在MySQL处于运行状态时,使用myisamchk检查MyISAM表 | ||
| flush | 默认FALSE。 在SQL命令之间,刷出MyISAM表到磁盘 | ||
| flush_time | 默认0。 如果大于0,每隔一段时间后,专用线程刷出所有表到磁盘 | ||
| gdb | 默认FALSE。 启用调试 | ||
| general_log | 默认FALSE。 将连接、查询信息都记录到表或者文件 | ||
| general_log_file | 默认$INS_DIR/data/hostname.log。 上述日志的文件名 | ||
| gtid_mode | 默认OFF。 是否启用全局事务标识符(Global Transaction Identifiers) | ||
| host_cache_size | 默认279。 为避免DNS解析,最多缓存多少主机名 | ||
| init_connect | 对于每一个新的连接,执行的命令 | ||
| init_file | 在服务器启动时,从文件读出并执行命令 | ||
| init_slave | Salve的SQL线程启动时执行的命令 | ||
| innodb | 默认ON。 | ||
| innodb_adaptive_flushing |
默认TRUE。 在检查点刷出脏页,以避免I/O暴增 自适应刷出(adaptive flushing)是InnoDB引入的一项刷出算法,通过引入检查点的概念,使I/O更加平缓,避免暴涨暴跌。该算法不是把所有脏页一次性从InnoDB缓冲池刷出到数据文件,而是周期性的刷出一小批脏页。该算法根据flush操作的频率、重做日志增长的速度决定最优化的刷出比率 |
||
| innodb_adaptive_flushing_lwm | 默认10。 上述刷出机制被禁用的最低水位(脏页占InnoDB重做日志缓冲的比例) | ||
| innodb_adaptive_hash_index | 默认TRUE。 启用InnoDB自适应哈希索引 | ||
| innodb_adaptive_max_sleep_delay | 默认150000。 最大休眠微秒数 | ||
| innodb_autoextend_increment | 默认64。 数据文件自动扩展的尺寸,MB | ||
| innodb_buffer_pool_dump_at_shutdown | 默认FALSE。 是否在关闭时Dump出InnoDB缓冲池 | ||
| innodb_buffer_pool_dump_now | 默认FALSE。 立即Dump出InnoDB缓冲池到@@innodb_buffer_pool_filename | ||
| innodb_buffer_pool_filename | 默认ib_buffer_pool。 DumpInnoDB缓冲池时的文件名 | ||
| innodb_buffer_pool_instances | 默认0。 缓冲池的数量,对于高档服务器,可以增加此值以提高可扩容性 | ||
| innodb_buffer_pool_load_abort | 默认FALSE。 立即中止正在执行的缓冲池加载(预热)动作 | ||
| innodb_buffer_pool_load_at_startup | 默认FALSE。 在启动时,从@@innodb_buffer_pool_filename读取缓冲池 | ||
| innodb_buffer_pool_load_now | 默认FALSE。 立即从@@innodb_buffer_pool_filename读取缓冲池 | ||
| innodb_buffer_pool_size |
默认134217728。 用于存储InnoDB数据和索引的缓冲池的大小 如果服务器是供MySQL专用的,可以尽量大,在为操作系统、MySQL其它组件预留足够的内存后,所有剩余的内存均可以分配给缓冲池,典型设置: 5-6GB(8GB内存),20-25GB(32GB内存),100-120GB(128GB内存) |
||
| innodb_buffer_pool_stats | 默认ON。 是否启用INNODB_BUFFER_POOL_STATS插件 | ||
| innodb_change_buffer_max_size | 默认25。 变更缓冲(磁盘文件)相对InnoDB缓冲池的最大比例。如果服务器增删改压力非常重,可以增加该参数的值 | ||
| innodb_change_buffering | 默认all。 使用变更缓冲的操作类型,可选值inserts、deletes、purges、changes、none、all | ||
| innodb_commit_concurrency | 默认0。 可以同时执行commit的线程数量,0表示不限制。在运行时不能在0和非0之间改变改变该参数 | ||
| innodb_compression_failure_threshold_pct |
默认 5。 当压缩失败的比率超过此阈值,InnoDB开始为新的压缩页预留空闲空间,预留空间的大小被动态调整,但不超过innodb_compression_pad_pct_max 关于OLTP场景使用压缩以节约磁盘空间:InnoDB压缩传统上主要用于只读或者几乎只读的场景。但是随着SSD这样快而贵的存储设备的出现,InnoDB压缩可以降低高流量、交互性网站的存储需求、IOPS 关于压缩失败:当InnoDB压缩表被执行DML操作时,如果对一个压缩页的更新时,会导致再次压缩,如果压缩后页空间不够,将导致MySQL执行页拆分,而新拆分的两个页又需要分别压缩,这是一个成本较高的场景。检查information_schema.innodb_cmp中compress_ops/compress_ops_ok的比值可以推测压缩失败出现的频度 |
||
| innodb_compression_level | 默认6 。 压缩级别,用于时空交换,范围0_9 | ||
| innodb_compression_pad_pct_max | 默认50。 每个压缩页预留空白的最大占比 | ||
| innodb_concurrency_tickets |
默认5000 。同时进入InnoDB的线程的数量具有限制,超过限制后的到达的线程将排队,一旦线程进入后,将得到该参数指定的票据数量,每次线程进入InnoDB都消耗一个票据,耗尽后将继续排队 该参数如果设置为较小的值,那么只牵涉到较少行的线程可以公平的与大量更新的线程竞争,其缺点是后者可能需要多次循环排队才能完成整个事务。show engine innodb status可以看到事务持有的票据数 |
||
| innodb_data_file_path | 默认ibdata1:10M:autoextend。指定系统表空间中InnoDB数据文件的文件名(目录innodb_data_home_dir)和大小。autoextend指定是否自动扩展,注意系统表空间永远不会收缩 | ||
| innodb_data_home_dir | 系统表空间中的InnoDB数据文件的统一存放目录。该参数不会影响innodb_file_per_table启用时每个表的数据文件位置 | ||
| innodb_disable_sort_file_cache | 默认FALSE。 禁用合并排序(merge_sort)临时文件的操作系统级缓存,效果上相当于使用O_DIRECT打开这样的临时文件 | ||
| innodb_doublewrite | 默认TRUE。 是否在写入数据文件之前,写入到双重缓冲 | ||
| innodb_fast_shutdown | 默认1。 InnoDB的关闭模式:设置为0则在关闭前执行完整的purge和change buffer合并;设置为1则跳过这些操作并关闭;设置为2则刷出innoDB并冷关闭,就像MySQL宕机一样,这会导致未提交的事务丢失 | ||
| innodb_file_format | 默认Antelope。 仅在innodb_file_per_table启用时有意义。选择Barracuda才能支持InnoDB压缩特性 | ||
| innodb_file_io_threads | 默认4。 InnoDB负责I/O操作的线程个数 | ||
| innodb_file_per_table |
默认ON。如果启用,InnoDB将新创建的表的数据、索引存放在独立的.ibd文件中,而不是存放在系统表空间。当表被drop或者truncate时,存储空间会被回收。如果要支持压缩,必须启用该选项。启用该选项后ALTER操作会导致表从系统表空间移出 开启该选项的好处:
开启该选项的缺点:
|
||
| innodb_flush_log_at_timeout | 默认1。 每隔N秒刷出InnoDB重做日志到文件系统。如果OS崩溃或者断电,肯定导致N秒的数据丢失 | ||
| innodb_flush_log_at_trx_commit |
默认1。 控制性能与完全的ACID保证之间的权衡。修改该参数能够提高性能,但是可能在崩溃时丢失数据
从5.6.6开始,日志文件刷出间隔由innodb_flush_log_at_timeout控制 不管该参数设置为多少,InnoDB崩溃恢复机制都会运行,事务要么被完整的应用,要么被彻底删除 |
||
| innodb_flush_method |
定义刷出数据到InnoDB数据文件、日志文件的方式,仅仅在Linux/Unix系统上可配置:
O_DIRECT选项用于跳过OS缓存直接写入 |
||
| innodb_flush_neighbors |
默认1。 指示在刷出InnoDB缓冲池中一页的时候,是否把同一extent中的脏页一起刷出:
对于传统HDD,开启此选项有利于减低I/O负载;对于SSD,由于不存在寻道问题,可以关闭该选项 |
||
| innodb_flushing_avg_loops | 默认30。 控制InnoDB自适应刷出机制相应工作负载变化的速度,设置的越大,响应速度越慢 | ||
| innodb_force_load_corrupted | 默认FALSE。 强制加载被污染的表,如果某些表因为数据损坏而无法访问,需要手工处理,可以打开此标记,处理完毕后再关闭 | ||
| innodb_force_recovery | 默认0。 可以设置0_6,只在非常验证的诊断场景下才需要更改 | ||
| innodb_io_capacity |
默认200。 设置InnoDB后台任务(从缓冲池刷出页、合并变更缓冲里的数据等)能执行的I/O活动的上限。该参数供所有缓冲池实例使用,多个缓冲池会平分这一参数 该参数可以设置的与系统的IOPS相近,但是在满足需要的前提下,应当尽量的低,如果设置的过高(例如100万),数据可能过快的移除、插入缓冲池,而导致缓冲池的缓存价值变低 对于5400/7200转的老旧硬盘,有可能需要设置到100。当前的默认值适应大部分现代设备和较高的I/O速率 对于具有多磁盘、SSD等能够支持高IOPS存储设备的系统,提高该参数可能获益 |
||
| innodb_io_capacity_max | 紧急情况下InnoDB后台任务最大I/O能力,如果不设置,默认值是innodb_io_capacity的2倍,并且大于2000 | ||
| innodb_lock_wait_timeout |
默认50。 在InnoDB事务放弃前,等待行锁的最长时间,默认50秒。放弃后,会打印Lock wait timeout exceeded信息,并且导致当前语句(而不是整个事务)回滚,innodb_rollback_on_timeout参数会在此场景下导致整个事务回滚 对于高交互性应用或者OLTP,该参数可能需要调低 注意:
|
||
| innodb_log_buffer_size |
默认8388608,范围在256KB到4GB之间。InnoDB重做日志的内存缓冲大小,InnoDB事务在修改任何数据时,总是先写入到该缓冲,只在缓冲已满、事务提交、或者过了N秒后,才会把该缓冲刷出到重做日志文件中。 如果存在大量的、增删改大量行或者LOB的事务,可以增加此参数,以减少磁盘I/O。 |
||
| innodb_log_compressed_pages | 默认TRUE。 指定是否重压缩的页镜像被存放在重做日志中 | ||
| innodb_log_file_size |
默认50331648。 InnoDB重做日志组中,单个文件的大小,innodb_log_file_size *innodb_log_files_in_group不得超过512G。 1MB到innodb_buffer_pool_size/innodb_log_files_in_group是合理的取值范围。该值设置的越大,InnoDB缓冲池需要的刷出操作越少,因而磁盘I/O也越少,对于高并发负载,可以设置到GB级别 尽管5.5以后,重做日志文件的大小对崩溃恢复速度的影响变小,但是,该参数越大,崩溃恢复时间仍然越长 注意修改此值要准守一定的步骤,在高性能MySQL学习笔记中有详细说明 |
||
| innodb_log_files_in_group | 默认2。 InnoDB重做日志组包含的文件个数,InnoDB采取循环写入的方式使用这些文件 | ||
| innodb_log_group_home_dir | InnoDB重做日志的存放目录 | ||
| innodb_lru_scan_depth | 默认1024。 影响InnoDB缓冲池的刷出操作,用于调优I/O敏感的工作负载。该参数指定了页面清理线程遍历(每秒执行一次)缓冲池LRU列表最大的深度。如果在某个工作负载下还具有空闲的I/O能力,可以增加该参数;如果具有大缓冲池,并且写敏感工作负载使I/O能力饱和,则可以减少该值 | ||
| innodb_max_dirty_pages_pct |
默认75。 InnoDB会把缓冲池中的页刷出到数据文件,以确保脏页占比不超过此参数指定的比例。该参数不会影响刷出操作的速率 该参数设置的很大时,如果重做日志空间不足,可能导致激烈的刷出操作 |
||
| innodb_max_dirty_pages_pct_lwm | 默认0。 脏页低水位,超过该比例后,预刷出(preflushing)机制被启用,以控制脏页比率。默认禁用 | ||
| innodb_max_purge_lag |
默认0。 当清理操作迟滞时,如何延迟insert/update/delete的执行,默认值表示不延迟。 InnoDB事务系统维护一个transactiond的列表,这些transaction执行了update/delete操作而导致某些索引记录被标记为删除。该列表的长度相当于清理迟滞(purge lag)的值,当purge lag大于innodb_max_purge_lag时所有insert/update/delete操作将被延迟执行。迟滞值会显示在InnoDB状态输出:
对于小事务(100bytes)典型的设置可能是100万,为了避免过分的延迟,可以设置innodb_max_purge_lag_delay |
||
| innodb_max_purge_lag_delay | 默认0。 最大延迟毫秒数,参考上一个参数 | ||
| innodb_monitor_disable | 启禁information_schema.innodb_metrics中一个或者多个计数器 | ||
| innodb_monitor_enable | |||
| innodb_monitor_reset | 重置information_schema.innodb_metrics中的计数器 | ||
| innodb_monitor_reset_all | |||
| innodb_old_blocks_pct | 默认37。 InnoDB缓冲池中供旧块(old block)子列表使用的比例,默认3/8,通常和innodb_old_blocks_time联用 | ||
| innodb_old_blocks_time |
默认1000。 非0值可以用来预防InnoDB缓冲池被仅仅短时间引用的数据(例如全表扫描)充满,增加此值可以增强前述预防功能。 该参数指定一个毫秒数的阈值,插入缓冲池old sublist的块,必须至少等待此阈值后,被访问时才被转移到new sublist中;如果设置为0,一旦old sublist中的块被访问,就插入到new sublist中 old/new块是InnoDB缓冲池改进的LRU算法引入的概念,该算法致力于尽量让hot pages(经常被访问的)驻留在缓冲池中。某些全表扫描、预读导致加入缓冲池的块,可能后续永远不会被使用,也就没有缓存价值,因此,InnoDB默认把新读进去的块存放在LRU列表的后面3/8部分,此部分即old list,存放在其中的块即old blocks |
||
| innodb_open_files | 默认0。 限制InnoDB最多同时打开的.ibd文件的数量,只在使用多个表空间(例如file per table)有意义 | ||
| innodb_page_size |
默认16384。 所有InnoDB表空间使用的页的大小。 较小的页更适合存在代码small write的OLTP场景,因为大页包含多个的多行可能出现争用;较小的页亦适用于SSD,因为SSD通常使用小的块,例如4KB。让InnoDB页大小与硬盘的块大小接近,可以避免对未更改数据的重新写入 默认值16KB适用于广泛的应用场景,特别是牵涉到表扫描、批量更新的DML操作的场景 |
||
| innodb_print_all_deadlocks |
默认FALSE。 启用后,所有的死锁信息记录在mysqld的错误日志中,否则只用通过InnoDB引擎状态查看最后的死锁。 偶发的死锁不需要特别关注,因为InnoDB会立即检测并回滚事务。如果应用程序没有合适的错误处理、重试逻辑,可以打开此选项进行检测。一般可能需要调整代码中锁的获取顺序,避免死锁 |
||
| innodb_purge_batch_size | 默认300。 重做日志中的记录数到达多少时,触发清理操作,这会导致InnoDB缓冲池中的脏页被刷出到数据文件,通常和innodb_purge_threads联用 | ||
| innodb_purge_threads | 默认1。 专用于InnoDB清理操作的后台线程的数量,最大值32 | ||
| innodb_random_read_ahead | 默认FALSE。 启用随机预读(random read-ahead )来优化InnoDB的I/O | ||
| innodb_read_ahead_threshold |
默认56,范围0-64。 控制线性预读(linear read-ahead)的敏感性。InnoDB会立即预读当前extent内至少innodb_read_ahead_threshold个页(注意默认一个extent是64页),并发起一个异步读,来读取整个extent后续的页 预读不一定有价值,状态变量Innodb_buffer_pool_read_ahead_evicted/Innodb_buffer_pool_read_ahead的比值可以看到哪些页在预读后没有被使用就清除了。此外,InnoDB状态输出中可以看到预读和预读立即清除的速率:
|
||
| innodb_read_io_threads | 默认4。 执行读操作的InnoDB线程数量 | ||
| innodb_read_only | 默认FALSE。 以只读模式运行,可以运用在数据仓库中,让多个MySQL实例共享一份数据文件 | ||
| innodb_replication_delay | 默认0。 当innodb_thread_concurrency到达时,Slave上的复制线程延迟的毫秒数 | ||
| innodb_rollback_on_timeout | 默认FALSE。 5.6版本的默认情况下,事务超时只会导致最后一个语句被回滚,指定该选项可以让整个事务回滚 | ||
| innodb_rollback_segments | 默认128。 指定系统表空间中有多少个回滚段,该参数会被innodb_undo_logs覆盖 | ||
| innodb_sort_buffer_size | 默认1048576。 当创建InnoDB索引的时候,可以使用多大的缓冲区来对数据进行排序。索引创建完毕后,此缓冲被释放,该参数不会影响后续的索引维护操作 | ||
| innodb_spin_wait_delay | 默认6。 轮询自旋锁时最大的延迟,由于硬件和OS的不同,该参数不能映射到具体的时间间隔 | ||
| innodb_stats_auto_recalc | 默认TRUE。 当表的数据发生足够量的改变时,导致InnoDB自动重新计算索引统计信息 | ||
| innodb_stats_method |
默认nulls_equal。 收集统计信息时,如何处理InnoDB索引中的NULL值:
生成表统计信息的方式,影响查询优化器对执行计划的选择 |
||
| innodb_stats_on_metadata | 默认FALSE。 如果启用,InnoDB在元数据语句(metadata statements,例如show table status;show index)被执行时或者查询information_schema.tables|statistics时,自动更新统计信息 | ||
| innodb_stats_persistent | 默认TRUE。 InnoDO索引统计信息是否持久化保存。create|alter表时使用stat persistent从句可以按单个表的设置此参数 | ||
| innodb_stats_persistent_sample_pages | 默认20。 进行索引信息统计时,采样的索引页的数量。增加此值会提高统计信息的精确度,但是导致analyze table的I/O成本变大。对innodb_stats_persistent=true的表有效 | ||
| innodb_stats_transient_sample_pages | 默认8。 类似上面,对innodb_stats_persistent=false的表有效 | ||
| innodb_strict_mode | 默认FALSE。 如果打开,在某些情况下返回错误,而不是警告 | ||
| innodb_support_xa | 默认TRUE。 启用两阶段提交的XA分布式事务支持。在master上不要关闭 | ||
| innodb_sync_spin_loops | 自旋锁的最大循环次数,修改此值可以在无谓的线程上下文切换以及浪费CPU时间之间进行平衡 | ||
| innodb_thread_concurrency |
默认0。 最大并发线程数,即InnoDB持有的,负责事务处理的最大操作系统线程数。一旦到达限制,其它线程按FIFO排队,因等待锁而阻塞的线程不计算为并发线程 值范围0-1000,0表示无限制,InnoDB会根据需要创建足够多的线程,0亦导致InnoDB状态输出的queries inside InnoDB、queries in queue counters段落被禁用 该参数合理的值依赖于具体的工作负载,特别是MySQL需要和其它应用程序共享CPU的时候。如果设置为某个值后性能很差,可以实时的修改为0 下面是一些帮助确定合理值的经验:
|
||
| innodb_thread_sleep_delay |
默认10000。 InnoDB加入队列前休眠的微秒数 对于5.6.3+,可以设置innodb_adaptive_max_sleep_delay为一个允许的最大休眠时间,并让InnoDB自适应的调整 |
||
| innodb_undo_directory | 默认 .。 InnoDB为撤销日志提供独立表空间的目录,典型的做法是把撤销日志存放在独立的磁盘上。该参数与innodb_undo_logs、innodb_undo_tablespaces联用。默认值.表示和其它日志文件放在一个目录 | ||
| innodb_undo_logs |
默认128。 撤销日志(或者说回滚段)的数量,每个撤销日志最多可以持有1024个事务。该参数覆盖innodb_rollback_segments。 当观察到针对撤销日志的争用时,可以调整该值,状态变量Innodb_available_undo_logs反应了目前可用的撤销日志的数量 |
||
| innodb_undo_tablespaces |
默认0。 撤销日志表空间的数量,撤销日志会被分配到这些表空间中。注意,系统表空间总是包含一个撤销日志表空间,后者默认用来存放所有撤销日志 额外的撤销表空间被创建在innodb_undo_directory目录中,命令为undoN,每个表空间的默认大小10MB 该参数必须在InnoDB初始前就设置,如果在运行过程中修改为更大的值,会导致MySQL启动失败 |
||
| innodb_use_native_aio |
默认TRUE。 仅用于Linux,是否使用操作系统的异步I/O子系统,在5.5+原先仅存在与Windows的异步I/O被添加到Linux版本中。该选项提高了I/O-bound系统的性能 开启此选项时,如果具有大量的InnoDB的I/O线程,可能导致超过Linux系统的限制,从而出现: EAGAIN: The specified maxevents exceeds the user's limit of available events. 错误,此时可以调整 /proc/sys/fs/aio-max-nr 中的限制值 |
||
| innodb_write_io_threads | 默认4。 执行写操作的InnoDB线程数量 | ||
| interactive_timeout | 默认28800。 交互式客户端超时时间, | ||
| join_buffer_size |
默认262144,32bit系统最大支持4GB-1。 用于普通索引扫描(plain index scans)、范围索引扫描或者不使用索引而进行全表扫描的join操作的缓冲区的最小值 加快join的最好方式是创建合适的索引,如果不能增加索引,才考虑调整此参数的值。每个缓冲只用于两个表的join,因此某些没有用到索引的复杂多表join查询,可能需要用到多个这样的缓冲 不应该将此参数的全局值设置的过大,最好只在执行大join的会话级别设置 |
||
| key_buffer_size |
默认8388608,32bit系统最大支持4GB-1。 MyISAM表的索引块(Index blocks)被缓冲,并由所有线程共享,这个缓冲池被称为Key buffer或者Key cache。该参数指定此缓冲池的大小 增加此参数的值,能够提高所有读操作、很多写操作的性能,对于专用MyISAM的服务器,可以设置到物理内存的25%。如果设置的过高,可能导致OS执行内存换页,导致极差的性能,由于MySQL依赖于OS提供的文件系统缓存来读取数据,必须为OS文件系统缓存预留内存 状态变量:Key_read_requests、Key_reads、 Key_write_requests、Key_writes用于监测此键缓存的性能,Key_reads/Key_read_requests正常情况下应当小于0.01 公式: 1 - ((Key_blocks_unused * key_cache_block_size) / key_buffer_size) 用于计算键缓存当前使用比 |
||
| key_cache_age_threshold | 默认300。 影响MyISAM键缓存的内部数据移动,设置的越小,数据从hot子列表转移到warm子列表的速度越快 | ||
| key_cache_block_size | 默认1024。 MyISAM键缓存的数据块的大小 | ||
| key_cache_division_limit | 默认100。 MyISAM键缓存hot/warm的比例,该参数指定了warm子列表的百分比 | ||
| large_pages | 默认FALSE。 是否启用大页(large page)支持 | ||
| large_pages_size | 大内存页的大小,目前仅Linux支持 | ||
| lock_wait_timeout |
默认31536000。 尝试获取元数据锁(metadata locks)的超时时间。该超时应用到所有使用元数据锁的语句,包括在表、视图上执行的DDL、DML;存储函数;lock tables;flush tables with read lock 该超时不会应用到针对mysql库中对象的隐式访问,例如grant/revoke语句,但是对系统表的显示访问,例如select/update,会使用到该超时 该超时会单独应用到每个元数据锁的获取 |
||
| log_bin | 默认FALSE。是否启用二进制日志的记录 | ||
| log_bin_basename | 默认datadir + '/' + hostname + '-bin'。二进制日志的路径和basename | ||
| log_bin_index | 二进制日志的索引文件名 | ||
| log_error | 默认hostname.err。记录启动消息和错误日志的文件名 | ||
| log_output | 默认FILE。 指定一般查询日志、缓慢查询日志的输出类型,可以选择FILE/TABLE/NONE,如果设置为TABLE,将在mysql库建立general_log、slow_log表以存放日志 | ||
| log_queries_not_using_indexes | 默认FALSE。 如果启用缓慢查询日志的同时启用该参数,那么没有使用索引的查询、虽然使用索引单进行了全表扫描的查询会被记录 | ||
| log_raw | 默认FALSE。 开启后在记录查询日志时,使用明文密码 | ||
| log_short_format | 默认FALSE。 记录更少的内容到二进制日志或者查询日志 | ||
| log_slave_updates | 默认FALSE。 Slave是否把从Master接收到的更新记录到自己的二进制日志中,如果开启,需要Slave启用二进制日志 | ||
| log_slow_admin_statements | 默认FALSE。 是否把管理性的缓慢查询记录到缓慢查询日志中,这些查询包括ALTER TABLE, ANALYZE TABLE, CHECK TABLE, CREATE INDEX, DROP INDEX, OPTIMIZE TABLE,REPAIR TABLE | ||
| log_slow_slave_statements | 默认FALSE。 是否把Slave上执行缓慢的查询记录到Slave的缓慢查询日志中 | ||
| log_throttle_queries_not_using_indexes | 默认0。 当log_queries_not_using_indexes启用的时候,该参数限制每分钟进入缓慢日志的最大查询个数 | ||
| log_warnings | 默认1。 是否打印额外的警告信息到错误日志中 | ||
| long_query_time | 默认10。 判断缓慢查询的阈值,单位秒。如果一个查询比执行时间超过此值,状态变量Slow_queries被增加,如果缓慢查询日志被启用,该查询会被写入日志 | ||
| low_priority_updates |
默认FALSE。 如果设置为TRUE,那么所有insert、update、delete、lock table write语句都会等待,直到所有未决的select、lock table for read操作完成 该参数只对那些仅仅使用表级锁定的引擎有效,例如MyISAM, MEMORY, MERGE |
||
| lower_case_table_names |
默认0。 只读属性,指示底层文件系统是否大小写敏感,0表示敏感 如果从Windows上Dump出数据库到Linux下,应该把该值设置为1,否则可能导致Table '***' doesn't exist的错误 |
||
| master_info_file | 默认master.info。 Slave记录Master信息的文件名 | ||
| master_info_repository | 默认FILE。 指示Slave记录Master的状态和连接信息到表而是文件 | ||
| master_retry_count | 默认86400。 在Slave放弃到Master的连接尝试前,重试的次数 | ||
| max_allowed_packet |
默认4194304,最大1GB,必须设置为1024的倍数。 客户端把整个查询在单个数据报中发送,如果使用很大的查询语句(例如包含大的LOB字段),就必须调整该参数。数据报缓冲的初始值会被设置为net_buffer_length,最大可以增长到max_allowed_packet 在数据复制场景中,集群中每台服务器应当设置一样的值 客户端应当同时设置max_allowed_packet,尽管客户端Library中给出的默认值是1GB,但是不同的客户端程序可能覆盖了这以默认值,例如mysql、mysqldump这两个程序分别使用16MB、24MB作为默认值 |
||
| max_binlog_cache_size | 默认18446744073709547520。 如果一个事务要求超过该参数指定的内存,MySQL发出一个 Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage 错误,适当的最大值应该设置为4GB,因为目前MySQL只能支持最大4GB的二进制日志缓冲 | ||
| max_binlog_size | 默认1073741824。 如果一个对二进制日志的写操作导致当前日志超过max_binlog_size,则MySQL轮换日志(关闭当前日志,打开下一个日志) | ||
| max_binlog_stmt_cache_size | 默认18446744073709547520。 二进制日志非事务性的语句缓存的最大大小 | ||
| max_connect_errors | 默认100。 如果某台主机连续这么多次连接是否,该主机(在重启前)将被禁止后续的连接尝试 | ||
| max_connections | 默认151。 最大允许的同时连接数,如果经常出现Too Many Connections的错误提示则可能需要增加此值 | ||
| max_error_count | 默认64。 show errors和show warnings语句能够显示的最大错误、警告的数量 | ||
| max_heap_table_size |
默认16777216。 用户创建的内存表的占用内存的最大数量,设置该参数对既有的内存表没有作用,除非这些内存表被某些DDL语句操控,例如create/truncate/alter 该参数常常和tmp_table_size联用,以限制MySQL内部内存表的尺寸 |
||
| max_join_size |
默认18446744073709551615。 可以用于禁止执行这样的查询:需要检查超过max_join_size行的单表查询;组合数超过max_join_size的链表查询;可能需要进行超过max_join_size次磁盘寻道的查询 通过设置该参数,可以捕获到没有合理使用键的、因而可能需要很长执行时间的查询 设置该参数为非默认值,将导致sql_big_selects变为0;设置sql_big_selects为1,则该参数的值被忽略 |
||
| max_length_for_sort_data | 默认1024。 导致filesort算法被激活的索引值列表深度的阈值 | ||
| max_prepared_stmt_count | 默认16382。 限制服务器上预编译语句的最大数量,设置为0则禁用预编译语句 | ||
| max_relay_log_size | 默认0。 如果Slave的中继日志超过该参数,那么将导致日志轮换——当前日志文件被关闭并打开新文件 | ||
| max_sort_length |
默认1024。 排序时,使用的字段的最大长度,这导致前max_sort_length个字符相等的字段被认为是相等的 对于5.6.9+,MySQL不对integer/decimal/float等数据类型应用该参数 |
||
| max_sp_recursion_depth | 默认0。 存储过程最多被递归调用的深度 | ||
| max_user_connections | 默认0。 每个MySQL账户最多同时创建的连接数 | ||
| max_write_lock_count | 默认18446744073709551615。 在此数量的写锁之后,允许某些未决的读锁请求被处理 | ||
| memlock | 默认FALSE。 将mysqld锁定在内存中,方式OS将其交换到磁盘 | ||
| metadata_locks_cache_size | 默认1024。 元数据锁缓存的大小,该缓存被MySQL用来避免同步对象的创建和销毁。对于创建同步对象代价较大的OS,例如Windows XP,该参数有用 | ||
| min_examined_row_limit | 默认0。 检查行数小于此值的查询,不会被记录到缓慢查询日志 | ||
| myisam_block_size | 默认1024。 MyISAM索引页的块大小 | ||
| myisam_max_sort_file_size | 默认9223372036853727232。 当重建MyISAM索引时,MySQL允许使用临时文件的最大尺寸 | ||
| myisam_mmap_size | 默认18446744073709551615。 用于MyISAM压缩文件的内存映射文件的最大内存占用,如果使用了大量MyISAM压缩表,可以减少此值以避免潜在的换页问题 | ||
| myisam_repair_threads | 默认1。 如果设置的值超过1,当Repair by sorting时,MyISAM索引会被并行的创建 | ||
| myisam_sort_buffer_size | 默认8388608。 用来排序MyISAM索引的缓冲区的大小,此排序会在repair table/create index/alter table时发生。该类操作的出现几率较小,提高此参数有利于增强性能 | ||
| myisam_stats_method | 默认nulls_unequal。 统计索引值分布时,处理MyISAM表null值的方法,该参数会影响优化器的行为 | ||
| myisam_use_mmap | 默认FALSE。 读写MyISAM表时,是否使用内存映射文件 | ||
| net_buffer_length |
默认16384。 每个线程会关联一个connection buffer和一个result buffer,其初始值都是net_buffer_length,最大值则是max_allowed_packet。在每个语句执行完毕后result buffer都会收缩到net_buffer_length 该参数通常不需要修改,但是如果服务器内存特别小,可以将其设置为客户端发送的语句的期望大小 |
||
| net_read_timeout | 默认30。 服务器在读取客户端数据时,最大的超时时间 | ||
| net_write_timeout | 默认60。 服务器在向客户端写数据时,最大的超时时间 | ||
| open_files_limit | 默认1024。 操作系统运行mysqld打开的文件的最大数量,如果设置的过小,可能导致too many open files错误,由于现代OS中打开文件几乎不需要消耗什么资源,可以设置为65535 | ||
| partition | 默认ON。 开启或者禁用用户定义的表分区功能 | ||
| pid_file | 默认$INS_DIR/data/hostname.pid。 进程标识符文件的名字 | ||
| plugin_dir | 默认$INS_DIR/lib/plugin/。插件目录 | ||
| port | 默认3306。 mysqld的TCP/IP监听端口 | ||
| port_open_timeout | 默认0。 端口打开的超时时间,某些系统可能对端口重用的时间间隔有限定 | ||
| preload_buffer_size | 默认32768。 预加载索引时分配的缓冲的大小 | ||
| profiling_history_size | 默认15,最大值100。 当启用profiling时,保留profiling信息的历史语句的最大数量 | ||
| query_cache_limit | 默认1048576。 单个查询能够使用的查询缓冲的大小,如果查询的结果超过此限制,将不被缓存 | ||
| query_cache_min_res_unit | 默认4096。 每一次对查询结果进行缓存时,需要申请缓存内存中的一个块,该参数指定其最小大小,块的分配属于相对较慢的操作,因为MySQL需要检查空闲块列表,并找到一个足够大的 | ||
| query_cache_size | 默认1048576。 设置全局的查询缓存的大小。修改此值后,MySQL立即清除所有的查询缓存,调整缓存的大小,并重新初始化缓存,由于MySQL是串行删除缓存的,所以可能导致服务器停顿较长时间。当一个查询语句执行完毕,其结果会被MySQL缓存,起来,如果后续到到来的SQL一模一样,则直接返回结果,不进入优化和执行阶段。但是,一旦缓存相关的任何表发生了变化,则所有缓存均必须被串行的删除,如果查询缓存特别大,则可能导致插入、更新的效率很低 | ||
| query_cache_type | 默认0。 查询缓存的使用方式:0表示关闭;1表示使用(除非select sql_no_cache);2表示按需(select sql_cache) | ||
| query_cache_wlock_invalidate | 默认FALSE。 默认的,当一个客户端获得一个MyISAM表的写锁时,其它线程发起的、结果存在与查询缓存的语句不会被阻塞。如果设置该参数为true,将导致MyISAM写锁获得时将该表的所有查询缓存禁用,这导致所有后续对该表的请求等待锁的释放 | ||
| query_prealloc_size |
默认8192。 用于查询解析和执行的缓冲的大小,该缓冲不会在一个语句执行后被释放。 如果需要运行复杂的查询,增大该值可能提高性能,因为它避免了在语句执行过程中的服务器段内存分配 |
||
| read_buffer_size |
默认131072。 每一个对MyISAM表进行顺序扫描(sequential scan)的线程,MySQL为它扫描的每个表分配read_buffer_size的缓冲,如果需要做很多顺序扫描(或者扫描速度较慢),可能需要增加该值,该缓冲直到需要时才会分配 该值必须设置为4KB的倍数 对于所有引擎,下面的场景下该参数亦有效:
对于memory引擎,该参数还用于判断memory block的大小 |
||
| read_only | 默认FALSE。 除了具有super权限的用户,禁止任何写操作 | ||
| read_rnd_buffer_size |
默认262144。随机读缓冲区的大小,该参数用于MyISAM表的数据读取,以及其它引擎的Multi-Range读操作的优化 对于基于键排序(key-sorting)的MyISAM查询,结果行将通过此缓冲来读取,以避免不必要的随机I/O 如果表很大或者没有存储在引擎的缓存中,基于辅助索引(secondary index,非聚簇索引)的范围扫描可能导致很多的随机磁盘访问。多范围读优化(Multi-Range Read Optimization,MRR)机制是MySQL用来减少此随机I/O的算法。该算法先仅仅扫描索引,然后收集相关行的主键并排序,最后依据排序后的主键来获取表数据,这样就可以减少一定的随机I/O。当使用到覆盖索引时,MRR不会被使用。当使用MRR时,在执行计划的Extra列可以看到Using MRR 在使用MRR时,read_rnd_buffer_size指示了主键缓冲区的大小,这限制了单次(single pass)能处理的数据量 该参数针对每个线程分配,因此不要设置过大的全局值,仅仅在必要时会话级别设置 |
||
| relay_log | 中继日志的名字格式,默认host_name-relay-bin | ||
| relay_log_index | 存放中继日志索引信息的文件,默认host_name-relay-bin.index | ||
| relay_log_info_file | 默认relay_log.info。 Slave存放关于中继日志信息的文件 | ||
| relay_log_info_repository | 默认FILE。 中继日志信息的保存形式,可以指定为表或者文件 | ||
| relay_log_purge | 默认TRUE。 是否在中继日志不需要时就进行清理 | ||
| relay_log_recovery | 默认FALSE。 是否在服务器启动后,立即进行中继日志的恢复 | ||
| relay_log_space_limit | 默认0。 所有中继日志使用的空间总额限制 | ||
| safe_user_create | 默认FALSE。 可以防止用户创建新的MySQL用户 | ||
| server_id | 默认0。 主从复制时,使用的服务器ID | ||
| server_uuid | 5.6+添加的,在用户提供的server_id的基础上新的全局唯一服务器标识符,和主从复制有关 | ||
| skip_external_locking | 当MySQL使用外部锁定(OS锁定)时,该参数为OFF。外部锁定仅对MyISAM引擎有意义 | ||
| skip_grant_tables | 默认FALSE。 使MySQL不适用授权系统来启动,因此任何人可以不受限制的访问所有数据库 | ||
| skip_name_resolve |
默认FALSE。 当检查客户端连接时,不适用DNS系统,如果设置为TRUE,grant tables中的Host列必须是localhost或者IP地址 |
||
| skip_networking | 默认FALSE。 不进行网络监听,所有和mysqld的交互必须通过命名管道、UNIX套接字或者Windows 的共享内存完成。可以用于限制仅允许本机访问 | ||
| skip_slave_start | 默认FALSE。 通知Slave不去启动slave threads。后续可以通过start slave启动这些线程 | ||
| slave_checkpoint_group | 默认512。 对于多线程Slave,在检查点(checkpoint )操作被调用前,最大能处理的事务数量,超过此数量后检查点操作被调用,以更新show slave status中显示的Slave状态信息。对于单线程的Slave该参数没有意义 | ||
| slave_checkpoint_period | 默认300。 类似上面,但是限制的是时间(毫秒)而不是事务数量 | ||
| slave_compressed_protocol | 默认FALSE。 是否使用压缩的Slave/Master协议,前提是主从都支持压缩 | ||
| slave_load_tmpdir | 默认/tmp。 load data infile时Slave使用的临时目录 | ||
| slave_max_allowed_packet | 默认1073741824。 Slave的SQL和I/O线程支持的最大包大小 | ||
| slave_net_timeout | 默认3600。 终止对mast/slave连接的读取操作前的超时 | ||
| slave_parallel_workers | 默认0。 并行执行复制事件(事务)的线程数 | ||
| slave_pending_jobs_size_max | 默认16777216。 对于多线程Slave,该参数设置Slave工作队列持有尚未入库的事件能占用内存的最大空间 | ||
| slave_skip_errors | 默认OFF。 通常,当发生错误时,Slave上的复制操作将终止,设置该参数为true则忽略错误,从而允许后续的手工处理 | ||
| slave_transaction_retries | 默认10。 如果因为InnoDB死锁导致Slave事务失败,最大的重试次数 | ||
| slow_launch_time | 默认2。 如果新建线程超过此时间,MySQL增加计数器Slow_launch_threads的值 | ||
| slow_query_log | 默认FALSE。 是否启用缓慢查询日志记录 | ||
| slow_query_log_file | 默认$INS_DIR/data/hostname_slow.log。缓慢查询日志的路径 | ||
| socket | 默认 /tmp/mysql.sock。 对于Unix系统,该参数是本地客户端连接使用的套接字文件的名称;对于Windows系统,该参数是用于本地客户端连接的命名管道的名称,默认为MySQL | ||
| sort_buffer_size |
默认262144。 每个会话都会被分配sort_buffer_size大小的排序缓冲,如果show global status输出每秒Sort_merge_passes增加很大,提示需要增加此参数的值,以便提高无法受益于索引、优化器的order by或者group by查询性能 该参数是为每个线程分配的,设置过大的全局值不但消耗内存(即使不用排序,该缓冲也分配给线程)而且会导致大部分查询变慢,因此最好是在session级别设置 |
||
| super_large_pages | 默认FALSE。 是否使用超大(内存)页的支持 | ||
| sync_binlog | 默认0。 仅用于master,每次事务提交时同步二进制日志,防止崩溃导致的数据丢失 | ||
| sync_frm | 默认TRUE。 如果设置为1,所有非临时表被创建后,其frm文件被同步到磁盘 | ||
| table_definition_cache | 默认值依据400 + (table_open_cache / 2)计算。 表定义缓存(.frm)存放表定义的最大数量。如果使用了大量表,增加此缓存可以提高open table的速度 | ||
| table_open_cache | 默认431。 所有线程能够同时打开的表数量,增加该参数则mysqld需要更多的文件描述符 | ||
| table_open_cache_instances | 默认1。 上述缓存的缓存池数量 | ||
| thread_cache_size |
默认8 + (max_connections / 100)。 服务器创建多少线程以备重用,当一个客户端断开时,如果线程池数量大于thread_cache_size,则该客户端的线程被销毁而不是返回池中。 新连接请求到达时,会首先检查线程池,如果没有空闲线程才会新建 在有良好的线程库的情况下,修改此参数不会有很大的性能提升,但是如果工作负载包含大量短时连接请求(100+/s),则有必要增大此参数 |
||
| thread_concurrency | 默认 10。 仅用于Solaris 8-,已废弃 | ||
| thread_handling | 默认one_thread_per_connection。 线程处理模型,no-threads用于Linux下的debug。如果使用了线程池插件,则可以设置为dynamically-loaded | ||
| thread_stack | 默认262144。 线程的栈的大小,32bit系统默认192KB,64bit系统默认256KB,这些默认值一般足够使用,如果该参数设置的过小,则服务器处理复杂查询的能力受限 | ||
| tmp_table_size |
默认16777216。 MySQL内部创建的内存临时表的最大尺寸,该尺寸同时受到max_heap_table_size的限制。如果某个内存临时表超过该参数的限制,MySQL自动将其转换为MyISAM磁盘表 如果需要大量复杂的group by查询并且用于很多内存,则增加max_heap_table_size和tmp_table_size的值 状态变量Created_tmp_disk_tables、Created_tmp_tables有利于判断是否需要增加此值 |
||
| tmpdir |
默认/tmp。 用于创建临时文件、临时表的目录多个文件用:(Linux)或者;(Windows)分隔 使用多个目录可以用来磁盘的负载均衡;使用SSD分区有利于提高性能 |
||
| transaction_alloc_block_size | 默认8192。 每个事务独占的内存池的增量分配大小 | ||
| transaction_isolation | 默认REPEATABLE_READ。事务的隔离级别,支持的值包括 READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE | ||
| transaction_prealloc_size |
默认4096。 每个事务独占的内存池的初始分配大小,如果事务内存池不足,则后续每次分配transaction_alloc_block_size字节,事务结束后,该内存池截断为transaction_prealloc_size 设置该参数足够大,以包含事务的全部语句,可以避免过多的malloc()操作 |
||
| transaction_read_only | 默认FALSE。 设置默认的事务访问级别,默认禁用了只读事务 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
[client] default_character_set=utf8 socket=/var/lib/mysql/mysql.sock port=3306 [mysql] default_character_set=utf8 [mysqld] character_set_server = utf8 basedir = /var/lib/mysql/ datadir = /var/lib/mysql/data/ socket = /var/lib/mysql/mysql.sock pid_file = /var/lib/mysql/mysql.pid user = mysql port = 3306 default_storage_engine = InnoDB transaction_isolation=READ-COMMITTED innodb_log_buffer_size = 8M innodb_buffer_pool_size = 4096M innodb_log_file_size = 512M innodb_log_files_in_group = 2 innodb_flush_log_at_trx_commit = 2 innodb_flush_method = O_DIRECT innodb_file_per_table = 1 innodb_thread_concurrency = 0 innodb_data_file_path = ibdata1:1024M:autoextend innodb_max_dirty_pages_pct = 90 innodb_lock_wait_timeout = 30 innodb_sync_spin_loops = 100 innodb_file_io_threads = 4 innodb_read_io_threads = 4 innodb_write_io_threads = 4 key_buffer_size = 2048M myisam_block_size = 4K skip_external_locking myisam-recover sort_buffer_size = 2M join_buffer_size = 2M read_buffer_size = 1M read_rnd_buffer_size = 16M bulk_insert_buffer_size = 64M tmp_table_size = 256M max_heap_table_size = 256M thread_stack = 192K query_cache_type = 0 query_cache_size = 64M query_cache_limit = 4M query_cache_min_res_unit = 2K max_connections = 3000 max_connect_errors = 32 max_allowed_packet = 32M thread_cache_size = 256 table_cache_size = 9000 open_files_limit = 65535 back_log = 600 log_error = /var/lib/mysql/mysql-error.log long_query_time = 2 slow_query_log_file = /var/lib/mysql/mysql-slow.log log_bin = /var/lib/mysql/mysql-bin server_id = 1 sync_binlog = 1 innodb_support_xa = 1 log_slave_updates = 1 relay_log = /var/lib/mysql/mysql-relay-bin skip_slave_start = 1 sync_master_info = 1 sync_relay_log = 1 sync_relay_log_info = 1 binlog_cache_size = 4M max_binlog_cache_size = 8M max_binlog_size = 512M read_only = 1 expire_logs_days = 7 lower_case_table_names = 1 skip_name_resolve = 1 [mysqldump] quick |
使用show status命令、mysqladmin extended-status可以查看服务器/连接的状态信息,这些状态是只读的:
|
1 2 3 4 5 6 7 8 9 |
mysql> show status like 'Innodb_buffer_pool_pages_d%'; +---------------------------------------+----------+ | Variable_name | Value | +---------------------------------------+----------+ | Innodb_buffer_pool_pages_data | 993 | +---------------------------------------+----------+ #使用information_schema亦可: mysql> SELECT * FROM information_schema.GLOBAL_STATUS WHERE VARIABLE_NAME LIKE 'INNODB_BUFFER_POOL%'; --显示全局状态 mysql> SELECT * FROM information_schema.SESSION_STATUS WHERE VARIABLE_NAME LIKE 'INNODB_BUFFER_POOL%'; --显示会话状态 |
MySQL5.0以后,show status的功能发生很大变化,MySQL把一部分变量全局的维护,另外一部分per-connection的维护,show status则是显示两者的混合。
通过比较一段时间前后的值,可以总体上评估MySQL的工作负载。使用innotop的命令摘要模式(Command Summary mode),可以很容易看到这种对比,亦可使用命令:
|
1 2 |
#每10秒更新一次包含Select的变量 mysqladmin -uroot -ppassword extended -r -i10 | grep Select |
或者这样的SQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT STRAIGHT_JOIN LOWER(gs0.VARIABLE_NAME) AS variable_name, gs0.VARIABLE_VALUE AS value_0, gs1.VARIABLE_VALUE AS value_1, ( s1.VARIABLE_VALUE - gs0.VARIABLE_VALUE ) AS diff, ( gs1.VARIABLE_VALUE - gs0.VARIABLE_VALUE ) / 10 AS per_sec, ( gs1.VARIABLE_VALUE - gs0.VARIABLE_VALUE ) * 60 / 10 AS per_min FROM ( SELECT VARIABLE_NAME, VARIABLE_VALUE FROM information_schema.GLOBAL_STATUS UNION ALL SELECT '', SLEEP(10) FROM DUAL ) AS gs0 JOIN information_schema.GLOBAL_STATUS gs1 USING (VARIABLE_NAME) WHERE gs1.VARIABLE_VALUE <> gs0.VARIABLE_VALUE; |
| 类别 | 说明 |
| 线程和连接统计 | 这些变量跟踪连接尝试、中断的连接、网络流量、线程统计信息 |
| 二进制日志状态 | Binlog_cache_use:已经存在于二进制缓存中的事务数 Binlog_cache_disk_use:有多少事务太大,导致其语句被存放在临时文件 Binlog_stmt_cache_use:对于非事务性语句,已经存在于缓存的数量 Binlog_stmt_cache_disk_use:对于非事务性语句,语句太大导致其被存放在临时文件 二进制缓存命中率对配置二进制缓存大小没有意义 |
| 命令计数器 |
Com_*开头的变量统计各种SQL、底层API命令被执行的次数 |
| 临时文件和表 | Created_tmp*显示系统内部创建的临时表和文件的信息 |
| Handler Operations | Handler API是MySQL与存储引擎的接口。Handler_*统计handler Op的数量 |
| MyISAM键缓冲 | Key_*显示MyISAM键缓冲的度量和计数信息 |
| 文件描述符 | 如果主要是用MyISAM,可以通过Open_*查看打开.frm、.MYI、.MYD文件的频繁度 |
| 查询缓存 | Qcache_*显示查询缓存相关的统计信息 |
| SELECT查询类型 |
Select_*显示各类查询操作的数量,可能提示查询性能问题 |
| 排序 |
Sort_*显示文件排序的状态信息 |
| 表锁定 | 显示服务器级别(不是引擎级别)的锁定信息,Table_locks_immediate、Table_locks_waited分别显示多少锁是立即分配,多少是必须等待的 |
| InnoDB相关 | Innodb_*开头的信息显示了一些包含在show engine innodb status中的内容。注意:检查这些值会导致对InnoDB缓冲池的全局锁定,因此会影响性能,对某些参数的准确性产生影响 |
| 变量 | 说明 |
| Aborted_clients | 表示客户端连接被中断,原因可能是程序忘记关闭连接,或者客户端意外终止 |
| Aborted_connects | 连接MySQL的尝试失败(错误的密码、数据库名、telnet了3306端口)的数量,如果值太高可能导致某个主机被阻拦。更细致的相关性信息可以从 Connection_errors_*查看 |
| Binlog_cache_disk_use | 使用了临时二进制日志缓存,并且超过binlog_cache_size限制,导致使用临时文件的事务的数量 |
| Binlog_cache_use | 使用了二进制日志缓存的事务数量 |
| Binlog_stmt_cache_disk_use | 使用了二进制日志语句缓存,并且超过binlog_stmt_cache_size限制,导致使用临时文件的非事务性语句的数量 |
| Binlog_stmt_cache_size | 使用了二进制日志语句缓存的非事务性语句的数量 |
| Bytes_received | 从所有客户端的接收到的总字节数 |
| Bytes_sent | 发送给所有客户端的总字节数 |
| Com_delete | 执行的delete语句的数量 |
| Com_delete_multi | 与上面类似,但是针对多表语法 |
| Com_flush | 执行的flush操作的数量,不管是flush tables、flush logs或者其它 |
| Com_update | 执行的update语句的数量 |
| Com_update_multi | 与上面类似,但是针对多表语法 |
| Com_select | 执行的select语句的数量,如果命中查询缓存,计数器Qcache_hits被增加,该计数器不变 |
| Com_stmt_* |
所有这些变量在预编译语句被处理时增加,不管预编译语句是否成功 |
| Compression |
指示客户端连接是否使用压缩 |
| Connection_errors_* |
客户端的各类型的连接失败的计数器: |
| Connections | 连接尝试的数量,不管是否成功 |
| Created_tmp_disk_tables | 执行语句时,服务器内部创建的磁盘临时表的数量。当服务器创建一个内存临时表,并且超过最大限制(tmp_table_size和max_heap_table_size中的较小值)时,会自动被转换为磁盘临时表。如果该计数器过大,可能需要增加前面提到的两个系统变量 |
| Created_tmp_files | mysqld创建的临时文件的总数 |
| Created_tmp_tables | 服务器内部创建的临时表的总数,包括内存表和磁盘表,该状态与Created_tmp_disk_tables的比值可以帮助判断是否需要增加tmp_table_size或max_heap_table_size |
| Flush_commands | 服务器刷空(flush)表的次数,不管因为用户执行flush tables语句,还是由于内部的原因 |
| Handler_commit | 内部commit语句的执行数量 |
| Handler_delete | 数据行被从表中删除的次数 |
| Handler_external_lock | 每当调用external_lock()函数,该计数器增加 |
| Handler_mrr_init | 服务器使用存储引擎自有的多范围(Multi-Range)读取机制来进行表访问的次数 |
| Handler_prepare | 两阶段提交操作的prepare阶段的次数 |
| Handler_read_first | 索引中第一个条目被读取的次数,如果该计数器很高,提示服务器执行了太多的全范围索引(Full index scan)扫描。例如select name from person,如果name是索引列,该语句会导致本计数器增加 |
| Handler_read_key | 基于键读取行的请求的次数,如果该计数器很高,提示表的索引很好的适应了查询需求 |
| Handler_read_last | 类似于Handler_read_first,但是由于order by desc导致索引的逆序扫描 |
| Handler_read_next | 按照所键顺序读取下一行数据的请求次数,当使用范围约束查询一个索引列或者执行索引扫描时,该计数器会增加 |
| Handler_read_prev | 类似于上面,但是由于order by desc导致索引的逆序扫描 |
| Handler_read_rnd | 基于固定位置读取行的请求次数,如果执行很多需要对结果集排序的查询时,该计数器会增高。该计数器升高可能提示很多的全表扫描,或者没有适当使用键的join操作 |
| Handler_read_rnd_next | 请求读取数据文件下一行的次数,如果做了很多表扫描,该计数器会增加。该计数器升高可能提示表没有被合适的索引或者查询语句没有用到索引 |
| Handler_rollback | 请求存储引擎执行回滚的次数 |
| Handler_savepoint | 请求存储引擎设置保存点的次数 |
| Handler_savepoint_rollback | 请求存储引擎回滚到保存点的次数 |
| Handler_update | 请求更新表中一行的次数 |
| Handler_write | 请求插入表中一行的次数 |
| Innodb_available_undo_logs | 总计可用的InnoDB撤销日志的数量。该状态变量是对系统变量innodb_undo_logs的补充,后者报告活动的撤销日志数量 |
| Innodb_buffer_pool_dump_status | InnoDB缓冲池Dump操作的进度,Dump可能由innodb_buffer_pool_dump_at_shutdown或者innodb_buffer_pool_dump_now触发 |
| Innodb_buffer_pool_load_status | InnoDB缓冲池Warmup操作的进度,预热可能由innodb_buffer_pool_load_at_startup、innodb_buffer_pool_load_now触发,并且可以被innodb_buffer_pool_load_abort中止。预热过程MySQL会加载一系列和早先时间点相关的数据页到缓冲池 |
| Innodb_buffer_pool_bytes_data | InnoDB缓冲池中包含数据字节数,包含脏数据 |
| Innodb_buffer_pool_pages_data | InnoDB缓冲池中包含数据的页的数量,包含脏页 |
| Innodb_buffer_pool_bytes_dirty | InnoDB缓冲池中包含脏数据的字节数 |
| Innodb_buffer_pool_pages_dirty | InnoDB缓冲池中脏页的数量 |
| Innodb_buffer_pool_pages_flushed | InnoDB缓冲池中刷出的页数量 |
| Innodb_buffer_pool_pages_free | InnoDB缓冲池中空闲页的数量 |
| Innodb_buffer_pool_pages_latched | InnoDB缓冲池中当前被锁住的页数量,这些页可能正在被读写,或者因为其他原因不能被移除、刷出 |
| Innodb_buffer_pool_pages_misc | 等于:Innodb_buffer_pool_pages_total - Innodb_buffer_pool_pages_free - Innodb_buffer_pool_pages_data。这些额外的页可能被分配用来执行行锁、自适应哈希索引 ( adaptive hash index ) |
| Innodb_buffer_pool_pages_total | InnoDB缓冲池的总页数 |
| Innodb_buffer_pool_read_ahead | 后台预读(read-ahead)线程读入InnoDB缓冲池的页数 |
| Innodb_buffer_pool_read_ahead_evicted | 符合上一条说明的页,在随后没有被任何查询使用时就被清除出缓冲池的页数 |
| Innodb_buffer_pool_read_requests | InnoDB缓冲池逻辑读请求次数 |
| Innodb_buffer_pool_reads | 没有命中缓冲的逻辑读请求次数,导致直接磁盘访问 |
| Innodb_buffer_pool_wait_free | 等待空闲页出现的次数。当InnoDB需要读取或者创建一个缓冲池页,而没有空白页可用时,InnoDB会刷出某些脏页并等待此操作完成。如果innodb_buffer_pool_size设置适当,该计数器应该很小 |
| Innodb_buffer_pool_write_requests | 对InnoDB缓冲池执行的写操作次数 |
| Innodb_data_fsyncs | 到目前为止fsync()操作的次数,该操作执行频率受到innodb_flush_method影响 |
| Innodb_data_pending_fsyncs | 当前未决fsync()操作的个数 |
| Innodb_data_pending_reads | 当前未决的读请求次数 |
| Innodb_data_pending_writes | 当前未决的写请求次数 |
| Innodb_data_read | 自服务器启动以来读取的数据量 |
| Innodb_data_reads | 总计读取数据的量 |
| Innodb_data_writes | 总计写入数据的量 |
| Innodb_data_written | 到目前为止写入的字节数 |
| Innodb_dblwr_pages_written | 写入双重缓冲的页数量 |
| Innodb_dblwr_writes | 双重缓冲写入的操作次数 |
| Innodb_log_waits | 因重做日志缓冲(log buffer)太小导致必须等待刷出操作完成的次数 |
| Innodb_log_write_requests | InnoDO重做日志写请求次数 |
| Innodb_log_writes | InnoDO重做日志物理写次数 |
| Innodb_num_open_files | InnoDB当前打开的文件句柄数量 |
| Innodb_os_log_fsyncs | 针对InnoDB重做日志的fsync()写操作次数 |
| Innodb_os_log_pending_fsyncs | 针对InnoDB重做日志的未决fsync()操作数量 |
| Innodb_os_log_pending_writes | 针对InnoDB重做日志的未决写操作数量 |
| Innodb_os_log_written | InnoDB重做日志的写入的字节数 |
| Innodb_page_size | InnoDB页大小,默认16KB |
| Innodb_pages_created | 因对InnoDB表执行操作而创建的页数量 |
| Innodb_pages_read | 因对InnoDB表执行操作而读取的页数量 |
| Innodb_pages_written | 因对InnoDB表执行操作而写入的页数量 |
| Innodb_row_lock_current_waits | 当前正在等待行锁的操作的数量 |
| Innodb_row_lock_time | 系统启动依赖,获取InnoDB行锁总计消耗的毫秒数 |
| Innodb_row_lock_time_avg | 获取InnoDB行锁平均消耗的毫秒数 |
| Innodb_row_lock_time_max | 获取InnoDB行锁最大消耗的毫秒数 |
| Innodb_row_lock_waits | 因对InnoDB表执行操作而等待行锁的总次数 |
| Innodb_rows_deleted | 从InnoDB表中删除的行数量 |
| Innodb_rows_inserted | 插入到InnoDB表中的行数量 |
| Innodb_rows_read | 从InnoDB表中读取的行数量 |
| Innodb_rows_updated | 更新InnoDB表中的行数量 |
| Innodb_truncated_status_writes | show engine innodb status命令的输出被截断的次数 |
| Key_blocks_not_flushed | MyISAM键缓存(Key cache)中已经被修改,但是尚未刷出的键块(Key blocks)数量 |
| Key_blocks_unused | MyISAM键缓存中未使用的键块数量 |
| Key_blocks_used | MyISAM键缓存中已使用过的键块数量,这变量显示高水位而不是当前值 |
| Key_read_requests | 从MyISAM键缓存中读取一个键块的请求数量 |
| Key_reads | 从磁盘上读取键块到MyISAM键缓存的操作的次数,如果该值太大,提示key_buffer_size太小。Key_reads/Key_read_requests为缓存丢失率 |
| Key_write_requests | 请求写入一个键块到MyISAM键缓冲的次数 |
| Key_writes | 从MyISAM键缓存把键块写入到磁盘的次数 |
| Last_query_cost |
会话级。查询优化器计算出的上一个编译的查询的总计成本,默认值0表示没有任何查询被编译。该状态可以用来比较同一查询在不同的执行计划下的成本。 注意该状态只能用于“扁平”的查询,如果存在子查询或者union,该状态返回0 |
| Max_used_connections | 从服务器启动开始,连接数使用的峰值 |
| Open_files | 处于打开状态的常规文件的数量,不包含套接字或者管道 |
| Open_table_definitions | 处于打开状态的缓存的.frm文件数量 |
| Open_tables | 处于打开状态的表的数量 |
| Opened_files | 使用my_open()打开的文件总数 |
| Opened_table_definitions | 打开的缓存的.frm文件的总数 |
| Opened_tables | 打开的表的总数。如果该状态太大,提示table_open_cache可能过小 |
| Performance_schema_xxx | performance_schema相关的状态变量 |
| Prepared_stmt_count | 当前预编译语句的数量。最大数量由max_prepared_stmt_count限制 |
| Qcache_free_blocks | 查询缓存中的空闲内存块数量 |
| Qcache_free_memory | 查询缓存中的空闲内存数量 |
| Qcache_hits | 查询缓存命中的总计次数 |
| Qcache_inserts | 总计添加到查询缓存的查询数目 |
| Qcache_lowmem_prunes | 由于内存不足,从查询缓存中删除的查询数目 |
| Qcache_not_cached | 没有被缓存(可能由于不可缓存,或者受query_cache_type制约)的查询总计数量 |
| Qcache_queries_in_cache | 查询缓存中注册的查询数目 |
| Qcache_total_blocks | 查询缓存总计块数 |
| Queries | 服务器总计执行的查询数量,包括客户端发起的查询、存储过程执行的查询 |
| Questions | 同上,但是不包含存储过程执行的查询 |
| Select_full_join | 由于不能使用索引(例如没有使用任何过滤条件),导致join操作执行表扫描的次数。如果该值非0,应当检查表索引的设计,如果快速增加,提示有严重性能问题 |
| Select_full_range_join | 使用第N个表中的某个值在第N+1个表(参考表)上进行索引范围扫描的次数 |
| Select_range | 在第一张表上使用范围扫描的join查询数量,即使很大一般也不是重大问题 |
| Select_range_check | 在第N+1个表中对第N个表中的每个值进行索引重评估(reevaluate)的join的次数。这说明在N+1表没有合适的索引,查询计划成本很高。如果非0,应当检查表索引的设计,如果快速增加,提示有严重性能问题 |
| Select_scan | 在第一个表上进行全表扫描的join次数,如果第一个表的数据全部需要参与查询,则不是特别致命的情况 |
| Slow_launch_threads | 超过slow_launch_time才创建的线程数量 |
| Slow_queries | 执行时间超过long_query_time的查询数量 |
| Sort_merge_passes | MySQL使用该排序缓冲来存放若干(a chunk of)行并进行排序,完成排序后,把这些行合并到结果集中,并增加此计数器的值。如果该计数器过大,考虑增加sort_buffer_size |
| Sort_range | 使用索引范围扫描完成的排序的次数 |
| Sort_rows | 排序总计牵涉的行数 |
| Sort_scan | 使用表扫描完成的排序的次数 |
| Table_locks_immediate | 请求表锁定并立即获取的次数 |
| Table_locks_waited | 请求表锁定但被迫等待的次数,该数字高提示有性能问题,应当首先优化查询、必要时考虑分区表或者复制 |
| Table_open_cache_hits | 命中已打开表缓存的次数 |
| Table_open_cache_misses | 丢失已打开表缓存的次数 |
| Table_open_cache_overflows | 打开的表缓存溢出的次数 |
| Threads_cached | 线程缓存中的线程数量 |
| Threads_connected | 当前打开的连接数 |
| Threads_created | 总计创建的线程数,如果该值过高,考虑增加thread_cache_size |
| Threads_running | 正在运行的(而不是休眠)线程,可能有查询正在执行 |
| Uptime | 服务器启动依赖流逝的秒数 |
| Uptime_since_flush_status | 执行flush status后流逝的秒数 |
进程列表(process list)是连接到MySQL的Connections(Threads)的列表。show processlist可以显示连接状态的列表。innotop可以显示自动更新的进程列表。show full processlist不会截断文字的显示。
显示InnoDB详细的互斥信息,对分析并发、可扩展性问题很有帮助。该命令的输出形式依MySQL版本的不同而变化,MySQL5.5的输出如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> SHOW ENGINE INNODB MUTEX; +--------+------------------------------+-------------+ | Type | Name | Status | +--------+------------------------------+-------------+ | InnoDB | &table->autoinc_mutex | os_waits=1 | | InnoDB | &dict_sys->mutex | os_waits=1 | | InnoDB | &log_sys->mutex | os_waits=12 | | InnoDB | &fil_system->mutex | os_waits=11 | | InnoDB | &kernel_mutex | os_waits=1 | | InnoDB | &dict_table_stats_latches[i] | os_waits=2 | | InnoDB | &dict_operation_lock | os_waits=13 | | InnoDB | &log_sys->checkpoint_lock | os_waits=66 | | InnoDB | combined &block->lock | os_waits=2 | +--------+------------------------------+-------------+ |
根据输出中等待的数量可以确定InnoDB的哪个部分存在性能瓶颈,任何互斥都代表着潜在的资源争用。
MySQL提供若干命令来监控数据复制的状态:
- show master status显示master的复制状态和配置:
123456mysql> SHOW MASTER STATUS*************************** 1. row ***************************File: mysql-bin.000079Position: 13847Binlog_Do_DB:Binlog_Ignore_DB: - show binary logs显示二进制日志的列表
- show binlog events显示日志中的事件
- show relaylog events显示转播日志中的事件
- show slave status显示replica的状态
从MySQL5.0+引入,包含一系列类似数据字典的功能。MySQL Forge 、common_schema提供很多针对这些字典的视图。
该schema的最大缺点是某些时候比相应的show命令缓慢。
InnoDB表
| 表 | 说明 |
| INNODB_CMP INNODB_CMP_RESET |
显示InnoDB压缩数据信息 与上个命令类似,但是具有副作用:重置其包含的数据 |
| INNODB_CMPMEM INNODB_CMPMEM_RESET |
显示InnoDB缓冲池被压缩数据使用的情况,第二个也是重置表 |
| INNODB_TRX INNODB_LOCKS INNODB_LOCK_WAITS |
显示事务、事务持有/等待的锁。对于诊断锁等待、长事务很重要。 |
| INNODB_METRICS | MySQL 5.6+,显示很多关于InnoDB的性能信息,可以用于代替performance_schema |
从MySQL5.5+引入,默认情况下被禁用,启用后可能导致8% - 11%的资源占用。
| TINYINT | 整数,8位空间 -2^7 (-128) 到 2^7 – 1 (127) |
| SMALLINT | 整数,16位空间 -2^15 (-32,768) 到 2^15 – 1 (32,767) |
| MEDIUMINT | 整数,24位空间 -2^23 (-8,388,608) 到 2^23 – 1 (8,388,607) |
| INT | 整数,32位空间 -2^31 (-2,147,483,648) 到 2^31 – 1 (2,147,483,647) |
| BIGINT | 整数,64位空间,存放不能用SMALLINT 或 INT描述的超大整数(19位数字) -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) |
| FLOAT | 单精度浮点型数据 |
| DOUBLE | 双精度浮点型数据 |
| DECIMAL | 用户自定义精度的浮点型数据 ,以特别高的精度存储小数数据。 |
| CHAR (M) | 固定长度的字符串 。默认255长度,最大65535 |
| VARCHAR(M) | 具有最大限制的可变长度的字符串 。默认255长度,最大65535 |
| TEXT | 字符串大对象。TinyText 最大 255,Text/SmallText 最大 65K,MediumText 中等16M,LongText 最大 4G。具体内存放多少个字符,与字符集相关 |
| BLOB | 二进制大对象。TinyBlob 最大 255,Blob/SmallBlog 最大 65K,MediumBlob 中等16M,LongBlob 最大 4G |
| DATE | yyyy-mm-dd格式的日期 |
| TIME | hh:mm:ss格式的时间 |
| DATETIME | yyyy-mm-ddhh:mm:ss格式结合日期和时间 |
| TIMESTAMP | 以yyyy-mm-ddhh:mm:ss格式结合日期和时间 |
| YEAR | yyyy格式的年份 |
| ENUM | 一组数据,用户可从中选择其中一个 |
| SET | 一组数据,用户可从中选择其中0,1或更多 |
| 数据库 | 数据字典表 | 说明 |
| information_schema | innodb_trx |
活动的事务,字段说明: trx_id 事务ID |
| information_schema | innodb_locks |
当前出现的锁,字段说明: lock_id 锁ID |
| information_schema | innodb_lock_waits |
锁等待的对应关系,字段说明: requesting_trx_id 请求锁的事务ID |
| information_schema | plugins |
显示插件版本信息 |
只需要在select语句前附加explain,即可获取其执行计划。explain命令包含两个变体:
- explain extended:提示服务器把执行计划“反编译”为SQL语句,通过后续的show warnings命令,即可看到该语句。
- explain partitions:显示查询需要访问的所有表分区
explain可能会导致语句的执行,例如对于from中包含子查询的SQL,则会执行子查询并把结果放入临时表。
使用pt-visual-explain可以使用树形结构来显示执行计划
执行计划返回的是近似的信息,其包含以下限制:
- explain不提供任何可能影响查询的触发器、存储函数、UDF信息
- 对存储过程无效
- 不提供MySQL执行时即时优化的信息
- 执行计划显示的统计信息只是近似的,有时会很不准确
- 某些情形下没有做合理的区分,例如filesort可以表示内存排序、临时文件排序;Using temporary可能指内存或者磁盘临时表
MySQL5.6针对执行计划做了以下改进:
- 支持update, insert之类语句的执行计划
- 尽量推迟临时表的物化,可以在不执行子查询的情况下完成执行计划的解释
- 添加optimizer trace功能,允许用户查看优化器的决定,以及作出决定的原因
| 列名称 | 说明 | ||||
| id |
显示当前行所属的select,如果没有子查询、union,则只会显示一行,否则inner查询会按照其在原始SQL中的出现顺序,每个一行的显示在执行计划的结果中。MySQL把select分为简单、复杂类型,后者包括简单子查询、导出表(derived tables,from中的子查询)、unions:
|
||||
| select_type |
显示当前行是简单还是某种复杂查询 SIMPLE:查询不包含子查询或者unions |
||||
| table |
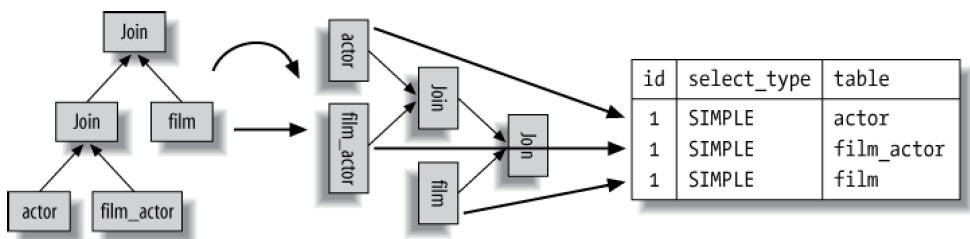
显示当前行访问的表,可能显示表名或者别名,从上而下的阅读此列,即为join操作实际发生的顺序:
注意MySQL查询计划是一棵最左最深数(left-deep tree),如果顺时针把该树旋转90度,可以很容易的查看JOIN节点与执行计划行的对应关系: 如果from子句中包含子查询,则该列显示,N表示子查询的ID 下面是一个复杂的例子:
|
||||
| type |
访问类型(access type,MySQL官方称为join type)——MySQL决定通过何种方式找到表中的行,从效率由差到好,有: |
||||
| possible_keys | 显示MySQL可能用在此查询上的索引,根据where子句访问的列、比较操作符确定。该列在优化的早期阶段完成,因此其列出的某些索引在后续优化阶段可能没用 | ||||
| key | 显示MySQL决定用来优化查询的索引,如果不在 possible_keys中存在,说明MySQL因为其它原因选择了该索引,例如,在没有WHERE子句的情况下,依然可能选择一个覆盖索引 | ||||
| key_len | 显示MySQL使用的索引长度,注意MySQL5.5-只能使用索引最左边的部分。比如某个表由两个smallint列构成的联合主键,那么其主键索引就是2*2bytes=4字节长,可以依据此值来推断查询只使用了索引左边的一部分还是全部 | ||||
| ref | 用来显示使用前面表(多表连接时)的哪个列或者常量来从key列中查找值 | ||||
| rows |
为了获得期望的结果,MySQL估计需要读取的数据行数,在嵌套循环(nested-loop)执行计划中,该值是针对单次循环的(平均值) 依据索引的选择度、表统计信息的准确性,该值可能相当的不准确。通过把join相关执行计划行的rows相乘,可以大概估算总计需要访问行数 |
||||
| filtered | MySQL 5.1+,使用explain extend时出现。显示表需要参与查询的行数的悲观估计 | ||||
| Extra |
显示不在其它列中的额外信息 Using index:提示MySQL使用覆盖索引来避免进行表访问 |
| MySQL类型 | Oracle类型 | Java类型 |
| BIGIHT | NUMBER(19,0) | java.lang.Long |
| BIT | RAW | byte[] |
| BLOB | BLOB RAW | byte[] |
| CHAR | CHAR | java.lang.String |
| DATE | DATE | java.sql.Date |
| DATETIME | DATE | java.sql.Timestamp |
| DECIMAL |
FLOAT(24)
|
java.math.BigDecimal |
| DOUBLE | FLOAT(24) | java.lang.Double |
| DOUBLE PRECISION | FLOAT(24) | java.lang.Double |
| ENUM | VARCHAR2 | java.lang.String |
| FLOAT | FLOAT | java.lang.Float |
| INT | NUMBER(10,0) | java.lang.Integer |
| INTEGER | NUMBER(10,0) | java.lang.Integer |
| LONGBLOB | BLOB RAW | byte[] |
| LONGTEXT | CLOB RAW | java.lang.String |
| MEDIUMBLOB | BLOB RAW | byte[] |
| MEDIUMINT | NUMBER(7,0) | java.lang.Integer |
| MEDIUMTEXT | CLOB RAW | java.lang.String |
| NUMERIC | NUMBER | |
| REAL | FLOAT(24) | |
| SET | VARCHAR2 | java.lang.String |
| SMALLINT | NUMBER(5,0) | java.lang.Integer |
| TEXT | VARCHAR2 CLOB | java.lang.String |
| TIME | DATE | java.sql.Time |
| TIMESTAMP | DATE | java.sql.Timestamp |
| TINYBLOB | RAW | byte[] |
| TINYINT | NUMBER(3,0) | java.lang.Byte |
| TINYTEXT | VARCHAR2 | java.lang.String |
| VARCHAR | VARCHAR2 CLOB | java.lang.String |
| YEAR | NUMBER | java.sql.Date |
与其它的show命令不同,该命令的输出是一个字符串,分为若干个段落,分别关注InnoDB的不同方面。
其输出包含一些自上一次命令输出以来的平均统计信息,例如fsync()每秒被调用的次数,如果需要分析这些统计信息,务必等待30秒或更长以保证统计的采样更加精确,并且通过多次采样来分析InnoDB的运行走势。诸如innotop之类的工具可以提供比该命令更方便的功能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
mysql> show engine innodb status; '第一部分是信息头' 1 ===================================== 2 070913 10:31:48 INNODB MONITOR OUTPUT 3 ===================================== 4 Per second averages calculated from the last 49 seconds '上一次统计以来的流逝的时间,最好大于30秒' '第二部分是信号量,对于高并发的工作负载的分析具有重要意义。InnoDB使用互斥量和信号量来保护代码关键区的独占访问' '以及在存在活动reader的时候限制writer的操作,等等。' '包含两类数据:1、事件计数器;2、一个当前等待的列表。如果出现性能瓶颈,这些数据有利于分析瓶颈的所在' '下面是信号量的简单输出示例:' 1 ---------- 2 SEMAPHORES 3 ---------- '下行显示操作系统等待数组的信息,这是一个插槽(slots)的队列,InnoDB为信号量保留数组中的插槽,操作系统' '使用信号量来提示(signal)线程可以继续并进行其正在等待(某种资源)去做的事情了,该行显示了InnoDB需要' '使用系统等待的次数。其中reservation count说明了InnoDB分配插槽的频度;signal count则说明了线程被通过' 'OS等待数组被signal的频度。相比起自旋等待(spin waits),操作系统等待的成本更高' 4 OS WAIT ARRAY INFO: reservation count 13569, signal count 11421 '5-12行显示了当前正在等待互斥量(mutex)的线程的信息,每个等待以Thread has waited at ...开头' '本例中,包含2个等待的线程,理想情况下,最好为0个,除非系统并发非常高,从而必须使用操作系统等待' '这些信息中最有价值的是线程等待的文件名,可以去分析资源争用出现什么地方,例如buf0buf.ic说明存在缓冲池争用' 5 --Thread 1152170336 has waited at ./../include/buf0buf.ic line 630 for 0.00 seconds '等待时间' the semaphore: 6 Mutex at 0x2a957858b8 created file buf0buf.c line 517, lock var 0 7 waiters flag 0 '多少个等待者正在等待该互斥量' 8 wait is ending '表示互斥量当前已经可用了,但是操作系统尚未调度线程运行' 9 --Thread 1147709792 has waited at ./../include/buf0buf.ic line 630 for 0.00 seconds the semaphore: 10 Mutex at 0x2a957858b8 created file buf0buf.c line 517, lock var 0 11 waiters flag 0 12 wait is ending 'InnoDB使用多阶段等待策略,首先,尝试对锁的自旋等待,如果失败,则进入比较昂贵的操作系统等待。尽管自旋等待需要' '占用CPU周期进行不停的检查,但是通常并不消耗太多资源,因为在CPU等待I/O的时候通常存在空闲CPU周期。除了自旋等待' '以外,另外一种方式是线程上下文切换,导致当前线程休眠,这期间其它线程可以运行,然后,休眠线程可以通过OS等待队列' '里面的信号量来激活(signal)。信号量激活是很快的,但是上下文切换则比较昂贵,特别是每秒上千次切换将消耗大量资源' '调整innodb_sync_spin_loops来在自旋和操作系统等待之间获得平衡,如果自旋循环(rounds)达到每秒成百上千,则可' '以考虑自旋等待的配置是否有问题。可以结合SHOW ENGINE INNODB MUTEX、performance_schema来解决问题' '显示几个与互斥有关的计数器。注意操作系统等待的次数' 13 Mutex spin waits 5672442, rounds 3899888, OS waits 4719 '显示与读/写共享锁、独占锁的计数器。注意操作系统等待的次数' 14 RW-shared spins 5920, OS waits 2918; RW-excl spins 3463, OS waits 3163 '第三部分是最近发生的外键错误记录,如果没有外键错误发生,该部分不会显示,如果出现新错误,旧的可能被覆盖' '外键错误发生时机:1、在进行增删改操作时违反外键约束时;2、尝试删除存在外键约束的表时' '增删改操作时违反外键约束的例子,依次执行下面三个SQL语句' 'INSERT INTO parent(parent_id) VALUES(1);' 'INSERT INTO child(parent_id) VALUES(1);' 'DELETE FROM parent;' '会出现错误:' 'ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint' 'fails (`test/child`, CONSTRAINT `child_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES' '`parent` (`parent_id`)) 执行SEIS命令,输出如下:' 1 ------------------------ 2 LATEST FOREIGN KEY ERROR 3 ------------------------ 4 070913 10:57:34 Transaction: '显示外键错误发生的时间' '5-9行显示违反外键约束的事务的详细信息' 5 TRANSACTION 0 3793469, ACTIVE 0 sec, process no 5488, OS thread id 52064 updating or deleting... 6 mysql tables in use 1, locked 1 7 4 lock struct(s), heap size 1216, undo log entries 1 8 MySQL thread id 9, query id 305 localhost baron updating 9 DELETE FROM parent '10-19行显示修改时出现错误的数据的精确信息' 10 Foreign key constraint fails for table `test/child`: 11 12 CONSTRAINT `child_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`parent_id`) 13 Trying to delete or update in parent table, in index `PRIMARY` tuple: 14 DATA TUPLE: 3 fields; 15 0: len 4; hex 80000001; asc ;; 1: len 6; hex 00000039e23d; asc 9 =;; 2: len 7; hex 000000002d0e24; asc - $;; 16 17 But in child table `test/child`, in index `parent_id`, there is a record: 18 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 19 0: len 4; hex 80000001; asc ;; 1: len 6; hex 000000000500; asc ;; '尝试删除存在外键约束的表的例子,执行下面的语句:' 'ALTER TABLE parent MODIFY parent_id INT UNSIGNED NOT NULL;会出现错误:' 'ERROR 1025 (HY000): Error on rename of ./test/#sql-1570_9 to ./test/parent' '上面的1025报错没有给出足够的信息, SEIS命令则阐明了详细的错误原因:' 1 ------------------------ 2 LATEST FOREIGN KEY ERROR 3 ------------------------ 4 070913 11:06:03 Error in foreign key constraint of table test/child: 5 there is no index in referenced table which would contain 6 the columns as the first columns, or the data types in the '外键类型必须完全匹配,包括类似UNSIGNED的修饰符' 7 referenced table do not match to the ones in table. Constraint: 8 , 9 CONSTRAINT child_ibfk_1 FOREIGN KEY (parent_id) REFERENCES parent (parent_id) 10 The index in the foreign key in table is parent_id 11 See http://dev.mysql.com/doc/refman/5.0/en/innodb-foreign-key-constraints.html 12 for correct foreign key definition. '第四部分是死锁相关的信息,如果不存在死锁,该部分不会显示,新的死锁可能覆盖旧的信息' '死锁是等待图(waits-for graph)中出现的闭环,该环可能具有任意的大小,每当事务需要等待一个锁时,InnoDB就会立即' '进行死锁检测,因此在InnoDB中死锁是即刻发现的,不需要超时机制。死锁可能非常复杂,但是该部分内容只会显示最后两个牵' '涉到死锁中的事务、每个事务最后执行的语句、以及在等待图中制造了闭环的锁。除了我们平常熟悉的死锁,InnoDB把检查闭环' '的开销过大的情形也认为是发生死锁,这些情形包括:等待图中超过100万个锁;检查时递归超过200个事务' '注意除了事务、等待的锁之外,该部分的输出还包括相关的记录本身,这可能非常大,导致内容阶段,可以使用Percona Server' '下面是一个简单的死锁的例子:' 1 ------------------------ 2 LATEST DETECTED DEADLOCK 3 ------------------------ 4 070913 11:14:21 '显示死锁发生的时间' '5-10行显示牵涉到死锁的第一个事务的基本信息' 5 *** (1) TRANSACTION: 6 TRANSACTION 0 3793488, ACTIVE 2 sec, process no 5488, OS thread id 1141287232 starting index read 7 mysql tables in use 1, locked 1 8 LOCK WAIT 4 lock struct(s), heap size 1216 9 MySQL thread id 11, query id 350 localhost baron Updating 10 UPDATE test.tiny_dl SET a = 0 WHERE a <> 0 '11=15行显示了死锁发生时,事务一正在等待的锁' 11 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: '这一行的内容最重要,说明事务一在等待test.tiny_dl表的GEN_CLUST_INDEX索引的独占锁' 12 RECORD LOCKS space id 0 page no 3662 n bits 72 index `GEN_CLUST_INDEX` of table `test/tiny_dl` trx id 0 3793488 lock_mode X waiting 13 Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 14 0: len 6; hex 000000000501 ...[ omitted ] ... '这边的信息用于调试InnoDB本身,被略去' 15 '16-21行显示牵涉到死锁的第二个事务的基本信息' 16 *** (2) TRANSACTION: 17 TRANSACTION 0 3793489, ACTIVE 2 sec, process no 5488, OS thread id 1141422400 starting index read, thread declared inside InnoDB 500 18 mysql tables in use 1, locked 1 19 4 lock struct(s), heap size 1216 20 MySQL thread id 12, query id 351 localhost baron Updating 21 UPDATE test.tiny_dl SET a = 1 WHERE a <> 1 '22-26行显示第二个事务持有的锁' 22 *** (2) HOLDS THE LOCK(S): 23 RECORD LOCKS space id 0 page no 3662 n bits 72 index `GEN_CLUST_INDEX` of table `test/tiny_dl` trx id 0 3793489 lock mode S 24 Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0 25 0: ... [ omitted ] ... '这边省略了若干牵涉到的记录' 26 '27-31行显示了死锁发生时,事务二正在等待的锁' 27 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: 28 RECORD LOCKS space id 0 page no 3662 n bits 72 index `GEN_CLUST_INDEX` of table `test/tiny_dl` trx id 0 3793489 lock_mode X waiting 29 Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 0 30 0: len 6; hex 000000000501 ...[ omitted ] ... 31 '通常上面的信息足够判断查询使用了什么索引,并可以确定是否可以避免死锁' '如果能使两个事务按照同样的顺序扫描同一个索引,可能减少死锁发生的次数,因为在同样顺序的情况下,不可能出现闭环' '例如,两个事务需要更新同一张表,那么在内存中按照主键排序,并且按照该顺序依次更新,则两个事务不会发生死锁' 32 *** WE ROLL BACK TRANSACTION (2) '事务二被回滚了,InnoDB会尝试回滚其认为代价最低的事务' '第五部分是事务相关一些摘要性的信息' 1 ------------ 2 TRANSACTIONS 3 ------------ 4 Trx id counter 0 80157601 '当前的事务标识符,对于每一个事务,值会递增' 'InnoDB清理MVCC旧版本的进度——已经到达的事务标识符。通过下面的值与当前事务标识符的差值,可以知道有多少旧版本' 'MMVC尚未被清理:80157601 - 80154573 = 3028。没有严格的规则来判断此差值的安全最大值:如果当前不存在任何' '数据更新,即使差值很大也不代表存在未清理的数据,因为所有事务都使用同样的版本;反之,如果很多行被更新,或者内' '内中有很多行的一个或多个版本,则应该尽快的提交事务,因为开启的事务即使什么都不做,也会禁止旧版本数据的清理' 5 Purge done for trxs n:o= 0 80157601, sees |
如果在Server级别发生锁争用,则show processlist中会有所证据。
Server级别锁包括以下几类:
表锁(Table Locks)
表锁可以是明确的或者隐含的,通过lock table语句可以创建明确锁:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- 在会话1上对表进行共享锁定 LOCK TABLES sakila.film READ; -- 在会话2上对表进行独占锁定,语句会挂起而无法完成: LOCK TABLES sakila.film WRITE; -- 显示进程列表,可以看到 SHOW PROCESSLIST mysql> SHOW PROCESSLIST\G *************************** 1. row *************************** Info: SHOW PROCESSLIST *************************** 2. row *************************** Id: 11 User: baron Host: localhost db: NULL Command: Query Time: 4 State: Locked --注意该线程的状态是被锁定,出现此状态表示在Server层被锁 Info: LOCK TABLES sakila.film WRITE -- 锁也可能是隐含获得的,例如在MyISAM上执行以下语句 SELECT SLEEP(30) FROM sakila.film LIMIT 1; -- 在30秒内,开启另外一个会话,运行LOCK TABLES sakila.film WRITE;会被锁定 |
注意InnoDB,对于明确锁,它会做你期望做的,但是对于隐含锁,InnoDB会在Server表锁和InnoDB表锁类型进行必要的转换。
mysqladmin debug命令可以用于发现持有MyISAM表锁的线程。
全局读锁(The Global Read Lock)
|
1 2 3 4 5 6 |
-- 使用下面的语句可以获取全局读锁 FLUSH TABLES WITH READ LOCK; -- 另外一个会话尝试锁定时: LOCK TABLES sakila.film WRITE; -- 会挂起,通过SHOW PROCESSLIST可以看到: State: Waiting for release of readlock --这意味着全局锁 |
名称锁(Name Locks)
这是一种表锁,当服务器进行表重命名或者DROP的时候会创建,该锁会与其他类型的表锁冲突并导致等待。
用户锁(User Locks)
本质上是一种命名的互斥量:
|
1 2 3 4 |
-- 会话1中执行: SELECT GET_LOCK('my lock', 100); -- 尝试在会话2上述语句,会导致挂起,SHOW PROCESSLIST显示: State: User lock |
任何支持row-level锁的存储引擎,在其内部实现锁定机制。
InnoDB通过show engine innodb status暴露了一些关于锁的信息,如果某个事务在等待一个锁,在transactions段可以看到相应的输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
mysql> SET AUTOCOMMIT=0; mysql> BEGIN; mysql> SELECT film_id FROM sakila.film LIMIT 1 FOR UPDATE; show engine innodb status //显示类似如下的类型 1 LOCK WAIT 2 lock struct(s), heap size 1216 2 MySQL thread id 8, query id 89 localhost baron Sending data 3 SELECT film_id FROM sakila.film LIMIT 1 FOR UPDATE 4 ------- TRX HAS BEEN WAITING 9 SEC FOR THIS LOCK TO BE GRANTED: //已经等待了9秒 //线程正在等待索引idx_fk_language_id的194页的独占锁(lock_mode X) 5 RECORD LOCKS space id 0 page no 194 n bits 1072 index `idx` of table `sakila/film` trx id 0 61714 lock_mode X waiting //最终,所等待会超时,显示以下内容: ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction //但是,无法看到是谁锁定了表,可以创建下面的表来激活InnoDB 锁监视器 CREATE TABLE innodb_lock_monitor(a int) ENGINE=INNODB; //上述语句执行后,InnoDB定期(通常每分钟数次)会打印增强版本的(亦可手工执行) //show engine innodb status信息到标准输出(通常是MySQL错误日志文件) //如果要停止监控,DROP innodb_lock_monitor //打开错误日志,可以看到类似下面的详细信息: 1 ---TRANSACTION 0 61717, ACTIVE 3 sec, process no 5102, OS thread id 1141152080 2 3 lock struct(s), heap size 1216 //显示进程ID,与process list的ID列一致 3 MySQL thread id 11, query id 108 localhost baron 4 show innodb status //该事务在film表上持有一个隐含的I独占锁X 5 TABLE LOCK table `sakila/film` trx id 0 61717 lock mode IX //显示索引上的锁的详细信息 6 RECORD LOCKS space id 0 page no 194 n bits 1072 index `idx` of table `sakila/film` trx id 0 61717 lock_mode X 7 Record lock, heap no 2 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 8 ... omitted ... //包含被锁定记录的DUMP,难以看懂,可以使用innotop、Percona Server或者MariaDB 9 10 RECORD LOCKS space id 0 page no 231 n bits 168 index `PRIMARY` of table `sakila/film` trx id 0 61717 lock_mode X locks rec but not gap 11 Record lock, heap no 2 PHYSICAL RECORD: n_fields 15; compact format; info bits 0 12 ... omitted ... |
可以使用information_schema中的表来获取锁的信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
-- 显示谁持有锁(blocking),谁在等待(waiting),等待了多久 SELECT r.trx_id AS waiting_trx_id, r.trx_mysql_thread_id AS waiting_thread, TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS wait_time, r.trx_query AS waiting_query, l.lock_table AS waiting_table_lock, b.trx_id AS blocking_trx_id, b.trx_mysql_thread_id AS blocking_thread, SUBSTRING(p.host, 1, INSTR(p.host, ':') - 1) AS blocking_host, SUBSTRING(p.host, INSTR(p.host, ':') +1) AS blocking_port, IF(p.command = "Sleep", p.time, 0) AS idle_in_trx, b.trx_query AS blocking_query FROM information_schema.INNODB_LOCK_WAITS AS w INNER JOIN information_schema.INNODB_TRX AS b ON b.trx_id = w.blocking_trx_id INNER JOIN information_schema.INNODB_TRX AS r ON r.trx_id = w.requesting_trx_id INNER JOIN information_schema.INNODB_LOCKS AS l ON w.requested_lock_id = l.lock_id LEFT JOIN information_schema.PROCESSLIST AS p ON p.id = b.trx_mysql_thread_id ORDER BY wait_time DESC *************************** 1. row *************************** waiting_trx_id: 5D03 waiting_thread: 3 wait_time: 6 --已经等待了6秒 waiting_query: select * from store limit 1 for update waiting_table_lock: `sakila`.`store` blocking_trx_id: 5D02 blocking_thread: 2 blocking_host: localhost blocking_port: 40298 idle_in_trx: 8 --持有锁,已经空闲了8秒 blocking_query: NULL -- 显示某个锁的持有者,多少线程在等待,等待了多久 SELECT CONCAT('thread ', b.trx_mysql_thread_id, ' from ', p.host) AS who_blocks, IF(p.command = "Sleep", p.time, 0) AS idle_in_trx, MAX(TIMESTAMPDIFF(SECOND, r.trx_wait_started, NOW())) AS max_wait_time, COUNT(*) AS num_waiters FROM information_schema.INNODB_LOCK_WAITS AS w INNER JOIN information_schema.INNODB_TRX AS b ON b.trx_id = w.blocking_trx_id INNER JOIN information_schema.INNODB_TRX AS r ON r.trx_id = w.requesting_trx_id LEFT JOIN information_schema.PROCESSLIST AS p ON p.id = b.trx_mysql_thread_id GROUP BY who_blocks ORDER BY num_waiters DESC *************************** 1. row *************************** who_blocks: thread 2 from localhost:40298 idle_in_trx: 1016 -- 线程2已经空闲了很久 max_wait_time: 37 -- 最长的线程已经等待了37秒 num_waiters: 8 -- 8个线程在等待2完成工作并提交 |
执行同步之前,首先要保证两个服务器的数据集一致。
主主复制和主从复制类似,只是互相指认对方为Master。需要注意可能存在的修改丢失问题 —— 如果SQL同步完成之间,同一条数据在目标库上修改,则随后发生的同步会覆盖此修改。
本节介绍一个主主复制的实例,服务器HK 47.90.76.189和BJ 39.107.94.255进行主主同步。
在两台机器上分别执行:
|
1 2 3 4 5 |
mysql -uroot <<SQL create user 'sync'@'localhost' identified by 'sync'; grant replication slave on *.* to 'sync'@'localhost'; flush privileges; SQL |
两台服务器位于公网上,因此必须使用安全信道。我们可以使用SSH隧道。
首先安装SSH隧道监控工具:
|
1 2 3 4 5 6 7 |
wget http://www.harding.motd.ca/autossh/autossh-1.4e.tgz tar xzf autossh-1.4e.tgz && rm autossh-1.4e.tgz cd autossh-1.4e/ ./configure --prefix=/usr make && make install cd .. rm -rf autossh-1.4e |
然后开启自我维护的SSH隧道:
|
1 2 3 4 5 |
# 在BJ执行: # localhost:3307:localhost:3306,将本机网络接口localhost上的3307端口绑定到远程主机localhost上的3306端口 autossh -M 22222 -fnN -L localhost:3307:localhost:3306 -i ~/Documents/puTTY/gmem.key root@hk.gmem.cc # 在HK执行: autossh -M 22222 -fnN -L localhost:3307:localhost:3306 -i ~/Documents/puTTY/gmem.key root@bj.gmem.cc |
主要相关的配置项如下表:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[mysqld] # 必须,服务器标识符全局唯一 server-id = 1 # 必须,启用二进制日志 log-bin = /var/lib/mysql/mysql-bin # 可选,混合二进制日志格式 binlog_format = mixed # 可选,二进制日志保存时间 expire-logs-days = 14 # 可选,每次事务提交后,都同步二进制日志缓存到磁盘 sync-binlog = 1 # Master相关配置 # 记录二进制日志的数据库列表,逗号分隔 binlog-do-db = gmem # 必须,不记录二进制日志的数据库 binlog-ignore-db = mysql,information_schema,performance_schema # 主主同步时,每个数据库都可能插入数据,因此需要防止自增长键的冲突 # 自增长键每次增长的步长 auto-increment-increment = 2 # 自增长键的偏移量 auto-increment-offset = 1 # SLAVE相关配置 # 重放二进制日志的数据库列表 replicate-do-db = gmem # 必须,忽略二进制日志的数据库 replicate-ignore-db = mysql,information_schema,performance_schema # 可选,开启中继日志。复制线程先把Master的日志拷贝到中继日志中,再异步入库 relay_log = /var/lib/mysql/relay-bin # 必须,中继日志执行之后将变化写入自己的二进制文件 log-slave-updates = ON # 可选,跳过所有的失败的SQL slave-skip-errors = all |
让两台服务器分别进入只读模式,然后获取二进制日志偏移量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# HK上的执行结果 mysql> FLUSH TABLES WITH READ LOCK; Query OK, 0 rows affected (0.00 sec) mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000002 Position: 1373523 Binlog_Do_DB: gmem Binlog_Ignore_DB: mysql,information_schema,performance_schema 1 row in set (0.00 sec) mysql> UNLOCK TABLES; # BJ上的执行结果: mysql> FLUSH TABLES WITH READ LOCK; Query OK, 0 rows affected (0.01 sec) mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000002 Position: 434 Binlog_Do_DB: gmem Binlog_Ignore_DB: mysql,information_schema,performance_schema 1 row in set (0.00 sec) |
|
1 2 3 4 |
# HK上的命令 mysql> CHANGE MASTER TO MASTER_HOST='localhost',MASTER_PORT=3307,MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=434; # BJ上的命令 mysql> CHANGE MASTER TO MASTER_HOST='localhost',MASTER_PORT=3307,MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=1373523; |
在两台服务器上分别执行:
|
1 2 3 4 5 6 |
mysql> start slave; # 查看状态: mysql> show slave status\G ... Slave_IO_Running: Yes Slave_SQL_Running: Yes |
除非手工停止,MySQL重启后Slave都会自动启动。
如果不希望继续进行数据同步,可以在服务器上执行:
|
1 |
mysql> stop slave; |
该列并非某种序列号,两个相邻的具有相同id的行,意味着基于标准的一遍扫描多次联接(single-sweep multi-join,从第一个表读取一行,然后从第二个表查找其匹配行)方式进行JOIN。
可以用于提示:
- 一个新的子作用域被打开
- 当前行和前面的行的某种关系
- 当前行执行何种操作
具体如下:
| 取值 | 说明 |
| SIMPLE | 整个查询没有子查询,或者UNION |
| PRIMARY | 这行是最外层的SELECT |
| UNION | UNION语句中第二个,以及后续的SELECT |
| DEPENDENT UNION | UNION语句中第二个,以及后续的SELECT,且依赖于外层查询 |
| UNION RESULT | UNION语句的结果 |
| SUBQUERY | 子查询中的第一个SELECT语句,打开了一个子作用域,出现在WHERE、SELECT中的子查询 |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT语句,且依赖于外层查询 |
| DERIVED | 出现在WHERE中的子查询 |
| UNCACHEABLE SUBQUERY | 子查询的结果不可以被缓存,必须为外层查询的每一行重新执行子查询 |
| UNCACHEABLE UNION | 子查询是一个UNION,子查询不可以被缓存。这种情况下第二个,以及后续的SELECT显示为此值 |
通常是表名或者别名。也可以是:
- derivedN:表示此行对ID为N的子查询所产生的临时表进行访问
- unionM,N:表示对ID为M~N的查询的UNION结果进行访问
查询匹配哪些分区,仅仅用于分区表。
说明表如何被JOIN:
| 取值 | 说明 |
| system | const的特例,表仅仅包含一行(系统表) |
| const |
表中最多包含一行匹配。因而,此唯一匹配行中的任何列的引用,都可以被查询优化器作为常量看待。const表非常快,因为它仅仅被读取一次 如果你在SQL中对主键、唯一性索引和常量值进行等于比较,则const出现 |
| eq_ref |
对于前表的所有行(或者前面N表的行的任何组合),当前表中的单行被读取,以便与其匹配 除了system/const之外,这是最好的JOIN方式。如果唯一性索引、主键索引被完整使用并且操作符为=,则eq_ref出现 |
| ref |
对于前表的所有行(或者前面N表的行的任何组合),当前表索引值匹配的全部行被读取,以便与前者匹配 使用索引前缀、使用非唯一性索引时,ref会出现 |
| fulltext | 使用全文索引进行JOIN |
| ref_or_null | 类似于ref,但是MySQL会额外检查NULL值的行 |
| index_merge | 提示使用了索引合并优化。在这种情况下,key列包含了一系列使用到的索引 |
| unique_subquery |
对于某些形式的子查询,替代eq_ref,例如: value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery |
类似于上一条,但是不使用唯一性索引,例如: value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range |
使用索引来匹配行,仅仅索引值在范围内的行被取出。在这种情况下,key列显示用到的索引,key_len显示用到的key长度,ref列显示为NULL 当你将索引列和常量进行=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()操作时,会出现range |
| index |
类似于ALL,但是进行索引树扫描,两种情况下发生:
|
| ALL |
对于前表的所有行(或者前面N表的行的任何组合),当前表的所有行都要被取出进行匹配 |
MySQL可以选择哪些索引来寻找当前表中的匹配行,如果显示NULL则意味着没有可用索引。
MySQL实际决定使用的索引。
MySQL使用索引的前多少字节。
使用到的索引(key字段)和什么列/常量进行比较,以获取匹配的行。
为了执行查询,MySQL需要检查的行数。对于InnoDB来说这一数值是大概的,不一定准确。
大概估算的被条件过滤的行的比例。rows × filtered / 100为实际和前表进行JOIN的行数量。
执行命令EXPLAIN EXTENDED时该列出现。
关于MySQL如何解析查询的额外信息。
用于将MySQL的执行计划转换为树状形式。命令格式:
|
1 2 3 4 |
# 从FILES读取执行计划 pt-visual-explain [OPTIONS] [FILES] # 从MySQL命令输出中读取执行计划 mysql -e SQL | pt-visual-explain |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
mysql -h 10.255.223.249 -P 13306 -uuser -ppasswd -D digital -e "EXPLAIN SELECT count(1) subscriptionCount FROM media_customer_subscription s LEFT JOIN media_chapter c ON s.media_id = c.media_id WHERE 1 = 1 AND s.media_id = 1960162291 AND s.cust_id = 274516853 AND c.last_modifyed_date >= '2018-03-21 19:35:19'" | pt-visual-explain # 输出 JOIN +- Filter with WHERE | +- Bookmark lookup | +- Table | | table c | | possible_keys index_media_id_index_order | +- Index lookup | key c->index_media_id_index_order | possible_keys index_media_id_index_order | key_len 9 | ref const | rows 2823 +- Filter with WHERE +- Index lookup key s->customer_subscription_cust_media_id possible_keys customer_subscription_media_id,customer_subscription_cust_id_index,customer_subscription_cust_media_id key_len 18 ref const,const rows 1 # 解释如下: # 1、对s表进行索引扫描,估计访问1行。ref分别为s.media_id、s.cust_id两个常量值 # 2、对c表进行索引扫描,预计访问2823行。ref为c.media_id # 3、对c表通过索引定位的每一行,进行bookmark查找,即根据非聚簇索引上的条目查找实际数据 # 4、执行JOIN |
频繁的对表进行插入、修改、删除,可能导致表空间上出现大量零散的空白,即碎片化,碎片会影响表的读取效率。下面的语句可以查看表的碎片化情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT ENGINE, TABLE_NAME, Round(DATA_LENGTH / 1024 / 1024) AS data_mb, round(INDEX_LENGTH / 1024 / 1024) AS index_mb, round(DATA_FREE / 1024 / 1024) AS data_free_mb FROM information_schema. TABLES WHERE DATA_FREE > 0 ORDER BY DATA_FREE DESC |
注意一个表空间中的所有表,会共享一个data_free,因此如果使用单独数据文件,可能看到很多重复的data_free值。使用下面的语句可以进行表优化:
|
1 2 3 4 5 |
optimize table wp_posts; -- 如果提示: Table does not support optimize, doing recreate + analyze instead -- 说明引擎不支持,可以改用: alter table wp_posts engine='InnoDB'; -- 注意,如果设置:innodb_file_per_table=1,那么alter将为表新建独立的.ibd文件 |
找到my.ini,定位datadir的位置,其目录下有日志文件:服务器名.error,里面包含详细错误信息。如果配置存在问题,可以通过bin\MySQLIntanceConfig.exe进行重新配置。
注意,MySQL错误日志文件路径可以通过log-error参数定制。
添加外键约束时出现此错误,可能原因是:外键字段与目标表的主键字段的类型不兼容,例如varchar与int。
属于授权问题,可以授予目标用户相关的权限来解决:
|
1 |
grant all privileges on *.* to root@"%" identified by "root"; |
大表删除速度慢,原因和聚簇索引(cluster index,此索引每张表只能有一个)有关,MySQL会使用主键、唯一键(作为聚簇索引列)来在物理磁盘上对表的数据行进行排序,一旦行被删除,就会进行整个表的重新排序,这个排序正是耗时操作所在。 解决方案:
- 规划主键的设计,如果删除的数据,其主键是集中在一个区间的,最好了
- 或者,添加一个BIT列,在删除的时候,将其状态改为false,在某个时候进行单次批量删除
|
1 2 3 4 5 6 7 |
rem 打印MySQL使用的运行参数,可以检测配置是否生效 mysql --print-defaults rem 执行命令 mysql --verbose --help | less rem 一直按回车,直到看见“Default options are read from the following files in the given order” rem 下一行即为读取的配置文件位置,例如 rem C:\Windows\my.ini C:\Windows\my.cnf C:\my.ini C:\my.cnf D:\Programs\MySQL\my.ini D:\Programs\MySQL\my.cnf |
另外,如果MySQL在Windows下作为服务运行,可能需要注意MySQL服务的配置,其命令行参数可能附带 --defaults-file参数,该参数指明了该服务实例使用的my.cnf文件。
|
1 2 3 4 |
sudo apt-get purge mysql* -y sudo apt-get autoremove -y sudo apt-get autoclean sudo apt-get install mysql-server -y |
|
1 2 |
# 执行命令行提供的SQL语句并退出 mysql -uroot -proot -e "create database newdb;" |
Leave a Reply