High Performance MySQL学习笔记
MySQL与其它数据库软件很不相同,其架构特性让其具有广泛的使用范围。
MySQL的逻辑架构可以简单的描述为下图:
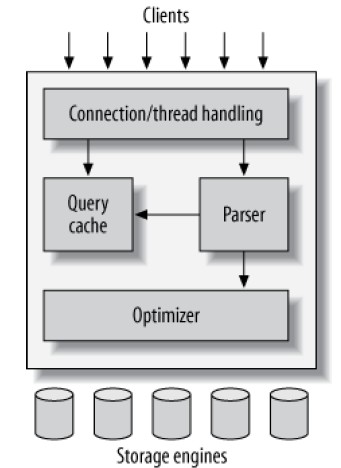
- 最上面的一层不是MySQL专有的组件,负责网络连接的处理、身份验证、安全性等逻辑
- 第二层是MySQL的核心所在,包括parsing, analysis, optimization, caching和内置函数在内的功能均在此实现。提供所有跨引擎的功能,例如procedures, triggers, views
- 第三层是存储引擎,负责存取数据。每种存储引擎各有特长。MySQL使用Storage engine API与之通信
连接管理与安全性
每个客户端连接在服务端都有自己对应的线程,连接进行的查询在单线程中运行,对应了一个CPU或者核,MySQL会缓存线程供不同连接重用。
客户端连接时需要身份验证,可以基于用户名密码的方式,使用SSL时,则可以基于X.509数字证书验证。
客户端连接成功后,其操作会被授权判断。
优化与执行
MySQL首先会针对SELECT语句来检查查询缓存——其中包含SELECT语句和它关联的结果集——如果语句完全一样,则简单的返回缓存的结果集。
然后MySQL会把SQL查询解析为内部的Parse tree结构,并进行一系列的优化,包括:
- 重写(rewriting)查询
- 确定读取表的顺序
- 选择使用的索引
通过在SQL语句中附加提示(Hint),可以影响上面的优化行为。
MySQL优化器不关心特定表使用了何种存储引擎,但是存储引擎会影响查询的优化,优化器根据引擎的特性、特定操作的成本、表的统计信息来决定如何优化。
任何超过一个SQL需要改变数据时,都存在并发问题。处理并发最简单的手段是锁机制,但是可能带来性能问题。
读写锁(Read/Write Locks)
共享锁(shared locks),又称读锁,只会阻塞其它的写锁
独占锁(exclusive locks),又称写锁,会阻塞其它的读锁、写锁
锁粒度(Lock Granularity)
进行选择性的锁定而不是锁住整个资源,可以增大并发。锁定策略(locking strategy)是一种数据安全性与锁定成本(lock overhead)的折衷。相比起其它数据库,MySQL给予用户给多的锁粒度选择的可能(不限制引擎的实现方式):
- 表锁(Table locks):写数据(insert, delete, update)时获取整张表的锁定,其它客户端不能读取或者写入此表。通常写锁在等待队列中具有比读锁更高的优先级
- 行锁(Row locks):允许最高的并发(和最高的锁定成本),InnoDB 、XtraDB支持行锁
考虑下面的场景:将Jane的200美元从她的活期账户转移到储蓄账户:
- 确保获取账户的余额大于200
- 把活期账户余额减去200
- 把储蓄账户的余额增加200
对应的SQL语句:
|
1 2 3 4 5 |
START TRANSACTION; SELECT balance FROM checking WHERE customer_id = 10233276; UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276; UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276; COMMIT; |
如果执行到上面第四行,数据库服务器崩溃了,会发生什么?白白扣除Jane 200美元?要实现事务性,必须通过ACID测试:
- 原子性(Atomicity):整个事务作为不可分操作完成,要么提交,要么回滚
- 一致性(Consistency):数据库只能在两个一致性状态之间变换,例如上面的例子,即使在第四行崩溃,也不会出现数据不一致性,因为事务绝不会提交
- 隔离性(Isolation):一般的,事务操作的结果在提交前,对其它事务不可见。这依赖于事务隔离级别的配置
- 持久性(Durability):一旦提交,事务对数据的改变即被持久化,不会因为系统崩溃而丢失
隔离级别
SQL标准定义了4种隔离级别,低的隔离级别带来更多的并发、更低的成本(overhead):
- 读取未提交(READ UNCOMMITTED):不同事务互相看到对方未提交的修改。允许脏读(dirty read)
- 读取已提交(READ COMMITTED):大部分数据库的默认隔离级别(MySQL不是),存在不可重复读问题,在同一个事务中两次运行同一个查询,结果可能不一样。允许不可重复读(nonrepeatable read)
- 可重复读(REPEATABLE READ):MySQL默认级别。保证在一个事务中,多次读取同一行,其数据保持一致。允许幻影读(phantom reads),幻影读在读取一个范围的数据时会发生,出现数据变多或变少的情况
- 串行化(SERIALIZABLE):最高的隔离级别,强制事务排队执行。
死锁
死锁在多个事务同时持有、而又请求对方的资源时发生。数据库依赖于死锁检测、超时等机制来解决死锁问题。例如InnoDB会立即检测到死锁并回滚持有最少独占行锁的事务。
锁的行为和次序是存储引擎相关的,所有同样的业务场景在某些引擎下死锁,另外一些则不会。
事务日志(Transaction Logging)
事务日志可以让事务处理的效率更高。存储引擎可以在发生数据变更时,不去写表,而是写在内存中,随后写入事务日志中。事务日志虽然和写表都是磁盘操作,但是前者是小范围的顺序写入,而后者是大范围的随机写入,故前者效率很高。
MySQL中的事务
自动提交(AUTOCOMMIT)
默认情况下,MySQL运作在自动提交模式——除非手工开启事务,否则每个语句在一个事务中运行。
运行:SET AUTOCOMMIT = 0;可以禁止自动提交,注意这个设置对非事务性表,例如MyISAM 、Memory表没有意义。
某些语句,例如DDL、LOCK TABLES可能强制性的进行提交。
事务中混合多种引擎(Mixing storage engines in transactions)
在一个事务中包含多种存储引擎的操作是不可靠的。例如:对于事务性表A、非事务性表B,在一个事务中进行,如果成功,则没有问题,如果失败,非事务性表是无法回滚的。
隐含和明确锁定(Implicit and explicit locking)
InnoDB使用两阶段锁定协议(two-phase locking protocol)。可以在事务的任何阶段获得锁,但是只有在提交或回滚时才释放锁——在同时释放所有锁。根据隔离级别的设置,InnoDB 隐含的处理所有锁。尽管如此, InnoDB支持明确锁定:
- SELECT ... LOCK IN SHARE MODE
- SELECT ... FOR UPDATE
此外,MySQL在上层支持表锁定和解锁(使用命令:LOCK TABLES、UNLOCK TABLES)
大部分MySQL引擎不是简单的使用行锁定,而是使用MultiVersion Concurrency Control (MVCC),这是很多数据库例如Oracle、PostgreSQL等都在使用的技术。MVCC在很多情况下避免锁定,因而性能较好,MVCC通常会实现无锁读(nonlocking reads),只有在写入时要求锁定。
MVCC通过保持某些时间点的数据快照来实现无锁读。这意味着,单个事务可以看到一致性的数据(事务开始的时间点);而不同事务在同一时间看同一张表,数据却可能是不同的。
每种存储引擎使用不同的方式实现MVCC,有些变种包括乐观、悲观并发控制的功能。InnoDB的实现方式:为每行添加额外的2个隐藏字段来记录行被创建的时间、过期(或删除)的时间,注意,InnoDB并不使用真实时间,而是数字的版本号(每个事务开始时版本号增加)来记录上述两个记录,在可重复度隔离级别下,InnoDB的MVCC的行为如下:
- SELECT:InnoDB必须检查每行确保满足以下2条规则:
a):必须找到行的至少小于等于事务的版本——即数据在事务前即存在,或者事务创建了此数据
b):行的删除版本必须未定义或者大于事务的版本——即数据不是在事务之前删除的 - INSERT:InnoDB把当前系统版本号设置为新行的版本号
- DELETE:InnoDB把当前系统的版本号设置为行的Deletion版本号
- UPDATE:InnoDB写入行的拷贝,把系统版本号赋予这一新行,同时把系统版本号赋予旧行的Delete版本号
以上行为保证了大部分的读不需要锁定,缺点是需要额外存储、管理许多数据。
MVCC仅与REPEATABLE READ 、READ COMMITTED一起工作。
MySQL存储每一个数据库(又称schema)在数据目录(data directory)下提供一个文件夹。创建表时,表的定义存放在table_name.frm文件中。
InnoDB引擎
最常用的引擎,也是默认的事务引擎。InnoDB把数据存放在单个或者一系列称为表空间(tablespace)的文件中,MySQL4.1以后InnoDB存储数据和索引到不同文件,支持在原始磁盘分区上(raw disk partitions)构建表空间。
InnoDB的默认隔离级别为REPEATABLE READ,在此级别下,使用next-key锁策略(next-key locking strategy)来防止幻影读——不仅仅锁定SQL涉及的行,还锁定索引结构中的间隙(gaps),阻止幻影数据被插入。
InnoDB表建立在聚簇索引(clustered index)上。InnoDB按主键查找的速度非常快,但是普通索引(secondary indexes)包含主键列信息,因此,如果主键大,则索引也会很大,因此对于具有很多索引的大表,选择较小的主键可以提高性能。
InnoDB索引的存储结构是平台中立的,从Windows上拷贝到Linux上没有任何问题。
InnoDB支持真正的热备份。
MyISAM引擎
MySQL 5.1或者更老版本的默认引擎。该引擎提供一系列特性,例如:全文索引、压缩、空间(spatial)数据库。但是不支持事务和行锁,此外,它还不是宕机安全的(non-crash-safe)。对于只读数据、表不是特别大(修复起来不是很痛苦),可以选择此引擎。
MyISAM引擎把数据文件和索引文件单独存放,扩展名分别为:.MYD 、.MYI。MyISAM支持定长(fixed-length)的行,会根据DDL自动选择是否启用。
MyISAM具有以下特性:
- 锁定与并发:MyISAM锁定整张表,而不是行。读操作共享锁定其涉及的所有表,写操作独占锁定目标表。但是,SELECT查询运行时,可以进行插入操作。
- 修复:支持手工或者自动修复表。使用REPAIR TABLE语句或者离线时使用myisamchk可以修复。修复的速度是非常慢的
- 索引特性:支持对BLOB 、TEXT前500字符进行索引,支持全文索引
- 延迟索引写入(Delayed key writes):创建时标记为DELAY_KEY_WRITE的表,不会立即写入索引数据到磁盘,而是使用内存缓冲。这可以提高性能,但是宕机后索引必定坏掉,需要修复
MyISAM重要的性能问题是表锁定,如果很多查询处于Locked状态,说明此问题严重。
选择正确的引擎
以下场景可以考虑MyISAM:
- 只读或者几乎只读的表
- 需要使用全文索引
可以使用sysbench来进行MySQL的性能测试。主要度量包括:吞吐量(Throughput,单位时间内的事务数)、响应时间(Response time or latency,任务消耗的时间,这是性能最根本的指标)、并发(Concurrency,高并发情况下的测试)、稳定性(Scalability)
分析服务器负载
缓慢查询日志(slow query log)可以整体上分析服务器的性能。服务器端变量long_query_time用于设定阈值,设为零可以捕获所有查询。
SHOW FULL PROCESSLIST也可以看到缓慢的语句。
分析单个查询
|
1 2 3 4 5 6 7 |
-- 启用当前会话的Session SET profiling = 1; -- 执行目标SQL -- 显示剖析结果 SHOW PROFILES; -- 显示单个查询的耗时 SHOW PROFILE FOR QUERY 1; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- 使用INFORMATION_SCHEMA.PROFILING表剖析 SET @query_id = 1; SELECT STATE, SUM(DURATION) AS "总计耗时", ROUND( 100 * SUM(DURATION) / ( SELECT SUM(DURATION) FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID = @query_id ),2 ) AS "耗时占比", COUNT(*) AS "调用次数", SUM(DURATION) / COUNT(*) AS "平均耗时" FROM INFORMATION_SCHEMA.PROFILING WHERE QUERY_ID = @query_id GROUP BY STATE ORDER BY Total_R DESC; |
使用SHOW STATUS
此命令显示一些计数器,缺点是没有时间的度量。可以使用FLUSH STATUS清空记录,并执行需要分析的SQL,再次查询检查状态的变化。
使用Performance Schema
选择正确的数据类型 ,对于MySQL的性能具有重要作用。以下是一些指导性规则:
- 数据尽可能的小,不论用什么类型
- 简单即可,例如整数类型比字符类型的性能好(后者具有字符集、字符比较问题)。应当使用MySQL内置类型表示时间日期、使用数字存储IP地址
- 仅可能的避免空值。可空列不利于MySQL进行查询优化
- 使用整数来代替实数(DECIMAL)
- 对于特别短的字符串(例如1字符),CHAR优于VARCHAR;对于定长、基本定长字符串,CHAR优于VARCHAR
- 对于变长(特别是最大长度比平均值大很多)字符串、UTF8字符串,适合VARCHAR
- 使用枚举代替字符串
整数类型
支持TINYINT,SMALLINT, MEDIUMINT, INT, BIGINT,分别占用8, 16, 24, 32, 64位空间。
支持UNSIGNED标记,这样不支持负数,可以增加一倍的最大值。有无符号对性能没有影响。
指定宽度,例如INT(11),对于引擎来说没有任何意义,只是为了交互式工具的需要。
实数类型
可以使用DECIMAL来代替BIGINT来存储非常大的整数
FLOAT 、DOUBLE的计算结果与平台上同类型相似,其计算不是精确的;DECIMAL支持精确的计算。这两者均支持设置精度(precision),对于DECIMAL可以指定小数点前后允许的尾数。
对于DECIMAL,MySQL存储9位数字需要4字节,例如DECIMAL(18, 9),支持9位整数9位小数,需要4+4+1=9字节,1为小数点自己需要的存储。MySQL 5.0以后的版本,DECIMAL最多支持65位数字,但是在计算时,只能支持到和DOUBLE一样的数值范围。
字符串类型
VARCHAR 和CHAR
字符串类型的存储方式是引擎决定的
VARCHAR是最常用的字符串类型,相比定长的CHAR,它更加节省空间(用多少存多少),一个例外是MyISAM定长行的表。VARCHAR使用1-2字节记录其长度,对于latin1字符集,VARCHAR(10)需要11字节,而VARCHAR(1000)需要1002字节。尽管VARCHAR通过节省磁盘提供性能,但是对于会发生Upadte的行,如果VARCHAR列变了,将会发生引擎依赖的行为,对于InnoDB,将会split the page 来适应行大小的改变。
CHAR则是定长的类型,MySQL会清除尾部的空格。
BLOB 和TEXT
这两者用来存储大的基于二进制、字符的字符串。唯一的区别是一个基于二进制,一个具有字符集
对于TEXT,有TINYTEXT, SMALL TEXT, TEXT, MEDIUMTEXT, LONGTEXT等具体类型,TEXT是SMALLTEXT的同义词
对于BLOG,有TINYBLOB, SMALLBLOB, BLOB, MEDIUMBLOB, and LONGBLOB等具体类型,BLOG是SMALLBLOG的同义词
和其他数据类型不同,MySQL将这两种字段作为具有自身标识符的对象来处理,对于InnoDB,这些数据类型并存放在外部(external)的空间。另外这两种字段的排序处理也特殊,只会排序max_sort_length前面的字符。
注意内存表不支持这两字段类型,不要使用。
枚举列
枚举列是具有预定义值列表的字符串列。值列表的修改必要DDL。在字符串上下文中,会转换为字符串比较
避免枚举与VARCHAR的连接查询。
日期和时间类型
MySQL支持多种日期时间类型,最细粒度为秒的存储,但是,支持毫秒级别的计算。
DATETIME
支持大范围的值,从1001 - 9999年,精确到秒。使用整数形式YYYYMMDDHHMMSS来存储其值,值与时区无关。默认的,MySQL使用可排序无歧义方式显示该字段类型,例如2008-01-16 22:37:08。需要8字节存储
TIMESTAMP
存储1970-01-01以来流逝的秒数,只需要4字节存储,支持1970-2038年。使用FROM_UNIXTIME() 、UNIX_TIMESTAMP()函数可以转换Unix时间戳、日期。MySQL 4.1+版本该字段的显示与DATETIME一致,与时区相关。
时间戳字段默认是NOT NULL的,插入时不指定值,会插入当前时间
位包装类型
MySQL支持一些用单独位来存储的类型,这些类型从技术上讲属于字符串类型
BIT
MySQL5.0之前只是TINYINT的同义词。可以使用BIT字段存放一个或者多个true/false字段,例如:BIT(8)可以存放8个布尔值。对于MyISAM,此数据类型比较节省空间,InnoDB则是使用足够存储其的最小INT类型。在字符串上下文中,会转换为字符串比较
选择标识符
整数是最适合最为标识符列的,因为速度快、可以自增长(AUTO_INCREMENT)
如果可能,避免使用字符串类型作为标识符。特别是使用MyISAM时,由于其默认对字符串使用packed indexes,则可能导致6倍的性能下降。特别小心使用随机性质的标识符,例如MD5(), SHA1(), UUID(),新插入的数据可能随机的进入大表空间的任何位置,导致插入INSERT、某些SELECT性能下降:
- INSERT慢的原因是,数据可能插入随机的索引位置,导致page splits、随机磁盘访问、聚簇索引碎片化(fragmentation)
- SELECT慢的原因是,逻辑上相邻的列,在物理、内存分布上相距很远
- 随机值导致所有查询的缓存效果低下,这和引用的位置(locality of reference)有关——如果整个数据集的热点程度一样,将导致内存缓存命中率低
如果必须使用UUID,可以去掉其中的横线,最好是使用UNHEX()转换为16字节的数字,并存储到BINARY(16)列。相比起MD5,UUID还是具有一定的非平均分布特征、序列性的,虽然这不能和INTEGER相比。
在设计MySQL表结构时,应注意不要:
- 过多的列:存储引擎和上层服务之间的数据格式需要转换,这种转换是以行为单位的,其成本与列数量成正比
- 过多的JOIN:表连接数量最好十个以下
- 过大的枚举值列表
规范化是指对范式的遵从程度。
规范化的优缺点
优点:
- UPDATE通常比反规范化设计快
- 由于没有冗余,需要更新的数据少
- 规范化设计的表通常比较小
缺点:要求过多的JOIN,这不但资源消耗大,并且会导致一些索引策略无效
反规范化的优缺点
优点:
- 避免JOIN,最糟糕的查询也就是全表扫描。如果数据不再内存中,这会比JOIN快很多,因为避免了随机访问
- 允许更高效的索引策略,考虑下面的场景:
1234567891011-- 这是一个规范化的表设计-- 需要查询高级用户的前十条(根据发布时间)消息SELECT message_text, user_nameFROM messageINNER JOIN user ON message.user_id=user.idWHERE user.account_type='premium'ORDER BY message.published DESC LIMIT 10;-- 在上述查询中,MySQL会扫描message表的published索引,对于每一行,需要查找user表-- 来看他是不是高级用户,如果只有很少的用户是高级的,这个索引策略将是低效的-- 问题就出在JOIN上,它导致无法在单个索引上同时完成过滤和排序,如果使用非规范化设计,并且在account_type, published上设计联合索引,则会很高效
有时候,相比起冗余字段设计,缓存表和摘要表是更好的选择,特别是在允许数据不准确(stale)的情况下。
这两种表并不是精确的概念,所谓缓存表,是指其存放获取需要很大成本的数据;所谓摘要表,是指其存放经过聚合(aggregated)的数据
物化视图(Materialized Views)
诸如Oracle、Microsoft SQL Server之类的DBMS提供了物化视图的概念,即预先计算并存放在磁盘、可以依据特定策略进行更新的视图。MySQL没有原生的实现,但是可以使用开源的Flexviews工具达到类似的效果,它有如下特性:
- 基于MySQL二进制日志的CDC(Change Data Capture)
- 一系列用于管理视图定义的存储过程
- 更新物化数据的工具
计数表(Counter Tables)
对于只有一行数据的计数表,将会导致所有事务并串行执行,极大的降低并发性,可以设置一个100行的计数表,然后使用where slot = RAND() * 100的方式进行随机插入,获取总数时,SUM即可。
索引(MySQL中又称keys)是用于快速寻找到行的数据结构。不适合的索引会引起性能问题,多索引的优化是最有效的提升查询速度的手段。索引的优化可能会要求查询语句的重写。
索引可以包含多个列,这种情况下列顺序很重要,因为MySQL只能对最左边的索引前缀做有效的检索。
过多的索引可能降低INSERT、UPDATE、DELETE的性能,特别是过多索引导致超过内存限制的时候。
索引的类型
索引工作在引擎级别,每个引擎的实现略有不同,某些引擎不能支持部分类型的索引
B树(B-Tree)索引
通常情况下所说的索引,就是这种类型,大部分引擎支持,Archive在5.1之前不支持。不同引擎的实现细节不同:例如MyISAM的索引通过物理位置来引用行;InnoDB则是通过主键值来引用行。
BTree索引之所以能提高性能,是因为避免了全表扫描。从一个ROOT节点开始(不在下图中),其slots存放指向子节点指针,引擎则是沿着这些指针,根据node pages中的值(定义了子节点的值范围)来寻找到合适的指针,最终引擎要么确定其寻找的值不存在,或者到达叶子节点: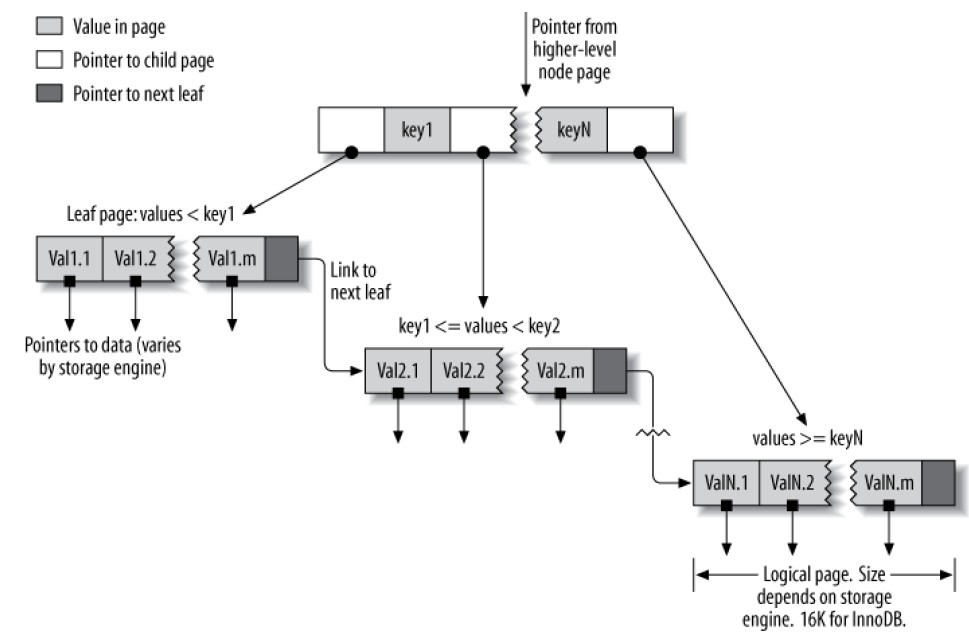
叶子节点的特殊之处在于,其存放了被索引数据的指针,而不是指向其它页的指针。
BTree适合多种查询:全值匹配、值范围匹配、值前缀匹配、多列索引的第一列匹配、多列索引的某列精确匹配+某列范围匹配、仅索引(Index-only,不去查行数据)查询。
由于BTree节点是排序的,因此该类索引不仅适合数据查找,还适合数据排序。WHERE子句依据索引列过滤的同时,使用该索引列ORDER BY、GROUP BY不会有额外的开销。
考虑BTree索引key(last_name, first_name, dob),下面是它的限制:
- 如果查找不是从最左边索引列开始、或者不是用单列索引列的前缀查询,则索引对查询无意义
- 不能跳过多列索引中的某列,如果在一个3列索引中,你不指定第2列的值,那么MySQL只会使用第一列进行索引查询
- 对于多列索引,第一个范围查询(非精确查询,例如 last_name = 'Wang' and first_name like 'Al%' and dob='1986-09-12'中的第二个查询条件)后的任何索引都用不到
Hash索引
Hash索引构建在Hash表中,仅仅在根据所有索引列进行查找时有效,引擎根据索引列计算各行的Hash Code。仅内存表支持此类索引
空间索引Spatial (R-Tree) indexes
针对各维度分别索引,用于GIS系统,但是MySQL这方面不是很好,最好选择PostGIS
全文(Full-text)索引
- 减少服务器需要检查的数据的量
- 避免服务器进行排序和临时表
- 将随机I/O变为顺序I/O
注意:对于 LIKE '%search%'形式的查询,无法使用索引。MySQL只支持在WHERE子句中使用等于、不等于、大于、小于等几种操作符来访问索引,对于 LIKE 'search%'这样形式的查询,MySQL会自动将其转换为大于、小于之类的操作符,从而使用索引。
隔离列
不要把列作为表达式或者函数调用的一部分,例如:WHERE actor_id + 1 = 5、TO_DAYS(CURRENT_DATE)
前缀索引和索引选择度
对于很长的列,可以选择前面若干字符进行索引,避免过大的空间占用。前缀索引导致低选择度(唯一索引具有最高的选择度:1)
多列索引
常见的错误包括,把大部分或者所有列单独索引,或者索引列的顺序不正确。
在很多列上分别建立索引,对于大部分查询来说,不能提高性能,MySQL 5.0以上版本有一种索引合并(index merge,通过解释计划可以看到类似Extra: Using union(PRIMARY,idx_fk_film_id)这样的字样)的策略可能对这种零散索引的表有点作用,老版本的MySQL则最多使用一个索引。索引合并有时候能有效工作,更多的时候则是提示表的索引质量较差:
- 如果服务器交叉索引(AND条件)往往以为着应该对相关列建立多列索引
- 如果服务器联合索引(OR条件),有时缓冲、排序、合并操作会消耗过多的CPU和内存,特别是相关索引的选择度均不高时
选择好的列顺序
BTree索引中列的顺序,依赖于查询如何使用索引。
多列索引首先根据第一列排序,然后第二列,依次类推。因此,列顺序应该和ORDER BY, GROUP BY, DISTINCT语句中声明的列顺序匹配。
一个老生常谈的规则是“把最具选择度的列放左边”,这个规则有时(没有分组、排序要求)有用,但是注意,避免随机I/O和排序更加重要。此外,效率不单单取决于选择度,也和用来做过滤的值有关。
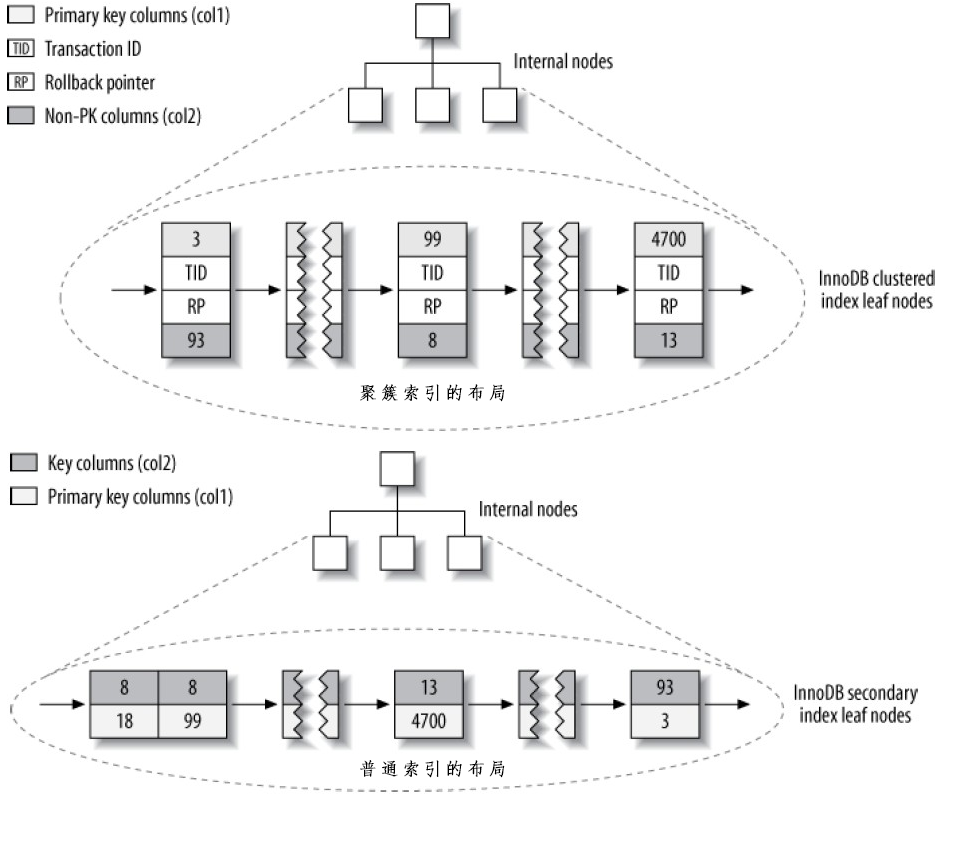
聚簇索引(Clustered Indexes)
聚簇索引不是一种索引类型,而是一种数据存储的方式,所谓聚簇,是指具有相邻键值(key)的行被存放在一起。对于InnoDB,聚簇索引把BTree索引和对应的行数据存放在一起。当表具有聚簇索引时,其行数据是存放在索引的叶子页(index’s leaf pages)上的,每张表只能具有一个聚簇索引。下图示意具有聚簇索引的表的布局,注意叶子节点包含整个行,其他节点只有索引列:
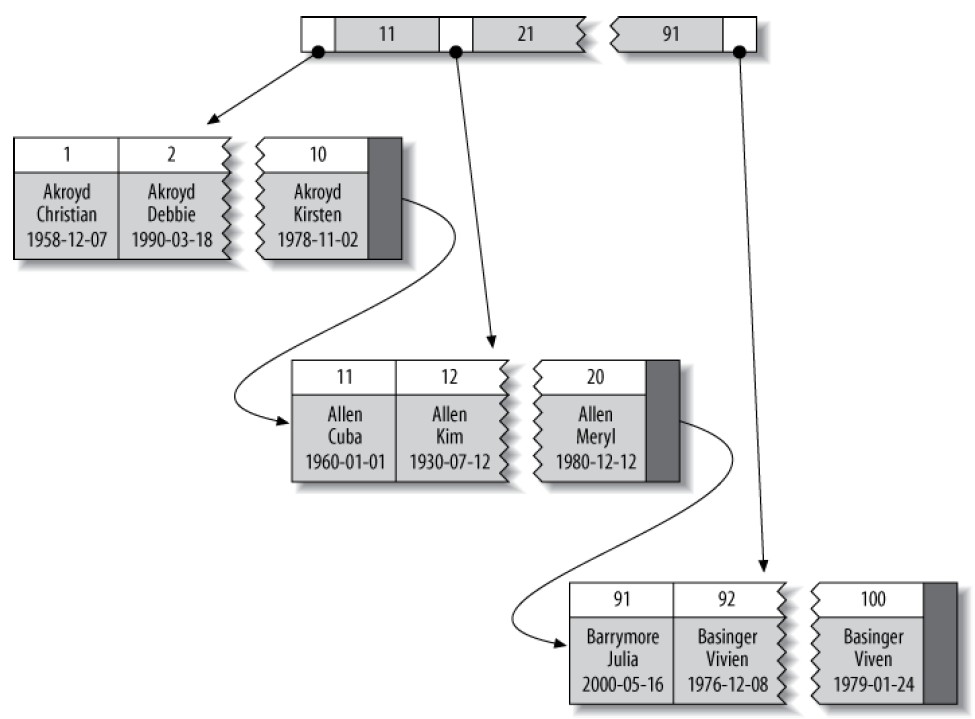
MySQL仅支持主键作为聚簇索引列,如果不定义主键,则MySQL会尝试使用一个非空、Unique索引代替。InnoDB只会以页为单位聚簇记录,相邻的页可能距离很远。
聚簇索引具有以下优点:
- 让相关的数据存放在一起
- 数据访问速度快,因为聚簇索引同时把索引、数据存放在一个BTree上
- 使用覆盖索引的查询,可以用到叶子节点上的主键
聚簇索引具有以下缺点:
- 插入顺序对插入速度影响大,最好是依据聚簇索引列的顺序来插入,乱序插入后,可以考虑OPTIMIZE TABLE
- 修改聚簇索引列的代价大,因为强制InnoDB移动其物理位置
- 构建了聚簇索引的表在插入数据时,受页拆分(Page Splits)的影响,如果被插入数据的key决定它将被插入到一个已满的页内,则split发生,页拆分会导致更多的磁盘占用
- 全表扫描的速度可能较慢,特别是数据因页拆分而非顺序的存放时
- 非聚簇索引(nonclustered)占用空间可能很大,因为其叶子节点需要存放主键列
- 非聚簇索引(nonclustered)的访问需要两次索引查找。InnoDB的Adaptive Hash Index可以减少此消耗
MyISAM和InnoDB数据布局的比较
考虑如下的具有两列的表结构:
|
1 2 3 4 5 6 |
CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) ); |
假设按随机顺序插入主键1-100000的数据,并使用OPTIMIZE TABLE来优化表(确保数据按最优方式排列在磁盘上),col1列使用1-100的随机值填充(很多重复值)。
MyISAM的数据布局
下图左侧标记了Row Number,由于这是一个Fixed-Size的表,所以根据Row Number可以迅速的定位到目标行。
主键索引的构建相当简单,就是针对主键顺序进行顺序布局,关联对应的Row Number。
普通索引和主键索引没有结构上的差异,只是不是Unique的而已。
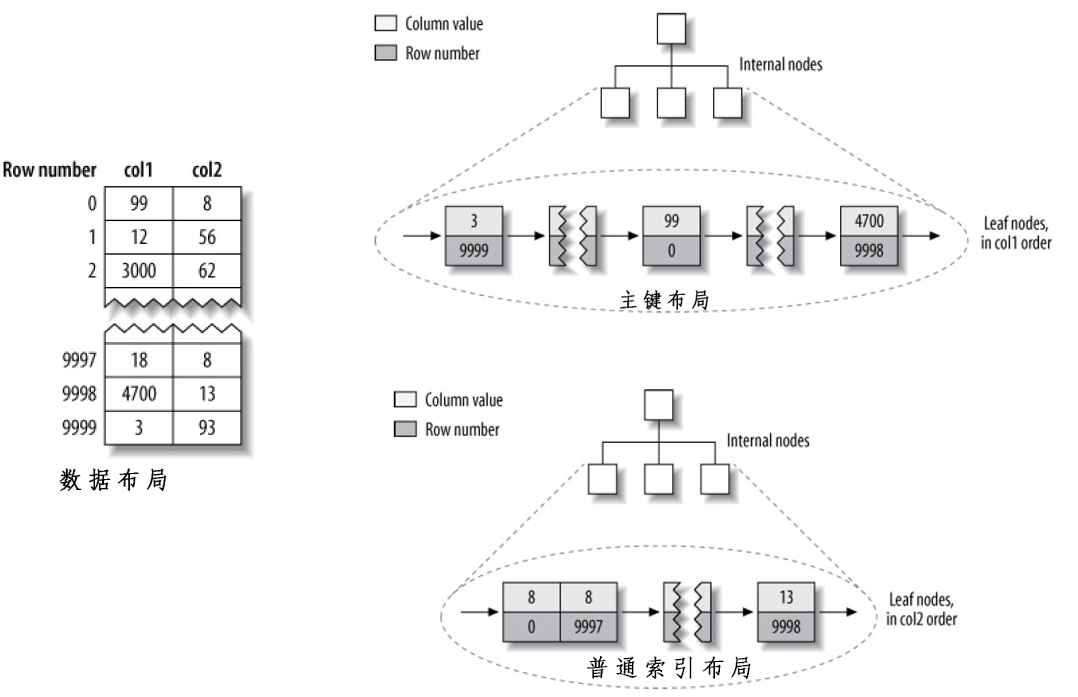
InnoDB的数据布局
由于聚簇索引的关系,InnoDB针对上表的布局完全不同。
首先,如下图,聚簇索引不单单是索引,表本身也包含在其中了:每一个BTree叶子节点包含主键值、事务ID、回滚指针(后面两者和事务、MMVC有关)、以及所有其他的列值。
其次,如下下图,与MyISAM的普通索引不同,InnoDB不是存储行号,而是存储被索引列+主键值。此策略可以减少行移动、页拆分时的资源消耗,缺点是索引体积大(特别是主键是很大字段时)
在InnoDB中按照主键顺序插入数据
如果没有任何特殊要求,最好使用自增长(AUTO_INCREMENT)主键,这保证数据按顺序插入,并提供更好的JOIN性能。
最好避免随机性质的主键,例如UUID。
自增长主键和UUID主键的插入性能差异,在到达某个数量级后(例如300万),可能有数倍的差距;索引大小也可能有成倍的差距。
在随机主键场景下,Page Splits以及其造成的碎片(fragmentation)无疑影响了性能,顺序主键和随机主键的数据页变化情况如下图:
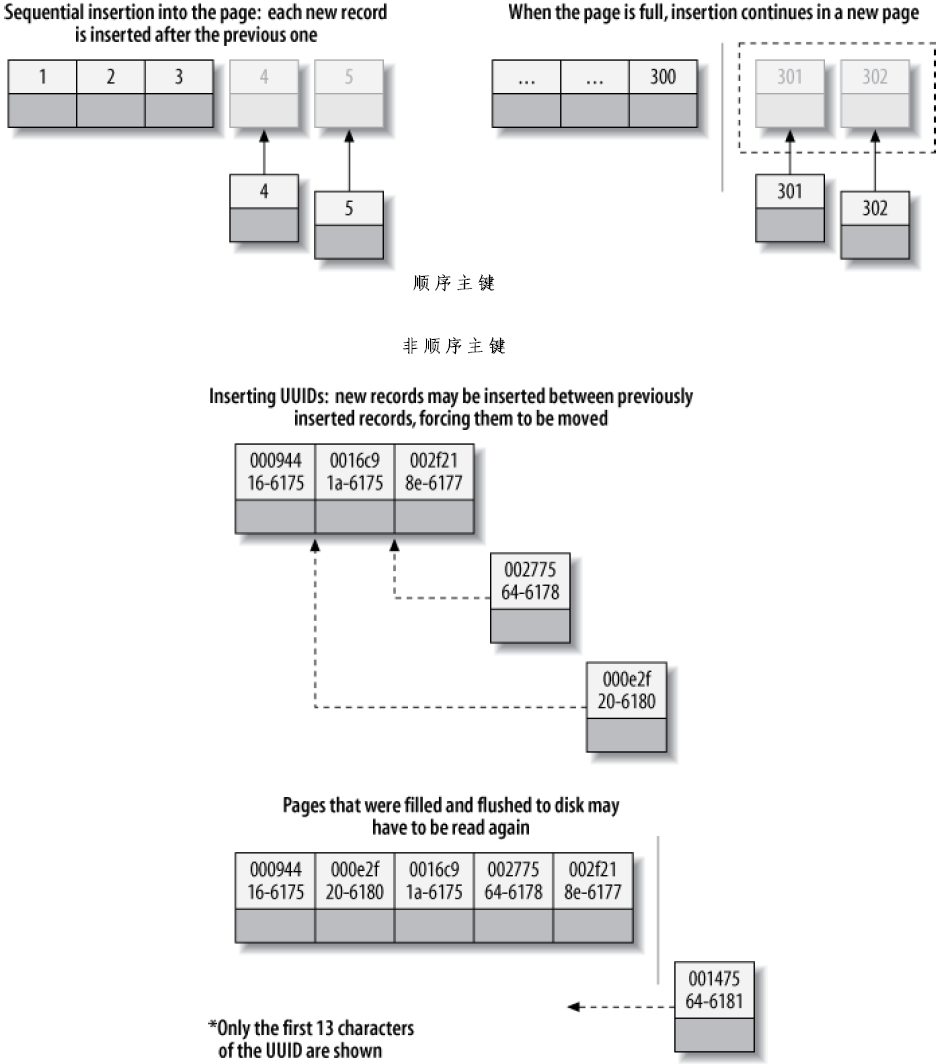
对于顺序主键,InnoDB直接在前一个插入的记录的后面插入新的记录,当前页满了(InnoDB默认页满因子为15/16,留下的空间用于防止修改)后,再下一个记录被插入到新的页中。如果数据加载时按照此顺序进行,那将是非常高效的。
而对于随机主键,由于新插入数据与前一个数据没有递增关系,所有InnoDB通常不能把新数据插入到索引的尾部,而是需要在已有页开辟新空间,则导致以下问题:
- 目标页可能已经被刷入磁盘,并移出缓存,或者目标页从来就没有进入过缓存,则导致了随机磁盘I/O
- InnoDB可能不断的分页,来开辟新空间供新插入的行,这导致需要移动很多数据、修改至少3个页
- 由于不断的分页,页变得稀疏、不规则,最终导致数据碎片化。一段时间后,可能需要运行OPTIMIZE TABLE来整理碎片
顺序主键导致更糟糕问题的场景
对于一个高并发的插入场景,顺序主键的最高值可能导致竞争热点:
- 大量的并发可能争用next-key locks
- AUTO_INCREMENT的本身的锁机制,可能需要修改innodb_autoinc_lock_mode
覆盖索引(covering indexes)
索引不仅仅需要为WHERE子句建立,还要考虑整个查询语句——MySQL不仅仅用索引快速的找到匹配行,还可以通过索引抓取列数据,但是,对于普通索引来说,不能抓取整个行的所有数据。覆盖索引可以模仿多聚簇索引(multiple clustered indexes),即,抓取查询需要的所有数据,不仅仅是被索引列。覆盖索引可以很好的提高性能,因为它只需要访问索引,而不需要访问数据,这种访问方式有以下好处:
- 索引条目往往比正行数据小的多,MySQL只需要读取很少的数据,特别是对于响应时间主要消耗与拷贝数据的缓存场景(cached workloads)
- 由于索引是按其索引值来存储的(至少在单个页内),因此,对比从随机磁盘数据获取行,覆盖索引需要较少的I/O。特别是对于MyISAM之类的引擎,通过优化表,可以保证简单的索引查询完全使用顺序索引访问
- 对于MyISAM之类的引擎,只在MySQL的内存中缓存索引,而由OS缓存数据,访问缓存数据通常意味着系统调用(System Call),这意味着高代价
- 覆盖索引对于InnoDB特别有意义,由于InnoDB的普通索引需要二次查找,如果使用覆盖索引,则可避免
只能使用BTree索引来创建覆盖索引,此外,内存引擎是不支持覆盖索引的。当发起一个被索引覆盖的查询,通过解释计划可以看到Extra列,其内容显示为Extra: Using index。而对于没有被索引覆盖的查询,则会显示Extra: Using where。
对于InnoDB,索引必定覆盖主键列。
基于索引扫描的排序
MySQL支持两种产生排序结果集的方法:
- 使用排序操作
- 按顺序扫描索引
MySQL可以使用索引同时完成数据过滤和排序。只有ORDER BY子句指定的方向(ASC、DESC)与索引顺序一致,并且对于多表连接,ORDER BY只引用第一个表的列时,才能进行基于索引的排序。此外,与WHERE子句类似,ORDER BY子句只能使用多列索引最左边的前缀进行排序,除非在WHERE子句中把左侧列作为常量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE TABLE rental ( PRIMARY KEY (rental_id), -- 包含三个列的多列索引 UNIQUE KEY rental_date (rental_date,inventory_id,customer_id), KEY idx_fk_inventory_id (inventory_id), KEY idx_fk_customer_id (customer_id), KEY idx_fk_staff_id (staff_id), ... ); -- 在WHERE子句指定了三列索引最左侧的值为常量 -- 这样仍然支持基于索引的排序,解释计划不会出现Extra: Using filesort EXPLAIN SELECT rental_id, staff_id FROM sakila.rental WHERE rental_date = '2005-05-25' -- 第一列常量 ORDER BY inventory_id, customer_id; --排序没有使用左侧列 -- 更多的例子 ... WHERE rental_date = '2005-05-25' ORDER BY inventory_id DESC; ... WHERE rental_date > '2005-05-25' ORDER BY rental_date, inventory_id; -- 下面的例子不能基于索引排序 -- 使用了两个不同的排序方向,而索引列均是升序排列 ... WHERE rental_date = '2005-05-25' ORDER BY inventory_id DESC, customer_id ASC; -- staff_id不再多列索引中 ... WHERE rental_date = '2005-05-25' ORDER BY inventory_id, staff_id; -- customer_id左边的列inventory_id必须存在于排序子句 ... WHERE rental_date = '2005-05-25' ORDER BY customer_id; -- 过滤条件不是常量 ... WHERE rental_date > '2005-05-25' ORDER BY inventory_id, customer_id; |
打包(前缀压缩的)的索引Packed (Prefix-Compressed) Indexes
MyISAM可以对索引前缀压缩,从而减小空间占用,易于在内存中完成匹配。默认MyISAM自动对字符串索引进行压缩操作,可以指定其对整数索引亦进行此操作(创建表时使用PACK_KEYS选项)。压缩索引有时可能降低性能
冗余、重复和无用索引
MySQL允许在同一列上创建多个索引,并独立的维护它们,这些索引可能影响查询的优化。
重复索引:同样列上、同样类型、同样顺序的索引。没有价值。
冗余索引:BTree索引(A,B)、(A)对于列A是冗余的,因为前者亦可单独用于A列。有时扩充已有索引可能降低性能,这是需要冗余索引,例如在已有一个整数列索引,需要扩充一个长的VARCHAR列的时候——如果建立索引(int_col,varchar_col),并保留(int_col)可能是最好的选择。
冗余索引可能导致插入性能降低,对于上面(int_col,varchar_col)的例子,百万数据的插入性能可能成倍下降(InnoDB)甚至数倍下降(MyISAM)。
对于从来不会使用的无用索引,应该删除。
索引与锁定
如果SQL语句(例如for update,注意普通查询不做任何锁定)不去touch其不需要的行,则需要锁定的行也很少,这提高了性能,因为:
- 尽管InnoDB具有很高效的行锁,且需要很少的内存,但是行锁定还是有一些成本
- 锁定更多的行,引起锁争用,降低了并发性
InnoDB仅在访问行时锁定它们,并且索引索引可以减少访问和锁定的行数,但是,只有InnoDB在引擎级别能够过滤掉不需要的行才能减少锁定,否则,InnoDB把结果集返回到MySQL Server层,结果集中的所有行都被锁定了(MySQL 5.1和以后的版本,InnoDB能够在Server层完成过滤后解锁相关行)
即使在使用索引的时候,也可能锁定不必要的行,如果没有索引,在引擎级别可能锁定所有的行(全表扫描)
本节使用一个在线交友网站的例子来简述索引的设计与使用,假设有一张用户信息表,需要支持country, state/region, city, sex, age, eye color等多种条件组合过滤、支持基于最后一次在线时间、排名进行排序。
支持多种方式过滤
需要考虑哪些列最常出现在WHERE子句中,哪些列的distinct值较多,这会成为建立索引的优选
country、sex列虽然distinct值较少,但是几乎会包含在所有查询中,所以,我们创建一系列以(sex,country)为前缀的索引,尽管这个决定与传统的最佳实现背道而驰,我们有足够的理由:
- 这两列几乎所有查询中都用到,甚至,我们可以设计为每次用户必须选择这两列作为查询条件
- 通过一定的技巧,可以使这样的索引没有什么负面作用:此技巧就是:如果用户没有指定sex,我们可以人工添加 sex in ('m','f'),这个技巧可以保证索引被使用,但是,如果distinct太多,会导致IN 列表过大
确认前缀后,需要考虑哪些条件组合会出现在WHERE子句中,并且在没有索引的情况下可能会很慢,明显(sex, country, age) 是一个候选,(sex, country, region, age) 、(sex, country, region, city, age)上也可能需要索引。
如果为它们分别建立索引,则索引可能太多了,需要考虑索引的重用,如果用IN技巧处理region,则(sex, country, age) 可以和(sex, country, region, age)合并为一个索引,但是要注意IN列表过大的问题
对于使用不多的查询列,例如has_pictures, eye_color, hair_color, education,有两个选择:
- 不进行索引,让MySQL进行少量的额外扫描
- 加入索引并使用IN技巧
注意我们把age放在索引的最后面,这是因为,age通常是一个范围查询,而其他的列要么是相等查询,要么是IN查询——这两个操作符可以常量化索引的左前缀,从而保证索引被优化器尽可能有效的使用。
IN列表过大可能导致查询速度严重下降,例如下面的语句需要4*3*2=12种组合,WHERE子句需要逐个组合的检查:
|
1 2 3 |
WHERE eye_color IN('brown','blue','hazel') AND hair_color IN('black','red','blonde','brown') AND sex IN('M','F') |
12种组合通常不是问题,但是如果组合数上千,就要注意了:对于老版本的MySQL,优化器可能需要很长时间的执行、消耗大量的内存;对于新版本的MySQL,则会在超过一定的组合数量后停止优化估算,这会影响索引使用效率。
避免多个范围查询
尽管从执行计划上分不出IN (20,21,22)和 >=20 and <=22的区别(都显示为type:range),但是这两种语句对应索引的处理是完全不同的,后者会导致MySQL忽视后续的索引。
考虑下面的查询:
|
1 2 3 4 5 |
WHERE eye_color IN('brown','blue','hazel') AND hair_color IN('black','red','blonde','brown') AND sex IN('M','F') AND last_online > DATE_SUB(NOW(), INTERVAL 7 DAY) --最近一周登陆过 AND age BETWEEN 18 AND 25 |
MySQL只会使用age或者last_online两者中的一个。如果age无法常量化(值列表过大),则无法把last_online放到索引的尾部,则必须使用某种变通的方法,例如:使用JOB来处理一个active字段,如果最近一周没有登陆,则设置为0,在用户登陆时设置为1,然后把索引改成类似(active, sex, country, age)的结构,即可满足需求。
未来版本的MySQL可能支持在单一索引上使用多个范围查询,这样的话,IN技巧就没有价值了。
优化排序
对于小结果集的排序,filesort就足够了。
对于大结果集,例如上百万数据,则可能需要为排序建立特殊索引:
|
1 2 |
-- 索引(sex, rating)可以供下面的查询使用: SELECT FROM profiles WHERE sex='M' ORDER BY rating LIMIT 10; |
大分页问题
如果用户请求离开始处很远的分页信息,例如:
|
1 2 |
SELECT FROM profiles WHERE sex='M' ORDER BY rating LIMIT 100000, 10; -- MySQL必须扫描大量的,而这些最终都是需要扔掉的 |
这将难以避免的导致性能问题,因为高offset导致太多的时间消耗在扫描没有意义的数据上,反正常化、预计算、缓存可能是有效的应对策略,最好的方式是限制用户能够访问的页数——谁会真正关心10000页后面的数据呢?
另外一种解决大分页的问题的策略是延迟连接(Deferred Join):
|
1 2 3 4 5 |
SELECT FROM profiles INNER JOIN ( -- 主键扫描,避免了MySQL收集其最终要扔掉的数据 SELECT FROM profiles WHERE x.sex='M' ORDER BY rating LIMIT 100000, 10 ) AS x USING(); |
寻找和修复表破坏(Corruption)
对于一张表来说,最严重的事情是破坏,对于MyISAM通常发生于Crash之后。索引破坏可能由于硬件故障、MySQL或者OS的BUG。
被破坏的索引可能返回不正确的结果,在没有重复值的时候报duplicate-key错误,甚至锁死和崩溃。
可以运行CHECK TABLE来检查表是否被破坏,该命令可以捕获大部分表和索引错误。使用REPAIR TABLE命令可以修复表的错误,某些引擎不支持该命令,这时可以使用NoOp的ALTER命令来修复,例如:ALTER TABLE tab ENGINE=INNODB。
InnoDB通常不会出现表破坏,除非出现硬件问题,例如内存或磁盘、或者数据文件被外部改动。使用innodb_force_recovery参数可以进入强制恢复模式,或者使用Percona InnoDB Data Recovery Toolkit从被破坏的数据文件中抽取数据。
更新索引统计信息
当存储引擎给出一个非精确的查询检查行数,或者查询计划过于复杂无法估算行数,优化器会使用索引统计信息来估算行数。MySQL优化器是基于成本的,主要度量依据是查询需要访问的数据量。如果索引统计信息不存在,或者过期,可能导致优化器做出错误决定。ANALYZE TABLE可以触发生成新的索引统计信息。
MyISAM把索引统计信息存放于磁盘,ANALYZE TABLE会导致表锁定及全表扫描
InnoDB从MySQL5.5开始存放在内存中,使用随机的索引采样来获取统计信息。采样的数据页数通过innodb_stats_sample_pages来设定,默认值为8,增大此值可能提高统计精确度,InnoDB在以下情况下会自动执行索引统计:
- 表第一次被打开时
- 运行ANALYZE TABLE时
- 表的尺寸发生重大变化时,例如变化了1/16,或者插入了20亿行数据
- 查询INFORMATION_SCHEMA中的某些表、执行 SHOW TABLE STATUS 、SHOW INDEX时,这可能导致性能下降,可以通过设置innodb_stats_on_metadata禁用
MySQL 5.6中,选项innodb_analyze_is_persistent可以使索引统计持久化到系统表中,这有利于系统预热、查询计划的稳定性。
减少索引和数据碎片
BTree索引可能因为Page Split变得碎片化(non-filled、nonsequential),从而影响性能(range scan、full index scan可能慢数倍,特别是使用覆盖索引的场景)
表数据同样可能碎片化,包括如下类型:
- 行碎片化:单行被分为多片存储于多个物理位置。即使结果集只需要一行,也会影响性能
- Intra-row碎片化:当逻辑上连续的页或者行,在磁盘上不是连续排列时发生。这会影响全表扫描、聚簇索引范围扫描的性能
- 自由空间碎片化:当数据页中包含大量空白空间时。这会导致服务器读取很多不需要的数据
MyISAM会发生各种碎片化,但是InnoDB则不会发生短行(short rows)的碎片化,它会移动行并写在一起。
通过OPTIMIZE TABLE或者dump/reload数据可以整理碎片。对于InnoDB的索引碎片的整理,可以通过删除/重建索引完成,对于不支持OPTIMIZE TABLE的存储引擎,可以做NoOp的ALTER TABLE操作。
查询是一个任务,并且被MySQL拆分为子任务,要优化查询,必须消除某些子任务、减少子任务的发生次数、或者加快子任务的执行速度。
基本上,一个查询需要的处理经过解析(Parsed)、计划(Planned)、执行(Executed)等步骤,其中执行是最重要的一步,包含很多存储引擎调用(为了获取rows)以及Post-retrieval处理(例如分组、排序)。MySQL需要在网络、CPU、特别是磁盘I/O(如果数据不在内存)中花费时间,对于某些存储引擎,可能需要很多上下文切换、系统调用。
最基本的查询缓慢的原因是,处理了太多的数据(绝大部分是不需要的,只是筛选),分析缓慢查询通常按以下的步骤进行:
- 检查应用程序是否获取了不需要的数据,例如:
访问太多行:使用limit语句限制返回的行数
在联表查询中返回不必要的表的列
返回所有列,这可能无法使用覆盖索引,并导致更多的CPU、内存和I/O
重复返回同样的数据 - 检查MySQL是否分析了不必要的行,在MySQL中,最简洁、粗略的查询成本估算度量是:响应时间、返回的行数、检查的行数。这些信息均会记录在slow query log中。
响应时间(Response time)由两部分组成:service time——MySQL真正用来处理查询的时间,queue time——等待某些资源(I/O的完成、行锁的获取)的时间,这两部分时间并不好区分
检查行数/返回行数:最理想的是只检查需要返回的行,现实中则很难实现,例如对于JOIN查询,需要访问两个以上表的多行,并生成结果集,这种情况下检查行通常要比返回行多很多。检查行过多也不一定意味着低效查询,因为较短的行访问起来交快,检查多点也没事
检查行的方式:有时,思考只返回一行数据的查询,有利于分析查询成本。执行计划结果的type字段反映了检查行的方式,包括:全表扫描(full table scan)、索引扫描(index scan)、范围扫描(range scan)、唯一索引扫描(unique index lookup)、常量(constants),后面的访问方式比前面的速度快。如果访问方式不佳,最好是添加适当的索引。MySQL可能以三种方式应用WHERE子句,效果从好多差为:
a)在存储引擎层,把过滤条件应用到索引查找操作,并消除不匹配的行
b)使用覆盖索引(Extra:Using index)在从索引中获取每一个行后,过滤掉不匹配的行,这发生Server层,但不需要表行的访问
c)从表中取得行,然后过滤掉不匹配的行(Extra:Using Where),这发生在Server层,并且需要表行的访问
复杂查询vs多个查询
在以前网络带宽比较缺乏的时代,倾向于在单个复杂查询中完成工作,但是现在没有这个必要了,MySQL设计为允许快速连接/断开、快速响应简单查询(在普通硬件上MySQL可以每秒响应超过十万个简单查询)。
网络上传输数据相比起在MySQL内存中完成数据处理,速度还是非常慢的,因此,尽可能的使用少的查询还是一个好主意。
查询分块(Chopping Up a Query)
把查询分为完全一样的“小块”,每次影响少量的数据,这在某些场景下也很有效,例如清除旧的数据。定期删除旧数据的JOB如果在一个巨大的DELETE语句中完成,将会导致很多行被长期锁定、事务日志被充满、阻塞其他小的语句。适当的使用LIMIT即可很好的改良。此外,在单个批次的DELETE让线程睡眠一会也是个好主意,避免负载过于集中,影响系统其他业务的运行。
连接分解(Join Decomposition)
很多高性能应用使用连接分解技术,即使用多个单表查询来代替一个连接查询,例如:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM tag JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; -- 上面的查询可以分解为: SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id in (123,456,567,9098,8904); |
咋一看似乎是多此一举,其实这种查询重构具有明显的性能优势:
- 缓存更加有效。某些应用具有缓存单表(映射为Map)数据的能力,如果缓存有效,3个查询中可能有些不需要执行。在使用Hibernate的场景中,查询缓存也会更加有效,因为这3张表中,如果只有一张表容易变化,那么JOIN查询的缓存将很快失效,而查询重构后,只有1个查询缓存容易失效。
- 单独执行查询,又是可以减少锁竞争
- 在应用中进行JOIN,更容易进行Scale,因为可以把表放在不同的服务器上
- 查询本身可以更加高效,上面的例子中,IN比起JOIN更好
- 可以减少冗余的行访问,在应用中进行JOIN,意味着每个行只需要获取一次,而JOIN属于反规范化,通常会重复访问很多数据。同样的,这样的重构也减少网络流量和内存消耗
- 某种程度上,可以认为这种技术是一个手工实现的Hash Join,作为MySQL嵌套循环算法(nested loops algorithm)的替代,Hash Join更加高效
当客户端发送一个查询给MySQL服务器时,会发生以下事件序列:
- 客户端把SQL语句送到服务器
- 服务器检查查询缓存,如果命中,则从缓存中获取结果集;否则进入下一步
- 服务器解析、预处理、优化SQL,并生成执行计划
- 查询执行引擎通过进行存储引擎API调用,完成计划的执行
- 服务器返回数据给客户端
MySQL Client/Server协议
协议是半双工的,任何时刻,MySQL服务器要么在接收数据,要么在发送数据,而不能同时进行。这样的设计使通信简单而快速,但是也有弱点:在接收完消息之前,无法做任何事情。
客户端把整个查询在单个数据报中发送,因此,如果使用很大的查询语句,max_allowed_packet参数就很重要。
相比之下,服务端通常在多个数据报中把响应发过来,客户端在接收完毕之前无法取消,除非强行断开连接,因此必要的LIMIT很重要。
大多数客户端库允许你要么抓取所有结果集并存放在内存,要么逐条抓取(游标),前者是默认行为,在抓取完毕之前,查询会处于“Sending data”状态,并不会释放锁和其它资源。
查询状态
每一个MySQL连接(或者说线程)具有一个说明当前其正在做什么的状态字段,使用SHOW FULL PROCESSLIST 命令即可看到当前状态,常见的状态如下表:
| 状态 | 说明 |
| Sleep | 线程正在等待来自客户端的新查询 |
| Query | 线程正在执行查询或者把结果集发送给客户端 |
| Locked | 线程正在等待Server层授予表锁。注意:基于存储引擎实现的索引,例如InnoDB的行锁,不会导致线程进入Locked状态 |
| Analyzing and statistics | 线程正在检查存储引擎统计信息,并优化查询 |
| Copying to tmp table |
线程正在处理查询,把结果集拷贝到临时表,可以是因为需要GROUP BY,或者filesort、或者UNION |
| Sorting result | 线程正在进行排序操作 |
| Sending data |
可能意味着几种状况:
|
查询缓存
在解析查询之前,MySQL就会检查查询缓存(如果查询缓存启用的话),这个查找操作是大小写敏感的HASH操作。只有语句完全一致,才可能命中缓存。
查询优化处理
该步骤完成执行计划的生成,包含几个子步骤:parsing、preprocessing、optimization
解析器和预处理器
解析器负责把语句转换为parse tree形式,检查语法的合法性。
预处理器对parse tree进行额外的语义检查,例如表和列的存在性、检查访问权限
查询优化器
MySQL使用基于成本的优化器。由于以下原因,有时优化器不能够得到最优执行计划:
- 统计信息错误。Server层依赖于存储引擎提供的统计信息,这些信息可能精确,或者仅仅是大概的数字。例如,由于MVCC,InnoDB不能维护精确的表行数统计信息
- 成本度量并不是和实际执行成本等价。有时侯读取更多页的计划反而会高效,如果这些页顺序的分布在磁盘上,或者已经被缓存在内存中——优化器并不知道这些信息
- MySQL的最优化和我们的理解有所不同,我们通常认为最优化意味着最短的执行时间,而MySQL则认为意味着最低的Cost
- MySQL不会考虑当前正在并发执行的SQL语句,这些语句可能影响当前语句的性能
- MySQL并不总是采用基于成本的优化,有时采用基于规则的方式,例如:如果语句中存在一个全文MATCH()子句,则会自动尝试使用全文索引
- 优化器不会考虑不再控制范围内的成本,例如执行存储函数、用户定义函数
- 优化器不能估算每一个可能的执行计划,这可能导致丢失最优计划
MySQL查询优化器是相当复杂的组件,优化可以分为:静态优化、动态优化两种:
- 静态优化仅仅通过分析parse tree即可完成,它与WHERE子句中传入的值无关,即时相同的语句使用不同的值执行,优化依旧有效,可以称为“编译时优化”
- 动态优化则需要根据多种上下文信息来完成,例如WHERE子句中传入的值、索引中具有多少distinct值。每次查询都需要重新优化,可以称为“运行时优化”
对于预编译语句、存储过程,MySQL可以只进行一次静态优化,而在每次执行时进行动态优化
以下是常见的MySQL优化:
- 重排连接(Reordering joins):不一定需要按照SQL中指定的顺序来JOIN,这是一个重要的优化内容
- 将OUTER JOIN转换为INNER JOIN:MySQL能够识别不必要的OUTER JOIN并自动转换
- 应用代数等价转换:例如(5=5 AND a>5)会自动转换为a>5
- COUNT(), MIN(), MAX()的优化:例如,如果需要寻找BTree最左侧列的MIN值,只需要请求索引中的第一行即可;寻找MAX值则请求最后一行。如果进行了这样的优化,在执行计划里可以看到“Select tables optimized away”。此外没有WHERE子句的COUNT(*)会被MyISAM引擎直接优化掉(因为所有表的总数均存放在数据字典)
- 常量化:如果MySQL发现某些表达式可以简化为常量,会进行优化。例如用户定义@变量在没有发生变化的时候,会被转换为常量表达式,算术表达式也会被转换为常量。此外,一些你可能认为不会常量化的场景下,MySQL也会进行常量化优化:
123456789101112EXPLAIN SELECT film.film_id, film_actor.actor_idFROM sakila.filmINNER JOIN sakila.film_actor USING(film_id) -- 常量化WHERE film.film_id = 1; -- 常量,只有一行匹配--- 结果如下,被优化为两个简单查询:+----+-------------+------------+-------+----------------+-------+------+| id | select_type | table | type | key | ref | rows |+----+-------------+------------+-------+----------------+-------+------+| 1 | SIMPLE | film | const | PRIMARY | const | 1 || 1 | SIMPLE | film_actor | ref | idx_fk_film_id | const | 10 |+----+-------------+------------+-------+----------------+-------+------+ - 覆盖索引:当SELECT子句中所有列被索引覆盖,则不会去寻找行数据
- 子查询优化:MySQL可以把某些子查询转换为效果等同的形式,将单独查询转换为索引查找
- 提前结束(Early termination):MySQL会在满足查询要求后尽快结束处理,例如:
a)LIMIT语句
b)WHERE id = -1发生在只有正数的主键上
c)Distinct/not-existsy优化,针对某些DISTINCT、 NOT EXISTS()、LEFT JOIN语句,示例如下:
12345SELECT film.film_idFROM sakila.filmLEFT OUTER JOIN sakila.film_actor USING(film_id)WHERE film_actor.film_id IS NULL;-- 一旦发现右表字段不为空,则立即结束对此电影的处理(通常电影都有很多演员) - 等同性传播(Equality propagation):MySQL可以识别查询中两列的等同性,例如JOIN的两列,并且把WHERE子句在等同列直接进行传播,示例如下:
12345SELECT film.film_idFROM sakila.filmINNER JOIN sakila.film_actor USING(film_id) -- USING强制file_actor.file_id与file表的PK相等-- WHERE 子句自动传播给file_actor表的file_id,减少了扫描范围WHERE film.film_id > 500; -- WHERE子句限制条件 - IN()列表比较:MySQL会自动排序IN()列表的值,并执行优化的二分查找(binary search)
表和索引统计
统计信息是由存储引擎来维护的,像Archive这样的引擎甚至不保存统计信息。Server层(优化器所在)询问存储引擎以下统计信息:
- 表或者索引的总页数
- 表或者索引的基数(cardinality)
- 行或者键的长度
- 键分布信息
优化器利用这些信息来协助制定何种执行计划
连接(JOIN)执行策略
MySQL比传统理解更多的使用术语join,它把所有查询看作join——不仅从两张表中匹配行的查询,子查询、单表查询都被看作join:
- 对于FROM中的子查询,首先单独执行它,结果放入临时表,然后将其视为普通表
- UNION则被看作多个单端的查询,结果存入临时表,再读取
- RIGHT OUTER JOIN被转换为等价的LEFT OUTER JOIN执行
MySQL的连接执行策略在目前非常简单:每一个JOIN被看作nested-loop join,下面的SQL与对应的伪代码形象的说明这种策略:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
SELECT tbl1.col1, tbl2.col2 FROM tbl1 INNER JOIN tbl2 USING(col3) WHERE tbl1.col1 IN(5,6); --- 伪代码 outer_iter = iterator over tbl1 where col1 IN(5,6) outer_row = outer_iter.next while outer_row -- 对于左表的每一行,右表的匹配行在嵌套循环里与之结合 inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next while inner_row output [ outer_row.col1, inner_row.col2 ] inner_row = inner_iter.next end outer_row = outer_iter.next end ----- 下面是外连接的例子: SELECT tbl1.col1, tbl2.col2 FROM tbl1 LEFT OUTER JOIN tbl2 USING(col3) WHERE tbl1.col1 IN(5,6); --- 伪代码 outer_iter = iterator over tbl1 where col1 IN(5,6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next if inner_row while inner_row output [ outer_row.col1, inner_row.col2 ] inner_row = inner_iter.next end else -- 如果右表没有匹配的,则设置一个空行与之匹配 output [ outer_row.col1, NULL ] end outer_row = outer_iter.next end |
执行计划
和很多数据库一样,MySQL不生成字节码来执行查询。查询计划实际上是一个树状的指令,查询执行引擎可以依次执行并最终获得结果:

连接优化器(The join optimizer)
MySQL优化器最重要的部分是是连接优化器,其决定连接多表的先后顺序。在Oracle的概念里,先执行查询的表称为后面表的驱动表。考虑下面的查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
SELECT film.film_id, film.title, film.release_year, actor.actor_id, actor.first_name, actor.last_name FROM sakila.film INNER JOIN sakila.film_actor USING(film_id) INNER JOIN sakila.actor USING(actor_id); -- MySQL的执行计划如下 *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor -- 和声明的顺序相反,从最后一个表开始驱动 type: ALL possible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 200 -- 如果使用SELECT STRAIGHT_JOIN 语句强制按照声明顺序来连接,这行是951,需要检查的行更多 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: film_actor -- 后续表通过PK引用扫描,需要扫描的数量决定于第一个表 type: ref possible_keys: PRIMARY,idx_fk_film_id key: PRIMARY key_len: 2 ref: sakila.actor.actor_id rows: 1 Extra: Using index *************************** 3. row *************************** id: 1 select_type: SIMPLE table: film type: eq_ref possible_keys: PRIMARY key: PRIMARY key_len: 2 ref: sakila.film_actor.film_id rows: 1 Extra: |
优化器会自动选择合适的顺序,除非你指定STRAIGHT_JOIN关键字(很少有必要)。N个表进行连接查询时,会导致需要检查的连接顺序达到N阶乘个(这称为可能执行计划的search space),例如,10个表的连接需要3,628,800个不同的检查,这将导致优化极为缓慢,因此,MySQL会在达到一定条件后停止检查,这由参数optimizer_search_depth控制。
排序优化
排序结果集可能是很耗时的操作,应该尽量在较少的行上进行排序。当MySQL无法使用索引进行排序时,Server层必须自行完成排序(通过磁盘或者内存,但都称为filesort),如果排序缓冲能装得下结果集,则MySQL会在内存中完成排序。
基本上,MySQL具有两种排序算法:
- 两阶段算法:这是老的算法,读取行指针、ORDER BY列,排序,然后读取排完序的列表,重新读取行,生成结果集。由于此算法需要两次读取行,这导致了很多的随机I/O,特别是对于MyISAM。
- 新算法:读取查询所需的所有列,根据 ORDER BY列排序,并根据排序结果生成结果集。在MySQL 4.1以上支持此算法,该算法把很多随机I/O变为顺序I/O,但是需要更多的空间。这导致排序缓冲容易被填满
如果查询所需所有列SIZE * ORDER BY列数 <= max_length_for_sort_data,则MySQL自动使用新算法。
MySQL排序所需的临时存储空间:为每个元组提供fixed-size的空间,该尺寸足够存放最大可能的元组(对于字符串还需要考虑字符集,例如对于UTF-8字符集,100长度的字符串需要300字节的空间)
联表查询时,如果ORDER BY仅引用join order中的第一个表,则MySQL可以根据此单表排序,然后进行JOIN处理,在执行计划里会显示:Extra:Using filesort。否则,必须先JOIN,然后再临时表里进行排序,执行计划会显示Extra:Using temporary; Using filesort。
LIMIT通常发生在排序完成之后,但是在MySQL5.6版本,可能会进行一些优化,在排序前丢弃一些不需要的行
返回结果集给客户端
即使不需要返回结果集,MySQL也会对客户端进行响应,例如通知影响的行数。MySQL使用增量的方式向客户端发送数据,当其生成第一条结果数据时,即可以并应该向客户端发送数据。这可以避免MySQL在内存中存放过多的数据。
相关性子查询(Correlated Subqueries)
MySQL有时把子查询优化的特别差,特别是 WHERE col IN (SELECT ...)这样的子查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
-- 很自然的子查询:查询演员1参演的所有电影 SELECT * FROM sakila.film WHERE film_id IN( SELECT film_id FROM sakila.film_actor WHERE actor_id = 1); -- 你可能期望MySQL这样优化: SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1; SELECT * FROM sakila.film WHERE film_id IN(1,23,25,106,140,166,277); -- 恰恰相反,MySQL尝试从outer表film推入一个关联性: SELECT * FROM sakila.film WHERE EXISTS ( SELECT * FROM sakila.film_actor WHERE actor_id = 1 -- 自作主张推入的关联性 -- 执行计划可以看到:DEPENDENT SUBQUERY -- 弱国outer表很大,这将导致非常严重的性能问题 AND film_actor.film_id = film.film_id); -- 建议如此重写此查询: SELECT film.* FROM sakila.film INNER JOIN sakila.film_actor USING(film_id) WHERE actor_id = 1; -- 或者使用GROUP_CONCAT()人工生成IN列表 |
但不是说不能用子查询,有时候子查询可能很快,一切以基准测试为依据。
等同性传播
当IN列表很大时,等同性传播可能拖慢优化速度
并行执行
MySQL不支持多处理器并行执行单个查询
Hash Join
MySQL没有内置的Hash Join支持
| 提示 | 说明 |
| HIGH_PRIORITY LOW_PRIORITY |
提示MySQL,相对于在同一个表上执行的查询,当前语句优先级如何。HIGH_PRIORITY让其进入待执行列表的最前面,LOW_PRIORITY则是放到最后面 通常可以用在MyISAM上(表锁),绝不要用在InnoDB上 |
| DELAYED | 与INSERT、REPLACE一起使用,可以使语句立即返回,待插入行则被放入缓冲,在表空闲时被批量插入。某些引擎没有实现此特性 |
| STRAIGHT_JOIN | 可以仅跟着SELECT,让MySQL根据语句指定的顺序进行JOIN |
| SQL_SMALL_RESULT SQL_BIG_RESULT |
用于SELECT语句,提示优化器如何、何时在GROUP BY、DISTINCT查询中使用临时表及排序。SQL_BIG_RESULT提示优化器结果集可能很大,最好使用磁盘临时表 |
| SQL_BUFFER_RESULT | 提示MySQL把结果集放入临时表并尽快释放锁 |
| SQL_CACHE SQL_NO_CACHE |
提示结果集是否可以缓存 |
| FOR UPDATE LOCK IN SHARE MODE |
对于支持行锁的引擎,可以对匹配行进行锁定 |
| USE INDEX IGNORE INDEX FORCE INDEX |
提示优化器使用或者忽略某个索引,在5.0以后,可以使用FOR ORDER BY 、FOR GROUP BY来影响排序与分组 |
COUNT(*)优化
要获取行数时,总是使用COUNT(*)
MyISAM只有在无WHERE子句的COUNT(*)时才有高性能
简单优化
对于MyISAM,有时可以利用其COUNT(*) 特性:
|
1 2 3 4 5 6 |
SELECT COUNT(*) FROM world.City WHERE ID > 5; -- 需要检查1000行 SELECT COUNT(*) FROM world.City WHERE ID <=5; -- 只需检查5行 -- 优化,使用总数减去<=5,即可得到>5的数目 SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*) FROM world.City WHERE ID <= 5; |
近似计数
使用EXPLAIN语句,可以得到大概需要检查的行数
复杂优化
可利用概要表(summary tables)、外部缓存(memcached等)来进行总数统计
优化表连接
- 确保连接列(ON或者USING子句)具有必要的索引
- 尽量保证GROUP BY、ORDER BY仅使用来自单个表的列
优化子查询
通常,尽量使用JOIN代替子查询。但是对于MySQL5.6或者MariaDB等MySQL变体,此规则不适用
优化GROUP BY和DISTINCT
MySQL可以使用临时表或者filesort来处理GROUP BY,通常,使用主键分组具有更高的效率,例如:
|
1 2 3 4 |
SELECT actor.first_name, actor.last_name, COUNT(*) FROM sakila.film_actor INNER JOIN sakila.actor USING(actor_id) GROUP BY film_actor.actor_id; -- first_name and last_name are dependent on the actor_id |
MySQL自动根据GROUP BY指定的列进行排序,如果不想排序引起filesort,可以指定ORDER BY NULL
优化LIMIT和OFFSET
分页查询时最常见的问题是高OFFSET值导致的,LIMIT 10000,20导致生成10020行,然后扔掉前面的10000行,这是非常昂贵的,这个问题有几个解决思路:
- 禁止访问过大的页
- 使用提前计算的摘要表
- 和只包含主键、ORDER BY列的冗余表进行JOIN
- 使用Sphinx
- 使用某种能够记录行位置信息的“书签”:
1234567-- 获取前20行SELECT * FROM sakila.rentalORDER BY rental_id DESC LIMIT 20;-- 获取第16049到16030行SELECT * FROM sakila.rentalWHERE rental_id < 16030 -- 如果此主键总是递增的,无论OFFSET多高,均不会影响性能ORDER BY rental_id DESC LIMIT 20; - 使用覆盖索引来进行OFFSET,然后再JOIN需要的其他列:
123456789SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;-- 如果film表非常大,可以优化为:SELECT film.film_id, film.descriptionFROM sakila.film--这是一个Deferred join,让MySQL在索引中检索尽量少的数据,而不去访问行INNER JOIN (SELECT film_id FROM sakila.filmORDER BY title LIMIT 50, 5) AS lim USING(film_id);
优化UNION
UNION总会使用到临时表。尽量使用UNION ALL而不是UNION,后者会自动增加DISTINCT,导致查询效率变低。
所谓分区表是指有多个物理子表(这些子表使用一样的存储引擎)组成的单个逻辑表。可以把分区表看作索引的一个粗略形式——Index以很低的成本获取相邻数据,相邻数据要么可以顺序的读取,要么在内存中匹配到;分区表则可以快速的判断出需要的数据在哪个分区里
MySQL的索引是按分区定义的,这与Oracle不同。PARTITION BY子句定义了如何分区的方式。
分区表可以减少表的数据访问、集中存储相关行,在以下场景下,分区表特别具有益处:
- 当表非常大,不能纳入内存,或者对于“热点行”集中在尾部的表(例如日志类的表)
- 分区表更加容易维护,例如,可以通过drop整个分区的方式来删除历史数据,这样做速度很快。可以按分区来优化、检查、修复
- 分区数据可以物理分布在多个磁盘上,这样可以更有效的使用多磁盘
- 在某些工作负载下,可以避免性能瓶颈,例如InnoDB的per-index互斥、ext3文件系统的per-inode锁定
- 可以按分区来备份和恢复
MySQL分区表具有一些限制,例如:
- 每个表最多有1024个分区
- MySQL5.1的分区表达式必须是整数,MySQL5.5在某些情况下可以根据列值进行分区
- 主键or唯一索引必须包含分区表达式中出现的所有列
- 不能使用外键约束
分区工作原理
对于存储引擎来说,表分区就是普通的表;对于用户来说,表分区由Handler Objects表示,无法直接访问。分区表按以下方式实现逻辑操作:
| 操作 | 实现方式 |
| SELECT | partitioning layer会打开并锁定所有分区,查询优化器会判断是否某些分区可以被忽略掉,然后partitioning layer通过Handler API调用管理分区的存储引擎完成查询 |
| INSERT | partitioning layer会打开并锁定所有分区,然后决定哪个分区接受此数据,并插入到分区 |
| DELETE | partitioning layer会打开并锁定所有分区,然后判断哪个分区包含此数据,并从分区删除 |
| UPDATE | partitioning layer会打开并锁定所有分区,然后判断哪个分区包含此数据,读取,修改,判断哪个分区接受新数据,然后插入目标分区,删除源分区的数据 |
注意:partitioning layer的锁定行为与存储引擎有关,与对普通表运行这些语句类似。
分区的类型
MySQL支持数种分区方式,其中最常用的是range分区——针对列(s)定义一个range值或者函数,例如:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE sales ( order_date DATETIME NOT NULL, -- Other columns omitted ) ENGINE=InnoDB PARTITION BY RANGE(YEAR(order_date)) ( -- 按年分区,其他任何返回确定性的整数的函数均可使用 PARTITION p_2010 VALUES LESS THAN (2010), PARTITION p_2011 VALUES LESS THAN (2011), PARTITION p_2012 VALUES LESS THAN (2012), PARTITION p_catchall VALUES LESS THAN MAXVALUE ); |
其它分区方式包括:key、hash、list。在MySQL5.5+可以使用RANGE COLUMNS分区方式,可以直接使用date-based列进行分区。下面列出一些使用分区的场景:
- 基于hash的子分区(Subpartitioning)可以减少热点行的per-index互斥竞争
- 基于key分区来减少InnoDB互斥竞争
- 基于取模函数的range分区,仅保留需要的一部分数据
- 在一个使用自增长主键的场景下,如果想通过表分区来使最近热点数据clustered在一起,如果想根据date-based列作为分区,其必须作为主键的一部分,这与自增长主键相悖。可以根据表达式HASH(id DIV 1000000)来进行分区,这样每100万行会自动形成一个分区,而且最近的数据因为HASH值一样,自动cluster在一起
如何使用分区
考虑如下场景:
- 需要查询一张包含若干年数据的巨大的表,数据量有10TB,使用传统机械磁盘
- 需要对最近几月的数据进行统计分析,数据量达1亿行
该场景下面临的问题:
- 表太大了,不能扫描整个表
- 几乎不能使用索引,因为维护成本、空间消耗太大,类似Infobright的系统完全抛弃的BTree索引
- 根据索引的情况,可能出现大量的碎片、聚簇很差的数据,大量随机I/O可能导致致命性能问题
只有两个选项是可行的:
- 查询必须是针对表的portion进行顺序扫描
- 期望的表、索引portion完整的在内存中匹配
有两个针对大数据量的策略:
- 扫描数据但不索引之:仅使用表分区作为导航至期望行的手段,只要WHERE子句仅仅跨越较少的分区,性能可以不错
- 索引数据,隔离热点数据:如果除了一小部分热点数据以外,很少使用。可以把热点数据分到足够小的区中,以便可以把数据连同其索引适合内存
可能的陷阱
- NULL值可能与表pruning相悖:如果分区函数可能返回NULL,那么对应的数据将被存放到定义的第一个分区中。如果第一分区很大,特别是使用扫描但不索引的策略时,性能可能低下。变通办法是创建一个dummy第一分区,只要不存放非法数据,这个分区将是空的,检查的代价也就很小了,注意,在MySQL5.5+使用PARTITION BY RANGE COLUMNS不需要此变通
- PARTITION BY 和索引不匹配:假设根据C1分区,而建立C2索引,那么根据C2索引查询需要检查每个分区的索引树,除非索引的所有非叶子节点在内存中,否则比不进行索引扫描更慢,因此,应当避免在非分区列上进行索引
- 分区的选择可能成本很高:不同分区方式具有不同的实现,因此性能表现也不会一样。特别是对于range分区,MySQL需要在分区列表里逐个寻找,如果分区表非常多,可能导致性能低下,这个问题在一行行插入数据时特别明显。解决此问题应该限制分区表的数量,通常100个分区在大多数情况下工作良好
- 打开和锁定分区可能成本很高:打开和锁定表发生在pruning之前,此成本是不可去除的,对于简单操作,例如基于主键的单行查询,影响较大
- 维护可能成本很高:诸如创建和DROP表分区的操作很快,但是REORGANIZE PARTITION之类的操作则可能相当耗时,因为其是基于逐行拷贝的方式进行的
MySQL5.5+以上版本的分区表技术比较成熟
查询优化
分区表优化的关键是利用分区函数减少需要访问的分区数量,因此,仅当尽可能在WHERE子句中指定partitioned key,使用EXPLAIN PARTITIONS可以检查优化器是否在修剪分区:
|
1 2 3 4 5 6 7 8 9 10 11 |
EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE day > '2011-01-01' *************************** 1. row *************************** id: 1 select_type: SIMPLE table: sales_by_day partitions: p_2011,p_2012 //注意:修剪只能发生在分区函数对应的列(即使基于表达式分区)上,而不能处理表达式的结果: EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE YEAR(day) = 2010 //可以把上面的语句转换为等价形式,以利用修剪 EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE day BETWEEN '2010-01-01' AND '2010-12-31' |
MySQL支持两种视图实现方式:
- TEMPTABLE:即根据视图的定义生成临时表,然后在临时表上进行查询。如果视图定义包含GROUP BY、 DISTINCT、UNION、聚合函数、子查询等构造,会使用此方式
- MERGE:即在查询时把视图定义合并到查询语句中,MySQL会尽可能的使用此方式
MySQL视图的限制:
- 不支持视图上的触发器
- 不支持物化视图,可以使用Flexviews实现类似功能
- 不支持索引的视图,可以使用Flexviews实现类似功能
可更新视图
可更新视图允许使用UPDATE, DELETE, INSERT 语句来修改潜在的表数据,如果视图包含GROUP BY, UNION, 或者聚合函数,则不支持更新。修改数据的SQL可以包含JOIN,但是被修改的列必须在一个表内。
|
1 2 3 4 5 |
CREATE VIEW Oceania AS SELECT * FROM Country WHERE Continent = 'Oceania' WITH CHECK OPTION; -- 强制任何基于此视图更新的数据匹配视图定义的WHERE约束 -- 因此,下面这样的更新会导致错误 UPDATE Oceania SET Continent = 'Atlantis'; |
InnoDB是唯一支持外键的引擎。
外键可能导致关联表被锁定:例如插入一条数据到子表时,其外键引用的父表的对应行也被锁定。这种现象可能导致意外的锁定甚至死锁。
外键可能引起重大的性能开销,某些场景下可以考虑以下代替方案:
- 在应用程序中控制数据约束
- 使用枚举值来代替外键来进行列表值约束
- 使用触发器来实现级联操作
MySQL支持触发器、存储过程、存储函数、以及周期性任务中的events。
MySQL提供只读、单向、服务器端的游标功能,供存储过程或者低级别Client API使用。
预编译语句对于需要重复执行的语句可以提高性能,因为:
- 服务器只需要解析语句一次
- 服务器只需要执行某些优化步骤一次,并缓存这一部分
- 基于二进制协议传送参数比ASCII方式更加高效(减少网络带宽、客户端内存消耗),特别是BLOB、TEXT字段
- MySQL把参数直接存储在服务器缓冲中,减少在服务器内存拷贝值的开销
此外,预编译语句也有利于安全,其避免了SQL注入的可能
预编译语句的优化过程
准备阶段:解析SQL,消除否定表达式、重写子查询
首次执行:如果可能,简化嵌套连接为OUTER JOINS或者INNER JOINS
每次执行:
- 修剪分区
- 如果可能,消除COUNT(), MIN(), MAX()
- 移除常量子表达式
- 检测constant tables
- 传播等同性
- 分析和优化ref, range, index_merge
- 优化JOIN的顺序
所谓UDF于存储函数不同,UDF可以基于任何语言编写,通过C进行调用,其性能较高。
MySQL支持插件机制,下面是一个简短的插件列表:
- Procedure 插件:可以对结果集进行后处理
- Daemon 插件:作为一个进程与MySQL一起运行,可以进行诸如监听网络连接、执行定期任务等工作。Percona Server的Handler
Socket plugin就是一个例子,它监听端口并允许使用NoSQL方式来访问MySQL - INFORMATION_SCHEMA 插件:支持提供INFORMATION_SCHEMA表
- Full-text 解析插件:用于支持全文检索
- Audit插件:在SQL语句的预定义点接收事件,可以进行记录日志
- 验证插件:支持例如PAM、LDAP的身份验证扩展
所谓字符集(Character Sets)是指二进制编码到符号集的映射。排序规则(Collation)是指对指定字符集下不同字符的比较规则。
MySQL字符集设置默认继承规则:
- 创建数据库时,从服务器character_set_server设置继承
- 创建表时,从数据库设置继承
- 创建列时,从表设置继承
客户端和服务器通信时,可能使用不同的字符集,服务器根据需要进行转换:
- 服务器假设客户端使用character_set_client指定的字符集来发送语句(statement)
- 服务器接收到语句后,使用character_set_connection来转换字符集,也用character_set_connection来决定如何把数字转换为字符串
- 当服务器返回结果集或者错误码时,使用character_set_result来转换
选择字符集合排序规则
MySQL 4.1+支持多种字符集合排序规则,包括使用UTF-8编码的多字节Unicode字符。排序规则的后缀:_cs, _ci, _bin用来标注使用大小写敏感、大小写不敏感、或者根据二进制值排序。
MySQL 5.6.4+以后的InnoDB支持全文检索,目前对中文的支持不是很好
MySQL5.0+以上版本,部分支持两阶段提交的XA事务,其可作为XA事务参与者(participants),但是不能作为协调者(coordinator)。
许多数据库系统能够缓存查询的执行计划,MySQL除此之外还能直接缓存SELECT的结果集,此即所谓Query Cache。
相关表一旦发生修改,查询缓存即失效。
随着服务器性能的提高,查询缓存往往成为整个服务器上的单点竞争热点,因此,可以考虑默认禁止查询缓存。如果的确有必要,可以设置不超过数十MB的缓存。
MySQL如何检查缓存命中
检查策略很简单,缓存类似一个HashMap,其key就是查询语句(不做任何处理)的Hash Code。
MySQL不会缓存结果集不是确定性的查询,例如带有NOW() 、CURRENT_DATE()函数的查询语句,包含用户定义函数、存储函数、用户变量、临时表、mysql数据库中的表的查询语句也不会缓存。考虑下面的例子:
|
1 2 |
... DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) -- 不能缓存 ... DATE_SUB('2014-07-14’, INTERVAL 1 DAY) -- 能缓存 |
MySQL5.1以前不支持预编译语句的查询缓存。
查询缓存在某些时候能够提高性能,但是对读与写均增加额外的消耗:
- 读操作之前必须检查缓存
- 如果查询是可缓存的,且尚未缓存,那么生成缓存需要一些额外的资源
- 对于写操作,其必须使相应的缓存条目失效,如果缓存碎片严重、缓存特别大,这将严重影响性能
对于InnoDB,一旦写操作开始,就会失效相应缓存,即使事务尚未提交,并且,事务提交前,相应表示不可缓存的。
查询缓存如何使用内存
MySQL完全把查询缓存置于内存中。查询缓存支持使用可变长度的内存块,每个块知道其类型(存放查询结果/查询语句使用的表/查询文本...)、大小、包含多少数据,并且持有指向前/后物理块/逻辑块的指针。
MySQL启动时,即为查询缓存分配对应的内存。每一次进行缓存时,申请缓存内存中的一个块,其最小大小为query_cache_min_res_unit字节。块的分配属于相对较慢的操作,因为MySQL需要检查空闲块列表,并找到一个足够大的。
何时使用查询缓存
最适合缓存的查询是生成耗时大、结果集小的查询,例如针对大表的COUNT(*)之类的聚合查询。
对于写负载很大的系统应当禁用查询缓存。
MySQL配置没有特定的公式,只能根据实际情况去优化————包括负载、数据、应用的需求、以及硬件,MySQL有大量的设置可以改变,但是不应当随意的修改、设置很多参数,这样可能导致内存耗尽、导致MySQL使用swap文件。应当调整好基本参数(例如InnoDB缓冲池大小、日志文件大小),并把精力放在Schema优化、索引、查询的设计上。如果某些参数需要优化,其必定会在查询响应时间上有所体现。
从哪里获取配置文件:通过命令行参数指定文件的位置,在Linux下,通常位于/etc/my.cnf、/etc/mysql/my.cnf :
|
1 2 3 |
which mysqld /usr/sbin/mysqld --verbose --help | grep -A 1 'Default options' #查找配置文件的位置 |
语法、作用范围、动态性
配置参数均为小写,单词使用下划线或者短横线连接,下面的两个设置(或命令行参数)是等价的:
|
1 2 |
/usr/sbin/mysqld --auto-increment-offset=5 /usr/sbin/mysqld --auto_increment_offset=5 |
配置参数可能有不同的作用域范围,有些事服务器全局范围的,有些是连接范围的,有些则是针对一个对象的。某些连接范围的参数具有全局等价参数,后者可以看作是其默认值:
- query_cache_size是全局参数
- sort_buffer_size具有全局默认值,每个SESSION可以设置自己的值
- join_buffer_size具有全局默认值,可以在SESSION上设置,并且,单个查询可以为每个JOIN设置一个join buffer
有些参数允许不停机的情况下动态修改(对已经创建的SESSION无效),这些修改在重启后会消失,例如下面的命令设置SESSION或者GLOBAL的sort_buffer_size:
|
1 2 3 4 5 |
SET sort_buffer_size = ; SET GLOBAL sort_buffer_size = ; SET @@sort_buffer_size := ; SET @@session.sort_buffer_size := DEFAULT; -- 设置为GLOBAL默认值 SET @@global.sort_buffer_size := ; |
动态参数设置的副作用
动态的设置参数可能具有边际效应,例如导致刷空缓冲中的脏块,常见的具有边际效应的动态参数如下表:
| 参数 | 说明 |
| key_buffer_size |
设置此值将导致分配指定数量的内存供key buffer(key cache,索引缓存),但是在使用之前,OS不会提交这些内存给MySQL。 MySQL支持创建多个key buffer |
| table_cache_size | 设置此值后,某个线程下次打开表时发生效果,如果设置的值大于缓存中表的数目,则插入缓存;反之,则把不用的表从缓存中删除 |
| thread_cache_size | 下一个Connection关闭后产生效果,如果超过线程缓存限制,则会销毁Connction对应线程而不是缓存之 |
| query_cache_size | 修改此值后,MySQL立即清除所有的查询缓存,调整缓存的大小,并重新初始化缓存。由于MySQL是串行删除缓存的,所以可能导致服务器停顿较长时间 |
| read_buffer_size | 直到查询需要读取缓冲时,MySQL才会分配整块的、指定大小的内存 |
| read_rnd_buffer_size | 直到查询需要读取缓冲时,MySQL才会分配足够其使用的内存 |
| sort_buffer_size | 直到查询需要进行排序时,MySQL才会分配整块的、指定大小的内存 |
不要把per-connection的参数全局默认值太高,例如sort_buffer_size,否则将造成巨大的浪费,应当在需要时设置,并在使用完后恢复默认:
|
1 2 3 |
SET @@session.sort_buffer_size := ; -- Execute the query... SET @@session.sort_buffer_size := DEFAULT; |
MySQL默认的示例文件中具有很多被注释的配置项,需要注意这些配置项的解释可能不是合理的、完整的,甚至是不正确的,这些示例文件对于现代硬件、工作负载来说,已经过期了。
最合适的做法是,从头编写一个配置文件,而不是以默认示例配置文件为基础进行修改,下面是一个推荐的配置模板:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
[mysqld] # GENERAL datadir = /var/lib/mysql #数据文件位置 socket = /var/lib/mysql/mysql.sock #Socket文件位置,最好不要使用默认值 pid_file = /var/lib/mysql/mysql.pid #PID文件位置,最好不要使用默认值 user = mysql #运行MySQL的OS用户 port = 3306 storage_engine = InnoDB #默认存储引擎,大部分时候InnoDB是最好的选择 # INNODB #InnoDB正常运行最基本的配置是缓冲池、日志文件大小,默认值均过小了 innodb_buffer_pool_size = #有些建议是设置为75%-80%服务器内存,这不科学 innodb_log_file_size = innodb_file_per_table = 1 #每张表一个文件,出于可管理性、灵活性的考虑 innodb_flush_method = O_DIRECT #仅对Unix有意义 # MyISAM key_buffer_size = # LOGGING log_error = /var/lib/mysql/mysql-error.log log_slow_queries = /var/lib/mysql/mysql-slow.log # OTHER tmp_table_size = 32M max_heap_table_size = 32M query_cache_type = 0 query_cache_size = 0 max_connections = thread_cache_size = table_cache_size = open_files_limit = 65535 #打开文件的限制,现代OS打开文件几乎不消耗什么资源,如果设置的过小,可能导致too many open files 错误 [client] socket = /var/lib/mysql/mysql.sock port = 3306 |
innodb_buffer_pool_size的正确设置方式
- 从服务器内存总量开始计算
- 减去操作系统、其它程序所需要的内存
- 减去MySQL其它组件需要的内存,例如每个查询操作需要的缓冲区
- 减去InnoDB日志文件所需要的内存,以便OS有足够内存来缓存之。最好留有一定的空间供二进制日志缓存使用,特别是使用延迟复制的场景,因为可能需要读取旧的master二进制日志
- 减去MySQL中其它缓冲、缓存需要空间,例如MyISAM的key cache、查询缓存
- 将剩余的值除以105%,以去除InnoDB管理buffer pool所需的内存
- 向下取整,作为目标值
举例:服务器192G内存,作为MySQL专用服务器,只使用InnoDB引擎,不使用查询缓存、没有过多的连接数,InnoDB日志总大小为4G,则InnoDB缓冲池大小估算过程可以如下:
- 考虑2GB或者5%的内存供OS、MySQL其它组件使用
- 减去4GB供InnoDB日志使用
- 剩余177GB,向下取整,设置为168GB
如果使用MyISAM并且需要缓存其索引,则会有所不同;在Windows下,MySQL存在大内存管理的缺陷,特别是MySQL5.5以前。
最好是设置一个安全、较大的值,然后运行服务一段时间,根据工作负载的需要调整,因为MySQL的连接本身占用内存很少,通常在256KB左右,但是如果查询使用了临时表、排序、存储过程等,则可能使用很大的内存。
MySQL的内存使用可以分为可控、不可控两类,后者包括:MySQL实例需要的内存、解析查询、管理内部状态需要的内存。内存配置的步骤与上一节类似,可以按以下步骤:
- 确定MySQL可以使用的内存上限
- 判断per-connection的内存用量,例如:排序缓冲、临时表
- 判断OS和其它程序需要的内存
- 其余的内存分配给MySQL缓存,例如InnoDB的buffer pool
MySQL可以使用多少内存?
对于32位的Linux内核,限制进程使用的寻址空间在2.5-2.7GB左右,超过寻址空间限制来使用内存可能导致崩溃。
不同OS对单进程的内存限制不一样,栈大小也需要考虑。
即使是64bit系统,某些限制仍然存在,例如,MyISAM的key buffer在MySQL5.0和以前的版本最多设置到4GB
每个连接需要的内存
MySQL只需要很少的内存来保持connection (thread)的开启状态,也需要一个基本数量的内存来执行任何SQL语句。需要确定执行查询时所需要的内存峰值并进行相应的设置,否则查询可能很慢或者失败。
一般不需要考虑最糟糕的峰值占用,例如对于100个连接,设置myisam_sort_buffer_size为256M,那么最糟糕的情况下需要25GB的内存,但是这种情况发生的可能性不大。合理的做法是在真实的Workload下观测服务器中MySQL进程的内存消耗。
为OS保留内存
OS内存不足的一个指征是频繁的使用Swapping(paging)虚拟内存到磁盘,通常应该至少保留2GB或者5%给OS。
为缓存分配内存
如果服务器供MySQL专用,那么OS保留内存、查询处理所需内存以外的所有内存,均可分配给缓存使用。MySQL缓存是需要内存最大的部分,它使用缓存来避免磁盘访问。对于大部分场景,下面是最重要的缓存类型:
- InnoDB缓冲池
- InnoDB日志文件、MyISAM数据的操作系统缓存
- MyISAM的key(索引)缓存
- 查询缓存
- 一些不能实际配置的缓存,例如二进制日志、表定义文件的缓存
其它类型的缓存使用内存的量很少,不必过分关注。
如果只使用MyISAM,可以完全禁用InnoDB;反之,只需要给MyISAM配置最少的资源(InnoDB内部会使用MyISAM表做一些操作)。
InnoDB缓冲池
如果主要使用InnoDB表,那么 InnoDB缓冲池将比其它任何组件需要更多的内存。InnoDB严重依赖该缓冲池——它负责缓存索引、保持行数据、自适应Hash索引、插入缓冲、锁、以及其它内部结构。InnoDB使用缓冲池实现延迟写入(delay writes),可以把多个写操作合并执行。
使用innotop之类的工具可以监视该缓冲池的使用,注意没有必要设置超过需要的大值。过大的缓冲池会导致过长的关闭(如果缓冲中有很多脏页,那么关闭时必须写入数据文件,即使强制关闭,在启动时也少不了恢复时间)、预热(warmup)时间。
减少关闭时间:在运行时设置innodb_max_dirty_pages_pct为一个较小值,等待flush线程刷空缓冲池,当脏页数较小(状态变量:Innodb_buffer_pool_pages_dirty)时关闭MySQL。
innodb_max_dirty_pages_pct并不保证在缓冲池中存储更少的脏页,而是控制MySQL停止延迟(lazy)行为的阈值——当脏页占比超过阈值时,MySQL的flush线程会尽快的刷出脏页,保证占比低于阈值。此外当事务日志的空间不足时,会出现“激进刷空”模式。
当大缓冲池搭配慢速磁盘时,服务器可能需要很长的时间来预热,Percona Server提供了一个在重启后重新载入数据页的功能来减少预热时间,MySQL 5.6+亦有类似功能。
MyISAM键缓存
MyISAM的key caches也称为key buffers,默认为一个,可以创建多个。与InnoDB不同,MyISAM只缓存索引,不缓存数据。如果只使用MyISAM,应当分配足够的内存给键缓存。
最重要的配置参数是key_buffer_size,在MySQL5.0-,单个键缓存具有4GB的最大值限制。没必要分配比索引总大小更大的内存:
|
1 2 |
-- 计算索引总大小 SELECT SUM(INDEX_LENGTH) FROM INFORMATION_SCHEMA.TABLES WHERE ENGINE='MYISAM'; |
默认情况下,只有一个键缓存,下面的语句示意如何创建新的键缓存并把表映射到其上(未明确映射的表,映射到默认缓存):
|
1 2 3 4 5 6 7 8 9 10 |
#配置文件添加两个新的键缓存 key_buffer_1.key_buffer_size = 1G key_buffer_2.key_buffer_size = 1G #现在有3个键缓存了 #把t1、t2表的索引缓存到key_buffer_1 mysql> CACHE INDEX t1, t2 IN key_buffer_1; #使用init_file选项和下面的命令预先加载索引 LOAD INDEX INTO CACHE t1, t2; |
使用SHOW STATUS 、SHOW VARIABLES可以监控键缓存的使用,计算公式为:
100 - ( (Key_blocks_unused * key_cache_block_size) * 100 / key_buffer_size )
如果运行一段时间后,服务器没有用满键缓存,可以考虑降低设置的值。
关于键缓存命中率(hit ratio):数字没有实际意义,不同工作场景下对命中率的要求不同。根据经验,每秒缓存miss更有价值:假设磁盘每秒支持100随机读,那么5次/秒的miss不会造成问题,80次/秒则可能造成问题。Key_reads / Uptime可以计算自服务启动以来的miss/s,下面的语句则可以计算最近的miss/s:
|
1 2 |
-- 每10秒统计 mysqladmin extended-status -r -i 10 | grep Key_reads |
需要注意的时,MyISAM使用OS缓存来处理数据文件,数据文件通常比索引大,因此,通常需要保留比key buffer更大的内存给OS。在完全不使用MyISAM表时,可以设置key_buffer_size=32M左右,因为有时候内部GROUP BY之类操作可能需要MyISAM临时表。
MyISAM key block size
键的块大小很重要,这与MyISAM与OS缓存、文件系统的交互方式有关,错误的设置可能导致read-around wirte——OS在写入数据前必须读出一定的数据,假设系统page size是4KB,而key block size设置为1KB,下面的场景演示了read-around write:
- MyISAM请求磁盘上的1KB key block
- OS从磁盘读取4KB数据并缓存之,然后把其中需要的1KB传递给MyISAM
- OS为了丢弃上面的数据,以便缓存其它数据
- MyISAM修改1KB数据,要求OS写回磁盘
- OS再次读取4KB,合并MyISAM写入的1KB,然后把整个4KB写回磁盘
设置myisam_block_size与系统page size一致,可以避免read-around write问题。
线程缓存
Thread cahce缓存没有和Connection关联的线程。Connection到达时,MySQL将其与某个缓存的Thread关联,或者创建新Thread,后者相对较慢。Connection关闭时,把Thread放回缓存,或者销毁。
参数thread_cache_size可以指定线程缓存的大小,观察Threads_created变量,保证其小于10/s即可。Threads_connected变量用于观察当前连接数。
此参数设置的过小并不会节省很多内存,因为缓存/休眠的线程通常仅占用256KB左右的内存。设置过大(例如几千)则可能导致另外的问题,因为有些OS不能很好的处理大量线程,即使大部分都处于休眠状态。
表缓存
与线程缓存类似,但是存放的是代表了表的对象。对象的具体属性与存储引擎相关。
在MySQL5.1+,表缓存分为两个部分:
- table_open_cache:打开的表的缓存。这个是每个线程单独的缓存
- table_definition_cache:已解析的表定义(.frm文件),足够存入所有表定义即可
InnoDB数据字典
InnoDB具有自己的per-table缓存,通常称作表定义缓存或者数据字典,目前不支持手工配置其大小。
如果使用innodb_file_per_table,那么同时打开的*.ibd(数据文件)文件的数量有限制,可以 通过innodb_open_files来控制。
一些选项控制MySQL如何把数据同步到磁盘、如何进行数据恢复。这些设置体现了数据安全性与性能之间的权衡,一般来说,保证数据立即、一致的写入磁盘是需要较大代价的。
InnoDB的I/O配置
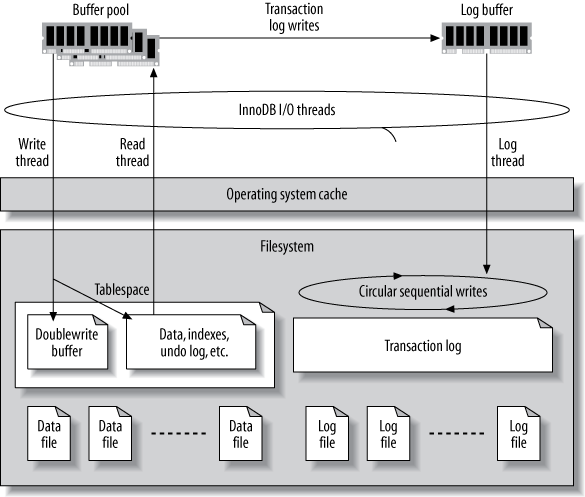
允许对InnoDB的数据恢复(recovers,InnoDB启动后总是会运行数据恢复处理)、打开和刷出(flush)数据的行为进行控制,从而很大程度上的影响恢复和整体性能。InnoDB具有一个复杂的buffer、file链来提高性能和保证ACID属性,链条中的每个环节都是可配置的,这个链条如下图所示:
InnoDB的事务日志
事务日志的意义在于降低提交的成本——把事务记录到文件(顺序I/O)而不是把buffer pool刷出到磁盘(事务对应索引、数据的修改往往映射到表空间的随机位置,从而导致random I/O)。需要注意的是,对于SSD,随机I/O的劣势不像机械磁盘那么严重。
一旦事务日志记录到文件,即实现了持久化,即使修改内容没有回写到数据文件中,如果突然宕机,MySQL会在启动时重做日志内容并恢复已提交的事务。
当然,InnoDB最终还是需要把修改内容回写到数据文件,因为事务日志具有固定的大小。InnoDB使用循环写入的方式使用日志文件,但是必须确保不能覆盖未回写到数据文件的日志。
InnoDB使用一个后台线程负责智能回写数据文件。其智能表现在:把写操作进行分组,以尽量实现顺序I/O。后台写入机制使I/O系统与查询负载解耦。
总体的InnoDB事务日志的大小由以下两个参数控制,对写性能具有很大的影响:
- innodb_log_file_size:默认5MB,单个日志文件的大小
- innodb_log_files_in_group:默认2个,日志文件的个数
默认值对于高性能工作负载来说太小了,应该设置为上百MB,甚至达到GB级别。通常不需要修改日志文件的个数,修改大小的步骤如下:
- 完全的(不能强行关闭,否则日志文件中会存在尚未刷出到数据文件的事务)关闭MySQL
- 移除旧的日志文件,例如ib_logfile0
- 重新配置日志文件大小,并重启MySQL
权衡日志文件的理想大小:
- 过小的问题:InnoDB需要更多的Checkpoints,导致更多的日志写操作,极端情况下,写查询需要等待日志刷出到磁盘,以腾出日志文件空间。
- 过大的问题:当进行恢复时,InnoDB需要做很多的工作,从而可能需要很多的时间。较新版本的MySQL在这一点上性能有所提高。注意恢复时间还与被修改的数据量、数据分布情况有关。
日志缓冲(log buffer):当InnoDB修改任何数据时,其会写入事务日志到内存的日志缓冲里,此缓冲默认大小为1MB,当以下三种情况之一发生时:缓冲满了、事务提交时,或者过了一秒,InnoDB把缓冲刷出到日志文件中。参数innodb_log_buffer_size控制此缓冲的大小。建议的大小范围是1-8MB,除非需要写入大量的BLOB,否则没必要设置的更大。通过SHOW INNODB STATUS查看状态变量Innodb_os_log_written,观察10-100秒,检查每秒写入数来判断日志缓冲是否足够大,例如:对于1MB的缓冲,每秒写入的峰值不超过100KB说明缓冲足够了。
Innodb_os_log_written也可以用来衡量日志文件是否足够大,例如峰值每秒写入100KB,那么256MB的日志文件基本够一小时使用了。
日志缓冲只有被刷出,事务才能持久化,设置innodb_flush_log_at_trx_commit可以控制日志缓冲刷出的频率:
| 值 | 说明 |
| 0 | 每秒把log buffer写入到log file(在大部分OS,这只是把数据从InnoDB内存移动到系统缓存,仍然在内存中),并刷出log file到持久化存储(Blocked I/O直到写入完成)。但是在事务提交时不做任何操作 |
| 1 |
每次事务提交时把log buffer写入到log file,并刷出log file到持久化存储。这是默认的、最安全的设置,不会丢失任何事务。设置为该值会导致trx/s大大减小,在高速机械磁盘上,只能达到几百次事务/秒 对于高性能事务性应用,应当设置为1,并且把日志文件放在具有电池支持的写缓存RAID磁盘上,这样快且安全。 |
| 2 | 每次事务提交时写入log buffer到log file,但是不flush(存放在OS的缓存中)。InnoDB每秒进行一次flush调度。与0相比,MySQL崩溃时2不会丢失数据,整个服务器宕机则可能丢失数据 |
InnoDB如何打开和刷出日志和数据文件
参数innodb_flush_method用于配置InnoDB与文件系统的交互方式(包括读和写,同时影响日志文件、数据文件):
| 值 | 说明 |
| fdatasync |
非Windows系统的默认值。InnoDB使用fsync()代替fdatasync()来刷出数据、日志文件。fsync与fdatasync的区别是后者仅写数据,前者同时写文件元数据 使用fsync的缺点是,OS至少会在自己的缓存内缓冲一部分数据,可能(依赖于OS与文件系统)导致不必要的双重缓冲 |
| O_DIRECT |
InnoDB使用O_DIRECT标记或者directio()来读写数据文件(对日志文件没影响),某些Unix类系统不支持(GNU/Linux、FreeBSD、Solaris均支持)。 该设置还是使用fsync(),但是指示OS不进行缓存或者预读取(read-ahead),从而避免双重缓冲的问题。该设置不能禁止RAID卡的预读取功能 |
| ALL_O_DIRECT | 与O_DIRECT类似,但是同时对日志文件起作用。在Percona Server、MariaDB上被支持。 |
| O_DSYNC | 对日志文件起作用,使写操作同步化——完成后才返回 |
| async_unbuffered | Windows下的默认值,使用Windows原生的异步(重叠)I/O仅需读写 |
| unbuffered | 仅WIndows,与async_unbuffered类似,但是不使用原生异步I/O |
| normal | 仅WIndows,导致InnoDB不使用异步I/O或者非缓冲I/O |
| nosync and littlesync | 仅开发时使用 |
InnoDB表空间
InnoDB把数据存放在表空间中,表空间是一种虚拟文件系统,可以跨越多个磁盘文件。除了数据和索引外,undo log、insert buffer、doublewrite buffer、一些其他的内部数据结构也存放于其中。使用下面的参数配置表空间:
|
1 2 3 4 |
#表空间的目录 innodb_data_home_dir = /var/lib/mysql/ #表空间文件名和大小,autoextend表示空间用完了自动增长(最好设置最大大小) innodb_data_file_path = ibdata1:1G;ibdata2:1G;ibdata3:1G:autoextend;ibdata4:1G:autoextend:max:2G |
这样的设置:innodb_data_file_path = /disk1/ibdata1:1G;/disk2/ibdata2:1G并不能分担负载到多个磁盘,因为InnoDB是逐个填满数据文件的,可以通过RAID来分担负载。
使用innodb_file_per_table可以为每个表创建一个名为tablename.ibd的数据文件,有利于把表分散到多个磁盘。这种方式下,对于小表可能存在额外的空间浪费,因为InnoDB页的大小是16KB,如果一个表的数据只有1KB,那么它至少需要占用16KB的空间。此外,innodb_file_per_table可能导致低下的DROP性能,原因如下:
- DROP表意味着删除文件。在某些文件系统(ext3)可能很慢。可以把ibd文件链接到零字节文件,然后手工删除之,而不是等待MySQL删除
- 每个表在InnoDB内具有自己的表空间。MySQL移除表空间时,需要锁定并扫描buffer pool来确定哪些页属于该表空间,如果buffer pool很大,该操作会相当耗时。Percona Server提供了innodb_lazy_drop_table参数来解决此问题
总之,建议使用innodb_lazy_drop_table配合具有容量上限的表空间,在出现问题时参考上面两条。
不建议使用裸分区(未格式化的)来存储表空间。因为性能提升不大。
其它I/O配置项
| 参数 | 说明 |
| sync_binlog |
控制MySQL刷出二进制日志到磁盘的方式。0表示由OS决定何时刷出;非0表示刷出前发生多少次二进制日志写操作(自动提交时每个语句对应一个写,否则每个事务对应一个写)。通常设置为0或1。 设置为0时,MySQL崩溃可能导致二进制日志与事务数据不同步,从而使数据复制、按时间点恢复无法完成。另一方面,设置为1在获取安全性的同时会导致较高的代价——同步二进制日志、事务日志使MySQL必须在两个单独的磁盘位置刷出数据,可能需要磁盘寻道。 在具有不断电写缓存的RAID卷上存放二进制日志能够极大的提高性能。 |
| expire_logs_days | 自动删除过期的二进制日志。 |
MyISAM的I/O配置
| 参数 | 说明 |
| delay_key_write |
控制延迟索引写入 OFF:MyISAM在每次写操作时都刷出key buffer中修改的块到磁盘。除非表被LOCK TABLES锁定
|
| myisam_recover_options |
控制MyISAM如何从错误中恢复 DEFAULT:指示MySQL修复所有标记为崩溃或者未完全关闭的表 可以使用上述多个选项,使用逗号分隔 |
| myisam_use_mmap |
允许通过系统page cache访问.MYD文件 |
InnoDB并发配置
InnoDB为高并发场景设计。最近数年InnoDB有很大进步单非完美,某些InnoDB性能指标在高并发时会下降,而有效的处理方法仅仅是降低并发或者升级MySQL版本。在MySQL5.1-高并发是灾难性场景——所有操作在全局互斥对象(例如buffer pool mutex)上列队,导致服务器常常处于挂起状态。
InnoDB具有其自己的线程调度器,来控制线程如何进入其“内核”进行数据访问、可以进行哪些操作。
innodb_thread_concurrency可以用于老版本MySQL的线程并发数控制,可以设置为磁盘数*CPU数*2。如果线程数满了,后续到达的线程首先休眠innodb_thread_sleep_delay(默认10ms,这个值对于大量小查询场景可能过大了)再次尝试,仍然失败则进入等待队列。
一旦线程进入内核,其持有若干票据(tickets)允许其免费再次返回内核(不经过并发检查)。innodb_concurrency_tickets控制票据数,这个参数是per-query而非per-transaction的,查询结束后剩余的票据即丢弃,一般不需要修改此参数,除非有很多长时运行(long-running)的查询。
innodb_commit_concurrency控制同时有多少线程能够进行提交操作。如果innodb_thread_concurrency已经设置的很低,很多线程仍然在等待,可以尝试设置该参数。
另外一个有价值的解决方案是使用线程池来限制并发,MariaDB中已经实现,Oracle也为MySQL5.5提供了商业插件。
MyISAM并发配置
在讨论MyISAM并发设置之前,有必要理解其如何插入和删除数据:
- 删除:不需要重新排序整个表,只是把被删除的行打个标记,在表上形成一个“洞”
- 插入:MyISAM会倾向于尝试填充删除的洞,以重用空间,如果无法填充或者没有洞,则附加到表的结尾
concurrent_insert参数控制MyISAM的并发插入行为:0表示不允许并发插入,每个INSERT锁定整张表;1表示允许并发插入,只要表中没有洞;2为MySQL5.0+引入的值,强制并发插入附加到表的尾部,即使存在洞(如果没有读线程存在,则会尝试填充洞)
优化BLOB和TEXT负载
MySQL对BLOB字段的处理和其他类型不同(本节把BLOB和TEXT统称为BLOB,因为其本质上是一样的数据类型),特别是:MySQL不能为BLOB值使用内存临时表,因此一个使用临时表的、包含BLOB的查询,不管表有多小,都会导致基于文件的临时表。解决此问题有两个方法:
- 使用SUBSTRING()函数将BLOB转换为VARCHAR
- 提高临时表的性能,例如将其存放在内存文件系统中(例如tmpfs)。参数tmpdir控制临时表的存放位置。
对于基于BLOB、TEXT等长列,如果内容大于768字节,InnoDB可能在行外部开辟存储空间(external storage space)存放其剩余的部分,将以16KB的页为单位,并且每个长列使用独立外部存储空间。此行为可能导致很大的空间浪费。
优化文件排序
MySQL5.6针对具有LIMIT子句的查询进行了优化,改变了其使用sort buffer的方式。
新版本的InnoDB引擎具有更多的特性和更好的性能,如果使用MySQL5.1+,可以设置ignore_builtin_innodb来忽视内置的InnoDB,然后配置plugin_load来把InnoDB作为插件配置。新版本的InnoDB包含若干可以提高性能、安全性的参数:
| 参数 | 说明 |
| innodb | 设置为FORCE,则InnoDB无法启动的情况下,MySQL启动会失败 |
| innodb_autoinc_lock_mode | 控制InnoDB生成自增长PK的方式,如果很多事务在等待autoincrement lock,则需要考虑此设置 |
| innodb_buffer_pool_instances |
在MySQL5.5+,可以把buffer pool分成多个segments,这是高并发、多核心CPU的情况下提供MySQL可扩展性(scalability)的最重要的方法。多缓冲池把把工作负载分区,全局性的互斥量不会有太多的争用。可以设置为8个。 Percona Server使用另外一种方式降低争用——细化锁定的粒度。特别是Percona Server5.5,同时支持多个buffer pool和细粒度互斥锁 |
| innodb_io_capacity |
InnoDB曾经硬编码的假设:其运行在支持100 I/O的单磁盘上。但是对于高速磁盘,例如SSD,这个假设太低了。 该值设置的越大,每次刷出脏页的数量也就越多。SSD可以配置到2000以上。 |
| innodb_read_io_threads innodb_write_io_threads |
这两个参数控制InnoDB后台读写I/O线程数,MySQL5.5默认设置为4读4写,对大多数服务器足够了。但是对于具有很多磁盘的高并发场景,可以增加这两个值,或者简单的设置为与物理磁盘的盘面转轴数相等 |
| innodb_strict_mode | 在某些情况下,使InnoDB抛出错误而不是发出警告 |
| innodb_old_blocks_time | 控制一个页从LRU年轻区转移到年老区需要经过的最少毫秒数,默认0,可以设置为1000。 |
多个CPU还是更快的CPU?
更快的CPU减低响应时间,更多的CPU则增加吞吐量。
现代服务器通常有多个CPU插槽,每个CPU会有多个核心(独立执行单元),每个核心可能有多个“硬件线程”(现代OS对超线程的支持很好)。本章所说的CPU速度指单个执行单元的速度,CPU数则指OS看到的CPU数(即:CPU数*核心数*线程数)。
对于计算密集型(CPU-bound)工作负载,更快的CPU常常比更多的CPU有优势。由于MySQL不能把单个查询fork到多个CPU上执行,所以对于计算密集型查询,只有提升其速度才能缩短响应时间。数据复制(replication)也得益于更快的CPU。
如果需要同时运行很多查询,则多个CPU更有优势,目前版本的MySQL可以很好的利用16或者24个CPU。
即使不存在很多查询同时执行,MySQL依然可以使用空闲CPU来进行后台工作,包括:InnoDB buffer purging、网络操作等。
另外一个判断更快还是更多的方式是检查查询实际做了什么。从硬件级别来看,一个查询要么在执行,要么在等待(例如在run queue等待,即所有process是runnable而所有CPU均忙;等待latch或者lock;等待磁盘或者网络)。如果查询在等待latch或者lock,那么最好是有更快的CPU;如果查询在run queue中,则更多更快CPU均可;如果在等待InnoDB log buffer mutex,则说明需要增强I/O能力。
需要大量内存的最重要原因不是需要在内存存放如此多的数据,而是为了避免磁盘I/O。
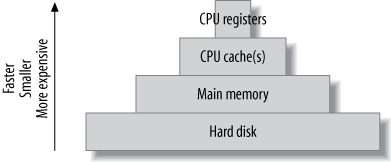
计算机具有金字塔状的缓存层次,越是上层的,越小越贵:
每个层次的缓存均应当缓存热点数据以便快速访问。应用程序特定的缓存(例如InnoDB的buffer pool)通常比OS的缓存更加高效,因为它知道自己需要缓存哪些数据。
随机I/O对比顺序I/O
随机I/O更多的从缓存中获益——缓存减少了昂贵的磁盘寻道时间,顺序I/O通常没必要缓存,除非目标数据完整的fit in 内存。具体分析如下:
- 顺序I/O本省就比随机I/O快,不管磁盘还是内存。例如,典型的机械磁盘可能支持每秒100次随机I/O、50MB的顺序I/O,那么对于100字节的row来说,随机读取每秒100行,顺序读取则达到500000行,差距达到5000倍!对于内存,每秒随机I/O可以达到25万次,顺序I/O则可以达到5百万行。可以看到,对于随机I/O,内存比磁盘快2500倍,顺序I/O则仅有10倍。
- 存储引擎能更快的处理顺序I/O。随机读取通常意味着存储引擎需要进行索引操作——对应了BTree结构导航和值比较,而顺序读通常只需要遍历一个较简单的数据结构。此外,随机读通常用于获取单独的行,但是读取的是整个16KB页——可能包括若干行的数据,这里面就存在浪费,因为大部分都是不需要的数据,顺序读则通常需要整个页上的所有数据。
添加内存是解决随机读问题的最好办法。
缓存,读取和写入
如果有足够的内存,那么可以让读取变成纯粹的内存操作——在服务器预热完成后。而写入则不然,或迟或早,写入必须被持久化到磁盘中。延迟的写入可以增加性能,除此之外,写入数据的分组有利于提高性能:
- Many writes,one flush:单行数据在刷出磁盘之前,可能在内存中被修改多次
- I/O merging:内存中发生的多个不同的数据修改可以合并为一个写操作
以上两点也是为何很多数据库系统使用写前日志(write-ahead logging)的原因,所谓写前日志就是指零散的数据更改不直接写回到数据文件,而是先写入到一个顺序的日志文件中,后台线程负责把日志中的更改写到数据文件,它可以进行必要的优化。
你的工作集(Working Set)是什么?
所谓工作集,是指工作真正需要的那一部分数据。在MySQL中,可以认为工作集是最频繁使用的页的集合,包括数据和索引。工作集应该以缓存单元(cache unit)度量,对于InnoDB,一个缓存单元为16KB(默认,页的大小),因此,即使只读取1条数据,也会导致整个页被载入buffer pool,这可能导致很大的浪费。聚簇索引把相关的数据放在一起,尽量的减少这种浪费。
寻找一个合适的内存/硬盘比率
通过性能基准测试,来确认一个可接受的缓存丢失率(cache miss rate)。缓存丢失率和CPU占用紧密相关,例如。如果一段时间内CPU处于used达到99%,而处于I/O等待为1%,那么缓存丢失率是可接受的。
加大内存和缓存丢失率并不是线性的关系,这和工作负载有关,例如,10GB内存对应了10%缓存丢失率,那么要减小到1%丢失率可能需要500G而不是50G内存。
选择硬盘
传统机械硬盘读取数据需要三个步骤:
- 把读取磁头移动到磁盘表面的适当位置
- 等待磁盘转动,直到需要的数据到达磁头下面
- 等待磁盘转过所有需要的数据
其中1、2步消耗的时间叫access time,小的随机访问主要的消耗时间是access time。3步消耗的时间主要取决于传输速度,大的顺序读取的主要消耗时间主要在第3步。
多种因素影响磁盘的选择,考虑一个流行新闻网站——需要很多小的随机读,需要考虑以下因子:
| 因素 | 说明 |
| 存储容量(Storage capacity) | 现代磁盘大部分足够大,如果不够,把小磁盘组成RAID |
| 传输速度(Transfer speed) | 现代磁盘的传输速度都非常快,速度取决于转轴速度和磁盘数据密度、以及与主机的接口(很多现代磁盘读取数据的速度大于接口传输速度)。对于在线网站来说,速度通常不是问题,因为主要是小的随机读 |
| 访问时间(Access time) | 这是影响随机读取速度最大的因素 |
| 转轴速度(Spindle rotation speed) | 包括7200、10000、15000转,对顺序读取、随机读取均有较大的影响 |
| 物理尺寸 | 其它参数相同的情况下,尺寸越小,磁头移动耗时也越小 |
InnoDB很容易扩展到多个磁盘。MyISAM则不是。
亦称非易失随机存取存储器(NVRAM),与传统硬盘的结构非常不同。主要可以分为两类:SSD、PCIe cards,前者通过实现SATA来模拟标准硬盘,后者则使用特殊驱动,作为块设备。固态存储具有以下特点:
- 相对于机械硬盘,具有很好的随机读、写性能。通常读性能相对于写更好一些
- 更好的顺序读、写性能。某些入门的固态存储,顺序读写速度可能不如高速传统硬盘
- 更好的并发支持
其中1和3对于数据库来说是最重要的提升。很多反规范化设计的Schema就是为了避免随机I/O。
在未来,RDBMS将因为固态存储技术发生深刻的改变,过去几十年RDBMS已经针对机械磁盘做了大量优化,对于固态存储则没有。
固态存储概览
固态存储最重要的一个特征是,可以多次快速的读取小的单元,而写的时候则有复杂的问题需要处理——除非擦除整个块(例如512KB),不能重新写入一个cell。经过多次擦除,最终数据块将坏掉,为了避免这种损坏,固态硬盘必须能够重新定位数据页并进行垃圾回收——所谓磨损均衡(wear leveling)。
由于固态硬盘重新定位、垃圾回收的特性,磁盘使用占比越大, 其效率会越低,对于100GB的文件,其位于160GB、320GB固态硬盘上,写效率是不一样的。
闪存技术
分为两种类型:
- single-level cell (SLC):每个cell存放一个bit,速度快,耐用,但是数据密度低。能够支持10万次循环写入。实际应用中能达到20年寿命
- multi-level cell (MLC):每个cell存放2个甚至3个bit,单位成本低,速度相对慢,不耐用。好的设备能够支持1万次循环写入。有些厂商对技术进行改进,称为企业级MLC(eMLC)
SSD组建RAID
建议使用SATA的SSD组成的RAID以避免单块磁盘的故障导致数据丢失。一些就的RAID控制器不能很好的支持SSD,仍然做诸如buffering、写入重排序之类浪费时间的操作。
MySQL针对固态存储的优化
| 优化内容 | 说明 |
| InnoDB的I/O能力配置 |
增大innodb_io_capacity,可以设置到2000-20000,根据SSD的IOPS(每秒输入输出数)确定 SSD比机械硬盘支持更高的并发访问,所以可以修改读写I/O线程数到10-15 |
| 增大InnoDB的日志文件大小 | 可以设置为4GB或者更大。Percona Server、MySQL 5.6支持4GB以上的日志文件,大日志文件可以提高和稳定性能,且对于SSD不会在宕机重启后因大量随机I/O导致的漫长恢复(crash recovery)等待 |
| 把某些文件从Flash移动到RAID |
除了把InnoDB日志改大以外,而可以将其存储位置移动出SSD,存放到具有电池支持的写缓存的RAID中,因为InnoDB日志主要是顺序写入,不会从SSD获益太多 处于类似的原因,可以把二进制日志、ibdata1文件(包含双重写入缓冲、插入缓冲)移动到RAID。 |
| 禁止预读取(read-ahead) |
有些时候预读取的成本比收益更大,特别是对于SSD。MySQL5.5提供一个参数来设置 |
| 配置InnoDB的flushing算法 |
标准InnoDB没有提供针对SSD的有价值的选项,但是Percona XtraDB(包括PerconaServer、MariaDB)可以: 设置innodb_adaptive_checkpoint=keep_average(默认值estimate),设置innodb_flush_neighbor_pages=0。 |
| 潜在的禁用doublewrite buffer | 除了考虑把双重缓冲移出SSD,可以考虑禁用它——某些设备声明支持16KB原子写入(一般要求O_DIRECT和XFS文件系统),这导致双重写入缓冲多余。这可能让MySQL的性能提高50%,但是可能不是100%安全。 |
| 限制插入缓冲的大小 |
insert buffer(新版本InnoDB称为change buffer)用于减少针对不在内存中的非唯一索引页的随机I/O(当对应行被update时)。 在使用普通硬盘的某些情况下,工作集比内存大很多时,增大插入缓冲可能减少两个数量级的随机I/O。 但是对于SSD,这没有必要了,因为其随机I/O快了很多,可以将其限制其最大尺寸为较小的值。MySQL 5.6支持此设置。 |
| 调整InnoDB页大小和checksum |
MySQL5.6允许调整默认的16KB页大小、checksum算法 |
如果出于failover的目的,Replica应当与Master一样高的配置;如果仅仅为了提高整体读取能力,则可以使用廉价的方案。
RAID可以提供冗余、存储容量、缓存和速度的优势。不同的RAID对数据库需求的满足情况如下:
| RAID | 特性 | 说明 |
| RAID0 |
廉价、高速、危险,不具备冗余 磁盘数:N |
最廉价、最高性能的RAID方案。不具有冗余特性,适用于不太关心(其数据可以从其它地方很容易的重新获取)的Replica。很简单,易于软件实现。 |
| RAID1 |
高速读、简单、安全 磁盘数:2(通常) |
在很多场景下提供更好的读性能,它把数据复制到多块硬盘上,具有很好的冗余性,其读性能比RAID0稍好。适合于日志或者类似的场景,因为顺序I/O不需要底层磁盘性能很高。很简单,易于软件实现。 |
| RAID5 |
安全、速度、成本的折衷 磁盘数:N+1 |
使用分布式奇偶校验块(distributed parity blocks)来把数据分散在多块磁盘上,其中一块磁盘损坏,可以通过奇偶校验重建数据。这是比较经济的RAID,因为只需要浪费阵列中单块磁盘的存储空间。 RAID5的随机写成本较高,因为每个写操作需要2次读+2次写(包括计算和存储校验位)。如果是顺序写,或者阵列中包含很多磁盘,则写性能会有一些提高。RAID5的随机读、顺序读性能均较好。 RAID5适合以读为主的工作负载,可以用来存放数据、日志。 RAID5在磁盘出现损坏时,替换新盘会导致严重的性能下降,因为它需要读取所有磁盘来完成数据重建。 |
| RAID10 |
昂贵、快速、安全 磁盘数:2N |
由若干镜像磁盘对组成。对于读、写性能都有很大的提升。如果一块磁盘坏掉,性能可能下降高达50%。成本高。 |
| RAID50 |
适合存放大量数据 磁盘数:2(N+1) |
相当于RAID5和RAID0的结合。每个RAID5磁盘组需要3+块硬盘。读写均较快。适用于海量数据存储(数据仓库、特大OLTP)。 |
RAID故障、恢复和监控
多块磁盘同时坏掉的可能性往往被低估。实时上,RAID并不能减少对备份的需求。
RAID缓存
RAID缓存置于RAID控制器之中,作为磁盘和主机之间的数据交换缓冲。RAID控制器可能因为以下原因使用缓存:
- Caching Reads:控制器从磁盘上读取数据返回给OS后,可以将其缓存起来,这种用法没有太大意义。因为控制器不知道哪些是热点数据,而且缓存容量很小
- Caching read-ahead data:如果控制器检测到顺序读,其可能预读取可能马上需要使用的数据。对于InnoDB没有价值,因为InnoDB自己管理预读取
- Caching writes:控制器可以把写请求缓存起来,安排在后续步骤中进行写入。这有两个好处:立即像OS返回Success信息;可以重排写入以达到高效目的
- Internal operations:某些RAID操作,特别是RAID5写操作非常复杂,控制器需要内部存储来进行计算
RAID缓存是稀缺资源,应当合理分配。某些控制器允许你分配缓存使用,通常将更多的缓存分配给写操作能够很好的提高性能。对于RAID1、0、10,可以分配100%给写缓存,对于RAID5,则需要保留一些供内部使用。
某些RAID控制器允许设置写入延迟时间,根据实际工作负载设置。
缺少battery backup unit (BBU)的写缓存可能造成数据损坏。此外,某些磁盘本身具有写缓存功能,这是没有电池保护的,这样的磁盘可能执行虚假的fsync()操作,可能需要禁止这种磁盘缓存。
MySQL创建多种类型的文件:
- 数据和索引文件
- 事务日志文件
- 二进制日志文件
- 其它日志文件:错误日志、查询日志、缓慢查询日志等
- 临时文件和表
MySQL没有复杂的表空间管理功能,默认情况下,它只是把单个Schema的文件统一存放在一个目录下。
出于性能的考虑来把日志和数据分到不同的分卷上是没有必要的,除非你有很多磁盘(20+)或者使用SSD。把数据和二进制日志分到不同卷上的真正价值在于避免因为崩溃(对于没有电池保护的写缓存)导致两种数据均丢失。
通过skip_name_resolve禁止DNS查找,使用IP地址,防止因为DNS缓慢导致的高延迟。
back_log控制入站TCP连接队列的容量,对于频繁打开、关闭连接的Web应用,默认值50可能太小。将其设置到上千并不会有什么坏处,但是要注意OS的配置,例如somaxconn默认为128、tcp_max_syn_backlog需要增大。
对网络结构、跃点数也需要加以关注,跃点数会增加延迟,网络结构不好可能限制了带宽。对于本地网络,至少应当保证1G带宽,在交换机主干网,应当保证10G带宽。
物理内存不够时会发生Swapping,这对MySQL性能有严重的影响。
MySQL内置的数据复制机制是构建大型高性能MySQL应用的基础。Replication允许将一台或者多台服务器配置为某个服务器的Replicas,以保持数据同步。这种机制是高性能、高可用性、可扩展性(scalability)、灾难恢复、备份、分析、数据仓库等任务的中心。
Replication要解决的基本问题是把数据在多台数据库之间保持同步。多台replica连接到同一台master,replica和master的角色可以相互转换。
MySQL支持两种类型的Replication:
- 基于语句(statement-based)的复制,亦称逻辑复制,从MySQL3.23即开始存在
- 基于行的复制,MySQL5.1引入
这两种复制均是通过录制master二进制日志的改变,并在replica中进行replay实现同步,并且都是异步的(同步时间没有保证)。
新版本的MySQL可以作为老版本的Replica,反之则可能存在问题。
Replication对master不会添加额外的压力,只要master开启二进制日志功能即可(开启这个功能对master性能有影响,但是这是数据备份、基于时间点恢复数据的基础)。Replica读取master日志会产生少许的网络I/O压力,特别是读取很老的日志时。
Replication解决的问题
以下是常见的Replication用法:
- 数据分布(Data distribution):可以进行异地数据备份,甚至是时断时开的网路状况下
- 负载均衡(Load balancing):可以把读请求分布到多台服务器上
- 备份(Backups):可以协助数据备份,但是数据复制并不是备份的代替技术
- 高可用性和故障转移:避免单点故障
Replication的工作方式
大体上说,数据复制包含三个步骤:
- master录制数据的变化(事件)到二进制日志
- replica复制事件到其自己的转播日志(relay log)
- replica回放转播日志中的事件,将数据变更应用到自己的数据文件
更细致的描述如下图:
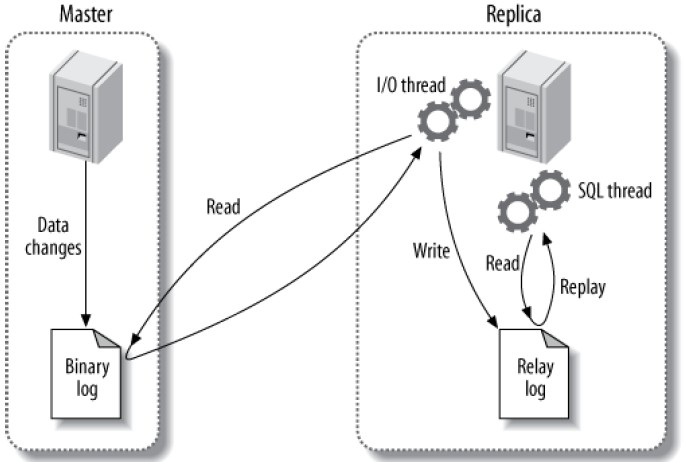
需要注意回放是在replica的单个线程上进行的,而变更则可能是在master上并发出现的,这可能导致性能瓶颈。
建立步骤根据场景不同有很多变种,对于新安装的主从MySQL服务器,步骤大概如下:
- 在各服务器上创建数据复制账户
- 配置master、replica
- 指示replica连接到master并进行数据复制
创建数据复制账户
MySQL具有一些和数据复制相关的特殊权限(privileges),下面是授权示意脚本:
|
1 2 3 |
-- 在master、replica上创建一个名为repl的账户,并授权 GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO repl@'192.168.0.%' IDENTIFIED BY 'p4ssword',; -- 显示用户在192.168.0本地网段 |
Master和Replica的配置
需要开启master的二进制日志,并赋予server_id:
|
1 2 3 4 5 6 7 8 9 10 |
log_bin = mysql-bin ;日志文件的名称,在MySQL命令行运行SET SQL_LOG_BIN=0可以临时禁止二进制日志 ;不能使用默认值1,在某些MySQL版本会导致冲突 server_id = 10 ;完成配置后重启,运行命令SHOW MASTER STATUS;检查是否正常: ;File名称可能不同 +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 98 | | | +------------------+----------+--------------+------------------+ |
在replica上需要类似的配置:
|
1 2 3 4 5 |
log_bin = mysql-bin server_id = 2 relay_log = /var/lib/mysql/mysql-relay-bin ;转播日志的名称 log_slave_updates = 1 ;把复制得到的事件存放到replica自己的二进制日志中 read_only = 1 ;使replica处于只读模式,不允许普通用户创建表、修改数据 |
启动复制
|
1 2 3 4 5 |
CHANGE MASTER TO MASTER_HOST='host name or ip', MASTER_USER='repl', MASTER_PASSWORD='p4ssword', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=0; |
检查确认replica的配置正常:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
mysql> SHOW SLAVE STATUS *************************** 1. row *************************** Slave_IO_State: //表示复制操作没有在进行 Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 4 //replica知道第一个有意义的事件的位置是4 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: No //表示复制操作没有在进行 Slave_SQL_Running: No //表示复制操作没有在进行 ...omitted... Seconds_Behind_Master: NULL mysql> START SLAVE; mysql> SHOW SLAVE STATUS *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event //IO线程正在等待master的新事件,这意味着所有事件已经被获取 Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 164 //日志位置改变,意味着某些日志已经被获取并回放 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 164 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes //注意IO、SQL线程都处于运行状态 Slave_SQL_Running: Yes ...omitted... Seconds_Behind_Master: 0 //在master上可以看到有replica创建的线程(连接) mysql> SHOW PROCESSLIST *************************** 1. row *************************** Id: 55 User: repl Host: replica1.webcluster_1:54813 db: NULL Command: Binlog Dump Time: 610237 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL //在replica上可以看到一个IO线程、一个SQL线程 mysql> SHOW PROCESSLIST\G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 611116 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 33 //SQL线程已经空闲33秒,意味着33秒内没有事件回放 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL //会显示其正在执行的语句 |
从其它服务器上初始化replica
更常见的常见是,master已经运行了一段时间后,创建replica进行数据复制,这种情况下replica和master处于不同步状态,需要三个条件才能完成replica的初始化:
- master某个时间点的快照
- master的当前日志文件,以及上述快照时间点在日志文件里的偏移量
- master从上述快照时间点到当前的二进制日志文件
从其它服务器上克隆一个replica有以下方法:
- 冷拷贝:关闭master,拷贝其文件到replica;启动master,其将会启动一个新二进制日志,使用CHANGE MASTER TO命令从新二进制日志启动replica
- 热拷贝:如果仅使用MyISAM,可以使用mysqlhotcopy或者rsync在服务启动的情况下拷贝文件
- 使用mysqldump:如果仅使用InnoDB,可以使用下面的命令把master的所有东西dump出来,全部加在到replica,并把replica的日志坐标移动到master二进制日志对应处:
12#-single-transaction导致读取事务开始点的所有数据mysqldump --single-transaction --all-databases --master-data=1 --host=server1 |mysql --host=server2 - 使用快照或者备份:如果知道对应的二进制日志坐标,可以通过把备份、快照还原到replica,然后使用该坐标运行CHANGE MASTER TO命令。支持的快照例如:LVM snapshots, SAN snapshots, EBS snapshots等。如果使用备份,那么备份时间点之后的二进制日志均需要存在
- 使用Percona XtraBackup
- 从其它replica复制数据
推荐的Replication配置
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
;对于master最重要的配置,每次事务提交时同步二进制日志,防止崩溃导致的数据丢失 sync_binlog=1 ;如果使用InnoDB的master,应该 innodb_flush_logs_at_trx_commit=1 ;日志提交刷出日志 innodb_support_xa=1 ;MySQL5.0+ innodb_safe_binlog ;仅MySQL4.1效果与上一条类似 log_bin=/var/lib/mysql/mysql-bin ;最好明确指定路径和基名(base name) ;对于replica relay_log=/path/to/logs/relay-bin skip_slave_start ;阻止replica在崩溃后自动启动 read_only ;除了具有SUPER权限的线程、replication SQL thread,不能修改库上的非临时表 sync_master_info = 1 sync_relay_log = 1 sync_relay_log_info = 1 |
MySQL5.0以上支持两种复制模式,默认使用基于语句的模式,如果出现无法录制的语句,则临时切换到基于行的模式。
基于语句的复制
MySQL 5.0-仅支持基于语句的复制,则在RDBMS的世界里很少见。这种方式是通过录制并回放master中修改了数据的SQL语句实现的。
优点:占用带宽小,易于理解和配合mysqlbinlog使用
缺点:语句中可能存在上下文相关的函数,例如CURRENT_USER(),这可能导致问题
基于行的复制
与其它RDBMS的实现类似,录制实实在在的行数据改变。主要的优势是它能正确的执行所有语句。缺点则是SQL语句不在日志中,很难弄清到底干了什么。
Replication相关的文件
除了上述的二进制日志文件,传播日志文件,还有以下文件和数据复制相关
| 文件名 | 说明 |
| mysql-bin.index | 具有和二进制日志一样的前缀,附加.index后缀。跟踪磁盘上的二进制日志文件。 |
| mysql-relay-bin.index | 与上一个类似,跟踪磁盘上的转播日志文件 |
| master.info | 包含replica连接master需要的信息。包含明码的密码 |
| relay-log.info | 包含replica当前二进制日志、转播日志的坐标 |
向其它replica转发Replication Events
log_slave_updates选项允许把当前replica作为其它replica的master使用。其工作原理示意图如下:

当log_slave_updates启用时,第一个replica接收到master的日志并回放后,会将其记录到自己的二进制日志里,这样,第二个replica就可以收到这个事件,进行类似的回放操作了。需要注意的时,master、第一个replica的日志position并不相同,不要做这种假设。
Replication Filters
复制过滤器允许仅复制master的部分数据,包含两种类别:
- 在master上过滤二进制日志事件的过滤器:包括binlog_do_db 、binlog_ignore_db,不应当使用
- 在replica上过滤转播日志事件的过滤器: 若干replicate_*选项过滤SQL线程从转播日志读取的事件。可以忽视/复制一个/多个数据库、重写一个数据库到另外一个、根据LIKE匹配语法忽视/复制表
MySQL支持多种复制拓扑结构,基本的规则是:
- 每个replica只能有一个master
- 每个replica必须具有惟一的server ID
- 每个master可以具有多个replica
- 通过设置log_slave_updates,replica可以传播来自master的事件,从而作为其它replica的master
Master and Multiple Replicas
这种拓扑和一主一从的结构没有本质区别,因为replica之间不进行任何通信:
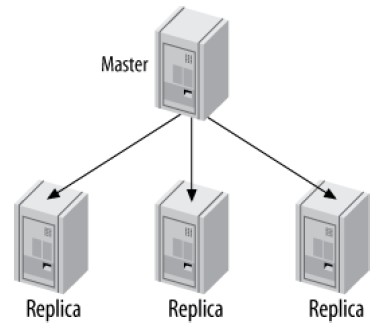
在有很多读请求、较少写请求时,这种拓扑非常有效。下面列出其常见应用场景:
- 不同replica作为不同的角色使用,例如使用不同的索引、不同的存储引擎
- 把一个replica作为备用master
- 把一个replica放到远程数据中心作为灾备
- 延时(Time-delay)某个replica作为灾备
- 将某个replica作为备份用,或者培训、开发用
该拓扑被广泛使用的一个原因是避免了复杂性。
Master-Master in Active-Active Mode
又称为dual-master、bidirectional replication。两个服务器各自配置为对方的master和replica:
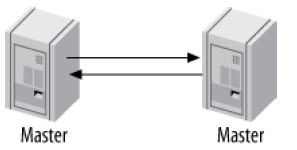
Active-Active模式有其用途,但是仅仅是在特殊的场景下,例如对于地理分布的办公室,每个办公室都需要本地可修改的数据副本的场景。
该模式最大的问题是冲突修改的处理,例如两个数据库同时修改了一行数据,或者在具有AUTO_INCREMENT的表上同时插入数据。MySQL5.0+提供auto_increment_increment、auto_increment_offset解决自增长主键冲突问题。
Master-Master in Active-Passive Mode
该模式是非常强大的设计容错(fault-tolerant)和高可用性系统的拓扑。与Active-Active的区别在于,其中一个服务器是被动的(passive)、只读的:
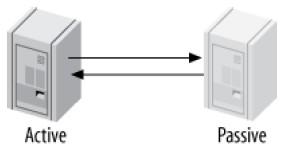
该配置允许轻松的进行Active、Passive角色的转换,因为两台服务器的配置是相同的,这让故障转移很方便。该模式亦支持不停机(downtime)维护、表优化、升级OS、硬件,考虑下面的场景:
- ALTER TABLE锁定整个表,阻塞读写操作,该操作可能需要很长时间完成,从而打断服务的运行
- 可以停止Active上的replication threads,这样Active不会从Passive上录制和回放任何事件
- 然后,在Passive上可以进行ALTER TABLE操作
- 完成后,把Passive切换为Active,应用程序连接到新的Active
- 新的Passive读取日志,并回放ALTER TABLE操作
使用active-passive master-master拓扑可以解决很多其他问题,已经回避MySQL的限制。
在两台服务器上同时进行以下配置,即可实现该模式:
- 确保两台服务器具有相同的数据
- 启用二进制日志,设置唯一的Server ID,创建replication账号
- 启用replica 更新日志(log_slave_updates),这对于故障转移、自动恢复(failback)非常重要
- 可选的,配置Passive为ead-only,防止冲突的修改
- 分别启动两台服务器的MySQL实例
- 分别配置为对方的replica,从新创建的二进制日志开始
当Active上发生一个数据变化时,会发生以下事件序列:
- 变化作为事件写入Active的二进制日志
- Passive读取到该事件,并存入自己的转播日志
- Passive执行转播日志,并记录到自己的二进制日志(由于设置了log_slave_updates)
- Active读取到该事件,由于发现事件的Server ID与自己相同,它忽略这个事件
后续章节包含主从角色切换的详细配置。
Master-Master with Replicas
可以为每一个master添加1个或者多个replicas:
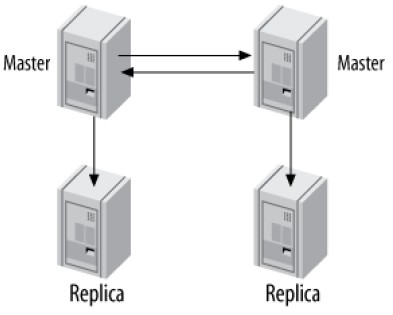
该拓扑的优点是提供额外的冗余,提供更好的读性能。在地理分布的数据复制场景,该拓扑排除了单点故障。
Ring Replication
其实上面几种具有连个master的拓扑,只是环形复制的特例。环形复制依赖于环上的每一个点,因此大大增加了整个系统失败的可能性:
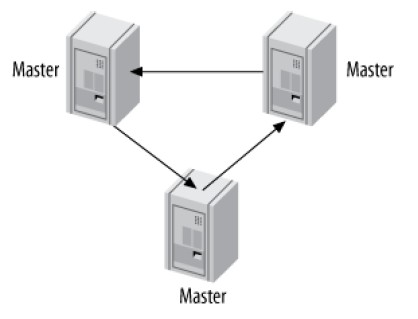
通常没有必要使用该拓扑
Master, Distribution Master, and Replicas
每个Replica都要在master上创建一个线程来使用binlog dump命令读取二进制日志并发送给replica,Replica很多时可能给master带来不可忽视的负载:
- 每个Replica的线程独立运行互不影响,这会导致很多重复的工作
- 如果Replica很多,且存在一个很大的二进制日志事件(例如LOAD DATA INFILE),master可能内存溢出并崩溃
- 如果每个Replica在读取二进制日志的不同部分,可能导致很多的磁盘操作,影响master的性能
为了把负载从master上移除,可以使用分布式master(distribution master)——它的唯一作用是读取master的日志并服务于replica:
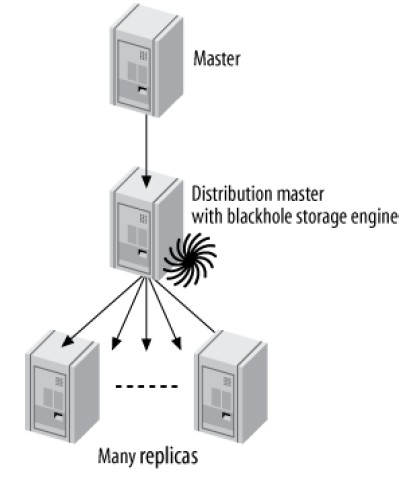
为了溢出实际执行查询的资源消耗,可以把分布式master的存储引擎改为Blackhole。
如何确定需要一个分布式master来减轻master的负载?一个大概的规则是,如果master已经全速运行了,可能不能再为它添加replica;另外如果master只有很少的写操作,则通常不需要分布式master。对于网络带宽敏感的场景,使用slave_compressed_protocol可以减轻master的网络压力。
分布式replica可以作为复制过滤器的集中执行点。
Blackhole引擎的表根本没有数据,因此其速度很快,但是Blackhole引擎具有一些BUG。
定制化的数据复制解决方案
选择性复制
复制master的一部分到某个replica上,某些情况下这与水平分区(horizontal data partitioning)概念上有相似,不同的是,在这里,master上具有全部的数据,写查询永远在master进行即可,读查询则根据需要可以在replica或者master上进行。
考虑需要把公司不同部门的数据分发在不同的replica上,可以在master上为每个部门创建一个数据库:sales, marketing, procurement…,每个replica则配置replicate_wild_do_table选项,仅录制和回放其感兴趣的库的数据,例如对于销售部门:
|
1 |
replicate_wild_do_table = sales.% |
分离功能
很多应用具有混合OLTP/OLAP的特征,这两类业务是截然不同的,前者多是小的事务性操作,后者则是大的缓慢的读查询且没有数据实时性的要求,他们需要不同的MySQL配置、索引、存储引擎甚至硬件。
一个通用的做法是把OLTP数据库的数据复制到一个OLAP的数据库
数据归档
可以在replica上备份数据,而从master上永久移除之。
创建一个日志服务器(log server)
日志服务器没有数据,它的唯一目的就是让回放、过滤二进制事件变得容易,它有利于在崩溃后重启应用、指定时间点(point-in-time)的数据恢复。
假设你有若干日志文件(somelog-bin.000001, somelog-bin.000002……)需要分析,只需要建立一个没有数据的数据库,然后设置:
|
1 2 |
log_bin = /var/log/mysql/somelog-bin log_bin_index = /var/log/mysql/somelog-bin.index ;注意把所有日志文件,每个一行的存入该文件,脚本:/bin/ls −1 /var/log/mysql/somelog-bin.[0-9]* > /var/log/mysql/somelog-bin.index |
让这个服务器把那些日志当作是他自己的,然后启动日志服务器,使用SHOW MASTER LOGS来验证它已经识别了那些日志。
日志服务器不需要执行日志,它只会让其它服务器来读取它的日志。
对于数据恢复来说,日志服务器比mysqlbinlog更有优势,因为:
- 数据复制其实就是应用二进制日志的过程,这种方式已经经过无数的生产环境的验证,相当稳定。而mysqlbinlog的工作方式有所不同,可能不能完整的重现二进制日志中的变化
- 日志服务器更快,因为它避免了从日志抽取SQL并到mysql中执行的过程
- 可以很容易的看到处理进度
- 容错性好,可以跳过复制失败的语句
- 很容易的过滤复制事件
- 如果日志是基于行的格式,mysqlbinlog可能无法读取二进制日志
监控Replication的状态
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> SHOW MASTER STATUS; #显示master当前日志的路径和配置 mysql> SHOW MASTER LOGS; #显示存在于磁盘上的二进制日志 +------------------+-----------+ | Log_name | File_size | +------------------+-----------+ | mysql-bin.000220 | 425605 | | mysql-bin.000221 | 1134128 | | mysql-bin.000222 | 13653 | | mysql-bin.000223 | 13634 | +------------------+-----------+ #显示日志中的事件 mysql> SHOW BINLOG EVENTS IN 'mysql-bin.000223' FROM 13634\G *************************** 1. row *************************** Log_name: mysql-bin.000223 Pos: 13634 Event_type: Query Server_id: 1 End_log_pos: 13723 Info: use `test`; CREATE TABLE test.t(a int) |
度量Replication延迟
SHOW SLAVE STATUS中的Seconds_behind_master理论上能够显示replica相对于master的延迟,但是往往不可靠。最好的方法是使用心跳记录(heartbeat record),即每秒在master上更新一次的记录。
确定replica是否与master处于同步状态
验证replica的同步性应当是日常工作的一部分,特别是replica作为备份使用的时候。Percona Toolkit包含一个叫pt-table-checksum的工具可以用于根据校验和来检验同步性。
replica的重新同步
传统做法是,停止replica,重新从master克隆数据,缺点是不方便,特别是数据量大的时候。Percona Toolkit包含一个叫pt-table-sync的工具可以提供帮助。
修改master
由于某些原因,例如服务器升级、master出现故障,可能需要把replica提升为master,并通知给所有replica。
Planned Promotions
整体步骤如下:
- 停止旧的master的写操作
- 等待replicas完成复制
- 把一个replica配置为master
- 把replica、写请求指向新的master,然后启用新master的写操作
更深入的讲,以下操作可能需要:
- 停止向发送当前master写请求,用可能需要强制客户端退出
- 使用FLUSH TABLES WITH READ LOCK停止master的所有写活动。或者通过read_only把master设为只读模式。注意,设置read_only不能阻止当前事务的提交,最好是kill所有活动的事务
- 选择一个replica作为新master,要确保它已经完全与旧master同步(已经执行完所有从旧master提取的转播日志)
- 可选的,验证新master与旧master的数据完全一样
- 在新master上执行STOP SLAVE、CHANGE MASTER TO MASTER_HOST=''、RESET SLAVE,这可以让新master从旧master断开连接,并且丢弃master.info中的信息
- 按照“推荐的Replication配置”来设置新master
- 执行SHOW MASTER STATUS来获取新master的二进制日志坐标
- 确保其它replica也与旧master同步
- 关闭旧master
- 在MySQL5.1+,如果需要的话激活新master上的事件
- 让客户端连接到新master
- 在各replica上执行CHANGE MASTER TO,指向新master,使用第6步获得的二进制日志坐标
Unplanned promotions
如果master崩溃了,你不得不提升一个replica来替换它,这种场景相对较为复杂。可能存在数据丢失,因为master上的某些事件可能没有被任何replica复制,甚至master上执行了一个回滚,而replica尚未执行,如果以后能获取崩溃master的数据,可能可以手工恢复。
下面是提升步骤:
- 确认哪个replica具有最新的数据,它将作为新的master。在每个replica上执行SHOW SLAVE STATUS,选择Master_Log_File/Read_Master_Log_Pos最新的一个
- 让所有replicas完成转播日志的执行
- 在新master上执行STOP SLAVE、CHANGE MASTER TO MASTER_HOST=''、RESET SLAVE,这可以让新master从旧master断开连接,并且丢弃master.info中的信息
- 执行SHOW MASTER STATUS来获取新master的二进制日志坐标
- 比较每个replica的Master_Log_File/Read_Master_Log_Pos与新master的差异,以计算这些replica相对于新master的二进制日志坐标。这里假设log_bin 、log_slave_updates在所有replica上开启,以确保能把所有replica恢复到一致的状态
- 执行上一节的10-12步
如何定位日志坐标
如果某个replica的日志坐标与新master不同,则必须计算出该replica相对于新master二进制日志的当前坐标。并且将此坐标在命令CHANGE MASTER TO中使用。除了使用SHOW SLAVE STATUS命令,亦可通过mysqlbinlog来获取replica最新的最后一条语句,并找到新master二进制日志里同样的语句的位置。
考虑一个具体的例子,如下图所示:
