KVM和QEMU学习笔记
Hypervisor,即虚拟机监管程序(virtual machine monitor ,VMM)。它可以是电脑上的软件、固件或者硬件,用于建立和执行虚拟机。拥有Hypervisor后,你可以执行一个或者多个虚拟机。这些虚拟机称为客户机(guest machine),相应的Hypervisor所在机器称为宿主机(host machine)。
传统的虚拟化技术都是基于Hypervisor的,它们被分为两类:
- bare-metal Hypervisor:裸机监管程序,直接运行在硬件上
- Hosted Hypervisor:被宿主监管程序,Hypervisor运行在操作系统之上,就像一个应用程序一样
X86处理器定义了定义了0-3个特权级,数字越小,权限越高。
对于Linux来说,在没有虚拟化的情况下,内核态对应了0级,用户态对应3级。
传统的虚拟化技术都是在宿主机、客户机之间加一个Hypervisor。因此,当在Linux上运行Linux虚拟机时,两个内核都需要运行在0级。根据解决此冲突(对于Host来说整个Client是用户程序)的方式的不同,虚拟化被分为3种类型:
| 虚拟化类型 | 说明 |
| 半虚拟化 |
Paravirtualization。此类型的特点是:
|
| 非硬件辅助全虚拟化 |
Full Virtualization without Hardware Assist。此类型的特点是:
|
| 硬件辅助全虚拟化 |
Full Virtualization with Hardware Assist。由Intel VT或AMD-V实现,此类型的特点是:
|
KVM,即基于内核的虚拟机(Kernel-based Virtual Machine),是构建于支持虚拟化扩展(Intel VT 或者 AMD-V)的x86平台、Linux操作系统之上的,完整虚拟化解决方案。使用KVM,你可以运行多个Linux或者Windows系统镜像,这些虚拟机拥有私有的虚拟化设备,包括网卡、磁盘、显卡等。
KVM主要包含两个内核组件:
- 可加载的内核模块 kvm.ko,负责核心的虚拟化基础功能
- 针对处理器的模块:kvm-intel.ko或者kvm-amd.ko
从2.6.20版本的Linux内核开始,KVM的内核组件就被包含在其中。从QEMU 1.3开始,KVM的用户空间组件被包含在其中。要查看你的机器是否支持KVM,可以执行: lsmod | grep kvm
QEMU是一个基于通用目的开源仿真器/虚拟器软件。它可以模拟:
- CPU
- Intel e1000 PCI等网卡
- 基于PCI IDE接口的硬盘、光驱
- 软驱
- 串口
- AC97兼容声卡以及其它声卡
- PS/2 键盘鼠标
- VGA显卡
等多种外围设备。QEMU最多支持255 CPU的SMP。
当作为仿真器(Emulator,模拟器)使用时,它可以在真实机器(例如你的x86_64台式机)上模拟一台机器 + 操作系统 + 程序,而这台模拟的机器的体系结构(例如ARM板)与宿主机器不同。
而作为虚拟器(Virtualizer)使用时,它可以在宿主机器上直接执行客户机(虚拟机)的代码,因而虚拟机的性能接近于宿主机。QEMU通过下列方式之一来支持虚拟化:
- 在XEN监管程序(Hypervisor)之上执行
- 在支持KVM的Linux操作系统下运行。使用KVM时QEMU可以虚拟化x86、PowerPC、S390客户机
注意Emulator和Virtualizer的区别,最重要的一点是客户机的代码是直接执行(意味着宿主和客户机体系结构兼容),还是模拟执行,后者的效率要低得多。很多同学喜欢在PC上玩街机游戏,这也是通过模拟器(例如Winkawaks)实现的。
和Vmware、VirtualBox 之类的虚拟机管理软件不同,QEMU不提供图形化的管理界面。你可以使用第三方的图形前端,例如qtemu,但是命令行的丰富性让QEMU更适合在服务器上使用。
单纯靠QEMU来模拟一系列硬件,因为存在指令转译,性能一般很差。而KVM可以基于Intel-VT、AMD-V实现硬件辅助的CPU虚拟化,客户机指令直接在真实CPU上运行。因此结合KVM可以很好的提高QEMU的CPU性能。另一方面KVM仅仅提供CPU的虚拟化,它无法构建一台完整的虚拟机。因此QEMU和KVM整合的需求就很明显了。
qemu-kvm项目就是来整合QEMU和KVM的,此项目在1.3.0版本开始正式合并到QEMU项目的master上。qemu-kvm(qemu-system-***)利用ioctl调用/dev/kvm,将有关CPU的部分交由KVM去做。
如果KVM内核模块存在、且CPU支持,你可以通过下面的选项启用KVM支持:
|
1 2 |
# 启用基于KVM的虚拟化加速 -enable-kvm |
CPU的性能问题解决了,但是QEMU模拟的其它硬件也存在同样的低效问题,于是Virtio被引入了。
Virtio是libvirt的一部分,它是一个关于网络、磁盘等设备的虚拟化标准,在此标准中客户机的设备驱动知道自己运行在虚拟化环境中,因而这些驱动可以和Hypervisor进行直接交互,获得接近于Native驱动的性能。
较新版本的Linux发行版都已经把Virtio编译进内核,因而客户机可以直接使用Virtio驱动。
KVM和XEN都是基于Hypervisor的虚拟化技术。它们的区别包括:
- Xen是裸机监管程序,而KVM某种程度上把Linux内核变成了Hosted Hypervisor
- Xen的整体性能高于KVM,但是I/O略差
- KVM要求CPU必须支持虚拟化技术,但Xen则没有此限制。这个限制在当前的硬件条件下,基本不是问题
- KVM的优势是它对Linux内核的整合程度,KVM本质上就是一个内核模块,因此你可以很容易的升级内核
VirtualBox是标准的2类Hypervisor,KVM与它的区别包括:
- VirtualBox它与商用软件Vmware Workstation一样,都以图形界面为主,适合个人用户。但是在商用环境下,大部分虚拟机都是Headless的(不需要图形界面),此时VirtualBox的GUI则是劣势,GUI浪费了资源
- VirtualBox支持大量的宿主操作系统,例如Windows、Linux、Mac OS X。而KVM显然仅支持Linux
- 一般情况下,轻量级的KVM的性能要比VirtualBox好的多
LXC即Linux容器(Containers),这是一种操作系统层(传统虚拟机是硬件层)虚拟化技术,要由liblxc库及其多语言绑定、一系列控制容器的工具组成。LXC将整个应用,包括:软件本身代码、所需库、支撑软件,打包为一个“容器”。通过Linux内核的特性,可以实现容器与系统之间的隔离,这些特性包括:
- 内核命名空间(IPC、uts、mount、pid、network、user)
- Apparmor(限制每个应用程序访问的资源)和SELinux配置
- Seccomp(提供应用程序沙盒机制)策略
- Chroots(通过pivot_root调用)
- cgroups,即控制组(control groups),用来限制、控制、分离进程组的资源(CPU、内存、磁盘等),此特性最初的名字就叫“进程容器”
通过LXC,你可以创建尽可能接近标准Linux的环境,同时不需要独立的内核。
基于LXC的虚拟化技术和KVM相比,区别如下:
- LXC的优势在于轻量化和高性能,但是隔离性不高
- LXC支持任何体系结构,例如x86、ARM、PowerPC等
LXD基于LXC,可以认为是一个Container的Hypervisor,LXD一般创建自包含的操作系统用户空间。也就是说,LXD容器内运行的是一个操作系统,虽然存在用户空间和内核空间隔离,但是这个操作系统和宿主系统共享一个内核。
有测试数据表明:LXD相比KVM可以减少50+%的延迟;LXD启动实例的速度比KVM块90+%
近年来非常流行的容器软件,与LXD最大的不同是,Docker打包应用程序+自包含的文件系统,而不是操作系统用户空间。每个Docker容器,仅仅包含一个应用程序。曾经Docker也是基于lxc技术的,但是现在它使用自己的库ibcontainer。
Docker中的文件系统、网络都是抽象的,而LXD直接使用宿主机的文件系统、网络,LXD可以方便的设置IP地址。
Docker比起LXD更加轻量,可以实现更高的部署密度。
大部分的Linux发行版已经内置了KVM内核模块以及用户空间工具,使用这些内置组件是最容易、推荐的方式:
- KVM内核模块现在是Linux内核的一部分,除非你使用的是精简过的内核
- 用户空间组件,软件包名称一般是qemu-kvm或者kvm,例如:
- Ubuntu下可以执行 apt-get install qemu-kvm 安装
- CentOS下可以执行 yum install kvm安装
- 客户机驱动:Linux客户机的驱动包含在内核中;Windows客户机的驱动需要下载
安装QEMU的依赖包:
|
1 |
sudo apt-get install gcc libsdl1.2-dev zlib1g-dev libasound2-dev linux-kernel-headers pkg-config libgnutls-dev libpci-dev |
下载用户空间组件:
- QEMU 1.3或者更老版本的,在Sourceforge下载
- 新版本,在QEMU官网下载
注意:2.6.29以上版本的内核,可以和任何版本的qemu-kvm搭配使用。
|
1 2 3 4 5 |
tar xzf qemu-kvm-release.tar.gz cd qemu-kvm-release ./configure --prefix=/usr/local/kvm make sudo make install |
如果你使用旧版本内核,或者内核精简了KVM,则需要此步骤:
|
1 2 3 4 5 |
tar xjf kvm-kmod-release.tar.bz2 cd kvm-kmod-release ./configure make sudo make install |
|
1 2 3 4 |
# 对于Intel CPU sudo /sbin/modprobe kvm-intel # 对于AMD CPU sudo /sbin/modprobe kvm-amd |
从3.0.0开始QEMU的版本大跃进,每年major版本增加1,目前已经是5.x版本。
|
1 2 3 4 5 |
wget https://download.qemu.org/qemu-5.1.0.tar.xz tar xvJf qemu-5.1.0.tar.xz cd qemu-5.1.0/ ./configure make |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 |
./configure --help # 方括号中是默认值 Standard options: --prefix=PREFIX install in PREFIX [/usr/local] --interp-prefix=PREFIX where to find shared libraries, etc. use %M for cpu name [/usr/gnemul/qemu-%M] # 目标列表,默认所有 # xxx-softmmu 生成qemu-system-xxx,用于运行xxx架构下的虚拟机 # xxx-linux-user 生成qemu-xxx,用于模拟运行xxx架构下的应用程序,可以配合binfmt_misc和Docker联用 --target-list=LIST set target list (default: build everything) Available targets: aarch64-softmmu alpha-softmmu arm-softmmu avr-softmmu cris-softmmu hppa-softmmu i386-softmmu lm32-softmmu m68k-softmmu microblazeel-softmmu microblaze-softmmu mips64el-softmmu mips64-softmmu mipsel-softmmu mips-softmmu moxie-softmmu nios2-softmmu or1k-softmmu ppc64-softmmu ppc-softmmu riscv32-softmmu riscv64-softmmu rx-softmmu s390x-softmmu sh4eb-softmmu sh4-softmmu sparc64-softmmu sparc-softmmu tricore-softmmu unicore32-softmmu x86_64-softmmu xtensaeb-softmmu xtensa-softmmu aarch64_be-linux-user aarch64-linux-user alpha-linux-user armeb-linux-user arm-linux-user cris-linux-user hppa-linux-user i386-linux-user m68k-linux-user microblazeel-linux-user microblaze-linux-user mips64el-linux-user mips64-linux-user mipsel-linux-user mips-linux-user mipsn32el-linux-user mipsn32-linux-user nios2-linux-user or1k-linux-user ppc64abi32-linux-user ppc64le-linux-user ppc64-linux-user ppc-linux-user riscv32-linux-user riscv64-linux-user s390x-linux-user sh4eb-linux-user sh4-linux-user sparc32plus-linux-user sparc64-linux-user sparc-linux-user tilegx-linux-user x86_64-linux-user xtensaeb-linux-user xtensa-linux-user --target-list-exclude=LIST exclude a set of targets from the default target-list Advanced options (experts only): --cross-prefix=PREFIX use PREFIX for compile tools [] --cc=CC use C compiler CC [cc] --iasl=IASL use ACPI compiler IASL [iasl] --host-cc=CC use C compiler CC [cc] for code run at build time --cxx=CXX use C++ compiler CXX [c++] --objcc=OBJCC use Objective-C compiler OBJCC [cc] --extra-cflags=CFLAGS append extra C compiler flags QEMU_CFLAGS --extra-cxxflags=CXXFLAGS append extra C++ compiler flags QEMU_CXXFLAGS --extra-ldflags=LDFLAGS append extra linker flags LDFLAGS --cross-cc-ARCH=CC use compiler when building ARCH guest test cases --cross-cc-flags-ARCH= use compiler flags when building ARCH guest tests --make=MAKE use specified make [make] --install=INSTALL use specified install [install] --python=PYTHON use specified python [/usr/bin/python3] --sphinx-build=SPHINX use specified sphinx-build [] --smbd=SMBD use specified smbd [/usr/sbin/smbd] --with-git=GIT use specified git [git] --static enable static build [no] --mandir=PATH install man pages in PATH --datadir=PATH install firmware in PATH/qemu --docdir=PATH install documentation in PATH/qemu --bindir=PATH install binaries in PATH --libdir=PATH install libraries in PATH --libexecdir=PATH install helper binaries in PATH --sysconfdir=PATH install config in PATH/qemu --localstatedir=PATH install local state in PATH (set at runtime on win32) --firmwarepath=PATH search PATH for firmware files --efi-aarch64=PATH PATH of efi file to use for aarch64 VMs. --with-confsuffix=SUFFIX suffix for QEMU data inside datadir/libdir/sysconfdir [/qemu] --with-pkgversion=VERS use specified string as sub-version of the package --enable-debug enable common debug build options --enable-sanitizers enable default sanitizers --enable-tsan enable thread sanitizer --disable-strip disable stripping binaries --disable-werror disable compilation abort on warning --disable-stack-protector disable compiler-provided stack protection --audio-drv-list=LIST set audio drivers list: Available drivers: oss alsa sdl pa --block-drv-whitelist=L Same as --block-drv-rw-whitelist=L --block-drv-rw-whitelist=L set block driver read-write whitelist (affects only QEMU, not qemu-img) --block-drv-ro-whitelist=L set block driver read-only whitelist (affects only QEMU, not qemu-img) --enable-trace-backends=B Set trace backend Available backends: dtrace ftrace log simple syslog ust --with-trace-file=NAME Full PATH,NAME of file to store traces Default:trace-<pid> --disable-slirp disable SLIRP userspace network connectivity --enable-tcg-interpreter enable TCG with bytecode interpreter (TCI) --enable-malloc-trim enable libc malloc_trim() for memory optimization --oss-lib path to OSS library # 为指定CPU构建 --cpu=CPU Build for host CPU [x86_64] --with-coroutine=BACKEND coroutine backend. Supported options: ucontext, sigaltstack, windows --enable-gcov enable test coverage analysis with gcov --gcov=GCOV use specified gcov [gcov] --disable-blobs disable installing provided firmware blobs --with-vss-sdk=SDK-path enable Windows VSS support in QEMU Guest Agent --with-win-sdk=SDK-path path to Windows Platform SDK (to build VSS .tlb) --tls-priority default TLS protocol/cipher priority string --enable-gprof QEMU profiling with gprof --enable-profiler profiler support --enable-debug-stack-usage track the maximum stack usage of stacks created by qemu_alloc_stack --enable-plugins enable plugins via shared library loading --disable-containers don't use containers for cross-building --gdb=GDB-path gdb to use for gdbstub tests [/usr/bin/gdb] Optional features, enabled with --enable-FEATURE and disabled with --disable-FEATURE, default is enabled if available: system all system emulation targets user supported user emulation targets linux-user all linux usermode emulation targets bsd-user all BSD usermode emulation targets docs build documentation guest-agent build the QEMU Guest Agent guest-agent-msi build guest agent Windows MSI installation package pie Position Independent Executables modules modules support (non-Windows) module-upgrades try to load modules from alternate paths for upgrades debug-tcg TCG debugging (default is disabled) debug-info debugging information sparse sparse checker safe-stack SafeStack Stack Smash Protection. Depends on clang/llvm >= 3.7 and requires coroutine backend ucontext. gnutls GNUTLS cryptography support nettle nettle cryptography support gcrypt libgcrypt cryptography support auth-pam PAM access control sdl SDL UI sdl-image SDL Image support for icons gtk gtk UI vte vte support for the gtk UI curses curses UI iconv font glyph conversion support vnc VNC UI support vnc-sasl SASL encryption for VNC server vnc-jpeg JPEG lossy compression for VNC server vnc-png PNG compression for VNC server cocoa Cocoa UI (Mac OS X only) virtfs VirtFS mpath Multipath persistent reservation passthrough xen xen backend driver support xen-pci-passthrough PCI passthrough support for Xen brlapi BrlAPI (Braile) curl curl connectivity membarrier membarrier system call (for Linux 4.14+ or Windows) fdt fdt device tree kvm KVM acceleration support hax HAX acceleration support hvf Hypervisor.framework acceleration support whpx Windows Hypervisor Platform acceleration support rdma Enable RDMA-based migration pvrdma Enable PVRDMA support vde support for vde network netmap support for netmap network linux-aio Linux AIO support linux-io-uring Linux io_uring support cap-ng libcap-ng support attr attr and xattr support vhost-net vhost-net kernel acceleration support vhost-vsock virtio sockets device support vhost-scsi vhost-scsi kernel target support vhost-crypto vhost-user-crypto backend support vhost-kernel vhost kernel backend support vhost-user vhost-user backend support vhost-vdpa vhost-vdpa kernel backend support spice spice rbd rados block device (rbd) libiscsi iscsi support libnfs nfs support smartcard smartcard support (libcacard) libusb libusb (for usb passthrough) live-block-migration Block migration in the main migration stream usb-redir usb network redirection support lzo support of lzo compression library snappy support of snappy compression library bzip2 support of bzip2 compression library (for reading bzip2-compressed dmg images) lzfse support of lzfse compression library (for reading lzfse-compressed dmg images) zstd support for zstd compression library (for migration compression and qcow2 cluster compression) seccomp seccomp support coroutine-pool coroutine freelist (better performance) glusterfs GlusterFS backend tpm TPM support libssh ssh block device support numa libnuma support libxml2 for Parallels image format tcmalloc tcmalloc support jemalloc jemalloc support avx2 AVX2 optimization support avx512f AVX512F optimization support replication replication support opengl opengl support virglrenderer virgl rendering support xfsctl xfsctl support qom-cast-debug cast debugging support tools build qemu-io, qemu-nbd and qemu-img tools bochs bochs image format support cloop cloop image format support dmg dmg image format support qcow1 qcow v1 image format support vdi vdi image format support vvfat vvfat image format support qed qed image format support parallels parallels image format support sheepdog sheepdog block driver support crypto-afalg Linux AF_ALG crypto backend driver capstone capstone disassembler support debug-mutex mutex debugging support libpmem libpmem support xkbcommon xkbcommon support rng-none dummy RNG, avoid using /dev/(u)random and getrandom() libdaxctl libdaxctl support |
要创建虚拟机,首先要创建一个虚拟磁盘,然后从光驱启动此虚拟机:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mkdir -p ~/Vmware/KVM # 以qcow2格式创建一个16G的虚拟磁盘,注意,默认不会预先分配空间 qemu-img create -f qcow2 ~/Vmware/KVM/centos7-base.img 16G # 指定光盘镜像,从光驱启动虚拟机 # -hda 第一块硬盘的镜像 # -cdrom 光驱的镜像,你可以把宿主的/dev/cdrom传入,这样可以使用物理光驱 # -boot 指定启动顺序,d表示第一个光驱,c表示第一块硬盘 # -m 为虚拟机分配多少内存,默认单位M,默认128M qemu-system-x86_64 -enable-kvm -hda ~/Vmware/KVM/centos7-base.img -boot d -m 512 -cdrom ~/Software/OS/CentOS-7-x86_64-Minimal-1503-01.iso |
上述命令执行完毕之后,会弹出一个窗口,该窗口相当于虚拟机的显示器。你可以在其中完成操作系统的安装。安装完毕后,执行下面的命令,即可启动虚拟机:
|
1 |
qemu-system-x86_64 -enable-kvm -hda ~/Vmware/KVM/centos7-base.img -m 512 |
后续几个章节,我们深入学习客户机硬件的定制,以满足不同应用场景的需要、提高客户机的性能。
使用选项 -cpu 选项可以选择客户机使用的CPU,执行 qemu-system-x86_64 -cpu help 可以列出QEMU支持的CPU名称、可用的CPUID标记。
你可以这样配置一个CPU:
|
1 2 |
-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,\ +xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme |
+表示启用CPU特性,如果要禁用CPU特性,可以使用 - 。
所谓对称多处理(Symmetrical Multi-Processing) ,是指在一个计算机上汇集了一组处理器,各处理器共享内存子系统以及总线结构。在PC机上QEMU最多可以模拟255个CPU。
你可以这样配置SMP: -smp 1,sockets=1,cores=1,threads=1 。这个配置表示主板上有一个CPU插槽、1个CPU、每个CPU具有1核心、每个核心具有1个硬件线程(超线程)。
你可以在宿主机上创建一个磁盘镜像文件,然后供客户机使用。客户机磁盘I/O都将针对此文件。镜像文件可以有几种格式。
这种镜像的特点是格式简单,性能较好。
你的文件系统(例如Ext3)必须支持稀疏文件(sparse file),才能避免不必要的磁盘空间占用。稀疏文件是一种高效使用磁盘空间的技术,当文件大小很大,而其绝大部分块都是空白(未使用)的时,可以基于文件元数据来表示那些空白的块(而不是真实的硬盘空间)。
创建Raw镜像:
|
1 2 3 4 5 6 7 8 |
qemu-img create -f raw hda.img 1G # 查看镜像信息 qemu-img info hda.img # image: hda.img # file format: raw # virtual size: 1.0G (1073741824 bytes) # disk size: 0 |
你也可以使用dd命令产生Raw镜像,例如:
|
1 2 3 4 |
# 产生非稀疏文件:块大小1MB,写入1024个块,虚拟大小1G,实际大小1G dd if=/dev/zero of=hda.img bs=1024k count=1024 # 产生稀疏文件:块大小1MB,写入0个块,虚拟大小1G,实际大小0 dd if=/dev/zero of=hda.img bs=1024k count=0 seek=1024 |
qcow2镜像的动态增长的,即使文件系统不支持稀疏文件,它也会尽可能的小。qcow2支持Copy-on-write、镜像、压缩、加密。
正是由于qcow2支持Copy-on-write,我们才可以使用backing file——用一个镜像保存针对另外一个镜像的改变,而后面那个镜像不需要被改动。这是多虚拟机公用一个Base镜像,以及Snapshot的基础。
qcow2镜像文件的结构如下图所示:
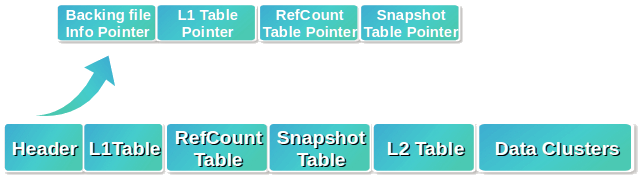
qcow2镜像文件由一个头、几张表、数据簇组成。所有数据都存放在数据簇(Data Clusters)中,每个数据簇是512字节的扇区。为了方便管理这些数据簇,qcow2建立了两级表:L1、L2。其中L1表的条目指向L2表,而L2表的条目指向数据簇。
要定位数据,需要3个偏移量构成的数组:
- 通过位于Header中的L1表指针 +offset[0],得到L2表的指针
- L2表指针 + offset[1],得到数据簇指针
- 数据簇指针 + offset[2],得到目标数据的指针
你可以这样创建一个qcow2镜像:
|
1 |
qemu-img create -f qcow2 hda-back.img 16G |
然后,在未来某个时刻把它作为backing file使用:
|
1 |
qemu-img create -f qcow2 -o backing_file=hda-back.img hda.img |
镜像hda.img在一开始是空白的,所有数据都是从hda-back.img中获取,一旦发生写入操作,hda.img就开始有数据而hda-base.img保持不变。
使用下面的命令可以压缩一个qcow2镜像:
|
1 |
qemu-img convert -c -f qcow2 -O qcow2 hda.img hda.compressed.img |
使用下面的命令可以为一个qcow2镜像设加密:
|
1 2 |
qemu-img convert -o encryption -f qcow2 -O qcow2 hda.img hda.encrypted.img # 提示输入密码 |
使用压缩镜像启动虚拟机时,必须在Monitor中输入密码才可以。
使用下面的命令,可以扩展一个qcow2镜像的大小:
|
1 |
qemu-img resize hda.img +10G |
注意:扩大得到的空间,不会被分区或者格式化。
要移除镜像中的spare space,直接qcow2-to-qcow2转换即可,压缩(-c)可选:
|
1 |
qemu-img convert -O qcow2 source.qcow2 shrunk.qcow2 |
rebase操作用于改变一个镜像的backing镜像:
|
1 2 3 4 5 6 7 8 9 10 11 |
# -u 表示unsafe模式,在此模式下,仅仅改变backing文件的路径,不对文件内容进行检查 # 用于backing文件移动的情况 # -p 表示safe模式,在此模式下,执行真正的rebase操作。backing文件的内容可能和之前 # 不同,qemu-img会小心处理,确保VM可见的内容不变。为达成这一点,新旧backing # 文件的差异,会合并到被改变镜像中 # 格式 qemu-img rebase -u -f qcow2 # 新的backing文件位置 新backing文件格式 -b /home/alex/Vmware/libvirt/images/sdd/xenial-base.qcow2 -F qcow2 # 被处理镜像文件 /home/alex/Vmware/libvirt/images/sdd/xenial-100.qcow2 |
你可以把一个镜像的格式在Raw和qcow2之间进行转换:
|
1 2 |
# 把Raw格式的hda.img转换为qcow2格式的hda.qcow2 qemu-img convert -f raw -O qcow2 hda.img hda.qcow2 |
快照(Snapshot)是Copy-on-write的一种应用。QEMU支持两种快照:
- 内部快照(internal snapshot):在qcow2镜像的snapshot table中维护的快照,所有快照都存放在一个镜像文件中
- 外部快照(external snapshot):与Backing file很类似,在外部文件中创建新的镜像,原先的镜像只读
内部快照的原理是:
- 创建一个Snapshot后,在Snapshot Table中新增一项,复制L1 Table
- 当L2 Table或者Data Cluster发生改变,则把改变前的数据复制一份(Copy-on-write),由新创建的Snapshot的L1 Table来管理
- L2 Table或者Data Cluster的变化,直接写到原始位置
- 要删除快照,很简单,直接把Snapshot Table对应项、以及复制的L1-L2-DS删除即可
- 要加载快照,则需要依据L1-L2-DS信息,将其合并到镜像的L1-L2-DS信息中
可以使用Monitor来创建、加载、删除内部快照:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 保存一个内部快照 (qemu) savevm snapshot-1 qemu-img info hda.img # 输出如下: #Snapshot list: #ID TAG VM SIZE DATE VM CLOCK #1 snapshot-1 112M 2016-09-07 18:05:48 00:00:21.536 #Format specific information: # compat: 1.1 # lazy refcounts: false # 加载内部快照 (qemu) loadvm snapshot-1 # 删除内部快照 (qemu) delvm snapshot-1 |
外部快照与内部快照相反:内部快照是原数据变化,外部快照则是新文件变化。
可以使用Monitor来管理外部快照:
|
1 |
snapshot_blkdev ide0-hd0 snapshot.img qcow2 |
有了磁盘镜像文件后,你需要为qemu-system-*指定参数,给客户机增加磁盘。有几种不同的配置方式:
|
1 2 3 4 5 6 7 8 9 10 |
# 最简单的方式 -hda hda.img # 使用-drive配置块设备,可以指定if为virtio来提升性能 -drive file=hda.img,index=0,media=disk,if=virtio # 使用-device配置通用设备 -drive file=hda.img,if=none,id=virtio-disk0,format=qcow2,cache=none # 可以指定virtio-blk-pci来提升性能 -device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=virtio-disk0,bootindex=1 |
QEMU中的网络,包含两部分的内容:
- 客户机使用的虚拟网络设备
- 和上述虚拟设备通信的网络后端,这些后端负责把虚拟设备的数据包发到宿主机的网络中
要创建一个网络后端,可以指定如下选项:
|
1 2 3 4 |
# TYPE为后端类型:user、tap、bridge、socket、vde等 # id为一个标识符,将虚拟网络设备和网络后端关联在一起 # 如果客户机有多个虚拟网络设备,则每一个都需要自己的网络后端 -netdev TYPE,id=NAME,... |
QEME支持多种网络后端。
如果没有指定网络选项,QEMU默认会模拟单张Intel e1000 PCI网卡,该网卡基于user后端(SLIRP)连接到宿主机:
|
1 2 3 4 5 6 |
# 不指定网络 qemu # 等价配置。自0.12开始废弃的配置方式 -net nic相当于-device DEVNAME;-net TYPE相当于-netdev TYPE qemu -hda disk.img -net nic -net user # 等价配置。-netdev指定网络后端,-device指定虚拟网络设备,后者通过netdev字段引用后端的ID qemu -netdev user,id=network0 -device e1000,netdev=network0 |
在客户机看来:
- 本身的IP地址被分配为 10.0.2.15+
- 分配IP的虚拟DHCP为 10.0.2.2
- 虚拟DNS服务器为 10.0.2.3
- 虚拟Samba服务器为 10.0.2.4,客户机可以通过此服务器访问宿主机的文件系统
用户模式网络可以很方便的访问网络资源。但是它有很多限制:
- 默认的,它运作方式类似于防火墙,且不允许任何入站流量。这个限制可以通过端口重定向解决
- 仅仅支持TCP、UDP协议,对于ICMP则不支持
- 性能比较差
为了支持入站请求,你可以使用端口重定向(Redirecting ports)——把针对宿主机某个端口的请求转发给客户机的某个端口。映射后,客户机可以对外提供SSH、HTTP等服务:
|
1 2 3 4 5 |
# 把宿主机的7080端口重定向到客户机的80端口;把宿主机的7022端口重定向到客户机的22端口 qemu-system-x86_64 -redir tcp:7080::80 -redir tcp:7022::22 -hda ~/Vmware/KVM/centos7-base.img -m 512 # 从宿主机SSH到客户机 ssh root@127.0.0.1 -p 7022 |
你可以不使用默认的10.0.2网段:
|
1 |
-netdev user,id=network0,net=192.168.5.0/24,dhcpstart=192.168.5.9 |
依据客户机安装的操作系统,可能需要进行一些配置,才能正常使用网络。以CentOS 7 Minimal + 用户模式网络为例,需要修改以下配置文件:
|
1 2 3 |
NETWORKING=yes # 如果不使用IPV6 NETWORKING_IPV6=no |
|
1 2 3 4 |
# 如果不使用IPV6 IPV6INIT=no # 开机启动此网卡,默认不启动 ONBOOT=yes |
网关、DNS不需要设置。修改完这些配置文件后,重启客户机网络: /etc/init.d/network restart 。然后执行 yum update 测试一下能否正常联网(不要使用ping测试)
QEMU的TAP后端利用宿主机的TAP设备,为客户机提供完整的桥接网络支持,如果外部需要使用标准端口连接到客户机, 或者多个客户机需要相互通信,可以使用该方式。 TAP后端还具有以下优势:
- 非常好的性能
- 可以配置以支持各种网络拓扑
但是,你需要在宿主机上进行网络拓扑的配置,而且各种系统的配置不同。
使用TAP后端前,你需要确认你的宿主机的内核支持TAP网络接口: /dev/net/tun 文件存在则说明支持。如果没有这样的文件,可以尝试手工创建:
|
1 2 3 |
sudo mkdir /dev/net sudo mknod /dev/net/tun c 10 200 sudo /sbin/modprobe tun |
如果你想创建几个客户机之间的私有网络,可以使用该方式。未参与进来的客户机、真实网络无法看到此网络。
如果你不是root,则你需要 /dev/kvm 的读写权限。
首先,添加一个以太网桥设备:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
sudo ip link add br0 type bridge # 也可以使用:sudo brctl addbr br0添加网桥 # 要删除网桥,执行: ip link delete br0 # 注意:网桥会在重启后消失 # 启用此网桥 sudo ip link set br0 up # 为网桥分配IP地址 sudo ip addr add 10.0.0.1 dev br0 # 在宿主机添加一条直接路由,便于它能和客户机通信 sudo ip route add 10.0.0.0/8 dev br0 |
创建一个创建TAP设备并桥接到网桥的脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/bin/sh switch=br0 if [ -n "$1" ];then # tunctl -u `whoami` -t $1 # 添加一个tap设备,在我的机器上不需要,原因见下面 # ip tuntap add $1 mode tap user `whoami` # 不知道从什么时候开始,QEMU会在执行此脚本之前就创建好tap设备,因此会报下面的错误 # ioctl(TUNSETIFF): Device or resource busy # 启动tap设备 ip link set $1 up # brctl addif $switch $1 # 将网桥和tap设备进行桥接 ip link set $1 master $switch exit 0 else echo "Error: no interface specified" exit 1 fi |
创建一个生成随机MAC地址的脚本:
|
1 2 3 |
#!/bin/bash # generate a random mac address for the qemu nic printf 'DE:AD:BE:EF:%02X:%02X\n' $((RANDOM%256)) $((RANDOM%256)) |
启动客户机的脚本:
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash # $1 base name of virtual disk # $2 memory size # $3 tap device id mac=`/usr/bin/qemu-genmac` src=/usr/bin/qemu-ifup sudo qemu-system-x86_64 -enable-kvm -device e1000,netdev=$3,mac=$mac -netdev tap,id=$3,script=$src,downscript=no \ -hda ~/Vmware/KVM/$1.img -m $2 |
为上面的脚本文件添加可执行权限:
|
1 2 3 |
sudo chmod +x /usr/bin/qemu-ifup-br0 sudo chmod +x /usr/bin/qemu-genmac sudo chmod +x /usr/bin/qemu-start-br0 |
执行下面的命令,启动一台客户机(或者更多虚拟机,但是命令中的tap0要更换为不同的名字):
|
1 |
/usr/bin/qemu-start centos7-base 512 tap0 |
修改客户机的IP地址,使用10.0.0.0/8网段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
TYPE=Ethernet BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=no NAME=ens3 UUID=d9f47102-b177-4a27-ae98-86f6939d6680 DEVICE=ens3 ONBOOT=yes IPADDR=10.0.0.10 PREFIX=8 GATEWAY=10.0.0.1 |
好了,你现在可以互相ping客户机和宿主机,应该可以正常连通了。
上一节介绍的这种基于TAP的私有桥接网络,可以让客户机、宿主机相互连通,但是客户机无法访问互联网。
要解决此问题,你可以选择以下方法之一:
- 让客户机通过宿主机暴露的HTTP/SOCKS代理上网
- 配置宿主机的路由规则,设置好源地址转换即可:
1234# 宿主机需要启用IP转发功能,这样它就可以像路由器那样中转IP封包了sudo sysctl -w net.ipv4.ip_forward=1# 对客户机网段进行源地址转换sudo iptables -t nat -A POSTROUTING -s 10.0.0.0/255.0.0.0 ! -d 10.0.0.0/255.0.0.0 -j MASQUERADE
此方式和私有桥接网络类似,主要区别是,除了TAP设备桥接到网桥之外,以太网卡(例如eth0)也桥接到网桥(例如br1)。
你可以通过发行版的配置文件来配置网桥:
|
1 2 3 4 5 6 7 8 9 10 11 |
# 注意网络管理器组件的影响 # 去掉 auto eth0,改为: auto br1 # 配置br1 iface br1 inet dhcp bridge_ports eth0 bridge_stp off bridge_maxwait 0 bridge_fd 0 # 这里附加上原来属于eth0的配置 |
或者基于脚本来配置:
|
1 2 3 4 5 6 7 |
sudo ip link add br1 type bridge sudo ip link set br1 up sudo ip link set eth0 master br1 # DHCP sudo killall dhclient && sudo ip addr flush dev eth0 sudo dhclient br1 |
无论用哪种方式,都应该注意到eth0的IP地址需要转移给br1,这样才能确保网络正常运作——br1必须在链路层接收到相关ARP请求,并决定是否需要转发给客户机,eth0没有这种转发能力。
如果eth0所在网络是基于DHCP的,那么客户机配置为DHCP后,会自动获取公共IP地址。否则,需要手工设置客户机的IP地址。
现在QEMU支持自动桥接TAP设备到宿主机的一个网桥,因此你不再需要编写脚本,修改网络后端为bridge即可:
|
1 |
-netdev bridge,id=tap0,br=br0 |
注意,使用上述选项时,QEMU需要读取配置文件/etc/qemu/bridge.conf,你只需在此文件中添加一行代码: allow br0
你可以编写如下脚本自动创建网桥、配置iptables规则。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Create private bridge link for QEMU /sbin/ip link add br0 type bridge /sbin/ip link set br0 up /sbin/ip addr add 10.0.0.1 dev br0 /sbin/ip route add 10.0.0.0/8 dev br0 # NAT for 10.0.0.0/8 /sbin/iptables -t nat -A POSTROUTING -s 10.0.0.0/255.0.0.0 ! -d 10.0.0.0/255.0.0.0 -j MASQUERADE # Create public bridge link for QEMU /sbin/ip link add br1 type bridge /sbin/ip link set br1 up /sbin/ip link set eth0 master br1 /usr/bin/killall dhclient && /sbin/ip addr flush dev eth0 /sbin/dhclient br1 |
建议和libvirt一起使用macvtap。
在使用libvirt时,客户机(Domain)的网络接口配置可以简化为:
|
1 2 3 4 5 6 |
<interface type='bridge'> <mac address='DE:AD:BE:EF:F1:00'/> <source bridge='br0'/> <target dev='tap0'/> <model type='virtio'/> </interface> |
可以使用libvrit的虚拟局域网,这样宿主机上不会为客户机创建专门的tap设备,那些手工编写的脚本也全都不需要了。虚拟网络配置示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<network> <name>default</name> <uuid>9bae4de8-ca58-48c5-ba58-109aebf8b954</uuid> <forward mode='nat'> </forward> <bridge name='virbr0' stp='on' delay='0'/> <ip address='10.0.0.1' netmask='255.0.0.0'> <dhcp> <range start='10.0.0.100' end='10.0.0.200'/> </dhcp> </ip> </network> |
客户机(Domain)的网络接口配置示例:
|
1 2 3 4 5 |
<interface type='network'> <mac address='DE:AD:BE:EF:F1:00'/> <source network='default'/> <model type='virtio'/> </interface> |
另外,libvirt的虚拟网络提供了DHCP功能,因此客户机的IP地址不需要静态设置。
SMBIOS即DMI表,存放了X86系统硬件信息,这个表依据DMI type分为数十个段,type0是BIOS、type1是系统信息、type2是主板信息……
QEMU支持模拟这些信息,例如:
|
1 2 |
# 设置客户机的type1信息 -smbios type=1,manufacturer=OpenStack Foundation,product=OpenStack Nova,version=2011,serial=8059dfb4,uuid=1f8ee7f308 |
要设置客户机的内存容量,可以使用 -m ,默认单位MB。
客户机没必要占据着空闲的内存不用,因此我们一般启用内存实际大小的动态调整功能,例如:
|
1 |
-device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x5 |
在本文的第一章,谈到周围硬件性能的时候,我们提及了virtio——它是规定了虚拟设备的前端驱动与宿主机硬件的后端驱动之间通信接口的标准,并且知道目前的很多Linux发行版已经把virtio驱动编译进内核了。前面的章节我们也使用了很多virtio驱动,包括磁盘、网络、内存相关的。
基于virtio驱动的虚拟设备,我们成为“半虚拟化设备”,因为这些设备驱动知道自己工作在虚拟化模式下。为客户机配置半虚拟化设备,可以提高内存、硬盘、网络方面的性能,由其对于网络,性能提升很明显。
除了virtio,Vmware Tools也属于半虚拟化驱动,QEMU客户机也可以利用Vmware Tools(例如-vga指定vmware)。virtio驱动的具体实现包括:virtio-blk、virtio-net、virtio-pci、virtio-balloon、virtio-console等。
半/全虚拟化的区别如下:
- 在全虚拟化状态下,Guest OS不知道自己是虚拟机,于是像发送普通的IO一样发送数据,被Hypervisor拦截,转发给真正的硬件。
- 在半虚拟化状态下,Guest OS知道自己是虚拟机(需安装半虚拟化驱动),所以数据直接发送给半虚拟化设备,经过特殊处理,发送给真正的硬件
这是一个特殊的半虚拟化设备,它能够动态(不需要重启客户机)的调整客户机的内存大小。如果你指定了-m参数,则不能调整的比-m更大。使用选项 -balloon virtio 可以添加Ballooning设备。
要基于半虚拟化来访问磁盘,可以使用选项: -drive file=vda.qcow2,if=virtio ,使用virto_blk驱动的硬盘,在客户机里对应的设备文件是/dev/vda(而IDE硬盘是/dev/hda、基于SATA的硬盘则显示为/dev/sda) 。
可以使用驱动virtio-blk-data-plane进一步提高性能(I/O性能较virtio-blk能提高10-20%),此驱动自QEMU 1.4开始引入。与传统的virtio-blk不同的是,virtio-blk-data-plane为每个块设备独立分配一个线程用于I/O处理,此线程不需要和QEMU执行线程同步、竞争锁。此驱动基于宿主机的原生AIO响应客户机的请求。启用此驱动的选项示例:
|
1 2 |
-drive if=none,id=drive0,cache=none,aio=native,format=raw,file=vda.img -device virtio-blk-pci,drive=drive0,scsi=off,x-data-plane=on |
但是,启用virtio-blk-data-plane后,存储迁移(storage migration)、热拔插、I/O限流(throttling) 等功能无法使用。而且该驱动仅支持Raw格式的磁盘。
要基于半虚拟化来访问网络,可以使用选项: -device virtio-net-pci,netdev=network0 。你应当总是考虑启用半虚拟化网卡,因为性能会有很大的提升。
宿主机网卡的某些特性可能会影响virtio的性能,例如:
- TSO(TCP Segmentation Offload):通过网络设备进行TCP段的分割,从而来提高网络性能
- GSO(Generic Segmentation Offload):类似,用TCPv6、UDP等传输层协议
你可以开关这些特性来测试对客户机网络性能的影响。要检查宿主机网卡是否支持、开启这些特性,可以执行命令: ethtool -k eth0 。
网络块设备(Network Block Device)是一种把虚拟块设备通过TCP/IP暴露出去,供远程共享访问的技术。
你可以通过UNIX套接字来暴露:
|
1 |
qemu-nbd -t -k /home/alex/Vmware/KVM/.images/fedora-108 fedora-108/hda.img |
也可以通过普通套接字来暴露:
|
1 |
qemu-nbd -p 1025 fedora-108/hda.img |
甚至是把镜像直接挂载到宿主机的NBD设备中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 在宿主机上启用NBD内核模块,最多16个分区: sudo modprobe nbd max_part=16 # 查看NBD设备文件 ls /dev/nbd* # 输出/dev/nbd0 ... /dev/nbd15 # 挂载 sudo qemu-nbd -c /dev/nbd0 fedora-108/hda.img # 查看nbd0的分区情况 sudo fdisk -l /dev/nbd0 # Device Boot Start End Blocks Id System # /dev/nbd0p1 * 2048 1026047 512000 83 Linux # /dev/nbd0p2 1026048 33554431 16264192 8e Linux LVM |
客户机可以直接使用NBD作为磁盘:
|
1 2 3 4 |
# 使用UNIX套接字: qemu-system-x86_64 -hda nbd:unix:/home/alex/Vmware/KVM/.images/fedora-108 # 使用普通套接字 qemu-system-x86_64 -hda nbd:10.0.0.1:1025 |
QEMU支持离线或者在线的迁移,你可以在Monitor中使用迁移命令。当迁移完毕后,虚拟机会在目标主机上继续运行。
AMD和Intel宿主机之间可以随意的迁移虚拟机,64位虚拟机只能迁移到64位宿主机上,32位则没有限制。某些老旧的Intel CPU不支持NX(禁止执行比特位),这种CPU处于启用NX的宿主机群中,会导致问题,你需要禁止客户机的NX: -cpu qemu64,-nx 。
QEMU的迁移功能具有以下特性:
- 极短暂的客户机停机时间
- 如果迁移成功,则客户机在目标主机上运行;如果迁移失败,则客户机继续在源主机上运行
- 几乎对硬件没有依赖
使用共享存储时,QEMU迁移会很便利,因为不牵涉到磁盘映像的移动。共享存储包括:NFS、NBD、SAN等。 我们以NBD为例说明:
- 启动供源、目的虚拟机共享的NBD服务: qemu-nbd -p 1025 --share=2 fedora-108/hda.img
- 确保源、目的虚拟机的配置,它们要具有相同的网络环境
- 启动源虚拟机:
12sudo qemu-system-x86_64 -netdev bridge,id=tap0,br=br0 -device virtio-net-pci,netdev=tap0,mac=DE:AD:BE:EF:F1:08-hda nbd:10.0.0.1:1025 -monitor stdio -enable-kvm - 源虚拟机运作一段时间后,其宿主机的硬件需要维护,因此准备迁移。在另外一台宿主机上启动目的虚拟机,并监听migration端口:
12# qemu选项同源虚拟机,附加:-incoming tcp:0:4444注意,这个监听端口是开在宿主机上的。实际上,以-incoming启动目的虚拟机后,虚拟机是处于Stopped状态的
- 登录到源虚拟机,确认它与目的虚拟机的宿主机之间的网络是畅通的
- 在源虚拟机的Monitor中,发起迁移命令: (qemu) migrate -d tcp:10.0.0.1:4444
- 在迁移过程中,可以通过 info migrate 查看迁移状态,完毕后会显示Migration status: completed,并列出迁移消耗的时间、停机时间
- 迁移完成后,源虚拟机变为Stopped,而目的虚拟机开始运行,获得源虚拟机的全部瞬时状态
这种情况下,源虚拟机的磁盘镜像需要拷贝到目标宿主机中。因而需要更长的时间、更多的网络带宽消耗。步骤如下:
- 查看源虚拟机的磁盘镜像信息: qemu-img info fedora-108/hda.img
- 在目的机器上创建与之大小(Virtual size)一致的空磁盘镜像: qemu-img create -f qcow2 fedora-108-m/hda.img 16G
- 使用与共享存储一样的步骤进行迁移,只是源、目的虚拟机使用各自的磁盘镜像
前面的章节我们已经多次使用QEMU的监控功能,通过使用QEMU的HMI(Monitor)可以在(qemu)提示符下进行各种监控操作,包括查看虚拟机信息、动态添加设备、执行迁移等等。在《QEMU命令与快捷键》一章我们会详细的讲解HMI命令,本章主要介绍监控相关的QEMU配置
你可以通过多种方式使用Monitor:
- 默认的,可以在QEMU的虚拟机窗口中,按Ctrl + Alt + 2切换到Monitor
- 可以使用 -monitor stdio ,让Monitor重定向到启动虚拟机的Terminal
- 可以启动一个TCP监听 -monitor tcp::4444,server,nowait ,这样你可以 telnet hostip:4444 访问Monitor
- 可以通过字符设备: -chardev stdio,id=x -monitor chardev=x 访问Monitor
非交互式监控时,QEMU监控协议(QEMU Monitor Protocol)是更好的选择,这是一个基于JSON格式的协议。要启用QMP,你可以:
- 基于stdio: -qmp stdio
- 基于TCP: -qmp tcp:localhost:4444,server
- 基于UNIX Socket: -qmp unix:./qmp-sock,server
以下列出一些应用基于QEMU/KVM的虚拟化方案时的最佳实践:
- 使用半虚拟化驱动virtio
- 性能好:延迟低、吞吐量高
- 纯虚拟设备的劣势:需要高吞吐能力的设备在硬件方面会有特殊的实现,这些纯虚拟设备是没法利用的
- 网络、块设备、内存,都可以使用virtio
- 兼容性较差
- 虚拟机最好直接使用块设备做存储
- 性能好、无需管理宿主机的文件系统、无需管理稀疏文件
- I/O 缓存以4K为边界
- 如果没有条件使用块设备,只能使用镜像文件
- 宿主机最好使用ext3文件系统,ext4的barrier会影响性能
- Raw格式镜像的性能优于qcow2
- 选择正确的缓存策略,缓存模式推荐none,I/O调度器推荐Deadline I/O scheduler
- CPU配置
- 每个客户机相当于一个进程,而每个客户机的虚拟CPU相当于一个线程。因此超配CPU是可行的
- CPU超配可能带来额外的上下文切换,影响性能
- 要保证客户机获得足够的时间片,可以利用cgroup的cpu.cfs_period_us、cpu.cfs_quota_us来干预CFS调度器的行为
- Pin CPU:可以将虚拟CPU Pin到一个物理CPU,或者一组共享缓存的物理CPU,便于缓存共享。缺点是Pin导致其它空闲CPU可能得不到利用
- 内存配置
- 使用内核特性KSM(Kernel Same Page Merging),KSM通过扫描将相同的内存区域设置为共享,并且Copy-on-write。共享内存节约可以内存空间,但是内存扫描同时影响性能
- 尽量避免使用swap,可以设置/proc/sys/vm/swappiness=0
- 网络配置
- 使用tap类型的网络后端
- 启用PCI passthough可以提高性能,但是影响迁移
HMI即 Human Monitor Interface,是QEMU在运行客户机时提供的一个console(下面我们称此console为Monitor),它让你可以和运行中的虚拟机进行交互,你可以获得内存Dump、列出虚拟设备树、获取屏幕截图等操作。
默认情况下QEMU使用SDL来显示客户机的视频输出,此所谓图形模式。如果启用-nographic选项则会禁用图形模式。
在图形模式下,你可以使用以下方式之一访问HMI:
- 在客户机的虚拟控制台(客户机弹窗)访问HMI,按Ctrl + Alt + 2可以切换到Monitor,在其中你可以调用HMI命令
- 指定-monitor stdio,则启动虚拟机的Terminal变为Monitor
在基于-nographic的非图形模式下,Monitor、虚拟串口都被重定向到stdio,你可以Ctrl + a c来切换。你可以同时把虚拟串口配置为系统控制台,这样你可以通过单个窗口完成客户机登录、HMI操作
| 命令 | 说明 | ||
| info |
显示客户机的相关信息,示例:
|
||
| memsave | Dump客户机内存到宿主机的文件 | ||
| screendump | 屏幕截图 | ||
| sendkey | 键盘控制,示例: sendkey ctrl-alt-f1 | ||
| quit | 退出客户机addr=0xM.0xN | ||
| system_powerdown | 关闭虚拟机电源 | ||
| system_reset | 重启虚拟机 | ||
| system_wakeup | 唤醒休眠中的虚拟机 | ||
| savevm |
保存一个虚拟机快照,示例: savevm blankos |
||
| loadvm | 从快照加载虚拟机,示例: loadvm blankos | ||
| delvm | 删除一个虚拟机快照 | ||
| snapshot_blkdev_internal | 创建一个内部的块设备(主要指硬盘)快照,示例:
|
||
| snapshot_delete_blkdev_internal | 删除一个内部的块设备快照 | ||
| snapshot_blkdev | 创建一个外部的块设备快照,示例:
如果指定了文件参数,则此文件成为新的root镜像 |
||
| migrate | 执行虚拟机迁移 | ||
| migrate_cancel | 取消虚拟机迁移 | ||
| migrate_set_speed | 限制迁移带宽消耗 |
该命令即QEMU模拟器,使用它可以指定硬件设备,并从虚拟磁盘镜像启动一台客户机。
| 选项 | 说明 | ||||
| -machine |
指定虚拟的客户机的类型及其属性,选项格式:
其中type为机器类型,可以调用 qemu-system-x86_64 -machine help 获得完整机器类型列表,每种机器都标注了主板芯片组的类型 你可以指定多个可选的属性: accel=accels1[:accels2[:...]] 启用加速器,可用的包括kvm、xen、tcg,加速器可以指定多个,后面的是备选 |
||||
| -cpu | 指定虚拟的CPU类型,可以通过 qemu-system-x86_64 -cpu help 查看可用CPU列表 | ||||
| -smp |
虚拟一个SMP系统,在PC机最多虚拟255CPU,选项格式:
你可以指定多个属性: |
||||
| -global | 设置驱动属性为指定的值,选项格式:
-global driver.prop=value ,示例:
使用该选项,你可以改变由机型(machine)预定义的设备属性,如果要添加设备,请使用-device |
||||
| -boot | 设置客户机的磁盘启动顺序,选项格式:
drives值指定为磁盘符号构成的字符串,这些符号的形式取决于客户机的架构,在X86 PC上: 你可以指定多个属性: |
||||
| -m | 设置客户机的内存大小,单位MB | ||||
| -mem-path | 从一个临时文件来创建客户机内存 可以同时指定 -mem-prealloc 来预分配内存 |
||||
| -soundhw | 启用声卡,选项格式:
|
||||
| -balloon |
控制KVM的Automatic Ballooning功能。virtio balloon设备可以减少KVM客户机的内存大小,该特性用于主持客户机内存的over-committing——宿主机只有2G内存的情况下,创建两台2G内存的客户机。只要客户机实际使用的内存不到2G,那么多余的部分就可以返还给宿主机 选项格式:
|
||||
| -device driver | 添加一个设备驱动,并指定驱动属性,可用的属性取决于具体的驱动,选项格式:
要获得可用驱动、属性列表,可以: -device help 和 -device driver,help 对于连接到PCI总线的设备,可以指定: 该选项可以用于添加客户机的多种虚拟设备并进行细节上的配置(代替部分选项例如-boolean、-net nic),例如:
|
||||
| -name | 设置客户机的名称 | ||||
| -uuid | 设置客户机的UUID | ||||
| 块设备选项 | |||||
| -fd* | -fda、-fdb指定0、1软盘的镜像文件,你可以使用主机的软盘,例如/dev/fd0 | ||||
| -hd* | -hda、-hdb、-hdc、-hdd指定0、1、2、3硬盘的镜像 | ||||
| -cdrom | 指定光驱镜像,你可以可以使用主机的光驱,例如/dev/cdrom | ||||
| -drive |
定义一个新的磁盘驱动器,选项格式: -drive option[,option[,option[,...]]] 你可以使用以下子选项: cache的默认取值是writeback,该选项意味着,一旦数据进入宿主机的页缓存,QEMU就向客户机报告“写入已完成”。如果客户机程序正确的flush磁盘缓存,此选项是安全的。否则,宿主机断电将会导致客户机数据损坏。 代替-cdrom的配置:
-drive file=file,index=2,media=cdrom
|
||||
| -mtdblock | 指定主板内置闪存的镜像文件 | ||||
| -sd | 指定SD卡镜像 | ||||
| -snapshot | 写入到临时文件,而非硬盘镜像文件,这样,原始硬盘文件就不会被改变 | ||||
| 显示选项 | |||||
| -display | 选择一个显示类型: curses 基于curses输出,如果客户机的图形设备支持文本模式,QEMU基于curses/ncurses接口显示输出;如果客户机图形设备运行在图形模式或者不支持文本模式,则不显示 none 不显示视频输出,客户机仍然可以模拟一个图形卡但是其输出不会显示给用户。该选项与-nographic不同,后者具有附加效果——改变串口、并口数据的目的地 gtk 在一个GTK窗口中显示视频输出 vnc 启动一个VNC服务器 |
||||
| -vnc | 配置VNC,例如 -vnc 0.0.0.0:10 | ||||
| -nographic |
通常情况下,QEMU基于SDL库来显示VGA输出,如果使用该选项,则QEMU成为完全的命令行程序 尽管如此,QEMU还是把虚拟的串口重定向到控制台、与monitor复用。你可以基于串口控制台来调试虚拟机的内核 你可以在console和monitor之间切换 |
||||
| -curses |
在文本模式下,直接在当前Terminal显示VGA输出,在图形模式下则什么都不显示,仅提示“1024 x 768 Graphic mode”之类的信息 |
||||
| -no-frame | 不显示虚拟机窗口的外框、标题栏 | ||||
| -vga | 指定虚拟的VGA显卡类型,可用的包括: cirrus 默认,Cirrus Logic GD5446显卡,对于Windows,所有Win95之后的系统都能够识别此卡 std 支持Bochs VBE扩展的标准VGA扩展,如果客户机OS支持VESA 2.0 VBE扩展(例如XP)并且你希望使用高分辨率 vmware Vmware的SVGA-II兼容显卡 qxl 使用spice协议时推荐此卡 none 禁用VGA显卡 |
||||
| -full-screen | 以全屏模式启动 | ||||
| -g | 设置初始的分辨率和颜色深度,选项格式: -g widthxheight[xdepth] | ||||
| 网络选项 | |||||
| -net nic |
创建一个新的网卡并把它连接到一个VLAN,选项格式:
你可以指定以下属性: |
||||
| -netdev user -net user |
添加一个User网络后端,选项格式:
你可以指定以下属性: |
||||
| -netdev tap -net tap |
添加一个TAP网络后端,连接宿主机的TAP网络接口到VLAN,选项格式:
你可以指定以下属性: |
||||
| -netdev bridge -net bridge |
添加一个TAP网络后端,连接宿主机的TAP网络接口到宿主机的一个网桥,这是TAP后端的script-free的简化版,选项格式:
你可以指定以下属性: 此后端需要读取配置文件:
|
||||
| 字符设备选项 | |||||
| -chardev |
字符设备选项的通用格式为:
backend 包括: null, socket, udp, msmouse, vc, ringbuf, file, pipe, console, serial, pty, stdio, braille, tty, parallel, parport, spicevmc. spiceport |
||||
| -chardev null | 其行为类似于/dev/null | ||||
| -chardev vc |
连接到QEMU的文本控制台(text console),选项格式:
width/height 控制台的宽度高度、单位像素 cols/rows 匹配文本控制台宽高 |
||||
| -chardev ringbuf |
创建一个固定大小的环形缓冲区,选项格式: -chardev ringbuf ,id=id [,size=size] size 必须是2的幂,默认64K |
||||
| -chardev pipe | 创建一个双向的管道文件,选项格式: -chardev pipe ,id=id ,path=path | ||||
| -chardev file | 记录来自客户端的流落到文件,选项格式: -chardev file ,id=id ,path=path | ||||
| -chardev console | 发送来自客户端的流量到QEMU的标准输出 | ||||
| -chardev serial |
发送来自客户端的流量到宿主机的一个串口设备,选项格式: -chardev serial ,id=id ,path=path path 宿主机的串口设备 |
||||
| -chardev pty | 在宿主机上创建一个新的伪终端,并连接到它 | ||||
| -chardev tty |
在Unix-like系统上可用,-chardev serial的别名 所谓TTY,即电传打字机,是由一个键盘、一个打印机组成的设备,在键盘上每打印一个字就会打印到纸张上。这个概念借用到UNIX领域,则打印的目标变成了屏幕。TTY可以用来指任何形式的Terminal,例如伪终端、虚拟控制台 |
||||
|
Linux/Multiboot相关 |
|||||
| -kernel |
指定内核镜像,目标镜像可以是Linux内核或者multiboot格式 |
||||
|
-append |
指定内核命令行参数 |
||||
| -initrd | 使用指定的文件作为初始内存盘(initial ram disk) | ||||
| 调试/专家选项 | |||||
| -serial |
-serial dev 重定向虚拟串口到宿主机的字符设备dev,默认设备:图形模式下是vs;非图形模式下是stdio 你可以指定此选项最多4次,模拟最多4个串口;指定 -serial none 禁用所有串口 可用的宿主机字符设备有: |
||||
| -monitor | -monitor dev 重定向monitor到主机的字符设备dev,可用设备同上 | ||||
| -qmp | -qmp dev 类似于-monitor但是以control模式开启 | ||||
| -debugcon | -debugcon dev 重定向调试控制台到宿主机字符设备 | ||||
| -pidfile | 存储QEMU进程的PID到文件 | ||||
| -enable-kvm | 启用基于KVM的全虚拟化支持 | ||||
| -no-reboot | 退出而不是重启 | ||||
| -no-shutdown | 当客户机关机时,不退出QEMU而仅仅是停止模拟。你可以切换到Monitor并提交修改到磁盘镜像 | ||||
| -loadvm | -loadvm file 从一个以保存的状态加载客户机 | ||||
| -daemonize |
在初始化后,让QEMU变成一个守护进程。使用该选项,可以让QEMU进程和当前Terminal解除关联 此选项在1.4之后不能和 -nographic 联用,但是可以和 -display none 联用 |
||||
| -readconfig | 从文件读取配置 | ||||
| -writeconfig | 把配置写入到文件,如果指定 - 则打印到屏幕 | ||||
在图形化模拟期间,你可以使用快捷键:
| 快捷键 | 说明 |
| Ctrl-Alt | 释放/获取鼠标键盘 |
| Ctrl-Alt-f | 切换全屏模式 |
| Ctrl-Alt-+ | 增大屏幕 |
| Ctrl-Alt-- | 减小屏幕 |
| Ctrl-Alt-u | 还原原始屏幕大小 |
| Ctrl-Alt-n | 切换到虚拟控制台n,标准控制台为: 1 客户机系统的显示 2 Monitor 3 串口 |
如果你使用了-nographic,则可以使用以下快捷键:
| 快捷键 | 说明 |
| Ctrl-a h | 打印帮助 |
| Ctrl-a x | 退出模拟器 |
| Ctrl-a s | 保存磁盘数据文件(如果使用-snapshot) |
| Ctrl-a c | 在控制台和Monitor之间切换 |
| Ctrl-a Ctrl-a | 发送Ctrl-a |
用于创建QEMU网络块设备(Network Block Device)服务器,即通过NBD协议把磁盘镜像暴露出去。 命令格式: qemu-nbd [OPTION]... diskimgfile 。
常用选项如下表:
| 选项 | 说明 |
| -p | NBD服务监听端口,默认1024 |
| -b | NBD服务器绑定的网络接口,默认0.0.0.0 |
| -k | NBD绑定的UNIX socket路径 |
| -o | 访问镜像文件的偏移量 |
| -f | 镜像文件格式 |
| -r | 仅允许只读访问镜像 |
| -P | --partition=num,仅暴露分区num |
| -s | 把diskimgfile作为外部快照使用,创建一个新的临时镜像,将其backing_file设置为diskimgfile,写操作都重定向到临时镜像 |
| -l | --load-snapshot=snapshot_param,加载diskimgfile中的一个内部快照,并暴露其为一个只读设备 snapshot_param可以是snapshot.id=id或者snapshot.name=name,或者直接写id/name |
| -n | 禁用缓存 |
| --cache=cache | 设置缓存模式,支持的模式参考qemu-system-x86 -drive cache= |
| --aio=aio | 选择AIO模式,threads或者native |
| -c | --connect=dev连接diskimgfile到一个NBD设备 |
| -d | 断开指定的设备 |
| -e | --shared=num 此设备可以被最多num个客户端使用 |
| -t | 即使最后一个连接断开,也不退出 |
报错信息:'virtio-9p-pci' is not a valid device model name
解决办法:参考下面的脚本构建QEMU:
|
1 2 3 |
apt install libattr1-dev configure --prefix=/usr --enable-virtfs make && make install |
报错信息:qemu-system-x86_64: -sdl: SDL support is disabled
解决办法:参考下面的脚本构建QEMU:
|
1 2 |
sudo apt install libsdl2-dev ./configure --prefix=/usr --enable-virtfs --enable-sdl |
报错信息:Image is corrupt; cannot be opened read/write
解决办法:
|
1 |
qemu-img check -r all /media/alex/v12n2/libvirt/images/xenial-23 |
Leave a Reply