Linux网络知识集锦
参考:
网络接口绑定(Network Interface Bonding)是Linux下的一项技术,它能够将多块物理网卡绑定为单一的逻辑网卡,从而实现:
- 带宽增加
- 提供容错能力,防止一根网线损坏的情况
也叫Teaming、 Link Aggregation Groups(LAG)。
你需要先安装bonding内核模块,并且用modprobe查看bonding驱动是否被加载:
|
1 2 |
sudo modprobe bonding lsmod | grep bond |
你需要先安装两块物理NIC,然后使用下面的命令将它们bond为新的逻辑接口:
|
1 2 3 |
sudo ip link add bond0 type bond mode 802.3ad sudo ip link set eth0 master bond0 sudo ip link set eth1 master bond0 |
或者永久化的配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
auto bond0 iface bond0 inet static address 192.168.1.150 netmask 255.255.255.0 gateway 192.168.1.1 dns-nameservers 192.168.1.1 8.8.8.8 dns-search domain.local slaves eth0 eth1 bond_mode 0 bond-miimon 100 bond_downdelay 200 bound_updelay 200 |
| 状态 | 说明 |
| LISTEN | 仅仅对于服务器端存在,正在指定的端口上监听 |
| ESTABLISHED | 三次握手完成,连接建立 |
| FIN_WAIT1 | |
| CLOSE_WAIT | |
| FIN_WAIT2 |
在FIN_WAIT_2状态,本端已经发送FIN,对端已经ACK。除非进行半关闭,否则对端的应用层已经意识到需要进行关闭,并向本端发送FIN来关闭另一方向的连接,只有对端完成这个关闭,本端才从FIN_WAIT_2进入TIME_WAIT状态。 这也意味着,本端可能一直处于FIN_WAIT_2,对端则一直处于CLOSE_WAIT,为了防止处于FIN_WAIT_2的无限等待,TCP实现中使用定时器进行处理 |
| TIME_WAIT |
TIME_WAIT又称2MSL等待状态。 每个TCP实现必须选择一个报文段最大生存时间(Maximum Segment Lifetime,MSL)—— 是任何报文段被丢弃前在网络内的最长时间。此外,由于IP数据报具有TTL,因此在网络上存在是有限制的。后者是基于跳数,而不是定时器。MSL的值通常是 30秒、1分钟或者2分钟。 对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIME_WAIT状态停留的时间为2倍的MSL,这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。 2MSL等待的结果是,2MSL期间定义连接的Socket(即:唯一标识Socket的四元组)不能再被使用。但是某些实现允许重用处于2MSL状态的端口(指定:SO_REUSEADDR) 服务器通常是被动关闭,不会进入TIME_WAIT状态 |
| CLOSED | 不是一个真实的状态,作为状态图假想的起终点 |
网络地址转换也称为网络掩蔽或者IP掩蔽(Masquerading),是一种在IP封包通过路由器或防火墙时重写源IP地址或目的IP地址的技术。该技术普遍用于只有一个公有IP的局域网中,允许局域网中多台主机与公网上的主机进行通信。NAT 功能通常被集成到路由器、防火墙、ISDN路由器或者单独的NAT设备中。
一个典型的局域网会使用一个专用网络来指定子网,最常用的是192.168.x.x,这个局域网中包含一个路由器,它占用一个IP地址(例如192.168.0.1)。路由器同时通过一个ISP提供的公有IP地址连接到因特网上。
当局域网上的主机需要和公网主机通信时,其发送IP封包,路由器将IP封包的源地址从专有地址192.168.0.x转换为公有地址(例如106.185.46.7),路由记住专有地址[:端口]与公有地址[:端口]的映射关系,当公网主机的IP封包到达时,利用此映射关系改写目的地址,进而转发给局域网主机。
上述的源地址、目的地址改写的过程即为NAT。
NAT的优势:
- 在IPv4短缺的情况下,可以使多台主机共享一个IP地址接入因特网
- 隐藏内网计算机,避免受到来自外部网络的攻击
NAT的缺点:
- 某些协议无法正常工作,例如主动模式的FTP。这些协议需要引入应用层网关(Application Layer Gateway,ALG)才能正常工作
亦可简称NAT或者静态NAT,仅支持地址转换,不支持端口映射。需要每一个连接对应一个公网IP地址,因此需要维护一个公网IP地址池。某些宽带路由器使用这种方式去指定一台局域网主机去接受所有外部连接,并称该机器为DMZ主机(并不是真正意义上的,因为DMZ主机必须与内网隔离)。
NAPT,该方式支持端口映射,允许多台内网主机共享一个公网IP地址,其包括两类转换功能:
- 源地址转换:发起连接的内网计算机的IP地址将会被重写,使得内网主机发出的数据包能够到达外网主机
- 目的地址转换:被连接内网计算机的IP地址将被重写,使得外网主机发出的数据包能够到达内网主机
这两种转换一般会一起使用,以支持双向通信。
NAPT需要维护一个NAT表,来基于内网IP/端口与公网IP/端口的对应关系,例如:
| 内网IP/端口 | 外网IP/端口 |
| 192.168.0.89:6443 | 106.185.46.7:9200 |
| 192.168.0.90:8897 | 106.185.46.7:9201 |
STUN标准将NAPT分为以下几个子类型:
| 类型 | 说明 |
| 完全圆锥型NAT | 一旦一个内部地址(iAddr:port1)映射到外部地址(eAddr:port2),所有发自iAddr:port1的包都经由eAddr:port2向外发送。任意外部主机(hAddr:*)都能通过给eAddr:port2发送封包到达iAddr:port1 |
| 地址受限圆锥型NAT |
与完全圆锥形 NAT类似,但是外部主机(hAddr:*)能通过eAddr:port2给iAddr:port1发送封包的前提是,之前iAddr:port1曾经发送封包到hAddr:*。星号表示任意端口 在应用受限圆锥形NAT时,外网主机不能主动发起最初的通信,内网主机为了让外网主机能与之通信,主动发起连接的行为,被称为“打洞” |
| 端口受限圆锥型NAT | 与地址受限圆锥形NAT类似,但是附加了一个端口限制,即:外部主机(hAddr:port3)能通过eAddr:port2给iAddr:port1发送封包的前提是,之前iAddr:port1曾经发送封包到hAddr:port3 |
| 对称NAT(symmetric) |
内部地址(iAddr:port1)向外部主机(hAddr:port3)发送封包,总是映射到同一个外部地址(eAddr:port2),不同的内部地址、外部主机地址组合总是映射到不同的外部地址。只有曾经收到过内部主机封包的外部主机,才能够把封包发回 一般注重安全性的大公司会启用对称NAT,以禁止P2P通信 |
NAT-T技术主要解决两台同时处于NAT设备后面的局域网主机建立网络连接的问题。
两台都处于NAT后面的主机,无法知道对方映射的公网地址/端口,因此,一般的NAT-T技术都需要一个公共服务器作为媒介:要么在建立连接的时候需要用到该服务器,要么所有的数据都通过此公共服务器中继。
假设:
- 位于NAT后的主机A(局域网IP:192.168.0.89,公网IP:106.185.46.7)
- 主机B(局域网IP:192.168.1.90,公网IP:106.185.46.10),以公网服务器S(106.185.46.1)为媒介(所谓STUN服务器),进行NAT-T的过程可能如下(A与B是对称的):
- A连接S,获得映射地址(192.168.0.89:35330 =>106.185.46.7:2250),将此地址信息告知S
- B连接S,获得映射地址(192.168.1.90:35330 =>106.185.46.10:3210),将此地址信息告知S
- A和B分别获取对方的两个地址
- A尝试连接B
- 如果B是完全圆锥型NAT,那么不论A是圆锥型、对称NAT,连接都立刻建立
- 如果B是地址或端口受限NAT,由于A之前从未与B通信过,因此无法建立连接
- 如果A是地址或端口受限NAT,与B的连接无法建立,但是A尝试发包到B的记录已经被A侧NAT记录。只要该记录没有过期,B就可以反过来向A发送数据,该数据 A必然收到,随后A和B即可双向通信
- 如果A是对称型NAT,B利用从S得到的关于A的信息(假设为192.168.0.89:35330 =>106.185.46.7:2250 => 106.185.46.1:3387),尝试向106.185.46.7:2250发送信息,由于A的对称NAT的限制,此尝试必然失败。但是,此尝试在B侧留下了NAT记录。如果
- B是地址受限NAT,那么A可以再次向B发送数据,这一次B必然收到
- B是端口受限NAT,则无法通信
- B是对称NAT的情况下,如果A是对称NAT或者端口受限圆锥型NAT,则双方无法通信
网桥(Bridge)是一种(可以是软件虚拟的)设备,该设备有两个或者多个网络接口,分别连接到多个局域网(不同网段)中。网桥将它连接的某个局域网发送的数据帧,统一转发到其它网络接口对应的局域网中,从而将多个网络在数据链路层无缝连接起来,就好像是一个局域网一样。任何真实设备(例如eth0)和虚拟设备(例如tap0)都可链接到网桥。
网桥与路由器不同,后者允许多个网络在保持独立的情况下能够相互通信。网桥的行为更像是一台虚拟的交换机,它能够透明的工作,其它主机不需要知道其存在。
Vmware中的桥接,和一般意义上的桥接原理是一样的,它让虚拟机网卡连接到一个虚拟的以太网交换机,虚拟以太网交换机与宿主机器的以太网卡通过一个“虚拟网桥”相连。
当你将一个网络接口(例如eth0)添加到Linux虚拟网桥(例如br0)时,你需要把IP地址从eth0移除,并添加到br0,这样才能保证网络正常工作。
这是因为,网桥br0负责处理本机eth0的入站流量,它应该响应ARP请求——这样它才能把流量转发给网桥中的其它网络接口,因而它拥有eth0的IP就很合理了(把网桥的MAC和IP关联)。
默认情况下,Bridge不允许包从收到包的端口发出。例如,当Bridge从一个端口接收到广播报文后,它会将报文向其它端口全部发出,而不包括接收的那个端口。
你可以在端口级别打开Hairpin模式,这样,从该端口进入网桥的包,还可以从此端口出去。在NAT场景下,例如Docker的NAT网络,从容器访问它映射(80)到的主机端口(8080)时:
- 容器访问hostip:8080
- 请求到达网桥,来自端口A
- 进入宿主机协议栈
- DNAT转换为continerip:80
- 协议包又要从A端口发出
为什么叫Hairpin,这是形象的描述流量的走向,就像最简单的U形发卡一样,封包经过网桥/路由处理后,从它来自的地方发回去。
当一张网卡被设置为混杂(Promicuous)模式,它就会接收网络上所有的数据帧,从而可以实现监听。
有多种方式可以检测处于混杂模式的网卡,假设现在怀疑硬件地址为38-83-45-09-0A-60、IP地址为192.168.1.5的网卡处于混杂模式,可以:
- 伪造ICMP报文:ECHO_REQUEST,即ping命令使用的报文,将其IP首部的目的地址设置为192.168.1.5,以太网帧首部的目的地址设置为虚假的地址00-00-00-00-00-00。如果192.168.1.5是正常的网卡,它将会检测硬件地址,发现与自己的地址不同,因而忽略此帧;反之,如果192.168.1.5处于混杂模式,则它不会做硬件地址的比较,报文直接交由上层处理,导致回复ICMP报文
- 以非广播方式在局域网内发送ARP请求,如果某个网卡回复之,则其可能处于混杂模式
首先要保证局域网的安全,因此这种监听只能出现在局域网内,因此必须有以太局域网主机被攻破。
另外数据加密也是比较好的手段,如果监听到的报文是加密的,没有什么用。
使用交换机也是一种常见的方式,交换机工作在数据链路层,与工作在物理层的HUB不同。交换机通常会维护一个ARP数据库,记录每个交换机端口绑定的MAC地址,当报文到达交换机时,它只会将其从匹配的端口发送出去。交换机只在两种情况下广播报文:
- 以太网帧的目的地址在本地ARP数据库中不存在
- 报文本身就是广播的
交换机可以在很大程度上解决监听问题,但是不能防止ARP欺骗。
所谓隧道(Tunneling),是指使用一种网络协议,并将另外一个网络协议封装在其载荷(或称负载,Payload)部分的技术。前者叫做隧道协议,后者叫做负载协议。使用隧道技术的目的一般是:
- 在不兼容的网络上传送网络协议数据报
- 在不安全的网络上提供安全性保证
- 规避防火墙,被防火墙阻挡的协议可以封装在不被阻挡的协议中,例如HTTP
通常,隧道协议往往位于负载协议的高层(例如PPTP,即点对点隧道协议,可以通过TCP来封装PPP,前者工作在传输层,而PPP是链路层协议),或者与负载协议处于同一层。
Linux L3的隧道技术,主要基于TUN设备实现。
常见的隧道协议包括:
| 协议 | 说明 |
| IPsec | 即互联网安全协定(Internet Protocol Security)。该协议通过对IP协议的分组进行加密、认证,来保护TCP/IP协议族的安全性 |
| GRE | 即通用路由封装(Generic Routing Encapsulation)。可以在虚拟的点对点链路中封装多种网络层协议 |
| IP in IP | 一种IP隧道协定,可以将IP封包封装进另外一个IP封包中 |
| L2TP |
即第二层隧道协议(Layer Two Tunneling Protocol)。是一种VPN的实现方式。L2TP本身不提供加密和验证功能,需要和某种安全协议搭配使用(例如IPsec) L2TP封包使用UDP来传送。每个高层协议,例如PPP,都可以在L2TP隧道中建立一个L2TP会话,一个隧道里面可以包含多个会话 |
| PPTP | 即点对点隧道协议(Point to Point Tunneling Protocol)。是一种VPN的实现方式。PPTP使用TCP来创建控制通道,来发送控制命令,并使用GRE通道来封装PPP协议数据报,以发送数据。该协议的加密方式容易被破解 |
| PPPoE | 即基于以太网的点对点隧道协议(Point-to-Point Protocol over Ethernet)。是将PPP协议封装在以太网中的一种隧道协议 |
| PPPoA | 即基于异步传输模式的点对点隧道协议(Point-to-Point Protocol over ATM) |
| SSH | 即安全外壳协议(Secure Shell Protocol)。是一项跨越多个层次的协议,为Shell提供安全的传输和使用环境。SSH提供了数据压缩的功能。 |
| SOCKS | 即套接字安全协议(Socket Secure)。用于通过一个代理服务器在客户端和服务器之间路由数据包 |
在传统TCP/IP术语中,网络设备只分为网关、主机(亦称终端系统)两种,前者能够在网络间传递数据报。网关的数据处理一般只到达第三层(IP层)。网关与路由器在传统TCP/IP术语中往往是一个概念。
现代网络术语中,网关与路由器不同,网关能够在不同协议之间移动数据;而路由器则是在不同网络之间移动数据。例如,语音网关可以连接公共交换电话网(PSTN)与以太网,实现网络电话。
多播(MultiCast)也称为组播,包括链路层、网络层、应用层等多播技术。多播通常指IP多播(网络层)。
由于在IPv4网络中,多播包可能不被路由,因此你只能在局域网中使用多播技术。DVMRP、MOSPF 之类的技术解决此问题,但是你需要能够对客户端 - 服务器之间所有路由器进行配置,或者创建隧道。IPv6网络是强制支持IP多播的。
网络虚拟化是一个很大的技术方向,可以包括硬件、软件或者相结合的实现方式。
Linux内核支持的网络虚拟化,主要包括两个方面:
- 软交换机:Linux Bridge, OpenVSwitch
- 虚拟网络适配器:tun、tap、veth等
VLAN(Virtual Local Area Network)是广泛应用的网络虚拟化(在一套物理网络设备上虚拟出多个二层网络)技术,它直接在Ethernet帧的头部加上4个字节的VLAN Tag,此Tag用于标识不同的二层网络。VLAN已经在大部分的网络设备和操作系统中得到了支持,它处理起来也比较简单,在读取Ethernet数据的时候,只需要根据EtherType相应的偏移4个字节就行。利用VLAN可以:
- 将主机进行分组,即使主机不是连接到同一交换机上
- 可以对连接到相同交换机/网桥上的主机/客户机进行隔离,划分到不同子网。这样一个交换机就可以表现的像是多个独立交换机一样
VLAN ID的范围是1 - 4095,对于规模较大的IT组织,需要谨慎规划子网,否则VLAN ID可能不够用。
假设你的IT环境下有一个物理交换机,连接着一系列物理主机,现在需要划分为三个独立网络。管理员配置交换机端口,将它们的VLAN ID分别设置为10 11 12,不同网络的主机分别连接到对应的端口。这种仅仅配置针对单个VLAND的端口,叫做access port。
随着规模的增大,一个交换机不够用了,管理员又引入一个交换机。这样,两个交换机必须都有一个端口,它允许任何以太网帧通过,而不管帧的VLAN ID,否则就无法联通了。这种不过滤VLAN ID的端口叫做trunk port。
在虚拟化环境下,交换机的所有端口都会配置为trunk port。这样,每个端口(也就是主机)上都可以运行不同虚拟网络的VM。
VXLAN(Virtual eXtensible Local Area Network)是目前最热门的网络虚拟化/Overlay/虚拟隧道技术之一,VXLAN协议将Ethernet帧封装在底层网络(Underlay)的三层报文(UDP)内,再加上8个字节的VXLAN header,用来标识不同的二层网络:

VXLAN数据是经过VTEP(VXLAN Tunnel EndPoint)封装和解封装的,相应的VXLAN数据的外层UDP封包的IP(源、目的)地址就是VTEP(本机、对方)的IP地址,端口就是VTEP设备的端口(默认4789)。最外层的MAC地址用来实现VTEP之间的数据传递。每个物理节点上的所有虚拟机可以共享VTEP。VTEP可以由软件(例如OVS)或硬件实现。
VXLAN因为提出的较晚,在设备上的支持率不如VLAN,而且,VXLAN数据的封装解封装,要比VLAN复杂的多。但是它具有以下优势:
- VLAN ID数量限制:8个字节的VXLAN Header。其中的24bit用来标识(VNI,VXLAN Network Identifier)不同的二层网络,这样总共可以标识1600多万个不同的二层网络
- TOR交换机MAC地址表限制:在网络虚拟化之前,TOR交换机的一个端口连接一个物理主机对应一个MAC地址,但现在交换机的一个端口虽然还是连接一个物理主机但是可能进而连接几十个甚至上百个虚拟机和相应数量的MAC地址,MAC地址表记录在交换机的内存中,而交换机的内存是有限的。如果使用VXLAN,虚拟机的以太网帧被VTEP封装在UDP里面,一个VTEP可以被一个物理主机上的所有虚拟机共用
- 灵活的虚机部署:采用VLAN网络的虚拟环境,不存在Overlay网络。虚拟机的网络数据,被打上VLAN Tag之后,直接在物理网络上传输,与物理网络上的VLAN是融合在一起的。这种实现机制的好处是:虚拟机能直接访问到物理网络的设备。而坏处是,无法突破物理网络的限制,通常不同的VLAN网络,会被分配不同的IP地址段,通过路由器或者其他的三层设备连接在一起,不同VLAN的虚拟机不能方便的进行L2通信。使用VXLAN后,由于基于UDP进行封装,因此可以在L2或L3网络上构建L2网络,这是一个独立于物理网络的Overlay network
和普通隧道(例如ipip)不同,VXLAN是一对多的,而不是1:1的隧道协议。VXLAN设备可以像网桥那样,动态添加对端IP地址。严格来说,VXLAN模型中并没有隧道的物理实体。
配置和管理VXLAN,需要内核版本3.7以上的iproute2包,ip命令即此包的用户空间工具。
VXLAN报文的转发过程如下:
- 原始报文经过源主机上的VTEP设备,被Linux内核添加VXLAN包头、外层UDP头,发送出去
- 对端VTEP设备接收到VXLAN报文,移除UDP头,然后根据VXLAN头决定发给哪个虚拟机
在通信之前,需要回答以下三个问题:
- 哪些VTEP需要加到同一VNI组
- 源虚拟机如何知道目的虚拟机的MAC地址
- 如何知道目的虚拟机在哪个节点
问题1,通常由管理员进行配置。问题2/3本质上是一个问题 —— VXLAN通信双方如何感知彼此:
- 内层报文,双方IP地址可以认为是已知
- 内层报文,对方MAC地址,需要实现一种ARP机制
- VXLAN头,只需要知道VNI,通常直接配置在VTEP上 —— 要么提前规划,要么根据内层报文自动生成
- UDP头,需要知道源、目的地址/端口。源地址端口自动获取,目的端口一般默认4789,目的IP地址亦即目标主机的VTEP地址,可以通过两种方式得到:
- 组播:同一个VXLAN网络的VTEP加入到同一组播网络中,通过组播同步信息
- 控制中心:集中式保存需要的信息
这种配置下,两台机器构成一个VXLAN网络,每个机器上配置一个VTEP,VTEP之间通过它们的IP地址进行通信。
首先,需要添加VXLAN类型的接口:
|
1 2 3 4 |
# 接口类型 VNI 对端端口 ip link add vxlan0 type vxlan id 1 dstport 4789 # 对端Underlay地址 本地Underlay地址 物理网络接口 remote 192.168.1.3 local 192.168.1.2 dev ens33 |
为VTEP分配IP地址并启用之:
|
1 2 3 |
# 自动添加路由 172.17.1.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan0 ip addr add 172.17.1.2/24 dev vxlan0 ip link set vxlan0 up |
此时你可以看到如下FDB(Forwarding information base,也叫MAC表)表项:
|
1 2 |
bridge fdb 00:00:00:00:00:00 dev vxlan0 dst 192.168.1.3 via ens33 self permanent |
该项的含义是, 默认的VTEP对端地址为192.168.1.3。原始报文经过vxlan0接口后,内核会为其添加VXLAN头部,外部封装的UDP包的目的IP地址会被设置为192.168.1.3。
在对端,你需要进行对应的配置,VNI必须保持一致。
该模式需要Underlay网络支持组播。首先创建VTEP:
|
1 2 |
# VNI # 使用ens33上的多播组239.1.1.1进行信息交换 ip link add vxlan0 type vxlan id 1 local 192.168.1.2 group 239.1.1.1 dev ens33 dstport 4789 |
和点对点模式类似的,你需要为VTEP配置IP地址并且启用之。此时,你可以看到如下FDB表项:
|
1 |
00:00:00:00:00:00 dev vxlan0 dst 239.1.1.1 via ens33 self permanent |
和点对点模式不同的是,dst字段的值设置为组播地址,而非对端Underlay IP地址。这个条目会导致默认情况下UDP头的目的地址被设置为组播地址239.1.1.1。
在所有参与到VXLAN的节点上,你需要进行对应的配置,VNI必须保持一致。
该模式下VTEP之间通信过程如下:
- 主机1通过vxlan0发起ping 172.17.1.3报文到主机2的vxlan0
- 主机1内核发现目的地址和源地址在同一二层网络中,需要获取对方MAC地址,但是本地没有缓存,因此发送ARP查询请求
- ARP报文源MAC地址为主机1的vxlan0的MAC地址,目的地址为广播地址255.255.255.255
- 内核将ARP报文封装到UDP中,设置VXLAN头。由于VTEP配置了多播组,同时不知道目标VTEP在哪台主机上,因此会从239.1.1.1发送组播报文
- 多播组中所有主机都会收到UDP报文,并根据VXLAN头发送给对应的VTEP
- VTEP去掉VXLAN头,得到ARP请求报文,并将源VTEP的MAC地址+源主机IP地址信息记录到FDB表中
- 主机2发现ARP请求是针对自己的,因此生成ARP应答,并且单播(因为已经知道主机1的IP-MAC对应关系)给主机1的VTEP
- ARP应答通过底层网络发送给主机1,解析后发送给vxlan0,VTEP解析ARP报文并更新VTEP缓存,同时根据报文学习得到目的VTEP所在的主机地址,添加到自己的FDB表
实际情况下,每个主机都可能有几十甚至上百个虚拟机/容器,需要加入到同一个VLAN中,而每个VLAN在一台主机上仅仅有一个VTEP。
一个简单的解决办法是桥接。对于容器场景,可以用VETH Pair将容器连接到网桥,然后将VTEP也连接到网桥。VTEP通过物理网络相互联系。
由于某些网络设备不支持多播,而且多播导致的不必要流量,在生产环境下VXLAN多播模式用的很少。
生产环境主要使用分布式控制中心架构,在每个VTEP节点部署Agent,Agent联系控制中心,获取通信所需要的信息(FDB+ARP)。
L2设备,一种虚拟的网桥(Bridge),它是:
- 一种网络设备,因此可以配置IP地址、MAC地址
- 虚拟交换机,具有和物理交换机类似的能力
普通网络设备只有两个Port,一端的数据会从另外一端出去。例如物理网卡,会从外部接收数据,发往内核协议栈,或者从内核协议栈接收数据发送到外部。
Bridge则不同,它具有多个Port,数据可以从任何端口进来,至于从哪个端口出去,原理类似于物理交换机 —— 要看MAC地址。
Bridge被广泛用于KVM/QEMU、容器技术。
下面的命令创建并启用一个网桥:
|
1 2 3 4 5 |
ip link add name br0 type bridge ip link set br0 up # 或者使用brctl命令 brctl addbr br0 |
刚创建的网桥,一端连接着网络协议栈,其余什么都没有连接,因此没有任何功能。
下面我们创建veth对:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
ip link add veth0 type veth peer name veth1 ip addr add 1.2.3.101/24 dev veth0 ip addr add 1.2.3.102/24 dev veth1 ip link set veth0 up ip link set veth1 up # 接受源自本地IP的ARP包 echo 1 > /proc/sys/net/ipv4/conf/all/accept_local # 不进行源地址校验 echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter # 现在测试是可以通的 # 由于目的地址是本地地址,默认会走lo,因此用 -I 强制指定PING请求的源地址/源接口 ping -c 1 -I veth0 1.2.3.102 |
并且将其一端连接到网桥:
|
1 2 3 |
ip link set dev veth0 master br0 # 或者使用brctl命令 brctl addif br0 veth0 |
使用下面的命令查看网桥上连接了哪些设备:
|
1 2 3 4 5 6 7 8 9 |
bridge link # 9: veth0 state UP : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2 # 或者使用brctl命令 brctl show # bridge name bridge id STP enabled interfaces # br0 8000.4a4c11893317 no veth0 # docker0 8000.02428b446c5b no # virbr0 8000.deadbeef0000 no virbr0-nic |
现在:
- br0和veth0连接起来,双向通道
- 协议栈和veth0是单向通道,协议栈可以发数据给veth0,veth0从外部接受的数据不能发送给协议栈
- br0的MAC地址变成veth0的MAC地址
相当于br0在veth0和协议栈之间做了拦截 —— 本来veth0发给协议栈的数据,全部转发给br0处理了。
而且,veth0和veth1之间也不通了:
|
1 2 |
ping -c 1 -I veth0 1.2.3.102 # From 1.2.3.101 icmp_seq=1 Destination Host Unreachable |
原因是什么呢?下面在veth1、veth0、br0上分别抓包:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
tcpdump -n -i veth0 # tcpdump: verbose output suppressed, use -v or -vv for full protocol decode # listening on veth0, link-type EN10MB (Ethernet), capture size 65535 bytes # 22:37:16.291125 ARP, Request who-has 1.2.3.102 tell 1.2.3.101, length 28 # 22:37:16.291165 ARP, Reply 1.2.3.102 is-at ce:97:9b:c2:d1:ee, length 28 tcpdump -n -i veth1 # tcpdump: verbose output suppressed, use -v or -vv for full protocol decode # listening on veth1, link-type EN10MB (Ethernet), capture size 65535 bytes # 22:37:16.291140 ARP, Request who-has 1.2.3.102 tell 1.2.3.101, length 28 # 22:37:16.291163 ARP, Reply 1.2.3.102 is-at ce:97:9b:c2:d1:ee, length 28 tcpdump -n -i br0 # tcpdump: WARNING: br0: no IPv4 address assigned # tcpdump: verbose output suppressed, use -v or -vv for full protocol decode # listening on br0, link-type EN10MB (Ethernet), capture size 65535 bytes # 22:37:16.291165 ARP, Reply 1.2.3.102 is-at ce:97:9b:c2:d1:ee, length 28 # 22:37:17.289325 ARP, Reply 1.2.3.102 is-at ce:97:9b:c2:d1:ee, length 28 |
可以看到,veth0、veth1正常进行了ARP请求、响应,br0则仅仅监控到响应。但是veth0却不能将ARP应答发给协议栈,因此无法通信。 具体分析:
- Ping命令发起ICMP请求,设置IP封包的源接口为veth0
- 内核接受到上述封包,发送到目的地址1.2.3.102之前,发现没有ARP缓存,无法生成L2帧
- 内核发送ARP请求,从veth0发出
- veth1接口接收到ARP请求,并正常响应之
- veth0接收到响应
- veth0将响应通过交换机br0发送,而非内核
- 内核没有接收到ARP响应,L2帧发送失败,Ping失败
下面,把veth0的IP地址转让给br0:
|
1 2 |
ip addr del 1.2.3.101/24 dev veth0 ip addr add 1.2.3.101/24 dev br0 |
现在,veth0没有IP地址了,因此协议栈在路由的时候,不会将数据包发送给veth0。这意味着,协议栈到veth0的单向通道也断了,veth0单纯变成了连接br0和veth1的网线。
从br0 Ping veth1现在可以收到ICMP应答报文。报文流转路线:内核 - br0 - veth0 - veth1 - 内核 - veth1 - veth0 - br0 - 内核,但是却还不能联系到外部网络。另外,veth0仍然无法Ping通veth1,原因还是无法将ARP应答返回给内核。
现在,再把物理网卡添加到网桥:
|
1 |
ip link set dev eth0 master br0 |
现在eth0也和veth0一样,接受到的封包直接转发给br0,而不发给协议栈,自己变为一根网线。eth0、veth0无法Ping通网关,而br0则通过eth0这根网线连接到网关,veth1也可以通过br0 ping通网关。
这时,eth0已经成为一根网线,它上面配置IP没有意义,反而会影响路由表:
|
1 |
ip addr del 192.169.1.105/24 dev eth0 |
eth0被删除后默认路由消失,重新添加默认路由后,可以从veth1连接外部网络。
对于虚拟机来说,通常通过tun/tap等网络设备,将虚拟机内的网卡连接到网桥,再由网桥转发给出去。
对于容器来说,每个则通常使用veth对。容器的网关被桥接到br0,且网关设置为br0。容器IP封包发到br0后,进入宿主机协议栈。宿主机需要配置IP转发功能,可以把容器IP封包转发出去。由于容器、宿主机物理网络通常不是一个网段,因此转发出去之前通常需要NAT。
混杂模式下,网卡会把所有接收到的流量交给协议栈处理,不管目的MAC地址是否匹配。
使用下面的命令,使网卡进入混杂模式:
|
1 |
ifconfig eth0 promisc |
使用下面的命令则退出混杂模式:
|
1 |
ifconfig eth0 -promisc |
需要注意的时,加入到网桥后,设备自动进入混杂模式。退出网桥后则自动退出混杂模式。另外加入网桥期间,设备无法退出混杂模式。
通过网桥,可以协助处理虚拟化/命名空间下的基于多VLAN的网络虚拟化。
VLAN filtering是在3.8引入的特性,可以简化基于VLAN的网络虚拟化的配置复杂度。利用VLAN filtering,管理员不需要创建大量的VLAN、Bridge。使用一个网桥,你就能够控制所有VLAN。
这里我们看一个在虚拟化中广泛使用的网络拓扑:不同子网的虚拟机通过网桥,通过bond做负载均衡,最后连接到物理网卡。
没有VLAN filtering之前,拓扑图如下:
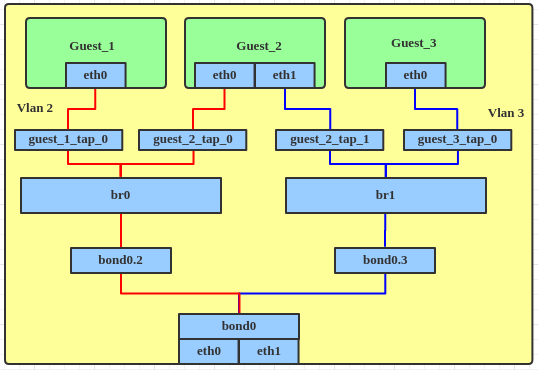
创建此拓扑的步骤:
- 创建bond设备,作为两张物理网卡的master:
12345678910ip link add bond0 type bondip link set bond0 type bond miimon 100 mode balance-albip link set eth0 downip link set eth0 master bond0ip link set eth1 downip link set eth1 master bond0ip link set bond0 up - 在bond0上创建VLAN子接口:
12345ip link add link bond0 name bond0.2 type vlan id 2ip link set bond0.2 upip link add link bond0 name bond0.3 type vlan id 3ip link set bond0.3 up -
将VLAN子接口分别连接到一个网桥:
1234567ip link add br0 type bridgeip link set bond0.2 master br0ip link set br0 upip link add br1 type bridgeip link set bond0.3 master br1ip link set br1 up -
将代表虚拟机的TAP设备也连接到网桥:
12345ip link set guest_1_tap_0 master br0ip link set guest_2_tap_0 master br0ip link set guest_2_tap_1 master br1ip link set guest_3_tap_0 master br1
如果使用了VLAN filtering,就不需要创建bond的VLAN子接口,也仅需要一个网桥:
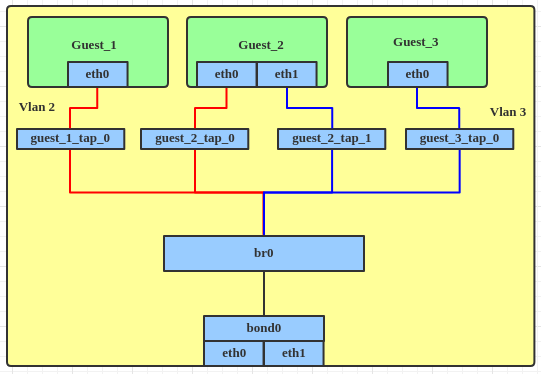
创建此拓扑的步骤:
-
创建bond设备:
1234567ip link add bond0 type bondip link set bond0 type bond miimon 100 mode balance-albip link set eth0 downip link set eth0 master bond0ip link set eth1 downip link set eth1 master bond0ip link set bond0 up -
创建网桥,启用VLAN Filtering:
12345ip link add br0 type bridgeip link set br0 upip link set br0 type bridge vlan_filtering 1ip link set bond0 master br0 -
将TAP连接到网桥:
12345ip link set guest_1_tap_0 master br0ip link set guest_2_tap_0 master br0ip link set guest_2_tap_1 master br0ip link set guest_3_tap_0 master br0 - 为这些TAP接口、Bond接口设置VLAN filter:
12345678bridge vlan add dev guest_1_tap_0 vid 2 pvid untagged masterbridge vlan add dev guest_2_tap_0 vid 2 pvid untagged masterbridge vlan add dev guest_2_tap_1 vid 3 pvid untagged masterbridge vlan add dev guest_3_tap_0 vid 3 pvid untagged masterbridge vlan add dev bond0 vid 2 masterbridge vlan add dev bond0 vid 3 master
简单的理解:TUN/TAP就是针对用户空间程序而不是物理媒体的网络接口,这种网络接口的一端连接着网络协议栈,另一端连接着用户空间程序。不同于普通靠硬件板卡实现的设备,TUN/TAP全部用软件实现,并向运行于操作系统上的软件提供与硬件的网络设备完全相同的功能。
TUN/TAP为用户空间程序提供数据包的收发功能,它可以呈现为简单的点对点设备或者以太网设备,与物理设备不同的是,它从用户空间程序接收数据包而不是物理媒体;同样的,它将数据包发送给用户空间程序,而不是物理媒体。操作系统通过TUN/TAP设备发送的数据包,被分发给关联到这些设备的用户空间程序中。用户空间程序也可以将数据包发给TUN/TAP设备,后者把数据包注入到操作系统的网络栈之中,模拟为来自外部的数据。
要使用TUN驱动,必须打开/dev/net/tun文件,并发起相应的ioctl()调用,来向内核注册一个网络设备,这些网络设备可以通过ifconfig看到,名字为tunXXX或者tapXXX(依据调用时的选项)。当关闭文件描述符时,这些网络设备连同相应的路由会消失。用户程序写入/dev/net/tun文件的数据,会写到内核网络协议栈;用户程序从/dev/net/tun文件读取时,则拿到内核发送给tun设备的IP封包。
要使用TAP驱动,基本和TUN完全相同,区别有几点:
- tun设备的/dev/tunX工作在L3,可以通过IP转发和物理网卡连通
- tap设备的/dev/tapX工作在L2,可以和物理网卡进行桥接
TUN模拟了网络层(点对点)设备,操作第三层数据包比如IP数据封包。普通的网卡通过网线收发数据包,但是 TUN 设备通过一个文件收发数据包。所有对这个文件的写操作会通过 TUN 设备转换成一个数据包送给内核;当内核发送一个包给 TUN 设备时,通过读这个文件可以拿到数据包的内容:
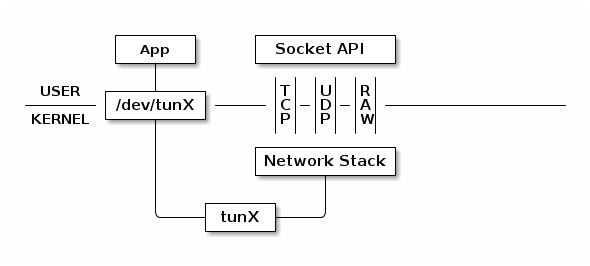
TUN 设备的 /dev/tunX 文件收发的是 IP 层数据包,只能工作在 IP 层,无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。
TUN的含义即隧道,实际上TUN的确和隧道技术有关系。tun/tap设备将协议栈的部分数据转发给用户空间程序,使之有处理数据包的机会,例如加密、压缩。VPN是最常见的应用场景。下面是基于TUN设备实现VPN的过程:
- 本地应用构造一个数据包,发送给tun0所在网段(虚拟网络)的IP地址192.168.1.3
- 数据包到达内核协议栈后,根据目的IP地址判断需要从tun0发出
- tun0的一端连接着内核协议栈,另一端则连接着用户空间应用 —— VPN程序
- VPN程序对数据包进行再次封装,源地址设置为eth0,目的地址设置为eth0所在网段的VPN对端物理机IP地址
- 封装后数据包发送到协议栈,走eth0发送到VPN对端
Linux的L3隧道技术都是基于TUN设备,包括ipip、GRE、sit、ISATAP、VTI等。
TAP 等同于一个以太网设备,它操作第二层数据包如以太网数据帧。TAP的工作方式和TUN完全相同。
TAP 设备的 /dev/tapX 文件收发的是 MAC 层数据包,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。
Libvirt创建的VM,会在宿主机上对应一个vnet*接口,这个接口桥接到网桥设备virbr*:
|
1 2 3 |
virbr0 8000.100000000000 no virbr0-nic vnet0 vnet1 |
这些vnet接口,就是TAP设备,它关联到一个进程,即运行qemu-kvm模拟器的那个进程。qemu-kvm写入到此接口的数据,在宿主机看来,就好像从vnet这个网卡接收到的封包似的。反之亦然,qemu-kvm从此接口读取的数据,会写入到虚拟机的eth0,在虚拟机看来,就好像是从网卡接收到封包似的。
也是虚拟的以太网设备,可以作为网络命名空间的隧道,让两个网络命名空间可以通信。VETH也能够作为独立网络设备使用。从效果上说,VETH就像是两个网络接口通过RJ45网线连接在一起似的。
VETH设备总是成对形式创建的:
|
1 2 3 4 5 6 7 8 9 |
# 创建一对veth,相互连接起来 ip link add veth0 type veth peer name veth1 # 查看veth对 ip link list # 13: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 # link/ether 72:a4:a7:eb:e8:db brd ff:ff:ff:ff:ff:ff # 14: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 # link/ether 46:ba:9b:5e:3a:27 brd ff:ff:ff:ff:ff:ff |
从一端发送的数据,会立即在另一端接收到。任何一端Down掉或删除,则veth对的状态被破坏。
可以把veth放到其他网络命名空间:
|
1 2 3 4 5 |
# 创建一个新的网络命名空间 ip netns add test # 移动veth1 ip link set veth1 netns test |
移动了以后,从当前命名空间看到的,Peer的名字会变化:
|
1 2 3 4 5 6 7 8 9 |
# 默认命名空间看veth1变为if13,表示Peer是test命名空间序号为13的网络接口 ip link show veth0 # 14: veth0@if13: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 # link/ether 46:ba:9b:5e:3a:27 brd ff:ff:ff:ff:ff:ff link-netnsid 3 # test命名空间看veth0变为if14,和上面的序号14匹配 ip netns exec test ip link show veth1 # 13: veth1@if14: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 # link/ether 72:a4:a7:eb:e8:db brd ff:ff:ff:ff:ff:ff link-netnsid 0 |
在宿主机上,通过设置路由,可以让其他网络命名空间的流量通过veth对出站。
VETH和TAP都是用来传递L2以太网帧的,TAP/TUN常用于用于加密、VPN、隧道、虚拟机,VETH常用于不同命名空间之间进行数据穿越。这有历史问题在里面。
下面是OpenStack创建了新的虚拟机vm0后的网络架构图:
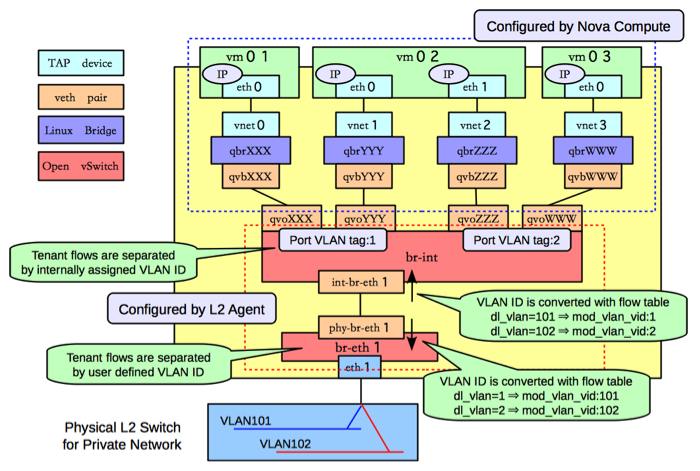
关于虚拟机vm0的网络模型,说明如下:
- 虚拟机中的eth0,连接到vnet0,vnet0是Linux网桥qbrXXX的TAP接口
- Linux网桥qbrXXX连接到OVS网桥br-int,通过一对VETH qvbXXX - qv0XXX
可以看到,通过TAP将虚拟机连接到第一个网桥qbrXXX,而VETH对则将第一个网桥连接到第二个。为什么需要两根RJ45网线呢?用其中一个不行么?
主要原因是遗留技术的存在:
- 当KVM产生一个虚拟机,它期望一个TAP接口连接到虚拟机的以太网端口(eth0),这样KVM就得到一个FD,它在其上读写以太网帧。也就是说TAP是去不掉的
- 而VETH是相对新的技术,能够支持Linux Bridge、命名空间、Open vSwitch等技术
有时我们需要一块物理网卡绑定多个 IP 以及多个 MAC 地址,虽然绑定多个 IP 很容易(通过网卡别名,例如eth0:1),但是这些 IP 会共享物理网卡的 MAC 地址,可能无法满足我们的设计需求,所以有了 macvlan设备,其工作方式如下:

配合网络命名空间机制,可以在不需要建立Bridge的情况下,为虚拟机建立独立的网络栈:
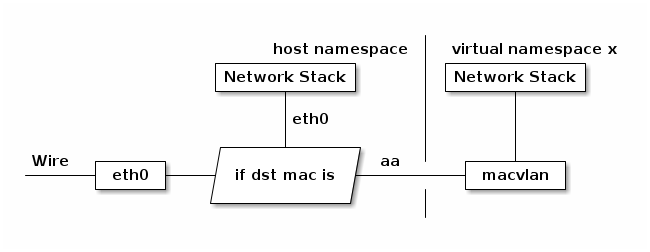
MacVLAN接口可以看做是物理以太网接口的N个虚拟子接口(sub interface),每个子接口都具有区别于父接口(parent interface)的MAC地址,并且可以像普通网卡一样分配IP地址。这种虚拟网卡在逻辑上,和物理网卡具有对等的地位。
父接口可以是一个物理接口(例如eth0),可以是一个 802.1q 的子接口(例如eth0.10),也可以是 bonding 接口。
除了虚拟化之外,Keepalived也通过MacVLAN来使用虚拟Mac地址。
需要注意,使用MacVLAN的虚拟机/容器,和主机共享一个网段。如果虚拟机/容器需要和宿主机通信,需要额外创建一个子接口给宿主机使用
MacVLAN支持5种模式:
| 模式 | 说明 | ||
| bridge |
类似于Linux Bridge,最常用。适合共享父接口的MacVLAN虚拟网卡直接进行通信的场景 这种模式下,共享父接口的虚拟网卡可以直接通信,不需要把流量发送到父接口外部 示例:
|
||
| VEPA |
Virtual Ethernet Port Aggregator,虚拟以太网端口聚合,这是默认的模式 所有虚拟接口发出的流量,不管目的地是什么(即使是共享父接口的兄弟虚拟接口),都发给父接口 需要连接父接口们的交换机支持Hairpin模式(可以把某个端口发出的包反射回去),把源、目的地址都是本地MacVLAN虚拟接口地址的流量,发给相应接口 大部分交换机设备不支持Hairpin模式,但是Linux Bridge可以支持:
|
||
| Private | 类似于VEPA,但是增强了隔离能力,阻止共享父接口的MacVLAN虚拟接口之间的通信 | ||
| Passthrough | 这种模式下一个父接口只能和单个MacVLAN虚拟接口绑定,并且子接口继承父接口的MAC地址 | ||
| Source | MacVLAN接口只接受指定源MAC地址的数据包 |
位于两台机器上的MacVLAN虚拟网卡要实现通信,需要满足:
- 两台机器的父接口都处于混杂模式
- 两台主机的MacVLAN子网IP段不重叠
在MacVLAN的虚拟网络中,父接口仅仅相当于一个交换机。对于进出子MacVLAN接口的数据包,物理网卡仅仅转发而不处理,这导致使用本机MacVLAN网卡的IP无法和物理网卡的IP进行通信。
MacVLAN是将虚拟机、容器连接到物理网络的简单方法。但是它有以下缺点:
- 每个虚拟接口都需要MAC地址,但是物理交换器支持的MAC地址数量会有限制,许多物理网卡支持的MAC地址数量也会有限制
- IEEE 802.11(WiFi)不支持一个客户端有多个MAC地址
- 在云上环境,VPC往往对入站报文的MAC地址进行校验,Linux Bridge面临同样的问题
面临这些缺点时,可以考虑使用IPVLAN。
类似于MacVLAN,都是在一个父接口下虚拟出多个子接口。不同之处是,IPVLAN的所有子接口MAC相同,仅仅IP不同。
IPVLAN从3.19开始支持,比较稳定的版本需要4.2+。Docker对老版本的支持存在缺陷。
某些DHCP服务器在分配IP地址时,以MAC地址作为机器的标识,这和IPVLAN无法协同工作。
IPVLAN支持L2、L3等模式,一个父接口同时只能在一种模式下工作。
IPVLAN无法从宿主机访问子接口的IP地址,也不能从子接口所在命名空间访问父接口的IP地址。你可以额外创建一对veth,配合路由,来解决这个问题。
这种模式下,和MacVLAN工作方式很类似。父接口作为交换机,转发子接口的数据。子接口直接加入父接口所在的二层网络。
实验:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
ip link add link eth0 ipvlan1 type ipvlan mode l2 ip link add link eth0 ipvlan2 type ipvlan mode l2 ip net add net1 ip net add net2 ip link set ipvlan1 netns net1 ip link set ipvlan2 netns net2 ip net exec net1 ip link set ipvlan1 up ip net exec net2 ip link set ipvlan2 up ip net exec net1 ip addr add 10.0.10.1/16 dev ipvlan1 ip net exec net2 ip addr add 10.0.10.2/16 dev ipvlan2 ip net exec net1 route add default dev ipvlan1 ip net exec net2 route add default dev ipvlan2 ip net exec net1 ip link set ipvlan1 up ip net exec net2 ip link set ipvlan2 up ip net exec net1 ip link set lo up ip net exec net2 ip link set lo up |
这种模式下, 父接口类似于路由器。它在各个虚拟网络和主机网络之间进行不同网络报文的路由转发工作。 只要父接口相同,即使虚拟机/容器不在同一个网络,也可以互相ping通对方,因为ipvlan会在中间做报文的转发工作。 L3模式下的虚拟接口不会接收到多播或者广播的报文,所有的 ARP 过程或者其他多播报文都是在底层的父接口完成的。
外部网络不会理解IPVLAN虚拟出来的网络,因此如果外部路由器上不配置适当路由规则,IPVLAN的虚拟IP无法被外部访问。
实验:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
ip netns add net1 ip netns add net2 # 添加L3模式的IPVLAN子接口 ip link add link eth0 ipvlan1 type ipvlan mode l3 ip link add link eth0 ipvlan2 type ipvlan mode l3 # 可以发现子接口的MAC地址和父接口相同 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 10:00:00:00:00:07 brd ff:ff:ff:ff:ff:ff 5: ipvlan1@eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 10:00:00:00:00:07 brd ff:ff:ff:ff:ff:ff 6: ipvlan2@eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 10:00:00:00:00:07 brd ff:ff:ff:ff:ff:ff # 移动到网络命名空间 ip link set ipvlan1 netns net1 ip link set ipvlan2 netns net2 |
注意,由于父子接口的MAC地址一样,因此不能通过DHCP分配IP地址,必须手工添加:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ip net exec net1 ip addr add 10.98.0.1/16 dev ipvlan1 ip net exec net1 ip link set dev ipvlan1 up ip net exec net2 ip addr add 10.99.0.1/16 dev ipvlan2 ip net exec net2 ip link set dev ipvlan2 up # 添加路由 ip net exec net1 route add default dev ipvlan1 ip net exec net2 route add default dev ipvlan2 ip net exec net1 ping 10.99.0.1 # OK # 在宿主机的L2网络的其它主机上,必须有路由才能访问IPVLAN子接口 # IPVLAN父接口IP ip route add 10.98.0.0/16 dev virbr0 via 10.0.0.7 ip route add 10.99.0.0/16 dev virbr0 via 10.0.0.7 |
类似于L3模式,但是L3S模式下出入流量均经过宿主机网络命名空间的三层网络(L2/L3模式则不经过),会被宿主机的netfilter框架过滤。
这意味着L3S可以支持kube-proxy,但是,它又会引入以下问题:
- 当K8S服务的客户端、Pod位于同一节点时,访问服务的应答报文会走ipvlan datapath,接收不到
- 同样场景下,同一方向流量多次进出宿主机 conntrack,datapath复杂,和iptables/ipvs也存在兼容性问题
可以为容器额外引入VETH(另外一端放在宿主机),通过路由设置,让K8S服务的流量从VETH出站,解决Service无法访问的问题。
Macvtap是一个新式驱动,用于简化虚拟化网络桥接。它基于macvlan设备驱动,将macvlan和TAP的优点进行整合。它使用macvlan的方式来收发数据包,但是收到的数据包不会交给独立网络栈处理,而是交给/dev/tapX文件:
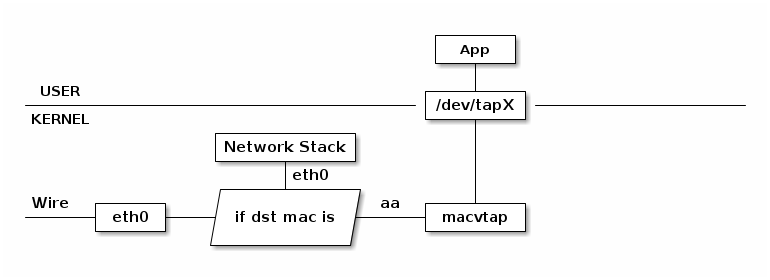
由于 macvlan是工作在 MAC 层的,所以 macvtap 也只能工作在 MAC 层,不会存在macvtun这样的设备。
一个macvtap端点(endpoint)是一个字符设备,它很大程度上遵循tun/tap ioctl接口,可以被KVM/QEMU或者其它支持tun/tap接口的hypervisors直接使用。macvtap端点扩展一个既有网络接口(底层设备,lower device),具有自己的MAC地址,位于与被扩展接口相同的网段。典型情况下,macvtap让宿主机、客户机一同出现在物理网络上。
类似于macvlan,一个macvtap可以工作在以下三种模式之一。这些模式定义了连接到同一lower device的macvtap端点之间的通信方式:
| 模式 | 说明 |
| VEPA |
即虚拟以太网端口聚合器(Virtual Ethernet Port Aggregator),这是默认的模式。从一个端点发送到另外一个端点的数据下发到lower device,进而发送到外部交换机,如果外部交换机支持hairpin模式,则以太网帧被发回lower device进而发送到目标端点。然而,大部分现代交换机都不支持hairpin模式,这意味着两个端点不能交换以太网帧(尽管它们可以通过TCP/IP路由器通信) |
| Bridge | 直接连接端点,两个同时处于bridge模式的macvlan可以直接交换以太网帧。对于典型的交换机,这是最有用的模式 |
| private | 类似于VEPA,但是即使交换机支持hairpin,也被忽略,这种模式下端点之间绝不能相互通信 |
亦称替代物(surrogate),这类代理可以假扮Web服务器,接收发给 Web 服务器的真实请求,它可以向一个或者多个服务器索取内容,并返回给客户端,在客户端看来,好像反向代理就是真正的服务器。 反向代理有以下应用场景:
- 反向代理可以缓存静态、动态内容,从而提高访问慢速Web服务器上公共内容时的性能,在此场景下反向代理被称为服务器加速器(Server accelerator)
- 隐藏原始服务器的存在和特性
- 为不支持SSL的服务器提供SSL支持
- 负载均衡:分散入站请求到多个服务器上
- 任何几个Web服务器需要通过同一IP地址访问的时候,可以将反向代理作为前置机
所谓透明代理,它透明在:
- 对于客户端,发起连接时连接的服务端是真实的服务器而不是代理服务器
- 对于服务器,收到的请求来自真实客户端而不是代理服务器
必须具有某种机制,在客户端毫无知觉的情况下,将它的请求劫持给代理服务器处理。同样的,真实服务器发回的响应也需要直接发给代理服务器,而不是客户端。
实现透明代理,需要多方面的配合。客户端(C)、代理(P)、服务器(S)的部署架构会很大程度上影响技术实现。主要关注点包括:
- 网络路由:目的地是S的IP包路由给P处理。如果S和P部署在一起(例如用于Sidecar部署的Envoy),通过Linux本身的能力就能达成
- IP_TRANSPARENT:P必须启用此套接字选项
当封包到达Linux内核时,它要么被路由,要么被丢弃,要么被Linux本地处理 —— 如果目的地址匹配本地地址的话。
什么是本地地址,是可以设置的,甚至你可以设置为0.0.0.0/0 —— 任何地址都是本地地址,但这样设置会导致系统无法连接到任何远程地址,因为所有地址都是本地地址了…应当发给本地进程处理。幸运的是,通过独立路由表,我们可以选择性的将一部分封包路由到本地:
|
1 2 3 4 5 6 |
# 对于任何目的端口是53的封包,设置标记 iptables -t mangle -I PREROUTING -p udp --dport 5301 -j MARK --set-mark 1 # 然后配置路由表,强制将其从lo网卡发出,而不管目的地址是什么 ip rule add fwmark 1 lookup 100 ip route add local 0.0.0.0/0 dev lo table 100 |
注意,需要启用IP转发功能:
|
1 2 |
sysctl net.ipv4.conf.all.forwarding=1 sysctl net.ipv6.conf.all.forwarding=1 |
某些情况下反向路径过滤器(reverse path filter)可能会丢弃你拦截的封包,禁用之:
|
1 |
sysctl net.ipv4.conf.eth0.rp_filter=0 |
套接字选项IP_TRANSPARENT可以绑定不属于本机的IP地址,P需要启用此选项。此选项的作用:
- 作为S的客户端时,此选项允许P使用不属于本机的IP地址作为源IP(也就是C的地址)发起连接
- 作为C的服务器时,可以侦听(绑定到)不属于本机的IP地址(也就是S的地址)的连接请求。比如开启此IP_TRANSPARENT选项同时监听0.0.0.0.80,那么本机接收到的DST地址是192.168.0.189:80的TCP请求可被监听
- 接受被TPROXY重定向的连接和封包
下面是一段基于simplesocket的代码,说明了IP_TRANSPARENT如何指定任意源地址的。注意需要CAP_NET_ADMIN权限才能运行:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 基于TCP/IP协议族的UDP套接字 Socket s(AF_INET, SOCK_DGRAM, 0); # 套接字选项,IP_TRANSPARENT SSetsockopt(s, IPPROTO_IP, IP_TRANSPARENT, 1); # 使用的源地址 ComboAddress local("1.2.3.4", 5300); # 使用的目的地址 ComboAddress remote("198.41.0.4", 53); # 绑定到源地址,注意此地址不是本机地址 SBind(s, local); # 发送UDP包 SSendto(s, "hi!", remote); |
使用tcpdump可以发现:
|
1 2 3 |
# tcpdump -n host 1.2.3.4 # 源地址不是本机 21:29:41.005856 IP 1.2.3.4.5300 > 198.41.0.4.53 |
Iptables支持一个特殊的目标TPROXY,它能够拦截流量,并将其转发给任意特定的本地IP地址,同时为封包设置标记:
|
1 2 3 4 5 6 7 |
# 修改针对25端口的TCP流量封包 iptables -t mangle -A PREROUTING -p tcp --dport 25 -j TPROXY # 设置0x1/0x1标记 --tproxy-mark 0x1/0x1 # 转发给127.0.0.1:10025,但是不改变IP封包头的任何信息 --on-port 10025 # 默认原始目的端口 --on-ip 127.0.0.1 # 默认接收到流量的网卡地址 |
注意:
- --tproxy-mark,它确保此封包通过正确的路由表发出。参考第一小节的路由,此封包 xxx:xxx:127.0.0.1:10025,将从lo网卡出网络栈
- TPROXY和REDIRECT不同,后者本质上是DNAT,会改变IP封包头的目的地址
Iptables匹配扩展socket能够匹配和本地套接字相关的封包,它会进行Socket Hash查找,并且在以下条件下匹配:
- 本地存在已经建立的套接字,匹配此封包
- 如果本地存在非零监听套接字,并且地址端口匹配封包的地址端口
示例:
|
1 2 3 4 5 6 7 |
iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT iptables -t mangle -N DIVERT iptables -t mangle -A DIVERT -j MARK --set-mark 1 iptables -t mangle -A DIVERT -j ACCEPT # 配合路由表 |
使用IP_TRANSPARENT时:
- 对于TCP连接,套接字的原始目的地址、端口可以通过getsockname()调用获得
- 对于UDP连接,你必须设置套接字选项IP_RECVORIGDSTADDR:
1setsockopt (s, IPPROTO_IP, IP_RECVORIGDSTADDR, &n, sizeof(int));然后,调用recvmsg()方法:
1234567891011121314char orig_ip[32] = {0};int orig_port = 0;struct sockaddr_in *orig_addr;for (cmsg = CMSG_FIRSTHDR(&msg); cmsg != NULL; cmsg = CMSG_NXTHDR(&msg,cmsg)) {if (cmsg->cmsg_level == SOL_IP && cmsg->cmsg_type == IP_ORIGDSTADDR) {orig_addr = (struct sockaddr_in *) CMSG_DATA(cmsg);transfer_sock_addr(orig_addr, orig_ip, 32, &orig_port);break;}}if (cmsg == NULL) {printf("IP_ORIGDSTADDR not enabled or small buffer or I/O error");return;}
参考Istio学习笔记。
- 需要通过Iptables来对封包进行标记。时用TPROXY目标可以在标记的同时,转发给指定IP:PORT,但却又不改包头
- 需要为被标记的封包设置路由表,不管其目的地址是什么(0.0.0.0/0),总是发送到lo接口
- lo接口接收到的封包,再次进入Iptables,这次不会走PREROUTING链
- 对于TPROXY,已经明确指定了接收者进程的IP:PORT,直接由此进程处理封包,前提是IP_TRANSPARENT被设置好
- SocketMatch的作用是识别本地相关的套接字并标记,它不是必须的,TPROXY也能够做标记工作
Loopback本来是通信学上的术语,和电信号、数字数据包的路由有关,将它们不做修改的路由给信号的发起者,主要用于测试通信基础设施。
在TCP/IP协议族的规范实现中,包含一个虚拟的网络接口,同一机器上的程序可以通过此虚拟接口进行网络通信,此接口完全是软件的,不会引起任何物理网卡的流量。程序发往lo接口的封包会简单的、立即发回网络栈,就好像是从网络上收到的一样。
如果路由将出口网卡设置为lo(不管目的地址是什么),则报文交由本地的应用程序处理,而不会真正路由出去。
在Linux中,dummy类型的网络接口类似于lo,区别在于,你可以创建多个dummy类型的网络接口。
此外,对于lo接口,内核会自动添加目的地址是CIDR的路由:
|
1 |
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1 |
而对于dummy接口则仅仅会添加针对其IP地址的路由。
Socket API原本是为网络通讯设计的,但后来在socket的框架上发展出一种IPC机制,就是UNIX Domain Socket。虽然网络socket也可用于同一台主机的进程间通讯(通过loopback地址127.0.0.1),但是UNIX Domain Socket用于IPC更有效率:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。这是因为,IPC机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。UNIX Domain Socket也提供面向流和面向数据包两种API接口,类似于TCP和UDP,但是面向消息的UNIX Domain Socket也是可靠的,消息既不会丢失也不会顺序错乱。
UNIX Domain Socket是全双工的,API接口语义丰富,相比其它IPC机制有明显的优越性,目前已成为使用最广泛的IPC机制,比如X Window服务器和GUI程序之间就是通过UNIX Domain Socket通讯的。
使用UNIX Domain Socket的过程和网络socket十分相似,也要先调用socket()创建一个socket文件描述符,address family指定为AF_UNIX,type可以选择SOCK_DGRAM或SOCK_STREAM,protocol参数仍然指定为0即可。
UNIX Domain Socket与网络socket编程最明显的不同在于地址格式不同,用结构体sockaddr_un表示:
|
1 2 3 4 |
struct sockaddr_un { sa_family_t sun_family; /*PF_UNIX或AF_UNIX */ char sun_path[UNIX_PATH_MAX]; /* 路径名 */ }; |
网络编程的socket地址是IP地址加端口号,而UNIX Domain Socket的地址是一个socket类型的文件在文件系统中的路径,这个socket文件由bind()调用创建,如果调用bind()时该文件已存在,则bind()错误返回。
所谓抽象套接字命名空间(Abstract Socket Namespace)是Linux的特性,用于创建一个不去绑定到文件系统中文件的UDS,从而获得以下好处:
- 不需要担心文件系统中的命名冲突
- 当完成套接字使用后,不需要关注unlink文件路径名的问题 —— 到套接字关闭后,抽象名称会自动删除
- 不需要在文件系统中创建对应路径,在chroot环境下可能有用,在没有缺陷操控特定文件系统路径时也有用
要创建抽象UDS套接字,需要指定sub_path的第一个字节为\0字符。在netstat lsof等命令的输出中,\0显示为@符号
现代以太网依赖于交换机进行帧的交换。它通常是具有多个端口的硬件盒子。如果目的地址对于交换机未知(它不知道关联到哪个端口),那么交换机会广播帧给所有端口。通过观察端口上的帧流量,交换机就能学习到端口-MAC对应关系,从而不再需要广播流量。交换机在FIB(forwarding information base,也叫forwarding table)中缓存对应关系。
交换机可以相互连接,从而构成更大的以太网。
Linux支持loopback设备,用于通过网络栈和主机自身进行通信。Linux能够和任何配置在本地网络接口上的IP进行通信,不管地址是不是在loopback设备上。
所有配置在本机网络接口的地址,即本地地址(Locally Hosted Addresses)。
这类地址来自和本机位于同一网段内的其它主机。这些主机通过交换机相互连接,地址本地可达(Locally Reachable Addresses)
所有其它地址,都必须依赖路由器(IP Routing Device)作为中介才能到达,并且,此路由器具有本地可达地址。
当封包从一个网络(经过路由器)到达另外一个网络,称为经过了一跳。跳的数量,即封包经过的中介路由器的数量。
对于一个路由路径,封包要经过的下一个网关(路由器),即下一跳。
任何在两个网络之间接受/转发封包的设备,都是路由器。路由器至少是dual-homed的 —— 每个接口接入到一个网络,网络接口通常是NIC。Linux主机经常扮演路由器的角色,NIC经常是VLAN接口之类的虚拟设备。
默认路由,即目的地是0/0的路由,是最一般的路由——如果找不到和封包目的地更匹配的路由,则自动使用默认路由。
对于连接到因特网的主机来说,默认路由通常是本地可达的路由器,此路由器也叫默认网关。
路由选择的基本原则是逐跳(hop-by-hop)进行,典型情况下以目的地址为选路的唯一标准。Linux作为路由器时,可能基于其它的封包特征进行选路,此所谓策略路由。
基于目的地址选路时,首先会查询路由缓存,然后查找主路由表。如果最近发送封包到了目的地址,则关于目的地址的路由会存在于缓存(本质上是一个hash表)中。如果最近没有发送封包到目的地,则需要查询路由表,匹配的原则是最长前缀匹配(longest prefix match) —— 也就是尽量选择精确的路由。最长前缀匹配能够针对大规模网络的路由规则,被更加精确的路由器(通常更靠近)或主机覆盖。
从2.2开始,Linux支持基于多路由表(multiple routing tables)和路由策略数据库(routing policy database,RPDB)的策略路由。
策略路由的依据,是封包的某些属性,例如源地址、ToS标记、fwmark(仅在内核中存在的、位于表示封包的数据结构中的字段)、接收封包接口名,等等。
启用策略路由的情况下,选路算法如下:
- 首先,仍然是查询路由缓存
- 基于优先级,来遍历RPDB。查找匹配的RPDB
- 对于每个匹配RPDB条目,使用最长前缀原则匹配封包目的地址,遍历条目对应的路由表
- 如果找到匹配路由,则终止迭代
伪代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 首先查找路由缓存 if packet.routeCacheLookupKey in routeCache : route = routeCache[ packet.routeCacheLookupKey ] else # 然后按优先级遍历RPDB,此数据库中是一条条规则 for rule in rpdb : # 如果封包匹配RPDB规则 if packet.rpdbLookupKey in rule : # 则遍历RPDB规则对应的路由表 routeTable = rule[ lookupTable ] # 根据最长前缀原则来匹配路由表中的路由 if packet.routeLookupKey in routeTable : route = route_table[ packet.routeLookup_key ] |
使用策略路由时,单个路由表的使用逻辑保持不变。
路由缓存,又叫转发信息库(forwarding information base,FIB)。它是一个存放了最近使用的路由条目的哈希表,在查询路由表之前,会优先检查FIB。
FIB由内核独立于路由表维护,修改路由表可能不会立即反应到FIB,要避免此延迟,可以调用:
|
1 |
ip route flush cache |
FIB清空后,新的封包,或者 ip route get命令会触发路由表查找、重新填充缓存。
FIB提供基于多种方式的哈希查找,包括:dst(目的地址)、src(源地址)、tos(服务类型)、fwmark(内核封包标记)、iif(入站网络接口)。
FIB的缓存条目上,存储了以下属性:cwnd、advmss(建议最大段大小)、src(Preferred Local源地址)、mtu、rtt、age、users、used。
Linux 2.2 / 2.4支持多路由表,除了广泛使用的local / main表外,内核最多支持额外的252张路由表。联合多个路由表(主要基于目的地址)和RPDB(主要基于源地址),Linux内核实现了灵活的路由功能。
支持多重路由表的内核,使用0-255之间的整数来引用路由表。最基本的路由表是local(255)、main(252),路由表序号和名字的映射关系定义在 /etc/iproute2/rt_tables中。
下面的命令显示所有路由表的路由:
|
1 |
ip route show table all |
下面的命令显示特定路由表中的路由:
|
1 2 |
ip route show table main ip route show table 2005 |
这是一张由内核维护的特殊表,条目可以删除,但是需要注意风险。ip address和ifconfig命令会导致内核修改local表(通常也同时修改main表)。
local表的主要用途有两个:
- 指定广播地址的规格,仅仅对于支持广播寻址的L2有用
- 用于路由到本机IP地址
local表中可以出现的路由类型包括:local、nat、broadcast。这些路由类型不会出现在其它表,其它路由类型不会出现在local表。
如果某个网络接口具有多个IP地址,则每个IP地址都在local表中具有一个路由条目。这是在Linux下为网络接口添加IP地址的正常附加效果。
命令route操控的是该表,如果ip route不指定目标表,则默认操作main表。
路由表可以包含任意多个(除了local表,它由内核维护)条目。
条目的形式为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
ip route { add | del | change | append | replace } ROUTE ROUTE := NODE_SPEC [ INFO_SPEC ] # 路由类型 匹配CIDR 路由表 路由协议 范围 NODE_SPEC := [ TYPE ] PREFIX [ tos TOS ] [ table TABLE_ID ] [ proto RTPROTO ] [ scope SCOPE ] [ metric METRIC ] TYPE := [ unicast | local | broadcast | multicast | throw | unreachable | prohibit | blackhole | nat ] TABLE_ID := [ local| main | default | all | NUMBER ] RTPROTO := [ kernel | boot | static | NUMBER ] SCOPE := [ host | link | global | NUMBER ] INFO_SPEC := NH OPTIONS FLAGS [ nexthop NH ] ... # 下一跳路由器地址 出口网卡名称 权重,在multipath路由中反应此路由的相对带宽或质量 NH := [ encap ENCAP ] [ via [ FAMILY ] ADDRESS ] [ dev STRING ] [ weight NUMBER ] NHFLAGS FAMILY := [ inet | inet6 | ipx | dnet | mpls | bridge | link ] NHFLAGS := [ onlink | pervasive ] OPTIONS := FLAGS [ mtu NUMBER ] [ advmss NUMBER ] [ as [ to ] ADDRESS ] rtt TIME ] [ rttvar TIME ] [ reordering NUMBER ] [ window NUMBER ] [ cwnd NUMBER ] [ ssthresh REALM ] [ realms REALM ] [ rto_min TIME ] [ initcwnd NUMBER ] [ initrwnd NUMBER ] [ features FEATURES ] [ quickack BOOL ] [ congctl NAME ] [ pref PREF ] [ expires TIME ] |
路由类型可以分为一下几种:
| 类型 | 说明 | ||
| unicast | 单播,最常见的路由条目,针对特定单一目的主机:
如果ip route命令不指定路由条目类型,则默认是unicast |
||
| broadcast | 用于支持广播地址的链路层设备,仅用在local表中,通常由内核管理:
|
||
| local | 每当一个IP地址添加到网络接口上时,内核自动在local表添加local类型的路由条目:
例如上面这个条目,是K8S的Kube Proxy IPVS模式下为kube-ipvs0配置10.96.0.1地址后,内核自动增加的条目 |
||
| nat | 当尝试配置无状态NAT时,内核添加这类条目到local表:
|
||
| unreachable | 当匹配这类路由条目时,会返回ICMP unreachable消息:
|
||
| prohibit | 当匹配这类路由条目时,会返回ICMP prohibited消息 | ||
| blackhole | 当匹配这类路由条目时,封包被丢弃,不会产生ICMP消息
|
||
| throw |
导致针对当前路由表的查找立即失败,返回RPDB(可能继续匹配后续规则并查找相应的其它路由表)
|
所谓route scope,是一个“指示符”,用来说明到目标网络的“距离”。
必须是定义在 /etc/iproute2/rt_scopes 中的名字或数字
| 取值 | 说明 |
| global universe |
此Scope提示目的地远于一跳 对于所有通过网关(gatewayed)的单播路由,这是默认值 |
| link |
此Scope提示目的地在本地网络上 对于直接单播路由、广播路由,这是默认值 |
| host |
此Scope提示目的地在本机上 对于local类型路由,这是默认值 |
| 取值 | 说明 |
| redirect | 因为ICMP重定向而安装此路由条目 |
| kernel | 因为内核执行指定配置而安装此路由条目 |
| boot | 路由条目在启动期间安装,当路由守护进程启动后,会清除所有这类条目 |
| static | 管理员手工添加,用于覆盖动态路由。路由守护进程会遵从此条目,甚至同步给它的peers |
| ra | 由路由发现协议安装 |
RPDB控制内核遍历多张路由表的顺序。RPDB中的每个条目,具有一个优先级,优先级是0-32767之间的数字,越小优先级越高。下面是一个示例的路由策略:
|
1 2 3 4 5 6 |
ip rule list 9: from all fwmark 0x200/0xf00 lookup 2004 10: from all fwmark 0xa00/0xf00 lookup 2005 100: from all lookup local 32766: from all lookup main 32767: from all lookup default |
当封包达到后,假设没有路由缓存,内核会首先检查优先级为0的RPDB规则,如果匹配,则使用该规则指向的路由表,如果不匹配,则依次检查低优先级的规则。
RPDB中的规则类型有若干种,和路由类型对应:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# unicast 这是最常见的规则类型,也是默认的规则类型。会导致查找某个路由表 # 如果源地址是192.168.100.17则查找表5 ip rule add unicast from 192.168.100.17 table 5 # 如果源接口是eth7则查找表5 ip rule add unicast iif eth7 table 5 # 如果封包具有标记4则查找4 ip rule add unicast fwmark 4 table 4 # nat 用于正确实现无状态NAT,通常和nat类型的路由条目耦合在一起。这种条目 # 会导致内核重写出站封包的源地址 # 对于源地址是172.16.82.184的封包,将源地址改写为193.7.255.184 ip rule add nat 193.7.255.184 from 172.16.82.184 ip rule add nat 10.40.0.0 from 172.40.0.0/16 # unreachable 如果匹配,则立即应答 ICMP unreachable 给源地址 # 如果是来自eth2的、服务类型0xc0的封包 ip rule add unreachable iif eth2 tos 0xc0 ip rule add unreachable iif wan0 fwmark 5 ip rule add unreachable from 192.168.7.0/25 # prohibit 如果匹配,则立即应答 ICMP prohibit 给源地址 ip rule add prohibit from 209.10.26.51 ip rule add prohibit to 64.65.64.0/18 ip rule add prohibit fwmark 7 # blackhole 如果匹配,封包被静默的丢弃 ip rule add blackhole from 209.10.26.51 ip rule add blackhole from 172.19.40.0/24 ip rule add blackhole to 10.182.17.64/28 |
对于具有多重IP地址的主机来说,进行相互通信时必须选择正确的源IP地址。
出站封包的源地址选择的原则如下:
- 如果应用程序已经在使用套接字,则源地址已经被选择过
- 应用程序可以显式请求一个源地址,这个地址甚至可以不是本机地址。很多应用程序支持选取源地址,例如:
12nc -s $BINDADDR $DEST $PORTsocat - TCP4:$REMOTEHOST:$REMOTEPORT,bind=$BINDADDR - 内核进行选路操作,如果匹配路由存在src参数,则内核会利用该参数作为源地址
- 如果没有src提示,则内核会根据目的地址,找到本机上第一个配置了与该地址在同一个网段、或者与该目的地址的路由下一跳地址在同一网段的IP地址的网络接口,并用此网络接口的IP地址作为源地址
Path MTU即(Path Maximum Transmission Unit),ICMP报文可以用于发现PMTU,它是整个路由路径中,最小的MTU。知道这个值以后,可以避免不必要的IP分片。
路由中任何一跳阻止ICMP报文,都会导致无法识别PMTU。
ICMP重定向是路由器提示发送者,具有更好路由路径的一种机制。配置静态路由可以防止不期望的ICMP重定向,尽管ICMP重定向不会导致危险,但是在良好管理的网络中是不应当发生的。
ECMP是一个逐跳的基于流的负载均衡策略,当路由器发现同一目的地址出现多个最优路径时,会更新路由表,为此目的地址添加多条规则,对应于多个下一跳。ECMP的路径选择策略有多种方法:
- 哈希,例如根据源IP地址的哈希为流选择路径
- 轮询,各个流在多条路径之间轮询传输
- 基于路径权重,根据路径的权重分配流,权重大的路径分配的流数量更多
OSPF、ISIS、EIGRP、BGP等多种路由协议均支持ECMP。
ECMP是一种较为简单的负载均衡策略,其在实际使用中面临的问题也不容忽视:
- 可能增加链路的拥塞:ECMP并没有拥塞感知的机制,只是将流分散到不同的路径上转发。对于已经产生拥塞的路径来说,很可能加剧路径的拥塞
- 非对称网络使用效果不好
参考:重温iptables
Offloading是Linux内核中一系列用于减轻CPU网络处理负担的技术。
随着技术的进步,网络接口的带宽越来越大。从早期的10Mbps发展到现在的10Gbps+,带宽增加了3个数量级。与此同时,网络中能够传递的单个封包的大小,受限于路径MTU。在简单的局域网环境下,可以使用Jumbo Frame将MTU提升到9KB,但是在复杂的因特网环境下,MTU一直都只能是1500左右。作为后果,带宽打满的情况下CPU单位时间需要处理的封包个数比早期多了3个数量级。现代处理器在处理1Gbps网络接口时,通常能够应对,不需要考虑Offloading。
尽管这些年CPU的性能也有很大的提升,包括频率升高和核心数增加,但是减少需要处理的封包数量对于提升性能仍然是很有价值的。每个封包都需要经过网络栈,处理过程相当复杂。
TCP Segmentation Offload,允许内核发送一个很大的封包,例如64KB,然后由(支持TSO的)网络适配器将封包分割为合适大小的TCP段传输。
TSO能够平均减少发送单个封包的开销达40倍,对于以发送为主的工作负载,例如下载服务器,足以让10Gbps网络全速工作。
Generic Segmentation Offload,更加一般的segmentation offloading机制,可以用于UDP协议。
即使在驱动层模拟GSO,也能提升性能。
在接收端进行Offloading的技术出现较晚,一方面早期的网络流量均是下行为主,另一方面接收端的处理难度要大的多。你无法控制什么时候接收封包,这是由对端控制的。
Large Receive Offload类似于GSO,它允许网络接口将接收到的封包进行合并,让操作系统看到的封包变少。即使在驱动层模拟LRO,也能提升性能。LRO被Linux中10Gbps网卡驱动广泛的支持。LRO仅仅支持TCP/IPv4。
LRO存在缺陷,它只是简单的将看到的封包都合并起来,如果包头中有差异这些差异会丢失。这些信息的丢失会导致问题:
- 如果Linux主机作为路由器运行,那么它任何时候都不应该改变包头中的信息
- 某些基于卫星网络的连接,依赖于特殊的头才能正常运作
- Linux网桥无法工作,导致很多虚拟化场景无法使用LRO
Generic Receive Offload,解决了LRO的缺陷。GRO严格限制了封包合并的条件:
- MAC地址必须相同
- 仅允许很少一部分的TCP或IP头不同
这些限制让合并后的封包能够被无损的重新分段。GRO code可以用于重新分段。
GRO不限制于TCP协议。
Leave a Reply