Linux知识集锦
参考:Linux编程知识集锦
Unix系统是指遵循特定规范的计算机操作系统,这个规范称为“单一UNIX规范”,定义了所有UNIX系统必须提供的系统函数的名称、接口、行为,该规范很大程度上是POSIX规范的超集。
类Unix系统都是可移植操作系统接口(POSIX)的实现,UNIX具有以下显著特点:
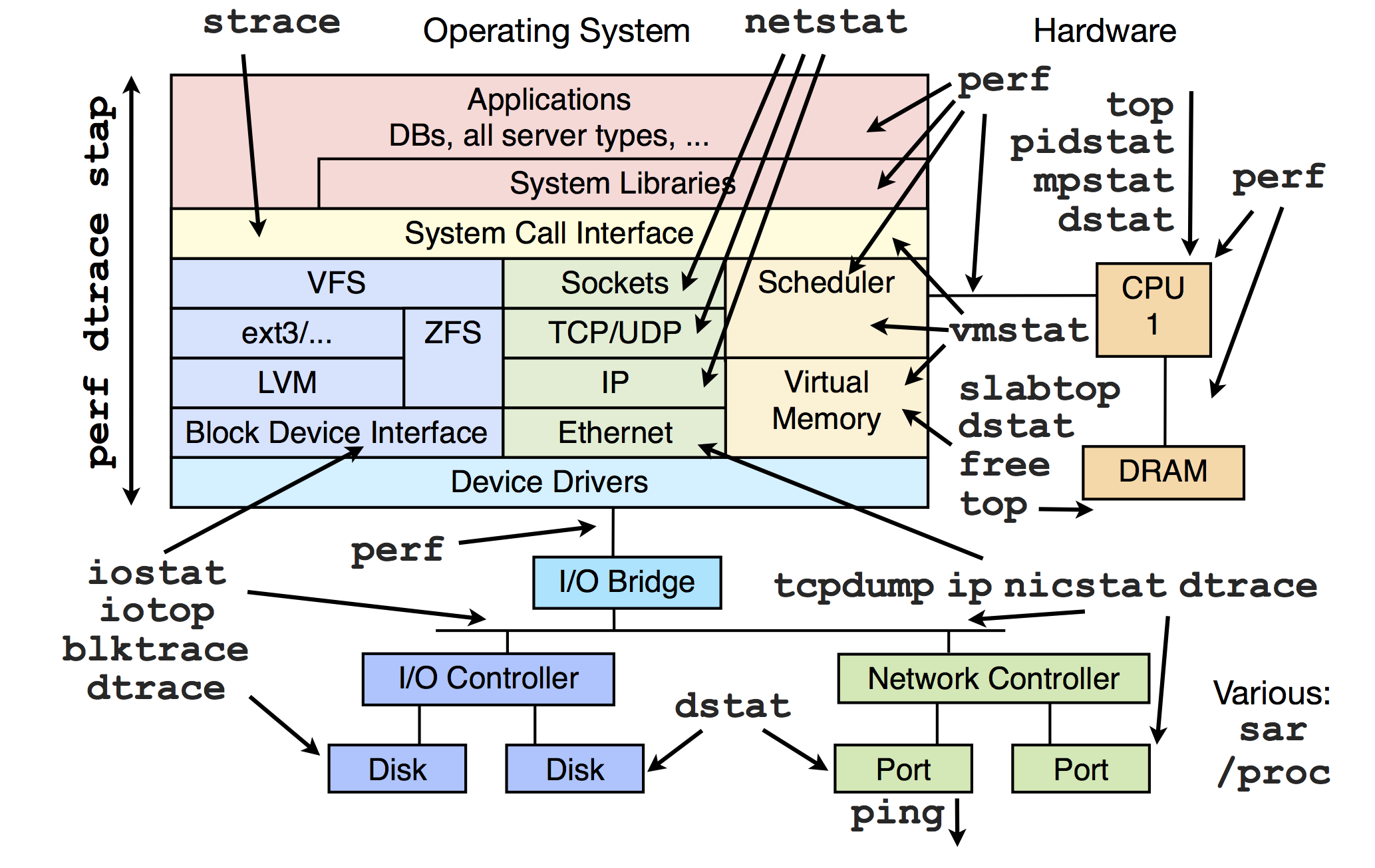
种IO轮询对比
- 简洁性:仅提供数百个目的明确的系统调用
- 所有的东西都被当做文件对待。这种抽象使对数据和对设备的操作是通过一套相同的系统调用接口来进行的:open、read、write、lseek和 close
- 系统内核和相关的系统工具软件是用C语言编写而成
- 进程的创建非常迅速,并且有一个非常独特的fork系统调用
- 提供了一套非常简单但又很稳定的进程间通信元语
Unix已经发展成为一个支持抢占式多任务、多线程、虚拟内存、换页、动态链接和 TCP/IP网络的现代化操作系统。Unix的不同变体被应用在大到数百个CPU的集群,小到嵌入式设备的各种系统上。
和Unix一样,Linux是单内核的操作系统,它与传统的Unix系统有以下不同点:
- Linux支持动态加载内核模块。尽管Linux内核是单内核,可是允许在需要的时候动态地卸除和加载部分内核代码
- Limix支持对称多处理(SMP)机制,传统的Unix 并不支持这种机制
- Linux内核可以抢占(preemptive)。与传统的Unix变体不同,Linux内核允许在内核运行的任务优先执行
- Linux内核支持内核线程,它并不区分线程和其他的一般进程。对于内核来说,所有的进程都一样,只是其中的一些共享内存资源
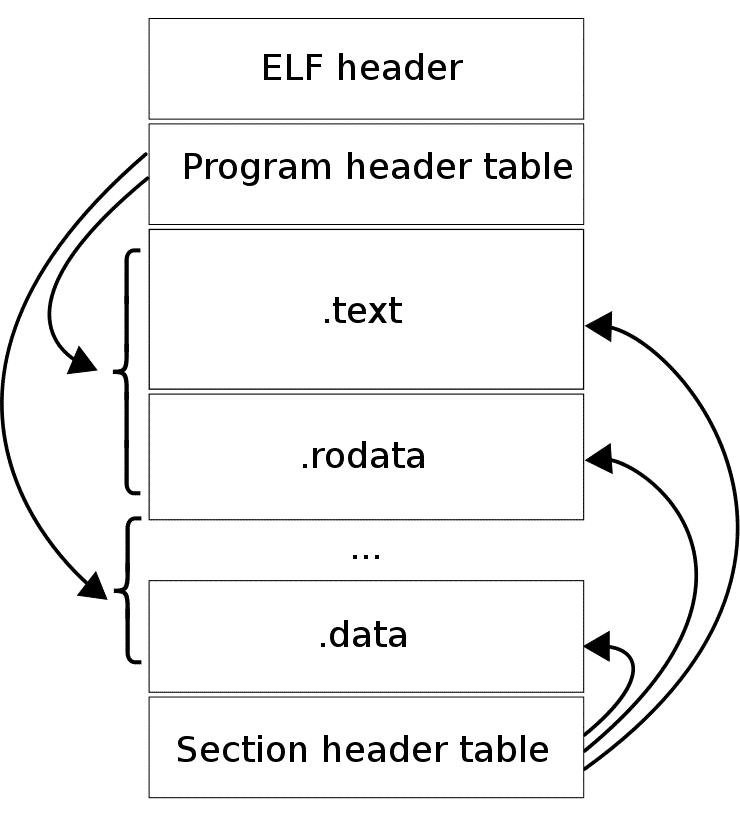
可执行/链接文件格式(Executable and Linkable Format,ELF)是一种可执行文件、对象代码、共享库、coredump的格式。ELF最初作为Unix的ABI规范发布在System V第四版上,现在是Unix-like的操作系统的标准二进制文件格式。
ELF格式具有灵活性、可扩展性、跨平台性:
- 支持不同的(endiannesses)端:也就是说同时支持BE/LE
- 支持不同的地址尺寸,不限制指令集或CPU类型
从使用上来说,主要的ELF文件的种类主要有三类:
- 可执行文件(.out):Executable File,包含代码和数据,是可以直接运行的程序。其代码和数据都有固定的地址 (或相对于基地址的偏移 ),系统可根据这些地址信息把程序加载到内存执行
- 可重定位文件(.o文件):Relocatable File,包含基础代码和数据,但它的代码及数据都没有指定绝对地址,因此它适合于与其他目标文件链接来创建可执行文件或者共享目标文件
- 共享对象文件(.so):Shared Object File,也称动态库文件,包含了代码和数据,这些数据是在链接时被链接器(ld)和运行时动态链接器(ld.so.l、libc.so.l、ld-linux.so.l)使用的
ELF文件由一个ELF头 + 数据组成,其中数据包括:
- Program header table:描述0-N个内存segments,这些segment在运行时使用
- Section header table:描述0-N个sections,这些section在链接、重定位时使用
- 由上面两个表所引用的数据
文件中的任何一个字节,最多被一个section所拥有。
使用下面的命令可以查看ELF头:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# readelf -h /usr/local/bin/cgdb ELF Header: # 魔法数字 Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 # 当取值为0时,是非法类别,1是32位的目标,2是64位的目标 Class: ELF64 # 表示数据的编码,当为0时,表示非法数据编码,1表示高位在前,2表示低位在前 Data: 2's complement, little endian # 头版本号 Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) # 该elf文件是针对哪个处理器架构的 Machine: Advanced Micro Devices X86-64 Version: 0x1 # 表示程序的入口地址 Entry point address: 0x405cb0 # Program segment 头表的位置 Start of program headers: 64 (bytes into file) # Section头表的位置 Start of section headers: 1859208 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 9 Size of section headers: 64 (bytes) Number of section headers: 39 Section header string table index: 36 |
在可从重定位的可执行文件中,Section header table描述了文件的组成,Section的位置等信息。通过下面的命令可以查看Section信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
readelf -S /usr/local/bin/mc There are 14 section headers, starting at offset 0x1c8: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .text PROGBITS 0000000000401000 00001000 # 代码段 0000000000969856 0000000000000000 AX 0 0 16 [ 2] .rodata PROGBITS 0000000000d6b000 0096b000 0000000000402661 0000000000000000 A 0 0 32 [ 3] .shstrtab STRTAB 0000000000000000 00d6d680 00000000000000a5 0000000000000000 0 0 1 [ 4] .typelink PROGBITS 000000000116d740 00d6d740 0000000000006f04 0000000000000000 A 0 0 32 [ 5] .itablink PROGBITS 0000000001174648 00d74648 0000000000002668 0000000000000000 A 0 0 8 [ 6] .gosymtab PROGBITS 0000000001176cb0 00d76cb0 0000000000000000 0000000000000000 A 0 0 1 [ 7] .gopclntab PROGBITS 0000000001176cc0 00d76cc0 00000000006298c2 0000000000000000 A 0 0 32 [ 8] .go.buildinfo PROGBITS 00000000017a1000 013a1000 0000000000000020 0000000000000000 WA 0 0 16 [ 9] .noptrdata PROGBITS 00000000017a1020 013a1020 000000000006032c 0000000000000000 WA 0 0 32 [10] .data PROGBITS 0000000001801360 01401360 # 数据段 0000000000034020 0000000000000000 WA 0 0 32 [11] .bss NOBITS 0000000001835380 01435380 # BSS段 0000000000030dd0 0000000000000000 WA 0 0 32 [12] .noptrbss NOBITS 0000000001866160 01466160 0000000000004148 0000000000000000 WA 0 0 32 [13] .note.go.buildid NOTE 0000000000400f9c 00000f9c 0000000000000064 0000000000000000 A 0 0 4 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), l (large) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific) |
在编译器将一个一个.o文件链接成一个可以执行的elf文件的过程中,同时也生成了一个Section Header 表。这个表记录了各个Section所处的区域,这个表的每个Header包含以下字段:
| 字段 | 说明 |
| sh_name | Section的名字,4字节,指向字符串表的索引 |
| sh_type |
Section的类型,4字节。下面是一些例子 1 程序数据,例如.text .data .rodata |
| sh_flags | Section标记,每位对应一个标记。32位4字节,64位8字节 |
| sh_addr | 程序执行时,Section所在的虚拟地址。32位4字节,64位8字节 |
| sh_offset | Section在文件内的偏移。32位4字节,64位8字节 |
| sh_size | Section的大小(字节数)。32位4字节,64位8字节 |
| sh_link | 指向其它Section的索引。4字节 |
| sh_info | 额外信息。4字节 |
| sh_addralign | Section载入内存时如何对其。32位4字节,64位8字节 |
| sh_entsize | Section内每条记录的字节数。32位4字节,64位8字节 |
如上,Section Header一共占用大小:32位40字节,64位64字节。
链接视图由Sections组成,而可执行的文件的内容由Segments组成:
- 每个Segments可以包含多个Sections
- 每个Sections可以属于多个Segments
- Segments之间可以有重合的部分
执行下面的命令可以得到Segment信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# readelf -l /usr/local/bin/mc Elf file type is EXEC (Executable file) Entry point 0x468ee0 There are 7 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040 0x0000000000000188 0x0000000000000188 R 1000 NOTE 0x0000000000000f9c 0x0000000000400f9c 0x0000000000400f9c 0x0000000000000064 0x0000000000000064 R 4 LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000 0x000000000096a856 0x000000000096a856 R E 1000 # R读W写E执行 LOAD 0x000000000096b000 0x0000000000d6b000 0x0000000000d6b000 0x0000000000a35582 0x0000000000a35582 R 1000 LOAD 0x00000000013a1000 0x00000000017a1000 0x00000000017a1000 0x0000000000094380 0x00000000000c92a8 RW 1000 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 8 LOOS+5041580 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 8 # Segment和Section的映射关系,M:N Section to Segment mapping: Segment Sections... 00 01 .note.go.buildid 02 .text .note.go.buildid 03 .rodata .typelink .itablink .gosymtab .gopclntab 04 .go.buildinfo .noptrdata .data .bss .noptrbss 05 06 |
这些信息和程序的加载执行相关。
Section中某些部分会映射到进程地址空间。 Stack、Heap等区域则是运行时动态在内存中创建的,在ELF中没有体现。下面是一个C语言编译出的程序的典型内存布局: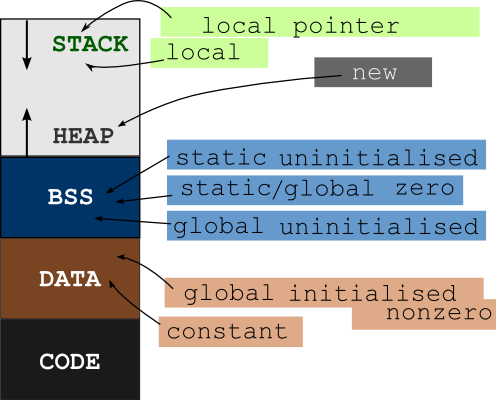
从下往上,内存地址从小变大。因此栈是向低地址方向增长的。
就是字节的顺序:多字节数据类型,其高、低字节,在内存中是如何分布(地址高低)的。类似的衍生到,在网络上,高、低字节谁先传输。
字节内部不存在顺序问题,大部分处理器以相同的顺序处理bit。
几乎所有机器中,多字节数据类型,都在内存中连续存储。如果一个int类型(4字节)x的地址位0x100,那么它的四个字节应该存储在0x100, 0x101, 0x102, 0x103 这些内存地址上(内存寻址的精度是字节)。
这4个字节的分布方式有两种:
- 小端(little-endian,LE):int的最低位字节,存放在最小内存地址上。依次排列其它字节。小端的处理器包括x86、MOS Technology 6502、Z80、VAX、PDP-11
- 大端(big-endian,BE):int的最低位字节,存放在最大内存地址上。依次排列其它字节。大端的处理器包括Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC
ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
由于不同结构的机器,可能通过网络进行通信,因此必须对字节顺序进行规定,否则会出现混乱。网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。
一般用于描述串口设备的传输顺序,网络协议中只有数据链路层会涉及到。
使用小端(先传低bit)的协议包括:RS-232、RS-422、RS-485、USB、以太网。其中以太网,在字节序上遵从大端要求,但是每个字节内部,先传递低bit。
使用大端(先传高bit)的协议包括:I2C、SPI、莫尔斯电码
所谓命名空间,是Linux系统资源的隔离机制。进程可以加入到命名空间,并共享其中的系统资源。命名空间是容器技术的基础之一。
对于外面的进程,命名空间中的资源不可见的, 反之,内部的进程感觉自己拥有完整的全局资源。举例来说,PID是一种系统资源,每个命名空间都可以拥有自己的、值为1的PID,而不会出现混乱。
大部分类型的命名空间,创建时都需要CAP_SYS_ADMIN能力(Capability,即权限)。所谓能力就是细粒度化的Linux系统(Root)权限,例如CAP_KILL允许进程向任意进程发送信号,CAP_SYS_TIME允许进程修改系统时间。
每个进程都有这样的一个目录,里面存放若干符号连接,提示进程所属的各种命名空间:
|
1 2 3 4 5 6 7 |
ls -la /proc/self/ns lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 ipc -> ipc:[4026531839] lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 mnt -> mnt:[4026531840] lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 net -> net:[4026531968] lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 pid -> pid:[4026531836] lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 user -> user:[4026531837] lrwxrwxrwx 1 alex alex 0 Nov 16 20:32 uts -> uts:[4026531838] |
如果两个进程指向同一符号连接(方括号内的inode相同),则它们属于同一命名空间。
只要/proc/PID/ns下的文件被打开,则相应的命名空间就会存在,即使命名空间内没有任何进程。 下面的挂载命令即可保证当前进程的网络命名空间持续存在:
|
1 2 3 4 5 6 7 8 |
touch mynetns sudo mount --bind /proc/self/ns/net mynetns # 绑定挂载具有打开被绑定者的文件描述符的效果 # 你甚至可以绑定挂载到自己,这种情况下,文件既是挂载目标,也是挂载点 # 尝试删除会提示Device or resource busy,需要先umount,再删除 # 绑定挂载后,你可以删除掉目标,此时挂载点的内容保持不变,底层文件依然存在 |
该命名空间虚拟化进程的Cgroups视图,也就是通过 /proc/[pid]/cgroup、 /proc/[pid]/mountinfo看到的Cgroup路径。
每个Cgroup命名空间具有自己的Cgroup根目录集合,文件/proc/[pid]/cgrpup中的路径,都是相对于这些根目录。在 clone或 unshare进程时,你可以指定 CLONE_NEWCGROUP标记,这会导致进程当前的cgroups目录变为新命名空间的cgroup根目录。此规则对于cgroups v1 v2均适用。
当你通过/proc/[pid]/cgrpup查看目标进程都归属于哪个Cgroup时,该文件的每一行的第3字段相对于当前(读取Cgroup文件的)进程的对应Cgroup子系统根目录。如果目标进程所属Cgroup目录在当前进程Cgroup对应子系统根目录之外,则第3字段中会出现 ../表示上级目录。
上面这段规则很拗口,我们结合例子看:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 在freezer子系统中创建一个子组 mkdir -p /sys/fs/cgroup/freezer/sub1 # 创建一个长时间运行的进程 sleep 10000 & [1] 20124 # 将上述进程加入新创建的子组 echo 20124 > /sys/fs/cgroup/freezer/sub1/cgroup.procs # 现在,创建一个新的子组 mkdir -p /sys/fs/cgroup/freezer/sub2 # 将当前Shell加入到新子组 echo $$ 30655 echo 30655 > /sys/fs/cgroup/freezer/sub2/cgroup.procs # 查看当前进程所属freezer组 cat /proc/self/cgroup | grep freezer # 输出 相对于当前组Cgroup根目录,也就是 /sys/fs/cgroup/freezer/sub2/ 7:freezer:/sub2 # 最后,在新的Cgroups中执行Shell: cat /proc/self/cgroup | grep freezer 7:freezer:/ cat /proc/20124/cgroup | grep freezer 7:freezer:/../sub1 |
该命名空间隔离进程间通信资源,也就是System V IPC对象、 POSIX消息队列。以下/proc接口在每个IPC命名空间都是独立的:
- /proc/sys/fs/mqueue POSIX消息队列
- /proc/sys/kernel下的System V接口,包括msgmax, msgmnb, msgmni, sem, shmall, shmmax, shmmni,shm_rmid_forced
- /proc/sysvipc下的System V接口
要启用IPC命名空间,在构建内核时需要指定 CONFIG_IPC_NS选项。
创建新进程时,使用 CLONE_NEWIPC标记可以启用新的IPC命名空间。
该命名空间隔离:
- 网络设备
- IPv4/IPv6网络栈
- IP路由表
- IPtables
- 端口(套接字)
- /proc/net(/proc/self/net)目录
- /sys/class/net目录
- /proc/sys/net下若干文件
- Unix Domain Socket
等网络相关资源。创建新进程时,使用 CLONE_NEWNET标记可以开启新的网络命名空间。要启用网络命名空间,在构建内核时需要指定 CONFIG_NET_NS选项。
每个物理网络设备,仅仅能存在于单个网络命名空间中。当网络命名空间终结(命名空间中最后一个进程退出)后,其中的网络设备归还到初始网络命名空间(而不是最后一个进程的父进程所属的网络命名空间)。
一个虚拟网络设备(veth)对,可以用于创建两个网络命名空间之间的、行为类似于管道的隧道,也可以用于创建到其它网络命名空间物理设备的网桥。当网络命名空间终结时,其veth设备自动销毁。
任何网络设备,包括veth都可以在不同网络命名空间中移动。在Kubernetes中基于Calico构建CNI时,对于每个Pod都会创建一个veth对,在Pod网络命名空间为eth0,在宿主机网络命名空间为cali***:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 在宿主机上执行 ip link list # ... 34: cali84f62caf29f@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP mode DEFAULT group default link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 16 # 在容器中执行 ip link list # ... 4: eth0@if34: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP mode DEFAULT group default link/ether c2:8a:a9:d4:b5:46 brd ff:ff:ff:ff:ff:ff # 容器以宿主机为路由器,和外部通信 # 在宿主机执行 route -n 172.27.68.135 0.0.0.0 255.255.255.255 UH 0 0 0 cali84f62caf29f |
上述命令的 @ifxx,显示了veth对端在它自己的命名空间的网络设备索引号。查看网络设备索引号的其它方法包括:
|
1 2 3 |
cat /sys/class/net/eth1/iflink sudo ethtool -S eth1 | grep peer_ifindex |
这组命令可以用于网络命名空间的管理。
使用下面的命令可以添加一个网络命名空间:
|
1 |
ip netns add netns1 |
网络命名空间创建后,会在 /var/run/netns下生成一个挂载点。
使用下面的命令,可以显示可用的网络命名空间列表:
|
1 |
ip netns list |
使用下面的命令,可以在指定的网络命名空间中执行ip子命令:
|
1 2 3 |
ip netns exec netns1 ip link list # 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default # link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 |
默认情况下,一个新的命名空间中仅有一个looback设备,而且处于DOWN状态,因此无法访问:
|
1 2 3 4 5 |
ip netns exec netns1 ping localhost # connect: Network is unreachable # 启用lo设备后即可访问 ip netns exec netns1 ip link set dev lo up |
仅仅有一个Loopback设备,是无法和外部通信的。
要达成通信的目的,必须创建一对虚拟以太网卡veth pair:
|
1 |
ip link add veth0 type veth peer name veth1 |
veth pair总是成对出现且相互连接,从一端发出的报文可以在另一端接收到。 最初创建的veth pair都位于初始网络命名空间中,我们需要将其中的一端移动到netns1:
|
1 2 3 4 5 6 7 8 9 |
ip link set veth1 netns netns1 # 物理设备无法放入到自定义的网络命名空间 ip link set wlan3 netns netns1 # RTNETLINK answers: Invalid argument # 把veth放回到初始命名空间 # 放到PID为1的进程所在的网络命名空间 ip netns exec netns1 ip link set veth1 netns 1 |
然后启用veth设备,配置IP地址:
|
1 2 3 4 5 6 7 8 9 |
# 配置netns1端 ip netns exec netns1 ifconfig veth1 10.1.1.1/24 up # 配置初始命名空间端 ifconfig veth0 10.1.1.2/24 up # 测试可以相互通信 ping 10.1.1.1 ip netns exec netns1 ping 10.1.1.2 |
新网络命名空间的路由表、Iptables也是隔离的:
|
1 2 3 4 5 6 7 |
ip netns exec netns1 route -n # Kernel IP routing table # Destination Gateway Genmask Flags Metric Ref Use Iface # 10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1 ip netns exec netns1 iptables -L # 空白 |
要访问外部网络,必须通过初始网络命名空间进行中转,具体方法有多种,例如:
- 在初始网络命名空间创建一个Linux Bridge,将veth1和eth0桥接
- 配置NAT规则,启用IP转发(net.ipv4.ip_forward=1)
使用下面的命令,可以删除网络命名空间:
|
1 |
ip netns delete netns1 |
如果网络命名空间中仍然有进程在运行,则不会真正删除命名空间,仅仅移除其挂载点。
该命名空间隔离挂载点,也就是隔离文件系统目录树中可以看到的内容。
文件 /proc/[pid]/mounts、 /proc/[pid]/mountinfo、 /proc/[pid]/mountstats中的内容,取决于目标进程所属的Mount命名空间。
创建新进程时,使用标记 CLONE_NEWNS可以创建新的Mount命名空间。新Mount命名空间的初始化挂载点列表如下:
- 如果命名空间通过 clone创建,则挂载点列表是父进程Mount命名空间挂载点列表的副本
- 如果命名空间通过 unshare创建,则挂载点列表取决于调用者的Mount命名空间
默认情况下,使用mount/umount系统调用修改挂载点列表,不会影响其它命名空间。
关于Mount命名空间,需要注意:
- 每个Mount命名空间归属于一个User命名空间。上文提到新创建Mount命名空间会复制挂载点,如果两个Mount命名空间所属的User命名空间不同,则新命名空间是less
privileged的 - 当前创建了less privileged的Mount命名空间时,Shared Mount退化为Slave Mount,以确保在less privileged空间进行的mapping不会传播到more priviledeged命名空间
- 来自more privileged命名空间的挂载点,是一个不可分割的整体,不能在less privileged命名空间中被分离
- mount调用的选项MS_RDONLY、MS_NOSUID、MS_NOEXEC,以及MS_NOATIME、MS_NODIRATIME、MS_RELATIME被锁定,不能在less privileged中被修改
- 一个文件或目录,在命名空间A中可能是挂载点,在命名空间B则不是挂载点(没有挂载文件系统)。这些目录或文件可能被重命名、unlink或者删除,其结果是,那些将其作为挂载点的命名空间,对应的挂载点会被删除。在3.18-版本中,重命名、unlink、删除这种挂载点目录,会导致EBUSY错误
在某些情况下,Mount命名空间提供的隔离太重了。举例来说,要让一个新载入的光盘能够在所有命名空间可见,必须在每个命名空间执行挂载操作。为了避免这种麻烦,从2.6.15开始,内核引入了共享子树特性,该特性允许跨越命名空间的、受控传播的自动mount/umount。
每个挂载点的传播类型,可以设置为:
- MS_SHARED:表示该挂载点在对等组(Peer Group,一组挂载点)成员之间共享mount/umount事件。也就是说组中任何命名空间进行了mount,其它命名空间自动的也进行mount
- MS_PRIVATE:表示该挂载点是私有的,不具有对等组
- MS_SLAVE:允许来自(Master)共享对等组的mount/umount事件传播到此挂载点。反之,该挂载点发起的mount/umount事件则不会传播。注意一个对等组可以是另外一个的Slave
- MS_UNBINDABLE:类似于MS_PRIVATE,增加一个额外限制,该挂载点不能作为绑定挂载的源(mount --bind,用于将某个目录挂载到另一个位置,两个地方内容一致)
强调两点:
- 传播类型是针对每个挂载点来设置的,一个挂载命名空间的中的不同挂载点可以具有不同设置
- 传播类型决定了挂载点下的mount/umount事件的传播:
- 在共享挂载点P下面,创建了一个子挂载点C,那么对等组的其它挂载点也会自动看到子挂载点C
- 但是,C下的子挂载点如何传播,取决于C的传播类型,而非P(取决于直接父挂载点)
下面是个实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 打开终端1 # 在初始命名空间,设置根挂载点为私有 mount --make-private / # 现在在根挂载点下,创建两个共享挂载点 mount --make-shared /dev/sda3 /X mount --make-shared /dev/sda5 /Y # 打开终端2,创建新的挂载命名空间 unshare -m --propagation unchanged bash # 返回终端1,创建一个Bind挂载 mkdir /Z mount --bind /X /Z # 回到终端2,你可以看到 X Y但是看不到Z # 原因是: # 1. X Y来自Unshare时复制的挂载点 # 2. 终端0、1的根挂载点是对等组 # 3. 由于根挂载点的传播类型为私有,因此它创建的新的绑定挂载Z不会传播 |
通过文件 /proc/PID/mountinfo可以查看传播类型、对等组信息:
|
1 2 3 4 5 6 7 8 9 |
cat /proc/self/mountinfo | sed 's/ - .*//' # 根挂载点是私有的,没有share标记 61 0 8:2 / / rw,relatime # 传播类型为共享,对等组编号为1 81 61 8:3 / /X rw,relatime shared:1 124 61 8:5 / /Y rw,relatime shared:2 # 通过绑定挂载mount的Z,因此和源X位于一个对等组 228 61 8:3 / /Z rw,relatime shared:1 # ID 父ID 注意在新mount命名空间复制的挂载点,具有自己的ID |
对等组是一组挂载点,它们相互传播mount/umount事件。
新创建的挂载点加入旧挂载点所在对等组的条件是:
- 旧挂载点被设置为MS_SHARED
- 并且,满足以下之一:
- 创建新命名空间时旧挂载点被复制
- 从旧挂载点创建了一个新的绑定挂载
新挂载点的默认传播类型为:
- 如果挂载点有父亲(即非根挂载点),并且父亲的传播类型是 MS_SHARED,则新挂载点的传播类型也是 MS_SHARED
- 否则,新挂载的传播类型为 MS_PRIVATE
Systemd将所有挂载点的传播类型设置为MS_SHARED,因此大部分现代Linux中,不经特别设置,传播类型为MS_SHARED。
该命名空间隔离进程ID空间,允许不同命名空间中的进程拥有相同的ID。要启用此特性,编译内核时需要指定 CONFIG_PID_NS选项。
PID命名空间允许容器:
- 暂停/恢复容器中的一组进程
- 将容器迁移到新的宿主机,而保持容器中进程的PID不变
利用PID命名空间,你可以暂停容器中的一组进程,并且在另外一台机器上恢复它们,而保持PID不变。
在新的PID命名空间中,生成的PID从1开始,看起来就像是独立的系统。fork/vfork/clone等系统调用会生成在当前命名空间中唯一的PID。
新命名空间中创建(执行clone/unshare系统调用时指定CLONE_NEWPID标记)的第一个进程,具有PID 1,作为命名空间的"init"进程。此进程将作为命名空间中任何孤儿进程(其父进程提前死亡)的养父进程。
如果PID 1死亡,则内核以SIGKILL信号杀死命名空间中所有其它进程,此行为遵循规则:Init进程是PID命名空间执行正确行为的基础。在此情况下,针对命名空间的后续fork调用会导致ENOMEM错误。
只有已经被Init进程设置了处理器的信号,才可以从命名空间其它进程发送给Init进程。即使是特权进程也不能违反此规则,这防止Init进程被意外的杀死。
类似的,祖先命名空间中的进程,也只有在Init进程设置了处理器的前提下,才能发送信号给Init。但是SIGKILL、SIGSTOP不受限制,这些信号被强制的从祖先命名空间递送给Init进程,并且这两个信号不能被Init进程捕获处理,结果就是导致Init进程终结。
从内核3.4开始,系统调用reboot会导致命名空间中的Init进程接收到信号。
PID命名空间可以形成树状层次,除了初始(root,initial)命名空间之外,所有PID命名空间都具有一个父命名空间。父命名空间就是调用clone/unshare生成新PID命名空间的那个进程,所属的PID命名空间。从3.7开始,PID命名空间树的深度被限制为最多32。
一个进程可以被以下进程看到:
- 同一命名空间内的进程
- 直接或者间接的祖先命名空间中的进程
这意味着初始命名空间可以看到所有进程。反之,子代命名空间则不能看到祖代命名空间中的进程。
所谓“看到”,是指可以以PID为参数,针对目标进程执行系统调用,例如kill、 setpriority。很显然,在每个祖代命名空间看到的,同一个实际进程的PID是不一样的。执行系统调用时,必须使用调用者所在命名空间的PID“视图”。
通过系统调用setns,进程可以自由的加入子代PID命名空间,但是却不能加入祖代命名空间。
该命名空间提供两种系统标识符 —— 主机名(hostname)、NIS域名——的隔离。
通过clone/unshare系统调用创建新的UTS命名空间时,来自调用者UTS命名空间的标识符会自动拷贝过来。
该命名空间隔离安全相关的标识符、属性。包括User IDs、Group IDs、root目录、密钥(keyrings)、能力( Capabilities)。
User命名空间是一个特殊的命名空间,它和其它命名空间具有交互性,它可以拥有(Own)其它命名空间。
一个进程的UID、GID在命名空间内外可以不同。一个进程可以在命名空间内部具有UID 0,而在外部仅仅具有一个非特权UID,这意味着进程可以在一个命名空间内进行特权操作,而在此命名空间之外却不可以。
类似于PID命名空间,User命名空间也是可以嵌套的。除了初始命名空间之外,所有User命名空间都具有一个父命名空间。父命名空间就是创建新命名空间(clone/unshares时指定标记CLONE_NEWUSER)的那个进程所属的User命名空间。
从3.11版本开始,内核限制User命名空间树的最大深度为32。
每个进程都是单个User命名空间的成员,单线程的进程如果具有CAP_SYS_ADMIN能力则可以调用setns来加入其它User命名空间,从而获得目标命名空间的所有能力(capabilities)。
执行系统调用execve会导致能力的重新计算,结果就是,除非进程在当前命名空间具有UID 0或者进程的可执行文件提供了一个非空的可继承的能力掩码(Capabilities mask),进程会丢失所有能力。
基于CLONE_NEWUSER创建的进程,拥有新创建的命名空间的所有能力。类似的,通过setns加入现有User命名空间后,进程具有目标命名空间的所有能力。相反的,进程在该命名空间的祖代命名空间、或者进程先前所在的User的命名空间,则没有任何能力。
确定命名空间中一个进程是否具有某项能力的规则如下:
- 如果进程的有效能力集(Effective capability set)中设置了能力A,则它具有所在命名空间的能力A。进程的有效能力集可以因多种原因设置:
- 执行了Set User ID的程序
- 执行了具有关联的能力的可执行文件
- 因为clone/unshare/setns调用而设置的能力
- 如果进程在命名空间中具有能力,则在该命名空间的所有子代命名空间中同样具有相同的能力
- 当User命名空间被创建时,内核将创建它的进程的有效UID记录为命名空间的Owner。此命名空间的父命名空间中 ,任何有效UID为Owner的进程,都具有该User命名空间的所有能力
如果进程在User命名空间中具有能力,那么它就可以对该命名空间管理的资源执行相应的特权操作。更精确的说,是对该User命名空间所拥有(关联)的(非User)命名空间所管理的资源具有特权操作。举例来说,进程P1属于UTS命名空间N1,N1属于User命名空间N2,那么,P1必须在N2中持有CAP_SYS_ADMIN能力,才能执行sethostname系统调用。
从另一角度来说,很多特权操作会影响到,不被任何命名空间管理的资源。例如:
- 修改时间(对应能力CAP_SYS_TIME)
- 加载内核模块(对应能力CAP_SYS_MODULE)
- 创建设备(对应能力CAP_MKNOD)
这些操作,仅仅能由位于初始User命名空间中的特权进程执行。
在拥有进程所属Mount命名空间的User命名空间中,持有CAP_SYS_ADMIN能力,允许进程:
- 创建Bind挂载
- 挂载以下类型的文件系统
- /proc,要求内核3.8+
- /sys,要求内核3.8+
- devpts,要求内核3.9+
- tmpfs,要求内核3.9+
- ramfs,要求内核3.9+
- mqueue,要求内核3.9+
- bpf,要求内核4.4+
在拥有进程所属Cgroup命名空间的User命名空间中,持有CAP_SYS_ADMIN能力,允许进程:
- 从内核4.6开始,挂载Cgroup v2文件系统
- 挂载Cgroup v1命名结构(即通过选项none,name=挂载的Cgroups文件系统)
但是,挂载块设备的文件系统,必须要求进程具有初始User命名空间的CAP_SYS_ADMIN能力。
在拥有进程所属PID命名空间的User命名空间中,持有CAP_SYS_ADMIN能力,允许进程:
- 挂载/proc文件系统
从3.8开始,非特权进程可以创建User命名空间,而其它类型的命名空间,只需要调用者进程具有所在User命名空间中的CAP_SYS_ADMIN能力。
当一个非User命名空间被创建时,它被创建者进程,在创建它的那个时刻,所属于的User命名空间,所拥有(Own)。
非User命名空间管理了某些系统资源,要对这些资源进行特权操作,则操作者进程必须在拥有这些命名空间的User命名空间中,持有必要的能力。
执行clone/unshare系统调用时,如果指定了CLONE_NEWUSER的同时,也指定了其它CLONE_NEW*标记,那么内核会确保User命名空间首先被创建。并且将随后创建的其它类型的命名空间的特权赋予子进程(clone)、调用者进程(unshare)。
执行clone/unshare系统调用时,如果指定了非CLONE_NEWUSER之外的CLONE_NEW*标记,则内核会将调用者进程的User命名空间作为新创建的命名空间的Owner。这种Owner关系是可以被改变的。
对于新创建的User命名空间,它的UID/GID到父User命名空间对应的UID/GID的映射关系,是空的。
UID/GID映射关系,通过文件 /proc/[pid]/uid_map 和 /proc/[pid]/gid_map暴露。这些文件可以在一个User命名空间中读取,可以被写入单次以定义映射关系。
注意,uid_map文件中定义的是,以读取者进程的视角来看,PID进程所属的User命名空间的UID ⇨ 读取者进程所属的User命名空间的UID的映射关系。对于gid_map类似。
- 进程在命名空间中
- 其它命名空间属于User命名空间
- User命名空间具有父User命名空间
- 父User命名空间就是创建它的进程,当时所在的User命名空间
- 进程具有所属的User命名空间的所有能力
- User命名空间具有Owner,它是创建它的那个进程的Effective UID
参考Linux命令知识集锦。
该系统调用用于将一个线程关联到命名空间:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#define _GNU_SOURCE #include <sched.h> // fd:引用目标命名空间的文件描述符,对应/proc/[pid]/ns/目录中的一个条目 // nstype:执行此系统调用的线程可以关联那些类型的命名空间: // 0 允许任何类型的命名空间 // CLONE_NEWIPC fd必须是IPC命名空间 // CLONE_NEWNET fd必须是网络命名空间 // CLONE_NEWUTS fd必须是UTS命名空间 // CLONE_NEWNS fd必须是Mount命名空间 // CLONE_NEWPID fd必须是PID命名空间 // CLONE_NEWUSER fd必须是User命名空间 // CLONE_NEWCGROUP fd必须是Cgroup命名空间(4.6+) // 返回值:0表示成功,-1表示错误,errno: // EBADF 无效文件描述符 // EINVAL fd引用的命名空间类型和nstype不匹配,或者关联线程到命名空间时出现错误 // ENOMEM 没有足够内存 // EPERM 调用者线程缺少必要的权限(CAP_SYS_ADMIN) int setns(int fd, int nstype); |
下面是一个例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#define _GNU_SOURCE #include <fcntl.h> #include <sched.h> #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(int argc, char *argv[]) { int fd = open("/proc/1/ns/mnt", O_RDONLY); /* 读取文件描述符 */ if (fd == -1) exit(EXIT_FAILURE); // 加入命名空间 if (setns(fd, 0) == -1) exit(EXIT_FAILURE); // 在命名空间中执行命令 char * argv[] = {"ls", "-l", "/proc", 0}; // execvp可以执行一个用户指定的命令 execvp( "ls", argv); } |
注意各种加入各种命名空间,都具有很多限制条件:
| 命名空间 | 说明 |
| User |
当前进程必须具有目标User命名空间的CAP_SYS_ADMIN权限,这意味着只能进入子代User命名空间 加入命名空间后,将获得目标命名空间的所有能力,不论进程的UID/PID 多线程上下文下(也就是多线程进程)不能通过setns修改User命名空间 进程也不能重新进入自己本来的User命名空间,这个限制防止已经丢弃某种能力的进程通过setns重新获得该能力 出于安全的考虑,如果进程和其它进程共享了文件系统有关的属性,则不能加入到新的mount命名空间 |
| Mount |
当前进程必须具有在其本身的User命名空间中具有CAP_SYS_CHROOT、CAP_SYS_ADMIN能力。同时,在拥有目标Mount命名空间的User命名空间中具有CAP_SYS_ADMIN能力 出于安全的考虑,如果进程和其它进程共享了文件系统有关的属性,则不能加入到新的mount命名空间 |
| PID |
当前进程在本身的User命名空间,拥有目标PID命名空间的User命名空间中都需要CAP_SYS_ADMIN能力 只有调用者创建的子进程的PID命名空间才被修改,调用者本身的不会修改,这是setns针对PID命名空间的特殊之处 只能切换到子代PID命名空间中 |
| Cgroup |
当前进程在本身的User命名空间,拥有目标PID命名空间的User命名空间中都需要CAP_SYS_ADMIN能力 此操作不会改变调用者的Cgroups成员关系 —— 也就是说不会将其移动到其它Cgourp |
| Network | 当前进程在本身的User命名空间,拥有目标PID命名空间的User命名空间中都需要CAP_SYS_ADMIN能力 |
| IPC | |
| UTS |
这个系统调用功能和setns相反,用于逃离某种命名空间:
|
1 |
int unshare(int flags); |
该调用的工作方式时,先创建flags指定的那些类型的命名空间,然后将进程移动到这些新的命名空间 。
控制组(Control Group)是Linux内核的一个特性,用于控制进程对CPU、磁盘I/O、内存、网络等资源的使用。cgroup具有树状层次,子cgroup会继承父cgroup的设置。cgroup被映射到Linux的文件系统树中,对应目录/sys/fs/cgroup,你可以基于文件系统接口来管理它。/sys/fs/cgroup的子目录对应cgroup的各controllers(子系统):
| 子目录 | 说明 |
| blkio | 为块设备设定输入/输出限制 |
| cpu | 控制cgroup中任务的CPU使用 |
| cpuacct | 自动生成cgroup中任务所使用的CPU报告 |
| cpuset | 为cgroup中的任务分配独立CPU和内存节点 |
| devices | 允许或者拒绝cgroup中的任务访问设备 |
| freezer | 挂起或者恢复cgroup中的任务 |
| memory | 设定cgroup中任务使用的内存限制,并自动生成由那些任务使用的内存资源的报告 |
| net_cls | 使用classid标记网络数据包,可允许Linux流量控制程序tc识别从具体cgroup中生成的数据报 |
| ns | 名称空间子系统 |
你可以执行mount命令看到多个类型为cgroup的文件系统,正好与上面这些子目录对应。
将任务(进程)的ID放入到一个cgroup中,该任务就受到cgroup的控制。
要新建一个cgroup,必须创建某个controller的子目录:
|
1 2 3 4 |
# 创建 mkdir /cgroup/cpu/test # 删除 rmdir /cgroup/cpu/test |
注意子目录可以嵌套,对应了cgroup的层次。子目录中可以有一些文件,对应了当前cgroup的配置:
|
1 2 3 4 |
# 修改参数,CPU占用权重 echo 2048 > /cgroup/cpu/test/cpu.shares # 将任务加入到cgroup echo $PID > /cgroup/cpu/test/tasks |
你可以在指定的cgroup中执行命令:
|
1 2 |
sudo apt-get install cgroup-bin cgexec -g cpu:test command args |
其它相关命令:
|
1 2 3 4 5 6 |
# 查看所有的cgroup lscgroup # 查看所有的子系统: lssubsys -am # 查看一个进程属于哪个cgroup ps -O cgroup |
追踪点(tracepoint)是内核中静态编写的挂钩点,它允许调用一个动态挂钩的函数。
追踪点的状态可以是on/off,如果没有函数挂钩,则状态为off。off状态的追踪点有很小的时间成本(需要检查一个条件分支)和空间成本(在被instrument函数尾部增加若干字节的代码、在单独的section增加一个数据结构)。on状态的追踪点,会在每次到达时,在caller的执行上下文中,调用你提供的函数。
Kprobe允许你动态的挂钩到几乎任何内核函数,从而无入侵的收集调试、性能信息。
Kprobe分为两类:
- kprobe:可以几乎在内核的任何指令处挂钩
- return probe:当被挂钩的函数退出时,执行钩子
命名服务交换机(Name Service Switch)是类UNIX系统的一种名称解析机制。它以:
- 本地系统配置文件,例如/etc/passwd、/etc/group、/etc/hosts
- DNS服务器
- 网络信息服务(Network Information Service,NIS)
- LDAP
等多种文件/服务作为数据来源。来提供针对各种系统数据库(System database)的查询服务。
通过调用GNU C库中的函数,可以发起NSS查询。GNU C库的主机名查找,就是通过这种方式实现的。
即数据库类型:
| 信息类型 | 说明 |
| aliases | 邮件别名 |
| ethers | 以太网编号 |
| group | 用户组信息 |
| hosts | 主机名信息 |
| netgroup | 网络范围的主机/用户信息 |
| networks | 网络名信息 |
| passwd | 用户身份信息 |
| protocols | 网络协议 |
| services | 网络服务信息 |
即数据库的源:
| 源类型 | 说明 |
| files | 存放在客户端的/etc目录中的文件 |
| nisplus | 一个NIS+表,例如hosts表 |
| nis | 一个NIS映射,例如hosts映射 |
| compat | 用于密码等敏感信息的/etc目录中的文件 |
| dns | 从DNS获取主机信息 |
| ldap | 从LDAP目录获取信息 |
| mdns4_minimal | Ubuntu中出现的源,它仅在名称以.local结尾时才尝试通过MDNS(multicast DNS)解析名称 |
此文件列出各种数据库(passwd, shadow, group等)以及一个或多个获取数据的源:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 数据库名字 可能的源的列表 passwd: compat group: compat shadow: compat gshadow: files # 发起针对hosts数据库的查询时,逐个尝试这些源 hosts: files mdns4_minimal [NOTFOUND=return] dns networks: files protocols: db files services: db files ethers: db files rpc: db files netgroup: nis |
除了为数据库指定源外,还可以指定规则 —— 针对特定查找结果的操作。例如上面的 [NOTFOUND=return],表示如果通过mdns4_minimal源得到的结果是NOTFOUND,则立即返回,不去尝试下一个源,也就是dns
| 状态 | 说明 |
| success | 没有错误,需要的条目已经找到 |
| notfound | 查找过程正常,但是找不到条目。默认操作是continue |
| unavail | 服务永久的不可用(可能表示需要的文件不存在,或者DNS这样的服务器不可用/不允许查询)。默认操作是continue |
| tryagain | 服务临时的不可用(可能表示需要的文件被锁住,或者DNS这样的服务器暂时无法处理连接)。默热年操作是continue |
| 操作 | 说明 |
| return |
停止查找过程:
|
| continue | 继续使用后面的源进行查找 |
| merge | 保留当前查找结果,后后续的源的查找结果进行合并 |
Locale直译为区域,是国际化/本地化过程中重要的概念。Localhe和某一个地域内的人们的语言习惯、文化传统和生活习惯有关。Linux下有多个与Locale相关的环境变量,可以影响OS的行为。
| 环境变量 | 说明 |
| LANGUAGE | 用于设置消息语言(LC_MESSAGES)为多重值,例如 zh:en 表示消息语言尽可能使用中文,缺失时使用英文 |
| LANG | 通常情况下,用户使用该环境变量设置Locale,为所有没有显式设置的LC_XXX提供默认值 |
| LC_XXX |
一系列环境变量,用于覆盖LANG并且影响Locale的某个方面 这些环境变量包括: |
| LC_ALL |
覆盖上面所有Locale的方面以及LANG,通常用于执行特定程序的脚本中,不应当在用户环境下使用 这些环境变量优先级从高到低:LC_ALL ⇨ LC_XXX ⇨ LANG |
| C_INCLUDE_PATH |
C头文件搜索位置 |
| CPLUS_INCLUDE_PATH |
C++头文件搜索位置 |
| CPATH |
C/C++头文件搜索位置 |
| LIBRARY_PATH |
编译期间,GCC基于此环境变量来定位库所在的目录 |
| LD_LIBRARY_PATH |
链接时,可以通过此环境变量指定目标共享库的位置 运行期间,基于此环境变量寻找共享库 |
Locale相关环境变量的值使用一个字符串表示,格式为: 语言[_地域[.字符集]] ,例如: zh_CN.GB2312 表示中文_中华人民共和国.国标2312字符集; zh_TW.BIG5 表示中文_台湾.大五码字符集; en_GB.ISO-8859-1 表示英文_英国.ISO-8859-1字符集; en_US.UTF-8 表示英语_美国.UTF-8字符集,等等。
| 环境变量 | 说明 | ||
| HTTP_PROXY | 指定一个代理服务器,应用程序可以基于此环境变量指定的代理连接到网络。示例:
|
||
| HTTPS_PROXY | 指定一个代理服务器,应用程序可以基于此环境变量指定的代理连接到网络,来访问HTTPS | ||
| NO_PROXY | 指定不通过代理连接的IP或者域名列表。示例:
|
参考:https://www.cnblogs.com/tolimit/p/5065761.html。
| kernel.acct | acct功能用于系统记录进程信息,正常结束的进程都会在该文件尾添加对应的信息。异常结束是指重启或其它致命的系统问题,不能够记录永不停止的进程。该设置需要配置三个值,分别是: 1.如果文件系统可用空间低于这个百分比值,则停止记录进程信息。 2.如果文件系统可用空间高于这个百分比值,则开始记录进程信息。 3.检查上面两个值的频率(以秒为单位)。 |
| kernel.auto_msgmni | 系统自动设置同时运行的消息队列个数。 0:不自动 1:自动 |
| kernel.blk_iopoll | |
| kernel.cad_pid | 接收Ctrl-alt-del操作的INT信号的进程的PID |
| kernel.cap_last_cap | 系统capabilities最高支持的权限等级。 详见:http://www.cnblogs.com/iamfy/archive/2012/09/20/2694977.html |
| kernel.compat-log | |
| kernel.core_pattern | 设置core文件保存位置或文件名,只有文件名时,则保存在应用程序运行的目录下 |
| kernel.core_pipe_limit | 定义了可以有多少个并发的崩溃程序可以通过管道模式传递给指定的core信息收集程序。如果超过了指定数,则后续的程序将不会处理,只在内核日志中做记录。0是个特殊的值,当设置为0时,不限制并行捕捉崩溃的进程,但不会等待用户程序搜集完毕方才回收/proc/pid目录(就是说,崩溃程序的相关信息可能随时被回收,搜集的信息可能不全)。 |
| kernel.core_uses_pid | Core文件的文件名是否添加应用程序pid做为扩展 0:不添加 1:添加 |
| kernel.ctrl-alt-del | 该值控制系统在接收到 ctrl+alt+delete 按键组合时如何反应: 1:不捕获ctrl-alt-del,将系统类似于直接关闭电源 0:捕获ctrl-alt-del,并将此信号传至cad_pid保存的PID号进程进行处理 |
| kernel.dmesg_restrict | 限制哪些用户可以查看syslog日志 0:不限制 1:只有特权用户能够查看 |
| kernel.domainname | 网络域名(重启失效) |
| kernel.ftrace_dump_on_oops | 确定是否将ftrace的缓冲区的信息打印出来,是通过printk来打印的 0:不打印 1:在系统oops时,自动dump堆栈信息到输出终端 |
| kernel.hostname | 主机名(重启失效) |
| kernel.hotplug | 该文件给出了当前系统支持热插拔(hotplug)时接收热插拔事件的程序的名字(包括路径)。 |
| kernel.hung_task_check_count | hung_task检查的进程数量最大值
hung_task用于检测一个进程是否在TASK_UNINTERRUPTIBLE状态过长,只有在等待IO的时候进程才会处于TASK_UNINTERRUPTIBLE状态,这个状态的进程内核不能够通过信号将其唤醒并杀死。 |
| kernel.hung_task_panic | 设置hung_task发生后是否引发panic 1:触发 0:不触发 |
| kernel.hung_task_timeout_secs | hung_task超时时间(以秒为单位),当一个进程在TASK_UNINTERRUPTIBLE状态超过这个时间后,会发生一个hung_task linux会设置40%的可用内存用来做系统cache,当flush数据时这40%内存中的数据由于和IO同步问题导致超时。 |
| kernel.hung_task_warnings | 最大产生警告数量,当发生一次hung_task时会产生一次警告,但警告数量到达此值后之后的hung_task就不会发生警告 |
| kernel.kexec_load_disabled | 表示kexec_load系统调用是否被禁止,此系统调用用于kdump。当发生了一次kexec_load后,此值会自动设置为1。 0:开启kexec_load系统调用 1:禁止kexec_load系统调用 |
| kernel.keys.gc_delay | |
| kernel.keys.maxbytes | |
| kernel.keys.maxkeys | |
| kernel.keys.persistent_keyring_expiry | |
| kernel.keys.root_maxbytes | |
| kernel.keys.root_maxkeys | |
| kernel.kptr_restrict | 是否启用kptr_restrice,此功能为安全性功能,用于屏蔽内核指针。 0:该特性被完全禁止; 1:那些使用“%pk”打印出来的内核指针被隐藏(会以一长串0替换掉),除非用户有CAP_SYSLOG权限,并且没有改变他们的UID/GID(防止在撤销权限之前打开的文件泄露指针信息); 2:所有内核指使用“%pk”打印的都被隐藏。 |
| kernel.max_lock_depth | 触发死锁检查的嵌套深度值 |
| kernel.modprobe | 该文件给出了当系统支持module时完成modprobe功能的程序的名字(包括路径)。 |
| kernel.modules_disabled | 表示是否禁止内核运行时可加载模块 0:不禁止 1:禁止 |
| kernel.msgmax | 消息队列中单个消息的最大字节数 |
| kernel.msgmnb | 单个消息队列中允许的最大字节长度(限制单个消息队列中所有消息包含的字节数之和) |
| kernel.msgmni | 系统中同时运行的消息队列的个数 |
| kernel.ngroups_max | 每个用户最大的组数 |
| kernel.nmi_watchdog | 使能nmi_watchdog 0:禁止 1:开启 |
| kernel.numa_balancing | 是否开启numa_balancing?这块具体看代码 |
| kernel.numa_balancing_scan_delay_ms | 单个进程每次进行numa_balancing扫描的间隔时间 |
| kernel.numa_balancing_scan_period_max_ms | 每次扫描最多花费的时间? |
| kernel.numa_balancing_scan_period_min_ms | 每次扫描最少花费的时间? |
| kernel.numa_balancing_scan_size_mb | 一次扫描进程多少MB的虚拟地址空间内存 |
| kernel.numa_balancing_settle_count | |
| kernel.osrelease | 内核版本(例:3.10.0-229.7.2.rs1.2.ppc64) |
| kernel.ostype | 操作系统的类型(例:Linux) |
| kernel.overflowgid | Linux的GID为32位,但有些文件系统只支持16位的GID,此时若进行写操作会出错;当GID超过65535时会自动被转换为一个固定值,这个固定值保存在这个文件中 |
| kernel.overflowuid | Linux的UID为32位,但有些文件系统只支持16位的UID,此时若进行写操作会出错;当UID超过65535时会自动被转换为一个固定值,这个固定值保存在这个文件中 |
| kernel.panic | 系统发生panic时内核重新引导之前的等待时间 0:禁止重新引导 >0:重新引导前的等待时间(秒) |
| kernel.panic_on_oops | 当系统发生oops或BUG时,所采取的措施 0:继续运行 1:让klog记录oops的输出,然后panic,若kernel.panic不为0,则等待后重新引导内核 |
| kernel.panic_on_warn | 0:只警告,不发生panic 1:发生panic |
| kernel.perf_cpu_time_max_percent | perf分析工具最大能够占用CPU性能的百分比 0:不限制 1~100:百分比值 |
| kernel.perf_event_max_sample_rate | 设置perf_event的最大取样速率,默认值为100000 |
| kernel.perf_event_mlock_kb | 设置非特权用户能够允许常驻内存的内存大小。默认为516(KB) |
| kernel.perf_event_paranoid | 用于限制访问性能计数器的权限 0:仅允许访问用户空间的性能计数器 1:内核与用户空间的性能计数器都可以访问 2:仅允许访问特殊的CPU数据(不包括跟踪点) -1:不限制 |
| kernel.pid_max | 进程pid号的最大值 |
| kernel.poweroff_cmd | 执行关机命令的进程(包括路径) |
| kernel.powersave-nap | PPC专用,如果开启,则使用nap节能模式,关闭则使用doze节能模式 0:关闭 1:开启 |
| kernel.print-fatal-signals | |
| kernel.printk | 该文件有四个数字值,它们根据日志记录消息的重要性,定义将其发送到何处。按顺序是: 1.控制台日志级别:优先级高于该值的消息将被打印至控制台 2.默认的消息日志级别:将用该优先级来打印没有优先级的消息 3.最低的控制台日志级别:控制台日志级别可被设置的最小值(最高优先级) 4.默认的控制台日志级别:控制台日志级别的缺省值 数值越小,优先级越高,级别有(0~7) |
| kernel.printk_delay | printk 消息之间的延迟毫秒数,此值不可设置 |
| kernel.printk_ratelimit | 等待允许再次printk的时间(以秒为单位),与printk_ratelimit()函数有关 详见:http://m.blog.csdn.net/blog/chenglinhust/8599159 |
| kernel.printk_ratelimit_burst | printk的缓存队列长度(每个printk为一个长度,比如此值为5,而有段代码是连续printk10次,系统的处理是先printk前5次,等待printk_ratelimit秒后,再打印后面5次) |
| kernel.pty.max | 所能分配的PTY的最多个数(pty为虚拟终端,用于远程连接时) |
| kernel.pty.nr | 当前分配的pty的个数 |
| kernel.pty.reserve | |
| kernel.random.boot_id | 此文件是个只读文件,包含了一个随机字符串,在系统启动的时候会自动生成这个uuid |
| kernel.random.entropy_avail | 此文件是个只读文件,给出了一个有效的熵(4096位) |
| kernel.random.poolsize | 熵池大小,一般是4096位,可以改成任何大小 |
| kernel.random.read_wakeup_threshold | 该文件保存熵的长度,该长度用于唤醒因读取/dev/random设备而待机的进程(random设备的读缓冲区长度?) |
| kernel.random.uuid | 此文件是个只读文件,包含了一个随机字符串,在random设备每次被读的时候生成 |
| kernel.random.write_wakeup_threshold | 该文件保存熵的长度,该长度用于唤醒因写入/dev/random设备而待机的进程(random设备的写缓冲区长度?) |
| kernel.randomize_va_space | 用于设置进程虚拟地址空间的随机化 0:关闭进程虚拟地址空间随机化 1:随机化进程虚拟地址空间中的mmap映射区的初始地址,栈空间的初始地址以及VDSO页的地址 2:在1的基础上加上堆区的随机化 (VDSO是用于兼容不同内核与glibc的接口的机制) |
| kernel.real-root-dev | 根文件系统所在的设备(写入格式是0x主设备号(16位)次设备号(16位),例如0x801,主设备号是8,次设备号是1),只有使用initrd.img此参数才有效 |
| kernel.sched_autogroup_enabled | 启用后,内核会创建任务组来优化桌面程序的调度。它将把占用大量资源的应用程序放在它们自己的任务组,这有助于性能提升 0:禁止 1:开启 |
| kernel.sched_cfs_bandwidth_slice_us | |
| kernel.sched_child_runs_first | 设置保证子进程初始化完成后在父进程之前先被调度 0:先调度父进程 1:先调度子进程 |
| kernel.sched_domain.{CPUID}.{域ID}.busy_factor | |
| kernel.sched_domain.{CPUID}.{域ID}.busy_idx | |
| kernel.sched_domain.{CPUID}.{域ID}.cache_nice_tries | |
| kernel.sched_domain.{CPUID}.{域ID}.flags | |
| kernel.sched_domain.{CPUID}.{域ID}.forkexec_idx | |
| kernel.sched_domain.{CPUID}.{域ID}.idle_idx | |
| kernel.sched_domain.{CPUID}.{域ID}.imbalance_pct | 判断该调度域是否已经均衡的一个基准值 |
| kernel.sched_domain.{CPUID}.{域ID}.max_interval | 设置此CPU进行负载均衡的最长间隔时间,上一次做了负载均衡经过了这个时间一定要再进行一次 |
| kernel.sched_domain.{CPUID}.{域ID}.min_interval | 设置此CPU进行负载均衡的最小间隔时间,在上一次负载均衡到这个时间内都不能再进行负载均衡 |
| kernel.sched_domain.{CPUID}.{域ID}.name | |
| kernel.sched_domain.{CPUID}.{域ID}.newidle_idx | |
| kernel.sched_domain.{CPUID}.{域ID}.wake_idx | |
| kernel.sched_latency_ns | 表示正在运行进程的所能运行的时间的最大值,即使只有一个处于running状态的进程,运行到这个时间也要重新调度一次(以纳秒为单位,在运行时会自动变化?) 同时这个值也是所有可运行进程都运行一次所需的时间,每个CPU的running进程数 = sched_latency_ns / sched_min_granularity_ns |
| kernel.sched_migration_cost_ns | 该变量用来判断一个进程是否还是hot,如果进程的运行时间(now - p->se.exec_start)小于它,那么内核认为它的code还在cache里,所以该进程还是hot,那么在迁移的时候就不会考虑它 |
| kernel.sched_min_granularity_ns | 表示一个进程在CPU上运行的最小时间,在此时间内,内核是不会主动挑选其他进程进行调度(以纳秒为单位,在运行时会自动变化?) |
| kernel.sched_nr_migrate | 在多CPU情况下进行负载均衡时,一次最多移动多少个进程到另一个CPU上 |
| kernel.sched_rr_timeslice_ms | 用来指示round robin调度进程的间隔,这个间隔默认是100ms。 |
| kernel.sched_rt_period_us | 该参数与sched_rt_runtime_us一起决定了实时进程在以sched_rt_period为周期的时间内,实时进程最多能够运行的总的时间不能超过sched_rt_runtime_us |
| kernel.sched_rt_runtime_us | 该参数与sched_rt_period一起决定了实时进程在以sched_rt_period为周期的时间内,实时进程最多能够运行的总的时间不能超过sched_rt_runtime_us |
| kernel.sched_shares_window_ns | |
| kernel.sched_time_avg_ms | |
| kernel.sched_tunable_scaling | 当内核试图调整sched_min_granularity,sched_latency和sched_wakeup_granularity这三个值的时候所使用的更新方法. 0:不调整 1:按照cpu个数以2为底的对数值进行调整 2:按照cpu的个数进行线性比例的调整 |
| kernel.sched_wakeup_granularity_ns | 该变量表示进程被唤醒后至少应该运行的时间的基数,它只是用来判断某个进程是否应该抢占当前进程,并不代表它能够执行的最小时间(sysctl_sched_min_granularity),如果这个数值越小,那么发生抢占的概率也就越高 |
| kernel.sem | 该文件包含4个值: 1.同一类信号的最多数量(semmsl) 2.系统中信号的最多数目,=semmni*semmsl (semmns) 3.每个semop系统调用所包含的最大的操作数(能调用的信号量的最多次数) (semopm) 4.系统中信号类型的数目的最大值,一个信号量标识符代表一个类型(semmni) 可见:http://www.cnblogs.com/jimeper/p/3141975.html |
| kernel.shmall | 系统上可以使用的共享内存的总量(以字节为单位)。 |
| kernel.shmmax | 系统所允许的最大共享内存段的大小(以字节为单位)。 |
| kernel.shmmni | 整个系统共享内存段的最大数量。 |
| kernel.shm_rmid_forced | 强制SHM空间和一个进程联系在一起,所以可以通过杀死进程来释放内存 0:不设置 1:设置 |
| kernel.softlockup_panic | 设置产生softlockup时是否抛出一个panic。Softlockup用于检测CPU可以响应中断,但是在长时间内不能调度(比如禁止抢占时间太长)的死锁情况。这个机制运行在一个hrtimer的中断上下文,每隔一段时间检测一下是否发生了调度,如果过长时间没发生调度,说明系统被死锁。 0:不产生panic 1:产生panic |
| kernel.sysrq | 该文件指定的值为非零,则激活键盘上的sysrq按键。这个按键用于给内核传递信息,用于紧急情况下重启系统。当遇到死机或者没有响应的时候,甚至连 tty 都进不去,可以尝试用 SysRq 重启计算机。 |
| kernel.tainted | 1:加载非GPL module 0:强制加载module |
| kernel.threads-max | 系统中进程数量(包括线程)的最大值 |
| kernel.timer_migration | |
| kernel.usermodehelper.bset | |
| kernel.usermodehelper.inheritable | |
| kernel.version | 版本号(例:#1 SMP Mon Sep 7 18:12:36 CST 2015) |
| kernel.watchdog | 表示是否禁止softlockup模式和nmi_watchdog(softlockup用于唤醒watchdog) 0:禁止 1:开启 |
| kernel.watchdog_thresh | 用于设置高精度定时器(hrtimer)、nmi事件、softlockup、hardlockup的阀值(以秒为单位) 0:不设置阀值 |
| vm.admin_reserve_kbytes | 给有cap_sys_admin权限的用户保留的内存数量(默认值是 min(free_page * 0.03, 8MB)) |
| vm.block_dump | 如果设置的是非零值,则会启用块I/O调试。 |
| vm.compact_memory | 进行内存压缩,只有在启用了CONFIG_COMPACTION选项才有效 1:开始进行内存压缩 |
| vm.dirty_background_bytes | 当脏页所占的内存数量超过dirty_background_bytes时,内核的flusher线程开始回写脏页。 |
| vm.dirty_background_ratio | 当脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_background_ratio时,write调用会唤醒内核的flusher线程开始回写脏页数据,直到脏页比例低于此值,与dirty_ratio不同,write调用此时并不会阻塞。 |
| vm.dirty_bytes | 当脏页所占的内存数量达到dirty_bytes时,执行磁盘写操作的进程自己开始回写脏数据。 注意: dirty_bytes参数和 dirty_ratio参数是相对的,只能指定其中一个。当其中一个参数文件被写入时,会立即开始计算脏页限制,并且会将另一个参数的值清零 |
| vm.dirty_expire_centisecs | 脏数据的过期时间,超过该时间后内核的flusher线程被唤醒时会将脏数据回写到磁盘上,单位是百分之一秒。 |
| vm.dirty_ratio | 脏页所占的百分比(相对于所有可用内存,即空闲内存页+可回收内存页)达到dirty_ratio时,write调用会唤醒内核的flusher线程开始回写脏页数据,直到脏页比例低于此值,注意write调用此时会阻塞。 |
| vm.dirty_writeback_centisecs | 设置flusher内核线程唤醒的间隔,此线程用于将脏页回写到磁盘,单位是百分之一秒 |
| vm.drop_caches | 写入数值可以使内核释放page_cache,dentries和inodes缓存所占的内存。 1:只释放page_cache 2:只释放dentries和inodes缓存 3:释放page_cache、dentries和inodes缓存 |
| vm.extfrag_threshold | |
| vm.hugepages_treat_as_movable | 用来控制是否可以从ZONE_MOVABLE内存域中分配大页面。如果设置为非零,大页面可以从ZONE_MOVABLE内存域分配。ZONE_MOVABLE内存域只有在指定了kernelcore启动参数的情况下才会创建,如果没有指定kernelcore启动参数, hugepages_treat_as_movable参数则没有效果。 |
| vm.hugetlb_shm_group | 指定组ID,拥有该gid的用户可以使用大页创建SysV共享内存段 |
| vm.laptop_mode | 设置开启laptop mode,此模式主要是通过降低硬盘的转速来延长电池的续航时间。 0:关闭 1:启动 |
| vm.legacy_va_layout | 进程地址空间内存布局模式 0:经典布局 1:新布局 对于64位系统,默认采用经典布局 |
| vm.lowmem_reserve_ratio | 决定了内核保护这些低端内存域的强度。预留的内存值和lowmem_reserve_ratio数组中的值是倒数关系,如果值是256,则代表1/256,即为0.39%的zone内存大小。如果想要预留更多页,应该设更小一点的值。 |
| vm.max_map_count | 定义了一个进程能拥有的最多的内存区域 |
| vm.memory_failure_early_kill | 控制发生某个内核无法处理的内存错误发生的时候,如何去杀掉这个进程。当这些错误页有swap镜像的时候,内核会很好的处理这个错误,不会影响任何应用程序,但是如果没有的话,内核会把进程杀掉,避免内存错误的扩大 1:在发现内存错误的时候,就会把所有拥有此内存页的进程都杀掉 0:只是对这部分页进行unmap,然后把第一个试图进入这个页的进程杀掉 |
| vm.memory_failure_recovery | 是否开启内存错误恢复机制 1:开启 0:一旦出现内存错误,就panic |
| vm.min_free_kbytes | 每个内存区保留的内存大小(以KB计算) |
| vm.min_slab_ratio | 只在numa架构上使用,如果一个内存域中可以回收的slab页面所占的百分比(应该是相对于当前内存域的所有页面)超过min_slab_ratio,在回收区的slabs会被回收。这样可以确保即使在很少执行全局回收的NUMA系统中,slab的增长也是可控的。 |
| vm.min_unmapped_ratio | 只有在当前内存域中处于zone_reclaim_mode允许回收状态的内存页所占的百分比超过min_unmapped_ratio时,内存域才会执行回收操作。 |
| vm.mmap_min_addr | 指定用户进程通过mmap可使用的最小虚拟内存地址,以避免其在低地址空间产生映射导致安全问题;如果非0,则不允许mmap到NULL页,而此功能可在出现NULL指针时调试Kernel;mmap用于将文件映射至内存; 该设置意味着禁止用户进程访问low 4k地址空间 |
| vm.nr_hugepages | 大页的最小数目,需要连续的物理内存;oracle使用大页可以降低TLB的开销,节约内存和CPU资源,但要同时设置memlock且保证其大于大页;其与11gAMM不兼容 |
| vm.nr_hugepages_mempolicy | 与nr_hugepages类似,但只用于numa架构,配合numactl调整每个node的大页数量 |
| vm.nr_overcommit_hugepages | 保留于紧急使用的大页数,系统可分配最大大页数= nr_hugepages + nr_overcommit_hugepages |
| vm.nr_pdflush_threads | 只读文件,保存了当前正在运行的pdflush线程的数量 |
| vm.numa_zonelist_order | 设置内核选择zonelist的模式: 0:让内核智能选择使用Node或Zone方式的zonelist 1:选择Node方式的zonelist,Node(0) ZONE_NORMAL -> Node(0) ZONE_DMA -> Node(1) ZONE_NORMAL 2:选择Zone方式的,Node(0) ZONE_NORMAL -> Node(1) ZONE_NORMAL -> Node(0) ZONE_DMA |
| vm.oom_dump_tasks | 如果启用,在内核执行OOM-killing时会打印系统内进程的信息(不包括内核线程),信息包括pid、uid、tgid、vm size、rss、nr_ptes,swapents,oom_score_adj和进程名称。这些信息可以帮助找出为什么OOM killer被执行,找到导致OOM的进程,以及了解为什么进程会被选中。 0:不打印系统内进程信息 1:打印系统内进程信息 |
| vm.oom_kill_allocating_task | 决定在oom的时候,oom killer杀哪些进程 非0:它会扫描进程队列,然后将可能导致内存溢出的进程杀掉,也就是占用内存最大的进程 0:它只杀掉导致oom的那个进程,避免了进程队列的扫描,但是释放的内存大小有限 |
| vm.overcommit_kbytes | 内存可过量分配的数量(单位为KB) |
| vm.overcommit_memory | 是否允许内存的过量分配,允许进程分配比它实际使用的更多的内存。 0:当用户申请内存的时候,内核会去检查是否有这么大的内存空间,当超过地址空间会被拒绝 1:内核始终认为,有足够大的内存空间,直到它用完了位置 2:内核禁止任何形式的过量分配内存 Memory allocation limit = swapspace + physmem * (overcommit_ratio / 100) |
| vm.overcommit_ratio | 内存可过量分配的百分比。 |
| vm.page-cluster | 参数控制一次写入或读出swap分区的页面数量。它是一个对数值,如果设置为0,表示1页;如果设置为1,表示2页;如果设置为2,则表示4页。 |
| vm.panic_on_oom | 用于控制如何处理out-of-memory,可选值包括0/1/2 0:当内存不足时内核调用OOM killer杀死一些rogue进程,每个进程描述符都有一个oom_score标示,oom killer会选择oom_score较大的进程 1:发生了OOM以后,如果有mempolicy/cpusets的进程限制,而这些nodes导致了内存问题的时候,OOM Killer会干掉这些中的一个,系统也会恢复 2:OOM后必然panic |
| vm.percpu_pagelist_fraction | 每个CPU能从每个zone所能分配到的pages的最大值(单位每个zone的1/X),0为不限制 |
| vm.stat_interval | VM信息更新频率(以秒为单位) |
| vm.swappiness | 该值越高则linux越倾向于将部分长期没有用到的页swap,即便有足够空余物理内存(1~100) |
| vm.user_reserve_kbytes | |
| vm.vfs_cache_pressure | 表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache |
| vm.zone_reclaim_mode | 参数只有在启用CONFIG_NUMA选项时才有效,zone_reclaim_mode用来控制在内存域OOM时,如何来回收内存。 0:禁止内存域回收,从其他zone分配内存 1:启用内存域回收 2:通过回写脏页回收内存 4:通过swap回收内存 |
| net.bridge.bridge-nf-call-arptables |
netfilter既可以在L2层过滤,也可以在L3层过滤 这些参数设置为0,则iptables不对bridge的数据进行处理 如果设置为1则意味着二层的网桥在转发包时也会被iptables的FORWARD规则所过滤,这样就会出现L3层的iptables rules去过滤L2的帧的问题,从而导致某些NAT不生效 |
||
| net.bridge.bridge-nf-call-ip6tables | |||
| net.bridge.bridge-nf-call-iptables | |||
| net.bridge.bridge-nf-filter-pppoe-tagged | |||
| net.bridge.bridge-nf-filter-vlan-tagged | |||
| net.bridge.bridge-nf-pass-vlan-input-dev | |||
| net.core.bpf_jit_enable | 基于时间规则的编译器,用于基于PCAP(packet capture library)并使用伯克利包过滤器(Berkeley Packet Filter,如tcpdump)的用户工具,可以大幅提升复杂规则的处理性能。 0:禁止 1:开启 2:开启并请求编译器将跟踪数据时间写入内核日志 |
||
| net.core.busy_poll | 默认对网络设备进行poll和select操作的超时时间(us),具体数值最好以sockets数量而定 | ||
| net.core.busy_read | 默认读取在设备帧队列上数据帧的超时时间(us),推荐值:50 | ||
| net.core.default_qdisc | |||
| net.core.dev_weight | 每个CPU一次NAPI中断能够处理网络包数量的最大值 | ||
| net.core.message_burst | 设置每十秒写入多少次请求警告;此设置可以用来防止DOS攻击 | ||
| net.core.message_cost | 设置每一个警告的度量值,缺省为5,当用来防止DOS攻击时设置为0 | ||
| net.core.netdev_budget | 每次软中断处理的网络包个数 | ||
| net.core.netdev_max_backlog | 设置当个别接口接收包的速度快于内核处理速度时允许的最大的包序列 | ||
| net.core.netdev_tstamp_prequeue | 0:关闭,接收的数据包的时间戳在RPS程序处理之后进行标记,这样有可能时间戳会不够准确 1:打开,时间戳会尽可能早的标记 |
||
| net.core.optmem_max | 表示每个socket所允许的最大缓冲区的大小(字节) | ||
| net.core.rmem_default | 设置接收socket的缺省缓存大小(字节) | ||
| net.core.rmem_max | 设置接收socket的最大缓存大小(字节) | ||
| net.core.rps_sock_flow_entries | |||
| net.core.somaxconn | 定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数。 | ||
| net.core.warnings | 已经不使用此参数 | ||
| net.core.wmem_default | 设置发送的socket缺省缓存大小(字节) | ||
| net.core.wmem_max | 设置发送的socket最大缓存大小(字节) | ||
| net.core.xfrm_acq_expires | |||
| net.core.xfrm_aevent_etime | |||
| net.core.xfrm_aevent_rseqth | |||
| net.core.xfrm_larval_drop | |||
| net.ipv4.cipso_cache_bucket_size | 限制cipso缓存项的数量,如果在缓存中新添加一行超出了这个限制,那么最旧的缓存项会被丢弃以释放出空间。 | ||
| net.ipv4.cipso_cache_enable | 是否启用cipso缓存。 0:不启用 1:启用 |
||
| net.ipv4.cipso_rbm_optfmt | 是否开启cipso标志优化选项,如果开启,数据包中标志将会在32bit对齐 0:关闭 1:开启 |
||
| net.ipv4.cipso_rbm_strictvalid | 是否开启cipso选项的严格检测 0:不开启 1:开启 |
||
| net.ipv4.conf.all.accept_local |
设置是否允许接收从本机IP地址上发送给本机的数据包 配合适当的路由,可以用于在两个本地网络接口之间(透过网线)传递封包。rp_filter必须设置为非0以配合 |
||
| net.ipv4.conf.all.accept_redirects | 收发接收ICMP重定向消息。对于主机来说默认为True,对于用作路由器时默认值为False 0:禁止 1:允许 |
||
| net.ipv4.conf.all.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv4.conf.all.arp_accept | 默认对不在ARP表中的IP地址发出的APR包的处理方式 0:不在ARP表中创建对应IP地址的表项 1:在ARP表中创建对应IP地址的表项 |
||
| net.ipv4.conf.all.arp_announce | 对网络接口上,本地IP地址的发出的,ARP回应,作出相应级别的限制: 确定不同程度的限制,宣布对来自本地源IP地址发出Arp请求的接口 0: 在任意网络接口(eth0,eth1,lo)上的任何本地地址 1:尽量避免不在该网络接口子网段的本地地址做出arp回应. 当发起ARP请求的源IP地址是被设置应该经由路由达到此网络接口的时候很有用.此时会检查来访IP是否为所有接口上的子网段内ip之一.如果改来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理. 2:对查询目标使用最适当的本地地址.在此模式下将忽略这个IP数据包的源地址并尝试选择与能与该地址通信的本地地址.首要是选择所有的网络接口的子网中外出访问子网中包含该目标IP地址的本地地址. |
||
| net.ipv4.conf.all.arp_filter | 0:内核设置每个网络接口各自应答其地址上的arp询问。这项看似会错误的设置却经常能非常有效,因为它增加了成功通讯的机会。在Linux主机上,每个IP地址是网络接口独立的,而非一个复合的接口。只有在一些特殊的设置的时候,比如负载均衡的时候会带来麻烦。
1:允许多个网络介质位于同一子网段内,每个网络界面依据是否内核指派路由该数据包经过此接口来确认是否回答ARP查询(这个实现是由来源地址确定路由的时候决定的),换句话说,允许控制使用某一块网卡(通常是第一块)回应arp询问。 |
||
| net.ipv4.conf.all.arp_ignore | 定义对目标地址为本地IP的ARP询问不同的应答模式 0:回应任何网络接口上对任何本地IP地址的arp查询请求 1:只回答目标IP地址是来访网络接口本地地址的ARP查询请求 2:只回答目标IP地址是来访网络接口本地地址的ARP查询请求,且来访IP必须在该网络接口的子网段内 3:不回应该网络界面的arp请求,而只对设置的唯一和连接地址做出回应 8:不回应所有(本地地址)的arp查询 |
||
| net.ipv4.conf.all.arp_notify | arp通知链操作 0:不做任何操作 1:当设备或硬件地址改变时自动产生一个arp请求 |
||
| net.ipv4.conf.all.bootp_relay | 接收源地址为0.a.b.c,目的地址不是本机的数据包,是为了支持bootp服务 0:关闭 1:开启 |
||
| net.ipv4.conf.all.disable_policy | 禁止internet协议安全性验证 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.all.disable_xfrm | 禁止internet协议安全性加密 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.all.force_igmp_version | |||
| net.ipv4.conf.all.forwarding | 在该接口打开转发功能 0:禁止 1:允许 |
||
| net.ipv4.conf.all.log_martians | 记录带有不允许的地址的数据报到内核日志中。 0:禁止 1:允许 |
||
| net.ipv4.conf.all.mc_forwarding | 是否进行多播路由。只有内核编译有CONFIG_MROUTE并且有路由服务程序在运行该参数才有效。 0:禁止 1:允许 |
||
| net.ipv4.conf.all.medium_id | 通常,这个参数用来区分不同媒介.两个网络设备可以使用不同的值,使他们只有其中之一接收到广播包.通常,这个参数被用来配合proxy_arp实现roxy_arp的特性即是允许arp报文在两个不同的网络介质中转发. 0:表示各个网络介质接受他们自己介质上的媒介 -1:表示该媒介未知。 |
||
| net.ipv4.conf.all.promote_secondaries | 0:当接口的主IP地址被移除时,删除所有次IP地址 1:当接口的主IP地址被移除时,将次IP地址提升为主IP地址 |
||
| net.ipv4.conf.all.proxy_arp | 打开arp代理功能。 0:禁止 1:允许 |
||
| net.ipv4.conf.all.proxy_arp_pvlan | 回应代理ARP的数据包从接收到此代理ARP请求的网络接口出去。 | ||
| net.ipv4.conf.all.route_localnet | |||
| net.ipv4.conf.all.rp_filter |
0:不进行源地址验证 当前推荐使用严格模式(1),如果使用非对称路由(来/回路径不一致)则推荐Loose模式 开启rp_filter的意义:
FIB:转发信息库,包含了最近使用的路由条目的哈希表 假设你有两网络接口 eth0 192.168.0.1 eth1 10.0.0.1,并且路由表如下:
如果rp_filter=1, 现在有一个IP封包172.21.0.1 -> 10.0.0.1,从eth1接收到,则校验会失败。因为从路由表上看,反向封包从eth0发出,而正向封包却来自eth0,不匹配,封包会被丢弃 |
||
| net.ipv4.conf.all.secure_redirects | 仅仅接收发给默认网关列表中网关的ICMP重定向消息 0:禁止 1:允许 |
||
| net.ipv4.conf.all.send_redirects | 允许发送重定向消息。(路由使用) 0:禁止 1:允许 |
||
| net.ipv4.conf.all.shared_media | 发送或接收RFC1620 共享媒体重定向。会覆盖ip_secure_redirects的值。 0:禁止 1:允许 |
||
| net.ipv4.conf.all.src_valid_mark | |||
| net.ipv4.conf.all.tag | |||
| net.ipv4.conf.{IF}.accept_local | 设置是否允许接收从本机IP地址上发送给本机的数据包 0:不允许 1:允许 |
||
| net.ipv4.conf.{IF}.accept_redirects | 收发接收ICMP重定向消息。对于主机来说默认为True,对于用作路由器时默认值为False 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv4.conf.{IF}.arp_accept | 默认对不在ARP表中的IP地址发出的APR包的处理方式 0:不在ARP表中创建对应IP地址的表项 1:在ARP表中创建对应IP地址的表项 |
||
| net.ipv4.conf.{IF}.arp_announce | 对网络接口上,本地IP地址的发出的,ARP回应,作出相应级别的限制: 确定不同程度的限制,宣布对来自本地源IP地址发出Arp请求的接口 0: 在任意网络接口(eth0,eth1,lo)上的任何本地地址 1:尽量避免不在该网络接口子网段的本地地址做出arp回应. 当发起ARP请求的源IP地址是被设置应该经由路由达到此网络接口的时候很有用.此时会检查来访IP是否为所有接口上的子网段内ip之一.如果改来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理. 2:对查询目标使用最适当的本地地址.在此模式下将忽略这个IP数据包的源地址并尝试选择与能与该地址通信的本地地址.首要是选择所有的网络接口的子网中外出访问子网中包含该目标IP地址的本地地址. |
||
| net.ipv4.conf.{IF}.arp_filter | 0:内核设置每个网络接口各自应答其地址上的arp询问。这项看似会错误的设置却经常能非常有效,因为它增加了成功通讯的机会。在Linux主机上,每个IP地址是网络接口独立的,而非一个复合的接口。只有在一些特殊的设置的时候,比如负载均衡的时候会带来麻烦。
1:允许多个网络介质位于同一子网段内,每个网络界面依据是否内核指派路由该数据包经过此接口来确认是否回答ARP查询(这个实现是由来源地址确定路由的时候决定的),换句话说,允许控制使用某一块网卡(通常是第一块)回应arp询问。 |
||
| net.ipv4.conf.{IF}.arp_ignore | 定义对目标地址为本地IP的ARP询问不同的应答模式 0:回应任何网络接口上对任何本地IP地址的arp查询请求 1:只回答目标IP地址是来访网络接口本地地址的ARP查询请求 2:只回答目标IP地址是来访网络接口本地地址的ARP查询请求,且来访IP必须在该网络接口的子网段内 3:不回应该网络界面的arp请求,而只对设置的唯一和连接地址做出回应 8:不回应所有(本地地址)的arp查询 |
||
| net.ipv4.conf.{IF}.arp_notify | arp通知链操作 0:不做任何操作 1:当设备或硬件地址改变时自动产生一个arp请求 |
||
| net.ipv4.conf.{IF}.bootp_relay | 接收源地址为0.a.b.c,目的地址不是本机的数据包,是为了支持bootp服务 0:关闭 1:开启 |
||
| net.ipv4.conf.{IF}.disable_policy | 禁止internet协议安全性验证 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.{IF}.disable_xfrm | 禁止internet协议安全性加密 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.{IF}.force_igmp_version | |||
| net.ipv4.conf.{IF}.forwarding | 在该接口打开转发功能 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.log_martians | 记录带有不允许的地址的数据报到内核日志中。 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.mc_forwarding | 是否进行多播路由。只有内核编译有CONFIG_MROUTE并且有路由服务程序在运行该参数才有效。 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.medium_id | 通常,这个参数用来区分不同媒介.两个网络设备可以使用不同的值,使他们只有其中之一接收到广播包.通常,这个参数被用来配合proxy_arp实现roxy_arp的特性即是允许arp报文在两个不同的网络介质中转发. 0:表示各个网络介质接受他们自己介质上的媒介 -1:表示该媒介未知。 |
||
| net.ipv4.conf.{IF}.promote_secondaries | 0:当接口的主IP地址被移除时,删除所有次IP地址 1:当接口的主IP地址被移除时,将次IP地址提升为主IP地址 |
||
| net.ipv4.conf.{IF}.proxy_arp | 打开arp代理功能。 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.proxy_arp_pvlan | 回应代理ARP的数据包从接收到此代理ARP请求的网络接口出去。 | ||
| net.ipv4.conf.{IF}.route_localnet | |||
| net.ipv4.conf.{IF}.rp_filter | 1:通过反向路径回溯进行源地址验证(在RFC1812中定义)。对于单穴主机和stub网络路由器推荐使用该选项。 0:不通过反向路径回溯进行源地址验证。 |
||
| net.ipv4.conf.{IF}.secure_redirects | 仅仅接收发给默认网关列表中网关的ICMP重定向消息 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.send_redirects | 允许发送重定向消息。(路由使用) 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.shared_media | 发送或接收RFC1620 共享媒体重定向。会覆盖ip_secure_redirects的值。 0:禁止 1:允许 |
||
| net.ipv4.conf.{IF}.src_valid_mark | |||
| net.ipv4.conf.{IF}.tag | |||
| net.ipv4.conf.default.accept_local | 设置是否允许接收从本机IP地址上发送给本机的数据包 0:不允许 1:允许 |
||
| net.ipv4.conf.default.accept_redirects | 收发接收ICMP重定向消息。对于主机来说默认为True,对于用作路由器时默认值为False 0:禁止 1:允许 |
||
| net.ipv4.conf.default.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv4.conf.default.arp_accept | 默认对不在ARP表中的IP地址发出的APR包的处理方式 0:不在ARP表中创建对应IP地址的表项 1:在ARP表中创建对应IP地址的表项 |
||
| net.ipv4.conf.default.arp_announce | 对网络接口上,本地IP地址的发出的,ARP回应,作出相应级别的限制: 确定不同程度的限制,宣布对来自本地源IP地址发出Arp请求的接口 0: 在任意网络接口(eth0,eth1,lo)上的任何本地地址 1:尽量避免不在该网络接口子网段的本地地址做出arp回应. 当发起ARP请求的源IP地址是被设置应该经由路由达到此网络接口的时候很有用.此时会检查来访IP是否为所有接口上的子网段内ip之一.如果改来访IP不属于各个网络接口上的子网段内,那么将采用级别2的方式来进行处理. 2:对查询目标使用最适当的本地地址.在此模式下将忽略这个IP数据包的源地址并尝试选择与能与该地址通信的本地地址.首要是选择所有的网络接口的子网中外出访问子网中包含该目标IP地址的本地地址. |
||
| net.ipv4.conf.default.arp_filter | 0:内核设置每个网络接口各自应答其地址上的arp询问。这项看似会错误的设置却经常能非常有效,因为它增加了成功通讯的机会。在Linux主机上,每个IP地址是网络接口独立的,而非一个复合的接口。只有在一些特殊的设置的时候,比如负载均衡的时候会带来麻烦。
1:允许多个网络介质位于同一子网段内,每个网络界面依据是否内核指派路由该数据包经过此接口来确认是否回答ARP查询(这个实现是由来源地址确定路由的时候决定的),换句话说,允许控制使用某一块网卡(通常是第一块)回应arp询问。 |
||
| net.ipv4.conf.default.arp_ignore | 定义对目标地址为本地IP的ARP询问不同的应答模式 0:回应任何网络接口上对任何本地IP地址的arp查询请求 1:只回答目标IP地址是来访网络接口本地地址的ARP查询请求 2:只回答目标IP地址是来访网络接口本地地址的ARP查询请求,且来访IP必须在该网络接口的子网段内 3:不回应该网络界面的arp请求,而只对设置的唯一和连接地址做出回应 8:不回应所有(本地地址)的arp查询 |
||
| net.ipv4.conf.default.arp_notify | arp通知链操作 0:不做任何操作 1:当设备或硬件地址改变时自动产生一个arp请求 |
||
| net.ipv4.conf.default.bootp_relay | 接收源地址为0.a.b.c,目的地址不是本机的数据包,是为了支持bootp服务 0:关闭 1:开启 |
||
| net.ipv4.conf.default.disable_policy | 禁止internet协议安全性验证 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.default.disable_xfrm | 禁止internet协议安全性加密 0:禁止禁止 1:开启禁止 |
||
| net.ipv4.conf.default.force_igmp_version | |||
| net.ipv4.conf.default.forwarding | 在该接口打开转发功能 0:禁止 1:允许 |
||
| net.ipv4.conf.default.log_martians | 记录带有不允许的地址的数据报到内核日志中。 0:禁止 1:允许 |
||
| net.ipv4.conf.default.mc_forwarding | 是否进行多播路由。只有内核编译有CONFIG_MROUTE并且有路由服务程序在运行该参数才有效。 0:禁止 1:允许 |
||
| net.ipv4.conf.default.medium_id | 通常,这个参数用来区分不同媒介.两个网络设备可以使用不同的值,使他们只有其中之一接收到广播包.通常,这个参数被用来配合proxy_arp实现roxy_arp的特性即是允许arp报文在两个不同的网络介质中转发. 0:表示各个网络介质接受他们自己介质上的媒介 -1:表示该媒介未知。 |
||
| net.ipv4.conf.default.promote_secondaries | 0:当接口的主IP地址被移除时,删除所有次IP地址 1:当接口的主IP地址被移除时,将次IP地址提升为主IP地址 |
||
| net.ipv4.conf.default.proxy_arp | 打开arp代理功能。 0:禁止 1:允许 |
||
| net.ipv4.conf.default.proxy_arp_pvlan | 回应代理ARP的数据包从接收到此代理ARP请求的网络接口出去。 | ||
| net.ipv4.conf.default.route_localnet | |||
| net.ipv4.conf.default.rp_filter | 1:通过反向路径回溯进行源地址验证(在RFC1812中定义)。对于单穴主机和stub网络路由器推荐使用该选项。 0:不通过反向路径回溯进行源地址验证。 |
||
| net.ipv4.conf.default.secure_redirects | 仅仅接收发给默认网关列表中网关的ICMP重定向消息 0:禁止 1:允许 |
||
| net.ipv4.conf.default.send_redirects | 允许发送重定向消息。(路由使用) 0:禁止 1:允许 |
||
| net.ipv4.conf.default.shared_media | 发送或接收RFC1620 共享媒体重定向。会覆盖ip_secure_redirects的值。 0:禁止 1:允许 |
||
| net.ipv4.conf.default.src_valid_mark | |||
| net.ipv4.conf.default.tag | |||
| net.ipv4.icmp_echo_ignore_all | 忽略所有接收到的icmp echo请求的包(会导致机器无法ping通) 0:不忽略 1:忽略 |
||
| net.ipv4.icmp_echo_ignore_broadcasts | 忽略所有接收到的icmp echo请求的广播 0:不忽略 1:忽略 |
||
| net.ipv4.icmp_errors_use_inbound_ifaddr | 当前为 ICMP 错误消息选择源地址的方式,是使用存在的接口地址 1:表示内核通过这个选项允许使用接收到造成这一错误的报文的接口的地址 |
||
| net.ipv4.icmp_ignore_bogus_error_responses | 某些路由器违背RFC1122标准,其对广播帧发送伪造的响应来应答。这种违背行为通常会被以警告的方式记录在系统日志中。 0:记录到系统日志中 1:忽略 |
||
| net.ipv4.icmp_ratelimit | 限制发向特定目标的匹配icmp_ratemask的ICMP数据报的最大速率。配合icmp_ratemask使用。 0:没有任何限制 >0:表示指定时间内中允许发送的个数。(以jiffies为单位) |
||
| net.ipv4.icmp_ratemask | 在这里匹配的ICMP被icmp_ratelimit参数限制速率. 匹配的标志位: IHGFEDCBA9876543210 默认的掩码值: 0000001100000011000 (6168) 0 Echo Reply 3 Destination Unreachable * 4 Source Quench * 5 Redirect 8 Echo Request B Time Exceeded * C Parameter Problem * D Timestamp Request E Timestamp Reply F Info Request G Info Reply H Address Mask Request I Address Mask Reply * 号的被默认限速 |
||
| net.ipv4.igmp_max_memberships | 限制加入一个多播组的最大成员数. | ||
| net.ipv4.igmp_max_msf | 限制多播源地址过滤数量. | ||
| net.ipv4.igmp_qrv | |||
| net.ipv4.inet_peer_maxttl | 条目的最大存活期。在此期限到达之后,如果缓冲池没有耗尽压力的话(例如:缓冲池中的条目数目非常少),不使用的条目将会超时。该值以 jiffies为单位测量。 |
||
| net.ipv4.inet_peer_minttl | 条目的最低存活期。在重组端必须要有足够的碎片(fragment)存活期。这个最低存活期必须保证缓冲池容积是否少于 inet_peer_threshold。该值以 jiffies为单位测量。 |
||
| net.ipv4.inet_peer_threshold | INET对端存储器某个合适值,当超过该阀值条目将被丢弃。该阀值同样决定生存时间以及废物收集通过的时间间隔。条目越多,存活期越低,GC 间隔越短。 |
||
| net.ipv4.ip_default_ttl | 该文件表示一个数据报的生存周期(Time To Live),即最多经过多少路由器。 |
||
| net.ipv4.ip_dynaddr | 拨号上网大部分都是使用动态IP地址,我们不知道远程拨号服务器的IP地址是多少,也不可能知道它会给电脑分配什么IP地址 0:使用静态IP 1:使用动态IP地址 |
||
| net.ipv4.ip_early_demux | |||
| net.ipv4.ip_forward | 是否打开ipv4的IP转发。 0:禁止 1:打开 |
||
| net.ipv4.ip_forward_use_pmtu | |||
| net.ipv4.ipfrag_high_thresh | 表示用于重组IP分段的内存分配最高值,一旦达到最高内存分配值,其它分段将被丢弃,直到达到最低内存分配值。 | ||
| net.ipv4.ipfrag_low_thresh | 表示用于重组IP分段的内存分配最低值 | ||
| net.ipv4.ipfrag_max_dist | 相同的源地址ip碎片数据报的最大数量. 这个变量表示在ip碎片被添加到队列前要作额外的检查.如果超过定义的数量的ip碎片从一个相同源地址到达,那么假定这个队列的ip碎片有丢失,已经存在的ip碎片队列会被丢弃,如果为0关闭检查 |
||
| net.ipv4.ipfrag_secret_interval | hash表中ip碎片队列的重建延迟.(单位 秒) | ||
| net.ipv4.ipfrag_time | 表示一个IP分段在内存中保留多少秒 | ||
| net.ipv4.ip_local_port_range | 本地发起连接时使用的端口范围,tcp初始化时会修改此值 | ||
| net.ipv4.ip_local_reserved_ports | |||
| net.ipv4.ip_nonlocal_bind | 允许进程绑定到非本地地址 0:禁止 1:允许 |
||
| net.ipv4.ip_no_pmtu_disc | 该文件表示在全局范围内关闭路径MTU探测功能。 | ||
| net.ipv4.neigh.{IF}.anycast_delay | 对相邻请求信息的回复的最大延迟时间(单位 秒) | ||
| net.ipv4.neigh.{IF}.app_solicit | 在使用多播探测前,通过netlink发送到用户空间arp守护程序的最大探测数 | ||
| net.ipv4.neigh.{IF}.base_reachable_time | 一旦发现相邻记录,至少在一段介于 base_reachable_time/2和3*base_reachable_time/2之间的随机时间内,该记录是有效的. 如果收到上层协议的肯定反馈, 那么记录的有效期将延长.(单位 秒) |
||
| net.ipv4.neigh.{IF}.base_reachable_time_ms | 一旦发现相邻记录,至少在一段介于 base_reachable_time/2和3*base_reachable_time/2之间的随机时间内,该记录是有效的. 如果收到上层协议的肯定反馈, 那么记录的有效期将延长.(单位 毫秒) |
||
| net.ipv4.neigh.{IF}.delay_first_probe_time | 发现某个相邻层记录无效后,发出第一个探测要等待的时间。(单位 秒) |
||
| net.ipv4.neigh.{IF}.gc_stale_time | 决定检查一次相邻层记录的有效性的周期. 当相邻层记录失效时,将在给它发送数据前,再解析一次.(单位 秒) |
||
| net.ipv4.neigh.{IF}.locktime | 防止相邻记录被过度频繁刷新,引起抖动,只有距邻居上次刷新时间超过这时才允许被再次刷新.(单位 秒) |
||
| net.ipv4.neigh.{IF}.mcast_solicit | 在把记录标记为不可达之前, 用多播/广播方式解析地址的最大次数. |
||
| net.ipv4.neigh.{IF}.proxy_delay | 当接收到有一个arp请求时,在回应前可以延迟的时间,这个请求是要得到一个已知代理arp项的地址.(单位 百毫秒) |
||
| net.ipv4.neigh.{IF}.proxy_qlen | 能放入代理 ARP 地址队列的数据包最大数目. | ||
| net.ipv4.neigh.{IF}.retrans_time | 重发一个arp请求前的等待的秒数 | ||
| net.ipv4.neigh.{IF}.retrans_time_ms | 重发一个arp请求前的等待的毫秒数 | ||
| net.ipv4.neigh.{IF}.ucast_solicit | arp请求最多发送次数 | ||
| net.ipv4.neigh.{IF}.unres_qlen | 最大挂起arp请求的数量,这些请求都正在被解析中. | ||
| net.ipv4.neigh.{IF}.unres_qlen_bytes | 最大处理arp包的字节数 | ||
| net.ipv4.neigh.default.anycast_delay | 对相邻请求信息的回复的最大延迟时间(单位 秒) | ||
| net.ipv4.neigh.default.app_solicit | 在使用多播探测前,通过netlink发送到用户空间arp守护程序的最大探测数 | ||
| net.ipv4.neigh.default.base_reachable_time | 一旦发现相邻记录,至少在一段介于 base_reachable_time/2和3*base_reachable_time/2之间的随机时间内,该记录是有效的. 如果收到上层协议的肯定反馈, 那么记录的有效期将延长.(单位 秒) |
||
| net.ipv4.neigh.default.base_reachable_time_ms | 一旦发现相邻记录,至少在一段介于 base_reachable_time/2和3*base_reachable_time/2之间的随机时间内,该记录是有效的. 如果收到上层协议的肯定反馈, 那么记录的有效期将延长.(单位 毫秒) |
||
| net.ipv4.neigh.default.delay_first_probe_time | 发现某个相邻层记录无效后,发出第一个探测要等待的时间。(单位 秒) |
||
| net.ipv4.neigh.default.gc_interval | 垃圾收集器收集相邻层记录和无用记录的运行周期(单位 秒) | ||
| net.ipv4.neigh.default.gc_stale_time | 决定检查一次相邻层记录的有效性的周期. 当相邻层记录失效时,将在给它发送数据前,再解析一次.(单位 秒) |
||
| net.ipv4.neigh.default.gc_thresh1 | 存在于ARP高速缓存中的最少个数,如果少于这个数,垃圾收集器将不会运行 | ||
| net.ipv4.neigh.default.gc_thresh2 | 保存在 ARP 高速缓存中的最多的记录软限制. 垃圾收集器在开始收集前,允许记录数超过这个数字,在创建新表项时如果发现5秒没有刷新过,那么进行强制回收 |
||
| net.ipv4.neigh.default.gc_thresh3 | 保存在 ARP 高速缓存中的最多记录的硬限制, 一旦高速缓存中的数目高于此, 垃圾收集器将马上运行 |
||
| net.ipv4.neigh.default.locktime | 防止相邻记录被过度频繁刷新,引起抖动,只有距邻居上次刷新时间超过这时才允许被再次刷新.(单位 秒) |
||
| net.ipv4.neigh.default.mcast_solicit | 在把记录标记为不可达之前, 用多播/广播方式解析地址的最大次数. |
||
| net.ipv4.neigh.default.proxy_delay | 当接收到有一个arp请求时,在回应前可以延迟的时间,这个请求是要得到一个已知代理arp项的地址.(单位 百毫秒) |
||
| net.ipv4.neigh.default.proxy_qlen | 能放入代理 ARP 地址队列的数据包最大数目. | ||
| net.ipv4.neigh.default.retrans_time | 重发一个arp请求前的等待的秒数 | ||
| net.ipv4.neigh.default.retrans_time_ms | 重发一个arp请求前的等待的毫秒数 | ||
| net.ipv4.neigh.default.ucast_solicit | arp请求最多发送次数 | ||
| net.ipv4.neigh.default.unres_qlen | 最大挂起arp请求的数量,这些请求都正在被解析中. | ||
| net.ipv4.neigh.default.unres_qlen_bytes | 最大处理arp包的字节数 | ||
| net.ipv4.ping_group_range | |||
| net.ipv4.route.error_burst | 这个参数和error_cast一起用于限制有多少个icmp不可达消息被发送.当数据包不能到达下一跳时会发送icmp不可达数据包. 当一些主机忽略我们的icmp重定向消息时也会打印一些错误信息到dmesg.这个选项也控制打印的次数.(单位 秒) |
||
| net.ipv4.route.error_cost | 这个参数和error_burst一起用于限制有多少个icmp不可达消息被发送.当数据包不能到达下一跳时会发送icmp不可达数据包. 当一些主机忽略我们的icmp重定向消息时也会打印一些错误信息到dmesg.这个选项也控制打印的次数. error_cost值越大,那么icmp不可达和写错误信息的频率就越低.(单位 秒) |
||
| net.ipv4.route.flush | 写这个文件就会刷新路由高速缓冲. | ||
| net.ipv4.route.gc_elasticity | 用来控制路由缓存垃圾回收机制的频率和行为.当路由表一个hash项的长度超过此值时,会进行缓存缩减,当路由缓存项长度超过 ip_rt_gc_elasticity << rt_hash_log(表示路由高速缓存hash table的容量以2为对数所得的值) 时会进行强烈的回收. |
||
| net.ipv4.route.gc_interval | 此参数定义了路由表垃圾回收的间隔(秒) | ||
| net.ipv4.route.gc_min_interval | 已不再使用,并被gc_min_interval_ms取代 | ||
| net.ipv4.route.gc_min_interval_ms | 此参数定义了路由表垃圾回收的最小间隔(ms) | ||
| net.ipv4.route.gc_thresh | 路由hash table的大小,当cache中的路由条数超过此值时,开始垃圾回收. |
||
| net.ipv4.route.gc_timeout | 设置一个路由表项的过期时长(秒). | ||
| net.ipv4.route.max_size | 路由高速缓存的最大项数,超过会进行清除旧项操作. | ||
| net.ipv4.route.min_adv_mss | 该文件表示最小的MSS(Maximum Segment Size)大小,取决于第一跳的路由器MTU。(以字节为单位) |
||
| net.ipv4.route.min_pmtu | 该文件表示最小路径MTU的大小。 | ||
| net.ipv4.route.mtu_expires | 该文件表示PMTU信息缓存多长时间(秒)。 | ||
| net.ipv4.route.redirect_load | 决定是否要向特定主机发送更多的ICMP重定向的时间因子.一旦达到load时间或number个数就不再发送. | ||
| net.ipv4.route.redirect_number | 决定是否要向特定主机发送更多的ICMP重定向的数量因子.一旦达到load时间或number个数就不再发送. | ||
| net.ipv4.route.redirect_silence | 重定向的超时.经过这么长时间后,重定向会重发,而不管是否已经因为超过load或者number限制而停止. | ||
| net.ipv4.tcp_abort_on_overflow | 守护进程太忙而不能接受新的连接,就向对方发送reset消息 0:关闭 1:开启 |
||
| net.ipv4.tcp_adv_win_scale | 计算缓冲开销bytes/2^tcp_adv_win_scale(如果tcp_adv_win_scale > 0)或者bytes-bytes/2^(-tcp_adv_win_scale)(如果tcp_adv_win_scale <= 0)。 |
||
| net.ipv4.tcp_allowed_congestion_control | 列出了tcp目前允许使用的拥塞控制算法,只能在下面可用的算法中选择. | ||
| net.ipv4.tcp_app_win | 保留max(window/2^tcp_app_win, mss)数量的窗口用于应用缓冲。当为0时表示不需要缓冲。 |
||
| net.ipv4.tcp_available_congestion_control | 列出了tcp目前可以使用的拥塞控制算法. | ||
| net.ipv4.tcp_base_mss | tcp探察路径上mtu的最低边界限制, mss+TCP头部+TCP选项+IP头+IP选项. |
||
| net.ipv4.tcp_challenge_ack_limit | |||
| net.ipv4.tcp_congestion_control | 当前正在使用的拥塞控制算法. | ||
| net.ipv4.tcp_dsack | 表示是否允许TCP发送“两个完全相同”的SACK。 0:禁止 1:启用 |
||
| net.ipv4.tcp_early_retrans | |||
| net.ipv4.tcp_ecn | 表示是否打开TCP的直接拥塞通告功能。 0:禁止 1:启用 |
||
| net.ipv4.tcp_fack | 表示是否打开FACK拥塞避免和快速重传功能。 0:禁止 1:打开 |
||
| net.ipv4.tcp_fastopen | |||
| net.ipv4.tcp_fastopen_key | |||
| net.ipv4.tcp_fin_timeout | 本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。过去在2.2版本的内核中是 180 秒。您可以设置该值,但需要注意,如果您的机器为负载很重的web服务器,您可能要冒内存被大量无效数据报填满的风险,FIN-WAIT-2 sockets 的危险性低于 FIN-WAIT-1,因为它们最多只吃 1.5K 的内存,但是它们存在时间更长。 |
||
| net.ipv4.tcp_frto | |||
| net.ipv4.tcp_keepalive_intvl | 表示发送TCP探测的频率,乘以tcp_keepalive_probes表示断开没有相应的TCP连接的时间。 | ||
| net.ipv4.tcp_keepalive_probes | 该文件表示丢弃TCP连接前,进行最大TCP保持连接侦测的次数。保持连接仅在SO_KEEPALIVE套接字选项被打开时才被发送。 | ||
| net.ipv4.tcp_keepalive_time | 表示从最后一个包结束后多少秒内没有活动,才发送keepalive包保持连接,默认7200s,理想可设为1800s,即如果非正常断开,1800s后可通过keepalive知道。 | ||
| net.ipv4.tcp_limit_output_bytes | |||
| net.ipv4.tcp_low_latency | 允许 TCP/IP 栈适应在高吞吐量情况下低延时的情况;这个选项一般情形是的禁用。(但在构建Beowulf 集群的时候,打开它很有帮助) 0:关闭 1:开启 |
||
| net.ipv4.tcp_max_orphans | 系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量,那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制,纯粹为了抵御那些简单的 DoS 攻击,千万不要依赖这个或是人为的降低这个限制。 |
||
| net.ipv4.tcp_max_ssthresh | |||
| net.ipv4.tcp_max_syn_backlog | 对于那些依然还未获得客户端确认的连接请求,需要保存在队列中最大数目。默认值是1024,可提高到2048。 | ||
| net.ipv4.tcp_max_tw_buckets | 系统在同时所处理的最大timewait sockets 数目。如果超过此数的话,time-wait socket 会被立即砍除并且显示警告信息。 |
||
| net.ipv4.tcp_mem | 该文件保存了三个值,分别是 low:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存。 presure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。 |
||
| net.ipv4.tcp_min_tso_segs | |||
| net.ipv4.tcp_moderate_rcvbuf | 接收数据时是否调整接收缓存 0:不调整 1:调整 |
||
| net.ipv4.tcp_mtu_probing | 是否开启tcp层路径mtu发现,自动调整tcp窗口等信 0:关闭 1:开启 |
||
| net.ipv4.tcp_no_metrics_save | 如果开启,tcp会在连接关闭时也就是LAST_ACK状态保存各种连接信息到路由缓存中,新建立的连接可以使用这些条件来初始化.。通常这会增加总体的系统性能,但是有些时候也会引起性能下降. 0:关闭 1:开启 |
||
| net.ipv4.tcp_orphan_retries | 针对孤立的socket(也就是已经从进程上下文中删除了,可是还有一些清理工作没有完成).在丢弃TCP连接之前重试的最大的次数 | ||
| net.ipv4.tcp_reordering | TCP流中重排序的数据报最大数量。 | ||
| net.ipv4.tcp_retrans_collapse | 对于某些有bug的打印机提供针对其bug的兼容性。 0:不启用 1:启用 |
||
| net.ipv4.tcp_retries1 | 该文件表示放弃回应一个TCP连接请求前进行重传的次数。 | ||
| net.ipv4.tcp_retries2 | 该文件表示放弃在已经建立通讯状态下的一个TCP数据包前进行重传的次数。 | ||
| net.ipv4.tcp_rfc1337 | 这个开关可以启动对于在RFC1337中描述的"tcp 的time-wait暗杀危机"问题的修复。启用后,内核将丢弃那些发往time-wait状态TCP套接字的RST 包. 0:关闭 1:开启 |
||
| net.ipv4.tcp_rmem | 此文件中保存有三个值,分别是 Min:为TCP socket预留用于接收缓冲的内存最小值。每个tcp socket都可以在建立后使用它。即使在内存出现紧张情况下tcp socket都至少会有这么多数量的内存用于接收缓冲 Default:为TCP socket预留用于接收缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.rmem_default 值,一般要低于net.core.rmem_default的值。该值决定了在tcp_adv_win_scale、tcp_app_win和tcp_app_win=0默认值情况下,TCP窗口大小为65535。 Max:用于TCP socket接收缓冲的内存最大值。该值不会影响net.core.rmem_max,"静态"选择参数SO_SNDBUF则不受该值影响。 |
||
| net.ipv4.tcp_sack | 表示是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。 0:不启用 1:启用 |
||
| net.ipv4.tcp_slow_start_after_idle | 如果设置满足RFC2861定义的行为,在从新开始计算拥塞窗口前延迟一些时间,这延迟的时间长度由当前rto决定. 0:关闭 1:开启 |
||
| net.ipv4.tcp_stdurg | 使用 TCP urg pointer 字段中的主机请求解释功能。大部份的主机都使用老旧的BSD解释,因此如果您在 Linux 打开它,或会导致不能和它们正确沟通。 0:关闭 1:打开 |
||
| net.ipv4.tcp_synack_retries | 对于远端的连接请求SYN,内核会发送SYN + ACK数据报,以确认收到上一个 SYN连接请求包。 这是所谓的三次握手.这里决定内核在放弃连接之前所送出的 SYN+ACK 数目. |
||
| net.ipv4.tcp_syncookies | 表示是否打开TCP同步标签(syncookie),内核必须打开了 CONFIG_SYN_COOKIES项进行编译。同步标签(syncookie)可以防止一个套接字在有过多试图连接到达时引起过载。 0:关闭 1:打开 |
||
| net.ipv4.tcp_syn_retries | 表示本机向外发起TCP SYN连接超时重传的次数,不应该高于255;该值仅仅针对外出的连接,对于进来的连接由tcp_retries1控制。 |
||
| net.ipv4.tcp_thin_dupack | |||
| net.ipv4.tcp_thin_linear_timeouts | |||
| net.ipv4.tcp_timestamps | 表示是否启用以一种比超时重发更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。 0:不启用 1:启用 |
||
| net.ipv4.tcp_tso_win_divisor | 控制根据拥塞窗口的百分比,是否来发送相应的延迟tso frame 0:关闭 >0:值越大表示tso frame延迟发送可能越小. |
||
| net.ipv4.tcp_tw_recycle | 打开快速 TIME-WAIT sockets 回收。除非得到技术专家的建议或要求,请不要随意修改这个值。 |
||
| net.ipv4.tcp_tw_reuse | 表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接。 0:关闭 1:打开 |
||
| net.ipv4.tcp_window_scaling | 表示设置tcp/ip会话的滑动窗口大小是否可变。 0:不可变 1:可变 |
||
| net.ipv4.tcp_wmem | 此文件中保存有三个值,分别是 Min:为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket都可以在建立后使用它。 Default:为TCP socket预留用于发送缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default 值,一般要低于net.core.wmem_default的值。 Max:用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,"静态"选择参数SO_SNDBUF则不受该值影响。 |
||
| net.ipv4.tcp_workaround_signed_windows | 0:假定远程连接端正常发送了窗口收缩选项,即使对端没有发送. 1:假定远程连接端有错误,没有发送相关的窗口缩放选项 |
||
| net.ipv4.udp_mem | 该文件保存了三个值,分别是 low:当UDP使用了低于该值的内存页面数时,UDP不会考虑释放内存。 presure:当UDP使用了超过该值的内存页面数量时,UDP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。 |
||
| net.ipv4.udp_rmem_min | |||
| net.ipv4.udp_wmem_min | |||
| net.ipv4.xfrm4_gc_thresh | |||
| net.ipv6.bindv6only | 默认监听ipv6端口(不管监听与否,都与是否关闭ipv4监听无关) 0:不监听 1:监听 |
||
| net.ipv6.conf.all.accept_dad | 0:取消DAD功能 1:启用DAD功能,但link-local地址冲突时,不关闭ipv6功能 2:启用DAD功能,但link-local地址冲突时,关闭ipv6功能 |
||
| net.ipv6.conf.all.accept_ra | 接受IPv6路由通告.并且根据得到的信息自动设定. 0:不接受路由通告 1:当forwarding禁止时接受路由通告 2:任何情况下都接受路由通告 |
||
| net.ipv6.conf.all.accept_ra_defrtr | 是否接受ipv6路由器发出的默认路由设置 0:不接受 1:接受 |
||
| net.ipv6.conf.all.accept_ra_pinfo | 当accept_ra开启时此选项会自动开启,关闭时则会关闭 | ||
| net.ipv6.conf.all.accept_ra_rt_info_max_plen | 在路由通告中路由信息前缀的最大长度。当 | ||
| net.ipv6.conf.all.accept_ra_rtr_pref | |||
| net.ipv6.conf.all.accept_redirects | 是否接受ICMPv6重定向包 0:拒绝接受ICMPv6,当forwarding=1时,此值会自动设置为0 1:启动接受ICMPv6,当forwarding=0时,此值会自动设置为1 |
||
| net.ipv6.conf.all.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv6.conf.all.autoconf | 设定本地连结地址使用L2硬件地址. 它依据界面的L2-MAC address自动产生一个地址如:"fe80::201:23ff:fe45:6789" |
||
| net.ipv6.conf.all.dad_transmits | 接口增加ipv6地址时,发送几次DAD包 | ||
| net.ipv6.conf.all.disable_ipv6 | 是否禁用ipv6 0:不禁用 1:禁用 |
||
| net.ipv6.conf.all.force_mld_version | |||
| net.ipv6.conf.all.force_tllao | |||
| net.ipv6.conf.all.forwarding | 所有网络接口开启ipv6转发 0:关闭 1:开启 |
||
| net.ipv6.conf.all.hop_limit | 缺省hop限制 | ||
| net.ipv6.conf.all.max_addresses | 所有网络接口自动配置IP地址的数量最大值 0:不限制 >0:最大值 |
||
| net.ipv6.conf.all.max_desync_factor | DESYNC_FACTOR的最大值,DESYNC_FACTOR是一个随机数,用于防止客户机在同一时间生成新的地址 | ||
| net.ipv6.conf.all.mc_forwarding | 是否使用多路广播进行路由选择,需要内核编译时开启了CONFIG_MROUTE选项并且开启了多路广播路由选择的后台daemon 0:关闭 1:开启 |
||
| net.ipv6.conf.all.mldv1_unsolicited_report_interval | 每次发送MLDv1的主动报告的时间间隔(ms) | ||
| net.ipv6.conf.all.mldv2_unsolicited_report_interval | 每次发送MLDv2的主动报告的时间间隔(ms) | ||
| net.ipv6.conf.all.mtu | ipv6的最大传输单元 | ||
| net.ipv6.conf.all.ndisc_notify | 如何向邻居设备通知地址和设备的改变 0:不通知 1:主动向邻居发送广播报告硬件地址或者设备发生了改变 |
||
| net.ipv6.conf.all.optimistic_dad | 是否启用optimistic DAD(乐观地进行重复地址检查) 0:关闭 1:开启 |
||
| net.ipv6.conf.all.proxy_ndp | 此功能类似于ipv4的nat,可将内网的包转发到外网,外网不能主动发给内网。 0:关闭 1:开启 |
||
| net.ipv6.conf.all.regen_max_retry | 尝试生成临时地址的次数 | ||
| net.ipv6.conf.all.router_probe_interval | 路由器探测间隔(秒) | ||
| net.ipv6.conf.all.router_solicitation_delay | 在发送路由请求之前的等待时间(秒). | ||
| net.ipv6.conf.all.router_solicitation_interval | 在每个路由请求之间的等待时间(秒). | ||
| net.ipv6.conf.all.router_solicitations | 假定没有路由的情况下发送的请求个数 | ||
| net.ipv6.conf.all.temp_prefered_lft | |||
| net.ipv6.conf.all.temp_valid_lft | |||
| net.ipv6.conf.all.use_tempaddr | |||
| net.ipv6.conf.{IF}.accept_dad | |||
| net.ipv6.conf.{IF}.accept_ra | |||
| net.ipv6.conf.{IF}.accept_ra_defrtr | |||
| net.ipv6.conf.{IF}.accept_ra_pinfo | |||
| net.ipv6.conf.{IF}.accept_ra_rt_info_max_plen | |||
| net.ipv6.conf.{IF}.accept_ra_rtr_pref | |||
| net.ipv6.conf.{IF}.accept_redirects | |||
| net.ipv6.conf.{IF}.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv6.conf.{IF}.autoconf | |||
| net.ipv6.conf.{IF}.dad_transmits | |||
| net.ipv6.conf.{IF}.disable_ipv6 | |||
| net.ipv6.conf.{IF}.force_mld_version | |||
| net.ipv6.conf.{IF}.force_tllao | |||
| net.ipv6.conf.{IF}.forwarding | |||
| net.ipv6.conf.{IF}.hop_limit | |||
| net.ipv6.conf.{IF}.max_addresses | |||
| net.ipv6.conf.{IF}.max_desync_factor | |||
| net.ipv6.conf.{IF}.mc_forwarding | |||
| net.ipv6.conf.{IF}.mldv1_unsolicited_report_interval | |||
| net.ipv6.conf.{IF}.mldv2_unsolicited_report_interval | |||
| net.ipv6.conf.{IF}.mtu | |||
| net.ipv6.conf.{IF}.ndisc_notify | |||
| net.ipv6.conf.{IF}.optimistic_dad | |||
| net.ipv6.conf.{IF}.proxy_ndp | |||
| net.ipv6.conf.{IF}.regen_max_retry | |||
| net.ipv6.conf.{IF}.router_probe_interval | |||
| net.ipv6.conf.{IF}.router_solicitation_delay | |||
| net.ipv6.conf.{IF}.router_solicitation_interval | |||
| net.ipv6.conf.{IF}.router_solicitations | |||
| net.ipv6.conf.{IF}.temp_prefered_lft | |||
| net.ipv6.conf.{IF}.temp_valid_lft | |||
| net.ipv6.conf.{IF}.use_tempaddr | |||
| net.ipv6.conf.default.accept_dad | |||
| net.ipv6.conf.default.accept_ra | |||
| net.ipv6.conf.default.accept_ra_defrtr | |||
| net.ipv6.conf.default.accept_ra_pinfo | |||
| net.ipv6.conf.default.accept_ra_rt_info_max_plen | |||
| net.ipv6.conf.default.accept_ra_rtr_pref | |||
| net.ipv6.conf.default.accept_redirects | |||
| net.ipv6.conf.default.accept_source_route | 接收带有SRR选项的数据报。主机设为0,路由设为1 | ||
| net.ipv6.conf.default.autoconf | |||
| net.ipv6.conf.default.dad_transmits | |||
| net.ipv6.conf.default.disable_ipv6 | |||
| net.ipv6.conf.default.force_mld_version | |||
| net.ipv6.conf.default.force_tllao | |||
| net.ipv6.conf.default.forwarding | |||
| net.ipv6.conf.default.hop_limit | |||
| net.ipv6.conf.default.max_addresses | |||
| net.ipv6.conf.default.max_desync_factor | |||
| net.ipv6.conf.default.mc_forwarding | |||
| net.ipv6.conf.default.mldv1_unsolicited_report_interval | |||
| net.ipv6.conf.default.mldv2_unsolicited_report_interval | |||
| net.ipv6.conf.default.mtu | |||
| net.ipv6.conf.default.ndisc_notify | |||
| net.ipv6.conf.default.optimistic_dad | |||
| net.ipv6.conf.default.proxy_ndp | |||
| net.ipv6.conf.default.regen_max_retry | |||
| net.ipv6.conf.default.router_probe_interval | |||
| net.ipv6.conf.default.router_solicitation_delay | |||
| net.ipv6.conf.default.router_solicitation_interval | |||
| net.ipv6.conf.default.router_solicitations | |||
| net.ipv6.conf.default.temp_prefered_lft | |||
| net.ipv6.conf.default.temp_valid_lft | |||
| net.ipv6.conf.default.use_tempaddr | |||
| net.ipv6.icmp.ratelimit | |||
| net.ipv6.ip6frag_high_thresh | |||
| net.ipv6.ip6frag_low_thresh | |||
| net.ipv6.ip6frag_secret_interval | |||
| net.ipv6.ip6frag_time | |||
| net.ipv6.mld_max_msf | |||
| net.ipv6.mld_qrv | |||
| net.ipv6.neigh.{IF}.anycast_delay | |||
| net.ipv6.neigh.{IF}.app_solicit | |||
| net.ipv6.neigh.{IF}.base_reachable_time | |||
| net.ipv6.neigh.{IF}.base_reachable_time_ms | |||
| net.ipv6.neigh.{IF}.delay_first_probe_time | |||
| net.ipv6.neigh.{IF}.gc_stale_time | |||
| net.ipv6.neigh.{IF}.locktime | |||
| net.ipv6.neigh.{IF}.mcast_solicit | |||
| net.ipv6.neigh.{IF}.proxy_delay | |||
| net.ipv6.neigh.{IF}.proxy_qlen | |||
| net.ipv6.neigh.{IF}.retrans_time | |||
| net.ipv6.neigh.{IF}.retrans_time_ms | |||
| net.ipv6.neigh.{IF}.ucast_solicit | |||
| net.ipv6.neigh.{IF}.unres_qlen | |||
| net.ipv6.neigh.{IF}.unres_qlen_bytes | |||
| net.ipv6.route.flush | |||
| net.ipv6.route.gc_elasticity | |||
| net.ipv6.route.gc_interval | |||
| net.ipv6.route.gc_min_interval | |||
| net.ipv6.route.gc_min_interval_ms | |||
| net.ipv6.route.gc_thresh | |||
| net.ipv6.route.gc_timeout | |||
| net.ipv6.route.max_size | |||
| net.ipv6.route.min_adv_mss | |||
| net.ipv6.route.mtu_expires | |||
| net.ipv6.xfrm6_gc_thresh | |||
| net.netfilter.nf_conntrack_acct | |||
| net.netfilter.nf_conntrack_buckets | 只读,描述当前系统的ip_conntrack的hash table大小. |
||
| net.netfilter.nf_conntrack_checksum | 验证协议是否错误是,是否对协议进行校验和验证 0:关闭 1:开启 |
||
| net.netfilter.nf_conntrack_count | 内存中ip_conntrack结构的数量. | ||
| net.netfilter.nf_conntrack_events | |||
| net.netfilter.nf_conntrack_events_retry_timeout | |||
| net.netfilter.nf_conntrack_expect_max | |||
| net.netfilter.nf_conntrack_generic_timeout | 通用或未知协议的conntrack被设置的超时时间(每次看到包都会用这值重新更新定时器),一旦时间到conntrack将被回收.(秒) | ||
| net.netfilter.nf_conntrack_helper | |||
| net.netfilter.nf_conntrack_icmp_timeout | icmp协议的conntrack被设置的超时时间,一旦到时conntrack将被回收.(秒) | ||
| net.netfilter.nf_conntrack_log_invalid | 调试时使用,可以指定一个数字,这个数字是内核定义的协议号比如IPPROTO_TCP是6,当指定协议解析时发现一些错误包会打印相关的错误信息到dmesg中. 最小值0,最大值255,默认不打印. |
||
| net.netfilter.nf_conntrack_max | 内存中最多ip_conntrack结构的数量. | ||
| net.netfilter.nf_conntrack_tcp_be_liberal | 当开启只有不在tcp窗口内的rst包被标志为无效,当关闭(默认)所有不在tcp窗口中的包都被标志为无效. 0:关闭 1:开启 |
||
| net.netfilter.nf_conntrack_tcp_loose | 当想追踪一条已经连接的tcp会话, 在系统可以假设sync和window追逐已经开始后要求每个方向必须通过的包的数量. 如果为0,从不追踪一条已经连接的tcp会话. |
||
| net.netfilter.nf_conntrack_tcp_max_retrans | 没有从目的端接收到一个ack而进行包重传的次数,一旦达到这限制nf_conntrack_tcp_timeout_max_retrans将作为ip_conntrack的超时限制. | ||
| net.netfilter.nf_conntrack_tcp_timeout_close | TCP处于close状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_close_wait | TCP处于close wait状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_established | TCP处于established状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_fin_wait | TCP处于fin wait状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_last_ack | TCP处于last ack状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_max_retrans | TCP处于max retrans状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_syn_recv | TCP处于syn recv状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_syn_sent | TCP处于syn sent状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_time_wait | TCP处于time wait状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_tcp_timeout_unacknowledged | TCP处于unacknowledged状态超时时间(秒) | ||
| net.netfilter.nf_conntrack_timestamp | |||
| net.netfilter.nf_conntrack_udp_timeout | udp协议的conntrack被设置的超时时间(每次看到包都会用这值重新更新定时器),一旦到时conntrack将被回收.(秒) | ||
| net.netfilter.nf_conntrack_udp_timeout_stream | 当看到一些特殊的udp传输时(传输在双向)设置的ip_conntrack超时时间(每次看到包都会用这值重新更新定时器).(秒) | ||
| net.netfilter.nf_log.0 | |||
| net.netfilter.nf_log.1 | |||
| net.netfilter.nf_log.10 | |||
| net.netfilter.nf_log.11 | |||
| net.netfilter.nf_log.12 | |||
| net.netfilter.nf_log.2 | |||
| net.netfilter.nf_log.3 | |||
| net.netfilter.nf_log.4 | |||
| net.netfilter.nf_log.5 | |||
| net.netfilter.nf_log.6 | |||
| net.netfilter.nf_log.7 | |||
| net.netfilter.nf_log.8 | |||
| net.netfilter.nf_log.9 | |||
| net.nf_conntrack_max | 内存中最多ip_conntrack结构的数量. | ||
| net.unix.max_dgram_qlen | 允许域套接字中数据包的最大个数,在初始化unix域套接字时的默认值. 在调用listen函数时第二个参数会复盖这个值. |
| fs.aio-max-nr | 最大允许aio请求数量(会涉及到数据库的aio请求) |
| fs.aio-nr | 当前aio请求数量 |
| fs.binfmt_misc.qemu-alpha | binfmt_misc用于支持当前芯片架构的系统是否支持通过qemu进行chroot到其他架构的根文件系统中进行操作。 |
| fs.binfmt_misc.qemu-arm | |
| fs.binfmt_misc.qemu-armeb | |
| fs.binfmt_misc.qemu-cris | |
| fs.binfmt_misc.qemu-i386 | |
| fs.binfmt_misc.qemu-i486 | |
| fs.binfmt_misc.qemu-m68k | |
| fs.binfmt_misc.qemu-microblaze | |
| fs.binfmt_misc.qemu-microblazeel | |
| fs.binfmt_misc.qemu-mips | |
| fs.binfmt_misc.qemu-mips64 | |
| fs.binfmt_misc.qemu-mips64el | |
| fs.binfmt_misc.qemu-mipsel | |
| fs.binfmt_misc.qemu-s390x | |
| fs.binfmt_misc.qemu-sh4 | |
| fs.binfmt_misc.qemu-sh4eb | |
| fs.binfmt_misc.qemu-sparc | |
| fs.binfmt_misc.qemu-sparc32plus | |
| fs.binfmt_misc.qemu-sparc64 | |
| fs.binfmt_misc.register |
用于注册或修改以上的binfmt_misc,输入格式是 :name:type:offset:magic:mask:interpreter:flags \xff\xff\xff\xff\xff\xfe\xfe\xff\xff\xff\xff\xff\xff\xff\xff\xff\xfb\xff\xff:/bin/em86:' |
| fs.binfmt_misc.status | 设置binfmt_misc开启 0:禁止 1:开启 |
| fs.dentry-state | 保存目录缓存的状态,保存有六个值,只有前三个有效 nr_dentry:当前已经分配的目录项数量 nr_unused:还没有使用的目录项数量 age_limit:当内存紧缺时,延迟多少秒后会回收目录项所占内存 |
| fs.dir-notify-enable | 设置是否启用dnotify,已被inotify取代,因为dnotify 需要您为每个打算监控是否发生改变的目录打开一个文件描述符。当同时监控多个目录时,这会消耗大量的资源,因为有可能达到每个进程的文件描述符限制。并且不允许卸载(unmount)支持的设备 0:不使用 1:使用 |
| fs.epoll.max_user_watches | IO复用epoll监听文件句柄的数量最大值 |
| fs.file-max | 系统中所有进程能够同时打开的文件句柄数量 |
| fs.file-nr | 此文件中保存了三个值,分别是:系统中已分配的文件句柄数量 已分配但没有使用的文件句柄数量 最大的文件句柄号 |
| fs.inode-nr | 此文件保存了两个值,是:已分配inode数 空闲inode数 |
| fs.inode-state | 此文件保存了三个值,前两个分别表示 已分配inode数和空闲inode数。第三个是已超出系统最大inode值的数量,此时系统需要清除排查inode列表 |
| fs.inotify.max_queued_events | inotify用于监控文件系统事件
该文件中的值为调用inotify_init函数时分配给inotify队列的事件数目的最大值,超出这个值得事件被丢弃,但会触发IN_Q_OVERFLOW事件 |
| fs.inotify.max_user_instances | 设置每个用户可以运行的inotifywait或inotifywatch命令的进程数。 |
| fs.inotify.max_user_watches | 设置inotifywait或inotifywatch命令可以监视的文件数量(单进程)。 |
| fs.lease-break-time | 当进程尝试打开一个被租借锁保护的文件时,该进程会被阻塞,同时,在一定时间内拥有该文件租借锁的进程会收到一个信号。收到信号之后,拥有该文件租借锁的进程会首先更新文件,从而保证了文件内容的一致性,接着,该进程释放这个租借锁。如果拥有租借锁的进程在一定的时间间隔内没有完成工作,内核就会自动删除这个租借锁或者将该锁进行降级,从而允许被阻塞的进程继续工作。 此保存租借锁的超时时间(以秒为单位) |
| fs.leases-enable | 是否启用文件的租借锁 1:启用 0:不启用 |
| fs.mqueue.msg_default | POSIX的消息队列 此文件保存一个消息队列中消息数量的默认值,如果此值超过msg_max,则会被设置为msg_max |
| fs.mqueue.msg_max | 一个消息队列的最大消息数 |
| fs.mqueue.msgsize_default | 消息队列中一个消息的默认大小(以字节为单位) |
| fs.mqueue.msgsize_max | 消息队列中一个消息的最大大小(以字节为单位) |
| fs.mqueue.queues_max | 系统中允许的消息队列的最大数量 |
| fs.nfs.idmap_cache_timeout | 设置idmapper缓存项的最大寿命,单位是秒 |
| fs.nfs.nfs_callback_tcpport | 设置NFSv4回复通道(callback channel)监听的TCP端口 |
| fs.nfs.nfs_congestion_kb | |
| fs.nfs.nfs_mountpoint_timeout | |
| fs.nfs.nlm_grace_period | 参数设置服务器重新引导后客户机回收NFSv3锁和NFSv4锁所需的秒数。因此,grace_period的值可控制NFSv3和NFSv4的锁定恢复的宽延期长度。 |
| fs.nfs.nlm_tcpport | 为NFS锁管理器指定TCP端口 |
| fs.nfs.nlm_timeout | 为NFS锁管理器指定默认超时时间,单位是秒。默认值是10秒。取值范围在[3-20] |
| fs.nfs.nlm_udpport | 为NFS锁管理器指定UDP端口 |
| fs.nfs.nsm_local_state | |
| fs.nfs.nsm_use_hostnames | |
| fs.nr_open | 一个进程最多同时打开的文件句柄数量 |
| fs.overflowgid | Linux的GID为32位,但有些文件系统只支持16位的GID,此时若进行写操作会出错;当GID超过65535时会自动被转换为一个固定值,这个固定值保存在这个文件中 |
| fs.overflowuid | Linux的UID为32位,但有些文件系统只支持16位的UID,此时若进行写操作会出错;当UID超过65535时会自动被转换为一个固定值,这个固定值保存在这个文件中 |
| fs.pipe-max-size | 此文件限制非特权程序使用pipe时的缓存最大大小(以字节为单位,最小设置为4096) |
| fs.protected_hardlinks | 用于限制普通用户建立硬链接 0:不限制用户建立硬链接 1:限制,如果文件不属于用户,或者用户对此用户没有读写权限,则不能建立硬链接 |
| fs.protected_symlinks | 用于限制普通用户建立软链接 0:不限制用户建立软链接 1:限制,允许用户建立软连接的情况是 软连接所在目录是全局可读写目录或者软连接的uid与跟从者的uid匹配,又或者目录所有者与软连接所有者匹配 |
| fs.quota.allocated_dquots | |
| fs.quota.cache_hits | |
| fs.quota.drops | |
| fs.quota.free_dquots | |
| fs.quota.lookups | |
| fs.quota.reads | |
| fs.quota.syncs | |
| fs.quota.warnings | |
| fs.quota.writes | |
| fs.suid_dumpable | |
| fscache.object_max_active | |
| fscache.operation_max_active |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
### 改善系统内存管理 ### # 取消文件句柄和inode缓存限制 fs.file-max = 2097152 # 减少Swap操作 vm.swappiness = 10 vm.dirty_ratio = 60 vm.dirty_background_ratio = 2 ### 一般性网络安全选项 ### # 被动TCP链接的SYNACKs重试次数 net.ipv4.tcp_synack_retries = 2 # 允许的本地端口访问 net.ipv4.ip_local_port_range = 2000 65535 # 防止 TCP Time-Wait问题 net.ipv4.tcp_rfc1337 = 1 # 减少tcp_fin_timeout超时 net.ipv4.tcp_fin_timeout = 15 # 减少TCP保活探测周期 net.ipv4.tcp_keepalive_time = 300 net.ipv4.tcp_keepalive_probes = 5 net.ipv4.tcp_keepalive_intvl = 15 ### 调整网络性能 ### # 默认套接字接收缓冲 net.core.rmem_default = 31457280 # 最大套接字接收缓冲 net.core.rmem_max = 12582912 # 默认套接字发送缓冲 net.core.wmem_default = 31457280 # 最大套接字发送缓冲 net.core.wmem_max = 12582912 # 最大入站连接数 net.core.somaxconn = 4096 # 最大入站连接排队数量 net.core.netdev_max_backlog = 65536 # 增加的option memory buffers最大量 net.core.optmem_max = 25165824 # 增大总计的允许分配的缓冲的数量(单位页,也就是4KB net.ipv4.tcp_mem = 65536 131072 262144 net.ipv4.udp_mem = 65536 131072 262144 # 总计可分配读缓冲 net.ipv4.tcp_rmem = 8192 87380 16777216 net.ipv4.udp_rmem_min = 16384 # 总计可分配写缓冲 net.ipv4.tcp_wmem = 8192 65536 16777216 net.ipv4.udp_wmem_min = 16384 # 增加tcp-time-wait桶(bucket)池的尺寸,应对简单的DOS攻击 net.ipv4.tcp_max_tw_buckets = 1440000 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 |
tuned是一个服务,它能够自适应的进行系统调优。它将一系列系统设置集合在一起,称为profile。
优化后的profile中包含CPU管理、IO调度、内核参数调整等指令。
执行下面的命令安装:
|
1 2 3 |
yum -y install tuned service tuned start chkconfig tuned on |
执行下面的命令查看可用的profile列表:
|
1 |
tuned-adm list |
切换到最大吞吐量模式:
|
1 |
tuned-adm profile throughput-performance |
修改net.ipv4.tcp_timestamps = 0后,出现和某个服务通信时,有1%几率Connection reset by peer的情况。抓包仅仅发现对方发送RST报文。恢复此参数为默认值后问题消失。
在Docker环境下出现,详见Docker学习笔记。
Leave a Reply