基于EFK构建日志分析系统
Fluentd是一个C编写的开源的日志收集器,支持100+不同系统的日志收集处理。
定义Fluentd的输入,需要指定一个输入插件。例如:
|
1 2 3 4 5 6 7 |
<source> # 使用什么插件 @type http # 你可以这样推送日志:http://localhost:8888/tag.name?json={...} port 8888 bind 0.0.0.0 </source> |
定义了一个HTTP输入。Fluentd会在8888端口上监听,等待外部传入事件。事件的例子:
|
1 |
curl -i -X POST -d 'json={"action":"login","user":2}' http://localhost:8888/test.cycle |
source捕获到的Fluentd事件,交由Fluentd路由引擎处理。
多个filter可以构成事件处理流水线。使用filter你可以将不需要的事件过滤掉,不再继续下一步处理。例如:
|
1 2 3 4 5 6 7 |
<filter test.cycle> @type grep <exclude> key action pattern ^logout$ </exclude> </filter> |
根据正则式匹配输入事件的action字段,如果匹配,路由给match处理,否则丢弃。
定义Fluentd的输出,并将匹配的事件传递给目标。例如:
|
1 2 3 |
<match test.cycle> @type stdout </match> |
会匹配具有Tag:test.cycle的输入事件,并传递给stdout这个输出插件。
用于定义一个可以被跳转到的路由片段,打破默认的从上到下的路由搜索顺序。该指令内部可以包含filter、match指令。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
<source> @type http bind 0.0.0.0 port 8888 # 指定路由标签 @label @STAGING </source> <filter test.cycle> </filter> # http源直接跳转到这里,不使用上面的filter <label @STAGING> <filter test.cycle> @type grep <exclude> key action pattern ^logout$ </exclude> </filter> <match test.cycle> @type stdout </match> </label> |
可以位于source、match、filter指令的内部。对于那些支持的插件,用于解析原始数据。示例:
|
1 2 3 4 5 6 7 8 9 |
<source> @type tail # 输入插件的参数 <parse> # 解析插件的类型 @type apache2 # 解析插件的参数 </parse> </source> |
每个Parser都可以覆盖这些参数的值:
| 参数 | 类型 | 说明 |
| types | hash |
指定如何将各字段转换为其它类型:field1:type,field2:type... 支持的类型:string、bool、integer、float、time、array |
| time_key | string | 事件的发生事件从什么字段中获取,如果该字段不存在,则取值当前时间 |
| null_value_pattern | string | 空值的Pattern |
| null_empty_string | bool | 是否将空串替换为nil,默认false |
| estimate_current_event | bool | 是否以当前时间作为time_key的值,默认false |
| keep_time_key | bool | 是否保留事件中的时间字段 |
| 参数 | 类型 | 说明 |
| time_type | enum |
可选值: float:UNIX时间.纳秒 |
| time_format | string |
除了遵循Ruby的时间格式化,还可以取值%iso8601 |
| localtime | bool | 是否使用本地时间而非UTC,默认true |
| utc | bool | 是否使用UTC而非本地时间,默认false |
| timezone | string | 指定时区,例如+09:00、+0900、+09、Asia/Tokyo |
可以位于match指令的内部,指定如何对事件进行缓冲(避免对输出的目的地造成压力)。Fluentd内置了两种缓冲插件:memory、file。
使用buffer指令时,你也需要通过@type来指定插件类型。如果省略@type,则使用输出插件(match)指定的默认插件,或者使用memory。
你可以为buffer指定分块键:
|
1 2 3 |
# 为空,或者逗号分隔的字符串 <buffer ARGUMENT_CHUNK_KEYS> </buffer> |
分块键决定了事件被收集到哪个缓冲块:
- 如果不指定分块键(并且输出插件也没有指定默认分块键),则输出插件将所有的事件都写到单个块中,直到此块充满
- 如果分块键被设置为“tag”,则不同标签(Tag)的事件被收集到不同的缓冲块
- 如果分块键被设置为“time”,且指定了timekey参数,则每个Time Key对应一个缓冲块:
12345<buffer time># 如果不指定单位,默认为秒timekey 1h # 每小时一个块timekey_wait 5m # 延迟5分钟刷出缓冲</buffer> - 如果分块键被设置为其它值,则认为是事件记录的字段名
- 使用事件记录的嵌套字段也支持: <buffer $.nest.field> # 访问记录的nest.field字段
- 联用多个分块键也支持: <buffer tag,time,$.nest.field>
某些输出插件,可以使用分块键作为变量:
|
1 2 3 4 5 6 |
<match log.*> @type file path /data/${tag}/access.${key1}.${$.nest.field}.log # 输出文件名使用变量,不同块输出到不同文件 <buffer tag,key1,$.nest.field> </buffer> </match> |
| 参数 | 类型 | 说明 |
| chunk_limit_size | size | 缓冲块的最大尺寸,默认值:内存缓冲8MB,文件缓冲256MB |
| chunk_limit_records | integer | 限制单个块最多包含的记录数 |
| total_limit_size | size | 此缓冲插件实例的总限制。默认值:内存缓冲512MB,文件缓冲64GB |
| chunk_full_threshold | float | 刷空缓冲块的阈值,默认0.95,也就是缓冲块占用超过95%刷出 |
| compress | enum | 取值text、gzip,缓冲块的压缩算法。默认text表示不压缩 |
| 参数 | 类型 | 说明 |
| flush_at_shutdown | bool | 关闭前是否刷空 |
| flush_mode | enum |
刷空模式: interval 以flush_interval为周期刷空 |
| flush_interval | time | 默认60s |
| flush_thread_count | integer | 输出插件的线程数量,默认1,增大可以并行刷出缓冲块 |
| flush_thread_interval | float | 如果没有缓冲块等待被刷出,则本次刷空后,线程休眠几秒以进行下一次尝试 |
| flush_thread_burst_interval | float | 如果有缓冲块排队等待被刷出时的休眠间隔 |
| delayed_commit_timeout | time | 输出插件认定异步写操作失败的超时,默认60s |
| overflow_action | enum |
当缓冲队列满了,输出插件的行为: throw_exception 抛出异常,打印错误 |
| 参数 | 类型 | 说明 |
| retry_timeout | time | 重试超时,默认72h |
| retry_forever | bool | 是否永远重试,默认false |
| retry_max_times | integer | 最大重试刷空的次数 |
| retry_type | enum |
重试方式: exponential_backoff 频率指数降低 对于指数方式,底数由参数retry_exponential_backoff_base确定,默认2 对于指数方式,最大重试间隔由retry_max_interval确定 |
| retry_wait | time | 下一次重试的等待间隔,默认1s |
| retry_randomize | bool | 是否随机化重试间隔,默认true。可以防止高并发 |
部分插件支持在内部包含format指令,用来指定如何对日志记录进行格式化。match、filter指令内部可以包含format指令:
|
1 2 3 4 5 6 |
<match tag.*> @type file <format> @type json </format> </match> |
内置的插件包括:out_file、json、ltsv、csv、msgpack、hash、single_value。下面的配置,将事件的log字段存储到文件:
|
1 2 3 4 5 6 7 8 |
<match **> @type file path /var/log/kubernetes <format> @type single_value message_key log </format> </match> |
可以位于match、filter指令内部,向事件记录注入额外的字段。
可以位于source、match、filter指令内部,从事件记录中抽取值。
部分插件支持此指令,用于指定如何存储插件的内部状态。可以位于source、match、filter指令内部。
使用server插件助手的source、match、filter插件,支持在内部配置该指令。用于说明如何处理网络连接。
该指令用于包含其它配置文件
该指令用于进行系统级的配置,包括配置项:
| 配置项 | 说明 |
| log_level | 日志级别,可以取值debug、info、error、fatal |
| suppress_repeated_stacktrace | |
| emit_error_log_interval | |
| suppress_config_dump | |
| without_source | |
| process_name | 配置fluentd的supervisor和worker进程的名称 |
每个Fluentd事件包含以下部分:
- Tag:标签,用于说明事件的“来源”,用于事件路由。标签是点号(.)分隔的多个字符串
- Time:事件发生的时间,必须是UNIX time格式
- Record:实际的日志内容,JSON对象形式
标签(Tag)是日志事件的一种属性。filter、match指令可以指定一个匹配Pattern,来声明它负责处理哪些事件:
| Pattern | 说明 |
| app.tag | 精确匹配 |
| app.* | 匹配app.tag1、app.tag2,但是不匹配app.tag1.xx |
| app.** | 匹配任何以app开头的标签 |
| app.{x,y}.* | 匹配app.x.*以及app.y.*,其中x、y可以是Pattern,例如app.{x,y.**} |
| app.tag app.tag | 或 |
Fluentd根据配置文件中声明的顺序,自上而下的尝试匹配,一旦找到匹配日志事件的filter、match就不再继续。
如果通过td-agent包安装,则配置文件位置为/etc/td-agent/td-agent.conf。
如果通过Ruby Gem安装,则配置文件位置为/etc/fluent/fluent.conf。
要修改配置文件的位置,使用环境变量FLUENT_CONF,或者命令行选项 -c
任何一个Fluentd插件都暴露若干可配置参数。
| 类型 | 说明 |
| string | 字符串 |
| integer | 整数 |
| float | 浮点数 |
| size | 字节数量 |
| time | 时间长度(Duration) |
| array | JSON数组,可以 ["key1", "key2"]形式,或者 key1,key2形式 |
| hash | JSON对象,可以 {"key1":"value1", "key2":"value2"}或者 key1:value1,key2:value2 |
Fluentd定义了一系列以@开头的参数:
| 参数 | 说明 |
| @type | 插件类型 |
| @id | 插件ID |
| @label | 指定路由标签 |
| @log_level | 插件的日志级别 |
type, id 和 log_level是对应上面几个参数,向后兼容用。
你可以在字符串中包含 #{}标记,其中可以包含合法的Ruby表达式,示例:
|
1 2 |
host_param "#{Socket.gethostname}" env_param "foo-#{ENV["FOO_BAR"]}" |
这是一个内置插件,不需要额外的安装步骤。该插件从目标配置文件的尾部开始读取新产生的日志。
| 参数 | 类型 | 说明 | ||
| tag | string | 支持使用通配符 * ,该符号会展开为日志文件的实际路径 | ||
| path | string |
需要读取的日志的路径,可以指定多个路径,逗号分隔 通配符*和strftime格式占位符可以使用,用以动态的添加/移除日志文件:
|
||
| exclude_path | array |
需要排除掉的日志路径,示例:
|
||
| read_from_head | bool | 从文件的头部开始读取日志,而非尾部 | ||
| <parse> | directive | 你必须为tail配置parse指令,说明如何解析日志内容 |
读取并解析Systemd日志。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<source> @type systemd @id in_systemd_kubelet # 读取Kubelet.service的0-5级别的日志 matches [{ "_SYSTEMD_UNIT": "kubelet.service", "PRIORITY": [0,1,2,3,4,5] }] <storage> @type local persistent true path /var/log/fluentd-journald-kubelet-cursor.json </storage> <entry> fields_strip_underscores true </entry> read_from_head false tag kubelet </source> |
支持以多种方式来修改事件。
| 参数 | 类型 | 说明 | ||||
| <record> | directive |
在该指令中,定义需要新增加的字段。配置示例:
支持以下方式来访问标签: tag_parts[N] 标签的第N段 |
||||
| enable_ruby | bool |
默认false。如果为true,则可以在${}中包含Ruby代码,代码可以使用变量: record 当前事件记录 配置示例:
代码示例:
|
||||
| auto_typecast | bool | 默认false。是否自动进行类型转换 | ||||
| renew_record | bool | 默认false。如果true则在空的新哈希上进行操作,而非修改incoming的记录 | ||||
| renew_time_key | string | 使用指定的字段来修改事件的时间,目标字段必须是UNIX time | ||||
| keep_keys | array | 仅当renew_record=true时有意义。列出记录中需要保留的键 | ||||
| remove_keys | array | 列出需要删除的键 |
根据事件的字段进行过滤,不匹配的记录被丢弃。
| 参数 | 类型 | 说明 | ||
| <and> | directive |
内部指定几个其它指令,进行与操作:
|
||
| <or> | directive | 内部指定几个其它指令,进行或操作 | ||
| <regexp> | directive |
指定基于正则式的匹配规则,不匹配的事件会被排除:
|
||
| <exclude> | directive | 类似上面,但是匹配的事件会被排除 |
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 针对所有以calico-node开头的日志 <filter kubernetes.var.log.containers.calico-node-*.log> @type grep @id filter_grep_container_calico_node <regexp> # 针对日志记录的log字段 key log # 仅仅保留警告、错误日志 pattern ^.{25}(W|E) </regexp> </filter> # 仅仅保留具有标签tier=application的Pod产生的日志 <filter kubernetes.**> @type grep @id filter_grep_kubernetes <regexp> key $.kubernetes.labels.tier pattern ^application$ </regexp> </filter> |
解析日志的字符串字段,并把事件记录替换为解析结果:
| 参数 | 类型 | 说明 |
| <parse> | directive | 指定解析器及其参数 |
| key_name | string | 需要被解析的记录字段名 |
| reserve_time | bool | 是否在新记录中保留原始事件的时间字段 |
| reserve_data | bool | 是否在新记录中保留原始时间的所有字段 |
| remove_key_name_field | bool | 如果解析成功,是否删除key_name指定的原始事件字段,1.2.2引入 |
| inject_key_prefix | string | 解析结果字段,统一增加的前缀 |
| hash_value_field | string | 解析结果字段,以哈希(对象)形式保存为该参数指定字段的值 |
| emit_invalid_record_to_error | bool | 是否将无法解析的记录发射给@ERROR标签 |
示例,解析ElasticSearch的JSON格式的日志,并把Wrapping Docker日志替换掉:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<filter kubernetes.var.log.containers.es-master-*.log> @type parser @id filter_parser_containers_es_master key_name log reserve_time true reserve_data true remove_key_name_field true <parse> @type json time_format %Y-%m-%dT%H:%M:%S.%NZ </parse> </filter> |
该插件非内置,执行 gem install fluent-plugin-concat安装。
用于将多个日志事件合并为一个。具有工作三种模式:
- n_lines 将连续的N个事件合并为一个
- multiline_start_regexp ... 根据正则式匹配来确定该事件是否作为合并后的第一个、中间事件、最后一个
- partial_key 取源事件中的某个字段,如果该字段的值为partial_value指定的值,则认为它应该合并到前面的事件
注意: 如果超时后仍然没有接收到被合并序例的的最后一个事件,则整个序列会被丢弃。
下面的示例用于处理被Docker的日志驱动按行收集的Java Logback日志信息,它会将日志中的异常栈合并到一起,然后与它们之前的(紧靠着的)那个事件合并:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<filter kubernetes.**> @type concat @log_level trace key log multiline_start_regexp /^(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)/ timeout_label @ES </filter> <match kubernetes.**> @type relabel @label @ES </match> <label @ES> ... </label> |
根据正则式来解析日志。指定的正则式至少需要指定一个命名捕获,命名捕获会作为记录的字段,名字为time的命名捕获,会作为事件的发生时间。
| 参数 | 类型 | 说明 | ||
| time_key | string | 事件的发生时间字段,默认time | ||
| time_format | string | 时间的格式 | ||
| keep_time_key | string | 是否在记录中保留时间字段,默认false | ||
| expression | regexp |
解析日志的正则式,需要指定至少一个命名捕获 下面的例子解析Containerd默认日志:
|
||
| types | string |
指定解析出的各字段的类型,如果不指定所有字段为string类型。格式:
支持的类型:string、bool、integer、float、time、array |
regexp的多行版本,支持将多行日志合并为一个事件,特别适用于解析异常栈。
| 参数 | 类型 | 说明 |
| time_key | string | 事件的发生时间字段,默认time |
| time_format | string | 时间的格式 |
| format_firstline | string | 匹配多行日志事件的第一行的正则式 |
| formatN | string | N可以是1-20,指定完整的日志事件格式 |
| keep_time_key | string | 是否在记录中保留时间字段,默认false |
Java异常日志的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<parse> @type multiline # 识别新记录的正则式 format_firstline /\d{4}-\d{1,2}-\d{1,2}/ # 解析完整记录的正则式 format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2}) \[(?<thread>.*)\] (?<level>[^\s]+)(?<message>.*)/ </parse> # 第一个记录 2013-3-03 14:27:33 [main] INFO Main - Start # 第二个记录 2013-3-03 14:27:33 [main] ERROR Main - Exception javax.management.RuntimeErrorException: null at Main.main(Main.java:16) ~[bin/:na] # 第三个记录 2013-3-03 14:27:33 [main] INFO Main - End |
Rails日志的例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<parse> @type multiline # 识别新记录的正则式 format_firstline /^Started/ # 分为多个参数,每个参数对应一行日志信息 format1 /Started (<method>[^ ]+) "(<path>[^"]+)" for (<host>[^ ]+) at (<time>[^ ]+ [^ ]+ [^ ]+)\n/ format2 /Processing by (<controller>[^\u0023]+)\u0023(<controller_method>[^ ]+) as (<format>[^ ]+)\n/ format3 /( Parameters: (<parameters>[^ ]+)\n)/ format4 / Rendered (<template>[^ ]+) within (<layout>.+) \([\d\.]+ms\)\n/ format5 /Completed (<code>[^ ]+) [^ ]+ in (<runtime>[\d\.]+)ms \(Views: (<view_runtime>[\d\.]+)ms \| ActiveRecord: (<ar_runtime>[\d\.]+)ms\)/ </parse> # 第一个记录 Started GET "/users/123/" for 127.0.0.1 at 2013-06-14 12:00:11 +0900 Processing by UsersController#show as HTML Parameters: {"user_id"=>"123"} Rendered users/show.html.erb within layouts/application (0.3ms) Completed 200 OK in 4ms (Views: 3.2ms | ActiveRecord: 0.0ms) |
在Fluentd 1.0,允许三种输出插件的缓冲/刷出模式:
- 无缓冲模式,直接写出到外部系统
- 同步缓冲模式,使用缓冲块(事件集),缓冲块排队等候刷出。行为由buffer段控制
- 异步缓冲模式,类似2,但是输出插件在后台异步的提交请求给外部系统
每个插件可以支持全部3种模式,也可以仅仅支持一种模式。如果对不支持缓冲的插件配置buffer段,fluentd会出错并终止。
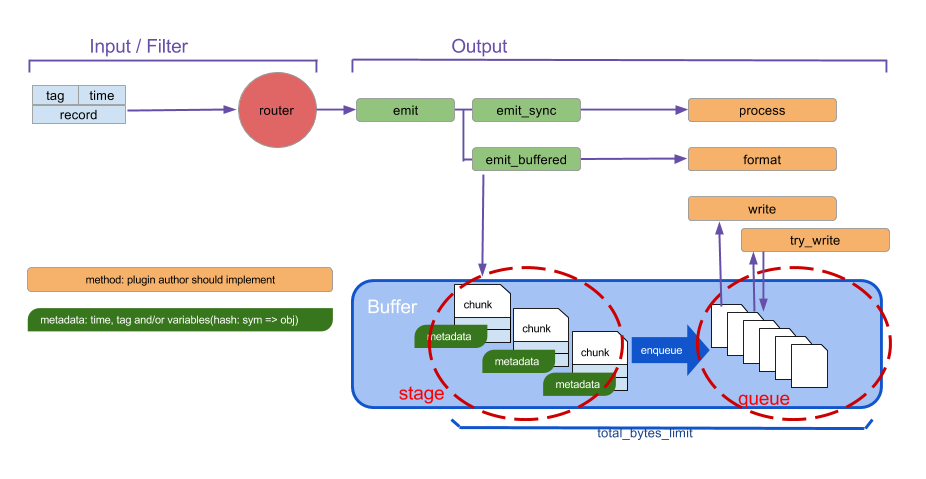
该插件非内置,执行 gem install fluent-plugin-route安装。
fluent-plugin-route支持修改标签,支持定义多个路由规则。可以实现事件复制分发:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
<match worker.**> @type route # 修改标签前缀 remove_tag_prefix worker add_tag_prefix metrics.event # 复制事件,走路由规则一 <route **> copy # 不使用COPY会导致路由在此结束 </route> # 复制事件,走路由规则二 <route **> copy @label @BACKUP </route> </match> # 路由规则一 <match metrics.event.**> @type stdout </match> # 路由规则二 <label @BACKUP> <match metrics.event.**> @type file path /var/log/fluent/bakcup </match> </label> |
fluent-plugin-rewrite-tag-filter支持根据日志事件的内容来修改标签。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<match app.**> @type rewrite_tag_filter # 根据内容的message字段,对齐进行正则式匹配,获取日志级别,捕获为$1,作为Tag的前缀 rewriterule1 message ^\[(\w+)\] $1.${tag} </match> # 错误消息路由到这里 <match error.app.**> @type mail </match> # 其它消息路由到这里 <match *.app.**> @type file </match> |
将日志记录输出到ES中。插件参数:
| 参数 | 类型 | 说明 |
| include_tag_key | bool |
是否将事件的Fluentd Tag作为ES文档的字段存储 字段名默认为tag,可以用参数tag_key修改 |
| logstash_format | bool |
兼容Logstash格式的索引命名,设置为true才能使用Kibana 如果设置为true自动忽视参数index_name,索引名称自动设置为: #{logstash_prefix}-#{formated_date} |
| time_key | string | 默认情况下,@timestamp自动会自动设置为消费日志的时间,如果要修改此行为,通过该参数指定一个记录字段名 |
| include_timestamp | bool | 是否包含一个@timestamp字段到输出文档中 |
| logstash_prefix | string | 索引名前缀,默认logstash |
| logstash_dateformat | string | 作为索引名后缀的日期格式 |
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<match *.**> @type elasticsearch host 10.0.10.2 port 9200 user logstash_system password logstash_system logstash_format true logstash_prefix openstack enable_ilm true index_date_pattern "now/m{yyyy.mm}" flush_interval 10s </match> |
简单的丢弃事件,示例:
|
1 2 3 |
<match fluent.**> @type null </match> |
将日志写入到Kafka主题中。
执行下面的命令安装此插件:
|
1 |
fluent-gem install fluent-plugin-kafka |
配置示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<match pattern> @type kafka_buffered # 种子代理列表 brokers <broker1_host>:<broker1_port>,<broker2_host>:<broker2_port> # 缓冲设置 buffer_type file buffer_path /var/log/td-agent/buffer/td flush_interval 3s # Kafka主题 default_topic messages # 数据类型设置 output_data_type json compression_codec gzip # 生产者配置 max_send_retries 1 required_acks -1 </match> |
此插件用于给事件重新打标签,例如:
|
1 2 3 4 5 6 7 8 9 10 |
<match pattern> @type relabel @label @foo </match> <label @foo> <match pattern> ... </match> </label> |
会给Tag匹配pattern的事件全部打上@foo标签,这些事件会全部交由名为@foo的label区段处理。
将事件写入到文件。不是记录写入后立即就生成文件,只有time_slice_format条件满足时文件才生成,默认情况下该插件每天生成一个文件。
插件参数:
| 参数 | 类型 | 说明 | ||
| path | string |
文件前缀,实际文件路径为path + time + .log,其中time取决于time_slice_format |
||
| append | bool |
刷出的chunk是否覆盖到已经存在的文件。默认情况下每个chunk都输出到不同位置(即取值false) 不同取值对应的文件布局:
|
||
| format | string | 输出文件格式 | ||
| time_format | string | 日期写出格式 | ||
| compress | string | 输出压缩算法,默认gzip | ||
| time_slice_format | string |
用于文件名中time部分的、时间的格式化方式: %Y: 年度 默认取值 %Y%m%d%H ,也就是每小时一个文件 |
||
| time_slice_wait | time | Fluentd等待迟到日志到达的最大时间,默认10m。用于处理事件到达fluentd节点有延迟的情况 | ||
| flush_interval | time | 刷出缓冲的间隔,默认60s |
一个实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<label @K8S_OUT_FILE> <match **> @type file # 目录 %Y-%m-%d.%H.${$.kubernetes.labels.application} 中会存放缓冲文件,每小时(3600)刷出 # 文件名称示意 2018-11-14.17.account.log.gz, log.gz自动添加,不需要在path中声明 path /var/log/kubernetes/%Y-%m-%d.%H.${$.kubernetes.labels.application} append true # 压缩文件可以这样浏览:gzip -dc 2018-11-14.17.account.log.gz | grep ERROR compress gzip <buffer time,$.kubernetes.labels.application> timekey 3600 timekey_wait 10 timekey_zone +0800 </buffer> <format> @type single_value message_key log </format> </match> </label> |
为了保证节点的时间戳精确,你需要安装NTP守护程序,例如chrony、ntpd。
文件描述符数量:
|
1 2 3 4 |
root soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536 |
对于高负载、多个Fluentd的环境,需要修改网络参数:
|
1 2 3 4 5 6 7 8 9 |
net.core.somaxconn = 1024 net.core.netdev_max_backlog = 5000 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216relabel net.ipv4.tcp_wmem = 4096 12582912 16777216 net.ipv4.tcp_rmem = 4096 12582912 16777216 net.ipv4.tcp_max_syn_backlog = 8096 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_tw_reuse = 1 |
重启或者 sysctl -p生效。
如果日志的目的地是远程设备、存储,可以使用该选项来并行化输出(默认1)。使用多线程可以缓和网络延迟的影响。
所有输出插件支持该参数。
Ruby提供了若干GC参数,你可以通过环境变量来设置它们。
要减少内存占用,可以设置RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR为较小的值,此参数默认值2.0。资源受限环境下可以设置为1.2-
处理10亿级别的日志输入时,CPU会出现瓶颈,这时考虑增加工作进程数量:
|
1 2 3 |
<system> workers 8 </system> |
Kibana是一个开源的分析和可视化平台,必须配合ES一起使用。可以使用Kibana来检索、分析ES索引中的数据,日志分析是最常用的应用场景。
用于交互式的日志查询,使用Lucene查询语法:
| 查询串示例 | 说明 |
| level:error | level字段包含单词error |
| level:(error OR warn) level:(error warn) |
level字段包含单词error或warn 操作符默认OR |
| message: "Connection Reset" | 精确包含短语Connection Reset |
| user.\*:(alex) | user的任何字段包含alex |
| _exists_:title | title字段不为空 |
| level:e?r* | 通配符:*匹配任意个数字符,?匹配单个字符 |
| name:/joh?n(ath[oa]n)/ | 支持正则式 |
| quikc~1 | 模糊查询操作符~,可以匹配拼写错误的情况。1为距离,默认2,取值1可以捕获80%的拼写错误 |
| age:>10 age:>=10 age:<10 age:<=10 |
比较操作符 |
| (quick OR brown) AND fox | 分组操作符 |
| date:[2012-01-01 TO 2012-12-31] count:[1 TO 5] |
范围查询,闭区间 |
| tag:{alpha TO omega} | 范围查询,开区间(不包含首尾) |
| count:[10 TO *] | 范围查询,无上限 |
Visualize用于设计一个小器件,例如饼图、曲线图。Dashboard则可以将小器件组合为仪表盘。
这里以曲线图为例,点击曲线图的图标,首先要选择数据源,也就是索引。点选fluentd-*索引,看到如下界面:
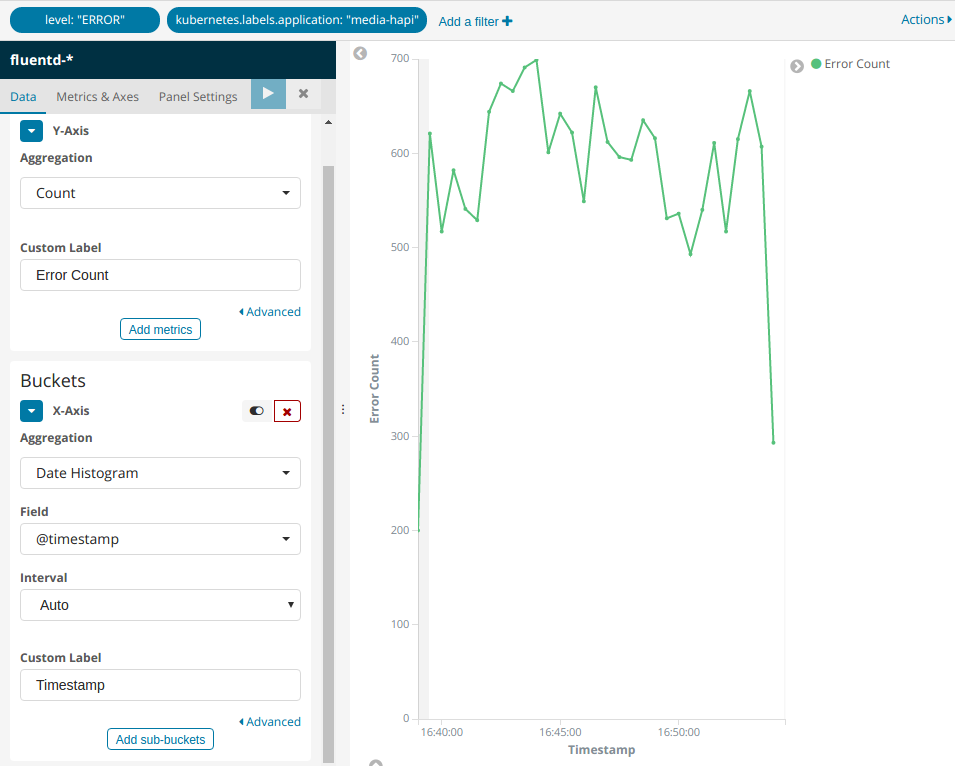
点击顶部的Add a filter,可以添加过滤条件。
Metrics区域用于定义统计指标(度量),支持多个度量。
Buckets区域用于指定如何分组展示,示例:
| 需求 | 配置步骤 |
| X轴显示时间,根据应用程序名称拆分Series |
|
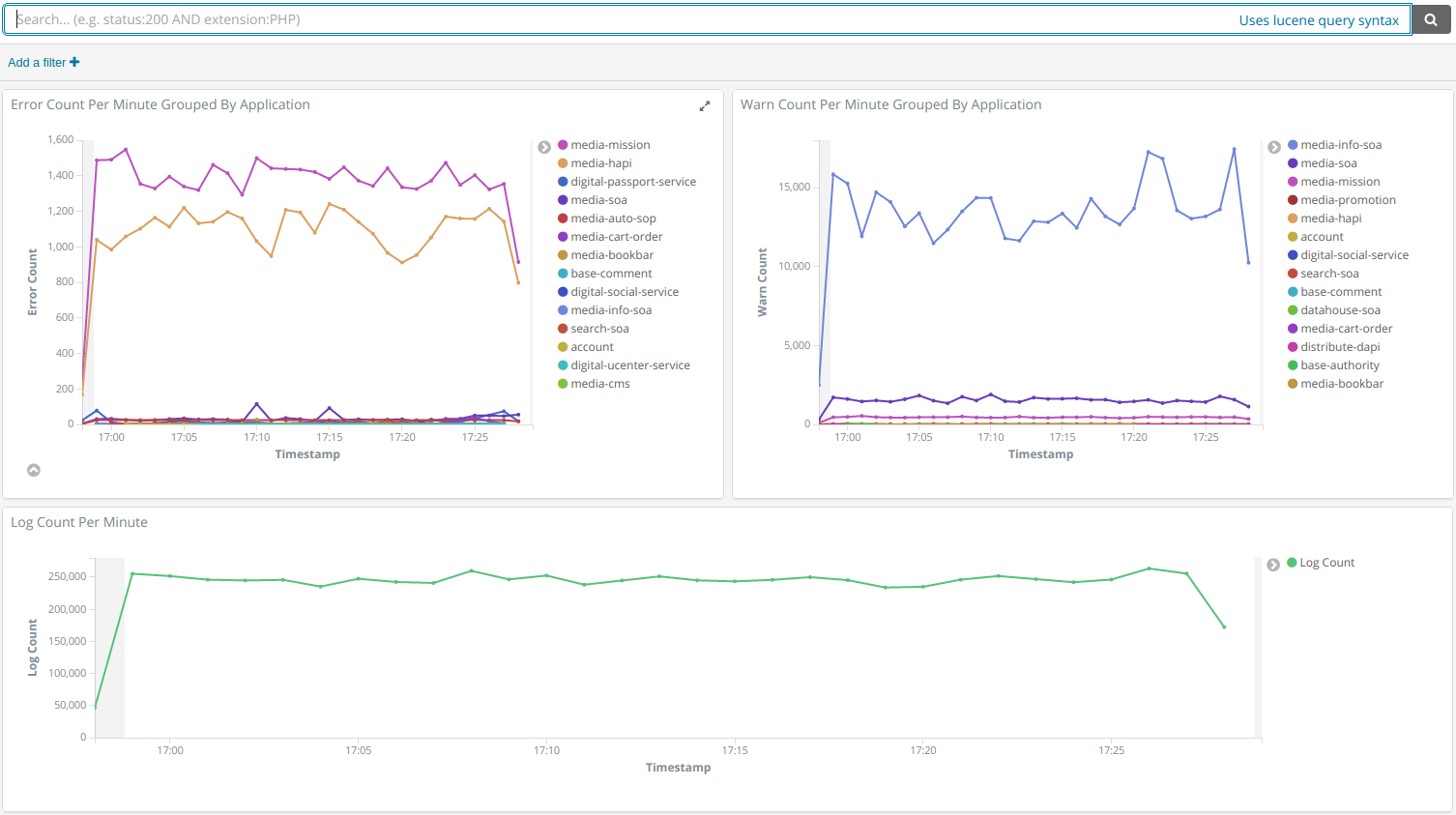
可以选取在“可视化“中定义的小器件,并拖拽以布局,效果示例:
首页是总体状态信息,包括ES、Kibana的健康状态,已用/可用的各类硬件资源信息:
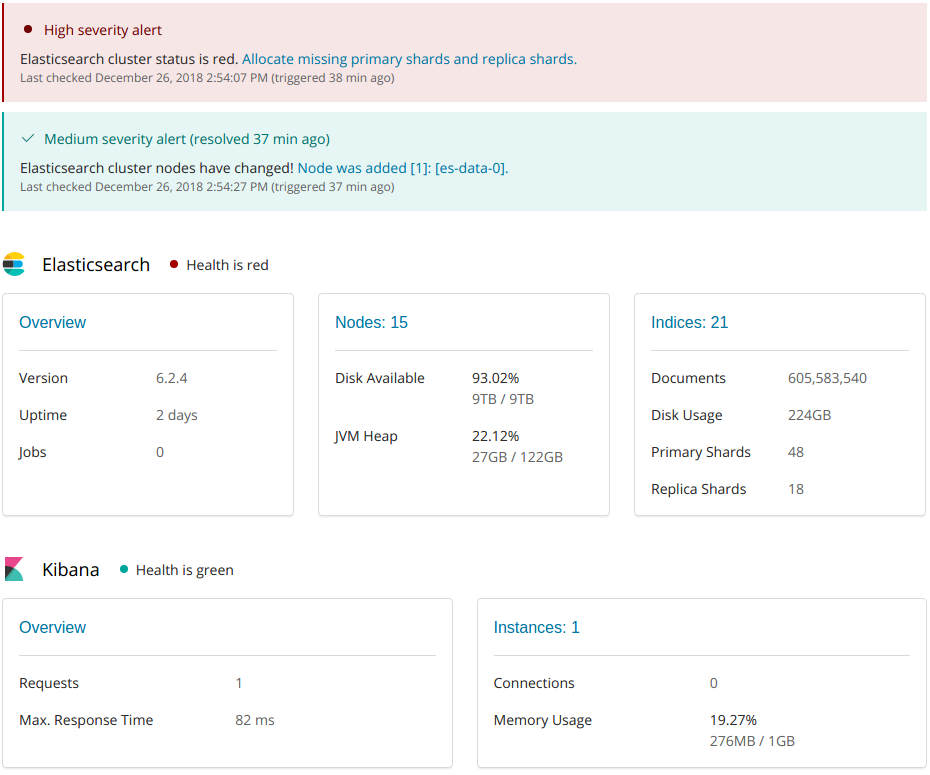
如果Elasticsearch的健康状态为red,则说明集群存在问题。截图中的情况是主分片尚未分配到节点导致。
点击上图Elasticsearch区域的Overview连接,可以看到ES集群更多的信息:
 本页面显示ES的读(检索)、写(索引)性能指标,包括QPS和延迟。
本页面显示ES的读(检索)、写(索引)性能指标,包括QPS和延迟。
Shard Activity通常是空的,上图中的情况是正在应用事务日志到ES数据节点。Translog是一种写前日志,记录所有针对ES的写操作。
此页面显示索引的列表,如果有红色说明索引存在问题。下图中第一个索引有一个分片不正常。
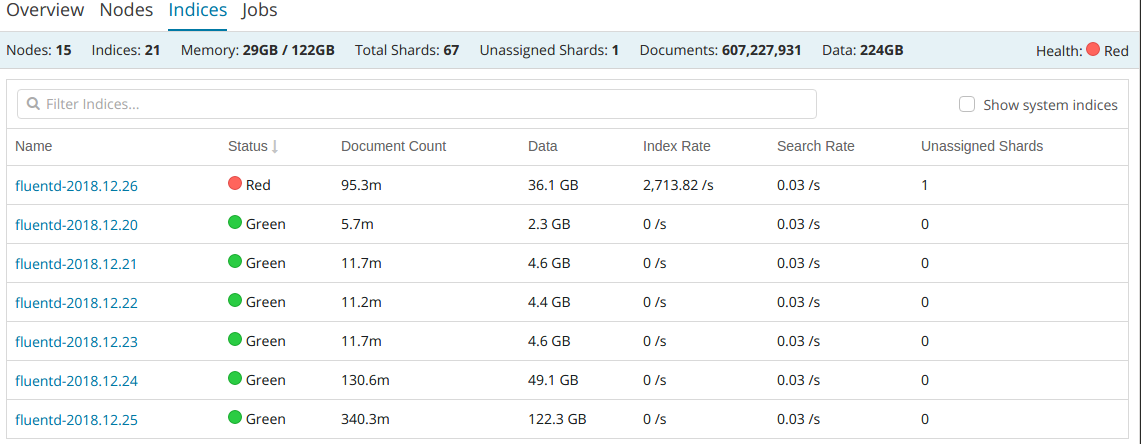
每个索引包含的文档数量、占用的磁盘空间、读写速率也显示在页面上。
该页面显示单个索引文档数量、占用的磁盘空间、读写速率随时间的变化曲线,以及索引各分片的状态。
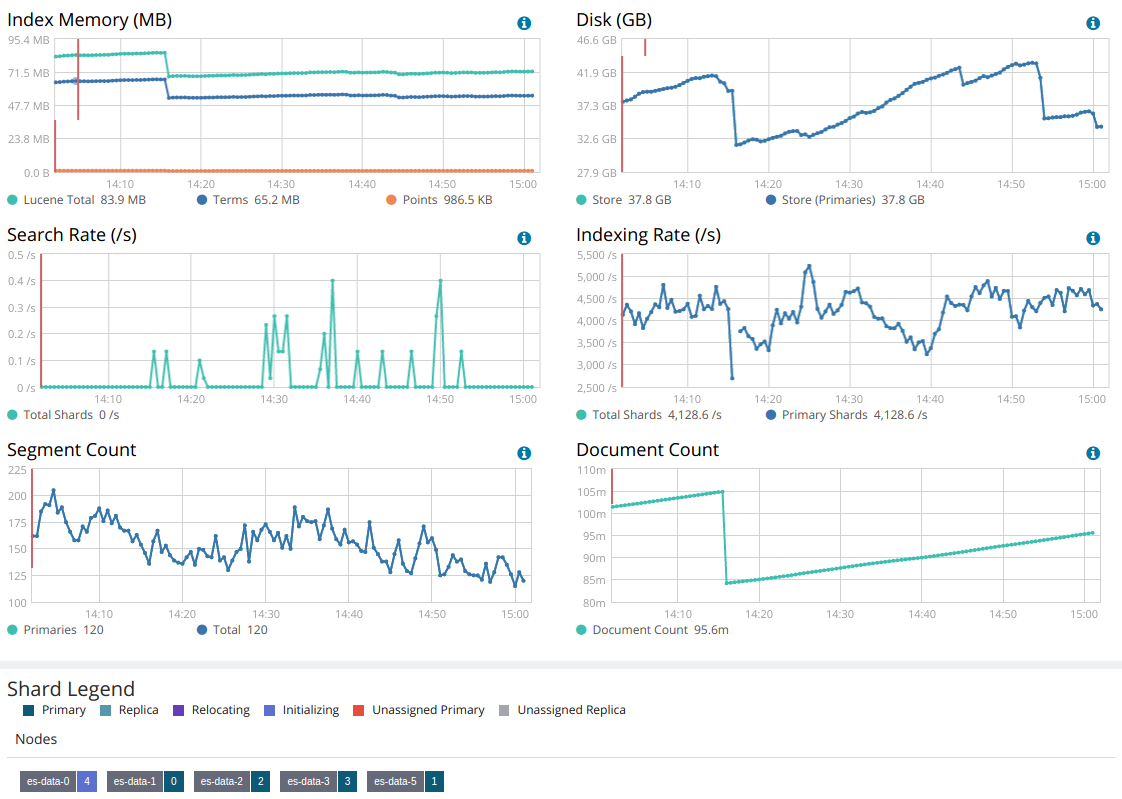
上图中,es-data-0分配了序号为4的分片,并且此分片正在初始化。其它分配均正常。
| 参数 | 说明 |
| dateFormat | 日期显示格式,例如MM-DD HH:mm:ss.SSS |
| truncate:maxHeight | 检索时,每条日志占用的最大UI高度 |
捆绑了X-pack的ElasticSearch镜像:https://git.gmem.cc/alex/docker-elasticsearch
ElasticSearch+Kibana的Helm Chart:https://git.gmem.cc/alex/oss-charts/src/branch/master/elasticsearch
Fluentd的Helm Chart:https://git.gmem.cc/alex/oss-charts/src/branch/master/fluentd
iotop看到fluentd进程有高达200M/s的读操作,但是定位不到针对的是什么文件
使用csysdig跟踪进程系统调用,发现大量内存映射操作,针对/var/log/journal/4f2be1039e944e028f2e86e02fe410e1目录,删除目录后问题消失。
设置Kibana的环境变量XPACK_MONITORING_UI_CONTAINER_ELASTICSEARCH_ENABLED为false
您好,想请教一个fluentd的问题:
我的架构是filebeat --> fluentd --> elasticsearch
说明:fluentd过滤处理filebeat采集到的日志数据,而filebeat中有自带的tags字段,如果我想取出tags数组里的值,fluentd应该怎么写法?我使用${record["tags"]["0"]}获取报错,但是使用stdout插件输出是有的,就是写入不进elasticsearch