人工智能知识 - 数学基础
这一篇整理 AI 所需的数学基础,包括基础数学、线性代数、微积分与概率论统计。它回答的核心问题是:模型里的向量、矩阵、导数、积分、概率分布、期望与信息量分别是什么意思,以及它们为什么会成为后续机器学习与深度学习的共同语言;后续篇章将在这些数学工具之上进入算法、学习理论与模型结构。
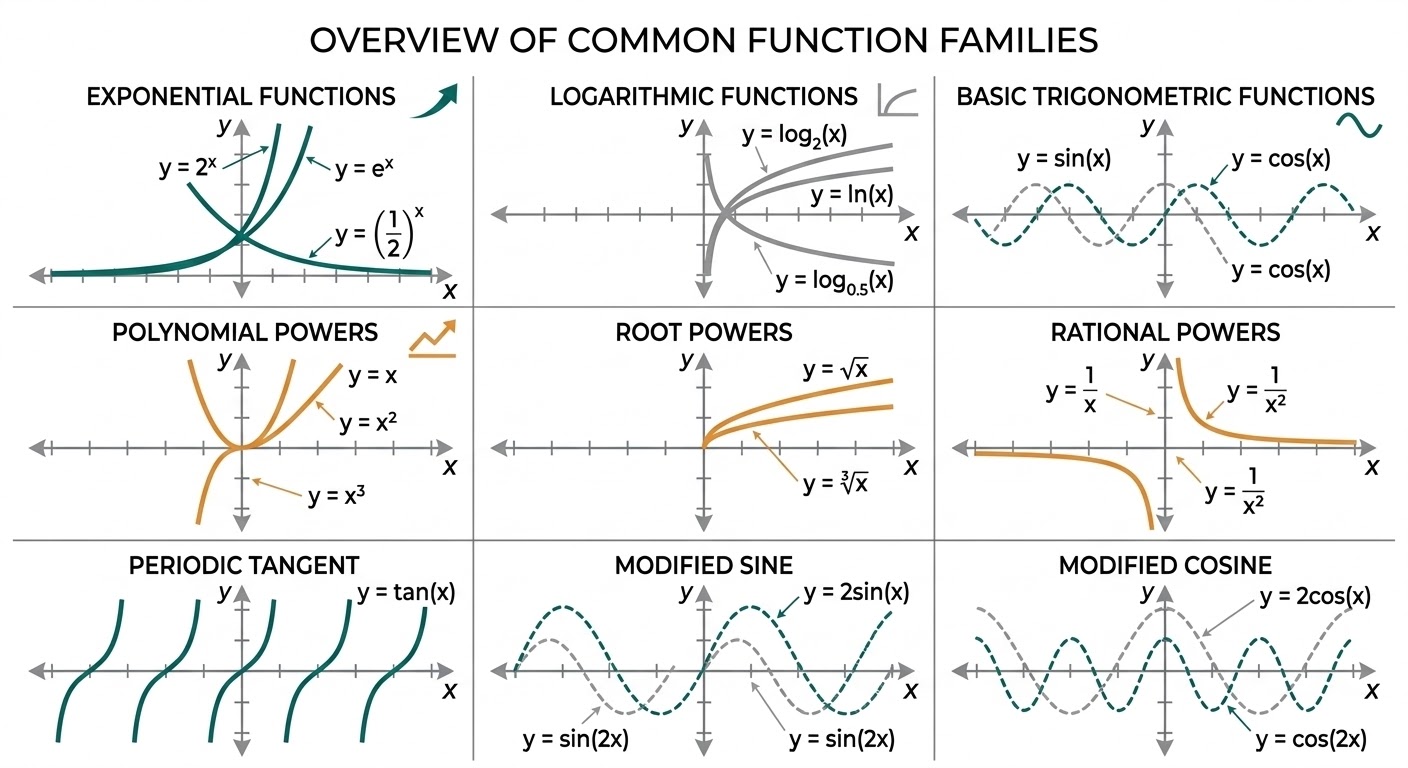
代数式(Algebraic Expression)由常数、变量与运算构成;给定变量取值后即可求值。化简(Simplification)的目标是把表达式写成更可读、更便于推导/比较的等价形式:合并同类项(Like Terms)、提取公因子(Common Factor)、展开(Expansion)与因式分解(Factorization)是最常见的操作。
运算律(Algebraic Laws)本质上是在某个数系/代数结构(例如实数域)中成立的恒等式(Identity);它们允许在不改变值的前提下重排/重写表达式。需要区分:加法/乘法满足交换律与结合律,但减法/除法一般不满足。
| 性质 | 公式 | 备注 |
| 交换律(Commutativity) | \(a+b=b+a\) \(ab=ba\) |
不适用于 \(a-b\)、\(a/b\) |
| 结合律(Associativity) | \((a+b)+c=a+(b+c)\) \((ab)c=a(bc)\) |
允许不改变括号结构地分组 |
| 分配律(Distributivity) | \(a(b+c)=ab+ac\) | 展开与提因式的核心 |
| 恒等元(Identity Element) | \(a+0=a\) \(a\cdot 1=a\) |
0 与 1 在代数推导中常被隐式使用 |
| 逆元(Inverse) | \(a+(-a)=0\) \(a\cdot a^{-1}=1\) |
第二式要求 \(a\ne 0\) |
| 零乘积原则(Zero Product) | \(ab=0\Rightarrow a=0\ \text{或}\ b=0\) | 把方程从“乘积=0”转为“因子=0” |
因式分解(Factorization)把一个表达式改写成若干因子(Factor)的乘积。它的直接价值是:把“值为 0 / 符号变化 / 约束条件”转成对各因子的分析。与之对偶的是展开(Expansion):把乘积写成和式。
对多项式(Polynomial)\(p(x)\),根(Root/Zero)与线性因子之间存在精确对应:若 \(p(r)=0\),则 \((x-r)\) 是 \(p(x)\) 的因子(因子定理(Factor Theorem))。
| 套路/恒等式 | 形式 | 备注 |
| 提公因子(Common Factor) | \(ax+ay=a(x+y)\) | 先把最大公因子提出来 |
| 平方差(Difference of Squares) | \(a^2-b^2=(a-b)(a+b)\) | 常用于构造可约因子 |
| 完全平方(Perfect Square) | \(a^2\pm 2ab+b^2=(a\pm b)^2\) | 与配方(Completing the Square)等价 |
| 立方和/差(Sum/Difference of Cubes) | \(a^3-b^3=(a-b)(a^2+ab+b^2)\) \(a^3+b^3=(a+b)(a^2-ab+b^2)\) |
二次因子在实数域可能不可再分 |
| 二次式按根分解 | \(ax^2+bx+c=a(x-r_1)(x-r_2)\) | \(r_1,r_2\) 可为复数 |
| 分组分解(Grouping) | \(ax+ay+bx+by=(a+b)(x+y)\) | 目标是制造共同因子 |
一元多项式(Univariate Polynomial)是形如 \(p(x)=\sum_{k=0}^{n} a_k x^k\) 的函数,其中 \(a_k\) 是系数(Coefficient),\(n\) 是次数(Degree)。多项式在实数域上处处可导、可积;在局部逼近(例如 Taylor)与特征构造中非常常用。
多元多项式(Multivariate Polynomial)可写成对多重指数(Multi-index)求和:若 \(x\in\mathbb{R}^d\),则
\[p(x)=\sum_{\alpha\in\mathbb{N}^d} c_\alpha\,x^\alpha,\quad x^\alpha=\prod_{i=1}^{d} x_i^{\alpha_i}\]补充:多元二次多项式(Quadratic Polynomial)的纯二次部分在线性代数里通常称为二次型(Quadratic Form),可写成矩阵形式 \(q(\mathbf{x})=\mathbf{x}^\top A\mathbf{x}\);其中 \(x_ix_j\)(例如 \(xy\))是交叉项(Cross Term)。
在机器学习里,多项式特征(Polynomial Features)把输入映射到包含高阶项的特征空间,等价于显式构造某些核函数(Kernel)的有限维版本。
| 概念 | 表述 | 用途 |
| 首项/首项系数(Leading Term/Coefficient) | \(a_n x^n\) / \(a_n\) | 决定远端增长阶与符号 |
| 余数定理(Remainder Theorem) | \(p(x)=q(x)(x-a)+p(a)\) | 快速计算 \(p(a)\) |
| 因子定理(Factor Theorem) | \(p(a)=0\Leftrightarrow (x-a)\mid p(x)\) | 把“根”与“线性因子”连接起来 |
一元二次方程(Quadratic Equation)标准形式为 \(ax^2+bx+c=0\)(\(a\ne 0\))。核心量是判别式(Discriminant)\(\Delta=b^2-4ac\):它决定解的个数与类型。
| 结论 | 公式 | 备注 |
| 求根公式(Quadratic Formula) | \(x=\frac{-b\pm\sqrt{\Delta}}{2a}\) | \(\Delta<0\) 时根为共轭复数 |
| 配方(Completing the Square) | \(ax^2+bx+c=a\left(x+\frac{b}{2a}\right)^2-\frac{\Delta}{4a}\) | 同时给出顶点与最值 |
| 顶点(Vertex) | \(x_v=-\frac{b}{2a},\quad f(x_v)=-\frac{\Delta}{4a}\) | \(a>0\) 时为全局最小;\(a<0\) 时为全局最大 |
| 韦达定理(Vieta) | \(r_1+r_2=-\frac{b}{a},\quad r_1r_2=\frac{c}{a}\) | 无需显式求根即可得到对称量 |
分式/有理式(Rational Expression)是两个多项式之比:\(\frac{p(x)}{q(x)}\),并要求 \(q(x)\ne 0\)。任何化简都必须保留定义域(Domain)约束:约分(Cancellation)只是在允许的点上重写表达式,不会“把不可取值点变得可取”。
典型例子: \(\frac{x^2-1}{x-1}=\frac{(x-1)(x+1)}{x-1}=x+1\),但仍需强调 \(x\ne 1\)。这里 \(x=1\) 是可去间断点(Removable Discontinuity):原式无定义,而约分后的表达式在该点有值。
| 操作 | 规则 | 要点 |
| 加减 | \(\frac{a}{b}\pm\frac{c}{d}=\frac{ad\pm bc}{bd}\) | 先通分(Common Denominator) |
| 乘除 | \(\frac{a}{b}\cdot\frac{c}{d}=\frac{ac}{bd}\) \(\frac{a}{b}\div\frac{c}{d}=\frac{a}{b}\cdot\frac{d}{c}\) |
除法要求 \(c\ne 0\) |
| 约分 | \(\frac{(x-r)u(x)}{(x-r)v(x)}=\frac{u(x)}{v(x)}\) | 仍需保留 \(x\ne r\) |
| 符号分析 | 把数轴按零点/极点分段 | 有理不等式常用“区间符号表” |
绝对值(Absolute Value)\(|x|\) 表示到 0 的距离(Distance to Zero)。它把“正负”信息丢掉,只保留大小;因此绝对值相关方程/不等式通常要通过分段(Piecewise)把符号情况拆开讨论。
\[|x|=\begin{cases}x,& x\ge 0\\ -x,& x<0\end{cases}\]| 形式 | 等价条件 | 前提 |
| \(|x|=a\) | \(x=a\ \text{或}\ x=-a\) | \(a\ge 0\) |
| \(|x|<a\) | \(-a<x<a\) | \(a>0\) |
| \(|x|\le a\) | \(-a\le x\le a\) | \(a\ge 0\) |
| \(|x|\ge a\) | \(x\le -a\ \text{或}\ x\ge a\) | \(a\ge 0\) |
三角不等式(Triangle Inequality)\(|x+y|\le |x|+|y|\) 是绝对值最重要的性质之一;它把“求和后的误差”上界化为“各自误差的和”,在误差分析与泛化界推导中高频出现。
深度学习里常见的 ReLU、hinge loss 等都是分段函数:分段点处通常不可导,但仍可用次梯度(Subgradient)做优化。
配方(Completing the Square)把二次式改写成“平方 + 常数”,从而直接读出最值、解的结构与可行区间:
\[ax^2+bx+c=a\left(x+\frac{b}{2a}\right)^2-\frac{b^2-4ac}{4a}\]例如 \(x^2+6x+5=(x+3)^2-4\),因此方程 \(x^2+6x+5=0\) 等价于 \((x+3)^2=4\),解为 \(x=-1,-5\)。
换元(Substitution)通过引入新变量,把原问题变成更低复杂度的标准形式,尤其适用于“重复结构”。例如:
\[x^4-5x^2+4=0,\ \text{令 }u=x^2\Rightarrow u^2-5u+4=0\]解得 \(u=1,4\),再回代得到 \(x=\pm 1,\pm 2\)。
估计(Bounding/Estimation)常把表达式改写为“非负项 + 常数”,或利用单调性把复杂项夹逼到可控区间。最常见的来源是“平方非负”(\((\cdot)^2\ge 0\)):
\[(x-1)^2\ge 0\Rightarrow x^2+1\ge 2x,\quad (|x|-1)^2\ge 0\Rightarrow x^2+1\ge 2|x|\]这类估计在证明最值、构造上界/下界、以及把损失函数改写成“凸的主项 + 可控余项”时很有效。
数系(Number Systems)描述“允许使用哪些数,以及这些数上哪些运算是封闭的”。常见链条是
\[\mathbb{N}\subset \mathbb{Z}\subset \mathbb{Q}\subset \mathbb{R}\subset \mathbb{C}\]其中实数(Real Numbers)是有序(Ordered)且完备(Complete)的;复数(Complex Numbers)扩展了方程可解性(例如 \(x^2+1=0\) 在实数无解,但在复数有解)。
| 数系 | 记号 | 典型元素 | 结构要点 |
| 自然数(Natural Numbers) | \(\mathbb{N}\) | 0,1,2,…(是否含 0 取决于约定) | 对加法/乘法封闭;一般不可做减法/除法 |
| 整数(Integers) | \(\mathbb{Z}\) | …,-2,-1,0,1,2,… | 对加减乘封闭;除法不封闭 |
| 有理数(Rational Numbers) | \(\mathbb{Q}\) | \(p/q\)(\(p,q\in\mathbb{Z},q\ne 0\)) | 域(Field):非零元素存在乘法逆元 |
| 实数(Real Numbers) | \(\mathbb{R}\) | 包含无理数(Irrational),如 \(\sqrt{2},\pi\) | 有序完备域;极限/连续的基础 |
| 复数(Complex Numbers) | \(\mathbb{C}\) | \(a+bi\) | 代数闭包(Algebraic Closure);不可定义全序 |
函数(Function)是映射:把输入集合中的每个元素映到一个输出。定义域(Domain)是允许的输入集合;值域(Range/Image)是实际能取到的输出集合(通常是陪域(Codomain)的子集)。常用记法:
\[f:D\to Y,\quad x\mapsto f(x)\]从表达式读定义域的常见约束:
- 分母不为 0: \(\frac{p(x)}{q(x)}\) 要求 \(q(x)\ne 0\)。
- 偶次根非负: \(\sqrt{g(x)}\) 要求 \(g(x)\ge 0\)(实数域)。
- 对数正数: \(\ln g(x)\) 要求 \(g(x)>0\)。
值域分析常用“解方程 + 约束”思路:令 \(y=f(x)\),把 \(x\) 表示成 \(y\) 并推导可行条件;若 \(f\) 在某区间单调,则可用反函数直接得到值域。
| 函数 | 定义域 | 值域 |
| \(\sqrt{x}\) | \(x\ge 0\) | \(y\ge 0\) |
| \(\ln x\) | \(x>0\) | \(\mathbb{R}\) |
| sigmoid(\(\sigma(z)=\frac{1}{1+e^{-z}}\)) | \(\mathbb{R}\) | \((0,1)\) |
| \(\tanh z\) | \(\mathbb{R}\) | \((-1,1)\) |
| ReLU(\(\max(0,z)\)) | \(\mathbb{R}\) | \([0,+\infty)\) |
复合函数(Function Composition)把一个函数的输出作为另一个函数的输入:若 \(g:D\to E\)、\(f:E\to Y\),则
\[(f\circ g)(x)=f(g(x))\]定义域必须同时满足两层约束: \(x\in\mathrm{dom}(g)\) 且 \(g(x)\in\mathrm{dom}(f)\)。例如 \(f(x)=\sqrt{x}\)、\(g(x)=x^2-1\),则 \((f\circ g)(x)=\sqrt{x^2-1}\) 的定义域是 \(|x|\ge 1\)。
复合满足结合律(Associativity):\((f\circ g)\circ h=f\circ(g\circ h)\),但一般不满足交换律: \(f\circ g\ne g\circ f\)。
反函数(Inverse Function)把映射“倒过来”。若 \(f:D\to Y\) 在 \(D\) 上是双射(Bijection),则存在 \(f^{-1}:\mathrm{range}(f)\to D\) 满足
\[f^{-1}(f(x))=x,\quad f(f^{-1}(y))=y\]注意 \(f^{-1}\) 表示反函数,并非倒数 \(1/f\)。求反函数的常用步骤是:设 \(y=f(x)\),交换 \(x,y\) 并解出 \(y\)。
例:线性函数 \(y=ax+b\)(\(a\ne 0\))的反函数是 \(f^{-1}(y)=\frac{y-b}{a}\)。sigmoid 的反函数是 logit:若 \(p=\sigma(z)\),则 \(z=\log\frac{p}{1-p}\)(要求 \(p\in(0,1)\))。
若函数不单调或不可一一对应(如 \(f(x)=x^2\) 在 \(\mathbb{R}\) 上),则必须限制定义域(例如限制为 \(x\ge 0\))才能得到真正的反函数。
奇偶性(Parity)描述对称性:偶函数(Even Function)满足 \(f(-x)=f(x)\)(关于 y 轴对称),奇函数(Odd Function)满足 \(f(-x)=-f(x)\)(关于原点对称)。
单调性(Monotonicity)描述“随输入增加,输出是否不减/不增”。在区间 \(I\) 上:
- 单调递增(Monotone Increasing):\(x_1<x_2\Rightarrow f(x_1)\le f(x_2)\)。
- 严格递增(Strictly Increasing):\(x_1<x_2\Rightarrow f(x_1)<f(x_2)\)。
- 单调递减/严格递减同理。
单调函数在区间上必为单射(Injective),因此在该区间上可定义反函数。很多“不可逆”的函数(如 \(x^2\))在限制到某个单调区间后就会变得可逆。
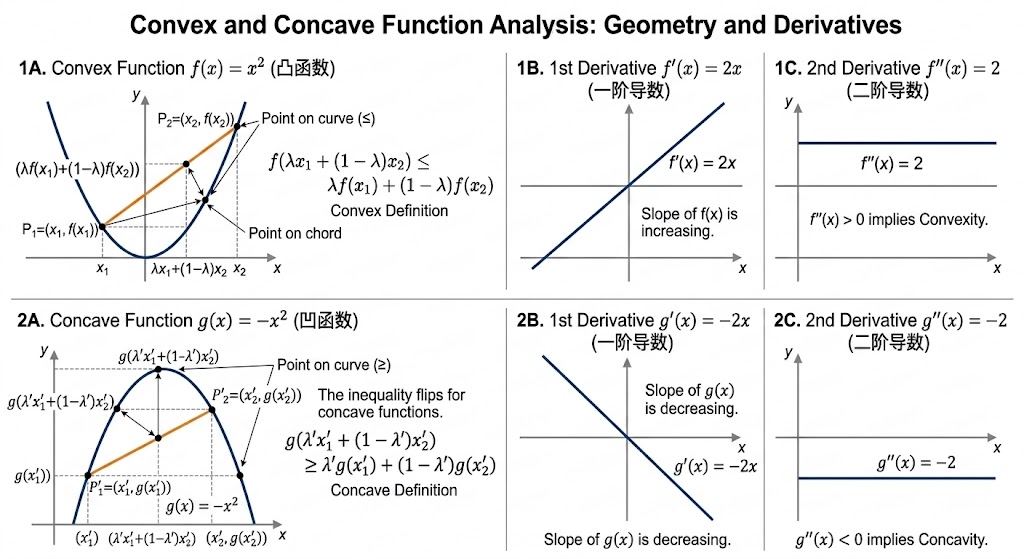
凸性(Convexity)是优化与泛化分析的核心几何性质。函数 \(f\) 在区间/凸集上是凸函数(Convex Function),当且仅当对任意 \(x_1,x_2\) 与 \(\lambda\in[0,1]\) 都有
\[f(\lambda x_1+(1-\lambda)x_2)\le \lambda f(x_1)+(1-\lambda)f(x_2)\]凹函数(Concave Function)则把不等号方向反过来。几何上:凸函数“弦在图像上方”,凹函数“弦在图像下方”。
若 \(f\) 二阶可导,则一维判别很简单: \(f''(x)\ge 0\) 则凸, \(f''(x)\le 0\) 则凹;多变量情形把 \(f''\) 替换为 Hessian,要求其半正定/半负定。
典型例子: \(x^2\) 与 \(e^x\) 是凸函数;\(\log x\)(\(x>0\))是凹函数。很多经典损失(如 MSE、logistic loss)对模型输出是凸的,但对深度网络参数整体通常非凸。
二维平面中,线性方程(Linear Equation)\(Ax+By+C=0\)(\((A,B)\ne(0,0)\))表示一条直线(Line)。向量 \((A,B)\) 是法向量(Normal Vector):它与直线方向垂直;常数项 \(C\) 控制沿法向量方向的平移。
该形式与超平面形式 \(\mathbf{w}\cdot\mathbf{x}+b=0\) 完全一致:只需取 \(\mathbf{x}=(x,y)^\top\)、\(\mathbf{w}=(A,B)^\top\)、\(b=C\)。
| 等价形式 | 表达式 | 条件/说明 |
| 斜截式(Slope-Intercept) | \(y=mx+b\) | \(B\ne 0\) 时 \(m=-A/B,\ b=-C/B\) |
| 截距(Intercepts) | \(x\text{-截距}=-C/A\) \(y\text{-截距}=-C/B\) |
分别要求 \(A\ne 0\)、\(B\ne 0\) |
| 点法式(Point-Normal) | \(\mathbf{w}\cdot(\mathbf{x}-\mathbf{x}_0)=0\) | \(\mathbf{x}_0\) 是直线上一点 |
| 点到直线距离 | \(\mathrm{dist}=\frac{|Ax_0+By_0+C|}{\sqrt{A^2+B^2}}\) | 来自把点沿法向量投影到直线 |
两条直线相交/平行可由法向量判断:若 \((A_1,B_1)\) 与 \((A_2,B_2)\) 共线,则两直线平行(或重合);否则相交,交点可由 2×2 线性方程组求解。
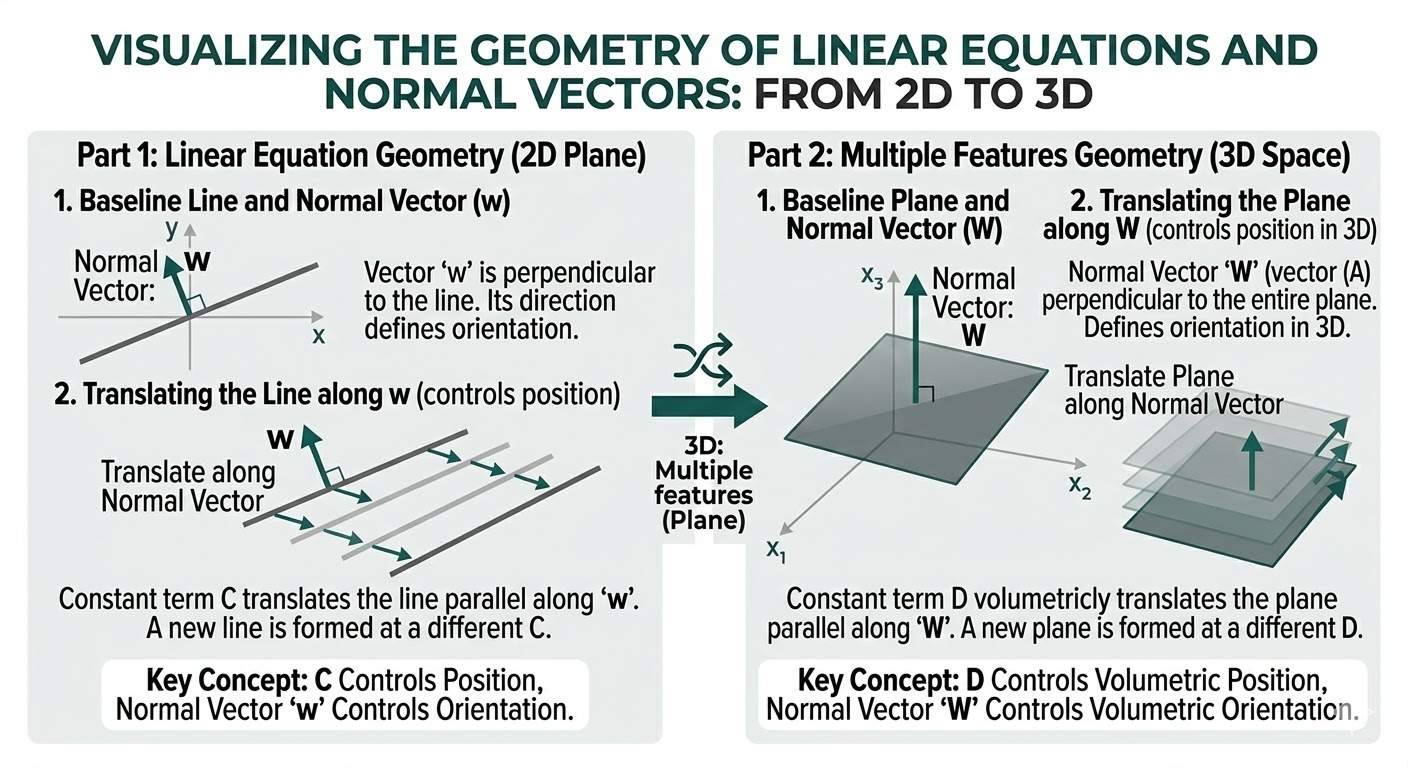
超平面(Hyperplane)是高维空间中的“线性边界”。在 \(\mathbb{R}^d\) 中,方程
\[\mathbf{w}\cdot \mathbf{x}+b=0\]定义一个 \((d-1)\) 维的仿射子空间(Affine Subspace)。其中 \(\mathbf{w}\) 是法向量(Normal Vector),决定边界的朝向;\(b\) 是偏置(Bias),决定边界沿法向量方向的平移。
工程与论文里常写成 \(\mathbf{w}^\top \mathbf{x}+b\):这里的转置(Transpose)符号 \(^\top\) 只是为了把列向量 \(\mathbf{w}\) 变成行向量,从而与列向量 \(\mathbf{x}\) 做矩阵乘法;数值上它等价于点积:
\[\mathbf{w}^\top \mathbf{x}=\sum_{i=1}^{d} w_i x_i\]例:令 \(\mathbf{w}=(2,3)^\top\)、\(\mathbf{x}=(4,5)^\top\),则 \(\mathbf{w}^\top \mathbf{x}=2\cdot4+3\cdot5=23\)。
在机器学习里,线性分类器(Linear Classifier)可写成 \(\hat y=\mathrm{sign}(\mathbf{w}^\top\mathbf{x}+b)\);逻辑回归(Logistic Regression)把它送入 sigmoid: \(p(y=1|\mathbf{x})=\sigma(\mathbf{w}^\top\mathbf{x}+b)\)。
超平面把空间划分成两个半空间(Half-space):
\[\mathbf{w}\cdot\mathbf{x}+b\ge 0,\quad \mathbf{w}\cdot\mathbf{x}+b\le 0\]法向量 \(\mathbf{w}\) 指向“值更大”的一侧:沿 \(\mathbf{w}\) 方向移动会增大 \(\mathbf{w}\cdot\mathbf{x}+b\)。因此,在线性分类里,得分的正负号自然对应类别划分。
点 \(\mathbf{x}_0\) 到超平面 \(\mathbf{w}\cdot\mathbf{x}+b=0\) 的欧氏距离(Euclidean Distance)为:
\[\mathrm{dist}(\mathbf{x}_0,\ \mathbf{w}\cdot\mathbf{x}+b=0)=\frac{|\mathbf{w}\cdot\mathbf{x}_0+b|}{\|\mathbf{w}\|_2}\]推导直觉:把 \(\mathbf{x}_0\) 沿法向量方向投影到超平面上;分子是“沿法向量方向的带符号位移”,除以 \(\|\mathbf{w}\|\) 把它变成真实距离。
约束优化中的边界通常由一个定义在整个空间上的标量函数(Scalar Function)\(g(x)\) 给出,并通过等值方程 \(g(x)=0\) 表示边界本身。函数 \(g\) 是求导对象;边界则是满足该方程的点集。梯度(Gradient)算子 \(\nabla\) 作用在约束函数 \(g\) 上,由此把边界的法向几何信息编码为一个向量场。
线性超平面的情形最直接。边界写成
\[g(\mathbf{x})=\mathbf{w}^\top\mathbf{x}+b=0\]其中 \(g\) 是定义在整个 \(\mathbb{R}^d\) 上的线性函数,而边界只是它的零等值面(Zero Level Set)。由于线性函数的一阶导数处处相同,立刻得到
\[\nabla g(\mathbf{x})=\mathbf{w}\]因此,线性超平面的法向量是 \(\mathbf{w}\),本质上等价于“定义该超平面的约束函数 \(g\) 的梯度等于 \(\mathbf{w}\)”。
这一结论对一般光滑边界同样成立。设 \(x^*\) 是边界 \(g(x)=0\) 上一点,且 \(\nabla g(x^*)\ne 0\)。若 \(t\) 是该点处的切向量(Tangent Vector),则沿着 \(t\) 做无穷小移动仍停留在同一条边界上,因而 \(g\) 的一阶变化为 0:
\[\frac{d}{d\epsilon}g(x^*+\epsilon t)\Big|_{\epsilon=0}=0\]应用链式法则(Chain Rule)得到
\[\nabla g(x^*)^\top t=0\]这表示边界上的任意切向量都与 \(\nabla g(x^*)\) 正交。因此 \(\nabla g(x^*)\) 沿法向方向指向边界外侧或内侧,而不沿边界本身滑动;梯度正是边界法向量的解析表达。
KKT 条件中的 \(\nabla g(x^*)\) 正是以这种方式出现的。约束优化核心是借助约束函数 \(g\) 的梯度,把边界的法向几何结构写入一阶最优性条件。驻点条件
\[\nabla f(x^*)+\lambda^*\nabla g(x^*)=0\]表达的是:在活跃边界上,目标函数剩余的下降趋势完全落在约束边界的法向空间里,并与乘子加权后的法向量达到平衡。
解析几何(Analytic Geometry)、向量(Vector)、三角函数(Trigonometric Functions)以及很多 AI 中的空间直觉,都建立在更基础的几何概念上。这里先把最常用的几块地基补齐:距离、角度、弧度、比例与面积。
平面几何最基本的对象是点(Point)、线段(Segment)、直线(Line)与角(Angle)。角度描述两条射线的张开程度;常见有两种单位:
\[360^\circ=2\pi\ \text{rad},\quad 180^\circ=\pi\ \text{rad},\quad 90^\circ=\frac{\pi}{2}\ \text{rad}\]度数(Degree)更适合日常表达,弧度(Radian)更适合数学推导,因为它和圆弧长度、三角函数、导数公式天然兼容。后面遇到旋转矩阵(Rotation Matrix)、复数极坐标(Polar Form)、傅里叶分析(Fourier Analysis)时,默认几乎都使用弧度。
勾股定理(Pythagorean Theorem)是平面距离公式的根源。对直角三角形,若两条直角边长为 \(a,b\),斜边长为 \(c\),则
\[a^2+b^2=c^2\]把它应用到坐标平面,就得到两点之间的欧氏距离(Euclidean Distance):
\[\mathrm{dist}(P_1,P_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\]在高维空间里,这个公式直接推广为 \(\|\mathbf{x}-\mathbf{y}\|_2\)。因此从二维几何到机器学习里的向量距离,本质上是一条连续的概念链。KNN、K-means、embedding 检索、对比学习(Contrastive Learning)都在反复使用这套“距离越小越相似”的几何直觉。
弧度由圆弧长度直接定义:若半径为 \(r\) 的圆上有一段弧长 \(s\),对应圆心角为 \(\theta\)(弧度),则
\[\theta=\frac{s}{r},\quad s=r\theta\]对应扇形面积(Sector Area)是:
\[A=\frac{1}{2}r^2\theta\]这正是弧度“自然”的原因:一旦用弧度记角,弧长与面积公式会变得非常干净。AI 里很多周期性表示都默认使用弧度输入,例如 \(\sin\theta\) / \(\cos\theta\) 的位置编码(Positional Encoding)、旋转位置编码(RoPE)以及频域特征(Fourier Features)。
相似(Similarity)指图形形状相同、大小可以不同;等价地说,对应角相等、对应边成比例。若把一个图形按比例 \(k\) 缩放,则长度变为原来的 \(k\) 倍,面积变为原来的 \(k^2\) 倍。
这个看似初等的事实,在 AI 图像处理中极其常见:图片 resize、本征尺度(Scale)、特征金字塔(Feature Pyramid)、多尺度检测(Multi-scale Detection)都在处理“同一对象在不同尺度下如何保持可识别性”的问题。若缩放时不保持纵横比(Aspect Ratio),就会引入几何畸变,进而影响分类、检测与分割结果。
基础几何里,面积(Area)衡量二维区域所占的大小。矩形面积是长乘宽,圆面积是
\[A=\pi r^2\]在 AI 的目标检测(Object Detection)与实例分割(Instance Segmentation)中,一个高频几何量是交并比(Intersection over Union, IoU):
\[\mathrm{IoU}=\frac{\text{Intersection Area}}{\text{Union Area}}\]它衡量预测框/预测区域与真实标注的重叠程度。这里用到的核心是最朴素的面积与重叠概念。
若把这些内容压缩成一句话,它们在 AI 中分别承担不同角色:
- 距离(Distance):支撑近邻搜索、聚类、向量检索与损失函数中的相似度刻画。
- 角度(Angle):支撑方向、夹角、余弦相似度(Cosine Similarity)与旋转直觉。
- 弧度(Radian):支撑三角函数、周期建模、位置编码与频域表示。
- 比例与缩放(Scale):支撑图像 resize、数据增强、特征金字塔与多尺度建模。
- 面积与重叠(Area & Overlap):支撑 IoU、检测框评估与分割质量度量。
解析几何(Analytic Geometry)的核心做法是:选定坐标系(Coordinate System),用代数方程描述几何对象。一个几何对象可以被理解为“满足某个方程(或方程组)的所有点”的集合。
高中阶段最常见的两类:
- 一次方程:直线(Line)/平面(Plane)/超平面(Hyperplane)。
- 二次方程:圆(Circle)与圆锥曲线(Conic Sections);在三维中推广为二次曲面(Quadric Surfaces)。
在直角坐标系(Cartesian Coordinate System)中,点 \(P\) 用坐标 \((x,y)\) 表示。两点 \(P_1(x_1,y_1)\) 与 \(P_2(x_2,y_2)\) 的欧氏距离(Euclidean Distance)是:
\[\mathrm{dist}(P_1,P_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\]圆(Circle)是到某个固定点距离恒定的点集;这个固定点叫圆心(Center)。若圆心为 \((h,k)\)、半径(Radius)为 \(r\),则圆的方程是:
\[(x-h)^2+(y-k)^2=r^2\]例:方程 \(x^2+y^2-4x+6y-12=0\) 通过配方(Completing the Square)可化为 \((x-2)^2+(y+3)^2=25\),因此它表示圆心 \((2,-3)\)、半径 \(5\) 的圆。
圆锥曲线(Conic Sections)最初来自“平面截圆锥”的几何构造,但在解析几何里,它们等价于二维的二次方程曲线(Second-degree Plane Curves,方程里变量的最高次数为 2):
\[Ax^2+Bxy+Cy^2+Dx+Ey+F=0\]其中 \(Bxy\) 是交叉项(Cross Term)。交叉项的存在通常意味着曲线的主轴(Principal Axes)与坐标轴不对齐;通过旋转坐标轴(Rotation of Axes)可以把交叉项消掉,从而得到更“标准”的形状表达。
而一次项 \(Dx+Ey\) 与常数项 \(F\) 扮演的是另一类角色:它们通常不改变主轴方向,而主要影响图形在平面中的位置与尺度。更具体地说,一次项往往意味着曲线的中心/顶点不在原点;在消去交叉项之后,再通过平移坐标(Translation of Axes)与配方(Completing the Square)可以把一次项吸收到平方项里。常数项则相当于改变“等号右边的阈值”,会影响曲线是否有实点、整体大小以及离原点的偏置。简言之:交叉项主要对应旋转,一次项主要对应平移,常数项主要对应整体偏移/尺度调整。
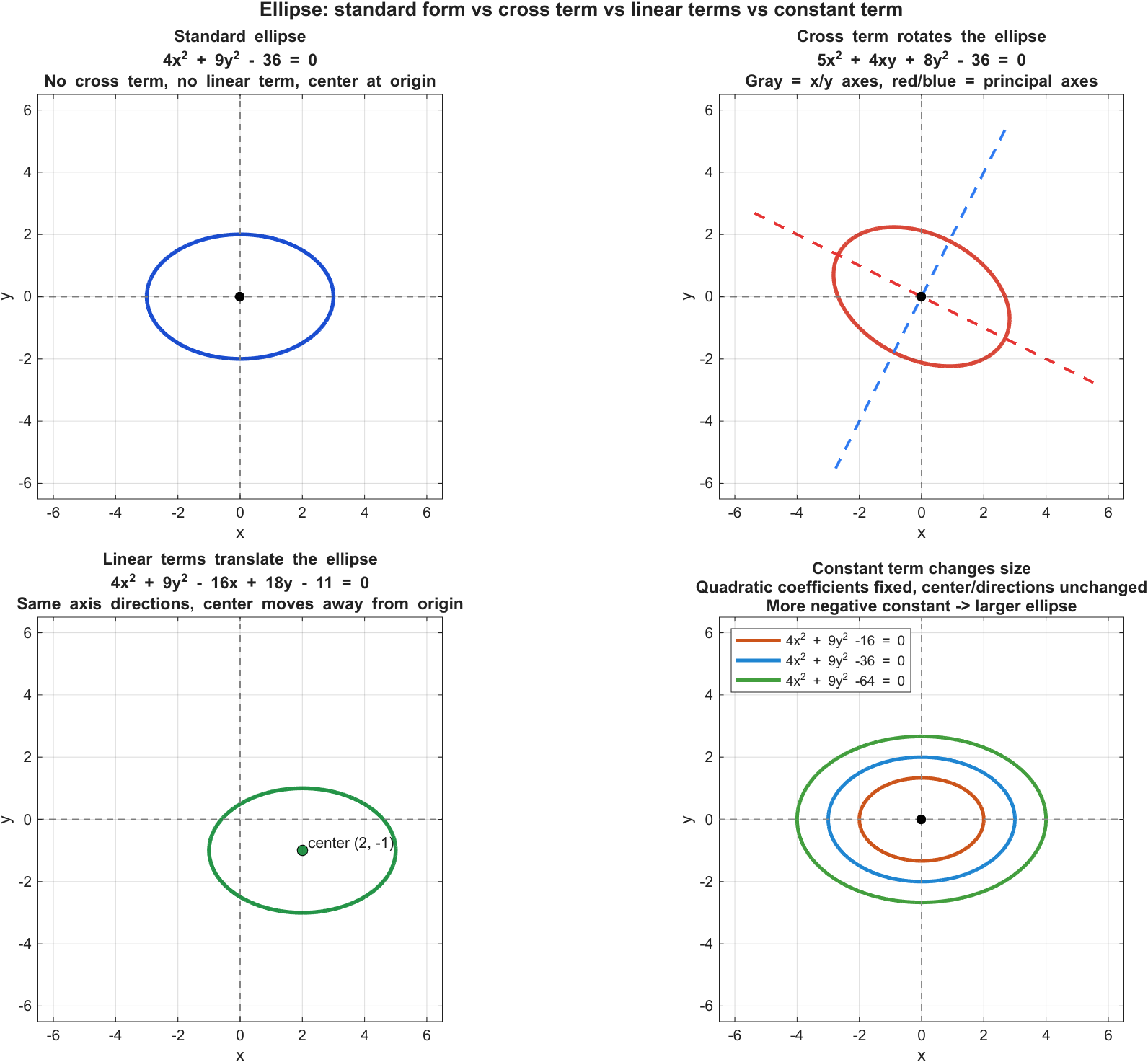
下面给出最常用的四类圆锥曲线的标准方程(Standard Form)与直观定义:
| 名称 | 标准方程 | 几何定义(直观) | 形状关键词 |
| 圆(Circle) | \(x^2+y^2=r^2\) | 到圆心距离恒为 \(r\) | 闭合;各向同性 |
| 椭圆(Ellipse) | \(\frac{x^2}{a^2}+\frac{y^2}{b^2}=1\ (a\ge b>0)\) | 到两个焦点(Focus)距离和为常数 | 闭合;主轴/次轴 |
| 抛物线(Parabola) | \(y^2=4px\ (p>0)\) | 到焦点(Focus)与准线(Directrix)距离相等 | 开口;无中心 |
| 双曲线(Hyperbola) | \(\frac{x^2}{a^2}-\frac{y^2}{b^2}=1\) | 到两个焦点(Focus)距离差的绝对值为常数 | 两支;有渐近线(Asymptotes) |
椭圆(Ellipse)可以用一句话定义:平面内到两个固定点 \(F_1,F_2\) 的距离之和为常数的点的集合。若该常数为 \(2a\),则对椭圆上任意点 \(P\) 有:
\[\mathrm{dist}(P,F_1)+\mathrm{dist}(P,F_2)=2a\]在以原点为中心、长轴沿 x 轴的标准位置下,椭圆方程是:
\[\frac{x^2}{a^2}+\frac{y^2}{b^2}=1,\quad a\ge b>0\]这里 \(a\) 与 \(b\) 分别是半长轴(Semi-major Axis)与半短轴(Semi-minor Axis)。焦距参数 \(c\) 定义为焦点到中心的距离,满足
\[c^2=a^2-b^2\]因此焦点坐标是 \((\pm c,0)\)。偏心率(Eccentricity)定义为 \(e=c/a\),它量化“椭圆有多扁”: \(e\in[0,1)\);当 \(a=b\) 时 \(e=0\),椭圆退化为圆。
例:若 \(a=5,b=3\),则 \(c=4\)、\(e=0.8\),椭圆为 \(\frac{x^2}{25}+\frac{y^2}{9}=1\),焦点为 \((\pm 4,0)\)。
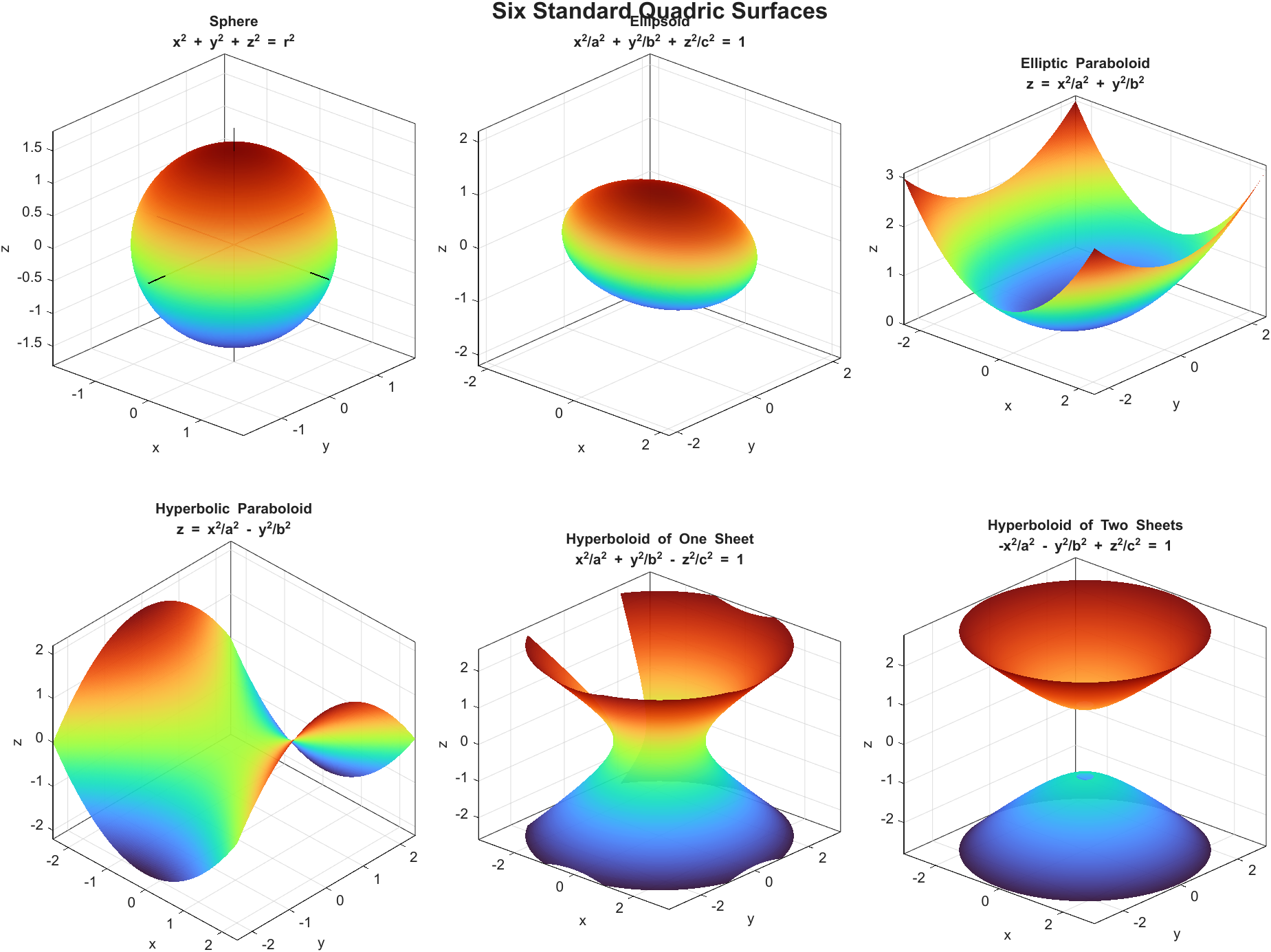
在三维中,圆锥曲线推广为二次曲面(Quadric Surfaces):满足三元二次方程的点集。最一般的形式是:
\[Ax^2+By^2+Cz^2+Dxy+Exz+Fyz+Gx+Hy+Iz+J=0\]其中 \(Dxy,Exz,Fyz\) 是交叉项(Cross Term),对应“坐标轴没有对齐到曲面的主轴方向”。通过平移(Translation)与旋转(Rotation)可以把它化为标准型(Standard Form):平移等价于把原点挪到合适的位置(通常是“中心”附近),旋转等价于把坐标轴转到主轴方向,从而一眼看出是“球/椭球/抛物面/双曲面”等哪一类。
| 名称 | 典型方程(标准型) | 直观描述 |
| 球(Sphere) | \(x^2+y^2+z^2=r^2\) | 到中心距离恒定的点集(3D 的圆) |
| 椭球(Ellipsoid) | \(\frac{x^2}{a^2}+\frac{y^2}{b^2}+\frac{z^2}{c^2}=1\) | 三个方向缩放不同的“球”;仍然闭合 |
| 椭圆抛物面(Elliptic Paraboloid) | \(z=\frac{x^2}{a^2}+\frac{y^2}{b^2}\) | “碗状”;水平截面是椭圆 |
| 双曲抛物面(Hyperbolic Paraboloid) | \(z=\frac{x^2}{a^2}-\frac{y^2}{b^2}\) | “马鞍形”;沿一个方向上凸、另一个方向下凹 |
| 单叶双曲面(Hyperboloid of One Sheet) | \(\frac{x^2}{a^2}+\frac{y^2}{b^2}-\frac{z^2}{c^2}=1\) | 连通的一张曲面;截面随方向变化 |
| 双叶双曲面(Hyperboloid of Two Sheets) | \(-\frac{x^2}{a^2}-\frac{y^2}{b^2}+\frac{z^2}{c^2}=1\) | 上下分离的两张曲面 |
二次曲面与优化中的“二次型/曲率”是同一套数学语言:把坐标轴旋到主轴方向后,表达式会变成各轴平方项的加权和/差,从而直接暴露“碗状(局部最小)”与“鞍形(Saddle)”的结构。
指数函数(Exponential Function)最常用的是自然指数 \(e^x\)。指数运算把“加法结构”映射为“乘法结构”,对数(Logarithm)作为反函数则把乘法结构拉平成加法结构。
| 性质/公式 | 表达式 | 备注 |
| 指数基本性质(Exponential Laws) | \(e^{a+b}=e^a e^b\) \(e^{a-b}=\frac{e^a}{e^b}\) |
\(a,b\in\mathbb{R}\) |
| 指数运算律(Exponent Rules) | \(a^0=1\) \(a^m a^n=a^{m+n}\) \(\frac{a^m}{a^n}=a^{m-n}\) \((a^m)^n=a^{mn}\) \((ab)^n=a^n b^n\) |
\(a>0,a\ne 1\);对整数指数最直接 |
| 自然常数(Euler's Number) | \(e=\lim_{n\to\infty}\left(1+\frac{1}{n}\right)^n\) | 极限刻画连续复利(Continuous Compounding) |
| 微积分性质 | \(\frac{d}{dx}e^x=e^x\) \(\frac{d}{dx}\ln x=\frac{1}{x}\) |
以 \(e\) 为底时形式最简 |
| 连续增长微分方程 | \(y'(t)=y(t),\ y(0)=1\Rightarrow y(t)=e^t\) | “增长率与当前值成正比” |
| 与对数互逆 | \(\ln(e^x)=x\) \(e^{\ln x}=x\) |
第二式要求 \(x>0\) |
常用取值:
| 输入 | \(e^x\) | 备注 |
| \(x=0\) | \(e^0=1\) | 基准点 |
| \(x=1\) | \(e^1=e\approx 2.71828\) | 自然对数底 |
| \(x=-1\) | \(e^{-1}=\frac{1}{e}\approx 0.36788\) | 常见衰减尺度 |
| \(x=\ln 2\) | \(e^{\ln 2}=2\) | 对数域与线性域互换时常用 |
| \(x=\ln 10\) | \(e^{\ln 10}=10\) | 与 \(\log_{10}\) 换底相关 |
对数函数(Logarithm)\(\log x\) 在 \(x>0\) 上严格单调递增(Strictly Increasing),因此 \(-\log x\) 在 \(x>0\) 上严格单调递减(Strictly Decreasing)。
复合后的单调性由内层决定:若 \(f(x)\) 在某区间上单调递增且 \(f(x)>0\),则 \(-\log(f(x))\) 在该区间上单调递减;若 \(f(x)\) 不单调,则外层单调并不能推出整体单调。
在损失函数里常见的形式是 \(-\log\sigma(z)\)(\(\sigma\) 为 sigmoid)。因为 sigmoid 单调递增,所以该损失对 \(z\) 单调递减:增大 \(z\) 会降低损失。这只说明“对中间量 z 的单调性”;对模型参数 \(\theta\) 的单调性一般不成立,因为 \(z=z(\theta)\) 是高维非线性函数。
| 性质/公式 | 表达式 | 备注 |
| 对数运算律(Logarithm Rules) | \(\log(ab)=\log a+\log b\) \(\log\!\left(\frac{a}{b}\right)=\log a-\log b\) \(\log(a^k)=k\log a\) |
同一底数;典型要求 \(a>0,b>0\) |
| 换底公式(Change of Base) | \(\log_a x=\frac{\ln x}{\ln a}\) | \(a>0,a\ne 1,x>0\) |
| 与指数互逆 | \(a^{\log_a x}=x\) \(\log_a(a^x)=x\) |
\(x>0\) |
常用取值:
| 表达式 | 值 | 备注 |
| \(\ln 1\) | \(0\) | \(x=1\) 为基准点 |
| \(\ln e\) | \(1\) | 自然对数的定义性质 |
| \(\ln 2\) | \(\approx 0.6931\) | 二进制相关常数 |
| \(\ln 10\) | \(\approx 2.3026\) | 十进制相关常数 |
| \(\log_{10}2\) | \(=\frac{\ln 2}{\ln 10}\approx 0.3010\) | 工程里常用于数量级估算 |
| \(\log_2 10\) | \(=\frac{\ln 10}{\ln 2}\approx 3.3219\) | bit 与十进制数量级换算 |
| \(\log_2 e\) | \(=\frac{1}{\ln 2}\approx 1.4427\) | nats 与 bits 换算常数 |
| \(\log_{10}e\) | \(=\frac{1}{\ln 10}\approx 0.4343\) | 自然对数与常用对数换算 |
在语言模型 softmax 中,logit 经过指数再归一化:\(\exp(\text{logit})\) 把分数映射为正数权重;取 log 则把乘法结构拉平成加法结构,便于用和式写出似然与损失。
幂函数(Power Function)里常见的两个扩展是负指数(Negative Exponent)与分数指数(Rational Exponent)。
| 类型 | 公式 | 条件/备注 |
| 负指数(Negative Exponent) | \(a^{-n}=\frac{1}{a^n}\) | \(a\ne 0\);\(n\) 为正整数 |
| 分数指数(Rational Exponent) | \(a^{p/q}=\sqrt[q]{a^p}\) | \(q>0,\gcd(p,q)=1\);实数域通常要求 \(a>0\) |
| 例 | \(2^{-3}=\frac{1}{8}\) \(9^{1/2}=3\) \(8^{2/3}=4\) |
偶次根要求被开方数非负 |
常用取值:
| 表达式 | 值 | 备注 |
| \(2^{-3}\) | \(=\frac{1}{8}=0.125\) | 负指数转倒数 |
| \(10^{-3}\) | \(=0.001\) | 毫(\(10^{-3}\))尺度 |
| \(2^{1/2}=\sqrt{2}\) | \(\approx 1.4142\) | 最常见的无理数根 |
| \(2^{-1/2}=\frac{1}{\sqrt{2}}\) | \(\approx 0.7071\) | 正交归一化、幅度缩放常用 |
| \(10^{1/2}=\sqrt{10}\) | \(\approx 3.1623\) | 对数刻度下的“半个数量级” |
| \(10^{-1/2}=\frac{1}{\sqrt{10}}\) | \(\approx 0.3162\) | 与上式互为倒数 |
三角函数(Trigonometric Functions)可以用单位圆(Unit Circle)定义:在圆上角度为 \(\theta\) 的点坐标是 \((\cos\theta,\sin\theta)\)。由此得到最基本恒等式:
| 类别 | 公式 | 备注 |
| 基本恒等式 | \(\sin^2\theta+\cos^2\theta=1\) \(\tan\theta=\frac{\sin\theta}{\cos\theta}\) |
\(\cos\theta\ne 0\) 时定义 \(\tan\theta\) |
| 与 \(\tan,\cot\) 相关 | \(1+\tan^2\theta=\sec^2\theta\) \(1+\cot^2\theta=\csc^2\theta\) |
定义域同 \(\tan,\cot\) |
| 和差公式(Angle Addition) | \(\sin(\alpha\pm\beta)=\sin\alpha\cos\beta\pm\cos\alpha\sin\beta\) \(\cos(\alpha\pm\beta)=\cos\alpha\cos\beta\mp\sin\alpha\sin\beta\) |
傅里叶分析、RoPE 等直觉常用 |
| 二倍角(Double-Angle) | \(\sin 2\theta=2\sin\theta\cos\theta\) \(\cos 2\theta=\cos^2\theta-\sin^2\theta=1-2\sin^2\theta=2\cos^2\theta-1\) |
同一恒等式的不同等价写法 |
| 周期性(Periodicity) | \(\sin(\theta+2\pi)=\sin\theta\) \(\cos(\theta+2\pi)=\cos\theta\) |
一个周期(Period)为 \(2\pi\) |
| 常用极限(\(x\to 0\)) | \(\lim_{x\to 0}\frac{\sin x}{x}=1\) \(\lim_{x\to 0}\frac{\tan x}{x}=1\) \(\lim_{x\to 0}\frac{1-\cos x}{x^2}=\frac{1}{2}\) |
推导导数与近似时高频出现 |
| \(\theta\)(弧度) | 角度制 | \(\sin\theta\) | \(\cos\theta\) | \(\tan\theta\) |
| \(0\) | 0° | \(0\) | \(1\) | \(0\) |
| \(\pi/6\) | 30° | \(\frac{1}{2}\) | \(\frac{\sqrt{3}}{2}\) | \(\frac{1}{\sqrt{3}}\) |
| \(\pi/4\) | 45° | \(\frac{\sqrt{2}}{2}\) | \(\frac{\sqrt{2}}{2}\) | \(1\) |
| \(\pi/3\) | 60° | \(\frac{\sqrt{3}}{2}\) | \(\frac{1}{2}\) | \(\sqrt{3}\) |
| \(\pi/2\) | 90° | \(1\) | \(0\) | 未定义(undefined) |
| \(\pi\) | 180° | \(0\) | \(-1\) | \(0\) |
| \(3\pi/2\) | 270° | \(-1\) | \(0\) | 未定义(undefined) |
| \(2\pi\) | 360° | \(0\) | \(1\) | \(0\) |
欧拉公式(Euler's Formula)把指数与三角函数在复数域(Complex Domain)里统一起来:
| 结论 | 公式 | 备注 |
| 欧拉公式(Euler's Formula) | \(e^{i\theta}=\cos\theta+i\sin\theta\) | 把“旋转”写成复指数 |
| 辐角相加对应指数相乘 | \(e^{i\theta_1}e^{i\theta_2}=e^{i(\theta_1+\theta_2)}\) | 复数乘法:模相乘、辐角相加 |
| 欧拉恒等式(Euler's Identity) | \(e^{i\pi}+1=0\) | 连接 \(e,i,\pi,1,0\) |
复数(Complex Number)是对实数系(Real Number System)的扩展,写作 \(a+bi\),其中 \(a,b\in\mathbb{R}\),虚数单位(Imaginary Unit)满足 \(i^2=-1\)。几何上,复数可以表示为复平面(Complex Plane)上的点 \((a,b)\);但更重要的是,它在二维平面上提供了一套封闭、可逆且与乘法兼容的代数结构。
因此,复数不能简单等同于 \(\mathbb{R}^2\) 里的二维向量。表面上看,二维向量 \((a,b)\) 与复数 \(a+bi\) 确实对应同一个平面点;但它们的代数结构完全不同,关键差别在于“乘法”是否自然、闭合且可逆。
对二维向量而言,加法非常自然,但乘法并不形成一个像实数那样稳定的数系:点乘(Inner Product)会把两个向量变成标量,叉乘(Cross Product)又会把结果带到垂直方向;因此二维向量空间本身并没有一个同时兼顾封闭性(Closure)与可除性的内建乘法。复数则不同:两个复数相乘后仍是复数,非零复数还总能做除法。这使得复平面不仅“几何上的二维平面”,还一个可自由做加减乘除的完整数系。
这带来两个二维向量本身不具备的优势。第一,复数把二维旋转直接写进了乘法:若 \(z=re^{i\theta}\),则乘以另一个复数时会自动实现“模相乘、角相加”。复数乘法天然就是缩放 + 旋转;而若只用二维向量,通常还需要额外引入旋转矩阵。第二,复数让多项式方程的可解性闭合:例如 \(x^2+1=0\) 在实数域无解,但在复数域有解 \(\pm i\)。更深一层地,代数基本定理(Fundamental Theorem of Algebra)说明任意非常数多项式在复数域里都有根,因此复数成为代数方程的自然终点。
因此,二维向量更像是在描述“箭头、位移、速度、受力”的线性对象;复数则是在同一个平面上额外安装了一套兼容乘法、旋转与方程求解的代数机制。对于信号处理(Signal Processing)、交流电分析、傅里叶变换(Fourier Transform)、量子力学以及很多 AI 中的频域方法,复数都核心是一个更强的二维代数系统。
复数(Complex Number)写作 \(z=a+bi\),其中 \(a,b\in\mathbb{R}\),虚数单位(Imaginary Unit)满足 \(i^2=-1\)。把 \(z\) 视为二维平面上的点 \((a,b)\),就得到直角坐标(Rectangular Form)。
同一个点也可用极坐标(Polar Form)表示:令 \(r=|z|\) 为模(Modulus),\(\theta=\arg(z)\) 为辐角(Argument),则
\[z=r(\cos\theta+i\sin\theta)=re^{i\theta}\]两种坐标之间的转换:
\[r=\sqrt{a^2+b^2},\quad a=r\cos\theta,\quad b=r\sin\theta\]\(\theta\) 通常用 \(\mathrm{atan2}(b,a)\) 计算,并且 \(\arg(z)\) 并非唯一的:加上任意 \(2\pi k\)(\(k\in\mathbb{Z}\))表示同一个方向。
例:\(z=1+i\) 的模是 \(\sqrt{2}\),辐角是 \(\pi/4\),因此 \(z=\sqrt{2}\,e^{i\pi/4}\)。
棣莫弗公式(De Moivre's Formula)给出幂运算的快捷形式:
\[(\cos\theta+i\sin\theta)^n=\cos(n\theta)+i\sin(n\theta)\]复数 \(z = a + bi\) 的模(Modulus)定义为 \(|z|=\sqrt{a^2+b^2}\),表示复平面(Complex Plane)中点 \((a,b)\) 到原点的欧氏距离(Euclidean Distance)。
共轭(Conjugate)记作 \(\bar z = a-bi\)。几何上,它把点 \((a,b)\) 关于实轴(Real Axis)镜像到 \((a,-b)\);数值上,它把“相位(Phase)”取反而保持“幅值(Magnitude)”不变。
共轭与模的核心关系是 \(z\bar z = |z|^2\),展开即可验证:
\[(a+bi)(a-bi)=a^2+b^2=|z|^2\]这个恒等式的一个直接用途是复数除法:为了避免分母含有虚部,把分母乘以共轭进行“有理化(Rationalization)”。
\[\frac{a+bi}{c+di}=\frac{(a+bi)(c-di)}{(c+di)(c-di)}=\frac{(a+bi)(c-di)}{c^2+d^2}\]例: \(\frac{1+2i}{3-4i}=\frac{(1+2i)(3+4i)}{3^2+4^2}=\frac{-5+10i}{25}=-\frac{1}{5}+\frac{2}{5}i\)。这里分母变成实数,是因为 \((3-4i)(3+4i)=3^2+4^2\)。
把复数写成极坐标(Polar Form):\(z=r(\cos\theta+i\sin\theta)=re^{i\theta}\)。此时复数乘法的几何意义非常直接:
\[z_1 z_2 = (r_1 e^{i\theta_1})(r_2 e^{i\theta_2}) = (r_1 r_2)e^{i(\theta_1+\theta_2)}\]模相乘、辐角相加。乘法同时完成缩放(Scaling)与旋转(Rotation)。
例:乘以 \(i=e^{i\pi/2}\) 会把任意复数逆时针旋转 90° 且不改变模;乘以 \(-1=e^{i\pi}\) 会旋转 180°。例如 \((1+2i)\cdot i=-2+i\),几何上就是把点 \((1,2)\) 旋到 \((-2,1)\)。
求和符号(Summation Symbol)\(\sum\) 与乘积符号(Product Symbol)\(\prod\) 是数列与级数推导里最常见的两个“聚合”记号:
\[\sum_{i=1}^{n} a_i=a_1+a_2+\cdots+a_n,\quad \prod_{i=1}^{n} a_i=a_1\cdot a_2\cdots a_n\]英文里通常把 \(\sum\) 读作 “sigma” 或 “summation”,把 \(\prod\) 读作 “capital pi” 或 “product”。
数列(Sequence)是一列按整数下标排列的数 \(\{a_n\}_{n\ge 1}\)。最常见的两类是等差数列(Arithmetic Sequence)与等比数列(Geometric Sequence)。它们都可用“递推定义 + 通项公式 + 前 n 项和”三件套描述。
| 类型 | 递推定义 | 通项(\(a_n\)) | 前 n 项和(\(S_n=\sum_{k=1}^{n} a_k\)) |
| 等差数列(Arithmetic) | \(a_{n}=a_{n-1}+d\) | \(a_n=a_1+(n-1)d\) | \(S_n=\frac{n}{2}(a_1+a_n)=\frac{n}{2}\left(2a_1+(n-1)d\right)\) |
| 等比数列(Geometric) | \(a_{n}=ra_{n-1}\) | \(a_n=a_1 r^{n-1}\) | \(S_n=\begin{cases}\frac{a_1(1-r^n)}{1-r},& r\ne 1 \\ na_1,& r=1\end{cases}\) |
例:若 \(a_1=1,d=2\),则 \(a_n=2n-1\) 且 \(S_n=n^2\)。若 \(a_1=1,r=\frac{1}{2}\),则 \(S_n=2\left(1-2^{-n}\right)\),并随 \(n\) 增大趋近于 2。
无穷级数(Infinite Series)\(\sum_{n=1}^{\infty} a_n\) 的核心对象是部分和(Partial Sum)序列 \(S_N=\sum_{n=1}^{N} a_n\)。若极限 \(\lim_{N\to\infty} S_N\) 存在且为有限值,则级数收敛(Convergence);否则发散(Divergence)。
必要条件:若 \(\sum_{n=1}^{\infty} a_n\) 收敛,则必有 \(\lim_{n\to\infty} a_n=0\)。反之不成立(例如调和级数 \(\sum 1/n\) 发散)。
绝对收敛(Absolute Convergence)指 \(\sum |a_n|\) 收敛;绝对收敛必推出原级数收敛。仅 \(\sum a_n\) 收敛但 \(\sum |a_n|\) 发散则为条件收敛(Conditional Convergence),此时项的重排可能改变和(甚至导致发散)。
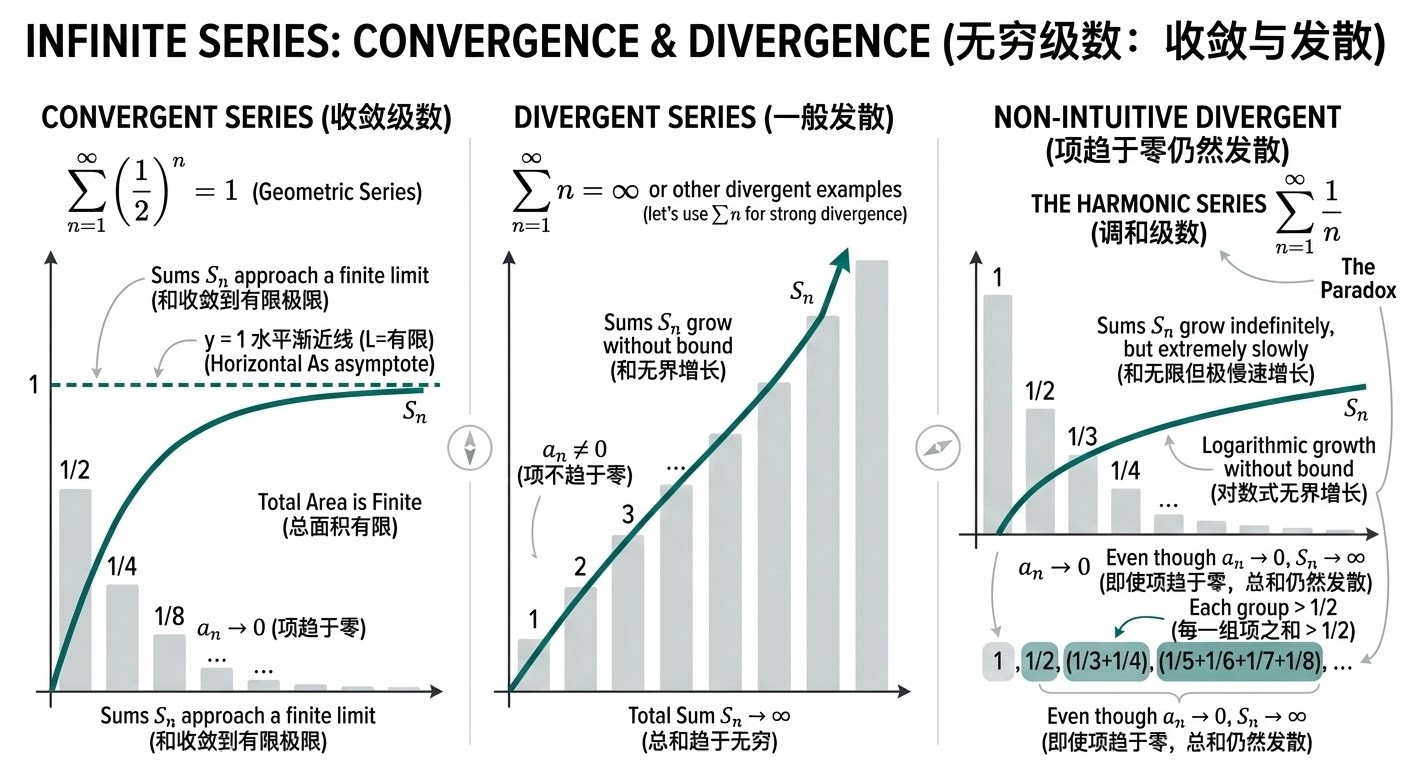
| 判别法 | 条件/计算量 | 结论 |
| 几何级数(Geometric Series) | \(\sum_{n=0}^{\infty} ar^n\) | \(|r|<1\) 时收敛,且和为 \(\frac{a}{1-r}\);\(|r|\ge 1\) 时发散 |
| p-级数(p-series) | \(\sum_{n=1}^{\infty}\frac{1}{n^p}\) | \(p>1\) 收敛;\(p\le 1\) 发散(调和级数为 \(p=1\)) |
| 比较判别(Comparison) | \(0\le a_n\le b_n\)(充分大时) | 若 \(\sum b_n\) 收敛,则 \(\sum a_n\) 收敛;若 \(\sum a_n\) 发散,则 \(\sum b_n\) 发散 |
| 比值判别(Ratio Test) | \(L=\limsup_{n\to\infty}\left|\frac{a_{n+1}}{a_n}\right|\) | \(L<1\) 绝对收敛;\(L>1\)(或无穷大)发散;\(L=1\) 不定 |
| 根值判别(Root Test) | \(\rho=\limsup_{n\to\infty}\sqrt[n]{|a_n|}\) | \(\rho<1\) 绝对收敛;\(\rho>1\) 发散;\(\rho=1\) 不定 |
| 交错级数(Alternating Series) | \(\sum (-1)^{n-1}b_n\),其中 \(b_n\downarrow 0\) | 收敛;截断误差满足 \(|S-S_N|\le b_{N+1}\) |
调和级数(Harmonic Series)是 \(\sum_{n=1}^{\infty}\frac{1}{n}\)。它是最经典的“项趋于 0 但级数仍发散”的例子:虽然 \(\lim_{n\to\infty}\frac{1}{n}=0\),但部分和会无界增长。
其部分和称为调和数(Harmonic Number):
\[H_n=\sum_{k=1}^{n}\frac{1}{k}\]调和数的渐近行为与对数紧密相关:\(H_n=\log n+\gamma+o(1)\),其中 \(\gamma\) 是欧拉-马歇罗尼常数(Euler–Mascheroni constant)。因此很多“累积量随步数缓慢增长”的分析最终都会出现 \(\log n\)。
在 AI/优化里,调和级数最常见的用途是解释与验证学习率(Learning Rate)衰减的收敛条件。经典随机逼近(Stochastic Approximation)的一个常用充分条件是:
\[\sum_{t=1}^{\infty}\eta_t=\infty,\quad \sum_{t=1}^{\infty}\eta_t^2<\infty\]取 \(\eta_t=\frac{1}{t}\) 时,第一项对应调和级数发散(保证“走得足够远”),第二项对应 \(\sum 1/t^2\) 收敛(保证噪声的累计影响有限)。很多 SGD(Stochastic Gradient Descent)及在线学习(Online Learning)的理论推导,会用这组“一个发散、一个收敛”的对比来控制偏差与方差项。
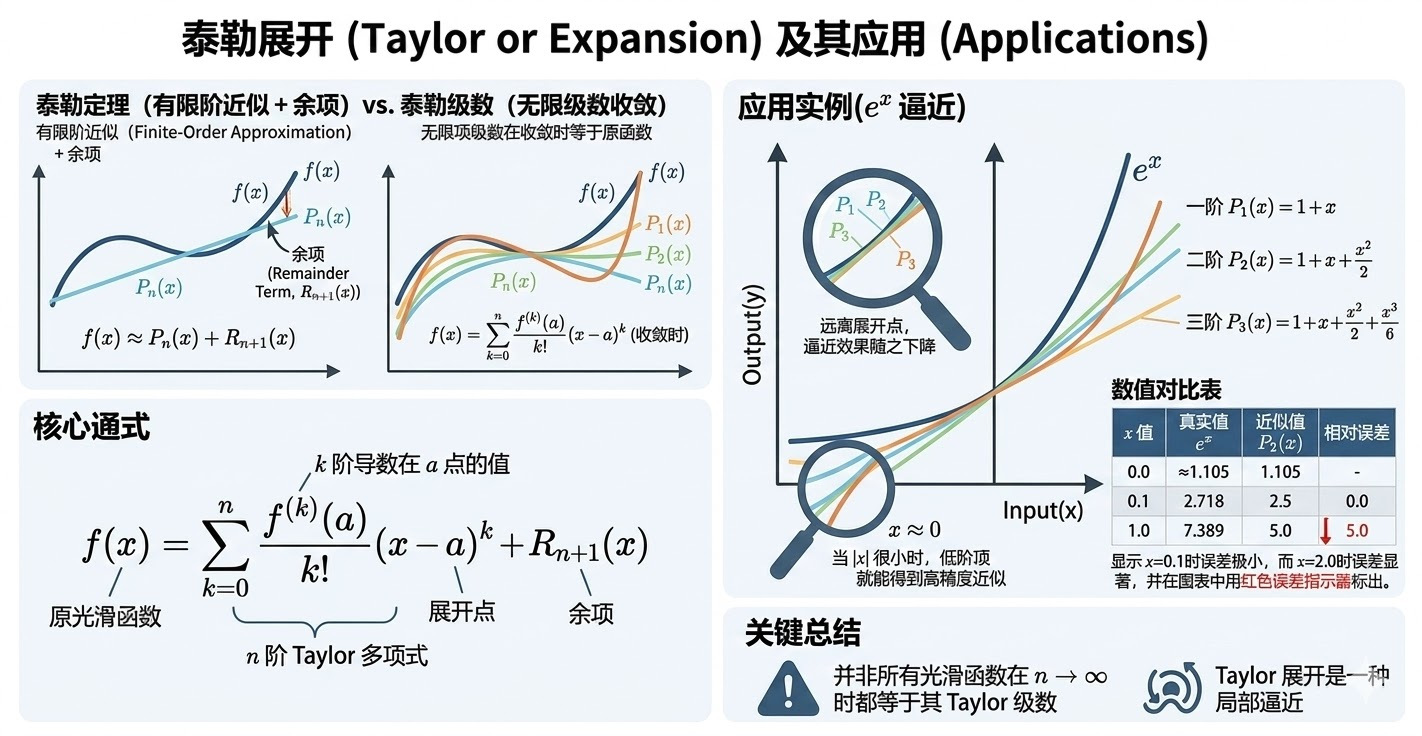
Taylor 展开(Taylor Expansion)用多项式在局部逼近光滑函数。Taylor 定理(Taylor's Theorem)强调“有限阶近似 + 余项(Remainder)”,Taylor 级数(Taylor Series)强调“无限项级数在收敛时等于原函数”。
\[f(x)=\sum_{k=0}^{n}\frac{f^{(k)}(a)}{k!}(x-a)^k+R_{n+1}(x)\]当余项在 \(n\to\infty\) 时收敛到 0,才有 \(f(x)=\sum_{k=0}^{\infty}\frac{f^{(k)}(a)}{k!}(x-a)^k\)。并非所有光滑函数都等于其 Taylor 级数。
例:在 \(a=0\) 展开,\(e^x\approx 1+x+\frac{x^2}{2}\);当 \(|x|\) 很小时,用低阶项就能得到高精度近似。
组合数学(Combinatorics)研究离散结构的计数、构造与存在性。它的典型问题是“有多少种可能”:当选择空间巨大时,计数结果直接决定搜索/采样的复杂度;当把计数结果归一化为概率时,就得到二项分布、超几何分布等常见模型。
排列(Permutation)与组合(Combination)的区别只在一个点:是否区分顺序。把“先选哪些元素”与“再怎么排序”分开理解,可以避免大量记忆负担。
| 对象 | 记号 | 公式 | 直觉 |
| 阶乘(Factorial) | \(n!\) | \(n!=n(n-1)\cdots 2\cdot 1,\ 0!=1\) | 把 \(n\) 个互异元素全部排列的方式数 |
| 排列(k-permutation) | \(P(n,k)\) | \(P(n,k)=\frac{n!}{(n-k)!}\) | 从 \(n\) 个里选 \(k\) 个并排序:一步一步填位置 |
| 组合(k-combination) | \({n \choose k}\) | \({n \choose k}=\frac{n!}{k!(n-k)!}\) | 从 \(n\) 个里选 \(k\) 个,不关心顺序:先选集合 |
| 排列与组合关系 | \(P(n,k)\) | \(P(n,k)={n \choose k}\,k!\) | 先选 \(k\) 个元素,再把它们排序 |
例:从 5 个候选特征里挑 3 个做一个无序子集,有 \({5 \choose 3}=10\) 种;如果还要给这 3 个特征排“处理顺序”,则变为排列 \(P(5,3)=5\cdot4\cdot3=60\) 种。
二项式定理(Binomial Theorem)描述 \((a+b)^n\) 的展开结构:
\[(a+b)^n=\sum_{k=0}^{n}{n \choose k}a^{n-k}b^k\]系数 \({n \choose k}\) 的组合解释非常直接:把 \((a+b)^n\) 看作 \(n\) 个括号相乘,每一项由“从每个括号里选 \(a\) 或 \(b\)”组成。若最终选了 \(k\) 次 \(b\),就需要从 \(n\) 个位置里挑出这 \(k\) 个位置,因此系数是 \({n \choose k}\)。
例:\((x+2)^4={4 \choose 0}x^4+{4 \choose 1}x^3\cdot2+{4 \choose 2}x^2\cdot2^2+{4 \choose 3}x\cdot2^3+{4 \choose 4}2^4=x^4+8x^3+24x^2+32x+16\)。
二项式系数还满足递推(Pascal's Rule):\({n \choose k}={n-1 \choose k-1}+{n-1 \choose k}\)。这等价于“选与不选某个固定元素”的分类讨论。
与概率的连接:若独立伯努利试验(Bernoulli Trial)成功概率为 \(p\),做 \(n\) 次恰好成功 \(k\) 次的概率是 \({n \choose k}p^k(1-p)^{n-k}\),其中 \({n \choose k}\) 计数的是“成功出现在哪些轮次”。
不等式(Inequality)是把“难算/难优化/难比较”的表达式替换为“可控的上界或下界”的工具。机器学习中的许多目标函数与泛化分析,本质上都在用不等式把复杂量压到可操作的形式(例如把非线性函数用线性或二次上界近似)。
基本不等式(Basic Inequalities)常见来源有两类:一类来自非负量(例如 \((\cdot)^2\ge 0\)),另一类来自范数(Norm)与凸性(Convexity)的结构性质。
| 不等式 | 形式 | 典型用途 |
| 平方非负 | \((a-b)^2\ge 0\Rightarrow a^2+b^2\ge 2ab\) | 把乘积项 \(ab\) 转成平方项,便于求界或优化(常见于“配方”) |
| 三角不等式(Triangle Inequality) | \(|x+y|\le |x|+|y|\) | 把“相加后的绝对值”上界成“绝对值之和”;用于误差传播与残差界 |
| 均值不等式(AM-GM) | \(\frac{a+b}{2}\ge \sqrt{ab}\quad (a,b\ge 0)\) | 在“和固定时乘积最大”或“乘积/几何平均”相关问题里给出最紧的经典界 |
例(AM-GM 的“最大乘积”直觉):在 \(a,b\ge 0\) 且 \(a+b=10\) 的约束下,乘积满足 \(ab\le \left(\frac{a+b}{2}\right)^2=25\),并且当且仅当 \(a=b=5\) 取等号。
Jensen 不等式(Jensen's Inequality)回答一个很具体的问题:“平均”与“非线性”交换顺序会发生什么。它是把抽象的凸性(Convexity)变成可用结论的最常用工具之一。
先把术语说清楚:
- 加权平均(Weighted Average):给一组数 \(x_1,\dots,x_n\) 分配权重 \(\lambda_i\ge 0\) 且 \(\sum_i\lambda_i=1\),则加权平均是 \(\sum_i\lambda_i x_i\)(把 \(\lambda_i\) 视为“占比”即可)。
- 凸函数(Convex Function):函数 \(\varphi\) 若满足对任意 \(x_1,x_2\) 与 \(\lambda\in[0,1]\) 都有 \(\varphi(\lambda x_1+(1-\lambda)x_2)\le \lambda\varphi(x_1)+(1-\lambda)\varphi(x_2)\),则称 \(\varphi\) 是凸的。直观上:它“向上弯”,因此对它做平均会被“惩罚”。
- 随机变量(Random Variable):一个在不同试验/样本上会取不同值的量;把 \(X\) 视为“每次取到的数”。
- 期望(Expectation)\(\mathbb{E}[\cdot]\):可把它理解为“按概率加权的平均”。
Jensen 的形式(离散加权平均):若 \(\varphi\) 凸,则
\[\varphi\!\left(\sum_i \lambda_i x_i\right)\le \sum_i \lambda_i \varphi(x_i)\]等价的期望形式:对随机变量 \(X\)(且 \(\mathbb{E}[X]\) 与 \(\mathbb{E}[\varphi(X)]\) 存在),有
\[\varphi(\mathbb{E}[X])\le \mathbb{E}[\varphi(X)]\]如果 \(\varphi\) 是凹函数(Concave Function),不等号方向会反过来。
场景 1:凸惩罚下,“波动”本身有代价。设某个系统的代价函数是 \(\varphi(t)=t^2\)(二次惩罚,Convex Penalty),比较两种延迟(Latency):
- 稳定方案:每次都是 100ms,则平均代价是 \(100^2=10000\)。
- 波动方案:一半时间 50ms、一半时间 150ms(平均同样是 100ms),则平均代价是 \(\frac{50^2+150^2}{2}=12500\)。
两者平均延迟一样,但二次代价更偏好稳定方案;这就是 Jensen 在 \(\varphi(t)=t^2\) 下的直接体现:\(\left(\frac{50+150}{2}\right)^2\le \frac{50^2+150^2}{2}\)。
场景 2:对数损失下,“偶尔很错”会被放大。分类里常用对数损失(Log Loss)\(\varphi(p)=-\log p\)(\(p\) 是正确类别的预测概率),它在 \((0,1]\) 上是凸函数。假设一个模型在同一个样本上两次输出 \(p=0.9\) 与 \(p=0.1\)(一次很自信、一次几乎反过来),则
\[-\log\!\left(\frac{0.9+0.1}{2}\right)=-\log 0.5\approx 0.693\le \frac{-\log 0.9-\log 0.1}{2}\approx 1.204\]含义:在凸损失下,预测的波动会提高平均损失;这也是许多“用不等式构造上界/下界”方法(例如把难优化的期望目标变成可算的界)背后的数学原因。
何时取等号:当所有 \(x_i\) 相等(没有波动),或 \(\varphi\) 在相关区间上近似线性时,不等式可取等号。
Cauchy-Schwarz 不等式(Cauchy–Schwarz Inequality)回答另一个非常基础的问题:两组数“对齐相乘再求和”的结果,最多能有多大。它是内积(Inner Product)与范数(Norm)体系的核心约束。
把术语说清楚后,这个不等式就不神秘:
- 向量(Vector):把一组数按顺序排成列表,例如 \(\mathbf{a}=(a_1,\dots,a_n)\)。
- 点积/内积(Dot Product / Inner Product):\(\mathbf{a}^\top\mathbf{b}=\sum_i a_i b_i\),可理解为“两组数在同一位置上的重叠程度”。
- L2 范数(\(\ell_2\) Norm):\(\|\mathbf{a}\|_2=\sqrt{\sum_i a_i^2}\),几何上是向量长度(Length)。
不等式本身是:
\[|\mathbf{a}^\top\mathbf{b}|\le \|\mathbf{a}\|_2\,\|\mathbf{b}\|_2\]几何解释:把 \(\mathbf{a}^\top\mathbf{b}\) 写成 \(\|\mathbf{a}\|_2\|\mathbf{b}\|_2\cos\theta\),Cauchy-Schwarz 等价于 \(|\cos\theta|\le 1\)。当且仅当两向量同向或反向(线性相关(Linearly Dependent))时取等号。
场景 1:为什么检索里常用“余弦相似度(Cosine Similarity)”。在向量检索中,常用点积 \(\mathbf{q}^\top\mathbf{d}\) 衡量查询向量 \(\mathbf{q}\) 与文档向量 \(\mathbf{d}\) 的相似度。但点积同时受“方向”和“长度”影响:如果某个向量范数很大,即使方向一般,点积也可能很大。
一个最小例子:令查询 \(\mathbf{q}=(1,1)\),两篇候选文档向量为 \(\mathbf{d}_1=(100,0)\)、\(\mathbf{d}_2=(2,2)\)。点积分别是 \(\mathbf{q}^\top\mathbf{d}_1=100\)、\(\mathbf{q}^\top\mathbf{d}_2=4\),点积会更偏向 \(\mathbf{d}_1\)。但如果把向量归一化到单位范数(Unit Norm)再比较,则
\[\cos(\mathbf{q},\mathbf{d}_1)=\frac{\mathbf{q}^\top\mathbf{d}_1}{\|\mathbf{q}\|_2\|\mathbf{d}_1\|_2}=\frac{1}{\sqrt{2}},\quad \cos(\mathbf{q},\mathbf{d}_2)=\frac{\mathbf{q}^\top\mathbf{d}_2}{\|\mathbf{q}\|_2\|\mathbf{d}_2\|_2}=1\]归一化后 \(\mathbf{d}_2\) 与 \(\mathbf{q}\) 方向完全一致,更符合“语义对齐”的直觉。Cauchy-Schwarz 保证余弦相似度一定落在 [-1,1],从而成为一个尺度稳定、可解释的相似度。
场景 2:为什么相关系数(Correlation Coefficient)不可能超过 1。把两组已中心化(Centered,均值为 0)的数据序列看成向量 \(\mathbf{x},\mathbf{y}\),它们的“协方差方向”可以写成点积 \(\mathbf{x}^\top\mathbf{y}\),而各自的尺度由 \(\|\mathbf{x}\|_2,\|\mathbf{y}\|_2\) 给出。Cauchy-Schwarz 直接推出
\[\left|\frac{\mathbf{x}^\top\mathbf{y}}{\|\mathbf{x}\|_2\|\mathbf{y}\|_2}\right|\le 1\]这就是“线性相关强度最多 100%”的数学原因;取等号对应完全线性关系,即 \(\mathbf{y}=c\mathbf{x}\)。
集合论(Set Theory)是现代数学语言的底座:几乎所有“对象 + 结构”的定义都能归结为集合及其上的运算。工程语境里,把对象抽象为集合的好处是:边界清晰、可组合、可用代数规则推导。
集合(Set)是元素(Element)的无序聚合。记 \(x\in A\) 表示 \(x\) 属于集合 \(A\),记 \(A\subseteq B\) 表示子集(Subset)。常用的运算如下。
| 运算 | 记号 | 定义 | 例子 |
| 并(Union) | \(A\cup B\) | \(\{x\mid x\in A\ \text{或}\ x\in B\}\) | \(\{1,2,3\}\cup\{3,4\}=\{1,2,3,4\}\) |
| 交(Intersection) | \(A\cap B\) | \(\{x\mid x\in A\ \text{且}\ x\in B\}\) | \(\{1,2,3\}\cap\{3,4\}=\{3\}\) |
| 差(Difference) | \(A\setminus B\) | \(\{x\mid x\in A,\ x\notin B\}\) | \(\{1,2,3\}\setminus\{3,4\}=\{1,2\}\) |
| 补(Complement) | \(A^c\) | 相对于全集 \(U\): \(A^c=U\setminus A\) | 若 \(U=\{1,2,3,4\}\),则 \(\{1,2,3\}^c=\{4\}\) |
De Morgan 律(De Morgan's Laws)是“补运算”与“并/交”之间的互换规则:
\[(A\cup B)^c=A^c\cap B^c,\quad (A\cap B)^c=A^c\cup B^c\]计数场景常用容斥原理(Inclusion–Exclusion):\(|A\cup B|=|A|+|B|-|A\cap B|\)。例:一个数据集里“命中规则 A”的样本有 120 个,“命中规则 B”的有 80 个,同时命中的有 30 个,则命中至少一个规则的样本数是 \(120+80-30=170\)。
映射(Mapping / Function)用来描述“从输入到输出”的确定性规则。写作 \(f:A\to B\),其中 \(A\) 是定义域(Domain),\(B\) 是陪域(Codomain)。对 \(x\in A\),输出写作 \(f(x)\in B\)。像集(Image / Range)为 \(f(A)=\{f(x)\mid x\in A\}\)。
关系(Relation)是更一般的概念:它不要求“每个输入对应唯一输出”。在集合论里,一个二元关系 \(R\) 可以看成笛卡尔积(Cartesian Product)上的子集:
\[R\subseteq A\times B,\quad (a,b)\in R\ \text{表示}\ a\ R\ b\]典型例子:
- 等价关系(Equivalence Relation):满足自反、对称、传递。例如定义 \(x\sim y\Leftrightarrow x-y\) 能被 \(m\) 整除(同余),它把整数划分为若干等价类(Equivalence Class)。
- 偏序(Partial Order):满足自反、反对称、传递。例如 \(\le\) 是实数上的偏序;集合的包含关系 \(\subseteq\) 也是偏序。
- 一般关系:例如“相似度大于阈值”定义了一个关系,但它通常不具备传递性,因此并非等价关系。
把关系写成矩阵/邻接矩阵(Adjacency Matrix)是常用表示:若 \(A=B=\{1,\ldots,n\}\),定义 \(M_{ij}=1\) 当且仅当 \((i,j)\in R\)。在图论(Graph Theory)与推荐/检索(Retrieval)里,这种表示会直接进入线性代数计算。
在 \(\mathbb{R}^n\) 中,向量加法与减法按分量(Component-wise)进行。对 \(\mathbf{a}=(a_1,\ldots,a_n)\)、\(\mathbf{b}=(b_1,\ldots,b_n)\):
\[\mathbf{a}+\mathbf{b}=(a_1+b_1,\ldots,a_n+b_n),\quad \mathbf{a}-\mathbf{b}=(a_1-b_1,\ldots,a_n-b_n)\]几何上,加法对应向量合成;减法 \(\mathbf{a}-\mathbf{b}\) 是从 \(\mathbf{b}\) 指向 \(\mathbf{a}\) 的位移向量。
例:若 \(\mathbf{a}=(1,2)\)、\(\mathbf{b}=(3,-1)\),则 \(\mathbf{a}+\mathbf{b}=(4,1)\),\(\mathbf{a}-\mathbf{b}=(-2,3)\)。
在 AI 里,残差连接(Residual Connection)是 \(\mathbf{x}+f(\mathbf{x})\);梯度下降(Gradient Descent)的更新可写成 \(\theta\leftarrow\theta-\eta\nabla L(\theta)\)。它们都直接依赖向量加减法。
点积(Dot Product)把两个向量映射为标量(Scalar),常用于相似度、投影和方向一致性判断。对 \(\mathbf{a},\mathbf{b}\in\mathbb{R}^n\),定义为 \(\mathbf{a}\cdot\mathbf{b}=\sum_{i=1}^n a_i b_i\)。当 \(\mathbf{a},\mathbf{b}\ne\mathbf{0}\) 时,也可写为 \(\mathbf{a}\cdot\mathbf{b}=\|\mathbf{a}\|\|\mathbf{b}\|\cos\theta\)。
点积满足交换律(Commutativity):\(\mathbf{a}\cdot\mathbf{b}=\mathbf{b}\cdot\mathbf{a}\)。若 \(\mathbf{a}\cdot\mathbf{b}=0\),两向量正交(Orthogonal)。
向量 \(\mathbf{a}\) 在 \(\mathbf{b}\) 方向上的标量投影是 \(\frac{\mathbf{a}\cdot\mathbf{b}}{\|\mathbf{b}\|}\)。投影更常用的是向量形式(Vector Projection):
\[\mathrm{proj}_{\mathbf{b}}(\mathbf{a})=\frac{\mathbf{a}\cdot\mathbf{b}}{\|\mathbf{b}\|^2}\mathbf{b}\]当把向量归一化到单位范数(Unit Norm)后,点积就等于余弦相似度(Cosine Similarity):\(\cos\theta=\mathbf{\hat a}\cdot\mathbf{\hat b}\),这也是检索与表示学习中常见的相似度度量。
单位向量(Unit Vector)是范数为 1 的向量,常用来“只表示方向”。对非零向量 \(\mathbf{a}\),其单位向量是 \(\mathbf{\hat a}=\frac{\mathbf{a}}{\|\mathbf{a}\|}\)。
方向角(Direction Angles)/方向余弦(Direction Cosines)描述单位向量与各坐标轴的夹角:在三维中,若单位向量 \(\mathbf{u}=(u_x,u_y,u_z)\),则 \(u_x=\cos\alpha\)、\(u_y=\cos\beta\)、\(u_z=\cos\gamma\),并满足 \(\cos^2\alpha+\cos^2\beta+\cos^2\gamma=1\)。
点积之所以会出现“乘积”,是因为它等于“被投影长度 × 参照向量长度”: \(\mathbf{a}\cdot\mathbf{b}=\|\mathbf{b}\|\cdot \mathrm{projLen}_{\mathbf{b}}(\mathbf{a})\)。当两向量同向时,投影长度就是 \(\|\mathbf{a}\|\),于是点积变为 \(\|\mathbf{a}\|\|\mathbf{b}\|\)。
在二维空间里,向量 \((a,b)\) 可以写成复数 \(z=a+bi\)。这核心是给同一个二维量换一种记法:实部对应 x 轴分量,虚部对应 y 轴分量。
若另一向量 \((c,d)\) 写成 \(w=c+di\),则复共轭乘积为
\[z\bar w=(a+bi)(c-di)=(ac+bd)+i(bc-ad)\]其中实部 \(ac+bd\) 恰好就是二维向量的点积:
\[\mathbf{a}\cdot\mathbf{b}=ac+bd=\mathrm{Re}(z\bar w)\]若再把它们写成极坐标形式 \(z=r_1e^{i\theta_1}\)、\(w=r_2e^{i\theta_2}\),则
\[\mathbf{a}\cdot\mathbf{b}=\mathrm{Re}(z\bar w)=r_1r_2\cos(\theta_1-\theta_2)\]这里实部的来源可以直接从指数形式读出:因为 \(\bar w=r_2e^{-i\theta_2}\),所以 \(z\bar w=r_1r_2e^{i(\theta_1-\theta_2)}\)。再用欧拉公式 \(e^{i\phi}=\cos\phi+i\sin\phi\) 展开,就得到 \(z\bar w=r_1r_2\big(\cos(\theta_1-\theta_2)+i\sin(\theta_1-\theta_2)\big)\);其中实部正是 \(r_1r_2\cos(\theta_1-\theta_2)\)。
因此,点积既可以看成分量乘加,也可以看成“复数乘积取实部”。后一种写法把长度与相位差放进同一个式子里,在位置编码、旋转表示与频域分析中尤其方便。后文 RoPE 的复数视角正是沿用这层关系:二维块先写成复数,再让相位随位置旋转。
例:令 \(\mathbf{a}=(3,4)\)、\(\mathbf{b}=(4,0)\)。则 \(\mathbf{a}\cdot\mathbf{b}=12\)、\(\|\mathbf{a}\|=5\)、\(\|\mathbf{b}\|=4\),所以 \(\cos\theta=\frac{12}{20}=0.6\)。而 \(\mathbf{a}\) 在 \(\mathbf{b}\) 方向上的标量投影是 \(\frac{12}{4}=3\),恰好对应 \(\mathbf{a}\) 的 x 分量。
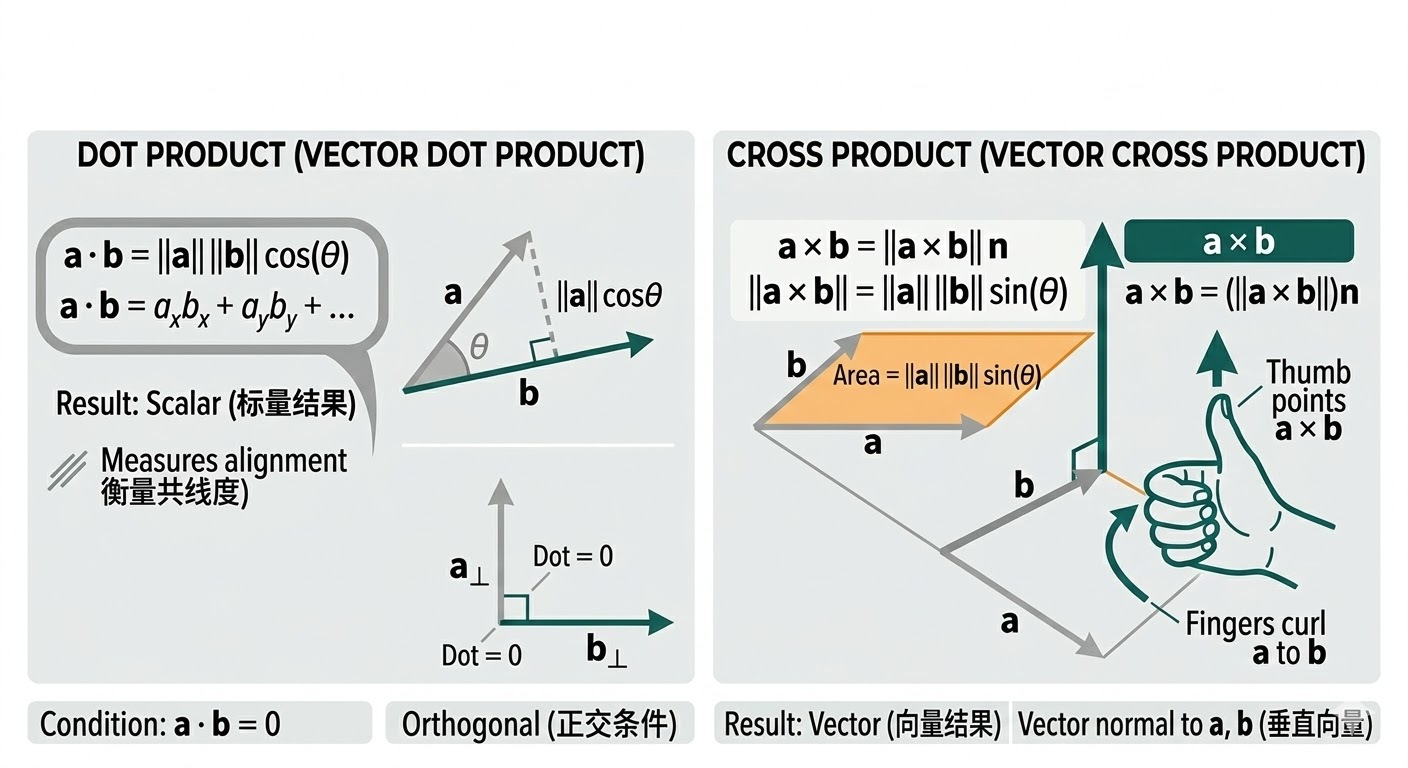
叉积(Cross Product)定义在三维空间(3D Space)。结果是同时垂直于两个输入向量的向量,大小为 \(\|\mathbf{a}\times\mathbf{b}\|=\|\mathbf{a}\|\|\mathbf{b}\|\sin\theta\),等于两向量张成平行四边形的面积。
计算上,若 \(\mathbf{a}=(a_1,a_2,a_3)\)、\(\mathbf{b}=(b_1,b_2,b_3)\),则:
\[\mathbf{a}\times\mathbf{b}=(a_2b_3-a_3b_2,\ a_3b_1-a_1b_3,\ a_1b_2-a_2b_1)\]例: \((1,0,0)\times(0,1,0)=(0,0,1)\)。这个例子在几何上对应两个单位正交基向量张成的“正方形面积为 1”,方向由右手定则给出。
叉积为零当且仅当两向量平行(Parallel/Colinear)或至少有一个为零向量:这是因为 \(\|\mathbf{a}\times\mathbf{b}\|=\|\mathbf{a}\|\|\mathbf{b}\|\sin\theta\),为 0 只能来自 \(\sin\theta=0\) 或 \(\|\mathbf{a}\|=0\) 或 \(\|\mathbf{b}\|=0\)。
方向由右手定则(Right-Hand Rule)确定:四指从 \(\mathbf{a}\) 旋向 \(\mathbf{b}\),拇指方向即 \(\mathbf{a}\times\mathbf{b}\) 方向。旋转“正负”核心是由坐标系(Coordinate System)与观察方向(View Direction)约定决定。
力矩(Torque)可作为叉积方向的直观例子: \(\boldsymbol{\tau}=\mathbf{r}\times\mathbf{F}\)。这里保留物理解释的唯一目的,是帮助理解叉积的方向性。
在 \(\mathbb{R}^n\) 中,一组向量 \(\{\mathbf{b}_1,\ldots,\mathbf{b}_n\}\) 若线性无关(Linearly Independent)且张成(Span)整个空间,则称为一组基(Basis)。任何向量 \(\mathbf{x}\) 都能唯一表示为 \(\mathbf{x}=\sum_{i=1}^{n} c_i\mathbf{b}_i\);系数向量 \(\mathbf{c}=(c_1,\ldots,c_n)^\top\) 就是 \(\mathbf{x}\) 在该基下的坐标(Coordinates)。
把基向量按列堆成矩阵 \(B=[\mathbf{b}_1\ \cdots\ \mathbf{b}_n]\in\mathbb{R}^{n\times n}\),则坐标与原向量满足 \(\mathbf{x}=B\mathbf{c}\)。换基(Change of Basis)在推导里本质就是在不同 \(B\) 之间切换坐标表示。
换基(Change of Basis)指的是:在不改变几何向量本身的前提下,改用另一组基(Basis)来描述它的坐标(Coordinates)。因此,换基改变的是表示方式,并非向量对象本身。直观上,可把几何向量理解为平面/空间里的一支箭头。
因此,“换基”不能理解成“把向量变形”。真正发生变化的是参考基(Basis),因此同一向量在不同基下的坐标数值会不同,而几何对象本身保持不变。
为了不混淆“向量本身”和“向量的坐标表示”,可以用一个约定把它们分开:
- \(\mathbf{x}\):把同一个几何向量用标准基(Standard Basis)写出来的分量列向量(数值计算里最常用的表示)。
- \(\mathbf{c}\):把同一个几何向量用某组新基 \(\{\mathbf{b}_i\}\) 写出来的坐标向量(Coordinate Vector),也就是“在新基上要乘的系数”。
把新基向量在标准基下的分量按列组成 \(B=[\mathbf{b}_1\ \cdots\ \mathbf{b}_n]\)(可称为基矩阵(Basis Matrix)),则
\[\mathbf{x}=B\mathbf{c}\]读法:右边 \(\mathbf{c}\) 是“在新基下的坐标”,左边 \(\mathbf{x}\) 是“在标准基下的分量”。乘上 \(B\) 就把“新基坐标”换算回“标准基分量”。
反过来,如果你已知标准基下的分量 \(\mathbf{x}\),想求新基坐标 \(\mathbf{c}\),就需要解线性方程组 \(B\mathbf{c}=\mathbf{x}\)。由于基向量线性无关,矩阵 \(B\) 必可逆(Invertible),因此可写成:
\[\mathbf{c}=B^{-1}\mathbf{x}\]更一般地,若旧基矩阵为 \(B\)、新基矩阵为 \(C\),同一几何向量满足 \(\mathbf{x}=B\mathbf{c}_{B}=C\mathbf{c}_{C}\),于是坐标之间的换算是:
\[\mathbf{c}_{C}=C^{-1}B\,\mathbf{c}_{B}\]矩阵 \(P=C^{-1}B\) 常被称为换基矩阵(Change-of-basis Matrix):它把“旧基坐标”直接映射为“新基坐标”。
例:在 \(\mathbb{R}^2\) 取 \(\mathbf{b}_1=(1,0)^\top,\ \mathbf{b}_2=(1,1)^\top\)。对 \(\mathbf{x}=(2,3)^\top\),解 \(\mathbf{x}=c_1\mathbf{b}_1+c_2\mathbf{b}_2\) 得 \(c_2=3,\ c_1=-1\),因此该基下坐标为 \(\mathbf{c}=(-1,3)^\top\)。同一个几何向量,在不同基下的坐标会不同。
把基矩阵写出来会更便于计算: \(B=[\mathbf{b}_1\ \mathbf{b}_2]=\begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\)。此时 \(B\mathbf{c}=\begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\begin{bmatrix}-1\\ 3\end{bmatrix}=\begin{bmatrix}2\\ 3\end{bmatrix}=\mathbf{x}\);反过来,解 \(B\mathbf{c}=\mathbf{x}\) 等价于 \(\mathbf{c}=B^{-1}\mathbf{x}\),因此“换基”在计算上就是解一个线性方程组。
标准基(Standard Basis)是最常用的一组基。第 \(i\) 个标准基向量 \(\mathbf{e}_i\) 只有第 \(i\) 个分量为 1,其余为 0:
\[\mathbf{e}_1=(1,0,\ldots,0)^\top,\ \mathbf{e}_2=(0,1,0,\ldots,0)^\top,\ \ldots,\ \mathbf{e}_n=(0,\ldots,0,1)^\top\]例:在 \(\mathbb{R}^2\) 中,\((2,3)^\top=2\mathbf{e}_1+3\mathbf{e}_2\)。把 \(\{\mathbf{e}_i\}\) 作为列组成矩阵就是单位矩阵 \(I\),因此标准基下 \(\mathbf{x}=I\mathbf{x}\) 对应“坐标与分量一致”。
正交基(Orthogonal Basis)是指基向量两两正交:对 \(i\ne j\) 有 \(\mathbf{b}_i^\top\mathbf{b}_j=0\)。它不要求单位长度。
正交基的一个关键性质是:坐标可以用投影直接算出。若 \(\mathbf{x}=\sum_i c_i\mathbf{b}_i\) 且 \(\{\mathbf{b}_i\}\) 正交,则
\[c_i=\frac{\mathbf{x}^\top\mathbf{b}_i}{\mathbf{b}_i^\top\mathbf{b}_i}\]例:取 \(\mathbf{b}_1=(1,1)^\top,\ \mathbf{b}_2=(1,-1)^\top\),它们点积为 0。对 \(\mathbf{x}=(2,1)^\top\),有 \(c_1=\frac{3}{2},\ c_2=\frac{1}{2}\),因此 \(\mathbf{x}=\frac{3}{2}\mathbf{b}_1+\frac{1}{2}\mathbf{b}_2\)。
正交标准基(Orthonormal Basis)要求两两正交且每个基向量单位长度: \(\|\mathbf{u}_i\|_2=1\),并满足 \(\mathbf{u}_i^\top\mathbf{u}_j=\delta_{ij}\)(克罗内克 delta(Kronecker Delta))。
此时坐标就是内积/投影:若 \(\mathbf{x}=\sum_i c_i\mathbf{u}_i\),则 \(c_i=\mathbf{x}^\top\mathbf{u}_i\)。计算上,这等价于把向量投影到各基方向。
例:令 \(\mathbf{u}_1=\frac{1}{\sqrt{2}}(1,1)^\top,\ \mathbf{u}_2=\frac{1}{\sqrt{2}}(1,-1)^\top\)。对 \(\mathbf{x}=(2,1)^\top\),有 \(c_1=\frac{3}{\sqrt{2}},\ c_2=\frac{1}{\sqrt{2}}\),于是 \(\mathbf{x}=c_1\mathbf{u}_1+c_2\mathbf{u}_2\)。
把 \(\{\mathbf{u}_i\}\) 按列组成矩阵 \(Q\),则 \(Q^\top Q=I\),并且坐标变换可写成 \(\mathbf{c}=Q^\top\mathbf{x}\)、重构为 \(\mathbf{x}=Q\mathbf{c}\)。在 PCA(Principal Component Analysis)与 SVD 中,主方向/奇异向量就是正交标准基;投影与重构只需要转置,不需要显式求逆。
矩阵运算(Matrix Operations)是机器学习(Machine Learning)中最核心的计算骨架。前向传播、反向传播和参数更新都可以表示为矩阵与向量的组合。
矩阵加法按元素(Element-wise)进行:若 \(X,B\in\mathbb{R}^{m\times n}\),则 \((X+B)_{ij}=X_{ij}+B_{ij}\)。减法同理。
在深度学习框架里常见的是广播(Broadcasting):例如对 batch 特征 \(X\in\mathbb{R}^{B\times d}\) 与偏置 \(\mathbf{b}\in\mathbb{R}^{d}\),写作 \(Y=X+\mathbf{b}\) 意味着把 \(\mathbf{b}\) 复制到每一行后再相加。这是线性层 \(Y=XW+\mathbf{b}\) 的标准形式。
令 \(X\in\mathbb{R}^{2\times 3}\)、\(\mathbf{b}\in\mathbb{R}^{3}\):
\[X=\begin{bmatrix}1 & 2 & 3\\ 4 & 5 & 6\end{bmatrix},\ \mathbf{b}=\begin{bmatrix}10 & 20 & 30\end{bmatrix}\]广播的语义是“把 \(\mathbf{b}\) 复制到每一行”,因此
\[Y=X+\mathbf{b}=\begin{bmatrix}11 & 22 & 33\\ 14 & 25 & 36\end{bmatrix}\]从线性代数角度,把 \(\mathbf{b}\) 视作行向量,则广播等价于 \(Y=X+\mathbf{1}\mathbf{b}\),其中 \(\mathbf{1}\in\mathbb{R}^{B\times 1}\) 是全 1 列向量。
矩阵乘法(Matrix Multiplication)在神经网络里通常对应线性层(Linear Layer):\(Y=XW\)。从“每个输出维度是一个点积”来看更容易记:
\[y_j=\sum_{i=1}^{d_{\text{in}}} x_i W_{ij}\]在批处理(Batch)场景下,常用形状约定是 \(X\in\mathbb{R}^{B\times d_{\text{in}}}\)、\(W\in\mathbb{R}^{d_{\text{in}}\times d_{\text{out}}}\)、\(Y=XW\in\mathbb{R}^{B\times d_{\text{out}}}\)。矩阵乘法一般不满足交换律(Non-commutativity),形状不匹配时也无法相乘。
从几何(Geometry)角度看,矩阵定义了一个线性变换(Linear Transformation):它把空间中的点/向量整体“变形”(旋转、缩放、剪切、投影等)。一种实用记法是看基向量(Basis Vectors)如何被映射:如果用列向量约定,矩阵的每一列就是某个基向量变换后的像。
例(二维):标准基向量(Standard Basis Vectors)为 \(\mathbf{e}_1=(1,0)^\top\) 与 \(\mathbf{e}_2=(0,1)^\top\)。对
\[A=\begin{bmatrix}a & c\\ b & d\end{bmatrix}\]有
\[A\mathbf{e}_1=\begin{bmatrix}a\\ b\end{bmatrix},\quad A\mathbf{e}_2=\begin{bmatrix}c\\ d\end{bmatrix}\]因此 \(A\) 的第 1/2 列分别是 \(\mathbf{e}_1,\mathbf{e}_2\) 的像。对任意 \(\mathbf{x}=x_1\mathbf{e}_1+x_2\mathbf{e}_2\),根据线性变换的线性性(Linearity)\(A(\alpha\mathbf{u}+\beta\mathbf{v})=\alpha A\mathbf{u}+\beta A\mathbf{v}\),可得
\[A\mathbf{x}=x_1A\mathbf{e}_1+x_2A\mathbf{e}_2=x_1\begin{bmatrix}a\\ b\end{bmatrix}+x_2\begin{bmatrix}c\\ d\end{bmatrix}\]数值例子:取
\[A=\begin{bmatrix}2 & 1\\ 0 & 1\end{bmatrix}\]则 \(A\mathbf{e}_1=(2,0)^\top\)、\(A\mathbf{e}_2=(1,1)^\top\)。若 \(\mathbf{x}=(3,4)^\top=3\mathbf{e}_1+4\mathbf{e}_2\),则
\[A\mathbf{x}=3A\mathbf{e}_1+4A\mathbf{e}_2=3\begin{bmatrix}2\\ 0\end{bmatrix}+4\begin{bmatrix}1\\ 1\end{bmatrix}=\begin{bmatrix}10\\ 4\end{bmatrix}\]这就是“看列向量理解变换”的核心:先画出两条基向量被送到哪里,整个网格会按相同线性组合随之平移/剪切/旋转/缩放。
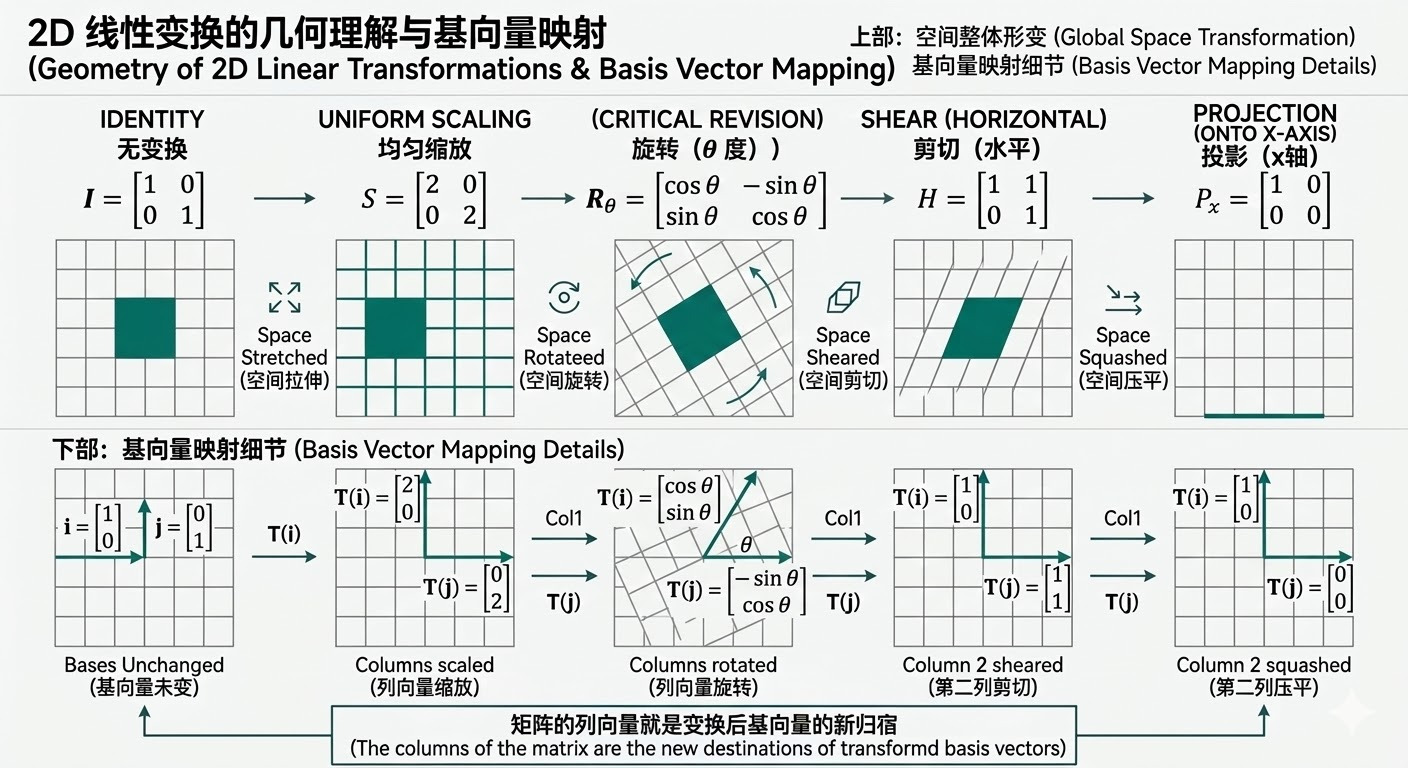
这对应两种等价视角:
- 变换向量(Active View):固定坐标轴,让向量 \(\mathbf{x}\) 变成 \(A\mathbf{x}\)。
- 变换坐标轴(Passive View):固定几何点,把坐标系按 \(A^{-1}\) 变换;同一个点在新坐标系下的坐标会变化。
两种视角描述的是同一个线性映射,只是“变的对象”不同。在做特征变换/白化(Whitening)/坐标变换推导时,这个区分能避免符号混乱。
矩阵乘法只有在内维度相等时才有定义:\((m\times n)(n\times p)=(m\times p)\)。把向量视为列向量(\(m\times 1\))或行向量(\(1\times m\))后,外积与点积也都可以统一为矩阵乘法的特例。
-
一般矩阵乘法:\((m\times n)(n\times p)=(m\times p)\)。
\[A=\begin{bmatrix}1 & 2 & 3\\ 4 & 5 & 6\end{bmatrix}\in\mathbb{R}^{2\times 3},\quad B=\begin{bmatrix}7 & 8\\ 9 & 10\\ 11 & 12\end{bmatrix}\in\mathbb{R}^{3\times 2}\] \[AB=\begin{bmatrix}58 & 64\\ 139 & 154\end{bmatrix}\in\mathbb{R}^{2\times 2}\] -
外积(Outer Product):\((m\times 1)(1\times n)=(m\times n)\)。
\[\mathbf{u}=\begin{bmatrix}1\\ 2\\ 3\end{bmatrix}\in\mathbb{R}^{3\times 1},\quad \mathbf{v}=\begin{bmatrix}4 & 5\end{bmatrix}\in\mathbb{R}^{1\times 2}\] \[\mathbf{u}\mathbf{v}=\begin{bmatrix}4 & 5\\ 8 & 10\\ 12 & 15\end{bmatrix}\in\mathbb{R}^{3\times 2}\]这是一个秩一(Rank-1)矩阵:它把“列向量 × 行向量”变成矩阵;在低秩近似、注意力权重构造与二阶统计量里都很常见。
-
点积(Dot Product):\((1\times m)(m\times 1)=(1\times 1)\)。
\[\mathbf{r}=\begin{bmatrix}1 & 2 & 3\end{bmatrix}\in\mathbb{R}^{1\times 3},\quad \mathbf{c}=\begin{bmatrix}4\\ 5\\ 6\end{bmatrix}\in\mathbb{R}^{3\times 1}\] \[\mathbf{r}\mathbf{c}=\begin{bmatrix}32\end{bmatrix}\in\mathbb{R}^{1\times 1}\equiv 32\]结果是标量 \(32\),等价于点积: \(\mathbf{r}\mathbf{c}=\sum_{i=1}^{m} r_i c_i\)。在实现里常写成 \(\mathbf{x}^\top\mathbf{y}\)。
仿射(Affine)是线性(Linear)的一个自然扩展。线性变换要求 \(f(\mathbf{x})=A\mathbf{x}\),必须把原点 \(\mathbf{0}\) 映到原点;仿射变换则允许再加一个平移项:
\[f(\mathbf{x})=A\mathbf{x}+\mathbf{b}\]这里 \(A\) 是线性部分,负责旋转、缩放、剪切、投影等形变; \(\mathbf{b}\) 是平移项(Translation / Bias),负责把整个空间整体推走一个位移。因此,仿射变换就是“先做线性变换,再做平移”。
几何上,线性变换像在原点固定不动的前提下拉伸或扭转整张网格;仿射变换则像先把网格按 \(A\) 变形,再把整张网格连同原点一起平移到别的位置。两者最核心的区别是:线性变换保原点,仿射变换不一定保原点。
最简单的一维例子是 \(f(x)=2x\) 与 \(g(x)=2x+3\)。前者是线性的,因为 \(f(0)=0\);后者是仿射的,因为它先把数轴按 2 倍拉伸,再整体平移 3 个单位,所以 \(g(0)=3\),不再经过原点。二维里也是同样: \(f(\mathbf{x})=\mathbf{x}\) 是恒等线性变换,而 \(g(\mathbf{x})=\mathbf{x}+\begin{bmatrix}1\\2\end{bmatrix}\) 会把整张平面网格整体向右平移 1、向上平移 2。
仿射函数(Affine Function)在优化与机器学习里极其常见。一维情形的 \(f(x)=ax+b\) 就是最简单的仿射函数;高维里则写成 \(f(\mathbf{x})=\mathbf{w}^\top\mathbf{x}+b\)。因此,神经网络里通常口头说“线性层(Linear Layer)”,但如果带偏置 \(b\),更严格的数学名称其实是仿射层(Affine Layer):
\[Y=XW+\mathbf{1}b^\top\]这里 \(X\) 是输入矩阵, \(W\) 是线性变换矩阵, \(b\) 是偏置向量, \(\mathbf{1}\) 是把偏置广播到每个样本上的全 1 列向量。若没有偏置,才是严格意义上的线性映射。
仿射还有一个重要性质:它保持仿射组合(Affine Combination)。若 \(\sum_i \alpha_i=1\),则
\[f\!\left(\sum_i \alpha_i \mathbf{x}_i\right)=\sum_i \alpha_i f(\mathbf{x}_i)\]这意味着直线、平面、平行关系和凸组合结构在仿射变换下会被保留;因此很多几何对象在经过仿射变换后,仍然保持“像线还是线,像平面还是平面”的基本类型,但位置和方向可能改变。
仿射子空间(Affine Subspace)则是“线性子空间整体平移后得到的集合”。若 \(U\) 是一个线性子空间, \(\mathbf{x}_0\) 是空间中的某个固定点,则
\[\mathcal{A}=\mathbf{x}_0+U=\{\mathbf{x}_0+\mathbf{u}:\mathbf{u}\in U\}\]就是一个仿射子空间。它和线性子空间的差别也在于是否经过原点:线性子空间必须包含原点,仿射子空间不必。例如二维中的直线 \(x+y=1\) 就是一个仿射子空间;它的方向部分与线性子空间 \(x+y=0\) 相同,但整条直线被平移开了,因此不经过原点。
这正是为什么超平面 \(\mathbf{w}^\top\mathbf{x}+b=0\) 被称为仿射子空间而非线性子空间:当 \(b\ne 0\) 时,它通常不经过原点,只是由某个线性超平面整体平移而来。优化里的等式约束 \(h_j(x)=0\) 若要求 \(h_j\) 是仿射函数,含义也正是“约束边界仍然保持平直结构,但允许存在偏置和平移”。
更进一步,双仿射(Biaffine)也是同一族概念的延伸。它通常在两个向量之间做一个双线性项 \(h_i^\top U h_j\),再加上线性项和偏置项,因此既包含“两个变量之间的乘性交互”,也包含仿射偏置修正。理解了仿射,就能把“线性 / 仿射 / 双线性 / 双仿射”看成一条逐步加复杂度的函数族谱。
把输出视为一个标量时,这条族谱可以写成一组并列的标准形式:
\[f_{\mathrm{linear}}(\mathbf{x})=\mathbf{w}^\top \mathbf{x}\] \[f_{\mathrm{affine}}(\mathbf{x})=\mathbf{w}^\top \mathbf{x}+b\] \[s_{\mathrm{bilinear}}(\mathbf{x},\mathbf{z})=\mathbf{x}^\top U\mathbf{z}\] \[s_{\mathrm{biaffine}}(\mathbf{x},\mathbf{z})=\mathbf{x}^\top U\mathbf{z}+\mathbf{a}^\top\mathbf{x}+\mathbf{c}^\top\mathbf{z}+b\]其中 \(\mathbf{x}\in\mathbb{R}^{m},\mathbf{z}\in\mathbb{R}^{n}\) 是两个输入向量, \(\mathbf{w},\mathbf{a}\in\mathbb{R}^{m}\), \(\mathbf{c}\in\mathbb{R}^{n}\), \(U\in\mathbb{R}^{m\times n}\), \(b\in\mathbb{R}\)。这里的 \(U\) 是双线性项的参数矩阵(Parameter Matrix):它不作用于单个向量本身;它给“ \(x_p\) 与 \(z_q\) 同时出现”这类二元交互分配权重。把式子展开后可写成 \(\mathbf{x}^\top U\mathbf{z}=\sum_{p=1}^{m}\sum_{q=1}^{n}x_p\,U_{pq}\,z_q\),因此 \(U_{pq}\) 直接控制第 \(p\) 个 \(\mathbf{x}\) 特征与第 \(q\) 个 \(\mathbf{z}\) 特征之间的交互强度。 \(\mathbf{a}^\top\mathbf{x}\) 与 \(\mathbf{c}^\top\mathbf{z}\) 是单边线性项,分别描述各自独立的角色偏好; \(b\) 是全局基线偏置。
把这个定义写成一个最小的 2×3 例子,会更容易直接看出“连接强度”来自哪里。令
\[\mathbf{x}=\begin{bmatrix}x_1\\x_2\end{bmatrix},\quad \mathbf{z}=\begin{bmatrix}z_1\\z_2\\z_3\end{bmatrix},\quad U=\begin{bmatrix}u_{11} & u_{12} & u_{13}\\u_{21} & u_{22} & u_{23}\end{bmatrix}\]则双线性项为
\[\mathbf{x}^\top U\mathbf{z}=\begin{bmatrix}x_1 & x_2\end{bmatrix}\begin{bmatrix}u_{11} & u_{12} & u_{13}\\u_{21} & u_{22} & u_{23}\end{bmatrix}\begin{bmatrix}z_1\\z_2\\z_3\end{bmatrix}\] \[=x_1u_{11}z_1+x_1u_{12}z_2+x_1u_{13}z_3+x_2u_{21}z_1+x_2u_{22}z_2+x_2u_{23}z_3\]这一步把抽象的矩阵乘法拆成了六条显式连接: \(u_{11}\) 控制 \(x_1\) 与 \(z_1\) 的连接强度, \(u_{23}\) 控制 \(x_2\) 与 \(z_3\) 的连接强度。若某个 \(u_{pq}\) 很大且为正,只要对应的 \(x_p\) 与 \(z_q\) 同时取大值,这一对特征就会显著抬高总分;若某个 \(u_{pq}\) 为负,则说明这对特征的共同出现会压低分数。
在同一个例子里,双仿射只是在双线性项之外再加上单边项与偏置:
\[s_{\mathrm{biaffine}}(\mathbf{x},\mathbf{z})=\mathbf{x}^\top U\mathbf{z}+\mathbf{a}^\top\mathbf{x}+\mathbf{c}^\top\mathbf{z}+b\] \[=\mathbf{x}^\top U\mathbf{z}+(a_1x_1+a_2x_2)+(c_1z_1+c_2z_2+c_3z_3)+b\]其中 \(a_1,a_2\) 描述 \(\mathbf{x}\) 一侧各特征自身的偏好, \(c_1,c_2,c_3\) 描述 \(\mathbf{z}\) 一侧各特征自身的偏好, \(b\) 给出无条件基线分数。于是,双线性回答的是“这两组特征配在一起有多合适”,双仿射回答的则是“它们配在一起有多合适,并且各自本身是否已经带有倾向”。
若输出包含 \(K\) 个关系类别或标签分数,则通常会为每个类别准备一张交互矩阵 \(U^{(k)}\),或等价地把它们堆成三阶张量 \(U\in\mathbb{R}^{K\times m\times n}\)。这时每个类别都拥有自己的一套“特征两两交互”权重。
从函数结构看,线性与仿射的区别在于是否含偏置;双线性与双仿射的区别同样在于是否在交互项之外再加入单边项与偏置。固定 \(\mathbf{z}\) 时, \(\mathbf{x}^\top U\mathbf{z}\) 对 \(\mathbf{x}\) 是线性的, \(s_{\text{biaffine}}(\mathbf{x},\mathbf{z})\) 对 \(\mathbf{x}\) 则是仿射的;固定 \(\mathbf{x}\) 时,对 \(\mathbf{z}\) 也是同样的性质。这正是 “biaffine” 这个名字的数学含义。
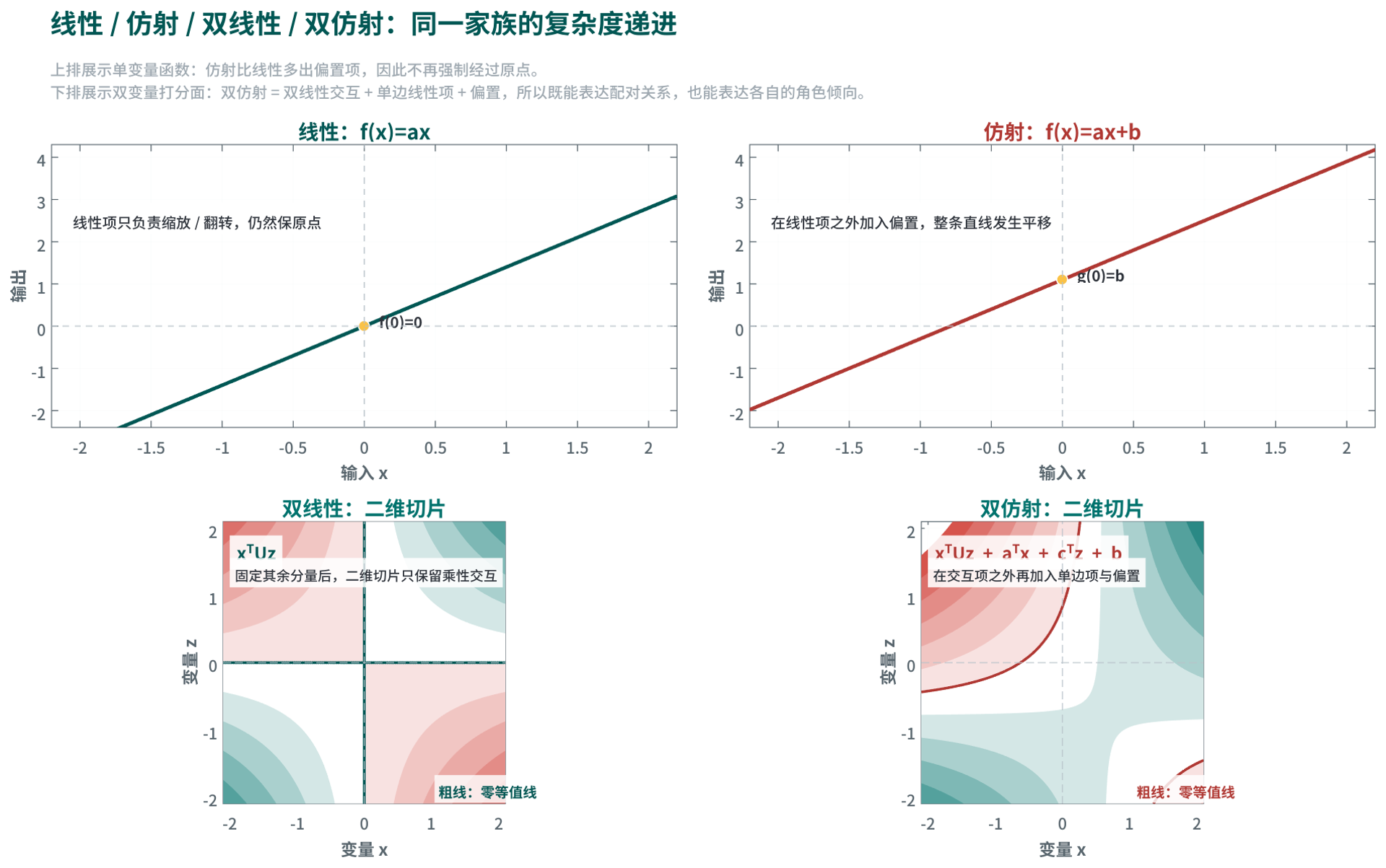
图中上排用一维切片显示“是否经过原点”这一关键差异: \(f(x)=ax\) 必然经过原点,而 \(f(x)=ax+b\) 由于加入偏置项,整条直线沿输出轴发生平移。下排保持与公式族谱一致,仍写成 \(\mathbf{x}^\top U\mathbf{z}\) 与 \(\mathbf{x}^\top U\mathbf{z}+\mathbf{a}^\top\mathbf{x}+\mathbf{c}^\top\mathbf{z}+b\);图像本身展示的是把高维向量关系压到二维后的一个切片。纯双线性项的零等值线体现为对称的交互边界;加入单边项与偏置后,零等值线整体偏移,分数面出现倾斜与平移,表示模型不仅关心“是否匹配”,还关心两个对象各自单独的倾向。
在依存句法(Dependency Parsing)、关系抽取(Relation Extraction)和成对匹配(Pairwise Matching)任务中,这个结构尤其有用。纯双线性项只能表达“组合后是否相容”,双仿射则进一步允许模型学习“某个对象本身就更像 head / dependent”或“某个实体本身就更像某类关系的一端”。因此,双仿射通常既比纯仿射更能表达交互,又比纯双线性更稳定。
转置(Transpose)把行列互换:对 \(A\in\mathbb{R}^{m\times n}\),其转置 \(A^\top\in\mathbb{R}^{n\times m}\) 满足 \((A^\top)_{ij}=A_{ji}\)。
它常用于对齐乘法形状、把点积写成矩阵乘法,以及在推导中“移动”矩阵:例如 \((AB)^\top=B^\top A^\top\)。Transformer 注意力中的 \(QK^\top\) 就是典型的“先转置再相乘”。
令
\[A=\begin{bmatrix}1 & 2 & 3\\ 4 & 5 & 6\end{bmatrix}\in\mathbb{R}^{2\times 3}\]则
\[A^\top=\begin{bmatrix}1 & 4\\ 2 & 5\\ 3 & 6\end{bmatrix}\in\mathbb{R}^{3\times 2}\]可以直接看到:原矩阵的第 1 行变成转置后的第 1 列;因此 \((m\times n)^\top=(n\times m)\)。
Hadamard 乘积(Hadamard Product)是逐元素(Element-wise)相乘:若 \(X,M\) 形状相同,则 \((X\odot M)_{ij}=X_{ij}M_{ij}\)。
典型用途是掩码(Masking)与门控(Gating)。例:令 \(M\in\{0,1\}^{B\times d}\),则 \(X\odot M\) 会把被屏蔽的特征位置直接置零;也可以用 \(M\in[0,1]^{B\times d}\) 做连续缩放。
矩阵分解(Decomposition)把矩阵写成更“易处理”的结构乘积,用于求解、降维与稳定计算。常见形式包括:
- SVD: \(A=U\Sigma V^\top\),用于 PCA(Principal Component Analysis)、低秩近似与数值稳健求解。
- QR: \(A=QR\)(\(Q\) 正交、\(R\) 上三角),常用于最小二乘与正交化。
- Cholesky:对对称正定(SPD)矩阵 \(A\),有 \(A=LL^\top\),常用于高斯模型与二次优化中的快速求解。
矩阵的迹(Trace)定义为对角线元素之和:对方阵 \(A\in\mathbb{R}^{n\times n}\),
\[\mathrm{tr}(A)=\sum_{i=1}^{n} A_{ii}\]迹在推导里常用的性质是循环不变性(Cyclic Property):\(\mathrm{tr}(AB)=\mathrm{tr}(BA)\)(形状匹配时)。一个高频等式是 \(\mathrm{tr}(A^\top A)=\|A\|_F^2\),它把“平方和”写成迹,便于做矩阵微分与正则化推导。
范数(Norm)刻画矩阵的“大小”。最常用的是 Frobenius 范数:
\[\|A\|_F=\sqrt{\sum_{i,j}A_{ij}^2}\]它等价于把矩阵按元素展平后的 \(\ell_2\) 范数,常用于权重衰减(Weight Decay)/L2 正则。另一个常见的是谱范数(Spectral Norm)\(\|A\|_2\)(最大奇异值),用于控制 Lipschitz 常数与训练稳定性(如 spectral normalization)。
外积(Outer Product)把两个向量映射为矩阵:对 \(\mathbf{u}\in\mathbb{R}^{m}\) 与 \(\mathbf{v}\in\mathbb{R}^{n}\),
\[\mathbf{u}\mathbf{v}^\top\in\mathbb{R}^{m\times n}\]它是一个秩一(Rank-1)矩阵。外积在统计与学习中常用于构造二阶量:例如样本协方差的无偏估计可写成中心化向量的外积平均 \(\Sigma\approx \frac{1}{N}\sum_{k=1}^{N}(\mathbf{x}_k-\bar{\mathbf{x}})(\mathbf{x}_k-\bar{\mathbf{x}})^\top\)。
例:令 \(\mathbf{u}=\begin{bmatrix}1\\ 2\\ 3\end{bmatrix}\)、\(\mathbf{v}=\begin{bmatrix}4\\ 5\end{bmatrix}\),则
\[\mathbf{u}\mathbf{v}^\top=\begin{bmatrix}4 & 5\\ 8 & 10\\ 12 & 15\end{bmatrix}\]直观上,外积得到的矩阵每一列都是 \(\mathbf{u}\) 的缩放:第 \(j\) 列等于 \(v_j\mathbf{u}\)。因此所有列共线,矩阵的秩最多为 1(除非 \(\mathbf{u}\) 或 \(\mathbf{v}\) 为零向量)。
把外积视为线性算子更直接:对任意 \(\mathbf{x}\in\mathbb{R}^{n}\),有 \((\mathbf{u}\mathbf{v}^\top)\mathbf{x}=\mathbf{u}(\mathbf{v}^\top\mathbf{x})\)。这表示先沿 \(\mathbf{v}\) 做一次投影/打分得到标量 \(\mathbf{v}^\top\mathbf{x}\),再沿 \(\mathbf{u}\) 方向输出。例:取 \(\mathbf{x}=\begin{bmatrix}1\\ 1\end{bmatrix}\),则 \(\mathbf{v}^\top\mathbf{x}=9\),从而 \((\mathbf{u}\mathbf{v}^\top)\mathbf{x}=9\mathbf{u}=\begin{bmatrix}9\\ 18\\ 27\end{bmatrix}\)。
秩一更新(Rank-1 Update)则是把矩阵写成 \(A\leftarrow A+\mathbf{u}\mathbf{v}^\top\):只引入一个方向上的低秩结构,常用于用较低代价注入统计量/二阶近似,或在保持主结构的前提下做小幅调整。
行列式(Determinant)把一个方阵 \(A\in\mathbb{R}^{n\times n}\) 映射为标量 \(\det(A)\)。几何上,它是线性变换对体积的缩放因子(Volume Scaling Factor):绝对值表示缩放倍数,符号表示是否翻转取向(Orientation Flip)。
二维情形最直观:若
\[A=\begin{bmatrix}a & b\\ c & d\end{bmatrix}\]则
\[\det(A)=ad-bc\]例: \(A=\begin{bmatrix}2 & 1\\ 0 & 3\end{bmatrix}\),则 \(\det(A)=6\):面积被放大 6 倍。
关键结论:方阵可逆(Invertible)当且仅当行列式非零。当 \(\det(A)=0\) 时,变换会把体积压扁到低维(丢失信息),对应列向量线性相关(Linearly Dependent)。
常用性质:
- \(\det(AB)=\det(A)\det(B)\)
- \(\det(A^\top)=\det(A)\)
- \(\det(I)=1\)
若把特征值(Eigenvalues)记作 \(\{\lambda_i\}_{i=1}^n\)(按代数重数计),则 \(\det(A)=\prod_i \lambda_i\)、\(\mathrm{tr}(A)=\sum_i \lambda_i\)。
矩阵的秩(Rank)刻画“列(或行)里最多有多少个线性无关(Linearly Independent)的方向”。对 \(A\in\mathbb{R}^{m\times n}\),秩定义为列空间(Column Space)的维数:
\[\mathrm{rank}(A)=\dim(\mathrm{col}(A))\]这一定义的直接含义是:若 \(\mathrm{rank}(A)=r\),那么 \(A\) 的所有列向量都只能张成一个 \(r\) 维子空间,超出这个子空间的方向它完全无法表达。反过来,若某一列可以由其他列线性组合得到,它就不提供新的维度,因此不会增加秩。
它也等于行空间(Row Space)的维数(行秩=列秩)。把 \(A\) 看作线性映射 \(\mathbb{R}^n\to\mathbb{R}^m\),秩就是输出子空间的维度:最多能输出多少个自由方向。
满秩(Full Rank)通常指 \(\mathrm{rank}(A)=\min(m,n)\)。对方阵 \(n\times n\) 而言,满秩等价于可逆(也等价于 \(\det(A)\ne 0\))。
线性方程组(Linear System)\(A\mathbf{x}=\mathbf{b}\) 的解与秩直接相关:设增广矩阵为 \([A\mid \mathbf{b}]\),则
- 若 \(\mathrm{rank}(A)\ne \mathrm{rank}([A\mid \mathbf{b}])\),无解。
- 若 \(\mathrm{rank}(A)=\mathrm{rank}([A\mid \mathbf{b}])=n\)(未知数个数),唯一解。
- 若 \(\mathrm{rank}(A)=\mathrm{rank}([A\mid \mathbf{b}])<n\),无穷多解(存在自由变量)。
与 SVD 的关系非常实用:秩等于非零奇异值(Singular Values)的个数,因此在数值计算里常用“奇异值是否接近 0”判断有效秩(Numerical Rank)。
在高中里,一元二次函数常写成 \(ax^2+bx+c\)。把“二次”推广到多元,并且只保留二次项(没有一次项与常数项),就得到二次型(Quadratic Form)。二维里最常见的形式是:
\[q(x,y)=ax^2+bxy+cy^2\]其中 \(bxy\) 是交叉项(Cross Term):它把不同变量“耦合在一起”。在解析几何(Analytic Geometry)里,交叉项常对应二次曲线(Conic Section)的主轴(Principal Axes)不与坐标轴对齐(图形呈旋转/倾斜)。
若再把一次项与常数项加回来,就得到更一般的二次多项式(Quadratic Polynomial)\(ax^2+bxy+cy^2+dx+ey+f\)。这时:交叉项 \(bxy\) 主要反映主轴旋转;一次项 \(dx+ey\) 往往表示图形的中心/顶点从原点平移出去;常数项 \(f\) 则改变整体基准值,进而影响图形的截距、大小以及是否与 \(q(x,y)=0\) 相交。只有把一次项和常数项都去掉时,我们讨论的才是纯粹的二次型。
下面两幅图都基于等值线(Level Set)生成:先固定常数 \(k\),在平面上求解 \(q(x,y)=k\) 得到等值线,再把不同 \(k\) 的结果叠加,并与 \(z=q(x,y)\) 的三维曲面对应显示。
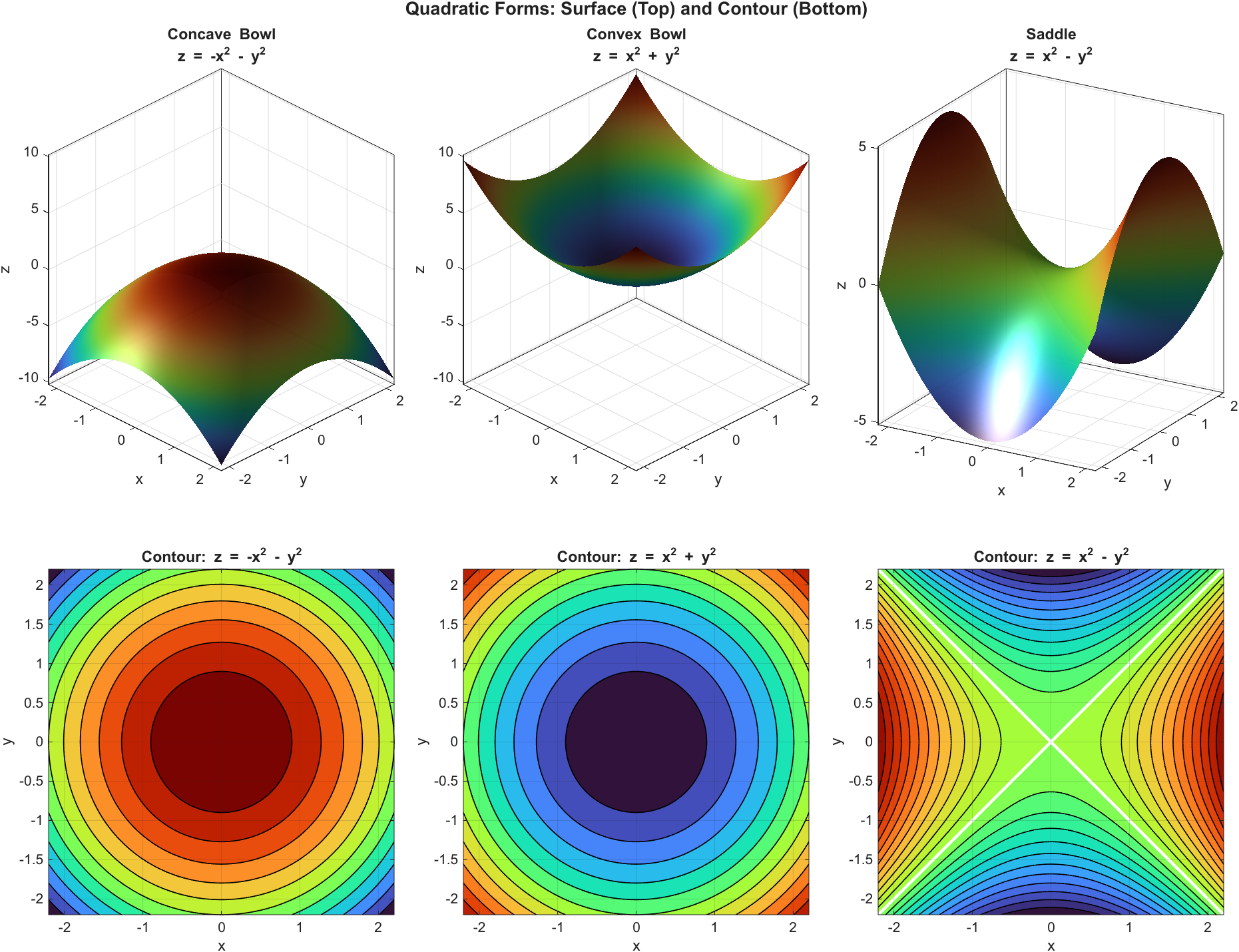
第一幅展示无交叉项(\(b=0\))的典型形态:等值线与坐标轴对齐,曲面主轴方向也与坐标轴一致。
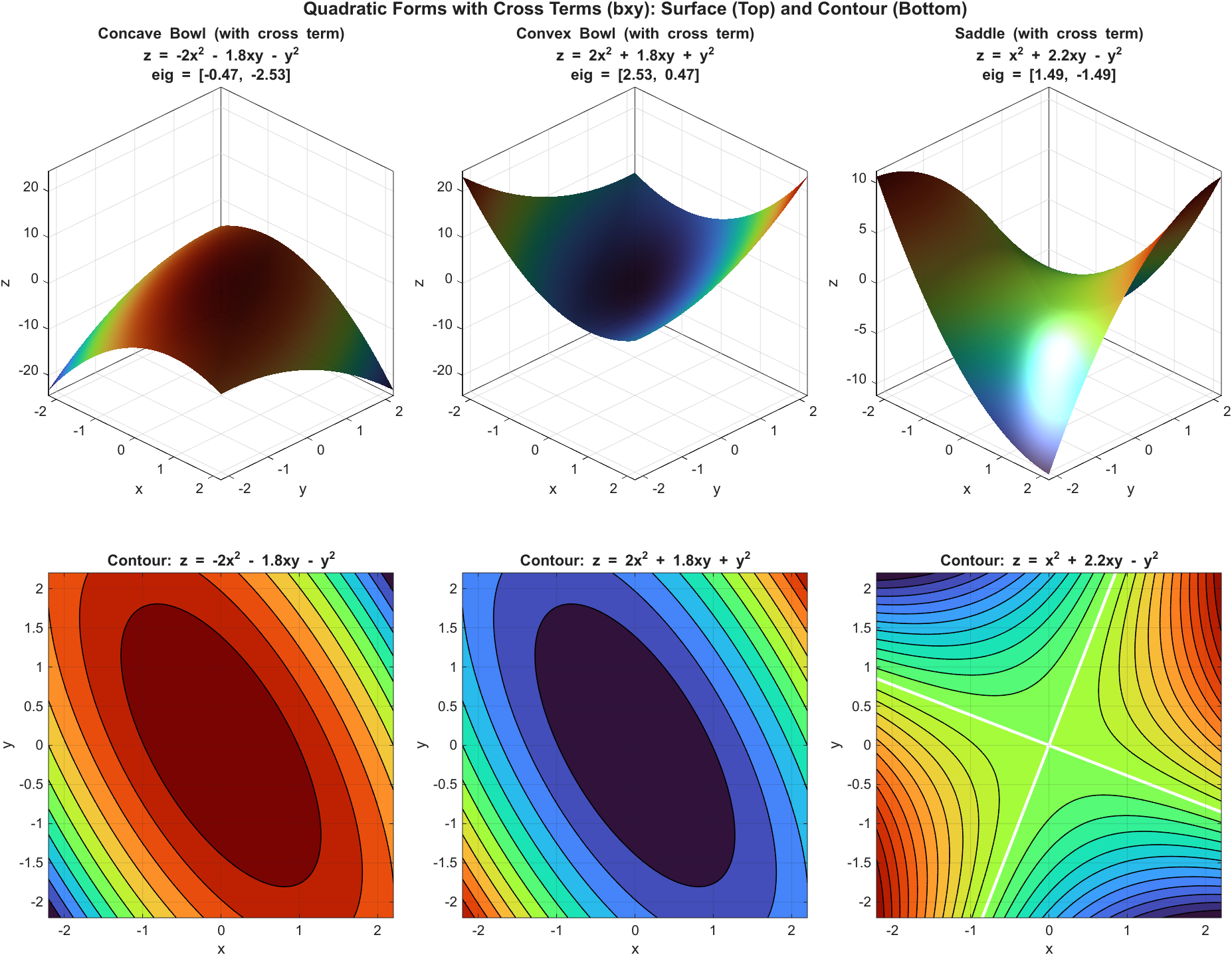
第二幅展示含交叉项(\(b\ne 0\))的情形:等值线整体发生旋转/倾斜,三维曲面看起来更“不规则”。
在线性代数里,用矩阵(Matrix)把系数组织起来更方便。令 \(\mathbf{x}=(x_1,\ldots,x_n)^\top\)、\(A\in\mathbb{R}^{n\times n}\),则
\[q(\mathbf{x})=\mathbf{x}^\top A\mathbf{x}=\sum_{i=1}^{n}\sum_{j=1}^{n}A_{ij}x_i x_j\]上面这条等式核心是把矩阵乘法按分量(Component)展开后的结果。把它分两步看最清楚:
- 先做一次矩阵-向量乘法:令 \(\mathbf{y}=A\mathbf{x}\),则第 \(i\) 个分量是
- 再做一次点积: \(\mathbf{x}^\top\mathbf{y}=\sum_{i=1}^{n}x_i y_i\)。把第 1 步的 \(y_i\) 代入,就得到
这就是“双重求和(Double Summation)”的含义:每一个矩阵元素 \(A_{ij}\) 都在给二次项 \(x_i x_j\) 分配一个权重;当 \(i=j\) 时就是平方项 \(x_i^2\),当 \(i\ne j\) 时就是交叉项 \(x_i x_j\)。
二维情形最直观:若希望展开后得到 \(ax^2+bxy+cy^2\),可以取
\[A=\begin{bmatrix}a & \frac{b}{2}\\ \frac{b}{2} & c\end{bmatrix}\]这里把向量写成 \(\mathbf{x}=(x,y)^\top\),按矩阵乘法展开一遍:
\[A\mathbf{x}=\begin{bmatrix}a & \frac{b}{2}\\ \frac{b}{2} & c\end{bmatrix}\begin{bmatrix}x\\ y\end{bmatrix}=\begin{bmatrix}ax+\frac{b}{2}y\\ \frac{b}{2}x+cy\end{bmatrix}\] \[\mathbf{x}^\top(A\mathbf{x})=\begin{bmatrix}x & y\end{bmatrix}\begin{bmatrix}ax+\frac{b}{2}y\\ \frac{b}{2}x+cy\end{bmatrix}=ax^2+\frac{b}{2}xy+\frac{b}{2}yx+cy^2=ax^2+bxy+cy^2\]可以看到:交叉项 \(xy\) 的系数 \(b\) 实际来自两处对称位置 \(A_{12}\) 与 \(A_{21}\) 的“合力”(各贡献一半)。这也会自然导向下一节的结论:二次型只依赖矩阵的对称部分。
例:取 \(q(x,y)=5x^2-4xy+5y^2\),对应 \(A=\begin{bmatrix}5 & -2\\ -2 & 5\end{bmatrix}\)。这一类表达式不仅在几何里出现(椭圆(Ellipse)/双曲线(Hyperbola)),在优化与统计里也高频出现(曲率(Curvature)、距离度量(Distance Metric))。
对任意方阵 \(A\),二次型只依赖其对称部分:
\[\mathbf{x}^\top A\mathbf{x}=\mathbf{x}^\top\left(\frac{A+A^\top}{2}\right)\mathbf{x}\]这句话的意思是:无论 \(A\) 的非对称部分长什么样,只要 \(\frac{A+A^\top}{2}\) 不变,二次型 \(\mathbf{x}^\top A\mathbf{x}\) 对所有 \(\mathbf{x}\) 的取值就完全不变。
把 \(A\) 拆开看更直观。定义对称部分(Symmetric Part)与反对称部分(Skew-symmetric Part):
- \(S=\frac{A+A^\top}{2}\),满足 \(S=S^\top\)。
- \(K=\frac{A-A^\top}{2}\),满足 \(K^\top=-K\)。
这里“对称部分(Symmetric Part)”是一个定义:对任意方阵 \(A\),把 \(S=\frac{A+A^\top}{2}\) 定义为它的对称部分。它与 \(A\) 同型(同大小),并且一定是对称矩阵;它并非 \(A\) 的某个“子矩阵”。
按元素(Entry-wise)写得更直观:对任意 \(i,j\),
\[S_{ij}=\frac{A_{ij}+A_{ji}}{2},\quad K_{ij}=\frac{A_{ij}-A_{ji}}{2}\]对称部分就是把每一对对称位置 \((i,j)\) 与 \((j,i)\) 的元素取平均;反对称部分则记录它们的“差的一半”。因此 \(A=S+K\) 是把任意矩阵分解成“对称 + 反对称”的标准方式,并且这个分解是唯一的(Unique)。
为什么“取 \(A\) 与 \(A^\top\) 的平均值”就得到对称部分?因为转置(Transpose)会把非对角元素成对交换: \(A_{ij}\leftrightarrow A_{ji}\)。把它们相加后,非对称性(即 \(A_{ij}-A_{ji}\))会被抵消,只留下“对称的那一半”(即 \(A_{ij}+A_{ji}\))。再除以 2,是为了把“加了两份”的量恢复到原始尺度:如果 \(A\) 本来就对称(\(A=A^\top\)),那么 \(\frac{A+A^\top}{2}=A\),不会把矩阵放大一倍。
于是 \(A=S+K\),并且
\[\mathbf{x}^\top A\mathbf{x}=\mathbf{x}^\top S\mathbf{x}+\mathbf{x}^\top K\mathbf{x}\]关键点在于:对任意 \(\mathbf{x}\),都有 \(\mathbf{x}^\top K\mathbf{x}=0\)。理由很短:它是一个标量,等于它自己的转置,而
\[(\mathbf{x}^\top K\mathbf{x})^\top=\mathbf{x}^\top K^\top \mathbf{x}=\mathbf{x}^\top(-K)\mathbf{x}=-(\mathbf{x}^\top K\mathbf{x})\]一个数如果等于它的相反数,只能是 0。于是 \(\mathbf{x}^\top A\mathbf{x}=\mathbf{x}^\top S\mathbf{x}\),二次型确实只由对称部分决定。
二维展开能直接看到“只依赖对称部分”的具体含义。令 \(A=\begin{bmatrix}a & b\\ c & d\end{bmatrix}\)、\(\mathbf{x}=(x_1,x_2)^\top\),则
\[\mathbf{x}^\top A\mathbf{x}=ax_1^2+(b+c)x_1x_2+dx_2^2\]交叉项系数只出现 \(b+c\)(也就是 \(A_{12}+A_{21}\)),而差值 \(b-c\)(反对称部分)完全不会出现。
下面给一个“看得见”的数值例子。取
\[A=\begin{bmatrix}2 & 4\\ -2 & 4\end{bmatrix}\]它显然并非对称矩阵(因为 \(A_{12}=4\ne -2=A_{21}\))。计算它的对称部分:
\[\frac{A+A^\top}{2}=\frac{1}{2}\left(\begin{bmatrix}2 & 4\\ -2 & 4\end{bmatrix}+\begin{bmatrix}2 & -2\\ 4 & 4\end{bmatrix}\right)=\begin{bmatrix}2 & 1\\ 1 & 4\end{bmatrix}=S\]现在比较二次型。对任意 \(\mathbf{x}=(x,y)^\top\):
\[A\mathbf{x}=\begin{bmatrix}2x+4y\\ -2x+4y\end{bmatrix}\Rightarrow \mathbf{x}^\top A\mathbf{x}=x(2x+4y)+y(-2x+4y)=2x^2+2xy+4y^2\] \[S\mathbf{x}=\begin{bmatrix}2x+y\\ x+4y\end{bmatrix}\Rightarrow \mathbf{x}^\top S\mathbf{x}=x(2x+y)+y(x+4y)=2x^2+2xy+4y^2\]两者对所有 \((x,y)\) 都完全相同;例如取 \(\mathbf{x}=(1,2)^\top\),都有 \(\mathbf{x}^\top A\mathbf{x}=\mathbf{x}^\top S\mathbf{x}=22\)。这就直观解释了“二次型只依赖对称部分”的含义:反对称的那一半怎么改,都不会改变 \(\mathbf{x}^\top A\mathbf{x}\) 的值。
因此讨论二次型时通常可假设 \(A=A^\top\)。这也解释了为什么二次型与对称矩阵/半正定性(Positive Semi-Definite, PSD)紧密绑定。
二次型 \(q(\mathbf{x})=\mathbf{x}^\top A\mathbf{x}\) 本身是一个几何对象;它在不同坐标系(Coordinate System)/基(Basis)下的矩阵表示会不同:同一个几何对象,用不同坐标轴/基表示时,系数矩阵 \(A\) 的元素会改变。
这里的标准型指的是:在一类允许的坐标变换(可逆线性变量替换(Invertible Linear Change of Variables))下,把同一个二次型写成某种约定的简化代表。不同教材的约定略有差异,但最常用的目标是:把交叉项(Cross Term)消掉,露出每个坐标轴方向上的“纯平方项”。
把 \(\mathbf{x}=T\mathbf{y}\) 理解成换基(Change of Basis)会更不容易出错: \(\mathbf{y}\) 是同一几何向量在新基下的坐标,矩阵 \(T\) 由新基向量在旧基下的坐标组成。因为 \(T\) 可逆,两套坐标是一一对应的,可以互相换回:
\[\mathbf{y}=T^{-1}\mathbf{x},\quad \mathbf{x}=T\mathbf{y}\]把 \(\mathbf{x}=T\mathbf{y}\) 代入可得
\[q(\mathbf{x})=\mathbf{x}^\top A\mathbf{x}=\mathbf{y}^\top(T^\top A T)\mathbf{y}\]这里要求 \(T\) 可逆(Invertible),意味着这个变量代换不会把空间压缩到低维(不会丢维度)。因此在新坐标 \(\mathbf{y}\) 下,二次型对应的系数矩阵变为 \(T^\top A T\)(这叫合同变换(Congruence Transformation))。可以把 \(T\) 理解为“旋转/缩放后的新坐标轴”在旧坐标里的表示:同一个二次型在新坐标系里的系数就由 \(T^\top A T\) 给出。标准型的目标就是选取合适的 \(T\),把 \(T^\top A T\) 化到更简单的结构。
对角标准型(Diagonal Form)指把二次型写成“只有平方项、没有交叉项”的形式(也常称对角规范形(Diagonal Canonical Form)):
\[q(\mathbf{x})=\sum_{i=1}^{n}\lambda_i y_i^2\]其中 \(\lambda_i\) 是系数,\(\mathbf{y}\) 是新坐标。对角标准型等价于:在新坐标系下,二次型对应的矩阵是对角矩阵(Diagonal Matrix);“交叉项” \(y_i y_j\)(\(i\ne j\))消失。
结论需要明确:标准型与原来的二次型描述的是同一个二次型/同一组几何等值集合,只是坐标系不同。给定可逆变换 \(\mathbf{x}=T\mathbf{y}\),任何关于 \(\mathbf{x}\) 的几何描述都可以无损地翻译成关于 \(\mathbf{y}\) 的描述,并且可以随时“还原”回去。矩阵层面也一样:若 \(A' = T^\top A T\) 是标准型里的系数矩阵,则 \(A=(T^{-1})^\top A' T^{-1}\) 可把它变回原坐标下的表示。
接下来真正关心的是:如何选 \(T\) 才能把交叉项消掉。对二次型而言,一个关键简化是:二次型只依赖矩阵的对称部分,因此总可以先把 \(A\) 对称化为 \(\frac{A+A^\top}{2}\) 而不改变 \(\mathbf{x}^\top A\mathbf{x}\) 的值。于是“消交叉项”的核心问题就变成:对实对称矩阵,能否通过一次正交变基(Orthogonal Change of Basis)把它对角化(Diagonalize)。
对实对称矩阵,对角化与“消掉交叉项”来自同一个结构事实:它总可以通过一次正交变基(Orthogonal Change of Basis)写成对角形式。数学依据就是谱定理(Spectral Theorem,也常表述为“实对称矩阵可正交对角化(Orthogonal Diagonalization)”)。若 \(A\in\mathbb{R}^{n\times n}\) 是实对称矩阵(Real Symmetric Matrix, \(A=A^\top\)),则存在正交矩阵(Orthogonal Matrix)\(Q\) 与实对角矩阵(Real Diagonal Matrix)\(\Lambda\) 使得
\[A=Q\Lambda Q^\top,\quad \text{等价于}\quad Q^\top A Q=\Lambda\]其中 \(Q=[\mathbf{v}_1,\ldots,\mathbf{v}_n]\) 的列向量是一组单位特征向量(Orthonormal Eigenvectors),\(\Lambda=\mathrm{diag}(\lambda_1,\ldots,\lambda_n)\) 的对角元素是对应特征值(Eigenvalues)。该定理同时包含两个常用事实:特征值都是实数;并且可以选出一组两两正交的特征向量作为基。
这就是你熟悉的特征值分解(Eigendecomposition / Eigenvalue Decomposition)的对称矩阵特例。
一般情况下,如果矩阵可对角化(Diagonalizable),可以写成 \(A=V\Lambda V^{-1}\)(或 \(V^{-1}AV=\Lambda\)),其中 \(V\) 的列是特征向量;但 \(V\) 不一定正交(Orthogonal),甚至矩阵可能不可对角化(Non-diagonalizable)。
对称矩阵的额外好处是:可以把 \(V\) 选成正交矩阵 \(Q\),因此 \(V^{-1}=Q^{-1}=Q^\top\),分解变成数值上更稳定、几何上更直观的 \(A=Q\Lambda Q^\top\)。
两个最小例子能把“\(V\) 不一定正交 / 甚至不可对角化”说得更具体:
-
例 1:可对角化,但 \(V\) 不正交。取
\[A_1=\begin{bmatrix}2 & 1\\ 0 & 1\end{bmatrix}\]它的特征值是 \(\lambda_1=2,\lambda_2=1\)(两个不同特征值意味着在二维里一定能找到两条线性无关的特征向量,因此可对角化)。对应一组特征向量可以取
\[\mathbf{v}_1=\begin{bmatrix}1\\ 0\end{bmatrix},\quad \mathbf{v}_2=\begin{bmatrix}1\\ -1\end{bmatrix}\]它们并不正交,因为 \(\mathbf{v}_1^\top\mathbf{v}_2=1\ne 0\)。把它们按列组成矩阵 \(V=[\mathbf{v}_1\ \mathbf{v}_2]\),则
\[V=\begin{bmatrix}1 & 1\\ 0 & -1\end{bmatrix},\quad \Lambda=\begin{bmatrix}2 & 0\\ 0 & 1\end{bmatrix},\quad V^{-1}=\begin{bmatrix}1 & 1\\ 0 & -1\end{bmatrix}\]注意:这个例子里 \(V^{-1}\) 恰好等于 \(V\)(只是代数上的巧合),但它仍然并非正交矩阵,因为正交要求 \(V^{-1}=V^\top\),而这里并不成立。
并且确实有 \(A_1=V\Lambda V^{-1}\)。这个例子说明:一般矩阵即使可对角化,特征向量也未必能选成“互相垂直的方向”。
-
例 2:不可对角化(特征值重复,但特征向量不够)。取
\[A_2=\begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\]它的特征值只有 \(\lambda=1\)(在二维里重复出现)。求特征向量需要解 \((A_2-I)\mathbf{v}=\mathbf{0}\):
\[A_2-I=\begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\Rightarrow (A_2-I)\begin{bmatrix}x\\ y\end{bmatrix}=\begin{bmatrix}y\\ 0\end{bmatrix}=\begin{bmatrix}0\\ 0\end{bmatrix}\Rightarrow y=0\]因此所有特征向量都形如 \((x,0)^\top\),只有 1 个线性无关方向。要写成 \(A_2=V\Lambda V^{-1}\),矩阵 \(V\) 必须可逆(Invertible),这要求有足够多(在二维里是 2 个)线性无关特征向量作为列;该矩阵做不到,所以它不可对角化。
把这个定理放回二次型就能立刻看出“交叉项为什么会消失”。令坐标变换 \(\mathbf{y}=Q^\top\mathbf{x}\)(把 \(\mathbf{x}\) 在特征向量基下的坐标记作 \(\mathbf{y}\)),则
\[\mathbf{x}^\top A\mathbf{x}=\mathbf{x}^\top(Q\Lambda Q^\top)\mathbf{x}=\mathbf{y}^\top\Lambda\mathbf{y}=\sum_{i=1}^{n}\lambda_i y_i^2\]注意这里同时出现了两种“换坐标”的写法:线性变换里常写 \(Q^{-1}AQ\)(相似变换(Similarity Transformation)),二次型里写 \(Q^\top A Q\)(合同变换(Congruence Transformation))。对正交矩阵而言 \(Q^{-1}=Q^\top\),所以它们在这里完全一致:同一个正交变换既给出特征值分解,也把二次型化到没有交叉项的对角标准型。
因此:在对称矩阵的情形,“换到特征向量基”与“把二次型旋转到主轴”是同一件事,只是用不同语言描述。
直观上,特征向量(Eigenvector)给出“主轴方向”(把坐标轴转到这些方向后,交叉项会消失),特征值(Eigenvalue)则是标准型里各平方项前的系数。
详细例子:取
\[A=\begin{bmatrix}5 & -2\\ -2 & 5\end{bmatrix}\]它是对称矩阵,因此可正交对角化。其特征值与一组单位特征向量可以取为:
\[\lambda_1=3,\ \mathbf{v}_1=\frac{1}{\sqrt{2}}\begin{bmatrix}1\\ 1\end{bmatrix};\quad \lambda_2=7,\ \mathbf{v}_2=\frac{1}{\sqrt{2}}\begin{bmatrix}1\\ -1\end{bmatrix}\]把它们组成正交矩阵与对角矩阵:
\[Q=[\mathbf{v}_1\ \mathbf{v}_2]=\frac{1}{\sqrt{2}}\begin{bmatrix}1 & 1\\ 1 & -1\end{bmatrix},\quad \Lambda=\begin{bmatrix}3 & 0\\ 0 & 7\end{bmatrix}\]则 \(A=Q\Lambda Q^\top\)。这里 \(\mathbf{y}\) 核心是 \(\mathbf{x}\) 在特征向量基 \(\{\mathbf{v}_1,\mathbf{v}_2\}\) 下的坐标: \(\mathbf{x}=y_1\mathbf{v}_1+y_2\mathbf{v}_2=Q\mathbf{y}\)。
由于 \(Q\) 是正交矩阵(\(Q^\top Q=I\)),左乘 \(Q^\top\) 可得 \(\mathbf{y}=Q^\top\mathbf{x}\)。这一步就是换基(Change of Basis):把向量从标准坐标系表达改写为主轴坐标系表达。
因此可显式写出两组坐标关系:
\[y_1=\frac{x_1+x_2}{\sqrt{2}},\quad y_2=\frac{x_1-x_2}{\sqrt{2}}\] \[x_1=\frac{y_1+y_2}{\sqrt{2}},\quad x_2=\frac{y_1-y_2}{\sqrt{2}}\]代入标准型:
\[\mathbf{x}^\top A\mathbf{x}=\mathbf{y}^\top\Lambda\mathbf{y}=3y_1^2+7y_2^2\]把 \(\mathbf{y}\) 用 \(\mathbf{x}\) 展开,可直接验证“交叉项被旋转消掉”:
\[3y_1^2+7y_2^2=\frac{3}{2}(x_1+x_2)^2+\frac{7}{2}(x_1-x_2)^2=5x_1^2-4x_1x_2+5x_2^2\]数值校验:取 \(\mathbf{x}=(1,2)^\top\),原式为 \(\mathbf{x}^\top A\mathbf{x}=17\);而 \(\mathbf{y}=Q^\top\mathbf{x}=\left(\frac{3}{\sqrt{2}},-\frac{1}{\sqrt{2}}\right)^\top\),代入 \(3y_1^2+7y_2^2\) 同样得到 17。
几何解释:正交矩阵 \(Q\) 表示旋转/换基,把坐标轴对齐到“主轴方向”(特征向量);对角矩阵 \(\Lambda\) 表示沿主轴的逐轴缩放(由特征值控制)。因此等值线在 \(\mathbf{y}\) 坐标系里与轴对齐,形状由 \(\lambda_i\) 决定。
若 \(\Lambda\) 中既有正特征值也有负特征值,则二次型是不定的(Indefinite):沿某些方向 \(q\) 增大,沿另一些方向 \(q\) 减小。二维里它的等值线(Level Set)典型呈双曲线(Hyperbola)形状,优化里对应鞍点(Saddle Point)结构。例:令 \(A=\begin{bmatrix}1 & 2\\ 2 & 1\end{bmatrix}\),其特征值为 3 与 -1,在某个正交坐标 \(\mathbf{y}\) 下有 \(\mathbf{x}^\top A\mathbf{x}=3y_1^2-y_2^2\),可取正也可取负。
进一步允许一般可逆线性变换(不要求是旋转)时,可把对角项缩放为 \(+1,-1,0\)(Sylvester 惯性定理(Law of Inertia)):二次型被分解为若干正平方项、负平方项与零方向,其中正/负/零项的个数在合同变换下保持不变;“正方向有几个、负方向有几个、平坦方向有几个”是坐标变换改不掉的性质。正/负项的个数也称为签名(Signature)。在优化里,它们分别对应局部最小、鞍点与平坦方向。
下面这些场景看起来不同,但核心都在计算“某个方向上的能量/代价”:给一个向量 \(\mathbf{v}\),二次型 \(\mathbf{v}^\top A\mathbf{v}\) 会告诉你它在矩阵 \(A\) 定义的几何里有多大、代价有多高。
- 平方范数(Squared \(L_2\) Norm):\(\|\mathbf{x}\|_2^2=\mathbf{x}^\top I\mathbf{x}\)。直白地说,它就是“向量长度的平方”,在训练里常作为最基础的“大小惩罚”。例如权重衰减(Weight Decay)把过大的参数拉回去,本质是在最小化 \(\|\theta\|_2^2\) 这种二次型。
- 最小二乘与二次损失(Least Squares / MSE):线性回归目标 \(\|X\mathbf{w}-\mathbf{y}\|_2^2\) 展开后是关于 \(\mathbf{w}\) 的二次型。通俗理解:模型每偏一点,代价按“平方”增长,所以大误差会被更重惩罚。它的闭式解来自正规方程(Normal Equations)\(X^\top X\mathbf{w}=X^\top\mathbf{y}\)。
- PCA(Principal Component Analysis):对中心化(Centering)数据,方向 \(\mathbf{u}\) 上的方差是 \(\mathbf{u}^\top\Sigma\mathbf{u}\)。这句话的直觉是:“把数据投影到某个方向后,能展开多宽”。PCA 就是在所有单位方向里找让这个二次型最大的方向(主成分),因此主成分就是“信息最密集”的方向。
- 马氏距离(Mahalanobis Distance)与高斯负对数似然(Gaussian NLL):核心项是 \((\mathbf{x}-\boldsymbol{\mu})^\top\Sigma^{-1}(\mathbf{x}-\boldsymbol{\mu})\)。可以把它理解成“先按数据真实尺度做校正,再测距离”:方差大的方向偏离一点不算太异常,方差小的方向偏离同样大小则更异常。异常检测(Anomaly Detection)和高斯判别模型都依赖这个量。
- 二阶近似与优化曲率(Second-order Approximation / Curvature):在参数点附近,损失变化可写成 \(\frac{1}{2}\Delta^\top H\Delta\)。它告诉你“往哪个方向走会涨得快/慢”:特征值大表示该方向很陡,特征值小表示平坦,正负混合则是鞍点(Saddle)。牛顿法、预条件(Preconditioning)和学习率调度之所以都关心 Hessian 的谱结构,原因就在这里。
在机器学习的实现层面,二次型也常先通过可逆变量替换 \(\mathbf{x}=T\mathbf{y}\) 化到更易计算的表示: \(q(\mathbf{x})=\mathbf{x}^\top A\mathbf{x}=\mathbf{y}^\top(T^\top A T)\mathbf{y}\)。若 \(A=A^\top\),原坐标有 \(\nabla_{\mathbf{x}}q=2A\mathbf{x}\)、\(\nabla^2_{\mathbf{x}}q=2A\);在新坐标下 \(\nabla_{\mathbf{y}}q=2A'\mathbf{y}\)(\(A'=T^\top A T\))。若进一步化到对角标准型 \(A'=\Lambda\),则 \(\frac{\partial q}{\partial y_i}=2\lambda_i y_i\),逐坐标解耦,推导与实现都会更直接。
这里要区分“性质不变”和“数值不变”:在可逆变量替换下,正定/半正定/不定性质与正负零方向个数(惯性(Inertia))保持不变,因此局部最小/鞍点等优化结构不变;但一般合同变换 \(T^\top A T\) 不要求逐个保留特征值数值,只有正交相似变换 \(Q^\top A Q\) 才逐个保留特征值。
对角矩阵(Diagonal Matrix)是只有对角线元素可能非零的方阵。写作 \(D=\mathrm{diag}(d_1,\ldots,d_n)\),其非对角元素全为 0:
\[D=\begin{bmatrix}d_1 & 0 & \cdots & 0\\ 0 & d_2 & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & d_n\end{bmatrix}\]对角矩阵乘以向量等价于“逐维缩放”:若 \(\mathbf{x}=(x_1,\ldots,x_n)^\top\),则 \(D\mathbf{x}=(d_1x_1,\ldots,d_nx_n)^\top\)。例:令 \(D=\mathrm{diag}(2,0.5)\)、\(\mathbf{x}=(3,4)^\top\),则 \(D\mathbf{x}=(6,2)^\top\)。
在 AI 里,对角矩阵最常见的用途是把“逐元素缩放”写成线性算子:例如 \(\mathbf{x}\odot \mathbf{s}=\mathrm{diag}(\mathbf{s})\mathbf{x}\)。很多优化器的自适应学习率也可以视为对角预条件(Diagonal Preconditioner):例如 Adam/Adagrad 里的 \(1/\sqrt{v+\epsilon}\) 本质上是按参数维度缩放梯度。
对角化(Diagonalization)研究的核心是能否通过换基把它变成对角矩阵。若存在可逆矩阵 \(P\) 与对角矩阵 \(\Lambda\) 使得
\[A=P\Lambda P^{-1}\]则称 \(A\) 可对角化(Diagonalizable)。这里 \(P\) 的列向量通常取为 \(A\) 的一组线性无关特征向量, \(\Lambda\) 的对角线上放的是对应特征值。对角化的本质,是寻找一个“最自然的坐标系”,使线性变换在这个坐标系里不再发生分量混合,而只剩逐坐标缩放。
这和前面的对角矩阵直接连在一起:对角矩阵本来就表示“各坐标轴彼此独立地缩放”;对角化则说明,很多看起来耦合很强的矩阵,只要换到合适基底,也能被还原成这种最简单的作用形式。因此,对角矩阵是结构最简单的目标形式,对角化是把一般矩阵化到这个目标形式的方法。
若写成特征分解的形式,这个关系更直接。设 \(A\) 有 \(n\) 个线性无关特征向量 \(\mathbf{v}_1,\dots,\mathbf{v}_n\),对应特征值为 \(\lambda_1,\dots,\lambda_n\)。令
\[P=[\mathbf{v}_1,\dots,\mathbf{v}_n],\quad \Lambda=\mathrm{diag}(\lambda_1,\dots,\lambda_n)\]则有 \(AP=P\Lambda\),进而得到 \(A=P\Lambda P^{-1}\)。这表明:可对角化的核心条件,就是能否找到足够多的线性无关特征向量,把整个空间铺满。
例:令
\[A=\begin{bmatrix}3 & 1\\ 0 & 2\end{bmatrix}\]它的特征值为 \(3\) 与 \(2\)。对应可取特征向量 \(\mathbf{v}_1=(1,0)^\top\)、\(\mathbf{v}_2=(1,-1)^\top\)。于是
\[P=\begin{bmatrix}1 & 1\\ 0 & -1\end{bmatrix},\quad \Lambda=\begin{bmatrix}3 & 0\\ 0 & 2\end{bmatrix},\quad A=P\Lambda P^{-1}\]在标准坐标下, \(A\) 既有缩放也有“串扰”;在特征向量基下,它只是在第一维乘 3、第二维乘 2。
为什么需要对角化,原因有三层。第一,计算会显著简化。例如
\[A^k=P\Lambda^k P^{-1}\]其中 \(\Lambda^k\) 只需把每个对角元素分别升到 \(k\) 次方,即 \(\Lambda^k=\mathrm{diag}(\lambda_1^k,\dots,\lambda_n^k)\)。这让离散动力系统、马尔可夫链、线性递推、RNN 线性稳定性分析都更容易做。
第二,几何结构会变透明。二次型、曲率、协方差传播等问题,本质都在问“哪些方向最重要、每个方向强度是多少”。对角化以后,每个方向对应一个特征值,方向之间不再耦合。前面讲二次型标准型、正定矩阵、谱分解时反复出现的“换到主轴方向再逐维看”,本质上都属于这种思路。
第三,稳定性与长期行为可以直接从特征值读出。例如在线性迭代 \(\mathbf{x}_{t+1}=A\mathbf{x}_t\) 中,若 \(|\lambda_i|<1\),对应方向会衰减;若 \(|\lambda_i|>1\),对应方向会放大;若 \(|\lambda_i|=1\),则处于临界状态。很多收敛性判断最终都落到这个层面。
对称矩阵是最理想的情形。它不仅可对角化,而且可以被正交对角化:
\[A=Q\Lambda Q^\top\]这里 \(Q\) 是正交矩阵,因此换基不会引入尺度扭曲,只是旋转坐标系。这正是 PCA、协方差分析、Hessian 主曲率分析最喜欢对称矩阵的原因。相比之下,一般矩阵即便可对角化,也可能需要非正交的 \(P\),数值稳定性通常更差。
单位矩阵(Identity Matrix)\(I_n\) 是对角线上全为 1、其他元素为 0 的方阵:
\[I_n=\begin{bmatrix}1 & 0 & \cdots & 0\\ 0 & 1 & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & 1\end{bmatrix}\]它是矩阵乘法的单位元:对任意形状匹配的矩阵 \(A\),有 \(AI=IA=A\);对任意向量 \(\mathbf{x}\),有 \(I\mathbf{x}=\mathbf{x}\)。例:若 \(I_2=\begin{bmatrix}1 & 0\\ 0 & 1\end{bmatrix}\),则 \(I_2(3,4)^\top=(3,4)^\top\)。
在 AI/数值计算里,\(A+\lambda I\)(\(\lambda>0\))用于改善条件数、提高可逆性与数值稳定性:例如岭回归(Ridge Regression)把 \(X^\top X\) 替换为 \(X^\top X+\lambda I\);在高斯模型与协方差估计里常见 \(\Sigma+\epsilon I\) 来保证 Cholesky 分解可用。
对称矩阵(Symmetric Matrix)是满足 \(A=A^\top\) 的实方阵,即 \(A_{ij}=A_{ji}\)。直观上,它的上三角与下三角互为镜像。
例: \(\begin{bmatrix}2 & 1\\ 1 & 3\end{bmatrix}\) 是对称矩阵;而 \(\begin{bmatrix}2 & 1\\ 0 & 3\end{bmatrix}\) 并非,因为非对角元素不成对相等。
对称矩阵拥有更“干净”的谱结构:所有特征值都是实数,并且可正交对角化(Spectral Theorem):\(A=Q\Lambda Q^\top\)(\(Q^\top Q=I\))。这使得很多推导都可以在旋转后的坐标系里逐维分析二次型、曲率与能量。
在 AI 里,对称矩阵高频出现于:
- 协方差矩阵(Covariance Matrix)\(\Sigma\):例如高斯模型与特征白化(Whitening)里,要求 \(\Sigma\succeq 0\),并常用 \(\Sigma+\epsilon I\) 保证数值稳定。
- Gram 矩阵(Gram Matrix)\(X^\top X\) 与核矩阵(Kernel Matrix)\(K\):它们天然对称/半正定,是最小二乘、岭回归与核方法的核心对象。
- 海森矩阵(Hessian):当目标函数二阶连续可导时,Hessian 对称;其特征值决定局部曲率,从而决定“极小/极大/鞍点”的类型与优化难度。
厄米矩阵(Hermitian Matrix)是复数域上与对称矩阵对应的概念。若复矩阵 \(A\in\mathbb{C}^{n\times n}\) 满足
\[A=A^\ast\]则称 \(A\) 为厄米矩阵,其中 \(A^\ast\) 表示共轭转置(Conjugate Transpose):先转置,再对每个元素取复共轭。因此,厄米矩阵满足按元素关系 \(A_{ij}=\overline{A_{ji}}\)。可以把它直接理解为复数版本的对称矩阵。
例: \(\begin{bmatrix}1 & 2+i\\ 2-i & 3\end{bmatrix}\) 是厄米矩阵,因为非对角元素互为复共轭,而对角线元素必须是实数。厄米矩阵保留了实对称矩阵最重要的好性质:特征值全为实数,并且可以被酉矩阵(Unitary Matrix)对角化。因此在复数信号处理、量子力学、复数优化与某些频域分析里,它扮演的角色与实对称矩阵在实数域中的角色完全对应。
可逆矩阵(Invertible Matrix)是存在逆矩阵的方阵:对 \(A\in\mathbb{R}^{n\times n}\),若存在 \(A^{-1}\) 使得 \(AA^{-1}=A^{-1}A=I\),则 \(A\) 可逆;否则称 \(A\) 为奇异矩阵(Singular Matrix)。
等价判据(常用):\(A\) 可逆 \(\Leftrightarrow \det(A)\ne 0 \Leftrightarrow \mathrm{rank}(A)=n\)(列向量线性无关)。
例(可逆):令 \(A=\begin{bmatrix}2 & 1\\ 1 & 1\end{bmatrix}\),则 \(\det(A)=1\),并且 \(A^{-1}=\begin{bmatrix}1 & -1\\ -1 & 2\end{bmatrix}\)。
例(奇异):令 \(B=\begin{bmatrix}1 & 2\\ 2 & 4\end{bmatrix}\),第二行是第一行的 2 倍,因此秩为 1、行列式为 0,无法求逆。对应线性方程组 \(B\mathbf{x}=\mathbf{b}\) 可能无解(例如 \(\mathbf{b}=(3,5)^\top\)),也可能有无穷多解(例如 \(\mathbf{b}=(3,6)^\top\))。
在 AI 里,奇异性最常出现在最小二乘与协方差:当特征共线、维度远大于样本数(\(d\gg N\))时,\(X^\top X\) 往往奇异或病态(Ill-conditioned)。常见处理是正则化(\(X^\top X+\lambda I\))或用 SVD/QR 求解并使用伪逆(Pseudoinverse)\(A^+\)。
实现上通常避免显式求 \(A^{-1}\):更稳定的做法是直接求解 \(A\mathbf{x}=\mathbf{b}\)(Solve),或用分解(Cholesky / QR / SVD)替代。
正交矩阵(Orthogonal Matrix)是满足 \(Q^\top Q=QQ^\top=I\) 的实方阵。它的列向量(或行向量)构成一组正交标准基(Orthonormal Basis),因此保持长度与点积:对任意向量 \(\mathbf{x}\) 有 \(\|Q\mathbf{x}\|_2=\|\mathbf{x}\|_2\),对任意向量 \(\mathbf{a},\mathbf{b}\) 有 \((Q\mathbf{a})^\top(Q\mathbf{b})=\mathbf{a}^\top\mathbf{b}\)。
正交矩阵的列向量不需要“沿着坐标轴方向”。要求只有一个:列向量两两正交且都是单位向量,也就是构成一组正交标准基。标准基(\(\mathbf{e}_1,\mathbf{e}_2,\ldots\))只是其中最常用的一组。
例(旋转 45°):令
\[Q=\frac{1}{\sqrt{2}}\begin{bmatrix}1 & -1\\ 1 & 1\end{bmatrix}\]它的两列分别是 \(\frac{1}{\sqrt{2}}(1,1)^\top\) 与 \(\frac{1}{\sqrt{2}}(-1,1)^\top\),都不与坐标轴对齐,但它们正交且单位长度,因此
\[Q^\top Q=\frac{1}{2}\begin{bmatrix}1 & 1\\ -1 & 1\end{bmatrix}\begin{bmatrix}1 & -1\\ 1 & 1\end{bmatrix}=\begin{bmatrix}1 & 0\\ 0 & 1\end{bmatrix}=I\]例(二维旋转 90°):令
\[R=\begin{bmatrix}0 & -1\\ 1 & 0\end{bmatrix},\quad R^\top=\begin{bmatrix}0 & 1\\ -1 & 0\end{bmatrix}\]则
\[R^\top R=RR^\top=\begin{bmatrix}1 & 0\\ 0 & 1\end{bmatrix}=I\]在 AI 里,正交矩阵常用于正交初始化(Orthogonal Initialization)、QR 分解与正交约束参数化;核心目的是把谱范数控制在 1 附近,改善深层网络与 RNN 的数值稳定性。
酉矩阵(Unitary Matrix)是复数域上的“长度保持”线性变换。对复矩阵 \(U\in\mathbb{C}^{n\times n}\),若满足
\[U^\ast U=UU^\ast=I\]则称 \(U\) 为酉矩阵,其中 \(U^\ast\) 是共轭转置(Conjugate Transpose)。酉矩阵的列向量构成一组正交归一基(Orthonormal Basis),因此对任意向量 \(\mathbf{x}\) 都有 \(\|U\mathbf{x}\|_2=\|\mathbf{x}\|_2\)。
实数域特例:当矩阵元素为实数时,酉矩阵退化为正交矩阵(Orthogonal Matrix),即满足 \(Q^\top Q=QQ^\top=I\)。
例(复数域):令
\[U=\begin{bmatrix}1 & 0\\ 0 & i\end{bmatrix},\quad U^\ast=\begin{bmatrix}1 & 0\\ 0 & -i\end{bmatrix}\]则可直接计算:
\[U^\ast U=\begin{bmatrix}1 & 0\\ 0 & -i\end{bmatrix}\begin{bmatrix}1 & 0\\ 0 & i\end{bmatrix}=\begin{bmatrix}1 & 0\\ 0 & 1\end{bmatrix}=I,\quad UU^\ast=\begin{bmatrix}1 & 0\\ 0 & i\end{bmatrix}\begin{bmatrix}1 & 0\\ 0 & -i\end{bmatrix}=I\]在 AI 里,正交/酉矩阵常用于控制数值稳定性:例如正交初始化(Orthogonal Initialization)与正交/酉参数化可把谱范数压在 1 附近,缓解深层网络与 RNN 中的梯度爆炸/消失;一些长序列建模会使用 unitary/orthogonal RNN 来更好地传播长程信息。
正定矩阵(Positive Definite Matrix)把“二次型总是正”形式化。对对称矩阵(Symmetric Matrix)\(A=A^\top\),若对任意非零向量 \(\mathbf{x}\ne\mathbf{0}\) 都有
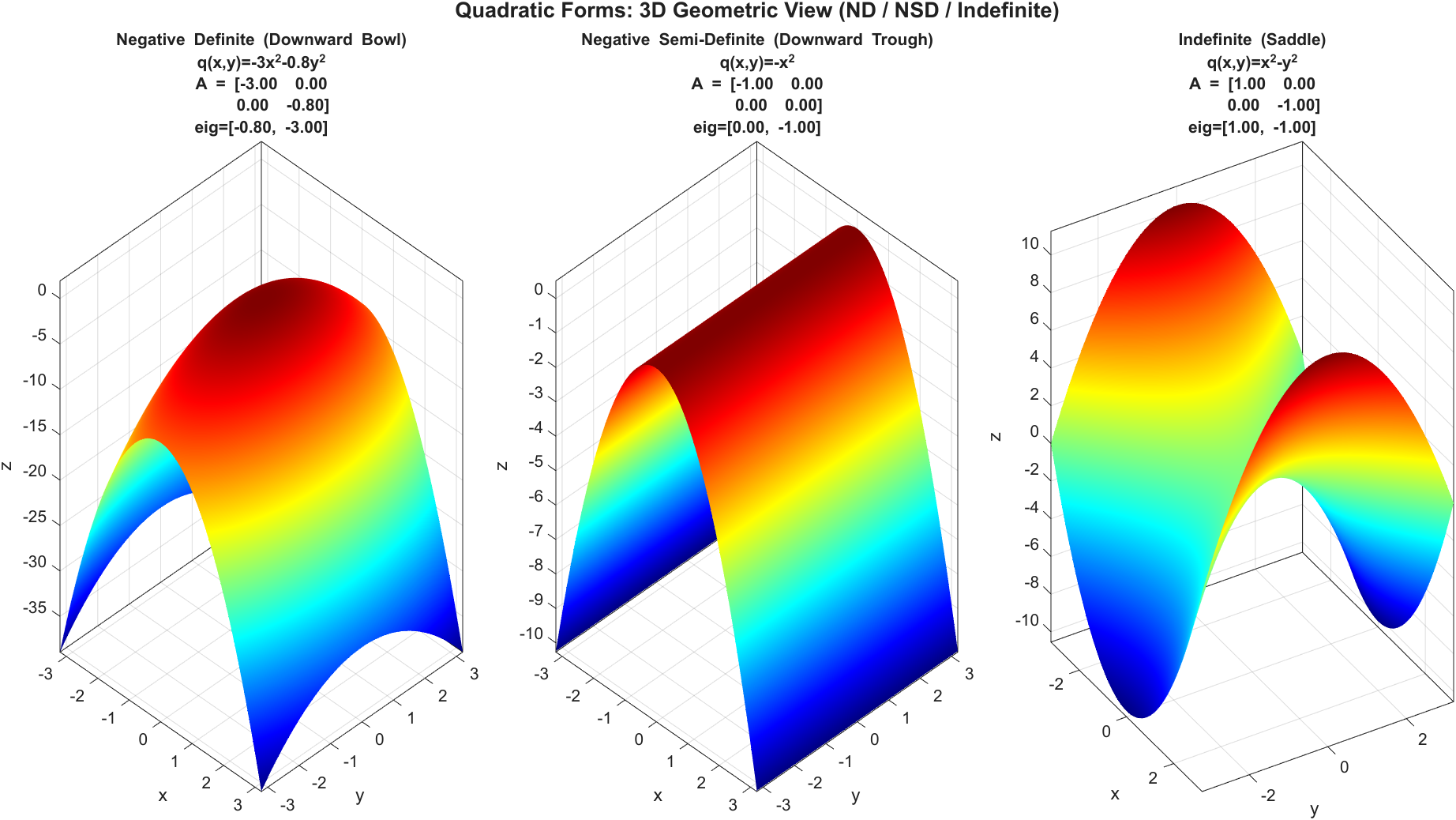
\[\mathbf{x}^\top A\mathbf{x} > 0\]则称 \(A\) 正定,记作 \(A\succ 0\)。若是 \(\ge 0\) 则为半正定(Positive Semi-Definite, PSD),记作 \(A\succeq 0\)。
几何上,把 \(q(x,y)=\mathbf{x}^\top A\mathbf{x}\) 画成 \(z=q(x,y)\) 的三维曲面时,正定对应“向上开口的碗”(椭圆抛物面(Elliptic Paraboloid)):原点是唯一最低点,任意非零方向都往上抬升。若没有交叉项(\(bxy\) 项为 0),等值线与坐标轴对齐;若有交叉项(\(b\ne 0\)),碗的主轴会旋转,但“向上碗”的本质不变。半正定则可能出现平坦方向(Flat Direction),典型形状是槽(Trough)而非严格碗底。
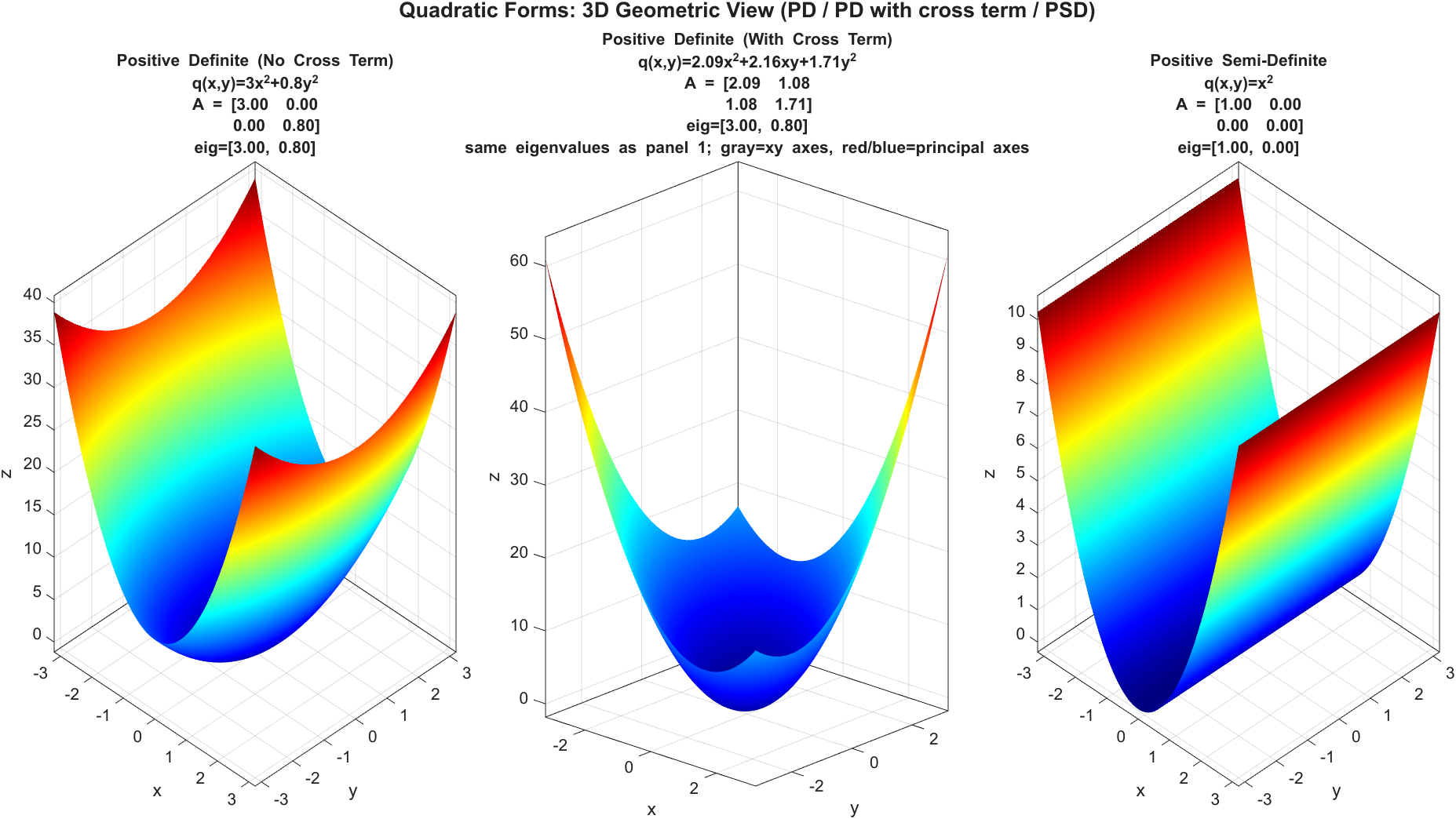
从特征值(Eigenvalues)角度看,对称矩阵 \(A\) 的二次型类型可直接由特征值符号判别(下述以二维 \(\lambda_1,\lambda_2\) 为例):
- \(\lambda_1>0,\lambda_2>0\):正定(Positive Definite, PD),向上开口碗。
- \(\lambda_1<0,\lambda_2<0\):负定(Negative Definite, ND),向下开口碗。
- 一个为 0、另一个大于 0:半正定(Positive Semi-Definite, PSD),出现平坦方向,形状更像槽。
- 一个为 0、另一个小于 0:半负定(Negative Semi-Definite, NSD),对应“倒槽”。
- 一正一负:不定(Indefinite),对应鞍面(Saddle Surface)。
因此图里“有交叉项”并不改变正负定类型;它主要改变主轴方向(旋转等值线),曲面属于碗、槽还是鞍,则由特征值符号决定。
例:令
\[A=\begin{bmatrix}2 & 1\\ 1 & 2\end{bmatrix}\]对任意 \(\mathbf{x}=(x_1,x_2)^\top\),有
\[\mathbf{x}^\top A\mathbf{x}=2x_1^2+2x_1x_2+2x_2^2=(x_1+x_2)^2+x_1^2+x_2^2>0\quad (\mathbf{x}\ne\mathbf{0})\]因此 \(A\succ 0\)。同时它的特征值为 3 与 1(均为正),并且存在 Cholesky 分解:
\[A=LL^\top,\quad L=\begin{bmatrix}\sqrt{2} & 0\\ \frac{1}{\sqrt{2}} & \sqrt{\frac{3}{2}}\end{bmatrix}\]等价刻画(常用):
- \(A\succ 0\) 当且仅当所有特征值 \(\lambda_i>0\)。
- \(A\succ 0\) 当且仅当存在 Cholesky 分解 \(A=LL^\top\)(\(L\) 下三角且对角为正)。
它在优化里非常关键:若函数的海森矩阵(Hessian)在某点正定,则该点是严格局部极小;若 Hessian 半正定,则函数局部凸(Locally Convex)。
特征值(Eigenvalue)与特征向量(Eigenvector)描述线性变换的“固有方向”:若存在非零向量 \(\mathbf{v}\ne\mathbf{0}\) 与标量 \(\lambda\) 使得
\[A\mathbf{v}=\lambda \mathbf{v}\]则 \(\mathbf{v}\) 是特征向量,\(\lambda\) 是对应特征值。几何上,沿特征向量方向的向量经过变换后方向不变,只被缩放(若 \(\lambda<0\) 还会翻转)。
当矩阵可对角化(Diagonalizable)时,可写为 \(A=V\Lambda V^{-1}\),其中 \(\Lambda\) 是特征值对角矩阵,列向量 \(V=[\mathbf{v}_1,\dots,\mathbf{v}_n]\) 是特征向量。
对称矩阵(Symmetric Matrix)是最重要的特例:它的特征向量可取为一组正交归一基(Orthonormal Basis),因此
\[A=Q\Lambda Q^\top,\quad Q^\top Q=I\]这正是 PCA(Principal Component Analysis)等方法背后的谱分解(Spectral Decomposition)基础。
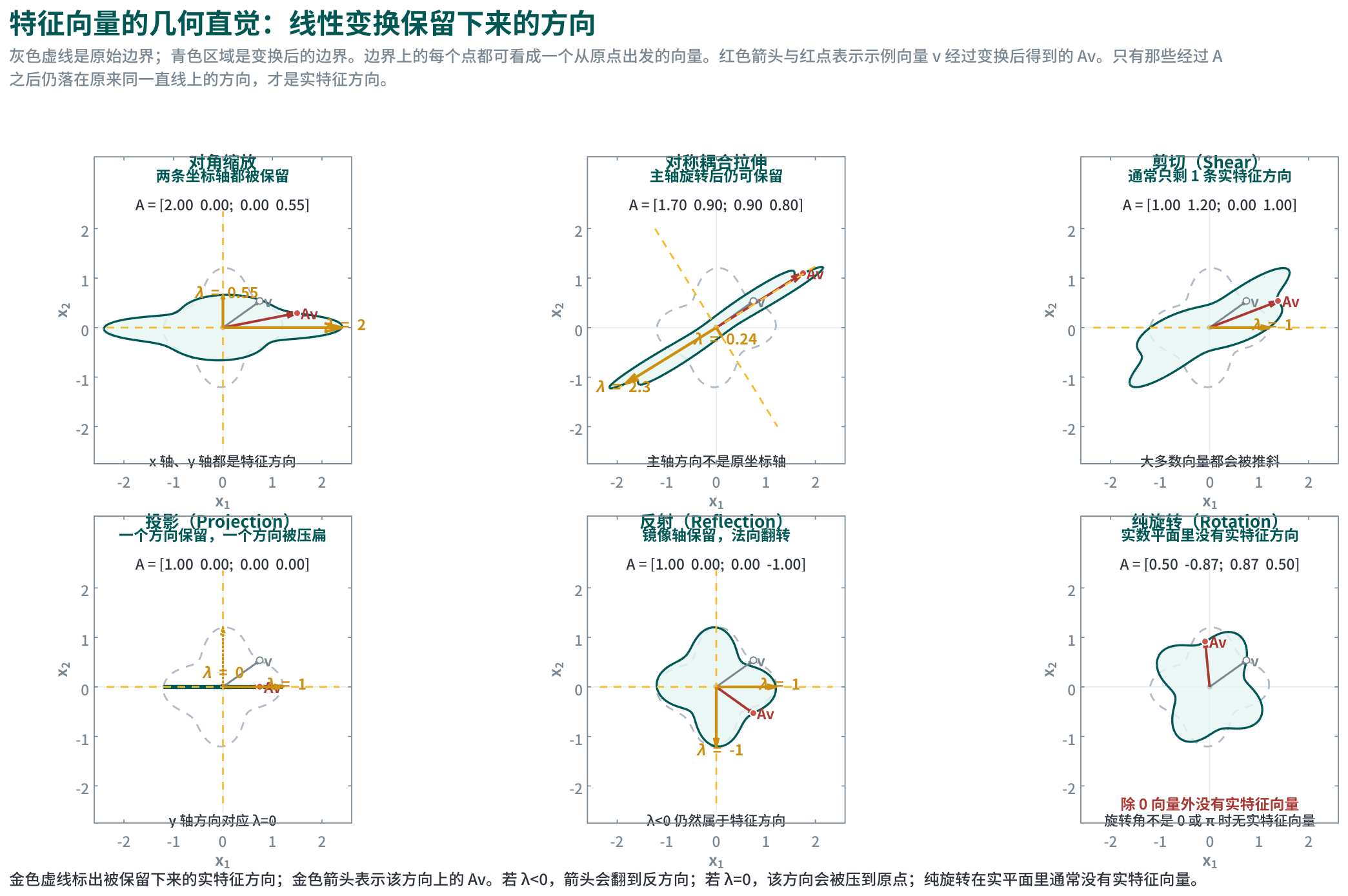
只看公式 \(A\mathbf{v}=\lambda \mathbf{v}\) 仍然容易抽象。二维里更直观的看法是:把原点周围一个闭合形状的边界看成“很多向量的端点集合”。边界上的每个点 \(\mathbf{v}\) 都对应一根从原点出发的向量;施加线性变换 \(A\) 后,这个端点会被送到新位置 \(A\mathbf{v}\),整个形状也随之被拉伸、压缩、剪切、翻折或旋转。
特征向量方向的判别标准正是:变换后是否仍落在原来的那条直线上。若某个非零向量满足 \(A\mathbf{v}=\lambda\mathbf{v}\),那么 \(A\mathbf{v}\) 只是 \(\mathbf{v}\) 的倍数,它仍位于通过原点和 \(\mathbf{v}\) 的那条一维子空间上。因此,特征向量真正对应的是一个被保留下来的方向,而非某个固定长度的箭头。
这里要把“方向”理解为过原点的一条直线,而非有朝向的箭头。若 \(\lambda>0\),变换后的向量和原向量同向,只是被拉长或缩短;若 \(\lambda<0\),变换后会翻到反方向,但仍留在同一条直线上,因此它依然是特征方向;若 \(\lambda=0\),该方向上的向量会被压到原点,这说明这条方向被完全消灭了,但它仍然对应一个特征值为 0 的特征方向。
很多常见变换都可以用这套语言重述:
- 对角缩放(Diagonal Scaling):例如 \(\mathrm{diag}(2,0.5)\)。坐标轴方向会被保留,因此 \(x\) 轴和 \(y\) 轴就是特征方向;对应特征值分别是 2 和 0.5。
- 对称耦合拉伸(Symmetric Coupled Stretch):矩阵含有非零交叉项时,保留下来的方向通常不再和原坐标轴对齐,而会旋转到主轴方向。因此,对称矩阵会和椭圆主轴、二次型标准型、PCA 主方向自然连到一起。
- 剪切(Shear):例如 \(\begin{bmatrix}1 & 1\\ 0 & 1\end{bmatrix}\)。多数向量都会被“推斜”,通常只有少数方向真正保持不变;在这个例子里, \(x\) 轴方向被保留,而绝大多数其他方向都并非特征方向。
- 投影(Projection):例如投影到 \(x\) 轴。被保留下来的子空间对应 \(\lambda=1\),被压扁掉的方向对应 \(\lambda=0\)。
- 反射(Reflection):关于某条直线做镜像时,镜像轴本身是 \(\lambda=1\) 的特征方向;与它正交的法向方向会被翻过去,因此是 \(\lambda=-1\) 的特征方向。
- 纯旋转(Rotation):在实数平面中,只要旋转角度并非 \(0\) 或 \(\pi\),就不存在非零向量在旋转后仍留在原来的直线上,因此没有实特征向量。二维纯旋转的特征值要到复数域里才会出现,形式是 \(e^{\pm i\theta}\)。
因此,特征值和特征向量核心是在回答一个非常几何的问题:这个线性变换到底保留了哪些一维方向,以及沿这些方向会放大、缩小、翻转还是压扁到 0。后面讲特征空间、可对角化、谱分解时,本质都在把这种“被保留下来的方向结构”系统化。
单个特征向量只是一条方向;特征空间(Eigenspace)则把所有属于同一特征值的特征向量连同零向量一起统一起来。对特征值 \(\lambda\),其特征空间定义为
\[E_\lambda(A)=\ker(A-\lambda I)=\{\mathbf{v}\in\mathbb{R}^n\mid A\mathbf{v}=\lambda \mathbf{v}\}\]这里 \(\ker(A-\lambda I)\) 表示核空间(Kernel / Null Space)。定义的含义很直接:凡是被 \(A\) 作用后只发生 \(\lambda\) 倍缩放的向量,全都落在同一个特征空间里。由于核空间本身是线性子空间,因此特征空间天然是一个子空间,而非若干零散向量的集合。
这件事的线性结构很重要。若 \(\mathbf{v}_1,\mathbf{v}_2\in E_\lambda(A)\),且 \(c_1,c_2\) 是任意标量,则
\[A(c_1\mathbf{v}_1+c_2\mathbf{v}_2)=c_1A\mathbf{v}_1+c_2A\mathbf{v}_2=c_1\lambda\mathbf{v}_1+c_2\lambda\mathbf{v}_2=\lambda(c_1\mathbf{v}_1+c_2\mathbf{v}_2)\]因此同一特征值对应的任意线性组合,仍然属于同一个特征空间。这就是为什么当某个特征值有多个线性无关特征向量时,不会把它们看成彼此无关的点,会整体看成一个方向簇所张成的子空间。
例:令
\[A=\begin{bmatrix}2 & 0\\ 0 & 2\end{bmatrix}=2I\]则对任意向量 \(\mathbf{v}\in\mathbb{R}^2\),都有 \(A\mathbf{v}=2\mathbf{v}\)。因此特征值 \(\lambda=2\) 的特征空间核心是整个平面 \(\mathbb{R}^2\)。这说明:同一个特征值可以对应一个高维子空间。
再看另一个例子。若
\[A=\begin{bmatrix}3 & 1\\ 0 & 3\end{bmatrix}\]则唯一特征值是 \(3\),但
\[A-3I=\begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\]它的核空间只有形如 \((x,0)^\top\) 的向量,因此特征空间是一维的,而非二维。这意味着虽然特征值按代数重数(Algebraic Multiplicity)出现了两次,但线性无关特征向量只有一个,矩阵就不可对角化。这里暴露出的关键区别是:
- 代数重数(Algebraic Multiplicity):\(\lambda\) 作为特征多项式根出现的次数。
- 几何重数(Geometric Multiplicity):特征空间 \(E_\lambda(A)\) 的维数,也就是线性无关特征向量的个数。
对任一特征值 \(\lambda\),总有 \(1\le \dim E_\lambda(A)\le m_\lambda\),其中 \(m_\lambda\) 表示 \(\lambda\) 的代数重数。矩阵可对角化,当且仅当所有特征空间的维数加起来达到 \(n\),也就是能从这些特征空间里取出一组基,铺满整个空间。
从几何上看,特征空间给出的核心是一整块在变换下保持不变的空间(Invariant Subspace):若 \(\mathbf{v}\in E_\lambda(A)\),那么 \(A\mathbf{v}\) 仍留在这个子空间内。对称矩阵的优势再次体现在这里:不同特征值对应的特征空间彼此正交,因此整个空间可以被分解为若干互相独立的主方向子空间。这也是谱分解、PCA 和二次型主轴分析能如此清晰的根本原因。
特征值(Eigenvalue)与秩(Rank)之间的关系,核心在于 \(\lambda=0\) 这个特征值。因为
\[A\mathbf{v}=0\cdot \mathbf{v}=\mathbf{0}\]说明:0 是特征值,当且仅当存在非零向量被 \(A\) 压到 0。而这正是核空间(Kernel / Null Space)非平凡的条件,也就是矩阵丢失维度、不能满秩、不可逆的根源。
对方阵 \(A\in\mathbb{R}^{n\times n}\),最稳定的一条结论是:
\[A\ \text{满秩}\ \Longleftrightarrow\ \mathrm{rank}(A)=n\ \Longleftrightarrow\ \det(A)\ne 0\ \Longleftrightarrow\ 0\notin \sigma(A)\]因此,若一个方阵满秩,那么它的所有特征值都非零;反过来,只要 0 是特征值,矩阵就一定并非满秩。这条结论并不要求矩阵可对角化,对任意方阵都成立。
若再加上“可对角化(Diagonalizable)”这个前提,秩与特征值个数之间就能写得更直接。设
\[A=P\Lambda P^{-1},\quad \Lambda=\mathrm{diag}(\lambda_1,\dots,\lambda_n)\]因为可逆变换 \(P\) 与 \(P^{-1}\) 不会改变秩,所以
\[\mathrm{rank}(A)=\mathrm{rank}(\Lambda)\]而对角矩阵的秩最容易读:它恰好等于非零对角元素的个数。因此在可对角化情形下,
\[\mathrm{rank}(A)=\#\{i\mid \lambda_i\ne 0\}\]这里计数的是按代数重数(Algebraic Multiplicity)展开后的特征值个数。对可对角化方阵,秩就是非零特征值的数量,零特征值的数量则等于亏格(Nullity)。
例:若
\[\Lambda=\mathrm{diag}(5,2,0,0)\]则 \(\mathrm{rank}(\Lambda)=2\)。任何与它相似且可对角化的矩阵 \(A=P\Lambda P^{-1}\),秩也都是 2,因为其中只有两个非零特征值。
这个结论在不可对角化时不能直接照搬。例:令
\[J=\begin{bmatrix}0 & 1\\ 0 & 0\end{bmatrix}\]它唯一的特征值是 0,但 \(\mathrm{rank}(J)=1\)。原因在于:虽然 0 是唯一特征值,但这个矩阵含有非平凡 Jordan 块(Jordan Block),它仍然会把某些向量送到非零方向。因此“秩等于非零特征值个数”必须以可对角化为前提;对一般方阵,只能稳妥地使用“满秩当且仅当 0 并非特征值”这条判据。
从线性映射角度看,这组关系也很自然。非零特征值对应的特征方向会被保留下来,只是被缩放;0 特征值对应的方向会被压扁到更低维空间。矩阵秩衡量的正是“最终还能保留下来的独立方向数目”,因此它会和 0 特征值是否存在、以及存在多少,在可对角化情形下发生直接对应。
矩阵的谱(Spectrum)指的是矩阵全部特征值构成的集合。对方阵 \(A\in\mathbb{C}^{n\times n}\),常记为 \(\sigma(A)\):
\[\sigma(A)=\{\lambda\in\mathbb{C}\mid \det(A-\lambda I)=0\}\]这里之所以会把行列式(Determinant)扯进来,是因为特征值定义本身就会自然导向这个条件。若 \(\lambda\) 是特征值,按定义必须存在某个非零向量 \(\mathbf{v}\ne \mathbf{0}\) 使得
\[A\mathbf{v}=\lambda \mathbf{v}\]把右边移到左边,就是
\[(A-\lambda I)\mathbf{v}=\mathbf{0}\]这说明:矩阵 \(A-\lambda I\) 对应的齐次线性方程组必须有非零解。而线性代数里,一个方阵齐次方程组有非零解,当且仅当该矩阵不可逆;对方阵而言,不可逆又等价于行列式为 0。因此就得到
\[\det(A-\lambda I)=0\]行列式在这里核心是“特征向量存在非零解”这一要求的等价写法。解这个方程得到的多项式根,就是矩阵的全部特征值。
这个定义的关键核心是把矩阵最核心的线性作用浓缩成一组标量。许多稳定性、可逆性、收敛性与几何性质,最终都可以回到谱上来判断。例:若 \(0\in \sigma(A)\),则 \(A\) 不可逆;若所有特征值都为正,且 \(A\) 对称,则它是正定矩阵。
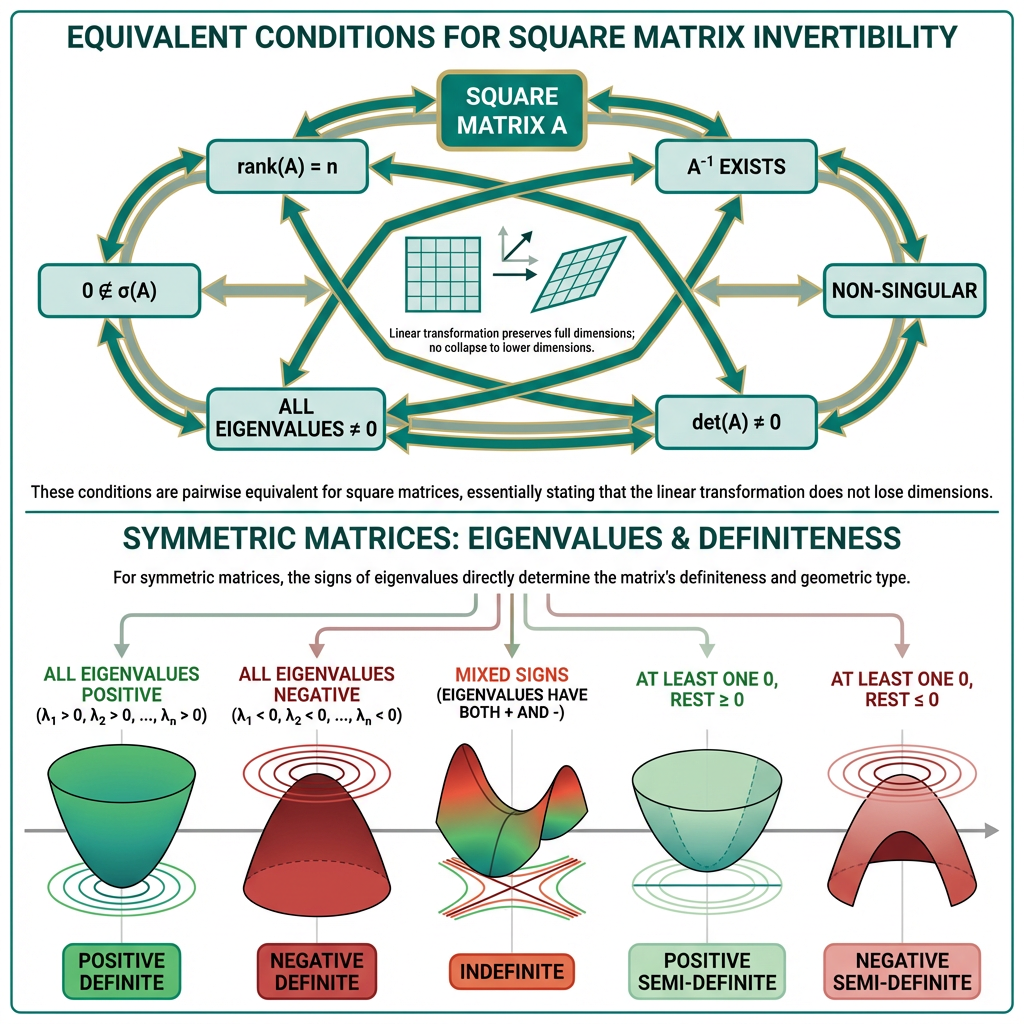
与谱紧密相关、但不能混为一谈的另一个概念是谱半径(Spectral Radius):
\[\rho(A)=\max_{\lambda\in\sigma(A)}|\lambda|\]它只取特征值模长中的最大者。谱是整个特征值集合,谱半径只是其中的最大模长摘要。在线性迭代、RNN 稳定性与幂法(Power Method)里,谱半径尤其常见。
谱定理(Spectral Theorem)是线性代数里最重要的结构定理之一。对实对称矩阵 \(A=A^\top\),存在正交矩阵 \(Q\) 与实对角矩阵 \(\Lambda\),使得
\[A=Q\Lambda Q^\top\]等价地说, \(Q\) 的列向量是一组两两正交的单位特征向量, \(\Lambda\) 的对角线上放着对应特征值。这条定理的含义非常深:对称矩阵不仅“有特征值”,而且它的全部作用都可以被解释为先换到特征向量基,再按各坐标轴独立缩放。二次型、协方差矩阵、Hessian、图 Laplacian 等对象一旦对称,分析通常都会变得异常清爽。
在复数域上,对应版本是厄米矩阵(Hermitian Matrix)\(A=A^\ast\) 可被酉矩阵(Unitary Matrix)对角化:
\[A=U\Lambda U^\ast\]这类“可由一组正交 / 酉基完全分解”的矩阵,在数值上更稳定、几何上更透明,也正因此成为机器学习里最重要的一类矩阵对象。
谱范数(Spectral Norm)记作 \(\|A\|_2\),定义为矩阵对单位向量能造成的最大放大倍数:
\[\|A\|_2=\max_{\|\mathbf{x}\|_2=1}\|A\mathbf{x}\|_2\]这一定义直接揭示了它的几何意义:找出所有长度为 1 的输入向量,看矩阵 \(A\) 最多能把哪一个方向拉得最长。对任意矩阵,都有
\[\|A\|_2=\sigma_{\max}(A)=\sqrt{\lambda_{\max}(A^\top A)}\]其中 \(\sigma_{\max}(A)\) 是最大奇异值。若 \(A\) 还是实对称矩阵,则奇异值等于特征值绝对值,于是谱范数进一步化为
\[\|A\|_2=\max_i |\lambda_i(A)|\]因此,对一般矩阵要通过奇异值来理解谱范数;对对称矩阵,则可以直接通过特征值来理解。要特别区分:谱范数与谱半径在对称 / 正规矩阵上常常一致,但对一般非正规矩阵并不总相同。
在 AI 中,谱范数最常用于表达“局部放大能力”与 Lipschitz 常数控制。若某层线性映射的谱范数过大,它会把某些方向的扰动显著放大,进而加重训练不稳定、梯度爆炸或对抗脆弱性;这也是谱归一化(Spectral Normalization)、正交初始化与某些鲁棒优化方法反复关注它的原因。
奇异值分解(SVD, Singular Value Decomposition)对任意矩阵 \(A\in\mathbb{R}^{m\times n}\) 都成立:
\[A=U\Sigma V^\top\]其中 \(U\in\mathbb{R}^{m\times m}\)、\(V\in\mathbb{R}^{n\times n}\) 是正交矩阵(Orthogonal Matrix),\(\Sigma\in\mathbb{R}^{m\times n}\) 是对角(更准确说是“对角形”)矩阵,其对角线元素 \(\sigma_1\ge\sigma_2\ge\cdots\ge 0\) 为奇异值(Singular Values)。
几何解释非常直接:先用 \(V^\top\) 旋转/换基,再用 \(\Sigma\) 沿坐标轴缩放,最后用 \(U\) 再旋转。因此 SVD 是“旋转-缩放-旋转”的标准分解。
SVD 与特征值的关系要分左右两侧一起看:
- 右奇异向量(Right Singular Vectors)是 \(A^\top A\) 的特征向量,即 \(A^\top A\mathbf{v}_i=\sigma_i^2\mathbf{v}_i\)。
- 左奇异向量(Left Singular Vectors)是 \(AA^\top\) 的特征向量,即 \(AA^\top\mathbf{u}_i=\sigma_i^2\mathbf{u}_i\)。
其中\(\sigma_i^2\) 是 \(A^\top A\) 与 \(AA^\top\) 的特征值;\(\sigma_i\) 为奇异值(即这些非零特征值的平方根)。
矩阵形式分别是 \(A^\top A=V\Sigma^\top\Sigma V^\top\) 与 \(AA^\top=U\Sigma\Sigma^\top U^\top\),因此非零奇异值满足 \(\sigma_i=\sqrt{\lambda_i(A^\top A)}=\sqrt{\lambda_i(AA^\top)}\)。这也解释了为什么奇异值总是非负,而一般矩阵的特征值可以为负甚至为复数。
若 \(\sigma_i>0\),左右奇异向量还可互相对应: \(\mathbf{u}_i=\frac{A\mathbf{v}_i}{\sigma_i}\)、\(\mathbf{v}_i=\frac{A^\top\mathbf{u}_i}{\sigma_i}\)。
特殊地,若 \(A\) 是对称矩阵,则它可正交对角化,此时奇异值等于特征值的绝对值:\(\sigma_i=|\lambda_i(A)|\);若 \(A\succeq 0\)(半正定),则 \(\sigma_i=\lambda_i(A)\)。
为什么 SVD 可用于压缩与降维(Compression & Dimensionality Reduction)?因为很多数据/权重矩阵在有效意义下是低秩(Low-rank)的:只有前几个 \(\sigma_i\) 很大,后面的奇异值接近 0。保留前 \(k\) 项得到秩 \(k\) 近似:
\[A_k=U_{(:,1:k)}\Sigma_{(1:k,1:k)}V_{(:,1:k)}^\top\]它在 Frobenius 范数(Frobenius Norm)与谱范数(Spectral Norm)意义下都是最优的秩 \(k\) 近似(Eckart–Young 定理):用最少的信息保留最大的能量(由奇异值平方决定)。
在 PCA 中,对中心化数据矩阵 \(X\) 做 SVD: \(X=U\Sigma V^\top\),右奇异向量 \(V\) 给出主方向(Principal Directions),奇异值刻画各方向的方差贡献(Variance Explained)。

范数(Norm)刻画“向量大小”。在 AI 中,它最常出现在三类地方:距离度量(Distance Metric)、正则化(Regularization)与鲁棒性约束(Robustness Constraint)。对 \(\mathbf{x}\in\mathbb{R}^d\),当 \(p\ge 1\) 时 \(L_p\) 范数定义为
\[\|\mathbf{x}\|_p=\left(\sum_{i=1}^{d}|x_i|^p\right)^{1/p},\quad p\ge 1\]并且 \(\|\mathbf{x}\|_\infty=\max_i |x_i|=\lim_{p\to\infty}\|\mathbf{x}\|_p\)。
\(\|\mathbf{x}\|_0\) 定义为非零分量的个数:
\[\|\mathbf{x}\|_0=\#\{i\mid x_i\ne 0\}\]严格来说它并非范数:例如对任意非零标量 \(\alpha\ne 0\),有 \(\|\alpha\mathbf{x}\|_0=\|\mathbf{x}\|_0\),不满足齐次性(Homogeneity)\(\|\alpha\mathbf{x}\|=|\alpha|\|\mathbf{x}\|\)。
例:若 \(\mathbf{x}=(3,0,-1,0)\),则 \(\|\mathbf{x}\|_0=2\)。
在 AI 里,\(\|\cdot\|_0\) 用来表达稀疏性(Sparsity):特征选择(Feature Selection)、压缩感知(Compressed Sensing)与网络剪枝(Pruning)常以“非零个数最少”为目标。但直接优化 \(\|\cdot\|_0\) 一般是组合优化,常用 \(\|\cdot\|_1\) 或其他可优化的替代目标近似。
例:若 \(\mathbf{x}=(3,4)\),则 \(\|\mathbf{x}\|_1=7\)。几何上,二维 \(L_1\) 等值线是菱形;与 \(L_2\) 的圆相比,它更容易在坐标轴上产生“尖角”,对应优化时更容易把部分坐标推到 0。
在 AI 里,\(L_1\) 正则化是稀疏学习(Sparse Learning)的标准工具:在凸模型中会得到稀疏解(例如 Lasso);在深度模型中也常用于诱导稀疏权重/稀疏特征、做轻量化。
例:若 \(\mathbf{x}=(3,4)\),则 \(\|\mathbf{x}\|_2=5\),对应欧氏距离(Euclidean Distance)。在连续优化中,\(\|\theta\|_2^2\) 具有良好的光滑性(Smoothness),使得许多推导与数值计算更稳定。
在 AI 里,\(L_2\) 正则化(权重衰减(Weight Decay))会惩罚大权重、改善泛化并缓解病态问题;在二次目标里它也对应“加 \(\lambda I\)”的稳定化(例如岭回归)。
例:若 \(\mathbf{x}=(3,0,-1,0)\),则 \(\|\mathbf{x}\|_\infty=3\)。它度量的是“最大坐标幅度”。
在 AI 里,\(L_\infty\) 最常与鲁棒性相关:对抗样本(Adversarial Examples)中的 \(L_\infty\) 约束表示“每个像素的改动幅度不超过 \(\epsilon\)”;一些鲁棒优化与最坏情况界也会用 \(\|\cdot\|_\infty\) 表达最大误差。
由范数诱导的距离(Norm-induced Distance)写作 \(d(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|\)。常见对应关系:
- \(L_2\):欧氏距离(Euclidean Distance),\(d_2(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|_2=\sqrt{\sum_{i=1}^{d}(x_i-y_i)^2}\)。
- \(L_1\):曼哈顿距离(Manhattan Distance),\(d_1(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|_1=\sum_{i=1}^{d}|x_i-y_i|\)。
- \(L_\infty\):切比雪夫距离(Chebyshev Distance),\(d_\infty(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|_\infty=\max_{i}|x_i-y_i|\)。它度量的是“最坏维度”的偏差:例如 \(d_\infty(\mathbf{x},\mathbf{y})\le \epsilon \Leftrightarrow \forall i,\ |x_i-y_i|\le \epsilon\),即每一维的误差都被同一个上界约束。直觉上,如果一次操作允许同时修改所有坐标、且每步每个坐标最多改 1,那么从 \(\mathbf{x}\) 变到 \(\mathbf{y}\) 的最少步数就是 \(\max_i|x_i-y_i|\)(更一般地,每步上限为 \(\epsilon\) 时步数为 \(d_\infty(\mathbf{x},\mathbf{y})/\epsilon\) 的向上取整)。
关于 \(L_0\):常见写法是 \(d_0(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|_0=\#\{i\mid x_i\ne y_i\}\),它统计两向量在多少个坐标上不相等。本质上这是逐坐标“相等/不相等”的计数度量;当取值来自离散集合时,它对应哈明距离(Hamming Distance)。但 \(\|\cdot\|_0\) 严格来说并非范数,因此 \(d_0\) 不属于“由范数诱导”的距离家族。
在学习目标中,正则化通常写成:
\[\min_{\theta}\ \frac{1}{m}\sum_{i=1}^{m}\ell\!\left(f_{\theta}(x^{(i)}),y^{(i)}\right)+\lambda\Omega(\theta)\]式中各成分含义如下:
- \(\theta\):模型参数(Parameters),优化的对象。
- \(m\):训练样本数(Number of Samples)。
- \((x^{(i)},y^{(i)})\):第 \(i\) 个样本与标签。
- \(f_{\theta}(x^{(i)})\):模型对第 \(i\) 个样本的预测。
- \(\ell(\cdot,\cdot)\):单样本损失函数(Per-sample Loss),衡量预测与标签偏差。
- \(\frac{1}{m}\sum_{i=1}^{m}\ell(\cdot)\):经验风险(Empirical Risk),即平均训练误差。
- \(\Omega(\theta)\):正则项(Regularizer),约束参数复杂度。
- \(\lambda\):正则化系数(Regularization Strength),平衡“拟合训练数据”与“控制模型复杂度”。
常见的 \(\Omega(\theta)\) 包括 \(\|\theta\|_1\)、\(\|\theta\|_2^2\)、\(\|\theta\|_0\)(稀疏性目标)与 \(\|\theta\|_\infty\)(最大幅度约束)。同一个思想也可写成“约束形式”(Constraint Form):\(\min_\theta \frac{1}{m}\sum_i \ell(\cdot)\ \text{s.t.}\ \Omega(\theta)\le c\)。惩罚系数 \(\lambda\) 与约束半径 \(c\) 在凸优化(Convex Optimization)里可通过对偶(Duality)联系起来。
极限(Limit)回答的问题是:当输入“逼近”某个值时,函数输出“逼近”什么值。它关心的是趋势而非是否刚好取到该点。
\[\lim_{x\to a}f(x)=L\]严格定义(\(\varepsilon-\delta\) 定义)可写为:
\[\forall \varepsilon \gt 0,\ \exists \delta \gt 0,\ \text{s.t.}\ 0 \lt |x-a| \lt \delta \Rightarrow |f(x)-L| \lt \varepsilon\]工程上可把它理解为:把输入控制得足够近,输出误差就能被压到任意小。
在 AI 里,极限直觉用于理解“收敛(Convergence)”:例如训练步长变小后,参数更新是否趋于稳定;以及损失函数在某点附近是否可被低阶展开近似。
连续(Continuity)可理解为“函数图像没有跳断”。在点 \(a\) 处连续的三个条件是:
- \(f(a)\) 有定义;
- \(\lim_{x\to a}f(x)\) 存在;
- \(\lim_{x\to a}f(x)=f(a)\)。
连续是可导(Differentiable)的前提之一(但连续不必然可导)。例如 \(|x|\) 在 \(x=0\) 连续但不可导。
在优化里,连续性保证“小步更新不会导致目标突变”,这也是学习率(Learning Rate)可调与训练可控的基础假设之一。
无穷小(Infinitesimal)描述“趋近于 0 的量”,无穷大(Infinity)描述“无界增长”。在推导里常通过渐近记号(Asymptotic Notation)表达量级关系:
这里的 \(o\) 与 \(O\) 核心是两种记号:小 \(o\)(little-o)表示“严格更小一个量级”,大 \(O\)(big-O)表示“至多同量级的上界”。
- \(f(x)=o(g(x))\):当 \(x\to a\) 时 \(f/g\to 0\)(高阶小量,增长/衰减速度严格慢于 \(g\))。
- \(f(x)=O(g(x))\):存在常数 \(C\) 使 \(|f(x)|\le C|g(x)|\)(同阶或更小的上界)。
例如一阶 Taylor 展开里的 \(o(\Delta x)\) 表示“比 \(\Delta x\) 更小得多”的误差项。算法分析中的时间复杂度 \(O(Nd)\)、\(O(N^2)\) 也属于同一套量级语言。
| 法则 | 公式 | 条件 |
| 常数倍法则 | \((Cu)' = C u'\) | \(C\) 为常数 |
| 和差法则 | \((u \pm v)' = u' \pm v'\) | \(u,v\) 可导 |
| 乘法法则 | \((uv)' = u'v + uv'\) | \(u,v\) 可导 |
| 除法法则 | \(\left(\frac{u}{v}\right)'=\frac{u'v-uv'}{v^2}\) | \(u,v\) 可导,且 \(v \ne 0\) |
| 链式法则 | \(\frac{d}{dx}f(g(x)) = f'(g(x))g'(x)\) | \(f,g\) 可导 |
| 函数 \(f(x)\) | 导数 \(f'(x)\) | 备注/条件 |
| \(c\) | \(0\) | \(c\) 为常数 |
| \(x^n\) | \(n x^{n-1}\) | \(n\) 为常数;非整数 \(n\) 时需注意实数域定义域 |
| \(\sqrt{x}\) | \(\frac{1}{2\sqrt{x}}\) | \(x>0\) |
| \(e^x\) | \(e^x\) | 自然指数(Natural Exponential) |
| \(a^x\) | \(a^x\ln a\) | \(a>0,a\ne 1\) |
| \(\ln x\) | \(\frac{1}{x}\) | \(x>0\) |
| \(\log_a x\) | \(\frac{1}{x\ln a}\) | \(x>0,\ a>0,\ a\ne 1\) |
| \(\sin x\) | \(\cos x\) | |
| \(\cos x\) | \(-\sin x\) | |
| \(\tan x\) | \(\sec^2 x\) | \(\cos x\ne 0\) |
| \(|x|\) | \(\mathrm{sign}(x)\) | \(x>0\) 时导数为 \(1\)
\(x<0\) 时导数为 \(-1\) 在 \(x=0\) 不可导(优化中常用次梯度 \(g\in[-1,1]\)) |
导数是点 \(x_0\) 处的瞬时变化率(Instantaneous Rate of Change):
\[f'(x_0)=\lim_{\Delta x\to 0}\frac{f(x_0+\Delta x)-f(x_0)}{\Delta x}\]\(x_0\) 核心是定义域中的固定位置;趋近于 0 的小量是 \(\Delta x\)(或记作 \(dx\))。
一阶展开把导数解释为“线性项的系数”:当 \(\Delta x\to 0\) 时,
\[f(x_0+\Delta x)=f(x_0)+f'(x_0)\Delta x+o(\Delta x)\]可按“等于三项相加”理解:左边 \(f(x_0+\Delta x)\) 是扰动后的真实函数值;右边第一项 \(f(x_0)\) 是基点函数值,第二项 \(f'(x_0)\Delta x\) 是一阶线性近似,第三项 \(o(\Delta x)\) 是比 \(\Delta x\) 更小的高阶余项(High-order Remainder)。
中值定理(Mean Value Theorems)是一组把“区间上的平均变化”与“某一点的瞬时变化率”连接起来的核心定理。它们在形式上不同,但共同结构是:在闭区间连续、在开区间可导,进而保证存在某个中间点 \(c\in(a,b)\) 使得斜率关系成立。
设 \(f\) 在 \([a,b]\) 上连续、在 \((a,b)\) 上可导,且 \(f(a)=f(b)\)。则存在 \(c\in(a,b)\) 使
\[f'(c)=0\]几何直觉:若曲线两端高度相同,那么中间至少有一点的切线是水平的。
设 \(f\) 在 \([a,b]\) 上连续、在 \((a,b)\) 上可导。则存在 \(c\in(a,b)\) 使
\[f'(c)=\frac{f(b)-f(a)}{b-a}\]几何直觉:区间割线斜率(平均变化率)等于某个点的切线斜率(瞬时变化率)。
设 \(f,g\) 在 \([a,b]\) 上连续、在 \((a,b)\) 上可导。则存在 \(c\in(a,b)\) 使
\[(f(b)-f(a))g'(c)=(g(b)-g(a))f'(c)\]当分母不为 0 时,可写成比值形式:
\[\frac{f'(c)}{g'(c)}=\frac{f(b)-f(a)}{g(b)-g(a)}\]它把“单函数斜率比较”推广为“两个函数变化率的比较”,是洛必达法则(L'Hospital's Rule)证明链中的关键步骤。
| 定理 | 涉及函数 | 额外条件 | 结论形式 | 关系 |
| 罗尔中值定理 | 1 个函数 \(f\) | \(f(a)=f(b)\) | \(f'(c)=0\) | 拉格朗日定理的特殊情形 |
| 拉格朗日中值定理 | 1 个函数 \(f\) | 无额外端点相等条件 | \(f'(c)=\frac{f(b)-f(a)}{b-a}\) | 柯西定理取 \(g(x)=x\) 的特例 |
| 柯西中值定理 | 2 个函数 \(f,g\) | 两个函数都满足连续+可导 | \((f(b)-f(a))g'(c)=(g(b)-g(a))f'(c)\) | 三者中最一般形式 |
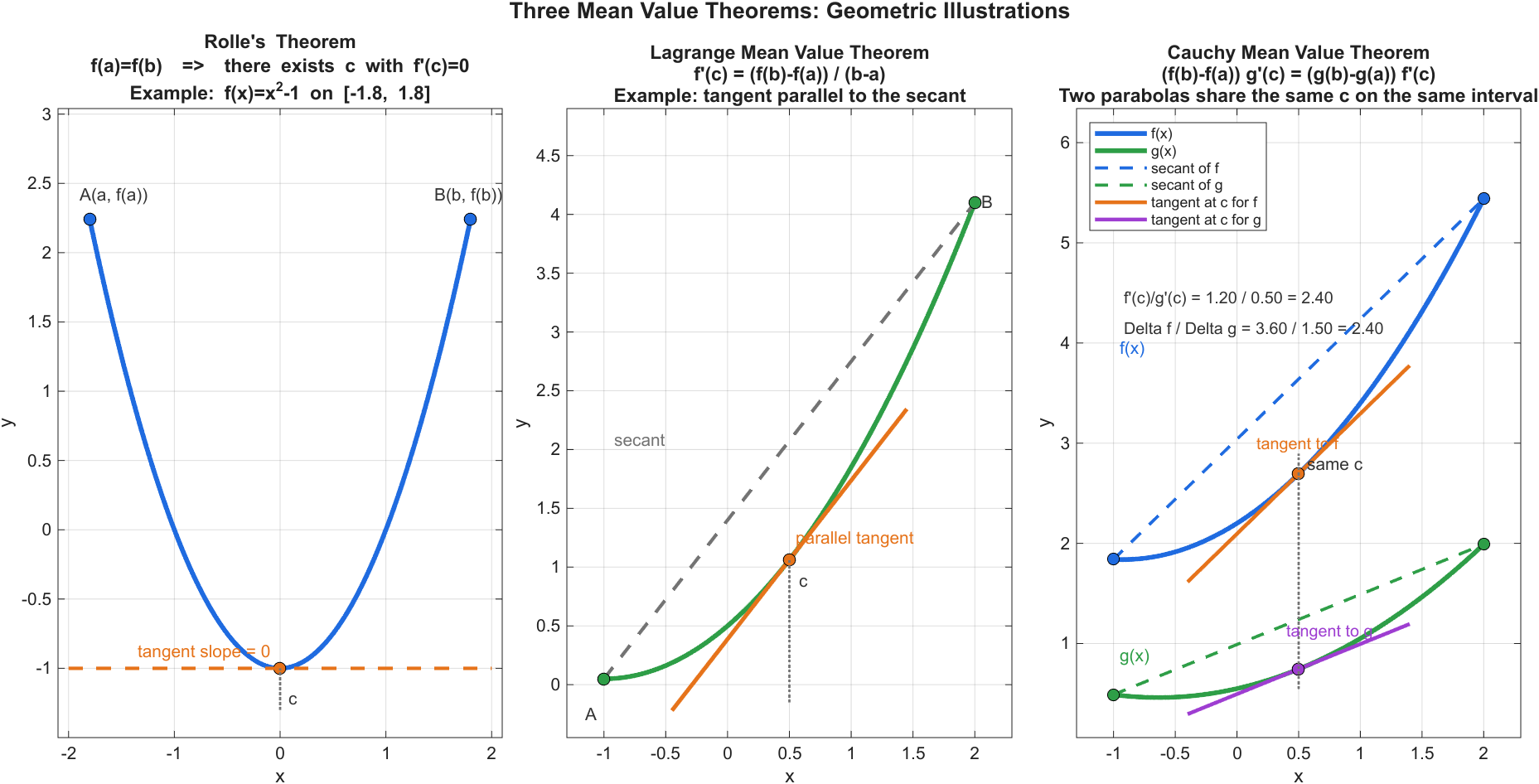
在 AI 系统中,中值定理主要作为理论工具出现:工程代码很少直接“调用定理”,但大量优化、稳定性与误差分析都在使用它的核心变形,即把“两个点的函数值差”转写为“某个中间点的导数(梯度)信息”。
- 优化收敛分析(Optimization Convergence):训练中常关心一步更新后损失变化 \(L(\theta+\Delta)-L(\theta)\)。中值定理把它连接到中间点的梯度,进而用于学习率条件与下降性证明。
- Lipschitz 界与鲁棒性(Lipschitz Bound & Robustness):中值定理给出“输入小扰动导致输出变化”的上界形式。若梯度有界,则输出变化可控;这正是对抗鲁棒性分析和梯度惩罚(Gradient Penalty)类方法的数学基础之一。
- 有限差分与梯度估计(Finite Difference / Gradient Estimation):割线斜率与切线斜率之间的关系来自拉格朗日中值定理,是数值优化里差分近似、线搜索(Line Search)和误差估计的核心依据。
从“纯数学”到“AI 实践”的桥梁可以一句话概括:中值定理把宏观变化量(函数值差)变成可优化的微观信息(导数/梯度)。
对多元函数 \(f:\mathbb{R}^n\to\mathbb{R}\),偏导数把“只沿某一坐标轴方向的导数”形式化:固定其余变量,只让第 \(i\) 个变量变化。先写成最直接的极限定义:
\[\frac{\partial f}{\partial x_i}(x_0)=\lim_{h\to 0}\frac{f(x_{0,1},\dots,x_{0,i-1},x_{0,i}+h,x_{0,i+1},\dots,x_{0,n})-f(x_0)}{h}\]这里的 \(h\) 是“第 \(i\) 个变量的微小增量”(Increment):只加在第 \(i\) 个坐标上,其他坐标保持不变。
在线性代数记号下,上式等价写成(更紧凑):令 \(e_i\) 为第 \(i\) 个标准基向量(Standard Basis Vector),则
\[\frac{\partial f}{\partial x_i}(x_0)=\lim_{h\to 0}\frac{f(x_0+h e_i)-f(x_0)}{h}\]更常用的导数视角(计算视角)是:把其余变量暂时当常数,把目标变量当自变量,直接套一元求导法则。极限定义负责“定义正确性”,日常计算通常用求导规则完成。
例如 \(f(x,y)=x^2y\):对 \(x\) 求偏导时把 \(y\) 视作常数,得 \(\frac{\partial f}{\partial x}=2xy\);对 \(y\) 求偏导时把 \(x\) 视作常数,得 \(\frac{\partial f}{\partial y}=x^2\)。
切换为极限视角,令 \(f(x,y)=x^2y\),在点 \((1,2)\)。
\[\frac{\partial f}{\partial x}(1,2)=\lim_{h\to 0}\frac{f(1+h,2)-f(1,2)}{h}\] \[=\lim_{h\to 0}\frac{2(1+h)^2-2}{h}\] \[=\lim_{h\to 0}(4+2h)=4\] \[\frac{\partial f}{\partial y}(1,2)=\lim_{h\to 0}\frac{f(1,2+h)-f(1,2)}{h}\] \[=\lim_{h\to 0}\frac{(2+h)-2}{h}=1\]可以看到:求 \(\partial f/\partial x\) 时把 \(y\) 当常数;求 \(\partial f/\partial y\) 时把 \(x\) 当常数。这正是“其余变量固定”的具体计算含义。
梯度(Gradient)就是把所有偏导数按坐标收集成向量: \(\nabla f(x)=(\partial f/\partial x_1,\dots,\partial f/\partial x_n)^\top\)。
在一元情形中,微分是“把函数增量线性化”的记号:给定一个小增量 \(dx\),定义
\[df\big|_{x_0}=f'(x_0)\,dx\]此时真实增量满足 \(\Delta f = df + o(dx)\)。给定 \(dx\) 后, \(df\) 才对应一个确定数值。
例:若 \(f(x)=x^2\),在 \(x_0=3\) 且 \(dx=0.1\) 时, \(df=2x_0dx=0.6\),而 \(\Delta f=f(3.1)-f(3)=0.61\)。微分给出一阶近似,误差来自高阶项。
对多元函数 \(f(x_1,\dots,x_n)\),全微分把“多方向小扰动下的一阶线性响应”写成:
\[df=\sum_{i=1}^n \frac{\partial f}{\partial x_i}dx_i\]令 \(d\mathbf{x}=(dx_1,\dots,dx_n)^\top\),则向量形式是:
\[df=(\nabla f(x))^\top d\mathbf{x}\]若进一步把扰动分解为“方向 + 步长”: \(d\mathbf{x}=\mathbf{u}\,ds\)(\(\|\mathbf{u}\|_2=1\)),则
\[\frac{df}{ds}=\nabla f(x)\cdot \mathbf{u}\]右侧就是方向导数(Directional Derivative):全微分给出任意小位移的一阶近似,方向导数则把位移约束在单位方向并除去步长。
例:令 \(f(x,y)=x^2y\),则 \(\frac{\partial f}{\partial x}=2xy\)、\(\frac{\partial f}{\partial y}=x^2\)。在点 \((x_0,y_0)=(1,2)\),若 \(dx=0.1\)、\(dy=-0.05\),则 \(df=2xy\,dx+x^2dy=2\cdot1\cdot2\cdot0.1+1\cdot(-0.05)=0.35\),给出 \(\Delta f\) 的一阶近似。
Nabla 算子(Nabla Operator)记作 \(\nabla\),本质上是把偏导算子按坐标排列成的“向量形式”:
\[\nabla=\left(\frac{\partial}{\partial x_1},\dots,\frac{\partial}{\partial x_n}\right)^\top\]它本身核心是一个算子(Operator)。作用在标量场上得到梯度(Gradient);与向量场点乘得到散度(Divergence);与向量场叉乘得到旋度(Curl);对标量场再取散度得到拉普拉斯(Laplacian)。
符号 \(\|\cdot\|\)(双竖线)表示范数(Norm)。因此 \(\|\nabla f(x)\|\) 是梯度向量的长度;而 \(\|\nabla\|\) 作为“算子范数”在工程推导中很少直接使用,通常需要明确它作用的函数空间与范数定义。
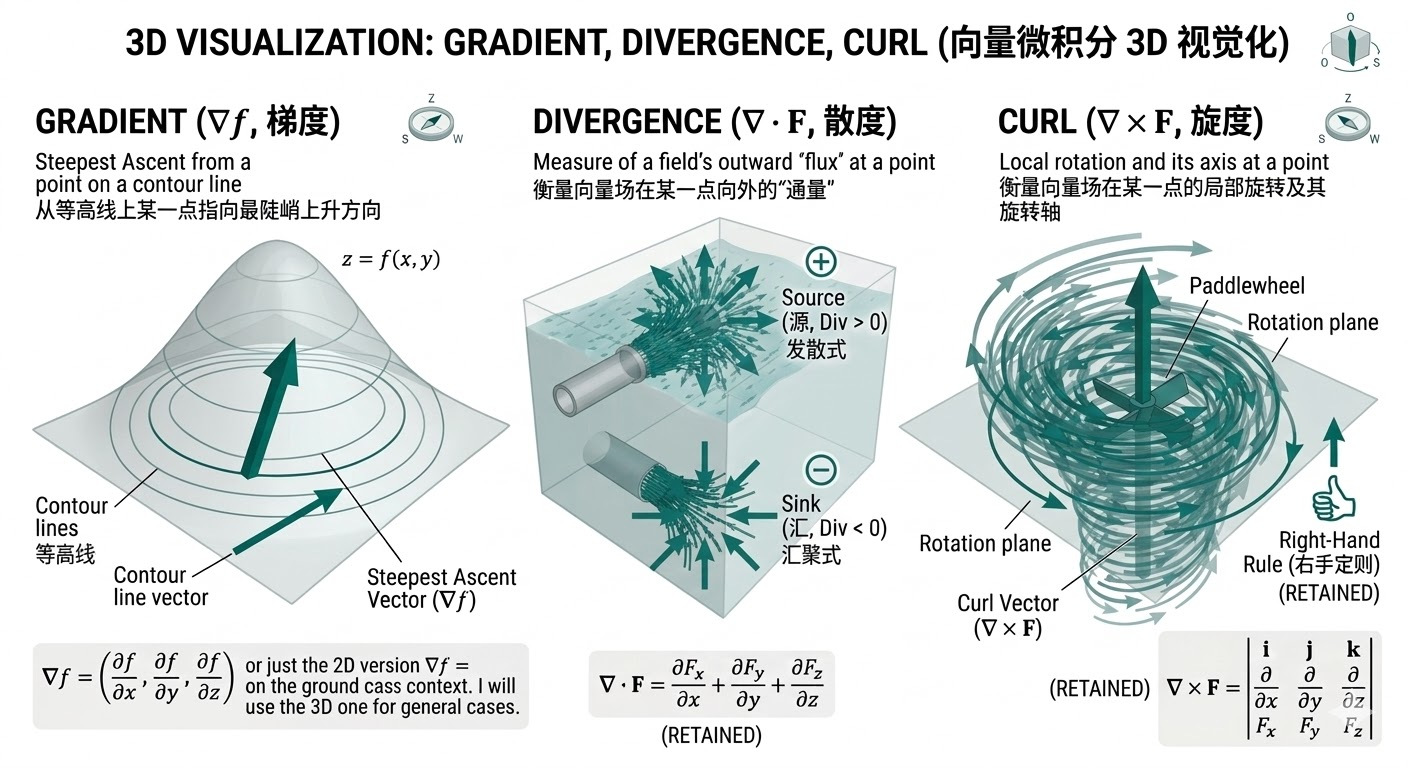
梯度(Gradient)把标量函数 \(f:\mathbb{R}^n\to\mathbb{R}\) 的局部变化率组织成向量:
\[\nabla f(x)=\left(\frac{\partial f}{\partial x_1},\dots,\frac{\partial f}{\partial x_n}\right)^\top\]它指向函数增长最快的方向(Steepest Ascent Direction),模长刻画该方向上的最大斜率。在优化里,梯度下降(Gradient Descent)沿 \(-\nabla f\) 走,是因为这是一阶近似下最快下降方向。
例: \(f(x,y)=x^2+2y^2\),则 \(\nabla f=(2x,4y)\),在点 \((1,1)\) 处梯度为 \((2,4)\),表示沿 y 方向的增长更陡。
方向导数(Directional Derivative)把“沿某个方向的变化率”写成点积:若 \(\mathbf{u}\) 是单位方向向量,则
\[D_{\mathbf{u}}f(x)=\nabla f(x)\cdot \mathbf{u}\]符号先约定: \(x\) 是当前点, \(\mathbf{u}\) 是单位方向(\(\|\mathbf{u}\|_2=1\)), \(\varepsilon\) 是沿该方向的步长(可正可负的小实数)。方向导数定义为
\[D_{\mathbf{u}}f(x)=\lim_{\varepsilon\to 0}\frac{f(x+\varepsilon\mathbf{u})-f(x)}{\varepsilon}\]对 \(f(x+\varepsilon\mathbf{u})\) 做一阶 Taylor 展开:
\[f(x+\varepsilon\mathbf{u})=f(x)+\varepsilon\,\nabla f(x)\cdot\mathbf{u}+o(\varepsilon)\]代回定义式:
\[\frac{f(x+\varepsilon\mathbf{u})-f(x)}{\varepsilon}\] \[=\nabla f(x)\cdot\mathbf{u}+\frac{o(\varepsilon)}{\varepsilon}\]令 \(\varepsilon\to 0\),由于 \(o(\varepsilon)/\varepsilon\to 0\),得到 \(D_{\mathbf{u}}f(x)=\nabla f(x)\cdot\mathbf{u}\)。
场(Field)是“把空间中每个点映射到一个量”的函数。标量场(Scalar Field)\(f(x)\) 在每个点输出一个标量;向量场(Vector Field)\(\mathbf{F}(x)\) 在每个点输出一个向量。梯度作用在标量场上,散度/旋度作用在向量场上。
散度(Divergence)作用在向量场 \(\mathbf{F}=(F_1,\dots,F_n)^\top:\mathbb{R}^n\to\mathbb{R}^n\) 上。这里先把两个术语说清楚:
\[J_{\mathbf{F}}(x)=\left[\frac{\partial F_i}{\partial x_j}\right]_{i,j=1}^n\]上式是雅可比矩阵(Jacobian):第 \(i\) 行第 \(j\) 列表示 \(F_i\) 对 \(x_j\) 的偏导。迹(Trace)是矩阵对角线元素之和,因此
\[\mathrm{tr}(J_{\mathbf{F}})=\sum_{i=1}^n \frac{\partial F_i}{\partial x_i}\]而散度按定义正是这条和式,所以“散度 = Jacobian 的迹”:
\[\nabla\cdot \mathbf{F}(x)=\mathrm{tr}(J_{\mathbf{F}}(x))=\sum_{i=1}^n \frac{\partial F_i}{\partial x_i}\]几何/物理直觉:把 \(\mathbf{F}\) 想成“流体速度场(Velocity Field)”,散度衡量一个点附近是否像“源(Source)/汇(Sink)”——单位体积的净流出率。散度为正表示净流出,为负表示净流入。
例:二维场 \(\mathbf{F}(x,y)=(x,y)\) 的 Jacobian 是 \(\begin{bmatrix}1&0\\0&1\end{bmatrix}\),其迹为 \(1+1=2\),所以散度也等于 2,在任意点都表现为均匀“发散”。
旋度(Curl)衡量向量场的局部旋转(Local Rotation)。在三维中:
\[\nabla\times \mathbf{F}=\left(\frac{\partial F_3}{\partial y}-\frac{\partial F_2}{\partial z},\ \frac{\partial F_1}{\partial z}-\frac{\partial F_3}{\partial x},\ \frac{\partial F_2}{\partial x}-\frac{\partial F_1}{\partial y}\right)\]直觉上,可把它理解为“放一个很小的桨轮(Paddle Wheel)在该点附近,桨轮是否会被带着转”。保守场(Conservative Field)满足 \(\nabla\times\mathbf{F}=\mathbf{0}\),这与“路径无关”/“存在势函数”是等价刻画。
例:二维旋转场 \(\mathbf{F}(x,y)=(-y,x,0)\) 的旋度为 \((0,0,2)\),表示绕 z 轴的均匀旋转趋势。
拉普拉斯算子(Laplacian)作用在标量场上,定义为梯度的散度:
\[\nabla^2 f=\nabla\cdot(\nabla f)=\sum_{i=1}^n \frac{\partial^2 f}{\partial x_i^2}\]它常出现在扩散(Diffusion)与平滑(Smoothing)问题中,也常被用作“曲率/粗糙度”的度量。例: \(f(x,y)=x^2+y^2\) 则 \(\nabla^2 f=2+2=4\)。
当函数的输出从一个标量转向一个向量时,梯度这个概念就不够用了。此时需要把“每个输出分量对每个输入变量的一阶变化率”统一收集起来,这个对象就是 Jacobian 矩阵(Jacobian Matrix)。它是一阶导数在向量值函数上的自然推广,也是 Hessian 的直接前置概念。
设向量值函数
\[\mathbf{F}:\mathbb{R}^n\to\mathbb{R}^m,\qquad \mathbf{F}(\mathbf{x})=\begin{bmatrix}F_1(\mathbf{x})\\ \vdots\\ F_m(\mathbf{x})\end{bmatrix}\]其中输入 \(\mathbf{x}=(x_1,\dots,x_n)^\top\),输出 \(\mathbf{F}(\mathbf{x})\) 有 \(m\) 个分量。Jacobian 矩阵定义为:
\[J_{\mathbf{F}}(\mathbf{x})=\left[\frac{\partial F_i}{\partial x_j}(\mathbf{x})\right]_{i=1,\dots,m;\,j=1,\dots,n}\]按矩阵展开,就是一个 \(m\times n\) 矩阵:
\[J_{\mathbf{F}}(\mathbf{x})= \begin{bmatrix} \frac{\partial F_1}{\partial x_1} & \frac{\partial F_1}{\partial x_2} & \cdots & \frac{\partial F_1}{\partial x_n}\\ \frac{\partial F_2}{\partial x_1} & \frac{\partial F_2}{\partial x_2} & \cdots & \frac{\partial F_2}{\partial x_n}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial F_m}{\partial x_1} & \frac{\partial F_m}{\partial x_2} & \cdots & \frac{\partial F_m}{\partial x_n} \end{bmatrix}\]这里第 \(i\) 行第 \(j\) 列的元素 \(\frac{\partial F_i}{\partial x_j}\) 表示:第 \(j\) 个输入变量发生微小变化时,第 \(i\) 个输出分量会怎样一阶变化。按矩阵读法,行对应输出分量,列对应输入变量,因此 Jacobian 本质上是一张局部灵敏度表(Local Sensitivity Table)。
它描述的核心是函数在某个点附近的局部线性映射:输入空间里的一个小扰动向量 \(d\mathbf{x}\) 经过 Jacobian 作用后,变成输出空间中的一阶近似扰动 \(d\mathbf{F}\)。因此,Jacobian 就是“该点附近最能代表原函数的一阶线性算子”。
它与全微分的关系最直接。若在点 \(\mathbf{x}\) 附近加入一个小扰动 \(d\mathbf{x}\),则输出的一阶变化满足:
\[d\mathbf{F}\approx J_{\mathbf{F}}(\mathbf{x})\,d\mathbf{x}\]这条式子就是向量值函数的一阶线性化。Jacobian 在局部扮演的角色,类似于一元函数里的导数:它给出“最好的线性近似”。若输出是一维,即 \(m=1\),Jacobian 就退化成一个 \(1\times n\) 的行向量;它与梯度本质上包含同一组偏导数,只是排布约定可能不同。
一个二维到二维的例子最容易看清。设
\[\mathbf{F}(x,y)=\begin{bmatrix}x^2y\\ x+y^2\end{bmatrix}\]则第一行来自分量函数 \(F_1(x,y)=x^2y\),第二行来自 \(F_2(x,y)=x+y^2\)。逐项求偏导可得:
\[J_{\mathbf{F}}(x,y)= \begin{bmatrix} 2xy & x^2\\ 1 & 2y \end{bmatrix}\]例如在点 \((1,2)\),Jacobian 为
\[J_{\mathbf{F}}(1,2)= \begin{bmatrix} 4 & 1\\ 1 & 4 \end{bmatrix}\]这表示:在该点附近,若输入发生微小变化 \((dx,dy)^\top\),则输出变化近似为
\[d\mathbf{F}\approx \begin{bmatrix} 4 & 1\\ 1 & 4 \end{bmatrix} \begin{bmatrix} dx\\ dy \end{bmatrix}\]第一行说明输出第一分量大致按 \(4dx+dy\) 变化,第二行说明输出第二分量大致按 \(dx+4dy\) 变化。Jacobian 因而可以被理解为局部灵敏度矩阵(Sensitivity Matrix)。
对标量函数 \(f:\mathbb{R}^n\to\mathbb{R}\),梯度 \(\nabla f:\mathbb{R}^n\to\mathbb{R}^n\) 本身就是一个向量值函数,因此 Hessian 可以直接看成梯度映射的 Jacobian:
\[\nabla^2 f(\mathbf{x})=J_{\nabla f}(\mathbf{x})\]这就是把 Jacobian 放在 Hessian 前面的原因:先理解“向量值函数的一阶导数如何组织成矩阵”,再看“标量函数的梯度再求一次导”,Hessian 的结构就不会显得突兀。
在机器学习中,Jacobian 最常出现在三类地方:
- 反向传播(Backpropagation):本质上是在链式法则(Chain Rule)下逐层组合这些局部 Jacobian。前一层输出的微小变化如何传到后一层,正是由对应层的 Jacobian 决定。
- 向量场分析:散度(Divergence)等于 Jacobian 的迹(Trace)。
- 生成模型、正则化与鲁棒性分析:常关心 Jacobian 的谱范数(Spectral Norm)或 Frobenius 范数,以度量局部放大效应。
若输出维度和输入维度都很大,显式构造完整 Jacobian 也会很贵,因此工程上常直接计算 Jacobian-Vector Product 或 Vector-Jacobian Product,而非把整块矩阵完全展开。
在神经网络语境里,Jacobian 到底“针对激活值还是针对权重”,取决于谁被当作自变量。若研究层与层之间的信号传播,常写成 \(\frac{\partial h^{(l+1)}}{\partial h^{(l)}}\),这时它针对的是激活值(Activation)或层表示;若研究模型输出对输入的敏感度,可写成 \(\frac{\partial y}{\partial x}\);若研究输出对参数的敏感度,也可以写成 \(\frac{\partial y}{\partial \theta}\)。因此,Jacobian 的本质是“一个向量怎样对另一个向量发生一阶变化”,并不预先限定变量一定是激活值还是权重。
梯度(Gradient)回答的是“函数沿各坐标方向的一阶变化率”;Hessian 矩阵(Hessian Matrix)进一步回答的是“这些一阶变化率本身又在怎样变化”。这一点可以直接从“梯度是一个向量值函数”展开出来。对标量函数 \(f:\mathbb{R}^n\to\mathbb{R}\),梯度写成
\[\nabla f(\mathbf{x})=\begin{bmatrix}\frac{\partial f}{\partial x_1}\\ \frac{\partial f}{\partial x_2}\\ \vdots\\ \frac{\partial f}{\partial x_n}\end{bmatrix}\]这里 \(\nabla f\) 已经核心是把输入向量 \(\mathbf{x}\) 映射为另一个向量的函数。因此可以像对任何向量值函数那样,对它再求一次 Jacobian:
\[J_{\nabla f}(\mathbf{x})=\frac{\partial (\nabla f)}{\partial \mathbf{x}}\]把梯度各分量逐项代进去,Jacobian 的第 \((i,j)\) 个元素就是“梯度第 \(i\) 个分量对输入第 \(j\) 个变量的偏导数”:
\[\big[J_{\nabla f}(\mathbf{x})\big]_{ij}=\frac{\partial}{\partial x_j}\left(\frac{\partial f}{\partial x_i}\right)=\frac{\partial^2 f}{\partial x_j\partial x_i}\]于是整块矩阵就是
\[J_{\nabla f}(\mathbf{x})=\begin{bmatrix}\frac{\partial^2 f}{\partial x_1\partial x_1} & \frac{\partial^2 f}{\partial x_2\partial x_1} & \cdots & \frac{\partial^2 f}{\partial x_n\partial x_1}\\ \frac{\partial^2 f}{\partial x_1\partial x_2} & \frac{\partial^2 f}{\partial x_2\partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n\partial x_2}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial^2 f}{\partial x_1\partial x_n} & \frac{\partial^2 f}{\partial x_2\partial x_n} & \cdots & \frac{\partial^2 f}{\partial x_n\partial x_n}\end{bmatrix}\]这正是 Hessian:
\[\nabla^2 f(\mathbf{x})=J_{\nabla f}(\mathbf{x})\]这个等式的含义很直接:Hessian 并非凭空引入的另一种矩阵,而就是“梯度这个向量场对输入的 Jacobian”。
直接从二阶导角度看,Hessian 是多元函数的二阶导数对象,用来描述局部曲率(Curvature)、凹凸性以及临界点附近的二阶形状。
设标量函数 \(f:\mathbb{R}^n\to\mathbb{R}\),输入向量为 \(\mathbf{x}=(x_1,\dots,x_n)^\top\)。Hessian 矩阵记作 \(\nabla^2 f(\mathbf{x})\) 或 \(H_f(\mathbf{x})\),定义为:
\[\nabla^2 f(\mathbf{x})=\left[\frac{\partial^2 f}{\partial x_i\partial x_j}(\mathbf{x})\right]_{i,j=1}^{n}\]这里 \(i\) 和 \(j\) 都从 \(1\) 遍历到 \(n\),因此 Hessian 会收集所有变量对 \((x_i,x_j)\) 的二阶偏导。之所以自然形成一个 \(n\times n\) 的“全组合”矩阵,是因为一阶导数 \(\nabla f\) 本身已经有 \(n\) 个分量;再对这 \(n\) 个分量分别对 \(n\) 个输入变量各求一次导,就得到 \(n\times n\) 个二阶偏导项。前面展开的 \(J_{\nabla f}(\mathbf{x})\) 就是这块矩阵,因此这里不再重复写一遍。
把梯度记为 \(\nabla f(\mathbf{x})=(g_1,\dots,g_n)^\top\),其中 \(g_i=\frac{\partial f}{\partial x_i}\),则 Hessian 的第 \((i,j)\) 个元素可以直接写成 \(H_{ij}=\frac{\partial g_i}{\partial x_j}\)。这个记号把它的意义说得很清楚:它衡量“第 \(i\) 个方向上的斜率”会不会随着第 \(j\) 个变量的变化而改变。
对角线元素 \(\frac{\partial^2 f}{\partial x_i^2}\) 描述沿单一坐标方向的纯二阶曲率,也就是该方向本身的弯曲强弱;非对角元素 \(\frac{\partial^2 f}{\partial x_i\partial x_j}\) 描述不同方向之间的局部耦合(Local Coupling)。当 \(H_{ij}=0\) 时,意味着在当前点附近,变量 \(x_j\) 的微小变化不会改变第 \(i\) 个方向上的一阶斜率;当 \(H_{ij}\neq 0\) 时,两个方向在局部二阶结构上发生耦合。
这种耦合会直接反映在等高线(Contour)形状上:若非对角项接近零,局部二次近似更接近与坐标轴对齐的“正椭圆碗”;若非对角项明显非零,等高线会发生倾斜,说明改变一个变量会连带改变另一个方向上的坡度。
若 \(f\) 足够光滑,满足二阶混合偏导连续,则由 Clairaut / Schwarz 定理可得
\[\frac{\partial^2 f}{\partial x_i\partial x_j}=\frac{\partial^2 f}{\partial x_j\partial x_i}\]因此 Hessian 矩阵是对称矩阵(Symmetric Matrix)。这点非常重要,因为一旦 Hessian 对称,就可以用特征值(Eigenvalue)来判断局部曲率:正特征值对应向上弯,负特征值对应向下弯,正负并存则意味着不同方向上的弯曲趋势相反。
Hessian 的几何意义可以通过二阶 Taylor 展开看得最清楚。对点 \(\mathbf{x}\) 附近的微小扰动 \(\Delta \mathbf{x}\),有:
\[f(\mathbf{x}+\Delta\mathbf{x})\approx f(\mathbf{x})+\nabla f(\mathbf{x})^\top \Delta\mathbf{x}+\frac{1}{2}\Delta\mathbf{x}^\top \nabla^2 f(\mathbf{x})\Delta\mathbf{x}\]这里第一项 \(f(\mathbf{x})\) 是当前函数值,第二项 \(\nabla f(\mathbf{x})^\top \Delta\mathbf{x}\) 是一阶线性变化,第三项 \(\frac{1}{2}\Delta\mathbf{x}^\top \nabla^2 f(\mathbf{x})\Delta\mathbf{x}\) 就是二阶曲率修正项。梯度告诉你“朝哪边走函数会立刻增减”,Hessian 则告诉你“地形本身是碗状、山丘状,还是马鞍状”。

二维情形最直观。设
\[f(x_1,x_2)=x_1^2+3x_1x_2+2x_2^2\]先求梯度:
\[\nabla f(x_1,x_2)=\begin{bmatrix}2x_1+3x_2\\3x_1+4x_2\end{bmatrix}\]再求二阶偏导,可得:
\[\frac{\partial^2 f}{\partial x_1^2}=2,\qquad \frac{\partial^2 f}{\partial x_1\partial x_2}=3,\qquad \frac{\partial^2 f}{\partial x_2^2}=4\]因此 Hessian 为:
\[\nabla^2 f(x_1,x_2)=\begin{bmatrix}2 & 3\\3 & 4\end{bmatrix}\]这个例子还有一个关键特征:Hessian 与 \((x_1,x_2)\) 无关,因此它说明该函数在整个空间里都是同一种二次曲面(Quadratic Surface)。对二次函数而言,Hessian 足以完整决定其曲率结构。
在极值判别里,Hessian 主要出现在临界点(Critical Point)附近。若某点 \(\mathbf{x}^*\) 满足 \(\nabla f(\mathbf{x}^*)=\mathbf{0}\),则:
- 若 \(\nabla^2 f(\mathbf{x}^*)\) 正定(Positive Definite),即对任意非零向量 \(\mathbf{v}\) 都有 \(\mathbf{v}^\top \nabla^2 f(\mathbf{x}^*)\mathbf{v}>0\),则该点是局部极小值(Local Minimum)。
- 若 \(\nabla^2 f(\mathbf{x}^*)\) 负定(Negative Definite),即对任意非零向量 \(\mathbf{v}\) 都有 \(\mathbf{v}^\top \nabla^2 f(\mathbf{x}^*)\mathbf{v}<0\),则该点是局部极大值(Local Maximum)。
- 若 Hessian 不定(Indefinite),即存在方向使二次型为正,也存在方向使其为负,则该点是鞍点(Saddle Point)。
- 若 Hessian 只有半正定、半负定,或出现零特征值,则二阶信息不足以单独判定,还需要更高阶分析或结合函数结构进一步判断。
这套判据和一维情形完全一致:一维里 \(f''(x^*)>0\) 表示“碗底”, \(f''(x^*)<0\) 表示“山顶”;Hessian 只是把这个二阶导概念推广到了多维空间。
在优化中,Hessian 的意义更直接。牛顿法(Newton's Method)用它近似局部曲面,并据此选择更合理的更新方向:
\[\mathbf{x}_{t+1}=\mathbf{x}_t-\big(\nabla^2 f(\mathbf{x}_t)\big)^{-1}\nabla f(\mathbf{x}_t)\]与只看一阶斜率的梯度下降不同,牛顿法还利用了局部曲率信息:若某个方向很陡但也弯得很厉害,步长就应更谨慎;若某个方向很平缓,更新可以相对更大。因此,Hessian 会出现在牛顿法、拟牛顿法(BFGS / L-BFGS)以及很多二阶优化分析中。
在机器学习里,Hessian 还常用来讨论损失面的尖锐度(Sharpness)、参数可辨识性以及训练稳定性。但深度学习模型维度极高,完整 Hessian 的存储与求逆代价非常大:若参数维度为 \(d\),Hessian 大小就是 \(d\times d\)。因此工程上更常用 Hessian 向量积(Hessian-Vector Product)、对角近似、低秩近似,或拟牛顿方法来间接利用二阶信息,而非显式构造整块矩阵。
在神经网络里,单独说 Hessian 时,默认通常指损失函数对参数向量 \(\theta\) 的 Hessian,即 \(\nabla_\theta^2 L(\theta)\)。原因很直接:优化真正要更新的是权重,因此人们最关心的是“损失面对参数空间的局部曲率”。当然,Hessian 也可以对输入或中间激活值来求,例如 \(\nabla_x^2 f(x)\) 或 \(\nabla_h^2 f(h)\),它们分别描述输入空间或表示空间中的局部弯曲;只是从工程语境看,这类用法通常并非默认含义。
不定积分(Indefinite Integral)也叫反导数、原函数。是“由变化率反推原函数(Antiderivative)”:已知 \(f\),寻找所有满足 \(F'(x)=f(x)\) 的函数 \(F\)。
一句话强调:不定积分就是“已知导函数(导数),求原函数”的过程。
\[\int f(x)\,dx=F(x)+C\]把导数看作“瞬时变化率”最容易理解积分的方向。若 \(s(t)\) 是位置、\(v(t)\) 是速度,则 \(s'(t)=v(t)\)。当只知道 \(v(t)\) 时,要恢复 \(s(t)\) 就是在做积分。
\[s'(t)=v(t)\ \Longrightarrow\ s(t)=\int v(t)\,dt\]因为微分会“抹掉常数项”。不同函数只要相差一个常数,导数就完全一样:
\[\frac{d}{dx}(x^2)=\frac{d}{dx}(x^2+5)=\frac{d}{dx}(x^2-100)=2x\]所以当你从 \(f(x)=2x\) 反推原函数时,只能确定主体是 \(x^2\),无法确定常数偏移。这就是积分常数(Constant of Integration)\(C\) 的来源。若再给一个初值条件(Initial Condition),例如 \(F(x_0)=y_0\),\(C\) 才会被唯一确定。
\(\int f(x)\,dx\) 的结果对应一族函数 \(\{F(x)+C\mid C\in\mathbb{R}\}\)。它们形状完全相同,只是沿 \(y\) 轴上下平移;在同一个 \(x\) 处,这族曲线的切线斜率都等于 \(f(x)\)。
验算: \(\frac{d}{dx}(x^2+C)=2x\)。这一步强调的是“求导与积分互为逆过程”,但逆过程会保留一个常数不确定性。
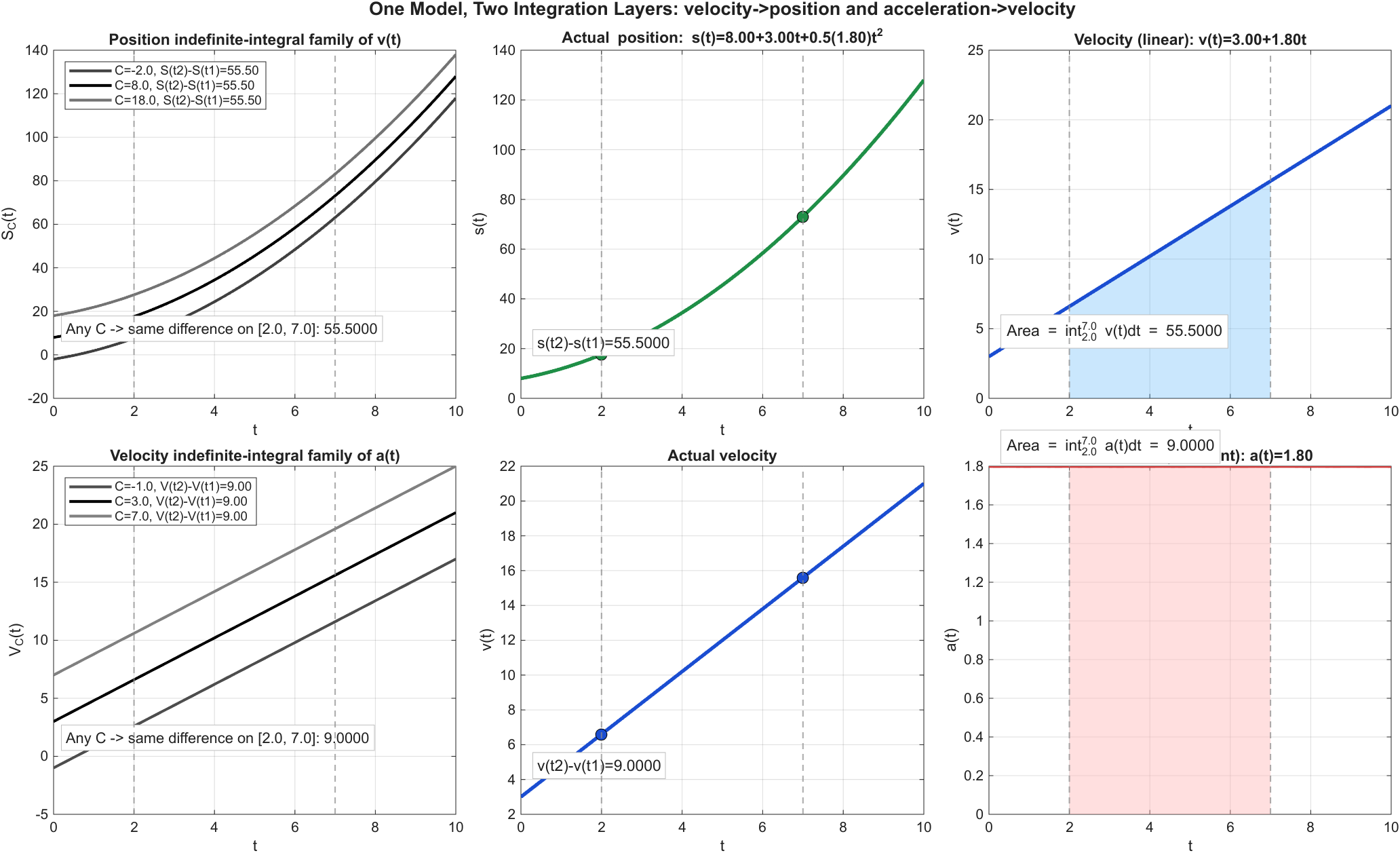
不定积分与定积分的连接点是微积分基本定理(Fundamental Theorem of Calculus)。它包含两条互补结论:
- 若 \(F'(x)=f(x)\),则 \(\int_a^b f(x)\,dx=F(b)-F(a)\)。这告诉我们:定积分可以通过任意一个原函数在端点处相减来计算。
- 定义 \(G(x)=\int_a^x f(t)\,dt\),则 \(G'(x)=f(x)\)。这告诉我们:把函数从 \(a\) 到 \(x\) 累积起来,得到的累积函数本身就是一个原函数。
一句话强调:定积分就是原函数(不定积分)在区间两端的函数值“收尾相减”,即 \(\int_a^b f(x)\,dx=F(b)-F(a)\)。
例: \(f(x)=2x\),取原函数 \(F(x)=x^2\),则
\[\int_1^3 2x\,dx=F(3)-F(1)=9-1=8\]定积分(Definite Integral)可看成“带符号面积(Signed Area)”或“连续求和”。Riemann 和定义为:
\[\int_a^b f(x)\,dx=\lim_{n\to\infty}\sum_{k=1}^{n}f(\xi_k)\Delta x_k\]若上下界中出现 \(\infty\) 或 \(-\infty\),它仍然属于定积分范畴,只是更准确地叫广义积分(Improper Integral)或广义定积分:本质上仍是在一个区间上求累积量,只是需要先把无穷区间截断,再用极限恢复。例如
\[\int_a^{\infty} f(x)\,dx:=\lim_{R\to\infty}\int_a^R f(x)\,dx\]因此“上下界无穷”核心是定积分的特殊形式。
在 AI 里,连续概率密度函数(Probability Density Function, PDF)的概率计算 \(P(a\le X\le b)=\int_a^b p(x)\,dx\) 本质上就是定积分。
| 被积函数 | 积分结果 | 备注 |
| \(x^n\) | \(\frac{x^{n+1}}{n+1}+C\) | \(n\ne -1\) |
| \(\frac{1}{x}\) | \(\ln|x|+C\) | \(x\ne 0\) |
| \(e^x\) | \(e^x+C\) | 指数函数 |
| \(\sin x\) | \(-\cos x+C\) | 三角函数 |
| \(\cos x\) | \(\sin x+C\) | 三角函数 |
| \(\frac{1}{1+x^2}\) | \(\arctan x+C\) | 反三角函数 |
多重积分(Multiple Integrals)是把一维积分的“连续求和”推广到更高维区域上的积分运算。它积分的对象已经从线段上的小长度扩展到平面区域上的小面积、空间区域中的小体积,或者曲面上的小面片。因此,多重积分处理的是“在二维、三维或更一般区域上,把局部量连续累加成整体量”的问题。
它的阅读难点通常不在计算本身,而在于符号会很快遮住几何直觉。理解的关键仍然是把“积分”看成连续求和,只不过求和对象已经从一维区间扩展到了更高维区域。
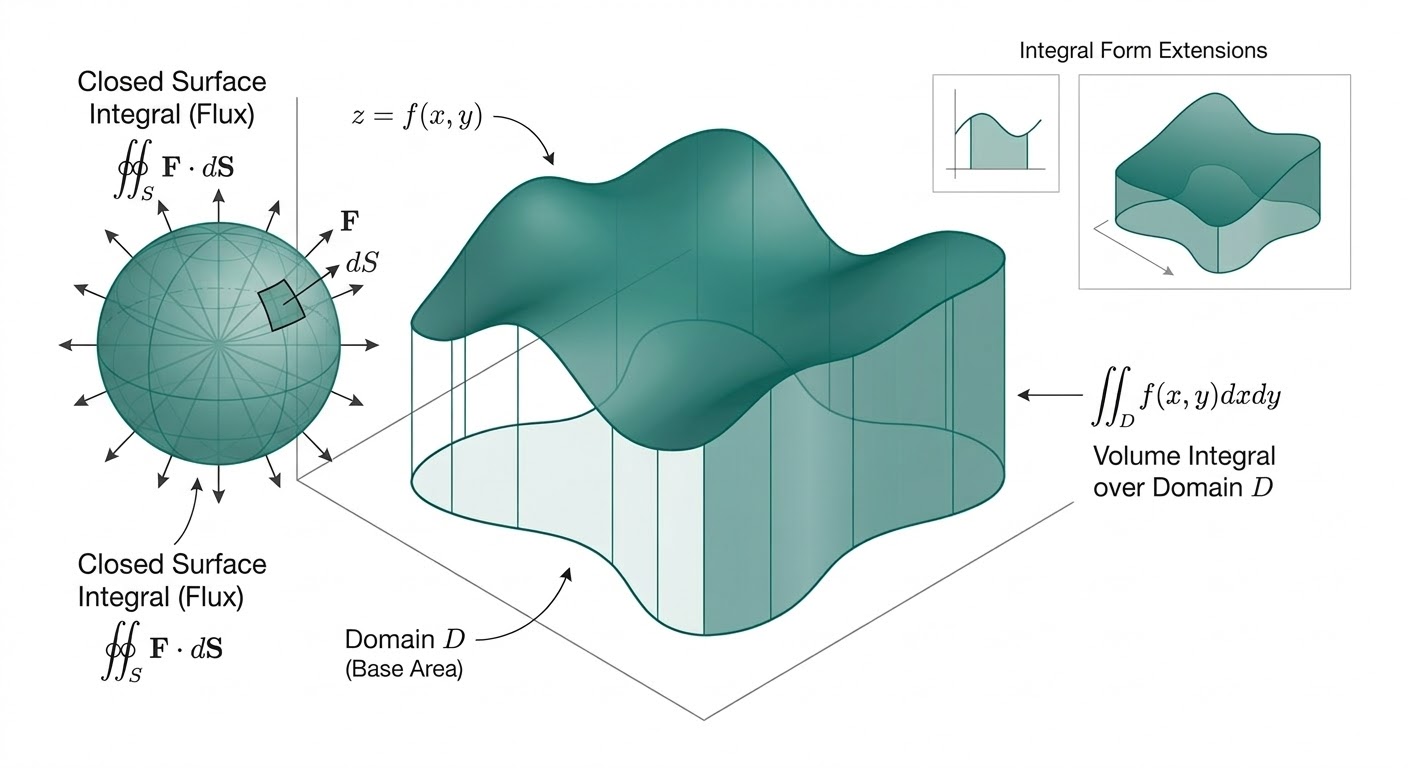
一重积分 \(\int f(x)\,dx\) 常被理解为曲线下的面积:在 \(x\) 轴上切出很多极窄的小条,每条小条的面积近似是“高度 \(\times\) 宽度”,也就是 \(f(x)\,dx\),再把它们全部加起来。
双重积分把这个想法从“一条线”推广到“一块区域”。设 \(D\) 是平面上的一块区域,曲面高度由 \(z=f(x,y)\) 给出,那么
\[\iint_D f(x,y)\,dx\,dy\]它对应的几何图像是:在区域 \(D\) 的每个小块 \(dx\,dy\) 上立起一根很细的小柱子,柱高是 \(f(x,y)\)。这些小柱子拼起来,形成曲面下方的一整块立体体积。于是双重积分最直观的几何意义就是:把区域上方由高度函数堆出来的整块三维体积连续累加起来。
再往上推广,三重积分
\[\iiint_\Omega f(x,y,z)\,dV\]表示在空间区域 \(\Omega\) 内,对每个微小体积元 \(dV\) 的函数值做累加。此时它不一定是在“求一个更高维体积”,也可以是在整个空间体内部对某个量做总汇总,例如总质量、总能量、总代价或总概率权重。可以把它和一重积分放在同一条理解链上来看:速度函数在时间上的累积给出位移,密度函数在空间上的累积给出质量,能量密度(Energy Density)在区域或体积上的累积给出总能量。若 \(\rho(x,y)\) 是面密度,则 \(\iint_D \rho(x,y)\,dA\) 表示区域 \(D\) 上的总质量;若 \(\rho(x,y,z)\) 是体密度,则 \(\iiint_\Omega \rho(x,y,z)\,dV\) 表示空间区域 \(\Omega\) 内的总质量。积分符号的重数,本质上对应的是累积区域的维度。
双重积分里最需要读懂的是 \(f(x,y)\)。\(f(x,y)\) 可以表示真实高度,也可以表示任意随位置变化的量。你可以把它看成“每个点上放了多少东西”。积分的过程,就是把整块区域上的这些局部贡献全部收集起来。
- 当 \(f(x,y)=1\) 时,每个位置的高度都恒为 1,所以积分值在数值上就等于区域 \(D\) 的面积。此时双重积分退化为“面积公式”。
- 当 \(f(x,y)\) 是密度函数(Density Function)时,积分得到的是总质量、总电荷或总概率。函数值越大,说明该位置“堆得越多”,对总量贡献越大。
- 当 \(f(x,y)\) 表示代价、风险、热量、响应强度等场量时,积分得到的是这类量在整个区域上的累积结果。
因此,多重积分做的是一件很具体的事:把无穷多个微小局部量累加成一个整体量。
有时会看到带圈的双积分号 ∯。这个圈表示积分域是闭合的(Closed):核心是一个完整包起来的曲面,例如球壳表面、气泡表面或任意封闭外壳。为了把这个“带圈”符号直接看出来,下面就直接写成在闭合曲面 \(S\) 上的积分。
∯S \(\mathbf{F}\cdot d\mathbf{S}\)
这里的含义通常核心是计算向量场(Vector Field)穿过闭合曲面的总通量(Flux)。直观地说,就是看有多少“流”从这个封闭外壳内部穿出,或者从外部流入。它和高斯散度定理(Gauss's Divergence Theorem)直接相关,因此在偏微分方程(PDE)、连续介质建模、计算流体以及物理信息神经网络(Physics-Informed Neural Networks, PINNs)中十分重要。
在 AI 中,多重积分最常见的身份是概率分布上的总量计算器。如果 \(p(x,y)\) 是二维随机变量的概率密度,那么
\[\iint p(x,y)\,dx\,dy=1\]表示整张概率曲面下方的总体积必须等于 1。这句话的本质是:所有可能情况加起来,概率总和必须是 100%。
进一步,期望(Expectation)就是在这个概率地形上做加权平均。以一维为例,
\[\mathbb{E}[X]=\int x\,p(x)\,dx\]表示每个位置 \(x\) 都按其概率权重 \(p(x)\) 参与平均;多维情形下则自然推广为多重积分。用几何语言说,期望就是这堆“概率质量”在各坐标方向上的重心位置。
高斯分布归一化、边缘分布(Marginal Distribution)、条件分布、变分推断(Variational Inference)、连续潜变量模型以及能量模型(Energy-Based Models)都离不开多重积分。很多时候模型真正要做的事,核心是在高维概率空间里累计、归一化、消去变量或计算期望。
卷积(Convolution)把两个函数/序列组合成第三个函数/序列,最常见的语义是:“一个信号在另一个信号的权重/响应下做累积叠加”。它同时是信号处理(Signal Processing)、系统理论(Systems Theory)与 CNN 的基础运算。
对连续函数 \(f(t)\) 与 \(g(t)\),卷积定义为:
\[(f*g)(t)=\int_{-\infty}^{+\infty} f(\tau)\,g(t-\tau)\,d\tau\]经典记忆法:翻转(Flip)→ 平移(Shift)→ 相乘(Multiply)→ 积分(Integrate)。其中 \(g(t-\tau)\) 这一项等价于把 \(g\) 先时间反转再按 \(t\) 平移。
对离散序列 \(x[n]\) 与 \(h[n]\),卷积定义为:
\[(x*h)[n]=\sum_{k=-\infty}^{+\infty} x[k]\,h[n-k]\]当序列有限长度时,上式求和区间会自然收缩为有限项。二维卷积(2D Convolution)/图像滤波可以视为把求和从一维扩展到二维索引。
工程系统常满足因果性(Causality):系统在时刻 \(t\) 的输出只依赖过去与当前输入,不依赖未来输入。若输入 \(f(t)\) 与系统的冲激响应(Impulse Response)\(g(t)\) 都是因果的(\(t<0\) 时为 0),则卷积积分可写成单侧形式:
\[(f*g)(t)=\int_{0}^{t} f(\tau)\,g(t-\tau)\,d\tau\]这个形式更符合直觉:时刻 \(t\) 的结果由 \([0,t]\) 区间内“所有过去输入”的贡献叠加而来。
把卷积理解成“累积药效”通常更直观。设 \(r(t)\) 是单位时间的滴注速率(Infusion Rate),\(h(t)\) 是“单位剂量在体内的药效/浓度随时间衰减曲线”(可以把它理解为冲激响应)。在时刻 \(t\) 的总药效/浓度 \(c(t)\) 可以写成:
\[c(t)=(r*h)(t)=\int_{0}^{t} r(\tau)\,h(t-\tau)\,d\tau\]解释:在过去每个时刻 \(\tau\) 滴入的一小部分药量 \(r(\tau)\,d\tau\),到现在时刻 \(t\) 已经“经过了” \(t-\tau\) 的代谢时间,因此它的残留贡献按 \(h(t-\tau)\) 衰减;把所有过去贡献叠加,就得到当前总效果。这正是卷积“用一个响应核去累积历史”的核心语义。
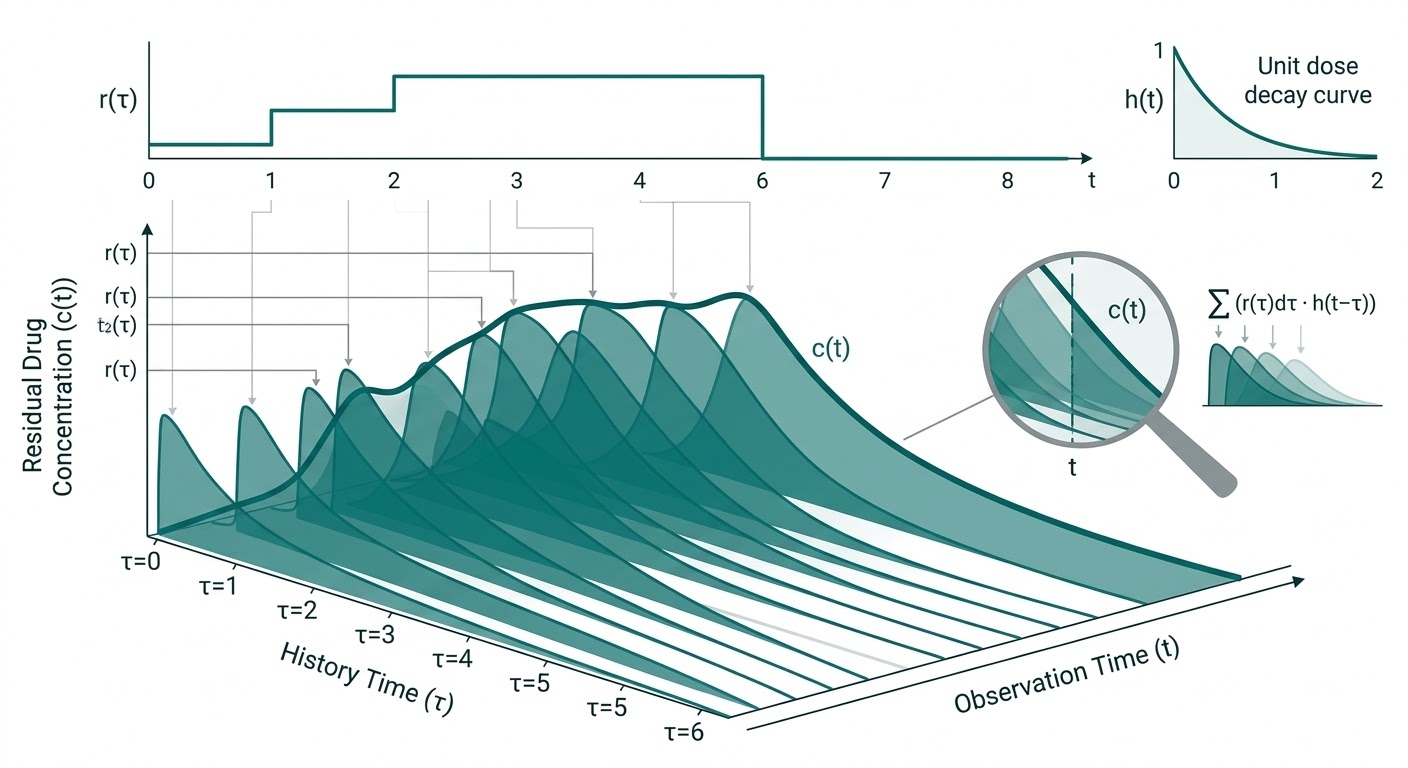
互相关(Cross-Correlation)与卷积的形式非常接近,但没有“核翻转”(Kernel Flip):一维离散互相关常写成 \(\sum_k x[k]\,w[n+k]\)(不同资料索引略有差异)。深度学习框架里多数“卷积层”实现的是互相关,而非严格数学卷积;由于卷积核参数是可学习的,翻不翻转并不会改变可表达的函数族,但在信号处理里二者语义不同,需注意约定。
傅里叶分析(Fourier Analysis,也常写作“傅立叶分析”)研究如何把复杂信号拆成一组简单的正弦/余弦波,再从这些频率成分中理解原信号。它和卷积紧密相连:卷积在原始时间域或空间域里是“滑动叠加”,而在频域里会变成逐点乘法,这就是很多信号处理、语音识别、图像滤波和快速卷积算法的数学基础。
一个信号可以从两个角度观察。时间域(Time Domain)或空间域(Spatial Domain)关心“每个位置的值是多少”;频域(Frequency Domain)关心“这个信号由哪些快慢不同的振荡成分组成”。前者像直接看一段声音波形或一张图像像素,后者像查看声音里低音、中音、高音各占多少,或查看图像中平滑背景、边缘纹理、噪声各占多少。
傅里叶分析的核心思想是:正弦波和余弦波可以作为一组基础积木。频率低的波变化慢,描述整体趋势;频率高的波变化快,描述边缘、尖峰、抖动和细节。把许多不同频率、不同幅度、不同相位的波叠加起来,就能重建相当复杂的信号。
傅里叶级数(Fourier Series)解决的问题是:给定一个会重复出现的周期函数,找出它由哪些固定频率的正弦波和余弦波组成,以及每个频率成分占多大权重。它的输入是一个周期函数 \(f(t)\),输出是一组频率系数 \(a_n,b_n\);这些系数共同构成这个周期函数的“频率配方”。若函数 \(f(t)\) 的周期为 \(T\),它可以写成一组基频(Fundamental Frequency,周期信号中最慢、最基本的重复频率)和谐波(Harmonics,基频整数倍上的频率成分)的叠加:
\[f(t)=\frac{a_0}{2}+\sum_{n=1}^{\infty}\left(a_n\cos(n\omega_0 t)+b_n\sin(n\omega_0 t)\right)\]其中 \(t\) 是时间或一维位置,\(T\) 是周期,\(\omega_0=2\pi/T\) 是基频角频率,\(n\) 是谐波编号。\(n=1\) 对应最慢的基频,\(n=2,3,\ldots\) 对应更快的二次、三次以及更高次谐波。\(a_n\) 控制余弦分量的权重,\(b_n\) 控制正弦分量的权重,\(a_0/2\) 表示整段函数的平均高度。
这些系数由函数和对应正弦/余弦基函数的重叠程度决定:
\[a_n=\frac{2}{T}\int_0^T f(t)\cos(n\omega_0 t)\,dt\] \[b_n=\frac{2}{T}\int_0^T f(t)\sin(n\omega_0 t)\,dt\]这里的积分可以理解成“相似度测量”。若 \(f(t)\) 中明显含有某个频率的余弦波,那么它和 \(\cos(n\omega_0 t)\) 相乘再积分后会留下较大的 \(a_n\);若二者振荡模式不匹配,正负区域会相互抵消,系数接近 0。
同一个频率除了“有多强”,还需要说明“峰值从哪里开始”。如果只使用 \(\cos(n\omega_0 t)\),峰值位置会被固定在参考相位上;真实周期信号中的同一频率成分可能整体向左或向右平移。正弦项 \(\sin(n\omega_0 t)\) 提供了与余弦项相差四分之一周期的正交方向,两者合起来就能表达任意相位平移。
这一点可以直接由三角恒等式看出:
\[A\cos(n\omega_0 t-\phi)=A\cos\phi\cos(n\omega_0 t)+A\sin\phi\sin(n\omega_0 t)\]其中 \(A\) 是该频率成分的幅度,\(\phi\) 是相位平移,\(A\cos\phi\) 就是余弦权重,\(A\sin\phi\) 就是正弦权重。傅里叶级数里的 \(a_n,b_n\) 正是在每个频率上学习这样一对权重。把它们看成二维向量 \((a_n,b_n)\) 时,向量长度表示强度,向量方向表示相位。
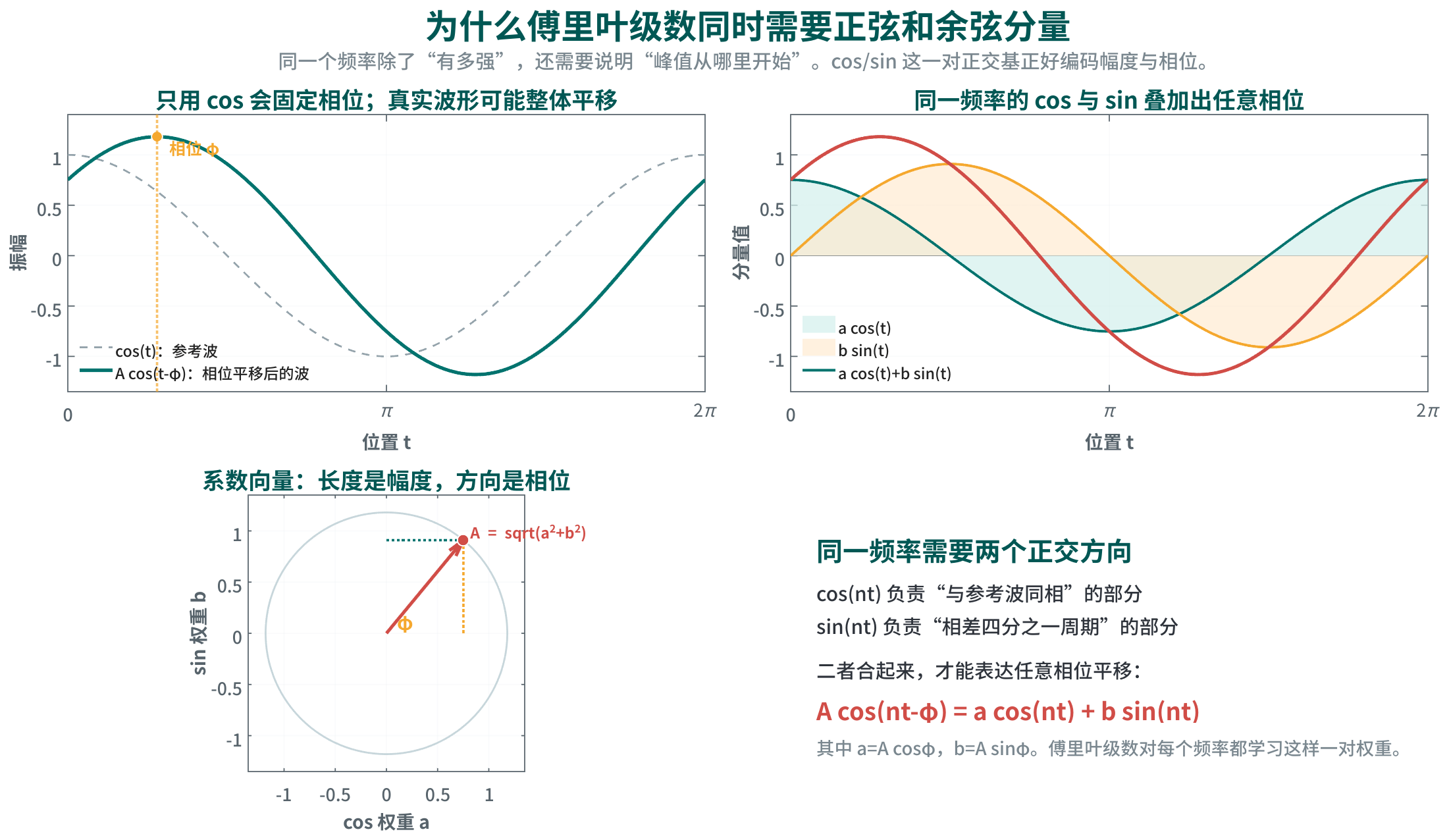
假设一个网站的访问量每天重复波动:凌晨低、午间上升、晚上达到高峰。最粗的周期成分是“每天重复一次”的基频;如果午间和晚间各有一个明显峰值,就需要更高次谐波补充细节;如果还有推送、活动、异常爬虫造成的尖峰,就会出现更高频的局部变化。
- 只保留低频项:曲线平滑,能看出一天内大致趋势。
- 加入中频项:午间峰、晚间峰等结构开始出现。
- 加入高频项:尖峰、噪声和边缘变化也会被复原。
这个例子说明了傅里叶级数的基本取舍:低频给出整体轮廓,高频补充局部细节。过度保留高频也可能把噪声当成结构,因此频域过滤在工程上常用于去噪、平滑和异常检测。
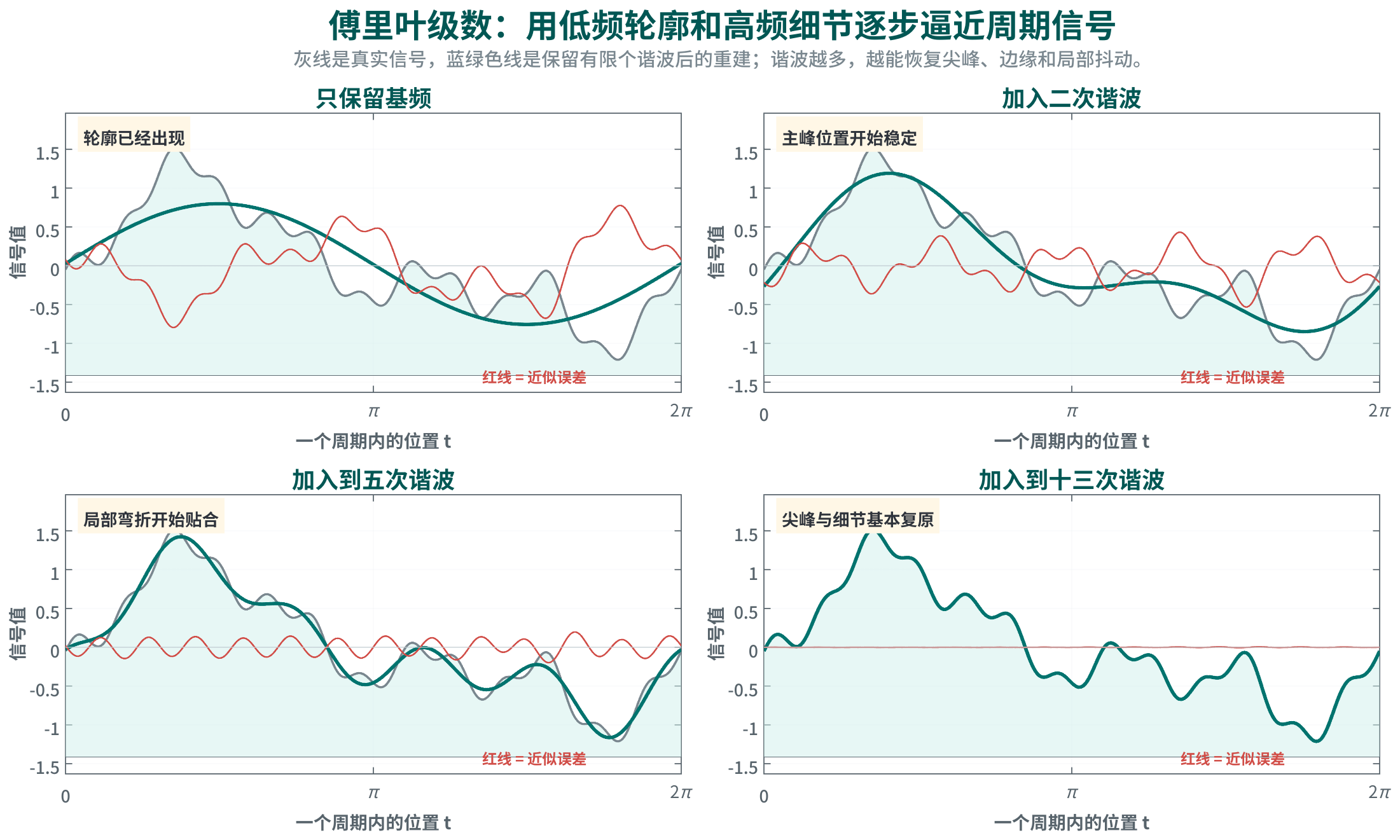
傅里叶变换(Fourier Transform)解决的问题是:给定一段不一定周期重复的连续信号,找出它在所有连续频率上的组成强度和相位。它的输入是时间域信号 \(x(t)\),输出是频域函数 \(X(\omega)\)。傅里叶级数只处理周期函数,并且频率只落在 \(\omega_0,2\omega_0,3\omega_0\) 这些离散点上;傅里叶变换把频率轴展开成连续变量 \(\omega\),因此可以描述非周期信号的频谱。
给定连续信号 \(x(t)\),其傅里叶变换定义为:
\[X(\omega)=\int_{-\infty}^{+\infty}x(t)e^{-i\omega t}\,dt\]其中 \(x(t)\) 是原始时间域信号,\(X(\omega)\) 是频域表示,\(\omega\) 是角频率,\(i\) 是虚数单位,\(e^{-i\omega t}\) 是复指数基函数。复指数可以通过欧拉公式写成正弦和余弦的组合,因此它同时携带幅度与相位信息。
逆变换把频域表示还原回原始信号:
\[x(t)=\frac{1}{2\pi}\int_{-\infty}^{+\infty}X(\omega)e^{i\omega t}\,d\omega\]这里的 \(X(\omega)\) 可以理解成每个频率分量的“配方表”。\(|X(\omega)|\) 表示该频率的强度,\(X(\omega)\) 的相位表示该频率波形相对参考位置的平移。把所有频率分量按这个配方重新叠加,就得到 \(x(t)\)。
一段录音在时间域里是一条不断上下起伏的波形,直接观察很难分辨里面有什么。做傅里叶变换后,频域图会显示不同频率的强度:低频可能是空调或麦克风底噪,中频集中在人声主体,高频可能包含齿音、摩擦声或尖锐噪声。语音识别和音频增强通常不会只看原始波形,而会使用频谱、短时傅里叶变换(Short-Time Fourier Transform, STFT)或梅尔频谱(Mel Spectrogram)等表示,把“随时间变化的频率结构”交给模型处理。
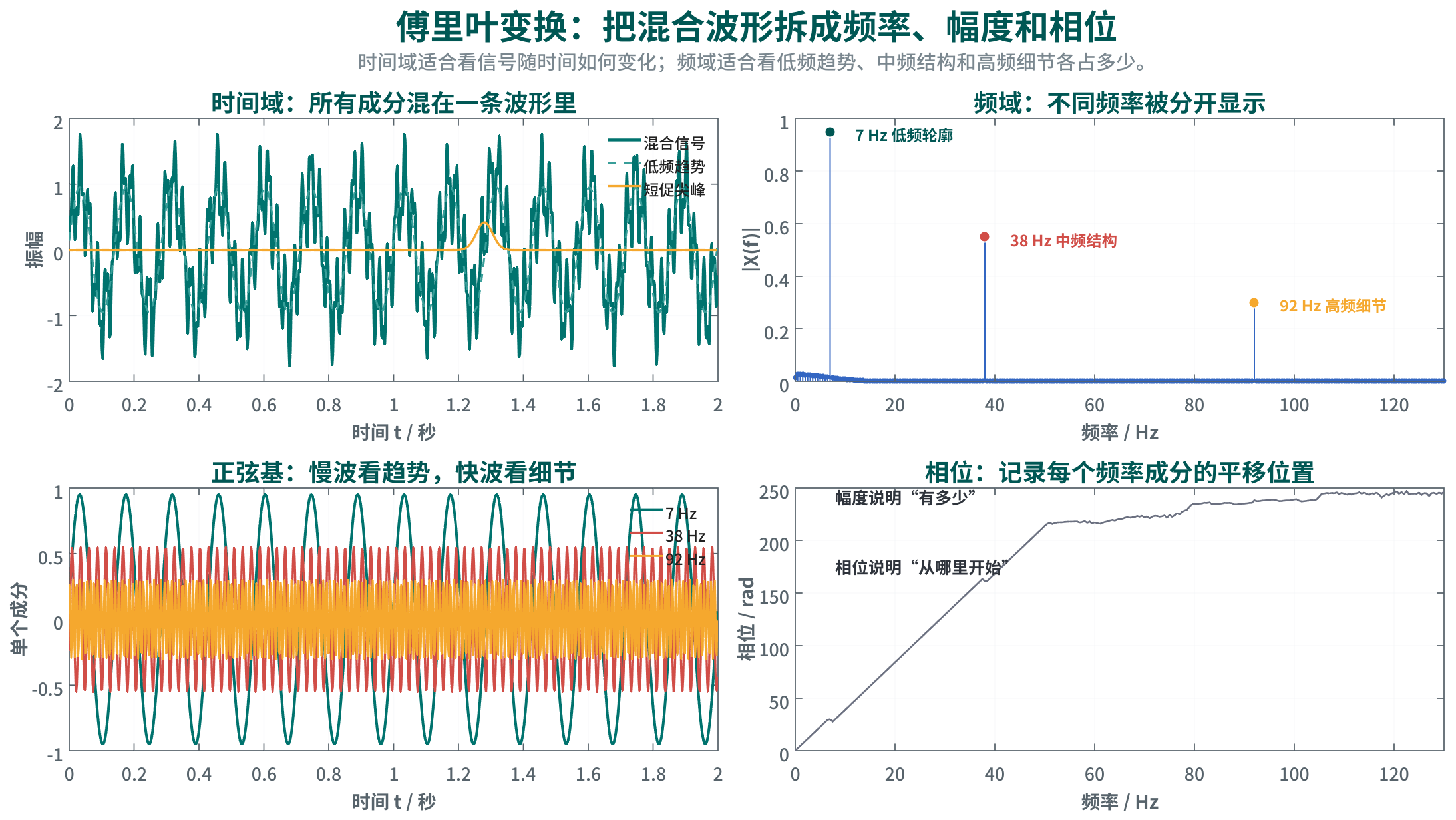
离散傅里叶变换(Discrete Fourier Transform, DFT)解决的问题是:给定一段有限长度的离散采样,计算它在有限个离散频率上的组成。它的输入是长度为 \(N\) 的数组 \(x[0],x[1],\ldots,x[N-1]\),输出是同样长度的频域数组 \(X[0],X[1],\ldots,X[N-1]\)。这正适合计算机处理音频采样、传感器序列、图像行列或局部图像块。DFT 定义为:
\[X[k]=\sum_{n=0}^{N-1}x[n]e^{-i2\pi kn/N},\quad k=0,1,\ldots,N-1\]其中 \(N\) 是序列长度,\(n\) 是原始序列的位置索引,\(k\) 是频率索引,\(x[n]\) 是第 \(n\) 个采样值,\(X[k]\) 是第 \(k\) 个离散频率上的复系数。这个式子的读法是:固定一个频率 \(k\),把整段信号 \(x[0],\ldots,x[N-1]\) 与这个频率对应的复指数波逐点相乘,再全部加起来;加出来的结果 \(X[k]\) 就表示原信号里“像不像这个频率”。
核心难点通常在 \(e^{-i2\pi kn/N}\)。它表示第 \(k\) 个频率基函数在第 \(n\) 个位置的取值。根据欧拉公式(Euler's Formula):
\[e^{-i\theta}=\cos\theta-i\sin\theta\]因此 DFT 里的虚指数可以展开为:
\[e^{-i2\pi kn/N}=\cos(2\pi kn/N)-i\sin(2\pi kn/N)\]这里的 \(2\pi kn/N\) 是角度。\(2\pi\) 表示绕单位圆一整圈,\(k\) 表示在长度为 \(N\) 的序列里转几圈,\(n/N\) 表示当前位置走到了整段序列的多少比例。虚指数并没有引入神秘的新信号,它只是把余弦和正弦打包成一个复数,使一个频率的“幅度”和“相位”可以同时记录。
可以把 \(e^{-i2\pi kn/N}\) 看成单位圆上的一根旋转指针。固定 \(k\) 后,随着 \(n=0,1,\ldots,N-1\) 前进,这根指针会沿单位圆转动:\(k=0\) 时不转,所有指针都指向同一个方向;\(k=1\) 时整段序列转一圈;\(k=2\) 时整段序列转两圈。不同的 \(k\) 就是不同转速的“频率尺”。
求和 \(\sum_n x[n]e^{-i2\pi kn/N}\) 的作用,是把每个采样值 \(x[n]\) 当成一段权重,挂到对应位置的旋转指针上,再把这些复平面上的箭头相加。
- 若信号 \(x[n]\) 真的含有频率 \(k\),许多箭头会朝相近方向叠加,结果长度 \(|X[k]|\) 会很大。
- 若信号和频率 \(k\) 不匹配,箭头会分散在不同方向,正负和相位会互相抵消,结果 \(|X[k]|\) 会较小。
- \(|X[k]|\) 表示该频率有多强,复数角度 \(\arg X[k]\) 表示该频率成分的相位,也就是它相对参考波形平移了多少。
因此,DFT 可以理解成一排频率探测器。第 \(k\) 个探测器拿着一根转速为 \(k\) 的旋转尺去扫描整段信号;如果信号的起伏节奏和这根尺对得上,累加结果就大;如果对不上,累加结果会互相抵消。
逆 DFT 为:
\[x[n]=\frac{1}{N}\sum_{k=0}^{N-1}X[k]e^{i2\pi kn/N}\]DFT 会保留原始信息,只是换了一套坐标系描述同一个长度为 \(N\) 的向量。原始坐标系问“每个采样点是多少”,频率坐标系问“每个离散频率成分是多少”。\(X[0]\) 是直流分量(Direct Current Component, DC Component),对应整段序列的平均水平;较小的 \(k\) 对应慢变化,较大的 \(k\) 对应快变化。
图像是二维离散信号。灰度图可以看成一个矩阵:每个像素位置 \((u,v)\) 上有一个亮度值 \(I[u,v]\)。二维 DFT 会把这个像素矩阵转换成频率矩阵 \(S[p,q]\),其中 \(p\) 表示水平方向频率索引,\(q\) 表示垂直方向频率索引。
在图像处理中,低频成分通常描述大面积的平滑亮度、阴影和整体形状;高频成分通常描述边缘、纹理、细线、噪声和压缩伪影。例如一张人脸照片中,脸部轮廓、光照渐变和背景色块主要落在低频;眼睫毛、发丝、衣服纹理和传感器噪声会落在较高频率。
- 只保留低频:图像会变得平滑,主体轮廓仍在,但边缘和纹理会模糊。
- 削弱高频:常用于去噪,因为很多随机噪声集中在高频区域。
- 增强高频:常用于锐化,因为边缘和细节需要更强的高频响应。
- 按块处理频率:图像压缩会把局部图像块变到频域,优先保留人眼更敏感的低频结构,压缩或量化高频细节。
这类操作说明了 DFT 在图像领域的直观意义:它把“像素值矩阵”改写成“二维波纹组合表”。横向变化慢、纵向变化慢的成分是低频;横向或纵向快速震荡的成分是高频。频域滤波之所以有效,正是因为许多视觉概念在频率轴上会自然分开。
DFT 也可以写成矩阵乘法:
\[\mathbf{X}=F\mathbf{x}\]其中 \(\mathbf{x}\) 是长度为 \(N\) 的原始向量,\(\mathbf{X}\) 是长度为 \(N\) 的频域向量,\(F\) 是由复指数基函数组成的 DFT 矩阵。矩阵的每一行对应一个频率基,矩阵乘法就是把原始向量投影到各个频率基上。
快速傅里叶变换(Fast Fourier Transform, FFT)解决的问题是:DFT 很有用,但按定义直接算太慢。FFT 的输入和输出与 DFT 相同,输入仍然是 \(x[0],\ldots,x[N-1]\),输出仍然是 \(X[0],\ldots,X[N-1]\);区别在于计算路线。DFT 是数学变换本身,FFT 是利用对称性和分治结构加速计算 DFT 的算法族。直接按定义计算 DFT 时,每个 \(X[k]\) 都要遍历 \(N\) 个输入点,总复杂度为 \(O(N^2)\);FFT 可以把复杂度降低到 \(O(N\log N)\)。
\[O(N^2)\rightarrow O(N\log N)\]以最经典的 Cooley-Tukey FFT 为例,它把序列拆成偶数位置和奇数位置两半:
\[X[k]=\sum_{m=0}^{N/2-1}x[2m]e^{-i2\pi k(2m)/N}+\sum_{m=0}^{N/2-1}x[2m+1]e^{-i2\pi k(2m+1)/N}\]这里 \(x[2m]\) 是偶数位置采样,\(x[2m+1]\) 是奇数位置采样。拆分后,两部分都具有更小规模 DFT 的结构,可以递归计算。每一层递归把问题规模减半,再用少量复指数因子把偶数频谱和奇数频谱合并。若 \(N=1024\),直接 DFT 需要约一百万级别的乘加量,而 FFT 只需要约 \(1024\log_2 1024\) 量级的组合步骤,差异非常明显。
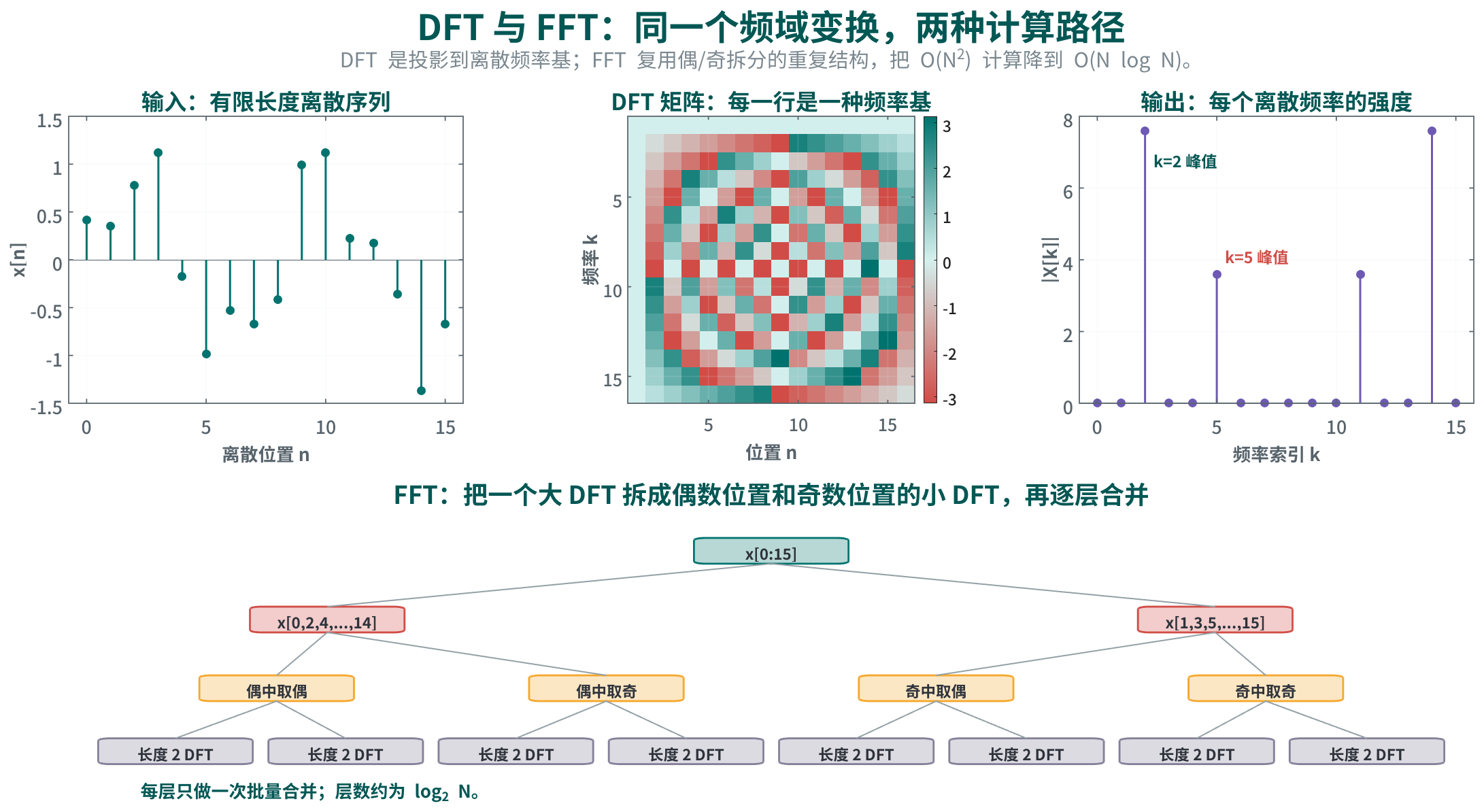
卷积定理(Convolution Theorem)解决的问题是:原始域里的卷积计算为什么可以转到频域里用乘法完成。它把前面的卷积章节和傅里叶分析连接起来。输入是两个函数或序列 \(f,g\),目标是计算它们的卷积 \(f*g\);定理说明,可以先把 \(f\) 和 \(g\) 分别变到频域,再逐点相乘,最后逆变换回来。若 \(F(\omega)\) 是 \(f(t)\) 的傅里叶变换,\(G(\omega)\) 是 \(g(t)\) 的傅里叶变换,则:
\[\mathcal{F}\{f*g\}(\omega)=F(\omega)G(\omega)\]其中 \(f*g\) 表示时间域卷积,\(\mathcal{F}\{\cdot\}\) 表示傅里叶变换,\(F(\omega)G(\omega)\) 表示频域逐点相乘。也就是说,原始空间里要滑动、翻转、相乘、积分的卷积,在频域里只需要把对应频率位置的复数系数相乘。
反方向也成立:原始域中的逐点相乘,对应频域中的卷积:
\[\mathcal{F}\{f(t)g(t)\}(\omega)=\frac{1}{2\pi}(F*G)(\omega)\]这个结论有很强的工程意义。对很长的序列或很大的卷积核,可以先做 FFT,把两个序列变到频域;再逐点相乘;最后做逆 FFT 回到原始域。对于小卷积核,直接卷积通常更划算;对于长序列、大核、一维信号处理和某些大图像滤波任务,FFT 卷积会显著降低计算量。
图像模糊可以看成二维卷积:每个像素用周围像素的加权平均替代。若滤镜核很小,例如 \(3\times 3\) 或 \(5\times 5\),直接滑动窗口计算很方便。若滤镜核很大,例如模拟大范围散焦或长距离扩散,直接卷积的滑动成本会迅速上升;此时可以把图像和滤镜核都变换到频域,相乘后再逆变换回来。频域相乘得到的结果和原始域卷积一致,但计算路径不同。
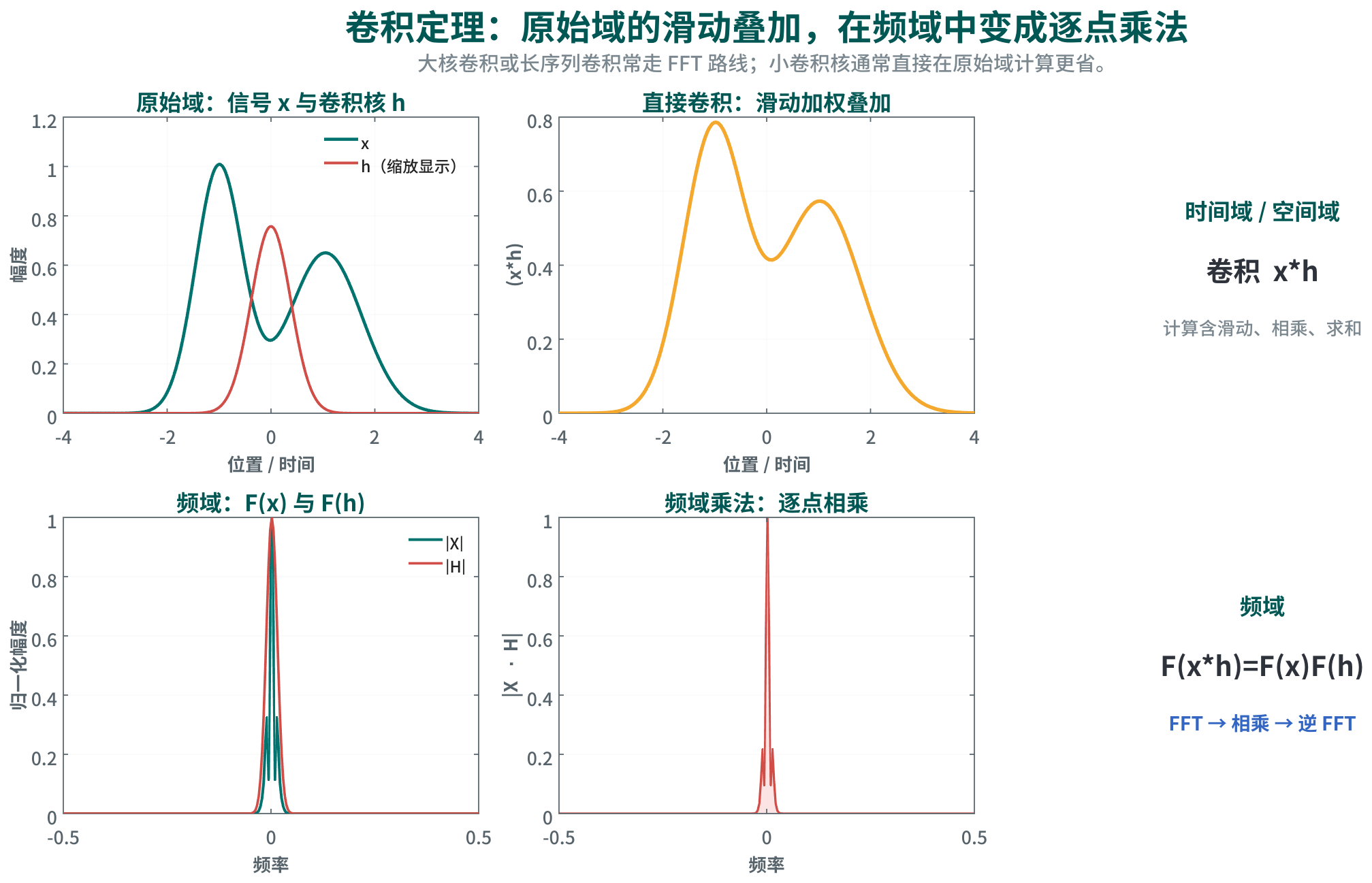
傅里叶分析在 AI 中既是数据表示工具,也是理解模型行为的工具。
- 语音与音频:原始波形常被转成 STFT、梅尔频谱或功率谱。模型看到的不只是每个时间点的振幅,还能看到不同频率成分随时间如何变化。
- 计算机视觉:频域可以分析图像的平滑区域、边缘、纹理和噪声。低频对应大尺度结构,高频对应边缘和细节;对抗样本、压缩伪影、去噪和超分辨率都常涉及频率视角。
- 卷积网络:CNN 中的小核卷积通常直接在空间域计算;大核卷积、信号处理卷积和某些加速算法会利用卷积定理。频域也能帮助解释滤波器学习到的是平滑、边缘还是纹理响应。
- 位置编码与傅里叶特征:正弦/余弦位置编码、旋转位置编码(RoPE)和傅里叶特征(Fourier Features)都使用周期函数表达位置或坐标。它们让模型更容易表示周期结构、相对位移和高频变化。
- 时间序列:周期性、季节性和异常检测经常依赖频谱分析。日周期、周周期、年周期可以在频域中表现为明显峰值。
从学习角度看,傅里叶分析提供的是一种“换坐标系”的能力。很多在原始域里混在一起的模式,到了频域会分开;很多在原始域里昂贵的卷积,到了频域会变成简单乘法。这也是它长期出现在信号处理、机器学习和深度学习系统中的原因。
链式法则(Chain Rule)是反向传播(Backpropagation)的核心:当计算图(Computation Graph)由一系列函数复合组成时,总导数等于沿路径的局部导数相乘。
在微分语言下更紧凑:若 \(y=g(x)\)、\(z=f(y)\),则 \(dz=f'(y)\,dy\) 且 \(dy=g'(x)\,dx\),合并得 \(dz=f'(g(x))g'(x)\,dx\)。反向传播做的就是把这些局部“系数”从输出一路乘回输入。
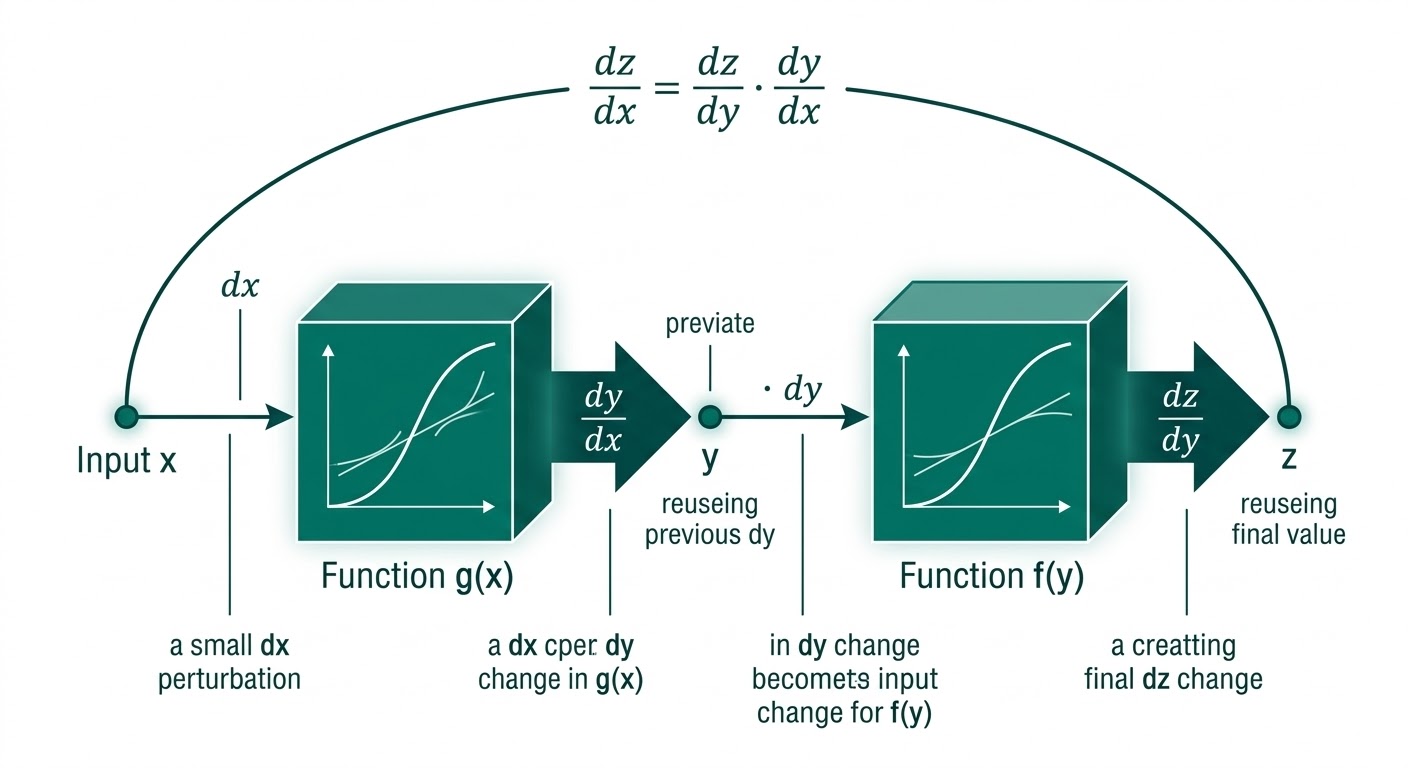
最小二乘法(Least Squares)解决“拟合误差最小”的问题。给定样本矩阵 \(X\) 与目标 \(\mathbf{y}\),线性模型 \(\hat{\mathbf{y}}=X\mathbf{w}\) 的目标是:
\[\min_{\mathbf{w}}\ \|X\mathbf{w}-\mathbf{y}\|_2^2\]当 \(X^\top X\) 可逆时,闭式解满足正规方程(Normal Equations):
\[X^\top X\mathbf{w}=X^\top\mathbf{y},\quad \mathbf{w}^*=(X^\top X)^{-1}X^\top\mathbf{y}\]几何直觉: \(X\mathbf{w}\) 只能落在 \(X\) 的列空间(Column Space)中,最小二乘解就是把 \(\mathbf{y}\) 正交投影(Orthogonal Projection)到这个空间上,剩余误差向量与列空间正交。
在 AI/统计实践中,若 \(X^\top X\) 病态或奇异,常用岭回归(Ridge Regression):
\[\min_{\mathbf{w}}\ \|X\mathbf{w}-\mathbf{y}\|_2^2+\lambda\|\mathbf{w}\|_2^2,\quad (X^\top X+\lambda I)\mathbf{w}=X^\top\mathbf{y}\]它本质上是把二次目标做稳定化,降低方差并提升泛化。
凸函数(Convex Function)是“碗状”的函数:任意两点连线上的函数值不超过端点函数值的线性插值。形式化定义:
\[f(\lambda x_1+(1-\lambda)x_2)\le \lambda f(x_1)+(1-\lambda)f(x_2),\quad \lambda\in[0,1]\]凸优化(Convex Optimization)之所以重要,是因为凸目标在凸可行域上没有“坏局部最小值”:任一局部最小值都是全局最小值。
若 \(f\) 二阶可导,则 Hessian 提供了最直接的局部判据:在一维中 \(f''(x)\ge 0\) 对应凸;在多维中,若对所有 \(x\) 都有 \(\nabla^2 f(x)\succeq 0\)(半正定,Positive Semidefinite),则 \(f\) 是凸函数。若处处 \(\nabla^2 f(x)\succ 0\)(正定,Positive Definite),则函数通常具有更强的严格凸性(Strict Convexity)。
损失函数的形状可以非常多样。需要区分两层含义:
- 损失形式本身:例如 BCE/CE(对概率或对线性模型的 logits)是凸的,MSE 也是凸的。
- 对参数的整体目标:当把损失与深度网络的非线性参数化组合后,目标函数通常变成非凸(Non-convex),这核心是“网络映射让问题不凸”。
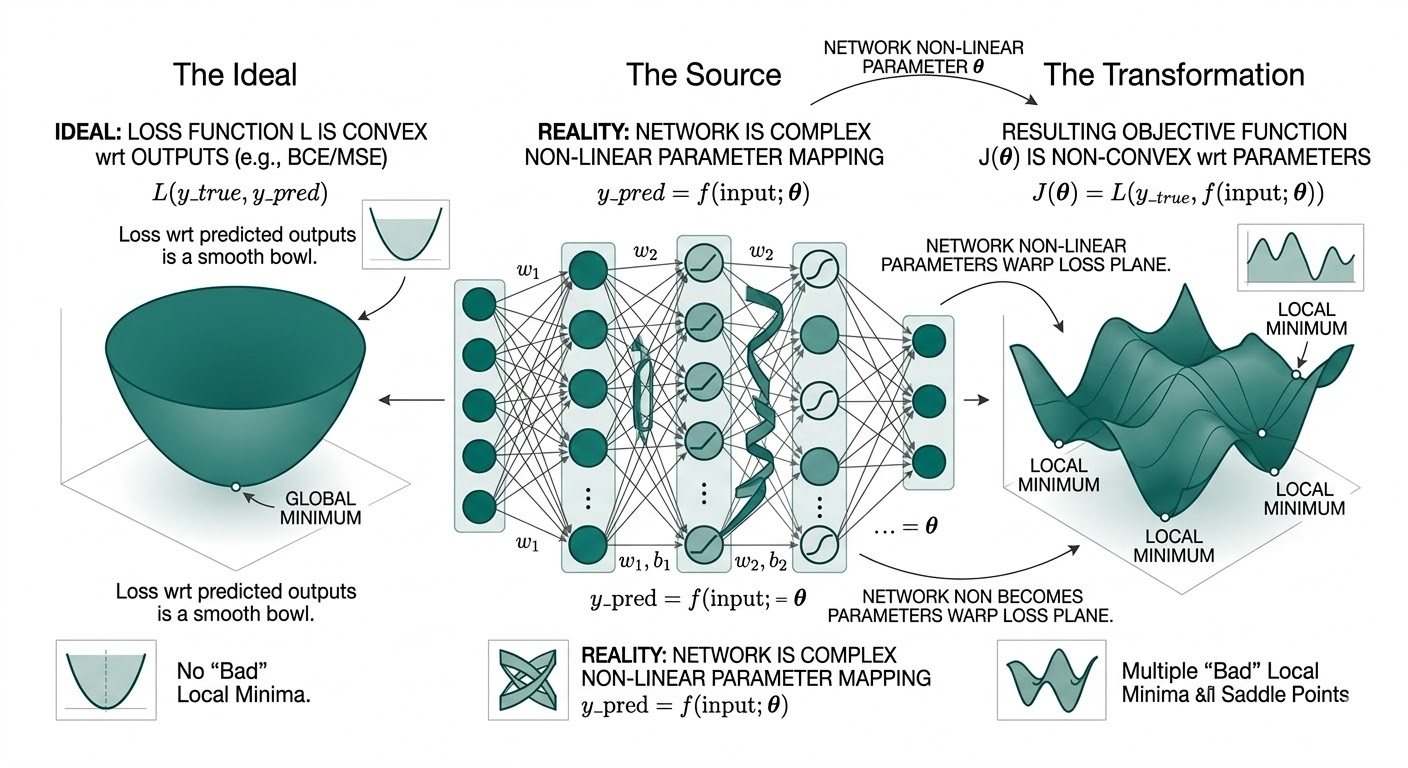
拉格朗日乘数法(Lagrange Multiplier Method)处理约束优化(Constrained Optimization):在满足约束的前提下最小化/最大化目标函数。常用写法是把约束写成函数形式:等式约束(Equality Constraints)\(g_i(x)=0\),不等式约束(Inequality Constraints)\(g_i(x)\le 0\)。
对等式约束,构造拉格朗日函数(Lagrangian):
\[\mathcal{L}(x,\lambda)=f(x)+\sum_{i=1}^{m}\lambda_i g_i(x)\]其中 \(f(x)\) 是目标函数(Objective),\(g_i(x)\) 是约束函数(Constraint Function),\(\lambda_i\) 是拉格朗日乘子(Lagrange Multiplier)。新增部分 \(\sum_i \lambda_i g_i(x)\) 称为拉格朗日项(Lagrange Term),单个约束对应的项是 \(\lambda_i g_i(x)\)。
在不同应用里乘子的记号可能不同:在优化理论里常写 \(\lambda_i\),在支持向量机(SVM)里常写 \(\alpha_i\)(每个样本约束对应一个乘子)。
把 \(\mathcal{L}(x,\lambda)\) 看作关于原变量 \(x\) 与乘子 \(\lambda\) 的二元函数后,鞍点(Saddle Point)结构是约束被编码进目标函数后的直接结果。 \(x\) 的角色是压低总代价, \(\lambda\) 的角色是放大任何尚未满足的约束,因此两者天然形成极小极大(Min-Max)结构。
先看等式约束 \(g(x)=0\)。这里必须先把“为什么内层是最大化”说清楚:这核心是为了把约束编码成一个可行点保留原目标、不可行点直接罚到 \(+\infty\) 的机制。因此,固定某个 \(x\) 后,内层写成 \(\max_\lambda \, (f(x)+\lambda g(x))\)。如果 \(g(x)\neq 0\),由于 \(\lambda\) 不受符号限制,最大化者总能把 \(\lambda\) 取到与 \(g(x)\) 同号且绝对值任意大,使 \(\mathcal{L}(x,\lambda)\to\infty\);只有当 \(g(x)=0\) 时,拉格朗日项才消失,内层最大值才退化为 \(f(x)\)。因此 \(\max_\lambda \mathcal{L}(x,\lambda)\) 的作用,是把所有不满足等式约束的点直接排除掉。
不等式约束更容易看出这种“过滤”机制。若约束是 \(g(x)\le 0\) 且乘子满足 \(\lambda\ge 0\),那么当 \(g(x)>0\) 时,最大化者会把 \(\lambda\) 推大,使 \(\lambda g(x)\to\infty\);当 \(g(x)\le 0\) 时,继续增大 \(\lambda\) 只会让值变小,因此最优选择是 \(\lambda=0\)。于是 \(\max_{\lambda\ge 0}\mathcal{L}(x,\lambda)\) 对可行点返回原始代价 \(f(x)\),对不可行点返回“无限罚款”。外层再对 \(x\) 做最小化,就等价于只在可行域内最小化 \(f(x)\)。
\[\min_x\ \max_\lambda\ \mathcal{L}(x,\lambda)\]几何上,这正对应马鞍形曲面:沿 \(x\) 方向切开, \(\mathcal{L}\) 像一个向上开的“碗”,因为这里在做最小化;沿 \(\lambda\) 方向切开, \(\mathcal{L}\) 像一个向下开的“拱”,因为这里在做最大化。鞍点 \((x^*,\lambda^*)\) 的含义是:固定 \(\lambda=\lambda^*\) 时, \(x^*\) 已经不能再把值压低;固定 \(x=x^*\) 时, \(\lambda^*\) 也已经不能再把值抬高。原问题的最优解与约束的恰当作用强度,就在这个交点同时确定。
记号约定:上标星号(Asterisk)\(^*\) 通常表示“最优/最优点处的取值”,例如 \(x^*\) 是最优解, \(\lambda^*\) 是与之对应的最优乘子。
在鞍点 \((x^*,\lambda^*)\),固定 \(\lambda=\lambda^*\) 时 \(x^*\) 使 \(\mathcal{L}\) 最小;固定 \(x=x^*\) 时 \(\lambda^*\) 使 \(\mathcal{L}\) 最大,可用不等式写成:
\[\mathcal{L}(x^*,\lambda)\le \mathcal{L}(x^*,\lambda^*)\le \mathcal{L}(x,\lambda^*)\]上面的鞍点不等式给出的是几何刻画;真正求解时,还需要把“这个点已经不能再降、也不能再升”的直观条件改写成可计算的方程。做法是检查拉格朗日函数(Lagrangian)\(\mathcal{L}\) 对各个变量的一阶变化:若在候选点附近,沿某个允许方向还能继续把值压低(对 \(x\))或继续把值抬高(对 \(\lambda\)),那么该点就不可能是鞍点。
这就是一阶必要条件(First-Order Necessary Condition)的来源:若 \(x^*\) 是最优解,则一阶(线性)变化项必须已经消失,否则还存在继续改进的方向。这里“必要”不同于“充分”:满足一阶条件只说明它有可能是最优点,不说明它一定最优;要得到充分结论,还需要二阶条件、凸性(Convexity)或其他结构。
无约束情形最直接。在一维中,若 \(x^*\) 是可微且不在边界上的局部最小点,则向左或向右移动都不能让函数更小,因此斜率必须满足 \(f'(x^*)=0\);多维里把“斜率”推广为梯度(Gradient),于是条件变为 \(\nabla f(x^*)=0\)。
把同样的思路移到等式约束上,求解目标就从“找原函数 \(f\) 的极小点”变成“找拉格朗日函数 \(\mathcal{L}(x,\lambda)\) 的鞍点”。对可导问题,一阶条件写成:
\[\nabla_x \mathcal{L}(x^*,\lambda^*)=0,\quad g_i(x^*)=0\]第一式表示:固定 \(\lambda=\lambda^*\) 后,已经找不到能继续降低 \(\mathcal{L}\) 的 \(x\) 方向;第二式就是可行性(Feasibility)本身。又因为 \(\frac{\partial \mathcal{L}}{\partial \lambda_i}=g_i(x)\),所以“对乘子求偏导为 0”本质上只是把约束 \(g_i(x)=0\) 原样写回。
不等式约束时,乘子必须满足 \(\lambda_i\ge 0\),因此鞍点结构相应写成:
\[\min_x\ \max_{\lambda\ge 0}\ \mathcal{L}(x,\lambda)\]此时除了驻点条件,还必须同时满足 KKT 条件(Karush–Kuhn–Tucker Conditions)。其中最关键的是互补松弛(Complementary Slackness)\(\lambda_i g_i(x^*)=0\):每个约束在最优点只有两种状态——要么它是紧的(Active),即 \(g_i(x^*)=0\);要么它不紧,此时对应乘子必须为 0,表示该约束在最优点处没有实际作用。
例(等式约束):最小化 \(f(x,y)=x^2+y^2\),约束 \(x+y=1\)。拉格朗日函数:
\[\mathcal{L}(x,y,\lambda)=x^2+y^2+\lambda(x+y-1)\]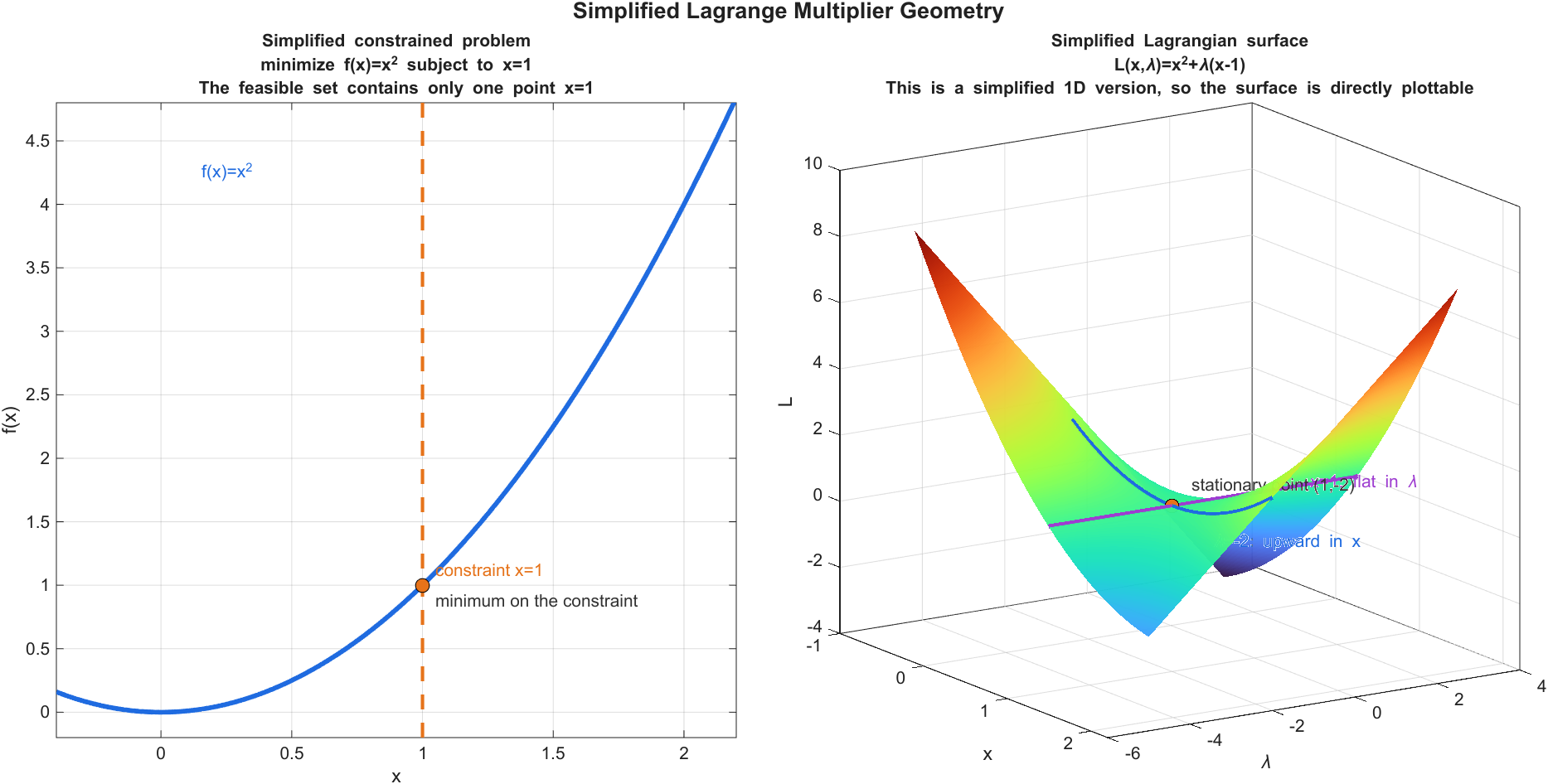
其中 \(\lambda(x+y-1)\) 是拉格朗日项(Lagrange Term):它把等式约束 \(x+y-1=0\) 以乘子加权的形式并入目标函数。
令偏导为零: \(\frac{\partial \mathcal{L}}{\partial x}=2x+\lambda=0\)、\(\frac{\partial \mathcal{L}}{\partial y}=2y+\lambda=0\)、\(\frac{\partial \mathcal{L}}{\partial \lambda}=x+y-1=0\)。注意 \(\frac{\partial \mathcal{L}}{\partial \lambda}=0\) 就是把约束 \(x+y=1\) 写回来;联立可得 \(x=y=\frac{1}{2}\)。几何上,这意味着最优点处目标函数等高线与约束曲线相切。
例(不等式约束):最小化 \(f(x)=x^2\),约束 \(x\ge 1\)。直觉上,无约束最小值在 \(x=0\),但它不满足约束,所以最优点只能落在边界 \(x=1\)。
- 把约束改写成标准形式:令 \(g(x)=1-x\),则 \(x\ge 1\Leftrightarrow g(x)\le 0\)。
- 构造拉格朗日函数: \(\mathcal{L}(x,\lambda)=f(x)+\lambda g(x)=x^2+\lambda(1-x)\)。其中 \(\lambda(1-x)\) 是拉格朗日项(Lagrange Term),不等式情形要求 \(\lambda\ge 0\)。
- 写出 KKT 的核心条件:可行性(Feasibility)\(1-x\le 0\);乘子非负 \(\lambda\ge 0\);驻点(Stationarity)\(\frac{d\mathcal{L}}{dx}=2x-\lambda=0\);互补松弛(Complementary Slackness)\(\lambda(1-x)=0\)。
- 解:由 \(2x-\lambda=0\) 得 \(\lambda=2x\)。互补松弛要求 \(\lambda=0\) 或 \(x=1\)。若 \(\lambda=0\) 则 \(x=0\),但违反 \(x\ge 1\);因此 \(x^*=1\),进而 \(\lambda^*=2\)。
- 解释:在最优点处 \(1-x^*=0\),该约束是“紧的”(Active),互补松弛允许乘子 \(\lambda^*>0\),它刻画了该约束在最优点处对解的影响强度。如果最优点落在可行域(Feasible Set)内部(约束不紧, \(1-x^*<0\)),互补松弛会强制 \(\lambda^*=0\)。
对偶问题(Dual Problem)从原始问题(Primal Problem)导出下界函数,用于分析可行性、间隙与最优性。标准形式:
\[\min_x\ f(x)\ \text{s.t.}\ g_i(x)\le 0,\ h_j(x)=0\] \[g(\lambda,\nu)=\inf_x\Big(f(x)+\sum_i \lambda_i g_i(x)+\sum_j \nu_j h_j(x)\Big),\ \lambda_i\ge 0\] \[\max_{\lambda,\nu}\ g(\lambda,\nu)\ \text{s.t.}\ \lambda\ge 0\]把括号中的表达式记为拉格朗日函数(Lagrangian)\(\mathcal{L}(x,\lambda,\nu)=f(x)+\sum_i \lambda_i g_i(x)+\sum_j \nu_j h_j(x)\),则对偶函数(Dual Function)就是 \(g(\lambda,\nu)=\inf_x \mathcal{L}(x,\lambda,\nu)\):固定乘子后先对原变量求下确界,把它“消去”,再对乘子最大化这个下界。
SVM 的对偶函数(Dual Function)来自一个标准过程:先写出原始问题(Primal Problem)的拉格朗日函数(Lagrangian),再对原变量取下确界(Infimum),把优化问题改写为只依赖乘子变量的形式。在线性支持向量机(Support Vector Machine, SVM)里,这个过程最清楚,因为 \(\boldsymbol{\alpha}\) 的出现既解释了“为什么叫对偶”,也把“把原变量消掉”变成了可逐步计算的代换。
考虑硬间隔(Hard-margin)线性 SVM。原始问题是:
\[\min_{\mathbf{w},b}\ \frac{1}{2}\|\mathbf{w}\|_2^2\quad \text{s.t.}\quad y_i(\mathbf{w}^\top \mathbf{x}_i+b)-1\ge 0,\ i=1,\dots,n\]把约束改写成标准不等式形式:
\[g_i(\mathbf{w},b)=1-y_i(\mathbf{w}^\top \mathbf{x}_i+b)\le 0\]于是拉格朗日函数为:
\[\mathcal{L}(\mathbf{w},b,\boldsymbol{\alpha})=\frac{1}{2}\|\mathbf{w}\|_2^2+\sum_{i=1}^{n}\alpha_i\big(1-y_i(\mathbf{w}^\top \mathbf{x}_i+b)\big),\quad \alpha_i\ge 0\]对偶函数(Dual Function)的定义是:固定乘子 \(\boldsymbol{\alpha}\),对原变量 \(\mathbf{w},b\) 取下确界:
\[g(\boldsymbol{\alpha})=\inf_{\mathbf{w},b}\mathcal{L}(\mathbf{w},b,\boldsymbol{\alpha})\]这里的关键结构已经出现了:原始问题直接优化 \(\mathbf{w},b\),而对偶函数先把 \(\boldsymbol{\alpha}\) 固定住,把 \(\mathbf{w},b\) 当成待消去变量。随后得到的最大化问题,只剩乘子变量 \(\boldsymbol{\alpha}\)。这就是“对偶”的来源:同一个最优化问题,被改写成了另一组变量上的伴随优化问题。
现在把 \(\mathbf{w},b\) 完整消掉。先求驻点条件(Stationarity Conditions)。对 \(\mathbf{w}\) 求偏导:
\[\frac{\partial \mathcal{L}}{\partial \mathbf{w}}=\mathbf{w}-\sum_{i=1}^{n}\alpha_i y_i \mathbf{x}_i=\mathbf{0}\]因此
\[\mathbf{w}=\sum_{i=1}^{n}\alpha_i y_i \mathbf{x}_i\]对 \(b\) 求偏导:
\[\frac{\partial \mathcal{L}}{\partial b}=-\sum_{i=1}^{n}\alpha_i y_i=0\]因此
\[\sum_{i=1}^{n}\alpha_i y_i=0\]把这些结果代回拉格朗日函数之前,先把它展开成便于逐项代换的形式:
\[\mathcal{L}(\mathbf{w},b,\boldsymbol{\alpha})=\frac{1}{2}\mathbf{w}^\top\mathbf{w}+\sum_{i=1}^{n}\alpha_i-\sum_{i=1}^{n}\alpha_i y_i\,\mathbf{w}^\top\mathbf{x}_i-b\sum_{i=1}^{n}\alpha_i y_i\]第一项代入 \(\mathbf{w}=\sum_{i=1}^{n}\alpha_i y_i \mathbf{x}_i\):
\[\frac{1}{2}\mathbf{w}^\top\mathbf{w}=\frac{1}{2}\Big(\sum_{i=1}^{n}\alpha_i y_i \mathbf{x}_i\Big)^\top\Big(\sum_{j=1}^{n}\alpha_j y_j \mathbf{x}_j\Big)\] \[=\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j\]第二项保持不变:
\[\sum_{i=1}^{n}\alpha_i\]第三项代入同一个 \(\mathbf{w}\) 表达式:
\[-\sum_{i=1}^{n}\alpha_i y_i\,\mathbf{w}^\top\mathbf{x}_i=-\sum_{i=1}^{n}\alpha_i y_i\Big(\sum_{j=1}^{n}\alpha_j y_j \mathbf{x}_j\Big)^\top\mathbf{x}_i\] \[=-\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_j^\top\mathbf{x}_i\] \[=-\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j\]最后一项利用 \(\sum_{i=1}^{n}\alpha_i y_i=0\) 直接消失:
\[-b\sum_{i=1}^{n}\alpha_i y_i=0\]因此
\[g(\boldsymbol{\alpha})=\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j+\sum_{i=1}^{n}\alpha_i-\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j\] \[=\sum_{i=1}^{n}\alpha_i-\frac{1}{2}\sum_{i=1}^{n}\sum_{j=1}^{n}\alpha_i\alpha_j y_i y_j\,\mathbf{x}_i^\top\mathbf{x}_j\]于是对偶问题(Dual Problem)就是:
\[\max_{\boldsymbol{\alpha}}\ g(\boldsymbol{\alpha})\quad \text{s.t.}\quad \alpha_i\ge 0,\ \sum_{i=1}^{n}\alpha_i y_i=0\]此时“对偶”二字的含义就精确了:原始问题在参数空间里直接求 \(\mathbf{w},b\),对偶问题则在乘子空间里求 \(\boldsymbol{\alpha}\);两者来自同一个拉格朗日结构,描述的是同一个最优解的两种表示。对 SVM 而言,更重要的结构变化是:数据 \(\mathbf{x}_i\) 不再单独出现,而只通过内积(Inner Product)\(\mathbf{x}_i^\top\mathbf{x}_j\) 进入目标函数,这正是核技巧(Kernel Trick)的入口。
若问题是凸的且满足 Slater 条件,则强对偶(Strong Duality)成立,可以用鞍点形式表达“先最小化再最大化”与“先最大化再最小化”等价:
\[\min_x\max_{\lambda\ge 0,\nu}\mathcal{L}(x,\lambda,\nu)=\max_{\lambda\ge 0,\nu}\min_x\mathcal{L}(x,\lambda,\nu)\]对偶函数之所以是“下界”,来自一个简单但关键的不等式:对任意可行解 \(x\)(满足所有约束)与任意 \(\lambda\ge 0\),都有
\[f(x)\ge f(x)+\sum_i \lambda_i g_i(x)+\sum_j \nu_j h_j(x)\ge \inf_{x'}\Big(f(x')+\sum_i \lambda_i g_i(x')+\sum_j \nu_j h_j(x')\Big)=g(\lambda,\nu)\]因此对任何 \((\lambda,\nu)\),都有 \(g(\lambda,\nu)\le p^*\)(原始最优值),这就是弱对偶(Weak Duality)。
弱对偶(Weak Duality)总成立,因此对偶问题给出的值永远不会高于原始问题的最优值。但弱对偶只保证“对偶值是下界”,并不保证这个下界恰好贴住原始最优值。若两者之间还差一截,这个差距就叫对偶间隙(Duality Gap)。
强对偶(Strong Duality)则更进一步:它要求原始最优值与对偶最优值完全相等,也就是对偶问题不仅给出一个保守下界,还精确刻画了原问题的最优值。对很多凸优化问题而言,Slater 条件正是让这种“下界刚好贴住最优值”的关键保证。
从直观上看,Slater 条件要求可行域内部真的存在一个严格可行点。这意味着约束系统核心是有真实的内部空间。可行域一旦有内部,拉格朗日乘子就更容易稳定地描述“目标函数下降趋势”和“约束反作用力”之间的平衡,因此原始问题与对偶问题之间更不容易出现缝隙。在凸优化里,这就是为什么 Slater 条件常被看作强对偶成立的重要通行证。
直观上,对偶变量(Dual Variables)可以看作约束的“影子价格(Shadow Price)”:如果把约束放宽一点点,最优目标值会如何变化。在很多问题中(例如支持向量机(SVM)),对偶化会把优化变量从“模型参数”转成“约束乘子”,并把数据依赖压缩为内积,从而自然导出核技巧(Kernel Trick)。
对偶变量(Dual Variable)常被称为影子价格(Shadow Price),因为它衡量的是:如果把某条约束稍微放宽一点,最优目标值会改善多少。这里的“价格”核心是“约束资源有多值钱”的边际刻度。
可以把约束想成一种稀缺资源。例如训练时有显存限制、预算限制、风险限制或几何边界限制;如果某条约束非常紧,那么它就像一个卡脖子的瓶颈。此时只要把这条约束稍微放宽一点,最优目标值就可能明显改善,于是它对应的对偶变量就会比较大。反过来,如果某条约束本来就很松,放宽它也几乎没有收益,那么它对应的对偶变量通常就是 0 或接近 0。
在数学上,这个直觉可以写成一种局部敏感度关系。若把约束写成
\[g_i(x)\le b_i\]其中 \(b_i\) 表示第 \(i\) 条约束允许的“资源上限”或“边界位置”,那么对应的最优值函数可以记为 \(p^*(b)\)。在适当条件下,对偶变量 \(\lambda_i^*\) 表示最优值对 \(b_i\) 的边际变化率,也就是“把第 \(i\) 条约束放宽一点,最优值会朝什么方向变化、变化多快”。
在最小化问题中,若某条约束对应的 \(\lambda_i^*\) 很大,通常表示这条约束非常关键:它一旦被放宽,最优目标值会明显下降;若 \(\lambda_i^*=0\),则说明该约束在当前最优点并没有真正起作用,放宽它也不会立刻带来收益。这与前面的互补松弛完全一致:只有真正卡住最优解的约束,才会拥有非零影子价格。
因此,影子价格提供了一个非常有用的解释视角:原始变量告诉我们“最优解长什么样”,而对偶变量告诉我们“哪些约束最贵、最紧、最值得被放宽”。在优化理论、经济学和机器学习里,对偶变量因此不仅是求解工具,也是理解模型结构的重要语言。
Slater 条件(Slater's Condition)是凸优化(Convex Optimization)里最常见的正则性条件(Regularity Condition)之一。它的作用核心是保证对偶理论能够“工作得很干净”:在满足它时,很多凸问题会满足强对偶(Strong Duality),也就是原始问题最优值与对偶问题最优值相等;同时,KKT 条件也更容易从“必要条件”提升为判定最优性的核心条件。
对标准凸优化问题
\[ \min_x f(x)\quad \text{s.t.}\quad g_i(x)\le 0,\ h_j(x)=0 \]如果 \(f(x)\) 和每个 \(g_i(x)\) 都是凸函数(Convex Function),每个 \(h_j(x)\) 都是仿射函数(Affine Function),那么 Slater 条件要求:至少存在一个严格可行点(Strictly Feasible Point) \(\tilde{x}\),使得所有不等式约束都被“严格满足”,也就是
\[ g_i(\tilde{x})<0,\ \forall i,\qquad h_j(\tilde{x})=0,\ \forall j \]这里“严格满足”四个字最关键。普通可行点只要求 \(g_i(x)\le 0\),也就是允许刚好压在边界上;而 Slater 条件要求存在某个点,能让所有不等式约束都留出一点余量,也就是完全处在可行域内部,而非贴着边界。
这个条件可以用一个非常直观的图像来理解。把不等式约束围成的可行域想成一个房间:
- 如果房间内部真的有空间,存在一个点站在房间里,不碰任何墙,这就是满足 Slater 条件。
- 如果所谓“可行域”其实只是几面墙交出来的一条线、一个角、甚至一个点,根本没有真正的内部空间,那么 Slater 条件通常就不满足。
因此,Slater 条件本质上是在说:这个凸约束系统不能只是勉强拼出一个边界碎片,而要有真正的内部。一旦内部存在,原始问题和对偶问题之间的间隙通常就会消失,拉格朗日乘子和 KKT 条件也会变得更稳定、更有解释力。
一个简单例子可以把它说清楚。考虑约束
\[x\ge 0\]写成标准形式是 \(g(x)=-x\le 0\)。这个约束满足 Slater 条件,因为取 \(\tilde{x}=1\) 时,有 \(g(1)=-1<0\)。这说明可行域 \([0,+\infty)\) 不仅边界点 \(x=0\),还真正包含内部区域。
再看一个不满足 Slater 条件的例子:
\[x^2\le 0\]由于 \(x^2\) 永远不小于 0,这个约束唯一允许的点只有 \(x=0\)。可行域虽然非空,但没有任何点能让 \(x^2<0\) 成立,所以不存在严格可行点,Slater 条件不成立。这样的约束系统只有边界、没有内部。
在机器学习常见的凸问题里,Slater 条件之所以频繁出现,是因为它几乎就是“强对偶成立的通行证”。例如在线性规划、逻辑回归的某些约束变体、支持向量机(SVM)的凸二次规划中,只要能找到一个严格可行点,就通常可以放心地从原始问题走到对偶问题,再用 KKT 条件解释最优解结构。反过来,如果没有 Slater 条件,就可能出现对偶间隙(Duality Gap),也就是对偶最优值严格小于原始最优值,此时只看对偶或只看 KKT 就不一定足够。
| 概念 | 它回答的问题 | 最核心的一句话 | 在这一章里的作用 |
| 弱对偶(Weak Duality) | 对偶问题和原始问题之间至少有什么关系 | 对偶最优值永远不会高于原始最优值;它天然是一个下界 | 先建立“对偶为什么有意义”的最低保证 |
| 对偶间隙(Duality Gap) | 为什么有时对偶值还不同于原始最优值 | 如果对偶下界还没贴住原始最优值,两者之间的差就是对偶间隙 | 解释为什么“有对偶”不同于“对偶已经足够” |
| 强对偶(Strong Duality) | 什么时候对偶问题就足以精确刻画原问题 | 原始最优值与对偶最优值完全相等,对偶不再只是保守下界 | 为从原始问题转到对偶问题提供理论正当性 |
| Slater 条件(Slater's Condition) | 凸优化里什么条件有助于强对偶成立 | 只要可行域内部存在严格可行点,很多凸问题就能消除对偶间隙 | 说明为什么强对偶和 KKT 在凸问题里经常可用 |
| 影子价格(Shadow Price) | 对偶变量到底在解释什么 | 它衡量“把某条约束放宽一点,最优值会改善多少” | 赋予拉格朗日乘子清晰的经济 / 几何解释 |
| KKT 条件 | 最优解在约束下必须满足哪些平衡关系 | 目标函数的下降趋势与约束施加的反作用力在最优点平衡 | 把可行性、乘子、驻点与互补松弛统一成最优性条件 |
KKT 条件(Karush–Kuhn–Tucker Conditions)讨论的是带约束优化问题在最优点必须满足什么条件。无约束优化里,常见做法是令梯度(Gradient)为 0;但一旦问题带有不等式约束或等式约束,只看 \(\nabla f(x)=0\) 就不够了,因为最优点很可能被约束“顶”在边界上,而非落在自由空间里的普通驻点。
标准形式写作:
\[\min_x f(x)\quad \text{s.t.}\quad g_i(x)\le 0,\ h_j(x)=0\]这里 \(f(x)\) 是目标函数(Objective Function),表示希望最小化的量;\(x\) 是优化变量(Optimization Variable);\(g_i(x)\le 0\) 是第 \(i\) 个不等式约束(Inequality Constraint);\(h_j(x)=0\) 是第 \(j\) 个等式约束(Equality Constraint)。KKT 条件给出的就是:当 \(x^*\) 真的是一个最优解时,它与对应的拉格朗日乘子(Lagrange Multipliers)之间必须满足一组相互配合的条件。
在凸优化(Convex Optimization)里,如果问题满足适当的正则性条件,例如 Slater 条件(Slater's Condition),KKT 条件往往不只是必要条件,还可以成为判定最优性的核心工具。在线性规划、二次规划、支持向量机(Support Vector Machine, SVM)和许多机器学习训练问题中,KKT 条件都直接参与求解过程。
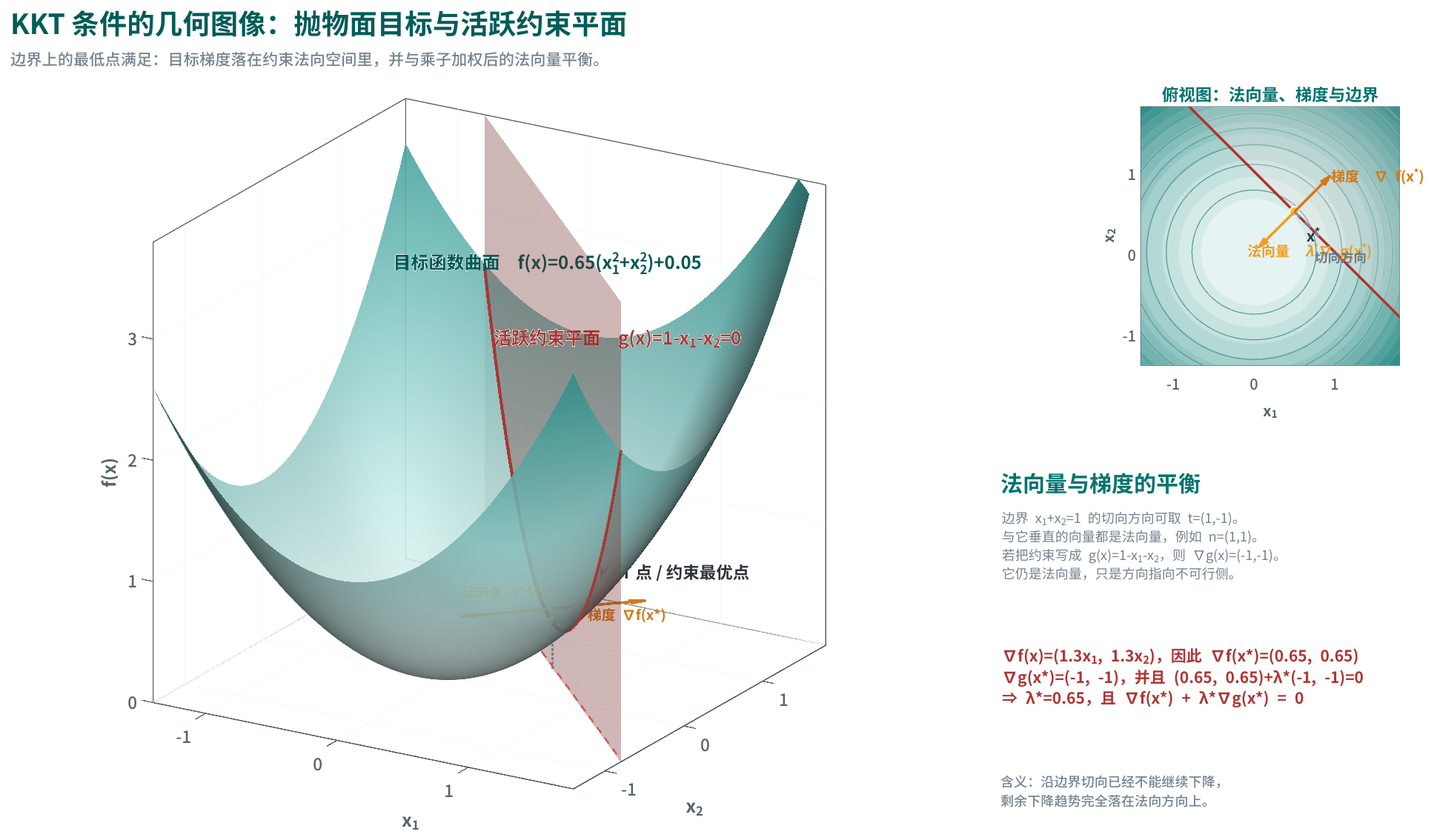
上图使用的是活跃边界 \(g(x)=1-x_1-x_2=0\)。边界 \(x_1+x_2=1\) 的切向方向可取 \((1,-1)\);与它垂直的向量都是法向量(Normal Vector),例如 \((1,1)\) 或 \((-1,-1)\)。如果把约束写成函数 \(g(x)=1-x_1-x_2\),那么梯度 \(\nabla g(x)=(-1,-1)\) 就是一条法向量;它指向 \(g(x)\) 增大的方向,也就是不可行侧。
图中的橙色箭头对应驻点条件(Stationarity)里真正参与平衡的两个向量:目标梯度 \(\nabla f(x^*)\) 与乘子加权后的约束法向量 \(\lambda^*\nabla g(x^*)\)。它们在最优点首尾相接后得到 0,于是 \(\nabla f(x^*)+\lambda^*\nabla g(x^*)=0\) 核心是边界最优点上的几何平衡:
- 原始可行性(Primal Feasibility):解必须落在可行域内。对这张图而言,可行域是半空间 \(x_1+x_2\ge 1\),最优点 \(x^*\) 落在它的活跃边界 \(x_1+x_2=1\) 上。
- 对偶可行性(Dual Feasibility):不等式约束的乘子必须非负,即 \(\lambda^*\ge 0\)。图中的计算给出 \(\lambda^*=0.65\),表示这条边界在最优点处确实对目标下降施加了正的“反作用”。
- 驻点条件(Stationarity):沿边界的切向方向已经不能继续下降,因此目标梯度不再含有切向分量,只能落在法向空间里。单个活跃约束时,这就变成 \(\nabla f(x^*)=-\lambda^*\nabla g(x^*)\)。图中的两根橙色箭头正是这两个大小相等、方向相反的向量。
- 互补松弛(Complementary Slackness):约束若不接触最优点,就不会产生乘子;约束一旦卡在最优点上,对应乘子才会变成正值。当前图像展示的是活跃边界情形,所以 \(g(x^*)=0\) 且 \(\lambda^*>0\) 同时成立。
法向量之所以关键,是因为它刻画了“离开边界最快”的方向;切向方向则刻画了“沿边界滑动”的方向。边界最优点的本质结论是:目标函数想继续下降的那一部分趋势,已经完全被约束边界的法向作用抵消;沿边界本身则不存在进一步下降方向。
可以把 KKT 条件想成一个“遛狗”问题。优化目标是:狗想尽可能往远处跑;约束条件是:主人手里只有一根 5 米长的狗绳,因此狗的活动范围不能超过这条绳子的长度。不等式约束 \(g_i(x)\le 0\) 的作用,就像在说“不能超过这根绳子允许的极限”;等式约束 \(h_j(x)=0\) 则对应那些必须被精确满足的固定条件。
这个比喻里最重要的是区分“绳子是否真正起作用”。如果狗最后只跑到 3 米处就停下,例如已经闻到味道、找到目标,或者在那里已经达到最优状态,那么绳子仍然是松的,还留有 2 米余量。这时约束虽然存在,但它没有真正限制住解。相反,如果狗拼命往前冲,最后正好跑到 5 米极限,绳子就会被拉紧;此时狗还想继续前进,但被约束挡住了。KKT 条件刻画的正是这种“目标继续改进的趋势,与约束施加的阻拦作用,在最优点达到平衡”的状态。
其中最形象的一条就是互补松弛(Complementary Slackness)。它表达的是:每一个不等式约束在最优点都只有两种状态。
- 如果某个约束正好卡在边界上,即 \(g_i(x^*)=0\),就像狗刚好把 5 米狗绳拉到极限,此时这条绳子真的“顶住了”最优解,它对应的乘子 \(\lambda_i^*\) 可以大于 0。
- 如果某个约束离边界还有余量,即 \(g_i(x^*)<0\),就像狗只跑到 3 米处,绳子仍然松弛,那么它对应的乘子必须是 0,也就是 \(\lambda_i^*=0\)。
因此,乘子 \(\lambda_i^*\) 可以直观理解为绳子的拉力,也就是约束对最优解施加的压力。在优化语言里,这个量也常被解释为影子价格(Shadow Price):如果把这条约束稍微放宽一点,最优目标值会改善多少。拉力不为 0,说明这条约束正在真正影响解;拉力为 0,说明这条约束虽然存在,但在最优点处并没有发挥作用。
把原问题写成统一形式后,先定义拉格朗日函数(Lagrangian):
\[\mathcal{L}(x,\lambda,\nu)=f(x)+\sum_i \lambda_i g_i(x)+\sum_j \nu_j h_j(x)\]这个式子里的每个元素都有明确含义:
- \(\mathcal{L}\):拉格朗日函数,把目标函数和约束统一写进一个式子里。
- \(x\):原始变量(Primal Variable),也就是模型真正要优化的参数。
- \(f(x)\):目标函数,表示希望最小化的代价、损失或能量。
- \(g_i(x)\):第 \(i\) 个不等式约束函数;要求它满足 \(g_i(x)\le 0\)。
- \(h_j(x)\):第 \(j\) 个等式约束函数;要求它满足 \(h_j(x)=0\)。
- \(\lambda_i\):第 \(i\) 个不等式约束对应的拉格朗日乘子;它衡量该约束施加的“压力”或“拉力”大小,也可理解为对应约束资源的影子价格。
- \(\nu_j\):第 \(j\) 个等式约束对应的拉格朗日乘子。
- \(\sum_i\) 和 \(\sum_j\):分别表示把所有不等式约束和所有等式约束的影响累加起来。
在此基础上,KKT 条件通常写成四组:
\[\text{Primal feasibility: } g_i(x^*)\le 0,\ h_j(x^*)=0\] \[\text{Dual feasibility: } \lambda_i^*\ge 0\] \[\text{Stationarity: } \nabla f(x^*)+\sum_i \lambda_i^*\nabla g_i(x^*)+\sum_j \nu_j^*\nabla h_j(x^*)=0\] \[\text{Complementary slackness: } \lambda_i^* g_i(x^*)=0\]这四组条件可以逐条理解:
- 原始可行性(Primal Feasibility):最优解 \(x^*\) 首先必须是合法的,不能跑到可行域之外。所有不等式约束都要满足 \(g_i(x^*)\le 0\),所有等式约束都要精确满足 \(h_j(x^*)=0\)。
- 对偶可行性(Dual Feasibility):不等式约束的乘子必须非负,即 \(\lambda_i^*\ge 0\)。这保证了它们表达的是“阻止变量越界的压力”,而非把解往不可行方向拉过去的反向力量。
- 驻点条件(Stationarity):在最优点处,目标函数的梯度 \(\nabla f(x^*)\) 与所有约束梯度加权后的合力必须平衡为 0。这里 \(\nabla f(x^*)\) 表示目标函数在 \(x^*\) 处最陡上升方向;\(\nabla g_i(x^*)\) 和 \(\nabla h_j(x^*)\) 分别表示约束边界的法向方向;乘子 \(\lambda_i^*\)、\(\nu_j^*\) 则控制这些方向各自施加多少“反作用力”。这条式子本质上是在说:最优点处已经不存在任何仍然可行且还能继续下降的方向。
- 互补松弛(Complementary Slackness):每个不等式约束都满足 \(\lambda_i^* g_i(x^*)=0\)。因为这是两个量的乘积等于 0,所以只能出现两种情况:要么 \(g_i(x^*)=0\),说明约束正好顶在边界上;要么 \(\lambda_i^*=0\),说明这条约束在最优点没有施加压力。它精确区分了“活跃约束(Active Constraint)”和“不活跃约束(Inactive Constraint)”。
一个一维例子可以把这些符号落到实处。考虑:
\[\min_x\ (x+1)^2\quad \text{s.t.}\quad x\ge 0\]把约束写成标准形式 \(g(x)=-x\le 0\),于是拉格朗日函数是:
\[\mathcal{L}(x,\lambda)=(x+1)^2+\lambda(-x)\]这里 \((x+1)^2\) 是目标函数;\(-x\le 0\) 是不等式约束;\(\lambda\) 是这条约束对应的乘子。KKT 条件变成:
\[x\ge 0,\quad \lambda\ge 0,\quad 2(x+1)-\lambda=0,\quad \lambda x=0\]这四项分别表示:解必须在 \(x\ge 0\) 的合法区域内;乘子必须非负;目标函数与约束施加的作用力在最优点平衡;约束要么卡住解、要么不施加压力。无约束时, \((x+1)^2\) 的最低点在 \(x=-1\),但这不满足 \(x\ge 0\),所以真正最优点被“推”到边界 \(x^*=0\);再代入驻点条件 \(2(x+1)-\lambda=0\),得到 \(\lambda^*=2\)。这正对应“边界在最优点处确实对解施加了压力”。
如果把目标函数换成 \(\min_x (x-2)^2\ \text{s.t.}\ x\ge 0\),无约束最优点就是 \(x=2\),它本来就在可行域内部,因此约束没有真正碰到最优点。此时 KKT 会给出 \(x^*=2\)、\(\lambda^*=0\)。这就是互补松弛最直观的含义:边界没有碰到解,压力就自动消失;边界一旦碰到解,乘子就会变成非零。
概率论与统计处理两类问题:第一类是在不确定性下如何描述事件、变量与数据生成过程;第二类是在只观察到有限样本时,如何反推总体规律与模型参数。在 AI 中,分类概率、回归噪声、采样、似然训练、置信评估与后验推断都建立在这套语言之上。
在进入公式前,先区分几个最常混淆的基础对象。概率论核心是先规定随机试验的结果空间、结果上的事件,以及把结果映射成数的随机变量,之后才谈分布、期望和统计推断。
- 样本空间(Sample Space)\(\Omega\):一次随机试验所有可能结果的集合,其中希腊字母 \(\Omega\) 只是“全部可能结果”的记号。掷骰子时 \(\Omega=\{1,2,3,4,5,6\}\),表示所有可能点数组成的集合。
- 事件(Event):样本空间的子集,表示“哪些结果算作某件事发生”。例如“点数为偶数”对应集合 \(\{2,4,6\}\);这句话的意思是,只要试验结果落在这个集合里,就说该事件发生。
- 随机变量(Random Variable)\(X\):把随机结果映射为数的函数,可写作 \(X:\Omega\to\mathbb{R}\)。这里 \(X\) 是这个函数的名字, \(\Omega\) 是输入端的样本空间,箭头 \(\to\) 表示“映射到”, \(\mathbb{R}\) 表示实数集合。每个随机结果都会被 \(X\) 变成一个实数。掷骰子时最自然的随机变量就是“点数本身”;在机器学习里,输入 \(X\)、标签 \(Y\)、噪声 \(\epsilon\) 都是随机变量。
- 概率分布(Probability Distribution):描述随机变量取不同值的概率规律。离散情形常写作 \(P(X=x)\),意思是“随机变量 \(X\) 恰好取值 \(x\) 的概率”;连续情形常写作密度 \(p(x)\),它核心是概率密度函数(Probability Density Function, PDF),需要在区间上积分才得到概率。
- 期望(Expectation)\(\mathbb{E}[X]\):按概率加权的平均,回答“长期来看这个随机变量的典型水平在哪里”。这里 \(\mathbb{E}\) 是 expectation 的标准记号,方括号中的 \(X\) 表示“对哪个随机变量取期望”。
- 方差(Variance)\(\mathrm{Var}(X)\):围绕期望的波动强度,回答“它通常偏离平均水平多大”。其中 \(\mathrm{Var}\) 是 variance 的记号,括号里的 \(X\) 表示“考察哪个随机变量的波动”。
- 参数(Parameter)与统计量(Statistic):参数描述总体,例如高斯分布中的 \(\mu\) 表示均值(Mean), \(\sigma^2\) 表示方差(Variance);统计量则由样本计算出来,例如 \(\bar{x}\) 表示样本均值(Sample Mean),上面的横线读作“x bar”,意思是“样本中所有 \(x\) 的平均值”。统计学习的核心任务之一,就是用统计量去估计未知参数。
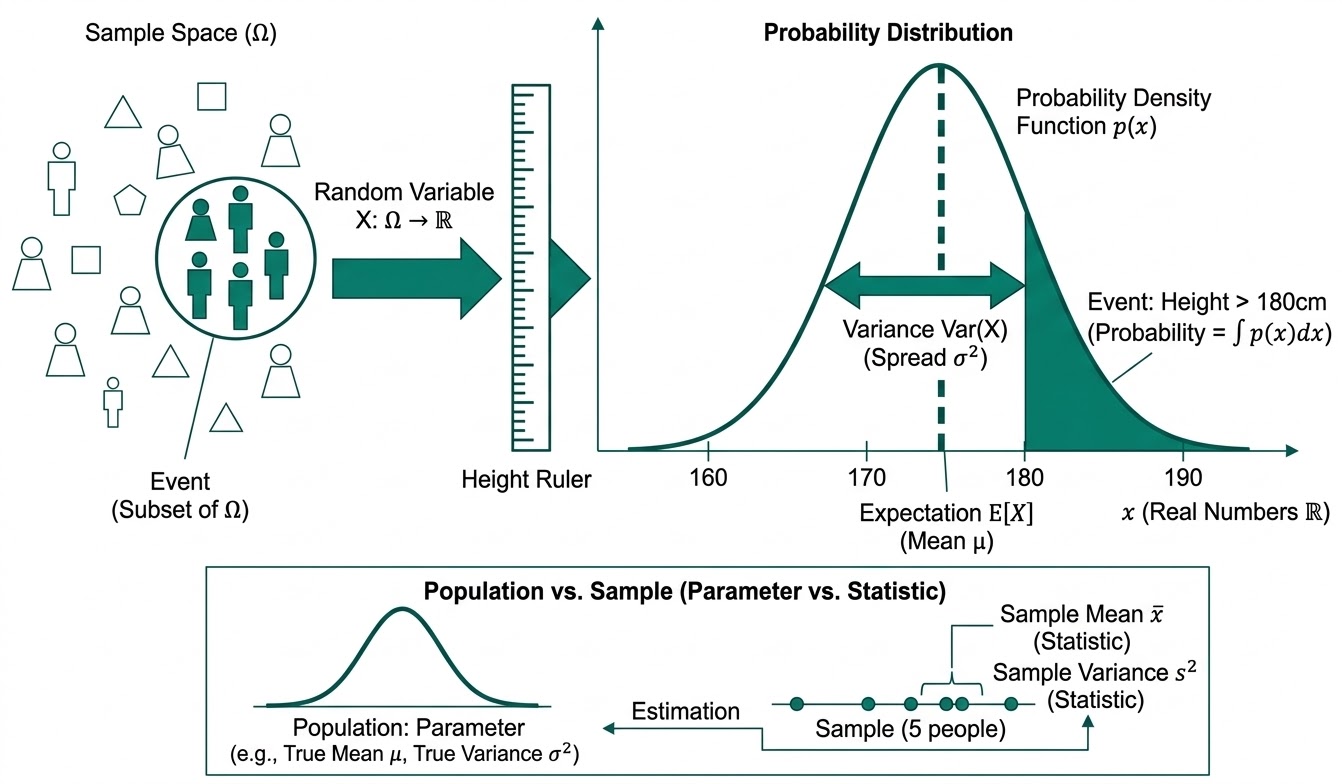
概率(Probability)与似然(Likelihood)都可以写成 \(p(x|\theta)\) 这样的形式,但它们把“谁是已知、谁是待判断对象”放在不同位置。概率把参数 \(\theta\) 视为已知、把数据 \(x\) 视为随机结果;似然则把数据 \(x\) 固定下来,把参数 \(\theta\) 当作待比较对象。
也正因为公式形式相同,二者很容易混淆;真正的区别不在写法,而在它们回答的是相反方向的问题。条件分布 \(p(x|\theta)\) 在统计里经常同时出现在两种语境中:当参数 \(\theta\) 固定、数据 \(x\) 变化时,它表示“在这个模型下观察到不同数据的概率有多大”;当数据 \(x\) 固定、参数 \(\theta\) 变化时,它表示“哪些参数更能解释这份已经观察到的数据”。
因此,概率的读法是参数已知,看数据。例如抛硬币模型里,若已知正面概率 \(\theta=0.7\),那么 10 次里出现 8 次正面的概率是
\[P(X=8|\theta=0.7)={10 \choose 8}0.7^8 0.3^2\]其中 \({10 \choose 8}\) 表示组合数(Binomial Coefficient):从 10 次试验里选出 8 次作为正面的不同选法一共有多少种。它负责计数“8 次正面可以出现在哪 8 个位置上”,并非额外的概率项。
而 \(0.7^8 0.3^2\) 来自独立重复试验的乘法法则:如果每次抛掷相互独立,且正面概率是 \(0.7\)、反面概率是 \(0.3\),那么任意一个“8 次正面、2 次反面”的具体序列,其概率都是 8 个 \(0.7\) 与 2 个 \(0.3\) 的乘积,也就是 \(0.7^8 0.3^2\)。
这里被当作变量的是结果 \(X\);问题是“给定参数,这样的数据是否常见”。这就是通常意义上的概率或概率密度。
似然的读法正好反过来:数据已知,看参数。假设现在已经观察到 10 次抛硬币里有 8 次正面,这组数据不再变化;真正变化的是候选参数 \(\theta\)。于是同一个模型被改写为似然函数(Likelihood Function):
\[L(\theta|X=8)=P(X=8|\theta)={10 \choose 8}\theta^8(1-\theta)^2\]此时 \(L(\theta|x)\) 核心是一个关于 \(\theta\) 的评分函数:哪个 \(\theta\) 让已观察到的数据 \(x\) 更容易出现,哪个 \(\theta\) 的似然就更大。最大似然估计(Maximum Likelihood Estimation, MLE)做的正是这件事:寻找使 \(L(\theta|x)\) 最大的参数。
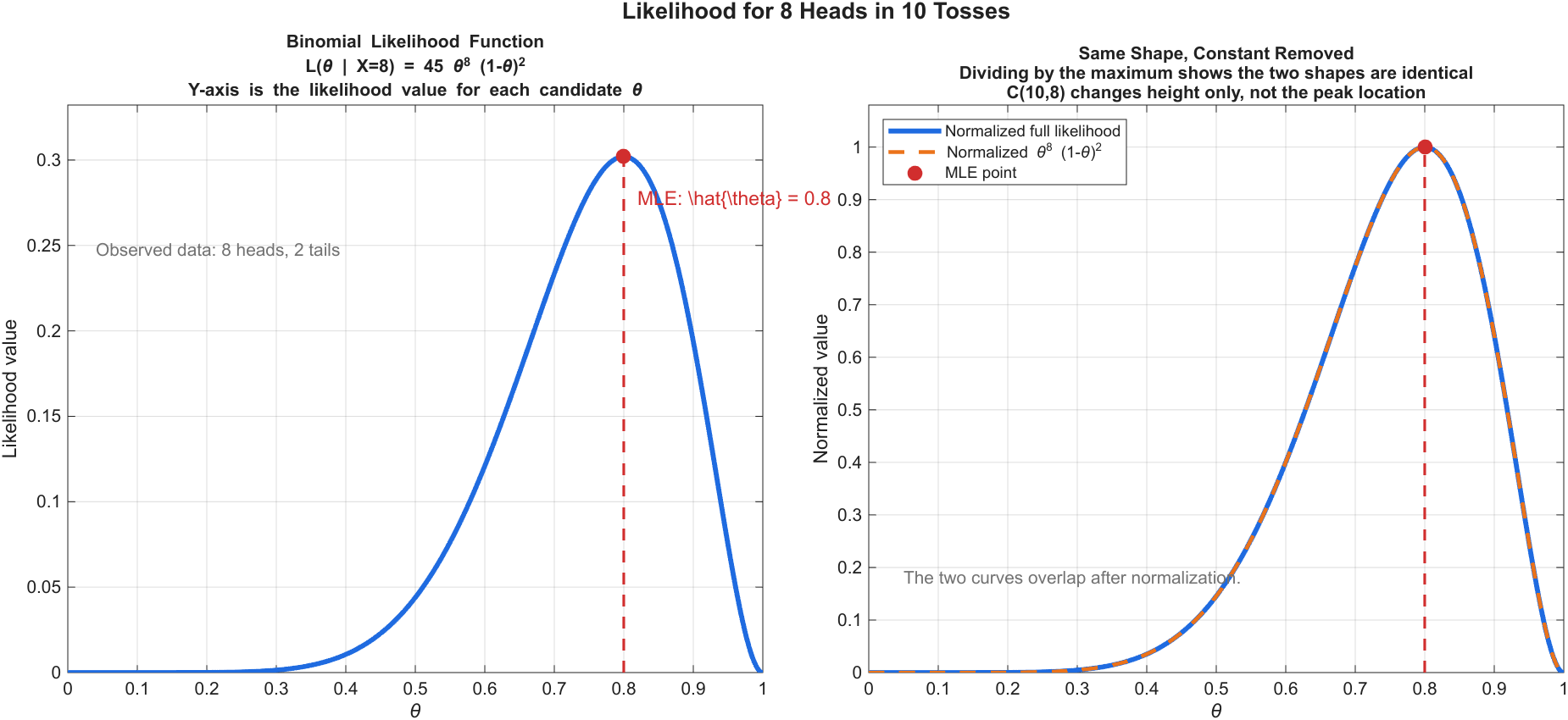
这里有一个必须严格区分的点:似然并非参数的概率分布。对固定数据来说, \(L(\theta|x)\) 不要求对 \(\theta\) 积分为 1,也不能直接解释为 \(P(\theta|x)\)。只有在贝叶斯框架里,把似然与先验(Prior) \(p(\theta)\) 相乘并做归一化之后,才得到参数的后验概率(Posterior):
\[p(\theta|x)=\frac{p(x|\theta)p(\theta)}{p(x)}\]所以可以把三者关系记成一条清晰的链: \(p(x|\theta)\) 作为“关于 \(x\) 的函数”时是概率模型;作为“关于 \(\theta\) 的函数”时是似然函数;再结合先验并归一化后,才变成参数的后验概率。很多机器学习教材里说“最小化交叉熵等价于最大化对数似然”,本质上就是固定数据后,在参数空间里寻找最能解释样本的模型。
在机器学习模型里,这种“同一个式子,换个视角名字就变”的现象非常常见。设模型写成 \(p_\theta(y|x)\),其中 \(x\) 是输入或上下文, \(y\) 是真实标签或真实 token, \(\theta\) 是模型参数。
当参数 \(\theta\) 固定、把输出 \(y\) 当作随机变量时, \(p_\theta(y|x)\) 是概率模型:它回答“在这个模型已经定好的前提下,不同输出有多可能”。例如语言模型会对整个词表输出一个条件概率分布,其中 \(c_t\) 表示第 \(t\) 个位置之前的上下文(context), \(y_t\) 表示该位置真实出现的 token,因此 \(p_\theta(y_t|c_t)\) 就是“在上下文 \(c_t\) 下,模型给真实 token \(y_t\) 分配的概率”。
当观测到的 \((x,y)\) 固定、把参数 \(\theta\) 当作变量时,同一个式子 \(p_\theta(y|x)\) 就变成似然:它回答“哪些参数更能让这条已经看到的数据显得合理”。于是训练时最大化似然,就等价于最小化负对数似然:
\[-\log p_\theta(y|x)\]因此可以把这个困惑直接拆开:固定参数看输出,它是概率;固定输出看参数,它是似然;对它取负对数后,它就是训练里使用的损失项。在语言建模里,对一个具体 token 而言,给定当前模型参数后, \(-\log p_\theta(y_t|c_t)\) 既可以看成该 token 的负对数概率,也可以在训练语境下看成该 token 对参数的负对数似然;两者是同一个数值对象,只是观察角度不同。
概率(Probability)描述不确定事件发生的可能性。设样本空间(Sample Space)为 \(\Omega\),事件(Event)为 \(A\subseteq\Omega\),则概率公理要求 \(P(A)\in[0,1]\)、\(P(\Omega)=1\),以及互斥事件可加。这里“互斥事件可加”的意思是:如果两个事件不能同时发生,即 \(A\cap B=\{\}\),那么“\(A\) 或 \(B\) 发生”的概率就是两者概率直接相加:
\[P(A\cup B)=P(A)+P(B),\quad A\cap B=\{\}\]之所以能直接相加,是因为两者没有重叠部分,不会重复计数。若有重叠,则不能直接相加,而要减去交集 \(P(A\cap B)\)。
最小例子:掷一枚公平六面骰。样本空间是 \(\Omega=\{1,2,3,4,5,6\}\)。若事件 \(A\) 表示“点数为 1”,事件 \(B\) 表示“点数为 2”,则它们互斥,因此 \(P(A\cup B)=1/6+1/6=1/3\)。再看一个非互斥例子:若事件 \(C\) 表示“点数为偶数”,则 \(C=\{2,4,6\}\),因此 \(P(C)=3/6=1/2\)。
联合概率(Joint Probability)表示多个事件同时发生的概率,即 \(P(A,B)=P(A\cap B)\)。它回答的是“这些条件一起成立的可能性有多大”。
\[P(A,B)=P(A\cap B)\]仍用骰子例子:令 \(A\) 表示“点数为偶数”,\(B\) 表示“点数至少为 4”,则 \(A\cap B=\{4,6\}\),所以 \(P(A,B)=2/6=1/3\)。在机器学习里,联合分布 \(p(x,y)\) 表示“输入 \(x\) 与标签 \(y\) 一起出现”的总体规律。
独立(Independence)表示一个事件是否发生,不会改变另一个事件发生的概率。若事件 \(A,B\) 相互独立,则它们同时发生的概率可直接写成概率乘积:
\[P(A\cap B)=P(A)P(B)\]更一般地,若 \(A_1,\dots,A_n\) 相互独立,则
\[P\!\left(\bigcap_{i=1}^{n}A_i\right)=\prod_{i=1}^{n}P(A_i)\]例:掷一枚公平硬币并同时掷一枚公平骰子。令 \(A\) 表示“硬币为正面”,\(B\) 表示“骰子为偶数”,则 \(P(A)=1/2\)、\(P(B)=1/2\),且二者独立,因此 \(P(A\cap B)=1/2\times 1/2=1/4\)。
独立时还可等价写成 \(P(A|B)=P(A)\):知道 \(B\) 发生,并不会改变对 \(A\) 的判断。
要注意:互斥(Mutually Exclusive)和独立(Independent)并非一回事。互斥表示不能同时发生;独立表示是否发生彼此无关。对非零概率事件而言,互斥通常意味着不独立,因为一旦知道 \(A\) 发生,就立刻知道 \(B\) 不可能发生。
条件概率(Conditional Probability)表示“已知 \(B\) 发生时,\(A\) 发生的概率”:
\[P(A|B)=\frac{P(A,B)}{P(B)},\quad P(B)>0\]关键点核心是样本空间被缩小了。在上面的骰子例子中,已知 \(B\)(点数至少为 4)后,只剩 \(\{4,5,6\}\) 三种可能,其中偶数是 \(\{4,6\}\),所以 \(P(A|B)=2/3\),明显不同于原来的 \(P(A)=1/2\)。
在建模中,几乎所有监督学习目标都可写成条件概率最大化,例如分类模型学习的是 \(P(y|x)\):给定特征 \(x\),标签 \(y\) 的概率有多大。
边缘概率(Marginal Probability)是把不关心的变量“求和/积分掉”后得到的概率:
\[P(A)=\sum_b P(A,b),\quad p(x)=\int p(x,z)\,dz\]这两个公式的意思完全一致,只是分别对应离散情形与连续情形。 \(P(A,b)\) 表示“\(A\) 与 \(b\) 同时发生”的联合概率;若现在只关心 \(A\),就必须把所有可能的 \(b\) 都加起来。连续情形下同理: \(p(x,z)\) 是关于 \((x,z)\) 的联合密度,若只关心 \(x\),就把所有 \(z\) 的可能性沿该维度积分掉,得到 \(p(x)\)。
几何上,可以把边缘化(Marginalization)理解为把高维分布沿某个方向压扁后得到的投影。设二维联合分布的两个维度分别是身高与体重,平面上的每个位置都对应一个联合概率密度 \(p(\text{height},\text{weight})\)。如果现在根本不关心体重,只想知道身高的总体分布,那么就把每个固定身高处、沿着体重方向的所有概率质量全部累加起来;累加后的结果就是该身高对应的边缘密度 \(p(\text{height})\)。
因此,求和符号 \(\sum_b P(A,b)\) 或积分符号 \(\int p(x,z)\,dz\) 的几何含义,核心是把那个维度上的所有可能性叠加到剩余维度上。它像从侧面看一个三维物体的投影:原来的结构仍然在,但你只保留了当前关心的坐标轴信息。
在 AI 中,边缘概率几乎总伴随着隐藏变量(Latent Variable)。例如主题模型里 \(z\) 可以表示隐藏主题(Hidden Topic),\(x\) 表示某个词;若只关心词出现的总体概率,就要把主题变量消去,得到 \(p(x)=\sum_z p(x,z)\)。很多推断算法的难点,本质上就是这个“沿隐藏维度求和/积分”的步骤代价很高。
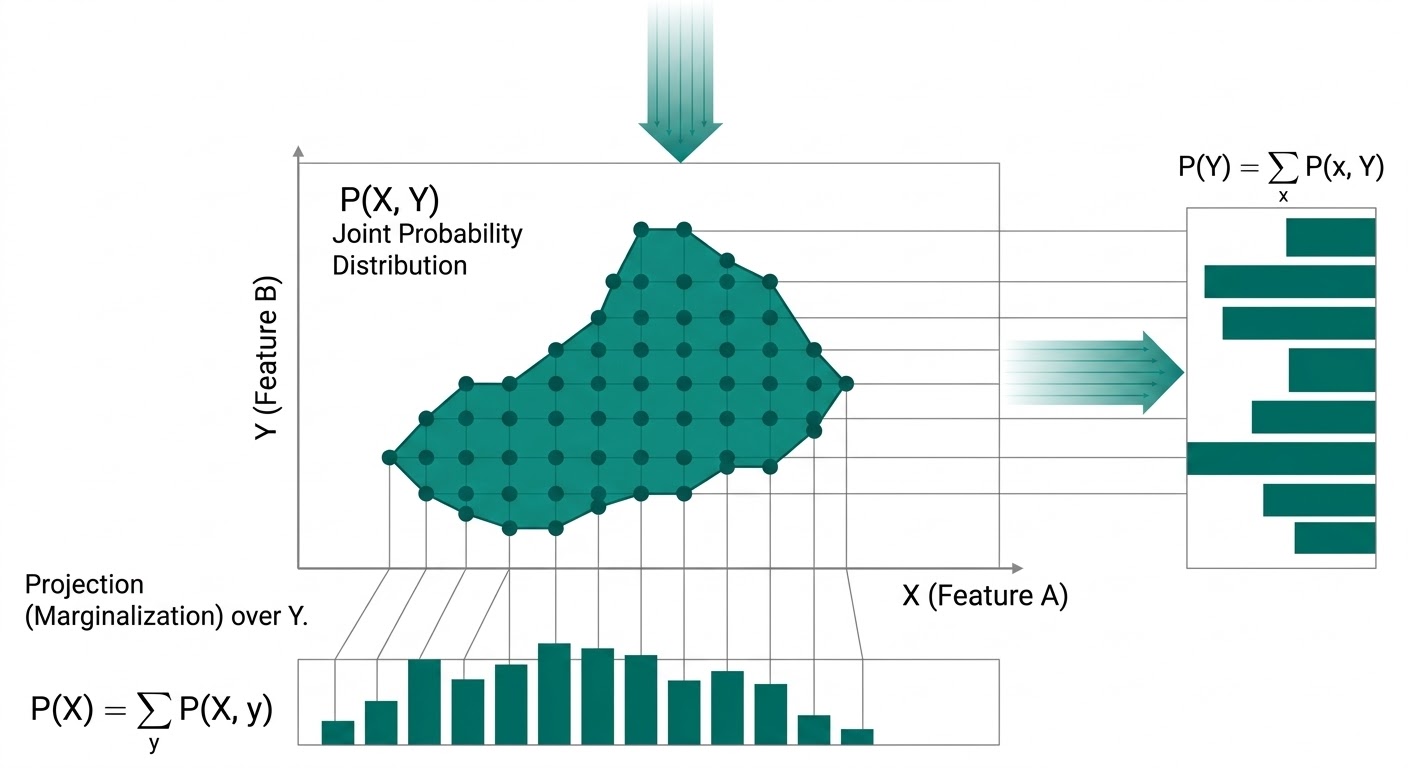
补事件(Complementary Event)满足
\[P(A^c)=1-P(A)\]它表示“\(A\) 不发生”的概率等于总概率 1 减去 \(A\) 发生的概率。
第二,若 \(A_1,\dots,A_n\) 把样本空间划分为互斥且完备的几部分(即两两互斥,且并集为 \(\Omega\)),则全概率公式(Law of Total Probability)为
\[P(B)=\sum_{i=1}^{n}P(B|A_i)P(A_i)\]它的含义是:事件 \(B\) 的总概率,可以拆成“先落入哪一种原因 \(A_i\),再在该原因下发生 \(B\)”的加权和。贝叶斯公式中的分母 \(P(B)\),很多时候就是用全概率公式展开出来的。
贝叶斯定理(Bayes' Theorem)把“从原因到结果”的概率反转为“从结果反推原因”:
\[P(A|B)=\frac{P(B|A)\,P(A)}{P(B)}\]把式子写出来并不难,真正容易混淆的是每一项到底在说什么。下面直接用一个具体场景来解释:设 \(A\) 表示“患者真的患病”,\(B\) 表示“检测结果为阳性”。已知患病率为 1%,检测的灵敏度(Sensitivity)为 99%,假阳性率(False Positive Rate)为 5%。则:
- 先验(Prior) \(P(A)\):在还没看到这次检测结果前,对“此人患病”的原始判断。在这个例子里,先验就是总体患病率 \(P(A)=0.01\)。
- 似然(Likelihood) \(P(B|A)\):如果一个人确实患病,那么检测为阳性的概率有多大。在这个例子里,检测灵敏度是 99%,因此 \(P(B|A)=0.99\)。
- 证据(Evidence) \(P(B)\):不管一个人是否患病,检测结果为阳性在总体上出现的概率。它等于“真阳性 + 假阳性”的总和: \(P(B)=0.99\times 0.01 + 0.05\times 0.99 = 0.0594\)。
- 后验(Posterior) \(P(A|B)\):在已经看到“检测阳性”这个证据之后,此人真正患病的更新后概率。代入上面的数值,有
因此,贝叶斯定理描述的是一个非常具体的更新过程:先从原始信念出发,用证据对它重新加权,再归一化,得到更新后的信念。它常被概括成:后验 = 似然 × 先验 ÷ 证据。
这个例子最重要的结论是:检测阳性后,真实患病概率只有约 16.7%。原因在于先验患病率本来就很低;假阳性虽然比例不高,但基数更大。证据不会凭空决定结论,证据必须结合基线发生率一起解释。在 AI 里,这就是“看到证据后更新信念”的统一公式:朴素贝叶斯分类、贝叶斯滤波、概率图模型都在做这件事。
从机器学习视角看,贝叶斯定理的价值在于它清楚地区分了只看数据解释能力与把数据证据和先验知识合并起来这两件事。前者对应似然(Likelihood)与最大似然估计(MLE),后者对应后验(Posterior)与最大后验估计(MAP)。
仍用上面的患病率例子。假设观测数据已经固定为“检测结果阳性”,把候选状态写成 \(\theta\in\{\text{患病},\text{未患病}\}\)。若只比较似然,则两个候选状态的评分分别是:
\[L(\theta=\text{患病})=P(+|\text{患病})=0.99\] \[L(\theta=\text{未患病})=P(+|\text{未患病})=0.05\]此时,按似然大小排序, \(\theta=\text{患病}\) 的确更优。这正是 MLE 式思路的核心:固定数据,寻找最能解释这份数据的候选参数或候选假设。但这里必须严格区分两件事:“似然更大”只表示这个假设更能解释当前观测,不同于“它的后验概率就是 99%”。因为似然没有把总体患病率只有 1% 这一先验事实算进去。
若进一步引入先验 \(P(\text{患病})=0.01\)、\(P(\text{未患病})=0.99\),就得到后验比较:
\[P(\text{患病}|+)\propto P(+|\text{患病})P(\text{患病})=0.99\times 0.01\] \[P(\text{未患病}|+)\propto P(+|\text{未患病})P(\text{未患病})=0.05\times 0.99\]归一化之后, \(P(\text{患病}|+)\approx 16.7\%\)。这就是 MAP / 贝叶斯决策与单纯 MLE 的差别:后验判断不仅问“谁更能解释这份数据”,还问“谁在看到数据之前本来就更常见”。在类别极不平衡、小样本、先验知识明确或误判成本不对称的问题里,这个差别往往是决定性的。
朴素贝叶斯(Naive Bayes)正是把这套思路直接写成分类器。给定特征向量 \(\boldsymbol{x}\) 和类别 \(y\),它比较的是后验概率
\[p(y|\boldsymbol{x})\propto p(y)\,p(\boldsymbol{x}|y)\]再在条件独立假设下展开成
\[p(y|\boldsymbol{x})\propto p(y)\prod_{j=1}^{d}p(x_j|y)\]其中 \(p(y)\) 是类别先验,负责表达“哪类样本本来就更常见”; \(p(x_j|y)\) 是条件似然,负责表达“若类别固定,这个特征出现得是否合理”。训练阶段通常先从数据中估计这些概率;最简单的做法是 MLE,即直接用频数比估计先验和条件概率。若再加入拉普拉斯平滑(Laplace Smoothing)或更一般的共轭先验(Conjugate Prior),则更接近 MAP 估计。预测阶段再把先验与似然相乘并归一化,得到后验分数最高的类别。
因此,从机器学习角度看,贝叶斯定理不仅概率论中的一条恒等式,还一个完整的建模分工:似然负责解释数据,先验负责表达归纳偏置,后验负责把两者合成为最终判断。后面的 MLE、MAP 与朴素贝叶斯,只是这套分工在不同任务上的具体实现。
这里的“分布(Distribution)”指随机变量取值的不确定性如何在取值空间上分配。严格地说,概率分布(Probability Distribution)是一种概率测度(Probability Measure),它为每个事件 \(A\) 赋予概率 \(P(A)\)。
对一维实值随机变量 \(X\),分布最常用的统一表述是累积分布函数(Cumulative Distribution Function, CDF)\(F(x)=P(X\le x)\)。离散与连续的差别,主要体现在如何从 \(F\) 得到“点上/区间上”的概率。
不同任务对应不同的数据分布假设(Distribution Assumption)。分布选得对,建模与推断会更稳定;分布假设错得太远,参数估计、置信区间乃至损失函数解释都会失真。
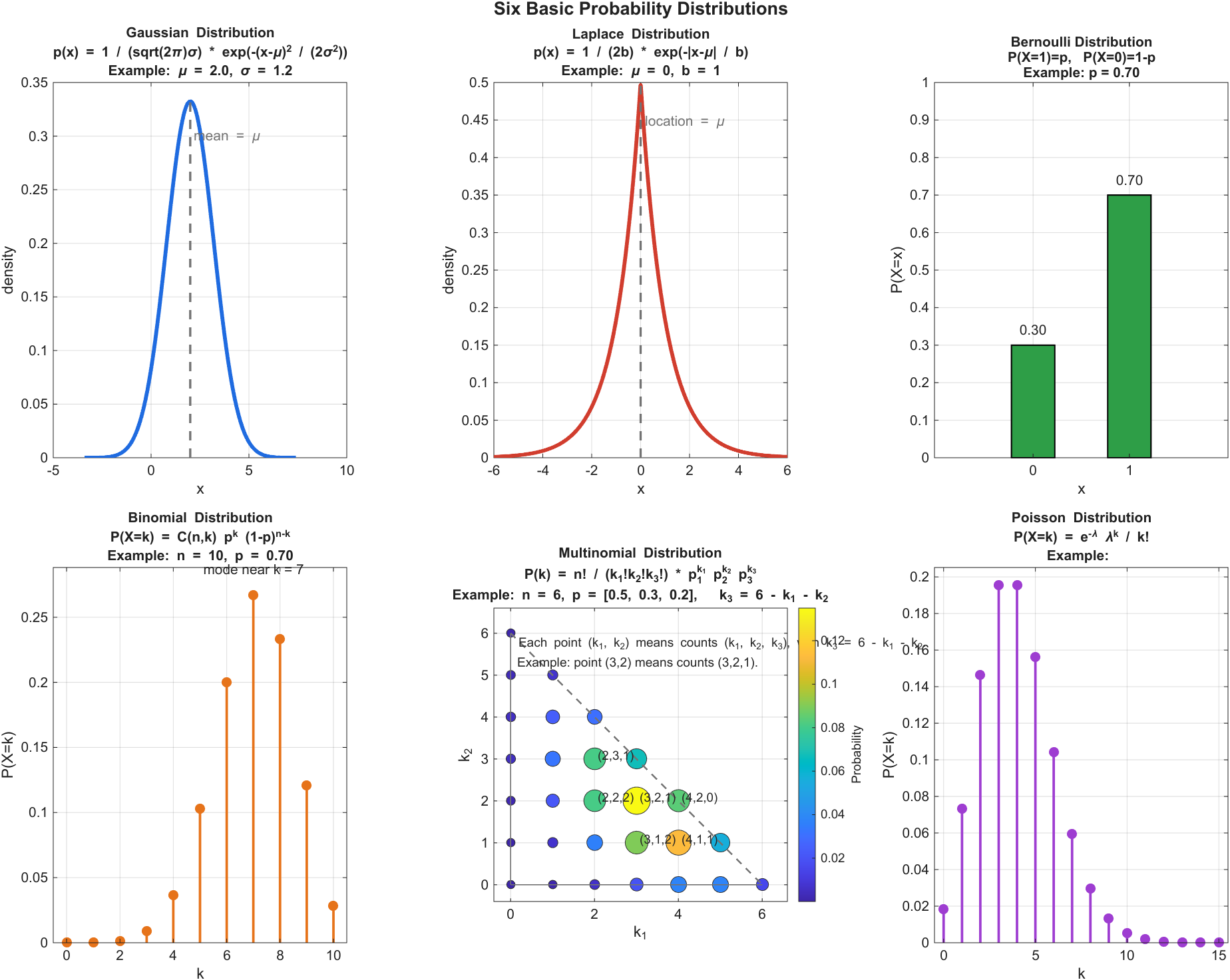
若 \(X\) 是离散型随机变量,其概率质量函数(Probability Mass Function, PMF)为 \(p(x)=P(X=x)\),并满足 \(\sum_x p(x)=1\)。
若 \(X\) 是连续型随机变量,其概率密度函数(Probability Density Function, PDF)为 \(p(x)\),满足 \(p(x)\ge 0\) 与 \(\int_{-\infty}^{+\infty} p(x)\,dx=1\);区间概率由积分给出:\(P(a\le X\le b)=\int_a^b p(x)\,dx\)。因此 \(p(x)\) 本身并非“点上概率”。
两者都可写成同一 CDF 关系:连续情形 \(F(x)=\int_{-\infty}^{x} p(t)\,dt\),离散情形 \(F(x)=\sum_{t\le x} p(t)\)。
高斯分布(Gaussian / Normal Distribution)由均值 \(\mu\) 与方差 \(\sigma^2\) 决定:
\[p(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\]它的图像是熟悉的“钟形曲线(Bell Curve)”:离 \(\mu\) 越近,概率密度越高;离得越远,概率密度衰减越快。大量独立小扰动叠加后常近似高斯(中心极限定理的结果),所以测量误差、回归残差、传感器噪声、嵌入向量某些方向上的统计近似都常采用高斯模型。
例:若成年男性身高近似服从 \(\mathcal{N}(170,6^2)\),则 170 cm 附近最常见,而 190 cm 属于离均值超过 3 个标准差的少见样本。回归里假设残差服从高斯,本质上是在说“误差多数小、极大误差少”。
拉普拉斯分布(Laplace Distribution)也是定义在实数轴上的连续分布,常用位置参数(Location) \(\mu\) 与尺度参数(Scale) \(b>0\) 描述:
\[p(x)=\frac{1}{2b}\exp\left(-\frac{|x-\mu|}{b}\right)\]它的图像在中心点 \(\mu\) 处更尖、尾部比高斯分布更厚(Heavier Tails)。这表示模型更偏好“大多数误差很小,但偶尔出现相对较大偏差”这一类数据形状,因此它对离群点(Outliers)的容忍度通常高于高斯模型。
拉普拉斯分布和绝对误差(Absolute Error)关系非常紧密:若回归残差假设服从拉普拉斯分布,那么最大似然估计会导向 \(L_1\) 损失;若把参数先验设为拉普拉斯分布,最大后验估计则会导向 \(L_1\) 正则。这也是它在稀疏建模(Sparse Modeling)和鲁棒回归(Robust Regression)里很常见的原因。
例:若某传感器大多数时刻误差接近 0,但偶尔会因为抖动或遮挡产生较大的偏差,那么用拉普拉斯分布描述误差,往往比高斯分布更贴近这种“中心尖、尾部较厚”的统计形状。
伯努利分布(Bernoulli Distribution)描述一次二元结果试验(0/1):
\[P(X=1)=p,\quad P(X=0)=1-p\]它是二分类标签建模的最小单元,也是逻辑回归与二分类交叉熵的概率基础。若 \(X\) 表示“用户是否点击广告”,则 \(X=1\) 代表点击、\(X=0\) 代表未点击,模型输出的 \(p\) 就是点击概率。
伯努利变量的期望是 \(\mathbb{E}[X]=p\),方差是 \(p(1-p)\)。因此当 \(p\) 接近 0 或 1 时,不确定性反而更小;当 \(p=0.5\) 时,不确定性最大。
如果把同一个伯努利试验独立重复 \(n\) 次,并把成功次数加总,那么得到的就是二项分布(Binomial Distribution)。伯努利分布描述“单次是否成功”,二项分布描述“总共成功了多少次”。
二项分布(Binomial Distribution)描述 \(n\) 次独立伯努利试验中的成功次数。若每次成功概率都是 \(p\),随机变量 \(X\) 表示总成功次数,则
\[P(X=k)={n \choose k}p^k(1-p)^{n-k},\quad k=0,1,\dots,n\]这里 \({n \choose k}\) 表示“从 \(n\) 次试验里选出 \(k\) 次成功”的组合数;后面的 \(p^k(1-p)^{n-k}\) 表示某一种具体排列出现的概率。两者相乘,就得到“恰好成功 \(k\) 次”的总概率。
如果 \(X_1,\dots,X_n\) 独立同分布且 \(X_i\sim\mathrm{Bernoulli}(p)\),那么它们的和
\[S_n=\sum_{i=1}^{n}X_i\sim\mathrm{Binomial}(n,p)\]因此,二项分布本质上就是“多个伯努利随机变量求和后的分布”。它的期望是 \(\mathbb{E}[X]=np\),方差是 \(np(1-p)\)。
例:若一枚硬币正面概率为 \(p=0.7\),连续抛 10 次,则“正面出现几次”服从二项分布。此时恰好出现 7 次正面的概率是
\[P(X=7)={10 \choose 7}0.7^7 0.3^3\]多项式分布(Multinomial Distribution)是“多类别计数版”的伯努利:进行 \(n\) 次独立试验,类别概率为 \(\mathbf{p}\),计数向量 \(\mathbf{k}\) 的概率为
\[P(\mathbf{k})=\frac{n!}{\prod_i k_i!}\prod_i p_i^{k_i},\quad \sum_i k_i=n\]若只有一次抽样,通常写作分类分布(Categorical Distribution):
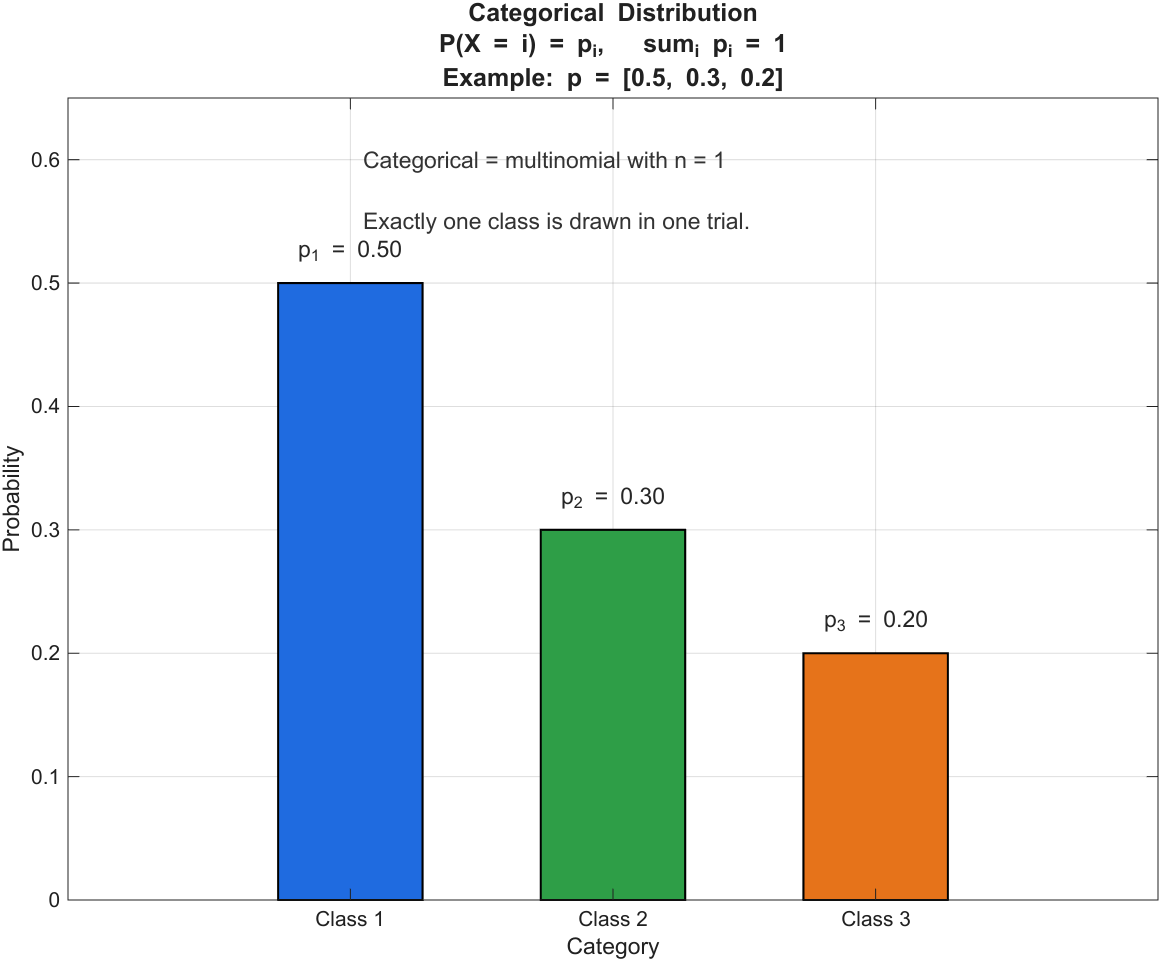
若把一次抽样重复 \(n\) 次并统计每类出现次数,就得到多项式分布,语言模型里的词频计数、主题模型中的词袋(Bag of Words)都与这种计数视角一致。概率分布一节的第三个图就是多项式分布:总计抽样6次,横轴表示分类1的次数,纵轴表示分类2的次数(因为只有3分类,因此不需要绘制三维),颜色表示抽取到不同分类的次数组合的概率。
泊松分布(Poisson Distribution)描述单位时间或单位空间内稀有事件的发生次数:
\[P(X=k)=e^{-\lambda}\frac{\lambda^k}{k!},\quad k=0,1,2,\ldots\]其中 \(\lambda\) 既是平均发生次数,也是方差。它适用于“事件相互独立、平均速率稳定、短时间内多次同时发生概率很小”的场景,例如单位分钟请求数、单位小时故障数、单位页面点击数。
例:若一个接口平均每分钟收到 3 次请求,则 \(\lambda=3\)。此时一分钟内 0 次请求的概率是 \(e^{-3}\approx 0.05\);5 次请求的概率是 \(e^{-3}3^5/5!\approx 0.10\)。泊松分布常被用来做“到达数 / 故障数 / 事件数”建模。
期望(Expectation)是随机变量的“按概率加权的平均”,回答“长期来看这个量的典型水平在哪里”。离散情形下,它把每个可能取值按对应概率加权;连续情形下,则对概率密度做积分:
\[\mathbb{E}[X]=\sum_x x\,p(x)\ \ (\text{或 } \int x\,p(x)\,dx)\]期望和均值很像,但并非同一个概念。 期望(Expectation)是总体分布层面的量,由概率模型 \(p(x)\) 决定,描述“如果无限次重复抽样,平均会稳定到哪里”;均值(Mean)通常有两种语境:一是把总体的中心位置也叫“总体均值”,这时它与期望是同一个量;二是指有限样本算出来的样本均值(Sample Mean) \(\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_i\),这是用样本近似期望的统计量。
因此可以把三者关系记成:总体均值 = 期望;样本均值 = 对期望的估计。例如公平骰子点数的期望是 \(\mathbb{E}[X]=3.5\);如果你真的掷 6 次,样本均值可能是 3、4 或 4.5,不必恰好等于 3.5,但随着试验次数增多,它会越来越接近期望。
期望最重要的性质之一是线性性(Linearity):\(\mathbb{E}[aX+b]=a\mathbb{E}[X]+b\),不要求独立。例:公平骰子点数 \(X\) 的期望是 \((1+2+3+4+5+6)/6=3.5\);若收入模型写成 \(Y=2X+1\),则 \(\mathbb{E}[Y]=2\times 3.5+1=8\)。
矩(Moment)是概率统计里用来概括分布形状的一组数。理论上,“第 \(k\) 阶”指对 \(k\) 次幂取期望:矩天然与期望/均值绑定。
常用两类定义是:
- 原点矩(Raw Moment / Non-central Moment):\(m_k=\mathbb{E}[X^k]\)(以 0 为参照)。
- 中心矩(Central Moment):\(\mu_k=\mathbb{E}\big[(X-\mathbb{E}[X])^k\big]\)(以均值为参照)。
直觉上可以用“跷跷板”来理解:把概率质量看作分布在数轴上的“重量”,期望/均值决定“支点放哪里”才平衡;更高阶矩描述“重量围绕支点如何分布”。
一阶矩(First Moment)回答“中心在哪里”:均值/期望 \(\mathbb{E}[X]\) 给出平衡点。但一阶矩无法刻画离散程度:例如 \(X\in\{-1,+1\}\) 与 \(X\in\{-10,+10\}\) 都满足 \(\mathbb{E}[X]=0\),但后者离中心更远。
二阶量用平方偏差的期望刻画离散程度:平方保证非负、避免正负偏差相互抵消,并对远离均值的样本赋予更大权重。在统计里,这对应二阶中心矩——方差 \(\mathrm{Var}(X)=\mathbb{E}[(X-\mathbb{E}[X])^2]\);在力学类比里,这与转动惯量(Moment of Inertia)中按 \(r^2\) 加权的直觉一致:远处的“重量”对系统的“难摆动/难转动”贡献更大。
二阶原点矩与方差之间满足恒等式:
\[\mathrm{Var}(X)=\mathbb{E}\big[(X-\mathbb{E}[X])^2\big]=\mathbb{E}[X^2]-\mathbb{E}[X]^2\] \[\mathbb{E}[X^2]=\mathrm{Var}(X)+\mathbb{E}[X]^2\]它说明二阶原点矩 \(\mathbb{E}[X^2]\) 以 0 为参照,会把两类效应叠加在一起:一是分布整体离 0 的偏移(由均值项 \(\mathbb{E}[X]^2\) 表示),二是围绕自身均值的离散/抖动(由方差项 \(\mathrm{Var}(X)\) 表示)。因此 \(\mathbb{E}[X^2]\) 变大并不等价于“波动更大”;把所有取值整体平移一个常数,方差不变,但二阶原点矩会随偏移显著改变。
一个最小例子可以把差异看得非常清楚。令 \(X\) 等概率取值 \(\{99,100,101\}\),则
\[\mathbb{E}[X]=\frac{99+100+101}{3}=100,\quad \mathbb{E}[X]^2=100^2=10000\] \[\mathbb{E}[X^2]=\frac{99^2+100^2+101^2}{3}=\frac{30002}{3}\approx 10000.67\] \[\mathrm{Var}(X)=\mathbb{E}[X^2]-\mathbb{E}[X]^2=\frac{30002}{3}-10000=\frac{2}{3}\]这句话表达的是:这组数“离 0 很远”(所以 \(\mathbb{E}[X^2]\) 很大),但“围绕自身均值很稳定”(所以方差很小)。
这也解释了 Adam 里的常见误解。Adam 说的“一阶矩/二阶矩”是把 mini-batch 梯度 \(g\) 当作随机变量,分别估计 \(\mathbb{E}[g]\) 与 \(\mathbb{E}[g^2]\)(逐参数维度)。它用的是二阶原点矩 \(\mathbb{E}[g^2]\),并非方差 \(\mathrm{Var}(g)\)。原因很直接:如果梯度在一段时间内几乎恒定(例如每步都是 \(g=10\)),那么方差为 0,拿它做除法会造成数值灾难;但 \(\mathbb{E}[g^2]=100\) 给出了稳定的“绝对尺度”,使更新项 \(\frac{\mathbb{E}[g]}{\sqrt{\mathbb{E}[g^2]}}\) 仍然是有界的(再加上 \(\epsilon\) 做数值稳定)。
方差(Variance)衡量随机变量围绕均值的波动大小。它核心是“偏离均值的平方再平均”;平方的作用是避免正负抵消,并放大大偏差:
\[\mathrm{Var}(X)=\mathbb{E}[(X-\mu)^2]\]因此,方差小表示样本更集中在均值附近;方差大表示波动更强。它刻画的是“不确定性的尺度”,而非取值本身的大小。例如两个模型的平均误差相同,方差更大的那个模型,输出往往更不稳定。
协方差(Covariance)描述两个变量是否倾向同向变化:
\[\mathrm{Cov}(X,Y)=\mathbb{E}[(X-\mu_X)(Y-\mu_Y)]\]若 \(\mathrm{Cov}(X,Y)>0\),说明 \(X\) 大时 \(Y\) 也倾向变大;若 \(\mathrm{Cov}(X,Y)<0\),说明一个变大时另一个倾向变小。直觉例子是:身高与体重常为正协方差,室外温度与暖气功率常为负协方差。
还要区分一点:协方差为 0 不必然意味着独立。例如令 \(X\) 在 \(\{-1,1\}\) 上等概率取值,定义 \(Y=X^2\),则 \(Y\) 被 \(X\) 完全决定,但 \(\mathrm{Cov}(X,Y)=0\)。因此“零相关”比“独立”弱得多。
协方差矩阵(Covariance Matrix)\(\Sigma\) 在 AI 中极其关键:PCA、马氏距离(Mahalanobis Distance)、卡尔曼滤波与高斯模型都直接依赖它。它编码的是“各方向上的尺度”与“不同维度之间的耦合”。
标准差(Standard Deviation)衡量数据相对均值(Mean)的离散程度(Dispersion)。总体标准差(Population Standard Deviation)定义为:
\[\sigma=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i-\mu)^2}\]样本标准差(Sample Standard Deviation)使用贝塞尔校正(Bessel's Correction):
\[s=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2}\]先平方再平均是为了避免正负抵消并加重大偏差;最后开平方是为了把单位恢复到原始尺度。若直接用方差,单位会变成“平方单位”,解释往往不直观;标准差则可以直接说成“典型偏离均值大约多少个原始单位”。
例:数据 \(\{2,4,4,4,5,5,7,9\}\) 的均值是 \(5\),总体方差是 \(4\),标准差是 \(2\)。这意味着一个典型样本与均值的偏离量级大约是 2,而非每个点都恰好偏 2。
标准差还常被用来做标准化(Standardization)。例如某考试分数 80 分,班级均值 70、标准差 5,则它的 z-score 是 \((80-70)/5=2\),表示它比均值高 2 个标准差。近似正态分布下,经验上约有 68% 样本落在 \(\mu\pm\sigma\),95% 落在 \(\mu\pm2\sigma\),99.7% 落在 \(\mu\pm3\sigma\);这就是常见的 68-95-99.7 规则。
最大似然估计(Maximum Likelihood Estimation, MLE)先把已经观察到的数据(例如上面抛硬币10次有8次正面)固定住,再在参数空间里寻找“最能生成这批数据”的参数。设数据集为 \(D=\{x_1,\dots,x_n\}\),参数为 \(\theta\),则定义是:
\[\hat{\theta}_{\mathrm{MLE}}=\arg\max_{\theta}p(D|\theta)\]其中\(p(D|\theta)\) 是“参数取 \(\theta\) 时看到整批数据 \(D\) 的概率/密度”; \(\arg\max\) 表示“找出让这个值最大的那个参数”。
若样本独立同分布(不相关且在同一个分布,例如抛硬币中10个独立事件。Independent and Identically Distributed, i.i.d.),联合似然可以拆成单个样本似然的乘积:
\[p(D|\theta)=\prod_{i=1}^{n}p(x_i|\theta)\]于是 MLE 常写成
\[\hat{\theta}_{\mathrm{MLE}}=\arg\max_{\theta}\prod_{i=1}^{n}p(x_i|\theta)\]实际训练几乎总是改为最大化对数似然(Log-Likelihood):
\[\ell(\theta)=\log p(D|\theta)=\sum_{i=1}^{n}\log p(x_i|\theta)\]取对数不会改变最优解,因为 \(\log\) 是单调递增函数;它只是把难处理的连乘变成易处理的求和。因此,最大化似然与最小化负对数似然(Negative Log-Likelihood, NLL)完全等价。
继续看抛硬币的例子。设单次结果 \(x_i\in\{0,1\}\),其中 1 表示正面,0 表示反面。设正面概率为 \(\theta\),那么单个样本就服从伯努利分布(Bernoulli Distribution)。它的概率质量函数(Probability Mass Function, PMF,用于描述离散随机变量,直接给出概率。对应概率密度函数PDF,给出给定连续随机变量对应位置的密度,因为连续,特定点的概率必须为0,只能密度和变量范围积分得到概率)写成:
\[p(x_i|\theta)=\theta^{x_i}(1-\theta)^{1-x_i},\quad x_i\in\{0,1\}\]左边的 \(p(\cdot|\theta)\) 里的 \(p\) 是“概率分布/概率质量函数”的记号, \(\theta\) 是模型参数,也就是“正面概率”。很多教材会把参数也记成 \(p\),写成 \(p(x_i|p)\);这并不算错,因为参数本身就是一个概率,但两个 \(p\) 同时出现时很容易视觉混淆,所以这里改用 \(\theta\) 来区分“模型符号”和“参数符号”。
当 \(x_i=1\) 时,
\[p(x_i=1|\theta)=\theta^1(1-\theta)^0=\theta\]当 \(x_i=0\) 时,
\[p(x_i=0|\theta)=\theta^0(1-\theta)^1=1-\theta\]如果 10 次里看到 7 次正面、3 次反面,那么整批数据的似然就是:
\[p(D|\theta)=\theta^7(1-\theta)^3\]对应的对数似然是
\[\ell(\theta)=7\log \theta+3\log(1-\theta)\]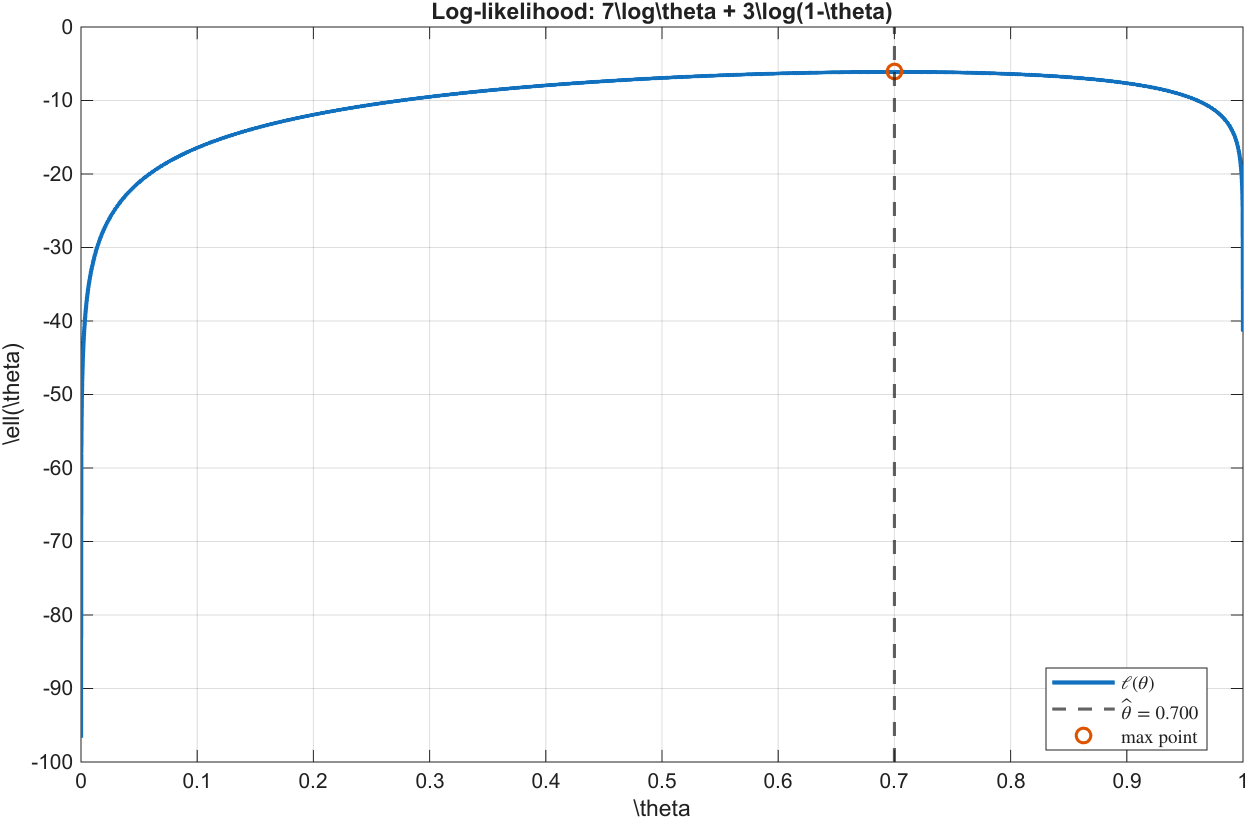
我们现在要最大化似然,需要对 \(\theta\) 求导并令导数为 0:
\[\frac{d\ell(\theta)}{d\theta}=\frac{7}{\theta}-\frac{3}{1-\theta}=0\Rightarrow \theta=0.7\]所以 \(\hat{\theta}_{\mathrm{MLE}}=0.7\)。即“在所有候选 \(\theta\) 里, \(\theta=0.7\) 最能让 7 正 3 反这份数据显得不奇怪”。
在机器学习里,损失函数往往由概率建模假设(Probabilistic Modeling Assumption)诱导出来。做法是先写下观测数据在参数 \(\theta\) 下的概率模型,再把训练集的负对数似然(Negative Log-Likelihood, NLL)当作优化目标。于是,最小化损失就已经从一个工程规定扩展到等价于最大化“已观测数据在模型下出现的可能性”。
以最常见的回归假设为例,若模型输出写成 \(f_\theta(x)\),并假设真实标签满足
\[y=f_\theta(x)+\varepsilon,\qquad \varepsilon\sim\mathcal{N}(0,\sigma^2)\]这里的高斯分布指的核心是误差项,也就是残差 \(y-f_\theta(x)\) 的分布。误差总是相对于模型当前给出的预测中心 \(f_\theta(x)\) 来计算:预测值附近最可能出现,偏离越远,概率越低。
从这个误差模型出发,可以把“误差分布”直接改写成“真实标签在给定输入下的条件分布”。因为 \(\varepsilon\) 服从均值为 0 的高斯分布,所以等价地,真实标签服从一个均值为 \(f_\theta(x)\) 的高斯分布:
\[y\,|\,x \sim \mathcal{N}(f_\theta(x),\sigma^2)\]这条式子的含义是:给定输入 \(x\) 之后,模型把输出 \(y\) 看成一个以预测值 \(f_\theta(x)\) 为中心、方差为 \(\sigma^2\) 的高斯随机变量。根据高斯分布的概率密度函数,可进一步写出条件概率密度:
\[p_\theta(y|x)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(y-f_\theta(x))^2}{2\sigma^2}\right)\]这时 \(p_\theta(y_i|x_i)\) 的含义就自然了:它评估的是在当前参数 \(\theta\) 下,训练集中已经观测到的真实标签 \(y_i\),作为“围绕 \(f_\theta(x_i)\) 摆动的一个样本”是否足够合理。被评分的始终是真实观测到的 \(y_i\),而非模型预测出来的 \(f_\theta(x_i)\)。\(f_\theta(x_i)\) 的作用核心是作为条件分布的均值或位置参数,决定观测值最可能出现的位置。
这种思路并不限于高斯回归。分类任务里,条件分布不再是高斯,而会改成 Bernoulli 或 Categorical;若把噪声假设换成拉普拉斯分布(Laplacian Distribution),则导出的损失也会从平方误差变成绝对误差。更严谨地说,损失函数是概率模型在训练集上的负对数似然写开后的结果:高斯噪声导出平方误差(Squared Error),拉普拉斯噪声导出绝对误差(Absolute Error),Bernoulli 与 Categorical 分布则导出二分类或多分类交叉熵(Cross-Entropy)。
先看监督回归(Supervised Regression)。训练集写成 \(D=\{(x_i,y_i)\}_{i=1}^N\),其中 \(x_i\) 是输入特征,\(y_i\) 是真实输出。按照上面的统一框架,这里仍然是把 \(x_i\) 当作给定条件,只为输出建模条件分布 \(p_\theta(y|x)\),并让真实观测到的 \(y_i\) 在模型下尽可能不意外:
\[\hat\theta_{\mathrm{MLE}}=\arg\max_{\theta}\prod_{i=1}^{N}p_\theta(y_i|x_i)\]这里的参数 \(\theta\) 不在 \(x_i\) 里;它出现在假设函数 \(f_\theta(x)\) 里。例如线性回归(Linear Regression)可写成 \(f_\theta(x)=\mathbf{w}^\top x+b\),其中 \(\theta=(\mathbf{w},b)\)。回归里常说的“高斯分布”,指的是误差项,也就是残差 \(y_i-f_\theta(x_i)\) 的分布。误差总是相对于当前模型给出的中心值 \(f_\theta(x_i)\) 来计算。
具体假设是:
\[y_i=f_\theta(x_i)+\varepsilon_i,\quad \varepsilon_i\sim\mathcal{N}(0,\sigma^2)\ \text{i.i.d.}\]等价写成条件分布:
\[y_i\,|\,x_i \sim \mathcal{N}(f_\theta(x_i),\sigma^2)\]上式的意思是:在给定输入 \(x_i\) 的条件下,输出 \(y_i\) 不再被视为确定值,而被建模为随机变量,并且服从均值为 \(f_\theta(x_i)\)、方差为 \(\sigma^2\) 的一维高斯分布(Gaussian Distribution),当然,这里的不确定性就是模型引入的。根据高斯分布的概率密度公式,并结合 i.i.d. 假设(联合似然为逐样本似然的乘积),整批数据的似然为
\[p(D|\theta,\sigma^2)=\prod_{i=1}^{N}\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(y_i-f_\theta(x_i))^2}{2\sigma^2}\right)\]取负对数似然(Negative Log-Likelihood, NLL)得到训练时真正被最小化的量:
\[-\log p(D|\theta,\sigma^2)=\frac{N}{2}\log(2\pi\sigma^2)+\frac{1}{2\sigma^2}\sum_{i=1}^{N}(y_i-f_\theta(x_i))^2\]当 \(\sigma^2\) 视为常数时,第一项与 \(\theta\) 无关,因此最小化 NLL 关于 \(\theta\) 等价于最小化平方误差和(Sum of Squared Errors, SSE):
\[\hat\theta_{\mathrm{MLE}}=\arg\min_\theta\sum_{i=1}^{N}(y_i-f_\theta(x_i))^2\]把残差(Residual)记为 \(r_i=y_i-f_\theta(x_i)\),则上式就是最小化 \(\sum_i r_i^2\)。因此,在“高斯噪声 + 固定方差”的回归假设下,最大化似然(等价最大化对数似然)就是最小化残差平方和。
这就是“最小二乘(Least Squares)”为什么会从概率建模里自然出现;均方误差(Mean Squared Error, MSE)只是把 SSE 再除以 \(N\),不改变最优解。
如果 \(\sigma^2\) 也未知,则 MLE 会同时估计 \((\theta,\sigma^2)\)。在固定 \(\theta\) 时,对 \(\sigma^2\) 的 MLE 为
\[\hat\sigma^2_{\mathrm{MLE}}=\frac{1}{N}\sum_{i=1}^{N}(y_i-f_\theta(x_i))^2\]注意这里是 \(1/N\)(MLE),而非无偏估计常用的 \(1/(N-1)\)。
顺带一提:把回归模型退化为“常数预测” \(f_\theta(x)\equiv \mu\),就回到“在高斯噪声下估计均值 \(\mu\)”,其 MLE 是样本均值。这也是很多教材先从 \(x_i=\mu+\varepsilon_i\) 入手的原因:那是回归的一个最小特例(此时 \(\theta=\mu\))。
分类任务与回归不同:标签通常是离散变量,因此这里使用的核心是概率质量函数(Probability Mass Function, PMF)。做最大似然估计时,最常见的做法同样是把输入 \(x\) 视为给定条件,只为标签建模条件分布 \(p_\theta(y|x)\),然后让已观测标签在模型下尽可能“显得合理”。
先看二分类(Binary Classification)。设标签 \(y_i\in\{0,1\}\),模型输出正类概率 \(\pi_\theta(x_i)=p_\theta(y_i=1|x_i)\),则单个样本服从伯努利分布(Bernoulli Distribution):
\[p_\theta(y_i|x_i)=\pi_\theta(x_i)^{y_i}\bigl(1-\pi_\theta(x_i)\bigr)^{1-y_i}\]在 i.i.d. 假设下,整批数据的似然为
\[p(D|\theta)=\prod_{i=1}^{N}\pi_\theta(x_i)^{y_i}\bigl(1-\pi_\theta(x_i)\bigr)^{1-y_i}\]取负对数似然,得到
\[-\log p(D|\theta)=-\sum_{i=1}^{N}\Big[y_i\log \pi_\theta(x_i)+(1-y_i)\log\bigl(1-\pi_\theta(x_i)\bigr)\Big]\]这正是二分类交叉熵(Binary Cross-Entropy, BCE)。因此,在“标签服从伯努利分布”的假设下,最大化似然等价于最小化二分类交叉熵。若再把 \(\pi_\theta(x)\) 写成 sigmoid 作用在 logit \(z_\theta(x)\) 上,即 \(\pi_\theta(x)=\sigma(z_\theta(x))\),就得到工程实现里最常见的 sigmoid + BCE 训练形式。
再看多分类(Multiclass Classification)。设类别总数为 \(C\),并用 one-hot 向量 \(y_i=(y_{i1},\dots,y_{iC})\) 表示真实标签,其中只有真实类别对应那一项为 1,其余为 0。若模型输出类别概率 \(\pi_{\theta,1}(x_i),\dots,\pi_{\theta,C}(x_i)\),且满足 \(\sum_{c=1}^{C}\pi_{\theta,c}(x_i)=1\),则单个样本服从类别分布(Categorical Distribution):
\[p_\theta(y_i|x_i)=\prod_{c=1}^{C}\pi_{\theta,c}(x_i)^{y_{ic}}\]整批数据的似然为
\[p(D|\theta)=\prod_{i=1}^{N}\prod_{c=1}^{C}\pi_{\theta,c}(x_i)^{y_{ic}}\]取负对数似然,得到
\[-\log p(D|\theta)=-\sum_{i=1}^{N}\sum_{c=1}^{C}y_{ic}\log \pi_{\theta,c}(x_i)\]这正是多分类交叉熵(Categorical Cross-Entropy)。若标签是标准 one-hot,那么每个样本只会保留真实类别那一项,损失就退化成 \(-\log \pi_{\theta,c^*}(x_i)\);若标签本身是软标签(Soft Label),则公式不变,只是 \(y_{ic}\) 已经从有 0 和 1扩展到一个分布。
若回归任务从假设误差服从高斯分布转向假设误差项 \(\varepsilon\) 服从拉普拉斯分布(Laplacian Distribution),即
\[y_i=f_\theta(x_i)+\varepsilon_i,\qquad \varepsilon_i\sim \mathrm{Laplace}(0,b)\ \text{i.i.d.}\]那么等价地,真实标签在给定输入后的条件分布可写成
\[y_i\,|\,x_i \sim \mathrm{Laplace}(f_\theta(x_i),b)\]其中 \(f_\theta(x_i)\) 是位置参数(Location Parameter),\(b\) 是尺度参数(Scale Parameter)。拉普拉斯分布的一维概率密度函数为
\[p_\theta(y_i|x_i)=\frac{1}{2b}\exp\left(-\frac{|y_i-f_\theta(x_i)|}{b}\right)\]在 i.i.d. 假设下,整批数据的似然为
\[p(D|\theta,b)=\prod_{i=1}^{N}\frac{1}{2b}\exp\left(-\frac{|y_i-f_\theta(x_i)|}{b}\right)\]取负对数似然,得到
\[-\log p(D|\theta,b)=N\log(2b)+\frac{1}{b}\sum_{i=1}^{N}|y_i-f_\theta(x_i)|\]当 \(b\) 视为常数时,第一项与 \(\theta\) 无关,因此最小化 NLL 关于 \(\theta\) 等价于最小化绝对误差和(Sum of Absolute Errors, SAE):
\[\hat\theta_{\mathrm{MLE}}=\arg\min_\theta\sum_{i=1}^{N}|y_i-f_\theta(x_i)|\]这正是平均绝对误差(Mean Absolute Error, MAE)背后的概率来源。与高斯分布相比,拉普拉斯分布在中心更尖、尾部更厚,因此它对应的损失从像平方误差那样强烈放大大残差转向按线性方式惩罚偏差。MAE 因而通常比 MSE 对离群点(Outlier)更稳健。
因此,高斯分布与最小二乘、拉普拉斯分布与绝对误差、Bernoulli / Categorical 分布与交叉熵,其实是同一个统计逻辑在不同任务类型下的三种展开:先假设观测数据服从某个条件分布,再对训练集做最大似然估计;把负对数似然写开后,就得到具体的训练损失。
最大后验估计(Maximum A Posteriori, MAP)在 MLE 的“数据解释能力”之外,再加入参数的先验(Prior)信息。它选择后验概率(Posterior)最大的参数:
\[\hat{\theta}_{\mathrm{MAP}}=\arg\max_{\theta}p(\theta|D)\]根据贝叶斯定理:
\[p(\theta|D)=\frac{p(D|\theta)p(\theta)}{p(D)}\]其中 \(p(D|\theta)\) 是似然(Likelihood), \(p(\theta)\) 是先验, \(p(D)\) 是证据(Evidence)。因为 \(p(D)\) 与参数 \(\theta\) 无关,所以在求最大值时它只是常数,可以直接忽略:
\[\hat{\theta}_{\mathrm{MAP}}=\arg\max_{\theta}p(D|\theta)p(\theta)=\arg\max_{\theta}\big(\log p(D|\theta)+\log p(\theta)\big)\]这个式子清楚地说明了 MAP 的结构: \(\log p(D|\theta)\) 负责拟合数据, \(\log p(\theta)\) 负责约束参数不要偏离先验认知。若改写成最小化形式,则有
\[\hat{\theta}_{\mathrm{MAP}}=\arg\min_\theta\big(-\log p(D|\theta)-\log p(\theta)\big)\]因此,MAP 可以理解为“负对数似然 + 先验诱导的惩罚项(Penalty)”。很多正则化(Regularization)都能够从贝叶斯视角解释:L2 正则通常对应高斯先验,L1 正则通常对应拉普拉斯先验。若先验在可行域内与 \(\theta\) 无关(例如均匀先验: \(p(\theta)=c\)),则 \(\log p(\theta)=\log c\) 是关于 \(\theta\) 的常数;在 \(\arg\max_\theta\) 中加上或去掉这一项都不改变最优点,因此 MAP 与 MLE 给出同一组参数(若均匀先验还隐含“只在某个范围内为常数、范围外为 0”,则等价于在该范围约束下做 MLE)。
继续用抛硬币解释。现在参数已经统一记作 \(\theta\),因此先验也写成 \(p(\theta)\),而不再写 \(p(p)\)。若对 \(\theta\) 设 Beta 分布(Beta Distribution)先验
Beta 分布是定义在区间 \([0,1]\) 上的连续分布,最常用来描述“某个概率值本身的不确定性”,因此非常适合作为伯努利参数 \(\theta\) 的先验。
\[p(\theta)\propto \theta^{\alpha-1}(1-\theta)^{\beta-1},\quad 0\le \theta\le 1\]这里 \(\propto\) 表示“正比于”,意思是左边真正的概率密度函数还差一个归一化常数(Normalization Constant),这个常数负责保证密度在区间 \([0,1]\) 上积分为 1。对 MAP 而言,这个常数不影响最大值位置,所以通常省略不写。
参数 \(\alpha\) 和 \(\beta\) 控制分布形状: \(\alpha\) 越大,分布越偏向较大的 \(\theta\); \(\beta\) 越大,分布越偏向较小的 \(\theta\)。例如 \(\mathrm{Beta}(2,2)\) 会把概率质量更多放在中间区域,表达“更倾向认为硬币接近公平”; \(\mathrm{Beta}(8,2)\) 则更偏向 \(\theta\) 接近 1。
那么它表达的是:在看到数据之前,我们已经对“硬币正面概率应该落在什么范围”有一个先验偏好。
把这个先验与 7 正 3 反的似然 \(p(D|\theta)=\theta^7(1-\theta)^3\) 相乘,得到后验:
\[p(\theta|D)\propto \theta^{7+\alpha-1}(1-\theta)^{3+\beta-1}\]这说明后验仍然是 Beta 分布:
\[p(\theta|D)=\mathrm{Beta}(7+\alpha,3+\beta)\]众数(Mode)指的是概率密度函数最高的那个位置,也就是“这个分布最偏好的参数值”。因为 MAP 的定义本来就是寻找后验概率/后验密度最大的参数,所以当后验分布已经写出来时,MAP 估计就是这个后验分布的众数。
因为后验与 \(\theta^{7+\alpha-1}(1-\theta)^{3+\beta-1}\) 成正比,所以只需最大化这个函数。取对数后,等价目标变成
\[(7+\alpha-1)\log \theta+(3+\beta-1)\log(1-\theta)\]对 \(\theta\) 求导并令导数为 0:
\[\frac{7+\alpha-1}{\theta}-\frac{3+\beta-1}{1-\theta}=0\]移项并整理可得
\[(7+\alpha-1)(1-\theta)=(3+\beta-1)\theta\Rightarrow \hat{\theta}_{\mathrm{MAP}}=\frac{7+\alpha-1}{10+\alpha+\beta-2}\]因此,当 \(\alpha,\beta>1\) 时,Beta 分布的众数(Mode)也就是 MAP 估计。
若取 \(\mathrm{Beta}(2,2)\) 先验,则
\[\hat{\theta}_{\mathrm{MAP}}=\frac{7+2-1}{10+2+2-2}=\frac{8}{12}=\frac{2}{3}\]它比 MLE 的 \(0.7\) 更靠近 \(0.5\)。原因很具体: \(\mathrm{Beta}(2,2)\) 可以理解为在真实观测之外,先额外放入了“1 次正面 + 1 次反面”的温和偏好,所以最终估计不会被7正3反的样本完全带着走。样本很少时,先验的影响明显;样本很多时,数据项占主导,MAP 会逐渐逼近 MLE。
在机器学习里,MAP 与正则化(Regularization)本质上是同一件事的两种表述。给参数指定先验后,取负对数,这个先验就会自动变成优化目标里的正则项。
先看一般形式。MAP 最大化的是后验概率 \(p(\theta|D)\),等价于最小化负对数后验:
\[-\log p(\theta|D)=-\log p(D|\theta)-\log p(\theta)+\mathrm{const}\]第一项 \(-\log p(D|\theta)\) 是数据拟合项,第二项 \(-\log p(\theta)\) 就是先验带来的惩罚项。因此“正则化”核心是贝叶斯先验在优化问题里的直接体现。
若参数向量 \(\theta\) 服从零均值各向同性高斯先验(Isotropic Gaussian Prior),可以写成
\[p(\theta)\propto \exp\left(-\frac{1}{2\tau^2}\|\theta\|_2^2\right)\]这里 \(\tau^2\) 控制先验方差:方差越小,越强地偏好参数靠近 0。对它取负对数得到
\[-\log p(\theta)=\frac{1}{2\tau^2}\|\theta\|_2^2+\mathrm{const}\]把常数 \(\frac{1}{2\tau^2}\) 记成 \(\lambda\),就得到熟悉的目标:
\[-\log p(D|\theta)+\lambda\|\theta\|_2^2\]这正是 \(L_2\) 正则。它的作用可以理解为:先验认为“大权重不太可信”,所以优化时不仅要拟合数据,还要为过大的参数付出代价。由于高斯先验在 0 附近平滑、尾部衰减快,它通常会把参数整体压小,但不特别鼓励大量参数精确等于 0。
若先验改成拉普拉斯(Laplacian)分布:
\[p(\theta)\propto \exp\big(-\lambda\|\theta\|_1\big)\]则负对数先验变成
\[-\log p(\theta)=\lambda\|\theta\|_1+\mathrm{const}\]于是 MAP 等价于最小化
\[-\log p(D|\theta)+\lambda\|\theta\|_1\]这就是 \(L_1\) 正则。它与 \(L_2\) 的关键区别在于:拉普拉斯先验在 0 处尖得更厉害,因此更强地偏好很多参数直接变成 0,也就是产生稀疏性(Sparsity)。
所以可以把对应关系记成一条很清楚的链:高斯先验对应 \(L_2\),拉普拉斯先验对应 \(L_1\);正则项的形状,本质上就是先验密度形状的负对数。很多看起来像“人为添加的惩罚项”,其实都可以解释为“在做 MAP”。
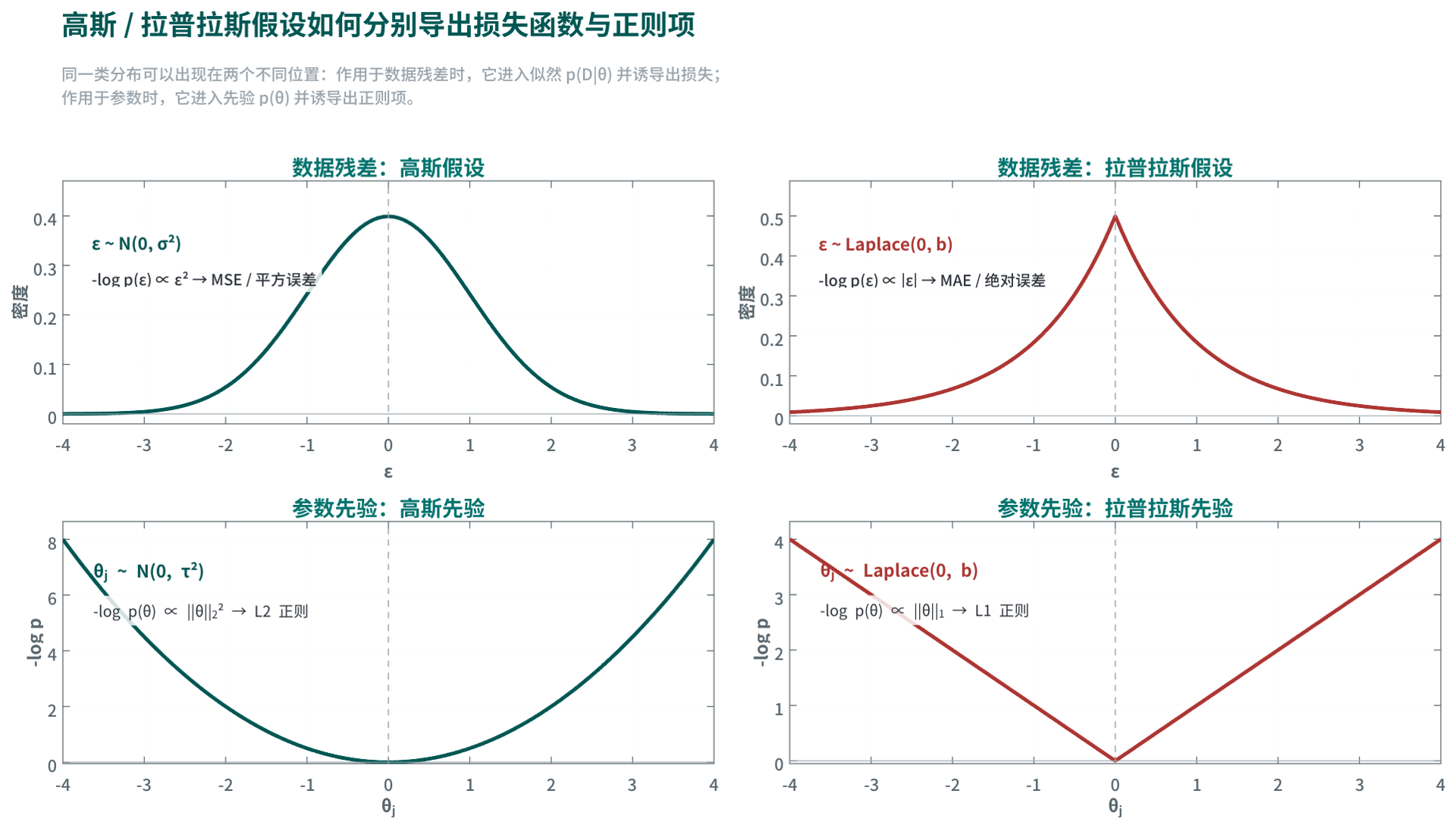
这里的分布假设有两个不同落点。若假设的是数据误差或残差 \(\epsilon\) 的分布,它进入的是似然 \(p(D|\theta)\),决定数据拟合项的形状;若假设的是参数 \(\theta\) 自身的分布,它进入的是先验 \(p(\theta)\),决定正则项的形状。前者回答“数据会怎样围绕模型波动”,后者回答“参数本身更可能落在什么区域”。
因此,高斯和拉普拉斯并不只用于描述数据集。高斯残差假设会把负对数似然化成平方误差,拉普拉斯残差假设会把负对数似然化成绝对误差;与此同时,零均值高斯参数先验会把负对数先验化成 \(L_2\) 正则,零均值拉普拉斯参数先验会把负对数先验化成 \(L_1\) 正则。它们使用的是同一类分布族,但一个作用在数据项 \(p(D|\theta)\),一个作用在参数项 \(p(\theta)\)。
最大边缘似然(Maximum Marginal Likelihood, MML)处理的是带潜变量(Latent Variable)的参数估计问题。设观测数据为 \(D\),模型参数为 \(\theta\),潜变量为 \(Z\)。潜变量表示模型内部假设存在、但训练数据中没有直接给出的变量,例如聚类模型里的簇编号、HMM 里的隐藏状态路径、主题模型里的隐主题分配。
如果潜变量 \(Z\) 也能被观察到,那么可以直接最大化完整数据似然(Complete-data Likelihood):
\[\hat{\theta}=\arg\max_\theta p(D,Z|\theta)\]现实中更常见的情况是只观察到 \(D\),看不到 \(Z\)。此时不能指定某一个潜变量取值作为真相,需要把所有可能的潜变量配置都纳入考虑。离散潜变量对应求和:
\[p(D|\theta)=\sum_Z p(D,Z|\theta)\]连续潜变量对应积分:
\[p(D|\theta)=\int p(D,Z|\theta)\,dZ\]这个过程叫边缘化(Marginalization):从联合分布 \(p(D,Z|\theta)\) 中把不可见的 \(Z\) 消掉,只留下观测数据自身的概率 \(p(D|\theta)\)。这个被边缘化之后的 \(p(D|\theta)\) 就是边缘似然(Marginal Likelihood)。最大边缘似然估计选择让观测数据边缘似然最大的参数:
\[\hat{\theta}_{\mathrm{MML}}=\arg\max_\theta p(D|\theta)=\arg\max_\theta \sum_Z p(D,Z|\theta)\]实际优化通常使用对数边缘似然(Log Marginal Likelihood):
\[\hat{\theta}_{\mathrm{MML}}=\arg\max_\theta \log p(D|\theta)=\arg\max_\theta \log\sum_Z p(D,Z|\theta)\]这里最难处理的是 \(\log\sum_Z\) 结构。对数在求和外面,不能把它简单拆成每个潜变量配置的对数似然之和。因此,带潜变量模型常需要专门的推断算法。期望最大化(Expectation-Maximization, EM)就是最经典的一类方法:E 步根据当前参数估计潜变量的后验分布或期望统计量,M 步在这些期望统计量上更新参数。GMM 的责任度更新、HMM 的 Baum-Welch 算法,都可以看作 EM 在具体模型里的实例。
MML、MLE 和 MAP 的差别可以放在同一张表里看:
| 方法 | 优化目标 | 核心使用场景 |
| 最大似然估计(MLE) | \(\arg\max_\theta p(D|\theta)\) | 数据全部可观测,直接寻找最能解释数据的参数。 |
| 最大后验估计(MAP) | \(\arg\max_\theta p(D|\theta)p(\theta)\) | 在似然之外加入参数先验,常对应正则化。 |
| 最大边缘似然(MML) | \(\arg\max_\theta \sum_Z p(D,Z|\theta)\) | 存在不可见潜变量,需要先把潜变量求和或积分掉。 |
从关系上看,MML 仍然属于“让观测数据在模型下尽可能合理”的似然路线;它的特殊之处在于模型内部多了一层不可见结构。MLE 面对的是可直接写下的 \(p(D|\theta)\),MAP 在此基础上乘上参数先验 \(p(\theta)\),MML 则先从完整联合分布 \(p(D,Z|\theta)\) 出发,通过边缘化得到观测数据似然。后续 HMM、GMM、主题模型和变分推断中出现的“边缘似然”“证据”“EM”,都属于这条主线。
大数定律说明:当独立同分布样本越来越多时,样本平均会稳定地靠近真实期望(Expectation)。若 \(X_1,\dots,X_n\) 独立同分布,且 \(\mathbb{E}[X]\) 存在,则
\[\frac{1}{n}\sum_{i=1}^{n}X_i \to \mathbb{E}[X],\quad n\to\infty\]这里的重点是“平均值会稳定下来”,而非“每一次新观测都会让结果更接近真值”。它描述的是长期趋势:样本量越大,随机波动在平均过程中被不断抵消,样本平均就越不容易偏离真实期望太远。
最经典的例子是抛公平硬币。设正面记为 1、反面记为 0,则单次试验的期望是 \(\mathbb{E}[X]=0.5\)。前几次抛掷时,正面比例可能是 1、0、0.67、0.25,波动很大;但抛掷次数达到几百、几千次后,样本平均 \(\bar{X}\) 会越来越稳定地靠近 0.5。大数定律回答的是“为什么频率会稳定到概率附近”。
中心极限定理(Central Limit Theorem, CLT)描述的是:在独立同分布且方差有限的条件下,样本均值经过适当标准化后,会趋近于正态分布(Normal Distribution)。它给出的核心是“平均值围绕真值波动时,波动形状如何分布”的规律。
因此,中心极限定理讨论的重点核心是样本均值在真值附近如何波动,以及这种波动的分布长什么样。标准写法是:
\[\frac{\sqrt{n}(\bar{X}-\mu)}{\sigma}\Rightarrow \mathcal{N}(0,1)\]这里 \(\mu=\mathbb{E}[X]\) 是总体均值, \(\sigma^2=\mathrm{Var}(X)\) 是总体方差。所谓标准化(Standardization),就是先减去均值 \(\mu\),把中心移到 0;再除以标准差 \(\sigma\),把尺度统一成“多少个标准差”;再乘上 \(\sqrt{n}\),把样本均值随着样本量增大而缩小的波动重新放回可比较的尺度。标准化之后,不同样本量下的波动可以放到同一个参考系里比较。
所谓方差有限,就是随机变量的波动强度并非无限大,满足 \(\mathrm{Var}(X)<\infty\)。直观上,这意味着样本虽然会波动,但不会被极端值以“无限强”的方式主导。像伯努利分布、二项分布、泊松分布、均匀分布和高斯分布都满足这个条件;而某些重尾分布则可能不满足,因此不能直接套用最基础的 CLT 表述。
为什么要乘上 \(\sqrt{n}\)?因为样本均值的波动规模大约是 \(\sigma/\sqrt{n}\):样本越多,均值越稳定。如果不乘 \(\sqrt{n}\),当 \(n\) 增大时, \(\bar{X}-\mu\) 会越来越接近 0,看不出其分布形状;乘上 \(\sqrt{n}\) 后,波动被拉回到常数量级,才会显现出稳定的正态极限。
继续看硬币例子。设 \(X_i\in\{0,1\}\) 且正面概率为 0.5,则 \(\mu=0.5\), \(\sigma^2=0.25\),标准差 \(\sigma=0.5\)。CLT 说的是:
\[\frac{\sqrt{n}(\bar{X}-0.5)}{0.5}\Rightarrow \mathcal{N}(0,1)\]例如当 \(n=100\) 时,正面比例 \(\bar{X}\) 的标准差大约是 \(0.5/\sqrt{100}=0.05\)。这意味着正面比例通常会落在 \(0.5\pm 0.1\) 这一量级附近;更精确地,用正态近似可写成
\[\bar{X}\approx \mathcal{N}\left(0.5,\frac{0.25}{100}\right)=\mathcal{N}(0.5,0.0025)\]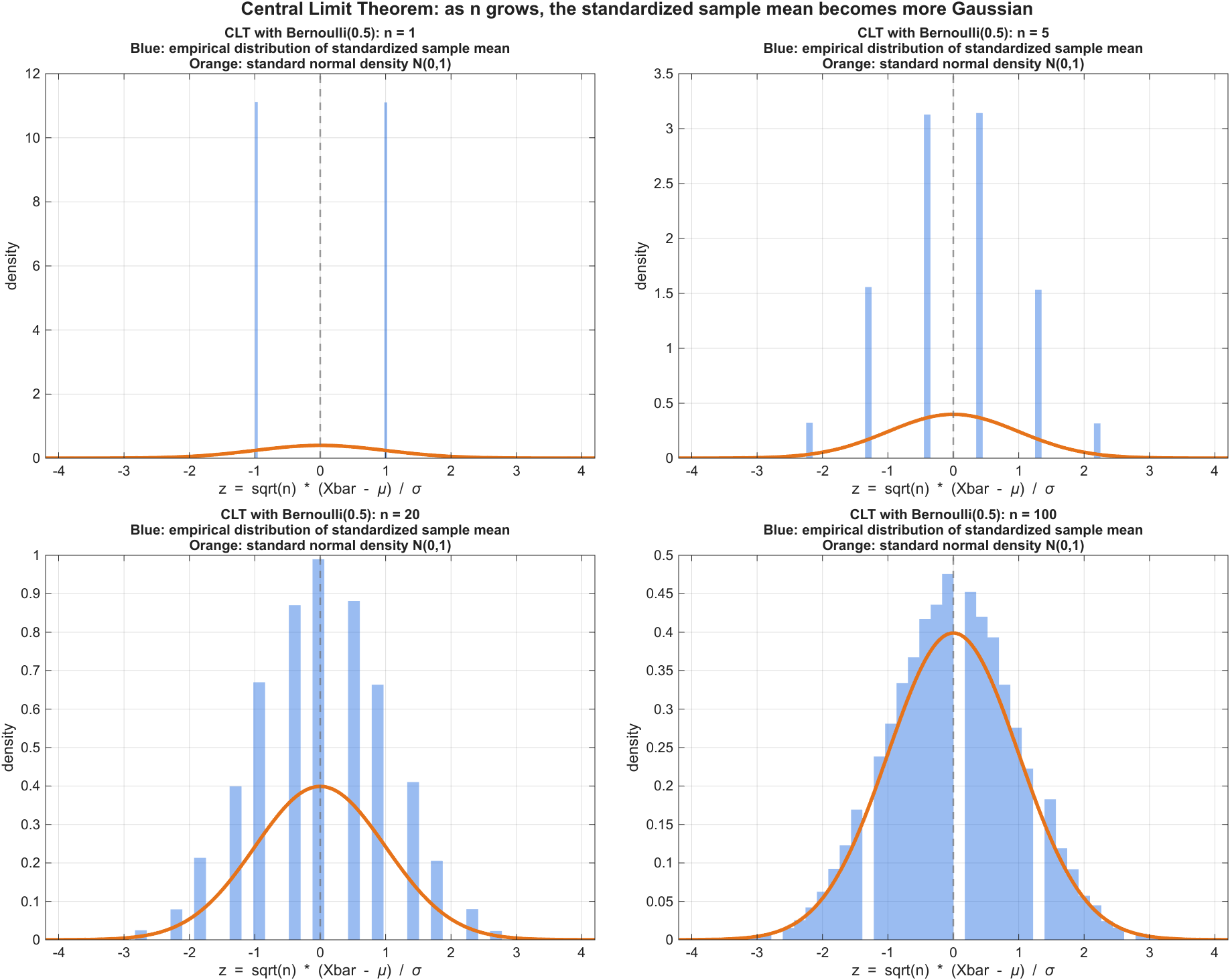
上图是样本量分别为1, 5, 20, 100的Bernoulli(0.5)分布,分别进行了30000轮测试,绘制的(每轮)标准化后的分布,可以看到样本量足够多时,其均值倾向于向中心(未标准化前的0.5对应此伯努利分布的总体均值)靠近。
所以 CLT 回答的是“为什么很多统计量在样本足够大时会近似高斯”,而 LLN 回答的是“为什么样本平均会逼近真值”。前者给出分布近似,后者给出收敛结论。置信区间、显著性检验、A/B test 和 mini-batch 梯度噪声分析,主要依赖的是 CLT 提供的近似正态性。
置信度(Confidence Level)与置信区间(Confidence Interval)属于统计推断(Statistical Inference)中的区间估计(Interval Estimation)。它们处理的核心是在只看到一批有限样本时,怎样给未知总体参数画出一个有覆盖保证的范围。在机器学习实验、A/B test、离线评测和指标报表里,样本均值、准确率、点击率、转化率和误差率后面常跟着一个区间,这个区间就是区间估计的产物。
若目标是估计总体均值 \(\mu\),样本均值为 \(\bar{X}\),且样本量足够大或总体近似正态,那么基于中心极限定理,可以构造近似的双侧置信区间:
\[\bar{X}\pm z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}\]若总体标准差 \(\sigma\) 未知,而样本来自正态总体或样本量适中且使用样本标准差 \(s\) 近似,则常写作:
\[\bar{X}\pm t_{1-\alpha/2,\,n-1}\frac{s}{\sqrt{n}}\]这里每个元素的含义分别是:
- \(\bar{X}\):样本均值(Sample Mean),是当前样本对总体均值的点估计(Point Estimate)。
- \(n\):样本量(Sample Size)。样本越多,区间通常越窄。
- \(\sigma\):总体标准差(Population Standard Deviation);若未知,常用样本标准差 \(s\) 替代。
- \(\frac{\sigma}{\sqrt{n}}\) 或 \(\frac{s}{\sqrt{n}}\):标准误(Standard Error),表示样本均值本身的波动尺度,而非单个样本点的波动。
- \(\alpha\):显著性水平(Significance Level)。若置信度为 95%,则 \(\alpha=0.05\)。
- \(z_{1-\alpha/2}\):标准正态分布的分位数(Quantile);95% 置信度时大约是 \(1.96\)。
- \(t_{1-\alpha/2,\,n-1}\):Student t 分布的分位数,带有 \(n-1\) 个自由度(Degrees of Freedom),用于总体方差未知时。
在这个表达式里,置信区间 指的是最终得到的区间本身,例如 \([1.8,2.4]\);置信度 指的是构造这个区间的方法在重复抽样下的长期覆盖率,例如 95%、99%。因此,95% 置信区间的严格含义是:如果用同一种抽样方式和同一种区间构造公式反复重复实验,那么大约 95% 的区间会覆盖真实参数。
这一定义有一个极其重要的解释边界。总体参数 \(\mu\) 在经典频率学派(Frequentist)统计里被视为固定但未知的常数;随机的是样本,因此随机的是区间端点。样本一旦观察完成,这次得到的区间要么覆盖 \(\mu\),要么不覆盖,概率意义已经不再施加在参数本身上。于是,95% 置信度描述的是区间构造程序的长期可靠性,而非“参数有 95% 概率落在这次区间里”的后验概率表述。
置信度并不局限于连续分布。它的定义依赖的是“重复抽样下的覆盖率”,而非总体分布是否连续。对伯努利分布(Bernoulli Distribution)、二项分布(Binomial Distribution)、泊松分布(Poisson Distribution)这类离散分布,同样可以对参数构造 95% 或 99% 的区间估计。例如对二项分布中的成功概率 \(p\),就可以根据观测到的成功次数构造 \(p\) 的置信区间;若参数或目标对象并非一维连续量,更宽泛的名称则是置信集合(Confidence Set)。
离散分布与连续分布的差别不在“能不能谈置信度”,而在于区间构造的细节。连续情形下,区间端点可以较平滑地调节到目标覆盖率附近;离散情形下,统计量只能取离散值,覆盖率往往无法恰好等于名义值,例如正好 95%,而常常只能做到“不低于 95%”。因此,离散分布里的精确区间常带有一定保守性(Conservativeness):区间更宽一些,但覆盖保证更稳。在离散统计推断里,除了近似正态区间外,也经常会看到 Clopper–Pearson 这类精确区间构造方法。
一个具体例子最容易说明这两个概念。设某模型在 100 次独立测试中的平均准确率估计为 \(\bar{X}=0.82\),样本标准差为 \(s=0.10\)。若采用近似 95% 置信区间,可写成:
\[0.82\pm 1.96\times \frac{0.10}{\sqrt{100}}=0.82\pm 0.0196\]于是区间约为:
\[[0.8004,\ 0.8396]\]这里 \([0.8004,0.8396]\) 是置信区间,95% 是置信度。它表示:按这种抽样和构造方式长期重复下去,约 95% 的此类区间会覆盖真实平均准确率;这次具体得到的这个区间只是其中一个实现结果。
区间宽度主要由三个因素共同决定:
- 样本波动越大,即 \(\sigma\) 或 \(s\) 越大,区间越宽。
- 样本量越大,即 \(n\) 越大,标准误越小,区间越窄。
- 置信度越高,例如从 95% 提高到 99%,对应分位数更大,区间也会变宽。
因此,置信区间是在样本有限时对参数估计可靠性的定量表达;置信度则是这套区间构造方法愿意给出的覆盖承诺。两者必须一起理解:只有区间没有置信度,范围没有统计保证;只有置信度没有区间,覆盖承诺也无法落到具体参数估计上。
前面讨论的随机变量(Random Variable)通常只对应一次不确定试验,例如抛一次硬币、测一次身高、抽取一个样本标签。随机过程(Stochastic Process)则讨论一串彼此有关、按时间或空间索引起来的随机变量。它适合描述会随时间演化的不确定系统,例如天气变化、股价波动、队列长度、用户行为序列、传感器读数,以及自然语言中的 token 序列。
形式上,随机过程可记为:
\[\{X_t\}_{t\in T}\]这里 \(T\) 是索引集合(Index Set),常表示时间; \(X_t\) 是时刻 \(t\) 的随机变量。若 \(T=\{0,1,2,\dots\}\),过程是离散时间(Discrete-time)的;若 \(T=[0,\infty)\),过程则是连续时间(Continuous-time)的。每个 \(X_t\) 都有自己的分布,但更重要的是这些随机变量之间的联合分布(Joint Distribution)与依赖结构,因为随机过程关心的核心是“整个序列怎样一起变化”。
从结果形态看,一次随机过程的实现从一个点转向一条轨迹(Trajectory)或样本路径(Sample Path)。例如,设 \(X_t\) 表示第 \(t\) 天的气温,那么一次观测得到的是一整段温度序列 \((X_1,X_2,\dots,X_T)\);若 \(X_t\) 表示语言模型在位置 \(t\) 生成的 token,那么一次实现就是一整句文本。
随机过程之所以在机器学习里重要,是因为很多任务天生就是时序问题。时间序列预测关心未来值如何演化,隐马尔可夫模型(Hidden Markov Model, HMM)关心隐藏状态如何随时间转移,强化学习关心状态—动作—奖励序列怎样展开,自回归语言模型则是在建模 token 序列的联合概率。因此,随机过程可以看作“把单个随机变量扩展到整条时间轴上的概率建模语言”。
马尔可夫性(Markov Property)讨论的是随机过程中的“记忆如何被压缩”。它刻画这样一种情形:如果当前状态已经把与未来演化有关的信息概括完整,那么预测下一步时就不再需要显式回看更久的历史。在这种表示下,过去对未来的影响已经通过当前状态被浓缩进来了。
设随机过程为 \(\{X_t\}_{t=0}^{\infty}\),其中 \(X_t\) 表示时刻 \(t\) 的随机状态。机器学习里默认使用的一般是一阶马尔可夫性(First-order Markov Property),它写成:
\[P(X_{t+1}\mid X_t,X_{t-1},\dots,X_0)=P(X_{t+1}\mid X_t)\]这条式子定义的是一阶版本:在已经知道当前状态 \(X_t\) 的前提下,再额外知道更早的历史 \(X_{t-1},\dots,X_0\),不会改变对下一时刻 \(X_{t+1}\) 的条件分布判断。左边是“条件在完整历史上的下一步分布”,右边是“条件在当前状态上的下一步分布”;两者相等,说明当前状态已经足以作为历史摘要。
马尔可夫性也可以推广到高阶。二阶马尔可夫性(Second-order Markov Property)允许下一步同时依赖最近两个状态:
\[P(X_{t+1}\mid X_t,X_{t-1},\dots,X_0)=P(X_{t+1}\mid X_t,X_{t-1})\]一般的 \(m\) 阶马尔可夫性(\(m\)-order Markov Property)允许下一步依赖最近 \(m\) 个状态:
\[P(X_{t+1}\mid X_t,X_{t-1},\dots,X_0)=P(X_{t+1}\mid X_t,X_{t-1},\dots,X_{t-m+1})\]这里 \(m\) 是保留的历史长度。若 \(m=1\),公式退化为一阶马尔可夫性;若 \(m=2\),下一步分布可以同时查看当前状态和前一个状态。阶数越高,模型能保留的短期历史越长,但状态组合和参数规模也会迅速变大。
高阶马尔可夫过程常可改写成一阶马尔可夫过程。做法是把最近 \(m\) 个状态打包成一个复合状态(Composite State):
\[S_t=(X_t,X_{t-1},\dots,X_{t-m+1})\]在复合状态表示下,下一步只需要依赖 \(S_t\),于是又可以写成一阶形式:
\[P(S_{t+1}\mid S_t,S_{t-1},\dots,S_0)=P(S_{t+1}\mid S_t)\]这个改写解释了为什么教材和机器学习模型经常直接讨论一阶马尔可夫性:只要状态定义足够充分,更长的历史可以被折进“当前状态”里。代价是状态空间膨胀。若原始状态数为 \(K\),保留 \(m\) 步历史后的复合状态最多有 \(K^m\) 种组合。
一个直接例子是天气变化。若把每天的天气记作随机变量 \(X_t\),状态空间为 \(\{\text{晴},\text{阴},\text{雨}\}\),那么常见建模假设是:明天是否下雨主要由今天的天气决定,而不需要把更早几天的天气逐项保留。此时“当前天气”就扮演了压缩历史信息的状态摘要。若今天是雨天,明天继续下雨的概率可以较大;若今天是晴天,明天下雨的概率可以较小。这种“只通过当前状态决定下一步分布”的结构,就是马尔可夫性。
满足给定阶数马尔可夫性的随机过程,称为马尔可夫过程(Markov Process)或马尔可夫链(Markov Chain,离散时间、有限或可数状态时的常见名称)。工程和机器学习语境里若未特别说明,马尔可夫链通常指一阶马尔可夫链。因此,马尔可夫性是一个性质,马尔可夫过程是满足该性质的一类随机过程。若状态空间有限,常把一阶的一步转移概率写成转移矩阵(Transition Matrix) \(P\),其中:
\[P_{ij}=P(X_{t+1}=j\mid X_t=i)\]这里 \(P_{ij}\) 表示“当前在状态 \(i\) 时,下一步转移到状态 \(j\) 的概率”。矩阵的每一行对应当前状态固定后的下一步分布,因此每一行元素都非负,且行和为 1。
马尔可夫过程之所以重要,是因为它把一个潜在上非常复杂的时序依赖问题,压缩成了局部转移规律。隐马尔可夫模型(Hidden Markov Model, HMM)、马尔可夫决策过程(Markov Decision Process, MDP)、很多时间序列状态模型,以及强化学习中的环境状态转移,都建立在这一思想之上。这些模型里的“一阶”通常是相对于所选状态表示而言的;把必要的历史、动作、缓存或环境变量折入状态后,模型仍可使用一阶转移形式。它们的差别主要体现在:状态是否可见、是否存在动作、是否附带奖励,以及是否只关心下一步还是关心长期回报。
马尔可夫性是一种建模假设,并非自然界自动保证的真理。若“当前状态”定义得不充分,历史信息就没有被真正压缩进去,此时过程在这个状态表示下就不具有马尔可夫性。例如,仅用“当前股价”预测明天走势通常不够,因为成交量、市场情绪、宏观事件等信息并未包含在状态中;但若把更完整的市场状态向量一并纳入,马尔可夫近似会更合理。因此,马尔可夫性的关键不仅在公式,还在于当前状态是否足以成为过去对未来影响的充分摘要。
信息论(Information Theory)研究的是:当事件具有不确定性时,信息应该如何被度量、压缩、传输和比较。在机器学习里,它不仅是一门“通信理论”,更是理解损失函数、语言模型、表示学习和分布距离的基础语言。熵(Entropy)回答“分布本身有多不确定”,KL 散度回答“两个分布相差多少”,交叉熵回答“用模型分布描述真实分布要付出多少平均代价”。这三者共同构成后续分类损失、语言模型 NLL 和困惑度(Perplexity)的理论基础。
信息论最基本的对象核心是单个事件的信息量(Information Content)。若事件 \(x\) 的概率为 \(p(x)\),则它的信息量定义为:
\[I(x)=-\log p(x)\]这里 \(p(x)\) 越小,说明事件越罕见、越难提前猜到,因此 \(-\log p(x)\) 越大; \(p(x)\) 越大,说明事件越常见、越不令人意外,因此信息量越小。这条定义并非任意拍脑袋得出的,它和最优编码(Optimal Coding)直接对应:概率大的事件应该分配更短的码字,概率小的事件应该分配更长的码字,而最优平均码长与 \(-\log p(x)\) 同阶。
对数的底决定单位。以 \(\log_2\) 为底,单位是比特(Bits);以自然对数为底,单位是纳特(Nats)。在机器学习推导里常用自然对数,因为它和指数族分布、梯度推导、对数似然更自然地连在一起;在编码与压缩直觉里,bit 往往更直观。
这也解释了语言模型里单个 token 的负对数概率 \(-\log p_\theta(y_t|c_t)\) 为何会被称为“惊奇(Surprise)”。这里 \(c_t\) 是当前位置之前的上下文, \(y_t\) 是当前位置真实出现的 token。若模型原本认为这个 token 很大概率出现,那么惊奇很小;若模型几乎没预料到它会出现,那么惊奇就很大。于是,单 token 的负对数概率就是单事件的信息量。
熵(Entropy)刻画的是一个概率分布整体的不确定性。对离散分布 \(p\):
\[H(p)=-\sum_i p_i\log p_i\]这条公式表达的是“信息量的期望”。因为单个事件的信息量是 \(-\log p(x)\),而熵就是对所有事件按真实概率做加权平均后的结果。因此,熵核心是针对整个分布:分布越均匀,平均越难预测,熵越大;分布越尖锐,平均越容易预测,熵越小。
例如,若 \(p\) 在 \(K\) 个类别上均匀,即 \(p_i=1/K\),则有:
\[H(p)=\log K\]这说明均匀分布的熵达到最大值,因为每个类别都一样可能,系统最难提前猜中。反过来,若某个类别概率接近 1,其余类别概率接近 0,那么熵会接近 0,因为结果几乎确定。
一个最简单的直觉例子是抛硬币。公平硬币的分布是 \(p=(0.5,0.5)\),熵为 \(-0.5\log_2 0.5-0.5\log_2 0.5=1\) bit;若硬币极度偏向正面,例如 \(p=(0.99,0.01)\),熵就会显著降低,因为结果基本可预测。熵衡量的核心是“类别概率结构到底有多分散”。
语言也能帮助建立对熵的直觉。以字符为单位时,汉字集合更大,单个常用字符的平均出现概率往往更低,因此 \(-\log p(x)\) 更大;同时,汉语序列里的下一字符通常也更难直接预测,所以常给人“字符级信息更密、熵更高”的直觉。对比之下,韩语的字符系统更小,序列模式也通常更规则,下一字符更容易预测,因此字符级冗余感更强、熵的直觉更低。
若再做一个极粗略的字符级估算:把常用汉字集合近似看作 \(V=3000\)、把韩文字母集合近似看作 \(V=40\),并暂时假设“下一字符”在各自词表上均匀分布,则最大熵分别约为 \(\log_2 3000\approx 11.55\) bits 与 \(\log_2 40\approx 5.32\) bits。这对应的就是:词表越大、单符号平均概率越低,单位符号的潜在信息量上界越高。
条件熵(Conditional Entropy)衡量的是:在已经知道一个随机变量 \(X\) 的前提下,另一个随机变量 \(Y\) 还剩多少不确定性。对离散变量,它定义为:
\[H(Y|X)=-\sum_{x,y}p(x,y)\log p(y|x)\]这里 \(p(x,y)\) 是联合分布, \(p(y|x)\) 是条件分布。与普通熵 \(H(Y)\) 相比,条件熵把“已知 \(X\)”这一额外信息纳入了计算,因此它描述的是看到上下文之后仍然无法消除的平均不确定性。
条件熵满足一个非常重要的链式法则(Chain Rule):
\[H(X,Y)=H(X)+H(Y|X)\]这条式子表达的是:联合不确定性等于“先确定 \(X\) 需要的信息量”加上“知道 \(X\) 之后再确定 \(Y\) 还需要的信息量”。如果 \(Y\) 完全由 \(X\) 决定,那么 \(H(Y|X)=0\);如果知道 \(X\) 对预测 \(Y\) 毫无帮助,那么 \(H(Y|X)=H(Y)\)。
这条概念在 AI 中非常重要。语言模型本质上就在最小化“给定上下文后的下一个 token 条件不确定性”;监督学习则在尝试让特征 \(X\) 尽可能降低标签 \(Y\) 的条件熵。一个好的表示,往往意味着:给定表示之后,目标变量剩余的不确定性更小。
互信息(Mutual Information)衡量的是:知道 \(X\) 之后,关于 \(Y\) 的不确定性到底减少了多少。它定义为:
\[I(X;Y)=H(Y)-H(Y|X)\]同一个量还可以写成对称形式:
\[I(X;Y)=H(X)+H(Y)-H(X,Y)\]以及分布距离形式:
\[I(X;Y)=D_{\mathrm{KL}}\bigl(p(x,y)\,\|\,p(x)p(y)\bigr)\]这三种写法分别强调了三个角度。第一种写法强调“减少了多少不确定性”;第二种写法强调“联合结构比两个独立分布拼起来少了多少冗余”;第三种写法强调“联合分布与独立分布之间到底偏离了多少”。若 \(X\) 与 \(Y\) 独立,则 \(p(x,y)=p(x)p(y)\),互信息为 0;若二者强相关,互信息就大。
互信息在机器学习里有很强的桥梁作用。特征选择希望保留与标签互信息高的特征;表示学习希望得到对目标变量更有信息量的表示;对比学习(Contrastive Learning)很多时候都可以理解为在间接提高表示与语义目标之间的互信息。它把“这个表示到底有没有用”转成了一个可度量的问题。
交叉熵(Cross-Entropy)衡量的是:若真实样本来自分布 \(p\),但预测或编码时使用分布 \(q\),平均需要多少信息量。它定义为:
\[H(p,q)=-\sum_i p_i\log q_i\]这里 \(p\) 是真实分布(True Distribution)或数据分布, \(q\) 是模型分布(Model Distribution)或预测分布。与熵 \(H(p)=-\sum_i p_i\log p_i\) 相比,交叉熵把“对真实分布的自我编码”改成了“用模型分布来编码真实分布”。因此它天然会把模型偏差也算进去。
交叉熵与熵、KL 散度之间满足最关键的一条关系:
\[H(p,q)=H(p)+D_{\mathrm{KL}}(p\|q)\]这条式子说明:交叉熵等于“真实分布本来就不可避免的信息量”加上“模型偏离真实分布所多付出的代价”。因此,在真实分布 \(p\) 固定时,最小化交叉熵就等价于最小化 \(D_{\mathrm{KL}}(p\|q)\)。KL 散度本身的方向性和更深层意义,会在本章最后单独展开。
分类问题里,真实标签通常写成 one-hot 分布。若某个样本的真实类别是 \(c^*\),则只有 \(p_{c^*}=1\),其他类别概率都为 0。此时交叉熵立刻化简成:
\[H(p,q)=-\log q_{c^*}\]这说明分类交叉熵损失(Cross-Entropy Loss)的本质,就是惩罚模型给真实类别分配过低概率。若模型把真实类别概率压到很小,损失会急剧上升;若模型给真实类别高概率,损失就很小。因此,交叉熵本质上就是负对数似然(Negative Log-Likelihood, NLL)在分类任务上的具体展开。
二分类情形下,若真实标签 \(y\in\{0,1\}\),模型输出正类概率 \(\pi\),则交叉熵退化为:
\[\ell_{\mathrm{BCE}}(y,\pi)=-y\log \pi-(1-y)\log(1-\pi)\]多分类情形下,若模型输出 softmax 概率 \(q_c\),则损失就是前面的 one-hot 交叉熵。于是 BCE、Categorical Cross-Entropy 和语言模型里的 token-level NLL,本质上都属于同一条信息论主线。
若继续使用前面的例子,真实分布 \(p=(0.5,0.5)\),模型分布 \(q=(0.9,0.1)\),则交叉熵为
\[H(p,q)=-0.5\log 0.9-0.5\log 0.1\approx 1.204\ (\text{nats})\]而真实熵 \(H(p)\approx 0.693\),两者差值正好就是前面算出的 \(D_{\mathrm{KL}}(p\|q)\approx 0.511\)。图像化地看,就是交叉熵把“分布自身的不确定性”和“模型额外犯的错”加在了一起:
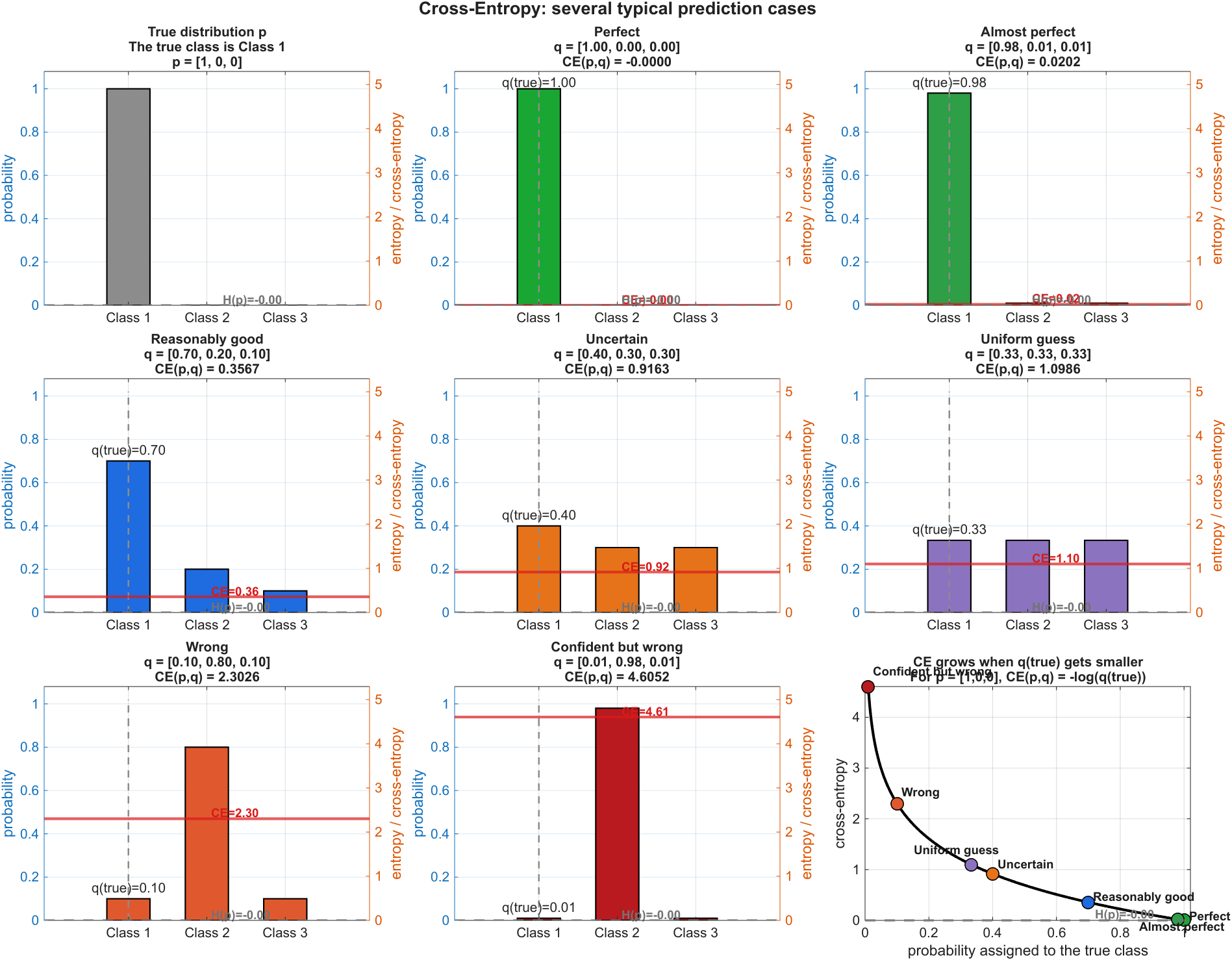
困惑度(Perplexity, PPL)主要用于语言模型评估。它把平均交叉熵或平均 NLL 指数化,得到一个更直观的尺度;这个尺度对应模型在每一步预测时面对的“有效分支数(Effective Branching Factor)”。对长度为 \(N\) 的 token 序列,若模型给出的条件概率是 \(q(x_t|x_{<t})\),则平均 NLL 为:
\[\mathrm{NLL}=-\frac{1}{N}\sum_{t=1}^{N}\log q(x_t|x_{<t})\]若使用自然对数,则困惑度定义为:
\[\mathrm{PPL}=\exp(\mathrm{NLL})\]因此,平均 NLL 越小,说明模型越能给真实 token 高概率,困惑度也越低;平均 NLL 越大,说明模型越“困惑”,困惑度就越高。若一个模型在某个位置总像是在若干个几乎等可能的候选之间摇摆,那么它的困惑度就高;若它常能把概率质量集中在极少数正确候选上,困惑度就低。
困惑度与熵的关系也很直接:若分布更均匀、不确定性更高,则平均惊奇更大,熵更高,困惑度也更高。对均匀分布而言,若有 \(K\) 个等可能结果,则困惑度恰好等于 \(K\)。这也是“有效分支数”这个直觉的来源。
不过,困惑度只能在相同 tokenization、相近评测语料和相同单位下比较。换了分词器、词表粒度或语料分布,PPL 的绝对值就会发生系统性变化。因此,困惑度非常适合同一模型家族内部比较,却不适合跨完全不同 tokenizer 和数据设定做简单横比。
KL 散度衡量两个概率分布之间的偏离程度。对离散分布 \(p,q\),定义为:
\[D_{\mathrm{KL}}(p\|q)=\sum_i p_i\log\frac{p_i}{q_i}=\mathbb{E}_{x\sim p}\!\left[\log\frac{p(x)}{q(x)}\right]\]这条公式可以逐块来读。这里 \(\mathbb{E}_{x\sim p}[\cdot]\) 表示“对 \(x\) 按照分布 \(p\) 取期望”,也就是用 \(p(x)\) 作为权重,对每个可能事件的括号内数值做加权平均。括号里的 \(\log \frac{p(x)}{q(x)}\) 表示:对同一个事件 \(x\),真实分布 \(p\) 给它的概率,与模型分布 \(q\) 给它的概率相比,相差了多少个对数尺度。若某个事件在 \(p\) 下概率高、但在 \(q\) 下概率低,那么这一项就为正,而且会把 KL 散度往上推;若某个事件在 \(q\) 下被高估,这一项可能变成负值,但最后整体仍会在按 \(p\) 加权平均后保持非负。
这里 \(p\) 通常代表真实分布、目标分布或参考分布, \(q\) 通常代表模型分布、近似分布或当前策略分布。把它按编码视角理解,KL 散度表示:如果样本真实来自 \(p\),但描述或编码时使用了按 \(q\) 设计的规则,那么平均会额外多付出多少码长。
这一定义非常重要,因为它把“模型到底离目标分布还有多远”变成了一个可以直接优化、直接推导的数学量。后面最大似然、交叉熵训练、变分推断、策略正则化和蒸馏,几乎都能在某个层面写成 KL 散度最小化。
第一条性质是不对称性:
\[D_{\mathrm{KL}}(p\|q)\ne D_{\mathrm{KL}}(q\|p)\]因此,KL 并非通常意义上的距离度量(Metric)。它没有“从 \(p\) 到 \(q\)”与“从 \(q\) 到 \(p\)”完全等价的性质。方向一旦交换,优化行为就可能完全不同,这正是后面正向 KL 与反向 KL 分歧的根源。
第二条性质是绝对非负性:
\[D_{\mathrm{KL}}(p\|q)\ge 0\]而且只有当 \(p=q\) 时才取 0。这意味着 KL 散度确实可以被理解为“分布差异的代价”,并且这个代价不会出现负数。很多机器学习目标之所以可以被解释为“逼近目标分布”,正是因为它们最后都能写成某个非负 KL 项再加一个与参数无关的常数。
第三条性质与支持集(Support)直接相关。若存在某个事件 \(x\) 使得 \(p(x)>0\),但 \(q(x)=0\),则
\[D_{\mathrm{KL}}(p\|q)=+\infty\]这意味着:只要真实分布认为某种情况会发生,而模型却把它的概率直接压成 0,正向 KL 的惩罚就会发散。这个性质会强烈约束模型不要遗漏真实分布支持集中的任何区域。因此,正向 KL 往往带有明显的“覆盖全部真实模式”的倾向。
由于 KL 不对称,优化 \(D_{\mathrm{KL}}(p\|q)\) 与优化 \(D_{\mathrm{KL}}(q\|p)\) 往往会导向两种完全不同的模型行为。通常把前者称为正向 KL(Forward KL),把后者称为反向 KL(Reverse KL)。
正向 KL:
\[\min_q D_{\mathrm{KL}}(p\|q)\]当真实分布 \(p\) 是多峰(Multi-modal)而模型 \(q\) 表达能力有限时,正向 KL 常表现出较强的模式覆盖(Mode-covering)倾向。因为若某个真实峰被 \(q\) 完全忽略,且该峰在 \(p\) 下概率不小,那么惩罚会非常大。于是模型更倾向于把多个真实峰都“罩进去”,哪怕这会让分布变宽、变平、甚至在峰与峰之间产生额外质量。
反向 KL:
\[\min_q D_{\mathrm{KL}}(q\|p)\]则更容易表现出模式寻优(Mode-seeking)倾向。因为现在期望是对 \(q\) 取的,模型只会为自己已经放置概率质量的区域付出代价。若它把质量集中到 \(p\) 里一个最高的峰附近,就可以避免在低概率区域“乱撒概率”;至于其他较小的峰,反向 KL 允许它忽略。于是结果通常更尖、更保守,也更容易集中在局部最优模式上。
这种差异可以用“求均值”与“求众数”的直觉来帮助理解。正向 KL 更像试图用一个近似分布去覆盖整个真实分布的平均形状;反向 KL 更像试图锁定真实分布里最值得相信的高概率模式。这个类比只是一种直觉,并非严格定理;真实行为还会受到模型族、参数化方式和优化过程的影响,但它非常适合帮助理解两种 KL 的整体倾向。
一个非常典型的具象化场景是:真实分布 \(p\) 由两个彼此分离的高斯峰组成,而模型 \(q\) 只能用一个单峰高斯去近似它。此时,若优化正向 KL,模型通常会把方差拉大、把两个峰尽量都罩住,哪怕峰与峰之间那段原本概率不高的区域也被分到一些质量;若优化反向 KL,模型则更容易直接贴到其中一个峰上,把另一个峰干脆忽略掉。这个双峰例子之所以经典,正是因为它把“模式覆盖”和“模式寻优”的差异几乎以最直观的几何方式暴露了出来。
监督学习最典型的设定是:训练样本来自某个真实数据分布 \(p_{\text{data}}(x,y)\),模型则定义一个条件分布 \(q_\theta(y|x)\)。训练的目标,是让模型分布尽可能贴近真实条件分布。若从总体风险角度写,最常见的最大似然或交叉熵训练可以写成:
\[\min_\theta \mathbb{E}_{(x,y)\sim p_{\text{data}}}\big[-\log q_\theta(y|x)\big]\]这正是经验版交叉熵。进一步展开后,它等价于最小化:
\[\mathbb{E}_{x\sim p_{\text{data}}}\big[D_{\mathrm{KL}}(p_{\text{data}}(y|x)\|q_\theta(y|x))\big]\]再加上与参数 \(\theta\) 无关的常数项。在监督学习中,模型通常是在用自己的预测分布去逼近真实标签条件分布,而这个逼近方向正是正向 KL。
因此,交叉熵训练常呈现“宁可多覆盖真实模式,也不愿漏掉真实可能性”的行为。分类模型若把真实类别概率压得过低,损失会立刻升高;密度估计模型若把真实样本区域概率分配得太小,代价同样会很大。
均方误差(Mean Squared Error, MSE)也能放进这条链里,但需要补上分布假设:当回归任务假设 \(y|x\) 服从均值为 \(f_\theta(x)\)、方差固定的高斯分布时,最小化 MSE 等价于最大化高斯似然;从分布角度看,它同样是在做一种正向 KL 逼近。于是,交叉熵、BCE 和 MSE 核心是不同观测分布假设下的同一条最大似然主线。
强化学习通过奖励函数(Reward Function)来定义哪些行为更值得偏好。若从最大熵强化学习(Maximum Entropy Reinforcement Learning)或控制即推断(Control as Inference)的视角写,最优轨迹分布可以表示为:
\[p^*(\tau)\propto \exp\!\left(\frac{1}{\alpha}R(\tau)\right)\]这里 \(\tau\) 是轨迹(Trajectory),表示从初始状态开始一路经历的状态、动作与转移序列; \(R(\tau)\) 是这条轨迹的总回报(Return); \(\alpha\) 是温度或熵正则系数,用来控制“更贪心地追高奖励”和“保留更多探索随机性”之间的权衡。式子里的 \(p^*(\tau)\) 核心是一个对高奖励轨迹赋予更高权重的目标分布。若某条轨迹奖励越高, \(\exp(R(\tau)/\alpha)\) 就越大,它在 \(p^*(\tau)\) 里的相对权重也越高。
当前策略记为 \(\pi\)。它表示智能体在给定状态 \(s\) 时采取动作 \(a\) 的条件分布,即 \(\pi(a|s)\)。一旦策略 \(\pi\) 固定,再结合环境的状态转移概率,整套交互过程就会诱导出一个“轨迹是怎样被生成出来”的概率分布,这个分布就记为 \(q_\pi(\tau)\)。因此 \(q_\pi(\tau)\) 的意思核心是由策略 \(\pi\) 所诱导出来的轨迹分布。
这时很多强化学习目标都可以写成:
\[\min_\pi D_{\mathrm{KL}}\bigl(q_\pi(\tau)\|p^*(\tau)\bigr)\]这里的关键点是:谁在逼近谁,不由 KL 公式左右两侧的位置决定,而由谁是优化变量决定。在监督学习里,常把真实分布记作 \(p\)、模型分布记作 \(q\),于是常见写法是 \(\min_\theta D_{\mathrm{KL}}(p\|q_\theta)\);但这只是一个常见写法,并非必须遵守的“左边一定是真实、右边一定是模型”的规则。只要被调的是 \(q_\theta\),那就是让模型分布去逼近目标分布 \(p\)。同理,这里被调的是策略 \(\pi\),因此真正会随训练改变的是 \(q_\pi(\tau)\);而 \(p^*(\tau)\) 是由奖励定义出的目标分布。于是这个目标的含义仍然是:通过调整策略,让 \(q_\pi(\tau)\) 靠近 \(p^*(\tau)\)。
式子写成 \(D_{\mathrm{KL}}(q_\pi(\tau)\|p^*(\tau))\),表达的是反向 KL 形式。它与前面的正向 KL 在“谁是目标分布”这件事上并没有变化,变化的是偏差如何被惩罚。由于期望是对 \(q_\pi(\tau)\) 取的,策略主要会为自己当前已经赋予概率质量的轨迹负责;那些自己几乎不去的区域,即使在 \(p^*(\tau)\) 里还有一定质量,也不会像正向 KL 那样受到强烈惩罚。结果就是策略更容易把概率质量集中到少数高奖励轨迹上,而非尽量覆盖所有还不错的行为。这正是反向 KL 常见的 mode-seeking 或“尖化”倾向。
这也解释了为什么很多强化学习或对齐过程具有明显的“尖化”倾向。只要某些动作或轨迹能显著提高回报,策略就会更愿意向这些高价值模式集中;低奖励区域即使仍然可能发生,也会被逐渐压低概率。这个行为与前面正向 KL 的“模式覆盖”倾向形成鲜明对照。
不过,这里必须保留一个边界:并非所有强化学习算法都可以无条件、逐字逐句地等同于“最小化反向 KL”。更准确的说法是:在最大熵强化学习、策略正则化 RL、RLHF / DPO 一类现代对齐与偏好优化框架中,反向 KL 视角尤其自然、尤其有解释力;而对更传统的值函数方法、时序差分方法和某些 actor-critic 变体,这个视角仍然有帮助,但不一定就是最直接的原始定义。
从 KL 散度视角看,监督学习与强化学习都在做同一件事:让人工构造的模型分布 \(q\) 去逼近某个目标分布 \(p\)。差别不在于“一个学分布,一个不学分布”,而在于目标分布如何定义、优化方向如何选、以及我们能否直接从目标分布采样。
在监督学习里, \(p\) 更接近真实数据分布或真实条件标签分布,样本可以直接观测,因此模型常落到正向 KL 或其等价目标,例如交叉熵、负对数似然和在特定噪声假设下的平方误差。模型为了不漏掉真实支持集中的区域,天然会更偏向全面覆盖。
在强化学习里, \(p\) 更接近由奖励函数诱导出的最优行为分布,通常无法直接拿到完整样本,只能通过环境交互和奖励反馈间接逼近。因此很多现代 RL / 对齐目标更自然地落到反向 KL 或带 KL 正则的变体上。模型为了把概率质量集中到高回报区域,天然会更偏向高峰聚焦。
这一统一视角的真正价值,在于它把许多表面不同的算法放回同一个底层问题:模型分布如何在高维空间中逼近目标分布。一旦把问题写成分布逼近,很多设计选择就有了统一解释:为什么有些训练目标鼓励覆盖全部模式,为什么有些目标鼓励策略更尖锐,为什么 KL 正则能稳定训练,为什么交叉熵、蒸馏、变分推断和策略约束会反复出现。KL 散度之所以重要,正是因为它把这些分散的现象压缩到了同一条数学主线上。
这一表按整篇出现频率和理解价值整理最常见的数学符号。需要特别注意:同一个符号在不同小节中可能复用,例如 \(p\) 可以表示概率、分布,也可以出现在最优值或目标分布的记号里;因此阅读时必须结合上下文判断。下面的说明以本篇最常见、最核心的含义为主。
| 符号 | 说明 | 示例 |
| \(\mathbb{R}\) | 读作 real numbers /ˈrɪəl ˈnʌmbərz/;表示实数集合。 | \(x\in\mathbb{R}\) |
| \(\mathbb{R}^n\)、\(\mathbb{R}^{m\times n}\) | 读作 R to the n /ɑːr tə ðiː ɛn/、real m by n /ˈrɪəl ɛm baɪ ɛn/;分别表示 \(n\) 维实向量空间和 \(m\times n\) 的实矩阵空间。 | \(\mathbf{x}\in\mathbb{R}^n\);\(A\in\mathbb{R}^{m\times n}\) |
| \(\mathbb{N}\)、\(\mathbb{Z}\) | 读作 natural numbers /ˈnætʃərəl ˈnʌmbərz/、integers /ˈɪntɪdʒərz/;分别表示自然数集合和整数集合。 | \(n\in\mathbb{N}\);\(k\in\mathbb{Z}\) |
| \(\mathbb{Q}\)、\(\mathbb{C}\) | 读作 rational numbers /ˈræʃənəl ˈnʌmbərz/、complex numbers /ˈkɒmplɛks ˈnʌmbərz/;分别表示有理数集合和复数集合。 | \(\mathbb{Q}\subset\mathbb{R}\subset\mathbb{C}\) |
| \(a,b,c\) | 读作 a /eɪ/、b /biː/、c /siː/;常表示常数、系数、标量或方程参数。 | \(ax+b=0\) |
| \(x\) | 读作 ex /ɛks/;常表示自变量、输入、样本点,或随机变量的某个取值。 | \(f(x)=x^2\);\(p(x)\) |
| \(y\) | 读作 wye /waɪ/;常表示输出、标签、因变量或目标值。 | \(y=f(x)\);\(q_\theta(y|x)\) |
| \(z\) | 读作 zee /ziː/;常表示中间变量、复合表达式中的辅助量,或模型未归一化输出。 | \(z=Wx+b\) |
| \(n,m,N\) | 读作 en /ɛn/、em /ɛm/、capital N /ˈkæpɪtəl ɛn/;常表示维度、样本数、类别数、矩阵大小或序列长度。 | \(\frac{1}{N}\sum_{i=1}^{N}x_i\) |
| \(i,j,k\) | 读作 eye /aɪ/、jay /dʒeɪ/、kay /keɪ/;常作求和、矩阵、序列或类别索引。 | \(A_{ij}\);\(\sum_{i=1}^{n}x_i\) |
| \(t\) | 读作 tee /tiː/;常表示时间步、位置、迭代轮次或序列下标。 | \(X_t\);\(x_t\) |
| \(h\) | 读作 aitch /eɪtʃ/;常表示极限中的微小增量,或构造性辅助变量。 | \(\lim_{h\to 0}\frac{f(x+h)-f(x)}{h}\) |
| \(f,g,h\) | 读作 ef /ɛf/、gee /dʒiː/、aitch /eɪtʃ/;常表示函数。 \(f\) 往往是目标函数, \(g\) 常表示约束或辅助函数。 | \(y=f(x)\);\(g(x)\le 0\) |
| \(\varphi\) | 读作 varphi /ˈvɑːrfaɪ/;常表示一般性标量函数,尤其用于凸分析、Jensen 不等式和抽象函数构造。 | \(\varphi(\mathbb{E}[X])\le \mathbb{E}[\varphi(X)]\) |
| \(\mathbf{x},\mathbf{y},\mathbf{w},\mathbf{b}\) | 读作 bold x /boʊld ɛks/ 等;黑体通常表示向量。 \(\mathbf{w}\) 常作参数向量, \(\mathbf{b}\) 常作偏置向量。 | \(\hat y=\mathbf{w}^\top\mathbf{x}+b\) |
| \(\boldsymbol{\theta}\) | 读作 bold theta /boʊld ˈθeɪtə/;常表示整组模型参数或一个高维参数向量。相比单个标量参数 \(\theta\),黑体/粗体版本强调“这是一个参数集合”。 | \(\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta})\) |
| \(A,B,C\) | 读作 capital A /ˈkæpɪtəl eɪ/ 等;大写拉丁字母常表示矩阵、集合或事件。 | \(A\mathbf{x}=\mathbf{b}\);\(P(A|B)\) |
| \(P(A)\)、\(P(A|B)\) | 读作 probability of A /ˌprɒbəˈbɪləti əv eɪ/、probability of A given B /ˌprɒbəˈbɪləti əv eɪ ˈɡɪvən biː/;分别表示事件 \(A\) 的概率,以及在 \(B\) 已发生条件下 \(A\) 的条件概率。 | \(P(A|B)=\frac{P(A\cap B)}{P(B)}\) |
| \(A\cap B\)、\(A\cup B\)、\(A^c\) | 读作 A cap B /eɪ kæp biː/、A cup B /eɪ kʌp biː/、A complement /eɪ ˈkɒmplɪmənt/;分别表示交集、并集和补集。 | \(P(A^c)=1-P(A)\);\(P(A\cup B)=P(A)+P(B)-P(A\cap B)\) |
| \(\subset\)、\(\subseteq\)、\(\notin\)、\(\setminus\) | 读作 proper subset /ˈprɒpər ˈsʌbsɛt/、subset or equal to /ˈsʌbsɛt ɔːr ˈiːkwəl tuː/、not in /nɒt ɪn/、set minus /sɛt ˈmaɪnəs/;分别表示真子集、子集、不属于和集合差。 | \(\mathbb{N}\subset\mathbb{Z}\);\(A\subseteq B\);\(x\notin B\);\(A\setminus B\) |
| \(X,Y\) | 读作 capital X /ˈkæpɪtəl ɛks/、capital Y /ˈkæpɪtəl waɪ/;常表示随机变量、随机向量或数据矩阵。 | \(P(X=x)\);\(I(X;Y)\) |
| \(X_t\) | 读作 X sub t /ɛks sʌb tiː/;表示时刻 \(t\) 的状态或随机变量取值。 | \(P(X_{t+1}|X_t)\) |
| \(x_t\)、\(x^2\)、\(x^{(i)}\) | 读作 x sub t /ɛks sʌb tiː/、x squared /ɛks skwerd/、x superscript i /ɛks ˈsuːpərskrɪpt aɪ/;下标 \(_{}\) 通常表示索引、时间步、类别或参数归属,上标 \(^{}\) 既可表示幂次,也可表示“第几个样本”“最优解”“逆”“转置”等附加标记,因此必须结合上下文判断。 | \(x_t\);\(x^2\);\(x^{(i)}\);\(p^*(\tau)\);\(A^{-1}\) |
| \(p,q\) | 读作 pee /piː/、cue /kjuː/;在概率与信息论中常表示分布、概率质量或模型分布。 | \(D_{\mathrm{KL}}(p\|q)\) |
| \(p_i,q_i\) | 读作 p sub i /piː sʌb aɪ/、q sub i /kjuː sʌb aɪ/;表示第 \(i\) 个类别或事件的概率。 | \(H(p)=-\sum_i p_i\log p_i\) |
| \(p(x)\)、\(q(x)\) | 读作 p of x /piː əv ɛks/、q of x /kjuː əv ɛks/;表示事件 \(x\) 在不同分布下的概率或密度。 | \(\log\frac{p(x)}{q(x)}\) |
| \(p(x,y)\) | 读作 p of x comma y /piː əv ɛks ˈkɑːmə waɪ/;表示联合分布。 | \(I(X;Y)=D_{\mathrm{KL}}(p(x,y)\|p(x)p(y))\) |
| \(p(y|x)\)、\(q_\theta(y|x)\) | 读作 p of y given x /piː əv waɪ ˈɡɪvən ɛks/;表示条件分布。带 \(\theta\) 的 \(q_\theta\) 常表示参数化模型分布。 | \(q_\theta(y|x)\) |
| \(p^*(\tau)\) | 读作 p star of tau /piː stɑːr əv taʊ/;常表示目标分布、最优分布或由奖励诱导出的理想轨迹分布。 | \(p^*(\tau)\propto \exp(R(\tau)/\alpha)\) |
| \(q_\pi(\tau)\) | 读作 q sub pi of tau /kjuː sʌb paɪ əv taʊ/;表示由策略 \(\pi\) 诱导出的轨迹分布。 | \(D_{\mathrm{KL}}(q_\pi(\tau)\|p^*(\tau))\) |
| \(\theta\) | 读作 theta /ˈθeɪtə/;常表示模型参数、待估计参数或高维参数向量。 | \(f_\theta(x)\) |
| \(\hat{\theta}\) | 读作 theta hat /ˈθeɪtə hæt/;表示参数估计值,常是 MLE 或 MAP 的最优解。 | \(\hat{\theta}_{\mathrm{MLE}}\) |
| \(\tilde{x}\) | 读作 x tilde /ɛks ˈtɪldə/;常表示经过变换、构造出来的辅助变量,或满足特殊条件的候选点,例如严格可行点。 | \(g_i(\tilde{x})<0\) |
| \(\mu\) | 读作 mu /mjuː/;常表示总体均值、高斯分布中心或期望位置。 | \(X\sim\mathcal{N}(\mu,\sigma^2)\) |
| \(\sigma\) | 读作 sigma /ˈsɪɡmə/;常表示标准差、尺度参数或高斯宽度。 | \(\sigma=\sqrt{\mathrm{Var}(X)}\) |
| \(\sigma^2\) | 读作 sigma squared /ˈsɪɡmə skwerd/;表示方差。 | \(X\sim\mathcal{N}(\mu,\sigma^2)\) |
| \(\mathcal{N}(\mu,\sigma^2)\) | 读作 normal of mu sigma squared /ˈnɔːrməl əv mjuː ˈsɪɡmə skwerd/;表示均值为 \(\mu\)、方差为 \(\sigma^2\) 的高斯分布(正态分布)。 | \(X\sim\mathcal{N}(170,6^2)\) |
| \(\pi\) | 读作 pi /paɪ/;在概率论里常表示成功概率,在强化学习里常表示策略。 | \(X\sim\mathrm{Bernoulli}(\pi)\);\(\pi(a|s)\) |
| \(\lambda\) | 读作 lambda /ˈlæmdə/;在优化里常表示拉格朗日乘子,在 Poisson 分布里常表示事件率参数。 | \(\mathcal{L}(x,\lambda)=f(x)+\lambda g(x)\);\(X\sim\mathrm{Poisson}(\lambda)\) |
| \(\nu\) | 读作 nu /njuː/;常表示对偶变量、等式约束乘子或辅助参数。 | \(\mathcal{L}(x,\lambda,\nu)\) |
| \(\alpha\) | 读作 alpha /ˈælfə/;常表示系数、温度、熵正则强度或显著性水平。 | \(p^*(\tau)\propto \exp(R(\tau)/\alpha)\) |
| \(\beta\) | 读作 beta /ˈbeɪtə/;常表示系数、权重或待估参数。 | \(y=\beta_0+\beta_1 x\) |
| \(\gamma\)、\(\eta\)、\(\xi\)、\(\phi\) | 读作 gamma /ˈɡæmə/、eta /ˈeɪtə/、xi /ksaɪ/、phi /faɪ/;这些希腊字母常用作常数、学习率、求和采样点、角度或中间变量。具体含义取决于上下文。 | \(H_n=\log n+\gamma+o(1)\);\(\theta\leftarrow\theta-\eta\nabla L(\theta)\);\(f(\xi_k)\Delta x_k\);\(e^{i\phi}\) |
| \(\varepsilon\)、\(\epsilon\) | 读作 epsilon /ˈɛpsɪlɒn/;常表示很小的正数、误差项、扰动或容差。 | \(y=f(x)+\varepsilon\) |
| \(\delta\)、\(\Delta\) | 读作 delta /ˈdɛltə/;小写常表示极限与连续中的邻域半径,大写常表示有限变化量。 | \(0<|x-a|<\delta\);\(\Delta x\) |
| \(\tau\) | 读作 tau /taʊ/;常表示轨迹、路径或时间展开后的完整序列。 | \(R(\tau)\) |
| \(\Omega\) | 读作 omega /oʊˈmeɪɡə/;常表示样本空间、全集或事件空间。 | \(\omega\in\Omega\) |
| \(\infty\) | 读作 infinity /ɪnˈfɪnəti/;表示无穷、极限发散方向,或某个量没有上界。 | \(\sum_{n=1}^{\infty}a_n\);\(D_{\mathrm{KL}}(p\|q)=+\infty\) |
| \(\mathcal{D}\) | 读作 calligraphic D /ˌkælɪˈɡræfɪk diː/;常表示数据分布、训练分布或样本集合。 | \((x,y)\sim\mathcal{D}\) |
| \(\mathcal{L}\) | 读作 calligraphic L /ˌkælɪˈɡræfɪk ɛl/;常表示损失函数或拉格朗日函数。 | \(\mathcal{L}(\theta)=-\log q_\theta(y|x)\) |
| \(\mathbb{E}\) | 读作 expectation /ˌɛkspɛkˈteɪʃən/;表示期望,即按某个分布加权后的平均。 | \(\mathbb{E}[X]\) |
| \(\bar{x}\) | 读作 x bar /ɛks bɑːr/;常表示样本均值。 | \(\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_i\) |
| \(\mathrm{Var}(X)\) | 读作 variance of X /ˈvɛəriəns əv ɛks/;表示随机变量的方差。 | \(\mathrm{Var}(X)=\mathbb{E}[(X-\mathbb{E}[X])^2]\) |
| \(\mathrm{Cov}(X,Y)\) | 读作 covariance of X and Y /koʊˈvɛəriəns əv ɛks ænd waɪ/;表示两个随机变量的协方差,用来描述它们是否倾向同向变化。 | \(\mathrm{Cov}(X,Y)=\mathbb{E}[(X-\mu_X)(Y-\mu_Y)]\) |
| \(\Sigma\) | 读作 capital sigma /ˈkæpɪtəl ˈsɪɡmə/;常表示协方差矩阵。 | \(\Sigma=\mathbb{E}[(\mathbf{x}-\mu)(\mathbf{x}-\mu)^\top]\) |
| \(\Lambda\) | 读作 capital lambda /ˈkæpɪtəl ˈlæmdə/;在线性代数里常表示由特征值组成的对角矩阵。 | \(A=Q\Lambda Q^\top\) |
| \(\sigma(A)\) | 读作 spectrum of A /ˈspɛktrəm əv eɪ/;表示矩阵 \(A\) 的谱,也就是全部特征值组成的集合。 | \(\rho(A)=\max_{\lambda\in\sigma(A)}|\lambda|\) |
| \(|\cdot|\) | 读作 absolute value /ˈæbsəluːt ˈvæljuː/;表示绝对值或标量大小。 | \(|x-a|\) |
| \(\mid\)、\(|\) | 读作 given /ˈɡɪvən/;在概率和条件分布里表示“在……条件下”。正文里 \(P(A|B)\) 与 \(P(A\mid B)\) 是同一种读法。 | \(P(A|B)\);\(p(y\mid x)\) |
| \(\|\cdot\|_0\)、\(\|\cdot\|_1\)、\(\|\cdot\|_2\) | 读作 L-zero /ɛl ˈzɪəroʊ/、L-one /ɛl wʌn/、L-two /ɛl tuː/;表示不同范数或准范数。 \(L_0\) 常表示非零元素个数, \(L_1\) 表示绝对值和, \(L_2\) 表示欧氏长度。 | \(\|\mathbf{x}\|_2\);\(\|\mathbf{x}\|_1\) |
| \(\cdot\) | 读作 dot /dɒt/;常表示点积或普通乘法。 | \(\mathbf{x}\cdot\mathbf{y}\) |
| \(\frac{a}{b}\)、\(\sqrt{x}\) | 读作 a over b /eɪ ˈoʊvər biː/、square root of x /skwer ruːt əv ɛks/;分别表示分式和平方根。 \(\frac{\cdot}{\cdot}\) 在概率、梯度、归一化和注意力缩放里都非常常见, \(\sqrt{\cdot}\) 则常出现在方差、范数和 \(1/\sqrt{d_k}\) 这类缩放因子里。 | \(\frac{\partial f}{\partial x}\);\(\frac{QK^\top}{\sqrt{d_k}}\) |
| \(\circ\)、\(\odot\) | 读作 composition /ˌkɒmpəˈzɪʃən/、Hadamard product /ˈhædəmɑːrd ˈprɒdʌkt/;前者常表示函数复合,也可在角度里作度数记号,后者表示逐元素乘法。 | \((f\circ g)(x)=f(g(x))\);\(X\odot M\) |
| \(^\top\) | 读作 transpose /trænˈspoʊz/;表示转置。 | \(A^\top\) |
| \(^{-1}\) | 读作 inverse /ɪnˈvɝːs/;表示逆矩阵、逆元素或倒数。 | \(A^{-1}\) |
| \(\det\) | 读作 determinant /dɪˈtɝːmɪnənt/;表示行列式。 | \(\det(A)\) |
| \(\mathrm{rank}\) | 读作 rank /ræŋk/;表示矩阵的秩。 | \(\mathrm{rank}(A)=1\) |
| \(\mathrm{tr}\) | 读作 trace /treɪs/;表示矩阵的迹。 | \(\mathrm{tr}(A)\) |
| \(\nabla\) | 读作 nabla /ˈnæblə/;表示梯度算子。 | \(\nabla f(\mathbf{x})\) |
| \(\nabla^2\) | 读作 nabla squared /ˈnæblə skwerd/;表示二阶导算子,常对应 Hessian 或 Laplacian 语境。 | \(\nabla^2 f(\mathbf{x})\) |
| \(\partial\) | 读作 partial /ˈpɑːrʃəl/;偏导符号。 | \(\frac{\partial f}{\partial x}\) |
| \(\sum\) | 读作 summation /səˈmeɪʃən/ 或 sum /sʌm/;表示求和。 | \(\sum_{i=1}^{n}x_i\) |
| \(S_n\)、\(H_n\) | 读作 S sub n /ɛs sʌb ɛn/、H sub n /eɪtʃ sʌb ɛn/;常分别表示前 \(n\) 项和与第 \(n\) 个调和数。 | \(S_n=\sum_{k=1}^{n}a_k\);\(H_n=\sum_{k=1}^{n}\frac{1}{k}\) |
| \(\prod\) | 读作 product /ˈprɒdʌkt/;表示连乘。 | \(\prod_{i=1}^{n}a_i\) |
| \(\times\)、\(\pm\) | 读作 times /taɪmz/、plus or minus /plʌs ɔːr ˈmaɪnəs/;分别表示乘号,以及“正负两种可能”或围绕中心的对称区间。 | \(0.99\times 0.01\);\(\mu\pm 2\sigma\) |
| \(\int\) | 读作 integral /ˈɪntɪɡrəl/;表示积分。 | \(\int_a^b f(x)\,dx\) |
| \(\lim\) | 读作 limit /ˈlɪmɪt/;表示极限。 | \(\lim_{h\to 0}\frac{f(x+h)-f(x)}{h}\) |
| \(\rho\) | 读作 rho /roʊ/;常表示半径、谱半径,或某个由极限定义出来的关键标量。 | \(\rho(A)=\max_{\lambda\in\sigma(A)}|\lambda|\) |
| \(\log\)、\(\ln\) | 读作 log /lɒɡ/、ell-en /ˌɛlˈɛn/;分别表示对数和自然对数。 | \(-\log q_{c^*}\);\(\ln x\) |
| \(\exp\) | 读作 exponential /ˌɛkspoʊˈnɛnʃəl/;表示指数函数,等价于以 \(e\) 为底的指数映射。 | \(\exp(R(\tau)/\alpha)\) |
| \(\sin\)、\(\cos\)、\(\tan\) | 读作 sine /saɪn/、cosine /ˈkoʊsaɪn/、tangent /ˈtændʒənt/;表示三角函数。 | \(\sin x\);\(\cos x\) |
| \(\min\)、\(\max\)、\(\arg\min\) | 读作 minimum /ˈmɪnɪməm/、maximum /ˈmæksɪməm/、arg min /ɑːrɡ mɪn/;分别表示最小值、最大值和使目标最小的自变量。 | \(\hat\theta=\arg\min_\theta \mathcal{L}(\theta)\) |
| \(\mapsto\)、\(\leftarrow\)、\(\leftrightarrow\) | 读作 maps to /mæps tuː/、is updated to /ɪz ʌpˈdeɪtɪd tuː/、corresponds to each other /ˌkɒrəˈspɒndz tuː iːtʃ ˈʌðər/;分别表示映射到、赋值/更新方向,以及双向对应或互换关系。 | \(x\mapsto f(x)\);\(\theta\leftarrow\theta-\eta\nabla L(\theta)\);\(A_{ij}\leftrightarrow A_{ji}\) |
| \(\ell\)、\(\ell(\cdot,\cdot)\) | 读作 ell /ɛl/;常表示损失函数,也常出现在 \(\ell_1\)、\(\ell_2\) 这类范数记号里。 | \(\min_{\theta}\frac{1}{m}\sum_{i=1}^{m}\ell(f_\theta(x^{(i)}),y^{(i)})\) |
| \(\in\)、\(\sim\)、\(\to\) | 读作 in /ɪn/、distributed as /dɪˈstrɪbjuːtɪd æz/、tends to /tɛndz tuː/;分别表示“属于”“服从某分布”“趋向于”。 | \(x\in\mathbb{R}\);\(X\sim\mathcal{N}(\mu,\sigma^2)\);\(h\to 0\) |
| \(\forall\)、\(\exists\) | 读作 for all /fɔːr ɔːl/、there exists /ðer ɪɡˈzɪsts/;分别表示“对所有”和“存在至少一个”,常用于定义、极限和约束条件。 | \(\forall \varepsilon > 0,\ \exists \delta > 0\) |
| \(\Rightarrow\)、\(\Leftrightarrow\) | 读作 implies /ɪmˈplaɪz/、if and only if /ɪf ænd ˈoʊnli ɪf/;分别表示“推出”和“当且仅当”,后者说明两边是双向等价。 | \(ab=0\Rightarrow a=0\ \text{或}\ b=0\);\(x\ge 1\Leftrightarrow 1-x\le 0\) |
| \(\le\)、\(\ge\)、\(\ne\)、\(\approx\) | 读作 less than or equal to /lɛs ðæn ɔːr ˈiːkwəl tuː/、greater than or equal to /ˈɡreɪtər ðæn ɔːr ˈiːkwəl tuː/、not equal to /nɒt ˈiːkwəl tuː/、approximately /əˈprɒksɪmətli/。 | \(g(x)\le 0\);\(x\ne y\);\(f(x)\approx g(x)\) |
| \(\ll\)、\(\gg\) | 读作 much less than /mʌtʃ lɛs ðæn/、much greater than /mʌtʃ ˈɡreɪtər ðæn/;表示数量级上的显著小于或显著大于,不只是普通不等号。在模型结构、复杂度和缓存分析里,它常用来表达“一个量相对另一个量小得多”。 | \(1<n_{\text{kv}}\ll n_q\);\(d_{\text{model}}\gg 1\) |
| \(\propto\) | 读作 proportional to /prəˈpɔːrʃənəl tuː/;表示“正比于”,通常意味着还差一个与当前变量无关的归一化常数或比例常数。 | \(p^*(\tau)\propto \exp(R(\tau)/\alpha)\) |
| \(\succ\)、\(\succeq\) | 读作 is positive definite /ɪz ˈpɒzətɪv ˈdɛfɪnɪt/、is positive semidefinite /ɪz ˈpɒzətɪv ˌsɛmiaɪˈdɛfɪnɪt/;在线性代数和优化里分别表示正定与半正定矩阵关系。 | \(A\succ 0\);\(\Sigma\succeq 0\) |
| \(H(p)\)、\(H(Y|X)\) | 读作 entropy of p /ˈɛntrəpi əv piː/、conditional entropy /kənˈdɪʃənəl ˈɛntrəpi/;表示熵和条件熵。 | \(H(p)=-\sum_i p_i\log p_i\) |
| \(I(X;Y)\) | 读作 mutual information /ˈmjuːtʃuəl ˌɪnfərˈmeɪʃən/;表示 \(X\) 与 \(Y\) 共享的信息量。 | \(I(X;Y)=H(Y)-H(Y|X)\) |
Leave a Reply