Docker学习笔记
Docker是一个容器化软件,所谓容器化即操作系统级别的虚拟化(Operating-system-level virtualization)。比起硬件虚拟化:
- 容器更加轻量,它不需要运行独立操作系统,因而减少了磁盘(操作系统文件占用GB+空间)、CPU(进程调度、硬件模拟等额外消耗)等基础资源的消耗,可扩容性更强
- 容器性能更高,虚拟硬件导致的低性能问题不复存在
- 容器启动非常迅速(小于1秒),普通VM启动时间可能需要1分钟
- 更加适合部署松耦合、分布式、弹性的微服务
容器化软件允许在同一个操作系统内核下存在多个相互隔离的用户空间实例,这些实例即被称为容器(Container)。从这些容器的所有者/用户的角度来看,它们就像是一个独立的服务器一样。除了隔离机制之外,容器化软件通常提供资源管理功能,限制一个容器的活动对其它容器的影响。
内核中用于支持容器化的特性:
- 名字空间机制,用于实现容器的隔离。名字空间包括:
- pid名字空间,不同空间中的PID可以重复
- net名字空间,管理多个网络协议栈的实例
- ipc名字空间,管理和访问IPC资源
- mnt名字空间,管理文件系统的挂载点
- 控制组(Cgroups),用于控制容器的资源用量
- UnionFS,联合文件系统
构建(Build)、分发(Ship)、运行(Run)是Docker提出的宣传口号,它的目标就是高效的完成这三件事,提高开发、测试、运维的效率:
- Docker将应用程序和它的运行环境(例如依赖、库)打包到一起,屏蔽不同运行环境的差异,实现可移植部署
- Docker让应用程序在一个被隔离的容器中运行,多个应用程序可以依赖相互冲突的库却不相互干扰(尽管它们运行在单个内核中)
下图阐述了Docker和硬件虚拟化的区别:
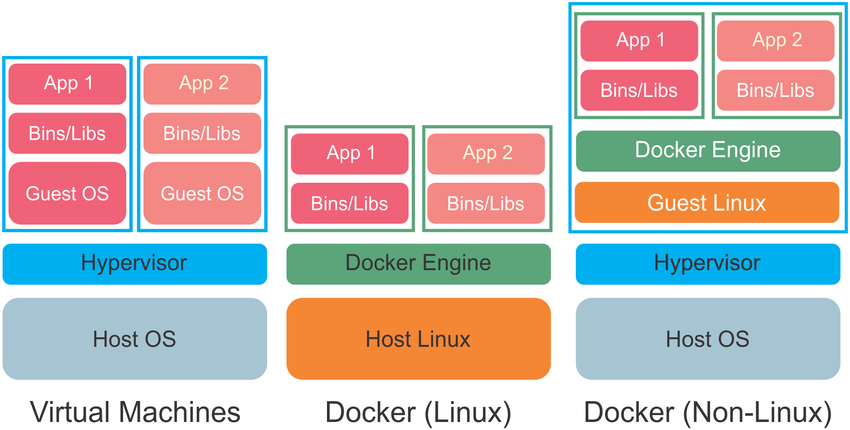
从用户的角度来看,使用Docker的典型工作流如下:
- 将应用程序代码及其依赖纳入到Docker容器中
- 编写一个Dockerfile,描述执行环境,并拉取代码
- 如果应用程序依赖于外部应用(例如MySQL、Redis),你需要在某个仓库(例如Docker Hub)中找到它们。某些收费的外部应用可以在Docker Store中找到
- 在Docker Compose file中引用应用程序,以及上面的那些外部应用,让他们能够同时运行
- 利用Docker Machine,在一个虚拟主机上构建、运行你的容器
- 如果需要,为你的解决方案配置网络、存储
- 可选的,上传你的构建结果到仓库(私有、Docker官方),与团队成员协作
- 如果出现扩容(scale)需求,考虑使用Swarm集群,通过Universal Control Plane你可以方便的管理Swarm集群
- 最终,利用Docker Cloud将容器镜像部署到自有服务器或者云上
| 概念 | 说明 |
| Dockerfile | 一段文本,Docker读取其中的指令以便自动化的构建Docker镜像。你可以在Dockerfile中声明任何命令 |
| Docker Compose | 一个工具,用来定义多容器(Multi-container)的Docker应用程序。你可以编写Composefile,来配置你的应用程序所依赖的服务,并通过单个命令来启动所有这些服务 |
| Docker Engine |
Docker的核心组件,它负责创建Docker镜像、运行Docker容器 包括三个组件:
|
| Docker Image |
Docker镜像是一个文件系统 + 参数集,供Docker运行容器时使用。镜像本身不包含状态 任何人可以通过Docker镜像的方式来创建、分享软件 首次使用镜像时,会从仓库下载,之后,除非镜像的源码改变,不会再次下载 |
| Layer |
层,或者叫镜像层(Image layer),是指对镜像的一个变更,或者指一个中间镜像(intermediate image)。之所以叫层,和UFS(联合文件系统)有关,UFS允许:其包含的文件和目录可以分布在多个其它文件系统中,这些文件/目录(称为Branches)可以被叠加(overlay)形成单个新的文件系统 在Dockerfile中指定的指令,例如FROM/RUN/COPY,会导致先前的镜像发生变化,因而导致创建新的层 层有利于缩短构建的时间,Dockerfile发生变化后,变化之前的中间镜像不需要重新构建,可以作为缓存使用 |
| Docker Container |
Docker容器是Docker镜像的运行时实例 容器的行为取决于镜像如何被配置,可能是简单的执行一条命令,也可能是启动数据库这样的复杂服务 |
| Docker Hub |
一种服务,用于构建、管理镜像。其角色类似于Maven仓库或者PyPI 在Docker Hub上你可以很轻松下载到大量已经容器化的应用镜像,即拉即用。这些镜像中,有些是Docker官方维护的,更多的是众多开发者自发上传分享的 你可以将Github账号绑定到Docker Hub账号,并配置自动生成镜像的功能。这样,当Github中代码更新时,Docker镜像会自动更新 |
| Docker Trusted Registry | DTR,企业级的Docker镜像存储方案,其角色类似于Docker Hub的私服 |
| Docker Cloud | 一种服务,能够构建、测试、部署镜像到你的主机上 |
| Docker Universal Control Plane | UCP,管理Docker宿主机的集群,让它们整体上表现的像是单台机器 |
| Docker Machine | 一个工具,使用它你可以:
当前,只有通过Docker Machine,你才能在Mac或者Windows上运行Docker。同时它也是管理大量基于各种Linux变体的宿主机的便捷方法 |
| libcontainer | 封装了名字空间、控制组、UnionFS的库,提供容器运行时基础功能 |
本章主要介绍Ubuntu 14.04 LTS下安装、配置Docker的步骤。
你需要安装64bit的操作系统,内核的最低版本是3.10。为了支持aufs存储驱动,最好安装额外的内核包:
|
1 2 |
sudo apt-get update sudo apt-get install linux-image-extra-$(uname -r) linux-image-extra-virtual |
添加Docker项目的APT源:
|
1 2 3 4 5 6 |
sudo echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" > /etc/apt/sources.list.d/docker.list # 添加GPG Key sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D sudo apt-get update # 可以查看当前系统支持的Docker引擎版本 apt-cache policy docker-engine |
安装Docker引擎并启动Docker守护程序:
|
1 2 |
sudo apt-get install docker-engine sudo service docker start |
验证安装是否成功:
|
1 2 3 4 5 6 7 |
# 通知Docker引擎,将hello-world镜像载入到新建的容器中 docker run hello-world # 执行下面的命令显示系统中容器的列表 docker ps -a # 执行下面的命令显示系统中镜像的列表 docker images |
上述命令将下载一个测试目的的Docker镜像,并在一个容器中运行。该镜像会打印一条消息,然后退出。
执行下面的命令,来升级或者删除Docker:
|
1 2 3 4 5 6 7 8 |
# 升级 sudo apt-get upgrade docker-engine # 删除 sudo apt-get purge docker-engine sudo apt-get autoremove --purge docker-engine # 上面的命令不会删除镜像、容器、卷或者用户创建的配置文件,你需要手工删除: rm -rf /var/lib/docker |
Docker最初是为Linux开发的,在Windows/Mac系统中,你可以借助Docker Machine来运行Docker。
从1.13开始,Windows和Mac具有基于原生虚拟化机制的Docker实现,不再依赖于Docker Machine。在Windows下,Docker基于Microsoft Hyper-V;在Mac下则基于HyperKit。
为Bash添加自动完成支持:
|
1 2 |
brew install bash-completion brew tap homebrew/completions |
在.bash_profile中添加:
|
1 2 3 |
if [ -f $(brew --prefix)/etc/bash_completion ]; then . $(brew --prefix)/etc/bash_completion fi |
添加Docker的自动完成脚本:
|
1 2 3 4 |
pushd /usr/local/etc/bash_completion.d ln -s /Applications/Docker.app/Contents/Resources/etc/docker.bash-completion ln -s /Applications/Docker.app/Contents/Resources/etc/docker-machine.bash-completion ln -s /Applications/Docker.app/Contents/Resources/etc/docker-compose.bash-completion |
执行一些必要的配置,可以让Ubuntu和Docker更好的一起工作。Docker配置文件默认为/etc/default/docker。
Docker的守护程序绑定到Unix套接字(而不是TCP/IP套接字)。默认的,该套接字的所有者是root,其它用户要访问它必须sudo。为此,Docker守护程序总是以root身份运行。
为了避免在调用 docker 命令时必须sudo,可以创建一个名为docker的UNIX组,并把你的用户添加到该组中。Docker守护程序启动时会为该组赋予读写权限
执行以下命令:
|
1 2 3 |
sudo groupadd docker sudo usermod -aG docker $USER # 用户$USER需要重新登录 |
当运行Docker时,你可能会看到类似下面的消息:
|
1 2 |
WARNING: Your kernel does not support cgroup swap limit. WARNING: Yourkernel does not support swap limit capabilities. Limitation discarded. |
在主机上启用内存和swap审计,可以避免该消息:
- 修改
/etc/default/grub ,设置内核选项:
1GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1" - 更新GRUB: sudo update-grub
- 重新启动系统
注意:启用后,即使不使用Docker,也会消耗额外1%左右的内存、降低10%左右的性能。
如果在Docker的宿主机上使用UFW,你需要额外的配置——由于UFW的默认行为是丢弃所有转发(路由)包,这会导致Docker无法正常工作。执行以下修改:
- 修改配置文件/etc/default/ufw,设置 DEFAULT_FORWARD_POLICY="ACCEPT"
- 重新加载配置文件: sudo ufw reload
- 允许针对Docker的入站连接: sudo ufw allow 2375/tcp
Ubuntu及其衍生的桌面版Linux,通常会自动设置/etc/resolv.conf,将127.0.0.1作为默认DNS,同时网络管理器启用dnsmasq,将DNS请求代理给真实的DNS服务器
在这样的配置下,启动Docker容器会导致如下警告:
|
1 2 |
WARNING: Local (127.0.0.1) DNS resolver found in resolv.conf and containers can't use it. Using default external servers : [8.8.8.8 8.8.4.4] |
出现此错误是因为Docker容器不能使用本地DNS服务器127.0.0.1,因此它默认使用了谷歌的DNS服务器
要避免此警告,依次执行:
- 修改 /etc/default/docker 设置 DOCKER_OPTS="--dns 10.0.0.1" ,其中10.0.0.1替换为你的内网DNS服务器。注意 --dns 选项可以指定多次,对应多个备选DNS服务器
- 重新启动Docker守护程序: sudo service docker restart
你也可以修改网络管理器配置,/etc/NetworkManager/NetworkManager.conf,禁用dnsmasq:
|
1 2 |
# 注释掉: dns=dnsmasq |
14.10以下的版本,已经自动通过upstart配置Docker为自启动。15.04版本开始,Ubuntu使用systemd作为启动/服务管理器,你需要执行:
|
1 |
sudo systemctl enable docker |
默认情况下,Docker将/var/lib/docker作为基目录,并在其子目录下存储下载的镜像,以及运行过的容器,可以为Docker序指定选项-g以改变基目录:
|
1 |
DOCKER_OPTS=" -g /home/alex/Vmware/docker" |
你也可以使用符号链接来改变镜像的位置。
国内访问Docker Hub比较缓慢,可以使用DaoCloud提供的Mirror(需要1.3.2+)。注册DaoCloud的账号后,进入仪表盘页面,点击“加速器”链接,在新的页面上会显示类似下面的命令:
|
1 |
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://0aa2e1e9.m.daocloud.io |
以root身份执行上面的命令后,文件/etc/docker/daemon.json被修改,添加以下内容:
|
1 |
{"registry-mirrors": ["http://0aa2e1e9.m.daocloud.io"]} |
你也可以手工修改/etc/default/docker文件,设置DOCKER_OPTS,追加:
|
1 |
DOCKER_OPTS= " --registry-mirror http://0aa2e1e9.m.daocloud.io" |
此外,也可以注册阿里云开发者账号,获得自己的Mirror URL。
默认的,当Docker守护程序退出时,所有正在运行的容器被自动关闭。自1.12开始,你可以配置守护程序,让容器在守护程序退出后保持运行状态。
要启用该特性,可以使用选项 sudo dockerd --live-restore ,或者在/etc/docker/daemon.json中配置:
|
1 2 3 |
{ "live-restore": true } |
该特性于Swarm模式不兼容。
whalesay是Docker官方提供的一个学习用镜像,运行此镜像,可以在屏幕上显示一头鲸和一句话:
|
1 2 3 |
# docker/whalesay为镜像名 # cowsay为执行的命令,boo-boo为命令行参数,即鲸说的那句话 docker run docker/whalesay cowsay boo-boo |
本节我们以whalesay镜像为基础,学习创建自己的Docker镜像
在前面的章节我们提到过,Dockerfile用于描述镜像如何被构建。创建镜像的第一步就是编写Dockerfile。
新建一个目录作为构建镜像的上下文目录,所谓上下文目录,意味着构建过程所需的全部文件都位于其中:
|
1 2 3 4 |
mkdir mywhalesay cd mywhalesay touch Dockerfile |
编辑Dockerfile文件,添加以下内容:
|
1 2 3 4 5 6 7 8 9 |
# FROM关键字说明当前镜像基于哪个镜像来构建 FROM docker/whalesay:latest # RUN关键字用于在构建时执行任意命令,这里安装fortunes,能够随机的输出名人名言 # 能够正常使用apt-get是因为docker/whalesay FROM ubuntu:14.04 RUN apt-get -y update && apt-get install -y fortunes # CMD关键字用来指定镜像被加载后执行的命令,现在这头鲸会自顾自的引用名言了 CMD /usr/games/fortune -a | cowsay |
在上下文执行下面的命令以构建镜像:
|
1 |
docker build -t mywhalesay . |
构建过程中控制台会打印详细过程,说明如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 发送构建上下文给守护程序检查,确保构建需要的文件完备 # Sending build context to Docker daemon 2.048 kB # 第一步,加载镜像docker/whalesay到临时容器,后续RUN关键字就是在修改此容器 Step 1 : FROM docker/whalesay:latest ---> 6b362a9f73eb # 这里显示的是镜像ID # 第二步,在临时容器中运行命令,安装新软件,这导致容器的文件系统发生改变,与其镜像变得不同 Step 2 : RUN apt-get -y update && apt-get install -y fortunes ---> Running in f8c9dec97efc # 这里显示的是容器ID Processing triggers for libc-bin (2.19-0ubuntu6.6) ... ---> 17c653933644 # 移除前面的临时容器 Removing intermediate container f8c9dec97efc # 第三步,固化前面临时容器对docker/whalesay的改变,作为新的镜像fd35a325caf4 # 创建新的临时容器,尝试运行CMD关键字指定的命令 Step 3 : CMD /usr/games/fortune -a | cowsay ---> Running in 8ae48258f958 ---> fd35a325caf4 # 新的镜像 Removing intermediate container 8ae48258f958 # 构建完毕 Successfully built fd35a325caf4 |
构建过程不会对上下文目录进行修改,构建好的镜像自动存放到/var/lib/docker目录下。可以运行命令查看:
|
1 2 3 4 |
docker images # REPOSITORY TAG IMAGE ID CREATED SIZE # mywhalesay latest c779eaff986e 2 minutes ago 275 MB # docker/whalesay latest 6b362a9f73eb 17 months ago 247 MB |
好了,看看这头智慧鲸都说了些什么吧:
|
1 |
docker run mywhalesay |
首先你需要注册一个账号, 然后创建一个仓库(Repository),这里的仓库类似于Git仓库,它以你的Docker Hub用户名作为默认的名字空间,例如gmemcc/mywhalesay。
标签(tag)是用于区分镜像变体的一种方法。
利用tag命令,你可以把一个本地镜像关联到Docker Hub仓库。首先,查询镜像的ID:
|
1 2 3 |
docker images # REPOSITORY TAG IMAGE ID CREATED SIZE # mywhalesay latest baa64efc0f1d 6 minutes ago 275 MB |
为之前构建的本地镜像mywhalesay打标签:
|
1 2 3 |
docker tag baa64efc0f1d gmemcc/mywhalesay:latest # 可以删除本地镜像 docker rmi -f baa64efc0f1d |
输入Docker Hub账号密码以登录:
|
1 |
docker login |
使用push子命令,可以把本地镜像推送到Docker Hub上的仓库中:
|
1 |
docker push gmemcc/mywhalesay |
推送完毕后,可以到仓库主页去看看Tags选项卡,会出现一个lastest标签。
在运行容器、构建镜像时,只要所需镜像在本地不存在,都会执行pull子命令拉取镜像。你也可以手工的拉取镜像:
|
1 |
docker pull gmemcc/mywhalesay |
为了方便企业内部Docker镜像的管理,你可以搭建Docker私服(registry server)。最简单的私服例子如下:
|
1 2 3 |
docker run -d -p 5000:5000 --restart=always -h registry --network local --dns 172.21.0.1 --ip 172.21.0.4 --name registry registry:2 # 如果宿主机是ARM平台,考虑使用镜像 budry/registry-arm # 否则你会收到错误 docker: no supported platform found in manifest list. |
现在,你可以从Docker Hub上拉取镜像,并tag到私服中:
|
1 2 |
docker pull ubuntu docker tag ubuntu localhost:5000/ubuntu |
然后,推送镜像到私服:
|
1 |
docker push localhost:5000/ubuntu |
之后,你可以再把镜像拉取下来:
|
1 |
docker pull localhost:5000/ubuntu |
默认情况下,私服中的数据存放在Docker卷中,此卷位于宿主机文件系统中。要改变存放位置,可以指定选项:
|
1 |
--volume /path/on/host:/var/lib/registry |
要想其它宿主机能访问私服,最好启用TLS,其配置类似于Web服务器的SSL配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 创建密钥对 openssl genrsa -out zircon.local.key 4096 openssl req -new -x509 -days 3650 -text -key zircon.local.key -out zircon.local.crt # 把证书复制到特定目录 mkdir -p /etc/docker/certs.d/docker.gmem.cc sudo cp zircon.local.crt /etc/docker/certs.d/zircon.local\:5000/domain.crt # 非本机: scp alex@zircon.local:~/Vmware/docker/registry/certs/zircon.local.crt /etc/docker/certs.d/zircon.local\:5000/domain.crt # 可选:全局启用证书 cp zircon.local.crt /usr/share/ca-certificates/ # 启用zircon.local的证书 sudo dpkg-reconfigure ca-certificates # 需要重启服务 sudo service docker restart # 重新运行私服 docker run -d -p 5000:5000 --restart=always --name registry \ -v /home/alex/Vmware/docker/registry/certs:/certs \ -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/zircon.local.crt \ -e REGISTRY_HTTP_TLS_KEY=/certs/zircon.local.key \ registry:2 |
这样,在网络中的机器都可以使用域名zircon.local代替localhost来访问私服了。
Mac版本的Docker目前无法访问自签名的私服,需要配置:
|
1 |
"insecure-registries":["zircon.local"] |
只需要注意把cert.pem、chain.pem合并到一起,作为证书即可:
|
1 2 3 4 5 |
cd /etc/letsencrypt/live/docker.gmem.cc/ cp privkey.pem domain.key cat cert.pem chain.pem > domain.crt chmod 777 domain.crt chmod 777 domain.key |
除了启用TLS,你可能还需要进行用户身份验证。首先,在宿主机上建立一个目录,并生成密码文件:
|
1 2 3 4 |
cd /home/alex/Vmware/docker/registry/ mkdir auth # 生成密码,输出到宿主机文件 docker run --entrypoint htpasswd registry:2 -Bbn user passwd > auth/htpasswd |
然后,运行私服:
|
1 2 3 4 5 6 7 8 9 |
docker run -d -p 5000:5000 --restart=always --name registry \ -v /home/alex/Vmware/docker/registry/auth:/auth \ -e "REGISTRY_AUTH=htpasswd" \ -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm" \ -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd \ -v /home/alex/Vmware/docker/registry/certs:/certs \ -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/zircon.local.crt \ -e REGISTRY_HTTP_TLS_KEY=/certs/zircon.local.key \ registry:2 |
现在你可以登录到私服了:
|
1 |
docker login docker.gmem.cc |
要运行容器,首先要获得相应的镜像。运行容器时,如果镜像在本地不存在,Docker会自动到仓库下载。默认的仓库是Docker Hub。执行docker run命令可以启动一个容器:
|
1 2 3 4 5 |
# 不指定tag,默认使用lastest docker run ubuntu # 指定tag docker run ubuntu:lastest docker run ubuntu:14.04 |
将镜像加载到容器中后,相当于得到一个预装了某些软件的操作系统。例如对于ubuntu镜像,你可以:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# 像使用普通虚拟机一样使用容器: # 调用echo命令 docker run ubuntu /bin/echo 'Hello world' # 交互式的命令行 # -t 在容器内分配Terminal或者伪TTY # -i 启动一个交互式的连接 docker run -t -i ubuntu /bin/bash # -d 在后台运行容器(daemonize)。启动后,Docker会输出当前容器的ID docker run -d ubuntu /bin/sh -c "while true; do echo hello world; sleep 1; done" # 216dd35d275a6c6e1e548232bdd9db7cab8a6b2f9078367a3c842762dc458c1a # 查看正在运行的容器,由于容器ID太长,难以记忆,因此Docker会为每一个容器生成一个名字,例如gloomy_bohr。这个名字可以修改 docker ps # CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES # 216dd35d275a ubuntu "/bin/sh -c 'while tr" 9 seconds ago Up 8 seconds gloomy_bohr # 查看所有已创建的容器,不管容器是否正在运行 docker ps --all # 指定容器名称,容器名称必须具有唯一性 docker run --name webserver training/webapp python app.py # 查看容器运行日志,打印标准输出 docker logs gloomy_bohr # 在任何时候,你可以附到一个运行中的容器,grab其标准输入/输出 docker attach gloomy_bohr # 停止容器。超时容器未停止,则发送SIGKILL信号 docker stop gloomy_bohr # 启动容器 docker start gloomy_bohr # 在一个正在运行的容器中执行命令 docker exec gloomy_bohr ping 8.8.8.8 # 连接到容器,交互式的执行命令 docker exec -it ubuntu-16.04 # 查看容器内运行的进程 docker top gloomy_bohr # 以JSON格式打印容器的详细配置信息 docker inspect gloomy_bohr # 删除容器 # -f 即使正在运行,也将容器删除 docker rm -f gloomy_bohr |
上面的每个docker命令调用,实际上都在使用Docker客户端。Docker是基于Go语言开发的,执行 version 子命令可以查看客户端、服务器的版本。
Docker的主要应用场景在服务器端,而后者运行的程序大多是网络应用。这里我们使用training/webapp这个镜像来说明如何在容器中运行Web服务器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# -P 自动将容器中的监听端口映射到宿主机的某个端口 docker run -d -P --name web training/webapp python app.py # 执行下面的命令查看端口如何映射 docker ps -l # PORTS 端口映射情况位于该列 # 0.0.0.0:32769->5000/tcp 宿主机的32769端口映射到容器的5000端口 # -p 手工指定端口映射,宿主机的80端口映射的哦容器的5000端口 docker run -d -p 80:5000 training/webapp python app.py # 查询端口映射 docker port hungry_payne 5000 # 查看Web应用日志 # -f的效果类似于tail -f docker logs -f hungry_payne |
利用网络驱动(network drivers) ,Docker为容器提供了网络支持。网络驱动主要有两类:bridge、overlay。默认随着Docker引擎一起安装了三个网络:
|
1 2 3 4 5 |
docker network ls # NETWORK ID NAME DRIVER SCOPE # f160b7cc8b94 bridge bridge local # fc47bb582730 host host local # 5ac20f3697f3 none null local |
除非明确指定,新启动的容器总是使用bridge这个网络。
执行network inspect子命令可以查看一个网络的详细信息,包括它为各连接到的容器分配的IP地址:
执行: docker network inspect bridge ,结果如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
[ { "Name": "bridge", "Id": "f160b7cc8b94b782e5fed8b2e50e72f14ad205917540b1dc464f509f7eb11dec", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.17.0.0/16", "Gateway": "172.17.0.1" } ] }, "Internal": false, /* 连接到此网络的容器的集合 */ "Containers": { "87afe74d233dcd2e6caf2d569c785b0457123d4ad25f1c1bd9850576ba3afd1c": { "Name": "web", "EndpointID": "e8a0db5f066fd13bc2cb432f375582cb92e445a982a0ed667d26d92adb19550f", "MacAddress": "02:42:ac:11:00:02", "IPv4Address": "172.17.0.2/16", "IPv6Address": "" } }, "Options": { "com.docker.network.bridge.default_bridge": "true", "com.docker.network.bridge.enable_icc": "true", "com.docker.network.bridge.enable_ip_masquerade": "true", "com.docker.network.bridge.host_binding_ipv4": "0.0.0.0", "com.docker.network.bridge.name": "docker0", "com.docker.network.driver.mtu": "1500" }, "Labels": {} } ] |
要把一个容器从网络中移除,可以执行:
|
1 2 |
# 把web从网络bridge中移除 docker network disconnect bridge web |
要创建一个简单的网络,可以执行:
|
1 |
docker network create -d bridge newbridge |
类似的,再不需要时,可以删除自定义网络:
|
1 |
docker network rm newbridge |
注意:名为bridge的默认网络不能被删除。
如果不希望容器使用默认网络,可以在运行容器的时候指定--network参数:
|
1 2 3 |
docker run -d --network=newbridge --name db training/postgres # 获得容器的IP地址 docker inspect --format='{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' db |
Docker允许在运行时将容器添加到任意多个网络:
|
1 |
docker network connect bridge db |
所谓数据卷(Data volumes),是一个或者多个容器中特定的目录,这些目录绕过容器的联合文件系统(UFS,可以将不同物理位置合并mount到Linux目录树的同一位置) ,数据卷的一系列特性有利于数据的持久化、共享:
- 数据卷在容器被创建时初始化,如果容器使用的基础镜像在数据卷的挂载点上包含数据,则这些数据被拷贝到新初始化的数据卷中。注意:当挂载宿主机目录作为数据卷时,拷贝行为不发生
- 数据卷可以被多个容器共享,或者被重用
- 对数据卷的更改是直接进行的
- 当你升级基础镜像时,对数据卷的修改不被包含其中
- 即使容器本身被删除,数据卷依然存在,数据卷独立于容器的生命周期
注意:作为挂载点的容器目录,其原有的文件全部不可见,不会进行Overlay。
要添加匿名数据卷,可以在启动容器时指定-v参数:
|
1 2 |
# 在容器的/webapp位置创建一个匿名数据卷 docker run -d -P --name web -v /webapp training/webapp python app.py |
在制作镜像时,你可以用VOLUME指令声明一个或者多个数据卷,任何基于此镜像的容器,自动添加这些数据卷。
匿名数据卷在宿主机上以目录的形式存在,要定位此目录,可以执行inspect子命令:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/* docker inspect web的部分输出 */ "Mounts": [ { "Name": "356707e2ddc02715db78b958b623707c2475f66258c14b68de48f0e29188bc0f", /* 在宿主机上的存放位置 */ "Source": "/mnt/c3d88ac1-b4d5-4cdd-86b4-4255aba9ddb1/docker/volumes/35670b68de.../_data", "Destination": "/webapp", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" } ] |
你也可以把任意宿主机目录挂载为数据卷,映射到容器的目录树中,仍然使用-v参数:
|
1 2 3 4 |
# 宿主机目录/src/webapp被挂载到容器的/webapp # 容器中的挂载点必须总是指定绝对路径 # 宿主机目录可以指定绝对路径,也可以指定一个名称,Docker引擎依据此名称创建/引用命名卷 docker run -d -P --name web -v /src/webapp:/webapp training/webapp python app.py |
上面的例子中,如果容器的基础镜像已经包含了/webapp目录,则它会被宿主机的/src/webapp覆盖,但是容器从基础镜像得到的/webapp中的内容不会被删除,一旦数据卷被卸载,则/webapp中的内容恢复原样。
挂载单个宿主机文件也被支持: -v ~/.bash_history:/root/.bash_history
除了挂载宿主机的本地目录,你也可以挂载共享存储为数据卷,Docker通过Volume plugins来支持iSCSI、NFS、FC等共享存储。使用共享存储的好处是它们是不依赖于主机的。
你可以在启动容器时,即时的在共享存储上创建命名卷(named volume):
|
1 2 3 4 |
# --volume-driver 指定卷驱动,可选 # my-named-volume为新创建的卷的名字 docker run -d -P --volume-driver=flocker -v my-named-volume:/webapp --name web training/webapp python app.py |
或者,先手工创建命名卷,然后引用命名卷:
|
1 2 |
docker volume create -d flocker -o size=20GB my-named-volume docker run -d -P -v my-named-volume:/webapp |
例子中的flocker是一个专为Docker设计的数据卷管理工具。flocker管理的数据卷可以位于集群中的任何主机上,而不是绑定到某台宿主机。
注意:
- 命名卷对应/var/lib/docker/volumes/my-named-volume/_data目录。该目录会自动创建
- 容器A、B共享一个命名卷,则A的写入B可以看到
- A使用 -v my-named-volume:/data,则data中原有(镜像自带)的文件可以在my-named-volume中看到
数据卷可以挂载为只读: -v /src/webapp:/webapp:ro #添加:ro后缀
可以参考下面的命令,来备份一个数据卷:
|
1 2 3 4 5 |
# --volumes-from 引用来自dbstore的数据卷/dbdata # -v 挂载宿主机当前目录到/backup # 容器启动后,使用tar命令,将/dbdata的内容压缩,存放到/backup,亦即宿主机的当前目录 # tar完成后,容器停止,备份完毕 docker run --rm --volumes-from dbstore -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /dbdata |
使用类似的方法,可以首先数据卷的恢复。 跨宿主机联用备份/恢复,可以实现数据卷迁移。
默认情况下,容器删除后,其挂载的数据卷会被保留。一般的,你可以指定:当容器被删除后,自动清理匿名卷:
|
1 2 3 |
# --rm示意自动清理匿名卷/foo # 挂载到/bar的命名卷awesone不会被清理 docker run --rm -v /foo -v awesome:/bar busybox top |
数据卷可以通过--volumes-from选项被其它容器引用,这种情况下,创建/引用数据卷的全部容器被删除之前,数据卷是无法删除的。要在删除容器时,同时删除数据卷,可以指定-v选项,例如
|
1 2 |
# 删除db3的同时,删除其使用的数据卷。注意,db3必须是最后一个使用它引用的所有数据卷的容器 docker rm -v db3 |
如果需要在多个容器之间共享持久化数据,或者期望在非持久化容器中使用持久化数据,最好的方法是创建命名数据卷容器——仅仅为了提供共享数据卷的容器,并在其中挂载数据卷供其它容器引用。
首先创建一个命名的容器,但是不需要它执行任何命令:
|
1 2 3 4 |
# 创建一个名为dbstore的容器,其包含一个数据卷/dbdata docker create -v /dbdata --name dbstore training/postgres /bin/true # 注意 -v 非常重要,如果不声明-v,则此容器的目录不会暴露出去 docker run -v /jdk --name jdk docker.gmem.cc/jdk:7u80 |
然后,你可以利用选项--volumes-from,在其它容器中挂载dbstore的/dbdata目录 :
|
1 2 3 |
docker run -d --volumes-from dbstore --name db1 training/postgres # 再创建一个容器,与db1共享来dbstore的/dbdata。两个容器的共享卷的挂载路径一致 docker run -d --volumes-from dbstore --name db2 training/postgres |
这样启动db1、db2后,如果postgres镜像包含/dbdata目录,它将被来自dbstore的数据卷mask掉,仅dbstore的/dbdata对于db1、db2可见。
选项--volumes-from 可以指定多次,这样你可以联合使用来自多个容器的数据卷。
选项--volumes-from可以通过链式的结构扩展——链条上的后面的容器可以使用前面任意容器声明的数据卷:
|
1 2 3 |
# 由于db1使用了dbstore的数据卷/dbdata # 因此db3也可以使用 docker run -d --name db3 --volumes-from db1 training/postgres |
注意,提供数据卷的容器不需要处于运行状态。
多个容器共享一个数据卷时,可能导致数据破坏,这是由并发的写操作导致的。并发写操作可能来自于容器或者宿主机。
所谓基本镜像(Base image),一般是指没有父镜像的镜像。此类镜像打包一个空白的操作系统。制作基本镜像的步骤依赖于你想打包的Linux发行版。
一般情况下,你可以在这样的Linux操作系统下完成基本镜像的创建——该操作系统就是你希望打包的Linux发行版。
某些工具可以简化镜像的创建,例如Debootstrap可以安装一个Debian/Ubuntu的基本操作系统到一个目录中。使用该工具的示例:
|
1 2 3 4 5 6 7 8 |
# 下载Ubuntu 16.04(xenial)基本操作系统到xenial目录 sudo debootstrap xenial xenial # tar -C切换工作目录 -c 创建压缩文件 # 压缩结果通过管道传递给docker import # import子命令创建一个空白文件系统镜像,然后把Tar的内容导入进去 # ubuntu:16.04 创建一个名为ubuntu的仓库,Tag为16.04 sudo tar -C xenial -c . | docker import - ubuntu:16.04 |
其它创建基本镜像的脚本,可以参考Create a base image
scratch是Docker保留的名称,它不是一个镜像,你也不能把任何仓库命名为scratch。scratch可以作为构建基本镜像的起点:
|
1 2 3 |
FROM scratch ADD hello / CMD ["/hello"] |
该主题包含以下关注点:
- 如何透明的依据体系结构,自动拉取镜像。这个需求可以通过镜像清单(Manifest)满足,清单包含同一功能的镜像(例如Alpine:3.10)对应到多个体系结构的版本。拉取镜像时,不管是什么平台,都使用alpine:3.10这个名字,Docker会自动拉取匹配体系结构的镜像
- 如何去构建其它体系结构的镜像,这个将是本节的主题
如果你使用了桌面版本的Docker,或者使用高于4.8+内核的Linux,你可以直接在x86_64的机器上,运行各种其它体系结构的镜像。
在Linux上启用Docker与QEMU集成的方式:
|
1 2 3 4 5 6 7 8 9 10 |
docker run --rm --privileged linuxkit/binfmt:v0.8 # 正常情况下,不会报错,并且 ls -1 /proc/sys/fs/binfmt_misc/qemu-* # 出现: # /proc/sys/fs/binfmt_misc/qemu-aarch64 # /proc/sys/fs/binfmt_misc/qemu-arm # /proc/sys/fs/binfmt_misc/qemu-ppc64le # /proc/sys/fs/binfmt_misc/qemu-riscv64 # /proc/sys/fs/binfmt_misc/qemu-s390x |
重启Docker守护进程后,可以看到默认Builder支持多种平台:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
docker buildx ls # BEFORE: # NAME/NODE DRIVER/ENDPOINT STATUS PLATFORMS # default * docker # default default running linux/amd64, linux/386 # AFTER: NAME/NODE DRIVER/ENDPOINT STATUS PLATFORMS default * docker default default running linux/amd64, linux/arm64, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/arm/v7, linux/arm/v6 |
这是一个Docker CLI插件,可以通过BuildKit进行Docker镜像的构建。使用buildx,你可以为不同体系结构构建镜像,并合并在一个镜像清单中,不需要作Dockerfile或源代码上的变动。
buildx把工作委托给builders:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 列出现有的builders docker buildx ls # 创建本地builder: docker buildx create --use --name local default # 注意,docker驱动使用守护进程中的代理设置,但是docker-container不使用。此外由于builder容器 # 不是CLI创建的,因此~/.docker下设置的代理也不会变为容器的环境变量 # 目前支持创建builder时指定代理设置 docker buildx create # 使用哪种驱动 # docker 使用编译到Docker守护进程中的BuildKit库,体验和原先的docker build相似 # docker-container 在容器中启动BuildKit # kubernetes --driver docker-container \ # 这些代理貌似也没什么价值,sh到builder容器中代理生效。但是Dockerfile中的命令,例如 # apk却不会使用这些代理,因此对构建过程没有价值 --driver-opt env.HTTP_PROXY=http://10.0.0.1:8088 \ --driver-opt env.HTTPS_PROXY=http://10.0.0.1:8088 \ --driver-opt network=host \ --driver-opt '"env.NO_PROXY='$NO_PROXY'"' \ --use --name proxied default # 添加远程builder: docker context create arm --docker "host=tcp://10.0.0.90:2376" docker context use arm docker buildx use arm # 切换使用的builder: docker buildx use default |
要使用buildx发起镜像构建,执行命令:
|
1 |
docker buildx build . |
buildx将使用BuildKit引擎进行构建,不需要设置 DOCKER_BUILDKIT=1环境变量。
buildx支持docker build的所有特性,包括19.03引入的输出配置、内联build缓存、指定目标platform。此外,buildx还支持manifest、分布式缓存、导出为OCI格式等docker build不支持的特性。
buildx可以在不同配置下运行,每个配置称为driver。默认使用编译到Docker守护进程中的BuildKit库,此驱动称为docker,该驱动使用你本地的Docker守护进程,并提供和docker build相似的体验。此外,你还可以使用docker-container驱动,它在容器中启动BuildKit。
驱动docker的输出,自动在docker images列表中可见。对于其它驱动,输出到何处需要 --output来指定。
通过创建新的builder实例,可以得到隔离的构建环境(不改变共享的Docker守护进程的状态),在CI中较为有用。 你甚至可以在远程Docker守护进程上创建多个builder,形成builder farm,并随意在这些builder之间切换。
Docker 19.03引入了类似Kubectl的context特性,可以为一个远程Docker守护进程的API端点提供一个名称。对于每个context,buildx会生成一个默认的builder实例。
|
1 |
docker buildx build --platform linux/amd64,linux/arm64 . |
执行命令: docker buildx install,则docker build命令变为docker buildx的别名,这就意味着docker build自动使用docker buildx进行构建。
执行 docker buildx uninstall移除别名。
Docker读取Dockerfile中的指令以构建新的镜像,Dockerfile中的指令说明了镜像应该如何一步步的被构建。
执行 docker build 命令,可以从一个Dockerfile、一个上下文构建镜像。构建过程是由Docker守护程序(而不是客户端)执行的,客户端(docker build命令)做的第一件事情就是把整个上下文发送给守护程序。
所谓上下文,是指定PATH(宿主机本地目录)或者URL(Git存储库)中的文件集合。上下文会被递归的处理,即子目录被包含在上下文中。在大部分情况下,最好将空白目录作为上下文,其中仅包含一个Dockerfile和构建过程必备的文件。
要使用上下文中的文件,你必须编写特定的指令,例如COPY。你可以在上下文目录中添加一个 .dockerignore 来排除某些文件、目录以提高构建性能。
按照约定,在上下文根目录中的名为Dockerfile的文件被作为“Dockerfile”,但是你可以指定任意文件作为“Dockerfile”:
|
1 |
docker build -f /path/to/a/Dockerfile . |
你可以为正在构建的镜像指定仓库(Repository):标签(tag),如果构建成功,镜像将被存放到相应的仓库:标签:
|
1 2 3 |
docker build -t gmemcc/myapp . # 指定多个仓库/标签也是允许的 docker build -t gmemcc/myapp:1.0.2 -t gmemcc/myapp:latest . |
Docker守护程序会逐条的执行Dockerfile中的指令,如果必要,将指令的执行结果提交到正在构建的那个新的镜像中去。在最终输出镜像ID之前,守护程序会自动清理客户端发送的上下文。
需要注意的是,每条指令都是独立的执行的,因此 RUN cd /tmp 这样的指令不会对下一条指令的“工作目录”产生影响。
为了提高构建的性能,Docker会重用中间的(intermediate )镜像(所谓缓存)。当使用缓存时,Docker会在控制台打印 Using cache 字样。
Dockerfile中只有注释、指令两类元素:
|
1 2 |
# Comment INSTRUCTION arguments |
指令名称大小写不敏感,通常使用全大写。第一条指令必须是FROM,指定基础镜像。 以#开头的行通常被作为注释看待,除非它是合法的解析器指令(parser directive)。
解析器指令(directive)影响Dockerfile中其它行的处理方式,该指令不会增加额外的层,也不会显示为构建步骤。
解析器指令的语法类似于一种特殊的注释: # directive=value ,单个指令仅能被使用一次。一旦处理过任何注释、空行、指令(instruction),Docker就不再尝试分析任何解析器指令,因此解析器指令必须位于Dockerfile的最开始处。
解析器指令同样是大小写不敏感的,但是通常都使用全小写。在解析器指令之后,通常留有空白行。编写解析器指令时不得使用行连接符(\)
目前支持的解析器指令包括:
| 解析器指令 | 说明 |
| escape |
设置Dockerfile中用来转义的前导字符,默认\。示例: # escape=` 转义前导字符可以用于行内转义,也可以转义换行符。这允许一个指令(instruction)跨越多行 注意:对于 RUN 指令,转义仅仅会在行尾发生,即仅转义换行符 一般在Windows上会将转义字符设置为`,因为反斜杠是Windows的路径分隔符 |
使用 ENV 指令可以声明环境变量,在Dockerfile中你可以声明Bash风格的变量替换: $variable_name 或者 ${variable_name} 。除了这两种基本格式以外,还可以使用某些Bash修饰符:
- ${variable:-word} ,如果设置了环境变量variable,表达式的结果是$variable,否则是word
- ${variable:+word} ,如果设置了环境变量variable,表达式的结果是word,否则是空串
以下指令支持变量替换:ADD、COPY、ENV、EXPOSE、LABEL、USER、WORKDIR、VOLUME、STOPSIGNAL。在1.4+,当ONBUILD与前述指令一起使用时,也支持环境变量。
注意:环境变量的值在同一个指令中保持不变,考虑下面的片断:
|
1 2 3 |
ENV abc=hello ENV abc=bye def=$abc # def值为hello而不是bye ENV ghi=$abc # ghi值为bye |
Docker客户端发送上下文到守护程序之前,会读取上下文根目录下名为.dockerignore的文件。如果此文件存在,则客户端会依据其中声明的规则来排除掉上下文中的部分文件或者目录。使用.dockerignore可以避免过多的、敏感的文件到守护程序,并被ADD/COPY命令复制到镜像中。
此文件中的每行是一个UNIX glob风格的匹配Pattern,上下文根目录被作为此Pattern的根目录,下面是一些示例:
| Pattern | 排除 |
| # comment | 注释,被忽略 |
| */temp* | 根目录的任意直接子目录中,任何以temp开头的目录或者文件 |
| */*/temp* | 根目录的任意孙子目录中,任何以temp开头的目录或者文件 |
| temp? | 根目录值中任意以temp开头,后面附加一个任意字符的目录或者文件 |
| **/*.go | 任意以.go结尾的文件。**匹配0-N个目录 |
| *.md !README.md |
根目录中任何.md文件,除了README.md,!用于为排除指定例外 |
指令格式:
|
1 2 3 4 5 6 7 8 9 |
FROM <image> FROM <image>:<tag> FROM <image>@<digest> # --platform 如果image是多平台的镜像,则此参数选择该镜像的特定平台版本 # 默认自动选择匹配构建目标平台的版本 # AS 为该build stage命名,名字可以被后续的stage引用 FROM [--platform=<platform>] <image> [AS <name>] |
用于指定正在构建镜像的Base镜像:
- 该指令必须是Dockerfile中第一个非注释指令
- 该指令可以在一个Dockerfile中出现多次,用于构建多个镜像
- tag、digest可选, 如果不指定,自动使用latest
一个Dockerfile中可以包含多个FROM指令,这叫多Stage构建。下面是一个例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ARG ARCH # 第一个stage,构建出二进制文件 FROM golang:1.13 as builder WORKDIR /workspace RUN CGO_ENABLED=0 GOOS=linux GOARCH=$ARCH GO111MODULE=on go build -a -o pause pause.go # 第二个stage,构建出镜像 FROM docker.gmem.cc/tcnp/alpine-${ARCH}:3.11 WORKDIR / # 用名字来引用前面的stage,复制出其中的文件 COPY --from=builder /workspace/pause . ENTRYPOINT ["/pause"] |
如上面的例子所示,FROM中可以使用在第一个FROM指令之前出现的ARG中定义的构建时变量。
指令格式: MAINTAINER <name> 。用于指定生成的镜像的Author字段
该指令具有两种格式:
|
1 2 3 4 5 6 |
# shell格式,command在Shell中运行,默认/bin/sh -c或者 cmd /S /C RUN <command> RUN ["executable", "param1", "param2"] # 示例: RUN ["/bin/bash", "-c", "echo hello"] |
该指令在当前intermediate镜像之上新建一层,并在其中执行任意命令,然后提交结果。提交结果后形成的新intermediate镜像被下一个指令使用。
运行RUN指令时触发分层(Layering)符合Docker的核心理念——提交(Commit)操作想对廉价,并且可以从镜像历史的任意位置(任意一层)创建容器。分层也是构建过程中镜像缓存的基础。
使用exec格式可以避免Shell字符串相关的陷阱,也可以在Base镜像中没有/bin/sh程序的情况下执行命令。使用exec格式时需要注意:
- 由于exec格式不调用Shell,因此也不会发生变量替换:
1234# $HOME不会被替换RUN [ "echo", "$HOME" ]# $HOME会被替换,因为虽然是exec格式,但是它调用了shRUN [ "sh", "-c", "echo $HOME" ] - exec指令的参数必须是规范化的JSON数组,所以:
- 字符串必须使用双引号包围
- 字符串中的反斜杠必须JavaScript语法转义,即 \\
使用shell格式时,你可以使用 \ 让命令跨越多行。
RUN指令导致的镜像缓存不会自动失效,要禁用缓存,可以在构建时指定 --no-cache选项。ADD指令可以导致RUN的缓存失效。
可以用SHELL指令,设置shell格式的RUN指令所使用的Shell程序,其它几个具有exec格式/shell格式区分的指令,也受到SHELL指令的影响。
该指令具有三种格式:
|
1 2 3 4 5 6 |
# exec格式,推荐的格式 CMD ["executable","param1","param2"] # 用作ENTRYPOINT的默认参数 CMD ["param1","param2"] # shell格式 CMD command param1 param2 |
Dockerfile中仅能包含一个CMD指令, 如果指定了多个CMD指令则仅最后一个有效。该指令的主要意图是为执行容器(executing container)提供默认值(defaults),这些默认值可以包含一个可执行文件,与ENTRYPOINT指令联用时,则仅仅包含执行选项。
使用CMD指令时要注意:
- CMD不会在构建阶段做任何事情
- 如果用CMD为ENTRYPOINT提供默认参数,则这两个指令的参数均为规范化的JSON数组
- exec、shell格式调用的注意点,参考RUN指令
如果使用了CMD指令,并且运行容器时没有指定需要执行的命令,则CMD中的命令会被执行。要让容器每次都运行同一个程序,应当联合使用ENTRYPOINT、CMD。
指令格式: LABEL <key>=<value> <key>=<value> <key>=<value> ...
该指令为镜像添加元数据(metadata),每个标签是一个键值对。如果需要为镜像添加多个标签,最好在单个LABEL指令中完成。下面是一些示例:
|
1 2 3 4 5 |
# 如果键/值中包含空格,可以用引号包围 LABEL "Author Name"="Alex Wong" # 可以使用反斜杠跨行 LABEL description="Hello \ There !" |
镜像会继承来自FROM镜像的标签,如果当前镜像的某个标签的键与FROM镜像冲突,则当前的覆盖FROM的。
使用 docker inspect 命令可以查看一个镜像的所有标签。
指令格式: EXPOSE <port> [<port>...]
该指令声明容器在运行时侦听的端口。该指令并不会让容器和宿主机之间发生端口映射,要真正映射(发布)端口,必须在创建容器时使用选项:
- 使用-p参数运行镜像,指定发布的端口范围
- 使用-P参数,发布所有EXPOSE声明的端口
该指令支持两种格式:
|
1 2 3 4 |
# 为单个变量(key)设置单个值(value)。第一个空格之后的全部内容被作为值看待,即使其中包含空格、引号 ENV <key> <value> # 允许设置多个环境变量 ENV <key>=<value> ... |
设置构建过程、运行期间均可见的环境变量,这些环境变量对任何后代Dockerfile都可用。
部分Dockerfile指令或者指令的某种形式,支持引用环境变量,语法和Bash一致。
在运行期间,可以使用docker inspect查看环境变量。在命令行中,可以使用 --env <key>=<value>覆盖环境变量设置。
该指令支持两种格式:
|
1 2 3 4 |
# src是上下文中的目录或者远程URI;dest为镜像中的目录 ADD <src>... <dest> # 用于路径中包含空格的情况 ADD ["<src>",... "<dest>"] |
拷贝本地目录、文件或者远程文件URI,将它们加入到容器文件系统的dest位置。注意以下几点:
- 可以指定多个src,src中可以包含*、?等通配符
- 如果src是目录、文件,必须指定相对于上下文根的相对路径,src目录/文件必须位于上下文内部。/something、../something均非法
- 当src是目录时,其内部所有内容,包括文件系统元数据都被拷贝。但是目录本身不被拷贝
- 当src是一个本地压缩文件时,它被解压为一个目录,然后拷贝到dest
- 当src是本地目录(包括解压后的压缩文件)时,覆盖到dest的行为类似于tar -x
- 当src是远程URI时:
- 如果dest以/结尾,则文件名从URI中推定,保存为<dest>/<filename>
- 如果dest不以/结尾,则文件保存为dest
- dest指定容器中的绝对路径。如果使用相对路径,则相对于WORKDIR
- 当dest以/结尾时,被看作目录,否则看作一般文件。如果dest不存在,会被自动创建
- 容器中所有的新文件,以UID=GID=0创建
- 如果src为远程URI,则dest的模式被设置为600。如果通过HTTP协议获取远程文件,则Last-Modified头用于设置dest中文件的mtime
- mtime不会影响缓存判断
- 当通过stdin读取Dockerfile并构建时: docker build - < somefile ,由于没有构建上下文,因此ADD指令必须使用基于URI的src。如果somefile是一个压缩包(tar.gz),则压缩包中根目录被作为构建上下文,而根目录中须有Dockerfile文件
- 由于ADD不支持身份认证,因此远程URI需要身份验证时,你必须使用RUN wget/curl代替ADD
- 如果src的内容发生变化,ADD会导致所有后续指令对应的Layer缓存失效
示例:
|
1 2 3 4 5 6 7 |
# 拷贝上下文根目录中所有hom开头的文件到镜像的/mydir/目录下 ADD hom* /mydir/ # 拷贝上下文目录中home.txt之类的文件,e可以是任何单字符 ADD hom?.txt /mydir/ # 拷贝到相对路径 $WORKDIR/relativeDir/下 ADD test relativeDir/ |
该指令支持两种格式:
|
1 2 3 |
COPY <src>... <dest> # 用于路径中包含空格的情况 COPY ["<src>",... "<dest>"] |
拷贝文件或者目录到容器文件系统中。 注意点类似于ADD,但是COPY不理解远程URI也不处理压缩文件。
该指令支持两种格式:
|
1 2 3 4 |
# 推荐的exec格式,参数以JSON数组传递。该方式不会调用Shell命令,因此不会发生参数替换等行为 ENTRYPOINT ["executable", "param1", "param2"] # shell格式,阻止传参。可以使用环境变量。容器运行时调用/bin/sh -c "command param1 param2" ENTRYPOINT command param1 param2 |
使用入口点,可以如同使用可执行文件那样运行一个镜像。docker run时,镜像名后面的所有参数,都作为参数传递给ENTRYPOINT指定的命令/可执行文件,并且覆盖CMD中指定的默认参数。当镜像名和可执行文件名一致的时候,dock run看起来就好像在执行一个文件,而不是运行镜像。
shell格式的调用,阻止CMD指定的默认参数和dock run指定的参数。但是这种格式下可执行文件将作为/bin/sh -c的子命令运行,这导致可执行文件的PID不是1并且不能接收UNIX信号。你的可执行文件将无法接收docker stop发送来的SIGTERM信号。
如果该指令使用多次,则仅仅最后一个被使用。
你可以使用 --entrypoint选项覆盖ENTRYPOINT,但是只能指定执行的程序:
|
1 2 |
# 以命令bash作为入口点,覆盖默认的入口点,将--version作为bash的参数 docker run -it --rm --entrypoint bash docker.gmem.cc/maven:3.5.2 --version |
使用该格式,可以方便的设置容器执行的默认命令及其稳定的默认参数: ENTRYPOINT ["top", "-b"]
然后,可以联用CMD指令,设置可覆盖的默认参数: CMD ["-c"]
下面的例子,在前台(PID为1)运行Apache服务器:
|
1 2 3 4 5 6 |
FROM debian:stable RUN apt-get update && apt-get install -y --force-yes apache2 EXPOSE 80 443 VOLUME ["/var/www", "/var/log/apache2", "/etc/apache2"] # -D FOREGROUND 不去fork出子进程 ENTRYPOINT ["/usr/sbin/apache2ctl", "-D", "FOREGROUND"] |
你可以使用任何脚本作为入口点可执行程序的启动脚本,为了确保底层可执行文件能够接收UNIX信号,必须使用exec命令替换进程:
|
1 |
ENTRYPOINT ["/usr/bin/start-postgres.sh"] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/bash set -e # 如果第一个参数是postgress,则启动postgress服务 if [ "$1" = 'postgres' ]; then # 初始化,改变目录所有权 chown -R postgres "$PGDATA" # 初始化数据库 if [ -z "$(ls -A "$PGDATA")" ]; then gosu postgres initdb fi # 使用exec、管理员权限运行postgres。exec确保postgres进程PID=1,能够接收UNIX信号 exec gosu postgres "$@" fi # 否则,运行参数指定的程序 exec "$@" |
如果需要进行清理工作,可以在入口点脚本中编写trap语句:
|
1 2 3 4 5 6 7 8 9 |
# 捕获多种信号,然后执行引号中的脚本,停止Apache服务 trap "stopping apache /usr/sbin/apachectl stop" HUP INT QUIT TERM # 在后台启动Apache服务,这种服务无法接收信号 usr/sbin/apachectl start echo "Press ENTER to exit" read # 回车后,也可以停止Apache服务 echo "stopping apache" /usr/sbin/apachectl stop |
这种方式指定的入口点,将在Shell中(默认 /bin/sh -c) 执行指定的程序,能够进行变量替换。该方式会忽略CMD指令和docker run image 后面的参数。
为了确保长时间运行的入口点程序能够正确接收docker stop发来的UNIX信号,应当使用exec来执行目标程序,例如: ENTRYPOINT exec top -b
指令格式:
|
1 2 |
VOLUME ["/mount/point"] VOLUME /mount/point1 /mount/point2 |
在镜像中创建一个挂载点,并将其标记为“承载来自宿主机、其它容器的外部卷”。
在构建阶段,你可以往挂载点写入数据,然后再声明VOLUME指令,这样数据会持久化在镜像中:
|
1 2 3 4 |
RUN echo "Hello Docker!" > /mount/point/greetings # 后声明VOLUME VOLUME /mount/point # 再此之后对/mount/point进行任何改动,都会被丢弃 |
在docker run时, 容器会在/mount/point挂载新的卷,并且把greetings文件拷贝到此卷中。
指令格式: USER username-or-uid ,指定RUN,CMD,ENTRYPOINT指令以什么身份运行。
在我机器上尝试MySQL镜像时,设置USER为mysql,生效的ID为999,而mysql用户的真实ID是118。直接设置USER为118,没有问题。
指令格式: WORKDIR /path/to/workdir
指定RUN, CMD, ENTRYPOINT, COPY,ADD指令的工作目录,你可以多次使用该指令,并且可以使用相对(于上一个WORKDIR)路径。示例:
|
1 2 3 4 5 |
ENV PREFIX /usr/local # 可以使用环境变量 WORKDIR $PREFIX/bin # 下面的指令导致工作目录变为/usr/local/bin/python WORKDIR python |
指令格式: ARG <name>[=<default value>] #该指令可以声明多次,也可以指定一个默认值
该指令定义一个构建时变量。变量的值可以通过 docker build --build-arg <varname>=<value> 指定、覆盖。如果用户通过build-arg传递没有通过ARG声明的变量,构建会失败。
ARG定义的变量,对Dockerfile当前行之后的指令生效。ARG变量不会持久化到镜像中。
使用ENV、ARG都可以向RUN指令传递变量,如果这两个指令声明同名的变量,则ENV总是覆盖ARG。
以下ARG是Docker预定义的,不需要声明即可使用:http_proxy、https_proxy、ftp_proxy、no_proxy以及这4个变量的全大写版本。
|
1 2 |
ARG JAR_FILE ADD target/$JAR_FILE /app.jar |
如果ARG的值在下一次构建时发生了修改,则第一次使用它定义的变量的那个指令对应的Layer缓存失效。
指令格式: ONBUILD [INSTRUCTION]
为镜像添加一个触发器指令( trigger instruction),该指令会在当前镜像被作为其它构建的Base镜像时执行。ONBUILD指定的指令会在子镜像构建时、在子镜像的构建上下文中立即执行,就好像把该指令直接插入到FROM指令后面一样。
所有构建指令都可以通过ONBUILD注册为触发器。
当你制作一个专用于被扩展的Base镜像ONBUILD很有用。举例来说,假设你构建了一个Pyhton的应用编译环境(Base镜像),它要求被构建的Python源码被放置在特定的目录,并在之后调用编译脚本。你无法在构建Base镜像的时候使用ADD、RUN完成前述的工作,因为Base镜像的构建者并不知道源码在哪——每个具体应用程序的源码位置都不同。这时,ONBUILD可以帮助你:
- 构建Base镜像时,当遇到ONBUILD时,Docker在镜像元数据中添加一条触发器数据。ONBUILD中的指令不会影响Base镜像的构建
- 在Base镜像构建完毕后,所有触发器的列表(对应多个ONBUILD)被存放到镜像的元数据清单(manifest)中,以OnBuild为Key。你可以对Base镜像执行docker inspect查看触发器列表
- 构建子镜像时,执行FROM指令时,ONBUILD触发器会按照它们在Base镜像中的声明顺序,依次执行,指有它们全部执行成功,子镜像才会继续构建,否则在FROM指令处失败
- 子镜像构建完毕后,ONBUILD触发器从子镜像的元数据中移除,这意味着孙子镜像不会感知到ONBUILD触发器
下面是一个具体的例子:
|
1 2 3 4 |
# 将子镜像的构建上下文拷贝到临时容器的特定位置 ONBUILD ADD . /app/src # 构建Python应用程序,结果的结果固化在子镜像中 ONBUILD RUN /usr/local/bin/python-build --dir /app/src |
构建子镜像时,只需要把Python程序源码放在上下文目录中,构建完毕后,子镜像的容器就直接可以使用与子镜像同时构建的Python程序了。
使用ONBUILD时需要注意:
- 不支持ONBUILD ONBUILD...
- 不支持ONBUILD FROM或者ONBUILD MAINTAINER
指令格式: STOPSIGNAL signal ,指定为了让容器退出时,向其发送的信号。支持信号名称或者数字,例如SIGKILL、9。
该指令支持两种格式:
|
1 2 3 4 5 6 7 8 9 10 |
# 在容器内运行一个命令以检测容器的健康状况 # command 要么是一个Shell命令字符串,要么是一个JSON数组 HEALTHCHECK [OPTIONS] CMD command # 在CMD之前,可以指定以下选项: --interval=DURATION # 默认30s,第一次运行健康检测,于容器启动后DURATION秒后,以后每隔DURATION秒检测一次 --timeout=DURATION # 默认30s,如果健康检测命令超过DURATION秒没有完成,则认为执行失败 --retries=N # 默认3, 健康检测命令连续失败的最大次数,超过此次数,认定容器处于unhealthy状态 # 禁用任何从Base镜像继承来的健康检测指令 HEALTHCHECK NONE |
该指令告知Docker,如何确认容器仍然在正常工作。正常工作不仅仅要求进程在运行,还要求特定于具体应用的检测可以通过(例如对于Web应用,能够正常处理HTTP登录请求)。
当指定了该指令后,在normal status之外,还多了一个health status。该状态的初始值为starting,当健康检测通过后,变为healthy;当检测不通过、或者若干次检测失败后,变为unhealthy。
command的退出状态用于判断容器是否健康:0 表示健康;1表示不健康;2为暂不使用的保留值。command的输出到stdout/stderr的信息,可以通过docker inspect命令查看到。
每个Dockerfile仅支持一个HEALTHCHECK指令,如果指定了多个,只有最后一个生效。
指令格式: SHELL ["executable", "parameters"]
用于覆盖那些使用shell格式的指令所使用的默认Shell:
- Linux下默认Shell为 ["/bin/sh", "-c"]
- Windows下默认Shell为 ["cmd", "/S", "/C"]
在Windows平台上该指令很有用,因为Windows提供了两个常用却完全不同的Shell:cmd和powershell。
SHELL指令可以出现多次,每次均覆盖之前的取值。
你可以在Dockerfile中使用多个FROM语句,每个FROM触发一个新的构建阶段(Stage)。你可以选择性的把某些构建从一个阶段拷贝到另外一个,而把任何不需要引入最终镜像的文件丢弃 —— 例如构建工具、依赖包。
下面是一个例子:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
FROM golang:1.7.3 WORKDIR /go/src/github.com/alexellis/href-counter/ RUN go get -d -v golang.org/x/net/html COPY app.go . RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app . FROM alpine:latest RUN apk --no-cache add ca-certificates WORKDIR /root/ # --from表示从前面的stage拷贝 COPY --from=0 /go/src/github.com/alexellis/href-counter/app . CMD ["./app"] |
这个例子的第一阶段使用Go SDK构建源码,第二阶段则将第一阶段中的文件拷贝过来。
除了使用序号,你还可以通过名称来引用Stage:
|
1 2 3 4 |
FROM golang:1.7.3 as builder ... FROM alpine:latest COPY --from=builder /go/src/github.com/alexellis/href-counter/app . |
你可以仅仅执行一部分Stage,然后就停止构建:
|
1 2 |
# 执行到builder这个stage即停止 docker build --target builder -t alexellis2/href-counter:latest . |
任何一个镜像都可以作为Stage使用,从中拷贝文件:
|
1 |
COPY --from=nginx:latest /etc/nginx/nginx.conf /nginx.conf |
为了编写易用、有效的Dockerfile,Docker官方发布了若干条最佳实践。如果你要构建官方镜像,则必须遵守这些实践。
容器的生命周期应该尽可能的短暂,创建、启动、停止、删除应当消耗最小化的时间。这意味着你应该尽可能的通过Dockerfile把内容放在镜像内。
大部分情况下,可以把Dockerfile放置在空白的目录中,后续仅在此目录中存放构建镜像时所必须的文件。
如果目录中包含一些你需要排除出构建过程的目录/文件,可以编写一个.dockerignore文件,其格式类似于 .gitignore。
尽可能少的安装Linux软件包,这样可以降低镜像的大小、构建过程的耗时
大部分情况下,你应该在单个容器中运行仅单个程序(例如Web服务、DB服务)。将应用程序解耦到不同容器中可以更好的实现容器重用、水平扩展。
当一个程序依赖于另外一个时,可以使用容器链接(container linking)。
应当十分谨慎的考虑Dockerfile使用的层数(Number of layers),在Dockerfile可读性(可维护性)和最小化层数之间寻求平衡。
尽可能的按照字典序对参数(特别是apt安装的软件包参数)进行排序,这样可以避免后续维护者添加重复的安装包。
在构建镜像时,Docker会遍历你的Dockerfile的指令,检查完这些指令后,它会到缓存中寻找已经构建的镜像,而不是构建“重复”镜像。要避免使用缓存,可以在docker build时指定 --no-cache=true 参数。
如果使用缓存,你必须明白它是如何寻找“重复”镜像的:
- 选取与当前Dockfile使用同一Base镜像的缓存镜像列表,遍历此列表,如果某个条目的构建指令与当前Dockerfile完全一致,则该条目可能是“重复镜像”
- 对于ADD、COPY指令,目标文件集合被检查并计算Checksum(不包含修改时间、最后访问时间信息),如果某个缓存镜像条目对应的ADD、COPY指令操控的文件集合的Checksum与前面的Checksum一致,则该条目匹配“重复”镜像
当找不到匹配的镜像时,Docker将从头开始,构建一个新镜像。
| 指令 | 最佳实践 | ||||
| FROM | 如果可能,使用Docker官方仓库作为基本镜像的来源,推荐使用debian:latest,因为此镜像作为一个完整发行版,一直并很好的控制并保持最小化(目前150MB) | ||||
| LABEL |
可以为镜像添加标签,以便更好的按照项目来组织镜像、记录License信息、辅助自动化。对于每个标签,以LABEL指令开头,后面跟随一个或者多个键值对信息。下面是一些示例:
|
||||
| RUN |
为了可读性、可维护性,应该把复杂的RUN语句编写在多行中,并用反斜杠分隔 apt-get 大部分RUN指令都是调用apt-get来安装软件包的。注意避免使用upgrade、dist-upgrade子命令,因为某些基本的软件包不能在非特权容器中升级。 应当总是同时使用update子命令和install子命令,例如:
因为单独使用RUN apt-get update指令,会导致软件包元信息驻留Docker缓存,以后的构建可能不更新软件包元信息。当然,你也可以指定软件包版本,这也可能避免上述缓存问题 一个RUN指令规范例子如下:
|
||||
| CMD |
该指令用于运行镜像中包含的软件,调用格式一般为: CMD ["executable", "param1", "param2"…] 对于那些作为服务的软件,应该让它在前端执行(而不是在fork出的子进程中执行),例如运行Apache时应该使用指令 CMD ["apache2","-DFOREGROUND" 对于大部分其它软件,CMD指令应该给出一个交互式的Shell,例如 CMD ["perl", "-de0"] 、 CMD ["python"] |
||||
| EXPOSE |
该指令声明容器用来监听外部连接的端口,你应该使用约定俗成的端口:
|
||||
| ENV |
可以使用该指令更新PATH环境变量的值,以简化软件的调用。例如: ENV PATH /usr/local/nginx/bin:$PATH 可以让Nginx通过简单的指令 CMD [“nginx”] 运行。 某些软件需要环境变量的设置,亦可通过该指令完成 |
||||
| ADD COPY |
两者功能类似,COPY应该更优先使用,因为它比ADD简单直观。COPY仅支持将本地文件拷贝到容器内这样的基本操作,而ADD则支持一些高级特性:
最常见的需要使用ADD的场景是解压文件到镜像中: ADD rootfs.tar.xz /. 如果在Dockerfile中存在多个步骤需要复制文件,不要把它们合并到单个COPY指令中。这样做的原因还是缓存,分开COPY可以减少不必要的缓存失效 |
||||
| ENTRYPOINT |
该指令最佳应用场景是设置镜像的main命令,让容器像一个可执行文件那样运行。你可以配合使用CMD指令,来指定main命令的默认选项:
这样,你就可以运行镜像,而不指定需要执行的命令:
由于镜像名、命令名相同, 省略了其中之一的效果,就好像docker run在直接执行一个命令 也可以将ENTRYPOINT设置为一个脚本文件的路径: ENTRYPOINT ["/docker-entrypoint.sh"] ,此脚本中的 $@ 对应docker run imgname后面的整个参数数组 |
||||
| VOLUME | 使用该指令暴露所有数据库的存储区域、配置文件的存储、以及容器创建的文件/目录,总之,所有容易变化的文件系统部分,都应该使用该指令暴露 | ||||
| USER |
如果容器运行的服务不需要特权,则应该使用该指令指定一个非root用户,但是注意要在Dockerfile中预先添加这样的用户,例如:
注意:自动分配的UID/GID在多次的镜像构建之间并不保持唯一 ,因此你最好手工指定UID/GID 避免安装/使用sudo,因为其不确定的TTY、信号转发行为会导致一些问题。如果必须使用类似于sudo的功能,可以安装gosu |
||||
| WORKDIR | 为了简洁、明确,使用WORKDIR指令时,应该总是使用绝对路径。应该使用WORKDIR来代替任何 RUN cd … && do-sth 风格的指令 |
要有效利用Docker的存储机制,首先需要搞清楚它是如何构建、存储镜像的,然后要理解镜像是如何被容器使用的。
一个镜像文件由一系列层层叠加的、只读的层(Layers)构成,这些层共同组成了镜像的根文件系统。Docker的存储驱动负责管理这些层,对外提供单一的文件系统视图。
当你创建一个容器时,Docker会在镜像的层叠之上,添加一个薄的、可读写的容器层(container layer)。容器运行过程中对文件系统的任何更改(增加、修改、删除文件),都持久化到容器层中。
所有镜像、容器的层都位于本地文件系统中,由存储驱动管理。在Linux下,默认存储目录为/var/lib/docker/。
下图是基于Ubuntu:15.04的容器的文件系统层叠示意图:
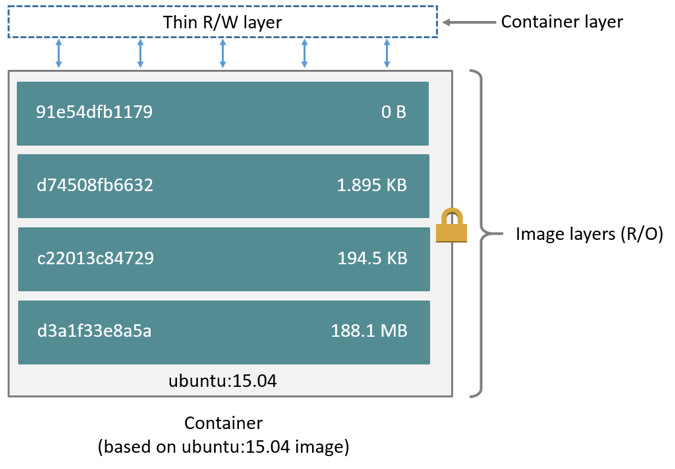
Docker从1.10开始,引入了一个新的内容寻址存储(Content addressable storage,CAS)模型。该模型提供了在磁盘上寻址镜像、层数据的全新方法。在此之前,镜像、层数据使用随机的UUID来引用和存储,CAS则使用内容哈希值(content hash)来引用镜像、层数据。
CAS增强了安全性,内置了防止ID冲突的机制,并且能在pull、push、load、save操作后保证数据完整性。它也提供了更好的层共享机制——允许很多镜像自由的共享层,即时这些层来自不同的构建。
使用CAS后,所有层的ID均变成基于其内容的哈希值。但是,容器的ID仍然是随机的UUID。
这一变化导致,从老版本的Docker升级到1.10后:
- 既有镜像需要迁移:由于层ID的生成规则发生变化,老版本Docker从仓库Pull下来的镜像的ID必须重新生成。新版本的Docker守护程序在初次运行时会自动执行这一迁移操作。迁移操作完毕后,所有镜像、标签具有新的secure IDs。如果本地镜像非常多,迁移操作可能消耗很长的时间才能完成,这期间Docker守护程序无法响应外部请求
从存储角度来看,镜像与容器的主要区别就在于后者的Layer栈顶部包含一个薄的可读写层。当容器创建后,该读写层一同创建;当容器删除后,该读写层也被删除;容器运行时,所有对文件系统的变更都落到这个读写层中。
由于一个镜像的所有容器具有自己的可读写层,因而它们能够安全的共享底层的镜像。Docker的存储驱动负责管理所有的层(不管是镜像还是容器的),如何管理取决于具体的驱动,但是两个关键技术是通用的:1、可层叠镜像层(stackable image layers);2、copy-on-write
这个策略在软件系统中很常见。例如在操作系统中,两个使用相同数据块的进程,可以安全共享数据块的单份拷贝。只有当其中一个进程需要对共享数据进行修改(而另外一个进程不进行修改)时,才需要共享数据的额外拷贝。
Docker同时对镜像、容器使用此CoW策略,以便节约存储空间并缩短容器启动时间。CoW依赖于存储驱动的支持,不是所有驱动支持CoW。
执行pull/push子命令时,Docker客户端会报告其操作的Layer:
|
1 2 3 4 5 6 7 |
docker pull ubuntu:15.04 # 9502adfba7f1: Pull complete # 4332ffb06e4b: Pull complete # 2f937cc07b5f: Pull complete # a3ed95caeb02: Pull complete # Digest: sha256:2fb27e433b3ecccea2a14e794875b086711f5d49953ef173d8a03e8707f1510f # Status: Downloaded newer image for ubuntu:15.04 |
可以看到,拉取Ubuntu镜像时,实际上下载了4个Layer,它们共同组成了完整的系统镜像。
如果使用AUFS驱动,在1.10版本之前,Layer以其ID为目录名,存放在本地存储的子目录/var/lib/docker/aufs/layers中。
不管Docker引擎的版本是多少,相同的Layer都会被共享,而不是重新拉取。
前面提到,对容器文件系统的所有修改都写在一个薄的顶部层中,来自镜像的层都是只读的,这意味着多个容器可以共享一个镜像。
当容器修改了一个文件后,Docker利用存储引擎来执行CoW策略,具体细节取决于引擎。对于AUFS、OverlayFS这两种存储引擎来说,CoW的大概步骤如下:
- 从顶层向下,逐层寻找,定位到被修改的文件
- 将找到的文件拷贝(Copy-up)到顶部的可写层
- 修改位于可写层中的文件副本
Copy-up操作可能带来重大的性能影响,影响程度取决于存储驱动。但是过大的文件、过多的层、过深的目录树都会加重影响程度。不过Copy-up操作对一个文件至多发生一次。
CoW让容器共享镜像,这一方面让容器本身的尺寸很小,另一方面则让容器高效的创建、执行,因为不需要牵涉到太多的I/O操作。
当容器被删除后,所有没有存储在数据卷(Data volume)中的数据都会被删除。数据卷是宿主机上的一个目录或者文件,它被直接挂载到容器的目录树中。
多个容器可以共享数据卷,但是要注意并发修改的问题。
数据卷不受存储驱动的控制,对其进行的I/O操作绕过存储驱动,直接由宿主机执行,其速度和宿主机上普通I/O操作一样快。
为了基于实际运行环境选择最好的驱动,Docker设计了可拔插的存储驱动架构。存储驱动基于一个Linux文件系统或者卷管理器,它们可以自由的实现镜像/容器Layer的管理。
在决定使用哪种驱动后,你需要设置Docker守护程序的启动参数。修改/etc/default/docker中的DOCKER_OPTS,添加 --storage-driver=<sd_name> 选项。
注意一个Docker守护程序同时只能使用一种存储驱动。执行命令:
|
1 2 |
docker info | grep "Storage Driver" # Storage Driver: aufs |
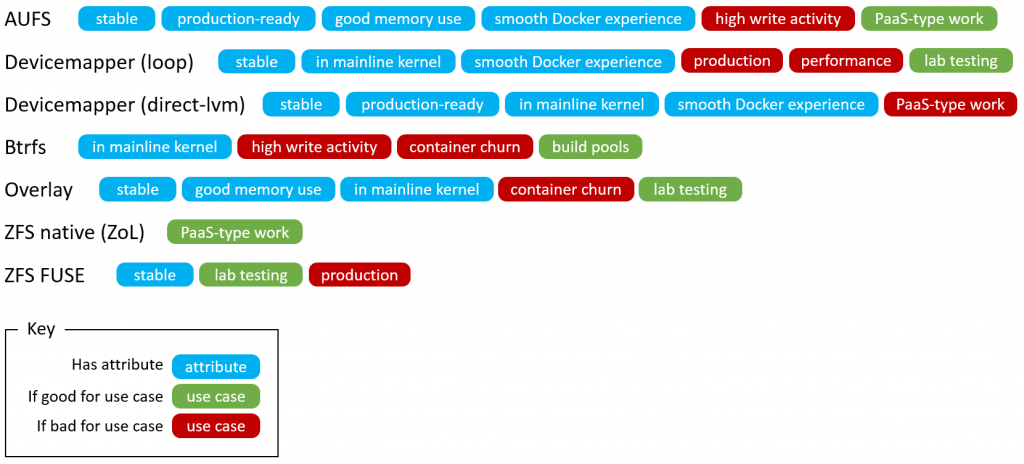
可以看到当前使用的存储驱动。上例中的aufs为存储驱动的名称,存储技术与存储驱动名称对照表如下:
| 存储技术 | 存储驱动名称 | 说明 |
| OverlayFS | overlay overlay2 |
内核的一部分,速度最快的UnionFS。支持页共享缓存,多个容器访问同一个文件时,可共享相同的页面缓存,因而其内存利用效率很高 overlay2是overlay的升级版,在4.0内核之后,添加额外的特性,防止过多的索引节点(inode)消耗 |
| AUFS | aufs |
Ubuntu/Debian系统默认的存储驱动,历史悠久、稳定 允许容器之间共享公共库的内存,因此如果有千百个相同的容器,其内存效率比较高
|
| Btrfs | btrfs | |
| Device Mapper | devicemapper |
Redhat/Fedora系统默认的存储驱动 Device Mapper是内核中支持LVM的通用设备映射机制,它为块设备驱动提供了一个模块化的内核架构 基于块设备而非文件系统,内置配额支持,其它驱动则不支持 |
| VFS | vfs | |
| ZFS | zfs |
许多企业使用SAN、NAS之类的共享存储技术以提高性能和可靠性,或者实现Thin Provisioning(避免预分配过多的容量)、数据复制、压缩等高级特性。
Docker存储驱动、数据卷均可以在这些共享存储系统之上工作,但是Docker不能直接与底层的共享存储技术集成。你需要选择与共享存储技术匹配的存储驱动。
OverlayFS是目前使用比较广泛的层次文件系统,实现简单,读写性能较好,并且稳定。
与OverlayFS相关的存储驱动有两个:overlay、overlay2。前者的缺陷包括inode耗尽和commit performance,后者就是为了解决这两个问题而生,但是需要4.0或者更高版本的Linux内核。
AUFS是第一个出现的Docker驱动,它非常稳定,在生产环境下有很多部署案例,并且社区支持很好。AUFS的优势包括:
- 容器启动时间短
- 存储利用效率高
- 内存利用效率高
对于PaaS或者其它需要高密度容器实例的应用场景,AUFS是很好的选择。但是由于CoW策略,第一次写文件操作可能带来很大的开销。
由于AUFS不在Linux内核主线中,因此某些发行版不会自带AUFS,需要手工下载和安装。
要验证当前系统是否支持AUFS,可以执行命令:
|
1 |
cat /proc/filesystems | grep aufs |
如果上述命令没有输出,先确保你的内核版本高于3.13,并参考如下命令安装:
|
1 |
sudo apt-get install linux-image-extra-$(uname -r) linux-image-extra-virtual |
安装完毕后,修改Docker守护程序的参数:
|
1 |
sudo dockerd --storage-driver=aufs |
上面的参数修改不是持久化的,要永久的修改,需要打开Docker配置文件,添加:
|
1 |
DOCKER_OPTS="--storage-driver=aufs" |
AUFS是一种联合文件系统(UFS),它管理单个Linux宿主机上的多个目录,并将其叠加在一起,在单个挂载点形成统一的视图。与UnionFS、OverlayFS类似,AUFS是一种union mounting实现。AUFS管理的每个Linux宿主机目录称为联合挂载点(union mount point)或者分支(branch)。
AUFS的思想与Docker的Layer机制天然吻合——每个branch对应一个镜像/容器的Layer。Copy-up操作实质上就是在宿主机文件系统的不同目录之间复制文件。
由于AUFS在文件级别上操作,这意味着,即使在仅仅修改文件一小部分的情况下,CoW操作也需要复制整个文件。因此,当写入一个体积很大的文件时,AUFS会遭遇一次性的性能问题。
当删除文件时,AUFS在顶层Layer添加一个所谓without文件,该文件命名为 .wh.filename ,用来标记目标文件在容器中被删除。
使用AUFS时,镜像、容器的文件默认被存放到dockerd所在机器的/var/lib/docker/aufs/目录下 。
安装Docker之后,会自动创建bridge、none、host这三个网络,可以通过命令 docker network ls 查看。如果启动容器时不指定 --network 参数,默认使用bridge网络,bridge在宿主机网络栈中映射为docker0。none表示容器不连接到任何网络,其本地网络设备仅仅lo这个环回网卡。host网络则把容器添加到宿主机网络栈中,在容器中执行ifconfig你会看到输出与宿主机一致。
在三个默认网络中,通常你只会和bridge做交互。这些网络不能被删除,因为Docker本身需要使用。
你可以创建其它自定义网络,并在不需要的时候删除它们。
为了更好的隔离容器,可以创建自定义网络。利用Docker提供的网络驱动,你可以创建桥接(Bridged)、重叠(Overlay)、MACVLAN等类型的网络。
自定义网络可以创建多个,每个容器也可以加入到多个网络中。容器仅仅能在网络内部而不能跨网络通信。当容器连接到多个网络时,其外网连接性由第一个(词法序)具有外部连接能力的网络提供。
Linux内核支持虚拟网桥,可以连接多个网络接口,功能类似于交换机。
在自定义网络中,桥接是最简单的一种。添加到桥接网络的容器,必须位于同一台宿主机上。网络中的所有容器可以相互通信,但是这些容器不能访问外部网络。
与Docker0不同,自定义桥接网络不支持--link。但是你可以暴露/发布容器的端口,这样桥接网络的一部分可以被外部访问。自定义桥接网络嵌入了DNS服务器,容器之间可以通过名字访问。
当你需要基于单宿主机建立一个简单的网络时,可以考虑自定义桥接网络。
桥接网络的示例:
|
1 |
docker network create -d bridge --subnet=172.21.0.0/16 --gateway=172.21.0.99 local |
这个特殊的本地桥接网络,在以下两种情况下,由Docker自动创建:
- 当你初始化或者加入到一个swarm时,Docker创建docker_gwbridge,以便跨主机的进行swarm节点之间的通信
- 如果容器所加入的任何网络都不具有外部连接性,Docker把容器连接到docker_gwbridge
你可以提前手工创建docker_gwbridge网络,进行定制化配置。
当使用overlay网络时,docker_gwbridge总是存在。
利用Overlay网络可以跨越多台宿主机组网。
在swarm模式下运行Docker引擎时,你可以在管理节点上创建overlay网络,这种网络不需要外部的key-value存储。
swarm可以让overlay网络仅仅对需要它以提供一个服务的swarm节点可用。当你创建一个使用overlay网络的服务时,管理节点会自动扩展overlay网络以覆盖运行服务的节点。
下面的命令示例如何在swarm管理节点创建overlay网络,并在服务中使用它:
|
1 2 3 4 |
# 创建一个overlay网络 docker network create --driver overlay --subnet 10.0.9.0/24 my-multi-host-network # 创建一个Nginx服务,并把刚刚创建的网络扩展到运行Nginx服务的那些节点 docker service create --replicas 2 --network my-multi-host-network --name my-web nginx |
注意:这种overlay网络对docker run启动的容器是不可用的,目标容器必须是swarm模式服务的一部分。
基于swarm模式的overlay网络默认具有安全保证。swarm节点使用gossip协议来交换overlay网络的信息,并且使用GCM模式的AES算法加密gossip协议,管理节点默认每12小时更换密钥。
如果要加密容器通过overlay网络交换的信息,需要使用选项:
|
1 |
docker network create --opt encrypted --driver overlay nw |
上述命令将自动为参与到overlay网络的节点创建IPSEC通道,这些通道也使用GCM模式的AES算法,每12小时更换密钥。
此方式的overlay网络与swarm模式的overlay网络不兼容。主要用于需要考虑兼容性的场景。
当不在swarm模式下使用Docker引擎时,启用overlay网络依赖于外部key-value存储的支持,这些存储包括Consul、Etcd、ZooKeeper。你需要手工安装这些存储,并确保它们可以和Docker宿主机自由通信。
宿主机必须开启4789、7946端口。如果启用加密的overlay网络(--opt encrypted)则需要允许protocol50(ESP)流量。此外KV服务也需要暴露端口。
各宿主机上的Docker引擎守护程序,需要配置dockerd选项以支持overlay网络:
| 选项 | 说明 |
| --cluster-store=PROVIDER://URL | 指名KV服务的位置 |
| --cluster-advertise=HOST_IP|HOST_IFACE:PORT | 指定用于集群的宿主机网络接口 |
| --cluster-store-opt=KEY-VALUE OPTIONS | 指定KV服务的配置项 |
这种网络不同于overlay,可以把容器直接暴露到物理网络中。
首先,创建网络:
|
1 2 3 4 |
# 设置目标网卡为混杂模式 sudo ip link set virbr0 promisc on # parent指定桥接到的宿主机网卡,以及子网信息 docker network create -d macvlan --subnet=10.0.0.0/8 --gateway=10.0.0.5 -o parent=virbr0 virbr0 |
然后,运行容器:
|
1 |
docker run -it --rm --network=virbr0 --ip=10.0.0.100 ubuntu:14.04 |
注意,如果不指定IP,则容器的IP会从当前网段的192.168.0.2开始分配,不管是否被占用。
连接到默认桥接网络,且以--link选项创建容器时:
- 可以解析其它容器的名字为IP
- 可以为其它容器指定任意别名: --link=CONTAINER-NAME:ALIAS
- 安全容器连接,即--icc=false
- 环境变量注入
当使用自定义桥接网络时,上述特性默认启用,不需要额外的选项。并且你可以:
- 基于网络内嵌的DNS服务器进行容器名到IP的解析
- 使用--link(仅用来)指定别名
link选项的示例:
|
1 2 3 4 |
# 创建容器,连接到isolated_nw,并且当前容器访问container5时可以使用别名c5 docker run --network=isolated_nw -itd --name=container4 --link container5:c5 busybox # 在连接到某个网络时,也可以指定link选项 docker network connect --link container5:foo local_alias container4 |
与--link不同 ,该选项可以指定当前容器在网络中的别名,网络中的其它容器都可以使用该别名:
|
1 |
docker run --network=isolated_nw -itd --name=container6 --network-alias app busybox |
多个容器可以声明相同的别名,这种情况下,其中一个容器(随机)会响应DNS解析。当该容器宕掉后,其它同名容器自动响应解析。这个特性可以用来实现简单的高可用性。
自定义网络中的容器的DNS查找行为与默认bridge网络不同,处于向后兼容的目的,后者的行为与旧版本保持一致。
自1.10版本开始,Docker守护程序嵌入了DNS服务,此服务支持基于容器link、name、net-alias配置的DNS查找。容器还可以通过--dns等选项来指定外部DNS服务器,当内嵌DNS服务器无法解析某个主机名时,会转给外部DNS处理。
默认情况下,容器不被施加资源限制,可以使用宿主机内核调度器允许的最大资源。Docker提供了控制内存、CPU、块I/O用量限制的方法。
你可以为容器施加硬性内存限制,确保容器不占用超过特定值的用户/系统内存。你也可以施加软性限制,允许容器按需使用内存,但当特定条件(例如内核检测到宿主机内存过低)发生时,限制容器内存占用。
内存限制通过docker run命令的选项给出,这些选项的值都是正整数,后面可以跟着b/k/m/g等单位:
| 选项 | 说明 |
| -m --memory | 限制容器能够使用的最大内存量,最小值4m |
| --memory-swap | 该容器可以被交换到磁盘的内存的量 |
| --memory-swappiness | 0-100之间, 允许宿主机交换出容器使用的匿名页的百分比 |
| --memory-reservation | 指定一个小与-m的软限制,当Docker检测到宿主机存在内存争用、内存低下情况时,限制容器使用不超过此数值的内存 |
| --kernel-memory | 限制容器能够使用的最大内核内存,最小值4m。注意内核内存不能被换出 |
| --oom-kill-disable | 默认情况下内存溢出错误发生后,Docker会杀死容器中的进程,此选项禁用该默认行为 |
默认的,容器可以无限制的使用CPU时钟周期。Docker提供了若干选项,对容器的CPU使用进行限制。这些选项支持CFS调度器,自1.13开始实时调度器也支持某些选项。
CFS是用于大部分Linux进程的调度器,Docker提供以下容器选项:
| 选项 | 说明 |
| --cpus |
指定容器可以使用多少CPU资源。如果宿主机具有2个CPU,你可以设置该选项为1.5表示容器最多使用1个半CPU的运算能力 --cpus=1.5和配置--cpu-period="100000" --cpu-quota="150000"等价 |
| --cpu-period | 指定CFS调度周期数 |
| --cpu-quota | 指定CFS调度配额数 |
| --cpuset-cpus | 限制容器能够使用的CPU核心,0-3表示可以使用第1-4个CPU核心,1,3表示可以使用第二个、第四个 |
| --cpu-shares |
默认值1024,设置更大或者更小的值,可以调整容器可以访问的CPU时钟周期的相对权重 如果足够的空闲CPU周期存在,此选项不会限制容器的CPU使用 在Swarm模式下,该选项不会限制容器被调度 |
自1.13版本开始,Docker支持配置容器使用实时调度器。作为前提条件,宿主机内核选项CONFIG_RT_GROUP_SCHED必须开启。
要使用实时调度器运行容器,需要设置dockerd选项 --cpu-rt-runtime 来指定在某个运行周期内,为实时任务保留的毫秒数。对于默认的10000微秒周期,设置--cpu-rt-runtime=95000意味着至少保留5000微秒给非实时任务使用。
相关配置选项:
| 选项 | 说明 |
| --cap-add | 授予容器CAP_SYS_NICE特性,这样容器可以提升进程的nice值、设置实时调度策略、设置CPU关联性(affinity) |
| --cpu-rt-runtime | 在Docker守护程序的实时调度周期内,容器最多可以使用的微秒数 |
| --ulimit | 容器的最大实时优先级 |
典型的容器在启动时,仅仅会发动一个进程——例如Apache或者SSH守护进程。要在容器中运行多个服务,你可以编写脚本,或者使用进程管理工具。
Supervisor是一个流行的进程管理工具,使用它可以更加方便的控制、管理、重启容器中的进程。本章以一个例子来说明如何使用Supervisor来管理容器中的多个服务。
|
1 2 3 4 5 6 7 8 9 10 |
# 安装Supervisor和两个服务 RUN apt-get update && apt-get install -y openssh-server apache2 supervisor # 守护进程需要的目录 RUN mkdir -p /var/lock/apache2 /var/run/apache2 /var/run/sshd /var/log/supervisor # 复制Supervisor配置文件到容器上下文 COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf # 暴露端口 EXPOSE 22 80 # 容器启动时执行supervisord CMD ["/usr/bin/supervisord"] |
该配置文件内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
; 第一段,配置Supervisor本身 ; nodaemon提示Supervisor以交互式运行,而不是守护式。这样可以确保它可以正常接收信号 [supervisord] nodaemon=true ; 以下的每个段,分别定义一个需要被控制的服务 [program:sshd] command=/usr/sbin/sshd -D [program:apache2] command=/bin/bash -c "source /etc/apache2/envvars && exec /usr/sbin/apache2 -DFOREGROUND" |
该命令可以实时监控容器的CPU、内存、网络、块I/O资源的占用情况。
Linux容器所依赖的内核机制——控制组(Cgroups),不仅仅支持跟踪进程组,还暴露了度量CPU、内存、块I/O的接口。
控制组通过一个伪文件系统 /sys/fs/cgroup 暴露,每一个子目录对应了一种Cgroup层次(子系统)。某些老的系统挂载位置可能有不同,你可以执行 grep cgroup /proc/mounts 命令以查看。
在每个子系统内部,可以存在多级子目录。这些目录的最深处,会包含1-N个伪文件,其中包含了统计信息。
查看文件/proc/cgroups可以查看系统中已经支持的Cgroup层次。输出中包含Cgroup子系统名称、包含的组数量等信息。
查看文件/proc/$PID/cgroup可以查看某个进程所属的Cgroup。输出 / 表示没有划分到特定的Cgroup,/lxc/pumpkin可能意味着进程属于容器pumpkin的成员。
子系统memory提供内存的统计信息。由于memory控制组会增加一定的overhead,因此某些发行版默认情况下禁用了它。你可能需要添加内核参数:
|
1 |
cgroup_enable=memory swapaccount=1 |
该子系统对应的伪文件是memory.stat。不包含total_前缀的数据项,与当前Cgroup中的进程有关,包含total_d前缀的数据项,则与当前Cgroup、所有子代Cgroup中的进程有关。
常用数据项列表如下:
| 度量 | 说明 |
| cache | 使用的系统缓存量,这些缓存代表映射到块文件系统中的内存页。当你读写文件(open/write/read系统调用)、进行内存映射(mmap系统调用)、挂载tmpfs时,该数据项值增加 |
| rss | 没有映射到块文件系统的内存页,包括栈、堆、匿名内存映射 |
| mapped_file | Cgroup中进程映射的内存的量 |
| pgfault, pgmajfault |
Cgroup中进程触发页错误(page fault)、页major fault的次数 当进程访问不存在(例如访问无效地址,这可能导致进程接收附带Segmentation fault消息的SIGSEGV信号进而被杀死)、或者被保护(进程读取当前已经被换出的页)的虚拟内存空间时,会触发页错误 Major错误在内核真实的从磁盘读取页时发生 |
| swap | Cgroup中进程当前使用的交换文件大小 |
| active_anon, inactive_anon |
被内核识别为活动、非活动的匿名内存的量。所谓匿名内存是指没有和磁盘页关联的内存 页一开始的状态是活动的,内核会定期扫描内存,并把某些页标记为非活动。一旦这些页再次被访问,立即重新标记为活动。当内存不足需要交换出磁盘时,非活动页被交换出 rss = active_anon + inactive_anon - tmpfs |
| active_file, inactive_file |
被内核识别为活动、非活动的非内存的量 cache = active_file + inactive_file + tmpfs |
| unevictable | 不可交换出磁盘的内存用量。某些敏感信息,例如密钥,会被mlock保护,防止被交换到磁盘上 |
| memory_limit, memsw_limit | 不是真正的度量信息,而是应用到Cgroup的资源限制。前者为物理内存用量限制,后者为物理内存+Swap |
该子系统对应的伪文件是cpuacct.stat,包含容器中进程累计的CPU使用信息。user、system分别表示用户空间、系统空间中代码消耗的时间。时间的单位为jiffies,在X86上通常为10ms。
| 度量 | 说明 |
| blkio.sectors | Cgroup中进程读取/写入的512字节的扇区总数 |
| blkio.io_service_bytes | Cgroup中进程读取/写入的字节数,每个设备包含4个数据,分别对应同步/异步的读/写 |
| blkio.io_serviced | Cgroup中进程读取/写入操作次数,每个设备包含4个数据,分别对应同步/异步的读/写 |
| blkio.io_queued |
Cgroup中进程发起的、正在排队的I/O操作数量。如果Cgroup没有执行任何I/O操作,则计数为0,如果Cgroup正在执行IO操作,计数可能为0——例如正在空闲设备上执行纯同步操作 注意此计数是一个相对值。可以用来判断哪个容器在给IO系统施加压力 |
Cgroup没有直接暴露网络度量信息。尽管内核可以计算出一个Cgroup中进程收发的网络包数量,但是意义不大。你可能需要基于网络接口的度量,因为lo接口上的流量没有太大价值。
单个Cgroup中的进程可以属于多个网络名字空间( network namespace),多个网络名字空间意味着多个lo甚至eth0,这导致难以收集Cgroup的网络流量。
你可以基于iptables规则设置计数器,然后使用命令获取度量。
获取网络接口级别的度量信息是可能的,因为每个容器都关联了宿主机上的一个虚拟以太网接口。但是难以知道这些接口和容器的对应关系。
命令 ip netns exec 允许你在宿主机上,进入任意网络名字空间,执行任意命令。这意味着宿主机可以进入容器的网络名字空间。参考如下命令:
|
1 2 3 4 5 6 7 8 |
# $CID为容器ID,TASKS为容器下进程的PID列表 TASKS=/sys/fs/cgroup/devices/docker/$CID*/tasks PID=$(head -n 1 $TASKS) # 创建后面命令需要的符号连接 mkdir -p /var/run/netns ln -sf /proc/$PID/ns/net /var/run/netns/$CID # 在容器的网络名字空间下执行netstat命令 ip netns exec $CID netstat -i |
对于每一个容器,在每一个Cgroup子系统中均会创建一个与之对应的组。
如果使用最近版本的LXC工具,Cgroup名字为lxc/$container_name。
对于使用Cgroup的Docker容器,Cgroup路径为/sys/fs/cgroup/$subsystem/docker/$longid/,其中longid为容器完整的ID。
要使用Swarm模式,你可以安装1.12版本以上的Docker。Swarm模式用于管理Docker引擎的集群。你可以使用Docker CLI来创建Swarm、部署应用服务到Swarm、管理Swarm的行为。
|
集成到Docker引擎的集群管理功能 你可以直接使用Docker CLI来管理Swarm,不需要额外的软件或者组件 |
|
去中心化设计 Docker引擎在运行时来处理节点角色的特殊化——Manager还是Worker,而不是在部署期间。你可以用单个镜像来部署整个Swarm |
|
声明式服务模型 Docker引擎基于一种声明式的途径来定义你的应用栈中各种服务的期望状态。例如你可以声明式的描述由三个组件构成的应用:前端Web服务、消息队列服务、数据库 |
|
扩容(Scaling) 对于每一个服务,你可以声明你期望运行的任务数(Tasks)。当Scale up/down时Docker引擎会自动add/remove任务,以维持期望的状态 |
|
期望状态协调(Desired state reconciliation) Swam管理节点会持续监控集群的状态,并且尽可能消除当前状态与期望状态之间的差别。例如,假设你定义一个运行容器10个实例的服务,而一台运行2个实例的宿主机宕机了,此时管理节点会自动创建两个实例代替之,并把实例分配给可用的Worker节点 |
|
跨主机网络支持 你可以为服务创建Overlay网络,管理节点会在初始化、更新应用程序时,自动为容器分配对应Overlay网络上的IP地址 |
|
服务发现 管理节点为Swarm中的每个服务分配唯一的DNS名称,你可以通过Swarm中内嵌的DNS进行服务查找 |
|
负载均衡 你可以选择暴露服务的端口给外部的负载均衡器。在内部,Swarm允许你指定如何在节点之间分发服务 |
|
安全性 Swarm中节点之间的通信基于TLS认证和加密。你可以使用自签名根证书 |
|
滚动更新(Rolling updates) 你可以增量的更新节点上的服务,Swarm允许控制不同节点集上服务部署的延迟。如果出现异常情况,你可以把一个Task回滚到上一个版本 |
|
Swarm 基于SwarmKit构建的、内嵌在Docker引擎中的集群管理和编排机制。参与到Swarm集群中的Docker引擎运行在Swarm模式。要切换到Swarm模式,你可以新建一个Swarm、或者加入一个既有的Swarm Swarm也可以指代基于上述机制的Docker引擎(或者叫节点)集群,你在Swarm中部署服务。CLI和Docker API包含管理节点、部署和编排服务的命令 在普通模式下,你执行容器命令;在Swarm模式下,你编排服务。在同一个Docker引擎下,你可以同时运行独立容器、Swarm服务 |
|
Node 节点即参与到Swarm中的Docker引擎。你可以在单台物理机器上运行一个或者多个节点。通常生产环境下Swarm由跨越多台物理机器的节点组成 要部署应用到Swarm,你需要把服务定义(service definition)到管理节点。管理节点负责分发称为任务(Task)的工作单元给Worker节点 管理节点也负责执行服务编排、集群管理功能,以维持集群处于期望的状态。管理节点们会推举一个Leader节点来主导编排工作 Worker节点接收、执行管理节点派发的任务,默认情况下管理节点也像Worker节点一样运行服务,但是你可以将其配置为Manager-only节点。Worker节点上运行着一个代理(Agent),此代理负责报告分配给Worker的Task的状态到Manager,这样Manager就可以维持期望状态 |
|
Service & Task 所谓Service,是关于需要在Worker节点上执行的Tasks的定义。服务是Swarm系统的核心结构,也是用户和Swarm交互的主要切入点 当定义服务时,你可以指定使用什么镜像,以及当运行容器时需要执行什么命令 在复制服务( replicated services)模型下,Manager节点会基于你在期望状态中设置的Scale,分发一定数量的复制Task 对于全局服务(global services),Swarm在集群中每个可用节点上,运行此服务的单个Task Task使用一个容器,并在其中执行特定的命令。Task是Swarm的原子调度单元。前面提到过,Swarm根据Service的Scale设定决定Task的数量并分发。分发的Task只能在某个节点上运行或者失败,而不能转移到其它节点 |
|
负载均衡 Swarm基于入口负载均衡(ingress load balancing )暴露对外服务。你可以为服务配置PublishedPort,如果不指定Swarm可以自动分配30000-32767之间的端口 诸如云负载均衡器之类的外部组件,可以访问Swarm集群中任意节点的PublishedPort以使用服务,不管节点是否运行服务的Task。所有节点都会自动把入口连接路由到运行了Task的节点 Swarm基于内部负载均衡(internal load balancing)将请求分配给服务的实例,其依据是服务的DNS名称。Swarm内置的DNS组件会自动的给所有Service分配DNS条目 |
准备三台宿主机,一台用作Manager,其它的用作Worker。Swarm中所有节点都必须能够访问Manager的IP地址。以下端口必须开启:
| 端口 | 类型 | 说明 |
| 2377 | TCP | 此端口用于集群管理通信 |
| 7946 | TCP/UDP | 用于Overlay网络的流量传输 |
| 4789 | UDP | 用于容器入口路由网 |
默认的,Swarm模式是禁用的。你可以创建新Swarm、加入既有Swarm,以使当前节点进入Swarm模式。
确保Docker引擎守护程序正在运行,然后登录到Manager节点,执行:
|
1 |
docker swarm init --advertise-addr 10.0.0.1 |
这样当前节点就称为新建Swarm集群的管理节点了。管理节点使用通知地址(advertise address)来允许集群中其它节点访问Swarmkit API以及Overlay网络,因此IP地址10.0.0.1必须可以被所有其它节点访问到。如果宿主机具有单个IP地址,你可以不指定--advertise-addr,反之则必须指定。
执行docker info,可以看到当前Swarm的基本信息;执行docker node ls则可以看到集群中的节点列表。
首先在Manager节点上执行:
|
1 2 3 4 5 6 |
# 获取Worker的加入令牌 docker swarm join-token worker --quiet # 输出 SWMTKN-1-5evgfnqh3xw67rtqucyq3cctxb929sqwfczv8s1gtz0cptpe5m-84evs0quy124fql5zcyxp7ppe # 获取Manager的加入令牌 docker swarm join-token manager --quiet |
登录到用作Worker节点的宿主机,执行:
|
1 |
docker swarm join --token SWMTKN-1-...-... 10.0.0.1:2377 |
作为工作节点加入时,swarm join子命令会执行以下操作:
- 把目标节点的Docker引擎切换到Swarm模式
- 向管理节点请求一个TLS证书
- 基于宿主机名来命名节点
- 通过管理节点的通知地址、基于令牌加入目标节点到集群中
- 设置目标节点的可用性为Active,使之能够接收Task
- 扩展ingress overlay网络,使之覆盖当前节点
作为管理节点加入时,执行的操作与上面类似。新的管理节点状态为Reachable,但是Swarm的Leader不变。
所谓令牌,是加入Swarm时需要的一个字符串,作为管理节点/工作节点加入时的令牌是不一样的。管理节点的令牌要特别注意保护。当发生以下情况下,考虑使用join-token子命令更改(rotate)令牌:
- 令牌被意外泄漏,例如签入到版本控制系统
- 如果怀疑某个节点被入侵
- 如果期望禁止任何可能的新节点加入到Swarm
- 建议最多每6个月更换令牌
下面的命令示例如何更换工作节点令牌:
|
1 |
docker swarm join-token --rotate worker |
在管理节点上运行 docker node ls 可以查看Swarm中所有节点的基本信息。
输出的AVAILABILITY列表示节点的可用性:
| 可用性 | 说明 |
| Active | 调度器可以分配任务给此节点 |
| Pause | 调度去不会分配新任务给此节点,但是既有的任务会保持运行 |
| Drain | 调度去不会分配新任务给此节点,并且节点上正在运行的任务会被停止,重新分配到Active节点上运行 |
输出的MANAGER STATUS表示节点参与Raft consensus的情况:
| 管理节点状态 | 说明 |
| Leader | 此节点是主管理节点,负责所有Swarm管理工作、编排决定 |
| Reachable | 此节点参与Raft consensus,如果当前的主管理节点宕机,此节点有望晋升 |
| Unavailable | 此节点无法和其它管理节点通信。这种情况下你要么重新添加一个管理节点,要么提升一个工作节点为管理节点 |
所谓服务就是在特定镜像上执行的命令,而任务即服务的实例,任务的数量即服务的replicas个数。
在管理节点上运行:
|
1 |
docker service create --replicas 4 --name ping ubuntu:14.04 ping 10.0.0.1 |
即可创建在Ubuntu 14.04上运行ping命令的服务,这个服务有4个实例(Task) 。
执行下面的命令可以查看任务执行的概要信息:
|
1 2 3 4 |
docker service ls # ID NAME REPLICAS IMAGE COMMAND # 48qbjfwd8u8r ping 1/4 ubuntu:14.04 ping 10.0.0.1 |
如果想让服务对Swarm外部可见,你需要暴露特定的端口。
你可以设置服务的环境变量、工作目录、运行身份:
|
1 |
docker service create --name ping --env MYVAR=myvalue --workdir /tmp --user my_user ... |
使用--secret选项,可以授予服务对Docker管理的Secret的访问权。
可以执行以下命令查看服务执行的详细信息:
|
1 2 |
docker service inspect --pretty ping docker service ps ping |
在管理节点上执行下面的命令,可以动态的修改服务的任务数量:
|
1 |
docker service scale ping=1 |
在管理节点上执行下面的命令可以删除服务:
|
1 |
docker service rm ping |
注意,尽管服务被删除,执行Task的容器可能还需要一段时间执行清理工作
所谓滚动更新,是指逐步的更新服务的每个实例。下面的例子演示如何从Redis 3.0.6滚动更新到Redis 3.0.7。
首先创建服务:
|
1 |
docker service create --replicas 3 --name redis --update-delay 10s --update-parallelism 1 redis:3.0.6 |
选项--update-delay定义了更新一个/一组任务的延迟时间,你可以使用10m30s这样的形式。 默认情况下是一个接着一个的更新,要每次更新多个Task可以使用选项--update-parallelism。
默认情况下,当正在更新的任务状态变为RUNNING后,调度器会调度下一个任务的更新,此步骤一直执行直到所有任务都被更新,如果更新过程中任何一个任务返回FAILED状态,则调度器暂停更新。选项--update-failure-action可以改变此行为。
执行下面的命令把Redis版本更改为3.0.7:
|
1 2 3 4 5 6 7 8 |
docker service update --image redis:3.0.7 redis # 更新步骤: # 1、停止第1个任务 # 2、调度此任务的更新操作 # 3、启动被更新过的任务 # 4、如果新任务返回RUNNING,继续更新下一个任务 # 5、如果新任务返回FAILED,暂停更新 |
要重启被暂停的更新,可以执行:
|
1 |
docker service update redis |
如果更新后的服务工作不正常,你可以回滚到前一个版本:
|
1 2 3 |
# --rollback 回滚服务 # --update-delay 0s 立即回滚 docker service update --rollback --update-delay 0s my_web |
当Swarm中的几个服务需要相互通信时,可以使用Overlay网络。
首先,在Swarm模式下的管理节点上创建Overlay网络:
|
1 |
docker network create --driver overlay my-network |
这样,所有管理节点都可以访问该Overlay网络了。创建服务:
|
1 |
docker service create --replicas 3 --network my-network --name my-web nginx |
这样,所有运行my-web服务的Task的节点,都被Overlay网络覆盖。
前面例子中的Worker节点,其可用性(availability)都是ACTIVE。Manager节点可以向ACTIVE派发任务。
某些时候(例如需要维护节点硬件),需要把可用性设置为DRAIN。DRAIN阻止管理节点派发新的任务,并且,停止DRAIN节点上正在运行的任务,在可用的ACTIVE节点上启动对应数量的任务副本。
执行下面的命令可以查看节点可用性:
|
1 2 3 4 5 6 |
docker node ls # ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS # 5imye5fakqgdd7jg6erkize8a coreos Ready Active # ap7gwtam1jjqvp3h4arco6vdz * Zircon Ready Active Leader # bfini24kw83rzrh2e5cb33g8f Jade Ready Active |
执行下面的命令可以设置DRAIN:
|
1 2 |
# 可以使用HOSTNAME或者ID docker node update --availability drain coreos |
维护完成后,重新设置为ACTIVE:
|
1 |
docker node update --availability active coreos |
为了让外部资源能够轻松的访问Swarm中的服务,Docker引擎提供了方便的端口暴露机制。所有Swarm节点均参与到一个入口路由网(Ingress Routing Mesh),此路由网允许Swarm中的任意节点接收某个服务暴露端口的请求——甚至在节点没有运行此服务的任务的情况下。路由网负责把对暴露端口的请求路由到活动的服务容器中。
要正常使用入口路由网,需要确保TCP/UDP端口7946、UDP端口4789开放。当然,Swarm服务暴露的端口也需要被外部资源(例如负载均衡器)正常访问。
要暴露端口,可以在创建服务时使用 --publish PUBLISHED-PORT:TARGET-PORT 选项。其中TARGET-PORT是运行服务实例(Task)的容器监听的端口,PUBLISHED-PORT则是Swarm对外暴露的端口。示例:
|
1 2 |
# 暴露端口8080,此端口自动转发给my-web服务运行节点上的80端口 docker service create --name my-web --publish 8080:80 --replicas 2 nginx |
对于已经存在的服务,可以在更新时指定 --publish-add PUBLISHED-PORT:TARGET-PORT 选项来新增暴露端口。
暴露的端口,默认是TCP端口,可以使用以下格式指定TCP或者UDP端口:
|
1 2 3 4 5 6 7 |
# TCP --publish 53:53 --publish 53:53/tcp # TCP和UDP --publish 53:53/tcp -p 53:53/udp # UDP --publish 53:53/udp |
使用入口路由网的端口暴露机制,可能不满足应用需求。你可能需要根据应用程序状态来决定如何路由请求,或者你需要对路由处理过程进行完全的控制。
要直接暴露服务所在运行的节点上的端口,可以使用 --publish mode=host 选项。如果不和 --mode=global 联用该选项,将难以知晓哪些节点运行了服务。
在1.13版本之后,在服务创建之后你可以使用 service update --image 更改服务基于的镜像。较老的版本则只能重新创建服务。
每个镜像Tag对应了一个摘要(Digest),就像Git的Hash一样。某些标签,例如latest,其指向的摘要会改变。当你运行service update --image时,管理节点根据Tag到Docker Hub或者本地私服查询。如果:
- 管理节点能够把Tag解析为Digest,则指示工作节点使用Digest对应的镜像来重新部署任务
- 如果工作节点已经缓存了此Digest对应的镜像,则使用之
- 否则,从Docker Hub或者私服拉取镜像
- 如果拉取成功,基于新镜像部署任务
- 否则,服务在工作节点上部署失败。Docker会尝试重新部署任务(可能在其它节点)
- 管理节点不能够正常解析Tag,则指示工作节点使用Tag对应的镜像重新部署任务
- 如果工作节点已经缓存了此Tag对应的镜像,则使用之
- 否则,从Docker Hub或者私服拉取镜像
- 如果拉取成功,基于新镜像部署任务
- 否则,服务在工作节点上部署失败。Docker会尝试重新部署任务(可能在其它节点)
可以使用--replicas选项设置服务的需要的任务数:
|
1 |
docker service create --name my_web --replicas 3 nginx |
可以使用--mode选项设置服务是全局模式还是复制模式:
|
1 |
docker service create --name myservice --mode global alpine top |
选项 --reserve-memory 和 --reserve-cpu 用于声明服务要求的空闲内存、CPU数量。如果节点不满足条件,则不会被分配任务。
你可以为Swarm服务创建两种类型的挂载:volume、bind。要创建挂载,指定--mount选项,如果不指定--type,默认类型为volume。
卷挂载(volume)是当运行任务的容器被移除后,仍然存在的存储。要利用既有的卷时,通常使用此类型的挂载:
|
1 2 3 4 5 |
docker service create --mount src=VOLUME-NAME,dst=CONTAINER-PATH --name myservice IMAGE # 在部署期间(调度器分发任务后、启动容器前)创建一个卷挂载: docker service create --mount type=volume,src=VOLUME-NAME,dst=CONTAINER-PATH,volume-driver=DRIVER,\ volume-opt=KEY0=VALUE0,volume-opt=KEY1=VALUE1 --name myservice IMAGE |
绑定挂载(Bind) 映射到运行服务容器的宿主机。在Swarm初始化容器前,宿主机路径必须存在。示例:
|
1 2 3 4 |
# 挂载为读写 docker service create --mount type=bind,src=HOST-PATH,dst=CONTAINER-PATH --name myservice IMAGE # 挂载为只读 docker service create --mount type=bind,src=HOST-PATH,dst=CONTAINER-PATH,readonly --name myservice IMAGE |
绑定挂载很有用,但是也可能很危险:
- 由于任务可能被分配到任何满足条件的节点上,而绑定挂载要求路径预先存在
- 调度器可能在任何时候重新分配某个任务
管理节点负责以下集群管理工作:
- 维护集群状态
- 调度服务
- 提供Swarm模式的HTTP API端点服务
基于Raft(一种算法),管理节点维护整个Swarm、所有运行中服务的一致性内部状态。
在测试环境下,你可以使用单管理节点,但是,一点此节点宕机,你需要重新创建Swarm才能恢复。
为了利用Swarm的容错特性,最好建立奇数节点数的管理节点。如果有多个管理节点,Swarm可以自动从管理节点宕机中恢复,没有downtime。当总计3个管理节点时,可以容忍1个宕机;当5个管理节点时,可以容忍2个宕机;当N个管理节点时,可以容忍(N-1)/2个管理节点宕机。Docker推荐每个Swarm中有7个管理节点。
工作节点的唯一任务就是执行容器。默认的,管理节点同时也是工作节点。
要阻止派发任务给管理节点,可以将后者的可用性设置为Drain,调度器会优雅的停止Drain上运行的任务并且在其它节点上重新调度。
要在Swarm模式下部署应用程序,你需要创建一个“服务”。通常情况下,服务是某个较大应用程序的上下文中的某个“微服务“, 例如HTTP服务、数据库服务、或者任何形式的可执行程序。
当创建服务时,你需要指定使用什么镜像,以及在基于此镜像的容器中运行什么命令。你可以同时指定:
- Swarm暴露的端口,这使得服务对外可用
- 让服务可以与Swarm中其它服务进行通信的Overlay网络
- CPU和内存限额、预留
- 滚动更新策略
- 服务的复制(replicas)份数
当你在Swarm中部署服务时,Swarm接受你给出的服务定义(service definition),作为目标服务的期望状态(desired state )。之后,Swarm调度服务,形成在节点上运行的一个或N个任务。每个任务独立于集群中其它节点运行。
下面是具有三个Replica的HTTP服务的例子:
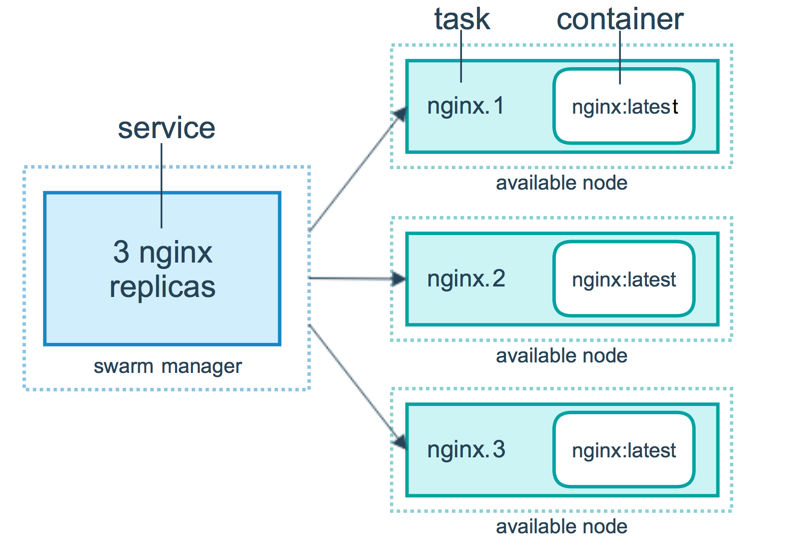
容器是一个被隔离的进程,在Swarm模式的模型中,每个任务调用仅一个容器。任务就好像是一个插槽,调度器将容器插入其中。一旦容器开始运行,调度器将任务设置为RUNNING状态;如果容器未通过健康检查、停止运行,则任务也被终结。
任务是Swarm调度的原子单元。当你通过创建/更新服务来声明服务的期望状态时,编排器(orchestrator)识别出被调度任务的期望状态——当你声明保持3个HTTP服务一直运行,编排器就会创建三个任务。
任务是一个插槽,调度器产生容器进程并填充到插槽。容器是任务的实例。任务是一种单向的机制,它从:已分配(assigned)、已准备(prepared)、正在运行(running)等一系列状态单向的前进。如果某个任务未通过健康检查或者终结,任务及其容器被编排器移除,新的副本任务以及对应的容器被创建,以满足期望状态。
Swarm模式底层组件包括了一般性用途的调度器、编排器。服务、任务的抽象实现,不理解容器这个概念。理论上你可以实现在非容器中运行的服务。
下图说明Swarm模式如何接受用户创建服务的请求,如何调度服务:
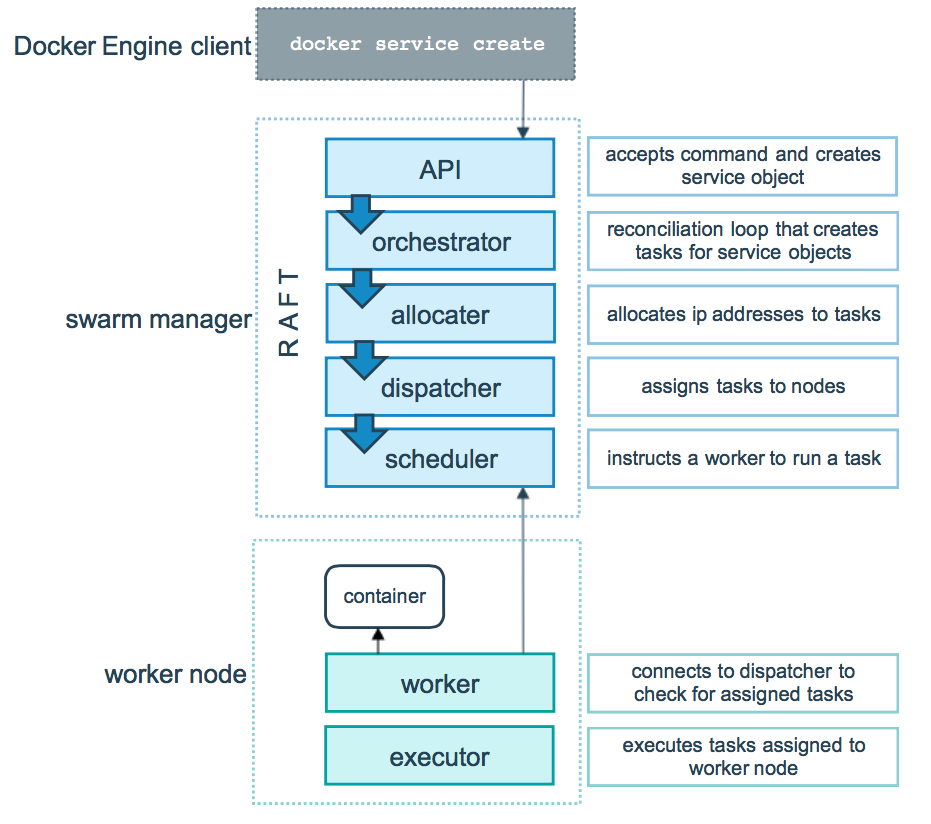
可以配置服务未悬挂的(pending),这样Swarm中没有节点可以运行该服务的任务。如果你仅仅需要防止服务被部署,只需要Scale到0,而不是尝试让服务进入pending状态。
下列情况下,服务会变为pending:
- 如果所有节点被paused或者drained,那么新创建的服务会保持pending状态,直到某个节点可用。在实际情况下,第一个可用的节点会获得所有任务
- 你可以为任务保留一定量的内存,如果Swarm中所有节点都没有足够的内存,则服务保持pending状态
从部署份数的角度来看,服务可以分为复制(replicated)、全局(global)两种。
复制服务,由指定数量的任务构成。全局服务则在每个节点运行单个任务。
Swarm模式下,我们可以使用Docker secrets管理敏感数据。所谓Secret是指一块数据,存放密码、SSH私钥、SSL证书或者其它不应该通过网络传递、明文存放在Dockerfile中的信息。
Compose是用于定义、运行多容器Docker应用程序的工具。通过编辑一个Compose文件,你可以配置应用程序的服务组件,然后,只需要单条命令,你就可以创建、启动所有需要的服务。
使用Compose通常包括以下三大步骤:
- 使用Dockerfile定义应用程序的环境,以便可以在任何地方重现
- 在文件docker-compose.yml中定义构成应用的服务组件,以便它们可以在一个隔离的环境下运行
- 最后,执行 docker-compose up 启动整个应用
|
单个宿主机上的多个隔离环境 Compose使用工程名称(project name)来隔离环境,你可以在几个上下文中使用工程名称:
工程名称默认为工程的目录名,你可以使用-p选项或者 COMPOSE_PROJECT_NAME 环境变量设置工程名称 |
|
在创建容器时保留卷数据 Compose会保留你的服务使用的所有卷。当执行docker-compose up时,如果发现某个容器之前运行过,则将其卷复制给新容器实例,确保你在卷中的数据不丢失 |
|
仅重建变化了的容器 Compose会缓存用于创建容器的配置信息,当你重启一个没有变化的服务时,它的容器会被重用,而不是重新创建 |
|
支持变量 你可以在Compose文件中设置变量,以便为不同的运行环境定义服务组合 |
Compose的典型应用场景包括:
|
开发环境 在开发软件时,能够在隔离环境中运行应用程序,并与之交互很关键。Compose很适合创建这样的环境 Compose文件能够配置应用程序的所有依赖(数据库、消息队列、缓存、WebService,等等)。通过一条命令,你可以为每个依赖启动一个或者多个容器 |
|
自动化测试环境 自动化测试套件是CI的重要组成部分。自动化的段对端测试要求一个运行环境,Compose可以方便的创建、销毁隔离的测试环境 |
|
部署环境 Compose典型的应用场景在开发、测试工作流中。但是,你也可以用Compose部署应用到远程Docker——包括单个Docker引擎或者整个Swarm集群 |
Compose可以在macOS、Windows或者64位Linux上运行。在Linux上的安装步骤可以参考:
|
1 2 3 4 5 6 |
sudo curl -L "https://github.com/docker/compose/releases/download/1.11.2/docker-compose-$(uname -s)-$(uname -m)" \ -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose # 查看版本 docker-compose --version |
使用Docker Machine,你可以:
- 在Windows或者Mac上安装、运行Docker。在1.12之前,DM是唯一在Windows/Mac上运行Docker的途径,之后这两个平台有了Native的Docker实现
- 划分/管理多台远程Docker宿主机。可以自动在宿主机上划分虚拟机,并在虚拟机上安装Docker
- 划分/管理Docker Swarm集群
Docker Machine是一套工具,它允许你在虚拟主机上安装Docker引擎,以及通过docker-machine命令来管理宿主机(Machine,通常是虚拟机,这些虚拟机通常由DM创建)。你可以使用DM在非Linux系统、公司网络、数据中心、云端来创建Docker宿主机。
使用docker-machine命令,你可以启动、查看、停止受管理的宿主机,升级Docker客户端/守护程序。
执行以下命令下载并安装:
|
1 2 3 4 5 6 |
curl -L https://github.com/docker/machine/releases/download/v0.10.0/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine chmod +x /tmp/docker-machine sudo cp /tmp/docker-machine /usr/local/bin/docker-machine # 执行命令查看版本信息 docker-machine version |
步骤通常为:
- 创建一个新的(或者启动既有的)宿主机
- 切换环境到宿主机
- 使用Docker客户端创建、载入、管理容器
使用下面的命令创建新的宿主机:
|
1 2 3 |
# 在不支持Hyper-V的老Windows下或者在Mac下,使用virtualbox驱动 # 在支持Hyper-V的Windows下,使用hyperv驱动 docker-machine create --driver virtualbox default |
注意,在Linux下需要VirtualBox预先被安装。
使用命令 docker-machine ls 可以列出现有的虚拟机。
使用下面的命令,可以切换环境变量,指向新创建的宿主机:
|
1 2 3 4 5 6 7 8 9 10 |
# 这个命令用于获取环境变量,这些环境变量导致当前Shell的连接目标改变 docker-machine env default # 输出 # export DOCKER_TLS_VERIFY="1" # export DOCKER_HOST="tcp://172.16.62.130:2376" # export DOCKER_CERT_PATH="/home/alex/.docker/machine/machines/default" # export DOCKER_MACHINE_NAME="default" # 执行下面的命令,切换到default这台宿主机 eval "$(docker-machine env default)" |
现在,你可以针对宿主机进行操作了。要停止或者启动宿主机,可以:
|
1 2 |
docker-machine stop default docker-machine start default |
你也可以连接到既有的宿主机,好处是,管理这台宿主机是,不需要每次提供URL:
|
1 |
docker-machine create --driver none --url=tcp://10.0.0.1:2376 fedora-10 |
宿主机必须预先配置,支持基于TLS的连接。
检查Docker安全性时,有4个主要方面需要考虑:
- 内核本身的安全性:名字空间的支持、Cgroups
- Docker守护程序本身的攻击面(attack surface )
- 容器配置的漏洞,这些漏洞可能是默认就附带的,或者用户定制而引入的
- 内核中固化的安全特性,这些特性如何与容器交互
Docker容器与LXC容器很类似,它们具有相似的安全特性。当你启动容器时,Docker会为容器创建一系列的名字空间和控制组。
名字空间提供第一级的、最直接的隔离性——容器中运行的进程看不到,甚至不能影响到其它容器、宿主机中运行的进程。内核名字空间机制从2.6.15 - 2.6.26版本开始引入,目前已经非常稳定。
每个容器具有自身的网络栈(network stack),这意味着容器不具有其它容器套接字、网络接口的访问权限。当然,如果宿主机正确的配置,容器之间可以基于各自的网络接口进行交互,就像与外部主机一样。
Cgroups是Linux容器的另一个关键组件,它实现了资源审计和限额,并提供很多有价值的度量信息。利用控制组,可以让容器获得公平的CPU、内存、磁盘I/O等资源。Cgroups能够有效的防范某些DoS攻击。Cgroups于2.6.24被合并到内核。
通过Docker运行容器,意味着需要运行Docker守护程序,后者需要Root权限。只有受信任用户才应该被允许控制守护程序。
由于Docker允许在宿主机、容器之间共享目录,这意味着容器可能任意的修改宿主机文件系统。
当在服务器上运行Docker时,推荐宿主机仅仅运行Docker,而把所有其它服务(除了SSH服务器这类管理工具)都放在容器中运行。
默认的,Docker以一组受限的能力(capabilities)来启动容器。能力把root/非root划分为细粒度的访问控制系统。需要绑定到1024-端口的进程不再需要root权限,而仅需要被授予net_bind_service能力。
容器也不需要被授予真正的root权限。事实上,容器中的root用户缺陷受到很大的限制,例如:
- 禁止任何mount操作
- 禁止访问原始套接字(避免包嗅探)
- 禁止某些文件系统操作,例如创建新设备节点、修改文件所有权、修改属性
- 禁止模块加载操作
由于这些限制的存在,即使攻击者获得容器的root权限,也难以进行严重的破坏。
你可以增加、删除容器的能力,以提升功能或安全性。
能力(capabilities)仅仅是现代Linux内核提供的众多安全特性之一。其它已知的著名安全系统包括:TOMOYO、AppArmor、SELinux、GRSEC等,它们都可以和Docker协作。
考虑以下建议:
- 可以基于GRSEC、PAX来运行内核。这样会增加额外的安全检查(编译时、运行时)并防御很多缺陷。不需要针对Docker的配置,因为这些安全特性是系统级的
- 如果你使用的发行版提供了针对Docker容器的安全模型模板(security model templates),你可以使用它们
- 你可以使用某种访问控制系统,定义自己的安全策略
从1.10开始,用户名字空间被Docker直接支持。这一特性允许容器中的root用户直接映射到容器外部的非0 UID的任何用户,进而减少安全风险。这一特性默认没有开启。
默认的,Docker通过非网络化的Unix套接字运行,你也可以基于HTTP套接字与之通信。
如果你期望通过网络安全的访问Docker,应当启用TLS。这样,在守护程序端,仅仅通过CA认证的客户端才允许连接;在客户端,则仅仅允许向通过CA认知的服务器发起连接。
在守护程序上启用TLS的示例:
|
1 |
dockerd --tlsverify --tlscacert=ca.pem --tlscert=server-cert.pem --tlskey=server-key.pem -H=0.0.0.0:2376 |
在客户端上启用TLS的示例:
|
1 |
docker --tlsverify --tlscacert=ca.pem --tlscert=cert.pem --tlskey=key.pem -H=127.0.0.1:2376 version |
在使用Docker的过程中,我们常常需要从/到Docker Hub或者私服pull/push镜像。内容信任(Content trust)机制允许验证数据的完整性、镜像的发布者,不论你是从什么渠道获得镜像。
内容信任机制可以强制客户端在与远程服务(Hub或私服,registry)交互时,进行客户端签名和镜像Tag验证。该机制默认情况下是禁用的,要启用,可以设置环境变量 DOCKER_CONTENT_TRUST 为1。
一旦内容信任被启用,镜像发布者就可以对自己的镜像进行签名。镜像的消费者则可以确保镜像是来自发布者,未经篡改。
每一个镜像记录由以下字段唯一的标识: [REGISTRY_HOST[:REGISTRY_PORT]/]REPOSITORY[:TAG] 。一个镜像仓库(REPOSITORY)可以具有多个标签,镜像构建者可以使用仓库+标签的组合多次构建并更新镜像。
内容信任与TAG部分关联,每个REPOSITORY具有一组供发布者签名镜像TAG的密钥。单个REPOSITORY中可以包含签名、未签名的TAG。对于启用内容信任的消费者,未签名的TAG是不可见的。
子命令push、build、create、pull、run与内容信任机制交互。例如,当你执行docker pull someimage:latest时,仅当someimage:latest被正确签名时,命令才会成功。除了指定TAG,你也可以直接指定签名Hash:
|
1 |
docker pull someimage@sha256:d149ab53f8718e987c3a3024bb8aa0e2caadf6c0328f1d9d850b2a2a67f2819a |
与镜像标签信任管理相关的是一系列的签名密钥。当第一次使用到内容信任功能时,密钥被创建。这些密钥包括:
- 作为内容信任根的离线密钥,该密钥属于发布镜像的组织或个人,必须被客户端妥善的秘密保存,丢弃此密钥将非常难以恢复
- 签名仓库、标签的密钥,该密钥与一个镜像仓库关联,使用该密钥可以pull/push模板仓库的任何标签,保存在客户端
- 服务器管理的密钥,例如时间戳密钥。保存在服务器端
除了通过环境变量来全局性的启用内容信任之外,你还可以在调用docker命令时指定 --disable-content-trust 来临时的禁用内容信任:
|
1 2 3 |
docker build --disable-content-trust -t gmemcc/nottrusttest:latest docker pull --disable-content-trust gmemcc/nottrusttest:latest docker push --disable-content-trust gmemcc/nottrusttest:latest |
当你第一次推送受信任内容时,Docker会提示你:
- 警告你,新的root密钥将被创建
- 提示输入root密钥的密码
- 在~/.docker/trust目录生成root密钥
- 提示输入仓库密钥的密码
- 在~/.docker/trust目录生成仓库密钥
如果启用内容信任机制,没有被签名的镜像是无法拉取的。
要使用自动化脚本来执行镜像TAG签名,你需要设置环境变量:
- DOCKER_CONTENT_TRUST_ROOT_PASSPHRASE 根密钥的密码
- DOCKER_CONTENT_TRUST_REPOSITORY_PASSPHRASE 仓库密钥的密码
本质上此命令行通过REST API和守护程序通信,和守护程序一样。该命令支持HTTP_PROXY、HTTPS_PROXY,并且优先使用后者。
| 子命令 | 说明 | ||||
| build |
基于Dockerfile构建镜像 格式: docker build [OPTIONS] PATH | URL | - 选项: --build-arg value 设置构建时(容器运行时看不到)变量,例如环境变量 |
||||
| info | 查看Docker守护程序的基本信息 | ||||
| images |
列出本地可用的镜像 格式:
选项: -a, --all 显示所有镜像,默认情况下中间镜像被隐藏 示例:
|
||||
| rmi |
示例:
|
||||
| commit |
把容器的变更提交到一个新的镜像中 格式: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] 选项: -a, --author string 镜像作者信息,例如Alex <alex@gmem.cc> 示例:
|
||||
| run |
从一个镜像创建容器并运行指定的命令 格式:
选项: 示例:
|
||||
| create |
创建,但不启动容器 格式: docker create [OPTIONS] IMAGE [COMMAND] [ARG...] |
||||
| start |
启动一个现有的容器 格式: docker start [OPTIONS] CONTAINER [CONTAINER...] 选项: 示例:
|
||||
| stop |
停止一个运行中的容器 格式: docker stop [OPTIONS] CONTAINER [CONTAINER...] 选项: -t, --time int 强制杀死前,等待的秒数,默认10 |
||||
| kill |
杀死一个或者多个容器 格式: docker kill [OPTIONS] CONTAINER [CONTAINER...] 选项: -s, --signal string 用于杀死容器的信号,默认KILL |
||||
| attach |
关联当前终端到运行中的容器,之后你可以按Ctrl+P , Ctrl+Q解除关联(保持容器运行) 格式:
选项: 示例:
|
||||
| exec |
在运行中的容器里执行命令 选项: --detach,-d 后台模式运行 示例:
|
||||
| rm |
删除容器 格式:
选项: -f, --force 强制删除,如果目标容器正在运行则发送SIGKILL信号 示例:
|
||||
| ps |
列出现有的容器 格式:
选项: 示例:
|
||||
| logs |
抓取一个容器的日志 格式: docker logs [OPTIONS] CONTAINER 选项: --details 显示额外信息 示例:
|
||||
| cp |
从容器中复制文件到宿主机,或者从宿主机拷贝文件到容器 格式:
示例:
|
||||
| stat |
显示容器的资源使用情况 格式:
选项: |
||||
| network |
网络相关子命令 通用网络选项: 桥接网络选项: com.docker.network.bridge.name Linux网桥的名称 示例:
|
||||
| load |
从TAR加载镜像,格式:
示例:
|
||||
| save |
保存一个或者多个镜像到TAR归档文件,镜像的层次历史保留 格式:
示例:
|
||||
| import |
从TAR归档文件导入内容,创建一个扁平的文件系统镜像 格式:
|
||||
| export |
导出一个容器的文件系统为TAR归档文件,镜像层次历史丢失 格式:
|
||||
| swarm init |
初始化Swarm集群 格式:
选项: |
||||
| swarm join |
以Worker或/和Manager身份加入到集群 格式:
选项: |
||||
| swarm join-token |
管理加入集群使用的令牌 格式:
-q, --quiet 仅仅显示令牌 |
||||
| swarm update |
更新Swarm集群 格式:
选项: |
||||
| swarm leave |
离开一个Swarm集群,仅用于Worker 格式:
选项: |
||||
| node demote |
把一个或者多个节点降级为Worker 格式: docker node demote NODE [NODE...] |
||||
| node inspect |
查看一个或者多个节点的详细信息 格式: docker node inspect [OPTIONS] self|NODE [NODE...] 选项: -f, --format string 基于给定的模板进行格式化 |
||||
| node ls |
列出集群中的节点 格式: docker node ls [OPTIONS] 选项: -f, --filter value 基于给定的选项过滤输出 |
||||
| node promote |
把一个或者多个节点提升为Manager 格式: docker node promote NODE [NODE...] |
||||
| node rm |
从Swarm中移除一个或者多个节点 格式: docker node rm [OPTIONS] NODE [NODE...] 选项: --force 强制移除活动节点 |
||||
| node ps |
列出节点上运行的Tasks 格式: docker node ps [OPTIONS] self|NODE 选项: -f, --filter value 基于给定的选项过滤输出 |
||||
| node update |
更新一个节点 格式: docker node update [OPTIONS] NODE 选项: --availability string 节点可用性:active/pause/drain |
||||
| service create |
创建一个新服务 格式:
选项: --constraint value 设置约束 |
||||
| service inspect |
查看一个或者多个服务的详细信息 格式: docker service inspect [OPTIONS] SERVICE [SERVICE...] 选项: -f, --format string 基于给定的模板进行格式化 |
||||
| service ps |
列出服务包含的任务 格式: docker service ps [OPTIONS] SERVICE 选项: -f, --filter value 基于给定的选项过滤输出 |
||||
| service ls |
列出服务 格式: docker service ls [OPTIONS] 选项: -f, --filter value 基于给定的选项过滤输出 |
||||
| service rm |
移除一个或者多个服务 格式: docker service rm [OPTIONS] SERVICE [SERVICE...] |
||||
| service scale |
扩容一个或者多个服务 格式:
|
||||
| service update |
更新一个服务 格式: docker service update [OPTIONS] SERVICE 选项: 参考service create子命令 |
||||
| system df | 查看Docker的磁盘占用情况 | ||||
| system prune |
删除停止的容器、无人使用的网络、dangling镜像、构建缓存 选项: -a 同时删除没有容器使用的镜像 |
||||
| volume create |
创建一个卷,卷可以被容器消费,并存储数据到其中 格式: docker volume create [OPTIONS] [VOLUME] 选项: --driver, -d 指定卷驱动名称,默认local 示例:
|
||||
| volume inspect |
显示一个或者多个卷的详细信息 格式: docker volume inspect [OPTIONS] VOLUME [VOLUME...] |
||||
| volume ls |
列出可用的卷 格式: docker volume ls [OPTIONS] 选项: --filter, -f 过滤条件 |
||||
| volume prune |
移除所有不被使用的卷 格式: docker volume prune [OPTIONS] 选项: --force, -f 强制删除不提示 |
||||
| volume rm |
删除一个或多个卷 格式: docker volume rm [OPTIONS] VOLUME [VOLUME...] 选项: --force, -f 强制删除不提示 |
||||
| manifest |
当前是Docker客户端的试验特性。用于管理清单(manifest)或清单列表 所谓清单,是关于镜像的信息,包括层、大小、摘要值。docker manifest命令可以在清单中增加镜像所针对的操作系统、体系结构的信息 清单列表则是通过指定1或多个镜像名称来创建的层列表。典型情况下,清单列表是基于一组功能相同、针对不同os_arch的镜像 当拉取镜像时,Docker会检查返回的清单信息,如果发现是支持multi arch的清单列表对象,则在列表中自动寻找匹配当前体系结构的镜像 注意:
|
||||
| manifest inspect |
查看镜像清单、或者清单列表的信息 格式: docker manifest inspect [OPTIONS] [MANIFEST_LIST] MANIFEST 示例:
|
||||
| manifest create |
创建一个本地清单列表,用于后续的标注、推送。清单的存放位置为: ${HOME}/.docker/manifests/$(REGISTRY_DOMAIN)_$(REGISTRY_PREFIX)_$(IMAGE)-$(VERSION) 要删除清单,删除上述文件即可。此外你也可以在push的时候指定--purge来删除本地清单 清单必须和镜像一同推送到镜像仓库,否则拉取镜像时会提示找不到manifest 格式: docker manifest create MANIFEST_LIST MANIFEST [MANIFEST...] 选项: -a, --amend 修改现有清单列表 示例:
|
||||
| manifest annotate |
为本地镜像清单标注额外的信息,设置清单列表中的某个清单对应的体系结构、操作系统 格式: docker manifest annotate [OPTIONS] MANIFEST_LIST MANIFEST 选项: --arch 标注架构 示例:
|
||||
| manifest push |
将镜像清单列表推送到仓库 格式: docker manifest push [OPTIONS] MANIFEST_LIST 选项: -p, --purge 推送后删除本地清单 示例:
|
| 子命令 | 说明 |
| active | 显示哪些宿主机是活动的 |
| config | 打印一个宿主机的连接配置 |
| create | 创建一个宿主机 |
| env | 打印用于准备连接到目标宿主机的Shell命令 |
| inspect | 显示一个宿主机的详细信息 |
| ip | 获取一个宿主机的IP地址 |
| kill | 杀死一个宿主机 |
| provision | 重新provision现有的宿主机 |
| regenerate-certs | 为一个宿主机准备TLS证书 |
| restart | 重启一个宿主机 |
| rm | 移除一个宿主机 |
| ssh | 通过SSH登录宿主机或者执行命令 |
| scp | 在宿主机之间复制文件 |
| start | 启动一个宿主机 |
| status | 获取宿主机状态 |
| stop | 停止一个宿主机 |
| upgrade | 升级宿主机的Docker到最新版本 |
| url | 获取一个宿主机的URL |
| version | 查看DM的版本信息 |
| 子命令 | 说明 |
| build | 构建或者重新构建服务 |
| bundle | 从Compose创建一个Docker分布式应用程序束(Distributed Application Bundle,ADB) |
| config | 验证并查看Compose文件 |
| create | 创建服务 |
| down | 停止并移除容器、网络、镜像、卷 |
| events | 从容器接收实时事件 |
| images | 列出镜像 |
| kill | 杀死容器 |
| logs | 查看容器的日志 |
| pause | 暂停服务 |
| port | 打印一个端口绑定的公共端口 |
| ps | 列出容器 |
| pull | 拉取服务镜像 |
| push | 推送服务镜像 |
| restart | 重启服务 |
| rm | 移除停止的容器 |
| run | 运行一次性命令 |
| scale | 扩充或减小一个服务的容器数量 |
| stop | 停止服务 |
| top | 显示运行中的进程 |
| unpause | 从暂停中恢复服务 |
| up | 创建并启动容器 |
|
1 2 3 4 5 6 7 8 |
{ "live-restore": true, "log-driver": "json-file", "log-opts": { "max-size": "50m", "max-file": "5" } } |
Docker通过libnetwork实现了此模型,CNM的架构如下:
其中:
- 网络沙盒:提供容器的网络栈,包括网络接口、路由表、DNS配置、Iptables等。实现技术包括Linux网络命名空间、FreeBSD Jail等
- 每个沙盒中可以包含来自多个网络的端点(Endpoint),端点是连接网络沙盒和后端网络的桥梁,实现技术包括Veth对、tap/tun设备、OVS内部端口等
- 容器网络(Backend Network):一组可以相互通信的端点的集合。对应的实现技术可以是Linux Bridge、VLAN等
此外,CNM还依赖于另外两个对象来完成Docker网络管理:
- Network Controller:对外提供分配、管理网络的APIs
- Drivers:负责一种网络的管理,包括IPAM
CNM的原生实现是Libnetwork,是Docker团队从Docker核心中分离出来的网络相关功能。
默认情况下,Docker使用Veth对的方案:
- 创建一个docker0网桥,如果没有容器运行,则此网桥是down状态
- 创建一个Veth对,一端接到网桥docker0,另外一端放在容器网络命名空间中,作为eth0
- 属于同一网络的容器,都会连接到docker0,因此可以相互通信
隧道网络也叫overlay网络,在IaaS网络中就被大量使用。
优势:几乎不依赖基础网络架构,只要3层互联即可。
劣势:
- 随着节点规模的增加,复杂度随之升高
- 封包二次包装,网络问题定位麻烦,而且影响性能
基于覆盖网络的插件包括:
- Weave,基于VXLAN
- Open vSwitch(OVS):基于VXLAN + GRE,性能方面损失较为严重
- flannel:支持自研UDP封包(性能较差,性能损失50%+),以及Linux内核的VXLAN(性能损失20-30%)
隧道方案解决的问题是,主机之间无法直接传递容器IP的封包。如果解决路由的问题,就可以避免二次包装的性能损失。
基于路由的方案包括:
- Calico,基于BGP,支持细致的ACL控制,混合云友好
- Macvlan,隔离性好,性能最优,需要二层网络,大多数云服务商不支持,难以实现混合云
- Metaswitch,容器内部分配一个路由只想宿主机地址,性能接近原生
位置在:/run/containerd/io.containerd.runtime.v1.linux/moby/$CONTAINER_ID/config.json
如果容器正在运行,可以通过nsenter进入。
如果容器已经死掉,可以通过命令:
|
1 |
docker inspect 3b7227ffdb88 | grep UpperDir |
得到UpperDir,然后进入UpperDir,即可在tmp子目录中看到容器修改后的/tmp目录的内容。
老版本Ubuntu: /var/log/upstart/docker.log
使用Systemd的: sudo journalctl -fu docker.service
CentOS: /var/log/daemon.log | grep docker
|
1 2 |
DOCKER_OPTS=" -H 10.0.0.1:2376 -H unix:///var/run/docker.sock" # 测试 docker -H 10.0.0.1:2376 ps |
要让启动的容器自动设置代理环境变量,可以:
|
1 2 3 4 5 6 7 8 9 10 |
{ "proxies": { "default": { "httpProxy": "http://10.0.0.1:8087", "httpsProxy": "http://10.0.0.1:8087", "noProxy": "localhost,127.0.0.1,172.21.*,172.17.*,172.27.*,192.168.*,10.0.*" } } } } |
然后启动容器,你就可以看到对应的环境变量了.
docker pull等操作是发生在守护进程中的,需要按此节的说明设置
必须配置Docker的配置文件,命令行直接设置代理无效:
|
1 2 3 |
# Ubuntu适用 export http_proxy="http://10.0.0.1:8088" export https_proxy="http://10.0.0.1:8088" |
如果使用Fedora,则:
|
1 |
mkdir -p /etc/systemd/system/docker.service.d |
|
1 2 |
[Service] Environment="HTTP_PROXY=http://10.0.0.1:8088/" |
刷出变更并重启服务:
|
1 2 |
systemctl daemon-reload systemctl restart docker |
可能原因是没有登陆到私服
报错信息:certificate has expired or is not yet valid docker
如果测试wget/curl等命令没问题,可能是由于Docker使用的代理导致。
由于NAT(Docker端口映射)导致。默认情况下Docker使用用于空间代理docker-proxy来处理NAT,性能较低。可以设置dockerd参数禁用:
|
1 |
dockerd ... --userland-proxy=false |
Mac OS下可能存在此问题,解决方案:
|
1 |
docker run -v /Users/alex/project:/project:cached alpine command |
进行docker login时出现此错误,可以把目标仓库的证书拷贝到 /etc/docker/certs.d/下,以仓库域名为子目录。
如果使用Let's Encrypt签名的证书,务必使用完整证书链。
在CentOS下,启动firewalld后,新创建Docker容器并进行端口映射会出现此错误。重启Docker即可。
如果无法在宿主机上通过 ip netns list看到容器的网络命名空间,可以调用命令:
|
1 |
ln -s /var/run/docker/netns /var/run/netns |
从1.12开始支持,该参数可以直接传递sysctl变量:
|
1 |
docker run --sysctl net.ipv4.ip_forward=1 |
用于配置命名空间化的内核参数(namespaced kernel parameters)。
注意,仅仅被Docker加入白名单的内核参数可以调整,否则你会收到错误:sysctl '***' is not whitelisted。白名单包括:
- kernel.sem、kernel.shmall、kernel.shmmax、kernel.shmmni、kernel.shm_rmid_forced
- fs.mqueue.***
- net.***
此外,被调整的内核参数还必须是:
- 在容器中可见,例如net.core.rmem_max
- 支持命名空间化,有些配置是全局的,不支持命名空间化
如果使用--net=host,则使用宿主机的网络栈,直接使用宿主机的内核参数,不需要特殊操作。
|
1 |
sudo rm /var/lib/docker/aufs -rf |
原因未知,可能和Docker的NAT存在问题,重启Docker后解决。
访问某通过LVS暴露的接口,20%几率出现Connection Reset By Peer。进一步检查发现:
- 此问题和Docker本身无关,但凡客户端通过NAT访问的,都有几率出现
- curl测试,有几率出现卡死,但是目标接口速度很快
当卡死时,最终提示:curl: (56) Recv failure: Connection timed out,Docker宿主机抓包如下:

可以看到发送HTTP请求后,出现重传,随后即RST。LVS发来的TCP Dup ACK中的SLE、SRE(选择性ACK时,已经Ack的字节范围,提示对方不再传输这些范围的数据)很不正常。在客户端禁用SACK后,问题消失:
|
1 2 3 |
net.ipv4.tcp_sack = 0 net.ipv4.tcp_dsack = 0 net.ipv4.tcp_fack = 0 |
值得注意的是:在NATed的客户端来看,是服务器主动RST,在NAT设备来看,是它主动RST,并谎报给NATed客户端说服务器进行了重置。
可能是DNS配置错误导致的,执行以下步骤修复:
- 修改/etc/default/docker,设置正确的Docker守护程序选项,例如: DOCKER_OPTS="--dns 178.79.131.110 --dns 8.8.8.8"
- 重启Docker守护程序: sudo service docker restart
- 重新构建,指定no-cache选项,强制Docker镜像重新获取DNS: docker build --no-cache=true ...
|
1 |
RUN rm /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime |
部分基础镜像没有/usr/share/zoneinfo目录,需要手工拷贝/etc/localtime文件
两个简单原则:
- 能够处理挂断信号。需要注意,docker stop / docker kill只会向PID为1的容器进程发送信号
- 能够阻止脚本退出
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/env bash # 捕获挂断信号,执行清理 sighdl() { service myservice stop TERM_FLAG=1 } trap sighdl HUP INT PIPE QUIT TERM # 启动服务 service myservice start # 防止脚本退出的命令 while [ "$TERM_FLAG" != "1" ] ; do :; done |
如果防止脚本退出的命令调用了其它程序,例如: tail -f /var/log/myservice.log,会出现一个子进程,虽然上述脚本的PID为1,但是子进程不会收到信号,因而容器仍然卡在那不会退出。
一个生产环境中入口点脚本的例子:Kurento的入口点脚本
层次过多的文件系统,不但访问效率较低,而且占用更大的磁盘空间。可以export容器并import为镜像,这样产生的镜像只有一个层次:
|
1 |
docker export container-name | docker import - image:tag |
在管理节点上预先登录到Docker Hub或者私服,然后:
|
1 2 |
docker service create --with-registry-auth # 添加该选项 --replicas 10 --network overlay --name ping docker.gmem.cc/ubuntu:14.04 ping 10.0.0.1 |
有些情况下,因为配置错误,容器启动后立即退出。如果想通过Shell交互式的查问题,可以:
|
1 2 3 4 5 6 7 8 |
# 提交为临时镜像 docker commit mongo-c6 tempimg # 使用Bash作为入口点进入 docker run --entrypoint=bash -it --rm tempimg # 解决完问题后,删除临时镜像 docker rmi tempimg |
|
1 2 3 4 5 |
# 列出孤儿卷 docker volume ls -qf dangling=true # 删除所有孤儿卷 docker volume rm $(docker volume ls -qf dangling=true) |
使用 docker -v命令把宿主机上不存在的目录挂载到容器指定位置时:
- 自动以root身份创建不存在的目录
- 容器中目录的所有者为root,即使目录本来存在(而被覆盖)且所有者不是root
这种行为会导致潜在的无权访问的问题。
解决办法:容器中的用户,和宿主机的用户,以ID对应。因此,你可以预先创建宿主机目录,并chown给容器中需要使用此目录的用户的ID。
最好确保你的应用程序的PID为1,如果Entrypoint Spawn的子进程中运行应用程序,则Entrypoint必须能够捕获信号并执行适当的命令来停止应用程序进程。
无法捕获信号的常见原因:
- 使用了Shell风格的Entrypoint,这种情况下,入口点变为/bin/sh的子进程,无法收到信号。你需要:
1234# 不要用这种形式ENTRYPOINT "/entrypoint.sh" arg1 arg2# 用下面的形式ENTRYPOINT ["/entrypoint.sh", "arg1", "arg2"] - 入口点调用了应用程序,但是没有替换当前进程。你需要以exec方式调用目标应用程序,例如:
1exec /jdk/bin/java $JAVA_OPTS -cp app.jar $JAVA_MAIN_CLASS $JAVA_MAIN_ARGS -
虽然使用exec替换进程,但是不是替换入口点进程。例如引入了管道:
12# 这会导致在子Shell中进行exec java | grep ... - 可能没有捕获信号并正确处理
报错:OCI runtime create failed: container_linux.go:348: starting container process caused "process_linux.go:297: copying bootstrap data to pipe caused \"write init-p: broken pipe\"": unknown
解决办法:
|
1 |
sudo apt-get install docker-ce=18.06.1~ce~3-0~ubuntu |
以Alpine作为基础镜像,运行动态链接的Go应用程序,出现此报错。
原因是,应用程序动态链接到了 GNU libc。Alpine的musl libc库提供了对GNU libc的部分兼容性,可用于尝试解决此问题:
|
1 |
apk add libc6-compat |
Docker配置信息可能位于:
- /usr/lib/systemd/system/docker.service
Docker服务相关命令:
|
1 2 |
systemctl daemon-reload systemctl restart docker |
|
1 |
apt-get install software-properties-common |
Leave a Reply